
Автор:
Robert Simon
Дата создания:
18 Июнь 2021
Дата обновления:
9 Апрель 2023
Содержание
- Шаг 1
- Шаг 2
- Шаг 3
- Шаг 4

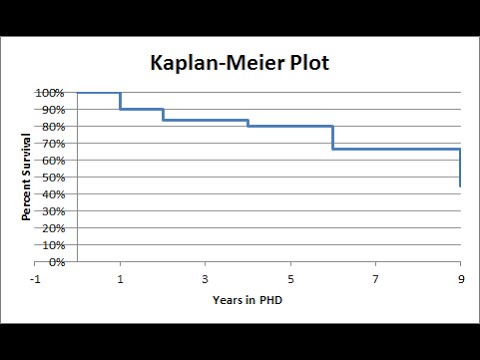
Диаграммы выживаемости Каплана-Мейера оценивают показатели выживаемости и настойчивость населения. Вы можете создать диаграмму Каплана-Мейера в Microsoft Excel. Организуйте свои данные для отображения правильной информации, создайте вычисляемый столбец для оценки выживаемости и график для отображения этой информации. Настройте свою графику, выбрав цветовую схему, стиль шрифта и эффекты. Поделитесь своими данными, распечатав, отправив по почте или вставив изображение в презентацию.
Шаг 1
Откройте электронную таблицу Excel, содержащую данные о вашей выживаемости. Поместите свой период времени в столбец A, популяцию в столбец B и количество выживших в столбце C. Пометьте все столбцы описательными заголовками в первой строке.
Шаг 2
Вычислите оценку Каплана-Мейера в столбце D, разделив количество выживших на популяцию, а затем умножив на предыдущие оценки. Например, введите выражение «= (C2 / B2)» без кавычек для первой записи, «= (C2 / B2)(C3 / B3) «для второй записи и» = (C2 / B2)(C3 / B3) * (C4 / B4) «для третьей записи. Завершите выражения и пометьте столбец.
Шаг 3
Выберите столбец Каплана-Мейера и щелкните вкладку «Вставка» на ленте вверху экрана. Щелкните инструмент «Линия» диаграммы и выберите первую опцию в верхнем левом углу. Щелкните вкладку «Макет» на ленте, выберите параметр «Выбрать данные», нажмите «Изменить» под меткой горизонтальной оси «Категория» и выберите столбец A в текстовом поле «Диапазон диапазона меток». ось».
Настройте диаграмму выживаемости Каплана-Мейера, выбрав вкладки «Макет» и «Презентация» на ленте. Измените цветовую схему в области «Стили графики» на вкладке «Дизайн». Добавьте метки осей, легенды и заголовки для диаграммы на вкладке «Презентация».
This tutorial will show you how to set up and interpret a Kaplan-Meier analysis in Excel including group comparison using the XLSTAT software.
Dataset to run a Kaplan-Meier analysis
The data have been obtained in [Gehan E.A. (1965). A generalized Wilcoxon test for comparing arbitrarily singly-censored samples. Biometrika, 52, pp 203—223] and represent a randomized clinical trial investigating the effect of the drug 6-mercaptopurine on remission times (in weeks) of acute leukemia patients.
Goal of this Kaplan-Meier analysis
Our goal is to determine if and how the drug influences the survival time, by comparing the survival curves for two groups of 21 patients, the first being treated, and the second being a control group. All 21 patients of the control group were observed to have a recurrence of their leukemia. Only 9 of the 6-MP patients had an observed recurrence time, while the 12 others were censored.
Setting up a Kaplan-Meier analysis
-
Open XLSTAT
-
In the ribbon, select XLSTAT > Survival analysis > Kaplan-Meier analysis
-
Once you’ve clicked on the button, the Kaplan-Meier analysis box will appear. Select the data on the Excel sheet. The Time data corresponds to the durations when the patients either relapsed or were censored. The Status indicator describes whether a patient relapsed (event code=1) or was censored (censored code = 0) at a given time.

-
In the Data options tab, activate the By group analysis and select the group information in the data field. Thus XLSTAT will take into account the information whether the patient belongs to the control or the treated group. Activate the Compare option so that the comparison tests are computed. The Filter option allows you to select precisely the groups on which you wish to perform the analysis.
-
In the Charts tab, activate the charts you wish to display, and choose the symbol you want to use to represent Censored data.
-
The computations begin once you have clicked on OK. The results will then be displayed on a new Excel sheet.
Interpreting the results of a Kaplan-Meier analysis
The first table displays a summary of the data for each group:

Then XLSTAT displays results specific to each group. It starts with the Control group.
First, the Kaplan-Meier table is displayed. It contains the results of the Kaplan-Meier analysis with several key indicators such as the Survival distribution function.

The next tables give the mean and median survival time and the respective confidence intervals.

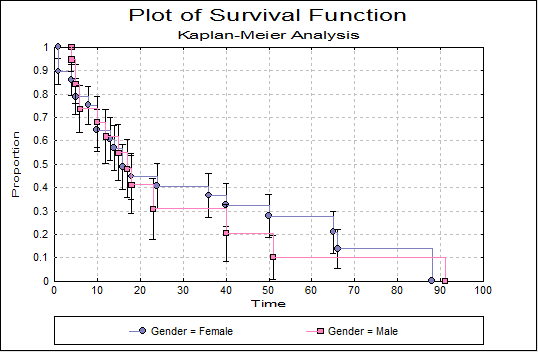
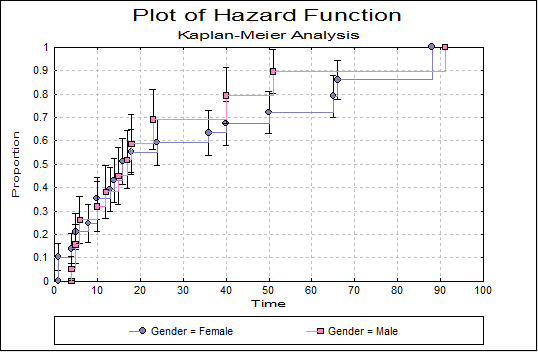
Then, we can visualize several curves, including the survival distribution function (SDF, or survivor function, or reliability function), bounded by the confidence intervals.

Next, the same series of results is displayed for the Drug 6-MP group.

The following results contain some values that are missing because they could not be computed.
We notice that the median survival time is a lot lower for the control group than for the 6-MP group (8.667 vs 21.943).

In the SDF, circles identify the censored data.

Then, we can compare the two groups. First, a series of tests is displayed in a table (Log-rank, Wilcoxon, Tarone-Ware). From the results we can see that the difference between the two survivor functions is very significant.

Last, the comparison of the two survival curves allows us to conclude to confirm that the drug significantly improves survival time of patients.

Was this article useful?
- Yes
- No
The goal of the Kaplan-Meier procedure is to create an estimator of the survival function based on empirical data, taking censoring into account.
Topics:
- Overview
- Survival Curve
- Standard Error and Confidence Intervals
- Hazard Function
- Log-Rank Test for Comparing Two Samples
- Alternative Tests for the Comparisons of Two Samples
- Hazard Ratio
- Real Statistics Capabilities
For those with a calculus background, you can also see the proofs of some of the properties described on the above webpages at
- Kaplan-Meier Theory
Перейти к содержанию
На чтение 3 мин Просмотров 47 Опубликовано 27 ноября, 2022
[ad_1]

Кривая Каплана-Мейера была разработана в 1958 году Эдвардом Капланом и Полом Мейером для работы с неполными наблюдениями и разным временем выживания. Кривая КМ, используемая в медицине и других областях, анализирует вероятность того, что субъект переживет важное событие. Событием может быть все, что знаменует собой важный момент времени или достижение. Субъекты в анализе МЗ имеют две переменные: период исследования (от начальной точки до конечной точки) и статус в конце периода исследования (событие произошло, или событие не произошло, или является неопределенным).
Содержание
- Настройте электронную таблицу Excel
- Шаг 1
- Шаг 2
- Шаг 3
- Шаг 4
- Создайте график выживания Каплана-Мейера
- Шаг 1
- Шаг 2
- Шаг 3
- Кончик
- Предупреждение
Настройте электронную таблицу Excel
Этот массажер настоящая находка!

Массажные ролики имитируют действия рук массажиста, даря вам незабываемые ощущения. Удобная лямка-фиксатор позволит закрепить подушку на любом стуле или сиденье авто.
- Полностью снимает мышечное напряжение, боли, усталость.
- Дешевле одного курса массажа. Прогревает и массажирует.
- Избавит от боли в спине и шее!
Заказать с скидкой >>>
Этот массажер настоящая находка!
Массажные ролики имитируют действия рук массажиста, даря вам незабываемые ощущения. Удобная лямка-фиксатор позволит закрепить подушку на любом стуле или сиденье авто.
- Полностью снимает мышечное напряжение, боли, усталость.
- Дешевле одного курса массажа. Прогревает и массажирует.
- Избавит от боли в спине и шее!
Заказать с скидкой >>>

Шаг 1
Назовите столбец A как «Период исследования», столбец B как «Количество в опасности», столбец C как «Число подвергнутых цензуре», столбец D как «Количество умерших», столбец E как «Количество выживших» и столбец F как «Выживание на КМ». «
ТОП-10 товаров которые вам захочется купить
Просмотрели множество интернет-магазинов и сделали подборку самых интересных товаров
Cмотреть
Шаг 2
Заполните значения столбца. Введите периоды исследования в столбце Период исследования. В столбце Число подвергшихся цензуре введите, сколько человек было исключено из исследования на данный момент. Человек может быть подвергнут цензуре, потому что он выбыл из исследования, его данные неполны или исследование закончилось до того, как для него произошло событие. В столбце «Число умерших» введите количество людей, умерших за этот период исследования.
Шаг 3
Заполните столбцы «Число в группе риска» и «Количество выживших». Для первой строки, начиная с ячейки B2, число в группе риска — это общее количество участников исследования. Число выживших равно числу подверженных риску минус число умерших, или = B2-D2. Вторая и последующие строки рассчитываются по-разному. Столбец «Число в опасности» — это количество выживших из предыдущего периода минус количество людей, подвергшихся цензуре, или = E3-C3. Количество выживших за этот период по-прежнему равно количеству людей, находящихся в группе риска, за вычетом числа умерших, или = B3-D3. Щелкните ячейку B3 и перетащите ее, чтобы автоматически заполнить оставшуюся часть столбца «Число риска». Щелкните ячейку E3 и перетащите, чтобы автоматически заполнить остальную часть столбца «Число выживших».
Шаг 4
Заполните столбец KM Survival, чтобы рассчитать вероятность выживания для каждого периода исследования. Для первого периода исследования вероятность выживания равна числу выживших, деленному на число подверженных риску, или =E2/B2. Для второго и последующих периодов исследования вероятность выживания представляет собой вероятность выживания предыдущего периода, умноженную на количество выживших, деленную на число подверженных риску, или =F2*(E3/B3). Щелкните ячейку F3 и перетащите ее, чтобы заполнить остальную часть столбца KM Survival.
Создайте график выживания Каплана-Мейера
Шаг 1
Выберите значения в столбце KM Survival от ячейки F2 до конца ваших данных.
Шаг 2
Нажмите на вкладку «Вставить». В разделе «Диаграммы» щелкните стрелку рядом со значком «Вставить линейную диаграмму». Нажмите «Линия с маркерами». На рабочем листе появится диаграмма.
Шаг 3
Нажмите «Выбрать данные» на вкладке «Дизайн», чтобы изменить ось X, чтобы отразить правильные периоды исследования. Откроется окно Выбор источника данных. В разделе «Метки горизонтальной (категории) оси» нажмите кнопку «Изменить». Щелкните ячейку A2 и перетащите в конец данных. Нажмите «ОК», а затем снова нажмите «ОК». Теперь у вас есть график выживания Каплана-Мейера.
Кончик
Если у вас несколько групп тем, добавьте столбец «Группа». Каждая группа должна иметь свою линию в создаваемой вами диаграмме.
Предупреждение
Информация в этой статье относится к Excel 2013. Для других версий или продуктов она может незначительно или существенно отличаться.
[ad_2]
The UNISTAT statistics add-in extends Excel with Kaplan-Meier Analysis capabilities.
For further information visit UNISTAT User’s Guide section 9.4.2. Kaplan-Meier Analysis.
Here we provide a sample output from the UNISTAT Excel statistics add-in for data analysis.
Kaplan-Meier Analysis
Product Limit Survival Table
Factor variable: Gender = Female
Time Variable: Survival time
Censor Variable: Status
Number of Cases Censored: 7 ( 24.1%)
Valid Number of Cases: 29, 19 Omitted
| Time | Status | Number Entering | Number Terminating | Cumulative Proportion Surviving | Standard Error of Cumulative Surviving | Lower 95% of Cumulative Surviving | Upper 95% of Cumulative Surviving | Cumulative Proportion Terminating |
|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 28 | 1 | * | * | * | * | * |
| 1 | 1 | 27 | 2 | * | * | * | * | * |
| 1 | 1 | 26 | 3 | 0.8966 | 0.0566 | 0.7126 | 0.9654 | 0.1034 |
| 3 | 0 | 25 | 3 | * | * | * | * | * |
| 4 | 1 | 24 | 4 | 0.8607 | 0.0647 | 0.6701 | 0.9453 | 0.1393 |
| 5 | 1 | 23 | 5 | * | * | * | * | * |
| 5 | 1 | 22 | 6 | 0.7890 | 0.0766 | 0.5891 | 0.8993 | 0.2110 |
| 8 | 1 | 21 | 7 | 0.7531 | 0.0811 | 0.5505 | 0.8740 | 0.2469 |
| 10 | 1 | 20 | 8 | * | * | * | * | * |
| 10 | 1 | 19 | 9 | * | * | * | * | * |
| 10 | 1 | 18 | 10 | 0.6455 | 0.0902 | 0.4411 | 0.7913 | 0.3545 |
| 10 | 0 | 17 | 10 | * | * | * | * | * |
| 13 | 1 | 16 | 11 | 0.6075 | 0.0926 | 0.4036 | 0.7606 | 0.3925 |
| 14 | 1 | 15 | 12 | 0.5696 | 0.0942 | 0.3673 | 0.7288 | 0.4304 |
| 15 | 0 | 14 | 12 | * | * | * | * | * |
| 16 | 1 | 13 | 13 | * | * | * | * | * |
| 16 | 1 | 12 | 14 | 0.4882 | 0.0968 | 0.2915 | 0.6590 | 0.5118 |
| 18 | 1 | 11 | 15 | 0.4475 | 0.0969 | 0.2559 | 0.6223 | 0.5525 |
| 24 | 1 | 10 | 16 | 0.4068 | 0.0962 | 0.2218 | 0.5844 | 0.5932 |
| 36 | 1 | 9 | 17 | 0.3662 | 0.0948 | 0.1892 | 0.5454 | 0.6338 |
| 40 | 1 | 8 | 18 | 0.3255 | 0.0926 | 0.1581 | 0.5051 | 0.6745 |
| 40 | 0 | 7 | 18 | * | * | * | * | * |
| 50 | 1 | 6 | 19 | 0.2790 | 0.0903 | 0.1227 | 0.4599 | 0.7210 |
| 52 | 0 | 5 | 19 | * | * | * | * | * |
| 56 | 0 | 4 | 19 | * | * | * | * | * |
| 65 | 1 | 3 | 20 | 0.2092 | 0.0907 | 0.0676 | 0.4031 | 0.7908 |
| 66 | 1 | 2 | 21 | 0.1395 | 0.0831 | 0.0284 | 0.3365 | 0.8605 |
| 76 | 0 | 1 | 21 | * | * | * | * | * |
| 88 | 1 | 0 | 22 | 0.0000 | 0.0000 | * | * | 1.0000 |
| Time | Standard Error of Cumulative Terminating | Lower 95% of Cumulative Terminating | Upper 95% of Cumulative Terminating | |||||
| 1 | * | * | * | |||||
| 1 | * | * | * | |||||
| 1 | 0.0566 | 0.0346 | 0.2874 | |||||
| 3 | * | * | * | |||||
| 4 | 0.0647 | 0.0547 | 0.3299 | |||||
| 5 | * | * | * | |||||
| 5 | 0.0766 | 0.1007 | 0.4109 | |||||
| 8 | 0.0811 | 0.1260 | 0.4495 | |||||
| 10 | * | * | * | |||||
| 10 | * | * | * | |||||
| 10 | 0.0902 | 0.2087 | 0.5589 | |||||
| 10 | * | * | * | |||||
| 13 | 0.0926 | 0.2394 | 0.5964 | |||||
| 14 | 0.0942 | 0.2712 | 0.6327 | |||||
| 15 | * | * | * | |||||
| 16 | * | * | * | |||||
| 16 | 0.0968 | 0.3410 | 0.7085 | |||||
| 18 | 0.0969 | 0.3777 | 0.7441 | |||||
| 24 | 0.0962 | 0.4156 | 0.7782 | |||||
| 36 | 0.0948 | 0.4546 | 0.8108 | |||||
| 40 | 0.0926 | 0.4949 | 0.8419 | |||||
| 40 | * | * | * | |||||
| 50 | 0.0903 | 0.5401 | 0.8773 | |||||
| 52 | * | * | * | |||||
| 56 | * | * | * | |||||
| 65 | 0.0907 | 0.5969 | 0.9324 | |||||
| 66 | 0.0831 | 0.6635 | 0.9716 | |||||
| 76 | * | * | * | |||||
| 88 | 0.0000 | * | * |
Product Limit Survival Table
Factor variable: Gender = Male
Time Variable: Survival time
Censor Variable: Status
Number of Cases Censored: 5 ( 26.3%)
Valid Number of Cases: 19, 29 Omitted
| Time | Status | Number Entering | Number Terminating | Cumulative Proportion Surviving | Standard Error of Cumulative Surviving | Lower 95% of Cumulative Surviving | Upper 95% of Cumulative Surviving | Cumulative Proportion Terminating |
|---|---|---|---|---|---|---|---|---|
| 4 | 1 | 18 | 1 | 0.9474 | 0.0512 | 0.6812 | 0.9924 | 0.0526 |
| 5 | 1 | 17 | 2 | * | * | * | * | * |
| 5 | 1 | 16 | 3 | 0.8421 | 0.0837 | 0.5865 | 0.9462 | 0.1579 |
| 6 | 1 | 15 | 4 | * | * | * | * | * |
| 6 | 1 | 14 | 5 | 0.7368 | 0.1010 | 0.4789 | 0.8810 | 0.2632 |
| 7 | 0 | 13 | 5 | * | * | * | * | * |
| 10 | 1 | 12 | 6 | 0.6802 | 0.1080 | 0.4214 | 0.8421 | 0.3198 |
| 11 | 0 | 11 | 6 | * | * | * | * | * |
| 12 | 1 | 10 | 7 | 0.6183 | 0.1145 | 0.3596 | 0.7978 | 0.3817 |
| 12 | 0 | 9 | 7 | * | * | * | * | * |
| 15 | 1 | 8 | 8 | 0.5496 | 0.1207 | 0.2928 | 0.7470 | 0.4504 |
| 17 | 1 | 7 | 9 | 0.4809 | 0.1236 | 0.2330 | 0.6922 | 0.5191 |
| 18 | 1 | 6 | 10 | 0.4122 | 0.1236 | 0.1791 | 0.6334 | 0.5878 |
| 18 | 0 | 5 | 10 | * | * | * | * | * |
| 18 | 0 | 4 | 10 | * | * | * | * | * |
| 23 | 1 | 3 | 11 | 0.3092 | 0.1287 | 0.0952 | 0.5566 | 0.6908 |
| 40 | 1 | 2 | 12 | 0.2061 | 0.1202 | 0.0385 | 0.4648 | 0.7939 |
| 51 | 1 | 1 | 13 | 0.1031 | 0.0944 | 0.0067 | 0.3567 | 0.8969 |
| 91 | 1 | 0 | 14 | * | * | * | * | * |
| Time | Standard Error of Cumulative Terminating | Lower 95% of Cumulative Terminating | Upper 95% of Cumulative Terminating | |||||
| 4 | 0.0512 | 0.0076 | 0.3188 | |||||
| 5 | * | * | * | |||||
| 5 | 0.0837 | 0.0538 | 0.4135 | |||||
| 6 | * | * | * | |||||
| 6 | 0.1010 | 0.1190 | 0.5211 | |||||
| 7 | * | * | * | |||||
| 10 | 0.1080 | 0.1579 | 0.5786 | |||||
| 11 | * | * | * | |||||
| 12 | 0.1145 | 0.2022 | 0.6404 | |||||
| 12 | * | * | * | |||||
| 15 | 0.1207 | 0.2530 | 0.7072 | |||||
| 17 | 0.1236 | 0.3078 | 0.7670 | |||||
| 18 | 0.1236 | 0.3666 | 0.8209 | |||||
| 18 | * | * | * | |||||
| 18 | * | * | * | |||||
| 23 | 0.1287 | 0.4434 | 0.9048 | |||||
| 40 | 0.1202 | 0.5352 | 0.9615 | |||||
| 51 | 0.0944 | 0.6433 | 0.9933 | |||||
| 91 | * | * | * |
Quantiles of Survival Function
Factor variable: Gender = Female
Time Variable: Survival time
Censor Variable: Status
Number of Cases Censored: 7 ( 24.1%)
Valid Number of Cases: 29, 19 Omitted
Epsilon: 0.05
| Value | Standard Error | Lower 95% | Upper 95% | |
|---|---|---|---|---|
| Mean | 32.8322 | 6.1632 | 20.7526 | 44.9118 |
| Quantile 1: 25% | 65.0000 | 12.6856 | 40.1367 | 89.8633 |
| Quantile 2: 50% | 16.0000 | 2.3784 | 11.3385 | 20.6615 |
| Quantile 3: 75% | 10.0000 | 2.9558 | 4.2067 | 15.7933 |
Quantiles of Survival Function
Factor variable: Gender = Male
Time Variable: Survival time
Censor Variable: Status
Number of Cases Censored: 5 ( 26.3%)
Valid Number of Cases: 19, 29 Omitted
Epsilon: 0.05
| Value | Standard Error | Lower 95% | Upper 95% | |
|---|---|---|---|---|
| Mean | 27.2386 | 7.4773 | 12.5833 | 41.8939 |
| Quantile 1: 25% | 40.0000 | 16.3232 | 8.0072 | 71.9928 |
| Quantile 2: 50% | 17.0000 | 3.5979 | 9.9483 | 24.0517 |
| Quantile 3: 75% | 6.0000 | 3.1191 | * | 12.1133 |
HR-Инструменты Учебник по STATISTICA
- Введение
в анализ выживаемости - Таблицы
времен жизни - Оценки Каплана—Мейера
- Сравнение
выживаемости в группах - Регрессионные
модели в анализе выживаемости - Модель Кокса
- Экспоненциальная
регрессия - Нормальная
и логнормальная регрессия - Обзор системы
- Альтернативные
процедуры - Пример
1. Таблицы времен жизни - Задание
параметров анализа - Пример
2. Регрессионная модель Кокса - Задание
параметров анализа - Оценивание
параметров - Результаты
Введение в анализ выживаемости
Методы анализа выживаемости интенсивно применяются в медицине, биологии, страховании и промышленности.
Одной из важных характеристик, описывающих течение болезни, является продолжительность жизни пациентов с момента поступления в клинику или после проведения операции.
В принципе, для описания средних времен жизни и сравнения новой методики со старой можно использовать стандартные статистические методы.
Однако рассматриваемые данные имеют специфику, которую следует учитывать. Дело в том, что в медицинской практике мы часто имеем дело с неполными данными.
Это связано с тем, что трудно наблюдать все время жизни пациента после операции, так как пациент мог быть выписан или переведен в другую клинику и связь с ним была утеряна. При этом мы располагаем не полной информацией о времени жизни пациента, а лишь частичной.
Естественное желание исследователя использовать все данные, т. е. анализировать как полные времена жизни, так и неполные, и не терять с трудом собранную информацию.
Для этого и предназначены методы анализа выживаемости, которые позволяют изучать неполные или цензурированные данные.
Наблюдения, которые содержат неполную информацию, называются неполными или цензурированными (например, «пациент А был жив по крайней мере 4 месяца после того, как был переведен в другую клинику и контакт с ним был потерян»). Это пример цензурированного наблюдения: информация о том, что пациент был жив 4 месяца, важна и может быть использована для построения оценок.
Наблюдения от момента операции до летального исхода называется полными.
Итак, в анализе выживаемости различают полные (по-английски complete) и неполные, или цензурированные, наблюдения (по-английски censored).
Конечно, можно было использовать только полные времена жизни, но тогда мы имели бы в своем распоряжении очень мало наблюдений и соответственно неточные оценки.
Использование, наряду с полными наблюдениями, неполных или цензурированных наблюдений является главной особенностью методов анализа выживаемости.
Таблицы времен жизни
Прежде всего, постараемся оценить вероятность того, что пациент прожил больше t дней после операции. Это важный показатель, называемый функцией выживания.
Наиболее естественный способ описания функции выживаемости состоит в построении Таблиц времен жизни.
Это один из старейших приемов анализа данных о выживаемости и традиционно используется, например, в страховании, где такие таблицы называются таблицами дожития.

Организация данных
Исходный файл данных имеет вид:

Организация файла следующая.
Пациенты располагаются в строках. В столбцах записаны даты операции и даты завершения пребывания в больнице. Например, из • первой строки видно, что пациенту была сделана операция 6 января 1968 (первые три клетки), выписался 21 января 1968 года (вторая тройка клеток). Далее связь с ним была утеряна, таким образом, это неполное наблюдение (значение переменной номер 7 — censored).
Восьмая переменная AGE содержит возраст пациентов.
Переменные 9, 10 содержат специальную медицинскую информацию об особенностях операции.
Значение переменной 11 — название госпиталя, где сделана операция. Ниже показана таблица жизни для этого файла данных.

Конечно, подобную таблицу жизни можно рассматривать как «расцшренную» таблицу частот. Однако обычная таблица частот строится по полным наблюдениям. В таблице жизни учтены как полные, так и неполные наблюдения.
Идея таблиц жизни, или дожития, в терминологии страхования, проста. Нам нужно вычислить простейшие статистики, чтобы описать время выживания пациентов.
Для этого временная ось разбивается на некоторое число интервалов. В приведенной выше таблице это число равно 12. В системе STATISTICA количество интервалов на временной оси пользователь может выбрать по своему усмотрению.
Для каждого интервала вычисляется число объектов, которые в начале рассматриваемого интервала были «живы» (см. соответствующий столбец в электронной таблице — переменная ЧИСЛО В НАЧАЛЕ), и число объектов, которые «умерли» в данном интервале (переменная ЧИСЛО УМЕРШИХ).
Также вычисляется число цензурированных или изъятых из наблюдения объектов на каждом интервале — переменная ЧИСЛО ИЗЪЯТЫХ (в таблицах жизни употребляют термин изъятые — withdrawn для цензурированных наблюдений, в данном примере это выписанные больные). Вычисляются доли этих объектов.
Для понимания таблиц полезно помнить, что на данном временном интервале наблюдение может быть либо цензурировано (больной выписан или переведен в другую клинику), либо наблюдается фатальный исход.
Рассмотрим более формально переменные в электронной таблице жизни.
Число в начале
Это число объектов, которые были «живы» в начале рассматриваемого временного интервала.
Число изъятых
Это число цензурированных на данном интервале объектов (объектов, изъятых из
наблюдения). Эти объекты имеют метку цензурированые (censored).
Число изучаемых
Это число объектов, которые были «живы» в начале рассматриваемого временного интервала, минус половина от числа изъятых.
Число умерших
Это число объектов, умерших на данном интервале. Умершие или отказавшие объекты обычно имеют метку complete.
Доля умерших
Эта отношение числа объектов, умерших в соответствующем интервале, к числу
объектов, изучаемых на этом интервале.
Прокрутим электронную таблицу вправо и рассмотрим оставшиеся переменные таблицы.

Доля выживших
Эта доля равна единице минус доля умерших.
Кумулятивная доля выживших объектов, или функция выживания Это — оценка функции выживания, то есть вероятность того, что пациент переживет данный интервал. Она равна произведению долей выживших объектов по всем предыдущим интервалам. Если посмотреть на столбец КУМ.ДОЛЯ ВЫЖИВШ. приведенной выше таблицы, то можно увидеть, например, что 0,582759= 0,672414
× 0,866667, 0,569514= 0,582759×0,977273 и т. д.
Плотность вероятности
Это плотность вероятности смерти на данном интервале, когда из функции выживания на данном интервале вычитается функция выживания на следующем интервале и делится на длину интервала, показанную во втором столбце таблицы.
Например, (1 — 0,672414)/161,3636= 0,00203.
На графике оценки плотности можно видно, что вероятность смерти в первые 160 дней после операции максимальна. Далее она резко падает.
Большие вероятности смерти расположены также в интервалах от 161 до 322, от 968 до 1129 и др.

Интенсивность отказов, или функция мгновенного риска
Это также одна из важных характеристик, описывающих течение болезни. Функция мгновенного риска является важной прогностической характеристикой, описывающей течение болезни.
Формально функция мгновенного риска равна вероятности того, что пациент умрет в следующем интервале наблюдения, при условии, что вначале он был жив.

График функции риска достаточно наглядно показывает, что в первые дни риск смерти очень велик, затем он падает и спустя некоторое время вновь начинает возрастать. Заметим, что именно функция риска используется для прогностических целей.
Позвольте сделать отступление. Один из лейтмотивов нашей книги является непредвзятость и критическое отношение к полученным результатам. Такая критичность особенно важна в медицине. Мы доверяем результатам, полученным с помощью компьютера, однако всесторонне их проверяем.
Итак, нас интересует функция риска, однако реально мы получаем лишь оценку риска. Поэтому важна точность полученных оценок. Из простых соображений следует, что мы не доверяем оценкам с большой погрешностью. Например, мы не будем доверять оценкам, погрешность которых имеет тот же порядок, что и сами оценки. Поэтому внимательно просмотрите построенную таблицу и выбросите из нее плохие оценки (оценки с большой погрешностью). Это чрезвычайно важный принцип анализа данных!
Известно, что для получения надежных оценок параметров и ошибок в таблицах жизни требуется как минимум 30 наблюдений.

Взгляните на таблицу. Заметьте, в ней наряду с оценками приведены стандартные ошибки полученных оценок.
Медиана ожидаемого времени жизни
Это моменты времени, в которых функция выживания равна ?. Например, из первой строчки таблицы следует, что пациент с вероятностью ? проживет больше 809 дней после операции.
Если пациент пережил первый интервал, то медиана его времени жизни равна 1036 и т. д.
В общем случае таблица времен жизни дает хорошее представление о распределении отказов или смертей, если наблюдений достаточно много.
Однако для прогноза часто необходимо знать форму функции выживания. Для этой цели используются различные семейства распределений.
Наиболее важны следующие семейства распределений:
экспоненциальное, Вей-булла и распределение Гомперца.
Эти распределения имеют неизвестные параметры, которые программа оценивает. Процедура оценивания параметров основана на методе наименьших квадратов. Для проведения оценивания применима модель линейной регрессии, поскольку все перечисленные семейства распределений могут быть «сведены к линейным» (относительно параметров) с помощью подходящих преобразований. Такие преобразования приводят иногда к тому, что дисперсия остатков зависит от интервалов (то есть дисперсия различна на разных интервалах). Чтобы учесть это, в алгоритмах подгонки дополнительно используются оценки взвешенных наименьших квадратов двух типов.
Оценки Каплана—Мейера
Напомним, что одна из задач в анализе выживаемости состоит в том, чтобы оценить функцию выживания, то есть вероятность того, что пациент проживет определенное время после операции.
Оказывается, что для цензурированных наблюдений функцию выживания можно оценить непосредственно, не используя таблицу времен жизни. Такой метод впервые предложили Каплан и Мейер в 1958 году.

Представьте, что вы имеете файл, в котором записаны в хронологическом порядке отдельные события. Тогда имеет место следующая оценка функции выживания:
S(t) = П[(n-j)/(n-j+l)õ(j)]
В этом выражении S(t) — оценка функции выживания,
n — общее число событий (объем выборки), j — порядковый (хронологически) номер отдельного события,
õ(j) равно 1, если j-е событие означает отказ (смерть) и
õ(j) равно 0, если j-е событие означает потерю наблюдения (индикатор цензурирования), П означает произведение по всем наблюдениям j, завершившимся к моменту t.
Данная оценка функции выживания состоит из произведения нескольких сомножителей, поэтому она также называется множительной оценкой.
Рассмотрим тот же файл данных; что и для таблиц времен жизни. Оценка Каплана—Мейера функции выживания, построенная по этим данным, показана в следующей таблице:

Из таблицы видно, например, что вероятность того, что пациент проживет больше 25 дней, равна 0,966, вероятность того, что пациент проживет больше 39 дней, равна 0,9299 и т. д.
В первом столбце таблицы показаны номера наблюдений, для которых в данный момент времени произошло некоторое событие, знак + означает, что пациент цензурирован (был выписан).
Прокрутите электронную таблицу с результатами вниз по временной оси:

Обратите внимание на ошибки оценок. Стандартная ошибка функция выживания достаточно мала (сравните с ошибками для таблиц времен жизни). Ниже показан график функции выживания.

Отметим, что для удобства интерпретации на графике полные наблюдения помечены точками, неполные наблюдения отмечены крестиками.
Преимущество метода Каплана—Мейера (по сравнению с методом таблиц жизни) состоит в том, что оценки не зависят от разбиения времен жизни на интервалы.
Таким образом, нам не нужно разбивать временную ось на интервалы. Оценки Каплана—Мейера строятся в STATISTICA одним щелчком мыши.
Сравнение выживаемости в группах
Интересно сравнить времена жизни пациентов в различных группах, например, в группах: мужчины и женщины. В STATISTICA имеются специальные процедуры для сравнения выживаемости в группах.
Если количество групп две, то используется диалог
Сравнение двух выборок.

Если количество групп больше двух, то используется диалог
Сравнение нескольких выборок.

Для сравнения выживаемости в группах имеется несколько критериев: вариант известного непараметрического критерия Вилкоксона, предложенный для неполных наблюдений Геханом и Пето, а также F-критерий Кокса и логарифмический ранговый критерий.
Большинство этих критериев приводят соответствующие z-значения (нормального приближения), которые могут быть использованы для статистической проверки различий между группами.
Однако критерии дают надежные результаты лишь при достаточно больших объемах выборок. При малых объемах выборок эти критерии не столь надежны. В любом случае всегда полезны визуальные методы.

Эти графики позволяют увидеть различие между группами.
Кроме этого STATISTICA содержит программу на STATISTICA BASIC (файл Ma.nthaen.stb), вычисляющую критерий Ментела-Хенцела для сравнения двух групп данных (см. Lee E. Т. (1992) Statistical methods for survival data analysis). Этот критерий может быть полезен во многих клинических и эпидемиологических работах для того, чтобы контролировать эффект смешивающих переменных.
Критерий основан на анализе таблиц 2×2 (например, Группировка 1/2 и Выживаемость), стратифицированных или расслоенных с помощью категориальной переменной (смешанной переменной; например, Положением). Критерий позволяет проверить, являются две переменные в таблицах
2×2, например, переменная Группировка и Выживаемость, зависимыми или нет.
Не существует твердо установленных рекомендаций по применению определенных критериев.
Известно, что F-критерий Кокса обычно мощнее, чем критерий Вилкоксона— Гехана, если:
- данных мало (объем группы n меньше 50);
- выборки извлекаются из экспоненциального распределения или распределения Вейбулла;
- нет цензурированных наблюдений.
В работе Lee, Desu, and Gehan (1975) A Monte-Carlo study of the power of some two-sample tests, Biometrika, 62, p. 425-532, критерий Гехана сравнивался с некоторыми другими критериями. Показано, например, что критерий Кокса—Ментела и логарифмический ранговый критерий являются более мощными, если выборки имеет определенное распределение, например, экспоненциальное или Вейбулла. При этих условиях между критерием Кокса—Ментела и логарифмическим ранговым критерием почти нет различия.
В работе Ли (Lee Е. Т. (1980) Statistical methods for survival data analysis. Belmont, CA: Lifitime Learning) обсуждается мощность различных критериев более детально. Если вас затрудняет выбор определенного критерия, рекомендуем обратиться к этим работам.
Если сравниваются две или более группы, важно проверить доли цензурированных наблюдений в каждой. В частности, в медицинских исследованиях степень цензурирования может зависеть, например, от различий в методике лечения: пациенты, которым стало много лучше или стало хуже, с большой вероятностью теряются из наблюдения. Различие в степени цензурирования может привести к смещению в статистических выводах.
Это очень важный момент. Чтобы подогнать результат, недобросовестный исследователь может искусственно исключить из исследования тяжелых больных. Поэтому при проведении сравнения различных методик нужно руководствоваться здравым смыслом. Ясно, что если в одной группе доля цензурированных наблюдений существенно больше, чем в другой, нужно принять естественные меры предосторожности, по крайней мере, точно указать проблему.
Регрессионные модели в анализе выживаемости
В предыдущих разделах мы кратко обсуждали задачу оценивания функции выживания на основе реальных данных.
Более трудной задачей является оценка функции мгновенного риска, которая представляет собой вероятность летального исхода в малый промежуток времени при условии, что в начале исследуемого промежутка пациент был жив. Это важная характеристика прогноза развития болезни.
Непосредственная оценка функции мгновенного риска может потребовать большого количества наблюдений, поэтому применяются специальные модели, одна из которых — это модель Кокса пропорциональных рисков, или, на языке теории надежности, пропорциональных интенсивностей.
Большая проблема медицинских и биологических исследований состоит в выяснении того, являются ли некоторые переменные связанными с наблюдаемыми временами жизни. Если зависимость есть, то ее нужно оценить численно.

Существуют две главные причины, по которым в таких исследованиях нельзя непосредственно использовать классическую регрессию. Во-первых, времена жизни обычно не являются простыми линейными функциями от соответствующих регрессоров, поэтому анализ методами Множественной регрессии может привести к ошибочным выводам, например, не позволит обнаружить важных регрессоров. Во-вторых, вновь возникает проблема неполных наблюдений, т. к. некоторые наблюдения могут быть незавершенными.
Анализ выживаемости предлагает пять общих регрессионных моделей для неполных данных:
1) Модель пропорциональных интенсивностей Кокса (Сох (1972) Regression models and life tables, Journal of the Royal Statistical Sociaty, 34, p. 187-220);
2) Модель Кокса с зависящими от времени ковариатами;
3) Экспоненциальную регрессионную модель (см. книги Prentice (1973) Exponential survivals with censoring and explanatory variables, Biometrika, 60, p. 279-288);
4) Нормальную линейную регрессионную модель (см. например, Wolynetz (1979) Maximum likelihood estimation in a linear model from confined and censored normal data, Applied Statistics, 28, p. 185-206);
5) Логнормальную линейную регрессионную модель (являющуюся модификацией нормальной модели).
Для каждой из этих моделей STATISTICA позволяет вычислить оценки максимального правдоподобия (Maximum likelihood
estimations).
Модель Кокса
Модель пропорциональных интенсивностей или пропорциональных рисков Кокса — наиболее общая регрессионная модель, в которой предполагается, что функция интенсивности имеет вид: h(t)
= h0(t) y(z1,…,zm). Множитель h0(t) называется базовой функцией интенсивности.
Модель может быть параметризована, например, в виде:
h[(t),(z1, z2,…, zm)] =
h0(t)× exp(b1 x z1 +…+ bm ×
zm)
Заметьте, в правой части стоит произведение двух функций, причем каждая из них зависит от своего множества переменных.
Функция интенсивности h0(t) может рассматриваться как функция интенсивности при равенстве нулю всех ковариат. Она не зависит от переменных z (называемых ковариатами). Второй сомножитель зависит от переменных z, которые, возможно, зависят от t.
Приведем пример такой модели.
Пусть изучается воздействие некоторого препарата на состояние больного, a z — категориальная переменная со значениями 1 для больных, принимавших новое лекарство, и 0 — для больных, не принимавших это лекарство. Тогда функцию риска можно записать в виде:
h(t,z) = h0(t) × exp{b1× z+b2×
[z × log(t)-100]}
Обратите внимание, что функция интенсивности в момент t (левая часть формулы) есть функция: 1) функции интенсивности
h0, 2) ковариаты z и 3) z, умноженной на логарифм времени.
Умножение ковариаты z на логарифм времени позволяет учесть, например, фактор времени при приеме нового лекарства.
Константа 100 в этом примере использована просто как нормировка, т. к. среднее логарифма времени жизни для этого множества данных равно 100.
Зная оценки параметров b1,b2 и функцию интенсивности
h0, можно оценить функцию мгновенного риска через время t после операции.
Самое замечательное, что такие модели позволяют учитывать интуицию медицинских исследователей. Построение и оценка адекватности модели в конкретных исследованиях — отдельная нетривиальная задача.
Другой пример,h(t,s,x)- риск коронарной смерти для пациента возраста t лет при условии, что в возрасте s его систолическое артериальное давление было х (см. Meshalkin L. D., Kagan А. В. (1972) A contribution to the discussion upon the paper «Regression models and life tables» by D. R. Cox, J. R. Statist. Soc. Ser. B, № 2).
Итак, функция мгновенного риска в модели Кокса представлена в виде произведения двух сомножителей, один из которых характеризует объект, другой — базовую функцию мгновенного риска.
Предикторы определяются постановкой задачи, например, пол пациента, возраст, наличие определенных сопутствующих заболеваний или прием нового лекарства. Выбор предикторов определяется интуицией исследователя. Врач может попытаться предсказать на основе определенного набора предикторов степень риска на ближайшие несколько дней. Имея прогноз, он может изменить методику лечения.
Займемся некоторой математической кухней. Модель Кокса можно линеаризовать, поделив обе части соотношения на
h0(t) и взяв натуральный логарифм от обеих частей:
log{h[(t),(z…)]/h0(t)} = b1× 2,+…+
bm× zm
Таким образом, мы получили линейную модель.
Итак, еще раз отметим, в основе модели Кокса лежат два предположения. Во-первых, зависимость между функцией интенсивности и логлинейной функцией ковариат является мультипликативной. Это предположение называется гипотезой пропорциональности. Реально оно означает, что для двух заданных наблюдений с различными значениями независимых переменных отношение их функций интенсивности не зависит от времени (чтобы ослабить это предположение, используются ковариаты, зависящие от времени; см. ниже). Второе предположение состоит в логлинейной зависимости функции интенсивности и регрессоров.
Предположение пропорциональности рисков часто подвергается сомнению. Например, рассмотрим гипотетическое исследование, в котором ковариатой является категориальная переменная, а именно индикатор того, подвергнут пациент хирургической операции или нет. Пусть пациент 1 подвергнут операции, в то время как пациент 2 — нет.
Согласно предположению пропорциональности, отношение функций интенсивностей для обоих пациентов не зависит от времени и означает, что риск для прооперированного пациента постоянно более высокий (или более низкий), чем риск пациента, не подвергнутого операции (при условии, что оба дожили до рассматриваемого момента).
Реалистичней другая модель, когда сразу после операции риск прооперированного пациента выше, но при благоприятном исходе операции с течением времени убывает и становится меньше риска не оперированного пациента. В этом случае используются регрессоры, зависящие от времени.
Можно привести много других примеров, где предположение о пропорциональности неприемлемо. Так, при изучении физического здоровья возраст является одним из факторов выживаемости после хирургической операции. Ясно, что возраст — более важный предиктор для риска сразу после операции, чем по прошествии некоторого времени после операции (например, вслед за первыми признаками выздоровления).
В случае категориальных ковариат, например, учитывающих, был или не был пациент подвергнут хирургической операции, рекомендуется обратиться к стратифицированному анализу выживаемости, в котором, исходя из априорных знаний, исследователь разбивает пациентов на однородные по фактору риска группы.
Можно провести подгонку модели пропорциональных интенсивностей отдельно для каждой группы наблюдений. Таким образом, можно явно представить функцию интенсивности для каждой группы. Иногда предположение пропорциональности не выполняется. В таком случае можно явно определить ковариаты как функции времени.
В главе Подгонка вероятностных распределений показано, как с помощью критерия хи-квадрат проверяется выполнимость предположений модели Кокса в системе STATISTICS
Заметим, что арифметические выражения, которые определяют ковариаты, не должны содержать ссылок на длительности жизни. Однако допускается, чтобы
некоторые ковариаты были функциями двух или большего числа других ковариат. Это, например, удобно в моделях многофакторных экспериментов. Для каждого фактора можно создать переменную в файле данных, чтобы установить желаемые контрасты. Логика и выбор априорных значений коэффициентов контрастов те же, что и в дисперсионном анализе. Если специфицируются ковариаты для регрессионной модели пропорциональных интенсивностей, то можно также определить взаимодействия факторов.
Например, предположим, что фактор А имеет 2 уровня. Всем субъектам, отнесенным к первому уровню этого фактора, мы приписываем -1 как значение соответствующей переменной (переменной А) в файле данных. Аналогично всем субъектам, отнесенным ко второму уровню, приписываем значение +1. Второй фактор, также с двумя уровнями, будет закодирован тем же способом (переменная В). После того как переменные АиВ определены как ковариаты, выражение А *В есть третья ковариата для проверки взаимодействия между этими двумя факторами.
Для задания зависящих от времени ковариат можно использовать тот же самый синтаксис, который используется в формулах электронной таблицы.
В некоторых случаях есть основание предполагать, что влияние одной или нескольких ковариат на функцию интенсивности не является непрерывным по времени. Например, риск для пациента после операции может зависеть от времени, прошедшего после операции в течение первых двух дней, и, во вторую очередь, от некоторых других факторов. В таком случае можно использовать некоторые логические операции, которые также поддерживаются при вводе формул электронных таблиц.
Например, можно определить зависящую от времени ковариату с помощью следующего выражения:
Age × (T_<2)
Логическое выражение Т< 2 равно 0 (ложь), если после операции прошло больше 2 дней, и равно 1 (истина), если меньше. Таким образом, здесь явно учтен эффект первых двух послеоперационных дней.
Экспоненциальная регрессия
Эта модель записывается в виде:
S(z) = ехр(а + b1 × Z1 + b2 × z2 + … +
bm × zm)
S(z) обозначает время жизни, а — неизвестная константа,
bi — параметры регрессии.
Вновь можно использовать критерий согласия хи-квадрат, чтобы оценить адекватность модели.
Статистика хи-квадрат может быть вычислена как функция логарифма правдоподобия для модели со всеми оцененными параметрами (L1)и логарифма правдоподобия модели, в которой все ковариаты обращаются в 0 (L0).
Если значение хи-квадрат значимо, отвергаем нулевую гипотезу и принимаем, что независимые переменные значимо влияют на время жизни.
Один из способов проверить адекватность экспоненциальной модели — построить остатки времен жизни и сравнить их со значениями стандартных экспоненциальных порядковых статистик.

Если предположение о том, что данные имеют экспоненциальное распределение, справедливо, то все точки на графике хорошо ложатся на прямую линию.
Нормальная и логнормальная регрессия
В этой модели предполагается, что времена жизни (или их логарифмы) имеют нормальное распределение. Модель совпадает с обычной моделью множественной регрессии и может быть записана следующим образом:
t = a + b1×z1 + b1×z1 + … + bm
× zm ,
где t — время жизни.
Если принимается модель логнормальной регрессии, то t заменяется
ln t.
Модель нормальной регрессии особенно полезна, поскольку часто данные можно преобразовать в приблизительно нормальные с помощью подходящего преобразования.
Таким образом, в некотором смысле это наиболее общая параметрическая модель (в противоположность модели пропорциональных интенсивностей Кокса, которая является непараметрической).
Для всех регрессионных моделей в системе STATISTICA доступен стратифицированный анализ, который открывается в окне
Результаты.

Цель стратифицированного анализа — проверить гипотезу о том, что одна и та же регрессионная кривая подходит для разных групп данных. Итак, стандартным образом мы разбиваем данные на несколько однородных групп.
Затем строятся регрессионные модели отдельно для каждой группы. Сумма логарифмов правдоподобия для разных моделей представляет собой логарифм правдоподобия модели с разными коэффициентами регрессии (и свободными членами, если требуется) в разных группах.
Далее ко всем данным обычным образом подгоняется регрессионная модель, не учитывая разбиение на группы, и вычисляется общий логарифм правдоподобия. По разности двух логарифмов правдоподобия проверяется значимость различия между группами.
В стратифицированном анализе на основе априорных соображений исследователь разбивает объекты на однородные группы риска, которые называются стратами, и проводит регрессионный анализ внутри каждой группы (см. например, книгу Кокрен У. (1976) «Методы выборочного исследования», где всесторонне обсуждаются методы построения групп). Во многих ситуациях риск-группы заранее известны, технически их можно получить, введя группирующие переменные.
Для модели пропорциональных интенсивностей Кокса система STATISTICA предлагает опцию подгонки к стратифицированным данным модели с общими коэффициентами для разных групп, но с разными базовыми функциями интенсивности. В результате наблюдения в отдельной группе удовлетворяют предположению пропорциональности, но это предположение не обязательно выполняется для наблюдений объединенных групп.
STATISTICA позволяет исследовать модель Кокса с ковариатами, зависящими от времени, а также сравнить модель с зависимыми от времени ковариатами и постоянными ковариатами.
Подробное введение в анализ выживаемости можно найти, например, в работах Bain (1978), Barlow and Proschan (1975) — русский перевод: Барлоу Р., Прошан Ф. Статистическая теория надежности и испытаний на безотказность. М. Наука, 1984, Сох and Oakes (1984) — русский перевод: Кокс Д. Р., Дукс Д. Анализ данных типа времени жизни. М., Финансы и статистика, 1988, Elandt-Johnson and Johnson (1980), Gross and Clark (1975), Lawless (1982), Lee (1980, 1992), Miller (1981), and Nelson (1982). Инженерные приложения этой техники обсуждены у Hahn and Shapiro (1967) — русский перевод: Хан Г., Шапиро С. Статистические модели в инженерных задачах. М., Мир, 1969.
На этом мы закончим общий обзор методов анализа выживаемости и перейдем к их реализации в системе STATISTICA, а также к примерам.
Обзор системы
Модуль Анализ выживаемости системы STATISTICA предназначен для анализа цензурированных или неполных данных о выживаемости и отказах.
Модуль содержит процедуры для описания времен жизни и оценивания функций выживания, интенсивности и плотности вероятности, для подгонки теоретических распределений выживаемости к данным и для сравнения выживаемости в двух и более выборках. Модуль Анализ выживаемости содержит также регрессионные процедуры для подгонки объясняющих моделей к цензурированным данным (модель пропорциональных интенсивностей Кокса, в том числе с зависящими от времени ковариатами, экспоненциальная регрессия, нормальная и логнормальная регрессия).
Все процедуры в модуле Анализ выживаемости автоматически преобразуют данные в числовой формат. Таким образом, чтобы получить интересующие данные, пользователь может записать даты начала и даты окончания наблюдений, связанные с отказами или цензурированием (потерями объектов).
Таблицы времен жизни могут быть построены по исходным данным. Однако можно анализировать и готовые таблицы времен жизни.
Для всех регрессионных моделей доступны оценки максимального правдоподобия. При вычислении этих оценок для моделей пропорциональных интенсивностей и экспоненциальной регрессионной модели используется процедура безусловной максимизации. Для нормальной и логнормальной регрессионных моделей оценки параметров проводятся с помощью
EМ-алгоритма. Этот алгоритм был впервые предложен в работе Dempster, Laird, and Rubin (1977) Maximum likelihood from incomplete data via the EM algorithm, Journal of the Royal Statistical Sociaty, 39, p. 1-38, и обсуждается в книге Сох and Oakes (1984) Analysis of survival data, New York: Chapman&Hall.
Общая значимость регрессионной модели может быть оценена с помощью критерия хи-квадрат, вычисляемого на основе логарифмов правдоподобия для подогнанной и нулевой моделей.
Для оценки адекватности подогнанной модели предоставляется большой выбор графических опций. В случае моделей пропорциональных интенсивностей пользователь может построить функции выживания для различных значений независимых переменных. Для экспоненциальной регрессионной модели есть возможность построения графиков зависимости остатков и экспоненциальной порядковой статистики, остатков и предсказанных с помощью регрессионного уравнения времен жизни, остатков и логарифмов наблюдаемых времен жизни. Для нормальной и логнормальной линейной регрессионной модели пользователь может воспроизвести на экране график зависимости наблюдаемых и подогнанных времена жизни, подогнанных времен жизни и остатков подгонки, а также нормальный вероятностный график остатков.
Альтернативные процедуры
Альтернативные процедуры возможны для нецензурированных данных.
Если данные о продолжительности жизни (безотказной работы) нецензурированы, то применимо большинство непараметрических статистик. Для нецензурированных данных можно также использовать нелинейное оценивание, чтобы подогнать определенную регрессионную модель (включая пробит, логит и экспоненциальную модели) к данным.
Если продолжительность жизни или безотказной работы описывается бинарной переменной, то могут быть применены логит или пробит регрессионные модели.
Другой общий метод сравнения выживаемости в различных группах реализуется с помощью таблиц частот. Если времена жизни, или наработки до момента отказа, распределены по нескольким временным интервалам, может быть использована общая логлинейная модель.
Пример 1. Таблицы времен жизни
В этом примере мы рассчитаем таблицу времен жизни, оценим функцию выживания, плотность вероятности и функцию интенсивности для различных временных интервалов, а также найдем теоретическое распределение, наилучшим образом согласующееся с данными. Данные основаны на работе Crowley, J., & Ни, М., (1977) Covariance analysis of heart transplant survival data, Journal of the American Statistical Association, 72, p. 27-36.
Задание параметров анализа
В модуле Анализ выживаемости откройте файл Heart.sta.

Далее выберите Таблицы и распределения времен жизни из стартовой панели
Анализ выживаемости и времен отказов.

Можно анализировать как исходный файл данных, так и сгруппированные данные. В данном случае мы анализируем исходные данные.
Нажмите кнопку Переменные и выберите 6 переменных в первом списке.
Первые три переменные — дата начала (например, дата операции), оставшиеся три переменные — дата наступления события.
Программа интерпретирует первую и четвертую переменные как месяцы, вторую и пятую — как дни, а третью и шестую — как год.
Заметим, что можно сразу ввести времена жизни (одна переменная в файле данных или даты в другом формате — 2 переменные).

Далее необходимо определить переменную Censored как индикатор цензурирования во втором списке.
Диалоговое окно Таблицы и распределения времен жизни будет теперь выглядеть так:

Поскольку были использованы коды по умолчанию для индикатора цензурирования (0 -полное, 1 — неполное), STATISTICA автоматически отображает Код для завершенных наблюдений и Код для неполных или цензурированных наблюдений.
Дополнительно можно определить для таблицы
времен жизни Число интервалов или Ширину интервалов.
Процедура подгонки теоретического распределения к данным невозможна при наличии интервалов, не содержащих ни смертей (отказов), ни изъятых наблюдений.
Если вы хотите сделать подгонку, установите флажокИсправить интервалы, не содержащие смертей/отказов.
Если таблица времен жизни используется только в описательных целях и не предполагается подгонка распределения, то корректировку интервалов делать не нужно.
Оставив опции по умолчанию, нажмите ОК. После того как все наблюдения обработаны, откроется диалоговое окно
Результаты для таблиц и распределений времен жизни.
Нажмите на кнопку Таблица времен жизни, чтобы отобразить на экране полную таблицу результатов времен жизни.


На рисунке показана часть полной таблицы жизни.
Можно подгонять к данным основные семейства распределений, используя обычный метод наименьших квадратов или две модификации метода взвешенных наименьших квадратов.
Чтобы выбрать наиболее подходящее семейство распределений, сначала рассмотрим модель с экспоненциальным распределением (выбрав позицию
Экспоненциальная в поле Модель).
Оценка согласия проводится с помощью критерия хи-квадарт.
Нажмите кнопку Оценки параметров, чтобы посмотреть оценки для данного семейства распределений, а также значение критерия хи-квадрат.

Если критерий значим, делается заключение, что подогнанное распределение значимо расходится с наблюдаемыми данными. Поэтому мы отвергаем это семейство распределений и говорим, что оно не согласуется с данными.
Из таблицы результатов следует, что ни один метод подгонки не дает экспоненциального распределения удовлетворительного согласия. Тот же результат хорошо виден на графиках.
Нажмите кнопку График функции выживания. На приведенных ниже графиках ни одна из экспонент также не аппроксимирует наблюдаемую функцию выживания удовлетворительно. Видно, что оцененная функция выживания сильно отклоняется от аппроксимирующих функций выживания.

Можно просмотреть оценки параметров для различных семейств распределений. Вначале выберите соответствующее семейство из поля списка
Модель, а затем нажмите кнопку Оценки параметров. Если проанализировать все эти семейства, можно сделать вывод, что только для семейства Вейбулла (см. главу Вероятностные распределения) нет значимого отличия от наблюдаемых значений при оценивании параметров по минимуму суммы взвешенных квадратов.

Ниже показаны графики функции выживания из семейства Вейбулла, подогнанные тремя разными способами.

Для третьего набора параметров (соответствующего Weight 3) имеется удовлетворительное согласие с данными. Хи-квадрат — критерий для этой ситуации — не дает значимого отклонения (р=0,56). Следовательно, можно сделать вывод, что распределение Вейбулла с этим набором параметров удовлетворительно описывает наблюдаемые времена жизни.
В заключение заметим, что модуль Анализ выживаемости STATISTICA позволяет анализировать также табулированные данные (для этого нужно выбрать опцию Таблица времен жизни в поле списка
Входные данные).

Файл с табулированными данными должен содержать 3 переменные со следующей информацией:
1) нижняя граница временных интервалов;
2) число цензурированных или неполных наблюдений;
3) число отказов (число умерших в каждом временном интервале).
После выбора Таблиц времен жизни откроется диалоговое окно
Таблицы и распределения времен жизни, в котором можно выбрать эти переменные.
Пример 2. Регрессионная модель Кокса
Файл данных Heart.sta содержит дополнительные переменные: возраст пациента во время трансплантации (переменная Возраст — Age) и медицинские характеристики: мера антигенной несовместимости (переменная Антиген — Antigen) и мера тканевой несовместимости (переменная Несовместимость — Mismatch).
Представляет интерес зависимость между переменными Возраст — Age, Антиген — Antigen и Несовместимость — Mismatch и временами жизни. Наиболее общей регрессионной моделью, не накладывающей ограничения на форму функции выживания, является модель пропорциональных интенсивностей Кокса. Рассмотрим, как можно оценить коэффициенты регрессии для этих трех независимых переменных для того, чтобы предсказать времена жизни с помощью модели пропорциональных интенсивностей Кокса.
Задание параметров анализа
Нажмите опциюРегрессионные модели на Стартовой панели, чтобы открыть диалоговое окно Регрессионные модели для цензурированных данных.
Чтобы выбрать переменные для анализа, нажмите кнопку переменные и задайте все времена жизни и цензурирующую переменную, как это было сделано ранее.
Необходимо также выбрать независимые переменные или регрессоры (Возраст — Age, Антиген — Antigen, Несовместимость — Mismatch).
Группирующую переменную в данном примере мы не отмечаем.

Теперь выберите коды для цензурирующей переменной. С помощью этих кодов STATISTICA разобьет данные на 2 группы: полные и неполные. По умолчанию STATISTICA использует следующий код: 0 = завершенное наблюдение, 1 = ценэури-рованное.
Если вы используете другой код, дважды щелкните по полю ввода
Коды завершенного наблюдения и Коды цензурированного наблюдения и выберите коды из списка.

Диалоговое окно Регрессионные методы для цензурированных данных появится на экране:

Оценивание параметров
Выберите в списке Модель позицию Регрессионная модель Кокса. Нажмите
ОК и откройте диалоговое окно Регрессионная модель, оценивание.

Это диалоговое окно позволяет задать параметры процедуры оценивания.
Процедура оценивания максимизирует логарифм правдоподобия регрессионной модели с помощью метода Ньютона — Рафсона.
Алгоритм оценивание параметров является итеративным и начинается с некоторых начальных значений параметров (кнопка
Начальные значения). Далее программа делает несколько итераций, последовательно приближаясь к оценкам неизвестных параметров. Разность между текущими оценками и оценками, полученными на предыдущем шаге, называется невязкой. Если невязка удовлетворяет критерию сходимости (см. поле Критерий сходимости), то процесс приближения завершается. Максимальное число итераций и критерий сходимости указываются в соответствующих полях.
Значения, предлагаемые программой по умолчанию, обычно приемлемы, поэтому просто нажмите
ОК и начните процедуру оценивания.

С помощью этого диалогового окна можно наглядно проследить, как происходит процесс оценивания. В столбцах
Параметры показаны оценки параметров на каждом таге.
После того как критерий сходимости будет выполнен, процедура оценивания останавливается.
Обычно процедура поиска быстро сходится, если приближения за заданное число итераций неудовлетворительны, программа запросит дополнительно некоторое количество итераций. Вы можете изменить начальные значения, используя, например, оценки параметров, полученные на предыдущем экспериментальном материале.

В данном примере наилучшие оценки параметров найдены, итеративная процедура сходится, поэтому предлагается нажать
ОК, чтобы перейти в диалоговое окно Результаты.

Результаты
Это диалоговое окно позволяет просмотреть результаты. Значение статистики критерия хи-квадрат для данной модели высокозначимо, поэтому можно заключить, что, по крайней мере, некоторые независимые переменные значимо действительно связаны с выживаемостью.
Нажмите кнопку Оценки параметров, чтобы увидеть оценки параметров и их стандартные ошибки.

Стандартные ошибки вычисляются как часть процедуры оценивания и по своей природе являются асимптотическими. Они вычисляются на основе частных производных второго порядка от логарифма функции правдоподобия. Это означает, что t-значения тоже должны рассматриваться только как приближенные. Обычно любая оценка параметра (регрессионной модели), которая по крайней мере в два раза превосходит свою стандартную ошибку (t>2,0), может рассматриваться как статистически значимая (на уровне р<0,05).
Электронная таблица С результатами также содержит статистику критерия Валъда для каждого коэффициента (см. книгу Рао С. Р. Линейные статистические методы и их применения). Из приведенной таблицы следует, что возраст пациента и тканевая несовместимость — наиболее важные предикторы для функции мгновенного риска.
Итак, значимые переменные в модели — AGE и MISMATCH. Рассмотрим графики функции выживания как функции независимых переменных. Пусть все независимые переменные равны своим средним значениям, тогда график функции выживания имеет вид (нажмите кнопку
График выживаемости для средних):

Средние значения независимых переменных и стандартные ошибки можно посмотреть в таблице:

Зададим определенные значения предикторов. Мы имеем значимые переменные: AGE — возраст и MISMATCH — тканевая несовместимость. Увеличим возраст больного до 55 лет.

График функции выживания изменится и будет иметь вид:

В заключение заметим, что с помощью кнопки Редактор данных графика
можно представить функцию выживания в численном виде:

Таким образом проводится регрессионный анализ в модуле
Анализ выживаемости.

Введение
На людях, для соответствия эффективности и безопасности, проводятся контролируемые эксперименты, которые называются клиническими исследованиями.[1] В клинических или общественных исследованиях эффект вмешательства оценивается путем измерения количества выживших или спасенных людей, которые затем вмешались в течение определенного периода времени. Иногда интересно сопоставить выживаемость испытуемых при двух или более вмешательствах. В ситуациях, когда выживание является то, что вопрос, то переменная интерес будет длительность вашего времени, которое проходит перед каким-либо событием, чтобы произойти. Во многих ситуациях эта продолжительность Вашего времени является чрезвычайно длительной, например, при лечении рака; в таком случае за единицу длительности Вашего времени часто оценивается количество событий, таких как смерть. В других ситуациях часто оценивается длительность долгого времени до рецидива рака или как долго происходит инфекция. Иногда это даже может быть использовано для выбранного исхода, например, как долго это занимает для нескольких, чтобы зачать. Время, варьирующееся от намеченной точки до наступления данного события, называется потому, что время выживания[2], и, следовательно, анализ данных по группе – потому, что анализ выживаемости[3].
Такой анализ часто бывает сложным, когда исследуемые субъекты отказываются сотрудничать и оставаться в рамках исследования, или когда некоторые темы могут не испытать событие или смерть до начала исследования, хотя у них может быть опыт или они могут умереть, или же мы теряем с ними связь в середине исследования. Мы классифицируем эти ситуации как правоцензурные наблюдения.[2] Для этих тем мы располагаем частичной информацией. Мы все знаем, что событие произошло (или произойдет) спустя некоторое время после даты последнего наблюдения. Мы не хотим игнорировать этих субъектов, потому что они предоставляют некоторую информацию о выживании. Мы будем знать, что они выжили после определенного момента, но мы не знаем точную дату смерти.
Иногда у нас есть подопытные, которые позже становятся соседями исследования, т.е. с самого начала прошло много времени. у нас есть более короткое время наблюдения для этих подопытных, и эти подопытные могут испытывать, а могут и не испытывать события, происходящие в течение короткого оговоренного времени. Однако мы не можем исключить эти предметы, так как в противном случае размер выборки в исследовании может стать небольшим. По оценке Каплана-Майера, самый простой метод вычисления выживаемости с течением времени, несмотря на эти трудности, связанные с испытуемыми или ситуациями

Кривая выживания Каплана-Майера определяется потому, что вероятность выживания в течение заданного промежутка времени при рассмотрении времени во многих небольших интервалах.[3] В этом анализе используются три предположения. Во-первых, мы предполагаем, что в любой момент времени у пациентов, прошедших цензуру, есть такие же перспективы выживания, как и у тех, кто все еще находится под наблюдением. Во-вторых, мы предполагаем, что вероятности выживания являются эквивалентом для испытуемых, завербованных в раннем и позднем возрасте в рамках исследования. В-третьих, мы предполагаем, что событие происходит в указанное время. Это создает проблему в некоторых условиях, когда событие будет обнаружено при ежедневном обследовании. Все, что мы знаем, это то, что событие произошло между двумя обследованиями. Расчетная выживаемость часто более точно рассчитывается путем завершения наблюдения за пациентами часто в более короткие промежутки времени; настолько короткая, насколько позволяет точность записи, т.е. в какой-то момент (максимум). Оценку Каплана-Майера дополнительно называют “оценкой предельных значений продукта”. Она включает в себя вычисление вероятности наступления события в определенный момент времени. Мы умножаем эти последовательные вероятности на любые ранее рассчитанные вероятности, чтобы получить окончательную оценку. Вероятность выживания в любой конкретный момент времени вычисляется по формуле, приведенной ниже:
Для каждого интервала вычисляется вероятность выживания, потому что число выживших людей делится на количество пациентов, находящихся в опасности. Субъекты, которые умерли, выбыли или съехали, не учитываются как “находящиеся в опасности”, т.е. субъекты, которые потерялись, считаются “прошедшими цензуру” и не засчитываются в знаменатель. Суммарная вероятность выживания до этого интервала времени рассчитывается путем умножения всех возможностей выживания в наименьших промежутках времени, предшествующих этой точке (путем применения закона умножения вероятности для вычисления кумулятивной вероятности). Например, вероятность выживания пациента через два дня после пересадки почки часто рассматривается как вероятность выживания в какой-то точке, умноженная на вероятность выживания на второй день до тех пор, пока пациент выжил в течение первичных суток. Эта вторая вероятность называется условной вероятностью. Хотя вероятность, вычисленная на любом заданном интервале, не очень точна из-за крошечного числа событий, общая вероятность выживания до каждой точки является более точной. Позвольте нам взять гипотетические данные по хихиканью пациентов, получающих стандартную антиретровирусную терапию. информация показывает время выживания (в днях) среди пациентов, поступивших во время клинического исследования – (например, 1)- 6, 12, 21, 27, 32, 39, 43, 43, 46F*, 89, 115F*, 139F*, 181F*, 211F*, 217F*, 261, 263, 270, 295F*, 311, 335F*, 346F*, 365F* (* означает, что эти пациенты все еще выживают после указанных дней в ходе исследования)
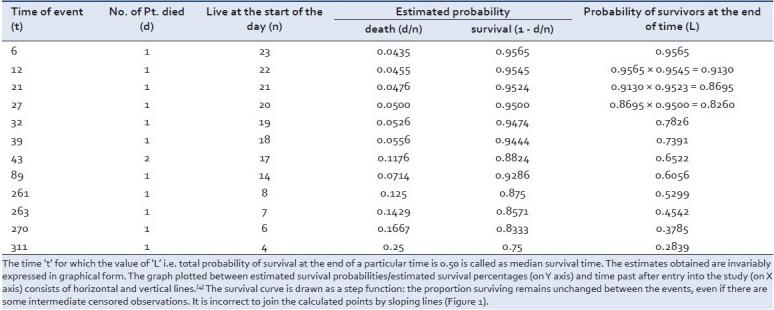
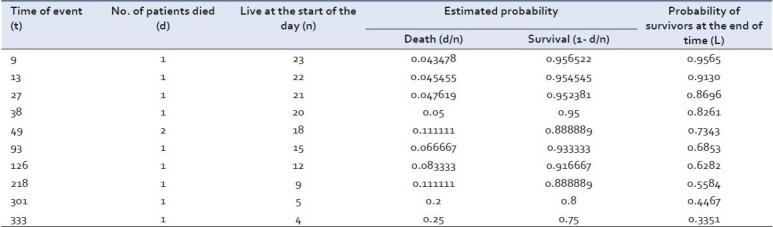
Мы знаем о времени события, т.е. о времени смерти в каждом субъекте, после того, как он вступил в суд, пусть это будет в разное время. Есть также пара субъектов, которые все еще выживают, т.е. в верхней части процесса. Даже в этих условиях мы рассчитаем оценки Каплана-Майера, приведенные в таблице 1.
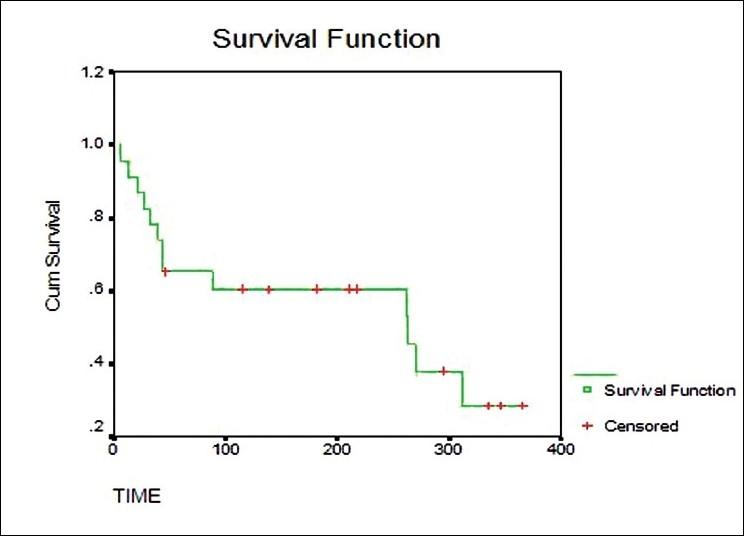
В качестве медианного времени выживания называется время “t”, которое стоит “L”, т.е. общая вероятность выживания в верхней части определенного времени равна 0,50. Полученные оценки неизменно выражаются в графической форме. График, построенный между оцененными вероятностями выживания/оцененными процентами выживания (по оси Y) и временем, прошедшим после вступления в исследование (по оси X), состоит из горизонтальных и вертикальных линий.[4] Кривая выживаемости построена как ступенчатая функция: доля выживающих между событиями остается неизменной, хотя есть и промежуточные цензурные наблюдения. неправильно зацеплять вычисленные точки наклонными линиями [рис. 1].
Мы можем сравнить кривые для 2 разных групп испытуемых. например, сравнить картину выживания испытуемых при типичной терапии с более модреновой терапией. мы будем искать пробелы в этих кривых в горизонтальном или вертикальном направлении. Вертикальный разрыв означает, что в выбранный момент времени в одной группе выживало больше людей. Горизонтальный разрыв означает, что одной группе потребовалось больше времени, чтобы пережить определенную долю смертей.
Возьмем другие гипотетические данные, например, о том, что пациенты получали новую аюрведическую терапию ВИЧ-инфекции. Информация показывает время выживания (в днях) среди пациентов, введенных во время клинического теста (как в e. g. 1) 9, 13, 27, 38, 45F*, 49, 49, 79F*, 93, 118F*, 118F*, 126, 159F*, 211F*, 218, 229F*, 263F*, 298F*, 301, 333, 346F*, 353F*, 362F* (* означает, что эти пациенты все еще выживают после указанных дней в рамках исследования).
Оценка Каплана-Майера для вышеприведенного примера обобщена в таблице 2.
Две кривые выживаемости часто сравниваются статистически путем проверки нулевой гипотезы, т.е. между двумя вмешательствами нет никакой разницы в отношении выживаемости. Эта нулевая гипотеза статистически проверяется с помощью другого теста, называемого лог-тестом и тестом пропорций Кокса.[5] В лог-тесте вычисляется ожидаемое количество событий в каждой группе, т.е. E1 и E2, а O1 и O2 – полное количество наблюдаемых событий в каждой группе, соответственно [Рисунок 2] . Тестовая статистика равна
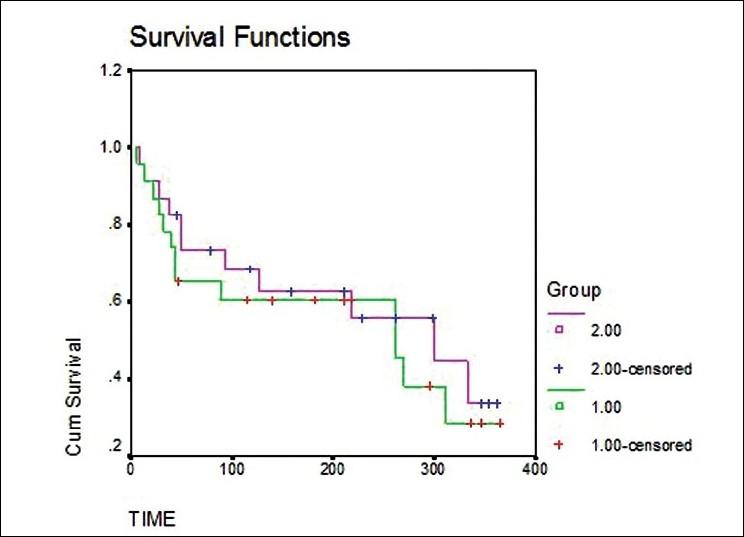
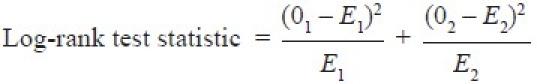
Общее количество ожидаемых событий в группе (например, E2) – это сумма ожидаемого количества событий на момент каждого события в любой из групп, объединяющая обе группы. В момент времени события в любой группе ожидаемое количество событий является то, что продукт риска события в этот момент с целым количеством субъектов, живых в начале времени события в этой же группе (например, в 6-й день, 46 пациентов были живы в начале дня, и один умер, поэтому риск события было 1/46 = 0,021739. Так как 23 больных были живы в начале дня в группе 2, ожидаемое количество событий на 6-й день в группе 2 было 23 × 0.021739 = 0.5). все количество ожидаемых событий во 2-й группе является суммой ожидаемых событий, вычисленных в разное время. все количество ожидаемых событий в другой группе (т.е. E1) вычисляется путем вычитания всего количества ожидаемых событий во 2-й группе, т.е. E 2, из всего количества наблюдаемых событий в обеих группах, т.е. O1 + O2. Учитывая вышеприведенный пример, можно применить лог-тест, как показано в таблице 3.
Таблица 3
Лог-статистика для пациентов, упомянутых в примерах 1 и 2
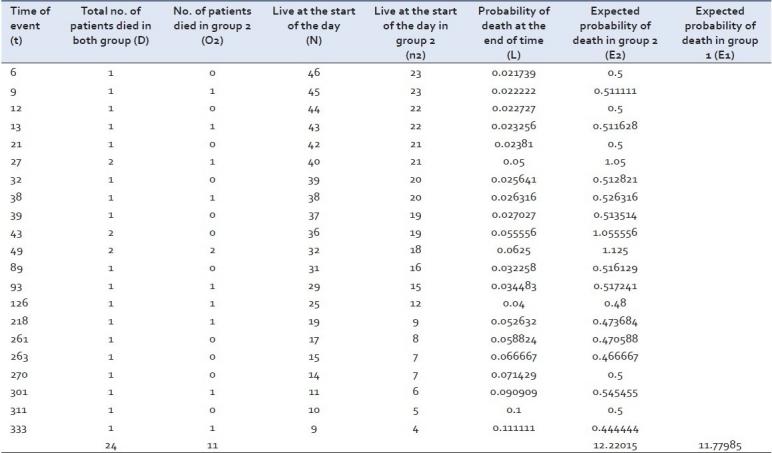
Расчеты всех значений в вышеупомянутой формуле дадут тестовое статистическое значение. Тестовая статистика и, следовательно, значение часто получают путем сравнения вычисленного значения с критическим (с помощью таблицы хи-квадрат) для степени свободы, адекватной единице. Тестовая статистика представляет собой меньшую величину, чем критическое значение (с использованием таблицы хи-квадрат) для степени свободы, адекватной единице. Следовательно, мы скажем, что существенной разницы между 2 группами в отношении выживания нет
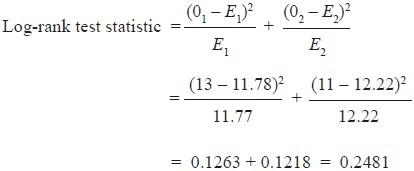
Тест лога используется для проверки того, является ли разница в времени выживания между двумя группами статистически разной или нет, но не позволяет проверить эффект противоположных независимых переменных. Модель пропорционального риска Кокса позволяет проверить влияние других независимых переменных на время выживания различных групп пациентов, немного похожее на модель множественной корреляции. Опасность является ничем иным, как переменной и может быть определена как вероятность смерти в заданное время при условии, что пациенты выжили до нее в заданное время. Соотношение опасностей дополнительно является критическим термином и определяется потому, что отношение опасностей, возникающих в любой данный момент времени в одной группе по сравнению с другой группой в данный момент времени, т.е. если H1, H2, H3 … и h1, h2, h3 … являются опасностями в данный момент времени T1, T2, T3 … в A и B соответственно, то отношение опасностей иногда T1, T2, T3 являются соответственно H1/h1, H2/h2, H3/h3 …. соответственно. Как тест на пропорции, так и тест на пропорции Кокса предполагают, что коэффициент опасности является постоянным во времени, т.е. в рамках вышеупомянутого сценария H1/h1 = H2/h2 = H3/h3.
В заключение следует отметить, что метод Каплана-Майера может быть умным методом статистической обработки времени выживания, который не только должным образом учитывает те наблюдения, которые подвергаются цензуре, но и использует знания, полученные от этих субъектов, вплоть до времени, когда они подвергаются цензуре. Такие ситуации часто встречаются в аюрведических исследованиях, когда используются два вмешательства и результат оценивается как выживание пациентов. Поэтому метод Каплана-Майера может быть полезным методом, который будет играть большую роль в получении доказательной информации о времени выживания.