
Содержание
- Вычисление коэффициента детерминации
- Способ 1: вычисление коэффициента детерминации при линейной функции
- Способ 2: вычисление коэффициента детерминации в нелинейных функциях
- Способ 3: коэффициент детерминации для линии тренда
- Вопросы и ответы

Одним из показателей, описывающих качество построенной модели в статистике, является коэффициент детерминации (R^2), который ещё называют величиной достоверности аппроксимации. С его помощью можно определить уровень точности прогноза. Давайте узнаем, как можно произвести расчет данного показателя с помощью различных инструментов программы Excel.
Вычисление коэффициента детерминации
В зависимости от уровня коэффициента детерминации, принято разделять модели на три группы:
- 0,8 – 1 — модель хорошего качества;
- 0,5 – 0,8 — модель приемлемого качества;
- 0 – 0,5 — модель плохого качества.
В последнем случае качество модели говорит о невозможности её использования для прогноза.
Выбор способа вычисления указанного значения в Excel зависит от того, является ли регрессия линейной или нет. В первом случае можно использовать функцию КВПИРСОН, а во втором придется воспользоваться специальным инструментом из пакета анализа.
Способ 1: вычисление коэффициента детерминации при линейной функции
Прежде всего, выясним, как найти коэффициент детерминации при линейной функции. В этом случае данный показатель будет равняться квадрату коэффициента корреляции. Произведем его расчет с помощью встроенной функции Excel на примере конкретной таблицы, которая приведена ниже.
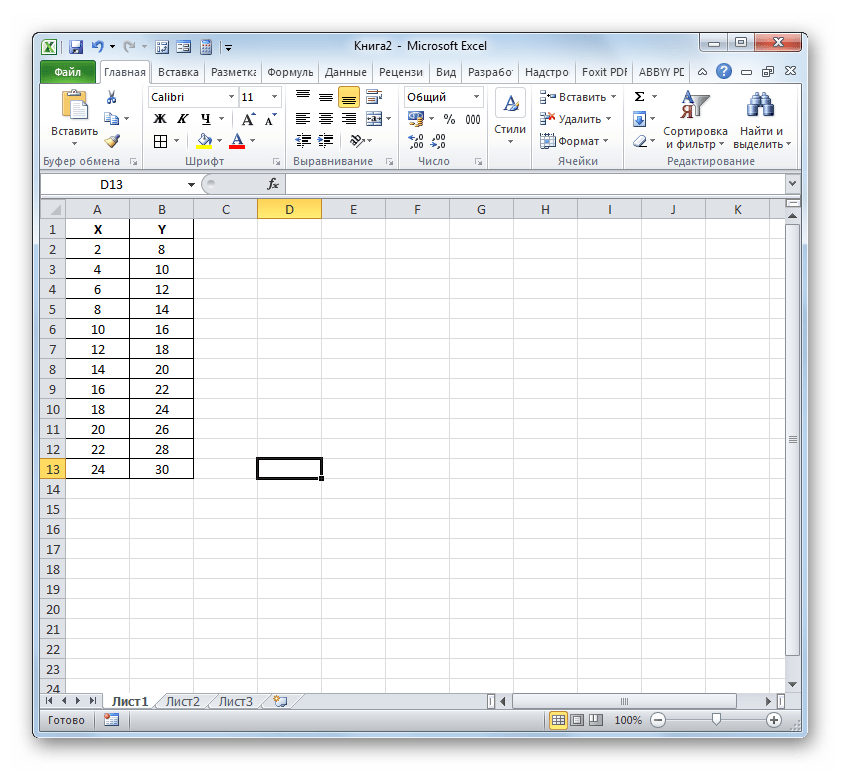
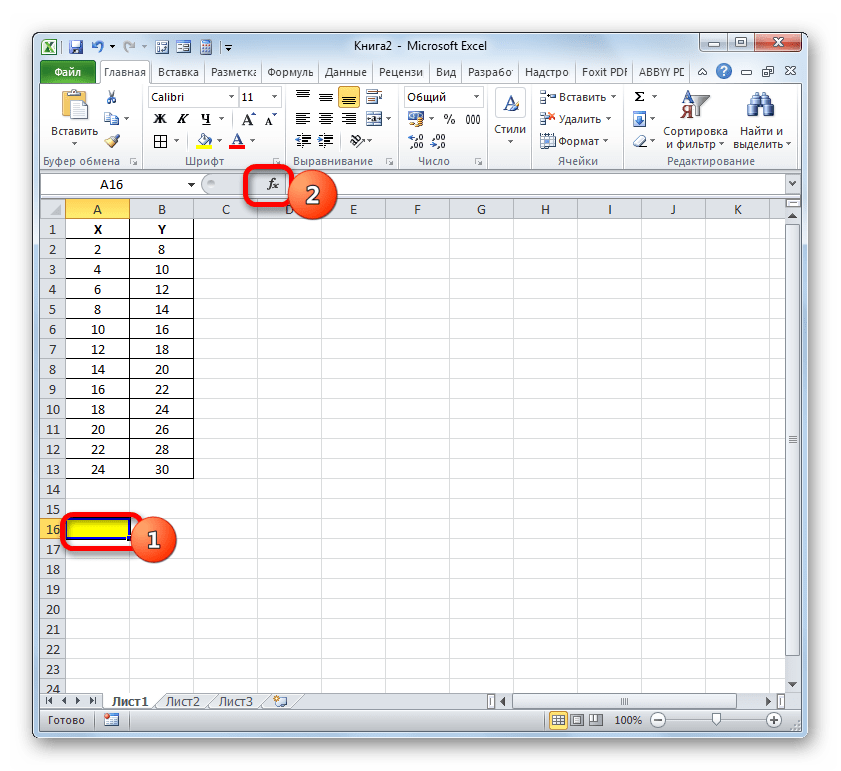
- Выделяем ячейку, где будет произведен вывод коэффициента детерминации после его расчета, и щелкаем по пиктограмме «Вставить функцию».
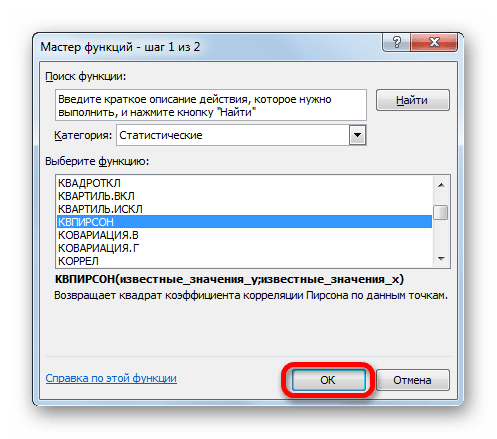
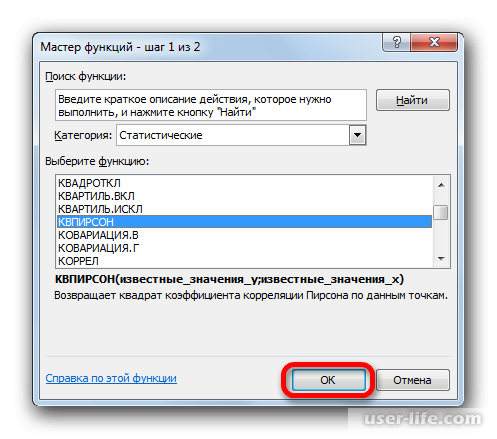
- Запускается Мастер функций. Перемещаемся в его категорию «Статистические» и отмечаем наименование «КВПИРСОН». Далее клацаем по кнопке «OK».
- Происходит запуск окна аргументов функции КВПИРСОН. Данный оператор из статистической группы предназначен для вычисления квадрата коэффициента корреляции функции Пирсона, то есть, линейной функции. А как мы помним, при линейной функции коэффициент детерминации как раз равен квадрату коэффициента корреляции.
Синтаксис этого оператора такой:
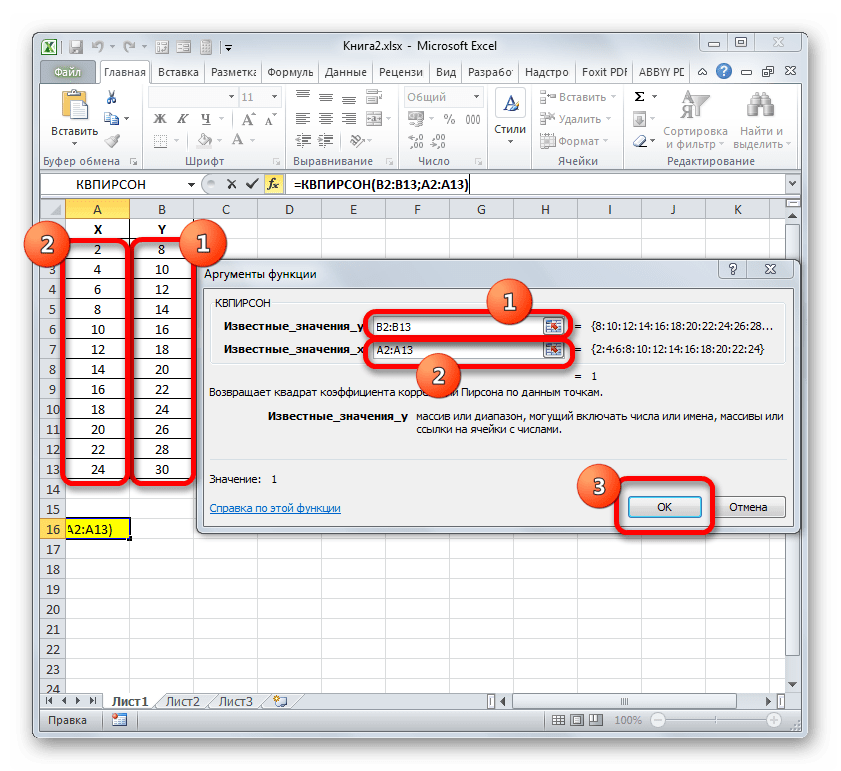
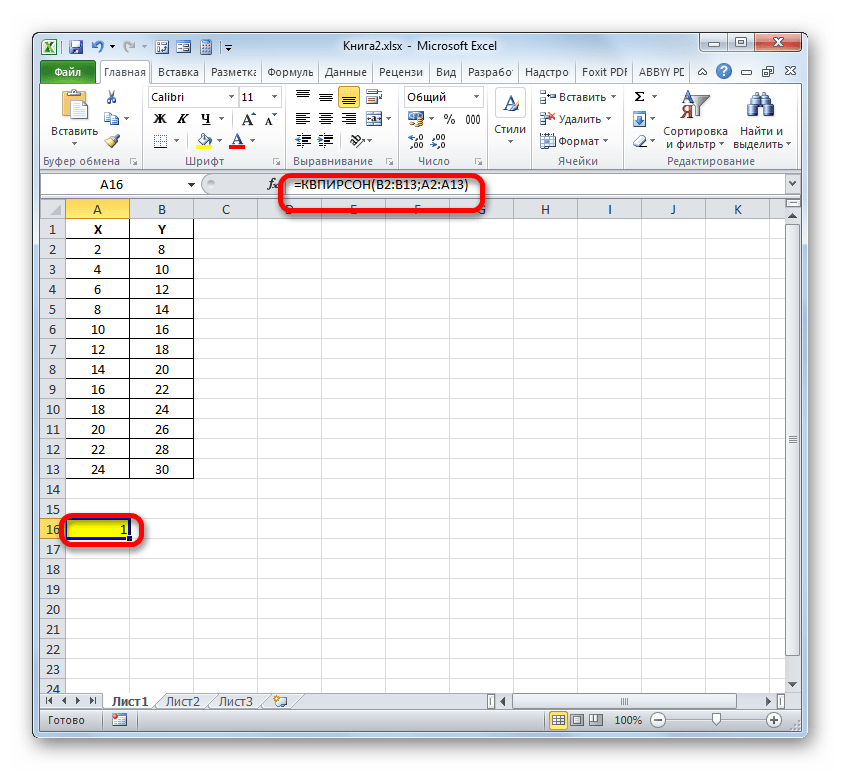
=КВПИРСОН(известные_значения_y;известные_значения_x)Таким образом, функция имеет два оператора, один из которых представляет собой перечень значений функции, а второй – аргументов. Операторы могут быть представлены, как непосредственно в виде значений, перечисленных через точку с запятой (;), так и в виде ссылок на диапазоны, где они расположены. Именно последний вариант и будет использован нами в данном примере.
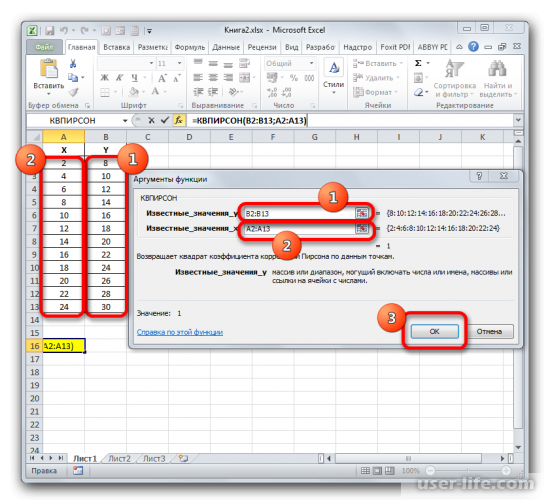
Устанавливаем курсор в поле «Известные значения y». Выполняем зажим левой кнопки мышки и производим выделение содержимого столбца «Y» таблицы. Как видим, адрес указанного массива данных тут же отображается в окне.
Аналогичным образом заполняем поле «Известные значения x». Ставим курсор в данное поле, но на этот раз выделяем значения столбца «X».
После того, как все данные были отображены в окне аргументов КВПИРСОН, клацаем по кнопке «OK», расположенной в самом его низу.
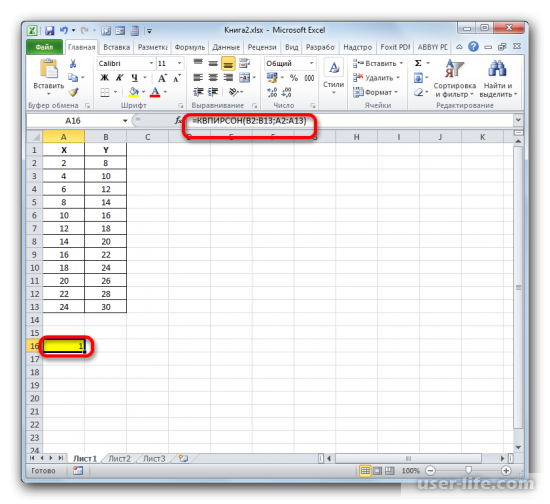
- Как видим, вслед за этим программа производит расчет коэффициента детерминации и выдает результат в ту ячейку, которая была выделена ещё перед вызовом Мастера функций. В нашем примере значение вычисляемого показателя получилось равным 1. Это значит, что представленная модель абсолютно достоверная, то есть, исключает погрешность.

Урок: Мастер функций в Microsoft Excel
Способ 2: вычисление коэффициента детерминации в нелинейных функциях
Но указанный выше вариант расчета искомого значения можно применять только к линейным функциям. Что же делать, чтобы произвести его расчет в нелинейной функции? В Экселе имеется и такая возможность. Её можно осуществить с помощью инструмента «Регрессия», который является составной частью пакета «Анализ данных».
- Но прежде, чем воспользоваться указанным инструментом, следует активировать сам «Пакет анализа», который по умолчанию в Экселе отключен. Перемещаемся во вкладку «Файл», а затем переходим по пункту «Параметры».
- В открывшемся окне производим перемещение в раздел «Надстройки» при помощи навигации по левому вертикальному меню. В нижней части правой области окна располагается поле «Управление». Из списка доступных там подразделов выбираем наименование «Надстройки Excel…», а затем щелкаем по кнопке «Перейти…», расположенной справа от поля.
- Производится запуск окна надстроек. В центральной его части расположен список доступных надстроек. Устанавливаем флажок около позиции «Пакет анализа». Вслед за этим требуется щелкнуть по кнопке «OK» в правой части интерфейса окна.
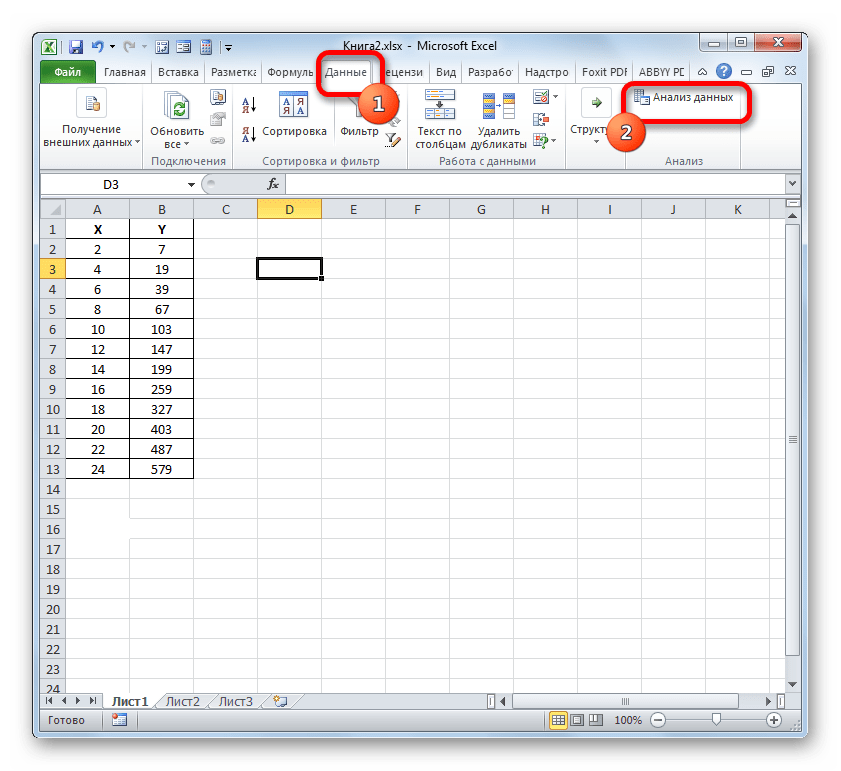
- Пакет инструментов «Анализ данных» в текущем экземпляре Excel будет активирован. Доступ к нему располагается на ленте во вкладке «Данные». Перемещаемся в указанную вкладку и клацаем по кнопке «Анализ данных» в группе настроек «Анализ».
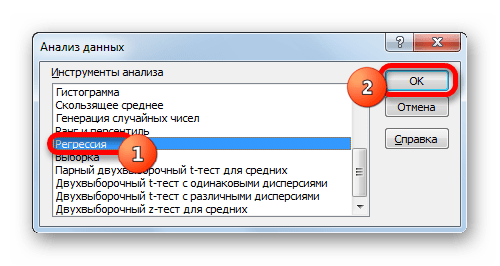
- Активируется окошко «Анализ данных» со списком профильных инструментов обработки информации. Выделяем из этого перечня пункт «Регрессия» и клацаем по кнопке «OK».
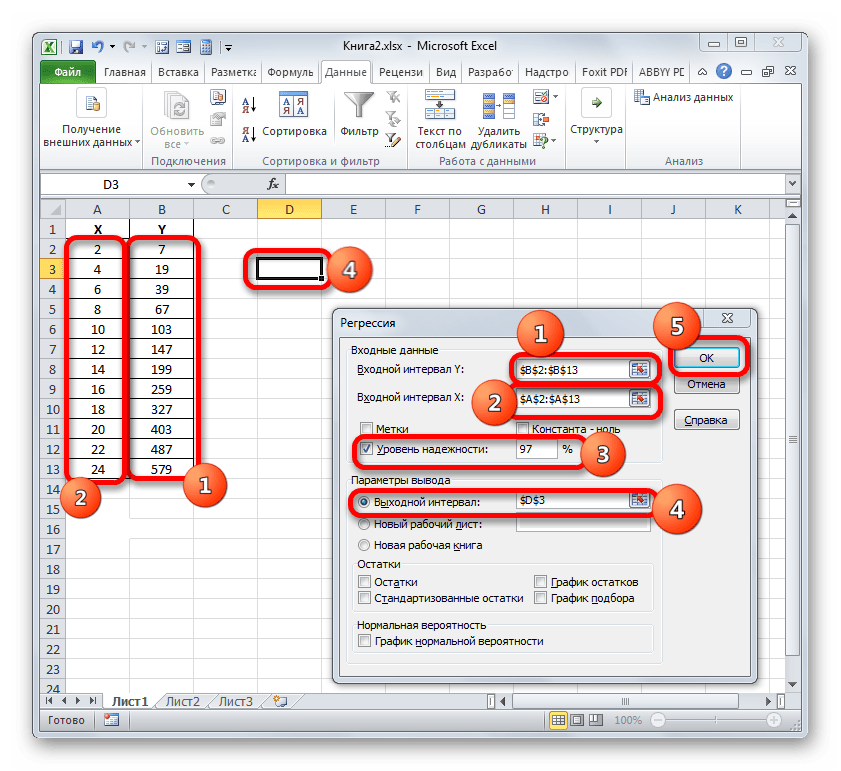
- Затем открывается окно инструмента «Регрессия». Первый блок настроек – «Входные данные». Тут в двух полях нужно указать адреса диапазонов, где находятся значения аргумента и функции. Ставим курсор в поле «Входной интервал Y» и выделяем на листе содержимое колонки «Y». После того, как адрес массива отобразился в окне «Регрессия», ставим курсор в поле «Входной интервал Y» и точно таким же образом выделяем ячейки столбца «X».
Около параметров «Метка» и «Константа-ноль» флажки не ставим. Флажок можно установить около параметра «Уровень надежности» и в поле напротив указать желаемую величину соответствующего показателя (по умолчанию 95%).
В группе «Параметры вывода» нужно указать, в какой области будет отображаться результат вычисления. Существует три варианта:
- Область на текущем листе;
- Другой лист;
- Другая книга (новый файл).
Остановим свой выбор на первом варианте, чтобы исходные данные и результат размещались на одном рабочем листе. Ставим переключатель около параметра «Выходной интервал». В поле напротив данного пункта ставим курсор. Щелкаем левой кнопкой мыши по пустому элементу на листе, который призван стать левой верхней ячейкой таблицы вывода итогов расчета. Адрес данного элемента должен высветиться в поле окна «Регрессия».
Группы параметров «Остатки» и «Нормальная вероятность» игнорируем, так как для решения поставленной задачи они не важны. После этого клацаем по кнопке «OK», которая размещена в правом верхнем углу окна «Регрессия».
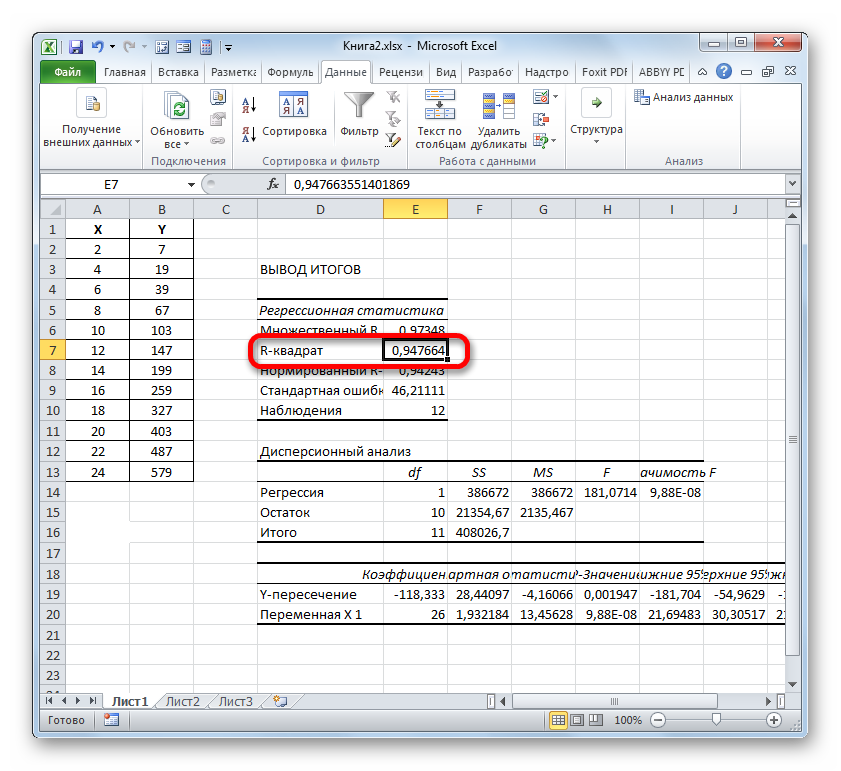
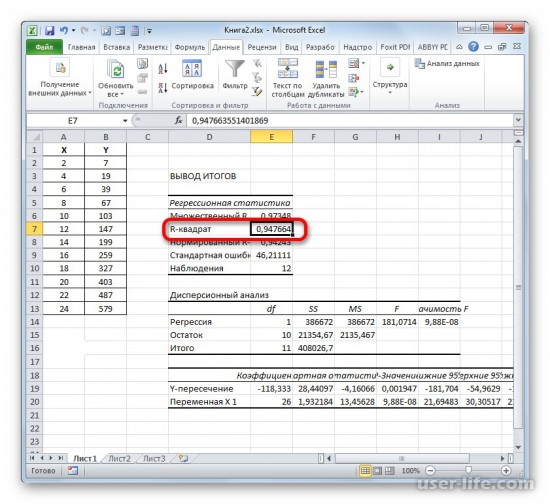
- Программа производит расчет на основе ранее введенных данных и выводит результат в указанный диапазон. Как видим, данный инструмент выводит на лист довольно большое количество результатов по различным параметрам. Но в контексте текущего урока нас интересует показатель «R-квадрат». В данном случае он равен 0,947664, что характеризует выбранную модель, как модель хорошего качества.
Способ 3: коэффициент детерминации для линии тренда
Кроме указанных выше вариантов, коэффициент детерминации можно отобразить непосредственно для линии тренда в графике, построенном на листе Excel. Выясним, как это можно сделать на конкретном примере.
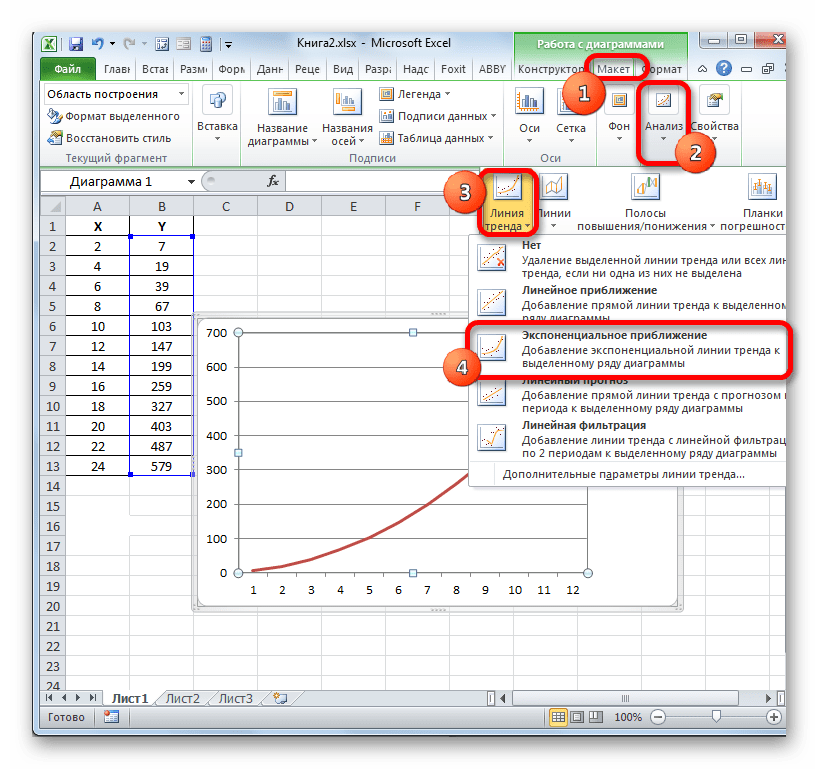
- Мы имеем график, построенный на основе таблицы аргументов и значений функции, которая была использована для предыдущего примера. Произведем построение к нему линии тренда. Кликаем по любому месту области построения, на которой размещен график, левой кнопкой мыши. При этом на ленте появляется дополнительный набор вкладок – «Работа с диаграммами». Переходим во вкладку «Макет». Клацаем по кнопке «Линия тренда», которая размещена в блоке инструментов «Анализ». Появляется меню с выбором типа линии тренда. Останавливаем выбор на том типе, который соответствует конкретной задаче. Давайте для нашего примера выберем вариант «Экспоненциальное приближение».
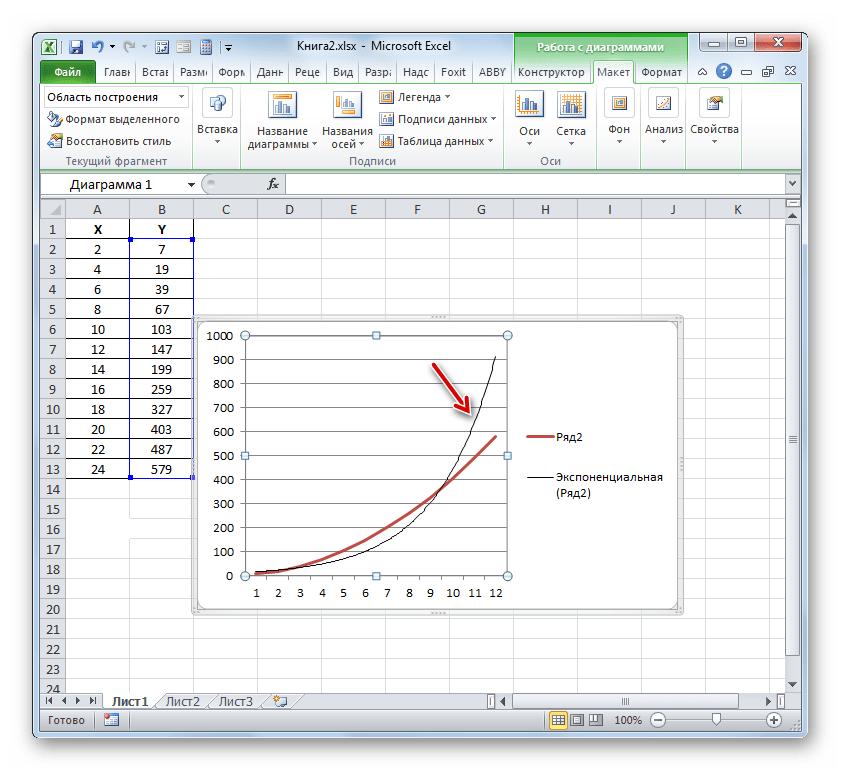
- Эксель строит прямо на плоскости построения графика линию тренда в виде дополнительной черной кривой.
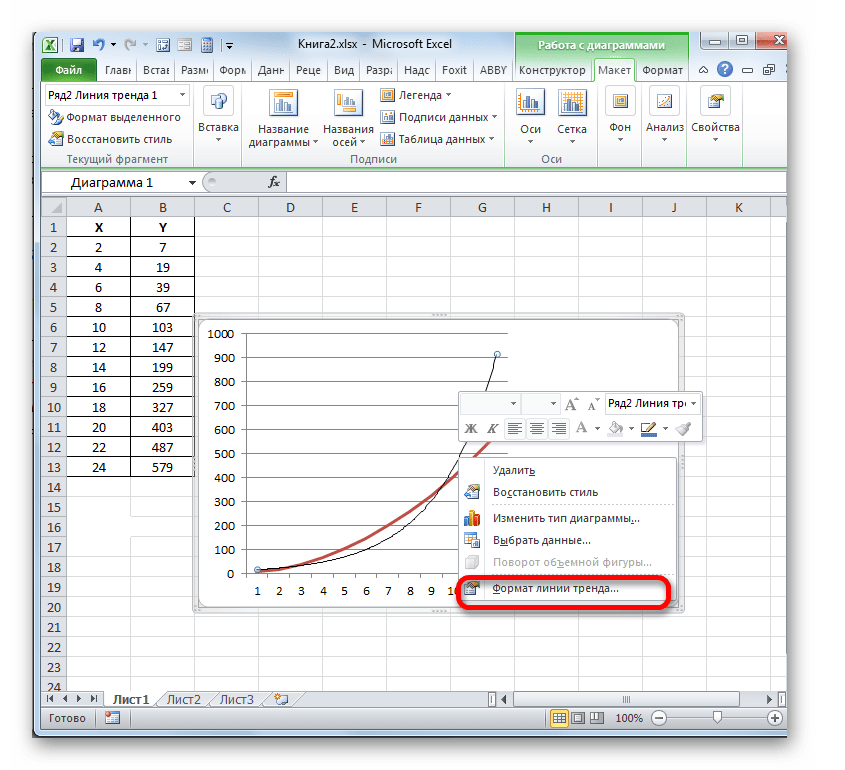
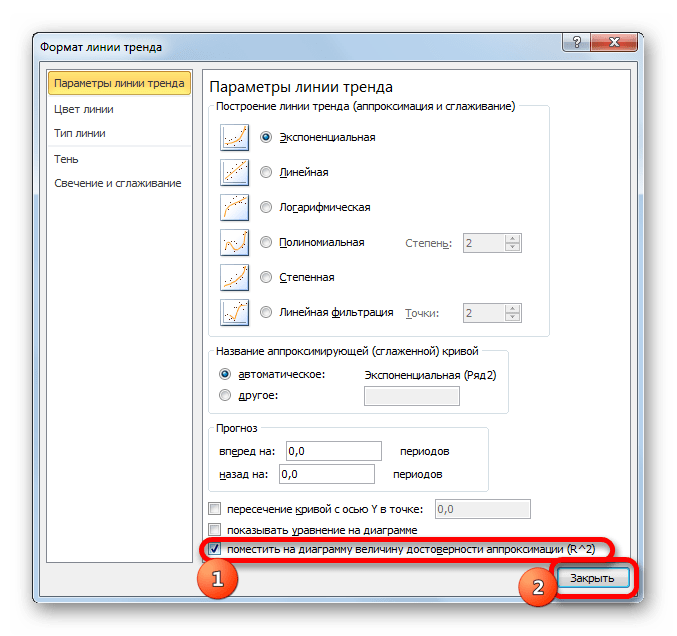
- Теперь нашей задачей является отобразить собственно коэффициент детерминации. Кликаем правой кнопкой мыши по линии тренда. Активируется контекстное меню. Останавливаем выбор в нем на пункте «Формат линии тренда…».

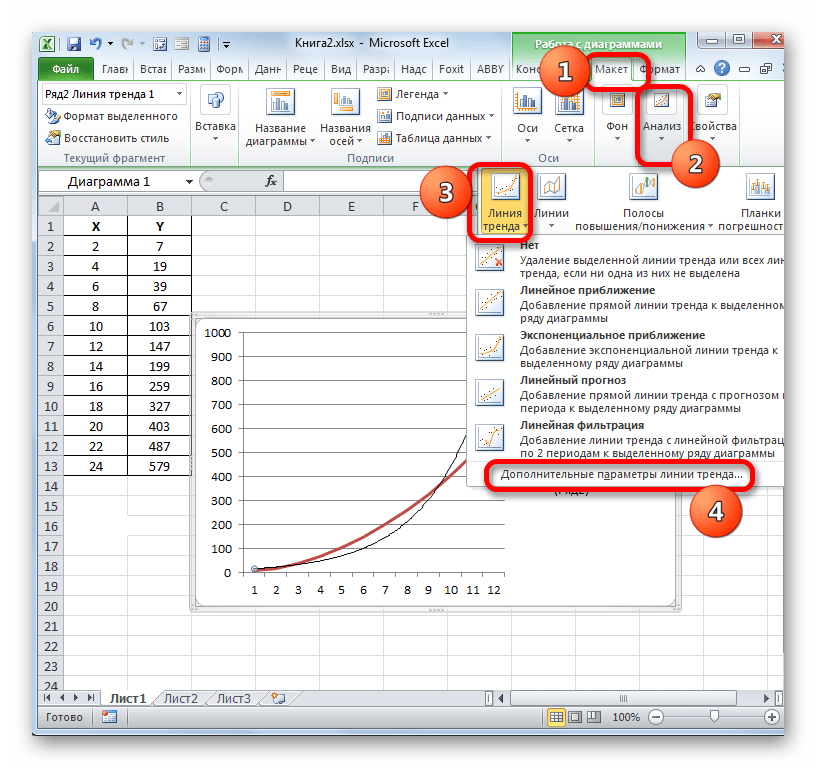
Для выполнения перехода в окно формата линии тренда можно выполнить альтернативное действие. Выделяем линию тренда кликом по ней левой кнопки мыши. Перемещаемся во вкладку «Макет». Клацаем по кнопке «Линия тренда» в блоке «Анализ». В открывшемся списке клацаем по самому последнему пункту перечня действий – «Дополнительные параметры линии тренда…».
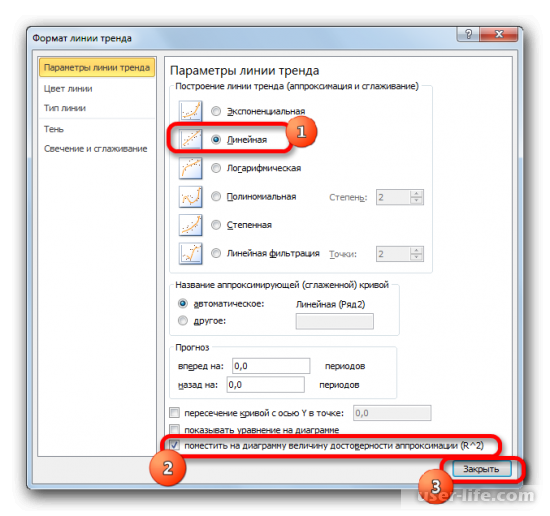
- После любого из двух вышеуказанных действий запускается окошко формата, в котором можно произвести дополнительные настройки. В частности, для выполнения нашей задачи необходимо установить флажок напротив пункта «Поместить на диаграмму величину достоверности аппроксимации (R^2)». Он размещен в самом низу окна. То есть, таким образом мы включаем отображение коэффициента детерминации на области построения. Затем не забываем нажать на кнопку «Закрыть» внизу текущего окна.
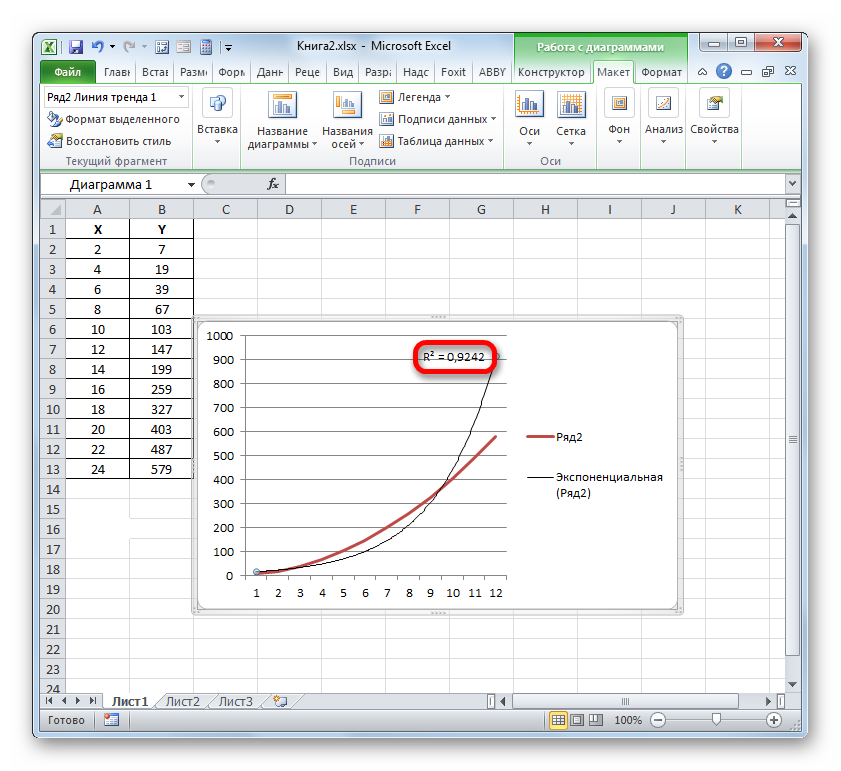
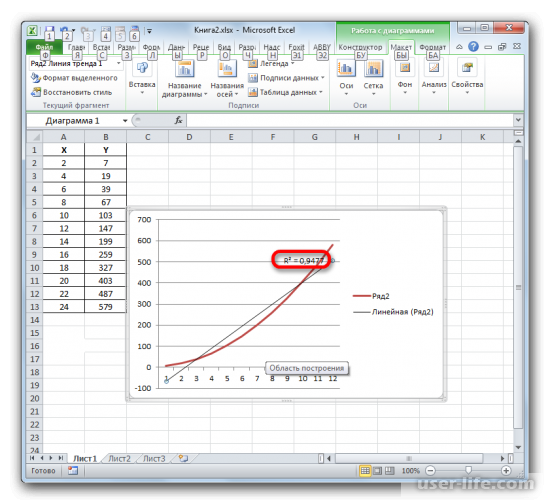
- Значение достоверности аппроксимации, то есть, величина коэффициента детерминации, будет отображено на листе в области построения. В данном случае эта величина, как видим, равна 0,9242, что характеризует аппроксимацию, как модель хорошего качества.
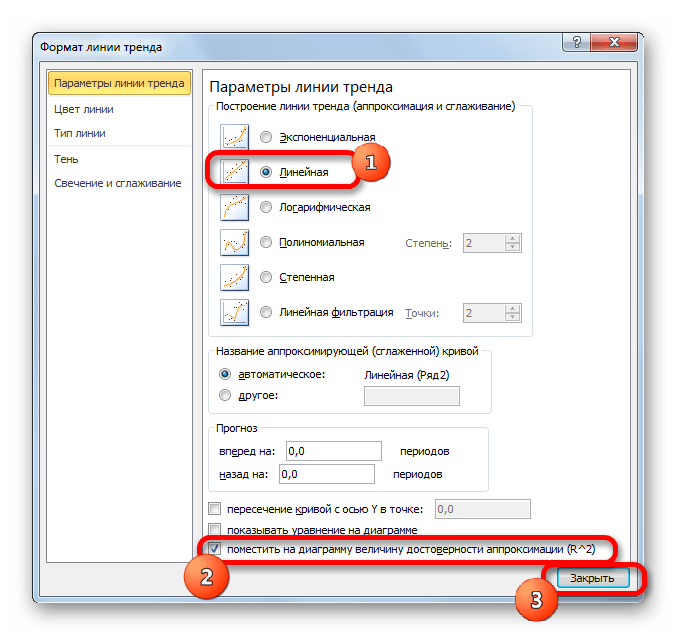
- Абсолютно точно таким образом можно устанавливать показ коэффициента детерминации для любого другого типа линии тренда. Можно менять тип линии тренда, произведя переход через кнопку на ленте или контекстное меню в окно её параметров, как было показано выше. Затем уже в самом окне в группе «Построение линии тренда» можно переключиться на другой тип. Не забываем при этом контролировать, чтобы около пункта «Поместить на диаграмму величину достоверности аппроксимации» был установлен флажок. Завершив вышеуказанные действия, щелкаем по кнопке «Закрыть» в нижнем правом углу окна.
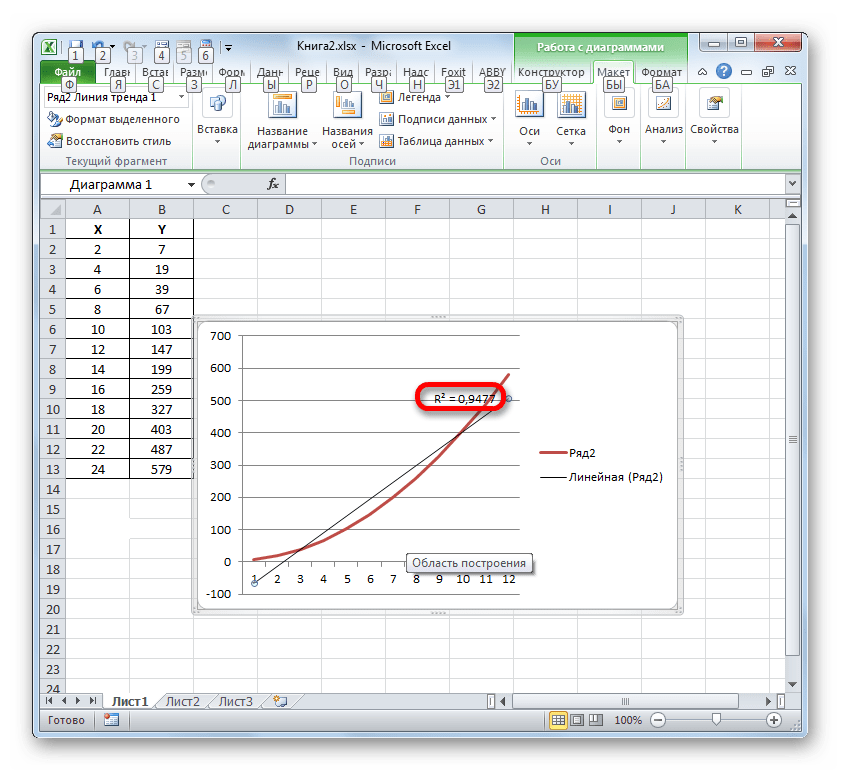
- При линейном типе линия тренда уже имеет значение достоверности аппроксимации равное 0,9477, что характеризует эту модель, как ещё более достоверную, чем рассматриваемую нами ранее линию тренда экспоненциального типа.
- Таким образом, переключаясь между разными типами линии тренда и сравнивая их значения достоверности аппроксимации (коэффициент детерминации), можно найти тот вариант, модель которого наиболее точно описывает представленный график. Вариант с самым высоким показателем коэффициента детерминации будет наиболее достоверным. На его основе можно строить самый точный прогноз.
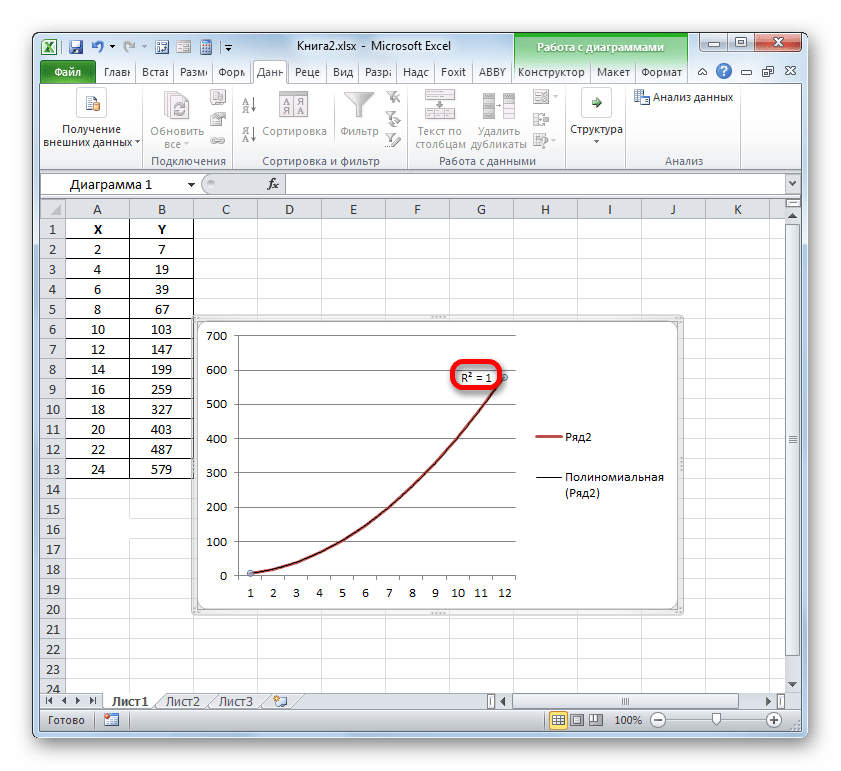
Например, для нашего случая опытным путем удалось установить, что самый высокий уровень достоверности имеет полиномиальный тип линии тренда второй степени. Коэффициент детерминации в данном случае равен 1. Это говорит о том, что указанная модель абсолютно достоверная, что означает полное исключение погрешностей.

Но, в то же время, это совсем не значит, что для другого графика тоже наиболее достоверным окажется именно этот тип линии тренда. Оптимальный выбор типа линии тренда зависит от типа функции, на основании которой был построен график. Если пользователь не обладает достаточным объемом знаний, чтобы «на глаз» прикинуть наиболее качественный вариант, то единственным выходом определения лучшего прогноза является как раз сравнение коэффициентов детерминации, как было показано на примере выше.
Читайте также:
Построение линии тренда в Excel
Аппроксимация в Excel
В Экселе существуют два основных варианта вычисления коэффициента детерминации: использование оператора КВПИРСОН и применение инструмента «Регрессия» из пакета инструментов «Анализ данных». При этом первый из этих вариантов предназначен для использования только в процессе обработки линейной функции, а другой вариант можно использовать практически во всех ситуациях. Кроме того, существует возможность отображения коэффициента детерминации для линии трендов графиков в качестве величины достоверности аппроксимации. С помощью данного показателя имеется возможность определить тип линии тренда, который располагает самым высоким уровнем достоверности для конкретной функции.
Еще статьи по данной теме:
Помогла ли Вам статья?
Содержание
- Коэффициент детерминации в Excel (Эксель)
- Расчет коэффициента детерминации в Microsoft Excel
- Вычисление коэффициента детерминации
- Способ 1: вычисление коэффициента детерминации при линейной функции
- Способ 2: вычисление коэффициента детерминации в нелинейных функциях
- Способ 3: коэффициент детерминации для линии тренда
Коэффициент детерминации в Excel (Эксель)
Для статистических моделей во многих случаях необходимо определить точность прогноза. Это производится с помощью специальных расчётов в Microsoft Excel, а использоваться будет коэффициент детерминации. Он обозначается как R^2.
Статистические модели можно разделить на качественные уровни в зависимости от коэффициента. От 0.8 до 1 относятся модели хорошего качества, модели достаточного качества имеют уровень от 0.5 до 0.8, а плохое качество имеет диапазон от 0 до 0.5.
Способ определения точности с помощью функции КВПИРСОН
В линейной функции коэффициент детерминации будет равен квадрату корреляционного коэффициента. Рассчитать его можно с помощью специальной функции. Для начала создадим таблицу с данными.
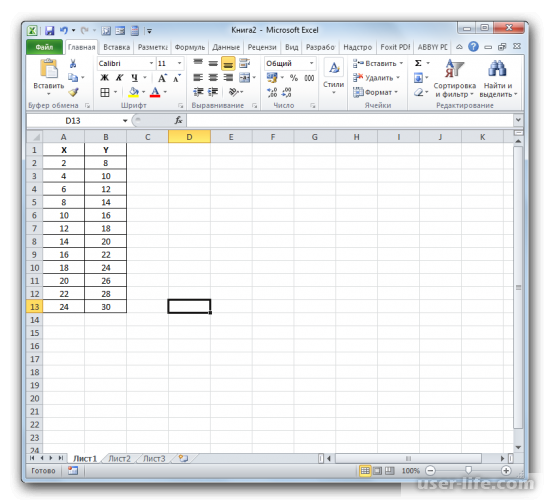
Потом нужно выбрать место, где будет показан результат расчёта и нажимаем на кнопку вставки функции.

После этого откроется специальное окно. Категорию нужно выбрать «Статистические» и выбираем КВПИРСОН. Эта функция позволяет определить коэффициент корреляции касательно функции Пирсона, соответственно квадратное значение коэффициента корреляции = коэффициенту детерминации.
После подтверждения действия, появится окно в котором нужно в полях выставить «Известные значения Х» и «Известные значения Y». Нажимаем мышкой поле «Известные значения Y» и в рабочем окне выделяем данные столбца Y. Аналогичное действие делаем и с другим полем выбирая данные уже с таблицы Х.
Как результат этих действий будет показано значение коэффициента детерминации в ячейке, которая ранее была выбрана для отображения результата.
Определение коэффициента детерминации если функция не является линейной.
Если функция нелинейная, то инструментарий Excel также позволяет рассчитать коэффициент с помощью инструмента «Регрессия». Его можно найти в пакете анализа данных. Но для начала нужно активировать этот пакет, перейдя в раздел «Файл» и в списке открыть «Параметры».
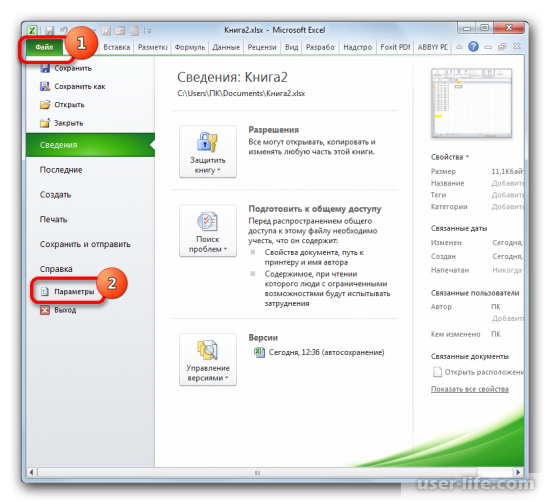
После этого можно увидеть новое окно, в котором нужно в меню выбрать «Надстройки», а в специальном поле по управлению надстройками выбираем «Надстройки Excel» и переходим к ним.
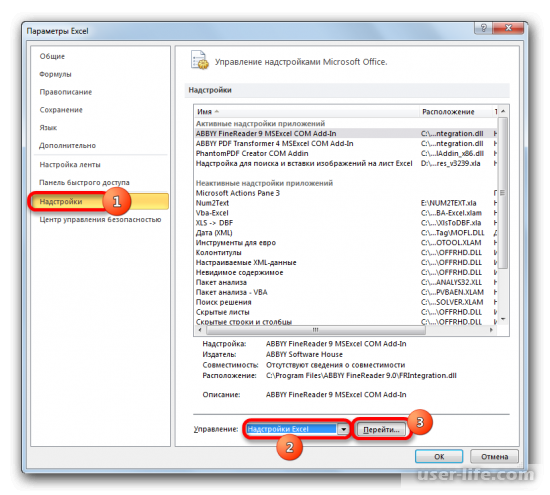
После перехода в надстройки Excel появится новое окно. В нём можно увидеть доступные для пользователя надстройки. Ставим галочку возле «Пакет анализа» и подтверждаем действие.
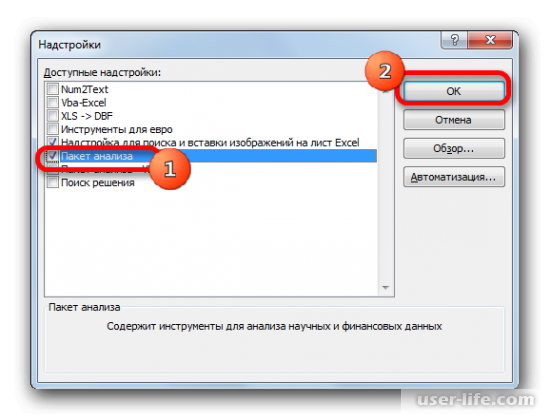
Найти его можно в разделе «Данные», после перехода в который нажимаем на «Анализ данных» в правой части экрана.
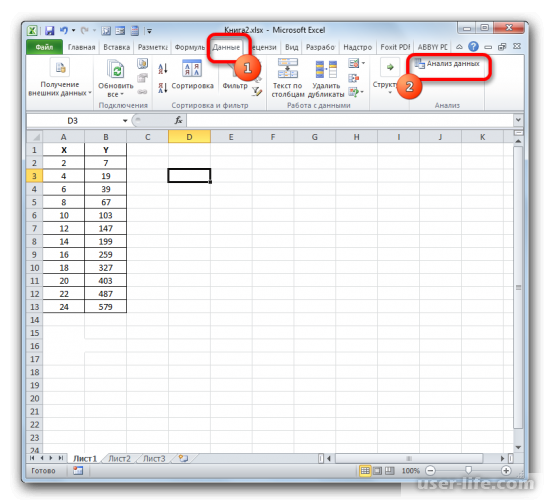
После его открытия, в списке выбираем «Регрессия»и подтверждаем действие.
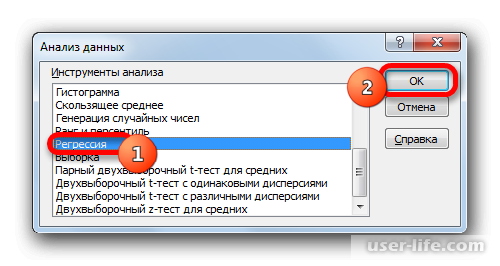
После этого появится новое окно в котором можно производить настройки. Входные данные позволяют настроить значение интервалов Х и Y, достаточно выделить соответствующие ячейки аргументов другого аргумента. В поле уровня надежности можно выставить нужный показатель. Параметры вывода позволяют задать где будет показан результат. Если к примеру выбрать показ на текущем листе, то для начала нужно выбрать пункт «Выходной интервал» — и нажать на области основного окна где будет в будущем отображаться результат и координаты ячейки будут показаны соответствующем поле. В конце подтверждаем действие.
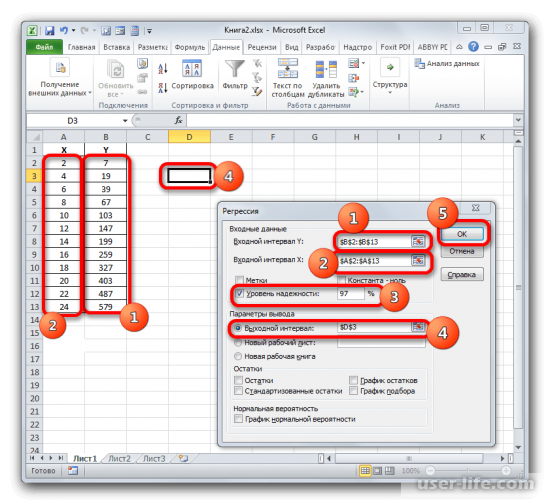
В рабочем окне появится результат. Так как мы вычисляем коэффициент детерминации, то в итогах нам нужен R-коэффициент. Если посмотреть на значение, то можно увидеть что оно относится к наилучшему качеству.
Способ определения коэффициента детерминации для линии тренда
Имея созданную таблицу с соответствующими значение, создаем график. Чтобы провести на нём линию тренда надо нажать на график, а именно на область где строится линия. Сверху в панели инструментов выбрать раздел «Макет», а в нём выбрать «Линия тренда». После этого в контексте данного примера в списке выбираем «Экспоненциальное приближение».
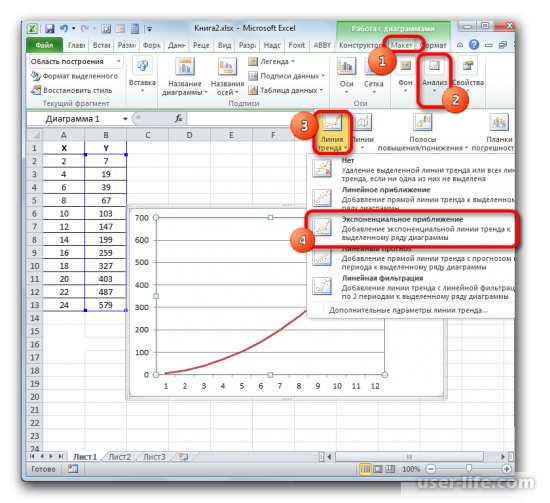
Линия тренда будет отображена на графике как кривая с черным цветом.
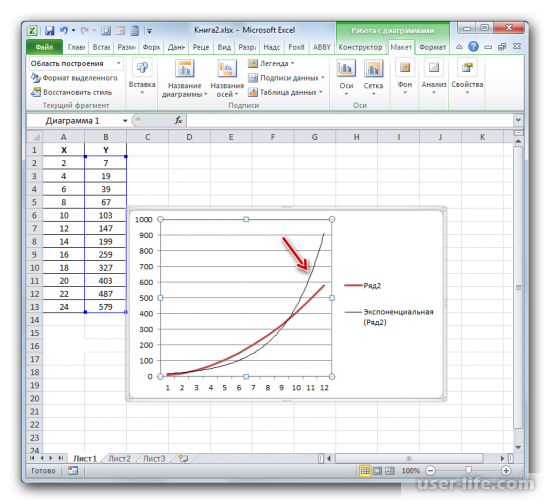
Для того чтобы показать коэффициент детерминации, нужно по черной кривой нажать правой кнопкой мыши и выбрать в списке «Формат линии тренда».
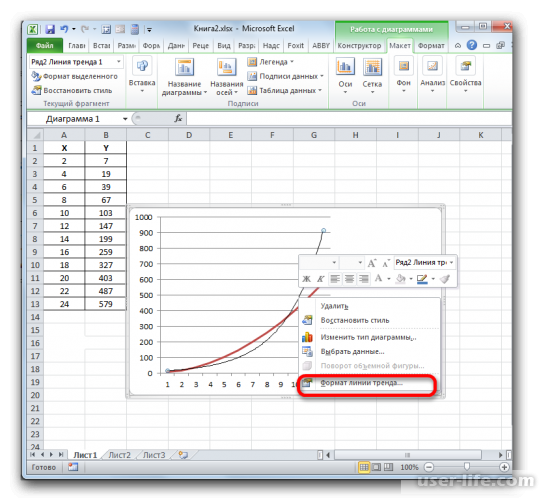
После этого появится новое окно. В нём нужно отметить флажком и выбрать нужное действие (показано на скриншоте). Благодаря этому коэффициент будет отображен на графике. После того как это было сделано, закрываем окно.
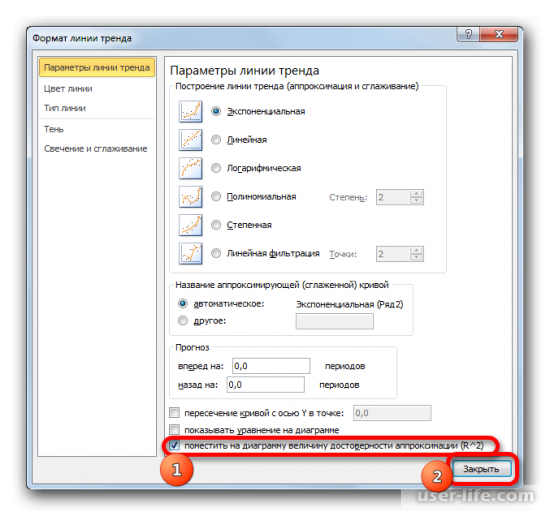
После закрытия окна формата линии тренда в рабочем окне можно увидеть значение коэффициента детерминации.
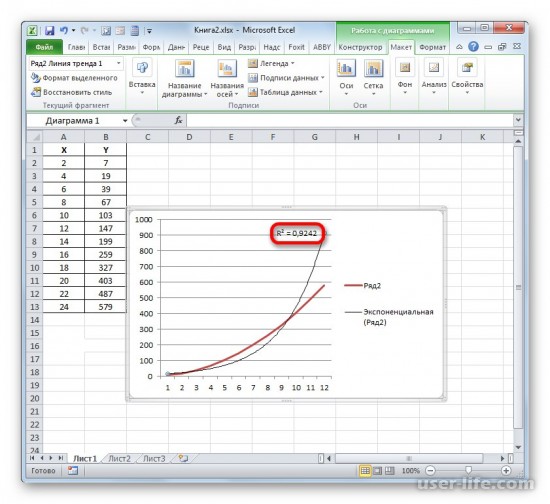
Если пользователю нужен другой типаж линии тренда, то в окне «Формат линии тренда» можно выбрать его. Не забыв задать его ранее при создании линии тренда в разделе «Макет» или в контекстном меню. Также не забываем ставить флажок для функции R^2.
Как результат можно увидеть изменение линии тренда и число достоверности.
После просмотра разных вариаций линий тренда, пользователь может определить наиболее подходящую для себя так как показатель достоверности может меняться в зависимости от выбора линии. Максимальный коэффициент это единица, что означает максимальную достоверность, однако не всегда можно достигнуть этого значения.
Так было рассмотрено несколько способов по нахождению коэффициента детерминации. Пользователь может выбрать наиболее оптимальный для своих целей.
Источник
Расчет коэффициента детерминации в Microsoft Excel
Одним из показателей, описывающих качество построенной модели в статистике, является коэффициент детерминации (R^2), который ещё называют величиной достоверности аппроксимации. С его помощью можно определить уровень точности прогноза. Давайте узнаем, как можно произвести расчет данного показателя с помощью различных инструментов программы Excel.
Вычисление коэффициента детерминации
В зависимости от уровня коэффициента детерминации, принято разделять модели на три группы:
- 0,8 – 1 — модель хорошего качества;
- 0,5 – 0,8 — модель приемлемого качества;
- 0 – 0,5 — модель плохого качества.
В последнем случае качество модели говорит о невозможности её использования для прогноза.
Выбор способа вычисления указанного значения в Excel зависит от того, является ли регрессия линейной или нет. В первом случае можно использовать функцию КВПИРСОН, а во втором придется воспользоваться специальным инструментом из пакета анализа.
Способ 1: вычисление коэффициента детерминации при линейной функции
Прежде всего, выясним, как найти коэффициент детерминации при линейной функции. В этом случае данный показатель будет равняться квадрату коэффициента корреляции. Произведем его расчет с помощью встроенной функции Excel на примере конкретной таблицы, которая приведена ниже.
- Выделяем ячейку, где будет произведен вывод коэффициента детерминации после его расчета, и щелкаем по пиктограмме «Вставить функцию».

- Запускается Мастер функций. Перемещаемся в его категорию «Статистические» и отмечаем наименование «КВПИРСОН». Далее клацаем по кнопке «OK».
- Происходит запуск окна аргументов функции КВПИРСОН. Данный оператор из статистической группы предназначен для вычисления квадрата коэффициента корреляции функции Пирсона, то есть, линейной функции. А как мы помним, при линейной функции коэффициент детерминации как раз равен квадрату коэффициента корреляции.
Синтаксис этого оператора такой:
Таким образом, функция имеет два оператора, один из которых представляет собой перечень значений функции, а второй – аргументов. Операторы могут быть представлены, как непосредственно в виде значений, перечисленных через точку с запятой (;), так и в виде ссылок на диапазоны, где они расположены. Именно последний вариант и будет использован нами в данном примере.
Устанавливаем курсор в поле «Известные значения y». Выполняем зажим левой кнопки мышки и производим выделение содержимого столбца «Y» таблицы. Как видим, адрес указанного массива данных тут же отображается в окне.
Аналогичным образом заполняем поле «Известные значения x». Ставим курсор в данное поле, но на этот раз выделяем значения столбца «X».
После того, как все данные были отображены в окне аргументов КВПИРСОН, клацаем по кнопке «OK», расположенной в самом его низу.
Способ 2: вычисление коэффициента детерминации в нелинейных функциях
Но указанный выше вариант расчета искомого значения можно применять только к линейным функциям. Что же делать, чтобы произвести его расчет в нелинейной функции? В Экселе имеется и такая возможность. Её можно осуществить с помощью инструмента «Регрессия», который является составной частью пакета «Анализ данных».
- Но прежде, чем воспользоваться указанным инструментом, следует активировать сам «Пакет анализа», который по умолчанию в Экселе отключен. Перемещаемся во вкладку «Файл», а затем переходим по пункту «Параметры».
- В открывшемся окне производим перемещение в раздел «Надстройки» при помощи навигации по левому вертикальному меню. В нижней части правой области окна располагается поле «Управление». Из списка доступных там подразделов выбираем наименование «Надстройки Excel…», а затем щелкаем по кнопке «Перейти…», расположенной справа от поля.
- Производится запуск окна надстроек. В центральной его части расположен список доступных надстроек. Устанавливаем флажок около позиции «Пакет анализа». Вслед за этим требуется щелкнуть по кнопке «OK» в правой части интерфейса окна.
- Пакет инструментов «Анализ данных» в текущем экземпляре Excel будет активирован. Доступ к нему располагается на ленте во вкладке «Данные». Перемещаемся в указанную вкладку и клацаем по кнопке «Анализ данных» в группе настроек «Анализ».
- Активируется окошко «Анализ данных» со списком профильных инструментов обработки информации. Выделяем из этого перечня пункт «Регрессия» и клацаем по кнопке «OK».
- Затем открывается окно инструмента «Регрессия». Первый блок настроек – «Входные данные». Тут в двух полях нужно указать адреса диапазонов, где находятся значения аргумента и функции. Ставим курсор в поле «Входной интервал Y» и выделяем на листе содержимое колонки «Y». После того, как адрес массива отобразился в окне «Регрессия», ставим курсор в поле «Входной интервал Y» и точно таким же образом выделяем ячейки столбца «X».
Около параметров «Метка» и «Константа-ноль» флажки не ставим. Флажок можно установить около параметра «Уровень надежности» и в поле напротив указать желаемую величину соответствующего показателя (по умолчанию 95%).
В группе «Параметры вывода» нужно указать, в какой области будет отображаться результат вычисления. Существует три варианта:
- Область на текущем листе;
- Другой лист;
- Другая книга (новый файл).
Остановим свой выбор на первом варианте, чтобы исходные данные и результат размещались на одном рабочем листе. Ставим переключатель около параметра «Выходной интервал». В поле напротив данного пункта ставим курсор. Щелкаем левой кнопкой мыши по пустому элементу на листе, который призван стать левой верхней ячейкой таблицы вывода итогов расчета. Адрес данного элемента должен высветиться в поле окна «Регрессия».
Группы параметров «Остатки» и «Нормальная вероятность» игнорируем, так как для решения поставленной задачи они не важны. После этого клацаем по кнопке «OK», которая размещена в правом верхнем углу окна «Регрессия».
Способ 3: коэффициент детерминации для линии тренда
Кроме указанных выше вариантов, коэффициент детерминации можно отобразить непосредственно для линии тренда в графике, построенном на листе Excel. Выясним, как это можно сделать на конкретном примере.
- Мы имеем график, построенный на основе таблицы аргументов и значений функции, которая была использована для предыдущего примера. Произведем построение к нему линии тренда. Кликаем по любому месту области построения, на которой размещен график, левой кнопкой мыши. При этом на ленте появляется дополнительный набор вкладок – «Работа с диаграммами». Переходим во вкладку «Макет». Клацаем по кнопке «Линия тренда», которая размещена в блоке инструментов «Анализ». Появляется меню с выбором типа линии тренда. Останавливаем выбор на том типе, который соответствует конкретной задаче. Давайте для нашего примера выберем вариант «Экспоненциальное приближение».
- Эксель строит прямо на плоскости построения графика линию тренда в виде дополнительной черной кривой.
- Теперь нашей задачей является отобразить собственно коэффициент детерминации. Кликаем правой кнопкой мыши по линии тренда. Активируется контекстное меню. Останавливаем выбор в нем на пункте «Формат линии тренда…».
Для выполнения перехода в окно формата линии тренда можно выполнить альтернативное действие. Выделяем линию тренда кликом по ней левой кнопки мыши. Перемещаемся во вкладку «Макет». Клацаем по кнопке «Линия тренда» в блоке «Анализ». В открывшемся списке клацаем по самому последнему пункту перечня действий – «Дополнительные параметры линии тренда…».
Например, для нашего случая опытным путем удалось установить, что самый высокий уровень достоверности имеет полиномиальный тип линии тренда второй степени. Коэффициент детерминации в данном случае равен 1. Это говорит о том, что указанная модель абсолютно достоверная, что означает полное исключение погрешностей.
Но, в то же время, это совсем не значит, что для другого графика тоже наиболее достоверным окажется именно этот тип линии тренда. Оптимальный выбор типа линии тренда зависит от типа функции, на основании которой был построен график. Если пользователь не обладает достаточным объемом знаний, чтобы «на глаз» прикинуть наиболее качественный вариант, то единственным выходом определения лучшего прогноза является как раз сравнение коэффициентов детерминации, как было показано на примере выше.
В Экселе существуют два основных варианта вычисления коэффициента детерминации: использование оператора КВПИРСОН и применение инструмента «Регрессия» из пакета инструментов «Анализ данных». При этом первый из этих вариантов предназначен для использования только в процессе обработки линейной функции, а другой вариант можно использовать практически во всех ситуациях. Кроме того, существует возможность отображения коэффициента детерминации для линии трендов графиков в качестве величины достоверности аппроксимации. С помощью данного показателя имеется возможность определить тип линии тренда, который располагает самым высоким уровнем достоверности для конкретной функции.
Источник
Регрессия позволяет прогнозировать зависимую переменную на основании значений фактора. В
MS
EXCEL
имеется множество функций, которые возвращают не только наклон и сдвиг линии регрессии, характеризующей линейную взаимосвязь между факторами, но и регрессионную статистику. Здесь рассмотрим простую линейную регрессию, т.е. прогнозирование на основе одного фактора.
Disclaimer
: Данную статью не стоит рассматривать, как пересказ главы из учебника по статистике. Статья не обладает ни полнотой, ни строгостью изложения положений статистической науки. Эта статья – о применении MS EXCEL для целей
Регрессионного анализа.
Теоретические отступления приведены лишь из соображения логики изложения. Использование данной статьи для изучения
Регрессии
– плохая идея.
Статья про
Регрессионный анализ
получилась большая, поэтому ниже для удобства приведены ее разделы:
- Немного теории и основные понятия
- Предположения линейной регрессионной модели
- Задачи регрессионного анализа
- Оценка неизвестных параметров линейной модели (используя функции MS EXCEL)
- Оценка неизвестных параметров линейной модели (через статистики выборок)
- Оценка неизвестных параметров линейной модели (матричная форма)
- Построение линии регрессии
- Коэффициент детерминации
- Стандартная ошибка регрессии
- Стандартные ошибки и доверительные интервалы для наклона и сдвига
- Проверка значимости взаимосвязи переменных
- Доверительные интервалы для нового наблюдения Y и среднего значения
- Проверка адекватности линейной регрессионной модели
Примечание
: Если прогнозирование переменной осуществляется на основе нескольких факторов, то имеет место
множественная регрессия
.
Чтобы разобраться, чем может помочь MS EXCEL при проведении регрессионного анализа, напомним вкратце теорию, введем термины и обозначения, которые могут отличаться в зависимости от различных источников.
Примечание
: Для тех, кому некогда, незачем или просто не хочется разбираться в теоретических выкладках предлагается сразу перейти к вычислительной части —
оценке неизвестных параметров линейной модели
.
Немного теории и основные понятия
Пусть у нас есть массив данных, представляющий собой значения двух переменных Х и Y. Причем значения переменной Х мы можем произвольно задавать (контролировать) и использовать эту переменную для предсказания значений зависимой переменной Y. Таким образом, случайной величиной является только переменная Y.
Примером такой задачи может быть производственный процесс изготовления некого волокна, причем
прочность этого волокна
(Y) зависит только от
рабочей температуры процесса
в реакторе (Х), которая задается оператором.
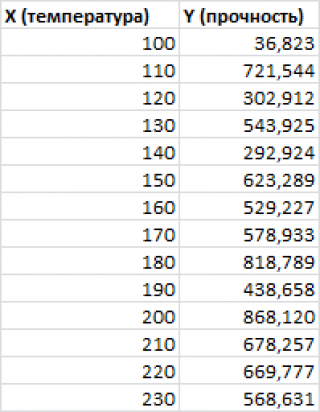
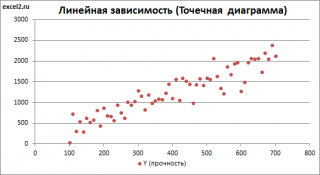
Построим
диаграмму рассеяния
(см.
файл примера лист Линейный
), созданию которой
посвящена отдельная статья
. Вообще, построение
диаграммы рассеяния
для целей
регрессионного анализа
де-факто является стандартом.
СОВЕТ
: Подробнее о построении различных типов диаграмм см. статьи
Основы построения диаграмм
и
Основные типы диаграмм
.
Приведенная выше
диаграмма рассеяния
свидетельствует о возможной
линейной взаимосвязи
между Y от Х: очевидно, что точки данных в основном располагаются вдоль прямой линии.
Примечание
: Наличие даже такой очевидной
линейной взаимосвязи
не может являться доказательством о наличии причинной взаимосвязи переменных. Наличие
причинной
взаимосвязи не может быть доказано на основании только анализа имеющихся измерений, а должно быть обосновано с помощью других исследований, например теоретических выкладок.
Примечание
: Как известно, уравнение прямой линии имеет вид
Y
=
m
*
X
+
k
, где коэффициент
m
отвечает за наклон линии (
slope
),
k
– за сдвиг линии по вертикали (
intercept
),
k
равно значению Y при Х=0.
Предположим, что мы можем зафиксировать переменную Х (
рабочую температуру процесса
) при некотором значении Х
i
и произвести несколько наблюдений переменной Y (
прочность нити
). Очевидно, что при одном и том же значении Хi мы получим различные значения Y. Это обусловлено влиянием других факторов на Y. Например, локальные колебания давления в реакторе, концентрации раствора, наличие ошибок измерения и др. Предполагается, что воздействие этих факторов имеет случайную природу и для каждого измерения имеются одинаковые условия проведения эксперимента (т.е. другие факторы не изменяются).
Полученные значения Y, при заданном Хi, будут колебаться вокруг некого
значения
. При увеличении количества измерений, среднее этих измерений, будет стремиться к
математическому ожиданию
случайной величины Y (при Х
i
) равному μy(i)=Е(Y
i
).
Подобные рассуждения можно привести для любого значения Хi.
Чтобы двинуться дальше, воспользуемся материалом из раздела
Проверка статистических гипотез
. В статье о
проверке гипотезы о среднем значении генеральной совокупности
в качестве
нулевой
гипотезы
предполагалось равенство неизвестного значения μ заданному μ0.
В нашем случае
простой линейной регрессии
в качестве
нулевой
гипотезы
предположим, что между переменными μy(i) и Хi существует линейная взаимосвязь μ
y(i)
=α* Х
i
+β. Уравнение μ
y(i)
=α* Х
i
+β можно переписать в обобщенном виде (для всех Х и μ
y
) как μ
y
=α* Х +β.
Для наглядности проведем прямую линию соединяющую все μy(i).
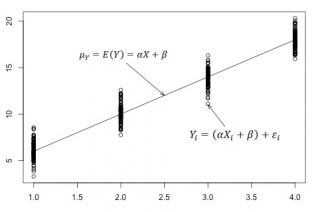
Данная линия называется
регрессионной линией генеральной совокупности
(population regression line), параметры которой (
наклон
a и
сдвиг β
) нам не известны (по аналогии с
гипотезой о среднем значении генеральной совокупности
, где нам было неизвестно истинное значение μ).
Теперь сделаем переход от нашего предположения, что μy=a* Х +
β
, к предсказанию значения случайной переменной Y в зависимости от значения контролируемой переменной Х. Для этого уравнение связи двух переменных запишем в виде Y=a*X+β+ε, где ε — случайная ошибка, которая отражает суммарный эффект влияния других факторов на Y (эти «другие» факторы не участвуют в нашей модели). Напомним, что т.к. переменная Х фиксирована, то ошибка ε определяется только свойствами переменной Y.
Уравнение Y=a*X+b+ε называют
линейной регрессионной моделью
. Часто Х еще называют
независимой переменной
(еще
предиктором
и
регрессором
, английский термин
predictor
,
regressor
), а Y –
зависимой
(или
объясняемой
,
response
variable
). Так как
регрессор
у нас один, то такая модель называется
простой линейной регрессионной моделью
(
simple
linear
regression
model
). α часто называют
коэффициентом регрессии.
Предположения линейной регрессионной модели перечислены в следующем разделе.
Предположения линейной регрессионной модели
Чтобы модель линейной регрессии Yi=a*Xi+β+ε
i
была адекватной — требуется:
-
Ошибки ε
i
должны быть независимыми переменными; -
При каждом значении Xi ошибки ε
i
должны быть иметь нормальное распределение (также предполагается равенство нулю математического ожидания, т.е. Е[ε
i
]=0); -
При каждом значении Xi ошибки ε
i
должны иметь равные дисперсии (обозначим ее σ
2
).
Примечание
: Последнее условие называется
гомоскедастичность
— стабильность, гомогенность дисперсии случайной ошибки e. Т.е.
дисперсия
ошибки σ
2
не должна зависеть от значения Xi.
Используя предположение о равенстве математического ожидания Е[ε
i
]=0 покажем, что μy(i)=Е[Yi]:
Е[Yi]= Е[a*Xi+β+ε
i
]= Е[a*Xi+β]+ Е[ε
i
]= a*Xi+β= μy(i), т.к. a, Xi и β постоянные значения.
Дисперсия
случайной переменной Y равна
дисперсии
ошибки ε, т.е. VAR(Y)= VAR(ε)=σ
2
. Это является следствием, что все значения переменной Х являются const, а VAR(ε)=VAR(ε
i
).
Задачи регрессионного анализа
Для проверки гипотезы о линейной взаимосвязи переменной Y от X делают выборку из генеральной совокупности (этой совокупности соответствует
регрессионная линия генеральной совокупности
, т.е. μy=a* Х +β). Выборка будет состоять из n точек, т.е. из n пар значений {X;Y}.
На основании этой выборки мы можем вычислить оценки наклона a и сдвига β, которые обозначим соответственно
a
и
b
. Также часто используются обозначения â и b̂.
Далее, используя эти оценки, мы также можем проверить гипотезу: имеется ли линейная связь между X и Y статистически значимой?
Таким образом:
Первая задача
регрессионного анализа
– оценка неизвестных параметров (
estimation
of
the
unknown
parameters
). Подробнее см. раздел
Оценки неизвестных параметров модели
.
Вторая задача
регрессионного анализа
–
Проверка адекватности модели
(
model
adequacy
checking
).
Примечание
: Оценки параметров модели обычно вычисляются
методом наименьших квадратов
(МНК),
которому посвящена отдельная статья
.
Оценка неизвестных параметров линейной модели (используя функции MS EXCEL)
Неизвестные параметры
простой линейной регрессионной модели
Y=a*X+β+ε оценим с помощью
метода наименьших квадратов
(в
статье про МНК подробно описано этот метод
).
Для вычисления параметров линейной модели методом МНК получены следующие выражения:
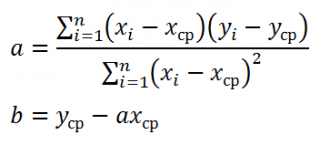
Таким образом, мы получим уравнение прямой линии Y=
a
*X+
b
, которая наилучшим образом аппроксимирует имеющиеся данные.
Примечание
: В статье про
метод наименьших квадратов
рассмотрены случаи аппроксимации
линейной
и
квадратичной функцией
, а также
степенной
,
логарифмической
и
экспоненциальной функцией
.
Оценку параметров в MS EXCEL можно выполнить различными способами:
-
с помощью функций
НАКЛОН()
и
ОТРЕЗОК()
; -
с помощью функции
ЛИНЕЙН()
; см. статьюФункция MS EXCEL ЛИНЕЙН()
-
формулами через статистики выборок
;
-
в матричной форме
;
-
с помощью
инструмента Регрессия надстройки Пакет Анализа
.
Сначала рассмотрим функции
НАКЛОН()
,
ОТРЕЗОК()
и
ЛИНЕЙН()
.
Пусть значения Х и Y находятся соответственно в диапазонах
C
23:
C
83
и
B
23:
B
83
(см.
файл примера
внизу статьи).
Примечание
: Значения двух переменных Х и Y можно сгенерировать, задав тренд и величину случайного разброса (см. статью
Генерация данных для линейной регрессии в MS EXCEL
).
В MS EXCEL наклон прямой линии
а
(
оценку
коэффициента регрессии
), можно найти по
методу МНК
с помощью функции
НАКЛОН()
, а сдвиг
b
(
оценку
постоянного члена
или
константы регрессии
), с помощью функции
ОТРЕЗОК()
. В английской версии это функции SLOPE и INTERCEPT соответственно.
Аналогичный результат можно получить с помощью функции
ЛИНЕЙН()
, английская версия LINEST (см.
статью об этой функции
).
Формула
=ЛИНЕЙН(C23:C83;B23:B83)
вернет наклон
а
. А формула =
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);2)
— сдвиг
b
. Здесь требуются пояснения.
Функция
ЛИНЕЙН()
имеет 4 аргумента и возвращает целый массив значений:
ЛИНЕЙН(известные_значения_y; [известные_значения_x]; [конст]; [статистика])
Если 4-й аргумент
статистика
имеет значение ЛОЖЬ или опущен, то функция
ЛИНЕЙН()
возвращает только оценки параметров модели:
a
и
b
.
Примечание
: Остальные значения, возвращаемые функцией
ЛИНЕЙН()
, нам потребуются при вычислении
стандартных ошибок
и для
проверки значимости регрессии
. В этом случае аргумент
статистика
должен иметь значение ИСТИНА.
Чтобы вывести сразу обе оценки:
- в одной строке необходимо выделить 2 ячейки,
-
ввести формулу в
Строке формул
-
нажать
CTRL
+
SHIFT
+
ENTER
(см. статью проформулы массива
).
Если в
Строке формул
выделить формулу =
ЛИНЕЙН(C23:C83;B23:B83)
и нажать
клавишу F9
, то мы увидим что-то типа {3,01279389265416;154,240057900613}. Это как раз значения
a
и
b
. Как видно, оба значения разделены точкой с запятой «;», что свидетельствует, что функция вернула значения «в нескольких ячейках одной строки».
Если требуется вывести параметры линии не в одной строке, а одном столбце (ячейки друг под другом), то используйте формулу =
ТРАНСП(ЛИНЕЙН(C23:C83;B23:B83))
. При этом выделять нужно 2 ячейки в одном столбце. Если теперь выделить новую формулу и нажать клавишу F9, то мы увидим что 2 значения разделены двоеточием «:», что означает, что значения выведены в столбец (функция
ТРАНСП()
транспонировала строку в столбец
).
Чтобы разобраться в этом подробнее необходимо ознакомиться с
формулами массива
.
Чтобы не связываться с вводом
формул массива
, можно
использовать функцию ИНДЕКС()
. Формула =
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);1)
или просто
ЛИНЕЙН(C23:C83;B23:B83)
вернет параметр, отвечающий за наклон линии, т.е.
а
. Формула
=ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);2)
вернет параметр
b
.
Оценка неизвестных параметров линейной модели (через статистики выборок)
Наклон линии, т.е. коэффициент
а
, можно также вычислить через
коэффициент корреляции
и
стандартные отклонения выборок
:
=
КОРРЕЛ(B23:B83;C23:C83) *(СТАНДОТКЛОН.В(C23:C83)/ СТАНДОТКЛОН.В(B23:B83))
Вышеуказанная формула математически эквивалентна отношению
ковариации
выборок Х и Y и
дисперсии
выборки Х:
=
КОВАРИАЦИЯ.В(B23:B83;C23:C83)/ДИСП.В(B23:B83)
И, наконец, запишем еще одну формулу для нахождения сдвига
b
. Воспользуемся тем фактом, что
линия регрессии
проходит через точку
средних значений
переменных Х и Y.
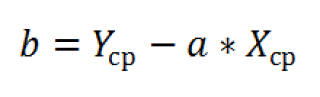
Вычислив
средние значения
и подставив в формулу ранее найденный наклон
а
, получим сдвиг
b
.
Оценка неизвестных параметров линейной модели (матричная форма)
Также параметры
линии регрессии
можно найти в матричной форме (см.
файл примера лист Матричная форма
).
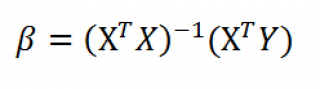
В формуле символом β обозначен столбец с искомыми параметрами модели: β0 (сдвиг
b
), β1 (наклон
a
).
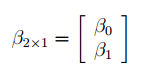
Матрица Х равна:
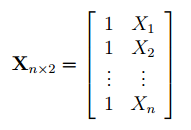
Матрица
Х
называется
регрессионной матрицей
или
матрицей плана
. Она состоит из 2-х столбцов и n строк, где n – количество точек данных. Первый столбец — столбец единиц, второй – значения переменной Х.
Матрица
Х
T
– это
транспонированная матрица
Х
. Она состоит соответственно из n столбцов и 2-х строк.
В формуле символом
Y
обозначен столбец значений переменной Y.
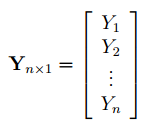
Чтобы
перемножить матрицы
используйте функцию
МУМНОЖ()
. Чтобы
найти обратную матрицу
используйте функцию
МОБР()
.
Пусть дан массив значений переменных Х и Y (n=10, т.е.10 точек).
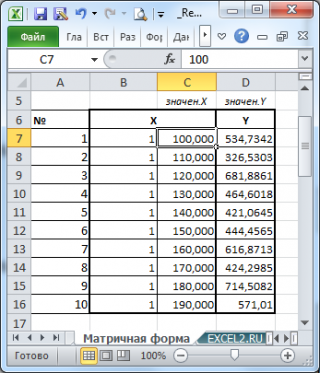
Слева от него достроим столбец с 1 для матрицы Х.
Записав формулу
=
МУМНОЖ(МОБР(МУМНОЖ(ТРАНСП(B7:C16);(B7:C16))); МУМНОЖ(ТРАНСП(B7:C16);(D7:D16)))
и введя ее как
формулу массива
в 2 ячейки, получим оценку параметров модели.
Красота применения матричной формы полностью раскрывается в случае
множественной регрессии
.
Построение линии регрессии
Для отображения
линии регрессии
построим сначала
диаграмму рассеяния
, на которой отобразим все точки (см.
начало статьи
).
Для построения прямой линии используйте вычисленные выше оценки параметров модели
a
и
b
(т.е. вычислите
у
по формуле
y
=
a
*
x
+
b
) или функцию
ТЕНДЕНЦИЯ()
.
Формула =
ТЕНДЕНЦИЯ($C$23:$C$83;$B$23:$B$83;B23)
возвращает расчетные (прогнозные) значения ŷi для заданного значения Хi из столбца
В2
.
Примечание
:
Линию регрессии
можно также построить с помощью функции
ПРЕДСКАЗ()
. Эта функция возвращает прогнозные значения ŷi, но, в отличие от функции
ТЕНДЕНЦИЯ()
работает только в случае одного регрессора. Функция
ТЕНДЕНЦИЯ()
может быть использована и в случае
множественной регрессии
(в этом случае 3-й аргумент функции должен быть ссылкой на диапазон, содержащий все значения Хi для выбранного наблюдения i).
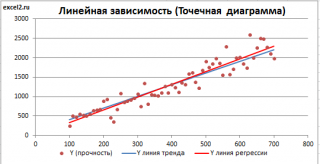
Как видно из диаграммы выше
линия тренда
и
линия регрессии
не обязательно совпадают: отклонения точек от
линии тренда
случайны, а МНК лишь подбирает линию наиболее точно аппроксимирующую случайные точки данных.
Линию регрессии
можно построить и с помощью встроенных средств диаграммы, т.е. с помощью инструмента
Линия тренда.
Для этого выделите диаграмму, в меню выберите
вкладку Макет
, в
группе Анализ
нажмите
Линия тренда
, затем
Линейное приближение.
В диалоговом окне установите галочку
Показывать уравнение на диаграмме
(подробнее см. в
статье про МНК
).
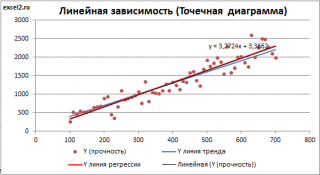
Построенная таким образом линия, разумеется, должна совпасть с ранее построенной нами
линией регрессии,
а параметры уравнения
a
и
b
должны совпасть с параметрами уравнения отображенными на диаграмме.
Примечание:
Для того, чтобы вычисленные параметры уравнения
a
и
b
совпадали с параметрами уравнения на диаграмме, необходимо, чтобы тип у диаграммы был
Точечная, а не График
, т.к. тип диаграммы
График
не использует значения Х, а вместо значений Х используется последовательность 1; 2; 3; … Именно эти значения и берутся при расчете параметров
линии тренда
. Убедиться в этом можно если построить диаграмму
График
(см.
файл примера
), а значения
Хнач
и
Хшаг
установить равным 1. Только в этом случае параметры уравнения на диаграмме совпадут с
a
и
b
.
Коэффициент детерминации R
2
Коэффициент детерминации
R
2
показывает насколько полезна построенная нами
линейная регрессионная модель
.
Предположим, что у нас есть n значений переменной Y и мы хотим предсказать значение yi, но без использования значений переменной Х (т.е. без построения
регрессионной модели
). Очевидно, что лучшей оценкой для yi будет
среднее значение
ȳ. Соответственно, ошибка предсказания будет равна (yi — ȳ).
Примечание
: Далее будет использована терминология и обозначения
дисперсионного анализа
.
После построения
регрессионной модели
для предсказания значения yi мы будем использовать значение ŷi=a*xi+b. Ошибка предсказания теперь будет равна (yi — ŷi).
Теперь с помощью диаграммы сравним ошибки предсказания полученные без построения модели и с помощью модели.
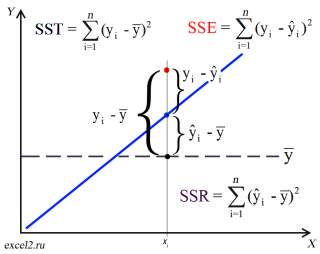
Очевидно, что используя
регрессионную модель
мы уменьшили первоначальную (полную) ошибку (yi — ȳ) на значение (ŷi — ȳ) до величины (yi — ŷi).
(yi — ŷi) – это оставшаяся, необъясненная ошибка.
Очевидно, что все три ошибки связаны выражением:
(yi — ȳ)= (ŷi — ȳ) + (yi — ŷi)
Можно показать, что в общем виде справедливо следующее выражение:
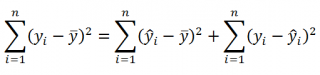
Доказательство:
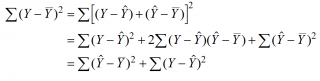
или в других, общепринятых в зарубежной литературе, обозначениях:
SST
=
SSR
+
SSE
Что означает:
Total Sum of Squares
=
Regression Sum of Squares
+
Error Sum of Squares
Примечание
: SS — Sum of Squares — Сумма Квадратов.
Как видно из формулы величины SST, SSR, SSE имеют размерность
дисперсии
(вариации) и соответственно описывают разброс (изменчивость):
Общую изменчивость
(Total variation),
Изменчивость объясненную моделью
(Explained variation) и
Необъясненную изменчивость
(Unexplained variation).
По определению
коэффициент детерминации
R
2
равен:
R
2
=
Изменчивость объясненная моделью / Общая изменчивость.
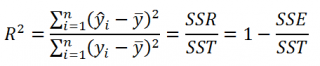
Этот показатель равен квадрату
коэффициента корреляции
и в MS EXCEL его можно вычислить с помощью функции
КВПИРСОН()
или
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);3)
R
2
принимает значения от 0 до 1 (1 соответствует идеальной линейной зависимости Y от Х). Однако, на практике малые значения R2 вовсе не обязательно указывают, что переменную Х нельзя использовать для прогнозирования переменной Y. Малые значения R2 могут указывать на нелинейность связи или на то, что поведение переменной Y объясняется не только Х, но и другими факторами.
Стандартная ошибка регрессии
Стандартная ошибка регрессии
(
Standard Error of a regression
) показывает насколько велика ошибка предсказания значений переменной Y на основании значений Х. Отдельные значения Yi мы можем предсказывать лишь с точностью +/- несколько значений (обычно 2-3, в зависимости от формы распределения ошибки ε).
Теперь вспомним уравнение
линейной регрессионной модели
Y=a*X+β+ε. Ошибка ε имеет случайную природу, т.е. является случайной величиной и поэтому имеет свою функцию распределения со
средним значением
μ и
дисперсией
σ
2
.
Оценив значение
дисперсии
σ
2
и вычислив из нее квадратный корень – получим
Стандартную ошибку регрессии.
Чем точки наблюдений на диаграмме
рассеяния
ближе находятся к прямой линии, тем меньше
Стандартная ошибка.
Примечание
:
Вспомним
, что при построении модели предполагается, что
среднее значение
ошибки ε равно 0, т.е. E[ε]=0.
Оценим
дисперсию σ
2
. Помимо вычисления
Стандартной ошибки регрессии
эта оценка нам потребуется в дальнейшем еще и при построении
доверительных интервалов
для оценки параметров регрессии
a
и
b
.
Для оценки
дисперсии
ошибки ε используем
остатки регрессии
— разности между имеющимися значениями
yi
и значениями, предсказанными регрессионной моделью ŷ. Чем лучше регрессионная модель согласуется с данными (точки располагается близко к прямой линии), тем меньше величина остатков.
Для оценки
дисперсии σ
2
используют следующую формулу:
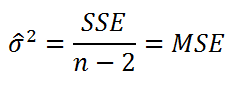
где SSE – сумма квадратов значений ошибок модели ε
i
=yi — ŷi (
Sum of Squared Errors
).
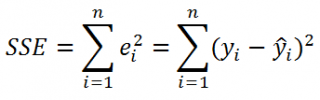
SSE часто обозначают и как SSres – сумма квадратов остатков (
Sum
of
Squared
residuals
).
Оценка
дисперсии
s
2
также имеет общепринятое обозначение MSE (Mean Square of Errors), т.е. среднее квадратов
ошибок
или MSRES (Mean Square of Residuals), т.е. среднее квадратов
остатков
. Хотя правильнее говорить сумме квадратов остатков, т.к. ошибка чаще ассоциируется с ошибкой модели ε, которая является непрерывной случайной величиной. Но, здесь мы будем использовать термины SSE и MSE, предполагая, что речь идет об остатках.
Примечание
: Напомним, что когда
мы использовали МНК
для нахождения параметров модели, то критерием оптимизации была минимизация именно SSE (SSres). Это выражение представляет собой сумму квадратов расстояний между наблюденными значениями yi и предсказанными моделью значениями ŷi, которые лежат на
линии регрессии.
Математическое ожидание
случайной величины MSE равно
дисперсии ошибки
ε, т.е.
σ
2
.
Чтобы понять почему SSE выбрана в качестве основы для оценки
дисперсии
ошибки ε, вспомним, что
σ
2
является также
дисперсией
случайной величины Y (относительно
среднего значения
μy, при заданном значении Хi). А т.к. оценкой μy является значение ŷi =
a
* Хi +
b
(значение
уравнения регрессии
при Х= Хi), то логично использовать именно SSE в качестве основы для оценки
дисперсии
σ
2
. Затем SSE усредняется на количество точек данных n за вычетом числа 2. Величина n-2 – это количество
степеней свободы
(
df
–
degrees
of
freedom
), т.е. число параметров системы, которые могут изменяться независимо (вспомним, что у нас в этом примере есть n независимых наблюдений переменной Y). В случае
простой линейной регрессии
число степеней свободы
равно n-2, т.к. при построении
линии регрессии
было оценено 2 параметра модели (на это было «потрачено» 2
степени свободы
).
Итак, как сказано было выше, квадратный корень из s
2
имеет специальное название
Стандартная ошибка регрессии
(
Standard Error of a regression
) и обозначается SEy. SEy показывает насколько велика ошибка предсказания. Отдельные значения Y мы можем предсказывать с точностью +/- несколько значений SEy (см.
этот раздел
). Если ошибки предсказания ε имеют
нормальное распределение
, то примерно 2/3 всех предсказанных значений будут на расстоянии не больше SEy от
линии регрессии
. SEy имеет размерность переменной Y и откладывается по вертикали. Часто на
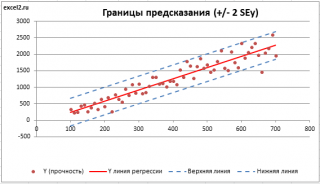
диаграмме рассеяния
строят
границы предсказания
соответствующие +/- 2 SEy (т.е. 95% точек данных будут располагаться в пределах этих границ).
В MS EXCEL
стандартную ошибку
SEy можно вычислить непосредственно по формуле:
=
КОРЕНЬ(СУММКВРАЗН(C23:C83; ТЕНДЕНЦИЯ(C23:C83;B23:B83;B23:B83)) /( СЧЁТ(B23:B83) -2))
или с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);3;2)
Примечание
: Подробнее о функции
ЛИНЕЙН()
см.
эту статью
.
Стандартные ошибки и доверительные интервалы для наклона и сдвига
В разделе
Оценка неизвестных параметров линейной модели
мы получили точечные оценки наклона
а
и сдвига
b
. Так как эти оценки получены на основе случайных величин (значений переменных Х и Y), то эти оценки сами являются случайными величинами и соответственно имеют функцию распределения со
средним значением
и
дисперсией
. Но, чтобы перейти от
точечных оценок
к
интервальным
, необходимо вычислить соответствующие
стандартные ошибки
(т.е.
стандартные отклонения
).
Стандартная ошибка коэффициента регрессии
a
вычисляется на основании
стандартной ошибки регрессии
по следующей формуле:
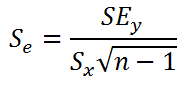
где Sx – стандартное отклонение величины х, вычисляемое по формуле:
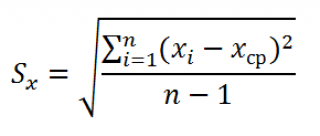
где Sey –
стандартная ошибка регрессии,
т.е. ошибка предсказания значения переменой Y
(
см. выше
).
В MS EXCEL
стандартную ошибку коэффициента регрессии
Se можно вычислить впрямую по вышеуказанной формуле:
=
КОРЕНЬ(СУММКВРАЗН(C23:C83; ТЕНДЕНЦИЯ(C23:C83;B23:B83;B23:B83)) /( СЧЁТ(B23:B83) -2))/ СТАНДОТКЛОН.В(B23:B83) /КОРЕНЬ(СЧЁТ(B23:B83) -1)
или с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);2;1)
Формулы приведены в
файле примера на листе Линейный
в разделе
Регрессионная статистика
.
Примечание
: Подробнее о функции
ЛИНЕЙН()
см.
эту статью
.
При построении
двухстороннего доверительного интервала
для
коэффициента регрессии
его границы определяются следующим образом:
![]()
где —
квантиль распределения Стьюдента
с n-2 степенями свободы. Величина
а
с «крышкой» является другим обозначением
наклона
а
.
Например для
уровня значимости
альфа=0,05, можно вычислить с помощью формулы
=СТЬЮДЕНТ.ОБР.2Х(0,05;n-2)
Вышеуказанная формула следует из того факта, что если ошибки регрессии распределены нормально и независимо, то выборочное распределение случайной величины
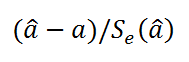
является
t-распределением Стьюдента
с n-2 степенью свободы (то же справедливо и для наклона
b
).
Примечание
: Подробнее о построении
доверительных интервалов
в MS EXCEL можно прочитать в этой статье
Доверительные интервалы в MS EXCEL
.
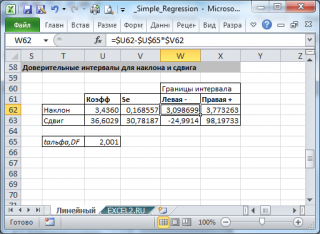
В результате получим, что найденный
доверительный интервал
с вероятностью 95% (1-0,05) накроет истинное значение
коэффициента регрессии.
Здесь мы считаем, что
коэффициент регрессии
a
имеет
распределение Стьюдента
с n-2
степенями свободы
(n – количество наблюдений, т.е. пар Х и Y).
Примечание
: Подробнее о построении
доверительных интервалов
с использованием t-распределения см. статью про построение
доверительных интервалов
для среднего
.
Стандартная ошибка сдвига
b
вычисляется по следующей формуле:
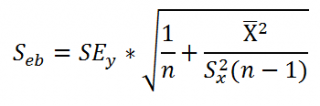
В MS EXCEL
стандартную ошибку сдвига
Seb можно вычислить с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);2;2)
При построении
двухстороннего доверительного интервала
для
сдвига
его границы определяются аналогичным образом как для
наклона
:
b
+/- t*Seb.
Проверка значимости взаимосвязи переменных
Когда мы строим модель Y=αX+β+ε мы предполагаем, что между Y и X существует линейная взаимосвязь. Однако, как это иногда бывает в статистике, можно вычислять параметры связи даже тогда, когда в действительности она не существует, и обусловлена лишь случайностью.
Единственный вариант, когда Y не зависит X (в рамках модели Y=αX+β+ε), возможен, когда
коэффициент регрессии
a
равен 0.
Чтобы убедиться, что вычисленная нами оценка
наклона
прямой линии не обусловлена лишь случайностью (не случайно отлична от 0), используют
проверку гипотез
. В качестве
нулевой гипотезы
Н
0
принимают, что связи нет, т.е. a=0. В качестве альтернативной гипотезы
Н
1
принимают, что a <>0.
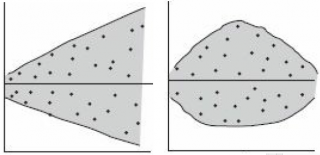
Ниже на рисунках показаны 2 ситуации, когда
нулевую гипотезу
Н
0
не удается отвергнуть.
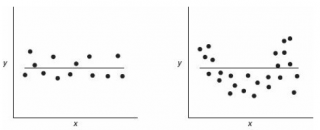
На левой картинке отсутствует любая зависимость между переменными, на правой – связь между ними нелинейная, но при этом
коэффициент линейной корреляции
равен 0.
Ниже — 2 ситуации, когда
нулевая гипотеза
Н
0
отвергается.
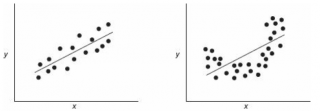
На левой картинке очевидна линейная зависимость, на правой — зависимость нелинейная, но коэффициент корреляции не равен 0 (метод МНК вычисляет показатели наклона и сдвига просто на основании значений выборки).
Для проверки гипотезы нам потребуется:
-
Установить
уровень значимости
, пусть альфа=0,05;
-
Рассчитать с помощью функции
ЛИНЕЙН()
стандартное отклонение
Se для
коэффициента регрессии
(см.предыдущий раздел
);
-
Рассчитать число степеней свободы: DF=n-2 или по формуле =
ИНДЕКС(ЛИНЕЙН(C24:C84;B24:B84;;ИСТИНА);4;2)
-
Вычислить значение тестовой статистики t
0
=a/S
e
, которая имеетраспределение Стьюдента
с
числом степеней свободы
DF=n-2; -
Сравнить значение
тестовой статистики
|t0| с пороговым значением t
альфа
,n-2. Если значение
тестовой статистики
больше порогового значения, то
нулевая гипотеза
отвергается (
наклон
не может быть объяснен лишь случайностью при заданном уровне альфа) либо -
вычислить
p-значение
и сравнить его с
уровнем значимости
.
В
файле примера
приведен пример проверки гипотезы:
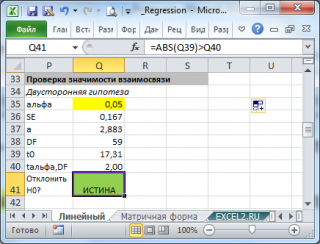
Изменяя
наклон
тренда k (ячейка
В8
) можно убедиться, что при малых углах тренда (например, 0,05) тест часто показывает, что связь между переменными случайна. При больших углах (k>1), тест практически всегда подтверждает значимость линейной связи между переменными.
Примечание
: Проверка значимости взаимосвязи эквивалентна
проверке статистической значимости коэффициента корреляции
. В
файле примера
показана эквивалентность обоих подходов. Также проверку значимости можно провести с помощью
процедуры F-тест
.
Доверительные интервалы для нового наблюдения Y и среднего значения
Вычислив параметры
простой линейной регрессионной модели
Y=aX+β+ε мы получили точечную оценку значения нового наблюдения Y при заданном значении Хi, а именно: Ŷ=
a
* Хi +
b
Ŷ также является точечной оценкой для
среднего значения
Yi при заданном Хi. Но, при построении
доверительных интервалов
используются различные
стандартные ошибки
.
Стандартная ошибка
нового наблюдения Y при заданном Хi учитывает 2 источника неопределенности:
-
неопределенность связанную со случайностью оценок параметров модели
a
и
b
; - случайность ошибки модели ε.
Учет этих неопределенностей приводит к
стандартной ошибке
S(Y|Xi), которая рассчитывается с учетом известного значения Xi.
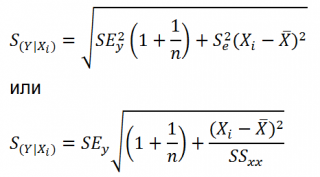
где SS
xx
– сумма квадратов отклонений от
среднего
значений переменной Х:
![]()
Примечание
: Se –
стандартная ошибка коэффициента регрессии
(
наклона
а
).
В
MS EXCEL 2010
нет функции, которая бы рассчитывала эту
стандартную ошибку
, поэтому ее необходимо рассчитывать по вышеуказанным формулам.
Доверительный интервал
или
Интервал предсказания для нового наблюдения
(Prediction Interval for a New Observation) построим по схеме показанной в разделе
Проверка значимости взаимосвязи переменных
(см.
файл примера лист Интервалы
). Т.к. границы интервала зависят от значения Хi (точнее от расстояния Хi до среднего значения Х
ср
), то интервал будет постепенно расширяться при удалении от Х
ср
.
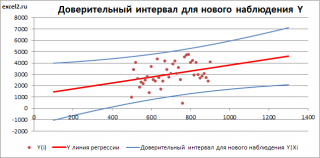
Границы
доверительного интервала
для
нового наблюдения
рассчитываются по формуле:
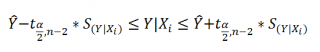
Аналогичным образом построим
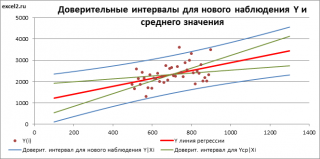
доверительный интервал
для
среднего значения
Y при заданном Хi (Confidence Interval for the Mean of Y). В этом случае
доверительный интервал
будет уже, т.к.
средние значения
имеют меньшую изменчивость по сравнению с отдельными наблюдениями (
средние значения,
в рамках нашей линейной модели Y=aX+β+ε, не включают ошибку ε).
Стандартная ошибка
S(Yср|Xi) вычисляется по практически аналогичным формулам как и
стандартная ошибка
для нового наблюдения:
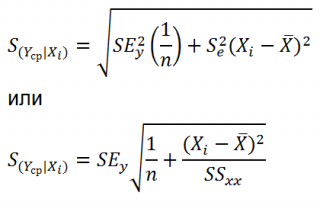
Как видно из формул,
стандартная ошибка
S(Yср|Xi) меньше
стандартной ошибки
S(Y|Xi) для индивидуального значения
.
Границы
доверительного интервала
для
среднего значения
рассчитываются по формуле:
![]()
Проверка адекватности линейной регрессионной модели
Модель адекватна, когда все предположения, лежащие в ее основе, выполнены (см. раздел
Предположения линейной регрессионной модели
).
Проверка адекватности модели в основном основана на исследовании остатков модели (model residuals), т.е. значений ei=yi – ŷi для каждого Хi. В рамках
простой линейной модели
n остатков имеют только n-2 связанных с ними
степеней свободы
. Следовательно, хотя, остатки не являются независимыми величинами, но при достаточно большом n это не оказывает какого-либо влияния на проверку адекватности модели.
Чтобы проверить предположение о
нормальности распределения
ошибок строят
график проверки на нормальность
(Normal probability Plot).
В
файле примера на листе Адекватность
построен
график проверки на нормальность
. В случае
нормального распределения
значения остатков должны быть близки к прямой линии.
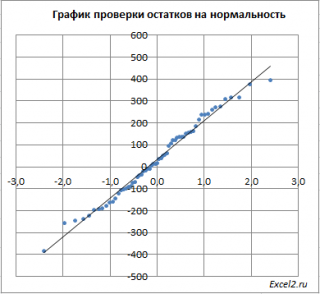
Так как значения переменной Y мы
генерировали с помощью тренда
, вокруг которого значения имели нормальный разброс, то ожидать сюрпризов не приходится – значения остатков располагаются вблизи прямой.
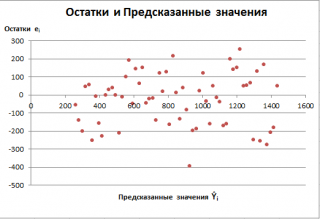
Также при проверке модели на адекватность часто строят график зависимости остатков от предсказанных значений Y. Если точки не демонстрируют характерных, так называемых «паттернов» (шаблонов) типа вор
о
нок или другого неравномерного распределения, в зависимости от значений Y, то у нас нет очевидных доказательств неадекватности модели.
В нашем случае точки располагаются примерно равномерно.
Часто при проверке адекватности модели вместо остатков используют нормированные остатки. Как показано в разделе
Стандартная ошибка регрессии
оценкой
стандартного отклонения ошибок
является величина SEy равная квадратному корню из величины MSE. Поэтому логично нормирование остатков проводить именно на эту величину.
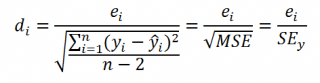
SEy можно вычислить с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);3;2)
Иногда нормирование остатков производится на величину
стандартного отклонения
остатков (это мы увидим в статье об инструменте
Регрессия
, доступного в
надстройке MS EXCEL Пакет анализа
), т.е. по формуле:
Вышеуказанное равенство приблизительное, т.к. среднее значение остатков близко, но не обязательно точно равно 0.
Простая линейная регрессия — это метод, который мы можем использовать для понимания взаимосвязи между объясняющей переменной x и переменной отклика y.
В этом руководстве объясняется, как выполнить простую линейную регрессию в Excel.
Пример: простая линейная регрессия в Excel
Предположим, нас интересует взаимосвязь между количеством часов, которое студент тратит на подготовку к экзамену, и полученной им экзаменационной оценкой.
Чтобы исследовать эту взаимосвязь, мы можем выполнить простую линейную регрессию, используя часы обучения в качестве независимой переменной и экзаменационный балл в качестве переменной ответа.
Выполните следующие шаги в Excel, чтобы провести простую линейную регрессию.
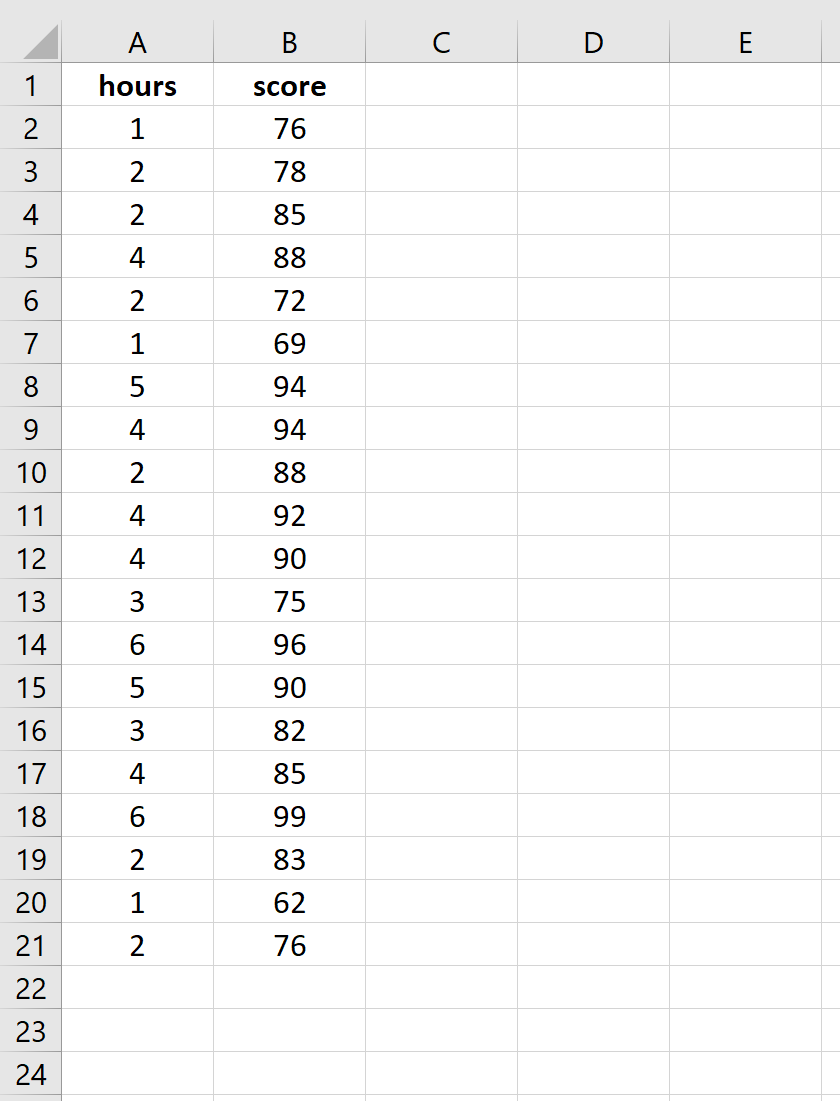
Шаг 1: Введите данные.
Введите следующие данные о количестве часов обучения и экзаменационном балле, полученном для 20 студентов:
Шаг 2: Визуализируйте данные.
Прежде чем мы выполним простую линейную регрессию, полезно создать диаграмму рассеяния данных, чтобы убедиться, что действительно существует линейная зависимость между отработанными часами и экзаменационным баллом.
Выделите данные в столбцах A и B. В верхней ленте Excel перейдите на вкладку « Вставка ». В группе « Диаграммы » нажмите « Вставить разброс» (X, Y) и выберите первый вариант под названием « Разброс ». Это автоматически создаст следующую диаграмму рассеяния:
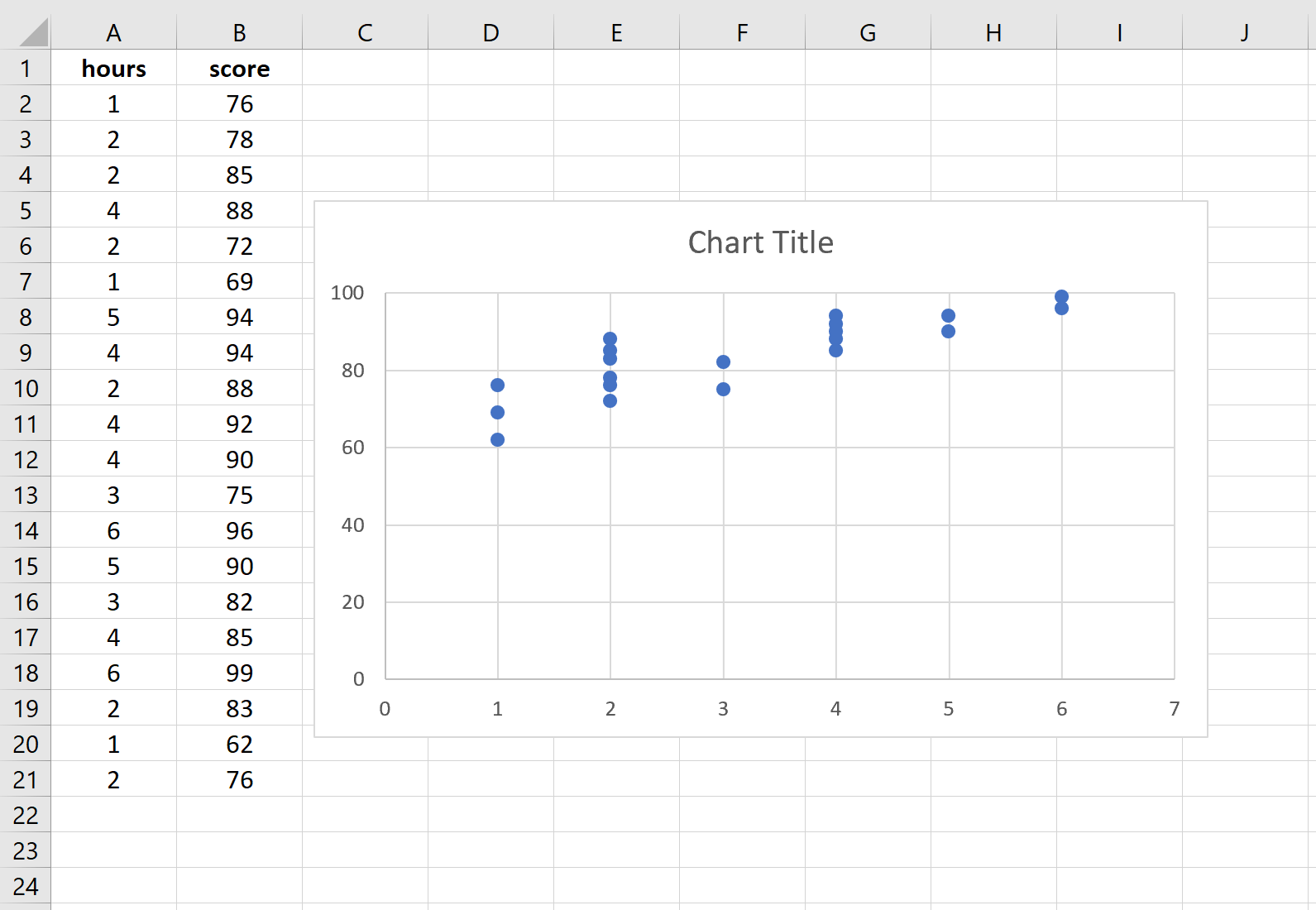
Количество часов обучения показано на оси x, а баллы за экзамены показаны на оси y. Мы видим, что между двумя переменными существует линейная зависимость: большее количество часов обучения связано с более высокими баллами на экзаменах.
Чтобы количественно оценить взаимосвязь между этими двумя переменными, мы можем выполнить простую линейную регрессию.
Шаг 3: Выполните простую линейную регрессию.
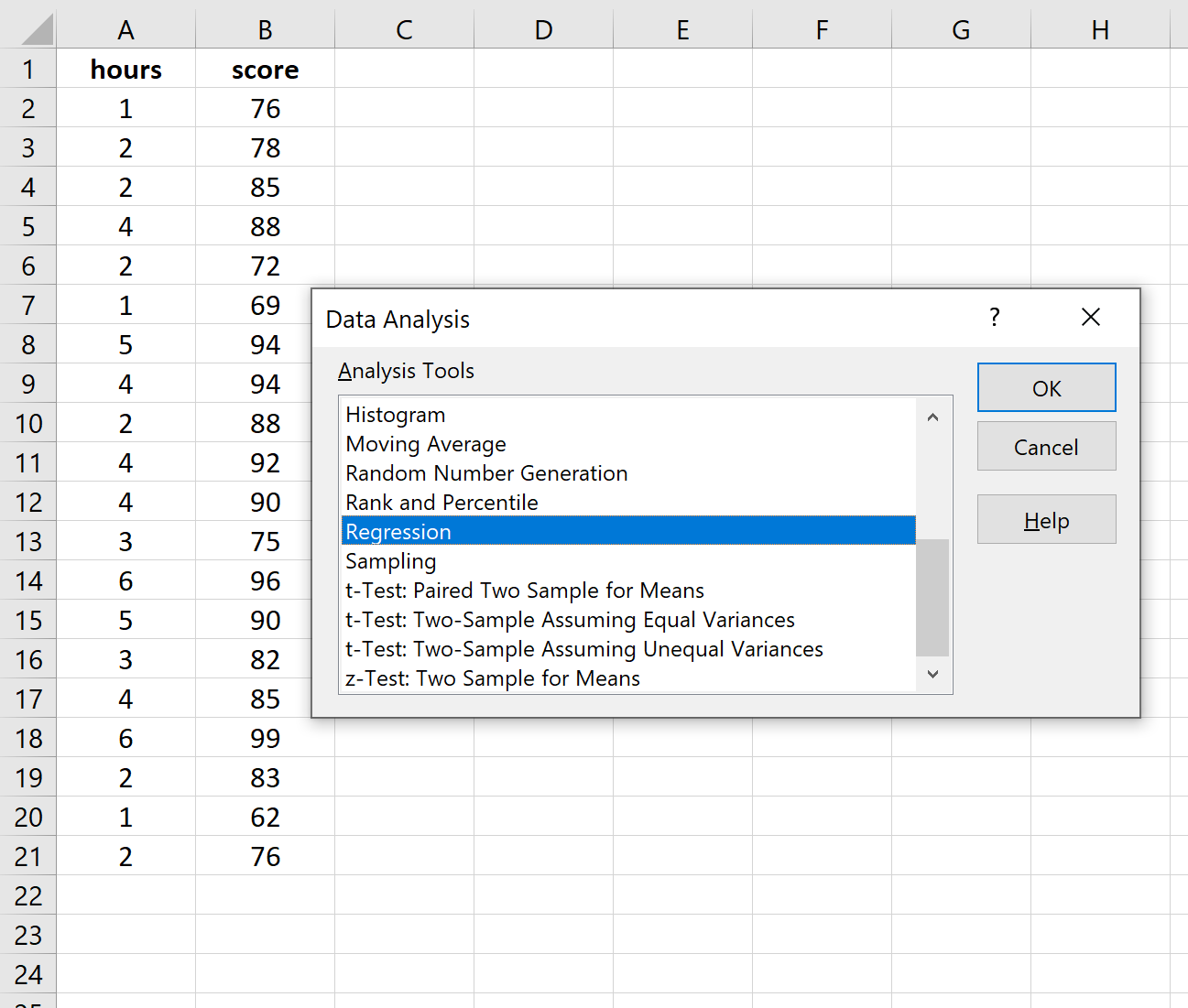
В верхней ленте Excel перейдите на вкладку « Данные » и нажмите « Анализ данных».Если вы не видите эту опцию, вам необходимо сначала установить бесплатный пакет инструментов анализа .

Как только вы нажмете « Анализ данных», появится новое окно. Выберите «Регрессия» и нажмите «ОК».
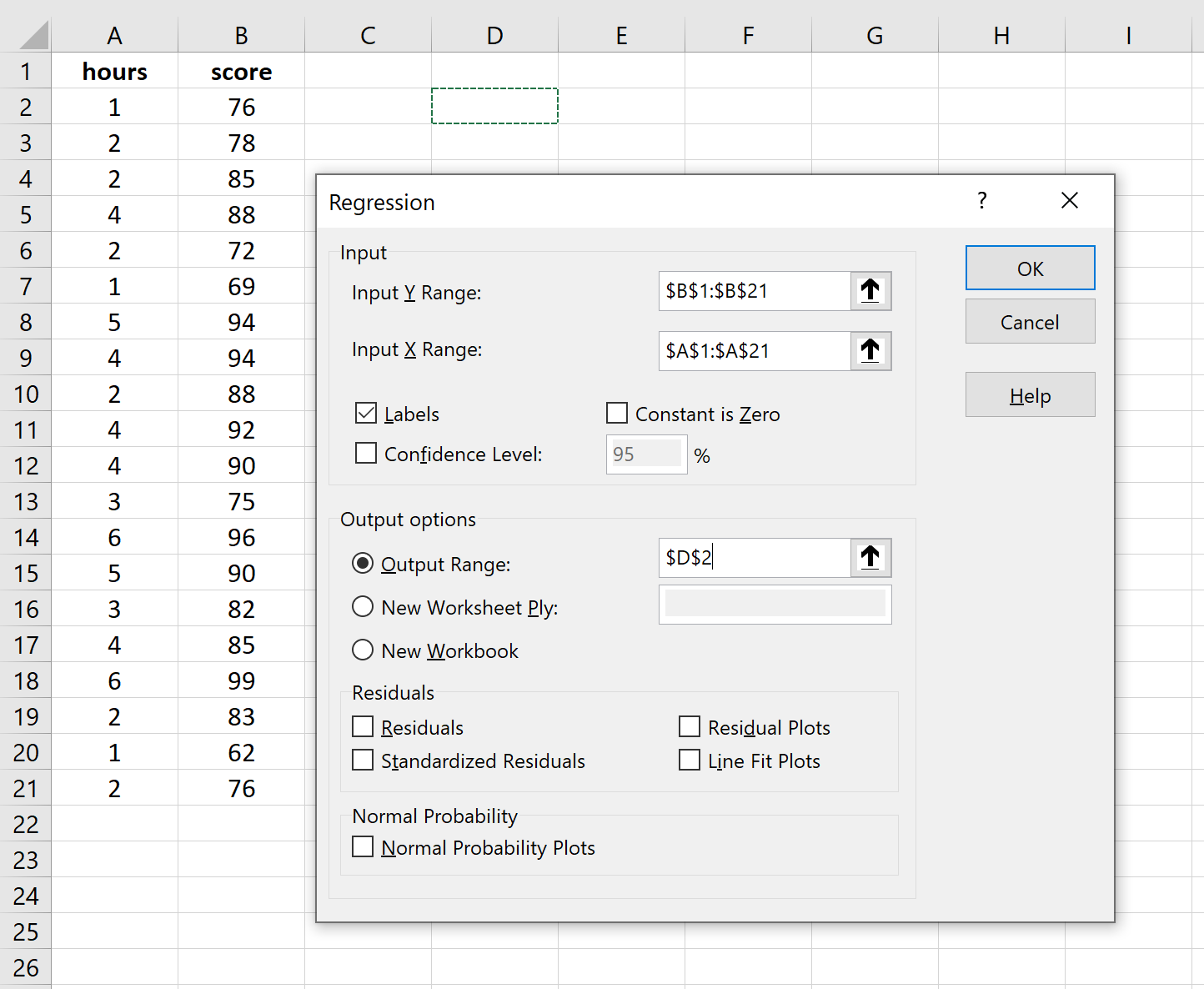
Для Input Y Range заполните массив значений для переменной ответа. Для Input X Range заполните массив значений для независимой переменной.
Установите флажок рядом с Метки , чтобы Excel знал, что мы включили имена переменных во входные диапазоны.
В поле Выходной диапазон выберите ячейку, в которой должны отображаться выходные данные регрессии.
Затем нажмите ОК .
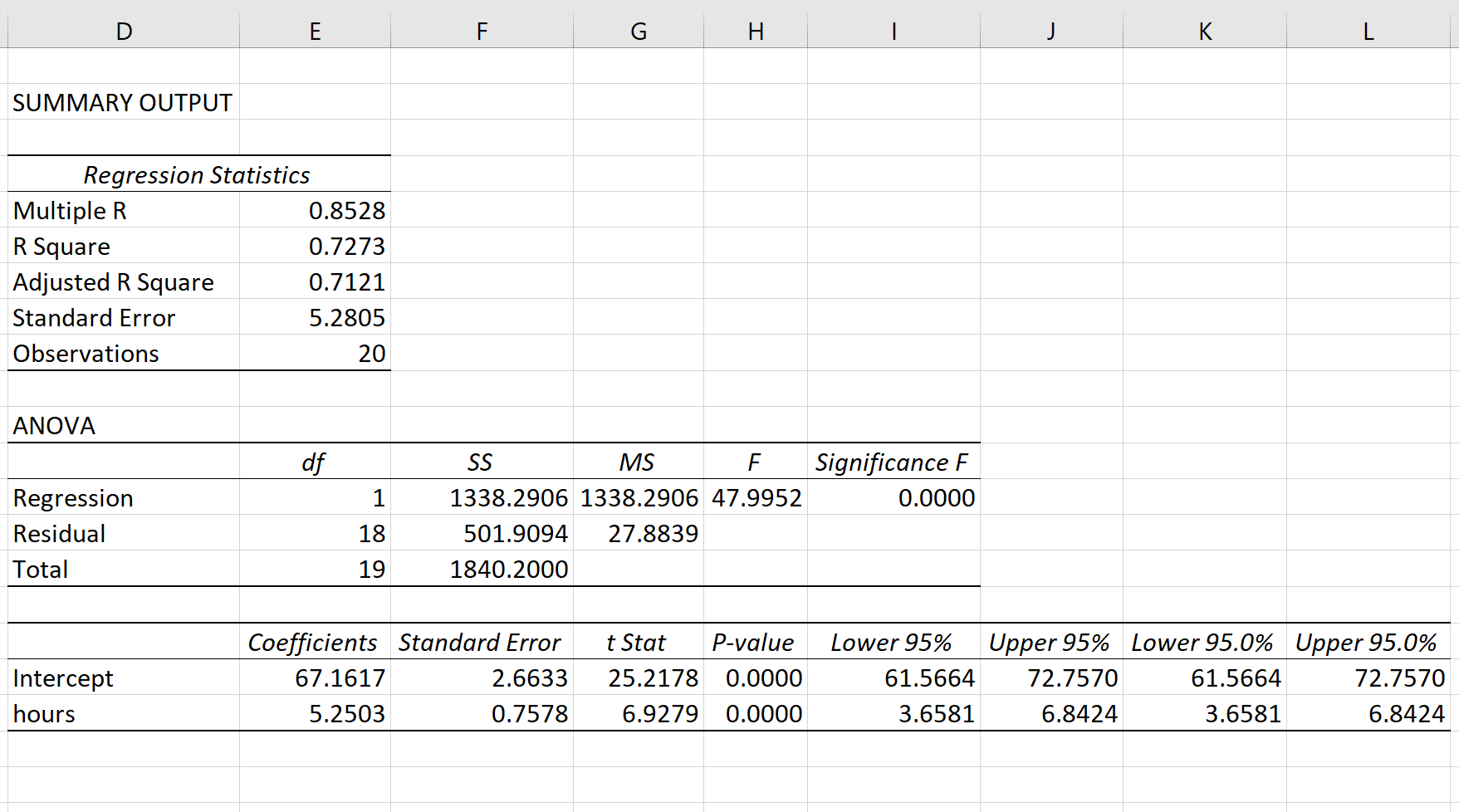
Автоматически появится следующий вывод:
Шаг 4: Интерпретируйте вывод.
Вот как интерпретировать наиболее релевантные числа в выводе:
R-квадрат: 0,7273.Это известно как коэффициент детерминации. Это доля дисперсии переменной отклика, которая может быть объяснена объясняющей переменной. В этом примере 72,73 % различий в баллах за экзамены можно объяснить количеством часов обучения.
Стандартная ошибка: 5.2805.Это среднее расстояние, на которое наблюдаемые значения отходят от линии регрессии. В этом примере наблюдаемые значения отклоняются от линии регрессии в среднем на 5,2805 единиц.
Ф: 47,9952.Это общая F-статистика для регрессионной модели, рассчитанная как MS регрессии / остаточная MS.
Значение F: 0,0000.Это p-значение, связанное с общей статистикой F. Он говорит нам, является ли регрессионная модель статистически значимой. Другими словами, он говорит нам, имеет ли независимая переменная статистически значимую связь с переменной отклика. В этом случае p-значение меньше 0,05, что указывает на наличие статистически значимой связи между отработанными часами и полученными экзаменационными баллами.
Коэффициенты: коэффициенты дают нам числа, необходимые для написания оценочного уравнения регрессии. В этом примере оцененное уравнение регрессии:
экзаменационный балл = 67,16 + 5,2503*(часов)
Мы интерпретируем коэффициент для часов как означающий, что за каждый дополнительный час обучения ожидается увеличение экзаменационного балла в среднем на 5,2503.Мы интерпретируем коэффициент для перехвата как означающий, что ожидаемая оценка экзамена для студента, который учится без часов, составляет 67,16 .
Мы можем использовать это оценочное уравнение регрессии для расчета ожидаемого экзаменационного балла для учащегося на основе количества часов, которые он изучает.
Например, ожидается, что студент, который занимается три часа, получит на экзамене 82,91 балла:
экзаменационный балл = 67,16 + 5,2503*(3) = 82,91
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные задачи в Excel:
Как создать остаточный график в Excel
Как построить интервал прогнозирования в Excel
Как создать график QQ в Excel
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
Регрессия бывает:
- линейной (у = а + bx);
- параболической (y = a + bx + cx2);
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.

Модель линейной регрессии имеет следующий вид:
У = а0 + а1х1 +…+акхк.
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
- Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».
- Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
- Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.



После активации надстройка будет доступна на вкладке «Данные».

Теперь займемся непосредственно регрессионным анализом.
- Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».
- Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.
- После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).



В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача: Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.

Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» — первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» — второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.

Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:

Корреляционно-регрессионный анализ
На практике эти две методики часто применяются вместе.
Пример:

- Строим корреляционное поле: «Вставка» — «Диаграмма» — «Точечная диаграмма» (дает сравнивать пары). Диапазон значений – все числовые данные таблицы.
- Щелкаем левой кнопкой мыши по любой точке на диаграмме. Потом правой. В открывшемся меню выбираем «Добавить линию тренда».
- Назначаем параметры для линии. Тип – «Линейная». Внизу – «Показать уравнение на диаграмме».
- Жмем «Закрыть».




Теперь стали видны и данные регрессионного анализа.
Коэффициент детерминации в Excel (Эксель)
Для статистических моделей во многих случаях необходимо определить точность прогноза. Это производится с помощью специальных расчётов в Microsoft Excel, а использоваться будет коэффициент детерминации. Он обозначается как R^2.
Статистические модели можно разделить на качественные уровни в зависимости от коэффициента. От 0.8 до 1 относятся модели хорошего качества, модели достаточного качества имеют уровень от 0.5 до 0.8, а плохое качество имеет диапазон от 0 до 0.5.
Способ определения точности с помощью функции КВПИРСОН
В линейной функции коэффициент детерминации будет равен квадрату корреляционного коэффициента. Рассчитать его можно с помощью специальной функции. Для начала создадим таблицу с данными.
Потом нужно выбрать место, где будет показан результат расчёта и нажимаем на кнопку вставки функции.
После этого откроется специальное окно. Категорию нужно выбрать “Статистические” и выбираем КВПИРСОН. Эта функция позволяет определить коэффициент корреляции касательно функции Пирсона, соответственно квадратное значение коэффициента корреляции = коэффициенту детерминации.
После подтверждения действия, появится окно в котором нужно в полях выставить “Известные значения Х” и “Известные значения Y”. Нажимаем мышкой поле “Известные значения Y” и в рабочем окне выделяем данные столбца Y. Аналогичное действие делаем и с другим полем выбирая данные уже с таблицы Х.
Как результат этих действий будет показано значение коэффициента детерминации в ячейке, которая ранее была выбрана для отображения результата.
Определение коэффициента детерминации если функция не является линейной.
Если функция нелинейная, то инструментарий Excel также позволяет рассчитать коэффициент с помощью инструмента “Регрессия”. Его можно найти в пакете анализа данных. Но для начала нужно активировать этот пакет, перейдя в раздел “Файл” и в списке открыть “Параметры”.
После этого можно увидеть новое окно, в котором нужно в меню выбрать “Надстройки”, а в специальном поле по управлению надстройками выбираем “Надстройки Excel” и переходим к ним.
После перехода в надстройки Excel появится новое окно. В нём можно увидеть доступные для пользователя надстройки. Ставим галочку возле “Пакет анализа” и подтверждаем действие.
Найти его можно в разделе “Данные”, после перехода в который нажимаем на “Анализ данных” в правой части экрана.
После его открытия, в списке выбираем “Регрессия”и подтверждаем действие.
После этого появится новое окно в котором можно производить настройки. Входные данные позволяют настроить значение интервалов Х и Y, достаточно выделить соответствующие ячейки аргументов другого аргумента. В поле уровня надежности можно выставить нужный показатель. Параметры вывода позволяют задать где будет показан результат. Если к примеру выбрать показ на текущем листе, то для начала нужно выбрать пункт “Выходной интервал” – и нажать на области основного окна где будет в будущем отображаться результат и координаты ячейки будут показаны соответствующем поле. В конце подтверждаем действие.
В рабочем окне появится результат. Так как мы вычисляем коэффициент детерминации, то в итогах нам нужен R-коэффициент. Если посмотреть на значение, то можно увидеть что оно относится к наилучшему качеству.
Способ определения коэффициента детерминации для линии тренда
Имея созданную таблицу с соответствующими значение, создаем график. Чтобы провести на нём линию тренда надо нажать на график, а именно на область где строится линия. Сверху в панели инструментов выбрать раздел “Макет”, а в нём выбрать “Линия тренда”. После этого в контексте данного примера в списке выбираем “Экспоненциальное приближение”.
Линия тренда будет отображена на графике как кривая с черным цветом.
Для того чтобы показать коэффициент детерминации, нужно по черной кривой нажать правой кнопкой мыши и выбрать в списке “Формат линии тренда”.
После этого появится новое окно. В нём нужно отметить флажком и выбрать нужное действие (показано на скриншоте). Благодаря этому коэффициент будет отображен на графике. После того как это было сделано, закрываем окно.
После закрытия окна формата линии тренда в рабочем окне можно увидеть значение коэффициента детерминации.
Если пользователю нужен другой типаж линии тренда, то в окне “Формат линии тренда” можно выбрать его. Не забыв задать его ранее при создании линии тренда в разделе “Макет” или в контекстном меню. Также не забываем ставить флажок для функции R^2.
Как результат можно увидеть изменение линии тренда и число достоверности.
После просмотра разных вариаций линий тренда, пользователь может определить наиболее подходящую для себя так как показатель достоверности может меняться в зависимости от выбора линии. Максимальный коэффициент это единица, что означает максимальную достоверность, однако не всегда можно достигнуть этого значения.
Так было рассмотрено несколько способов по нахождению коэффициента детерминации. Пользователь может выбрать наиболее оптимальный для своих целей.
Корреляционно-регрессионный анализ в Excel: инструкция выполнения
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
- линейной (у = а + bx);
- параболической (y = a + bx + cx 2 );
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.
Модель линейной регрессии имеет следующий вид:
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
- Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».
- Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
- Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.
После активации надстройка будет доступна на вкладке «Данные».
Теперь займемся непосредственно регрессионным анализом.
- Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».
- Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.
- После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).
В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача: Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.
Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» – первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» – второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.
Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:
Корреляционно-регрессионный анализ
На практике эти две методики часто применяются вместе.
- Строим корреляционное поле: «Вставка» – «Диаграмма» – «Точечная диаграмма» (дает сравнивать пары). Диапазон значений – все числовые данные таблицы.
- Щелкаем левой кнопкой мыши по любой точке на диаграмме. Потом правой. В открывшемся меню выбираем «Добавить линию тренда».
- Назначаем параметры для линии. Тип – «Линейная». Внизу – «Показать уравнение на диаграмме».
- Жмем «Закрыть».
Теперь стали видны и данные регрессионного анализа.
Расчет коэффициента детерминации в excel. Коэффициент детерминации в Excel (Эксель)
Метод линейной регрессии позволяет нам описывать прямую линию, максимально соответствующую ряду упорядоченных пар (x, y). Уравнение для прямой линии, известное как линейное уравнение, представлено ниже:
ŷ — ожидаемое значение у при заданном значении х,
x — независимая переменная,
a — отрезок на оси y для прямой линии,
b — наклон прямой линии.
На рисунке ниже это понятие представлено графически:
На рисунке выше показана линия, описанная уравнением ŷ =2+0.5х. Отрезок на оси у — это точка пересечения линией оси у; в нашем случае а = 2. Наклон линии, b, отношение подъема линии к длине линии, имеет значение 0.5. Положительный наклон означает, что линия поднимается слева направо. Если b = 0, линия горизонтальна, а это значит, что между зависимой и независимой переменными нет никакой связи. Иными словами, изменение значения x не влияет на значение y.
Часто путают ŷ и у. На графике показаны 6 упорядоченных пар точек и линия, в соответствии с данным уравнением

На этом рисунке показана точка, соответствующая упорядоченной паре х = 2 и у = 4. Обратите внимание, что ожидаемое значение у в соответствии с линией при х = 2 является ŷ. Мы можем подтвердить это с помощью следующего уравнения:
ŷ = 2 + 0.5х =2 +0.5(2) =3.
Значение у представляет собой фактическую точку, а значение ŷ — это ожидаемое значение у с использованием линейного уравнения при заданном значении х.
Следующий шаг – определить линейное уравнение, максимально соответствующее набору упорядоченных пар, об этом мы говорили в предыдущей статье, где определяли вид уравнения по .
Использование Excel для определения линейной регрессии
Для того, чтобы воспользоваться инструментом регрессионного анализа встроенного в Excel, необходимо активировать надстройку Пакет анализа . Найти ее можно, перейдя по вкладке Файл –> Параметры (2007+), в появившемся диалоговом окне Параметры Excel переходим во вкладку Надстройки. В поле Управление выбираем Надстройки Excel и щелкаем Перейти. В появившемся окне ставим галочку напротив Пакет анализа, жмем ОК.

Во вкладке Данные в группе Анализ появится новая кнопка Анализ данных.

Чтобы продемонстрировать работу надстройки, воспользуемся данными , где парень и девушка делят столик в ванной. Введите данные нашего примера с ванной в столбцы А и В чистого листа.
Перейдите во вкладку Данные, в группе Анализ щелкните Анализ данных. В появившемся окне Анализ данных выберите Регрессия , как показано на рисунке, и щелкните ОК.

Установите необходимыe параметры регрессии в окне Регрессия , как показано на рисунке:

Щелкните ОК. На рисунке ниже показаны полученные результаты:

Эти результаты соответствуют тем, которые мы получили путем самостоятельных вычислений в .
Линия регрессии является графическим отражением взаимосвязи между явлениями. Очень наглядно можно построить линию регрессии в программе Excel.
Для этого необходимо:
1.Открыть программу Excel
2.Создать столбцы с данными. В нашем примере мы будем строить линию регрессии, или взаимосвязи, между агрессивностью и неуверенностью в себе у детей-первоклассников. В эксперименте участвовали 30 детей, данные представлены в таблице эксель:
1 столбик — № испытуемого
2 столбик — агрессивность в баллах
3 столбик — неуверенность в себе в баллах

3.Затем необходимо выделить оба столбика (без названия столбика), нажать вкладку вставка , выбрать точечная , а из предложенных макетов выбрать самый первый точечная с маркерами .

4.Итак у нас получилась заготовка для линии регрессии — так называемая — диаграмма рассеяния . Для перехода к линии регрессии нужно щёлкнуть на получившийся рисунок, нажать вкладку конструктор, найти на панели макеты диаграмм и выбрать Ма кет9 , на нем ещё написано f(x)

5.Итак, у нас получилась линия регрессии. На графике также указано её уравнение и квадрат коэффициента корреляции

6.Осталось добавить название графика, название осей. Также по желанию можно убрать легенду, уменьшить количество горизонтальных линий сетки (вкладка макет , затем сетка ). Основные изменения и настройки производятся во вкладке Макет

Линия регрессии построена в MS Excel. Теперь её можно добавить в текст работы.
Построение линейной регрессии, оценивание ее параметров и их значимости можно выполнить значительнее быстрей при использовании пакета анализа Excel (Регрессия). Рассмотрим интерпретацию полученных результатов в общем случае (k объясняющих переменных) по данным примера 3.6.
В таблице регрессионной статистики приводятся значения:
Множественный R – коэффициент множественной корреляции ;
R – квадрат – коэффициент детерминации R 2 ;
Нормированный R – квадрат – скорректированный R 2 с поправкой на число степеней свободы;
Стандартная ошибка – стандартная ошибка регрессии S ;
Наблюдения – число наблюдений n .
В таблице Дисперсионный анализ приведены:
1. Столбец df – число степеней свободы, равное
для строки Регрессия df = k ;
2. Столбец SS – сумма квадратов отклонений, равная
для строки Регрессия ;
3. Столбец MS дисперсии, определяемые по формуле MS = SS /df :
для строки Регрессия – факторная дисперсия;
для строкиОстаток – остаточная дисперсия.
4. Столбец F – расчетное значение F -критерия, вычисляемое по формуле
5. Столбец Значимость F –значение уровня значимости, соответствующее вычисленной F -статистике.
Значимость F = FРАСП(F- статистика, df (регрессия), df (остаток)).
Если значимость F Виды регрессионного анализа
Существует несколько видов регрессий:
- параболическая;
- степенная;
- логарифмическая;
- экспоненциальная;
- показательная;
- гиперболическая;
- линейная регрессия.
О выполнении последнего вида регрессионного анализа в Экселе мы подробнее поговорим далее.
Линейная регрессия в программе Excel
Внизу, в качестве примера, представлена таблица, в которой указана среднесуточная температура воздуха на улице, и количество покупателей магазина за соответствующий рабочий день. Давайте выясним при помощи регрессионного анализа, как именно погодные условия в виде температуры воздуха могут повлиять на посещаемость торгового заведения.
Общее уравнение регрессии линейного вида выглядит следующим образом: У = а0 + а1х1 +…+акхк. В этой формуле Y означает переменную, влияние факторов на которую мы пытаемся изучить. В нашем случае, это количество покупателей. Значение x – это различные факторы, влияющие на переменную. Параметры a являются коэффициентами регрессии. То есть, именно они определяют значимость того или иного фактора. Индекс k обозначает общее количество этих самых факторов.


Разбор результатов анализа
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.

Одним из основных показателей является R-квадрат . В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты» . Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
3.5. Определение уравнения линии характеристики и коэффициента детерминации с помощью программы Excel
Линия характеристики представляет собой уравнение регрессии. Поэтому для ее построения необходимо оценить значения коэффициентов у. и Д в уравнении (3.21). Найти данные коэффициенты можно несколькими способами. Рассмотрим их на примерах.
Имеется выборка наблюдений доходности актива А и рыночного индекса (для примера ограничимся десятью значениями). Печатаем значения доходности актива в ячейках от А1 до А10, а индекса – от В1 до В10, как показано на рис. 3.15.

Определим вначале коэффициент /3 актива. Решение получим в ячейке А12, поэтому выделяем ее, т.е. наводим на нее курсор и щелкаем мышью. Открываем окно “Мастер функций”, т.е. наводим курсор на значок ?• на панели инструментов и щелкаем мышью. В поле “Категория” выбираем курсором строку “Статистические” и щелкаем мышью. В поле окна “Функция” выбираем курсором строку “НАКЛОН” и щелкаем мышью. Строка высветилась синим цветом. Наводим курсор на кнопку ОК и щелкаем мышью. Появилось окно “НАКЛОН”. В окне две строки: “Изв_знач_у” и “Извзначх”. В первую строку заносим значения доходности актива А. Для этого наводим курсор на знак 51 с правой стороны первой строки и щелкаем мышью. Окно “НАКЛОН” свернулось в поле первой строки. Наводим курсор на ячейку А1, нажимаем левую клавишу мыши и, удерживая ее в нажатом положении, проводим курсор вниз до ячейки А10 и отпускаем клавишу. Вновь наводим курсор на знак 53 и щелкаем мышью. Появилось развернутое окно “НАКЛОН”. Заносим доходности рыночного индекса во вторую строку. Для этого наводим курсор на знак 3 во второй строке и щелкаем мышью. Наводим курсор на ячейку В1, нажимаем левую клавишу мыши и, удерживая ее в нажатом положении, проводим курсор вниз до ячейки В10, отпускаем клавишу. Наводим курсор на кнопку 3 и щелкаем мышью. Появилось развернутое окно “НАКЛОН”. Наводим курсор на кнопку ОК и щелкаем мышью. В ячейке А12 появилась цифра 1,029884.
(Получить значение коэффициента /? можно другим способом: выбираем курсором ячейку А12 и печатаем в ней формулу:
и нажимаем клавишу Enter.)
Рассчитаем теперь коэффициент у. Решение получим в ячейке В12, поэтому наводим на нее курсор и щелкаем мышью. Открываем окно “Мастер функций” , т.е. наводим курсор на значок * на панели инструментов и щелкаем мышью. В поле “Категория” выбираем курсором строку “Статистические” и щелкаем мышью. В поле окна “Функция” выбираем курсором строку “ОТРЕЗОК” и щелкаем мышью. Строка высветилась синим цветом. Наводим курсор на кнопку ОК и щелкаем мышью. Появилось окно “ОТРЕЗОК”. В окне две строки: “Изв_знач_у” и “Изв_знач_х”. В первую строку заносим значения доходности актива А. Для этого наводим курсор на знак Э с правой стороны первой строки и щелкаем мышью. Окно “ОТРЕЗОК” свернулось в поле первой строки. Наводим курсор на ячейку А1, нажимаем левую клавишу мыши и, удерживая ее в нажатом положении, проводим курсор вниз до ячейки А10 и отпускаем клавишу. Вновь наводим курсор на знак !Щ и щелкаем мышью. Появилось развернутое окно “ОТРЕЗОК”. Заносим доходности рыночного индекса во вторую строку. Для этого наводим курсор на знак “Щ во второй строке и щелкаем мышью. Наводим курсор на ячейку В1, нажимаем левую клавишу мыши и, удерживая ее в нажатом положении, проводим курсор вниз до ячейки В10, отпускаем клавишу. Наводим курсор на кнопку Э и щелкаем мышью. Появилось развернутое окно “ОТРЕЗОК”. Наводим курсор на кнопку ОК и щелкаем мышью. В ячейке В12 появилась цифра 2,777476.
(Получить значение коэффициента (5 можно другим способом: выбираем курсором ячейку В12 и печатаем в ней формулу:
и нажимаем клавишу Enter.)
Рассчитать коэффициенты у и ft для данных примера 1 можно с помощью функции “ЛИНЕИН” “Мастера функций”. Решение получим в блоке ячеек А12 и В12. Поэтому выделяем их, т.е. наводим курсор на ячейку А12, нажимаем левую клавишу мыши и, удерживая ее, проводим курсор до ячейки В12, отпускаем клавишу. Открываем окно “Мастер функций”, т.е. наводим курсор на значок rj& на панели инструментов и щелкаем мышью. В поле “Категория” выбираем курсором строку “Статистические” и щелкаем мышью. В поле окна “Функция” выбираем курсором строку “ЛИНЕИН” и щелкаем мышью. Строка высветилась синим цветом. Наводим курсор на кнопку ОК и щелкаем мышью. Появилось окно “ЛИНЕИН”. Оно представлено на рис. 3.16.

В строку “Изв_знач_у” заносим значения доходности актива А. Для этого наводим курсор на знак 3 в первой строке и щелкаем мышью. Окно “ЛИНЕИН” свернулось в поле первой строки. Наводим курсор на ячейку А1, нажимаем левую клавишу мыши и, удерживая ее в нажатом положении, проводим курсор вниз до ячейки А10 и отпускаем клавишу. Вновь наводим курсор на знак 3t и щелкаем мышью. Появилось развернутое окно “ЛИНЕИН”. Заносим доходности рыночного индекса в строку “Извзначх”. Для этого наводим курсор на знак Щ во второй строке и щелкаем мышью. Наводим курсор на ячейку В1, нажимаем левую клавишу мыши и, удерживая ее в нажатом положении, проводим курсор вниз до ячейки В10, отпускаем клавишу. Наводим курсор на кнопку щ и щелкаем мышью. Появилось развернутое окно “ЛИНЕИН”. Одновременно нажимаем на клавиши Ctrl, Shift и Enter (удобно вначале нажать Ctrl и Shift и, удерживая их в нажатом положении, нажать Enter). В блоке ячеек А12 и В12 появились соответственно цифры 1,029884 и 2,777476 .
С помощью функции “ЛИНЕЙН” можно получить значение коэффициента детерминации. Для этого выделим блок из ячеек А12:В14, т.е. наводим курсор на ячейку А12, нажимаем левую клавишу мыши и, удерживая ее, доводим курсор до ячейки В14, отпускаем клавишу. После этого вводим значения доходно-стей актива А и рыночного индекса в строки “Изв_знач_у” и “Извзначх” окна “ЛИНЕЙН” как было сказано выше. Далее в открытом окне “ЛИНЕЙН” в строке “Стат” печатаем цифру 1 (Вместо цифры 1 также можно напечатать слово ИСТИНА) и одновременно нажимаем клавиши Ctrl, Shift и Enter. На экране получаем результат как показано на рис. 3.17.

В ячейках А12 и В12 представлены значения коэффициентов J3 и у. Значение коэффициента детерминации расположено в ячейке А14, это 0,627868.
Знаете ли Вы, что: Вы можете выиграть от $20 до $250 в конкурсе «Formula FX» от Альпари, заняв призовые места с 1-го по 20-е. Для участия необходим реальный счет, пополненный не менее чем на $20. Победитель может снять призовую сумму в любой момент времени без каких-либо ограничений.

Рассчитать коэффициенты у и Р и коэффициент детерминации для данных примера 1 можно с помощью пакета “Анализ данных”8. Для этого выбираем курсором меню “Сервис” и щелкаем мышью. Появилось выпадающее меню. Выбираем курсором строку “Анализ данных” и щелкаем мышью. Появилось окно” Анализ данных”. Выбираем курсором строку “Регрессия” и щелкаем мышью. Строка высвечивается синим цветом. Наводим курсор на кнопку ОК и щелкаем мышью. Появилось окно “Регрессия” (см. рис. 3.18).

Наводим курсор на знак 3 справа от поля строки “Входной интервал Y” и щелкаем мышью. Окно “Регрессия” свернулось в поле строки. Наводим курсор на ячейку А1, нажимаем левую клавишу мыши и, удерживая ее в нажатом положении, проводим курсор вниз до ячейки А10 и отпускаем клавишу. Вновь наводим курсор на знак 31 и щелкаем мышью. Появилось развернутое окно “Регрессия”. Наводим курсор на знак 3i справа от поля строки “Входной интервал X” и щелкаем мышью. Окно “Регрессия” свернулось в поле строки. Наводим курсор на ячейку В1, нажимаем левую клавишу мыши и, удерживая ее в нажатом положении, проводим курсор вниз до ячейки В10 и отпускаем клавишу. Вновь наводим курсор на знак 3 и щелкаем мышью. Появилось развернутое окно “Регрессия”. Если в круглом окне слева от надписи “Выходной интервал” не стоит точка, то надо навести курсор на данную строку и щелкнуть мышью: в окне появится точка. После этого наводим курсор на знак 3 в правой части этой строки и щелкаем мышью. Окно “Регрессия” свернулось в поле строки.
Пример нахождения коэффициента детерминации
Коэффициент детерминации рассчитывается для оценки качества подбора уравнения регрессии. Для приемлемых моделей предполагается, что коэффициент детерминации должен быть хотя бы не меньше 50%. Модели с коэффициентом детерминации выше 80% можно признать достаточно хорошими. Значение коэффициента детерминации R 2 = 1 означает функциональную зависимость между переменными.
Для линейной зависимости коэффициент детерминации равен квадрату коэффициента корреляции rxy: R 2 = rxy 2 .
2 “>Рассчитать свое значение
Например, значение R 2 = 0.83, означает, что в 83% случаев изменения х приводят к изменению y . Другими словами, точность подбора уравнения регрессии – высокая.
В общем случае, коэффициент детерминации находится по формуле: 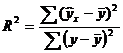 или
или 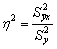
В этой формуле указаны дисперсии: 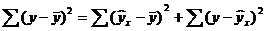 ,
,
где ∑(y- y ) – общая сумма квадратов отклонений;
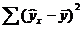 – сумма квадратов отклонений, обусловленная регрессией («объясненная» или «факторная»);
– сумма квадратов отклонений, обусловленная регрессией («объясненная» или «факторная»); 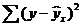 – остаточная сумма квадратов отклонений.
– остаточная сумма квадратов отклонений.
В случае нелинейной регрессии коэффициент детерминации рассчитывается через этот калькулятор. При множественной регрессии, коэффициент детемрминации можно найти через сервис Множественная регрессия
Пример . Дано:
- доля денежных доходов, направленных на прирост сбережений во вкладах, займах, сертификатах и в покупку валюты, в общей сумме среднедушевого денежного дохода, % (Y)
- среднемесячная начисленная заработная плата, тыс. руб. (X)
Следует выполнить: 1. построить поле корреляции и сформировать гипотезу о возможной форме и направлении связи; 2. рассчитать параметры уравнений линейной и A1; 3. выполнить расчет прогнозного значения результата, предполагая, что прогнозные значения факторов составят B2 % от их среднего уровня; 4. оценить тесноту связи с помощью показателей корреляции и детерминации, проанализировать их значения; 5. Дать с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом; 6. Оценить с помощью средней ошибки аппроксимации качество уравнений; 7. Оценить надежность уравнений в целом через F-критерий Фишера для уровня значимости а = 0,05. По значениям характеристик, рассчитанных в пп. 5,6 и данном пункте, выберете лучшее уравнение регрессии и дайте его обоснование.
- Решение онлайн
- Видео решение
Уравнение имеет вид y = ax + b
1. Параметры уравнения регрессии.
Средние значения
Связь между признаком Y фактором X сильная и прямая.
Уравнение регрессии
Коэффициент детерминации для линейной регрессии равен квадрату коэффициента корреляции.
R 2 = 0.91 2 = 0.83, т.е. в 83% случаев изменения х приводят к изменению y. Другими словами – точность подбора уравнения регрессии – высокая
| x | y | x 2 | y 2 | x ∙ y | y(x) | (y-y cp ) 2 | (y-y(x)) 2 | (x-x p ) 2 |
| 15.1 | 255 | 228.01 | 65025 | 3850.5 | 505.26 | 527451.17 | 62630.22 | 420.25 |
| 17 | 261 | 289 | 68121 | 4437 | 549.38 | 518772.07 | 83161.41 | 345.96 |
| 12 | 293 | 144 | 85849 | 3516 | 433.28 | 473699.53 | 19678.51 | 556.96 |
| 10 | 310 | 100 | 96100 | 3100 | 386.84 | 450587.75 | 5904.58 | 655.36 |
| 74 | 1425 | 5476 | 2030625 | 105450 | 1872.88 | 196906.67 | 200600 | 1474.56 |
| 83 | 1985 | 6889 | 3940225 | 164755 | 2081.86 | 1007497.33 | 9381.6 | 2246.76 |
| 85 | 2549 | 7225 | 6497401 | 216665 | 2128.3 | 2457813.93 | 176990.6 | 2440.36 |
| 81 | 2012 | 6561 | 4048144 | 162972 | 2035.42 | 1062428.38 | 548.49 | 2061.16 |
| 22 | 1562 | 484 | 2439844 | 34364 | 665.47 | 337260.88 | 803758.38 | 184.96 |
| 10 | 386 | 100 | 148996 | 3860 | 386.84 | 354332.48 | 0.71 | 655.36 |
| 4 | 383 | 16 | 146689 | 1532 | 247.52 | 357913.03 | 18353.53 | 998.56 |
| 14.1 | 354.1 | 198.81 | 125386.81 | 4992.81 | 482.04 | 393327.58 | 16368.87 | 462.25 |
| 427.2 | 11775.1 | 27710.82 | 19692405.81 | 709494.31 | 11775.1 | 8137990.81 | 1397376.9 | 12502.5 |
2. Оценка параметров уравнения регрессии
Значимость коэффициента корреляции
По таблице Стьюдента находим Tтабл
Tтабл (n-m-1;a) = (10;0.05) = 1.812
Поскольку Tнабл > Tтабл , то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициента корреляции статистически – значим
Анализ точности определения оценок коэффициентов регрессии
S a = 3.3432
Доверительные интервалы для зависимой переменной
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X = 1
(-557.64;913.38)
Проверка гипотез относительно коэффициентов линейного уравнения регрессии
1) t-статистика
Статистическая значимость коэффициента регрессии a подтверждается
Статистическая значимость коэффициента регрессии b не подтверждается
Доверительный интервал для коэффициентов уравнения регрессии
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(a – t a S a; a + t aS a)
(17.1616;29.2772)
(b – t b S b; b + t bS b)
(-136.4585;445.7528)
Fkp = 4.96
Поскольку F > Fkp, то коэффициент детерминации статистически значим
Расчет коэффициента детерминации в Microsoft Excel

Одним из показателей, описывающих качество построенной модели в статистике, является коэффициент детерминации (R^2), который ещё называют величиной достоверности аппроксимации. С его помощью можно определить уровень точности прогноза. Давайте узнаем, как можно произвести расчет данного показателя с помощью различных инструментов программы Excel.
Вычисление коэффициента детерминации
В зависимости от уровня коэффициента детерминации, принято разделять модели на три группы:
- 0,8 – 1 — модель хорошего качества;
- 0,5 – 0,8 — модель приемлемого качества;
- 0 – 0,5 — модель плохого качества.
В последнем случае качество модели говорит о невозможности её использования для прогноза.
Выбор способа вычисления указанного значения в Excel зависит от того, является ли регрессия линейной или нет. В первом случае можно использовать функцию КВПИРСОН, а во втором придется воспользоваться специальным инструментом из пакета анализа.
Способ 1: вычисление коэффициента детерминации при линейной функции
Прежде всего, выясним, как найти коэффициент детерминации при линейной функции. В этом случае данный показатель будет равняться квадрату коэффициента корреляции. Произведем его расчет с помощью встроенной функции Excel на примере конкретной таблицы, которая приведена ниже.

- Выделяем ячейку, где будет произведен вывод коэффициента детерминации после его расчета, и щелкаем по пиктограмме «Вставить функцию».

Запускается Мастер функций. Перемещаемся в его категорию «Статистические» и отмечаем наименование «КВПИРСОН». Далее клацаем по кнопке «OK».

Происходит запуск окна аргументов функции КВПИРСОН. Данный оператор из статистической группы предназначен для вычисления квадрата коэффициента корреляции функции Пирсона, то есть, линейной функции. А как мы помним, при линейной функции коэффициент детерминации как раз равен квадрату коэффициента корреляции.
Синтаксис этого оператора такой:
Таким образом, функция имеет два оператора, один из которых представляет собой перечень значений функции, а второй – аргументов. Операторы могут быть представлены, как непосредственно в виде значений, перечисленных через точку с запятой (;), так и в виде ссылок на диапазоны, где они расположены. Именно последний вариант и будет использован нами в данном примере.
Устанавливаем курсор в поле «Известные значения y». Выполняем зажим левой кнопки мышки и производим выделение содержимого столбца «Y» таблицы. Как видим, адрес указанного массива данных тут же отображается в окне.
Аналогичным образом заполняем поле «Известные значения x». Ставим курсор в данное поле, но на этот раз выделяем значения столбца «X».
После того, как все данные были отображены в окне аргументов КВПИРСОН, клацаем по кнопке «OK», расположенной в самом его низу.


Способ 2: вычисление коэффициента детерминации в нелинейных функциях
Но указанный выше вариант расчета искомого значения можно применять только к линейным функциям. Что же делать, чтобы произвести его расчет в нелинейной функции? В Экселе имеется и такая возможность. Её можно осуществить с помощью инструмента «Регрессия», который является составной частью пакета «Анализ данных».
- Но прежде, чем воспользоваться указанным инструментом, следует активировать сам «Пакет анализа», который по умолчанию в Экселе отключен. Перемещаемся во вкладку «Файл», а затем переходим по пункту «Параметры».

В открывшемся окне производим перемещение в раздел «Надстройки» при помощи навигации по левому вертикальному меню. В нижней части правой области окна располагается поле «Управление». Из списка доступных там подразделов выбираем наименование «Надстройки Excel…», а затем щелкаем по кнопке «Перейти…», расположенной справа от поля.

Производится запуск окна надстроек. В центральной его части расположен список доступных надстроек. Устанавливаем флажок около позиции «Пакет анализа». Вслед за этим требуется щелкнуть по кнопке «OK» в правой части интерфейса окна.

Пакет инструментов «Анализ данных» в текущем экземпляре Excel будет активирован. Доступ к нему располагается на ленте во вкладке «Данные». Перемещаемся в указанную вкладку и клацаем по кнопке «Анализ данных» в группе настроек «Анализ».

Активируется окошко «Анализ данных» со списком профильных инструментов обработки информации. Выделяем из этого перечня пункт «Регрессия» и клацаем по кнопке «OK».

Затем открывается окно инструмента «Регрессия». Первый блок настроек – «Входные данные». Тут в двух полях нужно указать адреса диапазонов, где находятся значения аргумента и функции. Ставим курсор в поле «Входной интервал Y» и выделяем на листе содержимое колонки «Y». После того, как адрес массива отобразился в окне «Регрессия», ставим курсор в поле «Входной интервал Y» и точно таким же образом выделяем ячейки столбца «X».
Около параметров «Метка» и «Константа-ноль» флажки не ставим. Флажок можно установить около параметра «Уровень надежности» и в поле напротив указать желаемую величину соответствующего показателя (по умолчанию 95%).
В группе «Параметры вывода» нужно указать, в какой области будет отображаться результат вычисления. Существует три варианта:
- Область на текущем листе;
- Другой лист;
- Другая книга (новый файл).
Остановим свой выбор на первом варианте, чтобы исходные данные и результат размещались на одном рабочем листе. Ставим переключатель около параметра «Выходной интервал». В поле напротив данного пункта ставим курсор. Щелкаем левой кнопкой мыши по пустому элементу на листе, который призван стать левой верхней ячейкой таблицы вывода итогов расчета. Адрес данного элемента должен высветиться в поле окна «Регрессия».
Группы параметров «Остатки» и «Нормальная вероятность» игнорируем, так как для решения поставленной задачи они не важны. После этого клацаем по кнопке «OK», которая размещена в правом верхнем углу окна «Регрессия».


Способ 3: коэффициент детерминации для линии тренда
Кроме указанных выше вариантов, коэффициент детерминации можно отобразить непосредственно для линии тренда в графике, построенном на листе Excel. Выясним, как это можно сделать на конкретном примере.
- Мы имеем график, построенный на основе таблицы аргументов и значений функции, которая была использована для предыдущего примера. Произведем построение к нему линии тренда. Кликаем по любому месту области построения, на которой размещен график, левой кнопкой мыши. При этом на ленте появляется дополнительный набор вкладок – «Работа с диаграммами». Переходим во вкладку «Макет». Клацаем по кнопке «Линия тренда», которая размещена в блоке инструментов «Анализ». Появляется меню с выбором типа линии тренда. Останавливаем выбор на том типе, который соответствует конкретной задаче. Давайте для нашего примера выберем вариант «Экспоненциальное приближение».

Эксель строит прямо на плоскости построения графика линию тренда в виде дополнительной черной кривой.

Теперь нашей задачей является отобразить собственно коэффициент детерминации. Кликаем правой кнопкой мыши по линии тренда. Активируется контекстное меню. Останавливаем выбор в нем на пункте «Формат линии тренда…».

Для выполнения перехода в окно формата линии тренда можно выполнить альтернативное действие. Выделяем линию тренда кликом по ней левой кнопки мыши. Перемещаемся во вкладку «Макет». Клацаем по кнопке «Линия тренда» в блоке «Анализ». В открывшемся списке клацаем по самому последнему пункту перечня действий – «Дополнительные параметры линии тренда…».

После любого из двух вышеуказанных действий запускается окошко формата, в котором можно произвести дополнительные настройки. В частности, для выполнения нашей задачи необходимо установить флажок напротив пункта «Поместить на диаграмму величину достоверности аппроксимации (R^2)». Он размещен в самом низу окна. То есть, таким образом мы включаем отображение коэффициента детерминации на области построения. Затем не забываем нажать на кнопку «Закрыть» внизу текущего окна.

Значение достоверности аппроксимации, то есть, величина коэффициента детерминации, будет отображено на листе в области построения. В данном случае эта величина, как видим, равна 0,9242, что характеризует аппроксимацию, как модель хорошего качества.

Абсолютно точно таким образом можно устанавливать показ коэффициента детерминации для любого другого типа линии тренда. Можно менять тип линии тренда, произведя переход через кнопку на ленте или контекстное меню в окно её параметров, как было показано выше. Затем уже в самом окне в группе «Построение линии тренда» можно переключиться на другой тип. Не забываем при этом контролировать, чтобы около пункта «Поместить на диаграмму величину достоверности аппроксимации» был установлен флажок. Завершив вышеуказанные действия, щелкаем по кнопке «Закрыть» в нижнем правом углу окна.

При линейном типе линия тренда уже имеет значение достоверности аппроксимации равное 0,9477, что характеризует эту модель, как ещё более достоверную, чем рассматриваемую нами ранее линию тренда экспоненциального типа.

Таким образом, переключаясь между разными типами линии тренда и сравнивая их значения достоверности аппроксимации (коэффициент детерминации), можно найти тот вариант, модель которого наиболее точно описывает представленный график. Вариант с самым высоким показателем коэффициента детерминации будет наиболее достоверным. На его основе можно строить самый точный прогноз.
Например, для нашего случая опытным путем удалось установить, что самый высокий уровень достоверности имеет полиномиальный тип линии тренда второй степени. Коэффициент детерминации в данном случае равен 1. Это говорит о том, что указанная модель абсолютно достоверная, что означает полное исключение погрешностей.

Но, в то же время, это совсем не значит, что для другого графика тоже наиболее достоверным окажется именно этот тип линии тренда. Оптимальный выбор типа линии тренда зависит от типа функции, на основании которой был построен график. Если пользователь не обладает достаточным объемом знаний, чтобы «на глаз» прикинуть наиболее качественный вариант, то единственным выходом определения лучшего прогноза является как раз сравнение коэффициентов детерминации, как было показано на примере выше.
В Экселе существуют два основных варианта вычисления коэффициента детерминации: использование оператора КВПИРСОН и применение инструмента «Регрессия» из пакета инструментов «Анализ данных». При этом первый из этих вариантов предназначен для использования только в процессе обработки линейной функции, а другой вариант можно использовать практически во всех ситуациях. Кроме того, существует возможность отображения коэффициента детерминации для линии трендов графиков в качестве величины достоверности аппроксимации. С помощью данного показателя имеется возможность определить тип линии тренда, который располагает самым высоким уровнем достоверности для конкретной функции.
Мы рады, что смогли помочь Вам в решении проблемы.
Помимо этой статьи, на сайте еще 11905 инструкций.
Добавьте сайт Lumpics.ru в закладки (CTRL+D) и мы точно еще пригодимся вам.
Отблагодарите автора, поделитесь статьей в социальных сетях.
history 26 января 2019 г.
- Группы статей
- Статистический анализ
Рассмотрим использование MS EXCEL для прогнозирования переменной Y на основании нескольких переменных Х, т.е. множественную регрессию.
Перед прочтением этой статьи рекомендуется освежить в памяти простую линейную регрессию – прогнозирование на основе значений только одного фактора.
Disclaimer : Данную статью не стоит рассматривать, как пересказ главы из учебника по статистике. Статья не обладает ни полнотой, ни строгостью изложения положений статистической науки. Эта статья – о применении MS EXCEL для целей Множественного регрессионного анализа. Теоретические отступления приведены лишь из соображения логики изложения. Использование данной статьи для изучения Регрессии – плохая идея.
Статья про Множественный регрессионный анализ получилась большая, поэтому ниже для удобства приведены ее разделы:
Прогнозирование единственной переменной Y на основании значений 2-х или более переменных Х называется множественной регрессией .
Множественная линейная регрессионная модель (Multiple Linear Regression Model) имеет вид Y=β 0 +β 1 *X 1 +β 2 *X 2 +…+β k *X k +ε. В этом случае переменная Y зависит от k поясняющих переменных Х, т.е. регрессоров . ε — случайная ошибка . Модель является линейной относительно неизвестных параметров β.
Оценка неизвестных параметров
В этой статье рассмотрим модель с 2-мя регрессорами. Сначала введем необходимые обозначения и понятия множественной регрессии.
Для описания зависимости Y от 2-х переменных линейная модель имеет вид:
Параметры этой модели β i нам неизвестны, но их можно оценить, используя случайную выборку (измеренные значения переменной Y от заданных Х). Оценки параметров модели (β 0 , β 1 , β 2 ) обычно вычисляются методом наименьших квадратов (МНК) , который минимизирует сумму квадратов ошибок прогнозирования (критерий минимизации в англоязычной литературе обозначают как SSE – Sum of Squared Errors).
Соответствующие оценки параметров будем обозначать как b 0 , b 1 и b 2 .
Ошибка ε имеет случайную природу и имеет свою функцию распределения со средним значением =0 и дисперсией σ 2 .
Оценки b 1 и b 2 называются коэффициентами регрессии , они определяют влияние соответствующей переменной X, когда все остальные независимые переменные остаются неизменными .
Сдвиг (intercept) или постоянный член b 0 , определяет прогнозируемое значение Y, когда все поясняющие переменные Х равны 0 (часто сдвиг не имеет физического смысла в рамках модели и обусловлен лишь математическими вычислениями МНК ).
Вычислив оценки, полученные методом МНК, позволяют прогнозировать значения переменной Y:
Y= b 0 + b 1 *X 1 + b 2 *X 2
Примечание : Для случая 2-х регрессоров, все спрогнозированные значения переменной Y будут лежать в плоскости (в плоскости регрессии ).
В качестве примера рассмотрим технологический процесс изготовления нити:
Инженер, на основе имеющегося опыта, предположил, что прочность нити Y зависит от концентрации исходного раствора (Х 1 ) и температуры реакции (Х 2 ), и соответствует модели линейной регрессии. Для нахождения комбинации переменных Х, при которых Y принимает максимальное значение, необходимо определить коэффициенты регрессии, сделав выборку.
В MS EXCEL коэффициенты множественной регрессии удобнее всего вычислить с помощью функции ЛИНЕЙН() . Это сделано в файле примера на листе Коэффициенты . Чтобы вычислить оценки:
- выделите 3 ячейки в одной строке (т.к. мы рассматриваем случай 2-х регрессоров, то будут вычислены 2 коэффициента регрессии + величина сдвига = 3 значения, для вывода которых понадобится 3 ячейки). Пусть это будет диапазон С8:Е8 ;
- в Строке формул введите = ЛИНЕЙН(D20:D50;B20:C50) . Предполагается, что в столбце В содержатся прогнозируемые значения Y (в нашей модели это Прочность нити), в столбцах С и D содержатся значения контролируемых параметров Х (Х1 – Концентрация в столбце С и Х2 – Температура в столбце D).
- нажмите CTRL+SHIFT+ENTER (т.к. это формула массива ).

В левой ячейке будет рассчитано значение коэффициента регрессии b 2 для переменной Х2, в средней ячейке — значение коэффициента регрессии b 1 для переменной Х1, в правой – сдвиг . Обратите внимание, что порядок вывода коэффициентов регрессии обратный по отношению к расположению столбцов с данными соответствующих переменных Х (вычисленный коэффициент b 2 располагается левее по отношению к b 1 , тогда как значения переменной Х2 располагаются правее значений переменной Х1). Это может привести к путанице, поэтому лучше разместить коэффициенты над соответствующими столбцами с данными, как это сделано в строке 17 файла примера .
Примечание : В принципе без функции ЛИНЕЙН() можно обойтись, записав альтернативные формулы. Для этого в файле примера на листе Коэффициенты в столбцах I : K вычислены отклонения значений переменных Х 1i , Х 2i , Y i от их средних значений , т.е.:
Далее коэффициенты регрессии рассчитываются по следующим формулам (эти формулы справедливы только при прогнозировании по 2-м независимым переменным Х):

При прогнозировании по 3-м и более независимым переменным Х формулы для вычисления коэффициентов регрессии значительно усложняются, поэтому следует использовать матричный подход.
В файле примера на листе Матричная форма выполнены расчеты коэффициентов регрессии с помощью матричного подхода.

Расчет можно произвести как пошагово, так и одной формулой массива :
Коэффициенты регрессии (вектор b ) в этом случае вычисляются по формуле b =(X T X) -1 (X T Y) или в другом виде записи b =(X ’ X) -1 (X ’ Y)
Под Х подразумевается матрица, состоящая из столбцов значений переменной Х с дополнительным столбцом единиц, а под Y – вектор-столбец значений Y.
Диаграмма рассеяния
В случае простой линейной регрессии (один регрессор, т.е. одна переменная Х) для визуализации связи между прогнозируемым значением Y и переменной Х строят диаграмму рассеяния (двумерную).

В случае множественной линейной регрессии двумерную диаграмму рассеяния можно построить только для анализа влияния каждого отдельного регрессора на Y (при этом остальные Х не меняются), т.е. так называемую Матричную диаграмму рассеивания (См. файл примера лист Диагр расс (матричная) ).
К сожалению, такую диаграмму трудно интерпретировать.

Более того, матричная диаграмма может вводить в заблуждение (см. Introduction to linear regression analysis / D . C . Montgomery , E . A . Peck , G . G . Vining , раздел 3.2.5 ), демонстрируя наличие или отсутствие линейной взаимосвязи между отдельным регрессором X i и Y.
Для случая с 2-мя регрессорами можно предложить альтернативный вид матричной диаграммы рассеяния . В стандартной диаграмме рассеяния строятся проекции на координатные плоскости Х1;Х2, Y;X1 и Y;X2. Однако, если взглянуть на точки относительно плоскости регрессии , то картину, на мой взгляд, будет проще интерпретировать.
Сравним две матричные диаграммы рассеяния (см. файл примера на листе «Диагр расс (в плоск регрессии)» , построенные для одних и тех же наблюдений. Первая – стандартная,

вторая представляет собой вид сверху на плоскость регрессии и 2 вида вдоль плоскости.

На второй диаграмме становится очевидно, что разброс точек относительно плоскости регрессии совсем не большой и поэтому, скорее всего, построенная модель является полезной, а выбранные 2 переменные Х позволяют прогнозировать Y (конечно, для подтверждения этой гипотезы нужно провести процедуру F-теста ).
Несколько слов о построении альтернативной матричной диаграммы рассеяния:
- Перед построением необходимо нормировать значения наблюдений (для каждой переменной вычесть среднее и разделить на стандартное отклонение ). В этом случае практически все точки на диаграммах будут находится в диапазоне +/-3 (по аналогии со стандартным нормальным распределением , 99% значений которого лежат в пределах +/-3 сигма). В этом случае, на диаграмме можно фиксировать мин/макс значений осей, чтобы EXCEL автоматически не модифицировал масштаб осей при изменении данных (это не всегда удобно);
- Теперь координаты точек необходимо рассчитать в системе отсчета относительно плоскости регрессии (в которой плоскость Оху’ совпадает с плоскостью регрессии). Для этого необходимо найти матрицу вращения , например, через вращение приводящее к совмещению нормали к плоскости регрессии и вектора оси Z (0;0;1);
- Новые координаты позволяют построить альтернативную матричную диаграмму. Кроме того, для удобства можно вращать систему координат вокруг новой оси Z, чтобы нагляднее представить себе распределение точек относительно плоскости регрессии (для этого использована Полоса прокрутки в ячейках Q31:S31 ).
Вычисление прогнозных значений Y (отдельное наблюдение и среднее значение) и построение доверительных интервалов
После того, как нами были найдены тем или иным способом коэффициенты регрессии можно приступать к вычислению прогнозных значений Y на основе заданных значений переменных Х.
Уравнение прогнозирования или уравнение регрессии в случае 2-х независимых переменных (регрессоров) записывается в виде:
Y= b 0 + b 1 * Х 1 + b 2 * Х 2
Примечание: В MS EXCEL прогнозное значение Y для заданных Х 1 и Х 2 можно также предсказать с помощью функции ТЕНДЕНЦИЯ() . При этом 2-й аргумент будет ссылкой на столбцы, содержащие все значения переменных Х 1 и Х 2 , а 3-й аргумент функции должен быть ссылкой на диапазон ячеек, содержащий 2 значения Х (Х 1i и Х 2i ) для выбранного наблюдения i (см. файл примера, лист Коэффициенты, столбец G ). Функция ПРЕДСКАЗ() , использованная нами в простой регрессии, не работает в случае множественной регрессии .
Найдя прогнозное значение Y, мы, таким образом, вычислим его точечную оценку. Понятно, что фактическое значение Y, полученное при наблюдении, будет, скорее всего, отличаться от этой оценки. Чтобы ответить на вопрос о том, на сколько хорошо мы можем предсказывать новые значения Y, нам потребуется построить доверительный интервал этой оценки, т.е. диапазон в котором с определенной заданной вероятностью, скажем 95%, мы ожидаем новое значение Y.
Доверительные интервалы построим при фиксированном Х для:
- нового наблюдения Y;
- среднего значения Y (интервал будет уже, чем для отдельного нового наблюдения)
Как и в случае простой линейной регрессии , для построения доверительных интервалов нам потребуется сначала вычислить стандартную ошибку модели (standard error of the model) , которая приблизительно показывает насколько велика ошибка предсказания значений переменной Y на основании значений переменных Х.
Для вычисления стандартной ошибки оценивают дисперсию ошибки ε, т.е. сигма^2 (ее часто обозначают как MS Е либо MSres ) . Затем, вычислив из полученной оценки квадратный корень, получим Стандартную ошибку регрессии (часто обозначают как SEy или sey ).
где SSE – сумма квадратов значений ошибок модели ei=yi — ŷi ( Sum of Squared Errors ). MSE означает Mean Square of Errors (среднее квадратов ошибок, точнее остатков).
Величина n-p – это количество степеней свободы ( df – degrees of freedom ), т.е. число параметров системы, которые могут изменяться независимо (вспомним, что у нас в этом примере есть n независимых наблюдений переменной Y, р – количество оцениваемых параметров модели). В случае простой множественной регрессии с 2-мя регрессорами число степеней свободы равно n-3, т.к. при построении плоскости регрессии было оценено 3 параметра модели b (т.е. на это было «потрачено» 3 степени свободы ).
В MS EXCEL стандартную ошибку SEy можно вычислить формулы (см. файл примера, лист Статистика ):
Стандартная ошибка нового наблюдения Y при заданных значениях Х (вектор Хi) вычисляется по формуле:
x i — вектор-столбец со значениями переменных Х (с дополнительной 1) для заданного наблюдения i.
Соответствующий доверительный интервал вычисляется по формуле:
где α (альфа) – уровень значимости (обычно принимают равным 0,05=5%)
р – количество оцениваемых параметров модели (в нашем случае = 3)
n-p – число степеней свободы
– квантиль распределения Стьюдента (задает количество стандартных ошибок , в +/- диапазоне которых вероятность обнаружить новое наблюдение равно 1-альфа). Т.е. если квантиль равен 2, то диапазон шириной +/- 2 стандартных ошибок относительно прогнозного значения Y будет с вероятностью 95% содержать новое наблюдение Y (для каждого заданного Хi). В MS EXCEL вычисления квантиля производят по формуле = СТЬЮДЕНТ.ОБР.2Х(0,05;n-p) , подробнее см. в статье про распределение Стьюдента .
– прогнозное значение Yi вычисляемое по формуле Yi= b 0+ b 1* Х1i+ b 2* Х2i (точечная оценка).
Стандартная ошибка среднего значения Y при заданных значениях Х (вектор Хi) будет меньше, чем стандартная ошибка отдельного наблюдения. Вычисления производятся по формуле:
x i — вектор-столбец со значениями переменных Х (с дополнительной 1) для заданного наблюдения i.
Соответствующий доверительный интервал вычисляется по формуле:
Прогнозное значение Yi (точечная оценка) используется тоже, что и для отдельного наблюдения.
Стандартные ошибки и доверительные интервалы для коэффициентов регрессии
В разделе Оценка неизвестных параметров мы получили точечные оценки коэффициентов регрессии . Так как эти оценки получены на основе случайных величин (значений переменных Х и Y), то эти оценки сами являются случайными величинами и соответственно имеют функцию распределения со средним значением и дисперсией . Но, чтобы перейти от точечных оценок к интервальным , необходимо вычислить соответствующие стандартные ошибки (т.е. стандартные отклонения ) коэффициентов регрессии .
Стандартная ошибка коэффициента регрессии b j (обозначается se ( b j ) ) вычисляется на основании стандартной ошибки по следующей формуле:
где C jj является диагональным элементом матрицы (X ’ X) -1 . Для коэффициента сдвига b 0 индекс j=1 (верхний левый элемент), для b 1 индекс j=2, b 2 индекс j=3 (нижний правый элемент).
SEy – стандартная ошибка регрессии (см. выше ).
В MS EXCEL стандартные ошибки коэффициентов регрессии можно вычислить с помощью функции ЛИНЕЙН() :
Примечание : Подробнее о функции ЛИНЕЙН() см. статью Функция MS EXCEL ЛИНЕЙН() .
Применяя матричный подход стандартные ошибки можно вычислить и через обычные формулы (точнее через формулу массива , см. файл примера лист Статистика ):
= КОРЕНЬ(СУММКВРАЗН(E13:E43;F13:F43) /(n-p)) *КОРЕНЬ (ИНДЕКС (МОБР (МУМНОЖ(ТРАНСП(B13:D43);(B13:D43)));j;j))
При построении двухстороннего доверительного интервала для коэффициента регрессии его границы определяются следующим образом:
b j +/- t*Se( b j )
где t – это t-значение , которое можно вычислить с помощью формулы = СТЬЮДЕНТ.ОБР.2Х(0,05;n-p) для уровня значимости 0,05.
В результате получим, что найденный доверительный интервал с вероятностью 95% (1-0,05) накроет истинное значение коэффициента регрессии b j . Здесь мы считаем, что коэффициент регрессии b j имеет распределение Стьюдента с n-p степенями свободы (n – количество наблюдений, т.е. пар Х и Y).
Проверка гипотез
Когда мы строим модель, мы предполагаем, что между Y и переменными X существует линейная взаимосвязь. Однако, как это иногда бывает в статистике, можно вычислять параметры связи даже тогда, когда в действительности она не существует, и обусловлена лишь случайностью.
Единственный вариант, когда Y не зависит X, возможен, когда все коэффициенты регрессии β равны 0.
Чтобы убедиться, что вычисленная нами оценка коэффициентов регрессии не обусловлена лишь случайностью (они не случайно отличны от 0), используют проверку гипотез . В качестве нулевой гипотезы Н 0 принимают, что линейной связи нет, т.е. ВСЕ β=0. В качестве альтернативной гипотезы Н 1 принимают, что ХОТЯ БЫ ОДИН коэффициент β <>0.
Процедура проверки значимости множественной регрессии, приведенная ниже, является обобщением дисперсионного анализа , использованного нами в случае простой линейной регрессии (F-тест) .
Если нулевая гипотеза справедлива, то тестовая F -статистика имеет F-распределение со степенями свободы k и n — k -1 , т.е. F k, n-k-1 :
Проверку значимости регрессии можно также осуществить через вычисление p -значения . В этом случае вычисляют вероятность того, что случайная величина F примет значение F 0 (это и есть p-значение ), затем сравнивают p-значение с заданным уровнем значимости α (альфа) . Если p-значение больше уровня значимости , то нулевую гипотезу нет оснований отклонить, и регрессия незначима.
В MS EXCEL значение F 0 можно вычислить на основании значений выборки по вышеуказанной формуле или с помощью функции ЛИНЕЙН() :
В MS EXCEL для проверки гипотезы через p -значение используйте формулу =F.РАСП.ПХ(F 0 ;k;n-k-1) файл примера лист Статистика , где показано эквивалентность обоих подходов проверки значимости регрессии).

В MS EXCEL критическое значение для заданного уровня значимости F 1-альфа, k, n-k-1 можно вычислить по формуле = F.ОБР(1- альфа;k;n-k-1) или = F.ОБР.ПХ(альфа;k; n-k-1) . Другими словами требуется вычислить верхний альфа- квантиль F -распределения с соответствующими степенями свободы .
Таким образом, при значении статистики F 0 > F 1-альфа, k, n-k-1 мы имеем основание для отклонения нулевой гипотезы.
В программах статистики результаты процедуры F -теста выводят с помощью стандартной таблицы дисперсионного анализа . В файле примера такая таблица приведена на листе Надстройка , которая построена на основе результатов, возвращаемых инструментом Регрессия надстройки Пакета анализа MS EXCEL .

Генерация данных для множественной регрессии с помощью заданного тренда
Иногда, бывает удобно сгенерировать значения наблюдений, имея заданный тренд.
Для решения этой задачи нам потребуется:
- задать значения регрессоров в нужном диапазоне (значения переменных Х);
- задать коэффициенты регрессии ( b );
- задать тренд (вычислить значения Y= b0 +b1 * Х 1 + b2 * Х 2 );
- задать величину разброса Y вокруг тренда (варианты: случайный разброс в заданных границах или заданная фигура, например, круг)
Все вычисления выполнены в файле примера, лист Тренд для случая 2-х регрессоров. Там же построены диаграммы рассеяния .

Коэффициент детерминации
Коэффициент детерминации R 2 показывает насколько полезна построенная нами линейная регрессионная модель .
По определению коэффициент детерминации R 2 равен:
R 2 = Изменчивость объясненная моделью ( SSR ) / Общая изменчивость ( SST ).
Этот показатель можно вычислить с помощью функции ЛИНЕЙН() :
При добавлении в модель новой объясняющей переменной Х, коэффициент детерминации будет всегда расти. Поэтому, рост коэффициента детерминации не может служить основанием для вывода о том, что новая модель (с дополнительным регрессором) лучше прежней.
Более подходящей статистикой, которая лишена указанного недостатка, является нормированный коэффициент детерминации (Adjusted R-squared):
где p – число независимых регрессоров (вычисления см. файл примера лист Статистика ).