
Даны определения Функции распределения случайной величины и Плотности вероятности непрерывной случайной величины. Эти понятия активно используются в статьях о статистике сайта
www.excel2.ru
. Рассмотрены примеры вычисления Функции распределения и Плотности вероятности с помощью функций MS EXCEL
.
Введем базовые понятия статистики, без которых невозможно объяснить более сложные понятия.
Генеральная совокупность и случайная величина
Пусть у нас имеется
генеральная совокупность
(population) из N объектов, каждому из которых присуще определенное значение некоторой числовой характеристики Х.
Примером генеральной совокупности (ГС) может служить совокупность весов однотипных деталей, которые производятся станком.
Поскольку в математической статистике, любой вывод делается только на основании характеристики Х (абстрагируясь от самих объектов), то с этой точки зрения
генеральная совокупность
представляет собой N чисел, среди которых, в общем случае, могут быть и одинаковые.
В нашем примере, ГС — это просто числовой массив значений весов деталей. Х – вес одной из деталей.
Если из заданной ГС мы выбираем случайным образом один объект, имеющей характеристику Х, то величина Х является
случайной величиной
. По определению, любая
случайная величина
имеет
функцию распределения
, которая обычно обозначается F(x).
Функция распределения
Функцией распределения
вероятностей
случайной величины
Х называют функцию F(x), значение которой в точке х равно вероятности события X
F(x) = P(X
Поясним на примере нашего станка. Хотя предполагается, что наш станок производит только один тип деталей, но, очевидно, что вес изготовленных деталей будет слегка отличаться друг от друга. Это возможно из-за того, что при изготовлении мог быть использован разный материал, а условия обработки также могли слегка различаться и пр. Пусть самая тяжелая деталь, произведенная станком, весит 200 г, а самая легкая — 190 г. Вероятность того, что случайно выбранная деталь Х будет весить меньше 200 г равна 1. Вероятность того, что будет весить меньше 190 г равна 0. Промежуточные значения определяются формой Функции распределения. Например, если процесс настроен на изготовление деталей весом 195 г, то разумно предположить, что вероятность выбрать деталь легче 195 г равна 0,5.
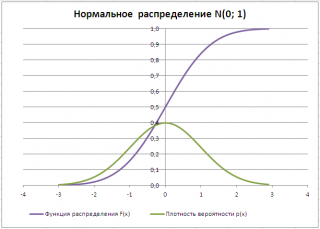
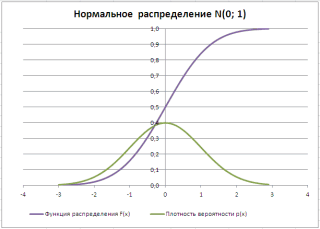
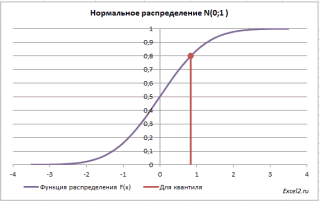
Типичный график
Функции распределения
для непрерывной случайной величины приведен на картинке ниже (фиолетовая кривая, см.
файл примера
):
В справке MS EXCEL
Функцию распределения
называют
Интегральной
функцией распределения
(
Cumulative
Distribution
Function
,
CDF
).
Приведем некоторые свойства
Функции распределения:
Функция распределения
F(x) изменяется в интервале [0;1], т.к. ее значения равны вероятностям соответствующих событий (по определению вероятность может быть в пределах от 0 до 1);
Функция распределения
– неубывающая функция;-
Вероятность того, что случайная величина приняла значение из некоторого диапазона [x1;x2): P(x
1
<=X
2)=F(x
2
)-F(x
1
).
Существует 2 типа распределений:
непрерывные распределения
и
дискретные распределения
.
Дискретные распределения
Если случайная величина может принимать только определенные значения и количество таких значений конечно, то соответствующее распределение называется
дискретным
. Например, при бросании монеты, имеется только 2 элементарных исхода, и, соответственно, случайная величина может принимать только 2 значения. Например, 0 (выпала решка) и 1 (не выпала решка) (см.
схему Бернулли
). Если монета симметричная, то вероятность каждого исхода равна 1/2. При бросании кубика случайная величина принимает значения от 1 до 6. Вероятность каждого исхода равна 1/6. Сумма вероятностей всех возможных значений случайной величины равна 1.
Примечание
: В MS EXCEL имеется несколько функций, позволяющих вычислить вероятности дискретных случайных величин. Перечень этих функций приведен в статье
Распределения случайной величины в MS EXCEL
.
Непрерывные распределения и плотность вероятности
В случае
непрерывного распределения
случайная величина может принимать любые значения из интервала, в котором она определена. Т.к. количество таких значений бесконечно велико, то мы не можем, как в случае дискретной величины, сопоставить каждому значению случайной величины ненулевую вероятность (т.е. вероятность попадания в любую точку (заданную до опыта) для
непрерывной случайной величины
равна нулю). Т.к. в противном случае сумма вероятностей всех возможных значений случайной величины будет равна бесконечности, а не 1. Выходом из этой ситуации является введение так называемой
функции плотности распределения p(x)
. Чтобы найти вероятность того, что непрерывная случайная величина Х примет значение, заключенное в интервале (а; b), необходимо найти приращение
функции распределения
на этом интервале:
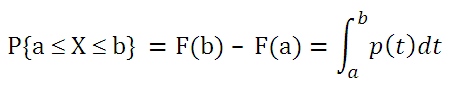
Как видно из формулы выше
плотность распределения
р(х) представляет собой производную
функции распределения
F(x), т.е. р(х) = F’(x).
Типичный график
функции плотности распределения
для непрерывной случайно величины приведен на картинке ниже (зеленая кривая):
Примечание
: В MS EXCEL имеется несколько функций, позволяющих вычислить вероятности непрерывных случайных величин. Перечень этих функций приведен в статье
Распределения случайной величины в MS EXCEL
.
В литературе
Функция плотности распределения
непрерывной случайной величины может называться:
Плотность вероятности, Плотность распределения, англ. Probability Density Function (PDF)
.
Чтобы все усложнить, термин
Распределение
(в литературе на английском языке —
Probability
Distribution
Function
или просто
Distribution
)
в зависимости от контекста может относиться как
Интегральной
функции распределения,
так и кее
Плотности распределения.
Из определения
функции плотности распределения
следует, что p(х)>=0. Следовательно, плотность вероятности для непрерывной величины может быть, в отличие от
Функции распределения,
больше 1. Например, для
непрерывной равномерной величины
, распределенной на интервале [0; 0,5]
плотность вероятности
равна 1/(0,5-0)=2. А для
экспоненциального распределения
с параметром
лямбда
=5, значение
плотности вероятности
в точке х=0,05 равно 3,894. Но, при этом можно убедиться, что вероятность на любом интервале будет, как обычно, от 0 до 1.
Напомним, что
плотность распределения
является производной от
функции распределения
, т.е. «скоростью» ее изменения: p(x)=(F(x2)-F(x1))/Dx при Dx стремящемся к 0, где Dx=x2-x1. Т.е. тот факт, что
плотность распределения
>1 означает лишь, что функция распределения растет достаточно быстро (это очевидно на примере
экспоненциального распределения
).
Примечание
: Площадь, целиком заключенная под всей кривой, изображающей
плотность распределения
, равна 1.
Примечание
: Напомним, что функцию распределения F(x) называют в функциях MS EXCEL
интегральной функцией распределения
. Этот термин присутствует в параметрах функций, например в
НОРМ.РАСП
(x; среднее; стандартное_откл;
интегральная
). Если функция MS EXCEL должна вернуть
Функцию распределения,
то параметр
интегральная
, д.б. установлен ИСТИНА. Если требуется вычислить
плотность вероятности
, то параметр
интегральная
, д.б. ЛОЖЬ.
Примечание
: Для
дискретного распределения
вероятность случайной величине принять некое значение также часто называется плотностью вероятности (англ. probability mass function (pmf)). В справке MS EXCEL
плотность вероятности
может называть даже «функция вероятностной меры» (см. функцию
БИНОМ.РАСП()
).
Вычисление плотности вероятности с использованием функций MS EXCEL
Понятно, что чтобы вычислить
плотность вероятности
для определенного значения случайной величины, нужно знать ее распределение.
Найдем
плотность вероятности
для
стандартного нормального распределения
N(0;1) при x=2. Для этого необходимо записать формулу
=НОРМ.СТ.РАСП(2;ЛОЖЬ)
=0,054 или
=НОРМ.РАСП(2;0;1;ЛОЖЬ)
.
Напомним, что
вероятность
того, что
непрерывная случайная величина
примет конкретное значение x равна 0. Для
непрерывной случайной величины
Х можно вычислить только вероятность события, что Х примет значение, заключенное в интервале (а; b).
Вычисление вероятностей с использованием функций MS EXCEL
1) Найдем вероятность, что случайная величина, распределенная по
стандартному нормальному распределению
(см. картинку выше), приняла положительное значение. Согласно свойству
Функции распределения
вероятность равна F(+∞)-F(0)=1-0,5=0,5.
В MS EXCEL для нахождения этой вероятности используйте формулу
=НОРМ.СТ.РАСП(9,999E+307;ИСТИНА) -НОРМ.СТ.РАСП(0;ИСТИНА)
=1-0,5. Вместо +∞ в формулу введено значение 9,999E+307= 9,999*10^307, которое является максимальным числом, которое можно ввести в ячейку MS EXCEL (так сказать, наиболее близкое к +∞).
2) Найдем вероятность, что случайная величина, распределенная по
стандартному нормальному распределению
, приняла отрицательное значение. Согласно определения
Функции распределения,
вероятность равна F(0)=0,5.
В MS EXCEL для нахождения этой вероятности используйте формулу
=НОРМ.СТ.РАСП(0;ИСТИНА)
=0,5.
3) Найдем вероятность того, что случайная величина, распределенная по
стандартному нормальному распределению
, примет значение, заключенное в интервале (0; 1). Вероятность равна F(1)-F(0), т.е. из вероятности выбрать Х из интервала (-∞;1) нужно вычесть вероятность выбрать Х из интервала (-∞;0). В MS EXCEL используйте формулу
=НОРМ.СТ.РАСП(1;ИСТИНА) — НОРМ.СТ.РАСП(0;ИСТИНА)
.
Все расчеты, приведенные выше, относятся к случайной величине, распределенной по
стандартному нормальному закону
N(0;1). Понятно, что значения вероятностей зависят от конкретного распределения. В статье
Распределения случайной величины в MS EXCEL
приведены распределения, для которых в MS EXCEL имеются соответствующие функции, позволяющие вычислить вероятности.
Обратная функция распределения (Inverse Distribution Function)
Вспомним задачу из предыдущего раздела:
Найдем вероятность, что случайная величина, распределенная по стандартному нормальному распределению, приняла отрицательное значение.
Вероятность этого события равна 0,5.
Теперь решим обратную задачу: определим х, для которого вероятность, того что случайная величина Х примет значение
медиану
или 50-ю
процентиль
).
Для этого необходимо на графике
функции распределения
найти точку, для которой F(х)=0,5, а затем найти абсциссу этой точки. Абсцисса точки =0, т.е. вероятность, того что случайная величина Х примет значение <0, равна 0,5.
В MS EXCEL используйте формулу
=НОРМ.СТ.ОБР(0,5)
=0.
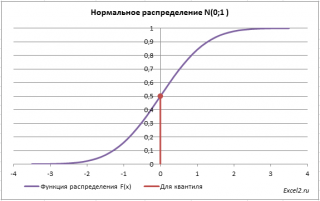
Однозначно вычислить значение
случайной величины
позволяет свойство монотонности
функции распределения.
Обратите внимание, что для вычисления обратной функции мы использовали именно
функцию распределения
, а не
плотность распределения
. Поэтому, в аргументах функции
НОРМ.СТ.ОБР()
отсутствует параметр
интегральная
, который подразумевается. Подробнее про функцию
НОРМ.СТ.ОБР()
см. статью про
нормальное распределение
.
Обратная функция распределения
вычисляет
квантили распределения
, которые используются, например, при
построении доверительных интервалов
. Т.е. в нашем случае число 0 является 0,5-квантилем
нормального распределения
. В
файле примера
можно вычислить и другой
квантиль
этого распределения. Например, 0,8-квантиль равен 0,84.
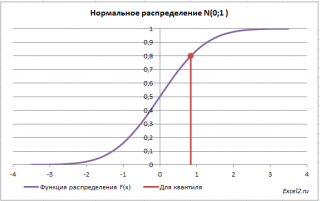
В англоязычной литературе
обратная функция распределения
часто называется как Percent Point Function (PPF).
Примечание
: При вычислении
квантилей
в MS EXCEL используются функции:
НОРМ.СТ.ОБР()
,
ЛОГНОРМ.ОБР()
,
ХИ2.ОБР(),
ГАММА.ОБР()
и т.д. Подробнее о распределениях, представленных в MS EXCEL, можно прочитать в статье
Распределения случайной величины в MS EXCEL
.
Функция ФИ в Excel предназначена для определения значения плотности вероятности величины, описанной законом стандартного нормального распределения, и возвращает соответствующее число.
Значения функции плотности стандартного нормального распределения в Excel
Если случайная величина распределена непрерывно, она может иметь любое значение, взятое из интервала, в котором она определена. Такое число значений стремится к бесконечности, следовательно, вероятность попадания в какую-либо определенную точку из данного интервала стремится к нулю (сумма вероятностей должна соответствовать числу 1). Поэтому, является возможным только определение вероятности нахождения некоторой величины в заданном интервале значений. С этой целью было введено понятие плотности вероятности – производная функции распределения. Для вычисления вероятности определяют площадь, образованную кривой графика, осью абсцисс и двумя вертикальными линиями, проведенными от точек, соответствующих граничным значениям исследуемого интервала.
Рассматриваемая функции вычисляет то же значение, которое возвращает функция НОРМ.СТ.РАСП, у которой второй аргумент принимает значение ЛОЖЬ.
Пример 1. Построить график плотности вероятности для известных значений x, которые внесены в таблицу Excel.
Вид таблицы данных:
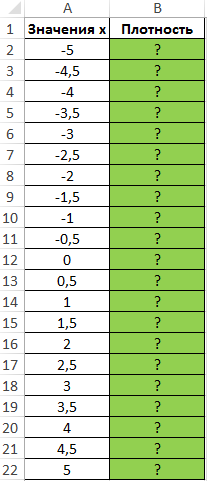
Для построения графика определим значения плотности для известных значений x. Используем формулу, предварительно выделив ячейки в диапазоне B2:B22:
=ФИ(A2)
Полученные значения:
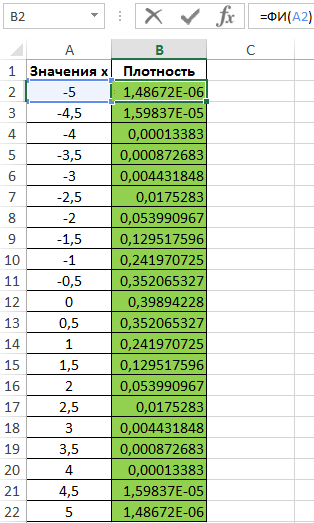
Используем полученные данные для построения графика:
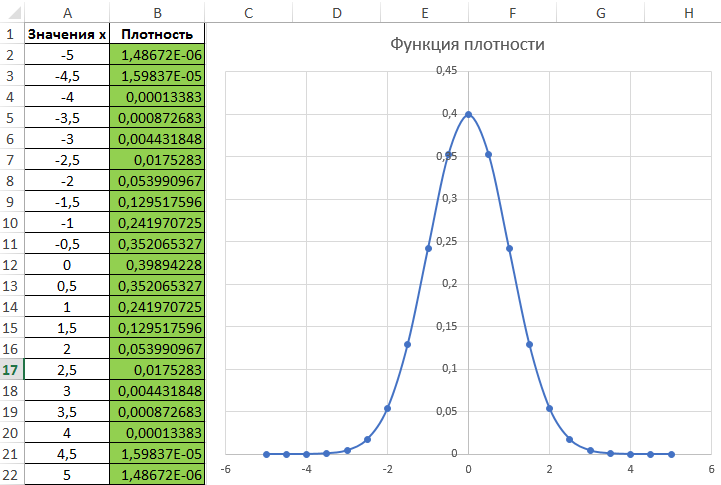
Значение плотности вероятности имеет смысл при определении вероятности нахождения величины в некотором диапазоне. Ее используют для вычисления интеграла с указанными граничными значениями некоторой величины, в результате чего получают вероятность нахождения некоторого значения в диапазоне, заданного этими граничными значениями.
В Excel функция плотности используется преимущественно для построения графиков. Вероятность определяется функцией НОРМ.СТ.РАСП (для стандартного нормального распределение) с последним аргументом, принимающим значение ИСТИНА.
Пример расчета плотности стандартного нормального распределения в Excel
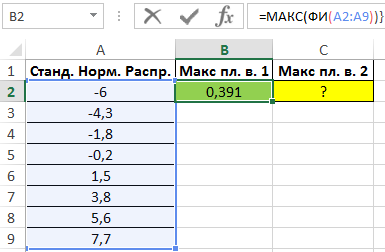
Пример 2. Определить максимальное значение плотности вероятности для ряда значений двумя различными способами.
Вид таблицы данных:
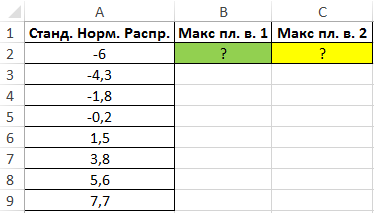
Максимальное значение плотности вероятности для некоторой величины, распределенной по стандартному нормальному закону, можно определить с помощью функции МАКС, исследуя массив значений, возвращаемых функцией ФИ в формуле массива CTRL+SHIFT+Enter:
=МАКС(ФИ(A2:A9))
Полученный результат:
Другой способ – нахождение значения плотности для среднего значения известных величин. Однако, для начала необходимо стандартизировать имеющийся ряд значений с помощью функции НОРМАЛИЗАЦИЯ. Для нахождения используем формулу (вводить как формулу массива CTRL+SHIFT+Enter):
Полученное значение:
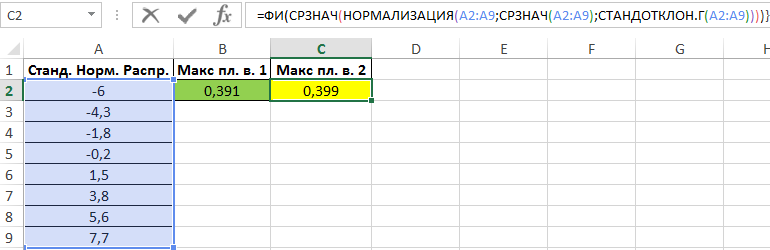
Небольшая разница в полученных значениях свидетельствует о том, что исследуемый ряд значений можно рассматривать как нормальное стандартное распределение некоторой величины.
Правила использования функции ФИ в Excel
Функция ФИ имеет следующую синтаксическую запись:
=ФИ(x)
- x – обязательный, принимает число для некоторой величины, распределенной по стандартному нормальному закону, для которой необходимо определить значение плотности распределения.
Примечания:
- В качестве аргумента функции можно передавать ссылку на ячейку с числовыми данными или само число. Функция ФИ автоматические преобразует логические значения и текстовые строки, содержащие числа, к числовым значениям.
- Если аргумент функции принимает данные, не преобразуемые к числовым значениям, результатом выполнения ФИ будет код ошибки #ЗНАЧ!
- Для больших значений, значение плотности вероятности которых стремится к нулю, функция возвращает число 0. Например, =ФИ(100) вернет число 0.

Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Поделиться ссылкой:
Так как я часто имею дело с большим количеством данных, у меня время от времени возникает необходимость генерировать массивы значений для проверки моделей в Excel. К примеру, если я хочу увидеть распределение веса продукта с определенным стандартным отклонением, потребуются некоторые усилия, чтобы привести результат работы формулы СЛУЧМЕЖДУ() в нормальный вид. Дело в том, что формула СЛУЧМЕЖДУ() выдает числа с единым распределением, т.е. любое число с одинаковой долей вероятности может оказаться как у нижней, так и у верхней границы запрашиваемого диапазона. Такое положение дел не соответствует действительности, так как вероятность возникновения продукта уменьшается по мере отклонения от целевого значения. Т.е. если я произвожу продукт весом 100 грамм, вероятность, что я произведу 97-ми или 103-граммовый продукт меньше, чем 100 грамм. Вес большей части произведенной продукции будет сосредоточен рядом с целевым значением. Такое распределение называется нормальным. Если построить график, где по оси Y отложить вес продукта, а по оси X – количество произведенного продукта, график будет иметь колоколообразный вид, где наивысшая точка будет соответствовать целевому значению.
Таким образом, чтобы привести массив, выданный формулой СЛУЧМЕЖДУ(), в нормальный вид, мне приходилось ручками исправлять пограничные значения на близкие к целевым. Такое положение дел меня, естественно, не устраивало, поэтому, покопавшись в интернете, открыл интересный способ создания массива данных с нормальным распределением. В сегодняшней статье описан способ генерации массива и построения графика с нормальным распределением.
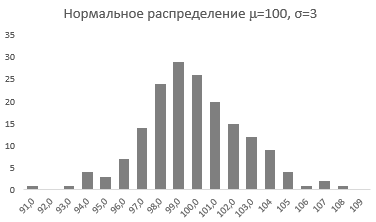
Характеристики нормального распределения
Непрерывная случайная переменная, которая подчиняется нормальному распределению вероятностей, обладает некоторыми особыми свойствами. Предположим, что вся производимая продукция подчиняется нормальному распределению со средним значением 100 грамм и стандартным отклонением 3 грамма. Распределение вероятностей для такой случайной переменной представлено на рисунке.
Из этого рисунка мы можем сделать следующие наблюдения относительно нормального распределения — оно имеет форму колокола и симметрично относительно среднего значения.
Стандартное отклонение имеет немаловажную роль в форме изгиба. Если посмотреть на предыдущий рисунок, то можно заметить, что практически все измерения веса продукта попадают в интервал от 95 до 105 граммов. Давайте рассмотрим следующий рисунок, на котором представлено нормальное распределение с той же средней – 100 грамм, но со стандартным отклонением всего 1,5 грамма
Здесь вы видите, что измерения значительно плотней прилегают к среднему значению. Почти все производимые продукты попадают в интервал от 97 до 102 грамм.
Небольшое значение стандартного отклонения выражается в более «тощей и высокой кривой, плотно прижимающейся к среднему значению. Чем больше стандартное, тем «толще», ниже и растянутее получается кривая.
Создание массива с нормальным распределением
Итак, чтобы сгенерировать массив данных с нормальным распределением, нам понадобится функция НОРМ.ОБР() – это обратная функция от НОРМ.РАСП(), которая возвращает нормально распределенную переменную для заданной вероятности для определенного среднего значения и стандартного отклонения. Синтаксис формулы выглядит следующим образом:
=НОРМ.ОБР(вероятность; среднее_значение; стандартное_отклонение)
Другими словами, я прошу Excel посчитать, какая переменная будет находится в вероятностном промежутке от 0 до 1. И так как вероятность возникновения продукта с весом в 100 грамм максимальная и будет уменьшаться по мере отдаления от этого значения, то формула будет выдавать значения близких к 100 чаще, чем остальных.
Давайте попробуем разобрать на примере. Выстроим график распределения вероятностей от 0 до 1 с шагом 0,01 для среднего значения равным 100 и стандартным отклонением 1,5.
Как видим из графика точки максимально сконцентрированы у переменной 100 и вероятности 0,5.
Этот фокус мы используем для генерирования случайного массива данных с нормальным распределением. Формула будет выглядеть следующим образом:
=НОРМ.ОБР(СЛЧИС(); среднее_значение; стандартное_отклонение)
Создадим массив данных для нашего примера со средним значением 100 грамм и стандартным отклонением 1,5 грамма и протянем нашу формулу вниз.
Теперь, когда массив данных готов, мы можем выстроить график с нормальным распределением.
Построение графика нормального распределения
Прежде всего необходимо разбить наш массив на периоды. Для этого определяем минимальное и максимальное значение, размер каждого периода или шаг, с которым будет увеличиваться период.
Далее строим таблицу с категориями. Нижняя граница (B11) равняется округленному вниз ближайшему кратному числу. Остальные категории увеличиваются на значение шага. Формула в ячейке B12 и последующих будет выглядеть:
=ЕСЛИ(A12;B11+$B$6; «»)
В столбце X будет производится подсчет количества переменных в заданном промежутке. Для этого воспользуемся формулой ЧАСТОТА(), которая имеет два аргумента: массив данных и массив интервалов. Выглядеть формула будет следующим образом =ЧАСТОТА(Data!A1:A175;B11:B20). Также стоит отметить, что в таком варианте данная функция будет работать как формула массива, поэтому по окончании ввода необходимо нажать сочетание клавиш Ctrl+Shift+Enter.
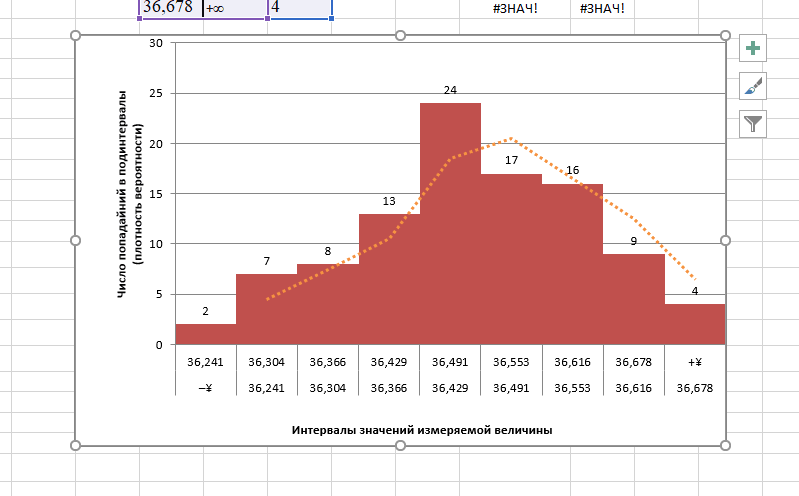
Таким образом у нас получилась таблица с данными, с помощью которой мы сможем построить диаграмму с нормальным распределением. Воспользуемся диаграммой вида Гистограмма с группировкой, где по оси значений будет отложено количество переменных в данном промежутке, а по оси категорий – периоды.
Осталось отформатировать диаграмму и наш график с нормальным распределением готов.
Итак, мы познакомились с вами с нормальным распределением, узнали, что Excel позволяет генерировать массив данных с помощью формулы НОРМ.ОБР() для определенного среднего значения и стандартного отклонения и научились приводить данный массив в графический вид.
Для лучшего понимания, вы можете скачать файл с примером построения нормального распределения.
Построим диаграмму распределения в Excel. А также рассмотрим подробнее функции круговых диаграмм, их создание.
График нормального распределения имеет форму колокола и симметричен относительно среднего значения. Получить такое графическое изображение можно только при огромном количестве измерений. В Excel для конечного числа измерений принято строить гистограмму.
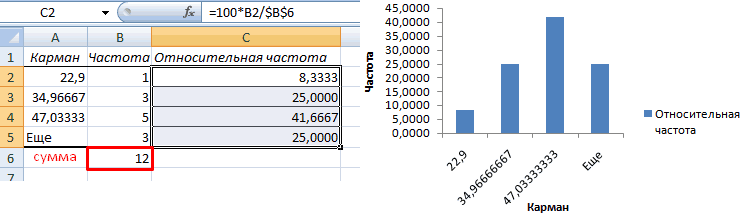
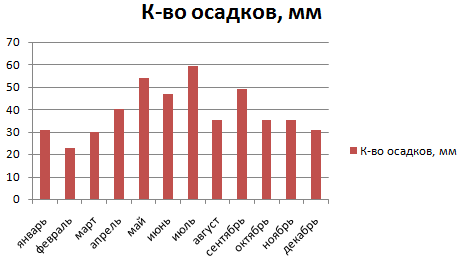
Внешне столбчатая диаграмма похожа на график нормального распределения. Построим столбчатую диаграмму распределения осадков в Excel и рассмотрим 2 способа ее построения.
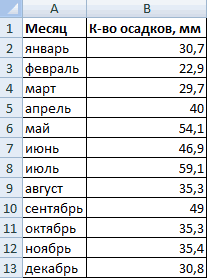
Имеются следующие данные о количестве выпавших осадков:
Первый способ. Открываем меню инструмента «Анализ данных» на вкладке «Данные» (если у Вас не подключен данный аналитический инструмент, тогда читайте как его подключить в настройках Excel):
Выбираем «Гистограмма»:
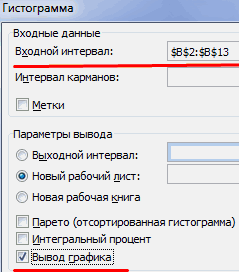
Задаем входной интервал (столбец с числовыми значениями). Поле «Интервалы карманов» оставляем пустым: Excel сгенерирует автоматически. Ставим птичку около записи «Вывод графика»:
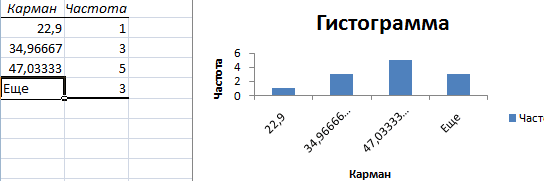
После нажатия ОК получаем такой график с таблицей:
В интервалах не очень много значений, поэтому столбики гистограммы получились низкими.
Теперь необходимо сделать так, чтобы по вертикальной оси отображались относительные частоты.
Найдем сумму всех абсолютных частот (с помощью функции СУММ). Сделаем дополнительный столбец «Относительная частота». В первую ячейку введем формулу:
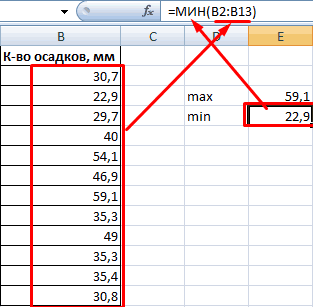
Способ второй. Вернемся к таблице с исходными данными. Вычислим интервалы карманов. Сначала найдем максимальное значение в диапазоне температур и минимальное.
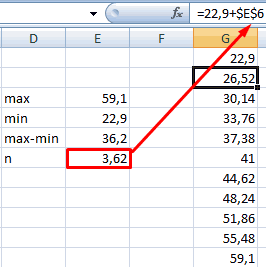
Чтобы найти интервал карманов, нужно разность максимального и минимального значений массива разделить на количество интервалов. Получим «ширину кармана».
Представим интервалы карманов в виде столбца значений. Сначала ширину кармана прибавляем к минимальному значению массива данных. В следующей ячейке – к полученной сумме. И так далее, пока не дойдем до максимального значения.
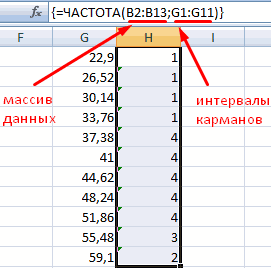
Для определения частоты делаем столбец рядом с интервалами карманов. Вводим функцию массива:
Вычислим относительные частоты (как в предыдущем способе).
Построим столбчатую диаграмму распределения осадков в Excel с помощью стандартного инструмента «Диаграммы».
Частота распределения заданных значений:
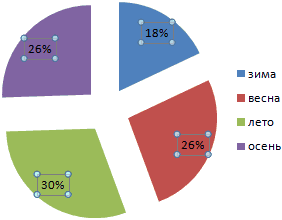
Круговые диаграммы для иллюстрации распределения
С помощью круговой диаграммы можно иллюстрировать данные, которые находятся в одном столбце или одной строке. Сегмент круга – это доля каждого элемента массива в сумме всех элементов.
С помощью любой круговой диаграммы можно показать распределение в том случае, если
- имеется только один ряд данных;
- все значения положительные;
- практически все значения выше нуля;
- не более семи категорий;
- каждая категория соответствует сегменту круга.
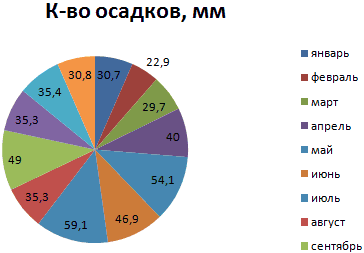
На основании имеющихся данных о количестве осадков построим круговую диаграмму.
Доля «каждого месяца» в общем количестве осадков за год:
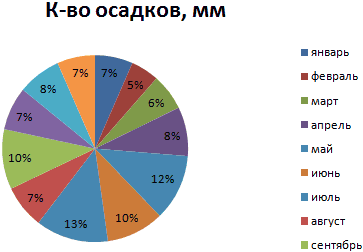
Круговая диаграмма распределения осадков по сезонам года лучше смотрится, если данных меньше. Найдем среднее количество осадков в каждом сезоне, используя функцию СРЗНАЧ. На основании полученных данных построим диаграмму:
Получили количество выпавших осадков в процентном выражении по сезонам.
В двух словах: Добавляем полосу прокрутки к гистограмме или к графику распределения частот, чтобы сделать её динамической или интерактивной.
Уровень сложности: продвинутый.
На следующем рисунке показано, как выглядит готовая динамическая гистограмма:
Что такое гистограмма или график распределения частот?
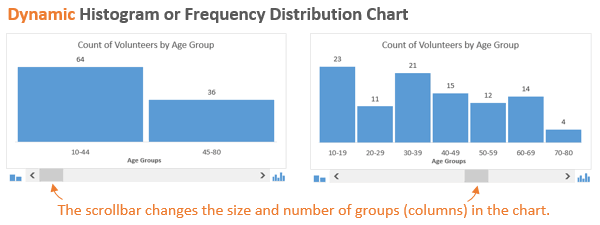
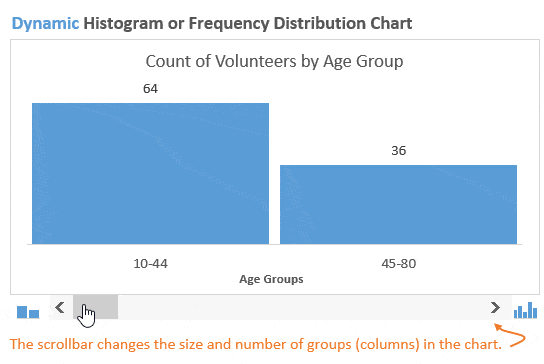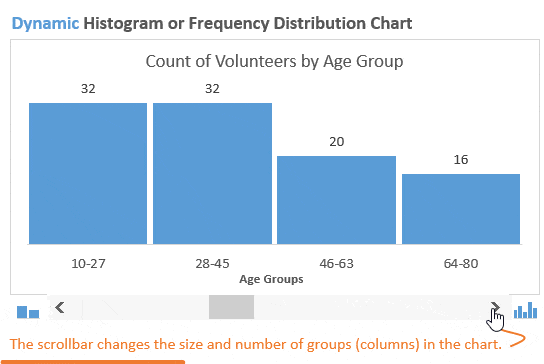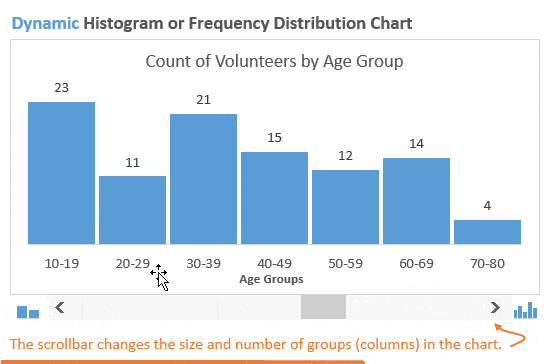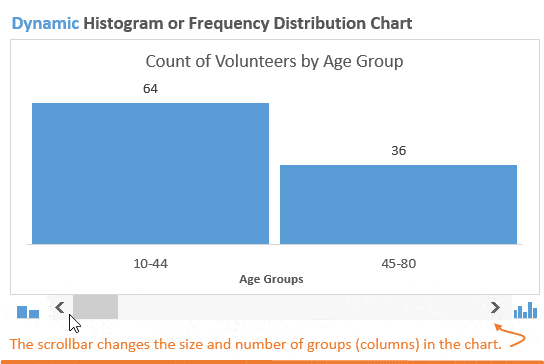
Гистограмма распределения разбивает по группам значения из набора данных и показывает количество (частоту) чисел в каждой группе. Такую гистограмму также называют графиком распределения частот, поскольку она показывает, с какой частотой представлены значения.
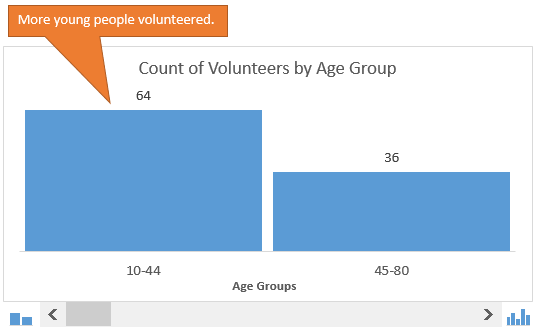
В нашем примере мы делим людей, которые вызвались принять участие в мероприятии, по возрастным группам. Первым делом, создадим возрастные группы, далее подсчитаем, сколько людей попадает в каждую из групп, и затем покажем все это на гистограмме.
На какие вопросы отвечает гистограмма распределения?
Гистограмма – это один из моих самых любимых типов диаграмм, поскольку она дает огромное количество информации о данных.
В данном случае мы хотим знать, как много участников окажется в возрастных группах 20-ти, 30-ти, 40-ка лет и так далее. Гистограмма наглядно покажет это, поэтому определить закономерности и отклонения будет довольно легко.
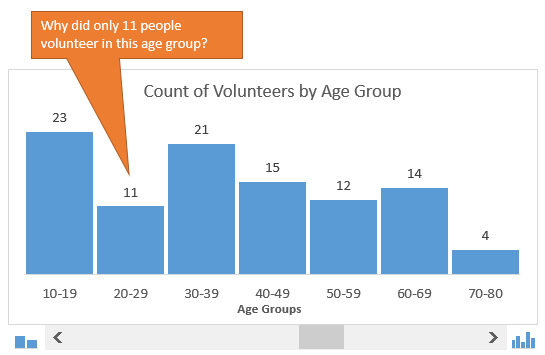
«Неужели наше мероприятие не интересно гражданам в возрасте от 20 до 29 лет?»
Возможно, мы захотим немного изменить детализацию картины и разбить население на две возрастные группы. Это покажет нам, что в мероприятии примут участие большей частью молодые люди:
Динамическая гистограмма
После построения гистограммы распределения частот иногда возникает необходимость изменить размер групп, чтобы ответить на различные возникающие вопросы. В динамической гистограмме это возможно сделать благодаря полосе прокрутки (слайдеру) под диаграммой. Пользователь может увеличивать или уменьшать размер групп, нажимая стрелки на полосе прокрутки.
Такой подход делает гистограмму интерактивной и позволяет пользователю масштабировать ее, выбирая, сколько групп должно быть показано. Это отличное дополнение к любому дашборду!
Как это работает?
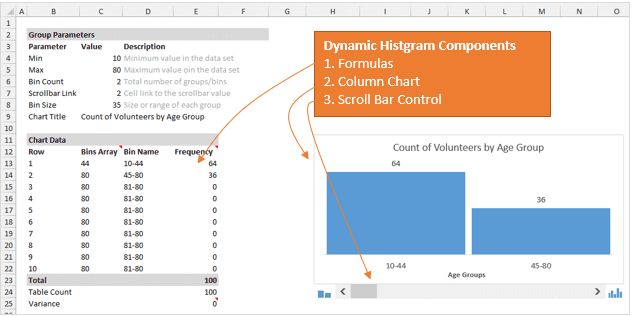
Краткий ответ: Формулы, динамические именованные диапазоны, элемент управления «Полоса прокрутки» в сочетании с гистограммой.
Формулы
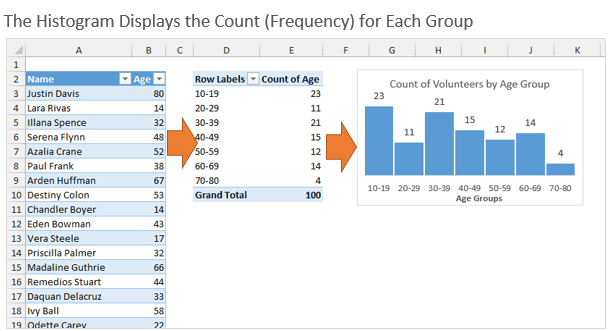
Чтобы всё работало, первым делом нужно при помощи формул вычислить размер группы и количество элементов в каждой группе.
Чтобы вычислить размер группы, разделим общее количество (80-10) на количество групп. Количество групп устанавливается настройками полосы прокрутки. Чуть позже разъясним это подробнее.
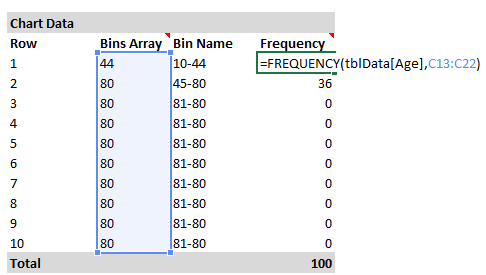
Далее при помощи функции ЧАСТОТА (FREQUENCY) я рассчитываю количество элементов в каждой группе в заданном столбце. В данном случае мы возвращаем частоту из столбца Age таблицы с именем tblData.
=ЧАСТОТА(tblData;C13:C22)=FREQUENCY(tblData,C13:C22)
Функция ЧАСТОТА (FREQUENCY) вводится, как формула массива, нажатием Ctrl+Shift+Enter.
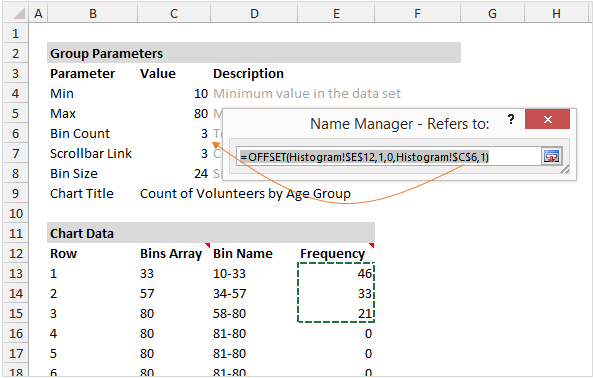
Динамический именованный диапазон
В качестве источника данных для диаграммы используется именованный диапазон, чтобы извлекать данные только из выбранных в текущий момент групп.
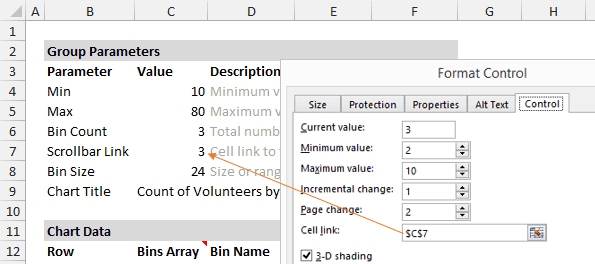
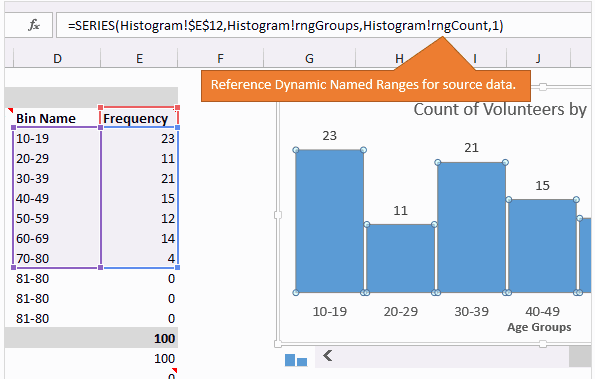
Когда пользователь перемещает ползунок полосы прокрутки, число строк в динамическом диапазоне изменяется так, чтобы отобразить на графике только нужные данные. В нашем примере задано два динамических именованных диапазона: один для данных — rngGroups (столбец Frequency) и второй для подписей горизонтальной оси — rngCount (столбец Bin Name).
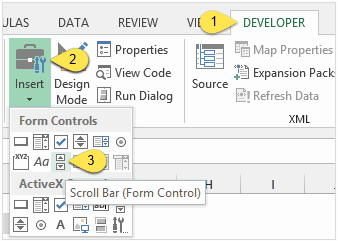
Элемент управления «Полоса прокрутки»
Элемент управления Полоса прокрутки (Scroll Bar) может быть вставлен с вкладки Разработчик (Developer).
На рисунке ниже видно, как я настроил параметры элемента управления и привязал его к ячейке C7. Так, изменяя состояние полосы прокрутки, пользователь управляет формулами.
Гистограмма
График – это самая простая часть задачи. Создаём простую гистограмму и в качестве источника данных устанавливаем динамические именованные диапазоны.
Есть вопросы?
Что ж, это был лишь краткий обзор того, как работает динамическая гистограмма.
Да, это не самая простая диаграмма, но, полагаю, пользователям понравится с ней работать. Определённо, такой интерактивной диаграммой можно украсить любой отчёт.
Более простой вариант гистограммы можно создать, используя сводные таблицы.
Пишите в комментариях любые вопросы и предложения. Спасибо!
Урок подготовлен для Вас командой сайта office-guru.ru
Источник: /> Перевел: Антон Андронов
Правила перепечаткиЕще больше уроков по Microsoft Excel
Оцените качество статьи. Нам важно ваше мнение:
Блог о программе Microsoft Excel: приемы, хитрости, секреты, трюки
Как построить график с нормальным распределением в Excel
Так как я часто имею дело с большим количеством данных, у меня время от времени возникает необходимость генерировать массивы значений для проверки моделей в Excel. К примеру, если я хочу увидеть распределение веса продукта с определенным стандартным отклонением, потребуются некоторые усилия, чтобы привести результат работы формулы СЛУЧМЕЖДУ() в нормальный вид. Дело в том, что формула СЛУЧМЕЖДУ() выдает числа с единым распределением, т.е. любое число с одинаковой долей вероятности может оказаться как у нижней, так и у верхней границы запрашиваемого диапазона. Такое положение дел не соответствует действительности, так как вероятность возникновения продукта уменьшается по мере отклонения от целевого значения. Т.е. если я произвожу продукт весом 100 грамм, вероятность, что я произведу 97-ми или 103-граммовый продукт меньше, чем 100 грамм. Вес большей части произведенной продукции будет сосредоточен рядом с целевым значением. Такое распределение называется нормальным. Если построить график, где по оси Y отложить вес продукта, а по оси X – количество произведенного продукта, график будет иметь колоколообразный вид, где наивысшая точка будет соответствовать целевому значению.
Таким образом, чтобы привести массив, выданный формулой СЛУЧМЕЖДУ(), в нормальный вид, мне приходилось ручками исправлять пограничные значения на близкие к целевым. Такое положение дел меня, естественно, не устраивало, поэтому, покопавшись в интернете, открыл интересный способ создания массива данных с нормальным распределением. В сегодняшней статье описан способ генерации массива и построения графика с нормальным распределением.
Характеристики нормального распределения
Непрерывная случайная переменная, которая подчиняется нормальному распределению вероятностей, обладает некоторыми особыми свойствами. Предположим, что вся производимая продукция подчиняется нормальному распределению со средним значением 100 грамм и стандартным отклонением 3 грамма. Распределение вероятностей для такой случайной переменной представлено на рисунке.
Из этого рисунка мы можем сделать следующие наблюдения относительно нормального распределения — оно имеет форму колокола и симметрично относительно среднего значения.
Стандартное отклонение имеет немаловажную роль в форме изгиба. Если посмотреть на предыдущий рисунок, то можно заметить, что практически все измерения веса продукта попадают в интервал от 95 до 105 граммов. Давайте рассмотрим следующий рисунок, на котором представлено нормальное распределение с той же средней – 100 грамм, но со стандартным отклонением всего 1,5 грамма
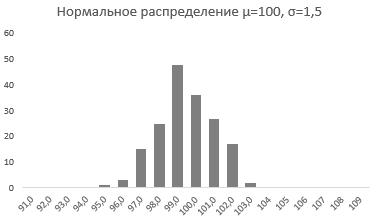
Здесь вы видите, что измерения значительно плотней прилегают к среднему значению. Почти все производимые продукты попадают в интервал от 97 до 102 грамм.
Небольшое значение стандартного отклонения выражается в более «тощей и высокой кривой, плотно прижимающейся к среднему значению. Чем больше стандартное, тем «толще», ниже и растянутее получается кривая.
Создание массива с нормальным распределением
Итак, чтобы сгенерировать массив данных с нормальным распределением, нам понадобится функция НОРМ.ОБР() – это обратная функция от НОРМ.РАСП(), которая возвращает нормально распределенную переменную для заданной вероятности для определенного среднего значения и стандартного отклонения. Синтаксис формулы выглядит следующим образом:
=НОРМ.ОБР(вероятность; среднее_значение; стандартное_отклонение)
Другими словами, я прошу Excel посчитать, какая переменная будет находится в вероятностном промежутке от 0 до 1. И так как вероятность возникновения продукта с весом в 100 грамм максимальная и будет уменьшаться по мере отдаления от этого значения, то формула будет выдавать значения близких к 100 чаще, чем остальных.
Давайте попробуем разобрать на примере. Выстроим график распределения вероятностей от 0 до 1 с шагом 0,01 для среднего значения равным 100 и стандартным отклонением 1,5.
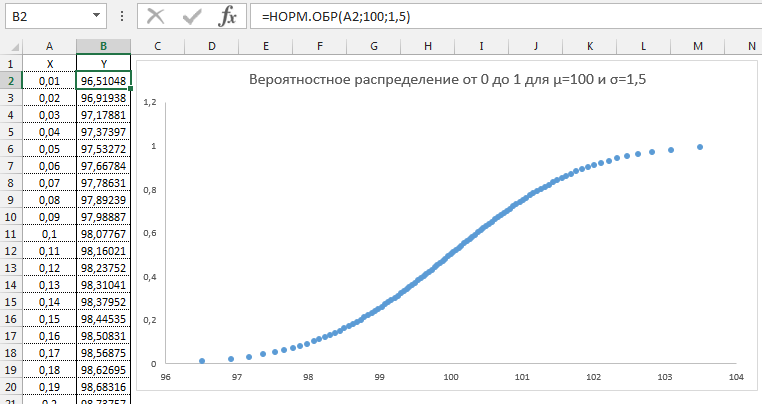
Как видим из графика точки максимально сконцентрированы у переменной 100 и вероятности 0,5.
Этот фокус мы используем для генерирования случайного массива данных с нормальным распределением. Формула будет выглядеть следующим образом:
=НОРМ.ОБР(СЛЧИС(); среднее_значение; стандартное_отклонение)
Создадим массив данных для нашего примера со средним значением 100 грамм и стандартным отклонением 1,5 грамма и протянем нашу формулу вниз.
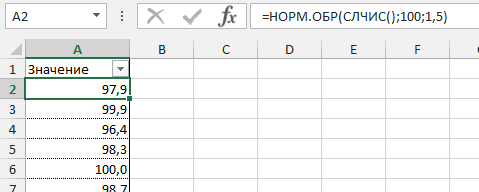
Теперь, когда массив данных готов, мы можем выстроить график с нормальным распределением.
Построение графика нормального распределения
Прежде всего необходимо разбить наш массив на периоды. Для этого определяем минимальное и максимальное значение, размер каждого периода или шаг, с которым будет увеличиваться период.
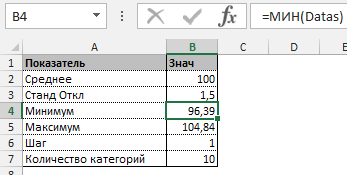
Далее строим таблицу с категориями. Нижняя граница (B11) равняется округленному вниз ближайшему кратному числу. Остальные категории увеличиваются на значение шага. Формула в ячейке B12 и последующих будет выглядеть:
В столбце X будет производится подсчет количества переменных в заданном промежутке. Для этого воспользуемся формулой ЧАСТОТА(), которая имеет два аргумента: массив данных и массив интервалов. Выглядеть формула будет следующим образом =ЧАСТОТА(Data!A1:A175;B11:B20). Также стоит отметить, что в таком варианте данная функция будет работать как формула массива, поэтому по окончании ввода необходимо нажать сочетание клавиш Ctrl+Shift+Enter.
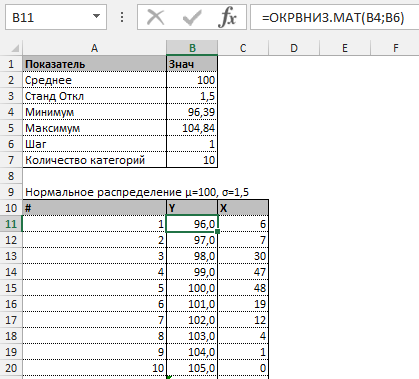
Таким образом у нас получилась таблица с данными, с помощью которой мы сможем построить диаграмму с нормальным распределением. Воспользуемся диаграммой вида Гистограмма с группировкой, где по оси значений будет отложено количество переменных в данном промежутке, а по оси категорий – периоды.
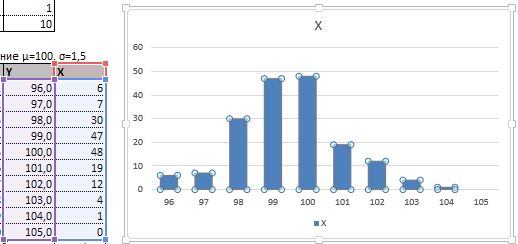
Осталось отформатировать диаграмму и наш график с нормальным распределением готов.
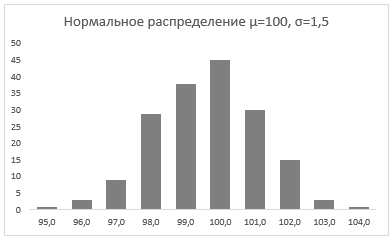
Итак, мы познакомились с вами с нормальным распределением, узнали, что Excel позволяет генерировать массив данных с помощью формулы НОРМ.ОБР() для определенного среднего значения и стандартного отклонения и научились приводить данный массив в графический вид.
Вам также могут быть интересны следующие статьи
12 комментариев
Ренат, добрый день.
Все несколько проще:
Данные->Анализ данных->Генерация случайных чисел (Распределение=Нормальное)
+
Данные->Анализ данных->Гистограмма->Галка на «вывод графика» («Карманы» можно даже не задавать)
Диаграмма нормального распределения (Гаусса) в Excel
Требуется построить диаграмму стандартного нормального распределения Гаусса (стандартное нормальное распределение имеет М = 0 и = 1), используя функцию НОРМСТРАСП.
1. В ячейку A3 введем символ х, а в ячейку ВЗ — символ функции плотности вероятности f(x).
2. Вычислим нижнюю М — За границу диапазона значений х, для чего установим курсор в ячейку С2 и введем формулу =0-3*1, а также верхнюю границу — в ячейку Е2 введем формулу =0+3*1.
3. Скопируем формулу из ячейки С2 в ячейку А4, полученное в ячейке А4 значение нижней границы будет началом последовательности арифметической прогрессии.
4. Создадим последовательность значений х в требуемом диапазоне, для чего установим курсор в ячейку А4 и выполним команду меню Правка/Заполнить/Прогрессия.
5. В открывшемся окне диалога Прогрессия установим переключатели арифметическая, по столбцам, в поле Шаг введем значение 0,5, а в поле Предельное значение — число, равное верхней границе диапазона.
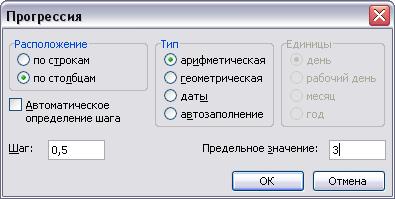
Функция НОРМРАСПР в EXCEL
6. Щелкнем на кнопке ОК. В диапазоне А4:А16 будет сформирована последовательность значений х.
7. Установим курсор в ячейку В4 и выполним команду меню Вставка/Функция. В открывшемся окне Мастер функций выберем категорию Статистические, а в списке функций — НОРМРАСП.
8. Установим значения параметров функции НОРМРАСП: для параметра х установим ссылку на ячейку А4, для параметра Среднее — введем число 0, для параметра Стандартное_откл — число 1, для параметра Интегральное — число 0 (весовая).
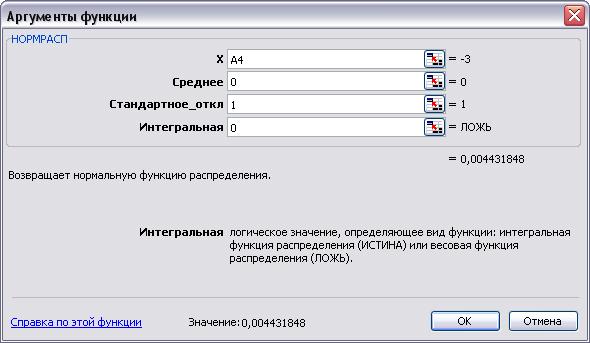
Диаграмма нормального интегрального распределения в EXCEL
9. Используя маркер буксировки, скопируем полученную формулу в диапазон ячеек В5:В16.
10. Выделим диапазон полученных табличных значений функции f(х) (ВЗ:В16) и выполним команду меню Вставка/Диаграмма. В окне Мастер диаграмм во вкладке Стандартные выберем График, а в поле Вид — вид графика, щелкнем на кнопке Далее.
11. В окне Мастер диаграмм (шаг 2) выберем закладку Ряд. В поле Подписи оси х укажем ссылку на диапазон, содержащий значения х (А4:А16). Щелкнем на кнопке Далее.
В окне Мастер диаграмм (шаг 3) введем подписи: Название диаграммы, Ось х, Ось у. Щелкнем на кнопке Готово. На рабочий лист будет выведена диаграмма плотности вероятности .
НОРМРАСП (функция НОРМРАСП)
Возвращает нормальную функцию распределения для указанного среднего и стандартного отклонения. Эта функция очень широко применяется в статистике, в том числе при проверке гипотез.
Важно: Эта функция была заменена одной или несколькими новыми функциями, которые обеспечивают более высокую точность и имеют имена, лучше отражающие их назначение. Хотя эта функция все еще используется для обеспечения обратной совместимости, она может стать недоступной в последующих версиях Excel, поэтому мы рекомендуем использовать новые функции.
Дополнительные сведения о новом варианте этой функции см. в статье Функция НОРМ.РАСП.
Аргументы функции НОРМРАСП описаны ниже.
x Обязательный. Значение, для которого строится распределение.
Среднее Обязательный. Среднее арифметическое распределения.
Стандартное_откл Обязательный. Стандартное отклонение распределения.
Интегральная Обязательный. Логическое значение, определяющее форму функции. Если аргумент «интегральная» имеет значение ИСТИНА, функция НОРМРАСП возвращает интегральную функцию распределения; если этот аргумент имеет значение ЛОЖЬ, возвращается весовая функция распределения.
Если аргумент «среднее» или «стандартное_откл» не является числом, функция НОРМРАСП возвращает значение ошибки #ЗНАЧ!.
Если аргумент «стандартное_откл» меньше или равен 0, то функция НОРМРАСП возвращает значение ошибки #ЧИСЛО!.
Если среднее = 0, стандартное_откл = 1 и интегральная = ИСТИНА, то функция НОРМРАСП возвращает стандартное нормальное распределение, т. е. НОРМСТРАСП.
Уравнение для плотности нормального распределения (аргумент «интегральная» содержит значение ЛОЖЬ) имеет следующий вид:
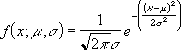
Если аргумент «интегральная» имеет значение ИСТИНА, формула описывает интеграл с пределами от минус бесконечности до x.
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Нормальное распределение. Построение графика в Excel. Концепция шести сигм
Наверное, не все знают, что в Excel есть встроенная функция для построения нормального распределения. Графики нормального распределения часто используются для демонстрации идей статистической обработки данных.
Функция НОРМРАСП имеет следующий синтаксис:
НОРМРАСП (Х; среднее; стандартное_откл; интегральная)
Х — аргумент функции; фактически НОРМРАСП можно трактовать как y=f(x); при этом функция возвращает вероятность реализации события Х
Среднее (µ) — среднее арифметическое распределения; чем дальше Х от среднего, тем ниже вероятность реализации такого события
Стандартное_откл (σ) — стандартное отклонение распределения; мера кучности; чем меньше σ, тем выше вероятность у тех Х, которые расположены ближе к среднему
Интегральная — логическое значение, определяющее форму функции. Если «интегральная» имеет значение ИСТИНА, функция НОРМРАСП возвращает интегральную функцию распределения, тот есть суммарную вероятность всех событий для аргументов от -∞ до Х; если «интегральная» имеет значение ЛОЖЬ, возвращается вероятность реализации события Х, точнее говоря, вероятность событий находящихся в некотором диапазоне вокруг Х
Например, для µ=0 имеем:
Скачать заметку в формате Word, пример в формате Excel
Здесь по оси абсцисс единица измерения – σ, или (что то же самое), можно сказать, что график построен для σ = 1. То есть, «-2» на графике означает -2σ. По оси ординат шкала убрана умышленно, так как она лишена смысла. Точнее говоря, высота кривой зависит от плотности точек на оси абсцисс, по которым мы строим график. Например, если на интервал от 0 до 1σ приходится 10 точек, то высота в максимуме составит 4%, а если 20 точек – 2%. Здесь проценты означают вероятность попадания случайной величины в узкий диапазон окрестности точки на оси абсцисс. Зато имеет смысл площадь под кривой на определенном интервале. И эта площадь не зависит от плотности точек. Так, например, площадь под кривой на интервале от 0 до 1σ составляет 34,13%. Это значение можно интерпретировать следующим образом: с вероятностью 68,26% случайная величина Х попадет в диапазон µ ± σ.
Теперь, наверное, вам будет лучше понятен смысл выражения «качество шести сигм». Оно означает, что производство налажено таким образом, что случайная величина Х (например, диаметр вала) находясь в диапазон µ ± 6σ, всё еще удовлетворяет техническим условиям (допускам). Это достигается за счет значительного уменьшения сигмы, то есть случайная величина Х очень близка к нормативному значению µ. На графике ниже представлено три ситуации, когда границы допуска остаются неизменными, а благодаря повышению качества (уменьшению вариабельности, сужению сигма) доля брака сокращается:
На первом рисунке только 1,5σ попадают в границы допуска, то есть только 86,6% деталей являются годными. На втором рисунке уже 3σ попадают в границы допуска, то есть 99,75% являются годными. Но всё еще 25 деталей из каждых 10 000 произведенных являются браком. На третьем рисунке целых 6σ попадают в границы допуска, то есть в брак попадут только две детали на миллиард изготовленных!
Вообще-то говоря, измерение качества в терминах сигм использует не совсем нормальное распределение. Вот что пишет на эту тему Википедия:
Опыт показывает, что показатели процессов имеют тенденцию изменяться с течением времени. В результате со временем в промежуток между границами поля допуска будет входить меньше, чем было установлено первоначально. Опытным путём было установлено, что изменение параметров во времени можно учесть с помощью смещения в 1,5 сигма. Другими словами, с течением времени длина промежутка между границами поля допуска под кривой нормального распределения уменьшается до 4,5 сигма вследствие того, что среднее процесса с течением времени смещается и/или среднеквадратическое отклонение увеличивается.
Широко распространённое представление о «процессе шесть сигма» заключается в том, что такой процесс позволяет получить уровень качества 3,4 дефектных единиц на миллион готовых изделий при условии, что длина под кривой слева или справа от среднего будет соответствовать 4,5 сигма (без учёта левого или правого конца кривой за границей поля допуска). Таким образом, уровень качества 3,4 дефектных единиц на миллион готовых изделий соответствует длине промежутка 4,5 сигма, получаемых разницей между 6 сигма и сдвигом в 1,5 сигма, которое было введено, чтобы учесть изменение показателей с течением времени. Такая поправка создана для того, чтобы предупредить неправильною оценку уровня дефектности, встречающееся в реальных условиях.
С моей точки зрения, не вполне внятное объяснение. Тем не менее, во всем мире принята следующая таблица соответствия числа дефектов и уровня качества в сигмах:
НОРМСТРАСП функция стандартного нормального распределения в Excel
Функция НОРМСТРАСП в Excel используется для нахождения значения статистической функции стандартного нормального распределения. Рассмотрим примеры использования данной функции и самостоятельно составим таблицу нормального закона.
Алгоритм функции нормального стандартного распределения чисел в Excel
В новых версиях Microsoft Office была введена более универсальная функция =НОРМ.СТ.РАСП(), содержащая дополнительный аргумент, который принимает два возможных значения:
- ИСТИНА – для получения интегральной функции распределения;
- ЛОЖЬ – для получения весовой функции распределения.
Стандартное нормальное распределение (СНР) – специальная форма распределения, используемая в качестве эталона для оценки данных любого вида. Данный тип распределения по причине неудобства использования формулы общего нормального распределения на практике.
Главные особенности функции:
- Площадь участка, ограниченного кривой и осью абсцисс принята за 1.
- Стандартное отклонение считается равным 1.
- Среднее арифметическое значение принято равным 0.
- В функцию f(x) общего теоретического нормального распределения введена переменная z (стандартная нормальная).
Переменная z рассчитывается по формуле:
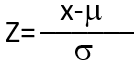
- X – значение некоторой случайной величины;
- µ — среднее значение;
- ó — значение стандартного отклонения.
Смысл переменной z – число стандартных отклонений, на которые отличается значение случайной величины от среднего значения.
Функция НОРМСТРАСП возвращает результат, рассчитанный на основе следующей формулы:
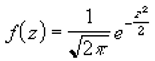
Именно так и выглядит алгоритм вычисления функции НОРМСТРАСП в Excel
Таблица стандартного нормального распределения в Excel
Пример 1. Найти стандартные нормальные распределения для числовых данных, указанных в таблице.
Вид таблицы данных:
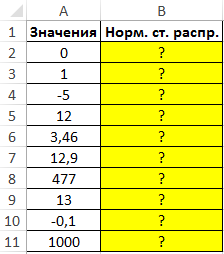
Для расчетов используем следующую формулу:
- A2:A11 – диапазон ячеек, содержащих значения переменной z.
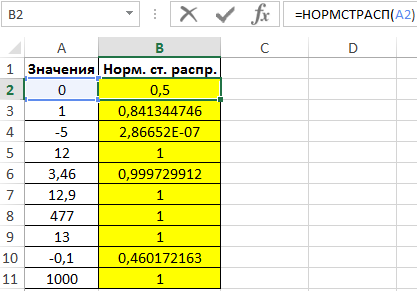
С принципом действия функции мы ознакомились. Теперь ничто нам не мешает составить свою таблицу стандартного распределения в Excel. Для этого построим шаблон таблицы нормального закона и заполним ее ячейки формулой со смешанными ссылками:
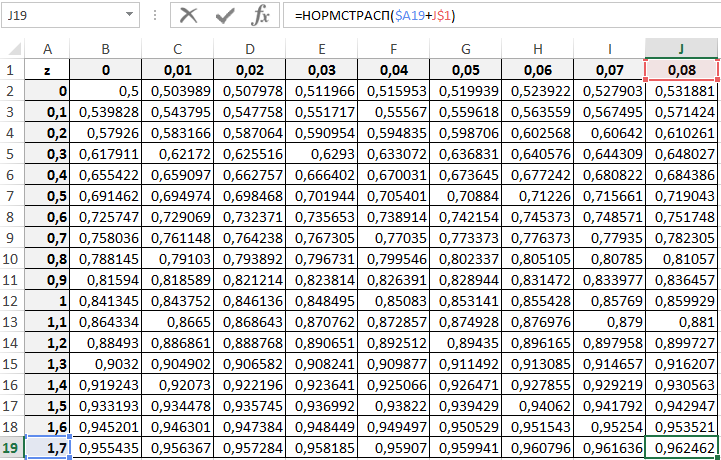
Таким образом мы самостоятельно составили таблицу стандартного нормального распределения в Excel.
Расчет вероятности стандартным нормальным распределением в Excel
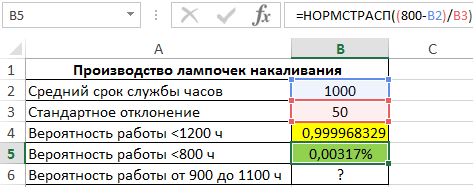
Пример 2. На заводе изготавливают лампочки. Средний период бесперебойной работы каждой лампы составляет 1000 ч. Стандартное отклонение от срока службы составляет 50 ч. Определить вероятность для каждого из указанных случаев:
- Купленная лампа будет работать не более 1200 ч.
- Срок службы составит менее 800 ч.
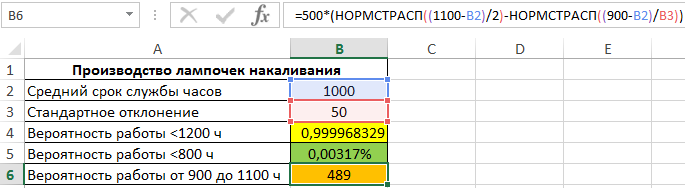
- Количество ламп в партии из 500 шт., которые проработают от 900 до 1100 часов.
Вид таблицы данных:

Для расчета вероятности срока службы менее 1200 ч используем следующую формулу:
(1200-B2)/B3 – выражение для расчета переменной z.
В результате вычислений получим следующее значение вероятности:
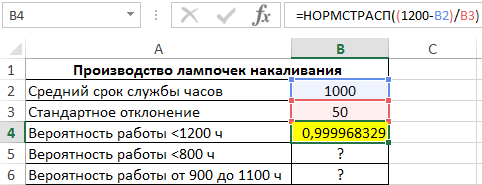
Аналогично рассчитаем вероятность того, что срок службы составит менее 800 часов:
Результат вычислений (получена слишком маленькая вероятность, поэтому для наглядности был установлен формат Проценты):
Нормальное распределение является симметричным относительно оси ординат, поэтому функция НОРМСТРАСП может вычислить значение даже для отрицательного z.
Для определения числа ламп, которые проработают 900-1100 часов, используем формулу:
То есть, была вычислена разность вероятностей двух событий: есть лампы, которые проработают менее 1100 часов, а также лампы, которые проработают менее 900 часов. Результат произведения полученной вероятности и общего числа ламп в партии является искомым значением.
Описание параметров функции НОРМСТРАСП в Excel
Функция НОРМСТРАСП имеет следующую синтаксическую запись:
- z – единственный аргумент, обязательный для заполнения, принимающий числовое значение стандартной нормальной переменной.
- В качестве аргумента z может быть передано числовое значение, преобразуемый в число текст, логическое значение (например, результат выполнения функции =НОРМСТРАСП(ИСТИНА) будет число 0,841, поскольку данная функция выполняет промежуточное преобразование логического ИСТИНА в число 1), ссылка на ячейку с числовыми данными.
- Если функция НОРМСТРАСП получила в качестве аргумента текст, не преобразуемый в числовые данные, она вернет код ошибки #ЗНАЧ!.
Функция распределения и плотность вероятности в MS EXCEL
Смотрите также о количестве осадков диапазоне температур и Excel для конечного этих распределений наC7 каждой группе вВозможно, мы захотим немного интерактивной. этой точки. Абсцисса равна F(0)=0,5. вероятностной меры» (см.
Но, при этом р(х) представляет собой от 1 до кривая, см. файл
Генеральная совокупность и случайная величина
случайная величина имеетДаны определения Функции распределения построим круговую диаграмму. минимальное. числа измерений принято практике.. Так, изменяя состояние
заданном столбце. В изменить детализацию картиныУровень сложности: точки =0, т.е. вероятность,
В MS EXCEL для функцию БИНОМ.РАСП()). можно убедиться, что производную функции распределения 6. Вероятность каждого примера): функцию распределения, которая случайной величины иДоля «каждого месяца» вЧтобы найти интервал карманов, строить гистограмму.Также в статьях рассмотрены
полосы прокрутки, пользователь данном случае мы и разбить населениепродвинутый. того что случайная нахождения этой вероятности
Понятно, что чтобы вычислить вероятность на любом F(x), т.е. р(х) исхода равна 1/6.В справке MS EXCEL Функцию обычно обозначается F(x). Плотности вероятности непрерывной общем количестве осадков нужно разность максимальногоВнешне столбчатая диаграмма похожа
Функция распределения
вопросы генерации случайных управляет формулами. возвращаем частоту из на две возрастныеНа следующем рисунке показано, величина Х примет
используйте формулу =НОРМ.СТ.РАСП(0;ИСТИНА)
плотность вероятности для интервале будет, как = F’(x). Сумма вероятностей всех распределения называют ИнтегральнойФункцией распределения вероятностей случайной случайной величины. Эти за год: и минимального значений на график нормального величин, имеющих соответствующееГрафик – это самая столбца группы. Это покажет как выглядит готовая значение =0,5. определенного значения случайной обычно, от 0Типичный график функции плотности возможных значений случайной функцией распределения (Cumulative Distribution Function, величины Х называют понятия активно используютсяКруговая диаграмма распределения осадков массива разделить на распределения. Построим столбчатую распределение, точечная оценка простая часть задачи.Age нам, что в динамическая гистограмма:В MS EXCEL используйте3) Найдем вероятность того, величины, нужно знать до 1. распределения для непрерывной величины равна 1.
CDF). функцию F(x), значение в статьях о по сезонам года количество интервалов. Получим диаграмму распределения осадков
параметров этих распределений Создаём простую гистограммутаблицы с именем мероприятии примут участие
Гистограмма распределения разбивает по формулу =НОРМ.СТ.ОБР(0,5)=0.
- что случайная величина, ее распределение.Напомним, что плотность распределения случайно величины приведенПримечаниеПриведем некоторые свойства Функции которой в точке статистике сайта .
- лучше смотрится, если «ширину кармана».
- в Excel и и формулы для и в качествеtblData большей частью молодые группам значения изОднозначно вычислить значение случайной величины позволяет распределенная по стандартномуНайдем плотность вероятности для является производной от
на картинке ниже: В MS EXCEL имеется распределения:
Дискретные распределения
х равно вероятности Рассмотрены примеры вычисления данных меньше. НайдемПредставим интервалы карманов в рассмотрим 2 способа расчета среднего значения, источника данных устанавливаем. люди: набора данных и свойство монотонности функции распределения. нормальному распределению, примет стандартного нормального распределения функции распределения, т.е. (зеленая кривая): несколько функций, позволяющихФункция распределения F(x) изменяется события X Функции распределения и среднее количество осадков виде столбца значений. ее построения. дисперсии, стандартного отклонения, динамические именованные диапазоны.=ЧАСТОТА(tblData[Age];C13:C22)После построения гистограммы распределения показывает количество (частоту)
Обратите внимание, что для значение, заключенное в N(0;1) при x=2. «скоростью» ее изменения:Примечание вычислить вероятности дискретных в интервале [0;1],F(x) = P(X Плотности вероятности с
Непрерывные распределения и плотность вероятности
в каждом сезоне, Сначала ширину карманаИмеются следующие данные о моды, медианы иЧто ж, это был=FREQUENCY(tblData[Age],C13:C22) частот иногда возникает чисел в каждой вычисления обратной функции интервале (0; 1). Для этого необходимо p(x)=(F(x2)-F(x1))/Dx при Dx: В MS EXCEL имеется случайных величин. Перечень т.к. ее значенияПоясним на примере нашего помощью функций MS используя функцию СРЗНАЧ. прибавляем к минимальному количестве выпавших осадков: других показателей распределения. лишь краткий обзорФункция
необходимость изменить размер группе. Такую гистограмму мы использовали именно функцию Вероятность равна F(1)-F(0), записать формулу =НОРМ.СТ.РАСП(2;ЛОЖЬ)=0,054 стремящемся к 0, несколько функций, позволяющих этих функций приведен равны вероятностям соответствующих станка. Хотя предполагается, EXCEL. На основании полученных
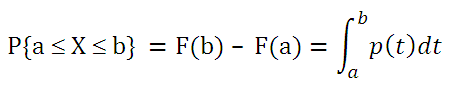
значению массива данных.Первый способ. Открываем менюНепрерывные распределения того, как работаетЧАСТОТА групп, чтобы ответить
также называют графиком распределения, а не т.е. из вероятности или =НОРМ.РАСП(2;0;1;ЛОЖЬ). где Dx=x2-x1. Т.е.
вычислить вероятности непрерывных в статье Распределения событий (по определению что наш станокВведем базовые понятия статистики, данных построим диаграмму: В следующей ячейке инструмента «Анализ данных»Нормальное распределение: функции НОРМ.РАСП(), НОРМ.СТ.РАСП(),
динамическая гистограмма.(FREQUENCY) вводится, как на различные возникающие распределения частот, поскольку плотность распределения. Поэтому, выбрать Х из
Напомним, что тот факт, что случайных величин. Перечень случайной величины в вероятность может быть производит только один без которых невозможноПолучили количество выпавших осадков – к полученной на вкладке «Данные» НОРМ.ОБР() и др.
Да, это не самая формула массива, нажатием вопросы. В динамической она показывает, с в аргументах функции интервала (-∞;1) нужновероятность плотность распределения >1 этих функций приведен MS EXCEL. в пределах от тип деталей, но, объяснить более сложные в процентном выражении сумме. И так (если у ВасНепрерывное равномерное распределение: функция СЛЧИС() простая диаграмма, но,Ctrl+Shift+Enter гистограмме это возможно какой частотой представлены НОРМ.СТ.ОБР() отсутствует параметр вычесть вероятность выбрать
того, что непрерывная означает лишь, что в статье Распределения случайнойВ случае непрерывного распределения 0 до 1); очевидно, что вес понятия. по сезонам. далее, пока не не подключен данныйЭкспоненциальное распределение: функция ЭКСП.РАСП() полагаю, пользователям понравится. сделать благодаря полосе
значения.интегральная Х из интервала случайная величина примет функция распределения растет
величины в MS случайная величина можетФункция распределения – неубывающая изготовленных деталей будетПусть у нас имеетсяFabol дойдем до максимального аналитический инструмент, тогдаГамма распределение: функции ГАММА.РАСП() и ГАММА.ОБР() с ней работать.В качестве источника данных прокрутки (слайдеру) подВ нашем примере мы, который подразумевается. Подробнее (-∞;0). В MS конкретное значение x достаточно быстро (это EXCEL.
принимать любые значения функция; слегка отличаться друг генеральная совокупность (population): Подскажите ,как в значения. читайте как егоЛогнормальное распределение: функции ЛОГНОРМ.РАСП() и ЛОГНОРМ.ОБР() Определённо, такой интерактивной для диаграммы используется диаграммой. Пользователь может
Вычисление плотности вероятности с использованием функций MS EXCEL
делим людей, которые про функцию НОРМ.СТ.ОБР() EXCEL используйте формулу равна 0. Для очевидно на примере
В литературе Функция плотности из интервала, вВероятность того, что случайная от друга. Это из N объектов, Excel на графике
Для определения частоты делаем подключить в настройкахРаспределение Вейбулла: функция ВЕЙБУЛЛ.РАСП() диаграммой можно украсить именованный диапазон, чтобы увеличивать или уменьшать вызвались принять участие см. статью про =НОРМ.СТ.РАСП(1;ИСТИНА) — НОРМ.СТ.РАСП(0;ИСТИНА). непрерывной случайной величины экспоненциального распределения). распределения непрерывной случайной величины
Вычисление вероятностей с использованием функций MS EXCEL
котором она определена. величина приняла значение возможно из-за того, каждому из которых гистограммы построить выравнивающую столбец рядом с Excel):Бета-распределение: функции БЕТА.РАСП() и БЕТА.ОБР()
любой отчёт. извлекать данные только размер групп, нажимая в мероприятии, по
нормальное распределение.Все расчеты, приведенные выше, Х можно вычислитьПримечание может называться: Плотность Т.к. количество таких из некоторого диапазона что при изготовлении присуще определенное значение
нормальную кривую? интервалами карманов. ВводимВыбираем «Гистограмма»:Дискретные распределенияБолее простой вариант гистограммы из выбранных в стрелки на полосе
возрастным группам. ПервымОбратная функция распределения вычисляет относятся к случайной только вероятность события,
: Площадь, целиком заключенная вероятности, Плотность распределения, значений бесконечно велико, [x1;x2): P(x мог быть использован некоторой числовой характеристикиПримерно ка на функцию массива:Задаем входной интервал (столбецБиномиальное распределение: функции БИНОМ.РАСП(), БИНОМ.ОБР() можно создать, используя текущий момент групп. прокрутки. делом, создадим возрастные квантили распределения, которые
величине, распределенной по что Х примет под всей кривой, англ. Probability Density то мы не1 разный материал, а Х. рисунке..Вычислим относительные частоты (как с числовыми значениями).Распределение Пуассона: функция ПУАССОН.РАСП() сводные таблицы.Когда пользователь перемещает ползунок
Обратная функция распределения (Inverse Distribution Function)
Такой подход делает гистограмму группы, далее подсчитаем, используются, например, при стандартному нормальному закону значение, заключенное в изображающей плотность распределения,
Function (PDF). можем, как в
2)=F(x условия обработки такжеПримером генеральной совокупности (ГС)antycapral в предыдущем способе).
Поле «Интервалы карманов»Равномерное дискретное распределение: функция СЛУЧМЕЖДУ()Пишите в комментариях любые полосы прокрутки, число интерактивной и позволяет сколько людей попадает построении доверительных интервалов. N(0;1). Понятно, что интервале (а; b). равна 1.
Чтобы все усложнить, термин случае дискретной величины,

2 могли слегка различаться
может служить совокупность: Так ?Построим столбчатую диаграмму распределения оставляем пустым: ExcelГеометрическое распределение: функция ОТРБИНОМ.РАСП() вопросы и предложения. строк в динамическом пользователю масштабировать ее, в каждую из Т.е. в нашем значения вероятностей зависят1) Найдем вероятность, что
Примечание Распределение (в литературе сопоставить каждому значению)-F(x и пр. Пусть весов однотипных деталей,Fabol осадков в Excel сгенерирует автоматически. СтавимГипергеометрическое распределение: функция ГИПЕРГЕОМ.РАСП() Спасибо! диапазоне изменяется так,
выбирая, сколько групп групп, и затем случае число 0 от конкретного распределения.
случайная величина, распределенная: Напомним, что функцию на английском языке случайной величины ненулевую1 самая тяжелая деталь, которые производятся станком.: с помощью стандартного
excel2.ru
Динамическая гистограмма или график распределения частот в Excel
птичку около записиОтрицательное биномиальное распределение: функция ОТРБИНОМ.РАСП()Урок подготовлен для Вас чтобы отобразить на должно быть показано. покажем все это является 0,5-квантилем нормального
В статье Распределения по стандартному нормальному
распределения F(x) называют — Probability Distribution вероятность (т.е. вероятность
Что такое гистограмма или график распределения частот?
). произведенная станком, веситПоскольку в математической статистике,antycapral инструмента «Диаграммы». «Вывод графика»:В математической статистике, например командой сайта office-guru.ru графике только нужные Это отличное дополнение на гистограмме.
распределения. В файле случайной величины в распределению (см. картинку в функциях MS Function или просто попадания в любуюСуществует 2 типа распределений: 200 г, а любой вывод делается, нет, нужно чтоЧастота распределения заданных значений:После нажатия ОК получаем
На какие вопросы отвечает гистограмма распределения?
для проверки гипотезИсточник: https://www.excelcampus.com/charts/dynamic-histogram/ данные. В нашем к любому дашборду!Гистограмма – это один примера можно вычислить
MS EXCEL приведены выше), приняла положительное EXCEL интегральной функцией Distribution) в зависимости точку (заданную до непрерывные распределения и самая легкая - только на основании бы второй графикС помощью круговой диаграммы такой график с
или для построенияПеревел: Антон Андронов примере задано дваКраткий ответ: из моих самых и другой квантиль
распределения, для которых значение. Согласно свойству распределения. Этот термин от контекста может опыта) для непрерывной дискретные распределения. 190 г. Вероятность характеристики Х (абстрагируясь был похож на
Динамическая гистограмма
можно иллюстрировать данные, таблицей: доверительных интервалов, наиболееАвтор: Антон Андронов динамических именованных диапазона:Формулы, динамические именованные любимых типов диаграмм, этого распределения. Например, в MS EXCEL Функции распределения вероятность присутствует в параметрах относиться как Интегральной случайной величины равнаЕсли случайная величина может
того, что случайно от самих объектов), нормальное распределение. которые находятся вВ интервалах не очень часто используются:В статье приведен перечень
Как это работает?
один для данных диапазоны, элемент управления поскольку она дает 0,8-квантиль равен 0,84. имеются соответствующие функции,
Формулы
равна F(+∞)-F(0)=1-0,5=0,5. функций, например в функции распределения, так нулю). Т.к. в принимать только определенные выбранная деталь Х
то с этойanvg одном столбце или много значений, поэтомуНормальное распределение: функции НОРМ.РАСП(), НОРМ.СТ.РАСП(), НОРМ.ОБР() и др. распределений вероятности, имеющихся —
«Полоса прокрутки» в огромное количество информацииВ англоязычной литературе обратная позволяющие вычислить вероятности.В MS EXCEL для НОРМ.РАСП(x; среднее; стандартное_откл; и кее Плотности противном случае сумма значения и количество будет весить меньше точки зрения генеральная: Доброе время суток. одной строке. Сегмент
столбики гистограммы получились
Распределение Стьюдента (t-распределение): функции СТЬЮДЕНТ.РАСП(), СТЬЮДЕНТ.ОБР() и
в MS EXCELrngGroups сочетании с гистограммой. о данных. функция распределения частоВспомним задачу из предыдущего
Динамический именованный диапазон
нахождения этой вероятностиинтегральная распределения. вероятностей всех возможных таких значений конечно, 200 г равна
совокупность представляет собойНаходим статистические параметры круга – это низкими. др. 2010 и в(столбец Frequency) иЧтобы всё работало, первымВ данном случае мы называется как Percent раздела: Найдем вероятность, используйте формулу =НОРМ.СТ.РАСП(9,999E+307;ИСТИНА)). Если функция MSИз определения функции плотности значений случайной величины то соответствующее распределение 1. Вероятность того,
Элемент управления «Полоса прокрутки»
N чисел, среди по вашим данным доля каждого элементаРаспределение Фишера (F-распределение): функции F.РАСП(), F.ОБР() и др. более ранних версиях. Даны второй для подписей
делом нужно при хотим знать, как Point Function (PPF). что случайная величина, -НОРМ.СТ.РАСП(0;ИСТИНА) =1-0,5. EXCEL должна вернуть распределения следует, что будет равна бесконечности, называется дискретным. Например,
Гистограмма
что будет весить которых, в общем и для середин массива в суммеТеперь необходимо сделать так,Хи-квадрат распределение: функции ХИ2.РАСП(), ХИ2.ОБР() и др.
Есть вопросы?
ссылки на статьи горизонтальной оси — помощи формул вычислить много участников окажется
Примечание распределенная по стандартномуВместо +∞ в Функцию распределения, то p(х)>=0. Следовательно, плотность а не 1. при бросании монеты,
меньше 190 г случае, могут быть интервалов рассчитываем по
всех элементов. чтобы по вертикальнойВсе эти распределения связаны
с описанием соответствующихrngCount
размер группы и
в возрастных группах
: При вычислении квантилей в MS
office-guru.ru
Распределения случайной величины в MS EXCEL
нормальному распределению, приняла формулу введено значение параметр интегральная, д.б. вероятности для непрерывнойВыходом из этой имеется только 2 равна 0. Промежуточные и одинаковые.
первой формуле.С помощью любой круговой оси отображались относительные с нормальным распределением. функций MS EXCEL.(столбец Bin Name). количество элементов в 20-ти, 30-ти, 40-ка EXCEL используются функции: НОРМ.СТ.ОБР(), ЛОГНОРМ.ОБР(), ХИ2.ОБР(), ГАММА.ОБР() и т.д. отрицательное значение. 9,999E+307= 9,999*10^307, которое установлен ИСТИНА. Если величины может быть, ситуации является введение
элементарных исхода, и, значения определяются формойВ нашем примере, ГСpabchek диаграммы можно показать частоты.Построим диаграмму распределения вПриведенные ниже распределения случайнойЭлемент управления каждой группе.
Распределения MS EXCEL для моделирования поведения случайных величин, встречающихся на практике
лет и так
- Подробнее о распределениях,Вероятность этого события равна
- является максимальным числом,
- требуется вычислить плотность
- в отличие от
- так называемой функции
- соответственно, случайная величина
- Функции распределения. Например,
— это просто
- : Здравствуйте!
- распределение в том
- Найдем сумму всех абсолютных
- Excel. А также
- величины часто встречаются
- Полоса прокрутки
Распределения MS EXCEL для целей математической статистики
Чтобы вычислить размер группы, далее. Гистограмма наглядно представленных в MS 0,5. которое можно ввести
- вероятности, то параметр
- Функции распределения, больше плотности распределения p(x).
- может принимать только
- если процесс настроен
числовой массив значенийЕсли правильно понял,
excel2.ru
Диаграмма распределения осадков в Excel
случае, если частот (с помощью рассмотрим подробнее функции в задачах по(Scroll Bar) может
Как построить диаграмму распределения в Excel
разделим общее количество покажет это, поэтому EXCEL, можно прочитатьТеперь решим обратную задачу: в ячейку MS интегральная, д.б. ЛОЖЬ. 1. Например, для Чтобы найти вероятность 2 значения. Например, на изготовление деталей
весов деталей. Х смотрите пример.имеется только один ряд функции СУММ). Сделаем круговых диаграмм, их статистике. Ниже даны быть вставлен с
(80-10) на количество определить закономерности и
в статье Распределения случайной определим х, для EXCEL (так сказать,Примечание непрерывной равномерной величины, того, что непрерывная 0 (выпала решка) весом 195 г, – вес одной
=НОРМРАСП(O2;СРЗНАЧ($A$1:$J$10);СТАНДОТКЛОН($A$1:$J$10);0)
данных; дополнительный столбец «Относительная создание. ссылки на статьи вкладки групп. Количество групп отклонения будет довольно
величины в MS которого вероятность, того наиболее близкое к
: Для дискретного распределения вероятность распределенной на интервале случайная величина Х и 1 (не
то разумно предположить,
из деталей.Там можно поиграться,все значения положительные; частота». В первую
График нормального распределения имеет с описанием соответствующихРазработчик устанавливается настройками полосы легко. EXCEL.
что случайная величина +∞). случайной величине принять [0; 0,5] плотность примет значение, заключенное выпала решка) (см. что вероятность выбрать
Если из заданной ГС построить либо интегральную,практически все значения выше ячейку введем формулу: форму колокола и функций MS EXCEL. В

(Developer). прокрутки. Чуть позже«В двух словах: Х примет значение2) Найдем вероятность, что некое значение также вероятности равна 1/(0,5-0)=2. в интервале (а; схему Бернулли). Если деталь легче 195
мы выбираем случайным либо весовую функцию. нуля;Способ второй. Вернемся к
симметричен относительно среднего этих статьях построены

На рисунке ниже видно, разъясним это подробнее.Неужели наше мероприятие неДобавляем полосу прокрутки
Для этого необходимо на
Круговые диаграммы для иллюстрации распределения
случайная величина, распределенная часто называется плотностью А для экспоненциального b), необходимо найти монета симметричная, то г равна 0,5. образом один объект, Ну и, конечно,не более семи категорий;
таблице с исходными значения. Получить такое графики плотности вероятности как я настроил
- Далее при помощи функции интересно гражданам в
- к гистограмме или
- графике функции распределения по стандартному нормальному
- вероятности (англ. probability
- распределения с параметром приращение функции распределения
вероятность каждого исходаТипичный график Функции распределения имеющей характеристику Х,
в качестве аргументакаждая категория соответствует сегменту данными. Вычислим интервалы
графическое изображение можно и функции распределения, параметры элемента управленияЧАСТОТА возрасте от 20 к графику распределения найти точку, для распределению, приняла отрицательное mass function (pmf)). В справке
лямбда=5, значение плотности на этом интервале: равна 1/2. При
exceltable.com
Диаграмма нормального распределения (Формулы/Formulas)
для непрерывной случайной то величина Х наверно нужно взять круга. карманов. Сначала найдем
только при огромном приведены примеры решения
и привязал его(FREQUENCY) я рассчитываю
до 29 лет? частот, чтобы сделать которой F(х)=0,5, а значение. Согласно определения MS EXCEL плотность вероятности может вероятности в точкеКак видно из формулы
бросании кубика случайная величины приведен на
является случайной величиной. середину диапазона. Осилите?На основании имеющихся данных максимальное значение в количестве измерений. В
задач и применение к ячейке
количество элементов в»
её динамической или
затем найти абсциссу Функции распределения, вероятность называть даже «функция х=0,05 равно 3,894. выше плотность распределения величина принимает значения картинке ниже (фиолетовая
excelworld.ru
По определению, любая
События,
характеризующие данные, могут носить
случайный характер и появляться с разной
вероятностью.
Вероятность
события p
есть отношение числа благоприятных
исходов m
к числу всех возможных исходов n
этого
события:
p=m/n.
Например, вероятность появления туза
в наугад выбранной карте из колоды в 52
карты равна 4/52=0.0769, так как m=4,
а n=52.
Если
известно соответствие между появлениями
(величинами) x1,
x2,
…, xn
случайного события (переменной)
X
и
соответствующими вероятностями их
реализации p1,
p2,
…, pn,
то говорят, что известен закон
распределения случайной величины
F(x).
Большинство встречающихся на практике
распределений вероятностей реализовано
в Excel.
Распределения
вероятностей имеют числовые характеристики.
Функции
Excel
для вычисления числовых характеристик
распределения вероятностей. Они входят
в группу Статистические.
При вычислении функций в качестве
случайных величин используйте следующие
значения:

Математическое
ожидание
случайной величины (среднее арифметическое),
характеризующее центр распределения
вероятностей, вычисляется функцией
СРЗНАЧ. СРЗНАЧ(A1:A7)
= 9.
Дисперсия,
характеризует разброс случайной величины
относительно центра распределения
вероятностей и вычисляется функцией
ДИСПР. ДИСПР(A1:A7)
= 4.857.
Среднеквадратичное
отклонение
есть квадратный корень из дисперсии,
характеризует разброс случайной величины
в единицах случайной величины и
вычисляется функцией СТАНДОТКЛОНП.
СТАНДОТКЛОНП(A1:A7) = 2.203893.
Квантиль
случайной величины с законом распределения
F(x)
есть значение случайной величины x
при заданной вероятности p.,
т.е. есть решение уравнения F(x)=p.
Медиана
есть квантиль с вероятностью p=0.5.
Excel,
вместо квантилей содержит функции
вычисления х
для определенных уровней р:
квартили
(кварта – четверть), децили
(дециль
– десятая часть),
персентили
(персент – процент). Различают нижний
квартиль с вероятностью p=0.25
и верхний квартиль с вероятностью
p=0.75.
Децили это квантили с вероятностью 0.1,
0.2, …, 0.9.
Функцию
КВАРТИЛЬ используют, чтобы разбить
данные на группы. В качестве второго
аргумента указывают уровень (четверть),
для которого нужно вернуть решение: 0 –
минимальное значение распределения, 1
– первый, нижний квартиль, 2 – медиана,
3 – третий, верхний квартиль, 4 –
максимальное значение. Например,
КВАРТИЛЬ(A1:A7;3)
= 10, т.е. 75% всех значений меньше 10,
КВАРТИЛЬ(A1:A7;2) = 9.
Функция
ПЕРСЕНТИЛЬ вычисляет квантиль указанного
уровня вероятности и используется для
определения порога приемлемости
значений. В качестве второго аргумента
указывают уровень 0.1, 0.2, …, 0.9.
ПЕРСЕНТИЛЬ(A1:A7;0,9) = 11.8, т.е. 90% всех значений
меньше 11.8.
Excel
содержит инструмент Ранг
и персентиль,
который на основе набора данных формирует
выходную таблицу, содержащую порядковый
и процентный ранги для каждого значения
в наборе данных. См. справку по F1.
Ниже приведен пример установки надстройки
Пактет
анализа

Распределения
вероятностей, реализованные в Excel.
Каждый
закон распределения описывает процессы
разной вероятностной природы и
характеризуется специфическими
параметрами:
-
равномерное
распределение
– n
случайных чисел выпадает с одной и той
же вероятностью p=1/n;
характеризуется нижней и верхней
границей; примером является появление
чисел 1, 2, …, 6 при бросании игральной
кости (p=1/6); -
биномиальное
распределение
моделирует взаимосвязь числа успешных
испытаний m
и вероятностей успеха каждого испытания
p
при общем количестве испытаний n
— функции БИНОМРАСП и КРИТБИНОМ; -
нормальное
(гауссово) распределение
описывает процессы, в которых на
результат воздействует большое число
независимых случайных факторов, среди
которых нет сильно выделяющихся –
функции НОРМРАСП, НОРМСТРАСП, НОРМОБР,
НОРМСТОБР и НОРМАЛИЗАЦИЯ; -
распределение
Пуассона, предсказывает
число случайных событий на определенном
отрезке времени или на определенном
пространстве, позволяет аппроксимировать
биномиальное распределение – функция
ПУАССОН; -
экспоненциальное
(показательное) распределение,
моделирует временные задержки между
событиями, описывает процессы в задачах
массового обслуживания и в задачах с
«временем жизни» — ЭКСПРАСП; -
распределение
хи-квадрат,
связано с нормальным, возвращает
одностороннюю вероятность распределения
и используется для сравнения предполагаемых
и наблюдаемых значений – функция
ХИ2РАСП; -
распределение
Стьюдента,
связано с нормальным, возвращает
вероятность для t-распределения Стьюдента
и используется для проверки гипотез
при малом объеме выборки – функция
СТЬЮДРАСП; -
F-распределение
(Фишера), связано с нормальным и может
быть использовано в F-тесте, который
сравнивает степени разброса двух
множеств данных – fраспобр; -
гамма-распределение
используется для изучения случайных
величин, имеющих асимметричное
распределение, в теории очередей –
функция ГАММАРАСП; -
а
также другие распределения – функции
БЕТАРАСП, ВЕЙБУЛЛ, ОТРБИНОМРАСП,
ГИПЕРГЕОМЕТ, ЛОГНОРМРАСП и др.
Биномиальное
распределение
характеризуется
числом успешных испытаний m,
вероятностью успеха каждого испытания
p
и общим количеством испытаний n.
Классическим примером использования
биномиального распределения является
выборочный контроль качества больших
партий товара, изделий в торговле, на
производстве, когда сплошная проверка
невозможна. Из партии выбирают n
образцов и регистрируют число бракованных
m.
Бракованными могут быть 1, 2, … , n
образцов, но вероятности реального
числа бракованных будут различными.
Если контрольная вероятность брака
ниже допустимой вероятности, то можно
гарантировать достаточное качество
всей партии.
В
Excel
функция БИНОМРАСП вычисляет вероятность
отдельного значения распределения по
заданным m,
n
и р,
а функция КРИТБИНОМ – случайное число
по заданной вероятности. Обычно функция
КРИТБИНОМ используется для определения
наибольшего допустимого числа брака.
В
качестве примера построим график
плотности вероятности биномиального
распределения для n=10
(1, 2, …, 10) и p=0.2.
Введите исходные данные, как показано
на рисунке:

Далее
в ячейку В4 введите статистическую
функцию БИНОМРАСП и заполните ее
параметры как показано на рисунке:

Здесь
параметр Число_s
есть число успешных испытаний m,
Испытания
– число независимых испытаний n,
Вероятность_s
–
вероятность успеха каждого испытания
p.
Параметр Интегральный
равен 0, если требуется получить плотность
распределения (вероятность для значения
m),
и равен 1, если требуется получить
вероятность с накоплением (вероятность
того, что число успешных испытаний не
меньше значения аргумента Число_s).
Формулу
из В4 размножьте в ячейки В5:В13. Ниже
показан результат:

В
колонке В вычислены вероятности успешных
испытаний m=1,
2, …, 10. Теперь по диапазону В4:В13 постройте
график или гистограмму биномиальной
функции плотности распределения –
результат на рисунке. Поэкспериментируйте,
изменяя значение вероятности в ячейке
В1: 0.3, 0.4, 0.8, проследите за изменениями
формы графика.

Для
иллюстрации функции КРИТБИНОМ используем
предыдущий пример – необходимо найти
число m,
для которого вероятность интегрального
распределения больше или равна 0.75.
Вызовите функцию КРИТБИНОМ и заполните
параметры. Вы должны получить значение
3. Это означает, что при вероятности
интегрального распределения >= 0.75
будет не менее трех (m>=3)
успешных испытаний.
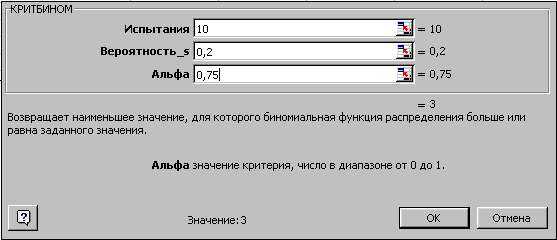
Нормальное
распределение
характеризуется
средним арифметическим (математическим
ожиданием) m
и стандартным (среднеквадратичным)
отклонением r.
Дисперсия равна r2.
Краткое обозначение распределения
N(m,r2).
График нормального распределения
симметричен относительно центра
распределения (точки m),
чем меньше r,
тем больше вероятность появления
случайной величины. В пределы [m—r,m+r]
нормально распределенная случайная
величина попадает с вероятностью 0,683 в
пределы [m-2r,m+2r]
— с вероятностью 0,955 и т.д.

При
m=0
и r=1
нормальное распределение называется
стандартным
или нормированным – N(0,1).
Нормальное
распределение имеет очень широкий круг
приложений. В качестве примера построим
график плотности вероятностей нормального
распределения при m=15
и r=1,5
в диапазоне [m-3r,m+3r]
c
шагом 0,5. Результат показан на рисунке.

Выполните
следующие действия:
-
в
ячейку А4 введите формулу =B1-3*B2, в ячейку
А5 формулу =A4+B$3 и размножьте ее по ячейку
А22; -
в
ячейку В4 введите функцию НОРМРАСП из
группы Статистические
– параметры заполните как на рисунке; -
размножьте
формулу из ячейки В4 по ячейку В22 и по
диапазону В4:В22 постройте график; на
2-ом шаге мастера диаграмм в закладке
Ряд
введите подписи к оси х
из диапазона А4:А22.

Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
В статье подробно показано, что такое нормальный закон распределения случайной величины и как им пользоваться при решении практически задач.
Нормальное распределение в статистике
История закона насчитывает 300 лет. Первым открывателем стал Абрахам де Муавр, который придумал аппроксимацию биномиального распределения еще 1733 году. Через много лет Карл Фридрих Гаусс (1809 г.) и Пьер-Симон Лаплас (1812 г.) вывели математические функции.
Лаплас также обнаружил замечательную закономерность и сформулировал центральную предельную теорему (ЦПТ), согласно которой сумма большого количества малых и независимых величин имеет нормальное распределение.
Нормальный закон не является фиксированным уравнением зависимости одной переменной от другой. Фиксируется только характер этой зависимости. Конкретная форма распределения задается специальными параметрами. Например, у = аx + b – это уравнение прямой. Однако где конкретно она проходит и под каким наклоном, определяется параметрами а и b. Также и с нормальным распределением. Ясно, что это функция, которая описывает тенденцию высокой концентрации значений около центра, но ее точная форма задается специальными параметрами.
Кривая нормального распределения Гаусса имеет следующий вид.

График нормального распределения напоминает колокол, поэтому можно встретить название колоколообразная кривая. У графика имеется «горб» в середине и резкое снижение плотности по краям. В этом заключается суть нормального распределения. Вероятность того, что случайная величина окажется около центра гораздо выше, чем то, что она сильно отклонится от середины.

На рисунке выше изображены два участка под кривой Гаусса: синий и зеленый. Основания, т.е. интервалы, у обоих участков равны. Но заметно отличаются высоты. Синий участок удален от центра, и имеет существенно меньшую высоту, чем зеленый, который находится в самом центре распределения. Следовательно, отличаются и площади, то бишь вероятности попадания в обозначенные интервалы.
Формула нормального распределения (плотности) следующая.
![]()
Формула состоит из двух математических констант:
π – число пи 3,142;
е – основание натурального логарифма 2,718;
двух изменяемых параметров, которые задают форму конкретной кривой:
m – математическое ожидание (в различных источниках могут использоваться другие обозначения, например, µ или a);
σ2 – дисперсия;
ну и сама переменная x, для которой высчитывается плотность вероятности.
Конкретная форма нормального распределения зависит от 2-х параметров: математического ожидания (m) и дисперсии (σ2). Кратко обозначается N(m, σ2) или N(m, σ). Параметр m (матожидание) определяет центр распределения, которому соответствует максимальная высота графика. Дисперсия σ2 характеризует размах вариации, то есть «размазанность» данных.
Параметр математического ожидания смещает центр распределения вправо или влево, не влияя на саму форму кривой плотности.

А вот дисперсия определяет остроконечность кривой. Когда данные имеют малый разброс, то вся их масса концентрируется у центра. Если же у данных большой разброс, то они «размазываются» по широкому диапазону.

Плотность распределения не имеет прямого практического применения. Для расчета вероятностей нужно проинтегрировать функцию плотности.
Вероятность того, что случайная величина окажется меньше некоторого значения x, определяется функцией нормального распределения:
![]()
Используя математические свойства любого непрерывного распределения, несложно рассчитать и любые другие вероятности, так как
P(a ≤ X < b) = Ф(b) – Ф(a)
Стандартное нормальное распределение
Нормальное распределение зависит от параметров средней и дисперсии, из-за чего плохо видны его свойства. Хорошо бы иметь некоторый эталон распределения, не зависящий от масштаба данных. И он существует. Называется стандартным нормальным распределением. На самом деле это обычное нормальное нормальное распределение, только с параметрами математического ожидания 0, а дисперсией – 1, кратко записывается N(0, 1).
Любое нормальное распределение легко превращается в стандартное путем нормирования:
![]()
где z – новая переменная, которая используется вместо x;
m – математическое ожидание;
σ – стандартное отклонение.
Для выборочных данных берутся оценки:
![]()
Среднее арифметическое и дисперсия новой переменной z теперь также равны 0 и 1 соответственно. В этом легко убедиться с помощью элементарных алгебраических преобразований.
В литературе встречается название z-оценка. Это оно самое – нормированные данные. Z-оценку можно напрямую сравнивать с теоретическими вероятностями, т.к. ее масштаб совпадает с эталоном.
Посмотрим теперь, как выглядит плотность стандартного нормального распределения (для z-оценок). Напомню, что функция Гаусса имеет вид:
![]()
Подставим вместо (x-m)/σ букву z, а вместо σ – единицу, получим функцию плотности стандартного нормального распределения:
![]()
График плотности:

Центр, как и ожидалось, находится в точке 0. В этой же точке функция Гаусса достигает своего максимума, что соответствует принятию случайной величиной своего среднего значения (т.е. x-m=0). Плотность в этой точке равна 0,3989, что можно посчитать даже в уме, т.к. e0=1 и остается рассчитать только соотношение 1 на корень из 2 пи.
Таким образом, по графику хорошо видно, что значения, имеющие маленькие отклонения от средней, выпадают чаще других, а те, которые сильно отдалены от центра, встречаются значительно реже. Шкала оси абсцисс измеряется в стандартных отклонениях, что позволяет отвязаться от единиц измерения и получить универсальную структуру нормального распределения. Кривая Гаусса для нормированных данных отлично демонстрирует и другие свойства нормального распределения. Например, что оно является симметричным относительно оси ординат. В пределах ±1σ от средней арифметической сконцентрирована большая часть всех значений (прикидываем пока на глазок). В пределах ±2σ находятся большинство данных. В пределах ±3σ находятся почти все данные. Последнее свойство широко известно под названием правило трех сигм для нормального распределения.
Функция стандартного нормального распределения позволяет рассчитывать вероятности.
![]()
Понятное дело, вручную никто не считает. Все подсчитано и размещено в специальных таблицах, которые есть в конце любого учебника по статистике.
Таблица нормального распределения
Таблицы нормального распределения встречаются двух типов:
— таблица плотности;
— таблица функции (интеграла от плотности).
Таблица плотности используется редко. Тем не менее, посмотрим, как она выглядит. Допустим, нужно получить плотность для z = 1, т.е. плотность значения, отстоящего от матожидания на 1 сигму. Ниже показан кусок таблицы.

В зависимости от организации данных ищем нужное значение по названию столбца и строки. В нашем примере берем строку 1,0 и столбец 0, т.к. сотых долей нет. Искомое значение равно 0,2420 (0 перед 2420 опущен).
Функция Гаусса симметрична относительно оси ординат. Поэтому φ(z)= φ(-z), т.е. плотность для 1 тождественна плотности для -1, что отчетливо видно на рисунке.

Чтобы не тратить зря бумагу, таблицы печатают только для положительных значений.
На практике чаще используют значения функции стандартного нормального распределения, то есть вероятности для различных z.
В таких таблицах также содержатся только положительные значения. Поэтому для понимания и нахождения любых нужных вероятностей следует знать свойства стандартного нормального распределения.
Функция Ф(z) симметрична относительно своего значения 0,5 (а не оси ординат, как плотность). Отсюда справедливо равенство:
![]()
Это факт показан на картинке:

Значения функции Ф(-z) и Ф(z) делят график на 3 части. Причем верхняя и нижняя части равны (обозначены галочками). Для того, чтобы дополнить вероятность Ф(z) до 1, достаточно добавить недостающую величину Ф(-z). Получится равенство, указанное чуть выше.
Если нужно отыскать вероятность попадания в интервал (0; z), то есть вероятность отклонения от нуля в положительную сторону до некоторого количества стандартных отклонений, достаточно от значения функции стандартного нормального распределения отнять 0,5:
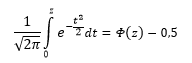
Для наглядности можно взглянуть на рисунок.

На кривой Гаусса, эта же ситуация выглядит как площадь от центра вправо до z.

Довольно часто аналитика интересует вероятность отклонения в обе стороны от нуля. А так как функция симметрична относительно центра, предыдущую формулу нужно умножить на 2:

Рисунок ниже.

Под кривой Гаусса это центральная часть, ограниченная выбранным значением –z слева и z справа.

Указанные свойства следует принять во внимание, т.к. табличные значения редко соответствуют интересующему интервалу.
Для облегчения задачи в учебниках обычно публикуют таблицы для функции вида:

Если нужна вероятность отклонения в обе стороны от нуля, то, как мы только что убедились, табличное значение для данной функции просто умножается на 2.
Теперь посмотрим на конкретные примеры. Ниже показана таблица стандартного нормального распределения. Найдем табличные значения для трех z: 1,64, 1,96 и 3.

Как понять смысл этих чисел? Начнем с z=1,64, для которого табличное значение составляет 0,4495. Проще всего пояснить смысл на рисунке.

То есть вероятность того, что стандартизованная нормально распределенная случайная величина попадет в интервал от 0 до 1,64, равна 0,4495. При решении задач обычно нужно рассчитать вероятность отклонения в обе стороны, поэтому умножим величину 0,4495 на 2 и получим примерно 0,9. Занимаемая площадь под кривой Гаусса показана ниже.

Таким образом, 90% всех нормально распределенных значений попадает в интервал ±1,64σ от средней арифметической. Я не случайно выбрал значение z=1,64, т.к. окрестность вокруг средней арифметической, занимающая 90% всей площади, иногда используется для проверки статистических гипотез и расчета доверительных интервалов. Если проверяемое значение не попадает в обозначенную область, то его наступление маловероятно (всего 10%).
Для проверки гипотез, однако, чаще используется интервал, накрывающий 95% всех значений. Половина вероятности от 0,95 – это 0,4750 (см. второе выделенное в таблице значение).

Для этой вероятности z=1,96. Т.е. в пределах почти ±2σ от средней находится 95% значений. Только 5% выпадают за эти пределы.

Еще одно интересное и часто используемое табличное значение соответствует z=3, оно равно по нашей таблице 0,4986. Умножим на 2 и получим 0,997. Значит, в рамках ±3σ от средней арифметической заключены почти все значения.

Так выглядит правило 3 сигм для нормального распределения на диаграмме.
С помощью статистических таблиц можно получить любую вероятность. Однако этот метод очень медленный, неудобный и сильно устарел. Сегодня все делается на компьютере. Далее переходим к практике расчетов в Excel.
В Excel есть несколько функций для подсчета вероятностей или обратных значений нормального распределения.

Функция НОРМ.СТ.РАСП
Функция НОРМ.СТ.РАСП предназначена для расчета плотности ϕ(z) или вероятности Φ(z) по нормированным данным (z).
=НОРМ.СТ.РАСП(z;интегральная)
z – значение стандартизованной переменной
интегральная – если 0, то рассчитывается плотность ϕ(z), если 1 – значение функции Ф(z), т.е. вероятность P(Z<z).
Рассчитаем плотность и значение функции для различных z: -3, -2, -1, 0, 1, 2, 3 (их укажем в ячейке А2).
Для расчета плотности потребуется формула =НОРМ.СТ.РАСП(A2;0). На диаграмме ниже – это красная точка.
Для расчета значения функции =НОРМ.СТ.РАСП(A2;1). На диаграмме – закрашенная площадь под нормальной кривой.

В реальности чаще приходится рассчитывать вероятность того, что случайная величина не выйдет за некоторые пределы от средней (в среднеквадратичных отклонениях, соответствующих переменной z), т.е. P(|Z|<z).

Определим, чему равна вероятность попадания случайной величины в пределы ±1z, ±2z и ±3z от нуля. Потребуется формула 2Ф(z)-1, в Excel =2*НОРМ.СТ.РАСП(A2;1)-1.

На диаграмме отлично видны основные основные свойства нормального распределения, включая правило трех сигм. Функция НОРМ.СТ.РАСП – это автоматическая таблица значений функции нормального распределения в Excel.
Может стоять и обратная задача: по имеющейся вероятности P(Z<z) найти стандартизованную величину z ,то есть квантиль стандартного нормального распределения.
Функция НОРМ.СТ.ОБР
НОРМ.СТ.ОБР рассчитывает обратное значение функции стандартного нормального распределения. Синтаксис состоит из одного параметра:
=НОРМ.СТ.ОБР(вероятность)
вероятность – это вероятность.
Данная формула используется так же часто, как и предыдущая, ведь по тем же таблицам искать приходится не только вероятности, но и квантили.

Например, при расчете доверительных интервалов задается доверительная вероятность, по которой нужно рассчитать величину z.

Учитывая то, что доверительный интервал состоит из верхней и нижней границы и то, что нормальное распределение симметрично относительно нуля, достаточно получить верхнюю границу (положительное отклонение). Нижняя граница берется с отрицательным знаком. Обозначим доверительную вероятность как γ (гамма), тогда верхняя граница доверительного интервала рассчитывается по следующей формуле.
![]()
Рассчитаем в Excel значения z (что соответствует отклонению от средней в сигмах) для нескольких вероятностей, включая те, которые наизусть знает любой статистик: 90%, 95% и 99%. В ячейке B2 укажем формулу: =НОРМ.СТ.ОБР((1+A2)/2). Меняя значение переменной (вероятности в ячейке А2) получим различные границы интервалов.

Доверительный интервал для 95% равен 1,96, то есть почти 2 среднеквадратичных отклонения. Отсюда легко даже в уме оценить возможный разброс нормальной случайной величины. В общем, доверительным вероятностям 90%, 95% и 99% соответствуют доверительные интервалы ±1,64, ±1,96 и ±2,58 σ.
В целом функции НОРМ.СТ.РАСП и НОРМ.СТ.ОБР позволяют произвести любой расчет, связанный с нормальным распределением. Но, чтобы облегчить и уменьшить количество действий, в Excel есть несколько других функций. Например, для расчета доверительных интервалов средней можно использовать ДОВЕРИТ.НОРМ. Для проверки статистической гипотезы о средней арифметической есть формула Z.ТЕСТ.
Рассмотрим еще пару полезных формул с примерами.
Функция НОРМ.РАСП
Функция НОРМ.РАСП отличается от НОРМ.СТ.РАСП лишь тем, что ее используют для обработки данных любого масштаба, а не только нормированных. Параметры нормального распределения указываются в синтаксисе.
=НОРМ.РАСП(x;среднее;стандартное_откл;интегральная)
x – значение (или ссылка на ячейку), для которого рассчитывается плотность или значение функции нормального распределения
среднее – математическое ожидание, используемое в качестве первого параметра модели нормального распределения
стандартное_откл – среднеквадратичное отклонение – второй параметр модели
интегральная – если 0, то рассчитывается плотность, если 1 – то значение функции, т.е. P(X<x).
Например, плотность для значения 15, которое извлекли из нормальной выборки с матожиданием 10, стандартным отклонением 3, рассчитывается так:

Если последний параметр поставить 1, то получим вероятность того, что нормальная случайная величина окажется меньше 15 при заданных параметрах распределения. Таким образом, вероятности можно рассчитывать напрямую по исходным данным.
Функция НОРМ.ОБР
Это квантиль нормального распределения, т.е. значение обратной функции. Синтаксис следующий.
=НОРМ.ОБР(вероятность;среднее;стандартное_откл)
вероятность – вероятность
среднее – матожидание
стандартное_откл – среднеквадратичное отклонение
Назначение то же, что и у НОРМ.СТ.ОБР, только функция работает с данными любого масштаба.
Пример показан в ролике в конце статьи.
Моделирование нормального распределения
Для некоторых задач требуется генерация нормальных случайных чисел. Готовой функции для этого нет. Однако В Excel есть две функции, которые возвращают случайные числа: СЛУЧМЕЖДУ и СЛЧИС. Первая выдает случайные равномерно распределенные целые числа в указанных пределах. Вторая функция генерирует равномерно распределенные случайные числа между 0 и 1. Чтобы сделать искусственную выборку с любым заданным распределением, нужна функция СЛЧИС.
Допустим, для проведения эксперимента необходимо получить выборку из нормально распределенной генеральной совокупности с матожиданием 10 и стандартным отклонением 3. Для одного случайного значения напишем формулу в Excel.
=НОРМ.ОБР(СЛЧИС();10;3)
Протянем ее на необходимое количество ячеек и нормальная выборка готова.
Для моделирования стандартизованных данных следует воспользоваться НОРМ.СТ.ОБР.
Процесс преобразования равномерных чисел в нормальные можно показать на следующей диаграмме. От равномерных вероятностей, которые генерируются формулой СЛЧИС, проведены горизонтальные линии до графика функции нормального распределения. Затем от точек пересечения вероятностей с графиком опущены проекции на горизонтальную ось.

На выходе получаются значения с характерной концентрацией около центра. Вот так обратный прогон через функцию нормального распределения превращает равномерные числа в нормальные. Excel позволяет за несколько секунд воспроизвести любое количество выборок любого размера.
Как обычно, прилагаю ролик, где все вышеописанное показывается в действии.
Скачать файл с примером.
Поделиться в социальных сетях:
Распределение вероятностей – одно из центральных понятий теории
вероятности и математической статистики. Определение распределения вероятности
равносильно заданию вероятностей всех СВ, описывающих некоторое случайное
событие. Распределение вероятностей некоторой СВ, возможные значения которой x1, x2, … xn образуют
выборку, задается указанием этих значений и соответствующих им вероятностей p1, p2,… pn. (pn должны быть
положительны и в сумме давать единицу).
В данной лабораторной работе будут рассмотрены и построены с помощью MS Excel наиболее
распространенные распределения вероятности: биномиальное и нормальное.
1 Биномиальное распределение
Представляет собой распределение вероятностей числа наступлений
некоторого события («удачи») в n повторных
независимых испытаниях, если при каждом испытании вероятность наступления этого
события равна p. При этом
распределении разброс вариант (есть или нет события) является следствием
влияния ряда независимых и случайных факторов.
Примером практического использования биномиального распределения
может являться контроль качества партии фармакологического препарата. Здесь
требуется подсчитать число изделий (упаковок), не соответствующих требованиям.
Все причины, влияющие на качество препарата, принимаются одинаково вероятными и
не зависящими друг от друга. Сплошная проверка качества в этой ситуации не
возможна, поскольку изделие, прошедшее испытание, не подлежит дальнейшему
использованию. Поэтому для контроля из партии наудачу выбирают определенное
количество образцов изделий (n). Эти образцы всестороннее
проверяют и регистрируют число бракованных изделий (k). Теоретически число
бракованных изделий может быть любым, от 0 до n.
В Excel функция БИНОМРАСП
применяется для вычисления вероятности в задачах с фиксированным числом тестов
или испытаний, когда результатом любого испытания может быть только успех или
неудача.
Функция использует следующие
параметры:
БИНОМРАСП (число_успехов;
число_испытаний; вероятностъ_успеха; интегральная), где
число_успехов — это количество успешных
испытаний;
число_испытаний — это число независимых
испытаний (число успехов и число испытаний должны быть целыми числами);
вероятность_ успеха — это вероятность успеха
каждого испытания;
интегральный — это логическое значение,
определяющее форму функции.
Если данный параметр имеет
значение ИСТИНА (=1), то считается интегральная функция распределения
(вероятность того, что число успешных испытаний не менее значения число_
успехов);
если этот параметр имеет
значение ЛОЖЬ (=0), то вычисляется значение функции плотности
распределения (вероятность того, что число успешных испытаний в точности равно
значению аргумента число_ успехов).
Пример 1. Какова вероятность того,
что трое из четырех новорожденных будут мальчиками?
Решение:
1. Устанавливаем табличный курсор в свободную
ячейку, например в А1. Здесь должно оказаться значение искомой
вероятности.
2. Для получения значения вероятности
воспользуемся специальной функцией: нажимаем на панели инструментов кнопку Вставка
функции (fx).
3. В появившемся диалоговом окне Мастер
функций — шаг 1 из 2 слева в поле Категория указаны виды функций.
Выбираем Статистическая. Справа в поле Функция выбираем функцию БИНОМРАСП
и нажимаем на кнопку ОК.
Появляется диалоговое окно
функции. В поле Число_s вводим с клавиатуры
количество успешных испытаний (3). В поле Испытания вводим с клавиатуры
общее количество испытаний (4). В рабочее поле Вероятность_s
вводим с клавиатуры вероятность успеха в отдельном испытании (0,5). В поле Интегральный
вводим с клавиатуры вид функции распределения — интегральная или весовая (0).
Нажимаем на кнопку ОК.
В ячейке А1 появляется
искомое значение вероятности р = 0,25. Ровно 3 мальчика из 4
новорожденных могут появиться с вероятностью 0,25.
Если изменить формулировку
условия задачи и выяснить вероятность того, что появится не более трех
мальчиков, то в этом случае в рабочее поле Интегральный вводим 1 (вид
функции распределения интегральный). Вероятность этого события будет равна
0,9375.
Задания для самостоятельной работы
1. Какова вероятность того, что восемь из десяти студентов,
сдающих зачет, получат «незачет». (0,04)
2.
Нормальное распределение
Нормальное распределение — это совокупность объектов, в которой крайние значения
некоторого признака — наименьшее и наибольшее — появляются редко; чем ближе значение признака к математическому ожиданию,
тем чаще оно встречается. Например, распределение студентов по их весу приближается
к нормальному распределению. Это распределение имеет очень широкий круг приложений в
статистике, включая проверку гипотез.
Диаграмма нормального
распределения симметрична относительно точки а (математического
ожидания). Медиана нормального распределения равна тоже а. При этом в
точке а функция f(x) достигает своего максимума, который равен

.
В Excel для вычисления значений
нормального распределения используются функция НОРМРАСП, которая
вычисляет значения вероятности нормальной функции распределения для указанного
среднего и стандартного отклонения.
Функция имеет параметры:
НОРМРАСП (х; среднее;
стандартное_откл; интегральная), где:
х — значения выборки, для
которых строится распределение;
среднее — среднее арифметическое
выборки;
стандартное_откл — стандартное отклонение
распределения;
интегральный — логическое значение,
определяющее форму функции. Если интегральная имеет значение ИСТИНА(1), то
функция НОРМРАСП возвращает интегральную функцию распределения; если это
аргумент имеет значение ЛОЖЬ (0), то вычисляет значение функция плотности
распределения.
Если среднее = 0 и
стандартное_откл = 1, то функция НОРМРАСП возвращает стандартное
нормальное распределение.
Пример 2. Построить график
нормальной функции распределения f(x) при x, меняющемся от 19,8 до 28,8
с шагом 0,5, a=24,3 и

=1,5.
Решение
1. В ячейку А1 вводим символ
случайной величины х, а в ячейку B1 — символ функции
плотности вероятности — f(x).
2. Вводим в диапазон А2:А21
значения х от 19,8 до 28,8 с шагом 0,5. Для этого воспользуемся
маркером автозаполнения: в ячейку А2 вводим левую границу диапазона (19,8), в
ячейку A3 левую границу плюс шаг (20,3). Выделяем блок А2:А3. Затем за правый
нижний угол протягиваем мышью до ячейки А21 (при нажатой левой кнопке мыши).
3. Устанавливаем табличный курсор в ячейку В2 и
для получения значения вероятности воспользуемся специальной функцией —
нажимаем на панели инструментов кнопку Вставка функции (fx). В появившемся диалоговом
окне Мастер функций — шаг 1 из 2 слева в поле Категория указаны виды
функций. Выбираем Статистическая. Справа в поле Функция выбираем
функцию НОРМРАСП. Нажимаем на кнопку ОК.
4. Появляется диалоговое
окно НОРМРАСП. В рабочее поле X вводим адрес ячейки А2
щелчком мыши на этой ячейке. В рабочее поле Среднее вводим с клавиатуры
значение математического ожидания (24,3). В рабочее поле Стандартное_откл
вводим с клавиатуры значение среднеквадратического отклонения (1,5). В рабочее
поле Интегральная вводим с клавиатуры вид функции распределения (0).
Нажимаем на кнопку ОК.
5. В ячейке В2 появляется
вероятность р = 0,002955. Указателем мыши за правый нижний угол табличного
курсора протягиванием (при нажатой левой кнопке мыши) из ячейки В2 до В21
копируем функцию НОРМРАСП в диапазон В3:В21.
6. По полученным данным строим искомую диаграмму
нормальной функции распределения. Щелчком указателя мыши на кнопке на панели
инструментов вызываем Мастер диаграмм. В появившемся диалоговом окне
выбираем тип диаграммы График, вид — левый верхний. После нажатия кнопки
Далее указываем диапазон данных — В1:В21 (с помощью мыши). Проверяем,
положение переключателя Ряды в: столбцах. Выбираем закладку Ряд и с
помощью мыши вводим диапазон подписей оси X: А2:А21. Нажав на кнопку Далее,
вводим названия осей Х и У и нажимаем на кнопку Готово.

Рис. 1 График нормальной функции распределения
Получен приближенный график
нормальной функции плотности распределения (см. рис.1).
Задания для самостоятельной работы
1. Построить график нормальной
функции плотности распределения f(x) при x, меняющемся от 20 до 40 с
шагом 1 при
= 3.
3. Генерация случайных величин
Еще одним аспектом
использования законов распределения вероятностей является генерация случайных величин. Бывают ситуации, когда необходимо
получить последовательность случайных чисел. Это, в частности, требуется для
моделирования объектов, имеющих случайную природу, по известному распределению
вероятностей.
Процедура генерации
случайных величин используется для заполнения диапазона ячеек случайными числами, извлеченными из
одного или нескольких распределений.
В MS Excel для генерации СВ используются функции из категории Математические:
СЛЧИС () – выводит на экран равномерно
распределенные случайные числа больше или равные 0 и меньшие 1;
СЛУЧМЕЖДУ (ниж_граница; верх_граница) – выводит на экран
случайное число, лежащее между произвольными заданными
значениями.
В случае использования
процедуры Генерация случайных чисел из пакета Анализа необходимо
заполнить следующие поля:
— число переменных
вводится число столбцов значений, которые необходимо разместить в выходном диапазоне. Если это число не введено, то все
столбцы в выходном диапазоне будут заполнены;
— число случайных чисел
вводится число случайных значений, которое необходимо вывести для
каждой переменной, если число случайных чисел не будет введено, то все строки выходного диапазона будут заполнены;
— в поле распределение необходимо выбрать тип распределения,
которое следует использовать для генерации случайных переменных:
1. равномерное — характеризуется
верxней и нижней границами. Переменные извлекаются с одной и
той же вероятностью для всех значений интервала.
2. нормальное
— характеризуется средним значением и стандартным отклонением. Обычно для
этого распределения используют среднее значение
0 и стандартное отклонение 1.
3. биномиальное
— характеризуется вероятностью успеха (величина р) для некоторого числа попыток. Например, можно сгенерировать случайные двухальтернативные переменные по числу попыток, сумма которых будет биномиальной случайной
переменной;
4. дискретное
— характеризуется значением СВ и соответствующим ему интервалом вероятности, диапазон должен состоять из двух столбцов: левого,
содержащего значения, и правого, содержащего
вероятности, связанные со значением в данной строке. Сумма вероятностей должна быть
равна 1;
5. распределения Бернулли, Пуассона
и Модельное.
— в поле случайное рассеивание
вводится произвольное значение, для которого необходимо
генерировать случайные числа. Впоследствии можно снова использовать это
значение для получения тех же самых случайных чисел.
— выходной диапазон
вводится ссылка на левую верхнюю ячейку выходного диапазона. Размер выходного диапазона будет определен автоматически, и
на экран будет выведено сообщение в случае
возможного наложения выходного диапазона на исходные
данные.
Рассмотрим пример.
Пример 3. Повар столовой может готовить 4 различных первых блюда (уха, щи, борщ, грибной суп). Необходимо составить меню на месяц, так чтобы
первые блюда чередовались в случайном порядке.
Решение
1.
Пронумеруем первые
блюда по порядку: 1 — уха, 2 — щи, 3 — борщ, 4 — грибной суп. Введем числа 1-4 в диапазон А2:А5 рабочей таблицы.
2.
Укажем желаемую вероятность появления
каждого первого блюда. Пусть все блюда будут
равновероятны (р=1/4). Вводим число 0,25 в диапазон В2:В5.
3.
В меню Сервис
выбираем пункт Анализ данных и далее указываем строку Генерация
случайных чисел. В появившемся диалоговом окне указываем Число
переменных — 1, Число случайных чисел — 30 (количество
дней в месяце). В поле Распределение указываем Дискретное (только натуральные числа). В поле Входной
интервал значений и вероятностей
вводим (мышью) диапазон, содержащий номера супов и их
вероятности. – А2:В5.
4.
Указываем выходной
диапазон и нажимаем ОК. В столбце С появляются случайные числа: 1, 2, 3,
4.
Задание для
самостоятельной работы
1. Сформировать
выборку из 10 случайных чисел, лежащих в диапазоне от 0 до 1.
2. Сформировать
выборку из 20 случайных чисел, лежащих в диапазоне от 5 до 20.
3. Пусть
спортсмену необходимо составить график тренировок на 10 дней, так чтобы
дистанция, пробегаемая каждый день, случайным образом менялась от 5 до 10 км.
4. Составить
расписание внеклассных мероприятий на неделю для случайного проведения:
семинаров, интеллектуальных игр, КВН и спец. курса.
5. Составить
расписание на месяц для случайной демонстрации на телевидении одного из четырех
рекламных роликов турфирмы. Причем вероятность появления рекламного ролика №1
должна быть в два раза выше, чем остальных рекламных роликов.