
17 авг. 2022 г.
читать 2 мин
Остаточный график — это тип графика, на котором сопоставленные значения отображаются с остаточными значениями для регрессионной модели.
Этот тип графика часто используется для оценки того, подходит ли модель линейной регрессии для данного набора данных, и для проверки гетероскедастичности остатков.
В этом руководстве объясняется, как создать остаточный график для простой модели линейной регрессии в Excel.
Как создать остаточный график в Excel
Используйте следующие шаги, чтобы создать остаточный график в Excel:
Шаг 1: Введите значения данных в первые два столбца. Например, введите значения предиктора в A2:A13 и значения ответной переменной в B2:B13.

Шаг 2: Создайте диаграмму рассеяния. Выделите значения в ячейках A2:B13. Затем перейдите на вкладку « ВСТАВИТЬ » на верхней ленте. Нажмите на первый вариант для Scatter в области диаграмм .

Появится следующая диаграмма:

Шаг 3: Отобразите уравнение линии тренда на диаграмме рассеивания. Нажмите «Добавить элементы диаграммы» на вкладке « ДИЗАЙН », затем «Линия тренда», а затем «Дополнительные параметры линии тренда». Оставьте выбранным «Линейный» и установите флажок «Отображать уравнение на графике». Закройте панель «Формат линии тренда».
Уравнение линии тренда теперь будет отображаться на диаграмме рассеяния:

Шаг 4: Рассчитайте прогнозируемые значения. Введите уравнение линии тренда в ячейку C2, заменив «x» на «A1» следующим образом:

Затем щелкните ячейку C2 и дважды щелкните маленькую «Ручку заполнения» в правом нижнем углу ячейки. Это скопирует формулу из ячейки C2 в остальные ячейки столбца:

Шаг 5: Рассчитайте остатки. Введите B2-C2 в ячейку D2. Затем щелкните ячейку D2 и дважды щелкните маленькую «Ручку заполнения» в правом нижнем углу ячейки. Это скопирует формулу из ячейки D2 в остальные ячейки столбца:

Шаг 6: Создайте остаточный график. Выделите ячейки A2:A13. Удерживая нажатой клавишу «Ctrl», выделите ячейки D2:D13. Затем перейдите на вкладку « ВСТАВИТЬ » на верхней ленте. Нажмите на первый вариант для Scatter в области диаграмм.Появится следующая диаграмма:

Это остаточный сюжет. На оси X отображаются подогнанные значения, а на оси Y — остатки.
Не стесняйтесь изменять заголовок, оси и линии сетки, чтобы график выглядел более визуально привлекательным:

Содержание
- Множественная регрессия в EXCEL
- Оценка неизвестных параметров
- Диаграмма рассеяния
- Вычисление прогнозных значений Y (отдельное наблюдение и среднее значение) и построение доверительных интервалов
- Стандартные ошибки и доверительные интервалы для коэффициентов регрессии
- Проверка гипотез
- Генерация данных для множественной регрессии с помощью заданного тренда
- Коэффициент детерминации
Множественная регрессия в EXCEL
history 26 января 2019 г.
Рассмотрим использование MS EXCEL для прогнозирования переменной Y на основании нескольких переменных Х, т.е. множественную регрессию.
Перед прочтением этой статьи рекомендуется освежить в памяти простую линейную регрессию – прогнозирование на основе значений только одного фактора.
Disclaimer : Данную статью не стоит рассматривать, как пересказ главы из учебника по статистике. Статья не обладает ни полнотой, ни строгостью изложения положений статистической науки. Эта статья – о применении MS EXCEL для целей Множественного регрессионного анализа. Теоретические отступления приведены лишь из соображения логики изложения. Использование данной статьи для изучения Регрессии – плохая идея.
Статья про Множественный регрессионный анализ получилась большая, поэтому ниже для удобства приведены ее разделы:
Прогнозирование единственной переменной Y на основании значений 2-х или более переменных Х называется множественной регрессией .
Множественная линейная регрессионная модель (Multiple Linear Regression Model) имеет вид Y=β 0 +β 1 *X 1 +β 2 *X 2 +…+β k *X k +ε. В этом случае переменная Y зависит от k поясняющих переменных Х, т.е. регрессоров . ε — случайная ошибка . Модель является линейной относительно неизвестных параметров β.
Оценка неизвестных параметров
В этой статье рассмотрим модель с 2-мя регрессорами. Сначала введем необходимые обозначения и понятия множественной регрессии.
Для описания зависимости Y от 2-х переменных линейная модель имеет вид:
Параметры этой модели β i нам неизвестны, но их можно оценить, используя случайную выборку (измеренные значения переменной Y от заданных Х). Оценки параметров модели (β 0 , β 1 , β 2 ) обычно вычисляются методом наименьших квадратов (МНК) , который минимизирует сумму квадратов ошибок прогнозирования (критерий минимизации в англоязычной литературе обозначают как SSE – Sum of Squared Errors).
Ошибка ε имеет случайную природу и имеет свою функцию распределения со средним значением =0 и дисперсией σ 2 .
Оценки b 1 и b 2 называются коэффициентами регрессии , они определяют влияние соответствующей переменной X, когда все остальные независимые переменные остаются неизменными .
Сдвиг (intercept) или постоянный член b 0 , определяет прогнозируемое значение Y, когда все поясняющие переменные Х равны 0 (часто сдвиг не имеет физического смысла в рамках модели и обусловлен лишь математическими вычислениями МНК ).
Вычислив оценки, полученные методом МНК, позволяют прогнозировать значения переменной Y:
Примечание : Для случая 2-х регрессоров, все спрогнозированные значения переменной Y будут лежать в плоскости (в плоскости регрессии ).
В качестве примера рассмотрим технологический процесс изготовления нити:
Инженер, на основе имеющегося опыта, предположил, что прочность нити Y зависит от концентрации исходного раствора (Х 1 ) и температуры реакции (Х 2 ), и соответствует модели линейной регрессии. Для нахождения комбинации переменных Х, при которых Y принимает максимальное значение, необходимо определить коэффициенты регрессии, сделав выборку.
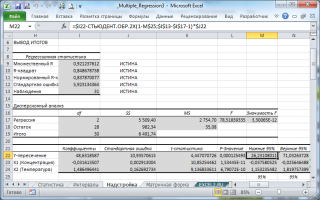
В MS EXCEL коэффициенты множественной регрессии удобнее всего вычислить с помощью функции ЛИНЕЙН() . Это сделано в файле примера на листе Коэффициенты . Чтобы вычислить оценки:
- выделите 3 ячейки в одной строке (т.к. мы рассматриваем случай 2-х регрессоров, то будут вычислены 2 коэффициента регрессии + величина сдвига = 3 значения, для вывода которых понадобится 3 ячейки). Пусть это будет диапазон С8:Е8 ;
- в Строке формул введите = ЛИНЕЙН(D20:D50;B20:C50) . Предполагается, что в столбце В содержатся прогнозируемые значения Y (в нашей модели это Прочность нити), в столбцах С и D содержатся значения контролируемых параметров Х (Х1 – Концентрация в столбце С и Х2 – Температура в столбце D).
- нажмите CTRL+SHIFT+ENTER (т.к. это формула массива ).
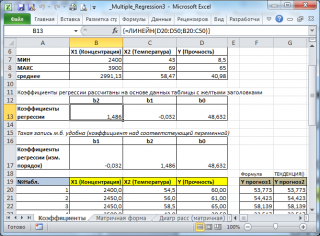
В левой ячейке будет рассчитано значение коэффициента регрессии b 2 для переменной Х2, в средней ячейке — значение коэффициента регрессии b 1 для переменной Х1, в правой – сдвиг . Обратите внимание, что порядок вывода коэффициентов регрессии обратный по отношению к расположению столбцов с данными соответствующих переменных Х (вычисленный коэффициент b 2 располагается левее по отношению к b 1 , тогда как значения переменной Х2 располагаются правее значений переменной Х1). Это может привести к путанице, поэтому лучше разместить коэффициенты над соответствующими столбцами с данными, как это сделано в строке 17 файла примера .
Примечание : В принципе без функции ЛИНЕЙН() можно обойтись, записав альтернативные формулы. Для этого в файле примера на листе Коэффициенты в столбцах I : K вычислены отклонения значений переменных Х 1i , Х 2i , Y i от их средних значений 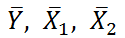 , т.е.:
, т.е.: 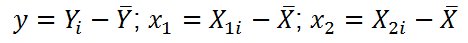
Далее коэффициенты регрессии рассчитываются по следующим формулам (эти формулы справедливы только при прогнозировании по 2-м независимым переменным Х):
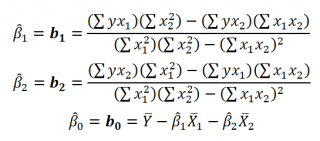
При прогнозировании по 3-м и более независимым переменным Х формулы для вычисления коэффициентов регрессии значительно усложняются, поэтому следует использовать матричный подход.
В файле примера на листе Матричная форма выполнены расчеты коэффициентов регрессии с помощью матричного подхода.
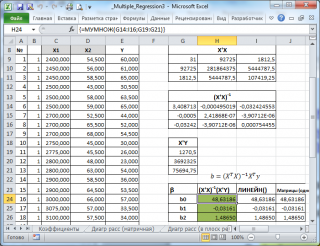
Расчет можно произвести как пошагово, так и одной формулой массива :
Коэффициенты регрессии (вектор b ) в этом случае вычисляются по формуле b =(X T X) -1 (X T Y) или в другом виде записи b =(X ’ X) -1 (X ’ Y)
Под Х подразумевается матрица, состоящая из столбцов значений переменной Х с дополнительным столбцом единиц, а под Y – вектор-столбец значений Y.
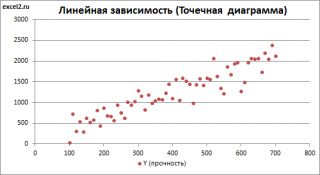
Диаграмма рассеяния
В случае простой линейной регрессии (один регрессор, т.е. одна переменная Х) для визуализации связи между прогнозируемым значением Y и переменной Х строят диаграмму рассеяния (двумерную).
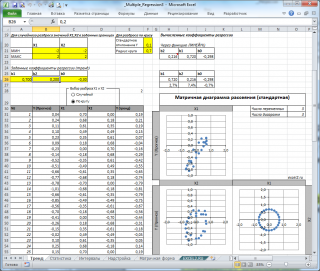
В случае множественной линейной регрессии двумерную диаграмму рассеяния можно построить только для анализа влияния каждого отдельного регрессора на Y (при этом остальные Х не меняются), т.е. так называемую Матричную диаграмму рассеивания (См. файл примера лист Диагр расс (матричная) ).
К сожалению, такую диаграмму трудно интерпретировать.
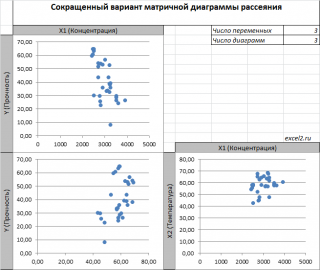
Более того, матричная диаграмма может вводить в заблуждение (см. Introduction to linear regression analysis / D . C . Montgomery , E . A . Peck , G . G . Vining , раздел 3.2.5 ), демонстрируя наличие или отсутствие линейной взаимосвязи между отдельным регрессором X i и Y.
Для случая с 2-мя регрессорами можно предложить альтернативный вид матричной диаграммы рассеяния . В стандартной диаграмме рассеяния строятся проекции на координатные плоскости Х1;Х2, Y;X1 и Y;X2. Однако, если взглянуть на точки относительно плоскости регрессии , то картину, на мой взгляд, будет проще интерпретировать.
Сравним две матричные диаграммы рассеяния (см. файл примера на листе «Диагр расс (в плоск регрессии)» , построенные для одних и тех же наблюдений. Первая – стандартная,

вторая представляет собой вид сверху на плоскость регрессии и 2 вида вдоль плоскости.
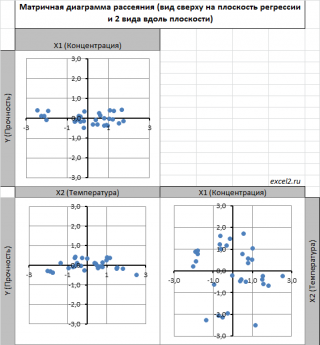
На второй диаграмме становится очевидно, что разброс точек относительно плоскости регрессии совсем не большой и поэтому, скорее всего, построенная модель является полезной, а выбранные 2 переменные Х позволяют прогнозировать Y (конечно, для подтверждения этой гипотезы нужно провести процедуру F-теста ).
Несколько слов о построении альтернативной матричной диаграммы рассеяния:
- Перед построением необходимо нормировать значения наблюдений (для каждой переменной вычесть среднее и разделить на стандартное отклонение ). В этом случае практически все точки на диаграммах будут находится в диапазоне +/-3 (по аналогии со стандартным нормальным распределением , 99% значений которого лежат в пределах +/-3 сигма). В этом случае, на диаграмме можно фиксировать мин/макс значений осей, чтобы EXCEL автоматически не модифицировал масштаб осей при изменении данных (это не всегда удобно);
- Теперь координаты точек необходимо рассчитать в системе отсчета относительно плоскости регрессии (в которой плоскость Оху’ совпадает с плоскостью регрессии). Для этого необходимо найти матрицу вращения , например, через вращение приводящее к совмещению нормали к плоскости регрессии и вектора оси Z (0;0;1);
- Новые координаты позволяют построить альтернативную матричную диаграмму. Кроме того, для удобства можно вращать систему координат вокруг новой оси Z, чтобы нагляднее представить себе распределение точек относительно плоскости регрессии (для этого использована Полоса прокрутки в ячейках Q31:S31 ).
Вычисление прогнозных значений Y (отдельное наблюдение и среднее значение) и построение доверительных интервалов
После того, как нами были найдены тем или иным способом коэффициенты регрессии можно приступать к вычислению прогнозных значений Y на основе заданных значений переменных Х.
Уравнение прогнозирования или уравнение регрессии в случае 2-х независимых переменных (регрессоров) записывается в виде:
Примечание: В MS EXCEL прогнозное значение Y для заданных Х 1 и Х 2 можно также предсказать с помощью функции ТЕНДЕНЦИЯ() . При этом 2-й аргумент будет ссылкой на столбцы, содержащие все значения переменных Х 1 и Х 2 , а 3-й аргумент функции должен быть ссылкой на диапазон ячеек, содержащий 2 значения Х (Х 1i и Х 2i ) для выбранного наблюдения i (см. файл примера, лист Коэффициенты, столбец G ). Функция ПРЕДСКАЗ() , использованная нами в простой регрессии, не работает в случае множественной регрессии .
Найдя прогнозное значение Y, мы, таким образом, вычислим его точечную оценку. Понятно, что фактическое значение Y, полученное при наблюдении, будет, скорее всего, отличаться от этой оценки. Чтобы ответить на вопрос о том, на сколько хорошо мы можем предсказывать новые значения Y, нам потребуется построить доверительный интервал этой оценки, т.е. диапазон в котором с определенной заданной вероятностью, скажем 95%, мы ожидаем новое значение Y.
Доверительные интервалы построим при фиксированном Х для:
- нового наблюдения Y;
- среднего значения Y (интервал будет уже, чем для отдельного нового наблюдения)
Как и в случае простой линейной регрессии , для построения доверительных интервалов нам потребуется сначала вычислить стандартную ошибку модели (standard error of the model) , которая приблизительно показывает насколько велика ошибка предсказания значений переменной Y на основании значений переменных Х.
Для вычисления стандартной ошибки оценивают дисперсию ошибки ε, т.е. сигма^2 (ее часто обозначают как MS Е либо MSres ) . Затем, вычислив из полученной оценки квадратный корень, получим Стандартную ошибку регрессии (часто обозначают как SEy или sey ).
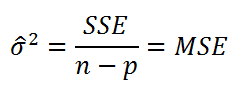
где SSE – сумма квадратов значений ошибок модели ei=yi — ŷi ( Sum of Squared Errors ). MSE означает Mean Square of Errors (среднее квадратов ошибок, точнее остатков).
Величина n-p – это количество степеней свободы ( df – degrees of freedom ), т.е. число параметров системы, которые могут изменяться независимо (вспомним, что у нас в этом примере есть n независимых наблюдений переменной Y, р – количество оцениваемых параметров модели). В случае простой множественной регрессии с 2-мя регрессорами число степеней свободы равно n-3, т.к. при построении плоскости регрессии было оценено 3 параметра модели b (т.е. на это было «потрачено» 3 степени свободы ).
В MS EXCEL стандартную ошибку SEy можно вычислить формулы (см. файл примера, лист Статистика ):
Стандартная ошибка нового наблюдения Y при заданных значениях Х (вектор Хi) вычисляется по формуле:
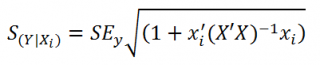
x i — вектор-столбец со значениями переменных Х (с дополнительной 1) для заданного наблюдения i.
Соответствующий доверительный интервал вычисляется по формуле:
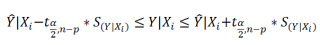
где α (альфа) – уровень значимости (обычно принимают равным 0,05=5%)
р – количество оцениваемых параметров модели (в нашем случае = 3)
n-p – число степеней свободы
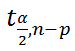 – квантиль распределения Стьюдента (задает количество стандартных ошибок , в +/- диапазоне которых вероятность обнаружить новое наблюдение равно 1-альфа). Т.е. если квантиль равен 2, то диапазон шириной +/- 2 стандартных ошибок относительно прогнозного значения Y будет с вероятностью 95% содержать новое наблюдение Y (для каждого заданного Хi). В MS EXCEL вычисления квантиля производят по формуле = СТЬЮДЕНТ.ОБР.2Х(0,05;n-p) , подробнее см. в статье про распределение Стьюдента .
– квантиль распределения Стьюдента (задает количество стандартных ошибок , в +/- диапазоне которых вероятность обнаружить новое наблюдение равно 1-альфа). Т.е. если квантиль равен 2, то диапазон шириной +/- 2 стандартных ошибок относительно прогнозного значения Y будет с вероятностью 95% содержать новое наблюдение Y (для каждого заданного Хi). В MS EXCEL вычисления квантиля производят по формуле = СТЬЮДЕНТ.ОБР.2Х(0,05;n-p) , подробнее см. в статье про распределение Стьюдента .
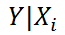 – прогнозное значение Yi вычисляемое по формуле Yi= b 0+ b 1* Х1i+ b 2* Х2i (точечная оценка).
– прогнозное значение Yi вычисляемое по формуле Yi= b 0+ b 1* Х1i+ b 2* Х2i (точечная оценка).
Стандартная ошибка среднего значения Y при заданных значениях Х (вектор Хi) будет меньше, чем стандартная ошибка отдельного наблюдения. Вычисления производятся по формуле:
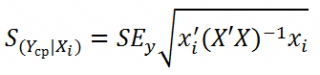
x i — вектор-столбец со значениями переменных Х (с дополнительной 1) для заданного наблюдения i.
Соответствующий доверительный интервал вычисляется по формуле:
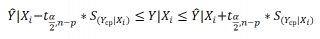
Прогнозное значение Yi (точечная оценка) используется тоже, что и для отдельного наблюдения.
Стандартные ошибки и доверительные интервалы для коэффициентов регрессии
В разделе Оценка неизвестных параметров мы получили точечные оценки коэффициентов регрессии . Так как эти оценки получены на основе случайных величин (значений переменных Х и Y), то эти оценки сами являются случайными величинами и соответственно имеют функцию распределения со средним значением и дисперсией . Но, чтобы перейти от точечных оценок к интервальным , необходимо вычислить соответствующие стандартные ошибки (т.е. стандартные отклонения ) коэффициентов регрессии .
Стандартная ошибка коэффициента регрессии b j (обозначается se ( b j ) ) вычисляется на основании стандартной ошибки по следующей формуле:
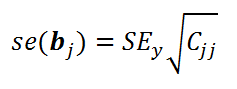
где C jj является диагональным элементом матрицы (X ’ X) -1 . Для коэффициента сдвига b 0 индекс j=1 (верхний левый элемент), для b 1 индекс j=2, b 2 индекс j=3 (нижний правый элемент).
SEy – стандартная ошибка регрессии (см. выше ).
В MS EXCEL стандартные ошибки коэффициентов регрессии можно вычислить с помощью функции ЛИНЕЙН() :
Примечание : Подробнее о функции ЛИНЕЙН() см. статью Функция MS EXCEL ЛИНЕЙН() .
Применяя матричный подход стандартные ошибки можно вычислить и через обычные формулы (точнее через формулу массива , см. файл примера лист Статистика ):
= КОРЕНЬ(СУММКВРАЗН(E13:E43;F13:F43) /(n-p)) *КОРЕНЬ (ИНДЕКС (МОБР (МУМНОЖ(ТРАНСП(B13:D43);(B13:D43)));j;j))
При построении двухстороннего доверительного интервала для коэффициента регрессии его границы определяются следующим образом:
где t – это t-значение , которое можно вычислить с помощью формулы = СТЬЮДЕНТ.ОБР.2Х(0,05;n-p) для уровня значимости 0,05.
В результате получим, что найденный доверительный интервал с вероятностью 95% (1-0,05) накроет истинное значение коэффициента регрессии b j . Здесь мы считаем, что коэффициент регрессии b j имеет распределение Стьюдента с n-p степенями свободы (n – количество наблюдений, т.е. пар Х и Y).
Проверка гипотез
Когда мы строим модель, мы предполагаем, что между Y и переменными X существует линейная взаимосвязь. Однако, как это иногда бывает в статистике, можно вычислять параметры связи даже тогда, когда в действительности она не существует, и обусловлена лишь случайностью.
Единственный вариант, когда Y не зависит X, возможен, когда все коэффициенты регрессии β равны 0.
Чтобы убедиться, что вычисленная нами оценка коэффициентов регрессии не обусловлена лишь случайностью (они не случайно отличны от 0), используют проверку гипотез . В качестве нулевой гипотезы Н 0 принимают, что линейной связи нет, т.е. ВСЕ β=0. В качестве альтернативной гипотезы Н 1 принимают, что ХОТЯ БЫ ОДИН коэффициент β <>0.
Процедура проверки значимости множественной регрессии, приведенная ниже, является обобщением дисперсионного анализа , использованного нами в случае простой линейной регрессии (F-тест) .
Если нулевая гипотеза справедлива, то тестовая F -статистика имеет F-распределение со степенями свободы k и n — k -1 , т.е. F k, n-k-1 :
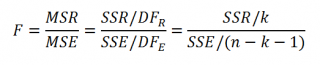
Проверку значимости регрессии можно также осуществить через вычисление p -значения . В этом случае вычисляют вероятность того, что случайная величина F примет значение F 0 (это и есть p-значение ), затем сравнивают p-значение с заданным уровнем значимости α (альфа) . Если p-значение больше уровня значимости , то нулевую гипотезу нет оснований отклонить, и регрессия незначима.
В MS EXCEL значение F 0 можно вычислить на основании значений выборки по вышеуказанной формуле или с помощью функции ЛИНЕЙН() :
В MS EXCEL для проверки гипотезы через p -значение используйте формулу =F.РАСП.ПХ(F 0 ;k;n-k-1) файл примера лист Статистика , где показано эквивалентность обоих подходов проверки значимости регрессии).
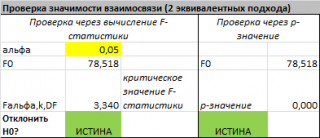
В MS EXCEL критическое значение для заданного уровня значимости F 1-альфа, k, n-k-1 можно вычислить по формуле = F.ОБР(1- альфа;k;n-k-1) или = F.ОБР.ПХ(альфа;k; n-k-1) . Другими словами требуется вычислить верхний альфа- квантиль F -распределения с соответствующими степенями свободы .
Таким образом, при значении статистики F 0 > F 1-альфа, k, n-k-1 мы имеем основание для отклонения нулевой гипотезы.
В программах статистики результаты процедуры F -теста выводят с помощью стандартной таблицы дисперсионного анализа . В файле примера такая таблица приведена на листе Надстройка , которая построена на основе результатов, возвращаемых инструментом Регрессия надстройки Пакета анализа MS EXCEL .
Генерация данных для множественной регрессии с помощью заданного тренда
Иногда, бывает удобно сгенерировать значения наблюдений, имея заданный тренд.
Для решения этой задачи нам потребуется:
- задать значения регрессоров в нужном диапазоне (значения переменных Х);
- задать коэффициенты регрессии ( b );
- задать тренд (вычислить значения Y= b0 +b1 * Х 1 + b2 * Х 2 );
- задать величину разброса Y вокруг тренда (варианты: случайный разброс в заданных границах или заданная фигура, например, круг)
Все вычисления выполнены в файле примера, лист Тренд для случая 2-х регрессоров. Там же построены диаграммы рассеяния .
Коэффициент детерминации
Коэффициент детерминации R 2 показывает насколько полезна построенная нами линейная регрессионная модель .
По определению коэффициент детерминации R 2 равен:
R 2 = Изменчивость объясненная моделью ( SSR ) / Общая изменчивость ( SST ).
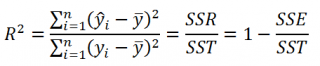
Этот показатель можно вычислить с помощью функции ЛИНЕЙН() :
При добавлении в модель новой объясняющей переменной Х, коэффициент детерминации будет всегда расти. Поэтому, рост коэффициента детерминации не может служить основанием для вывода о том, что новая модель (с дополнительным регрессором) лучше прежней.
Более подходящей статистикой, которая лишена указанного недостатка, является нормированный коэффициент детерминации (Adjusted R-squared):
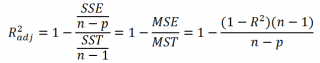
где p – число независимых регрессоров (вычисления см. файл примера лист Статистика ).
Источник
В предыдущих заметках предметом анализа часто становилась отдельная числовая переменная, например, доходность взаимных фондов, время загрузки Web-страницы или объем потребления безалкогольных напитков. В настоящей и следующих заметках мы рассмотрим методы предсказания значений числовой переменной в зависимости от значений одной или нескольких других числовых переменных. [1]
Материал будет проиллюстрирован сквозным примером. Прогнозирование объема продаж в магазине одежды. Сеть магазинов уцененной одежды Sunflowers на протяжении 25 лет постоянно расширялась. Однако в настоящее время у компании нет систематического подхода к выбору новых торговых точек. Место, в котором компания собирается открыть новый магазин, определяется на основе субъективных соображений. Критериями выбора являются выгодные условия аренды или представления менеджера об идеальном местоположении магазина. Представьте, что вы — руководитель отдела специальных проектов и планирования. Вам поручили разработать стратегический план открытия новых магазинов. Этот план должен содержать прогноз годового объема продаж во вновь открываемых магазинах. Вы полагаете, что торговая площадь непосредственно связана с объемом выручки, и хотите учесть этот факт в процессе принятия решения. Как разработать статистическую модель, позволяющую прогнозировать годовой объем продаж на основе размера нового магазина?
Как правило, для предсказания значений переменной используется регрессионный анализ. Его цель — разработать статистическую модель, позволяющую предсказывать значения зависимой переменной, или отклика, по значениям, по крайней мере одной, независимой, или объясняющей, переменной. В настоящей заметке мы рассмотрим простую линейную регрессию — статистический метод, позволяющий предсказывать значения зависимой переменной Y по значениям независимой переменной X. В последующих заметках будет описана модель множественной регрессии, предназначенная для предсказания значений независимой переменной Y по значениям нескольких зависимых переменных (Х1, Х2, …, Xk). [2]
Скачать заметку в формате Word или pdf, примеры в формате Excel2013
Виды регрессионных моделей
В заметке Представление числовых данных в виде таблиц и диаграмм для иллюстрации зависимости между переменными X и Y использовалась диаграмма разброса. На ней значения переменной X откладывались по горизонтальной оси, а значения переменной Y — по вертикальной. Зависимость между двумя переменными может быть разной: от самой простой до крайне сложной. Пример простейшей (линейной) зависимости показан на рис. 1.

Рис. 1. Положительная линейная зависимость
Простая линейная регрессия:
(1) Yi = β0 + β1Xi + εi
где β0 — сдвиг (длина отрезка, отсекаемого на координатной оси прямой Y), β1 — наклон прямой Y, εi— случайная ошибка переменной Y в i-м наблюдении.
В этой модели наклон β1 представляет собой количество единиц измерения переменной Y, приходящихся на одну единицу измерения переменной X. Эта величина характеризует среднюю величину изменения переменной Y (положительного или отрицательного) на заданном отрезке оси X. Сдвиг β0 представляет собой среднее значение переменной Y, когда переменная X равна 0. Последний компонент модели εi является случайной ошибкой переменной Y в i-м наблюдении. Выбор подходящей математической модели зависит от распределения значений переменных X и Y на диаграмме разброса. Различные виды зависимости переменных показаны на рис. 2.

Рис. 2. Диаграммы разброса, иллюстрирующие разные виды зависимостей
На панели А значения переменной Y почти линейно возрастают с увеличением переменной X. Этот рисунок аналогичен рис. 1, иллюстрирующему положительную зависимость между размером магазина (в квадратных футах) и годовым объемом продаж. Панель Б является примером отрицательной линейной зависимости. Если переменная X возрастает, переменная Y в целом убывает. Примером этой зависимости является связь между стоимостью конкретного товара и объемом продаж. На панели В показан набор данных, в котором переменные X и Y практически не зависят друг от друга. Каждому значению переменной X соответствуют как большие, так и малые значения переменной Y. Данные, приведенные на панели Г, демонстрируют криволинейную зависимость между переменными X и Y. Значения переменной Y возрастают при увеличении переменной X, однако скорость роста после определенных значений переменной X падает. Примером положительной криволинейной зависимости является связь между возрастом и стоимостью обслуживания автомобилей. По мере старения машины стоимость ее обслуживания сначала резко возрастает, однако после определенного уровня стабилизируется. Панель Д демонстрирует параболическую U-образную форму зависимости между переменными X и Y. По мере увеличения значений переменной X значения переменной Y сначала убывают, а затем возрастают. Примером такой зависимости является связь между количеством ошибок, совершенных за час работы, и количеством отработанных часов. Сначала работник осваивается и делает много ошибок, потом привыкает, и количество ошибок уменьшается, однако после определенного момента он начинает чувствовать усталость, и число ошибок увеличивается. На панели Е показана экспоненциальная зависимость между переменными X и Y. В этом случае переменная Y сначала очень быстро убывает при возрастании переменной X, однако скорость этого убывания постепенно падает. Например, стоимость автомобиля при перепродаже экспоненциально зависит от его возраста. Если перепродавать автомобиль в течение первого года, его цена резко падает, однако впоследствии ее падение постепенно замедляется.
Мы кратко рассмотрели основные модели, которые позволяют формализовать зависимости между двумя переменными. Несмотря на то что диаграмма разброса чрезвычайно полезна при выборе математической модели зависимости, существуют более сложные и точные статистические процедуры, позволяющие описать отношения между переменными. В дальнейшем мы будем рассматривать лишь линейную зависимость.
Вывод уравнения простой линейной регрессии
Вернемся к сценарию, изложенному в начале главы. Наша цель — предсказать объем годовых продаж для всех новых магазинов, зная их размеры. Для оценки зависимости между размером магазина (в квадратных футах) и объемом его годовых продаж создадим выборки из 14 магазинов (рис. 3).

Рис. 3. Площади и годовые объемы продаж 14 магазинов сети Sunflowers: (а) исходные данные; (б) диаграмма разброса
Анализ рис. 3 показывает, что между площадью магазина X и годовым объемом продаж Y существует положительная зависимость. Если площадь магазина увеличивается, объем продаж возрастает почти линейно. Таким образом, наиболее подходящей для исследования является линейная модель. Остается лишь определить, какая из линейных моделей точнее остальных описывает зависимость между анализируемыми переменными.
Метод наименьших квадратов
Данные, представленные на рис. 1а, получены для случайной выборки магазинов. Если верны некоторые предположения (об этом чуть позже), в качестве оценки параметров генеральной совокупности (β0 и β1) можно использовать сдвиг b0 и наклон b1 прямой Y. Таким образом, уравнение простой линейной регрессии принимает следующий вид:
![]()
где ![]() — предсказанное значение переменной Y для i-гo наблюдения, Xi — значение переменной X в i-м наблюдении.
— предсказанное значение переменной Y для i-гo наблюдения, Xi — значение переменной X в i-м наблюдении.
Для того чтобы предсказать значение переменной Y, в уравнении (2) необходимо определить два коэффициента регрессии — сдвиг b0 и наклон b1 прямой Y. Вычислив эти параметры, проведем прямую на диаграмме разброса. Затем исследователь может визуально оценить, насколько близка регрессионная прямая к точкам наблюдения. Простая линейная регрессия позволяет найти прямую линию, максимально приближенную к точкам наблюдения. Критерии соответствия можно задать разными способами. Возможно, проще всего минимизировать разности между фактическими значениями Yi, и предсказанными значениями ![]() . Однако, поскольку эти разности могут быть как положительными, так и отрицательными, следует минимизировать сумму их квадратов.
. Однако, поскольку эти разности могут быть как положительными, так и отрицательными, следует минимизировать сумму их квадратов.
Поскольку ![]() = b0 + b1Xi, сумма квадратов принимает следующий вид:
= b0 + b1Xi, сумма квадратов принимает следующий вид:

Параметры b0 и b1 неизвестны. Таким образом, сумма квадратов разностей является функцией, зависящей от сдвига b0 и наклона b1 выборки Y. Для того чтобы найти значения параметров b0 и b1, минимизирующих сумму квадратов разностей, применяется метод наименьших квадратов. При любых других значениях сдвига b0 и наклона b1 сумма квадратов разностей между фактическими значениями переменной Y и ее наблюдаемыми значениями лишь увеличится.
До того, как Excel взял на себя всю рутинную работу, вычисления по методу наименьших квадратов были очень трудоемкими. Excel позволяет решать подобные задачи двумя способами. Во-первых, можно воспользоваться Пакетом анализа (строка Регрессия). Результаты представлены на рис. 4. Во-вторых, можно, выделив точки на графике (как на рис. 3б), кликнуть правой кнопкой мыши и выбрать Добавить линию тренда. Далее можно выбрать вид линии тренда (в нашем случае – Линейная), отформатировать линию, показать на графике уравнение и величину достоверности аппроксимации (R2) (рис. 5).

Рис. 4. Результаты решения задачи о зависимости между площадями и годовыми объемами продаж в магазинах сети Sunflower (получены с помощью Пакета анализа Excel)
 в задаче о выборе магазина")
Рис. 5. Диаграмма разброса и линия регрессии (тренда) в задаче о выборе магазина
Как следует из рис. 4 и 5, b0 = 0,9645, а b1 = 1,6699. Таким образом, уравнение линейной регрессии для этих данных имеет следующий вид: ![]() = 0,9645 + 1,6699Xi. Вычисленный наклон b1 = +1,6699. Это означает, что при возрастании переменной X на единицу среднее значение переменной Y возрастает на 1,6699 единиц. Иначе говоря, увеличение площади магазина на один квадратный фут приводит к увеличению годового объема продаж на 1,67 тыс. долл. Таким образом, наклон представляет собой долю годового объема продаж, зависящую от размера магазина. Вычисленный сдвиг b0 = +0,9645 (млн. долл.). Эта величина представляет собой среднее значение переменной Y при X = 0. Поскольку площадь магазина не может равняться нулю, сдвиг можно считать долей годового дохода, зависящей от других факторов. Следует отметить, однако, что сдвиг переменной Y выходит за пределы диапазона переменной X. Следовательно, к интерпретации параметра b0 необходимо относиться внимательно.
= 0,9645 + 1,6699Xi. Вычисленный наклон b1 = +1,6699. Это означает, что при возрастании переменной X на единицу среднее значение переменной Y возрастает на 1,6699 единиц. Иначе говоря, увеличение площади магазина на один квадратный фут приводит к увеличению годового объема продаж на 1,67 тыс. долл. Таким образом, наклон представляет собой долю годового объема продаж, зависящую от размера магазина. Вычисленный сдвиг b0 = +0,9645 (млн. долл.). Эта величина представляет собой среднее значение переменной Y при X = 0. Поскольку площадь магазина не может равняться нулю, сдвиг можно считать долей годового дохода, зависящей от других факторов. Следует отметить, однако, что сдвиг переменной Y выходит за пределы диапазона переменной X. Следовательно, к интерпретации параметра b0 необходимо относиться внимательно.
Пример 1. Один экономист решил предсказать изменение индекса 500 наиболее активно покупаемых акций на Нью-Йоркской фондовой бирже, публикуемого агентством Standard and Poor, на основе показателей экономики США за 50 лет. В результате он получил следующее уравнение линейной регрессии: Ŷi = –5,0 + 7Хi. Какой смысл имеют параметры сдвига b0 и наклона b1.
Решение. Сдвиг регрессии b0 равен –5,0. Это значит, что если рост экономики США равен нулю, индекс акций за год снизится на 5%. Наклон b1 равен 7. Следовательно, при увеличении темпов роста экономики на 1% индекс акций возрастает на 7%.
Пример 2. Вернемся к сценарию, изложенному в начале заметки. Применим модель линейной регрессии для прогноза объема годовых продаж во всех новых магазинах в зависимости от их размеров. Предположим, что площадь магазина равна 4000 квадратных футов. Какой среднегодовой объем продаж можно прогнозировать?
Решение. Подставим значение X = 4 (тыс. кв. футов) в уравнение линейной регрессии: ![]() = 0,9645 + 1,6699Xi = 0,9645 + 1,6699*4 = 7,644 млн. долл. Итак, прогнозируемый среднегодовой объем продаж в магазине, площадь которого равна 4000 кв. футов, составляет 7 644 000 долл.
= 0,9645 + 1,6699Xi = 0,9645 + 1,6699*4 = 7,644 млн. долл. Итак, прогнозируемый среднегодовой объем продаж в магазине, площадь которого равна 4000 кв. футов, составляет 7 644 000 долл.
Прогнозирование в регрессионном анализе: интерполяция и экстраполяция
Применяя регрессионную модель для прогнозирования, необходимо учитывать лишь допустимые значения независимой переменной. В этот диапазон входят все значения переменной X, начиная с минимальной и заканчивая максимальной. Таким образом, предсказывая значение переменной Y при конкретном значении переменной X, исследователь выполняет интерполяцию между значениями переменной X в диапазоне возможных значений. Однако экстраполяция значений за пределы этого интервала не всегда релевантна. Например, пытаясь предсказать среднегодовой объем продаж в магазине, зная его площадь (рис. 3а), мы можем вычислять значение переменной Y лишь для значений X от 1,1 до 5,8 тыс. кв. футов. Следовательно, прогнозировать среднегодовой объем продаж можно лишь для магазинов, площадь которых не выходит за пределы указанного диапазона. Любая попытка экстраполяции означает, что мы предполагаем, будто линейная регрессия сохраняет свой характер за пределами допустимого диапазона.
Оценки изменчивости
Вычисление сумм квадратов. Для того чтобы предсказать значение зависимой переменной по значениям независимой переменной в рамках избранной статистической модели, необходимо оценить изменчивость. Существует несколько способов оценки изменчивости. Первый способ использует общую сумму квадратов (total sum of squares — SST), позволяющую оценить колебания значений Yi вокруг среднего значения ![]() . В регрессионном анализе полная вариация, представляющая собой полную сумму квадратов, разделяется на объяснимую вариацию, или сумму квадратов регрессии (regression sum of squares — SSR), и необъяснимую вариацию, или сумму квадратов ошибок (error sum of squares — SSE). Объяснимая вариация характеризует взаимосвязь между переменными X и Y, а необъяснимая зависит от других факторов (рис. 6).
. В регрессионном анализе полная вариация, представляющая собой полную сумму квадратов, разделяется на объяснимую вариацию, или сумму квадратов регрессии (regression sum of squares — SSR), и необъяснимую вариацию, или сумму квадратов ошибок (error sum of squares — SSE). Объяснимая вариация характеризует взаимосвязь между переменными X и Y, а необъяснимая зависит от других факторов (рис. 6).

Рис. 6. Оценки изменчивости в модели регрессии
Сумма квадратов регрессии (SSR) представляет собой сумму квадратов разностей между Ŷi (предсказанным значением переменной Y) и ![]() (средним значением переменной Y). Сумма квадратов ошибок (SSE) является частью вариации переменной Y, которую невозможно описать с помощью регрессионной модели. Эта величина зависит от разностей между наблюдаемыми и предсказанными значениями.
(средним значением переменной Y). Сумма квадратов ошибок (SSE) является частью вариации переменной Y, которую невозможно описать с помощью регрессионной модели. Эта величина зависит от разностей между наблюдаемыми и предсказанными значениями.
Полная сумма квадратов (SST) равна сумме квадратов регрессии плюс сумма квадратов ошибок:
(3) SST = SSR + SSE
Полная сумма квадратов (SST) равна сумме квадратов разностей между наблюдаемыми значениями переменной Y и ее средним значением:
![]()
Сумма квадратов регрессии (SSR) равна сумме квадратов разностей между предсказанными значениями переменной Y и ее средним значением:
![]()
Сумма квадратов ошибок (SSE) равна сумме квадратов разностей между наблюдаемыми и предсказанными значениями переменной Y:
![]()
Суммы квадратов, вычисленные с помощью программы Пакета анализа Excel при решении задачи о сети магазинов Sunflowers, представлены на рис. 4.
Полная сумма квадратов разностей равна SST = 116,9543. Эта величина состоит из суммы квадратов регрессии (SSR) равной 105,7476, и суммы квадратов ошибок (SSE), равной 11,2067.
Коэффициент смешанной корреляции. Величины SSR, SSE и SST не имеют очевидной интерпретации. Однако отношение суммы квадратов регрессии (SSR) к полной сумме квадратов (SST) представляет собой оценку полезности регрессионного уравнения. Это отношение называется коэффициентом смешанной корреляции r2:

Коэффициент смешанной корреляции оценивает долю вариации переменной Y, которая объясняется независимой переменной X в регрессионной модели. В задаче о сети магазинов Sunflowers SSR = 105,7476 и SST = 116,9543. Следовательно, r2 = 105,7476 / 116,9543 = 0,904. Таким образом, 90,4% вариации годового объема продаж объясняется изменчивостью площади магазинов, измеренной в квадратных футах. Данная величина r2 свидетельствует о сильной положительной линейной взаимосвязи между двумя переменными, поскольку применение регрессионной модели снижает изменчивость прогнозируемых годовых объемов продаж на 90,4%. Только 9,6% изменчивости годовых объемов продаж в выборке магазинов объясняются другими факторами, не учтенными в регрессионной модели.
Коэффициент смешанной корреляции в задаче о сети магазинов Sunflowers представлен в таблице Регрессионная статистика на рис. 4.
Среднеквадратичная ошибка оценки. Хотя метод наименьших квадратов позволяет вычислить линию, минимизирующую отклонение от наблюдаемых значений, наличие суммы квадратов ошибок (SSE) свидетельствует о том, что линейная регрессия не дает абсолютной точности прогноза, если, конечно, точки наблюдения не лежат на регрессионной прямой. Однако ожидать этого так же неестественно, как предполагать, что все выборочные значения точно равны их среднему арифметическому. Следовательно, необходима статистика, которая позволила бы оценить отклонение предсказанных значений переменной Y от ее реальных значений, аналогично тому, как стандартное отклонение, введенное ранее, позволяет оценить колебание данных вокруг их средней величины. Стандартное отклонение наблюдаемых значений переменной Y от ее регрессионной прямой называется среднеквадратичной ошибкой оценки. Отклонение реальных данных от регрессионной прямой в задаче о сети магазинов Sunflowers показано на рис. 5.
Среднеквадратичная ошибка оценки

где Yi — фактическое значение переменной Y при заданном значении Xi, Ŷi — предсказанное значение переменной Y при заданном значении Xi, SSE — сумма квадратов ошибок.
Поскольку SSE = 11,2067, по формуле (8) получаем:
![]()
Таким образом, среднеквадратичная ошибка оценки равна 0,9664 млн. долл. (т.е. 966 400 долл.). Этот параметр также рассчитывается Пакетом анализа (см. рис. 4). Среднеквадратичная ошибка оценки характеризует отклонение реальных данных от линии регрессии. Она измеряется в тех же единицах, что и переменная Y. По смыслу среднеквадратичная ошибка очень похожа на стандартное отклонение. В то время как стандартное отклонение характеризует разброс данных вокруг их среднего значения, среднеквадратичная ошибка позволяет оценить колебание точек наблюдения вокруг регрессионной прямой. Cреднеквадратичная ошибка оценки позволяет обнаружить статистически значимую зависимость, существующую между двумя переменными, и предсказать значения переменной Y.
Предположения
Обсуждая методы проверки гипотез и дисперсионного анализа, мы не раз подчеркивали важность условий, которые должны обеспечивать корректность сделанных выводов. Поскольку и регрессионный, и дисперсионный анализ используют линейную модель, условия их применения приблизительно одинаковы:
- Ошибка должна иметь нормальное распределение.
- Вариация данных вокруг линии регрессии должна быть постоянной.
- Ошибки должны быть независимыми.
Первое предположение, о нормальном распределении ошибок, требует, чтобы при каждом значении переменной X ошибки линейной регрессии имели нормальное распределение (рис. 7). Как и t— и F-критерий дисперсионного анализа, регрессионный анализ довольно устойчив к нарушениям этого условия. Если распределение ошибок относительно линии регрессии при каждом значении X не слишком сильно отличается от нормального, выводы относительно линии регрессии и коэффициентов регрессии изменяются незначительно.

Рис. 7. Предположение о нормальном распределении ошибок
Второе условие заключается в том, что вариация данных вокруг линии регрессии должна быть постоянной при любом значении переменной X. Это означает, что величина ошибки как при малых, так и при больших значениях переменной X должна изменяться в одном и том же интервале (см. рис. 7). Это свойство очень важно для метода наименьших квадратов, с помощью которого определяются коэффициенты регрессии. Если это условие нарушается, следует применять либо преобразование данных, либо метод наименьших квадратов с весами.
Третье предположение, о независимости ошибок, заключается в том, что ошибки регрессии не должны зависеть от значения переменной X. Это условие особенно важно, если данные собираются на протяжении определенного отрезка времени. В этих ситуациях ошибки, присущие конкретному отрезку времени, часто коррелируют с ошибками, характерными для предыдущего периода.
Анализ остатков
Чуть выше при решении задачи о сети магазинов Sunflowers мы использовали модель линейной регрессии. Рассмотрим теперь анализ ошибок — графический метод, позволяющий оценить точность регрессионной модели. Кроме того, с его помощью можно обнаружить потенциальные нарушения условий применения регрессионного анализа.
Оценка пригодности эмпирической модели. Остаток, или оценка ошибки еi, представляет собой разность между наблюдаемым (Yi) и предсказанным (Ŷi) значениями зависимой переменной при заданном значении Xi.
(9) ei = Yi – Ŷi
Для оценки пригодности эмпирической модели регрессии остатки откладываются по вертикальной оси, а значения Xi — по горизонтальной. Если эмпирическая модель пригодна, график не должен иметь ярко выраженной закономерности. Если же модель регрессии не пригодна, на рисунке проявится зависимость между значениями Xi и остатками еi.
Рассмотрим примеры (рис. 8). Панель А иллюстрирует возрастание переменной Y при увеличении переменной X. Однако зависимость между этими переменными носит нелинейный характер, поскольку скорость возрастания переменной Y падает при увеличении переменной X. Таким образом, для аппроксимации зависимости между этими переменными лучше подойдет квадратичная модель. Особенно ярко квадратичная зависимость между величинами Xi и ei проявляется на панели Б. Графическое изображение остатков позволяет отфильтровать или удалить линейную зависимость между переменными X и Y и выявить недостаточную точность модели простой линейной регрессии. Таким образом, в данной ситуации вместо простой линейной модели должна применяться квадратичная модель, обладающая более высокой точностью.

Рис. 8. Исследование эмпирической модели простой линейной регрессии
Вернемся к задаче о сети магазинов Sunflowers и посмотрим, хорошо ли подходит простая линейная регрессия для ее решения. Соответствующие данные и расчеты приведены на рис. 9а (формулы можно посмотреть в Excel-файле). Построим диаграмму разброса, откладывая по вертикальной оси остатки ei, а по горизонтальной — независимую переменную Xi (рис. 9б). Несмотря на большой разброс остатков, между ei и Хi нет ярко выраженной зависимости. Остатки одинаково часто принимают как положительные, так и отрицательные значения. Это позволяет сделать вывод, что модель линейной регрессии пригодна для решения задачи о сети магазинов Sunflowers.

Рис. 9. Остатки ei, вычисленные при решении задачи о сети магазинов Sunflowers
Значения остатков (таблица на рис. 9а) и график остатков (аналог рис. 9б) можно получить непосредственно в процедуре Регрессия Пакета анализа. Просто поставьте соответствующие галки (рис. 10).

Рис. 10. Остатки ei и график остатков полученные с помощью Пакета анализа
Проверка условий. График остатков позволяет оценить вариации ошибок. На рис. 10 нет особых различий между ошибками, соответствующими разным значениям Xi. Следовательно, вариации ошибок при разных значениях Хi приблизительно одинаковы. Рассмотрим гипотетическую ситуацию, в которой это условие не выполняется (рис. 11). На этом рисунке изображен эффект веера: при возрастании значений Хi ошибки увеличиваются. Таким образом, изменчивость значений Yi при разных значениях Хi является непостоянной.

Рис. 11. Пример нарушения условия независимости вариаций ошибок от Xi
Нормальность. Чтобы проверить предположение о нормальном распределении ошибок, построим график нормального распределения на основе точечного графика, на вертикальной оси которого отложены значения остатков, а на горизонтальной оси — соответствующие квантили стандартизованного нормального распределения (подробнее см. Проверка гипотезы о нормальном распределении). Для построения такого графика значения остатков должны быть упорядочены по возрастанию (рис. 12). График нормального распределения может быть построен одним кликом с помощью Пакета анализа Excel – просто поставьте соответствующую галочку в окне Регрессия (см. рис. 10, самый низ окна Регрессия – опция График нормальной вероятности).

Рис. 12. График нормального распределения для остатков
Без визуализации данных (с помощью гистограммы, диаграммы «ствол и листья», блочной диаграммы или графика как на рис. 12) проверить предположение о нормальном распределении ошибок очень трудно. Данные, изображенные на рис. 12, не слишком сильно отличаются от нормального распределения. Устойчивость регрессионного анализа и небольшой объем выборки позволяют утверждать, что условие о нормальном распределении ошибок нарушается незначительно.
Независимость. Предположение о независимости ошибок также проверяется с помощью графика остатков. Данные, собранные на протяжении некоторого периода времени, иногда демонстрируют эффект автокорреляции между последовательными наблюдениями. В таких ситуациях остатки зависят от значений предыдущих остатков. Подобная связь между остатками нарушает предположение о независимости ошибок. Эффект автокорреляции хорошо выявляется на графике. Кроме того, его можно измерить с помощью процедуры Дурбина-Уотсона (см. ниже). Если данные о размерах магазинов и объемах продаж собирались в течение одного и того же периода времени, гипотезу об их независимости проверять не имеет смысла.
Измерение автокорреляции: статистика Дурбина–Уотсона
Одним из основных предположений о регрессионной модели является гипотеза о независимости ее ошибок. Если данные собираются в течение определенного отрезка времени, это условие часто нарушается, поскольку остаток в определенный момент времени может оказаться приблизительно равным предыдущим остаткам. Такое поведение остатков называется автокорреляцией. Если набор данных обладает свойством автокорреляции, корректность регрессионной модели становится весьма сомнительной.
Распознавание автокорреляции с помощью графика остатков. Для выявления автокорреляции необходимо упорядочить остатки по времени и построить их график. Если данные обладают положительной автокорреляцией, на графике возникнут кластеры остатков, имеющие одинаковый знак. В случае отрицательной автокорреляции остатки будут скачкообразно принимать то положительные, то отрицательные значения. Этот вид автокорреляции очень редко встречается в регрессионном анализе, поэтому мы рассмотрим лишь положительную автокорреляцию. Проиллюстрируем ее следующим примером. Предположим, что менеджер магазина, доставляющего товары на дом, пытается предсказать объем продаж по количеству клиентов, совершивших покупки в течение 15 недель (рис. 13).

Рис. 13. Количество клиентов и объемы продаж за 15 недель
Поскольку данные собирались на протяжении 15 последовательных недель в одном и том же магазине, необходимо определить, наблюдается ли эффект автокорреляции. Построим регрессию с использованием Пакета анализа; включим вывод Остатков, но не будем включать График остатков (рис. 14).

Рис. 14. Параметры линейной регрессии, полученные с использованием Пакета анализа
Анализ рис. 14 показывает, что r2 = 0,657. Это значит, что 65,7% вариации объемов продаж объясняется изменчивостью количества клиентов. Кроме того, сдвиг b0 переменной Y равен –16,032, а наклон b1 = 0,0308. Однако, прежде чем применять эту модель, необходимо выполнить анализ остатков. Поскольку данные собирались на протяжении 15 последовательных недель, их следует отобразить на графике в том же порядке (рис. 15).

Рис. 15. Зависимость остатков от времени
Анализ рис. 15 показывает, что остатки циклически колеблются вверх и вниз. Эта цикличность является явным признаком автокорреляции. Следовательно, гипотезу о независимости остатков следует отклонить.
Статистика Дурбина-Уотсона. Автокорреляцию можно выявить и измерить с помощью статистики Дурбина-Уотсона. Эта статистика оценивает корреляцию между соседними остатками:

где еi — остаток, соответствующий i-му периоду времени.
Чтобы лучше понять статистику Дурбина-Уотсона, рассмотрим ее составные части. Числитель представляет собой сумму квадратов разностей между соседними остатками, начиная со второго и заканчивая n-м наблюдением. Знаменатель является суммой квадратов остатков. Вот, что по этому поводу написано в Википедии:

где ρ1 – коэффициент автокорреляции; если ρ1 = 0 (нет автокорреляции), D ≈ 2; если ρ1 ≈ 1 (положительная автокорреляции), D ≈ 0; если ρ1 = -1 (отрицательная автокорреляции), D ≈ 4.
На практике применение критерия Дурбина-Уотсона основано на сравнении величины D с критическими теоретическими значениями dL и dU для заданного числа наблюдений n, числа независимых переменных модели k (для простой линейной регрессии k = 1) и уровня значимости α. Если D < dL, гипотеза о независимости случайных отклонений отвергается (следовательно, присутствует положительная автокорреляция); если D > dU, гипотеза не отвергается (то есть автокорреляция отсутствует); если dL < D < dU, нет достаточных оснований для принятия решения. Когда расчётное значение D превышает 2, то с dL и dU сравнивается не сам коэффициент D, а выражение (4 – D).
Для вычисления статистики Дурбина-Уотсона в Excel обратимся к нижней таблице на рис. 14 Вывод остатка. Числитель в выражении (10) вычисляется с помощью функции =СУММКВРАЗН(массив1;массив2), а знаменатель =СУММКВ(массив) (рис. 16).

Рис. 16. Формулы расчета статистики Дурбина-Уотсона
В нашем примере D = 0,883. Основной вопрос заключается в следующем — какое значение статистики Дурбина-Уотсона следует считать достаточно малым, чтобы сделать вывод о существовании положительной автокорреляции? Необходимо соотнести значение D с критическими значениями (dL и dU), зависящими от числа наблюдений n и уровня значимости α (рис. 17).

Рис. 17. Критические значения статистики Дурбина-Уотсона (фрагмент таблицы)
Таким образом, в задаче об объеме продаж в магазине, доставляющем товары на дом, существуют одна независимая переменная (k = 1), 15 наблюдений (n = 15) и уровень значимости α = 0,05. Следовательно, dL= 1,08 и dU = 1,36. Поскольку D = 0,883 < dL= 1,08, между остатками существует положительная автокорреляция, метод наименьших квадратов применять нельзя.
Проверка гипотез о наклоне и коэффициенте корреляции
Выше регрессия применялась исключительно для прогнозирования. Для определения коэффициентов регрессии и предсказания значения переменной Y при заданной величине переменной X использовался метод наименьших квадратов. Кроме того, мы рассмотрели среднеквадратичную ошибку оценки и коэффициент смешанной корреляции. Если анализ остатков подтверждает, что условия применимости метода наименьших квадратов не нарушаются, и модель простой линейной регрессии является адекватной, на основе выборочных данных можно утверждать, что между переменными в генеральной совокупности существует линейная зависимость.
Применение t-критерия для наклона. Проверяя, равен ли наклон генеральной совокупности β1 нулю, можно определить, существует ли статистически значимая зависимость между переменными X и Y. Если эта гипотеза отклоняется, можно утверждать, что между переменными X и Y существует линейная зависимость. Нулевая и альтернативная гипотезы формулируются следующим образом: Н0: β1 = 0 (нет линейной зависимости), Н1: β1 ≠ 0 (есть линейная зависимость). По определению t-статистика равна разности между выборочным наклоном и гипотетическим значением наклона генеральной совокупности, деленной на среднеквадратичную ошибку оценки наклона:
(11) t = (b1 – β1) / Sb1
где b1 – наклон прямой регрессии по выборочным данным, β1 – гипотетический наклон прямой генеральной совокупности, ![]() , а тестовая статистика t имеет t-распределение с n – 2 степенями свободы.
, а тестовая статистика t имеет t-распределение с n – 2 степенями свободы.
Проверим, существует ли статистически значимая зависимость между размером магазина и годовым объемом продаж при α = 0,05. t-критерий выводится наряду с другими параметрами при использовании Пакета анализа (опция Регрессия). Полностью результаты работы Пакета анализа приведены на рис. 4, фрагмент, относящийся к t-статистике – на рис. 18.

Рис. 18. Результаты применения t-критерия, полученные с помощью Пакета анализа Excel
Поскольку число магазинов n = 14 (см. рис.3), критическое значение t-статистики при уровне значимости α = 0,05 можно найти по формуле: tL =СТЬЮДЕНТ.ОБР(0,025;12) = –2,1788, где 0,025 – половина уровня значимости, а 12 = n – 2; tU =СТЬЮДЕНТ.ОБР(0,975;12) = +2,1788.
Поскольку t-статистика = 10,64 > tU = 2,1788 (рис. 19), нулевая гипотеза Н0 отклоняется. С другой стороны, р-значение для Х = 10,6411, вычисляемое по формуле =1-СТЬЮДЕНТ.РАСП(D3;12;ИСТИНА), приближенно равно нулю, поэтому гипотеза Н0 снова отклоняется. Тот факт, что р-значение почти равно нулю, означает, что если бы между размерами магазинов и годовым объемом продаж не существовало реальной линейной зависимости, обнаружить ее с помощью линейной регрессии было бы практически невозможно. Следовательно, между средним годовым объемом продаж в магазинах и их размером существует статистически значимая линейная зависимость.

Рис. 19. Проверка гипотезы о наклоне генеральной совокупности при уровне значимости, равном 0,05, и 12 степенях свободы
Применение F-критерия для наклона. Альтернативным подходом к проверке гипотез о наклоне простой линейной регрессии является использование F-критерия. Напомним, что F-критерий применяется для проверки отношения между двумя дисперсиями (подробнее см. Однофакторный дисперсионный анализ). При проверке гипотезы о наклоне мерой случайных ошибок является дисперсия ошибки (сумма квадратов ошибок, деленная на количество степеней свободы), поэтому F-критерий использует отношение дисперсии, объясняемой регрессией (т.е. величины SSR, деленной на количество независимых переменных k), к дисперсии ошибок (MSE = SYX2).
По определению F-статистика равна среднему квадрату отклонений, обусловленных регрессией (MSR), деленному на дисперсию ошибки (MSE): F = MSR/MSE, где MSR = SSR / k, MSE = SSE/(n– k – 1), k – количество независимых переменных в регрессионной модели. Тестовая статистика F имеет F-распределение с k и n – k – 1 степенями свободы.
При заданном уровне значимости α решающее правило формулируется так: если F > FU, нулевая гипотеза отклоняется; в противном случае она не отклоняется. Результаты, оформленные в виде сводной таблицы дисперсионного анализа, приведены на рис. 20.

Рис. 20. Таблица дисперсионного анализа для проверки гипотезы о статистической значимости коэффициента регрессии
Аналогично t-критерию F-критерий выводится в таблицу при использовании Пакета анализа (опция Регрессия). Полностью результаты работы Пакета анализа приведены на рис. 4, фрагмент, относящийся к F-статистике – на рис. 21.

Рис. 21. Результаты применения F-критерия, полученные с помощью Пакета анализа Excel
F-статистика равна 113,23, а р-значение близко к нулю (ячейка Значимость F). Если уровень значимости α равен 0,05, определить критическое значение F-распределения с одной и 12 степенями свободы можно по формуле FU =F.ОБР(1-0,05;1;12) = 4,7472 (рис. 22). Поскольку F = 113,23 > FU = 4,7472, причем р-значение близко к 0 < 0,05, нулевая гипотеза Н0 отклоняется, т.е. размер магазина тесно связан с его годовым объемом продаж.

Рис. 22. Проверка гипотезы о наклоне генеральной совокупности при уровне значимости, равном 0,05, с одной и 12 степенями свободы
Доверительный интервал, содержащий наклон β1. Для проверки гипотезы о существовании линейной зависимости между переменными можно построить доверительный интервал, содержащий наклон β1 и убедиться, что гипотетическое значение β1 = 0 принадлежит этому интервалу. Центром доверительного интервала, содержащего наклон β1, является выборочный наклон b1, а его границами — величины b1 ± tn–2Sb1
Как показано на рис. 18, b1 = +1,670, n = 14, Sb1 = 0,157. t12 =СТЬЮДЕНТ.ОБР(0,975;12) = 2,1788. Следовательно, b1 ± tn–2Sb1 = +1,670 ± 2,1788 * 0,157 = +1,670 ± 0,342, или + 1,328 ≤ β1 ≤ +2,012. Таким образом, наклон генеральной совокупности с вероятностью 0,95 лежит в интервале от +1,328 до +2,012 (т.е. от 1 328 000 до 2 012 000 долл.). Поскольку эти величины больше нуля, между годовым объемом продаж и площадью магазина существует статистически значимая линейная зависимость. Если бы доверительный интервал содержал нуль, между переменными не было бы зависимости. Кроме того, доверительный интервал означает, что каждое увеличение площади магазина на 1 000 кв. футов приводит к увеличению среднего объема продаж на величину от 1 328 000 до 2 012 000 долларов.
Использование t-критерия для коэффициента корреляции. Ранее был введен коэффициент корреляции r, представляющий собой меру зависимости между двумя числовыми переменными. С его помощью можно установить, существует ли между двумя переменными статистически значимая связь. Обозначим коэффициент корреляции между генеральными совокупностями обеих переменных символом ρ. Нулевая и альтернативная гипотезы формулируются следующим образом: Н0: ρ = 0 (нет корреляции), Н1: ρ ≠ 0 (есть корреляция). Проверка существования корреляции:

где r = +![]() , если b1 > 0, r = –
, если b1 > 0, r = –![]() , если b1 < 0. Тестовая статистика t имеет t-распределение с n – 2 степенями свободы.
, если b1 < 0. Тестовая статистика t имеет t-распределение с n – 2 степенями свободы.
В задаче о сети магазинов Sunflowers r2 = 0,904, а b1— +1,670 (см. рис. 4). Поскольку b1 > 0, коэффициент корреляции между объемом годовых продаж и размером магазина равен r = +√0,904 = +0,951. Проверим нулевую гипотезу, утверждающую, что между этими переменными нет корреляции, используя t-статистику:

При уровне значимости α = 0,05 нулевую гипотезу следует отклонить, поскольку t = 10,64 > 2,1788. Таким образом, можно утверждать, что между объемом годовых продаж и размером магазина существует статистически значимая связь.
При обсуждении выводов, касающихся наклона генеральной совокупности, доверительные интервалы и критерии для проверки гипотез являются взаимозаменяемыми инструментами. Однако вычисление доверительного интервала, содержащего коэффициент корреляции, оказывается более сложным делом, поскольку вид выборочного распределения статистики r зависит от истинного коэффициента корреляции.
Оценка математического ожидания и предсказание индивидуальных значений
В этом разделе рассматриваются методы оценки математического ожидания отклика Y и предсказания индивидуальных значений Y при заданных значениях переменной X.
Построение доверительного интервала. В примере 2 (см. выше раздел Метод наименьших квадратов) регрессионное уравнение позволило предсказать значение переменной Y при заданном значении переменной X. В задаче о выборе места для торговой точки средний годовой объем продаж в магазине площадью 4000 кв. футов был равен 7,644 млн. долл. Однако эта оценка математического ожидания генеральной совокупности является точечной. Ранее для оценки математического ожидания генеральной совокупности была предложена концепция доверительного интервала. Аналогично можно ввести понятие доверительного интервала для математического ожидания отклика при заданном значении переменной X:
![]()
где  ,
, ![]() = b0 + b1Xi – предсказанное значение переменное Y при X = Xi, SYX – среднеквадратичная ошибка, n – объем выборки, Xi — заданное значение переменной X, µY|X=Xi – математическое ожидание переменной Y при Х = Хi, SSX =
= b0 + b1Xi – предсказанное значение переменное Y при X = Xi, SYX – среднеквадратичная ошибка, n – объем выборки, Xi — заданное значение переменной X, µY|X=Xi – математическое ожидание переменной Y при Х = Хi, SSX = 
Анализ формулы (13) показывает, что ширина доверительного интервала зависит от нескольких факторов. При заданном уровне значимости возрастание амплитуды колебаний вокруг линии регрессии, измеренное с помощью среднеквадратичной ошибки, приводит к увеличению ширины интервала. С другой стороны, как и следовало ожидать, увеличение объема выборки сопровождается сужением интервала. Кроме того, ширина интервала изменяется в зависимости от значений Xi. Если значение переменной Y предсказывается для величин X, близких к среднему значению ![]() , доверительный интервал оказывается уже, чем при прогнозировании отклика для значений, далеких от среднего.
, доверительный интервал оказывается уже, чем при прогнозировании отклика для значений, далеких от среднего.
Допустим, что, выбирая место для магазина, мы хотим построить 95%-ный доверительный интервал для среднего годового объема продаж во всех магазинах, площадь которых равна 4000 кв. футов:

Следовательно, средний годовой объем продаж во всех магазинах, площадь которых равна 4 000 кв. футов, с 95% -ной вероятностью лежит в интервале от 6,971 до 8,317 млн. долл.
Вычисление доверительного интервала для предсказанного значения. Кроме доверительного интервала для математического ожидания отклика при заданном значении переменной X, часто необходимо знать доверительный интервал для предсказанного значения. Несмотря на то что формула для вычисления такого доверительного интервала очень похожа на формулу (13), этот интервал содержит предсказанное значение, а не оценку параметра. Интервал для предсказанного отклика YX=Xi при конкретном значении переменной Xi определяется по формуле:

Предположим, что, выбирая место для торговой точки, мы хотим построить 95%-ный доверительный интервал для предсказанного годового объема продаж в магазине, площадь которого равна 4000 кв. футов:

Следовательно, предсказанный годовой объем продаж в магазине, площадь которого равна 4000 кв. футов, с 95%-ной вероятностью лежит в интервале от 5,433 до 9,854 млн. долл. Как видим, доверительный интервал для предсказанного значения отклика намного шире, чем доверительный интервал для его математического ожидания. Это объясняется тем, что изменчивость при прогнозировании индивидуальных значений намного больше, чем при оценке математического ожидания.
Подводные камни и этические проблемы, связанные с применением регрессии
Трудности, связанные с регрессионным анализом:
- Игнорирование условий применимости метода наименьших квадратов.
- Ошибочная оценка условий применимости метода наименьших квадратов.
- Неправильный выбор альтернативных методов при нарушении условий применимости метода наименьших квадратов.
- Применение регрессионного анализа без глубоких знаний о предмете исследования.
- Экстраполяция регрессии за пределы диапазона изменения объясняющей переменной.
- Путаница между статистической и причинно-следственной зависимостями.
Широкое распространение электронных таблиц и программного обеспечения для статистических расчетов ликвидировало вычислительные проблемы, препятствовавшие применению регрессионного анализа. Однако это привело к тому, что регрессионный анализ стали применять пользователи, не обладающие достаточной квалификацией и знаниями. Откуда пользователям знать об альтернативных методах, если многие из них вообще не имеют ни малейшего понятия об условиях применимости метода наименьших квадратов и не умеют проверять их выполнение?
Исследователь не должен увлекаться перемалыванием чисел — вычислением сдвига, наклона и коэффициента смешанной корреляции. Ему нужны более глубокие знания. Проиллюстрируем это классическим примером, взятым из учебников. Анскомб показал, что все четыре набора данных, приведенных на рис. 23, имеют одни и те же параметры регрессии (рис. 24).

Рис. 23. Четыре набора искусственных данных

Рис. 24. Регрессионный анализ четырех искусственных наборов данных; выполнен с помощью Пакета анализа (кликните на рисунке, чтобы увеличить изображение)
Итак, с точки зрения регрессионного анализа все эти наборы данных совершенно идентичны. Если бы анализ был на этом закончен, мы потеряли бы много полезной информации. Об этом свидетельствуют диаграммы разброса (рис. 25) и графики остатков (рис. 26), построенные для этих наборов данных.

Рис. 25. Диаграммы разброса для четырех наборов данных
Диаграммы разброса и графики остатков свидетельствуют о том, что эти данные отличаются друг от друга. Единственный набор, распределенный вдоль прямой линии, — набор А. График остатков, вычисленных по набору А, не имеет никакой закономерности. Этого нельзя сказать о наборах Б, В и Г. График разброса, построенный по набору Б, демонстрирует ярко выраженную квадратичную модель. Этот вывод подтверждается графиком остатков, имеющим параболическую форму. Диаграмма разброса и график остатков показывают, что набор данных В содержит выброс. В этой ситуации необходимо исключить выброс из набора данных и повторить анализ. Метод, позволяющий обнаруживать и исключать выбросы из наблюдений, называется анализом влияния. После исключения выброса результат повторной оценки модели может оказаться совершенно иным. Диаграмма разброса, построенная по данным из набора Г, иллюстрирует необычную ситуацию, в которой эмпирическая модель значительно зависит от отдельного отклика (Х8 = 19, Y8 = 12,5). Такие регрессионные модели необходимо вычислять особенно тщательно. Итак, графики разброса и остатков являются крайне необходимым инструментом регрессионного анализа и должны быть его неотъемлемой частью. Без них регрессионный анализ не заслуживает доверия.

Рис. 26. Графики остатков для четырех наборов данных
Как избежать подводных камней при регрессионном анализе:
- Анализ возможной взаимосвязи между переменными X и Y всегда начинайте с построения диаграммы разброса.
- Прежде чем интерпретировать результаты регрессионного анализа, проверяйте условия его применимости.
- Постройте график зависимости остатков от независимой переменной. Это позволит определить, насколько эмпирическая модель соответствует результатам наблюдения, и обнаружить нарушение постоянства дисперсии.
- Для проверки предположения о нормальном распределении ошибок используйте гистограммы, диаграммы «ствол и листья», блочные диаграммы и графики нормального распределения.
- Если условия применимости метода наименьших квадратов не выполняются, используйте альтернативные методы (например, модели квадратичной или множественной регрессии).
- Если условия применимости метода наименьших квадратов выполняются, необходимо проверить гипотезу о статистической значимости коэффициентов регрессии и построить доверительные интервалы, содержащие математическое ожидание и предсказанное значение отклика.
- Избегайте предсказывать значения зависимой переменной за пределами диапазона изменения независимой переменной.
- Имейте в виду, что статистические зависимости не всегда являются причинно-следственными. Помните, что корреляция между переменными не означает наличия причинно-следственной зависимости между ними.
Резюме. Как показано на структурной схеме (рис. 27), в заметке описаны модель простой линейной регрессии, условия ее применимости и способы проверки этих условий. Рассмотрен t-критерий для проверки статистической значимости наклона регрессии. Для предсказания значений зависимой переменной использована регрессионная модель. Рассмотрен пример, связанный с выбором места для торговой точки, в котором исследуется зависимость годового объема продаж от площади магазина. Полученная информация позволяет точнее выбрать место для магазина и предсказать его годовой объем продаж. В следующих заметках будет продолжено обсуждение регрессионного анализа, а также рассмотрены модели множественной регрессии.

Рис. 27. Структурная схема заметки
Предыдущая заметка Критерий согласия «хи-квадрат»
Следующая заметка Введение в множественную регрессию
К оглавлению Статистика для менеджеров с использованием Microsoft Excel
[1] Используются материалы книги Левин и др. Статистика для менеджеров. – М.: Вильямс, 2004. – с. 792–872
[2] Если зависимая переменная является категорийной, необходимо применять логистическую регрессию.
Содержание
- Подключение пакета анализа
- Виды регрессионного анализа
- Линейная регрессия в программе Excel
- Разбор результатов анализа
- Вопросы и ответы

Регрессионный анализ является одним из самых востребованных методов статистического исследования. С его помощью можно установить степень влияния независимых величин на зависимую переменную. В функционале Microsoft Excel имеются инструменты, предназначенные для проведения подобного вида анализа. Давайте разберем, что они собой представляют и как ими пользоваться.
Подключение пакета анализа
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.
- Перемещаемся во вкладку «Файл».
- Переходим в раздел «Параметры».
- Открывается окно параметров Excel. Переходим в подраздел «Надстройки».
- В самой нижней части открывшегося окна переставляем переключатель в блоке «Управление» в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «Перейти».
- Открывается окно доступных надстроек Эксель. Ставим галочку около пункта «Пакет анализа». Жмем на кнопку «OK».





Теперь, когда мы перейдем во вкладку «Данные», на ленте в блоке инструментов «Анализ» мы увидим новую кнопку – «Анализ данных».

Виды регрессионного анализа
Существует несколько видов регрессий:
- параболическая;
- степенная;
- логарифмическая;
- экспоненциальная;
- показательная;
- гиперболическая;
- линейная регрессия.
О выполнении последнего вида регрессионного анализа в Экселе мы подробнее поговорим далее.
Внизу, в качестве примера, представлена таблица, в которой указана среднесуточная температура воздуха на улице, и количество покупателей магазина за соответствующий рабочий день. Давайте выясним при помощи регрессионного анализа, как именно погодные условия в виде температуры воздуха могут повлиять на посещаемость торгового заведения.
Общее уравнение регрессии линейного вида выглядит следующим образом: У = а0 + а1х1 +…+акхк. В этой формуле Y означает переменную, влияние факторов на которую мы пытаемся изучить. В нашем случае, это количество покупателей. Значение x – это различные факторы, влияющие на переменную. Параметры a являются коэффициентами регрессии. То есть, именно они определяют значимость того или иного фактора. Индекс k обозначает общее количество этих самых факторов.
- Кликаем по кнопке «Анализ данных». Она размещена во вкладке «Главная» в блоке инструментов «Анализ».
- Открывается небольшое окошко. В нём выбираем пункт «Регрессия». Жмем на кнопку «OK».
- Открывается окно настроек регрессии. В нём обязательными для заполнения полями являются «Входной интервал Y» и «Входной интервал X». Все остальные настройки можно оставить по умолчанию.
В поле «Входной интервал Y» указываем адрес диапазона ячеек, где расположены переменные данные, влияние факторов на которые мы пытаемся установить. В нашем случае это будут ячейки столбца «Количество покупателей». Адрес можно вписать вручную с клавиатуры, а можно, просто выделить требуемый столбец. Последний вариант намного проще и удобнее.
В поле «Входной интервал X» вводим адрес диапазона ячеек, где находятся данные того фактора, влияние которого на переменную мы хотим установить. Как говорилось выше, нам нужно установить влияние температуры на количество покупателей магазина, а поэтому вводим адрес ячеек в столбце «Температура». Это можно сделать теми же способами, что и в поле «Количество покупателей».

С помощью других настроек можно установить метки, уровень надёжности, константу-ноль, отобразить график нормальной вероятности, и выполнить другие действия. Но, в большинстве случаев, эти настройки изменять не нужно. Единственное на что следует обратить внимание, так это на параметры вывода. По умолчанию вывод результатов анализа осуществляется на другом листе, но переставив переключатель, вы можете установить вывод в указанном диапазоне на том же листе, где расположена таблица с исходными данными, или в отдельной книге, то есть в новом файле.
После того, как все настройки установлены, жмем на кнопку «OK».






Разбор результатов анализа
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.

Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
Регрессия позволяет прогнозировать зависимую переменную на основании значений фактора. В
MS
EXCEL
имеется множество функций, которые возвращают не только наклон и сдвиг линии регрессии, характеризующей линейную взаимосвязь между факторами, но и регрессионную статистику. Здесь рассмотрим простую линейную регрессию, т.е. прогнозирование на основе одного фактора.
Disclaimer
: Данную статью не стоит рассматривать, как пересказ главы из учебника по статистике. Статья не обладает ни полнотой, ни строгостью изложения положений статистической науки. Эта статья – о применении MS EXCEL для целей
Регрессионного анализа.
Теоретические отступления приведены лишь из соображения логики изложения. Использование данной статьи для изучения
Регрессии
– плохая идея.
Статья про
Регрессионный анализ
получилась большая, поэтому ниже для удобства приведены ее разделы:
- Немного теории и основные понятия
- Предположения линейной регрессионной модели
- Задачи регрессионного анализа
- Оценка неизвестных параметров линейной модели (используя функции MS EXCEL)
- Оценка неизвестных параметров линейной модели (через статистики выборок)
- Оценка неизвестных параметров линейной модели (матричная форма)
- Построение линии регрессии
- Коэффициент детерминации
- Стандартная ошибка регрессии
- Стандартные ошибки и доверительные интервалы для наклона и сдвига
- Проверка значимости взаимосвязи переменных
- Доверительные интервалы для нового наблюдения Y и среднего значения
- Проверка адекватности линейной регрессионной модели
Примечание
: Если прогнозирование переменной осуществляется на основе нескольких факторов, то имеет место
множественная регрессия
.
Чтобы разобраться, чем может помочь MS EXCEL при проведении регрессионного анализа, напомним вкратце теорию, введем термины и обозначения, которые могут отличаться в зависимости от различных источников.
Примечание
: Для тех, кому некогда, незачем или просто не хочется разбираться в теоретических выкладках предлагается сразу перейти к вычислительной части —
оценке неизвестных параметров линейной модели
.
Немного теории и основные понятия
Пусть у нас есть массив данных, представляющий собой значения двух переменных Х и Y. Причем значения переменной Х мы можем произвольно задавать (контролировать) и использовать эту переменную для предсказания значений зависимой переменной Y. Таким образом, случайной величиной является только переменная Y.
Примером такой задачи может быть производственный процесс изготовления некого волокна, причем
прочность этого волокна
(Y) зависит только от
рабочей температуры процесса
в реакторе (Х), которая задается оператором.
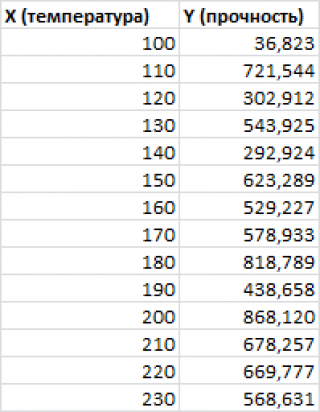
Построим
диаграмму рассеяния
(см.
файл примера лист Линейный
), созданию которой
посвящена отдельная статья
. Вообще, построение
диаграммы рассеяния
для целей
регрессионного анализа
де-факто является стандартом.
СОВЕТ
: Подробнее о построении различных типов диаграмм см. статьи
Основы построения диаграмм
и
Основные типы диаграмм
.
Приведенная выше
диаграмма рассеяния
свидетельствует о возможной
линейной взаимосвязи
между Y от Х: очевидно, что точки данных в основном располагаются вдоль прямой линии.
Примечание
: Наличие даже такой очевидной
линейной взаимосвязи
не может являться доказательством о наличии причинной взаимосвязи переменных. Наличие
причинной
взаимосвязи не может быть доказано на основании только анализа имеющихся измерений, а должно быть обосновано с помощью других исследований, например теоретических выкладок.
Примечание
: Как известно, уравнение прямой линии имеет вид
Y
=
m
*
X
+
k
, где коэффициент
m
отвечает за наклон линии (
slope
),
k
– за сдвиг линии по вертикали (
intercept
),
k
равно значению Y при Х=0.
Предположим, что мы можем зафиксировать переменную Х (
рабочую температуру процесса
) при некотором значении Х
i
и произвести несколько наблюдений переменной Y (
прочность нити
). Очевидно, что при одном и том же значении Хi мы получим различные значения Y. Это обусловлено влиянием других факторов на Y. Например, локальные колебания давления в реакторе, концентрации раствора, наличие ошибок измерения и др. Предполагается, что воздействие этих факторов имеет случайную природу и для каждого измерения имеются одинаковые условия проведения эксперимента (т.е. другие факторы не изменяются).
Полученные значения Y, при заданном Хi, будут колебаться вокруг некого
значения
. При увеличении количества измерений, среднее этих измерений, будет стремиться к
математическому ожиданию
случайной величины Y (при Х
i
) равному μy(i)=Е(Y
i
).
Подобные рассуждения можно привести для любого значения Хi.
Чтобы двинуться дальше, воспользуемся материалом из раздела
Проверка статистических гипотез
. В статье о
проверке гипотезы о среднем значении генеральной совокупности
в качестве
нулевой
гипотезы
предполагалось равенство неизвестного значения μ заданному μ0.
В нашем случае
простой линейной регрессии
в качестве
нулевой
гипотезы
предположим, что между переменными μy(i) и Хi существует линейная взаимосвязь μ
y(i)
=α* Х
i
+β. Уравнение μ
y(i)
=α* Х
i
+β можно переписать в обобщенном виде (для всех Х и μ
y
) как μ
y
=α* Х +β.
Для наглядности проведем прямую линию соединяющую все μy(i).
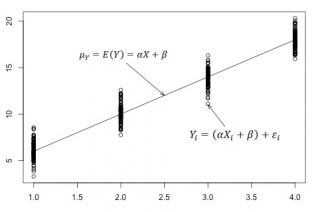
Данная линия называется
регрессионной линией генеральной совокупности
(population regression line), параметры которой (
наклон
a и
сдвиг β
) нам не известны (по аналогии с
гипотезой о среднем значении генеральной совокупности
, где нам было неизвестно истинное значение μ).
Теперь сделаем переход от нашего предположения, что μy=a* Х +
β
, к предсказанию значения случайной переменной Y в зависимости от значения контролируемой переменной Х. Для этого уравнение связи двух переменных запишем в виде Y=a*X+β+ε, где ε — случайная ошибка, которая отражает суммарный эффект влияния других факторов на Y (эти «другие» факторы не участвуют в нашей модели). Напомним, что т.к. переменная Х фиксирована, то ошибка ε определяется только свойствами переменной Y.
Уравнение Y=a*X+b+ε называют
линейной регрессионной моделью
. Часто Х еще называют
независимой переменной
(еще
предиктором
и
регрессором
, английский термин
predictor
,
regressor
), а Y –
зависимой
(или
объясняемой
,
response
variable
). Так как
регрессор
у нас один, то такая модель называется
простой линейной регрессионной моделью
(
simple
linear
regression
model
). α часто называют
коэффициентом регрессии.
Предположения линейной регрессионной модели перечислены в следующем разделе.
Предположения линейной регрессионной модели
Чтобы модель линейной регрессии Yi=a*Xi+β+ε
i
была адекватной — требуется:
-
Ошибки ε
i
должны быть независимыми переменными; -
При каждом значении Xi ошибки ε
i
должны быть иметь нормальное распределение (также предполагается равенство нулю математического ожидания, т.е. Е[ε
i
]=0); -
При каждом значении Xi ошибки ε
i
должны иметь равные дисперсии (обозначим ее σ
2
).
Примечание
: Последнее условие называется
гомоскедастичность
— стабильность, гомогенность дисперсии случайной ошибки e. Т.е.
дисперсия
ошибки σ
2
не должна зависеть от значения Xi.
Используя предположение о равенстве математического ожидания Е[ε
i
]=0 покажем, что μy(i)=Е[Yi]:
Е[Yi]= Е[a*Xi+β+ε
i
]= Е[a*Xi+β]+ Е[ε
i
]= a*Xi+β= μy(i), т.к. a, Xi и β постоянные значения.
Дисперсия
случайной переменной Y равна
дисперсии
ошибки ε, т.е. VAR(Y)= VAR(ε)=σ
2
. Это является следствием, что все значения переменной Х являются const, а VAR(ε)=VAR(ε
i
).
Задачи регрессионного анализа
Для проверки гипотезы о линейной взаимосвязи переменной Y от X делают выборку из генеральной совокупности (этой совокупности соответствует
регрессионная линия генеральной совокупности
, т.е. μy=a* Х +β). Выборка будет состоять из n точек, т.е. из n пар значений {X;Y}.
На основании этой выборки мы можем вычислить оценки наклона a и сдвига β, которые обозначим соответственно
a
и
b
. Также часто используются обозначения â и b̂.
Далее, используя эти оценки, мы также можем проверить гипотезу: имеется ли линейная связь между X и Y статистически значимой?
Таким образом:
Первая задача
регрессионного анализа
– оценка неизвестных параметров (
estimation
of
the
unknown
parameters
). Подробнее см. раздел
Оценки неизвестных параметров модели
.
Вторая задача
регрессионного анализа
–
Проверка адекватности модели
(
model
adequacy
checking
).
Примечание
: Оценки параметров модели обычно вычисляются
методом наименьших квадратов
(МНК),
которому посвящена отдельная статья
.
Оценка неизвестных параметров линейной модели (используя функции MS EXCEL)
Неизвестные параметры
простой линейной регрессионной модели
Y=a*X+β+ε оценим с помощью
метода наименьших квадратов
(в
статье про МНК подробно описано этот метод
).
Для вычисления параметров линейной модели методом МНК получены следующие выражения:
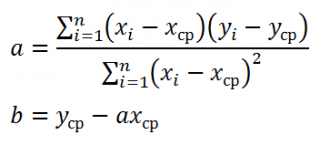
Таким образом, мы получим уравнение прямой линии Y=
a
*X+
b
, которая наилучшим образом аппроксимирует имеющиеся данные.
Примечание
: В статье про
метод наименьших квадратов
рассмотрены случаи аппроксимации
линейной
и
квадратичной функцией
, а также
степенной
,
логарифмической
и
экспоненциальной функцией
.
Оценку параметров в MS EXCEL можно выполнить различными способами:
-
с помощью функций
НАКЛОН()
и
ОТРЕЗОК()
; -
с помощью функции
ЛИНЕЙН()
; см. статьюФункция MS EXCEL ЛИНЕЙН()
-
формулами через статистики выборок
;
-
в матричной форме
;
-
с помощью
инструмента Регрессия надстройки Пакет Анализа
.
Сначала рассмотрим функции
НАКЛОН()
,
ОТРЕЗОК()
и
ЛИНЕЙН()
.
Пусть значения Х и Y находятся соответственно в диапазонах
C
23:
C
83
и
B
23:
B
83
(см.
файл примера
внизу статьи).
Примечание
: Значения двух переменных Х и Y можно сгенерировать, задав тренд и величину случайного разброса (см. статью
Генерация данных для линейной регрессии в MS EXCEL
).
В MS EXCEL наклон прямой линии
а
(
оценку
коэффициента регрессии
), можно найти по
методу МНК
с помощью функции
НАКЛОН()
, а сдвиг
b
(
оценку
постоянного члена
или
константы регрессии
), с помощью функции
ОТРЕЗОК()
. В английской версии это функции SLOPE и INTERCEPT соответственно.
Аналогичный результат можно получить с помощью функции
ЛИНЕЙН()
, английская версия LINEST (см.
статью об этой функции
).
Формула
=ЛИНЕЙН(C23:C83;B23:B83)
вернет наклон
а
. А формула =
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);2)
— сдвиг
b
. Здесь требуются пояснения.
Функция
ЛИНЕЙН()
имеет 4 аргумента и возвращает целый массив значений:
ЛИНЕЙН(известные_значения_y; [известные_значения_x]; [конст]; [статистика])
Если 4-й аргумент
статистика
имеет значение ЛОЖЬ или опущен, то функция
ЛИНЕЙН()
возвращает только оценки параметров модели:
a
и
b
.
Примечание
: Остальные значения, возвращаемые функцией
ЛИНЕЙН()
, нам потребуются при вычислении
стандартных ошибок
и для
проверки значимости регрессии
. В этом случае аргумент
статистика
должен иметь значение ИСТИНА.
Чтобы вывести сразу обе оценки:
- в одной строке необходимо выделить 2 ячейки,
-
ввести формулу в
Строке формул
-
нажать
CTRL
+
SHIFT
+
ENTER
(см. статью проформулы массива
).
Если в
Строке формул
выделить формулу =
ЛИНЕЙН(C23:C83;B23:B83)
и нажать
клавишу F9
, то мы увидим что-то типа {3,01279389265416;154,240057900613}. Это как раз значения
a
и
b
. Как видно, оба значения разделены точкой с запятой «;», что свидетельствует, что функция вернула значения «в нескольких ячейках одной строки».
Если требуется вывести параметры линии не в одной строке, а одном столбце (ячейки друг под другом), то используйте формулу =
ТРАНСП(ЛИНЕЙН(C23:C83;B23:B83))
. При этом выделять нужно 2 ячейки в одном столбце. Если теперь выделить новую формулу и нажать клавишу F9, то мы увидим что 2 значения разделены двоеточием «:», что означает, что значения выведены в столбец (функция
ТРАНСП()
транспонировала строку в столбец
).
Чтобы разобраться в этом подробнее необходимо ознакомиться с
формулами массива
.
Чтобы не связываться с вводом
формул массива
, можно
использовать функцию ИНДЕКС()
. Формула =
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);1)
или просто
ЛИНЕЙН(C23:C83;B23:B83)
вернет параметр, отвечающий за наклон линии, т.е.
а
. Формула
=ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);2)
вернет параметр
b
.
Оценка неизвестных параметров линейной модели (через статистики выборок)
Наклон линии, т.е. коэффициент
а
, можно также вычислить через
коэффициент корреляции
и
стандартные отклонения выборок
:
=
КОРРЕЛ(B23:B83;C23:C83) *(СТАНДОТКЛОН.В(C23:C83)/ СТАНДОТКЛОН.В(B23:B83))
Вышеуказанная формула математически эквивалентна отношению
ковариации
выборок Х и Y и
дисперсии
выборки Х:
=
КОВАРИАЦИЯ.В(B23:B83;C23:C83)/ДИСП.В(B23:B83)
И, наконец, запишем еще одну формулу для нахождения сдвига
b
. Воспользуемся тем фактом, что
линия регрессии
проходит через точку
средних значений
переменных Х и Y.
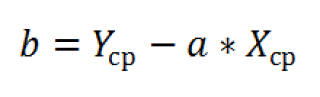
Вычислив
средние значения
и подставив в формулу ранее найденный наклон
а
, получим сдвиг
b
.
Оценка неизвестных параметров линейной модели (матричная форма)
Также параметры
линии регрессии
можно найти в матричной форме (см.
файл примера лист Матричная форма
).
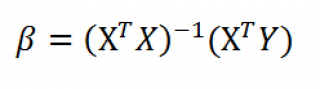
В формуле символом β обозначен столбец с искомыми параметрами модели: β0 (сдвиг
b
), β1 (наклон
a
).
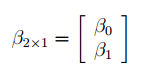
Матрица Х равна:
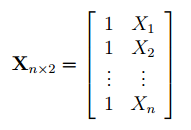
Матрица
Х
называется
регрессионной матрицей
или
матрицей плана
. Она состоит из 2-х столбцов и n строк, где n – количество точек данных. Первый столбец — столбец единиц, второй – значения переменной Х.
Матрица
Х
T
– это
транспонированная матрица
Х
. Она состоит соответственно из n столбцов и 2-х строк.
В формуле символом
Y
обозначен столбец значений переменной Y.
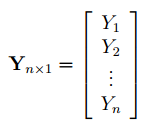
Чтобы
перемножить матрицы
используйте функцию
МУМНОЖ()
. Чтобы
найти обратную матрицу
используйте функцию
МОБР()
.
Пусть дан массив значений переменных Х и Y (n=10, т.е.10 точек).
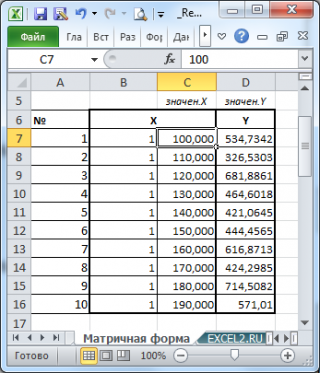
Слева от него достроим столбец с 1 для матрицы Х.
Записав формулу
=
МУМНОЖ(МОБР(МУМНОЖ(ТРАНСП(B7:C16);(B7:C16))); МУМНОЖ(ТРАНСП(B7:C16);(D7:D16)))
и введя ее как
формулу массива
в 2 ячейки, получим оценку параметров модели.
Красота применения матричной формы полностью раскрывается в случае
множественной регрессии
.
Построение линии регрессии
Для отображения
линии регрессии
построим сначала
диаграмму рассеяния
, на которой отобразим все точки (см.
начало статьи
).
Для построения прямой линии используйте вычисленные выше оценки параметров модели
a
и
b
(т.е. вычислите
у
по формуле
y
=
a
*
x
+
b
) или функцию
ТЕНДЕНЦИЯ()
.
Формула =
ТЕНДЕНЦИЯ($C$23:$C$83;$B$23:$B$83;B23)
возвращает расчетные (прогнозные) значения ŷi для заданного значения Хi из столбца
В2
.
Примечание
:
Линию регрессии
можно также построить с помощью функции
ПРЕДСКАЗ()
. Эта функция возвращает прогнозные значения ŷi, но, в отличие от функции
ТЕНДЕНЦИЯ()
работает только в случае одного регрессора. Функция
ТЕНДЕНЦИЯ()
может быть использована и в случае
множественной регрессии
(в этом случае 3-й аргумент функции должен быть ссылкой на диапазон, содержащий все значения Хi для выбранного наблюдения i).
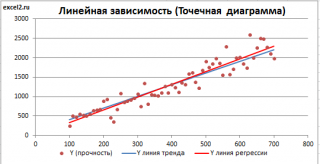
Как видно из диаграммы выше
линия тренда
и
линия регрессии
не обязательно совпадают: отклонения точек от
линии тренда
случайны, а МНК лишь подбирает линию наиболее точно аппроксимирующую случайные точки данных.
Линию регрессии
можно построить и с помощью встроенных средств диаграммы, т.е. с помощью инструмента
Линия тренда.
Для этого выделите диаграмму, в меню выберите
вкладку Макет
, в
группе Анализ
нажмите
Линия тренда
, затем
Линейное приближение.
В диалоговом окне установите галочку
Показывать уравнение на диаграмме
(подробнее см. в
статье про МНК
).
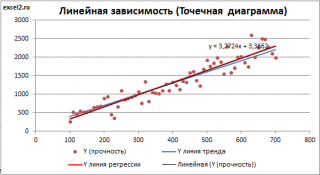
Построенная таким образом линия, разумеется, должна совпасть с ранее построенной нами
линией регрессии,
а параметры уравнения
a
и
b
должны совпасть с параметрами уравнения отображенными на диаграмме.
Примечание:
Для того, чтобы вычисленные параметры уравнения
a
и
b
совпадали с параметрами уравнения на диаграмме, необходимо, чтобы тип у диаграммы был
Точечная, а не График
, т.к. тип диаграммы
График
не использует значения Х, а вместо значений Х используется последовательность 1; 2; 3; … Именно эти значения и берутся при расчете параметров
линии тренда
. Убедиться в этом можно если построить диаграмму
График
(см.
файл примера
), а значения
Хнач
и
Хшаг
установить равным 1. Только в этом случае параметры уравнения на диаграмме совпадут с
a
и
b
.
Коэффициент детерминации R
2
Коэффициент детерминации
R
2
показывает насколько полезна построенная нами
линейная регрессионная модель
.
Предположим, что у нас есть n значений переменной Y и мы хотим предсказать значение yi, но без использования значений переменной Х (т.е. без построения
регрессионной модели
). Очевидно, что лучшей оценкой для yi будет
среднее значение
ȳ. Соответственно, ошибка предсказания будет равна (yi — ȳ).
Примечание
: Далее будет использована терминология и обозначения
дисперсионного анализа
.
После построения
регрессионной модели
для предсказания значения yi мы будем использовать значение ŷi=a*xi+b. Ошибка предсказания теперь будет равна (yi — ŷi).
Теперь с помощью диаграммы сравним ошибки предсказания полученные без построения модели и с помощью модели.
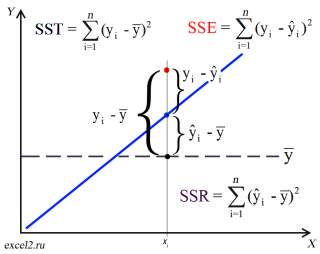
Очевидно, что используя
регрессионную модель
мы уменьшили первоначальную (полную) ошибку (yi — ȳ) на значение (ŷi — ȳ) до величины (yi — ŷi).
(yi — ŷi) – это оставшаяся, необъясненная ошибка.
Очевидно, что все три ошибки связаны выражением:
(yi — ȳ)= (ŷi — ȳ) + (yi — ŷi)
Можно показать, что в общем виде справедливо следующее выражение:
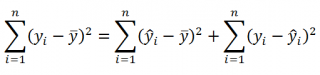
Доказательство:
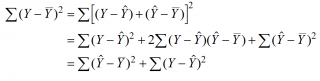
или в других, общепринятых в зарубежной литературе, обозначениях:
SST
=
SSR
+
SSE
Что означает:
Total Sum of Squares
=
Regression Sum of Squares
+
Error Sum of Squares
Примечание
: SS — Sum of Squares — Сумма Квадратов.
Как видно из формулы величины SST, SSR, SSE имеют размерность
дисперсии
(вариации) и соответственно описывают разброс (изменчивость):
Общую изменчивость
(Total variation),
Изменчивость объясненную моделью
(Explained variation) и
Необъясненную изменчивость
(Unexplained variation).
По определению
коэффициент детерминации
R
2
равен:
R
2
=
Изменчивость объясненная моделью / Общая изменчивость.
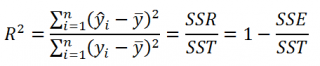
Этот показатель равен квадрату
коэффициента корреляции
и в MS EXCEL его можно вычислить с помощью функции
КВПИРСОН()
или
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);3)
R
2
принимает значения от 0 до 1 (1 соответствует идеальной линейной зависимости Y от Х). Однако, на практике малые значения R2 вовсе не обязательно указывают, что переменную Х нельзя использовать для прогнозирования переменной Y. Малые значения R2 могут указывать на нелинейность связи или на то, что поведение переменной Y объясняется не только Х, но и другими факторами.
Стандартная ошибка регрессии
Стандартная ошибка регрессии
(
Standard Error of a regression
) показывает насколько велика ошибка предсказания значений переменной Y на основании значений Х. Отдельные значения Yi мы можем предсказывать лишь с точностью +/- несколько значений (обычно 2-3, в зависимости от формы распределения ошибки ε).
Теперь вспомним уравнение
линейной регрессионной модели
Y=a*X+β+ε. Ошибка ε имеет случайную природу, т.е. является случайной величиной и поэтому имеет свою функцию распределения со
средним значением
μ и
дисперсией
σ
2
.
Оценив значение
дисперсии
σ
2
и вычислив из нее квадратный корень – получим
Стандартную ошибку регрессии.
Чем точки наблюдений на диаграмме
рассеяния
ближе находятся к прямой линии, тем меньше
Стандартная ошибка.
Примечание
:
Вспомним
, что при построении модели предполагается, что
среднее значение
ошибки ε равно 0, т.е. E[ε]=0.
Оценим
дисперсию σ
2
. Помимо вычисления
Стандартной ошибки регрессии
эта оценка нам потребуется в дальнейшем еще и при построении
доверительных интервалов
для оценки параметров регрессии
a
и
b
.
Для оценки
дисперсии
ошибки ε используем
остатки регрессии
— разности между имеющимися значениями
yi
и значениями, предсказанными регрессионной моделью ŷ. Чем лучше регрессионная модель согласуется с данными (точки располагается близко к прямой линии), тем меньше величина остатков.
Для оценки
дисперсии σ
2
используют следующую формулу:
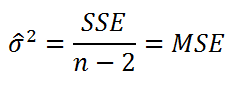
где SSE – сумма квадратов значений ошибок модели ε
i
=yi — ŷi (
Sum of Squared Errors
).
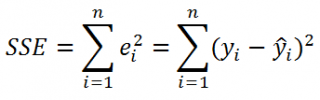
SSE часто обозначают и как SSres – сумма квадратов остатков (
Sum
of
Squared
residuals
).
Оценка
дисперсии
s
2
также имеет общепринятое обозначение MSE (Mean Square of Errors), т.е. среднее квадратов
ошибок
или MSRES (Mean Square of Residuals), т.е. среднее квадратов
остатков
. Хотя правильнее говорить сумме квадратов остатков, т.к. ошибка чаще ассоциируется с ошибкой модели ε, которая является непрерывной случайной величиной. Но, здесь мы будем использовать термины SSE и MSE, предполагая, что речь идет об остатках.
Примечание
: Напомним, что когда
мы использовали МНК
для нахождения параметров модели, то критерием оптимизации была минимизация именно SSE (SSres). Это выражение представляет собой сумму квадратов расстояний между наблюденными значениями yi и предсказанными моделью значениями ŷi, которые лежат на
линии регрессии.
Математическое ожидание
случайной величины MSE равно
дисперсии ошибки
ε, т.е.
σ
2
.
Чтобы понять почему SSE выбрана в качестве основы для оценки
дисперсии
ошибки ε, вспомним, что
σ
2
является также
дисперсией
случайной величины Y (относительно
среднего значения
μy, при заданном значении Хi). А т.к. оценкой μy является значение ŷi =
a
* Хi +
b
(значение
уравнения регрессии
при Х= Хi), то логично использовать именно SSE в качестве основы для оценки
дисперсии
σ
2
. Затем SSE усредняется на количество точек данных n за вычетом числа 2. Величина n-2 – это количество
степеней свободы
(
df
–
degrees
of
freedom
), т.е. число параметров системы, которые могут изменяться независимо (вспомним, что у нас в этом примере есть n независимых наблюдений переменной Y). В случае
простой линейной регрессии
число степеней свободы
равно n-2, т.к. при построении
линии регрессии
было оценено 2 параметра модели (на это было «потрачено» 2
степени свободы
).
Итак, как сказано было выше, квадратный корень из s
2
имеет специальное название
Стандартная ошибка регрессии
(
Standard Error of a regression
) и обозначается SEy. SEy показывает насколько велика ошибка предсказания. Отдельные значения Y мы можем предсказывать с точностью +/- несколько значений SEy (см.
этот раздел
). Если ошибки предсказания ε имеют
нормальное распределение
, то примерно 2/3 всех предсказанных значений будут на расстоянии не больше SEy от
линии регрессии
. SEy имеет размерность переменной Y и откладывается по вертикали. Часто на
диаграмме рассеяния
строят
границы предсказания
соответствующие +/- 2 SEy (т.е. 95% точек данных будут располагаться в пределах этих границ).
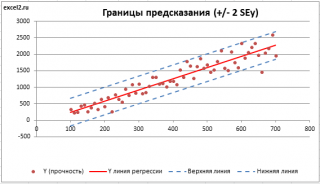
В MS EXCEL
стандартную ошибку
SEy можно вычислить непосредственно по формуле:
=
КОРЕНЬ(СУММКВРАЗН(C23:C83; ТЕНДЕНЦИЯ(C23:C83;B23:B83;B23:B83)) /( СЧЁТ(B23:B83) -2))
или с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);3;2)
Примечание
: Подробнее о функции
ЛИНЕЙН()
см.
эту статью
.
Стандартные ошибки и доверительные интервалы для наклона и сдвига
В разделе
Оценка неизвестных параметров линейной модели
мы получили точечные оценки наклона
а
и сдвига
b
. Так как эти оценки получены на основе случайных величин (значений переменных Х и Y), то эти оценки сами являются случайными величинами и соответственно имеют функцию распределения со
средним значением
и
дисперсией
. Но, чтобы перейти от
точечных оценок
к
интервальным
, необходимо вычислить соответствующие
стандартные ошибки
(т.е.
стандартные отклонения
).
Стандартная ошибка коэффициента регрессии
a
вычисляется на основании
стандартной ошибки регрессии
по следующей формуле:
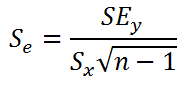
где Sx – стандартное отклонение величины х, вычисляемое по формуле:
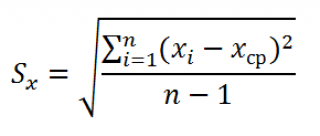
где Sey –
стандартная ошибка регрессии,
т.е. ошибка предсказания значения переменой Y
(
см. выше
).
В MS EXCEL
стандартную ошибку коэффициента регрессии
Se можно вычислить впрямую по вышеуказанной формуле:
=
КОРЕНЬ(СУММКВРАЗН(C23:C83; ТЕНДЕНЦИЯ(C23:C83;B23:B83;B23:B83)) /( СЧЁТ(B23:B83) -2))/ СТАНДОТКЛОН.В(B23:B83) /КОРЕНЬ(СЧЁТ(B23:B83) -1)
или с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);2;1)
Формулы приведены в
файле примера на листе Линейный
в разделе
Регрессионная статистика
.
Примечание
: Подробнее о функции
ЛИНЕЙН()
см.
эту статью
.
При построении
двухстороннего доверительного интервала
для
коэффициента регрессии
его границы определяются следующим образом:
![]()
где —
квантиль распределения Стьюдента
с n-2 степенями свободы. Величина
а
с «крышкой» является другим обозначением
наклона
а
.
Например для
уровня значимости
альфа=0,05, можно вычислить с помощью формулы
=СТЬЮДЕНТ.ОБР.2Х(0,05;n-2)
Вышеуказанная формула следует из того факта, что если ошибки регрессии распределены нормально и независимо, то выборочное распределение случайной величины
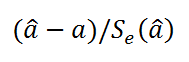
является
t-распределением Стьюдента
с n-2 степенью свободы (то же справедливо и для наклона
b
).
Примечание
: Подробнее о построении
доверительных интервалов
в MS EXCEL можно прочитать в этой статье
Доверительные интервалы в MS EXCEL
.
В результате получим, что найденный
доверительный интервал
с вероятностью 95% (1-0,05) накроет истинное значение
коэффициента регрессии.
Здесь мы считаем, что
коэффициент регрессии
a
имеет
распределение Стьюдента
с n-2
степенями свободы
(n – количество наблюдений, т.е. пар Х и Y).
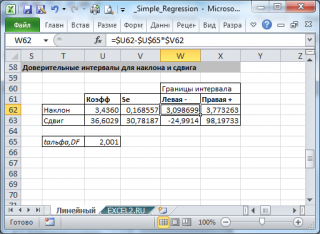
Примечание
: Подробнее о построении
доверительных интервалов
с использованием t-распределения см. статью про построение
доверительных интервалов
для среднего
.
Стандартная ошибка сдвига
b
вычисляется по следующей формуле:
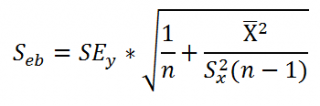
В MS EXCEL
стандартную ошибку сдвига
Seb можно вычислить с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);2;2)
При построении
двухстороннего доверительного интервала
для
сдвига
его границы определяются аналогичным образом как для
наклона
:
b
+/- t*Seb.
Проверка значимости взаимосвязи переменных
Когда мы строим модель Y=αX+β+ε мы предполагаем, что между Y и X существует линейная взаимосвязь. Однако, как это иногда бывает в статистике, можно вычислять параметры связи даже тогда, когда в действительности она не существует, и обусловлена лишь случайностью.
Единственный вариант, когда Y не зависит X (в рамках модели Y=αX+β+ε), возможен, когда
коэффициент регрессии
a
равен 0.
Чтобы убедиться, что вычисленная нами оценка
наклона
прямой линии не обусловлена лишь случайностью (не случайно отлична от 0), используют
проверку гипотез
. В качестве
нулевой гипотезы
Н
0
принимают, что связи нет, т.е. a=0. В качестве альтернативной гипотезы
Н
1
принимают, что a <>0.
Ниже на рисунках показаны 2 ситуации, когда
нулевую гипотезу
Н
0
не удается отвергнуть.
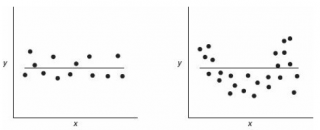
На левой картинке отсутствует любая зависимость между переменными, на правой – связь между ними нелинейная, но при этом
коэффициент линейной корреляции
равен 0.
Ниже — 2 ситуации, когда
нулевая гипотеза
Н
0
отвергается.
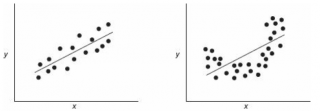
На левой картинке очевидна линейная зависимость, на правой — зависимость нелинейная, но коэффициент корреляции не равен 0 (метод МНК вычисляет показатели наклона и сдвига просто на основании значений выборки).
Для проверки гипотезы нам потребуется:
-
Установить
уровень значимости
, пусть альфа=0,05;
-
Рассчитать с помощью функции
ЛИНЕЙН()
стандартное отклонение
Se для
коэффициента регрессии
(см.предыдущий раздел
);
-
Рассчитать число степеней свободы: DF=n-2 или по формуле =
ИНДЕКС(ЛИНЕЙН(C24:C84;B24:B84;;ИСТИНА);4;2)
-
Вычислить значение тестовой статистики t
0
=a/S
e
, которая имеетраспределение Стьюдента
с
числом степеней свободы
DF=n-2; -
Сравнить значение
тестовой статистики
|t0| с пороговым значением t
альфа
,n-2. Если значение
тестовой статистики
больше порогового значения, то
нулевая гипотеза
отвергается (
наклон
не может быть объяснен лишь случайностью при заданном уровне альфа) либо -
вычислить
p-значение
и сравнить его с
уровнем значимости
.
В
файле примера
приведен пример проверки гипотезы:
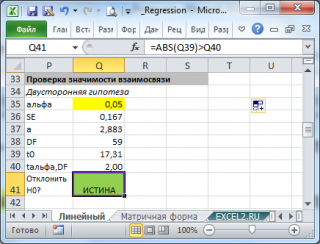
Изменяя
наклон
тренда k (ячейка
В8
) можно убедиться, что при малых углах тренда (например, 0,05) тест часто показывает, что связь между переменными случайна. При больших углах (k>1), тест практически всегда подтверждает значимость линейной связи между переменными.
Примечание
: Проверка значимости взаимосвязи эквивалентна
проверке статистической значимости коэффициента корреляции
. В
файле примера
показана эквивалентность обоих подходов. Также проверку значимости можно провести с помощью
процедуры F-тест
.
Доверительные интервалы для нового наблюдения Y и среднего значения
Вычислив параметры
простой линейной регрессионной модели
Y=aX+β+ε мы получили точечную оценку значения нового наблюдения Y при заданном значении Хi, а именно: Ŷ=
a
* Хi +
b
Ŷ также является точечной оценкой для
среднего значения
Yi при заданном Хi. Но, при построении
доверительных интервалов
используются различные
стандартные ошибки
.
Стандартная ошибка
нового наблюдения Y при заданном Хi учитывает 2 источника неопределенности:
-
неопределенность связанную со случайностью оценок параметров модели
a
и
b
; - случайность ошибки модели ε.
Учет этих неопределенностей приводит к
стандартной ошибке
S(Y|Xi), которая рассчитывается с учетом известного значения Xi.
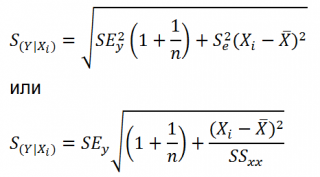
где SS
xx
– сумма квадратов отклонений от
среднего
значений переменной Х:
![]()
Примечание
: Se –
стандартная ошибка коэффициента регрессии
(
наклона
а
).
В
MS EXCEL 2010
нет функции, которая бы рассчитывала эту
стандартную ошибку
, поэтому ее необходимо рассчитывать по вышеуказанным формулам.
Доверительный интервал
или
Интервал предсказания для нового наблюдения
(Prediction Interval for a New Observation) построим по схеме показанной в разделе
Проверка значимости взаимосвязи переменных
(см.
файл примера лист Интервалы
). Т.к. границы интервала зависят от значения Хi (точнее от расстояния Хi до среднего значения Х
ср
), то интервал будет постепенно расширяться при удалении от Х
ср
.
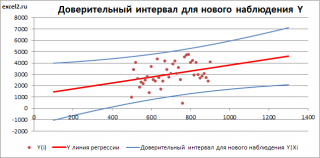
Границы
доверительного интервала
для
нового наблюдения
рассчитываются по формуле:
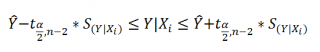
Аналогичным образом построим
доверительный интервал
для
среднего значения
Y при заданном Хi (Confidence Interval for the Mean of Y). В этом случае
доверительный интервал
будет уже, т.к.
средние значения
имеют меньшую изменчивость по сравнению с отдельными наблюдениями (
средние значения,
в рамках нашей линейной модели Y=aX+β+ε, не включают ошибку ε).
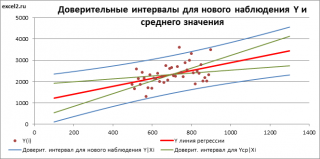
Стандартная ошибка
S(Yср|Xi) вычисляется по практически аналогичным формулам как и
стандартная ошибка
для нового наблюдения:
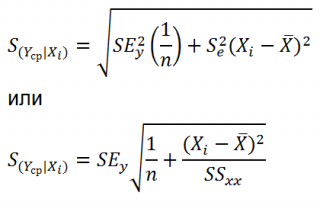
Как видно из формул,
стандартная ошибка
S(Yср|Xi) меньше
стандартной ошибки
S(Y|Xi) для индивидуального значения
.
Границы
доверительного интервала
для
среднего значения
рассчитываются по формуле:
![]()
Проверка адекватности линейной регрессионной модели
Модель адекватна, когда все предположения, лежащие в ее основе, выполнены (см. раздел
Предположения линейной регрессионной модели
).
Проверка адекватности модели в основном основана на исследовании остатков модели (model residuals), т.е. значений ei=yi – ŷi для каждого Хi. В рамках
простой линейной модели
n остатков имеют только n-2 связанных с ними
степеней свободы
. Следовательно, хотя, остатки не являются независимыми величинами, но при достаточно большом n это не оказывает какого-либо влияния на проверку адекватности модели.
Чтобы проверить предположение о
нормальности распределения
ошибок строят
график проверки на нормальность
(Normal probability Plot).
В
файле примера на листе Адекватность
построен
график проверки на нормальность
. В случае
нормального распределения
значения остатков должны быть близки к прямой линии.
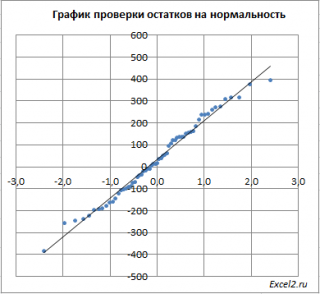
Так как значения переменной Y мы
генерировали с помощью тренда
, вокруг которого значения имели нормальный разброс, то ожидать сюрпризов не приходится – значения остатков располагаются вблизи прямой.
Также при проверке модели на адекватность часто строят график зависимости остатков от предсказанных значений Y. Если точки не демонстрируют характерных, так называемых «паттернов» (шаблонов) типа вор
о
нок или другого неравномерного распределения, в зависимости от значений Y, то у нас нет очевидных доказательств неадекватности модели.
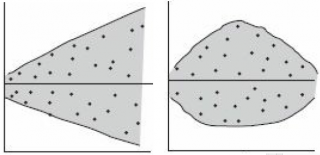
В нашем случае точки располагаются примерно равномерно.
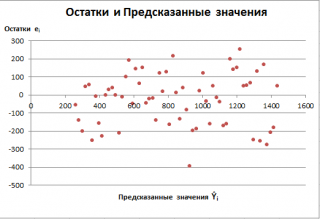
Часто при проверке адекватности модели вместо остатков используют нормированные остатки. Как показано в разделе
Стандартная ошибка регрессии
оценкой
стандартного отклонения ошибок
является величина SEy равная квадратному корню из величины MSE. Поэтому логично нормирование остатков проводить именно на эту величину.
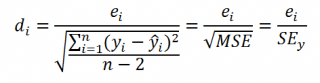
SEy можно вычислить с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);3;2)
Иногда нормирование остатков производится на величину
стандартного отклонения
остатков (это мы увидим в статье об инструменте
Регрессия
, доступного в
надстройке MS EXCEL Пакет анализа
), т.е. по формуле:
Вышеуказанное равенство приблизительное, т.к. среднее значение остатков близко, но не обязательно точно равно 0.