
Функция ЧАСТОТА используется для определения количества вхождения определенных величин в заданный интервал и возвращает данные в виде массива значений. Используя функцию ЧАСТОТА, мы узнаем, как посчитать частоту в Excel.
Пример использования функции ЧАСТОТА в Excel
Пример 1. Студенты одной из групп в университете сдали экзамен по физике. При оценке качества сдачи экзамена используется 100-бальная система. Для определения окончательной оценки по 5-бальной системе используют следующие критерии:
- От 0 до 50 баллов – экзамен не сдан.
- От 51 до 65 баллов – оценка 3.
- От 66 до 85 баллов – оценка 4.
- Свыше 86 баллов – оценка 5.
Для статистики необходимо определить, сколько студентов получили 5, 4, 3 баллов и количество тех, кому не удалось сдать экзамен.
Внесем данные в таблицу:
Для решения выделим области из 4 ячеек и введем следующую функцию:
Описание аргументов:
- B3:B20 – массив данных об оценках студентов;
- D3:D5 – массив критериев нахождения частоты вхождений в массиве данных об оценках.
Выделяем диапазон F3:F6 жмем сначала клавишу F2, а потом комбинацию клавиш Ctrl+Shift+Enter, чтобы функция ЧАСТОТА была выполнена в массиве. Подтверждением того что все сделано правильно будут служить фигурные скобки {} в строке формул по краям. Это значит, что формула выполняется в массиве. В результате получим:
То есть, 6 студентов не сдали экзамен, оценки 3, 4 и 5 получили 3, 4 и 5 студентов соответственно.
Пример определения вероятности используя функцию ЧАСТОТА в Excel
Пример 2. Известно то, что если существует только два возможных варианта развития событий, вероятности первого и второго равны 0,5 соответственно. Например, вероятности выпадения «орла» или «решки» у подброшенной монетки равны ½ и ½ (если пренебречь возможностью падения монетки на ребро). Аналогичное расчетное распределение вероятностей характерно для следующей функции СЛУЧМЕЖДУ(1;2), которая возвращает случайное число в интервале от 1 до 2. Было проведено 20 вычислений с использованием данной функции. Определить фактические вероятности появления чисел 1 и 2 соответственно на основании полученных результатов.
Заполним исходную таблицу случайными значениями от 1-го до 2-ух:
Для определения случайных значений в исходной таблице была использована специальная функция:
=СЛУЧМЕЖДУ(1;2)
Для определения количества сгенерированных 1 и 2 используем функцию:
=ЧАСТОТА(A2:A21;1)
Описание аргументов:
- A2:A21 – массив сгенерированных функцией =СЛУЧМЕЖДУ(1;2) значений;
- 1 – критерий поиска (функция ЧАСТОТА ищет значения от 0 до 1 включительно и значения >1).
В результате получим:
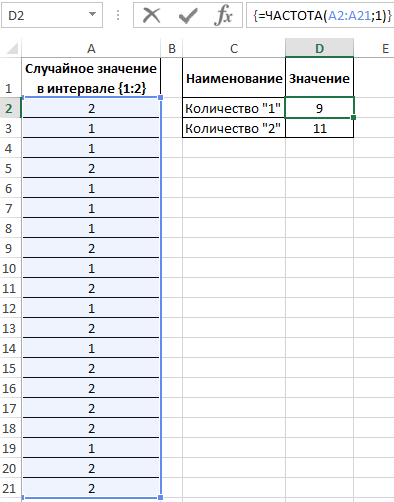
Вычислим вероятности, разделив количество событий каждого типа на общее их число:
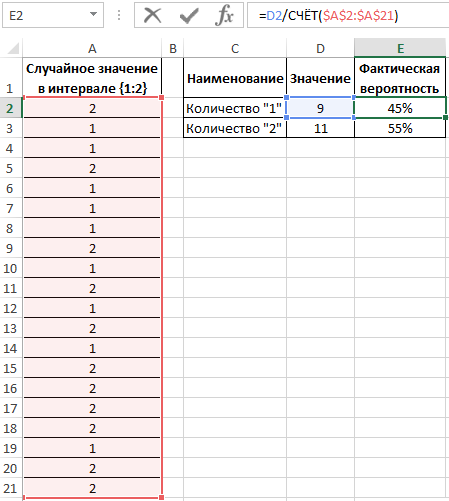
Для подсчета количества событий используем функцию =СЧЁТ($A$2:$A$21). Или можно просто разделить на значение 20. Если заранее не известно количество событий и размер диапазона со случайными значениями, тогда можно использовать в аргументах функции СЧЁТ ссылку на целый столбец: =СЧЁТ(A:A). Таким образом будет автоматически подсчитывается количество чисел в столбце A.
Вероятности выпадения «1» и «2» — 0,45 и 0,55 соответственно. Не забудьте присвоить ячейкам E2:E3 процентный формат для отображения их значений в процентах: 45% и 55%.
Теперь воспользуемся более сложной формулой для вычисления максимальной частоты повторов:
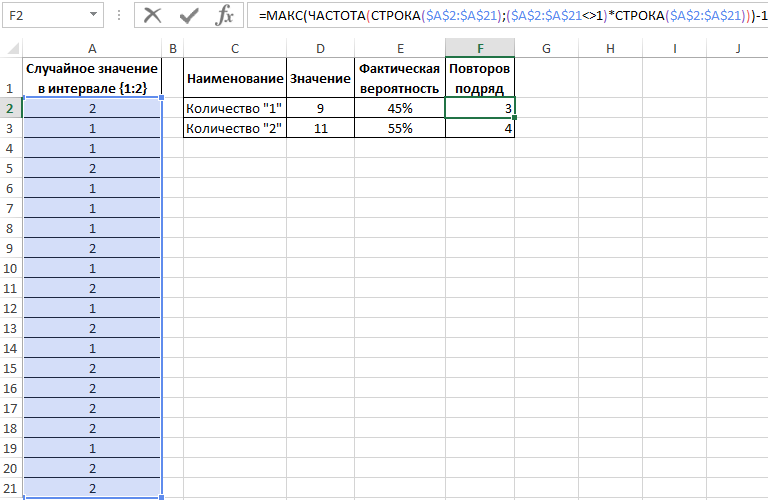
Формулы в ячейках F2 и F3 отличаются только одним лишь числом после оператора сравнения «не равно»: <>1 и <>2.
Интересный факт! С помощью данной формулы можно легко проверить почему не работает стратегия удвоения ставок в рулетке казино. Данную стратегию управления ставками в азартных играх называют еще Мартингейл. Дело в том, что количество случайных повторов подряд может достигать 18-ти раз и более, то есть восемнадцать раз подряд красные или черные. Например, если ставку в 2 доллара 18 раз удваивать – это уже более пол миллиона долларов «просадки». Это уже провал по любым техникам планирования рисков. Так же следует учитывать, что кроме «черные» и «красные» иногда выпадает еще и «зеро», что окончательно уничтожает все шансы. Так же интересно, что сумма всех чисел в рулетке от 0 до 36 равна 666.
Как посчитать неповторяющиеся значения в Excel?
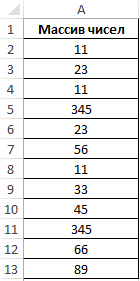
Пример 3. Определить количество уникальных вхождений в массив числовых данных, то есть не повторяющихся значений.
Исходная таблица:
Определим искомую величину с помощью формулы:
В данном случае функция ЧАСТОТА выполняет проверку наличия каждого из элементов массива данных в этом же массиве данных (оба аргумента совпадают). С помощью функции ЕСЛИ задано условие, которое имеет следующий смысл:
- Если искомый элемент содержится в диапазоне значений, вместо фактического количества вхождений будет возвращено 1;
- Если искомого элемента нет – будет возвращен 0 (нуль).
Полученное значение (количество единиц) суммируется.
В результате получим:
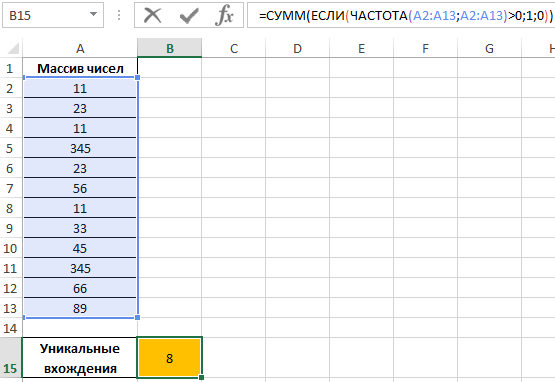
То есть, в указанном массиве содержится 8 уникальных значений.
Скачать пример функции ЧАСТОТА в Excel
Функция ЧАСТОТА в Excel и особенности ее синтаксиса
Данная функция имеет следующую синтаксическую запись:
Описание аргументов функции (оба являются обязательными для заполнения):
- массив_данных – данные в форме массива либо ссылка на диапазон значений, для которых необходимо определить частоты.
- массив_интервалов — данные в формате массива либо ссылка не множество значений, в которые группируются значения первого аргумента данной функции.
Примечания 1:
- Если в качестве аргумента массив_интервалов был передан пустой массив или ссылка на диапазон пустых значений, результатом выполнения функции ЧАСТОТА будет являться число элементов, входящих диапазон данных, которые были переданы в качестве первого аргумента.
- При использовании функции ЧАСТОТА в качестве обычной функции Excel будет возвращено единственное значение, соответствующее первому вхождению в массив_интервалов (то есть, первому критерию поиска частоты вхождения).
- Массив возвращаемых данной функцией элементов содержит на один элемент больше, чем количество элементов, содержащихся в массив_интервалов. Это происходит потому, что функция ЧАСТОТА вычисляет также количество вхождений величин, значения которых превышают верхнюю границу интервалов. Например, в наборе данных 2,7, 10, 13, 18, 4, 33, 26 необходимо найти количество вхождений величин из диапазонов от 1 до 10, от 11 до 20, от 21 до 30 и более 30. Массив интервалов должен содержать только их граничные значения, то есть 10, 20 и 30. Функция может быть записана в следующем виде: =ЧАСТОТА({2;7;10;13;18;4;33;26};{10;20;30}), а результатом ее выполнения будет столбец из четырех ячеек, которые содержат следующие значения: 4,2, 1, 1. Последнее значение соответствует количеству вхождений чисел > 30 в массив_данных. Такое число действительно является единственным – это 33.
- Если в состав массив_данных входят ячейки, содержащие пустые значения или текст, они будут пропущены функцией ЧАСТОТА в процессе вычислений.
Примечания 2:
- Функция может использоваться для выполнения статистического анализа, например, с целью определения наиболее востребованных для покупателей наименований продукции.
- Данная функция должна быть использована как формула массива, поскольку возвращаемые ей данные имеют форму массива. Для выполнения обычных формул после их ввода необходимо нажать кнопку Enter. В данном случае требуется использовать комбинацию клавиш Ctrl+Shift+Enter.
=ЧАСТОТА(массив_данных;массив_интервалов)
При анализе данных периодически возникает задача подсчитать количество значений, попадающих в заданные интервалы «от и до» (в статистике их называют «карманы»). Например, подсчитать количество звонков определенной длительности при разборе статистики по мобильной связи, чтобы понимать какой тариф для нас выгоднее:
")
Для решения подобной задачи можно воспользоваться функцией ЧАСТОТА (FREQUENCY). Ее синтаксис прост:
=ЧАСТОТА(Данные; Карманы)
где
- Карманы — диапазон с границами интервалов, попадание в которые нас интересует
- Данные — диапазон с исходными числовыми значениями, которые мы анализируем
Обратите внимание, что эта функция игнорирует пустые ячейки и ячейки с текстом, т.е. работает только с числами.
Для использования функции ЧАСТОТА нужно:
- заранее подготовить ячейки с интересующими нас интервалами-карманами (желтые F2:F5 в нашем примере)
- выделить пустой диапазон ячеек (G2:G6) по размеру на одну ячейку больший, чем диапазон карманов (F2:F5)
- ввести функцию ЧАСТОТА и нажать в конце сочетание Ctrl+Shift+Enter, т.е. ввести ее как формулу массива
Во всех предварительно выделенных ячейках посчитается количество попаданий в заданные интервалы. Само-собой, для реализации подобной задачи можно использовать и другие способы (функцию СЧЁТЕСЛИ, сводные таблицы и т.д.), но этот вариант весьма хорош.
Кроме того, с помощью функции ЧАСТОТА можно легко подсчитывать количество уникальных чисел в наборе с помощью простой формулы массива:

Ссылки по теме
- Как подсчитать количество уникальных элементов в списке
- Как сделать список без повторений
- Частотный анализ данных с помощью сводных таблиц и формул
17 авг. 2022 г.
читать 2 мин
Распределение частоты описывает, как часто разные значения встречаются в наборе данных. Это полезный способ понять, как значения данных распределяются в наборе данных.
К счастью, легко создать и визуализировать частотное распределение в Excel, используя следующую функцию:
=ЧАСТОТА(массив_данных,массив_бинов)
куда:
- data_array : массив необработанных значений данных
- bins_array: массив верхних пределов для бинов
В следующем примере показано, как использовать эту функцию на практике.
Пример: частотное распределение в Excel
Предположим, у нас есть следующий набор данных из 20 значений в Excel:
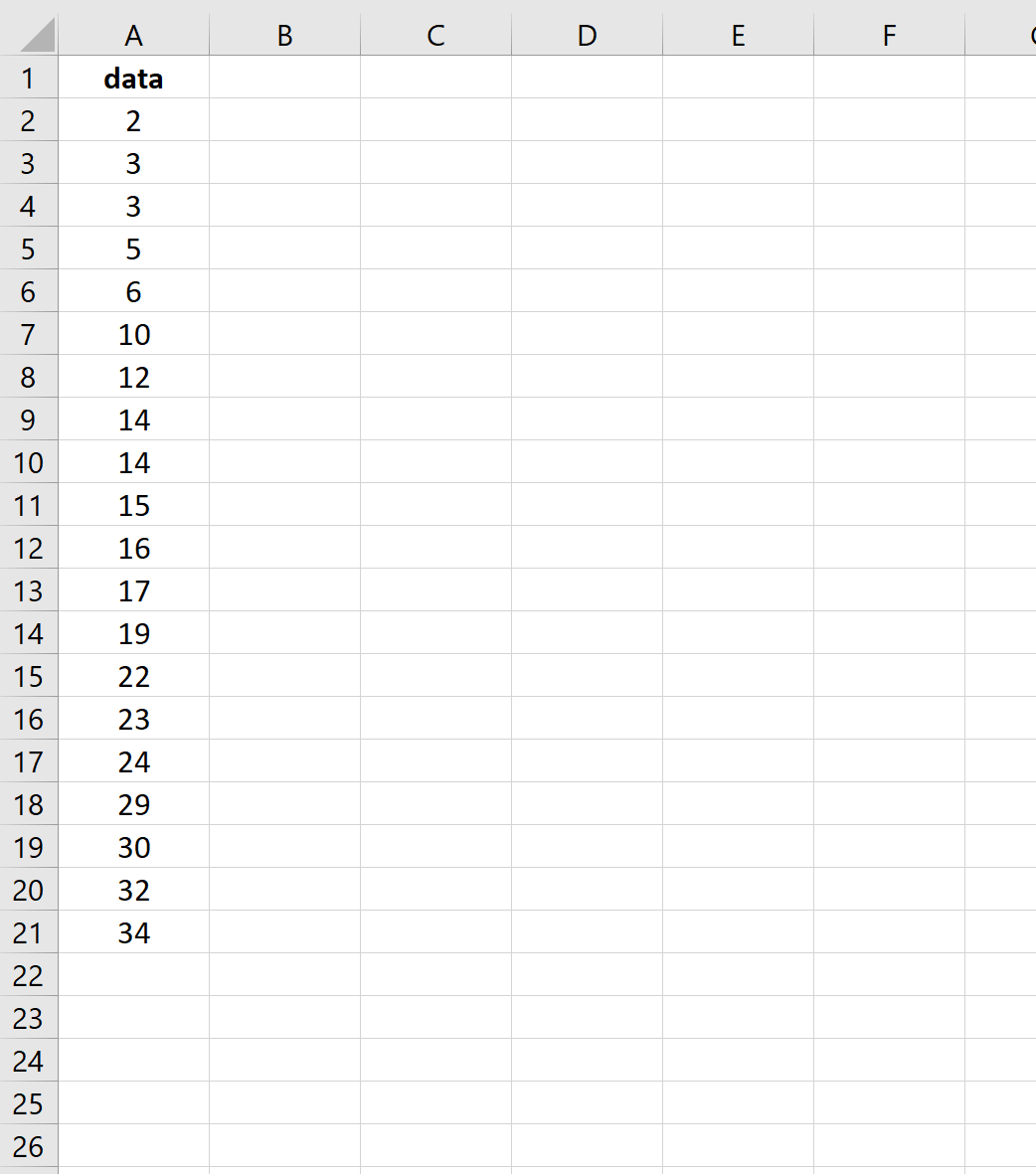
Во-первых, мы укажем Excel, какие верхние пределы мы хотели бы использовать для интервалов нашего частотного распределения. Для этого примера мы выберем 10, 20 и 30. То есть мы найдем частоты для следующих интервалов:
- от 0 до 10
- с 11 до 20
- от 21 до 30
- 30+
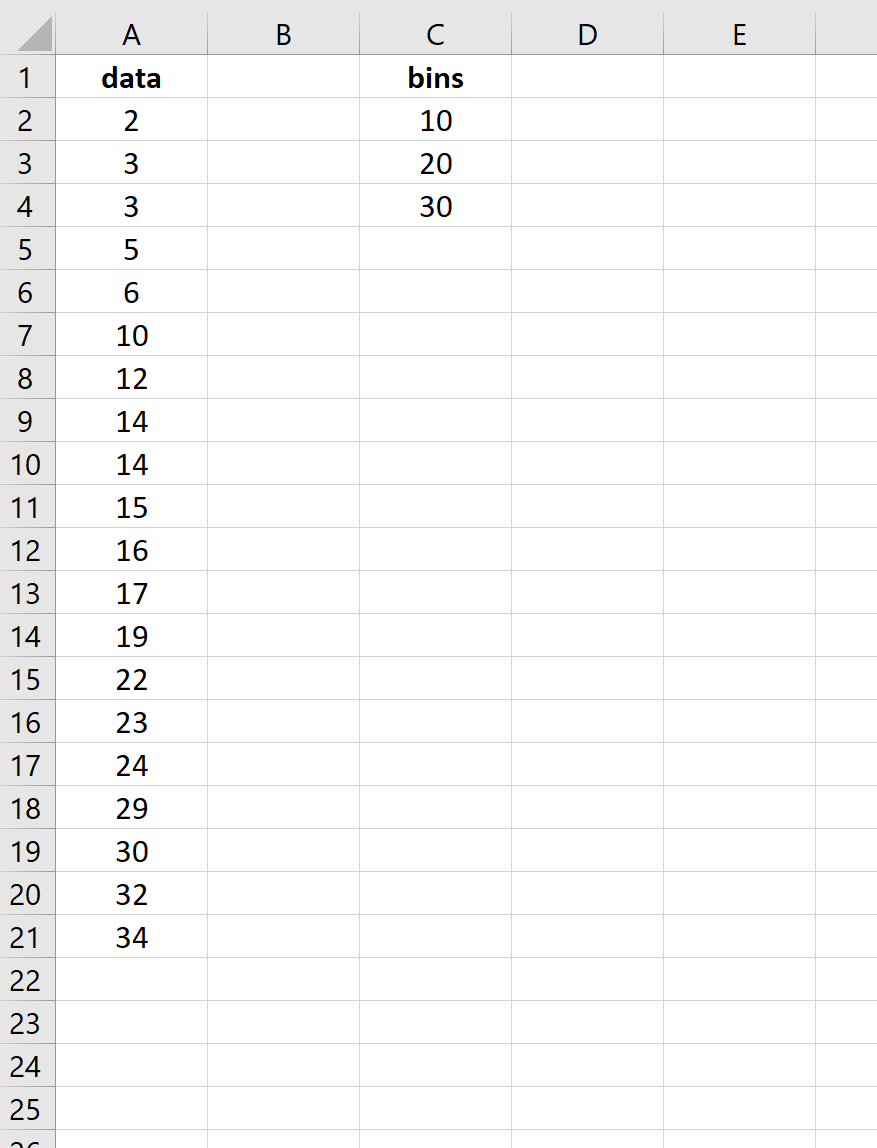
Далее мы будем использовать следующую функцию =FREQUENCY() для вычисления частот для каждого бина:
=ЧАСТОТА( A2:A21 , C2:C4 )
Вот результаты:
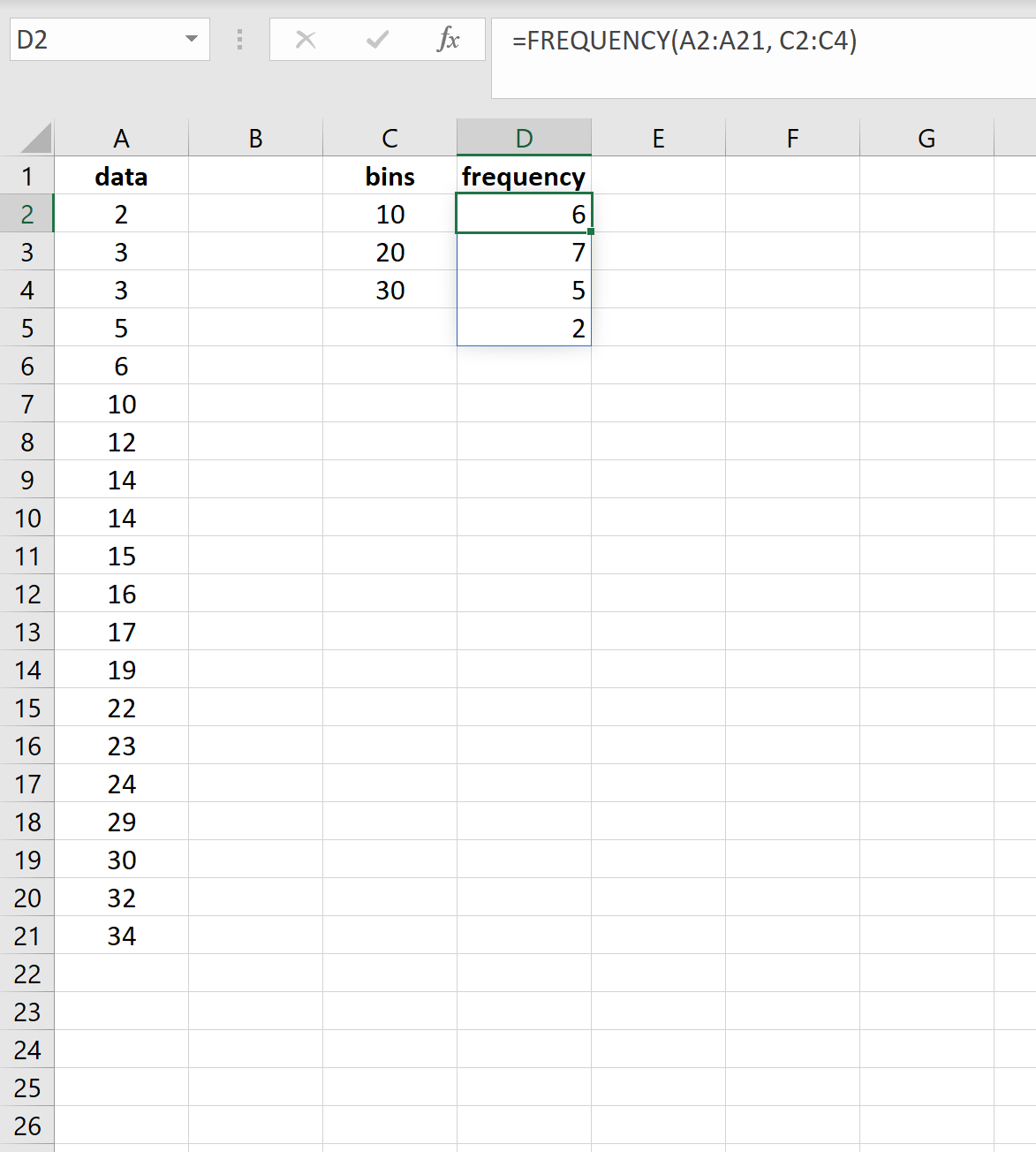
Результаты показывают, что:
- 6 значений в наборе данных находятся в диапазоне от 0 до 10.
- 7 значений в наборе данных находятся в диапазоне 11-20.
- 5 значений в наборе данных находятся в диапазоне 21-30.
- 2 значения в наборе данных больше 30.
Затем мы можем использовать следующие шаги для визуализации этого частотного распределения:
- Выделите частоты в диапазоне D2:D5 .
- Нажмите на вкладку « Вставка », затем нажмите на диаграмму под названием « Двухмерный столбец » в группе « Диаграммы ».
Появится следующая диаграмма, отображающая частоты для каждого бина:
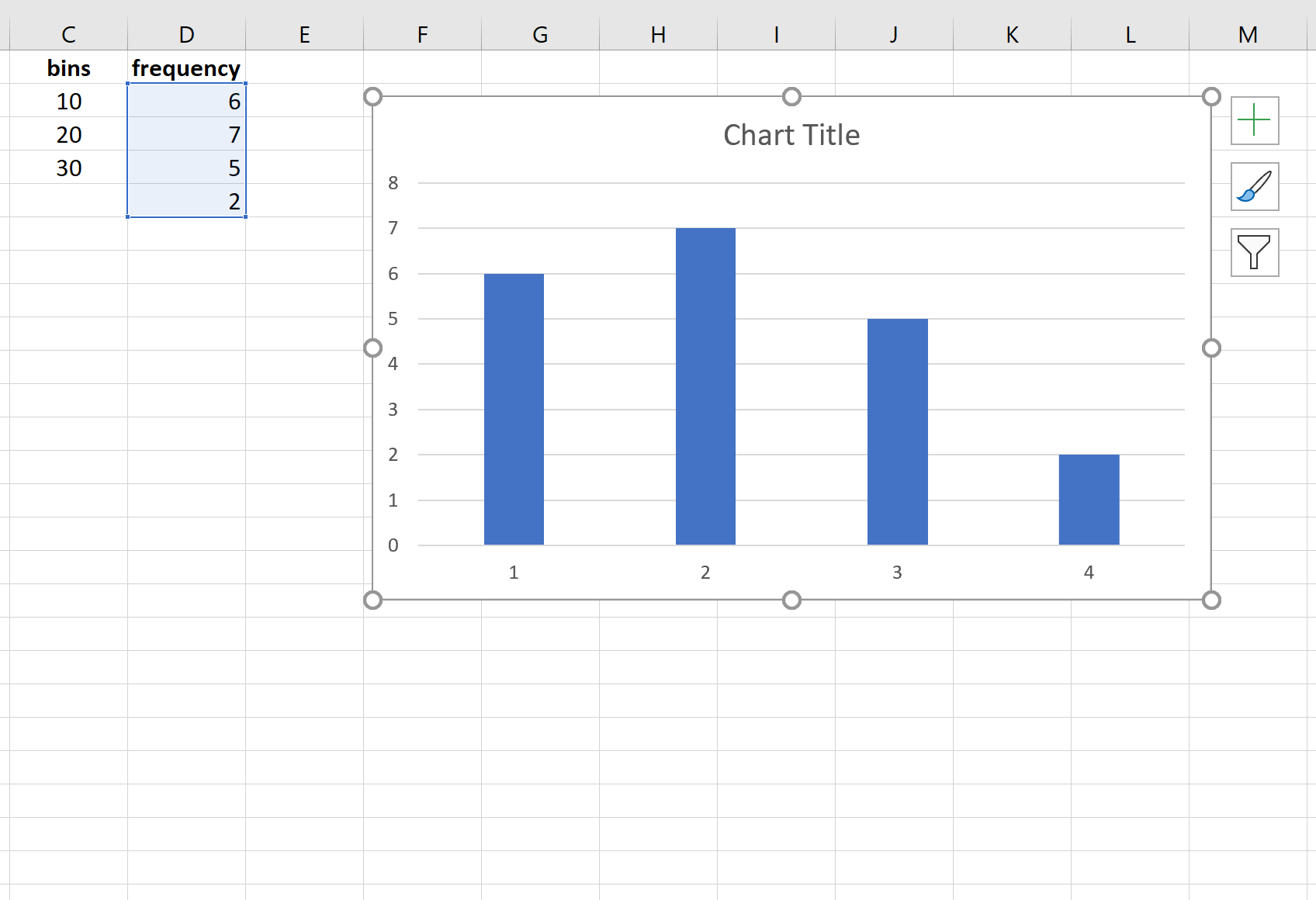
Не стесняйтесь изменять метки осей и ширину полос, чтобы сделать диаграмму более эстетичной:
Вы можете найти больше учебников по Excel здесь .
Написано
![]()
Замечательно! Вы успешно подписались.
Добро пожаловать обратно! Вы успешно вошли
Вы успешно подписались на кодкамп.
Срок действия вашей ссылки истек.
Ура! Проверьте свою электронную почту на наличие волшебной ссылки для входа.
Успех! Ваша платежная информация обновлена.
Ваша платежная информация не была обновлена.
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
Функция ЧАСТОТА вычисляет частоту ветвей значений в диапазоне значений и возвращает вертикальный массив чисел. Функцией ЧАСТОТА можно воспользоваться, например, для подсчета количества результатов тестирования, попадающих в интервалы результатов. Поскольку данная функция возвращает массив, ее необходимо вводить как формулу массива.
ЧАСТОТА(массив_данных;массив_интервалов)
Аргументы функции ЧАСТОТА описаны ниже.
-
data_array — обязательный аргумент. Массив или ссылка на множество значений, для которых вычисляются частоты. Если аргумент «массив_данных» не содержит значений, функция ЧАСТОТА возвращает массив нулей.
-
bins_array — обязательный аргумент. Массив или ссылка на множество интервалов, в которые группируются значения аргумента «массив_данных». Если аргумент «массив_интервалов» не содержит значений, функция ЧАСТОТА возвращает количество элементов в аргументе «массив_данных».
Примечание: Если у вас установлена текущая версия Microsoft 365, можно просто ввести формулу в верхней левой ячейке диапазона вывода и нажать клавишу ВВОД, чтобы подтвердить использование формулы динамического массива. Иначе формулу необходимо вводить с использованием прежней версии массива, выбрав диапазон вывода, введя формулу в левой верхней ячейке диапазона и нажав клавиши CTRL+SHIFT+ВВОД для подтверждения. Excel автоматически вставляет фигурные скобки в начале и конце формулы. Дополнительные сведения о формулах массива см. в статье Использование формул массива: рекомендации и примеры.
-
Количество элементов в возвращаемом массиве на единицу больше числа элементов в массиве «массив_интервалов». Дополнительный элемент в возвращаемом массиве содержит количество значений, превышающих верхнюю границу интервала, содержащего наибольшие значения. Например, при подсчете трех диапазонов значений (интервалов), введенных в три ячейки, убедитесь в том, что функция ЧАСТОТА возвращает значения в четырех ячейках. Дополнительная ячейка возвращает число значений в аргументе «массив_данных», превышающих значение верхней границы третьего интервала.
-
Функция ЧАСТОТА пропускает пустые ячейки и текст.
Пример
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
Нужна дополнительная помощь?
history 9 апреля 2013 г.
- Группы статей
- Формулы массива
- Подсчет Чисел
Функция ЧАСТОТА( ) , английская версия FREQUENCY() , вычисляет частоту попадания значений в заданные пользователем интервалы и возвращает соответствующий массив чисел.
Функцией ЧАСТОТА() можно воспользоваться, например, для подсчета количества результатов тестирования, попадающих в определенные интервалы (См. Файл примера )
Синтаксис функции
ЧАСТОТА ( массив_данных ; массив_интервалов )
Массив_данных — массив или ссылка на множество ЧИСЛОвых данных, для которых вычисляются частоты.
Массив_интервалов — массив или ссылка на множество интервалов, в которые группируются значения аргумента «массив_данных».
Функция ЧАСТОТА() вводится как формула массива после выделения диапазона смежных ячеек, в которые требуется вернуть полученный массив распределения (частот). Т.е. после ввода формулы необходимо вместо нажатия клавиши ENTER нажать сочетание клавиш CTRL+SHIFT+ENTER .
Количество элементов в возвращаемом массиве на единицу больше числа элементов в массиве « массив_интервалов ». Дополнительный элемент в возвращаемом массиве содержит количество значений, превышающих верхнюю границу интервала, содержащего наибольшие значения (см. пример ниже).
Пример
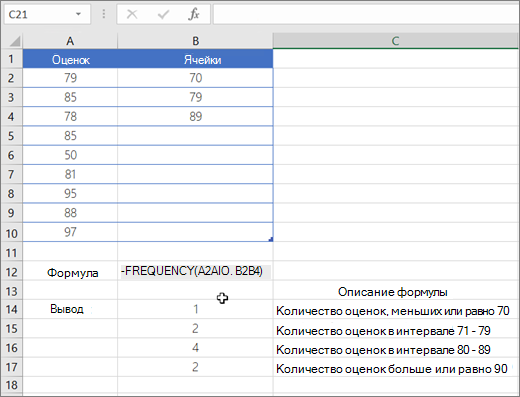
Пусть в диапазоне А2:А101 имеется исходный массив чисел от 1 до 100.

Подсчитаем количество чисел, попадающих в интервалы 1-10; 11-20; . 91-100.
Сформируем столбце С массив верхних границ диапазонов (интервалов). Для наглядности в столбце D сформируем текстовые значения соответствующие границам интервалов (1-10; 11-20; . 91-100).
Для ввода формулы выделим диапазон Е2:Е12 , состоящий из 11 ячеек (на 1 больше, чем число верхних границ интервалов). В Строке формул введем =ЧАСТОТА($A$2:$A$101;$C$2:$C$11) . После ввода формулы необходимо нажать сочетание клавиш CTRL+SHIFT+ENTER . Диапазон Е2:Е12 заполнится значениями:
- в Е2 — будет содержаться количество значений из А2:А101 , которые меньше или равны 10;
- в Е3 — количество значений из А2:А101 , которые меньше или равны 20, но больше 10;
- в Е11 — количество значений из А2:А101 , которые меньше или равны 100, но больше 90;
- в Е12 — количество значений из А2:А101 , которые больше 100 (таких нет, т.к. исходный массив содержит числа от 1 до 100).
Примечание . Функцию ЧАСТОТА() можно заменить формулой = СУММПРОИЗВ(($A$5:$A$104>C5)*($A$5:$A$104 (См. Файл примера )
Частотный анализ по интервалам функцией ЧАСТОТА (FREQUENCY)
При анализе данных периодически возникает задача подсчитать количество значений, попадающих в заданные интервалы «от и до» (в статистике их называют «карманы»). Например, подсчитать количество звонков определенной длительности при разборе статистики по мобильной связи, чтобы понимать какой тариф для нас выгоднее:

Для решения подобной задачи можно воспользоваться функцией ЧАСТОТА (FREQUENCY) . Ее синтаксис прост:
=ЧАСТОТА( Данные ; Карманы )
- Карманы — диапазон с границами интервалов, попадание в которые нас интересует
- Данные — диапазон с исходными числовыми значениями, которые мы анализируем
Обратите внимание, что эта функция игнорирует пустые ячейки и ячейки с текстом, т.е. работает только с числами.
Для использования функции ЧАСТОТА нужно:
- заранее подготовить ячейки с интересующими нас интервалами-карманами (желтые F2:F5 в нашем примере)
- выделить пустой диапазон ячеек (G2:G6) по размеру на одну ячейку больший, чем диапазон карманов (F2:F5)
- ввести функцию ЧАСТОТА и нажать в конце сочетание Ctrl+Shift+Enter, т.е. ввести ее как формулу массива
Во всех предварительно выделенных ячейках посчитается количество попаданий в заданные интервалы. Само-собой, для реализации подобной задачи можно использовать и другие способы (функцию СЧЁТЕСЛИ, сводные таблицы и т.д.), но этот вариант весьма хорош.
Кроме того, с помощью функции ЧАСТОТА можно легко подсчитывать количество уникальных чисел в наборе с помощью простой формулы массива:
A frequency distribution table is an organized representation of the frequency of each element in a dataset/record. It helps us to visualize data in terms of class range and the number of time each element belong to that class interval. The table usually consists of two columns, the first is the class interval and the second one is the frequency itself.
Calculate Frequency Distribution in Excel
Suppose, we want to distribute marks obtained by 40 students in a class using a frequency distribution table then a sampling frequency distribution table will look like this:
|
Marks |
Frequency |
|---|---|
|
0-20 |
5 |
|
21-40 |
7 |
|
41-60 |
13 |
|
61-80 |
9 |
|
81-100 |
6 |
In this article, we are going to see how we can calculate such a frequency distribution table inside Microsoft Excel.
Method 1: Using Pivot Table
Microsoft Excel has a powerful tool named Pivot table which helps users to analyze large amounts of data interactively by aggregating individual records of a table into different groups. A pivot table can be used to create a frequency distribution table as:
Step 1: Select the desired range of cells and then go to the Insert tab and select Pivot Table from the menu.

Step 2: A Create Pivot Table dialog box will pop up on the screen. Since we want to create the pivot table in the same worksheet. We can choose the Existing Worksheet radio check box in the dialog box and select the desired cell where we want to place the table (in the image shown below cell D1 is selected).

Step 3: A pivot table will become visible on the screen as shown in the image given below.

Step 4: From the right-hand side PivotTable Fields prompt, drag the Scores field name into the Values field and the Rows field one by one.

Step 5: We can notice the changes made in our pivot table. Now, right-click on the Sum of Scores field inside the Values section and select the Field Settings option from the menu.

Step 6: A Pivot Table Field dialog box will appear on the screen. Select the Count option from the list under the Summarise by tab and click OK.

Step 7: After hitting the OK button, we can notice the changes made to our pivot table. Now for each element, we have its frequency inside the table.

Step 8: Under the Row Labels column inside the pivot table select any record and right-click with the mouse to open a list of options. From the options menu, select the Group option.

Step 9: A dialog box named Grouping will appear on the screen. Fill out the starting and ending values in the respective fields. Since we want to divide our data into intervals of 10 hence we fill 10 in the “By” field and then click OK.

Step 10: On clicking the OK button, we can notice our data values are distributed across an interval and hence our final frequency distribution table is created.

Method 2: Using the COUNTIFS() function
We can even use the in-built COUNTIFS() function to create a frequency distribution table.
The syntax for the COUNTIFS() function is given as:
=COUNTIFS(range1,criteria1,range2,criteria2,….)
Where range1 and range2 are the cell range of the records and criteria1 and criteria2 are the logical expressions.
Step 1: Create a class Interval column manually assigning the appropriate values as per requirement.

Step 2: Now, click on the desired cell where you want to find out the frequency in the class interval (here, cell D2). Type the formula
=COUNTIFS(A2:A16,”>=10″,A2:A16,”<=19″)
And hit enter, it will generate the output 1 as only 18 is in the class range 10-19. Here, A2:A16 is the range as our data is stored in this cell we give A2:A16 as the range1 and range2 values, criteria1 is >=10 and criteria2 is <=19.

Step 3: Similarly, we can use the same COUNTIFS() formula for the next cells. Let’s say we want to find the count of records between the interval 20-29, then the formula will be,
=COUNTIFS(A2:A16,”>=20″,A2:A16,”<=29″)
It will generate 3 as the output as three numbers 25, 27 and 29 lie within this class interval.
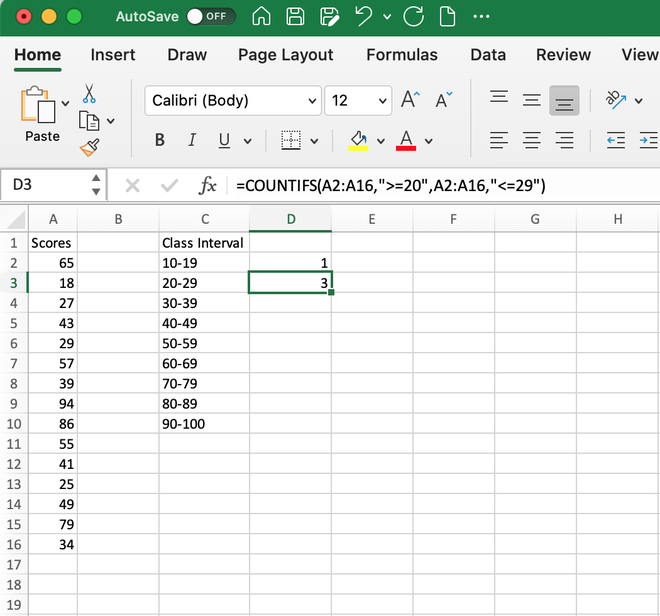
Step 4: We can use the same formula for finding the values for all class intervals and our values will be shown as:

Содержание
- 1 Пример использования функции ЧАСТОТА в Excel
- 2 Пример определения вероятности используя функцию ЧАСТОТА в Excel
- 3 Как посчитать неповторяющиеся значения в Excel?
- 4 Функция ЧАСТОТА в Excel и особенности ее синтаксиса
- 4.1 Ссылки по теме
Функция ЧАСТОТА используется для определения количества вхождения определенных величин в заданный интервал и возвращает данные в виде массива значений. Используя функцию ЧАСТОТА, мы узнаем, как посчитать частоту в Excel.
Пример 1. Студенты одной из групп в университете сдали экзамен по физике. При оценке качества сдачи экзамена используется 100-бальная система. Для определения окончательной оценки по 5-бальной системе используют следующие критерии:
- От 0 до 50 баллов – экзамен не сдан.
- От 51 до 65 баллов – оценка 3.
- От 66 до 85 баллов – оценка 4.
- Свыше 86 баллов – оценка 5.
Для статистики необходимо определить, сколько студентов получили 5, 4, 3 баллов и количество тех, кому не удалось сдать экзамен.
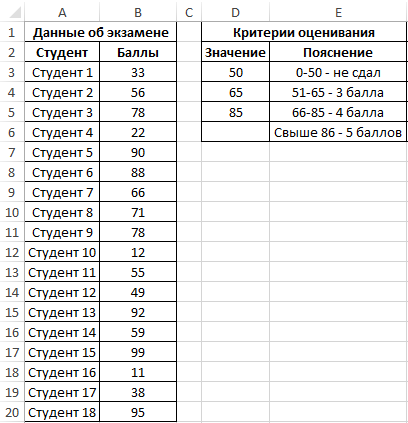
Внесем данные в таблицу:
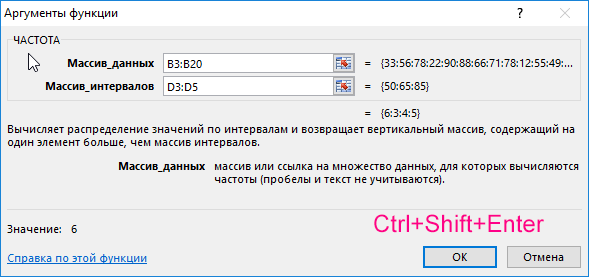
Для решения выделим области из 4 ячеек и введем следующую функцию:
Описание аргументов:
- B3:B20 – массив данных об оценках студентов;
- D3:D5 – массив критериев нахождения частоты вхождений в массиве данных об оценках.
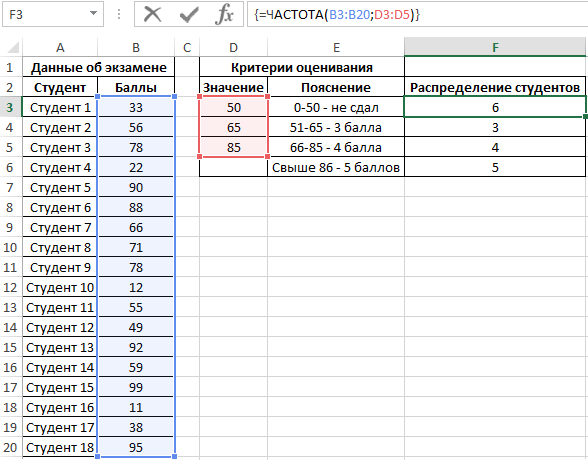
Выделяем диапазон F3:F6 жмем сначала клавишу F2, а потом комбинацию клавиш Ctrl+Shift+Enter, чтобы функция ЧАСТОТА была выполнена в массиве. Подтверждением того что все сделано правильно будут служить фигурные скобки {} в строке формул по краям. Это значит, что формула выполняется в массиве. В результате получим:
То есть, 6 студентов не сдали экзамен, оценки 3, 4 и 5 получили 3, 4 и 5 студентов соответственно.
Пример определения вероятности используя функцию ЧАСТОТА в Excel
Пример 2. Известно то, что если существует только два возможных варианта развития событий, вероятности первого и второго равны 0,5 соответственно. Например, вероятности выпадения «орла» или «решки» у подброшенной монетки равны ½ и ½ (если пренебречь возможностью падения монетки на ребро). Аналогичное расчетное распределение вероятностей характерно для следующей функции СЛУЧМЕЖДУ(1;2), которая возвращает случайное число в интервале от 1 до 2. Было проведено 20 вычислений с использованием данной функции. Определить фактические вероятности появления чисел 1 и 2 соответственно на основании полученных результатов.
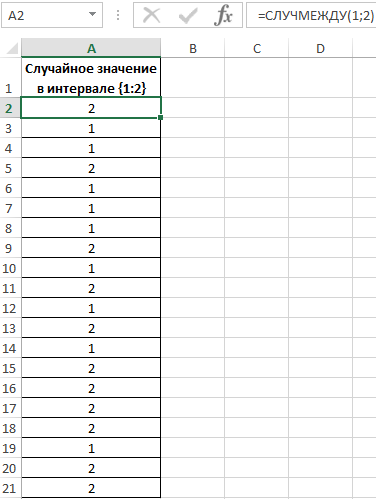
Заполним исходную таблицу случайными значениями от 1-го до 2-ух:
Для определения случайных значений в исходной таблице была использована специальная функция:
=СЛУЧМЕЖДУ(1;2)
Для определения количества сгенерированных 1 и 2 используем функцию:
=ЧАСТОТА(A2:A21;1)
Описание аргументов:
- A2:A21 – массив сгенерированных функцией =СЛУЧМЕЖДУ(1;2) значений;
- 1 – критерий поиска (функция ЧАСТОТА ищет значения от 0 до 1 включительно и значения >1).
В результате получим:
Вычислим вероятности, разделив количество событий каждого типа на общее их число:
Для подсчета количества событий используем функцию =СЧЁТ($A$2:$A$21). Или можно просто разделить на значение 20. Если заранее не известно количество событий и размер диапазона со случайными значениями, тогда можно использовать в аргументах функции СЧЁТ ссылку на целый столбец: =СЧЁТ(A:A). Таким образом будет автоматически подсчитывается количество чисел в столбце A.
Вероятности выпадения «1» и «2» — 0,45 и 0,55 соответственно. Не забудьте присвоить ячейкам E2:E3 процентный формат для отображения их значений в процентах: 45% и 55%.
Теперь воспользуемся более сложной формулой для вычисления максимальной частоты повторов:
Формулы в ячейках F2 и F3 отличаются только одним лишь числом после оператора сравнения «не равно»: 1 и 2.
Интересный факт! С помощью данной формулы можно легко проверить почему не работает стратегия удвоения ставок в рулетке казино. Данную стратегию управления ставками в азартных играх называют еще Мартингейл. Дело в том, что количество случайных повторов подряд может достигать 18-ти раз и более, то есть восемнадцать раз подряд красные или черные. Например, если ставку в 2 доллара 18 раз удваивать – это уже более пол миллиона долларов «просадки». Это уже провал по любым техникам планирования рисков. Так же следует учитывать, что кроме «черные» и «красные» иногда выпадает еще и «зеро», что окончательно уничтожает все шансы. Так же интересно, что сумма всех чисел в рулетке от 0 до 36 равна 666.
Как посчитать неповторяющиеся значения в Excel?
Пример 3. Определить количество уникальных вхождений в массив числовых данных, то есть не повторяющихся значений.
Исходная таблица:
Определим искомую величину с помощью формулы:
В данном случае функция ЧАСТОТА выполняет проверку наличия каждого из элементов массива данных в этом же массиве данных (оба аргумента совпадают). С помощью функции ЕСЛИ задано условие, которое имеет следующий смысл:
- Если искомый элемент содержится в диапазоне значений, вместо фактического количества вхождений будет возвращено 1;
- Если искомого элемента нет – будет возвращен 0 (нуль).
Полученное значение (количество единиц) суммируется.
В результате получим:
То есть, в указанном массиве содержится 8 уникальных значений.
Функция ЧАСТОТА в Excel и особенности ее синтаксиса
Данная функция имеет следующую синтаксическую запись:
=ЧАСТОТА(массив_данных;массив_интервалов)
Описание аргументов функции (оба являются обязательными для заполнения):
- массив_данных – данные в форме массива либо ссылка на диапазон значений, для которых необходимо определить частоты.
- массив_интервалов — данные в формате массива либо ссылка не множество значений, в которые группируются значения первого аргумента данной функции.
Примечания 1:
- Если в качестве аргумента массив_интервалов был передан пустой массив или ссылка на диапазон пустых значений, результатом выполнения функции ЧАСТОТА будет являться число элементов, входящих диапазон данных, которые были переданы в качестве первого аргумента.
- При использовании функции ЧАСТОТА в качестве обычной функции Excel будет возвращено единственное значение, соответствующее первому вхождению в массив_интервалов (то есть, первому критерию поиска частоты вхождения).
- Массив возвращаемых данной функцией элементов содержит на один элемент больше, чем количество элементов, содержащихся в массив_интервалов. Это происходит потому, что функция ЧАСТОТА вычисляет также количество вхождений величин, значения которых превышают верхнюю границу интервалов. Например, в наборе данных 2,7, 10, 13, 18, 4, 33, 26 необходимо найти количество вхождений величин из диапазонов от 1 до 10, от 11 до 20, от 21 до 30 и более 30. Массив интервалов должен содержать только их граничные значения, то есть 10, 20 и 30. Функция может быть записана в следующем виде: =ЧАСТОТА({2;7;10;13;18;4;33;26};{10;20;30}), а результатом ее выполнения будет столбец из четырех ячеек, которые содержат следующие значения: 4,2, 1, 1. Последнее значение соответствует количеству вхождений чисел > 30 в массив_данных. Такое число действительно является единственным – это 33.
- Если в состав массив_данных входят ячейки, содержащие пустые значения или текст, они будут пропущены функцией ЧАСТОТА в процессе вычислений.
Примечания 2:
- Функция может использоваться для выполнения статистического анализа, например, с целью определения наиболее востребованных для покупателей наименований продукции.
- Данная функция должна быть использована как формула массива, поскольку возвращаемые ей данные имеют форму массива. Для выполнения обычных формул после их ввода необходимо нажать кнопку Enter. В данном случае требуется использовать комбинацию клавиш Ctrl+Shift+Enter.
При анализе данных периодически возникает задача подсчитать количество значений, попадающих в заданные интервалы «от и до» (в статистике их называют «карманы»). Например, подсчитать количество звонков определенной длительности при разборе статистики по мобильной связи, чтобы понимать какой тариф для нас выгоднее:

Для решения подобной задачи можно воспользоваться функцией ЧАСТОТА (FREQUENCY). Ее синтаксис прост:
=ЧАСТОТА(Данные; Карманы)
где
- Карманы — диапазон с границами интервалов, попадание в которые нас интересует
- Данные — диапазон с исходными числовыми значениями, которые мы анализируем
Обратите внимание, что эта функция игнорирует пустые ячейки и ячейки с текстом, т.е. работает только с числами.
Для использования функции ЧАСТОТА нужно:
- заранее подготовить ячейки с интересующими нас интервалами-карманами (желтые F2:F5 в нашем примере)
- выделить пустой диапазон ячеек (G2:G6) по размеру на одну ячейку больший, чем диапазон карманов (F2:F5)
- ввести функцию ЧАСТОТА и нажать в конце сочетание Ctrl+Shift+Enter, т.е. ввести ее как формулу массива
Во всех предварительно выделенных ячейках посчитается количество попаданий в заданные интервалы. Само-собой, для реализации подобной задачи можно использовать и другие способы (функцию СЧЁТЕСЛИ, сводные таблицы и т.д.), но этот вариант весьма хорош.
Кроме того, с помощью функции ЧАСТОТА можно легко подсчитывать количество уникальных чисел в наборе с помощью простой формулы массива:

Ссылки по теме
- Как подсчитать количество уникальных элементов в списке
- Как сделать список без повторений
- Частотный анализ данных с помощью сводных таблиц и формул
Очень давно не писал блог. Расслабился совсем. Ну ничего, исправляюсь.
Продолжаю новую рубрику блога, посвященную анализу данных с помощью всем известного Microsoft Excel.
В современном мире к статистике проявляется большой интерес, поскольку это отличный инструмент для анализа и принятия решений, а также это отличное средство для поиска причин нарушений процесса и их устранения. Статистический анализ применим во многих сферах, где существуют большие массивы данных: естественно, в первую очередь я скажу, что металлургии, а также в экономике, биологии, политике, социологии и… много где еще. Статья эта будет, как несложно догадаться по ее названию, про использование некоторых средств статистического анализа, а именно — гистограммам.
Ну, поехали.
Статистический анализ в Excel можно осуществлять двумя способами:
• С помощью функций
• С помощью средств надстройки «Пакет анализа». Ее, как правило, еще необходимо установить.
Чтобы установить пакет анализа в Excel, выберите вкладку «Файл» (а в Excel 2007 это круглая цветная кнопка слева сверху), далее — «Параметры», затем выберите раздел «Надстройки». Нажмите «Перейти» и поставьте галочку напротив «Пакет анализа».
А теперь — к построению гистограмм распределения по частоте и их анализу.
Речь пойдет именно о частотных гистограммах, где каждый столбец соответствует частоте появления* значения в пределах границ интервалов. Например, мы хотим посмотреть, как у нас выглядит распределение значения предела текучести стали S355J2 в прокате толщиной 20 мм за несколько месяцев. В общем, хотим посмотреть, похоже ли наше распределение на нормальное (а оно должно быть таким).
*Примечание: для металловедческих целей типа оценки размера зерна или оценки объемной доли частиц этот вид гистограмм не пойдет, т.к. там высота столбика соответствует не частоте появления частиц определенного размера, а доле объема (а в плоскости шлифа — площади), которую эти частицы занимают.
График нормального распределения выглядит следующим образом:

График функции Гаусса
Мы знаем, что реально такой график может быть получен только при бесконечно большом количестве измерений. Реально же для конечного числа измерений строят гистограмму, которая внешне похожа на график нормального распределения и при увеличении количества измерений приближается к графику нормального распределения (распределения Гаусса).
Построение гистограмм с помощью программ типа Excel является очень быстрым способом проверки стабильности работы оборудования и добросовестности коллектива: если получим «кривую» гистограмму, значит, либо прибор не исправен или мы данные неверно собрали, либо кто-то где-то преднамеренно мухлюет или же просто неверно использует оборудование.
А теперь — построение гистограмм!
Способ 1-ый. Халявный.
- Идем во вкладку «Анализ данных» и выбираем «Гистограмма».
- Выбираем входной интервал.
- Здесь же предлагается задать интервал карманов, т.е. те диапазоны, в пределах которых будут лежать наши значения. Чем больше значений в интервале — тем выше столбик гистограммы. Если мы оставим поле «Интервалы карманов» пустым, то программа вычислит границы интервалов за нас.
- Если хотим сразу же вывести график,то ставим галочку напротив «Вывод графика».
- Нажимаем «ОК».
- Вот, вроде бы, и все: гистограмма готова. Теперь нужно сделать так, чтобы по вертикальной оси отображалась не абсолютная частота, а относительная.
- Под появившейся таблицей со столбцами «Карман» и «Частота» под столбцом «Частота» введем формулу «=СУММ» и сложим все абсолютные частоты.
- К появившейся таблице со столбцами «Карман» и «Частота» добавим еще один столбец и назовем его «Относительная частота».
- Во всех ячейках нового столбца введем формулу, которая будет рассчитывать относительную частоту: 100 умножить на абсолютную частоту (ячейка из столбца «частота») и разделить на сумму, которую мы вычислил в п. 7.
Способ 2-ой. Трудный, но интересный.
Будет полезен тому, кто по каким-либо причинам не смог установить Пакет анализа.
- Перво-наперво нужно задать интервалы тех самых карманов, которые мы не стали вычислять в способе, описанном выше.
- Интервал карманов вычисляют так: разность максимального значения и минимального значений массива, деленная на количество интервалов: (Xmax-Xmin)/n.
Для оценки оптимального для нашего массива данных количества интервалов можно воспользоваться формулой Стерджесса: n~1+3,322lgN, где N — количество всех значений величины. Например для N=100, n=7,6. Естественно, округляем до 8. - Для нахождения максимального и минимального значений воспользуемся соответствующими функциями: =МАКС(наш диапазон значений) и =МИН(наш диапазон значений).

- Найдем разность этих значений и разделим его на количество интервалов, которое нам захочется. Пусть будет 10. Так мы вычислили ширину нашего «кармана».
- Теперь в каждой ячейке шаг за шагом прибавляем полученное значение ширины кармана: сначала к минимальному значению нашего массива (п. 3), затем в следующей ячейке ниже — к полученной сумме и т.д. Так постепенно доходим до максимального значения. Вот мы и построили интервалы карманов в виде столбца значений. Интервалом считается следующий диапазон : (i-1; i] или iСкачать бесплатно видеокурc по Excel
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.


1. Построение вариационного ряда
Нужно выделить ячейки содержащие результаты эксперимента, и воспользоваться операцией сортировка по возрастанию (либо с панели инструментов, либо через главное меню Данные>Сортировка), и в появившемся окне сообщения – «обнаружены данные выходящие за пределы выделенного диапазона» выбрать действие – «сортировать в пределах указанного выделения»
2. Построение группировочного статистического ряда
Для вычисления абсолютной частоты нужна статистическая функция ЧАСТОТА. При её использовании нужно выполнить следующие действия:
а) выделить весь диапазон ячеек, в которых будет располагаться результат подсчёта частот (т.е. это ячейки под заголовком Абсолютная частота в количестве равном числу промежутков)
b) не снимая выделения, поставить курсор в строку формул и нажать на кнопку вставка функции (чуть левее курсора) или Главное меню – вставка – формула.
с) выбрать функцию ЧАСТОТА
d) ввести Массив_данных – диапазон, содержащий элементы выборки (в файле 2.xls это ячейки) B2:B101
e) ввести Массив_интервалов – диапазон ячеек под заголовком Начало промежутка начиная со строчки, соответствующей промежутку под номером 2 до строчки, соответствующей последнему промежутку.
f) нажмите на кнопку ОК и после закрытия окна для ввода аргументов функции ЧАСТОТА поставьте курсор обратно в строку формул.
g) Нажмите на три кнопки Ctrl+Shift+Enter (сначала на первые две, а потом, не отпуская их, нажмите на Enter).
Примечание. Формулу вычисления абсолютной частоты необходимо ввести как формулу массива. Нажатие комбинации клавиш CTRL+SHIFT+ENTER позволяет определить формулу как формулу массива. Если формула не будет введена как формула массива, единственное значение будет равно 1.
В результате изначально выделенный диапазон будет содержать абсолютные частоты попадания во все промежутка. Проверьте, что сумма всех абсолютных частот равна общему числу элементов выборки (100).
3. Построение гистограммы группировочного статистического ряда
При изучении величины, принимающей случайные значения (результатов физических измерений в серии экспериментов, экономических показателей, параметров технологических процессов и т.п.), мы имеем дело с выборками. Выборочное наблюдение – это способ наблюдения, при котором обследуется не вся совокупность значений изучаемой величины, а лишь часть ее, отобранная по определенным правилам выборки и обеспечивающая получение данных, характеризующих всю совокупность в целом.
При выборочном наблюдении обследованию подвергается определенная, заранее обусловленная часть совокупности, а результаты обследования распространяются на всю совокупность.
Ту часть единиц, которая отобрана для наблюдения, принято называть выборочной совокупностью или выборкой, а всю совокупность единиц, из которых производится отбор, – генеральной совокупностью.
Число единиц (элементов) статистической совокупности называется ее объемом. Объем генеральной совокупности обозначается N, а объем выборочной совокупности п.
Качество результатов выборочного наблюдения зависит от того, насколько состав выборки представляет генеральную совокупность, иначе говоря, от того, насколько выборка репрезентативна (представительна).
Элементами выборки (x1 х2, . хп) являются числовые значения, называемые вариантами, которые могут быть дискретными, т.е. изолированными (например, целыми числами), или могут принимать значения из некоторого интервала (а, b).
Вариационный ряд получается из выборки упорядочением по возрастанию (или убыванию) и подсчетом частоты каждого значения. Если вариационный ряд содержит значения признака и соответствующие ему частоты,то такой ряд носит название дискретный вариационный ряд. Если нам известно, что исследуемый показатель может принимать любые значения из некоторого интервала, то строим интервальный вариационный.
Удобнее всего ряды распределения анализировать с помощью их графического изображения, позволяющего судить о форме распределения. Наглядное представление о характере изменения частот вариационного ряда дают полигон и гистограмма.
Пример 2.1.
Известны следующие данные о результатах сдачи студентами экзамена (в баллах):
| 18 | 16 | 20 | 17 | 19 | 20 | 17 |
| 17 | 12 | 15 | 20 | 18 | 19 | 18 |
| 18 | 16 | 18 | 14 | 14 | 17 | 19 |
| 16 | 14 | 19 | 12 | 15 | 16 | 20 |
Необходимо построить ряд распределения числа студентов по баллу, представить графически результаты.
Введем данные в диапазоне A1: A29, в ячейку A1 введем текст «Балл» (рис.2.6).
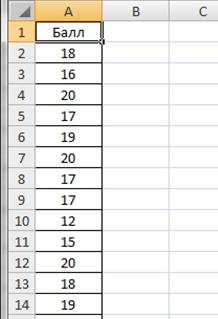
Рисунок 2.6. Баллы успеваемости студентов
Определим наименьший и наибольший балл по выборке. Для этого введем в ячейках С1 и С2 соответственно введем формулы =МИН(A2:A29) и =МАКС(A2:A29). Получим значения 12 и 20 соответственно (рис.2.7).
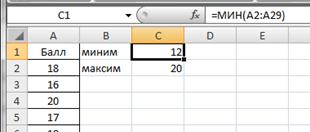
Рисунок 2.7. Минимальный и максимальный балл
Построим вариационный ряд. Для каждого значения необходимо подсчитать частоту. Так как значения признака (балл) отличаются на единицу, то можно воспользоваться следующим способом. В ячейку С4 введем формулу =С1, в С5 соответственно С4+1. Ячейку С5 протянем маркером заполнения (правый нижний угол ячейки) вниз до С12. Результаты представлены на рисунке 2.8.
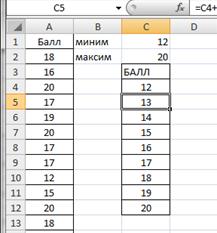
Рисунок 2.8. Значения признака
Вычислим частоту для каждого значения признака. В ячейку D4 введем формулу =СЧЕТЕСЛИ(A$2:A$29;C4) и протянем D4 маркером вниз до заполнения D12. В ячейке D13 просуммируем частоты с помощью формулы =СУММ(D4:D12).
Получим вариационный ряд (значения признака и соответствующие им частоты) на рисунке 2.9.
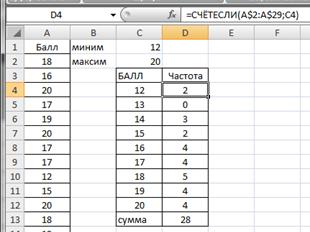
Рис.2.9. Частоты вариационного ряда
Вычислим частость (относительную частоту) для каждого значения признака. В ячейку Е4 введем формулу = D4/D$13. Протянем Е4 маркером заполнения вниз до Е12 (рис.2.10).
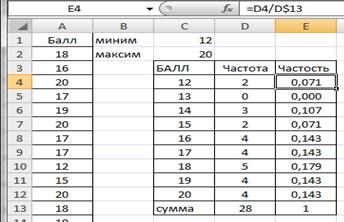
Рисунок 2.10. Частости ряда распределения
Вычислим накопленные частоты. В ячейку F4 введем формулу =D4, а в ячейку F5 – формулу = D5+F4. Протянем F5 маркером заполнения вниз до F12 (рис.2.11).
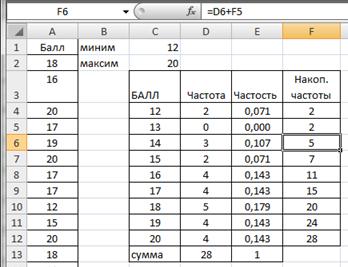
Рисунок 2.11. Накопленные частоты ряда
Построим эмпирическую функцию распределения, т.е. найдем наколенные частости. Выделим F4:F12 и маркером заполнения протянем вправо на соседний столбец (рис.2.12). В G4 получим формулу = Е4, в ячейке G5 формулу =Е5+ G4 и т.д.
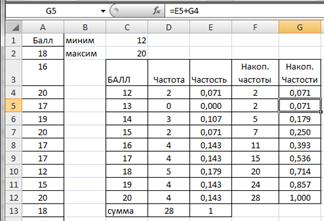
Рисунок 2.12. Накопленные частости ряда
Построим полигон распределения частот и частостей. Выделим диапазон ячеек С4:D12. Выполним команду меню «Диаграмма» и выберем тип «Точечная», вариант «Точечная с прямыми отрезками и маркерами». Полигон распределения частот представлен на рисунке 2.13.

Рисунок 2.13. Полигон распределения частот
Выделим диапазон ячеек С4:С12 и, удерживая клавишу CTRL, диапазон Е4:Е12. Выполним команду меню «Диаграмма» и выберем тип «Точечная», вариант «Точечная с прямыми отрезками и маркерами». Полигон распределения частостей представлен на рисунке 2.14.
Рисунок 2.14. Полигон распределения частостей
Построим гистограмму распределения частостей, для чего выделим диапазон Е4:Е12, выберем тип диаграммы «Гистограмма». Щелкнем правой кнопкой в области диаграммы, выберем «Выбрать данные», выберете «Ряд» – «Изменить», левой кнопкой щелкнем в строке «Подписи оси Х» и выделим диапазон С4:С12 (рис.2.15).
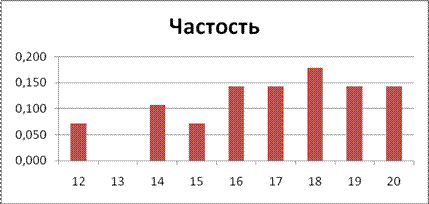
Рисунок 2.15. Гистограмма распределения частостей
Построим кумуляту частостей, для чего выделим диапазон ячеек С4:С12 и, удерживая клавишу CTRL, диапазон G4:G12. Выполним команду меню «Диаграмма» и выберем тип «Точечная», вариант «Точечная с прямыми отрезками». Кумулята представлена на рис.2.16.

Рисунок 2.16. Кумулята
Пример 2.2.
В таблице 2.7 представлены значения процентных ставок по кредитам по 30 коммерческим банкам.
Банковские процентные ставки
| № Банка | Процентная ставка, % |
| 1 | 20,3 |
| 2 | 17,1 |
| 3 | 14,2 |
| 4 | 11,0 |
| 5 | 17,3 |
| 6 | 19,6 |
| 7 | 20,5 |
| 8 | 23,6 |
| 9 | 14,6 |
| 10 | 17,5 |
| 11 | 20,8 |
| 12 | 13,6 |
| 13 | 24,0 |
| 14 | 17,5 |
| 15 | 15,0 |
| 16 | 21,1 |
| 17 | 17,6 |
| 18 | 15,8 |
| 19 | 18,8 |
| 20 | 22,4 |
| 21 | 16,1 |
| 22 | 17,9 |
| 23 | 21,7 |
| 24 | 18,0 |
| 25 | 16,4 |
| 26 | 26,0 |
| 27 | 18,4 |
| 28 | 16,7 |
| 29 | 12,2 |
| 30 | 13,9 |
Построим интервальный вариационный ряд. Для этого вычислим границы интервалов (карманов) с использованием формулы Стэрджесса.
Введем данные в диапазоне A1:A31 (рис.2.17). Определим максимальное и минимальное значения (ячейки С2 и С3 соответственно) так же как и в примере 2.1. Определим число интервалов по формуле Стэрджесса, для чего в ячейку С6 введем формулу =ЦЕЛОЕ(1+3,322*LOG10(30)) (рис.2.18).
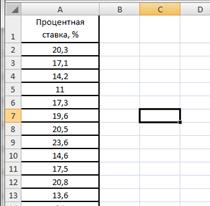
Рисунок 2.17. Процентные ставки банков

Рисунок 2.18. Число интервалов
Вычислим длину интервалов, для чего в ячейке С8 введем формулу =ОКРУГЛ((C3-C2)/C6;2) (рис.2.19).
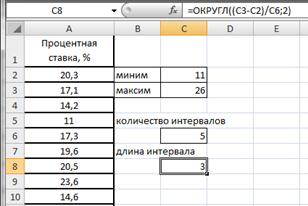
Рисунок 2.19. Длина интервала
Определим нижние и верхние границы интервалов (карманы), для чего в ячейке Е2 запишем формулу =С2, в ячейке Е3 запишем ==E2+$C$8. Протянем Е3 маркером заполнения вниз до Е7 (рис.2.20).
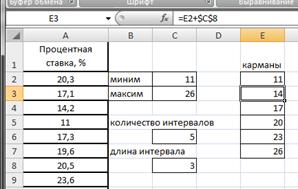
Рисунок 2.20. Границы интервалов
Подсчитаем частоты – в интервал считаем те значения, которые больше нижней границы интервала или равны ей и меньше верхней границы.
Воспользуемся функцией ЧАСТОТА. Для этого в ячейке F2 введем формулу =ЧАСТОТА(A2:A31;E2:E7). Протянем F2 маркером заполнения вниз до F8.
Формулу в этом примере необходимо ввести как формулу массива. Выделим диапазон F2:F8, нажмем клавишу F2, а затем нажмем клавиши CTRL+SHIFT+ВВОД (рис.2.21).
Если формула не будет введена как формула массива, отобразится только одно ее значение в ячейке F2.
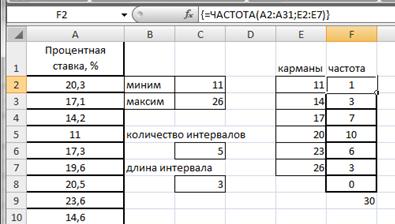
Рисунок 2.21. Частоты значений признака
Также можно воспользоваться средством Пакета анализа (Анализ данных в Office 2007) ГИСТОГРАММА (рис.2.22). Выберем входной интервал, интервал карманов, метки, интегральный процент, поместим результаты на этом же листе (укажем ячейку $H$2).
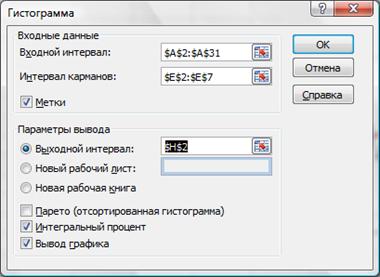
Рисунок 2.22. Построение гистограммы
Полученная гистограмма представлена на рис.2.23.
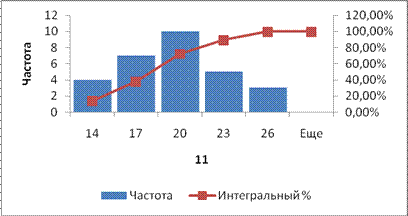
Рис.2.23. Гистограмма частот
Замечание. Если диапазон карманов не был введен, то набор отрезков, равномерно распределенных между минимальным и максимальным значениями данных, будет создан автоматически.
Дата добавления: 2018-11-12 ; просмотров: 1065 | Нарушение авторских прав
Вариационный ряд может быть:
– дискретным, когда изучаемый признак характеризуется определенным числом (как правило целым).
– интервальным, когда определены границы «от» и «до» для непрерывно варьируемого признака. Интервальный ряд также строят если множество значений дискретно варьируемого признака велико.
Рассмотрим пример построения дискретного вариационного ряда.
Пример 1. Имеются данные о количественном составе 60 семей.

Построить вариационный ряд и полигон распределения
Решение .
Алгоритм построения вариационного ряда:
1) Откроем таблицы Excel.
2) Введем массив данных в диапазон А1:L5. Если вы изучаете документ в электронной форме (в формате Word, например), для этого достаточно выделить таблицу с данными и скопировать ее в буфер, затем выделить ячейку А1 и вставить данные – они автоматически займут подходящий диапазон.
3) Подсчитаем объем выборки n – число выборочных данных, для этого в ячейку В7 введем формулу =СЧЁТ(А1:L5). Заметим, что для того, чтобы в формулу ввести нужный диапазон, необязательно вводить его обозначение с клавиатуры, достаточно его выделить.
4) Определим минимальное и максимальное значение в выборке, введя в ячейку В8 формулу =МИН(А1:L5), и в ячейку В9: =МАКС(А1:L5).
Рис.1.1 Пример 1. Первичная обработка статистических данных в таблицах Excel

5) Далее, подготовим таблицу для построения вариационного ряда, введя названия для столбца интервалов (значений варианты) и столбца частот. В столбец интервалов введем значения признака от минимального (1) до максимального (6), заняв диапазон В12:В17.
6) Выделим столбец частот, введем формулу =ЧАСТОТА(А1:L5;В12:В17) и нажмем сочетание клавиш CTRL+SHIFT+ENTER
Рис.1.2 Пример 1. Построение вариационного ряда

7) Для контроля вычислим сумму частот при помощи функции СУММ (значок функции S в группе «Редактирование» на вкладке «Главная»), вычисленная сумма должна совпасть с ранее вычисленным объемом выборки в ячейке В7.
Построим полигон:
1) выделив полученный диапазон частот, выберем команду «График» на вкладке «Вставка». По умолчанию значениями на горизонтальной оси будут порядковые числа – в нашем случае от 1 до 6, что совпадает со значениями варианты (номерами тарифных разрядов).
2) Название ряда диаграммы «ряд 1» можно либо изменить, воспользовавшись той же опцией «выбрать данные» вкладки «Конструктор», либо просто удалить.
Рис.1.3. Пример 1. Построение полигона частот
В реальных социально-экономических системах нельзя проводить активные эксперименты, поэтому данные обычно представляют собой наблюдения за происходящим процессом, например: курс валюты на бирже в течение месяца, урожайность пшеницы в хозяйстве за 30 лет, производительность труда рабочих за смену и т.д. Результаты наблюдений — это в общем случае ряд чисел, расположенных в беспорядке, который для изучения необходимо упорядочить (проранжи- ровать).
Операция, заключающаяся в расположении значений признака по возрастанию, называется ранжированием опытных данных.
После операции ранжирования опытные данные можно сгруппировать так, чтобы в каждой группе признак принимал одно и то же значение, которое называется вариантом (х,). Число элементов в каждой группе называется частотой варианта («,).
Размахом вариации называется число

где хтах — наибольший вариант;
x min — наименьший вариант.
Сумма всех частот равна определенному числу л, которое называется объемом совокупности:

Отношение частоты данного варианта к объему совокупности называется относительной частотой, или частостью, этого варианта:

Последовательность вариант, расположенных в возрастающем порядке, называется вариационным рядом (вариация — изменение).
Вариационные ряды бывают дискретными и непрерывными. Дискретным вариационным рядом называется ранжированная последовательность вариант с соответствующими частотами и (или) частостями.
Пример 1. В результате тестирования группа из 24 человек набрала баллы: 4, 0, 3, 4, 1, 0, 3, 1, 0, 4, 0, 0, 3, 1, 0, 1, 1, 3, 2, 3, 1, 2, 1, 2. Построить дискретный вариационный ряд.
Решение. Проранжируем исходный ряд, подсчитаем частоту и частость вариант: 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 3, 3, 3, 3, 3, 4, 4, 4.
В результате получим дискретный вариационный ряд (табл. 3.10).
Ранжированный ряд успеваемости
Число студентов, л,
Относительная частота, А
В Excel проранжируем исходный ряд. Для этого введем все данные в диапазон А1 :А24 и воспользуемся кнопкой Щ (Сортировка по возрастанию).
Подсчитаем частоту и частость вариант. Построим таблицу в диапазоне D2:G7 (рис. 3.13).

Рис. 3.13. Контекстное меню строки состояния
Рассмотрим два варианта подсчета частот:
- 1) выделим диапазон, в котором находятся нули. Щелкнем в нижней правой части окна Excel правой кнопкой мыши и выберем в контекстном меню вид итога, который по умолчанию будет появляться в итоговой строке при выделении произвольного диапазона (см. рис. 3.13) — количество. Таким образом, последовательно выделяя диапазоны с одинаковыми значениями вариант, мы получим все частоты;
- 2) выполним команду Сервис — Анализ данных — Гистограмма. Заполним диалоговое окно в соответствии с рис. 3.14.

Рис. 3.14. Диалоговое окно инструмента пакета анализа «Гистограмма»
В результате получим таблицу с частотами вариантов и соответствующий график (рис. 3.15).

Рис. 3.15. Результаты применения инструмента «Гистограмма)
Найдем объем выборки, заполнив все частоты вариант в диапазоне ЕЗ:Е7, выделим его левой кнопкой мыши и щелкнем по кнопке ? (автосумма).
В ячейку F3 введем формулу «=ЕЗ/$Е$8», за маркер заполнения (крест в правом нижнем углу ячейки) с помощью мыши скопируем до F7 и выберем кнопку автосумма, в результате получим частоты вариантов и их сумму (1). В ячейку G3 введем частоту варианта 0 — цифру 6 (или ссылку на ячейку, ее содержащую — ЕЗ), в ячейку G4 введем формулу «=G3+E4» и скопируем ее до ячейки G7, в результате получим накопленные частоты. Таким образом, мы получили дискретный вариационный ряд. Естественно, частоты необходимо округлить, но таким образом, чтобы их сумма равнялась 1. Для этого выделим левой кнопкой мыши диапазон частот (F3:F7), щелкнув по правой кнопке, откроем контекстное меню и выполним команду Формат ячеек — Числовой — Число знаков 3 — ОК. Преобразовав обозначения, получим дискретный вариационный ряд, представленный в табл. 3.11.