
Рассмотрим вычисление квантилей для некоторых функций распределений, представленных в
MS
EXCEL
.
Понятие
Квантиля
основано на определении
Функции распределения
. Поэтому, перед изучением
Квантилей
рекомендуем освежить в памяти понятия из статьи
Функция распределения вероятности
.
Содержание статьи:
- Определение
- Квантили специальных видов
- Квантили стандартного нормального распределения
- Квантили распределения Стьюдента
- Квантили распределения ХИ-квадрат
- Квантили F-распределения
- Квантили распределения Вейбулла
- Квантили экспоненциального распределения
Сначала дадим формальное определение
квантиля,
затем приведем примеры их вычисления в MS EXCEL.
Определение
Пусть случайная величина
X
, имеет
функцию распределения
F
(
x
).
α-квантилем
(
альфа-
квантиль,
x
a
,
квантиль
порядка
α, нижний
α-
квантиль
) называют решение уравнения
x
a
=F
-1
(α), где
α
— вероятность, что случайная величина х примет значение меньшее или равное x
a
, т.е. Р(х<= x
a
)=
α.
Из определения ясно, что нахождение
квантиля
распределения является обратной операцией нахождения вероятности. Т.е. если при вычислении
функции распределения
мы находим вероятность
α,
зная x
a
, то при нахождении
квантиля
мы, наоборот, ищем
x
a
зная
α
.
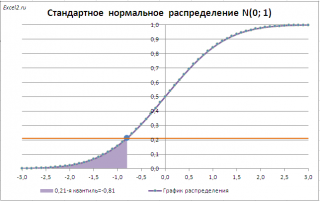
Чтобы пояснить определение, используем график функции
стандартного нормального распределения
(см.
файл примера Лист Определение
):
Примечание
: О построении графиков в MS EXCEL можно прочитать статью
Основные типы диаграмм в MS EXCEL
.
Например, с помощью графика вычислим 0,21-ю
квантиль
, т.е. такое значение случайной величины, что Р(X<=x
0,21
)=0,21.
Для этого найдем точку пересечения горизонтальной линии на уровне вероятности равной 0,21 с
функцией распределения
. Абсцисса этой точки равна -0,81. Соответственно, 0,21-я
квантиль
равна -0,81. Другими словами, вероятность того, что случайная величина, распределенная
стандартному нормальному закону,
примет значение
меньше
-0,81, равна 0,21 (21%).
Примечание
: При вычислении
квантилей
в MS EXCEL используются
обратные функции распределения
:
НОРМ.СТ.ОБР()
,
ЛОГНОРМ.ОБР()
,
ХИ2.ОБР(),
ГАММА.ОБР()
и т.д. Подробнее о распределениях, представленных в MS EXCEL, можно прочитать в статье
Распределения случайной величины в MS EXCEL
.
Точное значение
квантиля
в нашем случае можно найти с помощью формулы
=НОРМ.СТ.ОБР(0,21)
СОВЕТ
: Процедура вычисления
квантилей
имеет много общего с вычислением
процентилей
выборки
(см. статью
Процентили в MS EXCEL
).
Квантили специальных видов
Часто используются
Квантили
специальных видов:
-
процентили
x
p/100
, p=1, 2, 3, …, 99 -
квартили
x
p/4
, p=1, 2, 3 -
медиана
x
1/2
В качестве примера вычислим
медиану (0,5-квантиль)
логнормального распределения
LnN(0;1) (см.
файл примера лист Медиана
).
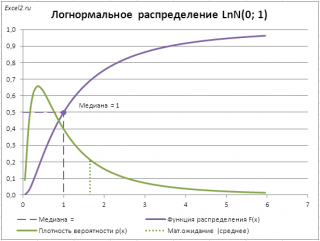
Это можно сделать с помощью формулы
=ЛОГНОРМ.ОБР(0,5; 0; 1)
Квантили стандартного нормального распределения
Необходимость в вычислении квантилей
стандартного нормального распределения
возникает при
проверке статистических гипотез
и при
построении доверительных интервалов.
Примечание
: Про
проверку статистических гипотез
см. статью
Проверка статистических гипотез в MS EXCEL
. Про
построение доверительных интервалов
см. статью
Доверительные интервалы в MS EXCEL
.
В данных задачах часто используется специальная терминология:
Нижний квантиль уровня
альфа
(
α
percentage point)
;
Верхний квантиль уровня альфа (upper
α
percentage point)
;
Двусторонние квантили уровня
альфа
.
Нижний квантиль уровня альфа
— это обычный
α-квантиль.
Чтобы пояснить название «
нижний» квантиль
, построим график
плотности вероятности
и
функцию вероятности
стандартного нормального
распределения
(см.
файл примера лист Квантили
).
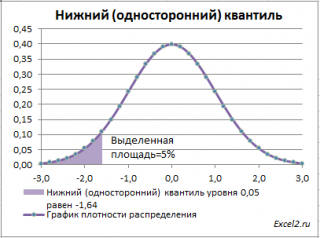
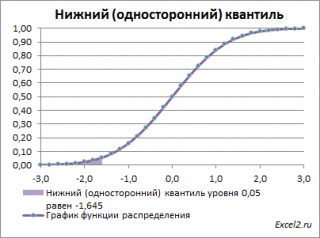
Выделенная площадь на рисунке соответствует вероятности, что случайная величина примет значение меньше
α-квантиля
. Из определения
квантиля
эта вероятность равна
α
. Из графика
функции распределения
становится понятно, откуда происходит название »
нижний квантиль» —
выделенная область расположена в нижней части графика.
Для
α=0,05,
нижний 0,05-квантиль
стандартного нормального распределения
равен -1,645. Вычисления в MS EXCEL можно сделать по формуле:
=НОРМ.СТ.ОБР(0,05)
Однако, при
проверке гипотез
и построении
доверительных интервалов
чаще используется «верхний»
α-квантиль.
Покажем почему.
Верхним
α
—
квантилем
называют такое значение x
α
, для которого вероятность, того что случайная величина X примет значение
больше или равное
x
α
равна
альфа:
P(X>= x
α
)=
α
. Из определения понятно, что
верхний альфа
—
квантиль
любого распределения равен
нижнему (1-
α)
—
квантилю.
А для распределений, у которых
функция плотности распределения
является четной функцией,
верхний
α
—
квантиль
равен
нижнему
α
—
квантилю
со знаком минус
.
Это следует из свойства четной функции f(-x)=f(x), в силу симметричности ее относительно оси ординат.
Действительно, для
α=0,05,
верхний 0,05-квантиль
стандартного нормального распределения
равен 1,645. Т.к.
функция плотности вероятности
стандартного нормального
распределения
является четной функцией, то вычисления в MS EXCEL
верхнего квантиля
можно сделать по двум формулам:
=НОРМ.СТ.ОБР(1-0,05)
=-НОРМ.СТ.ОБР(0,05)
Почему применяют понятие
верхний
α
—
квантиль?
Только из соображения удобства, т.к. он при
α<0,5
всегда положительный (в случае
стандартного нормального
распределения
). А при проверке гипотез
α
равно
уровню значимости
, который обычно берут равным 0,05, 0,1 или 0,01. В противном случае, в процедуре
проверки гипотез
пришлось бы записывать условие отклонения
нулевой гипотезы
μ>μ
0
как Z
0
>Z
1-
α
, подразумевая, что Z
1-
α
–
обычный
квантиль
порядка
1-
α
(или как Z
0
>-Z
α
). C верхнем квантилем эта запись выглядит проще Z
0
>Z
α
.
Примечание
: Z
0
— значение
тестовой статистики
, вычисленное на основе
выборки
. Подробнее см. статью
Проверка статистических гипотез в MS EXCEL о равенстве среднего значения распределения (дисперсия известна)
.
Чтобы пояснить название «
верхний»
квантиль
, построим график
плотности вероятности
и
функцию вероятности
стандартного нормального
распределения
для
α=0,05.
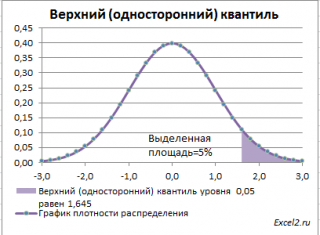
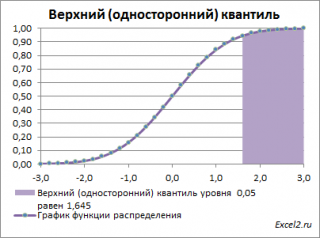
Выделенная площадь на рисунке соответствует вероятности, что случайная величина примет значение больше
верхнего 0,05-квантиля
, т.е.
больше
значения 1,645. Эта вероятность равна 0,05.
На графике
плотности вероятности
площадь выделенной области равна 0,05 (5%) от общей площади под графиком (равна 1). Из графика
функции распределения
становится понятно, откуда происходит название «верхний»
квантиль
—
выделенная область расположена в верхней части графика. Если Z
0
больше
верхнего квантиля
, т.е. попадает в выделенную область, то
нулевая гипотеза
отклоняется.
Также при
проверке двухсторонних гипотез
и построении соответствующих
доверительных интервалов
иногда используется понятие «двусторонний»
α-квантиль.
В этом случае условие отклонения
нулевой гипотезы
звучит как |Z
0
|>Z
α
/2
, где Z
α
/2
–
верхний
α/2-квантиль
. Чтобы не писать
верхний
α/2-квантиль
, для удобства используют «двусторонний»
α-квантиль.
Почему двусторонний? Как и в предыдущих случаях, построим график
плотности вероятности стандартного нормального распределения
и график
функции распределения
.
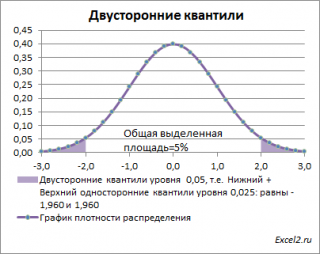
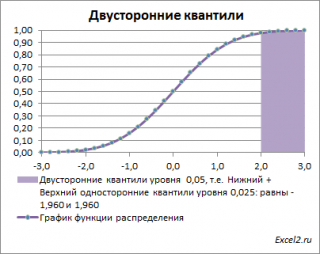
Невыделенная площадь на рисунке соответствует вероятности, что случайная величина примет значение
между
нижним квантилем уровня α
/2 и
верхним квантилем
уровня α
/2, т.е. будет между значениями -1,960 и 1,960 при α=0,05. Эта вероятность равна в нашем случае 1-(0,05/2+0,05/2)=0,95. Если Z
0
попадает в одну из выделенных областей, то
нулевая гипотеза
отклоняется.
Вычислить
двусторонний
0,05
—
квантиль
это можно с помощью формул MS EXCEL:
=НОРМ.СТ.ОБР(1-0,05/2)
или
=-НОРМ.СТ.ОБР(0,05/2)
Другими словами,
двусторонние α-квантили
задают интервал, в который рассматриваемая случайная величина попадает с заданной вероятностью α.
Квантили распределения Стьюдента
Аналогичным образом
квантили
вычисляются и для
распределения Стьюдента
. Например, вычислять
верхний
α/2-
квантиль
распределения Стьюдента с
n
-1 степенью свободы
требуется, если проводится
проверка двухсторонней гипотезы
о
среднем значении
распределения при
неизвестной
дисперсии
(
см. эту статью
).
Для
верхних квантилей
распределения Стьюдента
часто используется запись t
α/2,n-1
. Если такая запись встретилась в статье про
проверку гипотез
или про построение
доверительного интервала
, то это именно
верхний квантиль
.
Примечание
:
Функция плотности вероятности распределения Стьюдента
, как и
стандартного нормального распределения
, является четной функцией.
Чтобы вычислить в MS EXCEL
верхний
0,05/2
—
квантиль
для t-распределения с 10 степенями свободы (или тоже самое
двусторонний
0,05-квантиль
), необходимо записать формулу
=СТЬЮДЕНТ.ОБР.2Х(0,05; 10)
или
=СТЬЮДРАСПОБР(0,05; 10)
или
=СТЬЮДЕНТ.ОБР(1-0,05/2; 10)
или
=-СТЬЮДЕНТ.ОБР(0,05/2; 10)
.2X означает 2 хвоста, т.е.
двусторонний квантиль
.
Квантили распределения ХИ-квадрат
Вычислять
квантили
распределения ХИ-квадрат
с
n
-1 степенью свободы
требуется, если проводится
проверка гипотезы
о
дисперсии нормального распределения
(см. статью
Проверка статистических гипотез в MS EXCEL о дисперсии нормального распределения
).
При
проверке таких гипотез
также используются
верхние квантили.
Например, при
двухсторонней гипотезе
требуется вычислить 2
верхних
квантиля
распределения
ХИ
2
: χ
2
α/2,n-1
и
χ
2
1-
α/2,n-1
. Почему требуется вычислить два
квантиля
, не один, как при
проверке гипотез о среднем
, где используется
стандартное нормальное распределение
или
t-распределение
?
Дело в том, что в отличие от
стандартного нормального распределения
и
распределения Стьюдента
, плотность распределения
ХИ
2
не является четной (симметричной относительно оси х). У него все
квантили
больше 0, поэтому
верхний альфа-квантиль
не равен
нижнему (1-альфа)-квантилю
или по-другому:
верхний альфа-квантиль
не равен
нижнему альфа-квантилю
со знаком минус.
Чтобы вычислить
верхний
0,05/2
—
квантиль
для
ХИ
2
-распределения
с
числом степеней свободы
10, т.е.
χ
2
0,05/2,n-1
, необходимо в MS EXCEL записать формулу
=ХИ2.ОБР.ПХ(0,05/2; 10)
или
=ХИ2.ОБР(1-0,05/2; 10)
Результат равен 20,48. .ПХ означает правый хвост распределения, т.е. тот который расположен вверху на графике
функции распределения
.
Чтобы вычислить
верхний
(1-0,05/2)-
квантиль
при том же
числе степеней свободы
, т.е.
χ
2
1-0,05/2,n-1
и необходимо записать формулу
=ХИ2.ОБР.ПХ(1-0,05/2; 10)
или
=ХИ2.ОБР(0,05/2; 10)
Результат равен 3,25.
Квантили F-распределения
Вычислять
квантили
распределения Фишера
с
n
1
-1 и
n
2
-1 степенями свободы
требуется, если проводится
проверка гипотезы
о равенстве
дисперсий двух нормальных распределений
(см. статью
Двухвыборочный тест для дисперсии: F-тест в MS EXCEL
).
При
проверке таких гипотез
используются, как правило,
верхние квантили.
Например, при
двухсторонней гипотезе
требуется вычислить 2
верхних
квантиля
F
-распределения:
F
α/2,n1-1,
n
2
-1
и
F
1-α/2,n1-1,
n
2
-1
. Почему требуется вычислить два
квантиля
, не один, как при
проверке гипотез о среднем
? Причина та же, что и для распределения ХИ
2
– плотность
F-распределения
не является четной
.
Эти
квантили
нельзя выразить один через другой как для
стандартного нормального распределения
.
Верхний альфа-квантиль
F
-распределения
не равен
нижнему альфа-квантилю
со знаком минус.
Чтобы вычислить
верхний
0,05/2-квантиль
для
F
-распределения
с
числом степеней свободы
10 и 12, необходимо записать формулу
=F.ОБР.ПХ(0,05/2;10;12) =FРАСПОБР(0,05/2;10;12) =F.ОБР(1-0,05/2;10;12)
Результат равен 3,37. .ПХ означает правый хвост распределения, т.е. тот который расположен вверху на графике
функции распределения
.
Квантили распределения Вейбулла
Иногда
обратная функция распределения
может быть представлена в явном виде с помощью элементарных функций, например как для
распределения Вейбулла
. Напомним, что функция этого распределения задается следующей формулой:
![]()
После логарифмирования обеих частей выражения, выразим x через соответствующее ему значение F(x) равное P:
![]()
Примечание
: Вместо обозначения
α-квантиль
может использоваться
p
—
квантиль.
Суть от этого не меняется.
Это и есть обратная функция, которая позволяет вычислить
P
—
квантиль
(
p
—
quantile
). Для его вычисления в формуле нужно подставить известное значение вероятности P и вычислить значение х
p
(вероятность того, что случайная величина Х примет значение меньше или равное х
p
равна P).
Квантили экспоненциального распределения
Задача
:
Случайная величина имеет
экспоненциальное распределение
:
![]()
Требуется выразить
p
-квантиль
x
p
через параметр распределения λ и заданную вероятность
p
.
Примечание
: Вместо обозначения
α-квантиль
может использоваться
p-квантиль
. Суть от этого не меняется.
Решение
: Вспоминаем, что
p
-квантиль
– это такое значение x
p
случайной величины X, для которого P(X<=x
p
)=
p
. Т.е. вероятность, что случайная величина X примет значение меньше или равное x
p
равна
p
. Запишем это утверждение с помощью формулы:
![]()
По сути, мы записали
функцию вероятности экспоненциального распределения
: F(x
p
)=
p
.
Из определения
квантиля
следует, что для его нахождения нам потребуется
обратная функция распределения
.
Проинтегрировав вышеуказанное выражение, получим:
![]()
Используя это уравнение, выразим x
p
через λ и вероятность
p
.
![]()
Конечно, явно выразить
обратную функцию распределения
можно не для всех
функций распределений
.
Все, рассмотренные в этом разделе инструменты вычисляют значения квантилей как значения функций, обратных соответствующим функциям распределения. Все эти функции – библиотечные функции Excel из группы функций «Статистические»,.

Функция вычисления критических точек распределения Лапласа


Функция возвращает (вычисляет) значения квантили уровня, равного значению, введенному в поле «Вероятность» (понятно, что это число из промежутка (0б 1)) стандартного нормального распределения.
Функция вычисления критических точек распределения Стьюдента

Функция возвращает (вычисляет) значения квантили уровня, равного значению, введенному в поле «Вероятность» (понятно, что это число из промежутка (0б 1)) распределения Стьюдента с числом степеней свободы, равным значению, введенному в поле «Степени свободы» (понятно, что это натуральное число).
Важно знать, что функция Excel СТЬЮДРАСПОБР( p , k ) возвращает значение t , при котором P (| x | > t ) = p , x — значение случайной величины, имеющей распределение Стьюдента с k степенями свободы.
Поэтому решение уравнения в Excel возвращает функция СТЬЮДРАСПОБР( a , n – 1).

Функция вычисления критических точек распределения

Функция возвращает (вычисляет) значения квантили уровня, равного значению, введенному в поле «Вероятность» (понятно, что это число из промежутка (0б 1)) распределения с числом степеней свободы, равным значению, введенному в поле «Степени свободы» (понятно, что это натуральное число).
В Excel функция распределения случайной величины определена нестандартно: F x ( x ) = P ( x > x ). Поэтому для вычисления квантиля вводим в качестве аргумента функции ХИ2ОБР значение вероятности, равное , а для вычисления – .
Функция КВАРТИЛЬ
Возвращает квартиль множества данных. Квартиль часто используются при анализе продаж для разбиения генеральной совокупности на группы. Например, можно воспользоваться функцией КВАРТИЛЬ, чтобы найти среди всех предприятий 25 процентов наиболее доходных.
Важно: Эта функция была заменена одной или несколькими новыми функциями, которые обеспечивают более высокую точность и имеют имена, лучше отражающие их назначение. Хотя эта функция все еще используется для обеспечения обратной совместимости, она может стать недоступной в последующих версиях Excel, поэтому мы рекомендуем использовать новые функции.
Дополнительные сведения о новых функциях см. в разделах Функция КВАРТИЛЬ.ИСКЛ и Функция КВАРТИЛЬ.ВКЛ.
Синтаксис
Аргументы функции КВАРТИЛЬ описаны ниже.
Массив Обязательный. Массив или диапазон ячеек с числовыми значениями, для которых определяется значение квартиля.
Часть Обязательный. Значение, которое требуется вернуть.
Содержание
- Медиана и квартили
- Математическое описание
- Среднее значение
- Отклонение от среднего
- Квантиль
- Построение интервалов
- Двусторонний доверительный интервал
- Первый квартиль
- Третий квартиль
- Квартили непрерывного распределения
- Квартили в MS EXCEL
- Моменты случайной величины
- Статистический анализ роста доли дохода в Excel за период
- Анализ статистики случайно сгенерированных чисел в Excel
- Расчет квартилей в R и SAS
- Расчет децилей для дискретного ряда
- Квантили специальных видов
- Квантили стандартного нормального распределения
- Квантили распределения Стьюдента
- Квантили распределения ХИ-квадрат

![]()
Квантили нормального распределения
Основная статья: Медиана (статистика)
- 0,25-квантиль называется первым (или нижним) квартилем (от лат. quarta — четверть);
- 0,5-квантиль называется медианой (от лат. mediāna — середина) или вторым квартилем
- 0,75-квантиль называется третьим (или верхним) квартилем.
Интерквартильным размахом (англ. Interquartile range) называется разность между третьим и первым квартилями. Интерквартильный размах является характеристикой разброса распределения величины и является робастным аналогом дисперсии. Вместе, медиана и интерквартильный размах могут быть использованы вместо математического ожидания и дисперсии в случае распределений с большими выбросами, либо при невозможности вычисления последних.
Математическое описание
Смотря на закон распределения, мы можем понять, какова вероятность того или иного события, можем сказать, какова вероятность, что произойдёт группа событий, а в этой статье мы рассмотрим, как наши выводы “на глаз” перевести в математически обоснованное утверждение.
Крайне важное определение: математическое ожидание – это площадь под графиком распределения. Если мы говорим о дискретном распределении – это сумма событий умноженных на соответсвующие вероятности, также известно как момент:
(2) E(X) = Σ(pi•Xi) E – от английского слова Expected (ожидание)
Для математического ожидания справедливы равенства:
(3) E(X + Y) = E(X) + E(Y)
(4) E(X•Y) = E(X) • E(Y)
Момент степени k:
(5) νk = E(Xk)
Центральный момент степени k:
(6) μk = E[X – E(X)]k
Среднее значение
Среднее значение (μ) закона распределения – это математическое ожидание случайной величины (случайная величина – это событие), например, сколько в среднем посетителей заходит в магазин в час:
| Кол-во посетителей | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| Количество наблюдений | 114 | 115 | 52 | 52 | 24 | 13 | 30 |
| Таблица 1. Количество посетителей в час |
График 1. Количество посетителей в час
Чтобы найти среднее значение всех результатов необходимо сложить всё вместе и разделить на количество результатов:
μ = (114 • 0 + 115 • 1 + 52 • 2 + 52 • 3 + 24 • 4 + 13 • 5 + 30 • 6) / 400 = 716/400 = 1.79
То же самое мы можем проделать используя формулу 2:
μ = M(X) = Σ(Xi•pi) = 0 • 0.29 + 1 • 0.29 + 2 • 0.13 + 3 • 0.13 + 4 • 0.06 + 5 • 0.03 + 6 • 0.08 = 1.79 Момент первой степени, формула (5)
Собственно, формула 2 представляет собой среднее арифметическое всех значений
Итог: в среднем, 1.79 посетителя в час
| Количество посетителей | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| Вероятность (%) | 28.5 | 28.8 | 13 | 13 | 6 | 3.3 | 7.5 |
| Таблица 2. Закон распределения количества посетителей |
Отклонение от среднего
Посмотрите на это распределение, можно предположить, что в среднем случайная величина равна 100±5, поскольку кажется, что таких значений несравнимо больше чем тех, что меньше 95 или больше 105:
График 2. График функции вероятности. Распределение ≈ 100±5
Среднее значение по формуле (2): μ = 99.95, но как посчитать, насколько далеко все значения находятся от среднего? Вам должна быть знакома запись 100±5. Что бы получить это значение ±, нам необходимо определить диапазон значений вокруг среднего. И мы могли бы использовать в качестве меры удалённости “разность” между средним и случайными величинами:
(7) xi – μ
но сумма таких расстояний, а следовательно и любое производное от этого числа, будет равно нулю, поэтому в качестве меры выбрали квадрат разниц между величинами и средним значением:
(8) (xi – μ)2
Соответственно, среднее значение удалённости – это математическое ожидание квадратов удалённости:
(9) σ2 = E[(X – E(X))2] Поскольку вероятности любой удалённости равносильны – вероятность каждого из них – 1/n, откуда: (10) σ2 = E[(X – E(X))2] = ∑[(Xi – μ)2]/n Она же формула центрального момента (6) второй степени
σ возведена в квадрат, поскольку вместо расстояний мы взяли квадрат расстояний. σ2 называется дисперсией. Корень из дисперсии называется средним квадратическим отклонением, или среднеквадратическим отклоненим, и его используют в качестве меры разброса:
(11) μ±σ
(12) σ = √(σ2) = √[∑[(Xi – μ)2]/n]
Возвращаясь к примеру, посчитаем среднеквадратическое отклонение для графика 2:
σ = √(∑(x-μ)2/n) = √{[(90 – 99.95)2 + (91 – 99.95)2 + (92 – 99.95)2 + (93 – 99.95)2 + (94 – 99.95)2 + (95 – 99.95)2 + (96 – 99.95)2 + (97 – 99.95)2 + (98 – 99.95)2 + (99 – 99.95)2 + (100 – 99.95)2 + (101 – 99.95)2 + (102 – 99.95)2 + (103 – 99.95)2 + (104 – 99.95)2 + (105 – 99.95)2 + (106 – 99.95)2 + (107 – 99.95)2 + (108 – 99.95)2 + (109 – 99.95)2 + (110 – 99.95)2]/21} = 6.06
Итак, для графика 2 мы получили:
X = 99.95±6.06 ≈ 100±6 , что немного отличается от полученного “на глаз”
Квантиль
График 3. Функция распределения. Медиана
График 4. Функция распределения. 4-квантиль или квартиль
График 5. Функция распределения. 0.34-квантиль
Для анализа функции распределения ввели понятие квантиль. Квантиль – это случайная величина при заданном уровне вероятности, т.е.: квантиль для уровня вероятности 50% – это случайная величина на графике плотности вероятности, которая имеет вероятность 50%. На примере с графиком 3, квантиль уровня 0.5 = 99 (ближайшее значение, поскольку распределение дискретно и события со значением 99.3 просто не существует)
- 2-квантиль – медиана
- 4-квантиль – квартиль
- 10-квантиль – дециль
- 100-квантиль – перцентиль
То есть, если мы говорим о дециле (10-квантиле), то это означает, что мы разбили график на 10 частей, что соответствует девяти линяям, и для каждого дециля нашли значение случайной величины.
Также, используется обозначение x-квантиль, где х – дробное число, например, 0.34-квантиль, такая запись означает значение случайной величины при p = 0.34.
Для дискретного распределения квантиль необходимо выбирать следующим образом: квантиль гарантирует вероятность, поэтому, если рассчитанный квантиль не совпадает с одним и значений, необходимо выбирать меньшее значение.
Построение интервалов
Квантили используют для построения доверительных интервалов, которые необходимы для исследования статистики не одного конкретного события (например, интерес – случайное число = 98), а для группы событий (например, интерес – случайное число между 96 и 99). Доверительный интервал бывает двух видов: односторонний и двусторонний. Параметр доверительного интервала – уровень доверия. Уровень доверия означает процент событий, которые можно считать успешными.
Двусторонний доверительный интервал
Двусторонний доверительный интервал строится следующим образом: мы задаёмся уровнем значимости, например, 10%, и выделяем область на графике так, что 90% всех событий попадут в эту область. Поскольку интервал двусторонний, то мы отсекаем по 5% с каждой стороны, т.е. мы ищем 5й перцентиль, 95й перцентиль и значения случайной величины между ними будут являться доверительной областью, значения за пределами доверительной области называются “критическая область“
Первый квартиль
Значение квартиля Q1 находится в интервале 68,98 – 71,70, соответствующего частоте fQ1 = 150:4 = 37,5
Третий квартиль
Значение квартиля находится в интервале 68,98 – 71,70, соответствующего частоте fQ3 = (3*150):4 = 112,5
Квартили непрерывного распределения
Если функция распределения F (х) случайной величины х непрерывна, то 1-й квартиль является решением уравнения F(х) =0,25, второй – F(х) =0,5, а третий F(х) =0,75.
Примечание : Подробнее о Функции распределения см. статью Функция распределения и плотность вероятности в MS EXCEL .
Если известна функция плотности вероятности p (х) , то 1-й квартиль можно найти из уравнения: ![]()
Например, решив аналитическим способом это уравнение для Логнормального распределения lnN(μ; σ 2 ), получим, что медиана (2-й квартиль ) вычисляется по формуле e μ или в MS EXCEL =EXP(μ). При μ=1, медиана равна 2,718. 
Обратите внимание на точку Функции распределения , для которой F(х)=0,5 (см. картинку выше или файл примера , лист Квартиль-распределение) . Абсцисса этой точки равна 2,718. Это и есть значение 2-го квартиля ( медианы ), что естественно совпадает с ранее вычисленным значением по формуле e μ .
Примечание : Напомним, что интеграл от функции плотности вероятности по всей области задания случайной величины равен единице: ![]()
Поэтому, линии квартилей ( х=квартиль ) делят площадь под графиком функции плотности вероятности на 4 равные части.
Квартили в MS EXCEL
Чтобы вычислить в MS EXCEL квартили заданного распределения необходимо использовать соответствующую обратную функцию распределения .
При вычислении квартилей в MS EXCEL используются обратные функции распределения : НОРМ.СТ.ОБР() , ЛОГНОРМ.ОБР() , ХИ2.ОБР() , ГАММА.ОБР() и т.д. Подробнее о распределениях, представленных в MS EXCEL, можно прочитать в статье Распределения случайной величины в MS EXCEL .
Например, в MS EXCEL 1-й квартиль для логнормального распределения LnN(1;1) можно вычислить по формуле =ЛОГНОРМ.ОБР(0,25;1;1) , а 3-й квартиль для стандартного нормального распределения по формуле =НОРМ.СТ.ОБР(0,75) .
Моменты случайной величины
Моменты случайно величины описывают различные аспекты характера и формы нашего распределения.
#1 — первый момент случайной величины — среднее значение данных, которое показывает место распределения.
#2 — второй момент случайной величины — дисперсия, которая показывает разброс распределения. Большие значения имеют больший размах, чем маленькие.
#3 — третий момент случайной величины — коэффициент асимметрии — мера того, насколько неравномерным является распределение. Коэффициент асимметрии положителен, если распределение наклонено влево и левый хвост короче правого. То есть среднее значение находится правее. И наоборот:

#4 — четвертый момент случайной величины — коэффициент эксцесса, который описывает то, насколько толстый хвост и насколько острый пик распределения. Этот коэффициент показывает, насколько вероятно найти точки экстремума в данных. Чем выше значение, тем вероятнее выбросы. Это похоже на разброс (дисперсию), но между ними есть отличия.

Как видно на графике, чем выше значение пики, тем выше коэффициент эксцесса, т.е. у верхней кривой коэффициент эксцесса выше, чем у нижней.
Статистический анализ роста доли дохода в Excel за период
Пример 2. В таблице приведены данные о доходах предпринимателя за год. Доказать, что примерно 75% значений меньше, чем третий квартиль доходов.
Вид исходной таблицы:

Определим 3-й по формуле:


Определим соотношение чисел, меньше полученного числа, к общему количеству значений по формуле:
=СЧЁТЕСЛИ(B2:B13;”<“&B15)/СЧЁТ(B2:B13)
Полученные результаты:

Анализ статистики случайно сгенерированных чисел в Excel
Пример 3. Имеется диапазон случайных чисел, отсортированный в порядке возрастания. Определить соотношение суммы чисел, которые меньше 1-го квартиля, к сумме чисел, которые превышают значение 1-го квартиля.
Чтобы сгенерировать случайное число в Excel воспользуемся функцией:
=СЛУЧМЕЖДУ(0;1000)
После генерации отсортируем случайно сгенерированные числа по возрастанию. Вид исходной таблицы данных со случайными числами:

Формула для расчета имеет следующий вид (формула массива CTRL+SHIFT+ENTER):
Функции СУММ с вложенными функциями ЕСЛИ выполняют расчет суммы только тех чисел, которые меньше и больше соответственно значения, возвращаемого функцией для исследуемого диапазона. Из полученных значений вычисляется частное. Результат расчетов:

Общая сумма чисел исследуемого диапазона, которые меньше 1-го квартиля, составляет всего 8,57% от общей суммы чисел, которые больше 1-го квартиля.
Расчет квартилей в R и SAS
Функция quantile в R использует все девять алгоритмов расчета квантилей, в соответствии с нумерацией, предложенной Hyndman and Fan в работе 1996 г. (рис. 15; если вы не знакомы с R, рекомендую начать с Алексей Шипунов. Наглядная статистика. Используем R!). Квантиль при i-м методе расчета:
![]()
где i – номер метода, 1 ≤ i ≤ 9, (j–m)/n ≤ p < (j–m+1)/n, хj – j-ый порядковый элемент упорядоченного ряда, n – размер выборки, γ является функцией двух параметров: j = floor(np + m) и g = np + m – j, где floor – функция возвращающая наибольшее целое, но всё еще меньшее, чем аргумент функции (аналог в Excel – ОКРВНИЗ.МАТ), m – константа, определяемая типом алгоритма расчета квантиля. Если вас интересуют подробности, обратитесь к справочной системе R.
SAS предлгает 5 методов расчета квантилей.

Расчет децилей для дискретного ряда
-
Определяем номер дециля по формуле:
 ,
, -
Если номер дециля – целое число, то значение дециля будет равно величине элемента ряда, которое обладает накопленной частотой равной номеру дециля. Например, если номер дециля равен 20, его значение будет равно значению признака с S =20 (накопленной частотой равной 20).
 ,
,Если номер дециля – нецелое число, то дециль попадает между двумя наблюдениями. Значением дециля будет сумма, состоящая из значения элемента, для которого накопленная частота равна целому значению номера дециля, и указанной части (нецелая часть номера дециля) разности между значением этого элемента и значением следующего элемента.
Например, если номер дециля равна 20,25, дециль попадает между 20-м и 21-м наблюдениями, и его значение будет равно значению 20-го наблюдения плюс 1/4 разности между значением 20-го и 21-го наблюдений.
Квантили специальных видов
Часто используются Квантили специальных видов:
- процентили x p/100 , p=1, 2, 3, …, 99
- квартили x p/4 , p=1, 2, 3
- медиана x 1/2
В качестве примера вычислим медиану (0,5-квантиль) логнормального распределения LnN(0;1) (см. файл примера лист Медиана ). 
Это можно сделать с помощью формулы =ЛОГНОРМ.ОБР(0,5; 0; 1)
Квантили стандартного нормального распределения
Необходимость в вычислении квантилей стандартного нормального распределения возникает при проверке статистических гипотез и при построении доверительных интервалов.
Примечание : Про проверку статистических гипотез см. статью Проверка статистических гипотез в MS EXCEL . Про построение доверительных интервалов см. статью Доверительные интервалы в MS EXCEL .
В данных задачах часто используется специальная терминология:
- Нижний квантиль уровня альфа ( α percentage point)
- Верхний квантиль уровня альфа (upper α percentage point)
- Двусторонние квантили уровня альфа .
Нижний квантиль уровня альфа – это обычный α-квантиль. Чтобы пояснить название « нижний» квантиль , построим график плотности вероятности и функцию вероятности стандартного нормального распределения (см. файл примера лист Квантили ).


Выделенная площадь на рисунке соответствует вероятности, что случайная величина примет значение меньше α-квантиля . Из определения квантиля эта вероятность равна α . Из графика функции распределения становится понятно, откуда происходит название ” нижний квантиль” – выделенная область расположена в нижней части графика.
Для α=0,05, нижний 0,05-квантиль стандартного нормального распределения равен -1,645. Вычисления в MS EXCEL можно сделать по формуле:
=НОРМ.СТ.ОБР(0,05)
Однако, при проверке гипотез и построении доверительных интервалов чаще используется “верхний” α-квантиль. Покажем почему.
Верхним α – квантилем называют такое значение x α , для которого вероятность, того что случайная величина X примет значение больше или равное x α равна альфа: P(X>= x α )= α . Из определения понятно, что верхний альфа – квантиль любого распределения равен нижнему (1- α) – квантилю. А для распределений, у которых функция плотности распределения является четной функцией, верхний α – квантиль равен нижнему α – квантилю со знаком минус . Это следует из свойства четной функции f(-x)=f(x), в силу симметричности ее относительно оси ординат.
Действительно, для α=0,05, верхний 0,05-квантиль стандартного нормального распределения равен 1,645. Т.к. функция плотности вероятности стандартного нормального распределения является четной функцией, то вычисления в MS EXCEL верхнего квантиля можно сделать по двум формулам:
=НОРМ.СТ.ОБР(1-0,05)
=-НОРМ.СТ.ОБР(0,05)
Почему применяют понятие верхний α – квантиль? Только из соображения удобства, т.к. он при α всегда положительный (в случае стандартного нормального распределения ). А при проверке гипотез α равно уровню значимости , который обычно берут равным 0,05, 0,1 или 0,01. В противном случае, в процедуре проверки гипотез пришлось бы записывать условие отклонения нулевой гипотезы μ>μ 0 как Z 0 >Z 1- α , подразумевая, что Z 1- α – обычный квантиль порядка 1- α (или как Z 0 >-Z α ). C верхнем квантилем эта запись выглядит проще Z 0 >Z α .
Примечание : Z 0 – значение тестовой статистики , вычисленное на основе выборки . Подробнее см. статью Проверка статистических гипотез в MS EXCEL о равенстве среднего значения распределения (дисперсия известна) .
Чтобы пояснить название « верхний» квантиль , построим график плотности вероятности и функцию вероятности стандартного нормального распределения для α=0,05.


Выделенная площадь на рисунке соответствует вероятности, что случайная величина примет значение больше верхнего 0,05-квантиля , т.е. больше значения 1,645. Эта вероятность равна 0,05.
На графике плотности вероятности площадь выделенной области равна 0,05 (5%) от общей площади под графиком (равна 1). Из графика функции распределения становится понятно, откуда происходит название “верхний” квантиль – выделенная область расположена в верхней части графика. Если Z 0 больше верхнего квантиля , т.е. попадает в выделенную область, то нулевая гипотеза отклоняется.
Также при проверке двухсторонних гипотез и построении соответствующих доверительных интервалов иногда используется понятие “двусторонний” α-квантиль. В этом случае условие отклонения нулевой гипотезы звучит как |Z 0 |>Z α /2 , где Z α /2 – верхний α/2-квантиль . Чтобы не писать верхний α/2-квантиль , для удобства используют “двусторонний” α-квантиль. Почему двусторонний? Как и в предыдущих случаях, построим график плотности вероятности стандартного нормального распределения и график функции распределения .


Невыделенная площадь на рисунке соответствует вероятности, что случайная величина примет значение между нижним квантилем уровня α /2 и верхним квантилем уровня α /2, т.е. будет между значениями -1,960 и 1,960 при α=0,05. Эта вероятность равна в нашем случае 1-(0,05/2+0,05/2)=0,95. Если Z 0 попадает в одну из выделенных областей, то нулевая гипотеза отклоняется.
Вычислить двусторонний 0,05 – квантиль это можно с помощью формул MS EXCEL: =НОРМ.СТ.ОБР(1-0,05/2) или =-НОРМ.СТ.ОБР(0,05/2)
Другими словами, двусторонние α-квантили задают интервал, в который рассматриваемая случайная величина попадает с заданной вероятностью α.
Квантили распределения Стьюдента
Аналогичным образом квантили вычисляются и для распределения Стьюдента . Например, вычислять верхний α/2- квантиль распределения Стьюдента с n -1 степенью свободы требуется, если проводится проверка двухсторонней гипотезы о среднем значении распределения при неизвестной дисперсии ( см. эту статью ).
Для верхних квантилей распределения Стьюдента часто используется запись t α/2,n-1 . Если такая запись встретилась в статье про проверку гипотез или про построение доверительного интервала , то это именно верхний квантиль .
Примечание : Функция плотности вероятности распределения Стьюдента , как и стандартного нормального распределения , является четной функцией.
Чтобы вычислить в MS EXCEL верхний 0,05/2 – квантиль для t-распределения с 10 степенями свободы (или тоже самое двусторонний 0,05-квантиль ), необходимо записать формулу =СТЬЮДЕНТ.ОБР.2Х(0,05; 10) или =СТЬЮДРАСПОБР(0,05; 10) или =СТЬЮДЕНТ.ОБР(1-0,05/2; 10) или =-СТЬЮДЕНТ.ОБР(0,05/2; 10)
.2X означает 2 хвоста, т.е. двусторонний квантиль .
Квантили распределения ХИ-квадрат
Вычислять квантили распределения ХИ-квадрат с n -1 степенью свободы требуется, если проводится проверка гипотезы о дисперсии нормального распределения (см. статью Проверка статистических гипотез в MS EXCEL о дисперсии нормального распределения ).
При проверке таких гипотез также используются верхние квантили. Например, при двухсторонней гипотезе требуется вычислить 2 верхних квантиля распределения ХИ 2 : χ 2 α/2,n-1 и χ 2 1- α/2,n-1 . Почему требуется вычислить два квантиля , не один, как при проверке гипотез о среднем , где используется стандартное нормальное распределение или t-распределение ?
Дело в том, что в отличие от стандартного нормального распределения и распределения Стьюдента , плотность распределения ХИ 2 не является четной (симметричной относительно оси х). У него все квантили больше 0, поэтому верхний альфа-квантиль не равен нижнему (1-альфа)-квантилю или по-другому: верхний альфа-квантиль не равен нижнему альфа-квантилю со знаком минус.
Чтобы вычислить верхний 0,05/2 – квантиль для ХИ 2 -распределения с числом степеней свободы 10, т.е. χ 2 0,05/2,n-1 , необходимо в MS EXCEL записать формулу =ХИ2.ОБР.ПХ(0,05/2; 10) или =ХИ2.ОБР(1-0,05/2; 10)
Результат равен 20,48. .ПХ означает правый хвост распределения, т.е. тот который расположен вверху на графике функции распределения .
Чтобы вычислить верхний (1-0,05/2)- квантиль при том же числе степеней свободы , т.е. χ 2 1-0,05/2,n-1 и необходимо записать формулу =ХИ2.ОБР.ПХ(1-0,05/2; 10) или =ХИ2.ОБР(0,05/2; 10)
Результат равен 3,25.
Источники
- https://dic.academic.ru/dic.nsf/ruwiki/291015
- https://k-tree.ru/articles/statistika/analiz_dannyh/svoistva_raspredeleniia
- https://univer-nn.ru/zadachi-po-statistike-primeri/kvartili-v-statistike/
- https://excel2.ru/articles/kvartili-i-interkvartilnyy-interval-iqr-v-ms-excel
- https://nuancesprog.ru/p/3307/
- https://exceltable.com/funkcii-excel/primery-funkcii-kvartil
- https://baguzin.ru/wp/kvartil-kakie-formuly-rascheta-ispol/
- https://studfile.net/preview/5316597/page:4/
- https://excel2.ru/articles/kvantili-raspredeleniy-ms-excel
В статье проведена оценка показателей надежности безотказной работы системы. На примере показан расчет основных показателей средствами Excel.
Ключевые слова:
безотказная работа, доверительный интервал, испытания, нормальный закон распределения, число отказов.
Определение показателей надёжности необходимо для формулирования требования по надежности к проектируемым устройствам или системам. Показатель надежности — это количественная характеристика одного или нескольких свойств, составляющих надежность объекта [1].
Поскольку отказы и сбои элементов являются случайными событиями, то теория вероятностей и математическая статистика являются основным аппаратом, используемым при исследовании надежности, а сами характеристики надежности должны выбираться из числа показателей, принятых в теории вероятностей [2, с.
13].
Количественные характеристики надежности при нормальном законе распределения отказов могут быть определены из следующих выражений:
(1)
P(t)=
(2)
λ(
)=
(3),
где
нормированная и центрированная функция Лапласа.
Произведем расчет параметров надежности испытаний, проведенных в течение 100 часов на 100 деталях, 34 из которых вышли из строя.
Для построения статистического ряда время испытаний разбивают на интервалы (разряды) и подсчитывают частоту, интенсивность и вероятность отказов, используя выражения (1), (2) и (3). Определяют доверительные интервалы математического ожидания и среднеквадратичного отклонения при нормальном законе распределения отказов и заданном коэффициенте доверия [3, с. 60].
Результаты вычислений представлены в таблице Excel (Таблица 1).
Таблица 1
Результаты расчета основных показателей испытаний
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
10 |
20 |
30 |
40 |
50 |
60 |
70 |
80 |
90 |
100 |
|
|
5 |
3 |
5 |
2 |
2 |
3 |
3 |
3 |
5 |
3 |
|
|
0,935 |
0,917 |
0,896 |
0,870 |
0,841 |
0,805 |
0,767 |
0,725 |
0,680 |
0,633 |
|
|
0,983 |
0,986 |
0,988 |
0,990 |
0,991 |
0,992 |
0,993 |
0,993 |
0,994 |
0,994 |
|
λн(t) |
1,050 |
1,074 |
1,102 |
1,137 |
1,178 |
1,232 |
1,294 |
1,369 |
1,460 |
1,570 |
|
|
0,064 |
0,082 |
0,103 |
0,129 |
0,158 |
0,194 |
0,232 |
0,274 |
0,319 |
0,366 |
|
|
0,014 |
0,002 |
0,026 |
0,020 |
0,011 |
0,005 |
0,002 |
0,014 |
0,009 |
0,026 |
|
|
0,085065269 |
|||||||||
Листинг фрагмента программы расчета показателей при нормальном законе распределения:
‘Вычислим 43 строку таблицы(45)=============================Рн(t)
СтрокаТаблицы = 45
‘a=(t-Tср)/Сигма
СтолбецТаблицы = 4
For n = СтолбецТаблицы To (КоличествоСтолбцовТаблицы + СтолбецТаблицы — 1)
a = Abs(Sheets(«ОсновнаяТаблица»). Cells(3, n).Value — Tcp) / Сигма
Cells(3, n).Value — Tcp) / Сигма
‘b=Фо
СтрокаТаблФункцЛапласа = 2
While Sheets(«Таблица функции Лапласа»).Cells(СтрокаТаблФункцЛапласа, 1).Value <> «»
СтрокаТаблФункцЛапласа = СтрокаТаблФункцЛапласа + 1
Wend
If a <= Sheets(«Таблица функции Лапласа»).Cells(2, 1).Value Then
ф0 = Sheets(«Таблица функции Лапласа»).Cells(2, 2).Value
GoTo далее
End If
If a >= Sheets(«Таблица функции Лапласа»).Cells(СтрокаТаблФункцЛапласа — 1, 1).Value Then
ф0 = Sheets(«Таблица функции Лапласа»).Cells(СтрокаТаблФункцЛапласа — 1, 2).Value
GoTo далее
End If
СтрокаТаблФункцЛапласа = 2
While Sheets(«Таблица функции Лапласа»).Cells(СтрокаТаблФункцЛапласа, 1).Value <> «»
If Sheets(«Таблица функции Лапласа»).Cells(СтрокаТаблФункцЛапласа, 1).Value = a Then
ф0 = Sheets(«Таблица функции Лапласа»).Cells(СтрокаТаблФункцЛапласа, 2).Value
GoTo далее3
End If
If a < Sheets(«Таблица функции Лапласа»).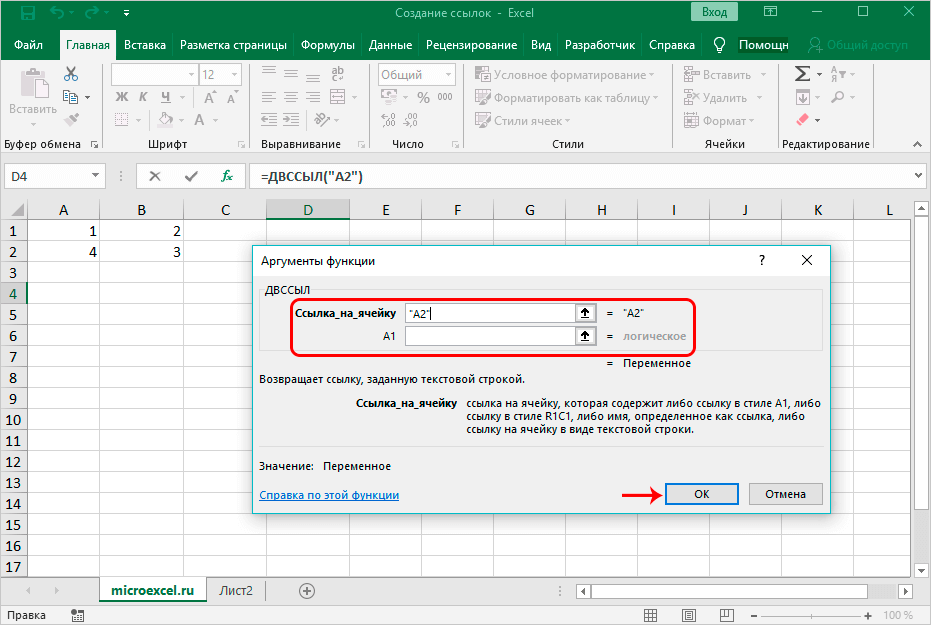 Cells(СтрокаТаблФункцЛапласа, 1).Value And a > Sheets(«Таблица функции Лапласа»).Cells(СтрокаТаблФункцЛапласа — 1, 1).Value Then
Cells(СтрокаТаблФункцЛапласа, 1).Value And a > Sheets(«Таблица функции Лапласа»).Cells(СтрокаТаблФункцЛапласа — 1, 1).Value Then
If Sheets(«Таблица функции Лапласа»).Cells(СтрокаТаблФункцЛапласа, 1).Value — a < a — Sheets(«Таблица функции Лапласа»).Cells(СтрокаТаблФункцЛапласа — 1, 1).Value Then
ф0 = Sheets(«Таблица функции Лапласа»).Cells(СтрокаТаблФункцЛапласа, 2).Value
Else
ф0 = Sheets(«Таблица функции Лапласа»).Cells(СтрокаТаблФункцЛапласа — 1, 2).Value
End If
GoTo далее3
End If
СтрокаТаблФункцЛапласа = СтрокаТаблФункцЛапласа + 1
Wend
далее3:
Sheets(«ОсновнаяТаблица»).Cells(СтрокаТаблицы, n).Value = 0.5 + ф0
Next
‘Вычислим 44 строку таблицы(46)=============================fн(t)
СтрокаТаблицы = 46
СтолбецТаблицы = 4
Pi = Application.WorksheetFunction.Pi
For n = СтолбецТаблицы To (КоличествоСтолбцовТаблицы + СтолбецТаблицы — 1)
Sheets(«ОсновнаяТаблица»). 2)))
2)))
Next
‘Заполним 45 строку таблицы(47)=============================Лямбда н(t)
СтрокаТаблицы = 47
СтолбецТаблицы = 4
For n = СтолбецТаблицы To (КоличествоСтолбцовТаблицы + СтолбецТаблицы — 1)
Sheets(«ОсновнаяТаблица»).Cells(СтрокаТаблицы, n).Value = Sheets(«ОсновнаяТаблица»).Cells(46, n).Value / Sheets(«ОсновнаяТаблица»).Cells(45, n).Value
Next
Для определения доверительного интервала для математического ожидания по таблице квантилей распределения Стьюдента находят квантиль вероятности. Используя выражения (4) и (5) проводят расчеты
(4)
(5)
‘Заполним 30 строку таблицы(32)=============================Tср min
СтрокаТаблицы = 32
СтолбецТаблицы = 4
For n = СтолбецТаблицы To (КоличествоСтолбцовТаблицы + СтолбецТаблицы — 1)
Next
СтепеньСвободыПриНормРаспред = КоличествоСтолбцовТаблицы + 1 — 2
Sheets(«ОсновнаяТаблица»).Cells(СтрокаТаблицы, 4).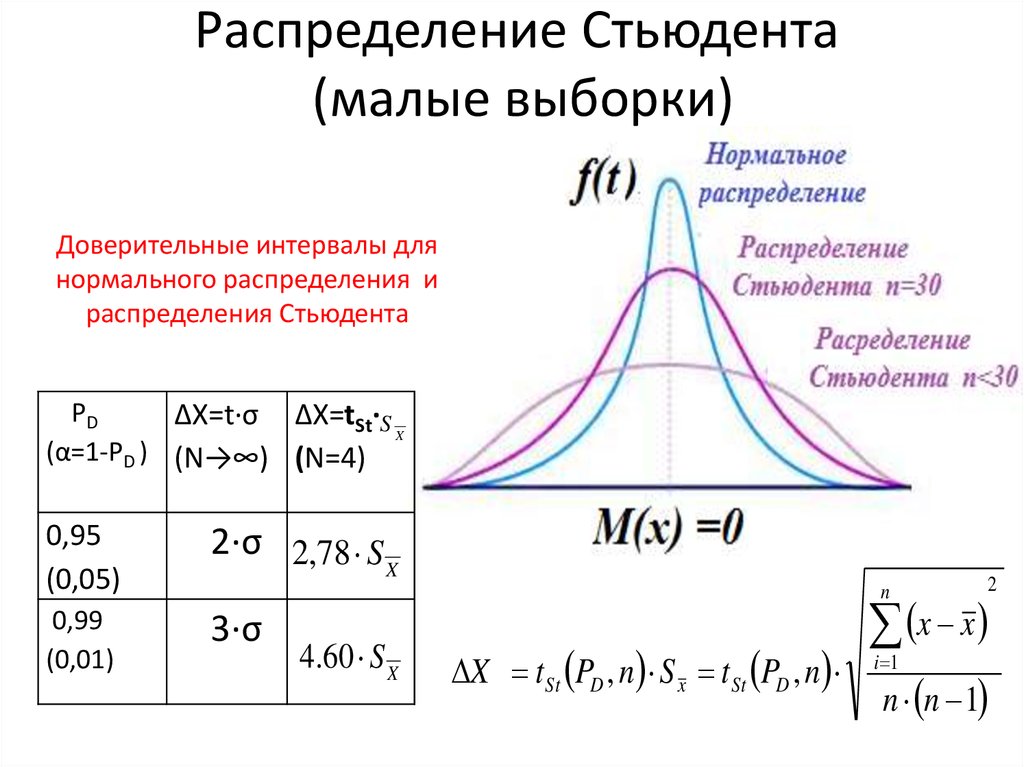 Value = Tcp — Sheets(«ОсновнаяТаблица»).Cells(31, 4).Value * Сигма / Sqr(СтепеньСвободыПриНормРаспред)
Value = Tcp — Sheets(«ОсновнаяТаблица»).Cells(31, 4).Value * Сигма / Sqr(СтепеньСвободыПриНормРаспред)
Sheets(«ОсновнаяТаблица»).Range(Cells(СтрокаТаблицы, 4), Cells(СтрокаТаблицы, n — 1)).MergeCells = True
Sheets(«ОсновнаяТаблица»).Range(Cells(СтрокаТаблицы, 4), Cells(СтрокаТаблицы, n — 1)).HorizontalAlignment = xlCenter
‘Заполним 31 строку таблицы(33)=============================Tср max
СтрокаТаблицы = 33
СтолбецТаблицы = 4
For n = СтолбецТаблицы To (КоличествоСтолбцовТаблицы + СтолбецТаблицы — 1)
Next
Sheets(«ОсновнаяТаблица»).Cells(СтрокаТаблицы, 4).Value = Tcp + Sheets(«ОсновнаяТаблица»).Cells(31, 4).Value * Сигма / Sqr(СтепеньСвободыПриНормРаспред)
Sheets(«ОсновнаяТаблица»).Range(Cells(СтрокаТаблицы, 4), Cells(СтрокаТаблицы, n — 1)).MergeCells = True
Sheets(«ОсновнаяТаблица»).Range(Cells(СтрокаТаблицы, 4), Cells(СтрокаТаблицы, n — 1)).HorizontalAlignment = xlCenter
|
Тср, min = |
79,29380755 ч. |
|
Тср, max = |
172,43129 ч. |
Для определения доверительного интервала для среднеквадратичного отклонения по таблице квантилей χ
2
– квадрат распределения определяют квантили для заданных вероятностей
P
1
и
P
2
.
|
(0,05) = |
3,32511 |
|
(0,95) = |
16,919 |
‘Заполним 32 строку таблицы(34)=============================X1(0,05)
СтрокаОсновнойТаблицы = 34
СтрокаТаблКвантили = 4
ВходнаяСтрочнаяВеличина = СтепеньСвободыПриНормРаспред
While Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили, 1).Value <> «»
СтрокаТаблКвантили = СтрокаТаблКвантили + 1
Wend
If ВходнаяСтрочнаяВеличина <= Sheets(«Квантили распределения хи»). Cells(4, 1).Value Then
Cells(4, 1).Value Then
СтрокаТабл = 4
GoTo СледующийПоиск10
End If
If ВходнаяСтрочнаяВеличина >= Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили — 1, 1).Value Then
СтрокаТабл = СтрокаТаблКвантили — 1
GoTo СледующийПоиск10
End If
СтрокаТаблКвантили = 4
While Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили, 1).Value <> «»
If Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили, 1).Value = ВходнаяСтрочнаяВеличина Then
СтрокаТабл = СтрокаТаблКвантили
GoTo СледующийПоиск10
End If
If ВходнаяСтрочнаяВеличина < Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили, 1).Value And ВходнаяСтрочнаяВеличина > Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили — 1, 1).Value Then
If Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили, 1).Value — ВходнаяСтрочнаяВеличина < ВходнаяСтрочнаяВеличина — Sheets(«Квантили распределения хи»). Cells(СтрокаТаблКвантили — 1, 1).Value Then
Cells(СтрокаТаблКвантили — 1, 1).Value Then
СтрокаТабл = СтрокаТаблКвантили
Else
СтрокаТабл = СтрокаТаблКвантили — 1
End If
GoTo СледующийПоиск10
End If
СтрокаТаблКвантили = СтрокаТаблКвантили + 1
Wend
СледующийПоиск10:
СтолбецТаблКвантили = 2
ВходнаяВертикальнаяВеличина = 0.05
While Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили).Value <> «»
СтолбецТаблКвантили = СтолбецТаблКвантили + 1
Wend
If ВходнаяВертикальнаяВеличина <= Sheets(«Квантили распределения хи»).Cells(3, 2).Value Then
СтолбецТабл = 2
GoTo СледующийПоиск11
End If
If ВходнаяВертикальнаяВеличина >= Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили — 1).Value Then
СтолбецТабл = СтолбецТаблКвантили — 1
GoTo СледующийПоиск11
End If
СледующийПоиск11:
СтолбецТаблКвантили = 11
While Sheets(«Квантили распределения хи»). Cells(3, СтолбецТаблКвантили).Value <> «»
Cells(3, СтолбецТаблКвантили).Value <> «»
If Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили).Value = ВходнаяВертикальнаяВеличина Then
СтолбецТабл = СтолбецТаблКвантили
GoTo СледующийПоиск12
End If
If ВходнаяСтрочнаяВеличина < Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили).Value And ВходнаяВертикальнаяВеличина > Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили — 1).Value Then
If Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили).Value — ВходнаяВертикальнаяВеличина < ВходнаяВертикальнаяВеличина — Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили — 1).Value Then
СтолбецТабл = СтолбецТаблКвантили
Else
СтолбецТабл = СтолбецТаблКвантили — 1
End If
GoTo СледующийПоиск12
End If
СтолбецТаблКвантили = СтолбецТаблКвантили + 1
Wend
СледующийПоиск12:
x1 = Sheets(«Квантили распределения хи»). Cells(СтрокаТабл, СтолбецТабл).Value
Cells(СтрокаТабл, СтолбецТабл).Value
Sheets(«ОсновнаяТаблица»).Cells(СтрокаОсновнойТаблицы, 4).Value = x1
Sheets(«ОсновнаяТаблица»).Range(Cells(СтрокаОсновнойТаблицы, 4), Cells(СтрокаОсновнойТаблицы, n — 1)).MergeCells = True
Sheets(«ОсновнаяТаблица»).Range(Cells(СтрокаОсновнойТаблицы, 4), Cells(СтрокаОсновнойТаблицы, n — 1)).HorizontalAlignment = xlCenter
‘Заполним 33 строку таблицы(35)=============================X2(0,95)
СтрокаОсновнойТаблицы = 35
СтрокаТаблКвантили = 4
ВходнаяСтрочнаяВеличина = СтепеньСвободыПриНормРаспред
While Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили, 1).Value <> «»
СтрокаТаблКвантили = СтрокаТаблКвантили + 1
Wend
If ВходнаяСтрочнаяВеличина <= Sheets(«Квантили распределения хи»).Cells(4, 1).Value Then
СтрокаТабл = 4
GoTo СледующийПоиск13
End If
If ВходнаяСтрочнаяВеличина >= Sheets(«Квантили распределения хи»). Cells(СтрокаТаблКвантили — 1, 1).Value Then
Cells(СтрокаТаблКвантили — 1, 1).Value Then
СтрокаТабл = СтрокаТаблКвантили — 1
GoTo СледующийПоиск13
End If
СтрокаТаблКвантили = 4
While Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили, 1).Value <> «»
If Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили, 1).Value = ВходнаяСтрочнаяВеличина Then
СтрокаТабл = СтрокаТаблКвантили
GoTo СледующийПоиск13
End If
If ВходнаяСтрочнаяВеличина < Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили, 1).Value And ВходнаяСтрочнаяВеличина > Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили — 1, 1).Value Then
If Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили, 1).Value — ВходнаяСтрочнаяВеличина < ВходнаяСтрочнаяВеличина — Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили — 1, 1).Value Then
СтрокаТабл = СтрокаТаблКвантили
Else
СтрокаТабл = СтрокаТаблКвантили — 1
End If
GoTo СледующийПоиск13
End If
СтрокаТаблКвантили = СтрокаТаблКвантили + 1
Wend
СледующийПоиск13:
СтолбецТаблКвантили = 2
ВходнаяВертикальнаяВеличина = 0. 95
95
While Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили).Value <> «»
СтолбецТаблКвантили = СтолбецТаблКвантили + 1
Wend
If ВходнаяВертикальнаяВеличина <= Sheets(«Квантили распределения хи»).Cells(3, 2).Value Then
СтолбецТабл = 2
GoTo СледующийПоиск14
End If
If ВходнаяВертикальнаяВеличина >= Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили — 1).Value Then
СтолбецТабл = СтолбецТаблКвантили — 1
GoTo СледующийПоиск14
End If
СледующийПоиск14:
СтолбецТаблКвантили = 2
While Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили).Value <> «»
If Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили).Value = ВходнаяВертикальнаяВеличина Then
СтолбецТабл = СтолбецТаблКвантили
GoTo СледующийПоиск15
End If
If ВходнаяСтрочнаяВеличина < Sheets(«Квантили распределения хи»).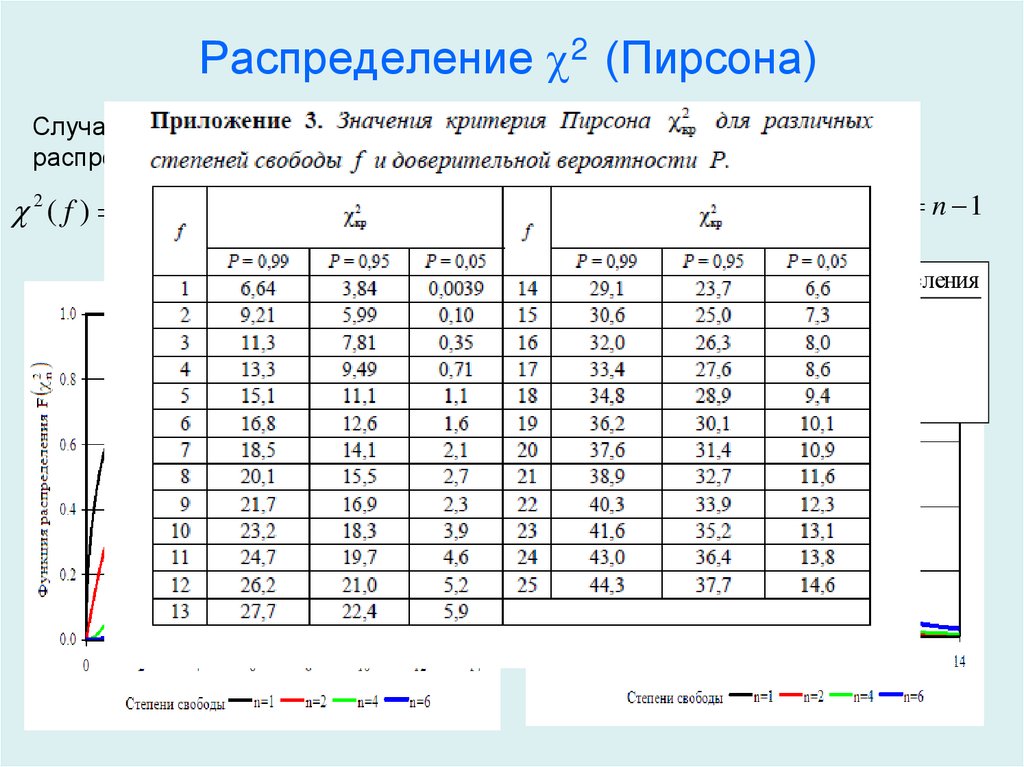 Cells(3, СтолбецТаблКвантили).Value And ВходнаяВертикальнаяВеличина > Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили — 1).Value Then
Cells(3, СтолбецТаблКвантили).Value And ВходнаяВертикальнаяВеличина > Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили — 1).Value Then
If Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили).Value — ВходнаяВертикальнаяВеличина < ВходнаяВертикальнаяВеличина — Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили — 1).Value Then
СтолбецТабл = СтолбецТаблКвантили
Else
СтолбецТабл = СтолбецТаблКвантили — 1
End If
GoTo СледующийПоиск15
End If
СтолбецТаблКвантили = СтолбецТаблКвантили + 1
Wend
СледующийПоиск15:
x1 = Sheets(«Квантили распределения хи»).Cells(СтрокаТабл, СтолбецТабл).Value
Sheets(«ОсновнаяТаблица»).Cells(СтрокаОсновнойТаблицы, 4).Value = x1
Sheets(«ОсновнаяТаблица»).Range(Cells(СтрокаОсновнойТаблицы, 4), Cells(СтрокаОсновнойТаблицы, n — 1)).MergeCells = True
Sheets(«ОсновнаяТаблица»).Range(Cells(СтрокаОсновнойТаблицы, 4), Cells(СтрокаОсновнойТаблицы, n — 1)). HorizontalAlignment = xlCenter
HorizontalAlignment = xlCenter
Получим минимальное σ
min
и максимальное σ
max
значения среднеквадратического отклонения:
(6)
(7)
‘Заполним 34 строку таблицы(36)=============================Сигма min
СтрокаТаблицы = 36
СтолбецТаблицы = 4
For n = СтолбецТаблицы To (КоличествоСтолбцовТаблицы + СтолбецТаблицы — 1)
Next
Sheets(«ОсновнаяТаблица»).Cells(СтрокаТаблицы, 4).Value = Сигма * Sqr((СтепеньСвободыПриНормРаспред — 1) / Sheets(«ОсновнаяТаблица»).Cells(35, 4).Value)
Sheets(«ОсновнаяТаблица»).Range(Cells(СтрокаТаблицы, 4), Cells(СтрокаТаблицы, n — 1)).MergeCells = True
Sheets(«ОсновнаяТаблица»).Range(Cells(СтрокаТаблицы, 4), Cells(СтрокаТаблицы, n — 1)).HorizontalAlignment = xlCenter
‘Заполним 35 строку таблицы(37)=============================Сигма max
СтрокаТаблицы = 37
СтолбецТаблицы = 4
For n = СтолбецТаблицы To (КоличествоСтолбцовТаблицы + СтолбецТаблицы — 1)
Next
СтепеньСвободыПриНормРаспред = КоличествоСтолбцовТаблицы + 1 — 2
Sheets(«ОсновнаяТаблица»). Cells(СтрокаТаблицы, 4).Value = Сигма * Sqr((СтепеньСвободыПриНормРаспред — 1) / Sheets(«ОсновнаяТаблица»).Cells(34, 4).Value)
Cells(СтрокаТаблицы, 4).Value = Сигма * Sqr((СтепеньСвободыПриНормРаспред — 1) / Sheets(«ОсновнаяТаблица»).Cells(34, 4).Value)
Sheets(«ОсновнаяТаблица»).Range(Cells(СтрокаТаблицы, 4), Cells(СтрокаТаблицы, n — 1)).MergeCells = True
Sheets(«ОсновнаяТаблица»).Range(Cells(СтрокаТаблицы, 4), Cells(СтрокаТаблицы, n — 1)).HorizontalAlignment = xlCenter
Число разрядов, на которые следует группировать статистический ряд, не должно быть слишком большим (тогда ряд распределения становится невыразительным, и часто в нем обнаруживают незакономерные колебания), с другой стороны, оно не должен быть слишком малым (свойства распределения при этом описываются статистическим рядом слишком грубо).
Литература:
-
ГОСТ 27. 002-89 Надежность в технике (ССНТ). Основные понятия. Термины и определения.
- Федотов, А. В. Основы теории надежности и технической диагностики: конспект лекций / А. В. Федотов, Н. Г. Скабкин. – Омск : Изд-во ОмГТУ, 2010 – 64 с.
- Коваленко, В. Н. Надежность устройств железнодорожной автоматики, телемеханики : учеб. пособие / В. Н. Коваленко. – Екатеринбург : Изд-во УрГУПС, 2013. – 87 с.
 002-89 Надежность в технике (ССНТ). Основные понятия. Термины и определения.
002-89 Надежность в технике (ССНТ). Основные понятия. Термины и определения.
Основные термины (генерируются автоматически): Таблица функции, строка таблицы, доверительный интервал, Сигма, математическое ожидание, распределение отказов, среднеквадратичное отклонение, статистический ряд, таблица, теория вероятностей.
КОРРЕЛЯЦИОННЫЙ И РЕГРЕССИОННЫЙ АНАЛИЗ В EXCEL
1. ОПРЕДЕЛЕНИЕ КОЭФФИЦИЕНТА ПАРНОЙ
КОРРЕЛЯЦИИ В ПРОГРАММЕ EXCEL
t-статистика=0,99*(КОРЕНЬ(20-2)/КОРЕНЬ(1-0,99*0,99))=29,7745296027549
Коэффициент корреляции=0,991477169252612
Распределение Стьюдента=2,10092204024104
Расчетное значение t-статистики больше квантиля распределения Стьюдента, следовательно величина коэффициента корреляции является значимой.
2. ПОСТРОЕНИЕ РЕГРЕССИОННОЙ МОДЕЛИ СВЯЗИ
МЕЖДУ ДВУМЯ ВЕЛИЧИНАМИ
1-ый способ
| a1= 0,5014 | a0= 2,5326 |
| Se1= 0,0155 | Se0= 0,7075 |
| R2= 0,9830 | Se= 0,5561 |
| Se= 0,5561 | n-k-1= 18 |
| QR= 322,4250 | Qe= 5,5670 |
Для проверки адекватности
модели нашли квантиль распределения Фишера Ff. с помощью функции FРАСПОБР
FРАСПОБР=4,4139
Проверили адекватность
построенной модели, используя расчетный уровень значимости (P):
2,18499711496499E-17
2 –й способ
|
а=2,532579627 |
|
в=0,50139175 |
Для данного примера
уравнение модели имеет вид:Y=2,53+0,5X
Проверка адекватности модели выполняется по расчетному уровню значимости P,
указанному в столбце Значимость F. Если
Если
расчетный уровень значимости меньше заданного уровня значимости α =0,05, то модель адекватна.
Проверка статистической значимости коэффициентов модели выполняется по расчетным
уровням значимости P, указанным в столбце P-значение. Если расчетный уровень значимости меньше заданного
уровня значимости α =0,05, то соответствующий
коэффициент модели статистически значим.
Множественный R – коэффициент корреляции. Чем ближе его величина к 1, тем более
тесная связь между изучаемыми показателями. Для данного примера R= 0,99. Это позволяет сделать
вывод, что качество земли – один из основных факторов, от которого зависит
урожайность зерновых культур.
R-квадрат – коэффициент
детерминации. Он получается возведением в квадрат коэффициента корреляции –
R2=0,98. Он
показывает, что урожайность зерновых культур на 98% зависит от качества почвы,
а на долю других факторов приходится 0,02%.
3-ий способ (графический)
Расчет квантилей или процентилей в Excel
В этом руководстве показано, как вычислять квантили или процентили, связанные с доверительными интервалами, в Excel с помощью программного обеспечения XLSTAT.
Квантиль и процентили
XLSTAT имеет полный инструмент для вычисления квантилей или процентилей, их доверительного интервала и графического представления.
Квантили являются важными статистическими показателями, их легко понять. Квантиль 0,5 — это значение, при котором половина выборки находится ниже, а другая половина — выше. Его еще называют средним. Квантиль называется процентилем, если он основан на шкале от 0 до 100. 0,95-квантиль эквивалентен 95-процентилю и таков, что 95 % выборки ниже его значения, а 5 % выше.
Набор данных для создания квантиля
Набор данных был получен от [Lewis T. and Taylor L.R. (1967). Введение в экспериментальную экологию, Нью-Йорк: Academic Press, Inc. Это касается 237 детей, описанных по полу и росту в сантиметрах (1 см = 0,4 дюйма).
Настройка расчета определенного квантиля
После открытия XLSTAT выберите XLSTAT / Description / Quantiles , или нажмите на соответствующую кнопку панели инструментов «Описание» (см. ниже).
ниже).
После нажатия кнопки появится диалоговое окно Quantile . Выберите данные на листе Excel.
В нашем случае; переменная — это «Высота». Данные должны быть количественными .
Поскольку для переменных был выбран заголовок столбца, необходимо активировать опцию Метки переменных .
Мы выбираем метод оценки по умолчанию ( средневзвешенное значение при x(Np) ) и оба типа доверительных интервалов с доверительной вероятностью 95 % .
Подробную информацию о статистических методах можно найти в справке XLSTAT.
Во вкладке диаграммы выбираем все диаграммы и нас интересует 67-процентиль (две трети детей меньше, а одна треть выше).
Вычисления начинаются после того, как вы нажмете на ОК . Затем будут отображены результаты.
Интерпретация результатов генерации квантилей
В первой таблице показаны некоторые описательные статистические данные о переменной высоты. Во второй таблице отображаются квантили и связанные с ними доверительные интервалы для различных часто используемых значений. Например, медиана 159,9 см. 95-процентиль показывает, что 95% детей меньше 174,98 см.
Во второй таблице отображаются квантили и связанные с ними доверительные интервалы для различных часто используемых значений. Например, медиана 159,9 см. 95-процентиль показывает, что 95% детей меньше 174,98 см.
Затем отображается значение 67-процентиля. Две трети детей меньше 164,58 см.
Первый график (см. ниже) позволяет нам визуализировать эмпирическую кумулятивную функцию распределения со значением 67-го процентиля.
Вторая и третья диаграммы представляют собой коробчатую диаграмму и диаграмму рассеяния. 67-процентиль отображается синей линией.
Вы также можете использовать подвыборки, например пол можно использовать в качестве групповой переменной. Веса, связанные с наблюдениями, также могут быть включены.
Была ли эта статья полезной?
- Да
- №
Квантиль (квартиль, дециль и процентиль): расчет вручную + Microsoft
Квантиль — важная статистическая концепция, позволяющая разделить данные на равные группы.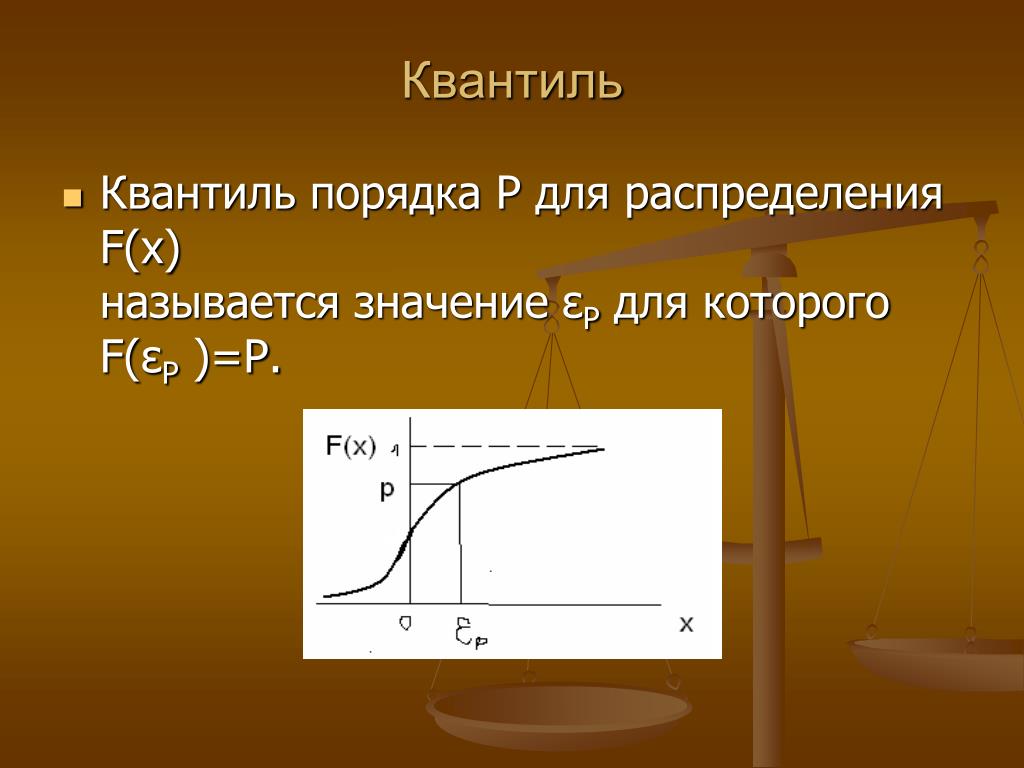 Они часто используются для выявления и анализа шаблонов данных и проведения значимых сравнений между различными наборами данных. В этом кратком руководстве мы рассмотрим основы квантилей и более подробно рассмотрим некоторые из наиболее распространенных типов: квартили, децили и процентили.
Они часто используются для выявления и анализа шаблонов данных и проведения значимых сравнений между различными наборами данных. В этом кратком руководстве мы рассмотрим основы квантилей и более подробно рассмотрим некоторые из наиболее распространенных типов: квартили, децили и процентили.
Квантиль
Квантиль — это мера, указывающая значение, ниже которого падает определенная доля наблюдений в группе наблюдений. Квантиль используется в статистике для разделения группы наблюдений на группы одинакового размера. Например, квантиль 0,25 — это значение, ниже которого падают 25% наблюдений; квантиль 0,50 — это значение, ниже которого падает 50%, и так далее. Другим родственным измерением является медиана, которая совпадает с квантилем 0,50, поскольку 50% данных находятся ниже медианы.
Какие общие квантили существуют?
Некоторые распространенные квантили включают:
1. Квартиль
Квартиль — это тип квантиля, который делит группу наблюдений на четыре группы одинакового размера. Например, в группе наблюдений первый квартиль (Q1) — это значение, ниже которого опускаются первые 25 % наблюдений, второй квартиль (Q2, также известный как медиана) — это значение, ниже которого средние 50 % наблюдений падают, а третий квартиль (Q3) — это значение, ниже которого падают последние 25% наблюдений.
Например, в группе наблюдений первый квартиль (Q1) — это значение, ниже которого опускаются первые 25 % наблюдений, второй квартиль (Q2, также известный как медиана) — это значение, ниже которого средние 50 % наблюдений падают, а третий квартиль (Q3) — это значение, ниже которого падают последние 25% наблюдений.
2. Дециль
Дециль – это мера, которая делит группу наблюдений на десять групп одинакового размера. Например, в группе наблюдений первый дециль (D1) — это значение, ниже которого попадают первые 10% наблюдений, второй дециль (D2) — это значение, ниже которого попадают первые 20% наблюдений, и скоро. 9-й дециль (D9) — это значение, ниже которого опускаются последние 10% наблюдений.
3. Процентиль
Процентиль — это мера, указывающая значение, ниже которого находится определенный процент наблюдений в группе наблюдений. Например, в группе наблюдений 20-й процентиль (P20) — это значение, ниже которого опускаются первые 20% наблюдений, 50-й процентиль (P50) — это значение, ниже которого опускаются средние 50% наблюдений, и 95-й процентиль (P95) — это значение, ниже которого падают последние 95% наблюдений.
50-й процентиль также является медианой, вторым квартилем и 5-м децилем.
Процентиль: Расчет вручную / Microsoft Excel
Процентиль — это мера, используемая в статистике для указания значения, ниже которого находится определенный процент наблюдений в группе наблюдений.
Чтобы найти местоположение определенного процентиля, такие программы, как Minitab, Python, R и Excel, используют следующие шаги:
- Расположите наблюдения в порядке возрастания.
- Используйте формулу для определения положения процентиля, чтобы вычислить положение, в котором будет располагаться значение процентиля, используя желаемое значение процентиля и общее количество наблюдений в качестве входных данных. Существует два подхода: EXC (Exclusive) и INC (Inclusive). Процентное положение в подходе EXC определяется формулой (K(N+1)), а положение в подходе INC определяется формулой (K(N-1)+1).
- Если местоположение процентиля является целым числом, значение в этой позиции в упорядоченном списке наблюдений является значением процентиля.
- Если местоположение процентиля не является целым числом, значение процентиля рассчитывается путем вычисления значения на пропорциональной основе между этими двумя числами.
Чтобы найти 65-й процентиль в группе из 8 наблюдений, вы должны сначала расположить наблюдения в порядке возрастания: 8, 9, 12, 22, 23, 33, 55, 61.
Затем вы должны использовать формулу для местоположения процентиля, чтобы вычислить положение, в котором будет расположен 65-й процентиль:
Для ПРОЦЕНТИЛЬ.ИСКЛ рассчитанный ранг равен (K(N+1)).
Расположение в процентиле (с использованием эксклюзивного подхода) = (left(frac{65}{100}right)(8+1)) = 5,85
Поскольку положение в процентиле не является целым числом, 65-й процентиль будет между 5-м пунктом (номер 23) и 6-м пунктом (номер 33) на пропорциональной основе. Это будет (23+0,85(33-23) = 31,5).
Для PERCENTILE.INC (и PERCENTILE) рассчитанный ранг равен (K(N-1)+1).
Расположение в процентах (с использованием инклюзивного подхода) = ((65/100) (8-1)+1) = 5,55
Поскольку местоположение процентиля не является целым числом, 65-й процентиль будет почти посередине между 5-м элементом (число 23) и 6-м элементом (число 33). Пропорционально получится (23+0,55(33-23)) = 28,5.
Пропорционально получится (23+0,55(33-23)) = 28,5.
Квартиль: пример расчета вручную
Квартиль — это статистическое значение, которое делит набор данных на четыре равные части или четверти. Первый квартиль, также известный как нижний квартиль или Q1, — это значение, которое отделяет самые низкие 25 % данных от остальных. Второй квартиль, также известный как медиана или Q2, представляет собой значение, которое отделяет самые низкие 50% данных от самых высоких 50% данных. Третий квартиль, также известный как верхний квартиль или Q3, — это значение, которое отделяет самые высокие 25% данных от остальных.
Например, если у нас есть следующие числа: 14, 9, 10, 11, 11 и 6, мы можем разделить данные на четыре равные группы, найдя первый, второй и третий квартили.
Чтобы найти квартили набора данных, нам сначала нужно расположить данные в порядке возрастания следующим образом: 6, 9, 10, 11, 11, 14.
Затем нам нужно найти медиану, или Q2, которая является средним значением в наборе данных. В этом случае в наборе данных шесть чисел, поэтому медиана — это среднее значение третьего и четвертого значений, равное 10,5.
В этом случае в наборе данных шесть чисел, поэтому медиана — это среднее значение третьего и четвертого значений, равное 10,5.
Чтобы найти нижний квартиль или Q1, мы берем медиану значений ниже медианы. В данном случае это будет медиана 9. Чтобы найти верхнюю квартиль или Q3, мы берем медиану значений выше медианы. В данном случае это будет медиана 11, 11 и 14, что равно 11.
Таким образом, для этого набора данных квартили: эти числа расчета квартиля не совпадают с расчетом Excel?
Квартиль Использование Excel:
Для расчета квартилей такие программы, как Microsoft Excel и Minitab, используют метод процентилей, как объяснялось ранее. Q1 рассчитывается как 25-й процентиль, Q2 — как 50-й и Q3 — как 75-й процентиль. Это приводит к тому, что значение квартиля иногда отличается от значения, рассчитанного с использованием обычного ручного метода расчета.
Возьмем тот же пример, который мы использовали ранее в ручном расчете для расчета первого квартиля (Q1).
Чтобы найти квартили набора данных, нам сначала нужно расположить данные в порядке возрастания следующим образом: 6, 9, 10, 11, 11, 14.
Вы можете использовать функцию КВАРТИЛЬ.ИСКЛ или КВАРТИЛЬ.ВКЛ. найти квартили набора чисел в Excel.
Quartile.Exc
Для QUARTILE.EXC расчетный ранг равен K*(N+1). Чтобы рассчитать положение Q1 (или 25-го процентиля), подставим в эту формулу соответствующие значения.
Местоположение 1-го квартиля (с использованием эксклюзивного подхода) = (25/100) * (6+1) = 1,75
Поскольку положение процентиля не является целым числом, 1-й квартиль будет между 1-м элементом (номер 6) и 2-м элементом (номер 9) на пропорциональной основе. Получится (6 + (9-6)*0,75) = 8,25.
Использование Minitab: Если вы используете Minitab для расчета Q1, это значение (8,25), которое вы получите в описательной статистике. Minitab использует метод EXC для расчета процентилей и квартилей.
Квартиль.Вкл
Для КВАРТИЛЬ.
Функция КВАРТИЛЬ в Excel используется для расчета квартиля диапазона числовых данных и возвращает соответствующее числовое значение.
Функция КВАРТИЛЬ.ВКЛ вычисляет на основе указанной процентили в качестве второго аргумента функции. Полностью соответствует первой функции. Последняя используется в Excel 2007 и более ранних версиях и оставлена для совместимости.
Функция КВАРТИЛЬ.ИСКЛ используется для расчета квартили диапазона числовых значений на основе известной процентили, за исключением граничных значений (минимального и максимального значения в диапазоне).
Квартили используются для распределения диапазона чисел на четыре равные части:
- Первый квартиль является числом из диапазона исследуемых значений, которое делит данный диапазон на две части так, что около 25% данного диапазона являются числами, которые меньше первого квартиля, а остальные (75%) – больше. Рассматриваемые функции могут возвращать результат интерполяции двух соседних значений из диапазона.
- Второй квартиль эквивалентен медиане выборки (исследуемого числового диапазона), то есть числовому значению, которое делит диапазон на две части: 50% чисел меньше медианы, остальные 50% чисел больше медианы. Так, запись =КВАРТИЛЬ.ВКЛ(A1:A10;2) возвращает значение, эквивалентное результату вычисления функции =МЕДИАНА(A1:A10), при условии, что ячейки из диапазона A1:A10 содержат числовые значения.
- Третий квартиль – числовое значение, делящее диапазон на две части, в первой из которой содержатся 75% чисел диапазона, которые меньше полученного значения, а во второй (25%) – больше.
Функция КВАРТИЛЬ.ВКЛ может быть использована не только для определения медианы выборки (второго квартиля), а и нахождения минимального и максимального значений соответственно. При работе с большими диапазонами чисел для подобных расчетов рекомендуется использовать функции МИН и МАКС соответственно.
Существует несколько алгоритмов расчета квартилей. Все рассмотренные функции используют следующую формулу:
Qp=(1-(x-i)∙Ai+(x-i)∙A(i+1), где:
- Qp – p-й квантиль (является частным случаем квантиля);
- x – индекс квантиля;
- i – индекс элемента из выборки;
- A1,A2…Ai – элементы выборки, отсортированной по возрастанию значений.
Для расчета индекса квантиля (x) функция КВАРТИЛЬ.ВКЛ используют формулу:
x=(n-1)p, где n – количество элементов в диапазоне.
Функция КВАРТИЛЬ.ИСКЛ использует формулу x=(n+1)p.
В Excel принято так, что первые выше указанные 2 функции используют метод N-1-интерполяцию, а третья функция – N+1-интерполяцию.
Примеры использования функций КВАРТИЛЬ в Excel
Пример 1. В столбце таблицы содержится числовая последовательность. Определить число, которое делит последовательность на 2 части, 25% первой – числа меньше полученного значения, а 75% — больше. Использовать N+1-интерполяцию.
Вид таблицы данных:
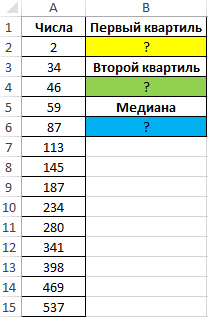
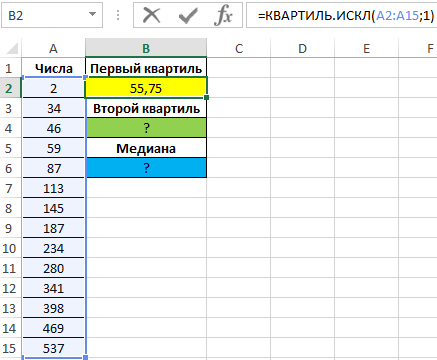
Для определения 1-го квартиля используем функцию:
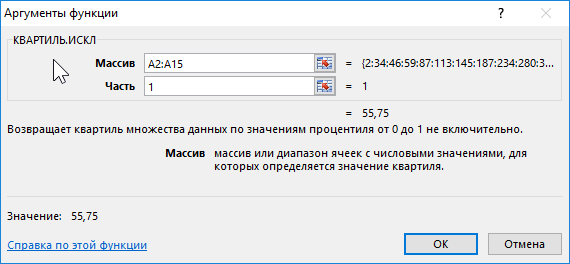
Описание аргументов:
- A2:A15 – диапазон ячеек с исследуемыми числами;
- 1 – номер вычисляемого квартиля.
Полученный результат:
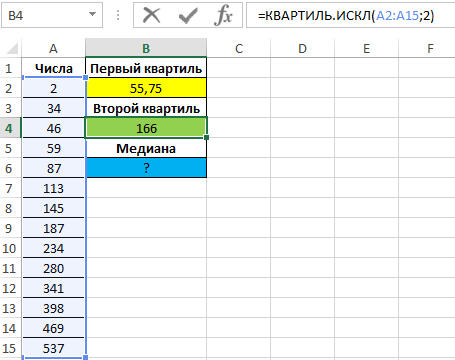
Проверим утверждение о том, что второй квартиль соответствует медиане выборке. Определим 2-й по формуле:
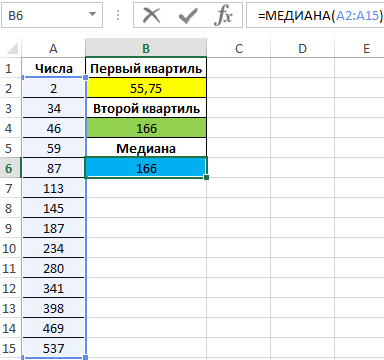
Вычислим медиану:
=МЕДИАНА(A2:A15)
Полученные значения совпадают:
В результате расчетов мы получили первый, второй квартили и медиану для исходного диапазона чисел.
Статистический анализ роста доли дохода в Excel за период
Пример 2. В таблице приведены данные о доходах предпринимателя за год. Доказать, что примерно 75% значений меньше, чем третий квартиль доходов.
Вид исходной таблицы:
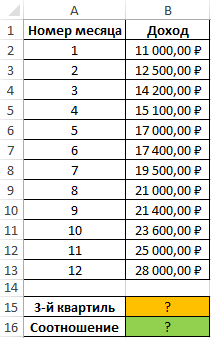
Определим 3-й по формуле:
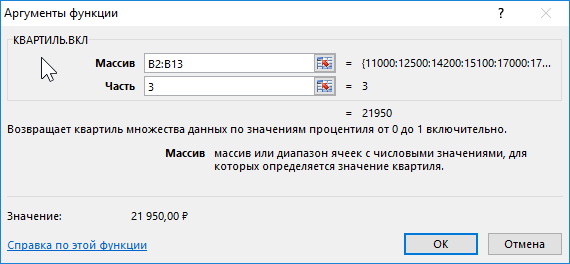
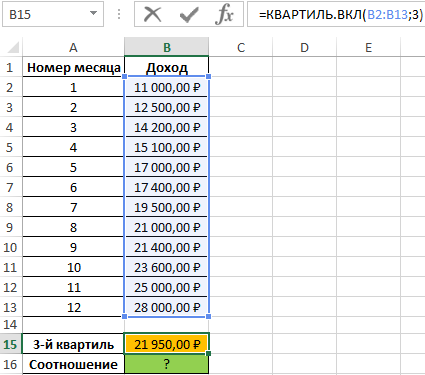
Определим соотношение чисел, меньше полученного числа, к общему количеству значений по формуле:
=СЧЁТЕСЛИ(B2:B13;»<«&B15)/СЧЁТ(B2:B13)
Полученные результаты:
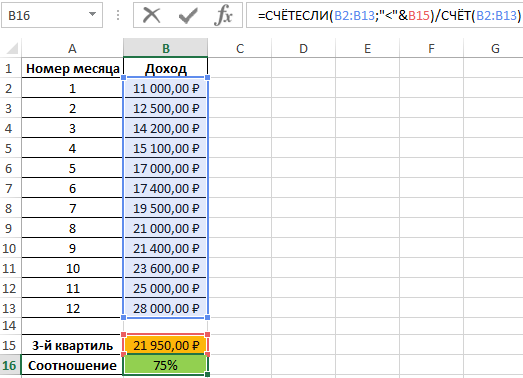
Анализ статистики случайно сгенерированных чисел в Excel
Пример 3. Имеется диапазон случайных чисел, отсортированный в порядке возрастания. Определить соотношение суммы чисел, которые меньше 1-го квартиля, к сумме чисел, которые превышают значение 1-го квартиля.
Чтобы сгенерировать случайное число в Excel воспользуемся функцией:
=СЛУЧМЕЖДУ(0;1000)
После генерации отсортируем случайно сгенерированные числа по возрастанию. Вид исходной таблицы данных со случайными числами:
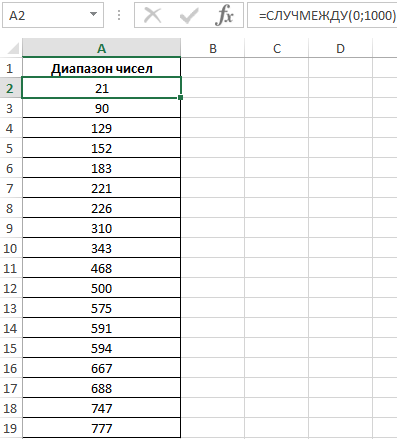
Формула для расчета имеет следующий вид (формула массива CTRL+SHIFT+ENTER):
Функции СУММ с вложенными функциями ЕСЛИ выполняют расчет суммы только тех чисел, которые меньше и больше соответственно значения, возвращаемого функцией для исследуемого диапазона. Из полученных значений вычисляется частное. Результат расчетов:
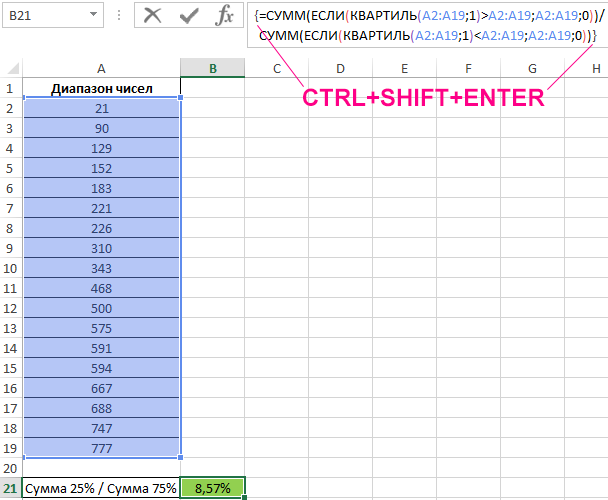
Общая сумма чисел исследуемого диапазона, которые меньше 1-го квартиля, составляет всего 8,57% от общей суммы чисел, которые больше 1-го квартиля.
Особенности использования функций расчета квартиля в Excel
Все рассматриваемые функции имеют одни и те же аргументы:
=КВАРТИЛЬ(массив;часть)
Описание аргументов:
- массив – обязательный аргумент, принимающий константу массива или ссылку на диапазон ячеек с числовыми значениями, для которых будет рассчитан требуемый квартиль;
- часть – обязательный аргумент, принимающий числовые значения, указывающие номер возвращаемого квартиля. В зависимости от используемой функции, может принимать числа из диапазонов:
- От 0 до 4 (КВАРТИЛЬ.ВКЛ), при этом числа 0 и 1 характеризуют минимальное и максимальное значения из исследуемого диапазона соответственно. Число 1 соответствует 1-й квартили, 2 – медиане, 3 – 3-й квартили.
- От 1 до 3 (функция КВАРТИЛЬ.ИСКЛ), соответствующие 1-й, 2-й и 3-й квартилям.
Примечания:
- Все рассматриваемые функции не учитывают имена и текстовые строки, которые не могут быть преобразованы к числам, логические значения и пустые ячейки. Ячейки, содержащие значение 0 (нуль), в расчет включаются.
- Если в качестве первого аргумента функций передан пустой массив или ссылка на диапазон пустых значений, все функции вернут код ошибки #ЧИСЛО!.
- Если в качестве второго аргумента функций было передано нецелое число из диапазона допустимых значений, дробная часть будет усечена.
- Если второй аргумент задан числом, взятым из вне диапазона допустимых значений, в результате вычислений будет возвращен код ошибки #ЧИСЛО!.
В статье подробно показано, что такое нормальный закон распределения случайной величины и как им пользоваться при решении практически задач.
Нормальное распределение в статистике
История закона насчитывает 300 лет. Первым открывателем стал Абрахам де Муавр, который придумал аппроксимацию биномиального распределения еще 1733 году. Через много лет Карл Фридрих Гаусс (1809 г.) и Пьер-Симон Лаплас (1812 г.) вывели математические функции.
Лаплас также обнаружил замечательную закономерность и сформулировал центральную предельную теорему (ЦПТ), согласно которой сумма большого количества малых и независимых величин имеет нормальное распределение.
Нормальный закон не является фиксированным уравнением зависимости одной переменной от другой. Фиксируется только характер этой зависимости. Конкретная форма распределения задается специальными параметрами. Например, у = аx + b – это уравнение прямой. Однако где конкретно она проходит и под каким наклоном, определяется параметрами а и b. Также и с нормальным распределением. Ясно, что это функция, которая описывает тенденцию высокой концентрации значений около центра, но ее точная форма задается специальными параметрами.
Кривая нормального распределения Гаусса имеет следующий вид.

График нормального распределения напоминает колокол, поэтому можно встретить название колоколообразная кривая. У графика имеется «горб» в середине и резкое снижение плотности по краям. В этом заключается суть нормального распределения. Вероятность того, что случайная величина окажется около центра гораздо выше, чем то, что она сильно отклонится от середины.

На рисунке выше изображены два участка под кривой Гаусса: синий и зеленый. Основания, т.е. интервалы, у обоих участков равны. Но заметно отличаются высоты. Синий участок удален от центра, и имеет существенно меньшую высоту, чем зеленый, который находится в самом центре распределения. Следовательно, отличаются и площади, то бишь вероятности попадания в обозначенные интервалы.
Формула нормального распределения (плотности) следующая.
![]()
Формула состоит из двух математических констант:
π – число пи 3,142;
е – основание натурального логарифма 2,718;
двух изменяемых параметров, которые задают форму конкретной кривой:
m – математическое ожидание (в различных источниках могут использоваться другие обозначения, например, µ или a);
σ2 – дисперсия;
ну и сама переменная x, для которой высчитывается плотность вероятности.
Конкретная форма нормального распределения зависит от 2-х параметров: математического ожидания (m) и дисперсии (σ2). Кратко обозначается N(m, σ2) или N(m, σ). Параметр m (матожидание) определяет центр распределения, которому соответствует максимальная высота графика. Дисперсия σ2 характеризует размах вариации, то есть «размазанность» данных.
Параметр математического ожидания смещает центр распределения вправо или влево, не влияя на саму форму кривой плотности.

А вот дисперсия определяет остроконечность кривой. Когда данные имеют малый разброс, то вся их масса концентрируется у центра. Если же у данных большой разброс, то они «размазываются» по широкому диапазону.

Плотность распределения не имеет прямого практического применения. Для расчета вероятностей нужно проинтегрировать функцию плотности.
Вероятность того, что случайная величина окажется меньше некоторого значения x, определяется функцией нормального распределения:
![]()
Используя математические свойства любого непрерывного распределения, несложно рассчитать и любые другие вероятности, так как
P(a ≤ X < b) = Ф(b) – Ф(a)
Стандартное нормальное распределение
Нормальное распределение зависит от параметров средней и дисперсии, из-за чего плохо видны его свойства. Хорошо бы иметь некоторый эталон распределения, не зависящий от масштаба данных. И он существует. Называется стандартным нормальным распределением. На самом деле это обычное нормальное нормальное распределение, только с параметрами математического ожидания 0, а дисперсией – 1, кратко записывается N(0, 1).
Любое нормальное распределение легко превращается в стандартное путем нормирования:
![]()
где z – новая переменная, которая используется вместо x;
m – математическое ожидание;
σ – стандартное отклонение.
Для выборочных данных берутся оценки:
![]()
Среднее арифметическое и дисперсия новой переменной z теперь также равны 0 и 1 соответственно. В этом легко убедиться с помощью элементарных алгебраических преобразований.
В литературе встречается название z-оценка. Это оно самое – нормированные данные. Z-оценку можно напрямую сравнивать с теоретическими вероятностями, т.к. ее масштаб совпадает с эталоном.
Посмотрим теперь, как выглядит плотность стандартного нормального распределения (для z-оценок). Напомню, что функция Гаусса имеет вид:
![]()
Подставим вместо (x-m)/σ букву z, а вместо σ – единицу, получим функцию плотности стандартного нормального распределения:
![]()
График плотности:

Центр, как и ожидалось, находится в точке 0. В этой же точке функция Гаусса достигает своего максимума, что соответствует принятию случайной величиной своего среднего значения (т.е. x-m=0). Плотность в этой точке равна 0,3989, что можно посчитать даже в уме, т.к. e0=1 и остается рассчитать только соотношение 1 на корень из 2 пи.
Таким образом, по графику хорошо видно, что значения, имеющие маленькие отклонения от средней, выпадают чаще других, а те, которые сильно отдалены от центра, встречаются значительно реже. Шкала оси абсцисс измеряется в стандартных отклонениях, что позволяет отвязаться от единиц измерения и получить универсальную структуру нормального распределения. Кривая Гаусса для нормированных данных отлично демонстрирует и другие свойства нормального распределения. Например, что оно является симметричным относительно оси ординат. В пределах ±1σ от средней арифметической сконцентрирована большая часть всех значений (прикидываем пока на глазок). В пределах ±2σ находятся большинство данных. В пределах ±3σ находятся почти все данные. Последнее свойство широко известно под названием правило трех сигм для нормального распределения.
Функция стандартного нормального распределения позволяет рассчитывать вероятности.
![]()
Понятное дело, вручную никто не считает. Все подсчитано и размещено в специальных таблицах, которые есть в конце любого учебника по статистике.
Таблица нормального распределения
Таблицы нормального распределения встречаются двух типов:
— таблица плотности;
— таблица функции (интеграла от плотности).
Таблица плотности используется редко. Тем не менее, посмотрим, как она выглядит. Допустим, нужно получить плотность для z = 1, т.е. плотность значения, отстоящего от матожидания на 1 сигму. Ниже показан кусок таблицы.

В зависимости от организации данных ищем нужное значение по названию столбца и строки. В нашем примере берем строку 1,0 и столбец 0, т.к. сотых долей нет. Искомое значение равно 0,2420 (0 перед 2420 опущен).
Функция Гаусса симметрична относительно оси ординат. Поэтому φ(z)= φ(-z), т.е. плотность для 1 тождественна плотности для -1, что отчетливо видно на рисунке.

Чтобы не тратить зря бумагу, таблицы печатают только для положительных значений.
На практике чаще используют значения функции стандартного нормального распределения, то есть вероятности для различных z.
В таких таблицах также содержатся только положительные значения. Поэтому для понимания и нахождения любых нужных вероятностей следует знать свойства стандартного нормального распределения.
Функция Ф(z) симметрична относительно своего значения 0,5 (а не оси ординат, как плотность). Отсюда справедливо равенство:
![]()
Это факт показан на картинке:

Значения функции Ф(-z) и Ф(z) делят график на 3 части. Причем верхняя и нижняя части равны (обозначены галочками). Для того, чтобы дополнить вероятность Ф(z) до 1, достаточно добавить недостающую величину Ф(-z). Получится равенство, указанное чуть выше.
Если нужно отыскать вероятность попадания в интервал (0; z), то есть вероятность отклонения от нуля в положительную сторону до некоторого количества стандартных отклонений, достаточно от значения функции стандартного нормального распределения отнять 0,5:
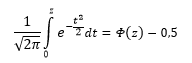
Для наглядности можно взглянуть на рисунок.

На кривой Гаусса, эта же ситуация выглядит как площадь от центра вправо до z.

Довольно часто аналитика интересует вероятность отклонения в обе стороны от нуля. А так как функция симметрична относительно центра, предыдущую формулу нужно умножить на 2:

Рисунок ниже.

Под кривой Гаусса это центральная часть, ограниченная выбранным значением –z слева и z справа.

Указанные свойства следует принять во внимание, т.к. табличные значения редко соответствуют интересующему интервалу.
Для облегчения задачи в учебниках обычно публикуют таблицы для функции вида:

Если нужна вероятность отклонения в обе стороны от нуля, то, как мы только что убедились, табличное значение для данной функции просто умножается на 2.
Теперь посмотрим на конкретные примеры. Ниже показана таблица стандартного нормального распределения. Найдем табличные значения для трех z: 1,64, 1,96 и 3.

Как понять смысл этих чисел? Начнем с z=1,64, для которого табличное значение составляет 0,4495. Проще всего пояснить смысл на рисунке.

То есть вероятность того, что стандартизованная нормально распределенная случайная величина попадет в интервал от 0 до 1,64, равна 0,4495. При решении задач обычно нужно рассчитать вероятность отклонения в обе стороны, поэтому умножим величину 0,4495 на 2 и получим примерно 0,9. Занимаемая площадь под кривой Гаусса показана ниже.

Таким образом, 90% всех нормально распределенных значений попадает в интервал ±1,64σ от средней арифметической. Я не случайно выбрал значение z=1,64, т.к. окрестность вокруг средней арифметической, занимающая 90% всей площади, иногда используется для проверки статистических гипотез и расчета доверительных интервалов. Если проверяемое значение не попадает в обозначенную область, то его наступление маловероятно (всего 10%).
Для проверки гипотез, однако, чаще используется интервал, накрывающий 95% всех значений. Половина вероятности от 0,95 – это 0,4750 (см. второе выделенное в таблице значение).

Для этой вероятности z=1,96. Т.е. в пределах почти ±2σ от средней находится 95% значений. Только 5% выпадают за эти пределы.

Еще одно интересное и часто используемое табличное значение соответствует z=3, оно равно по нашей таблице 0,4986. Умножим на 2 и получим 0,997. Значит, в рамках ±3σ от средней арифметической заключены почти все значения.

Так выглядит правило 3 сигм для нормального распределения на диаграмме.
С помощью статистических таблиц можно получить любую вероятность. Однако этот метод очень медленный, неудобный и сильно устарел. Сегодня все делается на компьютере. Далее переходим к практике расчетов в Excel.
В Excel есть несколько функций для подсчета вероятностей или обратных значений нормального распределения.

Функция НОРМ.СТ.РАСП
Функция НОРМ.СТ.РАСП предназначена для расчета плотности ϕ(z) или вероятности Φ(z) по нормированным данным (z).
=НОРМ.СТ.РАСП(z;интегральная)
z – значение стандартизованной переменной
интегральная – если 0, то рассчитывается плотность ϕ(z), если 1 – значение функции Ф(z), т.е. вероятность P(Z<z).
Рассчитаем плотность и значение функции для различных z: -3, -2, -1, 0, 1, 2, 3 (их укажем в ячейке А2).
Для расчета плотности потребуется формула =НОРМ.СТ.РАСП(A2;0). На диаграмме ниже – это красная точка.
Для расчета значения функции =НОРМ.СТ.РАСП(A2;1). На диаграмме – закрашенная площадь под нормальной кривой.

В реальности чаще приходится рассчитывать вероятность того, что случайная величина не выйдет за некоторые пределы от средней (в среднеквадратичных отклонениях, соответствующих переменной z), т.е. P(|Z|<z).

Определим, чему равна вероятность попадания случайной величины в пределы ±1z, ±2z и ±3z от нуля. Потребуется формула 2Ф(z)-1, в Excel =2*НОРМ.СТ.РАСП(A2;1)-1.

На диаграмме отлично видны основные основные свойства нормального распределения, включая правило трех сигм. Функция НОРМ.СТ.РАСП – это автоматическая таблица значений функции нормального распределения в Excel.
Может стоять и обратная задача: по имеющейся вероятности P(Z<z) найти стандартизованную величину z ,то есть квантиль стандартного нормального распределения.
Функция НОРМ.СТ.ОБР
НОРМ.СТ.ОБР рассчитывает обратное значение функции стандартного нормального распределения. Синтаксис состоит из одного параметра:
=НОРМ.СТ.ОБР(вероятность)
вероятность – это вероятность.
Данная формула используется так же часто, как и предыдущая, ведь по тем же таблицам искать приходится не только вероятности, но и квантили.

Например, при расчете доверительных интервалов задается доверительная вероятность, по которой нужно рассчитать величину z.

Учитывая то, что доверительный интервал состоит из верхней и нижней границы и то, что нормальное распределение симметрично относительно нуля, достаточно получить верхнюю границу (положительное отклонение). Нижняя граница берется с отрицательным знаком. Обозначим доверительную вероятность как γ (гамма), тогда верхняя граница доверительного интервала рассчитывается по следующей формуле.
![]()
Рассчитаем в Excel значения z (что соответствует отклонению от средней в сигмах) для нескольких вероятностей, включая те, которые наизусть знает любой статистик: 90%, 95% и 99%. В ячейке B2 укажем формулу: =НОРМ.СТ.ОБР((1+A2)/2). Меняя значение переменной (вероятности в ячейке А2) получим различные границы интервалов.

Доверительный интервал для 95% равен 1,96, то есть почти 2 среднеквадратичных отклонения. Отсюда легко даже в уме оценить возможный разброс нормальной случайной величины. В общем, доверительным вероятностям 90%, 95% и 99% соответствуют доверительные интервалы ±1,64, ±1,96 и ±2,58 σ.
В целом функции НОРМ.СТ.РАСП и НОРМ.СТ.ОБР позволяют произвести любой расчет, связанный с нормальным распределением. Но, чтобы облегчить и уменьшить количество действий, в Excel есть несколько других функций. Например, для расчета доверительных интервалов средней можно использовать ДОВЕРИТ.НОРМ. Для проверки статистической гипотезы о средней арифметической есть формула Z.ТЕСТ.
Рассмотрим еще пару полезных формул с примерами.
Функция НОРМ.РАСП
Функция НОРМ.РАСП отличается от НОРМ.СТ.РАСП лишь тем, что ее используют для обработки данных любого масштаба, а не только нормированных. Параметры нормального распределения указываются в синтаксисе.
=НОРМ.РАСП(x;среднее;стандартное_откл;интегральная)
x – значение (или ссылка на ячейку), для которого рассчитывается плотность или значение функции нормального распределения
среднее – математическое ожидание, используемое в качестве первого параметра модели нормального распределения
стандартное_откл – среднеквадратичное отклонение – второй параметр модели
интегральная – если 0, то рассчитывается плотность, если 1 – то значение функции, т.е. P(X<x).
Например, плотность для значения 15, которое извлекли из нормальной выборки с матожиданием 10, стандартным отклонением 3, рассчитывается так:

Если последний параметр поставить 1, то получим вероятность того, что нормальная случайная величина окажется меньше 15 при заданных параметрах распределения. Таким образом, вероятности можно рассчитывать напрямую по исходным данным.
Функция НОРМ.ОБР
Это квантиль нормального распределения, т.е. значение обратной функции. Синтаксис следующий.
=НОРМ.ОБР(вероятность;среднее;стандартное_откл)
вероятность – вероятность
среднее – матожидание
стандартное_откл – среднеквадратичное отклонение
Назначение то же, что и у НОРМ.СТ.ОБР, только функция работает с данными любого масштаба.
Пример показан в ролике в конце статьи.
Моделирование нормального распределения
Для некоторых задач требуется генерация нормальных случайных чисел. Готовой функции для этого нет. Однако В Excel есть две функции, которые возвращают случайные числа: СЛУЧМЕЖДУ и СЛЧИС. Первая выдает случайные равномерно распределенные целые числа в указанных пределах. Вторая функция генерирует равномерно распределенные случайные числа между 0 и 1. Чтобы сделать искусственную выборку с любым заданным распределением, нужна функция СЛЧИС.
Допустим, для проведения эксперимента необходимо получить выборку из нормально распределенной генеральной совокупности с матожиданием 10 и стандартным отклонением 3. Для одного случайного значения напишем формулу в Excel.
=НОРМ.ОБР(СЛЧИС();10;3)
Протянем ее на необходимое количество ячеек и нормальная выборка готова.
Для моделирования стандартизованных данных следует воспользоваться НОРМ.СТ.ОБР.
Процесс преобразования равномерных чисел в нормальные можно показать на следующей диаграмме. От равномерных вероятностей, которые генерируются формулой СЛЧИС, проведены горизонтальные линии до графика функции нормального распределения. Затем от точек пересечения вероятностей с графиком опущены проекции на горизонтальную ось.

На выходе получаются значения с характерной концентрацией около центра. Вот так обратный прогон через функцию нормального распределения превращает равномерные числа в нормальные. Excel позволяет за несколько секунд воспроизвести любое количество выборок любого размера.
Как обычно, прилагаю ролик, где все вышеописанное показывается в действии.
Скачать файл с примером.
Поделиться в социальных сетях:
A Q-Q plot, short for “quantile-quantile” plot, is often used to assess whether or not a set of data potentially came from some theoretical distribution. In most cases, this type of plot is used to determine whether or not a set of data follows a normal distribution.
This tutorial explains how to create a Q-Q plot for a set of data in Excel.
Example: Q-Q Plot in Excel
Perform the follow steps to create a Q-Q plot for a set of data.
Step 1: Enter and sort the data.
Enter the following data into one column:

Note that this data is already sorted from smallest to largest. If your data is not already sorted, go to the Data tab along the top ribbon in Excel, then go to the Sort & Filter group, then click the Sort A to Z icon.
Step 2: Find the rank of each data value.
Next, use the following formula to calculate the rank of the first value:
=RANK(A2, $A$2:$A$11, 1)

Copy this formula down to all of the other cells in the column:

Step 3: Find the percentile of each data value.
Next, use the following formula to calculate the percentile of the first value:
=(B2-0.5)/COUNT($B$2:$B$11)

Copy this formula down to all of the other cells in the column:

Step 4: Calculate the z-score for each data value.
Use the following formula to calculate the z-score for the first data value:
=NORM.S.INV(C2)

Copy this formula down to all of the other cells in the column:

Step 5: Create the Q-Q plot.
Copy the original data from column A into column E, then highlight the data in columns D and E.

Along the top ribbon, go to Insert. Within the Charts group, choose Insert Scatter (X, Y) and click the option that says Scatter. This will produce the follow Q-Q plot:

Click the plus sign on the top right-hand corner of the graph and check the box next to Trendline. This will add the following line to the chart:

Feel free to add labels for the title and axes of the graph to make it more aesthetically pleasing:

The way to interpret a Q-Q plot is simple: if the data values fall along a roughly straight line at a 45-degree angle, then the data is normally distributed. We can see in our Q-Q plot above that the data values tend to deviate from the 45-degree line quite a bit, especially on the tail ends, which could be an indication that the data set is not normally distributed.
Although a Q-Q plot isn’t a formal statistical test, it offers an easy way to visually check whether or not a data set is normally distributed.
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
Возвращает квартиль множества данных. Квартиль часто используются при анализе продаж для разбиения генеральной совокупности на группы. Например, можно воспользоваться функцией КВАРТИЛЬ, чтобы найти среди всех предприятий 25 процентов наиболее доходных.
Важно: Эта функция была заменена одной или несколькими новыми функциями, которые обеспечивают более высокую точность и имеют имена, лучше отражающие их назначение. Хотя эта функция все еще используется для обеспечения обратной совместимости, она может стать недоступной в последующих версиях Excel, поэтому мы рекомендуем использовать новые функции.
Дополнительные сведения о новых функциях см. в разделах Функция КВАРТИЛЬ.ИСКЛ и Функция КВАРТИЛЬ.ВКЛ.
Синтаксис
КВАРТИЛЬ(массив;часть)
Аргументы функции КВАРТИЛЬ описаны ниже.
-
Массив Обязательный. Массив или диапазон ячеек с числовыми значениями, для которых определяется значение квартиля.
-
Часть Обязательный. Значение, которое требуется вернуть.
|
Если часть равна |
КВАРТИЛЬ возвращает |
|---|---|
|
0 |
Минимальное значение |
|
1 |
Первую квартиль (25-ю персентиль) |
|
2 |
Значение медианы (50-ю персентиль) |
|
3 |
Третью квартиль (75-ю персентиль) |
|
4 |
Максимальное значение |
Замечания
-
Если массив пуст, КВАРТИЛЬ возвращает #NUM! значение ошибки #ЗНАЧ!.
-
Если значение аргумента «часть» не является целым числом, то оно усекается.
-
Если кварт < 0 или > 4, кВАРТИЛЬ возвращает #NUM! значение ошибки #ЗНАЧ!.
-
Функции МИН, МЕДИАНА и МАКС возвращают то же значение, что и функция КВАРТИЛЬ, если аргумент «часть» равен соответственно 0, 2 или 4.
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Данные |
||
|---|---|---|
|
1 |
||
|
2 |
||
|
4 |
||
|
7 |
||
|
8 |
||
|
9 |
||
|
10 |
||
|
12 |
||
|
Формула |
Описание (результат) |
Результат |
|
=КВАРТИЛЬ(A2:A9;1) |
Первая квартиль (25-я процентиль) для приведенных выше данных (3,5) |
3,5 |
Нужна дополнительная помощь?
События,
характеризующие данные, могут носить
случайный характер и появляться с разной
вероятностью.
Вероятность
события p
есть отношение числа благоприятных
исходов m
к числу всех возможных исходов n
этого
события:
p=m/n.
Например, вероятность появления туза
в наугад выбранной карте из колоды в 52
карты равна 4/52=0.0769, так как m=4,
а n=52.
Если
известно соответствие между появлениями
(величинами) x1,
x2,
…, xn
случайного события (переменной)
X
и
соответствующими вероятностями их
реализации p1,
p2,
…, pn,
то говорят, что известен закон
распределения случайной величины
F(x).
Большинство встречающихся на практике
распределений вероятностей реализовано
в Excel.
Распределения
вероятностей имеют числовые характеристики.
Функции
Excel
для вычисления числовых характеристик
распределения вероятностей. Они входят
в группу Статистические.
При вычислении функций в качестве
случайных величин используйте следующие
значения:

Математическое
ожидание
случайной величины (среднее арифметическое),
характеризующее центр распределения
вероятностей, вычисляется функцией
СРЗНАЧ. СРЗНАЧ(A1:A7)
= 9.
Дисперсия,
характеризует разброс случайной величины
относительно центра распределения
вероятностей и вычисляется функцией
ДИСПР. ДИСПР(A1:A7)
= 4.857.
Среднеквадратичное
отклонение
есть квадратный корень из дисперсии,
характеризует разброс случайной величины
в единицах случайной величины и
вычисляется функцией СТАНДОТКЛОНП.
СТАНДОТКЛОНП(A1:A7) = 2.203893.
Квантиль
случайной величины с законом распределения
F(x)
есть значение случайной величины x
при заданной вероятности p.,
т.е. есть решение уравнения F(x)=p.
Медиана
есть квантиль с вероятностью p=0.5.
Excel,
вместо квантилей содержит функции
вычисления х
для определенных уровней р:
квартили
(кварта – четверть), децили
(дециль
– десятая часть),
персентили
(персент – процент). Различают нижний
квартиль с вероятностью p=0.25
и верхний квартиль с вероятностью
p=0.75.
Децили это квантили с вероятностью 0.1,
0.2, …, 0.9.
Функцию
КВАРТИЛЬ используют, чтобы разбить
данные на группы. В качестве второго
аргумента указывают уровень (четверть),
для которого нужно вернуть решение: 0 –
минимальное значение распределения, 1
– первый, нижний квартиль, 2 – медиана,
3 – третий, верхний квартиль, 4 –
максимальное значение. Например,
КВАРТИЛЬ(A1:A7;3)
= 10, т.е. 75% всех значений меньше 10,
КВАРТИЛЬ(A1:A7;2) = 9.
Функция
ПЕРСЕНТИЛЬ вычисляет квантиль указанного
уровня вероятности и используется для
определения порога приемлемости
значений. В качестве второго аргумента
указывают уровень 0.1, 0.2, …, 0.9.
ПЕРСЕНТИЛЬ(A1:A7;0,9) = 11.8, т.е. 90% всех значений
меньше 11.8.
Excel
содержит инструмент Ранг
и персентиль,
который на основе набора данных формирует
выходную таблицу, содержащую порядковый
и процентный ранги для каждого значения
в наборе данных. См. справку по F1.
Ниже приведен пример установки надстройки
Пактет
анализа

Распределения
вероятностей, реализованные в Excel.
Каждый
закон распределения описывает процессы
разной вероятностной природы и
характеризуется специфическими
параметрами:
-
равномерное
распределение
– n
случайных чисел выпадает с одной и той
же вероятностью p=1/n;
характеризуется нижней и верхней
границей; примером является появление
чисел 1, 2, …, 6 при бросании игральной
кости (p=1/6); -
биномиальное
распределение
моделирует взаимосвязь числа успешных
испытаний m
и вероятностей успеха каждого испытания
p
при общем количестве испытаний n
— функции БИНОМРАСП и КРИТБИНОМ; -
нормальное
(гауссово) распределение
описывает процессы, в которых на
результат воздействует большое число
независимых случайных факторов, среди
которых нет сильно выделяющихся –
функции НОРМРАСП, НОРМСТРАСП, НОРМОБР,
НОРМСТОБР и НОРМАЛИЗАЦИЯ; -
распределение
Пуассона, предсказывает
число случайных событий на определенном
отрезке времени или на определенном
пространстве, позволяет аппроксимировать
биномиальное распределение – функция
ПУАССОН; -
экспоненциальное
(показательное) распределение,
моделирует временные задержки между
событиями, описывает процессы в задачах
массового обслуживания и в задачах с
«временем жизни» — ЭКСПРАСП; -
распределение
хи-квадрат,
связано с нормальным, возвращает
одностороннюю вероятность распределения
и используется для сравнения предполагаемых
и наблюдаемых значений – функция
ХИ2РАСП; -
распределение
Стьюдента,
связано с нормальным, возвращает
вероятность для t-распределения Стьюдента
и используется для проверки гипотез
при малом объеме выборки – функция
СТЬЮДРАСП; -
F-распределение
(Фишера), связано с нормальным и может
быть использовано в F-тесте, который
сравнивает степени разброса двух
множеств данных – fраспобр; -
гамма-распределение
используется для изучения случайных
величин, имеющих асимметричное
распределение, в теории очередей –
функция ГАММАРАСП; -
а
также другие распределения – функции
БЕТАРАСП, ВЕЙБУЛЛ, ОТРБИНОМРАСП,
ГИПЕРГЕОМЕТ, ЛОГНОРМРАСП и др.
Биномиальное
распределение
характеризуется
числом успешных испытаний m,
вероятностью успеха каждого испытания
p
и общим количеством испытаний n.
Классическим примером использования
биномиального распределения является
выборочный контроль качества больших
партий товара, изделий в торговле, на
производстве, когда сплошная проверка
невозможна. Из партии выбирают n
образцов и регистрируют число бракованных
m.
Бракованными могут быть 1, 2, … , n
образцов, но вероятности реального
числа бракованных будут различными.
Если контрольная вероятность брака
ниже допустимой вероятности, то можно
гарантировать достаточное качество
всей партии.
В
Excel
функция БИНОМРАСП вычисляет вероятность
отдельного значения распределения по
заданным m,
n
и р,
а функция КРИТБИНОМ – случайное число
по заданной вероятности. Обычно функция
КРИТБИНОМ используется для определения
наибольшего допустимого числа брака.
В
качестве примера построим график
плотности вероятности биномиального
распределения для n=10
(1, 2, …, 10) и p=0.2.
Введите исходные данные, как показано
на рисунке:

Далее
в ячейку В4 введите статистическую
функцию БИНОМРАСП и заполните ее
параметры как показано на рисунке:

Здесь
параметр Число_s
есть число успешных испытаний m,
Испытания
– число независимых испытаний n,
Вероятность_s
–
вероятность успеха каждого испытания
p.
Параметр Интегральный
равен 0, если требуется получить плотность
распределения (вероятность для значения
m),
и равен 1, если требуется получить
вероятность с накоплением (вероятность
того, что число успешных испытаний не
меньше значения аргумента Число_s).
Формулу
из В4 размножьте в ячейки В5:В13. Ниже
показан результат:

В
колонке В вычислены вероятности успешных
испытаний m=1,
2, …, 10. Теперь по диапазону В4:В13 постройте
график или гистограмму биномиальной
функции плотности распределения –
результат на рисунке. Поэкспериментируйте,
изменяя значение вероятности в ячейке
В1: 0.3, 0.4, 0.8, проследите за изменениями
формы графика.

Для
иллюстрации функции КРИТБИНОМ используем
предыдущий пример – необходимо найти
число m,
для которого вероятность интегрального
распределения больше или равна 0.75.
Вызовите функцию КРИТБИНОМ и заполните
параметры. Вы должны получить значение
3. Это означает, что при вероятности
интегрального распределения >= 0.75
будет не менее трех (m>=3)
успешных испытаний.
Нормальное
распределение
характеризуется
средним арифметическим (математическим
ожиданием) m
и стандартным (среднеквадратичным)
отклонением r.
Дисперсия равна r2.
Краткое обозначение распределения
N(m,r2).
График нормального распределения
симметричен относительно центра
распределения (точки m),
чем меньше r,
тем больше вероятность появления
случайной величины. В пределы [m—r,m+r]
нормально распределенная случайная
величина попадает с вероятностью 0,683 в
пределы [m-2r,m+2r]
— с вероятностью 0,955 и т.д.

При
m=0
и r=1
нормальное распределение называется
стандартным
или нормированным – N(0,1).
Нормальное
распределение имеет очень широкий круг
приложений. В качестве примера построим
график плотности вероятностей нормального
распределения при m=15
и r=1,5
в диапазоне [m-3r,m+3r]
c
шагом 0,5. Результат показан на рисунке.

Выполните
следующие действия:
-
в
ячейку А4 введите формулу =B1-3*B2, в ячейку
А5 формулу =A4+B$3 и размножьте ее по ячейку
А22; -
в
ячейку В4 введите функцию НОРМРАСП из
группы Статистические
– параметры заполните как на рисунке; -
размножьте
формулу из ячейки В4 по ячейку В22 и по
диапазону В4:В22 постройте график; на
2-ом шаге мастера диаграмм в закладке
Ряд
введите подписи к оси х
из диапазона А4:А22.

Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #