
В Python данные из файла Excel считываются в объект DataFrame. Для этого используется функция read_excel() модуля pandas.
Лист Excel — это двухмерная таблица. Объект DataFrame также представляет собой двухмерную табличную структуру данных.
- Пример использования Pandas read_excel()
- Список заголовков столбцов листа Excel
- Вывод данных столбца
- Пример использования Pandas to Excel: read_excel()
- Чтение файла Excel без строки заголовка
- Лист Excel в Dict, CSV и JSON
- Ресурсы

Предположим, что у нас есть документ Excel, состоящий из двух листов: «Employees» и «Cars». Верхняя строка содержит заголовок таблицы.

Ниже приведен код, который считывает данные листа «Employees» и выводит их.
import pandas
excel_data_df = pandas.read_excel('records.xlsx', sheet_name='Employees')
# print whole sheet data
print(excel_data_df)
Вывод:
EmpID EmpName EmpRole 0 1 Pankaj CEO 1 2 David Lee Editor 2 3 Lisa Ray Author
Первый параметр, который принимает функция read_excel ()— это имя файла Excel. Второй параметр (sheet_name) определяет лист для считывания данных.
При выводе содержимого объекта DataFrame мы получаем двухмерные таблицы, схожие по своей структуре со структурой документа Excel.
Чтобы получить список заголовков столбцов таблицы, используется свойство columns объекта Dataframe. Пример реализации:
print(excel_data_df.columns.ravel())
Вывод:
['Pankaj', 'David Lee', 'Lisa Ray']
Мы можем получить данные из столбца и преобразовать их в список значений. Пример:
print(excel_data_df['EmpName'].tolist())
Вывод:
['Pankaj', 'David Lee', 'Lisa Ray']
Можно указать имена столбцов для чтения из файла Excel. Это потребуется, если нужно вывести данные из определенных столбцов таблицы.
import pandas
excel_data_df = pandas.read_excel('records.xlsx', sheet_name='Cars', usecols=['Car Name', 'Car Price'])
print(excel_data_df)
Вывод:
Car Name Car Price 0 Honda City 20,000 USD 1 Bugatti Chiron 3 Million USD 2 Ferrari 458 2,30,000 USD
Если в листе Excel нет строки заголовка, нужно передать его значение как None.
excel_data_df = pandas.read_excel('records.xlsx', sheet_name='Numbers', header=None)
Если вы передадите значение заголовка как целое число (например, 3), тогда третья строка станет им. При этом считывание данных начнется со следующей строки. Данные, расположенные перед строкой заголовка, будут отброшены.
Объект DataFrame предоставляет различные методы для преобразования табличных данных в формат Dict , CSV или JSON.
excel_data_df = pandas.read_excel('records.xlsx', sheet_name='Cars', usecols=['Car Name', 'Car Price'])
print('Excel Sheet to Dict:', excel_data_df.to_dict(orient='record'))
print('Excel Sheet to JSON:', excel_data_df.to_json(orient='records'))
print('Excel Sheet to CSV:n', excel_data_df.to_csv(index=False))
Вывод:
Excel Sheet to Dict: [{'Car Name': 'Honda City', 'Car Price': '20,000 USD'}, {'Car Name': 'Bugatti Chiron', 'Car Price': '3 Million USD'}, {'Car Name': 'Ferrari 458', 'Car Price': '2,30,000 USD'}]
Excel Sheet to JSON: [{"Car Name":"Honda City","Car Price":"20,000 USD"},{"Car Name":"Bugatti Chiron","Car Price":"3 Million USD"},{"Car Name":"Ferrari 458","Car Price":"2,30,000 USD"}]
Excel Sheet to CSV:
Car Name,Car Price
Honda City,"20,000 USD"
Bugatti Chiron,3 Million USD
Ferrari 458,"2,30,000 USD"
- Документы API pandas read_excel()
Хотя многие Data Scientist’ы больше привыкли работать с CSV-файлами, на практике очень часто приходится сталкиваться с обычными Excel-таблицами. Поэтому сегодня мы расскажем, как читать Excel-файлы в Pandas, а также рассмотрим основные возможности Python-библиотеки OpenPyXL для чтения метаданных ячеек.
Дополнительные зависимости для возможности чтения Excel таблиц
Для чтения таблиц Excel в Pandas требуются дополнительные зависимости:
- xlrd поддерживает старые и новые форматы MS Excel [1];
- OpenPyXL поддерживает новые форматы MS Excel (.xlsx) [2];
- ODFpy поддерживает свободные форматы OpenDocument (.odf, .ods и .odt) [3];
- pyxlsb поддерживает бинарные MS Excel файлы (формат .xlsb) [4].
Мы рекомендуем установить только OpenPyXL, поскольку он нам пригодится в дальнейшем. Для этого в командной строке прописывается следующая операция:
pip install openpyxl
Затем в Pandas нужно указать путь к Excel-файлу и одну из установленных зависимостей. Python-код выглядит следующим образом:
import pandas as pd
pd.read_excel(io='temp1.xlsx', engine='openpyxl')
#
Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64
Читаем несколько листов
Excel-файл может содержать несколько листов. В Pandas, чтобы прочитать конкретный лист, в аргументе нужно указать sheet_name. Можно указать список названий листов, тогда Pandas вернет словарь (dict) с объектами DataFrame:
dfs = pd.read_excel(io='temp1.xlsx',
engine='openpyxl',
sheet_name=['Sheet1', 'Sheet2'])
dfs
#
{'Sheet1': Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64,
'Sheet2': Name Age Weight
0 Gosha 43 95
1 Anna 24 65
2 Lena 22 78}
Если таблицы в словаре имеют одинаковые атрибуты, то их можно объединить в один DataFrame. В Python это выглядит так:
pd.concat(dfs).reset_index(drop=True)
Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64
3 Gosha 43 95
4 Anna 24 65
5 Lena 22 78
Указание диапазонов
Таблицы могут размещаться не в самом начале, а как, например, на рисунке ниже. Как видим, таблица располагается в диапазоне A:F.
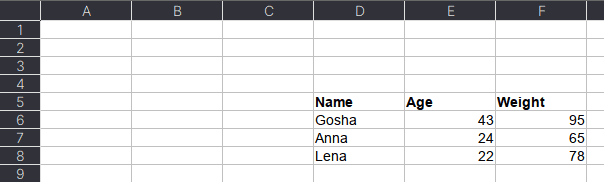
Чтобы прочитать такую таблицу, нужно указать диапазон в аргументе usecols. Также дополнительно можно добавить header — номер заголовка таблицы, а также nrows — количество строк, которые нужно прочитать. В аргументе header всегда передается номер строки на единицу меньше, чем в Excel-файле, поскольку в Python индексация начинается с 0 (на рисунке это номер 5, тогда указываем 4):
pd.read_excel(io='temp1.xlsx',
engine='openpyxl',
usecols='D:F',
header=4, # в excel это №5
nrows=3)
#
Name Age Weight
0 Gosha 43 95
1 Anna 24 65
2 Lena 22 78
Читаем таблицы в OpenPyXL
Pandas прочитывает только содержимое таблицы, но игнорирует метаданные: цвет заливки ячеек, примечания, стили таблицы и т.д. В таком случае пригодится библиотека OpenPyXL. Загрузка файлов осуществляется через функцию load_workbook, а к листам обращаться можно через квадратные скобки:
from openpyxl import load_workbook
wb = load_workbook('temp2.xlsx')
ws = wb['Лист1']
type(ws)
# openpyxl.worksheet.worksheet.Worksheet
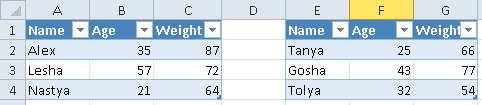
Допустим, имеется Excel-файл с несколькими таблицами на листе (см. рисунок выше). Если бы мы использовали Pandas, то он бы выдал следующий результат:
pd.read_excel(io='temp2.xlsx',
engine='openpyxl')
#
Name Age Weight Unnamed: 3 Name.1 Age.1 Weight.1
0 Alex 35 87 NaN Tanya 25 66
1 Lesha 57 72 NaN Gosha 43 77
2 Nastya 21 64 NaN Tolya 32 54
Можно, конечно, заняться обработкой и привести таблицы в нормальный вид, а можно воспользоваться OpenPyXL, который хранит таблицу и его диапазон в словаре. Чтобы посмотреть этот словарь, нужно вызвать ws.tables.items. Вот так выглядит Python-код:
ws.tables.items()
wb = load_workbook('temp2.xlsx')
ws = wb['Лист1']
ws.tables.items()
#
[('Таблица1', 'A1:C4'), ('Таблица13', 'E1:G4')]
Обращаясь к каждому диапазону, можно проходить по каждой строке или столбцу, а внутри них – по каждой ячейке. Например, следующий код на Python таблицы объединяет строки в список, где первая строка уходит на заголовок, а затем преобразует их в DataFrame:
dfs = []
for table_name, value in ws.tables.items():
table = ws[value]
header, *body = [[cell.value for cell in row]
for row in table]
df = pd.DataFrame(body, columns=header)
dfs.append(df)
Если таблицы имеют одинаковые атрибуты, то их можно соединить в одну:
pd.concat(dfs)
#
Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64
0 Tanya 25 66
1 Gosha 43 77
2 Tolya 32 54
Сохраняем метаданные таблицы
Как указано в коде выше, у ячейки OpenPyXL есть атрибут value, который хранит ее значение. Помимо value, можно получить тип ячейки (data_type), цвет заливки (fill), примечание (comment) и др.
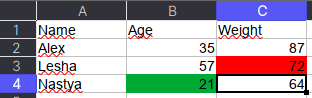
Например, требуется сохранить данные о цвете ячеек. Для этого мы каждую ячейку с числами перезапишем в виде <значение,RGB>, где RGB — значение цвета в формате RGB (red, green, blue). Python-код выглядит следующим образом:
# _TYPES = {int:'n', float:'n', str:'s', bool:'b'}
data = []
for row in ws.rows:
row_cells = []
for cell in row:
cell_value = cell.value
if cell.data_type == 'n':
cell_value = f"{cell_value},{cell.fill.fgColor.rgb}"
row_cells.append(cell_value)
data.append(row_cells)
Первым элементом списка является строка-заголовок, а все остальное уже значения таблицы:
pd.DataFrame(data[1:], columns=data[0])
#
Name Age Weight
0 Alex 35,00000000 87,00000000
1 Lesha 57,00000000 72,FFFF0000
2 Nastya 21,FF00A933 64,00000000
Теперь представим атрибуты в виде индексов с помощью метода stack, а после разобьём все записи на значение и цвет методом str.split:
(pd.DataFrame(data[1:], columns=data[0])
.set_index('Name')
.stack()
.str.split(',', expand=True)
)
#
0 1
Name
Alex Age 35 00000000
Weight 87 00000000
Lesha Age 57 00000000
Weight 72 FFFF0000
Nastya Age 21 FF00A933
Weight 64 0000000
Осталось только переименовать 0 и 1 на Value и Color, а также добавить атрибут Variable, который обозначит Вес и Возраст. Полный код на Python выглядит следующим образом:
(pd.DataFrame(data[1:], columns=data[0])
.set_index('Name')
.stack()
.str.split(',', expand=True)
.set_axis(['Value', 'Color'], axis=1)
.rename_axis(index=['Name', 'Variable'])
.reset_index()
)
#
Name Variable Value Color
0 Alex Age 35 00000000
1 Alex Weight 87 00000000
2 Lesha Age 57 00000000
3 Lesha Weight 72 FFFF0000
4 Nastya Age 21 FF00A933
5 Nastya Weight 64 00000000
Ещё больше подробностей о работе с таблицами в Pandas, а также их обработке на реальных примерах Data Science задач, вы узнаете на наших курсах по Python в лицензированном учебном центре обучения и повышения квалификации IT-специалистов в Москве.
Источники
- https://xlrd.readthedocs.io/en/latest/
- https://openpyxl.readthedocs.io/en/latest/
- https://github.com/eea/odfpy
- https://github.com/willtrnr/pyxlsb
Узнайте, как читать и импортировать файлы Excel в Python, как записывать данные в эти таблицы и какие библиотеки лучше всего подходят для этого.
Известный вам инструмент для организации, анализа и хранения ваших данных в таблицах — Excel — применяется и в data science. В какой-то момент вам придется иметь дело с этими таблицами, но работать именно с ними вы будете не всегда. Вот почему разработчики Python реализовали способы чтения, записи и управления не только этими файлами, но и многими другими типами файлов.
Из этого учебника узнаете, как можете работать с Excel и Python. Внутри найдете обзор библиотек, которые вы можете использовать для загрузки и записи этих таблиц в файлы с помощью Python. Вы узнаете, как работать с такими библиотеками, как pandas, openpyxl, xlrd, xlutils и pyexcel.
Данные как ваша отправная точка
Когда вы начинаете проект по data science, вам придется работать с данными, которые вы собрали по всему интернету, и с наборами данных, которые вы загрузили из других мест — Kaggle, Quandl и тд
Но чаще всего вы также найдете данные в Google или в репозиториях, которые используются другими пользователями. Эти данные могут быть в файле Excel или сохранены в файл с расширением .csv … Возможности могут иногда казаться бесконечными, но когда у вас есть данные, в первую очередь вы должны убедиться, что они качественные.
В случае с электронной таблицей вы можете не только проверить, могут ли эти данные ответить на вопрос исследования, который вы имеете в виду, но также и можете ли вы доверять данным, которые хранятся в электронной таблице.
Проверяем качество таблицы
- Представляет ли электронная таблица статические данные?
- Смешивает ли она данные, расчеты и отчетность?
- Являются ли данные в вашей электронной таблице полными и последовательными?
- Имеет ли ваша таблица систематизированную структуру рабочего листа?
- Проверяли ли вы действительные формулы в электронной таблице?
Этот список вопросов поможет убедиться, что ваша таблица не грешит против лучших практик, принятых в отрасли. Конечно, этот список не исчерпывающий, но позволит провести базовую проверку таблицы.
Лучшие практики для данных электронных таблиц
Прежде чем приступить к чтению вашей электронной таблицы на Python, вы также должны подумать о том, чтобы настроить свой файл в соответствии с некоторыми основными принципами, такими как:
- Первая строка таблицы обычно зарезервирована для заголовка, а первый столбец используется для идентификации единицы выборки;
- Избегайте имен, значений или полей с пробелами. В противном случае каждое слово будет интерпретироваться как отдельная переменная, что приведет к ошибкам, связанным с количеством элементов на строку в вашем наборе данных. По возможности, используйте:
- подчеркивания,
- тире,
- горбатый регистр, где первая буква каждого слова пишется с большой буквы
- объединяющие слова
- Короткие имена предпочтительнее длинных имен;
- старайтесь не использовать имена, которые содержат символы ?, $,%, ^, &, *, (,), -, #,? ,,, <,>, /, |, , [,], {, и };
- Удалите все комментарии, которые вы сделали в вашем файле, чтобы избежать добавления в ваш файл лишних столбцов или NA;
- Убедитесь, что все пропущенные значения в вашем наборе данных обозначены как NA.
Затем, после того, как вы внесли необходимые изменения или тщательно изучили свои данные, убедитесь, что вы сохранили внесенные изменения. Сделав это, вы можете вернуться к данным позже, чтобы отредактировать их, добавить дополнительные данные или изменить их, сохранив формулы, которые вы, возможно, использовали для расчета данных и т.д.
Если вы работаете с Microsoft Excel, вы можете сохранить файл в разных форматах: помимо расширения по умолчанию .xls или .xlsx, вы можете перейти на вкладку «Файл», нажать «Сохранить как» и выбрать одно из расширений, которые указаны в качестве параметров «Сохранить как тип». Наиболее часто используемые расширения для сохранения наборов данных в data science — это .csv и .txt (в виде текстового файла с разделителями табуляции). В зависимости от выбранного варианта сохранения поля вашего набора данных разделяются вкладками или запятыми, которые образуют символы-разделители полей вашего набора данных.
Теперь, когда вы проверили и сохранили ваши данные, вы можете начать с подготовки вашего рабочего окружения.
Готовим рабочее окружение
Как убедиться, что вы все делаете хорошо? Проверить рабочее окружение!
Когда вы работаете в терминале, вы можете сначала перейти в каталог, в котором находится ваш файл, а затем запустить Python. Убедитесь, что файл лежит именно в том каталоге, к которому вы обратились.
Возможно, вы уже начали сеанс Python и у вас нет подсказок о каталоге, в котором вы работаете. Тогда можно выполнить следующие команды:
# Import `os`
import os
# Retrieve current working directory (`cwd`)
cwd = os.getcwd()
cwd
# Change directory
os.chdir("/path/to/your/folder")
# List all files and directories in current directory
os.listdir('.')Круто, да?
Вы увидите, что эти команды очень важны не только для загрузки ваших данных, но и для дальнейшего анализа. А пока давайте продолжим: вы прошли все проверки, вы сохранили свои данные и подготовили рабочее окружение.
Можете ли вы начать с чтения данных в Python?
Установите библиотеки для чтения и записи файлов Excel
Даже если вы еще не знаете, какие библиотеки вам понадобятся для импорта ваших данных, вы должны убедиться, что у вас есть все, что нужно для установки этих библиотек, когда придет время.
Подготовка к дополнительной рабочей области: pip
Вот почему вам нужно установить pip и setuptools. Если у вас установлен Python2 ⩾ 2.7.9 или Python3 ⩾ 3.4, то можно не беспокоиться — просто убедитесь, что вы обновились до последней версии.
Для этого выполните следующую команду в своем терминале:
# Для Linux/OS X
pip install -U pip setuptools
# Для Windows
python -m pip install -U pip setuptoolsЕсли вы еще не установили pip, запустите скрипт python get-pip.py, который вы можете найти здесь. Следуйте инструкциям по установке.
Установка Anaconda
Другой вариант для работы в data science — установить дистрибутив Anaconda Python. Сделав это, вы получите простой и быстрый способ начать заниматься data science, потому что вам не нужно беспокоиться об установке отдельных библиотек, необходимых для работы.
Это особенно удобно, если вы новичок, но даже для более опытных разработчиков это способ быстро протестировать некоторые вещи без необходимости устанавливать каждую библиотеку отдельно.
Anaconda включает в себя 100 самых популярных библиотек Python, R и Scala для науки о данных и несколько сред разработки с открытым исходным кодом, таких как Jupyter и Spyder.
Установить Anaconda можно здесь. Следуйте инструкциям по установке, и вы готовы начать!
Загрузить файлы Excel в виде фреймов Pandas
Все, среда настроена, вы готовы начать импорт ваших файлов.
Один из способов, который вы часто используете для импорта ваших файлов для обработки данных, — с помощью библиотеки Pandas. Она основана на NumPy и предоставляет простые в использовании структуры данных и инструменты анализа данных Python.
Эта мощная и гибкая библиотека очень часто используется дата-инженерами для передачи своих данных в структуры данных, очень выразительных для их анализа.
Если у вас уже есть Pandas, доступные через Anaconda, вы можете просто загрузить свои файлы в Pandas DataFrames с помощью pd.Excelfile():
# импорт библиотеки pandas
import pandas as pd
# Загружаем ваш файл в переменную `file` / вместо 'example' укажите название свого файла из текущей директории
file = 'example.xlsx'
# Загружаем spreadsheet в объект pandas
xl = pd.ExcelFile(file)
# Печатаем название листов в данном файле
print(xl.sheet_names)
# Загрузить лист в DataFrame по его имени: df1
df1 = xl.parse('Sheet1')Если вы не установили Anaconda, просто выполните pip install pandas, чтобы установить библиотеку Pandas в вашей среде, а затем выполните команды, которые включены в фрагмент кода выше.
Проще простого, да?
Для чтения в файлах .csv у вас есть аналогичная функция для загрузки данных в DataFrame: read_csv(). Вот пример того, как вы можете использовать эту функцию:
# Импорт библиотеки pandas
import pandas as pd
# Загрузить csv файл
df = pd.read_csv("example.csv") Разделитель, который будет учитывать эта функция, по умолчанию является запятой, но вы можете указать альтернативный разделитель, если хотите. Перейдите к документации, чтобы узнать, какие другие аргументы вы можете указать для успешного импорта!
Обратите внимание, что есть также функции read_table() и read_fwf() для чтения файлов и таблиц с фиксированной шириной в формате DataFrames с общим разделителем. Для первой функции разделителем по умолчанию является вкладка, но вы можете снова переопределить это, а также указать альтернативный символ-разделитель. Более того, есть и другие функции, которые вы можете использовать для получения данных в DataFrames: вы можете найти их здесь.
Как записать Pandas DataFrames в файлы Excel
Допустим, что после анализа данных вы хотите записать данные обратно в новый файл. Есть также способ записать ваши Pandas DataFrames обратно в файлы с помощью функции to_excel().
Но, прежде чем использовать эту функцию, убедитесь, что у вас установлен XlsxWriter, если вы хотите записать свои данные в несколько листов в файле .xlsx:
# Установим `XlsxWriter`
pip install XlsxWriter
# Указать writer библиотеки
writer = pd.ExcelWriter('example.xlsx', engine='xlsxwriter')
# Записать ваш DataFrame в файл
yourData.to_excel(writer, 'Sheet1')
# Сохраним результат
writer.save()Обратите внимание, что в приведенном выше фрагменте кода вы используете объект ExcelWriter для вывода DataFrame.
Иными словами, вы передаете переменную Writer в функцию to_excel() и также указываете имя листа. Таким образом, вы добавляете лист с данными в существующую рабочую книгу: вы можете использовать ExcelWriter для сохранения нескольких (немного) разных DataFrames в одной рабочей книге.
Все это означает, что если вы просто хотите сохранить один DataFrame в файл, вы также можете обойтись без установки пакета XlsxWriter. Затем вы просто не указываете аргумент движка, который вы передаете в функцию pd.ExcelWriter(). Остальные шаги остаются прежними.
Аналогично функциям, которые вы использовали для чтения в файлах .csv, у вас также есть функция to_csv() для записи результатов обратно в файл, разделенный запятыми. Он снова работает так же, как когда вы использовали его для чтения в файле:
# Запишите DataFrame в csv
df.to_csv("example.csv")Если вы хотите иметь файл, разделенный табуляцией, вы также можете передать t аргументу sep. Обратите внимание, что есть другие функции, которые вы можете использовать для вывода ваших файлов. Вы можете найти их все здесь.
Пакеты для разбора файлов Excel и обратной записи с помощью Python
Помимо библиотеки Pandas, который вы будете использовать очень часто для загрузки своих данных, вы также можете использовать другие библиотеки для получения ваших данных в Python. Наш обзор основан на этой странице со списком доступных библиотек, которые вы можете использовать для работы с файлами Excel в Python.
Далее вы увидите, как использовать эти библиотеки с помощью некоторых реальных, но упрощенных примеров.
Использование виртуальных сред
Общий совет для установки — делать это в Python virtualenv без системных пакетов. Вы можете использовать virtualenv для создания изолированных сред Python: он создает папку, содержащую все необходимые исполняемые файлы для использования пакетов, которые потребуются проекту Python.
Чтобы начать работать с virtualenv, вам сначала нужно установить его. Затем перейдите в каталог, в который вы хотите поместить свой проект. Создайте virtualenv в этой папке и загрузите в определенную версию Python, если вам это нужно. Затем вы активируете виртуальную среду. После этого вы можете начать загрузку в другие библиотеки, начать работать с ними и т. д.
Совет: не забудьте деактивировать среду, когда закончите!
# Install virtualenv
$ pip install virtualenv
# Go to the folder of your project
$ cd my_folder
# Create a virtual environment `venv`
$ virtualenv venv
# Indicate the Python interpreter to use for `venv`
$ virtualenv -p /usr/bin/python2.7 venv
# Activate `venv`
$ source venv/bin/activate
# Deactivate `venv`
$ deactivateОбратите внимание, что виртуальная среда может показаться немного проблемной на первый взгляд, когда вы только начинаете работать с данными с Python. И, особенно если у вас есть только один проект, вы можете не понять, зачем вам вообще нужна виртуальная среда.
С ней будет гораздо легче, когда у вас одновременно запущено несколько проектов, и вы не хотите, чтобы они использовали одну и ту же установку Python. Или когда ваши проекты имеют противоречащие друг другу требования, виртуальная среда пригодится!
Теперь вы можете, наконец, начать установку и импорт библиотек, о которых вы читали, и загрузить их в таблицу.
Как читать и записывать файлы Excel с openpyxl
Этот пакет обычно рекомендуется, если вы хотите читать и записывать файлы .xlsx, xlsm, xltx и xltm.
Установите openpyxl с помощью pip: вы видели, как это сделать в предыдущем разделе.
Общий совет для установки этой библиотеки — делать это в виртуальной среде Python без системных библиотек. Вы можете использовать виртуальную среду для создания изолированных сред Python: она создает папку, которая содержит все необходимые исполняемые файлы для использования библиотек, которые потребуются проекту Python.
Перейдите в каталог, в котором находится ваш проект, и повторно активируйте виртуальную среду venv. Затем продолжите установку openpyxl с pip, чтобы убедиться, что вы можете читать и записывать файлы с ним:
# Активируйте virtualenv
$ source activate venv
# Установим `openpyxl` в `venv`
$ pip install openpyxlТеперь, когда вы установили openpyxl, вы можете загружать данные. Но что это за данные?
Доспутим Excel с данными, которые вы пытаетесь загрузить в Python, содержит следующие листы:
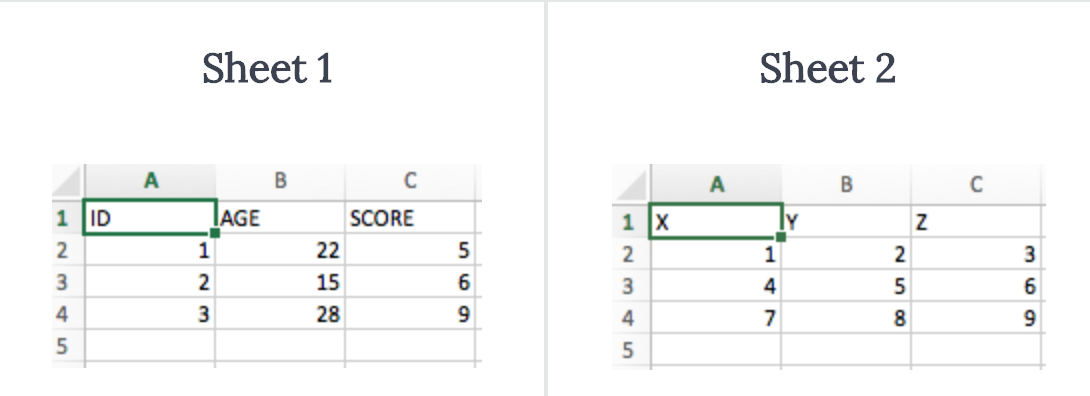
Функция load_workbook() принимает имя файла в качестве аргумента и возвращает объект рабочей книги, который представляет файл. Вы можете проверить это, запустив type (wb). Убедитесь, что вы находитесь в том каталоге, где находится ваша таблица, иначе вы получите error при импорте.
# Import `load_workbook` module from `openpyxl`
from openpyxl import load_workbook
# Load in the workbook
wb = load_workbook('./test.xlsx')
# Get sheet names
print(wb.get_sheet_names())Помните, что вы можете изменить рабочий каталог с помощью os.chdir().
Вы видите, что фрагмент кода выше возвращает имена листов книги, загруженной в Python.Можете использовать эту информацию, чтобы также получить отдельные листы рабочей книги.
Вы также можете проверить, какой лист в настоящее время активен с wb.active. Как видно из кода ниже, вы можете использовать его для загрузки другого листа из вашей книги:
# Get a sheet by name
sheet = wb.get_sheet_by_name('Sheet3')
# Print the sheet title
sheet.title
# Get currently active sheet
anotherSheet = wb.active
# Check `anotherSheet`
anotherSheetНа первый взгляд, с этими объектами рабочего листа вы не сможете многое сделать.. Однако вы можете извлечь значения из определенных ячеек на листе вашей книги, используя квадратные скобки [], в которые вы передаете точную ячейку, из которой вы хотите получить значение.
Обратите внимание, что это похоже на выбор, получение и индексирование массивов NumPy и Pandas DataFrames, но это не все, что вам нужно сделать, чтобы получить значение. Вам нужно добавить атрибут value:
# Retrieve the value of a certain cell
sheet['A1'].value
# Select element 'B2' of your sheet
c = sheet['B2']
# Retrieve the row number of your element
c.row
# Retrieve the column letter of your element
c.column
# Retrieve the coordinates of the cell
c.coordinateКак вы можете видеть, помимо значения, есть и другие атрибуты, которые вы можете использовать для проверки вашей ячейки, а именно: row, column и coordinate.
Атрибут row вернет 2;
Добавление атрибута column к c даст вам ‘B’
coordinate вернет ‘B2’.
Вы также можете получить значения ячеек с помощью функции cell(). Передайте row и column, добавьте к этим аргументам значения, соответствующие значениям ячейки, которую вы хотите получить, и, конечно же, не забудьте добавить атрибут value:
# Retrieve cell value
sheet.cell(row=1, column=2).value
# Print out values in column 2
for i in range(1, 4):
print(i, sheet.cell(row=i, column=2).value)Обратите внимание, что если вы не укажете атрибут value, вы получите <Cell Sheet3.B1>, который ничего не говорит о значении, которое содержится в этой конкретной ячейке.
Вы видите, что вы используете цикл for с помощью функции range(), чтобы помочь вам распечатать значения строк, имеющих значения в столбце 2. Если эти конкретные ячейки пусты, вы просто вернете None. Если вы хотите узнать больше о циклах for, пройдите наш курс Intermediate Python для Data Science.
Есть специальные функции, которые вы можете вызывать для получения некоторых других значений, например, get_column_letter() и column_index_from_string.
Две функции указывают примерно то, что вы можете получить, используя их, но лучше сделать их четче: хотя вы можете извлечь букву столбца с предшествующего, вы можете сделать обратное или получить адрес столбца, когда вы задаёте букву последнему. Вы можете увидеть, как это работает ниже:
# Импорт необходимых модулей из `openpyxl.utils`
from openpyxl.utils import get_column_letter, column_index_from_string
# Вывод 'A'
get_column_letter(1)
# Return '1'
column_index_from_string('A')Вы уже получили значения для строк, которые имеют значения в определенном столбце, но что вам нужно сделать, если вы хотите распечатать строки вашего файла, не сосредотачиваясь только на одном столбце? Использовать другой цикл, конечно!
Например, вы говорите, что хотите сфокусироваться на области между «А1» и «С3», где первая указывает на левый верхний угол, а вторая — на правый нижний угол области, на которой вы хотите сфокусироваться. ,
Эта область будет так называемым cellObj, который вы видите в первой строке кода ниже. Затем вы говорите, что для каждой ячейки, которая находится в этой области, вы печатаете координату и значение, которое содержится в этой ячейке. После конца каждой строки вы печатаете сообщение, которое указывает, что строка этой области cellObj напечатана.
# Напечатать строчку за строчкой
for cellObj in sheet['A1':'C3']:
for cell in cellObj:
print(cells.coordinate, cells.value)
print('--- END ---')Еще раз обратите внимание, что выбор области очень похож на выбор, получение и индексирование списка и элементов массива NumPy, где вы также используете [] и : для указания области, значения которой вы хотите получить. Кроме того, вышеприведенный цикл также хорошо использует атрибуты ячейки!
Чтобы сделать вышеприведенное объяснение и код наглядным, вы можете проверить результат, который вы получите после завершения цикла:
('A1', u'M')
('B1', u'N')
('C1', u'O')
--- END ---
('A2', 10L)
('B2', 11L)
('C2', 12L)
--- END ---
('A3', 14L)
('B3', 15L)
('C3', 16L)
--- END ---Наконец, есть некоторые атрибуты, которые вы можете использовать для проверки результата вашего импорта, а именно max_row и max_column. Эти атрибуты, конечно, и так — общие способы проверки правильности загрузки данных, но они все равно полезны.
# Вывести максимальное количество строк
sheet.max_row
# Вывести максимальное количество колонок
sheet.max_columnНаверное, вы думаете, что такой способ работы с этими файлами сложноват, особенно если вы еще хотите манипулировать данными.
Должно быть что-то попроще, верно? Так и есть!
openpyxl поддерживает Pandas DataFrames! Вы можете использовать функцию DataFrame() из библиотеки Pandas, чтобы поместить значения листа в DataFrame:
# Import `pandas`
import pandas as pd
# конвертировать Лист в DataFrame
df = pd.DataFrame(sheet.values)Если вы хотите указать заголовки и индексы, вам нужно добавить немного больше кода:
# Put the sheet values in `data`
data = sheet.values
# Indicate the columns in the sheet values
cols = next(data)[1:]
# Convert your data to a list
data = list(data)
# Read in the data at index 0 for the indices
idx = [r[0] for r in data]
# Slice the data at index 1
data = (islice(r, 1, None) for r in data)
# Make your DataFrame
df = pd.DataFrame(data, index=idx, columns=cols)Затем вы можете начать манипулировать данными со всеми функциями, которые предлагает библиотека Pandas. Но помните, что вы находитесь в виртуальной среде, поэтому, если библиотека еще не представлена, вам нужно будет установить ее снова через pip.
Чтобы записать ваши Pandas DataFrames обратно в файл Excel, вы можете легко использовать функцию dataframe_to_rows() из модуля utils:
# Import `dataframe_to_rows`
from openpyxl.utils.dataframe import dataframe_to_rows
# Initialize a workbook
wb = Workbook()
# Get the worksheet in the active workbook
ws = wb.active
# Append the rows of the DataFrame to your worksheet
for r in dataframe_to_rows(df, index=True, header=True):
ws.append(r)Но это точно не все! Библиотека openpyxl предлагает вам высокую гибкость при записи ваших данных обратно в файлы Excel, изменении стилей ячеек или использовании режима write-only. Эту библиотеку обязательно нужно знать, когда вы часто работаете с электронными таблицами ,
Совет: читайте больше о том, как вы можете изменить стили ячеек, перейти в режим write-only или как библиотека работает с NumPy здесь.
Теперь давайте также рассмотрим некоторые другие библиотеки, которые вы можете использовать для получения данных вашей электронной таблицы в Python.
Прежде чем закрыть этот раздел, не забудьте отключить виртуальную среду, когда закончите!
Чтение и форматирование Excel-файлов: xlrd
Эта библиотека идеально подходит для чтения и форматирования данных из Excel с расширением xls или xlsx.
# Import `xlrd`
import xlrd
# Open a workbook
workbook = xlrd.open_workbook('example.xls')
# Loads only current sheets to memory
workbook = xlrd.open_workbook('example.xls', on_demand = True)Когда вам не нужны данные из всей Excel-книги, вы можете использовать функции sheet_by_name() или sheet_by_index() для получения листов, которые вы хотите получить в своём анализе
# Load a specific sheet by name
worksheet = workbook.sheet_by_name('Sheet1')
# Load a specific sheet by index
worksheet = workbook.sheet_by_index(0)
# Retrieve the value from cell at indices (0,0)
sheet.cell(0, 0).valueТакже можно получить значение в определённых ячейках с вашего листа.
Перейдите к xlwt и xlutils, чтобы узнать больше о том, как они относятся к библиотеке xlrd.
Запись данных в Excel-файлы с xlwt
Если вы хотите создать таблицу со своими данными, вы можете использовать не только библиотеку XlsWriter, но и xlwt. xlwt идеально подходит для записи данных и форматирования информации в файлах с расширением .xls
Когда вы вручную создаёте файл:
# Import `xlwt`
import xlwt
# Initialize a workbook
book = xlwt.Workbook(encoding="utf-8")
# Add a sheet to the workbook
sheet1 = book.add_sheet("Python Sheet 1")
# Write to the sheet of the workbook
sheet1.write(0, 0, "This is the First Cell of the First Sheet")
# Save the workbook
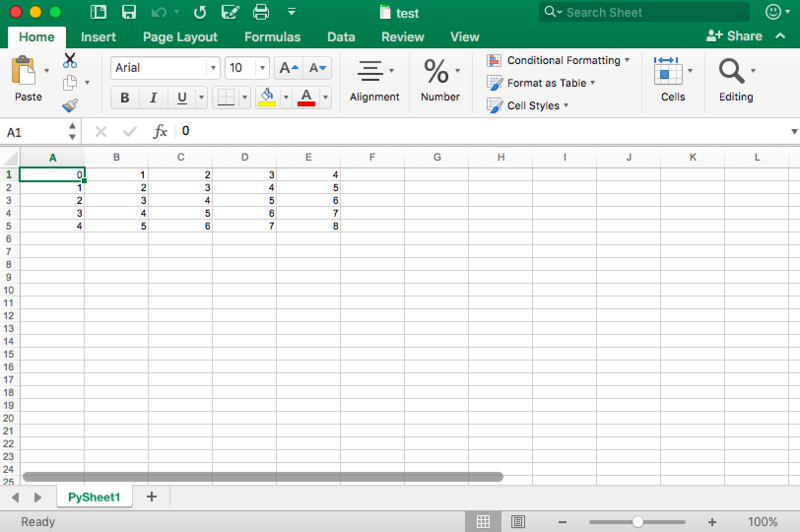
book.save("spreadsheet.xls")Если вы хотите записать данные в файл, но не хотите делать все самостоятельно, вы всегда можете прибегнуть к циклу for, чтобы автоматизировать весь процесс. Составьте сценарий, в котором вы создаёте книгу и в которую добавляете лист. Укажите список со столбцами и один со значениями, которые будут заполнены на листе.
Далее у вас есть цикл for, который гарантирует, что все значения попадают в файл: вы говорите, что для каждого элемента в диапазоне от 0 до 4 (5 не включительно) вы собираетесь что-то делать. Вы будете заполнять значения построчно. Для этого вы указываете элемент строки, который появляется в каждом цикле. Далее у вас есть еще один цикл for, который будет проходить по столбцам вашего листа. Вы говорите, что для каждой строки на листе, вы будете смотреть на столбцы, которые идут с ним, и вы будете заполнять значение для каждого столбца в строке. Заполнив все столбцы строки значениями, вы перейдете к следующей строке, пока не останется строк.
# Initialize a workbook
book = xlwt.Workbook()
# Add a sheet to the workbook
sheet1 = book.add_sheet("Sheet1")
# The data
cols = ["A", "B", "C", "D", "E"]
txt = [0,1,2,3,4]
# Loop over the rows and columns and fill in the values
for num in range(5):
row = sheet1.row(num)
for index, col in enumerate(cols):
value = txt[index] + num
row.write(index, value)
# Save the result
book.save("test.xls")На скриншоте ниже представлен результат выполнения этого кода:
Теперь, когда вы увидели, как xlrd и xlwt работают друг с другом, пришло время взглянуть на библиотеку, которая тесно связана с этими двумя: xlutils.
Сборник утилит: xlutils
Эта библиотека — сборник утилит, для которого требуются и xlrd и xlwt, и которая может копировать, изменять и фильтровать существующие данные. О том, как пользоваться этими командами рассказано в разделе по openpyxl.
Вернитесь в раздел openpyxl, чтобы получить больше информации о том, как использовать этот пакет для получения данных в Python.
Использование pyexcel для чтения .xls или .xlsx файлов
Еще одна библиотека, которую можно использовать для чтения данных электронных таблиц в Python — это pyexcel; Python Wrapper, который предоставляет один API для чтения, записи и работы с данными в файлах .csv, .ods, .xls, .xlsx и .xlsm. Конечно, для этого урока вы просто сосредоточитесь на файлах .xls и .xls.
Чтобы получить ваши данные в массиве, вы можете использовать функцию get_array(), которая содержится в пакете pyexcel:
# Import `pyexcel`
import pyexcel
# Get an array from the data
my_array = pyexcel.get_array(file_name="test.xls")Вы также можете получить свои данные в упорядоченном словаре списков. Вы можете использовать функцию get_dict():
# Import `OrderedDict` module
from pyexcel._compact import OrderedDict
# Get your data in an ordered dictionary of lists
my_dict = pyexcel.get_dict(file_name="test.xls", name_columns_by_row=0)
# Get your data in a dictionary of 2D arrays
book_dict = pyexcel.get_book_dict(file_name="test.xls")Здесь видно, что если вы хотите получить словарь двумерных массивов или получить все листы рабочей книги в одном словаре, вы можете прибегнуть к get_book_dict().
Помните, что эти две структуры данных, которые были упомянуты выше, массивы и словари вашей таблицы, позволяют вам создавать DataFrames ваших данных с помощью pd.DataFrame(). Это облегчит обработку данных.
Кроме того, вы можете просто получить записи из таблицы с помощью pyexcel благодаря функции get_records(). Просто передайте аргумент file_name в функцию, и вы получите список словарей:
# Retrieve the records of the file
records = pyexcel.get_records(file_name="test.xls")Чтобы узнать, как управлять списками Python, ознакомьтесь с примерами из документации о списках Python.
Запись в файл с pyexcel
С помощью этой библиотеки можно не только загружать данные в массивы, вы также можете экспортировать свои массивы обратно в таблицу. Используйте функцию save_as() и передайте массив и имя файла назначения в аргумент dest_file_name:
# Get the data
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# Save the array to a file
pyexcel.save_as(array=data, dest_file_name="array_data.xls")Обратите внимание, что если вы хотите указать разделитель, вы можете добавить аргумент dest_delimiter и передать символ, который вы хотите использовать в качестве разделителя между «».
Однако если у вас есть словарь, вам нужно использовать функцию save_book_as(). Передайте двумерный словарь в bookdict и укажите имя файла:
# The data
2d_array_dictionary = {'Sheet 1': [
['ID', 'AGE', 'SCORE']
[1, 22, 5],
[2, 15, 6],
[3, 28, 9]
],
'Sheet 2': [
['X', 'Y', 'Z'],
[1, 2, 3],
[4, 5, 6]
[7, 8, 9]
],
'Sheet 3': [
['M', 'N', 'O', 'P'],
[10, 11, 12, 13],
[14, 15, 16, 17]
[18, 19, 20, 21]
]}
# Save the data to a file
pyexcel.save_book_as(bookdict=2d_array_dictionary, dest_file_name="2d_array_data.xls")При использовании кода, напечатанного в приведенном выше примере, важно помнить, что порядок ваших данных в словаре не будет сохранен. Если вы не хотите этого, вам нужно сделать небольшой обход. Вы можете прочитать все об этом здесь.
Чтение и запись .csv файлов
Если вы все еще ищете библиотеки, которые позволяют загружать и записывать данные в файлы .csv, кроме Pandas, лучше всего использовать пакет csv:
# import `csv`
import csv
# Read in csv file
for row in csv.reader(open('data.csv'), delimiter=','):
print(row)
# Write csv file
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
outfile = open('data.csv', 'w')
writer = csv.writer(outfile, delimiter=';', quotechar='"')
writer.writerows(data)
outfile.close()Обратите внимание, что в пакете NumPy есть функция genfromtxt(), которая позволяет загружать данные, содержащиеся в файлах .csv, в массивы, которые затем можно поместить в DataFrames.
Финальная проверка данных
Когда у вас есть данные, не забудьте последний шаг: проверить, правильно ли загружены данные. Если вы поместили свои данные в DataFrame, вы можете легко и быстро проверить, был ли импорт успешным, выполнив следующие команды:
# Check the first entries of the DataFrame
df1.head()
# Check the last entries of the DataFrame
df1.tail()Если у вас есть данные в массиве, вы можете проверить их, используя следующие атрибуты массива: shape, ndim, dtype и т.д .:
# Inspect the shape
data.shape
# Inspect the number of dimensions
data.ndim
# Inspect the data type
data.dtype
Что дальше?
Поздравляем! Вы успешно прошли наш урок и научились читать файлы Excel на Python.
Если вы хотите продолжить работу над этой темой, попробуйте воспользоваться PyXll, который позволяет писать функции в Python и вызывать их в Excel.
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
It is not always possible to get the dataset in CSV format. So, Pandas provides us the functions to convert datasets in other formats to the Data frame. An excel file has a ‘.xlsx’ format.
Before we get started, we need to install a few libraries.
pip install pandas pip install xlrd
For importing an Excel file into Python using Pandas we have to use pandas.read_excel() function.
Syntax: pandas.read_excel(io, sheet_name=0, header=0, names=None,….)
Return: DataFrame or dict of DataFrames.
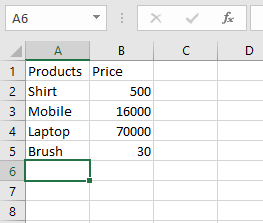
Let’s suppose the Excel file looks like this:
Now, we can dive into the code.
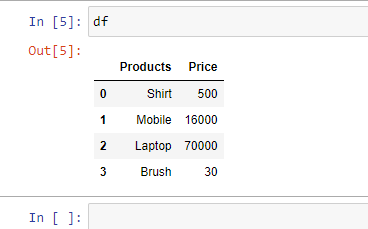
Example 1: Read an Excel file.
Python3
import pandas as pd
df = pd.read_excel("sample.xlsx")
print(df)
Output:
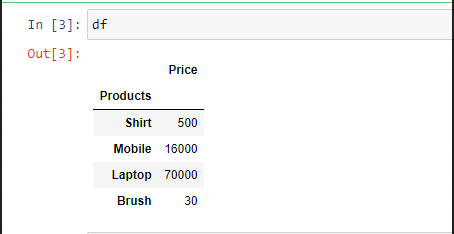
Example 2: To select a particular column, we can pass a parameter “index_col“.
Python3
import pandas as pd
df = pd.read_excel("sample.xlsx",
index_col = 0)
print(df)
Output:
Example 3: In case you don’t prefer the initial heading of the columns, you can change it to indexes using the parameter “header”.
Python3
import pandas as pd
df = pd.read_excel('sample.xlsx',
header = None)
print(df)
Output:
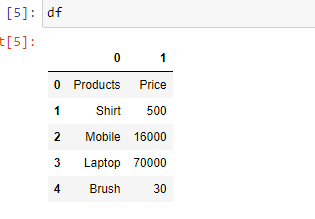
Example 4: If you want to change the data type of a particular column you can do it using the parameter “dtype“.
Python3
import pandas as pd
df = pd.read_excel('sample.xlsx',
dtype = {"Products": str,
"Price":float})
print(df)
Output:
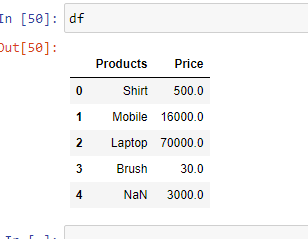
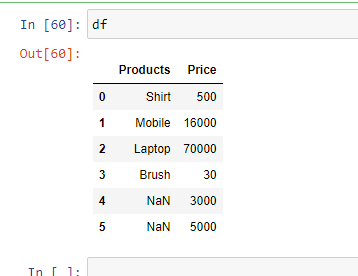
Example 5: In case you have unknown values, then you can handle it using the parameter “na_values“. It will convert the mentioned unknown values into “NaN”
Python3
import pandas as pd
df = pd.read_excel('sample.xlsx',
na_values =['item1',
'item2'])
print(df)
Output:
Like Article
Save Article
Время на прочтение
7 мин
Количество просмотров 172K
Если Вы только начинаете свой путь знакомства с возможностями Python, ваши познания еще имеют начальный уровень — этот материал для Вас. В статье мы опишем, как можно извлекать информацию из данных, представленных в Excel файлах, работать с ними используя базовый функционал библиотек. В первой части статьи мы расскажем про установку необходимых библиотек и настройку среды. Во второй части — предоставим обзор библиотек, которые могут быть использованы для загрузки и записи таблиц в файлы с помощью Python и расскажем как работать с такими библиотеками как pandas, openpyxl, xlrd, xlutils, pyexcel.
В какой-то момент вы неизбежно столкнетесь с необходимостью работы с данными Excel, и нет гарантии, что работа с таким форматами хранения данных доставит вам удовольствие. Поэтому разработчики Python реализовали удобный способ читать, редактировать и производить иные манипуляции не только с файлами Excel, но и с файлами других типов.
Отправная точка — наличие данных
ПЕРЕВОД
Оригинал статьи — www.datacamp.com/community/tutorials/python-excel-tutorial
Автор — Karlijn Willems
Когда вы начинаете проект по анализу данных, вы часто сталкиваетесь со статистикой собранной, возможно, при помощи счетчиков, возможно, при помощи выгрузок данных из систем типа Kaggle, Quandl и т. д. Но большая часть данных все-таки находится в Google или репозиториях, которыми поделились другие пользователи. Эти данные могут быть в формате Excel или в файле с .csv расширением.
Данные есть, данных много. Анализируй — не хочу. С чего начать? Первый шаг в анализе данных — их верификация. Иными словами — необходимо убедиться в качестве входящих данных.
В случае, если данные хранятся в таблице, необходимо не только подтвердить качество данных (нужно быть уверенным, что данные таблицы ответят на поставленный для исследования вопрос), но и оценить, можно ли доверять этим данным.
Проверка качества таблицы
Чтобы проверить качество таблицы, обычно используют простой чек-лист. Отвечают ли данные в таблице следующим условиям:
- данные являются статистикой;
- различные типы данных: время, вычисления, результат;
- данные полные и консистентные: структура данных в таблице — систематическая, а присутствующие формулы — работающие.
Ответы на эти простые вопросы позволят понять, не противоречит ли ваша таблица стандарту. Конечно, приведенный чек-лист не является исчерпывающим: существует много правил, на соответствие которым вы можете проверять данные в таблице, чтобы убедиться, что таблица не является “гадким утенком”. Однако, приведенный выше чек-лист наиболее актуален, если вы хотите убедиться, что таблица содержит качественные данные.
Бест-практикс табличных данных
Читать данные таблицы при помощи Python — это хорошо. Но данные хочется еще и редактировать. Причем редактирование данных в таблице, должно соответствовать следующим условиям:
- первая строка таблицы зарезервирована для заголовка, а первый столбец используется для идентификации единицы выборки;
- избегайте имен, значений или полей с пробелами. В противном случае, каждое слово будет интерпретироваться как отдельная переменная, что приведет к ошибкам, связанным с количеством элементов в строке в наборе данных. Лучше использовать подчеркивания, регистр (первая буква каждого раздела текста — заглавная) или соединительные слова;
- отдавайте предпочтение коротким названиям;
- старайтесь избегать использования названий, которые содержат символы ?, $,%, ^, &, *, (,),-,#, ?,,,<,>, /, |, , [ ,] ,{, и };
- удаляйте любые комментарии, которые вы сделали в файле, чтобы избежать дополнительных столбцов или полей со значением NA;
- убедитесь, что любые недостающие значения в наборе данных отображаются как NA.
После внесения необходимых изменений (или когда вы внимательно просмотрите свои данные), убедитесь, что внесенные изменения сохранены. Это важно, потому что позволит еще раз взглянуть на данные, при необходимости отредактировать, дополнить или внести изменения, сохраняя формулы, которые, возможно, использовались для расчета.
Если вы работаете с Microsoft Excel, вы наверняка знаете, что есть большое количество вариантов сохранения файла помимо используемых по умолчанию расширения: .xls или .xlsx (переходим на вкладку “файл”, “сохранить как” и выбираем другое расширение (наиболее часто используемые расширения для сохранения данных с целью анализа — .CSV и.ТХТ)). В зависимости от варианта сохранения поля данных будут разделены знаками табуляции или запятыми, которые составляют поле “разделитель”. Итак, данные проверены и сохранены. Начинаем готовить рабочее пространство.
Подготовка рабочего пространства
Подготовка рабочего пространства — одна из первых вещей, которую надо сделать, чтобы быть уверенным в качественном результате анализа.
Первый шаг — проверка рабочей директории.
Когда вы работаете в терминале, вы можете сначала перейти к директории, в которой находится ваш файл, а затем запустить Python. В таком случае необходимо убедиться, что файл находится в директории, из которой вы хотите работать.
Для проверки дайте следующие команды:
# Import `os`
import os
# Retrieve current working directory (`cwd`)
cwd = os.getcwd()
cwd
# Change directory
os.chdir("/path/to/your/folder")
# List all files and directories in current directory
os.listdir('.')
Эти команды важны не только для загрузки данных, но и для дальнейшего анализа. Итак, вы прошли все проверки, вы сохранили данные и подготовили рабочее пространство. Уже можно начать чтение данных в Python?  К сожалению пока нет. Нужно сделать еще одну последнюю вещь.
К сожалению пока нет. Нужно сделать еще одну последнюю вещь.
Установка пакетов для чтения и записи Excel файлов
Несмотря на то, что вы еще не знаете, какие библиотеки будут нужны для импорта данных, нужно убедиться, что у все готово для установки этих библиотек. Если у вас установлен Python 2> = 2.7.9 или Python 3> = 3.4, нет повода для беспокойства — обычно, в этих версиях уже все подготовлено. Поэтому просто убедитесь, что вы обновились до последней версии
Для этого запустите в своем компьютере следующую команду:
# For Linux/OS X
pip install -U pip setuptools
# For Windows
python -m pip install -U pip setuptoolsВ случае, если вы еще не установили pip, запустите скрипт python get-pip.py, который вы можете найти здесь (там же есть инструкции по установке и help).
Установка Anaconda
Установка дистрибутива Anaconda Python — альтернативный вариант, если вы используете Python для анализа данных. Это простой и быстрый способ начать работу с анализом данных — ведь отдельно устанавливать пакеты, необходимые для data science не придется.
Это особенно удобно для новичков, однако даже опытные разработчики часто идут этим путем, ведь Anakonda — удобный способ быстро протестировать некоторые вещи без необходимости устанавливать каждый пакет отдельно.
Anaconda включает в себя 100 наиболее популярных библиотек Python, R и Scala для анализа данных в нескольких средах разработки с открытым исходным кодом, таких как Jupyter и Spyder. Если вы хотите начать работу с Jupyter Notebook, то вам сюда.
Чтобы установить Anaconda — вам сюда.
Загрузка файлов Excel как Pandas DataFrame
Ну что ж, мы сделали все, чтобы настроить среду! Теперь самое время начать импорт файлов.
Один из способов, которым вы будете часто пользоваться для импорта файлов с целью анализа данных — импорт с помощью библиотеки Pandas (Pandas — программная библиотека на языке Python для обработки и анализа данных). Работа Pandas с данными происходит поверх библиотеки NumPy, являющейся инструментом более низкого уровня. Pandas — мощная и гибкая библиотека и она очень часто используется для структуризации данных в целях облегчения анализа.
Если у вас уже есть Pandas в Anaconda, вы можете просто загрузить файлы в Pandas DataFrames с помощью pd.Excelfile ():
# Import pandas
import pandas as pd
# Assign spreadsheet filename to `file`
file = 'example.xlsx'
# Load spreadsheet
xl = pd.ExcelFile(file)
# Print the sheet names
print(xl.sheet_names)
# Load a sheet into a DataFrame by name: df1
df1 = xl.parse('Sheet1')Если вы не установили Anaconda, просто запустите pip install pandas, чтобы установить пакет Pandas в вашей среде, а затем выполните команды, приведенные выше.
Для чтения .csv-файлов есть аналогичная функция загрузки данных в DataFrame: read_csv (). Вот пример того, как вы можете использовать эту функцию:
# Import pandas
import pandas as pd
# Load csv
df = pd.read_csv("example.csv") Разделителем, который эта функция будет учитывать, является по умолчанию запятая, но вы можете, если хотите, указать альтернативный разделитель. Перейдите к документации, если хотите узнать, какие другие аргументы можно указать, чтобы произвести импорт.
Как записывать Pandas DataFrame в Excel файл
Предположим, после анализа данных вы хотите записать данные в новый файл. Существует способ записать данные Pandas DataFrames (с помощью функции to_excel ). Но, прежде чем использовать эту функцию, убедитесь, что у вас установлен XlsxWriter, если вы хотите записать свои данные на несколько листов в файле .xlsx:
# Install `XlsxWriter`
pip install XlsxWriter
# Specify a writer
writer = pd.ExcelWriter('example.xlsx', engine='xlsxwriter')
# Write your DataFrame to a file
yourData.to_excel(writer, 'Sheet1')
# Save the result
writer.save()
Обратите внимание, что в фрагменте кода используется объект ExcelWriter для вывода DataFrame. Иными словами, вы передаете переменную writer в функцию to_excel (), и указываете имя листа. Таким образом, вы добавляете лист с данными в существующую книгу. Также можно использовать ExcelWriter для сохранения нескольких разных DataFrames в одной книге.
То есть если вы просто хотите сохранить один файл DataFrame в файл, вы можете обойтись без установки библиотеки XlsxWriter. Просто не указываете аргумент, который передается функции pd.ExcelWriter (), остальные шаги остаются неизменными.
Подобно функциям, которые используются для чтения в .csv-файлах, есть также функция to_csv () для записи результатов обратно в файл с разделителями-запятыми. Он работает так же, как когда мы использовали ее для чтения в файле:
# Write the DataFrame to csv
df.to_csv("example.csv")Если вы хотите иметь отдельный файл с вкладкой, вы можете передать a t аргументу sep. Обратите внимание, что существуют различные другие функции, которые можно использовать для вывода файлов. Их можно найти здесь.
Использование виртуальной среды
Общий совет по установке библиотек — делать установку в виртуальной среде Python без системных библиотек. Вы можете использовать virtualenv для создания изолированных сред Python: он создает папку, содержащую все необходимое для использования библиотек, которые потребуются для Python.
Чтобы начать работу с virtualenv, сначала нужно его установить. Потом перейти в директорию, где будет находится проект. Создать virtualenv в этой папке и загрузить, если нужно, в определенную версию Python. После этого активируете виртуальную среду. Теперь можно начинать загрузку других библиотек и начинать работать с ними.
Не забудьте отключить среду, когда вы закончите!
# Install virtualenv
$ pip install virtualenv
# Go to the folder of your project
$ cd my_folder
# Create a virtual environment `venv`
$ virtualenv venv
# Indicate the Python interpreter to use for `venv`
$ virtualenv -p /usr/bin/python2.7 venv
# Activate `venv`
$ source venv/bin/activate
# Deactivate `venv`
$ deactivate
Обратите внимание, что виртуальная среда может показаться сначала проблематичной, если вы делаете первые шаги в области анализа данных с помощью Python. И особенно, если у вас только один проект, вы можете не понимать, зачем вообще нужна виртуальная среда.
Но что делать, если у вас несколько проектов, работающих одновременно, и вы не хотите, чтобы они использовали одну и ту же установку Python? Или если у ваших проектов есть противоречивые требования. В таких случаях виртуальная среда — идеальное решение.
Во второй части статьи мы расскажем об основных библиотеках для анализа данных.
Продолжение следует…