
Дадим определение терминам уровень надежности и уровень значимости. Покажем, как и где они используется в
MS
EXCEL
.
Уровень значимости
(Level of significance) используется в
процедуре проверки гипотез
и при
построении доверительных интервалов
.
СОВЕТ
: Для понимания терминов
Уровень значимости и
Уровень надежности
потребуется знание следующих понятий:
-
выборочное распределение среднего
;
-
стандартное отклонение
;
-
проверка гипотез
;
-
нормальное распределение
.
Уровень значимости
статистического теста – это вероятность отклонить
нулевую гипотезу
, когда на самом деле она верна. Другими словами, это допустимая для данной задачи вероятность
ошибки первого рода
(type I error).
Уровень значимости
обычно обозначают греческой буквой α (
альфа
). Чаще всего для
уровня значимости
используют значения 0,001; 0,01; 0,05; 0,10.
Например, при построении
доверительного интервала для оценки среднего значения распределения
, его ширину рассчитывают таким образом, чтобы вероятность события «
выборочное среднее (Х
ср
) находится за пределами доверительного интервала
» было равно
уровню значимости
. Реализация этого события считается маловероятным (практически невозможным) и служит основанием для отклонения нулевой гипотезы о
равенстве среднего заданному значению
.
Ошибка первого рода
часто называется риском производителя. Это осознанный риск, на который идет производитель продукции, т.к. он определяет вероятность того, что годная продукция может быть забракована, хотя на самом деле она таковой не является. Величина
ошибки первого рода
задается перед
проверкой гипотезы
, таким образом, она контролируется исследователем напрямую и может быть задана в соответствии с условиями решаемой задачи.
Чрезмерное уменьшение
уровня значимости α
(т.е. вероятности
ошибки первого рода
) может привести к увеличению вероятности
ошибки второго рода
, то есть вероятности принять
нулевую гипотезу
, когда на самом деле она не верна. Подробнее об
ошибке второго рода
см. статью
Ошибка второго рода и Кривая оперативной характеристики
.
Уровень значимости
обычно указывается в аргументах
обратных функций MS EXCEL
для вычисления
квантилей
соответствующего распределения:
НОРМ.СТ.ОБР()
,
ХИ2.ОБР()
,
СТЬЮДЕНТ.ОБР()
и др. Примеры использования этих функций приведены в статьях про
проверку гипотез
и про построение
доверительных интервалов
.
Уровень надежности
Уровень
доверия
(этот термин более распространен в отечественной литературе, чем
Уровень надежности
) — означает вероятность того, что
доверительный интервал
содержит истинное значение оцениваемого параметра распределения.
Уровень
доверия
равен
1-α,
где α –
уровень значимости
.
Термин
Уровень надежности
имеет синонимы:
уровень доверия, коэффициент доверия, доверительный уровень
и
доверительная вероятность (англ.
Confidence
Level
,
Confidence
Coefficient
).
В математической статистике обычно используют значения
уровня доверия
90%; 95%; 99%, реже 99,9% и т.д.
Например,
Уровень
доверия
95% означает, что событие, вероятность которого 1-0,95=5% исследователь считать маловероятным или невозможным. Разумеется, выбор
уровня доверия
полностью зависит от исследователя. Так, степень доверия авиапассажира к надежности самолета, несомненно, должна быть выше степени доверия покупателя к надежности электрической лампочки.
Примечание
: Стоит отметить, что математически не корректно говорить, что
Уровень
доверия
является вероятностью, того что оцениваемый параметр распределения принадлежит
доверительному интервалу
, вычисленному на основе
выборки
. Поскольку, считается, что в математической статистике отсутствуют априорные сведения о параметре распределения. Математически правильно говорить, что
доверительный интервал
, с вероятностью равной
Уровню
доверия,
накроет истинное значение оцениваемого параметра распределения.
Уровень надежности в MS EXCEL
В MS EXCEL
Уровень надежности
упоминается в
надстройке Пакет анализа
. После вызова надстройки, в диалоговом окне необходимо выбрать инструмент
Описательная статистика
.

После нажатия кнопки
ОК
будет выведено другое диалоговое окно.
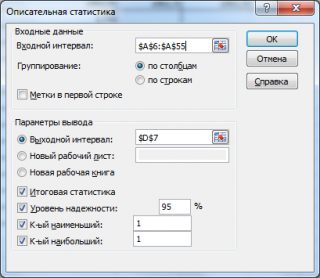
В этом окне задается
Уровень надежности,
т.е.значениевероятности в процентах. После нажатия кнопки
ОК
в
выходном интервале
выводится значение равное
половине ширины
доверительного интервала
. Этот
доверительный интервал
используется для оценки
среднего значения распределения, когда дисперсия не известна
(подробнее см.
статью про доверительный интервал
).
Необходимо учитывать, что данный
доверительный интервал
рассчитывается при условии, что
выборка
берется из
нормального распределения
. Но, на практике обычно принимается, что при достаточно большой
выборке
(n>30),
доверительный интервал
будет построен приблизительно правильно и для распределения, не являющегося
нормальным
(если при этом это распределение не будет иметь
сильной асимметрии
).
Примечание
: Понять, что в диалоговом окне речь идет именно об оценке
среднего значения распределения
, достаточно сложно. Хотя в английской версии диалогового окна это указано прямо:
Confidence
Level
for
Mean
.
Если
Уровень надежности
задан 95%, то
надстройка Пакет анализа
использует следующую формулу (выводится не сама формула, а лишь ее результат):
=СТАНДОТКЛОН.В(Выборка)/КОРЕНЬ(СЧЁТ(Выборка)) *СТЬЮДЕНТ.ОБР.2Х(1-0,95;СЧЁТ(Выборка)-1)
или эквивалентную ей
=СТАНДОТКЛОН.В(Выборка)/КОРЕНЬ(СЧЁТ(Выборка)) *СТЬЮДЕНТ.ОБР((1+0,95)/2;СЧЁТ(Выборка)-1)
где
=СТАНДОТКЛОН.В(Выборка)/КОРЕНЬ(СЧЁТ(Выборка))
– является
стандартной ошибкой среднего
(формулы приведены в
файле примера
).
или
=ДОВЕРИТ.СТЬЮДЕНТ(1-0,95; СТАНДОТКЛОН.В(Выборка); СЧЁТ(Выборка))
Подробнее см. в
статьях про доверительный интервал
.
Содержание
- Определение термина
- Расчет показателя в Excel
- Способ 1: Мастер функций
- Способ 2: работа со вкладкой «Формулы»
- Способ 3: ручной ввод
- Вопросы и ответы

Одним из наиболее известных статистических инструментов является критерий Стьюдента. Он используется для измерения статистической значимости различных парных величин. Microsoft Excel обладает специальной функцией для расчета данного показателя. Давайте узнаем, как рассчитать критерий Стьюдента в Экселе.
Определение термина
Но, для начала давайте все-таки выясним, что представляет собой критерий Стьюдента в общем. Данный показатель применяется для проверки равенства средних значений двух выборок. То есть, он определяет достоверность различий между двумя группами данных. При этом, для определения этого критерия используется целый набор методов. Показатель можно рассчитывать с учетом одностороннего или двухстороннего распределения.
Теперь перейдем непосредственно к вопросу, как рассчитать данный показатель в Экселе. Его можно произвести через функцию СТЬЮДЕНТ.ТЕСТ. В версиях Excel 2007 года и ранее она называлась ТТЕСТ. Впрочем, она была оставлена и в позднейших версиях в целях совместимости, но в них все-таки рекомендуется использовать более современную — СТЬЮДЕНТ.ТЕСТ. Данную функцию можно использовать тремя способами, о которых подробно пойдет речь ниже.
Способ 1: Мастер функций
Проще всего производить вычисления данного показателя через Мастер функций.
- Строим таблицу с двумя рядами переменных.
- Кликаем по любой пустой ячейке. Жмем на кнопку «Вставить функцию» для вызова Мастера функций.
- После того, как Мастер функций открылся. Ищем в списке значение ТТЕСТ или СТЬЮДЕНТ.ТЕСТ. Выделяем его и жмем на кнопку «OK».
- Открывается окно аргументов. В полях «Массив1» и «Массив2» вводим координаты соответствующих двух рядов переменных. Это можно сделать, просто выделив курсором нужные ячейки.
В поле «Хвосты» вписываем значение «1», если будет производиться расчет методом одностороннего распределения, и «2» в случае двухстороннего распределения.
В поле «Тип» вводятся следующие значения:
- 1 – выборка состоит из зависимых величин;
- 2 – выборка состоит из независимых величин;
- 3 – выборка состоит из независимых величин с неравным отклонением.
Когда все данные заполнены, жмем на кнопку «OK».



Выполняется расчет, а результат выводится на экран в заранее выделенную ячейку.

Способ 2: работа со вкладкой «Формулы»
Функцию СТЬЮДЕНТ.ТЕСТ можно вызвать также путем перехода во вкладку «Формулы» с помощью специальной кнопки на ленте.
- Выделяем ячейку для вывода результата на лист. Выполняем переход во вкладку «Формулы».
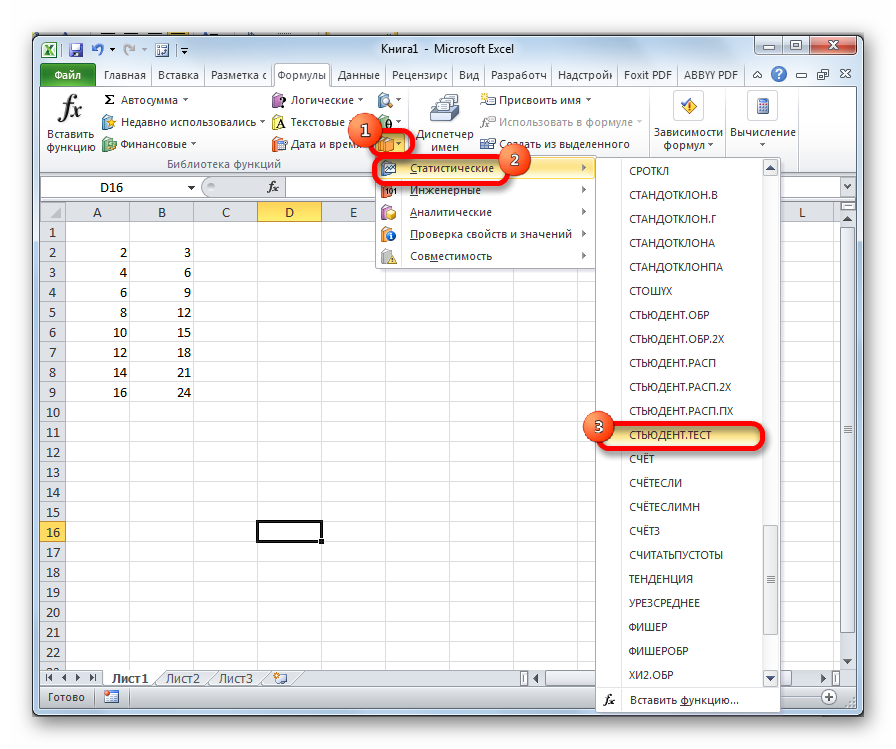
- Делаем клик по кнопке «Другие функции», расположенной на ленте в блоке инструментов «Библиотека функций». В раскрывшемся списке переходим в раздел «Статистические». Из представленных вариантов выбираем «СТЬЮДЕНТ.ТЕСТ».
- Открывается окно аргументов, которые мы подробно изучили при описании предыдущего способа. Все дальнейшие действия точно такие же, как и в нём.


Способ 3: ручной ввод
Формулу СТЬЮДЕНТ.ТЕСТ также можно ввести вручную в любую ячейку на листе или в строку функций. Её синтаксический вид выглядит следующим образом:
= СТЬЮДЕНТ.ТЕСТ(Массив1;Массив2;Хвосты;Тип)
Что означает каждый из аргументов, было рассмотрено при разборе первого способа. Эти значения и следует подставлять в данную функцию.
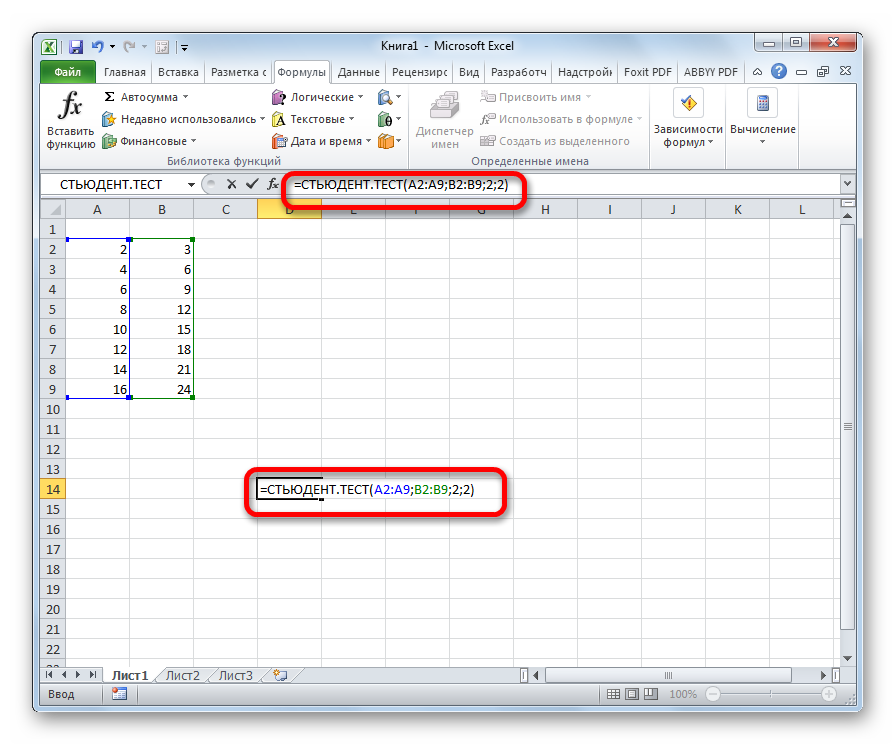
После того, как данные введены, жмем кнопку Enter для вывода результата на экран.
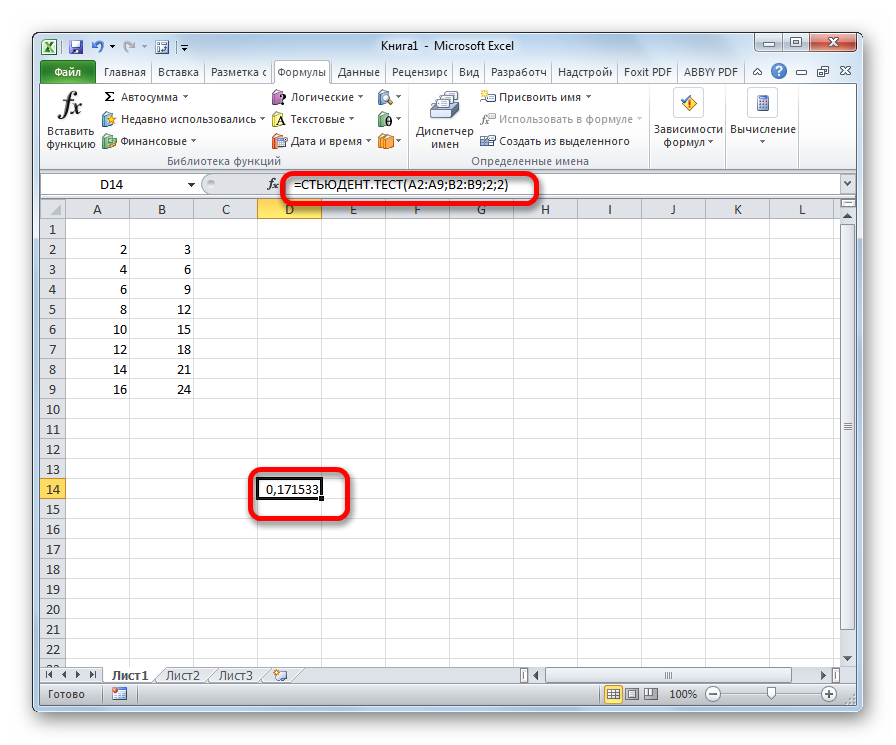
Как видим, вычисляется критерий Стьюдента в Excel очень просто и быстро. Главное, пользователь, который проводит вычисления, должен понимать, что он собой представляет и какие вводимые данные за что отвечают. Непосредственный расчет программа выполняет сама.
Еще статьи по данной теме:
Помогла ли Вам статья?
Содержание
- Описание статистических функций ДОВЕРИТ в Excel
- Сводка
- Дополнительные сведения
- Синтаксис
- Пример использования
- Интерпретация результатов проверки доверия
- Выводы
- Вычисление доверительного интервала в Microsoft Excel
- Процедура вычисления
- Способ 1: функция ДОВЕРИТ.НОРМ
- Способ 2: функция ДОВЕРИТ.СТЮДЕНТ
Описание статистических функций ДОВЕРИТ в Excel
Сводка
В этой статье описана функция ДОВЕРИТ в Microsoft Office Excel 2003 и Microsoft Office Excel 2007, а также сравнивает результаты функции для Excel 2003 и Excel 2007 с результатами функции ДОВЕРИТ в более ранних версиях Excel.
Значение доверительных интервалов часто неправильно интерпретировано, и мы стараемся предоставить объяснение допустимой и недопустимой выписки, которые могут быть сделаны после определения доверительного значения на основе данных.
Дополнительные сведения
Функция ДОВЕРИТ(альфа; сигма, n) возвращает значение, которое можно использовать для построения доверительный интервал для многая населения. Доверительный интервал — это диапазон значений, вы центр на основе известного значения выборки. Предполагается, что результаты наблюдений в выборке взяты из нормального распределения с известным стандартным отклонением, сигмой, а количество наблюдений в выборке — n.
Синтаксис
Параметры: альфа — вероятность и 0
Пример использования
Предположим, что оценки коэффициента аналитики следуют за обычным распределением со стандартным отклонением 15. Вы тестировали IQ-тест для 50 учащихся в вашем учебном замещаемом учебном замещаке и получили пример средней 105. Необходимо вычислить доверительный интервал в 95 % для математических вычислений. Доверительный интервал 95 % или 0,95 соответствует альфа = 1 – 0,95 = 0,05.
Чтобы проиллюстрировать функцию ДОВЕРИТ, создайте пустой Excel, скопируйте таблицу ниже и выберите ячейку A1 на Excel листе. В меню Правка выберите команду Вставить.
Примечание: В Excel 2007 нажмите кнопку Вировать в группе Буфер обмена на вкладке Главная.
Элементы в таблице ниже заполняют ячейки A1:B7 на вашем компьютере.
После вжатия этой таблицы на новый Excel нажмите кнопку Параметры вжатия и выберите пункт Найти формат назначения.
Вы можете выбрать в меню Формат пункт Столбец, а затем выбрать пункт Авто подбор по столбцу.
Примечание: В Excel 2007 г. с выбранным диапазоном ячеек нажмите кнопку Формат в группе Ячейки на вкладке Главная, а затем выберите Авто ширина столбца.
Ячейка A6 отображает значение ДОВЕРИТ. Ячейка A7 имеет то же значение, так как звонок на значение ДОВЕРИТ(альфа; сигма, n) возвращает результат вычисления:
NORMSINV(1 – alpha/2) * sigma / SQRT(n)
Непосредственно в доверии не внося изменений, но в Microsoft Excel 2002 г. была улучшена норм.В.ВОСЬМ, а затем в Excel 2002 и Excel 2007 г. были внесены дополнительные улучшения. Поэтому в этих более поздних версиях стандарта ДОВЕРИТ могут возвращаться другие (и улучшенные Excel) результаты, так как доверит их на основе нормСИНВ.
Это не означает, что в более ранних версиях Excel доверие к доверию. Неточности в нормОЛИНВ обычно связаны со значениями аргумента, близкими к 0 или очень близко к 1. На практике альфа обычно имеет 0,05, 0,01 или, возможно, 0,001. Значения альфа-значения должны быть намного меньше, чем это, например 0,0000001, прежде чем ошибки округления в НОРМСИНВ, скорее всего, будут заметили.
Примечание: В этой статье на сайте НОРМ.В.ВН можно узнать о различиях в вычислениях в нормСИНХНОВ.
Для получения дополнительных сведений щелкните номер следующей статьи, чтобы просмотреть статью в базе знаний Майкрософт:
826772 Excel статистические функции: НОРМСИНВ
Интерпретация результатов проверки доверия
Файл Excel справки для confidence был перезаписан в Excel 2003 и Excel 2007, так как все более ранние версии файла справки вводили в заблуждение при интерпретации результатов. В примере говорится: «Предположим, что в нашем примере из 50 сотрудников в пути средняя продолжительность поездки на работу составляет 30 минут со стандартным отклонением в 2,5. Мы можем быть уверены в том, что значение «0,692951» находится в интервале 30 +/- 0,692951″, где значение 0,692951 — это значение, возвращаемого значением ДОВЕРИТ(0,05, 2,5, 50).
В этом же примере в заключение говорится, что средняя продолжительность поездки на работу равна 30 ± 0,692951 минуты или от 29,3 до 30,7 минуты. Это также утверждение о том, что численность населения находится в интервале [30 –0,692951, 30 + 0,692951] с вероятностью 0,95.
Перед проведением эксперимента, который дает данные в данном примере, статистический статистик (в отличие от байеса) не может делать никаких заявлений о распределении вероятности распределения по численности населения. Вместо этого статистический статистик в классической версии имеет дело с проверкой гипотез.
Например, классическому статистику может потребоваться провести двухбоговую проверку гипотезы на основе гипотезы на основе гипотезы о нормальном распределении с известным стандартным отклонением (например, 2,5), заранее выбранным значением μ0 и предопределенным уровнем значимости (например, 0,05). Результат проверки будет основан на значении наблюдаемого значения выборки (например, 30), а гипотеза null о том, что это μ0, будет отклонена на уровне значимости 0,05, если наблюдаемое значение имеет значение слишком далеко от μ0 в любом направлении. Если гипотеза NULL отклонена, то интерпретация состоит в том, что выборка означает, что выборка означает, что гораздо больше μ0 может возникнуть менее 5 % времени при позиции, что μ0 — это истинное подмногление численности населения. После проведения этого теста статистический статистик по-прежнему не может сделать никаких заявлений о распределении вероятностей для распределения по численности населения.
С другой стороны, байесский статистический статистик начинается с предполагается распределение вероятности для распределения по численности населения (априори), собирает экспериментальные признаки так же, как и статистический статистик, и использует его для изменения его распределения вероятности для многубного распределения по численности населения и тем самым получения задняя часть распределения. Excel не предусмотрены статистические функции, которые помогли бы байесам в этом случае. Excel статистические функции классической статистики.
Доверительный интервал связан с проверкой гипотез. Учитывая экспериментальные признаки, доверительный интервал делает краткое утверждение о значениях среднего среднего гипотезы μ0, которое позволит принять нулевую гипотезу о том, что это μ0, и значения μ0, которые подавят отклонение гипотезы null о том, что это значение имеет значение μ0. Статистический статистик не может сделать ни одного заявления о вероятности того, что оно попадает в определенный интервал, так как он никогда не делает предопределенные предположения относительно этого распределения вероятности, и такие предположения потребуются, если они будут использовать экспериментальные признаки для их изменения.
Изучение связи между проверками гипотез и доверитными интервалами с помощью примера в начале этого раздела. Связь между доверим и НОРМСИНХОV, которая была заверяема в последнем разделе, имеется:
CONFIDENCE(0.05, 2.5, 50) = NORMSINV(1 – 0.05/2) * 2.5 / SQRT(50) = 0.692951
Так как выборка имеет 30-е, доверительный интервал составляет 30 +/- 0,692951.
Теперь рассмотрим двухбудную проверку гипотезы с уровнем значимости 0,05, как описано выше, в котором предполагается нормальное распределение со стандартным отклонением 2,5, выборку размером 50 и определенным гипотезой о среднего распределения ( μ0). Если это истинное решение по численности населения, то выборка будет взята из нормального распределения со стандартным отклонением μ0 и стандартным отклонением 2,5/SQRT(50). Это распределение симметрично о μ0, и вы хотите отклонить гипотезу null, если abS(выборка μ0) > некого конечного значения. Конечное значение будет таким, что если μ0 — это истинное значение по численности населения, значение выборки — μ0 больше, чем это обрезка, или значение μ0 — выборочная величина выше, чем это обрезка будет возникать с вероятностью 0,05/2. Это вырезание
NORMSINV(1 – 0.05/2) * 2.5/SQRT(50) = CONFIDENCE(0.05, 2.5, 50) = 0. 692951
Отклонить нулевую гипотезу (о численности населения = μ0), если одно из следующих заявлений истинно:
выборка «mean» — μ0 > 0. 692951
0 — пример > 0. 692951
Так как в нашем примере примере выборка » = 30″, эти две выписки становятся следующими:
30 — μ0 > 0. 692951
μ0 –30 > 0. 692951
При переописи слева отображается только μ0, что приводит к следующим утверждениям:
μ0 30 + 0. 692951
Это точно те значения μ0, которые не находятся в доверительный интервал [30 – 0,692951, 30 + 0,692951]. Поэтому доверительный интервал [30 –0,692951, 30 + 0,692951] содержит значения μ0, где null-гипотеза о том, что это μ0, не будет отклонена с учетом примеров признаков. Для значений μ0 вне этого интервала гипотеза null о том, что это μ0, будет отклонена с учетом примеров признаков.
Выводы
Неточности в более ранних версиях Excel обычно возникают при очень небольших или очень больших значениях p в нормУРОВН(p). Доверит оценивается с помощью вызовов НОРМ.СТ.ВВ(p), поэтому точность НОРМСИНВ является потенциальной проблемой для пользователей ДОВЕРИТ. Однако значения p, которые используются на практике, вряд ли являются достаточно крайними, чтобы вызывать существенные ошибки округленного округления в нормУРОВН, и производительность доверит пользователям любой версии Excel.
В большинстве статей основное внимание уделялось анализу результатов проверки доверить. Другими словами, мы спросили: «В чем смысл доверительный интервал?» Доверительный интервал часто неправильно понимается. К сожалению, Excel этой теме были Excel справки во всех версиях Excel 2003. Улучшен Excel 2003.
Источник
Вычисление доверительного интервала в Microsoft Excel

Одним из методов решения статистических задач является вычисление доверительного интервала. Он используется, как более предпочтительная альтернатива точечной оценке при небольшом объеме выборки. Нужно отметить, что сам процесс вычисления доверительного интервала довольно сложный. Но инструменты программы Эксель позволяют несколько упростить его. Давайте узнаем, как это выполняется на практике.
Процедура вычисления
Этот метод используется при интервальной оценке различных статистических величин. Главная задача данного расчета – избавится от неопределенностей точечной оценки.
В Экселе существуют два основных варианта произвести вычисления с помощью данного метода: когда дисперсия известна, и когда она неизвестна. В первом случае для вычислений применяется функция ДОВЕРИТ.НОРМ, а во втором — ДОВЕРИТ.СТЮДЕНТ.
Способ 1: функция ДОВЕРИТ.НОРМ
Оператор ДОВЕРИТ.НОРМ, относящийся к статистической группе функций, впервые появился в Excel 2010. В более ранних версиях этой программы используется его аналог ДОВЕРИТ. Задачей этого оператора является расчет доверительного интервала с нормальным распределением для средней генеральной совокупности.
Его синтаксис выглядит следующим образом:
«Альфа» — аргумент, указывающий на уровень значимости, который применяется для расчета доверительного уровня. Доверительный уровень равняется следующему выражению:
«Стандартное отклонение» — это аргумент, суть которого понятна из наименования. Это стандартное отклонение предлагаемой выборки.
«Размер» — аргумент, определяющий величину выборки.
Все аргументы данного оператора являются обязательными.
Функция ДОВЕРИТ имеет точно такие же аргументы и возможности, что и предыдущая. Её синтаксис таков:
Как видим, различия только в наименовании оператора. Указанная функция в целях совместимости оставлена в Excel 2010 и в более новых версиях в специальной категории «Совместимость». В версиях же Excel 2007 и ранее она присутствует в основной группе статистических операторов.
Граница доверительного интервала определяется при помощи формулы следующего вида:
Где X – это среднее выборочное значение, которое расположено посередине выбранного диапазона.
Теперь давайте рассмотрим, как рассчитать доверительный интервал на конкретном примере. Было проведено 12 испытаний, вследствие которых были получены различные результаты, занесенные в таблицу. Это и есть наша совокупность. Стандартное отклонение равно 8. Нам нужно рассчитать доверительный интервал при уровне доверия 97%.
- Выделяем ячейку, куда будет выводиться результат обработки данных. Щелкаем по кнопке «Вставить функцию».

- Появляется Мастер функций. Переходим в категорию «Статистические» и выделяем наименование «ДОВЕРИТ.НОРМ». После этого клацаем по кнопке «OK».
- Открывается окошко аргументов. Его поля закономерно соответствуют наименованиям аргументов.
Устанавливаем курсор в первое поле – «Альфа». Тут нам следует указать уровень значимости. Как мы помним, уровень доверия у нас равен 97%. В то же время мы говорили, что он рассчитывается таким путем:
Значит, чтобы посчитать уровень значимости, то есть, определить значение «Альфа» следует применить формулу такого вида:
То есть, подставив значение, получаем:
Путем нехитрых расчетов узнаем, что аргумент «Альфа» равен 0,03. Вводим данное значение в поле.
Как известно, по условию стандартное отклонение равно 8. Поэтому в поле «Стандартное отклонение» просто записываем это число.
В поле «Размер» нужно ввести количество элементов проведенных испытаний. Как мы помним, их 12. Но чтобы автоматизировать формулу и не редактировать её каждый раз при проведении нового испытания, давайте зададим данное значение не обычным числом, а при помощи оператора СЧЁТ. Итак, устанавливаем курсор в поле «Размер», а затем кликаем по треугольнику, который размещен слева от строки формул.
Появляется список недавно применяемых функций. Если оператор СЧЁТ применялся вами недавно, то он должен быть в этом списке. В таком случае, нужно просто кликнуть по его наименованию. В обратном же случае, если вы его не обнаружите, то переходите по пункту «Другие функции…». 
Группа аргументов «Значения» представляет собой ссылку на диапазон, в котором нужно рассчитать количество заполненных числовыми данными ячеек. Всего может насчитываться до 255 подобных аргументов, но в нашем случае понадобится лишь один.
Устанавливаем курсор в поле «Значение1» и, зажав левую кнопку мыши, выделяем на листе диапазон, который содержит нашу совокупность. Затем его адрес будет отображен в поле. Клацаем по кнопке «OK». 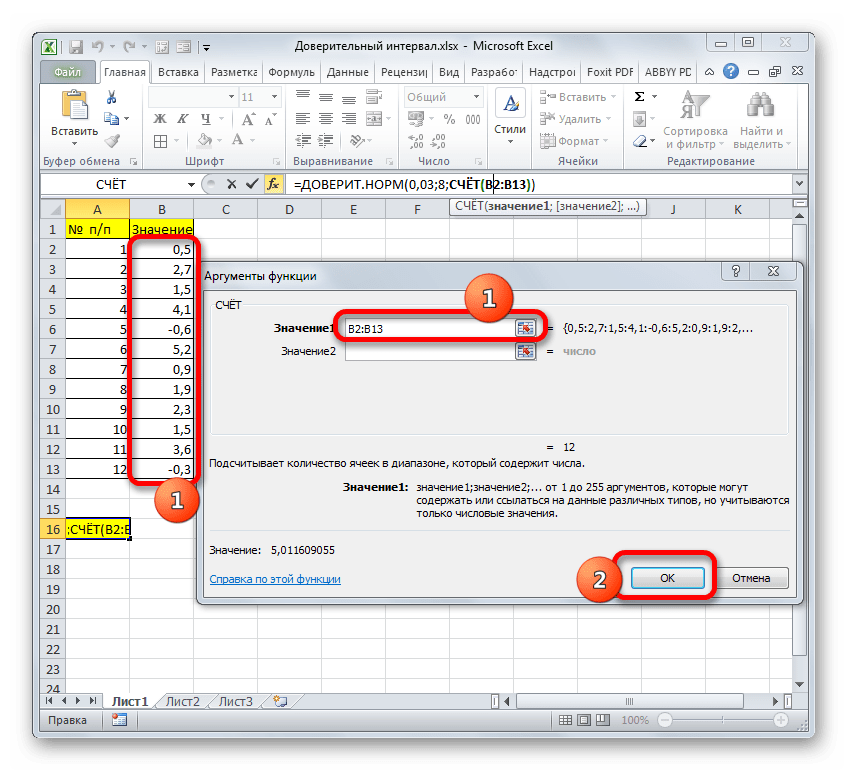
После этого приложение произведет вычисление и выведет результат в ту ячейку, где она находится сама. В нашем конкретном случае формула получилась такого вида:
Общий результат вычислений составил 5,011609. 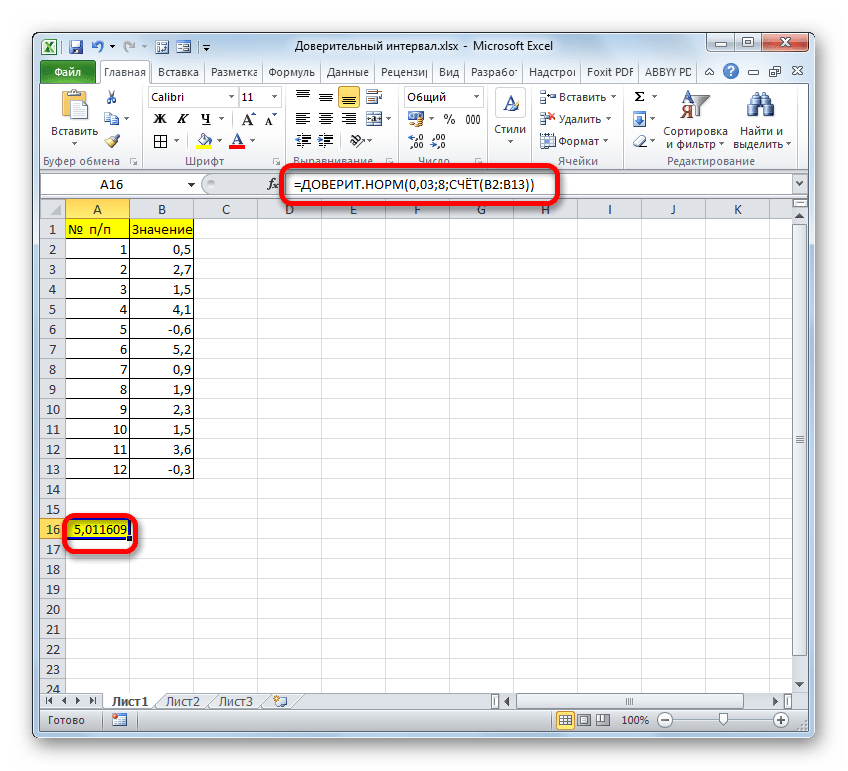
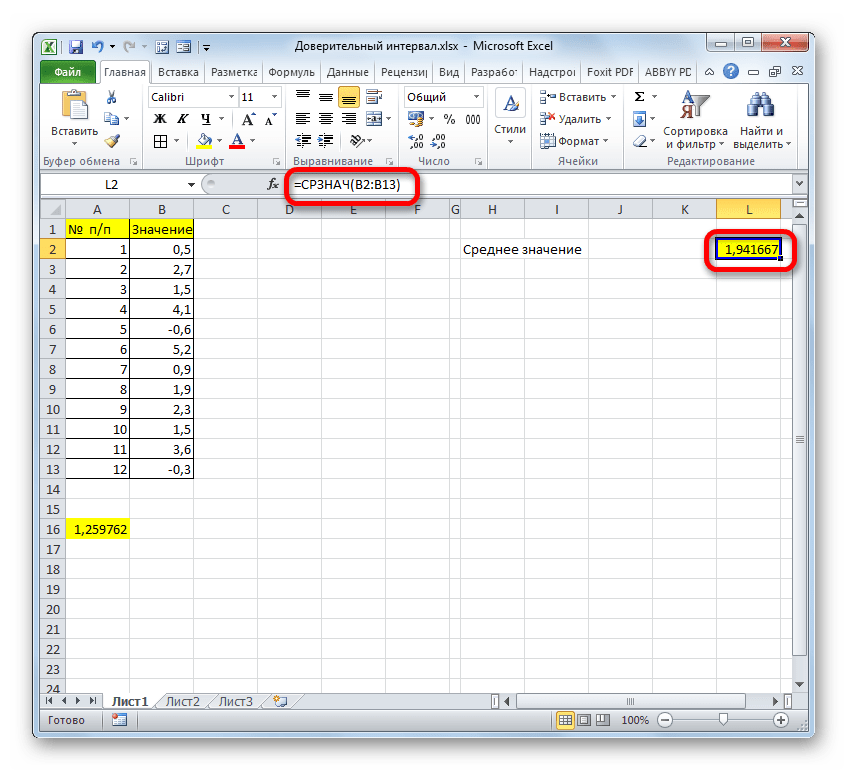
Но это ещё не все. Как мы помним, граница доверительного интервала вычисляется путем сложения и вычитания от среднего выборочного значения результата вычисления ДОВЕРИТ.НОРМ. Таким способом рассчитывается соответственно правая и левая граница доверительного интервала. Само среднее выборочное значение можно рассчитать при помощи оператора СРЗНАЧ.
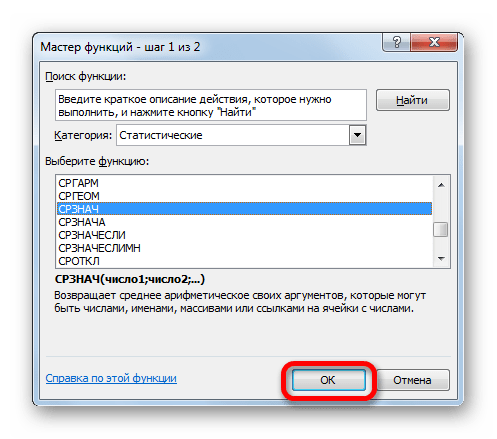
Данный оператор предназначен для расчета среднего арифметического значения выбранного диапазона чисел. Он имеет следующий довольно простой синтаксис:
Аргумент «Число» может быть как отдельным числовым значением, так и ссылкой на ячейки или даже целые диапазоны, которые их содержат.
Итак, выделяем ячейку, в которую будет выводиться расчет среднего значения, и щелкаем по кнопке «Вставить функцию». 
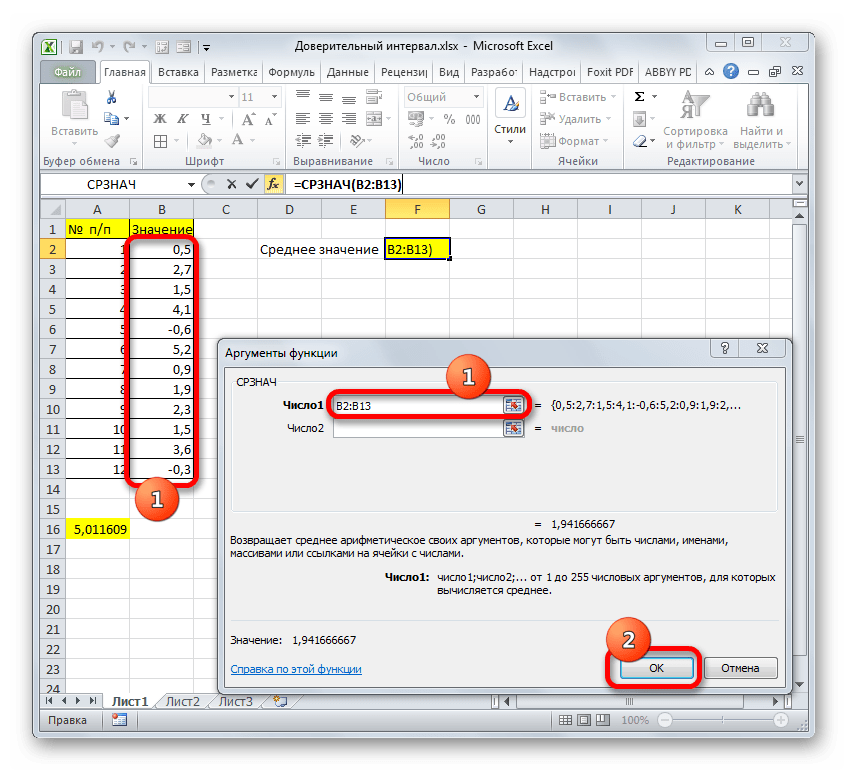
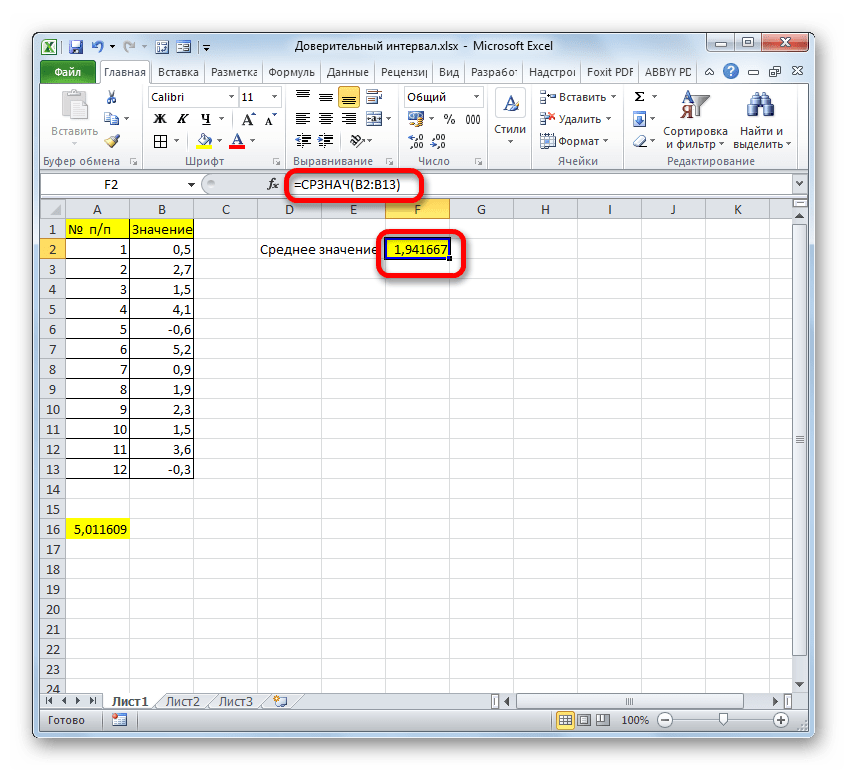
Результат вычисления: 6,953276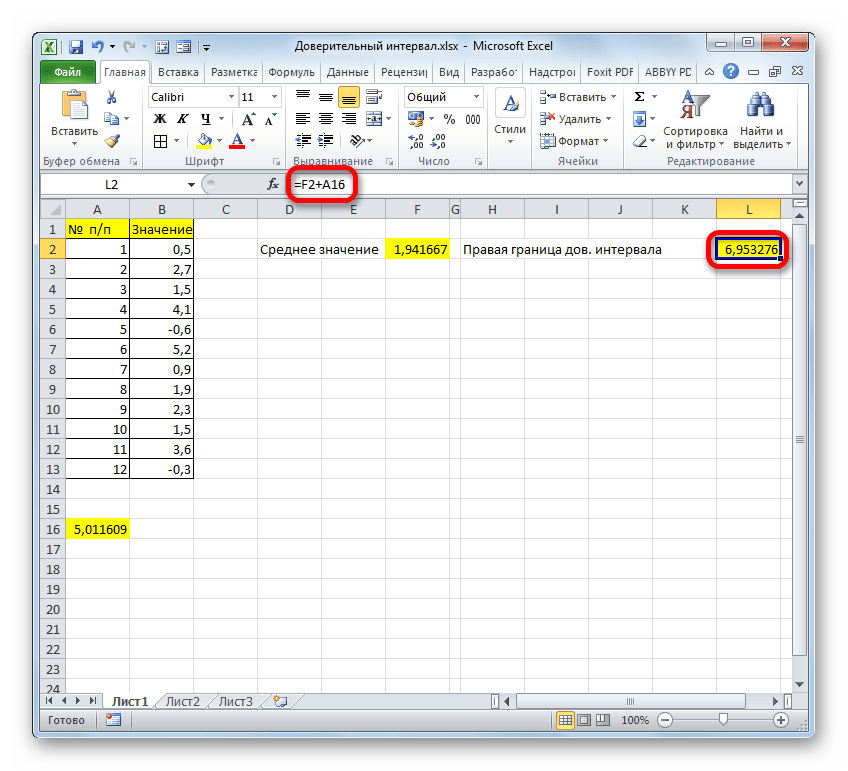
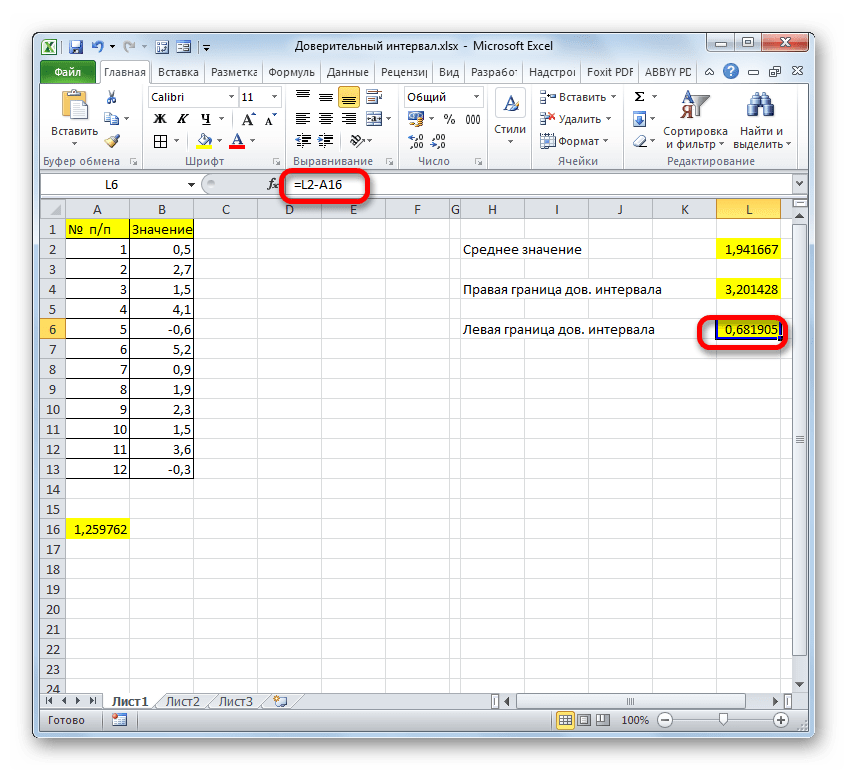
Таким же образом производим вычисление левой границы доверительного интервала, только на этот раз от результата вычисления СРЗНАЧ отнимаем результат вычисления оператора ДОВЕРИТ.НОРМ. Получается формула для нашего примера следующего типа:
Результат вычисления: -3,06994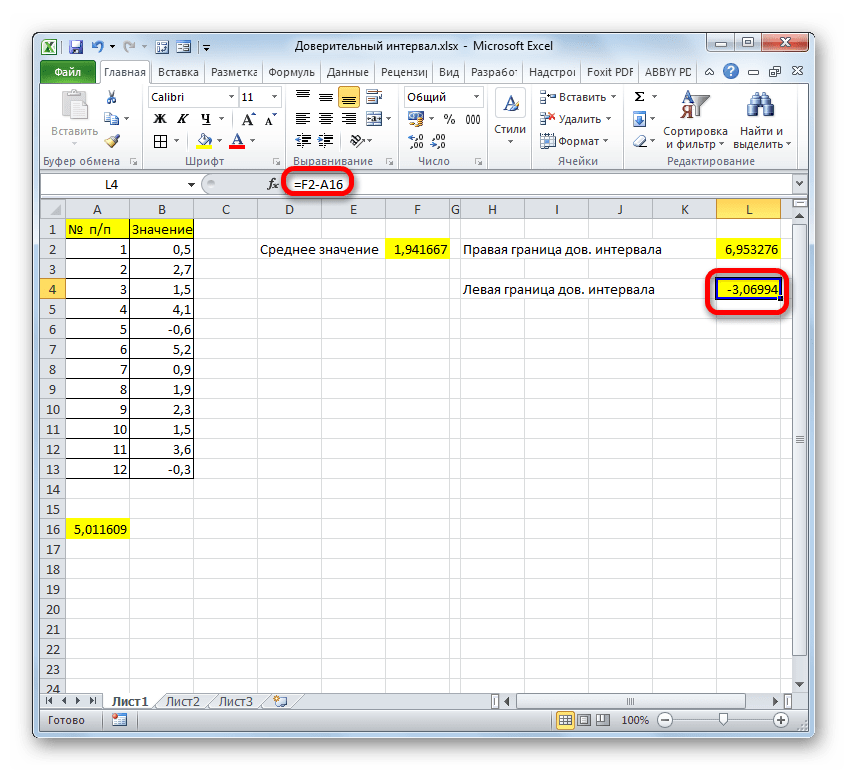
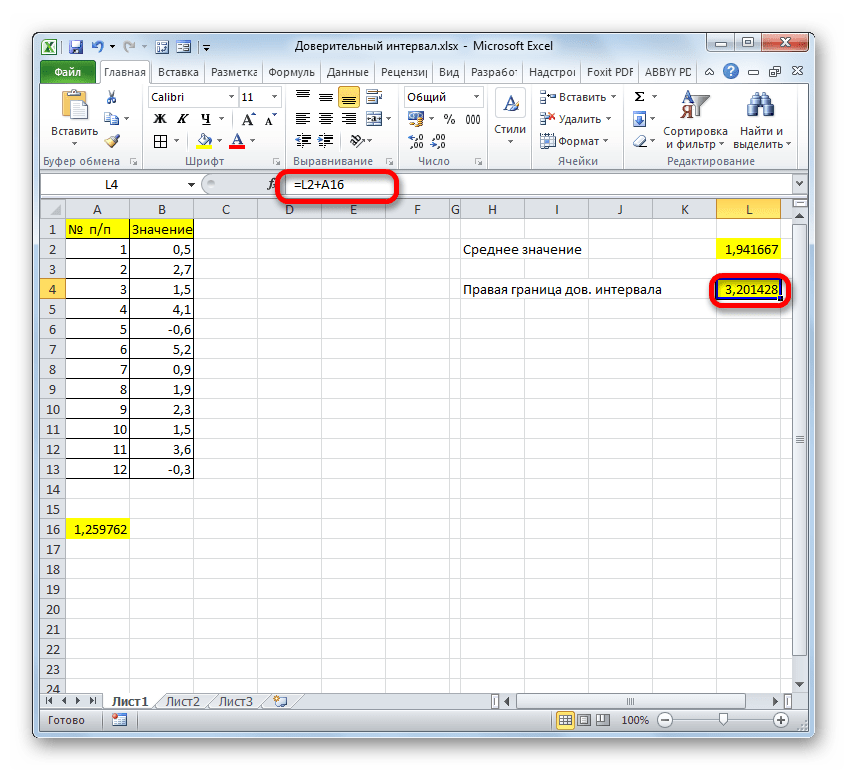
Мы попытались подробно описать все действия по вычислению доверительного интервала, поэтому детально расписали каждую формулу. Но можно все действия соединить в одной формуле. Вычисление правой границы доверительного интервала можно записать так:
=СРЗНАЧ(B2:B13)+ДОВЕРИТ.НОРМ(0,03;8;СЧЁТ(B2:B13)) 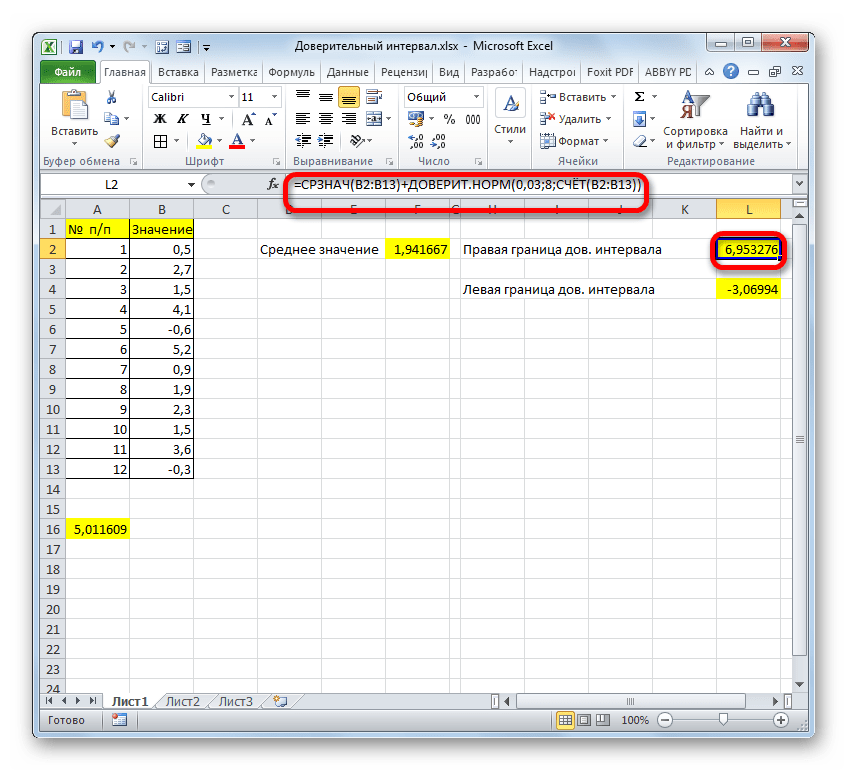
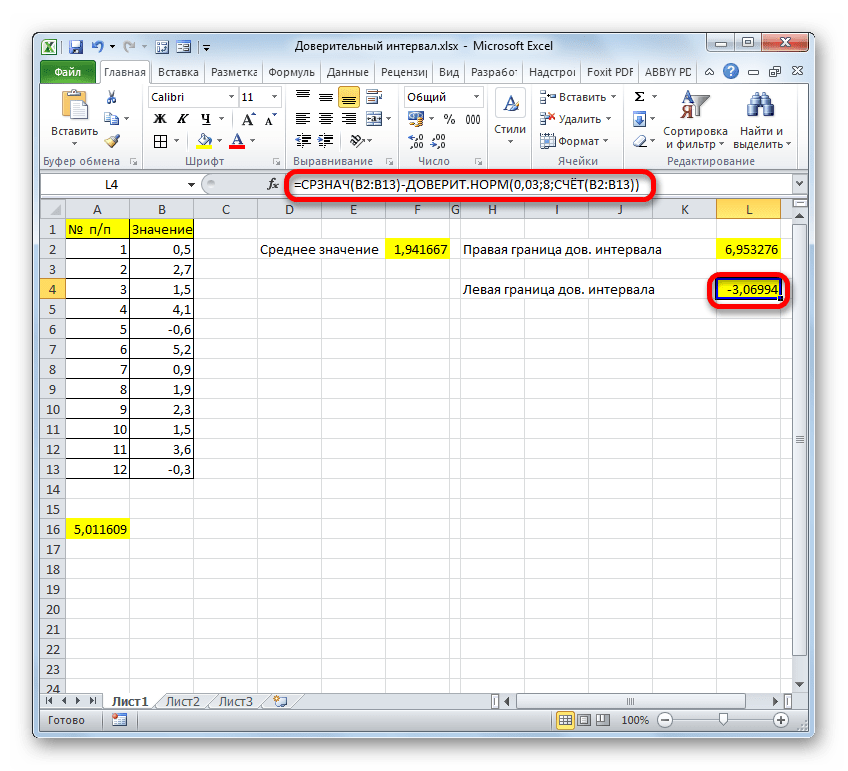
Аналогичное вычисление левой границы будет выглядеть так:
=СРЗНАЧ(B2:B13)-ДОВЕРИТ.НОРМ(0,03;8;СЧЁТ(B2:B13))
Способ 2: функция ДОВЕРИТ.СТЮДЕНТ
Кроме того, в Экселе есть ещё одна функция, которая связана с вычислением доверительного интервала – ДОВЕРИТ.СТЮДЕНТ. Она появилась, только начиная с Excel 2010. Данный оператор выполняет вычисление доверительного интервала генеральной совокупности с использованием распределения Стьюдента. Его очень удобно использовать в том случае, когда дисперсия и, соответственно, стандартное отклонение неизвестны. Синтаксис оператора такой:
Как видим, наименования операторов и в этом случае остались неизменными.
Посмотрим, как рассчитать границы доверительного интервала с неизвестным стандартным отклонением на примере всё той же совокупности, что мы рассматривали в предыдущем способе. Уровень доверия, как и в прошлый раз, возьмем 97%.
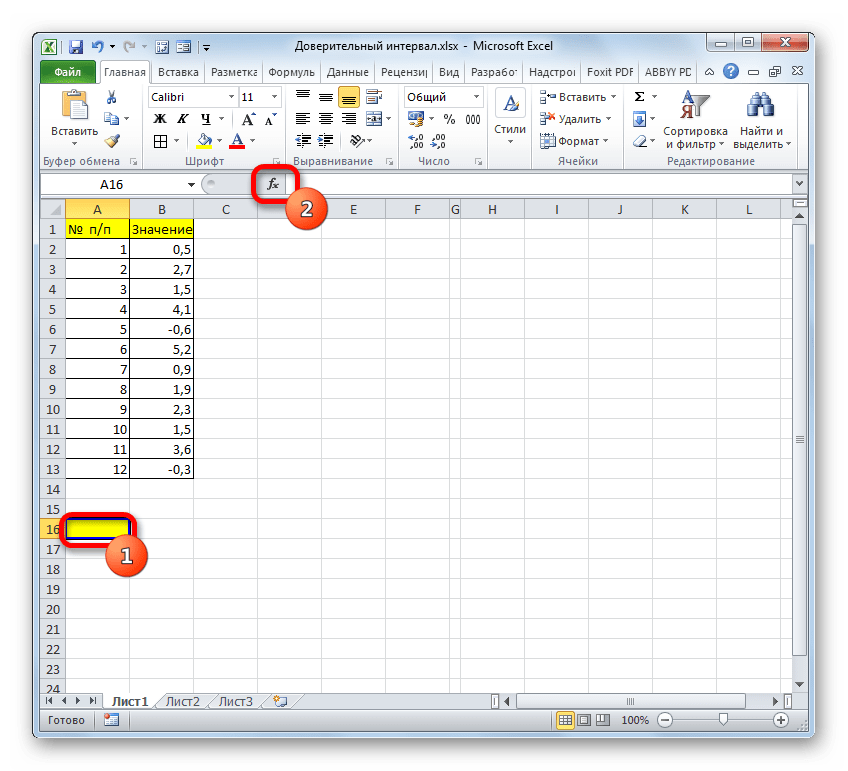
- Выделяем ячейку, в которую будет производиться расчет. Клацаем по кнопке «Вставить функцию».
- В открывшемся Мастере функций переходим в категорию «Статистические». Выбираем наименование «ДОВЕРИТ.СТЮДЕНТ». Клацаем по кнопке «OK».
- Производится запуск окна аргументов указанного оператора.
В поле «Альфа», учитывая, что уровень доверия составляет 97%, записываем число 0,03. Второй раз на принципах расчета данного параметра останавливаться не будем.
После этого устанавливаем курсор в поле «Стандартное отклонение». На этот раз данный показатель нам неизвестен и его требуется рассчитать. Делается это при помощи специальной функции – СТАНДОТКЛОН.В. Чтобы вызвать окно данного оператора, кликаем по треугольнику слева от строки формул. Если в открывшемся списке не находим нужного наименования, то переходим по пункту «Другие функции…». 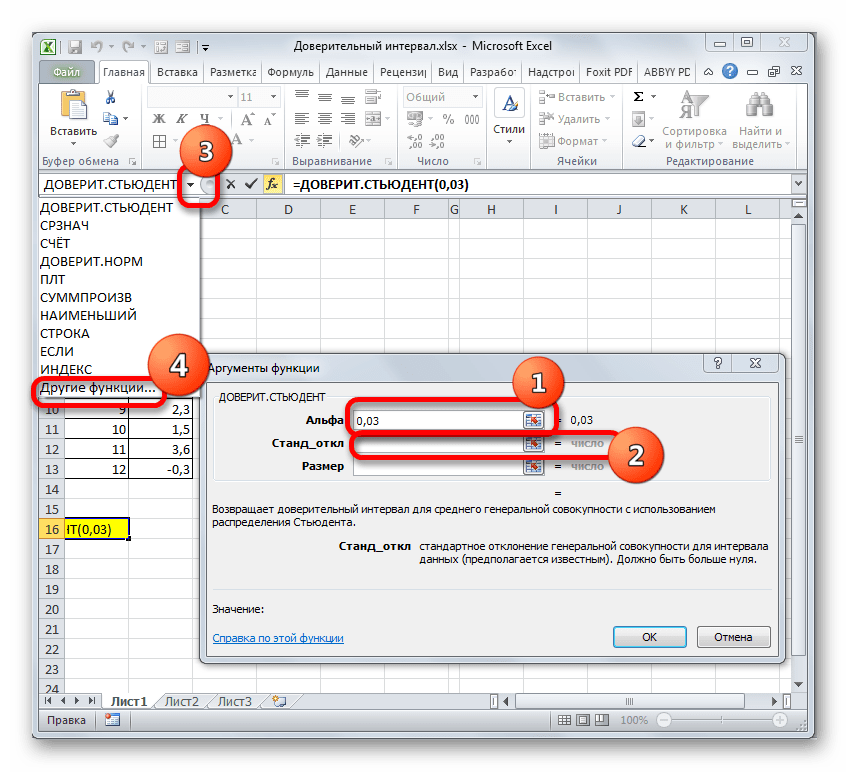
Нетрудно догадаться, что аргумент «Число» — это адрес элемента выборки. Если выборка размещена единым массивом, то можно, использовав только один аргумент, дать ссылку на данный диапазон.
Устанавливаем курсор в поле «Число1» и, как всегда, зажав левую кнопку мыши, выделяем совокупность. После того, как координаты попали в поле, не спешим жать на кнопку «OK», так как результат получится некорректным. Прежде нам нужно вернуться к окну аргументов оператора ДОВЕРИТ.СТЮДЕНТ, чтобы внести последний аргумент. Для этого кликаем по соответствующему наименованию в строке формул. 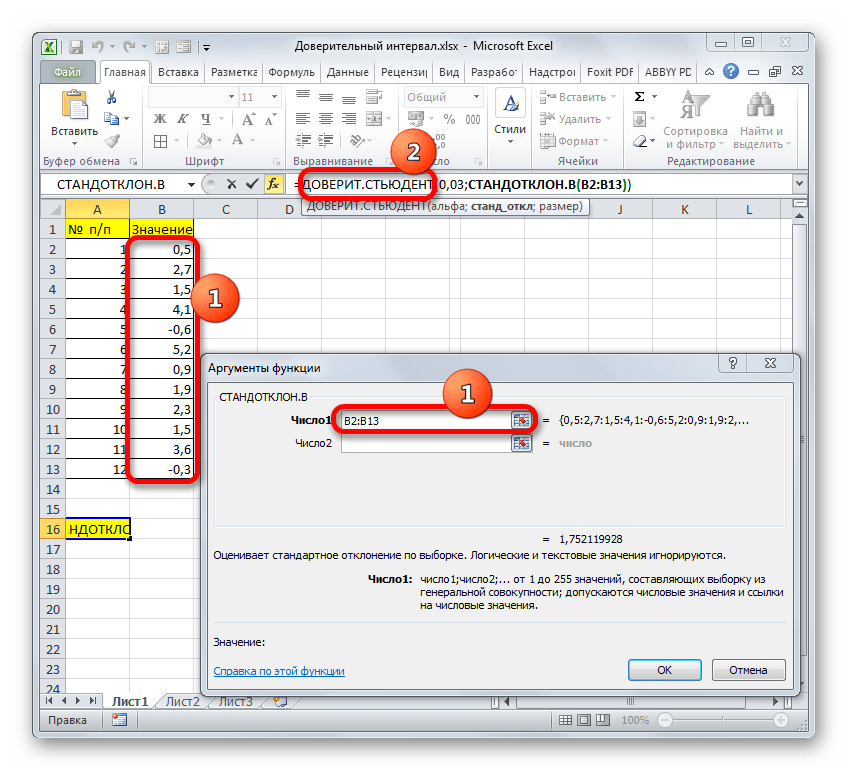
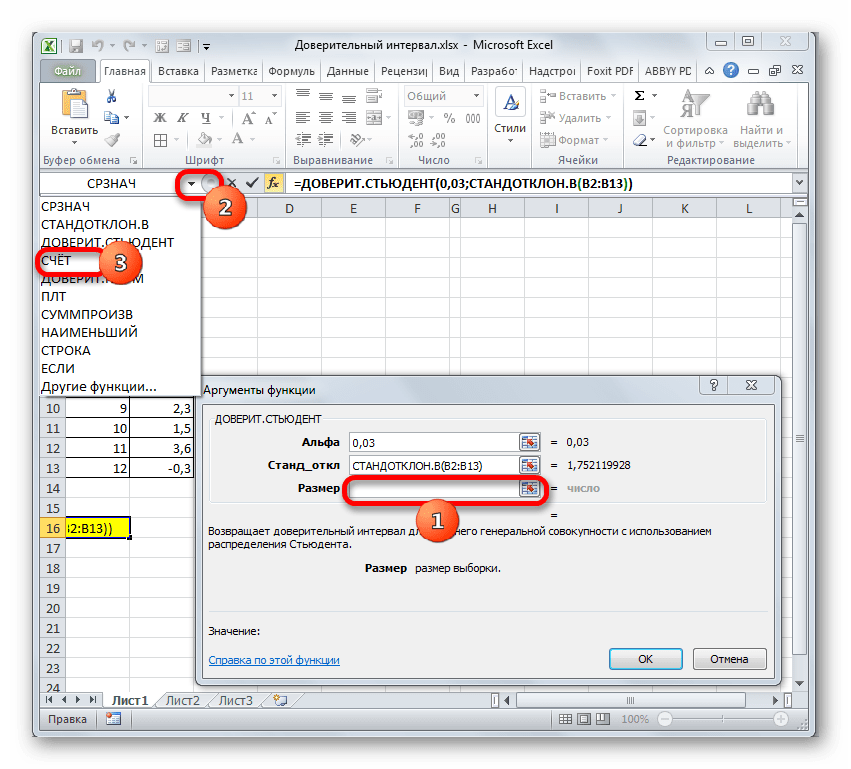
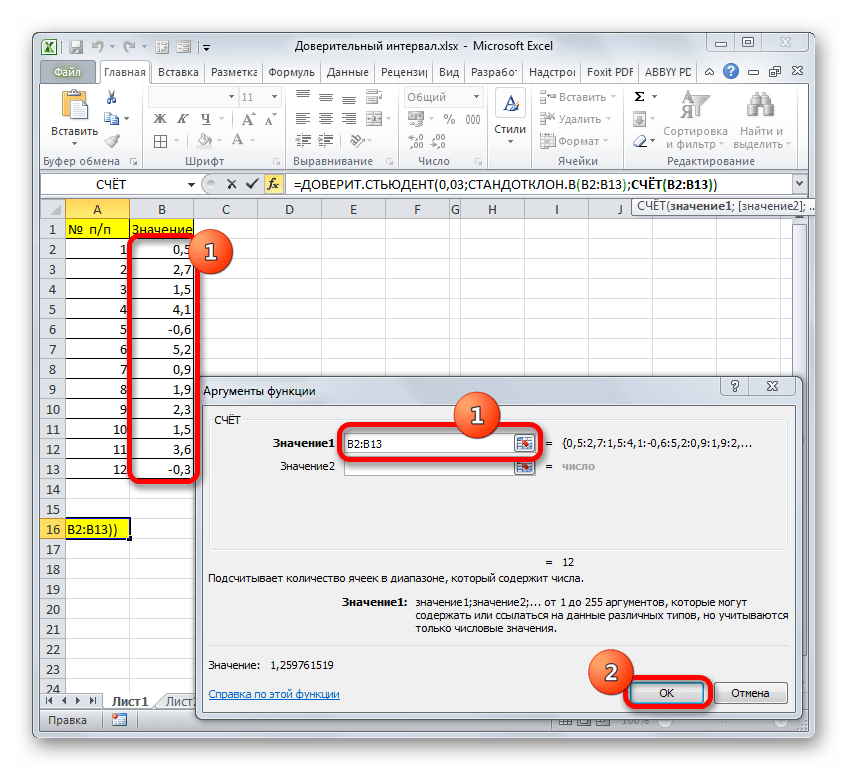
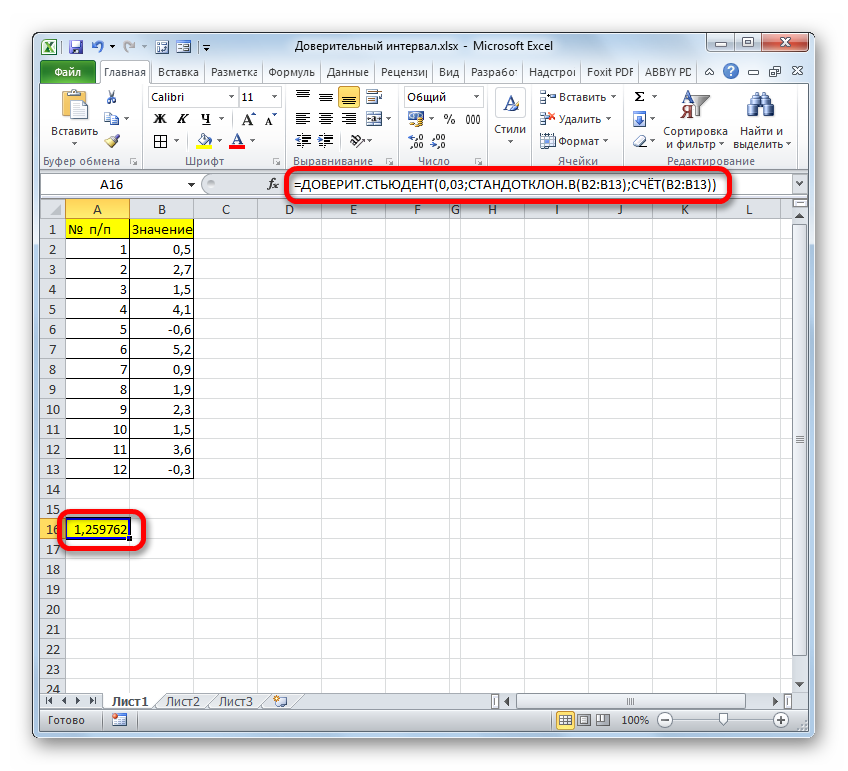
=СРЗНАЧ(B2:B13)+ДОВЕРИТ.СТЬЮДЕНТ(0,03;СТАНДОТКЛОН.В(B2:B13);СЧЁТ(B2:B13)) 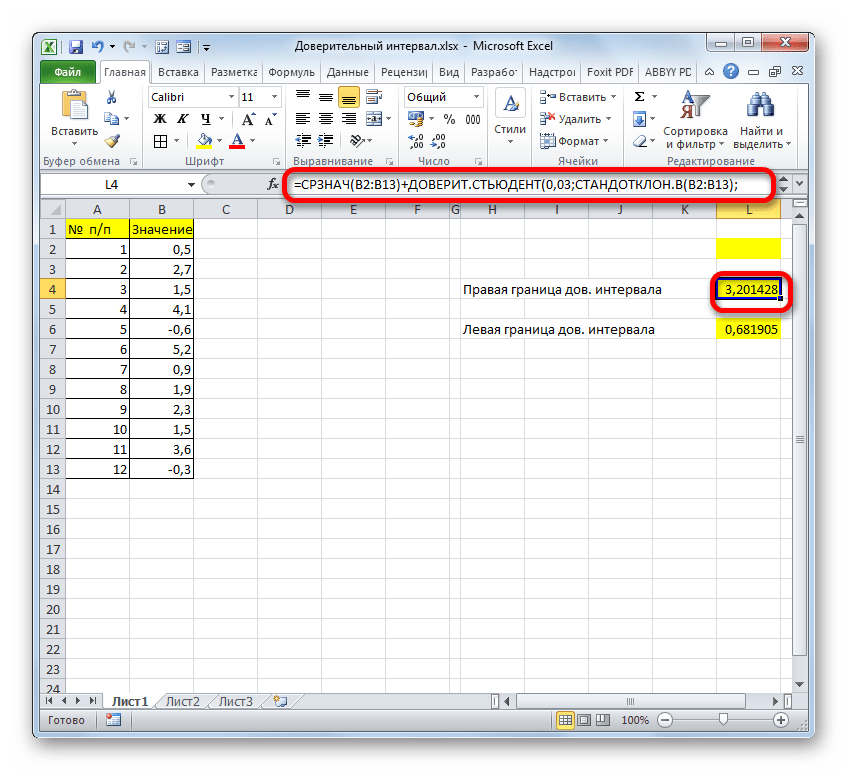
Соответственно, формула расчета левой границы будет выглядеть так:
=СРЗНАЧ(B2:B13)-ДОВЕРИТ.СТЬЮДЕНТ(0,03;СТАНДОТКЛОН.В(B2:B13);СЧЁТ(B2:B13))
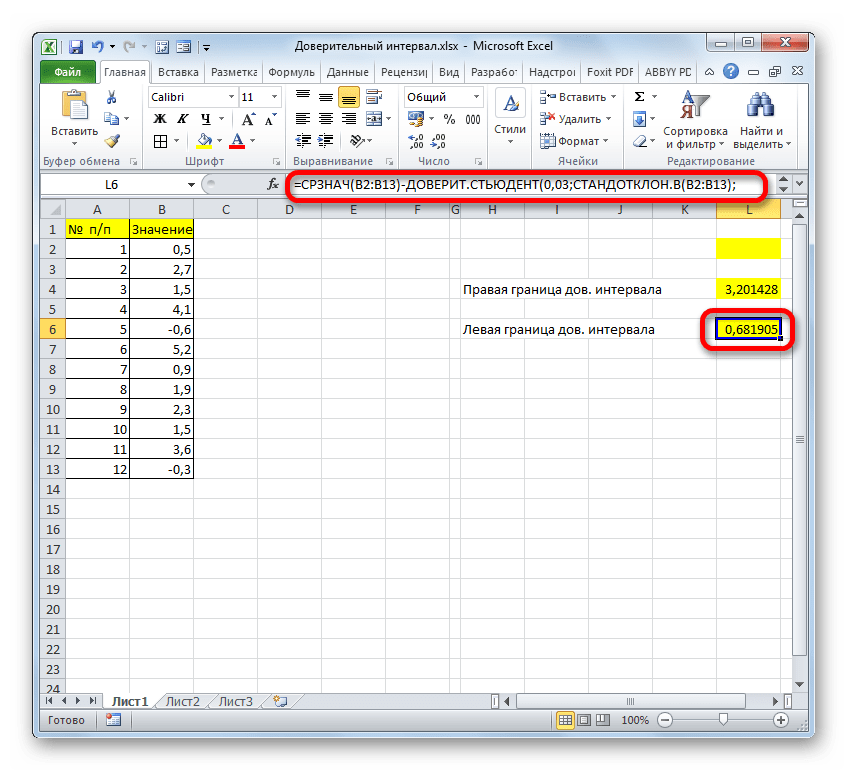
Как видим, инструменты программы Excel позволяют существенно облегчить вычисление доверительного интервала и его границ. Для этих целей используются отдельные операторы для выборок, у которых дисперсия известна и неизвестна.
Источник
17 авг. 2022 г.
читать 2 мин
Всякий раз, когда вы проводите t-тест, в результате вы получаете тестовую статистику. Чтобы определить, являются ли результаты t-теста статистически значимыми, можно сравнить статистику теста с критическим значением T. Если абсолютное значение тестовой статистики больше критического значения Т, то результаты теста статистически значимы.
Критическое значение T можно найти с помощью таблицы распределения t или с помощью статистического программного обеспечения.
Чтобы найти критическое значение T, необходимо указать:
- Уровень значимости (обычно выбирают 0,01, 0,05 и 0,10).
- Степени свободы
- Тип теста (односторонний или двусторонний)
Используя эти три значения, вы можете определить критическое значение T для сравнения со статистикой теста.
Связанный: Как найти критическое значение Z в Excel
Как найти критическое значение T в Excel
Excel предлагает две функции для нахождения критического значения T.
Т.ОБР.
Чтобы найти критическое значение T в Excel для одностороннего теста , вы можете использовать функцию T.ОБР.() , которая использует следующий синтаксис:
T.INV (вероятность, град_свободы)
- вероятность: уровень значимости для использования
- deg_freedom : Степени свободы
Эта функция возвращает критическое значение из распределения t для одностороннего теста на основе уровня значимости и предоставленных степеней свободы.
Т.ОБР.2Т
Чтобы найти критическое значение T в Excel для двустороннего теста , вы можете использовать функцию T.ОБР.2T() , которая использует следующий синтаксис:
T.INV.2T (вероятность, град_свободы)
- вероятность: уровень значимости для использования
- deg_freedom : Степени свободы
Эта функция возвращает критическое значение из распределения t для двустороннего теста на основе уровня значимости и предоставленных степеней свободы.
Примеры поиска критического значения T в Excel
В следующих примерах показано, как найти критическое значение T для левостороннего, правостороннего и двустороннего критериев.
Левосторонний тест
Чтобы найти критическое значение T для левостороннего критерия с уровнем значимости 0,05 и степенями свободы = 11, мы можем ввести в Excel следующую формулу: T.ОБР(0,05, 11)

Это возвращает значение -1,79588.Это критическое значение для левостороннего теста с уровнем значимости 0,05 и степенями свободы = 11.
Правосторонний тест
Чтобы найти критическое значение T для правостороннего критерия с уровнем значимости 0,05 и степенями свободы = 11, мы можем ввести в Excel следующую формулу: ABS( T.ОБР(0,05, 11))

Это возвращает значение 1,79588.Это критическое значение для двустороннего теста с уровнем значимости 0,05 и степенями свободы = 11.
Двусторонний тест
Чтобы найти критическое значение T для двустороннего критерия с уровнем значимости 0,05 и степенями свободы = 11, мы можем ввести в Excel следующую формулу: T.ОБР.2T(0,05, 11)

Это возвращает значение 2.200985.Это критическое значение для двустороннего теста с уровнем значимости 0,05 и степенями свободы = 11.
Обратите внимание, что это также соответствует числу, которое мы нашли бы в таблице распределения t с α = 0,05 для двух хвостов и DF (степени свободы) = 11.

Предостережения по поиску критического значения T в Excel
Обратите внимание, что обе функции T.ОБР () и T.ОБР.2T() в Excel выдают ошибку, если происходит одно из следующих событий:
- Если какой-либо аргумент не является числовым.
- Если значение вероятности меньше нуля или больше 1.
- Если значение для deg_freedomменьше 1.
A T-test is a way of deciding if there are statistically significant differences between datasets, using a Student’s t-distribution. The T-Test in Excel is a two-sample T-test comparing the means of two samples. This article explains what statistical significance means and shows how to do a T-Test in Excel.
Instructions in this article apply to Excel 2019, 2016, 2013, 2010, 2007; Excel for Microsoft 365 and Excel Online.
What is Statistical Significance?
Imagine you want to know which of two dice will give a better score. You roll the first die and get a 2; you roll the second die and get a 6. Does this tell you the second die usually gives higher scores? If you answered, “Of course not,” then you already have some understanding of statistical significance. You understand the difference was due to the random change in the score, each time a die is rolled. Because the sample was very small (only one roll) it didn’t show anything significant.
Now imagine you roll each die 6 times:
- The first die rolls 3, 6, 6, 4, 3, 3; Mean = 4.17
- The second die rolls 5, 6, 2, 5, 2, 4; Mean = 4.00
Does this now prove the first die gives higher scores than the second? Probably not. A small sample with a relatively small difference between the means makes it likely the difference is still due to random variations. As we increase the number of dice rolls it becomes difficult to give a common sense answer to the question — is the difference between the scores the result of random variation or is one actually more likely to give higher scores than the other?
Significance is the probability that an observed difference between samples is due to random variations. Significance is often called the alpha level or simply ‘α.’ The confidence level, or simply ‘c,’ is the probability that the difference between the samples is not due to random variation; in other words, that there’s a difference between the underlying populations. Therefore: c = 1 – α
We can set ‘α’ at whatever level we want, to feel confident we’ve proven significance. Very often α=5% is used (95% confidence), but if we want to be really sure that any differences are not caused by random variation, we might apply a higher confidence level, using α=1% or even α=0.1%.
Various statistical tests are used to calculate significance in different situations. T-tests are used to determine whether the means of two populations are different and F-tests are used to determine whether the variances are different.
Why Test for Statistical Significance?
When comparing different things, we need to use significance testing to determine if one is better than the other. This applies to many fields, for example:
- In business, people need to compare different products and marketing methods.
- In sports, people need to compare different equipment, techniques, and competitors.
- In engineering, people need to compare different designs and parameter settings.
If you want to test whether something performs better than something else, in any field, you need to test for statistical significance.
What is a Student’s T-Distribution?
A Student’s t-distribution is similar to a normal (or Gaussian) distribution. These are both bell-shaped distributions with most results close to the mean, but some rare events are quite far from the mean in both directions, referred to as the tails of the distribution.
The exact shape of the Student’s t-distribution depends on the sample size. For samples of more than 30 it’s very similar to the normal distribution. As the sample size is reduced, the tails get larger, representing the increased uncertainty that comes from making inferences based on a small sample.
How to Do a T-Test in Excel
Before you can apply a T-Test to determine whether there’s a statistically significant difference between the means of two samples, you must first perform an F-Test. This is because different calculations are performed for the T-Test depending on whether there’s a significant difference between the variances.
You will need the Analysis Toolpak add-in enabled to perform this analysis.
Checking and Loading the Analysis Toolpak Add-In
To check and activate the Analysis Toolpak follow these steps:
-
Select the FILE tab >select Options.
-
In the Options dialogue box, select Add-Ins from the tabs on the left-hand side.
-
At the bottom of the window, select the Manage drop-down menu, then select Excel Add-ins. Select Go.
-
Ensure the check-box next to Analysis Toolpak is checked, then select OK.
-
The Analysis Toolpak is now active and you are ready to apply F-Tests and T-Tests.
Performing an F-Test and a T-Test in Excel
-
Enter two datasets into a spreadsheet. In this case, we’re considering the sales of two products during a week. The mean daily sales value for each product is also calculated, together with its standard deviation.
-
Select the Data tab > Data Analysis
-
Select F-Test Two-Sample for Variances from the list, then select OK.
The F-Test is highly sensitive to non-normality. It may therefore be safer to use a Welch test, but this is more difficult in Excel.
-
Select the Variable 1 Range and Variable 2 Range; set the Alpha (0.05 gives 95% confidence); select a cell for the top left corner of the output, considering that this will fill 3 columns and 10 rows. Select OK.
For the for Variable 1 Range, the sample with the largest standard deviation (or variance) must be selected.
-
View the F-Test results to determine whether there is a significant difference between the variances. The results give three important values:
- F: The ratio between the variances.
- P(F<=f) one-tail: The probability that variable 1 doesn’t actually have a larger variance than variable 2. If this is larger than alpha, which is generally 0.05, then there’s no significant difference between the variances.
- F Critical one-tail: The value of F that would be required to give P(F<=f)=α. If this value is greater than F, this also indicates there’s no significant difference between the variances.
P(F<=f) can also be calculated using the FDIST function with F and the degrees of freedom for each sample as its inputs. Degrees of freedom is simply the number of observations in a sample minus one.
-
Now that you know whether there is a difference between the variances you can select the appropriate T-Test. Select the Data tab > Data Analysis, then select either t-Test: Two-Sample Assuming Equal Variances or t-Test: Two-Sample Assuming Unequal Variances.
-
Regardless of which option you chose in the previous step, you will be presented with the same dialogue box to enter the details of the analysis. To start, select the ranges containing the samples for Variable 1 Range and Variable 2 Range.
-
Assuming you want to test for no difference between the means, set the Hypothesized Mean Difference to zero.
-
Set the significance level Alpha (0.05 gives 95% confidence), and select a cell for the top left corner of the output, considering that this will fill 3 columns and 14 rows. Select OK.
-
Review the results to decide if there’s a significant difference between the means.
Just as with the F-Test, if the p-value, in this case P(T<=t), is greater than alpha, then there’s no significant difference. However, in this case there are two p-values given, one for a one-tail test and the other for a two-tail test. In this case, use the two-tail value since either variable having a greater mean would be a significant difference.
Thanks for letting us know!
Get the Latest Tech News Delivered Every Day
Subscribe