
Недавно возникла необходимость выделить в таблице дублирующие элементы другим цветом.
Для 2003 экселя я нашел такой способ
Выделяем весь список, начиная в нашем примере с ячейки А2 и идем в меню Формат — Условное форматирование (Format — Conditional Formatting). Выбираем из выпадающего списка вариант условия Формула и вводим такую проверку:
=СЧЁТЕСЛИ($A:$A;A2)>1
в английском Excel это будет соответственно =COUNTIF($A:$A;A2)>1
Для тех у кого Excel 2007 есть способ попроще.

1. Выделяем ячейки в которых ищем дубликаты.

2. Выбираем «Условное форматирование»->»Правила выделения ячеек»->»Другие правлиа».
3. Выбираем тип правила — «Форматировать только уникальные или повторяющиеся значения».

4. Из списка внизу выбираем — «Повторяющиеся», выбираем формат (цвет) ячейки и нажимаем «Ok».
Готово!.
Поиск и удаление дубликатов в Excel: 5 методов
Большие таблицы Эксель могут содержать повторяющиеся данные, что зачастую увеличивает объем информации и может привести к ошибкам в результате обработки данных при помощи формул и прочих инструментов. Это особенно критично, например, при работе с денежными и прочими финансовыми данными.
В данной статье мы рассмотрим методы поиска и удаления дублирующихся данных (дубликатов), в частности, строк в Excel.
Метод 1: удаление дублирующихся строк вручную
Первый метод максимально прост и предполагает удаление дублированных строк при помощи специального инструмента на ленте вкладки “Данные”.
- Полностью выделяем все ячейки таблицы с данными, воспользовавшись, например, зажатой левой кнопкой мыши.
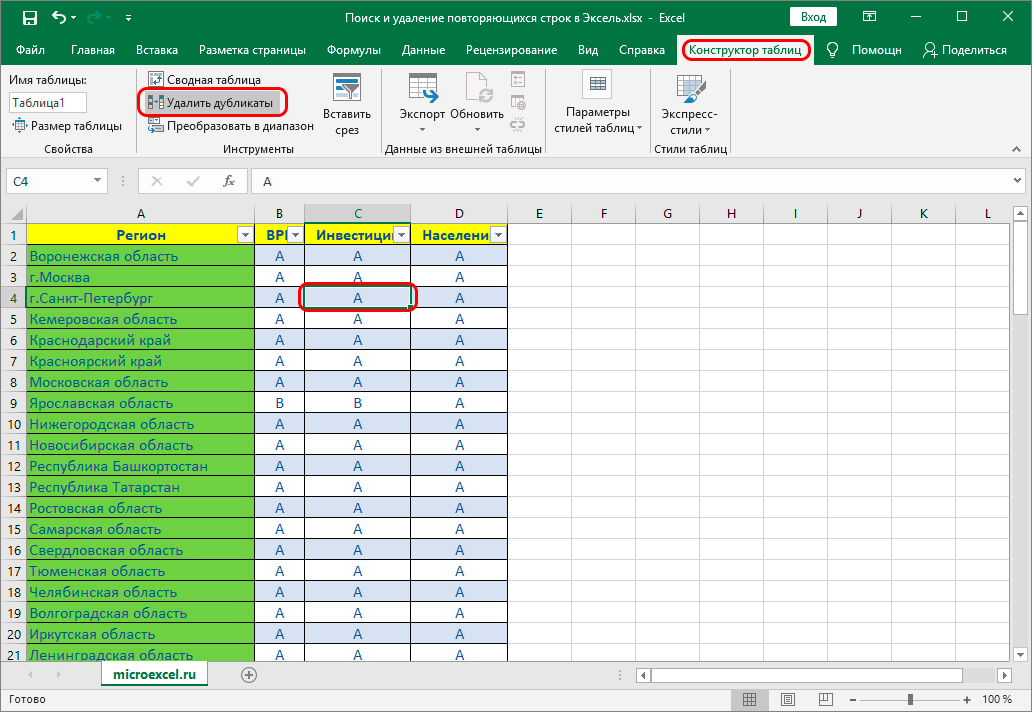
- Во вкладке “Данные” в разделе инструментов “Работа с данными” находим кнопку “Удалить дубликаты” и кликаем на нее.

- Переходим к настройкам параметров удаления дубликатов:
- Если обрабатываемая таблица содержит шапку, то проверяем пункт “Мои данные содержат заголовки” – он должен быть отмечен галочкой.
- Ниже, в основном окне, перечислены названия столбцов, по которым будет осуществляться поиск дубликатов. Система считает совпадением ситуацию, в которой в строках повторяются значения всех выбранных в настройке столбцов. Если убрать часть столбцов из сравнения, повышается вероятность увеличения количества похожих строк.
- Тщательно все проверяем и нажимаем ОК.
- Далее программа Эксель в автоматическом режиме найдет и удалит все дублированные строки.
- По окончании процедуры на экране появится соответствующее сообщение с информацией о количестве найденных и удаленных дубликатов, а также о количестве оставшихся уникальных строк. Для закрытия окна и завершения работы данной функции нажимаем кнопку OK.



Метод 2: удаление повторений при помощи “умной таблицы”
Еще один способ удаления повторяющихся строк – использование “умной таблицы“. Давайте рассмотрим алгоритм пошагово.
- Для начала, нам нужно выделить всю таблицу, как в первом шаге предыдущего раздела.
- Во вкладке “Главная” находим кнопку “Форматировать как таблицу” (раздел инструментов “Стили“). Кликаем на стрелку вниз справа от названия кнопки и выбираем понравившуюся цветовую схему таблицы.
- После выбора стиля откроется окно настроек, в котором указывается диапазон для создания “умной таблицы“. Так как ячейки были выделены заранее, то следует просто убедиться, что в окошке указаны верные данные. Если это не так, то вносим исправления, проверяем, чтобы пункт “Таблица с заголовками” был отмечен галочкой и нажимаем ОК. На этом процесс создания “умной таблицы” завершен.
- Далее приступаем к основной задаче – нахождению задвоенных строк в таблице. Для этого:
- ставим курсор на произвольную ячейку таблицы;
- переключаемся во вкладку “Конструктор” (если после создания “умной таблицы” переход не был осуществлен автоматически);
- в разделе “Инструменты” жмем кнопку “Удалить дубликаты“.
- Следующие шаги полностью совпадают с описанными в методе выше действиями по удалению дублированных строк.



Примечание: Из всех описываемых в данной статье методов этот является наиболее гибким и универсальным, позволяя комфортно работать с таблицами различной структуры и объема.
Метод 3: использование фильтра
Следующий метод не удаляет повторяющиеся строки физически, но позволяет настроить режим отображения таблицы таким образом, чтобы при просмотре они скрывались.
- Как обычно, выделяем все ячейки таблицы.
- Во вкладке “Данные” в разделе инструментов “Сортировка и фильтр” ищем кнопку “Фильтр” (иконка напоминает воронку) и кликаем на нее.
- После этого в строке с названиями столбцов таблицы появятся значки перевернутых треугольников (это значит, что фильтр включен). Чтобы перейти к расширенным настройкам, жмем кнопку “Дополнительно“, расположенную справа от кнопки “Фильтр“.
- В появившемся окне с расширенными настройками:
- как и в предыдущем способе, проверяем адрес диапазон ячеек таблицы;
- отмечаем галочкой пункт “Только уникальные записи“;
- жмем ОК.
- После этого все задвоенные данные перестанут отображаться в таблицей. Чтобы вернуться в стандартный режим, достаточно снова нажать на кнопку “Фильтр” во вкладке “Данные”.




Метод 4: условное форматирование
Условное форматирование – гибкий и мощный инструмент, используемый для решения широкого спектра задач в Excel. В этом примере мы будем использовать его для выбора задвоенных строк, после чего их можно удалить любым удобным способом.
- Выделяем все ячейки нашей таблицы.
- Во вкладке “Главная” кликаем по кнопке “Условное форматирование“, которая находится в разделе инструментов “Стили“.
- Откроется перечень, в котором выбираем группу “Правила выделения ячеек“, а внутри нее – пункт “Повторяющиеся значения“.
- Окно настроек форматирования оставляем без изменений. Единственный его параметр, который можно поменять в соответствии с собственными цветовыми предпочтениями – это используемая для заливки выделяемых строк цветовая схема. По готовности нажимаем кнопку ОК.
- Теперь все повторяющиеся ячейки в таблице “подсвечены”, и с ними можно работать – редактировать содержимое или удалить строки целиком любым удобным способом.


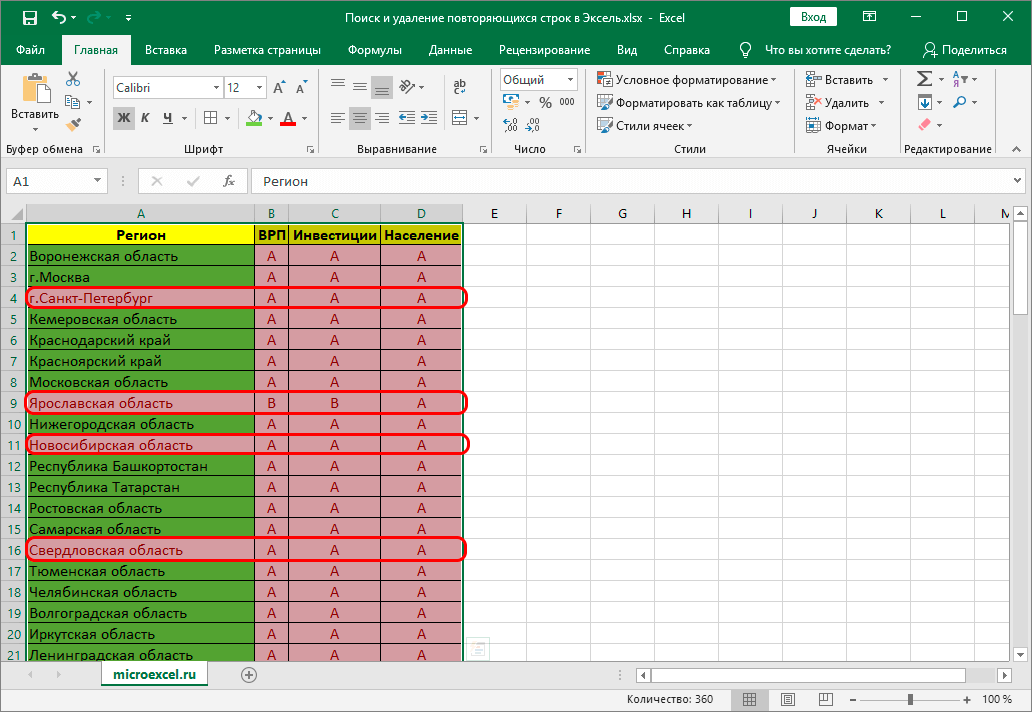
Важно! Этом метод не настолько универсален, как описанные выше, так как выделяет все ячейки с одинаковыми значениями, а не только те, для которых совпадает вся строка целиком. Это видно на предыдущем скриншоте, когда нужные задвоения по названиям регионов были выделены, но вместе с ними отмечены и все ячейки с категориями регионов, потому что значения этих категорий повторяются.
Метод 5: формула для удаления повторяющихся строк
Последний метод достаточно сложен, и им мало, кто пользуется, так как здесь предполагается использование сложной формулы, объединяющей в себе несколько простых функций. И чтобы настроить формулу для собственной таблицы с данными, нужен определенный опыт и навыки работы в Эксель.
Формула, позволяющая искать пересечения в пределах конкретного столбца в общем виде выглядит так:
Давайте посмотрим, как с ней работать на примере нашей таблицы:
- Добавляем в конце таблицы новый столбец, специально предназначенный для отображения повторяющихся значений (дубликаты).
- В верхнюю ячейку нового столбца (не считая шапки) вводим формулу, которая для данного конкретного примера будет иметь вид ниже, и жмем Enter:
=ЕСЛИОШИБКА(ИНДЕКС(A2:A90;ПОИСКПОЗ(0;СЧЁТЕСЛИ(E1:$E$1;A2:A90)+ЕСЛИ(СЧЁТЕСЛИ(A2:A90;A2:A90)>1;0;1);0));»») . - Выделяем до конца новый столбец для задвоенных данных, шапку при этом не трогаем. Далее действуем строго по инструкции:
- ставим курсор в конец строки формул (нужно убедиться, что это, действительно, конец строки, так как в некоторых случаях длинная формула не помещается в пределах одной строки);
- жмем служебную клавишу F2 на клавиатуре;
- затем нажимаем сочетание клавиш Ctrl+SHIFT+Enter.
- Эти действия позволяют корректно заполнить формулой, содержащей ссылки на массивы, все ячейки столбца. Проверяем результат.



Как уже было сказано выше, этот метод сложен и функционально ограничен, так как не предполагает удаления найденных столбцов. Поэтому, при прочих равных условиях, рекомендуется использовать один из ранее описанных методов, более логически понятных и, зачастую, более эффективных.
Заключение
Excel предлагает несколько инструментов для нахождения и удаления строк или ячеек с одинаковыми данными. Каждый из описанных методов специфичен и имеет свои ограничения. К универсальным варианту мы, пожалуй, отнесем использование “умной таблицы” и функции “Удалить дубликаты”. В целом, для выполнения поставленной задачи необходимо руководствоваться как особенностями структуры таблицы, так и преследуемыми целями и видением конечного результата.
Ищем дубликаты значений в ячейках
Воспользуемся возможностями условного форматирования. Эту тему мы уже рассматривали в статье «Закрасить ячейку по условию или формуле», а теперь применим для решения другой задачи.
Ищем повторяющиеся записи в Excel 2007
Выделим столбец, в котором будем искать дубликаты (в нашем примере это столбец с каталожными номерами), и на главной вкладке ищем кнопку «Условное форматирование». Далее по пунктам, как на рисунке. 
В новом окне нам остается только согласиться с предлагаемым цветовым решением (или выбрать другое) и нажать «ОК». 
Теперь повторяющиеся значения у нас окрашены в красный цвет. Но они разбросаны по всей таблице и это неудобно. Нужно отсортировать строки, чтобы собрать их в кучку. Обратите внимание, что в приведенной таблице есть столбец «№ п/п», содержащий номера строк. Если у вас его нет, его следует сделать, чтобы мы потом смогли восстановить исходный порядок данных в таблице.
Выделяем всю таблицу, переходим на вкладку «Данные» и жмем на кнопку «Сортировка». В новом окне нам нужно задать порядок сортировки. Выставляем нужные нам значения и добавляем следующий уровень. Нам нужно отсортировать строки сначала по цвету ячеек, а потом по значению в ячейке, чтобы дубликаты оказались рядом друг с другом. 
Разбираемся с найденными дубликатами. В данном случае повторяющиеся строки можно просто удалить. 
Обратите внимание, что по мере удаления дубликатов красные ячейки возвращают себе белый цвет.
Избавившись от цветных ячеек, снова выделим всю таблицу и отсортируем ее по столбцу «№п/п». После этого останется только поправить сбившуюся из-за удаленных строк нумерацию.
Как это сделать в Excel 2003
Здесь будет немного сложнее – придется использовать логическую функцию «СЧЕТЕСЛИ()».
Войдите в ячейку с первым значением, среди которых вы будете искать дубликаты.
В первом поле выберите «Формула» и введите формулу «=СЧЕТЕСЛИ(C;RC)>1». Только не забудьте вовремя переключить раскладку – «СЧЕТЕСЛИ» набирается в русской раскладке, а «(C;RC)>1» в английской. 
Цвет выберите, нажав на кнопку «Формат» на закладке «Вид».
Теперь нам нужно скопировать этот формат на весь столбец.
Выделяем весь столбец с проверяемыми данными.

Выбираем «Форматы», «ОК» и условное форматирование скопировалось на весь столбец.
Покоряйте Excel и до новых встреч!
Комментарии:
- asd — 10.11.2015 13:37
Найти дубли в экселе +100500. Спасибо!! А я то голову ломал ))
Как удалить дубли в Excel 2003
 Кроха сын к отцу пришел, и спросила кроха…
Кроха сын к отцу пришел, и спросила кроха…
Нет, не так. На самом деле подошел сотрудник и сказал — а не поставить ли нам эксель 2010? По опыту знаю, что ему требуется пару раз в день заполнять небольшую таблицу, ничего архисложного. Поэтому сразу возник логичный вопрос — а тебе зачем? На что вполне логичный ответ — а там можно одной командой дублирующиеся ячейки удалить. Угу. То есть 3-4 т.р. за то, чтобы дубли удалить. А надо сказать, я вообще очень плохо отношусь к неоправданным расходам в бизнесе. Одно дело, когда что-то требуется для непосредственного выполнения какой-либо функции, которую ни в чем другом выполнить нельзя. Или занимает столько времени, что дешевле оптимизировать, или написать под это специальную программу — вот сейчас, например, пишем за полторы штуки баксов одну такую. А другое дело, когда кто-то хочет на 10 минут подольше посидеть во вконтакте в рабочее время, и просто ленится разобраться, как пару кнопок нажать.
Ну ладно, сейчас расскажу, как удалить дубликаты в excel 2003, и можно идти дальше придумывать, зачем еще 2010-й тебе может понадобиться (не, для чего он нужен мне — я прекрасно знаю :-)).
Самый простой способ а) — как удалить повторяющиеся значения excel:
1. Берем, выделяем диапазон ячеек с дублями, нажимаем на Данные -> Фильтр -> Расширенный фильтр…
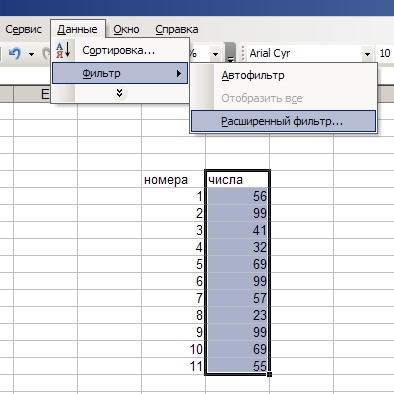
2. Дальше — в появившемся окошке отмечаем чек-бокс «Только уникальные записи», нажимаем ОК.
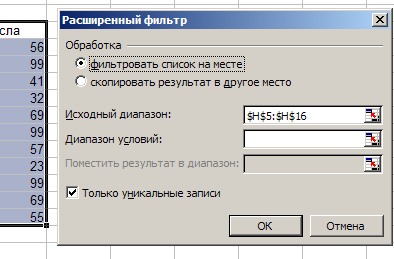
3. Получаем результат, который можно сделать Ctrl+C — Ctrl+V на нужное место/лист.
Теперь вариант B), для тех, кто не боится сложностей 🙂
1. Левее крайнего левого столбца нашей таблицы вставляем дополнительный столбец (допустим, у нас был А — вставим еще один А, чтобы наш стал B), и в нем проставляем порядковые номера (обычным вводом в ячейках цифр 1 и 2, выделяя эти две ячейки и двойным кликом на черной точке в правом нижнем углу все распространяется до конца диапазона). Это нам потребуется потом, если мы захотим восстановить порядок следования записей, если он не важен — так можно и не делать. Получится примерно так:
2. Дальше, выделяем две ячейки в строчке 2, с зажатым шифтом щелкаем на нижней границе выделения, таким образом — выделив все с A2 по B12. Жмем Данные ->Сортировка.

3. Сортируем список по столбцу B, скажем, по возрастанию.
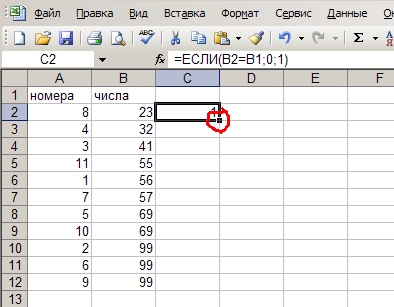
4. В ячейку C2 вставляем формулу =ЕСЛИ(B2=B1;0;1), которая сравнивает каждое значение с предыдущим. Если строка — дубль, то ей будет присвоено значение 0, если нет — то 1. Ну, конечно, значения B2 и B1 — это на моем примере, все зависит, сколько столбцов в таблице.
5. Щелкаем на обведенную красным кружочком точку в правом нижнем углу ячейки, чтобы продлить формулу на всю колонку (аналогично, как мы вставляли порядковые номера):
6. С полученным результатом делаем Ctrl+C, идем в Правка -> Специальная вставка
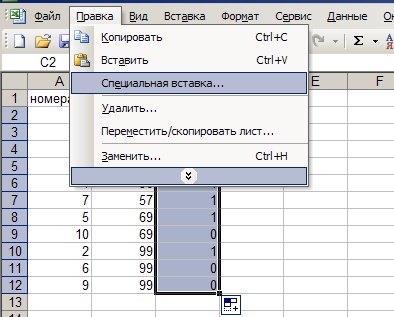
7. В открывшемся диалоге выбираем — Вставить Значения
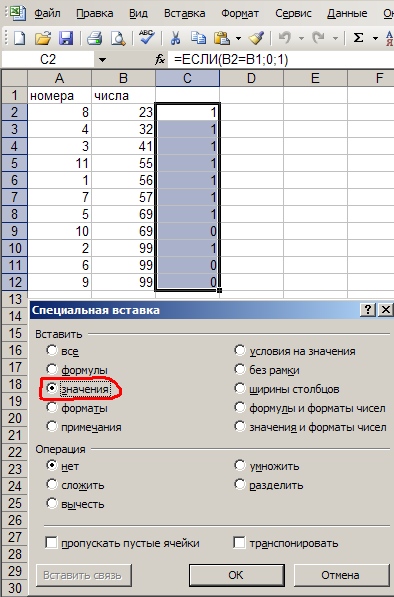
8. Теперь выделяем первые три ячейки в строке 2, с зажатым шифтом щелкаем на нижней границе выделения, таким образом — выделив все с A2 по С12. Жмем Данные ->Сортировка, сортируем по столбцу С, по убыванию (это важно — отсортировать именно по убыванию! Если бы мы дублям назначили 1, а не 0 — то надо было бы отсортировывать наоборот, по возрастанию). Скриншот приводить не буду, поскольку абсолютно аналогично шагам 2 и 3.
9. Выделяем столбец С, нажимаем Ctrl-F, вводим в форму поиска 0, и ищем в этом столбце первую по порядку ячейку с нулем.
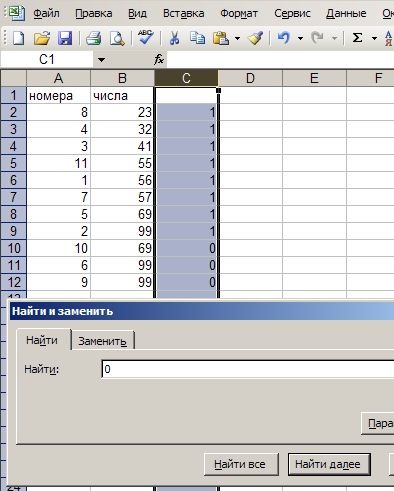
10. Выделяем всю строку, с А по С, в которой ноль впервые нашелся, с зажатым шифтом щелкаем мышкой на нижней границе выделения, таким образом — выделив все значения ниже. Далее делаем с ними все, что захотим: можем удалить к чертовой матери, а можем скопировать куда-либо эти дубли. Предположим, что удалили.
11. Удаляем значения из столбца С — он тоже свою роль сыграл.
12. Выделяем целиком столбцы А и B, жмем Данные ->Сортировка, и сортируем по столбцу А (в моем случае — по номерам) по возрастанию.
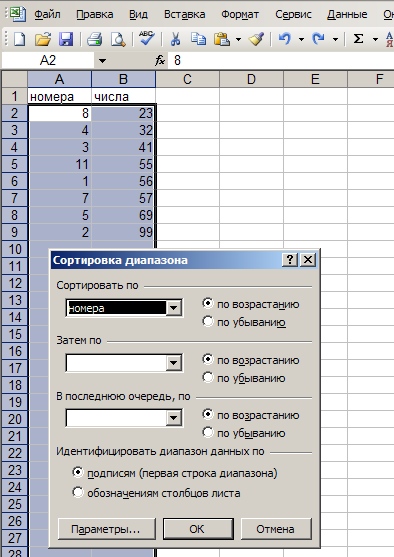
13. В получившемся списке удаляем колонку А, и получаем в результате таблицу, аналогичную исходной, но без дублей. Для сравнения в столбце D привел то, как она выглядела до всех этих итераций.
Описывать это все гораздо дольше, чем делать, в принципе — уходит максимум 30 секунд.
Как найти одинаковые значения в столбце Excel
Поиск дублей в Excel – это одна из самых распространенных задач для любого офисного сотрудника. Для ее решения существует несколько разных способов. Но как быстро как найти дубликаты в Excel и выделить их цветом? Для ответа на этот часто задаваемый вопрос рассмотрим конкретный пример.
Как найти повторяющиеся значения в Excel?
Допустим мы занимаемся регистрацией заказов, поступающих на фирму через факс и e-mail. Может сложиться такая ситуация, что один и тот же заказ поступил двумя каналами входящей информации. Если зарегистрировать дважды один и тот же заказ, могут возникнуть определенные проблемы для фирмы. Ниже рассмотрим решение средствами условного форматирования.
Чтобы избежать дублированных заказов, можно использовать условное форматирование, которое поможет быстро найти одинаковые значения в столбце Excel.
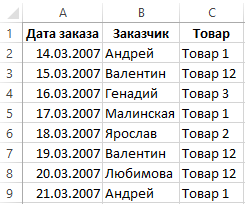
Пример дневного журнала заказов на товары:
Чтобы проверить содержит ли журнал заказов возможные дубликаты, будем анализировать по наименованиям клиентов – столбец B:
- Выделите диапазон B2:B9 и выберите инструмент: «ГЛАВНАЯ»-«Стили»-«Условное форматирование»-«Создать правило».
- Вберете «Использовать формулу для определения форматируемых ячеек».
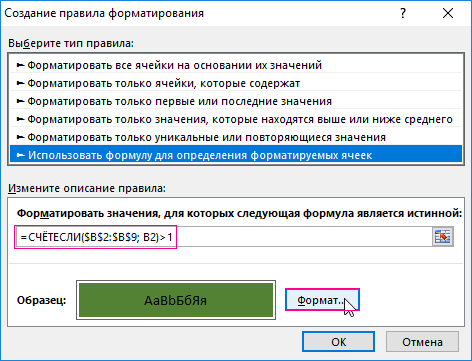
- Чтобы найти повторяющиеся значения в столбце Excel, в поле ввода введите формулу: =СЧЁТЕСЛИ($B$2:$B$9; B2)>1.
- Нажмите на кнопку «Формат» и выберите желаемую заливку ячеек, чтобы выделить дубликаты цветом. Например, зеленый. И нажмите ОК на всех открытых окнах.
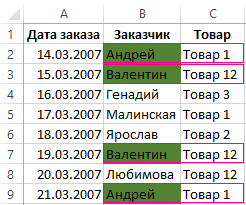
Как видно на рисунке с условным форматированием нам удалось легко и быстро реализовать поиск дубликатов в Excel и обнаружить повторяющиеся данные ячеек для таблицы журнала заказов.
Пример функции СЧЁТЕСЛИ и выделение повторяющихся значений
Принцип действия формулы для поиска дубликатов условным форматированием – прост. Формула содержит функцию =СЧЁТЕСЛИ(). Эту функцию так же можно использовать при поиске одинаковых значений в диапазоне ячеек. В функции первым аргументом указан просматриваемый диапазон данных. Во втором аргументе мы указываем что мы ищем. Первый аргумент у нас имеет абсолютные ссылки, так как он должен быть неизменным. А второй аргумент наоборот, должен меняться на адрес каждой ячейки просматриваемого диапазона, потому имеет относительную ссылку.
Самые быстрые и простые способы: найти дубликаты в ячейках.
После функции идет оператор сравнения количества найденных значений в диапазоне с числом 1. То есть если больше чем одно значение, значит формула возвращает значение ИСТЕНА и к текущей ячейке применяется условное форматирование.
Skip to content
В этой статье мы рассмотрим разные подходы к одной из самых распространенных и, по моему мнению, важных задач в Excel — как найти в ячейках и в столбцах таблицы повторяющиеся значения.
Работая с большими наборами данных в Excel или объединяя несколько небольших электронных таблиц в более крупные, вы можете столкнуться с большим числом одинаковых строк.
И сегодня я хотел бы поделиться несколькими быстрыми и эффективными методами выявления дубликатов в одном списке. Эти решения работают во всех версиях Excel 2016, Excel 2013, 2010 и ниже. Вот о чём мы поговорим:
- Поиск повторяющихся значений включая первые вхождения
- Поиск дубликатов без первых вхождений
- Определяем дубликаты с учетом регистра
- Как извлечь дубликаты из диапазона ячеек
- Как обнаружить одинаковые строки в таблице данных
- Использование встроенных фильтров Excel
- Применение условного форматирования
- Поиск совпадений при помощи встроенной команды «Найти»
- Определяем дубликаты при помощи сводной таблицы
- Duplicate Remover — быстрый и эффективный способ найти дубликаты
Самой простой в использовании и вместе с тем эффективной в данном случае будет функция СЧЁТЕСЛИ (COUNTIF). С помощью одной только неё можно определить не только неуникальные позиции, но и их первые появления в столбце. Рассмотрим разницу на примерах.
Поиск повторяющихся значений включая первые вхождения.
Предположим, что у вас в колонке А находится набор каких-то показателей, среди которых, вероятно, есть одинаковые. Это могут быть номера заказов, названия товаров, имена клиентов и прочие данные. Если ваша задача — найти их, то следующая формула для вас:
=СЧЁТЕСЛИ(A:A; A2)>1
Где А2 — первая ячейка из области для поиска.
Просто введите это выражение в любую ячейку и протяните вниз вдоль всей колонки, которую нужно проверить на дубликаты.

Как вы могли заметить на скриншоте выше, формула возвращает ИСТИНА, если имеются совпадения. А для встречающихся только 1 раз значений она показывает ЛОЖЬ.
Подсказка! Если вы ищите повторы в определенной области, а не во всей колонке, обозначьте нужный диапазон и “зафиксируйте” его знаками $. Это значительно ускорит вычисления. Например, если вы ищете в A2:A8, используйте
=СЧЕТЕСЛИ($A$2:$A$8, A2)>1
Если вас путает ИСТИНА и ЛОЖЬ в статусной колонке и вы не хотите держать в уме, что из них означает повторяющееся, а что — уникальное, заверните свою СЧЕТЕСЛИ в функцию ЕСЛИ и укажите любое слово, которое должно соответствовать дубликатам и уникальным:
=ЕСЛИ(СЧЁТЕСЛИ($A$2:$A$17; A2)>1;»Дубликат»;»Уникальное»)
Если же вам нужно, чтобы формула указывала только на дубли, замените «Уникальное» на пустоту («»):

=ЕСЛИ(СЧЁТЕСЛИ($A$2:$A$17; A2)>1;»Дубликат»;»»)

В этом случае Эксель отметит только неуникальные записи, оставляя пустую ячейку напротив уникальных.
Поиск неуникальных значений без учета первых вхождений
Вы наверняка обратили внимание, что в примерах выше дубликатами обозначаются абсолютно все найденные совпадения. Но зачастую задача заключается в поиске только повторов, оставляя первые вхождения нетронутыми. То есть, когда что-то встречается в первый раз, оно однозначно еще не может быть дубликатом.
Если вам нужно указать только совпадения, давайте немного изменим:
=ЕСЛИ(СЧЁТЕСЛИ($A$2:$A2; A2)>1;»Дубликат»;»»)
На скриншоте ниже вы видите эту формулу в деле.

Нетрудно заметить, что она не обозначает первое появление слова, а начинает отсчет со второго.
Чувствительный к регистру поиск дубликатов
Хочу обратить ваше внимание на то, что хоть формулы выше и находят 100%-дубликаты, есть один тонкий момент — они не чувствительны к регистру. Быть может, для вас это не принципиально. Но если в ваших данных абв, Абв и АБВ — это три разных параметра – то этот пример для вас.
Как вы могли уже догадаться, выражения, использованные нами ранее, с такой задачей не справятся. Здесь нужно выполнить более тонкий поиск, с чем нам поможет следующая функция массива:
{=ЕСЛИ(СУММ((—СОВПАД($A$2:$A$17;A2)))<=1;»»;»Дубликат»)}
Не забывайте, что формулы массива вводятся комбиинацией Ctrl + Shift + Enter.
Если вернуться к содержанию, то здесь используется функция СОВПАД для сравнения целевой ячейки со всеми остальными ячейками с выбранной области. Результат возвращается в виде ИСТИНА (совпадение) или ЛОЖЬ (не совпадение), которые затем преобразуются в массив из 1 и 0 при помощи оператора (—).
После этого, функция СУММ складывает эти числа. И если полученный результат больше 1, функция ЕСЛИ сообщает о найденном дубликате.
Если вы взглянете на следующий скриншот, вы убедитесь, что поиск действительно учитывает регистр при обнаружении дубликатов:

Смородина и арбуз, которые встречаются дважды, не отмечены в нашем поиске, так как регистр первых букв у них отличается.
Как извлечь дубликаты из диапазона.
Формулы, которые мы описывали выше, позволяют находить дубликаты в определенном столбце. Но часто речь идет о нескольких столбцах, то есть о диапазоне данных.
Рассмотрим это на примере числовой матрицы. К сожалению, с символьными значениями этот метод не работает.

При помощи формулы массива
{=ИНДЕКС(НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11);СТРОКА($1:$100)); НАИМЕНЬШИЙ(ЕСЛИОШИБКА(ЕСЛИ(ПОИСКПОЗ(НАИМЕНЬШИЙ(ЕСЛИ( СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11);СТРОКА($1:$100)); НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11); СТРОКА($1:$100));0)=СТРОКА($1:$100);СТРОКА($1:$100));»»);СТРОКА()-1))}
вы можете получить упорядоченный по возрастанию список дубликатов. Для этого введите это выражение в нужную ячейку и нажмите Ctrl+Alt+Enter.
Затем протащите маркер заполнения вниз на сколько это необходимо.
Чтобы убрать сообщения об ошибке, когда дублирующиеся значения закончатся, можно использовать функцию ЕСЛИОШИБКА:
=ЕСЛИОШИБКА(ИНДЕКС(НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11); СТРОКА($1:$100));НАИМЕНЬШИЙ(ЕСЛИОШИБКА(ЕСЛИ(ПОИСКПОЗ( НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11); СТРОКА($1:$100));НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11); СТРОКА($1:$100));0)=СТРОКА($1:$100);СТРОКА($1:$100));»»);СТРОКА()-1));»»)
Также обратите внимание, что приведенное выше выражение рассчитано на то, что оно будет записано во второй строке. Соответственно выше него будет одна пустая строка.
Поэтому если вам нужно разместить его, к примеру, в ячейке K4, то выражение СТРОКА()-1 в конце замените на СТРОКА()-3.
Обнаружение повторяющихся строк
Мы рассмотрели, как обнаружить одинаковые данные в отдельных ячейках. А если нужно искать дубликаты-строки?
Есть один метод, которым можно воспользоваться, если вам нужно просто выделить одинаковые строки, но не удалять их.
Итак, имеются данные о товарах и заказчиках.
Создадим справа от наших данных формулу, объединяющую содержание всех расположенных слева от нее ячеек.
Предположим, что данные хранятся в столбцах А:C. Запишем в ячейку D2:
=A2&B2&C2
Добавим следующую формулу в ячейку E2. Она отобразит, сколько раз встречается значение, полученное нами в столбце D:
=СЧЁТЕСЛИ(D:D;D2)
Скопируем вниз для всех строк данных.
В столбце E отображается количество появлений этой строки в столбце D. Неповторяющимся строкам будет соответствовать значение 1. Повторам строкам соответствует значение больше 1, указывающее на то, сколько раз такая строка была найдена.
Если вас не интересует определенный столбец, просто не включайте его в выражение, находящееся в D. Например, если вам хочется обнаружить совпадающие строки, не учитывая при этом значение Заказчик, уберите из объединяющей формулы упоминание о ячейке С2.
Обнаруживаем одинаковые ячейки при помощи встроенных фильтров Excel.
Теперь рассмотрим, как можно обойтись без формул при поиске дубликатов в таблице. Быть может, кому-то этот метод покажется более удобным, нежели написание выражений Excel.
Организовав свои данные в виде таблицы, вы можете применять к ним различные фильтры. Фильтр в таблице вы можете установить по одному либо по нескольким столбцам. Давайте рассмотрим на примере.
В первую очередь советую отформатировать наши данные как «умную» таблицу. Напомню: Меню Главная – Форматировать как таблицу.
После этого в строке заголовка появляются значки фильтра. Если нажать один из них, откроется выпадающее меню фильтра, которое содержит всю информацию по данному столбцу. Выберите любой элемент из этого списка, и Excel отобразит данные в соответствии с этим выбором.
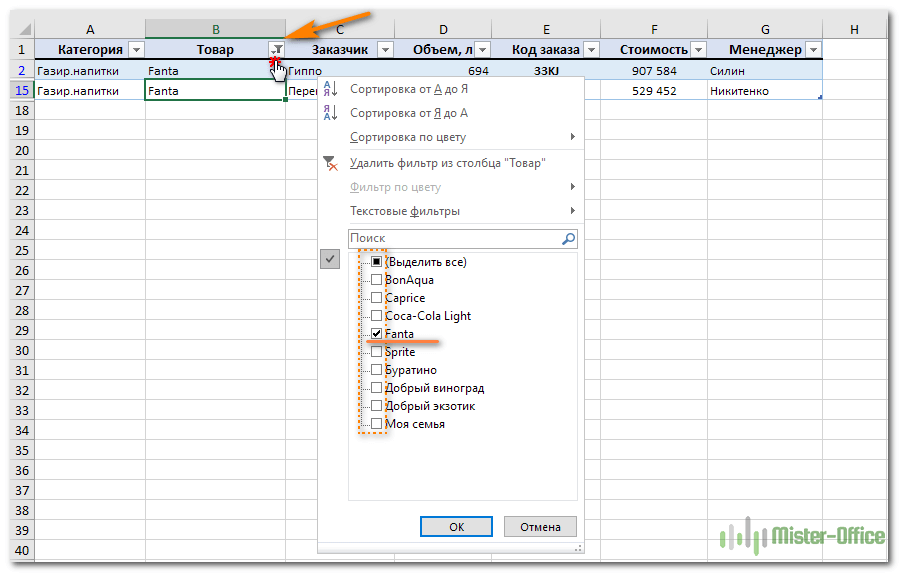
Вы можете убрать галочку с пункта «Выделить все», а затем отметить один или несколько нужных элементов. Excel покажет только те строки, которые содержат выбранные значения. Так можно обнаружить дубликаты, если они есть. И все готово для их быстрого удаления.
Но при этом вы видите дубли только по отфильтрованному. Если данных много, то искать таким способом последовательного перебора будет несколько утомительно. Ведь слишком много раз нужно будет устанавливать и менять фильтр.
Используем условное форматирование.
Выделение цветом по условию – весьма важный инструмент Excel, о котором достаточно подробно мы рассказывали.
Сейчас я покажу, как можно в Экселе найти дубли ячеек, просто их выделив цветом.
Как показано на рисунке ниже, выбираем Правила выделения ячеек – Повторяющиеся. Неуникальные данные будут подсвечены цветом.
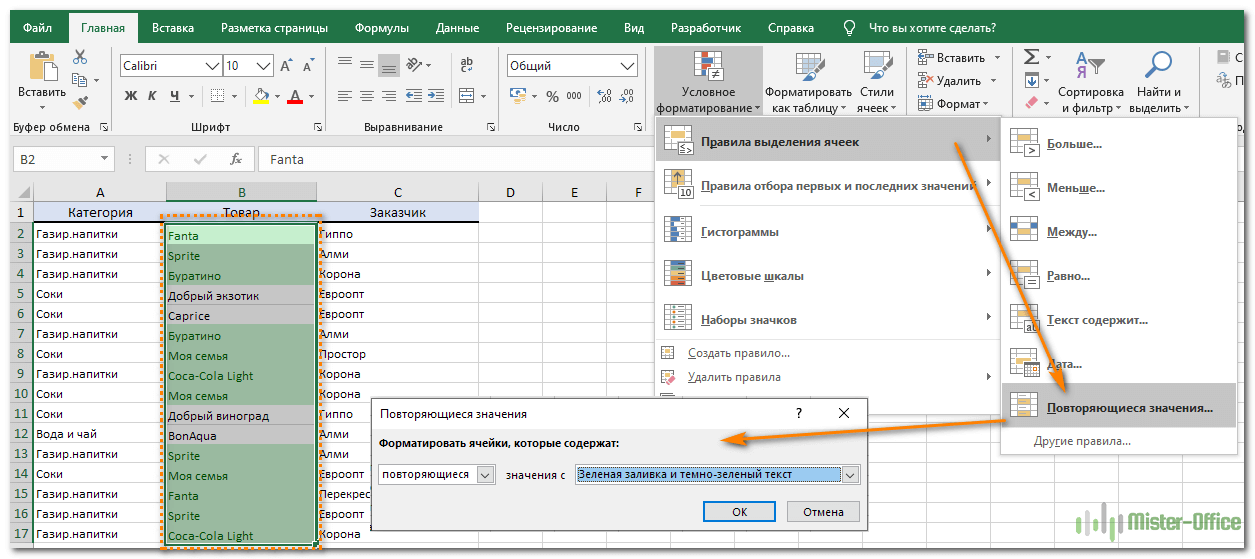
Но здесь мы не можем исключить первые появления – подсвечивается всё.
Но эту проблему можно решить, использовав формулу условного форматирования.
=СЧЁТЕСЛИ($B$2:$B2; B2)>1

Результат работы формулы выденения повторяющихся значений вы видите выше. Они выделены зелёным цветом.
Чтобы освежить память, можете руководствоваться нашим материалом «Как изменить цвет ячейки в зависимости от значения».
Поиск совпадений при помощи команды «Найти».
Еще один простой, но не слишком технологичный способ – использование встроенного поиска.
Зайдите на вкладку Главная и кликните «Найти и выделить». Откроется диалоговое окно, в котором можно ввести что угодно для поиска в таблице. Чтобы избежать опечаток, можете скопировать искомое прямо из списка данных.
Затем нажимаем «Найти все», и видим все найденные дубликаты и места их расположения, как на рисунке чуть ниже.

В случае, когда объём информации очень велик и требуется ускорить работу поиска, предварительно выделите столбец или диапазон, в котором нужно искать, и только после этого начинайте работу. Если этого не сделать, Excel будет искать по всем имеющимся данным, что, конечно, медленнее.
Этот метод еще более трудоемкий, нежели использование фильтра. Поэтому применяют его выборочно, только для отдельных значений.
Как применить сводную таблицу для поиска дубликатов.
Многие считают сводные таблицы слишком сложным инструментом, чтобы постоянно им пользоваться. На самом деле, не все так запутано, как кажется. Для новичков рекомендую к ознакомлению наше руководство по созданию и работе со сводными таблицами.
Для более опытных – сразу переходим к сути вопроса.
Создаем новый макет сводной таблицы. А затем в качестве строк и значений используем одно и то же поле. В нашем случае – «Товар». Поскольку название товара – это текст, то для подсчета таких значений Excel по умолчанию использует функцию СЧЕТ, то есть подсчитывает количество. А нам это и нужно. Если будет больше 1, значит, имеются дубликаты.

Вы наблюдаете на скриншоте выше, что несколько товаров дублируются. И что нам это дает? А далее мы просто можем щелкнуть мышкой на любой из цифр, и на новом листе Excel покажет нам, как получилась эта цифра.
К примеру, откуда взялись 3 дубликата Sprite? Щелкаем на цифре 3, и видим такую картину:

Думаю, этот метод вполне можно использовать. Что приятно – никаких формул не требуется.
Duplicate Remover — быстрый и эффективный способ найти дубликаты в Excel
Теперь, когда вы знаете, как использовать формулы для поиска повторяющихся значений в Excel, позвольте мне продемонстрировать вам еще один быстрый, эффективный и без всяких формул способ: инструмент Duplicate Remover для Excel.
Этот универсальный инструмент может искать повторяющиеся или уникальные значения в одном столбце или же сравнивать два столбца. Он может находить, выбирать и выделять повторяющиеся записи или целые повторяющиеся строки, удалять найденные дубли, копировать или перемещать их на другой лист. Я думаю, что пример практического использования может заменить очень много слов, так что давайте перейдем к нему.
Как найти повторяющиеся строки в Excel за 2 быстрых шага
Сначала посмотрим в работе наиболее простой инструмент — быстрый поиск дубликатов Quick Dedupe. Используем уже знакомую нам таблицу, в которой мы выше искали дубликаты при помощи формул:

Как видите, в таблице несколько столбцов. Чтобы найти повторяющиеся записи в этих трех столбцах, просто выполните следующие действия:
- Выберите любую ячейку в таблице и нажмите кнопку Quick Dedupe на ленте Excel. После установки пакета Ultimate Suite для Excel вы найдете её на вкладке Ablebits Data в группе Dedupe. Это наиболее простой инструмент для поиска дубликатов.
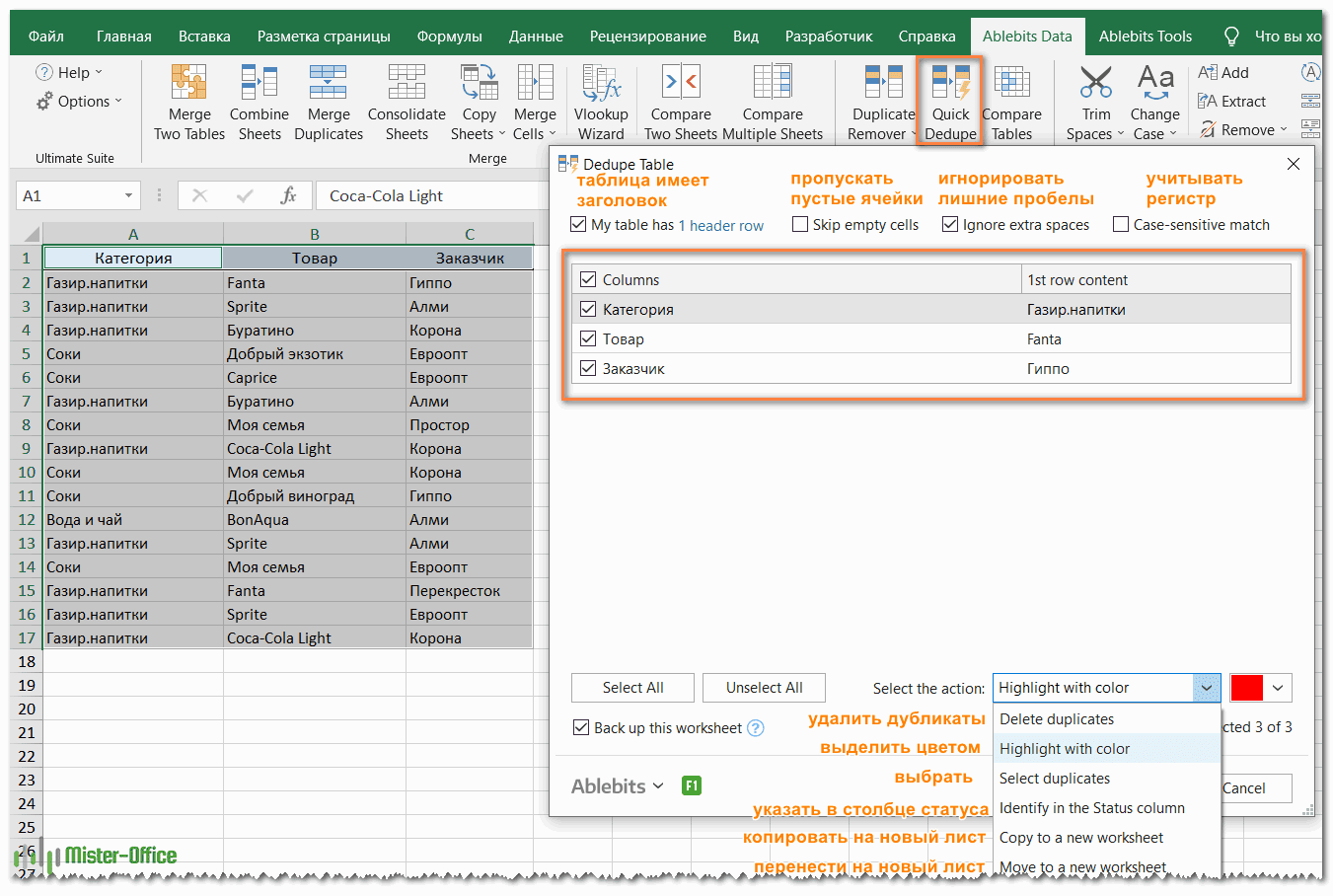
- Интеллектуальная надстройка возьмет всю таблицу и попросит вас указать следующие две вещи:
- Выберите столбцы для проверки дубликатов (в данном примере это все 3 столбца – категория, товар и заказчик).
- Выберите действие, которое нужно выполнить с дубликатами. Поскольку наша цель — выявить повторяющиеся строки, я выбрал «Выделить цветом».
Помимо выделения цветом, вам доступен ряд других опций:
- Удалить дубликаты
- Выбрать дубликаты
- Указать их в столбце статуса
- Копировать дубликаты на новый лист
- Переместить на новый лист
Нажмите кнопку ОК и подождите несколько секунд. Готово! И никаких формул 😊.
Как вы можете видеть на скриншоте ниже, все строки с одинаковыми значениями в первых 3 столбцах были обнаружены (первые вхождения не идентифицируются как дубликаты).

Если вам нужны дополнительные возможности для работы с дубликатами и уникальными значениями, используйте мастер удаления дубликатов Duplicate Remover, который может найти дубликаты с первыми вхождениями или без них, а также уникальные значения. Подробные инструкции приведены ниже.
Мастер удаления дубликатов — больше возможностей для поиска дубликатов в Excel.
В зависимости от данных, с которыми вы работаете, вы можете не захотеть рассматривать первые экземпляры идентичных записей как дубликаты. Одно из возможных решений — использовать разные формулы для каждого сценария, как мы обсуждали в этой статье выше. Если же вы ищете быстрый, точный метод без формул, попробуйте мастер удаления дубликатов — Duplicate Remover. Несмотря на свое название, он не только умеет удалять дубликаты, но и производит с ними другие полезные действия, о чём мы далее поговорим подробнее. Также умеет находить уникальные значения.
- Выберите любую ячейку в таблице и нажмите кнопку Duplicate Remover на вкладке Ablebits Data.
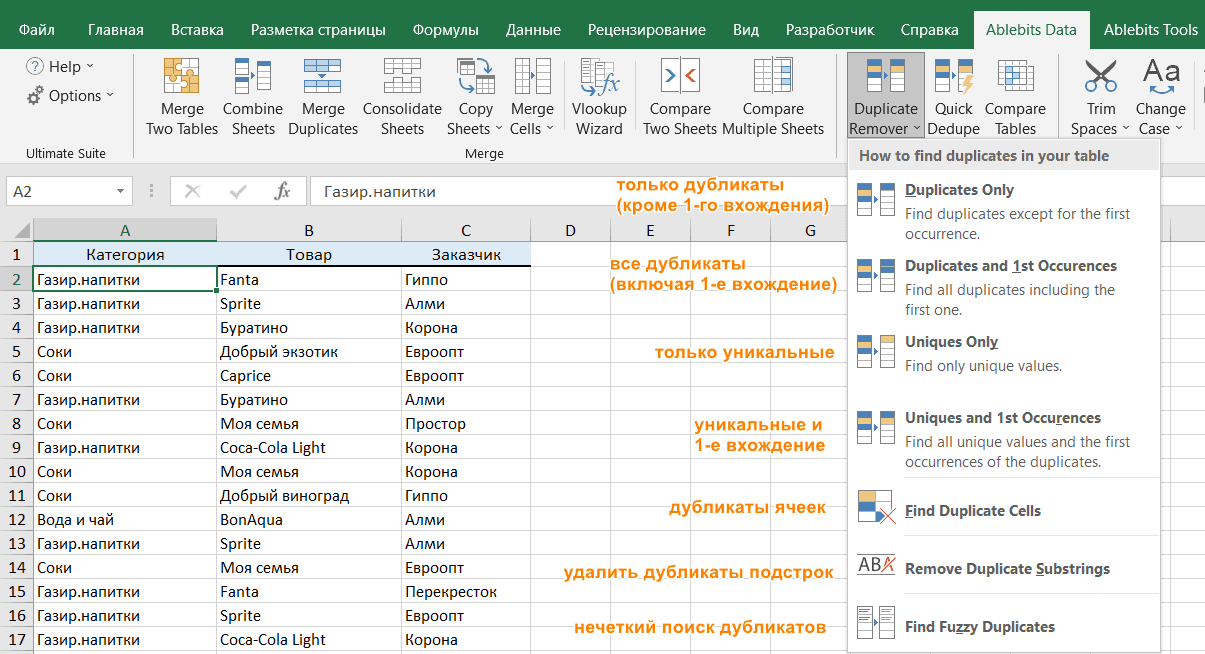
- Вам предложены 4 варианта проверки дубликатов в вашем листе Excel:
- Дубликаты без первых вхождений повторяющихся записей.
- Дубликаты с 1-м вхождением.
- Уникальные записи.
- Уникальные значения и 1-е повторяющиеся вхождения.
В этом примере выберем второй вариант, т.е. Дубликаты + 1-е вхождения:

- Теперь выберите столбцы, в которых вы хотите проверить дубликаты. Как и в предыдущем примере, мы возьмём первые 3 столбца:
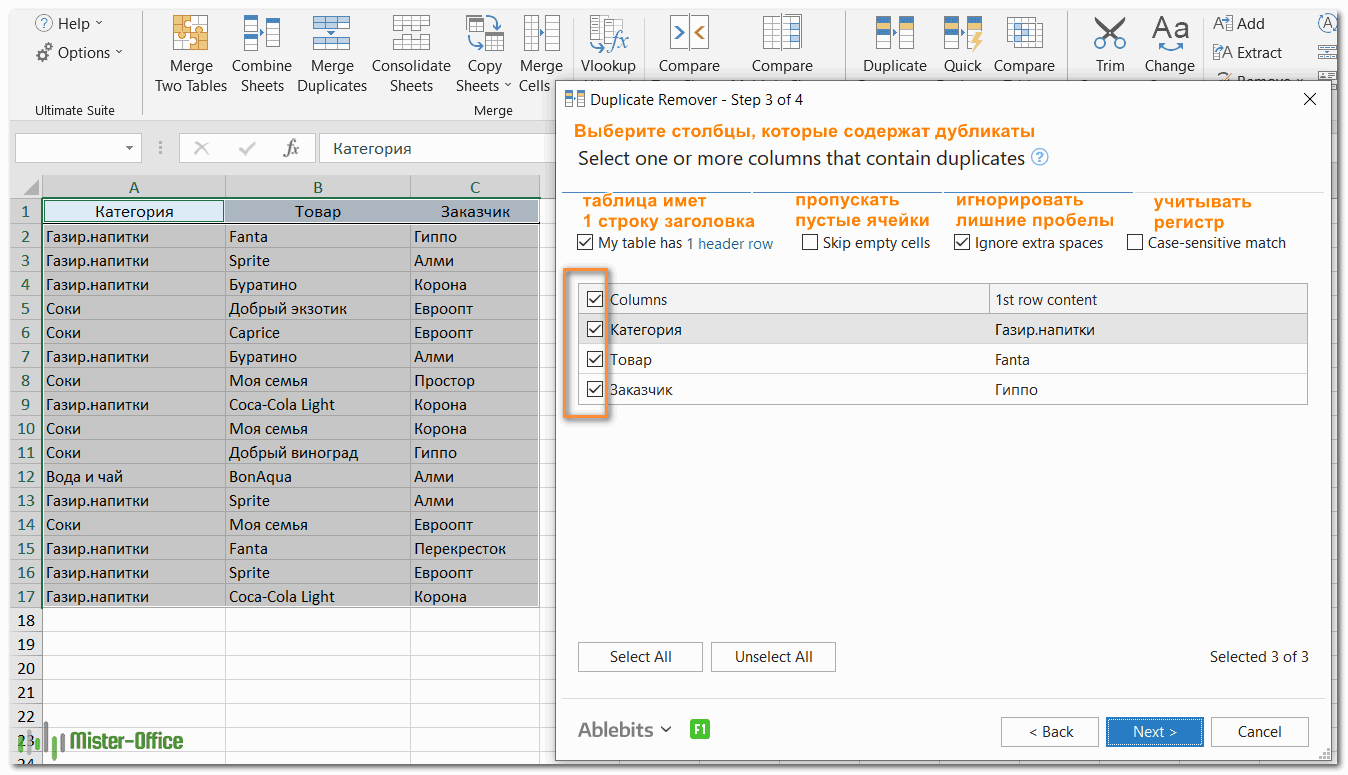
- Наконец, выберите действие, которое вы хотите выполнить с дубликатами. Как и в случае с инструментом быстрого поиска дубликатов, мастер Duplicate Remover может идентифицировать, выбирать, выделять, удалять, копировать или перемещать повторяющиеся данные.

Поскольку цель этого примера – продемонстрировать различные способы определения дубликатов в Excel, давайте отметим параметр «Выделить цветом» (Highlight with color) и нажмите Готово.
Мастеру Duplicate Remover требуется всего лишь несколько секунд, чтобы проверить вашу таблицу и показать результат:

Как видите, результат аналогичен предыдущему. Но здесь мы выделили дубликаты, включая и первое появление повторяющихся записей.
Никаких формул, никакого стресса, никаких ошибок — всегда быстрые и безупречные результаты 
Итак, мы с вам научились различными способами обнаруживать повторяющиеся записи в таблице Excel. В следующих статьях разберем, что мы с этим можем полезного сделать.
Если вы хотите попробовать эти инструменты для поиска дубликатов в таблицах Excel, вы можете загрузить полнофункциональную ознакомительную версию программы. Будем очень признательны за ваши отзывы в комментариях!
Кроха сын к отцу пришел, и спросила кроха…
Нет, не так. На самом деле подошел сотрудник и сказал – а не поставить ли нам эксель 2010? По опыту знаю, что ему требуется пару раз в день заполнять небольшую таблицу, ничего архисложного. Поэтому сразу возник логичный вопрос – а тебе зачем? На что вполне логичный ответ – а там можно одной командой дублирующиеся ячейки удалить. Угу. То есть 3-4 т.р. за то, чтобы дубли удалить. А надо сказать, я вообще очень плохо отношусь к неоправданным расходам в бизнесе. Одно дело, когда что-то требуется для непосредственного выполнения какой-либо функции, которую ни в чем другом выполнить нельзя. Или занимает столько времени, что дешевле оптимизировать, или написать под это специальную программу – вот сейчас, например, пишем за полторы штуки баксов одну такую. А другое дело, когда кто-то хочет на 10 минут подольше посидеть во вконтакте в рабочее время, и просто ленится разобраться, как пару кнопок нажать.
Ну ладно, сейчас расскажу, как удалить дубликаты в excel 2003, и можно идти дальше придумывать, зачем еще 2010-й тебе может понадобиться (не, для чего он нужен мне – я прекрасно знаю :-)).
Самый простой способ а) – как удалить повторяющиеся значения excel:
1. Берем, выделяем диапазон ячеек с дублями, нажимаем на Данные -> Фильтр -> Расширенный фильтр…
2. Дальше – в появившемся окошке отмечаем чек-бокс “Только уникальные записи”, нажимаем ОК.
3. Получаем результат, который можно сделать Ctrl+C – Ctrl+V на нужное место/лист.
Теперь вариант B), для тех, кто не боится сложностей 🙂
1. Левее крайнего левого столбца нашей таблицы вставляем дополнительный столбец (допустим, у нас был А – вставим еще один А, чтобы наш стал B), и в нем проставляем порядковые номера (обычным вводом в ячейках цифр 1 и 2, выделяя эти две ячейки и двойным кликом на черной точке в правом нижнем углу все распространяется до конца диапазона). Это нам потребуется потом, если мы захотим восстановить порядок следования записей, если он не важен – так можно и не делать. Получится примерно так:
2. Дальше, выделяем две ячейки в строчке 2, с зажатым шифтом щелкаем на нижней границе выделения, таким образом – выделив все с A2 по B12. Жмем Данные ->Сортировка.
3. Сортируем список по столбцу B, скажем, по возрастанию.
4. В ячейку C2 вставляем формулу =ЕСЛИ(B2=B1;0;1), которая сравнивает каждое значение с предыдущим. Если строка – дубль, то ей будет присвоено значение 0, если нет – то 1. Ну, конечно, значения B2 и B1 – это на моем примере, все зависит, сколько столбцов в таблице.
5. Щелкаем на обведенную красным кружочком точку в правом нижнем углу ячейки, чтобы продлить формулу на всю колонку (аналогично, как мы вставляли порядковые номера):
6. С полученным результатом делаем Ctrl+C, идем в Правка -> Специальная вставка
7. В открывшемся диалоге выбираем – Вставить Значения
8. Теперь выделяем первые три ячейки в строке 2, с зажатым шифтом щелкаем на нижней границе выделения, таким образом – выделив все с A2 по С12. Жмем Данные ->Сортировка, сортируем по столбцу С, по убыванию (это важно – отсортировать именно по убыванию! Если бы мы дублям назначили 1, а не 0 – то надо было бы отсортировывать наоборот, по возрастанию). Скриншот приводить не буду, поскольку абсолютно аналогично шагам 2 и 3.
9. Выделяем столбец С, нажимаем Ctrl-F, вводим в форму поиска 0, и ищем в этом столбце первую по порядку ячейку с нулем.
10. Выделяем всю строку, с А по С, в которой ноль впервые нашелся, с зажатым шифтом щелкаем мышкой на нижней границе выделения, таким образом – выделив все значения ниже. Далее делаем с ними все, что захотим: можем удалить к чертовой матери, а можем скопировать куда-либо эти дубли. Предположим, что удалили.
11. Удаляем значения из столбца С – он тоже свою роль сыграл.
12. Выделяем целиком столбцы А и B, жмем Данные ->Сортировка, и сортируем по столбцу А (в моем случае – по номерам) по возрастанию.
13. В получившемся списке удаляем колонку А, и получаем в результате таблицу, аналогичную исходной, но без дублей. Для сравнения в столбце D привел то, как она выглядела до всех этих итераций.
14. Вуаля.
Описывать это все гораздо дольше, чем делать, в принципе – уходит максимум 30 секунд.
В следующий раз будем смотреть, как удалить все изображения в excel.

2
Содержание
- 0.1 Способ 1. Если у вас Excel 2007 или новее
- 0.2 Способ 2. Если у вас Excel 2003 и старше
- 0.3 Способ 3. Если много столбцов
- 0.4 Ссылки по теме
- 1 1. Удаление повторяющихся значений в Excel (2007+)
- 2 2. Использование расширенного фильтра для удаления дубликатов
- 3 3. Выделение повторяющихся значений с помощью условного форматирования в Excel (2007+)
- 4 4. Использование сводных таблиц для определения повторяющихся значений
- 5 Как найти одинаковые значения в столбце Excel
- 6 Как найти повторяющиеся значения в Excel?
- 7 Post navigation
- 7.1 Пример функции СЧЁТЕСЛИ и выделение повторяющихся значений
- 8 Как найти и выделить цветом повторяющиеся значения в Excel
- 9 Как выделить повторяющиеся ячейки в Excel
- 10 Повторяющиеся значения в Excel
- 11 Выделяем цветом дубликаты в таблице
- 12 Выборочная подсветка или удаление одинаковых значений в Excel
- 13 Удаляем все одинаковые значения в Excel с помощью расширенного фильтра
- 14 Еще один способ быстро удалить дубли в таблице
- 15 Как предотвратить появление дубликатов – 5 простых шагов
- 15.1 Если наша борьба с дубликатами допускает исключения
Допустим, что у нас имеется длинный список чего-либо (например, товаров), и мы предполагаем, что некоторые элементы этого списка повторяются более 1 раза. Хотелось бы видеть эти повторы явно, т.е. подсветить дублирующие ячейки цветом, например так:

Способ 1. Если у вас Excel 2007 или новее
В последних версиях Excel начиная с 2007 года функция подсветки дубликатов является стандартной.
Выделяем все ячейки с данными и на вкладке Главная (Home) жмем кнопку Условное форматирование (Conditional Formatting), затем выбираем Правила выделения ячеек — Повторяющиеся значения (Highlight Cell Rules — Duplicate Values):

В появившемся затем окне можно задать желаемое форматирование (заливку, цвет шрифта и т.д.)
Способ 2. Если у вас Excel 2003 и старше
В более древних версиях Excel придется чуточку сложнее. Выделяем весь список (в нашем примере — диапазон А2:A10), и идем в меню Формат — Условное форматирование (Format — Conditional Formatting). Выбираем из выпадающего списка вариант условия Формула (Formula) и вводим такую проверку:
=СЧЁТЕСЛИ($A:$A;A2)>1
в английском Excel это будет соответственно =COUNTIF($A:$A;A2)>1
Эта простая функция ищет сколько раз содержимое текущей ячейки встречается в столбце А. Если это количество повторений больше 1, т.е. у элемента есть дубликаты, то срабатывает заливка ячейки. Для выбора цвета выделения в окне Условное форматирование нажмите кнопку Формат… (Format) и перейдите на вкладку Вид (Pattern).
Способ 3. Если много столбцов
Усложним задачу. Допустим, нам нужно искать и подсвечивать повторы не по одному столбцу, а по нескольким. Например, имеется вот такая таблица с ФИО в трех колонках:

Задача все та же — подсветить совпадающие ФИО, имея ввиду совпадение сразу по всем трем столбцам — имени, фамилии и отчества одновременно.
Самым простым решением будет добавить дополнительный служебный столбец (его потом можно скрыть) с текстовой функцией СЦЕПИТЬ (CONCATENATE), чтобы собрать ФИО в одну ячейку:

Имея такой столбец мы, фактически, сводим задачу к предыдущему способу. Для выделения совпадающих ФИО теперь можно выделить все три столбца с данными и создать новое правило форматирования, аналогичное Способу 2. А именно:
- в Excel 2003 и старше — выбрать в меню Формат — Условное форматирование — Формула (Format — Conditional Formatting — Formula)
- в Excel 2007 и новее — нажать на вкладке Главная (Home) кнопку Условное форматирование — Создать правило (Conditional Formatting — New Rule) и выбрать тип правила Использовать формулу для опеределения форматируемых ячеек (Use a formula to determine which cell to format)
Затем ввести формулу проверки количества совпадений и задать цвет с помощью кнопки Формат (Format) — все, как в Способе 2:

Ссылки по теме
- Сравнение двух диапазонов данных, поиск различий и совпадений
- Извлечение уникальных элементов из диапазона
В сегодняшних Excel файлах дубликаты встречаются повсеместно. К примеру, когда вы создаете составную таблицу из других таблиц, вы можете обнаружить в ней повторяющиеся значения, или в файле с общим доступом внесли одинаковые данные два разных пользователя, что привело к задвоению и т.д. Дубликаты могут возникнуть в одном столбце, в нескольких столбцах или даже во всем листе. В Microsoft Excel реализовано несколько инструментов поиска, выделения и, при необходимости, удаления повторяющихся значений. Ниже описаны основные методики определения дубликатов в Excel.
1. Удаление повторяющихся значений в Excel (2007+)
Предположим, у вас имеется таблица, состоящая из трех столбцов, в которой присутствуют одинаковые записи и вам необходимо избавится от них. Выделяем область таблицы, в которой хотите удалить повторяющиеся значения. Вы можете выделить один или несколько столбцов, или всю таблицу целиком. Переходим по вкладке Данные в группу Работа с данными, щелкаем по кнопке Удалить дубликаты.
Если в каждом столбце таблицы имеется заголовок, установить маркер Мои данные содержат заголовки. Также проставляем маркеры напротив тех столбцов, в которых требуется произвести поиск дубликатов.
Щелкаем ОК, диалоговое окно будет закрыто и строки, содержащие дубликаты будут удалены.
Данная функция предназначена для удаления записей, которые полностью дублируют строки в таблице. Если вы выделили не все столбцы для определения дубликатов, строки с повторяющимися значениями также будут удалены.
2. Использование расширенного фильтра для удаления дубликатов
Выберите любую ячейку в таблице, перейдите по вкладке Данные в группу Сортировка и фильтр, щелкните по кнопке Дополнительно.
В появившемся диалоговом окне Расширенный фильтр, необходимо установить переключатель в положение скопировать результат в другое место, в поле Исходный диапазон указать диапазон, в котором находится таблица, в поле Поместить результат в диапазон указать верхнюю левую ячейку будущей отфильтрованной таблицы и установить маркер Только уникальные значения. Щелкаем ОК.
На месте, указанном для размещения результатов работы расширенного фильтра, будет создана еще одна таблица, но уже с отфильтрованными, по уникальным значениям, данными.
3. Выделение повторяющихся значений с помощью условного форматирования в Excel (2007+)
Выделяем таблицу, в которой необходимо обнаружить повторяющиеся значения. Переходим по вкладке Главная в группу Стили, выбираем Условное форматирование -> Правила выделения ячеек -> Повторяющиеся значения.
В появившемся диалоговом окне Повторяющиеся значения, необходимо выбрать формат выделения дубликатов. У меня по умолчанию установлено светло-красная заливка и темно-красный цвет текста. Обратите внимание, в данном случае Excel будет сравнивать на уникальность не всю строку таблицы, а лишь ячейку столбца, поэтому если у вас имеются повторяющиеся значения только в одном столбце, Excel отформатирует их тоже. На примере вы можете увидеть, как Excel залил некоторые ячейки третьего столбца с именами, хотя вся строка данной ячейки таблицы уникальна.
4. Использование сводных таблиц для определения повторяющихся значений
Воспользуемся уже знакомой нам таблицей с тремя столбцами и добавим четвертый, под названием Счетчик, и заполним его единицами (1). Выделяем всю таблицу и переходим по вкладке Вставка в группу Таблицы, щелкаем по кнопке Сводная таблица.
Создаем сводную таблицу. В поле Название строк помещаем три первых столбца, в поле Значения помещаем столбец со счетчиком. В созданной сводной таблице, записи со значением больше единицы будут дубликатами, само значение будет означать количество повторяющихся значений. Для большей наглядности, можно отсортировать таблицу по столбцу Счетчик, чтобы сгруппировать дубликаты.
Posted On 09.12.2017
Если Вы работаете с большими таблицами в Excel и регулярно добавляете в них, например, данные про учеников школы или сотрудников компании, то в таких таблицах могут появиться повторяющиеся значения, другими словами – дубликаты.
В данной статье мы рассмотрим, как найти, выделить, удалить и посчитать количество повторяющихся значений в Эксель.
Найти и выделить дубликаты в таблице можно, используя условное форматирование в Эксель. Выделите весь диапазон данных в нужной таблице. На вкладке «Главная» кликните на кнопочку «Условное форматирование», выберите из меню «Правила выделения ячеек» – «Повторяющиеся значения».

В следующем окне выберите из выпадающего списка «повторяющиеся», цвет для ячейки и текста, в который нужно закрасить найденные дубликаты. Затем нажмите «ОК» и программа выполнит поиск дубликатов.

Excel выделил повторяющиеся значения в таблице. Как видите, сравниваются не строки таблицы, а ячейки в столбцах. Поэтому выделена ячейка «Саша В.». Таких учеников может быть несколько, но с разными фамилиями. Теперь можете выполнить сортировку в Эксель по цвету ячейки и текста, и удалить найденные повторяющиеся значения.

Чтобы удалить дубликаты в Excel можно воспользоваться следующими способами. Выделяем заполненную таблицу, переходим на вкладку «Данные» и нажимаем кнопочку «Удалить дубликаты».

В следующем окне ставим галочку в пункте «Мои данные содержат заголовки», если Вы выделили таблицу вместе с заголовками. Дальше отметьте галочками столбцы таблицы, в которых нужно найти повторяющиеся значения, и нажмите «ОК».

Появится диалоговое окно с информацией, сколько было найдено и удалено повторяющихся значений.
Второй способ для удаления дубликатов – это использование фильтра. Выделяем нужные столбцы таблицы вместе с шапкой. Переходим на вкладку «Данные» и в группе «Сортировка и фильтр» нажимаем на кнопочку «Дополнительно».
В следующем окне в поле «Исходный диапазон» уже указаны ячейки. Отмечаем маркером пункт «скопировать результат в другое место» и в поле «Поместить результат в диапазон» указываем адрес одной ячейки, которая будет левой верхней в новой таблице. Ставим галочку в поле «Только уникальные записи» и нажимаем «ОК».
Будет создана новая таблица, в которой не будет строк с повторяющимися значениями. Если у Вас большая исходная таблица, то создать на ее основе таблицу с уникальными записями, можно на другом рабочем листе Excel. Чтобы подробнее узнать об этом, прочтите статью: фильтр в Эксель.
Если Вам нужно найти и посчитать количество повторяющихся значений в Excel, создадим для этого сводную таблицу Excel. Добавляем в исходную таблицу столбец «Код» и заполняем его «1»: ставим 1, 1 в первых двух ячейка, выделяем их и протягиваем вниз. Когда будут найдены дубликаты для строк, каждый раз значение в столбце «Код» будет увеличиваться на единицу.
Выделяем всю таблицу вместе с заголовками, переходим на вкладку «Вставка» и нажимаем кнопочку «Сводная таблица».
Чтобы более подробно узнать, как работать со сводными таблицами в Эксель, прочтите статью перейдя по ссылке.
В следующем окне уже указаны ячейки диапазона, маркером отмечаем «На новый лист» и нажимаем «ОК».
Справой стороны перетаскиваем первые три заголовка таблицы в область «Названия строк», а поле «Код» перетаскиваем в область «Значения».
В результате получим сводную таблицу без дубликатов, а в поле «Код» будут стоять числа, соответствующие повторяющимся значениям в исходной таблице – сколько раз в ней повторялась данная строка.
Для удобства, выделим все значения в столбце «Сумма по полю Код», и отсортируем их в порядке убывания.
Думаю теперь, Вы сможете найти, выделить, удалить и даже посчитать количество дубликатов в Excel для всех строк таблицы или только для выделенных столбцов.
Поделитесь статьёй с друзьями:
Автор: Аня Каминская| Дата: 2016-05-03| Просмотров:(30118)| Комментов:(0)
Поиск дублей в Excel – это одна из самых распространенных задач для любого офисного сотрудника. Для ее решения существует несколько разных способов. Но как быстро как найти дубликаты в Excel и выделить их цветом? Для ответа на этот часто задаваемый вопрос рассмотрим конкретный пример.
Как найти повторяющиеся значения в Excel?
Допустим мы занимаемся регистрацией заказов, поступающих на фирму через факс и e-mail. Может сложиться такая ситуация, что один и тот же заказ поступил двумя каналами входящей информации. Если зарегистрировать дважды один и тот же заказ, могут возникнуть определенные проблемы для фирмы. Ниже рассмотрим решение средствами условного форматирования.
Чтобы избежать дублированных заказов, можно использовать условное форматирование, которое поможет быстро найти одинаковые значения в столбце Excel.
Пример дневного журнала заказов на товары:
Чтобы проверить содержит ли журнал заказов возможные дубликаты, будем анализировать по наименованиям клиентов – столбец B:
- Выделите диапазон B2:B9 и выберите инструмент: «ГЛАВНАЯ»-«Стили»-«Условное форматирование»-«Создать правило».
- Вберете «Использовать формулу для определения форматируемых ячеек».
- Чтобы найти повторяющиеся значения в столбце Excel, в поле ввода введите формулу: =СЧЁТЕСЛИ($B$2:$B$9; B2)>1.
- Нажмите на кнопку «Формат» и выберите желаемую заливку ячеек, чтобы выделить дубликаты цветом.
Post navigation
Например, зеленый. И нажмите ОК на всех открытых окнах.
Скачать пример поиска одинаковых значений в столбце.
Как видно на рисунке с условным форматированием нам удалось легко и быстро реализовать поиск дубликатов в Excel и обнаружить повторяющиеся данные ячеек для таблицы журнала заказов.
Пример функции СЧЁТЕСЛИ и выделение повторяющихся значений
Принцип действия формулы для поиска дубликатов условным форматированием – прост. Формула содержит функцию =СЧЁТЕСЛИ(). Эту функцию так же можно использовать при поиске одинаковых значений в диапазоне ячеек. В функции первым аргументом указан просматриваемый диапазон данных. Во втором аргументе мы указываем что мы ищем. Первый аргумент у нас имеет абсолютные ссылки, так как он должен быть неизменным. А второй аргумент наоборот, должен меняться на адрес каждой ячейки просматриваемого диапазона, потому имеет относительную ссылку.
Самые быстрые и простые способы: найти дубликаты в ячейках.
После функции идет оператор сравнения количества найденных значений в диапазоне с числом 1. То есть если больше чем одно значение, значит формула возвращает значение ИСТЕНА и к текущей ячейке применяется условное форматирование.
Как найти и выделить цветом повторяющиеся значения в Excel
Список с выделенным цветом групп данных безусловно выглядит намного читабельнее, чем белые ячейки в столбцах с черным шрифтом значений. Даже элементарное выделение цветом каждой второй строки существенно облегчает визуальный анализ данных таблицы. Для реализации данной задачи в Excel применяется универсальный инструмент – условное форматирование.
Как выделить повторяющиеся ячейки в Excel
Иногда можно столкнуться со ситуацией, когда нужно выделить цветом группы данных, но из-за сложной структуры нельзя четко определить и указать для Excel какие ячейки выделить.
Повторяющиеся значения в Excel
Пример такой таблицы изображен ниже на рисунке:
Данная таблица отсортирована по городам (значения третьего столбца в алфавитном порядке). Необходимо выделить цветом строки каждой второй группы данных по каждому городу. Одна группа строк без изменений, следующая цветная и так далее в этой последовательности до конца таблицы. Для этого:
- Выделите диапазон ячеек A2:C19 и выберите инструмент: «ГЛАВНАЯ»-«Стили»-«Условное форматирование»-«Создать правило».
- В появившемся диалоговом окне выделите опцию: «Использовать формулу для определения форматируемых ячеек», а в поле ввода введите следующую формулу:
- Нажмите на кнопку «Формат» и на закладке заливка укажите зеленый цвет. И нажмите ОК на всех открытых окнах.
В результате мы выделили целые строки условным форматированием и получаем эффект как изображено на рисунке:
Теперь работать с такой читабельна таблицей намного удобнее. Можно комфортно проводить визуальный анализ всех показателей.
Привет всем. Сегодня я хочу рассказать вам, как найти повторяющиеся значения в Excel и что с ними можно сделать. Если вам приходиться работать с таблицей, где есть дублирующиеся данные, то хотелось бы знать, как их отыскать. Именно этим, в этом уроке, мы и займемся.
Для примера я взял вот такую таблицу. Взял людей из какой-то группы вКонтакте, разделил имена и фамилии, и наделал несколько ячеек с дублями.
Выделяем цветом дубликаты в таблице
Первым способом я покажу вам, каким образом можно найти дубликаты и выделить их цветом. Это может вам потребоваться, для сравнения каких-либо данных без их удаления. В моем примере это будут одинаковые имена и фамилии людей.
Открывает вкладку «Главная», в разделе «Стили» выбираем «Условное форматирование» — «Правила выделения ячеек» — «Повторяющиеся значения».
Открылось окно, в котором есть два пункта: что выделить – уникальные или повторяющиеся значения, и, как их выделить – в какую цветовую гамму. И, конечно же, кнопка «ОК».
Чтобы поиск был осуществлен не по всей таблице, предварительно выделите один или несколько столбцов.
Посмотрите на мой результат. Правда такой способ имеет существенный недостаток: нет выборки, выделяет все, что встречается более одного раза.
Выборочная подсветка или удаление одинаковых значений в Excel
Способ, может быть, банальный, но действенный. Воспользуемся функцией «Поиск».
Открывает вкладку «Главная» — раздел «Редактирование» — «Найти и выделить» (CTRL+F).
В окне в поле «Найти» набираем, что мы ищем. Затем жмем по кнопке «Найти все», нажимаем сочетание клавиш CTRL+A, чтобы выделить все результаты поиска, и выделяю их цветом. Так же их можно удалить, а не выделять.
Удаляем все одинаковые значения в Excel с помощью расширенного фильтра
Для использования расширенного фильтра, выберем любую ячейку в таблице. Я выбрал верхнюю левую. Затем открываем вкладку «Данные», переходим в раздел «Сортировка и фильтр», и жмем по кнопке «Дополнительно».
Теперь нужно настроить в этом окне, каким образом будет произведена фильтровка. Можно скопировать результаты фильтра в другое место (ставим галочку и указываем место, куда скопируется результат), либо результат оставить в том же месте. И, обязательно, ставим галочку «Только уникальные значения».
Вот мой результат применения к таблице расширенного фильтра. Как видим, в результате Excel смог найти и удалить дубликаты.
Еще один способ быстро удалить дубли в таблице
Этот способ удалит все одинаковые значения, которые встречаются в таблице. Если вам нужен поиск только в некоторых столбцах, то выделите их.
Теперь откройте вкладку «Данные», раздел «Работа с данными», «Удалить дубликаты».
Расставим нужные галочки. Мне нужен поиск по двум столбцам, потому оставляю, как есть, и жму на кнопку «ОК».
На этом метод закончился. Вот мой результат его работы.
Спасибо за прочтение. Не забывайте делиться с друзьями с помощью кнопок социальных сетей, и комментируйте.
Сегодня я расскажу Вам о том, как избежать появления дубликатов в столбце данных на листе Excel. Этот приём работает в Microsoft Excel 2013, 2010, 2007 и более ранних версиях.
Мы уже касались этой темы в одной из статей. Поэтому, возможно, Вы уже знаете, как в Excel сделать так, чтобы введённые повторно данные автоматически выделялись цветом в процессе ввода.
Из этой статьи Вы узнаете, как предотвратить появление дубликатов в одном или нескольких столбцах на листе Excel. Как сделать так, чтобы в первом столбце таблицы были только уникальные данные, появляющиеся лишь однажды, к примеру, номера счетов-фактур, номенклатурные записи или даты.
Как предотвратить появление дубликатов – 5 простых шагов
В Excel есть инструмент, о котором часто незаслуженно забывают – «Проверка данных». С его помощью можно избежать ошибок, возникающих при вводе. Позже мы обязательно посвятим отдельную статью этому полезному инструменту. А пока, для разогрева, покажем его работу на простом примере
Предположим, у нас есть таблица данных с информацией о клиентах, состоящая из столбцов с именами (Name), телефонными номерами (Phone) и адресами электронной почты (e-mail). Нам требуется, чтобы адреса электронной почты не повторялись. Следующие шаги помогут избежать повторной отправки письма на один и тот же адрес.
- Просматриваем таблицу и, если необходимо, удаляем все повторяющиеся записи. Для этого сначала выделим дубликаты цветом, а затем, проверив все значения, удалим их вручную.
- Выделяем весь столбец, в котором хотим избежать появления дубликатов. Для этого щёлкаем мышью по первой ячейке с данными и, удерживая клавишу Shift нажатой, щёлкаем по последней ячейке. Если этот столбец крайний в таблице, как в нашем случае, то можем использовать комбинацию клавиш Ctrl+Shift+End. Самое главное сначала выделите именно первую ячейку с данными.
Замечание: Если данные оформлены, как обычный диапазон, а не как полноценная таблица Excel, то необходимо выделить все ячейки столбца, в том числе пустые. В нашем примере это будет диапазон D2:D1048576.
- Откройте вкладку Данные (Data) и кликните по иконке Проверка данных (Data Validation), чтобы вызвать диалоговое окно Проверка вводимых значений (Data Validation).
- На вкладке Параметры (Settings) в выпадающем списке Тип данных (Allow) выберите Другой (Custom) и в поле Формула (Formula) введите такое выражение:
=СЧЁТЕСЛИ($D:$D;D2)=1=COUNTIF($D:$D,D2)=1Здесь $D:$D – это адреса первой и последней ячейки в столбце. Обратите внимание, что мы использовали знак доллара, чтобы записать абсолютную ссылку. D2 – это адрес первой выделенной ячейки столбца, это не абсолютная ссылка.
Эта формула подсчитывает количество повторений значения ячейки D2 в диапазоне D1:D1048576. Если это значение встречается в заданном диапазоне только однажды, тогда всё в порядке. Если значение встречается несколько раз, то Excel покажет сообщение, текст которого мы запишем на вкладке Сообщение об ошибке (Error Alert).
Подсказка: Мы можем искать повторяющиеся значения, записанные не только в текущем, но и в другом столбце. Этот столбец может находиться на другом листе или даже в другой рабочей книге. Таким образом, вводя электронные адреса в столбец, мы можем сравнивать их с адресами, которые занесены в чёрный список и с которыми решено прекратить сотрудничество. Я расскажу подробнее о таком применении инструмента «Проверка данных» в одной из будущих статей.
- Открываем вкладку Сообщение об ошибке (Error Alert) и заполняем поля Заголовок (Title) и Сообщение (Error message). Именно это сообщение будет показано в Excel при попытке ввести повторяющееся значение в столбец. Постарайтесь доступно пояснять в своём сообщении детали ошибки, чтобы Вам и Вашим коллегам было понятно в чём причина. Иначе по прошествии длительного времени, например, через месяц, Вы можете забыть, что означает данное сообщение.Например, так:Заголовок: Повторяющийся email.
Сообщение: Введённый Вами адрес email уже используется в данном столбце. Допускается вводить только уникальные адреса email.
- Нажмите ОК, чтобы закрыть диалоговое окно Проверка вводимых значений (Data validation).
Теперь при попытке ввести в столбец e-mail адрес, который в нём уже существует, будет показано созданное нами сообщение об ошибке. Это сработает, как при создании записи e-mail для нового клиента, так и при попытке изменить e-mail существующего клиента:
Если наша борьба с дубликатами допускает исключения
На шаге 4 в выпадающем списке Вид (Style) выбираем Предупреждение (Warning) или Сообщение (Information). Поведение сообщения об ошибке изменится следующим образом:
Предупреждение: В диалоговом окне будет предложен набор кнопок Да (Yes) / Нет (No) / Отмена (Cancel). Если нажать Да (Yes), то введённое значение будет добавлено в ячейку. Чтобы вернуться к редактированию ячейки, нажмите Нет (No) или Отмена (Cancel). По умолчанию активна кнопка Нет (No).
Сообщение: В диалоговом окне будет предложено нажать кнопку ОК или Отмена (Cancel). По умолчанию активна кнопка ОК – введённое повторяющееся значение останется в ячейке. Если хотите изменить данные в ячейке, нажмите Отмена (Cancel), чтобы вернуться к редактированию.
Замечание: Хочу ещё раз обратить Ваше внимание на то обстоятельство, что сообщение о появлении повторяющегося значения будет показано только при попытке ввести это значение в ячейку. Инструмент «Проверка данных» в Excel не обнаружит дубликаты среди уже введённых записей, даже если этих дубликатов сотни!
Урок подготовлен для Вас командой сайта office-guru.ru
Источник: /> Перевел: Антон Андронов
Правила перепечаткиЕще больше уроков по Microsoft Excel
Оцените качество статьи. Нам важно ваше мнение: