
17 авг. 2022 г.
читать 2 мин
В этом руководстве объясняется, как рассчитать межквартильный диапазон набора данных в Excel.
Что такое межквартильный диапазон?
Межквартильный диапазон , часто обозначаемый IQR, — это способ измерения разброса средних 50% набора данных. Он рассчитывается как разница между первым квартилем* (Q1) и третьим квартилем (Q3) набора данных.
*Квартили — это просто значения, которые делят набор данных на четыре равные части.
Например, предположим, что у нас есть следующий набор данных:
[58, 66, 71, 73, 74, 77, 78, 82, 84, 85, 88, 88, 88, 90, 90, 92, 92, 94, 96, 98]
Третий квартиль оказывается равным 91 , а первый квартиль равен 75,5.Таким образом, межквартильный размах (IQR) для этого набора данных составляет 91 – 75,5 = 15.Это говорит нам о том, насколько распределены средние 50% значений в этом наборе данных.
Как рассчитать межквартильный диапазон в Excel
В Microsoft Excel нет встроенной функции для расчета IQR набора данных, но мы можем легко найти ее с помощью функции КВАРТИЛЬ() , которая принимает следующие аргументы:
КВАРТИЛЬ(массив, кварта)
- массив: массив данных, которые вас интересуют.
- квартиль : квартиль, который вы хотите рассчитать.
Пример: поиск IQR в Excel
Предположим, мы хотим найти IQR для следующего набора данных:
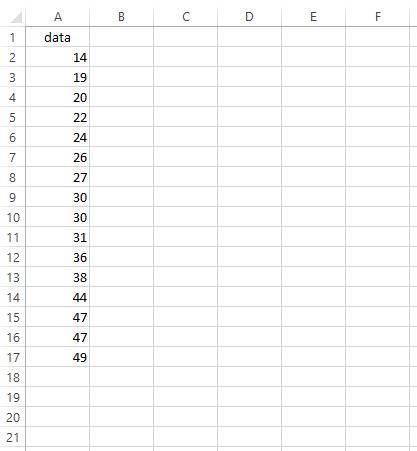
Чтобы найти IQR, мы можем выполнить следующие шаги:
Шаг 1: Найдите Q1 .
Чтобы найти первый квартиль, мы просто вводим =КВАРТИЛЬ(A2:A17, 1) в любую выбранную ячейку:
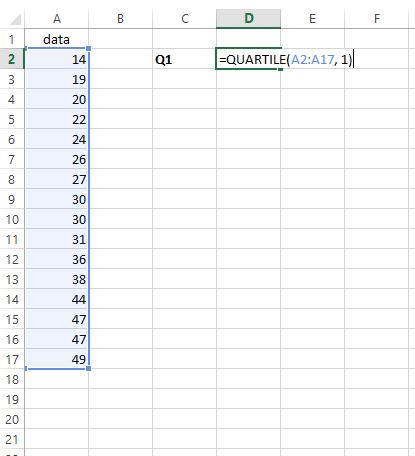
Шаг 2: Найдите Q3 .
Чтобы найти третий квартиль, мы вводим =КВАРТИЛЬ(A2:A17, 3) в любую выбранную ячейку:
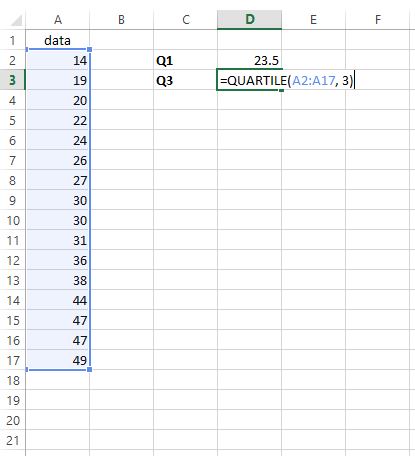
Шаг 3: Найдите IQR .
Чтобы найти межквартильный размах (IQR), мы просто вычитаем Q1 из Q3:
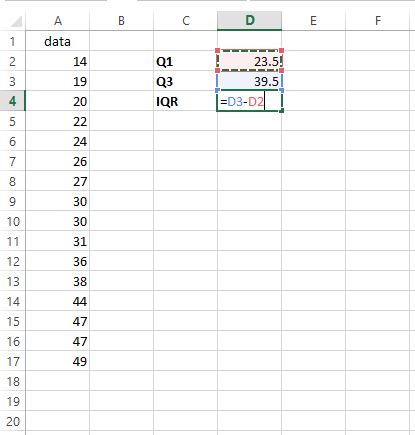
IQR оказывается равным 39,5 – 23,5 = 16.Это говорит нам о том, насколько распределены средние 50% значений в этом конкретном наборе данных.
Более короткий подход
Обратите внимание, что мы могли бы также найти межквартильный диапазон набора данных в предыдущем примере, используя одну формулу:
=КВАРТИЛЬ(A2:A17, 3) – КВАРТИЛЬ(A2:A17, 1)
Это также приведет к значению 16 .
Вывод
Межквартильный диапазон представляет собой только один из способов измерения «разброса» набора данных. Другими способами измерения разброса являются диапазон, стандартное отклонение и дисперсия .
Преимущество использования IQR для измерения спреда заключается в том, что он устойчив к выбросам.Поскольку он сообщает нам только разброс средних 50% набора данных, на него не влияют необычно маленькие или необычно большие выбросы.
Это делает его более предпочтительным способом измерения дисперсии по сравнению с таким показателем, как диапазон, который просто сообщает нам разницу между наибольшим и наименьшим значениями в наборе данных.
Связанный: Как рассчитать средний диапазон в Excel
В Excel функция КВАРТИЛЬ используется для разделения данных на равные доли. Также еще часто используют эту функцию для поиска отстающих показателей, то есть существенно отличающихся от остальных значений в исходных данных.
Пример расчета межквартильного диапазона для статистического анализа в Excel
Ниже на рисунке представлен другой список работников с показателями производственных браков на 1000 шт. выпущенной продукции. Допустим нам необходимо узнать, какие работники делают большое и малое количество браков, существенно выходящее за пределы допустимой нормы (отстающие и превышающие ее — так называемые выборсы от медианы), чтобы потом проанализировать их. С целью поиска аномальных отклонений от показателей нормы в данном примере будет использован метод расширенного межквартильного диапазона. Межквартильный диапазон – это просто данные лежащие в среднем диапазоне, который охватывает 50% всего объема данных (находящийся между 75% и 25%). Определение «расширенный» значит, что средний диапазон данных может быть расширен с учетом определенного коэффициента, определяющего его границы. Все значения, лежащие вне границ, воспринимаются как показатели выборсы:
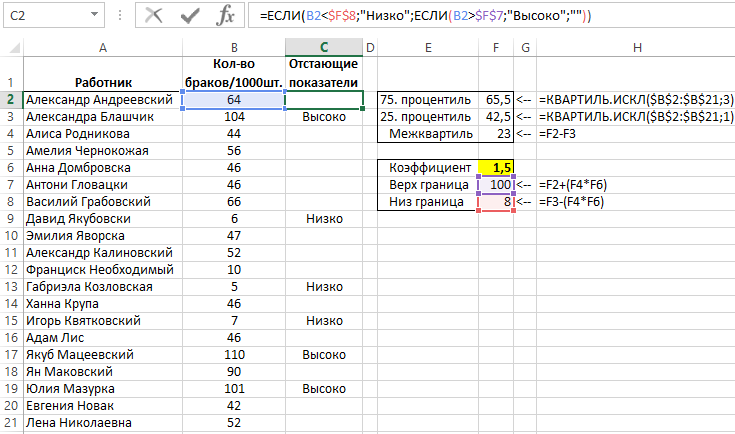
Для определения значения в среднем диапазоне между 75% и 25% следует воспользоваться функцией КВАРТИЛЬ.ИСКЛ вместе с указанными аргументами 3 и 1 – соответственно. Межквартильным диапазоном является разницей между этими значениями.
В случае нерасширенного межквартильного диапазона с целью определения его нижней границы достаточно всего лишь вычитать значение диапазона от 25%. А для верхней границы, нужно добавить его до 75%. Результатом применения данного метода могло бы получиться слишком большое число для найденных показателей выбросов. Умножая межквартильный диапазон на расширяющий коэффициент (в данном примере равен 1,5) расширяются границы. Таким образом, можно выбрать только особенно экстремальные значения.
Схема вычисления межквартильного диапазона в Excel
Ниже на рисунке представленные те же данные, что и в предыдущем примере, отсортированы по столбцу с показателями количества браков на 1000 шт. готовой продукции. Также для наглядности линиями наложены границы расширенного диапазона четверти и верхние с нижними границами остальных диапазонов четверти:

Чтобы определить верхнюю границу диапазона четверти, необходимо умножить расширяющий коэффициент на диапазон четверти и добавить его результат к 75%.
Чтобы определить нижнюю границу необходимо от 25% вычитать результат, полученный после умножения диапазона на коэффициент.
Может оказаться так, что расширяющий коэффициент равен 1,5 привел к исключению значения, которое казались отстающими или были выбраны значения, которые казались нормальными. В этом нет ничего особенного. Просто увеличьте или уменьшите расширяющий коэффициент, если его текущее значение не согласуются с Вашими исходными данными.
После определения границ используйте формулу со вложенными функциями ЕСЛИ с целью проверки: является ли данное значение большим чем верхнее или ниже от нижнего граничного значения. В случае значительных отклонений показателей (выбросов) от нормы формула со вложенными функциями ЕСЛИ возвращает слово «Выше» или «Ниже», а в случае значения лежащего внутри границ формула возвращает пустую строку («»).
In statistics, the five-number summary is mostly used as it gives a rough idea about the dataset. It is basically a summary of the dataset describing some key features in statistics. The five key features are :
- Minimum value: It is the minimum value in the data set.
- First Quartile, Q1: It is also known as the lower quartile where 25% of the scores fall below it.
- Median (middle value) or second quartile: It is basically the mid-value in the dataset.
- Third Quartile, Q3: It is also known as the Upper quartile in which 25% of the data is above it and the rest 75% falls below it.
- Maximum value: It is the maximum value in the dataset.
Using two quartiles of the five-number summary we can easily calculate the IQR abbreviated as Interquartile Range.
In this article, we are going to see how to calculate the Interquartile range in Excel using a sample dataset as an example.
Interquartile Range
In terms of Mathematics, it is basically defined as the difference between the third quartile (75th percentile) and the first quartile (25th percentile).
Q3-Q1
IQR denotes the middle 50% hence also known as midspread or H-spread in statistics. It can be easily observed using a box plot.
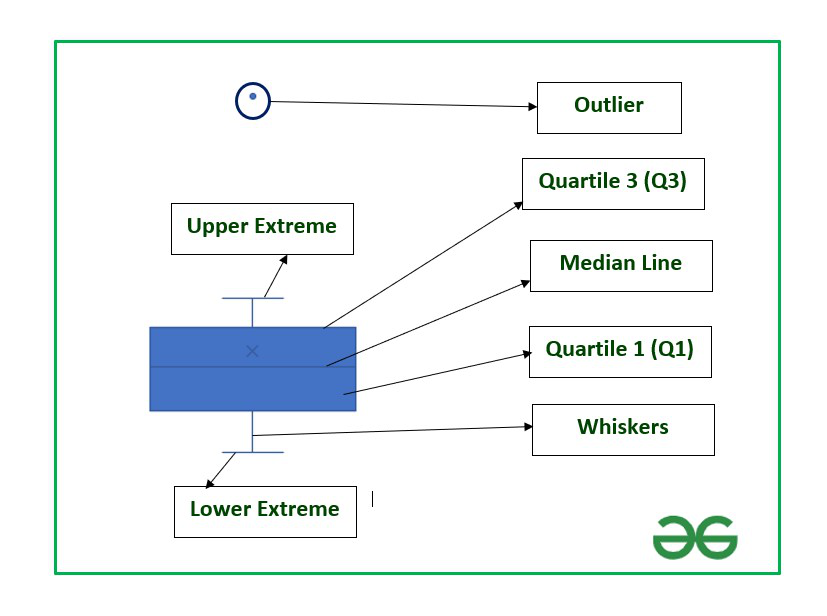
The vertical lines of the rectangular box plot denote the Interquartile range which lies between Quartile 1 and Quartile 3.
Example: Consider the dataset consisting of the BMI of ten students in a class.
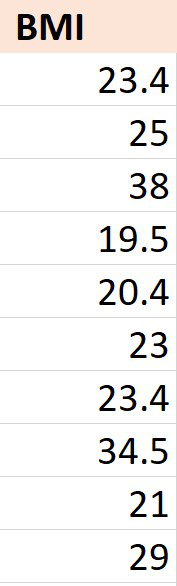
Now, in order to calculate the IQR we need to first calculate the two quartile values Q1 and Q3. The function used is :
QUARTILE(Array,quart) // Used in Excel 2007 version and lower or QUARTILE.INC(Array,quart) // Used in latest version of Excel Array : Cell range quart : The five quart values from 0 to 4 0- Minimum value 1- First Quartile (25 percent) 2- Median Value (50 percentile) 3- Third Quartile (75 percentile) 4- Maximum value
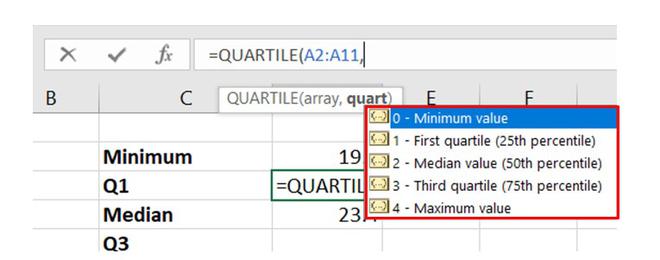
quart values
Calculation
Follow the below steps to calculate the same:
Step 1: Insert the dataset.
Step 2: Select any cell where you want to write the formula to calculate the values of Q1, Q3, and IQR.
Step 3: First find the values of Q1 and Q3 using the quart values as 1 and 3 respectively.
The dataset is stored in column “A” of the worksheet and the observations are stored from cell A2 to A11.
So the array will start from A2 and end at A11.
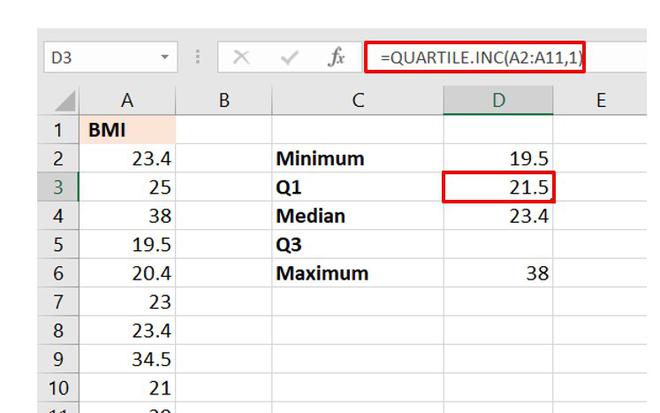
Calculation of Q1
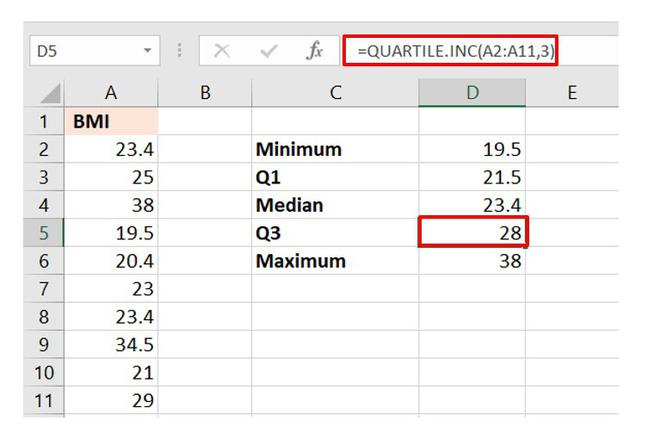
Calculation of Q3
You can also find the remaining three parameters of a five-number summary using the same formula just by changing the quart value. But to find the IQR, we only need the values of Q1 and Q3.
The value of Q3 is stored in cell D4 and that of Q1 in cell D3. The formula will be :
=Cell_no_Q3-Cell_no_Q1
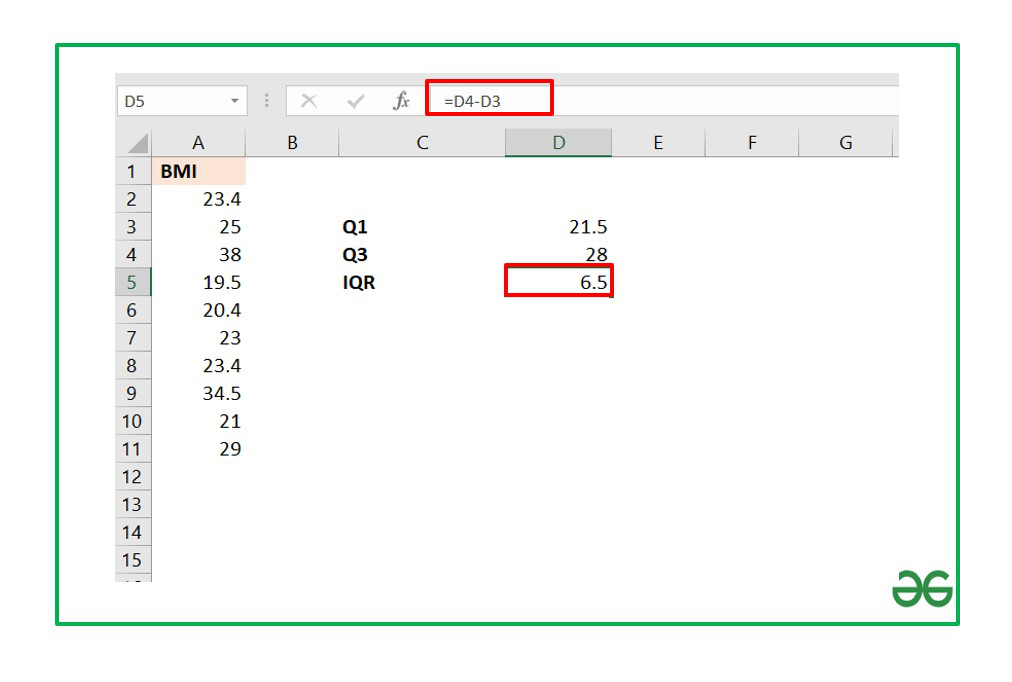
The Interquartile range for the above dataset turns out to be 6.5.
Для вычисления квартилей в MS EXCEL существует специальная функция
КВАРТИЛЬ()
. В этой статье дадим определение квартилей и научимся их вычислять для выборки и для непрерывного распределения. Также вычислим интерквартильный интервал.
Квартили
(Quartiles) — значения, которые делят
выборку
(набор значений) на четыре части, содержащие приблизительно равное количество наблюдений (по 25%).
Поясним определение
квартиля
на примере. Пусть имеется
выборка
, состоящая из 50 значений в ячейках
А7:А56
(см.
файл примера
, лист Квартиль-выборка). Для наглядности
отсортируем значения по возрастанию
и построим
гистограмму
.
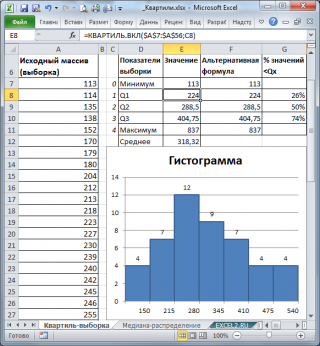
Чтобы разделить
выборку
на 4 части достаточно 3-х
квартилей
.
Первый
квартиль
(или
нижний квартиль
, Q1) делит
выборку
, на 2 части: примерно 25% значений в
выборке
меньше Q1, остальные 75% — больше. Для вычисления
1-го квартиля
используйте формулу
=КВАРТИЛЬ.ВКЛ(A7:A56;1)
. Для нашей выборки формула вернет значение 224. Значения 224 нет в
выборке
, формула произвела интерполяцию на основе 2-х соседних значений 223 и 227.
Примечание
: Функция
КВАРТИЛЬ.ВКЛ()
появилась в MS EXCEL 2010. В более ранних версиях использовалась аналогичная ей функция
КВАРТИЛЬ()
.
Чтобы убедиться, что примерно 25% значений меньше, чем 224, используем формулу
=СЧЁТЕСЛИ(A7:A56;»<«&224)/СЧЁТ(A7:A56)
. В результате получим, что 26% меньше, чем 1-й
квартиль
.
Чем в
выборке
больше значений и меньше
повторов
, тем точнее деление
выборки квартилями
на четверти.
Примечание
: Первый квартиль — это то же самое, что и 25-я
процентиль
. Подробнее см.
статью про процентили
.
Второй
квартиль
(или
медиана
, Q2) также делит
выборку
, на 2 равные части: половина чисел множества больше, чем
медиана
, а половина чисел меньше, чем
медиана
. Для вычисления 2-го
квартиля
используйте формулу
=КВАРТИЛЬ.ВКЛ(A7:A56;2)
или
=МЕДИАНА(A7:A56)
Третий
квартиль
(или верхний
квартиль
, Q3) делит
выборку
, на 2 части: примерно 75% значений в
выборке
меньше Q3, остальные 25% — больше. Для вычисления 3-го
квартиля
используйте формулу
=КВАРТИЛЬ.ВКЛ(A7:A56;3)
или
=ПРОЦЕНТИЛЬ.ВКЛ(A7:A56;0,75)
Примечание
: Третий
квартиль
— это то же самое, что и 75-я
процентиль
.
Второй аргумент функции
КВАРТИЛЬ.ВКЛ()
может также принимать значения 0 и 4. В первом случае функция вернет
минимальное значение
, во втором –
максимальное
.
Интерквартильный размах
Интерквартильным размахом
или
интерквартильным интервалом
(InterQuartile range, IQR) называется разность между третьим и первым
квартилями
(Q3 — Q1).
Интерквартильный размах
является характеристикой разброса значений в
выборке
.
Примечание
: Характеристикой разброса значений в
выборке
является также
дисперсия и стандартное отклонение
.
Интерквартильный размах
, а также
квартили
используются при построении
Блочной диаграммы
, которая полезна для оценки разброса значений (variation) в небольших
выборках
или для сравнения нескольких
выборок
имеющих сходные распределения.
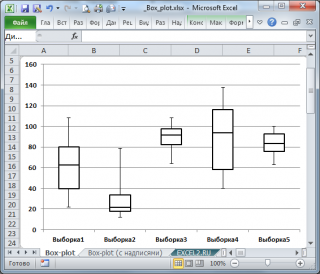
Подробнее о построении
Блочной диаграммы
см. статью
Блочная диаграмма в MS EXCEL
.
Квартили непрерывного распределения
Если
функция распределения
F
(х)
случайной величины
х
непрерывна, то 1-й
квартиль
является решением уравнения
F(х)
=0,25, второй —
F(х)
=0,5, а третий
F(х)
=0,75.
Примечание
: Подробнее о
Функции распределения
см. статью
Функция распределения и плотность вероятности в MS EXCEL
.
Если известна
функция плотности вероятности
p
(х)
, то 1-й
квартиль
можно найти из уравнения:
![]()
Например, решив аналитическим способом это уравнение для
Логнормального распределения
lnN(μ; σ
2
), получим, что
медиана
(2-й
квартиль
) вычисляется по формуле e
μ
или в MS EXCEL =EXP(μ). При μ=1,
медиана
равна 2,718.
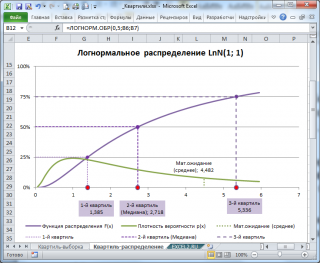
Обратите внимание на точку
Функции распределения
, для которой
F(х)=0,5
(см. картинку выше или
файл примера
, лист Квартиль-распределение)
.
Абсцисса этой точки равна 2,718. Это и есть значение 2-го
квартиля
(
медианы
), что естественно совпадает с ранее вычисленным значением по формуле e
μ
.
Примечание
: Напомним, что интеграл от
функции плотности вероятности
по всей области задания случайной величины равен единице:
![]()
Поэтому, линии
квартилей
(
х=квартиль
) делят площадь под графиком
функции плотности вероятности
на 4 равные части.
Квартили в MS EXCEL
Чтобы вычислить в MS EXCEL
квартили
заданного распределения необходимо использовать соответствующую
обратную функцию распределения
.
При вычислении
квартилей
в MS EXCEL используются
обратные функции распределения
:
НОРМ.СТ.ОБР()
,
ЛОГНОРМ.ОБР()
,
ХИ2.ОБР()
,
ГАММА.ОБР()
и т.д. Подробнее о распределениях, представленных в MS EXCEL, можно прочитать в статье
Распределения случайной величины в MS EXCEL
.
Например, в MS EXCEL 1-й
квартиль
для
логнормального распределения
LnN(1;1) можно вычислить по формуле
=ЛОГНОРМ.ОБР(0,25;1;1)
, а 3-й
квартиль
для
стандартного нормального распределения
по формуле
=НОРМ.СТ.ОБР(0,75)
.
Содержание
- Использование Excel для расчета статистических характеристик случайной величины
- Как рассчитать межквартильный диапазон (IQR) в Excel
- Что такое межквартильный диапазон?
- Как рассчитать межквартильный диапазон в Excel
- Пример: поиск IQR в Excel
- Более короткий подход
- Вывод
Использование Excel для расчета статистических характеристик случайной величины
Разделы: Математика
- Совершенствование умений и навыков нахождения статистических характеристик случайной величины, работа с расчетами в Excel;
- применение информационно коммутативных технологий для анализа данных; работа с различными информационными носителями.
- Сегодня на уроке мы научимся рассчитывать статистические характеристики для больших по объему выборок, используя возможности современных компьютерных технологий.
- Для начала вспомним:
– что называется случайной величиной? (Случайной величиной называют переменную величину, которая в зависимости от исхода испытания принимает одно значение из множества возможных значений.)
– Какие виды случайных величин мы знаем? (Дискретные, непрерывные.)
– Приведите примеры непрерывных случайных величин (рост дерева), дискретных случайных величин (количество учеников в классе).
– Какие статистические характеристики случайных величин мы знаем (мода, медиана, среднее выборочное значение, размах ряда).
– Какие приемы используются для наглядного представления статистических характеристик случайной величины (полигон частот, круговые и столбчатые диаграммы, гистограммы).
- Рассмотрим, применение инструментов Excel для решения статистических задач на конкретном примере.
Пример. Проведена проверка в 100 компаниях. Даны значения количества работающих в компании (чел.):
| 23 25 24 25 30 24 30 26 28 26 32 33 31 31 25 33 25 29 30 28 23 30 29 24 33 30 30 28 26 25 26 29 27 29 26 28 27 26 29 28 29 30 27 30 28 32 28 26 30 26 31 27 30 27 33 28 26 30 31 29 27 30 30 29 27 26 28 31 29 28 33 27 30 33 26 31 34 28 32 22 29 30 27 29 34 29 32 29 29 30 29 29 36 29 29 34 23 28 24 28 |
рассчитать числовые характеристики:
|
1. Занести данные в EXCEL, каждое число в отдельную ячейку.
| 23 | 25 | 24 | 25 | 30 | 24 | 30 | 26 | 28 | 26 |
| 32 | 33 | 31 | 31 | 25 | 33 | 25 | 29 | 30 | 28 |
| 23 | 30 | 29 | 24 | 33 | 30 | 30 | 28 | 26 | 25 |
| 26 | 29 | 27 | 29 | 26 | 28 | 27 | 26 | 29 | 28 |
| 29 | 30 | 27 | 30 | 28 | 32 | 28 | 26 | 30 | 26 |
| 31 | 27 | 30 | 27 | 33 | 28 | 26 | 30 | 31 | 29 |
| 27 | 30 | 30 | 29 | 27 | 26 | 28 | 31 | 29 | 28 |
| 33 | 27 | 30 | 33 | 26 | 31 | 34 | 28 | 32 | 22 |
| 29 | 30 | 27 | 29 | 34 | 29 | 32 | 29 | 29 | 30 |
| 29 | 29 | 36 | 29 | 29 | 34 | 23 | 28 | 24 | 28 |
2. Для расчета числовых характеристик используем опцию Вставка – Функция. И в появившемся окне в строке категория выберем — статистические, в списке: МОДА

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили Мо = 29 (чел) – Фирм у которых в штате 29 человек больше всего.
Используя тот же путь вычисляем медиану.
Вставка – Функция – Статистические – Медиана.

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили Ме = 29 (чел) – среднее значение сотрудников в фирме.
Размах ряда чисел – разница между наименьшим и наибольшим возможным значением случайной величины. Для вычисления размаха ряда нужно найти наибольшее и наименьшее значения нашей выборки и вычислить их разность.
Вставка – Функция – Статистические – МАКС.

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили наибольшее значение = 36.
Вставка – Функция – Статистические – МИН.

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили наименьшее значение = 22.
36 – 22 = 14 (чел) – разница между фирмой с наибольшим штатом сотрудников и фирмой с наименьшим штатом сотрудников.
Для построения диаграммы и полигона частот необходимо задать закон распределения, т.е. составить таблицу значений случайной величины и соответствующих им частот. Мы ухе знаем, что наименьшее число сотрудников в фирме = 22, а наибольшее = 36. Составим таблицу, в которой значения xi случайной величины меняются от 22 до 36 включительно шагом 1.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni |
Чтобы сосчитать частоту каждого значения воспользуемся
Вставка – Функция – Статистические – СЧЕТЕСЛИ.
В окне Диапазон ставим курсор и выделяем нашу выборку, а в окне Критерий ставим число 22

Нажимаем клавишу ОК, получаем значение 1, т.е. число 22 в нашей выборке встречается 1 раз и его частота =1. Аналогичным образом заполняем всю таблицу.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni | 1 | 3 | 4 | 5 | 11 | 9 | 13 | 18 | 16 | 6 | 4 | 6 | 3 | 0 | 1 |
Для проверки вычисляем объем выборки, сумму частот (Вставка – Функция – Математические — СУММА). Должно получиться 100 (количество всех фирм).
Чтобы построить полигон частот выделяем таблицу – Вставка – Диаграмма – Стандартные – Точечная (точечная диаграмма на которой значения соединены отрезками)

Нажимаем клавишу Далее, в Мастере диаграмм указываем название диаграммы (Полигон частот), удаляем легенду, редактируем шкалу и характеристики диаграммы для наибольшей наглядности.


Для построения столбчатой и круговой диаграмм используем тот же путь (выбирая нужный нам тип диаграммы).
Диаграмма – Стандартные – Круговая.

Диаграмма – Стандартные – Гистограмма.

4. Сегодня на уроке мы научились применять компьютерные технологии для анализа и обработки статистической информации.
Источник
Как рассчитать межквартильный диапазон (IQR) в Excel
В этом руководстве объясняется, как рассчитать межквартильный диапазон набора данных в Excel.
Что такое межквартильный диапазон?
Межквартильный диапазон , часто обозначаемый IQR, — это способ измерения разброса средних 50% набора данных. Он рассчитывается как разница между первым квартилем* (Q1) и третьим квартилем (Q3) набора данных.
*Квартили — это просто значения, которые делят набор данных на четыре равные части.
Например, предположим, что у нас есть следующий набор данных:
[58, 66, 71, 73, 74, 77, 78, 82, 84, 85, 88, 88, 88, 90, 90, 92, 92, 94, 96, 98]
Третий квартиль оказывается равным 91 , а первый квартиль равен 75,5.Таким образом, межквартильный размах (IQR) для этого набора данных составляет 91 – 75,5 = 15.Это говорит нам о том, насколько распределены средние 50% значений в этом наборе данных.
Как рассчитать межквартильный диапазон в Excel
В Microsoft Excel нет встроенной функции для расчета IQR набора данных, но мы можем легко найти ее с помощью функции КВАРТИЛЬ() , которая принимает следующие аргументы:
- массив: массив данных, которые вас интересуют.
- квартиль : квартиль, который вы хотите рассчитать.
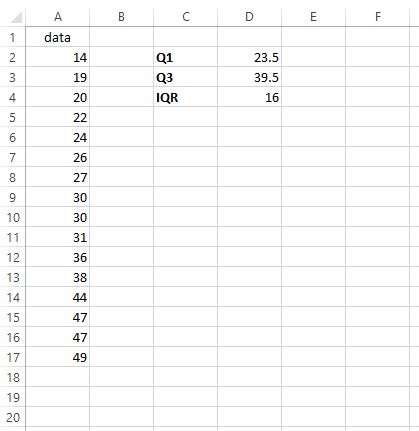
Пример: поиск IQR в Excel
Предположим, мы хотим найти IQR для следующего набора данных:
Чтобы найти IQR, мы можем выполнить следующие шаги:
Шаг 1: Найдите Q1 .
Чтобы найти первый квартиль, мы просто вводим =КВАРТИЛЬ(A2:A17, 1) в любую выбранную ячейку:
Шаг 2: Найдите Q3 .
Чтобы найти третий квартиль, мы вводим =КВАРТИЛЬ(A2:A17, 3) в любую выбранную ячейку:
Шаг 3: Найдите IQR .
Чтобы найти межквартильный размах (IQR), мы просто вычитаем Q1 из Q3:
IQR оказывается равным 39,5 – 23,5 = 16.Это говорит нам о том, насколько распределены средние 50% значений в этом конкретном наборе данных.
Более короткий подход
Обратите внимание, что мы могли бы также найти межквартильный диапазон набора данных в предыдущем примере, используя одну формулу:
=КВАРТИЛЬ(A2:A17, 3) – КВАРТИЛЬ(A2:A17, 1)
Это также приведет к значению 16 .
Вывод
Межквартильный диапазон представляет собой только один из способов измерения «разброса» набора данных. Другими способами измерения разброса являются диапазон, стандартное отклонение и дисперсия .
Преимущество использования IQR для измерения спреда заключается в том, что он устойчив к выбросам.Поскольку он сообщает нам только разброс средних 50% набора данных, на него не влияют необычно маленькие или необычно большие выбросы.
Это делает его более предпочтительным способом измерения дисперсии по сравнению с таким показателем, как диапазон, который просто сообщает нам разницу между наибольшим и наименьшим значениями в наборе данных.
Источник
Быстрый пример
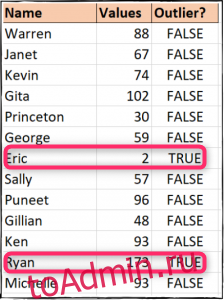
На изображении ниже выбросы довольно легко обнаружить — значение два присвоено Эрику, а значение 173 — Райану. В таком наборе данных достаточно легко обнаружить и обработать эти выбросы вручную.
В большем наборе данных этого не будет. Возможность идентифицировать выбросы и удалять их из статистических расчетов важна — и это то, что мы рассмотрим, как это сделать в этой статье.
Как найти выбросы в ваших данных
Чтобы найти выбросы в наборе данных, мы используем следующие шаги:
Вычислите 1-й и 3-й квартили (мы немного поговорим о том, что это такое).
Оцените межквартильный размах (мы также объясним это немного ниже).
Верните верхнюю и нижнюю границы нашего диапазона данных.
Используйте эти границы для определения отдаленных точек данных.
Диапазон ячеек справа от набора данных, показанного на изображении ниже, будет использоваться для хранения этих значений.
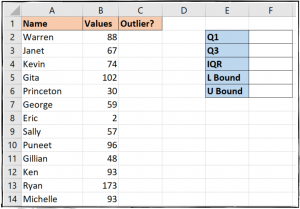
Давайте начнем.
Шаг 1. Рассчитайте квартили
Если вы разделите данные на кварталы, каждый из этих наборов называется квартилем. Самые низкие 25% чисел в диапазоне составляют 1-й квартиль, следующие 25% — 2-й квартиль и т. Д. Мы делаем этот шаг в первую очередь, потому что наиболее широко используемое определение выброса — это точка данных, которая более чем на 1,5 интерквартильных диапазонов (IQR) ниже 1-го квартиля и на 1,5 межквартильных диапазонов выше 3-го квартиля. Чтобы определить эти значения, мы сначала должны выяснить, каковы квартили.
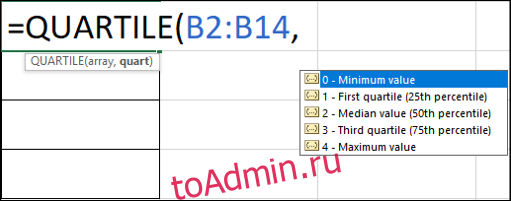
Excel предоставляет функцию КВАРТИЛЬ для расчета квартилей. Для этого требуются две части информации: массив и кварта.
=QUARTILE(array, quart)
Массив — это диапазон значений, которые вы оцениваете. Кварта — это число, которое представляет квартиль, который вы хотите вернуть (например, 1 для 1-го квартиля, 2 для 2-го квартиля и т. Д.).
Примечание. В Excel 2010 Microsoft выпустила функции QUARTILE.INC и QUARTILE.EXC как усовершенствования функции QUARTILE. QUARTILE более обратно совместима при работе с несколькими версиями Excel.
Вернемся к нашему примеру таблицы.
Для вычисления 1-го квартиля мы можем использовать следующую формулу в ячейке F2.
=QUARTILE(B2:B14,1)
Когда вы вводите формулу, Excel предоставляет список параметров для аргумента кварты.
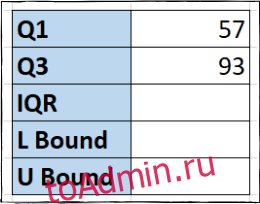
Чтобы вычислить 3-й квартиль, мы можем ввести формулу, аналогичную предыдущей, в ячейку F3, но используя тройку вместо единицы.
=QUARTILE(B2:B14,3)
Теперь у нас есть точки данных квартилей, отображаемые в ячейках.
Шаг второй: оцените межквартильный размах
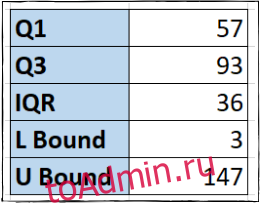
Межквартильный диапазон (или IQR) — это средние 50% значений в ваших данных. Он рассчитывается как разница между значением 1-го квартиля и значением 3-го квартиля.
Мы собираемся использовать простую формулу в ячейке F4, которая вычитает 1-й квартиль из 3-го квартиля:
=F3-F2
Теперь мы можем видеть наш межквартильный размах.

Шаг третий: верните нижнюю и верхнюю границы
Нижняя и верхняя границы — это наименьшее и наибольшее значение диапазона данных, который мы хотим использовать. Любые значения, меньшие или большие, чем эти связанные значения, являются выбросами.
Мы рассчитаем нижний предел в ячейке F5, умножив значение IQR на 1,5, а затем вычтя его из точки данных Q1:
=F2-(1.5*F4)

Примечание. Скобки в этой формуле не нужны, потому что часть умножения будет вычисляться перед частью вычитания, но они облегчают чтение формулы.
Чтобы вычислить верхнюю границу в ячейке F6, мы снова умножим IQR на 1,5, но на этот раз добавим его к точке данных Q3:
=F3+(1.5*F4)
Шаг четвертый: выявление выбросов
Теперь, когда мы настроили все наши базовые данные, пришло время определить наши отдаленные точки данных — те, которые ниже значения нижней границы или выше значения верхней границы.
Мы будем использовать Функция ИЛИ для выполнения этого логического теста и отображения значений, соответствующих этим критериям, введите следующую формулу в ячейку C2:
=OR(B2$F$6)
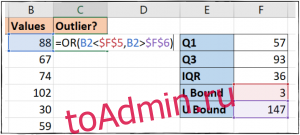
Затем мы скопируем это значение в наши ячейки C3-C14. Значение ИСТИНА указывает на выброс, и, как видите, в наших данных их два.
Игнорирование выбросов при вычислении среднего среднего
Использование функции КВАРТИЛЬ позволяет нам рассчитать IQR и работать с наиболее широко используемым определением выброса. Однако при вычислении среднего среднего для диапазона значений и игнорировании выбросов существует более быстрая и простая функция. Этот метод не будет определять выбросы, как раньше, но он позволит нам быть гибкими в выборе того, что мы можем считать своей частью выбросов.
Нужная нам функция называется TRIMMEAN, синтаксис для нее вы можете увидеть ниже:
=TRIMMEAN(array, percent)
Массив — это диапазон значений, которые вы хотите усреднить. Процент — это процент точек данных, которые необходимо исключить из верхней и нижней части набора данных (вы можете ввести его как процентное или десятичное значение).
В нашем примере мы ввели приведенную ниже формулу в ячейку D3, чтобы вычислить среднее значение и исключить 20% выбросов.
=TRIMMEAN(B2:B14, 20%)
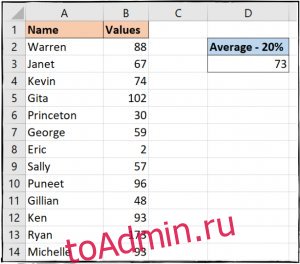
Здесь у вас есть две разные функции для обработки выбросов. Независимо от того, хотите ли вы идентифицировать их для каких-либо потребностей в отчетности или исключить их из вычислений, таких как средние значения, в Excel есть функция, соответствующая вашим потребностям.
Содержание:
- Что такое выбросы и почему их важно найти?
- Найдите выбросы путем сортировки данных
- Поиск выбросов с помощью квартильных функций
- Поиск выбросов с помощью функций НАИБОЛЬШИЙ / МАЛЕНЬКИЙ
- Как правильно обращаться с выбросами
- Удалить выбросы
- Нормализовать выбросы (отрегулировать значение)
При работе с данными в Excel у вас часто возникают проблемы с обработкой выбросов в наборе данных.
Выбросы довольно часто встречаются во всех видах данных, и важно идентифицировать и обрабатывать эти выбросы, чтобы убедиться, что ваш анализ правильный и значимый.
В этом уроке я покажу вам как найти выбросы в Excel, а также некоторые методы, которые я использовал в своей работе для обработки этих выбросов.
Что такое выбросы и почему их важно найти?
Выброс — это точка данных, которая выходит за рамки других точек данных в наборе данных. Если у вас есть выброс в данных, это может исказить ваши данные, что может привести к неверным выводам.
Приведу простой пример.
Допустим, 30 человек едут на автобусе из пункта назначения A в пункт назначения B. Все люди относятся к одной весовой группе и группе доходов. Для целей этого руководства давайте предположим, что средний вес составляет 220 фунтов, а средний годовой доход — 70 000 долларов.
Сейчас где-то посередине нашего маршрута автобус останавливается, и в него садится Билл Гейтс.
Как вы думаете, как это повлияет на средний вес и средний доход людей в автобусе?
Хотя средний вес вряд ли сильно изменится, средний доход пассажиров автобуса резко вырастет.
Это связано с тем, что доход Билла Гейтса является исключением в нашей группе, и это дает нам неправильную интерпретацию данных. Средний доход каждого пассажира автобуса составит несколько миллиардов долларов, что намного превышает реальную стоимость.
При работе с фактическими наборами данных в Excel вы можете иметь выбросы в любом направлении (например, положительный выброс или отрицательный выброс).
И чтобы убедиться, что ваш анализ верен, вам нужно каким-то образом идентифицировать эти выбросы, а затем решить, как лучше всего их лечить.
Теперь давайте рассмотрим несколько способов найти выбросы в Excel.
Найдите выбросы путем сортировки данных
С небольшими наборами данных быстрый способ определить выбросы — просто отсортировать данные и вручную просмотреть некоторые значения в верхней части отсортированных данных.
А так как выбросы могут быть в обоих направлениях, убедитесь, что вы сначала отсортировали данные в порядке возрастания, а затем в порядке убывания, а затем перебрали самые верхние значения.
Позвольте мне показать вам пример.
Ниже у меня есть набор данных, в котором у меня есть продолжительность звонков (в секундах) для 15 звонков в службу поддержки.

Ниже приведены шаги по сортировке этих данных, чтобы мы могли идентифицировать выбросы в наборе данных:
- Выберите заголовок столбца, который вы хотите отсортировать (в этом примере ячейка B1).
- Перейдите на вкладку «Главная«

- В группе «Редактирование» щелкните значок «Сортировка и фильтр».
- Щелкните Custom Sort (Пользовательская сортировка).
- В диалоговом окне «Сортировка» выберите «Продолжительность» в раскрывающемся списке «Сортировка по» и «От наибольшего к наименьшему» в раскрывающемся списке «Порядок».
- Нажмите ОК




Вышеупомянутые шаги сортируют столбец продолжительности звонка с наивысшими значениями вверху. Теперь вы можете вручную просмотреть данные и посмотреть, есть ли выбросы.

В нашем примере я вижу, что первые два значения намного выше остальных значений (а два нижних намного ниже).
Примечание. Этот метод работает с небольшими наборами данных, где вы можете вручную сканировать данные. Это не научный метод, но он хорошо работает
Поиск выбросов с помощью квартильных функций
Теперь давайте поговорим о более научном решении, которое поможет вам определить, есть ли какие-то выбросы.
В статистике квартиль составляет четверть набора данных. Например, если у вас есть 12 точек данных, то первый квартиль будет тремя нижними точками данных, второй квартиль будет следующими тремя точками данных и так далее.
Ниже приведен набор данных, по которому я хочу найти выбросы. Для этого мне нужно будет вычислить 1-й и 3-й квартили, а затем с его помощью вычислить верхний и нижний предел.

Ниже приведена формула для вычисления первого квартиля в ячейке E2:
= QUARTILE.INC ($ B $ 2: $ B $ 15,1)

и вот тот, который вычисляет третий квартиль в ячейке E3:
= QUARTILE.INC ($ B $ 2: $ B $ 15,3)

Теперь я могу использовать два вышеупомянутых вычисления, чтобы получить межквартильный размах (который составляет 50% наших данных в пределах 1-го и 3-го квартилей).
= F3-F2

Теперь мы будем использовать межквартильный диапазон, чтобы найти нижний и верхний предел, который будет содержать большую часть наших данных.
Все, что выходит за эти нижние и верхние пределы, будет считаться выбросом.
Ниже приведена формула для расчета нижнего предела:
= Квартиль1 - 1,5 * (Межквартильный диапазон)
который в нашем примере становится:
= F2-1,5 * F4

И формула для расчета верхнего предела:
= Квартиль3 + 1,5 * (Межквартильный диапазон)
который в нашем примере становится:
= F3 + 1,5 * F4

Теперь, когда у нас есть верхний и нижний предел в нашем наборе данных, мы можем вернуться к исходным данным и быстро определить те значения, которые не лежат в этом диапазоне.
Быстрый способ сделать это — проверить каждое значение и вернуть ИСТИНА или ЛОЖЬ в новом столбце.
Я использовал приведенную ниже формулу ИЛИ, чтобы получить ИСТИНА для тех значений, которые являются выбросами.
= ИЛИ (B2 $ F $ 6)

Теперь вы можете фильтровать столбец Outlier и отображать только те записи, для которых значение TRUE.
Кроме того, вы также можете использовать условное форматирование, чтобы выделить все ячейки, в которых значение TRUE.
Примечание: Хотя это более распространенный метод поиска выбросов в статистике. Я считаю, что этот метод немного непригоден для использования в реальных сценариях. В приведенном выше примере нижний предел, рассчитанный по формуле, равен -103, в то время как набор данных, который у нас есть, может быть только положительным. Таким образом, этот метод может помочь нам найти выбросы в одном направлении (высокие значения), он бесполезен при выявлении выбросов в другом направлении.
Поиск выбросов с помощью функций НАИБОЛЬШИЙ / МАЛЕНЬКИЙ
Если вы работаете с большим количеством данных (значения в нескольких столбцах), вы можете извлечь 5 или 7 наибольших и наименьших значений и посмотреть, есть ли в них выбросы.
Если есть какие-либо выбросы, вы сможете их идентифицировать, не просматривая все данные в обоих направлениях.
Предположим, у нас есть приведенный ниже набор данных, и мы хотим знать, есть ли какие-либо выбросы.
Ниже приведена формула, которая даст вам наибольшее значение в наборе данных:
= БОЛЬШОЙ ($ B $ 2: $ B $ 16,1)
Точно так же второе по величине значение будет равно
= БОЛЬШОЙ ($ B $ 2: $ B $ 16,1)
Если вы не используете Microsoft 365, в которой есть динамические массивы, вы можете использовать приведенную ниже формулу, и она даст вам пять наибольших значений из набора данных с помощью одной формулы:
= БОЛЬШОЙ ($ B $ 2: $ B $ 16; СТРОКА ($ 1: 5))

Точно так же, если вам нужны 5 наименьших значений, используйте следующую формулу:
= МАЛЕНЬКИЙ ($ B $ 2: $ B $ 16; СТРОКА ($ 1: 5))
или следующее, если у вас нет динамических массивов:
= МАЛЕНЬКИЙ ($ B $ 2: $ B $ 16,1)
Когда у вас есть эти значения, очень легко обнаружить любые выбросы в наборе данных.
Хотя я решил извлечь 5 наибольших и наименьших значений, вы можете выбрать 7 или 10 в зависимости от размера вашего набора данных.
Я не уверен, является ли это приемлемым методом для поиска выбросов в Excel или нет, но это метод, который я использовал, когда мне приходилось работать с большим количеством финансовых данных на моей работе несколько лет назад. По сравнению со всеми другими методами, описанными в этом руководстве, я считаю этот наиболее эффективным.
Как правильно обращаться с выбросами
До сих пор мы видели методы, которые помогут нам найти выбросы в нашем наборе данных. Но что делать, если вы знаете, что есть выбросы.
Вот несколько методов, которые вы можете использовать для обработки выбросов, чтобы ваш анализ данных был правильным.
Удалить выбросы
Самый простой способ удалить выбросы из набора данных — просто удалить их. Таким образом, это не исказит ваш анализ.
Это более жизнеспособное решение, когда у вас большие наборы данных и удаление пары выбросов не повлияет на общий анализ. И, конечно же, перед удалением данных обязательно создайте копию и выясните, что вызывает эти выбросы.
Нормализовать выбросы (отрегулировать значение)
Нормализация выбросов — это то, что я делал, когда работал полный рабочий день. Для всех значений выбросов я бы просто изменил их на значение, немного превышающее максимальное значение в наборе данных.
Это гарантирует, что я не удаляю данные, но в то же время не позволяю им искажать мои данные.
Чтобы дать вам реальный пример, если вы анализируете маржу чистой прибыли компаний, где большинство компаний находится в пределах от -10% до 30%, а есть несколько значений, превышающих 100%, я просто изменит эти выбросы на 30% или 35%.
Итак, вот некоторые из методов, которые вы можете использовать в Excel, чтобы найти выбросы.
После того, как вы определили выбросы, вы можете углубиться в данные и посмотреть, что их вызывает, и в то же время выбрать один из методов обработки этих выбросов (который может удалить их или нормализовать, изменив значение)
Надеюсь, вы нашли этот урок полезным.
Содержание
- Использование описательной статистики
- Подключение «Пакета анализа»
- Размах вариации
- Вычисление коэффициента вариации
- Шаг 1: расчет стандартного отклонения
- Шаг 2: расчет среднего арифметического
- Шаг 3: нахождение коэффициента вариации
- Простая формула для расчета объема выборки
- Пример расчета объема выборки
- Задачи о генеральной доле
- По части судить о целом
- Как рассчитать объем выборки
- Как определить статистические выбросы и сделать выборку для их удаления в Excel
- Способ 1: применение расширенного автофильтра
- Способ 2: применение формулы массива
- СРЗНАЧ()
- СРЗНАЧЕСЛИ()
- МАКС()
- МИН()
Использование описательной статистики
Под описательной статистикой понимают систематизацию эмпирических данных по целому ряду основных статистических критериев. Причем на основе полученного результата из этих итоговых показателей можно сформировать общие выводы об изучаемом массиве данных.
В Экселе существует отдельный инструмент, входящий в «Пакет анализа», с помощью которого можно провести данный вид обработки данных. Он так и называется «Описательная статистика». Среди критериев, которые высчитывает данный инструмент следующие показатели:
- Медиана;
- Мода;
- Дисперсия;
- Среднее;
- Стандартное отклонение;
- Стандартная ошибка;
- Асимметричность и др.
Рассмотрим, как работает данный инструмент на примере Excel 2010, хотя данный алгоритм применим также в Excel 2007 и в более поздних версиях данной программы.
Подключение «Пакета анализа»
Как уже было сказано выше, инструмент «Описательная статистика» входит в более широкий набор функций, который принято называть Пакет анализа. Но дело в том, что по умолчанию данная надстройка в Экселе отключена. Поэтому, если вы до сих пор её не включили, то для использования возможностей описательной статистики, придется это сделать.
- Переходим во вкладку «Файл». Далее производим перемещение в пункт «Параметры».
- В активировавшемся окне параметров перемещаемся в подраздел «Надстройки». В самой нижней части окна находится поле «Управление». Нужно в нем переставить переключатель в позицию «Надстройки Excel», если он находится в другом положении. Вслед за этим жмем на кнопку «Перейти…».
- Запускается окно стандартных надстроек Excel. Около наименования «Пакет анализа» ставим флажок. Затем жмем на кнопку «OK».



После вышеуказанных действий надстройка Пакет анализа будет активирована и станет доступной во вкладке «Данные» Эксель. Теперь мы сможем использовать на практике инструменты описательной статистики.
Размах вариации
Размах вариации – разница между максимальным и минимальным значением:
![]()
Ниже приведена графическая интерпретация размаха вариации.

Видно максимальное и минимальное значение, а также расстояние между ними, которое и соответствует размаху вариации.
С одной стороны, показатель размаха может быть вполне информативным и полезным. К примеру, максимальная и минимальная стоимость квартиры в городе N, максимальная и минимальная зарплата по профессии в регионе и проч. С другой стороны, размах может быть очень широким и не иметь практического смысла, т.к. зависит лишь от двух наблюдений. Таким образом, размах вариации очень неустойчивая величина.
Вычисление коэффициента вариации
Этот показатель представляет собой отношение стандартного отклонения к среднему арифметическому. Полученный результат выражается в процентах.
В Экселе не существует отдельно функции для вычисления этого показателя, но имеются формулы для расчета стандартного отклонения и среднего арифметического ряда чисел, а именно они используются для нахождения коэффициента вариации.
Шаг 1: расчет стандартного отклонения
Стандартное отклонение, или, как его называют по-другому, среднеквадратичное отклонение, представляет собой квадратный корень из дисперсии. Для расчета стандартного отклонения используется функция СТАНДОТКЛОН. Начиная с версии Excel 2010 она разделена, в зависимости от того, по генеральной совокупности происходит вычисление или по выборке, на два отдельных варианта: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В.
Синтаксис данных функций выглядит соответствующим образом:
= СТАНДОТКЛОН(Число1;Число2;…)
= СТАНДОТКЛОН.Г(Число1;Число2;…)
= СТАНДОТКЛОН.В(Число1;Число2;…)
- Для того, чтобы рассчитать стандартное отклонение, выделяем любую свободную ячейку на листе, которая удобна вам для того, чтобы выводить в неё результаты расчетов. Щелкаем по кнопке «Вставить функцию». Она имеет внешний вид пиктограммы и расположена слева от строки формул.

Выполняется активация Мастера функций, который запускается в виде отдельного окна с перечнем аргументов. Переходим в категорию «Статистические» или «Полный алфавитный перечень». Выбираем наименование «СТАНДОТКЛОН.Г» или «СТАНДОТКЛОН.В», в зависимости от того, по генеральной совокупности или по выборке следует произвести расчет. Жмем на кнопку «OK».

Открывается окно аргументов данной функции. Оно может иметь от 1 до 255 полей, в которых могут содержаться, как конкретные числа, так и ссылки на ячейки или диапазоны. Ставим курсор в поле «Число1». Мышью выделяем на листе тот диапазон значений, который нужно обработать. Если таких областей несколько и они не смежные между собой, то координаты следующей указываем в поле «Число2» и т.д. Когда все нужные данные введены, жмем на кнопку «OK»


Шаг 2: расчет среднего арифметического
Среднее арифметическое является отношением общей суммы всех значений числового ряда к их количеству. Для расчета этого показателя тоже существует отдельная функция – СРЗНАЧ. Вычислим её значение на конкретном примере.
- Выделяем на листе ячейку для вывода результата. Жмем на уже знакомую нам кнопку «Вставить функцию».

В статистической категории Мастера функций ищем наименование «СРЗНАЧ». После его выделения жмем на кнопку «OK».

Запускается окно аргументов СРЗНАЧ. Аргументы полностью идентичны тем, что и у операторов группы СТАНДОТКЛОН. То есть, в их качестве могут выступать как отдельные числовые величины, так и ссылки. Устанавливаем курсор в поле «Число1». Так же, как и в предыдущем случае, выделяем на листе нужную нам совокупность ячеек. После того, как их координаты были занесены в поле окна аргументов, жмем на кнопку «OK».


Шаг 3: нахождение коэффициента вариации
Теперь у нас имеются все необходимые данные для того, чтобы непосредственно рассчитать сам коэффициент вариации.
- Выделяем ячейку, в которую будет выводиться результат. Прежде всего, нужно учесть, что коэффициент вариации является процентным значением. В связи с этим следует поменять формат ячейки на соответствующий. Это можно сделать после её выделения, находясь во вкладке «Главная». Кликаем по полю формата на ленте в блоке инструментов «Число». Из раскрывшегося списка вариантов выбираем «Процентный». После этих действий формат у элемента будет соответствующий.

Снова возвращаемся к ячейке для вывода результата. Активируем её двойным щелчком левой кнопки мыши. Ставим в ней знак «=». Выделяем элемент, в котором расположен итог вычисления стандартного отклонения. Кликаем по кнопке «разделить» (/) на клавиатуре. Далее выделяем ячейку, в которой располагается среднее арифметическое заданного числового ряда. Для того, чтобы произвести расчет и вывести значение, щёлкаем по кнопке Enter на клавиатуре.


Таким образом мы произвели вычисление коэффициента вариации, ссылаясь на ячейки, в которых уже были рассчитаны стандартное отклонение и среднее арифметическое. Но можно поступить и несколько по-иному, не рассчитывая отдельно данные значения.
- Выделяем предварительно отформатированную под процентный формат ячейку, в которой будет выведен результат. Прописываем в ней формулу по типу:
Вместо наименования «Диапазон значений» вставляем реальные координаты области, в которой размещен исследуемый числовой ряд. Это можно сделать простым выделением данного диапазона. Вместо оператора СТАНДОТКЛОН.В, если пользователь считает нужным, можно применять функцию СТАНДОТКЛОН.Г.


Существует условное разграничение. Считается, что если показатель коэффициента вариации менее 33%, то совокупность чисел однородная. В обратном случае её принято характеризовать, как неоднородную.
Как видим, программа Эксель позволяет значительно упростить расчет такого сложного статистического вычисления, как поиск коэффициента вариации. К сожалению, в приложении пока не существует функции, которая высчитывала бы этот показатель в одно действие, но при помощи операторов СТАНДОТКЛОН и СРЗНАЧ эта задача очень упрощается. Таким образом, в Excel её может выполнить даже человек, который не имеет высокого уровня знаний связанных со статистическими закономерностями.
Разделы: Математика
- Совершенствование умений и навыков нахождения статистических характеристик случайной величины, работа с расчетами в Excel;
- применение информационно коммутативных технологий для анализа данных; работа с различными информационными носителями.
- Сегодня мы научимся рассчитывать статистические характеристики для больших по объему выборок, используя возможности современных компьютерных технологий.
- Для начала вспомним:
– что называется случайной величиной? (Случайной величиной называют переменную величину, которая в зависимости от исхода испытания принимает одно значение из множества возможных значений.)
– Какие виды случайных величин мы знаем? (Дискретные, непрерывные.)
– Приведите примеры непрерывных случайных величин (рост дерева), дискретных случайных величин (количество учеников в классе).
– Какие статистические характеристики случайных величин мы знаем (мода, медиана, среднее выборочное значение, размах ряда).
– Какие приемы используются для наглядного представления статистических характеристик случайной величины (полигон частот, круговые и столбчатые диаграммы, гистограммы).
- Рассмотрим, применение инструментов Excel для решения статистических задач на конкретном примере.
Пример. Проведена проверка в 100 компаниях. Даны значения количества работающих в компании (чел.):
| 23 25 24 25 30 24 30 26 28 26 32 33 31 31 25 33 25 29 30 28 23 30 29 24 33 30 30 28 26 25 26 29 27 29 26 28 27 26 29 28 29 30 27 30 28 32 28 26 30 26 31 27 30 27 33 28 26 30 31 29 27 30 30 29 27 26 28 31 29 28 33 27 30 33 26 31 34 28 32 22 29 30 27 29 34 29 32 29 29 30 29 29 36 29 29 34 23 28 24 28 |
рассчитать числовые характеристики:
|
1. Занести данные в EXCEL, каждое число в отдельную ячейку.
| 23 | 25 | 24 | 25 | 30 | 24 | 30 | 26 | 28 | 26 |
| 32 | 33 | 31 | 31 | 25 | 33 | 25 | 29 | 30 | 28 |
| 23 | 30 | 29 | 24 | 33 | 30 | 30 | 28 | 26 | 25 |
| 26 | 29 | 27 | 29 | 26 | 28 | 27 | 26 | 29 | 28 |
| 29 | 30 | 27 | 30 | 28 | 32 | 28 | 26 | 30 | 26 |
| 31 | 27 | 30 | 27 | 33 | 28 | 26 | 30 | 31 | 29 |
| 27 | 30 | 30 | 29 | 27 | 26 | 28 | 31 | 29 | 28 |
| 33 | 27 | 30 | 33 | 26 | 31 | 34 | 28 | 32 | 22 |
| 29 | 30 | 27 | 29 | 34 | 29 | 32 | 29 | 29 | 30 |
| 29 | 29 | 36 | 29 | 29 | 34 | 23 | 28 | 24 | 28 |
2. Для расчета числовых характеристик используем опцию Вставка – Функция. И в появившемся окне в строке категория выберем – статистические, в списке: МОДА

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили Мо = 29 (чел) – Фирм у которых в штате 29 человек больше всего.
Используя тот же путь вычисляем медиану.
Вставка – Функция – Статистические – Медиана.

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили Ме = 29 (чел) – среднее значение сотрудников в фирме.
Размах ряда чисел – разница между наименьшим и наибольшим возможным значением случайной величины. Для вычисления размаха ряда нужно найти наибольшее и наименьшее значения нашей выборки и вычислить их разность.
Вставка – Функция – Статистические – МАКС.

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили наибольшее значение = 36.
Вставка – Функция – Статистические – МИН.

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили наименьшее значение = 22.
36 – 22 = 14 (чел) – разница между фирмой с наибольшим штатом сотрудников и фирмой с наименьшим штатом сотрудников.
Для построения диаграммы и полигона частот необходимо задать закон распределения, т.е. составить таблицу значений случайной величины и соответствующих им частот. Мы ухе знаем, что наименьшее число сотрудников в фирме = 22, а наибольшее = 36. Составим таблицу, в которой значения xi случайной величины меняются от 22 до 36 включительно шагом 1.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni |
Чтобы сосчитать частоту каждого значения воспользуемся
Вставка – Функция – Статистические – СЧЕТЕСЛИ.
В окне Диапазон ставим курсор и выделяем нашу выборку, а в окне Критерий ставим число 22

Нажимаем клавишу ОК, получаем значение 1, т.е. число 22 в нашей выборке встречается 1 раз и его частота =1. Аналогичным образом заполняем всю таблицу.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni | 1 | 3 | 4 | 5 | 11 | 9 | 13 | 18 | 16 | 6 | 4 | 6 | 3 | 0 | 1 |
Для проверки вычисляем объем выборки, сумму частот (Вставка – Функция – Математические – СУММА). Должно получиться 100 (количество всех фирм).
Чтобы построить полигон частот выделяем таблицу – Вставка – Диаграмма – Стандартные – Точечная (точечная диаграмма на которой значения соединены отрезками)

Нажимаем клавишу Далее, в Мастере диаграмм указываем название диаграммы (Полигон частот), удаляем легенду, редактируем шкалу и характеристики диаграммы для наибольшей наглядности.


Для построения столбчатой и круговой диаграмм используем тот же путь (выбирая нужный нам тип диаграммы).
Диаграмма – Стандартные – Круговая.

Диаграмма – Стандартные – Гистограмма.

4. Сегодня на уроке мы научились применять компьютерные технологии для анализа и обработки статистической информации.
Простая формула для расчета объема выборки

где: n – объем выборки;
z – нормированное отклонение, определяемое исходя из выбранного уровня доверительности. Этот показатель характеризует возможность, вероятность попадания ответов в специальный – доверительный интервал. На практике уровень доверительности часто принимают за 95% или 99%. Тогда значения z будут соответственно 1,96 и 2,58;
p – вариация для выборки, в долях. По сути, p – это вероятность того, что респонденты выберут той или иной вариант ответа. Допустим, если мы считаем, что четверть опрашиваемых выберут ответ «Да», то p будет равно 25%, то есть p = 0,25;
q = (1 – p);
e – допустимая ошибка, в долях.
Пример расчета объема выборки
Компания планирует провести социологическое исследование с целью выявить долю курящих лиц в населении города. Для этого сотрудники компании будут задавать прохожим один вопрос: «Вы курите?». Возможных вариантов ответа, таким образом, только два: «Да» и «Нет».
Объем выборки в этом случае рассчитывается следующим образом. Уровень доверительности принимается за 95%, тогда нормированное отклонение z = 1,96. Вариацию принимаем за 50%, то есть условно считаем, что половина респондентов может ответить на вопрос о том, курят ли они – «Да». Тогда p = 0,5. Отсюда находим q = 1 – p = 1 – 0,5 = 0,5. Допустимую ошибку выборки принимаем за 10%, то есть e = 0,1.
Подставляем эти данные в формулу и считаем:

Получаем объем выборки n = 96 человек.
Задачи о генеральной доле
На вопрос «Накрывает ли доверительный интервал заданное значение p0?» — можно ответить, проверив статистическую гипотезу H0:p=p0. При этом предполагается, что опыты проводятся по схеме испытаний Бернулли (независимы, вероятность p появления события А постоянна). По выборке объема n определяют относительную частоту p* появления события A:![]() где m — количество появлений события А в серии из n испытаний. Для проверки гипотезы H0 используется статистика, имеющая при достаточно большом объеме выборки стандартное нормальное распределение (табл. 1).
где m — количество появлений события А в серии из n испытаний. Для проверки гипотезы H0 используется статистика, имеющая при достаточно большом объеме выборки стандартное нормальное распределение (табл. 1).
Таблица 1 – Гипотезы о генеральной доле
|
Гипотеза |
H0:p=p0 | H0:p1=p2 |
| Предположения | Схема испытаний Бернулли | Схема испытаний Бернулли |
| Оценки по выборке |  |
|
| Статистика K |  |
 |
| Распределение статистики K | Стандартное нормальное N(0,1) | Стандартное нормальное N(0,1) |
Пример №1. С помощью случайного повторного отбора руководство фирмы провело выборочный опрос 900 своих служащих. Среди опрошенных оказалось 270 женщин. Постройте доверительный интервал, с вероятностью 0.95 накрывающий истинную долю женщин во всем коллективе фирмы.
Решение. По условию выборочная доля женщин составляет ![]() (относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
(относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле ![]() (относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
(относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
Значение uкр находим по таблице функции Лапласа из соотношения 2Ф(uкр)=γ, т.е. ![]() Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка
Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка ![]() Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка и искомый доверительный интервал
Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка и искомый доверительный интервал
(p – ε, p + ε) = (0.3 – 0.18; 0.3 + 0.18) = (0.12; 0.48)
Итак, с вероятностью 0.95 можно гарантировать, что доля женщин во всем коллективе фирмы находится в интервале от 0.12 до 0.48.
Пример №2. Владелец автостоянки считает день «удачным», если автостоянка заполнена более, чем на 80 %. В течение года было проведено 40 проверок автостоянки, из которых 24 оказались «удачными». С вероятностью 0.98 найдите доверительный интервал для оценки истинной доли «удачных» дней в течение года.
Решение. Выборочная доля «удачных» дней составляет ![]()
По таблице функции Лапласа найдем значение uкр при заданной
доверительной вероятности ![]()
По таблице функции Лапласа найдем значение uкр при заданной
доверительной вероятности
Ф(2.23) = 0.49, uкр = 2.33.
Считая отбор бесповторным (т.е. две проверки в один день не проводилось), найдем предельную ошибку: ![]()
где n=40, N = 365 (дней). Отсюда ![]()
где n=40, N = 365 (дней). Отсюда
и доверительный интервал для генеральной доли: (p – ε, p + ε) = (0.6 – 0.17; 0.6 + 0.17) = (0.43; 0.77)
С вероятностью 0.98 можно ожидать, что доля «удачных» дней в течение года находится в интервале от 0.43 до 0.77.
Пример №3. Проверив 2500 изделий в партии, обнаружили, что 400 изделий высшего сорта, а n–m – нет. Сколько надо проверить изделий, чтобы с уверенностью 95% определить долю высшего сорта с точностью до 0.01?
Решение ищем по формуле определения численности выборки для повторного отбора.
Ф(t) = γ/2 = 0.95/2 = 0.475 и этому значению по таблице Лапласа соответствует t=1.96
Выборочная доля w = 0.16; ошибка выборки ε = 0.01
Пример №4. Партия изделий принимается, если вероятность того, что изделие окажется соответствующим стандарту, составляет не менее 0.97. Среди случайно отобранных 200 изделий проверяемой партии оказалось 193 соответствующих стандарту. Можно ли на уровне значимости α=0,02 принять партию?
Решение. Сформулируем основную и альтернативную гипотезы.
H0:p=p0=0,97 — неизвестная генеральная доля p равна заданному значению p0=0,97. Применительно к условию — вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, равна 0.97; т.е. партию изделий можно принять.
H1:p<0,97 – вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Наблюдаемое значение статистики K (таблица) вычислим при заданных значениях p0=0,97, n=200, m=193

Критическое значение находим по таблице функции Лапласа из равенства
![]()
По условию α=0,02 отсюда Ф(Ккр)=0,48 и Ккр=2,05. Критическая область левосторонняя, т.е. является интервалом (-∞;-Kkp)= (-∞;-2,05). Наблюдаемое значение Кнабл=-0,415 не принадлежит критической области, следовательно, на данном уровне значимости нет оснований отклонять основную гипотезу. Партию изделий принять можно.
Пример №5. Два завода изготавливают однотипные детали. Для оценки их качества сделаны выборки из продукции этих заводов и получены следующие результаты. Среди 200 отобранных изделий первого завода оказалось 20 бракованных, среди 300 изделий второго завода — 15 бракованных.
На уровне значимости 0.025 выяснить, имеется ли существенное различие в качестве изготавливаемых этими заводами деталей.
Решение. Это задача о сравнении генеральных долей двух совокупностей. Сформулируем основную и альтернативную гипотезы.
H0:p1=p2 — генеральные доли равны. Применительно к условию — вероятность появления бракованного изделия в продукции первого завода равна вероятности появления бракованного изделия в продукции второго завода (качество продукции одинаково).
H0:p1≠p2 — заводы изготавливают детали разного качества.
Для вычисления наблюдаемого значения статистики K (таблица) рассчитаем оценки по выборке.
![]()
![]()
Наблюдаемое значение равно

Так как альтернативная гипотеза двусторонняя, то критическое значение статистики K≈ N(0,1) находим по таблице функции Лапласа из равенства ![]()
Так как альтернативная гипотеза двусторонняя, то критическое значение статистики K≈ N(0,1) находим по таблице функции Лапласа из равенства
По условию α=0,025 отсюда Ф(Ккр)=0,4875 и Ккр=2,24. При двусторонней альтернативе область допустимых значений имеет вид (-2,24;2,24). Наблюдаемое значение Kнабл=2,15 попадает в этот интервал, т.е. на данном уровне значимости нет оснований отвергать основную гипотезу. Заводы изготавливают изделия одинакового качества.
По части судить о целом
О возможности судить о целом по части миру рассказал российский математик П.Л. Чебышев. «Закон больших чисел» простым языком можно сформулировать так: количественные закономерности массовых явлений проявляются только при
достаточном числе наблюдений
. Чем больше выборка, тем лучше случайные отклонения компенсируют друг друга и проявляется общая тенденция.
А.М. Ляпунов чуть позже сформулировал центральную предельную теорему. Она стала фундаментом для создания формул, которые позволяют рассчитать вероятность ошибки (при оценке среднего по выборке) и размер выборки, необходимый для достижения заданной точности.
Строгие формулировки:
С увеличением числа случайных величин их среднее арифметическое стремится к среднему арифметическому математических ожиданий и перестает быть случайным. Общий смысл закона больших чисел — совместное действие большого числа случайных факторов приводит к результату, почти не зависящему от случая.
Таким образом з.б.ч. гарантирует устойчивость для средних значений некоторых случайных событий при достаточно длинной серии экспериментов.
Распределение случайной величины, которая получена в результате сложения большого числа независимых случайных величин (ни одно из которых не доминирует, не вносит в сумму определяющего вклада и имеет дисперсию значительно меньшею по сравнению с дисперсией суммы) имеет распределение, близкое к нормальному.
Из ц.п.т. следует, что ошибки выборки также подчиняется нормальному распределению.
Еще раз: чтобы корректно оценивать популяцию по выборке, нам нужна не обычная выборка, а репрезентативная выборка достаточного размера. Начнем с определения этого самого размера.
Как рассчитать объем выборки
Достаточный размер выборки зависит от следующих составляющих:
- изменчивость признака (чем разнообразней показания, тем больше наблюдений нужно, чтобы это уловить);
- размер эффекта (чем меньшие эффекты мы стремимся зафиксировать, тем больше наблюдений необходимо);
- уровень доверия (уровень вероятности при который мы готовы отвергнуть нулевую гипотезу)
ЗАПОМНИТЕ
Объем выборки зависит от изменчивости признака и планируемой строгости эксперимента
Формулы для расчета объема выборки:

Формулы расчета объема выборки
Ошибка выборки значительно возрастает, когда наблюдений меньше ста. Для исследований в которых используется 30-100 объектов применяется особая статистическая методология: критерии, основанные на распределении Стьюдента или бутстрэп-анализ. И наконец, статистика совсем слаба, когда наблюдений меньше 30.

График зависимости ошибки выборки от ее объема при оценке доли признака в г.с.
Чем больше неопределенность, тем больше ошибка. Максимальная неопределенность при оценке доли — 50% (например, 50% респондентов считают концепцию хорошей, а другие 50% плохой). Если 90% опрошенных концепция понравится — это, наоборот, пример согласованности. В таких случаях оценить долю признака по выборке проще.
Для экспонирования и выделения цветом значений статистических выбросов от медианы можно использовать несколько простых формул и условное форматирование.
Первым шагом в поиске значений выбросов статистики является определение статистического центра диапазона данных. С этой целью необходимо сначала определить границы первого и третьего квартала. Определение границ квартала – значит разделение данных на 4 равные группы, которые содержат по 25% данных каждая. Группа, содержащая 25% наибольших значений, называется первым квартилем.
Границы квартилей в Excel можно легко определить с помощью простой функции КВАРТИЛЬ. Данная функция имеет 2 аргумента: диапазон данных и номер для получения желаемого квартиля.
В примере показанному на рисунке ниже значения в ячейках E1 и E2 содержат показатели первого и третьего квартиля данных в диапазоне ячеек B2:B19:

Вычитая от значения первого квартиля третьего, можно определить набор 50% статистических данных, который называется межквартильным диапазоном. В ячейке E3 определен размер межквартильного диапазона.
В этом месте возникает вопрос, как сильно данное значение может отличаться от среднего значения 50% данных и оставаться все еще в пределах нормы? Статистические аналитики соглашаются с тем, что для определения нижней и верхней границы диапазона данных можно смело использовать коэффициент расширения 1,5 умножив на значение межквартильного диапазона. То есть:
- Нижняя граница диапазона данных равна: значение первого квартиля – межкваритльный диапазон * 1,5.
- Верхняя граница диапазона данных равна: значение третьего квартиля + расширенных диапазон * 1,5.
Как показано на рисунке ячейки E5 и E6 содержат вычисленные значения верхней и нижней границы диапазона данных. Каждое значение, которое больше верхней границы нормы или меньше нижней границы нормы считается значением статистического выброса.
Чтобы выделить цветом для улучшения визуального анализа данных можно создать простое правило для условного форматирования.
Способ 1: применение расширенного автофильтра
Наиболее простым способом произвести отбор является применение расширенного автофильтра. Рассмотрим, как это сделать на конкретном примере.
- Выделяем область на листе, среди данных которой нужно произвести выборку. Во вкладке «Главная» щелкаем по кнопке «Сортировка и фильтр». Она размещается в блоке настроек «Редактирование». В открывшемся после этого списка выполняем щелчок по кнопке «Фильтр».

Есть возможность поступить и по-другому. Для этого после выделения области на листе перемещаемся во вкладку «Данные». Щелкаем по кнопке «Фильтр», которая размещена на ленте в группе «Сортировка и фильтр».
- После этого действия в шапке таблицы появляются пиктограммы для запуска фильтрования в виде перевернутых острием вниз небольших треугольников на правом краю ячеек. Кликаем по данному значку в заглавии того столбца, по которому желаем произвести выборку. В запустившемся меню переходим по пункту «Текстовые фильтры». Далее выбираем позицию «Настраиваемый фильтр…».
- Активируется окно пользовательской фильтрации. В нем можно задать ограничение, по которому будет производиться отбор. В выпадающем списке для столбца содержащего ячейки числового формата, который мы используем для примера, можно выбрать одно из пяти видов условий:
- равно;
- не равно;
- больше;
- больше или равно;
- меньше.
Давайте в качестве примера зададим условие так, чтобы отобрать только значения, по которым сумма выручки превышает 10000 рублей. Устанавливаем переключатель в позицию «Больше». В правое поле вписываем значение «10000». Чтобы произвести выполнение действия, щелкаем по кнопке «OK».
- Как видим, после фильтрации остались только строчки, в которых сумма выручки превышает 10000 рублей.
- Но в этом же столбце мы можем добавить и второе условие. Для этого опять возвращаемся в окно пользовательской фильтрации. Как видим, в его нижней части есть ещё один переключатель условия и соответствующее ему поле для ввода. Давайте установим теперь верхнюю границу отбора в 15000 рублей. Для этого выставляем переключатель в позицию «Меньше», а в поле справа вписываем значение «15000».
Кроме того, существует ещё переключатель условий. У него два положения «И» и «ИЛИ». По умолчанию он установлен в первом положении. Это означает, что в выборке останутся только строчки, которые удовлетворяют обоим ограничениям. Если он будет выставлен в положение «ИЛИ», то тогда останутся значения, которые подходят под любое из двух условий. В нашем случае нужно выставить переключатель в положение «И», то есть, оставить данную настройку по умолчанию. После того, как все значения введены, щелкаем по кнопке «OK».
- Теперь в таблице остались только строчки, в которых сумма выручки не меньше 10000 рублей, но не превышает 15000 рублей.
- Аналогично можно настраивать фильтры и в других столбцах. При этом имеется возможность сохранять также фильтрацию и по предыдущим условиям, которые были заданы в колонках. Итак, посмотрим, как производится отбор с помощью фильтра для ячеек в формате даты. Кликаем по значку фильтрации в соответствующем столбце. Последовательно кликаем по пунктам списка «Фильтр по дате» и «Настраиваемый фильтр».
- Снова запускается окно пользовательского автофильтра. Выполним отбор результатов в таблице с 4 по 6 мая 2016 года включительно. В переключателе выбора условий, как видим, ещё больше вариантов, чем для числового формата. Выбираем позицию «После или равно». В поле справа устанавливаем значение «04.05.2016». В нижнем блоке устанавливаем переключатель в позицию «До или равно». В правом поле вписываем значение «06.05.2016». Переключатель совместимости условий оставляем в положении по умолчанию – «И». Для того, чтобы применить фильтрацию в действии, жмем на кнопку «OK».
- Как видим, наш список ещё больше сократился. Теперь в нем оставлены только строчки, в которых сумма выручки варьируется от 10000 до 15000 рублей за период с 04.05 по 06.05.2016 включительно.
- Мы можем сбросить фильтрацию в одном из столбцов. Сделаем это для значений выручки. Кликаем по значку автофильтра в соответствующем столбце. В выпадающем списке щелкаем по пункту «Удалить фильтр».
- Как видим, после этих действий, выборка по сумме выручки будет отключена, а останется только отбор по датам (с 04.05.2016 по 06.05.2016).
- В данной таблице имеется ещё одна колонка – «Наименование». В ней содержатся данные в текстовом формате. Посмотрим, как сформировать выборку с помощью фильтрации по этим значениям.
Кликаем по значку фильтра в наименовании столбца. Последовательно переходим по наименованиям списка «Текстовые фильтры» и «Настраиваемый фильтр…».
- Опять открывается окно пользовательского автофильтра. Давайте сделаем выборку по наименованиям «Картофель» и «Мясо». В первом блоке переключатель условий устанавливаем в позицию «Равно». В поле справа от него вписываем слово «Картофель». Переключатель нижнего блока так же ставим в позицию «Равно». В поле напротив него делаем запись – «Мясо». И вот далее мы выполняем то, чего ранее не делали: устанавливаем переключатель совместимости условий в позицию «ИЛИ». Теперь строчка, содержащая любое из указанных условий, будет выводиться на экран. Щелкаем по кнопке «OK».
- Как видим, в новой выборке существуют ограничения по дате (с 04.05.2016 по 06.05.2016) и по наименованию (картофель и мясо). По сумме выручки ограничений нет.
- Полностью удалить фильтр можно теми же способами, которые использовались для его установки. Причем неважно, какой именно способ применялся. Для сброса фильтрации, находясь во вкладке «Данные» щелкаем по кнопке «Фильтр», которая размещена в группе «Сортировка и фильтр».

Второй вариант предполагает переход во вкладку «Главная». Там выполняем щелчок на ленте по кнопке «Сортировка и фильтр» в блоке «Редактирование». В активировавшемся списке нажимаем на кнопку «Фильтр».

















При использовании любого из двух вышеуказанных методов фильтрация будет удалена, а результаты выборки – очищены. То есть, в таблице будет показан весь массив данных, которыми она располагает.

Способ 2: применение формулы массива
Сделать отбор можно также применив сложную формулу массива. В отличие от предыдущего варианта, данный метод предусматривает вывод результата в отдельную таблицу.
- На том же листе создаем пустую таблицу с такими же наименованиями столбцов в шапке, что и у исходника.
- Выделяем все пустые ячейки первой колонки новой таблицы. Устанавливаем курсор в строку формул. Как раз сюда будет заноситься формула, производящая выборку по указанным критериям. Отберем строчки, сумма выручки в которых превышает 15000 рублей. В нашем конкретном примере, вводимая формула будет выглядеть следующим образом:
=ИНДЕКС(A2:A29;НАИМЕНЬШИЙ(ЕСЛИ(15000<=C2:C29;СТРОКА(C2:C29);"");СТРОКА()-СТРОКА($C$1))-СТРОКА($C$1))Естественно, в каждом конкретном случае адрес ячеек и диапазонов будет свой. На данном примере можно сопоставить формулу с координатами на иллюстрации и приспособить её для своих нужд.
- Так как это формула массива, то для того, чтобы применить её в действии, нужно нажимать не кнопку Enter, а сочетание клавиш Ctrl+Shift+Enter. Делаем это.
- Выделив второй столбец с датами и установив курсор в строку формул, вводим следующее выражение:
=ИНДЕКС(B2:B29;НАИМЕНЬШИЙ(ЕСЛИ(15000<=C2:C29;СТРОКА(C2:C29);"");СТРОКА()-СТРОКА($C$1))-СТРОКА($C$1))Жмем сочетание клавиш Ctrl+Shift+Enter.
- Аналогичным образом в столбец с выручкой вписываем формулу следующего содержания:
=ИНДЕКС(C2:C29;НАИМЕНЬШИЙ(ЕСЛИ(15000<=C2:C29;СТРОКА(C2:C29);"");СТРОКА()-СТРОКА($C$1))-СТРОКА($C$1))Опять набираем сочетание клавиш Ctrl+Shift+Enter.
Во всех трех случаях меняется только первое значение координат, а в остальном формулы полностью идентичны.
- Как видим, таблица заполнена данными, но внешний вид её не совсем привлекателен, к тому же, значения даты заполнены в ней некорректно. Нужно исправить эти недостатки. Некорректность даты связана с тем, что формат ячеек соответствующего столбца общий, а нам нужно установить формат даты. Выделяем весь столбец, включая ячейки с ошибками, и кликаем по выделению правой кнопкой мыши. В появившемся списке переходим по пункту «Формат ячейки…».
- В открывшемся окне форматирования открываем вкладку «Число». В блоке «Числовые форматы» выделяем значение «Дата». В правой части окна можно выбрать желаемый тип отображения даты. После того, как настройки выставлены, жмем на кнопку «OK».
- Теперь дата отображается корректно. Но, как видим, вся нижняя часть таблицы заполнена ячейками, которые содержат ошибочное значение «#ЧИСЛО!». По сути, это те ячейки, данных из выборки для которых не хватило. Более привлекательно было бы, если бы они отображались вообще пустыми. Для этих целей воспользуемся условным форматированием. Выделяем все ячейки таблицы, кроме шапки. Находясь во вкладке «Главная» кликаем по кнопке «Условное форматирование», которая находится в блоке инструментов «Стили». В появившемся списке выбираем пункт «Создать правило…».
- В открывшемся окне выбираем тип правила «Форматировать только ячейки, которые содержат». В первом поле под надписью «Форматировать только ячейки, для которых выполняется следующее условие» выбираем позицию «Ошибки». Далее жмем по кнопке «Формат…».
- В запустившемся окне форматирования переходим во вкладку «Шрифт» и в соответствующем поле выбираем белый цвет. После этих действий щелкаем по кнопке «OK».
- На кнопку с точно таким же названием жмем после возвращения в окно создания условий.











Теперь у нас имеется готовая выборка по указанному ограничению в отдельной надлежащим образом оформленной таблице.

СРЗНАЧ()
Статистическая функция СРЗНАЧ возвращает среднее арифметическое своих аргументов.

Данная функция может принимать до 255 аргументов и находить среднее сразу в нескольких несмежных диапазонах и ячейках:

Если в рассчитываемом диапазоне встречаются пустые или содержащие текст ячейки, то они игнорируются. В примере ниже среднее ищется по четырем ячейкам, т.е. (4+15+11+22)/4 = 13

Если необходимо вычислить среднее, учитывая все ячейки диапазона, то можно воспользоваться статистической функцией СРЗНАЧА. В следующем примере среднее ищется уже по 6 ячейкам, т.е. (4+15+11+22)/6 = 8,6(6).

Статистическая функция СРЗНАЧ может использовать в качестве своих аргументов математические операторы и различные функции Excel:

СРЗНАЧЕСЛИ()
Если необходимо вернуть среднее арифметическое значений, которые удовлетворяют определенному условию, то можно воспользоваться статистической функцией СРЗНАЧЕСЛИ. Следующая формула вычисляет среднее чисел, которые больше нуля:

В данном примере для подсчета среднего и проверки условия используется один и тот же диапазон, что не всегда удобно. На этот случай у функции СРЗНАЧЕСЛИ существует третий необязательный аргумент, по которому можно вычислять среднее. Т.е. по первому аргументу проверяем условие, по третьему – находим среднее.
Допустим, в таблице ниже собрана статистика по стоимости лекарств в городе. В одной аптеке лекарство стоит дороже, в другой дешевле. Чтобы посчитать стоимость анальгина в среднем по городу, воспользуемся следующей формулой:

Если требуется соблюсти несколько условий, то всегда можно применить статистическую функцию СРЗНАЧЕСЛИМН, которая позволяет считать среднее арифметическое ячеек, удовлетворяющих двум и более критериям.
МАКС()
Статистическая функция МАКС возвращает наибольшее значение в диапазоне ячеек:

МИН()
Статистическая функция МИН возвращает наименьшее значение в диапазоне ячеек:

Источники
- https://lumpics.ru/descriptive-statistics-in-excel/
- https://statanaliz.info/statistica/opisanie-dannyx/variatsiya-razmakh-srednee-linejnoe-otklonenie/
- https://www.hd01.ru/info/kak-poschitat-razmah-v-excel/
- http://galyautdinov.ru/post/formula-vyborki-prostaya
- https://math.semestr.ru/group/interval-estimation-share.php
- https://tidydata.ru/sample-size
- https://exceltable.com/formuly/raschet-statisticheskih-vybrosov
- https://lumpics.ru/how-to-make-a-sample-in-excel/
- https://office-guru.ru/excel/statisticheskie-funkcii-excel-kotorye-neobhodimo-znat-96.html