
Вычислим среднее значение выборки и математическое ожидание случайной величины в MS EXCEL.
Выборочное среднее
Среднее выборки
или
выборочное среднее
(sample average, mean) представляет собой
среднее
арифметическое
всех значений
выборки
.
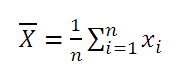
В MS EXCEL для вычисления
среднего выборки
можно использовать функцию
СРЗНАЧ()
. В качестве аргументов функции нужно указать ссылку на диапазон, содержащий значения
выборки
.
Выборочное среднее
является «хорошей» (несмещенной и эффективной) точечной оценкой
математического ожидания
случайной величины (см.
ниже
), т.е.
среднего значения
исходного распределения, из которого взята
выборка
.
Примечание
: О вычислении
доверительных интервалов
при оценке
математического ожидания
можно прочитать, например, в статье
Доверительный интервал для оценки среднего (дисперсия известна) в MS EXCEL
.
Некоторые свойства
среднего арифметического
:
-
Сумма всех отклонений от
среднего значения
равна 0:
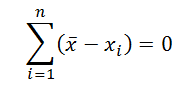
-
Если к каждому из значений x
i
прибавить одну и туже константу
с
, то
среднее арифметическое
увеличится на такую же константу; -
Если каждое из значений x
i
умножить на одну и туже константу
с
, то
среднее арифметическое
умножится на такую же константу.
Математическое ожидание
Среднее значение
можно вычислить не только для выборки, но для случайной величины, если известно ее
распределение
. В этом случае
среднее значение
имеет специальное название —
Математическое ожидание.
Математическое ожидание
характеризует «центральное» или среднее значение случайной величины.
Примечание
: В англоязычной литературе имеется множество терминов для обозначения
математического ожидания
: expectation, mathematical expectation, EV (Expected Value), average, mean value, mean, E[X] или first moment M[X].
Если случайная величина имеет
дискретное распределение
, то
математическое ожидание
вычисляется по формуле:
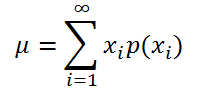
где x
i
– значение, которое может принимать случайная величина, а р(x
i
) – вероятность, что случайная величина примет это значение.
Если случайная величина имеет
непрерывное распределение
, то
математическое ожидание
вычисляется по формуле:
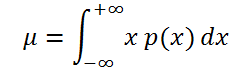
где р(x) –
плотность вероятности
(именно
плотность вероятности
, а не вероятность, как в дискретном случае).
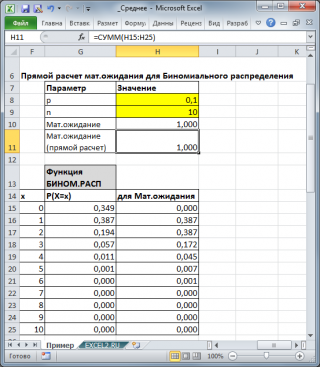
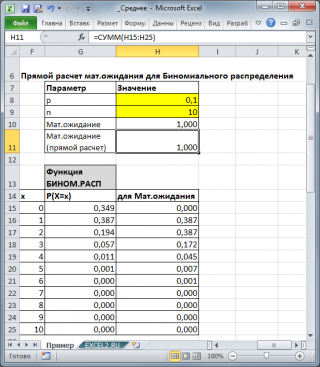
Для каждого распределения, из представленных в MS EXCEL,
Математическое ожидание
можно вычислить аналитически, как функцию от параметров распределения (см. соответствующие
статьи про распределения
). Например, для
Биномиального распределения
среднее значение
равно произведению его параметров: n*p (см.
файл примера
).
Свойства математического ожидания
E[a*X]=a*E[X], где а — const
E[X+a]=E[X]+a
E[a]=a
E[E[X]]=E[X] — т.к. величина E[X] — является const
E[X+Y]=E[X]+E[Y] — работает даже для случайных величин не являющихся независимыми.
СОВЕТ
: Про другие показатели распределения —
Дисперсию
и
Стандартное отклонение,
можно прочитать в статье
Дисперсия и стандартное отклонение в MS EXCEL
.
Среднее выборки или выборочное среднее (sample average, mean) представляет собой среднее арифметическое всех значений выборки .
В MS EXCEL для вычисления среднего выборки можно использовать функцию СРЗНАЧ() . В качестве аргументов функции нужно указать ссылку на диапазон, содержащий значения выборки .
Выборочное среднее является «хорошей» (несмещенной и эффективной) точечной оценкой математического ожидания случайной величины (см. ниже ), т.е. среднего значения исходного распределения, из которого взята выборка .
Примечание : О вычислении доверительных интервалов при оценке математического ожидания можно прочитать, например, в статье Доверительный интервал для оценки среднего (дисперсия известна) в MS EXCEL .
Некоторые свойства среднего арифметического :
- Сумма всех отклонений от среднего значения равна 0:
- Если к каждому из значений x i прибавить одну и туже константу с , то среднее арифметическое увеличится на такую же константу;
- Если каждое из значений x i умножить на одну и туже константу с , то среднее арифметическое умножится на такую же константу.
Математическое ожидание
Среднее значение можно вычислить не только для выборки, но для случайной величины, если известно ее распределение . В этом случае среднее значение имеет специальное название — Математическое ожидание. Математическое ожидание характеризует «центральное» или среднее значение случайной величины.
Примечание : В англоязычной литературе имеется множество терминов для обозначения математического ожидания : expectation, mathematical expectation, EV (Expected Value), average, mean value, mean, E[X] или first moment M[X].
Если случайная величина имеет дискретное распределение , то математическое ожидание вычисляется по формуле:
где x i – значение, которое может принимать случайная величина, а р(x i ) – вероятность, что случайная величина примет это значение.
Если случайная величина имеет непрерывное распределение , то математическое ожидание вычисляется по формуле:
где р(x) – плотность вероятности (именно плотность вероятности , а не вероятность, как в дискретном случае).
Для каждого распределения, из представленных в MS EXCEL, Математическое ожидание можно вычислить аналитически, как функцию от параметров распределения (см. соответствующие статьи про распределения ). Например, для Биномиального распределения среднее значение равно произведению его параметров: n*p (см. файл примера ).
Свойства математического ожидания
E[a*X]=a*E[X], где а — const
E[E[X]]=E[X] — т.к. величина E[X] — является const
E[X+Y]=E[X]+E[Y] — работает даже для случайных величин не являющихся независимыми.
СОВЕТ : Про другие показатели распределения — Дисперсию и Стандартное отклонение, можно прочитать в статье Дисперсия и стандартное отклонение в MS EXCEL .
Среднее арифметическое в Excel
Среднее арифметическое значение — самый известный статистический показатель. В этой заметке рассмотрим его смысл, формулы расчета и свойства.
Средняя арифметическая как оценка математического ожидания
Теория вероятностей занимается изучением случайных величин. Для этого строятся различные характеристики, описывающие их поведение. Одной из основных характеристик случайной величины является математическое ожидание, являющееся своего рода центром, вокруг которого группируются остальные значения.
Формула матожидания имеет следующий вид:
![]()
где M(X) – математическое ожидание
xi – это случайные величины
То есть, математическое ожидание случайной величины — это взвешенная сумма значений случайной величины, где веса равны соответствующим вероятностям.
Математическое ожидание суммы выпавших очков при бросании двух игральных костей равно 7. Это легко подсчитать, зная вероятности. А как рассчитать матожидание, если вероятности не известны? Есть только результат наблюдений. В дело вступает статистика, которая позволяет получить приблизительное значение матожидания по фактическим данным наблюдений.
Математическая статистика предоставляет несколько вариантов оценки математического ожидания. Основное среди них – среднее арифметическое.
Среднее арифметическое значение рассчитывается по формуле, которая известна любому школьнику.
![]()
где xi – значения переменной,
n – количество значений.
Среднее арифметическое – это соотношение суммы значений некоторого показателя с количеством таких значений (наблюдений).
Свойства средней арифметической (математического ожидания)
Теперь рассмотрим свойства средней арифметической, которые часто используются при алгебраических манипуляциях. Правильней будет вновь вернутся к термину математического ожидания, т.к. именно его свойства приводят в учебниках.
Матожидание в русскоязычной литературе обычно обозначают как M(X), в иностранных учебниках можно увидеть E(X). Встречается обозначение греческой буквой μ (читается «мю»). Для удобства предлагаю вариант M(X).
Итак, свойство 1. Если имеются переменные X, Y, Z, то математическое ожидание их суммы равно сумме их математических ожиданий.
M(X+Y+Z) = M(X) + M(Y) + M(Z)
Допустим, среднее время, затрачиваемое на мойку автомобиля M(X) равно 20 минут, а на подкачку колес M(Y) – 5 минут. Тогда общее среднее арифметическое время на мойку и подкачку составит M(X+Y) = M(X) + M(Y) = 20 + 5 = 25 минут.
Свойство 2. Если переменную (т.е. каждое значение переменной) умножить на постоянную величину (a), то математическое ожидание такой величины равно произведению матожидания переменной и этой константы.
К примеру, среднее время мойки одной машины M(X) 20 минут. Тогда среднее время мойки двух машин составит M(aX) = aM(X) = 2*20 = 40 минут.
Свойство 3. Математическое ожидание постоянной величины (а) есть сама эта величина (а).
Если установленная стоимость мойки легкового автомобиля равна 100 рублей, то средняя стоимость мойки нескольких автомобилей также равна 100 рублей.
Свойство 4. Математическое ожидание произведения независимых случайных величин равно произведению их математических ожиданий.
Автомойка за день в среднем обслуживает 50 автомобилей (X). Средний чек – 100 рублей (Y). Тогда средняя выручка автомойки в день M(XY) равна произведению среднего количества M(X) на средний тариф M(Y), т.е. 50*100 = 500 рублей.
Формула среднего значения в Excel
Среднее арифметическое чисел в Excel рассчитывают с помощью функции СРЗНАЧ. Выглядит примерно так.
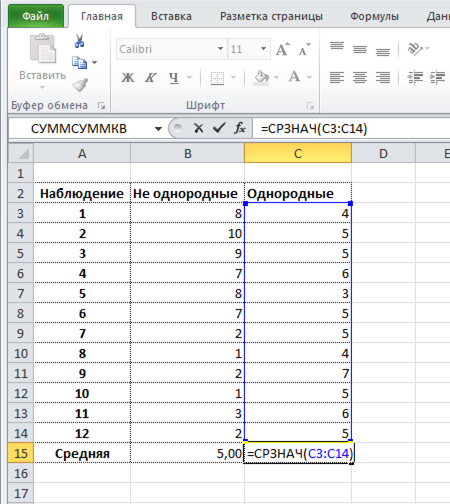
У этой формулы есть замечательное свойство. Если в диапазоне, по которому рассчитывается формула, присутствуют пустые ячейки (не нулевые, а именно пустые), то они исключается из расчета.
Вызвать функцию можно разными способами. Например, воспользоваться командой автосуммы во вкладке Главная:
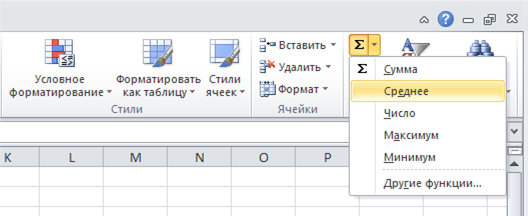
После вызова формулы нужно указать диапазон данных, по которому рассчитывается среднее значение.
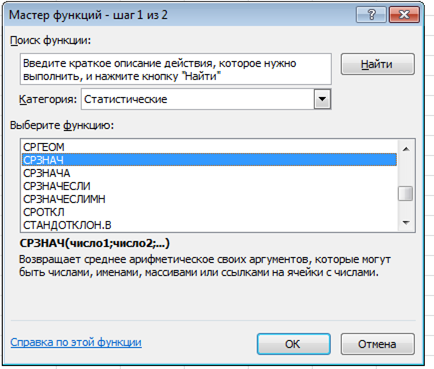
Есть и стандартный способ для всех функций. Нужно нажать на кнопку fx в начале строки формул. Затем либо с помощью поиска, либо просто по списку выбрать функцию СРЗНАЧ (в категории «Статистические»).
Средняя арифметическая взвешенная
Рассмотрим следующую простую задачу. Между пунктами А и Б расстояние S, которые автомобиль проехал со скоростью 50 км/ч. В обратную сторону – со скоростью 100 км/ч.
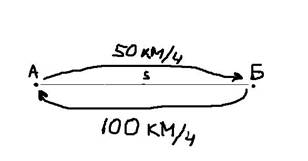
Какова была средняя скорость движения из А в Б и обратно? Большинство людей ответят 75 км/ч (среднее из 50 и 100) и это неправильный ответ. Средняя скорость – это все пройденное расстояние, деленное на все потраченное время. В нашем случае все расстояние – это S + S = 2*S (туда и обратно), все время складывается из времени из А в Б и из Б в А. Зная скорость и расстояние, время найти элементарно. Исходная формула для нахождения средней скорости имеет вид:
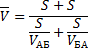
Теперь преобразуем формулу до удобного вида.
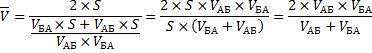
![]()
Правильный ответ: средняя скорость автомобиля составила 66,7 км/ч.
Средняя скорость – это на самом деле среднее расстояние в единицу времени. Поэтому для расчета средней скорости (среднего расстояния в единицу времени) используется средняя арифметическая взвешенная по следующей формуле.
![]()
где x – анализируемый показатель; f – вес.
Аналогичным образом по формуле средневзвешенной средней рассчитывается средняя цена (средняя стоимость на единицу продукции), средний процент и т.д. То есть если средняя считается по другим усредненным значениям, нужно применить среднюю взвешенную, а не простую.
Формула средневзвешенного значение в Excel
Обычная функция среднего значения в Excel СРЗНАЧ, к сожалению, считает только среднюю простую. Готовой формулы для среднего взвешенного значения в Excel нет. Однако расчет несложно сделать подручными средствами.
Самый понятный вариант создать дополнительный столбец. Выглядит примерно так.
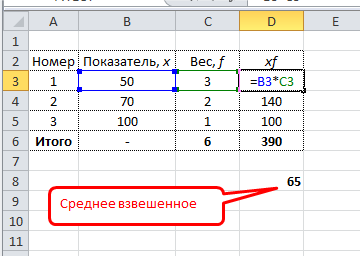
Имеется возможность сократить количество расчетов. Есть функция СУММПРОИЗВ. С ее помощью можно рассчитать числитель одним действием. Разделить на сумму весов можно в этой же ячейке. Вся формула для расчета среднего взвешенного значения в Excel выглядит так:
Интерпретация средней взвешенной такая же, как и у средней простой. Средняя простая – это частный случай взвешенной, когда все веса равны 1.
Физический смысл средней арифметической
Представим, что имеется спица, на которой в разных местах нанизаны грузики различной массы.
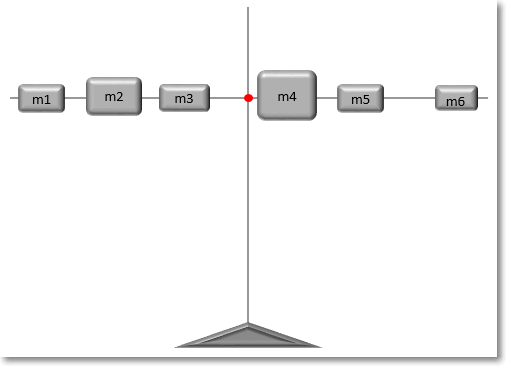
Как отыскать центр тяжести? Центр тяжести – это такая точка, за которую можно ухватиться, и спица при этом останется в горизонтальном положении и не будет переворачиваться под действием силы тяжести. Она должна быть в центре всех масс, чтобы силы слева равнялись силам справа. Для нахождения точки равновесия следует рассчитать среднее арифметическое взвешенное расстояний от начала спицы до каждого грузика. Весами будут являться массы грузиков (mi), что в прямом смысле слова соответствует понятию веса. Таким образом, среднее арифметическое расстояние – это центр равновесия системы, когда силы с одной стороны точки уравновешивают силы с другой стороны.
И последнее. В русском языке так сложилось, что под словом «средний» обычно понимают именно среднее арифметическое. То есть моду и медиану как-то не принято называть средним значением. А вот на английском языке слово «средний» (average) может трактоваться и как среднее арифметическое (mean), и как мода (mode), и как медиана (median). Так что при чтении иностранной литературы следует быть бдительным.
Формула математическое ожидания в MS Excel – расчет по шагам
Среднее выборки или выборочное среднее (sample average, mean) представляет собой среднее арифметическое всех значений выборки.
В MS EXCEL для вычисления среднего выборки можно использовать функцию СРЗНАЧ() . В качестве аргументов функции нужно указать ссылку на диапазон, содержащий значения выборки.
Выборочное среднее является «хорошей» (несмещенной и эффективной) точечной оценкой математического ожидания случайной величины (см. ниже), т.е. среднего значения исходного распределения, из которого взята выборка.
Примечание: О вычислении доверительных интервалов при оценке математического ожидания можно прочитать, например, в статье Доверительный интервал для оценки среднего (дисперсия известна) в MS EXCEL.
Некоторые свойства среднего арифметического:
- Сумма всех отклонений от среднего значения равна 0:
- Если к каждому из значений xi прибавить одну и туже константу с, то среднее арифметическое увеличится на такую же константу;
- Если каждое из значений xi умножить на одну и туже константу с, то среднее арифметическое умножится на такую же константу.
Математическое ожидание
Среднее значение можно вычислить не только для выборки, но для случайной величины, если известно ее распределение. В этом случае среднее значение имеет специальное название – Математическое ожидание. Математическое ожидание характеризует «центральное» или среднее значение случайной величины.
Примечание: В англоязычной литературе имеется множество терминов для обозначения математического ожидания: expectation, mathematical expectation, EV (Expected Value), average, mean value, mean, E[X] или first moment M[X].
Если случайная величина имеет дискретное распределение, то математическое ожидание вычисляется по формуле:
где xi – значение, которое может принимать случайная величина, а р(xi) – вероятность, что случайная величина примет это значение.
Если случайная величина имеет непрерывное распределение, то математическое ожидание вычисляется по формуле:
где р(x) – плотность вероятности (именно плотность вероятности, а не вероятность, как в дискретном случае).
Для каждого распределения, из представленных в MS EXCEL, Математическое ожидание можно вычислить аналитически, как функцию от параметров распределения (см. соответствующие статьи про распределения). Например, для Биномиального распределения среднее значение равно произведению его параметров: n*p (см. файл примера ).
Функция СРОТКЛ в Excel используется для анализа числового ряда, передаваемого в качестве аргумента, и возвращает число, соответствующее среднему значению, рассчитанному для модулей отклонений относительно среднего арифметического для исследуемого ряда.
Примеры методов анализа числовых рядов в Excel
Смысл данной функции становится предельно ясен после рассмотрения примера. Допустим, на протяжении суток каждые 3 часа фиксировались показатели температуры воздуха. Был получен следующий ряд значений: 16, 14, 17, 21, 25, 26, 22, 18. С помощью функции СРЗНАЧ можно определить среднее значение температуры – 19,88 (округлим до 20).
Для определения отклонения каждого значения от среднего необходимо вычесть из него полученное среднее значение. Например, для первого замера температуры это будет равно 16-20=-4. Получаем ряд значений: -4, -6, -3, 1, 5, 6, 2, -2. Поскольку СРОТКЛ по определению работает с модулями отклонений, итоговый ряд значений имеет вид: 4, 6, 3, 1, 5, 6, 2, 2. Теперь нужно получить среднее значение для данного ряда с помощью функции СРЗНАЧ – примерно 3,63. Именно таков алгоритм работы рассматриваемой функции.
Таким образом, значение, вычисляемое функцией СРОТКЛ, можно рассчитать с помощью формулы массива без использования этой функции. Допустим, перечисленные результаты замеров температур записаны в столбец (ячейки A1:A8). Тогда для определения среднего значения отклонений можно использовать формулу =СРЗНАЧ(ABS(A1:A8-СРЗНАЧ(A1:A8))). Однако, рассматриваемая функция значительно упрощает расчеты.
Пример 1. Имеются два ряда значений, представляющих собой результаты наблюдений одного и того же физического явления, сделанные в ходе двух различных экспериментов. Определить, среднее отклонение от среднего значения результатов для какого эксперимента является максимальным?
Вид таблицы данных:
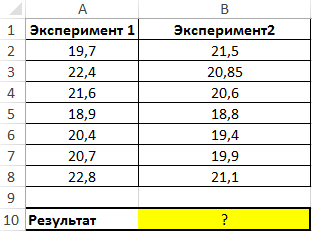
Используем следующую формулу:
Сравниваем результаты, возвращаемые функцией СРОТКЛ для первого и второго ряда чисел с использованием функции ЕСЛИ, возвращаем соответствующий результат.
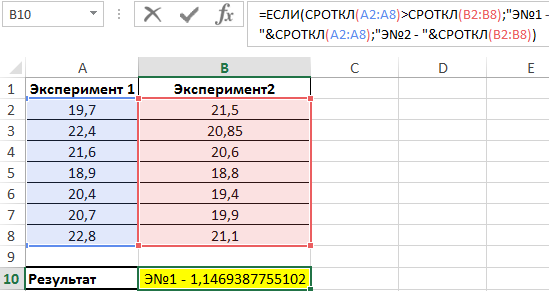
В результате мы получили среднее отклонение от среднего значения. Это весьма интересная функция для технического анализа финансовых рынков, прогнозов курсов валют и даже позволяет повысить шансы выигрышей в лотереях.
Формула расчета линейного коэффициента вариации в Excel
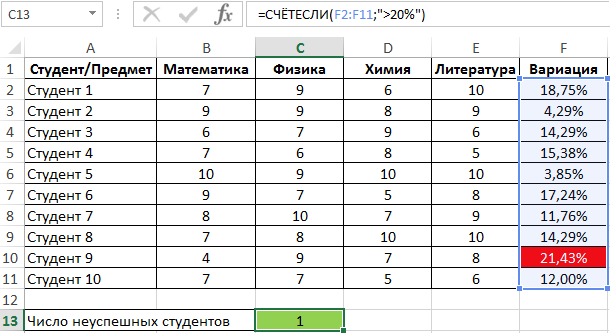
Пример 2. Студенты сдали экзамены по различным предметам. Определить число студентов, которые удовлетворяют следующему критерию успеваемости – линейный коэффициент вариации оценок не превышает 15%.
Вид таблицы данных:
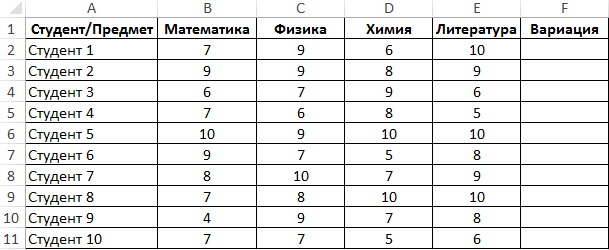
Линейный коэффициент вариации определяется как отношение среднего отклонения к среднему значению. Для расчета используем следующую формулу:
Растянем ее вниз по столбцу и получим следующие значения:
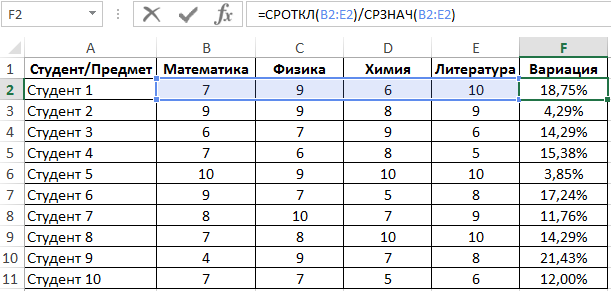
Для определения числа неуспешных студентов по указанному критерию используем функцию:
Правила использования функции СРОТКЛ в Excel
Функция имеет следующий синтаксис:
=СРОТКЛ( число1 ;[число2];. )
- число1 – обязательный, принимает числовое значение, характеризующее первый член ряда значений, для которых необходимо определить среднее отклонение от среднего;
- [число2];… – необязательный, принимает второе и последующие значения из исследуемого числового ряда.
- При использовании функции СРОТКЛ удобнее задавать первый аргумент в виде ссылки на диапазон ячеек, например =СРОТКЛ(A1:A8) вместо перечисления (=СРОТКЛ(A1;A2:A3…;A8)).
- В качестве аргумента функции может быть передана константа массива, например =СРОТКЛ(<2;5;4;7;10>).
- Для получения достоверного результата необходимо привести все значения ряда к единой системе измерения величин. Например, если часть длин указана в мм, а остальные – в см, результат расчетов будет некорректен. Необходимо преобразовать все значения в мм или см соответственно.
- Если в качестве аргументов функции переданы нечисловые данные, которые не могут быть преобразованы к числам, функция вернет код ошибки #ЧИСЛО!. Если хотя бы одно значение из ряда является числовым, функция выполнит расчет, не возвращая код ошибки.
- Не преобразуемые к числам текстовые строки и пустые ячейки не учитываются в расчете. Если ячейка содержит значение 0 (нуль), оно будет учтено.
- Логические данные автоматически преобразуются к числовым: ИСТИНА – 1, ЛОЖЬ – 0 соответственно.
1. Вычислить математическое ожидание:
1) Пуск > Все программы > Microsoft Office > Microsoft Excel
2) Так как функция математического ожидания – это т оже самое, что и функция среднего арифметического, то: в пустой ячейке вводим «=», далее нажимаем fx, выбираем функцию СРЗНАЧ, выделяем числовые данные нашей исходной таблицы.
2. Вычислить дисперсию:
Вводим =, далее – fx, “Статистические” – “ДИСП”, выделить числовые данные нашей исходной таблицы.
3. Среднее квадратичесое отклонение (не смещённое):
Вводим =, далее – fx, “Статистические” – “СТАНДТОТКЛОН”, выделить числовые данные нашей исходной таблицы.
4. Среднее квадратическое отклонение (смещённое):
Вводим =, далее – fx, “Статистические” – “СТАНДТОТКЛОН”, выделить числовые данные нашей исходной таблицы.
Вывод: Microsoft Excel является одной из самых удобных компьютерных программ, с помощью которых можно высчитать статические данные. В этом я убедился, когда высчитывал вышеуказанные данные.
На чтение 6 мин Просмотров 8к.
Содержание
- Выборочное среднее
- Математическое ожидание
- Примеры методов анализа числовых рядов в Excel
- Формула расчета линейного коэффициента вариации в Excel
Вычислим среднее значение выборки и математическое ожидание случайной величины в MS EXCEL.
Выборочное среднее
Среднее выборки или выборочное среднее (sample average, mean) представляет собой среднее арифметическое всех значений выборки.
В MS EXCEL для вычисления среднего выборки можно использовать функцию СРЗНАЧ() . В качестве аргументов функции нужно указать ссылку на диапазон, содержащий значения выборки.
Выборочное среднее является «хорошей» (несмещенной и эффективной) точечной оценкой математического ожидания случайной величины (см. ниже), т.е. среднего значения исходного распределения, из которого взята выборка.
Примечание: О вычислении доверительных интервалов при оценке математического ожидания можно прочитать, например, в статье Доверительный интервал для оценки среднего (дисперсия известна) в MS EXCEL.
Некоторые свойства среднего арифметического:
- Сумма всех отклонений от среднего значения равна 0:
- Если к каждому из значений xi прибавить одну и туже константу с, то среднее арифметическое увеличится на такую же константу;
- Если каждое из значений xi умножить на одну и туже константу с, то среднее арифметическое умножится на такую же константу.
Математическое ожидание
Среднее значение можно вычислить не только для выборки, но для случайной величины, если известно ее распределение. В этом случае среднее значение имеет специальное название – Математическое ожидание. Математическое ожидание характеризует «центральное» или среднее значение случайной величины.
Примечание: В англоязычной литературе имеется множество терминов для обозначения математического ожидания: expectation, mathematical expectation, EV (Expected Value), average, mean value, mean, E[X] или first moment M[X].
Если случайная величина имеет дискретное распределение, то математическое ожидание вычисляется по формуле:
где xi – значение, которое может принимать случайная величина, а р(xi) – вероятность, что случайная величина примет это значение.
Если случайная величина имеет непрерывное распределение, то математическое ожидание вычисляется по формуле:
где р(x) – плотность вероятности (именно плотность вероятности, а не вероятность, как в дискретном случае).
Для каждого распределения, из представленных в MS EXCEL, Математическое ожидание можно вычислить аналитически, как функцию от параметров распределения (см. соответствующие статьи про распределения). Например, для Биномиального распределения среднее значение равно произведению его параметров: n*p (см. файл примера ).
Функция СРОТКЛ в Excel используется для анализа числового ряда, передаваемого в качестве аргумента, и возвращает число, соответствующее среднему значению, рассчитанному для модулей отклонений относительно среднего арифметического для исследуемого ряда.
Смысл данной функции становится предельно ясен после рассмотрения примера. Допустим, на протяжении суток каждые 3 часа фиксировались показатели температуры воздуха. Был получен следующий ряд значений: 16, 14, 17, 21, 25, 26, 22, 18. С помощью функции СРЗНАЧ можно определить среднее значение температуры – 19,88 (округлим до 20).
Для определения отклонения каждого значения от среднего необходимо вычесть из него полученное среднее значение. Например, для первого замера температуры это будет равно 16-20=-4. Получаем ряд значений: -4, -6, -3, 1, 5, 6, 2, -2. Поскольку СРОТКЛ по определению работает с модулями отклонений, итоговый ряд значений имеет вид: 4, 6, 3, 1, 5, 6, 2, 2. Теперь нужно получить среднее значение для данного ряда с помощью функции СРЗНАЧ – примерно 3,63. Именно таков алгоритм работы рассматриваемой функции.
Таким образом, значение, вычисляемое функцией СРОТКЛ, можно рассчитать с помощью формулы массива без использования этой функции. Допустим, перечисленные результаты замеров температур записаны в столбец (ячейки A1:A8). Тогда для определения среднего значения отклонений можно использовать формулу =СРЗНАЧ(ABS(A1:A8-СРЗНАЧ(A1:A8))). Однако, рассматриваемая функция значительно упрощает расчеты.
Пример 1. Имеются два ряда значений, представляющих собой результаты наблюдений одного и того же физического явления, сделанные в ходе двух различных экспериментов. Определить, среднее отклонение от среднего значения результатов для какого эксперимента является максимальным?
Вид таблицы данных:
Используем следующую формулу:
Сравниваем результаты, возвращаемые функцией СРОТКЛ для первого и второго ряда чисел с использованием функции ЕСЛИ, возвращаем соответствующий результат.
В результате мы получили среднее отклонение от среднего значения. Это весьма интересная функция для технического анализа финансовых рынков, прогнозов курсов валют и даже позволяет повысить шансы выигрышей в лотереях.
Формула расчета линейного коэффициента вариации в Excel
Пример 2. Студенты сдали экзамены по различным предметам. Определить число студентов, которые удовлетворяют следующему критерию успеваемости – линейный коэффициент вариации оценок не превышает 15%.
Вид таблицы данных:
Линейный коэффициент вариации определяется как отношение среднего отклонения к среднему значению. Для расчета используем следующую формулу:
Растянем ее вниз по столбцу и получим следующие значения:
Для определения числа неуспешных студентов по указанному критерию используем функцию:
Правила использования функции СРОТКЛ в Excel
Функция имеет следующий синтаксис:
=СРОТКЛ( число1 ;[число2];. )
- число1 – обязательный, принимает числовое значение, характеризующее первый член ряда значений, для которых необходимо определить среднее отклонение от среднего;
- [число2];… – необязательный, принимает второе и последующие значения из исследуемого числового ряда.
- При использовании функции СРОТКЛ удобнее задавать первый аргумент в виде ссылки на диапазон ячеек, например =СРОТКЛ(A1:A8) вместо перечисления (=СРОТКЛ(A1;A2:A3…;A8)).
- В качестве аргумента функции может быть передана константа массива, например =СРОТКЛ(<2;5;4;7;10>).
- Для получения достоверного результата необходимо привести все значения ряда к единой системе измерения величин. Например, если часть длин указана в мм, а остальные – в см, результат расчетов будет некорректен. Необходимо преобразовать все значения в мм или см соответственно.
- Если в качестве аргументов функции переданы нечисловые данные, которые не могут быть преобразованы к числам, функция вернет код ошибки #ЧИСЛО!. Если хотя бы одно значение из ряда является числовым, функция выполнит расчет, не возвращая код ошибки.
- Не преобразуемые к числам текстовые строки и пустые ячейки не учитываются в расчете. Если ячейка содержит значение 0 (нуль), оно будет учтено.
- Логические данные автоматически преобразуются к числовым: ИСТИНА – 1, ЛОЖЬ – 0 соответственно.
1. Вычислить математическое ожидание:
1) Пуск > Все программы > Microsoft Office > Microsoft Excel
2) Так как функция математического ожидания это т оже самое, что и функция среднего арифметического, то: в пустой ячейке вводим «=», далее нажимаем fx, выбираем функцию СРЗНАЧ, выделяем числовые данные нашей исходной таблицы.
2. Вычислить дисперсию:
Вводим =, далее – fx, “Статистические” – “ДИСП”, выделить числовые данные нашей исходной таблицы.
3. Среднее квадратичесое отклонение (не смещённое):
Вводим =, далее – fx, “Статистические” – “СТАНДТОТКЛОН”, выделить числовые данные нашей исходной таблицы.
4. Среднее квадратическое отклонение (смещённое):
Вводим =, далее – fx, “Статистические” – “СТАНДТОТКЛОН”, выделить числовые данные нашей исходной таблицы.
Вывод: Microsoft Excel является одной из самых удобных компьютерных программ, с помощью которых можно высчитать статические данные. В этом я убедился, когда высчитывал вышеуказанные данные.

1 .
.
Выборочная оценка математического
ожидания – выборочное среднее![]()
в Excel
вычисляется с помощью
функция СРЗНАЧ,
при этом
реализуется формула
 .
.
2 .
.
Оценка дисперсии – несмещенная
(исправленная) выборочная дисперсия![]() может быть получена с помощью функцииДИСП.
может быть получена с помощью функцииДИСП.
В Excel
реализована формула
 .
.
3.
Несмещенное выборочное средние
квадратические отклонения (стандартное
отклонение)
![]() вычисляется
вычисляется
с помощью функции
СТАНДОТКЛОН.
Вычисления
в Excel
выполнены по формуле
 .
.
4 .
.
Выборочная (смещенная) оценка дисперсии

вычисляется с помощью
функция ДИСПР.
Результат
вычисления выборочных оценок
![]() ,
,
![]() ,
,
![]() и
и![]()
показан на рис.1.

… … … …
… … …

Рис.
1. Фрагмент листа Excel
с исходными данными и выборочными
оценками параметров.
2. Описательная статистика.
Выполните
процедуру Описательная
статистика.
В
главном меню Excel
выбрать: Данные
→ Анализ данных → Описательная статистика
→ ОК.
В
появившемся окне Описательная
статистика
ввести:
Входной
интервал –
100 случайных чисел в ячейках $A$3:
$A$102;
Группирование
— по столбцам;
Выходной
интервал –
адрес ячейки, с которой начинается
таблица Описательная
статистика – например,
$D$8;
Итоговая
статистика
– поставить галочку. ОК.
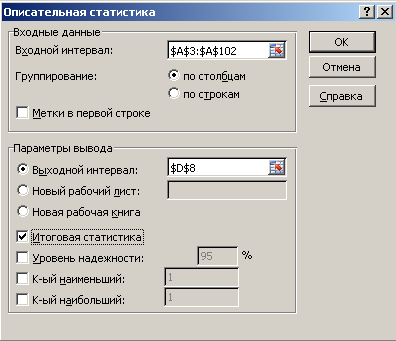
Рис.
2. Диалоговое окно Описательная
статистика
с заполненными полями ввода.
На
листе Excel
появится таблица – Столбец
1. В
таблице даются все необходимые параметры,
кроме моды Mo(X).

Рис.
3. Таблица Описательная
статистика
Таблица содержит
описательные статистики, в частности:
Среднее
– оценка математического ожидания
![]() ;
;
Стандартное
отклонение
– оценка среднего квадратического
отклонения![]() ;
;
Дисперсия
– выборочная исправленная дисперсия
![]() ;
;
Эксцесс
и Асимметричность
– оценки эксцесса и асимметрии;
Медиана
– оценка
медианы;
Мода
– оценка
моды, #Н/Д – нет данных (наиболее часто
встречающееся значение случайной
величины в выборке).
Приблизительное
равенство нулю оценок эксцесса и
асимметрии, и приблизительное равенство
оценки среднего оценке медианы дает
предварительное основание выбрать в
качестве основной гипотезы H0
распределения элементов генеральной
совокупности — нормальный закон.
Интервал
– размах выборки;
Минимум
– минимальное значение случайной
величины в выборке ![]() ;
;
Максимум
– максимальное значение случайной
величины в выборке ![]() .
.
Результаты
процедуры Описательная
статистика
потребуются в дальнейшем при построении
теоретического закона распределения.
3. Построение гистограммы
В
главном меню Excel
выбрать Данные
→ Анализ данных → Гистограмма → ОК.
Далее
необходимо заполнить поля ввода в
диалоговом окне Гистограмма.
Входной
интервал:
100 случайных чисел в ячейках $A$3:
$A$102;
Интервал
карманов:
не
заполнять;
Выходной
интервал:
адрес ячейки, с которой начинается вывод
результатов процедуры Гистограмма;
Вывод
графика –
поставьте галочку.
Если
поле ввода Интервал
карманов не
заполняется, то процедура вычисляет
число интервалов группировки k
и границы интервалов автоматически по
формуле.
![]() ,
,
где,
скобки
![]() означают – округление до целой части
означают – округление до целой части
числа в меньшую сторону.
В
рассматриваемом варианте n
= 100,
следовательно, k
= 11.
Действительно:

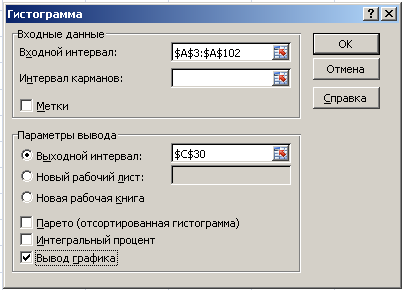
Рис.
4. Диалоговое окно Гистограмма.
В
результате выполнения процедуры
Гистограмма
появляется таблица, содержащая границы
xi
интервалов
группировки (столбец – Карман)
и частоту попадания случайных величин
выборки mi
в i–ый
интервал (столбец
–
Частота).
Справа от таблицы
– график гистограммы.
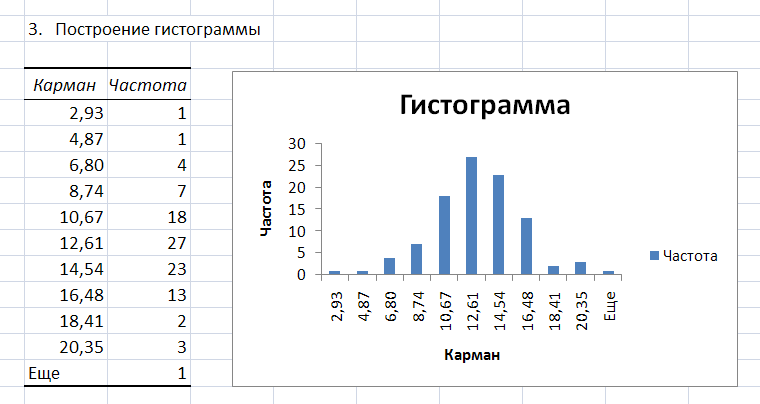
Рис.
5. Фрагмент листа Excel
с результатами процедуры Гистограмма.
По
виду гистограммы можно предположить
(принять гипотезу) о том, что выборка
случайных чисел подчиняется нормальному
закону распределения.
Далее,
для того чтобы убедиться в правильности
выбранной гипотезы (по крайней мере
визуально) надо, первое – построить
график гипотетического нормального
закона распределения, выбрав в качестве
параметров (математического ожидания
и среднего квадратического отклонении)
их оценки (среднее и стандартное
отклонение), и совместить график
гипотетического распределения с графиком
гистограммы.
И,
второе – используя критерий согласия
Пирсона установить справедливость
выбранной гипотезы.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Не все явления измеряются в количественной шкале типа 1, 2, 3 … 100500 … Не всегда явление может принимать бесконечное или большое количество различных состояний. Например, пол у человека может быть либо М, либо Ж. Стрелок либо попадает в цель, либо не попадает. Голосовать можно либо «За», либо «Против» и т.д. и т.п. Другими словами, такие данные отражают состояние альтернативного признака – либо «да» (событие наступило), либо «нет» (событие не наступило). Наступившее событие (положительный исход) еще называют «успехом».
Эксперименты с такими данными называются схемой Бернулли, в честь известного швейцарского математика, который установил, что при большом количестве испытаний соотношение положительных исходов и общего количества испытаний стремится к вероятности наступления этого события.
Переменная альтернативного признака
Для того, чтобы в анализе задействовать математический аппарат, результаты подобных наблюдений следует записать в числовом виде. Для этого положительному исходу присваивают число 1, отрицательному – 0. Другими словами, мы имеем дело с переменной, которая может принимать только два значения: 0 или 1.
Какую пользу отсюда можно извлечь? Вообще-то не меньшую, чем от обычных данных. Так, легко подсчитать количество положительных исходов – достаточно просуммировать все значения, т.е. все 1 (успехи). Можно пойти далее, но для этого потребуется ввести парочку обозначений.
Первым делом нужно отметить, что положительные исходы (которые равны 1) имеют некоторую вероятность появления. Например, выпадение орла при подбрасывании монеты равно ½ или 0,5. Такая вероятность традиционно обозначается латинской буквой p. Следовательно, вероятность наступления альтернативного события равна 1 — p, которую еще обозначают через q, то есть q = 1 – p. Указанные обозначения можно наглядно систематизировать в виде таблички распределения переменной X.

Мы получили перечень возможных значений и их вероятности. Можно рассчитать математическое ожидание и дисперсию. Матожидание – это сумма произведений всех возможных значений на соответствующие им вероятности:
![]()
Вычислим матожидание, используя обозначения в таблицы выше.
![]()
Получается, что математическое ожидание альтернативного признака равно вероятности этого события – p.
Теперь определим, что такое дисперсия альтернативного признака. Дисперсия – есть средний квадрат отклонений от математического ожидания. Общая формула (для дискретных данных) имеет вид:
![]()
Отсюда дисперсия альтернативного признака:

Нетрудно заметить, что эта дисперсия имеет максимум 0,25 (при p=0,5).
Стандартное отклонение – корень из дисперсии:
![]()
Максимальное значение не превышает 0,5.
Как видно, и математическое ожидание, и дисперсия альтернативного признака имеют очень компактный вид.
Биномиальное распределение случайной величины
Рассмотрим ситуацию под другим углом. Действительно, кому интересно, что среднее выпадение орлов при одном бросании равно 0,5? Это даже невозможно представить. Интересней поставить вопрос о числе выпадения орлов при заданном количестве бросков.
Другими словами, исследователя часто интересует вероятность наступления некоторого числа успешных событий. Это может быть количество бракованных изделий в проверяемой партии (1- бракованная, 0 — годная) или количество выздоровлений (1 – здоров, 0 – больной) и т.д. Количество таких «успехов» будет равно сумме всех значений переменной X, т.е. количеству единичных исходов.
![]()
Случайная величина B называется биномиальной и принимает значения от 0 до n (при B = 0 – все детали годные, при B = n – все детали бракованные). Предполагается, что все значения x независимы между собой. Рассмотрим основные характеристики биномиальной переменной, то есть установим ее математическое ожидание, дисперсию и распределение.
Матожидание биномиальной переменной получить очень легко. Математическое ожидание суммы величин есть сумма математических ожиданий каждой складываемой величины, а оно у всех одинаковое, поэтому:
![]()
Например, математическое ожидание количества выпавших орлов при 100 подбрасываниях равно 100 × 0,5 = 50.
Теперь выведем формулу дисперсии биномиальной переменной. Дисперсия суммы независимых случайных величин есть сумма дисперсий. Отсюда
![]()
Стандартное отклонение, соответственно
![]()
Для 100 подбрасываний монеты стандартное отклонение количества орлов равно
![]()
И, наконец, рассмотрим распределение биномиальной величины, т.е. вероятности того, что случайная величина B будет принимать различные значения k, где 0≤ k ≤n. Для монеты эта задача может звучать так: какова вероятность выпадения 40 орлов при 100 бросках?
Чтобы понять метод расчета, представим, что монета подбрасывается всего 4 раза. Каждый раз может выпасть любая из сторон. Мы задаемся вопросом: какова вероятность выпадения 2 орлов из 4 бросков. Каждый бросок независим друг от друга. Значит, вероятность выпадения какой-либо комбинации будет равна произведению вероятностей заданного исхода для каждого отдельного броска. Пусть О – это орел, Р – решка. Тогда, к примеру, одна из устраивающих нас комбинаций может выглядеть как ООРР, то есть:

Вероятность такой комбинации равняется произведению двух вероятностей выпадения орла и еще двух вероятностей не выпадения орла (обратное событие, рассчитываемое как 1 — p), т.е. 0,5×0,5×(1-0,5)×(1-0,5)=0,0625. Такова вероятность одной из устраивающих нас комбинации. Но вопрос ведь стоял об общем количестве орлов, а не о каком-то определенном порядке. Тогда нужно сложить вероятности всех комбинаций, в которых присутствует ровно 2 орла. Ясно, все они одинаковы (от перемены мест множителей произведение не меняется). Поэтому нужно вычислить их количество, а затем умножить на вероятность любой такой комбинации. Подсчитаем все варианты сочетаний из 4 бросков по 2 орла: РРОО, РОРО, РООР, ОРРО, ОРОР, ООРР. Всего 6 вариантов.

Следовательно, искомая вероятность выпадения 2 орлов после 4 бросков равна 6×0,0625=0,375.
Однако подсчет подобным образом утомителен. Уже для 10 монет методом перебора получить общее количество вариантов будет очень трудно. Поэтому умные люди давно изобрели формулу, с помощью которой рассчитывают количество различных сочетаний из n элементов по k, где n – общее количество элементов, k – количество элементов, варианты расположения которых и подсчитываются. Формула сочетания из n элементов по k такова:
![]()
Подобные вещи проходят в разделе комбинаторики. Всех желающих подтянуть знания отправляю туда. Отсюда, кстати, и название биномиального распределения (формула выше является коэффициентом в разложении бинома Ньютона).
Формулу для определения вероятности легко обобщить на любое количество n и k. В итоге формула биномиального распределения имеет следующий вид.
![]()
Количество подходящих под условие комбинаций умножить на вероятность одной из них.
Для практического использования достаточно просто знать формулу биномиального распределения. А можно даже и не знать – ниже показано, как определить вероятность с помощью Excel. Но лучше все-таки знать.
Рассчитаем по этой формуле вероятность выпадения 40 орлов при 100 бросках:
![]()
Или всего 1,08%. Для сравнения вероятность наступления математического ожидания этого эксперимента, то есть 50 орлов, равна 7,96%. Максимальная вероятность биномиальной величины принадлежит значению, соответствующему математическому ожиданию.
Расчет вероятностей биномиального распределения в Excel
Если использовать только бумагу и калькулятор, то расчеты по формуле биномиального распределения, несмотря на отсутствие интегралов, даются довольно тяжело. К примеру значение 100! – имеет более 150 знаков. Раньше, да и сейчас тоже, для вычисления подобных величин использовали приближенные формулы. В настоящий момент целесообразно использовать специальное ПО, типа MS Excel. Таким образом, любой пользователь (даже гуманитарий по образованию) вполне может вычислить вероятность значения биномиально распределенной случайной величины.
Для закрепления материала задействуем Excel пока в качестве обычного калькулятора, т.е. произведем поэтапное вычисление по формуле биномиального распределения. Рассчитаем, например, вероятность выпадения 50 орлов. Ниже приведена картинка с этапами вычислений и конечным результатом.

Как видно, промежуточные результаты имеют такой масштаб, что не помещаются в ячейку, хотя везде и используются простые функции типа: ФАКТР (вычисление факториала), СТЕПЕНЬ (возведение числа в степень), а также операторы умножения и деления. Более того, этот расчет довольно громоздок, во всяком случаен не является компактным, т.к. задействовано много ячеек. Да и разобраться с ходу трудновато.
В общем в Excel предусмотрена готовая функция для вычисления вероятностей биномиального распределения. Функция называется БИНОМ.РАСП.

Синтаксис функции состоит из 4 аргументов:

Поля имеют следующие назначения:
Число успехов – количество успешных испытаний. У нас их 50.
Число испытаний – количество бросков: 100 раз.
Вероятность успеха – вероятность выпадения орла при одном подбрасывании 0,5.
Интегральная – указывается либо 1, либо 0. Если 0, то рассчитается вероятность P(B=k); если 1, то рассчитается функция биномиального распределения, т.е. сумма всех вероятностей от B=0 до B=k включительно.
Нажимаем ОК и получаем тот же результат, что и выше, только все рассчиталось одной функцией.

Очень удобно. Эксперимента ради вместо последнего параметра 0 поставим 1. Получим 0,5398. Это значит, что при 100 подкидываниях монеты вероятность выпадения орлов в количестве от 0 до 50 равна почти 54%. А поначалу то казалось, что должно быть 50%. В общем, расчеты производятся легко и быстро.
Настоящий аналитик должен понимать, как ведет себя функция (каково ее распределение), поэтому произведем расчет вероятностей для всех значений от 0 до 100. То есть зададимся вопросом: какова вероятность, что не выпадет ни одного орла, что выпадет 1 орел, 2, 3, 50, 90 или 100. Расчет приведен в следующей картинке. Синяя линия – само биномиальное распределение, красная точка – вероятность для конкретного числа успехов k.

Кто-то может спросить, а не похоже ли биномиальное распределение на… Да, очень похоже. Еще Муавр (в 1733 г.) говорил, что биномиальное распределение при больших выборках приближается к нормальному закону (не знаю, как это тогда называлось), но его никто не слушал. Только Гаусс, а затем и Лаплас через 60-70 лет вновь открыли и тщательно изучили нормальной закон распределения. На графике выше отлично видно, что максимальная вероятность приходится на математическое ожидание, а по мере отклонения от него, резко снижается. Также, как и у нормального закона.
Биномиальное распределение имеет большое практическое значение, встречается довольно часто. С помощью Excel расчеты проводятся легко и быстро.
Поделиться в социальных сетях: