
При изучении развития явления во времени часто возникает необходимость оценить степень взаимосвязи в изменениях уровней 2-х или более рядов динамики различного содержания, но связанных между собой. Эта задача решается методами коррелирования:
- уровней ряда динамики
- отклонений фактических уровней от тренда
- последовательных разностей
Коррелирование уровней динамических рядов с применением парного коэффициента корреляции правильно показывает тесноту связи лишь в том случае, если в каждом из них отсутствует автокорреляция . Наличие зависимости между последующими и предшествующими уровнями динамического ряда в статистической литературе называют автокорреляцией .
Поэтому прежде, чем коррелировать ряды динамики по уровням, необходимо проверить каждый из рядов на наличие или отсутствие в них автокорреляции . Применение методов классической теории корреляции в динамических рядах связано с некоторыми особенностями. Прежде всего, это наличие для большинства динамических рядов зависимости последующих уровней от предыдущих.
Коэффициент автокорреляции вычисляется по непосредственным данным рядов динамики, когда фактические уровни одного ряда рассматриваются как значения факторного признака, а уровни этого же ряда со сдвигом на один период, принимаются в качестве результативного признака (этот сдвиг называется лагом). Коэффициент автокорреляции рассчитывается на основе формулы коэффициента корреляции для парной зависимости:

где:
- yt – фактические уровни ряда,
- yt+1– уровни того же ряда со сдвигом на 1 период (коэффициент автокорреляции первого порядка).
Примечание: во избежание путаницы, следует обратить внимание на порядок, по которому будет производиться сдвиг уровней, а именно, вниз или вверх. Соответственно и в формулах по разным источникам, ряд со сдвигом отображают либо так yt-1 либо yt+1
Формула для расчета коэффициента автокорреляции уровней ряда 1-го порядка:

Формула для расчета коэффициента автокорреляции уровней ряда 2-го порядка:

Для суждения о наличии или отсутствии автокорреляции в исследуемом ряду, фактическое значение коэффициента автокорреляции сопоставляют с табличным для 5% или 1% уровня значимости (т. е. по величине вероятности допустить ошибку при принятии гипотезы о независимости уровней ряда). Если расчетное значение меньше табличного, то гипотеза об отсутствии автокорреляции принимается и, наоборот, в противном случае, отвергается.
Последовательность коэффициентов автокорреляции 1, 2 и т.д. порядков называют автокорреляционной функцией временного ряда. График зависимости значений коэффициентов автокорреляции от величины лага (порядка коэффициента автокорреляции ) называют коррелограммой.
Анализ автокорреляционной функции и коррелограммы позволяет выявить структуру ряда, т. е. определить присутствие в ряде той или иной компоненты. Так, если наиболее высоким оказался коэффициент автокорреляции первого порядка, то исследуемый ряд содержит только тенденцию. Если наиболее высоким оказался коэффициент автокорреляции порядка m, то ряд содержит циклические колебания с периодичностью в m моментов времени. Если же ни один из коэффициентов автокорреляции не является значимым, то можно сделать одно из двух предположений:
- либо ряд не содержит тенденции и циклических колебаний, а его уровень определяется только случайной компонентой;
- либо ряд содержит сильную нелинейную тенденцию, для выявления которой нужно провести дополнительный анализ.
Необходимо подчеркнуть, что линейные коэффициенты автокорреляции характеризуют тесноту только линейной связи текущего и предыдущих уровней ряда. Поэтому, по коэффициентам автокорреляции можно судить только о наличии или отсутствии линейной зависимости (или близкой к линейной). Для некоторых временных рядов, имеющих сильную нелинейную тенденцию (например, параболу второго порядка или экспоненту), коэффициент автокорреляции уровней исходного ряда может приближаться к нулю. По знаку коэффициента автокорреляции нельзя делать вывод о возрастающей или убывающей тенденции в уровнях ряда. Большинство временных рядов экономических данных содержат положительную автокорреляцию уровней, однако, при этом могут иметь убывающую тенденцию.
Для проверки ряда на наличие нелинейной тенденции рекомендуется вычислить линейные коэффициенты автокорреляции для временного ряда, состоящего из логарифмов исходных уровней. Отличные от нуля значения коэффициентов автокорреляции будут свидетельствовать о наличии нелинейной тенденции.
Пример расчета:
Коэффициент автокорреляции 1 порядка
Расчет коэффициента автокорреляции 1-го порядка
Сдвигаем исходный ряд на 1 уровень. Следует учитывать, что с увеличением лага на единицу, число пар значений, по которым рассчитывается коэффициент автокорреляции , уменьшается на 1. Считается целесообразным для обеспечения статистической достоверности коэффициентов автокорреляции использовать правило: максимальный лаг не должен превышать n : 4 (n-число уровней ряда). Исходный ряд состоял из 8 уровней. Расчет производится не по 8, а по 7 парам наблюдений. Получаем следующие данные:
|
yt |
14017 |
14909 |
15333.5 |
15381.1 |
15548.8 |
22214.2 |
32267.6 |
|
yt — 1 |
14909 |
15333.5 |
15381.1 |
15548.8 |
22214.2 |
32267.6 |
42597.5 |
Для расчета коэффициента автокорреляции , необходимо рассчитать параметры уравнения авторегрессии:

Линейный коэффициент автокорреляции (L=1):

|
yt |
yt-1 |
yt 2 |
yt-1 2 |
yt • yt-1 |
|
14017 |
14909 |
196476289 |
222278281 |
208979453 |
|
14909 |
15333.5 |
222278281 |
235116222.25 |
228607151.5 |
|
15333.5 |
15381.1 |
235116222.25 |
236578237.21 |
235846096.85 |
|
15381.1 |
15548.8 |
236578237.21 |
241765181.44 |
239157647.68 |
|
15548.8 |
22214.2 |
241765181.44 |
493470681.64 |
345404152.96 |
|
22214.2 |
32267.6 |
493470681.64 |
1041198009.76 |
716798919.92 |
|
32267.6 |
42597.5 |
1041198009.76 |
1814547006.25 |
1374519091 |
|
129671.2 |
158251.7 |
2666882902.3 |
4284953619.55 |
3349312512 |
Так как коэффициент автокорреляции первого порядка оказался высоким, то исследуемый ряд содержит только тенденцию. Проверка значимости коэффициента автокорреляции дает следующий результат:

По таблице распределения Стьюдента (двусторонняя критическая область) с уровнем значимости α=0.05 и степенями свободы k=5 находим: tкрит (n-m-1; α/2) > (5; 0.025) = 2.571. Поскольку 2,16<2,571 (tнабл < tкрит), то принимаем гипотезу о равенстве коэффициента автокорреляции =0, что, в свою очередь, подтверждает наличие сильной нелинейной тенденции. Другими словами, коэффициент автокорреляции статистически — не значим.
Коэффициент автокорреляции 2 порядка
Расчет коэффициента автокорреляции 2-го порядка
Теперь cдвигаем исходный ряд на 2 уровня. Исходный ряд состоял из 8 уровней. Расчет производится не по 8, а уже по 6 парам наблюдений. Получаем следующую таблицу:
|
yt |
14017 |
14909 |
15333.5 |
15381.1 |
15548.8 |
22214.2 |
|
yt — 2 |
15333.5 |
15381.1 |
15548.8 |
22214.2 |
32267.6 |
42597.5 |
Проведя аналогичные расчеты, как при сдвиге исходного ряда на 1 уровень, получаем:
Линейный коэффициент автокорреляции (L=2):

|
yt |
yt-2 |
yt 2 |
yt-2 2 |
yt • yt-2 |
|
14017 |
15333.5 |
196476289 |
235116222.25 |
214929669.5 |
|
14909 |
15381.1 |
222278281 |
236578237.21 |
229316819.9 |
|
15333.5 |
15548.8 |
235116222.25 |
241765181.44 |
238417524.8 |
|
15381.1 |
22214.2 |
236578237.21 |
493470681.64 |
341678831.62 |
|
15548.8 |
32267.6 |
241765181.44 |
1041198009.76 |
501722458.88 |
|
22214.2 |
42597.5 |
493470681.64 |
1814547006.25 |
946269384.5 |
|
97403.6 |
143342.7 |
1625684892.54 |
4062675338.55 |
2472334689.2 |
Коэффициент автокорреляции второго порядка также оказался высоким — исследуемый ряд содержит только тенденцию. Но проверка значимости коэффициента автокорреляции опять не подтверждает значимость коэффициента автокорреляции :

По таблице распределения Стьюдента (двусторонняя критическая область) с уровнем значимости α=0.05 и степенями свободы k=4 находим: tкрит (n-m-1; α/2) > (4; 0.025) = 2.776. Поскольку 1,73<2,776 (tнабл < tкрит), то принимаем гипотезу о равенстве коэффициента автокорреляции =0, тем самым подтверждая наличие сильной нелинейной тенденции. Другими словами, коэффициент автокорреляции статистически — не значим.
Коэффициенты автокорреляции в MS Excel
Для расчета значений автокорреляционной функции в MS Excel целесообразно использовать функцию КОРРЕЛ (массив1; массив2). Так, если уровни исходного временного ряда располагаются в ячейках А1:А20, то для расчета коэффициентов автокорреляции можно вводить функции:
r1: =КОРРЕЛ (А1:А19; А2:А20)
r2: =КОРРЕЛ (А1:А18; А3:А20)
r3: =КОРРЕЛ (А1:А17; А4:А20)
r4:=КОРРЕЛ (А1:А16; А5:А20)
И т. д., постоянно сдвигая диапазон ячеек массива 1-вверх, массива 2- вниз, в зависимости от количества уровней в ряду динамики.
Остальные коэффициенты автокорреляции рассчитаем в MS Excel:
|
Лаг |
Коэффициент автокорреляции уровней |
Коррелограмма |
|
1 |
0,96538 |
********** |
|
2 |
0,86291 |
******** |
|
3 |
0,74906 |
******* |
|
4 |
0,88313 |
********* |
При анализе наиболее высоким оказался коэффициент автокорреляции уровней первого и четвертого порядков. Следовательно, исследуемый ряд содержит тенденцию и циклические колебания.
Проверка значимости коэффициентов
Существует другая методика проверки значимости коэффициентов автокорреляции , что, в свою очередь, дает основания подтвердить (отклонить) наличие в ряду динамики автокорреляции .
Значимость каждого в отдельности коэффициента автокорреляции принято проверять с помощью критерия стандартной ошибки. С его помощью удается выявить среди запаздывающих переменных те, которые необходимо включить в модель. Коэффициент автокорреляции можно считать значимым, если не выполняется неравенство с принятым уровнем надежности (95%):
![[- 1.96frac{1}{{sqrt n }}; le ;{r_k}; le 1.96frac{1}{{sqrt n }}]](https://helpstat.ru/wp-content/ql-cache/quicklatex.com-d1332b7d1520d28c7c9421a1ca33acca_l3.png "Rendered by QuickLaTeX.com")
где n – число пар наблюдений временного ряда, k – лаг (смещение данных ряда). Если рассчитанное значение автокорреляции попадает в этот интервал, то можно сделать вывод, что данные не показывают наличие автокорреляции k-го порядка с 95% уровнем надежности:
Для r1 объем выборки составляет (n-1)=(8-1)=7 пар наблюдений:
![[- 1.96frac{1}{{sqrt 7 }}; le ;{r_1}; le 1.96frac{1}{{sqrt 7 }}; Rightarrow ; - 0.7408; le ;0.9654; le ;0.7405]](https://helpstat.ru/wp-content/ql-cache/quicklatex.com-c412650e9a7b89609f69e975e000aeb3_l3.png "Rendered by QuickLaTeX.com")
Неравенство не выполняется – наличие автокорреляции .
Для r2 объем выборки составляет (n-2)=(8-2)=6 пар наблюдений:
![[- 1.96frac{1}{{sqrt 6 }}; le ;{r_2}; le 1.96frac{1}{{sqrt 6 }}; Rightarrow ; - 0.8001; le ;0.8629; le ;0.8001]](https://helpstat.ru/wp-content/ql-cache/quicklatex.com-2de31988efc78fc0e09e8e4c053e8800_l3.png "Rendered by QuickLaTeX.com")
Неравенство не выполняется – наличие автокорреляции .
Для r3 объем выборки составляет (n-3)=(8-3)=5 пар наблюдений:
![[- 1.96frac{1}{5}; le ;{r_3}; le 1.96frac{1}{{sqrt 5 }}; Rightarrow ; - 0.8765; le ;0.7491; le ;0.8756]](https://helpstat.ru/wp-content/ql-cache/quicklatex.com-a8a473d13826dcc34c96e948b06bc821_l3.png "Rendered by QuickLaTeX.com")
Неравенство выполняется – автокорреляция отсутствует.
Для r4 объем выборки составляет (n-4)=(8-4)=4 пары наблюдений:
![[- 1.96frac{1}{4}; le ;{r_4}; le 1.96frac{1}{{sqrt 4 }}; Rightarrow ; - 0.98; le ;0.8831; le ;0.98]](https://helpstat.ru/wp-content/ql-cache/quicklatex.com-cae44309ee57e7bcec2ff657e1993cae_l3.png "Rendered by QuickLaTeX.com")
Неравенство выполняется – автокорреляция отсутствует.
Данный анализ подтвердил наличие автокорреляции в ряду динамики, что дало основание отклонить применение парного линейного коэффициента корреляции при коррелировании уровней. В этом случае необходимо коррелировать отклонения или последовательные разности (см. ниже корреляция взаимосвязанных рядов динамики). Статистическая недостоверность коэффициентов корреляции подтвердила наличие в ряду динамики сильной нелинейной тенденции, для выявления которой необходимо провести дополнительный анализ, а также циклические колебания с периодичностью в k моментов времени. Конечно же, важным моментом анализа является сама содержательная характеристика исследуемого показателя (в данном примере он обезличен, но на практике этот показатель подвержен сильному влиянию конъюнктуры рынка по объему его производства и международных цен, что, в свою очередь, дает основание утверждать о присутствии циклической компоненты).
Аналитическое выравнивание по параболе 2-го порядка и анализ коррелированности отклонений исходного уровня (yi) от выравненного (yt) с использованием статистики Дарбина-Уотсона, дает следующие результаты:
|
yi |
yt= 1048.72t2 -5775.81t+20782.31 |
ei = yi-yt |
e2 |
(ei — ei-1)2 |
|
14017 |
16055.22 |
-2038.22 |
4154344.17 |
0 |
|
14909 |
13425.58 |
1483.42 |
2200547.96 |
12401985.18 |
|
15333.5 |
12893.38 |
2440.12 |
5954201.3 |
915272.61 |
|
15381.1 |
14458.62 |
922.48 |
850961.22 |
2303254.3 |
|
15548.8 |
18121.32 |
-2572.52 |
6617851.19 |
12214983.39 |
|
22214.2 |
23881.46 |
-1667.26 |
2779752.33 |
819494.81 |
|
32267.6 |
31739.05 |
528.55 |
279369.51 |
4821595.15 |
|
42597.5 |
41694.08 |
903.42 |
816169.2 |
140525.02 |
|
23653196.89 |
33617110.46 |

Критические значения d1(dL) и d2 (dU) определяются на основе специальных таблиц для требуемого уровня значимости (α) и числа наблюдений n = 8, где количество объясняющих переменных m=1. Автокорреляция отсутствует, если выполняется следующее условие: d1 < DW и d2 < DW < 4 — d2. По таблице распределений Дарбина-Уотсона для n=8 и k=1 (уровень значимости 5%) находим: d1 = 1.08; d2 = 1.36. Поскольку 1.08 < 1.42 и 1.36 < 1.42 < 4 — 1.36, то автокорреляция остатков отсутствует.
В зависимости от величины и знака расчетного значения статистики Дарбина-Уотсона, возможны следующие ситуации.
Возможные варианты:
1. Если коэффициент автокорреляции является положительной величиной (DW>0), то при проверке гипотез возможно возникновение следующих ситуаций:
- Если наблюдаемое значение критерия Дарбина-Уотсона меньше критического значения его нижней границы DW<d1, то нулевая гипотеза (H0) об отсутствии автокорреляции первого порядка между остатками модели регрессии отклоняется.
- Если наблюдаемое значение критерия Дарбина-Уотсона больше критического значения его верхней границы DW>d2, то нулевая гипотеза (H0) об отсутствии автокорреляции первого порядка между остатками модели регрессии принимается.
- Если наблюдаемое значение критерия Дарбина-Уотсона находится между верхней и нижней критическими границами d1<DW< d2 нет достаточных оснований для принятия единственно правильного решения, необходимы дополнительные исследования.
2. Если коэффициент автокорреляции является отрицательной величиной (DW<0), то при проверке гипотез возможно возникновение следующих ситуаций:
- Если наблюдаемое значение критерия Дарбина-Уотсона больше критической величины (4–d1) DW>4–d1, то нулевая гипотеза (H0) об отсутствии автокорреляции первого порядка между остатками модели регрессии отклоняется
- Если наблюдаемое значение критерия Дарбина-Уотсона меньше критической величины (4–d2) DW<4–d2, то нулевая гипотеза (H0) об отсутствии автокорреляции первого порядка между остатками модели регрессии принимается.
- Если наблюдаемое значение критерия Дарбина-Уотсона находится в критическом интервале между величинами (4–d1) и (4–d2) 4–d1<DW<4–d2, то достаточных оснований для принятия единственно правильного решения нет, необходимы дополнительные исследования.

Данный временной ряд наилучшим образом аппроксимируется параболой 3-го порядка, нежели параболой 2-го порядка, тем самым, подтверждая сильную нелинейную тенденцию ряда (R2=0.9898).

Далее, для анализа второго временного ряда, который будет выбран в качестве взаимосвязанного с рассмотренным выше, так же необходимо провести анализ на наличие (отсутствие) автокорреляции . Затем произвести расчет и анализ коэффициента корреляции 2-х взаимосвязанных рядов динамики по нижеприведенным формулам.
Взаимосвязанные ряды динамики
Применение корреляции в динамических рядах имеет ряд особенностей, недоучет которых не позволяет получить правильной оценки взаимосвязи между рядами динамики, которые, в свою очередь, рассматриваются как результативный и факторный признаки.
В рядах динамики из-за автокорреляции (влияние изменений уровней предыдущих рядов на последующие), необходимо из уровней каждого ряда исключить тренд — основную тенденцию, налагаемую на ряд развитием во времени и найти корреляцию отклонений от тренда по формулам:

где: dy (dx) — остаточные отклонения фактических уровней ряда от выровненных, соответственно, для уровней временного ряда, принятого в качестве результативного (dy) и в качестве факторного (dx) признаков, либо использовать последовательные разности уровней взаимосвязанных рядов динамики (цепные абсолютные приросты) — (Δx, Δy).
Коррелируя отклонения или последовательные разности взаимосвязанных динамических рядов, при переходе от самих уровней к их отклонениям от выровненных значений, исключается влияние общей тенденции на колеблемость (изменчивость) самих уровней.
Смотри также:
- Корреляция и регрессия
- Компоненты и сезонная декомпозиция временного ряда
- Сезонная корректировка временного ряда
- Проверка выполнимости предпосылок МНК
- Метод наименьших квадратов
17 авг. 2022 г.
читать 2 мин
Автокорреляция измеряет степень сходства между временным рядом и его запаздывающей версией в течение последовательных интервалов времени.
Его также иногда называют «последовательной корреляцией» или «запаздывающей корреляцией», поскольку он измеряет взаимосвязь между текущими значениями переменной и ее историческими значениями.
Когда автокорреляция во временном ряду высока, становится легко предсказать будущие значения, просто ссылаясь на прошлые значения.
Автокорреляция в Excel
В Excel нет встроенной функции для расчета автокорреляции, но мы можем использовать единую формулу для расчета автокорреляции для временного ряда для заданного значения задержки.
Например, предположим, что у нас есть следующий временной ряд, который показывает значение определенной переменной в течение 15 различных периодов времени:
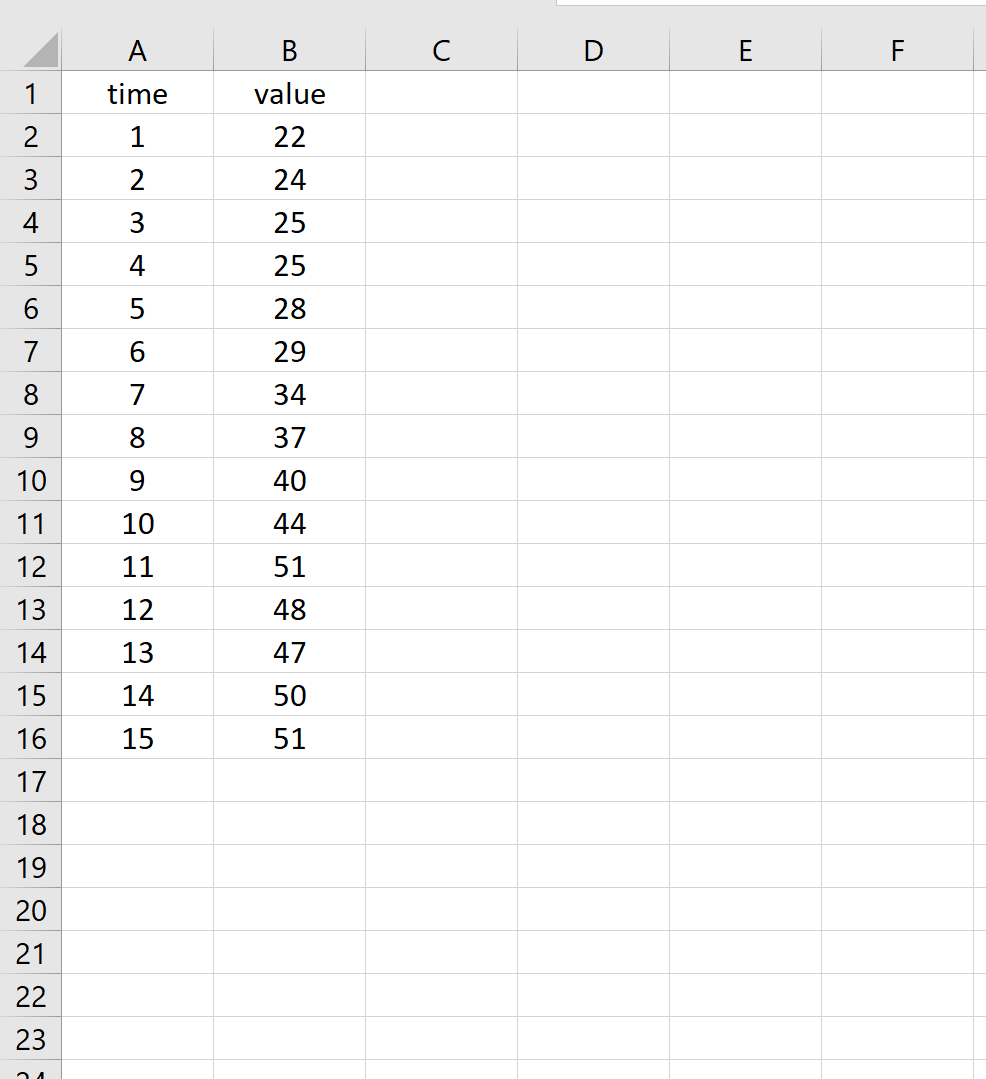
Мы можем использовать следующую формулу для расчета автокорреляции при задержке k = 2.
=(SUMPRODUCT( B2:B14 -AVERAGE( B2:B16 ), B4:B16 -AVERAGE( B2:B16 ))/COUNT( B2:B16 ))/VAR.P( B2:B16 )
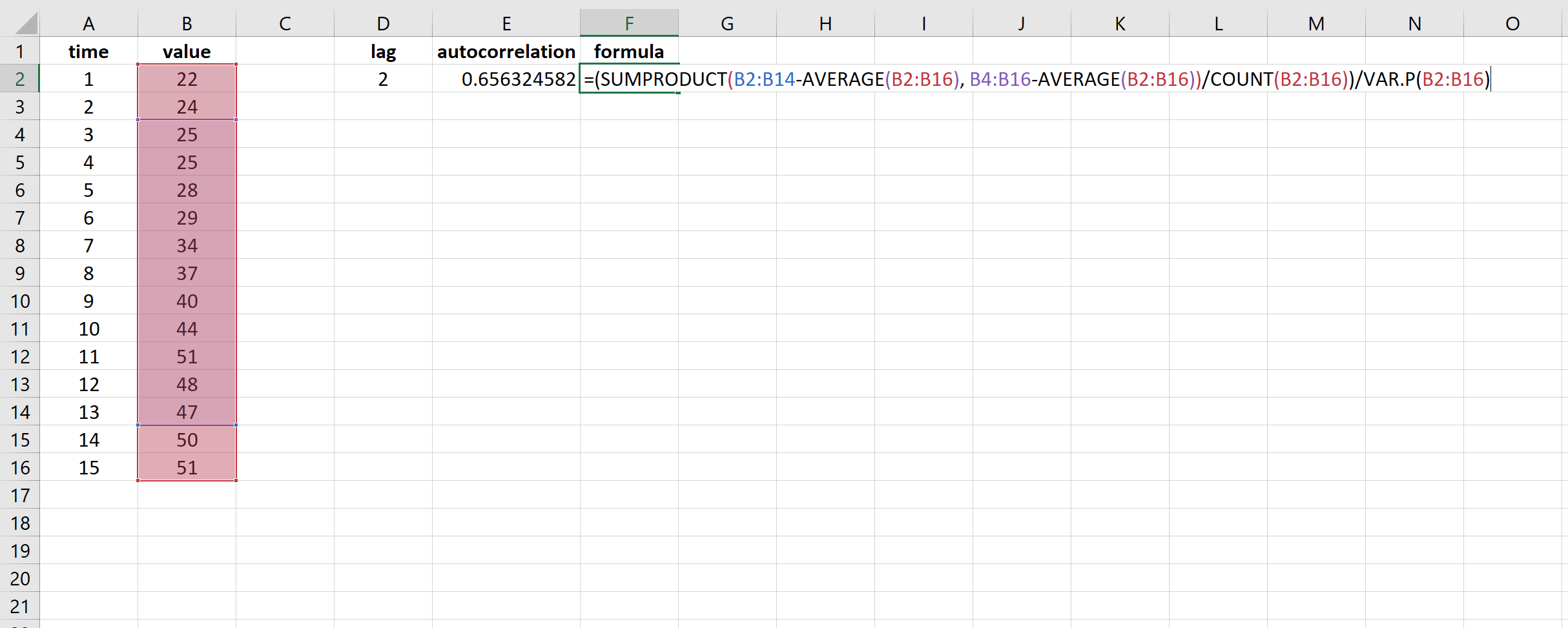
В результате получается значение 0,656325.Это автокорреляция при задержке k = 2.
Мы можем вычислить автокорреляцию при лаге k = 3, изменив диапазон значений в формуле:
=(SUMPRODUCT( B2:B13 -AVERAGE( B2:B16 ), B5:B16 -AVERAGE( B2:B16 ))/COUNT( B2:B16 ))/VAR.P( B2:B16 )
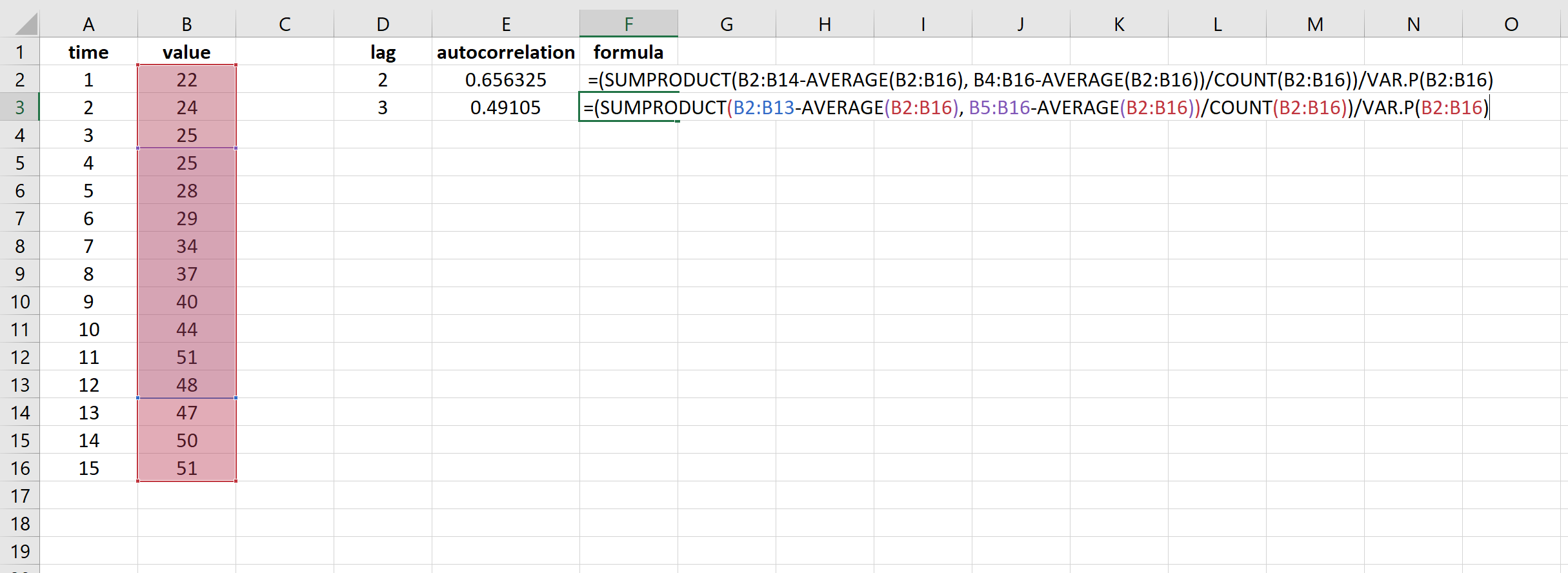
В результате получается значение 0,49105.Это автокорреляция при задержке k = 3.
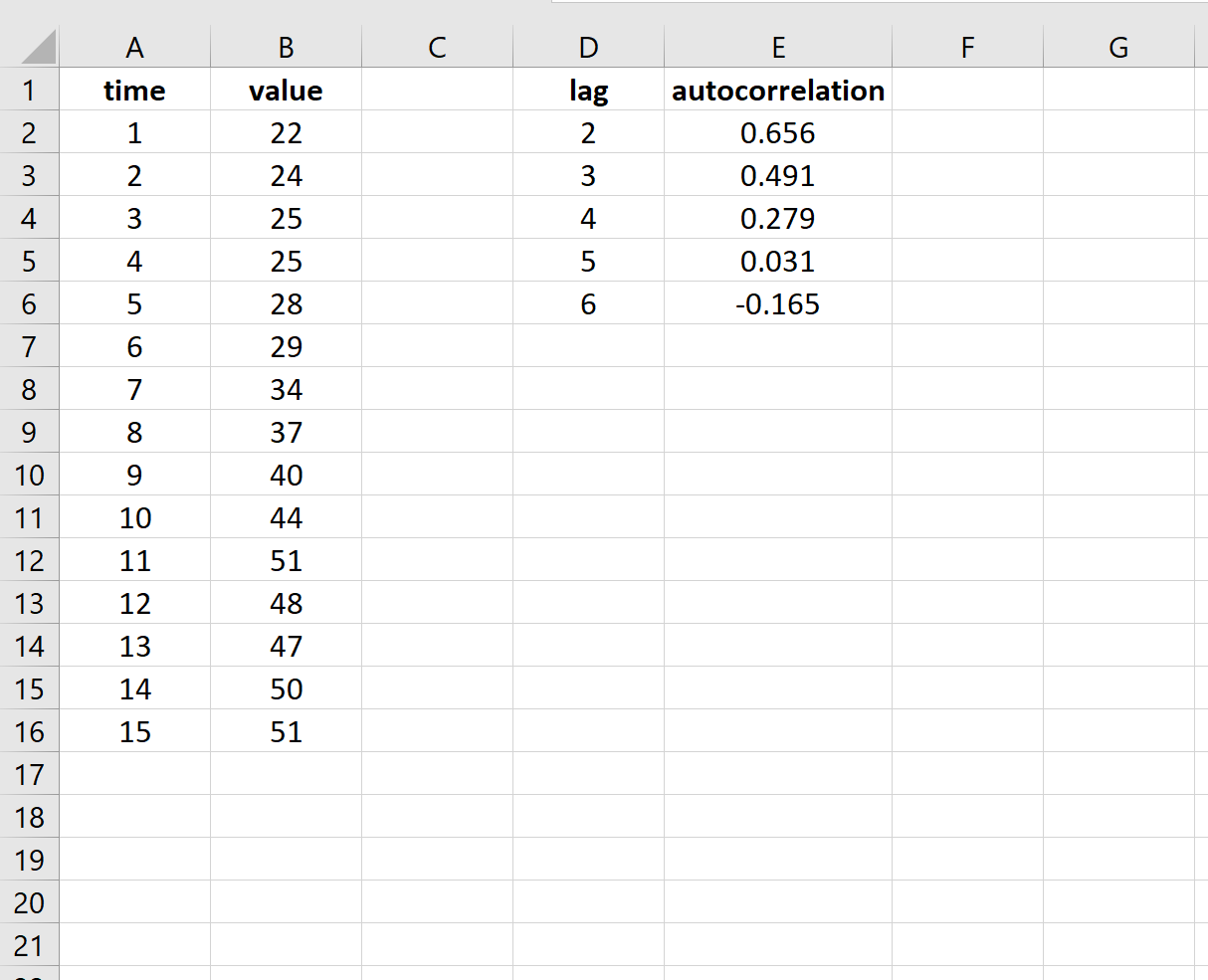
Мы можем найти автокорреляцию для каждого лага, используя аналогичную формулу. Вы заметите, что чем выше задержка, тем ниже автокорреляция. Это типично для процесса авторегрессионного временного ряда.
Вы можете найти больше руководств по временным рядам Excel на этой странице .
Написано
![]()
Замечательно! Вы успешно подписались.
Добро пожаловать обратно! Вы успешно вошли
Вы успешно подписались на кодкамп.
Срок действия вашей ссылки истек.
Ура! Проверьте свою электронную почту на наличие волшебной ссылки для входа.
Успех! Ваша платежная информация обновлена.
Ваша платежная информация не была обновлена.
Autocorrelation measures the degree of similarity between a time series and a lagged version of itself over successive time intervals.
It’s also sometimes referred to as “serial correlation” or “lagged correlation” since it measures the relationship between a variable’s current values and its historical values.
When the autocorrelation in a time series is high, it becomes easy to predict future values by simply referring to past values.
Autocorrelation in Excel
There is no built-in function to calculate autocorrelation in Excel, but we can use a single formula to calculate the autocorrelation for a time series for a given lag value.
For example, suppose we have the following time series that shows the value of a certain variable during 15 different time periods:

We can use the following formula to calculate the autocorrelation at lag k =2.
=(SUMPRODUCT(B2:B14-AVERAGE(B2:B16), B4:B16-AVERAGE(B2:B16))/COUNT(B2:B16))/VAR.P(B2:B16)

This results in a value of 0.656325. This is the autocorrelation at lag k = 2.
We can calculate the autocorrelation at lag k = 3 by changing the range of values in the formula:
=(SUMPRODUCT(B2:B13-AVERAGE(B2:B16), B5:B16-AVERAGE(B2:B16))/COUNT(B2:B16))/VAR.P(B2:B16)

This results in a value of 0.49105. This is the autocorrelation at lag k = 3.
We can find the autocorrelation at each lag by using a similar formula. You’ll notice that the higher the lag, the lower the autocorrelation. This is typical of an autoregressive time series process.

You can find more Excel time series tutorials on this page.
history 4 августа 2021 г.
- Группы статей
Сам метод скользящего среднего рассмотрен в статье Скользящее среднее в MS EXCEL, в которой показано как для этого использовать инструмент MS EXCEL Пакет анализа, а также линию тренда и формулы.
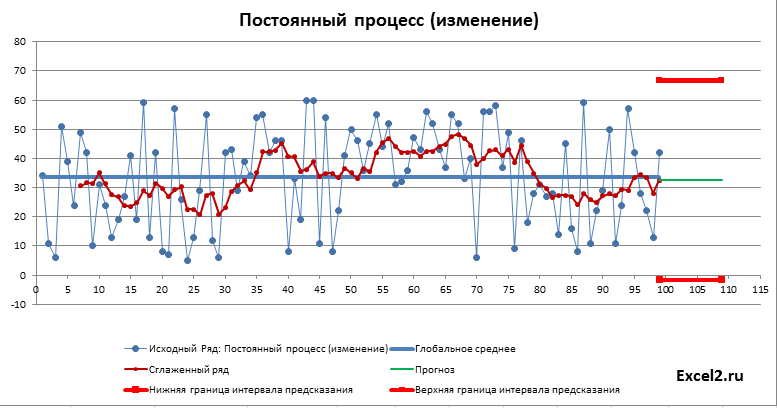
В этой статье рассмотрим не сам метод сглаживания, а его применение для прогнозирования. Как было сказано во вводной статье про прогнозирование, метод прогнозирования подбирается в соответствии с процессом, который генерирует значения временного ряда. Поэтому в файле примера используется как стационарные процессы, будем называть их постоянными, т.к. у них среднее и дисперсия постоянные (хотя фактически это белый шум со смещенным средним), и растущий тренд. Для оценки точности прогнозирования рассчитываются ошибки модели, строится интервал прогнозирования (на самом деле не интервал прогнозирования, а некий доверительный интервал на основе вычисленной ошибки). Так же оценивается адекватность модели.
Примечание: Конечно, прогнозировать процессы типа белого шума, бесперспективное занятие, но, во-первых в файле примера демонстрируются характеристики этого процесса (строится диаграмма рассеяния, функция автокорреляции, диаграмма разброса ошибок и пр.), а во-вторых таблицу с исходными значениями можно заменить и все характеристики будут пересчитаны в файле примера автоматически.
Построение исходного и сглаженного ряда
Для построения рядов можно использовать диаграмму типа График или Точечная. Выберем последний тип – Точечная (ниже будет пояснено почему Точечная в данном случае удобнее).
Для исходных рядов нам понадобится 4 столбца с данными (2 «постоянных» процесса, ряд с цикличностью и тренд). В файле примера на листе Исходный и сглаженный ряд это столбцы T:W.
Один из исходных рядов – динамический (столбец U, назовем его «постоянный» процесс с изменениями), т.е. его значения пересчитываются при любом изменении данных листа или после нажатии клавиши F9. Это сделано с помощью формулы =СЛУЧМЕЖДУ($T$10-2*$T$9;$T$10+2*$T$9)
За среднее значение этого ряда взято среднее значение ряда из столбца T =СРЗНАЧ(T13:T111), а диапазон изменения – 2 стандартных отклонения того же ряда =СТАНДОТКЛОН.В(T13:T112).
Такой автоматически генерирующийся ряд удобен для оценки модели – можно получить целый набор прогнозных значений, ошибок и доверительных интервалов. Фактически, конечно, функция СЛУЧМЕЖДУ() генерирует белый шум (с заданным смещением среднего относительно 0).
Примечание: Про функцию СЛУЧМЕЖДУ() можно почитать здесь. Эта функция генерирует непрерывное равномерное распределение, чтобы сгенерировать выборку из нормального или любого другого распределения см. эту статью.
Выбор нужно типа процесса организован с помощью группы переключателей, которая связана с ячейкой I11.

Значения выбранного исходного ряда подставляются в столбце В с помощью формулы =СМЕЩ(T13;;$I$11-1). Подробнее про функцию СМЕЩ() см. здесь.
Сглаженный ряд разместим рядом в столбце С, этот ряд будет формироваться для заданного периода усреднения (ячейка A7) с помощью формулы =ЕСЛИ(A13<$A$7;НД();СРЗНАЧ(СМЕЩ(B13;-$A$7+1;;$A$7)))
Примечание: Про построение сглаженного ряда см. Скользящее среднее в MS EXCEL.
Период усреднения для удобства задается с помощью элемента управления счетчик.
Осталось сформировать данные для линии среднего значений исходного ряда. Для этого понадобится только 2 точки (см. диапазон F43:G44).
Теперь все готово для построения диаграммы.
Примечание: для тех, кто не имеет большого опыта в построении диаграмм MS EXCEL предлагается прочитать эту статью.
Для тренда сглаженный ряд будет выглядеть так: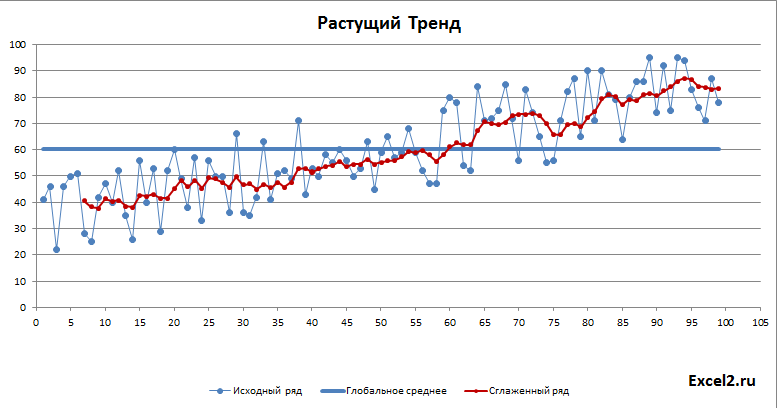
Расчет прогнозного значения
Напомним, что метод скользящего среднего состоит в вычислении средних значений на основе предшествующих значений исследуемого числового ряда. Пусть последнее значение ряда произошло в момент i.
В случае усреднения за 3 периода скользящее среднее в момент i равно:
Yскол.i=(Yi+ Yi-1+ Yi-2)/3
Именно так считает инструмент Пакета Анализа «Скользящее среднее». Понятно, что нас интересует прогноз в будущий момент времени i+1. Положим, что прогнозное значение ряда в момент i+1 равно Yпрогнозн.i+1= Yскол.i
В итоге получаем эквивалентную формулу
Yпрогнозн.i+1=(Yi+ Yi-1+ Yi-2)/3
Для наглядности прогнозное значение на диаграмме изобразим в виде горизонтальной линии зеленого цвета (длина линии ничего не значит). Для этого понадобится только 2 точки (см. диапазон F8:G9).
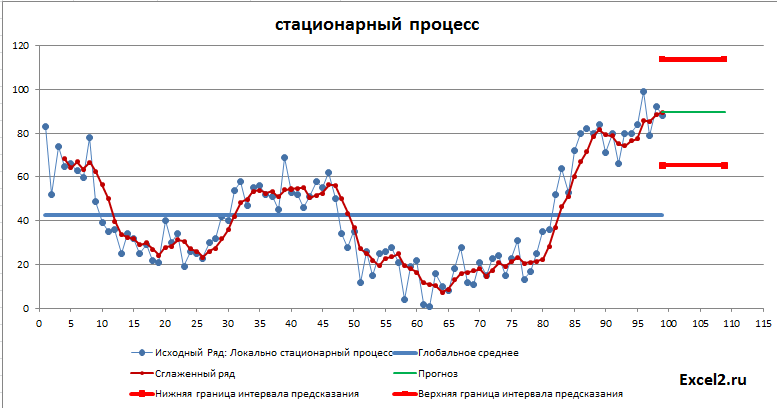
Хотя использование метода скользящего среднего для прогнозирования носит скорее академический, нежели практический интерес, все же покажем как построить что-то типа «интервала предсказания». Для построения интервала воспользуемся ошибкой, которая вычисляется в надстройке Пакет анализа по формуле:
=КОРЕНЬ(СУММКВРАЗН(ИР;СР)/m)
Где m – количество периодов усреднения
ИР — m последних значений Исходного Ряда (ИР)
СР — m последних значений Сглаженного Ряда (СР)
Т.е. данная стандартная ошибка вычисляется по формуле: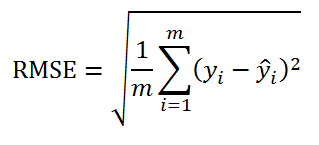
RMSE – это Root Mean Squared Error (среднеквадратическая ошибка).
В файле примера на листе «Прогнозное значение» эта ошибка вычислена по формуле
=КОРЕНЬ(СУММКВРАЗН(СМЕЩ($B$112;-A7;;A7);СМЕЩ($C$112;-A7;;A7))/$A$7)
A7 содержит количество периодов усреднения
СМЕЩ($B$112;-A7;;A7) – это ссылка на диапазон исходного ряда (последние m значений)
СМЕЩ($C$112;-A7;;A7) – это ссылка на диапазон сглаженного ряда
СУММКВРАЗН() вычисляет сумму квадратов разностей
Если вычислить ошибки прогнозирования в отдельном столбце D, то формула для RMSE упростится:
=КОРЕНЬ(СУММКВ(СМЕЩ($D$112;-A7;;A7))/$A$7)
Границы интервала (для заданного уровня значимости альфа) вычисляются как:
Верхняя граница = Yпрогнозн.i+1 + RMSE*tm-1,1-альфа/2
Нижняя граница = Yпрогнозн.i+1 — RMSE*tm-1,1-альфа/2
tm-1,1-альфа/2 — верхний α/2-квантиль распределения Стьюдента с m-1 степенью свободы (это просто число, которое показывает сколько ошибок RMSE нужно, чтобы «интервал предсказания» накрыл прогнозное значение с вероятностью 1-альфа).
Примечание: «Интервал предсказания» вычислен лишь по аналогии с построением доверительного интервала для оценки среднего, для которого у нас была статистическая модель. Для случая скользящего среднего корректность такого построения обосновывается отдельно. В данной статье «Интервал предсказания» построен лишь с целью демонстрации самого процесса построения интервалов предсказания.
Верхний α/2-квантиль вычислим по формуле =СТЬЮДЕНТ.ОБР.2Х(C8;A7-1)
в ячейке С8 находится альфа – уровень значимости (обычно 5%).
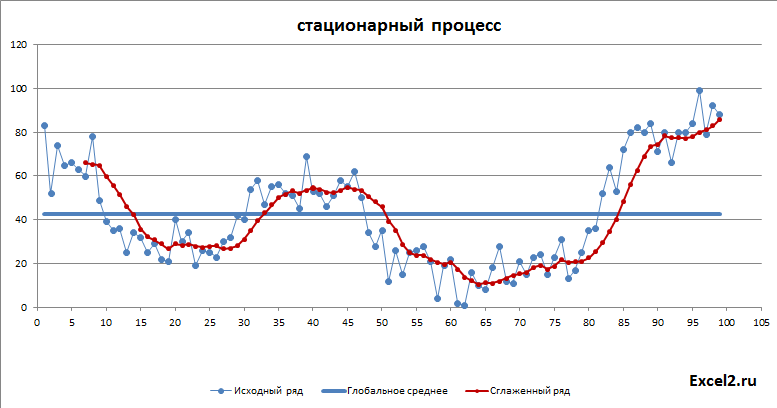
Как видно из диаграммы выше для нашего стационарного процесса (фактически белый шум) прогнозное значение ожидаемо находится около глобального среднего, а доверительный интервал охватывает весь диапазон изменений исходного ряда, т.е. будущее значение этого ряда может появиться на всем интервале, что фактически говорит нам о невозможности предсказания.
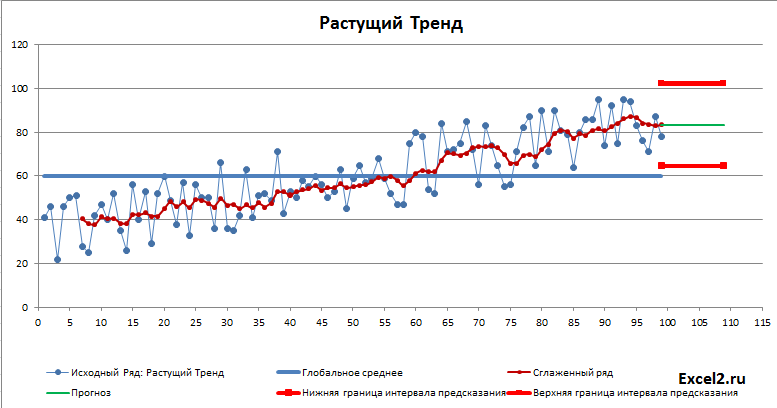
Как и следовало ожидать, для растущего тренда картинка существенно отличается: доверительный интервал уже в 2 раза меньше и прогнозное значение находится вдали от глобального среднего.
Автокорреляция исходного ряда
Исследуем исходный ряд на наличие автокорреляции. Подробно об автокорреляции см. отдельную статью.
Автокорреляция (Autocorrelation, Lagged correlation, Serial correlation) – корреляция значений временного ряда с собственными значениями, сдвинутыми по времени на один или несколько периодов (лагов). Ниже показана диаграмма содержащая исходный ряд и ряд сдвинутый на лаг k=4 (общее количество значений ряда N уменьшится на k, глобальное среднее на диаграмме оставлено как у исходного ряда).
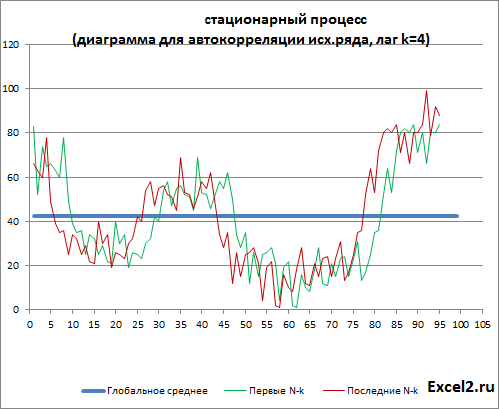
Примечание: Диаграмма построена на листе «Автокорреляция ИР» в файле примера. ИР – Исходный Ряд.
Для оценки автокорреляции используют 3 основных инструмента: график временного ряда (Time Series Plot), диаграмму рассеивания (Lagged Scatterplot) в зависимости от лага и функцию автокорреляции (Autocorelation Function, ACF).
Диаграмма рассеяния используется для отображения возможной взаимосвязи между двумя переменными.
В нашем случае будем исследовать корреляционную зависимость между двумя рядами данных, сдвинутых на лаг k относительно друг друга (см. диаграмму выше).
Для лага k=4 диаграмма рассеяния, очевидно, демонстрирует наличие линейной положительной корреляции.
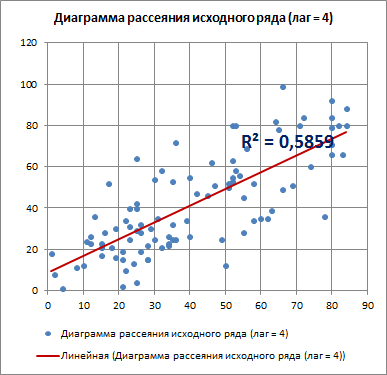
С помощью инструмента диаграммы «Линия тренда» построена линия регрессии и вычислим коэффициент детерминации R2. Ниже мы вычислим R2 с помощью формул, т.к. это просто квадрат коэффициента автокорреляции.
Примечание: Линия тренда подробно описана в разделе Построение линии регрессии статьи про Простую линейную регрессию.
Вычислим коэффициенты автокорреляции для лагов от 1 до 15.
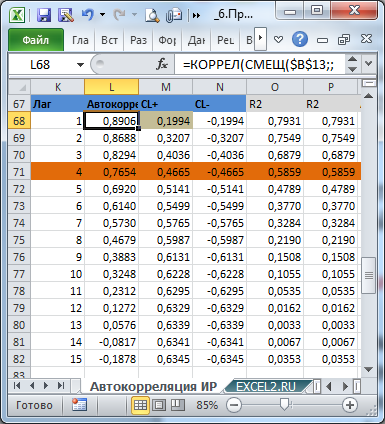
=КОРРЕЛ(СМЕЩ($B$13;;;$B$10-K68);СМЕЩ($B$13;K68;;$B$10-K68))
Два массива в аргументах функции КОРРЕЛ() – это просто 2 ряда, которые сдвинуты на лаг k (ячейка K68) относительно друг друга:
СМЕЩ($B$13;;;$B$10-K68)
СМЕЩ($B$13;K68;;$B$10-K68)
Зависимость коэффициента автокорреляции от лага – это функция автокорреляции (ACF). График ACF – это коррелограмма. Для стационарного процесса (у нас это «постоянный» процесс, фактически белый шум) коррелограмма имеет следующий вид:
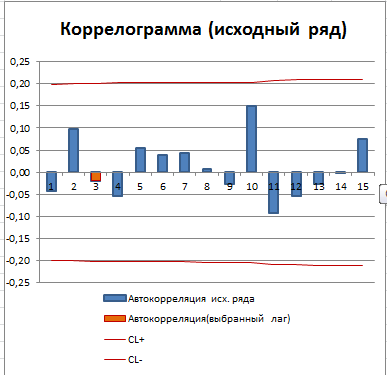
Для другого стационарного процесса (с апериодической цикличностью) коррелограмма имеет совершенно другой вид:
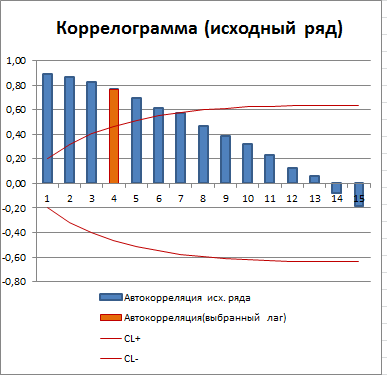
Все коэффициенты автокорреляции, которые выше границ доверительного интервала, являются статистически значимыми (про расчет доверительного интервала для ACF см. статью про Автокорреляцию). Диаграмма рассеяния для выбранного лага (столбец гистограммы, который выделен цветом) также подтверждает отсутствие автокорреляции.
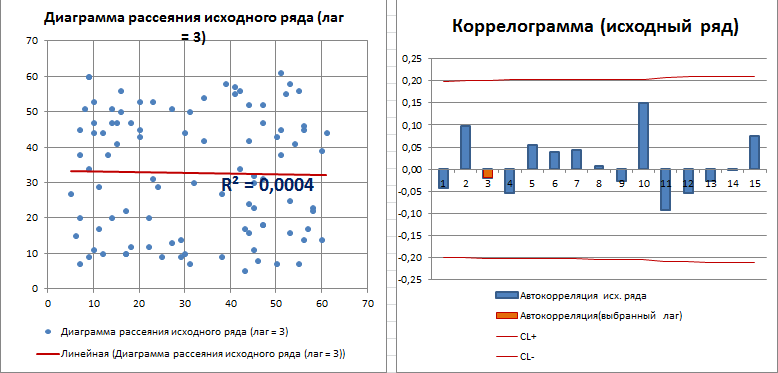
Коэффициент детерминации R2, указанный на диаграмме рассеяния можно рассчитать возведя в квадрат коэффициент корреляции или применив формулу
=КВПИРСОН(СМЕЩ($B$13;;;$B$10-K68);СМЕЩ($B$13;K68;;$B$10-K68))
для тех же массивов, полученных из исходного ряда.
Вычисление ошибок модели
Для прогнозирования значения временного ряда мы использовали модель скользящего среднего с определенным периодом усреднения m. Какое значение является лучшим для прогнозирования?
Критерием оптимальности m является минимизация ошибки модели.
Существует целый ряд формул для вычисления ошибок, но самой лучшей ошибкой для оценки точности модели является среднеквадратичная ошибка (RMSE), вычисленная нами ранее.
Кроме применяются еще несколько других ошибок:
• MAE (Mean Absolute Error, Средняя Абсолютная ошибка). В EXCEL вычисляется по формуле =СРЗНАЧ(ABS(СМЕЩ($D$112;-D10;;D10))). Сначала диапазон ошибок СМЕЩ($D$112;-D10;;D10) в столбце D берется по модулю, затем находится среднее значение. Эта ошибка менее чувствительна к одиночным выбросам, т.к. значения ошибок не возводятся в квадрат.
• MAPE (Mean Absolute Percentage Error, Средняя Абсолютная Процентная Ошибка). В EXCEL вычисляется по формуле =СРЗНАЧ(ABS(СМЕЩ($D$112;-D10;;D10)/СМЕЩ($B$112;-D10;;D10))) Вычисляется практически аналогично MAE, но вместо просто ошибки берется по модулю ее отношение к значению исходного ряда. Получается безразмерная величина. Подходит для исходных рядов с трендом или ярко выраженной сезонностью.
• ME (Mean Error, Средняя ошибка). Эта ошибка показывает имеет ли прогноз смещение. МЕ должна быть около 0. =СРЗНАЧ(СМЕЩ($D$112;-D10;;D10)). ME может быть положительной и отрицательной.
• MPE (Mean Percentage Error, Средняя Процентная ошибка). Вычисляется практически аналогично ME, но вместо просто ошибки берется ее отношение к значению исходного ряда. MPE может быть положительной и отрицательной. =СРЗНАЧ((СМЕЩ($D$112;-D10;;D10)/СМЕЩ($B$112;-D10;;D10)))
Все ошибки вычислены в файле примера на листе Ошибки модели в диапазоне M7:Q11.
Как было сказано выше, для построения «интервала предсказания» прогнозного значения использовалась среднеквадратичная ошибка (RMSE) причем вычисленная не для всего ряда, а лишь на периоде усреднения. Это соответствует формулам MS EXCEL в Пакете анализа. На обоих горизонтах расчета RMSE дает близкие значения, причем в зависимости от лага или значений ряда RMSE вычисленная на периоде усреднения m может давать непредсказуемо либо меньшее либо большее значение по сравнению с RMSE вычисленной для всего ряда (в этом можно убедиться проанализировав RMSE для динамически изменяемого постоянного процесса).
Проверка адекватности модели
На листе Ошибки модели построена диаграмма разброса ошибок и гистограмма ошибок. Эти диаграммы автоматически перестраиваются в зависимости от выбранного лага или типа исходного ряда.
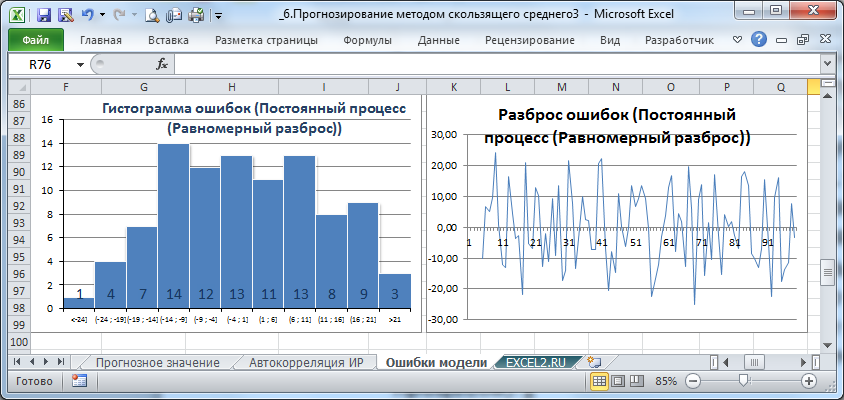
Диаграмму разброса ошибок можно построить на основе диаграммы MS EXCEL типа График. Специальных знаний построения диаграмм практически не требуется. Впрочем, как и для построения Гистограммы. Несколько сложнее построить таблицу исходных данных для гистограммы. Об этом подробно рассказано в статье Гистограмма распределения
Диаграмма разброса ошибок должна демонстрировать колебания ошибок около 0, а гистограмма — типичную выборку из нормального распределения. Проверить распределение ошибок на нормальность можно построить соответствующий график.
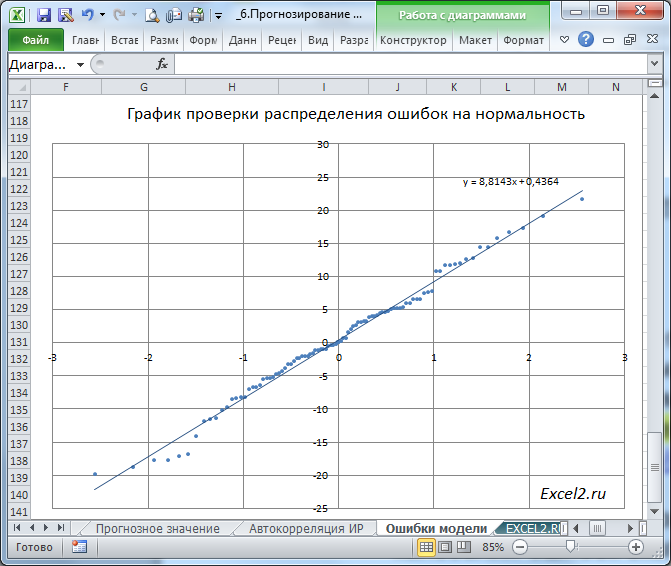
Подробнее о проверке распределения на нормальность см. в этой статье.
В заключение, по аналогии с проверкой исходного ряда на автокорреляцию можно вычислить автокорреляцию ошибок и построить диаграммы рассеяния и коррелограмм.
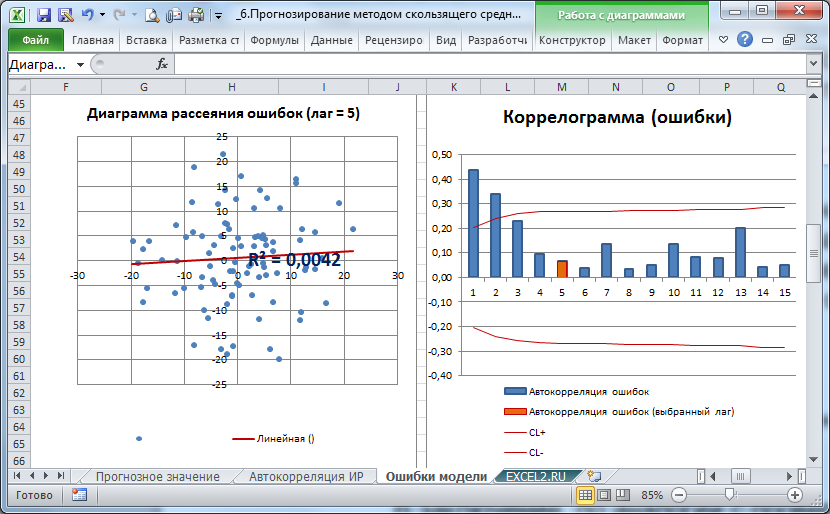
На картинке выше приведены диаграмма рассеяния и коррелограмм для ошибок «постоянного» процесса.
Примечание: На листе «скользящее среднее» объединены все диаграммы, о которых рассказывалось выше в статье.
Все данные взяты с сайта http://e3.prime-tass.ru/macro/
Пример 1. ВВП РФ
Приведем данные о ВВП РФ
|
Год |
квартал |
ВВП |
первая разность |
|
2001 |
I |
1900,9 |
|
|
II |
2105,0 |
204,1 |
|
|
III |
2487,9 |
382,9 |
|
|
IV |
2449,8 |
-38,1 |
|
|
2002 |
I |
2259,5 |
-190,3 |
|
II |
2525,7 |
266,2 |
|
|
III |
3009,2 |
483,5 |
|
|
IV |
3023,1 |
13,9 |
|
|
2003 |
I |
2850,7 |
-172,4 |
|
II |
3107,8 |
257,1 |
|
|
III |
3629,8 |
522,0 |
|
|
IV |
3655,0 |
25,2 |
|
|
2004 |
I |
3516,8 |
-138,2 |
|
II |
3969,8 |
453,0 |
|
|
III |
4615,2 |
645,4 |
|
|
IV |
4946,4 |
331,2 |
|
|
2005 |
I |
4479,2 |
-467,2 |
|
II |
5172,9 |
693,7 |
|
|
III |
5871,7 |
698,8 |
|
|
IV |
6096,2 |
224,5 |
|
|
2006 |
I |
5661,8 |
-434,4 |
|
II |
6325,8 |
664,0 |
|
|
III |
7248,1 |
922,3 |
|
|
IV |
7545,4 |
297,3 |
|
|
2007 |
I |
6566,2 |
-979,2 |
|
II |
7647,5 |
1081,3 |
Исследуем ряд


На диаграммах показаны: исходный ряд (сверху) и автокорреляционная функция до лага 9 (снизу). На нижней диаграмме штриховой линией обозначен уровень «белого шума» — граница статистической значимости коэффициентов корреляции. Видно, что имеется сильная корреляция 1 и 2 порядка, соседних членов ряда, но и удаленных на 1 единицу времени друг от друга. Корреляционные коэффициенты значительно превышают уровень «белого шума». По графику автокорреляции видим наличие четкого тренда.
Ниже даны значения автокорреляционной функции и уровня белого шума
|
АКФ(…) |
Ошибка АКФ |
||
|
1 |
0,856 |
0,203 |
-0,203 |
|
2 |
0,762 |
0,616 |
-0,616 |
|
3 |
0,658 |
0,747 |
-0,747 |
|
4 |
0,550 |
0,831 |
-0,831 |
|
5 |
0,418 |
0,885 |
-0,885 |
|
6 |
0,315 |
0,915 |
-0,915 |
|
7 |
0,224 |
0,932 |
-0,932 |
|
8 |
0,131 |
0,940 |
-0,940 |
Если нас интересует внутренняя динамика ряда необходимо найти первую разность его членов, т.е. для каждого квартала найти изменение значения по сравнению с предыдущим кварталом. Для первой разности построим автокорреляционную функцию.
  Статистика Дарбина-Ватсона (DW) =1,813 Статистика Дарбина-Ватсона (DW) =1,813 |
|
DW Up= 1,450 |
|
DW Low=1,290 |
Статистика Дарбина-Уотсона показывает, что автокорреляции 1-го порядка нет. По графику можно видеть, что первые разности возрастают, т. к. тренд восходящий. Видна автокорреляция 2 и 4-го порядков, что говорит о полугодовой и годовой сезонности. Значения функции и границы для «белого шума» представлены ниже
|
АКФ(…) |
Ошибка АКФ |
||
|
1 |
-0,203 |
0,392 |
-0,392 |
|
2 |
-0,530 |
0,416 |
-0,416 |
|
3 |
-0,003 |
0,513 |
-0,513 |
|
4 |
0,637 |
0,513 |
-0,513 |
|
5 |
-0,087 |
0,627 |
-0,627 |
|
6 |
-0,423 |
0,629 |
-0,629 |
|
7 |
-0,028 |
0,673 |
-0,673 |
Пример 2. Импорт
Дано
|
год |
квартал |
номер |
значение |
разность |
|
1999 |
I |
1 |
3,10 |
|
|
II |
2 |
3,40 |
0,30 |
|
|
III |
3 |
3,33 |
-0,07 |
|
|
IV |
4 |
3,80 |
0,47 |
|
|
2000 |
I |
5 |
3,20 |
-0,60 |
|
II |
6 |
3,60 |
0,40 |
|
|
III |
7 |
3,70 |
0,10 |
|
|
IV |
8 |
4,33 |
0,63 |
|
|
2001 |
I |
9 |
3,60 |
-0,73 |
|
II |
10 |
4,43 |
0,83 |
|
|
III |
11 |
4,30 |
-0,13 |
|
|
IV |
12 |
5,17 |
0,87 |
|
|
2002 |
I |
13 |
4,13 |
-1,03 |
|
II |
14 |
4,77 |
0,63 |
|
|
III |
15 |
5,20 |
0,43 |
|
|
IV |
16 |
5,97 |
0,77 |
|
|
2003 |
I |
17 |
5,10 |
-0,87 |
|
II |
18 |
5,90 |
0,80 |
|
|
III |
19 |
6,33 |
0,43 |
|
|
IV |
20 |
7,23 |
0,90 |
|
|
2004 |
I |
21 |
6,43 |
-0,80 |
|
II |
22 |
7,70 |
1,27 |
|
|
III |
23 |
8,17 |
0,47 |
|
|
IV |
24 |
9,08 |
0,92 |
|
|
2005 |
I |
25 |
8,17 |
-0,92 |
|
II |
26 |
9,80 |
1,63 |
|
|
III |
27 |
10,50 |
0,70 |
|
|
IV |
28 |
12,47 |
1,97 |
|
|
2006 |
I |
29 |
10,40 |
-2,07 |
|
II |
30 |
12,67 |
2,27 |
|
|
III |
31 |
14,20 |
1,53 |
|
|
IV |
32 |
17,10 |
2,90 |
Построим автокорреляционную функцию
|
АКФ(…) |
Ошибка АКФ |
||
|
1 |
0,802 |
0,211 |
-0,211 |
|
2 |
0,693 |
0,535 |
-0,535 |
|
3 |
0,585 |
0,637 |
-0,637 |
|
4 |
0,566 |
0,701 |
-0,701 |
|
5 |
0,423 |
0,756 |
-0,756 |
|
6 |
0,343 |
0,785 |
-0,785 |
|
7 |
0,255 |
0,803 |
-0,803 |
|
8 |
0,231 |
0,813 |
-0,813 |
|
9 |
0,131 |
0,822 |
-0,822 |
|
10 |
0,072 |
0,824 |
-0,824 |


Видим, что есть автокорреляция 1-го и 2-го порядков. График показывает наличие тренда. Положительная автокорреляция объясняется неправильно выбранной спецификацией, т. к. линейный тренд тут непригоден, он скорее экспоненциальный. Поэтому сделаем ряд стационарным, взяв первую разность.
|
АКФ(…) |
Ошибка АКФ |
||
|
1 |
-0,297 |
0,343 |
-0,343 |
|
2 |
0,309 |
0,390 |
-0,390 |
|
3 |
-0,420 |
0,420 |
-0,420 |
|
4 |
0,636 |
0,471 |
-0,471 |
|
5 |
-0,226 |
0,571 |
-0,571 |
|
6 |
0,214 |
0,583 |
-0,583 |
|
7 |
-0,311 |
0,593 |
-0,593 |
|
8 |
0,444 |
0,613 |
-0,613 |
|
9 |
-0,229 |
0,653 |
-0,653 |


Видим наличие автокорреляции 4-го порядка, что соответствует корреляции данных, отдаленных на год. Автокорреляцию первого порядка не имеем.
|
Статистика Дарбина-Ватсона (DW) =2,023 |
|
DW Up=1,500 |
|
DW Low=1,360 |
Пример 3. Экспорт
Приведем данные
|
год |
квартал |
номер |
значение |
разность |
|
2000 |
I |
1 |
22,30 |
|
|
II |
2 |
22,80 |
0,50 |
|
|
III |
3 |
24,80 |
2,00 |
|
|
IV |
4 |
24,80 |
0,00 |
|
|
2001 |
I |
5 |
25,50 |
0,70 |
|
II |
6 |
25,50 |
0,00 |
|
|
III |
7 |
25,90 |
0,40 |
|
|
IV |
8 |
26,20 |
0,30 |
|
|
2002 |
I |
9 |
26,30 |
0,10 |
|
II |
10 |
28,60 |
2,30 |
|
|
III |
11 |
28,70 |
0,10 |
|
|
IV |
12 |
30,30 |
1,60 |
|
|
2003 |
I |
13 |
30,50 |
0,20 |
|
II |
14 |
31,00 |
0,50 |
|
|
III |
15 |
33,80 |
2,80 |
|
|
IV |
16 |
36,40 |
2,60 |
|
|
2004 |
I |
17 |
38,00 |
1,60 |
|
II |
18 |
41,40 |
3,40 |
|
|
III |
19 |
47,20 |
5,80 |
|
|
IV |
20 |
52,36 |
5,16 |
|
|
2005 |
I |
21 |
52,50 |
0,14 |
|
II |
22 |
60,40 |
7,90 |
|
|
III |
23 |
65,70 |
5,30 |
|
|
IV |
24 |
67,40 |
1,70 |
|
|
2006 |
I |
25 |
69,00 |
1,60 |
|
II |
26 |
76,60 |
7,60 |
|
|
III |
27 |
79,80 |
3,20 |
|
|
IV |
28 |
71,00 |
-8,80 |
|
|
2007 |
I |
29 |
80,50 |
9,50 |
Для исходного ряда имеем:
 
АКФ(…) |
Ошибка АКФ |
||
|
1 |
0,896 |
0,165 |
-0,165 |
|
2 |
0,822 |
0,600 |
-0,600 |
|
3 |
0,712 |
0,739 |
-0,739 |
|
4 |
0,592 |
0,828 |
-0,828 |
|
5 |
0,483 |
0,884 |
-0,884 |
|
6 |
0,372 |
0,920 |
-0,920 |
|
7 |
0,261 |
0,941 |
-0,941 |
|
8 |
0,150 |
0,950 |
-0,950 |
|
9 |
0,062 |
0,954 |
-0,954 |
Очевидно наличие четкого тренда, значимыми являются коэффициенты автокорреляции 1-го и 2-го порядков. Для первой разности
|
АКФ(…) |
Ошибка АКФ |
||
|
1 |
-0,173 |
0,372 |
-0,372 |
|
2 |
-0,090 |
0,389 |
-0,389 |
|
3 |
0,353 |
0,392 |
-0,392 |
|
4 |
0,240 |
0,435 |
-0,435 |
|
5 |
-0,106 |
0,454 |
-0,454 |
|
6 |
-0,088 |
0,457 |
-0,457 |
|
7 |
0,315 |
0,460 |
-0,460 |
|
8 |
-0,136 |
0,490 |
-0,490 |


Автокорреляции уже не видим, остатки распределены как «белый шум».
При цитировании материалов в рефератах, курсовых, дипломных работах правильно указывайте источник цитирования, для удобства можете скопировать из поля ниже: