
Содержание
- Создать Excel в visual studio c#
- Русские Блоги
- Использование Visual Studio для Excel Разработка расширений VSTO: инструкции и основные операции
- Разработать расширение VSTO для Excel
- Новая надстройка Excel VSTO
- Основные пространства имен и абстрактные типы
- Узнайте о двух часто используемых библиотеках
- Понимать абстрактные типы в разработке Excel
- Основная операция
- Расширенные элементы управления Excel
- 1. Используйте ObjectList, чтобы расширить элемент управления на таблицу Excel и связать источник данных
- Вариант использования 1: привязка DataTable к ObjectList
- Пошаговое руководство. Создание первой надстройки VSTO для Excel
- Предварительные требования
- Создание проекта
- Создание проекта надстройки VSTO Excel в Visual Studio
- Написание кода для добавления текста в сохраненную книгу
- Добавление строки текста в сохраненную книгу
- Тестирование проекта
- Тестирование проекта
- Очистка проекта
- Очистка завершенного проекта на компьютере разработчика
- Дальнейшие действия
- Сопоставление и сортировка данных в R или Excel
- 4 ответа
Создать Excel в visual studio c#
Давайте научимся быстро и просто создавать и записывать файлы Excel с помощью visual studio c#. Наше самое простое приложение Windows Forms будет брать из текстбокса текст и заносить его в первую ячейку. Статья написана специально для Сергея =).
Начать необходимо с подключения библиотеки Microsoft.Office.Interop.Excel. Выглядеть это должно так:
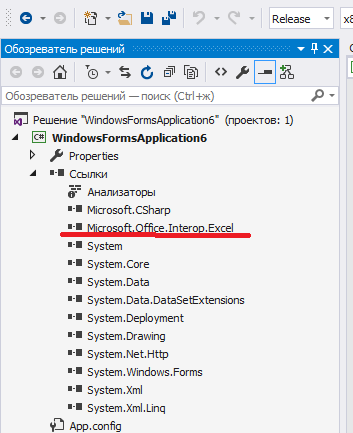
Если у вас при открытии обозревателя решений – Ссылки – правая кнопка – Добавить ссылку – Сборки – в списке нет Microsoft.Office.Interop.Excel, то добавьте её через Nuget. Проект – управление пакетами NuGet – в строке поиска Excel:
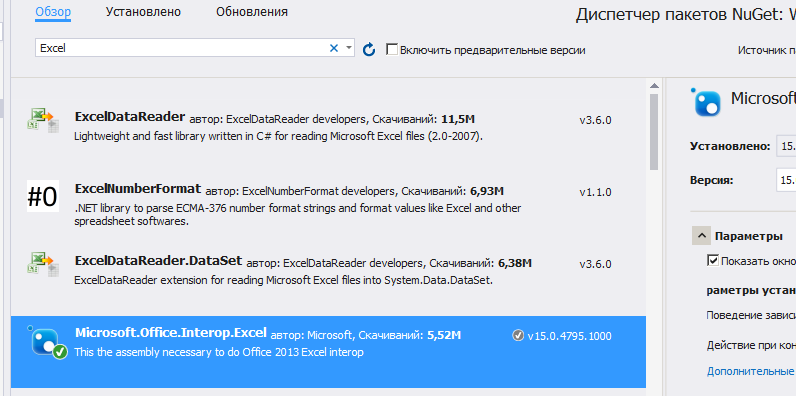
Теперь создайте новый проект Windows Forms и на форму закиньте текстбокс и кнопку. На кнопки кликните два раза, откроется исходный код. В самом верху допишите следующее:
А в методе button1_Click замените так:
Вот, собственно говоря и все. Текст из текстбокса запишется в ячейку A1. Обратите внимание, что папка temp на диске уже должна существовать.
Дополнение. Прочитать первую ячейку
Это тоже просто:

Автор этого материала — я — Пахолков Юрий. Я оказываю услуги по написанию программ на языках Java, C++, C# (а также консультирую по ним) и созданию сайтов. Работаю с сайтами на CMS OpenCart, WordPress, ModX и самописными. Кроме этого, работаю напрямую с JavaScript, PHP, CSS, HTML — то есть могу доработать ваш сайт или помочь с веб-программированием. Пишите сюда.
 заметки, си шарп, excel
заметки, си шарп, excel
Источник
Русские Блоги
Использование Visual Studio для Excel Разработка расширений VSTO: инструкции и основные операции
Разработать расширение VSTO для Excel
Excel должен быть эффективным инструментом, который мы обычно используем в нашей повседневной работе. Если вы хотите расширить больше бизнес-функций Excel, вы можете разработать расширения VSTO для Excel в среде разработки VS. Интерфейс Excel, после добавления вкладок и элементов управления в функциональную область Office, выполняет некоторые необходимые нам бизнес-функции: 
Новая надстройка Excel VSTO
Создайте новое приложение расширения Excel в VS. Если вы не найдете эту опцию, перейдите к установщику VS в красном поле и выберите вариант разработки Office (версия VS, которую я использую — 2015 и 2017) 
ThisAddIn.cs является основной точкой входа в программу расширения VSTO, которая предоставляет нам множество событий обратного вызова для использования

Щелкните правой кнопкой мыши в решении нового проекта, чтобы создать функциональную область для проекта Excel, эта функциональная область является пользовательским интерфейсом внешней программы Excel VSTO. 
Основные пространства имен и абстрактные типы
Узнайте о двух часто используемых библиотеках
При разработке VSTO часто используются две библиотеки:
- Пространство имен Interop.Excel
- Интерфейс COM, предоставляемый Microsoft для доступа к Excel, наиболее широко используется: он может использоваться для непосредственного чтения и записи содержимого в версии Excel для Windows, например:
- Получить все листы в Excel
- Получить Изменить ячейки в Excel
- Добавить страницу листа
- и многое другое
- Интерфейс COM, предоставляемый Microsoft для доступа к Excel, наиболее широко используется: он может использоваться для непосредственного чтения и записи содержимого в версии Excel для Windows, например:
- Tools.Excel namespace
- Это библиотека классов для расширения поддержки объектной модели Office Excel, с помощью которой вы можете комбинировать другие компоненты .NET с Excel для достижения некоторых функций, таких как:
- Используйте интерфейс ListObject, чтобы связать экземпляр DataTable с таблицей листов Excel.
- Используйте интерфейс Chart для добавления диаграммы в лист Excel
- Это библиотека классов для расширения поддержки объектной модели Office Excel, с помощью которой вы можете комбинировать другие компоненты .NET с Excel для достижения некоторых функций, таких как:
Понимать абстрактные типы в разработке Excel
1、Application
В программе VSTO интерфейс приложения представляет все приложение Excel
2、WorkSheet
Объект WorkSheet является членом набора объектов WorkSheets и является абстракцией страницы листа в Excel.
3、Range
Объект Range — это абстракция каждой ячейки в Excel или выделенной области, содержащей один или несколько блоков ячеек (эта область может быть непрерывной или прерывистой) )
Вышеупомянутые три элемента — три наиболее часто используемых абстрактных интерфейса для Excel в VSTO
Основная операция
В проекте Excel, в файле ThisAddIn и других файлах проекта,Способ чтения и записи элементов Excel отличается:
- В файле ThisAddIn.cs получить доступ к элементам в Excel и получить прямой доступ к нему с помощью приложения
- Однако в файлах не-ThisAddIn .cs, таких как событие кнопки новой ленты, если вы хотите получить доступ к элементу Excel, вы должны добавить Globals.ThisAddIn впереди, чтобы получить к нему обычный доступ.
- При нормальных обстоятельствах бизнес-операции вообще не будут выполняться в основной программе, поэтому все основные примеры операций в будущем будут приведены в соответствии с методом доступа неосновной программы:
Расширенные элементы управления Excel
Microsoft предоставляет несколько полезных расширенных элементов управления для Excel, которые могут помочь Excel выполнить более расширенные функции, такие как:
- Добавить таблицу на лист и связать источник данных
- Добавить диаграмму на лист и связать источник данных
- Подождите, как показано ниже:

1. Используйте ObjectList, чтобы расширить элемент управления на таблицу Excel и связать источник данных
Все операции, описанные выше, являются операциями над каждым отдельным элементом в Excel, но если есть одинисточник данныхНеобходимо связать с рабочим листом в Excel, это роль ListObject. Элемент управления ListObject поддерживает простое и сложное связывание данных, самое простое, например: например, связывание источника данных DataTable в памяти
Вариант использования 1: привязка DataTable к ObjectList
Добавление ListObject в WorkSheet of Excel с использованием программирования VSTO аналогично добавлению таблицы в Excel. Операция в Excel заключается в следующем:

Используя разработку кода в VSTO, эффект тот же:
Источник
Пошаговое руководство. Создание первой надстройки VSTO для Excel
Область применения: Visual Studio Visual Studio для Mac Visual Studio Code
В этом вводном пошаговом руководстве показано, как создавать надстройки уровня приложения для Microsoft Office Excel. Функции, создаваемые в подобном решении, доступны для приложения независимо от того, какие книги открыты.
Применимо к: Сведения в этом разделе относятся к проектам надстроек VSTO для Excel. Дополнительные сведения см. в разделе «Функции», доступные по Office приложению и типу проекта.
Заинтересованы в разработке решений, расширяющих возможности Office на нескольких платформах? Ознакомьтесь с новой моделью надстроек Office. Office надстройки имеют небольшое пространство по сравнению с надстройками и решениями VSTO, и их можно создавать с помощью практически любой технологии веб-программирования, таких как HTML5, JavaScript, CSS3 и XML.
В этом пошаговом руководстве описаны следующие задачи:
Создание проекта надстройки VSTO Excel для Excel.
Написание кода с использованием объектной модели Excel, которая при сохранении книги добавляет в нее текст.
Построение и запуск проекта для тестирования.
Удаление завершенного проекта для прекращения автоматического запуска надстройки VSTO на компьютере разработчика.
Отображаемые на компьютере имена или расположения некоторых элементов пользовательского интерфейса Visual Studio могут отличаться от указанных в следующих инструкциях. Это зависит от имеющегося выпуска Visual Studio и используемых параметров. Дополнительные сведения см. в разделе Персонализация среды IDE.
Предварительные требования
Для выполнения этого пошагового руководства требуются следующие компоненты:
Выпуск Visual Studio, включающий инструменты разработчика Microsoft Office. Дополнительные сведения см. в статье «Настройка компьютера для разработки Office решений».
Excel 2013 или Excel 2010.
Создание проекта
Создание проекта надстройки VSTO Excel в Visual Studio
Запустите Visual Studio.
В меню Файл выберите пункт Создать, а затем команду Проект.
В области шаблонов разверните узел Visual C# или Visual Basic, а затем узел Office/SharePoint.
В развернутом узле Office/SharePoint выберите узел Надстройки Office .
В списке шаблонов проектов выберите Надстройку Excel 2010 или Надстройку Excel 2013.
В поле Имя введите FirstExcelAddIn.
Нажмите кнопку ОК.
Visual Studio создает проект FirstExcelAddIn и открывает файл кода ThisAddIn в редакторе.
Написание кода для добавления текста в сохраненную книгу
Затем добавьте код в файл ThisAddIn. Новый код использует объектную модель Excel для вставки стандартного текста в первую строку активного листа. Активным является лист, открытый в момент сохранения книги пользователем. По умолчанию файл кода ThisAddIn содержит следующий созданный код:
Частичное определение класса ThisAddIn . Этот класс предоставляет точку входа для кода и обеспечивает доступ к объектной модели Excel. Дополнительные сведения см. в разделе «Программные надстройки VSTO». Оставшаяся часть ThisAddIn класса определена в скрытом файле кода, который не следует изменять.
Обработчики событий ThisAddIn_Startup и ThisAddIn_Shutdown . Эти обработчики событий вызываются, когда Excel загружает и выгружает надстройку VSTO. Их можно использовать для инициализации надстройки VSTO в процессе ее загрузки, а также для освобождения используемых надбавкой ресурсов при ее выгрузке. Дополнительные сведения см. в разделе «События» в проектах Office.
Добавление строки текста в сохраненную книгу
В файл кода ThisAddIn добавьте в класс ThisAddIn указанный ниже код. Новый код определяет обработчик событий для события WorkbookBeforeSave , которое возникает при сохранении книги.
Когда пользователь сохраняет книгу, обработчик событий добавляет новый текст в начало активного листа.
Если используется C#, добавьте в обработчик событий ThisAddIn_Startup указанный ниже код. Он используется для подключения обработчика событий Application_WorkbookBeforeSave к событию WorkbookBeforeSave .
Для изменения книги при ее сохранении в приведенных выше примерах кода используются следующие объекты:
Поле Application класса ThisAddIn . Поле Application возвращает объект Application , который представляет текущий экземпляр Excel.
Параметр Wb обработчика событий для события WorkbookBeforeSave . Параметр Wb является объектом Workbook , который представляет сохраняемую книгу. Дополнительные сведения см. в Excel обзоре объектной модели.
Тестирование проекта
Тестирование проекта
Нажмите клавишу F5 для построения и запуска проекта.
При построении проекта код компилируется в сборку, которая включается в выходную папку сборки для проекта. Visual Studio также создает ряд записей реестра, которые позволяют Excel обнаружить и загрузить надстройку VSTO, и настраивает параметры безопасности на компьютере разработчика, разрешая запуск надстройки VSTO. Дополнительные сведения см. в статье «Сборка Office решений».
Сохраните книгу в Excel.
Убедитесь, что в книгу добавляется указанный ниже текст.
Этот текст добавляется с помощью кода.
Очистка проекта
Завершив разработку проекта, удалите с компьютера сборку надстройки VSTO, записи реестра и параметры безопасности. В противном случае надстройка VSTO будет запускаться при каждом открытии программы Excel на компьютере разработчика.
Очистка завершенного проекта на компьютере разработчика
- В Visual Studio в меню Построение выберите пункт Очистить решение.
Дальнейшие действия
Теперь, когда вы создали базовую надстройку VSTO для Excel, изучите более подробную информацию о разработке надстроек VSTO в следующих разделах.
Общие задачи программирования, которые можно выполнять в надстройках VSTO: программные надстройки VSTO.
Задачи программирования, относящиеся к надстройкам VSTO Excel: Excel решения.
Использование объектной модели Excel: обзор Excel объектной модели.
Настройка пользовательского интерфейса Excel, например путем добавления настраиваемой вкладки на ленту или создания собственной настраиваемой области задач: Office настройки пользовательского интерфейса.
Создание и отладка надстроек VSTO для Excel: создание решений Office.
Развертывание надстроек VSTO для Excel: развертывание решения Office.
Источник
Сопоставление и сортировка данных в R или Excel
У меня есть список бактерий, каждая из которых имеет свое изобилие в данных. У меня также есть тот же список бактерий, но в другом порядке в том же кадре данных.
Я хочу сопоставить изобилие с этим вторым списком, но я не уверен, как это сделать.
dplyr содержит несколько методов для сортировки данных, но я не знаю, как сопоставить численность и вывести ее в новый столбец, чтобы он теперь соответствовал второму списку бактерий.
Вот начало моего набора данных:
Итак, численность соответствует данным в столбце Таксон, и я хочу, чтобы численность также сопоставлялась с бактериями в столбце «Советы».
Например, Acaricomes phytoseiuli имеет численность 0,000382414, поэтому в столбце D будет напечатано 0,000382414 рядом с местом, где находится Acaricomes phytoseiuli. Опять же, Таксон и Советы содержат точно такие же данные, только в другом порядке.
Я надеюсь, что в этом есть смысл.
Неважно, если это сделано в R или Excel, спасибо.
4 ответа
Как уже упоминали другие, сложно протестировать без каких-либо соответствующих данных, но что-то вроде этого должно работать, используя match для сопоставления значений.
В Excel в столбце D вы можете сделать следующее:
C3 — это TIP и A3: B13 диапазон, в котором он ищет это, A — имя бактерии и B численность и, если найдено, вернут соответствующее количество совпадений.
Если вы получили сообщение об ошибке #N/A , то совпадения нет. Вы также можете избежать этих ошибок, используя эту формулу:
Изменить . Настройте диапазоны для своего файла!
Изменить 2 . Имейте в виду, что я использую разделитель ; , и ваш Excel может использовать разделитель запятых ,
Прежде всего, если ваши столбцы Taxon и Tips содержат одни и те же данные, только в разном порядке, им не будет места вместе в одном фрейме данных. Вам нужно либо иметь два фрейма данных, либо придумать какой-то ключ, чтобы определить место элемента Таксона в филогенетическом дереве, а затем пересортировать фрейм данных по мере необходимости, либо в алфавитном порядке, либо по филогении. В качестве быстрого решения я сначала извлеку столбец Tips в отдельный фрейм данных, соединил его с исходным фреймом данных столбцами Tips и Taxon, получив таким образом правильный порядок значений численности в новом фрейме данных и (если вы все еще настаивать) с помощью cbind приклеить вновь пересортированный столбец чисел обратно в исходный фрейм данных. Примерно так, при условии, что вы используете dplyr (df — фиктивная замена для вашего набора данных):
Я предполагаю, что ваш список бактерий уникален как образец данных:
Теперь мы найдем ряды бактерий и вставим их содержание:
Источник
Я занимаюсь анализом данных в течение десяти лет. Первоначально, из-за потребностей работы, мой менеджер бросил мне кучу данных, и мне нужно было обработать данные. В то время я всегда использовал Excel, потому что это инструмент, которым я хорошо владею.
Три года назад я начал связываться с R. Сначала я решительно отказался от использования из-за слишком большого количества функций. Позже я начал думать о том, как его использовать. Сейчас я редко использую Excel. Это только мое личное мнение, но если вы хотите проанализировать данные, R более компетентен для этой задачи. Давайте поговорим о том, почему R больше подходит для анализа данных.

Эти два инструмента используются по-разному. При использовании Excel вы можетеЩелчок мышиВыполнив большую часть работы, вы можете получить доступ к различным инструментам в разных местах интерфейса. Поэтому Excel очень прост в использовании (практика делает идеальным), но использование Excel для обработки данных занимает очень много времени, и если вы берете на себя новый проект, вы должныПовторите эти процессы монотонно.При использовании R, тоЗавершите все операции через код, Вы загружаете данные в память, а затем запускаете сценарий для изучения и обработки данных. Этот инструмент может быть неудобным для пользователя, но он имеет следующие преимущества.
Я думаю, что концептуально R проще в использовании. Если вы имеете дело с несколькими столбцами данных, хотя вы имеете дело только с одной задачей, но вы увидите все данные. При использовании R данные находятся в памяти, и только данные могут быть просмотрены.Если вы выполняете преобразование или расчет, вы обработаете подмножество связанных столбцов или строк, а все остальные данные будут в фоновом режиме.Я думаю, что это облегчает сосредоточиться на задаче. После выполнения задачи вы можете сохранить ее во фрейме данных, который содержит только необходимые данные столбца или строки.Вы установили правильный набор данных для решения текущей проблемы.Это может показаться неуместным, но на самом деле это очень полезно.
С помощью R вы можете легко повторить ту же операцию с другими наборами данных. Поскольку все данные обрабатываются и изучаются с помощью кода, очень легко выполнять те же операции с новым набором данных. При использовании Excel большинство операций выполняются с помощью щелчков мыши, хотя пользовательский опыт хороший,Но повторение операций с новыми данными очень трудоемко и скучно. R нужно только загрузить новый набор данных и снова запустить скрипт.
Фактически,Код операции также легко диагностировать и обмениваться результатами анализа.При использовании Excel большинство результатов анализа основано на памяти (здесь находится сводная таблица, редактор формул находится в другой таблице и т. Д.). В R все операции выполняются через код с первого взгляда.
Если вы исправляете ошибку, вы точно знаете, где это сделать, и если вам нужно поделиться результатами анализа, просто скопируйте и вставьте код.При поиске помощи в Интернете вы можете точно описать используемые данные и задать конкретные вопросы. Фактически, в большинстве случаев, когда вы задаете вопросы онлайн, люди напрямую публикуют точные коды для решения ваших проблем.
Организация проекта в R проще.В Excel я хочу подготовить серию таблиц, а также может подготовить несколько рабочих книг с соответствующим именем, и каждое имя файла не должно повторяться.Мои заметки проекта хранятся в отдельных файлах. У моей организации проекта на языке R есть отдельная папка, и весь контент, который я обработал, помещается в нее. Очистить данные, исследовательские карты и модели. Это облегчает мне понимание и поиск, а также другим, кто работает со мной. Конечно, Excel также может быть организован. Я думаю, что простота R проще в использовании.
Можно сказать, что вышеперечисленные пункты являются лишь глазурью на торте, но не являются существенными. До этих функций я тоже несколько лет пользовался Excel, и вы должны быть такими же. Теперь я хочу поговорить о реальной разнице между R и Excel. Что я хочу сказать, так это то, что, помимо вышеперечисленных небольших преимуществ, R больше подходит для анализа данных. Причина в следующем.
Вы можете загрузить любые данные в R.Расположение или формат данных не важны. Вы можете загружать файлы CSV, читать JSON, выполнять запросы SQL или извлекать веб-сайты. Вы даже можете обрабатывать большие данные с помощью Hadoop в R.
R — полный набор инструментов, который использует пакеты данных. При анализе данных R более практичен, чем Excel.Для управления данными, классификации и регрессии вы можете использовать R. Вы также можете обрабатывать изображения и выполнять все другие операции.Если машинное обучение — ваша основная задача, то любой алгоритм, который вы можете придумать, — это кусок пирога. В настоящее время R имеет более 5000 доступных пакетов данных, поэтому независимо от того, какой тип данных вы хотите обработать, R легко справится с этим.

Эффект визуализации данных R превосходен. Честно говоря, диаграммы Excel превосходны и просты для понимания. Но R работает лучше.
Я думаю, что это одна из самых полезных функций R.С помощью ggplot2 вы можете быстро создавать различные диаграммы и настраивать их в соответствии с формой диаграммы.После того, как вы ознакомитесь с тем, как создать диаграмму с помощью ggplot2, любые другие диаграммы не станут проблемой. ggplot2 также может создавать больше типов диаграмм. Можете ли вы использовать Excel для создания матрицы рассеяния? Эта матрица может быть легко создана с помощью R, как и график CDF. Excel имеет значение.
Git контроль версий. Я всегда использовал для сохранения нескольких версий результатов анализа. Git — безусловно лучший инструмент, который я нашел. Используйте RStudio в качестве редактора, который поддерживает проект. Создайте хранилище проектов, и тогда вы сможете отслеживать разные версии исследования данных. Вы можете создавать разные версии файлов Excel, но эти сохраненные двоичные файлы не могут отображать изменения между собой.
R очень прост. Я сказал много причин. Коротко,Excel — хороший инструмент для анализа данных. Я считаю, что это может оправдать ожидания и выполнить все задачи. Однако, если у вас есть только один этот инструмент, это сильно повлияет на эффективность вашей работы.Напротив, R проще в использовании и обеспечивает более полный модуль набора инструментов. Недостатком является то, что не очень легко начать работу: пользователи изначально тратят много времени на изучение и использование.
Если вы будете упорны, вы получите что-то, не только лучше поймете данные, но и улучшите свои способности.
У каждого разные привычки использования: для анализа данных, будь то язык R или Excel, это хороший инструмент, если его можно эффективно использовать в работе.
End.

Библиотека
Аналитика рекламы
Power BI и К50:BI — что выбрать для анализа маркетинга и рекламы?
В этой статье мы рассмотрим два решения для сбора, визуализации и аналитики данных.
В этой статье мы рассмотрим два решения для сбора, визуализации и аналитики различных данных — Power BI и К50:BI.
Если вы уже используете Power BI, то K50:BI поможет упростить хранение, обработку данных и оперативно решать проблемы с недостающими коннекторами.
Если вы только думаете о подключении одной из этих систем, в статье мы расскажем об особенностях и преимуществах каждой из них.
Power BI — это комплексное программное обеспечение компании Microsoft, в которое входит несколько программных продуктов и web-сервисов для бизнес-аналитики (BI). Сервис позволяет собирать различные статистические данные, визуализировать их в удобном формате и принимать на их основе решения.
Используется по всему миру бизнес-аналитиками, владельцами бизнеса и маркетологами для различных целей, в зависимости от профиля и задач.

Пример дашборда разработанного в Power BI
K50:BI — это сервис по созданию и визуализации любых отчётов в сфере маркетинга и рекламы для аналитики и принятия бизнес-решений. Представляет собой единую систему по сбору, обработке, хранению и визуализации данных. Сервис позволяет строить отчёты для решения различных задач:
- Мониторинг эффективности рекламных каналов.
- Предоставление информации о бизнесе: остатки на складе, продажи и многое другое.
- Построение сквозной аналитики.

Пример дашборда разработанного в K50:BI
Также сервис может использоваться в качестве ETL-системы, собирая и предобрабатывая данные, и отправлять их в системы визуализации: Power BI, Google Data Studio или Excel.
Как устроена инфраструктура сервисов PBI и K50:BI?
Как построить отчёт в Power BI
Power BI состоит из приложения для Microsoft Windows — Power BI Desktop, службы Power BI (веб-службы SaaS), и мобильных приложений Power BI. Power BI позволяет работать с данными из таблиц Excel, локальных и облачных хранилищ, а также использовать информацию с сайтов и сервисов, в которых есть возможность экспортировать данные через API.
Для построения отчёта необходимо:
- Указать в системе ссылки на источники, из которых нужно получить данные, и загрузить их через запросы.
- Обозначить, какой именно набор данных нужно скачать.
- Настроить связи между данными из источников, чтобы их корректно объединить, и преобразования, которые нужно с ними сделать (например, прибавлять НДС к расходам).
- Визуализировать данные. Можно выбрать, каким образом будут разбиты данные, и в каком виде их отобразить.

Эти операции придётся проделывать отдельно для каждого источника. К примеру, вы не сможете сохранить названия полей и применить эти настройки к 60 источникам. Каждый раз придётся заново их указывать вручную.
Чтобы добавить в сформированный отчёт новый источник, необходимо сначала вручную его добавить в систему для скачивания, а потом также вручную добавить данные источника в отчёт.
Визуализация
Power BI предоставляет широкий выбор визуализаций как в самом сервисе, так и на дополнительных ресурсах. Это различные виды диаграмм, графиков, карт, таблиц и других визуальных элементов. Также пользователи сервиса могут скачать дополнительные визуализации с сайта сообщества Microsoft AppSource, созданные самой корпорацией и членами сообщества.

Панель визуализаций в Power BI

Ленточная диаграмма

Карты ArcGIS
Хранение данных
Сервис ограничивает объём хранения на один проект (1 гб в тарифе Pro, 10 гб в тарифе Premium) и максимальный объём хранилища (10 ГБ на пользователя в тарифе Pro, 100 ТБ в тарифе Premium).
Бесплатная версия сервиса не позволяет часто обновлять отчёты и работать с большим объёмом данных.
Коннекторы
Определённую сложность при работе с Power BI составляет разработка и поддержание коннекторов к рекламным и веб-аналитическим системам, к которым нет готовых коннекторов. Чтобы решить эту проблему, нужен квалифицированный специалист с высоким уровнем экспертности для написания коннекторов и поддержки выстроенной системы.
К части российских систем можно найти самописные решения. Их разрабатывают эксперты-энтузиасты. Зачастую такие коннекторы распространяются бесплатно.
При использовании и разработке коннекторов не стоит забывать и об их поддержании. Если API у подключенной рекламной/аналитической системы изменится, Power BI перестанет корректно работать. Если коннектор был разработан вами, его необходимо будет обновить. Если вы используете бесплатный коннектор, то обновится он до последней версии API или нет — будет зависеть от разработчиков.
Как строится работа в K50:BI
K50:BI универсальный сервис. Клиентам не нужно думать о том, как скачивать и хранить данные.
Добавить новый источник можно также в несколько кликов, после чего он автоматически появится в отчёте после скачивания, и с ним сразу можно будет работать.
Также при обработке нескольких источников, нужно всего один раз указать в настройках тип данных, которые необходимо скачать (например, даты и клики по рекламным объявлениям). После этого можно применить эти условия ко всем рекламным аккаунтам.
Визуализация
В K50:BI довольно большой выбор визуализаций отчётов, хотя и не такой обширный как в Power BI. На одном дашборде можно располагать графики и виджеты по различным системам. Это даёт возможность оценивать эффективность рекламных кампаний в целом.
Также мы разработали коннекторы к Google Data Studio, Google BigQuery, Excel и Power BI. Теперь мы можем передавать уже обработанные данные в Power BI, чтобы вы могли при желании визуализировать их там.

Пример дашборда разработанного в K50:BI
Хранение данных
Данные хранятся на серверах К50. Лимитов по общему объёму данных или объёму отчётов в К50 нет.
Коннекторы
Ко всем популярным рекламным системам и социальным сетям уже есть готовые коннекторы.

Доступные источники данных
Если необходимо разработать коннектор к системе, которого у нас ещё нет, мы можем это реализовать. Клиент получает кнопочное решение, с помощью которого можно скачивать данные в несколько кликов.
Также стоит отметить, что мы сами поддерживаем свои коннекторы, и если API изменится, мы их оперативно обновим. Клиентам не нужно за этим следить.
Сэмплинг данных из Google Analytics
При работе с большими объёмами данных, бесплатная версия Google Analytics анализирует только часть данных, чтобы снизить нагрузку на серверы и решать эту задачу с приемлемой скоростью. Сэмплинг негативно влияет на точность аналитики, но стоимость платной версии довольно высокая, поэтому ей редко пользуется малый и средний бизнес.
Power BI не решает эту проблему. Чтобы получить необходимую BI-отчётность для средних и крупных организаций, нужно самостоятельно реализовать один из следующих вариантов:
- Можно использовать готовые сервисы для стриминга данных. Их основное предназначение — выгрузка данных из системы аналитики, различных рекламных систем, CRM и других сервисов в какое-либо хранилище. Удобно, быстро и практично, но не бесплатно. На больших объёмах данных или данных со множеством источников суммы довольно большие.
- Если перечисленные инструменты обходятся компании слишком дорого, можно попробовать реализовать свою систему выгрузки данных и использовать Power BI + Python + Любой Cloud Server (или Яндекс.Облако) + PostgreSQL.
- Можно найти бесплатные коннекторы с открытым кодом, которые выкачивают данные постранично. Опять же для внедрения подобных решений нужны квалифицированные специалисты.
В К50:BI проблема сэмплинга данных из Google Analytics успешно решается выкачиваем данных отдельно по дням. Для этого мы используем Google Analytics Core Reporting API. Функционал уже реализован на нашей стороне. Никаких специальных навыков для его использования не требуется.
Как делиться данными
В тарифе Pro Power BI позволяет предоставлять доступ к отчётам лицензированным пользователям. Правда, придётся платить $9.99 в месяц за каждого. Тариф Premium позволяет распространять данные без ограничений, но он обойдётся в $4,995 в месяц.
В K50:BI можно дать доступ любому пользователю, и он сможет просматривать в интерфейсе сервиса всё без ограничений. Это никак не отражается на цене.
Информационная и техническая поддержка
У Power BI есть развёрнутая справка про продукт, пошаговое обучение и ответы на типичные вопросы в текстовом варианте на русском языке, вебинары и чат пользователей на английском языке. Об ошибках можно сообщать в support.
В K50:BI также есть обширная справка на сайте, в которой кроме подробного описания есть кейс в текстовом формате и видеомануал по настройке дашборда.
Если тариф подразумевает персонального менеджера, он поможет в настройке и оперативно проконсультирует по любым вопросам. Технические вопросы также решаются через менеджера.
В остальных тарифах коммуникация происходит через чат поддержки на сайте. В любом варианте вы получаете своевременную помощь.
Заключение
Power BI помогает выполнять обширный круг задач, предлагает большое количество визуализаций, а интерфейс сервиса знаком и удобен для многих аналитиков. К50:BI в свою очередь разрабатывался специально для анализа маркетинга и рекламы на российском рынке, в том числе чтобы максимально упростить работу профильных специалистов. Сервис позволяет выполнять большинство задач в несколько кликов, не обладая специальными навыками.
При работе с К50:BI не нужно заботиться о разработке коннекторов, хранении данных и поддержке системы. Всё это реализуется на стороне К50. Сервис позволяет быстро начать работу, получать точные результаты и без ограничений делиться отчётами со всеми коллегами и партнёрами. Кроме того, наша поддержка поможет в настройке и при необходимости разработает для вас персональные решения.
K50: BI можно использовать и как самостоятельный сервис, и как ETL-решение для Power BI, которое решит вопросы с коннекторами и хранением данных. Это позволит освободить время специалистов, которые тратится на решение этих задач и обеспечить более стабильную работу самой системы.
Что ещё почитать
У меня есть список бактерий, каждая из которых имеет свое изобилие в данных. У меня также есть тот же список бактерий, но в другом порядке в том же кадре данных.
Я хочу сопоставить изобилие с этим вторым списком, но я не уверен, как это сделать.
dplyr содержит несколько методов для сортировки данных, но я не знаю, как сопоставить численность и вывести ее в новый столбец, чтобы он теперь соответствовал второму списку бактерий.
Вот начало моего набора данных:
Taxon Total_abundance Tips
Acaricomes phytoseiuli 0.000382414 Methanothermobacter thermautotrophicus
Acetivibrio cellulolyticus 0.013979274 Methanobacterium beijingense
Acetobacter aceti 0.181150551 Methanobacterium bryantii
Acetobacter estunensis 0.023074895 Methanosarcina mazei
Acetobacter tropicalis 0.014615221 Persephonella marina
Achromobacter piechaudii 0.031811039 Sulfurihydrogenibium azorense
Achromobacter xylosoxidans 0.041558442 Balnearium lithotrophicum
Acidicapsa borealis 0.035525932 Isosphaera pallida
Acidimicrobium ferrooxidans 0.013841209 Simkania negevensis
Acidiphilium angustum 0.041702984 Parachlamydia acanthamoebae
Acidiphilium cryptum 0.039265944 Leptospira biflexa
Acidiphilium rubrum 0.041702984 Leptospira fainei
...
Итак, численность соответствует данным в столбце Таксон, и я хочу, чтобы численность также сопоставлялась с бактериями в столбце «Советы».
Например, Acaricomes phytoseiuli имеет численность 0,000382414, поэтому в столбце D будет напечатано 0,000382414 рядом с местом, где находится Acaricomes phytoseiuli. Опять же, Таксон и Советы содержат точно такие же данные, только в другом порядке.
Я надеюсь, что в этом есть смысл.
Неважно, если это сделано в R или Excel, спасибо.
4 ответа
Лучший ответ
Как уже упоминали другие, сложно протестировать без каких-либо соответствующих данных, но что-то вроде этого должно работать, используя match для сопоставления значений.
df$D <- df$Total_abundance[ match( df$Tips, df$Taxon ) ]
1
rosscova
21 Фев 2018 в 12:16
В Excel в столбце D вы можете сделать следующее:
=VLOOKUP(C3;A3:B13;2;FALSE)
C3 — это TIP и A3: B13 диапазон, в котором он ищет это, A — имя бактерии и B численность и, если найдено, вернут соответствующее количество совпадений.
Если вы получили сообщение об ошибке #N/A, то совпадения нет. Вы также можете избежать этих ошибок, используя эту формулу:
=IFNA(VLOOKUP(C3;$A$3:B13;2;FALSE);"No match")
Изменить . Настройте диапазоны для своего файла!
Изменить 2 . Имейте в виду, что я использую разделитель ;, и ваш Excel может использовать разделитель запятых ,
1
MONZTAAA
21 Фев 2018 в 12:25
Прежде всего, если ваши столбцы Taxon и Tips содержат одни и те же данные, только в разном порядке, им не будет места вместе в одном фрейме данных. Вам нужно либо иметь два фрейма данных, либо придумать какой-то ключ, чтобы определить место элемента Таксона в филогенетическом дереве, а затем пересортировать фрейм данных по мере необходимости, либо в алфавитном порядке, либо по филогении. В качестве быстрого решения я сначала извлеку столбец Tips в отдельный фрейм данных, соединил его с исходным фреймом данных столбцами Tips и Taxon, получив таким образом правильный порядок значений численности в новом фрейме данных и (если вы все еще настаивать) с помощью cbind приклеить вновь пересортированный столбец чисел обратно в исходный фрейм данных. Примерно так, при условии, что вы используете dplyr (df — фиктивная замена для вашего набора данных):
df <- data.frame(Taxon=c("a","b","c","d","e"), Abundance=c(1:5), Tips=c("b","a","d","c","e"))
new_df <- select(df, Tips)
new_df <- left_join(new_df, df, by=c("Tips"= "Taxon"))
df <- cbind(df, New_Abund=new_df$Abundance)
rm(new_df)
0
lontche
21 Фев 2018 в 13:46
Я предполагаю, что ваш список бактерий уникален как образец данных:
dff <- data.frame(bacteria1=letters[1:10], abundance1=runif(10,0,1),
bacteri2=sample(letters[1:10],10), abundance2=0)
Теперь мы найдем ряды бактерий и вставим их содержание:
for(i in 1:nrow(dff)){
s <- which(dff$bacteri2[i]==dff$bacteria1)
dff$abundance2[i] <- dff$abundance1[s]
}
1
Mahdi Baghbanzadeh
21 Фев 2018 в 12:16
Давайте научимся быстро и просто создавать и записывать файлы Excel с помощью visual studio c#. Наше самое простое приложение Windows Forms будет брать из текстбокса текст и заносить его в первую ячейку. Статья написана специально для Сергея =).
Начать необходимо с подключения библиотеки Microsoft.Office.Interop.Excel. Выглядеть это должно так:
Если у вас при открытии обозревателя решений – Ссылки – правая кнопка – Добавить ссылку – Сборки – в списке нет Microsoft.Office.Interop.Excel, то добавьте её через Nuget. Проект – управление пакетами NuGet – в строке поиска Excel:
Теперь создайте новый проект Windows Forms и на форму закиньте текстбокс и кнопку. На кнопки кликните два раза, откроется исходный код. В самом верху допишите следующее:
using Excel = Microsoft.Office.Interop.Excel;
А в методе button1_Click замените так:
private void button1_Click(object sender, EventArgs e)
{
string fileName = "D:\temp\test.xls";
try
{
var excel = new Excel.Application();
var workBooks = excel.Workbooks;
var workBook = workBooks.Add();
var workSheet = (Excel.Worksheet)excel.ActiveSheet;
workSheet.Cells[1, "A"] = textBox1.Text;
workBook.SaveAs(fileName);
workBook.Close();
}
catch (Exception ex) {
MessageBox.Show("Ошибка: "+ ex.ToString());
}
MessageBox.Show("Файл "+ Path.GetFileName (fileName) + " записан успешно!");
}
Вот, собственно говоря и все. Текст из текстбокса запишется в ячейку A1. Обратите внимание, что папка temp на диске уже должна существовать.
Дополнение. Прочитать первую ячейку
Это тоже просто:
string fileName = "D:\temp\test.xls"; Excel.Application xlApp = new Excel.Application(); Excel.Workbook xlWorkbook = xlApp.Workbooks.Open(fileName, 0, true, 5, "", "", true, Excel.XlPlatform.xlWindows, "t", false, false, 0, true, 1, 0); Excel._Worksheet xlWorksheet = (Excel._Worksheet)xlWorkbook.Sheets[1]; Excel.Range xlRange = xlWorksheet.UsedRange; string temp = (string)(xlRange.Cells[1, 1] as Excel.Range).Value2;// 1 1 - адрес 1-й ячейки MessageBox.Show(temp);
Автор этого материала — я — Пахолков Юрий. Я оказываю услуги по написанию программ на языках Java, C++, C# (а также консультирую по ним) и созданию сайтов. Работаю с сайтами на CMS OpenCart, WordPress, ModX и самописными. Кроме этого, работаю напрямую с JavaScript, PHP, CSS, HTML — то есть могу доработать ваш сайт или помочь с веб-программированием. Пишите сюда.
![]() заметки, си шарп, excel
заметки, си шарп, excel