
I have the following regular expression, that I am compiling with Pattern class.
bIntegrateds+Healths+Systems+(IHS)b
Why is this not matching this string?
«test pattern case Integrated Health System (IHS).»
If I try bpatternb, it seems to work, but for the above phrase it does not. I have the parenthesis in the pattern escaped, so not sure why it doesn’t work. It does match if I remove the parenthesis portion of the pattern, but I want to match the whole thing.
asked Jan 5, 2010 at 23:22
![]()
EqbalEqbal
4,67212 gold badges37 silver badges45 bronze badges
4
1) escape the parens, otherwise they are capturing and group metacharacters, not literal parenthesis ( )
2) remove the final b you can’t use a word boundary after a literal ), since ) is not considered part of a word.
bIntegrateds+Healths+Systems+(IHS)W
answered Jan 5, 2010 at 23:26
![]()
Paul CreaseyPaul Creasey
28.2k10 gold badges54 silver badges90 bronze badges
6
You’ve got (IHS) — a group — where you want (IHS) as the literal brackets.
answered Jan 5, 2010 at 23:24
![]()
cyborgcyborg
5,6081 gold badge19 silver badges25 bronze badges
You need to escape the parentheses
bIntegrateds+Healths+Systems+(IHS)b
Parentheses delimit a capture group. To match a literal set of parentheses, you can escape them like this ( )
answered Jan 5, 2010 at 23:24
![]()
mopokemopoke
10.5k1 gold badge31 silver badges31 bronze badges
1
In this Java regex word boundary example, we will learn to match a specific word in a string. e.g. We will match “java” in “java is object oriented language”. But it should not match “javap” in “javap is another tool in JDL bundle”.
1. java regex word boundary matchers
Boundary matchers help to find a particular word, but only if it appears at the beginning or end of a line. They do not match any characters. Instead, they match at certain positions, effectively anchoring the regular expression match at those positions.
The following table lists and explains all the boundary matchers.
| Boundary token | Description |
|---|---|
^ |
The beginning of a line |
$ |
The end of a line |
b |
A word boundary |
B |
A non-word boundary |
A |
The beginning of the input |
G |
The end of the previous match |
Z |
The end of the input but for the final terminator, if any |
z |
The end of the input |
Solution Regex : bwordb
The regular expression token "b" is called a word boundary. It matches at the start or the end of a word. By itself, it results in a zero-length match.
Strictly speaking, “b” matches in these three positions:
- Before the first character in the data, if the first character is a word character
- After the last character in the data, if the last character is a word character
- Between two characters in the data, where one is a word character and the other is not a word character
To run a “spcific word only” search using a regular expression, simply place the word between two word boundaries.
String data1 = "Today, java is object oriented language";
String regex = "\bjava\b";
Pattern pattern = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(data1);
while (matcher.find())
{
System.out.print("Start index: " + matcher.start());
System.out.print(" End index: " + matcher.end() + " ");
System.out.println(matcher.group());
}
Output:
Start index: 7 End index: 11 java
Please note that matching above regex with “Also, javap is another tool in JDL bundle” doesn’t produce any result i.e. doesn’t match any place.
3. Java regex to match word with nonboundaries – contain word example
Suppose, you want to match “java” such that it should be able to match words like “javap” or “myjava” or “myjavaprogram” i.e. java word can lie anywhere in the data string. It could be start of word with additional characters in end, or could be in end of word with additional characters in start as well as in between a long word.
"B" matches at every position in the subject text where "B" does not match. "B" matches at every position that is not at the start or end of a word.
To match such words, use below regex :
Solution Regex : \Bword|word\B
String data1 = "Searching in words : javap myjava myjavaprogram";
String regex = "\Bjava|java\B";
Pattern pattern = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(data1);
while (matcher.find())
{
System.out.print("Start index: " + matcher.start());
System.out.print(" End index: " + matcher.end() + " ");
System.out.println(matcher.group());
}
Output:
Start index: 21 End index: 25 java
Start index: 29 End index: 33 java
Start index: 36 End index: 40 java
Please note that it will not match “java” word in first example i.e. “Today, java is object oriented language” because “\B” does not match start and end of a word.
3. Java regex to match word irrespective of boundaries
This is simplest usecase. You want to match “java” word in all four places in string “Searching in words : java javap myjava myjavaprogram”. To able to do so, simply don’t use anything.
Solution regex : word
String data1 = "Searching in words : java javap myjava myjavaprogram";
String regex = "java";
Pattern pattern = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(data1);
while (matcher.find())
{
System.out.print("Start index: " + matcher.start());
System.out.print(" End index: " + matcher.end() + " ");
System.out.println(matcher.group());
}
Output:
Start index: 21 End index: 25 java
Start index: 26 End index: 30 java
Start index: 34 End index: 38 java
Start index: 41 End index: 45 java
That’s all for this java regex contain word example related to boundary and non-boundary matches of a specific word using java regular expressions.
Happy Learning !!
References:
Java regex docs
Java RegEx – OR Condition example shows how to specify OR condition in Java regular expression pattern. The logical OR in regex is specified by the pipe (“|”) character.
How to specify an OR condition in the Java regex pattern?
Many times we want to find patterns that may have alternate forms. For example, we could be looking for either the word dog or cat in a string content. This can be achieved using the logical OR condition in Java regular expression.
The pipe (“|”) character is used to specify the OR condition in the regex pattern. For example, if you are looking for a character ‘a’, ‘b’, or ‘c’, then you can write an OR condition in the pattern like given below.
The above pattern means ‘a’, ‘b’, OR ‘c’. Now consider below-given example pattern that uses the OR condition.
It means ‘c’, ‘b’, OR ‘c’ as the first character that is followed by characters ‘a’ and ‘t’. This pattern will match with all three words “cat”, “bat”, and “fat”.
Let’s move on to a somewhat difficult pattern as compared to the above one. Suppose you want to validate a number that should be between 1 and 35 (both inclusive). For this, you can write a pattern using the logical OR condition like below.
|
^[1-9]|1[0-9]|2[0-9]|3[0-5]$ |
Where,
|
^ — Start of the string [1-9] — Any digit from 1 to 9 (covers 1 to 9 number) | — OR 1[0-9] — Digit 1 followed by any digit between 0 to 9 (covers 10 to 19 numbers) | — OR 2[0-9] — Digit 2 followed by any digit between 0 to 9 (covers 20 to 29 numbers) | — OR 3[0-5] — Digit 3 followed by any digit between 0 to 5 (covers 30 to 35 numbers) $ — End of the String |
Let’s test this pattern against some numbers.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
package com.javacodeexamples.regex; public class RegExORConditionExample { public static void main(String[] args) { String[] strNumbers = { «0», «36», «19», «40», «100», «1000», «10», «1», «35», «11», «22», «30» }; String strPattern = «^[1-9]|1[0-9]|2[0-9]|3[0-5]$»; for(String strNumber : strNumbers) { System.out.println(strNumber + » => « + strNumber.matches(strPattern)); } } } |
Output
|
0 => false 36 => false 19 => true 40 => false 100 => false 1000 => false 10 => true 1 => true 35 => true 11 => true 22 => true 30 => true |
As you can see from the output, our pattern worked perfectly for the numbers between 1 and 35. It did not match with the numbers below 1 and above 35 as per our pattern having OR conditions.
If you want to learn more about the regular expressions, you can visit the full Java RegEx tutorial.
Please let me know your views in the comments section below.
About the author
- Author
- Recent Posts
Rahim
I have a master’s degree in computer science and over 18 years of experience designing and developing Java applications. I have worked with many fortune 500 companies as an eCommerce Architect. Follow me on LinkedIn and Facebook.
Java Regex является официальным API регулярных выражений Java. Находится в пакете java.util.regex, который является частью стандартной JSE начиная с версии 1.4.
Регулярное выражение – это текстовый шаблон, используемый для поиска в тексте. Вы делаете это путем «сопоставления» его с текстом. Результат:
- Значение true / false, указывающее соответствует ли регулярное выражение тексту.
- Набор совпадений – одно совпадение для каждого вхождения, найденного в тексте.
Например, вы можете использовать регулярное выражение для поиска в строке адресов электронной почты, URL-адресов, телефонных номеров, дат и т. д. Это можно сделать путем сопоставления различных выражений со строкой. Результатом сопоставления каждого из них будет набор совпадений – один набор совпадений для каждого выражения (может совпадать более одного раза).
Java Regex Core Classes
Состоит из двух основных классов:
- Шаблон (java.util.regex.Pattern)
- Соответствия (java.util.regex.Matcher)
Класс Pattern используется для создания шаблонов. Шаблон – это предварительно скомпилированное регулярное выражение в форме объекта (как экземпляр шаблона), способное сопоставляться с текстом.
Класс Matcher используется для сопоставления заданного экземпляра Pattern с текстом несколько раз. Другими словами, искать несколько вхождений в тексте. Matcher скажет вам, где в тексте (индекс символа) он нашел вхождения. Вы можете получить экземпляр Matcher из экземпляра Pattern.
Пример Pattern
Вот простой пример, чтобы проверить, содержит ли текст подстроку http: //:
String text =
"This is the text to be searched " +
"for occurrences of the http:// pattern.";
String regex = ".*http://.*";
boolean matches = Pattern.matches(regex, text);
System.out.println("matches = " + matches);
Текстовая переменная содержит текст для проверки с помощью регулярного выражения.
Переменная pattern содержит выражение в виде String. Оно соответствует всем текстам, содержащим один или несколько символов (. *), за которыми следует текст http: //, а за ним следует один или несколько символов (. *).
В третьей строке используется статический метод Pattern.matches(), чтобы проверить, соответствует ли шаблон тексту. Если да, то Pattern.matches() возвращает true. Если нет, false.
В этом примере фактически не проверяется, является ли найденная строка http: // частью действительного URL с именем домена и суффиксом (.com, .net и т. д.).
Пример Matcher
Используем класс Matcher для поиска нескольких вхождений подстроки «is» внутри текста:
String text =
"This is the text which is to be searched " +
"for occurrences of the word 'is'.";
String regex = "is";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(text);
int count = 0;
while(matcher.find()) {
count++;
System.out.println("found: " + count + " : "
+ matcher.start() + " - " + matcher.end());
}
Из экземпляра Pattern получается экземпляр Matcher. С помощью него пример находит все вхождения регулярного выражения в тексте.
Синтаксис
Сопоставление символов
Первое, на что нужно обратить внимание – как написать регулярное выражение, которое сопоставляет символы с заданным текстом. Например, выражение, определенное здесь:
String regex = "http://";
будет соответствовать всем строкам, которые точно соответствуют ему. Не может быть символов до или после http: // – или выражение не будет соответствовать тексту. Например, приведенный выше синтаксис будет соответствовать этому тексту:
String text1 = "http://";
Но не этот текст:
String text2 = "The URL is: http://mydomain.com";
Вторая строка содержит символы как до, так и после http: //, с которым сопоставляется.
Метасимволы
Метасимволы – это символы в выражении, которые интерпретируются как имеющие специальные значения. Эти метасимволы:
| < | > | ( | ) | [ |
| ] | { | } | ^ | |
| – | = | $ | ! | | |
| ? | * | + | . |
Если вы включите, например, “.” (Fullstop) в выражение, оно не будет соответствовать символу fullstop, но будет соответствовать чему-то еще, что определено этим метасимволом.
Экранирование метасимволов
Если вы действительно хотите сопоставить эти символы в их буквальной форме, а не в значении метасимвола, вы должны «экранировать» метасимвол, которому хотите соответствовать. Для этого вы используете escape-символ – символ обратной косой черты. Выход из символа означает предшествующий ему символ обратной косой черты. Например, вот так:
.
В этом примере. символу предшествует (экранированный) символ . После экранирования символ полной остановки будет фактически соответствовать символу полной остановки во входном тексте. Особое значение метасимвола для экранированного метасимвола игнорируется – используется только его фактическое буквальное значение (например, точка полного останова).
Синтаксис использует символ обратной косой черты в качестве escape-символа, как это делают строки. Это немного затрудняет написание выражения в строке. Посмотрите на этот пример:
String regex = "\.";
Обратите внимание, что выражение String содержит две обратные косые черты друг за другом, а затем .
Причина в том, что сначала компилятор интерпретирует два \ символа как экранированный символ Java String. После завершения компиляции остается только один , поскольку \ означает символ . Таким образом, строка выглядит так:
.
Теперь включается интерпретатор выражений и интерпретирует оставшуюся обратную косую черту как escape-символ. Следующий персонаж. теперь интерпретируется как фактическая полная остановка, а не специальное регулярное выражение, означающее, что оно имеет иное значение. Таким образом, оставшееся выражение соответствует символу полной остановки и ничего более.
Несколько символов имеют особое значение в синтаксисе. Если вы хотите сопоставить этот явный символ и не использовать его с его специальным значением, вам нужно сначала экранировать его с помощью символа обратной косой черты. Например, чтобы соответствовать символу полной остановки, вам нужно написать:
String regex = "\.";
Чтобы соответствовать самому символу обратной косой черты, вам нужно написать:
String regex = "\\";
Получить экранирование символов в выражениях может быть сложно.
Соответствие любому символу
Вы можете просто сопоставить любой символ, независимо от того, какой он. Синтаксис позволяет делать это, используя. символ (точка / полная остановка). Вот пример:
String regex = ".";
Это выражение соответствует одному символу, независимо от того, какой это символ.
. символ может быть объединен с другими для создания более сложных выражений:
String regex = "H.llo";
Это регулярное выражение будет соответствовать любой строке Java, которая содержит символы «H», за которыми следует любой символ, за которым следуют символы «llo». Таким образом, это регулярное выражение будет соответствовать всем строкам “Hello”, “Hallo”, “Hullo”, “Hxllo” и т. Д.
Соответствие любому из набора символов
Поддерживается сопоставление любого из указанного набора символов, используя так называемые классы символов. Вот пример класса символов:
String regex = "H[ae]llo";
Класс символов (набор символов для сопоставления) заключен в квадратные скобки – другими словами, часть выражения [ae]. Квадратные скобки не совпадают – только символы внутри них.
Класс символов будет соответствовать одному из вложенных символов независимо от того, какой, но не более одного. Таким образом, приведенное выше выражение будет соответствовать любой из двух строк «Hallo» или «Hello», но никаких других строк. Только «а» или «е» допускается между «Н» и «llo».
Вы можете сопоставить диапазон символов, указав первый и последний символ в диапазоне с тире между ними. Например, класс символов [az] будет соответствовать всем символам между строчными буквами a и строчными буквами z, включая a и z.
Вы можете иметь более одного диапазона символов в пределах класса символов. Например, класс символов [a-zA-Z] будет соответствовать всем буквам между a и z или между A и Z.
Вы также можете использовать диапазоны для цифр. Например, класс символов [0-9] будет соответствовать символам от 0 до 9, включая оба.
Если вы действительно хотите сопоставить одну из квадратных скобок в тексте, вам нужно будет их избежать. Вот как выглядят экранирующие квадратные скобки:
String regex = "H\[llo";
\ [является левой квадратной скобкой Это выражение будет соответствовать строке “H [llo”.
Если вы хотите сопоставить квадратные скобки внутри класса символов, вот как это выглядит:
String regex = "H[\[\]]llo";
Класс символов – это часть: [\ [\]]. Он содержит две квадратных скобки(\ [и \]). Будет соответствовать строкам “H [llo” и “H] llo”.
Соответствие диапазону символов
Можно указать диапазон символов для сопоставления. Задать диапазон символов проще, чем явно указать каждый символ для сопоставления. Например, вы можете сопоставить символы от a до z следующим образом:
String regex = "[a-z]";
Это выражение будет соответствовать любому отдельному символу от a до z в алфавите.
Классы символов чувствительны к регистру. Чтобы сопоставить все символы от a до z независимо от регистра, вы должны включить как прописные, так и строчные диапазоны:
String regex = "[a-zA-Z]";
Соответствующие цифры
Вы можете сопоставить цифры номера с предопределенным классом символов с помощью кода d. Класс символов цифр соответствует классу символов [0-9].
Поскольку символ также является escape-символом, вам нужно две обратные косые черты в строке, чтобы получить d в выражении:
String regex = "Hi\d";
Это регулярное выражение будет соответствовать строкам, начинающимся с «Hi», за которым следует цифра (от 0 до 9). Таким образом, он будет соответствовать строке «Hi5», но не строке «Hip».
Соответствие не цифр
Совпадение не цифр может быть сделано с помощью предопределенного класса символов [ D] (заглавная D):
String regex = "Hi\D";
Будет соответствовать любой строке, которая начинается с «Hi», за которым следует один символ, который не является цифрой.
Соответствующие слова
Вы можете сопоставить символы слова с предопределенным классом символов с кодом w. Слово символьный класс соответствует классу символов [a-zA-Z_0-9].
String regex = "Hi\w";
Будет соответствовать любой строке, которая начинается с «Hi», за которым следует символ одного слова.
Соответствующие несловесные символы
Вы можете сопоставить несловесные символы с предопределенным классом символов [ W] (заглавными буквами W). Поскольку символ также является escape-символом, вам нужно две обратные косые черты в строке, чтобы получить w:
String regex = "Hi\W";
Границы
Java Regex API также может соответствовать границам в строке, а именно началом или концом строки, началом слова и т. д. API Java Regex поддерживает следующие границы:
| Символ | Описание |
|---|---|
| ^ | Начало строки |
| $ | Конец строки |
| b | Граница слова (где слово начинается или заканчивается, например, пробел, табуляция и т. д.). |
| B | Несловесная граница |
| A | Начало ввода. |
| G | Конец предыдущего совпадения |
| Z | Конец ввода, кроме конечного объекта (если есть) |
| z |
Начало строки
Соответствие границ ^ соответствует началу строки в соответствии со спецификацией API Java. Например, следующий пример получает только одно совпадение с индексом 0:
String text = "Line 1nLine2nLine3";
Pattern pattern = Pattern.compile("^");
Matcher matcher = pattern.matcher(text);
while(matcher.find()){
System.out.println("Found match at: " + matcher.start() + " to " + matcher.end());
}
Даже если входная строка содержит несколько разрывов строк, символ ^ соответствует только началу входной строки, а не началу каждой строки (после каждого переноса строки).
Начало соответствия строки / строки часто используется в сочетании с другими символами, чтобы проверить, начинается ли строка с определенной подстроки. Например, этот пример проверяет, начинается ли строка ввода с подстроки http: //:
String text = "http://jenkov.com";
Pattern pattern = Pattern.compile("^http://");
Matcher matcher = pattern.matcher(text);
while(matcher.find()){
System.out.println("Found match at: " + matcher.start() + " to " + matcher.end());
}
В этом примере найдено одно совпадение подстроки http: // из индекса 0 в индекс 7 во входном потоке. Даже если бы входная строка содержала больше экземпляров подстроки http: //, они не соответствовали бы этому регулярному выражению, так как оно начиналось с символа ^.
Конец строки
Соответствие $ соответствует концу строки в соответствии со спецификацией Java. На практике, однако, похоже, что он соответствует только концу входной строки.
Соответствие начала строки часто используется в сочетании с другими символами, чаще всего для проверки, заканчивается ли строка определенной подстрокой:
String text = "http://jenkov.com";
Pattern pattern = Pattern.compile(".com$");
Matcher matcher = pattern.matcher(text);
while(matcher.find()){
System.out.println("Found match at: " + matcher.start() + " to " + matcher.end());
}
В этом примере будет найдено одно совпадение в конце входной строки.
Границы слова
Сопоставитель границ b соответствует границе слова, что означает местоположение во входной строке, где слово либо начинается, либо заканчивается:
String text = "Mary had a little lamb";
Pattern pattern = Pattern.compile("\b");
Matcher matcher = pattern.matcher(text);
while(matcher.find()){
System.out.println("Found match at: " + matcher.start() + " to " + matcher.end());
}
Этот пример соответствует всем границам слов, найденным во входной строке.
Обратите внимание, как сопоставитель границ слова записывается как \ b – с двумя символами \ (обратная косая черта). Причина этого объясняется в разделе об экранировании символов.
Found match at: 0 to 0 Found match at: 4 to 4 Found match at: 5 to 5 Found match at: 8 to 8 Found match at: 9 to 9 Found match at: 10 to 10 Found match at: 11 to 11 Found match at: 17 to 17 Found match at: 18 to 18 Found match at: 22 to 22
В выводе перечислены все места, где слово либо начинается, либо заканчивается во входной строке. Как видите, индексы начала слова указывают на первый символ слова, тогда как окончания слова указывают на первый символ после слова.
String text = "Mary had a little lamb";
Pattern pattern = Pattern.compile("\bl");
Matcher matcher = pattern.matcher(text);
while(matcher.find()){
System.out.println("Found match at: " + matcher.start() + " to " + matcher.end());
}
В этом примере будут найдены все места, где слово начинается с буквы l (строчные буквы). Фактически он также найдет концы этих совпадений, что означает последний символ шаблона, который является строчной буквой l.
Несловесные границы
String text = "Mary had a little lamb";
Pattern pattern = Pattern.compile("\B");
Matcher matcher = pattern.matcher(text);
while(matcher.find()){
System.out.println("Found match at: " + matcher.start() + " to " + matcher.end());
}
Found match at: 1 to 1 Found match at: 2 to 2 Found match at: 3 to 3 Found match at: 6 to 6 Found match at: 7 to 7 Found match at: 12 to 12 Found match at: 13 to 13 Found match at: 14 to 14 Found match at: 15 to 15 Found match at: 16 to 16 Found match at: 19 to 19 Found match at: 20 to 20 Found match at: 21 to 21
Обратите внимание, что эти индексы соответствия соответствуют границам между символами в одном и том же слове.
Квантификаторы
Квантификаторы можно использовать для сопоставления символов более одного раза. Существует несколько типов, которые перечислены в синтаксисе Java Regex. Наиболее часто используемые:
String regex = "Hello*";
Это регулярное выражение сопоставляет строки с текстом «Hell», за которым следует ноль или более символов. Таким образом, регулярное выражение будет соответствовать «Hell», «Hello», «Helloo» и т. д.
Если бы квантификатором был символ + вместо символа *, строка должна была бы заканчиваться 1 или более символами o.
String regex = "Hell\+";
Будет соответствовать строке «Hell+»;
String regex = "Hello{2}";
Будет соответствовать строке «Helloo»(с двумя символами o в конце).
String regex = "Hello{2,4}";
Будет соответствовать строкам “Helloo”, “Hellooo” и “Helloooo”. Другими словами, строка «Hell» с 2, 3 или 4 символами в конце.
Логические Операторы
Java Regex API поддерживает набор логических операторов, которые можно использовать для объединения нескольких подшаблонов в одном регулярном выражении, а именно оператор and и оператор or.
String text = "Cindarella and Sleeping Beauty sat in a tree";
Pattern pattern = Pattern.compile("[Cc][Ii].*");
Matcher matcher = pattern.matcher(text);
System.out.println("matcher.matches() = " + matcher.matches());
Обратите внимание на 3 подшаблона [Cc], [Ii] и. *
Поскольку в регулярном выражении между этими подшаблонами нет символов, между ними неявно существует оператор and. Это означает, что целевая строка должна соответствовать всем 3 подшаблонам в данном порядке, чтобы соответствовать регулярному выражению в целом. Как видно из строки, выражение соответствует строке. Строка должна начинаться с заглавной или строчной буквы C, за которой следует заглавная или строчная буква I, а затем ноль или более символов. Строка соответствует этим критериям.
String text = "Cindarella and Sleeping Beauty sat in a tree";
Pattern pattern = Pattern.compile(".*Ariel.*|.*Sleeping Beauty.*");
Matcher matcher = pattern.matcher(text);
System.out.println("matcher.matches() = " + matcher.matches());
Как вы можете видеть, шаблон будет соответствовать либо подчиненному шаблону Ariel, либо подчиненному шаблону Sleeping Beauty где-то в целевой строке. Поскольку целевая строка содержит текст «Sleeping Beauty», выражение соответствует целевой строке.
Методы выражений Java String
Класс Java String также имеет несколько методов регулярных выражений.
matches()
Метод принимает регулярное выражение в качестве параметра и возвращает true, если соответствует строке, и false, если нет.
String text = "one two three two one";
boolean matches = text.matches(".*two.*");
split()
Метод разбивает строку на N подстрок и возвращает массив String с этими подстроками. Принимает регулярное выражение в качестве параметра и разбивает строку на все позиции в строке, где выражение соответствует части строки. Выражение не возвращается как часть возвращаемых подстрок.
String text = "one two three two one";
String[] twos = text.split("two");
Этот пример вернет три строки: «один», «три» и «один».
replaceFirst()
Метод возвращает новую строку с первым совпадением регулярного выражения, переданного в качестве первого параметра, со строковым значением второго параметра.
String text = "one two three two one";
String s = text.replaceFirst("two", "five");
Этот пример вернет строку «один пять три два один».
replaceAll()
Метод возвращает новую строку со всеми совпадениями регулярного выражения, переданного в качестве первого параметра, со строковым значением второго параметра.
String text = "one two three two one";
String t = text.replaceAll("two", "five");
Рассмотрим регулярные выражения в Java, затронув синтаксис и наиболее популярные конструкции, а также продемонстрируем работу RegEx на примерах.
- Основы регулярных выражений
- Регулярные выражения в Java
- Примеры использования регулярных выражений в Java
Основы регулярных выражений
Мы подробно разобрали базис в статье Регулярные выражения для новичков, поэтому здесь пробежимся по основам лишь вскользь.
Определение
Регулярные выражения представляют собой формальный язык поиска и редактирования подстрок в тексте. Допустим, нужно проверить на валидность e-mail адрес. Это проверка на наличие имени адреса, символа @, домена, точки после него и доменной зоны.
Вот самая простая регулярка для такой проверки:
^[A-Z0-9+_.-]+@[A-Z0-9.-]+$В коде регулярные выражения обычно обозначается как regex, regexp или RE.
Синтаксис RegEx
Символы могут быть буквами, цифрами и метасимволами, которые задают шаблон:

Есть и другие конструкции, с помощью которых можно сокращать регулярки:
- d — соответствует любой одной цифре и заменяет собой выражение [0-9];
- D — исключает все цифры и заменяет [^0-9];
- w — заменяет любую цифру, букву, а также знак нижнего подчёркивания;
- W — любой символ кроме латиницы, цифр или нижнего подчёркивания;
- s — поиск символов пробела;
- S — поиск любого непробельного символа.
Квантификаторы
Это специальные ограничители, с помощью которых определяется частота появления элемента — символа, группы символов, etc:
?— делает символ необязательным, означает0или1. То же самое, что и{0,1}.*—0или более,{0,}.+—1или более,{1,}.{n}— означает число в фигурных скобках.{n,m}— не менееnи не болееmраз.*?— символ?после квантификатора делает его ленивым, чтобы найти наименьшее количество совпадений.
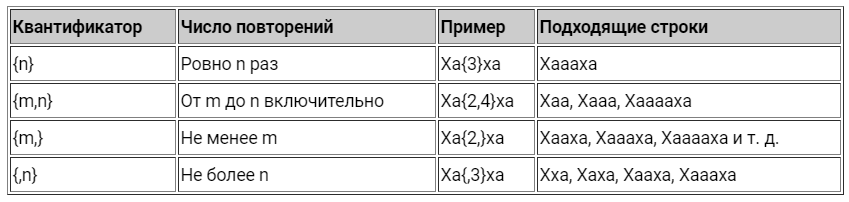
Примеры использования квантификаторов в регулярных выражениях
Обратите внимание, что квантификатор применяется только к символу, который стоит перед ним.
Также квантификаторов есть три режима:
"А.+а" //жадный режим — поиск самого длинного совпадения
"А.++а" //сверхжадный режим — как жадный, но без реверсивного поиска при захвате строки
"А.+?а" //ленивый режим — поиск самого короткого совпаденияПо умолчанию квантификатор всегда работает в жадном режиме. Подробнее о квантификаторах в Java вы можете почитать здесь.
Примеры их использования рассмотрим чуть дальше.
Поскольку мы говорим о регекспах в Java, то следует учитывать спецификации данного языка программирования.
Экранирование символов в регулярных выражениях Java
В коде Java нередко можно встретить обратную косую черту : этот символ означает, что следующий за ним символ является специальным, и что его нужно особым образом интерпретировать. Так, n означает перенос строки. Посмотрим на примере:
String s = "Это спецсимвол Java. nОн означает перенос строки.";
System.out.println(s);Результат:
Это спецсимвол Java.
Он означает перенос строки.Поэтому в регулярных выражениях для, например, метасимволов, используется двойная косая черта, чтобы указать компилятору Java, что это элемент регулярки. Пример записи поиска символов пробела:
String regex = "\s";Ключевые классы
Java RegExp обеспечиваются пакетом java.util.regex. Здесь ключевыми являются три класса:
- Matcher — выполняет операцию сопоставления в результате интерпретации шаблона.
- Pattern — предоставляет скомпилированное представление регулярного выражения.
- PatternSyntaxException — предоставляет непроверенное исключение, что указывает на синтаксическую ошибку, допущенную в шаблоне RegEx.
Также есть интерфейс MatchResult, который представляет результат операции сопоставления.
Примеры использования регулярных выражений в Java
e-mail адрес
В качестве первого примера мы упомянули регулярку, которая проверяет e-mail адрес на валидность. И вот как эта проверка выглядит в Java-коде:
List emails = new ArrayList();
emails.add("name@gmail.com");
//Неправильный имейл:
emails.add("@gmail.com");
String regex = "^[A-Za-z0-9+_.-]+@(.+)$";
Pattern pattern = Pattern.compile(regex);
for(String email : emails){
Matcher matcher = pattern.matcher(email);
System.out.println(email +" : "+ matcher.matches());
}
Результат:
name@gmail.com : true
@gmail.com : false
Телефонный номер
Регулярное выражение для валидации номера телефона:
^((8|+7)[- ]?)?((?d{3})?[- ]?)?[d- ]{7,10}$Эта регулярка ориентирована на российские мобильные номера, а также на городские с кодом из трёх цифр. Попробуйте написать код самостоятельно по принципу проверки e-mail адреса.
IP адрес
А вот класс для определения валидности IP адреса, записанного в десятичном виде:
private static boolean checkIP(String input) {
return input.matches("((0|1\d{0,2}|2([0-4][0-9]|5[0-5]))\.){3}(0|1\d{0,2}|2([0-4][0-9]|5[0-5]))");
}Правильное количество открытых и закрытых скобок в строке
На каждую открытую должна приходиться одна закрытая скобка:
private static boolean checkExpression(String input) {
Pattern pattern = Pattern.compile("\([\d+/*-]*\)");
Matcher matcher = pattern.matcher(input);
do {
input = matcher.replaceAll("");
matcher = pattern.matcher(input);
} while (matcher.find());
return input.matches("[\d+/*-]*");
}Извлечение даты
Теперь давайте извлечём дату из строки:
private static String[] getDate(String desc) {
int count = 0;
String[] allMatches = new String[2];
Matcher m = Pattern.compile("(0[1-9]|[12][0-9]|3[01])[- /.](0[1-9]|1[012])[- /.](19|20)\d\d").matcher(desc);
while (m.find()) {
allMatches[count] = m.group();
count++;
}
return allMatches;
}Проверка:
public static void main(String[] args) throws Exception{
String[] dates = getDate("coming from the 25/11/2020 to the 30/11/2020");
System.out.println(dates[0]);
System.out.println(dates[1]);
}Результат:
25/11/2020
30/11/2020А вот использование различных режимов квантификаторов, принцип работы которых мы рассмотрели чуть ранее.
Жадный режим
Pattern pattern = Pattern.compile("a+");
Matcher matcher = pattern .matcher("aaa");
while (matcher.find()){
System.out.println("Найдено от " + matcher.start() +
" до " + (matcher.end()-1));
}Результат:
Найдено от 0 дo 2В заданном шаблоне первый символ – a. Matcher сопоставляет его с каждым символом текста, начиная с нулевой позиции и захватывая всю строку до конца, в чём и проявляется его «жадность». Вот и получается, что заданная стартовая позиция – это 0, а последняя – 2.
Сверхжадный режим
Pattern pattern = Pattern.compile("a++");
Matcher matcher = pattern .matcher("aaa");
while (matcher.find()){
System.out.println("Найдено от " + matcher.start() +
" до " + (matcher.end()-1));
}Результат:
Найдено от 0 дo 2Принцип, как и в жадном режиме, только поиск заданного символа в обратном направлении не происходит. В приведённой строке всё аналогично: заданная стартовая позиция – это 0, а последняя – 2.
Ленивый режим
Pattern pattern = Pattern.compile("a+?");
Matcher matcher = pattern .matcher("aaa");
while (matcher.find()){
System.out.println("Найдено от " + matcher.start() +
" до " + (matcher.end()-1));
}Результат:
Найдено от 0 дo 0
Найдено от 1 дo 1
Найдено от 2 дo 2Здесь всё просто: самое короткое совпадение находится на первой, второй и третьей позиции заданной строки.
Выводы
Общий принцип использования регулярных выражений сохраняется от языка к языку, однако если мы всё-таки говорим о RegEx в конкретном языке программирования, следует учитывать его спецификации. В Java это экранирование символов, использование специальной библиотеки java.util.regex и её классов.
А какие примеры использования регулярных выражений в Java хотели бы видеть вы? Напишите в комментариях.