
im trying to figure out the regex to use to split an essay into words WITHOUT punctuation. I tried splitting by whitespace, but that gives some tokens with the punctuation. I also tried to split by word chars, which returned an array of empty strings for some reason:
String[] words = line.split("\w+");
asked Mar 16, 2014 at 5:50
![]()
HukeLau_DABAHukeLau_DABA
2,4255 gold badges33 silver badges51 bronze badges
7
try this
String[] words = line.split("\W+");
answered Mar 16, 2014 at 5:56
![]()
Evgeniy DorofeevEvgeniy Dorofeev
133k29 gold badges198 silver badges272 bronze badges
1
In this Java regex word boundary example, we will learn to match a specific word in a string. e.g. We will match “java” in “java is object oriented language”. But it should not match “javap” in “javap is another tool in JDL bundle”.
1. java regex word boundary matchers
Boundary matchers help to find a particular word, but only if it appears at the beginning or end of a line. They do not match any characters. Instead, they match at certain positions, effectively anchoring the regular expression match at those positions.
The following table lists and explains all the boundary matchers.
| Boundary token | Description |
|---|---|
^ |
The beginning of a line |
$ |
The end of a line |
b |
A word boundary |
B |
A non-word boundary |
A |
The beginning of the input |
G |
The end of the previous match |
Z |
The end of the input but for the final terminator, if any |
z |
The end of the input |
Solution Regex : bwordb
The regular expression token "b" is called a word boundary. It matches at the start or the end of a word. By itself, it results in a zero-length match.
Strictly speaking, “b” matches in these three positions:
- Before the first character in the data, if the first character is a word character
- After the last character in the data, if the last character is a word character
- Between two characters in the data, where one is a word character and the other is not a word character
To run a “spcific word only” search using a regular expression, simply place the word between two word boundaries.
String data1 = "Today, java is object oriented language";
String regex = "\bjava\b";
Pattern pattern = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(data1);
while (matcher.find())
{
System.out.print("Start index: " + matcher.start());
System.out.print(" End index: " + matcher.end() + " ");
System.out.println(matcher.group());
}
Output:
Start index: 7 End index: 11 java
Please note that matching above regex with “Also, javap is another tool in JDL bundle” doesn’t produce any result i.e. doesn’t match any place.
3. Java regex to match word with nonboundaries – contain word example
Suppose, you want to match “java” such that it should be able to match words like “javap” or “myjava” or “myjavaprogram” i.e. java word can lie anywhere in the data string. It could be start of word with additional characters in end, or could be in end of word with additional characters in start as well as in between a long word.
"B" matches at every position in the subject text where "B" does not match. "B" matches at every position that is not at the start or end of a word.
To match such words, use below regex :
Solution Regex : \Bword|word\B
String data1 = "Searching in words : javap myjava myjavaprogram";
String regex = "\Bjava|java\B";
Pattern pattern = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(data1);
while (matcher.find())
{
System.out.print("Start index: " + matcher.start());
System.out.print(" End index: " + matcher.end() + " ");
System.out.println(matcher.group());
}
Output:
Start index: 21 End index: 25 java
Start index: 29 End index: 33 java
Start index: 36 End index: 40 java
Please note that it will not match “java” word in first example i.e. “Today, java is object oriented language” because “\B” does not match start and end of a word.
3. Java regex to match word irrespective of boundaries
This is simplest usecase. You want to match “java” word in all four places in string “Searching in words : java javap myjava myjavaprogram”. To able to do so, simply don’t use anything.
Solution regex : word
String data1 = "Searching in words : java javap myjava myjavaprogram";
String regex = "java";
Pattern pattern = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(data1);
while (matcher.find())
{
System.out.print("Start index: " + matcher.start());
System.out.print(" End index: " + matcher.end() + " ");
System.out.println(matcher.group());
}
Output:
Start index: 21 End index: 25 java
Start index: 26 End index: 30 java
Start index: 34 End index: 38 java
Start index: 41 End index: 45 java
That’s all for this java regex contain word example related to boundary and non-boundary matches of a specific word using java regular expressions.
Happy Learning !!
References:
Java regex docs
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
Given a string, extract words from it. “Words” are defined as contiguous strings of alphabetic characters i.e. any upper or lower case characters a-z or A-Z.
Examples:
Input : Funny?? are not you?
Output : Funny
are
not
you
Input : Geeks for geeks??
Output : Geeks
for
geeks
Recommended: Please try your approach on {IDE} first, before moving on to the solution.
We have discussed a solution for C++ in this post : Program to extract words from a given String
We have also discussed basic approach for java in these posts : Counting number of lines, words, characters and paragraphs in a text file using Java and Print first letter in word using Regex.
In this post, we will discuss Regular Expression approach for doing the same. This approach is best in terms of Time Complexity and is also used for large input files. Below is the regular expression for any word.
[a-zA-Z]+
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Test
{
public static void main(String[] args)
{
String s1 = "Geeks for Geeks";
String s2 = "A Computer Science Portal for Geeks";
Pattern p = Pattern.compile("[a-zA-Z]+");
Matcher m1 = p.matcher(s1);
Matcher m2 = p.matcher(s2);
System.out.println("Words from string "" + s1 + "" : ");
while (m1.find()) {
System.out.println(m1.group());
}
System.out.println("Words from string "" + s2 + "" : ");
while (m2.find()) {
System.out.println(m2.group());
}
}
}
Output:
Words from string "Geeks for Geeks" : Geeks for Geeks Words from string "A Computer Science Portal for Geeks" : A Computer Science Portal for Geeks
This article is contributed by Gaurav Miglani. If you like GeeksforGeeks and would like to contribute, you can also write an article using contribute.geeksforgeeks.org or mail your article to contribute@geeksforgeeks.org. See your article appearing on the GeeksforGeeks main page and help other Geeks.
Please write comments if you find anything incorrect, or you want to share more information about the topic discussed above.
Like Article
Save Article
Рассмотрим регулярные выражения в Java, затронув синтаксис и наиболее популярные конструкции, а также продемонстрируем работу RegEx на примерах.
- Основы регулярных выражений
- Регулярные выражения в Java
- Примеры использования регулярных выражений в Java
Основы регулярных выражений
Мы подробно разобрали базис в статье Регулярные выражения для новичков, поэтому здесь пробежимся по основам лишь вскользь.
Определение
Регулярные выражения представляют собой формальный язык поиска и редактирования подстрок в тексте. Допустим, нужно проверить на валидность e-mail адрес. Это проверка на наличие имени адреса, символа @, домена, точки после него и доменной зоны.
Вот самая простая регулярка для такой проверки:
^[A-Z0-9+_.-]+@[A-Z0-9.-]+$В коде регулярные выражения обычно обозначается как regex, regexp или RE.
Синтаксис RegEx
Символы могут быть буквами, цифрами и метасимволами, которые задают шаблон:

Есть и другие конструкции, с помощью которых можно сокращать регулярки:
- d — соответствует любой одной цифре и заменяет собой выражение [0-9];
- D — исключает все цифры и заменяет [^0-9];
- w — заменяет любую цифру, букву, а также знак нижнего подчёркивания;
- W — любой символ кроме латиницы, цифр или нижнего подчёркивания;
- s — поиск символов пробела;
- S — поиск любого непробельного символа.
Квантификаторы
Это специальные ограничители, с помощью которых определяется частота появления элемента — символа, группы символов, etc:
?— делает символ необязательным, означает0или1. То же самое, что и{0,1}.*—0или более,{0,}.+—1или более,{1,}.{n}— означает число в фигурных скобках.{n,m}— не менееnи не болееmраз.*?— символ?после квантификатора делает его ленивым, чтобы найти наименьшее количество совпадений.
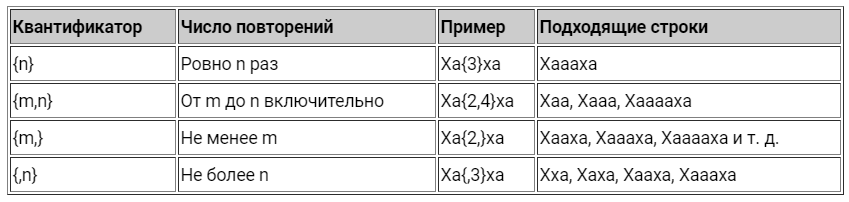
Примеры использования квантификаторов в регулярных выражениях
Обратите внимание, что квантификатор применяется только к символу, который стоит перед ним.
Также квантификаторов есть три режима:
"А.+а" //жадный режим — поиск самого длинного совпадения
"А.++а" //сверхжадный режим — как жадный, но без реверсивного поиска при захвате строки
"А.+?а" //ленивый режим — поиск самого короткого совпаденияПо умолчанию квантификатор всегда работает в жадном режиме. Подробнее о квантификаторах в Java вы можете почитать здесь.
Примеры их использования рассмотрим чуть дальше.
Поскольку мы говорим о регекспах в Java, то следует учитывать спецификации данного языка программирования.
Экранирование символов в регулярных выражениях Java
В коде Java нередко можно встретить обратную косую черту : этот символ означает, что следующий за ним символ является специальным, и что его нужно особым образом интерпретировать. Так, n означает перенос строки. Посмотрим на примере:
String s = "Это спецсимвол Java. nОн означает перенос строки.";
System.out.println(s);Результат:
Это спецсимвол Java.
Он означает перенос строки.Поэтому в регулярных выражениях для, например, метасимволов, используется двойная косая черта, чтобы указать компилятору Java, что это элемент регулярки. Пример записи поиска символов пробела:
String regex = "\s";Ключевые классы
Java RegExp обеспечиваются пакетом java.util.regex. Здесь ключевыми являются три класса:
- Matcher — выполняет операцию сопоставления в результате интерпретации шаблона.
- Pattern — предоставляет скомпилированное представление регулярного выражения.
- PatternSyntaxException — предоставляет непроверенное исключение, что указывает на синтаксическую ошибку, допущенную в шаблоне RegEx.
Также есть интерфейс MatchResult, который представляет результат операции сопоставления.
Примеры использования регулярных выражений в Java
e-mail адрес
В качестве первого примера мы упомянули регулярку, которая проверяет e-mail адрес на валидность. И вот как эта проверка выглядит в Java-коде:
List emails = new ArrayList();
emails.add("name@gmail.com");
//Неправильный имейл:
emails.add("@gmail.com");
String regex = "^[A-Za-z0-9+_.-]+@(.+)$";
Pattern pattern = Pattern.compile(regex);
for(String email : emails){
Matcher matcher = pattern.matcher(email);
System.out.println(email +" : "+ matcher.matches());
}
Результат:
name@gmail.com : true
@gmail.com : false
Телефонный номер
Регулярное выражение для валидации номера телефона:
^((8|+7)[- ]?)?((?d{3})?[- ]?)?[d- ]{7,10}$Эта регулярка ориентирована на российские мобильные номера, а также на городские с кодом из трёх цифр. Попробуйте написать код самостоятельно по принципу проверки e-mail адреса.
IP адрес
А вот класс для определения валидности IP адреса, записанного в десятичном виде:
private static boolean checkIP(String input) {
return input.matches("((0|1\d{0,2}|2([0-4][0-9]|5[0-5]))\.){3}(0|1\d{0,2}|2([0-4][0-9]|5[0-5]))");
}Правильное количество открытых и закрытых скобок в строке
На каждую открытую должна приходиться одна закрытая скобка:
private static boolean checkExpression(String input) {
Pattern pattern = Pattern.compile("\([\d+/*-]*\)");
Matcher matcher = pattern.matcher(input);
do {
input = matcher.replaceAll("");
matcher = pattern.matcher(input);
} while (matcher.find());
return input.matches("[\d+/*-]*");
}Извлечение даты
Теперь давайте извлечём дату из строки:
private static String[] getDate(String desc) {
int count = 0;
String[] allMatches = new String[2];
Matcher m = Pattern.compile("(0[1-9]|[12][0-9]|3[01])[- /.](0[1-9]|1[012])[- /.](19|20)\d\d").matcher(desc);
while (m.find()) {
allMatches[count] = m.group();
count++;
}
return allMatches;
}Проверка:
public static void main(String[] args) throws Exception{
String[] dates = getDate("coming from the 25/11/2020 to the 30/11/2020");
System.out.println(dates[0]);
System.out.println(dates[1]);
}Результат:
25/11/2020
30/11/2020А вот использование различных режимов квантификаторов, принцип работы которых мы рассмотрели чуть ранее.
Жадный режим
Pattern pattern = Pattern.compile("a+");
Matcher matcher = pattern .matcher("aaa");
while (matcher.find()){
System.out.println("Найдено от " + matcher.start() +
" до " + (matcher.end()-1));
}Результат:
Найдено от 0 дo 2В заданном шаблоне первый символ – a. Matcher сопоставляет его с каждым символом текста, начиная с нулевой позиции и захватывая всю строку до конца, в чём и проявляется его «жадность». Вот и получается, что заданная стартовая позиция – это 0, а последняя – 2.
Сверхжадный режим
Pattern pattern = Pattern.compile("a++");
Matcher matcher = pattern .matcher("aaa");
while (matcher.find()){
System.out.println("Найдено от " + matcher.start() +
" до " + (matcher.end()-1));
}Результат:
Найдено от 0 дo 2Принцип, как и в жадном режиме, только поиск заданного символа в обратном направлении не происходит. В приведённой строке всё аналогично: заданная стартовая позиция – это 0, а последняя – 2.
Ленивый режим
Pattern pattern = Pattern.compile("a+?");
Matcher matcher = pattern .matcher("aaa");
while (matcher.find()){
System.out.println("Найдено от " + matcher.start() +
" до " + (matcher.end()-1));
}Результат:
Найдено от 0 дo 0
Найдено от 1 дo 1
Найдено от 2 дo 2Здесь всё просто: самое короткое совпадение находится на первой, второй и третьей позиции заданной строки.
Выводы
Общий принцип использования регулярных выражений сохраняется от языка к языку, однако если мы всё-таки говорим о RegEx в конкретном языке программирования, следует учитывать его спецификации. В Java это экранирование символов, использование специальной библиотеки java.util.regex и её классов.
А какие примеры использования регулярных выражений в Java хотели бы видеть вы? Напишите в комментариях.