
Муниципальное бюджетное общеобразовательное учреждение средняя общеобразовательная школа № 15 имени Пяти Героев Советского Союза
Иследовательская работа
Тема:
«Создание и исследование моделей
в электронной таблице Excel»
Секция информатики
Выполнила: Сотникова Полина Андреевна,
ученица 10 «А» класса
Руководитель: Титаренко Алексей Анатольевич,
учитель информатики
г. Хабаровск
2016
Содержание
Актуальность темы…………………………………………………………………………………………………………………3
Введение………………………………………………………………………………………………………………………………..4
Создание информационных моделей…………………………………………………………………………………..5
Формулы в Excel…………………………………………………………………………………………………………………….7
Этапы разработки и исследования моделей………………………………………………………………………..10
Исследование физических моделей в электронных таблицах…………………………………………..11
Исследование биологической модели развития популяций………………………………………………14
Оптимизационное моделирование в экономике…………………………………………………………………17
Заключение…………………………………………………………………………………………………………………………….20
Список использованной литературы…………………………………………………………………………………….21
2
Актуальность темы
Часто для исследования предметов, процессов и явлений человек создает модели окружающего мира.
Наглядные модели часто используются в процессе обучения. На уроке географии мы изучаем нашу планету используя её модели – карты и глобусы, при изучении химии мы используем модели молекул и кристаллических решеток, изучаем строение человека по анатомическим муляжам скелета и органов на биологии.
Модели играют чрезвычайно важную роль в проектировании и создании различных технических устройств, машин и механизмов, зданий, электрических цепей и т.д. Без предварительного создания чертежей невозможно изготовить даже простую деталь, не говоря уже о сложном механизме. Кроме чертежей,в проектировании часто изготавливают макеты. Разработка электрической схемы обязательно предшествует созданию электрических цепей.
Развитие науки невозможно без создания теоретических моделей (теорий, законов, гипотез), отражающих строение, свойства и поведение реальных объектов. Соответствие теоретических моделей действительности проверяется с помощью опытов и экспериментов.
Все художественное творчество фактически является процессом создания моделей. Например, такой литературный жанр, как басня, переносит реальные отношения между людьми на отношения между животными и фактически создает модели человеческих отношений.
3
Введение
Моделирование – это метод познания, состоящий в создании и исследовании моделей – неких новых объектов, которые отражают существенные особенности изучаемого объекта, явления или процесса.Модель – это некий новый объект, который отражает существенные особенности изучаемого объекта,явления или процесса. Модели позволяют представить в наглядной форме объекты и процессы, недоступные для непосредственного восприятия (очень большие или очень маленькие объекты, очень быстрые или очень медленные процессы).
Компьютерные модели стали обычным инструментом математического моделирования и применяются в физике, астрофизике, механике, химии, биологии, экономике, социологии, метеорологии, других науках и прикладных задачах в различных областях радиоэлектроники, машиностроения, автомобилестроения и прочих. Компьютерные модели используются для получения новых знаний о моделируемом объекте или для приближенной оценки поведения систем, слишком сложных для аналитического исследования. Компьютерное моделирование является одним из эффективных методов изучения сложных систем. Компьютерные модели проще и удобнее исследовать в силу их возможности проводить вычислительные эксперименты, в тех случаях когда реальные эксперименты затруднены из-за финансовых или физических препятствий или могут дать непредсказуемый результат. Логичность и формализованность компьютерных моделей позволяет определить основные факторы, определяющие свойства изучаемого объекта-оригинала (или целого класса объектов). В частности, моделирование в электронных таблицах может быть использовано для описания ряда объектов, обладающих одинаковыми наборами свойств. С помощью таблиц могут быть построены как статические, так и динамические информационные модели в различных предметных областях, а простота использования программ создания таблиц помогает составлять модели людям без знания сложных языков программирования.
4
Создание информационных моделей:
Информационные модели отражают различные типы систем объектов, в которых реализуются различные структуры взаимодействия и взаимосвязи между элементами системы. Для отражения систем с различными структурами используются различные типы информационных моделей: табличные, иерархические и сетевые. В программе Excelдоступно создание табличного типа моделей.
Табличные информационные модели:
Одним из наиболее часто используемых типов информационных моделей является прямоугольная таблица, состоящая из столбцов и строк. Такой тип моделей применяется для описания ряда объектов, обладающих одинаковыми наборами свойств.
В табличной информационной модели обычно перечень объектов размещен в ячейках первого столбца таблицы, а значения их свойств – в других столбцах.
С помощью электронной таблицы Excelпостроим таблицу стоимости продуктов. В первом столбце таблицы будет содержаться перечень продуктов, а во втором – интересующее нас свойство (цена).

С помощью специальных инструментов, встроенных в программу Excelможно визуализировать таблицу, представив ее в виде графика или круговой диаграммы. Для этого нужно выделить таблицу, зайти во вкладку «Вставка» и выбрать нужный формат визуализации.
5

Визуализация круговой диаграммой

Визуализация столбчатой диаграммой
6
Формулы в Excel
В таблицах Excelможно не только вводить и визуализировать данные, но и производить простые и сложные расчеты над данными.Все это реализуется при помощи формул в ячейках. Формула выполняет вычисления или другие действия с данными в листе.
Порядок ввода формулы
Для начала определим, в какой ячейке должен стоять результат расчета. Затем выделим эту ячейку (нажмем на нее левой кнопкой мышки и ячейка станет активной).
Вводить формулу надо со знака равенства. Это надо для того, чтобы Excel понял, что в ячейку вводится именно формула, а не данные.
Выделим произвольную ячейку, например D1. В строке формул введем =2+3 и нажмем Enter. В ячейке появится результат (5). А в строке формул сверху останется сама формула.

При обработке формулы с большим количеством вычислений, наблюдается определенный приоритет.
- В первую очередь выполняются выражения внутри скобок.
- Умножение и деление имеют более высокий приоритет чем сложение и вычитание.
- Операторы с одинаковым приоритетом выполняются слева направо.
 7
7
Так, в примере выше, сначала выполняется действие в скобках (5-4=1), потом первое умножение (100*1=100), затем второе умножение (38*2=76), сложение (100+26=126), и в конце вычитание (126-76=50).
Также, можно выполнять действия над числами, содержащимися в ячейках. Для этого, вместо цифр, в формулах нужно использовать ссылки на ячейки – букву латинского алфавита, обозначающую столбец и цифру, обозначающую строку.

Так, в ячейку D3 была введена формула D1+D2. В результате сложились числа,стоящие в ячейках D1(4) и D2(6) и полученный результат – 10 был записан в ячейку D3.
Для складывания нескольких ячеек используется функция СУММ. Для суммирования трех чисел формула запишется следующим образом
Но можно облегчить себе работу и вместо перечисления каждой ячейки записать диапазон, с помощью двоеточия
Истинное значение функции СУММ раскрывается, когда необходимо сложить большое количество ячеек в Excel. В примере ниже требуется просуммировать 12 значений. Функция СУММ позволяет сделать это несколькими щелчками мышью, если же использовать оператор сложения, то провозиться придется долго.
8

В таблицах Excelможно не только проводить простейшие вычисления над числами, но и возводить в степень, извлекать корень, производить сравнение чисел и многое другое.
9
Этапы разработки и исследования моделей
Использование компьютера для исследования информационных моделей различных объектов и систем позволяет изучить их изменения в зависимости от значения тех или иных параметров. Процесс разработки моделей и их исследования на компьютере можно разделить на несколько основных этапов.
На первом этапе исследования объекта или процесса обычно строится описательная информационная модель. Такая модель выделяет существенные с точки зрения целей проводимого исследования параметры объекта, а несущественными параметрами пренебрегает.
На втором этапе создается формализованная модель, то есть описательная информационная модель записывается с помощью какого-либо формального языка. В такой модели с помощью формул, уравнений, неравенств и пр. фиксируются формальные соотношения между начальными и конечными значениями свойств объектов, а также накладываются ограничения на допустимые значения этих свойств.
Однако далеко не всегда удается найти формулы, явно выражающие искомые величины через исходные данные. В таких случаях используются приближенные математические методы, позволяющие получать результаты с заданной точностью.
На третьем этапе необходимо формализованную информационную модель преобразовать в компьютерную модель, то есть выразить ее на понятном для компьютера языке. Существуют два принципиально различных пути построения компьютерной модели:
1) построение алгоритма решения задачи и его кодирование на одном из языков программирования;
2) построение компьютерной модели с использованием одного из приложений (электронных таблиц, СУБД и пр.).
В процессе создания компьютерной модели полезно разработать удобный графический интерфейс, который позволит визуализировать формальную модель, а также реализовать интерактивный диалог человека с компьютером на этапе исследования модели.
Четвертый этап исследования информационной модели состоит в проведении компьютерного эксперимента. Если компьютерная модель существует в виде программы на одном из языков программирования, ее нужно запустить на выполнение и получить результаты.
Если компьютерная модель исследуется в приложении, например в электронных таблицах, можно провести сортировку или поиск данных, построить диаграмму или график и так далее.
Пятый этап состоит в анализе полученных результатов и корректировке исследуемой модели. В случае различия результатов, полученных при исследовании информационной модели, с измеряемыми параметрами реальных объектов можно сделать вывод, что на предыдущих этапах построения модели были допущены ошибки или неточности. Например, при построении описательной качественной модели могут быть неправильно отобраны существенные свойства объектов, в процессе формализации могут быть допущены ошибки в формулах и так далее. В этих случаях необходимо провести корректировку модели, причем уточнение модели может проводиться многократно, пока анализ результатов не покажет их соответствие изучаемому объекту.
10
Исследование физических моделей в электронных таблицах:
Рассмотрим процесс построения и исследования модели на конкретном примере движения тела, брошенного под углом к горизонту.
Задача: В процессе тренировке теннисистов используются автоматы по бросания мячика в определенное место площадки. Необходимо задать автомату необходимую скорость и угол бросания мячика для попадания в мишень определенного размера, находящуюся на известном расстоянии.
Качественная описательная модель: Сначала построим качественную описательную модель процесса движения тела с использованием физических объектов, понятия и законов, то есть в данном случае идеализированную модель движения объекта. Из условия задачи можно сформулировать следующие основные предположения:
- Мячик мал по сравнению с Землей, поэтому его можно считать материальной точкой;
- Изменение высоты мячика мало, поэтому ускорение свободного падения можно считать постоянной величиной g= 9,8 мс и движение по оси ОУ можно считать равноускоренным;
- Скорость бросания тела мала, поэтому сопротивлением воздуха можно пренебречь и движение по оси ОХ можно считать равномерным
Формальная модель: Для формализации модели используем известные из курса физики формулы равномерного и равноускоренного движения. При заданных начальной скорости v0 и угле бросания aзначения координат дальности полета х и высоты у от времени можно записать следующими формулами:
X=v0*cos *t;
*t;
Y=v0*sinα*t – g*t²/2
Пусть мишень высотой h будет размещаться на расстоянии sот автомата. Из первой формулы выражаем время, которое понадобится мячику, чтобы преодолеть расстояние s:
t = s/(v0*cos2α)
Представляем это значение для tв формулу для у. Получаем l – высоту мячика над землей на расстоянии s:
l = s*tgα – g*s²/(2*v0²*cosα²)
Формализуем теперь условие попадания мячика в мишень. Попадание произойдет, если значение высоты lмячика в мишень. Попадание произойдет, если значение высоты lмячика будет удовлетворять условию в форме неравенства:
0≤l ≤ h
Если l<0, то это означает «недолет», а если l>h, то это означает «перелет».
Создание модели:
- Для ввода начальной скорости будем использовать ячейку В1, а для ввода угла – ячейку В2
- Введем в ячейки А5:А18 значения времени с интервалом в 0,2 с.
- В ячейки В5 и С5 введем формулы:
11
=$B$1*cos(Радианы($B$2))*А5
=$B$1*sin(РАДИАНЫ($B$2))*A5-4,9*A5*A5
- Скопируем формулы в ячейки В6:В18 и С6:С18 соответственно.

Визуализируем модель, построив график зависимости координаты у от координаты х (траекторию движения тела).
- Построить диаграмму типа График, в которой используется в качестве категории диапазон ячеек В5:В18, а в качестве значений – диапазон ячеек С5:С18.

Исследование модели: Исследуем модель и определим с заданной точностью 0,1 диапазон изменений угла, который обеспечивает попадание в мишень, находящуюся на расстоянии 30 м и имеющую высоту 1 м, при заданной начальной скорости 18 м/с. Воспользуемся для этого методом Подбор параметра.
- Установить для ячеек точность один знак после запятой
12
- Ввести в ячейки B21, B22 и В23 значения расстояния до мишени S = 30 м, начальной скорости Vо = 18 м/с и угла α= 35⁰, а в ячейку В25 – формулу для вычисления высоты мячика над поверхностью для заданных условий:
=B21*TAN(РАДИАНЫ(B23))-(9,81*B21^2)/(2*B22^2*COS(РАДИАНЫ(B23))^2)

Для заданных начальных условий определим углы, которые обеспечивают попадание в мишень на высотах 0 и 1 м.
- Выделить ячейку В25 и ввести команду [Сервис-Подбор параметра…]. На появившейся диалоговой панели ввести в поле Значение: наименьшую высоту попадания в мишень ( то есть 0). В поле Изменяя значение ячейки: ввести адрес ячейки, содержащей значение угла (в данном случае $B$23).

- В ячейке В23 появится значение 32,6. Повторить процедуру подбора параметра для максимальной высоты попадания в мишень – в ячейке В23 получим значение 36,1.
Таким образом, исследование компьютерной модели в электронных таблицах показало, что существует диапазон значений для угла бросания от 32,6 до 36,1⁰, который обеспечивает попадание в мишень высотой 1 м, находящуюся на расстоянии 30 м, мячиком брошенным со скоростью 18 м/с.
13
Исследование биологической модели развития популяций
В биологии при исследовании развития биосистем строятся динамические модели изменения численности популяций различных живых существ (бактерий, рыб, животных и пр.) с учетом различных факторов. Взаимовлияние популяций рассматривается в моделях типа «хищник-жертва».
Формальная модель. Изучение динамики численности популяций естественно начать с простейшей модели неограниченного роста, в которой численность популяции ежегодно увеличивается на определенный процент. Математическую модель можно записать с помощью рекуррентной формулы, связывающей численность популяции следующего года с численностью популяции текущего года, с использованием коэффициента роста а:
X(n+1) = a * x(n)
Например, если ежегодный прирост численности популяции составляет 5%, то а = 1,05. В модели ограниченного роста учитывается эффект перенаселенности, связанный с нехваткой питания, болезнями и так далее, который замедляет рост популяции с увеличением ее численности. Введем коэффициент перенаселенности b, значение которого обычно существенно меньше а (b<<а). Тогда коэффициент ежегодного увеличения численности равен (а — b*х(n)) и формула принимает вид:
X(n+1) = (a – b * x(n)) * x(n)
В модели ограниченного роста с отловом учитывается, что на численность популяций промысловых животных и рыб оказывает влияние величина ежегодного отлова. Если величина ежегодного отлова равна с, то формула принимает вид:
X(n+1) = (a – b * x(n)) * x(n) — c
Популяции обычно существуют не изолированно, а во взаимодействии с другими популяциями. Наиболее важным типом такого взаимодействия является взаимодействие между жертвами и хищниками (например, караси-щуки, зайцы-волки и так далее). В модели «хищник-жертва» количество жертв х(n) и количество хищников у(n) связаны между собой. Количество встреч жертв с хищниками можно считать пропорциональным произведению количеств жертв и хищников, а коэффициент f характеризует возможность гибели жертвы при встрече с хищниками. В этом случае численность популяции жертв ежегодно уменьшается на величину f * х(n)* у(n) и формула для расчета численности жертв принимает вид:
X(n+1) = (a – b * x(n)) * x(n) – c – f* x(n) * y(n)
Численность популяции хищников в отсутствие жертв (в связи с отсутствием пищи) уменьшается, что можно описать рекуррентной формулой
Y(n+1) = d* y(n)
где значение коэффициента d < 1 характеризует скорость уменьшения численности популяции хищников. Увеличение популяции хищников можно считать пропорциональной произведению собственно количеств жертв и хищников, а коэффициент е характеризует величину роста численности хищников за счет жертв. Тогда для численности хищников можно использовать
14
формулу:
y(n+1) = d*y(n) + e*x(n)*y(n)
Компьютерная модель. Построим в электронных таблицах компьютерную модель, позволяющую исследовать численность популяций с использованием различных моделей: неограниченного роста, ограниченного роста, ограниченного роста с отловом и «хищник—жертва».
- В ячейки В1 и В6 внести начальные значения численности популяций жертв и хищников.
В ячейки В2:В5 внести значения коэффициентов a, b, cи f, влияющих на изменение численности жертв.
В ячейки В7 и В8 внести значения коэффициентов dи е, влияющих на изменение численности хищников

В столбце Dбудем вычислять численность популяции в соответствии с моделью неограниченного роста, в столбце Е – ограниченного роста, в столбце F–ограниченного роста с отловом, в столбцах Gи H–«хищник-жертва».
- В ячейки D1, E1, F1 и G1 внести значения начальной численности популяций жертв, в ячейку Н1 – хищников.
В ячейку D2 внести рекуррентную формулу неограниченного роста =$B$2*D1
В ячейку Е2 внести рекуррентную формулу неограниченного роста =($B$2-$B$3*E1)*E1
В ячейку F2 внести рекуррентную формулу ограниченного роста с отловом =($B$2-$B$3*F1)*F1-$B$4
В ячейку G2 внести рекуррентную формулу изменения количества жертв =($B$2-$B$3*G1)*G1-$B$4-$B$5*G1*H1
В ячейку Н2 внести рекуррентную формулу изменения количества хищников =$B$7*H1+$B$8*G1*H1
- Скопировать внесенные формулы в ячейки столбцов командой [Правка-Заполнить-Вниз].
В ячейках столбцов ознакомиться с динамикой изменения численности популяций.
15

- Выделить столбцы данных и построить диаграмму типа График. Появятся графики изменения численности популяций в соответствии с моделями неограниченного роста, ограниченного роста, ограниченного роста с отловом, моделью хищник-жертва.

Исследование модели: Изменяя значения начальных численностей популяций, а также коэффициенты, можно получать различные варианты изменения численности популяций в зависимости от времени.
16
Оптимизационное моделирование в экономике
В сфере управления сложными системами (например, в экономике) применяется оптимизационное моделирование, в процессе которого осуществляется поиск наиболее оптимального пути развития системы.
Критерием оптимальности могут быть различные параметры; например, в экономике можно стремиться к максимальному количеству выпускаемой продукции, а можно к ее низкой себестоимости. Оптимальное развитие соответствует экстремальному (максимальному или минимальному) значению выбранного целевого параметра.
Развитие сложных систем зависит от множества факторов (параметров), следовательно, значение целевого параметра зависит от множества параметров. Выражением такой зависимости является целевая функция
К = F(X1,X2,…,Xn),
где К — значение целевого параметра; X1,X2,…,Xn — параметры, влияющие на развитие системы.
Цель исследования состоит в нахождении экстремума этой функции и определении значений параметров, при которых этот экстремум достигается. Если целевая функция нелинейна, то она имеет экстремумы, которые находятся определенными методами.
Однако часто целевая функция линейна и, соответственно, экстремумов не имеет. Задача поиска оптимального режима при линейной зависимости приобретает смысл только при наличии определенных ограничений на параметры. Если ограничения на параметры (система неравенств) также имеют линейный характер, то такие задачи являются задачами линейного программирования. (Термин «линейное программирование» в имитационном моделировании понимается как поиск экстремумов линейной функции, на которую наложены ограничения.) Рассмотрим в качестве примера экономического моделирования поиск вариантов оптимального раскроя листов материала на заготовки определенного размера.
Содержательная постановка проблемы. В ходе производственного процесса из листов материала получают заготовки деталей двух типов А и Б тремя различными способами, при этом количество получаемых заготовок при каждом методе различается.
|
Тип Заготовки |
1 способ раскроя |
2 способ раскроя |
3 способ раскроя |
|
А |
10 |
3 |
8 |
|
Б |
3 |
6 |
4 |
Необходимо выбрать оптимальное сочетание способов раскроя, для того чтобы получить 500 заготовок первого типа и 300 заготовок второго типа при расходовании наименьшего количества листов материала.
Формальная модель. Параметрами, значения которых требуется определить, являются количества листов материала, которые будут раскроены различными способами:
Х1 — количество листов, раскроенное способом 1;
Х2 — количество листов, раскроенное способом 2;
Х3 — количество листов, раскроенное способом 3.
Тогда целевая функция, значением которой является количество листов материала, примет вид:
17
F = Х1+ Х2 + Х3.
Ограничения определяются значениями требуемых количеств заготовок типа А и Б, тогда с учетом количеств заготовок, получаемых различными способами, должны выполняться два равенства: 10Х1+ ЗХ2 + 8Х3 = 500;
ЗХ1 + 6Х2 + 4Х3 = 300.
Кроме того, количества листов не могут быть отрицательными, поэтому должны выполняться неравенства:
X1>= 0; Х2>= 0; Х3 >= 0.
Таким образом, необходимо найти удовлетворяющие ограничениям значения параметров, при которых целевая функция принимает минимальное значение. Компьютерная модель. Будем искать решение задачи путем создания и исследования компьютерной модели в электронных таблицах Excel.
Оптимизационное моделирование
- Ячейки В2, С2 и D2 выделить для значений параметров Х1, Х2 и Х3.
В ячейку В4 ввести формулу для вычисления целевой функции:
=В2+С2+D2
В ячейку В7 ввести формулу вычисления количества заготовок типа А:
=10*B2+3*C2+8*D2.
В ячейку В8 ввести формулу вычислений количества заготовок типа Б:
=3*B2+6*C2+4*D2

Исследование модели: Для поиска оптимального набора значений параметров, который соотвествует минимальному значению целевой функции, воспользоваться надстройкой электронных таблиц Поиск решения.
- На вкладке Данные нажмите кнопку Поиск решения.
- На появившейся диалоговой панели Поиск решения установить:
- Адрес целевой ячейки
- Вариант оптимизации значения целевой ячейки (максимизация, минимизация или подбор значения)
- Адреса ячеек, значения которых изменяются в процессе поиска решения ( в которых хранятся значения параметров)
18
- Ограничения (типа «=» для ячеек, хранящих количество деталей, и типа «≥» для параметров).

- Щелкнуть по кнопке Выполнить. В ячейке целевой функции появится значение 69,4, а в ячейках параметров значения 0,11,58.

Таким образом, для изготовления 500 деталей А и 300 деталей Б требуется 71 лист материала, при этом 12 листов нужно раскроить по второму, а 59 по третьему способу.
19
Заключение
Моделирование глубоко проникает в теоретическое мышление. Более того, развитие любой науки в целом можно трактовать — в весьма общем, но вполне разумном смысле, — как «теоретическое моделирование». Важная познавательная функция моделирования состоит в том, чтобы служить импульсом, источником новых теорий. Нередко бывает так, что теория первоначально возникает в виде модели, дающей приближённое, упрощённое объяснение явления, и выступает как первичная рабочая гипотеза, которая может перерасти в «предтеорию» — предшественницу развитой теории. При этом в процессе моделирования возникают новые идеи и формы эксперимента, происходит открытие ранее неизвестных фактов. Такое «переплетение» теоретического и экспериментального моделирования особенно характерно для развития физических теорий.
Моделирование — не только одно из средств отображения явлений и процессов реального мира, но и — несмотря на описанную выше его относительность — объективный практический критерий проверки истинности наших знаний, осуществляемой непосредственно или с помощьюустановления их отношения с другой теорией, выступающей в качестве модели, адекватность которой считается практически обоснованной. Применяясь в органическом единстве с другими методами познания, моделирование выступает как процесс углубления познания, его движения от относительно бедных информацией моделей к моделям более содержательным, полнее раскрывающим сущность исследуемых явлений действительности.
В своем проекте я показала, как использовать электронные таблицы Excelдля моделирования и анализа созданных моделей.
20
Список использованной литературы
- Н. Угринович «Информатика и информационные технологии»
- Н. Угринович «Информатика и ИКТ»
- http://on-line-teaching.com/excel/lsn003.html
- http://www.excel-office.ru/formulivexcel/formulivexcel
21
Excel – одна из лучших программ для аналитика данных. А почти каждому человеку на том или ином этапе жизни приходилось иметь дело с цифрами и текстовыми данными и обрабатывать их в условиях жестких дедлайнов. Если вам и сейчас нужно это делать, то мы опишем техники, которые помогут существенно улучшить вам жизнь. А чтобы было более наглядно, покажем, как их воплощать, с помощью анимаций.
Содержание
- Анализ данных через сводные таблицы Excel
- Как работать со сводными таблицами
- Анализ данных с помощью 3D-карт
- Как работать с 3D-картами в Excel
- Лист прогноза в Excel
- Как работать с листом прогноза
- Быстрый анализ в Excel
- Как работать
Анализ данных через сводные таблицы Excel
Сводные таблицы – один из самых простых способов автоматизировать обработку информации. Он позволяет свести в кучу огромный массив данных, которые абсолютно не структурированы. Если его использовать, можно почти навсегда забыть о том, что такое фильтр и ручная сортировка. А чтобы их создать, достаточно нажать буквально пару кнопок и внести несколько несложных параметров в зависимости от того, какой способ представления результатов нужен конкретно вам в определенной ситуации.
Существует множество способов автоматизации анализа данных в Excel. Это как встроенные инструменты, так и дополнения, которые можно скачать на просторах интернета. Также есть дополнение «Пакет анализа», которое было разработано компанией Майкрософт. Она имеет все необходимые возможности, чтобы вы могли получать все необходимые результаты в одном файле Excel.
Пакет анализа данных, разработанный Майкрософт, можно использовать исключительно на едином листе в одну единицу времени. Если он будет обрабатывать информацию, расположенную на нескольких, то итоговая информация будет отображаться исключительно на одном. В других же будут показываться диапазоны без какой-либо значений, в которых есть исключительно форматы. Чтобы осуществить проанализировать информацию на нескольких листах, нужно использовать этот инструмент по отдельности. Это очень большой модуль, который поддерживает огромное количество возможностей, в частности, позволяет выполнять следующие типы обработки:
- Дисперсионный анализ.
- Корреляционный анализ.
- Ковариация.
- Вычисление скользящего среднего. Очень популярный метод в статистике и в трейдинге.
- Получать случайные числа.
- Выполнять операции с выборкой.
Эта надстройка не активирована по умолчанию, но входит в стандартный пакет. Чтобы ею воспользоваться, необходимо ее включить. Для этого сделайте следующие шаги:
- Перейдите в меню «Файл», и там найдите кнопку «Параметры». После этого перейдите в «Надстройки». Если же вы установили 2007 версию Эксель, то нужно нажать на кнопку «Параметры Excel», которая находится в меню Office.
- Далее появляется всплывающее меню, озаглавленное словом «Управление». Там находим пункт «Надстройки Excel», нажимаем на него, а потом – на кнопку «Перейти». Если же вы используете компьютер Apple, то достаточно открыть вкладку «Средства» в меню, а потом в раскрывающемся перечне найти пункт «Надстройки для Excel».
- В том диалоге, который появился после этого, нужно поставить галочку возле пункта «Пакет анализа», после чего подтвердить свои действия, нажав кнопку «ОК».
В некоторых ситуациях может оказаться так, что этого дополнения найти не удалось. В этом случае его не будет в перечне аддонов. Для этого надо нажать на кнопку «Обзор». Может также появиться информация о том, что пакет полностью отсутствует на этом компьютере. В этом случае необходимо его установить. Для этого нужно нажать на кнопку «Да».
Перед тем, как включить пакет анализа, необходимо сначала активировать VBA. Для этого его нужно загрузить таким же способом, как и саму надстройку.
Как работать со сводными таблицами
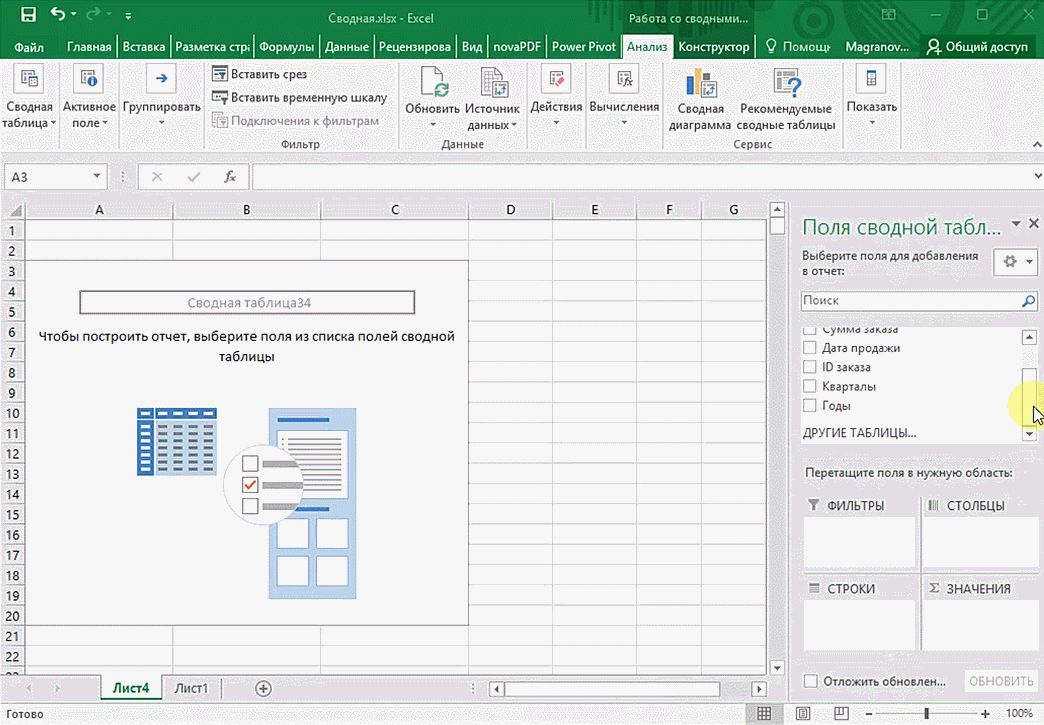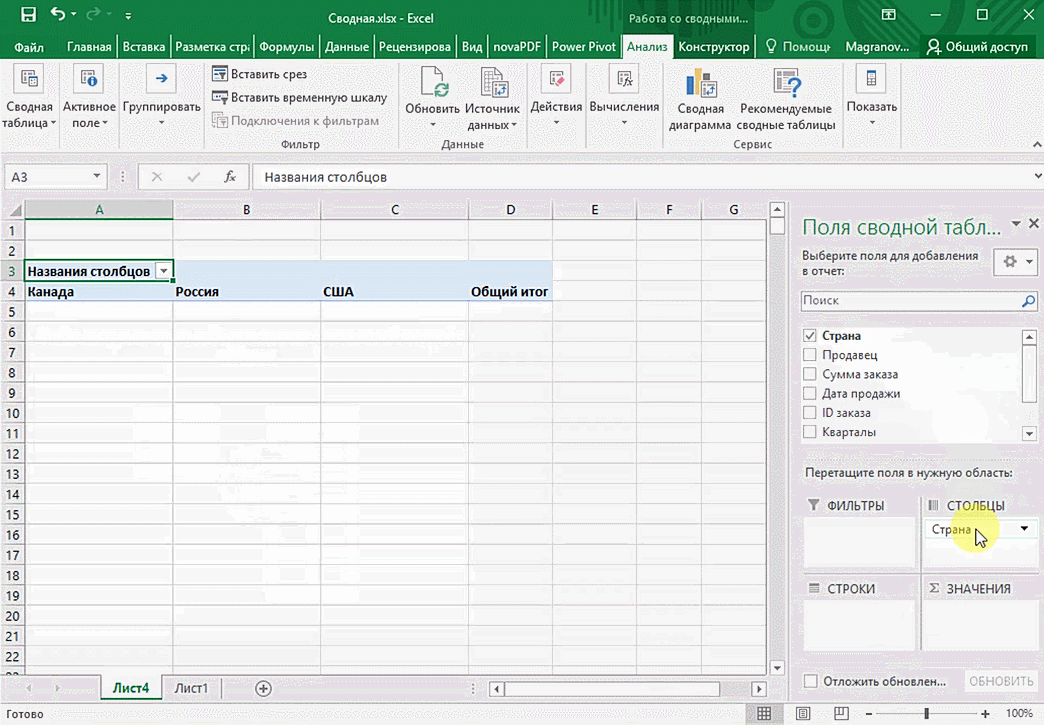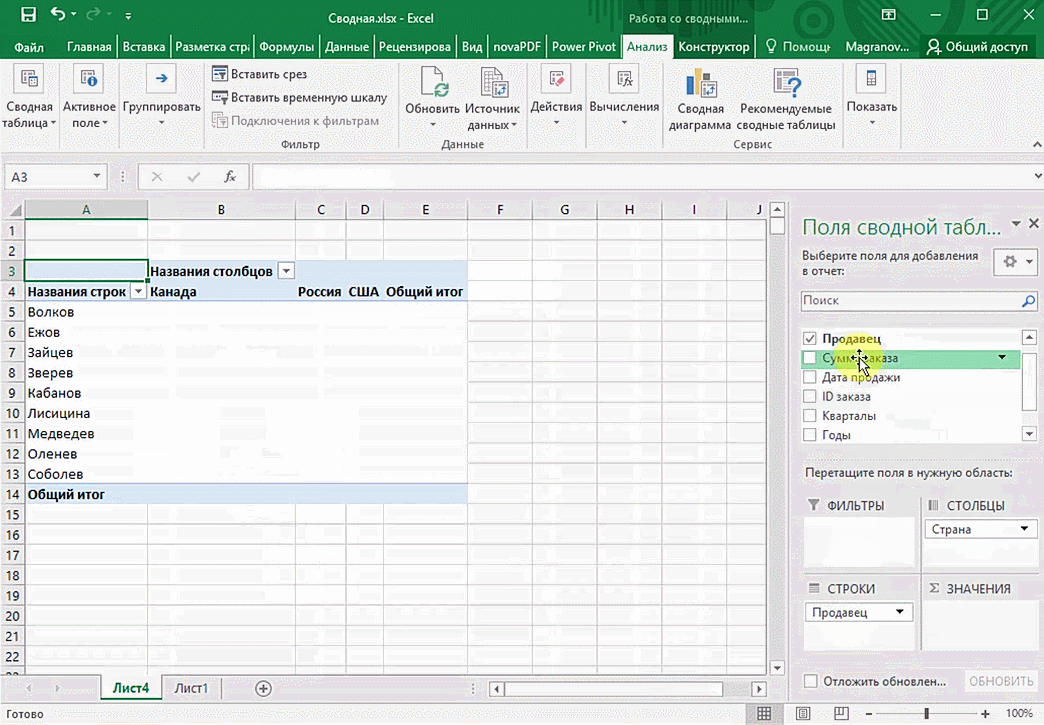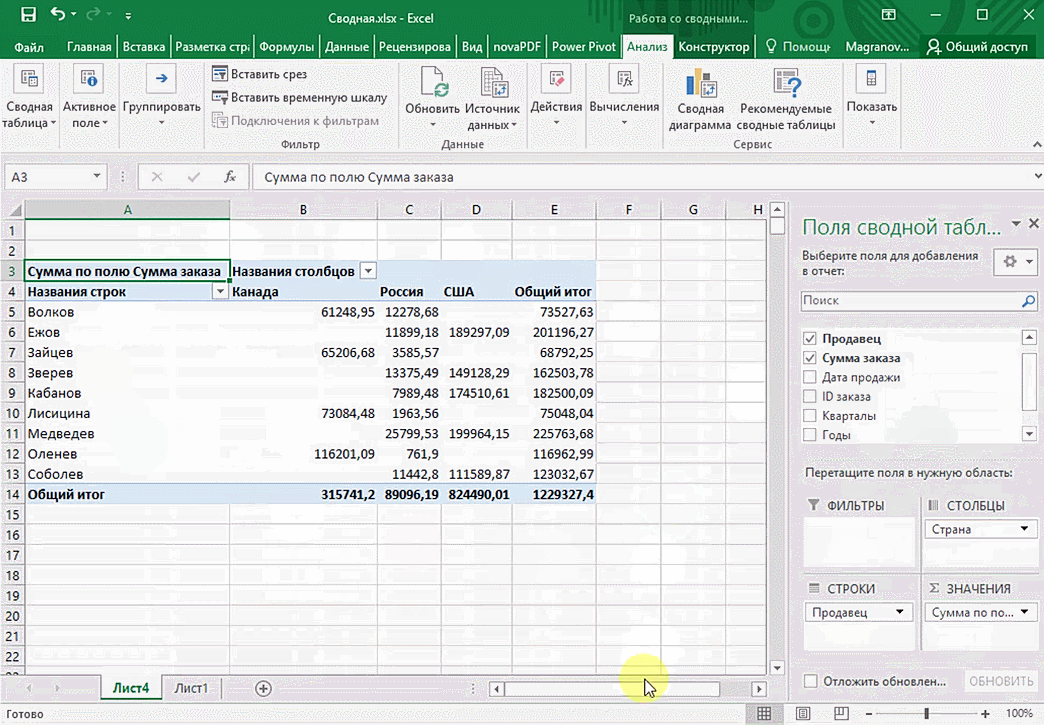
Первоначальная информация может быть какой-угодно. Это могут быть сведения о продажах, доставке, отгрузках продукции и так далее. Независимо от этого, последовательность шагов будет всегда одинаковой:
- Откройте файл, в котором содержится таблица.
- Выделите диапазон ячеек, которые мы будем анализировать с помощью сводной таблицы.
- Откройте вкладку «Вставка, и там надо найти группу «Таблицы», где есть кнопка «Сводная таблица». Если же используется компьютер под операционной системой Mac OS, то нужно открыть вкладку «Данные», и эта кнопка будет находиться во вкладке «Анализ».
- После этого откроется диалог с заголовком «Создание сводной таблицы».
- Затем выставите такое отображение данных, которое соответствует выделенному диапазону.
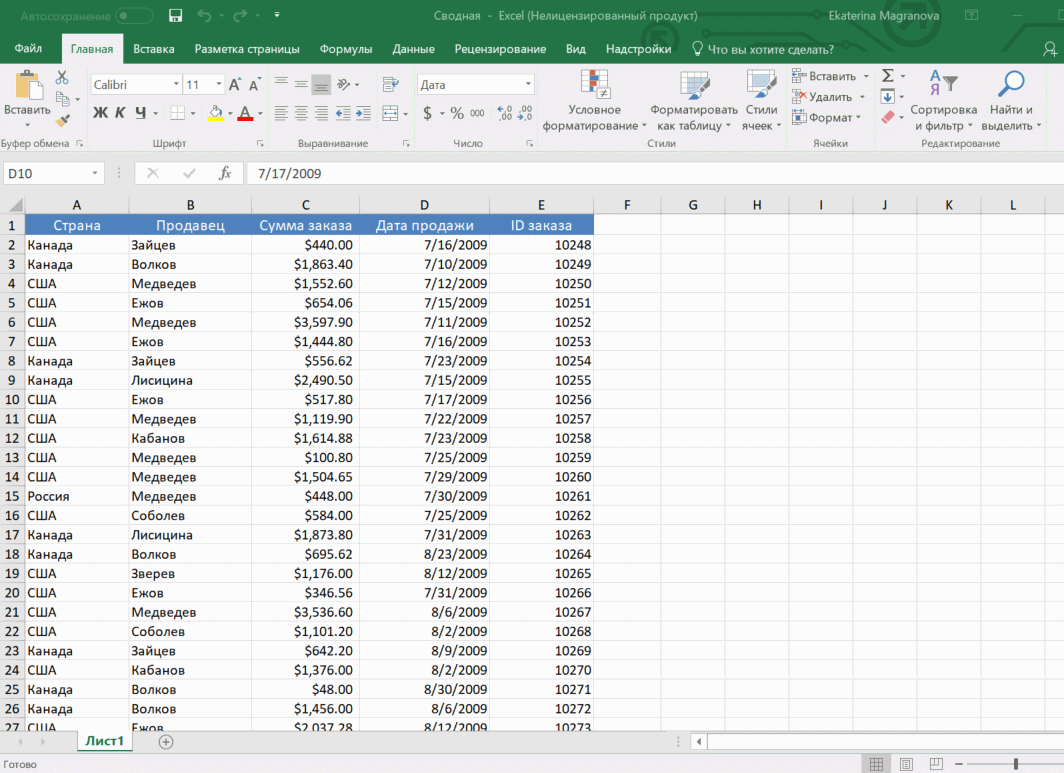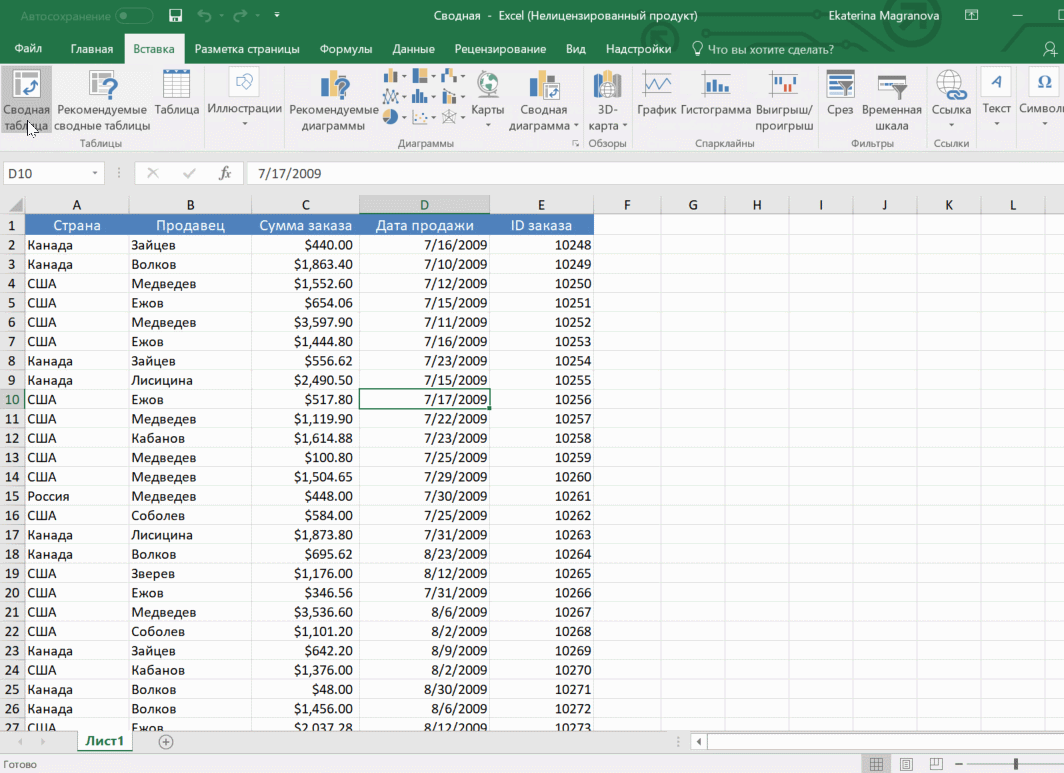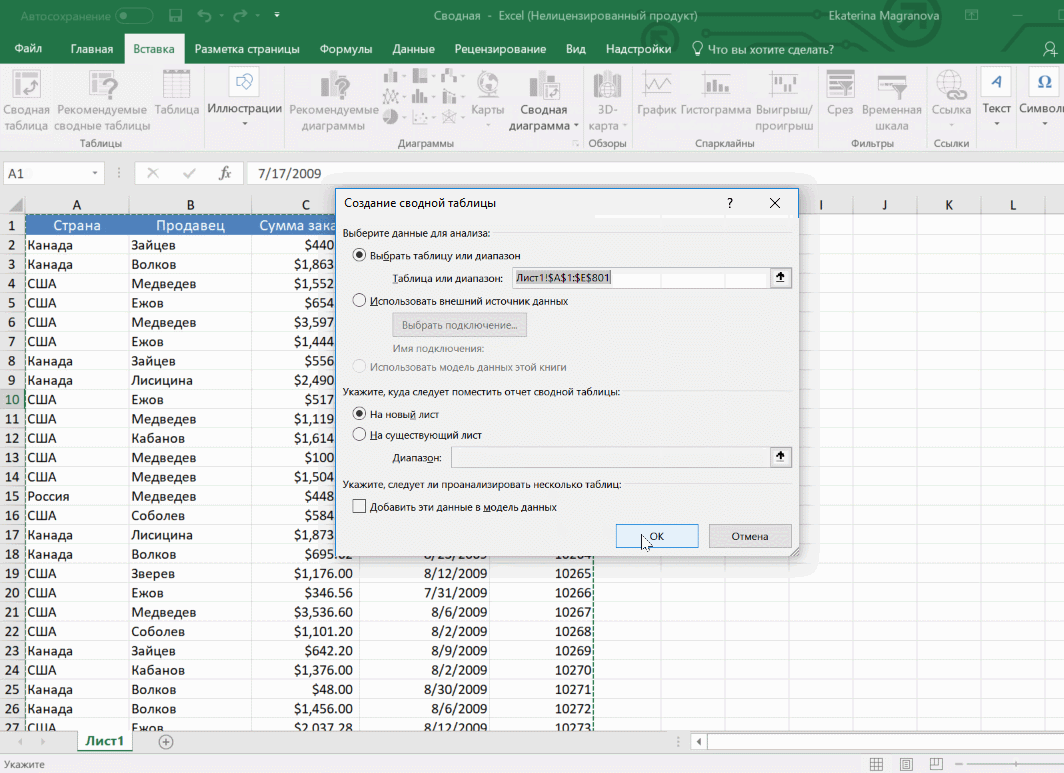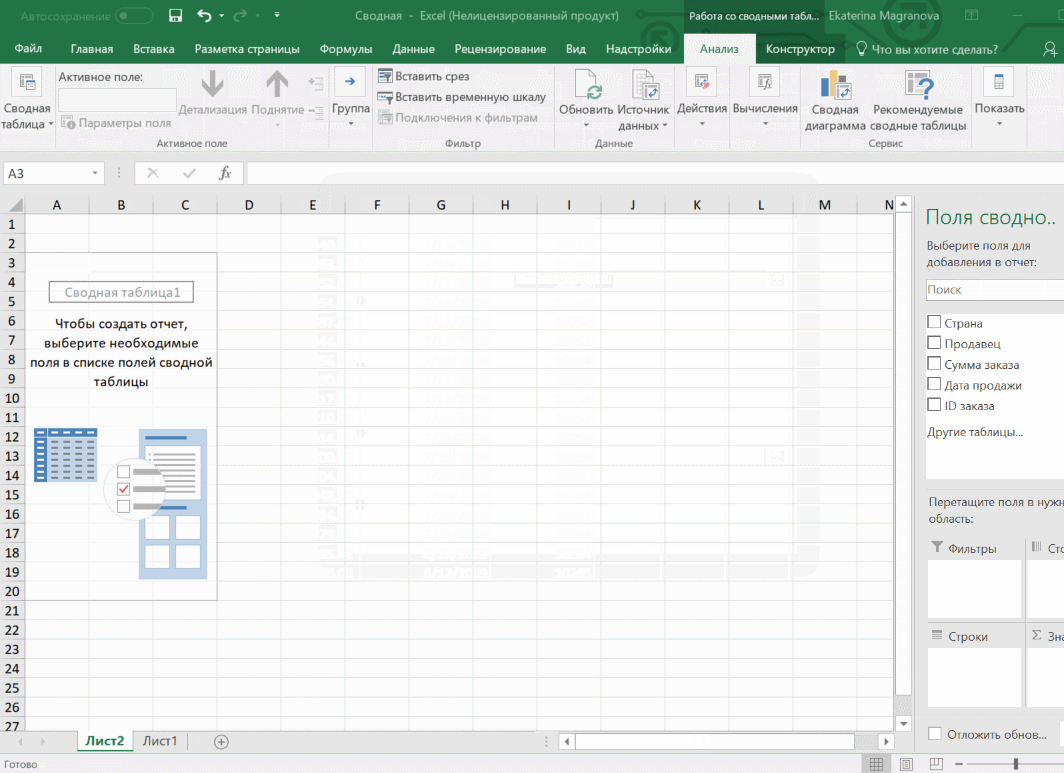
Мы открыли таблицу, информация в которой никоим образом не структурирована. Чтобы это сделать, можно воспользоваться настройками полей сводной таблицы в правой стороне экрана. Например, отправим в поле «Значения» «Сумму заказов», а информацию про продавцов и дату продажи – в строки таблицы. Исходя из данных, которые содержатся в этой таблице, автоматически определились суммы. Если есть необходимость, можно открыть информацию по каждому году, кварталу или месяцу. Это позволит получить детальную информацию, которая надо в конкретный момент.
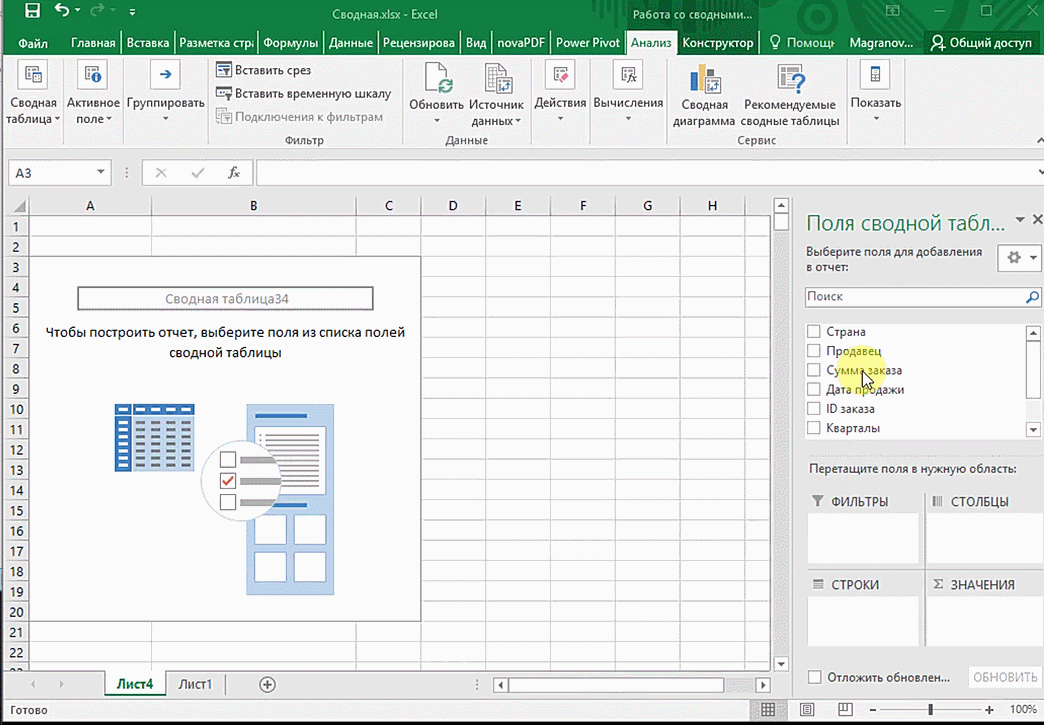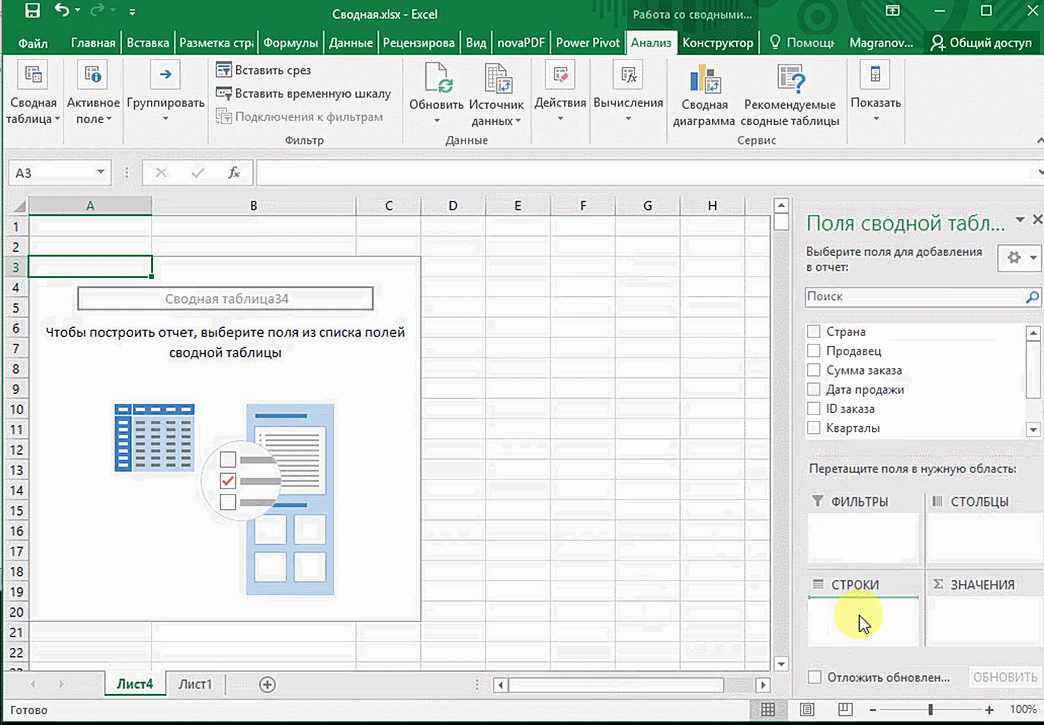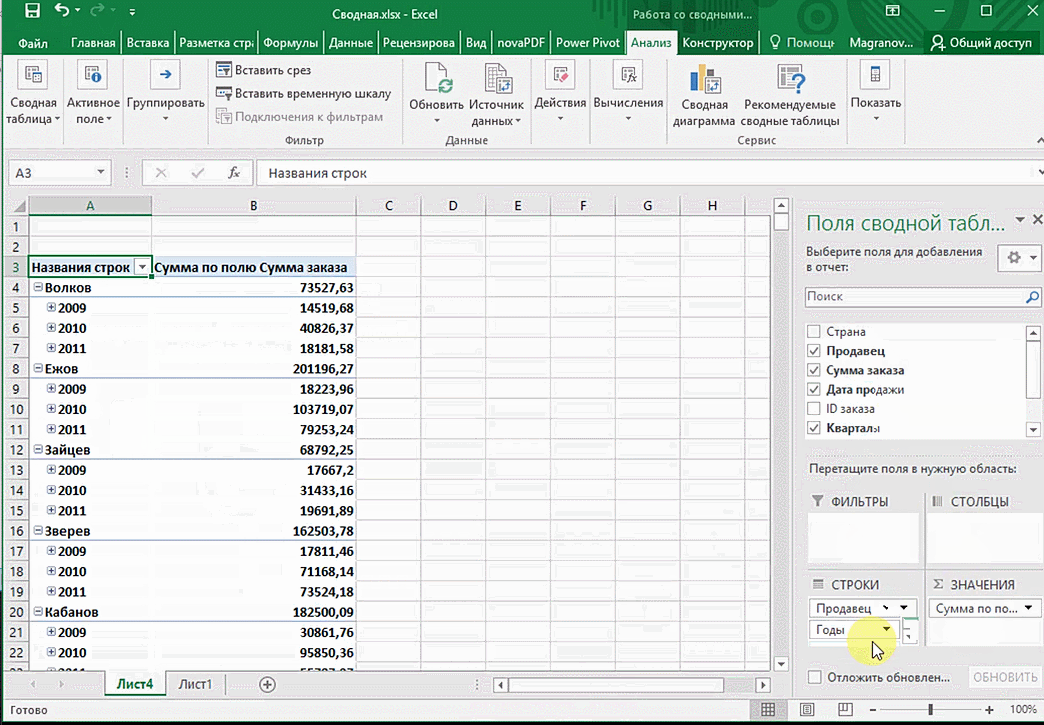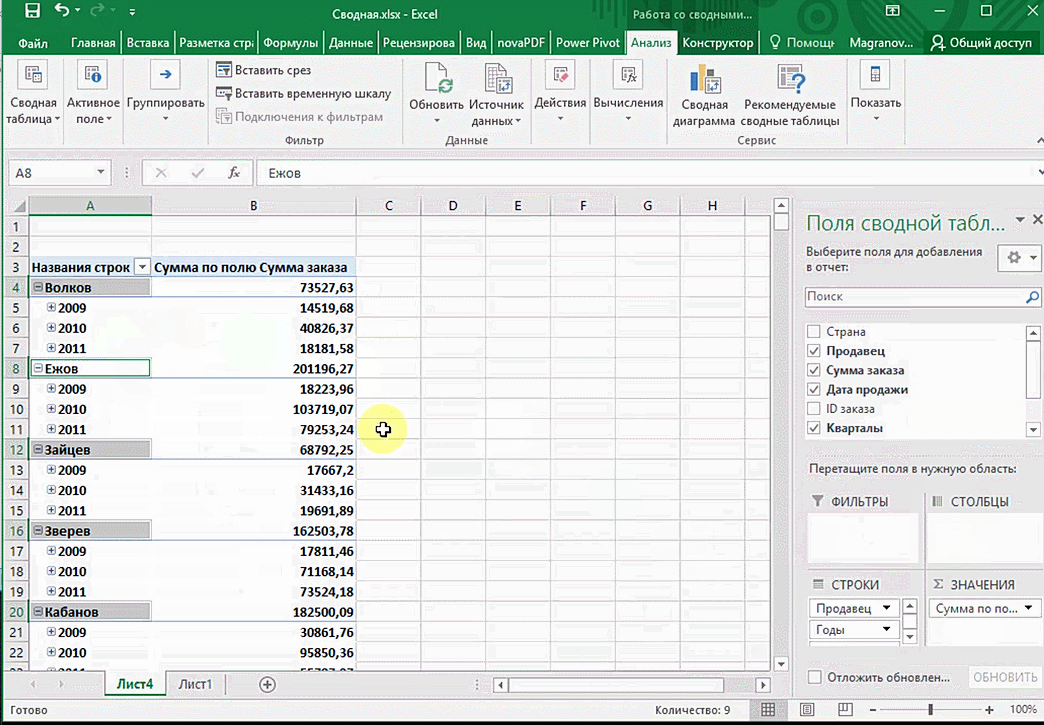
От того, сколько колонок есть, будет отличаться и набор имеющихся параметров. Например, общее число столбцов – 5. И нам надо просто разместить и выбрать их верным образом, а показать сумму. В таком случае выполняем действия, показанные на этой анимации.
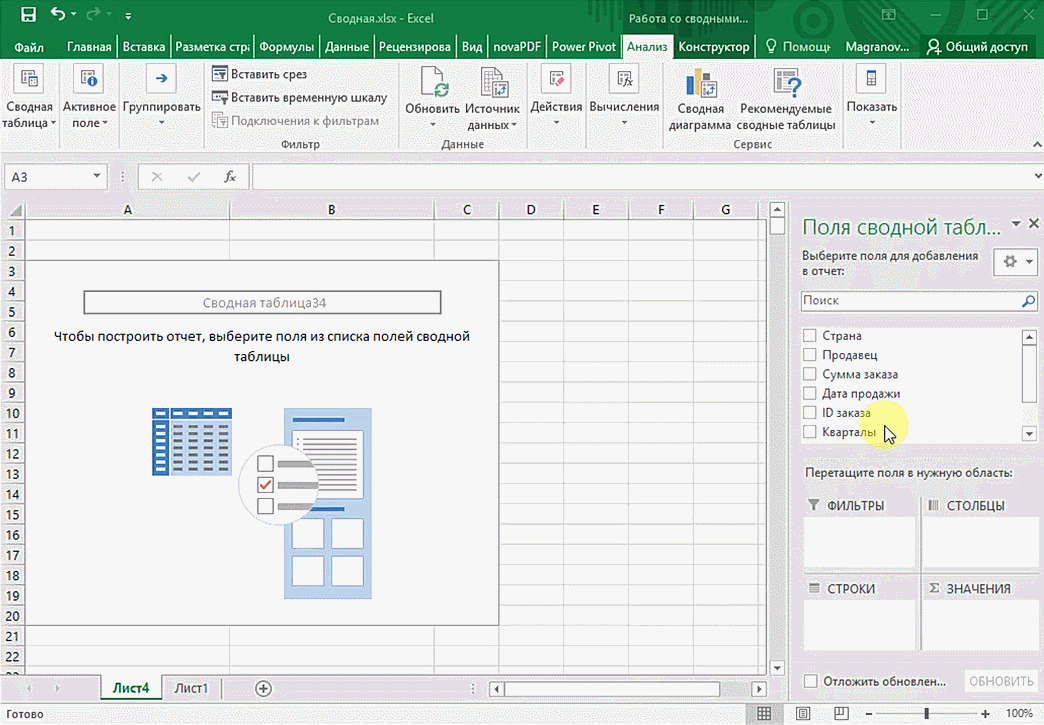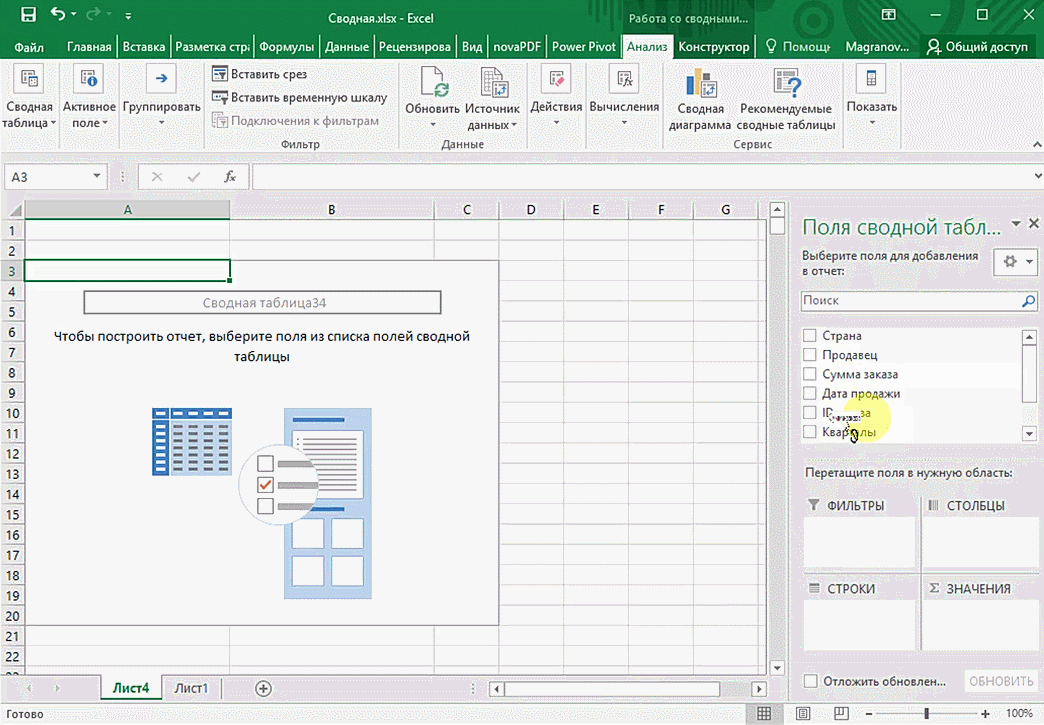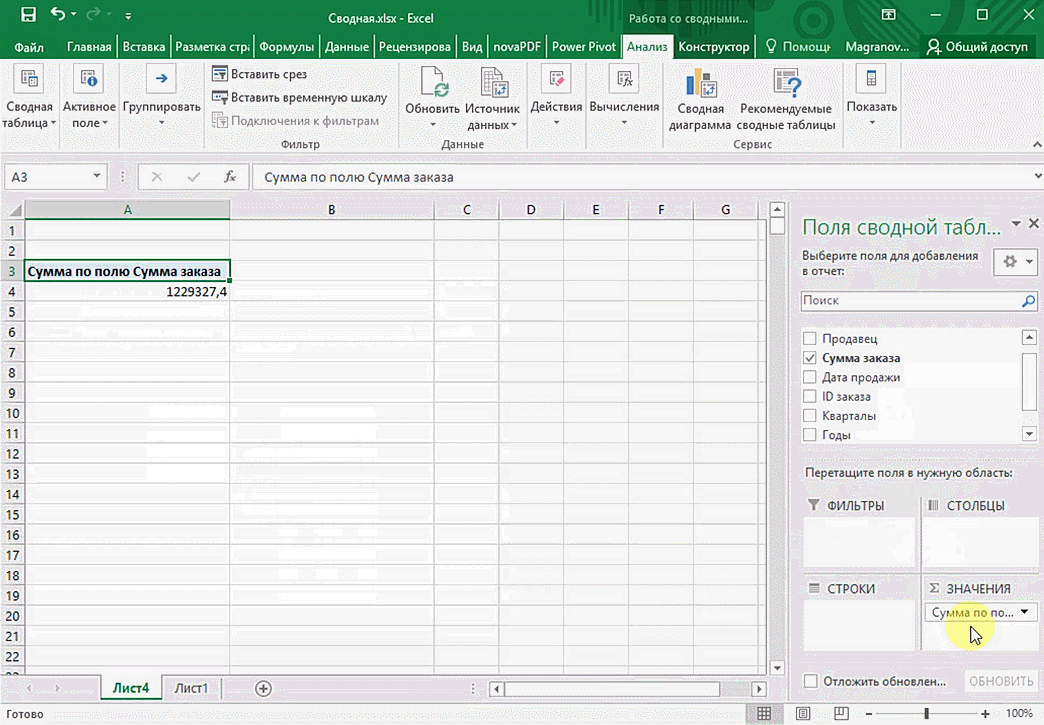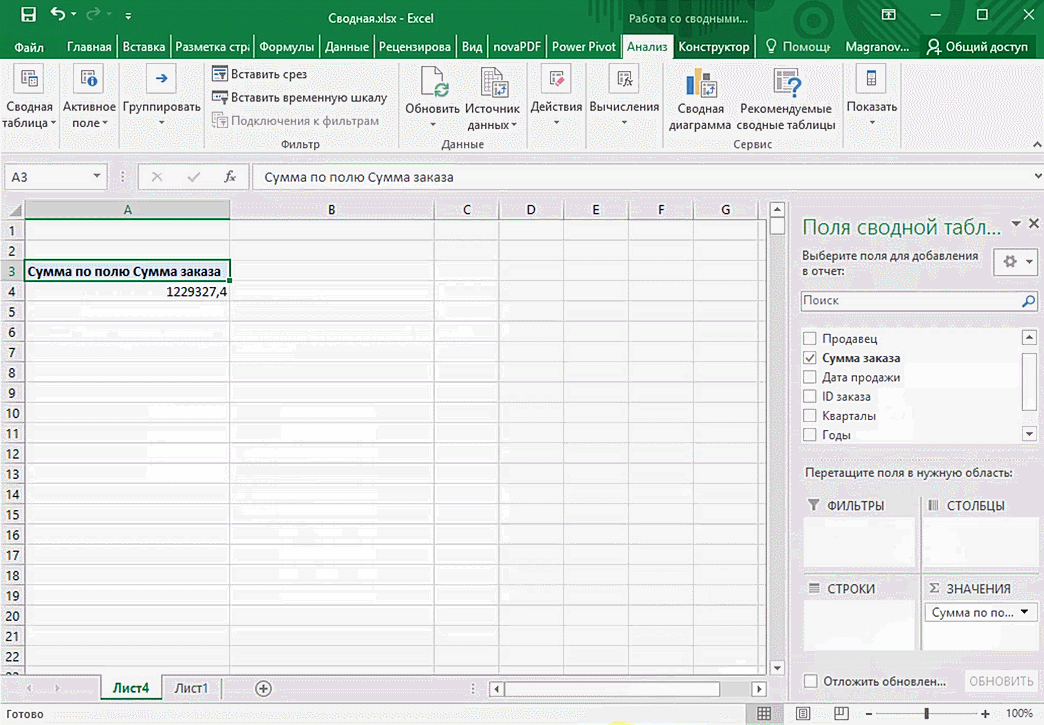
Можно сводную таблицу конкретизировать, указав, например, страну. Для этого мы включаем пункт «Страна».
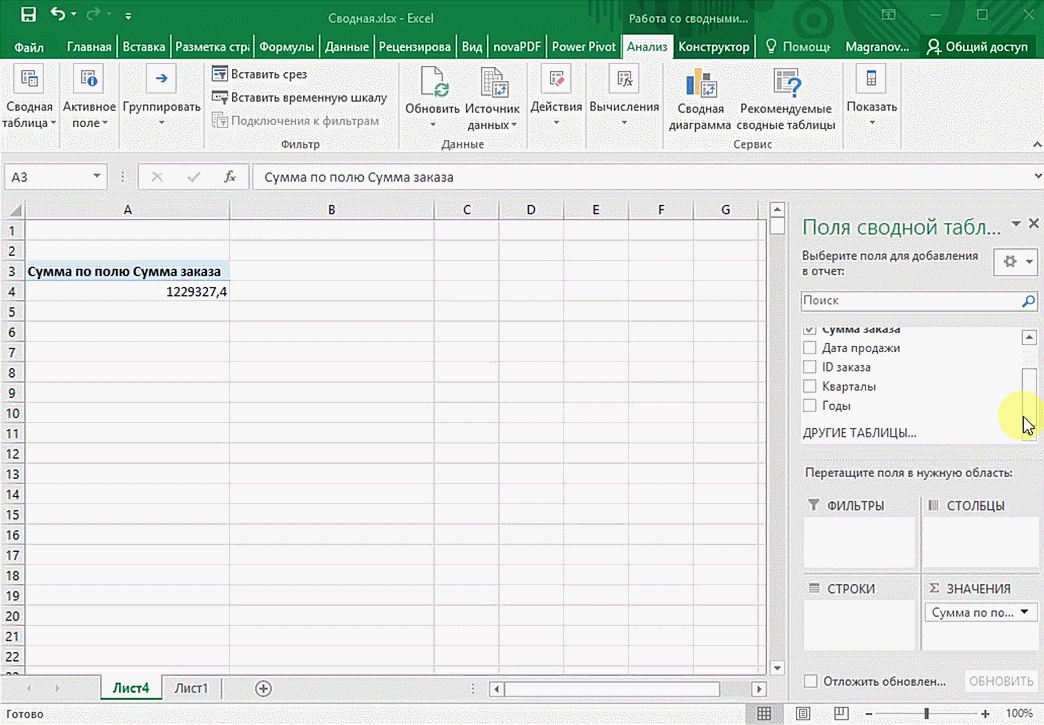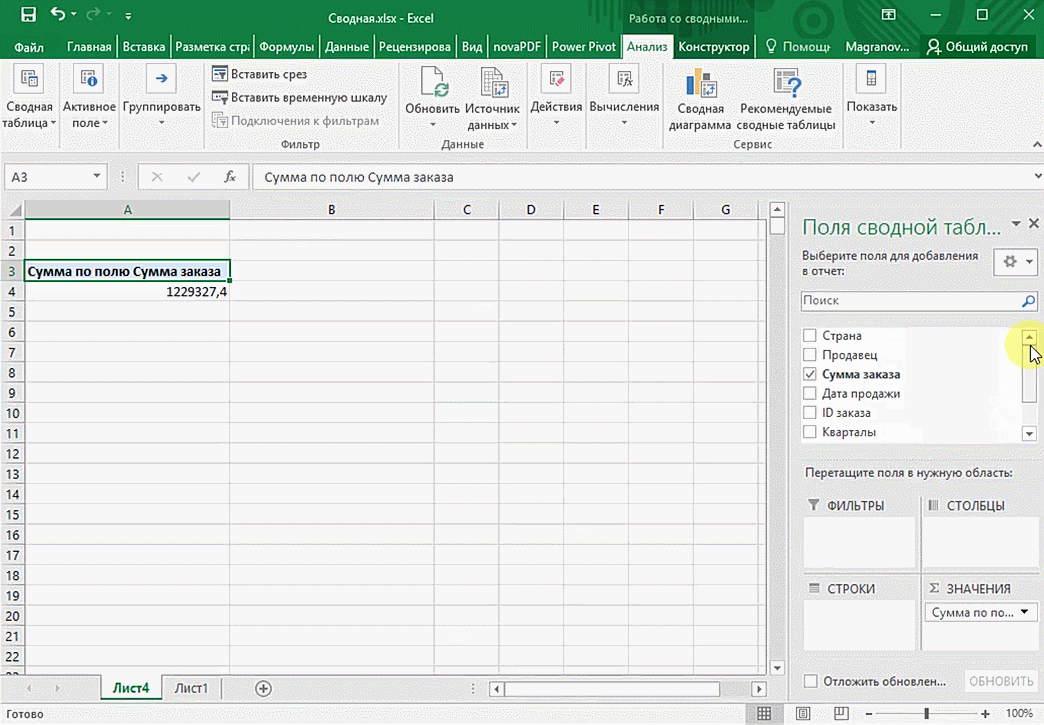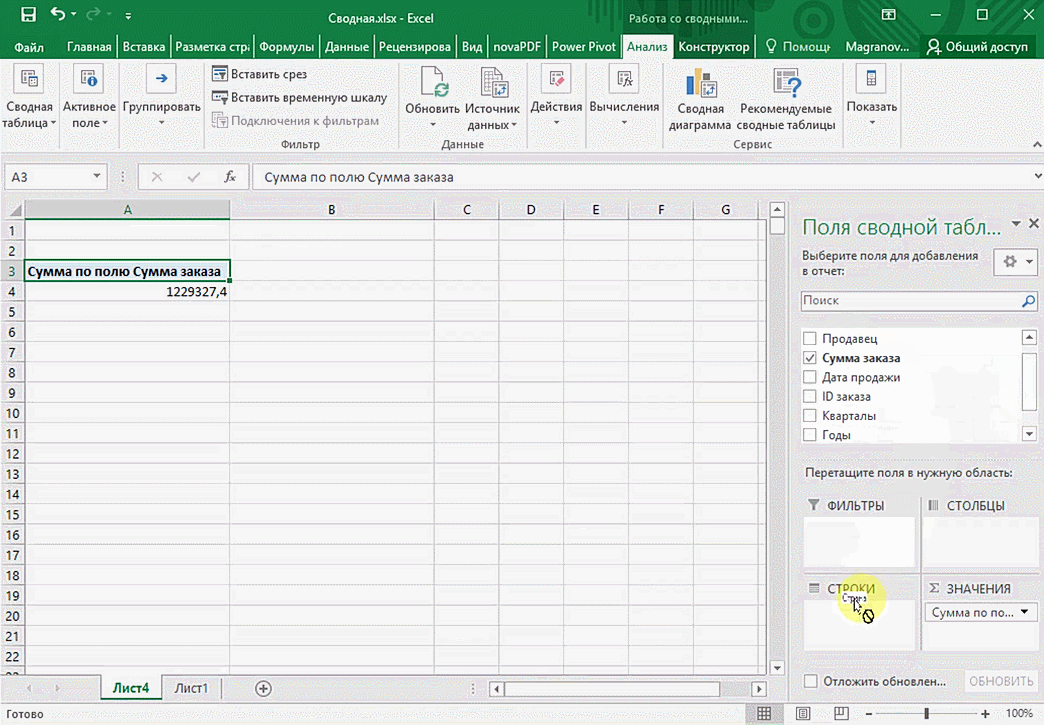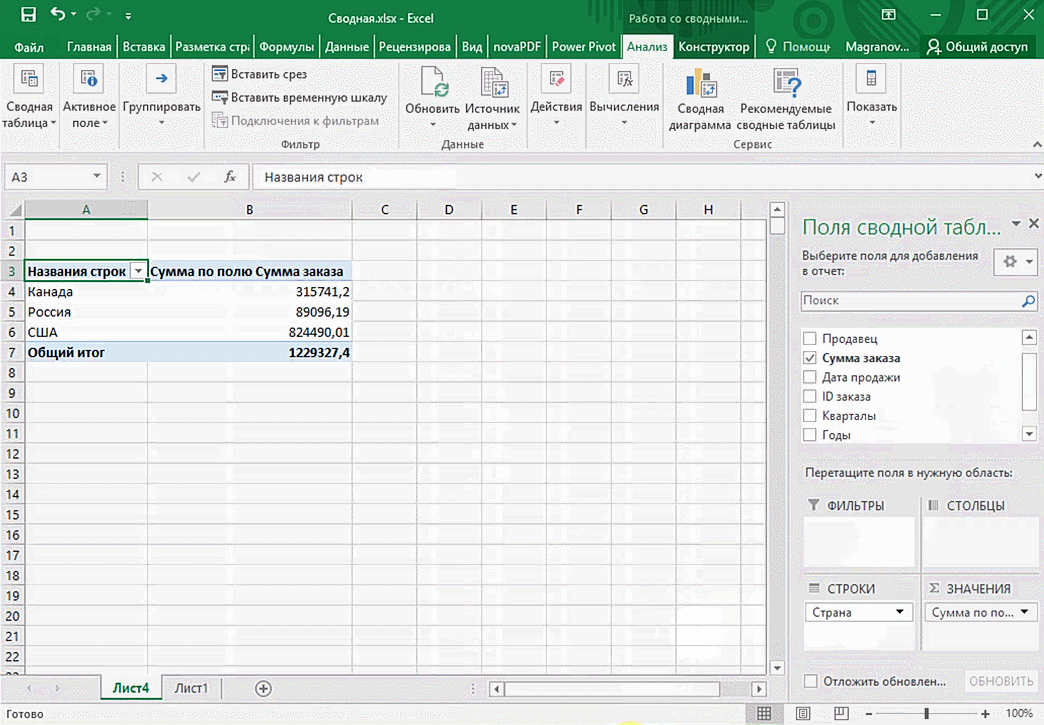
Можно также посмотреть информацию про продавцов. Для этого мы заменяем колонку «Страна» на «Продавец». Результат получится следующий.
Анализ данных с помощью 3D-карт
Данный метод визуального представления с географической привязкой дает возможность искать закономерности, привязанные к регионам, а также анализировать информацию этого типа.
Преимущество этого способа в том, что нет необходимости отдельно прописывать координаты. Необходимо просто правильно написать географическое положение в таблице.
Как работать с 3D-картами в Excel
Последовательность действий, которую вам необходимо выполнить, чтобы работать с 3Д-картами, следующая:
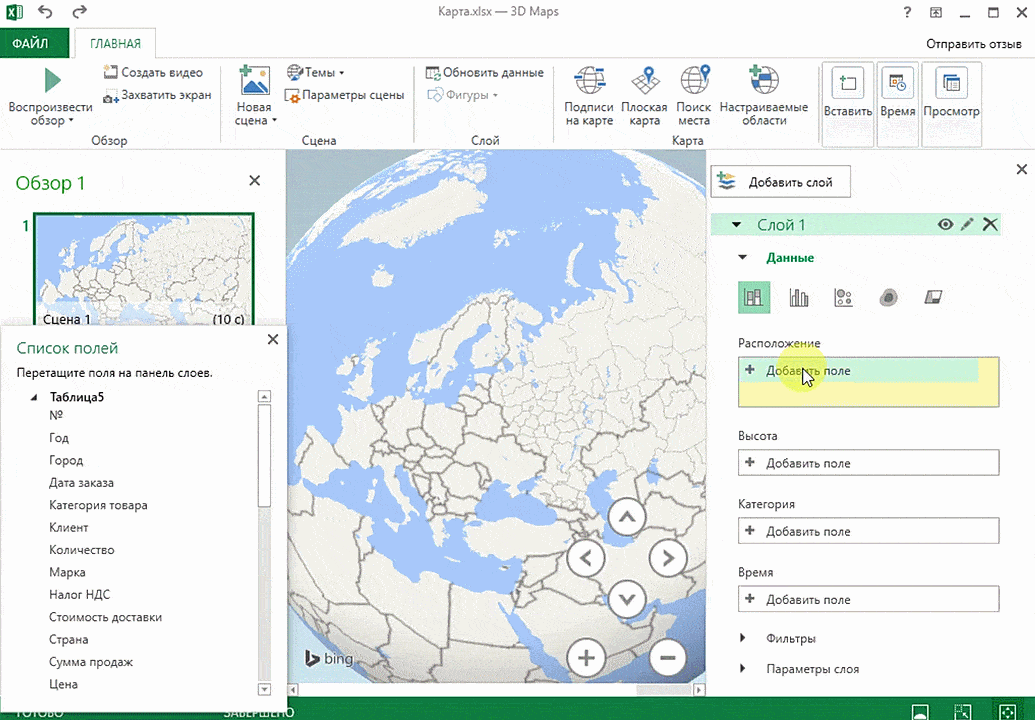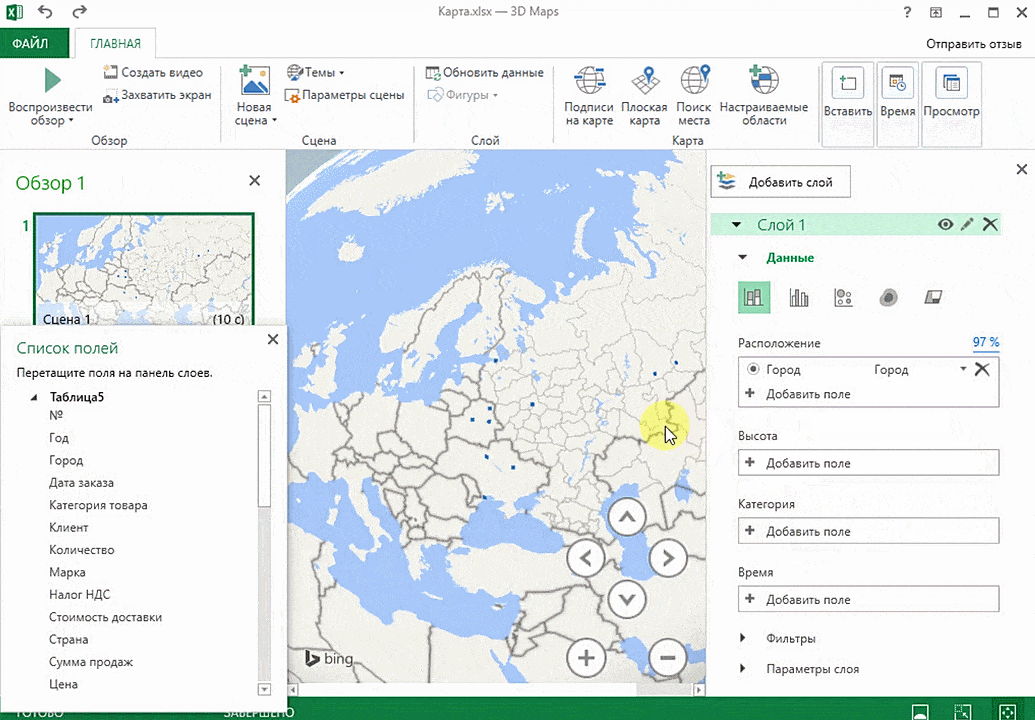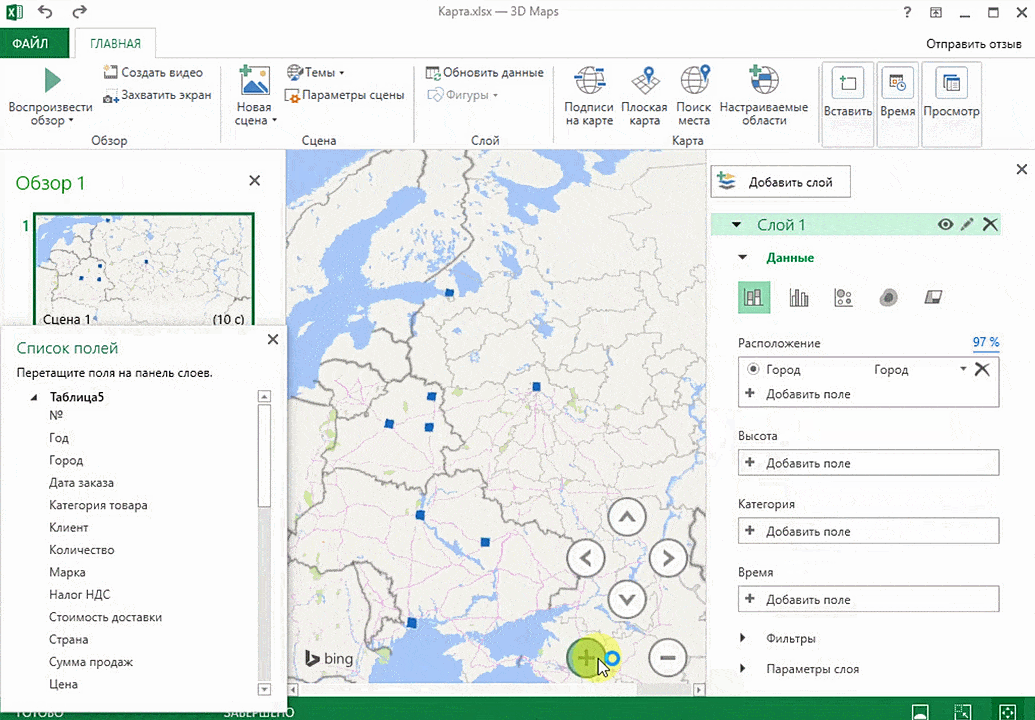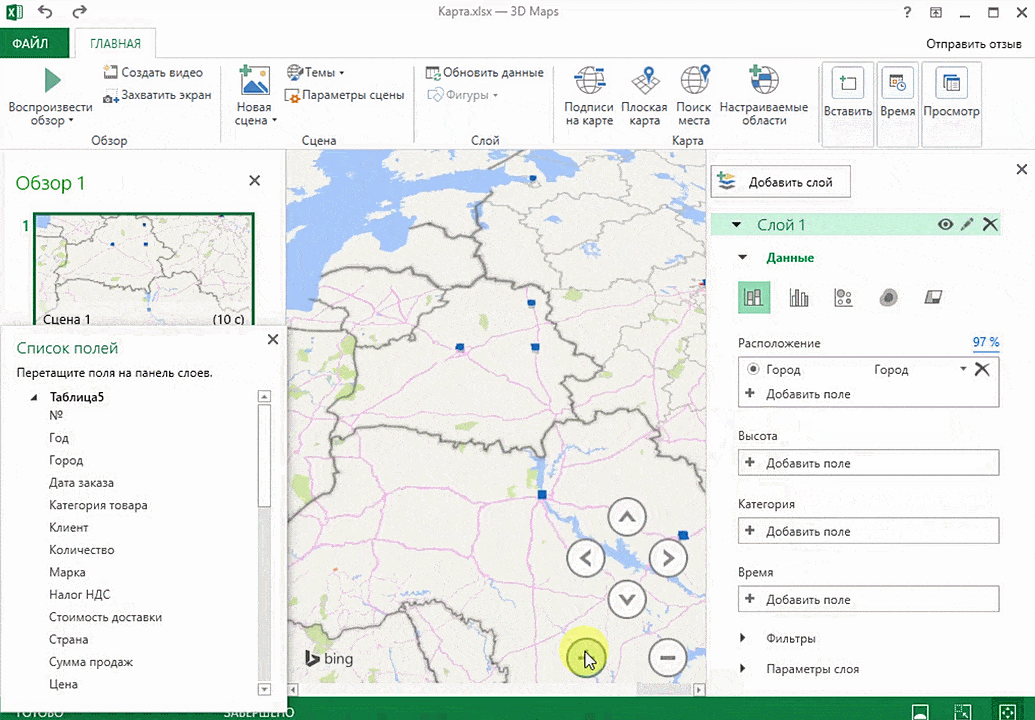
- Откройте файл, в котором есть интересующий диапазон данных. Например, таблица, где есть колонка «Страна» или «Город».
- Информацию, которая будет показываться на карте, нужно сначала отформатировать, как таблицу. Для этого надо найти соответствующий пункт на вкладке «Главная».
- Выделите те ячейки, которые будут анализироваться.
- После этого переходим на вкладку «Вставка», и там находим кнопку «3Д-карта».
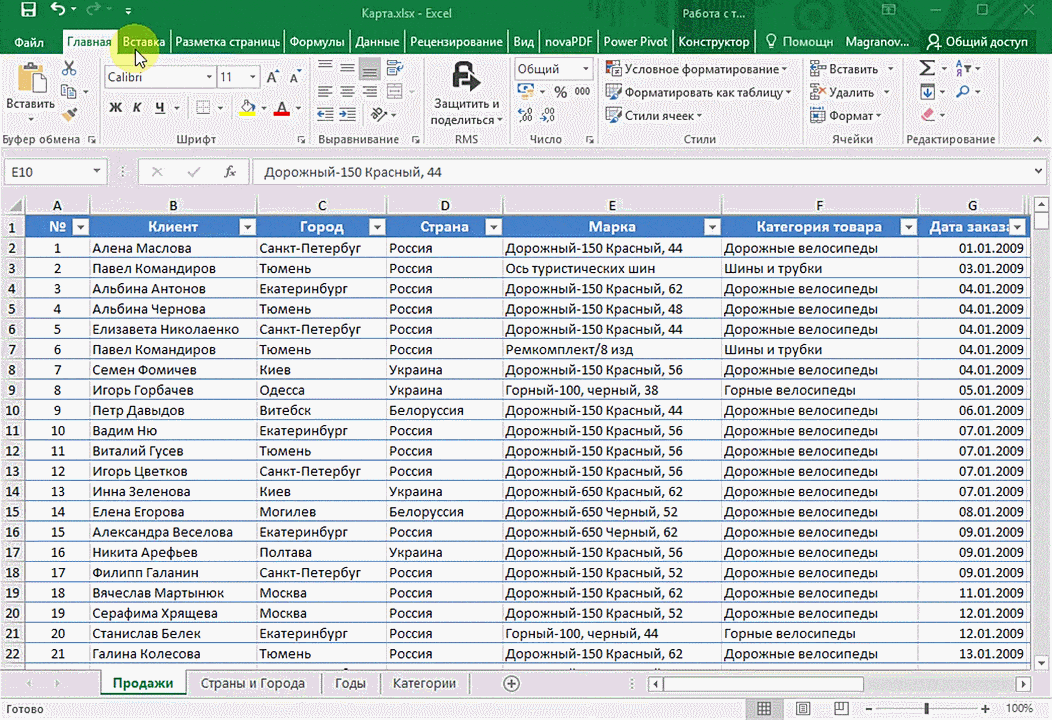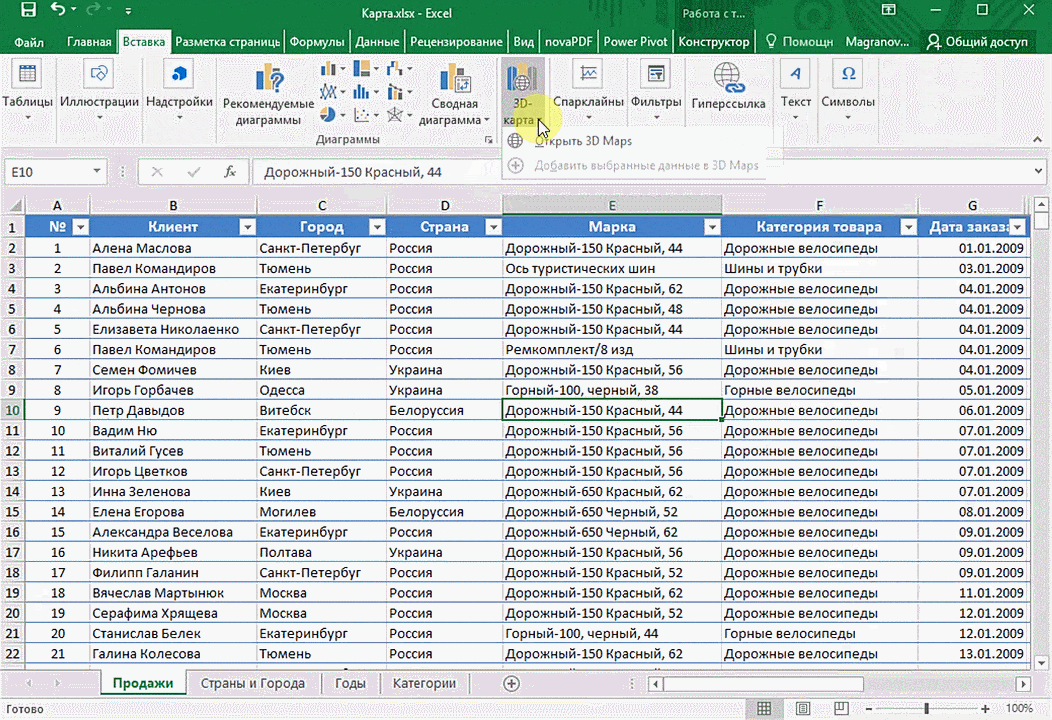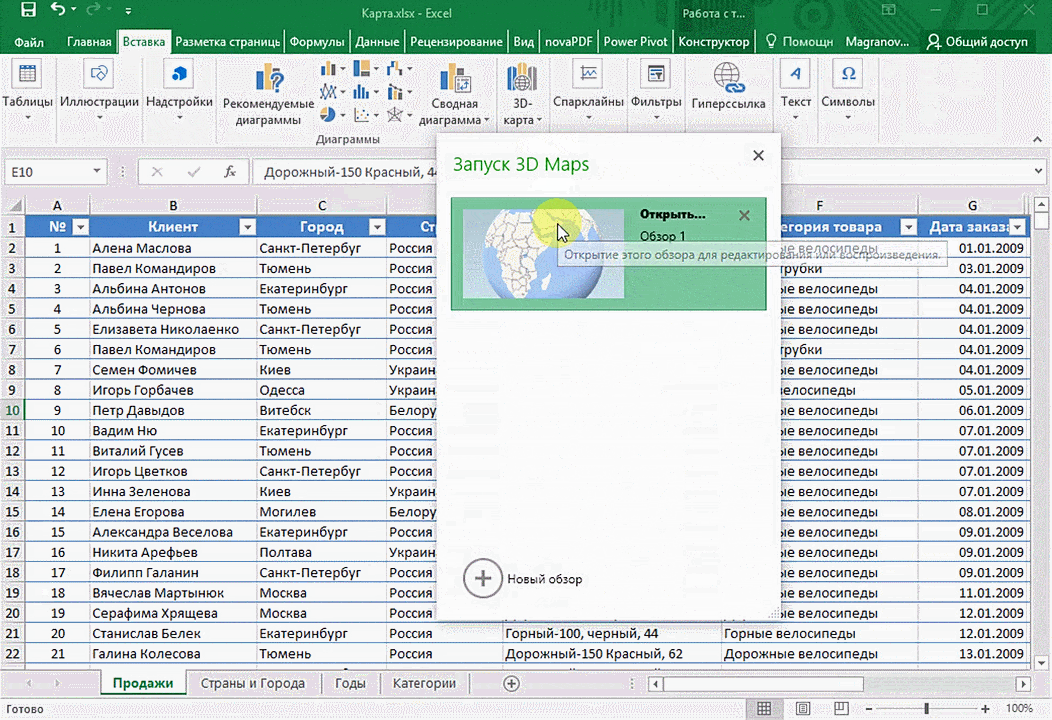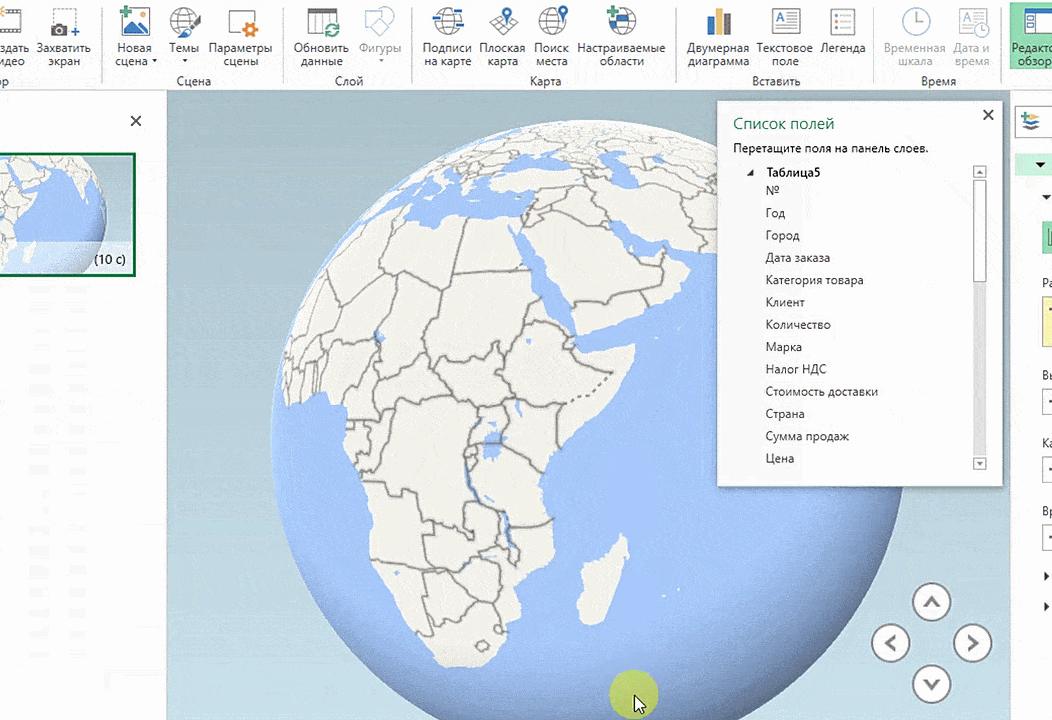
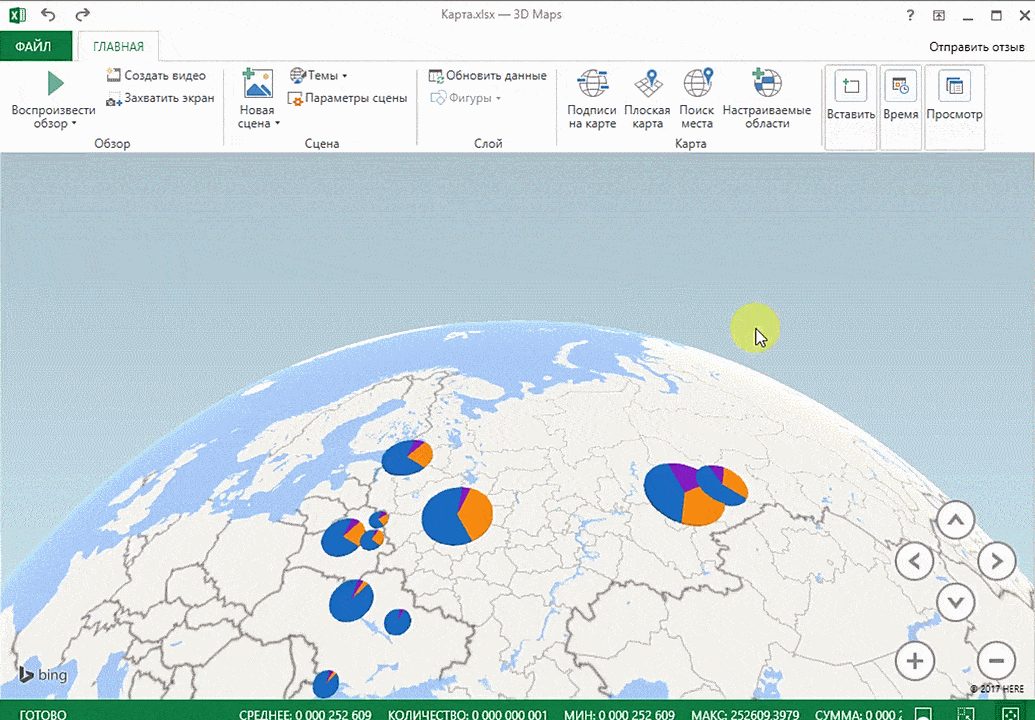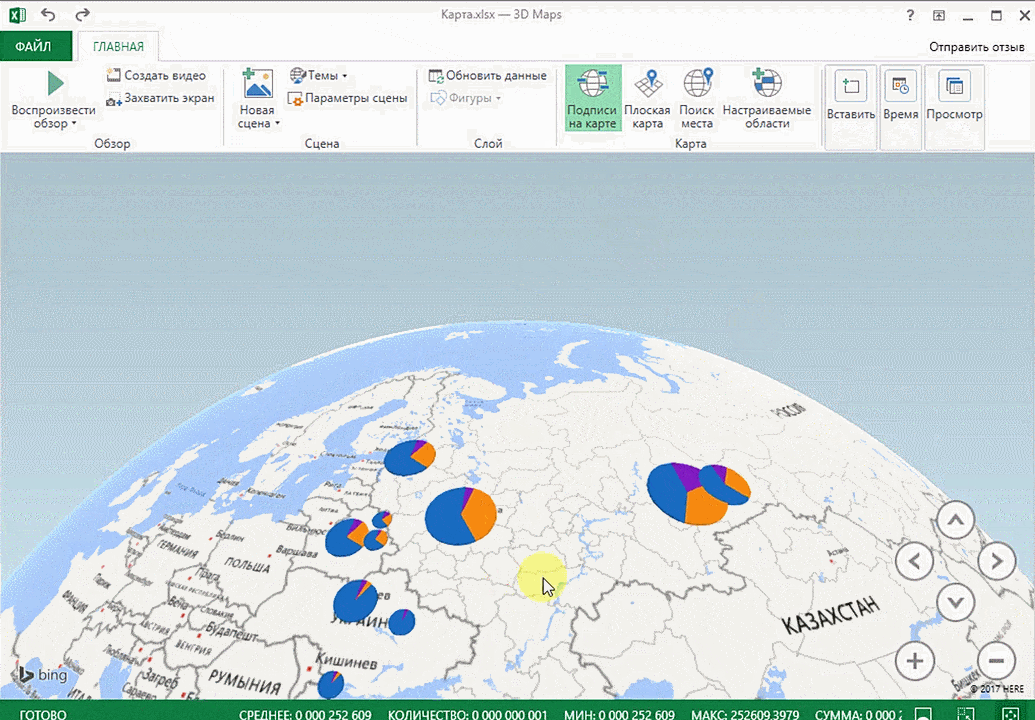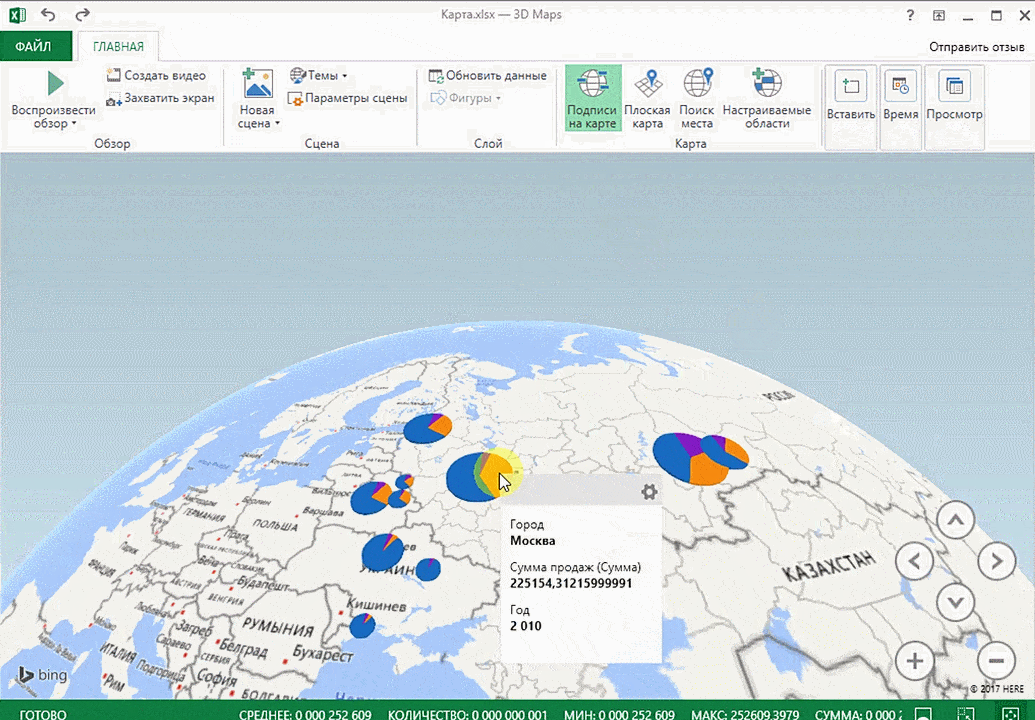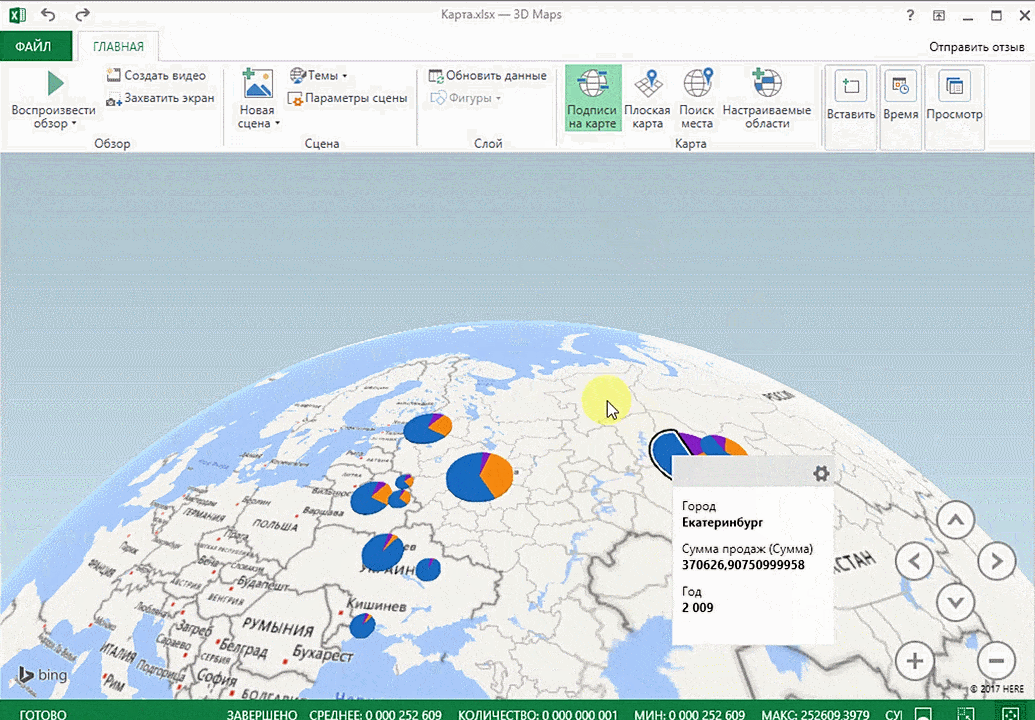
Затем показывается наша карта, где города в таблице представлены в виде точек. Но нам не особо нужно просто наличие информации о населенных пунктах на карте. Нам гораздо важнее видеть ту информацию, которая привязана к ним. Например, те суммы, которые можно показать, как высоту столбика. После того, как мы выполним действия, указанные на этой анимации, при наведении курсора на соответствующий столбик будут отображаться привязанные к нему данные.
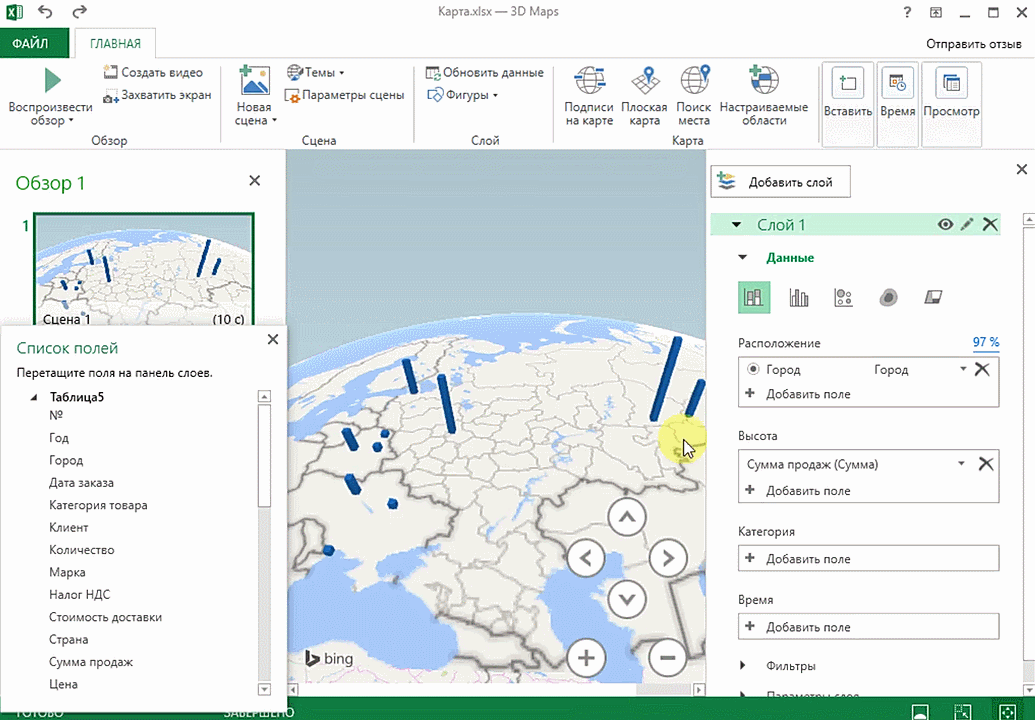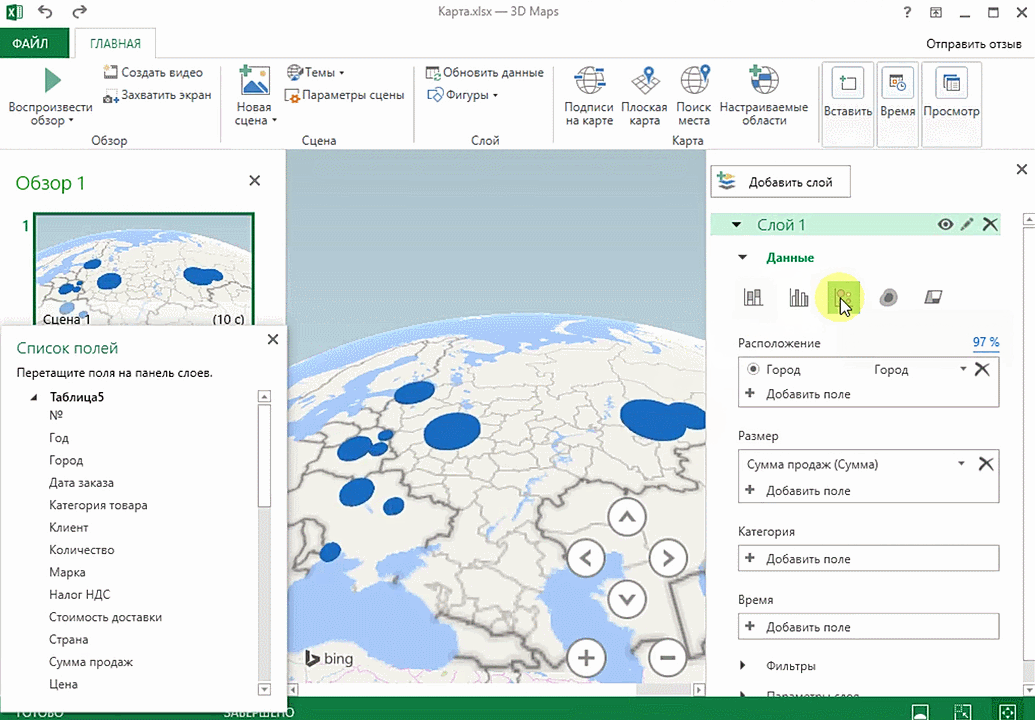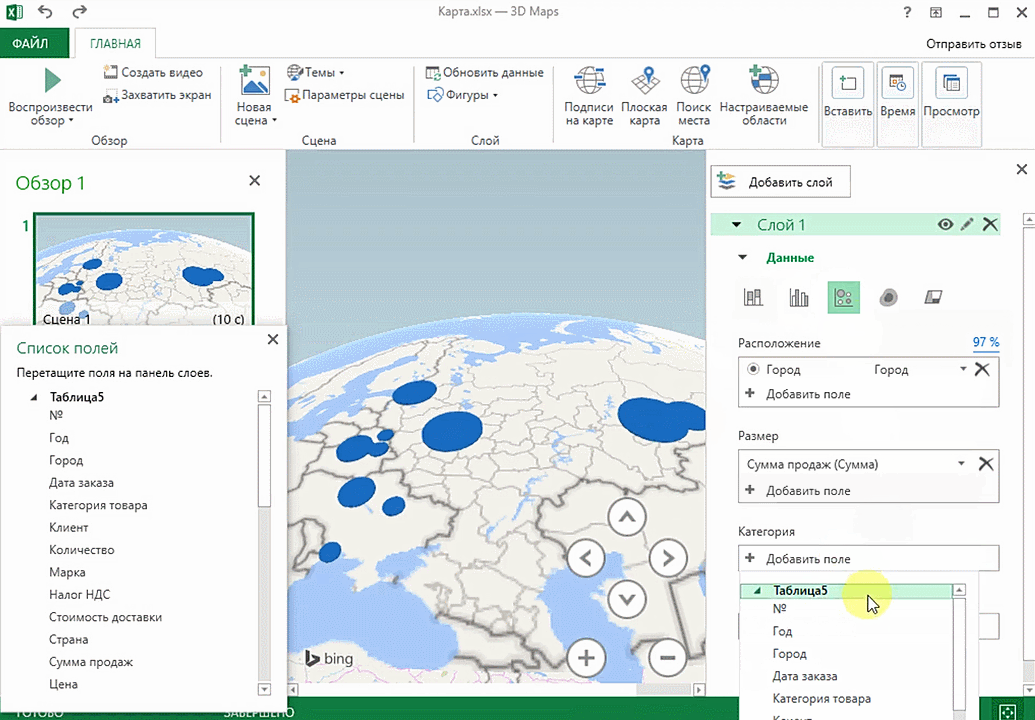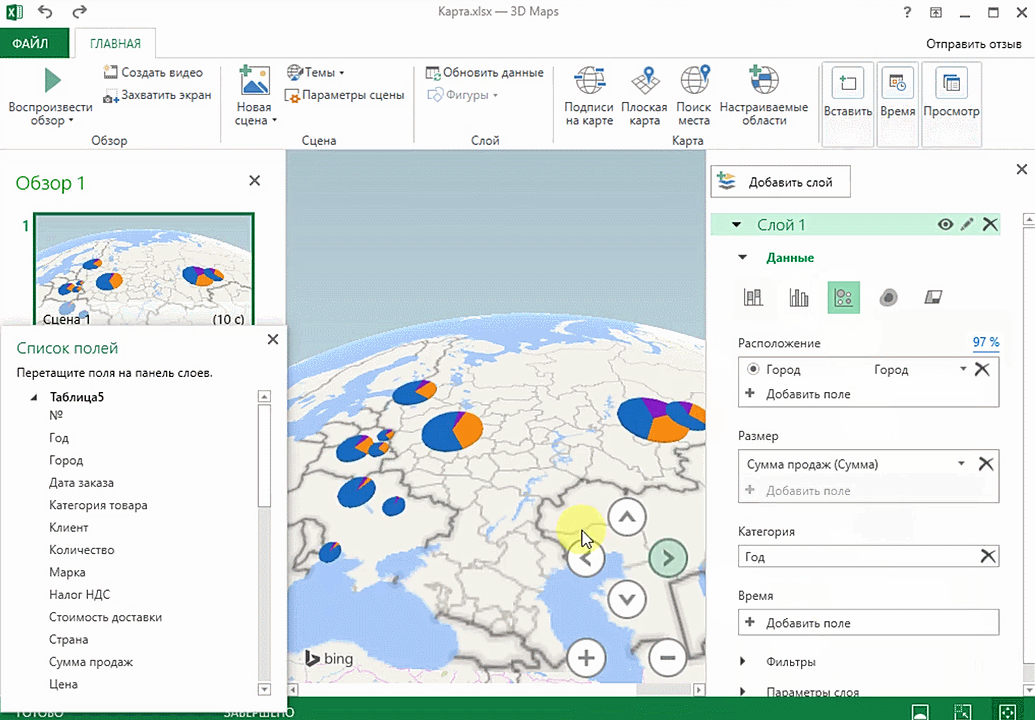
Также можно воспользоваться круговой диаграммой, которая является намного более информативной в некоторых случаях. От того, какая общая сумма по величине, зависит размер круга.
Лист прогноза в Excel
Нередко бизнес-процессы зависят от сезонных особенностей. И такие факторы надо обязательно принимать в учет на этапе планирования. Для этого существует специальный инструмент Excel, который понравится вам своей высокой точностью. Он значительно более функциональный, чем все описанные выше методы, какими бы отличными они ни были. Точно так же, очень широкой является сфера его использования – коммерческие, финансовые, маркетинговые и даже государственные структуры.
Важно: чтобы рассчитать прогноз, необходимо получить информацию за предыдущее время. От того, насколько долгосрочные данные, зависит качество прогнозирования. Рекомендуется иметь данные, которые разбиты по одинаковым интервалам (например, поквартально или помесячно).
Как работать с листом прогноза
Чтобы работать с листом прогноза, необходимо выполнять следующие действия:
- Откройте файл, в котором содержится большой объем информации по тем показателям, которые нам надо проанализировать. Например, в течение прошлого года (хотя чем больше, тем лучше).
- Выделите две строки с информацией.
- Перейдите в меню «Данные», и там кликните по кнопке «Лист прогноза».
- После этого откроется диалог, в котором можно выбрать тип визуального представления прогноза: график или гистограмма. Выберите тот, который подходит под вашу ситуацию.
- Установите дату, когда прогноз должен закончиться.
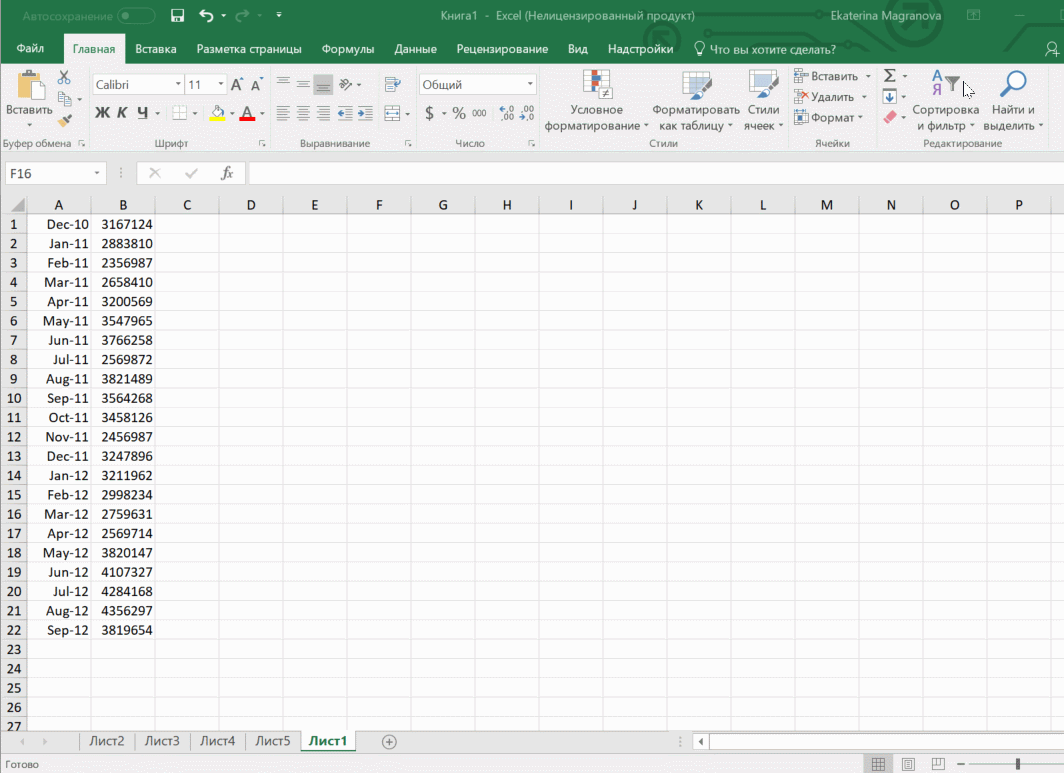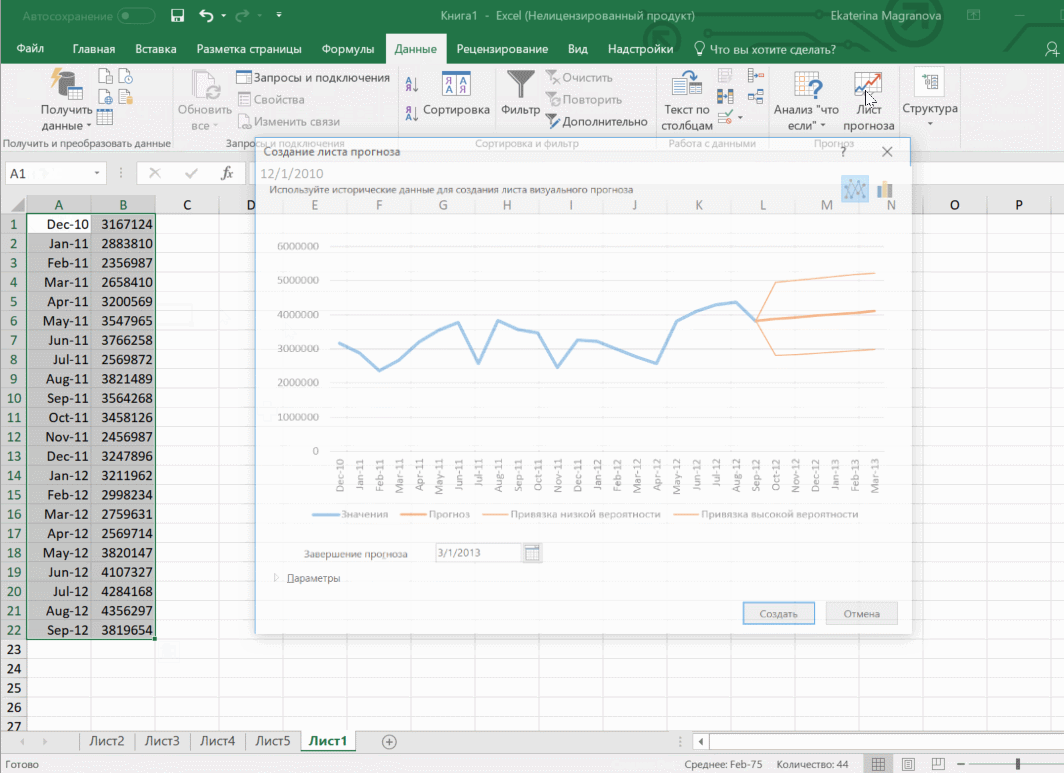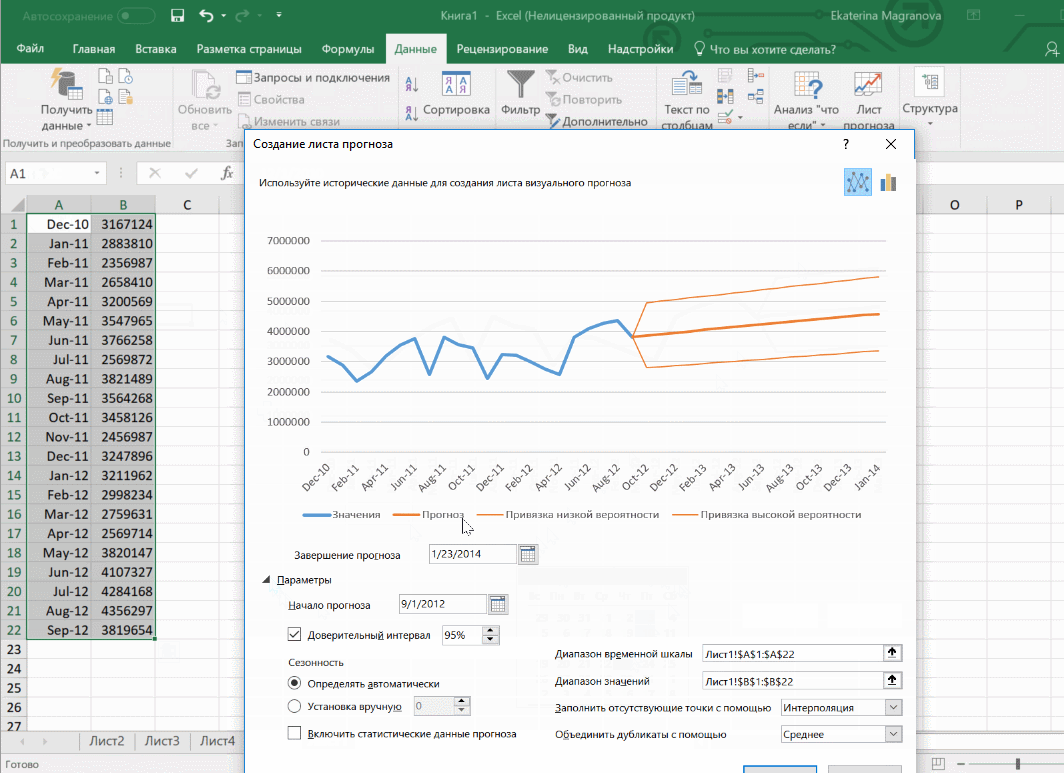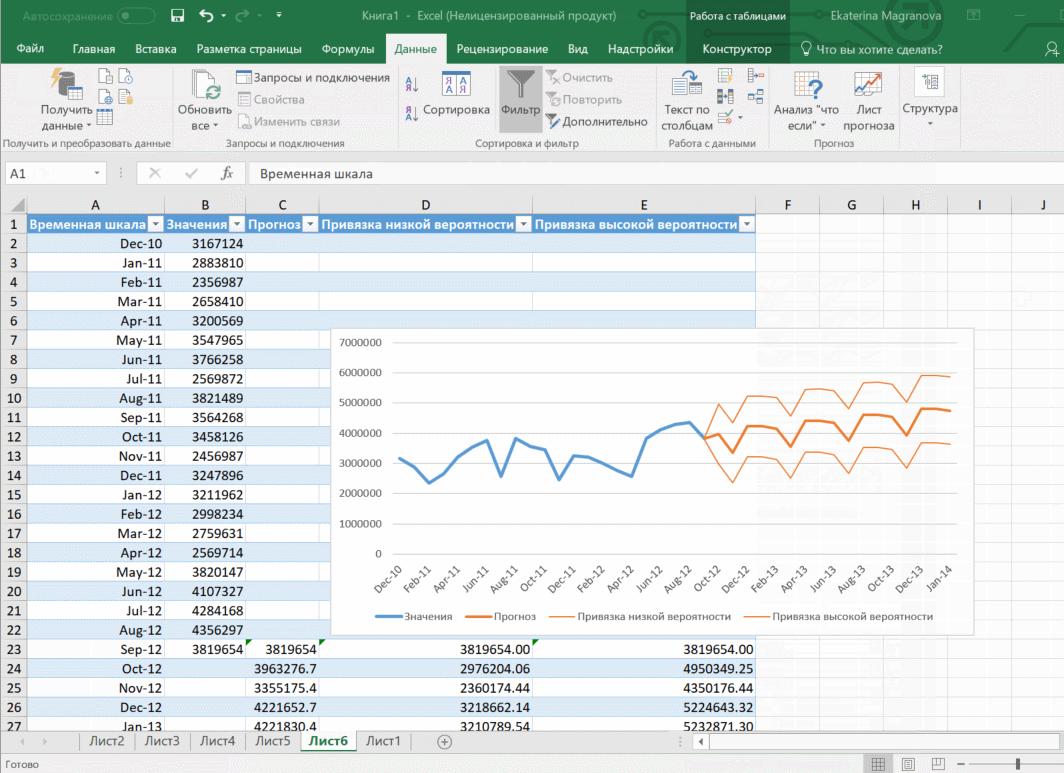
В приводимом нами ниже примере даются сведения за три года – 2011-2013. При этом рекомендуется указывать временные промежутки, а не конкретные числа. То есть, лучше писать март 2013, а не конкретное число типа 7 марта 2013 года. Чтобы исходя из этих данных получить прогноз на 2014 год необходимо получить данных, расположенные в рядах с датой и показателями, которые были на этот момент. Выделяем эти строки.
Затем переходим на вкладку «Данные» и ищем группу «Прогноз». После этого переходим в меню «Лист прогноза». После этого появится окно, в котором снова выбираем способ представления прогноза, а затем устанавливаем дату, к которой прогноз должен быть закончен. После этого нажимаем на «Создать», после чего получаем три варианта прогноза (показываются оранжевой линией).
Быстрый анализ в Excel
Предыдущий способ действительно хорош, потому что позволяет составлять реальные прогнозы, основываясь на статистических показателях. Но этот метод позволяет фактически проводить полноценную бизнес-аналитику. Очень классно, что эта возможность создана максимально эргономичной, поскольку для достижения желаемого результата необходимо совершить буквально несколько действий. Никаких ручных подсчетов, записи каких-либо формул. Достаточно просто выбрать диапазон, который будет анализироваться и задать конечную цель.
Есть возможность прямо в ячейке создавать самые разные диаграммы и микрографики.
Как работать
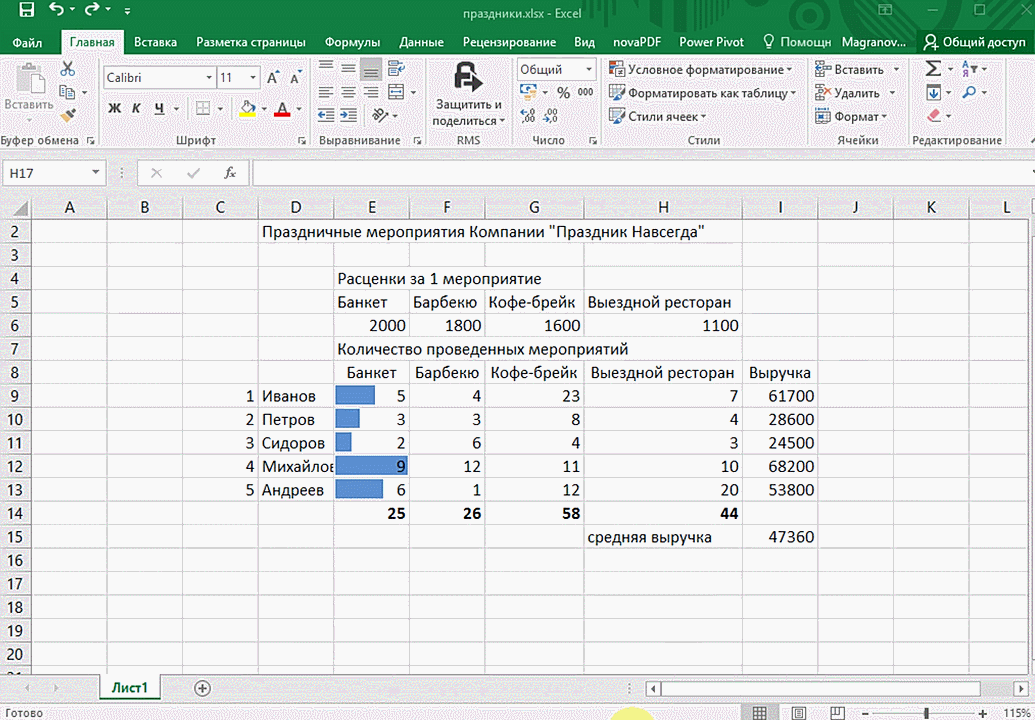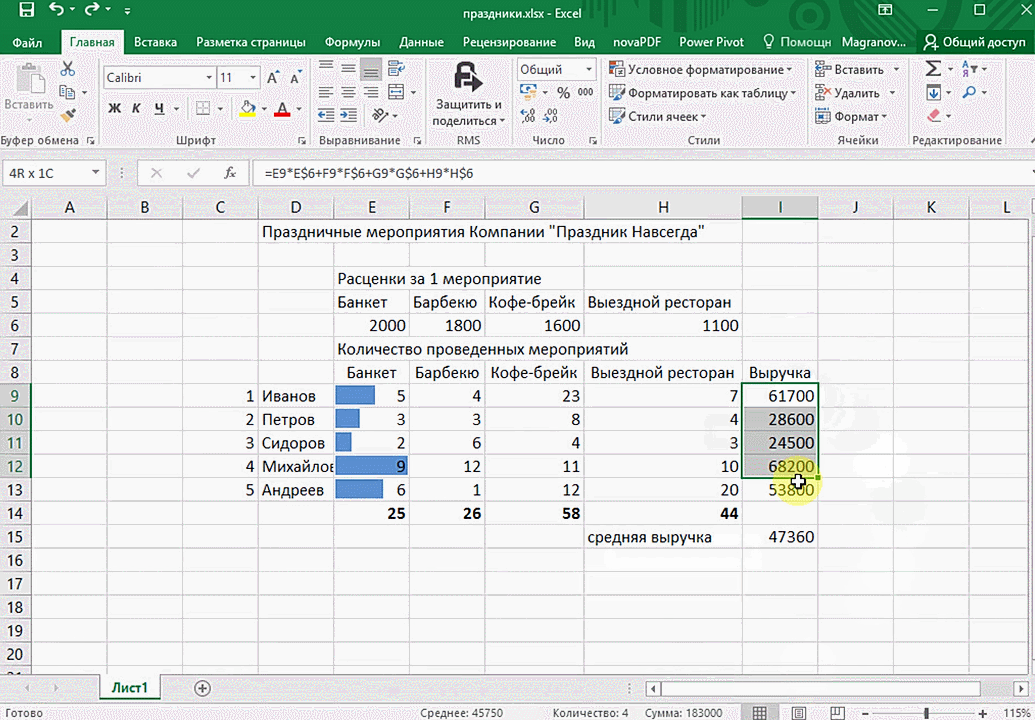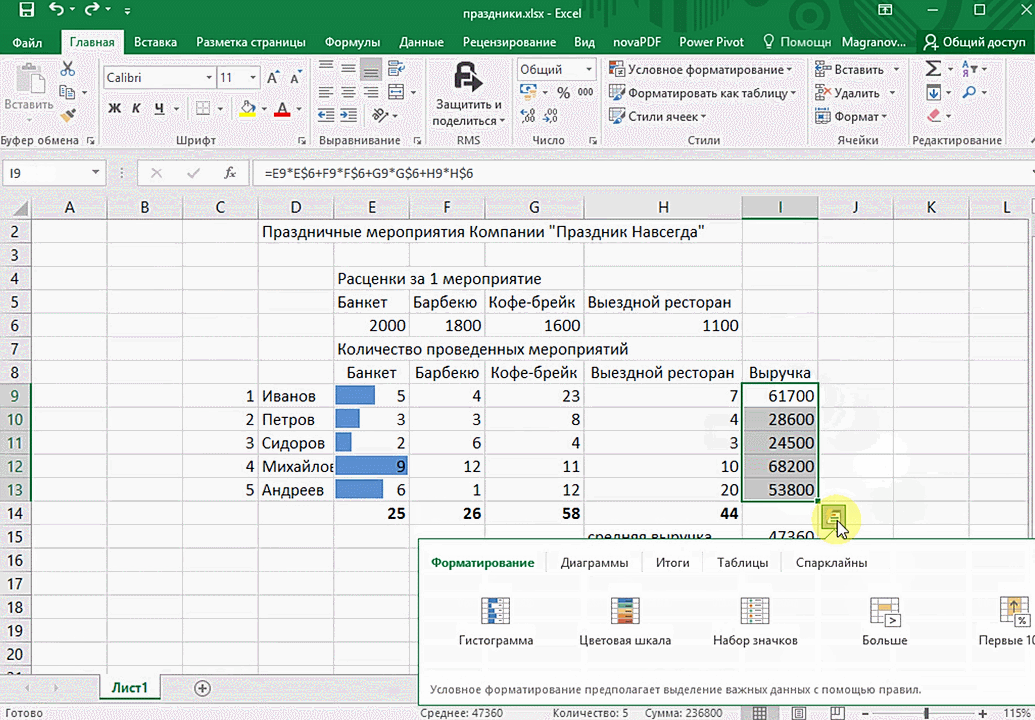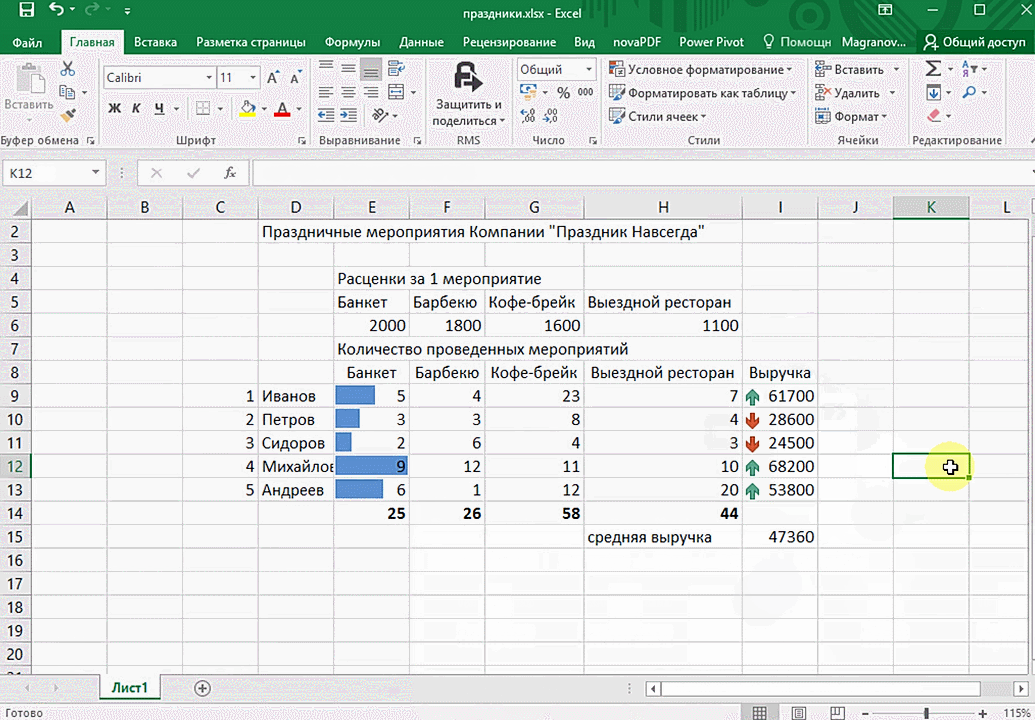
Итак, чтобы работать, нам надо надо открыть файл, в котором содержится тот набор данных, который надо анализировать и выделить соответствующий диапазон. После того, как мы его выделим, у нас автоматически появится кнопка, дающая возможность составить итоги или же выполнить набор других действий. Называется она быстрым анализом. Также мы можем определить суммы, которые автоматически будут проставлены внизу. Более наглядно посмотреть, как это работает, можете на этой анимации.
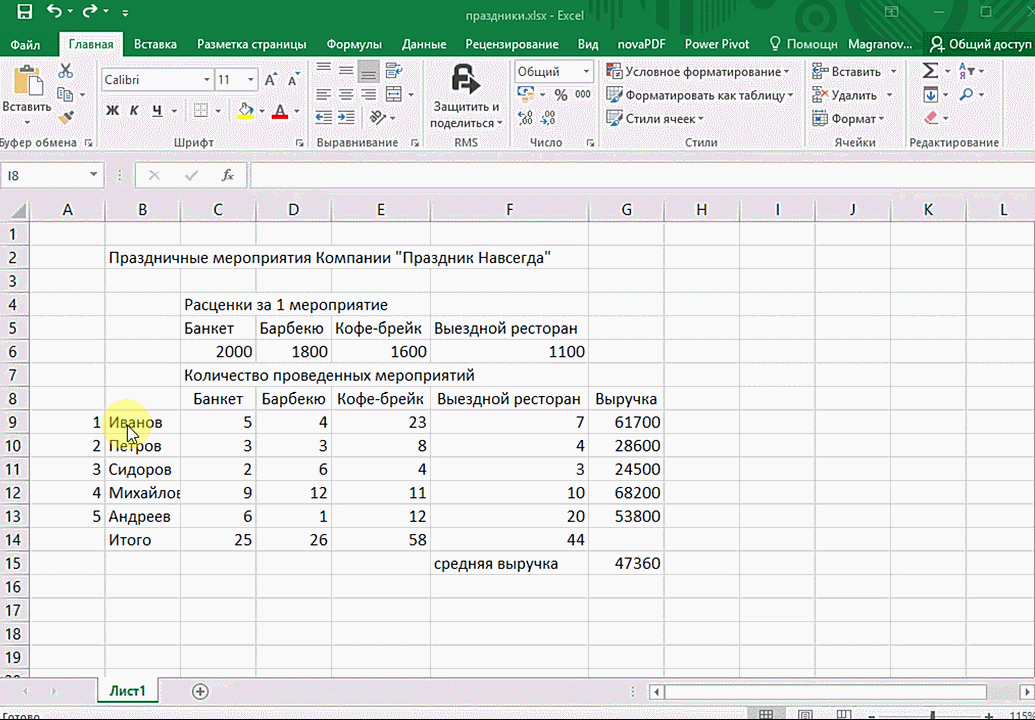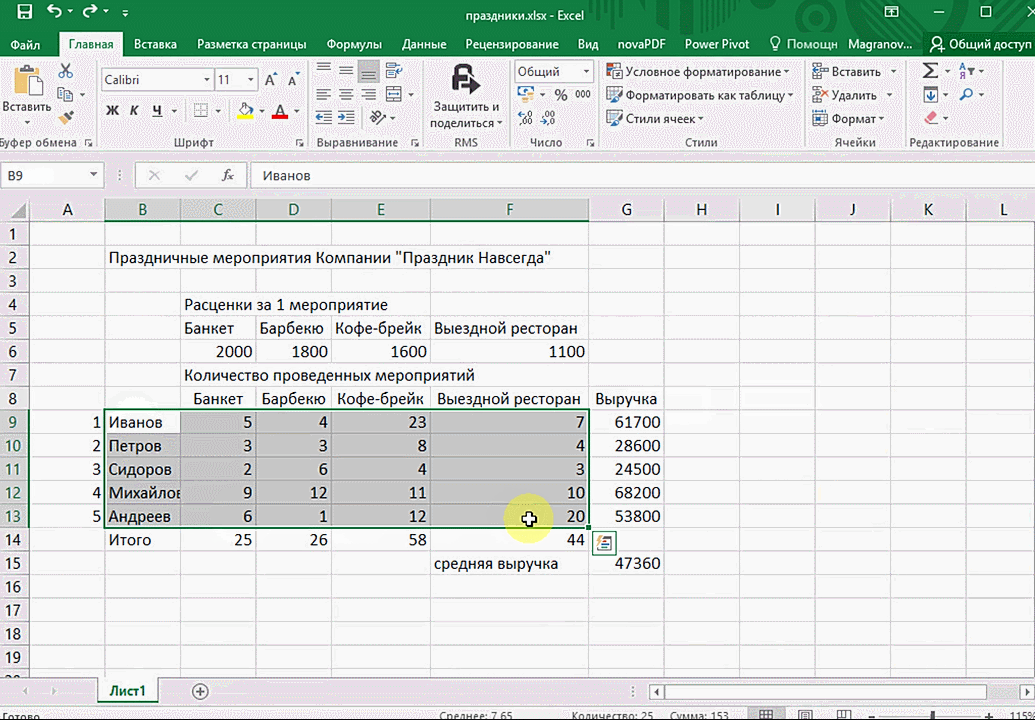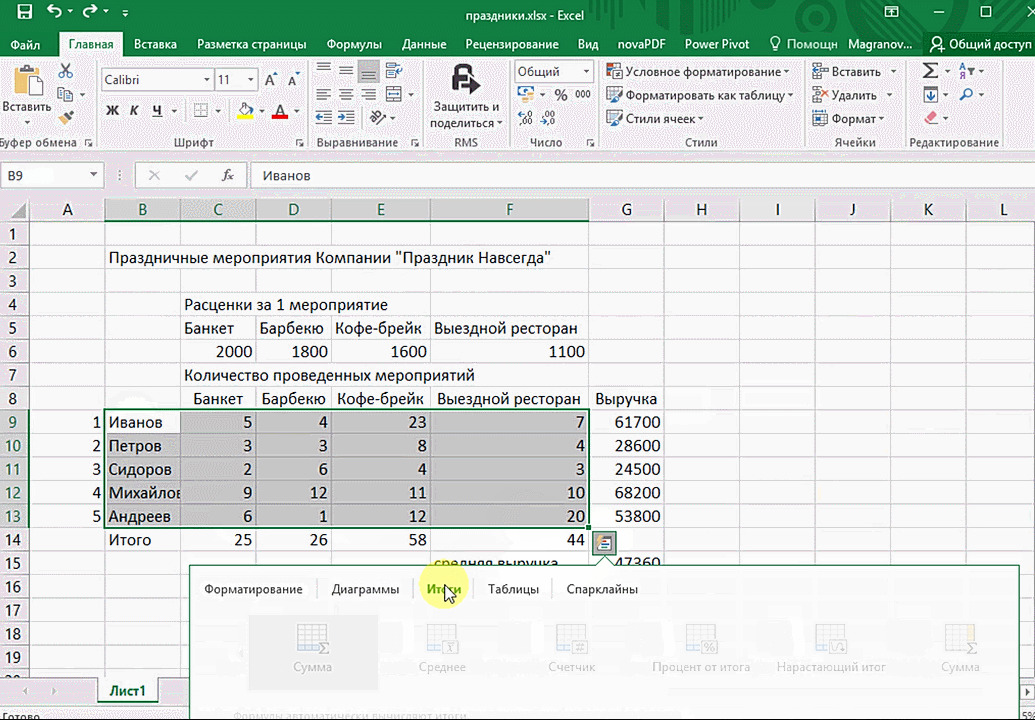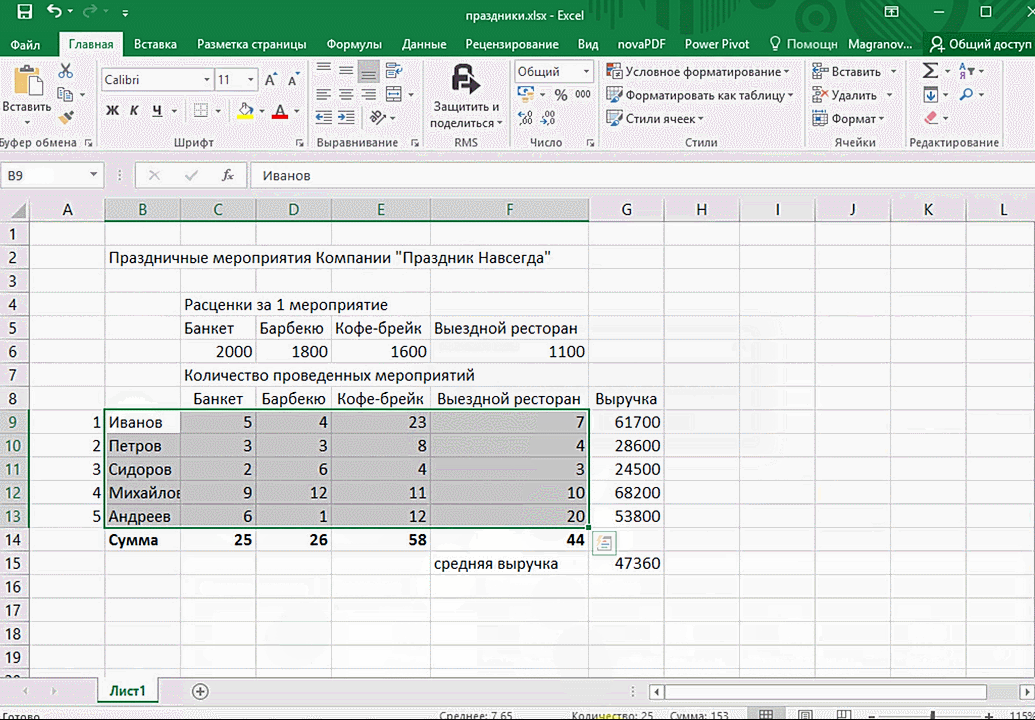
Функция быстрого анализа позволяет также по-разному форматировать получившиеся данные. А определить, какие значения больше или меньше, можно непосредственно в ячейках гистограммы, которая появляется после того, как мы настроим этот инструмент. 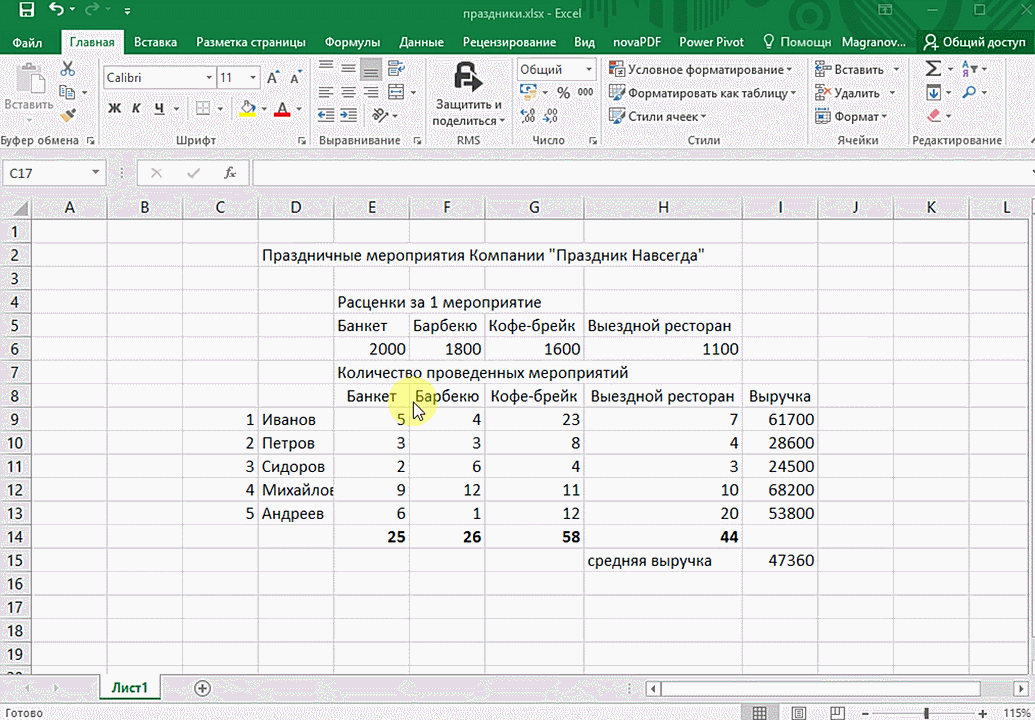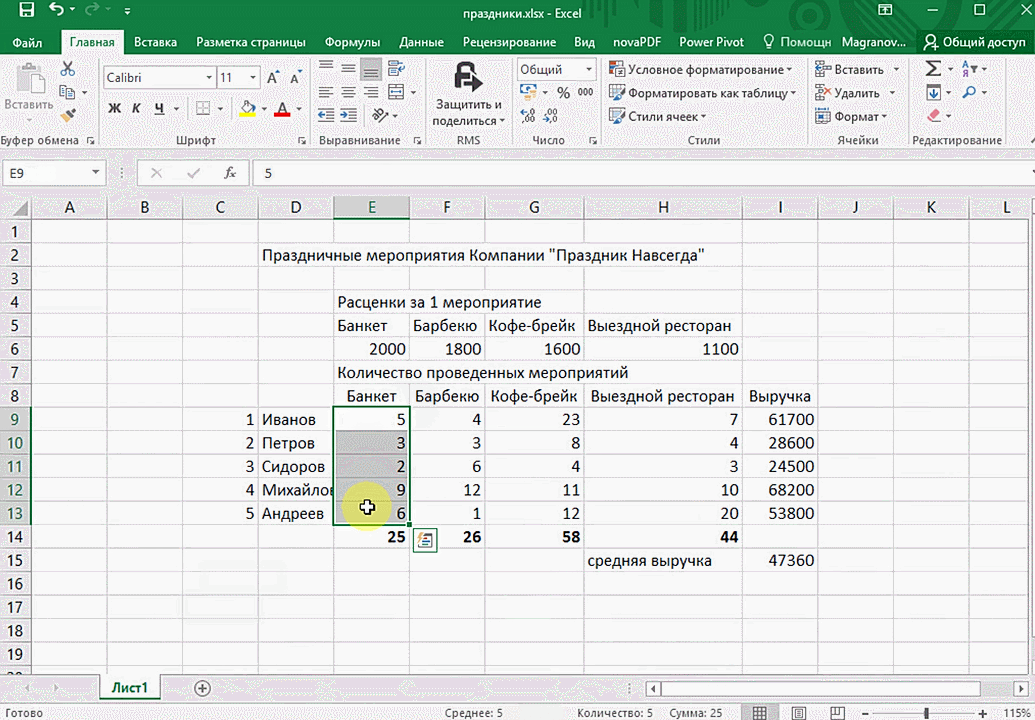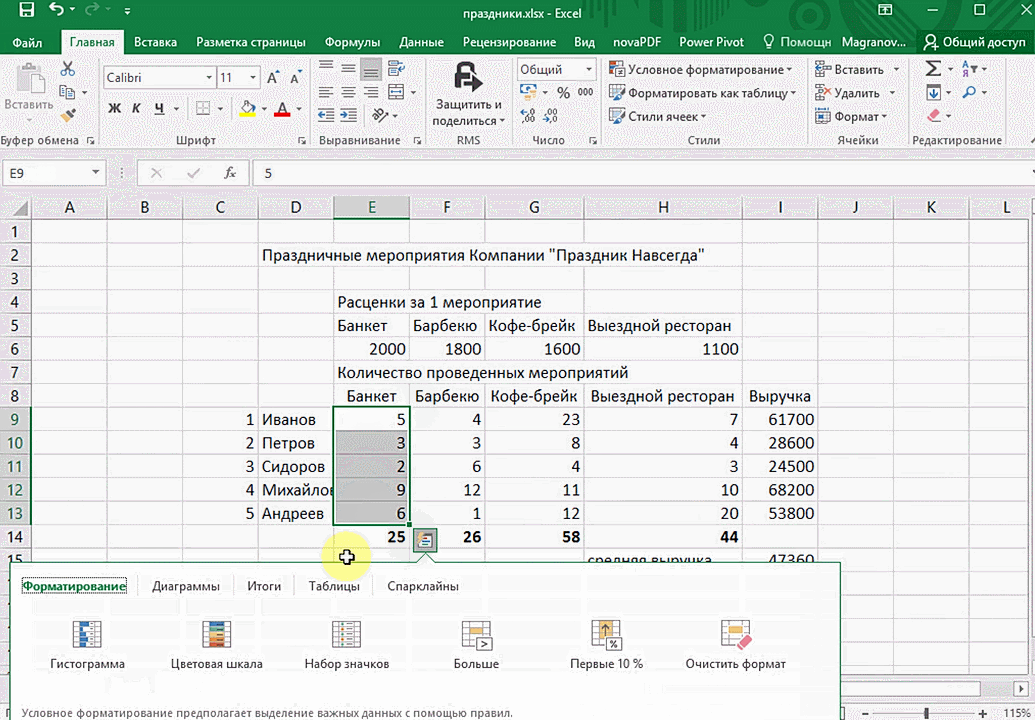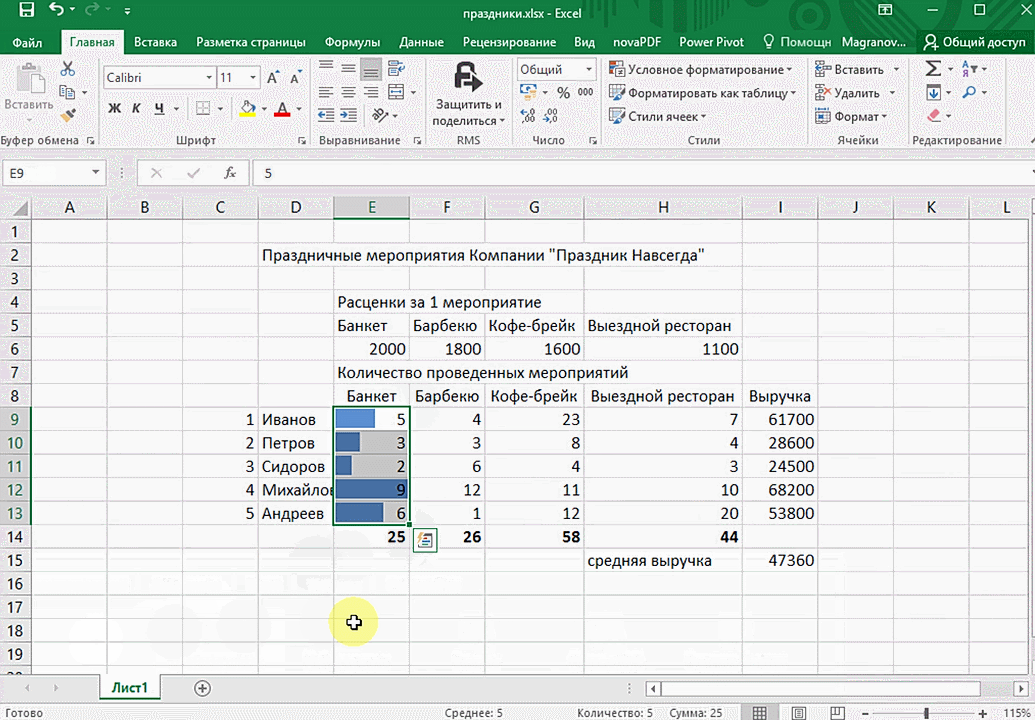
Также пользователь может поставить самые разные маркеры, которые обозначают большие и меньшие значения относительно тех, которые есть в выборке. Так, зеленым цветом будут показываться самые большие значения, а красным – наиболее маленькие.
Очень хочется верить, что эти приемы позволят вам значительно повысить эффективность вашей работы с электронными таблицами и максимально быстро добиться всего, что вы желаете. Как видим, эта программа для работы с электронными таблицами дает очень широкие возможности даже в стандартном функционале. А что уже говорить про дополнения, которых очень много на просторах интернета. Важно только обратить внимание, что все аддоны должны быть тщательно проверены на вирусы, потому что модули, написанные другими людьми, могут содержать вредоносный код. Если же надстройки разработаны компанией Майкрософт, то ее можно использовать смело.
Пакет анализа от Майкрософт – очень функциональная надстройка, которая делает пользователя настоящим профессионалом. Она позволяет выполнить почти любую обработку количественных данных, но она довольно сложная для начинающего пользователя. На официальном сайте справки Майкрософт есть детальная инструкция по тому, как использовать разные виды анализа с помощью этого пакета.
Оцените качество статьи. Нам важно ваше мнение:
II. Основные функциональные возможности
современных табличных процессоров
Современные табличные процессоры имеют очень широкие функциональные
и вспомогательные возможности, обеспечивающие удобную и эффективную работу
пользователя (Приложение 1).
Перечислим основные такие возможности, общие для всех систем этого
класса.
Контекстная подсказка. Вызывается из контекстного меню или нажатием
соответствующей кнопки в пиктографическом меню.
Контекстное меню. Разворачивается по щелчку кнопки (обычно правой) мыши на
выбранном объекте. Речь идет, например, о месте таблицы, где в данный момент
хочет работать пользователь. Наиболее часто используемые функции обработки,
доступные в данной ситуации, собраны в контекстном меню (Приложение 2).
Справочная система. Организована в виде гипертекста и позволяет легко и быстро
осуществлять поиск нужной темы (Приложение 3).
Многовариантность выполнения операций. Практически все операции могут быть
выполнены одним из трех-четырех способов, пользователь выбирает наиболее
удобный.
Пиктографическое меню. Наиболее часто используемым командам соответствуют
пиктограммы, расположенные под строкой меню. Они образуют пиктографическое
меню. Вследствие щелчка мышью на пиктограмме выполняется связанная с ней
команда. Пиктографические меню могут быть составлены индивидуально (Приложение
4).
Рабочие группы или рабочие папки. Документы можно объединять в рабочие
папки, так что они могут рассматриваться как одно единое целое, если речь идет
о копировании, загрузке, изменении или других процедурах. В нижней части
электронной таблицы расположен алфавитный указатель (регистр), который
обеспечивает доступ к рабочим листам. Пользователь может задавать название
листам в папке (вместо алфавитного указателя), что делает наглядным содержимое
регистра, а значит облегчает поиск и переход от документа к документу.
Средства для оформления и модификации экрана и таблиц. Внешний вид рабочего окна и
прочих элементов экранного интерфейса может быть определен в соответствии с
требованиями пользователя, что позволяет сделать работу максимально удобной.
Среди таких возможностей — разбивка экрана на несколько окон, фиксация заголовков
строк и столбцов и так далее.
Средства оформления и вывода на печать таблиц. Для удобства пользователя предусмотрены
все функции, обеспечивающие печать таблиц, такие как выбор размера страницы,
разбивка на страницы, установка размера полей страниц, оформление колонтитулов,
а также предварительный просмотр получившейся страницы (Приложение 5).
Средства оформления рабочих листов. Современные табличные процессоры
предоставляют широкие возможности по форматированию таблиц, такие как выбор шрифта
и стиля, выравнивание данных внутри клетки, выбор цвета фона клетки и шрифта,
изменение высоты строк и ширины колонок, черчение рамок различного вида,
определение формата данных внутри клетки (например: числовой, текстовый,
финансовый, дата и т. д.), а также обеспечение автоматического форматирования,
когда в систему уже встроены различные варианты оформления таблиц, и
пользователь может выбрать наиболее подходящий формат из уже имеющихся
(Приложение 6).
Шаблоны. Табличные процессоры, как и текстовые, позволяют создавать шаблоны
рабочих листов, которые применяются для создания бланков писем и факсов,
различных калькуляций. Если шаблон создается для других пользователей, то можно
разрешить заполнять такие бланки, но запретить изменять формы бланка (Приложение
7).
Связывание данных. Абсолютная и относительная адресации являются характерной чертой
всех табличных процессоров, в современных системах они дают возможность
работать одновременно с несколькими таблицами, которые могут быть тем или иным
образом связаны друг с другом. Например, трехмерные связи, позволяющие работать
с несколькими листами, идущими подряд; консолидация рабочих листов, с ее
помощью можно обрабатывать суммы, средние значения и вести статистическую
обработку, используя данные разных областей одного рабочего листа, нескольких
рабочих листов и даже нескольких рабочих книг; связанная консолидация позволяет
не только получить результат вычислений по нескольким таблицам, но и
динамически его пересчитывать в зависимости от изменения исходных значений
(Приложение 8).
Вычисления. Для удобства вычисления в табличных процессорах имеются
встроенные функции, а именно: математические, статистические, финансовые,
функции даты и времени, логические и другие. Менеджер функций позволяет выбрать
нужную функцию и, проставив значения, получить результат (Приложение 9).
Деловая графика. Трудно представить современный табличный процессор без
возможности построения различного типа двумерных, трехмерных и смешанных
диаграмм. Насчитывается более 20 различных типов и подтипов диаграмм, которые
можно построить в современной системе данного класса. А возможности оформления
диаграмм также многообразны и доступны, например, вставка и оформление легенд,
меток данных; оформление осей — возможность вставки линий сеток и другие.
Помимо этого, современные системы работы с электронными таблицами снабжены
такими мощными средствами построения и анализа деловой графики, как вставка
планок погрешностей, возможность построения тренда и выбор функции линии тренда
(Приложение 10).
Выполнение табличными процессорами функций баз данных. Эта возможность обеспечивает
заполнение таблиц аналогично заполнению базы данных, то есть через экранную
форму; защиту данных, сортировку по ключу или по нескольким ключам, обработку
запросов к базе данных, создание сводных таблиц. Кроме этого все современные
программы работы с электронными таблицами включают средства обработки внешних
баз данных, которые позволяют работать с файлами, созданными, например, в
формате dBase или PARADOX или других форматах.
Моделирование. Подбор параметров и моделирование — одни из самых важных
возможностей табличных процессоров. С помощью простых приемов можно находить
оптимальные решения для многих задач. Методы оптимизации варьируются от
простого подбора (при этом значения ячеек-параметров изменяются так, чтобы
число в целевой ячейке стало равным заданному) до метода линейной оптимизации
со многими переменными и ограничениями. При моделировании иногда желательно
сохранять промежуточные результаты и варианты поиска решения. Это можно делать,
создавая сценарии, которые представляют собой описание решаемой задачи
(Приложение 11)
Программирование. В простейшем случае для автоматизации выполнения часто
повторяемых действий можно воспользоваться встроенным языком программирования макрокоманд.
Разделяют макрокоманды и макрофункции. Применяя макрокоманды, можно упростить
работу с табличным процессором и расширить список его собственных команд. При
помощи макрофункций можно определять собственные формулы и функции, расширив,
таким образом, набор функций, предоставляемый системой. Самый простой макрос —
это записанная последовательность нажатия клавиш, перемещений и щелчков
кнопками мыши. Эта последовательность может быть воспроизведена, как
магнитофонная запись. Ее можно обработать и изменить, добавив стандартные
макрокоманды и макрофункции. Например, организовать цикл, переход,
подпрограмму. Современные программы обработки электронных таблиц позволяют
пользователю создавать на базе табличного процессора новые приложения со
специализированными диалоговыми окнами, что делает работу с приложением
максимально удобным. Для создания приложений табличные процессоры содержат в
качестве дополнительной компоненты язык программирования высокого уровня
(например, компоненты языка Visual Basic для составляющих Microsoft Office)
(Приложение 12).
III.
Достоинства программы Excel
Расширение возможностей таблиц Excel
В
Office Excel 2007 можно использовать новый пользовательский интерфейс для
быстрого создания, форматирования и расширения таблицы Excel (называемой в
Microsoft Excel 2003 листом Excel) в целях более удобной организации данных в
листе. Новая улучшенная функциональность таблиц включает следующие элементы.
Строки
заголовка таблицы. Можно включать или отключать строки
заголовка таблицы. Когда заголовки таблицы отображаются, при перемещении по
длинной таблице они всегда остаются видимыми для данных в столбцах.
Вычисляемые
столбцы. Вычисляемый столбец использует одну формулу, которая
применяется к каждой строке. Он автоматически расширяется, включая
дополнительные строки, так что формула немедленно распространяется и на эти
строки. Нужно всего лишь один раз ввести формулу — использование команд
«Заливка» или «Копирование» не нужно.
Автоматический
автофильтр. Для обеспечения возможности использования мощных средств
сортировки и фильтрации табличных данных автофильтр в таблице по умолчанию
включен.
Структурированные
ссылки. Данный тип ссылки позволяет использовать в формулах имена
заголовков столбцов таблицы вместо ссылок на ячейки, например A1 или R1C1.
Строки
итоговых значений. В строке итоговых значений теперь можно
использовать ввод пользовательских формул и текста.
Стили
таблиц. Для быстрого форматирования таблиц на уровне профессионального
дизайнера можно применять стиль таблицы. Если в таблице включен стиль с
чередующимися строками, приложение Excel в ходе операций будет поддерживать
этот стиль, что обычно разбивал макет на части, например, при фильтрации,
скрытии строк или при изменении порядка строк и столбцов вручную
Новые дополнительные возможности Excel 2007, 2010
При
больших объёмах обработки информации свою работу с данными в Microsoft Office
Excel 2007, 2010 можно улучшить, используя дополнительное расширение — новые
утилиты в виде панели Excel 2007 можно существенно повысить свою производительность
за счёт увеличения скорости и автоматизации:
— поиска
данных, поиска повторов данных, самых встречающихся элементов, поиска
отрицательных, максимальных значений, констант, счёта выделенных ячеек, строк,
столбцов, импорта данных из других баз (в т.ч. из баз данных Access, *.dbf),
экспорта данных в текстовые файлы, в т.ч. примечаний, извлечения чисел из
текста, разбор текста из выбранных ячеек по колонкам;
— проверки
и поиска ошибок по цепочке связанных формулами ячеек с указанием ячейки —
первоисточника ошибки и всех ячеек получателей ошибки (поиск ошибки, а не
просто просмотр связанных ячеек);
—
преобразования формул в значения, чисел в текст, перевода ячеек в целом и слов
в ячейках по отдельности, в т.ч. имён, реверс текстовых данных, контроль ячеек
с текстом на предмет кодировки символов (рус.англ.), транслитерация;
— поиска
ячеек с формулами, ячеек с формулами содержащими ссылки на другие источники:
листы, а также на другие файлы, ячеек с пропущенными формулами независимо от
цвета шрифта и цвета заливки фона;
—
повышения скорости оформления табличных данных и заголовков таблиц;
— удаления
двойных пробелов, удаления лишних строк, ячеек (раздельно) не содержащих
данные, переноса строк, колонок одним движением, оценкой объёмов печати,
управления печатью чётных, нечётных страниц, управления колонтитулами для
печати, изменения регистра символов в выбранных ячейках, переноса слов в
ячейках;
—
автоматического составления на отдельном листе содержания файла по названиям
листов с переходом по ссылкам на эти листы, сортировки листов книги;
— забыв
пароль — работа с паролями листов, книг, файлов Excel (числовыми);
—
непосредственная работа из Excel с Internet;
—
применения новинки — синхронизации выделенного диапазона ячеек во всех листах
книги;
—
применения работы с цветом, звуком, скрытыми именами диапазонов ячеек;
— переписи
на рабочий лист наименований файлов выбранных папок на дисках и т.д. и т.п.
Файлы и
шаблоны предыдущих версий Excel могли содержать пользовательские панели
инструментов.
Все новые
дополнительные пункты меню расположены в линейке меню в последовательности
выполняемых действий. Называется новый дополнительный пункт главного меню
«Надстройки»
При этом
появляется дополнительный пункт (один) в главном меню и серия новых
дополнительных пунктов в подменю (более 80 шт) открывающих дополнительные
возможности.
Малоиспользуемые
новые дополнительные пункты меню Excel 2007 можно убрать (с возможностью
последующего восстановления) вручную (или все сразу одной кнопкой), выбрав тем
самым наиболее подходящий вариант для удобной повседневной работы.
Новые
дополнительные возможности представлены также и новыми функциями Excel 2007
Microsoft office:
— файловые
функции, дисковые функции
— функции
адресов электронной почты и гиперссылок
— функции
чисел: миллионы, тысячи, случайные числа в указанном диапазоне, извлечения
чисел из текстовых ячеек или извлечения только текста
— функции
адресов и перечня адресов ячеек, диапазонов по условию
— функции
формул
— функции
шрифтов, размера строки, колонки, цвета
— функции
поиска крайних значений, уникальных значений, примечаний
— функции
определения типа объекта
— функции
реверса, транслитерации текста, проверки кодировки русских символов.
Модифицированная
формула поиска в таблице данных (ищет значение во всей таблице, а не только в
первой колонке, находит указанное, а не обязательно первое вхождение данных в
таблице, возвращает значение ячейки по найденной строке по указанному номеру
столбца для вывода данных) функции сортировки и конкатенации значений указанных
ячеек
функции
звукового и цветового контроля за правильностью заполнения ячеек данными по
установленному условию. Всего более 70 новых дополнительные функций Excel.
Все новые
дополнительные возможности офисной программы доступны без всякой инсталляции,
справочная информация прямо в файле, при желании справка может быть удалена в
целях сокращения размера файла.
Новый внешний вид диаграмм
В Office Excel 2007 можно использовать
новые инструменты для работы с диаграммами, облегчающие создание
профессионально-оформленных диаграмм, эффективно представляющих данные.
Основанные на используемой в книге Excel теме, новые, современные формы
диаграмм содержат специальные эффекты, такие как объемность, прозрачность и мягкие
тени.
Новый пользовательский интерфейс упрощает изучение
существующих типов диаграмм, так что пользователь легко может создать для своих
данных нужную диаграмму. Предусмотрено множество заранее определенных стилей и
макетов диаграмм, которые позволяют быстро применить понравившийся формат и
включить в диаграмму необходимые детали.
Простые в использовании сводные таблицы
В Office Excel 2007 сводные таблицы стали значительно
проще в использовании, чем в предыдущих версиях приложения Excel. Благодаря новому
пользовательскому интерфейсу сводной таблицы сведения о данных можно получить с
помощью нескольких щелчков мыши — больше не нужно перетаскивать данные в
специальные области, куда не всегда легко попасть. Вместо этого можно просто
выделить поля, которые необходимо просматривать в списке полей новой сводной
таблицы.
После создания сводной таблицы можно воспользоваться
преимуществами множества новых и улучшенных функциональных возможностей для
суммирования, анализа и форматирования данных сводной таблицы.
Использование команды «Отменить» в
сводных таблицах.
Теперь существует возможность отмены большинства действий, выполненных для
создания или перегруппировки сводной таблицы.
Индикаторы приемов работы «плюс» и
«минус». Эти
индикаторы показывают, можно ли развернуть или свернуть части сводной таблицы
для просмотра большего или меньшего количества сведений.
Сортировка и фильтрация. Для сортировки теперь
достаточно выбрать элемент в столбце, в котором нужно выполнить сортировку, и
нажать кнопку сортировки. Можно также отфильтровать данные с помощью фильтров
сводной таблицы, таких как фильтры по дате, фильтры по подписи, фильтры по
значению или ручные фильтры.
Условное форматирование. Условное форматирование в
Office Excel 2007 можно применять к сводным таблицам по ячейкам или
пересечениям ячеек.
Стиль и макет сводной таблицы. К сводным таблицам можно быстро
применить заранее определенный или пользовательский стиль, как к обычным
таблицам и диаграммам Excel. Изменение макета сводной таблицы в новом
пользовательском интерфейсе также значительно упростилось.
Сводные диаграммы. Благодаря новому интерфейсу
стало гораздо проще создавать не только сводные таблицы, но и сводные
диаграммы. Все улучшения, связанные с фильтрацией данных, доступны также и для
сводных диаграмм. При создании сводной диаграммы доступны специальные инструменты
сводной диаграммы и контекстные меню, позволяющие анализировать данные в
диаграмме. Можно также изменять макет, стиль и формат диаграммы или ее
элементов таким же образом, как и для обычных диаграмм. В Office Excel 2007
форматирование диаграммы при изменении сводной диаграммы сохраняется, что
является шагом вперед по сравнению с предыдущими версиями Excel.
Быстрое подключение к
внешним источникам данных
При работе с Office Excel 2007 больше не нужно знать
имена серверов или баз корпоративных данных. С помощью средства «Быстрый
запуск» можно выбрать их в списке источников данных, которые администратор или
эксперт рабочей группы сделали доступными для пользователя. Диспетчера подключений
в приложении Excel позволяет просмотреть все подключения в книге и упрощает их
повторное использование или замену.
Улучшенная печать
Режим разметки. Кроме видов Обычный и Страничный
режим, Office Excel 2007 поддерживает режим Разметка страницы. Данный вид можно
использовать для создания листа, следя при этом за тем, как он будет выглядеть
при печати. В этом виде можно работать с заголовками таблиц, колонтитулами и
настройками границ непосредственно на листе, а также помещать объекты, например
диаграммы и фигуры, именно туда, куда нужно. Можно также легко получить доступ
ко всем параметрам страницы на вкладке Разметка страницы нового пользовательского интерфейса, что
дает возможность быстро задать их значения, например ориентацию страницы. Можно
легко увидеть, что будет напечатано на каждой странице, и это помогает избежать
многочисленных попыток печати и усечения данных при печати.
Заключение
Программа Microsoft Excel – одна из наиболее практически значимых,
востребованных. Электронные таблицы не только позволяют автоматизировать
расчеты, но и являются эффективным средством моделирования различных вариантов
и ситуаций. Меняя значения исходных данных, можно проследить за изменением
получаемых результатов и из множества вариантов решения задачи выбрать наиболее
подходящий.
Современные
табличные процессоры обеспечивают:
—
ввод,
хранение и корректировку большого количества данных;
—
автоматическое
проведение вычислений при изменении исходных данных;
—
дружественный
интерфейс (средства диалога человека и компьютера);
—
наглядность
и естественную форму документов, представляемых пользователю на экране;
—
эффективную
систему документирования информации;
—
графическую
интерпретацию данных в виде диаграмм;
—
вывод
на печать профессионально оформленных отчетов;
—
вставку
отчетной информации, подготовленной с помощью электронных таблиц, в другие
документы.
Все эти
возможности позволяют пользователю успешно решать задачи, требующие обработки
больших массивов информации, не владея при этом специальными знаниями в области
программирования.
Программа Excel обеспечивает как легкость
при обращении с данными, так и их сохранность. Excel позволяет быстро выполнить
работу для которой не нужно затрачивать много бумаги и времени, а также
привлекать профессиональных бухгалтеров и финансистов.
Данная программа сумеет вычислить суммы по
строкам и столбцам таблиц, посчитать среднее арифметическое, банковский процент
или дисперсию, здесь вообще можно использовать множество стандартных функций:
финансовых, математических, логических, статистических [2].
У Excel есть еще масса преимуществ. Это
очень гибкая система «растет» вместе с потребностями пользователя,
меняет свой вид и подстраивается под Вас. Основу Excel составляет поле клеток и
меню в верхней части экрана. Кроме этого на экране могут быть расположены до 10
панелей инструментов с кнопками и другими элементами управления. Есть
возможность не только использовать стандартные панели инструментов, но и
создавать свои собственные.
Советы, которые следует прочитать до начала работы
-
Позвольте приложению Excel выбрать для вас сводную таблицу Чтобы быстро отбирать данные, которые вы хотите проанализировать в Excel, сначала нужно выбрать с помощью макета Excel для ваших данных.
-
Анализ данных в нескольких таблицах
Вы можете анализировать данные из двух таблиц в отчете Excel, даже если не используете Power Pivot. Функция модели данных встроена в Excel. Просто добавьте данные в несколько таблиц в Excel а затем создайте связи между ними на листе таблицы или Power View. Готово! Теперь у вас есть модель данных, которая добавляет больше энергии для анализа данных. -
Наносите данные непосредственно на интерактивную сводную диаграмму В Excel можно создать автономный (автономный) сводная диаграмма, который позволяет взаимодействовать с данными и фильтровать их прямо на диаграмме.
-
Использовать все Power Pivot и Power View Если у вас установлен Office профессиональный плюс, попробуйте воспользоваться преимуществами этих мощных надстройок:
-
Встроенной модели данных может быть достаточно для анализа содержимого нескольких таблиц, однако Power Pivot позволяет создать более сложную модель в отдельном окне Power Pivot. Прежде чем приступать к работе, ознакомьтесь с различиями.
-
Надстройка Power View позволяет превратить данные Power Pivot (или любую другую информацию в таблице Excel) в многофункциональный интерактивный отчет, имеющий профессиональный вид. Чтобы начать, просто нажмите кнопку Power View на вкладке Вставка.
-
Создание и создание сводная диаграмма
|
Создание сводной таблицы для анализа данных на листе |
Принимайте более обоснованные бизнес-решения на основе данных в отчетах сводных таблиц, на которые можно взглянуть под разным углом. Excel поможет вам приступить к работе, порекомендовав модель, оптимальную для имеющихся данных. |
|---|---|
|
Создание сводной таблицы для анализа внешних данных |
Если данные, которые требуется обработать, хранятся в другом файле за пределами Excel (например, в базе данных Access или в файле куба OLAP), вы можете подключиться к этому источнику внешних данных и проанализировать их в отчете сводной таблицы. |
|
Создание сводной таблицы для анализа данных в нескольких таблицах |
Если вы хотите проанализировать данные в нескольких таблицах, это можно сделать в Excel. Узнайте о различных способах создания связей между несколькими таблицами в отчете таблицы для мощного анализа данных. В этом Excel создается модель данных. |
|
Учебник. Импорт данных в Excel и создание модели данных |
Прежде чем приступать к самостоятельной работе, воспользуйтесь инструкциями, приведенными в этом учебнике. Они помогут вам создать в Excel учебную сводную таблицу, которая объединяет информацию из нескольких таблиц в общую модель данных. |
|
Упорядочение полей сводной таблицы с помощью списка полей |
Создав сводную таблицу на основе данных листа, внешних данных или информации из нескольких таблиц, воспользуйтесь списком полей, который позволяет добавлять, упорядочивать и удалять поля в отчете сводной таблицы. |
|
Создание сводной диаграммы |
Чтобы провести наглядную презентацию, создайте сводную диаграмму с интерактивными элементами фильтрации, позволяющими анализировать отдельные подмножества исходных данных. Приложение Excel даже может порекомендовать вам подходящую сводную диаграмму. Если вам необходима просто интерактивная диаграмма, создавать для этого сводную таблицу не требуется. |
|
Удаление сводной таблицы |
Если требуется удалить сводную таблицу, перед нажатием клавиши DELETE необходимо выделить всю таблицу, которая может содержать довольно много данных. В этой статье рассказывается, как быстро выделить всю сводную таблицу. |
Изменение формата вашей скайп-формы
|
Разработка макета и формата сводной таблицы |
После создания сводной таблицы и добавления в нее полей можно изменить макет данных, чтобы информацию было удобнее просматривать и изучать. Чтобы мгновенно сменить макет данных, достаточно выбрать другой макет отчета. |
|---|---|
|
Изменение стиля сводной таблицы |
Если вам не нравится, как выглядит созданная вами сводная таблица, попробуйте выбрать другой стиль. Например, если в ней много данных, лучше включить чередование строк или столбцов, чтобы информацию было проще просматривать, либо выделить важные сведения. |
Отображение сведений сводной таблицы
|
Сортировка данных в сводной таблице |
Сортировка помогает упорядочивать большие объемы данных в сводных таблицах, чтобы упростить поиск объектов анализа. Данные можно отсортировать в алфавитном порядке, по убыванию или возрастанию. |
|---|---|
|
Фильтрация данных в сводной таблице |
Чтобы провести более подробный анализ определенного подмножества исходных данных сводной таблицы, их можно отфильтровать. Сделать это можно несколькими способами. Например, можно добавить один или несколько срезов, которые позволяют быстро и эффективно фильтровать информацию. |
|
Группировка и отмена группировки данных в отчете сводной таблицы |
Группировка позволяет выделить для анализа определенное подмножество данных сводной таблицы. |
|
Изучение данных сводной таблицы на разных уровнях |
Переход на разные уровни при больших объемах данных в иерархии сводной таблицы всегда занимал много времени, включая многочисленные операции развертывания, свертывания и фильтрации. В Excel новая функция «Быстрое изучение» позволяет детализтировать данные в кубе OLAP или иерархии на основе модели данных для анализа данных на разных уровнях. Эта функция позволяет переходить к нужным сведениям и действует как фильтр при их детализации. Соответствующая кнопка отображается при выборе элемента в поле. |
|
Создание временной шкалы сводной таблицы для фильтрации дат |
Вместо создания фильтров для отображения данных в сводной таблице теперь можно воспользоваться временной шкалой. Ее можно добавить в сводную таблицу, а затем с ее помощью осуществлять фильтрацию по времени и переходить к различным периодам. |
Расчет значений сводной таблицы
|
Добавление промежуточных итогов в сводную таблицу |
Промежуточные итоги в сводных таблицах вычисляются автоматически и отображаются по умолчанию. Если итогов не видно, их можно добавить. Кроме того, вы можете узнать, как рассчитывать процентные величины для промежуточных итогов, а также скрывать промежуточные и общие итоги, чтобы удалить их из таблицы. |
|---|---|
|
Сведение данных в сводной таблице |
Для сведения данных в сводных таблицах предназначены функции расчета суммы, количества и среднего значения. Функции сведения недоступны в сводных таблицах на базе источников данных OLAP. |
Изменение и обновление данных сводной таблицы
|
Изменение исходных данных сводной таблицы |
После создания сводной таблицы может потребоваться изменить исходные данные для анализа (например, добавить или исключить те или иные сведения). |
|---|---|
|
Обновление данных в сводной таблице |
Если сводная таблица подключена к внешним данным, ее необходимо периодически обновлять, чтобы информация в таблице оставалась актуальной. |
Использование богатых возможностей Power Pivot
|
Power Pivot: мощные средства анализа и моделирования данных в Excel |
Если вы уже установили Office профессиональный плюс, запустите надстройку Power Pivot, которая поставляется вместе с Excel для проведения мощного анализа данных. После этого вы сможете создавать сложные модели данных в окне Power Pivot. |
|---|---|
|
Учебник. Импорт данных в Excel и создание модели данных |
В этом учебнике рассказано, как импортировать сразу несколько таблиц с данными. Во второй его части описывается работа с моделью данных в окне Power Pivot. |
|
Получение данных с помощью надстройки PowerPivot |
Вместо импорта данных или подключения к ним в Excel можно воспользоваться быстрой и эффективной альтернативой: импортом реляционных данных в окне Power Pivot. |
|
Создание связи между двумя таблицами |
Расширить возможности анализа данных помогают связи между таблицами, которые содержат сходную информацию (например, одинаковые поля с идентификаторами). Связи позволяют создавать отчеты сводных таблиц, использующие поля из каждой таблицы, даже если они происходят из разных источников. |
|
Вычисления в Power Pivot |
Для решения задач, связанных с анализом и моделированием данных в Power Pivot, можно использовать возможности вычисления, такие как функция автосуммирования, вычисляемые столбцы и формулы вычисляемых полей, а также настраиваемые формулы на языке выражений анализа данных (DAX). |
|
Добавление ключевых показателей эффективности в сводную таблицу |
С помощью Power Pivot можно создавать ключевые показатели эффективности и добавлять их в сводные таблицы. |
|
Оптимизация модели данных для отчетов Power View |
В этом учебнике показано, как вносить изменения в модель данных для улучшения отчетов Power View. |
Анализ данных с помощью Power View
|
Power View: исследование, визуализация и представление данных |
Надстройка Power View, которая входит в состав Office профессиональный плюс, позволяет создавать интерактивные диаграммы и другие наглядные объекты на отдельных листах Power View, напоминающих панели мониторинга, которые можно представить всем заинтересованным лицам. В конце учебника: импорт данных в Excel и Создание модели данных вы найдете полезные инструкции по оптимизации Power Pivot данных для Power View. |
|---|---|
|
Примеры использования Power View и Power Pivot |
Из этих видеороликов вы узнаете, каких результатов можно добиться с помощью надстройки Power View, функции которой дополняются возможностями Power Pivot. |
- Авторы
- Руководители
- Файлы работы
- Наградные документы
Приходько Д.С. 1
1МБОУ «Гимназия №3″ 9″А» класс
Белова Т.А. 1
1МБОУ «Гимназия №3»
Текст работы размещён без изображений и формул.
Полная версия работы доступна во вкладке «Файлы работы» в формате PDF
ВВЕДЕНИЕ
В настоящее время статистические методы прогнозирования заняли видное место в экономической практике. Широкому внедрению методов анализа и прогнозирования данных способствовало появление персональных компьютеров. Распространение статистических программных пакетов позволило сделать доступными и наглядными многие методы обработки данных.
Теперь уже не требуется проводить вручную трудоемкие расчеты, строить таблицы и графики – всю эту черновую работу выполняет компьютер. Человеку же остается исследовательская, творческая работа: постановка задачи, выбор методов прогнозирования, оценка качества полученных моделей, интерпретация результатов. Для этого необходимо иметь определенную подготовку в области статистических методов обработки данных и прогнозирования.
Поэтому мы решили изучить основные статистические методы анализа одномерных временных рядов и прогнозирования и возможность их реализации в электронной таблице Excel.
Цель исследования: освоение основных понятий, математических моделей и методов для решения задач прогнозирования различных процессов и явлений, их практическая реализация в электронной таблице Excel.
Задачи исследования: изучить основные понятия теории временных рядов, статистические методы прогнозирования, научиться применять полученные знания для построения прогнозов.
Актуальность выбранной темы очевидна. Необходимость предвидеть будущее осознавалась во все времена. Но особенно сильно роль прогнозирования возросла в наши дни, при стремительных темпах развития общества, науки и техники, производства и производственных отношений. Сегодня прогнозов, основанных на интуиции, уже явно недостаточно. Теперь необходимо прогнозирование, основанное на объективных закономерностях, на использовании математического аппарата, проводимое на основе научных методов и моделей, на обработке первичных данных с помощью информационных технологий.
ОСНОВНАЯ ЧАСТЬ
В современных условиях управленческие решения должны приниматься лишь на основе тщательного анализа имеющейся информации. Для решения задач, связанных с анализом данных при наличии случайных воздействий, предназначен мощный аппарат прикладной статистики, составной частью которого являются статистические методы прогнозирования. Эти методы позволяют выявлять закономерности на фоне случайностей, делать обоснованные прогнозы и оценивать вероятность их выполнения.
Статистические методы прогнозирования
1.1. Экономические прогнозы
Под прогнозом понимается научно обоснованное описание возможных состояний объектов в будущем, а также альтернативных путей и сроков достижения этого состояния. Процесс разработки прогнозов называется прогнозированием (от греч. prognosis – предвидение, предсказание).
Важной характеристикой является время (период) упреждения прогноза – отрезок времени от момента, для которого имеются последние статистические данные об изучаемом объекте, до момента, к которому относится прогноз.
По времени упреждения экономические прогнозы делятся на:
оперативные (с периодом упреждения до одного месяца);
краткосрочные (период упреждения – от одного, нескольких месяцев до года);
среднесрочные (период упреждения более 1 года, но не превышает 5 лет);
долгосрочные (с периодом упреждения более 5 лет).
Прогнозирование экономических явлений и процессов включает в себя следующие этапы:
1. постановка задачи и сбор необходимой информации;
2. первичная обработка исходных данных;
3. определение круга возможных моделей прогнозирования;
4. оценка параметров моделей;
5. исследование качества выбранных моделей, адекватности их реальному процессу и выбор лучшей из моделей;
6. построение прогноза;
7. содержательный анализ полученного прогноза.
1.2. Виды временных рядов. Требования, предъявляемые к исходной информации
Статистическое описание развития экономических процессов во времени осуществляется с помощью временных рядов.
Временным (динамическим) рядом называется последовательность значений показателя (признака), упорядоченная в хронологическом порядке, т.е. в порядке возрастания временного параметра. Отдельные наблюдения временного ряда называются уровнями этого ряда.
Каждый временной ряд содержит два элемента: значения времени; соответствующие им значения уровней ряда.
В качестве показателя времени в рядах динамики могут указываться либо определенные моменты времени (даты), либо отдельные периоды (сутки, месяцы, кварталы, полугодия, годы и т.д.). В зависимости от характера временного параметра ряды делятся на моментные и интервальные.
В моментных рядах динамики уровни характеризуют значения показателя по состоянию на определенные моменты времени. В интервальных рядах уровни характеризуют значение показателя за определенные интервалы (периоды) времени.
Важной особенностью интервальных рядов динамики абсолютных величин является возможность суммирования их уровней. Суммирование уровней моментного ряда динамики не практикуется, т.к. полученные накопленные итоги лишены всякого смысла. Моментные ряды динамики, в отличие от интервальных не обладают свойством аддитивности (термин происходит от английского глагола to add – добавлять).
При исследовании моментного ряда динамики определенный смысл имеет расчет разностей уровней, характеризующих изменение показателя за некоторый отрезок времени.
Успешность статистического анализа развития процессов во времени во многом зависит от правильного построения временных рядов.
Большое значение для дальнейшего исследования процесса имеет выбор интервалов между соседними уровнями ряда. Удобнее всего иметь дело с равноотстоящими друг от друга уровнями ряда.
Одним из важнейших условий, необходимых для правильного отражения временным рядом реального процесса развития, является сопоставимость уровней ряда. Для несопоставимых величин неправомерно проводить исследование динамики.
Чаще всего несопоставимость встречается в стоимостных показателях, что вызвано изменением цен в разные периоды времени, поэтому на практике осуществляют пересчет уровней в сопоставимые цены (цены одного периода).
Уровни рядов динамики могут содержать аномальные значения или «выбросы». Часто появление таких значений может быть вызвано ошибками при сборе, записи и передаче информации. Выявление, исключение таких значений, замена их истинными или расчетными является необходимым этапом первичной обработки данных, т.к. применение математических методов к «засоренной» информации приводит к искажению результатов анализа.
Соответствие исходной информации всем указанным требованиям проверяется на этапе предварительного анализа временных рядов. Лишь после этого переходят к расчету и анализу основных показателей динамики развития, построению моделей прогнозирования, получению прогнозных оценок.
1.3. Компоненты временных рядов
В практике исследования динамики явлений и прогнозирования принято считать, что значения уровней временных рядов экономических показателей могут содержать следующие компоненты (составные части или структурно-образующие элементы):
тренд;
сезонную компоненту;
циклическую компоненту;
случайную составляющую.
Под трендом понимают изменение, определяющее общее направление развития, основную тенденцию временного ряда. Это систематическая составляющая долговременного действия.
Наряду с долговременными тенденциями во временных рядах экономических процессов часто имеют место более или менее регулярные колебания – периодические составляющие рядов динамики.
Если период колебаний не превышает одного года, то их называют сезонными. Чаще всего причиной их возникновения считаются природно-климатические условия.
При большем периоде колебания считают, что во временных рядах имеет место циклическая составляющая. Примерами могут служить демографические, инвестиционные и другие циклы.
Если из временного ряда удалить тренд и периодические составляющие, то останется нерегулярная компонента.
Экономисты разделяют факторы, под действием которых формируется нерегулярная компонента, на 2 вида:
факторы резкого, внезапного действия;
текущие факторы.
Факторы первого вида (например, стихийные бедствия, эпидемии и др.), как правило, вызывают более значительные отклонения. Иногда такие отклонения называют катастрофическими колебаниями.
Факторы второго вида вызывают случайные колебания, являющиеся результатом действия большого числа побочных причин. Влияние каждого из текущих факторов незначительно, но ощущается их суммарное воздействие.
Если временной ряд представляется в виде суммы соответствующих компонент, то полученная модель носит название аддитивной (1.1), если в виде произведения – мультипликативной (1.2) или смешанного типа (1.3):
; (1)
; (2)
, (3)
где: – уровни временного ряда;
– трендовая составляющая;
– сезонная компонента;
– циклическая компонента;
– случайная компонента.
Решение любой задачи по анализу и прогнозированию временных рядов начинается с построения графика исследуемого показателя. Иногда на стадии графического анализа можно определить характер сезонных колебаний: аддитивный или мультипликативный. Отличительной особенностью аддитивной модели является то, что амплитуда сезонных колебаний, отражающая отклонения от тренда или среднего, остается примерно постоянной, неизменной во времени.
1.4. Сглаживание временных рядов с помощью простых скользящих средних
Распространенным приемом при выявлении и анализе тенденции развития является сглаживание временного ряда. Суть различных приемов сглаживания сводится к замене фактических уровней временного ряда расчетными уровнями, которые в меньшей степени подвержены колебаниям. Это способствует более четкому проявлению тенденции развития.
Мы рассмотрим методы сглаживания временных рядов с помощью скользящих средних. Скользящие средние позволяют сгладить как случайные, так и периодические колебания, выявить имеющуюся тенденцию в развитии процесса, и поэтому служат важным инструментом при фильтрации компонент временного ряда.
Алгоритм сглаживания по простой скользящей средней может быть представлен в виде следующей последовательности шагов:
1. Определяют длину интервала сглаживания , включающего в себя последовательных уровней ряда ( ). При этом надо иметь в виду, что чем шире интервал сглаживания, тем в большей степени взаимопогашаются колебания, и тенденция развития носит более плавный, сглаженный характер. Чем сильнее колебания, тем шире должен быть интервал сглаживания.
2. Разбивают весь период наблюдения на участки, при этом интервал сглаживания как бы скользит по ряду с шагом, равным 1.
3. Рассчитывают средние арифметические из уровней ряда, образующих каждый участок.
4. Заменяют фактические значения ряда, стоящие в центре каждого участка, на соответствующие средние значения.
При этом удобно брать длину интервала сглаживания в виде нечетного числа: , т.к. в этом случае полученные значения скользящей средней приходятся на средний член интервала.
Процедура сглаживания приводит к устранению периодических колебаний во временном ряду, если длина интервала сглаживания берется равной или кратной периоду колебаний.
Для устранения сезонных колебаний часто требуется использовать четырех- и двенадцатичленные скользящие средние, но при этом не будет выполняться условие нечетности длины интервала сглаживания.
При четной базе в сглаживаемой серии отсутствует член, соответствующий среднему промежутку времени. Нет промежутка, которому можно корректно приписать результат.
В таких ситуациях используют двухэтапное сглаживание. На первом этапе проводят сглаживание при четной длине интервала сглаживания (скажем, при ). Среднего промежутка времени здесь нет, и результат приписывают не точно середине, а со сдвигом на полпериода вперед или назад (например, назад). После этого проводят повторное сглаживание уже сглаженного ряда при длине интервала, который во всех случаях равен 2. База опять четная, и на этот раз результат опять сдвигают на полпериода, но в противоположную сторону (в нашем примере вперед). В итоге такой двухэтапной процедуры окончательный результат оказывается центрированным корректно.
При использовании скользящей средней с длиной активного участка первые и последние уровней ряда сгладить нельзя, их значения теряются.
1.5. Прогнозирование развития по линии тренда
Под тенденцией развития понимают общее направление развития, долговременную эволюцию. На практике для описания тенденции развития явления широко используются модели кривых роста, представляющие собой различные функции времени . При таком подходе изменение исследуемого показателя связывают лишь с течением времени; считается, что влияние других факторов несущественно или косвенно сказывается через фактор времени.
Прогнозирование на основе модели кривой роста базируется на экстраполяции, т.е. на продлении в будущее тенденции, наблюдавшейся в прошлом. При этом предполагается, что во временном ряду присутствует тренд, характер развития показателя обладает свойством инерционности, сложившаяся тенденция не должна претерпевать существенных изменений в течение периода упреждения.
Прогнозирование на основе кривых роста предполагает выбор формы кривой, оценивание ее параметров, проверку адекватности, а также точечный и интервальный прогноз с помощью этой функции.
Наиболее распространенным вариантом кривой роста является полином:
, (4)
где
– параметры многочлена,
– независимая переменная (время), .
Коэффициенты полиномов невысоких степеней могут иметь конкретную интерпретацию в зависимости от содержания динамического ряда. Например, их можно трактовать как скорость роста ( ), ускорение роста ( ), изменение ускорения ( ), начальный уровень ряда при ( ).
Обычно в экономических исследованиях применяются полиномы не выше третьего порядка.
Оценки параметров в модели (4) определяются методом наименьших квадратов. Суть его состоит в нахождении таких параметров, при которых сумма квадратов отклонений расчетных значений уровней от фактических значений, была бы минимальной. Таким образом, эти оценки находятся в результате минимизации выражения:
где
– фактическое значение уровня временного ряда;
– расчетное значение;
– длина временного ряда.
В качестве другого варианта кривой роста можно рассмотреть простую показательную кривую, которая имеет вид:
. (6)
Если b, то кривая растет вместе с ростом , и падает, если . Параметр характеризует начальные условия развития, а параметр b – постоянный темп роста.
Существует несколько практических подходов, облегчающих процесс выбора формы кривой роста. Наиболее простой путь – визуальный анализ, опирающийся на изучение графического изображения временного ряда. Подбирают такую кривую роста, форма которой соответствует фактическому развитию процесса.
На практике чаще всего к выбору формы кривой подходят исходя из значений критерия, в качестве которого принимают сумму квадратов отклонений фактических значений уровней от расчетных, получаемых выравниванием. Из рассматриваемых кривых предпочтение будет отдано той, которой соответствует минимальное значение критерия, т.к. чем меньше значение критерия, тем ближе к кривой ложатся данные наблюдений.
Также в качестве критерия выбора кривой роста используется средняя квадратическая ошибка:
(7)
где
– фактическое значение уровня ряда;
– расчетное значение уровня ряда, полученное по модели;
– длина ряда.
Средняя квадратическая ошибка всегда имеет положительное значение, которое уменьшается по мере приближения ошибки к нулю. Большее значение показывает больший разброс значений в представленном множестве со средней величиной множества; меньшее значение, соответственно, показывает, что значения в множестве сгруппированы вокруг среднего значения.
Заключительным этапом применения кривых роста является экстраполяция тенденции на базе выбранного уравнения. Прогнозные значения исследуемого показателя вычисляют путем подстановки в уравнение кривой значений времени , соответствующих периоду упреждения. Полученный таким образом прогноз называют точечным, так как для каждого момента времени определяется только одно значение прогнозируемого показателя.
На практике в дополнении к точечному прогнозу желательно определить границы возможного изменения прогнозируемого показателя, задать «вилку» возможных значений прогнозируемого показателя, т.е. вычислить прогноз интервальный.
Несовпадение фактических данных с точечным прогнозом, полученным путем экстраполяции тенденции по кривым роста, может быть вызвано:
1. субъективной ошибочностью выбора вида кривой;
2. погрешностью оценивания параметров кривых;
3. погрешностью, связанной с отклонением отдельных наблюдений от тренда, характеризующего некоторый средний уровень ряда на каждый момент времени.
Погрешность, связанная со вторым и третьим источником, может быть отражена в виде доверительного интервала прогноза. Границы доверительного интервала, учитывающего неопределенность, связанную с положением тренда, и возможность отклонения от этого тренда, упрощенно определяется в виде:
, (8)
где
– расчетное значение уровня ряда, полученное по модели,
– средняя квадратическая ошибка,
– одно из чисел: 1, 2 или 3. При границы доверительного интервала обеспечивают приблизительно 68% надежность прогноза, при обеспечивается 95% надежность, при обеспечивается 99% надежность.
Построение модели сезонности с использование электронной таблицы Excel
В настоящее время существует большое количество программного обеспечения, специализирующегося именно на прогнозировании. Но и обычная электронная таблица Excel имеет в своем арсенале инструменты для выполнения прогнозирования, которые по своей эффективности мало чем уступают профессиональным программам. В данном разделе нашей работы мы выясним, что это за инструменты и постоим модель сезонности на практике.
В качестве исходных данных возьмем данные по объему перевозки пассажиров за 2019-2021 года.
Таблица 1.
Объем перевозки пассажиров за 2019-2021 года
|
Год |
Квартал |
Данные |
|
2019 |
1 кв. |
464,39 |
|
2 кв. |
369,45 |
|
|
3 кв. |
350,3 |
|
|
4 кв. |
199,62 |
|
|
2020 |
1 кв. |
809,63 |
|
2 кв. |
440,88 |
|
|
3 кв. |
501,51 |
|
|
4 кв. |
327,26 |
|
|
2021 |
1 кв. |
842,55 |
|
2 кв. |
715,45 |
|
|
3 кв. |
813,8 |
|
|
4 кв. |
545,1 |
Задача прогнозирования заключается в том, чтобы вычислить прогнозные значения квартальных объемов перевозок за 2022 года при условии, что сохранятся существующие тенденции.
Как мы знаем решение любой задачи по анализу и прогнозированию временных рядов начинается с построения графика исследуемого показателя. Для этого перенесем исходные данные в Excel и построим график.
Рис. 1. Диаграмма «Данные по перевозкам»
Данный график наглядно демонстрируют устойчивые сезонные колебания при повышающемся тренде.
При изучении сезонности имеют дело с периодическим воздействием, связанным с календарным циклом. Эти воздействия рассматриваются как внешние по отношению к основным причинам, характеризующим поведение системы. Поэтому при изучении ряда сезонные колебания отделяют от тренда.
Построение прогноза предполагает:
Выявление обобщенных характеристик циклических колебаний.
Расчет трендового прогноза, выражающего общую тенденцию ряда.
Совмещение трендового прогноза с характеристиками циклических колебаний.
Такое построение может быть основано на аддитивной модели или на мультипликативной модели.
В обеих моделях (1), (3) предполагается, что исходный ряд данных представляет собой комбинацию трех составляющих:
– трендовая составляющая, характеризующая основную долговременную тенденцию ряда;
– циклическая (обычно сезонная) составляющая, характеризующая регулярно повторяющиеся изменения исходного ряда;
– остаточная составляющая, отражающая случайные воздействия (ее называют также ошибкой модели).
2.1. Построение аддитивной модели
Аддитивная модель предполагает, что к тренду ряда прибавляется циклическая составляющая в виде периодически изменяющегося дополнительного слагаемого, принимающего положительные и отрицательные значения. Значения, лежащие на линии тренда, в связи с этим увеличиваются в одни периоды времени (циклическая составляющая для таких периодов положительна) и уменьшаются в другие периоды времени (циклическая составляющая отрицательна). Средняя величина всех таких слагаемых, входящих в циклическую составляющую, за время одного цикла равна 0.
Пошаговая процедура построения аддитивной модели:
1. Устранение циклических колебаний из исходного ряда (сглаживание ряда методом скользящей средней по базе, равной длине цикла; в случае четной базы проведение двухэтапного сглаживания).
2. Выявление колебаний ряда (построение разности между исходным и сглаженным рядом).
3. Определение средних значений циклических характеристик (вычисление средних значений по однородным периодам).
4. Нормирование средних значений циклических характеристик (определение их среднего значения с последующим смещением всех характеристик на эту величину так, чтобы среднее значение смещенных характеристик было равно 0). Результат рассматривается как циклическая составляющая ряда .
5. Устранение циклической составляющей из исходного временного ряда (построение разности между исходным и циклическим рядом). Результатом является трендовая составляющая.
6. Выбор вида тренда и расчет его параметров (определение формулы тренда).
7. Расчет прогнозных значений по формуле тренда.
8. Наложение нормированных циклических характеристик на трендовый прогноз (их суммирование с трендовым прогнозом).
9. Построение графика исходного ряда, продолженного прогнозными значениями.
10. Построение доверительного интервала.
Полученные результаты при условии прогнозирования на 1 год вперед приведены ниже. Описание построения модели приведено в Приложении 1.
Рис. 2. Прогноз по аддитивной модели на основе экспоненциального тренда
Рис. 3. Прогноз по аддитивной модели на основе экспоненциального тренда с доверительным интервалом
2.2. Построение мультипликативной модели
В мультипликативной модели предполагается, что тренд ряда умножается на циклическую составляющую , имеющую вид периодически изменяющегося коэффициента, принимающего значения большие и меньшие единицы. Этот коэффициент увеличивает значения, лежащие на линии тренда, в те периоды времени, когда циклическая составляющая больше 1, и уменьшаются, в те периоды, когда циклическая составляющая меньше 1. Средняя величина всех таких слагаемых за время одного цикла равна 1.
Пошаговая процедура построения мультипликативной модели:
1. Устранение циклических колебаний из исходного ряда (сглаживание ряда методом скользящей средней по базе, равной длине цикла; в случае четной базы проведение двухэтапного сглаживания).
2. Выявление колебаний ряда (деление исходного ряда на сглаженный).
3. Определение средних значений циклических характеристик (вычисление средних значений по однородным периодам).
4. Нормирование средних значений циклических характеристик (определение их среднего значения с последующим смещением всех характеристик на эту величину так, чтобы среднее значение смещенных характеристик было равно 1). Результат рассматривается как циклическая составляющая ряда .
5. Устранение циклической составляющей из исходного временного ряда (деление исходного ряда на циклический).
6. Выбор вида тренда и расчет его параметров (определение формулы тренда).
7. Расчет прогнозных значений по формуле тренда.
8. Наложение нормированных циклических характеристик на трендовый прогноз (их перемножение с трендовым прогнозом).
9. Построение графика исходного ряда, продолженного прогнозными значениями.
10. Построение доверительного интервала.
Полученные результаты приведены ниже. Описание построения модели приведено в Приложении 2.
Рис. 4. Прогноз по мультипликативной модели на основе линейного и экспоненциального трендов
Рис. 5. Прогноз по мультипликативной модели на основе экспоненциального тренда с доверительным интервалом
ЗАКЛЮЧЕНИЕ
Статистические методы все шире проникают в экономическую практику. С развитием компьютеров, распространением пакетов прикладных программ эти методы вышли за стены учебных и научно-исследовательских институтов. Они стали важным инструментом в деятельности аналитических, плановых, маркетинговых отделов различных фирм и предприятий.
При прогнозировании часто исходят из того, что уровни временных рядов экономических показателей могут содержать следующие компоненты: тренд, сезонную, циклическую и случайную составляющие. В зависимости от способа сочетания этих компонент модели временных рядов делятся на аддитивные, мультипликативные или модели смешанного типа.
По результатам проведенного исследования были сделаны следующие выводы:
Статистические методы прогнозирования имеют важное практическое значение в современном мире.
Электронная таблица Excel имеет достаточно средств для быстрого построения разнообразных функций для выделения трендовой составляющей модели данных и для построения на этой основе прогноза.
Как мы увидели построение качественного прогноза – процесс весьма трудоемкий. Качественный прогноз может дать только качественная модель данных. Прогнозирование действительно помогает заглянуть за горизонт завтрашнего дня и тем приносит несомненную пользу в процессах принятия решений.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
Дуброва Т.А. Статистические методы прогнозирования в экономике: Учебное пособие, практикум, тесты, программа курса. – М.: Московский государственный университет экономики, статистики и информатики, 2004. – 136 с.
Литвинчук С.Ю. Информационные технологии в экономике. Анализ и прогнозирование временных рядов с помощью Excel: учебное пособие. – Нижний Новгород: Нижегородский государственный архитектурно-строительный университет, 2010. – 78 с. .
Кувайская Ю.Г. Статистические методы прогнозирования: учебное пособие.– Ульяновск: УлГТУ, 2019. – 197 с.
Приложение 1.
Построение аддитивной модели в электронной таблице Excel на основе линейного тренда
В исходные данные добавим столбец с порядковым номера квартала (). Учитываем, что мы хотим построить прогноз на 2022 год (4 шага вперед):
Подготовим шаблон модели в соответствии с шагами, описанными в разделе 2.1 работы.
ШАГ 1. Устранение циклических колебаний из исходного ряда .
Как мы увидели из графического анализа исходных данных, имеют место устойчивые циклические колебания. Потому необходимо провести сглаживание ряда методом скользящей средней (в наш случае длина интервала сглаживания равна 4). Так как длина интервала представляет собой четное число, то мы будем проводить двухэтапное сглаживание.
На первом этапе проведем сглаживание при определенной нами длине интервала ( ), результат укажем в ячейке Е5 со сдвигом на полпериода вперед. Для вычисления среднего значения воспользуемся встроенной функцией СРЗНАЧ, которая возвращает среднее арифметическое своих аргументов. В ячейку Е5 вводим функцию СРЗНАЧ со следующими аргументами:
и протягиваем ее до ячейки Е13. В результате получим сглаженные годовые данные.
Теперь проведем повторное сглаживание уже сглаженного ряда при длине интервала, равному 2. База опять четная, и на этот раз результат мы сдвинем на полпериода назад. В ячейку F6 вводим функцию СРЗНАЧ со следующими аргументами:
и протягиваем ее до ячейки F13. В результате получим сглаженные, центрированные корректно, годовые данные
ШАГ 2. Выявление колебаний ряда.
Для того, чтобы выделить сезонные колебания, необходимо из исходного ряда данных вычесть полученный на шаге 1 ряд сглаженных данных.
В ячейку G6 вводим формулу: «=D6-F6» и протягиваем ее до ячейки G13. В итоге мы получим сезонные колебания нашего исходного ряда.
ШАГ 3. Определение средних значений циклических характеристик.
Для каждого однородного периода найдем среднее значение сезонных колебаний. Для 1 квартала найдем среднее значение колебаний, относящихся к первому кварталу, для 2 кварталу – ко второму и т.д. В ячейку H16 вводим формулу «=СРЗНАЧ(G8;G12)», в ячейку H17 вводим формулу «=СРЗНАЧ(G9;G13)», в H18 – «=СРЗНАЧ(G6;G10)», в H19 – «=СРЗНАЧ(G7;G11)». Получим поквартальные средние значения циклических колебаний.
ШАГ 4. Нормирование средних значений циклических характеристик.
Определим среднее значение поквартальных средних значений циклических колебаний. В ячейку H2 вводим формулу: «=СРЗНАЧ(H16:H19)».
Получаем среднее значение, равное -5. Смещаем все характеристики поквартальных средних значений циклические колебаний на эту величину так, чтобы среднее значение смещенных характеристик было равно 0.
В ячейку I16 вводим формулу: «=H16-$H$2», закрепляя ячейку H2 и протягиваем ее до ячейки I19. В итоге мы получим нормированные средние значения сезонных колебаний.
Проверим, что среднее значение нормированных поквартальных средних значений циклических колебаний равняется 0. В ячейку I2 вводим формулу: =СРЗНАЧ(I16:I19)». Результатом вычисления является 0.
В итоге мы получили – циклическую составляющую исходного ряда . Внесем полученные данные в соответствующий столбец.
ШАГ 5. Устранение циклической составляющей из исходного временного ряда .
Для устранения цикличности и построения обессезоненного ряда данных необходимо построить разность между исходным рядом и циклическим рядом . В ячейку К4 вводим формулу «=D4-J4» и протягиваем ее до ячейки К15. В результате получим обессезоненную составляющую исходного ряда.
Отобразим на диаграмме полученные на Шагах 1-5 данные: исходные данные , сезонную составляющую и обессезоненные данные.
ШАГ 6. Выбор вида тренда и расчет его параметров (определение формулы тренда).
Средство построения диаграмм и графиков Excel автоматически строит линии тренда и автоматически рассчитывает его параметры. Обратим внимание, что линию тренда нельзя добавить в объемную, лепестковую, круговую и кольцевую диаграммы, а также в диаграмму с накоплением.
Для построения линии тренда необходимо сначала построить график обессезоненных данных. Для этого выделим в таблице столбец обессезоненных данных вместе с заголовком, затем во вкладке «Вставка» в блоке «Диаграммы» выберем пункт «Вставить график» и тип «График с маркерами».
С помощью кнопки блока «Диаграммы» перенесем диаграмму на отдельный лист.
Чтобы по этому ряду данных построить линию тренда, выполним следующие действия.
Щелкнем по графику правой клавишей мыши, чтобы вызвать контекстное меню .
Выбираем раздел «Добавить линию тренда», чтобы открыть диалоговое окно «Формат линия тренда»:
В диалоговом окне «Формат линии тренда» выберем тип линии тренда. Для выбора предоставляются следующие типы линии тренда:
Экспоненциальная,
Линейная,
Логарифмическая,
Полиномиальная,
Степенная,
Линейная фильтрация.
Если ряд данных содержит нулевые или отрицательные значения, то линии тренда Экспоненциальная и Степенная будут недоступны.
В диалоговом окне «Формат линии тренда» также предлагается:
определить название линии тренда, которое будут включено в легенду,
задать количество периодов, на которые будут прогнозироваться данные (вперед и назад).
Три дополнительные опции позволяют отобразить на диаграмме:
пересечение линии тренда с осью Y (опция Пересечение кривой с осью Y в точке);
уравнение линии тренда (опция Показывать уравнение на диаграмме);
значение коэффициента детерминации , определяющее достоверность аппроксимации (опция Поместить на диаграмму величину достоверности аппроксимации (R^2)).
Построим линейную, степенную и экспоненциальную линии тренда с отображением уравнения и коэффициента детерминации на 4 месяца вперед.
Коэффициент детерминации характеризует степень близости линии тренда к исходным данным. Он может принимать значения от 0 до 1. Чем больше его значение, тем лучше линия тренда аппроксимирует исходные данные.
Как мы видим ближе всего к 1 значение коэффициента детерминации у степенной линии тренда.
На основе полученных уравнений можно рассчитать точечный прогноз путем подстановки в уравнение кривой значений времени , соответствующие периоду упреждения.
ШАГ 7. Расчет прогнозных значений по формуле тренда.
Прогнозирование с помощью встроенных функций Excel предоставляет большие возможности, чем графические средства.
Для быстрого вычисления прогнозных значений переменной без явного построения функции тренда используют статистические функции РОСТ и ТЕНДЕНЦИЯ.
Функция ТЕНДЕНЦИЯ возвращает значения в соответствии с линейным трендом.
Функция РОСТ рассчитывает прогнозируемый экспоненциальный рост на основе имеющихся данных.
Функции ТЕНДЕНЦИЯ и РОСТимеют одинаковый синтаксис:
=ТЕНДЕНЦИЯ(Известные_значения_Y; [Известные_значения_Х]; [Новые_значения_х]; [Конст])
=РОСТ(Известные_значения_Y; [Известные_значения_Х]; [Новые_значения_х]; [Конст]),
где
Известные_значения_Y – обязательный аргумент. Множество значений переменной Y, которые уже известны;
Известные_значения_Х – обязательный аргумент. Множество значений факторов;
Новые_значения_х – обязательный аргумент. Значения факторов, для которых вычисляется прогнозное значение;
Константа – необязательный аргумент.
Если в функциях ТЕНДЕНЦИЯ и РОСТ аргумент Известные_значения_Х опущен, то предполагается, что это массив натуральных чисел {1; 2; 3; …} такого же размера, как и массив аргумента Известные_значения_Y. Если опущен аргумент Новые_значения_х, то по умолчанию предполагается, что он совпадает с аргументом Известные_значения_Х.
Рассчитаем прогнозные значения с помощью функции ТЕНДЕНЦИЯ (сделаем прогноз на основе линейного тренда). Для этого в ячейку L4 введем функцию ТЕНДЕНЦИЯ со следующими аргументами, предварительно закрепив нужные диапазоны данных, где
Известные_значения_Y – множество обессезоненных данных (диапазон данных $K$4:$K$15);
Известные_значения_Х – множество значений периодов (диапазон данных $A$4:$A$15);
Новые_значения_х – значения времени , соответствующие периоду построения прогноза (значение ячейки A4).
Протягиваем формулу до ячейки L19. Таким образом, мы получим – трендовую составляющую исходного ряда , рассчитанную на основе линейного тренда.
ШАГ 8. Наложение нормированных циклических характеристик на трендовый прогноз.
Построим окончательный прогноз на основе линейного тренда, для этого сложим сезонную и трендовые составляющие. В ячейку М4 введем формулу: «=L4+J4» и протянем ее до ячейки M19. В итоге получим прогнозные значения.
ШАГ 9. Построение графика исходного ряда, продолженного прогнозными значениями.
Построим графики исходного ряда и полученных прогнозных значений. Для этого выделим два столбца соответствующих данных вместе с заголовками, затем во вкладке «Вставка» в блоке «Диаграммы» выберем пункт «Вставить график» и тип «График с маркерами».
ШАГ 10. Построение доверительного интервала.
На данном шаге мы определим границы возможного изменения прогнозируемого показателя, зададим «вилку» возможных значений прогнозируемых показателей, т.е. вычислим прогноз интервальный.
Границы доверительного интервала, учитывающего неопределенность, связанную с положением тренда, и возможность отклонения от этого тренда, упрощенно определяется в виде:
где
– расчетное значение уровня ряда, полученное по модели,
– средняя квадратическая ошибка,
– одно из чисел: 1, 2 или 3. При границы доверительного интервала обеспечивают приблизительно 68% надежность прогноза, при обеспечивается 95% надежность, при обеспечивается 99% надежность.
В работе мы рассмотрели формулу средней квадратической ошибки:
где
– фактическое значение уровня ряда;
– расчетное значение уровня ряда, полученное по модели;
– длина ряда.
Для расчета средней квадратической ошибки воспользуемся встроенной в Excel функцией СУММКВРАЗН, которая возвращает сумму квадратов разностей соответствующих значений в двух массивах и встроенной функцией СЧЕТ, которая подсчитывает количество ячеек, содержащих числа.
Функция СУММКВРАЗН имеет следующий синтаксис:
СУММКВРАЗН(массив_x; массив_y)
где
Массив_x – обязательный аргумент. Первый массив или диапазон значений;
Массив_y – обязательный аргумент. Второй массив или диапазон значений.
Введем в ячейку N2 формулу: «=(СУММКВРАЗН(D4:D15;M4:M15)/(СЧЁТ($D:$D)-2))^0,5». Таким образом, мы рассчитаем среднюю квадратическую ошибку.
Ограничим ввод данных в ячейке О2. Мы хотим, чтобы в нее можно было вводить только числа 1, 2 или 3. Для этого выделяем эту ячейку, затем во вкладке «Данные» в блоке «Работа с данными» выберем пункт «Проверка данных» и подпункт «Проверка данных».
В диалоговом окне «Проверка вводимых значений» во вкладке «Параметры» задаем следующие ограничения:
Во вкладках «Сообщение для ввода» и «Сообщение об ошибке» следующие данные:
Теперь в ячейку О2 мы сможем внести только значения 1, 2 или 3.
Осталось только отобразить в ячейке Р2 надежность нашего доверительного интервала. Сделаем это при помощи функции ЕСЛИ, которая возвращает одно значение, если указанное условие дает в результате значение ИСТИНА, и другое значение, если условие дает в результате значение ЛОЖЬ.
Функция ЕСЛИ имеет следующий синтаксис:
ЕСЛИ(лог_выражение; [значение_если_истина]; [значение_если_ложь])
Лог_выражение – обязательный аргумент. Любое значение или выражение, дающее в результате значение ИСТИНА или ЛОЖЬ. В этом аргументе может использоваться любой оператор сравнения.
Значение_если_истина – необязательный аргумент. Значение, которое возвращается, если аргумент лог_выражение соответствует значению ИСТИНА. Если аргумент лог_выражение соответствует значению ИСТИНА, а аргумент значение_если_истина опущен (т.е. после аргумента лог_выражение есть только запятая), возвращается значение 0.
Значение_если_ложь – необязательный аргумент. Значение, которое возвращается, если аргумент лог_выражение соответствует значению ЛОЖЬ. Если аргумент лог_выражение соответствует значению ЛОЖЬ, а аргумент значение_если_ложь опущен (т.е. после аргумента значение_если_истина нет запятой), функция ЕСЛИ возвращает логическое значение ЛОЖЬ. Если аргумент лог_выражение соответствует значению ЛОЖЬ, а значение аргумента значение_если_ложь пусто (т. е. после аргумента значение_если_истина стоит только запятая), функция ЕСЛИ возвращает значение 0 (ноль).
Введем в ячейку Р2 функцию если со следующими параметрами:
Теперь при значении , в ячейке Р2 отобразится 68%, при значении – 95%, при – значение 99%.
Построим доверительный интервал при надежности 95%.
Для построения нижней границы доверительного интервала введем в ячейку N4 формулу: «=$M4-$N$2*$O$2», закрепив при этом необходимые ячейки, и протянем ее до ячейки N19. Таким образом мы найдем значения нижней границы доверительного интервала.
Для построения верхней границы доверительного интервала введем в ячейку О4 формулу: «=$M4+$N$2*$O$2», закрепив при этом необходимые ячейки, и протянем ее до ячейки О19. Таким образом мы найдем значения верхней границы доверительного интервала.
Наша аддитивная модель сезонности на основе линейного тренда построена. Осталось только изобразить ее графически. Добавим на диаграмму, полученную на шаге 9, верхнюю и нижнюю границы доверительного интервала. Для этого выделим соответствующие столбцы данных вместе с заголовками, скопируем их, перейдем на лист с диаграммой и нажнем кнопку «Вставить». Соответствующие графики отобразятся на исходной диаграмме.
Построение аддитивной модели в электронной таблице Excel на основе экспоненциального тренда
Подготовим шаблон модели в соответствии с шагами, описанными в разделе 2.1 работы.
Повторим Шаги с 1 по 6, описанные первом разделе данного приложения.
ШАГ 7. Расчет прогнозных значений по формуле тренда.
Прогнозирование с помощью встроенных функций Excel предоставляет большие возможности, чем графические средства.
Для быстрого вычисления прогнозных значений переменной без явного построения функции тренда используют статистические функции РОСТ и ТЕНДЕНЦИЯ.
Функция ТЕНДЕНЦИЯ возвращает значения в соответствии с линейным трендом.
Функция РОСТ рассчитывает прогнозируемый экспоненциальный рост на основе имеющихся данных.
Функции ТЕНДЕНЦИЯ и РОСТимеют одинаковый синтаксис:
=ТЕНДЕНЦИЯ(Известные_значения_Y; [Известные_значения_Х]; [Новые_значения_х]; [Конст])
=РОСТ(Известные_значения_Y; [Известные_значения_Х]; [Новые_значения_х]; [Конст]),
где
Известные_значения_Y – обязательный аргумент. Множество значений переменной Y, которые уже известны;
Известные_значения_Х – обязательный аргумент. Множество значений факторов;
Новые_значения_х – обязательный аргумент. Значения факторов, для которых вычисляется прогнозное значение;
Константа – необязательный аргумент.
Если в функциях ТЕНДЕНЦИЯ и РОСТ аргумент Известные_значения_Х опущен, то предполагается, что это массив натуральных чисел {1; 2; 3; …} такого же размера, как и массив аргумента Известные_значения_Y. Если опущен аргумент Новые_значения_х, то по умолчанию предполагается, что он совпадает с аргументом Известные_значения_Х.
Рассчитаем прогнозные значения с помощью функции РОСТ (сделаем прогноз на основе экспоненциального тренда). Для этого в ячейку L4 введем функцию РОСТ со следующими аргументами, предварительно закрепив нужные диапазоны данных, где
Известные_значения_Y – множество обессезоненных данных (диапазон данных $K$4:$K$15);
Известные_значения_Х – множество значений периодов (диапазон данных $A$4:$A$15);
Новые_значения_х – значения времени , соответствующие периоду построения прогноза (значение ячейки A4).
Протягиваем формулу до ячейки L19. Таким образом, мы получим – трендовую составляющую исходного ряда , рассчитанную на основе экспоненциального тренда.
ШАГ 8. Наложение нормированных циклических характеристик на трендовый прогноз.
Построим окончательный прогноз на основе экспоненциального тренда, для этого сложим сезонную и трендовые составляющие. В ячейку М4 введем формулу: «=L4+J4» и протянем ее до ячейки M19. В итоге получим прогнозные значения.
ШАГ 9. Построение графика исходного ряда, продолженного прогнозными значениями.
Построим графики исходного ряда и полученных прогнозных значений. Для этого выделим два столбца соответствующих данных вместе с заголовками, затем во вкладке «Вставка» в блоке «Диаграммы» выберем пункт «Вставить график» и тип «График с маркерами».
ШАГ 10. Построение доверительного интервала.
На данном шаге мы определим границы возможного изменения прогнозируемого показателя, зададим «вилку» возможных значений прогнозируемых показателей, т.е. вычислим прогноз интервальный.
Границы доверительного интервала, учитывающего неопределенность, связанную с положением тренда, и возможность отклонения от этого тренда, упрощенно определяется в виде:
,
где
– расчетное значение уровня ряда, полученное по модели,
– средняя квадратическая ошибка,
– одно из чисел: 1, 2 или 3. При границы доверительного интервала обеспечивают приблизительно 68% надежность прогноза, при обеспечивается 95% надежность, при обеспечивается 99% надежность.
В работе мы рассмотрели формулу средней квадратической ошибки:
где
– фактическое значение уровня ряда;
– расчетное значение уровня ряда, полученное по модели;
– длина ряда.
Для расчета средней квадратической ошибки воспользуемся встроенной в Excel функцией СУММКВРАЗН, которая возвращает сумму квадратов разностей соответствующих значений в двух массивах и встроенной функцией СЧЕТ, которая подсчитывает количество ячеек, содержащих числа.
Функция СУММКВРАЗН имеет следующий синтаксис:
СУММКВРАЗН(массив_x; массив_y)
где
Массив_x – обязательный аргумент. Первый массив или диапазон значений;
Массив_y – обязательный аргумент. Второй массив или диапазон значений.
Введем в ячейку N2 формулу: «=(СУММКВРАЗН(D4:D15;M4:M15)/(СЧЁТ($D:$D)-2))^0,5». Таким образом, мы рассчитаем среднюю квадратическую ошибку.
Ограничим ввод данных в ячейке О2. Мы хотим, чтобы в нее можно было вводить только числа 1, 2 или 3. Для этого выделяем эту ячейку, затем во вкладке «Данные» в блоке «Работа с данными» выберем пункт «Проверка данных» и подпункт «Проверка данных».
В диалоговом окне «Проверка вводимых значений» во вкладке «Параметры» задаем следующие ограничения:
В
о вкладках «Сообщение для ввода» и «Сообщение об ошибке» следующие данные:
Теперь в ячейку О2 мы сможем внести только значения 1, 2 или 3.
Осталось только отобразить в ячейке Р2 надежность нашего доверительного интервала. Сделаем это при помощи функции ЕСЛИ, которая возвращает одно значение, если указанное условие дает в результате значение ИСТИНА, и другое значение, если условие дает в результате значение ЛОЖЬ.
Функция ЕСЛИ имеет следующий синтаксис:
ЕСЛИ(лог_выражение; [значение_если_истина]; [значение_если_ложь])
Лог_выражение – обязательный аргумент. Любое значение или выражение, дающее в результате значение ИСТИНА или ЛОЖЬ. В этом аргументе может использоваться любой оператор сравнения.
Значение_если_истина – необязательный аргумент. Значение, которое возвращается, если аргумент лог_выражение соответствует значению ИСТИНА. Если аргумент лог_выражение соответствует значению ИСТИНА, а аргумент значение_если_истина опущен (т.е. после аргумента лог_выражение есть только запятая), возвращается значение 0.
Значение_если_ложь – необязательный аргумент. Значение, которое возвращается, если аргумент лог_выражение соответствует значению ЛОЖЬ. Если аргумент лог_выражение соответствует значению ЛОЖЬ, а аргумент значение_если_ложь опущен (т.е. после аргумента значение_если_истина нет запятой), функция ЕСЛИ возвращает логическое значение ЛОЖЬ. Если аргумент лог_выражение соответствует значению ЛОЖЬ, а значение аргумента значение_если_ложь пусто (т. е. после аргумента значение_если_истина стоит только запятая), функция ЕСЛИ возвращает значение 0 (ноль).
Введем в ячейку Р2 функцию если со следующими параметрами:
Теперь при значении , в ячейке Р2 отобразится 68%, при значении – 95%, при – значение 99%.
Построим доверительный интервал при надежности 95%.
Для построения нижней границы доверительного интервала введем в ячейку N4 формулу: «=$M4-$N$2*$O$2», закрепив при этом необходимые ячейки, и протянем ее до ячейки N19. Таким образом мы найдем значения нижней границы доверительного интервала.
Для построения верхней границы доверительного интервала введем в ячейку О4 формулу: «=$M4+$N$2*$O$2», закрепив при этом необходимые ячейки, и протянем ее до ячейки О19. Таким образом мы найдем значения верхней границы доверительного интервала.
Наша аддитивная модель сезонности на основе экспоненциального тренда построена. Осталось только изобразить ее графически. Добавим на диаграмму, полученную на шаге 9, верхнюю и нижнюю границы доверительного интервала. Для этого выделим соответствующие столбцы данных вместе с заголовками, скопируем их, перейдем на лист с диаграммой и нажнем кнопку «Вставить». Соответствующие графики отобразятся на исходной диаграмме.
Приложение 2.
Построение мультипликативной модели в электронной таблице Excel на основе линейного и экспоненциального трендов
В исходные данные добавим столбец с порядковым номера квартала (). Учитываем, что мы хотим построить прогноз на 2022 год (4 шага вперед):
Подготовим шаблон модели в соответствии с шагами, описанными в разделе 2.2 работы.
ШАГ 1. Устранение циклических колебаний из исходного ряда .
Как мы увидели из графического анализа исходных данных, имеют место устойчивые циклические колебания. Потому необходимо провести сглаживание ряда методом скользящей средней (в наш случае длина интервала сглаживания равна 4). Так как длина интервала представляет собой четное число, то мы будем проводить двухэтапное сглаживание.
На первом этапе проведем сглаживание при определенной нами длине интервала ( ), результат укажем в ячейке Е5 со сдвигом на полпериода вперед. Для вычисления среднего значения воспользуемся встроенной функцией СРЗНАЧ, которая возвращает среднее арифметическое своих аргументов. В ячейку Е5 вводим функцию СРЗНАЧ со следующими аргументами:
и
протягиваем ее до ячейки Е13. В результате получим сглаженные годовые данные.
Теперь проведем повторное сглаживание уже сглаженного ряда при длине интервала, равному 2. База опять четная, и на этот раз результат мы сдвинем на полпериода назад. В ячейку F6 вводим функцию СРЗНАЧ со следующими аргументами:
и протягиваем ее до ячейки F13. В результате получим сглаженные, центрированные корректно, годовые данные
Ш
АГ 2. Выявление колебаний ряда.
Для того, чтобы выделить сезонные колебания, необходимо разделить исходный ряд данных на полученный на шаге 1 ряд сглаженных данных.
В
ячейку G6 вводим формулу: «=D6/F6» и протягиваем ее до ячейки G13. В итоге мы получим сезонные колебания нашего исходного ряда.
ШАГ 3. Определение средних значений циклических характеристик.
Для каждого однородного периода найдем среднее значение сезонных колебаний. Для 1 квартала найдем среднее значение колебаний, относящихся к первому кварталу, для 2 кварталу – ко второму и т.д. В ячейку H16 вводим формулу «=СРЗНАЧ(G8;G12)», в ячейку H17 вводим формулу «=СРЗНАЧ(G9;G13)», в H18 – «=СРЗНАЧ(G6;G10)», в H19 – «=СРЗНАЧ(G7;G11)». Получим поквартальные средние значения циклических колебаний.
ШАГ 4. Нормирование средних значений циклических характеристик.
Определим среднее значение поквартальных средних значений циклических колебаний. В ячейку H2 вводим формулу: «=СРЗНАЧ(H16:H19)».
Получаем среднее значение, равное 0,9797. Смещаем все характеристики поквартальных средних значений циклические колебаний на эту величину так, чтобы среднее значение смещенных характеристик было равно 1.
В ячейку I16 вводим формулу: «=H16/$H$2», закрепляя ячейку H2 и протягиваем ее до ячейки I19. В итоге мы получим нормированные средние значения сезонных колебаний.
Проверим, что среднее значение нормированных поквартальных средних значений циклических колебаний равняется 1. В ячейку I2 вводим формулу: =СРЗНАЧ(I16:I19)». Результатом вычисления является 1.
В итоге мы получили – циклическую составляющую исходного ряда . Внесем полученные данные в соответствующий столбец.
ШАГ 5. Устранение циклической составляющей из исходного временного ряда .
Д
ля устранения цикличности и построения обессезоненного ряда данных необходимо поделить исходный ряд на циклический ряд . В ячейку К4 вводим формулу «=D4/J4» и протягиваем ее до ячейки К15. В результате получим обессезоненную составляющую исходного ряда.
Отобразим на диаграмме полученные на Шагах 1-5 данные: исходные данные , сезонную составляющую и обессезоненные данные.
Так как значения ряда сезонности изменяется в диапазоне от 0 до 2, то диаграмма в таком виде неинформативна. Добавим для данного ряда значений дополнительную ось. Для этого выделим диаграмму, затем в пункте меню «Работа с диаграммами» во вкладке «Конструктор» в блоке «Тип» нажимаем кнопку «Изменить тип диаграммы». Во всплывающем диалоговом окне «Изменение типа диаграммы» переходим на вкладку «Вид диаграммы». Выбираем вид – комбинированная и напротив ряда данных «Сезонность» указываем необходимость наличия дополнительной оси.
Получим более информативный график, на котором видно цикличность изменения ряда данных сезонности.
ШАГ 6. Выбор вида тренда и расчет его параметров (определение формулы тренда).
Средство построения диаграмм и графиков Excel автоматически строит линии тренда и автоматически рассчитывает его параметры. Обратим внимание, что линию тренда нельзя добавить в объемную, лепестковую, круговую и кольцевую диаграммы, а также в диаграмму с накоплением.
Для построения линии тренда необходимо сначала построить график обессезоненных данных. Для этого выделим в таблице столбец обессезоненных данных вместе с заголовком, затем во вкладке «Вставка» в блоке «Диаграммы» выберем пункт «Вставить график» и тип «График с маркерами».
С помощью кнопки блока «Диаграммы» перенесем диаграмму на отдельный лист.
Чтобы по этому ряду данных построить линию тренда, выполним следующие действия.
Щелкнем по графику правой клавишей мыши, чтобы вызвать контекстное меню .
Выбираем раздел «Добавить линию тренда», чтобы открыть диалоговое окно «Формат линия тренда»:
.
В диалоговом окне «Формат линии тренда» выберем тип линии тренда. Для выбора предоставляются следующие типы линии тренда:
Экспоненциальная,
Линейная,
Логарифмическая,
Полиномиальная,
Степенная,
Линейная фильтрация.
Если ряд данных содержит нулевые или отрицательные значения, то линии тренда Экспоненциальная и Степенная будут недоступны.
В диалоговом окне «Формат линии тренда» также предлагается:
определить название линии тренда, которое будут включено в легенду,
задать количество периодов, на которые будут прогнозироваться данные (вперед и назад).
Три дополнительные опции позволяют отобразить на диаграмме:
пересечение линии тренда с осью Y (опция Пересечение кривой с осью Y в точке);
уравнение линии тренда (опция Показывать уравнение на диаграмме);
значение коэффициента детерминации , определяющее достоверность аппроксимации (опция Поместить на диаграмму величину достоверности аппроксимации (R^2)).
Построим линейную, степенную и экспоненциальную линии тренда с отображением уравнения и коэффициента детерминации на 4 месяца вперед.
Коэффициент детерминации характеризует степень близости линии тренда к исходным данным. Он может принимать значения от 0 до 1. Чем больше его значение, тем лучше линия тренда аппроксимирует исходные данные.
Как мы видим ближе всего к 1 значение коэффициента детерминации у экспоненциальной линии тренда.
На основе полученных уравнений можно рассчитать точечный прогноз путем подстановки в уравнение кривой значений времени , соответствующие периоду упреждения.
2.1 Построение мультипликативной модели в электронной таблице Excel на основе линейного тренда
ШАГ 7. Расчет прогнозных значений по формуле тренда.
Прогнозирование с помощью встроенных функций Excel предоставляет большие возможности, чем графические средства.
Для быстрого вычисления прогнозных значений переменной без явного построения функции тренда используют статистические функции РОСТ и ТЕНДЕНЦИЯ.
Функция ТЕНДЕНЦИЯ возвращает значения в соответствии с линейным трендом.
Функция РОСТ рассчитывает прогнозируемый экспоненциальный рост на основе имеющихся данных.
Функции ТЕНДЕНЦИЯ и РОСТимеют одинаковый синтаксис:
=ТЕНДЕНЦИЯ(Известные_значения_Y; [Известные_значения_Х]; [Новые_значения_х]; [Конст])
=РОСТ(Известные_значения_Y; [Известные_значения_Х]; [Новые_значения_х]; [Конст]),
где
Известные_значения_Y – обязательный аргумент. Множество значений переменной Y, которые уже известны;
Известные_значения_Х – обязательный аргумент. Множество значений факторов;
Новые_значения_х – обязательный аргумент. Значения факторов, для которых вычисляется прогнозное значение;
Константа – необязательный аргумент.
Если в функциях ТЕНДЕНЦИЯ и РОСТ аргумент Известные_значения_Х опущен, то предполагается, что это массив натуральных чисел {1; 2; 3; …} такого же размера, как и массив аргумента Известные_значения_Y. Если опущен аргумент Новые_значения_х, то по умолчанию предполагается, что он совпадает с аргументом Известные_значения_Х.
Рассчитаем прогнозные значения с помощью функции ТЕНДЕНЦИЯ (сделаем прогноз на основе линейного тренда). Для этого в ячейку L4 введем функцию ТЕНДЕНЦИЯ со следующими аргументами, предварительно закрепив нужные диапазоны данных, где
Известные_значения_Y – множество обессезоненных данных (диапазон данных $K$4:$K$15);
Известные_значения_Х – множество значений периодов (диапазон данных $A$4:$A$15);
Новые_значения_х – значения времени , соответствующие периоду построения прогноза (значение ячейки A4).
Протягиваем формулу до ячейки L19. Таким образом, мы получим – трендовую составляющую исходного ряда , рассчитанную на основе линейного тренда.
ШАГ 8. Наложение нормированных циклических характеристик на трендовый прогноз.
П
остроим окончательный прогноз на основе линейного тренда, для этого перемножим сезонную и трендовые составляющие. В ячейку М4 введем формулу: «=L4*J4» и протянем ее до ячейки M19. В итоге получим прогнозные значения.
ШАГ 9. Построение графика исходного ряда, продолженного прогнозными значениями.
Построим графики исходного ряда и полученных прогнозных значений. Для этого выделим два столбца соответствующих данных вместе с заголовками, затем во вкладке «Вставка» в блоке «Диаграммы» выберем пункт «Вставить график» и тип «График с маркерами».
ШАГ 10. Построение доверительного интервала.
На данном шаге мы определим границы возможного изменения прогнозируемого показателя, зададим «вилку» возможных значений прогнозируемых показателей, т.е. вычислим прогноз интервальный.
Границы доверительного интервала, учитывающего неопределенность, связанную с положением тренда, и возможность отклонения от этого тренда, упрощенно определяется в виде:
,
где
– расчетное значение уровня ряда, полученное по модели,
– средняя квадратическая ошибка,
– одно из чисел: 1, 2 или 3. При границы доверительного интервала обеспечивают приблизительно 68% надежность прогноза, при обеспечивается 95% надежность, при обеспечивается 99% надежность.
В работе мы рассмотрели формулу средней квадратической ошибки:
где
– фактическое значение уровня ряда;
– расчетное значение уровня ряда, полученное по модели;
– длина ряда.
Для расчета средней квадратической ошибки воспользуемся встроенной в Excel функцией СУММКВРАЗН, которая возвращает сумму квадратов разностей соответствующих значений в двух массивах и встроенной функцией СЧЕТ, которая подсчитывает количество ячеек, содержащих числа.
Функция СУММКВРАЗН имеет следующий синтаксис:
СУММКВРАЗН(массив_x; массив_y)
где
Массив_x – обязательный аргумент. Первый массив или диапазон значений;
Массив_y – обязательный аргумент. Второй массив или диапазон значений.
Введем в ячейку N2 формулу: «=(СУММКВРАЗН($D$4:$D$15;M4:M15)/(СЧЁТ($D:$D)-2))^0,5». Таким образом, мы рассчитаем среднюю квадратическую ошибку.
Ограничим ввод данных в ячейке О2. Мы хотим, чтобы в нее можно было вводить только числа 1, 2 или 3. Для этого выделяем эту ячейку, затем во вкладке «Данные» в блоке «Работа с данными» выберем пункт «Проверка данных» и подпункт «Проверка данных».
В диалоговом окне «Проверка вводимых значений» во вкладке «Параметры» задаем следующие ограничения:
В
о вкладках «Сообщение для ввода» и «Сообщение об ошибке» следующие данные:
Теперь в ячейку О2 мы сможем внести только значения 1, 2 или 3.
Осталось только отобразить в ячейке T2 надежность нашего доверительного интервала. Сделаем это при помощи функции ЕСЛИ, которая возвращает одно значение, если указанное условие дает в результате значение ИСТИНА, и другое значение, если условие дает в результате значение ЛОЖЬ.
Функция ЕСЛИ имеет следующий синтаксис:
ЕСЛИ(лог_выражение; [значение_если_истина]; [значение_если_ложь])
Лог_выражение – обязательный аргумент. Любое значение или выражение, дающее в результате значение ИСТИНА или ЛОЖЬ. В этом аргументе может использоваться любой оператор сравнения.
Значение_если_истина – необязательный аргумент. Значение, которое возвращается, если аргумент лог_выражение соответствует значению ИСТИНА. Если аргумент лог_выражение соответствует значению ИСТИНА, а аргумент значение_если_истина опущен (т.е. после аргумента лог_выражение есть только запятая), возвращается значение 0.
Значение_если_ложь – необязательный аргумент. Значение, которое возвращается, если аргумент лог_выражение соответствует значению ЛОЖЬ. Если аргумент лог_выражение соответствует значению ЛОЖЬ, а аргумент значение_если_ложь опущен (т.е. после аргумента значение_если_истина нет запятой), функция ЕСЛИ возвращает логическое значение ЛОЖЬ. Если аргумент лог_выражение соответствует значению ЛОЖЬ, а значение аргумента значение_если_ложь пусто (т. е. после аргумента значение_если_истина стоит только запятая), функция ЕСЛИ возвращает значение 0 (ноль).
Введем в ячейку T2 функцию если со следующими параметрами:
Теперь при значении , в ячейке T2 отобразится 68%, при значении – 95%, при – значение 99%.
Построим доверительный интервал при надежности 95%.
Для построения нижней границы доверительного интервала введем в ячейку N4 формулу: «=$M4-$N$2*$O$2», закрепив при этом необходимые ячейки, и протянем ее до ячейки N19. Таким образом мы найдем значения нижней границы доверительного интервала.
Для построения верхней границы доверительного интервала введем в ячейку О4 формулу: «=$M4+$N$2*$O$2», закрепив при этом необходимые ячейки, и протянем ее до ячейки О19. Таким образом мы найдем значения верхней границы доверительного интервала.
Наша мультипликативная модель сезонности на основе линейного тренда построена. Осталось только изобразить ее графически. Добавим на диаграмму, полученную на шаге 9, верхнюю и нижнюю границы доверительного интервала. Для этого выделим соответствующие столбцы данных вместе с заголовками, скопируем их, перейдем на лист с диаграммой и нажнем кнопку «Вставить». Соответствующие графики отобразятся на исходной диаграмме.
Построение мультипликативной модели в электронной таблице Excel на основе экспоненциального тренда
ШАГ 7. Расчет прогнозных значений по формуле тренда.
Прогнозирование с помощью встроенных функций Excel предоставляет большие возможности, чем графические средства.
Для быстрого вычисления прогнозных значений переменной без явного построения функции тренда используют статистические функции РОСТ и ТЕНДЕНЦИЯ.
Функция ТЕНДЕНЦИЯ возвращает значения в соответствии с линейным трендом.
Функция РОСТ рассчитывает прогнозируемый экспоненциальный рост на основе имеющихся данных.
Функции ТЕНДЕНЦИЯ и РОСТимеют одинаковый синтаксис:
=ТЕНДЕНЦИЯ(Известные_значения_Y; [Известные_значения_Х]; [Новые_значения_х]; [Конст])
=РОСТ(Известные_значения_Y; [Известные_значения_Х]; [Новые_значения_х]; [Конст]),
где
Известные_значения_Y – обязательный аргумент. Множество значений переменной Y, которые уже известны;
Известные_значения_Х – обязательный аргумент. Множество значений факторов;
Новые_значения_х – обязательный аргумент. Значения факторов, для которых вычисляется прогнозное значение;
Константа – необязательный аргумент.
Если в функциях ТЕНДЕНЦИЯ и РОСТ аргумент Известные_значения_Х опущен, то предполагается, что это массив натуральных чисел {1; 2; 3; …} такого же размера, как и массив аргумента Известные_значения_Y. Если опущен аргумент Новые_значения_х, то по умолчанию предполагается, что он совпадает с аргументом Известные_значения_Х.
Рассчитаем прогнозные значения с помощью функции РОСТ (сделаем прогноз на основе экспоненциального тренда). Для этого в ячейку Р4 введем функцию РОСТ со следующими аргументами, предварительно закрепив нужные диапазоны данных, где
Известные_значения_Y – множество обессезоненных данных (диапазон данных $K$4:$K$15);
Известные_значения_Х – множество значений периодов (диапазон данных $A$4:$A$15);
Новые_значения_х – значения времени , соответствующие периоду построения прогноза (значение ячейки A4).
Протягиваем формулу до ячейки P19. Таким образом, мы получим – трендовую составляющую исходного ряда , рассчитанную на основе экспоненциального тренда.
ШАГ 8. Наложение нормированных циклических характеристик на трендовый прогноз.
Построим окончательный прогноз на основе экспоненциального тренда, для этого перемножим сезонную и трендовые составляющие. В ячейку Q4 введем формулу: «=P4*J4» и протянем ее до ячейки Q19. В итоге получим прогнозные значения.
ШАГ 9. Построение графика исходного ряда, продолженного прогнозными значениями.
Построим графики исходного ряда и полученных прогнозных значений. Для этого выделим два столбца соответствующих данных вместе с заголовками, затем во вкладке «Вставка» в блоке «Диаграммы» выберем пункт «Вставить график» и тип «График с маркерами».
ШАГ 10. Построение доверительного интервала.
На данном шаге мы определим границы возможного изменения прогнозируемого показателя, зададим «вилку» возможных значений прогнозируемых показателей, т.е. вычислим прогноз интервальный.
Границы доверительного интервала, учитывающего неопределенность, связанную с положением тренда, и возможность отклонения от этого тренда, упрощенно определяется в виде:
,
где
– расчетное значение уровня ряда, полученное по модели,
– средняя квадратическая ошибка,
– одно из чисел: 1, 2 или 3. При границы доверительного интервала обеспечивают приблизительно 68% надежность прогноза, при обеспечивается 95% надежность, при обеспечивается 99% надежность.
В работе мы рассмотрели формулу средней квадратической ошибки:
где
– фактическое значение уровня ряда;
– расчетное значение уровня ряда, полученное по модели;
– длина ряда.
Для расчета средней квадратической ошибки воспользуемся встроенной в Excel функцией СУММКВРАЗН, которая возвращает сумму квадратов разностей соответствующих значений в двух массивах и встроенной функцией СЧЕТ, которая подсчитывает количество ячеек, содержащих числа.
Функция СУММКВРАЗН имеет следующий синтаксис:
СУММКВРАЗН(массив_x; массив_y)
где
Массив_x – обязательный аргумент. Первый массив или диапазон значений;
Массив_y – обязательный аргумент. Второй массив или диапазон значений.
Введем в ячейку R2 формулу: «=(СУММКВРАЗН($D$4:$D$15;Q4:Q15)/(СЧЁТ($D:$D)-2))^0,5». Таким образом, мы рассчитаем среднюю квадратическую ошибку.
Ограничим ввод данных в ячейке S2. Мы хотим, чтобы в нее можно было вводить только числа 1, 2 или 3. Для этого выделяем эту ячейку, затем во вкладке «Данные» в блоке «Работа с данными» выберем пункт «Проверка данных» и подпункт «Проверка данных».
В диалоговом окне «Проверка вводимых значений» во вкладке «Параметры» задаем следующие ограничения:
В
о вкладках «Сообщение для ввода» и «Сообщение об ошибке» следующие данные:
Теперь в ячейку S2 мы сможем внести только значения 1, 2 или 3.
Осталось только отобразить в ячейке U2 надежность нашего доверительного интервала. Сделаем это при помощи функции ЕСЛИ, которая возвращает одно значение, если указанное условие дает в результате значение ИСТИНА, и другое значение, если условие дает в результате значение ЛОЖЬ.
Функция ЕСЛИ имеет следующий синтаксис:
ЕСЛИ(лог_выражение; [значение_если_истина]; [значение_если_ложь])
Лог_выражение – обязательный аргумент. Любое значение или выражение, дающее в результате значение ИСТИНА или ЛОЖЬ. В этом аргументе может использоваться любой оператор сравнения.
Значение_если_истина – необязательный аргумент. Значение, которое возвращается, если аргумент лог_выражение соответствует значению ИСТИНА. Если аргумент лог_выражение соответствует значению ИСТИНА, а аргумент значение_если_истина опущен (т.е. после аргумента лог_выражение есть только запятая), возвращается значение 0.
Значение_если_ложь – необязательный аргумент. Значение, которое возвращается, если аргумент лог_выражение соответствует значению ЛОЖЬ. Если аргумент лог_выражение соответствует значению ЛОЖЬ, а аргумент значение_если_ложь опущен (т.е. после аргумента значение_если_истина нет запятой), функция ЕСЛИ возвращает логическое значение ЛОЖЬ. Если аргумент лог_выражение соответствует значению ЛОЖЬ, а значение аргумента значение_если_ложь пусто (т. е. после аргумента значение_если_истина стоит только запятая), функция ЕСЛИ возвращает значение 0 (ноль).
Введем в ячейку U2 функцию если со следующими параметрами:
Теперь при значении , в ячейке U2 отобразится 68%, при значении – 95%, при – значение 99%.
Построим доверительный интервал при надежности 99%.
Для построения нижней границы доверительного интервала введем в ячейку R4 формулу: «=$Q4-$R$2*$S$2», закрепив при этом необходимые ячейки, и протянем ее до ячейки R19. Таким образом мы найдем значения нижней границы доверительного интервала.
Для построения верхней границы доверительного интервала введем в ячейку S4 формулу: «=$Q4+$R$2*$S$2», закрепив при этом необходимые ячейки, и протянем ее до ячейки S19. Таким образом мы найдем значения верхней границы доверительного интервала.
Наша мультипликативная модель сезонности на основе экспоненциального тренда построена. Осталось только изобразить ее графически. Добавим на диаграмму, полученную на шаге 9, верхнюю и нижнюю границы доверительного интервала. Для этого выделим соответствующие столбцы данных вместе с заголовками, скопируем их, перейдем на лист с диаграммой и нажнем кнопку «Вставить». Соответствующие графики отобразятся на исходной диаграмме.
Просмотров работы: 31