
Статистические функции Excel
Применение статистических функций облегчает пользователю статистический анализ данных. Количество доступных статистических функций в седьмой версии программы увеличилось, и можно утверждать, что по спектру доступных функций Excel сегодня почти не уступает специальным программам обработки статистических данных. Для того чтобы иметь возможность использовать все статистические функции, следует загрузить надстройку Пакет анализа.
Основу статистического анализа составляет исследование совокупностей и выборок. Выборка представляет собой подмножество совокупности. В качестве примера выборки можно привести опросы общественного мнения. Исследуя выборки с помощью вычисления отклонений и отслеживания взаимосвязей с генеральной совокупностью, можно проследить, насколько репрезентативна выборка.
Целый ряд статистических функций Excel предназначен для анализа вероятностей.
Ниже приведено описание некоторых наиболее распространенных функций. Информацию о других функциях пользователь может найти в справочной подсистеме.
FРАСП
Синтаксис:
FРАСП(х,степени_свободы1,степени_свободы2)
Результат:
F-распределение вероятности. Эту функцию можно использовать, чтобы определить, имеют ли два множества данных различные степени плотности. Например, можно исследовать результаты тестирования мужчин и женщин, окончивших высшую школу, и определить, зависит ли разброс результатов от пола.
Аргументы:
х- значение, для которого вычисляется функция;
степени_свободы1- числитель степеней свободы;
степени_свободы2- знаменатель степеней свободы.
ВЕРОЯТНОСТЬ
Синтаксис:
ВЕРОЯТНОСТЬ(х_интервал,интервал_вероятностей,нижний_предел,zверхний_предел)
Результат:
Значение вероятности того, что значение из интервала находится внутри заданных пределов. Вели аргумент верхний_предел не задан, то возвращается значение вероятности того, что значения в аргументе х_интервал равны значению аргумента нижний_предел.
Аргументы:
х_интервал- интервал числовых значений х;
интервал_вероятностей- множество вероятностей возникновения значений, входящих в аргумент х_интервал;
нижний_предел- нижняя граница значения, для которого вычисляется вероятность;
верхний_предел- необязательная верхняя граница значения, для которого требуется вычислить вероятность.
ДИСП
Синтаксис:
ДИСП(число1,число2,…)
Результат:
Дисперсия выборки. Аргументы рассматриваются как выборка из генеральной совокупности.
Аргументы:
число1,число2,…- не более 30 аргументов; текстовые, логические и пустые поля приводят к ошибке.
ДИСПР
Синтаксис:
ДИСПР(число1,число2, …)
Результат:
Дисперсия генеральной совокупности. Аргументы представляют всю генеральную совокупность.
Аргументы:
число1,число2,…- не более 30 аргументов; текстовые, логические и пустые поля приводят к ошибке.
ДИСПА
Синтаксис:
ДИСПА(значение1,значение2,…)
Результат:
Дисперсия выборки. Аргументы рассматриваются как выборка из генеральной совокупности, содержащей наряду с числовыми и логические значения, а также текст.
Аргументы:
См. описание функции СТАНДОТКЛОНА.
ПРИМЕЧАНИЕ
Вычисления производятся по той же формуле, что и в функции ДИСП, однако учитываются ячейки с текстовыми и логическими значениями.
ДИСПРА
Синтаксис:
ДИСПРА (значение1,значение2,…)
Результат:
Дисперсия генеральной совокупности. Аргументы представляют всю генеральную совокупность.
Аргументы:
См. описание функции СТАНДОТКЛОНА.
ПРИМЕЧАНИЕ
Вычисления производятся по той же формуле, что и в функции ДИСПР, однако учитываются ячейки с текстовыми и логическими значениями.
ДОВЕРИТ
Синтаксис:
ДОВЕРИТ (альфа,станд_откл,размер)
Результат:
Доверительный интервал для среднего генеральной совокупности. Доверительный интервал — окрестность среднего выборки (интервал, содержащий значение среднего выборки, равноудаленное от концов интервала). Например, заказав товар по почте, вы можете определить с конкретным уровнем надежности самую раннюю и самую позднюю даты его прибытия.
Аргументы:
альфа- уровень значимости, используемый для вычисления уровня надежности (уровень надежности равен 100*(1 — альфа)% другими словами, значение альфа, равное 0,05, означает уровень надежности, равный 95%);
станд_откл- стандартное отклонение генеральной совокупности для интервала данных (предполагается известным);
размер- размер выборки.
КВАДРОТКЛ
Синтаксис:
КВАДРОТКЛ(число1,число2,…)
Результат:
Сумма квадратов отклонений точек данных от их среднего.
Аргументы:
число1,число2,…- от 1 до 30 аргументов, для которых вычисляется сумма квадратов отклонений; в функции КВАДРОТКЛ вместо аргументов можно использовать массив или ссылку на массив.
КВПИРСОН
Синтаксис:
КВПИРСОН(известные_значения_у,известные_значения_х)
Результат:
Квадрат коэффициента корреляции Пирсона для точек данных в аргументах известные_значения_у и известные_значения_х. Значение r-квадрат можно интерпретировать как отношение дисперсии для у к дисперсии для х.
Аргументы:
известные_значения_у- массив или интервал точек данных;
известные_значения_х- массив или интервал точек данных.
КОВАР
Синтаксис:
КОВАР(массив1,массив2)
Результат:
Ковариация (среднее произведений отклонений для каждой пары точек данных). Ковариация используется для определения связи между двумя множествами данных. Например, можно проверить, соответствует ли более высокому уровню доходов более высокий уровень образования.
Аргументы:
массив1- первый массив или интервал данных;
массив2- второй массив или интервал данных.
КОРЕЛ
Синтаксис:
КОРЕЛ(массив1,массив2)
Результат:
Коэффициент корреляции между интервалами ячеек аргументов массив1 и массив2. Коэффициент корреляции используется для определения наличия взаимосвязи между двумя свойствами. Например, можно установить зависимость между средней температурой в помещении и наличием кондиционера.
Аргументы:
массив1- первый массив интервала данных;
массив2- второй массив интервала данных.
ЛГРФПРИБЛ
Синтаксис:
ЛГРФПРИБЛ(известные_значения_у,известные_значения_х,конст, статистика)
Результат:
Возвращает матрицу, описывающую экспоненциальную кривую (у = bm/х), которая была рассчитана из заданных значений: первое значение результирующей матрицы есть основание экспоненты (т), второе значение — коэффициент (Ь).
Аргументы:
известные_значения_у- множество значений у (если массив известные_значения_у имеет один столбец, то каждый столбец массива известные_значения_х интерпретируется как отдельная переменная; если массив извест-ные_значения_у имеет одну строку, то каждая строка массива известные_значения_х интерпретируется как отдельная переменная);
известные_значения_х- необязательное множество значений х, которые уже известны для соотношения у = mх + b (массив известиые_знанения_х может содержать одно или несколько множеств переменных; если используется только одна переменная, то аргументы известные_значения_у известные_значения_х могут быть массивами любой формы при условии, что они имеют одинаковую размерность; если используется более одной переменной, то аргумент извест-ные_значения_у должен быть вектором (то есть интервалом высотой в одну строку или шириной в один столбец); если аргумент известные_значения_х опущен, то предполагается, что это массив {1;2;3;…} такого же размера, как и массив известные_значе-ния_у);
конст- логическое значение; если аргумент отсутствует или имеет значение ИСТИНА, то b вычисляется обычным способом; если аргумент имеет значение ЛОЖЬ, то Ь полагается равным 1 и знамения т подбираются так, чтобы выполнялось соотношение у = m/х;
статистика- логическое значение, которое указывает, требуется ли возвращать дополнительную статистику по регрессии (если аргумент имеет значение ИСТИНА, то функция ЛГРФПРИБЛ возвращает дополнительную регрессионную статистику, так что возвращаемый массив будет иметь вид: {mn;mn-1;…;m1;b:sen;sen-1;…;se1; seb:r2;sey:F;df:ssreg;ssresid}; если аргумент имеет значение ЛОЖЬ или опущен, то функция ЛГРФПРИБЛ возвращает только коэффициенты т и постоянную Ь).
ЛИНЕЙН
Синтаксис:
ЛИНЕЙН(известные_значения_у,известные_значения_х,конст, статистика)
Результат:
Эта функция использует метод наименьших квадратов, чтобы найти уравнение прямой линии, которая наилучшим образом аппроксимирует имеющиеся данные. Функция возвращает массив, который описывает полученную прямую. Уравнение прямой линии имеет следующий вид:
у = m1*1+m2*2+…+b или у=mх+b
где зависимое значение у является функцией независимого значения х, т — матрица значений углового коэффициента результирующей прямой, а Ь — абсцисса точки пересечения прямой с Y-осью. Аргумент ЛИНЕЙН может также возвращать дополнительную регрессионную статистику.
Аргументы:
См. функцию ЛГРФПИБЛ.
ЛОГНОРМОБР
Синтаксис:
ЛОГНОРМОБР(вероятность,среднее,стандартное_отклонение)
Результат:
Обратная функция логарифмического нормального распределения х, где 1/(х) имеет нормальное распределение с параметрами среднее и стандартное>_отклотние. Если р = ЛОГНОРМОБР(х,…), то ЛОГНОРМОБР(p,…)= х, Логарифмическое нормальное распределение используется для анализа логарифмически преобразованных данных.
Аргументы:
вероятность- вероятность, связанная с нормальным логарифмическим распределением;
среднее- среднее ln(x);
стандартное_отклонение- стандартное отклонение ln(х).
МАКС
Синтаксис:
МАКС(число1,число2,…)
Результат:
Наибольшее значение в списке аргументов.
Аргументы:
число1,число2,…- от 1 до 30 чисел, среди которых ищется максимальное значение. Можно задавать аргументы, которые являют -ся числами, пустыми ячейками, логическими значениями или текстовыми представлениями чисел; аргументы, которые являются значениями ошибки или текстами, не преобразуемыми в числа, приводят к появлению значений ошибки. Если аргумент является массивом или ссылкой, то в нем учитываются только числа. Пустые ячейки, логические значения, тексты или значения ошибок в массиве или ссылке игнорируются. Если аргументы не содержат чисел, то функция МАКС возвращает 0.
МЕДИАНА
Синтаксис:
МEДИАНА (число1,число2,…)
Результат:
Медиана заданного множества чисел (число, которое является серединой множества чисел: половина чисел больше, чем медиана, а половина чисел меньше, чем медиана).
Аргументы:
число1,число2,…- числа или имена, массивы или адресные ссылки на диапазон ячеек, содержащий ссылки.
МИН
Синтаксис:
МИН(число1,число2,…)
Результат:
Наименьшее значение в списке аргументов.
Аргументы:
число1,число2,…- не более 30 аргументов; игнорируются только значения ошибки и текст, который не может быть преобразован в числа; если ни один аргумент не содержит чисел, функция МИН возвращает 0.
МОДА
Синтаксис:
МОДА(число1,число2,…)
Результат:
Наиболее часто встречающееся значение в массиве или интервале данных. Так же, как и функция МЕДИАНА, функция МОДА является мерой взаимного расположения значений.
Аргументы:
число1,число2,…- от 1 до 30 аргументов, для которых вычисляется функция МОДА; в функции МОДА можно использовать вместо аргументов массив или ссылку на массив.
НОРМАЛИЗАЦИЯ
Синтаксис:
НОРМАЛИЗАЦИЯ(х,среднее,стандартное_откл)
Результат:
Нормализованное значение для распределения, характеризуемого средним и стандартным отклонением.
Аргументы:
х- нормализуемое значение;
среднее- среднее арифметическое распределения; стандартное_откл стандартное отклонение распределения.
ПРИМЕЧАНИЕ
ргументы должны быть числами или именами, массивами или ссылками, содержащими числа. Microsoft Excel проверяет все числа, содержащиеся в аргументах, которые являются массивами или ссылками. Если аргумент, который является ссылкой, содержит пустые ячейки, текстовые или логические значения, то такие значения игнорируются; однако ячейки, которые содержат нулевые значения, учитываются.
НОРМРАСП
Синтаксис:
НОРМРАСП(х,среднее,стандартное_откл,интегральная)
Результат:
Нормальная функция распределения для указанного среднего и стандартного отклонения. Эта функция имеет очень широкий диапазон применения в статистике, включая проверку гипотез.
Аргументы:
х- значение, для которого строится распределение;
среднее- среднее арифметическое распределения;
стандартное_откл- стандартное отклонение распределения;
интегральная- логическое значение, определяющее форму функции (если аргумент интегральная имеет значение ИСТИНА, то функция НОРМРАСП возвращает интегральную функцию распределения; если этот аргумент имеет значение ЛОЖЬ, то возвращается функция плотности распределения).
ПРЕДСКАЗ
Синтаксис:
ПРЕДСКАЗ(х,известные_значения_у,известные_значения_х)
Результат:
Значение функции в точке х, предсказанное на основе линейной регрессии, для массивов известных значений х и у или интервалов данных. Эту функцию можно использовать для прогнозирования будущих продаж, потребностей в оборудовании или тенденций потребления.
Аргументы:
х- точка данных, для которой прогнозируется значение;
известные_значения_у- зависимый массив или интервал данных;
известные_значения_х- независимый массив или интервал данных.
РАНГ
Синтаксис:
РАНГ(число,ссылка,порядок)
Результат:
Ранг числа в списке чисел. Ранг числа — это показатель его величины относительно других значений в списке. (Если список отсортировать, то ранг числа будет его позицией.)
Аргументы:
число- число, для которого определяется ранг;
ссылка- массив или ссылка на список чисел (нечисловые значения в ссылке игнорируются);
порядок- число, определяющее способ упорядочения (если порядок равен 0 или опущен, то Excel определяет ранг числа так, как если бы ссылка была списком, отсортированным в порядке убывания; если порядок — это любое ненулевое число, то Excel определяет ранг числа так, как если бы ссылка была списком, отсортированным в порядке возрастания).
ПРИМЕЧАНИЕ
Одинаковые числа получают одинаковый ранг в списке.
РОСТ
Синтаксис:
РОСТ(известные_значения_у,известные_значения_х,новые_значения_х,конст)
Результат:
Аппроксимирует экспериментальной кривой известные_значения_у и извест-ные_значения_х и возвращает значения этой кривой, соответствующие значениям х, которые определяются аргументом новые_значения_х.
Аргументы:
известные_значения_у- множество значений у, которые уже изиестны для соотношения у — b*m/х (если массив известные_значения_у имеет один столбец, то каждый столбец массива известные_значения_х интерпретируется как отдельная переменная; если массив известные^ значения_у имеет одну строку, то каждая строка массива известные_значения_х интерпретируется как отдельная переменная; если какие-либо числа в массиве известные_значения_у равны 0 или отрицательны, то функция РОСТ возвращает значение ошибки #ЧИСЛО!);
известные_значения_х- необязательное множество значений х, которые уже известны для соотношения у = b *m/х (массив известные_значения_х может содержать одно или несколько множеств переменных; если используется только одна переменная, то извест-ные_значения_у и известные_значения_х могут иметь любую форму при условии, что они имеют одинаковую размерность; если используется более одной переменной, то известные:_значения_у должны быть вектором (то есть интервалом высотой в одну строку или шириной в один столбец); если аргумент известные_значения_х опущен, то предполагается, что это массив {1;2;3;…} такого же размера, как и известные_значения_у);
новые_значения_х- новые значения х, для которых функция РОСТ возвращает соответствующие значения у (аргумент новые_значения_х должен содержать столбец (или строку) для каждой независимой переменной, как и известные_значения_х таким образом, если аргумент известные_значения_у — это один столбец, то аргументы известные_значения_х и но-вые_значения_х должны иметь такое же количество столбцов; если аргумент известные_значения_у — это одна строка, то аргументы известные_зна-чения_х и новые__значения_х должны иметь такое же количество строк; если аргумент новые_значения_х опущен, то предполагается, что он совпадает с аргументом известные_значения_х если оба аргумента известные_значения_х и новые_ значе-ния_х опущены, то предполагается, что это массив {1;2;3;…} такого же размера, как и извест-ныезначения_у);
конст- логическое значение; если аргумент конст отсутствует или имеет значение ИСТИНА, то b вычисляется традиционно; если аргумент конст имеет значение ЛОЖЬ, то Ъ полагается равным 1 и значения т подбираются так, чтобы выполнялось соотношение у=m/х.
СРГЕОМ
Синтаксис:
СРГЕОМ(число1,число2,…)
Результат:
Среднее геометрическое значений массива или интервала положительных чисел. Например, функцию СРГЕОМ можно использовать для вычисления средних темпов роста, если задан составной доход с переменными ставками.
Аргументы:
число 1,число2,…- от 1 до 30 аргументов, для которых вычисляется среднее геометрическое; в функции СРГЕОМ вместо аргументов можно использовать массив или ссылку на массив.
СРЗНАЧ
Синтаксис:
СРЗНАЧ(число1,число2,…)
Результат:
Среднее значение (среднее арифметическое) аргументов.
Аргументы:
число1,число2,…- числа или имена, массивы или адресные ссылки на диапазон ячеек, содержащий ссылки. Функция СРЗНАЧ позволяет задавать от 1 до 30 аргументов.
СРОТКЛ
Синтаксис:
СРОТКЛ(число1,число2,…)
Результат:
Среднее абсолютных значений отклонений точек данных от среднего. Функция СРОТКЛ является мерой разброса множества данных.
Аргументы:
число1,число2,…- от 1 до 30 аргументов, для которых определяется среднее абсолютных отклонений; вместо аргументов в функции СРОТКЛ можно использовать массив или ссылку на массив.
СТАНДОТКЛОН
Синтаксис:
СТАНДОТКЛОН(число1,число2,…)
Результат:
Оценка стандартного отклонения по выборке. Стандартное отклонение — это мера того, насколько широко разбросаны точки данных относительно их среднего.
Аргументы:
число 1,число2,…- от 1 до 30 числовых аргументов, соответствующих выборке из генеральной совокупности.
ПРИМЕЧАНИЕ
Используйте эту функцию, чтобы вычислить стандартное отклонение генеральной совокупности на основании выборки.
СТАНДОТКЛОНП
Синтаксис:
СТАНДОТКЛОНП(число1,число2,…)
Результат:
Стандартное отклонение по генеральной совокупности. Стандартное отклонение — это мера того, насколько широко разбросаны точки данных относительно их среднего.
Аргументы:
число1,число2,…- от 1 до 30 числовых аргументов, соответствующих генеральной совокупности; можно использовать массив или ссылку на массив вместо аргументов, разделяемых точкой с запятой.
ПРИМЕЧАНИЕ
Используйте эту функцию, чтобы вычислить стандартное отклонение генеральной совокупности на основе всех данных.
СТАНДОТКЛОНА
Синтаксис:
СТАНДОТКЛОНА(значение1,значение2,…)
Результат:
Оценка стандартного отклонения по выборке, содержащей наряду с числовыми и логические значения, а также текст.
Аргументы:
значение1,значение2,…- От 1 до 30 аргументов, соответствующих выборке из генеральной совокупности. Можно использовать массив или ссылку на массив вместо перечисляемых через запятую аргументов. Для вычисления стандартного отклонения применяется та же формула, которая используется в функции СТАНДОТКЛ. Однако значения аргументов могут быть не только числовыми, но и текстовыми, а также логическими значениями. Аргумент, содержащий значение ИСТИНА, при вычислении заменяется на 1, а аргумент, включающий значение ЛОЖЬ или текст, — на 0.
СТАНДОТКЛОНПА
Синтаксис:
СТАНДОТКЛОНПА (значение1,значение2,…)
Результат:
Оценка стандартного отклонения по генеральной совокупности, содержащей наряду с числовыми и логические значения, а также текст.
Аргументы:
См. описание функции СТАНДОТКЛОНА.
ПРИМЕЧАНИЕ
Для выборок большого объема СТАНДОТКЛОНПА и СТАНДОТКЛОНА дают близкие результаты. Функция СТАНДОТКЛОНА возвращает несмещенную оценку стандартного отклонения, а функция СТАНДОТКЛОНПА — смещенную оценку.
СЧЕТ
Синтаксис:
СЧЕТ(значение1,значение2,…)
Результат:
Количество чисел в списке аргументов. Функция СЧЕТ используется для получения количества числовых ячеек в интервалах или массивах ячеек.
Аргументы:
значение1,значение2,…- не более 30 аргументов; если аргуменг является матрицей или адресной ссылкой, то в нем при подсчете учитываются только числа, в остальных случаях учитываются пустые поля, числовые поля, логические значения и текстовые представления чисел (но не значения ошибки или не преобразуемы и текст).
СЧЕТЗ
Синтаксис:
СЧЕТЗ(значение1,значение2, … )
Результат:
Количество всех значений (любого типа), приведенных в качестве аргументов.
Аргументы:
значение1,значение2,…- не более 30 аргументов; в матрицах и адресуемых диапазонах пустые поля игнорируются.
ЧАСТОТА
Синтаксис:
ЧАСТОТА(массив_данных,массив_карманов)
Результат:
Распределение частот в виде вертикального массива. Для данного множества значений и данного множества карманов («карман» соответствует понятию интервала в математике) частотное распределение показывает, сколько исходных значений попадает в каждый интервал.
Аргументы:
массив_данных- массив или ссылка на множество данных, для которых вычисляются частоты; если аргумент массив_данных не содержит значений, то функция ЧАСТОТА возвращает массив нулей;
массив_карманов- массив или ссылка на множество интервалов, в которые группируются значения аргумента массив_дан-ных если аргумент массив_карманов не содержит значений, то функция ЧАСТОТА возвращает количество элементов в аргументе массив_данных.
ПРИМЕЧАНИЕ
Функция ЧАСТОТА не учитывает ни текст, ни пустые ячейки.
ЭКСПРАСП
Синтаксис:
ЭКСПРАСП(х,лямбда,интегральная)
Результат:
Экспоненциальное распределение. Функция ЭКСПРАСП используется для моделирования временных задержек между событиями, например для определения того, сколько времени займет денежный перевод в автоматизированном банке. С помощью функции ЭКСПРАСП можно подсчитать вероятность того, что этот процесс займет, предположим, не более минуты.
Аргументы:
х- значение функции;
лямбда- значение параметра;
интегральная- логическое значение, которое указывает, какую форму экспоненциальной функции использовать (если аргумент интегральная имеет значение ИСТИНА, то функция ЭКСПРАСП возвращает интегральную функцию распределения; если этот аргумент имеет значение ЛОЖЬ, то возвращается функция плотности распределения).
Источник информации: http://www.realcoding.net/article/view/3961
Статистика на Excel
Введение
Пакет анализа. В состав
Microsoft Excel входит набор средств анализа данных (так называемый пакет
анализа), предназначенный для решения сложных статистических и инженерных
задач. Для проведения анализа данных с помощью этих инструментов следует
указать входные данные и выбрать параметры; анализ будет проведен с помощью
подходящей статистической или инженерной макрофункции, а результат будет
помещен в выходной диапазон. Другие средства позволяют представить результаты
анализа в графическом виде.
Доступные средства.
Чтобы просмотреть список доступных инструментов анализа, выберите команду Анализ
данных в меню Сервис. Если команда Анализ данных в меню Сервис
отсутствует — необходима установка пакета анализа.
Необходимые знания.
Для успешного применения процедур анализа необходимы начальные знания в области
статистических и инженерных расчетов, для которых эти инструменты были
разработаны.
Инструменты пакета
анализа в Microsoft
Excel
Дисперсионный анализ
Пакет анализа включает в себя три средства
дисперсионного анализа. Выбор конкретного инструмента определяется числом
факторов и числом выборок в исследуемой совокупности данных.
Однофакторный дисперсионный анализ — Однофакторный
дисперсионный анализ используется для проверки гипотезы о сходстве средних
значений двух или более выборок, принадлежащих одной и той же генеральной
совокупности. Этот метод распространяется также на тесты для двух средних (к
которым относится, например, t-критерий).
Двухфакторный дисперсионный анализ с повторениями — Представляет
собой более сложный вариант однофакторного анализа, включающее более чем одну
выборку для каждой группы данных.
Двухфакторный дисперсионный анализ без повторения —
Представляет собой двухфакторный анализ дисперсии, не включающий более одной
выборки на группу. Используется для проверки гипотезы о том, что средние
значения двух или нескольких выборок одинаковы (выборки принадлежат одной и той
же генеральной совокупности). Этот метод распространяется также на тесты для
двух средних, такие как t-критерий.
Корреляционный анализ
Используется для количественной оценки взаимосвязи
двух наборов данных, представленных в безразмерном виде. Коэффициент корреляции
выборки представляет собой ковариацию двух наборов данных, деленную на
произведение их стандартных отклонений.
Корреляционный анализ дает возможность установить,
ассоциированы ли наборы данных по величине, то есть, большие значения из одного
набора данных связаны с большими значениями другого набора (положительная
корреляция), или, наоборот, малые значения одного набора связаны с большими
значениями другого (отрицательная корреляция), или данные двух диапазонов никак
не связаны (корреляция близка к нулю).
Ковариационный анализ
Используется для вычисления среднего произведения
отклонений точек данных от относительных средних. Ковариация является мерой
связи между двумя диапазонами данных.
Ковариационный анализ дает возможность установить,
ассоциированы ли наборы данных по величине, то есть, большие значения из одного
набора данных связаны с большими значениями другого набора (положительная
ковариация), или, наоборот, малые значения одного набора связаны с большими
значениями другого (отрицательная ковариация), или данные двух диапазонов никак
не связаны (ковариация близка к нулю).
Описательная статистика
Это средство анализа служит для создания одномерного
статистического отчета, содержащего информацию о центральной тенденции и
изменчивости входных данных. Чтобы получить более подробные сведения о
параметрах диалогового окна
Экспоненциальное сглаживание
Предназначается
для предсказания значения на основе прогноза для предыдущего периода,
скорректированного с учетом погрешностей в этом прогнозе. Использует константу
сглаживания a, по величине которой определяет, насколько сильно влияют
на прогнозы погрешности в предыдущем прогнозе.
Анализ Фурье
Предназначается для решения задач в линейных
системах и анализа периодических данных, используя метод быстрого
преобразования Фурье (БПФ). Эта процедура поддерживает также обратные
преобразования, при этом, инвертирование преобразованных данных возвращает
исходные данные.
Двухвыборочный F-тест для дисперсий
Двухвыборочный F-тест применяется для сравнения
дисперсий двух генеральных совокупностей. Например, F-тест можно использовать
для выявления различия в дисперсиях временных характеристик, вычисленных по
двум выборкам.
Гистограмма
Используется для вычисления выборочных и
интегральных частот попадания данных в указанные интервалы значений, при этом,
генерируются числа попаданий для заданного диапазона ячеек. Например,
необходимо выявить тип распределения успеваемости в группе из 20 студентов.
Таблица гистограммы состоит из границ шкалы оценок и количеств студентов,
уровень успеваемости которых находится между самой нижней границей и текущей
границей. Наиболее часто повторяемый уровень является модой интервала данных.
Скользящее среднее
Используется для расчета значений в прогнозируемом
периоде на основе среднего значения переменной для указанного числа
предшествующих периодов. Каждое прогнозируемое значение основано на формуле:
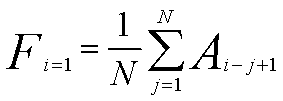
где
·
N число предшествующих периодов, входящих в скользящее
среднее
·
Aj фактическое значение в момент времени j
·
Fj прогнозируемое значение в момент времени j
Скользящее среднее, в отличие от простого среднего
для всей выборки, содержит сведения о тенденциях изменения данных. Процедура
может использоваться для прогноза сбыта, инвентаризации и других процессов.
Проведение t-теста
Пакет анализа включает в себя три средства анализа
среднего для совокупностей различных типов:
Двухвыборочный t-тест с одинаковыми дисперсиями —
Двухвыборочный t-тест Стьюдента служит для проверки гипотезы о равенстве
средних для двух выборок. Эта форма t-теста предполагает совпадение дисперсий
генеральных совокупностей и обычно называется гомоскедастическим t-тестом.
Двухвыборочный t-тест с разными дисперсиями —
Двухвыборочный t-тест Стьюдента используется для проверки гипотезы о равенстве
средних для двух выборок данных из разных генеральных совокупностей. Эта форма
t-теста предполагает несовпадение дисперсий генеральных совокупностей и обычно
называется гетероскедастическим t-тестом. Если тестируется одна и та же
генеральная совокупность, используйте парный тест.
Парный двухвыборочный t-тест для средних — Парный
двухвыборочный t-тест Стьюдента используется для проверки гипотезы о различии
средних для двух выборок данных. В нем не предполагается равенство дисперсий
генеральных совокупностей, из которых выбраны данные. Парный тест используется,
когда имеется естественная парность наблюдений в выборках, например, когда
генеральная совокупность тестируется дважды.
Генерация случайных чисел
Используется для заполнения диапазона случайными
числами, извлеченными из одного или нескольких распределений. С помощью данной
процедуры можно моделировать объекты, имеющие случайную природу, по известному
распределению вероятностей. Например, можно использовать нормальное
распределение для моделирования совокупности данных по росту индивидуумов, или
использовать распределение Бернулли для двух вероятных исходов, чтобы описать
совокупность результатов бросания монетки.
Ранг и персентиль
Используется для вывода таблицы, содержащей
порядковый и процентный ранги для каждого значения в наборе данных. Данная
процедура может быть применена для анализа относительного взаиморасположения
данных в наборе.
Регрессия
Линейный регрессионный анализ заключается в подборе
графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия
используется для анализа воздействия на отдельную зависимую переменную значений
одной или более независимых переменных. Например, на спортивные качества атлета
влияют несколько факторов, включая возраст, рост и вес. Регрессия
пропорционально распределяет меру качества по этим трем факторам на основе
данных функционирования атлета. Результаты регрессии впоследствии могут быть
использованы для предсказания качеств нового, непроверенного атлета.
Выборка
Создает выборку из генеральной совокупности,
рассматривая входной диапазон как генеральную совокупность. Если совокупность
слишком велика для обработки или построения диаграммы, можно использовать
представительную выборку. Кроме того, если предполагается периодичность входных
данных, то можно создать выборку, содержащую значения только из отдельной части
цикла. Например, если входной диапазон содержит данные для квартальных продаж,
создание выборки с периодом 4 разместит в выходном диапазоне значения продаж из
одного и того же квартала.
Двухвыборочный z-тест для средних
Двухвыборочный z-тест для средних с известными
дисперсиями используется для проверки гипотезы о различии между средними двух
генеральных совокупностей. Например, этот тест может использоваться для
определения различия между характеристиками двух моделей автомобилей.
Статистические функции
Возможность использования формул и функций является
одним из важнейших свойств программы обработки электронных таблиц. Это, в
частности, позволяет проводить статистический анализ числовых значений в
таблице.
Текст формулы, которая вводится в ячейку таблицы, должен начинаться со
знака равенства (=), чтобы программа Excel могла отличить формулу от
текста. После знака равенства в ячейку записывается математическое выражение,
содержащее аргументы, арифметические операции и функции.
В качества аргументов в формуле обычно используются числа и адреса
ячеек. Для обозначения арифметических операций могут использоваться следующие
символы: + (сложение); — (вычитание); * (умножение); / (деление).
Формула может содержать ссылки на ячейки, которые расположены на
другом рабочем листе или даже в таблице другого файла. Однажды введенная
формула может быть в любое время модифицирована. Встроенный
Менеджер формул помогает пользователю найти ошибку или неправильную
ссылку в большой таблице.
Кроме этого, программа Excel позволяет работать со сложными формулами,
содержащими несколько операций. Для наглядности можно включить текстовый
режим, тогда программа Excel будет выводить в ячейку не результат вычисления
формулы, а собственно формулу.
Программа Excel интерпретирует вводимые данные либо как текст (выравнивается
по левому краю), либо как числовое значение (выравнивается по правому
краю). Для ввода формулы необходимо ввести алгебраическое выражение,
которому должен предшествовать знак равенства (=).
Предположим, что в ячейке А1 таблицы находится число 100, а в ячейке В1 —
число 20. Чтобы разделить первое число на второе и результат поместить в
ячейку С1, в ячейку С1 следует ввести соответствующую формулу (=А1/В1) и
нажать [Enter].
Ввод формул можно существенно упростить, используя
маленький трюк. После ввода знака равенства следует просто щелкнуть мышью
по первой ячейке, затем ввести операцию деления и щелкнуть по второй ячейке
Виды
статистических функций в Microsoft
Excel 2000:
FРАСП Возвращает
F-распределение вероятности
Возвращает
F-распределение вероятности. Эту функцию можно использовать, чтобы определить,
имеют ли два множества данных различные степени плотности. Например, можно исследовать
результаты тестирования мужчин и женщин, окончивших высшую школу и определить
отличается ли разброс результатов для мужчин и женщин.
FРАСПОБР Возвращает
обратное значение для F-распределения вероятности
ZТЕСТ Возвращает
двустороннее P-значение z-теста
БЕТАОБР Возвращает
обратную функцию к интегральной функции плотности бета-вероятности
БЕТАРАСП Возвращает
интегральную функцию плотности бета-вероятности
БИНОМРАСП Возвращает
отдельное значение биномиального распределения
ВЕЙБУЛЛ Возвращает
распределение Вейбулла
ВЕРОЯТНОСТЬ Возвращает
вероятность того, что значение из днапазона находится внутри заданных пределов
ГАММАНЛОГ Возвращает
натуральный логарифм гамма функции, Γ(x)
ГАММАОБР Возвращает
обратное гамма-распределение
ГАММАРАСП Возвращает
гамма-распределение
ГИПЕРГЕОМЕТ Возвращает
гипергеометрическое распределение
ДИСП Оценивает
дисперсию по выборке
ДИСПА Оценивает
дисперсию по выборке, включая числа, текст и логические значения
ДИСПР Вычисляет
дисперсию для генеральной совокупности
ДИСПРА Вычисляет
дисперсию для генеральной совокупности, включая числа, текст и логические
значения
ДОВЕРИТ Возвращает
доверительный интервал для среднего значения по генеральной совокупности
КВАДРОТКЛ Возвращает
сумму квадратов отклонений
КВАРТИЛЬ Возвращает
квартиль множества данных
КВПИРСОН Возвращает
квадрат коэффициента корреляции Пирсона
КОВАР Возвращает
ковариацию, то есть среднее произведений отклонений для каждой пары точек
КОРРЕЛ Возвращает
коэффициент корреляции между двумя множествами данных
КРИТБИНОМ Возвращает
наименьшее значение, для которого биномиальная функция распределения меньше или
равна заданному значению
ЛГРФПРИБЛ Возвращает
параметры экспоненциального тренда
ЛИНЕЙН Возвращает
параметры линейного тренда
ЛОГНОРМОБР Возвращает
обратное логарифмическое нормальное распределение
ЛОГНОРМРАСП Возвращает
интегральное логарифмическое нормальное распределение
МАКС Возвращает
максимальное значение из списка аргументов
МАКСА Возвращает
максимальное значение из списка аргументов, включая числа, текст и логические
значения
МЕДИАНА Возвращает
медиану заданных чисел
МИН Возвращает
минимальное значение из списка аргументов
МИНА Возвращает
минимальное значение из списка аргументов, включая числа, текст и логические
значения
МОДА Возвращает
значение моды множества данных
НАИМЕНЬШИЙ Возвращает
k-ое наименьшее значение в множестве данных
НАКЛОН Возвращает
наклон линии линейной регрессии
НОРМАЛИЗАЦИЯ Возвращает
нормализованное значение
НОРМОБР Возвращает
обратное нормальное распределение
НОРМРАСП Возвращает
нормальную функцию распределения
НОРМСТОБР Возвращает
обратное значение стандартного нормального распределения
НОРМСТРАСП Возвращает
стандартное нормальное интегральное распределение
ОТРБИНОМРАСП Возвращает
отрицательное биномиальное распределение
ОТРЕЗОК Возвращает
отрезок, отсекаемый на оси линией линейной регрессии
ПЕРЕСТ Возвращает
количество перестановок для заданного числа объектов
ПЕРСЕНТИЛЬ Возвращает
k-ую персентиль для значений из интервала
ПИРСОН Возвращает
коэффициент корреляции Пирсона
ПРЕДСКАЗ Возвращает
значение линейного тренда
ПРОЦЕНТРАНГ Возвращает
процентную норму значения в множестве данных
ПУАССОН Возвращает
распределение Пуассона
РАНГ Возвращает
ранг числа в списке чисел
РОСТ Возвращает
значения в соответствии с экспоненциальным трендом
СКОС Возвращает
асимметрию распределения
СРГАРМ Возвращает
среднее гармоническое
СРГЕОМ Возвращает
среднее геометрическое
СРЗНАЧ Возвращает
среднее арифметическое аргументов
СРЗНАЧА Возвращает
среднее арифметическое аргументов, включая числа, текст и логические значения.
СРОТКЛ Возвращает
среднее абсолютных значений отклонений точек данных от среднего
СТАНДОТКЛОН Оценивает
стандартное отклонение по выборке
СТАНДОТКЛОНА Оценивает
стандартное отклонение по выборке, включая числа, текст и логические значения
СТАНДОТКЛОНП Вычисляет
стандартное отклонение по генеральной совокупности
СТАНДОТКЛОНПА Вычисляет
стандартное отклонение по генеральной совокупности, включая числа, текст и
логические значения
СТОШYX Возвращает
стандартную ошибку предсказанных значений y для каждого значения x в регрессии
СТЬЮДРАСП Возвращает
t-распределение Стьюдента
СТЬЮДРАСПОБР Возвращает
обратное t-распределение Стьюдента
СЧЁТ Подсчитывает
количество чисел в списке аргументов
СЧЁТЗ Подсчитывает
количество значений в списке аргументов
ТЕНДЕНЦИЯ Возвращает
значения в соответствии с линейным трендом
ТТЕСТ Возвращает
вероятность, соответствующую критерию Стьюдента
УРЕЗСРЕДНЕЕ Возвращает
среднее внутренности множества данных
ФИШЕР Возвращает
преобразование Фишера
ФИШЕРОБР Возвращает
обратное преобразование Фишера
ФТЕСТ Возвращает
результат F-теста
ХИ2ОБР Возвращает
обратное значение односторонней вероятности распределения хи-квадрат
ХИ2РАСП Возвращает
одностороннюю вероятность распределения хи-квадрат
ХИ2ТЕСТ Возвращает
тест на независимость
ЧАСТОТА Возвращает
распределение частот в виде вертикального массива
ЭКСПРАСП Возвращает
экспоненциальное распределение
ЭКСЦЕСС Возвращает
эксцесс множества данных
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
1. Петрик
Дж. Бернс, Элисон Берроуз «Секреты Excel 97.» –
М.:Веста, 1999 -753с.
2. Фигурнов
Виктор Эдмундович «IBM PC для пользователя» – М.:ИНФРА, 1998-
680с.
3. А.
Гончаров «Microsoft Excel 7.0 в примерах» — С.-П.:Питер, 1996
4. Андрей Пробитюк «Excel 7.0 для Windows 95 в бюро» – К.:BHV, 1996
1. Назначение и функциональные возможности
электронных таблиц
Табличный процессор MS Excel
(электронные таблицы) – одно из наиболее часто используемых приложений
интегрированного пакета MS Office, мощнейший инструмент в умелых руках,
значительно упрощающий рутинную повседневную работу. Основное назначение MS
Excel – решение практически любых задач расчетного характера, входные данные
которых можно представить в виде таблиц. Применение электронных таблиц упрощает
работу с данными и позволяет получать результаты без программирования расчётов.
Особенность электронных таблиц
заключается в возможности применения формул для описания связи между значениями
различных ячеек. Расчёт по заданным формулам выполняется автоматически.
Изменение содержимого какой-либо ячейки приводит к пересчёту значений всех
ячеек, которые с ней связаны формульными отношениями и, тем самым, к обновлению
всей таблицы в соответствии с изменившимися данными.
Основные возможности электронных
таблиц:
1. проведение
однотипных сложных расчётов над большими наборами данных;
2.
автоматизация итоговых вычислений;
3.
решение задач путём подбора значений
параметров;
4.
обработка (статистический анализ) результатов
экспериментов;
5.
проведение поиска оптимальных значений
параметров (решение оптимизационных задач);
6.
подготовка табличных документов;
7.
построение диаграмм (в том числе и
сводных) по имеющимся данным;
8. создание
и анализ баз данных (списков).
Загрузку программы MS Excel можно
выполнить следующими способами:
1. Двойным
щелчком по ярлыку Microsoft Excel на рабочем столе, если ярлык там находится.
2.
Выполнением последовательности команд
Пуск, Программы, Стандартные, ярлык Microsoft Excel.
3. Выполнением
последовательности команд Пуск, Найти, Файлы и папки. В появившемся диалоговом
окне в строке Имя ввести Microsoft Excel (имя файла ярлыка программы MS Excel)
и щелкнуть по кнопке Найти. После окончания поиска выполнить двойной щелчок по
ярлыку Microsoft Excel. По завершению загрузки MS Excel закрыть окно поиска.
Загрузка процессора MS Excel
заканчивается появлением на экране монитора окна приложения с открытым рабочим
листом по имени Лист1 стандартной рабочей книги с именем по умолчанию Книга1.
При создании своей рабочей книги
необходимо выполнить следующие действия:
1. Щелчком
левой кнопки мышки развернуть меню Сервис,
щёлкнуть левой кнопкой мышки по строке Параметры…
и в появившемся диалоговом окне щёлкнуть мышкой по закладке Общие. В окошечке Листов в
новой книге: установить требуемое число листов и щёлкнуть по кнопке OK.
2.
На панели инструментов Стандартная
щёлкнуть по кнопке Создать.
3.
Щелчком левой кнопки мышки развернуть меню Файл и
щёлкнуть мышкой по строке Сохранить как….
В появившемся окне щёлкнуть по стрелке окна Мои документы. В раскрывшемся меню
щёлкнуть по строке с адресом вашего каталога, а затем в нижнем окне Имя файла
вместо стандартного имени записать название своей рабочей книги, после чего
щёлкнуть по кнопке Сохранить. В последующем при работе с этим файлом такие
действия не выполнять, если не требуется замена имени файла, а достаточно
периодически щёлкать по кнопке Сохранить на панели инструментов Стандартная.
2. Возможности Excel при работе с функциями
Функции в Excel используются для выполнения
стандартных вычислений в рабочих книгах. Значения, которые используются для
вычисления функций, называются аргументами. Значения, возвращаемые функциями в
качестве ответа, называются результатами. Помимо встроенных функций вы можете
использовать в вычислениях пользовательские функции, которые создаются при
помощи средств Excel. Чтобы использовать функцию, нужно ввести ее как часть
формулы в ячейку рабочего листа. Последовательность, в которой должны
располагаться используемые в формуле символы, называется синтаксисом функции. Все
функции используют одинаковые основные правила синтаксиса. Если вы нарушите
правила синтаксиса, Excel выдаст сообщение о том, что в формуле имеется ошибка.
Если функция появляется в самом начале формулы,
ей должен предшествовать знак равенства, как и во всякой другой формуле.
Аргументы функции записываются в круглых скобках
сразу за названием функции и отделяются друг от друга символом точка с запятой
“;”. Скобки позволяют Excel определить, где начинается и где заканчивается
список аргументов. Внутри скобок должны располагаться аргументы. Помните о том,
что при записи функции должны присутствовать открывающая и закрывающая скобки,
при этом не следует вставлять пробелы между названием функции и скобками.
В качестве аргументов можно использовать числа,
текст, логические значения, массивы, значения ошибок или ссылки. Аргументы
могут быть как константами, так и формулами. В свою очередь эти формулы могут
содержать другие функции. Функции, являющиеся аргументом другой функции,
называются вложенными. В формулах Excel можно использовать до семи уровней
вложенности функций.
Задаваемые входные параметры должны иметь
допустимые для данного аргумента значения. Некоторые функции могут иметь
необязательные аргументы, которые могут отсутствовать при вычислении значения функции.
Типы функций:
Для удобства работы функции в Excel разбиты по категориям:
функции управления базами данных и списками, функции даты и времени,
DDE/Внешние функции, инженерные функции, финансовые, информационные,
логические, функции просмотра и ссылок. Кроме того, присутствуют следующие
категории функций: статистические, текстовые и математические.
При помощи текстовых
функций имеется возможность
обрабатывать текст: извлекать символы, находить нужные, записывать символы в
строго определенное место текста и многое другое.
Логические функции помогают создавать сложные формулы, которые в
зависимости от выполнения тех или иных условий будут совершать различные виды
обработки данных.
В Excel широко представлены математические функции. Например,
можно выполнять различные операции с матрицами: умножать, находить обратную,
транспонировать.
Функции просмотра и ссылок позволяет «просматривать» информацию, хранящуюся
в списке или таблице, а также обрабатывать ссылки.
3. Построение интервального
и кумулятивного рядов распределения с помощью Excel.
Интервальный ряд распределения строится в
виде групповой таблицы, в сказуемом которой
показывается число единиц в каждой группе
(частота) или их удельный вес в общей численности единиц совокупности
(частость). Кумулятивный ряд — это ряд, в котором подсчитываются накопленные частоты, он показывает, сколько единиц совокупности имеют значение признака не
больше, чем данное значение, и вычисляется путем последовательного прибавления
к частоте первого интервала частот последующих интервалов.
Число
предприятий определяется с помощью функции ЧАСТОТА (Диапазон исходных данных; Диапазон
групп). Диапазон исходных данных — это
столбец, содержащий группировочный признак
(расход кормов на одну голову); Диапазон групп — столбец, содержащий
верхние границы выделенных интервалов.
ЧАСТОТА — функция массива, поэтому необходимо перед вводом формулы выделить диапазон, где будет размещаться результат вычисления, заканчивать ввод нужно
комбинацией клавиш Ctrl + Shift + Enter.
Для
графического изображения интервального ряда распределения применяется гистограмма частот. При построении гистограммы на оси абсцисс откладываются равные отрезки,
которые в принятом масштабе
соответствуют величине интервалов ряда. На отрезках прямоугольниками с высотой
в масштабе оси ординат изображают частоты ряда (рис.1).
В таблице 2 выделить номера групп и число предприятий (для выделения несмежных областей необходимо удерживать
клавишу Ctrl), выбрать Вставка —
Диаграмма —Гистограмма.
Для
изображения кумулятивного ряда распределения используется кумулятивная кривая
(кумулята). Накопленные частоты наносятся на чертеж в виде ординат; соединяя вершины
отдельных ординат прямыми,
получают ломаную линию, которая, начиная с нуля, непрерывно поднимается над
осью абсцисс до тех пор, пока не достигает высоты, соответствующей общей сумме частот ряда (рис. 1).

Заключение
Обработка статистических
данных уже давно применяется в самых разнообразных видах человеческой
деятельности. Вообще говоря, трудно назвать ту сферу, в которой она бы не
использовалась. Но, пожалуй, ни в одной области знаний и практической
деятельности обработка статистических данных не играет такой исключительно
большой роли, как в экономике, имеющей дело с обработкой и анализом огромных
массивов информации о социально-экономических явлениях и процессах.
Всесторонний и глубокий анализ этой информации, так называемых статистических
данных, предполагает использование различных специальных методов, важное место
среди которых занимают возможности табличного процессора MS Excel.
Представление экономических и
других данных в электронных таблицах в наши дни стало простым и естественным.
Оснащение же электронных таблиц средствами анализа способствует тому, что из
группы сложных, глубоко научных и потому редко используемых, почти экзотических
методов, статистический анализ превращается для специалиста в повседневный,
эффективный и оперативный аналитический инструмент. Электронные таблицы делают
такой анализ легко доступным.
Усвоив технологию
использования табличного процессора MS Excel, можно применять его по мере
необходимости, получая знание о скрытых связях, улучшая аналитическую поддержку
принятия решений и повышая их обоснованность.
Табличный процессор MS Excel
обладает огромными возможностями для решения задач статистики, облегчая работу
специалистов, работающих в этой области.
Список
использованных источников
1. Бернс
Дж., Берроуз Э. ,Секреты Excel
97. – М.:Веста, 2009.
2. Фигурнов
В. Э. ,IBM PC
для пользователя. – М.:ИНФРА, 2008.
3. А.
Гончаров «Microsoft Excel
7.0 в примерах» — С.-П.:Питер, 2008
4. Пробитюк
А., Excel
7.0 для Windows
95 в бюро. – К.:BHV, 2008
5. Лаврёнов
С.М.,Excel:
сборник примеров и задач-М: финансы и статистика,2010.-336с.
6.
Макарова Н.В.,Трофимец В.Я., Статистика в Excel:учеб.
пособие.-М.:финансы и статистика,2009.-386с.
7.
Сидоров М.Г., Обработка данных в Excel
//информатика и образование.-2010.-№6.-с. 25-36.
8.
Гутовская Г.В., Использование Excel
для решения финансово-экономических задач//информатика и образование.-2010.-№3.-с.
15-21.
9.
Ивинская Н.Л., решение прикладных задач в Excel//информатика
и образование.-2010.-№6.-с.62-64.
10. Кирей
Е.А., Базовый курс Excel
для учащихся профильных экономических классов//информатика и образование.-2012.-№5.-с.39-41.
11. Андрусенко
Н.Е., Использование стандартных функций Excel
для поиска и связи данных в таблице//информатика и образование.-2011.-№11.-с.7-12.
12. [Электронный
ресурс]. – Режим доступа: http://www.realcoding.net/article/view/3961
Статистика
в Excel
1. Общие сведения
Microsoft
Excel
предоставляет широкие возможности для
анализа статистических данных. В
статистике совокупность результатов
измерений называют распределением.
Microsoft
Excel
дает возможность анализировать
распределения, используя встроенные
статистические функции, функции анализа
выборки и генеральной совокупности и
другие инструменты.
2. Основные встроенные
статистические функции
Функция
СРЗНАЧ()
вычисляет среднее арифметическое или
просто среднее для последовательности
чисел: суммируются числовые значения
в интервале ячеек и результат делится
на количество этих значений. Эта функция
игнорирует пустые, логические и текстовые
ячейки.
Функция
МЕДИАНА()
вычисляет медиану множества чисел.
Медиана – это число, являющееся серединой
множества: количества чисел, меньшие и
большие медианы, равны. Если количество
чисел или ячеек четное, то результатом
будет среднее двух чисел в середине
множества.
Функция
МОДА()
вычисляет
наиболее часто встречающееся значение
во множестве чисел.
Функция
МАКС()
вычисляет
наибольшее значение среди заданных
чисел.
Функция
МИН()
вычисляет
минимальное значение среди заданных
чисел.
Функция
СУММПРОИЗВ()
вычисляет
сумму произведений соответствующих
членов двух и более массивов-аргументов
(но не более 30 аргументов). Встречающиеся
в аргументах нечисловые значения
интерпретируются нулями.
Функция
СУММКВ()
вычисляет
сумму квадратов аргументов.
3. Анализ выборки и
генеральной совокупности
Дисперсия
и стандартное отклонение – это
статистические характеристики
распределения наборов или генеральной
совокупности данных. Стандартное
отклонение определяется как квадратный
корень из дисперсии. Как правило, около
68% данных генеральной совокупности с
нормальным распределением находится
в пределах одного стандартного отклонения
и около 95% – в пределах двух стандартных
отклонений. При большой величине
стандартного отклонения данные широко
разбросаны относительно среднего
значения, а при маленькой – они
группируются близко к среднему значению.
Четыре
статистические функции ДИСП(),
ДИСПР(), СТАНДОТКЛОН()
и СТАНДОТКЛОНП()
– предназначены для вычисления дисперсии
и стандартного отклонения чисел в
интервале ячеек. Перед тем как вычислять
дисперсию и стандартное отклонение
набора данных, нужно определить,
представляют ли эти данные генеральную
совокупность или выборку из генеральной
совокупности. В случае выборки из
генеральной совокупности следует
использовать функции ДИСП()
и СТАНДОТКЛОН(),
а в случае генеральной совокупности –
функции ДИСПР()
и СТАНДОТЛОНП().
Функция
СУММСУММКВ()
вычисляет сумму сумм квадратов
соответствующих элементов в массивах.
Функция
СУММКВРАЗН()
вычисляет сумму квадратов разности
соответствующих элементов в массивах.
4. Использование
статистических функций при решении
задач
1)
В задачах с
дискретными таблицами частот
можно использовать следующие математические
функции:
СУММ(диапазон
ni)
– для нахождения объёма выборки n
как суммы частот ni
(или
объёма генеральной совокупности N
как суммы частот Ni);
СУММПРОИЗВ(диапазон
xi;диапазон
ni)
– для нахождения выборочной средней
xв
(или аналогично генеральной средней
xГ);
СУММПРОИЗВ((диапазон
xi
— xв)^2;
диапазон ni)
– для нахождения выборочной дисперсии
Dв
(или аналогично генеральной дисперсии
DГ).
2)
В задачах, где все
значения вариант xi
находятся в отдельных ячейках,
можно использовать статистические
функции:
СЧЁТ(диапазон
данных) – для нахождения объёма выборки
n
(или объёма генеральной совокупности
N)
как подсчёта всех непустых ячеек;
СЧЁТЕСЛИ(диапазон
данных;варианта xi)
– для нахождения частоты
ni
данной варианты в исходном диапазоне
при построении дискретной таблицы
частот;
СЧЁТЕСЛИМН(диапазон
данных;условие 1; диапазон данных;условие
2) – для нахождения суммы частот вариант,
попавших в заданный интервал, при
построении интервальной таблицы частот;
например,
для подсчёта числа вариант, попавших в
интервал (5,5 – 6], функция будет выглядеть
так: =СЧЁТЕСЛИМН(диапазон данных;»>5,5″;
диапазон данных;»<=6″);
СРЗНАЧ(диапазон
данных) – для нахождения выборочной
или генеральной средней (xв
или xГ);
ДИСП(диапазон
данных) – для нахождения выборочной
дисперсии
Dв;
ДИСПР(диапазон
данных) – для нахождения генеральной
дисперсии
DГ;
СТАНДОТКЛОН(диапазон
данных) – для нахождения выборочного
среднего квадратического отклонения
(выборочного стандарта) σв;
СТАНДОТКЛОНП(диапазон
данных) – для нахождения генерального
среднего квадратического отклонения
(генерального стандарта)
σГ;
МАКС(диапазон
данных)-МИН(диапазон данных) – для
нахождения размаха совокупности R;
МЕДИАНА(диапазон
данных) – для нахождения медианы;
МОДА(диапазон
данных) – для нахождения моды (при этом
в случае, когда все данные совокупности
различны, то в результате будет выдана
ошибка #Н/Д, которая в данном случае
означает, что совокупность не имеет
моды; а если совокупность мультимодальна,
т.е. имеет несколько значений, встречающихся
одинаковое максимальное число раз, то
ответом данной функции будет первое из
таких значений).
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Статистика – наука, которая используется для любых других исследований, а также обработки большого количества количественных и даже качественных данных. И что важно, это одно из главных применений электронных таблиц Excel, поэтому давайте более подробно рассмотрим, статистические формулы. Во-первых, что они нам дают? Прежде всего, они позволяют структурировать информацию и осуществить ее анализ. Статистические функции в Excel относятся к совершенно отдельной категории.
Содержание
- Как пользоваться статистическими функциями
- Перечень статистических функций
- Функция СРГЕОМ
- Функция СТАНДОТКЛОН
- Функция МОДА.ОДН
- Функция НАИМЕНЬШИЙ
- Функция НАИБОЛЬШИЙ
- Функция МЕДИАНА
- Функция СРЗНАЧЕСЛИ
- Функция МИН
- Функция МАКС
- Функции СРЗНАЧ и СРЗНАЧА
- Функция РАНГ.СР
Как пользоваться статистическими функциями
Есть несколько способов ввода любой функции, и статистические не являются исключением:
- Ввести непосредственно в ячейке, предварительно нажав клавишу =. Это касается самых простых функций, несложных для запоминания и содержащих один или два аргумента. Например, так можно делать для операции умножения, сложения, вычитания и деления. А вот если функция сложная, то можно воспользоваться помощником. Это уже второй способ.
- Помощник по использованию функций. Он не только подсказывает, какая формула что означает, а и помогает ввести правильные аргументы применительно к конкретной функции.
Вызвать помощник можно несколькими способами:
- Воспользоваться кнопкой «Вставить функцию», расположенной слева от строки формул.

- Вызвать мастер ввода функций через кнопку «Вставить функцию», которая находится в левой части панели, которая открывается по клику на вкладку «Формулы».

- Воспользовавшись горячими клавишами Shift+F3.
Любой из этих методов приводит к одному результату – вызову мастера функций. Можно использовать тот, который больше всего подходит в конкретной ситуации. После того, как окно откроется, нам первым делом нужно выбрать категорию: статистические функции. 
После того, как тип функции будет выбран, нам нужно выбрать подходящую формулу из списка. Под перечнем видим, что есть описание, в котором рассказывается, что конкретная функция делает. 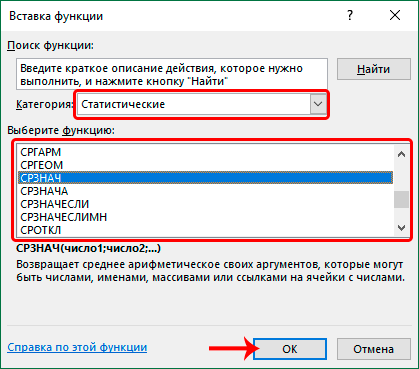
Чтобы подтвердить выбор функции, которая будет вводиться, нужно нажать клавишу ОК. После этого появится такое окно, в котором можно ввести параметры функции (или, как их еще называют, аргументы). 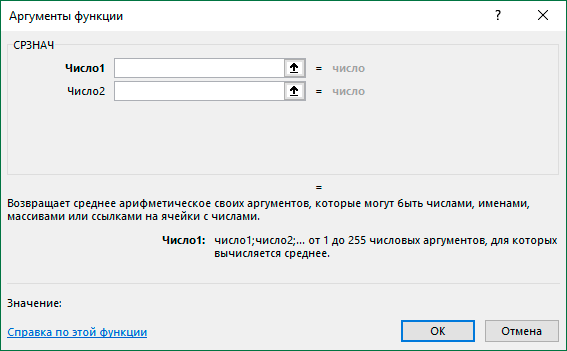
Интересный факт. Можно выбрать функцию еще одним способом. Для этого нужно перейти на вкладку «Формулы» и нажать на кнопку «Другие функции», расположенной на ленте.
Далее будет пункт «Другие функции» – «Статистические» и в появившемся списке ищем подходящую функцию и выбираем ее. Этот перечень может прокручиваться. 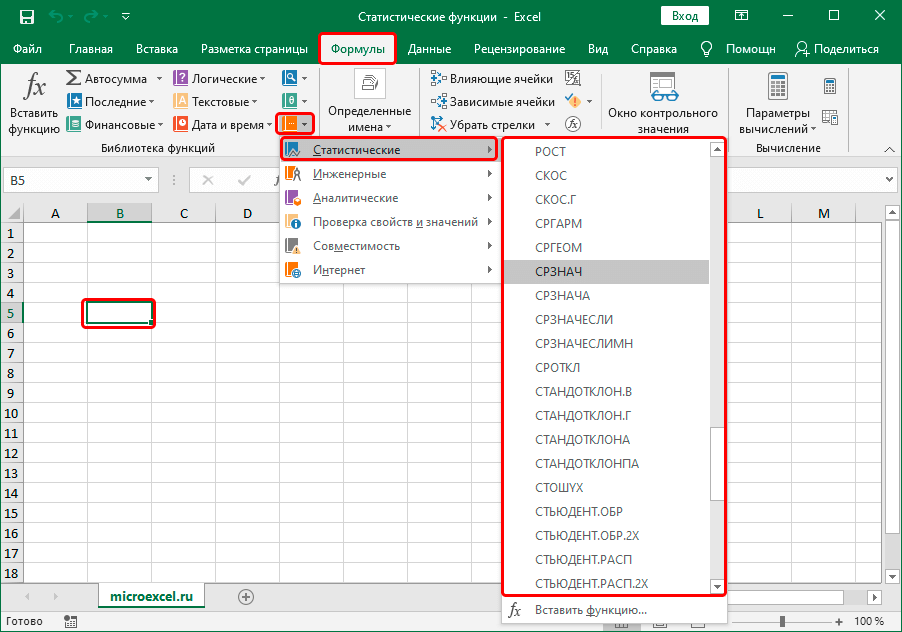
Перечень статистических функций
А теперь давайте перейдем непосредственно к рассмотрению статистических функций.
Функция СРГЕОМ
Много кто знает о таком параметре, как среднее арифметическое. Вычисляется оно с помощью функции, о которой мы еще сегодня обязательно поговорим. Но есть еще одна функция, которая определяет среднее геометрическое. 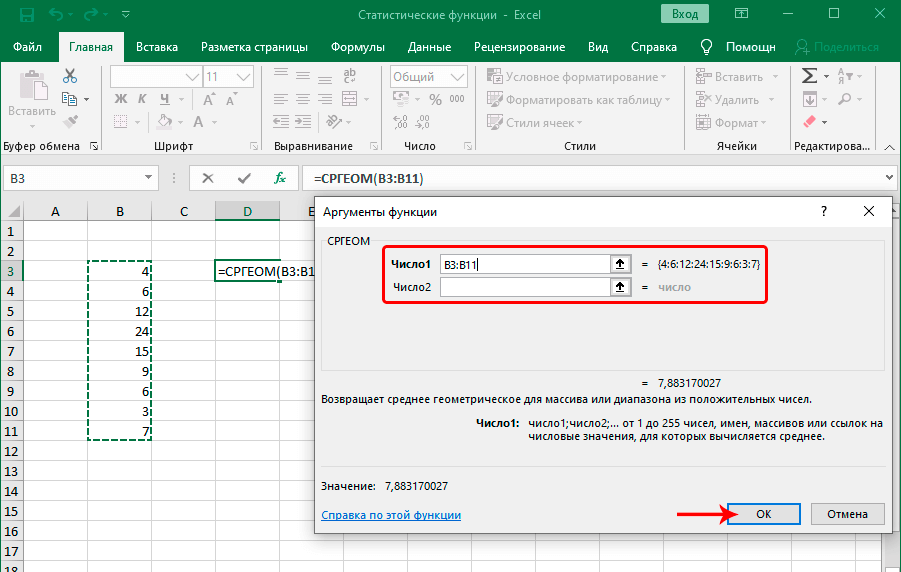
Формула очень простая: =СРГЕОМ(число1;число2;…). Кроме чисел также можно указать диапазон значений, которые учитываются этой функцией. Что же такое среднее геометрическое? Это число, которое может заменять любое из чисел в последовательности таким образом, чтобы не менялось произведение этих значений. Еще один часто используемый термин – среднее пропорциональное. Это синоним к среднему геометрическому. Такой второй термин используется, потому что среднее геометрическое пропорционально к первому и второму числам.
Функция СТАНДОТКЛОН
Один из главных статистических параметров, который должен рассчитываться вместо со средним арифметическим – стандартное отклонение. Это мера, демонстрирующая степень разброса значений. Выполняет ту же функцию, что и дисперсия, просто представлена в том же виде, что и среднее значение, в отличие от дисперсии.
Вообще, стандартное отклонение рассчитывается, как квадратный корень из дисперсии. Но в Эксель есть специальная формула, которая сразу вычисляет степень дисперсии, после чего на основе полученного значения получает стандартное (или среднеквадратическое) отклонение.
Сама эта формула довольно старая, но знать о ней надо, потому что время от времени ее можно найти в готовых таблицах. Сейчас уже есть более новые версии этой функции – СТАНДОТКЛОН.В и СТАНДОТКЛОН.Г. Последняя функция находит среднеквадратическое отклонение по генеральной совокупности, в то время как первая ориентируется исключительно на выборку.
В остальном, синтаксис обеих функций такой же, как и для вычисления среднего арифметического (об этом мы поговорим позже) – числа, которые перечислены через скобку.
Функция МОДА.ОДН
Мода выборки абсолютно не связана с одеждой или популярными машинами. Но при этом она связана со словом «популярный». Если говорить о статистике, то это значение в выборке, которое встречается наиболее часто. Соответственно, функция МОДА.ОДН дает возможность определить это значение.
Если говорить о синтаксисе, то он похож на многие другие статистические функции. Сначала пишется оператор, после чего в скобках записываются его аргументы, которые являют собой числа, разделенные запятой. В качестве значения аргумента может выступать не только число, но и отдельные ячейки, диапазоны значений. Это дает возможность более гибко управлять выборкой. На этом скриншоте отчетливо видно, как это работает на практике.
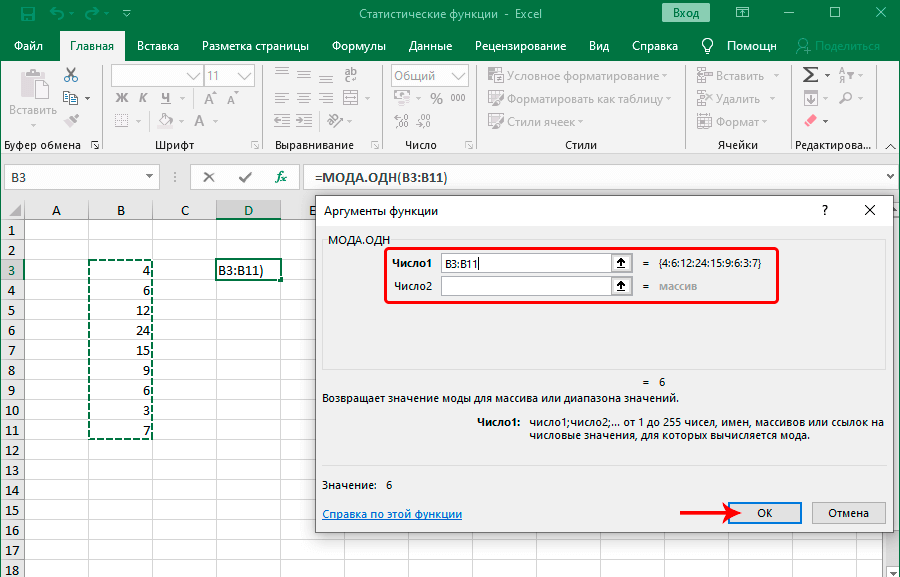
Эта функция подходит для горизонтальных массивов. Если же нужно определить моду выборки для вертикального массива, используется похожая функция МОДА.НСК. Общий внешний вид функции следующий: =МОДА.ОДН(аргумент 1, аргумент 2; аргумент …).
Функция НАИМЕНЬШИЙ
Задача этой функции – выполнение поиска из того набора значений, который был указан пользователем. Принцип ее работы такой же, как и следующий, только поиск осуществляется по направлению снизу вверх, от наименьшего числа к самому большому. Синтаксис этой функции предельно простой: =НАИМЕНЬШИЙ(массив;k).
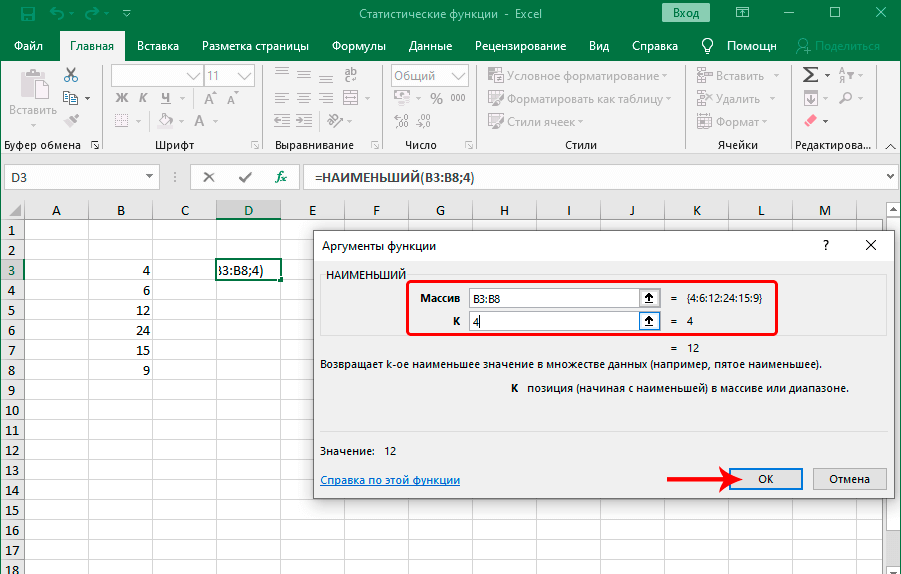
Функция имеет два основных аргумента: массив данных, по которым будет осуществляться поиск и порядковый номер элемента, который надо найти. Далее функция работает следующим образом: сначала она ищет самое маленькое значение, потом начинает перебирать цифры снизу вверх. Первое значение считается 1. То есть, если использовать число 1 во втором аргументе, то результат будет эквивалентным функции МИН, о которой мы поговорим немного позже.
Функция НАИБОЛЬШИЙ
Функция НАИБОЛЬШИЙ является аналогичной, только отсчет выполняет, начиная с самого большого значения. После того, как передать ей коэффициент, она ищет в порядковом ряду с большего в меньший число, занимающее соответствующее место и возвращает его. Работают обе функции аналогичным образом. Предположим, у нас есть числовой ряд. Если в нем в качестве числа k указать 2, то в результате получится число 15, поскольку оно является вторым по величине в диапазоне, который прописан в первом аргументе.
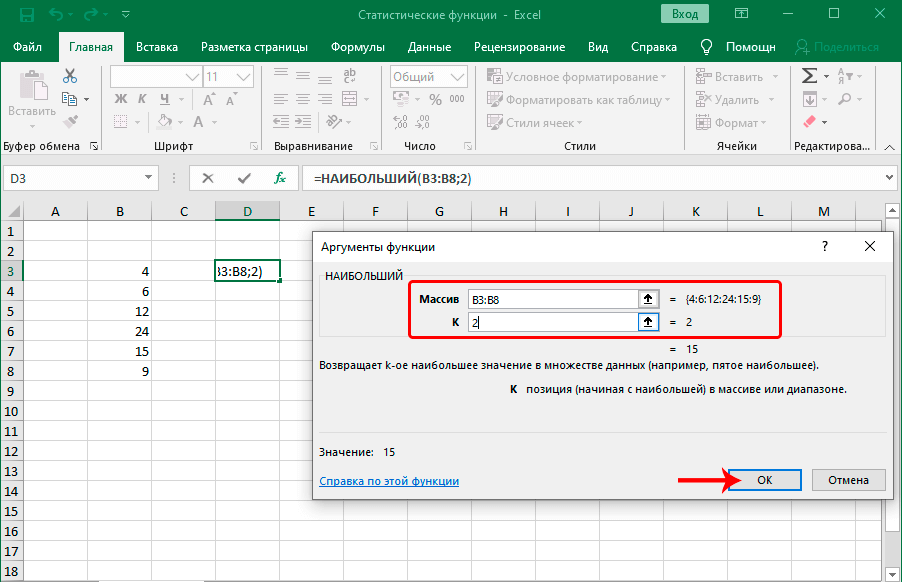
Эта функция может быть полезной в ситуациях, например, когда товар поступал в определенной последовательности, и нужно определить, сколько стоила, например, шубка, которая пришла второй по счету.
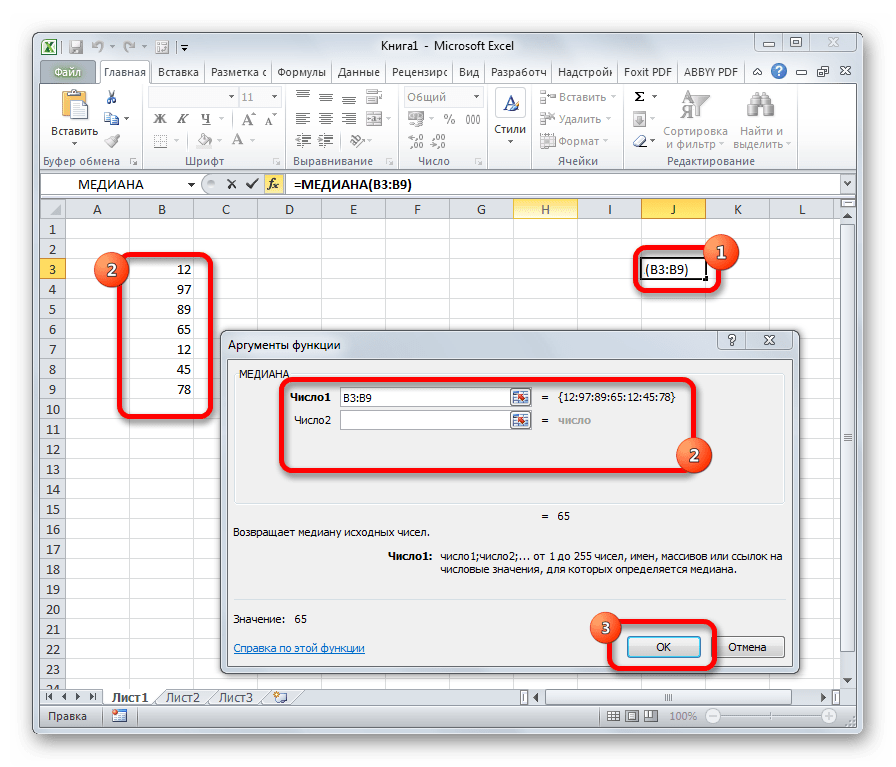
Функция МЕДИАНА
В статистике медиана – это разновидность среднего числа, которое находится ровно посередине числового ряда. Очень часто медиана является лучшим решением, чем стандартное среднее арифметическое, потому что позволяет определить действительно среднестатистическое значение. Синтаксис этой функции аналогичен тому, который имеет любой другой оператор, определяющий среднее значение – перечень цифр, ячеек или диапазонов, из которых данные будут получаться.
На этом примере видно, как на практике осуществляется работа с функцией. В диалоговом окне «Аргументы функции» можно вводить большое количество чисел, ячеек и диапазонов. На картинке мы попробовали ввести число в первую строку, ячейку во вторую и диапазон значений в третью. Получили в результате число 12. Максимальное количество аргументов этой функции – 255, что более, чем достаточно для полноценного использования этой функции. 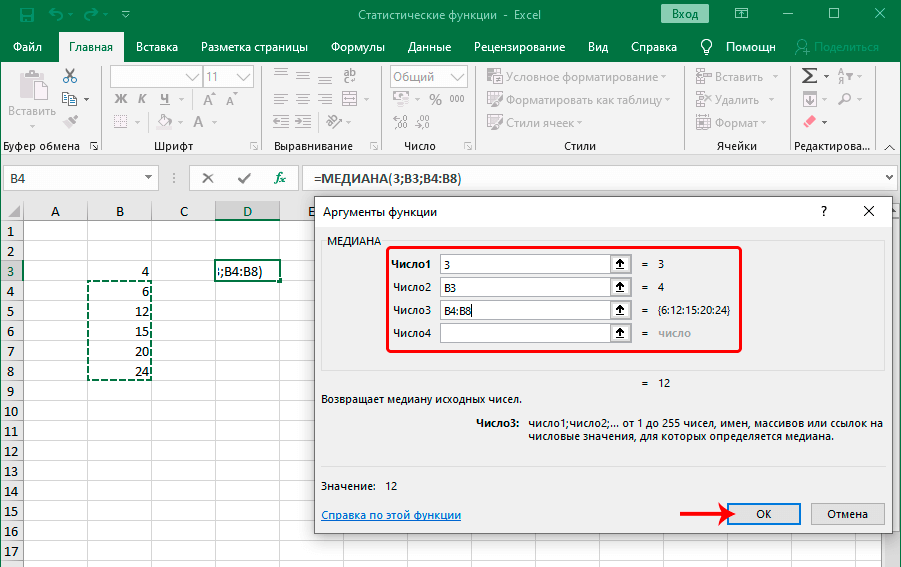
Функция СРЗНАЧЕСЛИ
Это улучшенная версия функции СРЗНАЧ, задача которой – находить среднее арифметическое, но лишь при условии, что определенное условие выполняется. Эта функция уже несколько сложнее тех, которые приводились выше: =СРЗНАЧЕСЛИ(диапазон;условие;диапазон_усреднения). Давайте рассмотрим каждый аргумент более подробно:
- Диапазон. Это ячейки, которые проверяются на предмет соответствия определенному условию.
- Условие. Это критерий, на предмет соответствия которому проверяется диапазон.
- Диапазон усреднения. Это тот диапазон, из которого будет доставаться среднее арифметическое. Этот аргумент вводить необязательно, поскольку диапазон ячеек и диапазон усреднения могут совпадать.
Функция МИН
В статистических подсчетах нередко нужно не только определить среднее значение, среднеквадратическое отклонение и вычислить другие показатели. Также важно значение наименьшего и наибольшего числа, в том числе, для получения указанных показателей. Практическое применение этой функции довольно обширное:
- На рынке акций для определения времени, когда цела была наиболее низкой.
- Для определения слабых мест в годовом бюджете (например, в каком месяце доходы компании были минимальными) с целью их дальнейшего исправления. Например, можно определить наименее доходный месяц и проанализировать факторы, которые этому способствовали.
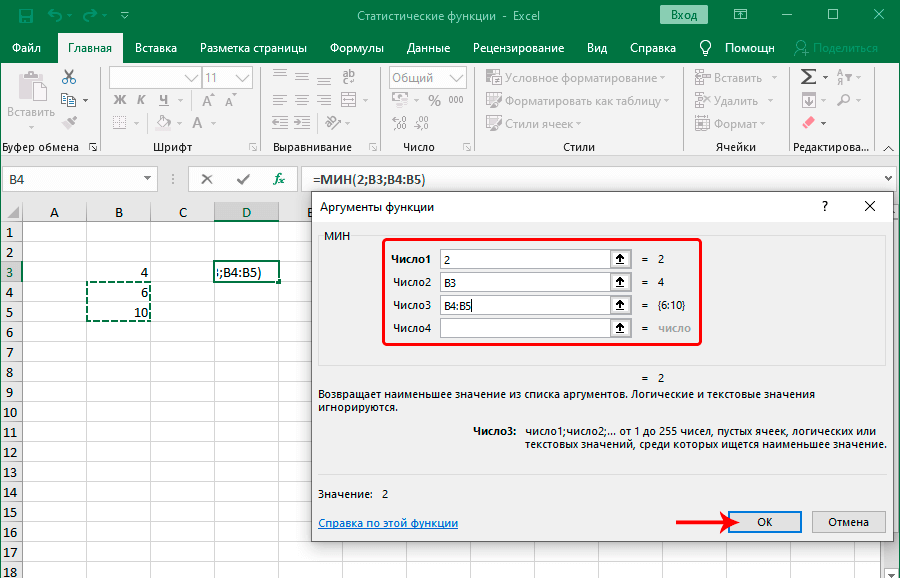
Существует огромное количество других ситуаций, когда можно использовать функцию МИН. В самом общем виде она выглядит следующим образом: =МИН(число1;число2;…). Принцип заполнения аргументов этой функции аналогичен функции МАКС.
Функция МАКС
Как становится понятно из названия, эта функция ищет максимальное значение в определенной числовой выборке. Ситуации, в которых она может использоваться, в принципе, те же за тем лишь исключением, что все в противоположную сторону. Например, компания может с помощью функции МАКС определить самый доходный месяц и понять, каковы причины этого успеха.
Функции СРЗНАЧ и СРЗНАЧА
Стандартная функция СРЗНАЧ определяет среднее арифметическое в числовой выборке. Общий вид формулы такой же, как и для любой другой выборки значений. Сначала пишется название функции, после чего в скобках приводятся числа и диапазоны, которые необходимо обработать с помощью этой функции. То есть, общий вид формулы следующий: =СРЗНАЧ(число1;число2;…).
Как мы поняли, можно использовать как обычные числа (очень полезно для использования значений, которые не будут меняться в течение ближайшего времени), ссылки на ячейку (они применяются для тех значений, которые в будущем изменятся) и на диапазон (в этом случае будет использоваться целый набор чисел за один раз). Чтобы после ввода одного аргумента начать записывать другой, достаточно нажать на соответствующее поле в мастере функций или просто нажать на клавишу Tab.
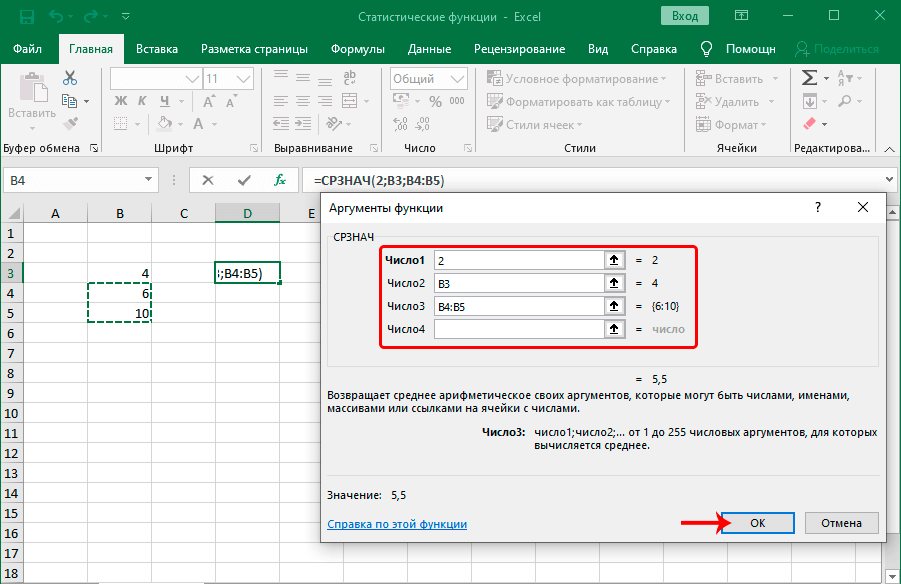
Максимальное количество аргументов, которые можно использовать в этой функции – 255. При этом обязательным аргументом является только первое число. В качестве аргументов не могут использоваться текстовые и логические значения. Они просто не учитываются формулой, в которой используется указанный оператор. Основное отличие функции СРЗНАЧА от СРЗНАЧ заключается в том, что текстовые значения и «ЛОЖЬ» считаются нулевыми, а значение «Истина» приравнивается к единице.
Функция РАНГ.СР
С помощью функции РАНГ.СР пользователь может вернуть ранг числа. Если несколько чисел в одном диапазоне относятся к одному рангу, то возвращается среднее. Имеет три аргумента, два из которых – обязательные:
- Число. Это то число, для которого осуществляется определение ранга.
- Ссылка. Это массив чисел, или ссылка на этот массив.
- Порядок. Это число, которое влияет на способ, в который значения будут упорядочиваться.
Таким образом, статистические функции Excel – это превосходный инструмент для обработки больших массивов информации.
Оцените качество статьи. Нам важно ваше мнение:
Содержание
- Статистические функции
- МАКС
- МИН
- СРЗНАЧ
- СРЗНАЧЕСЛИ
- МОДА.ОДН
- МЕДИАНА
- СТАНДОТКЛОН
- НАИБОЛЬШИЙ
- НАИМЕНЬШИЙ
- РАНГ.СР
- Вопросы и ответы

Статистическая обработка данных – это сбор, упорядочивание, обобщение и анализ информации с возможностью определения тенденции и прогноза по изучаемому явлению. В Excel есть огромное количество инструментов, которые помогают проводить исследования в данной области. Последние версии этой программы в плане возможностей практически ничем не уступают специализированным приложениям в области статистики. Главными инструментами для выполнения расчетов и анализа являются функции. Давайте изучим общие особенности работы с ними, а также подробнее остановимся на отдельных наиболее полезных инструментах.
Статистические функции
Как и любые другие функции в Экселе, статистические функции оперируют аргументами, которые могут иметь вид постоянных чисел, ссылок на ячейки или массивы.
Выражения можно вводить вручную в определенную ячейку или в строку формул, если хорошо знать синтаксис конкретного из них. Но намного удобнее воспользоваться специальным окном аргументов, которое содержит подсказки и уже готовые поля для ввода данных. Перейти в окно аргумента статистических выражений можно через «Мастер функций» или с помощью кнопок «Библиотеки функций» на ленте.
Запустить Мастер функций можно тремя способами:
- Кликнуть по пиктограмме «Вставить функцию» слева от строки формул.
- Находясь во вкладке «Формулы», кликнуть на ленте по кнопке «Вставить функцию» в блоке инструментов «Библиотека функций».
- Набрать на клавиатуре сочетание клавиш Shift+F3.

При выполнении любого из вышеперечисленных вариантов откроется окно «Мастера функций».
Затем нужно кликнуть по полю «Категория» и выбрать значение «Статистические».

После этого откроется список статистических выражений. Всего их насчитывается более сотни. Чтобы перейти в окно аргументов любого из них, нужно просто выделить его и нажать на кнопку «OK».

Для того, чтобы перейти к нужным нам элементам через ленту, перемещаемся во вкладку «Формулы». В группе инструментов на ленте «Библиотека функций» кликаем по кнопке «Другие функции». В открывшемся списке выбираем категорию «Статистические». Откроется перечень доступных элементов нужной нам направленности. Для перехода в окно аргументов достаточно кликнуть по одному из них.


Урок: Мастер функций в Excel
МАКС
Оператор МАКС предназначен для определения максимального числа из выборки. Он имеет следующий синтаксис:
=МАКС(число1;число2;…)

В поля аргументов нужно ввести диапазоны ячеек, в которых находится числовой ряд. Наибольшее число из него эта формула выводит в ту ячейку, в которой находится сама.
МИН
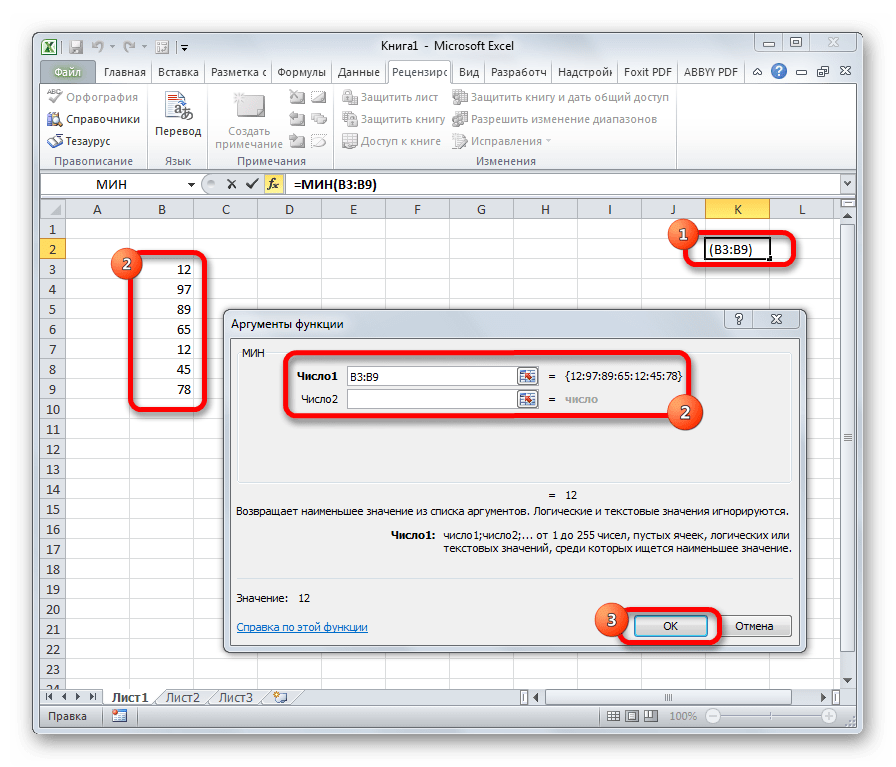
По названию функции МИН понятно, что её задачи прямо противоположны предыдущей формуле – она ищет из множества чисел наименьшее и выводит его в заданную ячейку. Имеет такой синтаксис:
=МИН(число1;число2;…)
СРЗНАЧ
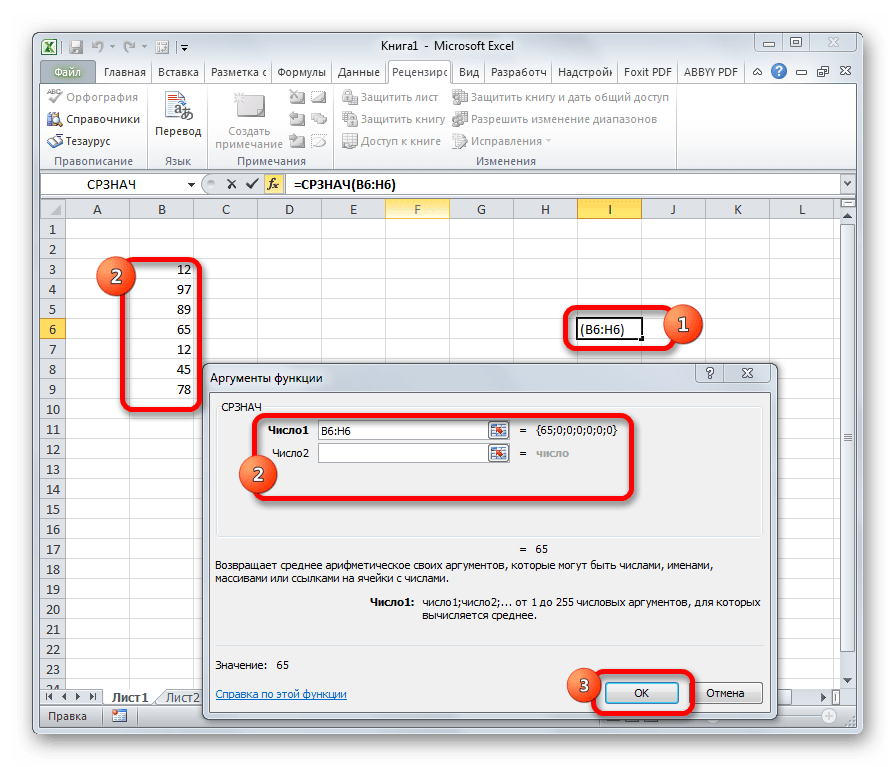
Функция СРЗНАЧ ищет число в указанном диапазоне, которое ближе всего находится к среднему арифметическому значению. Результат этого расчета выводится в отдельную ячейку, в которой и содержится формула. Шаблон у неё следующий:
=СРЗНАЧ(число1;число2;…)
СРЗНАЧЕСЛИ
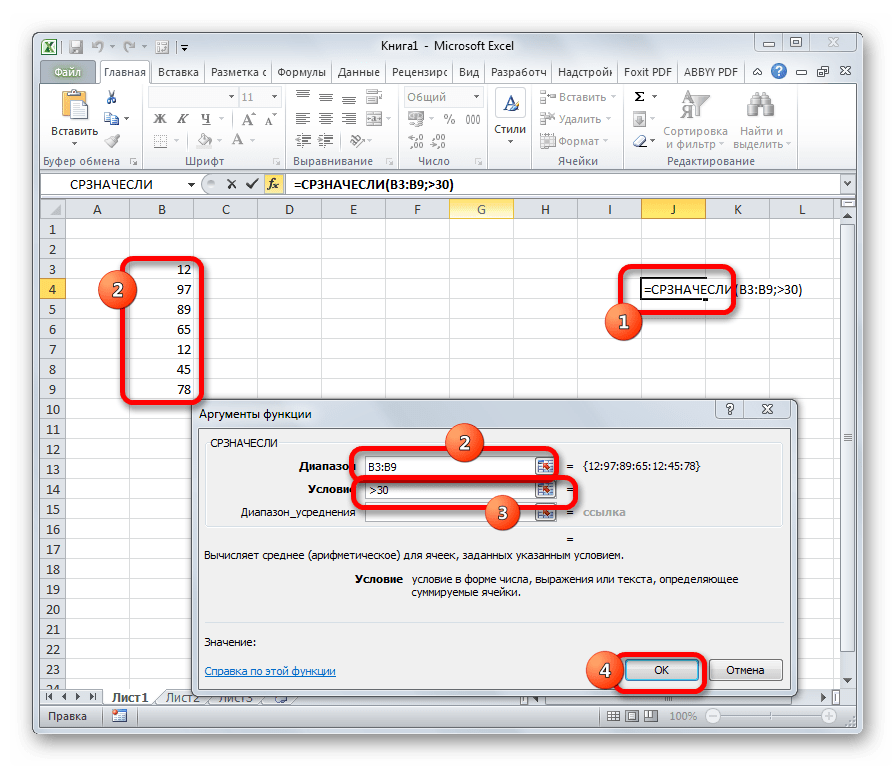
Функция СРЗНАЧЕСЛИ имеет те же задачи, что и предыдущая, но в ней существует возможность задать дополнительное условие. Например, больше, меньше, не равно определенному числу. Оно задается в отдельном поле для аргумента. Кроме того, в качестве необязательного аргумента может быть добавлен диапазон усреднения. Синтаксис следующий:
=СРЗНАЧЕСЛИ(число1;число2;…;условие;[диапазон_усреднения])
МОДА.ОДН
Формула МОДА.ОДН выводит в ячейку то число из набора, которое встречается чаще всего. В старых версиях Эксель существовала функция МОДА, но в более поздних она была разбита на две: МОДА.ОДН (для отдельных чисел) и МОДА.НСК(для массивов). Впрочем, старый вариант тоже остался в отдельной группе, в которой собраны элементы из прошлых версий программы для обеспечения совместимости документов.
=МОДА.ОДН(число1;число2;…)
=МОДА.НСК(число1;число2;…)
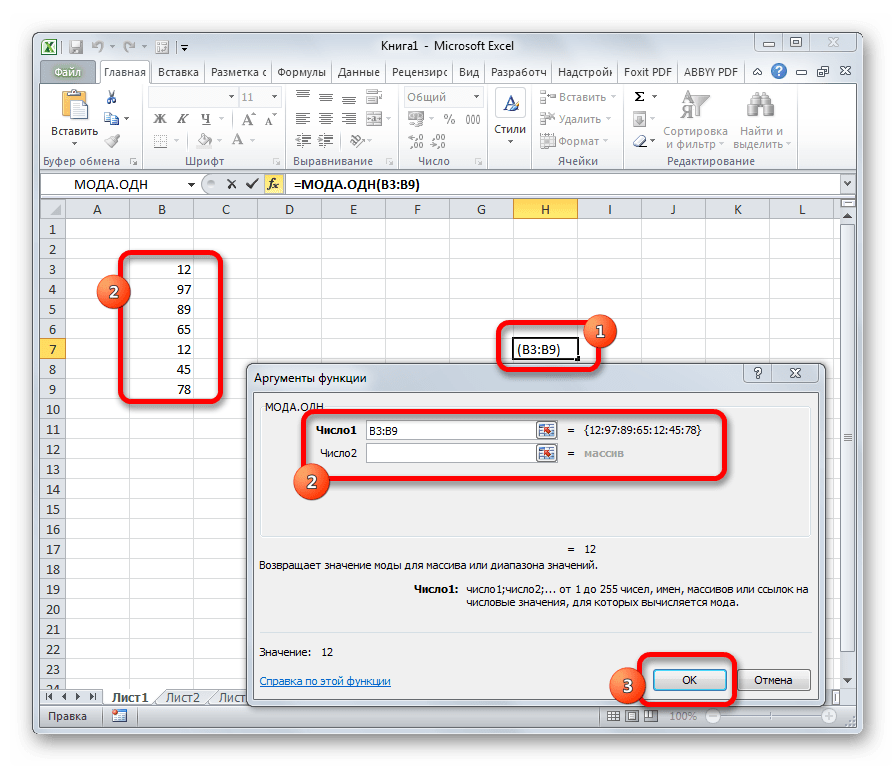
МЕДИАНА
Оператор МЕДИАНА определяет среднее значение в диапазоне чисел. То есть, устанавливает не среднее арифметическое, а просто среднюю величину между наибольшим и наименьшим числом области значений. Синтаксис выглядит так:
=МЕДИАНА(число1;число2;…)
СТАНДОТКЛОН
Формула СТАНДОТКЛОН так же, как и МОДА является пережитком старых версий программы. Сейчас используются современные её подвиды – СТАНДОТКЛОН.В и СТАНДОТКЛОН.Г. Первая из них предназначена для вычисления стандартного отклонения выборки, а вторая – генеральной совокупности. Данные функции используются также для расчета среднего квадратичного отклонения. Синтаксис их следующий:
=СТАНДОТКЛОН.В(число1;число2;…)
=СТАНДОТКЛОН.Г(число1;число2;…)
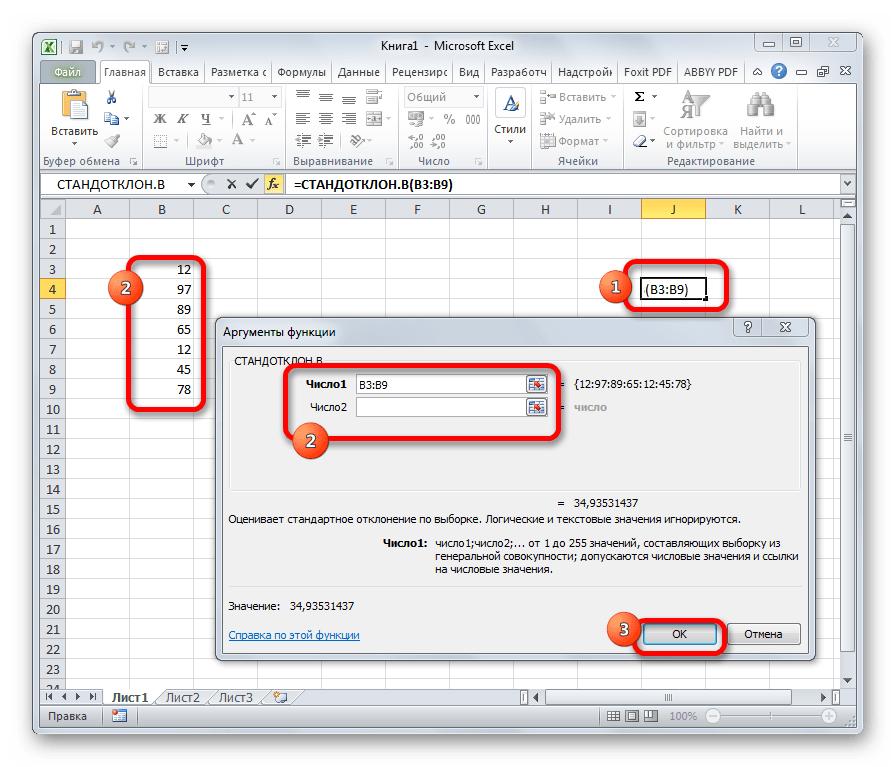
Урок: Формула среднего квадратичного отклонения в Excel
НАИБОЛЬШИЙ
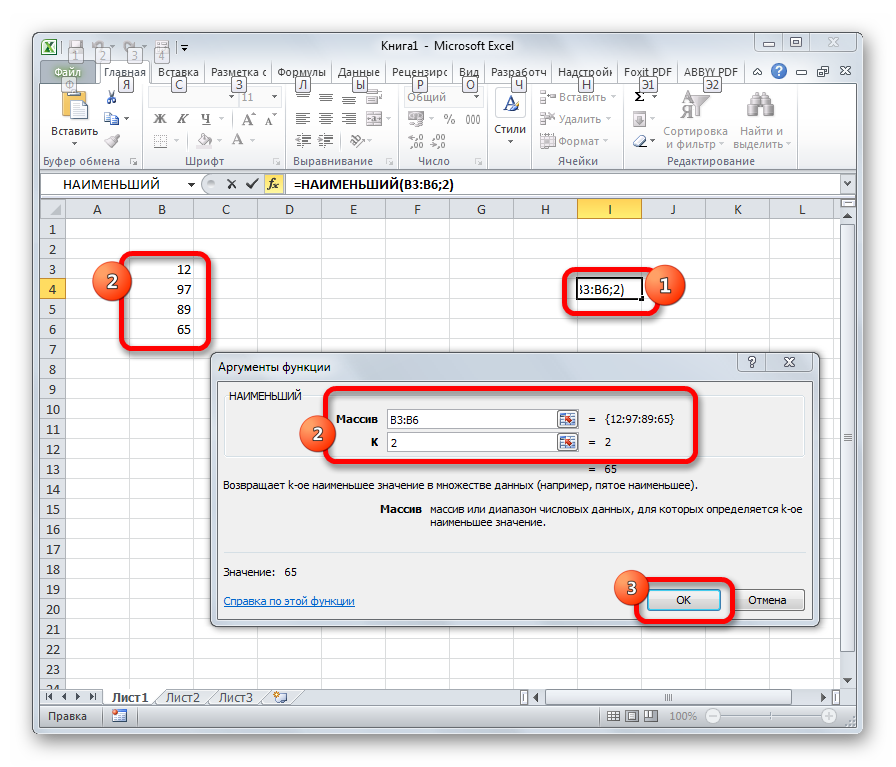
Данный оператор показывает в выбранной ячейке указанное в порядке убывания число из совокупности. То есть, если мы имеем совокупность 12,97,89,65, а аргументом позиции укажем 3, то функция в ячейку вернет третье по величине число. В данном случае, это 65. Синтаксис оператора такой:
=НАИБОЛЬШИЙ(массив;k)
В данном случае, k — это порядковый номер величины.
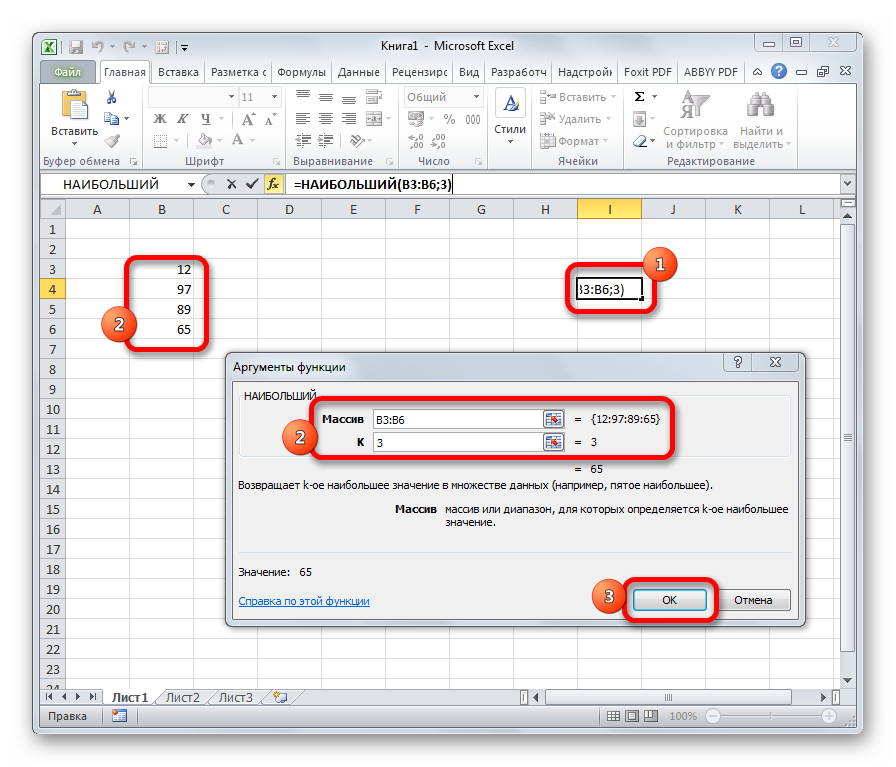
НАИМЕНЬШИЙ
Данная функция является зеркальным отражением предыдущего оператора. В ней также вторым аргументом является порядковый номер числа. Вот только в данном случае порядок считается от меньшего. Синтаксис такой:
=НАИМЕНЬШИЙ(массив;k)
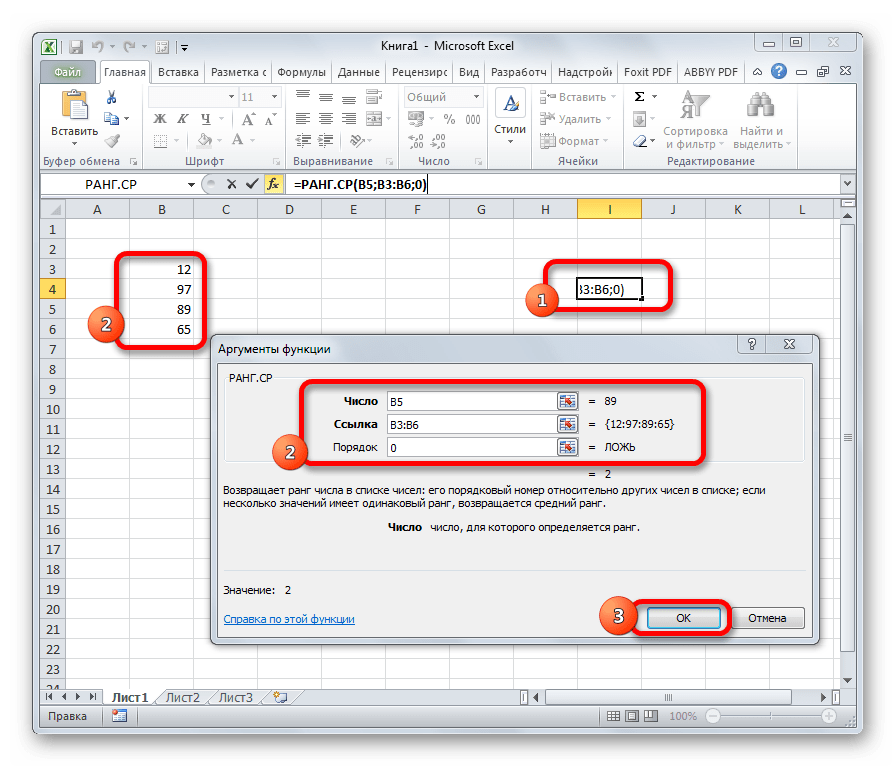
РАНГ.СР
Эта функция имеет действие, обратное предыдущим. В указанную ячейку она выдает порядковый номер конкретного числа в выборке по условию, которое указано в отдельном аргументе. Это может быть порядок по возрастанию или по убыванию. Последний установлен по умолчанию, если поле «Порядок» оставить пустым или поставить туда цифру 0. Синтаксис этого выражения выглядит следующим образом:
=РАНГ.СР(число;массив;порядок)
Выше были описаны только самые популярные и востребованные статистические функции в Экселе. На самом деле их в разы больше. Тем не менее, основной принцип действий у них похожий: обработка массива данных и возврат в указанную ячейку результата вычислительных действий.