
I try to be grammatically correct in my naming*. I’ve always used filename instead of fileName. The java convention also seems to use this, but FxCop prefers fileName.
There’s a discussion on WikiPedia about it. The more I read, the more I feel I’m right (which is quite usual!  ). Does anyone have a definitive answer or is this merely something subjective?
). Does anyone have a definitive answer or is this merely something subjective?
* I just hope there are no grammar errors in this post!
asked Apr 12, 2009 at 17:55
![]()
Steve DunnSteve Dunn
20.8k11 gold badges62 silver badges87 bronze badges
5
Lower camel case is recommended for fields and parameters.
Example 1:
fileName // for fields, parameters, etc.
FileName // for properties, class names, etc.
Generally, fileName is used and NOT filename; you can verify that by reading source code of open source stuff created by Microsoft, such as Enterprise Library.
Reasons:
- The main point behind this is that names are more readable in this case.
- Also this approach adds consistency when several parameters (fields, variables..) are used in the same method (class..) and the with same prefix «file», as demonstrated below:
- …there are a few other reasons, but they are more subjective.
Example 2:
fileName, fileSize... // instead of filename AND filesize
See also:
- Naming Conventions at Wikipedia
- General Naming Conventions at MSDN
For a full set of naming convention rules, I recommend checking this book:
- Framework Design Guidelines: Conventions, Idioms, and Patterns for Reusable .NET Libraries
(2nd Edition) by Krzysztof, published on Nov, 2008
(personally we don’t use 100% recomendations from this book, but in overall there are pretty good guidelines)
And also check some stuff at IDesign.net
8
'filename' assumes that this word describes a singular object like ‘cow’ or ‘chair’
'fileName' assumes that this is a complex object, that there is an object called file and that this object describes the name of that file.
Two philosophical approaches, take your pick.
answered Apr 12, 2009 at 18:01
![]()
shooshshoosh
76.1k54 gold badges208 silver badges323 bronze badges
It is acceptable English to write «filename» or «file name». When you translate that into coding, capitalizing the «n» or not capitalizing the «n» can go either way (assuming camelCase or PascalCase).
By the way, you did make a grammatical error in the question—ironically, in the very sentence in which you were expressing your hope that there were no grammatical errors. You said, «I just hope there’s no grammar errors in this post!» But «errors» is plural, therefore the «is» of «there’s» represents a subject-verb disagreement.
* I just hope there are no grammatical errors in this post!
answered Jun 22, 2018 at 17:28
![]()
mannyglovermannyglover
2,07914 silver badges17 bronze badges
0
As far as I am concerned,
thisIsMuchMoreReadablethan
readingthis.
![]()
Yves M.
29.5k23 gold badges107 silver badges142 bronze badges
answered Apr 12, 2009 at 17:59
![]()
NaveenNaveen
73.9k47 gold badges174 silver badges233 bronze badges
3
I think the answers here are spanning two issues.
-
‘FileName’ vs ‘Filename’ (should
‘name’ be a separate word)and
-
‘fileName’ vs ‘FileName’ (should first
character be lower case).
In most cases, I prefer to treat this word as a single whole word ‘filename’.
I also prefer starting variables/methods with lower case for easier code completion menu navigation.
I guess the issue of camel case is here too which I think should be used to distinguish multi-word names.
answered Apr 12, 2009 at 18:18
![]()
Arnold SpenceArnold Spence
21.8k7 gold badges74 silver badges67 bronze badges
1
Isn’t the obvious answer that FxCop is an automated tool? It recognizes that «name» is a word, so it suggests starting it with a capital N. We happen to know that «filename» is also a word, and so only the first F should be capitalized.
answered Apr 12, 2009 at 18:05
![]()
jalfjalf
241k51 gold badges342 silver badges549 bronze badges
There can be no real right or wrong here.
This is something that is purely subjective and relates completely to the community you are working in. If FxCop and StyleCop and the .net code that you regularly encounter is using fileName, then use fileName. If it is using something else, then use whatever that is.
Your first priority should probably be to be consistent to the pattern in your own code and then consistent with your community.
In this particular case, .net Reflector shows a lot of .net code using fileName so I would go with that pattern personally.
If you were in the java world and running PMD and checkstyle and their apis made frequent use of filename, then I would go with that.
In addition to the wikipedia naming article, there is also The Practice of Programming by Kernighan and Pike. The first chapter in it touches on a lot of naming and code consistency issues.
answered Apr 12, 2009 at 18:11
![]()
Filename ~ an identifying name given to an electronically stored computer file, conforming to limitations imposed by the operating system, as in length or restricted choice of characters.
In the past this was considered two words but now is defined as one word so
var filename = ……
if it was two words it would be
var fileName = ….
answered Apr 22, 2016 at 22:01
![]()
1
If you are writing c/c++ there is a strong tendency to use names that people can actually read; i.e. filename is good, and so is yet_another_file_name (assuming you are not considering filename as a proper english word — I usually do).
See google coding standards
answered Apr 12, 2009 at 20:13
![]()
David LehaviDavid Lehavi
1,1767 silver badges16 bronze badges
Which is correct: «Filename», «File Name» or «FileName»?
![]()
RegDwigнt
96.4k39 gold badges305 silver badges399 bronze badges
asked Nov 22, 2010 at 3:21
![]()
4
The original form of the word was «file name», as in the name of a file. These days (and probably for a good few years), the compound «filename» is widely accepted and perhaps most commonly used. Either is of course perfectly acceptable.
Do not, however, capitalise letters in the middle of a word, under any circumstances. (Unless you are writing variable names in code.)
answered Nov 22, 2010 at 10:28
![]()
NoldorinNoldorin
13k3 gold badges58 silver badges66 bronze badges
14
Filename is in my experience the most common and in my opinion the best looking. File name is also acceptable, but I would only use it rarely, perhaps in a parallel construction such as the file name and size. I find word-medial capital letters distracting and unpleasant anywhere but program source code, so I would never even think of FileName. Edit: if that’s the reason you’re asking, in program source I would still use Filename for a class or filename for a variable, not FileName nor fileName, respectively.
The British National Corpus has 240 cites for filename and 72 cites for file name. It’s not possible to search case-sensitively, but several reloads of the random sample of specific entries gave me no matches for FileName.
answered Nov 22, 2010 at 4:53
![]()
Jon PurdyJon Purdy
31.9k11 gold badges103 silver badges146 bronze badges
7
The AHD has an entry for “filename”, so it is, at least, an established American English word. Thus it is “correct” for some situations.
Update: the word “pathname” is also included in the American Heritage Dictionary: Fifth Edition. So over time I will be changing my program variables from SettingFilePathName to SettingFilePathname.
answered Nov 23, 2010 at 17:21
![]()
None of them. «filename» is not a proper noun, and thus should not be capitalized. If you begin a sentence with the word, then it should be «Filename».
answered Nov 22, 2010 at 5:58
![]()
SparrSparr
1,2559 silver badges18 bronze badges
Generally, I would say «filename», as that is what I have seen used in most software development textbooks. That’s not to say that this is the standard by which all words should be measured, but given that the word is generally used in relation to computers I would imagine that it is safe to use.
answered Nov 22, 2010 at 16:36
![]()
WillWill
1,3743 gold badges15 silver badges25 bronze badges
Any two words (such as ‘file name’) used together for long enough periods of time end up with a single meaning in our collective language. When that happens, you can combine the two, though it’s not advisable for formal usage.
Words such as, for example, ‘himself’ are older, and common examples from the computer age include ‘username’, ’email’, and ‘desktop’.
For formal usage, consider spacing the words or using a hyphen, where appropriate.
answered Nov 23, 2010 at 14:44
Michael KozakewichMichael Kozakewich
5
The OED has no entry for «filename.» However, being a technical writer of 25 years, I have adopted this spelling because programmers and engineers prefer it. Still, it seems odd to me.
answered Jan 16, 2014 at 20:47
![]()
1

Screenshot of a Windows command shell showing filenames in a directory

Filename list, with long filenames containing comma and space characters as they appear in a software display.
A filename or file name is a name used to uniquely identify a computer file in a file system. Different file systems impose different restrictions on filename lengths.
A filename may (depending on the file system) include:
- name – base name of the file
- extension – may indicate the format of the file (e.g.
.txtfor plain text,.pdffor Portable Document Format,.datfor unspecified binary data, etc.)
The components required to identify a file by utilities and applications varies across operating systems, as does the syntax and format for a valid filename.
Filenames may contain any arbitrary bytes the user chooses. This may include things like a revision or generation number of the file such as computer code, a numerical sequence number (widely used by digital cameras through the DCF standard), a date and time (widely used by smartphone camera software and for screenshots), and/or a comment such as the name of a subject or a location or any other text to facilitate the searching the files. In fact, even unprintable characters, including bell, 0x00, Return and LineFeed can be part of a filename, although most utilities do not handle them well.
Some people use of the term filename when referring to a complete specification of device, subdirectories and filename such as the Windows C:Program FilesMicrosoft GamesChessChess.exe. The filename in this case is Chess.exe. Some utilities have settings to suppress the extension as with MS Windows Explorer.
History[edit]
On early personal computers using the CP/M operating system, with the File Allocation Table (FAT) filesystem, filenames were always 11 characters. This was referred to as the 8.3 filename with a maximum of an 8 byte name and a maximum of a 3 byte extension. Utilities and applications allowed users to specify filenames without trailing spaces and include a dot before the extension. The dot was not actually stored in the directory. Using only 7 bit characters allowed several file attributes [1]to be included in the actual filename by using the high-order-bit. These attributes included Readonly, Archive, HIDDEN and SYS. Eventually this was too restrictive and the number of characters allowed increased. The attribute bits were moved to a special block of the file including additional information. This led to compatibility problems when moving files between different file systems.[2]
During the 1970s, some mainframe and minicomputers where files on the system were identified by a user name, or account number.
For example, on Digital Equipment Corporation RSTS/E and TOPS-10 operating systems, files were identified by
- optional device name (one or two characters) followed by an optional unit number, and a colon «:». If not present, it was presumed to be SY:
- the account number, consisting of a bracket «[«, a pair of numbers separated by a comma, and followed by a close bracket «]». If omitted, it was presumed to be yours.
- mandatory file name, consisting of 1 to 6 characters (upper-case letters or digits)
- optional 3-character extension.
On the IBM OS/VS1, OS/390 and MVS operating systems, a file name was up to 44 characters, consisting of upper case letters, digits, and the period. A file name must start with a letter or number, a period must occur at least once each 8 characters, two consecutive periods could not appear in the name, and must end with a letter or digit. By convention, the letters and numbers before the first period was the account number of the owner or the project it belonged to, but there was no requirement to use this convention.
On the McGill University MUSIC/SP system, file names consisted of
- Optional account number, which was one to four characters followed by a colon.If the account number was missing, it was presumed to be in your account, but if it was not, it was presumed to be in the *COM: pseudo-account, which is where all files marked as public were catalogued.
- 1-17 character file name, which could be upper case letters or digits, and the period, with the requirement it not begin or end with a period, or have two consecutive periods.
The Univac VS/9 operating system had file names consisting of
- Account name, consisting of a dollar sign «$», a 1-7 character (letter or digit) username, and a period («.»). If not present it was presumed to be in your account, but if it wasn’t, the operating system would look in the system manager’s account $TSOS. If you typed in a dollar sign only as the account, this would indicate the file was in the $TSOS account unless the first 1-7 character of the file name before the first period matched an actual account name, then that account was used, e.g. ABLE.BAKER is a file in your account, but if not there the system would search for $TSOS.ABLE.BAKER, but if $ABLE.BAKER was specified, the file $TSOS.ABLE.BAKER would be used unless $ABLE was a valid account, then it would look for a file named BAKER in that account.
- File name, 1-56 characters (letters and digits) separated by periods. File names cannot start or end with a period, nor can two consecutive periods appear.
In 1985, RFC 959 officially defined a pathname to be the character string that must be entered into a file system by a user in order to identify a file.[3]
Around 1995, VFAT, an extension to the MS-DOS FAT filesystem, was introduced in Windows 95 and Windows NT. It allowed mixed-case Unicode long filenames (LFNs), in addition to classic «8.3» names.
References: absolute vs relative[edit]
An absolute reference includes all directory levels. In some systems, a filename reference that does not include the complete directory path defaults to the current working directory. This is a relative reference. One advantage of using a relative reference in program configuration files or scripts is that different instances of the script or program can use different files.
This makes an absolute or relative path composed of a sequence of filenames.
Number of names per file[edit]
Unix-like file systems allow a file to have more than one name; in traditional Unix-style file systems, the names are hard links to the file’s inode or equivalent. Windows supports hard links on NTFS file systems, and provides the command fsutil in Windows XP, and mklink in later versions, for creating them.[4][5] Hard links are different from Windows shortcuts, classic Mac OS/macOS aliases, or symbolic links. The introduction of LFNs with VFAT allowed filename aliases. For example, longfi~1.??? with a maximum of eight plus three characters was a filename alias of «long file name.???» as a way to conform to 8.3 limitations for older programs.
This property was used by the move command algorithm that first creates a second filename and then only removes the first filename.
Other filesystems, by design, provide only one filename per file, which guarantees that alteration of one filename’s file does not alter the other filename’s file.
Length restrictions[edit]
Some filesystems restrict the length of filenames. In some cases, these lengths apply to the entire file name, as in 44 characters on IBM S/370.[6] In other cases, the length limits may apply to particular portions of the filename, such as the name of a file in a directory, or a directory name. For example, 9 (e.g., 8-bit FAT in Standalone Disk BASIC), 11 (e.g. FAT12, FAT16, FAT32 in DOS), 14 (e.g. early Unix), 21 (Human68K), 31, 30 (e.g. Apple DOS 3.2 and 3.3), 15 (e.g. Apple ProDOS), 44 (e.g. IBM S/370),[6] or 255 (e.g. early Berkeley Unix) characters or bytes. Length limits often result from assigning fixed space in a filesystem to storing components of names, so increasing limits often requires an incompatible change, as well as reserving more space.
A particular issue with filesystems that store information in nested directories is that it may be possible to create a file with a complete pathname that exceeds implementation limits, since length checking may apply only to individual parts of the name rather than the entire name. Many Windows applications are limited to a MAX_PATH value of 260, but Windows file names can easily exceed this limit [1]. From Windows 10, version 1607, MAX_PATH limitations have been removed.[7]
Filename extensions[edit]
Many file systems, including FAT, NTFS, and VMS systems, consider as filename extension the part of the file name that consists of one or more characters following the last period in the filename, dividing the filename into two parts: a base name or stem and an extension or suffix used by some applications to indicate the file type. Multiple output files created by an application use the same basename and various extensions. For example, a compiler might use the extension FOR for source input file (for Fortran code), OBJ for the object output and LST for the listing. Although there are some common extensions, they are arbitrary and a different application might use REL and RPT. Extensions have been restricted, at least historically on some systems, to a length of 3 characters, but in general can have any length, e.g., html.
Encoding interoperability[edit]
There is no general encoding standard for filenames.
File names have to be exchanged between software environments for network file transfer, file system storage, backup and file synchronization software, configuration management, data compression and archiving, etc. It is thus very important not to lose file name information between applications. This led to wide adoption of Unicode as a standard for encoding file names, although legacy software might not be Unicode-aware.
Encoding indication interoperability[edit]
Traditionally, filenames allowed any character in their filenames as long as they were file system safe.[2] Although this permitted the use of any encoding, and thus allowed the representation of any local text on any local system, it caused many interoperability issues.
A filename could be stored using different byte strings in distinct systems within a single country, such as if one used Japanese Shift JIS encoding and another Japanese EUC encoding. Conversion was not possible as most systems did not expose a description of the encoding used for a filename as part of the extended file information. This forced costly filename encoding guessing with each file access.[2]
A solution was to adopt Unicode as the encoding for filenames.
In the classic Mac OS, however, encoding of the filename was stored with the filename attributes.[2]
Unicode interoperability[edit]
The Unicode standard solves the encoding determination issue.
Nonetheless, some limited interoperability issues remain, such as normalization (equivalence), or the Unicode version in use. For instance, UDF is limited to Unicode 2.0; macOS’s HFS+ file system applies NFD Unicode normalization and is optionally case-sensitive (case-insensitive by default.) Filename maximum length is not standard and might depend on the code unit size. Although it is a serious issue, in most cases this is a limited one.[2]
On Linux, this means the filename is not enough to open a file: additionally, the exact byte representation of the filename on the storage device is needed. This can be solved at the application level, with some tricky normalization calls.[8]
The issue of Unicode equivalence is known as «normalized-name collision». A solution is the Non-normalizing Unicode Composition Awareness used in the Subversion and Apache technical communities.[9] This solution does not normalize paths in the repository. Paths are only normalized for the purpose of comparisons. Nonetheless, some communities have patented this strategy, forbidding its use by other communities.[clarification needed]
Perspectives[edit]
To limit interoperability issues, some ideas described by Sun are to:
- use one Unicode encoding (such as UTF-8)
- do transparent code conversions on filenames
- store no normalized filenames
- check for canonical equivalence among filenames, to avoid two canonically equivalent filenames in the same directory.[2]
Those considerations create a limitation not allowing a switch to a future encoding different from UTF-8.
Unicode migration[edit]
One issue was migration to Unicode.
For this purpose, several software companies provided software for migrating filenames to the new Unicode encoding.
- Microsoft provided migration transparent for the user throughout the VFAT technology
- Apple provided «File Name Encoding Repair Utility v1.0».[10]
- The Linux community provided “convmv”.[11]
Mac OS X 10.3 marked Apple’s adoption of Unicode 3.2 character decomposition, superseding the Unicode 2.1 decomposition used previously. This change caused problems for developers writing software for Mac OS X.[12]
Uniqueness[edit]
Within a single directory, filenames must be unique. Since the filename syntax also applies for directories, it is not possible to create a file and directory entries with the same name in a single directory. Multiple files in different directories may have the same name.
Uniqueness approach may differ both on the case sensitivity and on the Unicode normalization form such as NFC, NFD.
This means two separate files might be created with the same text filename and a different byte implementation of the filename, such as L»x00C0.txt» (UTF-16, NFC) (Latin capital A with grave) and L»x0041x0300.txt» (UTF-16, NFD) (Latin capital A, grave combining).[13]
Letter case preservation[edit]
Some filesystems, such as FAT, store filenames as upper-case regardless of the letter case used to create them. For example, a file created with the name «MyName.Txt» or «myname.txt» would be stored with the filename «MYNAME.TXT». Any variation of upper and lower case can be used to refer to the same file. These kinds of file systems are called case-insensitive and are not case-preserving. Some filesystems prohibit the use of lower case letters in filenames altogether.
Some file systems store filenames in the form that they were originally created; these are referred to as case-retentive or case-preserving. Such a file system can be case-sensitive or case-insensitive. If case-sensitive, then «MyName.Txt» and «myname.txt» may refer to two different files in the same directory, and each file must be referenced by the exact capitalization by which it is named. On a case-insensitive, case-preserving file system, on the other hand, only one of «MyName.Txt», «myname.txt» and «Myname.TXT» can be the name of a file in a given directory at a given time, and a file with one of these names can be referenced by any capitalization of the name.
From its original inception, Unix and its derivative systems were case-preserving. However, not all Unix-like file systems are case-sensitive; by default, HFS+ in macOS is case-insensitive, and SMB servers usually provide case-insensitive behavior (even when the underlying file system is case-sensitive, e.g. Samba on most Unix-like systems), and SMB client file systems provide case-insensitive behavior. File system case sensitivity is a considerable challenge for software such as Samba and Wine, which must interoperate efficiently with both systems that treat uppercase and lowercase files as different and with systems that treat them the same.[14]
Reserved characters and words[edit]
File systems have not always provided the same character set for composing a filename. Before Unicode became a de facto standard, file systems mostly used a locale-dependent character set. By contrast, some new systems permit a filename to be composed of almost any character of the Unicode repertoire, and even some non-Unicode byte sequences. Limitations may be imposed by the file system, operating system, application, or requirements for interoperability with other systems.
Many file system utilities prohibit control characters from appearing in filenames. In Unix-like file systems, the null character[15] and the path separator / are prohibited.
In Windows[edit]
File system utilities and naming conventions on various systems prohibit particular characters from appearing in filenames or make them problematic:[16]
| Character | Name | Reason for prohibition |
|---|---|---|
/
|
slash | Used as a path name component separator in Unix-like, Windows, and Amiga systems. (For as long as the SwitChar setting is set to ‘/ ’, the DOS COMMAND.COM shell would consume it as a switch character, but DOS and Windows themselves always accept it as a separator on API level.) The big solidus ⧸ (Unicode code point U+29F8) is permitted in Windows filenames. |
|
backslash | Used as the default path name component separator in DOS, OS/2 and Windows (even if the SwitChar is set to ‘-‘; allowed in Unix filenames, see Note 1). The big reverse solidus ⧹ (U+29F9) is permitted in Windows filenames. |
?
|
question mark | Used as a wildcard in Unix, Windows and AmigaOS; marks a single character. Allowed in Unix filenames, see Note 1. The glottal stop ʔ (U+0294), the interrobang ‽ (U+203D), the inverted question mark ¿ (U+00BF) and the double question mark ⁇ (U+2047) are allowed in all filenames. |
%
|
percent | Used as a wildcard in RT-11; marks a single character. Not special on Windows. |
*
|
asterisk or star |
Used as a wildcard in Unix, DOS, RT-11, VMS and Windows. Marks any sequence of characters (Unix, Windows, DOS) or any sequence of characters in either the basename or extension (thus «*.*» in DOS means «all files». Allowed in Unix filenames, see Note 1. See Star (glyph) for many asterisk-like characters allowed in filenames. |
:
|
colon | Used to determine the mount point / drive on Windows; used to determine the virtual device or physical device such as a drive on AmigaOS, RT-11 and VMS; used as a pathname separator in classic Mac OS. Doubled after a name on VMS, indicates the DECnet nodename (equivalent to a NetBIOS (Windows networking) hostname preceded by «\».). Colon is also used in Windows to separate an alternative data stream from the main file. The letter colon ꞉ (U+A789) and the ratio symbol ∶ (U+2236) are permitted in Windows filenames. In the Segoe UI font, used in Windows Explorer, the glyphs for the colon and the letter colon are identical. |
|
|
vertical bar or pipe |
Designates software pipelining in Unix, DOS and Windows; allowed in Unix filenames, see Note 1. The mathematical operator ∣ (U+2223) is permitted in Windows filenames. |
"
|
straight double quote | A legacy restriction carried over from DOS. The single quotes ‘ (U+0027), ‘ (U+2018), and ’ (U+2019) and the curved double quotes “ (U+201C) and ” (U+201D) are permitted anywhere in filenames. See Note 1. |
<
|
less than | Used to redirect input, allowed in Unix filenames, see Note 1. The spacing modifier letter ˂ (U+2C2) is permitted in Windows filenames. |
>
|
greater than | Used to redirect output, allowed in Unix filenames, see Note 1. The spacing modifier letter ˃ (U+2C3) is permitted in Windows filenames. |
.
|
period or dot |
Folder names cannot end with a period in Windows, though the name can end with a period followed by a whitespace character such as a non-breaking space. Elsewhere, the period is allowed, but the last occurrence will be interpreted to be the extension separator in VMS, DOS, and Windows. In other OSes, usually considered as part of the filename, and more than one period (full stop) may be allowed. In Unix, a leading period means the file or folder is normally hidden. |
,
|
comma | Allowed, but treated as separator by the command line interpreters COMMAND.COM and CMD.EXE on DOS and Windows. |
;
|
semicolon | Allowed, but treated as separator by the command line interpreters COMMAND.COM and CMD.EXE on DOS and Windows. |
=
|
equals sign | Allowed, but treated as separator by the command line interpreters COMMAND.COM and CMD.EXE on DOS and Windows. |
|
space | Allowed, but the space is also used as a parameter separator in command line applications. This can be solved by quoting the entire filename. |
Note 1: While they are allowed in Unix file and folder names, most Unix shells require specific characters such as spaces, <, >, |, , and sometimes :, (, ), &, ;, #, as well as wildcards such as ? and *, to be quoted or escaped:
five and six<seven(example of escaping)'five and six<seven'or"five and six<seven"(examples of quoting)
The character å (0xE5) was not allowed as the first letter in a filename under 86-DOS and MS-DOS/PC DOS 1.x-2.x, but can be used in later versions.
In Windows utilities, the space and the period are not allowed as the final character of a filename.[17] The period is allowed as the first character, but some Windows applications, such as Windows Explorer, forbid creating or renaming such files (despite this convention being used in Unix-like systems to describe hidden files and directories). Workarounds include appending a dot when renaming the file (that is then automatically removed afterwards), using alternative file managers, creating the file using the command line, or saving a file with the desired filename from within an application.[18]
Some file systems on a given operating system (especially file systems originally implemented on other operating systems), and particular applications on that operating system, may apply further restrictions and interpretations. See comparison of file systems for more details on restrictions.
In Unix-like systems, DOS, and Windows, the filenames «.» and «..» have special meanings (current and parent directory respectively). Windows 95/98/ME also uses names like «…», «….» and so on to denote grandparent or great-grandparent directories.[19] All Windows versions forbid creation of filenames that consist of only dots, although names consist of three dots («…») or more are legal in Unix.
In addition, in Windows and DOS utilities, some words are also reserved and cannot be used as filenames.[18] For example, DOS device files:[20]
CON, CONIN$, CONOUT$, PRN, AUX, CLOCK$, NUL COM0, COM1, COM2, COM3, COM4, COM5, COM6, COM7, COM8, COM9[21] LPT0, LPT1, LPT2, LPT3, LPT4, LPT5, LPT6, LPT7, LPT8, LPT9[21] LST (only in 86-DOS and DOS 1.xx) KEYBD$, SCREEN$ (only in multitasking MS-DOS 4.0) $IDLE$ (only in Concurrent DOS 386, Multiuser DOS and DR DOS 5.0 and higher) CONFIG$ (only in MS-DOS 7.0-8.0)
Systems that have these restrictions cause incompatibilities with some other filesystems. For example, Windows will fail to handle, or raise error reports for, these legal UNIX filenames: aux.c,[22] q»uote»s.txt, or NUL.txt.
NTFS filenames that are used internally include:
$Mft, $MftMirr, $LogFile, $Volume, $AttrDef, $Bitmap, $Boot, $BadClus, $Secure, $Upcase, $Extend, $Quota, $ObjId and $Reparse
Comparison of filename limitations[edit]
| System | Case sensitive |
Case preserving |
Allowed character set | Reserved characters | Reserved words | Maximum length (characters) | Comments |
|---|---|---|---|---|---|---|---|
| 8-bit FAT | ? | ? | 7-bit ASCII (but stored as bytes) | first character not allowed to be 0x00 or 0xFF | 9 | Maximum 9 character base name limit for sequential files (without extension), or maximum 6 and 3 character extension for binary files; see 6.3 filename | |
| FAT12, FAT16, FAT32 | No | No | any SBCS/DBCS OEM codepage | 0x00-0x1F 0x7F " * / : < > ? | + , . ; = [ ] (in some environments also: ! @; DOS 1/2 did not allow 0xE5 as first character)
|
Device names including: $IDLE$ AUX COM1…COM4 CON CONFIG$ CLOCK$ KEYBD$ LPT1…LPT4 LST NUL PRN SCREEN$ (depending on AVAILDEV status everywhere or only in virtual DEV directory)
|
11 | Maximum 8 character base name limit and 3 character extension; see 8.3 filename |
| VFAT | No | Yes | Unicode, using UCS-2 encoding | 0x00-0x1F 0x7F " * / : < > ? |
|
255 | ||
| exFAT | No | Yes | Unicode, using UTF-16 encoding | 0x00-0x1F 0x7F " * / : < > ? |
|
255 | ||
| NTFS | Optional | Yes | Unicode, using UTF-16 encoding | 0x00-0x1F 0x7F " * / : < > ? |
|
Only in root directory: $AttrDef $BadClus $Bitmap $Boot $LogFile $MFT $MFTMirr pagefile.sys $Secure $UpCase $Volume $Extend $Extend$ObjId $Extend$Quota $Extend$Reparse ($Extend is a directory) | 255 | Paths can be up to 32,000 characters.
Forbids the use of characters in range 1-31 (0x01-0x1F) and characters » * / : < > ? | unless the name is flagged as being in the Posix namespace. NTFS allows each path component (directory or filename) to be 255 characters long[dubious – discuss]. Windows forbids the use of the MS-DOS device names AUX, CLOCK$, COM0, …, COM9, CON, LPT0, …, LPT9, NUL and PRN, as well as these names with any extension (for example, AUX.txt), except when using Long UNC paths (ex. \.C:nul.txt or \?D:auxcon). (CLOCK$ may be used, if an extension is provided.) The Win32 API strips trailing period (full-stop), and leading and trailing space characters from filenames, except when UNC paths are used. These restrictions only apply to Windows; in Linux distributions that support NTFS, filenames are written using NTFS’s Posix namespace, which allows any Unicode character except / and NUL. |
| OS/2 HPFS | No | Yes | any 8-bit set | |?*<«:>/ | 254 | ||
| Mac OS HFS | No | Yes | any 8-bit set | : | 255 | old versions of Finder are limited to 31 characters | |
| Mac OS HFS+ | Optional | Yes | Unicode, using UTF-16 encoding | : on disk, in classic Mac OS, and at the Carbon layer in macOS; / at the Unix layer in macOS | 255 | Mac OS 8.1 — macOS | |
| macOS APFS | Optional | Yes | Unicode, using UTF-16 encoding[citation needed] | In the Finder, filenames containing / can be created, but / is stored as a colon (:) in the filesystem, and is shown as such on the command line. Filenames containing : created from the command line are shown with / instead of : in the Finder, so that it is impossible to create a file that the Finder shows as having a : in its filename. | 255 | macOS[clarification needed] | |
| most UNIX file systems | Yes | Yes | any 8-bit set | / null | 255 | a leading . indicates that ls and file managers will not show the file by default
|
|
| z/OS classic MVS filesystem (datasets) | No | No | EBCDIC code pages | other than $ # @ — x’C0′ | 44 | first character must be alphabetic or national ($, #, @)
«Qualified» contains |
|
| CMS file system | No | No | EBCDIC code pages | 8 + 8 | Single-level directory structure with disk letters (A–Z). Maximum of 8 character file name with maximum 8 character file type, separated by whitespace. For example, a TEXT file called MEMO on disk A would be accessed as «MEMO TEXT A». (Later versions of VM introduced hierarchical filesystem structures, SFS and BFS, but the original flat directory «minidisk» structure is still widely used.) | ||
| early UNIX (AT&T Corporation) | Yes | Yes | any 8-bit set | / | 14 | a leading . indicates a «hidden» file | |
| POSIX «Fully portable filenames»[24] | Yes | Yes | A–Z a–z 0–9 . _ -
|
/ null | 14 | hyphen must not be first character. A command line utility checking for conformance, «pathchk», is part of the IEEE 1003.1 standard and of The Open Group Base Specifications[25] | |
| ISO 9660 | No | ? | A–Z 0–9 _ . | «close to 180″(Level 2) or 200(Level 3) | Used on CDs; 8 directory levels max (for Level 1, not level 2,3) | ||
| Amiga OFS | No | Yes | any 8-bit set | : / null | 30 | Original File System 1985 | |
| Amiga FFS | No | Yes | any 8-bit set | : / null | 30 | Fast File System 1988 | |
| Amiga PFS | No | Yes | any 8-bit set | : / null | 107 | Professional File System 1993 | |
| Amiga SFS | No | Yes | any 8-bit set | : / null | 107 | Smart File System 1998 | |
| Amiga FFS2 | No | Yes | any 8-bit set | : / null | 107 | Fast File System 2 2002 | |
| BeOS BFS | Yes | Yes | Unicode, using UTF-8 encoding | / | 255 | ||
| DEC PDP-11 RT-11 | No | No | RADIX-50 | 6 + 3 | Flat filesystem with no subdirs. A full «file specification» includes device, filename and extension (file type) in the format: dev:filnam.ext. | ||
| DEC VAX VMS | No | From v7.2 |
A–Z 0–9 $ - _
|
32 per component; earlier 9 per component; latterly, 255 for a filename and 32 for an extension. | a full «file specification» includes nodename, diskname, directory/ies, filename, extension and version in the format: OURNODE::MYDISK:[THISDIR.THATDIR]FILENAME.EXTENSION;2 Directories can only go 8 levels deep.
|
||
| Commodore DOS | Yes | Yes | any 8-bit set | :, = | $ | 16 | length depends on the drive, usually 16 |
| HP 250 | Yes | Yes | any 8-bit set | SPACE ", : NULL CHR$(255)
|
6 | Disks and tape drives are addressed either using a label (up to 8 characters) or a unit specification. The HP 250 file system does not use directories, nor does it use extensions to indicate file type. Instead the type is an attribute (e.g. DATA, PROG, BKUP or SYST for data files, program files, backups and the OS itself).[26] |
See also[edit]
- File system
- Fully qualified file name
- Long filename
- Path (computing)
- Slug (Web publishing)
- Symbolic link
- Uniform Resource Identifier (URI)
- Uniform Resource Locator (URL) and Internationalized resource identifier
- Windows (Win32) File Naming Conventions (Filesystem Agnostic)
References[edit]
- ^ «CPM — CP/M disk and file system format».
- ^ a b c d e f David Robinson; Ienup Sung; Nicolas Williams (March 2006). «Solaris presentations: File Systems, Unicode, and Normalization» (PDF). San Francisco: Sun.com. Archived from the original (PDF) on July 4, 2012.
- ^ RFC 959 IETF.org RFC 959, File Transfer Protocol (FTP)
- ^ «Fsutil command description page». Microsoft.com. Retrieved September 15, 2013.
- ^ «NTFS Hard Links, Directory Junctions, and Windows Shortcuts». Flex hex. Inv Softworks. Retrieved March 12, 2011.
- ^ a b «ddname support with FTP, z/OS V1R11.0 Communications Server IP User’s Guide and Commands z/OS V1R10.0-V1R11.0 SC31-8780-09». IBM.com.
- ^ «Maximum Path Length Limitation — Win32 apps».
- ^ «Filenames with accents». Ned Batchelder. June 2011. Retrieved September 17, 2013.
- ^ «NonNormalizingUnicodeCompositionAwareness — Subversion Wiki». Wiki.apache.org. January 21, 2013. Retrieved September 17, 2013.
- ^ «File Name Encoding Repair Utility v1.0». Support.apple.com. June 1, 2006. Retrieved October 2, 2018.
- ^ «convmv — converts filenames from one encoding to another». J3e.de. Retrieved September 17, 2013.
- ^ «Re: git on MacOSX and files with decomposed utf-8 file names». KernelTrap. May 7, 2010. Archived from the original on March 15, 2011. Retrieved July 5, 2010.
- ^ «Cross platform filepath naming conventions — General Programming». GameDev.net. Retrieved September 17, 2013.
- ^ «CaseInsensitiveFilenames — The Official Wine Wiki». Wiki.winehq.org. November 8, 2009. Archived from the original on August 18, 2010. Retrieved August 20, 2010.
- ^ «The Open Group Base Specifications Issue 6». IEEE Std 1003.1-2001. The Open Group. 2001.
- ^ «Naming Files, Paths, and Namespaces (Windows)». Msdn.microsoft.com. August 26, 2013. Retrieved September 17, 2013.
- ^ «Windows Naming Conventions». MSDN, Microsoft.com. See last bulleted item.
- ^ a b Naming a file msdn.microsoft.com (MSDN), filename restrictions on Windows
- ^ Microsoft Windows 95 README for Tips and Tricks, Microsoft, retrieved August 27, 2015
- ^ MS-DOS Device Driver Names Cannot be Used as File Names., Microsoft
- ^ a b Naming Files, Paths, and Namespaces, Microsoft
- ^ Ritter, Gunnar (January 30, 2007). «The tale of «aux.c»«. Heirloom Project.
- ^ «Subparameter Definition, z/OS V1R11.0 MVS JCL Reference». IBM.com. Retrieved September 17, 2013.
- ^ Lewine, Donald. POSIX Programmer’s Guide: Writing Portable UNIX Programs 1991 O’Reilly & Associates, Inc. Sebastopol, CA pp63-64
- ^ pathchk — check pathnames
- ^ Hewlett-Packard Company Roseville, CA HP 250 Syntax Reference Rev 1/84 Manual Part no 45260-90063
External links[edit]
- Data Formats Filename at Curlie
- File Extension Library
- File Extension Database
- FILExt
- WikiExt — File Extensions Encyclopedia
- Naming Files, Paths, and Namespaces (MSDN)
- 2009 POSIX portable filename character set
- Standard ECMA-208, December 1994, System-Independent Data Format
- Best Practices for File Naming, USA: Stanford University Libraries, Data Management Services
Your question title says «files containing» a word. However, in your question, you do mention «get the filenames containing» a word. These are different things. Fortunately, they are both rather simple, so I will simply show you both.
To find files containing a word:
grep -iR «word1» .
The -i says to ignore case. The -R is recursive (meaning sub-directories are searched). (Capital letter is documented by OpenBSD and more similar to ls, so I prefer that over -r.) The period specifies where to start looking.
To find filenames containing a word:
find . -iname «word1«
The -iname is a case-insensitive version of «name».
The period specifies where to start looking. The current directory is often a good choice.
Note: You referenced «.» in one of your examples. That was great for DOS, and typically good in Microsoft Windows, but is a really bad habit for Unix environment. Seeing that makes me think you’re familiar with Windows. Well, understand that in Windows, «FIND» (or «find») locates text in files. Unix is different: «grep» locates text in files, and «find» locates filenames.
Now, to exclude word 99, and to place that in a text file, add the following text:
| grep -v word99 >> output.txt
This is the pipe key, almost always Shift-Backslash.
So, as an example, if you wanted to do both, use:
grep -iR «word1» . | grep -v word99 >> output.txt
find . -iname «word1» | grep -v word99 >> output.txt
The part before the pipe character will run a command, and send the output into a Unix-style pipe. Then, the content gets sent from the pipe into the next command’s standard input. grep -v will look at the standard input it receives, and exclude what you want. grep -v will send the remaining results to its standard output. The >> will redirect the prior command’s standard output to the end of the specified text file.
The reason why you don’t see documented options in the «find» command, about how to exclude text, is that Unix was very heavily designed with this idea of making simpler programs, and using the piping technique to cause elaborate effects. In the Microsoft environments, old Microsoft code was particularly more cumbersome with pipe-handling, so programs basically tried to incorporate more functionality into each program. On one hand, that seems simpler for the end user (having everything built-in), but that approach lacks consistency. When you’re using Unix, don’t be afraid of the piping: once you get used to it, you may find it simplifies things greatly, but cause you can use your simple tools in many situations, and so you don’t need to re-learn simple techniques over and over (for each different program).
работая в Office 2007, я хотел бы добавить поле имени файла в заголовок документа. Документ позже будет PDF, поэтому я не хочу расширения.
Я играл с Insert — > QuickParts — > поле, безрезультатно. У меня такое чувство, что для этого нужна формула…
заранее спасибо, если вы можете помочь.
5 ответов
ваше чувство совершенно правильно.
Insert > QuickParts > Field > FileName это путь, но, как вы видите на скриншоте ниже, у вас нет возможности включить или выключить расширение файла.
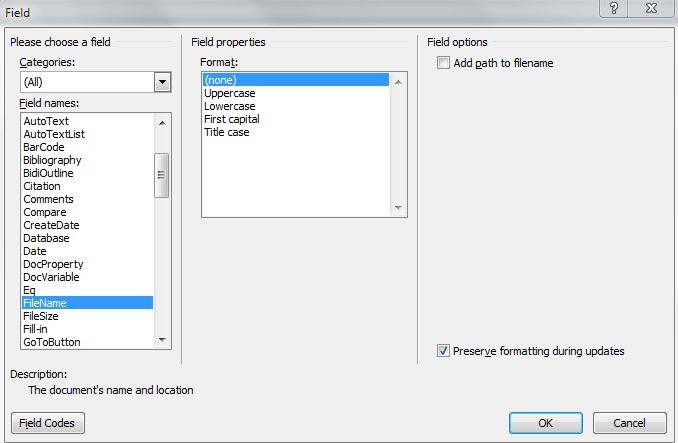
Чтобы показать или не показать (шекспировский стиль) расширение чисто до настройки Проводника Windows, чтобы показать или скрыть известные расширения файлов. Итак, либо вы измените эту настройку, либо вам нужен код.
очень простой макрос будет следующим:
Sub InsertCurrentFileName()
Selection.InsertBefore Text:=Left(ActiveDocument.Name, Len(ActiveDocument.Name) - 4)
End Sub
что это does просто удаляет последние 4 символа «строки имени файла», например «.doc «- if you safe a».docx «the».»будут сохранены. Также этот макрос будет работать один раз, и вам нужно будет запустить его снова, когда имя файла изменится.
может быть, вы могли бы объяснить, что вы хотите достичь с именем файла в заголовке документа? Вы пытаетесь использовать имя файла в заголовке документа для установки некоторого свойства PDF во время преобразования? Почему бы не использовать заголовок документа? Вам нужно исходное имя файла в PDF позже — почему?
еще две страницы, чтобы помочь вам с вашей проблемой (оба полагаются на макросы…):
- вставить имя файла без расширения .doc с использованием полей?
- вставка имени файла без расширения
добавить [Title] вместо имя файла
и, может быть, добавить некоторые из других Свойства Документа перечислил
создать макрос что-то вроде:
Dim f As String
f = Dir(ActiveDocument.FullName)
intPos = InStr(1, f, ".")
If intPos > 0 Then
f = Left(f, intPos - 1)
End If
doc.Variables("BaseFileName").Value = f
вставить поле типа:
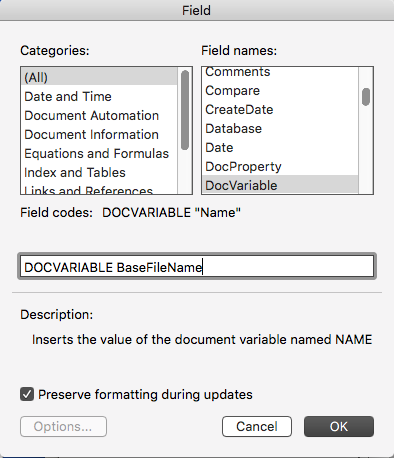
сделано.
действительно, для поля FileName нет опции» только базовое имя».
долгосрочный: запрос функции
в долгосрочной перспективе я сделал запрос с Microsoft в:
https://office365.uservoice.com/forums/264636-general/suggestions/13860672-for-word-create-a-basename-only-field-option-for
Я приглашаю вас и других, посещающих этот пост, проголосовать за это предложение.
краткосрочного решения
макро (Код VBA)
написание макроса, как предположил @DennisG, вероятно, является наиболее удобной работой.
свойства
но вы можете не связывать макрос с документом word, чтобы избежать проблем с безопасностью (например, если вы распространяете документ). Таким образом, другим обходным путем является создание пользовательского свойства FileBaseName с жестко закодированным значением «MyDocumentBaseName»:
создайте пользовательское свойство FileBaseName и назначьте его значение:
- откройте пустой документ в MS Word.
- сохраните его как » MyTempReport.файлы DOCX».
- в меню MS Word с MyTempReport.docx открыть > файл [вкладка] > информация > свойства: нажмите > Дополнительные свойства … > Пользовательский [tab]…
- введите «Name»: «FileBaseName»; «Value»: «MyTempReport».
вставьте свойство пользовательского документа,FileBaseName в своем документе:
- меню MS Word > вставить [вкладка] > текст [группа] > быстрые детали > поле …
- из «имена полей» выберите «DocProperty».
- из поля «свойства» > «свойства»: выбрать «FileBaseName» > «ОК».
вы теперь должны иметь «MyTempReport» вставить как поле в документе.
ограничения:
- если вы переименуете файл это не отразиться в вашем
вставьте поле Имя файла, как показано на диаграмме выше, и сохраните его как имя файла. Просмотр в режиме предварительного просмотра и возврат в режим редактирования: имя файла теперь должно отображаться вместо Documentn
Как только у вас есть имя файла, вы можете форматировать разные части с разными цветами: поэтому измените цвет .расширение до цвета фона документа (возможно, белого).
Я сделал это в нижнем колонтитуле, чтобы версия pdf не отображалась».файлы DOCX’.
1, Naming conventions
Naming conventions commonly used in the market:
- Camel case (small hump nomenclature – initial lowercase)
- PascalCase (hump nomenclature – initial capital)
- Kebab case
- Snake (underlined)
1.1 naming of project documents
Rules can be quickly remembered as «static file underline, compiled file dashes».
1.1.1 project name
All in lowercase, separated by dashes. Example: my project name
1.1.2 directory name
Refer to the project naming rules. If there is a plural structure, the plural naming method shall be adopted. Examples: docs, assets, components, directives, mixins, utils, views
my-project-name/
|- BuildScript // Pipeline deployment file directory
|- docs // Detailed document directory for the project (optional)
|- nginx // Front end project nginx agent file directory deployed on container
|- node_modules // Downloaded dependent packages
|- public // Static page directory
|- index.html // Project entrance
|- src // Source directory
|- api // http request directory
|- assets // Static resource directory, where the resources will be built by wabpack
|- icon // icon storage directory
|- img // Picture storage directory
|- js // Public js file directory
|- scss // Public style scss storage directory
|- frame.scss // Entry file
|- global.scss // Common style
|- reset.scss // reset styles
|- components // assembly
|- plugins // plug-in unit
|- router // route
|- routes // Detailed route splitting directory (optional)
|- index.js
|- store // Global state management
|- utils // Tool storage directory
|- request.js // Public request tool
|- views // Page storage directory
|- App.vue // Root component
|- main.js // Entry file
|- tests // test case
|- .browserslistrc// Browser compatibility profile
|- .editorconfig // Editor profile
|- .eslintignore // eslint ignore rule
|- .eslintrc.js // eslint rule
|- .gitignore // git ignore rule
|- babel.config.js // babel rule
|- Dockerfile // Docker deployment file
|- jest.config.js
|- package-lock.json
|- package.json // rely on
|- README.md // Project README
|- vue.config.js // webpack configuration
1.1.3 image file name
All are in lowercase. Single word naming is preferred, and multiple word names are separated by underline.
banner_sina.gif menu_aboutus.gif menutitle_news.gif logo_police.gif logo_national.gif pic_people.jpg pic_TV.jpg
1.1.4 HTML file name
All are in lowercase. Single word naming is preferred, and multiple word names are separated by underline.
|- error_report.html |- success_report.html
1.1.5 CSS file name
All are in lowercase. Single word naming is preferred, and multiple word names are separated by a dash.
|- normalize.less |- base.less |- date-picker.scss |- input-number.scss
1.1.6 JavaScript file name
All are in lowercase. Single word naming is preferred, and multiple word names are separated by a dash.
|- index.js |- plugin.js |- util.js |- date-util.js |- account-model.js |- collapse-transition.js
The above rules can be quickly remembered as «static file underline, compiled file dashes».
1.2 Vue component naming
1.2.1 single file component name
Single file components with a file extension of. vue. Single file component names should always start with uppercase words (PascalCase).
components/ |- MyComponent.vue
1.2.2 single instance component name
Components with only a single active instance should be named with The prefix to show their uniqueness.
This does not mean that the component can only be used for a single page, but_ Each page_ Use only once. These components will never accept any props because they are customized for your application. If you find it necessary to add prop, it indicates that it is actually a reusable component_ Just now_ Use only once per page.
For example, the header and sidebar components are used in almost every page and do not accept prop. This component is specially customized for the application.
components/ |- TheHeading.vue |- TheSidebar.vue
1.2.3 basic component name
Basic components: basic components that do not contain business, independent and specific functions, such as date selector, modal box, etc. As the basic control of the project, such components will be widely used. Therefore, the API of components is abstracted too much, and different functions can be realized through different configurations.
The basic components that apply specific styles and conventions (that is, the components that display classes, are illogical or stateless, and are not doped with business logic) should all begin with a specific prefix — Base.
Basic components can be used multiple times in one page and can be reused in different pages. They are highly reusable components.
components/ |- BaseButton.vue |- BaseTable.vue |- BaseIcon.vue
1.2.4 business components
Business component: unlike the basic component, which only contains a function, it is reused by multiple pages in the business (with reusability). The difference between it and the basic component is that the business component will only be used in the current project, not universal, and will contain some businesses, such as data requests; The basic component contains no business and can be used in any project. It has a single function, such as an input box with data verification function.
Components doped with complex business (with their own data and prop related processing) that is, business components should be named with the prefix Custom.
A business component is in a page. For example, there is a card list in a page, and the card whose style and logic are closely related to the business is a business component.
components/ |- CustomCard.vue
1.2.5 tightly coupled component name
Child components closely coupled with the parent component should be named with the parent component name as a prefix.
Because editors usually organize files alphabetically, this can put the associated files together.
components/ |- TodoList.vue |- TodoListItem.vue |- TodoListItemButton.vue
1.2.6 word order in component name
Component names should start with high-level (usually general) words and end with descriptive modifiers.
Because editors usually organize files alphabetically, the important relationships between components are now clear. The following components are mainly used for search and setting functions.
components/ |- SearchButtonClear.vue |- SearchButtonRun.vue |- SearchInputQuery.vue |- SearchInputExcludeGlob.vue |- SettingsCheckboxTerms.vue |- SettingsCheckboxLaunchOnStartup.vue
There is another multi-level directory method. Put all search components in the «search» directory and all setting components in the «settings» directory. We only recommend doing this in very large applications (such as 100 + components), because it takes more effort to find between multi-level directories than to scroll through a single component directory.
1.2.7 component name of complete word
Component names should tend to be complete words rather than abbreviations.
Automatic completion in the editor has made the cost of writing long names very low, but the clarity it brings is very valuable. In particular, infrequently used abbreviations should be avoided.
components/ |- StudentDashboardSettings.vue |- UserProfileOptions.vue
1.3 code parameter naming
1.3.1 name
The component name should always be multiple words and should always be PascalCase. Except for the root component and Vue built-in components such as App and. This avoids conflicts with existing and future HTML elements, because all HTML element names are single words.
export default {
name: 'ToDoList',
// ...
}
1.3.2 prop
When declaring prop, its name should always use camelCase, while kebab case should always be used in templates and JSX.
We simply follow the conventions of each language. In JavaScript, camelCase is more natural. In HTML, it is kebab case.
<WelcomeMessage greeting-text="hi"/>
export default {
name: 'MyComponent',
// ...
props: {
greetingText: {
type: String,
required: true,
validator: function (value) {
return ['syncing', 'synced',].indexOf(value) !== -1
}
}
}
}
1.3.3 router
Vue Router Path is named in kebab case format. Words using Snake (such as: / user_info) or camelCase (such as: / userInfo) will be regarded as a word, and search engines cannot distinguish semantics.
// bad
{
path: '/user_info', // user_info as a word
name: 'UserInfo',
component: UserInfo,
meta: {
title: ' - user',
desc: ''
}
},
// good
{
path: '/user-info', // Can be parsed into user info
name: 'UserInfo',
component: UserInfo,
meta: {
title: ' - user',
desc: ''
}
},
1.3.4 components in formwork
For most projects, the component name should always be Pascal case in single file components and string templates, but always kebab case in DOM templates.
<!-- In single file components and string templates --> <MyComponent/> <!-- stay DOM In template --> <my-component></my-component>
1.3.5 self closing assembly
Components without content in single file components, string templates, and JSX should be self closing — but never in DOM templates.
<!-- In single file components and string templates --> <MyComponent/> <!-- Everywhere --> <my-component></my-component>
1.3.6 variables
- Naming method: camelCase
- Naming convention: type + method of object description or attribute
// bad var getTitle = "LoginTable" // good let tableTitle = "LoginTable" let mySchool = "My school"
1.3.7 constants
- Naming method: all uppercase underline split
- Naming convention: use capital letters and underscores to combine names, and underscores are used to divide words
const MAX_COUNT = 10 const URL = 'http://test.host.com'
1.3.8 method
- Naming method: camelCase
- Naming standard: use verb or verb + noun form uniformly
// 1. In general, use the verb + noun form // bad go,nextPage,show,open,login // good jumpPage,openCarInfoDialog // 2. Request data method, ending with data // bad takeData,confirmData,getList,postForm // good getListData,postFormData // 3. Single verb situation init,refresh
| verb | meaning | Return value |
|---|---|---|
| can | Determine whether an action can be performed (right) | Function returns a Boolean value. true: executable; false: not executable |
| has | Determine whether there is a value | Function returns a Boolean value. true: contains this value; false: does not contain this value; |
| is | Determine whether it is a value | Function returns a Boolean value. true: a value; false: not a value; |
| get | Get a value | Function returns a non Boolean value |
| set | Set a value | No return value, setting success or chained object |
1.3.9 user defined events
Custom events should always use the event name of kebab case.
Unlike components and prop s, there is no automatic case conversion for event names. Instead, the triggered event name needs to exactly match the name used to listen to this event.
this.$emit('my-event')
<MyComponent @my-event="handleDoSomething" />
Unlike components and props, event names are not used as JavaScript variable names or property names, so there is no reason to use camelCase or PascalCase. In addition, the v-on event listener will be automatically converted to all lowercase in the DOM template (because HTML is case insensitive), so v-on:myevent will become v-on:myevent — making it impossible for myEvent to be monitored.
- Native event reference list [1]
It can be found from the native event that its usage is as follows:
<div @blur="toggleHeaderFocus" @focus="toggleHeaderFocus" @click="toggleMenu" @keydown.esc="handleKeydown" @keydown.enter="handleKeydown" @keydown.up.prevent="handleKeydown" @keydown.down.prevent="handleKeydown" @keydown.tab="handleKeydown" @keydown.delete="handleKeydown" @mouseenter="hasMouseHoverHead = true" @mouseleave="hasMouseHoverHead = false"> </div>
And to distinguish_ Native event_ And_ Custom event_ For the use in Vue, it is suggested that in addition to using kebab case for multi word event names, the naming should also follow the form of on + verb, as follows:
<!-- Parent component --> <div @on-search="handleSearch" @on-clear="handleClear" @on-clickoutside="handleClickOutside"> </div>
// Subcomponents
export default {
methods: {
handleTriggerItem () {
this.$emit('on-clear')
}
}
}
1.3.10 event method
Naming method: camelCase
Naming convention: handle + name (optional) + verb
<template>
<div
@click.native.stop="handleItemClick()"
@mouseenter.native.stop="handleItemHover()">
</div>
</template>
<script>
export default {
methods: {
handleItemClick () {
//...
},
handleItemHover () {
//...
}
}
}
</script>
2, Code specification
2.1 Vue
2.1.1 code structure
<template>
<div id="my-component">
<DemoComponent />
</div>
</template>
<script>
import DemoComponent from '../components/DemoComponent'
export default {
name: 'MyComponent',
components: {
DemoComponent
},
mixins: [],
props: {},
data () {
return {}
},
computed: {},
watch: {}
created () {},
mounted () {},
destroyed () {},
methods: {},
}
</script>
<style lang="scss" scoped>
#my-component {
}
</style>
2.1.2 data
The data of the component must be a function.
// In a .vue file
export default {
data () {
return {
foo: 'bar'
}
}
}
2.1.3 prop
Prop definitions should be as detailed as possible.
export default {
props: {
status: {
type: String,
required: true,
validator: function (value) {
return [
'syncing',
'synced',
'version-conflict',
'error'
].indexOf(value) !== -1
}
}
}
}
2.1.4 computed
Complex computational attributes should be divided into as many simpler attributes as possible.
Small, focused computing attributes reduce the hypothetical restrictions on the use of information, so there is no need for so much refactoring when requirements change.
// bad
computed: {
price: function () {
var basePrice = this.manufactureCost / (1 - this.profitMargin)
return (
basePrice -
basePrice * (this.discountPercent || 0)
)
}
}
// good
computed: {
basePrice: function () {
return this.manufactureCost / (1 - this.profitMargin)
},
discount: function () {
return this.basePrice * (this.discountPercent || 0)
},
finalPrice: function () {
return this.basePrice - this.discount
}
}
2.1.5 setting key values for v-for
key must be used with v-for on components to maintain the state of internal components and their subtrees. Even maintain predictable behavior on elements, such as object constancy in animation [2].
<ul>
<li
v-for="todo in todos"
:key="todo.id">
{{ todo.text }}
</li>
</ul>
2.1.6 v-if and v-for are mutually exclusive
Never use v-if and v-for on the same element at the same time.
<!-- bad: Console error -->
<ul>
<li
v-for="user in users"
v-if="shouldShowUsers"
:key="user.id">
{{ user.name }}
</li>
</ul>
We tend to do this in two common situations:
- To filter items in a list (such as v-for = «user in users» v-if = «user.isActive»). In this case, replace users with a calculated attribute (such as activeUsers) to return the filtered list.
computed: {
activeUsers: function () {
return this.users.filter((user) => {
return user.isActive
})
}
}
<ul>
<li
v-for="user in activeUsers"
:key="user.id">
{{ user.name }}
</li>
</ul>
- To avoid rendering lists that should have been hidden (such as v-for = «user in users» v-if = «shouldShowUsers»). In this case, move the v-if to the container element (such as ul, ol).
<!-- bad -->
<ul>
<li
v-for="user in users"
v-if="shouldShowUsers"
:key="user.id">
{{ user.name }}
</li>
</ul>
<!-- good -->
<ul v-if="shouldShowUsers">
<li
v-for="user in users"
:key="user.id">
{{ user.name }}
</li>
</ul>
2.1.7 elements of multiple attribute s
The elements of multiple attributes should be written in multiple lines, one line for each attribute.
<!-- bad --> <img src="https://vuejs.org/images/logo.png" alt="Vue Logo"> <MyComponent foo="a" bar="b" baz="c"/>
<!-- good --> <img src="https://vuejs.org/images/logo.png" alt="Vue Logo"> <MyComponent foo="a" bar="b" baz="c"/>
2.1.8 simple expressions in templates
The component template should contain only simple expressions, and complex expressions should be refactored to evaluate properties or methods
Complex expressions can make your template less explicit. We should try to describe what should happen, not how to calculate that value. Moreover, computing properties and methods make the code reusable.
// bad
{{
fullName.split(' ').map((word) => {
return word[0].toUpperCase() + word.slice(1)
}).join(' ')
}}
Better practices:
<!-- In template -->
{{ normalizedFullName }}
// Complex expression has been moved into a calculated property
computed: {
normalizedFullName: function () {
return this.fullName.split(' ').map(function (word) {
return word[0].toUpperCase() + word.slice(1)
}).join(' ')
}
}
2.1.9 quoted attribute value
Non empty HTML attribute values should always be enclosed in double quotes.
<!-- bad -->
<input type=text>
<AppSidebar :style={width:sidebarWidth+'px'}>
<!-- good -->
<input type="text">
<AppSidebar :style="{ width: sidebarWidth + 'px' }">
2.1.10 abbreviations of directives
- Use: to represent v-bind:
- Use @ for v-on:
- Use # to represent v-slot:
<input :value="newTodoText" :placeholder="newTodoInstructions"> <input @input="onInput" @focus="onFocus"> <template #header> <h1>Here might be a page title</h1> </template> <template #footer> <p>Here's some contact info</p> </template>
2.2 HTML
2.2.1 document template
HTML5 file template:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>HTML5 Standard template</title>
</head>
<body>
</body>
</html>
Mobile terminal:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport"
content="width=device-width, initial-scale=1.0, maximum-scale=1.0, user-scalable=no, shrink-to-fit=no">
<meta name="format-detection" content="telephone=no">
<title>Mobile terminal HTML Template</title>
<!-- S DNS Pre analysis -->
<link rel="dns-prefetch" href="">
<!-- E DNS Pre analysis -->
<!-- S For online style page slice development, please directly cancel the annotation reference -->
<!-- #include virtual="" -->
<!-- E Online style page slice -->
<!-- S Local debugging. Select the debugging mode according to the development mode. Please delete it -->
<link rel="stylesheet" href="css/index.css">
<!-- /Local debugging mode -->
<link rel="stylesheet" href="http://srcPath/index.css">
<!-- /Development machine debugging mode -->
<!-- E Local debugging -->
</head>
<body>
</body>
</html>
PC end:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="keywords" content="your keywords">
<meta name="description" content="your description">
<meta name="author" content="author,email address">
<meta name="robots" content="index,follow">
<meta http-equiv="X-UA-Compatible" content="IE=Edge,chrome=1">
<meta name="renderer" content="ie-stand">
<title>PC end HTML Template</title>
<!-- S DNS Pre analysis -->
<link rel="dns-prefetch" href="">
<!-- E DNS Pre analysis -->
<!-- S For online style page slice development, please directly cancel the annotation reference -->
<!-- #include virtual="" -->
<!-- E Online style page slice -->
<!-- S Local debugging. Select the debugging mode according to the development mode. Please delete it -->
<link rel="stylesheet" href="css/index.css">
<!-- /Local debugging mode -->
<link rel="stylesheet" href="http://srcPath/index.css">
<!-- /Development machine debugging mode -->
<!-- E Local debugging -->
</head>
<body>
</body>
</html>
2.2.2 closure of elements and labels
There are five types of HTML elements:
- Empty elements: area, base, br, col, command, embed ded, hr, img, input, keygen, link, meta, param, source, track, wbr
- Original text elements: script, style
- RCDATA elements: textarea, title
- Foreign elements: elements from MathML namespace and SVG namespace
- Regular elements: other elements allowed by HTML are called regular elements
In order to enable the browser to better parse the code and make the code more readable, there are the following conventions:
- All elements with start and end labels shall be written with start and end labels, and some elements that allow the omission of start labels or bundle labels shall also be written.
- Empty element labels are not marked with «/».
<!-- good -->
<div>
<h1>I am h1 title</h1>
<p>I am a text, I have a beginning and an end, and the browser can interpret it correctly</p>
</div>
<br data-tomark-pass>
<!-- bad -->
<div>
<h1>I am h1 title</h1>
<p>I am a text, I have a beginning but no end, and the browser can interpret it correctly
</div>
<br/>
2.2.3 code nesting
Element nesting specification, each block element has an independent line, and inline elements are optional.
<!-- good -->
<div>
<h1></h1>
<p></p>
</div>
<p><span></span><span></span></p>
<!-- bad -->
<div>
<h1></h1><p></p>
</div>
<p>
<span></span>
<span></span>
</p>
Paragraph and title elements can only nest inline elements.
<!-- good --> <h1><span></span></h1> <p><span></span><span></span></p> <!-- bad --> <h1><div></div></h1> <p><div></div><div></div></p>
2.3 CSS
2.3.1 style file
- recommend:
@charset "UTF-8";
.jdc {}
- Not recommended:
/* @charset Rule does not start with the first character on the first line of the file */
@charset "UTF-8";
.jdc {}
/* @charset The rule is not in lowercase */
@CHARSET "UTF-8";
.jdc {}
/* No @ charset rule */
.jdc {}
2.3.2 code formatting
There are generally two types of style writing: one is Compact format and the other is Expanded format.
- Recommended: Expanded format
.jdc {
display: block;
width: 50px;
}
- Not recommended: Compact format
.jdc { display: block; width: 50px;}
2.3.3 code case
Style selectors, attribute names, attribute values and keywords are all written in lowercase letters, and attribute strings are allowed to use case.
- recommend:
.jdc {
display: block;
}
- Not recommended:
.JDC {
DISPLAY: BLOCK;
}
2.3.4 code legibility
- There is a space between the left parenthesis and the class name, and a space between the colon and the attribute value.
- recommend:
.jdc {
width: 100%;
}
- Not recommended:
.jdc{
width:100%;
}
- Comma separated values, followed by a space.
- recommend:
.jdc {
box-shadow: 1px 1px 1px #333, 2px 2px 2px #ccc;
}
- Not recommended:
.jdc {
box-shadow: 1px 1px 1px #333,2px 2px 2px #ccc;
}
- Open a new line for a single CSS selector or new declaration.
- recommend:
.jdc, .jdc_logo, .jdc_hd {
color: #ff0;
}
.nav{
color: #fff;
}
- Not recommended:
.jdc, .jdc_logo, .jdc_hd {
color: #ff0;
}.nav{
color: #fff;
}
- The color value rgb() rgba() hsl() hsla() rect() does not need spaces, and the value should not have unnecessary 0.
- recommend:
.jdc {
color: rgba(255,255,255,.5);
}
- Not recommended:
.jdc {
color: rgba( 255, 255, 255, 0.5 );
}
- If the hexadecimal value of the attribute value can be abbreviated, use abbreviated as far as possible.
- recommend:
.jdc {
color: #fff;
}
- Not recommended:
.jdc {
color: #ffffff;
}
- Do not specify units for 0.
- recommend:
.jdc {
margin: 0 10px;
}
- Not recommended:
.jdc {
margin: 0px 10px;
}
2.3.5 attribute value quotation marks
When quotation marks are required for CSS attribute values, single quotation marks shall be used uniformly.
- recommend:
.jdc {
font-family: 'Hiragino Sans GB';
}
- Not recommended:
.jdc {
font-family: "Hiragino Sans GB";
}
2.3.6 attribute writing suggestions
The following sequence is recommended:
- Office location attribute: display / position / float / clear / visibility / overflow
- Self attribute: width / height / margin / padding / border / background
- Text attribute: color / font / text decoration / text align / vertical align / white space / break word
- Other attributes (CSS3): content / cursor / border radius / box shadow / text shadow / background: linear gradient
.jdc {
display: block;
position: relative;
float: left;
width: 100px;
height: 100px;
margin: 0 10px;
padding: 20px 0;
font-family: Arial, 'Helvetica Neue', Helvetica, sans-serif;
color: #333;
background: rgba(0,0,0,.5);
-webkit-border-radius: 10px;
-moz-border-radius: 10px;
-o-border-radius: 10px;
-ms-border-radius: 10px;
border-radius: 10px;
}
3.3.7 CSS3 browser private prefix
CSS3 browser private prefix comes first and standard prefix comes last.
.jdc {
-webkit-border-radius: 10px;
-moz-border-radius: 10px;
-o-border-radius: 10px;
-ms-border-radius: 10px;
border-radius: 10px;
}
2.4 JavaScript
2.4.1 single line code block
Use spaces in single line blocks.
- Not recommended:
function foo () {return true}
if (foo) {bar = 0}
- recommend:
function foo () { return true }
if (foo) { bar = 0 }
2.4.2 brace style
In the process of programming, curly braces style is closely related to indentation style. There are many methods to describe the position of curly braces relative to code blocks. In JavaScript, there are three main styles, as follows:
- [recommended] One True Brace Style
if (foo) {
bar()
} else {
baz()
}
- Stroustrup
if (foo) {
bar()
}
else {
baz()
}
- Allman
if (foo)
{
bar()
}
else
{
baz()
}
2.4.3 spaces in code
- Spaces before and after commas can improve the readability of the code. The team agreed to use spaces after commas and no spaces before commas.
- recommend:
var foo = 1, bar = 2
- Not recommended:
var foo = 1,bar = 2 var foo = 1 , bar = 2 var foo = 1 ,bar = 2
- There cannot be a space between the key and value of an object literal, and a space is required between the colon and value of an object literal.
- recommend:
var obj = { 'foo': 'haha' }
- Not recommended:
var obj = { 'foo' : 'haha' }
- Add a space before the code block.
- recommend:
if (a) {
b()
}
function a () {}
- Not recommended:
if (a){
b()
}
function a (){}
- A space should be added before the parentheses of a function declaration.
- recommend:
function func (x) {
// ...
}
- Not recommended:
function func(x) {
// ...
}
- Spaces are prohibited in function calls.
- recommend:
fn()
- Not recommended:
fn () fn ()
- You need to add spaces before and after the operator
- recommend:
var sum = 1 + 2
- Not recommended:
var sum = 1+2
3, Annotation specification
Purpose of note:
- Improve the readability of the code, so as to improve the maintainability of the code
Principles of notes: - As short as possible if not necessary
- As long as necessary
3.1 HTML file comments
3.1.1 single line notes
It is generally used for simple descriptions, such as some state descriptions, attribute descriptions, etc.
There is a space character before and after the comment content. The comment is located above the code to be commented and occupies a separate line.
- recommend:
<!-- Comment Text --> <div>...</div>
- Not recommended:
<div>...</div><!-- Comment Text --> <div><!-- Comment Text --> ... </div>
3.1.2 module notes
It is generally used to describe the name of the module and the position where the module starts and ends.
One space character before and after the comment content,
Indicates the start of the module,
Indicates the end of the module, with one line between modules.
- recommend:
<!-- S Comment Text A --> <div class="mod_a"> ... </div> <!-- E Comment Text A --> <!-- S Comment Text B --> <div class="mod_b"> ... </div> <!-- E Comment Text B -->
- Not recommended:
<!-- S Comment Text A --> <div class="mod_a"> ... </div> <!-- E Comment Text A --> <!-- S Comment Text B --> <div class="mod_b"> ... </div> <!-- E Comment Text B -->
3.1.3 nested module notes
When module comments appear again in the module comments, nested modules are no longer used in order to highlight the main modules.
<!-- S Comment Text --> <!-- E Comment Text -->
Instead, use
<!-- /Comment Text -->
Comments are written on a separate line at the bottom of the tag at the end of the module.
<!-- S Comment Text A -->
<div class="mod_a">
<div class="mod_b">
...
</div>
<!-- /mod_b -->
<div class="mod_c">
...
</div>
<!-- /mod_c -->
</div>
<!-- E Comment Text A -->
3.2 CSS file comments
3.2.1 single line notes
The first character and the last character of the comment content are a space character, which occupy a separate line, separated by a line.
- recommend:
/* Comment Text */
.jdc {}
/* Comment Text */
.jdc {}
- Not recommended:
/*Comment Text*/
.jdc {
display: block;
}
.jdc {
display: block;/*Comment Text*/
}
3.2.2 module notes
The first character and the last character of the comment content are a space character, / * and module information description occupy one line, multiple horizontal separators — and * / occupy one line, and there are two lines between lines.
- recommend:
/* Module A
---------------------------------------------------------------- */
.mod_a {}
/* Module B
---------------------------------------------------------------- */
.mod_b {}
- Not recommended:
/* Module A ---------------------------------------------------- */
.mod_a {}
/* Module B ---------------------------------------------------- */
.mod_b {}
3.2.3 document notes
Note the page name, author, creation date and other information under the style file encoding declaration @ charset statement.
@charset "UTF-8"; /** * @desc File Info * @author Author Name * @date 2015-10-10 */
3.3 JavaScript file comments
3.3.1 single line notes
Single line comments use / /. Comments should be written on a separate line above the annotated object and should not be appended to a statement.
- recommend:
// is current tab const active = true
- Not recommended:
const active = true // is current tab
An empty line is required above the comment line (unless the top of a block is above the comment line) to increase readability.
- recommend:
function getType () {
console.log('fetching type...')
// set the default type to 'no type'
const type = this.type || 'no type'
return type
}
// A blank line is not required when the top of a block is above the comment line
function getType () {
// set the default type to 'no type'
const type = this.type || 'no type'
return type
}
- Not recommended:
function getType () {
console.log('fetching type...')
// set the default type to 'no type'
const type = this.type || 'no type'
return type
}
3.3.2 multiline notes
Multiline comments use / * *… * /, not multiline / /.
- recommend:
/**
* make() returns a new element
* based on the passed-in tag name
*/
function make (tag) {
// ...
return element
}
- Not recommended:
// make() returns a new element
// based on the passed in tag name
function make (tag) {
// ...
return element
}
3.3.3 comment space
A space is required between the comment content and the comment character to increase readability. eslint: spaced-comment.
- recommend:
// is current tab
const active = true
/**
* make() returns a new element
* based on the passed-in tag name
*/
function make(tag) {
// ...
return element
}
- Not recommended:
//is current tab
const active = true
/**
*make() returns a new element
*based on the passed-in tag name
*/
function make(tag) {
// ...
return element
}
3.3.4 special marks
Sometimes we find a possible bug, but it can’t be fixed for some reasons; Or there are some functions to be completed in a certain place. At this time, we need to use the corresponding special tag comments to inform ourselves or partners in the future. There are two common special marks:
- //FIXME: explain what the problem is
- //TODO: explain what else to do or the solution to the problem
class Calculator extends Abacus {
constructor () {
super ()
// FIXME: shouldn't use a global here
total = 0
// TODO: total should be configurable by an options param
this.total = 0
}
}
3.3.5 document notes
Document annotations, such as functions, classes, files, events, etc; All use the jsdoc specification.
/**
* Book Class, representing a book
* @constructor
* @param {string} title - The title of a book
* @param {string} author - The author of a book
*/
function Book (title, author) {
this.title = title
this.author = author
}
Book.prototype = {
/**
* Get the title of the book
* @returns {string|*}
*/
getTitle: function () {
return this.title
},
/**
* Set the number of pages in the book
* @param pageNum {number} the number of pages
*/
setPageNum: function (pageNum) {
this.pageNum=pageNum
}
}
3.3.6 annotation tools
ESLint is the most popular JS code checking tool at present. There are some annotation related rules in ESLint, which users can choose to open:
-
valid-jsdoc
-
require-jsdoc
-
no-warning-comments
-
capitalized-comments
-
line-comment-position
-
lines-around-comment
-
multiline-comment-style
-
no-inline-comments
-
spaced-comment
4, Others
- Use two spaces to indent and wrap lines.
- It is recommended to add a semicolon at the end of JavaScript code for large team multi person collaborative projects.
- Small individual innovation and hand training projects can try to use the style without semicolon at the end of JavaScript code, which is more refreshing and concise.
If there are any mistakes, I hope you can remind me in the comments!!!
(the article comes from an article in the front end of the official account, «the most complete Vue front-end code style guide»).
Link address: https://mp.weixin.qq.com/s/2GLfEHXDTCOD1q-etlGMEQ
In this article, we are going to learn How to Read text File word by word in C. We will read each word from the text file in each iteration.
C fscanf Function
The fscanf() function is available in the C library. This function is used to read formatted input from a stream. The syntax of the fscanf function is:
Syntax
int fscanf(FILE *stream, const char *format, ...)
Parameters :
- stream − This is the pointer to a FILE object that identifies the stream.
- format − This is the C string that contains one or more of the following items − Whitespace character, Non-whitespace character, and Format specifiers.
- A format specifier will be as [=%[*][width][modifiers]type=].
1. Read File Word by Word in C using fscanf Function
Here we are making use of the fscanf function to read the text file. The first thing we are going to do is open the file in reading mode. So using fopen() function and “r” read mode we opened the file. The next step is to find the file stats like what is the size of the data this file contains. so we can allocate exact memory for the buffer that is going to hold the content of this file. We are using the stat() function to find the file size.
- Once we have the size and buffer allocated for this size, we start reading the file by using the fscanf() function.
- We keep reading the file word by word until we reach the end of file.In fscanf function, we are passing “%39[^-n] as the argument so we can read the text until we find the next word.
- The code will look like this:
fscanf(in_file, "%39[^-n]", file_contents)
C Program to Read text File word by word
To run this program, we need one text file with the name Readme.txt in the same folder where we have our code.The content of the file is:
Hello My name is John danny
#include <stdio.h>
#include <stdlib.h>
#include <sys/stat.h>
const char* filename = "Readme.txt";
int main(int argc, char *argv[])
{
FILE *in_file = fopen(filename, "r");
if (!in_file)
{
perror("fopen");
return 0;
}
struct stat sb;
if (stat(filename, &sb) == -1)
{
perror("stat");
return 0;
}
char *file_contents = malloc(sb.st_size);
while (fscanf(in_file, "%[^-n ] ", file_contents) != EOF) {
printf("> %sn", file_contents);
}
fclose(in_file);
return 0;
}
Output
Hello My name is John danny