In this article, we will be exporting HTML to Word doc file with images using jQuery plugin or without using any plugin, with pure javascript. Although there are many plugin available on internet which converts html page into word document but we will be using jquery.wordexport.js which also requires filesaver.js to save files on client browser, using HTML 5 Localstorage.
HTML page to Word Doc with images using Javascript
In the method, we will not be using any jquery plugin, we will be converting complete HTML with image into doc using javascript code.
1. Create the javascript function to export to doc
function ExportToDoc(filename = ''){
var HtmlHead = "<html xmlns:o='urn:schemas-microsoft-com:office:office' xmlns:w='urn:schemas-microsoft-com:office:word' xmlns='http://www.w3.org/TR/REC-html40'><head><meta charset='utf-8'><title>Export HTML To Doc</title></head><body>";
var EndHtml = "</body></html>";
//complete html
var html = HtmlHead +document.getElementById("MainHTML").innerHTML+EndHtml;
//specify the type
var blob = new Blob(['ufeff', html], {
type: 'application/msword'
});
// Specify link url
var url = 'data:application/vnd.ms-word;charset=utf-8,' + encodeURIComponent(html);
// Specify file name
filename = filename?filename+'.doc':'document.doc';
// Create download link element
var downloadLink = document.createElement("a");
document.body.appendChild(downloadLink);
if(navigator.msSaveOrOpenBlob ){
navigator.msSaveOrOpenBlob(blob, filename);
}else{
// Create a link to the file
downloadLink.href = url;
// Setting the file name
downloadLink.download = filename;
//triggering the function
downloadLink.click();
}
document.body.removeChild(downloadLink);
}In the above code, we are getting contents of element with id «MainHTML» and then converting it into blob of type MSWord. You can also modify code to pass element dynamically by adding an argument in «ExportToDoc» function and then passing that element’s html.
2. Let’s create the HTML which we will export
<div id="MainHTML">
<h1>
<center>Centered HTML H1 Heading</center>
</h1>
<h2>
Heading 2
</h2>
<p>
Some text inside paragraph.
</p>
<p>
<img src="https://res.cloudinary.com/dmsxwwfb5/image/upload/v1580916756/buy-me-min.png">
</p>
</div>
<div>
<a class="word-export" href="javascript:void(0)" onclick="ExportToDoc()">Export to Doc</a>
</div>Codepen sample
Output:

HTML page to word doc with images using jQuery plugin
Let’s create a simple HTML page with image, which we will be using to convert to MS word Document.
<div id="MainHTML">
<h1>
<center>Centered HTML H1 Heading</center>
</h1>
<h2>
Heading 2
</h2>
<p>
Some text inside paragraph.
</p>
<p>
<img src=" data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAWEAAADkCAYAAABJ9ZUIAAABG2lUWHRYTUw6Y29tLmFkb2JlLnhtcAAAAAAAPD94cGFja2V0IGJlZ2luPSLvu78iIGlkPSJXNU0wTXBDZWhpSHpyZVN6TlRjemtjOWQiPz4KPHg6eG1wbWV0YSB4bWxuczp4PSJhZG9iZTpuczptZXRhLyIgeDp4bXB0az0iWE1QIENvcmUgNS41LjAiPgogPHJkZjpSREYgeG1sbnM6cmRmPSJodHRwOi8vd3d3LnczLm9yZy8xOTk5LzAyLzIyLXJkZi1zeW50YXgtbnMjIj4KICA8cmRmOkRlc2NyaXB0aW9uIHJkZjphYm91dD0iIi8+CiA8L3JkZjpSREY+CjwveDp4bXBtZXRhPgo8P3hwYWNrZXQgZW5kPSJyIj8+Gkqr6gAAAYBpQ0NQc1JHQiBJRUM2MTk2Ni0yLjEAACiRdZHPK0RRFMc/Hhr5XSgLi0lYoUGJjcWIobAYT/m1efPmvRk1M17vjSRbZTtFiY1fC/4CtspaKSIlGxtrYoOe88zUTDL3du/53O8953TuuaCoCT3plAUgmUrb4VDQPzs37/c9o1ArswmfpjvW5PSoStHxcUeJZ2+6vFzF/f4dVVHD0aGkQnhIt+y08JjwxGra8nhbuFGPa1HhU+FOWwoUvvX0SJZfPI5l+ctjWw0Pg1Iv7I8VcKSA9bidFJaX05ZMrOi5eryXVBupmWmxrbJacAgTIoifcUYYpp8eBmXvp4teuuVEkfjAb/wUyxKry26xhs0SMeKk6RR1RbIbYk3RDZkJ1rz+/+2rY/b1ZrNXB6H8yXXf2sG3Bd8Z1/08dN3vIyh9hItUPn75AAbeRc/ktbZ9qNuAs8u8FtmB801ofrA0W/uVSmUppgmvJ1AzBw3XULmQ7VnunuN7UNflq65gdw86xL9u8QcNCme9tGiQ+AAAAAlwSFlzAAAOxAAADsQBlSsOGwAAHfBJREFUeJzt3X1sVFd6BvAn2Wi19liCCmOjthhjb1OWhdhlg0SCU3s1FBZGXVySarakAieFtCAlmHw1kRLisEgQsoSPbGET0K6xFKujBWJHGqgtRjtu7MQShNp8eKlg7DG0ko2NFktzzVb80z/u3DAYz9xzZ+7HuXOfn2Rhe87MvJnYj8+899xzH0EW/IFgNYBqAOXZ3N9kfQDuOF2EC8Qj4VDc6SKI6EGPiA70B4J1ABoA1AOYYVE9RE6bgPqHnfRFdW6/A6AvEg7pjfM03RBOhm8TgFqriyGivNUP9Y9bFECU78ruyxjC/kCwCcB79pRCRB4yDDWQ26CGsmdbitOGsD8QnAngAICN9pZDRB7VjmQoe22WnC6E2wCstbkWIiIA6ALQDDWQ836G/FAI+wPBAwC2OVALEdFUx6GGcZvThVjlgRBOHoT7nTOlEBGlNQx1dnwg32bHU0M4DmCeyB1LS4pRtfiHmFM624q6hPVdHHD0+d0iNhSHokw6XQaRGY4DaMqX3vG3IewPBBsA/EbvDpXz52HrSxtRtXihlXUROWJkdAyjt8acLkN6CUVBbHA4/e0JBdcHh3HxsqWTpHaoM+OolU9itdQQjkNnFrzSX4utL21Akc9ndV1ElCdig3H0XRpAf/LDgndkXVBnxlGzH9gOjwCAPxCsB/B5poGV8+dh354dDGAiyokWyp1nuxAbSj+bzkIXgMZIOOSqMx61EG6GzprgTw7tQWVFuQ0lEZFXjIyOof/SAHp6z+Gr3vNmPayresbfAYCKxxcdADAz3aCV/lr87Zq/sa0oIvKGoiIfvl9Rjh//9dNY6a9Faels3Pyf/821ZVEN4IWKxxd9b+jalag5lVrnkeTZcX/INGjf7h08EEdEtokNxnGy/Qx6es/lGsjDABpk7hc/orc22OcrRHvo1/ZVRESUlFAUdJztwqn20xi9NZ7LQ7VDDWPp1hg/qjegcn659VUQEU2jyOfDs2vX4LNf/xJvNG5BaUlxtg+1FkA8uQhBKrohTEQkg1UravHZr3+Jfbt34IlFWbVHZwD43B8INifbsFJgCBORq1QtXoiP9uzIZWa8EUBf8gpBjmMIE5EraTPjNxq3wOcrNHr3eQD+yx8INlpQmiEMYSJyNTWMP8a6n67O5u77nW5PMISJyPWKfD5sfWkjPjm0J5t+8UYAUaeCmCFMRHmjsqIcH+3ZgS2bNxhtUVRBXT1he5+YIUxEeefZtWvwyaEPjM6KZ0CdEdu6jI0hTER5aU7pbHy0Zwc2rH/OyN20ZWwN1lT1sEcB1GUa8P0KoT3eiYiktGH9c/jk0B6jy9l+Y1cQ686Ei4q4dSURuVtlRTk++dhwe8KWIGY7gog8ocjnw0d7dhhdymZ5EDOEichTtr60EW80bjFyF0uDmCFMRJ6zakUt9u3eYWQZm2VBzBAmIk+qWrwQHxkPYtPXETOEicizKivKjQZx1OwgZggTkacZDOIZAEzda4IhTESeZzCIqwC0mfXcDGEiIhgO4lp/INhkxvMyhImIkgwG8XvJa3TmhCFMRJSisqIcb24XXkfclmt/mCFMRDTF8mVLsWXzBpGhM5Bjf5ghTEQ0jWfXrsFKf63I0NpcLpPEECYiSmPrSxtQOV9oJ8kmfyBYns1zMISJiNIo8vnw/juvixyomwGgOZvnYAgTEWUwp3Q2tm7eKDK0NpurcjCEiYh0rFpRi6eXPSky9IDR1RKPZVcSEblNT+859F8cwPXB4Ydum1M6G3NKZ5v6fD5fIaoXL0RlRbmpj+uUN7dvwfMvvgxFmcw0bB6ARgBNoo/LECbygL37j6Az0pX29ouXrXvuyvnzsHJFLVatqEWRz71X6iny+fDm9i14b9c+vaGN/kCwORIOxUUel+0IojzXcbYrYwBbLTY0jCNHW/D8iy9j7/4jGBkdc6yWXC1ftlSkLTEDBmbCDGGiPNdx1rkATqUok+iMdOEf/8ndYbx180aR1RIbRZesMYSJyHZaGLe0nkBCUZwux5A5pbPx7No1IkObRAYxhInIMS2tJ/D8iy+jp/ec06UYsm7tatNmwwxhInKUokzivV37sGPXL1wzKy7y+UTXDjfpDWAIE5EUvuo976pZ8aoVtSgtKdYbpjsb5hI1Itqe/Ne0S/YAqAaw1uidtFnxup+uxtaXhGaajtqw/u/x4YEjesMakGFGzBAmor5IOBQ1+0GTZ441Qg0hoV1wNKe+OIPrg8PY+e5rUq8tXrWiFi2tv8XorfFMwzKevMF2BBFZIhIO3YmEQ02RcKgcwAsAHj5VL4OLlwfw2ls7pe8Tr9NfKTHDHwg2pLuRIUxElouEQ81QWxTvA5gQvV9saBjPv/gyYoNxiyrL3aoVtSIrJRrS3cAQJiJbaDNjqGHcLno/RZnEq2/vlDaIi3w+rNLf/L023QE69oStMjkJ3Lihfn71avpxZWVAYSFQXKx+5DvtdblxQ/18fFz9mEp7PQoL1ddIe53I9ZJ7KtQn36IfgHqab0aKMokdu36BTz7+QMoe8bq1a3DqizN6wxowTW+YIWyGyUk1aK9eVcMlU+jqmTsXmDdPDZ0FC9R/3Wx8HLhwQX1NhoeB27ezf6xZs4Af/EB9XZYsYSi7XCQcavYHglGo12ir0hs/emscr721E/v27JAuiOeUzsYTixbi4uWBTMMawBA2kRYuX34J3Lxp3uPevPng4xUUqMGzZIl7gmd8HOjsBL75JrfQner2baC7W/0A7r8mbnld6CGRcCievGz8AQC6a9JiQ8PYu/8Idr7zuuW1GbVqRa1eCM/zB4LVkXCoL/WbDGGjtBDIZbZrxN27athfuKB+vWQJUFOj/isbu18b7XUpKACeeQZYudIbLR2DFMlXF0TCoTsAGvyB4B0A2/TGf9V7Hi2tJ7Bh/XPWF2fA8qeexOGjhXr7DTdAXbL2LYawqO5u4PPPzZ3ZZUMLnlmz7gePk7PAyUl11vvll869NnfvqjV0dqp/oOrrGcYpYkOZV4ZZsUY4G5FwqNEfCPYB+I3e2JbWE1i+7EmpNowv8vmwfNlSvW1D66Z+g6sj9Fy4ALz2GnDsmPMBnOr2baCtTa2trU0NQztNTj74/LK8Nt3dwOuvA62t9r8mlLPkUrYXRMbKuNfE8qd09xqumrpKgiGczvg4sGcPcOiQPAEznbt3HwxDO3R3A+++qz7f3bv2PKdRnZ3qa6K1ccg1kkF8XG/c6K1xnGrXXZFgq+XLlooMe+BioAzh6Vy4oIaMXb1NM6SGsVV1a3+YZHtXkM7du+of0UOHOCt2mUg41ACBtcQtrSek2xxe4MobdalfMISnam1Vf2llneHpuX37/gzezOBpa1Pf5rvpD5NG+6Oqrdsmt2gA0K83aO9+3Q10bCUwG65L/YIhnOrYMfVtbD4wazY/Pn6/9eBmt28Du3ffX95G0tNWTeiNu3h5AP2XMi4Ns1XV4oV6Q2b4A8Fq7QuGMKDOGN99N/9+QbVZcbYBqgW5meugnXT3rvqHNt/+P+ex5Jra9/XGHf/shA3ViJlTOltkn+E67ROGMKC2IPIlaKbT1ma8PeH2tkwmDGJXSe43kXGd3cXLA1L1hqsW/1BvSJ32CUO4tdUbv5AXLqhvx6fbpyHV5KQ6e86Xtkw6DGK3adQb0NIqz2xYoCXBdgQA9Zcw38Mm1c2bmQ9QjY+rQe3Gg2/ZOHbMO/+tLhcJh9oAZDwLoqf3nDTrhgVCeF5y03sPh/D4OPDZZ05XYb+7d9WgnRrEN27kV/9X1MGD+u8OSBbNmW5UlEn0fH3eplIym1M6W2SP4WrAyyF87Fh+9jtFTA3iGzfUr734emgH60h6yZM4MvaGZbpIaOX8cr0hdYBXQ1jbWtHLtCDu7vZuAGuuXnX/EjzvaM5041e9csyEAaD6Cd2WRDmghnB5plECU2r38WIbYjraLNDLAazp6GBbwh2a9QbIMhuurNC9tmk5IBDC35dolyJTdHe745Rbspd22jdJLXlVjoxn0cUGDV1P1DJzSmbrDakFvNiO+PxzpysgWdm5FzLlIprpxr6Lcpw9J7LNpj8QnOmtEL56lbNgyoxrh90g41sWnatb2ErgzLlqb4Uwf8FIT3c3e8Py69MbIMvZc6UlJXpDPDYT/uYbpysgN/DSCTwulNzYJ2Pjd/SWHCE8p1S3L+yhmfCFC1wFQGL4x9oN4pluvD6Y8WbbCISwhw7M8YALibp9m3sPyy+a6Uadi23aRmCJb513Qvj3v3e6AnITHj9wtURCjj0kRJb4eieEvbYnAuWGf7RlF89043VJ1gqL8EYIsxVBRvGPtuziThdgknJvhDAv8kjZ4B9vypHIlpbeCGEeZKFs8OeGbOCNECbKBt9BkQ28EcJ8W0nZ4M8N2cAbIUxEJCmGMBG5UV2mG0XOVJMFQ5gonTE59h8g4xjCRPmA256SDRjCROkUFDhdAaVXl+lGN12WjSFMlM483WuEkaTcdFk2b4TwggVOV0BE5qp1ugAR/Zd0r/Ix4Y0QJqK84Q8EZ+qNEThdWBZ93gjhYt3rPBE9jD83sqrOdKPAdd2kwhAmSoc/N7Kqy3SjwHXdbCNyhQ9vhHBZmdMVkBvx50ZWGWfC1U/I04oQuMJH1BshXFjI5UZkHGfCsqrLdGNlhTyrWjgTTsXlRmQUZ8LS8QeC1QBmZBpTOb/cllpEJBK6M2GPHJgDuEyNjOHPi6waMt1YWlIs1SnLsaG43pA7DGGi6fDnRVb1mW5cvmypXXXoSiiKbk84Eg55pCcM8K0lGcMQlk6yFZGxr1gl0UG5mP7FRicAL/WECwv5i0ViCgr4syKnxkw3+nyFUs2EBc6W6wO8FMIAsGSJ0xWQG/zoR05XQFMkz5JzTSsCEFoZwRAmmhZ/TmTUCJ1VEcufetKmUsTEGMLTKC4G5s51ugqS2axZDGHJJGfBGVsRpSXFUs2ER0bHMHprXG+YB0MYAJ55xukKSGb8+ZCR7ix41Yo6eyoRJLJ7WiQc8mgI19Q4XQHJjD8fUvEHguUA3ss0xucrxLq1q+0pSJBACEe1T7wXwoWF/EWj6dXU8FRl+TTrDXh27RoU+Xw2lCKu/9IVvSFR7RPvhTDAEKbp1Wc8+E428weCjdDZvF3GWXBsMC7SD45qn3gzhBcs4DpQehBnwVJJnpixX2+cjLPgPgP9YMCrIQxwNkwP4ixYGsk+cFRvXGlJsXSzYADoPNulN6Qt9Qtvh/CsWU5XQTJYuZKzYEkkl6O1QWc1BABsfWmjdLPgkdExxIZ0T1eOpn7h3RAGgM2bna6AnFZQwFmwJJIBHAVQpTf26WVPSrUuWNMZ0Z0FA5wJp2BvmDZvVlfMkKOSPeAoBAK4tKQYb27fYnlN2eg4G9Ub0h4Jh+6kfsPbIQwAmzY5XQE5ZckSnh0nAX8gWAfBAPb5CrHzndela0MA6tpggVURbVO/wRAuLubbUS8qKOAfYAn4A8EmAL+DQA8YALZu3ojKinIrS8pah/4BuQlME8KPWVKN29TXA998A9y86XQlZJdt29iGcFByBUQzdNYBp9qyeQNWrRAebquEooj0g9umtiIAzoTv27yZFwP1ivXreSzAIf5AcGZy9jsEAwG80l+LZ9eusayuXJ1qPyMyrHm6bzKENWVlwPPPO10FWa2mRl2SRrbzB4INAOLQ2QtiqpX+WmkPxAHqLPhk+2m9YcORcCg63Q1sR6SqqQGuXgW6u52uhKywYAH7wDZLLjtrgLoTmuFLnr/RuEXaFoSm5+vzuteSA3Ag3Q0M4ak2bQLGx9Uwpvwxdy7wyitOV+EZySVnjVCvhiF00C2Vz1eIrZs3Sh/AANDS+lu9IRPIsBERQ3g6r7wC7N7NA3X5YtYs4O23eSDOQsllZgCgha/hWa+mcv48vLl9i7SrIFKdbD8tsiyteboDchqG8HQKC9Wj5+++C9y963Q1lIuCAq6E0OEPBKNTvtUHIDU0qgHMnOaupk9T1/10NTY8/5yU64CnSigKWlpPiAxN24oAGMLpFRers6fduxnEblVQoP4/LCtzuhLZTQ1T23sA6llwW1G1WJ5L1us51X5GpBd8PBIOxTMN4OqITMrK1F9iLl1zp23bGMAusGH9c/jk4w9cFcAjo2Ois+AmvQGcCevRlq4dO+Z0JWTEpk1cCyy5lf5abFj/HOaUzna6FMMOHz0uMkx3FgwwhMVoew8ziN1h0ybuFy0xN4cvAPT0nsNXvef1hk1A5wrRGoawKAaxOzCAH1I5f57IHreWKi0pxqoVdVi3drUrDrqlk1AUHP5UaBZ8INOKiFQMYSMYxHJbv54BPI03t2/Bq2/vFDmIZLqV/losf0rOvX+z0fLZCZElacPQWRGRiiFsFINYTjwdOa3KinJ8tHsHjreeQP+lAUvCuLSkGKUlJQCA6icWorRkNpY/9aSrZ71T9fSew6kvhPaIaBSdBQMM4ezU1Khn1bU9tCsdOaGmhqcj66isKMfOd15/4Hv901yQMqEoiA0+2LooLZk9bf823ffzUUJRsHf/EZGhXZFwyFAwMISzVV+vBjH3mXAWAzhr6ZaE5UvrwEw7fr5P5B3EBNR9MgzhOuFc8CCQsxjAZIPDnx7Hxcu6l7EHgCaRJWlTMYRzxSB2BgOYbNBxtku0D9wVCYeED8alYgibgUFsLwYw2SA2GBc9KSOrNoSGIWwWBrE9GMBkg4SiGFnW15BNG0LDEDYTg9haDGCyQUJR8NpbwgF83OhqiKkYwmbbtIlXb7YCA5hsoAWw4BmG/ZFwqCHX52QIW6G+noFhJgYw2cBgAE9AvWpIzhjCVmFwmIOvI9nAYAADQF0ufeBUDGErMUByw9ePbJBFAL8QCYf6zHp+hrDVGCTZ4etGNsgigLdHwqFmM2vgact24KY/xjCAyQaxwTj27j9iJICPZ3tCRiYMYbswiMUwgMkGscG40e09j5uxEmI6DGE7MYgzYwCTDTrOduHDA0I7omksC2CAIWy/mhr1unW8ivODGMBkMfWqGC3ojHQZuZulAQzwwJwzeBXnBzGAyWKxwThee2undAEMMISdwyBWMYDJYifbT+PVtw2tgACAg3YEMMAQdpbXg5gBTBYaGR3Dq2/txJGjLUYv6fRCJBwSulKyGRjCTvNqEK9fzwAmy5xsP41/fuVfRTdj10wA+Duz1wHr4YE5GZSVAfv2qQfrbt50uhrrcbc5skhsMI5/+7TFaPgC6hWS6808E04UQ1gWhYXqjDjfg5gBTBZIKApaPjshehWMqbqgBrDwFZLNxBCWSb4HMQOYTJZQFJxqP4OT7aeN9n0170fCoSaTyzKEISybfA1iBjCZrONsF1paf4vRW+PZ3H0Y6hUxouZWZRxDWEaFhcDPf66eWdfd7XQ1uWMAk0kSiqJefLP9dLbhCwDtUAPYkfbDVAxhmWmrB9waxAUF6qy+rMzpSsjlRkbH0BnpyqXtACQvyJnr5YjMxhCWnVuDmAFMJui/NICOs11Gz3SbznEAjbLMflMxhN1g0ya1RdHZ6XQlYhjAlANt1ttxNppLy0EjTe83HYawW6xfr4aa7DuwMYApCyOjY+jpPYfOs11GTy9OZwJAkxX7/5qNIewmsm+FOXcusHkzA5iExAbj6Ok9j56vz5kVvJqDUANYutbDdBjCbiNrEM+dq86ACwudroQkFRuM4/rgMPovDaCn91wuB9jSOQ41fONmP7CVGMJuVFMDFBcDBw/KsScxA5imSCgKYsnAvT4YR/+lAStCV+PK8NUwhN1qwYL7J3U4GcQMYE+LDcaRUCbRf2kAiYSC64PDiA3FrQxczQSAZgAH3Bq+Goawm2k7sDkVxEuW3F+5QdJKKAp6vj6P0VtjD3y/avHCtPcZGR17aHzfxfub4mSxQY5ZhgE0AWhzS89XD0PY7bQgPngQuH3bvuflXsCuEBuMY8euX5ix1MtpxwE0y7zULFsM4XxQVqae5mzXfhMMYNdweQB3QW055M2sdzoM4Xxh18Y/K1eqa5ZJev2XBtwYwO0AolCDN+5sKfZgCOcTq4OYG/GQ+Yahhm4UeT7jTYchnG+s2oGNAUzmmMD90I06cSUL2TCE85WZG/8wgCk7EwD6oAZuH4A+r7QYjGAI57Ncg5j7QJAYbYuzKIA7uB+4nmstZIMhnO82bVLPrmszuIUqA9j1rg/G9YYMA8g0qA9qqKaKJv+9w1aCORjCXlBfrwax6H4Ts2YB27YxgF1O4Ky1Zqevr0YMYe8Q3fiHpyET2epRpwsgG+mdZMEAJrIdZ8Jeo+3AdvTog6c5cx8IIkc8hocb7w8YGR1D1WKbqiF7LFgA7NsHXL2qfl1crH5QXkndcCeNuA1lkI7HoB4BXZtuwNSdlCiPLFjgdAXkrLjTBRB7wkR5a/TWLadLIAEMYaI8JbB5D9f5SoAhTJSHRkb124g8o00ODGGiPCRwLKffjjpIH0OYKA/1X9JdGcFZsCQYwkR5SKAdEbWhDBLAECbKQzH9zXt0B5A9GMJEeSahKIgNDesN48oISTCEifKMQD8Y3IZSHrohnEgodtRBRCbp1z9duUtvANnnUegcJb0+qPu2hogkIjATjtpQBgl6FDq9IUXhTJjILUZGx0T6wVEbSiFBujNhgf+hRCSJnt5zekMmIuFQ1IZSSNCjIg16geUuRCSBzrO67d6oDWWQAdqBuYynMPYJHG0lImcJtiIMXvGVrKaFcMbZcIwH54ikd6r9tMgwhrBkhEJYoM9ERA5KKAo6IrqtiHbunCYfLYSjmQYpyiT7wkQS6zjbJXSJextKIYMeBb49e2Yi08AO/YY/ETlEoBUxHAmH2IqQUOoZcxn/Bwm81SEiB7S0nhC5ikazDaVQFoRDWFEmORsmkkxCUXBS7IDcAatroex8G8LJtypsSRC5yOFPW0R6wcd5QE5eUzfwac40+OLlAaEdmojIev2XBtAp1iZssrgUysHUENZ9y7J3/2GLSiEiUQlFEf1dPB4Jh+IWl0M5+E7qF0PXrtypeHzRjwGUp7uD9tanavFCSwsjovR27T2Eq/99XW/YBICfDF278kcbSqIsTbefcJPenU62n+a6YSKHnGw/ja96z4sMPcBesPy+M/UbQ9euxPVmw/fu3cPvr17Dj2ufxne/+10r6yOiFD295/DhgV+JDO2PhEM/s7oeyl26K2s06N0xNjSMw5+2mFsNEaUVG4xj7/4josMbLCyFTPTQTBj4tjf8JwCWZbpzbGgYI6NjWP7UUkuKIyJVbDCOV9/eKbIcDQDej4RD/251TWSOaUMYACoeX9QL4B8AzMz0AAxiImv19J7Djl37RAO4KxIONVhcEpkobQgPXbvyx4rHF0UB/IvegzCIiaxxsv00PjzwK9y7d09k+DCAOq6GcJe0IQwAQ9eujFQ8vmgCwE/0Hig2NIyer89h6Y+qUVTkM61AIi9KKAp27T2Ez784I3qXCQA/4Zpg98kYwgAwdO1Kb8Xji+YDqNYb+4c7E+iIdKFs7p+i7M//zJQCibym/9IA3t6xW2QdsGYCQJ3IpcpIProhDADJtsRqAHP0xt67dw/R//wa1wfj+MFf/gVnxUSCRkbHcPhoC44cFdoPItWWSDj0H1bVRdZ6RHSgPxCcCXXz9yrR+/h8hXh27RqsW7saRT6GMdF0EoqCU+1ncLL9tNHwnQDQwH2C3U04hIHsghi4H8Yr/bWYUzrbyF2J8tbI6BhOtZ9GR0ToqhhTsQWRJwyFMPBtELcBqM3mCZ9e9iRWrajF8mVcSUHe1HG2Cz2950RPPZ5OP9QZMAM4DxgOYY0/EGwGsDHb+/t8hVi+bCmqFi9E1eKFnCFT3kooCnq+Po/+SwPo6T2Xzaw3VTvUAOaeEHki6xAGAH8g2AB1+8sZuRZSWlKMyopyfL+iHFWLF6LIV4jKivJcH5bIdrHBOK4PDiM2GEf/pQHEhobNeNgJAE2RcIhXyMgzOYUwAPgDwXKom8Fn1Z4gIl1dUGe/cacLIfPlHMIafyDYCHUbzJxnxUQEQJ39NkbCoWanCyHrCK0TFpE8qeNXAP4PwF8B+J5Zj03kMRMAPgDws0g41Ot0MWQt02bCqZIrKBqTH5wZE4mZgHqMhZuxe4glIaxJhnE91DA2tLaYyEP6oYZvG8PXeywN4VT+QLAa6kbT9QDm2fW8RJIahrrevpnrfb3NthBOlVxRUQ+gLvnBlgV5QRfUM07bGLykcSSEp0qGcnXKx8zkvwxncqt+AHEAfQCikXAo6mg1JK3/B3DUdh/UDJ/eAAAAAElFTkSuQmCC">
</p>
</div>
<div>
<a class="word-export" href="javascript:void(0)">Export to Doc</a>
</div>In the above code, we have simply added few headings and a image file in base64 format.
Now, let’s add the required plugins, which is filesaver.js, jquery.js
<script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/3.3.1/jquery.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/FileSaver.js/1.3.8/FileSaver.min.js"></script>I have not added link to jQuery.wordexport.js, as we will be using direct plugin code because it is not available on cdn as of now, and here the complete function code
// jQuery html to word plugin function
if (typeof jQuery !== "undefined" && typeof saveAs !== "undefined") {
(function($) {
$.fn.wordExport = function(fileName) {
fileName = typeof fileName !== 'undefined' ? fileName : "jQuery-Word-Export";
var static = {
mhtml: {
top: "Mime-Version: 1.0nContent-Base: " + location.href + "nContent-Type: Multipart/related; boundary="NEXT.ITEM-BOUNDARY";type="text/html"nn--NEXT.ITEM-BOUNDARYnContent-Type: text/html; charset="utf-8"nContent-Location: " + location.href + "nn<!DOCTYPE html>n<html>n_html_</html>",
head: "<head>n<meta http-equiv="Content-Type" content="text/html; charset=utf-8">n<style>n_styles_n</style>n</head>n",
body: "<body>_body_</body>"
}
};
var options = {
maxWidth: 624
};
// Clone selected element before manipulating it
var markup = $(this).clone();
// Remove hidden elements from the output
markup.each(function() {
var self = $(this);
if (self.is(':hidden'))
self.remove();
});
// Embed all images using Data URLs
var images = Array();
var img = markup.find('img');
for (var i = 0; i < img.length; i++) {
// Calculate dimensions of output image
var w = Math.min(img[i].width, options.maxWidth);
var h = img[i].height * (w / img[i].width);
// Create canvas for converting image to data URL
var canvas = document.createElement("CANVAS");
canvas.width = w;
canvas.height = h;
// Draw image to canvas
var context = canvas.getContext('2d');
context.drawImage(img[i], 0, 0, w, h);
// Get data URL encoding of image
var uri = canvas.toDataURL("image/png");
$(img[i]).attr("src", img[i].src);
img[i].width = w;
img[i].height = h;
// Save encoded image to array
images[i] = {
type: uri.substring(uri.indexOf(":") + 1, uri.indexOf(";")),
encoding: uri.substring(uri.indexOf(";") + 1, uri.indexOf(",")),
location: $(img[i]).attr("src"),
data: uri.substring(uri.indexOf(",") + 1)
};
}
// Prepare bottom of mhtml file with image data
var mhtmlBottom = "n";
for (var i = 0; i < images.length; i++) {
mhtmlBottom += "--NEXT.ITEM-BOUNDARYn";
mhtmlBottom += "Content-Location: " + images[i].location + "n";
mhtmlBottom += "Content-Type: " + images[i].type + "n";
mhtmlBottom += "Content-Transfer-Encoding: " + images[i].encoding + "nn";
mhtmlBottom += images[i].data + "nn";
}
mhtmlBottom += "--NEXT.ITEM-BOUNDARY--";
//TODO: load css from included stylesheet
var styles = "";
// Aggregate parts of the file together
var fileContent = static.mhtml.top.replace("_html_", static.mhtml.head.replace("_styles_", styles) + static.mhtml.body.replace("_body_", markup.html())) + mhtmlBottom;
// Create a Blob with the file contents
var blob = new Blob([fileContent], {
type: "application/msword;charset=utf-8"
});
saveAs(blob, fileName + ".doc");
};
})(jQuery);
} else {
if (typeof jQuery === "undefined") {
console.error("jQuery Word Export: missing dependency (jQuery)");
}
if (typeof saveAs === "undefined") {
console.error("jQuery Word Export: missing dependency (FileSaver.js)");
}
}Now, add the jQuery code to call the above function on click and convert html to doc
jQuery(document).ready(function($) {
$("a.word-export").click(function(event) {
$("#MainHTML").wordExport();
});
});That’s, it, we are ready, here is the Codepen sample
Output is same as above, but in this approach we are using jQuery plugin and also converting image into base64 to get it work.
You may also to read:
Export html table to excel using jQuery / Javascript
How to get user location using Javascript / HTML5 Geolocation?
Closure in Javascript and its use
Read Excel in Javascript
I’m currently creating a Word document by generating HTML and changing the header information to display as a .doc file. It’s a poor man’s method, but it works just fine (until now).
I was just asked to include an image in the file. My best idea was to base64 embed the image. This works fine in a browser, however Word just gives me a box with an X in it.
Suggestions on how I can embed an image into this file and have it display in Microsoft Word?
asked Feb 24, 2010 at 21:56
![]()
St. John JohnsonSt. John Johnson
6,5807 gold badges35 silver badges56 bronze badges
5
That’s a tough one, Word isn’t able to handle data: base64 encoded images in HTML, at least that’s the outcome in this question and this MSDN discussion.
You have three options:
-
Create a folder in the location of the document, store it alongside the document, and reference images relatively (
<img src='imageFolder/image1.jpg'>) -
Work with absolute URLs or file paths (even more sucky)
-
Look into the new Word > 2003 XML based file format(s), it is definitely possible there.
The only other option I can think of is actually creating a native Word file, e.g. using OpenOffice.
![]()
answered Feb 24, 2010 at 22:12
![]()
3
I just achieved this by printing the DOCX to PDF then using Acrobat to Save As to HTML. Images showed up small, but there.
answered Jun 4, 2017 at 16:23
![]()
Время на прочтение
6 мин
Количество просмотров 5.1K
В статье Не очень честная генерация DOC файлов на PHP был описан описан способ генерации DOC файла при помощи генерации MHT (MIME HTML) используя стороннюю библиотеку. Сегодня я расскажу о своей собственной генерации в этот формат. Плюсы моего способа следующие:
1) В OpenOffice читаемый текст и картинки.
2) В Word открывается файл в электронном виде, а не на весь экран.
3) Наш скрипт будет принимать HTML и отдавать сразу DOC файл на скачивание.
Ко всему прочему, вы поймете как преобразовать голый HTML в MHT собственными руками. Ошибки если и будут, то копаться в коде будет проще.
Начнем с функции, которая отдаст DOC файл на скачивание и будет работать во всех браузерах и со всеми протоколами(у меня с этим были проблемы):
/* Отсылаем файл на закачку */
function send_download($filename, $charset = 'cp1251')
{
header ($_SERVER["SERVER_PROTOCOL"] . ' 200 OK');
if (ereg('Opera(/| )([0-9].[0-9]{1,2})', $_SERVER['HTTP_USER_AGENT']))
$UserBrowser = "Opera";
elseif (ereg('MSIE ([0-9].[0-9]{1,2})', $_SERVER['HTTP_USER_AGENT']))
$UserBrowser = "IE";
else
$UserBrowser = '';
$mime_type = ($UserBrowser == 'IE' || $UserBrowser == 'Opera') ?
'application/octetstream' : 'application/octet-stream';
header("Content-Type: application/msword; charset=".$charset);
$ua = (isset($_SERVER['HTTP_USER_AGENT']))?$_SERVER['HTTP_USER_AGENT']:'';
$isMSIE = preg_match('@MSIE ([0-9].[0-9]{1,2})@', $ua);
if ($isMSIE)
{
header('Content-Disposition: attachment; filename="' . $filename . '"');
header('Cache-Control: must-revalidate, post-check=0, pre-check=0');
header('Pragma: public');
}
else
{
header('Content-Disposition: attachment; filename="' . $filename . '"');
header('Pragma: no-cache');
}
}
Теперь перейдем к самой генерации DOC файла, для этого создадим форму, которая будет отправлять нам html с картинками, картинки лежат на нашем сайте.
<form action="getFile.php" method="POST">
<textarea name="text" rows ="10" cols="60"><?=str_replace(array('<', '>'), array('<', '>'), 'Это всего лишь <b>пример</b><img src="/images/logo.gif">');?></textarea>
<input type="submit" value="HTML TO DOC"/>
</form>
Преобразовывать изображения мы будем при помощи base64, создадим функцию — callback для этого:
/* Преобразование изображений */
function prepareImage($matches) {
global $IMAGES, $IMAGE_NAMES, $IMAGE_COUNT,$gldir,$SITE;
$imgfile = $_SERVER['DOCUMENT_ROOT'].'/'.$matches[2];
$imgbinary = fread(fopen($imgfile, "r"), filesize($imgfile));
$url = $SITE.$matches[1];
$data = chunk_split(base64_encode($imgbinary));
$IMAGE_COUNT++;
$ext = substr($matches[2], strpos($matches[2], '.') + 1, strlen($matches[2]));
$imgName = 'images'.$IMAGE_COUNT.'.'.$ext;
$IMAGES .= '
--doc_file_part_na_habrahabr
Content-Location: '.$gldir.'images/'.$imgName.'
Content-Transfer-Encoding: base64
Content-Type: image/'.$ext.'
'.$data.'
';
$pr1 = $matches[1];
$pr2 = $matches[3];
$IMAGE_NAMES .= '
<o:File HRef=3D"'.$imgName.'"/>';
return '<v:imagedata src=3D"'.$gldir.'images/'.$imgName.'" o:href=3D"'.$url.'"/></v:shape><![endif]--><![if !vml]><span style=3D"mso-ignore:vglayout"><img border=3D0 src=3D"'$gldir'.images/'.$imgName.'" alt=3DHaut v:shapes=3D"_x0000_i1057" '.$p1.' '.$pr2.'></span><![endif]>';
}
Сразу извиняюсь, за то, что код написан в функциях, а все данные храниться в глобальных переменных. Код был написан, когда я ещё только начинал писать на PHP. Теперь создадим функцию, которая поможет нам с текстом, чтобы он хотя бы читался и в OpenOffice.
/* Преобразование текста */
function xml_entities($text, $charset = 'cp1251'){
global $SITE;
/* Ищем изображения и добавляем их в файл */
$text = preg_replace_callback(
'/<img([a-zA-Z0-9:/.-?=_&s;"]*)src="([А-Яа-яa-zA-Zds:/.-?=_&]*)"([a-zA-Z0-9:/.-?=_&s;"]*)>/',
"prepareImage",
$text);
/* Преобразовываем ссылки относительные на глобальные */
$text = preg_replace('/href="/','href=3D"'.$SITE, $text);
/* Все пробелы должны быть закодированы как =3D, 3D - это шестнадцатиричный код пробела */
$text = preg_replace('/=(?=[^3])/','=3D',$text);
$text = preg_replace('/s?=s?"/','=3D"',$text);
/* Кодируем текст, чтобы читался в OpenOffice */
$text = htmlentities($text, null, $charset);
$fi = array(""","&","'","<",">");
$re = array('"',"&","'","<",">");
return str_replace($fi, $re, $text);
}
Теперь сам код скрипта:
global $SITE;
/* Имя сайта, на который будут вести ссылки и с которого нужно будет загрузить изображения */
$SITE = 'http://pihpi.ru';
function htmlToDoc($name, $html, $charset = 'cp1251') {
$nameFile = $name.'.doc';
global $IMAGES, $IMAGE_NAMES, $IMAGE_COUNT, $gldir, $SITE;
$IMAGE_COUNT = 0;
$IMAGE_NAMES = '';
$IMAGES = '';
$gldir = 'file:///C:/AF22D505/';
/* doc_file_part_na_habrahabr - это название части файла может быть любым. Для того, чтобы узнать подробнее, читайте про MIME или как отправить по почте файл с картинками, аналогия очевидна. */
$head = 'MIME-Version: 1.0
Content-Type: multipart/related; boundary="doc_file_part_na_habrahabr"
--doc_file_part_na_habrahabr
Content-Location: '.$gldir.$nameFile.'
Content-Transfer-Encoding: quoted-printable
Content-Type: text/html; charset="windows-1251"
<html xmlns:o=3D"urn:schemas-microsoft-com:office:office"
xmlns:w=3D"urn:schemas-microsoft-com:office:word"
xmlns=3D"http://www.w3.org/TR/REC-html40">
<head>
<meta http-equiv=3DContent-Type content=3D"text/html; charset=3Dwindows-1251">
<meta name=3DProgId content=3DWord.Document>
<meta name=3DGenerator content=3D"Microsoft Word 11">
<meta name=3DOriginator content=3D"Microsoft Word 11">
<link rel=3DFile-List href=3D"filelist.xml">
<!--[if gte mso 9]><xml>
<w:WordDocument>
<w:View>Print</w:View>
<w:GrammarState>Clean</w:GrammarState>
<w:ValidateAgainstSchemas/>
<w:SaveIfXMLInvalid>false</w:SaveIfXMLInvalid>
<w:IgnoreMixedContent>false</w:IgnoreMixedContent>
<w:AlwaysShowPlaceholderText>false</w:AlwaysShowPlaceholderText>
<w:BrowserLevel>MicrosoftInternetExplorer4</w:BrowserLevel>
</w:WordDocument>
</xml><![endif]--><!--[if gte mso 9]><xml>
<w:LatentStyles DefLockedState=3D"false" LatentStyleCount=3D"156">
</w:LatentStyles>
</xml><![endif]-->
<style>
<!--
/* Style Definitions */
p.MsoNormal, li.MsoNormal, div.MsoNormal
{mso-style-parent:"";
margin:0cm;
margin-bottom:.0001pt;
mso-pagination:widow-orphan;
font-size:12.0pt;
font-family:"Tahoma";
mso-fareast-font-family:"Tahoma";}
@page Section1
{size:595.3pt 841.9pt;
margin:18.0pt 19.3pt 18.0pt 18.0pt;
mso-header-margin:35.4pt;
mso-footer-margin:35.4pt;
mso-paper-source:0;}
div.Section1
{page:Section1;}
-->
</style>
<!--[if gte mso 10]>
<style>
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"41E43144B44743D43044F 44243043143B=
0438446430";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-parent:"";
mso-padding-alt:0cm 5.4pt 0cm 5.4pt;
mso-para-margin:0cm;
mso-para-margin-bottom:.0001pt;
mso-pagination:widow-orphan;
font-size:10.0pt;
font-family:"Tahoma";
mso-ansi-language:#0400;
mso-fareast-language:#0400;
mso-bidi-language:#0400;
width:100%;
}
td.br1{
border:1px solid black;
}
</style>
<![endif]-->
</head>
<body>';
$end = '
</body>
</html>
';
$html = xml_entities($html, $charset);
/* Мы получили все картинки, теперь сгенерим xml файл с ними */
$fileList = '
--doc_file_part_na_habrahabr
Content-Location: '.$gldir.'filelist.xml
Content-Transfer-Encoding: quoted-printable
Content-Type: text/xml; charset="utf-8"
<xml xmlns:o=3D"urn:schemas-microsoft-com:office:office">
<o:MainFile HRef=3D"../'.$nameFile.'"/>
'.$IMAGE_NAMES.'
<o:File HRef=3D"filelist.xml"/>
</xml>
';
$content = $head.$html.$end.$IMAGES.$fileList.'--doc_file_part_na_habrahabr--';
send_download($nameFile);
echo $content;
exit();
}
Ну и наконец само преобразование HTML в DOC в действии:
if (isset($_POST['text'])) {
htmlToDoc('article', str_replace('\', '', $_POST['text']));
}
Пример работы скрипта, вы можете посмотреть по следующей ссылке:
http://pihpi.ru/getFile.php
Несколько слов о Libre Office:
Текст выводиться, а вот картинки увы. Почитав про Mime пытался сделать через Content-ID, не вышло. Либо я чего-то не знаю, либо Libre Office вообще не хочет поддерживать MIME HTML.
Information and examples
-
-
Introduction to HTML to Word conversion with xmldocx
-
Basic Examples:- Simple HTML code
- External HTML source
- HTML code embeded within a Word table
- Embedding images
-
Supported HTML tags and attributes
-
Supported CSS properties
-
Using native Word formatting with HTML
-
Other general options
-
Inserting HTML into Word templates
-
HTML Extended
-
The conversion of HTML into Word is one of the most requested functionalities of xmldocx.
Since v1.0 xmldocx offers pretty sophisticated ways to include HTML formatted content into a Word document. The purpose of this tutorial is to offer a detailed account on how one can do it and how to get the most of it.
There are currently two elements to include HTML into a Word document generated from scratch (the case of templates will be treated further below) with phpdocx:
The first of them uses internally the “alternative content” element available in the OOXML standard (on which Word is based) and it is simple to use although it has two main drawbacks:
This said, it may be an interesting option if none of the above represents an issue for a given application.
In what follows we will concentrate in the pdx:embedHTML element and the replaceVariableByHTML (its avatar for working with Word templates).
The main advantages of the pdx:embedHTML element are summarised in:
Let us now get down to the nitty-gritty.
Let us first offer a few simple examples that illustrate the basic procedures:
Simple HTML code
The code needed to insert some plain HTML is as simple as this:
![]()
And you will get as a result (download the corresponding document):

![]()
And you will get as a result (download the corresponding document):
External HTML source
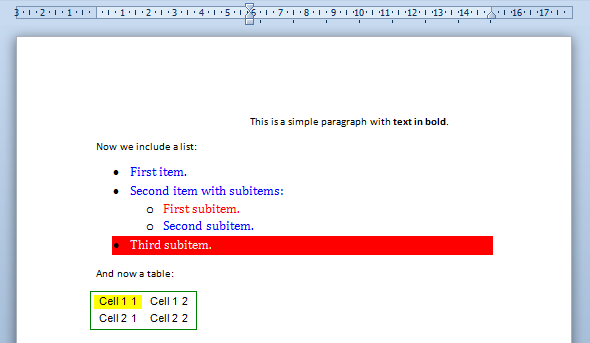
Sometimes one may need to get the HTML and CSS from existing external files but as we will now show this also turns to be extremely simple.
Let us assume that the HTML code above proceeds from an external html page: simpleHTML.html that links to a CSS stylesheet: styles.css.
Then the following code will render exactly the same results:
Notices that the only differences are:
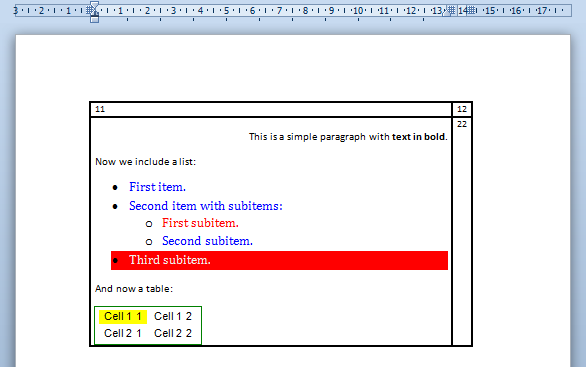
HTML code embeded within a Word table
It may well be that we choose not to embed directly the HTML code into the document but rather insert it within another document element like a table or a header/footer.
This can be achieved in a very simple way by setting the rawWordML option to true.
We may modify slightly the previous example:
![]()
And you will get as a result (download the corresponding document):
Embedding images
To include images is equally simple. One may choose to include the images within the document (with the attribute downloadImages set to true) or keep them as an externally linked resource (in that case you should make sure that the image is available to the final users).
A simple example that makes use of this simple web page with an image reads as follows:
![]()
And you will get as a result (download the corresponding document):
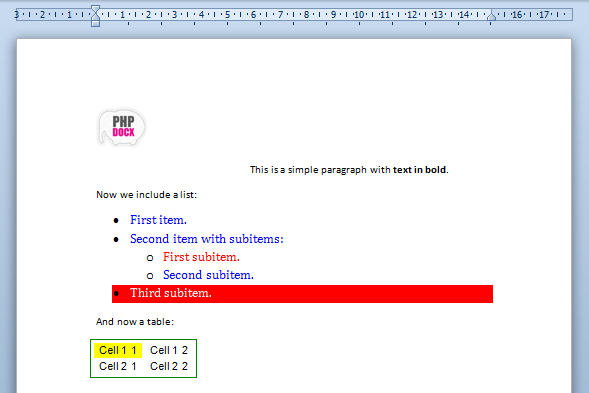
Notice that like in this case we have not declared the width and height attributes of the image, xmldocx reads its properties from the image header and inserts it with a resolution of 96 dpi (default resolution). One may, of course, choose custom width and height to obtain the desired results.
Supported HTML tags and attributes
xmldocx parses all the most commonly used HTML tags and attibutes.
It is important to take into account that the HTML and OOXML that Word is based on have different goals so at some points the translation from one to the other should include certain compromises that are not universally valid for all applications. Fortunately it is not difficult to find convenient workarounds that offer a close to perfect Word rendering.
The list of currently parsed HTML elements include:
Block type HTML elements
Inline type HTML elements
HTML web form elements
WARNINGS:
That a tag is not parsed does not mean that its content dissapears from the Word document. It only implies that their associated HTML properties are not taken directly into account. Their childs and text content will be parsed and rendered with their corresponding styles into the Word document.
Currently almost all CSS properties, that are posibly applicable to a document, are parsed and translated into their Word counterparts.
In order to achieve the best posible results it is important to know how these CSS properties are applied and their known limitations regarding the final document rendering.
The list of currently parsed CSS styles include:
Border styles and background color
The following border properties are parsed:
Margins and paddings
The concept of padding has not a general direct counterpart in Word so it is usually interpreted as extra margin space.
Page break properties
This properties are partially supported:
Font and text properties
The units may be pixels, points or ems and the colors follow the same scheme as above. The suported properties include:
Positioning
xmldocx tries to adapt as best as posible the positioning properties of elements to equivalent Word properties. If you need to position precisely elements in the resulting Word document the best and simplest way is to use tables.
You may also instruct xmldocx to parse divs as tables (see, for example, above) or to parse floats with the «parseFloats» set to true (image floats are always parsed by default).
In any case results are usually pretty good and cover all but the most sophisticated examples.
The parsed properties include:
Lists
xmldocx handles pretty well the rendering f HTML lists and their associated CSS styles. Nevertheless, if you want to use bullets beyond the most standard ones you should the xmldocx embedding HTML element in conjunction with the createListStyle element (by setting the ‘useCustomStyles’ attribute to true) to obtain the desired results.
In order to do so one should create a custom style that mimics the HTML result and give it the same name that is used in the HTML code for the corresponding class or id attribute. xmldocx will automatically use the corresponding formatting (bullets, indents, etcetera) previously defined by us.
In any case results are usually pretty good and cover all but the most sophisticated examples.
In case that we do not bother to define any custom list style the corresponding CSS list style property is parsed as follows:
Using native Word formatting with HTML
One of the nicest features of the embedHTML element is that it allows to use customized Word formatting for paragraphs and tables.
One may write plain HTML with little or none styling and yet generate a very sophisticated Word document.
The default base template already includes all standard Word styles for headings, paragraphs and tables. You may get all the available styles via the xmldocx parseStyles element.
Of course, yo may use a different base template that better suit your needs or even explicitely import styles from other docx via the xmldocx importStyles element.
Let us now go over a simple example that illustrates this functionality:
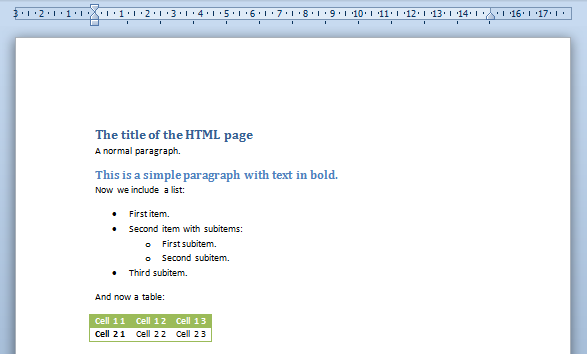
Notice that we have set the option strictWordStyles to true so the HTML parser will ignore the CSS properties and will apply exclusively the selected Word styles.
![]()
And you will get as a result (download the corresponding document):
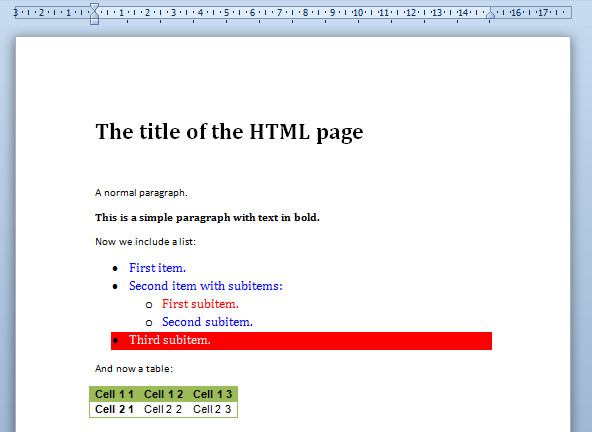
If one removes the option strictWordStyles or set it to false (its default value), phpdocx will try to combine the Word and HTML styles.
![]()
And you will get as a result (download the corresponding document):
Besides all the options that have been carefully analysed before there are are other general options that we now pass to comment briefly.
Inserting HTML into Word templates
All the precceding examples have their match in the case we are working with templates by means of the replaceVariableByHTML element.
All the available attributes are the same as before although we have to give two extra pieces of extra info, namely:
A simple example will better illustrate all this.
![]()
Let us start with a simple template that looks like this:
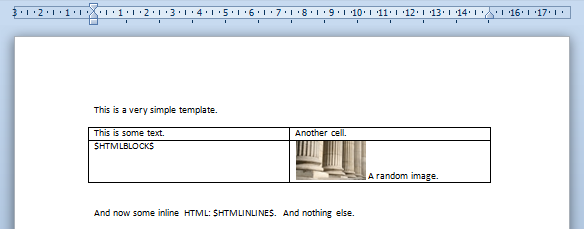
The following code:
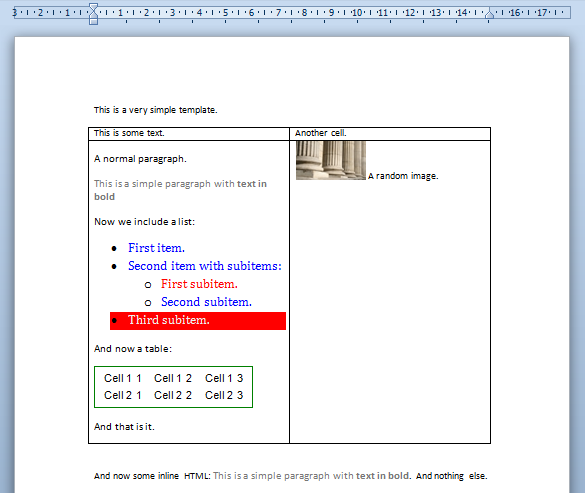
![]()
Fields (download the corresponding Word document):
Premium licenses include the HTML Extended mode to invoke xmldocx tags with custom HTML tags.
Thus, it is possible to insert headers, footers, comments, table of contents, cross-references, sections and many other contents. All of it integrated with the supported HTML tags and CSS styles.
An easy example of use of HTML Extended would be the creation of a DOCX with bookmarks, breaks and cross-references:
All the documentation regarding this feature is available in the HTML Extended page.
This is the best way I found to convert an HTML page to a Word docx file. You can use this approach if you need a Word version of any web page.
1. Save the Web Page as HTML
Navigate to the page you want to convert. Open the menu in your browser and choose Save page as… (or use Ctrl+S) and save it somewhere on your computer.
2. Open the Web Page in Word
You should now have an .htm or .html file. Right-click this file and choose Open with.. | Microsoft Word.
3. Save as DOCX
Go to the File Menu and choose Save as…. Change the file type to .docx and save. (If you see an info dialog, just click ok).
4. Embed Images
If the document contains images those images might only be linked. Usually you’ll want all images to be embedded inside the Word document.
Go to the File Menu and choose Info. If there are linked images you should see a link icon on the right. Click on Edit Links to Files.
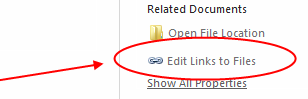
In the dialog select all images you want to embed in the list (use shift-key to select multiple images).
Click the Break Link button and then OK. All links are removed and the images are embedded in the document.
5. Clean Up
We can do some clean up to get rid of unwanted elements. Just delete the navigation, website logo, etc.
The web page usually opens in Web Layout View in Word. Change to the “normal” Print Layout View to see how it would fit on printed pages.
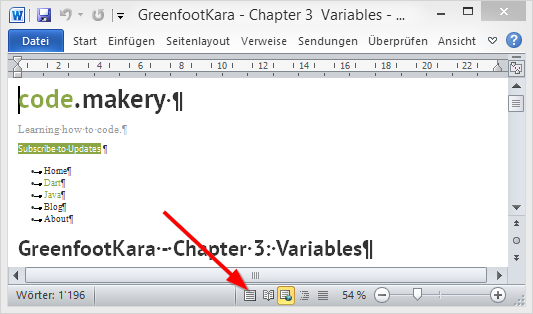
After some layouting you should have a pretty good word document of the web page.
Note: The heading Styles are automatically applied so you can just change the Styles and they will be applied to all headers.