
Introduction
Reports are one of the key requirements for management from any application whether it is a web application or Windows and they are interested to see it in Excel sheet. So, how about connecting an Excel sheet to a stored procedure and executing it directly from Excel sheet and get the result in the same sheet?
Yes, in this article, I am going to show you how to execute a stored procedure from Excel sheet. Let us consider a scenario where we have two tables in SQL Server database MyOrg, i.e., Department and Employee and say I want to execute a stored procedure GetAllEmpByDid as shown below:
Create procedure [dbo].[GetAllEmpByDid] (@Did as int) as select * from Employee where Did=@Did
Now, below are the steps that we need to perform to execute the stored procedure “GetAllEmpByDid” from Excel sheet.
Step 1
Open an Excel sheet, then go to:
DATA -> From Other Sources -> From Microsoft Query

Step 2
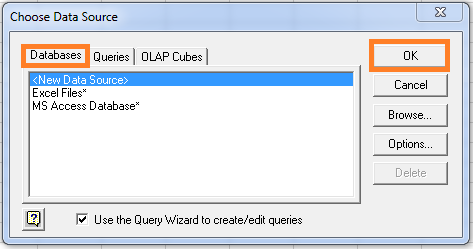
Once you select From Microsoft Query option, it will fire a Choose Data Source popup. Now from Databases tab select <new> and click OK.
Step 3
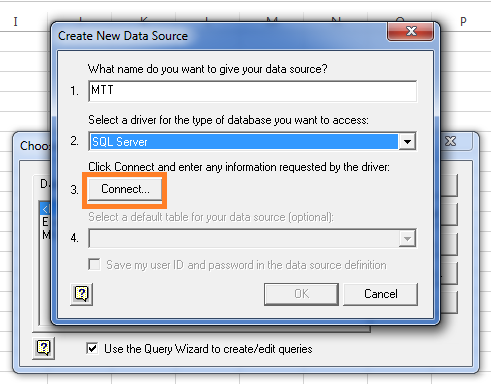
As you click OK, it will open another popup, i.e., Create New Data Source. Now give a name of data source, say “MTT” in textbox 1 and select driver as SQL Server from the dropdown list 2. Then click Connect button.
Step 4
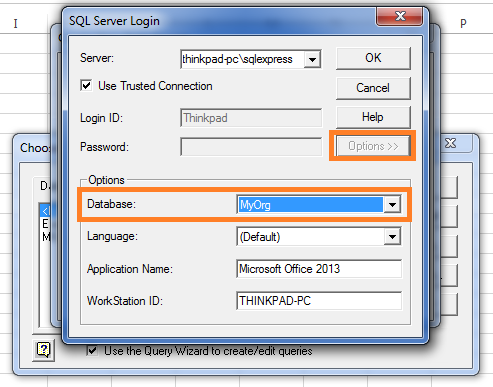
Once you click Connect, it will open one more popup SQL Server Login now give the SQL Server name in Server text box “thinkpad-pcsqlexpress”, for valid server name it will enable Options button. Now click Options button.

Step 5
Clicking on Options button will dropdown a form Options. Now select the database name from Databases dropdown list, say “MyOrg”. Finally click OK.
Step 6
As soon as you click OK, it will close SQL Server Login. Now Click OK button of Create New Data Source popup, which will close Create New Data Source popup. Finally click OK button of Choose Data Source popup and it will close Choose Data Source popup and will open new popup, i.e., Query Wizard – Choose Columns.

Step 7
Now click Cancel button of Query Wizard – Choose Columns which will prompt an alert Microsoft Query just click Yes button. Which will prompt another popup Add Tables. Now click on Close button of Add Tables, it will leave you on Microsoft Query Popup Window.

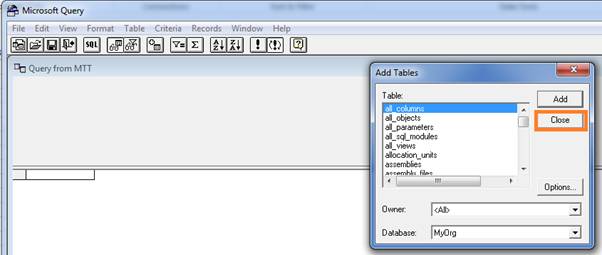
Step 8
From Microsoft Query Popup Window, click SQL button to open SQL popup window. Write the below query in SQL Statement box and press OK. It will prompt Microsoft Query alert once again and again press OK.
//{CaLL DatabaseName.dbo.StoredProcedureName(one question mark for each parameter)}
{CALL MyOrg.dbo.GetAllEmpByDid (?)}
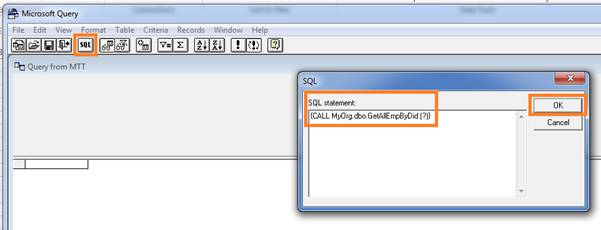
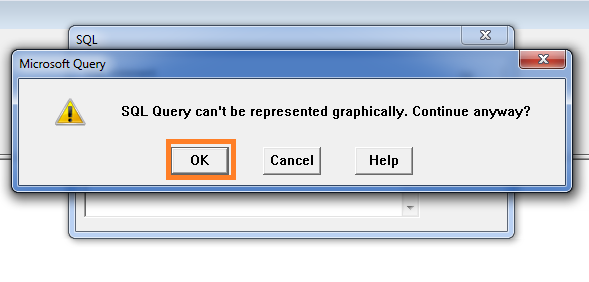
Step 9
After pressing OK of Microsoft Query alert, it will prompt a Parameter value window. Just give some default value say “1003”. And press OK and it will execute that stored procedure and give you the result set in Microsoft Query Window.
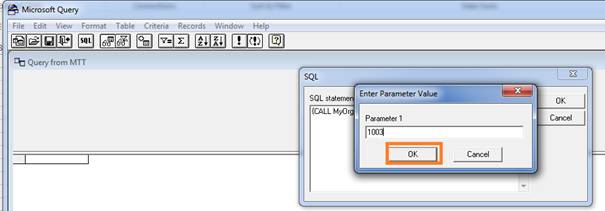
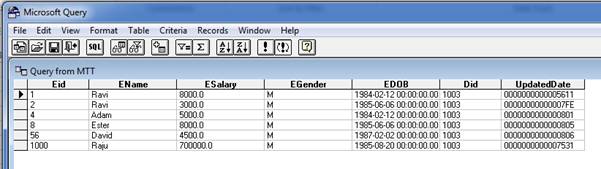
Step 10
Now close the Microsoft Query window. It will prompt another window, i.e., Import Data. Finally press OK to generate data on Excel sheet.
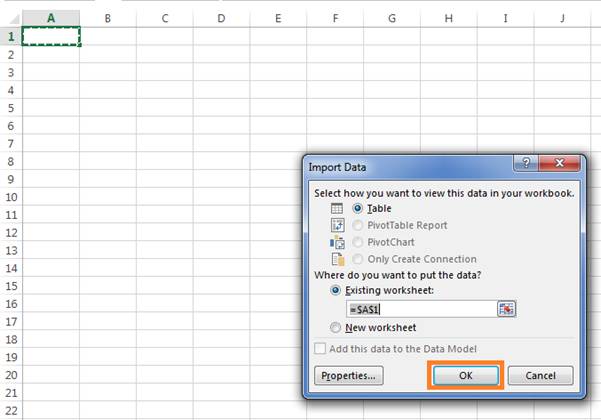

Step 11
Now we are ready with our Excel sheet executing stored procedure. If you want to execute once again, then go to DESIGN -> and click Refresh. It will prompt a Parameter value window once again, now give some other value say “1004”. And press OK to produce new result.
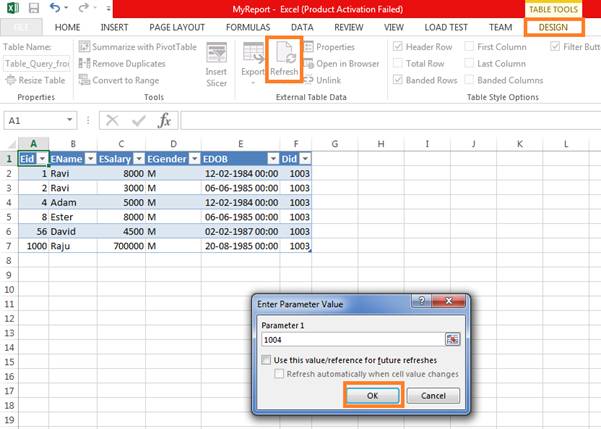

Step 12
Now save the Excel sheet and close it. Whenever you want to execute the procedure, just open the Excel sheet and refresh (Alt+F5) it from DESIGN tab.
Note
My special thanks to my friend Abhishek who helped me in creating this article.
Thanks for reading.
Today’s author is Mike Alexander, an Excel MVP who shows us how to run a Stored Procedure to get data from a SQL server.
We all know we can use MS Query to get data from a SQL server. Typically though, we pull from a Table or a View. Well in some organizations, the IT department wants all interaction with the server to be done through Stored Procedure. This adds a level of risk management and makes the DBAs feel better.
So today, I’ll show you how to easily make Excel run a Stored Procedure to get data.
Step 1: Data tab – > From Other Sources -> From SQL Server
Step 2: Enter Credentials. Your server name can be an IP address
Step 3: Choose any old table or view. Pick a small one because we’ll discard it later anyway.
Step 4: Excel will pop up the Import Data dialog box. Click Properties here (NOT THE OK BUTTON).
Step 5: Click on the Definition tab. There, change Command Type to SQL, and then enter your Stored Procedure name in the Command Text input.
Step 6: Excel complains about something….blah…blah…blah. Click Yes – (as in yes I know what I’m doing).
Step 7: Excel will activate the Import Data dialog box again. This time click OK to fire the Stored Procedure and return the results.
Step 8: Marvel at your results
Notes:
· Excel will fire the Stored Procedure each time you “Refresh”
· If you have to pass a parameter, you can enter it in the command text like this:
· If you have to pass dynamic parameters you’ll have to turn to VBA. I’ll do a post on this later this week.
· I assume you can do this with ORACLE databases too.
· I’ve yet to test whether this will fire a Stored Procedure that doesn’t return data. In other words, Stored Procedures that perform Insert, Update or Delete actions. I assume that if you can, there is the possibility of updating SQL from Excel through a simple connection. Pretty cool.
Время на прочтение
8 мин
Количество просмотров 39K
Цели, которых я хотел достичь
- Excel, как результат селекта, текст которого процедура узнает только в runtime
- Селект перед выпонением видоизменяется в соответствии с параметрами, которые получает процедура
- Процедуре передаются параметры файла, который будет создан
- Возможность получения результирующего файла в форматах Excel Workbook,CSV,HTML,XML
Хранимая PL/SQL процедура получает в параметрах
- текст селекта
- параметры файла Excel
- параметры выполнения
и создает полноценный Excel с несколькими таблицами(sheets).
Я знаю, что есть Crystal Reports и Oracle BI Publisher.
Но, во-первых, это крупные продукты(с большими ценами…), а Publisher, насколько я знаю не работает как отдельный модуль без Oracle Business Intelligence Enterprise Edition. И кроме того, речь шла о довольно узкой задаче создания файла без layout.
В конце, я написал один PL/SQL пакет, который находится в database и может быть вызван из любой аппликации. В ходе написания я столкнулся со многими ограничениями и хочу рассказать о том, как их поборол.
Для тех — кто сомневается, я этого, конечно не мог знать заранее, но за несколько лет, что пакет работает в большой компании, у меня не было проблем свести RDF любой сложности, с многими триггерами/формулами, в один селект, хвала Ораклу. Наоборот, так как селект — стринговый параметр и его можно построить динамически, это дает большую гибкость. В параметрах можно задать даже имя таблицы.
Прежде всего не судите строго за обилие англицизмов(так, по-моему, это называется), я просто давно вне русского программного сообщества и не знаю, чем заменяют эти слова.
Очень часто в аппликациях, написанных в Oracle Forms/Reports для создания файла Excel используют Oracle*Reports, потому что там есть возможность использовать параметры и видоизменять селект до его выполнения. Потом в триггер на уровне строки вывода пишут вывод в файл. Получается csv файл. Ну что же, можно и так, конечно.
Если вместе с Excel нужно создать pdf, то никуда не денешься, пользуйся Reports и не жалуйся как тебя достала эта программа. Но ведь часто нужен только Excel и городить для этого RDF как-то не хочется.
Итак, к делу.
Параметры файла
Тут все просто,
<DIR_NAME> </DIR_NAME>
<FILE_NAME> </FILE_NAME>
<OUT_TYPE> </OUT_TYPE>
<LIMIT_ROWS> </LIMIT_ROWS>
<LIMIT_LEN> </LIMIT_LEN>
<EXCEL_TITLE> </EXCEL_TITLE>
<SUBTITLE></SUBTITLE>
<SUBTITLE2></SUBTITLE2>
<DIRECTION> ltr/rtl </DIRECTION>
<CHARSET> </CHARSET>
<LITERAL_PARAMS> Y/N</LITERAL_PARAMS>
<DIVIDE_BY>FILES|SHEETS</DIVIDE_BY>
<PARAM_TITLE> </PARAM_TITLE>
<PAR_NAME_HEAD> </PAR_NAME_HEAD>
<PAR_VALUE_HEAD> </PAR_VALUE_HEAD>
<NOT_FOUND_MSG> </NOT_FOUND_MSG>
<LONG_OUT>Y/N</LONG_OUT>
<MULTI_VALUE_DELIMITER> </MULTI_VALUE_DELIMITER>
<CURR_DATE_PROMPT> </CURR_DATE_PROMPT>
<DEFAULT_DATE_MASK> </DEFAULT_DATE_MASK>
<OUTPUT_DATE_FORMAT></OUTPUT_DATE_FORMAT>
<CURRENT_SHEET></CURRENT_SHEET>
<TOTAL_SHEETS></TOTAL_SHEETS>
Примерно такой набор. Думаю, тут все понятно. Несколько слов:
LIMIT_ROWS, LIMIT_LEN позволяют делить результирующий файл в процессе создания по мере достижения предельных значений на несколько Excel корректных.
LITERAL_PARAMS говорит о том, как использовать параметры выполнения — вставлять значения или выполнять селект в dbms_sql с dbms_sql.bind_variable.
OUT_TYPE задает формат: Excel Workbook,CSV,HTML,XML
Как обеспечить динамичность селекта с параметрами, получаемыми в runtime
Параметры выполнения
Параметры передаем так:
<PARAMS>
<PARAM>
<NAME> </NAME>
<DATATYPE> [ALPHANUMERIC|CHAR|DATE|NUMBER|AS_IS] </DATATYPE>
<FORMAT_MASK>[Date format]</FORMAT_MASK>
<PROMPT> </PROMPT>
<LABEL> </LABEL>
<VALUE> </VALUE>
</PARAM>
..
</PARAMS>
Язык предвыполнения
Нужен некий язык, на котором можно написать инструкции, что делать в зависимости от значений параметров выполнения.
- Получаем параметры выполнения.
- Компилируем текст селекта.
- Подаем его для выполнения следующему шагу.
Вот язык, который в конце покрывал все мои потребности
В тексте селекта это выглядит как комментарий(hint)
/*!<HINT> [{]operand1[}] [ [{]operand2[}][{]operand3[}] ] ; !*/
Первое слово — это hint, определяющий команду
VAR CHAR | NUMBER | AS_IS | DATE [date format] {PL/SQL expression};
IF_CONTINUE {PL/SQL expression}
IF_EXECUTE {PL/SQL expression}
EXPR {PL/SQL expression};
IIF_EXPR {boolean expression} {String if true} {String if false};
IS_NOT_NULL {Bind variable} {String if Bind variable is not null};
IS_NULL {Bind variable} {String if Bind variable is null};
BOTTOM_SUM {Total bottom title} B C …Z;
ROW_SUM {Total column title} B C D… Z;
BEFORE {PL/SQL block};
TITLE {Title};
ALIAS {column_name} {alias};
AFTER {PL/SQL block};
Шаг компиляции заключается в том, что я нахожу в тексте команду, если один из операндов требует выполнения — выполняю это как select (expression) from dual или как PL/SQL блок в execute immediate и заменяю всю команду на результат выполнения.
Например
/*! VAR :Max_salary_dep number {select department_id
from (select ee.department_id,
sum(ee.salary)
from employee ee
/*! IS_NOT_NULL :emp_id {where ee.employee_id = :emp_id}; !*/
group by ee.department_id
order by sum(ee.salary) desc)
where rownum = 1} !*/
/*! VAR :Debug_print char 'Y' ; !*/
select e.first_name "First Name",
e.last_name,
d.name "Department name",
j.function,e.hire_date,e.salary,e.commission
/*! IS_NOT_NULL :loc_id {,l.regional_group}; !*/
from department d,employee e,job j
/*! IS_NOT_NULL :loc_id {,loc l}; !*/
where e.department_id=d.department_id
and e.job_id=j.job_id
/*! IS_NOT_NULL :loc_id { and l.loc_id=d.loc_id}; !*/
/*! IS_NOT_NULL :hire_date { and hire_date >= :hire_date}; !*/
/*! IS_NOT_NULL :function { and j.function=upper(:function)}; !*/
/*! IIF_EXPR {:dep_id is not null} {and d.department_id = :dep_id}
{and d.department_id = :Max_salary_dep}; !*/
/*! IS_NOT_NULL :emp_id {and employee_id = :emp_id}; !*/
/*! ROW_SUM {Total row} F G; !*/
/*! BOTTOM_SUM Total F G /*! IS_NOT_NULL :loc_id I ; !*/
/*! IS_NULL :loc_id H; !*/ ; !*/
В зависимости от передаваемых значений можно получить всякие селекты
select e.first_name "First Name",
e.last_name,
d.name "Department name",
j.function,e.hire_date,e.salary,e.commission
from department d,employee e,job j
where e.department_id=d.department_id
and e.job_id=j.job_id
and d.department_id = 20
select e.first_name "First Name",
e.last_name,
d.name "Department name",
j.function,e.hire_date,e.salary,e.commission
,l.regional_group
from department d,employee e,job j
,loc l
where e.department_id=d.department_id
and e.job_id=j.job_id
and l.loc_id=d.loc_id
and hire_date >= to_date('1985-09-08','yyyy-mm-dd')
and j.function=upper('SALESPERSON')
and d.department_id = 30
или
select e.first_name "First Name",
e.last_name,
d.name "Department name",
j.function,e.hire_date,e.salary,e.commission
from department d,employee e,job j
where e.department_id=d.department_id
and e.job_id=j.job_id
and hire_date >= to_date('1985-09-08','yyyy-mm-dd')
and j.function=upper('SALESPERSON')
and d.department_id = 30
ну и так далее…
Я это описал для того, чтобы вы поверили, что эти приемы позволяют писать действительно эффективные селекты.
Никаких » and (:param1 is null or table_field=:param1)»
Парсинг и выполнение
Ради этого раздела я затеялся писать эту статью. Здесь я напишу об опыте, который приобрел, и который наверняка не нужен тому, кто не ходил на границах допустимого в Оракле. Например, все знают, что максимальная длина текстового поля в таблице — 4000, но многие ли знают, что предел для конкатенации строкового поля в селекте в оракле тоже 4000 байтов.
Все знают
А может я не прав, может, это только я не знал.
Получили селект после предкомпиляции с параметрами выполнения. Он у нас в переменной l_Stmt.
К сожалению, в PL/SQL нет легкой возможности организовать цикл по полям селекта, как это можно было бы сделать в Java. Будем пользоваться процедурой dbms_sql.parse, которая возвращает поля селекта как таблицу, по которой сделаем цикл в дальнейшем.
Что мы хотим сделать?
Выполнить парсинг и получить список полей с datatype.
Для этого применяем
dbms_sql.parse
l_CursorId := dbms_sql.open_cursor;
begin
dbms_sql.parse(l_CursorId, substr('select * from (' || l_Stmt || ')', 1, 32765),1);
exception
when others then
v_Msg := '--After parse: ' || sqlerrm;
put_str_to_output(substr('select * from (' || l_Stmt || ')',1,32765));
raise ParsingException;
end;
dbms_sql.describe_columns
begin
dbms_sql.describe_columns(l_CursorId, l_ColumnCnt, l_LogColumnTblInit);
exception
when others then
v_Msg := '--After describe_columns: ' || sqlerrm;
put_str_to_output(substr('select * from (' || l_Stmt || ')', 1, 32765));
raise ParsingException;
end;
Мы получили самое главное — список полей селекта в PL/SQL таблице l_LogColumnTblInit.
Это для нас выполнил великий пакет DBMS_SQL. Теперь мы можем организовать цикл по полям селекта.
Тот, кто пишет на Java(в том числе и я теперешний) посмеется над такой победой, там это всегда было — перебор полей в PreparedStatement.
Сейчас, зная Java, я бы написал бы, может, по другому, но принципиальные вещи не изменились бы.
Кстати, здесь я встретил ограничение на размер селекта 32К, не сразу, в ходе эксплуатации, когда начали писать серьезные селекты. И тут меня снова порадовал Оракл. Оказывается, длинный селект можно разбить на порции 256 байт, зарузить в PL/SQL таблицу l_LongSelectStmt dbms_sql.varchar2s и передать в overload версию dbms_sql.parse.
begin
dbms_sql.parse(l_CursorId
,l_LongSelectStmt
,1
,l_LongSelectStmt.count
,false
,1);
exception
when others then
v_Msg := '--After parse long 2: ' || sqlerrm;
raise ParsingException;
end;
Теперь пришло время подумать о форматах вывода.
Допустим, наш селект выглядит так:
select a,b
from table1
where ...
Для вывода в формате CSV нужно написать
select a||chr(9)||b
from( select a,b
from table1
where ...
)
Для вывода в формате HTML нужно написать
select '<tr><td>'||a||'</td><td>'||b||'</td></tr>'
from( select a,b
from table1
where ...
)
Для создания самого красивого, но и самого сложного формата Excel Workbook, мне пришлось поэкспериментировать с Excel. Excel Workbook — это не бинарный, а текстовый файл, его можно посмотреть и понять, как там все устроено.
Там есть CSS, определения Workbook,Worksheet, заголовков таблиц. Не буду углубляться, это не очень сложно понять, если вы встречали раньше HTML.
В Excel Workbook строка вывода будет выглядеть примерно так
select '<Row> <Cell ss:StyleID="s24"><Data ss:Type="String">'||a|| '</Data></Cell>'||
'<Cell ss:StyleID="s25"><Data ss:Type="DateTime">'||b||'</Data></Cell>'||
'<Cell ss:StyleID="s24"><Data ss:Type="String">'||c||'</Data></Cell></Row>'
from ( select a,b,c
from table2
)
Здесь, как вы видите, нам может пригодиться знание типов данных из виртуальной таблицы, полученной в dbms_sql.describe_columns.
Если сравнивать типы вывода, то можно сказать следующее:
CSV — маленький по размеру(это плюс), некрасивый, нет возможности нескольких таблиц(spreadshhets)
HTML — средний по размеру, достаточно сексуальный, нет возможности нескольких таблиц
Excel Workbook — большой файл, красивый, есть возможность создания нескольких таблиц
Алгоритм работы
Цикл по полям
Двигаясь по таблице выходных полей, заворачиваем очередное поле в соответствующие формату тэги или просто добавляем табуляцию(CSV). Теперь вы поняли, как я ударился об эти 4000 байтов. Мне пришлось проверять перед слиянием строк длину результата и, если она была больше 4000, то начинал новое поле вывода, примерно так:
select '<Row> <Cell ss:StyleID="s24"><Data ss:Type="String">'||a|| '</Data></Cell>'||
'<Cell ss:StyleID="s25"><Data ss:Type="DateTime">'||b||'</Data></Cell>' а1,
'<Cell ss:StyleID="s24"><Data ss:Type="String">'||c||'</Data></Cell></Row>' а2
from ( select a,b,c
from table2
)
Когда селект построен, выполняем его. Если селект большой, то его надо загрузить в dbms_sql.varchar2s таблицу и выполнить в dbms_sql. Если ваш DBA сказал, что он не потерпит литералы и требует, чтобы параметры были bind variable, то тоже нужно использовать dbms_sql с dbms_sql.bind_variable.
Иначе, если ваш селект поместился в 32К вашей varchar2 переменной l_Stmt можете открыть ref cursor:
begin
open l_RefCursor for l_Stmt;
exception
when others then
v_Msg := '--After open: ' || sqlerrm;
raise ParsingException;
end;
Цикл по курсору
Делаем fetch и пишем в utl_file. Следим за количеством строк и за величиной выводимого файла, если нужно, завершаем его(красиво, Excel корректно) и начинаем следующий.
В конце, или, если это Excel Workbook в отдельном sheet, выводим параметры, с которыми выполнен отчет.
Ну вот, наверно и все по большому счету.
Наверное теперь можно показать результат:
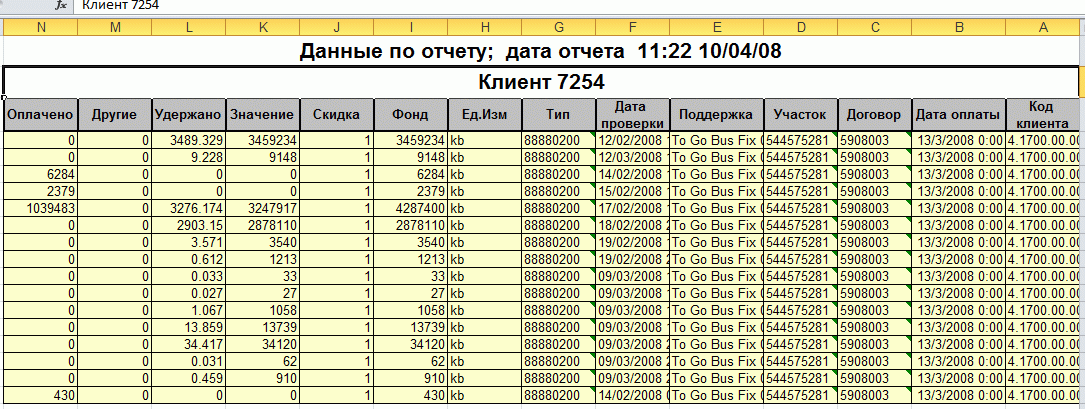
Если кому интересно, я могу рассказать, как я завернул этот пакет в другой, который зиповал файл, если он был большой, посылал его по мейлу как ссылку или как attachment, но главное, это определения параметров и типовой экран ввода.
This VBA is very similar to @Excellll’s answer, and I’ve used it to good effect in my own work.
Use this little utility function:
Public Function IsEmptyRecordset(rs As Recordset) As Boolean
IsEmptyRecordset = ((rs.BOF = True) And (rs.EOF = True))
End Function
And then here’s the big function (I apologize for the crummy-looking paragraph alignment):
Option Explicit
Public Sub OpenConnection()
Dim conn As ADODB.Connection
Dim str As String
Dim cmd As ADODB.Command
Dim rs As ADODB.Recordset
Dim myPath
Dim fld
Dim i As Integer
On Error GoTo errlbl
'Open database connection
Set conn = New ADODB.Connection
'First, construct the connection string.
'NOTE: YOU CAN DO THIS WITH A STRING SPELLING OUT THE ENTIRE CONNECTION...
'conn.ConnectionString = _
' "Provider=Microsoft.Jet.OLEDB.4.0;" & _
' "Data Source=" & _
' myPath & "ConnectionTest.mdb"
'...OR WITH AN ODBC CONNECTION YOU'VE ALREADY SET UP:
conn.ConnectionString = "DSN=myDSN"
conn.Open 'Here's where the connection is opened.
Debug.Print conn.ConnectionString 'This can be very handy to help debug!
Set rs = New ADODB.Recordset
'Construct string. This can "Select" statement constructed on-the-fly,
'str = "Select * from vwMyView order by Col1, Col2, Col3"
'or an "Execute" statement:
str = "exec uspMyStoredProc"
rs.Open str, conn, adOpenStatic, adLockReadOnly ‘recordset is opened here
If Not IsEmptyRecordset(rs) Then
rs.MoveFirst
'Populate the first row of the sheet with recordset’s field names
i = 0
For Each fld In rs.Fields
Sheet1.Cells(1, i + 1).Value = rs.Fields.Item(i).Name
i = i + 1
Next fld
'Populate the sheet with the data from the recordset
Sheet1.Range("A2").CopyFromRecordset rs
Else
MsgBox "Unable to open recordset, or unable to connect to database.", _
vbCritical, "Can't get requested records"
End If
'Cleanup
rs.Close
Set rs = Nothing
conn.Close
Set conn = Nothing
exitlbl:
Debug.Print "Error: " & Err.Number
If Err.Number = 0 Then
MsgBox "All data has been pulled and placed on Sheet1", vbOKOnly, "All Done."
End If
Exit Sub
errlbl:
MsgBox "Error #: " & Err.Number & ", Description: " & Err.Description, _ vbCritical, "Error in OpenConnection()"
Exit Sub
'Resume exitlbl
End Sub
Hope this helps.
|
Хранимая процедура в SQL запросе |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |


 только я не знаю как вложенные хранимки писать (
только я не знаю как вложенные хранимки писать (
Data on a server can be modified by examining the records ‘client-side’ in Excel VBA, changing them as required, and saving them back to the server.
A more efficient way of doing this, particularly if the database is at a remote location and there’s a lot of traffic involved, is to do the work ‘server-side’. This exercise calls a stored procedure from Excel to categorise employees into age-ranges according to their dates of birth (i.e. 18-25 years, 26-35 years, etc.), without a copious exchange of data between the server and Excel.
This article assumes the reader has the Developer ribbon displayed and is familiar with the VBA Editor. If not, please Google “Excel Developer Tab” or “Excel Code Window”.
There are three elements to the exercise:
- A data table tblStaff within a database TestDB;
- A stored procedure spAgeRange;
- An Excel xlsm, which we’ll call xlsm. A sample Excel file can be found here
Data Table
Create a database in SQL Server called DBTest.
Set up the following columns for a table tblStaff.

Copy the following into the table:
| 2017/05/25 | 1 | Brown | J | 1946/12/02 | M | ||
| 2017/05/25 | 2 | Smart | A | 1976/03/26 | F | ||
| 2017/05/25 | 3 | Cruise | T | 1962/07/03 | M | ||
| 2017/05/25 | 4 | Lohan | L | 1986/07/02 | F | ||
| 2017/05/25 | 5 | Fredricksen | F | 1964/03/15 | M | ||
| 2017/05/25 | 6 | Snyder | L | 1968/07/05 | F | ||
| 2017/05/25 | 7 | Lipnicki | J | 1983/11/25 | M | ||
| 2017/05/25 | 8 | Hoover | S | 2002/12/08 | F | ||
| 2017/05/25 | 9 | Watson | E | 1990/04/15 | F |
Stored Procedure.
Run this script against TestDB to create the stored procedure:
USE [TestDB] GO /****** Object: StoredProcedure [dbo].[spAgeRange] Script Date: 2017/05/10 12:16:28 PM ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE PROCEDURE [dbo].[spAgeRange] @PayrollDate varchar(50) AS BEGIN SET NOCOUNT ON; UPDATE tblStaff SET Age = CONVERT(int, DATEDIFF(day, DateOfBirth, GETDATE()) / 365.25, 0) WHERE tblStaff.PayrollDate = @PayrollDate Update tblStaff set AgeRange = '>56' where Age >= 56 and PayrollDate = @PayrollDate Update tblStaff set AgeRange = '46 to 55' where Age >= 46 and Age < 56 and PayrollDate = PayrollDate Update tblStaff set AgeRange = '39 to 45' where Age >= 39 and Age < 46 and PayrollDate = @PayrollDate Update tblStaff set AgeRange = '31 to 38' where Age >= 30 and Age < 39 and PayrollDate = @PayrollDate Update tblStaff set AgeRange = '25 to 30' where Age >= 25 and Age < 30 and PayrollDate = @PayrollDate Update tblStaff set AgeRange = '18 to 24' where Age >= 18 and Age < 25 and PayrollDate = @PayrollDate Update tblStaff set AgeRange = '<18' where Age < 18 and PayrollDate = @PayrollDate END
The stored procedure will saved under “Programmability” in the database.
Excel VBA
All that remains is to call the stored procedure from Excel, providing the PayrollDate parameter of “2017/05/25”. You will note I have simply data-typed PayrollDate as a string rather than wrestle with varying date formats. It is simple enough to convert a string to a date using the Convert function if PayrollDate is to be used for arithmetic purposes.
Create a new workbook. Open the VBA code window and insert a module.
From the code window’s Tools menu, reference the appropriate Active X 2.nn library to facilitate use of data objects.
Paste the following code into the Code window. This, once activated, will connect to SQL Server, as per the ConnectDatabase sub procedure
'All "public" in case the code is spread over several modules.
Public connDB As New ADODB.Connection
Public rs As New ADODB.Recordset
Public strSQL As String
Public strConnectionstring As String
Public strServer As String
Public strDBase As String
Public strUser As String
Public strPwd As String
Public PayrollDate As String
Sub WriteStoredProcedure()
PayrollDate = "2017/05/25"
Call ConnectDatabase
On Error GoTo errSP
strSQL = "EXEC spAgeRange '" & PayrollDate & "'"
connDB.Execute (strSQL)
Exit Sub
errSP:
MsgBox Err.Description
End Sub
Sub ConnectDatabase()
If connDB.State = 1 Then connDB.Close
On Error GoTo ErrConnect
strServer = "SERVERNAME" ‘The name or IP Address of the SQL Server
strDBase = "TestDB"
strUser = "" 'leave this blank for Windows authentication
strPwd = ""
If strPwd > "" Then
strConnectionstring = "DRIVER={SQL Server};Server=" & strServer & ";Database=" & strDBase & ";Uid=" & strUser & ";Pwd=" & strPwd & ";Connection Timeout=30;"
Else
strConnectionstring = "DRIVER={SQL Server};SERVER=" & strServer & ";Trusted_Connection=yes;DATABASE=" & strDBase 'Windows authentication
End If
connDB.ConnectionTimeout = 30
connDB.Open strConnectionstring
Exit Sub
ErrConnect:
MsgBox Err.Description
End Sub
Add a button to Sheet1 and assign it to sub procedure “WriteStoredProcedure”
The Results
Press the button, then examine tblStaff, which should be updated with ages and age ranges. The processing has taken place server-side.
Recovering corrupted workbooks
Should Excel crash it might well take your only copy of the workbook down with it. A good percentage of the time Excel is often unable to recover damaged workbooks; in such a case, all the work done since the creation of the workbook might be irrevocably lost, unless you have a tool to repair Excel xlsx or xlsm files.
Author Introduction:
Felix Hooker is a data recovery expert in DataNumen, Inc., which is the world leader in data recovery technologies, including rar repair and sql recovery software products. For more information visit www.datanumen.com
Я установил соединение с моим SQL-сервером в базу данных, где хранится хранимая процедура. Хранимая процедура отлично работает в SQLServer. Хранимая процедура запускается из соединения с жестко закодированными параметрами в Excel просто отлично. Я получаю свой набор данных, и он вставлен в мою таблицу. Макрос не работает. В макросе я пытаюсь указать диапазон в электронной таблице, содержащий мои значения параметров, чтобы я мог вводить значения в электронную таблицу, а затем макрос забирал их и передавал их в хранимую процедуру. Я использую формат даты как для значений электронной таблицы, так и для параметров в хранимой процедуре. Я хочу, чтобы набор данных возвращался для обновления в электронной таблице с новыми данными при запуске макроса. Вот мой макрос:
Sub GetHeatMapData()With ActiveWorkbook.Connections("CARLA-PC-Billing-SP").OLEDBConnection.CommandText = "EXECUTE dbo.GetBillingHeatMap '" & Range("A9").Value & "" & Range("B9").Value & "'"
End With
ActiveWorkbook.Connections("CARLA-PC-Billing-SP").Refresh
End Sub
Однако, если я попытаюсь запустить хранимую процедуру из макроса в Excel, произойдет одна из двух вещей:
Если в электронной таблице, которая была создана запущенная хранимая процедура из окна подключения, существует существующий набор данных, макрос работает без ошибок, но он не подбирает динамические переменные, поэтому данные не изменяются, как следует.
Если я удалю набор данных, созданный при запуске Хранимой процедуры в окне подключения, выберите ячейку, где должны начинаться данные, затем запустите макрос, чтобы получить ошибку «индекс вне диапазона», и ничего не происходит.
Я устанавливаю NOCOUNT в конце моей хранимой процедуры. Ниже приведены определения параметров в хранимой процедуре:
-- Add the parameters for the stored procedure here
@StartDate Date,
@EndDate Date
Вот мои настройки соединения: 
Мой вопрос в том, почему хранимая процедура не получает мои параметры из ячеек электронной таблицы Excel и использует их для фильтрации возвращаемых данных?
В своей прошлой статье я рассказывал про программные возможности языка SQL и обещал поделиться кейсом по созданию автоматизированного отчета на основе стека технологий MS SQL Server и Power BI.
Почему именно эти технологии?
За время работы аналитиком, я перепробовал различные варианты сбора отчетности. Начиная с ручной выгрузки данных из кабинетов рекламных систем, с последующим сведением в Excel, и заканчивая созданием специальных отчетов в Google Analytics или дашбордов в Data Studio.
Но ни один из вариантов не был идеальным и каждый имел свои недостатки. Все изменилось, когда я открыл для себя Power BI.
Microsoft Power BI — это один из самых технологичных на данный момент инструментов по визуализации данных, обладающий большим набором коннекторов к различным системам.
Но и Power BI сам по себе не идеален и без грамотного использования будет работать медленно и неэффективно. Приведу два примера:
- Если вы попытаетесь собрать модель данных из различных источников, с большим количеством связей и рассчитываемых показателей на стороне Power BI, то отчет будет жутко тормозить, а ведь именно таким принципам работы учит большое количество курсов по данному инструменту.
- Еще пример, если вы пытаетесь загрузить в модель данные из Google Analytics при помощи встроенного коннектора, то столкнетесь как минимум с двумя проблемами — ограничениями API GA и долгой выгрузкой данных.
Вышеописанные проблемы привели меня к мысли о загрузке всех данных сначала в базу, моделировании отчета при помощи SQL и только потом их визуализации в Power BI.
Переходим к делу
Для примера возьмем задачу по автоматизации отчета по эффективности контекстной рекламы.
К данному отчету заказчиком предъявляются следующие требования:
- Отчет должен содержать исторические данные по вчерашний день;
- Отчет должен обновляться ежедневно в автоматизированном режиме;
- Помимо Power BI, должна быть возможность подключения к отчету через Excel.
Также отчет должен содержать следующие параметры и показатели:
- Дата;
- Источник/Канал
- Кампания
- Сумма расходов;
- Кол-во показов;
- Кол-во кликов;
- Кол-во сеансов;
- Кол-во заказов;
- Доход;
- Рассчитываемые показатели — CPC, CR и ROMI.
Естественно, все данные должны быть предварительно загружены в хранилище, но это тема отдельного поста и обычно этим занимаются data-инженеры. Мы же с вами аналитики и используем те данные, которые для нас любезно сложили в DWH (хранилище данных).
В моем случае DWH работает на базе MS SQL Server и содержит следующие таблицы:
- sessions — данные из Google Analytics загруженные посредством коннектора к Reporting API v4;
- costs — данные по расходам, предварительно загруженные в Google Analytics;
- orders — данные по заказам и доходу из внутренней CRM-системы.
Для работы нам потребуется установить:
- SQL Server Management Studio — для подключения к DWH;
- Power BI Desktop — для создания отчета.
Опущу совсем уж базовые вещи, такие как регистрация аккаунтов и установка программ, с этим вы без проблем справитесь и сами.
Готовим данные
Итак, задача понятна, инструменты готовы — за дело!
Создаем таблицу
Для того чтобы создать отчет, нам необходимо свести данные по расходам, сеансам и заказам в одной таблице. Для этого напишем SQL-запрос, в котором объединим таблицы по следующим ключам:
date;sourceMedium;campaign.
Кстати, никакой сквозной аналитики у вас никогда не получится, если вы не умеете грамотно размечать рекламу utm-метками. О том как правильно ставить метки, читайте в одном из уроков бесплатного онлайн-курса «Digital-аналитика для новичков».
Но вернемся к задаче и после некоторых манипуляций с SQL получим вот такой скрипт:
-- Создаем переменные с датами отчета
SET DATEFIRST 1
DECLARE @startDate date, @endDate date;
SET @startDate = '2020-03-10'
SET @endDate = '2020-03-10';
-- Запрашиваем сеансы
WITH [sessions] AS (
SELECT
[date]
, sourceMedium
, campaign
, SUM([sessions]) AS 'sessions'
-- Желательно использовать 'WITH (NOLOCK)', чтобы не блокировать высоконагруженную базу
FROM [GoogleAnalytics].[dbo].[sessions] WITH (NOLOCK)
-- Задаем период
WHERE [date] BETWEEN @startDate AND @endDate
-- Указываем источники трафика, по которым будем строить отчет
AND sourceMedium IN ('google / cpc', 'yandex / cpc')
GROUP BY [date], [sourceMedium], [campaign]
)
-- Запрашиваем расходы
, costs AS (
SELECT
[date]
, sourceMedium
, campaign
, SUM(cost) AS 'cost'
, SUM(impressions) AS 'impressions'
, SUM(clicks) AS 'clicks'
FROM [GoogleAnalytics].[dbo].[cost] WITH (NOLOCK)
WHERE [date] BETWEEN @startDate AND @endDate
AND sourceMedium IN ('google / cpc', 'yandex / cpc')
GROUP BY [date], [sourceMedium], [campaign]
)
-- Объединяем сеансы с расходами
, costs_sessions AS (
SELECT
-- 'ISNULL' используем для того, чтобы не получить результат 'NULL' там где не было расходов по источнику, но был сеанс
ISNULL(costs.[date], [sessions].[date]) AS 'date'
, ISNULL(costs.sourceMedium, [sessions].sourceMedium) AS 'sourceMedium'
, ISNULL(costs.campaign, [sessions].campaign) AS 'campaign'
, ISNULL(SUM(costs.cost),0) AS 'cost'
, ISNULL(SUM(costs.impressions),0) AS 'impressions'
, ISNULL(SUM(costs.clicks),0) AS 'clicks'
, ISNULL(SUM([sessions].[sessions]), 0) AS 'sessions'
FROM costs
FULL JOIN [sessions]
ON costs.[date] = [sessions].[date] AND costs.sourceMedium = [sessions].sourceMedium AND costs.campaign = [sessions].campaign
GROUP BY ISNULL(costs.[date], [sessions].[date]), ISNULL(costs.sourceMedium, [sessions].sourceMedium), ISNULL(costs.campaign, [sessions].campaign)
)
-- Запрашиваем заказы и доход
, orders AS (
SELECT
[date]
, sourceMedium
, campaign
, SUM(orders) AS 'orders'
, SUM(revenue) AS 'revenue'
FROM [Crm].[dbo].[orders] WITH (NOLOCK)
WHERE [date] BETWEEN @startDate AND @endDate
AND sourceMedium IN ('google / cpc', 'yandex / cpc')
GROUP BY [date], [sourceMedium], [campaign]
)
-- Объединяем данные по трафику с данными о заказах
, join_table AS (
SELECT
ISNULL(costs_sessions.[date], orders.[date]) AS 'date'
, ISNULL(costs_sessions.sourceMedium, orders.sourceMedium) AS 'sourceMedium'
, ISNULL(costs_sessions.campaign, orders.campaign) AS 'campaign'
, ISNULL(SUM(costs_sessions.cost), 0) AS 'cost'
, ISNULL(SUM(costs_sessions.impressions), 0) AS 'impressions'
, ISNULL(SUM(costs_sessions.clicks), 0) AS 'clicks'
, ISNULL(SUM(costs_sessions.[sessions]), 0) AS 'sessions'
,ISNULL(SUM(orders.orders), 0) AS 'orders'
, ISNULL(SUM(orders.revenue), 0) AS 'revenue'
FROM costs_sessions
FULL JOIN orders
ON costs_sessions.[date] = orders.[date] AND costs_sessions.sourceMedium = orders.sourceMedium AND costs_sessions.campaign = orders.campaign
GROUP BY ISNULL(costs_sessions.[date], orders.[date]), ISNULL(costs_sessions.sourceMedium, orders.sourceMedium), ISNULL(costs_sessions.campaign, orders.campaign)
)
-- Выводим итоговый результат
SELECT *
FROM join_table
Запустим его и порадуемся получившемуся результату:

Создаем таблицу
Скрипт работает и выдает отчет, в принципе его уже можно использовать для автоматизации вставив в Power BI при помощи встроенного коннектора. Но не советую так делать, потому что если данных в отчете будет много, например заказчик захочет посмотреть как работали рекламные кампании в течение года, на выполнение скрипта может уйти несколько часов.
Гораздо более правильным решением будет создать промежуточную таблицу в базе данных и докладывать туда ежедневно данные за прошедшие сутки. Что мы и сделаем:

Таблица будет иметь следующую структуру (подробнее о типах данных):

При сохранении таблицы укажем название:

И теперь, чтобы получить все данные из нее, достаточно выполнить простой SELECT:
SELECT * FROM paid_traffic_report
Создаем хранимую процедуру
Отлично! Настало время автоматизации 😉
А поможет нам в этом функционал хранимых процедур (подробнее рассказывал о них тут).
Засучим рукава и обернем наш скрипт в код процедуры:
CREATE PROCEDURE fill_paid_traffic_report
(
@startDate date,
@endDate date
)
AS
BEGIN
-- Уберем из кода переменные, они нам понадобятся позже при настройке расписания
-- Запрашиваем сеансы
WITH [sessions] AS (
SELECT
[date]
, sourceMedium
, campaign
, SUM([sessions]) AS 'sessions'
-- Желательно использовать 'WITH (NOLOCK)', чтобы не блокировать высоконагруженную базу
FROM [GoogleAnalytics].[dbo].[sessions] WITH (NOLOCK)
-- Задаем период
WHERE [date] BETWEEN @startDate AND @endDate
-- Указываем источники трафика, по которым будем строить отчет
AND sourceMedium IN ('google / cpc', 'yandex / cpc')
GROUP BY [date], [sourceMedium], [campaign]
)
-- Запрашиваем расходы
, costs AS (
SELECT
[date]
, sourceMedium
, campaign
, SUM(cost) AS 'cost'
, SUM(impressions) AS 'impressions'
, SUM(clicks) AS 'clicks'
FROM [GoogleAnalytics].[dbo].[cost] WITH (NOLOCK)
WHERE [date] BETWEEN @startDate AND @endDate
AND sourceMedium IN ('google / cpc', 'yandex / cpc')
GROUP BY [date], [sourceMedium], [campaign]
)
-- Объединяем сеансы с расходами
, costs_sessions AS (
SELECT
-- 'ISNULL' используем для того, чтобы не получить результат 'NULL' там где не было расходов по источнику, но был сеанс
ISNULL(costs.[date], [sessions].[date]) AS 'date'
, ISNULL(costs.sourceMedium, [sessions].sourceMedium) AS 'sourceMedium'
, ISNULL(costs.campaign, [sessions].campaign) AS 'campaign'
, ISNULL(SUM(costs.cost),0) AS 'cost'
, ISNULL(SUM(costs.impressions),0) AS 'impressions'
, ISNULL(SUM(costs.clicks),0) AS 'clicks'
, ISNULL(SUM([sessions].[sessions]), 0) AS 'sessions'
FROM costs
FULL JOIN [sessions]
ON costs.[date] = [sessions].[date] AND costs.sourceMedium = [sessions].sourceMedium AND costs.campaign = [sessions].campaign
GROUP BY ISNULL(costs.[date], [sessions].[date]), ISNULL(costs.sourceMedium, [sessions].sourceMedium), ISNULL(costs.campaign, [sessions].campaign)
)
-- Запрашиваем заказы и доход
, orders AS (
SELECT
[date]
, sourceMedium
, campaign
, SUM(orders) AS 'orders'
, SUM(revenue) AS 'revenue'
FROM [Crm].[dbo].[orders] WITH (NOLOCK)
WHERE [date] BETWEEN @startDate AND @endDate
AND sourceMedium IN ('google / cpc', 'yandex / cpc')
GROUP BY [date], [sourceMedium], [campaign]
)
-- Объединяем данные по трафику с данными о заказах
, join_table AS (
SELECT
ISNULL(costs_sessions.[date], orders.[date]) AS 'date'
, ISNULL(costs_sessions.sourceMedium, orders.sourceMedium) AS 'sourceMedium'
, ISNULL(costs_sessions.campaign, orders.campaign) AS 'campaign'
, ISNULL(SUM(costs_sessions.cost), 0) AS 'cost'
, ISNULL(SUM(costs_sessions.impressions), 0) AS 'impressions'
, ISNULL(SUM(costs_sessions.clicks), 0) AS 'clicks'
, ISNULL(SUM(costs_sessions.[sessions]), 0) AS 'sessions'
,ISNULL(SUM(orders.orders), 0) AS 'orders'
, ISNULL(SUM(orders.revenue), 0) AS 'revenue'
FROM costs_sessions
FULL JOIN orders
ON costs_sessions.[date] = orders.[date] AND costs_sessions.sourceMedium = orders.sourceMedium AND costs_sessions.campaign = orders.campaign
GROUP BY ISNULL(costs_sessions.[date], orders.[date]), ISNULL(costs_sessions.sourceMedium, orders.sourceMedium), ISNULL(costs_sessions.campaign, orders.campaign)
)
-- Вставляем данные в таблицу
INSERT INTO paid_traffic_report
SELECT *
FROM join_table
END;
Теперь протестируем и вручную вызовем процедуру:

Скорость отработки процедуры 3 секунды на одном дне — вполне приемлемо. Проверим появились ли данные в ранее созданной таблице:

Осталось настроить ежедневное обновление.
Настраиваем расписание
Настроим вызов нашей процедуры каждое утро по расписанию, благо в Management Studio для этого предусмотрена специальная служба под названием «Агент SQL Server».
Зайдем в агент и добавим новое задание:

Укажем название и придумаем описание:

Далее создадим новый шаг, в котором будем вызывать процедуру с данными за прошедшие сутки (обратите внимание, объявление переменных с датами из нашего скрипта мы перенесли в расписание и немного изменили):

Настраиваем время запуска, периодичность и сохраняем:

Теперь данные автоматически будут поступать в отчет ежедневно в 9 утра.
Визуализируем данные
Данные готовы, обновление настроено, самое время приступить к визуализации.
Останавливаться на том как установить Power BI и как им пользоваться не буду, так как этой теме посвящен целый урок нашего курса.
Создаем отчет
Заходим в desktop-версию Power BI и открываем коннектор к SQL Server:

Вводим данные для подключения к серверу, название базы данных и наш короткий SQL-запрос к ранее созданной табличке:

И это все! Никаких сложных моделей в Power BI строить не нужно, так как мы уже это сделали на стороне SQL-запроса.
Наиболее правильным считаю подход, когда инструмент визуализации используется именно для этой самой визуализации и еще для создания рассчитываемых показателей (например, CPC, CPO, ROMI). Используйте эти рекомендации и ваши отчеты будут летать.
После того как будет готов дизайн отчета, его нужно загрузить в облако Microsoft:

Настраиваем расписание
Отчет опубликован! Остался финальный шаг, для этого переходим в веб-версию Power BI и настраиваем расписание обновления.
Но перед этим не забываем поставить на компьютер, с которого будет происходить обновление, локальный шлюз Power BI (а лучше всего завести под это дело отдельную виртуальную машину):

Важно так подгадать расписание, чтобы оно запускалось в тот момент, когда на стороне SQL Server уже отработает наша процедура и положит в табличку свежие данные. Плюс нужно заложить небольшой запас времени, на возможные проблемы с сервером при его перегрузке:

Готово. Теперь можем пользоваться отчетом внутри веб-интерфейса, опубликовать отчет в интернете, либо отправить коллегам ссылку на него.

А как же Excel?
Иногда заказчики могут попросить загрузить данные в Excel для более детального анализа.
Для этого зайдем в Excel на вкладку «Данные» и создадим новое подключение к серверу баз данных:

После чего останется только указать SQL-запрос и сохранить:

С этого момента данные из нашей таблицы на сервере станут доступны в Excel.
Итог
В итоге мы получили автообновляемую отчетность, без привлечения каких-то гигантских ресурсов разработки и без особых денежных затрат.
Буду рад ответить на ваши вопросы.
- Об авторе
- Свежие записи
