
Download PC Repair Tool to quickly find & fix Windows errors automatically
If you want to check duplicate text online using Word, it is possible to get the job done without using any third-party add-in now. You do not need to spend money on a duplicate text finder since Word can do the job pretty well. It is via the new Microsoft Editor included in the Word program a few months back.
Let’s assume that you want to check several documents every day and find out if someone has copied any text from any source. There are two options in your hands. One, you can search for a dedicated duplicate text finder or Plagiarism Checker software, which is quite common on the internet. However, the problem is most of them have a limitation on words. Two, you can use Microsoft Word’s Similarity feature to find the duplicate text. If the second option seems reasonable for you, you can use this tutorial to get the job done.
Microsoft introduced Editor quite a few months back. It helps you edit the document flawlessly. It does everything pretty well, from finding formal writing, clarity, grammar to inclusiveness, punctuation, etc. One of the features of this Editor is finding duplicate text. For your information, it uses the Bing search engine to find similar text online. In other words, your entered text needs to be indexed on Bing in order to find the similarity.
You can use the Similarity feature in Editor to check for duplicate text online using Microsoft Word. To check for duplicate text online in Word, follow these steps:
- Open the document in Word on your computer.
- Click on the Editor icon visible in the top right corner.
- Click on the Similarity option.
- Click on each duplicate line/text to find the original source.
To get started, you need to open the document in Word on your PC. However, if it is already opened, you can skip this step. Then, click on the Editor icon, which is visible on the top-right corner of the Word window.
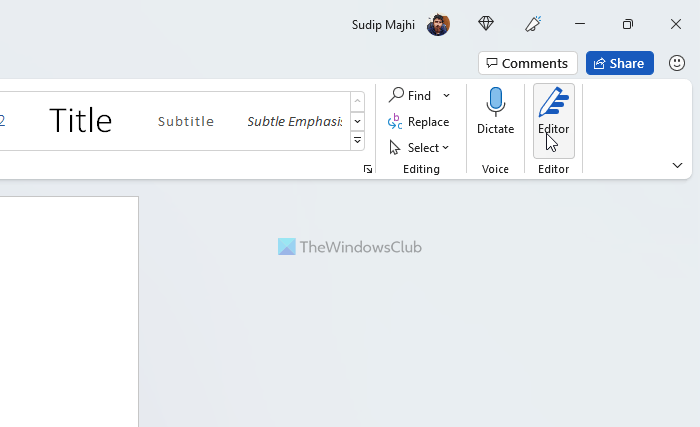
Give it a few seconds to find all the things. Once done, you need to head over to the Similarity section and click on the Check for similarity to online sources option.
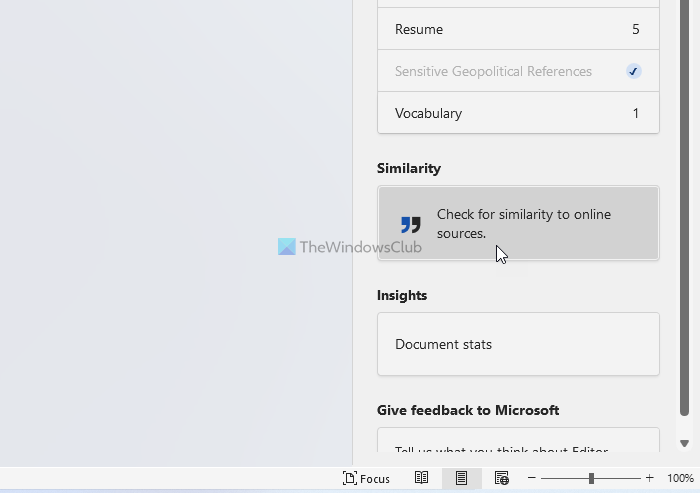
Then, it again takes some time to find all the similar or duplicate texts. Now, you can click on each duplicate text to find the original source.

From here, you can copy the full citation by clicking the Copy full citation button. On the other hand, if you want, you can use the in-text citation as well. For that, you need to use the Add in-text citation option. However, if you think that the duplicate text is ignorable, you can click on the Ignore button as well. By clicking this button, you are acknowledging the similar text and ignoring it from appearing again.
How do I find duplicate text in Word?
To find duplicate text in Word, you have two options. First, you can use the Editor panel to find the duplicate text online through Word. Second, you can use the Ctrl+F keyboard shortcut to find duplicate texts within the Word document. The main difference between the first and second methods is that the former method allows you to find the duplicate text online.
How do I remove duplicate text in Word?
To remove duplicate text in Word, you need to use the Find menu. For that, open a document in Word and press Ctrl+F. Then, type the word or text you want to find a duplicate for. Following that, you will get all the highlights of duplicate texts. From there, you can remove or keep the word as per your requirements.
Hope this guide helped you.
Read: How to Add, Change, Remove Author from Author Property in Office document.

When he is not writing about Microsoft Windows or Office, Sudip likes to work with Photoshop. He has managed the front end and back end of many websites over the years. He is currently pursuing his Bachelor’s degree.
If you run a small business, you probably work with Microsoft Office Word documents quite often. If you have a large document listing hundreds or even thousands of items, finding duplicate words is very important. Microsoft Office Word enables you to quickly find such words and Word even highlights them for you in the document. You must use the Advanced Find feature to find full words, excluding anything that just contains the term you’re searching for.
-
Click the «Home» tab at the top of the Word window if it’s not selected already.
-
Click the small arrowhead next to Find in the Editing group at the top and select «Advanced Find» from the drop-down menu. The «Find and Replace» window pops up.
-
Type the word you want to search for in the Find What box.
-
Click the «More» button at the bottom of the window to view more options.
-
Place a check mark in front of the «Find whole words only» option.
-
Click the «Reading Highlight» button and then «Highlight All» to find all duplicate words and highlight them.
-
Click «Close» to close the Find And Replace window. The results remain highlighted.
To complement other answers:
You can featurize both sentences and then look at cosine similarity between their feature representations.
To featurize text, there are many methods you can use; from simple counting-based operators like TFIDF to word embeddings like word2vec or more complex language models like BERT.
The TextWiser Library might come in handy if you want to experiment with several text featurization methods including their transformations for dimensionality reduction like SVD, LDA, UMAP etc.
Here is a usage example:
# Conceptually, TextWiser is composed of an Embedding, potentially with a pretrained model,
# that can be chained into zero or more Transformations
from textwiser import TextWiser, Embedding, Transformation, WordOptions, PoolOptions
# Data
documents = ["Some document", "More documents. Including multi-sentence documents."]
# Model: TFIDF `min_df` parameter gets passed to sklearn automatically
emb = TextWiser(Embedding.TfIdf(min_df=1))
# Model: TFIDF followed with an NMF + SVD
emb = TextWiser(Embedding.TfIdf(min_df=1), [Transformation.NMF(n_components=30), Transformation.SVD(n_components=10)])
# Model: Word2Vec with no pretraining that learns from the input data
emb = TextWiser(Embedding.Word(word_option=WordOptions.word2vec, pretrained=None), Transformation.Pool(pool_option=PoolOptions.min))
# Model: BERT with the pretrained bert-base-uncased embedding
emb = TextWiser(Embedding.Word(word_option=WordOptions.bert), Transformation.Pool(pool_option=PoolOptions.first))
# Features
vecs = emb.fit_transform(documents)
You can easily switch between different Embedding and Transformation options and see how they impact your downstream tasks, in your case, the similarity between the sentences.
Notice you can even chain the Transformations; e.g., NMF followed by SVD operation.
Disclaimer: I am a member of the TextWiser team.
WordNet indexes concepts (aka Synsets) not words.
Use lemma_names() to access root words (aka Lemma) in WordNet.
>>> from nltk.corpus import wordnet as wn
>>> for ss in wn.synsets('phone'): # Each synset represents a diff concept.
... print(ss.lemma_names())
...
['telephone', 'phone', 'telephone_set']
['phone', 'speech_sound', 'sound']
['earphone', 'earpiece', 'headphone', 'phone']
['call', 'telephone', 'call_up', 'phone', 'ring']
Lemma being the root form or a word shouldn’t have additional affixes so you’ll not find plural or different form of the words as you have listed in the list of words you wanted.
See also:
- https://simple.wikipedia.org/wiki/Lemma_(linguistics)
- https://en.wikipedia.org/wiki/WordNet
- All synonyms for word in python?
Also, words are ambiguous and may need to be disambiguated by context or my Parts-of-Speech (POS) before you can get «similar» words, e.g you see that «phone» in the verb meaning is not exactly the same meaning as phone as in the «noun».
>>> for ss in wn.synsets('phone'): # Each synset represents a diff concept.
... print(ss.lemma_names(), 't', ss.definition())
...
['telephone', 'phone', 'telephone_set'] electronic equipment that converts sound into electrical signals that can be transmitted over distances and then converts received signals back into sounds
['phone', 'speech_sound', 'sound'] (phonetics) an individual sound unit of speech without concern as to whether or not it is a phoneme of some language
['earphone', 'earpiece', 'headphone', 'phone'] electro-acoustic transducer for converting electric signals into sounds; it is held over or inserted into the ear
['call', 'telephone', 'call_up', 'phone', 'ring'] get or try to get into communication (with someone) by telephone
In this shot, we are going to build an NLP engine that will show similarity between two given words.
For this, we are going to use Gensim’s word2vec model. Gensim provides an optimum implementation of word2vec’s CBOW model and Skip-Gram model.
Similarity between two words
Before moving on, you need to download the word2vec vectors.
Click here to download the vectors. Remember the file size is ~1.5GB.
We suggest you work on Google Colab for this, as the file size is very large.
Open your Google Colab and run the command below to get your word vectors.
!wget -P /root/input/ -c "https://s3.amazonaws.com/dl4j-distribution/GoogleNews-vectors-negative300.bin.gz"
This command will download it on Google servers and save a lot of time.
Now, let’s install the packages we require.
pip install gensim
pip install scikit-learn
You can run the above command in both Google Colab and on your local machine (if you’re using that).
Lets move on to the coding part by first importing the packages, as shown below.
In this article, you will learn how to find duplicates in word with only 4 simple steps as follows.
Use the Find and Replace function in WPS Writer to find duplicates.
1. First, click the Home tab,and select the Find and replace feature. Then, we click the Find button.
2. Input the contents to be found in the Find what” input box. So here we can input the text of development .
3. Once the text content has been entered, we can click Read Highlight and select Highlight All to find all duplicates in the document.
4. The corresponding contents in the article would be highlighted. Then, you can easily find duplicates in Word.
What is WPS Writer?
WPS Writer is mainly used for word processing and it can edit not only text but also images and tables. You can use it to write, edit, type and print articles.
Moreover, in WPS Office, Writer can convert file formats with each other with Office software, such as PDF and Presentation.
WPS Writer is similar to Microsoft Word. You can also download Word Document Processor for freeOf course, it also has many special features, for example, we can quickly edit a resume according to a resume template.
More advanced features of find duplicates in WPS academy:
Compare two sheets for duplicate rows in WPS Office Excel | WPS Academy Free Office Courses
More features in Remove Duplicates | WPS Academy Free Office Courses
How to find, replace, and locate content | WPS Academy Free Office Courses
Whether you’re new to Word or need to speed quickly with Word, free WPS Writer training will give tips to apply immediately to your business work. Discover professional training in WPS Writer, you’ll practice creating different types of documents by using Word.
1. Как использовать NLTK, чтобы найти похожие слова в тексте
Если мы хотим искать подобные слова (Word) в тексте, вы можете использовать мощные модули NLP NLTK. Ниже приведен пример в наборе данных Shakespeare поставляется с NLTK.
Впервые, используя NLTK, вам необходимо запустить следующий код для загрузки набора данных Shakespeare.
import nltk
nltk.download('shakespeare')
Тогда мы можем загрузить данные Shakespeare, чтобы сделать эксперименты:
import nltk
text = nltk.Text(word.lower() for word in nltk.corpus.shakespeare.words(('hamlet.xml')))
До тех пор, пока вы используетеnltk.Text.similar(word)Вы можете найти все остальные слова, похожие на слово в тексте, как описано ниже
text.similar('woman')
Мы можем получитьwomanПодобные все слова:
matter at eaten but fit this to vulcan by like servant disclose
follows twice laertes it cat such sin
Видно, что в этих выходных словах некоторые действительноwomanТам немного похоже, например «вулкан» и «слуга». Но есть еще много слов.womanНет отношений, таких как «дважды».
Проблема приходит, nltk.text.similar — это то, что является сходством двух слов?
2. nltk.text.similar исходный код
В Интернете не так много в Интернете, поэтому можно увидеть только исходный код.
NLTK.Text.simil — исходный код в https://github.com/nltk/nltk/blob/develop/nltk/text.py, где есть функцияsimilar(self, word, num=20)Это реализация NLTK.Text.similar, основной код выглядит следующим образом:
def similar(self, word, num=20):
"""
Distributional similarity: find other words which appear in the
same contexts as the specified word; list most similar words first.
:param word: The word used to seed the similarity search
:type word: str
:param num: The number of words to generate (default=20)
:type num: int
:seealso: ContextIndex.similar_words()
"""
Word = word.lower () # равномерное преобразование в строчные
wci = self._word_context_index._word_to_contexts
if word in wci.conditions():
# Найти другие слова как контекст контекста
contexts = set(wci[word])
fd = Counter(
w
for w in wci.conditions()
for c in wci[w]
if c in contexts and not w == word
)
#Mash_common основан на количестве вхождений от низкого уровня
words = [w for w, _ in fd.most_common(num)]
print(tokenwrap(words))
Из исходного кода мы видим, nltk.text.similar используетсяDistributional similarityЧтобы измерить, похоже ли два слова.Distributional similarityПодход, сначала найдите все слова с тем же контекстом), а затем в соответствии с количеством вхождений этих слов, количество раз от высокого к низкому последовательному выходу (сначала подобные слова).
Например, если у вас есть следующий документ:
C3 W4 C4
C1 W3 C2
C1 W3 C2
C1 W3 C2
C1 W2 C2
C1 W2 C2
C1 W1 C2
C1 W C2
С таким же контекстом (C1 X C2) это слово W1, W2, W3. Однако W3 появился 3 раза, W2 появился дважды, поэтому выход W3, выход W2.
Читая nltk.text.similar Источник, мы понимаем, что определяется, похоже ли два слова, и он определяется в соответствии с контекстом, а не сходством нашего понимания. Поскольку nltk.text.similar может найти подобные или недобрые слова в соответствии с контекстом, поэтому невозможно сделать количественное измерение сходства (например, W1 и W2 сходства до 0,8).
Мы снова приходим, чтобы построить несколько примеров, понять NLTK.Text.
3. Контекст аналогичный экземпляр
Со следующим кодом мы можем найти другие слова, похожие на мальчик в корпусе S.
import nltk
s = '''A B C boy D E F G
A B C dog D E F G
A B C cat D E F G
A A A man B B B B
'''
tokens = nltk.word_tokenize(s)
text = nltk.Text(tokens)
text.similar('boy')
Его можно получить как «кошка собака», которая легко понять, контекст «кота» и «собака» (A B C X d e F G) такой же, как «мальчик». Ожидаемый «мужчина», хотя и логически и «мальчик» должен быть больше сходства, он должен быть NLTK.Text.similar для определения сходства в соответствии с контекстом, а не определяющим сходство на основе логики, поэтому нет «человека».
Определение аналогичного () в исходном кодеsimilar(self, word, num=20)Мы также нашли другой параметр подобных ()numПо умолчанию по умолчанию относится к выходу 20, аналогично данному слова, и мы изменяем код в этом примере для NUM = 1, т.е.text.similar('boy',1)Тогда вывод всего 1 «кошка».
В этом примере контекст мальчика — «ab C» и «defg», который аналогичен () так же, он полностью похож на «defg», как «D EF G» полностью на основе «defg» в прогресс? Тем не менее контекст имеет ограничение длины поиска, таких как 3 слова перед мальчиком и 3 слова после мальчика? Я обнаружил, что в исходном коде нет аналогичных параметров, поэтому был разработан следующий эксперимент для проверки.
4. Что такое длина контекста?
Вот контекст контекста (Word) каждого слова (Word) для проверки длины контекста (слово, похожее на мальчика):
import nltk
s = '''A B C boy D E F G
C dog D
A B B cat D E F G
A A c man d B B B
'''
tokens = nltk.word_tokenize(s)
text = nltk.Text(tokens)
text.similar('boy')
Выход кода — «собака», поэтому мы получаем два вывода.
-
Контекст, учитывайте только предыдущие слова и последние слова, которые будут искать, то есть мальчик (контекст C X D), похожий на собаку (контекст C X D)
-
Когда поиск контекста, случай не рассматривается, то есть мальчик (контекст C x d) аналогичен человеку (контекст к C x d).
5. Ссылка
- How to load and analysis corpus shakespeare
- Understand nltk.Text.similar
- nltk source code here