
AWL
Words on this page from the academic word list
Show AWL words on this page.
Show sorted lists of these words.
Donate
Dictionary
Look it up
Any words you don’t know? Look them up in the website’s built-in
dictionary.

General vocabulary Aka high-frequency vocabulary
 Podcast is loading. Problems? Too slow? You can also access the Podcast by
Podcast is loading. Problems? Too slow? You can also access the Podcast by
clicking here.
This message will disappear when then podcast has fully loaded.
This page discusses general vocabulary. It begins with a
definition of general vocabulary, then considers
how many words should comprise general vocabulary, looking
at two common models of vocabulary: one by
Nation (2001), and a more recent one by
Schmitt and Schmitt (2014).
What is general vocabulary?
General vocabulary, also called high-frequency vocabulary, is vocabulary that occurs frequently in all kinds of texts and everyday language.
It is likely to comprise the majority of the words and phrases learners encounter on a
General English course at school.
General vocabulary accounts for the vast majority of the content of spoken and written English. For example, the 10 most frequent words in English
account for around 25% of all words in writing and speaking, the 100 most frequent words account for 50%, the most frequent 1000 words account for
around 70% of English use, and the most frequent 2000 words for around 80%.
To illustrate this, below are the first two sentences of the paragraph above, with different levels highlighted (the 10, 100 and 1000 most
common words).
- General vocabulary, also called high-frequency vocabulary,
is vocabulary that occurs frequently
in all kinds
of texts
and everyday language.
It accounts for
the vast majority
of
the content
of spoken
and written English. — 10 most common words [10/34] - General vocabulary,
also called high-frequency vocabulary,
is vocabulary
that occurs frequently
in
all kinds
of texts
and everyday language.
It accounts
for
the vast majority
of
the content
of spoken
and written English. — 100 most common words [14/34]
General vocabulary,
also
called
high-frequency vocabulary,
is vocabulary
that occurs frequently
in
all
kinds
of texts
and
everyday
language.
It
accounts
for
the vast majority
of
the
content
of
spoken
and
written
English. — 1000 most common words [25/34]
How many words are general vocabulary?
There is no precise figure of how many words should comprise general vocabulary. However, there are two models that categorise vocabulary which
suggest an answer: one by
Nation (2001), the other by
Schmitt and Schmitt (2014).
General vs academic/technical/low-frequency vocabulary
A traditional way to categorise vocabulary (from Nation, 2001) has been as general (i.e. high-frequency) vocabulary,
academic vocabulary,
technical vocabulary, and
low-frequency vocabulary. Using this categorisation, general vocabulary has typically been set at around 2000 word families. This is the number
of word families in the original
General Service List (GSL), which is the foundation for the
Academic Word List (AWL), which remains the most commonly used list of academic
words. While more recent general word lists appear to contain more words (the
NGSL has 2801 words, the
New-GSL has 2494 words), these are lemma-based lists,
i.e. words and inflected forms, not word families. The NGSL has 2368 word families, while the New-GSL has 1883 word families,
which are both close to the 2000 word family range.
High- vs mid- vs low-frequency vocabulary
A more recent way to categorise vocabulary (from Schmitt and Schmitt, 2014) is as high-frequency, mid-frequency, and low-frequency vocabulary.
This categorisation expands the high-frequency range to the most frequent 3000 words, with mid-frequency words representing words from 3001 to 9000
frequency levels, and low-frequency representing words from 9001 and lower.
The level of 3000 was chosen based on various factors, including the range of vocabulary for graded readers (which typically finish
around the 3000 word level), lists of defining vocabulary for learner dictionaries (which range from 2000 to 3000 words),
and the fact that comfortable English listening comprehension requires around 95% comprehension of words, which needs knowledge of around 3000
word families (plus proper nouns).
A similar 95% comprehension of reading texts requires more words (around 4000-5000 word families), and would be sufficient for assisted reading,
i.e. in a classroom setting. Independent reading has been shown to
require a higher comprehension level of 98% of words in a text,
which requires knowledge of 8000-9000 word families, which is where the mid-frequency range ends.
The following diagrams represent the above two categorisations of vocabulary. The area of the boxes shows the relative frequency of each type
of vocabulary, for reading texts.
In the first diagram, below, general vocabulary (at the 2000 level) is assumed to comprise around 80%, academic vocabulary 10%,
and technical and low-frequency vocabulary 5% each.
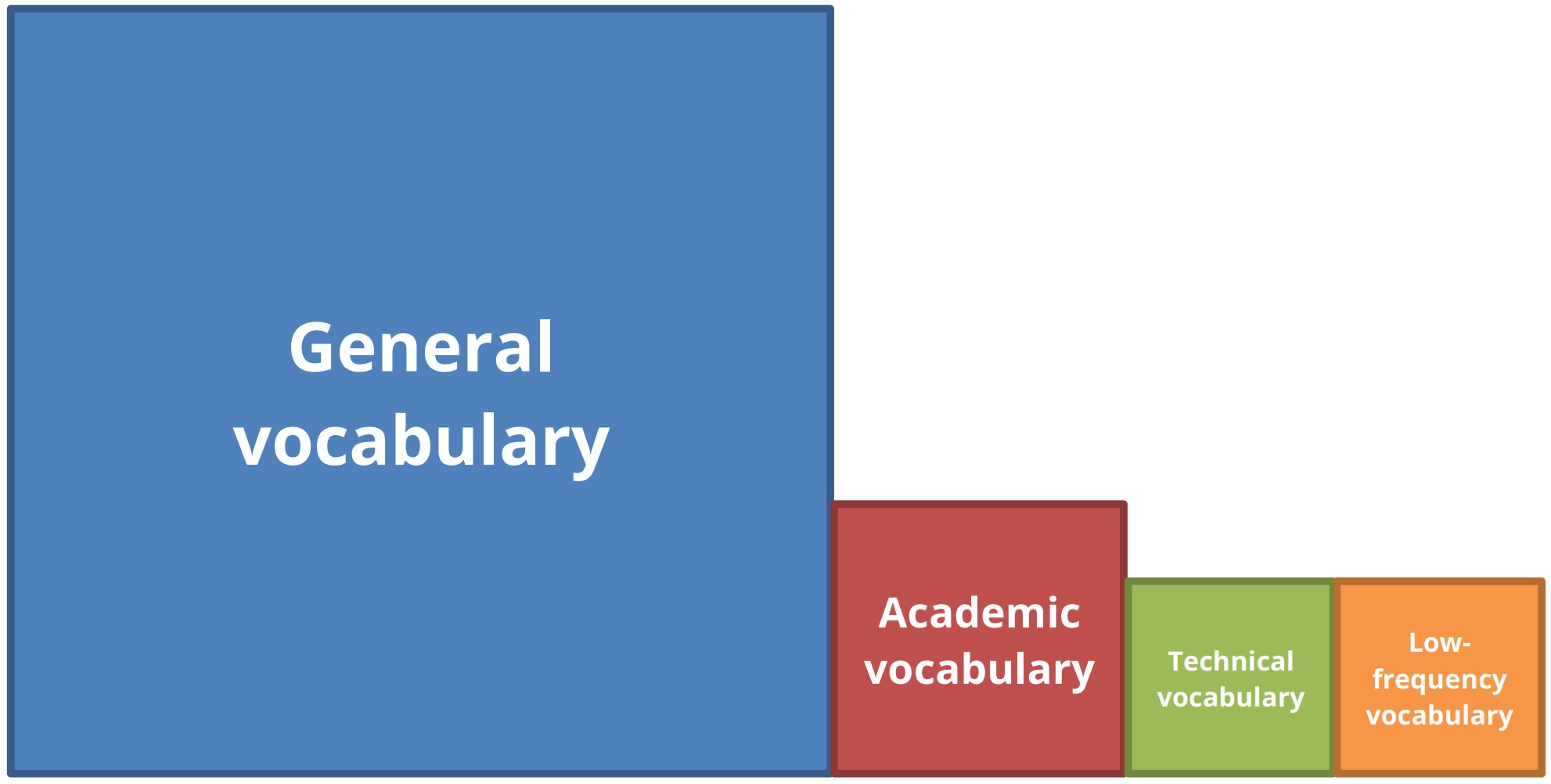
Figure 1: General, academic, technical and low-frequency model.
In the second figure, below, general vocabulary (at the 3000 level) is assumed to comprise around
90%, mid-frequency vocabulary 8%, and low-frequency 2%.

Figure 2: High-, mid-, and low-frequency model.
References
Greene, J.W. and Coxhead, A. (2015) Academic Vocabulary for Middle School Students. Baltimore: Paul H. Brooks Publishing Company.
Masrai, A. (2019) ‘Vocabulary and Reading Comprehension Revisited: Evidence for High-, Mid-, and Low-Frequency Vocabulary Knowledge’, SAGE Open, April-June 2019: 1–13, https://doi.org/10.1177/2158244019845.
Nation, I.S.P. (2001) Learning vocabulary in another language. Cambridge: Cambridge University Press.
Nation, I.S.P. (2016) Making and Using Word Lists for Language Learning and Testing. Amsterdam: John Benjamins Publishing Company.
Schmitt, N. and Schmitt, D. (2014) ‘A reassessment of frequency and vocabulary size in L2 vocabulary teaching’, Language Teaching, 47 (4). pp.484-503.

GET FREE EBOOK
Like the website? Try the books. This extract from Unlock the Academic Wordlist: Sublists 1-3 contains all sublist 1 words, plus exercises, answers and more!


The
interdependence of various features of the word may be easily
observed through a comparative analysis of these aspects in relation
to any chosen individual feature. Thus choosing, for example, the
semantic structure as a starting point we observe that there is a
certain interdependence between the number of meanings in a word and
its structural and derivational type, its etymological character,
its stylistic reference. The analysis may start with any other
aspect of the word — its structure, style or origin — it will
generally reveal the same type of interdependence of all the
aspects. Words of highest frequency, those that come into the first
2000
of
most frequently occurring words all tend to be polysemantic and
structurally simple. It should be noted, however, that structure and
etymology by themselves are not
177
always
indicative of other aspects of the word
— simple
words are not necessarily polysemantic, words that etymologically
belong to late borrowings may be simple in structure. Frequency most
clearly reflects the close interconnection between polysemy
and
the
structure
of the word. The higher the frequency, the more polysemantic is the
word, the simpler it is in structure. The latest data of linguistic
investigation show that the number of meanings is inversely
proportional to the number of morphemes the word consists of. Derived
and compound words rarely have high frequency of occurrence and are
rarely polysemantic. Comparison of the words, members of the same
word-cluster, for example heart
— hearty
— heartily
— heartless
— heartiness-heartsick
shows
that it is the simple word of the cluster heart
that
is
marked
by the highest frequency (it belongs to the first 500
most
frequently occurring words). We also find that the word is highly
polysemantic, heart
has
6
meanings.1
Other members of the cluster which are all polymorphic and complex
have fewer meanings and many of them are practically monosemantic,
e.g. hearty
has
3
meanings,
heartily
— 2 and
the
rest only 1.
All
of these words have much lower frequences as compared with the simple
member of the cluster
— heartily
belongs
to the 6th
thousand,
heartless
to
the 13th, heartiness
and
heartsick
to the 20th thousand.
The
same is observed in the simple word man
having
9
meanings
and polymorphic derived words manful,
manly, manliness which
have only one meaning, etc. Thus the interdependence of frequency,
polysemy and structure manifests itself not only in the morphemic
structure of the word, but also in its derivational structure.
Derived words are as a rule
poorer in
the number of meanings and have much lower frequencies than the
corresponding simple words though they may be morphemically identical
It may be very well exemplified by nouns and verbs formed by
conversion, e.g. the simple noun hand
has
15
meanings
while the derived verb (to)
hand has
only one meaning and covers only 4%
of
the
total
occurrences of both.2
§ 3. Frequency and Stylistic Reference
Frequency
is also indicative of the interdependence between polysemy,
stylistic
reference
and emotive
charge.
It can easily be observed in any group of synonyms. Analysing
synonymic groupings like
make
— manufacture
— fabricate;
heavy
— ponderous
— weighty
— cumbrous;
gather
— assemble;
face
— countenance
— mug
we
find that the neutral member of the synonymic group, e.g. make
(the
first 500
words)
has
28
meanings,
whereas its literary synonyms manufacture
(the
2nd
thousand)
has 2
and
fabricate
(the
14th thousand) which has a narrow, specific stylistic reference has
only one meaning. A similar relation is observed in other synonymic
groups. The inference, consequently, is that
1
Here
and below the number of meanings is given according to A. Hornby, The
Oxford
Advanced Learner’s Dictionary of Current English, and
the frequency values according to the Thorndike
Teacher’s Word Book of 30,000
Words.
2
According
to M.
West. A
General Service List of English Words. Longmans, 1959,
178
stylistically
neutral vocabulary units tend to be polysemantic and to have higher
frequency value, whereas words of narrow or specific stylistic
reference or non-literary vocabulary units are mostly monosemantic
and have a low frequency value. The following examples may serve as
illustration: the neutral word horse,
in
addition to its basic meaning, has the meanings
— ‘a
frame’, ‘a rope’, ‘cavalry’; its poetic synonym steed
has
only one meaning. The neutral word face
forms
a variety of word-groups in its basic meaning, in addition, it has at
least 3
more
meanings
— ‘boldness’,
‘impudence’, e.g. to
have the face to do smth; ‘an
outer part’, ‘a surface’, e.g. the
face of a coin, the face of a clock. The
word face
also
enters a number of phraseological units, e.g. to
put a new face on a matter, on the face of it. Its
literary bookish synonym countenance
has
only two meanings and a much poorer collocability; its third synonym
mug
belongs
to slang, has a heavy emotive charge, is monosemantic and its lexical
valency is greatly restricted. The frequency values of these words
speak for themselves —
face
belongs
to the first 500
words,
countenance
to the 4th thousand and mug
to
the 6th thousand of the most frequently occurring words.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
From Wikipedia, the free encyclopedia
The word frequency effect is a psychological phenomenon where recognition times are faster for words seen more frequently than for words seen less frequently.[1] Word frequency depends on individual awareness of the tested language.[2] The phenomenon can be extended to different characters of the word in non-alphabetic languages such as Chinese.[3]
A word is considered to be high frequency if the word is commonly used in daily speech, such as the word «the». A word is considered to be low frequency if the word is not commonly used, such as the word «strait».[4] Some languages such as Chinese have multiple levels of daily speech that impact frequency of words. There is frequency at the character level or at the word level.[3] There is also an effect of frequency at the orthographic level.[5] Lower frequency words benefit more from a single repetition than higher frequency words.[6]
Examples[edit]
| Word | Ranking |
|---|---|
| The | 1st[7] |
| At | 20th |
| So | 50th |
| Did | 70th |
| Got | 100th |
| Mind | 300th |
| Chaos | 5,000th |
| Falkland | 20,000th |
| Marche | 45,000th |
| Tisane | 85,000th |
Methods for measuring the word frequency effect[edit]
Most studies looking at the word frequency effect use eye tracking data. When words have a higher frequency, readers fixate on them for shorter amounts of time.[8] In one study, participants’ eye movements were recorded as they scanned single sentence stimuli for topic relevant words.[9] Researchers used an Eyelink eye tracker to record the movements of the participants’ eyes. Reading times were found to be longer when focusing for comprehension due to increased average fixation durations. Results showed that reading for comprehension rather than scanning for certain words took longer fixations on the text.[9]
A second method used to measure the word frequency effect is electroencephalogram (EEG).[8] The results collected using EEG data vary depending on the context of the word. Expected or high frequency words exhibit a reduced N400 response at the beginning of the sentence.[8] This study found that predictable words showed a lower N400 amplitude, but did not find a significant effect of frequency.[8] More research is needed to see how frequency affects EEG data.
A third method of measuring the word frequency effect is reaction time. Reaction time is used particularly when reading aloud. Participants pronounce words differing in frequency as fast as they can. Higher frequency words are read faster than the low frequency words.[10][11][12]
A fourth method of measuring the word frequency effect is accuracy. Accuracy is used for recognition memory and free recall. Participants recognise and recall items that are studied differing in frequency. In recognition memory, higher-frequency words are more error prone less than lower frequency items.[13] In free recall, higher-frequency words are less error prone than lower-frequency items.[13]
Cognitive influences[edit]
The word frequency effect changes how the brain encodes the information. Readers began spelling the higher frequency words faster than the lower frequency words when spelling the words from dictation. The length of saccade varies depending on the frequency of words and the validity of the previous (preview) word in predicting the target word.[5] For higher frequency target words, the saccades as the reader approaches the word is longer when there is a valid preview word in front of it than for lower frequency words. When the preview word is invalid, there is no difference in saccades between high or low frequency words.[14] Fixations follow an opposite pattern with longer fixations on low frequency words.[5] Research has also found that high frequency words are skipped more when read than low frequency words. Gaze duration is also shorter when reading high frequency words than low frequency words.[14] Module connections are strengthened as words increase in frequency assisting to explain differences in brain processing.[6]
Real world applications[edit]
Written words[edit]
Leading character effect (LCF)[edit]
In many languages, certain characters are used more frequently than others. Examples of more frequent characters in English are the vowels, m, r, s, t…etc. In other languages such as Chinese, characters are morphemes that are individual words.[3] More than 100,000 words in Chinese are made of the same 5,000 characters.[3] As people process the first character of the word, they make a mental prediction of what the word is before reading the rest of the characters. If the character and other preprocessing information indicates that the word is short and familiar, the reader is more likely to skip the entire word.[15]
The character frequency may be more important when reading than the frequency of the word as a whole. In a study examining the Chinese language, reaction times for target words with a first character that was high frequency was shorter than those with first characters that were low frequency when simply naming the Chinese word. When making a lexical decision, target words with higher LCF took longer to respond to than low LCF. An example of a high frequency character in Chinese is the character for family (家) which appears before many other characters.[3] These effects were moderated by the predictability of the next words as well as the predictability of the target word given the previous word.[14] The surrounding words also being high frequency results In faster reaction times particularly when the target word is high frequency as compared to low frequency words.[3]
Test-taking[edit]
The quick recognition of a word would potentially be important during a timed written assessment. With a strict limit on time available to complete a test, the presence of higher frequency words on the assessment would be more beneficial to the test-taker than low frequency words, as the high frequency words would be recognized faster and thus time could be utilized on other areas of the assessment.
Bilingualism[edit]
With more people becoming fluent in multiple languages, the word frequency effect could present differently in a first language than a second language. One study examined differences in reading across participants who were bilingual in Spanish and English. The participants had varying levels of competence in the second language with more fluent participants demonstrating a stronger word frequency effect.[2] As the word frequency effect increased in both languages, total reading time decreased. In L1 (first language) there were higher skipping rates than in L2 (second language). This suggests that lower frequency words in L2 were harder to process than both high and low frequency words in L1. Familiarity of the language plays a large role in reacting to the frequency of words.[2] Reaction rates of bilingual adults could also be impacted by age. Older adults were significantly slower to respond to lower frequency words but were faster to process higher frequency words.[2]
Spoken words[edit]
In several studies, participants read a list of high or low frequency words along with nonwords (or pseudowords). They were tasked with pronouncing the words or nonwords as fast as possible.[10] High frequency words were read aloud faster than low frequency words.[10] Participants read the nonwords the slowest.[10][11] More errors were made when pronouncing the low frequency words than the high frequency words.[10]
Physical activities[edit]
Driving[edit]
Quick recognition of a word could also be important when reading road signs while driving. As a vehicle moves and passed road signs on the side of the road, there is only a short amount of time available to be able to read the road signs. The presence of higher frequency words on the road sign would allow for faster recognition and processing of road sign meaning, which could be critical in such a time sensitive situation.
Criticisms[edit]
Daniel Voyer proposed some criticism for the word frequency effect in 2003 after experiments on laterality effects in lexical decisions.[16] His experiments demonstrated two findings:
- (1) Word frequency effect was only significant for the left visual field presentation
- (2) In a case-altered condition, the word frequency effect meaningful for right visual field presentations.[clarification needed]
Voyer further posits that hemispheric asymmetries may play a role in the word frequency effect.
Future directions[edit]
Psycholinguists believe that future study of the word frequency effect needs to consider the role of heuristics to determine the difference in eye movements between high and low frequency words.[14]
See also[edit]
- Word lists by frequency
- tf–idf
- Missing letter effect
- Zipf’s law
References[edit]
- ^ Daniel Smilek; Scott Sinnett; Alan Kingstone. «Cognition». Oxford University Press Canada. Retrieved 7 May 2014.
- ^ a b c d Whitford, Veronica (2017). «The effects of word frequency and word predictability during first- and second-language paragraph reading in bilingual older and younger adults». Psychology and Aging. 32 (2): 158–177. doi:10.1037/pag0000151. PMID 28287786. S2CID 25819451.
- ^ a b c d e f Li, Meng-Feng; Gao, Xin-Yu; Chou, Tai-Li; Wu, Jei-Tun (2017-02-01). «Neighborhood Frequency Effect in Chinese Word Recognition: Evidence from Naming and Lexical Decision». Journal of Psycholinguistic Research. 46 (1): 227–245. doi:10.1007/s10936-016-9431-5. ISSN 0090-6905. PMID 27119658. S2CID 24411450.
- ^ «Word Frequency Effect». Oxford University Press. Retrieved 21 October 2014.
- ^ a b c Bonin, Patrick; Laroche, Betty; Perret, Cyril (2016). «Locus of word frequency effects in spelling to dictation: Still at the orthographic level!». Journal of Experimental Psychology: Learning, Memory, and Cognition. 42 (11): 1814–1820. doi:10.1037/xlm0000278. PMID 27088496.
- ^ a b Besner, Derek; Risko, Evan F. (2016). «Thinking outside the box when reading aloud: Between (localist) module connection strength as a source of word frequency effects». Psychological Review. 123 (5): 592–599. doi:10.1037/rev0000041. PMID 27657439.
- ^ Harris, Jonathan. «Wordcount». Retrieved 4 November 2014.
- ^ a b c d Kretzschmar, Franziska; Schlesewsky, Matthias; Staub, Adrian (2015). «Dissociating word frequency and predictability effects in reading: Evidence from coregistration of eye movements and EEG» (PDF). Journal of Experimental Psychology: Learning, Memory, and Cognition. 41 (6): 1648–1662. doi:10.1037/xlm0000128. PMID 26010829.
- ^ a b White, Sarah J.; Warrington, Kayleigh L.; McGowan, Victoria A.; Paterson, Kevin B. (2015). «Eye movements during reading and topic scanning: Effects of word frequency» (PDF). Journal of Experimental Psychology: Human Perception and Performance. 41 (1): 233–248. doi:10.1037/xhp0000020. hdl:2381/31659. PMID 25528014.
- ^ a b c d e O’Malley, Shannon; Besner, Derek (2008). «Reading aloud: Qualitative differences in the relation between stimulus quality and word frequency as a function of context» (PDF). Journal of Experimental Psychology: Learning, Memory, and Cognition. 34 (6): 1400–1411. doi:10.1037/a0013084. hdl:10012/3853. PMID 18980404.
- ^ a b White, Darcy; Besner, Derek (2017). «Reading aloud: On the determinants of the joint effects of stimulus quality and word frequency». Journal of Experimental Psychology: Learning, Memory, and Cognition. 43 (5): 749–756. doi:10.1037/xlm0000344. PMID 27936847. S2CID 3560733.
- ^ Elsherif, M. M.; Preece, E.; Catling, J. C. (2023-01-09). «Age-of-acquisition effects: A literature review». Journal of Experimental Psychology: Learning, Memory, and Cognition. doi:10.1037/xlm0001215. ISSN 1939-1285. PMID 36622701. S2CID 255545091.
- ^ a b Lau, Mabel C; Goh, Winston D; Yap, Melvin J (October 2018). «An item-level analysis of lexical-semantic effects in free recall and recognition memory using the megastudy approach». Quarterly Journal of Experimental Psychology. 71 (10): 2207–2222. doi:10.1177/1747021817739834. ISSN 1747-0218. PMID 30226433. S2CID 52292000.
- ^ a b c d Liu, Yanping; Reichle, Erik D.; Li, Xingshan (2016). «The effect of word frequency and parafoveal preview on saccade length during the reading of Chinese». Journal of Experimental Psychology: Human Perception and Performance. 42 (7): 1008–1025. doi:10.1037/xhp0000190. PMC 4925191. PMID 27045319.
- ^ Angele, Bernhard; Laishley, Abby E.; Rayner, Keith; Liversedge, Simon P. (2014). «The effect of high- and low-frequency previews and sentential fit on word skipping during reading». Journal of Experimental Psychology: Learning, Memory, and Cognition. 40 (4): 1181–1203. doi:10.1037/a0036396. PMC 4100595. PMID 24707791.
- ^ Voyer, Daniel (2003). «Word frequency and laterality effects in lexical decision: Right hemisphere mechanisms». Brain and Language. 87 (3): 421–431. doi:10.1016/s0093-934x(03)00143-3. PMID 14642544. S2CID 38332364.
What is Lexical Access?[edit | edit source]
In order to understand what lexical access is, it is first important to briefly explain what the mental lexicon, lexical entries and lexical storage are. The lexicon refers to a systematic organization of vocabulary that is stored in the mind in the form of individual lexical entries [1]. It has been referred to as our mental dictionary and analogies between accessing a written dictionary and accessing the mental lexicon have emerged. For further insight into the concept of the lexicon, please refer to the section of this course titled The Mental Lexicon. Lexical entries are defined as the information stored in the mind regarding a specific word. In order to recognize and comprehend words, also known as lexical items, information about its content is needed. Levelt (1989) suggested that lexical entries contain two types of information that allows individuals to recognize and understand words. This information includes content about the form and meaning of lexical items, Figure 1 [2]. The form component of lexical entries refers to phonological and morphological information, while in contrast, the meaning component refers to the syntax and semantic information of lexical entries [1].
Lexical storage refers to the way in which lexical items are organized for optimal accessibility in the lexicon. It is important to mention here that there are two types of items: lexical items which carry a meaning (i.e. nouns, verbs, adjective and adverbs) and grammatical items which do not have a clear meaning but contribute to syntactic structure (i.e. conjunctions) [3]. Only words which carry meaning are stored in the lexicon; these words are stored associatively in the mind in relation to other items [1]. For example, when searching our lexicon for the word apple, the storage of associated items may appear as illustrated below, Figure 2.
Now that some background information has been provided on the mental lexicon, lexical entries, and lexical storage — lexical access will be discussed. Lexical access is defined as the way which individuals access words in the mental lexicon [3]. Studies have identified several factors that can affect lexical access, such as: the frequency effect, the word/non-word effect, word superiority effect, the length effect and the imageability effect [3] [4] [5] [6] [7] [8] [9] [10]. Some of the above mentioned factors will be discussed in greater depth below. Much research has been devoted to investigating the concept of lexical access, as understanding how lexical items are accessed is central to speech and writing comprehension.
Figure 1: A lexical entry (Adaptation based on Levelt, 1989) [2] Figure 2: An example of lexical storage (Adaptation based on Field 2004) [1] 

Factors that affect Lexical Access[edit | edit source]
Lexical Frequency[edit | edit source]
In visual and auditory modalities, the more frequently a lexical item is used the more quickly it is recognized [11]. Zipf’s Law (1949) developed by George Kingsley Zipf draws upon the relationship between probability of usage and frequency. Further, this law is based on the principle of least effort [12]. The basis of the least effort principle can be outlined by the following logic: the more frequently a word is used the easier it is to process, as mentioned above. Studies have suggested that low-frequency lexical items produce longer decision times and therefore are accessed more slowly in comparison to high-frequency lexical items [13]. As such frequency plays an important role in determining which lexical item is chosen in models of lexical access that involve competition between two items. Moreover, the frequency effect has been well attested to in studies of lexical access [3] [12] [13]. For example, a study by Balota & Chumbly (1984) revealed that high frequency words were named more rapidly than low-frequency words [13].
Word Concreteness and Imagery[edit | edit source]
Words such as camera and banana are easy to imagine in our mind, where as words such as justice and evil are more difficult to mentally picture. This issue which relates to the difficulty and ease of picturing some words in comparison to others refers to the concept of word concreteness and abstractness. Word concreteness is also known as imageability and as implied by its name, is the ability to visualize lexical items. Concrete words are those that describe tangible nouns where as, abstract words describe nouns which may be intangible (i.e., apple and freedom) respectively. Please see Figure 3 for further examples of concrete and abstract words. Several studies have attested to the notion that concrete lexical items such as apple are easier to imagine, while abstract words such as evil are not as easy to imagine [14]. Moreover, studies on the word concreteness effect have revealed consistent findings that concrete lexical items have been found to be processed more accurately and quickly than abstract concepts in a variety of cognitive tasks [15] [16]. These tasks include but not limited to: cognitive recall, lexical decision, word recognition and sentence comprehension [15] [16].
More specifically, Paivio (1969) found that high-imagery words were more easily recalled in an memory test than low-imagery words [17]. This study also found that the principle of imageability interacts with the principle of frequency in word access. In short, that high-frequency high-imagery words such as student were more accurately accessed and recalled where as low-frequency low-imagery words such as excuse were least easily accessed [17]. Bleasdale (1987) also found that in a lexical decision task, words primed other words only when both words were of the same, for example concrete-concrete, rather than concrete-abstract. From this it was concluded that the lexicon organizes concrete and abstract words separately [18].
Two models have emerged in an attempt to explain the concreteness effect, one of which is the dual-coding theory and the other, the context availability theory. The latter theory supports that concrete words are activated with broader contextual verbal support and greater contextual associations in semantic memory [19] [16]. The context availability theory further asserts that concrete words automatically activate more associative information in comparison to abstract words, thus resulting in faster processing. In contrast, the dual-coding theory as proposed by Paivio (1986) upholds that concrete words result in faster processing due to access to semantic meaning [15] [16]. This theory support that the meaning of concrete words is facilitated easier because concrete words have verbal and visual semantic representations, while abstract words generally have a verbal semantic representation [15]. The superiority effect of concrete words being processed more accurately and quickly than abstract words in cognitive tasks has been attributed to three reasons. First, it is believed that abstract words lack the direct sensory referents of concrete words, therefore supporting a slower processing for abstract words. Second, there is a greater availability of contextual information for concrete words than abstract words [19] [16]. Lastly, the notion that concrete words have more associative meanings than abstract words is thought to attribute to this superiority findings swayed toward concrete words [16].
Figure 3: Examples of Concrete and Abstract Words (Adaptation based on Jessen et al, 2000) [16]
Lexical Ambiguity[edit | edit source]
Ambiguities in spoken or written language can arise in a number of ways. For example, homophones are two words that sound the same however have two different meanings (i.e., air; heir). In light of the existence of ambiguities in language, a great deal of research has been devoted to understanding lexical ambiguity to date [6]. The primary goal of this research is to address how readers and listeners retrieve the contextually appropriate meaning of lexical items which have multiple meanings [20]. One key discovery that has fueled research into this topic is the understanding that words and meanings do not necessarily a one to one ratio [3]. As most individuals have likely experienced, one meaning can be shared by numerous words and conversely, one word can share numerous meanings. To illustrate my latter example, I would like to use the phrase “tick the right box” [3]. Without context, the reader is left wondering if right refers to the correct box or the box opposite to the left. Through examples such as the one used above it was suggested that individuals use more cognitive resources when processing ambiguous words than words with only one meaning [1] [5]. Readers and listeners often use the context of a word to disambiguate its meaning [7]. To emphasize the importance of context and its effect on disambiguating words, studies such as one by Swinney (1979) have been conducted. In this study, experimenters provided participants with the following sentence: «The man was surprised when he found spiders and other bugs in the room» [5]. The targeted word was bug and participants were tested to see if context had an effect on which meanings were activated; the possible answers for bug were either an insect, a spy gadget or the control word sew [5]. The results showed that if the answer choices were given in less than 200 milliseconds after the target sentence was read, both meanings of the word were activated; but if the answer choices were given after 200 milliseconds the irrelevant meaning was suppressed [7]. These results support that if given time to reflect on the sentence, context helps individuals disambiguate the word bug to correctly mean an insect.
Exhaustive and Selective Lexical Access[edit | edit source]
There are two major theories that examine the role of context in influencing what meanings of lexical ambiguous words are activated. The first theory known as selective access which supports that context biases the interpretation of an ambiguous word, so that only the intended meaning is accessed [21]. In essence this view considers context to sufficiently provide enough information that only the most relevant meaning of an ambiguous word is activated. In contrast, the alternative theory claims that even with contextual cues, multiple meanings for ambiguous words are still activated; this theory is known as exhaustive access [21]. Further, some advocates of the exhaustive access theory have argued that ambiguous words do not all simultaneously get activated, but rather the more frequently used meanings and those influenced by context are activated first. Currently, the exhaustive access theory has more empirical support from studies than the selective access theory [14].
Dominant and Subordinate Meanings[edit | edit source]
As mentioned above, several studies have revealed that lexical access of ambiguous words can be dependent on context. Ambiguous words can also be subcategorized into dominant and subordinate meanings as often two meanings of a word not equally used [11]. Thus the dominance of a meaning refers to the relative frequency each meaning of an ambiguous word is used. For example, if we were to review the word «cram», a university student would be more likely activate the dominant meaning of studying, rather than a subordinate meaning of try and squeeze something into an insufficient space. To view some examples of dominant and subordinate meanings, please see Figure 4. Furthermore, dominant and subordinate meanings can be divided into polarized and balanced ambiguous words. Polarized words are those with meanings that have a predominant meaning which is most frequently used in relation to the word. In comparison, balanced words are ambiguous words which do not have one dominant interpretation for the word (i.e. right can mean either correct or a direction).
Figure 4: Examples of Dominant and Subordinate Words (Adaptation based on Simpson, 1984) [6] 
Words and Word Recognition[edit | edit source]
Lexical Access and Semantic Priming[edit | edit source]
Semantics is the study of word meaning and the ways in which words are related to one another in our mental lexicon. Semantic priming is the unintentional increase in speed or accuracy when responding to a stimulus such as a word or a picture that has been previously primed. For example, if an individual sees a target word of doctor and then subsequently is shown the word nurse, their response time would be expected to decrease. To visualize semantic priming in action, please see Figure 5 which depicts Collins & Loftus’s (1975) Spreading Activation Model [22]. As predicted, studies have shown that when participants are shown a word or picture that relates to a target word, their response time decreases as a result of semantic priming [5]. Please refer to Psycholinguistics/Semantics_in_the_Brain for more information on semantics and how it relates to lexical access.
Figure 5: The Spreading Activation Model (Adaptation based on Collins & Loftus, 1975) [22]
Models of Lexical Access[edit | edit source]
How language users recognize a lexical item’s meaning is an important concept. Thus the models of lexical access attempt to explain how individuals access words and their related meanings in our minds. There are two major classes of models that detail how lexical entries are retrieved during reading and listening tasks. The first type of model are known as serial search models, where as the second type are parallel access models [14].
Serial search models believe that when we encounter a word, we look through all lexical entries to determine whether the item is a word or not, and then retrieve the necessary information about a word (i.e., its semantics or orthography). Serial search means propose that lexical access occurs by sequentially scanning one lexical entry at a time [14]. An example of a serial search model is Forster’s (1976) autonomous search model. In contrast, the parallel access models propose that perceptual input about a word activate lexical items directly, and that multiple entries can be activated at once. That is, a number of potential candidates are activated simultaneously and the lexical item which shares the most features with the targeted stimulus is the one that is chosen [14]. Examples of the parallel search model are Marslen-Wilson’s (1987) cohort model, McClelland & Seidenberg’s (1989) connectionist model and Morton’s (1969) logogen model [14][11]. The factors that influence word access and lexical organization are addressed in both the serial and parallel processing models. At the present time there is a greater acceptance toward the parallel access models than the serial search models when explaining lexical access [14].
The Autonomous Search Model[edit | edit source]
The autonomous search model was developed by Kenneth Forster and views the word recognition process as being divided into several parts [23]. More specifically this model upholds that lexical access is carried out in a two-stage process. Forster’s (1976) model of lexical access is best illustrated by comparing the lexicon to a library. A word similar to a book, can be in only one place in the lexicon and library. However, several catalogs (i.e., title, author, year) can be used to determine where the book or lexical item are located in both locations [14]. Forster proposed three major types of access files which included: orthographic, phonological and semantic/syntactic [24]. The first type of access file mentioned (orthographic) means that words are accessed based on their visual features; words accessed through the phonological access file are done so through how they sound; and lastly, words retrieved using the syntactic/semantic file are done so according to their meaning. Moreover, input from any modality (visual, auditory) can only access these files one at a time. Lastly, orthographic and phonological access files contain information about the beginning parts of words (i.e., the first few letters of their spelling or first few sounds they begin with) [3]. When a word is presented either visually or phonologically, a complete perceptual representation of the word is constructed and subsequently activates in the access file based on its initial spelling or sound [14]. Once a word’s location has been established based on its access files, a search for the word entry in the lexicon must still be carried out [25]. Relating this model back to the analogy of a library, lexical access is thought to occur by first locating the file in which the information is (i.e., searching for which section a book is in) and then the lexicon is searched for the actual location of the word (retrieving the book of the shelf). It should be clarified that all information of the lexical entry (i.e. its spelling, semantics, pronunciation, etc) are contained in the lexicon and not the individual access files [14].
The master lexicon is assumed to be organized into bins with the most frequent entries stored on the top of the bins. This belief further explores why high-frequency words are accessed more quickly than low-frequency words. Entries in this model are said to be searched one by one until an exact match to the perceptual representation is found; Figure 6 depicts how this process takes place. The process of lexical access proposed by Forster’s model occurs in more of a step by step process (serial search) rather than a simultaneous process (parallel access) [14]. When the relevant lexical entry is found it is then cross referenced against the targeted input to ensure accuracy [14]. If the selection is deemed correct, the search is terminated. However, if the selection is deemed incorrect a more exhaustive search is continued until the correct lexical entry is retrieved from the lexicon. Incorrect selections can comprise of either non-words which do not adhere to the rules of English grammar such as zdkj, or a non-word that resembles a real word such as shure. Several studies have revealed that individuals require more time to reject the non-words which represent a real word in comparison to words which clearly do not [14] . In short, lexical access of a word is terminated only once the correct lexical entry is located, which are scanned one at a time.
Figure 6: Forster’s Serial Search Model of Word Recognition (Adaptation based on Forster, 1976) [24]
The Logogen Model[edit | edit source]
Morton (1969) proposed that words are not accessed by determining their locations in the lexicon but by being activated by a certain threshold [26]. An analogy between Morton’s model and a light bulb can be made in that a word similar to a light bulb is activated when enough energy is being delivered to the source. Thus in relation to the logogen model, words are activated when its threshold has received enough energy to access the lexical entry [14].
Morton (1969) claimed that each lexical entry had its own logogen which tracked of the number of features a lexical entry had in common with a targeted stimulus [3]. Words are said to be at a resting level and have a zero-feature count when they are not being activated as a potential candidate of a the targeted word [14]. Morton proposed that each logogen had an individual threshold which required a particular amount of input/energy for the lexicon to access a particular lexical entry [26]. Input can be received in the form of orthographic, phonological or semantic information as individuals read or listen to language. Once all the input is received for the lexical entry candidates, the number of features for each logogen is summed up and the certain logogens reach their predetermined thresholds [14]. Among the logogens which do reach their threshold, the lexical entry which has the highest feature count thus the most similarities with the targeted word is chosen. Once lexical access has been completed, all logogens return to their zero-feature count resting level [26]. Logogens that have reached their threshold take longer to return to their resting level than those that have not [1]. As depicted in Figure 7, contrary to Forster’s (1976) autonomous search model, Morton’s logogen model provides no separate access routes in which the lexicon is searched for lexical items. In contrast, individuals use all available input (i.e., orthographic, phonological) in order to activate logogens with similar features to the targeted word. In addition, Morton’s model allows for simultaneous parallel searches of input from multiple modalities, where as Forster’s model only allows one access file to be used at a time [14].
Figure 7: The Logogen Model (Adaptation based on Morton & Patterson (1998) [26] 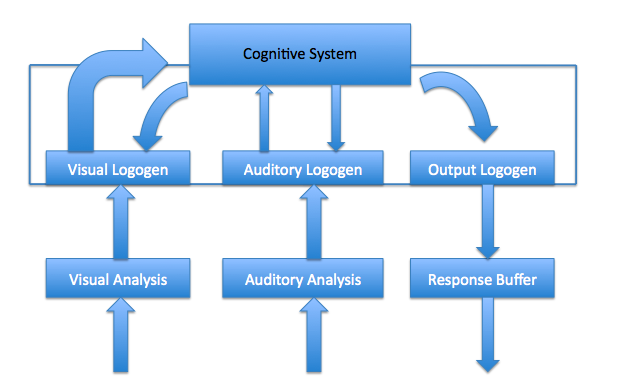
Similar to Forster’s model, high-frequency words are accessed more quickly than low-frequency words in the logogen model. This model asserts that the frequency effects are the result of the lower activation threshold for frequently used word. That is, it takes less activation to fire a high frequency word than a low frequency word. For example, the word bear which is used more frequently would require less input to reach its threshold than a word like anteater, see Figure 8. Priming on the other hand, is accomplished by a quick and temporal lowering of the threshold of logogens related to a prime. [26].
Morton’s (1969) logogen model has been one of the most influential of the parallel word access models and served as the basis for all the parallel models that followed [14]. As with any model, however, modifications were made from the original 1969 model exactly a decade later (1979). The newest version of the model asserts that separate input paths and logogens exist for words presented by reading (visually) versus listening (auditory) [14].
Figure 8: Example of Frequency Effect in the Logogen Model (Adaptation based on Morton & Patterson (1998) [26] 
The Cohort Model[edit | edit source]
Marslen-Wilson et al (1978) proposed that when individuals hear a word, its phonological neighbours also get activated. To simplify this concept refer back to Figure 5: The Spreading Activation Model. Rather than words of similar semantics being primed, the cohort model proposes that words with similar sounds are primed. The cohort model is comprised of three main stages. During stage one, also known as the access stage, the first few sounds of the target word activate all words with a similar sound. For example, in the sentence “Renee went to go buy a toy from the st-…,” stand, store, stranger as well as other similar phonological words would accessed during the first stage. The set of words which become activated are known as the «cohort» [27]. The cohort model bares similarities to Morton’s (1969) logogen model in that multiple words can be activated, and the system continues searching through all activated words until it settles on a single choice. The second stage of Marslen-Wilson’s (1978) model is known as the selection stage, during which all activated words are progressively eliminated thus narrowing the cohort [27]. An activated lexical item in the cohort can be eliminated either based on inappropriate context or if a better candidate is activated. All lexical items in the cohort continue to be eliminated until a single lexical item remains, known as the integration stage. Figure 9 depicts the three stages of lexical access and elimination as described above in the cohort model.
The original cohort model asserted that an exact match between a lexical item and its phonological properties was required [27]. However subsequent studies revealed that individuals are still able to access a correct lexical item, even if words are mispronounced or left out (i.e., if an individual yawned part way though a word) [14]. In light of this information, the cohort model was revised and currently maintains that an exact match between a lexical item and its phonology are not necessary for lexical access. The cohort model also accounts for frequency and non-word effects similar to Morton’s logogen model [14]. Both theories assume that context and primed words narrow the original set of activated lexical items, thus leading to a quicker recognition of targeted stimulus [14].
Figure 9: The Cohort Model (Adaptation based Marslen-Wilson, 1987) [27]
The Connectionist Model[edit | edit source]
McClelland and Seidenberg founded the connectionist model for lexical entry recognition in 1989. Please refer to Psycholinguistics/Connectionist_Models #McClelland_and_Seidenberg_Model for further insight into the connectionist model of lexical access.
Figure 10: Structure of the Seidenberg and McClelland Connectionist Model (Adaptation based on Seidenberg & McClelland, 1989) [28]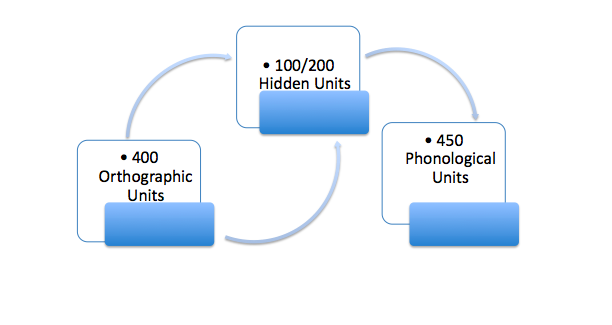
Glossary[edit | edit source]
Ambiguous : a lexical item or sentence that has more than one meaning (i.e., right — correct; direction).
Dominant Meaning : the view that ambiguous words are most activated a dominant meaning.
Exhaustive Access : the view that multiple meanings of ambiguous words are activated regardless of contextual cues.
Homograph : different words that are spelled the same but may have different pronunciations (i.e., bear-animal; bear-carry).
Homonym : a word with two meanings.
Homophone : two words that sound the same (i.e., there; their).
Imageability : the degree to which a concept can be visualized. Highly imageable words are more easily accessed than low imageability words.
Lemma : a level of representation of a word between its semantic and phonological representations it is syntactically specified but not contain sound-level information.
Lexical Access : the process of accessing and retrieving a lexical entry from the lexicon.
Lexicon : the system of vocabulary which is stored in the mind in the form of lexical entries for each item; commonly referred to as our mental dictionary.
Parallel Search Model : models of lexical item access that claim each item in the lexicon are activated simultaneously in an attempt to find to correct lexical item.
Selective Access : the view that context provides sufficient cues to activate one interpretation of an ambiguous word which is most relevant.
Semantics: the study of word meaning and the ways in which words are related to one another in our mental lexicon.
Serial Search Model : models of lexical item access that claim each item item in the lexicon is activated one at a time until the correct item is found.
Subordinate Meaning : the subordinate meanings for ambiguous words are usually those which are not the first to be activated upon reading or hearing the ambiguous word.
Learning Activity[edit | edit source]
Exercises[edit | edit source]
Exercises
Part 1: Fill-in-the-Blank Challenge[edit | edit source]
Instructions: Using the information provided in this chapter, please compete the following statements by filling in the blanks with the appropriate word.
Part 2: Short Answer Questions on Lexical Access[edit | edit source]
Instructions: Please answer the following questions to test your comprehension and application skills regarding lexical access. All questions should be answered in a short answer response (between 2-5 sentences).
- Swinney’s (1979) Cross-Modality Priming Study was conducted to demonstrate the semantic priming effects in relationship to lexical access. Based on the following target sentence: «Rumor had it that for years the government building had been plagued with problems. The man was surprised when he found spiders and other bugs in the room,» the words ant, sew and spy were visually presented immediately or after two seconds. Based on this description, what do you anticipate the outcome of this experiment would be? Would lexical decision occur faster, slower or be unaffected by the use of the primed sentence? Would the duration of time between presenting the above sentence and the target word affect the speed of lexical access? Lastly, does the duration of time between presenting the target sentence and target word affect which semantic meaning is accessed?
- Does context affect lexical access? What are the advantages and disadvantages of bringing context into the process of lexical access at an early stage.
- List two benefits and two criticisms of the selective and exhaustive access of word meanings. Which model is better supported by experimental research? Why does this model better explain lexical access than the other?
- Thinking back to the description of the Logogen Model by Morton, identify two features that characterize this model. Then, identify another model of lexical access and compare the similarities and differences between the Logogen model and your selected model.
- What are the most important factors that influence lexical access? What experimental support are there for these factors?
- Explain the difference between words which have dominant meanings and those which have subordinate meanings. Provide one example for each type of meaning that differs from the information in this chapter.
- Identify the three types of lexical access «files» in Forster’s (1976) Autonomous Search Model. Briefly explain what type of information would be stored in each file.
- Identify which of the following sentences are lexically ambiguous. Identify which word in each sentence is the cause of this ambiguity.
* The lady hit the man with an umbrella.
* John saw her duck.
* He gave her cat food.
* Margaret could not read the note.
* The man saw the boy with the binoculars.
9. The meaning association of words are usually paired based on meaning categories rather then physical similarities (i.e., pen and paper rather than pen and highlighter). Common associations are based on co-ordination (i.e., salt and pepper), collection (i.e., salt and water), opposite (salt and sweet), and superordination (i.e., butterfly and insect). Figure 11 below is required to complete the following word association question. Please review the ten most common word association responses for the following stimuli: butterfly, hungry, red, and salt and identify which given words appear to have the strongest semantic links with each stimuli. Why do think some words listed have a stronger semantic link to the stimuli then others? Classify the word association relationship for all ten words for each category (i.e., superordination, opposite, collection).

Figure 11: Common Word Associations (Adaptation based on Aitchison, 1994 ) [25]
10. Examine your answers from Question 9. Was one type of word association significantly more represented than the others? Identify what type of word association response this would be and why you believe it was the most salient in comparison to other types of word association relationship (i.e., superordination, opposite, collection).
Part 3: How to conduct Lexical Access Experimental Tasks[edit | edit source]
Experiment 1
Apparatus Required: an audio-recoding device and a list of 20 common high-frequency nouns (further described below).
To conduct a word association task similar to the Question 9 in Part 2 above, first begin by choosing 20 high-frequency nouns (i.e., dog, car). You can either type out your list or write it down on a single sheet of paper. You will need to recruit a minimum of 10 participants to conduct this experiment. Based on the types of word associations described in Part 2 (i.e., opposites, superordinate, etc), hypothesize which type of word association will be most frequently represented by participants’ responses.
Bring the participants into a quiet study space individually and turn on the audio-recording device. As you read aloud the list of 30 nouns aloud to each participant, they are required to respond with the first word that come into their head for each item on the list. Once you have conducted this experiment on all your participants, look at your data and categorized the types of responses into a type of word association (i.e., opposites). Is one type of word association significantly more represented by participants’ responses than the others? If so, does your findings support your hypothesis? Provide some explanations why your hypothesis may or may not have turned out as you thought.
Experiment 2
Apparatus Required: a stopwatch, one frequent/non-word list, and one non-frequent/non-word list (further described below).
As learned in this chapter, lexical items that are accessed most frequently are also accessed more quickly. To illustrate this frequency effect, please conduct the following lexical decision test. First, you must create a list of 15 monosyllabic four-letter words that are used frequently in English. For example, your list could include the following: GAME, PLAY, FISH, TIME, BOOK, CALL. It is important to choose a variety of words and avoid choosing all 15 words from the same category (i.e. 15 types of four-letter word fish: bass, pike, tuna, etc.) Next, create a list of 15 monosyllabic four-letter words that are used infrequently in English. It is important for both lists to have the same balance of word categories. (i.e both should have two frequently and infrequent words from a colour category. Frequent — pink, blue and infrequent jade, rose). Lastly, you will need to compile a list of 30 four-letter monosyllabic non-words that represent possible words within the rules of English spelling (i.e., BINK rather than XYJA). You will need to divide this list of 30 non-words equally and randomly among the lists of frequently and infrequently used words in English. You should end up with two lists. One list will be comprised of 15 frequent words and 15 non-words in four-letter monosyllables. The other list will be comprised of 15 infrequent words and 15 non-words in four-letter monosyllables. In both lists, do not place all non-words as the first 15 and frequent/infrequent words as the second 15 on the list. It is important to insert the words and non-words randomly and evenly into the two lists.
Type or write out the two lists of 30 entries onto a single sheet of paper. To examine frequency effects in lexical decisions, you will need to recruit a minimum of 10 participants to conduct this experiment. Each participant will be instructed to read both the frequent/non-word and non-frequent/non-word lists quietly. Participants should also be randomly assigned to two conditions, in which one condition will be presented with the frequent/non-word list first, while the other half should be presented with the infrequent/non-word list first. Hypothesize what you expect to find when comparing participants’ reaction times between these two lists (i.e., equal in length, one greater than the other, etc).
To conduct this experiment, bring the participants into a quiet study space individually and ensure a stopwatch is accessible. Hand the participants the the first word-list (in correspondence to their group condition) and start recording the time (seconds). Have participants inform you when they have completed reading all 30-items on the word list and stop recording the time. You will then need to write the duration the participant’s response took on a data collection (please see Figure 12 for a sample). Then, hand the participant the second 30-item sheet and being recording their response time (seconds). Once again, write the duration the participant’s response took on a data collection. Once you have conducted this experiment on all your participants, look at your data and examine if there is a notable difference in response times between the frequent/non-word list and infrequent/non-word list first. Does your findings support your hypothesis? Based on the information given in this chapter, provide some explanations as to why your hypothesis may or may not have turned out as you thought.

Figure 12: Example of Data Collection Sheet for Experiment 2
References[edit | edit source]
- ↑ 1.0 1.1 1.2 1.3 1.4 1.5 Cite error: Invalid
<ref>tag; no text was provided for refs namedField 2004 - ↑ 2.0 2.1 Cite error: Invalid
<ref>tag; no text was provided for refs namedLevelt - ↑ 3.0 3.1 3.2 3.3 3.4 3.5 3.6 3.7 Cite error: Invalid
<ref>tag; no text was provided for refs namedField 2003 - ↑ Cite error: Invalid
<ref>tag; no text was provided for refs namedChumbley - ↑ 5.0 5.1 5.2 5.3 5.4 Cite error: Invalid
<ref>tag; no text was provided for refs namedSwinney - ↑ 6.0 6.1 6.2 Cite error: Invalid
<ref>tag; no text was provided for refs namedSimpson 1984 - ↑ 7.0 7.1 7.2 Cite error: Invalid
<ref>tag; no text was provided for refs namedSimpson 1994 - ↑ Cite error: Invalid
<ref>tag; no text was provided for refs namedMason - ↑ Cite error: Invalid
<ref>tag; no text was provided for refs namedTabossi - ↑ Cite error: Invalid
<ref>tag; no text was provided for refs namedVakoch - ↑ 11.0 11.1 11.2 Cite error: Invalid
<ref>tag; no text was provided for refs namedWhitney - ↑ 12.0 12.1 Cite error: Invalid
<ref>tag; no text was provided for refs namedZipf - ↑ 13.0 13.1 13.2 Cite error: Invalid
<ref>tag; no text was provided for refs namedBalota 1984 - ↑ 14.00 14.01 14.02 14.03 14.04 14.05 14.06 14.07 14.08 14.09 14.10 14.11 14.12 14.13 14.14 14.15 14.16 14.17 14.18 14.19 14.20 14.21 Cite error: Invalid
<ref>tag; no text was provided for refs namedGleason - ↑ 15.0 15.1 15.2 15.3 Cite error: Invalid
<ref>tag; no text was provided for refs namedPaivio - ↑ 16.0 16.1 16.2 16.3 16.4 16.5 16.6 Cite error: Invalid
<ref>tag; no text was provided for refs namedJessen - ↑ 17.0 17.1 Cite error: Invalid
<ref>tag; no text was provided for refs namedPaivio 1969 - ↑ Cite error: Invalid
<ref>tag; no text was provided for refs namedBleasdale - ↑ 19.0 19.1 Cite error: Invalid
<ref>tag; no text was provided for refs namedSchwanenflugel - ↑ Cite error: Invalid
<ref>tag; no text was provided for refs namedMacDonald - ↑ 21.0 21.1 Cite error: Invalid
<ref>tag; no text was provided for refs namedBarsalou - ↑ 22.0 22.1 Cite error: Invalid
<ref>tag; no text was provided for refs namedCollins - ↑ Cite error: Invalid
<ref>tag; no text was provided for refs namedScott - ↑ 24.0 24.1 Cite error: Invalid
<ref>tag; no text was provided for refs namedForster - ↑ 25.0 25.1 Cite error: Invalid
<ref>tag; no text was provided for refs namedAitchison - ↑ 26.0 26.1 26.2 26.3 26.4 26.5 Cite error: Invalid
<ref>tag; no text was provided for refs namedMorton - ↑ 27.0 27.1 27.2 27.3 Cite error: Invalid
<ref>tag; no text was provided for refs namedMarslen - ↑ Cite error: Invalid
<ref>tag; no text was provided for refs namedSeidenberg
[1]
[2]
[3]
[4]
[5]
[6]
[7]
[8]
[9]
[10]
[11]
[12]
[13]
[14]
[15]
[16]
[17]
[18]
[19]
[20]
[21]
[22]
[23]
[24]
[25]
[26]
[27]
[28]
</references>
- ↑ Aitchison, J. (1994). Words in the mind: An introduction to the mental lexicon, 2nd ed. Oxford: Basil Blackwell.
- ↑ Balota, D. A., & Chumbley, J. I. (1984). Are lexical decisions a good measure of lexical access? The role of word frequency in the neglected decision stage. Journal of Experimental Psychology: Human Perception and Performance, 10(3), 340-357. doi:10.1037/0096-1523.10.3.340.
- ↑ Barsalou W. L. (1992). Cognitive Psychology: an Overview for Cognitive Scientists. (p. 221-244). New Jersey, Hillsdale: Lawrence Erlbaum Associates Publishers.
- ↑ Chumbley, J. I., & Balota, D. A. (1984). A word’s meaning affects the decision in lexical decision. Memory & Cognition, 12(6), 590-606.
- ↑ Collins, A. M., & Loftus, E. F. (1975). A spreading-activation theory of semantic processing. Psychological Review, 82(6), 407-428. doi:10.1037/0033-295X.82.6.407.
- ↑ Field, J. (2003). Psycholinguistics: a Resource Book for Students. United Kingdom, London: Routledge.
- ↑ Field, J. (2004). Psycholinguistics: the Key Concepts. United Kingdom, London: Routledge.
- ↑ Forster, K. I (1976). Accessing the mental lexicon. In F. Wales & E. Walker (Eds). New approaches to language mechanisms (p. 257-287). Amsterdam: North Holland.
- ↑ Gleason, J. B., & Bernstein, N. R. (1998). Psycholinguistics. Toronto: Harcourt Brace College Publishers.
- ↑ Jessen, F., Heun, R. R., Erb, M. M., Granath, D. O., Klose, U. U., Papassotiropoulos, A. A., & Grodd, W. W. (2000). The concreteness effect: Evidence for dual coding and context availability. Brain and Language, 74(1), 103-112. doi:10.1006/brln.2000.2340.
- ↑ Levelt, W. J. M. (1989). Speaking (p. 188). Cambridge, MA: MIT.
- ↑ MacDonald, M. C., Pearlmutter, N. J., & Seidenberg, M. S. (1994). The lexical nature of syntactic ambiguity resolution. Psychological Review, 101(4), 676-703. doi:10.1037/0033-295X.101.4.676.
- ↑ Mason, R. A., & Just, M. (2007). Lexical ambiguity in sentence comprehension. Brain Research, 1146115-127. doi:10.1016/j.brainres.2007.02.076.
- ↑ Morton. J., & Patterson, K. (1998). A new attempt at an interpretation or an attempt at new interpretation. In M. Coltheart, K. Patterson & J. Marshall (Eds.) Deep Dsylexia (p. 91-118) London: Routledge.
- ↑ Marslen-Wilson, W.D. (1987). Functional parallelism in spoken word- recognition. Cognition, 25, 71-102.
- ↑ Paivio, A. (1991). Dual coding theory: Retrospect and current status. Canadian Journal of Psychology, 45, 255–287.
- ↑ Schwanenflugel, P., & Shoben, E. (1983). Differential context effects in the comprehension of abstract and concrete verbal materials. Journal of Experimental Psychology: Learning, Memory and Cognition, 9, 82–102.
- ↑ Simpson, G. B. (1984). Lexical ambiguity and its role in models of word recognition. Psychological Bulletin, 96(2), 316-340. doi:10.1037/0033-2909.96.2.316.
- ↑ Simpson, G. B. (1994). Context and the processing of ambiguous words. In M. Gernsbacher, M. Gernsbacher (Eds.), Handbook of psycholinguistics (pp. 359-374). San Diego, CA US: Academic Press. Retrieved from EBSCOhost.
- ↑ Scott, J., & Pavlenko, A. (2008) Crosslinguistic Influence in Language and Cognition (p. 72-88). New York, New York: Routledge.
- ↑ Seidenberg, M. S., & McClelland, L. J. (1989). A distributed developmental model of word recognition and naming. Psychological Review, 96(4):527. doi:10.1037/0033-295X.96.4.523.
- ↑ Swinney, D. (1979). Lexical access during sentence comprehension: (Re)-consideration of Context Effects’. Journal of Verbal Learning and Verbal Behaviour, 18: 21-39.
- ↑ Tabossi, P., & Zardon, F. (1993). Processing ambiguous words in context. Journal of Memory and Language, 32(3), 359-372. doi:10.1006/jmla.1993.1019.
- ↑ Vakoch, D. A., & Wurm, L. H. (1997). Emotional connotation in speech perception: Semantic associations in the general lexicon. Cognition and Emotion, 11(4), 337-349. doi:10.1080/026999397379827.
- ↑ Zipf, G.K. (1949). Human behaviour and the principle of least effort. Massachusetts, Reading: Addison-Wesley.
- ↑ Bleasdale, F. A. (1987). Concreteness-dependent associative priming: Separate lexical organization for concrete and abstract words. Journal of Experimental Psychology: Learning, Memory and Cognition, 13, 582-594.
- ↑ Paivio, A. (1969). Mental imagery in associative learning and memory. Psychological Review, 76, 241-263.
- ↑ Whitney, P. (1998). The psychology of language. Boston: Houghton Mifflin.