
|
Расрывающийся список в форме по брендам и моделям. |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |


Excel удобно использовать для создания телефонных справочников. Причем информация не просто надежно хранится там, но и ее всегда может использоваться для выполнения различных манипуляций, сопоставления с другими списками и т.п.
Чтобы впоследствии справочник стал действительно полезным массивом, нужно правильно его создать.
Шаблон телефонного справочника
Как сделать справочник в Excel? Для создания телефонного справочника нужны, минимум, два столбца: имя человека или организации и, собственно, номер телефона. Но можно сразу сделать список более информативным, добавив дополнительные строки.

Шаблон готов. Шапка может быть другой, какие-то столбцы должны быть добавлены, какие-то исключены. Осталось только заполнить справочник информацией.
Дополнительно можно провести еще одну манипуляцию: определить формат ячеек. По умолчанию формат каждой ячейки значится как ОБЩИЙ. Можно оставить все как есть, но для столбца с номером телефона можно задать специальный формат. Для этого надо выделить ячейки из этого столбца, правой кнопкой вызвать меню, выбрать ФОРМАТ ЯЧЕЕК.
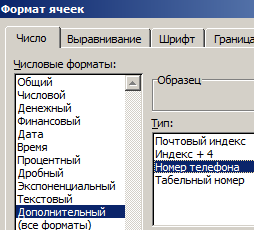
Среди предоставленных вариантов выбрать ДОПОЛНИТЕЛЬНЫЙ. Справа откроется мини-список, среди которых можно будет выбрать НОМЕР ТЕЛЕФОНА.
Как пользоваться справочником
Любой справочник нужен для того, чтобы по одному критерию можно было легко узнать остальные. Так, в телефонном справочнике мы можем ввести необходимую фамилию и узнать номер телефона этого человека. В Excel сделать это помогают функции ИНДЕКС и ПОИСКПОЗ.
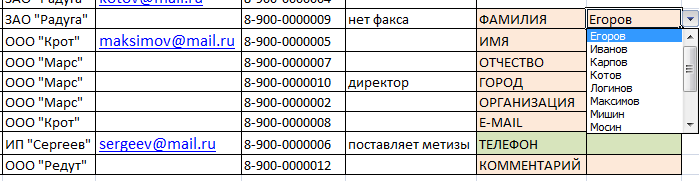
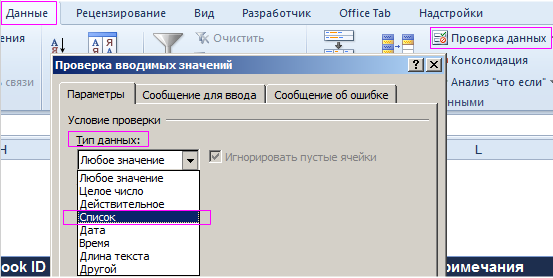
Имеем небольшой справочник. В действительности, в фирмах обычно более длинные списки, поэтому и искать в них информацию вручную сложно. Составим заготовку, в которой будет значиться вся информация. А появляться она будет по заданному критерию – фамилия, поэтому сделаем этот пункт в виде выпадающего списка (ДАННЫЕ – ПРОВЕРКА ДАННЫХ – ТИП ДАННЫХ – СПИСОК).
Нужно сделать так, чтобы при выборе какой-то фамилии, в остальных ячейках автоматически проставлялись соответствующие данные. Ячейки с телефоном выделили зеленым, потому что это самая важная информация.
В ячейку J6 (там, где ИМЯ) вводим команду =ИНДЕКС и начинаем заполнять аргументы.
- Массив: выделяем всю таблицу заказов вместе с шапкой. Делаем его абсолютным, фиксируя клавишей F4.
- Номер строки: сюда вводим ПОИСКПОЗ и заполняем уже аргументы этой функции. Искомым значением будет ячейка с выпадающим списком – J6 (плюс F4). Просматриваемым массивом является столбец с фамилиями (вместе с шапкой): A1:A13 (плюс F4). Тип сопоставления: точное совпадение, т.е. 0.
- Номер столбца: снова нужен ПОИСКПОЗ. Искомое значение: I7. Просматриваемый массив: шапка массива, т.е. А1:Н1 (плюс F4). Тип сопоставления: 0.

Получили следующее. Формула универсальна, ее можно протянуть и на остальные строки в заготовке. Теперь, при выборе фамилии, будет выпадать вся остальная информация. В том числе и номер телефона.
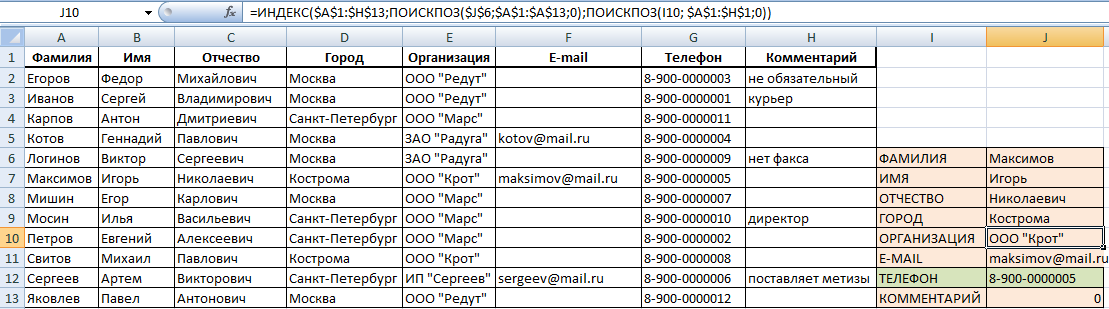
Получается, что команда ИНДЕКС при задании критерия из массива, выдает нам номер его строки и столбца. Но т.к. критерий плавающий, и мы постоянно будем менять фамилии, чтобы узнавать номера телефонов людей, мы дополнительно воспользовались функцией ПОИСКПОЗ. Она помогает искать позиции нужных нам строки и столбца.
Как сопоставить два списка в Excel
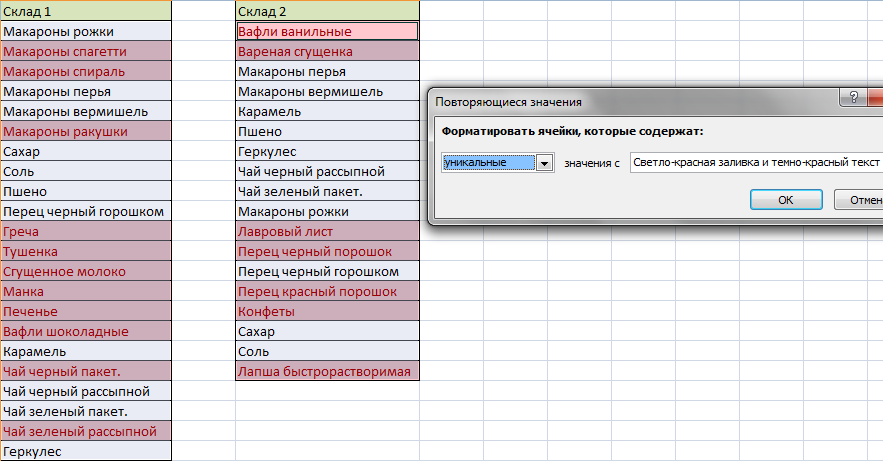
Работа со списками в Excel подразумевает их сопоставление. Т.е. сравнивание данных, нахождение одинаковых или уникальных позиций. Попробуем для примера сопоставить два простых списка.
Имеется информация по двум складам. Задача: проверить, каких позиций нет на том и другом складе, чтобы в будущем сделать заказ и довезти недостающие продукты.
Выделим оба списка (без шапок) с помощью клавиши CTRL. Свободное место между списками (т.е. столбец B) нам не нужно. Затем на вкладке ГЛАВНАЯ выбираем УСЛОВНОЕ ФОРМАТИРОВАНИЕ – ПРАВИЛА ВЫДЕЛЕНИЯ ЯЧЕЕК – ПОВТОРЯЮЩИЕСЯ ЗНАЧЕНИЯ.
Появится небольшое окно, где можно выбрать, чтобы команда показывала повторяющиеся или уникальные значения. Выберем УНИКАЛЬНЫЕ. Они подсветятся цветом, который можно выбрать справа. У нас это красный.
Скачать телефонный справочник шаблон в Excel
Теперь можно скопировать все красные ячейки из левого столбца и добавить их в правый и наоборот. Получатся два равнозначных списка.
ФЕДЕРАЛЬНОЕ
АГЕНТСТВО ЖЕЛЕЗНОДОРОЖНОГО ТРАНСПОРТА
Федеральное
государственное бюджетное образовательное
учреждение
высшего
образования
«Петербургский
государственный университет путей
сообщения
Императора
Александра I»
(ФГБОУ
ВО ПГУПС)
Кафедра
«Информационные
и вычислительные системы»
Направление
23.05.03 «Подвижной состав железных дорог»
Специализация
«Технология производства и ремонта
подвижного состава»
Курсовая
работа
по
дисциплине
«Информатика»
на
тему: «Создание
и обработка базы данных»
Форма
обучения – очная
Вариант:
|
Выполнил Курс Группа |
__________________ подпись, |
Баранов |
|
Руководитель |
__________________ подпись, |
Носонов |
Санкт-Петербург
2019
ФЕДЕРАЛЬНОЕ
АГЕНТСТВО ЖЕЛЕЗНОДОРОЖНОГО ТРАНСПОРТА
Федеральное
государственное
бюджетное образовательное учреждение
высшего
образования
«Петербургский
государственный университет путей
сообщения
Императора
Александра I»
(ФГБОУ
ВО ПГУПС)
Кафедра
«Информационные
и вычислительные системы»
Направление
23.05.03 «Подвижной состав железных дорог»
Специализация
«Технология производства и ремонта
подвижного состава»
Задание
на выполнение курсовой работы
по
дисциплине
«Информатика»
Баранов
Александр Сергеевич
Тема:
«Создание и обработка базы данных»
Срок
сдачи обучающимся законченной работы:
24
декабря 2019 года
Исходные
данные для выполнения проекта:
База
данных должна содержать следующие
элементы:
-
модель
телефона; -
оптовая
цена; -
наценка
магазина; -
количество
проданных телефонов; -
выручка
от продаж по каждой модели телефона
(расчет); -
сведения
о фирме-изготовителе (фирма, страна,
телефон).
Функции,
выполняемые информационной технологией:
-
Заполнение
и редактирование таблиц базы данных. -
Вычисление
стоимости телефона в магазине с учетом
наценки и подсчет выручки по каждой
модели. -
Получение
информации о телефоне, который дает
наибольшую величину прибыли от продаж. -
Получение
данных о телефонах, указанной пользователем
страны с указанием города, в котором
изготовлен телефон. -
Формирование
отчета, содержащего следующие данные:
название и модель телефона, количество
проданных телефонов, общую сумму
выручки с подсчетом общего количества
проданных телефонов и группировкой по
странам.
В
соответствии с индивидуальным заданием
в курсовой работе необходимо:
Спроектировать
базу данных.
Для
Excel:
-
подготовить
таблицу и заполнить ее данными с
использованием стандартной формы по
тематике задания (не менее 20 строк в
таблице); -
выполнить
необходимые вычисления, фильтрацию и
сортировку данных, подведение итогов
по группам. -
создать
сводную таблицу -
создать
к трём пунктам макросы (отредактировать
макрос -
,
если требуется по смыслу задания) -
построить
к 5-му пункту диаграмму (с макросом)
Для
Access:
-
спроектировать
структуру базы данных, разработать
связанные таблицы отвечающие условиям
нормализации, создать схему данных, с
установкой целостности данных.
-
создать
необходимые формы для ввода и корректировки
данных в таблицах, заполнить таблицы
данными, выбирая их из соответствующих
источников, либо (при невозможности
найти), произвольными, но близкими
реальным (порядка 20 строк в таблице).
Данные подбирать так, чтобы в группу
попадало не менее трёх и не более трети
записей. -
в
соответствии с заданием сформировать
и выполнить запросы, создать для них
формы; -
подготовить
требуемые отчеты. -
По
результатам выполнения задания, создать
презентацию, демонстрирующую основные
части базы данных: описание предметной
области задания, схему базы данных,
задачи запросов и отчётов и их вид в
режиме конструкторов.
Дата
выдачи задания:31 октября 2019 года
Руководитель:
__________________
Задание
принял к исполнению: _________________ Носонов
В.И.
ФЕДЕРАЛЬНОЕ
АГЕНТСТВО ЖЕЛЕЗНОДОРОЖНОГО ТРАНСПОРТА
Федеральное
государственное бюджетное образовательное
учреждение
высшего
образования
«Петербургский
государственный университет путей
сообщения
Императора
Александра I»
(ФГБОУ
ВО ПГУПС)
Кафедра
«Информационные
и вычислительные системы»
Направление
23.05.03 «Подвижной состав железных дорог»
Специализация
«Технология производства и ремонта
подвижного состава»
Календарный
план выполнения и защиты курсовой работы
по
дисциплине
«
Информатика »
Баранов
Александр Сергеевич
Тема:
«Создание и обработка базы данных»
|
№ п/п |
Наименование |
Планируемая |
Фактическая |
Подпись |
Примечание |
|
1 |
Выдача |
31.10.2019 |
|||
|
2 |
Сдача |
01.12-07.12 |
|||
|
3 |
Сдача |
||||
|
4 |
Допуск |
01.12 |
|||
|
5 |
Защита |
01.12-28.12 |
Руководитель
_____________________
(подпись)
«____»
____________ 2019 г.
ФЕДЕРАЛЬНОЕ
АГЕНТСТВО ЖЕЛЕЗНОДОРОЖНОГО ТРАНСПОРТА
Федеральное
государственное бюджетное образовательное
учреждение
высшего
образования
«Петербургский
государственный университет путей
сообщения
Императора
Александра I»
(ФГБОУ
ВО ПГУПС)
Кафедра
«Информационные
и вычислительные системы»
Направление
23.05.03 «Подвижной состав железных дорог»
Специализация
«Технология производства и ремонта
подвижного состава»
Оценочный
лист на курсовую работу
по
дисциплине
«
Информатика »
Баранов
Александр Сергеевич
Тема:
«Создание
и обработка базы данных»
Оценка
курсовой работы
|
№ п/п |
Материалы и |
Показатель оценивания |
Критерии оценивания |
Шкала |
Полученные |
|
1 |
Пояснительная |
1. |
Соответствует |
5 |
|
|
Не |
0 |
||||
|
2. |
Все |
20 |
|||
|
Принятые |
10 |
||||
|
Принятые |
0 |
||||
|
3. |
Использованы |
5 |
|||
|
Не |
0 |
||||
|
4. |
Использовано |
5 |
|||
|
Не |
0 |
||||
|
Итого |
35 |
||||
|
2 |
Графические |
1. |
Соответствует |
10 |
|
|
Не |
0 |
||||
|
2. |
Соответствует |
15 |
|||
|
Не |
0 |
||||
|
3. |
Высокий |
10 |
|||
|
Низкий |
0 |
||||
|
Итого |
35 |
||||
|
ИТОГО |
70 |
||||
|
Защита |
|
30 |
|||
|
Итоговая |
«Отлично»
«Хорошо»
«Удовлетворительно» «Неудовлетворительно» |
Заключение:
рецензируемая курсовая работа
соответствует требованиям основной
образовательной программы (23.05.03)
Направление «Подвижной состав железных
дорог» Специализация «Технология
производства и ремонта подвижного
состава»
Итоговая
оценка –
Руководитель
_________________
(подпись)
«____»
____________ 2019 г.
Оглавление
1.Введение 8
1.Работа
в MS Excel 9
1.1.Заполнение
и редактирование таблиц базы данных. 9
1.2.Вычисление
стоимости телефона в магазине с учетом
наценки и подсчет выручки по каждой
модели. 9
1.3.Получение
информации о телефоне, который дает
наибольшую величину прибыли от продаж. 12
1.4.Получение
данных о телефонах, указанной пользователем
страны с указанием города, в котором
изготовлен телефон. 14
1.5.Формирование
отчета, содержащего следующие данные:
название и модель телефона, количество
проданных телефонов, общую сумму выручки
с подсчетом общего количества проданных
телефонов и группировкой по странам. 16
2.Работа
в MS Access 26
2.1Разработка
связанных таблиц , Создание и редактирование
базы данных. 26
2.2Создание форм 27
2.3Вычисление
стоимости телефона в магазине с учетом
наценки и подсчет выручки по каждой
модели. 31
2.4Получение
информации о телефоне, который дает
наибольшую величину прибыли от продаж. 33
2.5Получение данных
о телефонах, указанной пользователем
страны с указанием города, в котором
изготовлен телефон. 34
2.6Формирование
отчета, содержащего следующие данные:
название и модель телефона, количество
проданных телефонов, общую сумму выручки
с подсчетом общего количества проданных
телефонов и группировкой по странам. 35
Заключение 41
Список
использованной литературы 42
-
Введение
Цель:
Рассмотрение основных особенностей
создания, редактирования и выполнение
запросов в базе данных, созданной в MS
Excel
и MS
Access.
Создать
базу данных в MS
Excel
по заданной теме “Телефоны”. Определить
основные характеристики таблицы:
количество ячеек. Выполнить запросы в
базе данных MS
Excel
с иллюстрацией и создать макросы к ним.
Создание
формы для заполнения и редактирования
базы данных в MS
Access.
Деление данных на связанные таблицы.
Выполнение запросов и создание отчета
с иллюстрацией.
-
Работа в ms Excel
-
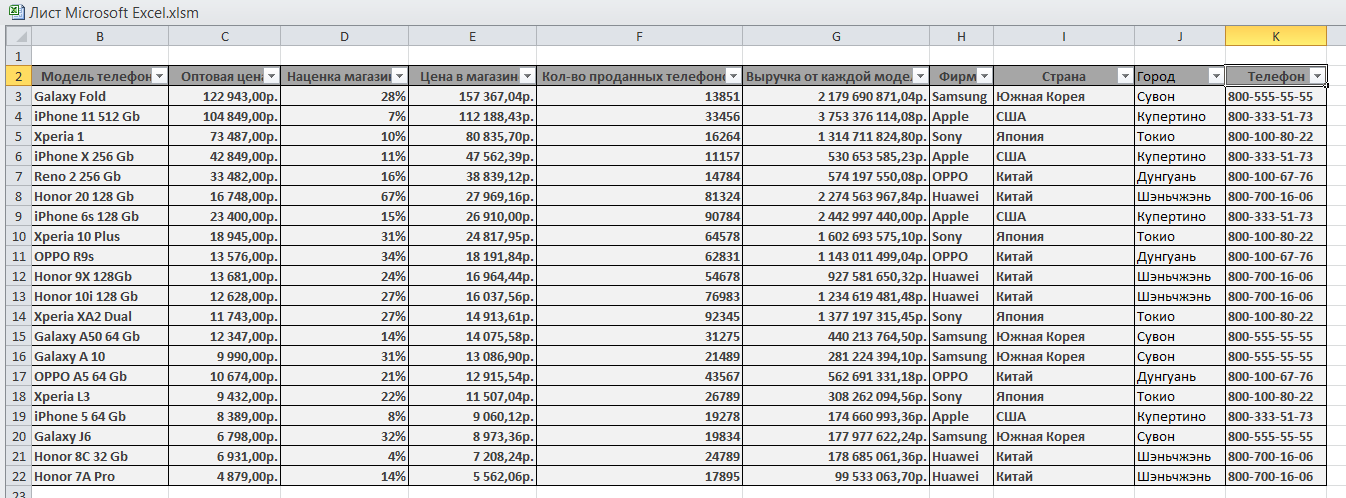
Заполнение и редактирование таблиц базы данных.
-
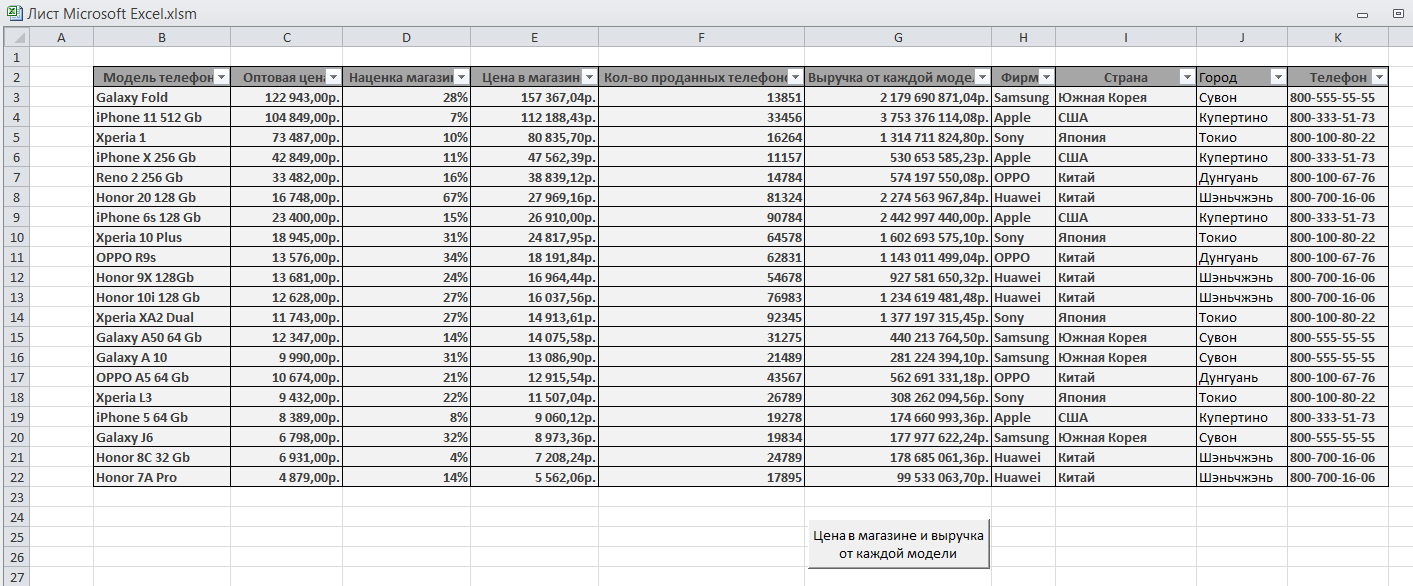
Вычисление стоимости телефона в магазине с учетом наценки и подсчет выручки по каждой модели.
Запись макроса



Код макроса
Sub
ЦенаВМагазинеИВыручкаОтКаждойМодели()
‘
‘
ЦенаВМагазинеИВыручкаОтКаждойМодели
Макрос
‘
‘
Сочетание клавиш: Ctrl+w
‘
Range(«F39,B2:D22,F2:F22,H2:K22»).Select
Range(«H2»).Activate
Selection.EntireColumn.Hidden
= True
End
Sub
Стоимость
телефона в магазине вычисляется по
формуле =C3+C3*D3
Подсчет
выручки от каждой модели по формуле
=E3*F3
При
нажатии кнопки «Цена в магазине и выручка
от каждой модели» запускается макрос
и выполняется сортировка
-
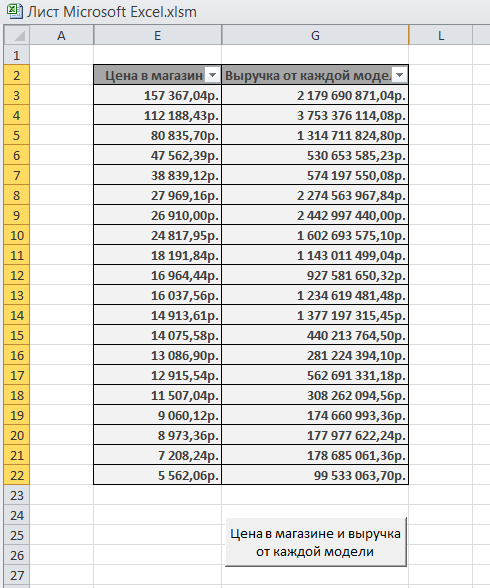
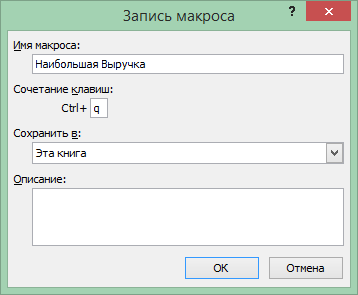
Получение информации о телефоне, который дает наибольшую величину прибыли от продаж.

Запись макроса
Код макроса
Sub
НаибольшаяВыручка()
‘
‘
НаибольшаяВыручка Макрос
‘
‘
Сочетание клавиш: Ctrl+q
‘
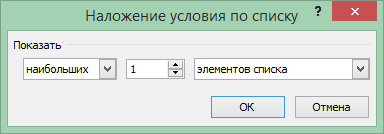
ActiveSheet.Range(«$B$2:$J$22″).AutoFilter
Field:=6, Criteria1:=»1», _
Operator:=xlTop10Items
End
Sub
При
нажатии кнопки «Наибольшая выручка»
запускается макрос и выполняется
сортировка

-
Получение данных о телефонах, указанной пользователем страны с указанием города, в котором изготовлен телефон.

Соседние файлы в папке Курсовая работа
- #
- #
- #
07.07.2020376.83 Кб9Данные.mdb
- #
- #
- #
07.07.202021.5 Кб20Решение.xls
Рассмотрим инструмент Описательная статистика, входящий в надстройку Пакет Анализа. Рассчитаем показатели выборки: среднее, медиана, мода, дисперсия, стандартное отклонение и др.
Задача
описательной статистики
(descriptive statistics) заключается в том, чтобы с использованием математических инструментов свести сотни значений
выборки
к нескольким итоговым показателям, которые дают представление о
выборке
.В качестве таких статистических показателей используются:
среднее
,
медиана
,
мода
,
дисперсия, стандартное отклонение
и др.
Опишем набор числовых данных с помощью определенных показателей. Для чего нужны эти показатели? Эти показатели позволят сделать определенные
статистические выводы о распределении
, из которого была взята
выборка
. Например, если у нас есть
выборка
значений толщины трубы, которая изготавливается на определенном оборудовании, то на основании анализа этой
выборки
мы сможем сделать, с некой определенной вероятностью, заключение о состоянии процесса изготовления.
Содержание статьи:
- Надстройка Пакет анализа;
-
Среднее выборки
;
-
Медиана выборки
;
-
Мода выборки
;
-
Мода и среднее значение
;
-
Дисперсия выборки
;
-
Стандартное отклонение выборки
;
-
Стандартная ошибка
;
-
Ассиметричность
;
-
Эксцесс выборки
;
-
Уровень надежности
.
Надстройка Пакет анализа
Для вычисления статистических показателей одномерных
выборок
, используем
надстройку Пакет анализа
. Затем, все показатели рассчитанные надстройкой, вычислим с помощью встроенных функций MS EXCEL.
СОВЕТ
: Подробнее о других инструментах надстройки
Пакет анализа
и ее подключении – читайте в статье
Надстройка Пакет анализа MS EXCEL
.
Выборку
разместим на
листе
Пример
в файле примера
в диапазоне
А6:А55
(50 значений).
Примечание
: Для удобства написания формул для диапазона
А6:А55
создан
Именованный диапазон
Выборка.
В диалоговом окне
Анализ данных
выберите инструмент
Описательная статистика
.

После нажатия кнопки
ОК
будет выведено другое диалоговое окно,
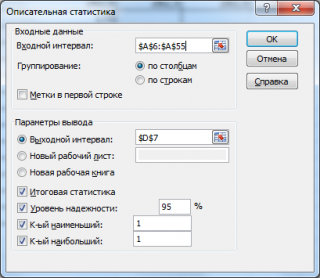
в котором нужно указать:
входной интервал
(Input Range) – это диапазон ячеек, в котором содержится массив данных. Если в указанный диапазон входит текстовый заголовок набора данных, то нужно поставить галочку в поле
Метки в первой строке (
Labels
in
first
row
).
В этом случае заголовок будет выведен в
Выходном интервале.
Пустые ячейки будут проигнорированы, поэтому нулевые значения необходимо обязательно указывать в ячейках, а не оставлять их пустыми;
выходной интервал
(Output Range). Здесь укажите адрес верхней левой ячейки диапазона, в который будут выведены статистические показатели;
Итоговая статистика (
Summary
Statistics
)
. Поставьте галочку напротив этого поля – будут выведены основные показатели выборки:
среднее, медиана, мода, стандартное отклонение
и др.;-
Также можно поставить галочки напротив полей
Уровень надежности (
Confidence
Level
for
Mean
)
,
К-й наименьший
(Kth Largest) и
К-й наибольший
(Kth Smallest).
В результате будут выведены следующие статистические показатели:
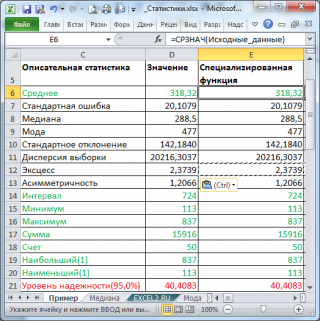
Все показатели выведены в виде значений, а не формул. Если массив данных изменился, то необходимо перезапустить расчет.
Если во
входном интервале
указать ссылку на несколько столбцов данных, то будет рассчитано соответствующее количество наборов показателей. Такой подход позволяет сравнить несколько наборов данных. При сравнении нескольких наборов данных используйте заголовки (включите их во
Входной интервал
и установите галочку в поле
Метки в первой строке
). Если наборы данных разной длины, то это не проблема — пустые ячейки будут проигнорированы.
Зеленым цветом на картинке выше и в
файле примера
выделены показатели, которые не требуют особого пояснения. Для большинства из них имеется специализированная функция:
Интервал
(Range) — разница между максимальным и минимальным значениями;
Минимум
(Minimum) – минимальное значение в диапазоне ячеек, указанном во
Входном интервале
(см.статью про функцию
МИН()
);
Максимум
(Maximum)– максимальное значение (см.статью про функцию
МАКС()
);
Сумма
(Sum) – сумма всех значений (см.статью про функцию
СУММ()
);
Счет
(Count) – количество значений во
Входном интервале
(пустые ячейки игнорируются, см.статью про функцию
СЧЁТ()
);
Наибольший
(Kth Largest) – выводится К-й наибольший. Например, 1-й наибольший – это максимальное значение (см.статью про функцию
НАИБОЛЬШИЙ()
);
Наименьший
(Kth Smallest) – выводится К-й наименьший. Например, 1-й наименьший – это минимальное значение (см.статью про функцию
НАИМЕНЬШИЙ()
).
Ниже даны подробные описания остальных показателей.
Среднее выборки
Среднее
(mean, average) или
выборочное среднее
или
среднее выборки
(sample average) представляет собой
арифметическое среднее
всех значений массива. В MS EXCEL для вычисления среднего выборки используется функция
СРЗНАЧ()
.
Выборочное среднее
является «хорошей» (несмещенной и эффективной) оценкой
математического ожидания
случайной величины (подробнее см. статью
Среднее и Математическое ожидание в MS EXCEL
).
Медиана выборки
Медиана
(Median) – это число, которое является серединой множества чисел (в данном случае выборки): половина чисел множества больше, чем
медиана
, а половина чисел меньше, чем
медиана
. Для определения
медианы
необходимо сначала
отсортировать множество чисел
. Например,
медианой
для чисел 2, 3, 3,
4
, 5, 7, 10 будет 4.
Если множество содержит четное количество чисел, то вычисляется
среднее
для двух чисел, находящихся в середине множества. Например,
медианой
для чисел 2, 3,
3
,
5
, 7, 10 будет 4, т.к. (3+5)/2.
Если имеется длинный хвост распределения, то
Медиана
лучше, чем
среднее значение
, отражает «типичное» или «центральное» значение. Например, рассмотрим несправедливое распределение зарплат в компании, в которой руководство получает существенно больше, чем основная масса сотрудников.
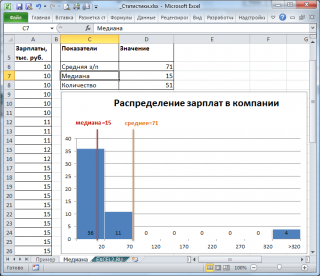
Очевидно, что средняя зарплата (71 тыс. руб.) не отражает тот факт, что 86% сотрудников получает не более 30 тыс. руб. (т.е. 86% сотрудников получает зарплату в более, чем в 2 раза меньше средней!). В то же время медиана (15 тыс. руб.) показывает, что
как минимум
у 50% сотрудников зарплата меньше или равна 15 тыс. руб.
Для определения
медианы
в MS EXCEL существует одноименная функция
МЕДИАНА()
, английский вариант — MEDIAN().
Медиану
также можно вычислить с помощью формул
=КВАРТИЛЬ.ВКЛ(Выборка;2) =ПРОЦЕНТИЛЬ.ВКЛ(Выборка;0,5).
Подробнее о
медиане
см. специальную статью
Медиана в MS EXCEL
.
СОВЕТ
: Подробнее про
квартили
см. статью, про
перцентили (процентили)
см. статью.
Мода выборки
Мода
(Mode) – это наиболее часто встречающееся (повторяющееся) значение в
выборке
. Например, в массиве (1; 1;
2
;
2
;
2
; 3; 4; 5) число 2 встречается чаще всего – 3 раза. Значит, число 2 – это
мода
. Для вычисления
моды
используется функция
МОДА()
, английский вариант MODE().
Примечание
: Если в массиве нет повторяющихся значений, то функция вернет значение ошибки #Н/Д. Это свойство использовано в статье
Есть ли повторы в списке?
Начиная с
MS EXCEL 2010
вместо функции
МОДА()
рекомендуется использовать функцию
МОДА.ОДН()
, которая является ее полным аналогом. Кроме того, в MS EXCEL 2010 появилась новая функция
МОДА.НСК()
, которая возвращает несколько наиболее часто повторяющихся значений (если количество их повторов совпадает). НСК – это сокращение от слова НеСКолько.
Например, в массиве (1; 1;
2
;
2
;
2
; 3;
4
;
4
;
4
; 5) числа 2 и 4 встречаются наиболее часто – по 3 раза. Значит, оба числа являются
модами
. Функции
МОДА.ОДН()
и
МОДА()
вернут значение 2, т.к. 2 встречается первым, среди наиболее повторяющихся значений (см.
файл примера
, лист
Мода
).
Чтобы исправить эту несправедливость и была введена функция
МОДА.НСК()
, которая выводит все
моды
. Для этого ее нужно ввести как
формулу массива
.
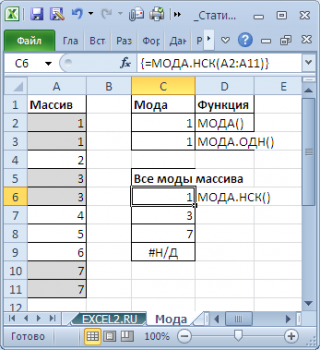
Как видно из картинки выше, функция
МОДА.НСК()
вернула все три
моды
из массива чисел в диапазоне
A2:A11
: 1; 3 и 7. Для этого, выделите диапазон
C6:C9
, в
Строку формул
введите формулу
=МОДА.НСК(A2:A11)
и нажмите
CTRL+SHIFT+ENTER
. Диапазон
C
6:
C
9
охватывает 4 ячейки, т.е. количество выделяемых ячеек должно быть больше или равно количеству
мод
. Если ячеек больше чем м
о
д, то избыточные ячейки будут заполнены значениями ошибки #Н/Д. Если
мода
только одна, то все выделенные ячейки будут заполнены значением этой
моды
.
Теперь вспомним, что мы определили
моду
для выборки, т.е. для конечного множества значений, взятых из
генеральной совокупности
. Для
непрерывных случайных величин
вполне может оказаться, что выборка состоит из массива на подобие этого (0,935; 1,211; 2,430; 3,668; 3,874; …), в котором может не оказаться повторов и функция
МОДА()
вернет ошибку.
Даже в нашем массиве с
модой
, которая была определена с помощью
надстройки Пакет анализа
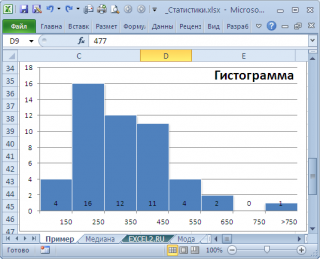
, творится, что-то не то. Действительно,
модой
нашего массива значений является число 477, т.к. оно встречается 2 раза, остальные значения не повторяются. Но, если мы посмотрим на
гистограмму распределения
, построенную для нашего массива, то увидим, что 477 не принадлежит интервалу наиболее часто встречающихся значений (от 150 до 250).
Проблема в том, что мы определили
моду
как наиболее часто встречающееся значение, а не как наиболее вероятное. Поэтому,
моду
в учебниках статистики часто определяют не для выборки (массива), а для функции распределения. Например, для
логнормального распределения
мода
(наиболее вероятное значение непрерывной случайной величины х), вычисляется как
exp
(
m
—
s
2
)
, где m и s параметры этого распределения.
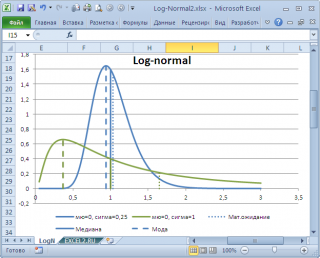
Понятно, что для нашего массива число 477, хотя и является наиболее часто повторяющимся значением, но все же является плохой оценкой для
моды
распределения, из которого взята
выборка
(наиболее вероятного значения или для которого плотность вероятности распределения максимальна).
Для того, чтобы получить оценку
моды
распределения, из
генеральной совокупности
которого взята
выборка
, можно, например, построить
гистограмму
. Оценкой для
моды
может служить интервал наиболее часто встречающихся значений (самого высокого столбца). Как было сказано выше, в нашем случае это интервал от 150 до 250.
Вывод
: Значение
моды
для
выборки
, рассчитанное с помощью функции
МОДА()
, может ввести в заблуждение, особенно для небольших выборок. Эта функция эффективна, когда случайная величина может принимать лишь несколько дискретных значений, а размер
выборки
существенно превышает количество этих значений.
Например, в рассмотренном примере о распределении заработных плат (см. раздел статьи выше, о Медиане),
модой
является число 15 (17 значений из 51, т.е. 33%). В этом случае функция
МОДА()
дает хорошую оценку «наиболее вероятного» значения зарплаты.
Примечание
: Строго говоря, в примере с зарплатой мы имеем дело скорее с
генеральной совокупностью
, чем с
выборкой
. Т.к. других зарплат в компании просто нет.
О вычислении
моды
для распределения
непрерывной случайной величины
читайте статью
Мода в MS EXCEL
.
Мода и среднее значение
Не смотря на то, что
мода
– это наиболее вероятное значение случайной величины (вероятность выбрать это значение из
Генеральной совокупности
максимальна), не следует ожидать, что
среднее значение
обязательно будет близко к
моде
.
Примечание
:
Мода
и
среднее
симметричных распределений совпадает (имеется ввиду симметричность
плотности распределения
).
Представим, что мы бросаем некий «неправильный» кубик, у которого на гранях имеются значения (1; 2; 3; 4; 6; 6), т.е. значения 5 нет, а есть вторая 6.
Модой
является 6, а среднее значение – 3,6666.
Другой пример. Для
Логнормального распределения
LnN(0;1)
мода
равна =EXP(m-s2)= EXP(0-1*1)=0,368, а
среднее значение
1,649.
Дисперсия выборки
Дисперсия выборки
или
выборочная дисперсия (
sample
variance
) характеризует разброс значений в массиве, отклонение от
среднего
.
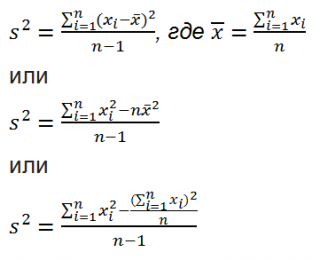
Из формулы №1 видно, что
дисперсия выборки
это сумма квадратов отклонений каждого значения в массиве
от среднего
, деленная на размер выборки минус 1.
В MS EXCEL 2007 и более ранних версиях для вычисления
дисперсии выборки
используется функция
ДИСП()
. С версии MS EXCEL 2010 рекомендуется использовать ее аналог — функцию
ДИСП.В()
.
Дисперсию
можно также вычислить непосредственно по нижеуказанным формулам (см.
файл примера
):
=КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1) =(СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/ (СЧЁТ(Выборка)-1)
– обычная формула
=СУММ((Выборка -СРЗНАЧ(Выборка))^2)/ (СЧЁТ(Выборка)-1)
–
формула массива
Дисперсия выборки
равна 0, только в том случае, если все значения равны между собой и, соответственно, равны
среднему значению
.
Чем больше величина
дисперсии
, тем больше разброс значений в массиве относительно
среднего
.
Размерность
дисперсии
соответствует квадрату единицы измерения исходных значений. Например, если значения в выборке представляют собой измерения веса детали (в кг), то размерность
дисперсии
будет кг
2
. Это бывает сложно интерпретировать, поэтому для характеристики разброса значений чаще используют величину равную квадратному корню из
дисперсии – стандартное отклонение
.
Подробнее о
дисперсии
см. статью
Дисперсия и стандартное отклонение в MS EXCEL
.
Стандартное отклонение выборки
Стандартное отклонение выборки
(Standard Deviation), как и
дисперсия
, — это мера того, насколько широко разбросаны значения в выборке
относительно их среднего
.
По определению,
стандартное отклонение
равно квадратному корню из
дисперсии
:
![]()
Стандартное отклонение
не учитывает величину значений в
выборке
, а только степень рассеивания значений вокруг их
среднего
. Чтобы проиллюстрировать это приведем пример.
Вычислим стандартное отклонение для 2-х
выборок
: (1; 5; 9) и (1001; 1005; 1009). В обоих случаях, s=4. Очевидно, что отношение величины стандартного отклонения к значениям массива у
выборок
существенно отличается.
В MS EXCEL 2007 и более ранних версиях для вычисления
Стандартного отклонения выборки
используется функция
СТАНДОТКЛОН()
. С версии MS EXCEL 2010 рекомендуется использовать ее аналог
СТАНДОТКЛОН.В()
.
Стандартное отклонение
можно также вычислить непосредственно по нижеуказанным формулам (см.
файл примера
):
=КОРЕНЬ(КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)) =КОРЕНЬ((СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/(СЧЁТ(Выборка)-1))
Подробнее о
стандартном отклонении
см. статью
Дисперсия и стандартное отклонение в MS EXCEL
.
Стандартная ошибка
В
Пакете анализа
под термином
стандартная ошибка
имеется ввиду
Стандартная ошибка среднего
(Standard Error of the Mean, SEM).
Стандартная ошибка среднего
— это оценка
стандартного отклонения
распределения
выборочного среднего
.
Примечание
: Чтобы разобраться с понятием
Стандартная ошибка среднего
необходимо прочитать о
выборочном распределении
(см. статью
Статистики, их выборочные распределения и точечные оценки параметров распределений в MS EXCEL
) и статью про
Центральную предельную теорему
.
Стандартное отклонение распределения выборочного среднего
вычисляется по формуле σ/√n, где n — объём
выборки, σ — стандартное отклонение исходного
распределения, из которого взята
выборка
. Т.к. обычно
стандартное отклонение
исходного распределения неизвестно, то в расчетах вместо
σ
используют ее оценку
s
—
стандартное отклонение выборки
. А соответствующая величина s/√n имеет специальное название —
Стандартная ошибка среднего.
Именно эта величина вычисляется в
Пакете анализа.
В MS EXCEL
стандартную ошибку среднего
можно также вычислить по формуле
=СТАНДОТКЛОН.В(Выборка)/ КОРЕНЬ(СЧЁТ(Выборка))
Асимметричность
Асимметричность
или
коэффициент асимметрии
(skewness) характеризует степень несимметричности распределения (
плотности распределения
) относительно его
среднего
.
Положительное значение
коэффициента асимметрии
указывает, что размер правого «хвоста» распределения больше, чем левого (относительно среднего). Отрицательная асимметрия, наоборот, указывает на то, что левый хвост распределения больше правого.
Коэффициент асимметрии
идеально симметричного распределения или выборки равно 0.

Примечание
:
Асимметрия выборки
может отличаться расчетного значения асимметрии теоретического распределения. Например,
Нормальное распределение
является симметричным распределением (
плотность его распределения
симметрична относительно
среднего
) и, поэтому имеет асимметрию равную 0. Понятно, что при этом значения в
выборке
из соответствующей
генеральной совокупности
не обязательно должны располагаться совершенно симметрично относительно
среднего
. Поэтому,
асимметрия выборки
, являющейся оценкой
асимметрии распределения
, может отличаться от 0.
Функция
СКОС()
, английский вариант SKEW(), возвращает коэффициент
асимметрии выборки
, являющейся оценкой
асимметрии
соответствующего распределения, и определяется следующим образом:
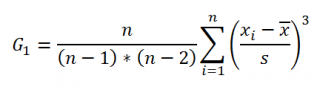
где n – размер
выборки
, s –
стандартное отклонение выборки
.
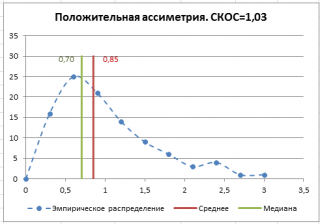
В
файле примера на листе СКОС
приведен расчет коэффициента
асимметрии
на примере случайной выборки из
распределения Вейбулла
, которое имеет значительную положительную
асимметрию
при параметрах распределения W(1,5; 1).
Эксцесс выборки
Эксцесс
показывает относительный вес «хвостов» распределения относительно его центральной части.
Для того чтобы определить, что относится к хвостам распределения, а что к его центральной части, можно использовать границы μ +/-
σ
.
Примечание
: Не смотря на старания профессиональных статистиков, в литературе еще попадается определение
Эксцесса
как меры «остроконечности» (peakedness) или сглаженности распределения. Но, на самом деле, значение
Эксцесса
ничего не говорит о форме пика распределения.
Согласно определения,
Эксцесс
равен четвертому
стандартизированному моменту:
![]()
Для
нормального распределения
четвертый момент равен 3*σ
4
, следовательно,
Эксцесс
равен 3. Многие компьютерные программы используют для расчетов не сам
Эксцесс
, а так называемый Kurtosis excess, который меньше на 3. Т.е. для
нормального распределения
Kurtosis excess равен 0. Необходимо быть внимательным, т.к. часто не очевидно, какая формула лежит в основе расчетов.
Примечание
: Еще большую путаницу вносит перевод этих терминов на русский язык. Термин Kurtosis происходит от греческого слова «изогнутый», «имеющий арку». Так сложилось, что на русский язык оба термина Kurtosis и Kurtosis excess переводятся как
Эксцесс
(от англ. excess — «излишек»). Например, функция MS EXCEL
ЭКСЦЕСС()
на самом деле вычисляет Kurtosis excess.
Функция
ЭКСЦЕСС()
, английский вариант KURT(), вычисляет на основе значений выборки несмещенную оценку
эксцесса распределения
случайной величины и определяется следующим образом:
![]()
Как видно из формулы MS EXCEL использует именно Kurtosis excess, т.е. для выборки из
нормального распределения
формула вернет близкое к 0 значение.
Если задано менее четырех точек данных, то функция
ЭКСЦЕСС()
возвращает значение ошибки #ДЕЛ/0!
Вернемся к
распределениям случайной величины
.
Эксцесс
(Kurtosis excess) для
нормального распределения
всегда равен 0, т.е. не зависит от параметров распределения μ и σ. Для большинства других распределений
Эксцесс
зависит от параметров распределения: см., например,
распределение Вейбулла
или
распределение Пуассона
, для котрого
Эксцесс
= 1/λ.
Уровень надежности
Уровень
надежности
— означает вероятность того, что
доверительный интервал
содержит истинное значение оцениваемого параметра распределения.
Вместо термина
Уровень
надежности
часто используется термин
Уровень доверия
. Про
Уровень надежности
(Confidence Level for Mean) читайте статью
Уровень значимости и уровень надежности в MS EXCEL
.
Задав значение
Уровня
надежности
в окне
надстройки Пакет анализа
, MS EXCEL вычислит половину ширины
доверительного интервала для оценки среднего (дисперсия неизвестна)
.
Тот же результат можно получить по формуле (см.
файл примера
):
=ДОВЕРИТ.СТЬЮДЕНТ(1-0,95;s;n)
s —
стандартное отклонение выборки
, n – объем
выборки
.
Подробнее см. статью про
построение доверительного интервала для оценки среднего (дисперсия неизвестна)
.
Обзор функций для работы с текстом
Мы подготовили обзорное видео, где собрали полезные сочетания текстовых функций в Excel и Google таблицах.
Все примеры основаны на реальных задачах, с которыми мы очень часто сталкиваемся в рабочих моментах. Предполагаем, что большинство пользователей найдут это видео полезным и сохранят комбинации рассматриваемых функций для работы с подобными текстовыми данными.
Скачать файлы из этой статьи
Рабочие файлы
Сохраняйте, чтобы знать, где искать ответы на похожие задачи.
Обзор полезных текстовых функций смотрите ниже. Приятного просмотра!
Как привести телефонные номера к единому формату?
Как показывает практика, несмотря на наличие продвинутых автоматизированных систем, большинство компаний малого и среднего бизнеса продолжают вести свои базы (в том числе клиентские) в Excel или Google таблицах.
В идеальном мире все данные в таблицах упорядочены и имеют одинаковый вид.

Что же касается реальной жизни — так данные немного в хаосе.
Посмотрите на вид хранения телефонов в одной из баз. Лишние символы – дефисы, пробелы, двоеточия, пояснительная бригада в виде надписей – номер телефона, сотовый, тел.
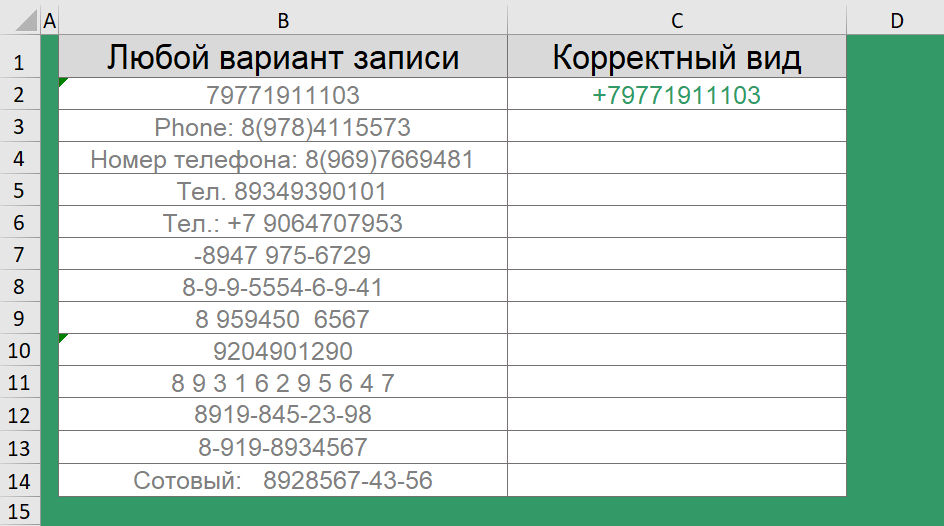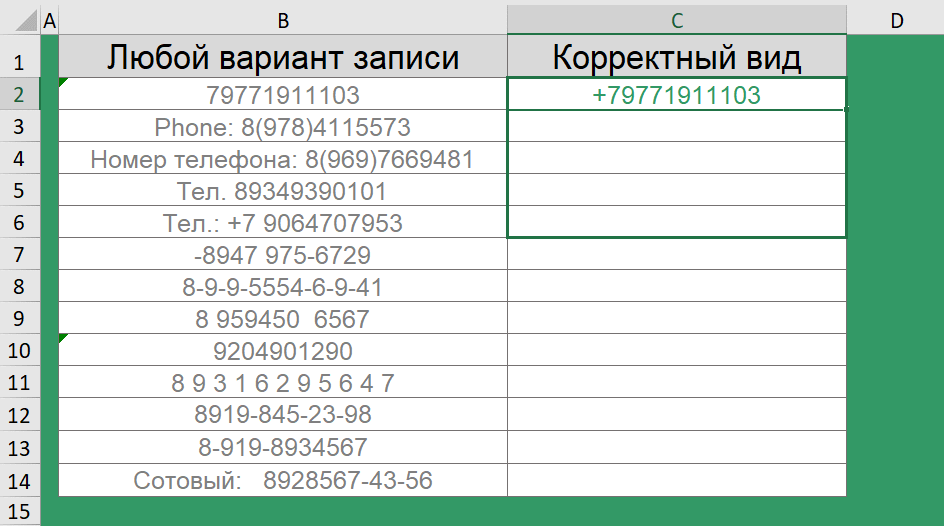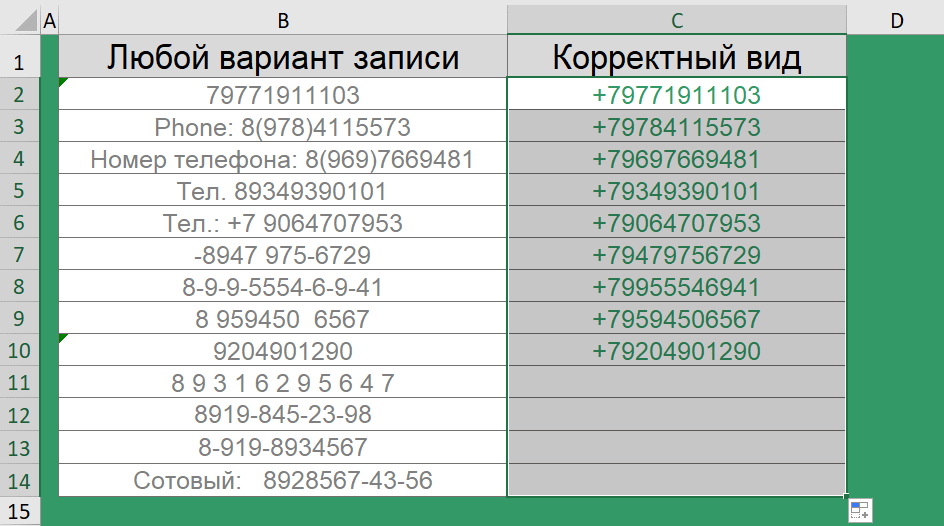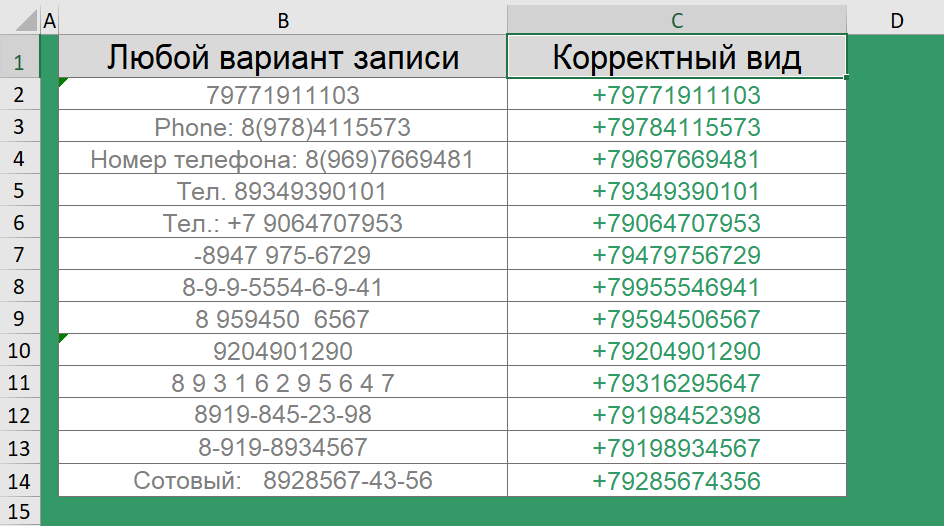
Согласитесь, это, во-первых, выглядит неопрятно, во-вторых – обрабатывать такие данные ой как не просто.
Поэтому, давайте договоримся, если мы и ведем свои базы в Excel или Google таблицах, то делаем это грамотно. Все номера в одном формате. В конце концов, Вы же не просто так эти номера собираете? Предполагается работа с этими номерами. Любому сотруднику будет удобнее ориентироваться в упорядоченной базе, плюс ко всему, по корректному списку номеров без проблем можно запустить массовую рассылку (например, в WhatsApp).
Ну а если Ваша база уже в легком хаосе, то самое время привести ее в порядок. Так, сочетание функций ПРАВСИМВ() и ПОДСТАВИТЬ() помогут преобразовать различные варианты записи телефона в стандартный вид.
="+7"&ПРАВСИМВ(ПОДСТАВИТЬ(ПОДСТАВИТЬ(ПОДСТАВИТЬ(ПОДСТАВИТЬ(ПОДСТАВИТЬ(B2;"(";"");")";"");" ";"");"-";"");" ";"");10)
Аналогичные функции применяются к данным в Google таблице.
Как извлечь домены адресов электронной почты?
Следующий кейс для тех, кто работает с электронными адресами в таблицах. Есть список адресов электронной почты, нужно из них получить домены.
Цели такой задачи могут быть абсолютно разными. Например, подбить статистику какими почтовыми клиентами пользуются Ваши клиенты, или же получить из почтового адреса сайт компании.
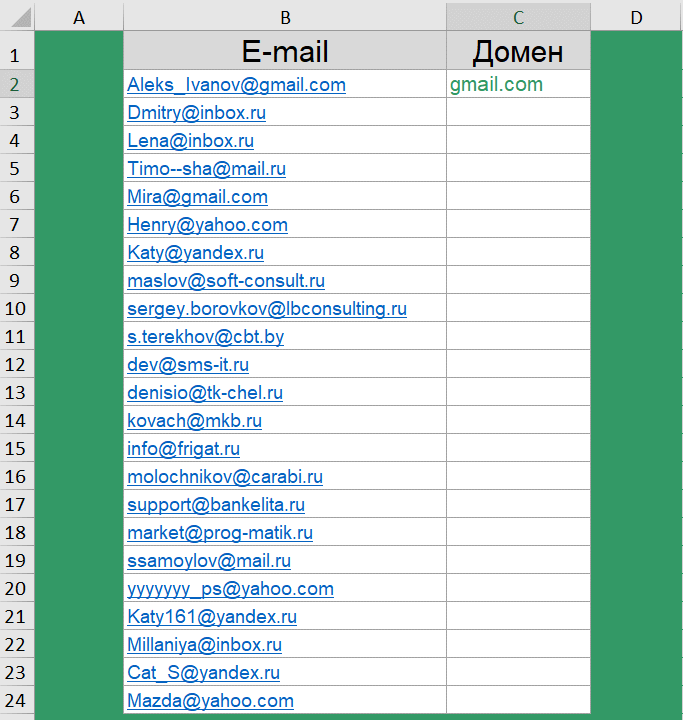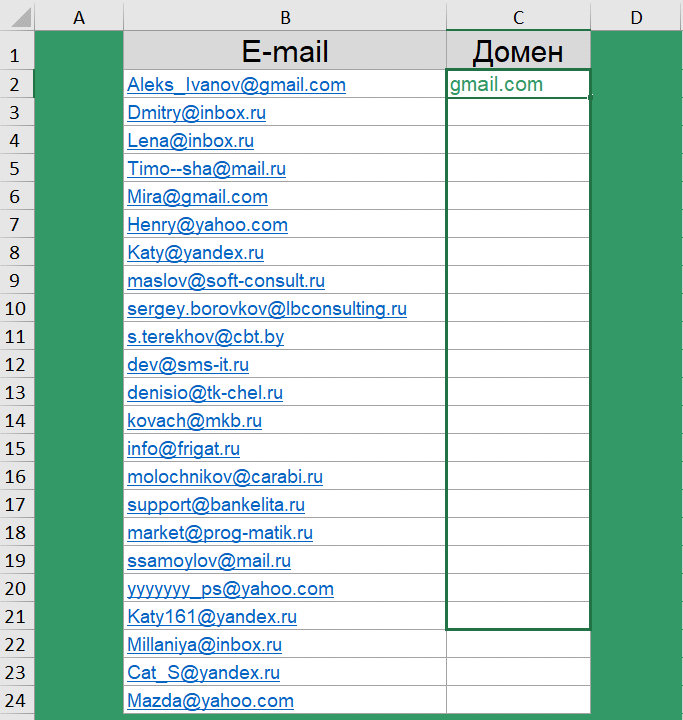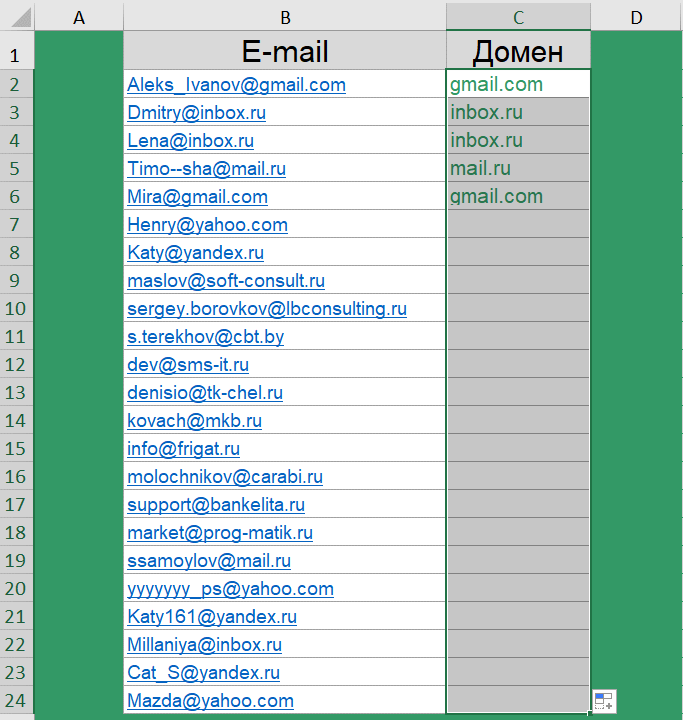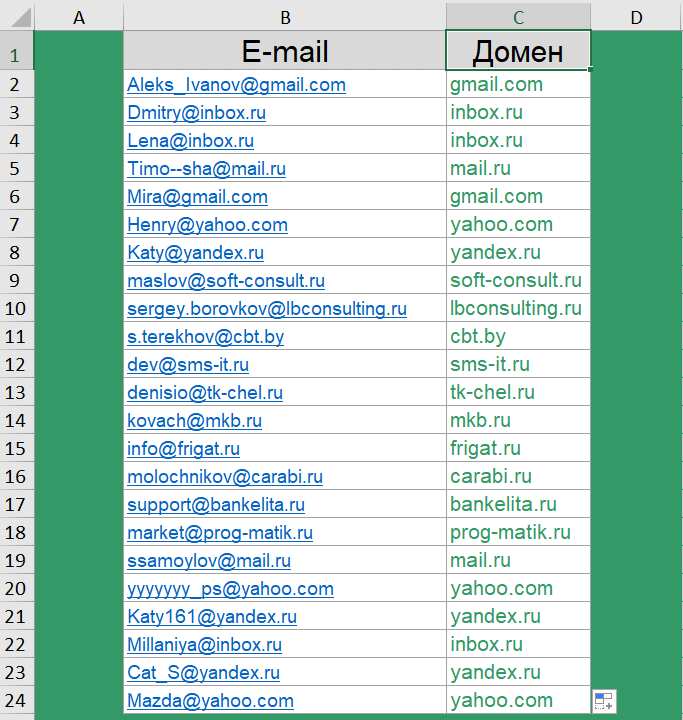
Сочетание функций для извлечения домена: =ПРАВСИМВ(B2;ДЛСТР(B2)-ПОИСК("@";B2))
Аналогичное сочетание функций работает для Google таблиц.
Как сократить длинные ссылки?
Следующая задача, немного похожа на предыдущую. Мы запускали парсер, который собрал нам ссылки на различные источники данных. По итогу, у нас имеется список полных URL.
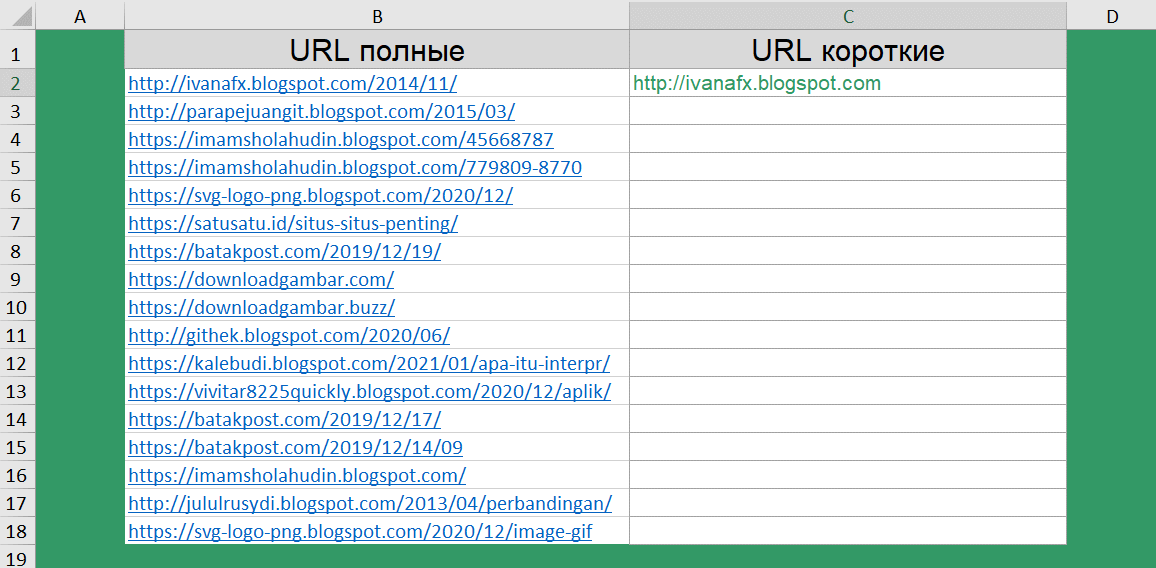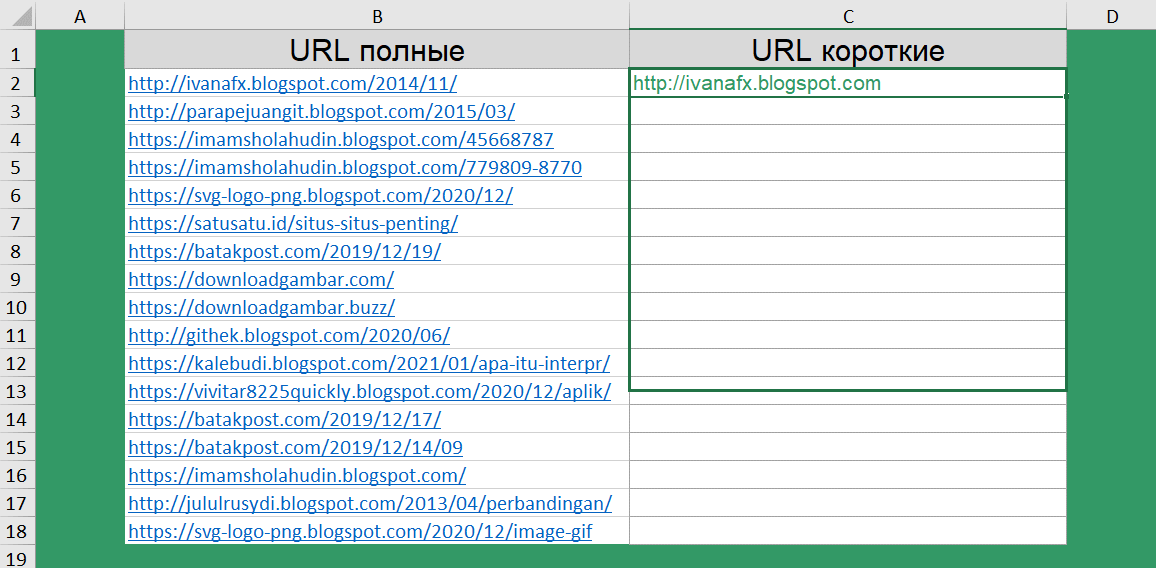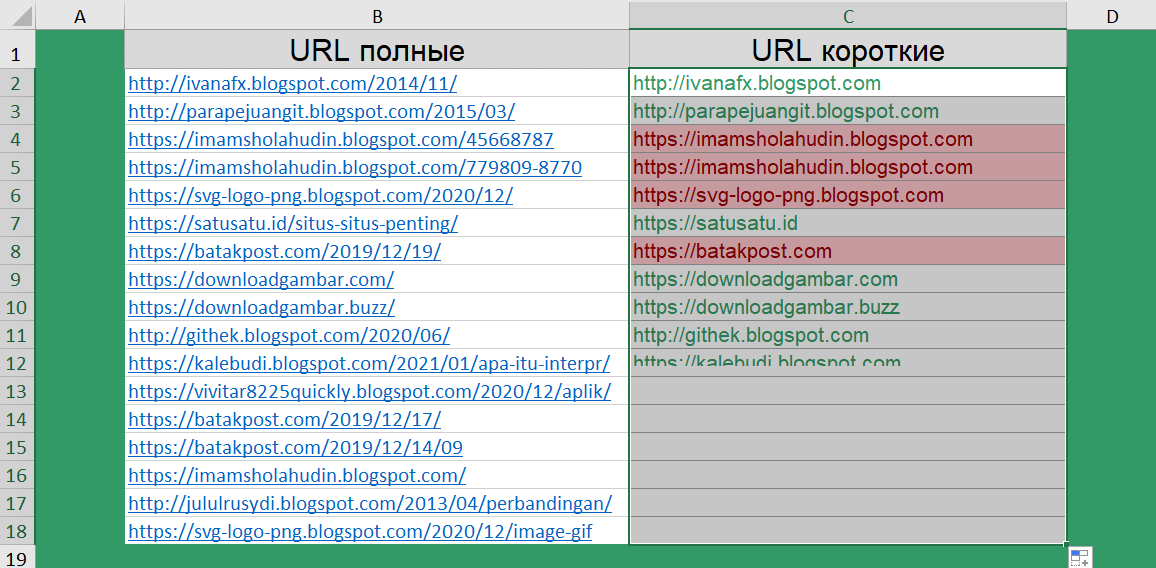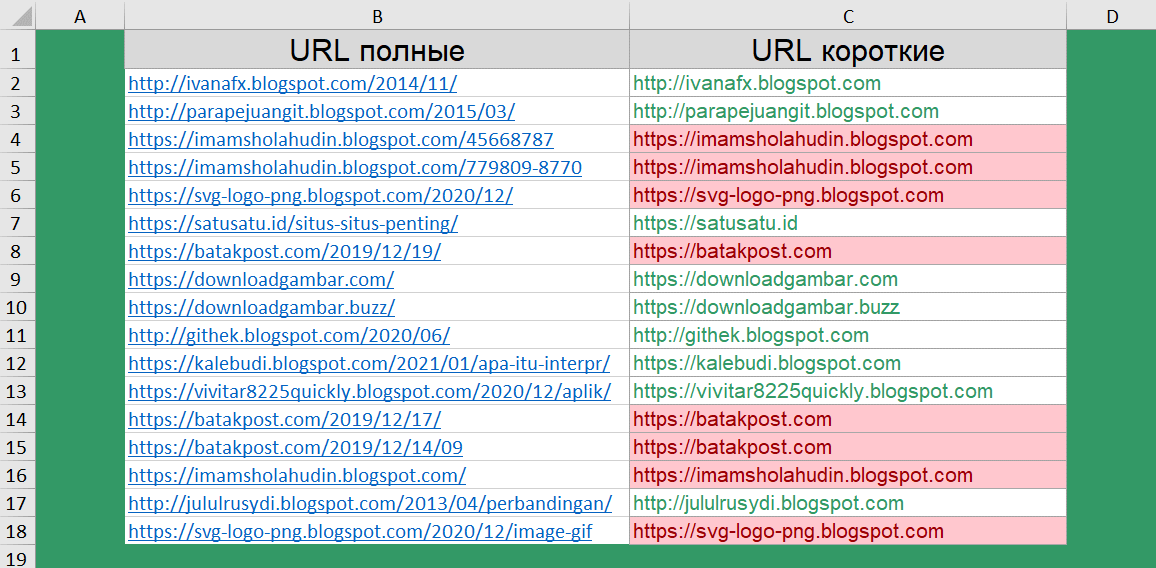
Для дальнейшей обработки этих данных, нам нужно получить только ссылку на сайт, без указания конкретной страницы. А далее, мы уже планируем оценить популярность источников.
Чтобы получить короткий URL воспользуемся уже знакомым сочетанием функций ПОДСТАВИТЬ(), НАЙТИ(), ДЛСТР() и ЛЕВСИМВ().
=ЛЕВСИМВ(B2;ДЛСТР(B2)-(ДЛСТР(B2)-НАЙТИ("/@";ПОДСТАВИТЬ(B2;"/";"/@";3))+1))
Аналогичное сочетание функций работает для Google таблиц.
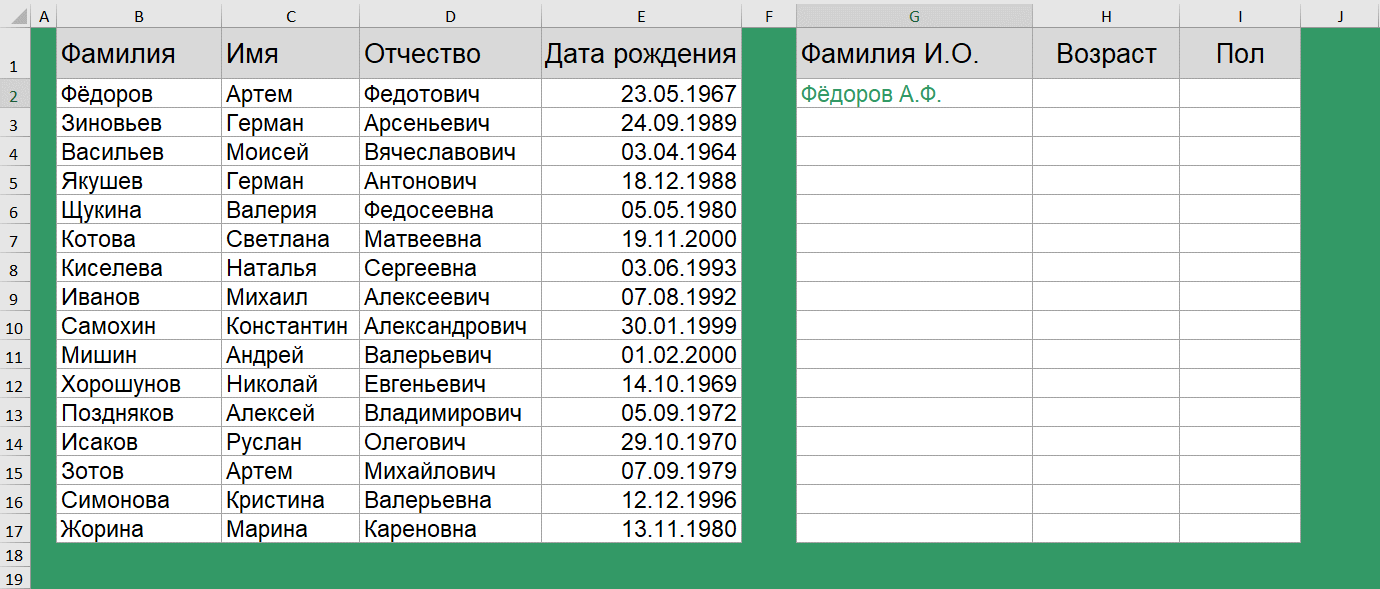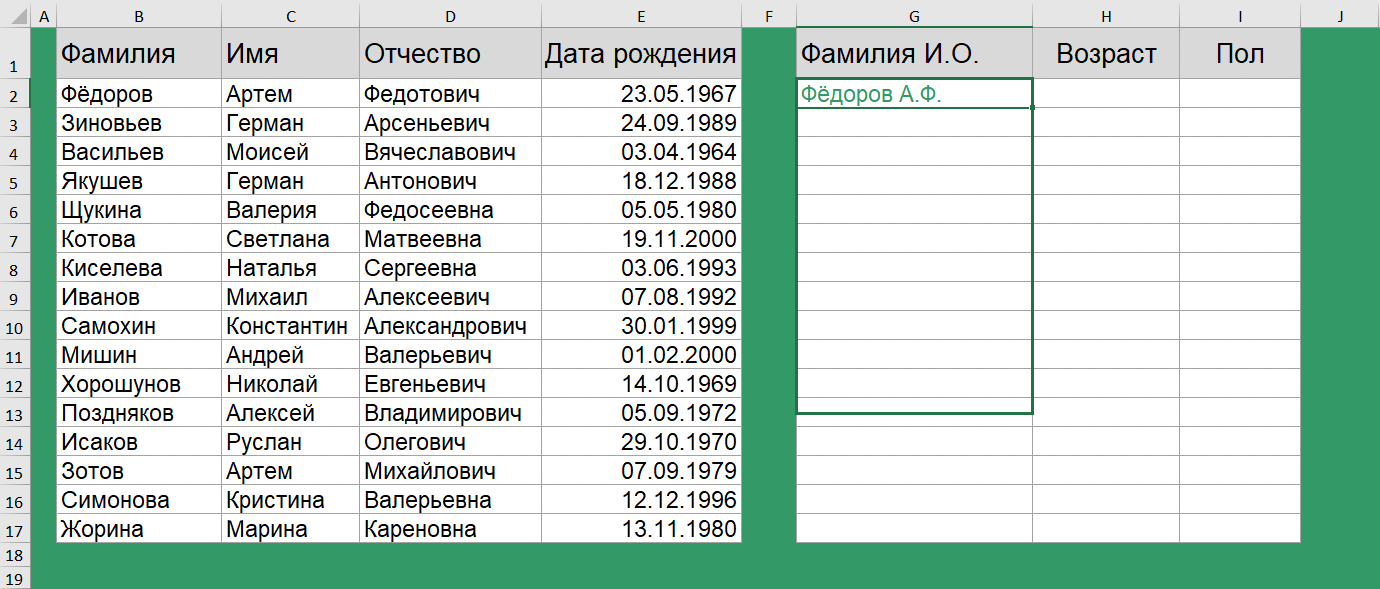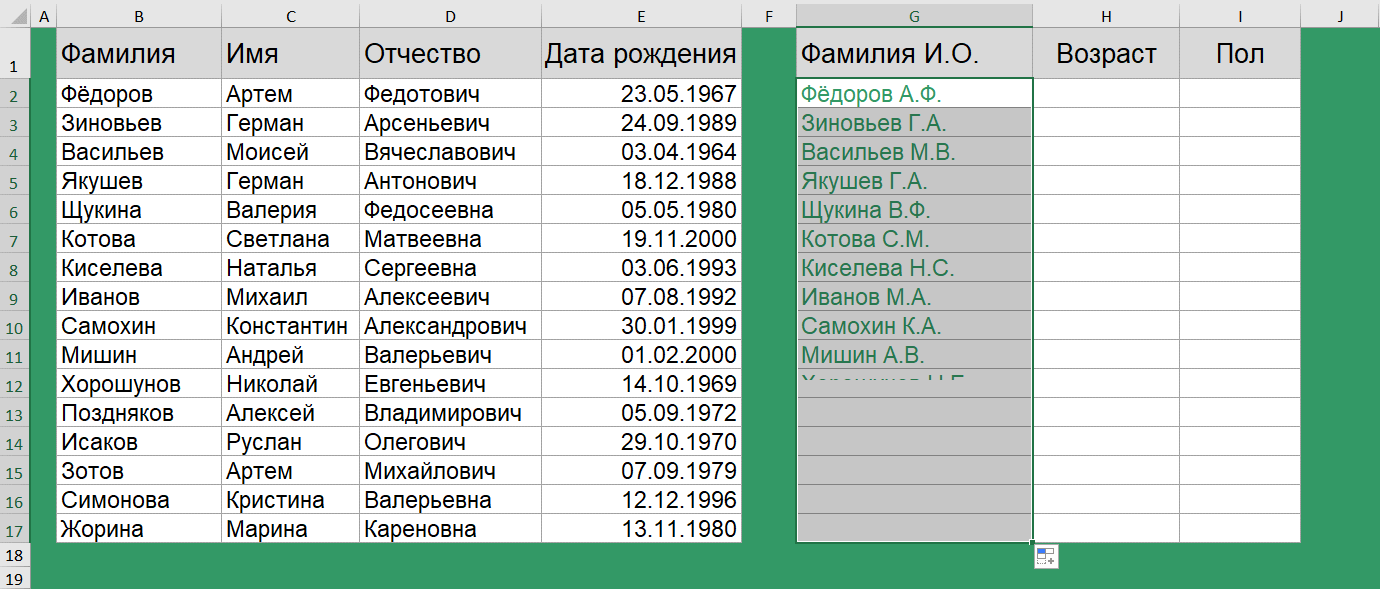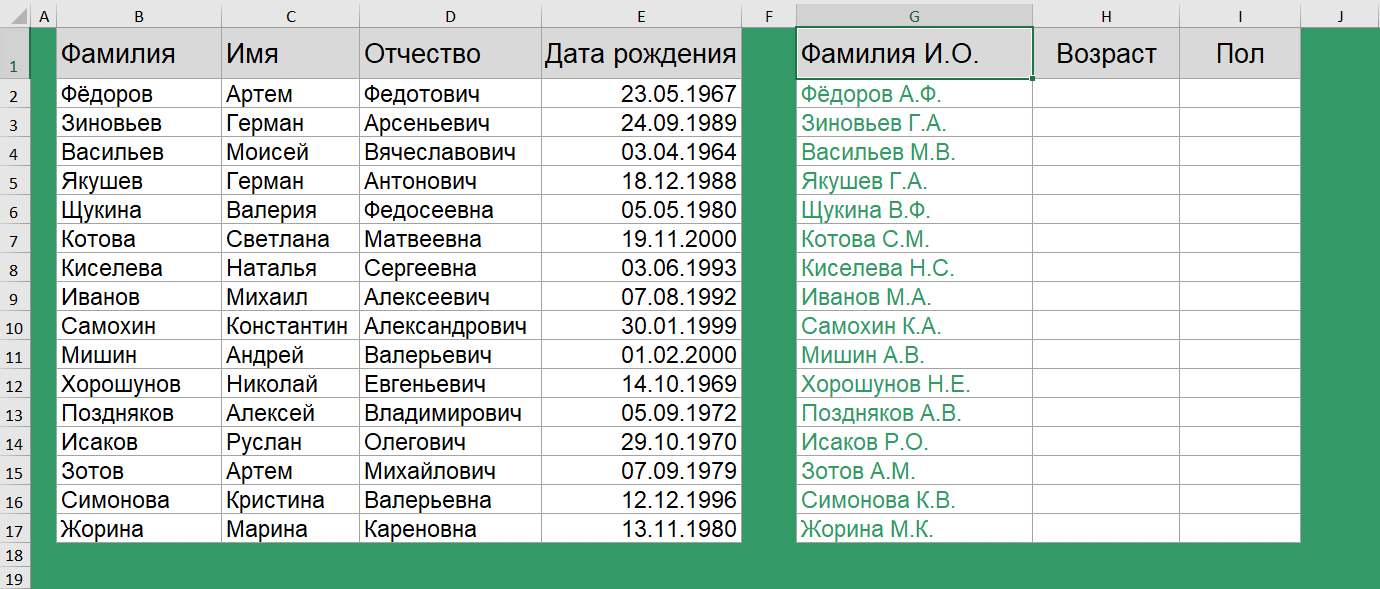
Как перевести ФИО в сокращенный вид?
Следующая задача, скорее больше знакома менеджерам, ведущим клиентскую базу или эйчарам. Есть полная база ФИО и дата рождения.
Хотим получить сокращенную форму ФИО, а также возраст сотрудника и по возможности определить пол.
Получить сокращенную форму ФИО очень просто. Для этого используются функции СЦЕПИТЬ() и ЛЕВСИМВ().
=СЦЕПИТЬ(B2;" ";ЛЕВСИМВ(C2;1);".";ЛЕВСИМВ(D2;1);".")
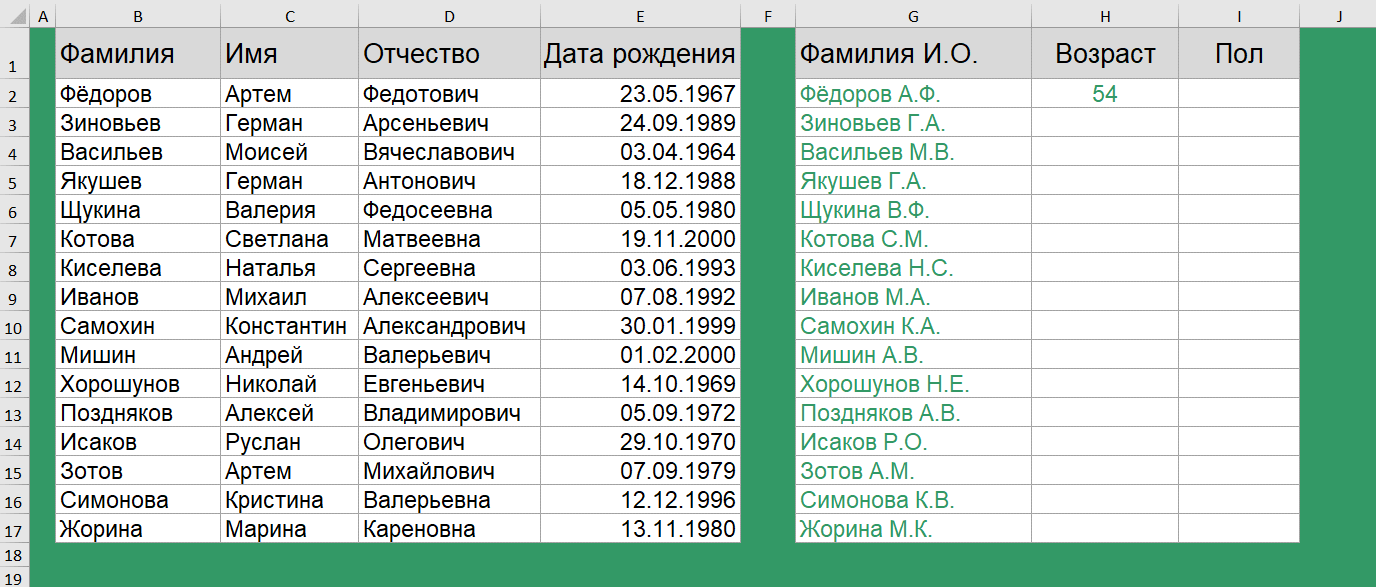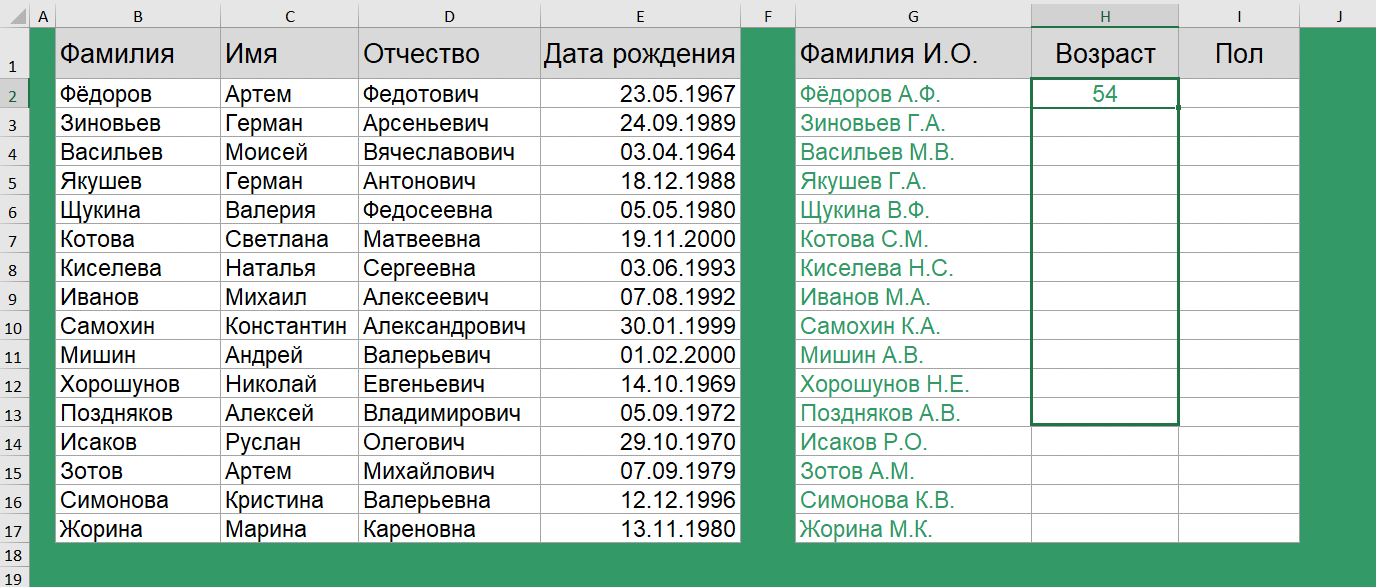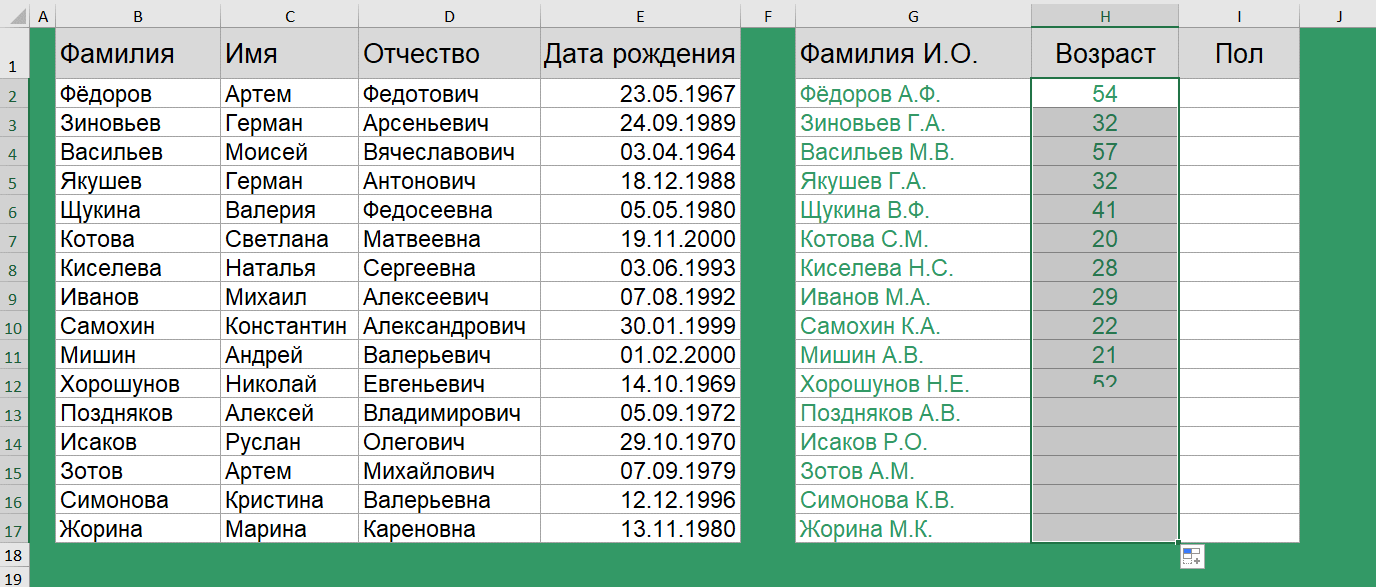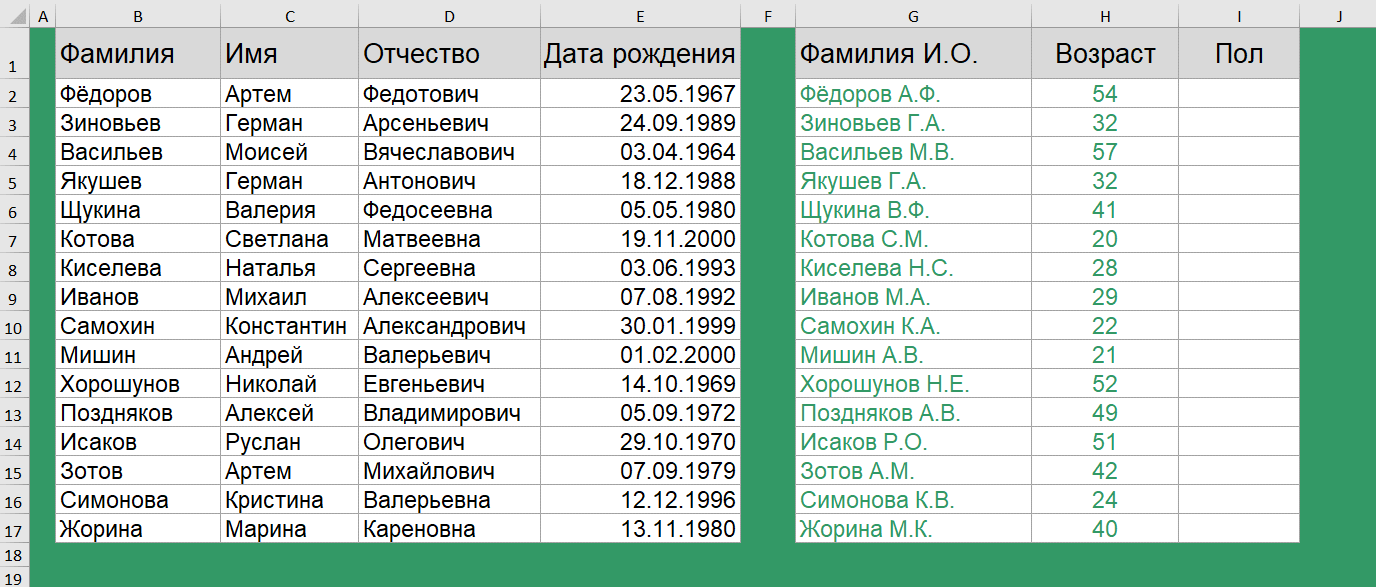
Как вычислить возраст по дате рождения?
Для вычисления возраста по дате рождения используется функция РАЗНДАТ(). История с функцией РАЗНДАТ() очень интересная. Вы не найдете её в справке. Более того, её нет в мастере функций, и даже при наборе вручную первых букв названия функции никакой подсказки вам не выйдет!
=РАЗНДАТ(E2;СЕГОДНЯ();"y")
Поэтому, друзья, просто запоминаем, что такая функция есть и она способствует вычислению количества дней, месяцев или лет между двумя датами.
Чтобы ей воспользоваться, задаем начальную дату, конечную дату и в скобках указываем в каких именно единицах нужно вернуть разницу дат. В нашем случае – число полных лет в периоде.
В Google таблицах используются аналогичные функции.
Как определить пол по отчеству?
Определить пол на 100% мы вряд ли сможем, особенно если у нас нестандартные варианты отчества, но для большей части данных – это реально. Так, самым простым вариантом, является проверка последней буквы отчества.
=ЕСЛИ(ПРАВСИМВ(D2)="ч";"М";ЕСЛИ(ПРАВСИМВ(D2)="а";"Ж";"н/о"))
Если отчество заканчивается на букву Ч, Антонович, Арсеньевич – то пол мужской, если отчество заканчивается на букву А – Сергеевна, Валерьевна – то пол женский, в противном случае пол не определен.
Это один из вариантов. Конечно, можно добавить проверку и по другим критериям. Например, добавить развернутый список женских и мужских имен и проверять имена по нему. В общем, вариант есть и не один, все зависит от конкретной задачи.
В Google таблицах все работает аналогично.
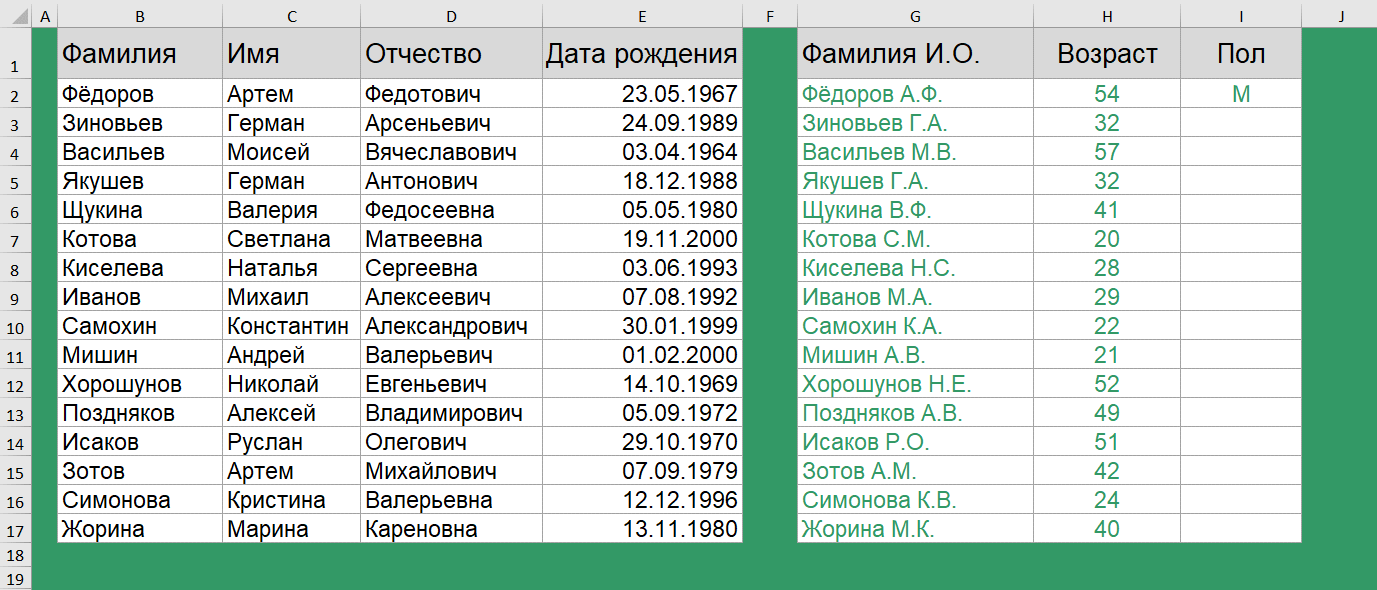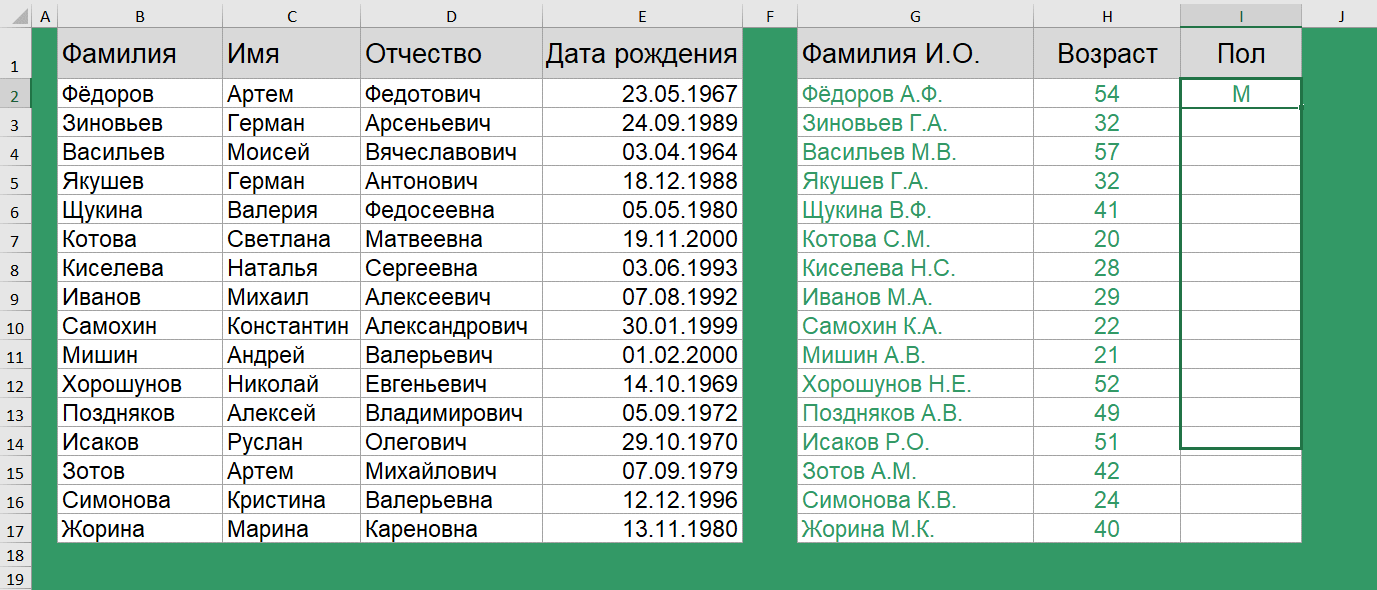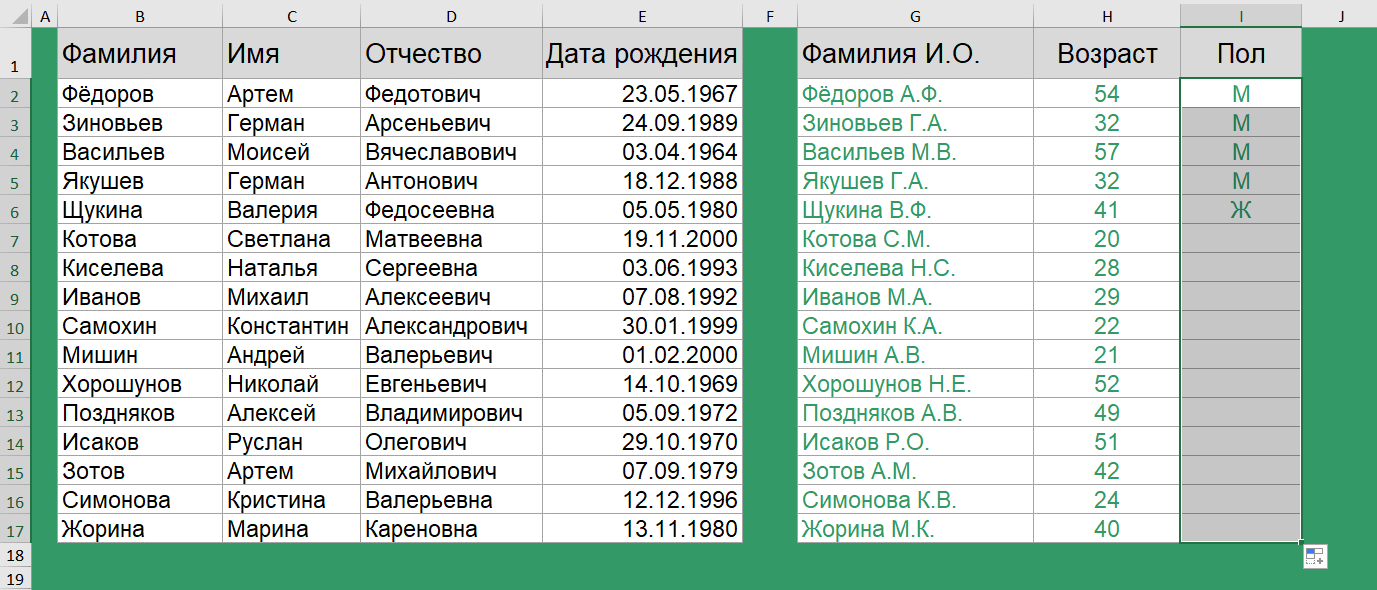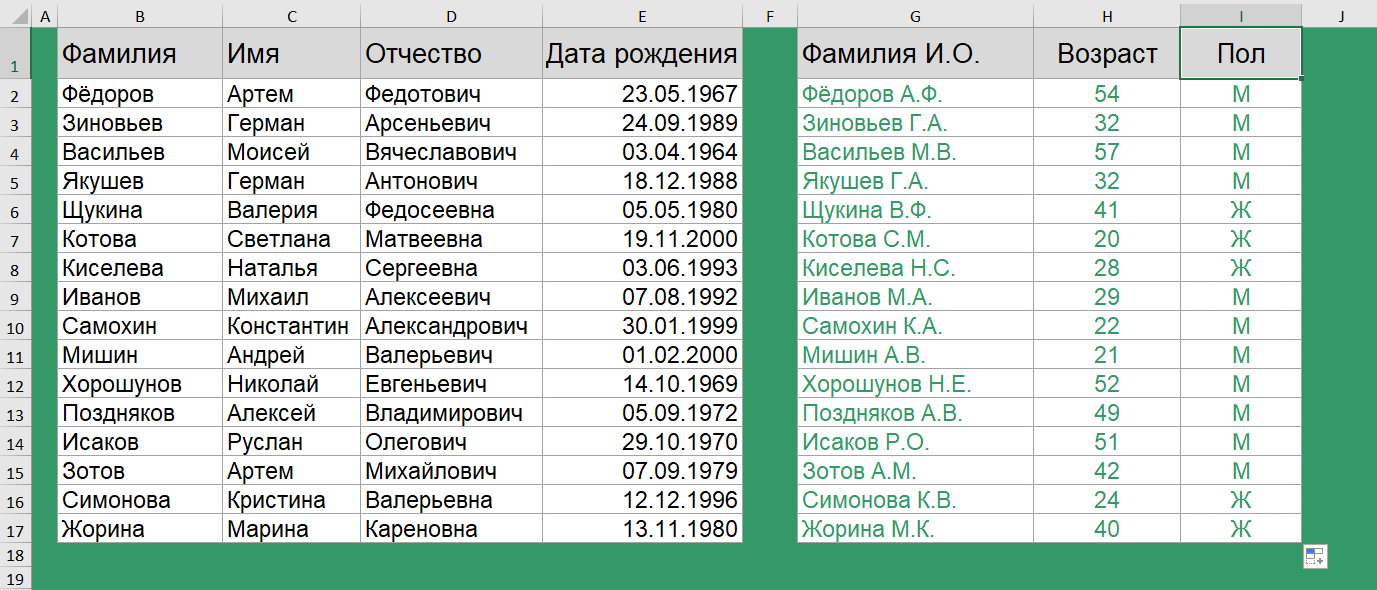
И, напоследок, суперлегкая, но все также часто запрашиваемая задача.
Получили «корявую» выгрузку с нестандартным количеством пробелов. Некорректный ручной ввод или баги выгрузки.
Удалить лишние пробелы и, тем самым привести список к корректному виду поможет функция сжатия пробелов — СЖПРОБЕЛЫ().
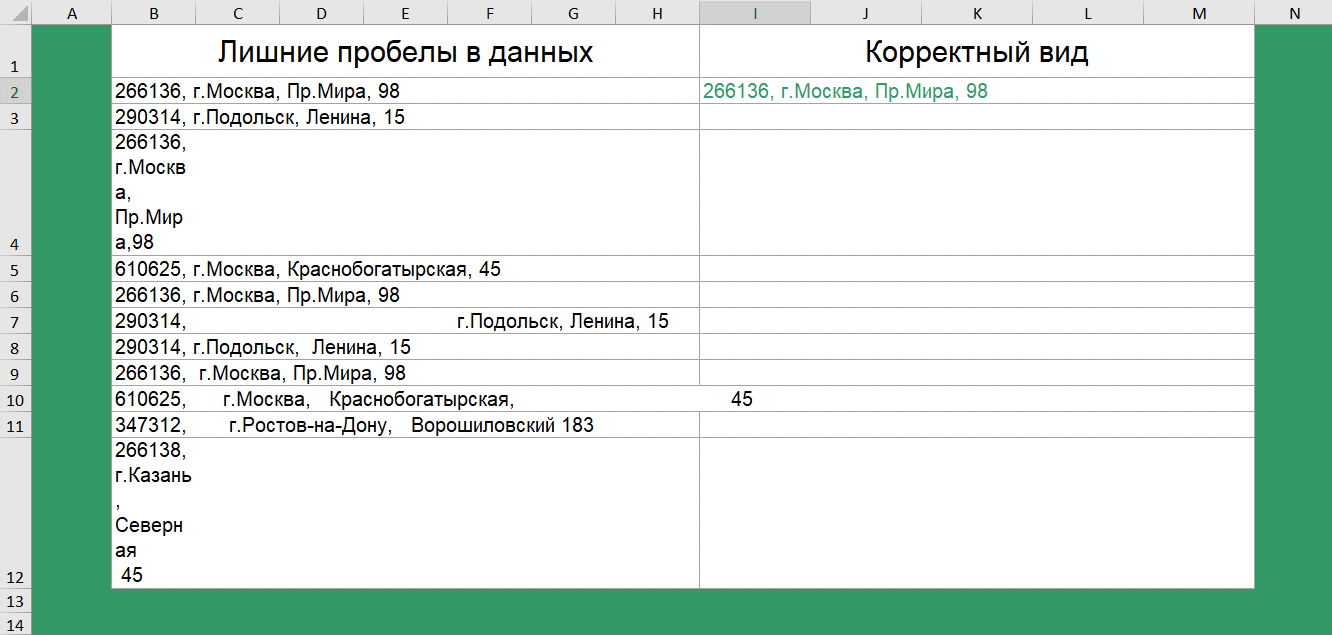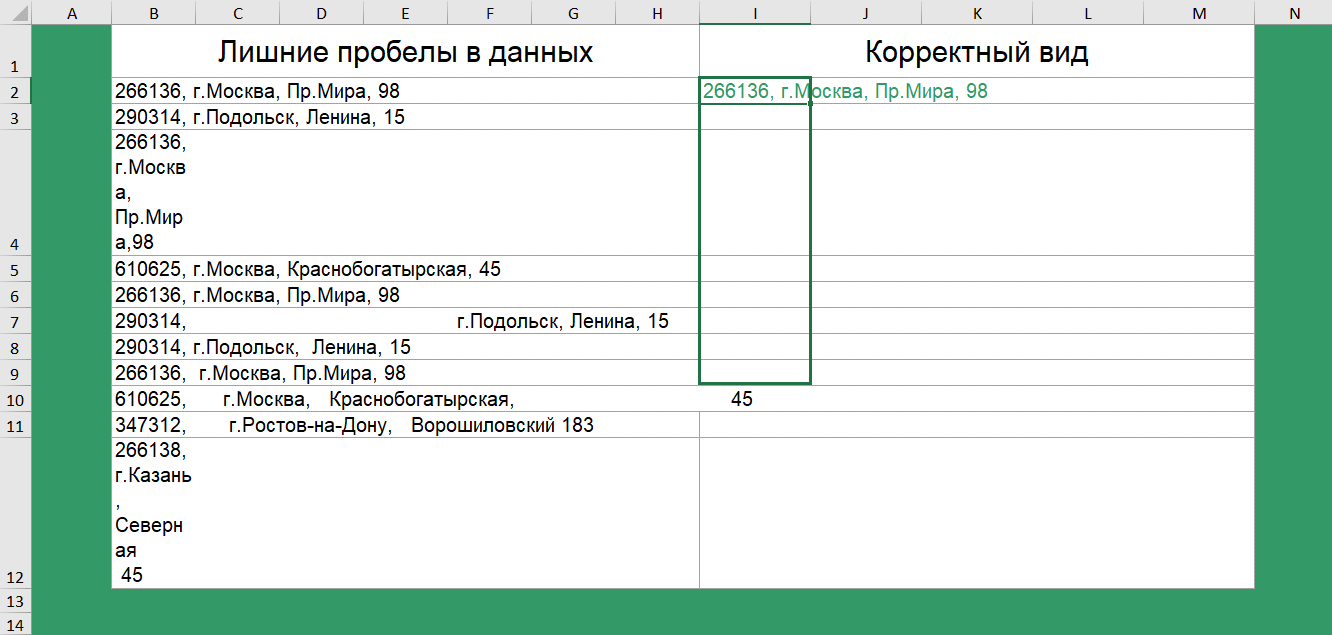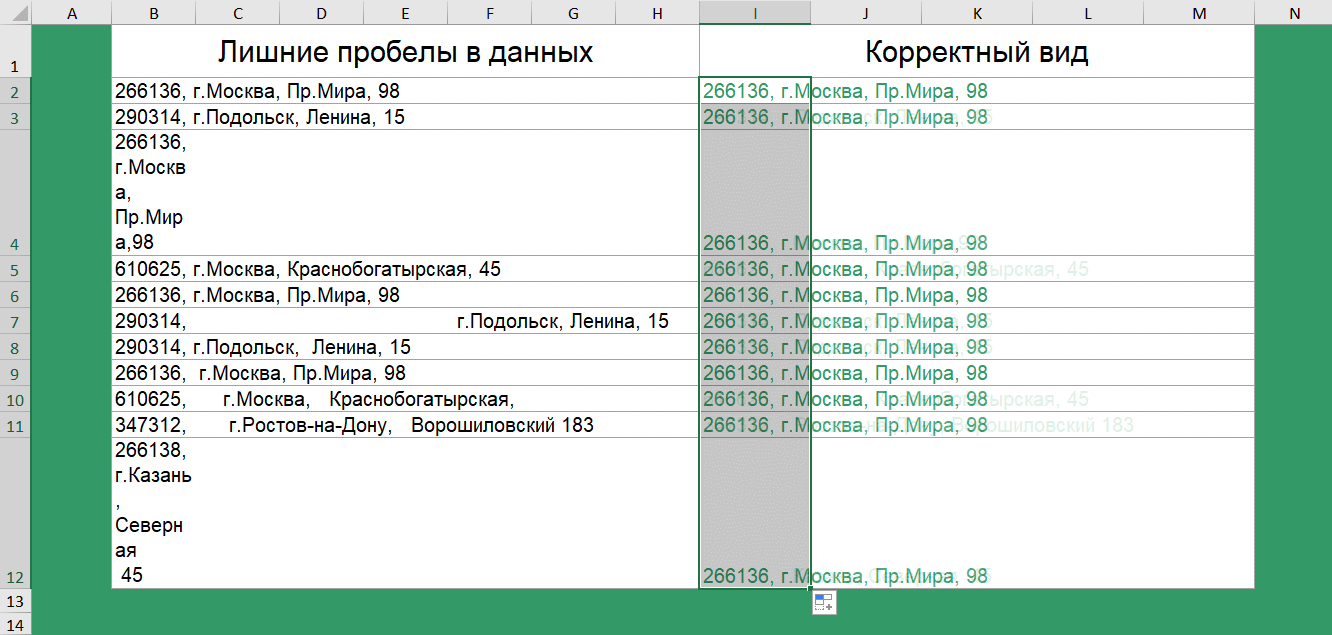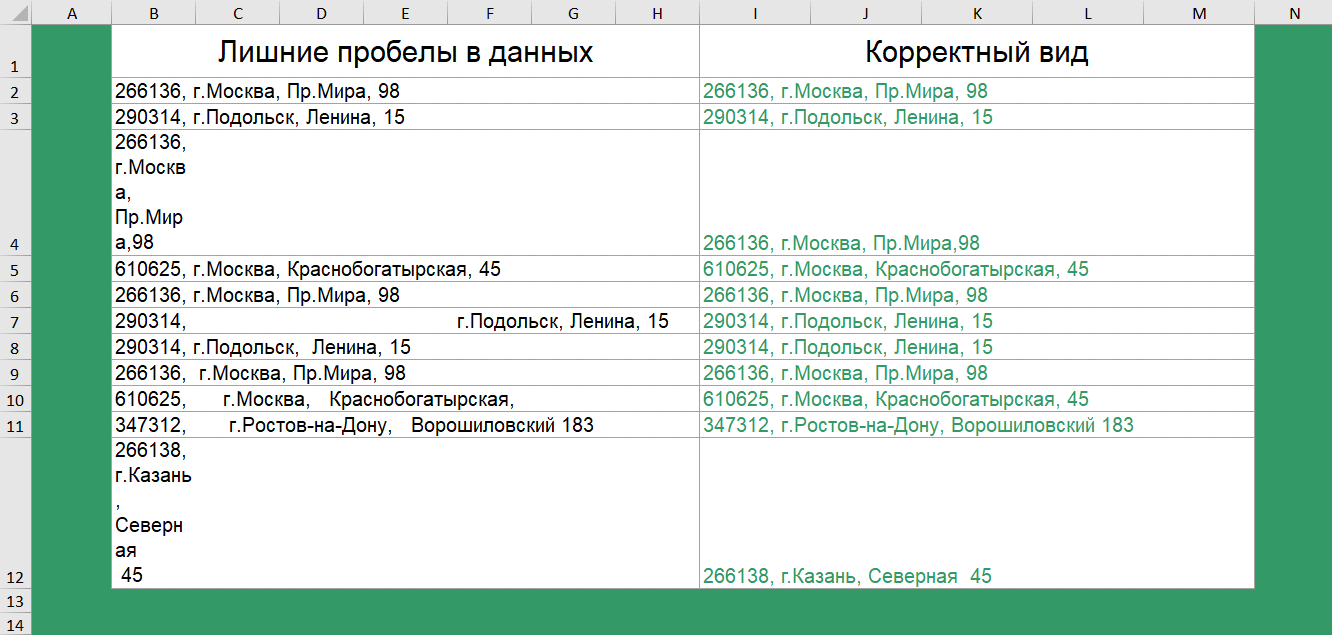
Аналогичная функция доступна в Google таблицах.
Почему знания Excel или Google таблиц сегодня важны каждому?
В век развития технологий и инноваций, умение работать с большими объемами данных становится преимуществом в глазах потенциальных работодателей.
Электронные таблицы вроде MS Excel, Google Sheets – универсальные и многофункциональные помощники, способные облегчить работу и сэкономить ваше время. С их помощью, можно без труда структурировать большие объемы информации в удобные форматы, визуализировать данные в графики и диаграммы, а также вычислять показатели и создавать отчеты.
Умение работать с электронными таблицами позволяет уверенно использовать навыки на практике в любой профессиональной области. Бухгалтеры производят анализ информации со сводными таблицами, составляют отчеты. Финансовые аналитики и экономисты проводят исследования рынка и создают прогнозы продаж, составляют наглядные дашборды. С помощью табличных редакторов, аналитики и администраторы баз данных производят создание и заполнение базы, фильтруют массивы информации по различным категориям.
Пользователи Microsoft Excel и Google таблиц уверенно решают различные многофункциональные задачи, оптимизируя рабочее время. Инструменты этих программ просты и понятны в использовании, при этом приносят колоссальное количество пользы.
О проекте BIRDYX
Мы оказываем помощь в получении полного представления о работе в программах MS Excel и Google Sheets.
На нашем YouTube канале мы регулярно публикуем видео о секретах, фишках и лайфхаках MS Excel и Google Sheets, а также делимся решениями реальных задач из практики. Там же доступен бесплатный курс «Основы Excel» для начинающих. Подписывайтесь на наш канал, там много полезной и интересной информации.
Тем, кто желает освоить MS Excel или Google Sheets в кратчайшие сроки, мы можем предложить персональные консультации онлайн в удобное время.
А также, Вы можете пройти бесплатные онлайн курсы по MS Excel с заданиями
Мы выполняем задачи любой сложности в Excel и Google таблицах: сложные формулы, дашборды, макросы и многое другое.