
I am using the following command to grep stuff in subdirs
find . | xargs grep -s 's:text'
However, this also finds stuff like <s:textfield name="sdfsf"...../>
What can I do to avoid that so it just finds stuff like <s:text name="sdfsdf"/>
OR for that matter….also finds <s:text somethingElse="lkjkj" name="lkkj"
basically s:text and name should be on same line….
![]()
shiri
7456 silver badges24 bronze badges
asked May 21, 2010 at 1:41
![]()
2
You want the -w option to specify that it’s the end of a word.
find . | xargs grep -sw 's:text'
answered May 21, 2010 at 1:47
![]()
Elle HElle H
11.7k7 gold badges39 silver badges42 bronze badges
2
Use b to match on «word boundaries», which will make your search match on whole words only.
So your grep would look something like
grep -r "bSTRINGb"
adding color and line numbers might help too
grep --color -rn "bSTRINGb"
From http://www.regular-expressions.info/wordboundaries.html:
There are three different positions that qualify as word boundaries:
- Before the first character in the string, if the first character is a
word character.- After the last character in the string, if the last
character is a word character.- Between two characters in the string,
where one is a word character and the other is not a word character.
answered Dec 3, 2015 at 19:25
![]()
cs01cs01
5,1271 gold badge29 silver badges28 bronze badges
2
You can drop the xargs command by making grep search recursively. And you normally don’t need the ‘s’ flag. Hence:
grep -wr 's:text'
answered Jul 3, 2013 at 10:33
![]()
jocteejoctee
2,4001 gold badge23 silver badges19 bronze badges
Use -w option for whole word match. Sample given below:
[binita@ubuntu ~]# a="abcd efg"
[binita@ubuntu ~]# echo $a
abcd efg
[binita@ubuntu ~]# echo $a | grep ab
abcd efg
[binita@ubuntu ~]# echo $a | grep -w ab
[binita@ubuntu ~]# echo $a | grep -w abcd
abcd efg
answered Dec 3, 2021 at 7:18
![]()
Binita BharatiBinita Bharati
4,9881 gold badge40 silver badges24 bronze badges
This is another way of setting the boundaries of the word, note that it doesn’t work without the quotes around it:
grep -r '<s:text>' .
answered Jun 11, 2021 at 17:14
![]()
1
If you just want to filter out the remainder text part, you can do this.
xargs grep -s 's:text '
This should find only s:text instances with a space after the last t. If you need to find s:text instances that only have a name element, either pipe your results to another grep expression, or use regex to filter only the elements you need.
answered May 21, 2010 at 1:47
![]()
Stefan KendallStefan Kendall
65.8k68 gold badges252 silver badges405 bronze badges
1
Grep in Microsoft Word?
I’d like to pull all lines with a given string from a word document. In unix world… grep does this without a glitch. Windows is less than obvious for me.
![]()
fretje
10.7k5 gold badges39 silver badges63 bronze badges
asked Nov 13, 2009 at 18:42
0
With Cygwin (or access to a Linux machine) you could
antiword file.doc | grep "my phrase"
or
catdoc file.doc | grep "my phrase"
There are lots of command-line file format converters out there to grep in a similar fashion.
Purely in-Word solution could be to Ctrl+F (Find), and then Find All — however, I’m not sure if all versions of MS Word have Find All button.
answered Nov 13, 2009 at 20:54
![]()
chronoschronos
1,2097 silver badges7 bronze badges
4
I know this sounds primitive, but what’s stopping you from saving the file as .txt and then ripping it apart to your liking.
answered Nov 14, 2009 at 0:51
![]()
RookRook
23.5k32 gold badges125 silver badges212 bronze badges
1
Not got enough rep to comment but I can see this doc vs docx issue discussed so anyone chasing the thread (like I was) may find this helpful.
You do not need a special tool for docx files. docx are zipped XML files.
To extract and strip the XML try something based on
unzip -p "*.docx" word/document.xml | sed -e 's/<[^>]{1,}>//g; s/[^[:print:]]{1,}//g'
from command line fu
answered Jul 18, 2018 at 10:21
![]()
What does «line» mean in a Word context? The displayed line, which changes if you do anything to the page formatting? The paragraph? Something else?
You can do a bunch of stuff with Word’s find-and-replace functions, including changing the formatting and other non-obvious things, but all of them will only act on the find-what text itself, not on any surrounding text.
answered Nov 14, 2009 at 0:10
![]()
MarthaMartha
9301 gold badge12 silver badges23 bronze badges
1
There is support for MS documents — Word, PowerPoint, Excel — in CRGREP which I’ve developed as a free opensource tool. It also greps other hard to search stuff like database tables, images, audio, archives, PDF and combinations of these. Have fun.
answered Jul 14, 2015 at 15:14
![]()
CraigCraig
1111 bronze badge
PowerGREP will do exactly that for you, and fast — but not free. It’s worth every penny, though, in my opinion. Plus, there is a 30-day free trial.
![]()
Gaff
18.4k15 gold badges57 silver badges68 bronze badges
answered Dec 15, 2009 at 7:56
![]()
Tim PietzckerTim Pietzcker
2,64010 gold badges42 silver badges49 bronze badges
The grep filter searches a file for a particular pattern of characters, and displays all lines that contain that pattern. The pattern that is searched in the file is referred to as the regular expression (grep stands for global search for regular expression and print out).
Syntax:
grep [options] pattern [files]
Options Description -c : This prints only a count of the lines that match a pattern -h : Display the matched lines, but do not display the filenames. -i : Ignores, case for matching -l : Displays list of a filenames only. -n : Display the matched lines and their line numbers. -v : This prints out all the lines that do not matches the pattern -e exp : Specifies expression with this option. Can use multiple times. -f file : Takes patterns from file, one per line. -E : Treats pattern as an extended regular expression (ERE) -w : Match whole word -o : Print only the matched parts of a matching line, with each such part on a separate output line. -A n : Prints searched line and nlines after the result. -B n : Prints searched line and n line before the result. -C n : Prints searched line and n lines after before the result.
Sample Commands
Consider the below file as an input.
$cat > geekfile.txt
unix is great os. unix was developed in Bell labs. learn operating system. Unix linux which one you choose. uNix is easy to learn.unix is a multiuser os.Learn unix .unix is a powerful.
1. Case insensitive search : The -i option enables to search for a string case insensitively in the given file. It matches the words like “UNIX”, “Unix”, “unix”.
$grep -i "UNix" geekfile.txt
Output:
unix is great os. unix was developed in Bell labs. Unix linux which one you choose. uNix is easy to learn.unix is a multiuser os.Learn unix .unix is a powerful.
2. Displaying the count of number of matches : We can find the number of lines that matches the given string/pattern
$grep -c "unix" geekfile.txt
Output:
2
3. Display the file names that matches the pattern : We can just display the files that contains the given string/pattern.
$grep -l "unix" * or $grep -l "unix" f1.txt f2.txt f3.xt f4.txt
Output:
geekfile.txt
4. Checking for the whole words in a file : By default, grep matches the given string/pattern even if it is found as a substring in a file. The -w option to grep makes it match only the whole words.
$ grep -w "unix" geekfile.txt
Output:
unix is great os. unix was developed in Bell labs. uNix is easy to learn.unix is a multiuser os.Learn unix .unix is a powerful.
5. Displaying only the matched pattern : By default, grep displays the entire line which has the matched string. We can make the grep to display only the matched string by using the -o option.
$ grep -o "unix" geekfile.txt
Output:
unix unix unix unix unix unix
6. Show line number while displaying the output using grep -n : To show the line number of file with the line matched.
$ grep -n "unix" geekfile.txt
Output:
1:unix is great os. unix is free os. 4:uNix is easy to learn.unix is a multiuser os.Learn unix .unix is a powerful.
7. Inverting the pattern match : You can display the lines that are not matched with the specified search string pattern using the -v option.
$ grep -v "unix" geekfile.txt
Output:
learn operating system. Unix linux which one you choose.
8. Matching the lines that start with a string : The ^ regular expression pattern specifies the start of a line. This can be used in grep to match the lines which start with the given string or pattern.
$ grep "^unix" geekfile.txt
Output:
unix is great os. unix is free os.
9. Matching the lines that end with a string : The $ regular expression pattern specifies the end of a line. This can be used in grep to match the lines which end with the given string or pattern.
$ grep "os$" geekfile.txt
10.Specifies expression with -e option. Can use multiple times :
$grep –e "Agarwal" –e "Aggarwal" –e "Agrawal" geekfile.txt
11. -f file option Takes patterns from file, one per line.
$cat pattern.txt Agarwal Aggarwal Agrawal
$grep –f pattern.txt geekfile.txt
12. Print n specific lines from a file: -A prints the searched line and n lines after the result, -B prints the searched line and n lines before the result, and -C prints the searched line and n lines after and before the result.
Syntax:
$grep -A[NumberOfLines(n)] [search] [file] $grep -B[NumberOfLines(n)] [search] [file] $grep -C[NumberOfLines(n)] [search] [file]
Example:
$grep -A1 learn geekfile.txt
Output:
learn operating system. Unix linux which one you choose. -- uNix is easy to learn.unix is a multiuser os.Learn unix .unix is a powerful. (Prints the searched line along with the next n lines (here n = 1 (A1).) (Will print each and every occurrence of the found line, separating each output by --) (Output pattern remains the same for -B and -C respectively) Unix linux which one you choose. -- uNix is easy to learn.unix is a multiuser os.Learn unix .unix is a powerful. Unix linux which one you choose. -- uNix is easy to learn.unix is a multiuser os.Learn unix .unix is a powerful.
13. Search recursively for a pattern in the directory: -R prints the searched pattern in the given directory recursively in all the files.
Syntax
$grep -R [Search] [directory]
Example :
$grep -iR geeks /home/geeks
Output:
./geeks2.txt:Well Hello Geeks ./geeks1.txt:I am a big time geek ---------------------------------- -i to search for a string case insensitively -R to recursively check all the files in the directory.
This article is contributed by Akshay Rajput. If you like GeeksforGeeks and would like to contribute, you can also write an article using write.geeksforgeeks.org or mail your article to review-team@geeksforgeeks.org. See your article appearing on the GeeksforGeeks’ main page and help other Geeks.
Please write comments if you find anything incorrect, or you want to share more information about the topic discussed above.
Introduction
This guide details the most useful grep commands for Linux / Unix systems.
After going through all the commands and examples, you will learn how to use grep to search files for a text from the terminal.

Prerequisites
- Linux or UNIX-like system
- Access to a terminal/command line
- A user with permissions to access the desired files and directories
Note: A line does not represent a line of text as viewed on the terminal screen. A line in a text file is a sequence of characters until a line break is introduced. The output of grep commands may contain whole paragraphs unless the search options are refined.
What is the grep Command?
Grep is an acronym that stands for Global Regular Expression Print.
Grep is a Linux / Unix command-line tool used to search for a string of characters in a specified file. The text search pattern is called a regular expression. When it finds a match, it prints the line with the result. The grep command is handy when searching through large log files.
Using the grep Command
The grep command consists of three parts in its most basic form. The first part starts with grep, followed by the pattern that you are searching for. After the string comes the file name that the grep searches through.
The simplest grep command syntax looks like this:

The command can contain many options, pattern variations, and file names. Combine as many options as necessary to get the results you need. Below are the most common grep commands with examples.
Note: Grep is case-sensitive. Make sure to use the correct case when running grep commands.
To Search a File
To print any line from a file that contains a specific pattern of characters, in our case phoenix in the file sample2, run the command:
grep phoenix sample2Grep will display every line where there is a match for the word phoenix. When executing this command, you do not get exact matches. Instead, the terminal prints the lines with words containing the string of characters you entered. Here is an example:

Tip: If your search pattern includes characters other than alphanumeric, use quotation marks. This includes blank spaces or any symbol.
To Search Multiple Files
To search multiple files with the grep command, insert the filenames you want to search, separated with a space character.
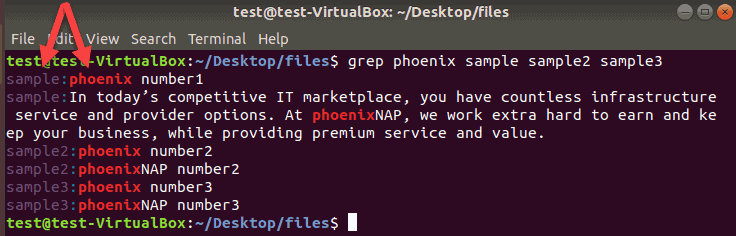
In our case, the grep command to match the word phoenix in three files sample, sample2, and sample3 looks like this example:
grep phoenix sample sample2 sample3The terminal prints the name of every file that contains the matching lines, and the actual lines that include the required string of characters.
You can append as many filenames as needed. The terminal prints a new line with the filename for every match it finds in the listed files.
Tip: Refer to our article Xargs Commands to learn how to use xargs with grep to search for a string in the list of files.
Search All Files in Directory
To search all files in the current directory, use an asterisk instead of a filename at the end of a grep command.
In this example, we use nix as a search criterion:
grep nix *The output shows the name of the file with nix and returns the entire line.
To Find Whole Words Only
Grep allows you to find and print the results for whole words only. To search for the word phoenix in all files in the current directory, append -w to the grep command.
grep -w phoenix *This option only prints the lines with whole-word matches and the names of the files it found them in:

When -w is omitted, grep displays the search pattern even if it is a substring of another word.
If you would like to search for multiple strings and word patterns, check out our article on how to grep for multiple strings, patterns or words.
To Ignore Case in Grep Searches
As grep commands are case sensitive, one of the most useful operators for grep searches is -i. Instead of printing lowercase results only, the terminal displays both uppercase and lowercase results. The output includes lines with mixed case entries.
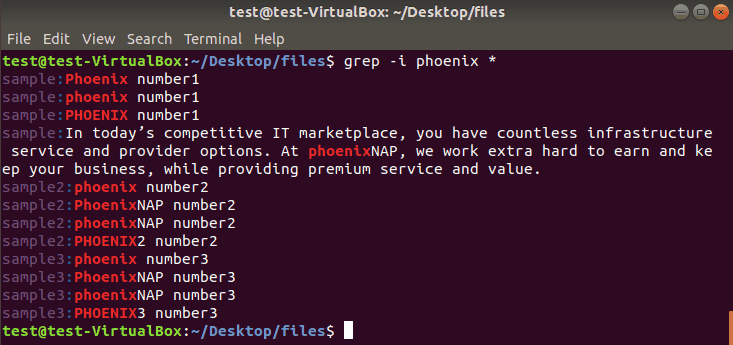
An example of this command:
grep -i phoenix *If we use the -i operator to search files in the current directory for phoenix, the output looks like this:
To Search Subdirectories
To include all subdirectories in a search, add the -r operator to the grep command.
grep -r phoenix *
This command prints the matches for all files in the current directory, subdirectories, and the exact path with the filename. In the example below, we also added the -w operator to show whole words, but the output form is the same.
Inverse grep Search
You can use grep to print all lines that do not match a specific pattern of characters. To invert the search, append -v to a grep command.
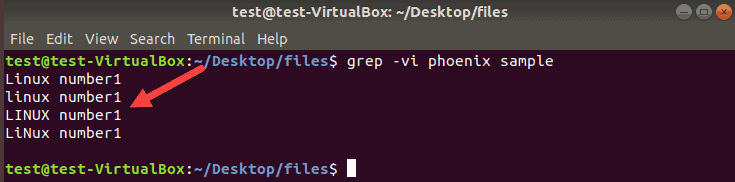
To exclude all lines that contain phoenix, enter:
grep -v phoenix sampleThe terminal prints all lines that do not contain the word used as a search criterion. Use -i to ignore case to exclude completely the word used for this search:
To Show Lines That Exactly Match a Search String
The grep command prints entire lines when it finds a match in a file. To print only those lines that completely match the search string, add the -x option.
grep -x “phoenix number3” *The output shows only the lines with the exact match. If there are any other words or characters in the same line, the grep does not include it in the search results. Do not forget to use quotation marks whenever there is a space or a symbol in a search pattern.
Here is a comparison of the results without and with the -x operator in our grep command:
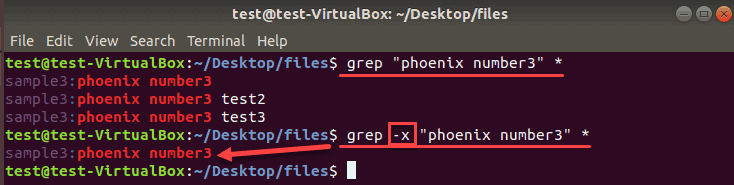
To List Names of Matching Files
Sometimes, you only need to see the names of the files that contain a word or string of characters and exclude the actual lines. To print only the filenames that match your search, use the -l operator:
grep -l phoenix *
The output shows the exact filenames that contain phoenix in the current directory but does not print the lines with the corresponding word:
As a reminder, use the recursive search operator -r to include all subdirectories in your search.
To Count the Number of Matches
Grep can display the filenames and the count of lines where it finds a match for your word.
Use the -c operator to count the number of matches:
grep -c phoenix *
To Display the Number of Lines Before or After a Search String
Sometimes you need more content in search results to decide what is most relevant.
Use the following operators to add the desired lines before, after a match, or both:
- Use -A and a number of lines to display after a match:
grep -A 3 phoenix sample— this command prints three lines after the match. - Use -B and a number of lines to display before a match:
grep -B 2 phoenix sample— this command prints two lines before the match. - Use -C and a number of lines to display before and after the match:
grep -C 2 phoenix sample— this command prints two lines before and after the match.
To Display Line Numbers with grep Matches
When grep prints results with many matches, it comes handy to see the line numbers. Append the -n operator to any grep command to show the line numbers.
We will search for Phoenix in the current directory, show two lines before and after the matches along with their line numbers.
grep -n -C 2 Phoenix sample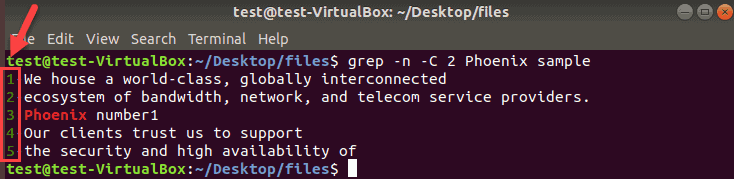
Limit grep Output to a Fixed Number of Lines
Individual files, such as log files, can contain many matches for grep search patterns. Limit the number of lines in the grep output by adding the -m option and a number to the command.
grep -m2 Phoenix sampleIn this case, the terminal prints the first two matches it finds in the sample file.
If you do not specify a file and search all files in a directory, the output prints the first two results from every file along with the filename that contains the matches.
Conclusion
Now you know how to use the grep command in Linux/Unix.
The grep command is highly flexible with many useful operators and options. By combining grep commands, you can get powerful results and find the text hiding in thousands of files. To get started, check out our grep regex guide article.
Introduction
The grep command, which stands for «global regular expression print,» is one of Linux’s most powerful and widely used commands.
grep looks for lines that match a pattern in one or more input files and outputs each matching line to standard output. grep reads from the standard input, which is usually the output of another command, if no files are specified.
In this tutorial, you will use grep command that looks for lines that match a pattern in one or more input files and outputs.
grep Command Syntax
The grep command has the following syntax:
grep [OPTIONS] PATTERN [FILE...]
Optional items are those in square brackets.
File— Names of one or more input files.PATTERN— Look for a pattern.OPTIONS— A set of zero or more choices.grephas a lot of settings that govern how it behaves.The user performing the command must have read access to the file in order to search it.
In Files, Look for a String
The grep command’s most basic use is to look for a string (text) in a file.
For example, to see all the entries in the /etc/passwd file that contains the string bash, use the following command:
grep bash /etc/passwd
This is what the output should look like:
root:x:0:0:root:/root:/bin/bash
vega:x:1000:1000:vega:/home/vega:/bin/bash
If the string contains spaces, use single or double quotation marks to surround it:
grep "Gnome Display Manager" /etc/passwd
Invert Match (Exclude)
Use the -v (or --invert-match) option to display lines that do not match a pattern.
To print the lines that do not contain the string nologin, for example, type:
grep -v nologin /etc/passwd
Output
root:x:0:0:root:/root:/bin/bash
colord:x:124:124::/var/lib/colord:/bin/false
git:x:994:994:git daemon user:/:/usr/bin/git-shell
vega:x:1000:1000:vega:/home/vega:/bin/bash
Use Grep to Filter the Output of a Command
The output of a command can be filtered using grep and pipe, with just the lines matching a specific pattern being printed on the terminal.
You can use the ps command to see which processes are running on your system as user www-data, for example:
ps -ef | grep www-data
Output
www-data 18247 12675 4 16:00 ? 00:00:00 php-fpm: pool www
root 18272 17714 0 16:00 pts/0 00:00:00 grep --color=auto --exclude-dir=.bzr --exclude-dir=CVS --exclude-dir=.git --exclude-dir=.hg --exclude-dir=.svn www-data
www-data 31147 12770 0 Oct22 ? 00:05:51 nginx: worker process
www-data 31148 12770 0 Oct22 ? 00:00:00 nginx: cache manager process
You can also use a single command to bring in several pipes. There is also a line in the output above that contains the grep process, as you can see. Pass the output to another grep instance as described below if you don’t want that line to be displayed.
ps -ef | grep www-data | grep -v grep
Output
www-data 18247 12675 4 16:00 ? 00:00:00 php-fpm: pool www
www-data 31147 12770 0 Oct22 ? 00:05:51 nginx: worker process
www-data 31148 12770 0 Oct22 ? 00:00:00 nginx: cache manager process
Recursive Search
Invoke grep with the -r option to recursively search for a pattern (or --recursive). When this option is supplied, grep will scan all files in the specified directory, skipping any recursively encountered symlinks.
Instead of -r, use the -R option to follow all symbolic links (or --dereference-recursive).
Here’s an example of how to search all files in the /etc directory for the string vegastack.com:
grep -r vegastack.com /etc
You will get an output like below:
Output
/etc/hosts:127.0.0.1 node2.vegastack.com
/etc/nginx/sites-available/vegastack.com: server_name vegastack.com www.vegastack.com;
grep will follow all symbolic links if you use the -R option:
grep -R vegastack.com /etc
Take note of the output’s last line. Because files in Nginx’s sites-enabled directory are symlinks to configuration files in the sites-available directory, that line is not shown when grep is run with -r.
Output
/etc/hosts:127.0.0.1 node2.vegastack.com
/etc/nginx/sites-available/vegastack.com: server_name vegastack.com www.vegastack.com;
/etc/nginx/sites-enabled/vegastack.com: server_name vegastack.com www.vegastack.com;
Show Only the Filename
Use the -l (or --files-with-matches) option to suppress the default grep output and only print the names of files containing the matched pattern.
The command below searches the current working directory for all files ending in .conf and prints just the names of the files that contain the string vegastack.com:
grep -l vegastack.com *.conf
You will get an output like below:
tmux.conf
haproxy.conf
Usually, the -l option is combined with the recursive option -R:
grep -Rl vegastack.com /tmp
Case Insensitive Search
grep is case-sensitive by default. The uppercase and lowercase characters are treated separately in this scenario.
When using grep, use the -i option to ignore case when searching (or --ignore-case).
When searching for Zebra without any options, for example, the following command will not return any results, despite the fact that there are matching lines:
grep Zebra /usr/share/words
However, if you use the -i option to perform a case-insensitive search, it will match both upper and lower case letters:
grep -i Zebra /usr/share/words
«Zebra» will match «zebra», «ZEbrA», or any other upper and lower case letter combination for that string.
zebra
zebra's
zebras
Search for Full Words
grep will display all lines where the string is embedded in larger strings while searching for a string.
If you search for «gnu,» for example, you’ll find all lines where «gnu» is embedded in larger terms like «cygnus» or «magnum»:
grep gnu /usr/share/words
Output
cygnus
gnu
interregnum
lgnu9d
lignum
magnum
magnuson
sphagnum
wingnut
Use the -w (or --word-regexp) option to return only lines where the provided string is a whole word (contained by non-word characters).
🤔
Alphanumeric characters (a-z, A-Z, and 0-9) and underscores (_) make up word characters. Non-word characters are all the rest of the characters.
If you execute the same program with the -w option, the grep command will only return lines that contain the word gnu as a distinct word.
grep -w gnu /usr/share/words
Output
gnu
Show Line Numbers
The -n (or --line-number) option instructs grep to display the line number of lines containing a pattern-matching string. grep prints the matches to standard output, prefixed with the line number, when this option is used.
You may use the following command to display the lines from the /etc/services file containing the string bash prefixed with the corresponding line number:
grep -n 10000 /etc/services
The matches are found on lines 10123 and 10124, as seen in the output below.
Output
10123:ndmp 10000/tcp
10124:ndmp 10000/udp
Count Matches
Use the -c (or --count) option to print a count of matching lines to standard output.
We’re measuring the number of accounts that use /usr/bin/zsh as a shell in the example below.
regular expression
grep -c '/usr/bin/zsh' /etc/passwd
Output
4
Quiet Mode
The -q (or --quiet) option instructs grep to execute in silent mode, with no output to the standard output. The command leaves with status 0 if a match is found. This is handy when using grep in shell scripts to check if a file contains a string and then conduct a specific action based on the result.
Here’s an example of using grep as a test command in an if statement in quiet mode:
if grep -q PATTERN filename
then
echo pattern found
else
echo pattern not found
fi
Basic Regular Expression
Basic, Extended, and Perl-compatible regular expression feature sets are available in GNU Grep.
grep interprets the pattern as a basic regular expression by default, with all characters except the meta-characters being regular expressions that match each other.
The following is a list of the most prevalent meta-characters:
- To match a phrase at the beginning of a line, use the
^(caret) symbol. The string kangaroo will only match in the following example if it appears at the very beginning of a line.
grep "^kangaroo" file.txt
- To match an expression at the end of a line, use the $ (dollar) sign. In the example below, the string kangaroo will only match if it appears at the end of a line.
grep "kangaroo$" file.txt
- To match a single character, use the
.(period) sign. For example, you could use the following pattern to match anything that starts with kan, then has two characters, and ends with the string roo:
grep "kan..roo" file.txt
- To match any single character wrapped in brackets, use
[](brackets). To discover the lines that contain the words «accept» or «accent,» apply the following pattern:
grep "acce[np]t" file.txt
- To match any single character that isn’t enclosed in brackets, use
[]. The following pattern will match any combination of strings containing co(any letter except l) a, such as coca, cobalt, and so on, but not cola.
grep "co[^l]a" file.txt
Use the (backslash) symbol to get around the next character’s specific meaning.
Extended Regular Expressions
Use the -E (or --extended-regexp) option to interpret the pattern as an extended regular expression. To generate more complicated and powerful search patterns, extended regular expressions include all of the fundamental meta-characters as well as additional meta-characters. Here are a few examples:
- All email addresses in a given file are matched and extracted:
grep -E -o "b[A-Za-z0-9._%+-][email protected][A-Za-z0-9.-]+.[A-Za-z]{2,6}b" file.txt
- From a given file, find and extract all valid IP addresses:
grep -E -o '(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)' file.txt
Only the matching string is printed using the -o option.
Search for Multiple Strings (Patterns)
The OR operator | can be used to connect two or more search patterns.
grep reads the pattern as a normal regular expression by default, which means that meta-characters like | lose their special significance and should be replaced with their backslashed variants.
We’re looking for all occurrences of the words fatal, error, and critical in the Nginx log error file in the example below:
grep 'fatal|error|critical' /var/log/nginx/error.log
The operator | should not be escaped if you use the extended regular expression option -E, as demonstrated below:
grep -E 'fatal|error|critical' /var/log/nginx/error.log
Print Lines Before a Match
Use the -B (or --before-context) option to print a certain number of lines before matching lines.
For example, you could use the following command to display five lines of leading context before matching lines:
grep -B 5 root /etc/passwd
Print Lines After a Match
Use the -A (or --after-context) option to output a certain number of lines following matching lines.
For example, you could use the following command to display five lines of trailing context after matching lines:
grep -A 5 root /etc/passwd
Conclusion
You can use the grep command to look for a pattern within files. If grep finds a match, it outputs the lines that contain the provided pattern.
The Grep User’s Manual page has a lot more information on grep.
If you have any queries, please leave a comment below and we’ll be happy to respond to them.