
Introduction
GloVe is an unsupervised learning algorithm for obtaining vector representations for words. Training is performed on aggregated global word-word co-occurrence statistics from a corpus, and the resulting representations showcase interesting linear substructures of the word vector space.
Getting started (Code download)
- Download the latest latest code
(licensed under the
Apache License, Version 2.0).
Look for «Clone or download» - Unpack the files: unzip master.zip
- Compile the source: cd GloVe-master && make
- Run the demo script: ./demo.sh
- Consult the included README for further usage details, or ask a question
Download pre-trained word vectors
- Pre-trained word vectors. This data is made available under the Public Domain Dedication
and License v1.0 whose full text can be found at:
http://www.opendatacommons.org/licenses/pddl/1.0/.- Wikipedia 2014 + Gigaword 5 (6B tokens, 400K vocab, uncased, 50d, 100d, 200d, & 300d vectors, 822 MB download): glove.6B.zip
- Common Crawl (42B tokens, 1.9M vocab, uncased, 300d vectors, 1.75 GB download): glove.42B.300d.zip
- Common Crawl (840B tokens, 2.2M vocab, cased, 300d vectors, 2.03 GB download): glove.840B.300d.zip
- Twitter (2B tweets, 27B tokens, 1.2M vocab, uncased, 25d, 50d, 100d, & 200d vectors, 1.42 GB download): glove.twitter.27B.zip
- Ruby script for preprocessing Twitter data
Citing GloVe
Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014.
GloVe: Global Vectors for Word Representation.
[pdf] [bib]
Highlights
1. Nearest neighbors
The Euclidean distance (or cosine similarity) between two word vectors provides an effective method for measuring the linguistic or semantic similarity of the corresponding words. Sometimes, the nearest neighbors according to this metric reveal rare but relevant words that lie outside an average human’s vocabulary. For example, here are the closest words to the target word frog:
- frog
- frogs
- toad
- litoria
- leptodactylidae
- rana
- lizard
- eleutherodactylus

3. litoria

4. leptodactylidae

5. rana

7. eleutherodactylus
2. Linear substructures
The similarity metrics used for nearest neighbor evaluations produce a single scalar that quantifies the relatedness of two words. This simplicity can be problematic since two given words almost always exhibit more intricate relationships than can be captured by a single number. For example, man may be regarded as similar to woman in that both words describe human beings; on the other hand, the two words are often considered opposites since they highlight a primary axis along which humans differ from one another.
In order to capture in a quantitative way the nuance necessary to distinguish man from woman, it is necessary for a model to associate more than a single number to the word pair. A natural and simple candidate for an enlarged set of discriminative numbers is the vector difference between the two word vectors. GloVe is designed in order that such vector differences capture as much as possible the meaning specified by the juxtaposition of two words.
The underlying concept that distinguishes man from woman, i.e. sex or gender, may be equivalently specified by various other word pairs, such as king and queen or brother and sister. To state this observation mathematically, we might expect that the vector differences man — woman, king — queen, and brother — sister might all be roughly equal. This property and other interesting patterns can be observed in the above set of visualizations.
Training
The GloVe model is trained on the non-zero entries of a global word-word co-occurrence matrix, which tabulates how frequently words co-occur with one another in a given corpus. Populating this matrix requires a single pass through the entire corpus to collect the statistics. For large corpora, this pass can be computationally expensive, but it is a one-time up-front cost. Subsequent training iterations are much faster because the number of non-zero matrix entries is typically much smaller than the total number of words in the corpus.
The tools provided in this package automate the collection and preparation of co-occurrence statistics for input into the model. The core training code is separated from these preprocessing steps and can be executed independently.
Model Overview
GloVe is essentially a log-bilinear model with a weighted least-squares objective. The main intuition underlying the model is the simple observation that ratios of word-word co-occurrence probabilities have the potential for encoding some form of meaning. For example, consider the co-occurrence probabilities for target words ice and steam with various probe words from the vocabulary. Here are some actual probabilities from a 6 billion word corpus:
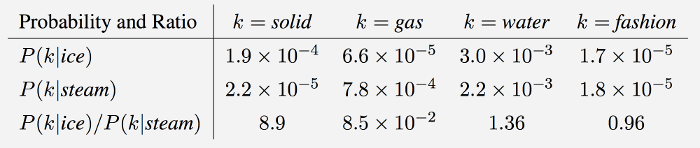
As one might expect, ice co-occurs more frequently with solid than it does with gas, whereas steam co-occurs more frequently with gas than it does with solid. Both words co-occur with their shared property water frequently, and both co-occur with the unrelated word fashion infrequently. Only in the ratio of probabilities does noise from non-discriminative words like water and fashion
cancel out, so that large values (much greater than 1) correlate well with properties specific to ice, and small values (much less than 1) correlate well with properties specific of steam. In this way, the ratio of probabilities encodes some crude form of meaning associated with the abstract concept of thermodynamic phase.
The training objective of GloVe is to learn word vectors such that their dot product equals the logarithm of the words’ probability of co-occurrence. Owing to the fact that the logarithm of a ratio equals the difference of logarithms, this objective associates (the logarithm of) ratios of co-occurrence probabilities with vector differences in the word vector space. Because these ratios can encode some form of meaning, this information gets encoded as vector differences as well. For this reason, the resulting word vectors perform very well on word analogy tasks, such as those examined in the word2vec package.
Visualization
GloVe produces word vectors with a marked banded structure that is evident upon visualization:
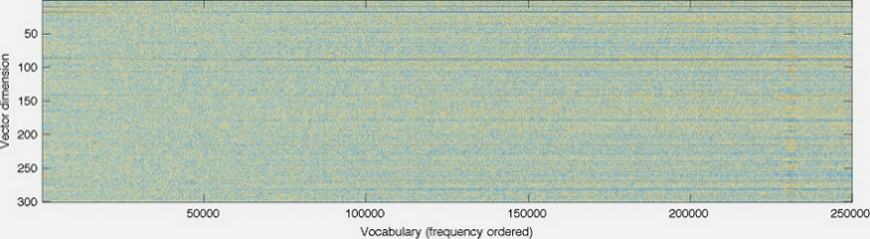
The horizontal bands result from the fact that the multiplicative interactions in the model occur component-wise. While there are additive interactions resulting from a dot product, in general there is little room for the individual dimensions to cross-pollinate.
The horizontal bands become more pronounced as the word frequency increases. Indeed, there are noticeable long-range trends as a function of word frequency, and they are unlikely to have a linguistic origin. This feature is not unique to GloVe — in fact, I’m unaware of any model for word vector learning that avoids this issue.
The vertical bands, such as the one around word 230k-233k, are due to local densities of related words (usually numbers) that happen to have similar frequencies.
Release history
- GloVe v.1.2: Minor bug
fixes in code (memory, off-by-one, errors). Eval code now also
available in Python and Octave. UTF-8 encoding of largest data file
fixed. Prepared by Russell Stewart and Christopher Manning. Oct 2015. - GloVe v.1.0: Original
release. Prepared by Jeffrey Pennington. Aug 2014.
Bugs/Issues/Discussion
GitHub: GloVe is on
GitHub. For bug reports and patches, you’re best off using the
GitHub Issues and Pull requests features.
Google Group: The Google Group
globalvectors
can be used for questions and general discussion on GloVe.
Jeffrey Pennington
|
August 2014
Site design courtesy of Jason Chuang
Одна из задач языкового моделирования – предсказать следующее слово, опираясь на знание предыдущего текста. Это нужно для исправления опечаток, автодополнения, чат-ботов и т. д. В интернете можно найти много разрозненной информации о моделях обработки естественного языка. Мы собрали четвёрку популярных NLP-моделей в одном месте и сравнили их, опираясь на документацию и научные источники.
1. Рекуррентная нейросетевая языковая модель (RNNLM)
Возникшая в 2001 г. идея привела к рождению одной из первых embedding-моделей.
Embeddings
В языковом моделировании отдельные слова и группы слов сопоставляются векторам – некоторым численным представлениям с сохранением семантической связи. Сжатое векторное представление слова называют эмбеддингом.
Модель принимает на вход векторные представления n предыдущих слов и может «понимать» семантику предложения. Обучение модели базируется на алгоритме непрерывного мешка слов. Контекстные (соседние) слова подаются на вход нейронной сети, которая предсказывает центральное слово.
Мешок слов
Мешок слов – это модель представления текста в виде вектора (набора слов). Каждому слову в тексте сопоставляется число его вхождений.
Сжатые векторы объединяются, передаются в скрытый слой, где срабатывает softmax функция активации, определяющая, какие сигналы пройдут дальше (если эта тема вызывает трудности, прочитайте наше Наглядное введение в нейросети).
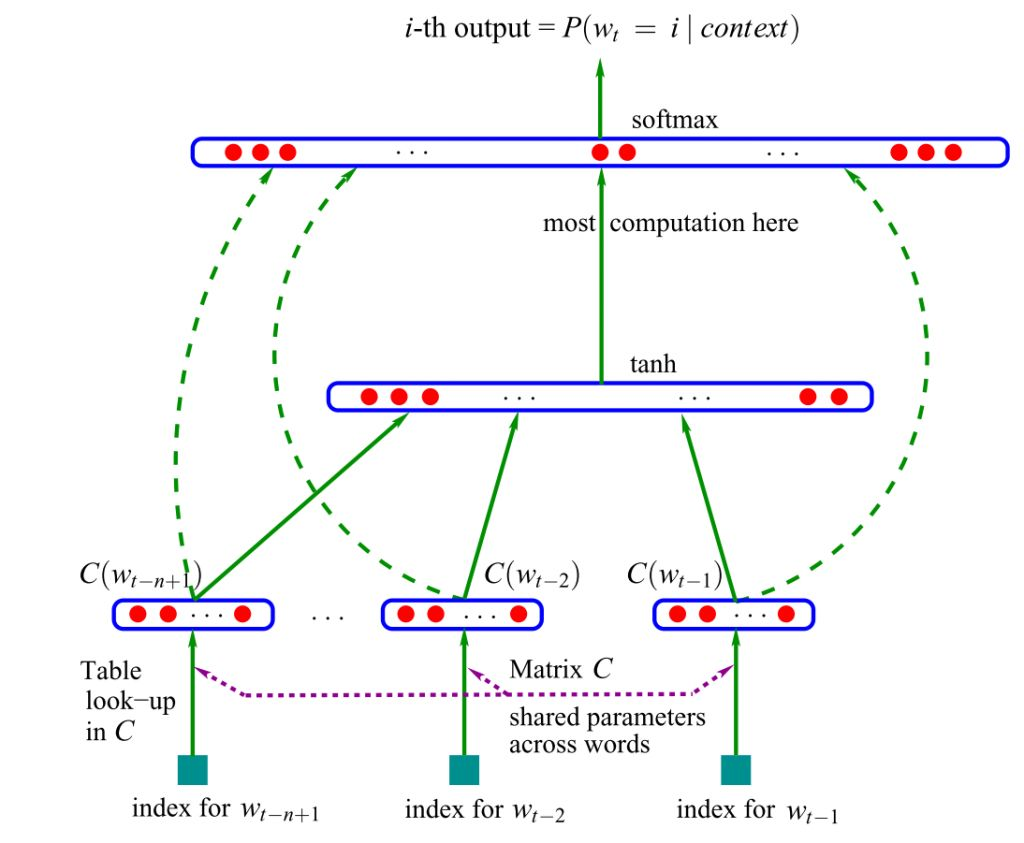
Оригинальная версия основывалась на нейросетях прямого распространения – сигнал шёл строго от входного слоя к выходному. Позднее была предложена альтернатива в виде рекуррентных нейронных сетей (RNN) – именно на «ванильной» RNN, а не на управляемых рекуррентных блоках (GRUs) или на долгой краткосрочной памяти (LSTM).
Рекуррентные нейронные сети (RNN)
Нейронные сети с направленными связями между элементами. Выход нейрона может снова подаваться на вход. Такая структура позволяет иметь подобие «памяти» и обрабатывать последовательности данных, например, тексты естественного языка.
Готовые модели
У Google есть предварительно обученные open-source модели для большинства языков (английская версия). Модель использует три скрытых слоя нейронной сети прямого распространения, обучена на корпусе English Google News 200B и генерирует 128-мерный эмбеддинг.
Преимущества
- Простота. Модель быстро обучается и генерирует эмбеддинги, что достаточно для большинства простых приложений.
- Предварительно обученные версии доступны на многих языках.
Недостатки
- Не учитывает долгосрочные зависимости.
- Простота ограничивает возможности использования.
- Новые embeddings модели намного мощнее.
Источник: Yoshua Bengio, Réjean Ducharme, Pascal Vincent, Christian Jauvin, A Neural Probabilistic Language Model (2003), Journal of Machine Learning Research
2. Word2vec
В 2013 году Томас Миколов (Tomas Mikolov) из Google предложил более эффективную модель обучения векторных представлений слов – Word2vec. Метод основывался на предположении, что слова, которые часто находятся в одинаковых контекстах, имеют схожие значения. Изменения были просты – устранение скрытого слоя и аппроксимация (упрощение) цели – но стали поворотной точкой в развитии языковых моделей NLP.
Вместо алгоритма непрерывного мешка слов модель Word2Vec использует Skip-gram (словосочетание с пропуском). Цель этой модели прямо противоположная предыдущей модели – предсказать окружающие слова на основе центрального.
Skip-Gram
Формируется «контекстное окно» – последовательность из k слов в тексте. Одно из этих слов пропускается, и нейросеть пытается его предсказать. Таким образом, слова, которые часто встречаются в похожем контексте, будут иметь похожие векторы.
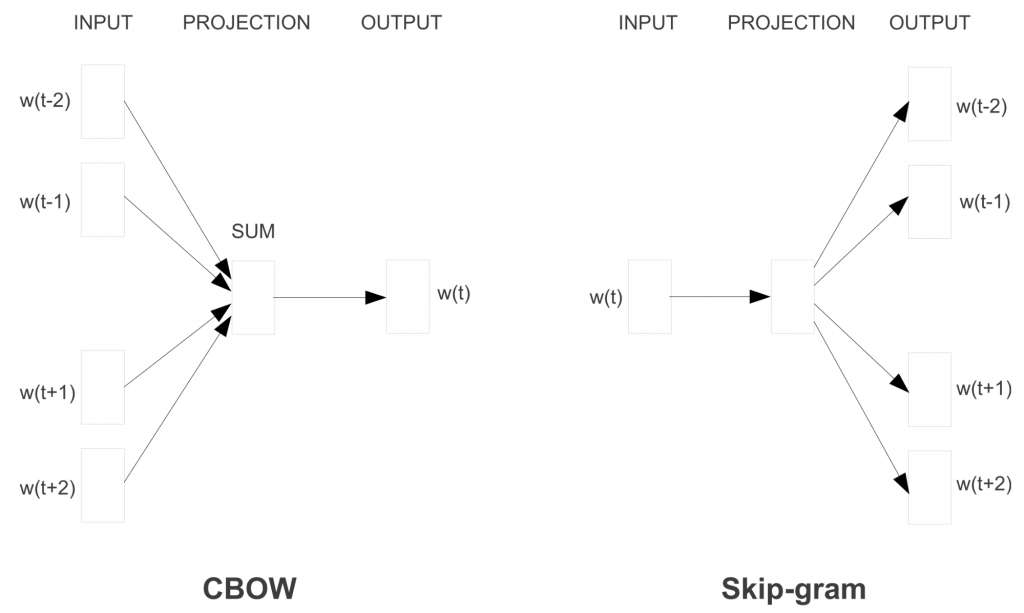
Чтобы сделать обучение эффективнее, используется негативное семплирование (Negative Sampling): модели предоставляются слова, которые не являются контекстными соседями.
Negative Sampling
Многие слова в текстах не встречаются вместе, поэтому модель выполняет много лишних вычислений. Подсчёт softmax — вычислительно дорогая операция. Подход Negative Sampling позволяет максимизировать вероятность встречи нужного слова в контексте, который является для него типичным, и минимизировать – в редком/нетипичном контексте.
Векторная магия
Модель Word2vec поразила исследователей своей «интерпретируемостью». Обучение на больших корпусах текстов позволяет определять глубокие отношения между формами слов, например, гендерные. Если из вектора, соответствующего слову Мужчина (Man) вычесть вектор Женщина (Woman), результат будет очень похож на разность векторов Король (King) и Королева (Queen).
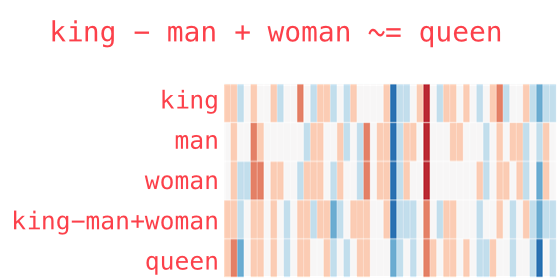
Одно время такое отношения между словами и их векторами казалось почти магией. Ещё несколько забавных примеров векторной арифметики вы можете найти в статье Во что превращается жизнь без любви. Несмотря на огромный вклад, который модель внесла в NLP, сейчас она почти не используется – на смену пришли достойные наследники.
Готовые модели
Предварительно обученная модель легко доступна в интернете. В Python-проект её можно импортировать с помощью библиотеки gensim.
Преимущества
- Простая архитектура: feed-forward, 1 вход, 1 скрытый слой, 1 выход.
- Модель быстро обучается и генерирует эмбеддинги (даже ваши собственные).
- Эмбеддинги наделены смыслом, спорные моменты поддаются расшифровке.
- Методология может быть распространена на множество других областей/проблем (например, Lda2vec).
Недостатки
- Обучение на уровне слов: нет информации о предложении или контексте, в котором используется слово.
- Совместная встречаемость игнорируется. Модель не учитывает то, что слово может иметь различное значение в зависимости от контекста использования. Это основная причина, по которой GloVe обычно предпочтительнее Word2Vec.
- Не очень хорошо обрабатывает неизвестные и редкие слова.
Источник: Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean, Efficient Estimation of Word Representations in Vector Space (2013), International Conference on Learning Representations
3. GloVe (Global Vectors)
GloVe тесно ассоциируется с Word2Vec: алгоритмы появились примерно в одно и то же время и опираются на интерпретируемость векторов слов. Модель GloVe пытается решить проблему эффективного использования статистики совпадений. GloVe минимизирует разницу между произведением векторов слов и логарифмом вероятности их совместного появления с помощью стохастического градиентного спуска. Полученные представления отражают важные линейные подструктуры векторного пространства слов: получается связать вместе разные спутники одной планеты или почтовый код города с его названием.
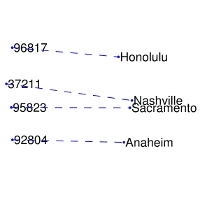
В Word2Vec частота совместной встречаемости слов не имеет большого значения, она лишь помогает генерировать дополнительные обучающие выборки. GloVe учитывает совместную встречаемость, а не полагается только на контекстную статистику. Векторы слов группируются вместе на основе их глобальной схожести.
Готовые модели
Эмбеддинги GloVe легко доступны на веб-сайте Стэнфордского университета.
Преимущества
- Простая архитектура без нейронной сети.
- Модель быстрая, и этого может быть достаточно для простых приложений.
- GloVe улучшает Word2Vec. Она добавляет частоту встречаемости слов и опережает Word2Vec на большинстве бенчмарков.
- Осмысленные эмбеддинги.
Недостатки
- Хотя матрица совместной встречаемости предоставляет глобальную информацию, GloVe остаётся обученной на уровне слов и даёт немного данных о предложении и контексте, в котором слово используется.
- Плохо обрабатывает неизвестные и редкие слова.
Источник: Jeffrey Pennington, Richard Socher, and Christopher D. Manning, GloVe: Global Vectors for Word Representation (2014), Empirical Methods in Natural Language Processing
4. fastText
Созданная в Facebook библиотека fastText – ещё один серьёзный шаг в развитии моделей естественного языка. В её разработке принял участие Томас Миколов, уже знакомый нам по Word2Vec. Для векторизации слов используются одновременно и skip-gram, и негативное семплирование, и алгоритм непрерывного мешка.
К основной модели Word2Vec добавлена модель символьных n-грамм. Каждое слово представляется композицией нескольких последовательностей символов определённой длины. Например, слово they в зависимости от гиперпараметров может состоять из «th», «he», «ey», «the», «hey». По сути, вектор слова – это сумма всех его n-грамм.
Результаты работы классификатора хорошо подходят для слов с небольшой частотой встречаемости, так как они разделяются на n-граммы. В отличие от Word2Vec и Glove, модель способна генерировать эмбеддинги для неизвестных слов.
Готовые модели
В сети доступна подготовленная модель для 157 языков (в том числе русского).
Преимущества
- Относительно простая архитектура: feed-forward, 1 вход, 1 скрытый слой, один выход (хотя n-граммы добавляют сложность в генерацию эмбеддингов).
- Благодаря n-граммам неплохо работает на редких и устаревших словах.
Недостатки
- Обучение на уровне слов: нет информации о предложении или контексте, в котором используется слово.
- Игнорируется совместная встречаемость, то есть модель не учитывает различное значение слова в разных контекстах (поэтому GloVe может быть предпочтительнее).
Источник: Armand Joulin, Edouard Grave, Piotr Bojanowski and Tomas Mikolov, Bag of Tricks for Efficient Text Classification (2016), European Chapter of the Association for Computational Linguistics
***
Все четыре модели имеют много общего, но каждая из них должна использоваться в подходящем контексте. К сожалению, этот момент часто игнорируется, что приводит к получению неоптимальных результатов.
Если вам интересна тема обработки естественного языка, у нас есть ещё пара материалов:
- Обработка естественного языка: с чего начать и что изучать дальше
- NLP – это весело! Обработка естественного языка на Python
GloVe: Global Vectors for Word Representation
Что такое перчатка?
Так какGloVe: Global Vectors for Word RepresentationС точки зрения статьи, полное название GloVe — «Глобальные векторы для представления в Word», основанное наГлобальная статистика частоты словИнструмент для представления слов (основанный на подсчете и общей статистике), который может выразить слово как вектор действительных чисел, эти векторы отражают некоторые семантические характеристики между словами, такие как сходство (подобие), аналогия (Аналогия) и тд. Мы можем вычислить семантическое сходство между двумя словами с помощью операций над векторами, такими как евклидово расстояние или косинусное сходство.
-
Цель модели — выполнить векторизованное представление слов так, чтобы как можно больше семантической и грамматической информации содержалось между векторами.
-
Вход: корпус
-
Вывод: слово вектор
-
Обзор метода: сначала строится матрица совпадений слов на основе корпуса, а затем изучается вектор слов на основе матрицы совпадений и модели GloVe.

Статистическая матрица совпадений
Пусть матрица совместного вхождения будет
X
X
Чьи элементы
X
i
,
j
X_{i,j}
。
X
i
,
j
X_{i,j}
Значение: количество раз, когда слово i и слово j появляются вместе в окне во всем корпусе.
например:
имеет корпус:
i love you but you love him i am sad
Этот небольшой корпус состоит только из одного предложения и состоит из 7 слов: я люблю тебя, но он, я и грустный.
Если мы используем статистическое окно с шириной окна 5 (длина левой и правой стороны равна 2), то у нас будет следующее содержимое окна:

Длина окон 0 и 1 меньше 5, потому что содержимое на левой стороне заголовка слова меньше 2, а длина окон 8 и 9 также меньше 5.
Возьмем окно 5 в качестве примера, чтобы проиллюстрировать, как построить матрицу совместного использования:
Центральное слово — любовь, а слова контекста — но, вы, он, я; затем выполните:
X
l
o
v
e
,
b
u
t
+
=
1
X_{love,but} +=1
X
l
o
v
e
,
y
o
u
+
=
1
X_{love,you} +=1
X
l
o
v
e
,
h
i
m
+
=
1
X_{love,him} +=1
X
l
o
v
e
,
i
+
=
1
X_{love,i} +=1
Используйте окно, чтобы пройти весь корпус один раз, чтобы получить матрицу совместного вхождения
X
X
。
Как реализован GloVe?
Реализация GloVe разделена на следующие три этапа:
- Построить матрицу совместного вхождения (корпус) в соответствии с корпусом
X
X
(Что такое матрица совместного появления?),Каждый элемент в матрицеX
i
j
X_{ij}
Репрезентативные слова и контекстные словаj
j
Сколько раз они появляются вместе в контекстном окне определенного размера, Вообще говоря, минимальная единица этого числа равна 1, но GloVe так не считает: он основан на расстоянии двух слов в контекстном окне.d
d
Предложена функция затухания (уменьшение веса):d
e
a
c
y
=
1
/
d
deacy=1/d
Используется для расчета веса, то естьЧем больше вес общего количества двух слов, которые находятся дальше, тем меньше。
In all cases we use a decreasing weighting function, so that word pairs that are d words apart contribute 1/d to the total count.
- Для построения приблизительной взаимосвязи между Word Vector и матрицей сопутствующих явлений автор статьи предлагает следующую формулу для аппроксимации взаимосвязи между ними:
w
i
T
w
~
j
+
b
i
+
b
j
=
l
o
g
(
X
i
j
)
w^T_{i}tilde{w}_j+b_i+b_j=log(X_{ij})
(1)
среди них,
w
i
T
w^T_{i}
с участием
w
j
~
tilde{w_j}
Является ли слово вектор, который мы наконец просим;
b
i
b_{i}
с участием
b
j
~
tilde{b_j}
Это смещения двух векторов слов. Конечно, у вас должно быть много вопросов об этой формуле, например, откуда она взялась, почему вы должны использовать эту формулу и почему вы должны построить два вектора слов
w
i
T
w^T_{i}
с участием
w
j
~
tilde{w_j}
? Мы представим их подробно ниже.
- С Формулой 1 мы можем построить функцию потерь:
J
=
J=
∑
i
,
j
=
1
V
sum_{i,j=1}^V
f
(
X
i
j
)
(
w
i
T
w
~
j
+
b
i
+
b
j
−
l
o
g
(
X
i
j
)
)
2
f(X_{ij})(w^T_{i}tilde{w}_j+b_i+b_j-log(X_{ij}))^2
Основной формой этой функции потерь является простейшая среднеквадратичная потеря, за исключением того, что добавляется весовая функция.
f
(
X
i
j
)
f(X_{ij})
, Так какую роль играет эта функция, почему мы должны добавить эту функцию? Мы знаем, что в корпусе должно быть много слов, которые часто встречаются вместе (частые совпадения), тогда мы надеемся:
- 1. Вес этих слов более важен, чем слова, которые редко появляются вместе (редкие совпадения), поэтому, если эта функция является неубывающей (неубывающей);
- 2. Но мы также не хотим, чтобы этот вес был завышенным и не должен увеличиваться после достижения определенного уровня;
- 3. Если два слова не появляются вместе, то есть
X
i
j
=
0
X_{ij}=0
Тогда они не должны участвовать в расчете функции потерь, то естьf
(
x
)
f(x)
Удовлетворитьf
(
0
)
=
0
f(0)=0
Существует множество функций, удовлетворяющих двум вышеуказанным условиям, и автор использует следующую форму кусочной функции:
f
(
x
)
=
{
(
x
/
x
m
a
x
)
α
,
if
x
<
x
m
a
x
1
,
otherwise
f(x)=begin{cases} (x/x_{max})^α,&text{if $x<x_{max}$ }\1,&text{otherwise}end{cases}
Изображение функции показано ниже:

Во всех экспериментах в этой работе значение α составляет 0,75, и
x
m
a
x
x_{max}
Значение равно 100. Выше приведены детали реализации GloVe, так как же тренируется GloVe?
Как тренируется GloVe?
Хотя многие люди утверждают, что GloVe является методом обучения без надзора (поскольку он не требует ручной маркировки), у него все еще есть метка. Эта метка является журналом (в формуле 2).
X
i
j
X_{ij}
) и вектор в уравнении 2
w
w
с участием
w
~
tilde{w}
Он заключается в постоянном обновлении / изучении параметров, поэтому, по сути, его метод обучения ничем не отличается от контролируемого метода обучения, основанного на градиентном спуске. В частности, эксперимент в этой статье делается следующим образом:Используется алгоритм градиентного спуска Адаграда
X
X
Все ненулевые элементы в случайной выборке, кривизна обучения установлена на 0,05 и повторяется 50 раз, когда размер вектора меньше 300, и повторяется 100 раз на векторах других размеров до сходимости, Окончательное изучение состоит в том, что два вектора
w
w
с участием
w
~
tilde{w}
,так как
X
X
Симметрично, так что в принципе
w
w
с участием
w
~
tilde{w}
Это также симметрично, единственное различие между ними состоит в том, что начальное значение отличается, а конечное значение отличается. Таким образом, эти два на самом деле эквивалентны и могут быть использованы в качестве конечного результата.Но чтобы улучшить надежность, мы в конечном итоге выберем сумму двух
w
w
+
w
~
tilde{w}
Как конечный вектор (различная инициализация этих двух эквивалентна добавлению разных случайных шумов, поэтому это может улучшить устойчивость), После обучения корпуса из 40 миллиардов токенов полученные экспериментальные результаты показаны ниже:

На этом графике используются три показателя: семантическая точность, грамматическая точность и общая точность. Тогда нетрудно обнаружить, что Vector Dimension может достичь наилучшего результата при 300, а размер контекстного окна составляет примерно от 6 до 10.
Сравнение Glove и LSA, word2vec
LSA (скрытый семантический анализ) — это более ранний инструмент представления вектора слов на основе подсчета, который также основан на матрице сопутствующих явлений, но использует технологию разложения матриц, основанную на разложении по сингулярным значениям (SVD), для уменьшения больших матриц. Размерность, и мы знаем, что сложность SVD очень высока, поэтому его вычислительные затраты относительно высоки. Другое дело, что его статистический вес для всех слов постоянен. Эти недостатки преодолеваются один за другим в GloVe. Самым большим недостатком word2vec является то, что он не в полной мере использует весь корпус, поэтому GloVe фактически сочетает в себе преимущества обоих. Судя по экспериментальным результатам, приведенным в этой статье, производительность GloVe намного превосходит LSA и word2vec, но некоторые люди в Интернете также говорят, что фактическая производительность GloVe и word2vec на самом деле похожа.
Формула Деривация
На этом содержание GloVe в основном закончено. Единственное сомнение в том, как появилась Формула 1? Если вы заинтересованы, вы можете продолжить чтение, если нет, вы можете закрыть окно браузера. Чтобы прояснить эту проблему, мы сначала определим некоторые переменные:
-
X
i
j
X_{ij}
слово
j
j
Появляются в словах
i
i
Времена в контексте
-
X
i
X_{i}
слово
i
i
Общее количество вхождений всех слов в контексте, т.е.
X
i
=
∑
k
X
i
k
X_{i}=sum^kX_{ik}
;
-
P
i
j
=
P
(
j
∣
i
)
=
X
i
j
/
X
i
P_{ij}=P(j|i)=X_{ij}/X_{i}
слово
j
j
Появляются в словах
i
i
Вероятность в контексте
С этими определениями, давайте посмотрим на таблицу:

Ключом к пониманию этой таблицы является последняя строка, которая представляет отношение двух вероятностей (отношение),Мы можем использовать это, чтобы соблюдать два слова
i
i
с участием
j
j
По отношению к словам
k
k
Что более актуально (уместно), Например, лед и твердое тело более связаны, но поток и твердое тело явно не связаны, поэтому мы найдем
P
(
s
o
l
i
d
∣
i
c
e
)
/
P
(
s
o
l
i
d
∣
s
t
e
a
m
)
P(solid|ice)/P(solid|steam)
Гораздо больше, чем 1. Тот же газ и пар более связаны, но не связаны со льдом, тогда
P
(
s
o
l
i
d
∣
i
c
e
)
/
P
(
s
o
l
i
d
∣
s
t
e
a
m
)
P(solid|ice)/P(solid|steam)
Это намного меньше 1, когда все это связано (например, вода) или вообще отсутствует, соотношение между ними близко к 1, это очень интуитивно понятно. следовательно,Приведенный выше вывод может объяснить, что это может быть более подходящий метод для изучения векторов слов по отношению вероятности, а не самой вероятности.Таким образом, все содержание ниже находится вокруг этой точки.
Таким образом, чтобы отразить коэффициент вероятности, упомянутый выше, мы можем построить следующую функцию:
F
(
w
i
,
w
j
,
w
~
k
)
=
P
i
k
/
P
j
k
F(w_{i},w_j,tilde{w}_k)=P_{ik}/P_{jk}
Среди них функция
F
F
Параметры и конкретная форма не определены, он имеет три параметра
w
i
,
w
j
с участием
w
~
k
w_ {i}, w_j и tilde {w} _k
,
w
с участием
w
~
w и tilde {w}
Есть разные векторы;
Поскольку векторное пространство является линейным, самый простой способ выразить пропорциональную разницу между двумя вероятностями — это сделать разницу, поэтому мы получаем:
F
(
w
i
−
w
j
,
w
~
k
)
=
P
i
k
P
j
k
F(w_{i}-w_j,tilde{w}_k)=frac{P_{ik}}{P_{jk}}
В это время мы обнаружили, что правая часть формулы 5 является величиной, а левая сторона — вектором, поэтому мы преобразуем левую сторону во внутреннюю форму произведения двух векторов:
F
(
(
w
i
−
w
j
)
T
w
~
k
)
=
P
i
k
P
j
k
F((w_{i}-w_j)^Ttilde{w}_k)=frac{P_{ik}}{P_{jk}}
(6)
мы знаем
X
X
Это симметричная матрица, и слова и контекстные слова на самом деле являются относительными, то есть если мы обмениваемся следующим образом:
w
w
↔
leftrightarrow
w
~
k
tilde{w}_k
,
X
X
↔
leftrightarrow
X
T
X^T
Формула 6 должна остаться без изменений, тогда понятно, что нынешняя формула не выполняется. Чтобы выполнить это условие, во-первых, нам требуется функция
F
F
Чтобы удовлетворить гомоморфизм:
F
(
(
w
i
−
w
j
)
T
w
~
k
)
=
F
(
w
i
T
w
~
k
)
F
(
w
j
T
w
~
k
)
F((w_{i}-w_j)^Ttilde{w}_k)=frac{F(w^T_{i}tilde{w}_k)}{F(w^T_{j}tilde{w}_k)}
В сочетании с формулой 6 мы можем получить:
F
(
w
i
T
w
~
k
)
=
P
i
k
=
X
i
k
X
i
F(w^T_{i}tilde{w}_k)=P_{ik}=frac{X_{ik}}{X_i}
Тогда пусть F = exp, поэтому мы имеем:
w
i
T
w
~
k
=
l
o
g
(
P
i
k
)
=
l
o
g
(
X
i
k
)
−
l
o
g
(
X
i
)
w^T_{i}tilde{w}_k=log(P_{ik})=log(X_{ik})-log(X_i)
(9)
Потому что правая сторона знака равенства
l
o
g
(
X
i
)
log(X_i)
Существование формулы 9 не удовлетворяет симметрии, и это
l
o
g
(
X
i
)
log(X_i)
Фактически
k
k
Независимо, это только следует
i
i
Связанные, поэтому мы можем целиться
w
i
w_i
Добавить термин смещения
b
i
b_i
Замените его, поэтому мы имеем:
w
i
T
w
~
k
+
b
i
=
l
o
g
(
X
i
k
)
w^T_{i}tilde{w}_k+b_i=log(X_{ik})
(10)
Но формула 10 все еще не удовлетворяет симметрии, поэтому мы стремимся к
w
k
w_k
Добавить термин смещения
b
k
b_k
Чтобы получить формула формулы 1:
w
i
T
w
~
k
+
b
i
+
b
k
=
l
o
g
(
X
i
k
)
w^T_{i}tilde{w}_k+b_i+b_k=log(X_{ik})
(1)
На самом деле, вышеупомянутое содержание не может быть полностью названо деривацией, потому что существует много строгости, он может только объяснить автору, как построить эту формулу шаг за шагом, не более того.
ссылка:
1. Тезис:GloVe: Global Vectors for Word Representation。
2.GloVe объяснил
3.Понимать модель GloVe (Глобальные векторы для представления слов)
GloVe is an unsupervised learning algorithm for obtaining vector representations for word.In this tutorial we will see
how to generate vector for a given word.
Prerequisites
- Run below code snippets with
Google ColaborJupyter Notebookas we have to execute someUnixcommands as well.
Download GloVe pre-trained vectors
!wget http://nlp.stanford.edu/data/glove.6B.zip
Unzip downloaded zip file
!unzip glove.6B.zip
You should see output similar to the below one
Archive: glove.6B.zip
inflating: glove.6B.50d.txt
inflating: glove.6B.100d.txt
inflating: glove.6B.200d.txt
inflating: glove.6B.300d.txt
View files after unzipping
!ls -lrt
You should see output similar to the below one
total 3039136
-rw-rw-r-- 1 root root 347116733 Aug 4 2014 glove.6B.100d.txt
-rw-rw-r-- 1 root root 693432828 Aug 4 2014 glove.6B.200d.txt
-rw-rw-r-- 1 root root 171350079 Aug 4 2014 glove.6B.50d.txt
-rw-rw-r-- 1 root root 1037962819 Aug 27 2014 glove.6B.300d.txt
-rw-r--r-- 1 root root 862182613 Oct 25 2015 glove.6B.zip
From the output we can see there are four text files glove.6B.100d.txt, glove.6B.200d.txt, glove.6B.50d.txt and glove.6B.300d.txt.
These text files generate vectors of length 100, 200, 50 and 300 respectively , for this tutorial we will generate vectors of length 50,
so we will use glove.6B.50d.txt .
Create a dictionary having word as key and vector as value for all of the entries in file glove.6B.50d.txt
import os
import numpy as np
# Create Empty dictionary
word2vector = {}
#Create a dictionary with word and corresponding vector
with open(os.path.join('./glove.6B.50d.txt')) as file:
for line in file:
list_of_values = line.split()
word = list_of_values[0]
vector_of_word = np.asarray(list_of_values[1:], dtype='float32')
word2vector[word] = vector_of_word
msg = f"Total number of words and corresponding vectors in word2vectors are {len(word2vector)}"
print(msg)
# View first record in word2vector dictionary
for word, vector in word2vector.items():
print(word)
print(vector)
print(vector.shape)
break
You should see output similar to the below one
Total number of words and corresponding vectors in word2vectors are 400000
the
[ 4.1800e-01 2.4968e-01 -4.1242e-01 1.2170e-01 3.4527e-01 -4.4457e-02
-4.9688e-01 -1.7862e-01 -6.6023e-04 -6.5660e-01 2.7843e-01 -1.4767e-01
-5.5677e-01 1.4658e-01 -9.5095e-03 1.1658e-02 1.0204e-01 -1.2792e-01
-8.4430e-01 -1.2181e-01 -1.6801e-02 -3.3279e-01 -1.5520e-01 -2.3131e-01
-1.9181e-01 -1.8823e+00 -7.6746e-01 9.9051e-02 -4.2125e-01 -1.9526e-01
4.0071e+00 -1.8594e-01 -5.2287e-01 -3.1681e-01 5.9213e-04 7.4449e-03
1.7778e-01 -1.5897e-01 1.2041e-02 -5.4223e-02 -2.9871e-01 -1.5749e-01
-3.4758e-01 -4.5637e-02 -4.4251e-01 1.8785e-01 2.7849e-03 -1.8411e-01
-1.1514e-01 -7.8581e-01]
(50,)
Generate word vectors for a sentence
#Sample sentence with four words
sample_sentence = "convert word into vectors"
for i in sample_sentence.split():
print(i, word2vector[i], word2vector[i].shape)
You should see output similar to the below one
convert [ 0.33661 -0.51168 0.87064 -0.95326 0.74852 0.12839
-0.37988 0.10754 -0.36786 1.4141 0.62383 0.45762
0.62611 -0.11105 -0.41305 0.67618 0.43104 -0.57291
0.016154 -0.0049896 0.40332 -0.59646 -0.43036 0.20764
-0.1147 -0.99394 0.68397 -1.089 0.51071 -0.37707
2.0347 -0.13211 -0.35318 0.01808 0.40005 -0.13595
-0.058802 0.073057 0.12816 0.0078398 0.70848 -0.36644
0.25745 0.75544 -0.037074 0.50653 -0.055351 -0.20353
-0.37791 -0.67328 ] (50,)
word [-0.1643 0.15722 -0.55021 -0.3303 0.66463 -0.1152
-0.2261 -0.23674 -0.86119 0.24319 0.074499 0.61081
0.73683 -0.35224 0.61346 0.0050975 -0.62538 -0.0050458
0.18392 -0.12214 -0.65973 -0.30673 0.35038 0.75805
1.0183 -1.7424 -1.4277 0.38032 0.37713 -0.74941
2.9401 -0.8097 -0.66901 0.23123 -0.073194 -0.13624
0.24424 -1.0129 -0.24919 -0.06893 0.70231 -0.022177
-0.64684 0.59599 0.027092 0.11203 0.61214 0.74339
0.23572 -0.1369 ] (50,)
into [ 6.6749e-01 -4.1321e-01 6.5755e-02 -4.6653e-01 2.7619e-04 1.8348e-01
-6.5269e-01 9.3383e-02 -8.6802e-03 -1.8874e-01 -6.3057e-03 4.4894e-02
-6.6801e-01 4.8506e-01 -1.1850e-01 1.9968e-01 1.8180e-01 3.3144e-02
-5.9108e-01 -2.1829e-01 4.1438e-01 5.6740e-02 4.2155e-01 2.7798e-01
-1.1322e-01 -1.9227e+00 3.5513e-02 6.1928e-01 6.2206e-01 -6.3987e-01
3.9115e+00 -2.1078e-02 -2.4685e-01 -1.3922e-01 -2.2545e-01 5.9131e-01
-7.3220e-01 1.1620e-01 4.1550e-01 -1.5188e-01 -1.4933e-01 4.0739e-02
-1.0415e-01 2.3733e-01 -4.3800e-01 6.0590e-02 5.5073e-01 -9.6571e-01
-2.6875e-01 -1.1741e+00] (50,)
vectors [ 1.3247 -0.38281 0.27162 0.82353 1.7431 0.63094 1.9888
-1.0854 0.97619 -0.79769 0.70562 0.28915 -0.44682 0.16009
-0.25901 -0.35215 0.10791 -0.71015 -0.80975 -0.70704 -1.0186
-1.619 0.93473 1.1258 -0.22782 0.71059 0.22179 -0.42324
0.61644 0.30039 1.1298 0.075558 0.049487 -0.40429 -0.4642
-0.41281 0.193 0.29502 -0.74731 1.3598 1.2449 0.30083
-0.63276 1.5004 -0.30381 0.21208 1.1786 -0.036461 -0.3919
0.71549 ] (50,)
GloVe: Global Vectors for Word Representation
| nearest neighbors of frog |
Litoria | Leptodactylidae | Rana | Eleutherodactylus |
|---|---|---|---|---|
| Pictures |  |
|
|
|
| Comparisons | man -> woman | city -> zip | comparative -> superlative |
|---|---|---|---|
| GloVe Geometry | |
|
|
We provide an implementation of the GloVe model for learning word representations, and describe how to download web-dataset vectors or train your own. See the project page or the paper for more information on glove vectors.
Download pre-trained word vectors
The links below contain word vectors obtained from the respective corpora. If you want word vectors trained on massive web datasets, you need only download one of these text files! Pre-trained word vectors are made available under the Public Domain Dedication and License.
- Common Crawl (42B tokens, 1.9M vocab, uncased, 300d vectors, 1.75 GB download): glove.42B.300d.zip [mirror]
- Common Crawl (840B tokens, 2.2M vocab, cased, 300d vectors, 2.03 GB download): glove.840B.300d.zip [mirror]
- Wikipedia 2014 + Gigaword 5 (6B tokens, 400K vocab, uncased, 300d vectors, 822 MB download): glove.6B.zip [mirror]
- Twitter (2B tweets, 27B tokens, 1.2M vocab, uncased, 200d vectors, 1.42 GB download): glove.twitter.27B.zip [mirror]
Train word vectors on a new corpus
If the web datasets above don’t match the semantics of your end use case, you can train word vectors on your own corpus.
$ git clone https://github.com/stanfordnlp/glove
$ cd glove && make
$ ./demo.sh
Make sure you have the following prerequisites installed when running the steps above:
- GNU Make
- GCC (Clang pretending to be GCC is fine)
- Python and NumPy
The demo.sh script downloads a small corpus, consisting of the first 100M characters of Wikipedia. It collects unigram counts, constructs and shuffles cooccurrence data, and trains a simple version of the GloVe model. It also runs a word analogy evaluation script in python to verify word vector quality. More details about training on your own corpus can be found by reading demo.sh or the src/README.md
License
All work contained in this package is licensed under the Apache License, Version 2.0. See the include LICENSE file.