

Добавил:
Upload
Опубликованный материал нарушает ваши авторские права? Сообщите нам.
Вуз:
Предмет:
Файл:
лаб стат 4.doc
Скачиваний:
1
Добавлен:
05.05.2019
Размер:
399.87 Кб
Скачать
Самостоятельно
приведите график к следующему виду:
Наблюдения на
экспериментальной животноводческой
ферме показали, что имеется следующая
зависимость между скоростью роста
животных и содержанием белков в
материнском молоке:
|
Животные |
Время удвоения |
Содержание белков |
|
Лошадь |
75 |
2,4 |
|
Корова |
60 |
2,6 |
|
Коза |
43 |
3,3 |
|
Овца |
27 |
4,8 |
|
Мул |
15 |
5,6 |
|
Свинья |
14 |
7,5 |
Найти уравнение
гиперболической зависимости между
скоростью роста животных и содержанием
белков в материнском молоке и построить
график этой зависимости и эмпирических
точек.
Для выполнения
этого задания проделайте следующие
пункты.
-
Перейдите
на следующий рабочий лист. -
Поскольку
в Excel
нет возможности быстрого построения
с помощью стандартных процедур линии
гиперболической регрессии, то для
нахождения ее коэффициентов придется
использовать формулы (4.16-4.17). Содержащиеся
в этих формулах суммы удобнее всего
вычислить с помощью вспомогательной
расчетной таблицы. -
Наберите
в заголовки столбцов расчетной таблицы:
в ячейку А1 –;
в ячейку В1 –;
в ячейку С1 – 1/
;
в ячейку D1
–/
;
в ячейку Е1 –

. -
В
интервал ячеек А2:А7 наберите данные о
времени удвоения массы новорожденных;
а в интервал ячеек В2:В7 наберите данные
о содержании белков в молоке матерей. -
В
ячейку С2 наберите формулу: =1/А2 и
распространите ее с помощью Маркера
заполнения на интервал
ячеек С2:С7. -
В
ячейку D2
наберите формулу: =В2*С2 (или =В2/А2, что
тоже самое) и распространите ее на
интервал ячеек D2:D7
с помощью Маркера
заполнения. -
В
ячейку Е2 наберите формулу: =С2^2 (или
1/A2^2,
что тоже самое) и распространите ее с
помощью Маркера
заполнения на интервал
ячеек Е2:Е7. -
Выделите
ячейку А8 и нажмите на кнопку Автосумма
на панели инструментов. Тогда в этой
ячейке появится сумма чисел диапазона
А2:А7, т.е.

. -
Распространите
полученную формулу Маркером
заполнения на ячейки
диапазона А8:Е8. Тогда:
-
в
ячейке В8 будет сумма

; -
в
ячейке С8 —

; -
в
ячейке D8
—

; -
в
ячейке Е8 —

.
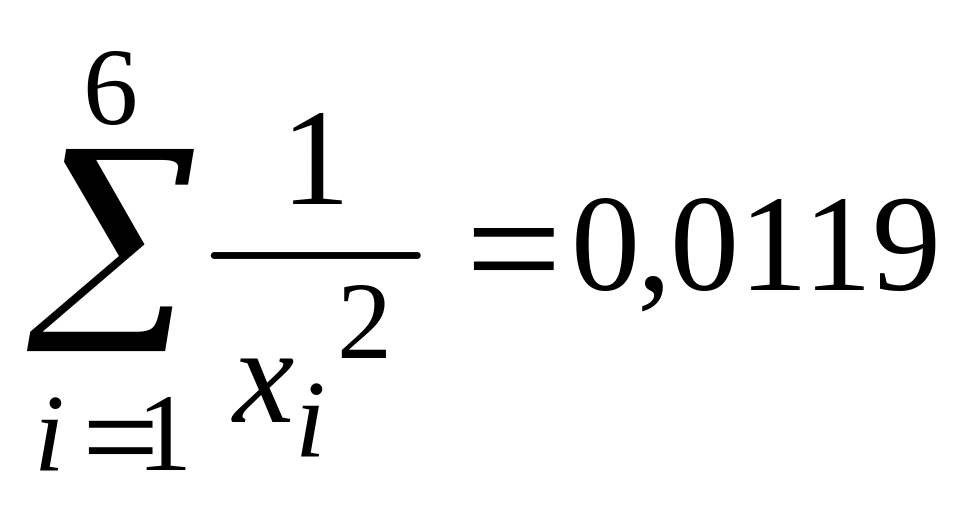
Поскольку
именно эти суммы входят в формулы
(4.17), то по ним легко найти величины Dа
и Db.
Для этого в ячейку А9 наберите: D
=; в ячейку А10 наберите:
«Dа=»;
в ячейку А11: «Db=».
(Греческую заглавную букву D
— «дельта» можно
набрать, если выбрать шрифт Symbol
и нажать одновременно клавиши Shift
и D.)
Теперь
в ячейку В9 наберите формулу: =С8^2-6*Е8; в
ячейку В10 наберите формулу: =С8*В8-6*D8;
в ячейку В11 наберите формулу: =С8*D8-В8*Е8.
Теперь
по формулам (4.16) осталось найти
коэффициенты гиперболической регрессии.
Для этого в ячейку С9 наберите: «а=»;
в ячейку С10: «b=».
Оформите содержание этих ячеек курсивом
и выровняйте их по правому краю.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
Регрессия бывает:
- линейной (у = а + bx);
- параболической (y = a + bx + cx2);
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.

Модель линейной регрессии имеет следующий вид:
У = а0 + а1х1 +…+акхк.
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
- Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».
- Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
- Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.



После активации надстройка будет доступна на вкладке «Данные».

Теперь займемся непосредственно регрессионным анализом.
- Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».
- Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.
- После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).



В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача: Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.

Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» — первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» — второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.

Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:

Корреляционно-регрессионный анализ
На практике эти две методики часто применяются вместе.
Пример:

- Строим корреляционное поле: «Вставка» — «Диаграмма» — «Точечная диаграмма» (дает сравнивать пары). Диапазон значений – все числовые данные таблицы.
- Щелкаем левой кнопкой мыши по любой точке на диаграмме. Потом правой. В открывшемся меню выбираем «Добавить линию тренда».
- Назначаем параметры для линии. Тип – «Линейная». Внизу – «Показать уравнение на диаграмме».
- Жмем «Закрыть».




Теперь стали видны и данные регрессионного анализа.
Показательное уравнение регрессии
В случае b = e (примерное значение экспоненты e ≈ 2.718281828 ), показательное уравнение регрессии называется экспоненциальным и записывается как y=a·e x .
Здесь b — темп изменения в разах или константа тренда, которая показывает тенденцию ускоренного и все более ускоряющегося возрастания уровней.
Пример . Необходимо изучить зависимость потребительским расходами на моторное масло (у) и располагаемым личным доходом (х).
Составляем систему нормальных уравнений с помощью онлайн-калькулятора Нелинейная регрессия .
Для наших данных система уравнений имеет вид
21a + 20439.4 b = 32.32
20439.4 a + 20761197.38 b = 31007.03
Из первого уравнения выражаем а и подставим во второе уравнение:
Получаем эмпирические коэффициенты регрессии: b = -0.000515, a = 2.04
Уравнение регрессии (эмпирическое уравнение регрессии):
y = e 2.04 *e -0.000515x = 7.69529*0.99948 x
Эмпирические коэффициенты регрессии a и b являются лишь оценками теоретических коэффициентов βi, а само уравнение отражает лишь общую тенденцию в поведении рассматриваемых переменных.
Для расчета параметров регрессии построим расчетную таблицу (табл. 1)
a•n + b∑x = ∑y a∑x + b∑x 2 = ∑y•x
| log(y) 2 | x·log(y) | |||
| 622.9 | 1.59 | 388004.41 | 2.53 | 989.93 |
| 658 | 1.65 | 432964 | 2.72 | 1084.82 |
| 700.4 | 1.7 | 490560.16 | 2.91 | 1194.01 |
| 740.6 | 1.72 | 548488.36 | 2.97 | 1275.88 |
| 774.4 | 1.72 | 599695.36 | 2.97 | 1334.11 |
| 816.2 | 1.67 | 666182.44 | 2.78 | 1361.18 |
| 853.5 | 1.61 | 728462.25 | 2.59 | 1373.66 |
| 876.8 | 1.55 | 768778.24 | 2.39 | 1356.9 |
| 900 | 1.53 | 810000 | 2.33 | 1373.45 |
| 951.4 | 1.61 | 905161.96 | 2.59 | 1531.22 |
| 1007.9 | 1.69 | 1015862.41 | 2.84 | 1699.72 |
| 1004.8 | 1.44 | 1009623.04 | 2.06 | 1441.97 |
| 1010.8 | 1.44 | 1021716.64 | 2.06 | 1450.58 |
| 1056.2 | 1.53 | 1115558.44 | 2.33 | 1611.82 |
| 1105.4 | 1.48 | 1221909.16 | 2.2 | 1637.77 |
| 1162.3 | 1.55 | 1350941.29 | 2.39 | 1798.73 |
| 1200.7 | 1.55 | 1441680.49 | 2.39 | 1858.16 |
| 1209.5 | 1.36 | 1462890.25 | 1.85 | 1646.1 |
| 1248.6 | 1.28 | 1559001.96 | 1.64 | 1599.37 |
| 1254.4 | 1.28 | 1573519.36 | 1.64 | 1606.8 |
| 1284.6 | 1.39 | 1650197.16 | 1.92 | 1780.83 |
| 20439.4 | 32.32 | 20761197.38 | 50.1 | 31007.03 |
1. Параметры уравнения регрессии.
Выборочные средние.

Выборочные дисперсии:
Среднеквадратическое отклонение
Регрессионный анализ в Microsoft Excel

Регрессионный анализ является одним из самых востребованных методов статистического исследования. С его помощью можно установить степень влияния независимых величин на зависимую переменную. В функционале Microsoft Excel имеются инструменты, предназначенные для проведения подобного вида анализа. Давайте разберем, что они собой представляют и как ими пользоваться.
Подключение пакета анализа
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.
-
Перемещаемся во вкладку «Файл».


Открывается окно параметров Excel. Переходим в подраздел «Надстройки».

В самой нижней части открывшегося окна переставляем переключатель в блоке «Управление» в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «Перейти».


Теперь, когда мы перейдем во вкладку «Данные», на ленте в блоке инструментов «Анализ» мы увидим новую кнопку – «Анализ данных».

Виды регрессионного анализа
Существует несколько видов регрессий:
- параболическая;
- степенная;
- логарифмическая;
- экспоненциальная;
- показательная;
- гиперболическая;
- линейная регрессия.
О выполнении последнего вида регрессионного анализа в Экселе мы подробнее поговорим далее.
Линейная регрессия в программе Excel
Внизу, в качестве примера, представлена таблица, в которой указана среднесуточная температура воздуха на улице, и количество покупателей магазина за соответствующий рабочий день. Давайте выясним при помощи регрессионного анализа, как именно погодные условия в виде температуры воздуха могут повлиять на посещаемость торгового заведения.
Общее уравнение регрессии линейного вида выглядит следующим образом: У = а0 + а1х1 +…+акхк . В этой формуле Y означает переменную, влияние факторов на которую мы пытаемся изучить. В нашем случае, это количество покупателей. Значение x – это различные факторы, влияющие на переменную. Параметры a являются коэффициентами регрессии. То есть, именно они определяют значимость того или иного фактора. Индекс k обозначает общее количество этих самых факторов.
- Кликаем по кнопке «Анализ данных». Она размещена во вкладке «Главная» в блоке инструментов «Анализ».

Открывается небольшое окошко. В нём выбираем пункт «Регрессия». Жмем на кнопку «OK».

Открывается окно настроек регрессии. В нём обязательными для заполнения полями являются «Входной интервал Y» и «Входной интервал X». Все остальные настройки можно оставить по умолчанию.
В поле «Входной интервал Y» указываем адрес диапазона ячеек, где расположены переменные данные, влияние факторов на которые мы пытаемся установить. В нашем случае это будут ячейки столбца «Количество покупателей». Адрес можно вписать вручную с клавиатуры, а можно, просто выделить требуемый столбец. Последний вариант намного проще и удобнее.
В поле «Входной интервал X» вводим адрес диапазона ячеек, где находятся данные того фактора, влияние которого на переменную мы хотим установить. Как говорилось выше, нам нужно установить влияние температуры на количество покупателей магазина, а поэтому вводим адрес ячеек в столбце «Температура». Это можно сделать теми же способами, что и в поле «Количество покупателей».

С помощью других настроек можно установить метки, уровень надёжности, константу-ноль, отобразить график нормальной вероятности, и выполнить другие действия. Но, в большинстве случаев, эти настройки изменять не нужно. Единственное на что следует обратить внимание, так это на параметры вывода. По умолчанию вывод результатов анализа осуществляется на другом листе, но переставив переключатель, вы можете установить вывод в указанном диапазоне на том же листе, где расположена таблица с исходными данными, или в отдельной книге, то есть в новом файле.

После того, как все настройки установлены, жмем на кнопку «OK».

Разбор результатов анализа
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.

Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
Помимо этой статьи, на сайте еще 12704 инструкций.
Добавьте сайт Lumpics.ru в закладки (CTRL+D) и мы точно еще пригодимся вам.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Показательная парная регрессия.

1.4 Гиперболическая парная регрессия рассчитывается по формуле:

Для определения параметров a и b необходимо линеаризировать предыдущую формулу. Для этого сделаем замену:

Тогда 
Для определения параметров a и b используем следующие формулы:

В таблице рассчитываем средние значения величин x, x*, y, x*y, x* 2 .
| n | у | х | x*=1/x | x*x* | x*y |
| 11,92 | 18,26 | 0,0548 | 0,002999 | 0,652793 | |
| 8,34 | 21,90 | 0,0457 | 0,002085 | 0,380822 | |
| 7,08 | 12,12 | 0,0825 | 0,006808 | 0,584158 | |
| 10,52 | 17,52 | 0,0571 | 0,003258 | 0,600457 | |
| 18,68 | 26,28 | 0,0381 | 0,001448 | 0,710807 | |
| 8,24 | 11,86 | 0,0843 | 0,007109 | 0,694772 | |
| 10,50 | 15,08 | 0,0663 | 0,004397 | 0,696286 | |
| 7,34 | 10,56 | 0,0947 | 0,008968 | 0,695076 | |
| 7,28 | 10,40 | 0,0962 | 0,009246 | 0,7 | |
| 6,72 | 10,78 | 0,0928 | 0,008605 | 0,623377 | |
| 8,18 | 10,80 | 0,0926 | 0,008573 | 0,757407 | |
| 9,04 | 13,64 | 0,0733 | 0,005375 | 0,662757 | |
| 7,34 | 10,74 | 0,0931 | 0,008669 | 0,683426 | |
| 6,56 | 11,78 | 0,0849 | 0,007206 | 0,556876 | |
| 9,20 | 12,52 | 0,0799 | 0,00638 | 0,734824 | |
| 7,60 | 10,42 | 0,0960 | 0,00921 | 0,729367 | |
| 8,78 | 12,52 | 0,0799 | 0,00638 | 0,701278 | |
| 6,88 | 10,42 | 0,0960 | 0,00921 | 0,660269 | |
| 8,02 | 13,16 | 0,0760 | 0,005774 | 0,609422 | |
| 10,28 | 14,92 | 0,0670 | 0,004492 | 0,689008 | |
| среднее | 8,9250 | 13,7840 | 0,0775 | 0,0063 | 0,6562 |
Вычислим значение коэффициента регрессии b:

Вычислим значение коэффициента регрессии a:

Тогда показательное уравнение регрессии будет выглядеть следующим образом:

Гиперболическая парная регрессия.

- Оцените тесноту связи с помощью показателей корреляции и детерминации.
Оценка тесноты связи с помощью показателей корреляции.
2.1.1 Показатель корреляции для линейной регрессии:
 , где
, где 
 .
.
| n | у | х | xx | xy | yy |
| 11,92 | 18,26 | 333,4276 | 217,6592 | 142,0864 | |
| 8,34 | 21,9 | 479,6100 | 182,6460 | 69,5556 | |
| 7,08 | 12,12 | 146,8944 | 85,8096 | 50,1264 | |
| 10,52 | 17,52 | 306,9504 | 184,3104 | 110,6704 | |
| 18,68 | 26,28 | 690,6384 | 490,9104 | 348,9424 | |
| 8,24 | 11,86 | 140,6596 | 97,7264 | 67,8976 | |
| 10,5 | 15,08 | 227,4064 | 158,3400 | 110,2500 | |
| 7,34 | 10,56 | 111,5136 | 77,5104 | 53,8756 | |
| 7,28 | 10,4 | 108,1600 | 75,7120 | 52,9984 | |
| 6,72 | 10,78 | 116,2084 | 72,4416 | 45,1584 | |
| 8,18 | 10,8 | 116,6400 | 88,3440 | 66,9124 | |
| 9,04 | 13,64 | 186,0496 | 123,3056 | 81,7216 | |
| 7,34 | 10,74 | 115,3476 | 78,8316 | 53,8756 | |
| 6,56 | 11,78 | 138,7684 | 77,2768 | 43,0336 | |
| 9,2 | 12,52 | 156,7504 | 115,1840 | 84,6400 | |
| 7,6 | 10,42 | 108,5764 | 79,1920 | 57,7600 | |
| 8,78 | 12,52 | 156,7504 | 109,9256 | 77,0884 | |
| 6,88 | 10,42 | 108,5764 | 71,6896 | 47,3344 | |
| 8,02 | 13,16 | 173,1856 | 105,5432 | 64,3204 | |
| 10,28 | 14,92 | 222,6064 | 153,3776 | 105,6784 | |
| среднее | 8,925 | 13,784 | 207,236 | 132,2868 | 86,6963 |
Определим среднеквадратические отклонения:

Определим показатель корреляции:  .
.
2.1.2 Показатель корреляции для степенной регрессии:
 ,где
,где

 .
.
| n | у | х | x*=lg(x) | y*=lg(y) | y*y* | ŷ* | e=y*-ŷ* | ee |
| 11,92 | 18,26 | 1,2615 | 1,0763 | 1,1584 | 1,0435 | 0,0328 | 0,0011 | |
| 8,34 | 21,90 | 1,3404 | 0,9212 | 0,8485 | 1,1048 | -0,1836 | 0,0337 | |
| 7,08 | 12,12 | 1,0835 | 0,8500 | 0,7226 | 0,9053 | -0,0553 | 0,0031 | |
| 10,52 | 17,52 | 1,2435 | 1,0220 | 1,0445 | 1,0296 | -0,0075 | 0,0001 | |
| 18,68 | 26,28 | 1,4196 | 1,2714 | 1,6164 | 1,1663 | 0,1051 | 0,0111 | |
| 8,24 | 11,86 | 1,0741 | 0,9159 | 0,8389 | 0,8980 | 0,0179 | 0,0003 | |
| 10,50 | 15,08 | 1,1784 | 1,0212 | 1,0428 | 0,9790 | 0,0422 | 0,0018 | |
| 7,34 | 10,56 | 1,0237 | 0,8657 | 0,7494 | 0,8589 | 0,0068 | 0,0000 | |
| 7,28 | 10,40 | 1,0170 | 0,8621 | 0,7433 | 0,8537 | 0,0084 | 0,0001 | |
| 6,72 | 10,78 | 1,0326 | 0,8274 | 0,6845 | 0,8658 | -0,0385 | 0,0015 | |
| 8,18 | 10,80 | 1,0334 | 0,9128 | 0,8331 | 0,8664 | 0,0463 | 0,0021 | |
| 9,04 | 13,64 | 1,1348 | 0,9562 | 0,9143 | 0,9452 | 0,0110 | 0,0001 | |
| 7,34 | 10,74 | 1,0310 | 0,8657 | 0,7494 | 0,8646 | 0,0011 | 0,0000 | |
| 6,56 | 11,78 | 1,0711 | 0,8169 | 0,6673 | 0,8957 | -0,0788 | 0,0062 | |
| 9,20 | 12,52 | 1,0976 | 0,9638 | 0,9289 | 0,9163 | 0,0475 | 0,0023 | |
| 7,60 | 10,42 | 1,0179 | 0,8808 | 0,7758 | 0,8544 | 0,0264 | 0,0007 | |
| 8,78 | 12,52 | 1,0976 | 0,9435 | 0,8902 | 0,9163 | 0,0272 | 0,0007 | |
| 6,88 | 10,42 | 1,0179 | 0,8376 | 0,7016 | 0,8544 | -0,0168 | 0,0003 | |
| 8,02 | 13,16 | 1,1193 | 0,9042 | 0,8175 | 0,9331 | -0,0289 | 0,0008 | |
| 10,28 | 14,92 | 1,1738 | 1,0120 | 1,0241 | 0,9754 | 0,0366 | 0,0013 | |
| среднее | 8,9250 | 13,7840 | 1,1234 | 0,9363 | 0,8876 | 0,936325 | 0,000003 | 0,003364 |
Определим индекс корреляции:
 ;
;  ;
;
 .
.
2.1.3 Показатель корреляции для показательной регрессии:
,где
| n | у | х | y*=lg(y) | y*y* | ŷ* | e=y*-ŷ* | ee |
| 11,92 | 18,26 | 1,0763 | 1,1584 | 1,0303 | 0,0460 | 0,0021 | |
| 8,34 | 21,90 | 0,9212 | 0,8485 | 1,1067 | -0,1855 | 0,0344 | |
| 7,08 | 12,12 | 0,8500 | 0,7226 | 0,9013 | -0,0513 | 0,0026 | |
| 10,52 | 17,52 | 1,0220 | 1,0445 | 1,0147 | 0,0073 | 0,0001 | |
| 18,68 | 26,28 | 1,2714 | 1,6164 | 1,1987 | 0,0727 | 0,0053 | |
| 8,24 | 11,86 | 0,9159 | 0,8389 | 0,8959 | 0,0201 | 0,0004 | |
| 10,50 | 15,08 | 1,0212 | 1,0428 | 0,9635 | 0,0577 | 0,0033 | |
| 7,34 | 10,56 | 0,8657 | 0,7494 | 0,8686 | -0,0029 | 0,0000 | |
| 7,28 | 10,40 | 0,8621 | 0,7433 | 0,8652 | -0,0031 | 0,0000 | |
| 6,72 | 10,78 | 0,8274 | 0,6845 | 0,8732 | -0,0458 | 0,0021 | |
| 8,18 | 10,80 | 0,9128 | 0,8331 | 0,8736 | 0,0392 | 0,0015 | |
| 9,04 | 13,64 | 0,9562 | 0,9143 | 0,9332 | 0,0229 | 0,0005 | |
| 7,34 | 10,74 | 0,8657 | 0,7494 | 0,8723 | -0,0066 | 0,0000 | |
| 6,56 | 11,78 | 0,8169 | 0,6673 | 0,8942 | -0,0773 | 0,0060 | |
| 9,20 | 12,52 | 0,9638 | 0,9289 | 0,9097 | 0,0541 | 0,0029 | |
| 7,60 | 10,42 | 0,8808 | 0,7758 | 0,8656 | 0,0152 | 0,0002 | |
| 8,78 | 12,52 | 0,9435 | 0,8902 | 0,9097 | 0,0338 | 0,0011 | |
| 6,88 | 10,42 | 0,8376 | 0,7016 | 0,8656 | -0,0280 | 0,0008 | |
| 8,02 | 13,16 | 0,9042 | 0,8175 | 0,9232 | -0,0190 | 0,0004 | |
| 10,28 | 14,92 | 1,0120 | 1,0241 | 0,9601 | 0,0519 | 0,0027 | |
| среднее | 8,9250 | 13,7840 | 0,9363 | 0,8876 | 0,9363 | 0,0001 | 0,0033 |
Определим индекс корреляции:
 ;
;  ;
;
 .
.
2.1.4 Показатель корреляции для гиперболической регрессии:
,где

| n | у | х | x*=1/x | y*y | ŷ | e=y-ŷ | ee |
| 11,92 | 18,26 | 0,0548 | 142,0864 | 11,6717 | 0,2483 | 0,0617 | |
| 8,34 | 21,90 | 0,0457 | 69,5556 | 12,7713 | -4,4313 | 19,6367 | |
| 7,08 | 12,12 | 0,0825 | 50,1264 | 8,3200 | -1,2400 | 1,5376 | |
| 10,52 | 17,52 | 0,0571 | 110,6704 | 11,3922 | -0,8722 | 0,7608 | |
| 18,68 | 26,28 | 0,0381 | 348,9424 | 13,6907 | 4,9893 | 24,8929 | |
| 8,24 | 11,86 | 0,0843 | 67,8976 | 8,1015 | 0,1385 | 0,0192 | |
| 10,50 | 15,08 | 0,0663 | 110,2500 | 10,2765 | 0,2235 | 0,0499 | |
| 7,34 | 10,56 | 0,0947 | 53,8756 | 6,8475 | 0,4925 | 0,2426 | |
| 7,28 | 10,40 | 0,0962 | 52,9984 | 6,6715 | 0,6085 | 0,3703 | |
| 6,72 | 10,78 | 0,0928 | 45,1584 | 7,0810 | -0,3610 | 0,1303 | |
| 8,18 | 10,80 | 0,0926 | 66,9124 | 7,1017 | 1,0783 | 1,1627 | |
| 9,04 | 13,64 | 0,0733 | 81,7216 | 9,4308 | -0,3908 | 0,1527 | |
| 7,34 | 10,74 | 0,0931 | 53,8756 | 7,0392 | 0,3008 | 0,0905 | |
| 6,56 | 11,78 | 0,0849 | 43,0336 | 8,0323 | -1,4723 | 2,1677 | |
| 9,20 | 12,52 | 0,0799 | 84,6400 | 8,6385 | 0,5615 | 0,3153 | |
| 7,60 | 10,42 | 0,0960 | 57,7600 | 6,6938 | 0,9062 | 0,8212 | |
| 8,78 | 12,52 | 0,0799 | 77,0884 | 8,6385 | 0,1415 | 0,0200 | |
| 6,88 | 10,42 | 0,0960 | 47,3344 | 6,6938 | 0,1862 | 0,0347 | |
| 8,02 | 13,16 | 0,0760 | 64,3204 | 9,1077 | -1,0877 | 1,1831 | |
| 10,28 | 14,92 | 0,0670 | 105,6784 | 10,1906 | 0,0894 | 0,0080 | |
| среднее | 8,9250 | 13,7840 | 0,0775 | 86,6963 | 8,9195 | 0,0055 | 2,6829 |
Определим индекс корреляции:
 ;
;  ;
;
 .
.
Вывод:
Связи между признаками могут быть слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока:
0.1
источники:
http://lumpics.ru/regression-analysis-in-excel/
http://zdamsam.ru/b52151.html
Ниже приведены условия задач, и текстовый отчет о решении. Закачка полного решения(документы doc и xlsx в архиве zip) начнется автоматически через 10 секунд.
Задача 1. По данным приведенным в таблице 1 провести регрессионный анализ, используя следующие зависимости: линейную, квадратическую, гиперболическую, показательную, степенную, логарифмическую. Выбрать лучшую модель.
Таблица 1 – Исходные данные
|
№ п/п |
X |
Y |
|
1 |
1 |
12 |
|
2 |
2 |
18 |
|
3 |
3 |
15 |
|
4 |
4 |
25 |
|
5 |
5 |
26 |
|
6 |
6 |
34 |
|
7 |
7 |
37 |
|
8 |
8 |
47 |
Решение.
Для решения поставленной задачи и упрощения расчетов воспользуемся средствами табличного процессора MS Excel.
Первым этапом будет ввод исходных данных и построение линейной модели регрессии.
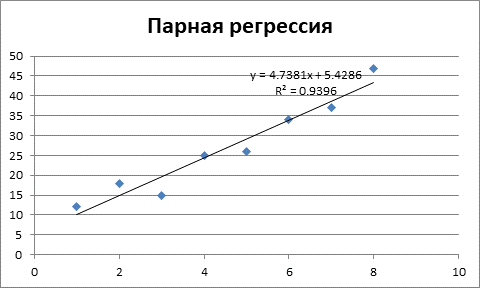
Рисунок 1 – Получение параметров линейной модели регрессии.
Таким образом, получили следующее линейное уравнение регрессии:
![]()
На рисунке 1 показано значение коэффициента детерминации R2 = 0,94. То есть 94% значений переменной Y объясняется значениями переменной X. Таким образом, можно говорить о высоком качестве уравнения регрессии.
Следующим этапом будет построение квадратического уравнения регрессии.
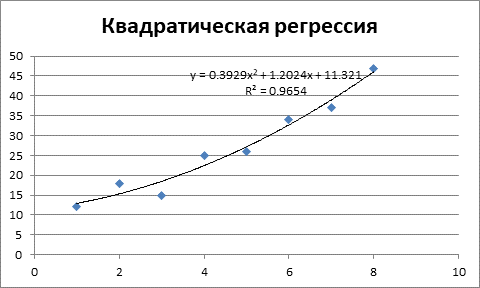
Рисунок 2 – Квадратическое уравнение регрессии и коэффициент детерминации.
Как видим из рисунка 2, коэффициент детерминации составляет R2 = 0,9654, то есть качество уравнения несколько выше линейного уравнения.
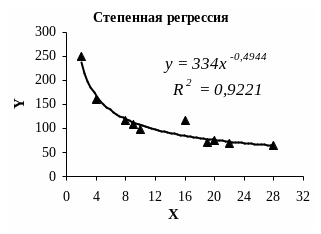
Следующим этапом будет получение показательного уравнения регрессии.
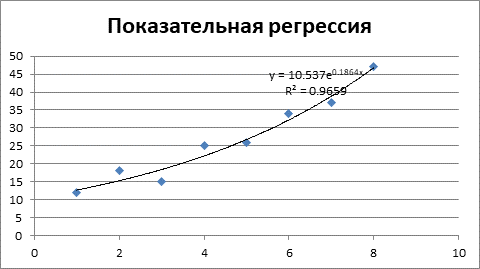
Рисунок 3 – Показательная регрессия и коэффициент детерминации.
Уравнение показательной регрессии объясняет 94,06% значений зависимой переменной Y от факторной переменной X.
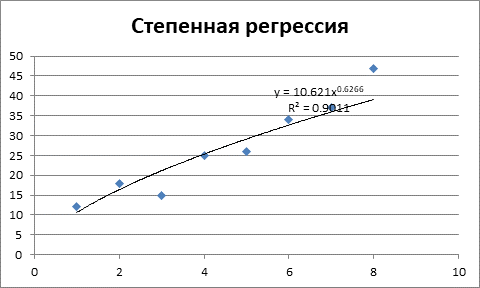
Рисунок 4 – Степенная регрессия и коэффициент детерминации.
Согласно рис. 4 полученное уравнение регрессии объясняет 87,7% значений зависимой переменной Y. Данное уравнение достаточно хуже по качеству, чем предыдущие.
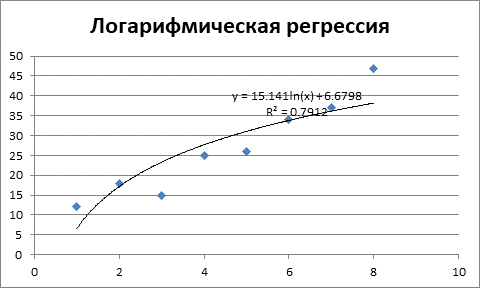
Рисунок 5 – Логарифмическая регрессия и коэффициент детерминации
Коэффициент детерминации логарифмического уравнения регрессии говорит о достаточно хорошем качестве уравнения регрессии, однако оно уступает по качеству предыдущим уравнениям.
В заключении строим график гиперболической регрессии.
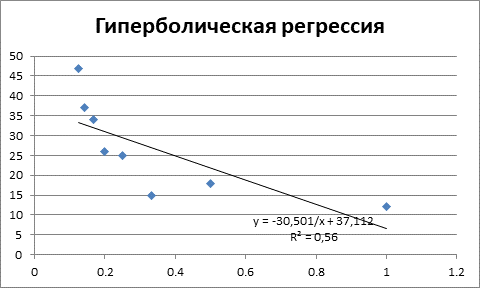
Рисунок 6 – Гиперболическая регрессия и коэффициент детерминации
Как видим данное уравнение регрессии является наихудшим по качеству, поскольку объясняет только 56% значений зависимой переменной Y.
Наилучшим по качеству уравнением регрессии в данной задаче является уравнение квадратической регрессии. Данное уравнение объясняет 96,54% значений зависимой переменной Y.
Задача 2. По данным приведенным в таблице 2 требуется:
1. Построить линейное уравнение регрессии Y по X.
2. Рассчитать линейный коэффициент корреляции, коэффициент детерминации и среднюю ошибку аппроксимации.
3. Рассчитать коэффициент эластичности.
Таблица 2 – Исходные данные
|
№ п / п |
X |
Y |
|
1 |
10 |
33 |
|
2 |
9 |
40 |
|
3 |
9 |
20 |
|
4 |
7 |
34 |
|
5 |
9 |
35 |
|
6 |
12 |
44 |
|
7 |
10 |
37 |
|
8 |
6 |
30 |
Решение.
Для решения поставленной задачи воспользуемся средствами табличного процессора MS Excel.
Для этого создаем новый лист и вводим исходные данные
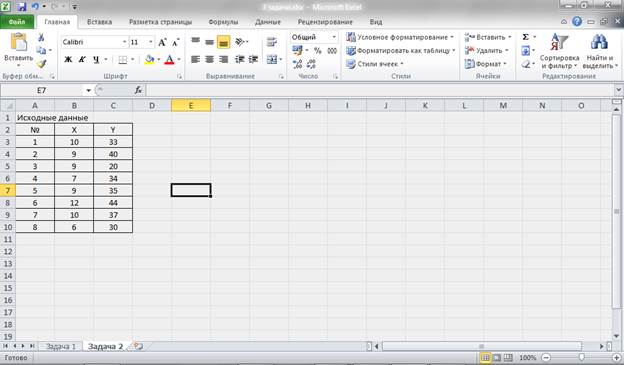
Рисунок 7 – Исходные данные.
Уравнение парной регрессии имеет вид:
![]()
— x, y – факторная и зависимые переменные;
— a, b – коэффициенты уравнения.
Коэффициенты уравнения парной линейной регрессии будем искать с помощью метода наименьших квадратов и табличного процессора MS Excel. Согласно МНК коэффициенты уравнения находятся по следующим формулам:
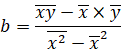
![]()
Составим дополнительную таблицу и произведем промежуточные расчеты в табличном процессоре:
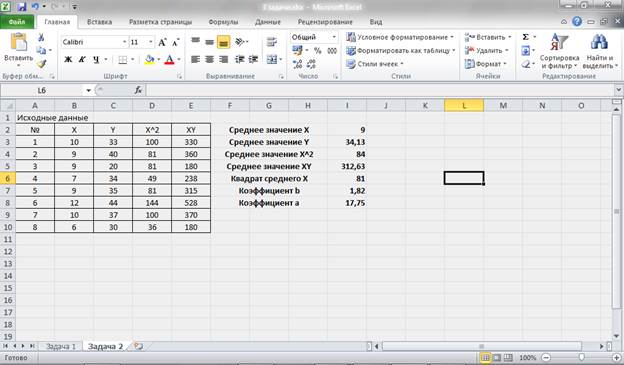
Рисунок 8 – Промежуточные расчеты и расчет коэффициентов уравнения.
В результате мы получили уравнение парной линейной регрессии:
![]()
Коэффициент корреляции, как правило используется для оценки направления и тесноты связи между зависимой и факторной переменными. Однако уже сейчас мы можем предположить направление связи между X и Y по знаку в уравнении регрессии.
Поскольку в уравнении стоит знак «+», то можно предположить наличие прямой связи между X и Y, т.е. значения Y напрямую зависят от значений X.
С помощью средств табличного процессора оценим тесноту этой связи:
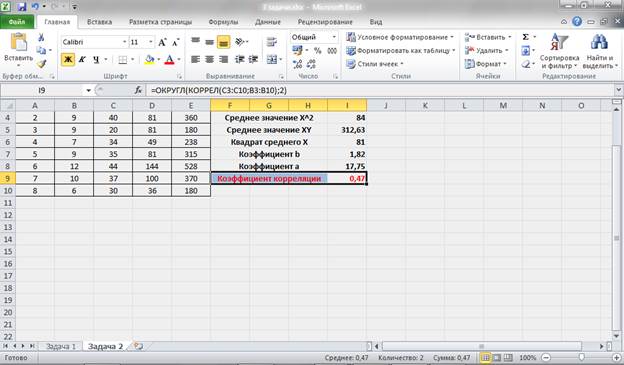
Рисунок 9 – Оценка тесноты связи с помощью коэффициента корреляции.
Коэффициент корреляции ryx = 0,47. Отсюда можно сделать вывод, что между переменными X и Y существует умеренная связь. Положительное значение коэффициента корреляции подтверждает наше предположение о направлении связи – Y зависит от X.
Между коэффициентом корреляции и коэффициентом детерминации существует взаимосвязь:
![]()
Отсюда получаем значение коэффициента детерминации: R2 = 0,22. То есть уравнение регрессии объясняет 22% значений зависимой переменной. Можно говорить о невысоком качестве уравнения регрессии.
Для подтверждения наших выводов о качестве уравнения рассчитаем показатель средней ошибки аппроксимации:
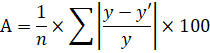
Проведем дополнительные расчеты:
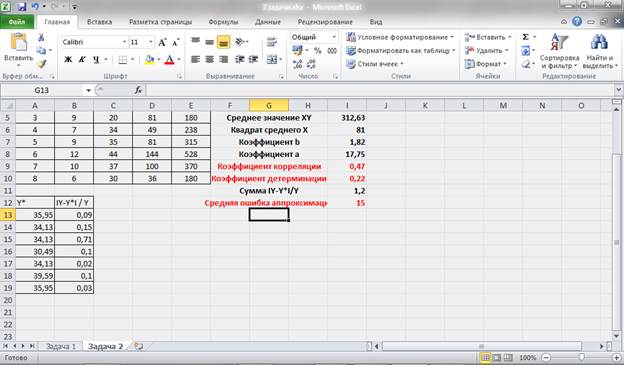
Рисунок 10 – Промежуточные расчеты и расчет средней ошибки аппроксимации.
Получаем, что средняя ошибка аппроксимации не попадает в предел до 5 – 8% (А = 15%), что подтверждает наш вывод о невысоком качестве уравнения регрессии.
Коэффициент эластичности определим по следующей формуле:
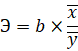
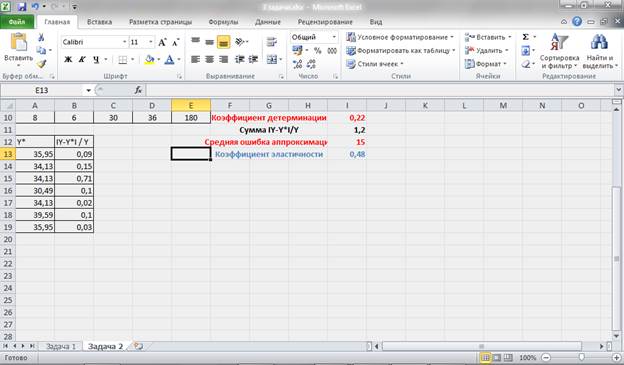
Рисунок 11 – Расчет коэффициента эластичности.
Таким образом, при изменении значения Х на 1% значение Y изменится на 0,48%.
Задача 3. По данным приведенным в таблице 3 требуется:
1. Построить линейную модель множественной регрессии.
2. Записать стандартизированное уравнение множественной регрессии.
3. Рассчитать коэффициенты парной, частной и множественной корреляции. Проанализировать их.
Таблица 3 – Исходные данные
|
№ п / п |
Х1 |
X2 |
Y |
|
1 |
12 |
12 |
133 |
|
2 |
8 |
22 |
135 |
|
3 |
8 |
15 |
120 |
|
4 |
7 |
19 |
125 |
|
5 |
9 |
17 |
130 |
|
6 |
10 |
11 |
144 |
|
7 |
7 |
10 |
137 |
|
8 |
9 |
28 |
121 |
Решение.
Для решения поставленной задачи используем возможности и средства табличного процессора MS Excel. Вводим исходные данные.
Для построения модели множественной регрессии проведем дополнительные расчеты:
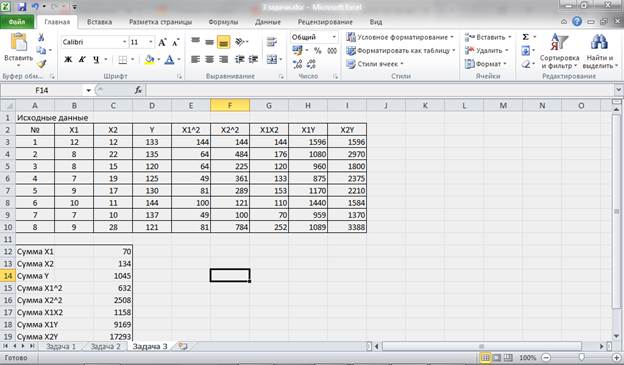
Рисунок 12 – Промежуточные расчеты.
Параметры уравнения множественной регрессии для двухфакторной модели можно определить из системы уравнений:
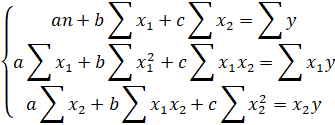
Запишем действующую систему уравнений:
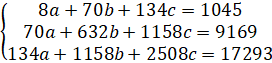
Данную систему можно решить методом Крамера при условии, что матрица, составленная из коэффициентов при неизвестных, не являтся вырожденной, т.е. Δ ≠ 0.
Для упрощения вычислений рассчитываем определитель матрицы, составленной из коэффициентов при неизвестных:
Δ = 39 424
Поскольку исходная матрица не является вырожденной система уравнений имеет решение.
Δ1 = 5 399 564
Δ2 = 28 780
Δ3 = -29 948
Отсюда находим коэффициенты при неизвестных в уравнении регрессии:
— a = 136,96
— b = 0,73
— c = -0,76.
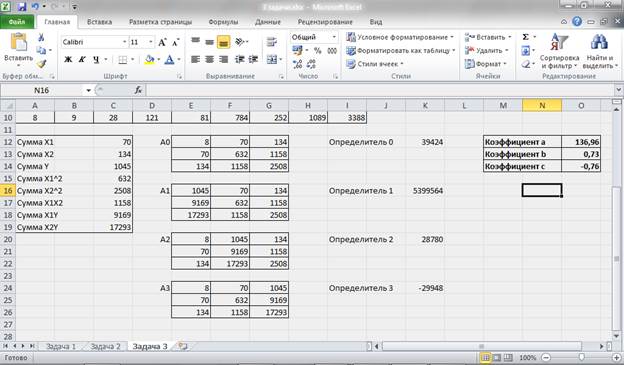
Рисунок 13 – Расчет параметров уравнения множественной регрессии.
Таким образом, мы получаем следующее уравнение множественной регрессии:
![]()
Для построения уравнения множественной регрессии в стандартизированной форме проведем расчет стандартных ошибок и коэффициентов стандартизированного уравнения:
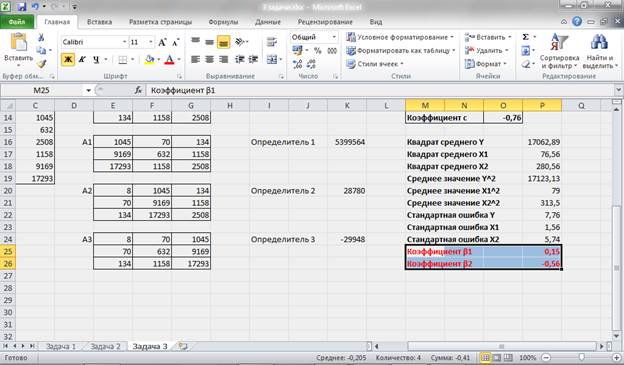
Рисунок 14 – Расчет коэффициентов стандартизированного уравнения.
Таким образом, стандартизированное уравнение множественной регрессии примет вид: ty = 0,15tx1 – 0,56tx2
Для расчета парной, частной и множественной корреляции воспользуемся таким инструментом табличного процессора, как пакет анализа, для построения корреляционной матрицы:
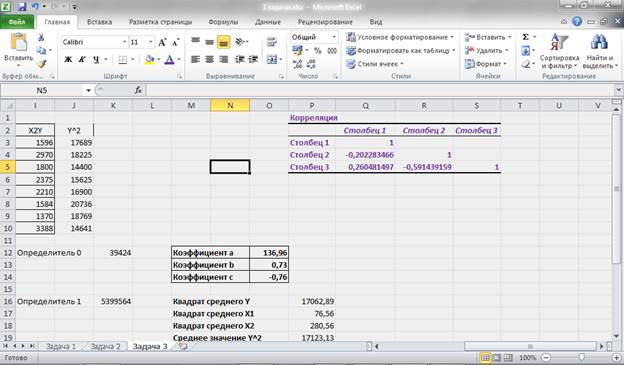
Рисунок 15 – Расчет корреляционной матрицы.
Как видим из рис. 15. Наибольшая связь обратного направления присутствует между переменными Y и X2, т.е. по сути Х2 зависит от значений Y. Прямая же связь между Y и X1 хоть и присутствует, но она достаточно слабая.
Также присутствует слабая обратная связь между переменными X1 и X2.
Список литературы
Список литературы
1. Айвазян С.А., Мхитарян В.С. Прикладная статистика и основы эконометрики. Учебник для вузов. – М.ЮНИТИ, 1998. – с. 621 – 632; 751 – 766.
2. Бородич С.А. Эконометрика: Учебное пособие. – Мн.: Новое знание, 2001. – с. 98 – 115; 121 – 147; 200 – 222
3. Доугерти К. Введение в эконометрику: Пер. с англ. – М.: ИНФРА-М, 1999. – XIV, с. 53 – 111
4. Кремер Н.Ш., Путко Б.А. Эконометрика: Учебник для вузов / Под ред. Проф. Н.Ш. Кремера. – М.: ЮНИТИ-ДАНА, 2002. – с. 50 – 80
5. Кулинич Е.И. Эконометрия. – М.: Финансы и статистика, 2001. с. 43 – 83
6. Магнус Я.Р., Катышев П.К., Пересецкий А.А. Эконометрика. Начальный курс. Учебное пособие. 2-е изд. – М.: Дело, 1998. – с. 17 – 42
7. Практикум по эконометрике: Учебное пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др.; Под ред. И.И. Елисеевой. – М.: Финансы и статистика, 2002. – с. 5 – 48
Регрессионный анализ – это набор статистических методов, позволяющих изучить влияние одной или нескольких независимых переменных на зависимую. Давайте разберемся, каким образом можно выполнить данный анализ в программе Excel.
Содержание
- Включение функции анализа в программе
- Линейный регрессионный анализ
- Анализ полученных результатов
- Заключение
Включение функции анализа в программе
Для начала нужно активировать функцию программы, с помощью которой мы будем проводить анализ. Для этого делаем следующее:
- Открываем меню “Файл”.

- Щелкаем по пункту “Параметры”.

- В нижней части содержимого подраздела “Надстройки” выбираем значение “Надстройки Excel” для параметра “Управление”, после чего кликаем “Перейти”.

- В окне управления надстройками выбираем “Пакет анализа” и щелкаем OK.

- Переходим во вкладку “Данные”, чтобы проверить, появилась ли функция “Анализ данных” в группе инструментов “Анализ”.






Линейный регрессионный анализ
Выделяют несколько разновидностей регрессий: линейная, гиперболическая, множественная, логарифмически линейная, нелинейная, обратная, парная.
В рамках данной статьи мы рассмотрим линейную регрессию. В общем виде ее функция выглядит так:
y = a0+a1x1+a2x2+…anxn
В данном уравнении:
- Y – переменная, влияние на которую нужно найти;
- X – факторы, влияющие на переменную;
- A – коэффициенты регрессии, определяющие значимости факторов;
- N – общее количество факторов.
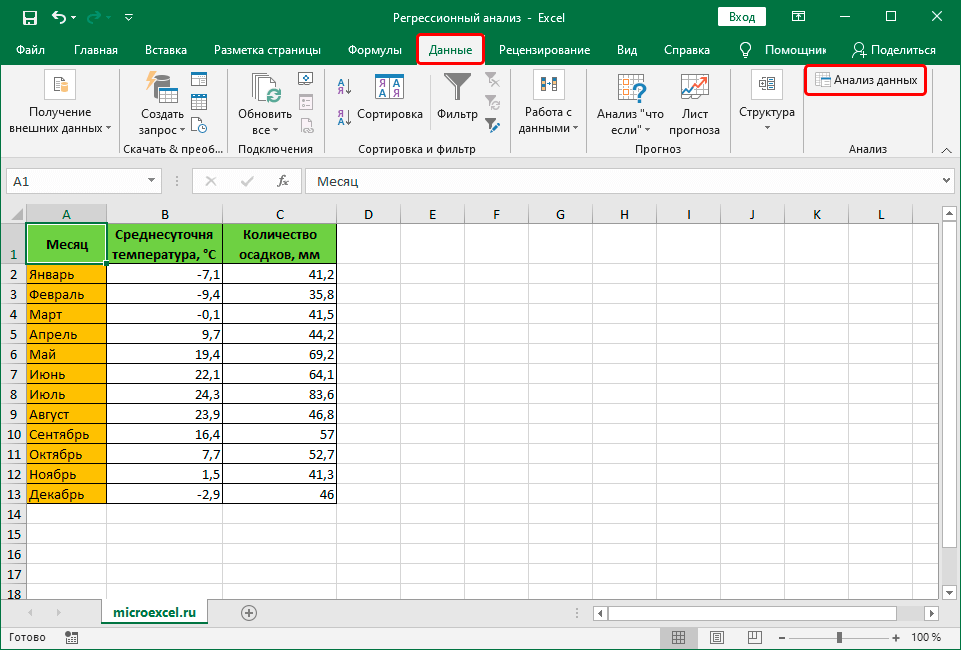
Чтобы было понятнее, давайте разберем конкретный практический пример. Допустим, у нас есть таблица, в которой представлена информация по среднесуточной температуре и количеству осадков с разбивкой по месяцам.

Наша задача – выяснить, как температура влияет на осадки. Приступи к ее выполнению.
- Щелкаем по кнопке “Анализ данных”.

- В открывшемся окошке отмечаем пункт “Регрессия”, после чего щелкаем OK.

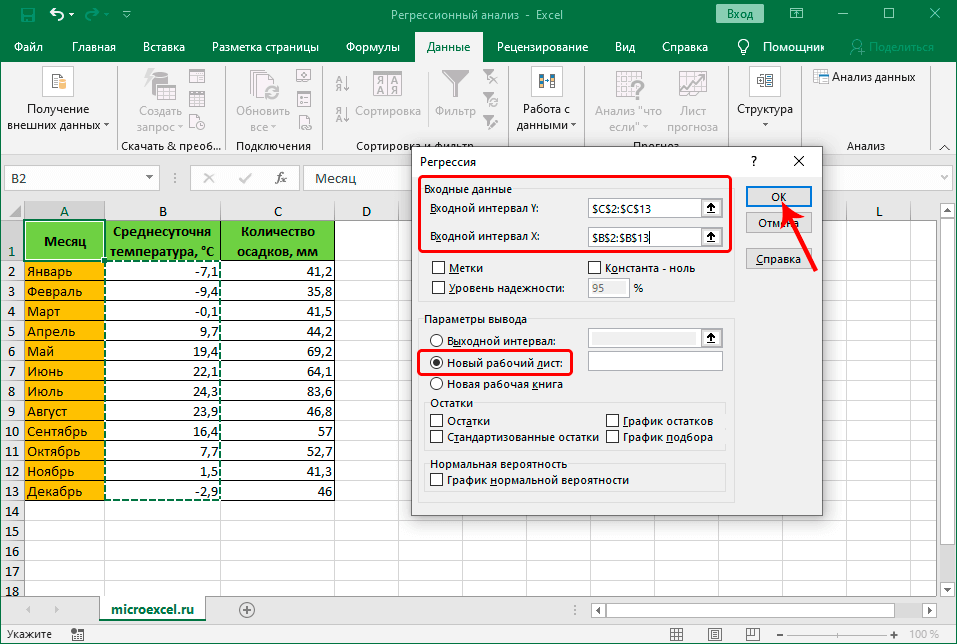
- Перед нами появится окно, в котором нужно настроить параметры регрессии:
- в поле “Входной интервал_Y” пишем координаты диапазона ячеек, в которых находятся переменные, влияние на которые нам нужно выяснить. У нас это столбец “Количество осадков, мм”. Координаты диапазона можно указать как вручную, используя клавиши на клавиатуре, так и выделив его в самой таблице с помощью зажатой левой кнопки мыши.
- в поле “Входной интервал_X” указываем координаты диапазона ячеек с данными, влияние которых нам нужно найти. В нашем случае – это столбец “Среднесуточная температура”.
- Остальные параметры не являются обязательными и, чаще всего, остаются незаполненными. У нас есть возможность установить метки, значения уровня надежности в процентах, константу-ноль, график нормальной вероятности и т.д. Пожалуй, самым важным здесь является способ вывода результатов анализа. Доступны следующие варианты: на новом листе (по умолчанию), в новой книге или в указанном диапазоне на этом же листе. Мы оставим все как есть и жмем кнопку OK.


Анализ полученных результатов
После корректного заполнения всех параметров и нажатия кнопки OK отобразятся результаты анализа (в зависимости от выбранного способа). В нашем случае – на отдельном листе.

Ключевым показателем здесь является R-квадрат (коэффициент детерминации), значение которого характеризует качество модели. Приемлемым считается значение не менее 0,5 (или 50%).
Также следует обратить внимание на ячейку, расположенную на пересечении строки “Y-пересечение” и столбца “Коэффициенты”. Здесь показывается, каким будет значение Y (количество осадков), если все остальные факторы будут равны нулю.
Ячейка на пересечении строки “Переменная X 1” и столбца “Коэффициенты” содержит значение, характеризующее степень зависимости Y от X. Коэф. 0,89 в нашем случае говорит о достаточно сильной связи между переменными.
Заключение
Регрессионный анализ – сложная и трудоемкая задача, которая требует определенных математических и статистических знаний. Но с помощью стандартных инструментов Эксель ее выполнение можно значительно облегчить.