
Время на прочтение
8 мин
Количество просмотров 309K
Cтатья написана в соавторстве с Ренатом Шагабутдиновым.

В этой статье речь пойдет о нескольких очень полезных функциях Google Таблиц, которых нет в Excel (SORT, объединение массивов, FILTER, IMPORTRANGE, IMAGE, GOOGLETRANSLATE, DETECTLANGUAGE)
Очень много букв, но есть разборы интересных кейсов, все примеры, кстати, можно рассмотреть поближе в Google Документе goo.gl/cOQAd9 (файл-> создать копию, чтобы скопировать файл себе на Google Диск и иметь возможность редактирования).
Оглавление:
— Если результат формулы несколько ячеек
— Объединение нескольких диапазонов данных для использования в формулах
— SORT
— Как в SORT добавить заголовки таблицы?
— FILTER
— FILTER, два условия и работа с датой
— Интерактивный график при помощи FILTER и SPARKLINE
— IMPORTRANGE
— Импорт форматирования из исходной таблицы
— IMPORTRANGE как аргумент другой функции
— IMAGE: добавляем изображения в ячейки
— GOOGLETRANSLATE и DETECTLANGUAGE: переводим текст в ячейках
Если результат формулы занимает больше одной ячейки
Сначала про важную особенность отображения результатов формул в Google Таблицах. Если ваша формула возвращает более одной ячейки, то весь этот массив отобразится сразу и займет столько ячеек и столбцов, сколько для него потребуется (в Excel для этого нужно было бы во все эти ячейки ввести формулу массива). На следующем примере посмотрим, как это работает.
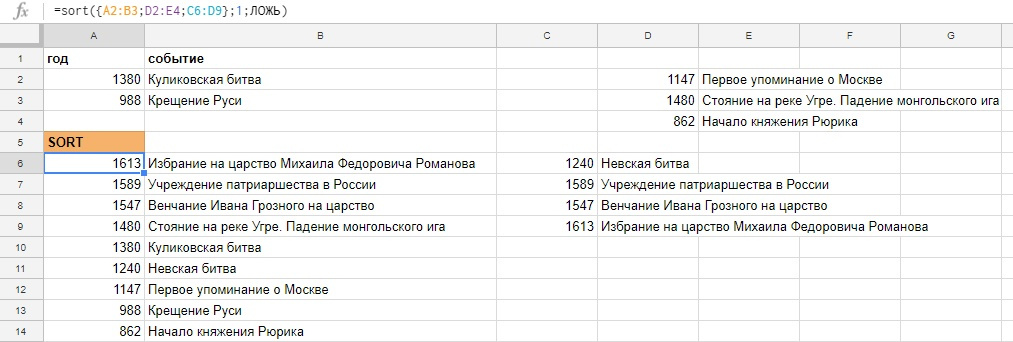
SORT
Поможет отсортировать диапазон данных по одному или нескольким столбцам и сразу вывести результат.
Синтаксис функции:
=SORT(сортируемые данные; столбец_для_сортировки; по_возрастанию; [столбец_для_сортировки_2, по_возрастанию_2; …])
Пример на скриншоте ниже, мы ввели формулу только в ячейку D2 и сортируем данные по первому столбцу (вместо ИСТИНА/ЛОЖЬ можно вводить TRUE/FALSE).
(здесь и далее — примеры для российских региональных настроек таблицы, рег. настройки меняются в меню файл → настройки таблицы)

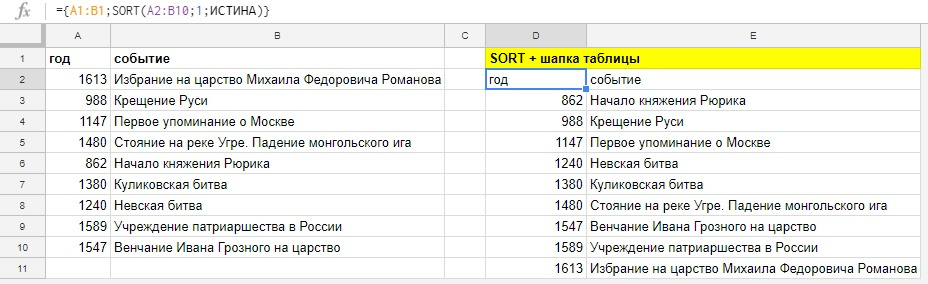
Как в SORT добавить заголовки таблицы?
С помощью фигурных скобок {} создаем массив из двух элементов, шапки таблицы A1:B1 и функции SORT, элементы отделяем друг-от-друга с помощью точки с запятой.
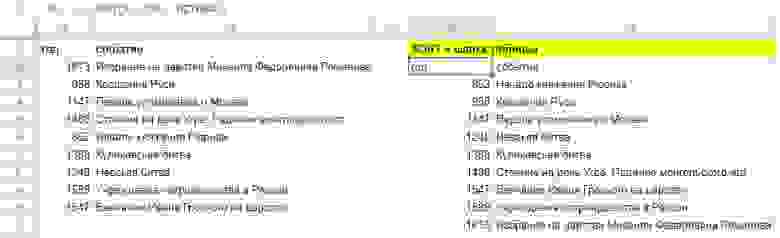
Как объединить несколько диапазонов данных и отсортировать (и не только)?
Давайте рассмотрим, как можно объединять диапазоны для использования в функциях. Это касается не только SORT, этим приемом можно пользоваться в любых функциях, где это возможно, например в ВПР или ПОИСКПОЗ.
Кто читал предыдущий пример уже догадался, что делать: открываем фигурную скобку и собираем массивы для объединения, отделяя их друг-от-друга точкой с запятой и закрываем фигурную скобку.

Можно объединить массивы и не использовать их в формуле, а просто вывести на лист, скажем, собрав данные с нескольких листов вашей книги. Для вертикального объединения необходимо соблюсти только одинаковое кол-во столбцов во всех фрагментах (у нас везде по два столбца).
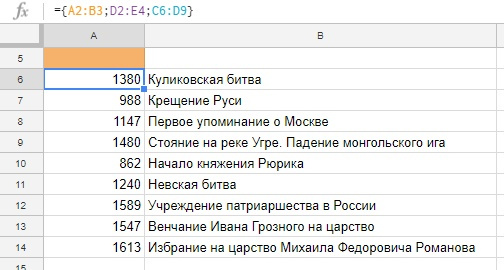
А на скриншоте ниже — пример горизонтального объединения, в нем вместо точки с запятой используется обратный слэш и нужно, чтобы кол-во строк во фрагментах совпадало, иначе вместо объединенного диапазона формула вернет ошибку.
(точка с запятой и обратный слэш — это разделители элементов массива в российских региональных настройках, если у вас не работают примеры, то через файл — настройки таблицы, убедитесь, что у вас стоят именно они)
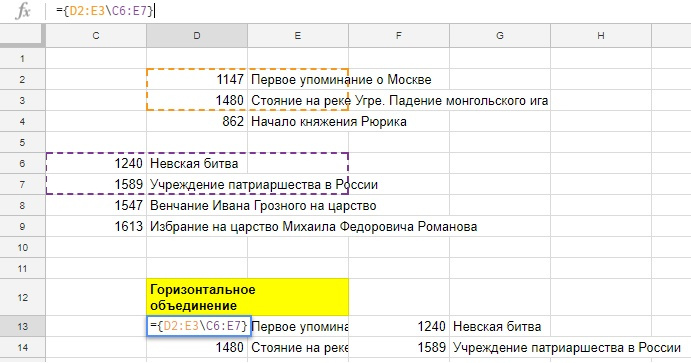
Ну а теперь вернемся к горизонтальному массиву и вставим его в функцию SORT. Будем сортировать данные по первому столбцу, по убыванию.

Объединение можно использовать в любых функциях, главное — соблюдать одинаковое количество столбцов для вертикального или строк для горизонтального объединения.
Все разобранные примеры можно рассмотреть поближе в
Google Документе.
FILTER
С помощью FILTER мы можем отфильтровать данные по одному или нескольким условиям и вывести результат на рабочий лист или использовать результат в другой функции, как диапазон данных.
Синтаксис функции:
FILTER(диапазон; условие_1; [условие_2; …])
Одно условие
Пример, у нас есть таблица с продажами наших сотрудников, выведем из нее данные по одному работнику.
Введем в ячейку E3 вот такую формулу:
=FILTER(A3:C7;B3:B7=«Наталья Чистякова»)
Обратите внимание, синтаксис немного отличается от привычных формул, вроде СУММЕСЛИН, там диапазон условия и само условие отделялось бы при помощи точки с запятой.

Введенная в одну ячейку формула возвращает нам массив из 9-ти ячеек с данными, но после примеров с функцией SORT мы этому уже не удивляемся.
Помимо знака равенства (=) в условиях можно использовать еще >, >=, <> (не равно), <, <=. Для текстовых условий подходят только = и <>, а для чисел или дат можно использовать все эти знаки.
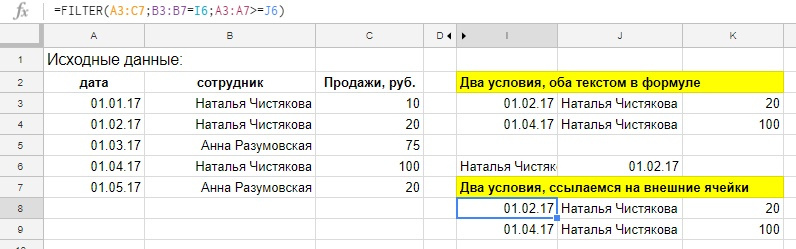
Два условия и работа с датой
Давайте усложним формулу и добавим в нее еще одно условие, по дате продаж, оставим все продажи начиная с 01.02.17
Так будет выглядеть формула, если вводить аргументы условия сразу в нее, обратите внимание на конвертацию текстовой записи даты при помощи ДАТАЗНАЧ:
=FILTER(A3:C7;B3:B7=«Наталья Чистякова»;A3:A7>=ДАТАЗНАЧ(«01.02.17»))
Или вот так, если ссылаться на ячейки с аргументами:
=FILTER(A3:C7;B3:B7=I6;A3:A7>=J6)

Интерактивный график при помощи FILTER и SPARKLINE
А знаете, как еще можно использовать функцию FILTER? Мы можем не выводить результат функции на рабочий лист, а использовать его как данные для другой функции, например, спарклайна. Спарклайн — это функция, которая строит график в ячейке на основе наших данных, у спарклайна существует много настроек, таких, как вид графика, цвет элементов, но сейчас мы не будем на них останавливаться и воспользуемся функцией без дополнительных настроек. Перейдем к примеру.
Выпадающий список.
Наш график будет меняться в зависимости от выбранного сотрудника в выпадающем списке, список делаем так:
- выделяем ячейку Е2;
- меню Данные → Проверка данных;
- правила: Значение из диапазона и в диапазоне выбираем столбец с сотрудниками из исходных данных, не переживайте, что фамилии повторяются, в выпадающем списке останутся лишь уникальные значения;

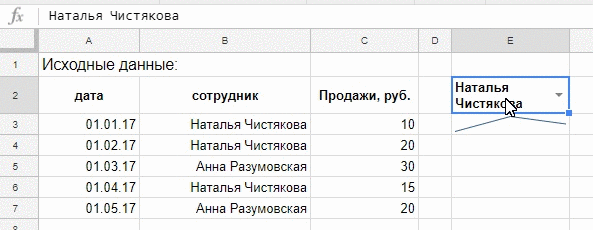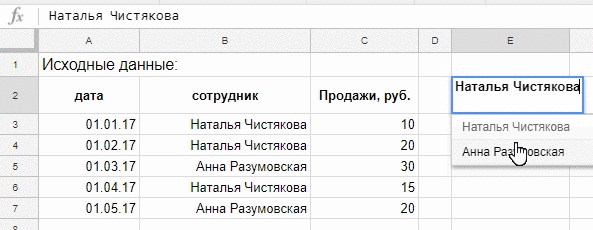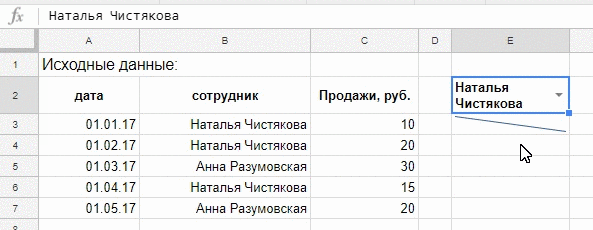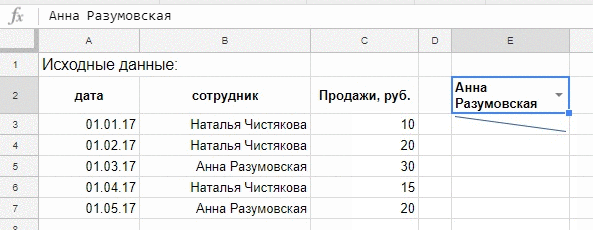
Нажимаем «Сохранить» и получаем выпадающий список в выбранной ячейке:
Ячейка с выпадающим список станет условием для формулы FILTER, напишем ее.
=FILTER(C3:C7;B3:B7=E2)
И вставим эту формулу в функцию SPARKLINE, которая на основе полученных данных будет рисовать в ячейке график.
=sparkline(FILTER(C3:C7;B3:B7=E2))

Так это выглядит в динамике:
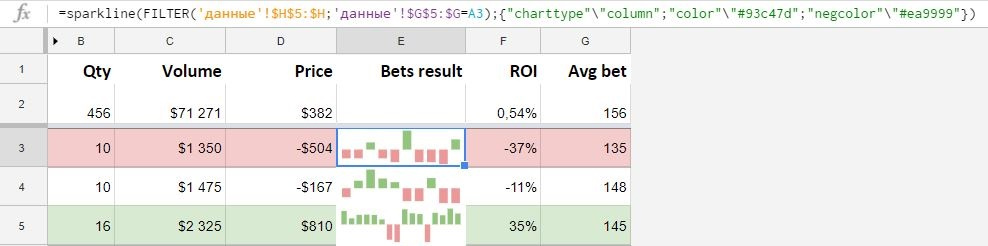
А вот как нарядно может выглядеть SPARKLINE с дополнительным настройками, в реальной работе, диаграмма выводит результаты деятельности за один день, зеленые столбцы — положительные значения, розовые — отрицательные.
IMPORTRANGE
Для переноса данных из одного файла в другой в Google Таблицах используется функция IMPORTRANGE.
В каких случаях она может пригодиться?
- Вам нужны актуальные данные из файла ваших коллег.
- Вы хотите обрабатывать данные из файла, к которому у вас есть доступ «Только для просмотра».
- Вы хотите собрать в одном месте таблицы из нескольких документов, чтобы обрабатывать или просматривать их.
Эта формула позволяет получить копию диапазона из другой Google Таблицы. Форматирование при этом не переносится — только данные (как быть с форматированием — мы расскажем чуть ниже).
Синтаксис формулы следующий:
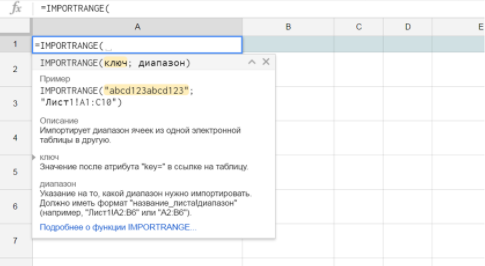
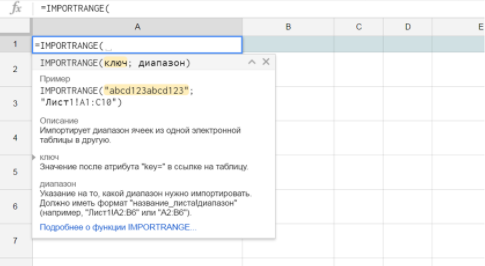
IMPORTRANGE(spreadsheet key; range string)
IMPORTRANGE(ключ; диапазон)
spreadsheet_key (ключ) — последовательность символов атрибута «key=» (ключа) в ссылке на таблицу (после «spreadsheets/…/»).
Пример формулы с ключом:
=IMPORTRANGE(«abcd123abcd123»; «sheet1!A1:C10»)
Вместо ключа таблицы вы можете использовать полную ссылку на документ:
=IMPORTRANGE(«docs.google.com/a/company_site.ru/spreadsheet/ccc?key=0A601pBdE1zIzHRxcGZFVT3hyVyWc»; «Лист1!A1:CM500»)
В вашем файле будет отображаться диапазон A1:CM500 с Листа1 из файла, который находится по соответствующей ссылке.

Если в исходном файле может меняться количество столбцов или строк, вводите во втором аргументе функции открытый диапазон (см. также подраздел «Диапазоны вида A2:A»), например:
Лист1!A1:CM (если будут добавляться строки)
Лист1!A1:1000 (если будут добавляться столбцы)
! Имейте в виду, что если вы загружаете открытый диапазон (например, A1:D), то вы не сможете вставить никакие данные вручную в столбцы A:D в файле, где находится формула IMPORTRANGE (то есть в конечном, куда загружаются данные). Они как бы “зарезервируются” под весь открытый диапазон — ведь его размерность неизвестна заранее.
Ссылку на файл и ссылку на диапазон можно вводить не в формулу, а в ячейки вашего документа и ссылаться на них.
Так, если в ячейку A1 вы введете ссылку на документ (без кавычек), из которого нужно загрузить данные, а в ячейку B1 — ссылку на лист и диапазон (тоже без кавычек), то импортировать данные можно будет с помощью следующей формулы:
=IMPORTRANGE(A1;B1)

Вариант со ссылками на ячейки предпочтительнее в том смысле, что вы всегда можете легко перейти к исходному файлу (щелкнув по ссылке в ячейке) и/или увидеть, какой диапазон и из какой вкладки импортируется.
Импорт форматирования из исходной таблицы
Как мы уже заметили, IMPORTRANGE загружает только данные, но не форматирование исходной таблицы. Как с этим быть? Заранее «подготовить почву», скопировав форматирование из исходного листа. Для этого зайдите на исходный лист и скопируйте его в вашу книгу:
После нажатия кнопки Копировать в… выберите книгу, в которую будете импортировать данные. Обычно нужная таблица есть на вкладке Недавние (если вы действительно недавно работали с ней).
После копирования листа выделите все данные (нажав на левый верхний угол):

И нажмите Delete. Все данные исчезнут, а форматирование останется. Теперь можно ввести функцию IMPORTRANGE и получить полное соответствие исходного листа — как в части данных, так и в части формата:
IMPORTRANGE как аргумент другой функции
IMPORTRANGE может быть аргументом другой функции, если диапазон, который вы импортируете, подходит на эту роль.
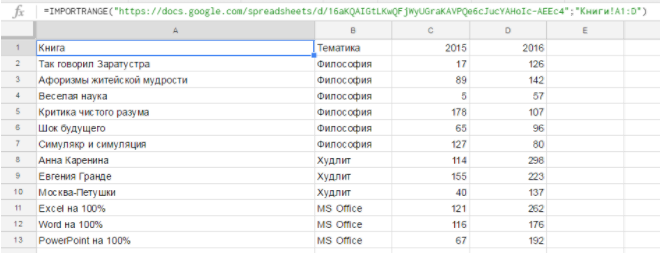
Рассмотрим простой пример — среднее значение по продажам из диапазона, находящегося в другом документе.
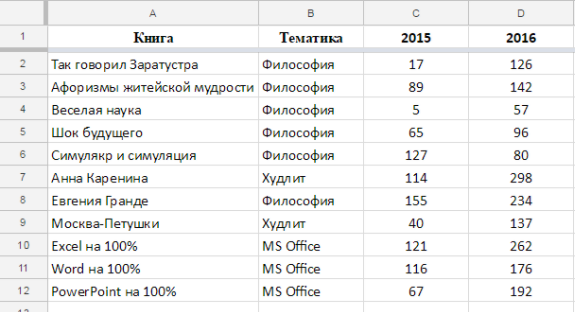
Это исходный документ. Пусть данные будут добавляться и нам нужно среднее по продажам 2016 (то есть от ячейки D2 и до упора вниз).
Сначала импортируем этот диапазон:
IMPORTRANGE(«docs.google.com/spreadsheets/d/16aKQAIGtLKwQFjWyUGraKAVPQe6cJucYAHoIc-AEEc4»;«Книги!D2:D»)
А потом используем это как аргумент функции СРЗНАЧ (AVERAGE):
=СРЗНАЧ(IMPORTRANGE(«docs.google.com/spreadsheets/d/16aKQAIGtLKwQFjWyUGraKAVPQe6cJucYAHoIc-AEEc4»;«Книги!D2:D»))
=AVERAGE(IMPORTRANGE(«docs.google.com/spreadsheets/d/16aKQAIGtLKwQFjWyUGraKAVPQe6cJucYAHoIc-AEEc4»;«Книги!D2:D»))

Получаем результат, который будет обновляться при добавлении новых строк в исходном файле в столбце D.
IMAGE: добавляем изображения в ячейки
Функция IMAGE позволяет добавлять в ячейки Google Таблиц изображения.
У функции следующий синтаксис:
IMAGE(URL, [mode], [height], [width])
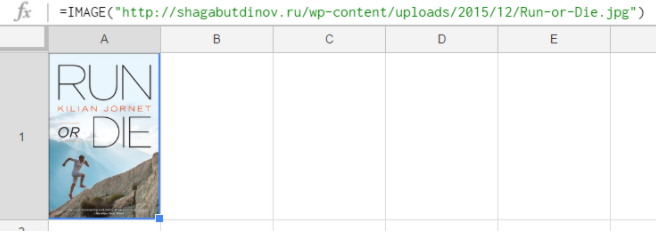
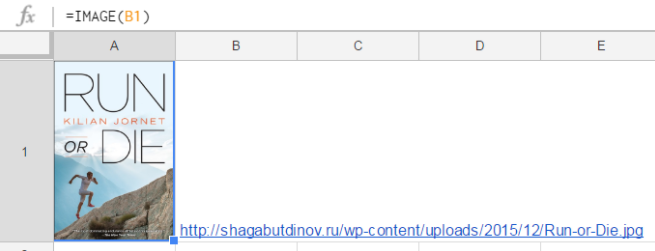
URL – единственный обязательный аргумент. Это ссылка на изображение. Ссылку можно указать напрямую в формуле, взяв в кавычки:
=IMAGE(“http://shagabutdinov.ru/wp-content/uploads/2015/12/Run-or-Die.jpg”)
Или же поставить ссылку на ячейку, в которой ссылка хранится:
= IMAGE(B1)
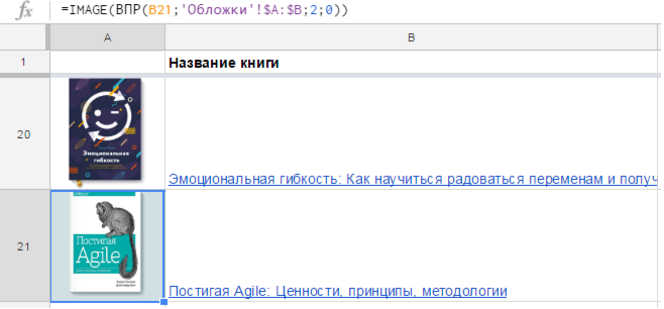
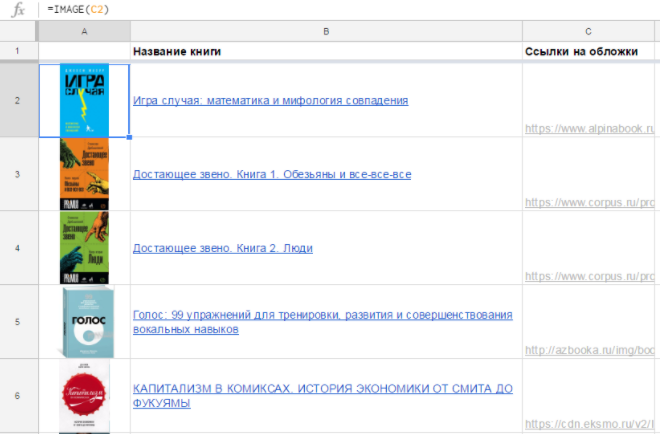
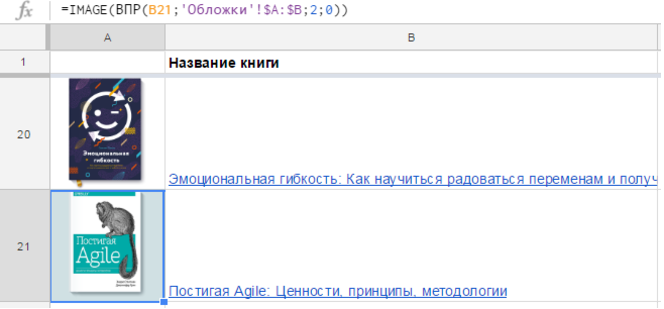
Последний вариант удобнее в большинстве случаев. Так, если у вас есть список книг и ссылки на обложки, достаточно одной формулы, чтобы отобразить их все:
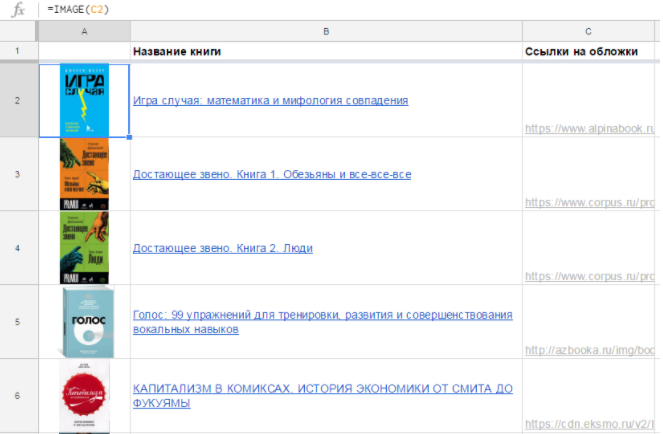
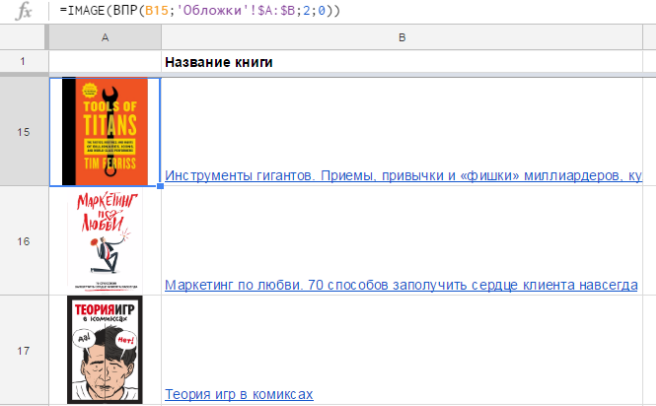
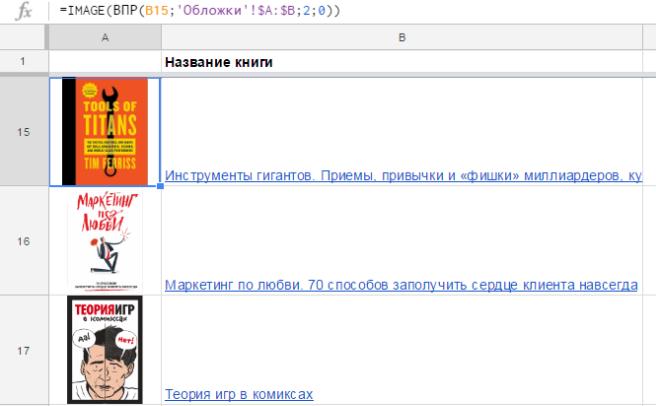
На практике бывает, что ссылки на изображения хранятся на отдельном листе, и вы достаете их с помощью функции ВПР (VLOOKUP) или как-то иначе.
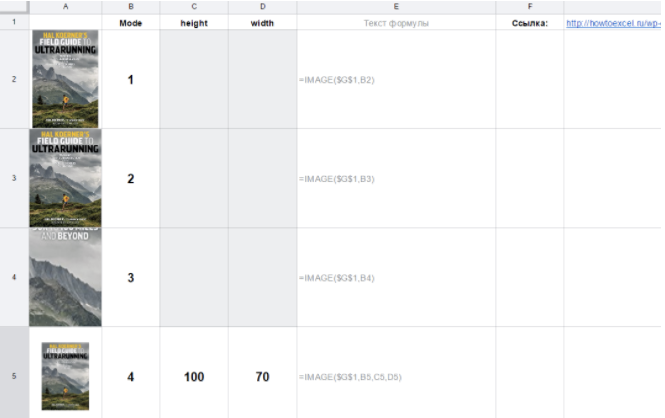
Аргумент mode может принимать четыре значения (если его пропустить, по умолчанию будет первое):
- изображение растягивается до размеров ячейки с сохранением соотношения сторон;
- изображение растягивается без сохранения соотношения сторон, целиком заполняя
- изображение вставляется с оригинальным размером;
- вы указываете размеры изображения в третьем и четвертом аргументам функции [height] и [width]. [height], [width], соответственно, нужны только при значении аргумента mode = 4. Они задаются в пикселях.
Посмотрим, как на практике выглядят изображения с четыремя разными значениями аргумента mode:
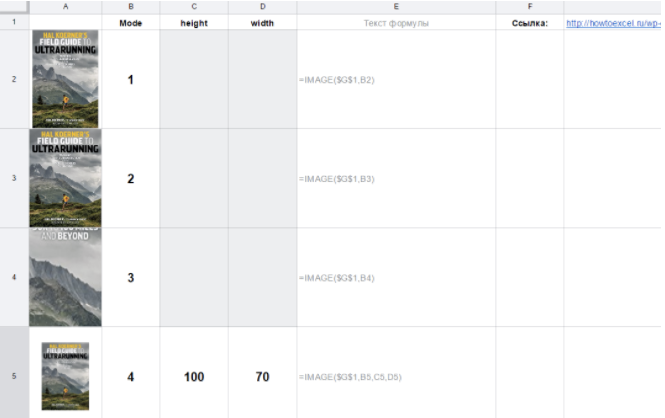
Четвертый режим может быть удобен, если вам нужно подбирать точный размер изображения в пикселях, меняя параметры height (высота) и width (ширина). Картинка будет сразу обновляться.
Обратите внимание, что при всех режимах, кроме второго, могут оставаться незаполненные области в ячейке, и их можно залить цветом:
GOOGLETRANSLATE и DETECTLANGUAGE: переводим текст в ячейках
В Google Таблицах есть занятная функция GOOGLETRANSLATE, позволяющая переводить текст прямо в ячейках:

Синтаксис функции следующий:
GOOGLETRANSLATE (text,[source_language], [target_language])
text – это текст, который нужно переводить. Можно взять текст в кавычки и записать прямо в формулу, но удобнее сослаться на ячейку, в которой текст записан.
[source_language] – язык, с которого мы переводим;
[target_language] – язык, на который мы переводим.
Второй и третий аргументы задаются двухзначным кодом: es, fr, en, ru. Их тоже можно указать в самой функции, но можно брать из ячейки, а язык исходного текста и вовсе можно автоматически определять.

А как быть, если мы хотим переводить на разные языки? И при этом не хотим каждый раз указывать язык исходника вручную?
Тут пригодится функция DETECTLANGUAGE. У нее единственный аргумент – текст, язык которого нужно определить:
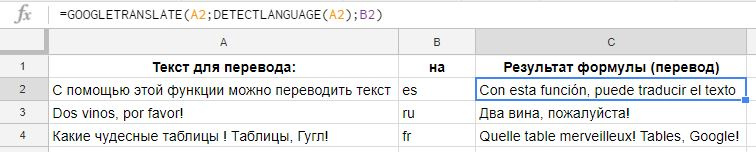
Как и с любой другой функцией, прелесть здесь в автоматизации. Можно быстро поменять текст или язык; быстро перевести одну фразу на 10 языков и так далее. Конечно, мы понимаем, что это текст онлайн-переводчика – качество будет соответствующим.
Евгений Намоконов и Ренат Шагабутдинов, а еще мы ведем канал в телеграмме, где разбираем разные кейсы с Google Таблицами, если вам интересно — заглядывайте в гости, ссылку можно найти в моем профиле.
Google API, Алгоритмы, Data Mining, Big Data
Рекомендация: подборка платных и бесплатных курсов создания сайтов — https://katalog-kursov.ru/
Cтатья написана в соавторстве с Ренатом Шагабутдиновым.

В этой статье речь пойдет о нескольких очень полезных функциях Google Таблиц, которых нет в Excel (SORT, объединение массивов, FILTER, IMPORTRANGE, IMAGE, GOOGLETRANSLATE, DETECTLANGUAGE)
Очень много букв, но есть разборы интересных кейсов, все примеры, кстати, можно рассмотреть поближе в Google Документе goo.gl/cOQAd9 (файл-> создать копию, чтобы скопировать файл себе на Google Диск и иметь возможность редактирования).
Если результат формулы занимает больше одной ячейки
Сначала про важную особенность отображения результатов формул в Google Таблицах. Если ваша формула возвращает более одной ячейки, то весь этот массив отобразится сразу и займет столько ячеек и столбцов, сколько для него потребуется (в Excel для этого нужно было бы во все эти ячейки ввести формулу массива). На следующем примере посмотрим, как это работает.
SORT
Поможет отсортировать диапазон данных по одному или нескольким столбцам и сразу вывести результат.
Синтаксис функции:
=SORT(сортируемые данные; столбец_для_сортировки; по_возрастанию; [столбец_для_сортировки_2, по_возрастанию_2; …])
Пример на скриншоте ниже, мы ввели формулу только в ячейку D2 и сортируем данные по первому столбцу (вместо ИСТИНА/ЛОЖЬ можно вводить TRUE/FALSE).
(здесь и далее — примеры для российских региональных настроек таблицы, рег. настройки меняются в меню файл > настройки таблицы)

Как в SORT добавить заголовки таблицы?
С помощью фигурных скобок {} создаем массив из двух элементов, шапки таблицы A1:B1 и функции SORT, элементы отделяем друг-от-друга с помощью точки с запятой.
Как объединить несколько диапазонов данных и отсортировать (и не только)?
Давайте рассмотрим, как можно объединять диапазоны для использования в функциях. Это касается не только SORT, этим приемом можно пользоваться в любых функциях, где это возможно, например в ВПР или ПОИСКПОЗ.
Кто читал предыдущий пример уже догадался, что делать: открываем фигурную скобку и собираем массивы для объединения, отделяя их друг-от-друга точкой с запятой и закрываем фигурную скобку.

Можно объединить массивы и не использовать их в формуле, а просто вывести на лист, скажем, собрав данные с нескольких листов вашей книги. Для вертикального объединения необходимо соблюсти только одинаковое кол-во столбцов во всех фрагментах (у нас везде по два столбца).

А на скриншоте ниже — пример горизонтального объединения, в нем вместо точки с запятой используется обратный слэш и нужно, чтобы кол-во строк во фрагментах совпадало, иначе вместо объединенного диапазона формула вернет ошибку.
(точка с запятой и обратный слэш — это разделители элементов массива в российских региональных настройках, если у вас не работают примеры, то через файл — настройки таблицы, убедитесь, что у вас стоят именно они)
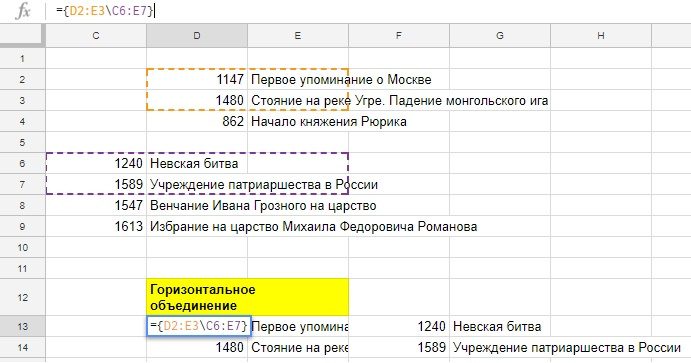
Ну а теперь вернемся к горизонтальному массиву и вставим его в функцию SORT. Будем сортировать данные по первому столбцу, по убыванию.
Объединение можно использовать в любых функциях, главное — соблюдать одинаковое количество столбцов для вертикального или строк для горизонтального объединения.
Все разобранные примеры можно рассмотреть поближе в Google Документе.
FILTER
С помощью FILTER мы можем отфильтровать данные по одному или нескольким условиям и вывести результат на рабочий лист или использовать результат в другой функции, как диапазон данных.
Синтаксис функции:
FILTER(диапазон; условие_1; [условие_2; …])
Одно условие
Пример, у нас есть таблица с продажами наших сотрудников, выведем из нее данные по одному работнику.
Введем в ячейку E3 вот такую формулу:
=FILTER(A3:C7;B3:B7=«Наталья Чистякова»)
Обратите внимание, синтаксис немного отличается от привычных формул, вроде СУММЕСЛИН, там диапазон условия и само условие отделялось бы при помощи точки с запятой.
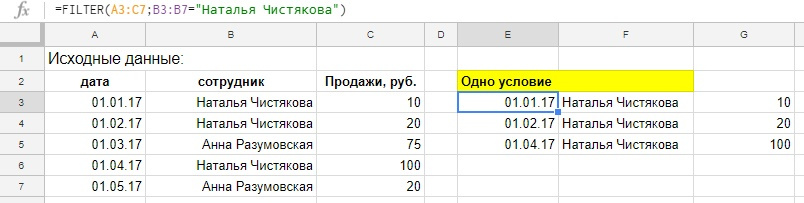
Введенная в одну ячейку формула возвращает нам массив из 9-ти ячеек с данными, но после примеров с функцией SORT мы этому уже не удивляемся.
Помимо знака равенства (=) в условиях можно использовать еще >, >=, <> (не равно), <, <=. Для текстовых условий подходят только = и <>, а для чисел или дат можно использовать все эти знаки.
Два условия и работа с датой
Давайте усложним формулу и добавим в нее еще одно условие, по дате продаж, оставим все продажи начиная с 01.02.17
Так будет выглядеть формула, если вводить аргументы условия сразу в нее, обратите внимание на конвертацию текстовой записи даты при помощи ДАТАЗНАЧ:
=FILTER(A3:C7;B3:B7=«Наталья Чистякова»;A3:A7>=ДАТАЗНАЧ(«01.02.17»))
Или вот так, если ссылаться на ячейки с аргументами:
=FILTER(A3:C7;B3:B7=I6;A3:A7>=J6)
Интерактивный график при помощи FILTER и SPARKLINE
А знаете, как еще можно использовать функцию FILTER? Мы можем не выводить результат функции на рабочий лист, а использовать его как данные для другой функции, например, спарклайна. Спарклайн — это функция, которая строит график в ячейке на основе наших данных, у спарклайна существует много настроек, таких, как вид графика, цвет элементов, но сейчас мы не будем на них останавливаться и воспользуемся функцией без дополнительных настроек. Перейдем к примеру.
Выпадающий список.
Наш график будет меняться в зависимости от выбранного сотрудника в выпадающем списке, список делаем так:
- выделяем ячейку Е2;
- меню Данные > Проверка данных;
- правила: Значение из диапазона и в диапазоне выбираем столбец с сотрудниками из исходных данных, не переживайте, что фамилии повторяются, в выпадающем списке останутся лишь уникальные значения;
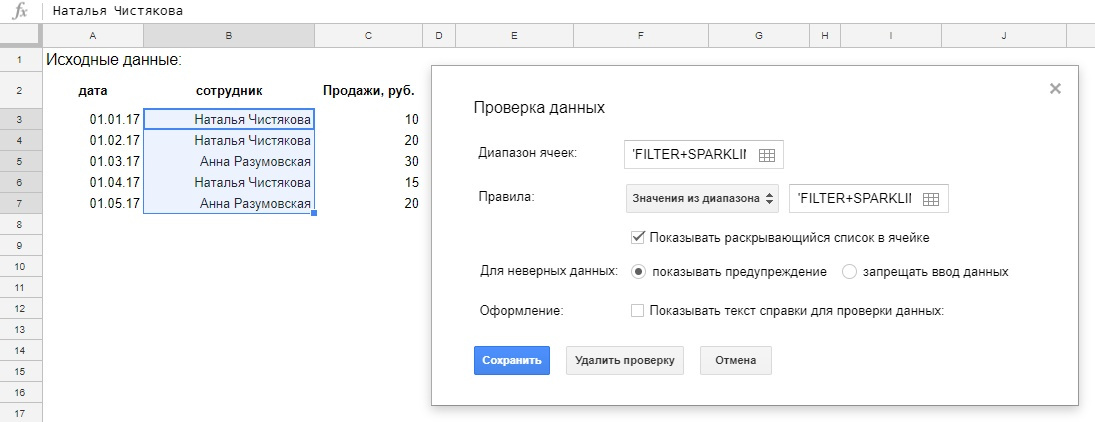
Нажимаем «Сохранить» и получаем выпадающий список в выбранной ячейке:
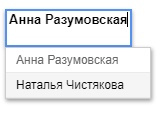
Ячейка с выпадающим список станет условием для формулы FILTER, напишем ее.
=FILTER(C3:C7;B3:B7=E2)
И вставим эту формулу в функцию SPARKLINE, которая на основе полученных данных будет рисовать в ячейке график.
=sparkline(FILTER(C3:C7;B3:B7=E2))

Так это выглядит в динамике:
А вот как нарядно может выглядеть SPARKLINE с дополнительным настройками, в реальной работе, диаграмма выводит результаты деятельности за один день, зеленые столбцы — положительные значения, розовые — отрицательные.
IMPORTRANGE
Для переноса данных из одного файла в другой в Google Таблицах используется функция IMPORTRANGE.
В каких случаях она может пригодиться?
- Вам нужны актуальные данные из файла ваших коллег.
- Вы хотите обрабатывать данные из файла, к которому у вас есть доступ «Только для просмотра».
- Вы хотите собрать в одном месте таблицы из нескольких документов, чтобы обрабатывать или просматривать их.
Эта формула позволяет получить копию диапазона из другой Google Таблицы. Форматирование при этом не переносится — только данные (как быть с форматированием — мы расскажем чуть ниже).
Синтаксис формулы следующий:
IMPORTRANGE(spreadsheet key; range string)
IMPORTRANGE(ключ; диапазон)
spreadsheet_key (ключ) — последовательность символов атрибута «key=» (ключа) в ссылке на таблицу (после «spreadsheets/…/»).
Пример формулы с ключом:
=IMPORTRANGE(«abcd123abcd123»; «sheet1!A1:C10»)
Вместо ключа таблицы вы можете использовать полную ссылку на документ:
=IMPORTRANGE(«docs.google.com/a/company_site.ru/spreadsheet/ccc?key=0A601pBdE1zIzHRxcGZFVT3hyVyWc»; «Лист1!A1:CM500»)
В вашем файле будет отображаться диапазон A1:CM500 с Листа1 из файла, который находится по соответствующей ссылке.
Если в исходном файле может меняться количество столбцов или строк, вводите во втором аргументе функции открытый диапазон (см. также подраздел «Диапазоны вида A2:A»), например:
Лист1!A1:CM (если будут добавляться строки)
Лист1!A1:1000 (если будут добавляться столбцы)
! Имейте в виду, что если вы загружаете открытый диапазон (например, A1:D), то вы не сможете вставить никакие данные вручную в столбцы A:D в файле, где находится формула IMPORTRANGE (то есть в конечном, куда загружаются данные). Они как бы “зарезервируются” под весь открытый диапазон — ведь его размерность неизвестна заранее.
Ссылку на файл и ссылку на диапазон можно вводить не в формулу, а в ячейки вашего документа и ссылаться на них.
Так, если в ячейку A1 вы введете ссылку на документ (без кавычек), из которого нужно загрузить данные, а в ячейку B1 — ссылку на лист и диапазон (тоже без кавычек), то импортировать данные можно будет с помощью следующей формулы:
=IMPORTRANGE(A1;B1)
Вариант со ссылками на ячейки предпочтительнее в том смысле, что вы всегда можете легко перейти к исходному файлу (щелкнув по ссылке в ячейке) и/или увидеть, какой диапазон и из какой вкладки импортируется.
Импорт форматирования из исходной таблицы
Как мы уже заметили, IMPORTRANGE загружает только данные, но не форматирование исходной таблицы. Как с этим быть? Заранее «подготовить почву», скопировав форматирование из исходного листа. Для этого зайдите на исходный лист и скопируйте его в вашу книгу:
После нажатия кнопки Копировать в… выберите книгу, в которую будете импортировать данные. Обычно нужная таблица есть на вкладке Недавние (если вы действительно недавно работали с ней).
После копирования листа выделите все данные (нажав на левый верхний угол):
И нажмите Delete. Все данные исчезнут, а форматирование останется. Теперь можно ввести функцию IMPORTRANGE и получить полное соответствие исходного листа — как в части данных, так и в части формата:
IMPORTRANGE как аргумент другой функции
IMPORTRANGE может быть аргументом другой функции, если диапазон, который вы импортируете, подходит на эту роль.
Рассмотрим простой пример — среднее значение по продажам из диапазона, находящегося в другом документе.
Это исходный документ. Пусть данные будут добавляться и нам нужно среднее по продажам 2016 (то есть от ячейки D2 и до упора вниз).
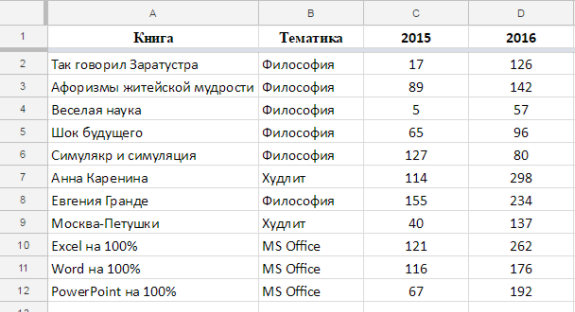
Сначала импортируем этот диапазон:
IMPORTRANGE(«docs.google.com/spreadsheets/d/16aKQAIGtLKwQFjWyUGraKAVPQe6cJucYAHoIc-AEEc4»;«Книги!D2:D»)
А потом используем это как аргумент функции СРЗНАЧ (AVERAGE):
=СРЗНАЧ(IMPORTRANGE(«docs.google.com/spreadsheets/d/16aKQAIGtLKwQFjWyUGraKAVPQe6cJucYAHoIc-AEEc4»;«Книги!D2:D»))
=AVERAGE(IMPORTRANGE(«docs.google.com/spreadsheets/d/16aKQAIGtLKwQFjWyUGraKAVPQe6cJucYAHoIc-AEEc4»;«Книги!D2:D»))

Получаем результат, который будет обновляться при добавлении новых строк в исходном файле в столбце D.
IMAGE: добавляем изображения в ячейки
Функция IMAGE позволяет добавлять в ячейки Google Таблиц изображения.
У функции следующий синтаксис:
IMAGE(URL, [mode], [height], [width])
URL – единственный обязательный аргумент. Это ссылка на изображение. Ссылку можно указать напрямую в формуле, взяв в кавычки:
=IMAGE(“http://shagabutdinov.ru/wp-content/uploads/2015/12/Run-or-Die.jpg”)
Или же поставить ссылку на ячейку, в которой ссылка хранится:
= IMAGE(B1)
Последний вариант удобнее в большинстве случаев. Так, если у вас есть список книг и ссылки на обложки, достаточно одной формулы, чтобы отобразить их все:
На практике бывает, что ссылки на изображения хранятся на отдельном листе, и вы достаете их с помощью функции ВПР (VLOOKUP) или как-то иначе.
Аргумент mode может принимать четыре значения (если его пропустить, по умолчанию будет первое):
- изображение растягивается до размеров ячейки с сохранением соотношения сторон;
- изображение растягивается без сохранения соотношения сторон, целиком заполняя
- изображение вставляется с оригинальным размером;
- вы указываете размеры изображения в третьем и четвертом аргументам функции [height] и [width]. [height], [width], соответственно, нужны только при значении аргумента mode = 4. Они задаются в пикселях.
Посмотрим, как на практике выглядят изображения с четыремя разными значениями аргумента mode:
Четвертый режим может быть удобен, если вам нужно подбирать точный размер изображения в пикселях, меняя параметры height (высота) и width (ширина). Картинка будет сразу обновляться.
Обратите внимание, что при всех режимах, кроме второго, могут оставаться незаполненные области в ячейке, и их можно залить цветом:
GOOGLETRANSLATE и DETECTLANGUAGE: переводим текст в ячейках
В Google Таблицах есть занятная функция GOOGLETRANSLATE, позволяющая переводить текст прямо в ячейках:

Синтаксис функции следующий:
GOOGLETRANSLATE (text,[source_language], [target_language])
text – это текст, который нужно переводить. Можно взять текст в кавычки и записать прямо в формулу, но удобнее сослаться на ячейку, в которой текст записан.
[source_language] – язык, с которого мы переводим;
[target_language] – язык, на который мы переводим.
Второй и третий аргументы задаются двухзначным кодом: es, fr, en, ru. Их тоже можно указать в самой функции, но можно брать из ячейки, а язык исходного текста и вовсе можно автоматически определять.

А как быть, если мы хотим переводить на разные языки? И при этом не хотим каждый раз указывать язык исходника вручную?
Тут пригодится функция DETECTLANGUAGE. У нее единственный аргумент – текст, язык которого нужно определить:
Как и с любой другой функцией, прелесть здесь в автоматизации. Можно быстро поменять текст или язык; быстро перевести одну фразу на 10 языков и так далее. Конечно, мы понимаем, что это текст онлайн-переводчика – качество будет соответствующим.
Евгений Намоконов и Ренат Шагабутдинов, а еще мы ведем канал в телеграмме, где разбираем разные кейсы с Google Таблицами, если вам интересно — заглядывайте в гости, ссылку можно найти в моем профиле.
Не только СУММ и СЦЕПИТЬ: Google Таблицы (или Google Spreadsheets) намного функциональнее и мощнее, чем это может показаться при поверхностном знакомстве.
На конкретных примерах разбираем полезные и интересные фичи, которые могут пригодиться в работе самым разным людям: владельцам бизнеса, руководителям, специалистам.
Этот обзор — только часть полезного образовательного контента от центра CyberMarketing. Вас ждут статьи, вебинары и курсы по интернет-маркетингу: SEO, PPC, SMM, веб-аналитике и другим важным тематикам.
IMPORTRANGE
IMPORTRANGE (русскоязычного названия нет) — функция, которая загружает данные из одной Google Таблицы в другую. Принимает два параметра: URL таблицы и диапазон, откуда нужно импортировать данные. Например: =IMPORTRANGE(«1iufABCDBDfT5BtDq1RJJw968xEDUWH80uM3u9ByATdoE»;»Декабрь 2017!A:B»)
Ссылку на таблицу можно вставить целиком или же взять лишь ее уникальный ID. Еще обратите внимание на второй аргумент: кириллическое название листа — без одинарных кавычек, хотя мы используем их, когда ссылаемся на такой лист в таблице.
Главное преимущество по сравнению с элементарным «Копировать → Вставить» — автоматическая загрузка новых данных. И эти новые данные легко сразу же использовать в других функциях или сводных таблицах благодаря возможности Google Spreadsheets задавать открытые диапазоны (к примеру, A2:B вместо A2:B20).
А еще IMPORTRANGE можно вложить в ВПР или QUERY, о которых речь пойдет дальше, или в другие функции, которые работают с диапазонами. Тогда можно будет не содержать дополнительный лист специально под импорт.
IMPORTHTML и IMPORTXML
Google Таблицы могут извлекать данные не только из таблиц, но и прямо с сайтов, то есть парсить их. Всего таких функций четыре, но больше пригождаются IMPORTHTML и IMPORTXML (у них тоже нет русскоязычных названий).
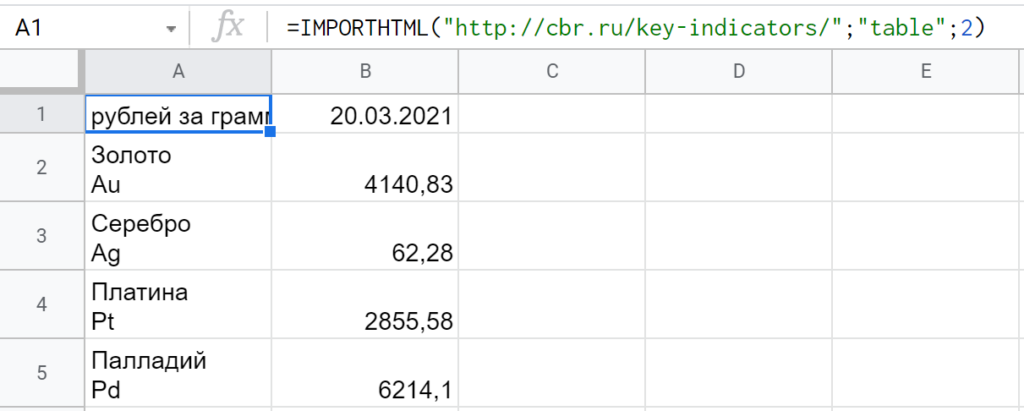
IMPORTHTML — функция, которая может импортировать данные с веб-страницы, если они представлены в виде таблицы или списка. Например, она может выглядеть так: =IMPORTHTML(«http://cbr.ru/key-indicators/»;»table»;2), где:
- URL или ссылка на ячейку с адресом сайта.
- Запрос, у которого только два варианта: «table» и «list» для таблиц и списков соответственно.
- Индекс, порядковый номер элемента. (Не всегда цифра очевидна, придется методом перебора выяснять, под каким именно номером на странице будут нужные данные.)
В данном случае функция выводит таблицу с ценами на драгоценные металлы — это информация с сайта Банка России:
IMPORTXML тоже принимает первым параметром адрес страницы, а вторым — запрос XPath (это специальный язык для работы с XML-документами). Среди прочего эту функцию можно использовать для парсинга метатегов. Так, чтобы получить заголовок страницы, нужно вставить в ячейку текст вида: =IMPORTXML(«https://www.ozon.ru/category/tehnika-dlya-krasoty-i-zdorovya-10737/»;»//title»)
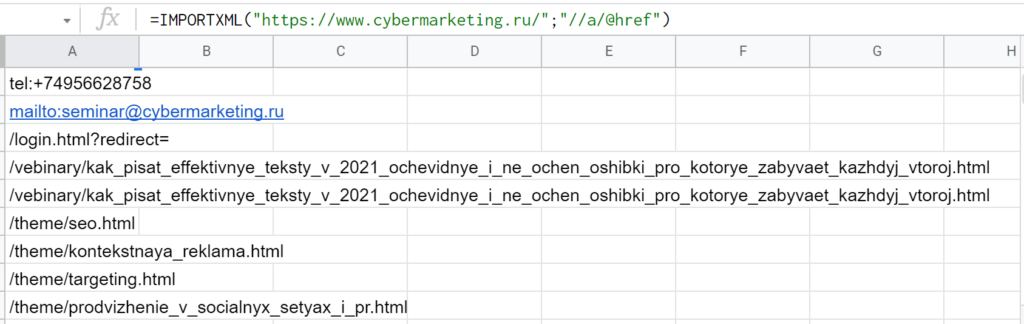
Если взять запрос «//meta[@name=’description’]/@content», Google Таблицы извлекут описание (дескрипшн), а если «//h1» — заголовок первого уровня соответственно. Чтобы выгрузить список ссылок со страницы, подойдет «//a/@href»:
Еще есть IMPORTDATA, которая работает с данными в формате CSV (значения, разделенные запятыми) или TSV (значения, разделенные табуляцией), и IMPORTFEED, которая загружает фид RSS или Atom. Но на практике они используются гораздо реже.
Конечно, есть и более удобные инструменты для парсинга метатегов и заголовков, например, Click.ru. Тем более этим функциональность не ограничивается: специалисты активно используют кластеризацию запросов, генерацию объявлений из YML, медиапланирование, создание отчетов и др. Бонус: вознаграждение до 18 % с рекламного оборота.
ВПР (VLOOKUP) и ГПР (GLOOKUP)
ВПР (VLOOKUP) — незаменимая функция для объединения данных из разных источников: листов и даже таблиц (если использовать вложенный IMPORTRANGE). Синтаксис: =ВПР(A2; ‘Отчет’!$A$2:$C; 4; 0), где:
- запрос, по которому нужно искать (здесь он будет взят из указанной ячейки);
- диапазон, в первом столбце которого нужно искать;
- номер столбца (от начала диапазона, а не листа), откуда нужно взять значение;
- дополнительный параметр, который настраивает точность поиска (по умолчанию 1, но лучше ставить 0, тогда будет возвращаться только точное совпадение).
Допустим, есть два листа: на одном список URL с названиями страниц, на другом — тоже список URL, но с показателями по продажам или трафику. С помощью ВПР легко объединить эти данные в один отчёт.
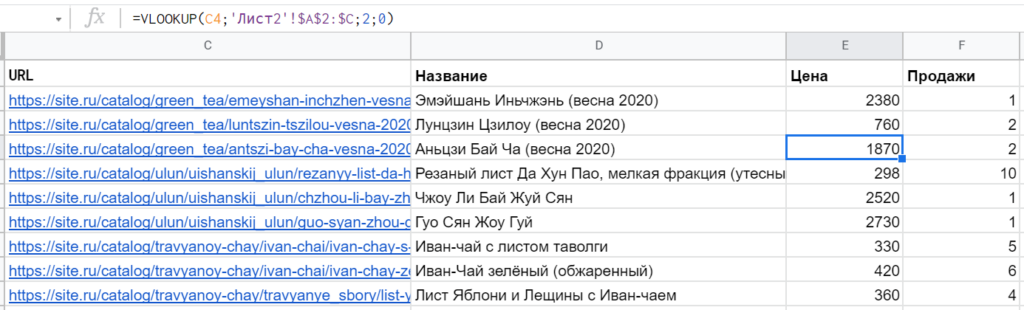
Важные моменты:
- Использовать абсолютные ссылки на диапазон (со знаками доллара), иначе при протягивании ВПР они тоже будут меняться, в результате поиск может работать некорректно.
- Третьим параметром передавать номер столбца от начала диапазона, а не от начала листа. (Необязательно ссылаться на весь лист — нужные ячейки могут лежать не в A:B, а в E:F, например).
- ВПР ищет совпадения только в первом столбце диапазона и берет значения только справа от него. В остальных случаях по умолчанию эта функция не справится, но хорошо, что есть другие варианты.
Чтобы функция ВПР возвращала значения не только правее, но и левее первого столбца диапазона, есть лайфхак с использованием массива. Суть: создать виртуальную таблицу, где столбцы будут расположены в порядке, необходимом для корректной работы VLOOKUP.
Например =VLOOKUP(C2;{‘Лист2’!D:D ‘Лист2’!B:B ‘Лист2’!C:C};2;0) успешно произведет поиск по четвертому столбцу и передаст данные из второго. Потому что в массиве значения диапазона D:D идут первым столбцом — нет никаких противоречий.
Функция-побратим — ГПР (HLOOKUP) — работает похожим образом, только ищет по строкам, а не столбцам. На практике это может понадобиться гораздо реже.
ПОИСКПОЗ (MATCH) и ИНДЕКС (INDEX)
Совместное использование ПОИСКПОЗ (MATCH) и ИНДЕКС (INDEX) — еще один способ обойти ограничение функций ВПР (VLOOKUP) и ГПР (HLOOKUP), которые ищут только по первому столбцу или первой строке диапазона.
Алгоритм такой: MATCH находит значение в диапазоне (строка или столбец) и возвращает его порядковый номер, а INDEX — передает содержимое ячейки, у которой такой же порядковый номер, просто она находится в соседней строке или столбце.
Пример: =INDEX(‘Лист2′!$B$2:$B;MATCH(C3;’Лист2’!$D$2:$D;0)). Сначала запускается MATCH: находит значение из C3 на другом листе в столбце D, затем возвращает порядковый номер. INDEX берет этот номер и ищет по нему уже в столбце B, затем возвращает результат:
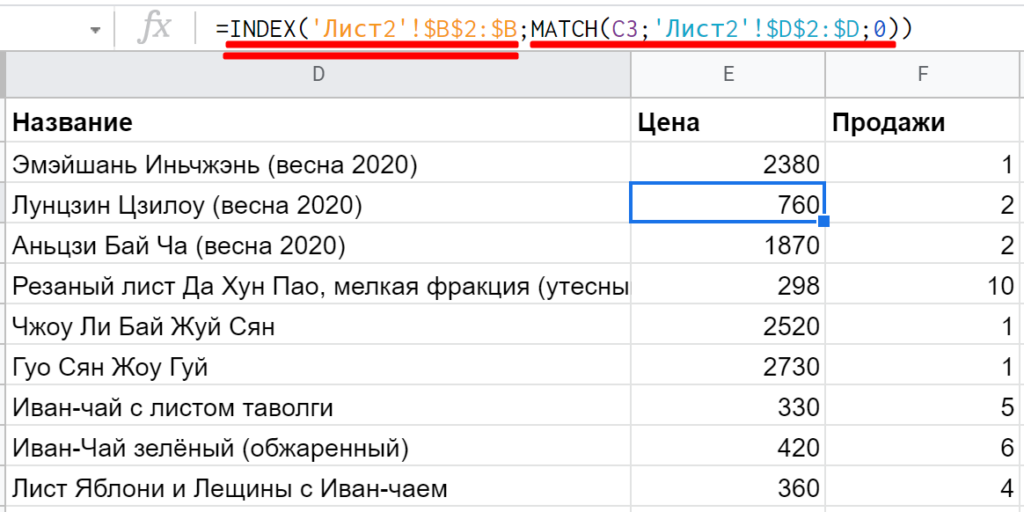
Важные моменты:
- ПОИСКПОЗ (MATCH) может работать только с одной строкой или с одним столбцом. Если попытаться отправить многомерный массив вроде A:D, функция выдаст #Н/Д! Третий параметр функции — метод поиска. Ноль требует точный поиск, показывает, что диапазон никак не отсортирован.
- ИНДЕКС (INDEX) может работать с любыми диапазонами, но в сочетании с ПОИСКПОЗ понадобится только поиск по столбцу. Поэтому третий параметр не используется — в ИНДЕКС передаются только диапазон (столбец, откуда нужно взять значение) и номер строки (его возвращает ПОИСКПОЗ).
- ИНДЕКС и ПОИСКПОЗ оперируют номерами строк/столбцов именно заданных диапазонов, а не листов — важно помнить об этом при работе.
Читайте также: 20+ ресурсов для обучения веб-аналитике: блоги, курсы, каналы, сообщества, рассылки
SPARKLINE
Спарклайн — интересный инструмент визуализации, который не требует много места: диаграмма умещается в одну ячейку. Аргументов два: диапазон или массив данных и набор опций (необязательный). В последнем можно задать, например:
- Тип диаграммы (charttype) — по умолчанию line (график), но можно поменять на bar (гистограмму) или column (столбчатую диаграмму).
- Цвет линии или столбцов диаграммы (color) — зеленый (green), желтый (yellow) и любой другой по шестнадцатеричному коду.
- Максимальное (max, ymax) и минимальное (min, ymin) значения по горизонтальной или вертикальной оси.
Такие дополнительные параметры можно передать массивом, — вставив его прямо в функцию — или сослаться на ячейки, где в первом столбце будет название параметра, а во втором — его значение.
Допустим, есть задача: изучить динамику трафика на страницы по месяцам. Если таких страниц сотни, бессмысленно для каждой из них строить большой график или диаграмму. А если оставить просто цифры, придется долго их считывать, чтобы разобраться. Тут на помощь и приходит функция SPARKLINE (русскоязычного названия нет).
Синтаксис: =SPARKLINE(B2:E2;{«charttype»»column»;»color»»green»}) где первым параметром идет диапазон с данными для визуализации, а вторым — массив с набором опций, который в данном случае указывает рисовать столбчатую диаграмму, а не график по умолчанию, и покрасить ее в зеленый цвет:
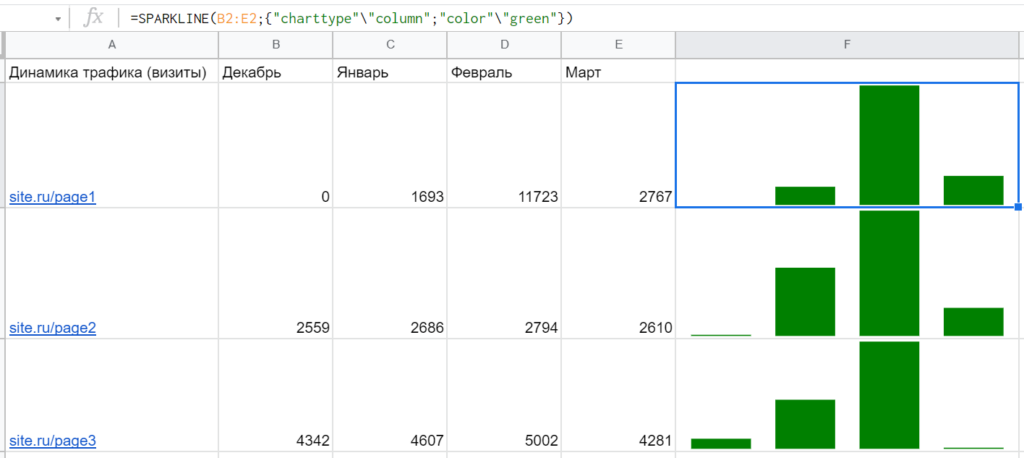
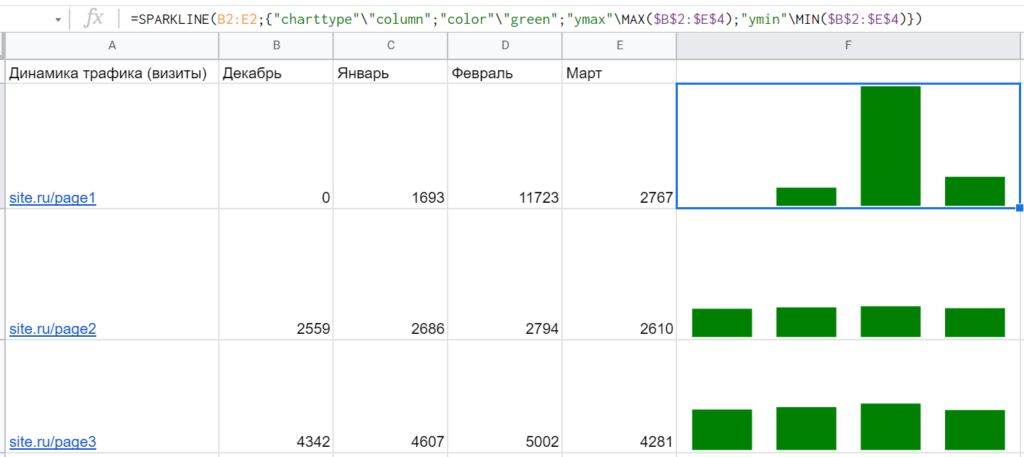
Но посмотрите внимательно на данные и сами диаграммы на этом примере. Сейчас кажется, что страница №3 сильнее всех просела по трафику в марте, хотя потеря составила всего 721 визит. Тогда как страница №1 потеряла целых 8956 визитов. Чтобы решить такую проблему, нужно как-то связать данные — например, с помощью опций ymin и ymax, которые передают максимальное и минимальное значение по всем страницам: =SPARKLINE(B2:E2;{«charttype»»column»;»color»»green»;»ymax»MAX($B$2:$E$4);»ymin»MIN($B$2:$E$4)}) Тогда получается гораздо нагляднее и реалистичнее:
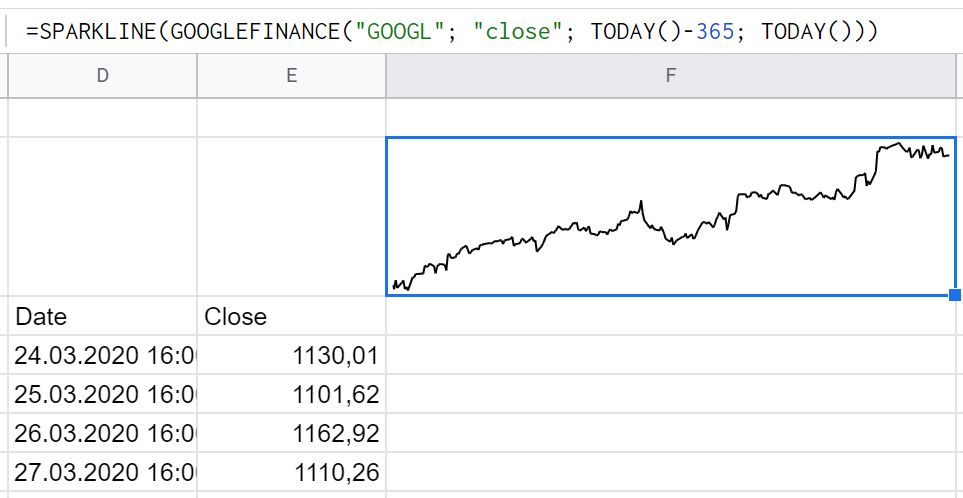
Кстати, если вы увлекаетесь инвестициями, комбинация SPARKLINE и GOOGLEFINANCE поможет изучать динамику котировок акций и курсов валют. На скриншоте — визуализация изменения стоимости акций Google за прошедший год:
ТРАНСП (TRANSPOSE)
ТРАНСП (TRANSPOSE) пригодится, когда нужно транспонировать таблицу (матрицу), то есть поменять строки и столбцы местами. В качестве аргумента можно передать диапазон или массив, например, так: =ТРАНСП(A35:G40)
Допустим, вы выгружаете из Яндекс.Метрики отчет с данными графика — чтобы посмотреть динамику трафика по определенным разделам:
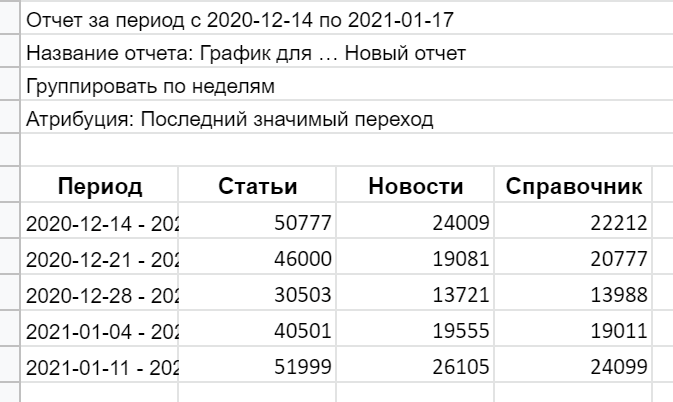
Голые цифры считываются плохо, гораздо нагляднее будет сделать визуализацию с помощью спарклайнов — диаграмм, которые умещаются в ячейку. Но для этих целей нужно расположить визиты по конкретному разделу в одну строку. Тогда сразу будет понятно, в какой временной период трафик просел или взлетел:
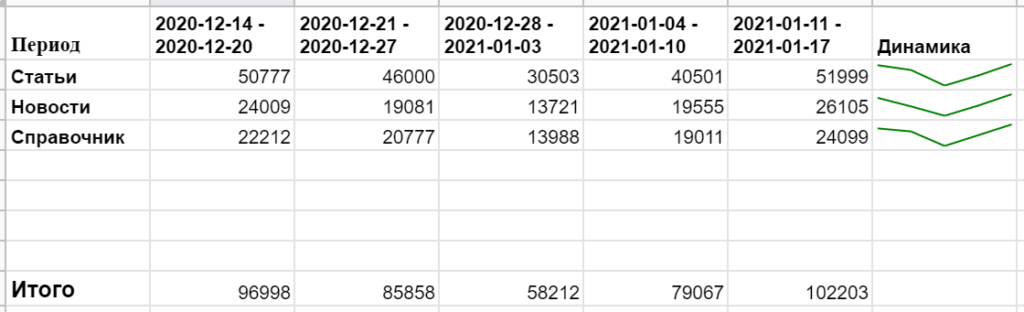
Чтобы функция создала транспонированную таблицу, необходимые для этого ячейки должны быть свободны от значений — иначе будет ошибка.
Конечно, есть и альтернативное решение без использования этой функции: скопировать нужный диапазон, кликнуть правой кнопкой мыши и выбрать «Специальная вставка → Вставить с изменением положения строк и столбцов».
IFS (множественное IF)
IFS (русскоязычного аналога нет) — расширенная версия функции ЕСЛИ (IF), которая позволяет оценивать сразу несколько условий. Возвращает то значение, которое соответствует первому истинному условию (TRUE). То есть сначала проверяет первое условие (слева), если оно истинно — отправляет первое значение, если ложно — идет дальше вправо. Синтаксис: =IFS(условие1; значение1; условие2; значение2; …) Если все условия ложные, вернёт #Н/Д!
Допустим, вы выгрузили (из системы аналитики или CMS) список URL с какими-то дополнительными данными: названиями, датами публикаций, количеством визитов, продажами и т. д. Например, такой:
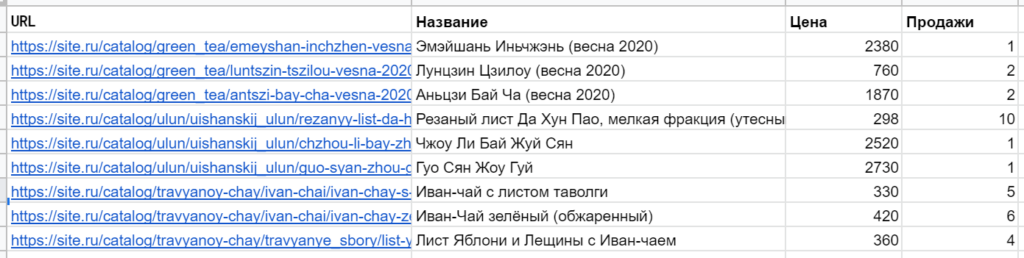
И для удобства работы и отчетности хотите создать дополнительный столбец, где будут просто и понятно указаны категории (типы), извлеченные из адресов страниц. Чтобы легко можно было отсортировать или отфильтровать таблицу, посчитать сумму показателей по конкретной категории и т. п.
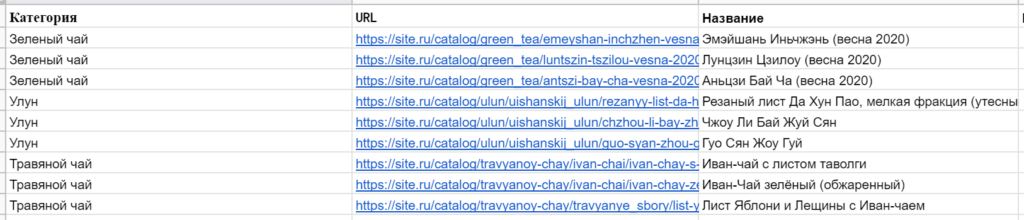
Есть разные варианты решений. Например, правее можно прописать и протянуть функцию =SPLIT(B2;»/») — она разложит URL на составляющие. Далее достаточно посмотреть, в какой ячейке лежит нужная часть адреса, и составить формулу вида: =IFS(I5=»green_tea»;»Зеленый чай»;I5=»ulun»;»Улун»;I2=»travyanoy-chay»;»Травяной чай») Недостаток такого подхода — множество лишних «технических» ячеек, они могут мешать, их придется скрывать.
Другой способ — вложить в IFS несколько других функций: НЕ (NOT), ЕОШИБКА (ISERROR), НАЙТИ (FIND). Тогда формула примет более сложный вид, но зато не нужны будут никакие дополнительные ячейки: =IFS(NOT(ISERROR(FIND(«/green_tea/»;B2)));»Зеленый чай»;NOT(ISERROR(FIND(«/ulun/»;B2)));»Улун»;NOT(ISERROR(FIND(«/travyanoy-chay/»;B2)));»Травяной чай»)
Почему такая сложная конструкция? Дело в том, что FIND возвращает #Н/Д, если не находит запрос в тексте, а это прерывает проверку всех условий в IFS. Поэтому приходится использовать ISERROR, что возвращает TRUE, если функция FIND выдает ошибку. Но TRUE опять прервет выполнение IFS — ведь условие должно наоборот быть ложным, чтобы начать проверять следующее условие. Поэтому приходится усложнять и добавлять NOT, которая поменяет TRUE на FALSE.
Есть и другой вариант реализации — через регулярные выражения и соответствующие функции Google Таблиц.
REGEXMATCH, REGEXEXTRACT, REGEXREPLACE
Эти три функции Google Таблиц предназначены для работы с регулярными выражениями (специальный язык для работы со строками и символами). REGEXMATCH ищет соответствия, REGEXEXTRACT извлекает нужный фрагмент, а REGEXREPLACE заменяет одну часть текста на другую. Синтаксис похожий: первый аргумент — текст, а второй — само регулярное выражение; в REGEXREPLACE есть еще третий — текст, который нужно вставить.
Допустим, нужно из URL конкретной страницы извлечь название сайта. Для этой цели можно использовать такой вариант: =REGEXEXTRACT(C23;»https://(.*?)/») Функция возьмет все символы, что находятся между «https://» и следующим слешем, включая дефисы и точки. Поэтому нормально будут экстрагироваться и домены второго уровня:
С помощью REGEX можно также решить задачу с категориями из предыдущего раздела про IFS. Тогда получится так: =IFS(REGEXEXTRACT(C2;»/catalog/([^/]+)»)=»travyanoy-chay»;»Травяной чай»;REGEXEXTRACT(C2;»/catalog/([^/]+)»)=»ulun»;»Улун»;REGEXEXTRACT(C2;»/catalog/([^/]+)»)=»green_tea»;»Зеленый чай»)
Почему такой вариант, и как он работает? «/catalog/» — общая часть у всех URL, поэтому можно смело начинать поиск совпадений с нее. Далее нужно взять все символы, что находятся между «/catalog/» и следующим слешем. Конструкция ([^/]+) как раз за это отвечает. Получается, функция ищет любое число любых символов, кроме слеша, на котором она и остановится. ‘^’ здесь используется как оператор отрицания, ‘+’ задаёт 1 или более повторений символов, а круглые скобки — что нужно брать только эту группу, не включая остальные части текста.
Читайте также: 15 сервисов для проверки текста
ARRAYFORMULA
ARRAYFORMULA (русскоязычного названия нет) — функция для работы с массивами. В качестве параметра принимает формулу массива или другую функцию.
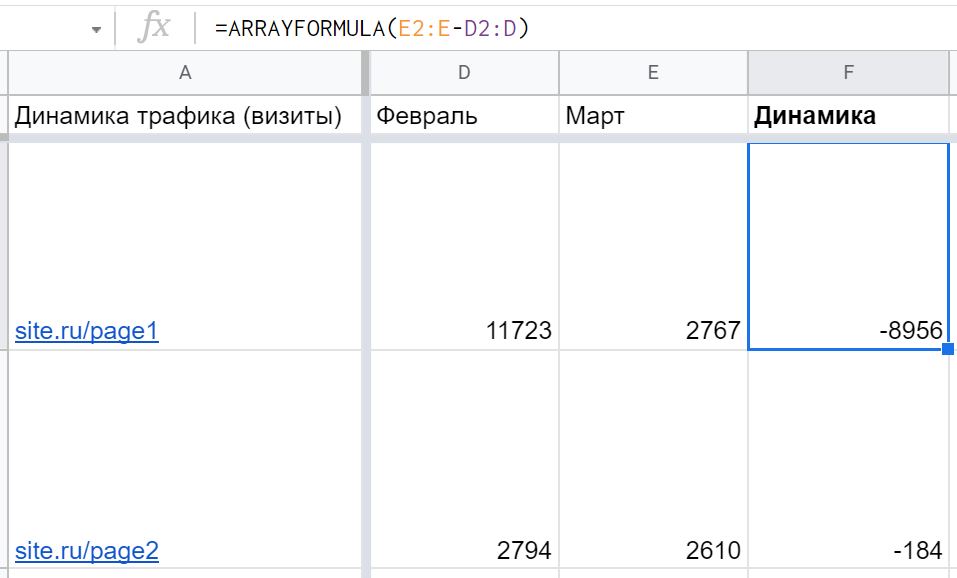
Допустим, справа от основной таблицы нужно создать столбец с каким-то вычисляемым показателем, например, чтобы тот считал разницу между другими. Конечно, это можно сделать через обычное протягивание формулы, но если таблица постоянно пополняется новыми строками — придется постоянно протягивать ее вручную все ниже и ниже. ARRAYFORMULA же позволяет автоматизировать процесс: за счет вычитания одного массива с открытым диапазоном из другого:
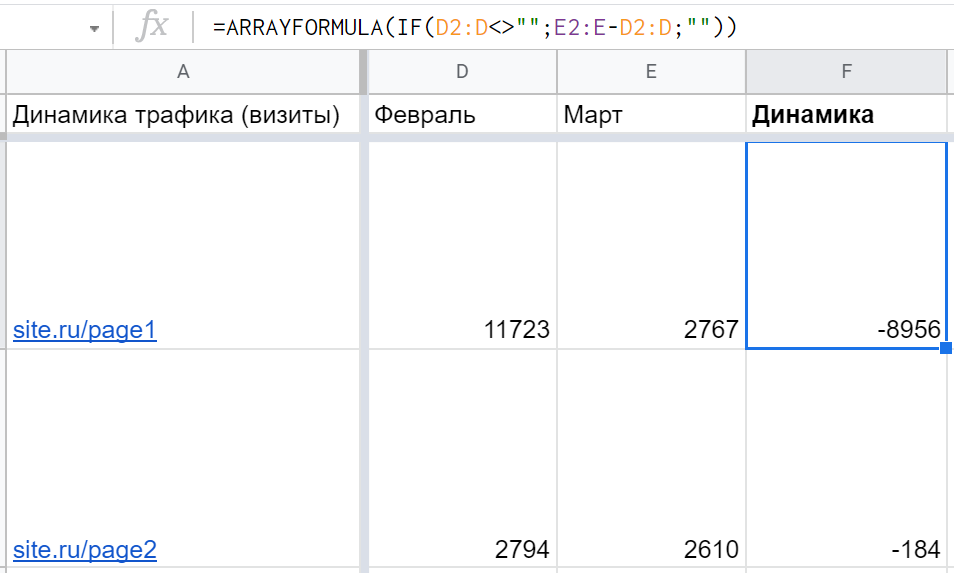
Единственное, что в данном случае формула будет заполнять ячейки до самого конца таблицы — а лишние нули это не очень красиво. Решение — дополнительно использовать IF: =ARRAYFORMULA(IF(D2:D<>»»;E2:E-D2:D;»»)) которое сообщает следующее: если в ячейке D пусто, то и вычитание не нужно, оставить ячейку пустой.
Аналогичным способом ARRAYFORMULA можно использовать вместе с ВПР(VLOOKUP), к примеру: =ARRAYFORMULA(IFERROR(VLOOKUP(A2:A;feb!$A:$D;2;0);»»)) Только здесь от лишних #N/A до конца таблицы спасает функция ЕСЛИОШИБКА (IFERROR).
Увлечение ARRAYFORMULA (особенно если еще в большом количестве используются такие функции, как VLOOKUP, MATCH, INDEX, QUERY) может существенно замедлять работу Google Таблицы. Ускориться помогает удаление лишних строк (по умолчанию их 1 000, сотни могут совсем не использоваться и только зря обрабатываться функцией ARRAYFORMULA).
SORTN
SORTN — расширенная версия функции SORT, которая может не только сортировать данные по нескольким столбцам, но и ограничивать количество возвращаемых результатов. Параметры:
- Диапазон для сортировки и вывода. (Впрочем, столбцы, по которому данные сортируются, можно не включать в этот диапазон, указать их отдельно в четвертом параметре.)
- Количество возвращаемых элементов. (Можно сделать топ-3, топ-5 и т. д.)
- Режим показа совпадений. (По умолчанию ноль. Единица, например, будет выводить дополнительные строки, — больше, чем указано во втором параметре — если в столбце для сортировки найдутся повторяющиеся значения.)
- Столбец для сортировки. (Может быть вне диапазона, указанного в первом параметре.)
- Способ сортировки столбца. ИСТИНА (TRUE) сортирует данные по возрастанию (от меньшего к большему), а ЛОЖЬ (FALSE) – по убыванию (от большего к меньшему).
(Если нужно, дальше можно также задать дополнительные столбцы и варианты сортировки.)
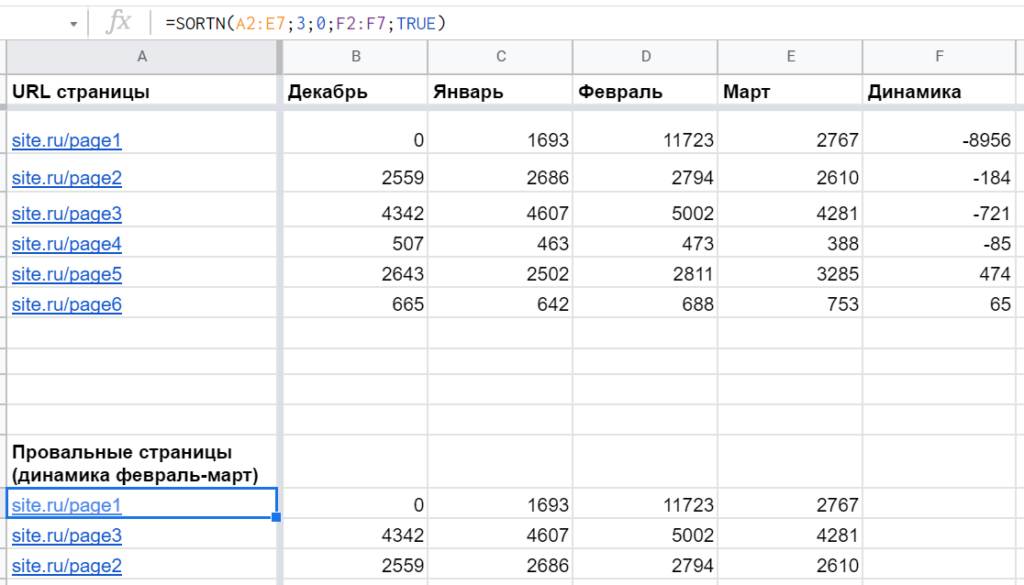
Допустим, есть таблица с показателями трафика за несколько месяцев. И нужно подготовить топ лучших или худших страниц по динамике за последние два. Для этого как раз хорошо подходит функция SORTN.
Пример: =SORTN(A2:F7;3;0;6;TRUE), которая выводит данные из A2:F7, но только первые три строки, отсортированные по шестому столбцу (F) по возрастанию:
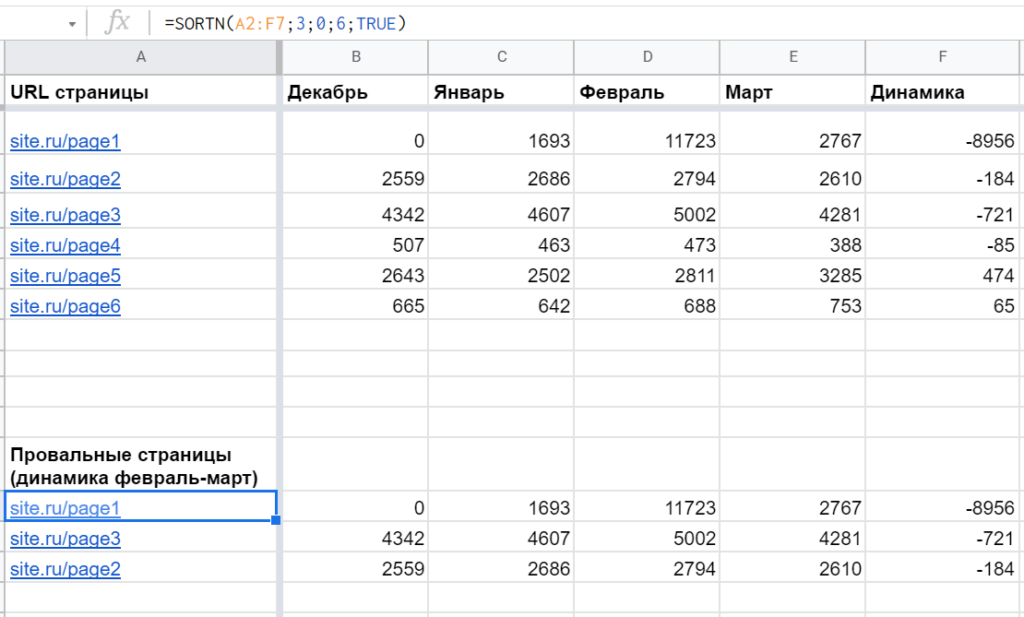
Если столбец для сортировки не входит в первый диапазон, нужно передать его четвертым параметром (главное условие — такое же количество элементов, как у первого). Пример: =SORTN(A2:E7;3;0;F2:F7;TRUE)
Читайте также: Где в интернет-маркетинге можно автоматизировать, а где — только ручками (пока)
FILTER
FILTER (опять без русского аналога) — мощная функция Google Таблиц, которая выводит только те строки и столбцы, которые соответствуют заданным условиям. Первым аргументом принимает диапазон, вторым и последующими — условия для фильтрации.
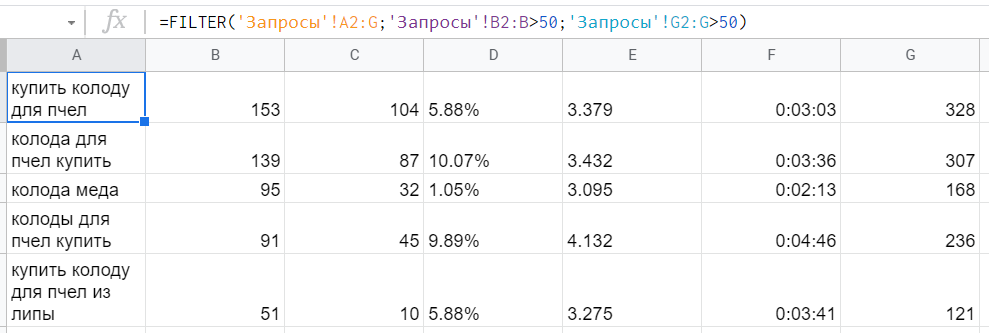
Допустим, есть стандартный отчет по поисковым фразам и поведению пользователей, которые пришли по ним на сайт. (Первый столбец — сами запросы, второй — визиты, дальше отказы, глубина просмотра и время на сайте, в конце — достижения любой цели.) И нужно узнать наиболее приоритетные ключи для продвижения. Например, выбрать те, что дали больше 50 визитов и больше 50 конверсий за отчетный период.
Здесь подойдет такой вариант: =FILTER(‘Запросы’!A2:G;’Запросы’!B2:B>50;’Запросы’!G2:G>50), где мы сначала указываем диапазон данных для фильтрации и вывода, затем условия — во-первых, значения в столбце B должны быть больше 50, во-вторых, значения в столбце G тоже должны быть больше 50.
Столбцы или строки, по которым фильтруются данные, не обязаны входить в первый диапазон. Например, нет смысла в столбце, где все значения будут повторяться — а так и будет, если FILTER отбирает данные по какой-то одной единственной категории. Если в этом примере формулы поменять Запросы!A2:G на Запросы!A2:A, ничего не сломается — просто будет выводиться только первый столбец.
Теперь другой, более сложный пример использования FILTER. Допустим, вы сделали копию прайс-листа поставщика, потому что так с данными удобнее работать, но нужно периодически проверять оригинальную таблицу — что нового там появилось и стоит ли обновить свою. И нужно проверять не все позиции, а самые приоритетные и прибыльные. Это можно осуществить, сочетая FILTER с IMPORTRANGE, MATCH и ISERROR. Например, так:
=FILTER(IMPORTRANGE(«1znX3hxN9cKEvZyh_0XOj7gHpjYze8p-40cZchiDvTxY»;»Каталог!A2:E»);IMPORTRANGE(«1znX3hxN9cKEvZyh_0XOj7gHpjYze8p-40cZchiDvTxY»;»Каталог!A2:A»)=1;(ISERROR(MATCH(IMPORTRANGE(«1znX3hxN9cKEvZyh_0XOj7gHpjYze8p-40cZchiDvTxY»;»Каталог!B2:B»);B3:B7;0))))
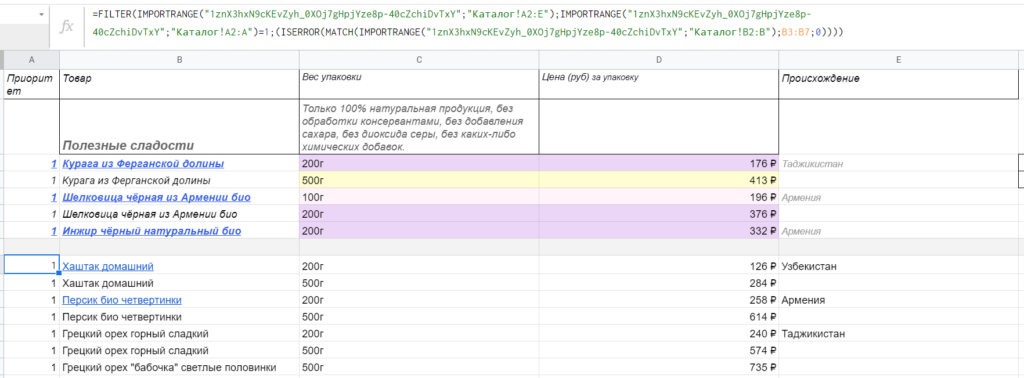
Что здесь происходит? Первый параметр — диапазон внешней таблицы A2:E, взятый с листа «Каталог». Второй — условие: значение в столбце A должно быть равно 1 (самые приоритетные позиции). Третий — подробнее:
- IMPORTRANGE подгружает столбец B из листа «Каталог».
- MATCH ищет совпадения между импортируемыми и имеющимися данными (между названиями товаров в скопированном и оригинальном прайс-листах).
- ISERROR вернет FALSE, когда MATCH найдет совпадения, и, соответственно, вернет TRUE, если таких совпадений не будет.
Получается, FILTER выдаст только те позиции с приоритетом №1, которые есть во внешнем документе, но которых нет в этой таблице.
Еще несколько моментов:
- FILTER фильтрует или строки, или столбцы. Чтобы фильтровать их одновременно, можно вложить одну функцию в другую — то есть одна FILTER будет обрабатывать выходные данные из другой FILTER.
- Не очень удобно постоянно копировать и вставлять заголовки из одной таблицы в другую. Но благодаря массиву можно подгружать их автоматически и в правильном порядке. Немного усовершенствованный предыдущий пример: ={‘Запросы’!A1:G1;FILTER(‘Запросы’!A2:G;’Запросы’!B2:B>50;’Запросы’!G2:G>50)}
БДСУММ(DSUM), БСЧЁТА(DCOUNTA), БИЗВЛЕЧЬ(DGET), ДСРЗНАЧ (DAVERAGE)…
Функции БД — серьезные инструменты, когда нужно работать с большим количеством данных и условий, — и стандартные FILTER, СУММЕСЛИ, СРЗНАЧЕСЛИ, ВПР и другие не справляются или не очень удобны в использовании.
К примеру, есть подробная база публикаций в соцсетях с указанием тематик и типов контента, названиями и датами, количеством лайков, комментариев и шеров. И интересно узнать, какая в среднем вовлеченность у постов с видео по сравнению с более текстовыми форматами.
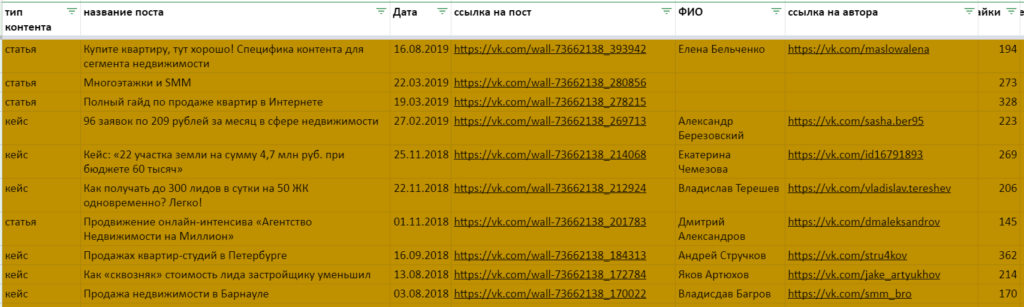
Здесь лучше всего подойдет ДСРЗНАЧ (DAVERAGE). Синтаксис у этой и остальных Д-функций похожий:
- Массив или диапазон данных — в общем, таблица, с которой нужно работать. (Первая строка обязательно должна содержать заголовки столбцов!)
- Столбец, в котором находятся нужные данные. (Можно передать номер столбца, адрес ячейки или даже просто название столбца текстом в кавычках.)
- Критерии, условия для фильтрации — можно передать их как массивом, так и диапазоном. (Важно: первый элемент должен соответствовать заголовку столбца с искомыми данными, что указан во втором параметре.)
Для начала на отдельном листе нужно подготовить критерии — список типов контента, по которым нужно рассчитать показатели. Затем уже использовать, немного модифицируя, такую формулу: =DAVERAGE(Book!A4:J;8;B1:B13). Она считает среднее арифметическое по всем значениям из столбца №8 диапазона Book!A4:J, которые соответствуют данным из диапазона B1:B13. (Напоминаем: в обоих диапазонах первыми строками идут заголовки. А вместо номера столбца — 8 — можно сослаться на ячейку его заголовка — Book!H4 — или просто передать название текстом — «лайки»).
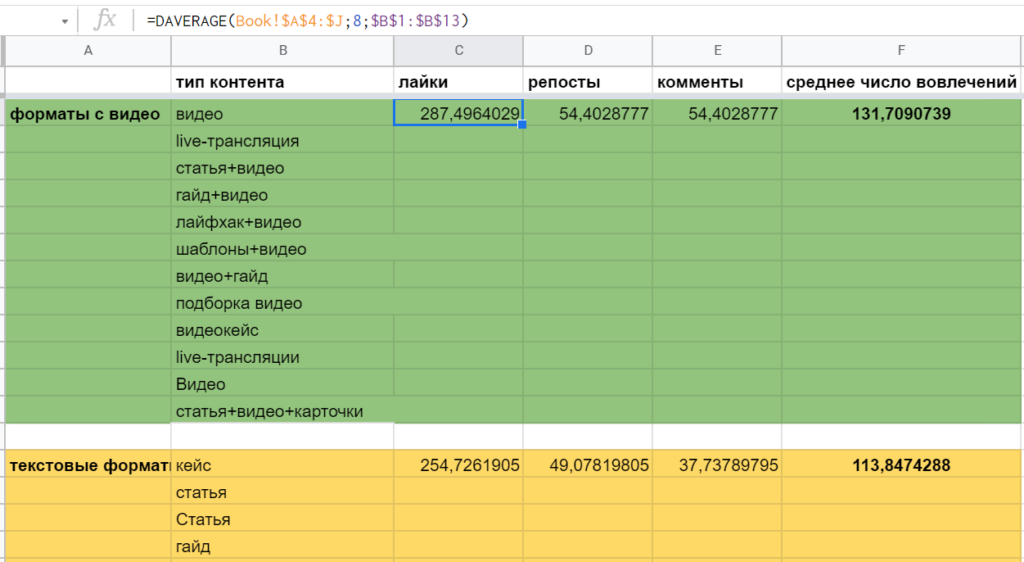
Репосты и комментарии считаются аналогично, меняется только номер столбца (8→9→10). Ну а среднее число вовлечений легко получить через обычный =AVERAGE (C2:E2).
Показатели для текстовых типов контента можно получить точно так же, единственное — нужно будет снова передавать название заголовка. Писать его ниже необязательно, можно просто добавить через массив: =DAVERAGE(Book!$A$4:$J;8;{«тип контента»;$B$15:$B$38})
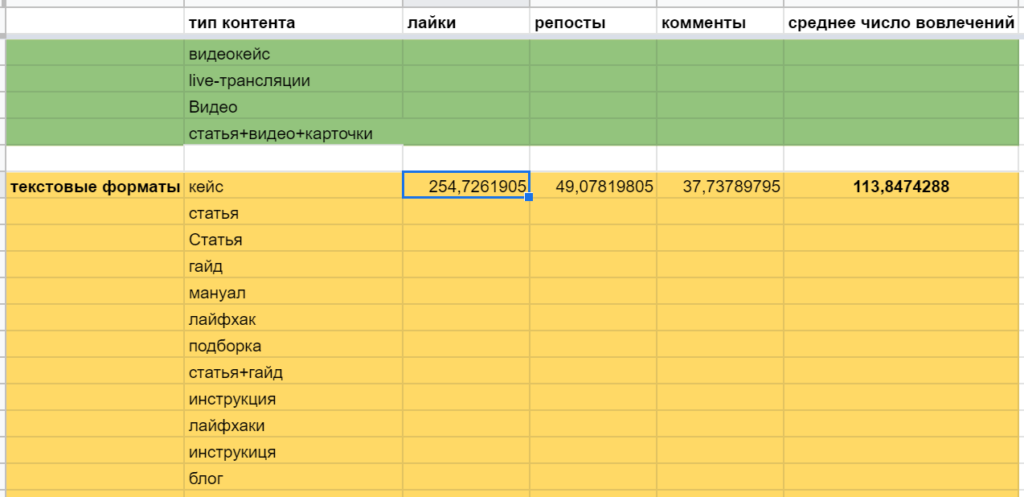
Другие функции баз данных работают аналогично, разница в функциональности: так, БСЧЁТА — считает количество числовых и текстовых значений, БДСУММ — соответственно, сумму, БДПРОИЗВЕД — произведение, БИЗВЛЕЧЬ(DGET) — извлекает нужные данные из таблицы.
Важные моменты:
- Не забывать про заголовки в столбцах/массивах — именно они являются «мостиком» между данными и позволяют находить и считать нужное.
- Нет ограничений по количеству столбцов — можно задать несколько условий для фильтрации (например, не только типы контента, но и тематики). Главное — правильно написать заголовки.
- Не использовать открытый диапазон в критериях — Д-функции не будут игнорировать пустые ячейки, будут искать по ним тоже, что драматично исказит результаты.
- В БСЧЁТ и БСЧЁТА можно указать любой столбец — ведь эти функции считают общее количество, а не производят математические операции с конкретными цифрами.
Читайте также: 10 функциональных сервисов для анализа социальных сетей
QUERY
Если FILTER — просто мощная функция, то QUERY — мощнейшая. Она выполняет запросы на языке аналогичном SQL, позволяет строить самые разные отчеты и сводные таблицы, в том числе интерактивные дашборды. Вообще по QUERY стоит писать отдельный большой гайд, поэтому тут рассмотрим лишь часть возможностей.
Синтаксис:
- Диапазон ячеек, собственно, база данных. (Можно импортировать из другой таблицы через IMPORTRANGE.)
- Запрос, записанный на языке API визуализации Google (аналог SQL). Передается в текстовом формате — можно написать в кавычках внутри функции или взять из ячейки.
- Заголовки — количество строк в верхней части раздела данных, необязательный параметр. (Заголовки можно присоединять и через массив).
QUERY очень чувствительна к синтаксису и порядку написания кляуз — так называют отдельные части запроса, которые отделяются между собой пробелами:
1. SELECT — указывает нужные столбцы и их порядок. Например, » SELECT A, B, D « Здесь сразу же можно создать пользовательский столбец, допустим: » SELECT A, B, C, H+I+J « Если же нужно просто вывести все столбцы, какие есть в исходном диапазоне, достаточно прописать » SELECT * « (Нюанс: если QUERY обрабатывает массив или импортируемый диапазон, нужно в SELECT указывать номер столбца (Col1), а не название (A).)

2. WHERE — задает условия для фильтрации данных. Можно написать » WHERE B > 50 AND D < 0 «, чтобы отсечь строки, где B < 50 и D > 0. Другой пример: » WHERE F IS NOT NULL OR G IS NULL «, который говорит: «Взять данные, где в столбце F есть какое-то значение или, наоборот, G — пустой». Для сравнения текстовых строк есть свои операторы: например, matches ищет соответствия регулярному выражению, contains — содержание в любом месте строки, starts with — в начале… Пример: » WHERE A=’Маркетинг’ AND B starts with ‘Статья’ « (Строки внутри запроса QUERY передаются в одинарных кавычках.)

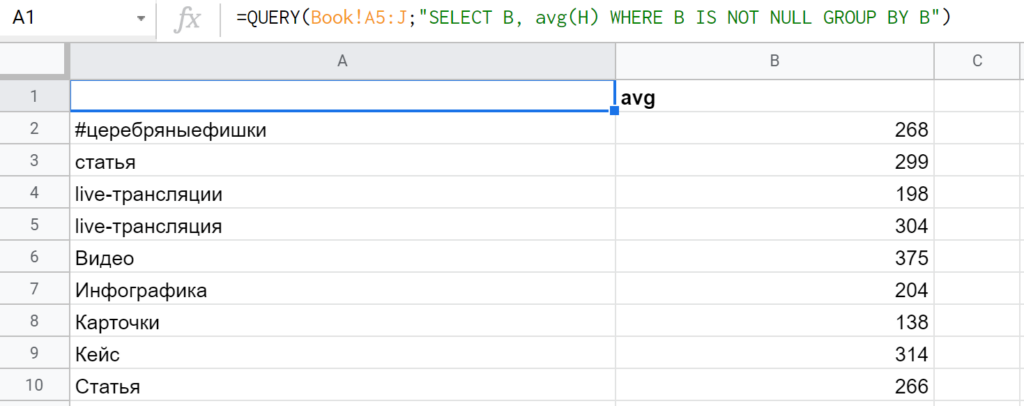
3. GROUP BY — условия для группировки данных по строкам. Работает, только когда в SELECT есть агрегирующие функции: sum (считает сумму), avg (рассчитывает среднее), min (находит минимальное значение), max (выдает максимальное значение), count (подсчитывает количество). Допустим: » SELECT A, B, C, avg(H) GROUP BY B, C, A « (Каждый столбец, указанный в SELECT без агрегирующей функции, должен быть указан и в GROUP BY.)
4. PIVOT — работает аналогично GROUP BY, только группирует данные по столбцам, например: » SELECT B, AVG(H) GROUP BY B PIVOT A « (Кстати, помимо агрегирующих, QUERY поддерживает и скалярные функции. Например, day возвращает номер дня из даты, now выдает текущую дату и время, а lower — приводит строку к нижнему регистру.)
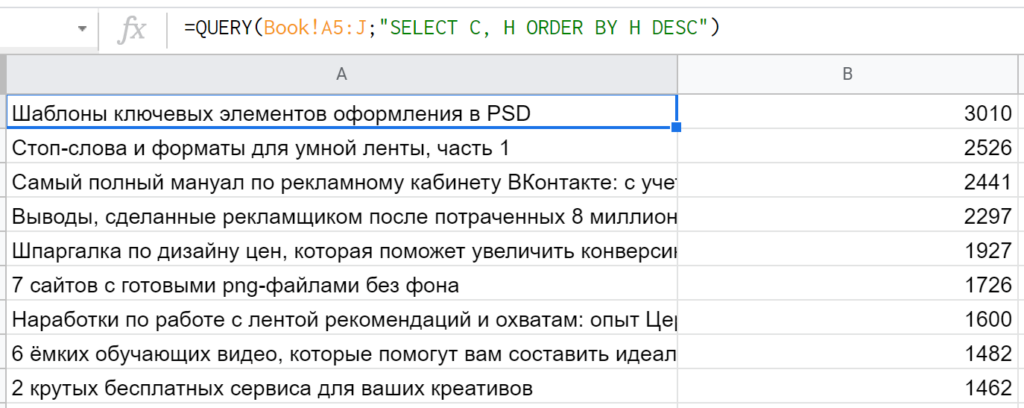
5. ORDER BY — отвечает за сортировку результатов. В запросе достаточно перечислить поля и способ сортировки (по умолчанию ASC, то есть по возрастанию, если указать DESC — функция будет сортировать по убыванию.) Пример: » SELECT C, H ORDER BY H DESC «
6. LIMIT — ограничивает количество возвращаемых строк. Так » SELECT * LIMIT 10 « вернет только первые 10 строк, других условий здесь нет. Это удобная кляуза для формирования всяческих топов, аутсайдеров, замены вышеупомянутой SORTN.
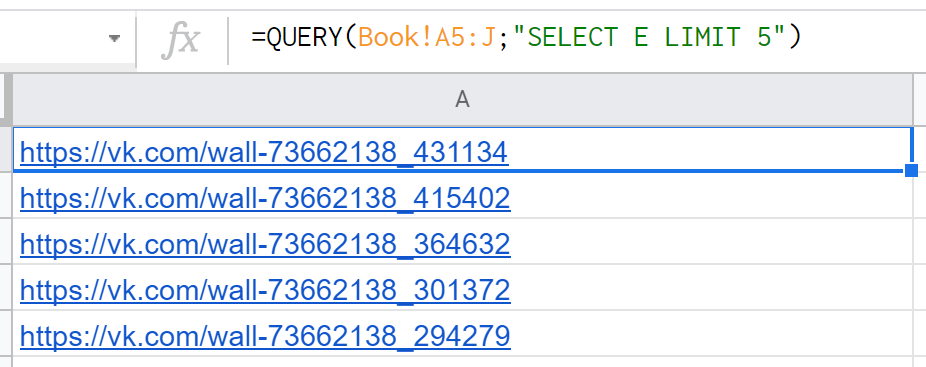
7. OFFSET — действует аналогично, только, наоборот, пропускает N-ое количество первых строк. Соответственно » SELECT * OFFSET 10 « будет возвращать все строки, начиная с 11 от начала диапазона.
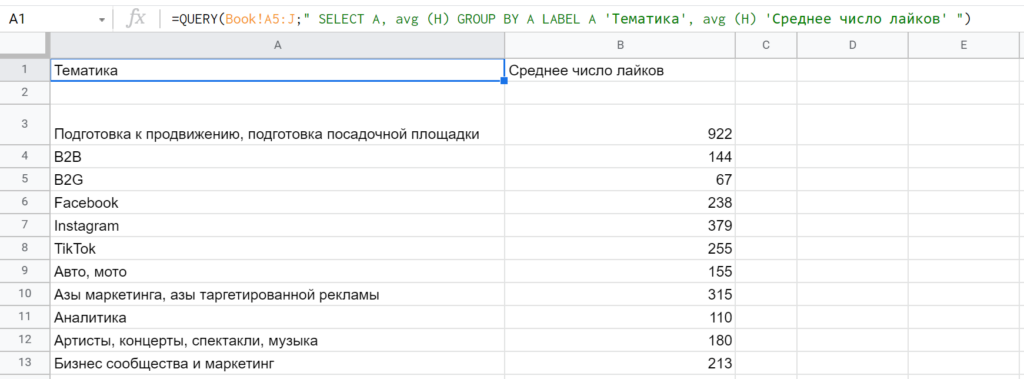
8. LABEL устанавливает подписи для столбцов. В запросе нужно сначала указать столбец или функцию, затем в одинарных кавычках — новое название. Если меток несколько, они перечисляются через запятую, как и другие параметры кляуз. Например: » SELECT A, avg (H) GROUP BY A LABEL A ‘Тематика’, avg (H) ‘Среднее число лайков’ «
9. FORMAT задает правила форматирования для ячеек в одном или нескольких столбцах. Синтаксис как у LABEL, но в кавычках нужно передавать специальные коды. Так » SELECT A, H FORMAT H ‘ #,## ‘ » будет выводить числа с разделителями разрядов. (Нужные коды можно узнать в разделе «Формат → Числа → Другие форматы«.)

Особая прелесть QUERY в том, что запрос целиком — и его отдельные параметры — можно не указывать прямо в функции, а брать из ячеек. Для соединения строк между собой достаточно обычной конкатенации через ‘&’. Пример: » SELECT A, B, C, H WHERE H < «&H1&» LIMIT «&H2 — параметры для WHERE и LIMIT будут взяты из ячеек H1 и H2 соответственно.
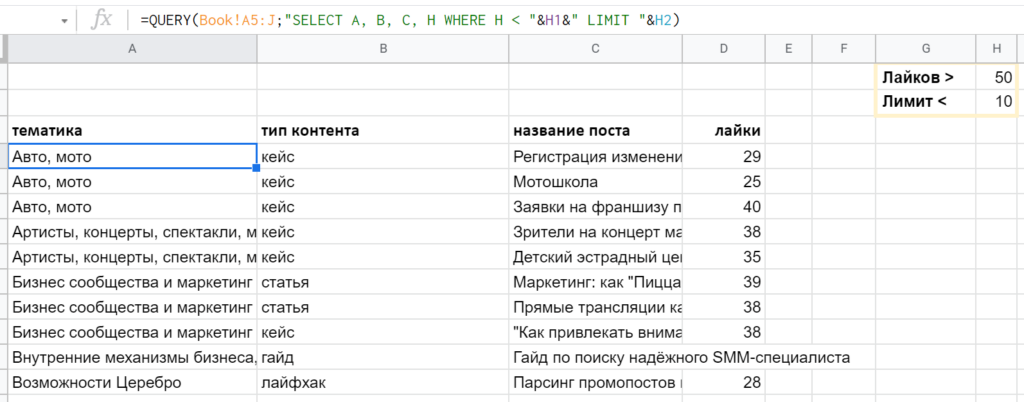
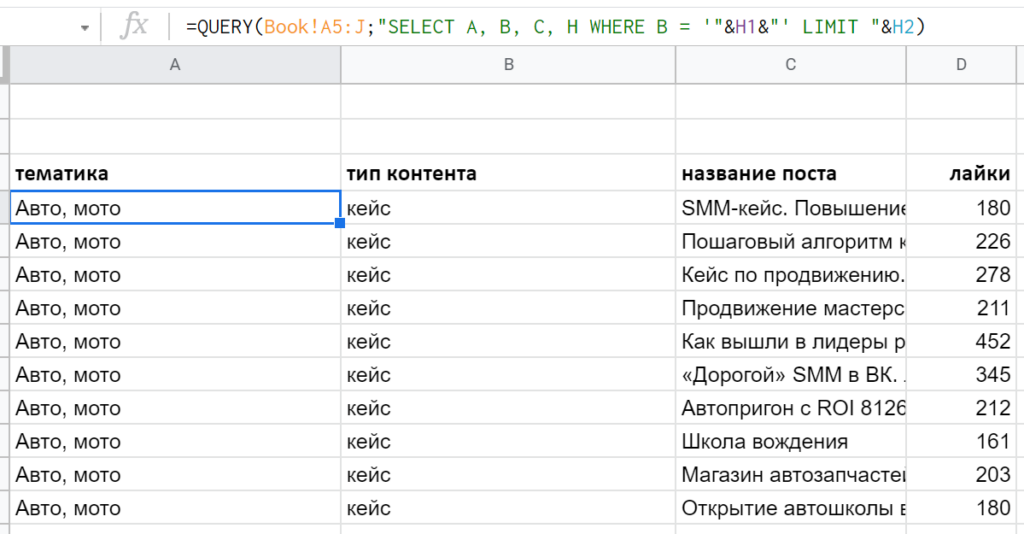
Если будете брать из ячеек текстовые значения, надо помнить про одинарные кавычки. Пример такого варианта: » SELECT A, B, C, H WHERE B = ‘ «&H1&» ‘ LIMIT «&H2
Подытожим
Google Таблицы — интересный и многофункциональный инструмент, который может решать самые разные задачи по многим направлениям: финансовому планированию, SEO, HR, SMM, веб-аналитике и т. д. и т. п. Но чтобы эффективно использовать любой, даже самый мощный сервис, нужно хорошо понимать — зачем и что именно нужно делать, какие данные брать и обрабатывать, как использовать результаты.
Обучающий центр CyberMarketing поможет освоить с нуля и дальше развиваться по всем основным тематикам интернет-маркетинга: созданию сайтов, контекстной рекламе, продвижению в соцсетях и др. У нас только полезный и качественный контент — статьи, вебинары, курсы для владельцев бизнеса, руководителей и специалистов.
Как быстро перенести данные в одну таблицу, перевести текст, вставить в ячейку картинку — показываем с помощью гифок.

Юлия Перминова
Тренер Учебного центра Softline с 2008 года.
«Google Таблицы» находятся в тени своего прославленного конкурента. Казалось бы, все трюки и приёмы, которые человеческий разум может придумать с электронными таблицами, уже воплощены в Microsoft Excel. Но продуктологи Google разработали целый ряд возможностей, которые удачно используют облачную природу сервиса. Представляем три функции, реализация которых простым и понятным способом пока присуща только продукту Google.
1. Подтягиваем данные в одну таблицу из разных книг и файлов
Представьте ситуацию: вам необходимо свести информацию из разных книг и даже из разных файлов с таблицами. Некоторые данные в исходных таблицах получены в ходе вычислений. Переносить их в Excel — работа несложная, но кропотливая и порой длительная.
В «Google Таблицах» можно переносить данные из одной таблицы или книги в другую и сохранять их единообразие. Если изменить цифры в исходном файле, откуда они были взяты, эти данные поменяются и в других документах, куда они были из исходника перенесены.
В этом пользователю помогает функция =IMPORTRANGE (импортирование диапазона). Чтобы воспользоваться ею:
- В файле и книге, куда следует перенести данные из других таблиц, выберите конкретную ячейку, куда бы вы хотели поместить данные.
- Задайте команду =IMPORTRANGE.
- Во всплывающем окне укажите ссылку на книгу или файл с таблицей, откуда требуется взять данные.
- Там же укажите диапазон данных (конкретные ячейки), которые вам нужно импортировать.
Готово. Если перейти в исходный файл и поменять данные там, они автоматически изменятся в новом документе. Это очень удобно, когда вы имеете дело с курсами валют и другими данными, которые постоянно меняются. Или когда от этих меняющихся данных зависят важные для вас цифры, например план продаж. Вы можете смело использовать их в других таблицах и быть уверенными, что они будут именно такими, как в исходном документе.
2. Используем «Google Переводчик» для содержимого ячеек
Очень простая и удобная функция, которая реализована на популярном продукте «Google Переводчик». Она использует функцию =TRANSLATE и умеет автоматически определять язык исходного слова или выражения.
Чтобы воспользоваться переводчиком в таблице:
- Выделите ячейку, куда будет помещён результат перевода.
- Задайте функцию =TRANSLATE.
- Укажите ячейку, контент из которой вам хотелось бы перевести.
- Если функция не определит язык перевода автоматически, задайте язык исходного слова и язык результата.
Функциональности «Google Переводчика» в «Google Таблицах» достаточно даже для перевода фраз и предложений.
3. Вставляем изображение в ячейку
Эта функция заставит пользователей Microsoft Excel с завистью посмотреть на юзеров «Google Таблиц».
Удивительно, но факт: в суперфункциональном редакторе таблиц из Редмонда вставка картинок в таблицы реализована очень неудобно. Да, если вам часто приходится создавать иллюстрированные прайс-листы в Excel, вы определённо набили руку. Но в «Google Таблицах» похожая задача решается гораздо проще.
Картинки вставляются с помощью функции =IMAGE в несколько шагов:
- Выделите ячейку, в которую вы хотите поместить изображение.
- Скопируйте прямую ссылку на изображение из адресной строки браузера.
- Отформатируйте картинку так, как вам нужно, просто изменяя размеры ячейки, где она расположена. Размер картинки в «Google Таблицах» меняется пропорционально и не даёт искажать изображение. Это очень удобно.
Эти три возможности «Google Таблиц» — прекрасный пример того, как разработчики наилучшим образом использовали облачную природу сервиса. Надеемся, что они будут полезны читателям.
ДНИ(дата_окончания; дата_начала)ДОЛЯГОДА(дата_начала; дата_окончания; [способ_расчета])РАБДЕНЬ(дата_начала, число_дней, [праздничные_дни])ISOWEEKNUM(дата)ВРЕМЗНАЧ(строка_времени)ВРЕМЯ(часы; минуты; секунды)ГОД(дата)ДАТА(год; месяц; день)ДАТАЗНАЧ(строка с датой)ДАТАМЕС(начальная дата)ДЕНЬ(дата)ДЕНЬНЕД(дата; тип недели)ДНЕЙ360(начальная дата; конечная дата; метод подсчета)КОНМЕСЯЦА(начальная дата; число месяцев)МЕСЯЦ(дата)МИНУТЫ(время)НОМНЕДЕЛИ(дата, [тип])РАЗНДАТ(начальная_дата, конечная_дата, период)СЕГОДНЯ()СЕКУНДЫ(время)ТДАТА()ЧАС(время)ЧИСТРАБДНИ(начальная дата; конечная дата; праздничные дни)ЧИСТРАБДНИ.INTL(дата _начала, дата_окончания, [выходные], [праздничные_дни])EPOCHTODATE(временная_метка, [единица]) БИТ.И(значение1; значение2)БИТ.ИЛИ(значение1; значение2)БИТ.ИСКЛИЛИ(значение1; значение2)БИТ.СДВИГЛ(значение; количество_битов)БИТ.СДВИГП(значение; количество_битов)ВОСЬМ.В.ШЕСТН(восьмеричное_число_со_знаком; [количество_знаков])ДЕС.В.ШЕСТН(десятичное_число; [количество_знаков])МНИМ.CSC(число)МНИМ.SIN (число)МНИМ.TAN(число)ПОРОГ(значение; [порог])ФОШ.ТОЧН(нижняя_граница; [верхняя_граница])IMCOSH(число)IMCOT(число)IMCOTH(число)IMCSCH(число)IMEXP(степень)IMLOG(значение; основание)IMLOG10(число)IMLOG2(значение)IMSEC(число)IMSECH(число)IMSINH(число)IMTANH(число)ВОСЬМ.В.ДВ(восьмеричное_число_со_знаком; количество_знаков)ВОСЬМ.В.ДЕС(восьмеричное_число_со_знаком)ДВ.В.ВОСЬМ(двоичное_число_со_знаком; количество_знаков)ДВ.В.ДЕС(двоичное_число_со_знаком)ДВ.В.ШЕСТН(двоичное_число_со_знаком; количество_знаков)ДЕЛЬТА(число1, [число2])ДЕС.В.ВОСЬМ(десятичное_число; количество_знаков)ДЕС.В.ДВ(десятичное_число; количество_знаков)ШЕСТН.В.ВОСЬМ(шестнадцатеричное_число_со_знаком; количество_знаков)ШЕСТН.В.ДЕС(шестнадцатеричное_число_со_знаком)COMPLEX(действительное_число; мнимая_единица; [суффикс])HEX2BIN(шестнадцатеричное_число_со_знаком; [количество_знаков])IMABS(число)IMAGINARY(комплексное_число)IMCONJUGATE(число)IMDIV(делимое; делитель)IMPRODUCT(значение1; [значение2; ...])IMREAL(комплексное_число)IMSUB(первое_число; второе_число)IMSUM(значение1; [значение2; ...])SORTN(диапазон; [n]; [режим_показа_совпадений]; [столбец_для_сортировки1, по_возрастанию1]; ...)FILTER(диапазон; условие_1; условие_2)SORT(диапазон; столбец_для_сортировки; по_возрастанию; столбец_для_сортировки_2, по_возрастанию_2)UNIQUE(диапазон)АМОРУВ(стоимость; дата_покупки; окончание_первого_периода; после_амортизации; период; ставка; [годовая_норма])ДАТАКУПОНДО(дата_расчета; дата_погашения; периодичность; [способ_расчета])ДАТАКУПОНПОСЛЕ(дата_расчета; дата_погашения; периодичность; [способ_расчета])НАКОПДОХОД(дата_выпуска; первый_срок_выплат; дата_расчета; ставка; номинальная_стоимость; периодичность; [способ_расчета])ПУО(стоимость; после_амортизации; срок_службы; начальный_период; конечный_период; [коэффициент]; [нет_переключения])СКИДКА(дата_расчета; дата_погашения; цена; номинальная_стоимость; [способ_расчета])PDURATION(ставка; текущее_значение; целевое_значение)RRI(число_периодов; текущее_значение; целевое_значение)АПЛ(стоимость; после_амортизации; срок_службы)АСЧ(стоимость; после_амортизации; срок_службы; период)БЗРАСПИС(стоимость; процентные_ставки)БС(ставка; число_платежей; сумма_платежа; текущий_размер_выплат; конец_или_начало)ВСД(денежные_потоки; примерная_ставка)ДДОБ(стоимость; после_амортизации; срок_службы; период; коэффициент)ДЛИТ(дата_расчета; дата_погашения; ставка; доходность; периодичность; [способ_расчета]).ДНЕЙКУПОНДО(дата_расчета; дата_погашения; периодичность; способ_расчета)ДОХОД(дата_расчета; дата_погашения; ставка; цена; номинальная_стоимость; периодичность; способ_расчета)ДОХОДКЧЕК(дата_расчета; дата_погашения; цена)ДОХОДСКИДКА(дата_расчета; дата_погашения; цена; номинальная_стоимость; способ_расчета)ИНОРМА(дата_покупки; дата_продажи; стоимость_при_покупке; стоимость_при_продаже; способ_расчета)КПЕР(ставка; сумма_платежа; текущий_размер_выплат; остаток; конец_или_начало)МВСД(денежные_потоки; ставка_инвестирования; ставка_реинвестирования)МДЛИТ(дата_расчета; дата_погашения; ставка; доходность; периодичность; способ_расчета)НАКОПДОХОДПОГАШ(дата_выпуска; дата_погашения; ставка; номинальная_стоимость; способ_расчета)НОМИНАЛ(эффективная_ставка; число_периодов)ОБЩДОХОД(ставка; число_платежей; текущий_размер_выплат; начальный_период; конечный_период; конец_или_начало)ОБЩПЛАТ(ставка; число_платежей; текущий_размер_выплат; начальный_период; конечный_период; конец_или_начало)ОСПЛТ(ставка; период; число_платежей; текущий_размер_выплат; желаемая_стоимость; конец_или_начало)ПЛТ(ставка; число_платежей; текущий_размер_выплат; желаемая_стоимость; конец_или_начало)ПРПЛТ(ставка; период; число_платежей; текущий_размер_выплат; остаток; конец_или_начало)ПС(ставка; число_платежей; сумма_платежа; желаемая_стоимость; конец_или_начало)РАВНОКЧЕК(дата_расчета; дата_погашения; ставка_дисконтирования)РУБЛЬ.ДЕС(десятичная_дробь; знаменатель)РУБЛЬ.ДРОБЬ(десятичное_число; знаменатель)СТАВКА(число_платежей; платеж; текущий_размер_выплат; желаемая_стоимость; конец_или_начало; примерная_ставка)ФУО(стоимость; после_амортизации; срок_службы; период; месяц)ЦЕНА(дата_расчета; дата_погашения; ставка; доходность; номинальная_стоимость; периодичность; способ_расчета)ЦЕНАКЧЕК(дата_расчета; дата_погашения; ставка_дисконтирования)ЦЕНАПОГАШ(дата_расчета; дата_погашения; дата_выпуска; ставка; доходность; способ_расчета)ЧИСЛКУПОН(дата_расчета; дата_погашения; периодичность; способ_расчета)ЧИСТВНДОХ(денежные_потоки; даты_выплат; примерная_ставка)ЧИСТНЗ(ставка_дисконтирования; денежные_потоки; даты_выплат)ЧПС(ставка_дисконтирования; платеж_1; платеж_2)ЭФФЕКТ(номинальная_ставка; число_периодов)COUPDAYS(дата_расчета; дата_погашения; периодичность; [способ_расчета])COUPDAYSNC(дата_расчета; дата_погашения; периодичность; [способ_расчета])PRICEDISC(дата_расчета; дата_погашения; ставка_дисконтирования; номинальная_стоимость; [способ_расчета])RECEIVED(дата_расчета; дата_погашения; размер_инвестиций; ставка_дисконтирования; [способ_расчета])ARRAYFORMULA(формула_массива)DETECTLANGUAGE(текст_или_диапазон)GOOGLEFINANCE(код; атрибут; начало; конец|количество_дней; интервал)GOOGLETRANSLATE(текст; язык_оригинала; язык_перевода)IMAGE(ссылка; размер)QUERY(данные; запрос; заголовки)SPARKLINE(данные; параметры)ISDATE(значение)ЕЛОГИЧ(значение)ЕНД(значение)ЕНЕТЕКСТ(значение)ЕОШ(значение)ЕОШИБКА(значение)ЕПУСТО(адрес)ЕССЫЛКА(значение)ЕТЕКСТ(значение)ЕЧИСЛО(значение)НД()ТИП.ОШИБКИ(источник)Ч(значение)ISEMAIL(значение)ISFORMULA(cell)TYPE(значение)ЯЧЕЙКА(тип_данных, ссылка)IFNA(значение; значение_при_ошибке_na)ЕСЛИ(источник; значение_при_соблюдении_условия; значение_при_несоблюдении_условия)ЕСЛИМН(условие1; значение1; [условие2; значение2]; …)ЕСЛИОШИБКА(значение; [значение_при_ошибке])И(логическое_значение_1; логическое_значение_2)ИЛИ(логическое_значение_1; логическое_значение_2)ИСТИНА()ЛОЖЬ()НЕ(источник)LAMBDA(имя, формула)LET(name1, value_expression1, [name2, …], [value_expression2, …], formula_expression )SWITCH(выражение; результат1; значение1, [по_умолчанию или результат2; значение2]; …)ПОЛУЧИТЬ.ДАННЫЕ.СВОДНОЙ.ТАБЛИЦЫ(название_значения; любая_ячейка_сводной_таблицы; [исходный_столбец, ...]; [элемент_сводной_таблицы, ...]FORMULATEXT(ячейка)АДРЕС(строка; столбец; тип_адреса; стиль_a1)ВПР(запрос; диапазон; номер_столбца; отсортировано)ВЫБОР(индекс; значение_1; значение_2)ГПР(запрос; диапазон; номер_строки; отсортировано)ДВССЫЛ(ссылка)ИНДЕКС(ссылка; строка; столбец)ПОИСКПОЗ(запрос; диапазон; метод_поиска)ПРОСМОТР(запрос, диапазон_поиска|массив_результатов_поиска, [диапазон_результатов])СМЕЩ(адрес_ячейки; число_строк; число_столбцов; высота; ширина)СТОЛБЕЦ(адрес_ячейки)СТРОКА(адрес_ячейки)ЧИСЛСТОЛБ(диапазон)ЧСТРОК(диапазон)XLOOKUP(запрос, диапазон, диапазон_результатов, отсутствующее_значение, [режим_соответствия], [режим_поиска])ГАММАНЛОГ.ТОЧН(значение)ДФОШ(z)ОКРВВЕРХ.МАТ(число; [точность]; [режим])ОКРВВЕРХ.ТОЧН(число; [точность])ОКРВНИЗ.МАТ(число; [точность]; [режим])ОСНОВАНИЕ(значение; основание; [мин_длина])ЧИСЛКОМБА(n; k)ACOT(число)ACOTH(число)COT(угол)COTH(значение)CSC(угол)ISO.ОКРВВЕРХ(число; [точность])MUNIT(размерность)SEQUENCE(число_строк; число_столбцов; первое_значение; шаг)ГАММАНЛОГ(значение)ГРАДУСЫ(угол)ДВФАКТР(значение)ДФОШ(Z)ЕНЕЧЁТ(значение)ЕЧЁТН(значение)ЗНАК(значение)КОРЕНЬ(значение)КОРЕНЬПИ(значение)МУЛЬТИНОМ(значение_1; значение_2)НЕЧЁТ(значение)НОД(значение_1; значение_2)НОК(значение_1; значение_2)ОКРВВЕРХ(значение; точность)ОКРВНИЗ(значение; точность)ОКРУГЛ(значение; число_знаков)ОКРУГЛВВЕРХ(значение; число_знаков)ОКРУГЛВНИЗ(значение; число_знаков)ОКРУГЛТ(значение; точность)ОСТАТ(делимое; делитель)ОТБР(значение; число_знаков)ПИ()ПРОИЗВЕД(значение_1; значение_2)ПРОМЕЖУТОЧНЫЕ.ИТОГИ(код_функции; диапазон_1; диапазон_2)РАДИАНЫ(угол)РЯД.СУММ(X; n; m; a)i – это число коэффициентов в массиве a. Подробнее…
СЛУЧМЕЖДУ(от; до)СЛЧИС()СТЕПЕНЬ(исходное_число; степень)СУММ(значение_1; значение_2)СУММЕСЛИ(диапазон; условие; сумма_диапазона)СУММЕСЛИМН(сумма_диапазона, диапазон_критериев1, критерий1, [диапазон_критериев2, критерий2 и т. д.])СУММКВ(значение_1; значение_2)СЧЁТЕСЛИ(диапазон; условие)СЧЁТЕСЛИМН(диапазон_критериев1, критерий1, [диапазон_критериев2, критерий2 и т. д.])СЧИТАТЬПУСТОТЫ(диапазон)ФАКТР(значение)ЦЕЛОЕ(значение)ЧАСТНОЕ(делимое; делитель)ЧЁТН(значение)ЧИСЛКОМБ(n; k)ABS(значение)ACOS(значение)ACOSH(значение)ASIN(значение)ASINH(значение)ATAN(значение)ATAN2(X; Y)ATANH(значение)COS(угол)COSH(значение)COUNTUNIQUE(значение_1; значение_2)EXP(степень)LN(значение)LOG(значение; основание)LOG10(значение)SIN(угол)SINH(значение)TAN(угол)TANH(значение)ADD(значение_1; значение_2)CONCAT(значение_1; значение_2)DIVIDE(делимое; делитель)EQ(значение_1; значение_2)GT(значение_1; значение_2)GTE(значение_1; значение_2)ISBETWEEN(value_to_compare, lower_value, upper_value, lower_value_is_inclusive, upper_value_is_inclusive)LT(значение_1; значение_2)LTE(значение_1; значение_2)MINUS(значение_1; значение_2)MULTIPLY(значение_1; значение_2)NE(значение_1; значение_2)POW(исходное_число; степень)UMINUS(значение)UNARY_PERCENT(проценты)UNIQUE(range, by_column, exactly_once)UPLUS(значение)БЕТА.ОБР(вероятность; альфа; бета; нижняя_граница; верхняя_граница)БЕТАРАСП(значение; альфа; бета; нижняя_граница; верхняя_граница)БИНОМ.ОБР(число_попыток; вероятность_успеха; вероятность)БИНОМ.РАСП(успешные_попытки; число_попыток; вероятность_успеха; интегральная)ВЕЙБУЛЛ.РАСП(x; форма; масштаб; интегральная)ГИПЕРГЕОМЕТ(успешные_попытки; число_попыток; число_успешных; размер_выборки)ДИСП.Р(значение1; [значение2; ...])ДИСП.С(значение1; [значение2; ...])КВАРТИЛЬ.ВКЛ(данные; номер_квартиля) ЛОГНОРМ.ОБР(x; среднее; стандартное_отклонение)ЛОГНОРМ.РАСП(x; среднее; стандартное_отклонение)НОРМ.ОБР(x; среднее; стандартное_отклонение)НОРМ.РАСП(x; среднее; стандартное_отклонение; интегральная)НОРМ.СТ.ОБР(x)НОРМ.СТ.РАСП(x)ОТРБИНОМ.РАСП(число_неудач; успешные_попытки; вероятность)ПЕРСЕНТИЛЬ.ВКЛ(данные; процентиль)ПРЕДСКАЗ.ЛИНЕЙН(x; данные_y; данные_х)СТАНДОТКЛОН.П(значение1; [значение2; ...])СТАНДОТКЛОН.С(значение1; [значение2; ...])ХИ2.ТЕСТ(фактический_диапазон; ожидаемый_диапазон)ХИ2ТЕСТ(фактический_интервал, ожидаемый_интервал)ЭКСПРАСП(x, LAMBDA, интегральная_функция)AVERAGE.WEIGHTED(значения; взвешенные; [дополнительные_значения]; [дополнительные_взвешенные])BETA.DIST(значение; альфа; бета; интегральная_функция; нижняя_граница; верхняя_граница)CONFIDENCE.NORM(альфа; стандартное_отклонение; выборка)CONFIDENCE.T(альфа; стандартное_отклонение; размер)COVARIANCE.P(данные_y; данные_x)COVARIANCE.S(данные_y; данные_x)F.TEST(диапазон1; диапазон2)GAMMA(число)GAMMAINV(вероятность; альфа; бета)MODE.MULT(значение1; значение2)MODE.SNGL(значение1; [значение2; ...])PERCENTILE.EXC(данные; процентиль)PERMUTATIONA(число; число_выбранных)POISSON.DIST(x; среднее; [интегральная_функция])QUARTILE.EXC(данные; номер_квартиля)SKEW.P(значение1; значение2)T.DIST(x; степени_свободы; интегральная_функция)T.DIST.2T(x; степени_свободы)T.DIST.RT(x; степени_свободы)T.TEST(диапазон1; диапазон2; хвосты; тип)Z.TEST(данные; значение; [стандартное_отклонение])БИНОМРАСП(успешные_испытания; попытки; успех; распределение)ВЕЙБУЛЛ(X; форма; масштаб; распределение)ВЕРОЯТНОСТЬ(данные; вероятности; нижняя_граница; верхняя_граница)ГАММА.РАСП(x; альфа; бета; распределение)ГАММАРАСП(x; альфа; бета; распределение)ГИПЕРГЕОМЕТ(успешные_испытания; выборка; успех; всего_испытаний)ДИСП(значение1, значение2)ДИСПА(значение_1; значение_2)ДИСПР(значение1, значение2)ДИСПРА(значение1, значение2)ДОВЕРИТ(альфа; стандартное_отклонение; выборка)КВАДРОТКЛ(значение_1; значение_2)КВАРТИЛЬ(данные; тип_квартиля)КВПИРСОН(данные_y; данные_x)КОВАР(данные_y; данные_x)КОРРЕЛ(данные_y; данные_x)КРИТБИНОМ(попытки; успех; вероятность)ЛОГНОРМОБР(X; среднее; стандартное_отклонение)ЛОГНОРМРАСП(X; среднее; стандартное_отклонение)МАКС(значение_1; значение_2)МАКСА(значение_1; значение_2)МАКСЕСЛИ(диапазон; диапазон_критериев1; критерий1; [диапазон_критериев2; критерий2]; …)МЕДИАНА(значение_1; значение_2)МИН(значение_1; значение_2)МИНА(значение_1; значение_2)МИНЕСЛИ(диапазон; диапазон_критериев1; критерий1; [диапазон_критериев; критерий2]; …)МОДА(значение_1; значение_2)НАИБОЛЬШИЙ(данные; n)НАИМЕНЬШИЙ(данные; n)НАКЛОН(данные_y; данные_x)НОРМАЛИЗАЦИЯ(значение; среднее; стандартное_отклонение)НОРМОБР(X; среднее; стандартное_отклонение)НОРМРАСП(X; среднее; стандартное_отклонение; распределение)НОРМСТОБР(X)НОРМСТРАСП(X)ОТРБИНОМРАСП(неудачи; успешные_испытания; успех)ОТРЕЗОК(данные_y; данные_x)ПЕРЕСТ(n; k)ПЕРСЕНТИЛЬ(данные; процентиль)ПРЕДСКАЗ(X; данные_y; данные_x)ПРОЦЕНТРАНГ.ВКЛ(данные, значение, [количество_знаков])ПРОЦЕНТРАНГ.ИСКЛ(данные, значение, [количество_знаков])ПРОЦЕНТРАНГ(данные, значение, [количество_знаков])ПУАССОН(X; среднее; распределение)РАНГ.РВ(значение, данные, [сортировка])РАНГ.СР(значение, данные, [сортировка])РАНГ(значение; данные; сортировка)СКОС(значение_1; значение_2)СРГАРМ(значение_1; значение_2)СРГЕОМ(значение_1; значение_2)СРЗНАЧ(значение_1; значение_2)СРЗНАЧА(значение_1; значение_2)СРЗНАЧЕСЛИ(диапазон_критериев, критерий, [средний_диапазон])СРЗНАЧЕСЛИМН(средний_диапазон, диапазон_критериев1, критерий1, [диапазон_критериев2, критерий2 и т. д.])СРОТКЛ(значение_1; значение_2)СТАНДОТКЛОН(значение1, значение2)СТАНДОТКЛОНА(значение1, значение2)СТАНДОТКЛОНП(значение1, значение2)СТАНДОТКЛОНПА(значение1, значение2)СТОШYX(данные_y; данные_x)СТЬЮДЕНТ.ОБР.2Х(вероятность, степени_свободы)СТЬЮДЕНТ.ОБР(вероятность, степени_свободы)СТЬЮДРАСП(x, степени_свободы, хвосты)СТЬЮДРАСПОБР(вероятность, степени_свободы)СЧЁТ(значение1, [значение2, ...])СЧЁТЗ(значение1; [значение2; ...])ТТЕСТ(диапазон1, диапазон2, хвосты, тип)УРЕЗСРЕДНЕЕ(данные; исключения)ФИШЕР(значение)ФИШЕРОБР(значение)ХИ2.ОБР(вероятность, степени_свободы)ХИ2.ОБР.ПХ(вероятность, степени_свободы)ХИ2.РАСП(x, степени_свободы, интегральная)ХИ2.РАСП.ПХ(x, степени_свободы)ХИ2ОБР(вероятность, степени_свободы)ХИ2РАСП(x, степени_свободы)ЭКСПРАСП(x, лямбда, интегральная_функция)ЭКСЦЕСС(значение_1; значение_2)F.ОБР(вероятность, степени_свободы1, степени_свободы2)F.ОБР.ПХ(вероятность, степени_свободы1, степени_свободы2)F.РАСП.ПХ(x, степени_свободы1, степени_свободы2)F.РАСП(х, степени_свободы1, степени_свободы2, интегральная_функция)FОБР(вероятность; степени_свободы1; степени_свободы2)FРАСП(х, степени_свободы1, степени_свободы2)FТЕСТ(диапазон1; диапазон2)MARGINOFERROR(диапазон, доверие)PEARSON(данные_y; данные_x)ZТЕСТ(данные; значение; стандартное_отклонение)ASC(текст)LEFTB(строка; число_байтов)LENB(строка)MIDB(строка)REPLACEB(текст; начало; число_байтов; замена)RIGHTB(строка; число_байтов)UNICHAR(номер)SPLIT(текст; разделитель; [тип_разделителя]; [удаление_пустых_ячеек])АРАБСКОЕ(число)ДЛСТР(текст)ЗАМЕНИТЬ(текст; начало; длина; замена)ЗНАЧЕН(данные)КОДСИМВ(строка)ЛЕВСИМВ(строка; число_символов)НАЙТИ(запрос; текст; начало)НАЙТИБ(запрос, текст, [начало])ПЕЧСИМВ(текст)ПОВТОР(текст; повтор)ПОДСТАВИТЬ(текст; запрос; замена; номер_соответствия)ПОИСК(запрос; текст; начало)ПОИСКБ(запрос, текст, [начало])ПРАВСИМВ(строка; число_символов)ПРОПИСН(текст)ПРОПНАЧ(текст)ПСТР(строка; начало; длина_отрезка)РИМСКОЕ(число; упрощение)РУБЛЬ(число; десятичные_разряды)СЖПРОБЕЛЫ(текст)СИМВОЛ(код)СОВПАД(строка_1; строка_2)СТРОЧН(текст)СЦЕПИТЬ(строка_1; строка_2)ТЕКСТ(число; формат)ФИКСИРОВАННЫЙ(число; десятичные_разряды; убрать_разделитель)JOIN(разделитель; значение_или_массив_1; значение_или_массив_2)REGEXEXTRACT(текст; регулярное_выражение)REGEXMATCH(текст; регулярное_выражение)REGEXREPLACE(текст; регулярное_выражение; замена)T(значение)TEXTJOIN(разделитель; игнорировать_пустые; текст1; [текст2]; …)UNICODE(текст)БДДИСП(данные; столбец; критерии)БДДИСПП(данные; столбец; критерии)БДПРОИЗВЕД(данные; столбец; критерии)БДСУММ(данные; столбец; критерии)БИЗВЛЕЧЬ(данные; столбец; критерии)БСЧЁТ(данные; столбец; критерии)БСЧЁТА(данные; столбец; критерии)ДМАКС(данные; столбец; критерии)ДМИН(данные; столбец; критерии)ДСРЗНАЧ(данные; столбец; критерии)ДСТАНДОТКЛ(данные; столбец; критерии)ДСТАНДОТКЛП(данные; столбец; критерии)ПРЕОБР(значение, исходная_единица_измерения, конечная_единица_измерения)TO_DATE(значение)TO_DOLLARS(значение)TO_PERCENT(значение)TO_PURE_NUMBER(значение)TO_TEXT(значение)ЛГРФПРИБЛ(исходные_данные_y; исходные_данные_x; b; статистика)ЛИНЕЙН(исходные_данные_y; исходные_данные_x; b; статистика)МОБР(квадратная_матрица)МОПРЕД(квадратная_матрица)МУМНОЖ(матрица_1; матрица_2)РОСТ(исходные_данные_y; исходные_данные_x; новые_данные_x; b)СУММКВРАЗН(массив_x; массив_y)СУММПРОИЗВ(массив_1; массив_2)СУММРАЗНКВ(массив_x; массив_y)СУММСУММКВ(массив_x; массив_y)ТЕНДЕНЦИЯ(исходные_данные_y; исходные_данные_x; новые_данные_x; b)ТРАНСП(массив)ЧАСТОТА(данные; классы)ARRAY_CONSTRAIN(диапазон, количество_строк, количество_столбцов)BYCOL(массив_или_диапазон, LAMBDA)BYROW(массив_или_диапазон, LAMBDA)CHOOSECOLS(массив, номер_столбца1, [номер_столбца2])CHOOSEROWS(массив, номер_строки1, [номер_строки2])FLATTEN(диапазон1, [диапазон2,…])HSTACK(диапазон1; [диапазон2, …])MAKEARRAY(число_строк, число_столбцов, LAMBDA)MAP(массив1, [массив2, …], LAMBDA)REDUCE(начальное_значение, массив_или_диапазон, LAMBDA)SCAN(начальное_значение, массив_или_диапазон, LAMBDA)TOCOL(array_or_range, [ignore], [scan_by_column])TOROW(array_or_range, [ignore], [scan_by_column])VSTACK(диапазон1; [диапазон2, …])WRAPCOLS(диапазон, количество_ячеек, [заполняющее_значение])WRAPROWS(диапазон, количество_ячеек, [заполняющее_значение])КОДИР.URL(текст)HYPERLINK(ссылка, [текст_ссылки]).IMPORTDATA(ссылка).IMPORTFEED(ссылка; [запрос]; [заголовки]; [число_объектов]).IMPORTHTML(ссылка; запрос; индекс).IMPORTRANGE(ключ_таблицы; диапазон).IMPORTXML(ссылка; запрос_xpath).ISURL(значение).