
Содержание
- Вычисление дисперсии
- Способ 1: расчет по генеральной совокупности
- Способ 2: расчет по выборке
- Вопросы и ответы

Среди множества показателей, которые применяются в статистике, нужно выделить расчет дисперсии. Следует отметить, что выполнение вручную данного вычисления – довольно утомительное занятие. К счастью, в приложении Excel имеются функции, позволяющие автоматизировать процедуру расчета. Выясним алгоритм работы с этими инструментами.
Вычисление дисперсии
Дисперсия – это показатель вариации, который представляет собой средний квадрат отклонений от математического ожидания. Таким образом, он выражает разброс чисел относительно среднего значения. Вычисление дисперсии может проводиться как по генеральной совокупности, так и по выборочной.
Способ 1: расчет по генеральной совокупности
Для расчета данного показателя в Excel по генеральной совокупности применяется функция ДИСП.Г. Синтаксис этого выражения имеет следующий вид:
=ДИСП.Г(Число1;Число2;…)
Всего может быть применено от 1 до 255 аргументов. В качестве аргументов могут выступать, как числовые значения, так и ссылки на ячейки, в которых они содержатся.
Посмотрим, как вычислить это значение для диапазона с числовыми данными.
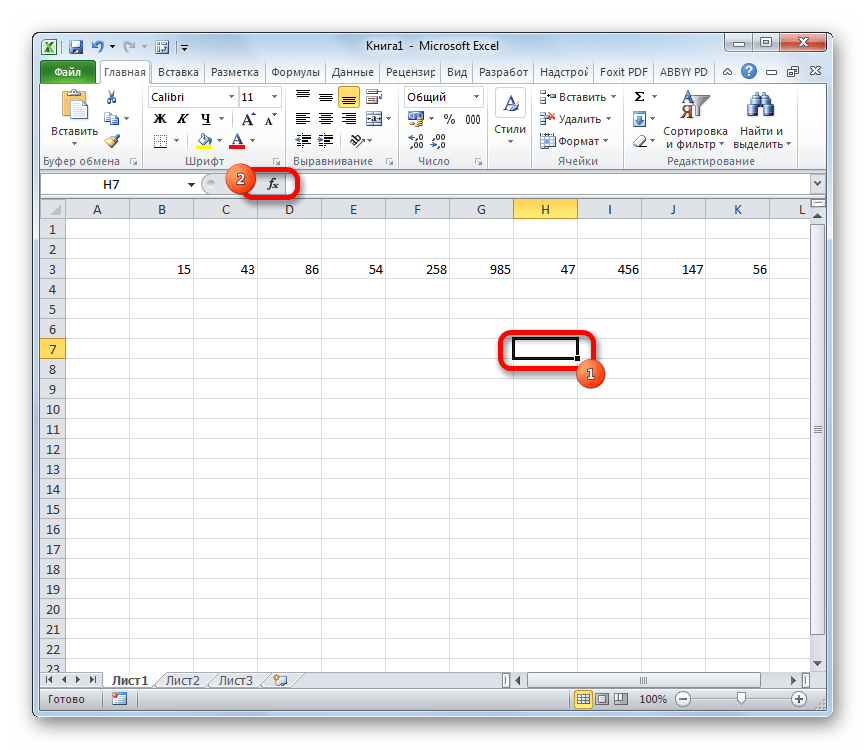
- Производим выделение ячейки на листе, в которую будут выводиться итоги вычисления дисперсии. Щелкаем по кнопке «Вставить функцию», размещенную слева от строки формул.
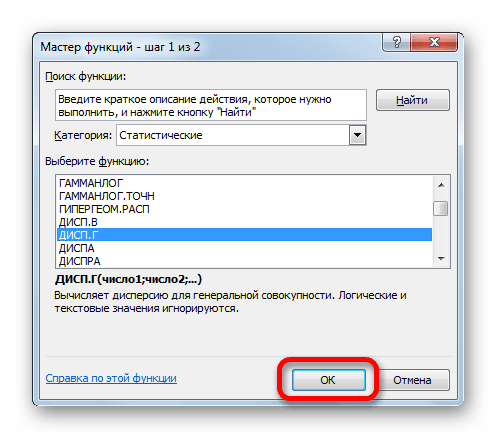
- Запускается Мастер функций. В категории «Статистические» или «Полный алфавитный перечень» выполняем поиск аргумента с наименованием «ДИСП.Г». После того, как нашли, выделяем его и щелкаем по кнопке «OK».
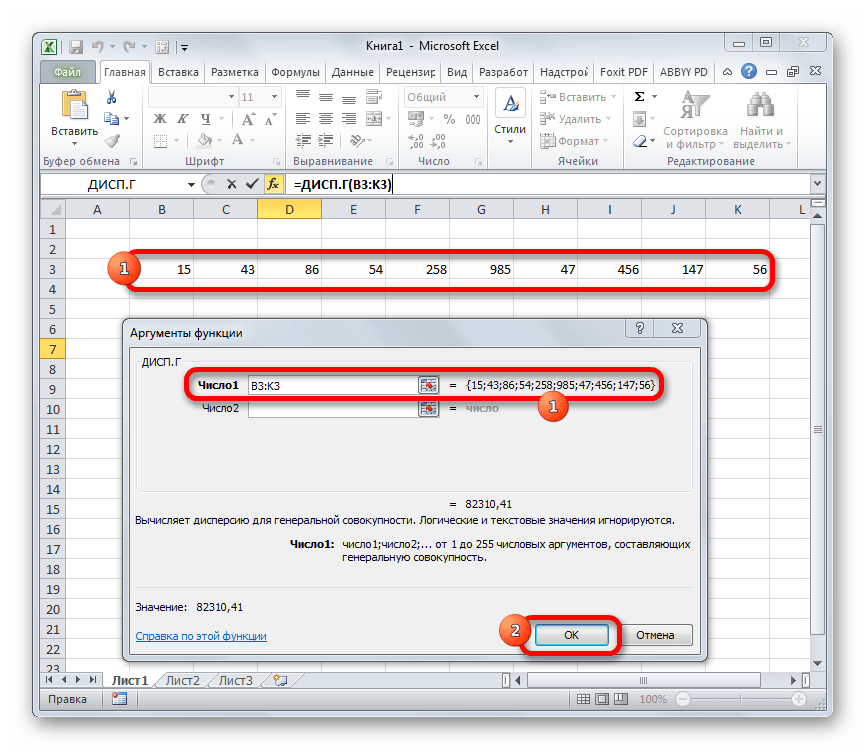
- Выполняется запуск окна аргументов функции ДИСП.Г. Устанавливаем курсор в поле «Число1». Выделяем на листе диапазон ячеек, в котором содержится числовой ряд. Если таких диапазонов несколько, то можно также использовать для занесения их координат в окно аргументов поля «Число2», «Число3» и т.д. После того, как все данные внесены, жмем на кнопку «OK».
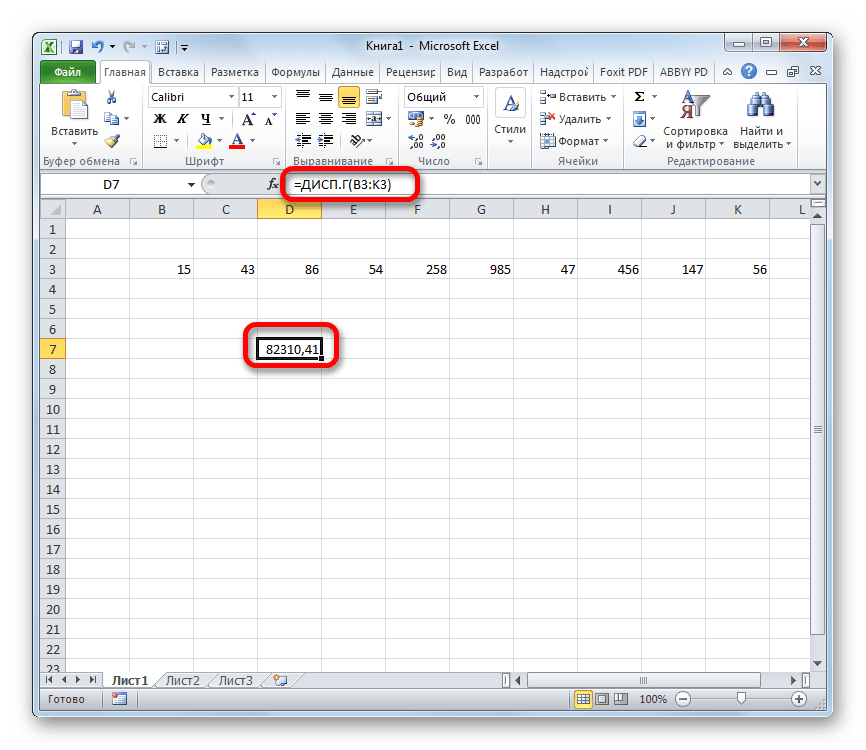
- Как видим, после этих действий производится расчет. Итог вычисления величины дисперсии по генеральной совокупности выводится в предварительно указанную ячейку. Это именно та ячейка, в которой непосредственно находится формула ДИСП.Г.
Урок: Мастер функций в Эксель
Способ 2: расчет по выборке
В отличие от вычисления значения по генеральной совокупности, в расчете по выборке в знаменателе указывается не общее количество чисел, а на одно меньше. Это делается в целях коррекции погрешности. Эксель учитывает данный нюанс в специальной функции, которая предназначена для данного вида вычисления – ДИСП.В. Её синтаксис представлен следующей формулой:
=ДИСП.В(Число1;Число2;…)
Количество аргументов, как и в предыдущей функции, тоже может колебаться от 1 до 255.

- Выделяем ячейку и таким же способом, как и в предыдущий раз, запускаем Мастер функций.
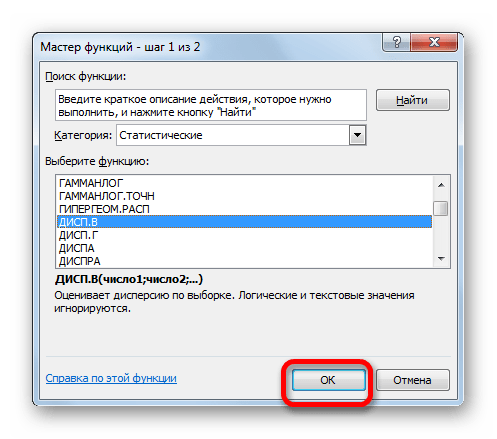
- В категории «Полный алфавитный перечень» или «Статистические» ищем наименование «ДИСП.В». После того, как формула найдена, выделяем её и делаем клик по кнопке «OK».
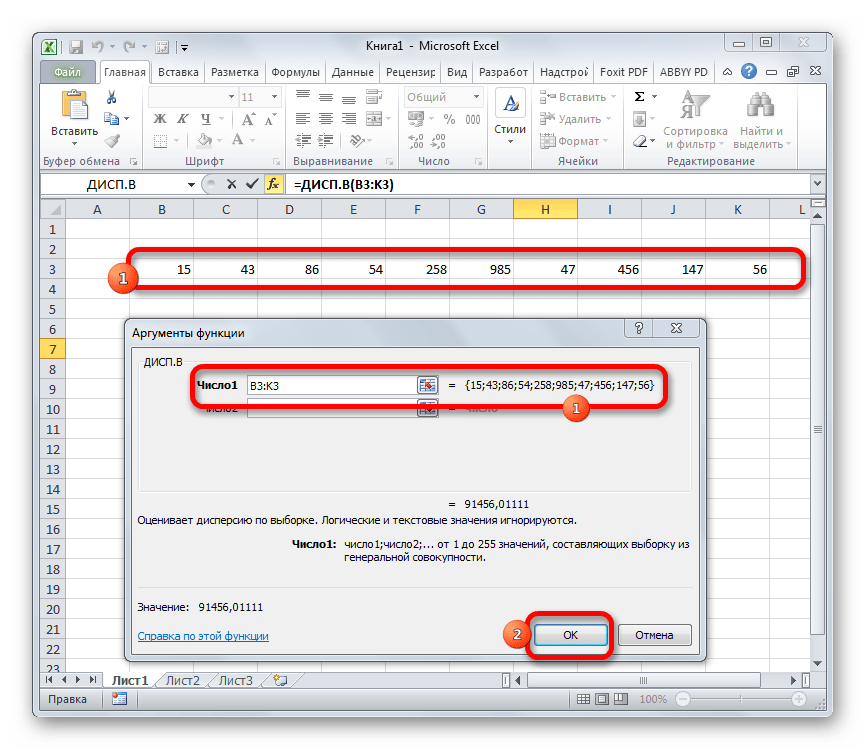
- Производится запуск окна аргументов функции. Далее поступаем полностью аналогичным образом, как и при использовании предыдущего оператора: устанавливаем курсор в поле аргумента «Число1» и выделяем область, содержащую числовой ряд, на листе. Затем щелкаем по кнопке «OK».
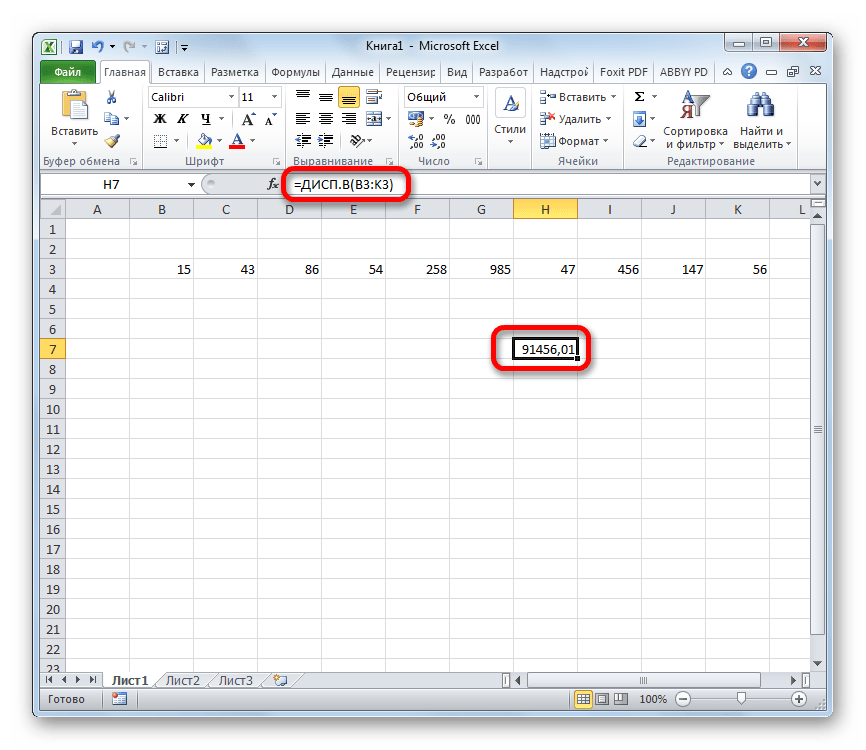
- Результат вычисления будет выведен в отдельную ячейку.
Урок: Другие статистические функции в Эксель
Как видим, программа Эксель способна в значительной мере облегчить расчет дисперсии. Эта статистическая величина может быть рассчитана приложением, как по генеральной совокупности, так и по выборке. При этом все действия пользователя фактически сводятся только к указанию диапазона обрабатываемых чисел, а основную работу Excel делает сам. Безусловно, это сэкономит значительное количество времени пользователей.
Еще статьи по данной теме:
Помогла ли Вам статья?
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
Оценивает стандартное отклонение по выборке. Стандартное отклонение — это мера того, насколько широко разбросаны точки данных относительно их среднего.
Важно: Эта функция была заменена одной или несколькими новыми функциями, которые обеспечивают более высокую точность и имеют имена, лучше отражающие их назначение. Хотя эта функция все еще используется для обеспечения обратной совместимости, она может стать недоступной в последующих версиях Excel, поэтому мы рекомендуем использовать новые функции.
Дополнительные сведения о новом варианте этой функции Функция СТАНДОТКЛОН.В.
Синтаксис
СТАНДОТКЛОН(число1;[число2];…)
Аргументы функции СТАНДОТКЛОН описаны ниже.
-
Число1 Обязательный. Первый числовой аргумент, соответствующий выборке из генеральной совокупности.
-
Число2… Необязательный. Числовые аргументы 2—255, соответствующие выборке из генеральной совокупности. Вместо аргументов, разделенных точкой с запятой, можно использовать массив или ссылку на массив.
Замечания
-
Функция СТАНДОТКЛОН предполагает, что аргументы являются только выборкой из генеральной совокупности. Если данные представляют всю генеральную совокупность, то стандартное отклонение следует вычислять с помощью функции СТАНДОТКЛОНП.
-
Стандартное отклонение вычисляется с использованием «n-1» метода.
-
Аргументы могут быть либо числами, либо содержащими числа именами, массивами или ссылками.
-
Учитываются логические значения и текстовые представления чисел, которые непосредственно введены в список аргументов.
-
Если аргумент является массивом или ссылкой, то учитываются только числа. Пустые ячейки, логические значения, текст и значения ошибок в массиве или ссылке игнорируются.
-
Аргументы, которые представляют собой значения ошибок или текст, не преобразуемый в числа, вызывают ошибку.
-
Чтобы включить логические значения и текстовые представления чисел в ссылку как часть вычисления, используйте функцию СТАНДОТКЛОНА.
-
Функция СТАНДОТКЛОН вычисляется по следующей формуле:

где x — выборочное среднее СРЗНАЧ(число1,число2,…), а n — размер выборки.
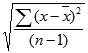
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Данные |
||
|---|---|---|
|
Прочность |
||
|
1345 |
||
|
1301 |
||
|
1368 |
||
|
1322 |
||
|
1310 |
||
|
1370 |
||
|
1318 |
||
|
1350 |
||
|
1303 |
||
|
1299 |
||
|
Формула |
Описание (результат) |
Результат |
|
=СТАНДОТКЛОН(A3:A12) |
Стандартное отклонение предела прочности (27,46392) |
27,46392 |
Нужна дополнительная помощь?
Из предыдущей статьи мы узнали о таких показателях, как размах вариации, межквартильный размах и среднее линейное отклонение. В этой статье изучим дисперсию, среднеквадратичное отклонение и коэффициент вариации.
Дисперсия
Дисперсия случайной величины – это один из основных показателей в статистике. Он отражает меру разброса данных вокруг средней арифметической.
Сейчас небольшой экскурс в теорию вероятностей, которая лежит в основе математической статистики. Как и матожидание, дисперсия является важной характеристикой случайной величины. Если матожидание отражает центр случайной величины, то дисперсия дает характеристику разброса данных вокруг центра.
Формула дисперсии в теории вероятностей имеет вид:
![]()
То есть дисперсия — это математическое ожидание отклонений от математического ожидания.
На практике при анализе выборок математическое ожидание, как правило, не известно. Поэтому вместо него используют оценку – среднее арифметическое. Расчет дисперсии производят по формуле:
![]()
где
s2 – выборочная дисперсия, рассчитанная по данным наблюдений,
X – отдельные значения,
X̅– среднее арифметическое по выборке.
Стоит отметить, что у такого расчета дисперсии есть недостаток – она получается смещенной, т.е. ее математическое ожидание не равно истинному значению дисперсии. Подробней об этом здесь. Однако при увеличении объема выборки она все-таки приближается к своему теоретическому аналогу, т.е. является асимптотически не смещенной.
Простыми словами дисперсия – это средний квадрат отклонений. То есть вначале рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат, складывается и затем делится на количество значений в данной совокупности. Разница между отдельным значением и средней отражает меру отклонения. В квадрат возводится для того, чтобы все отклонения стали исключительно положительными числами и чтобы избежать взаимоуничтожения положительных и отрицательных отклонений при их суммировании. Затем, имея квадраты отклонений, просто рассчитываем среднюю арифметическую. Средний – квадрат – отклонений. Отклонения возводятся в квадрат, и считается средняя. Теперь вы знаете, как найти дисперсию.
Генеральную и выборочную дисперсии легко рассчитать в Excel. Есть специальные функции: ДИСП.Г и ДИСП.В соответственно.

В чистом виде дисперсия не используется. Это вспомогательный показатель, который нужен в других расчетах. Например, в проверке статистических гипотез или расчете коэффициентов корреляции. Отсюда неплохо бы знать математические свойства дисперсии.
Свойства дисперсии
Свойство 1. Дисперсия постоянной величины A равна 0 (нулю).
D(A) = 0
Свойство 2. Если случайную величину умножить на постоянную А, то дисперсия этой случайной величины увеличится в А2 раз. Другими словами, постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат.
D(AX) = А2 D(X)
Свойство 3. Если к случайной величине добавить (или отнять) постоянную А, то дисперсия останется неизменной.
D(A + X) = D(X)
Свойство 4. Если случайные величины X и Y независимы, то дисперсия их суммы равна сумме их дисперсий.
D(X+Y) = D(X) + D(Y)
Свойство 5. Если случайные величины X и Y независимы, то дисперсия их разницы также равна сумме дисперсий.
D(X-Y) = D(X) + D(Y)
Среднеквадратичное (стандартное) отклонение
Если из дисперсии извлечь квадратный корень, получится среднеквадратичное (стандартное) отклонение (сокращенно СКО). Встречается название среднее квадратичное отклонение и сигма (от названия греческой буквы). Общая формула стандартного отклонения в математике следующая:
![]()
На практике формула стандартного отклонения следующая:
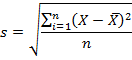
Как и с дисперсией, есть и немного другой вариант расчета. Но с ростом выборки разница исчезает.
Расчет cреднеквадратичного (стандартного) отклонения в Excel
Для расчета стандартного отклонения достаточно из дисперсии извлечь квадратный корень. Но в Excel есть и готовые функции: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В (по генеральной и выборочной совокупности соответственно).
 отклонение в Excel")
Среднеквадратичное отклонение имеет те же единицы измерения, что и анализируемый показатель, поэтому является сопоставимым с исходными данными.
Коэффициент вариации
Значение стандартного отклонения зависит от масштаба самих данных, что не позволяет сравнивать вариабельность разных выборках. Чтобы устранить влияние масштаба, необходимо рассчитать коэффициент вариации по формуле:
![]()
По нему можно сравнивать однородность явлений даже с разным масштабом данных. В статистике принято, что, если значение коэффициента вариации менее 33%, то совокупность считается однородной, если больше 33%, то – неоднородной. В реальности, если коэффициент вариации превышает 33%, то специально ничего делать по этому поводу не нужно. Это информация для общего представления. В общем коэффициент вариации используют для оценки относительного разброса данных в выборке.
Расчет коэффициента вариации в Excel
Расчет коэффициента вариации в Excel также производится делением стандартного отклонения на среднее арифметическое:
=СТАНДОТКЛОН.В()/СРЗНАЧ()
Коэффициент вариации обычно выражается в процентах, поэтому ячейке с формулой можно присвоить процентный формат:

Коэффициент осцилляции
Еще один показатель разброса данных на сегодня – коэффициент осцилляции. Это соотношение размаха вариации (разницы между максимальным и минимальным значением) к средней. Готовой формулы Excel нет, поэтому придется скомпоновать три функции: МАКС, МИН, СРЗНАЧ.

Коэффициент осцилляции показывает степень размаха вариации относительно средней, что также можно использовать для сравнения различных наборов данных.
Таким образом, в статистическом анализе существует система показателей, отражающих разброс или однородность данных.
Ниже видео о том, как посчитать коэффициент вариации, дисперсию, стандартное (среднеквадратичное) отклонение и другие показатели вариации в Excel.
Поделиться в социальных сетях:
Вычислим в
MS
EXCEL
дисперсию и стандартное отклонение выборки. Также вычислим дисперсию случайной величины, если известно ее распределение.
Сначала рассмотрим
дисперсию
, затем
стандартное отклонение
.
Дисперсия выборки
Дисперсия выборки
(
выборочная дисперсия,
sample
variance
) характеризует разброс значений в массиве относительно
среднего
.
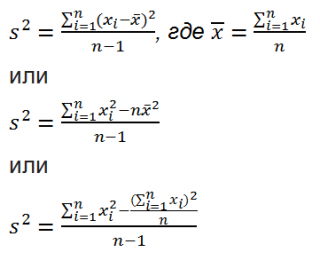
Все 3 формулы математически эквивалентны.
Из первой формулы видно, что
дисперсия выборки
это сумма квадратов отклонений каждого значения в массиве
от среднего
, деленная на размер выборки минус 1.
В MS EXCEL 2007 и более ранних версиях для вычисления
дисперсии
выборки
используется функция
ДИСП()
, англ. название VAR, т.е. VARiance. С версии MS EXCEL 2010 рекомендуется использовать ее аналог
ДИСП.В()
, англ. название VARS, т.е. Sample VARiance. Кроме того, начиная с версии MS EXCEL 2010 присутствует функция
ДИСП.Г(),
англ. название VARP, т.е. Population VARiance, которая вычисляет
дисперсию
для
генеральной совокупности
. Все отличие сводится к знаменателю: вместо n-1 как у
ДИСП.В()
, у
ДИСП.Г()
в знаменателе просто n. До MS EXCEL 2010 для вычисления дисперсии генеральной совокупности использовалась функция
ДИСПР()
.
Дисперсию выборки
можно также вычислить непосредственно по нижеуказанным формулам (см.
файл примера
)
=КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)
=(СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/ (СЧЁТ(Выборка)-1)
– обычная формула
=СУММ((Выборка -СРЗНАЧ(Выборка))^2)/ (СЧЁТ(Выборка)-1
) –
формула массива
Дисперсия выборки
равна 0, только в том случае, если все значения равны между собой и, соответственно, равны
среднему значению
. Обычно, чем больше величина
дисперсии
, тем больше разброс значений в массиве.
Дисперсия выборки
является точечной оценкой
дисперсии
распределения случайной величины, из которой была сделана
выборка
. О построении
доверительных интервалов
при оценке
дисперсии
можно прочитать в статье
Доверительный интервал для оценки дисперсии в MS EXCEL
.
Дисперсия случайной величины
Чтобы вычислить
дисперсию
случайной величины, необходимо знать ее
функцию распределения
.
Для
дисперсии
случайной величины Х часто используют обозначение Var(Х).
Дисперсия
равна
математическому ожиданию
квадрата отклонения от среднего E(X): Var(Х)=E[(X-E(X))
2
]
Если случайная величина имеет
дискретное распределение
, то
дисперсия
вычисляется по формуле:
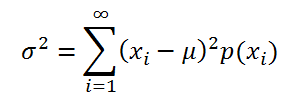
где x
i
– значение, которое может принимать случайная величина, а μ – среднее значение (
математическое ожидание случайной величины
), р(x) – вероятность, что случайная величина примет значение х.
Если случайная величина имеет
непрерывное распределение
, то
дисперсия
вычисляется по формуле:
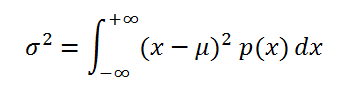
где р(x) –
плотность вероятности
.
Для распределений, представленных в MS EXCEL
,
дисперсию
можно вычислить аналитически, как функцию от параметров распределения. Например, для
Биномиального распределения
дисперсия
равна произведению его параметров: n*p*q.
Примечание
:
Дисперсия,
является
вторым центральным моментом
, обозначается D[X], VAR(х), V(x). Второй центральный момент — числовая характеристика распределения случайной величины, которая является мерой разброса случайной величины относительно
математического ожидания
.
Примечание
: О распределениях в MS EXCEL можно прочитать в статье
Распределения случайной величины в MS EXCEL
.
Размерность
дисперсии
соответствует квадрату единицы измерения исходных значений. Например, если значения в выборке представляют собой измерения веса детали (в кг), то размерность дисперсии будет кг
2
. Это бывает сложно интерпретировать, поэтому для характеристики разброса значений чаще используют величину равную квадратному корню из
дисперсии
–
стандартное отклонение
.
Некоторые свойства
дисперсии
:
Var(Х+a)=Var(Х), где Х — случайная величина, а — константа.
Var(aХ)=a
2
Var(X)
Var(Х)=E[(X-E(X))
2
]=E[X
2
-2*X*E(X)+(E(X))
2
]=E(X
2
)-E(2*X*E(X))+(E(X))
2
=E(X
2
)-2*E(X)*E(X)+(E(X))
2
=E(X
2
)-(E(X))
2
Это свойство дисперсии используется в
статье про линейную регрессию
.
Var(Х+Y)=Var(Х) + Var(Y) + 2*Cov(Х;Y), где Х и Y — случайные величины, Cov(Х;Y) — ковариация этих случайных величин.
Если случайные величины независимы (independent), то их
ковариация
равна 0, и, следовательно, Var(Х+Y)=Var(Х)+Var(Y). Это свойство дисперсии используется при выводе
стандартной ошибки среднего
.
Покажем, что для независимых величин Var(Х-Y)=Var(Х+Y). Действительно, Var(Х-Y)= Var(Х-Y)= Var(Х+(-Y))= Var(Х)+Var(-Y)= Var(Х)+Var(-Y)= Var(Х)+(-1)
2
Var(Y)= Var(Х)+Var(Y)= Var(Х+Y). Это свойство дисперсии используется для построения
доверительного интервала для разницы 2х средних
.
Примечание
: квадратный корень из дисперсии случайной величины называется Среднеквадратическое отклонение (или другие названия — среднее квадратическое отклонение, среднеквадратичное отклонение, квадратичное отклонение, стандартное отклонение, стандартный разброс).
Стандартное отклонение выборки
Стандартное отклонение выборки
— это мера того, насколько широко разбросаны значения в выборке относительно их
среднего
.
По определению,
стандартное отклонение
равно квадратному корню из
дисперсии
:
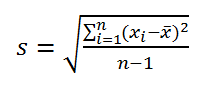
Стандартное отклонение
не учитывает величину значений в
выборке
, а только степень рассеивания значений вокруг их
среднего
. Чтобы проиллюстрировать это приведем пример.
Вычислим стандартное отклонение для 2-х выборок: (1; 5; 9) и (1001; 1005; 1009). В обоих случаях, s=4. Очевидно, что отношение величины стандартного отклонения к значениям массива у выборок существенно отличается. Для таких случаев используется
Коэффициент вариации
(Coefficient of Variation, CV) — отношение
Стандартного отклонения
к среднему
арифметическому
, выраженного в процентах.
В MS EXCEL 2007 и более ранних версиях для вычисления
Стандартного отклонения выборки
используется функция
=СТАНДОТКЛОН()
, англ. название STDEV, т.е. STandard DEViation. С версии MS EXCEL 2010 рекомендуется использовать ее аналог
=СТАНДОТКЛОН.В()
, англ. название STDEV.S, т.е. Sample STandard DEViation.
Кроме того, начиная с версии MS EXCEL 2010 присутствует функция
СТАНДОТКЛОН.Г()
, англ. название STDEV.P, т.е. Population STandard DEViation, которая вычисляет
стандартное отклонение
для
генеральной совокупности
. Все отличие сводится к знаменателю: вместо n-1 как у
СТАНДОТКЛОН.В()
, у
СТАНДОТКЛОН.Г()
в знаменателе просто n.
Стандартное отклонение
можно также вычислить непосредственно по нижеуказанным формулам (см.
файл примера
)
=КОРЕНЬ(КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)) =КОРЕНЬ((СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/(СЧЁТ(Выборка)-1))
Другие меры разброса
Функция
КВАДРОТКЛ()
вычисляет с умму квадратов отклонений значений от их
среднего
. Эта функция вернет тот же результат, что и формула
=ДИСП.Г(
Выборка
)*СЧЁТ(
Выборка
)
, где
Выборка
— ссылка на диапазон, содержащий массив значений выборки (
именованный диапазон
). Вычисления в функции
КВАДРОТКЛ()
производятся по формуле:
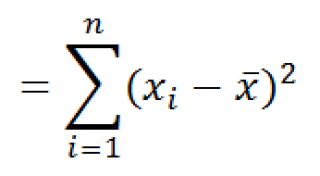
Функция
СРОТКЛ()
является также мерой разброса множества данных. Функция
СРОТКЛ()
вычисляет среднее абсолютных значений отклонений значений от
среднего
. Эта функция вернет тот же результат, что и формула
=СУММПРОИЗВ(ABS(Выборка-СРЗНАЧ(Выборка)))/СЧЁТ(Выборка)
, где
Выборка
— ссылка на диапазон, содержащий массив значений выборки.
Вычисления в функции
СРОТКЛ
()
производятся по формуле:
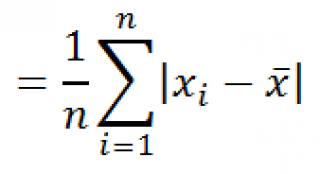
133
133 people found this article helpful
Find the spread of your data using variance and standard deviation
Updated on December 8, 2022
What to Know
- Use the VAR.P function. The syntax is: VAR.P(number1,[number2],…)
- To calculate standard deviation based on the entire population given as arguments, use the STDEV.P function.
This article explains data summarization and how to use deviation and variance formulas in Excel for Microsoft 365, Excel 2019, 2016, 2013, 2010, 2007, and Excel Online.
Summarizing Data: Central Tendency and Spread
The central tendency tells you where the middle of the data is, or the average value. Some standard measures of the central tendency include the mean, the median, and the mode.
The spread of data means how much individual results differ from the average. The most straightforward measure of spread is the range, but it’s not very useful because it tends to keep increasing as you sample more data. Variance and standard deviation are much better measures of spread. The variance is simply the standard deviation squared.
A sample of data is often summarized using two statistics: its average value and a measure of how spread out it is. Variance and standard deviation are both measures of how spread out it is. Several functions let you calculate variance in Excel. Below, we’ll explain how to decide which one to use and how to find variance in Excel.
Standard Deviation and Variance Formula
Both the standard deviation and the variance mesure how far, on average, each data point is from the mean.
If you were calculating them by hand, you would start by finding the mean for all your data. You would then find the difference between each observation and the mean, square all those differences, add them all together, then divide by the number of observation.
Doing so would give the variance, a kind of average for all the squared differences. Taking the variance’s square root corrects the fact that all the differences were squared, resulting in the standard deviation. You will use it to measure the spread of data. If this is confusing, don’t worry. Excel does the actual calculations.
Sample or Population?
Often your data will be a sample taken from some larger population. You want to use that sample to estimate the variance or standard deviation for the population as a whole. In this case, instead of dividing by the number of observation (n), you divide by n-1. These two different types of calculation have different functions in Excel:
- Functions with P: Gives the standard deviation for the actual values you have entered. They assume your data is the whole population (dividing by n).
- Functions with an S: Gives the standard deviation for a whole population, assuming your data is a sample taken from it (dividing by n-1). It can be confusing, as this formula provides the estimated variance for the population; the S indicates the dataset is a sample, but the result is for the population.
Using the Standard Deviation Formula in Excel
To calculate the standard deviation in Excel, follow these steps.
-
Enter your data into Excel. Before you can use the statistics functions in Excel, you need to have all your data in an Excel range: a column, a row, or a group matrix of columns and rows. You need to be able to select all the data without selecting any other values.
For the rest of this example, the data is in the range A1:A20.
-
If your data represents the entire population, enter the formula «=STDEV.P(A1:A20).» Alternatively, if your data is a sample from some larger population, enter the formula «=STDEV(A1:A20).»
If you’re using Excel 2007 or earlier, or you want your file to be compatible with these versions, the formulas are «=STDEVP(A1:A20),» if your data is the entire population; «=STDEV(A1:A20),» if your data is a sample from a larger population.
-
The standard deviation will be displayed in the cell.
How to Calculate Variance in Excel
Calculating variance is very similar to calculating standard deviation.
-
Ensure your data is in a single range of cells in Excel.
-
If your data represents the entire population, enter the formula «=VAR.P(A1:A20).» Alternatively, if your data is a sample from some larger population, enter the formula «=VAR.S(A1:A20).»
If you’re using Excel 2007 or earlier, or you want your file to be compatible with these versions, the formulas are: «=VARP(A1:A20),» if your data is the entire population, or «=VAR(A1:A20),» if your data is a sample from a larger population.
-
The variance for your data will be displayed in the cell.
FAQ
-
How do I find the coefficient of variation in Excel?
There’s no built-in formula, but you can calculate the coefficient of variation in a data set by dividing the standard deviation by the mean.
-
How do I use the STDEV function in Excel?
The STDEV and STDEV.S functions provide an estimate of a set of data’s standard deviation. The syntax for STDEV is =STDEV(number1, [number2],…). The syntax for STDEV.S is =STDEV.S(number1,[number2],…).
Thanks for letting us know!
Get the Latest Tech News Delivered Every Day
Subscribe

Стандартное отклонение является одним из тех статистических терминов в корпоративном мире, которое позволяет поднять авторитет людей, сумевших удачно ввернуть его в ходе беседы или презентации, и оставляет смутное недопонимание тех, кто не знает, что это такое, но стесняется спросить. На самом деле большинство менеджеров не понимают концепцию стандартного отклонения и, если вы один из них, вам пора перестать жить во лжи. В сегодняшней статье я расскажу вам, как эта недооцененная статистическая мера позволит лучше понять данные, с которыми вы работаете.
Что измеряет стандартное отклонение?
Представьте, что вы владелец двух магазинов. И чтобы избежать потерь, важно, чтобы был четкий контроль остатков на складе. В попытке выяснить, кто из менеджеров лучше управляет запасами, вы решили проанализировать стоки последних шести недель. Средняя недельная стоимость стока обоих магазинов примерно одинакова и составляет около 32 условных единиц. На первый взгляд среднее значение стока показывает, что оба менеджера работают одинаково.
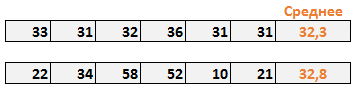
Но если внимательнее изучить деятельность второго магазина, можно убедится, что хотя среднее значение корректно, вариабельность стока очень высокая (от 10 до 58 у.е.). Таким образом, можно сделать вывод, что среднее значение не всегда правильно оценивает данные. Вот где на выручку приходит стандартное отклонение.
Стандартное отклонение показывает, как распределены значения относительно среднего в нашей выборке. Другими словами, можно понять на сколько велик разброс величины стока от недели к неделе.
В нашем примере, мы воспользовались функцией Excel СТАНДОТКЛОН, чтобы рассчитать показатель стандартного отклонения вместе со средним.
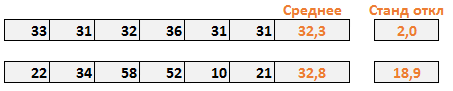
В случае с первым менеджером, стандартное отклонение составило 2. Это говорит нам о том, что каждое значение в выборке в среднем откланяется на 2 от среднего значения. Хорошо ли это? Давайте рассмотрим вопрос под другим углом – стандартное отклонение равное 0, говорит нам о том, что каждое значение в выборке равно его среднему значению (в нашем случае, 32,2). Так, стандартное отклонение 2 ненамного отличается от 0, и указывает на то, что большинство значений находятся рядом со средним значением. Чем ближе стандартное отклонение к 0, тем надежнее среднее. Более того, стандартное отклонение близкое к 0, говорит о маленькой вариабельности данных. То есть, величина стока со стандартным отклонением 2, указывает на невероятную последовательность первого менеджера.
В случае со вторым магазином, стандартное отклонение составило 18,9. То есть стоимость стока в среднем отклоняется на величину 18,9 от среднего значения от недели к неделе. Сумасшедший разброс! Чем дальше стандартное отклонение от 0, тем менее точно среднее значение. В нашем случае, цифра 18,9 указывает на то, что среднему значению (32,8 у.е. в неделю) просто нельзя доверять. Оно также говорит нам о том, что еженедельная величина стока обладает большой вариабельностью.
Такова концепция стандартного отклонения в двух словах. Хотя оно не дает представление о других важных статистических измерениях (Мода, Медиана…), фактически стандартное отклонение играет решающую роль в большинстве статистических расчетов. Понимание принципов стандартного отклонения прольет свет на суть многих процессов вашей деятельности.
Как рассчитать стандартное отклонение?
Итак, теперь мы знаем, о чем говорит цифра стандартного отклонения. Давайте разберемся, как она считается.
Рассмотрим набор данных от 10 до 70 с шагом 10. Как видите, я уже рассчитал для них значение стандартного отклонения с помощью функции СТАНДОТКЛОН в ячейке H2 (оранжевым).
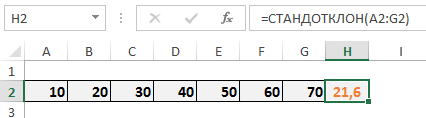
Ниже описаны шаги, которые предпринимает Excel, чтобы прийти к цифре 21,6.
Обратите внимание, что все расчеты визуализированы, для лучшего понимания. На самом деле в Excel расчет происходит мгновенно, оставляя все шаги за кулисами.
Для начала Excel находит среднее значение выборки. В нашем случае, среднее получилось равным 40, которое на следующем шаге отнимают от каждого значения выборки. Каждую полученную разницу возводят в квадрат и суммируют. У нас получилась сумма равная 2800, которую необходимо разделить на количество элементов выборки минус 1. Так как у нас 7 элементов, получается необходимо 2800 разделить на 6. Из полученного результата находим квадратный корень, это цифра будет стандартным отклонением.

Для тех, кому не совсем ясен принцип расчета стандартного отклонения с помощью визуализации, привожу математическую интерпретацию нахождения данного значения.
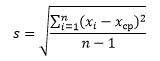
В Excel присутствует несколько разновидностей формул стандартного отклонения. Вам достаточно набрать =СТАНДОТКЛОН и вы сами в этом убедитесь.

Стоит отметить, что функции СТАНДОТКЛОН.В и СТАНДОТКЛОН.Г (первая и вторая функция в списке) дублируют функции СТАНДОТКЛОН и СТАНДОТКЛОНП (пятая и шестая функция в списке), соответственно, которые были оставлены для совместимости с более ранними версиями Excel.
Вообще разница в окончаниях .В и .Г функций указывают на принцип расчета стандартного отклонения выборки или генеральной совокупности. Разницу между двумя этими массивами я уже объяснял в предыдущей статье расчета дисперсии.
Особенностью функций СТАНДОТКЛОНА и СТАНДОТКЛОНПА (третья и четвертая функция в списке), является то, что при расчете стандартного отклонения массива в расчет принимаются логические и текстовые значения. Текстовые и истинные логические значения равняются 1, а ложные логические значения равняются 0. Мне трудно представить ситуацию, когда бы мне могли понадобится эти две функции, поэтому, думаю, что их можно игнорировать.
Оригинал http://statanaliz.info/index.php/excel/formuly/37-raschet-pokazatelej-variatsii-v-excel
Добрый день, уважаемые любители статистического анализа данных, а сегодня еще и программы Excel.
Проведение любого статанализа немыслимо без расчетов. И сегодня в рамках рубрики «Работаем в Excel» мы научимся рассчитывать показатели вариации. Теоретическая основа была рассмотрена ранее в ряде статей о вариации данных. Кстати, на этом указанная тема не закончилась, к выпуску планируются новые статьи — следите за рекламой! Однако сухая теория без инструментов реализации — вещь не сильно полезная. Поэтому по мере появления теоретических выкладок, я стараюсь не отставать с заметками о соответствующих расчетах в программе Excel.
Сегодняшняя публикация будет посвящена расчету в Excel следующих показателей вариации:
— максимальное и минимальное значение
— среднее линейное отклонение
— дисперсия (по генеральной совокупности и по выборке)
— среднее квадратическое отклонение (по генеральной совокупности и по выборке)
— коэффициент вариации
Факт возможности расчета упомянутых показателей в Excel свидетельствует о практическом их использовании. И, несмотря на очевидность некоторых моментов, я постараюсь расписать все подробно.
Максимальное и минимальное значение
Начнем с формул максимума и минимума. Что такое максимальное и минимальное значение, уверен, знают почти все. Максимум — самое большое значение из анализируемого набора данных, минимум — самое маленькое (может быть и отрицательным числом). Это крайние значения в совокупности данных, обозначающие границы их вариации. Примеры реального использования каждый может придумать сам — их полно. Это и минимальные/максимальные цены на что-нибудь, и выбор наилучшего или наихудшего решения задачи, и всего, чего угодно. Минимум и максимум — весьма информативные показатели. Давайте теперь их рассчитаем в Excel.
Как нетрудно догадаться, делается сие элементарно — как два клика об асфальт. В Мастере функций следует выбрать: МАКС — для расчета максимального значения, МИН — для расчета минимального значения. Для облегчения поиска перечень всех функций можно отфильтровать по категории «Статистические».

Выбираем нужную формулу, в следующем окошке указываем диапазон данных (в котором ищется максимальное или минимальное значение) и жмем «ОК».
Функции МАКС и МИН достаточно часто используются, поэтому разработчики Экселя предусмотрительно добавили соответствующие кнопки в ленту. Они находятся там же, где суммаи среднее значение — в разворачивающемся списке.

В общем, для вызова функции максимума или минимума действий потребуется не больше, чем для расчета средней арифметической. Все архипросто.
Среднее линейное отклонение
Среднее линейное отклонение, напоминаю, представляет собой среднее из абсолютных (по модулю) отклонений от средней арифметической в анализируемой совокупности данных. Математическая формула имеет вид:
где
a — среднее линейное отклонение,
x — анализируемый показатель, с черточкой сверху — среднее значение показателя,
n — количество значений в анализируемой совокупности данных.
В Excel эта функция называется СРОТКЛ.

После выбора функции СРОТКЛ указываем диапазон данных, по которому должен произойти расчет. Нажимаем «ОК». Наслаждаемся результатом.
Дисперсия
Дисперсия — это средний квадрат отклонений, мера характеризующая разброс данных вокруг среднего значения. Математическая формула дисперсии по генеральной совокупности имеет вид:
где
D — дисперсия,
x — анализируемый показатель, с черточкой сверху — среднее значение показателя,
n — количество значений в анализируемой совокупности данных.
Excel также предлагает готовую функцию для расчета генеральной дисперсии ДИСП.Г.
При анализе выборочных данных, следует использовать выборочную дисперсию, так как генеральная оказывается смещенной в сторону занижения.
Математическая формула выборочной дисперсии имеет вид:
в Excel выборочная дисперсия рассчитывает через функцию ДИСП.В.

Выбираем в Мастере функций нужную дисперсию (генеральную или выборочную), указываем диапазон, жмем кнопку «ОК». Полученное значение может оказаться очень большим из-за предварительного возведения отклонений в квадрат, поэтому дисперсия сама по себе мало о чем говорит. Ее обычно используют для дальнейших расчетов.
Среднее квадратическое отклонение
Среднеквадратическое отклонение по генеральной совокупности — это корень из генеральной дисперсии.
Выборочное среднеквадратическое отклонение — это корень из выборочной дисперсии.
Для расчета можно извлечь корень из формул дисперсии, указанных чуть выше, но в Excel есть и готовые функции:
— Среднеквадратическое отклонение по генеральной совокупности СТАНДОТКЛОН.Г
— Среднеквадратическое отклонение по выборке СТАНДОТКЛОН.В.

С названием этого показателя может возникнуть путаница, т.к. часто можно встретить синоним «стандартное отклонение». Пугаться не нужно — смысл тот же.
Далее, как обычно, указываем нужный диапазон и нажимаем на «ОК». Среднее квадратическое отклонение имеет те же единицы измерения, что и анализируемый показатель, поэтому является сопоставимым с исходными данными. Об этом ниже.
Коэффициент вариации
Все показатели, рассмотренные выше, имеют привязку к масштабу исходных данных и не позволяют получить образное представление о вариации анализируемой совокупности. Для получения относительной меры разброса данных используют коэффициент вариации, который рассчитывается путем деления среднего квадартического отклонения на среднее арифметическое значение. Математическая формула такова:
В Экселе нет готовой функции для расчета коэффициента вариации, что не есть большая проблема. Расчет можно произвести простым делением стандартного отклонения на среднее значение. Для этого в строке формул пишем:
=СТАНДОТКЛОН.Г(диапазон)/СРЗНАЧ(диапазон)
В скобках должен быть указан диапазон данных. При необходимости используется среднее квадратическое отклонение по выборке (СТАНДОТКЛОН.В).
Коэффициент вариации обычно выражается в процентах, поэтому ячейку с формулой можно обрамить процентным форматом. Нужная кнопка находится на ленте на закладке «Главная»:

Изменить формат также можно, выбрав «Формат ячеек» из выпадающего списка после выделения нужной ячейки правой кнопкой мышки.
Коэффициент вариации, в отличие от других показателей разброса значений, используется как самостоятельный и весьма информативный индикатор вариации данных. В статистике принято считать, что если коэффициент вариации менее 33%, то совокупность данных является однородной, если более 33%, то — неоднородной. Эта информация может быть полезна для предварительного описания данных и определения возможностей проведения дальнейшего анализа. Кроме того, коэффициент вариации, измеряемый в процентах, позволяет сравнивать степень разброса различных данных независимо от их масштаба и единиц измерений. Полезное свойство.
В целом, с помощью Excel все, или почти все, статистические показатели рассчитываются очень просто. Если что-то непонятно, всегда можно воспользоваться окошком для поиска в Мастере функций. Ну, и Гугл в помощь.
Легкой работы в Excel и до встречи на блоге statanaliz.info.
Оригинал и другие статьи http://statanaliz.info/index.php/excel/formuly/37-raschet-pokazatelej-variatsii-v-excel
Функция СТАНДОТКЛОН.В возвращает значение стандартного отклонения, рассчитанного для определенного диапазона числовых значений.
Функция СТАНДОТКЛ.Г используется для определения стандартного отклонения генеральной совокупности числовых значений и возвращает величину стандартного отклонения с учетом, что переданные значения являются всей генеральной совокупностью, а не выборкой.
Функция СТАНДОТКЛОНА возвращает значение стандартного отклонения для некоторого диапазона чисел, которые являются выборкой, а не всей генеральной совокупностью.
Функция СТАНДОТЛОНПА возвращает значение стандартного отклонения для всей генеральной совокупности, переданной в качестве ее аргументов.
Примеры использования СТАНДОТКЛОН.В, СТАНДОТКЛОН.Г, СТАНДОТКЛОНА и СТАНДОТКЛОНПА
Пример 1. На предприятии работают два менеджера по привлечению клиентов. Данные о количестве обслуженных клиентов в день каждым менеджером фиксируются в таблице Excel. Определить, какой из двух сотрудников работает эффективнее.
Таблица исходных данных:
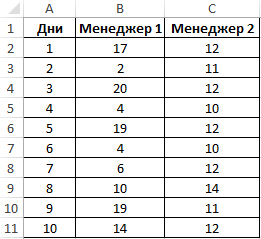
Вначале рассчитаем среднее количество клиентов, с которыми работали менеджеры ежедневно:
=СРЗНАЧ(B2:B11)
Данная функция выполняет расчет среднего арифметического значения для диапазона B2:B11, содержащего данные о количестве клиентов, принимаемых ежедневно первым менеджером. Аналогично рассчитаем среднее количество клиентов за день у второго менеджера. Получим:
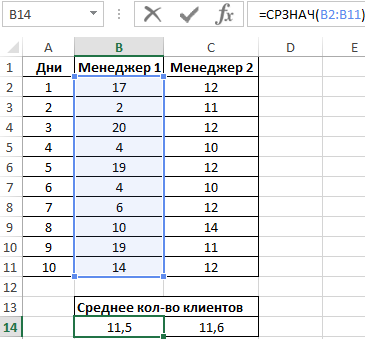
На основе полученных значений создается впечатление, что оба менеджера работают примерно одинаково эффективно. Однако визуально виден сильный разброс значений числа клиентов у первого менеджера. Произведем расчет стандартного отклонения по формуле:
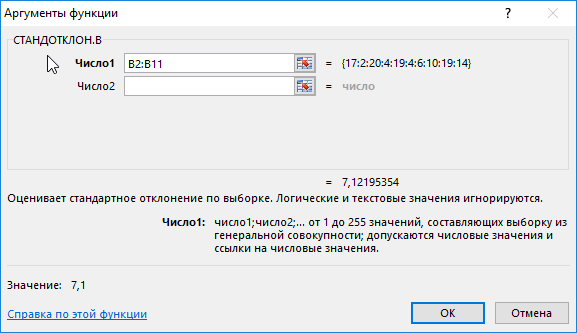
=СТАНДОТКЛОН.В(B2:B11)
B2:B11 – диапазон исследуемых значений. Аналогично определим стандартное отклонение для второго менеджера и получим следующие результаты:
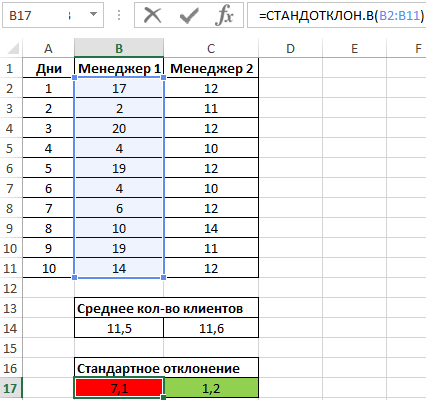
Как видно, показатели работы первого менеджера отличаются высокой вариабельностью (разбросом) значений, в связи с чем среднее арифметическое значение абсолютно не отражает реальную картину эффективности работы. Отклонение 1,2 свидетельствует о более стабильной, а, значит, и эффективной работе второго менеджера.
Пример использования функции СТАНДОТКЛОНА в Excel
Пример 2. В двух различных группах студентов колледжа проводился экзамен по одной и той же дисциплине. Оценить успеваемость студентов.
Таблица исходных данных:
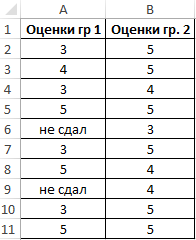
Определим стандартное отклонение значений для первой группы по формуле:
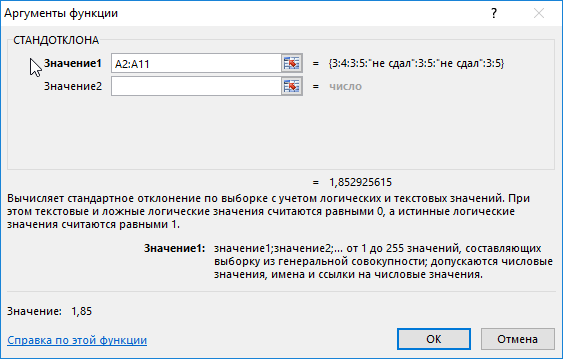
=СТАНДОТКЛОНА(A2:A11)
Аналогичный расчет произведем для второй группы. В результате получим:
Полученные значения свидетельствуют о том, что студенты второй группы намного лучше подготовились к экзамену, поскольку разброс значений оценок относительно небольшой. Обратите внимание на то, что функция СТАНДОТКЛОНА преобразует текстовое значение «не сдал» в числовое значение 0 (нуль) и учитывает его в расчетах.
Пример функции СТАНДОТКЛОН.Г в Excel
Пример 3. Определить эффективность подготовки студентов к экзамену для всех групп университета.
Примечание: в отличие от предыдущего примера, будет анализироваться не выборка (несколько групп), а все число студентов – генеральная совокупность. Студенты, не сдавшие экзамен, не учтены.
Заполним таблицу данных:
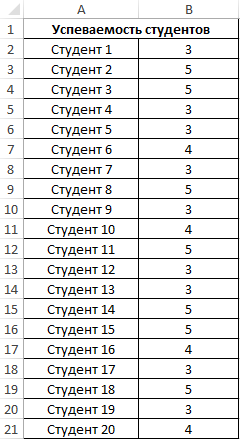
Для оценки эффективности будем оперировать двумя показателями: средняя оценка и разброс значений. Для определения среднего арифметического используем функцию:
=СРЗНАЧ(B2:B21)
Для определения отклонения введем формулу:
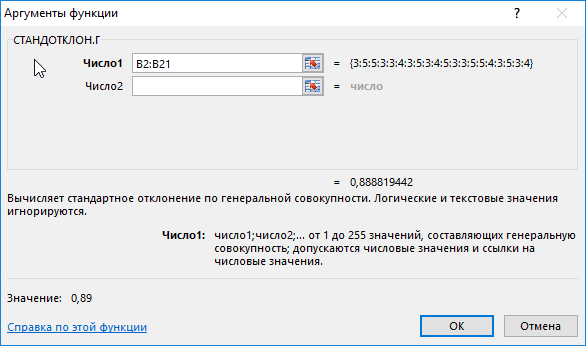
=СТАНДОТКЛОН.Г(B2:B21)
В результате получим:
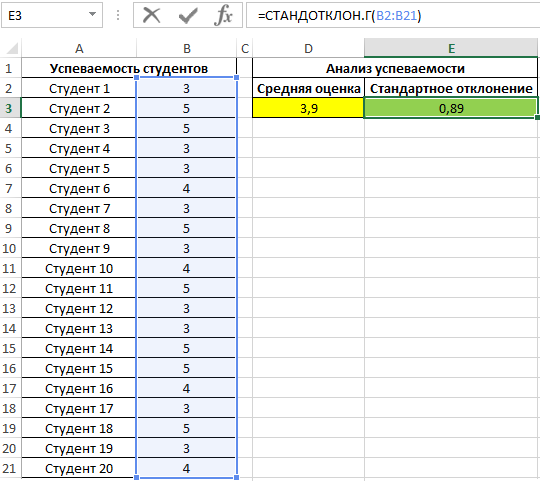
Полученные данные свидетельствует об успеваемости немного ниже среднего (<4), величина разброса характеризует довольно большое количество студентов, получивших 5 и 3 соответственно (учитывая, что анализировались только данные из диапазона от 3 до 5).
Пример функции СТАНДОТКЛОНПА в Excel
Пример 4. Проанализировать успеваемость студентов по результатам сдачи экзамена с учетом тех студентов, которым не удалось сдать этот экзамен.
Таблица данных:
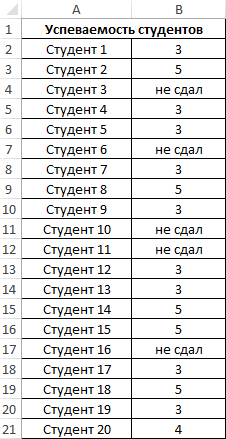
В данном примере также анализируем генеральную совокупность, однако некоторые поля данных содержат текстовые значения. Для определения стандартного отклонения используем функцию:
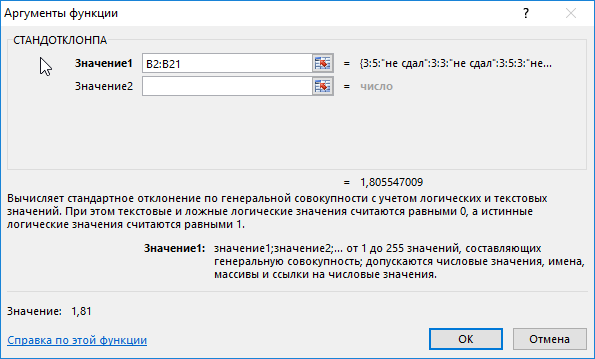
=СТАНДОТКЛОНПА(B2:B21)
В результате получим:
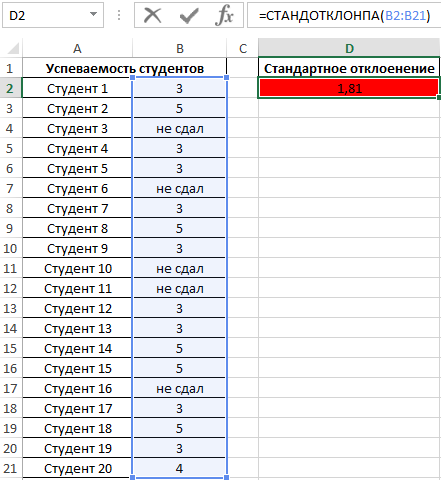
Высокий разброс значений в последовательности свидетельствует о большом числе не сдавших экзамен студентов.
Особенности использования СТАНДОТКЛОН.В, СТАНДОТКЛОН.Г, СТАНДОТКЛОНА и СТАНДОТКЛОНПА
Функции СТАНДОТКЛОНА И СТАНДОТКЛОНПА имеют идентичную синтаксическую запись типа:
=ФУНКЦИЯ (значение1; [значение2];…)
Описание:
- ФУНКЦИЯ – одна из двух рассмотренных выше функций;
- значение1 – обязательный аргумент, характеризующий одно из значений выборки (либо генеральной совокупности);
- [значени2] – необязательный аргумент, характеризующий второе значение исследуемого диапазона.
Примечания:
- В качестве аргументов функций могут быть переданы имена, числовые значения, массивы, ссылки на диапазоны числовых данных, логические значения и ссылки на них.
- Обе функции игнорируют пустые значения и текстовые данные, содержащиеся в диапазоне переданных данных.
- Функции возвращают код ошибки #ЗНАЧ!, если в качестве аргументов были переданы значения ошибок или текстовые данные, которые не могут быть преобразованы в числовые значения.
Функции СТАНДОТКЛОН.В и СТАНДОТКЛОН.Г имеют следующую синтаксическую запись:
=ФУНКЦИЯ(число1;[число2];…)
Описание:
- ФУНКЦИЯ – любая из функций СТАНДОТКЛОН.В или СТАНДОТКЛОН.Г;
- число1 – обязательный аргумент, характеризующий числовое значение, взятое из выборки или всей генеральной совокупности;
- число2 – необязательный аргумент, характеризующий второе числовое значение исследуемого диапазона.
Примечание: обе функции не включают в процесс вычисления числа, представленные в виде текстовых данных, а также логические значения ИСТИНА и ЛОЖЬ.
Примечания:
- Стандартное отклонение широко используется в статистических расчетах, когда нахождение среднего значения диапазона величин не дает верное представление о распределении данных. Оно демонстрирует принцип распределения величин относительно среднего значения в конкретной выборке или всей последовательности целиком. В Примере 1 будет наглядно рассмотрено практическое применение данного статистического параметра.
- Функции СТАНДОТКЛОНА и СТАНДОТКЛОН.В следует использовать для анализа только части генеральной совокупности и производят расчет по первой формуле, а СТАНДОТКЛОН.Г и СТАНДОТКЛОНПА должны принимать на вход данные о всей генеральной совокупности и производят расчет по второй формуле.
- В Excel содержатся встроенные функции СТАНДОТКЛОН и СТАНДОТКЛОНП, оставленные для совместимости с более старыми версиями Microsoft Office. Они могут быть не включены в более поздние версии программы, поэтому их использование не рекомендуется.
- Для нахождения стандартного отклонения используются две распространенные формулы: S=√((∑_(i=1)^n▒(x_i-x_ср )^2 )/(n-1)) и S=√((∑_(i=1)^n▒(x_i-x_ср )^2 )/n), где:
- S – искомое значение стандартного отклонения;
- n – рассматриваемый диапазон значений (выборка);
- x_i – отдельно взятое значение из выборки;
- x_ср – среднее арифметическое значение для рассматриваемого диапазона.