
Содержание
- Выполнение аппроксимации
- Способ 1: линейное сглаживание
- Способ 2: экспоненциальная аппроксимация
- Способ 3: логарифмическое сглаживание
- Способ 4: полиномиальное сглаживание
- Способ 5: степенное сглаживание
- Вопросы и ответы

Среди различных методов прогнозирования нельзя не выделить аппроксимацию. С её помощью можно производить приблизительные подсчеты и вычислять планируемые показатели, путем замены исходных объектов на более простые. В Экселе тоже существует возможность использования данного метода для прогнозирования и анализа. Давайте рассмотрим, как этот метод можно применить в указанной программе встроенными инструментами.
Выполнение аппроксимации
Наименование данного метода происходит от латинского слова proxima – «ближайшая» Именно приближение путем упрощения и сглаживания известных показателей, выстраивание их в тенденцию и является его основой. Но данный метод можно использовать не только для прогнозирования, но и для исследования уже имеющихся результатов. Ведь аппроксимация является, по сути, упрощением исходных данных, а упрощенный вариант исследовать легче.
Главный инструмент, с помощью которого проводится сглаживания в Excel – это построение линии тренда. Суть состоит в том, что на основе уже имеющихся показателей достраивается график функции на будущие периоды. Основное предназначение линии тренда, как не трудно догадаться, это составление прогнозов или выявление общей тенденции.
Но она может быть построена с применением одного из пяти видов аппроксимации:
- Линейной;
- Экспоненциальной;
- Логарифмической;
- Полиномиальной;
- Степенной.
Рассмотрим каждый из вариантов более подробно в отдельности.
Урок: Как построить линию тренда в Excel
Способ 1: линейное сглаживание
Прежде всего, давайте рассмотрим самый простой вариант аппроксимации, а именно с помощью линейной функции. На нем мы остановимся подробнее всего, так как изложим общие моменты характерные и для других способов, а именно построение графика и некоторые другие нюансы, на которых при рассмотрении последующих вариантов уже останавливаться не будем.
Прежде всего, построим график, на основании которого будем проводить процедуру сглаживания. Для построения графика возьмем таблицу, в которой помесячно указана себестоимость единицы продукции, производимой предприятием, и соответствующая прибыль в данном периоде. Графическая функция, которую мы построим, будет отображать зависимость увеличения прибыли от уменьшения себестоимости продукции.
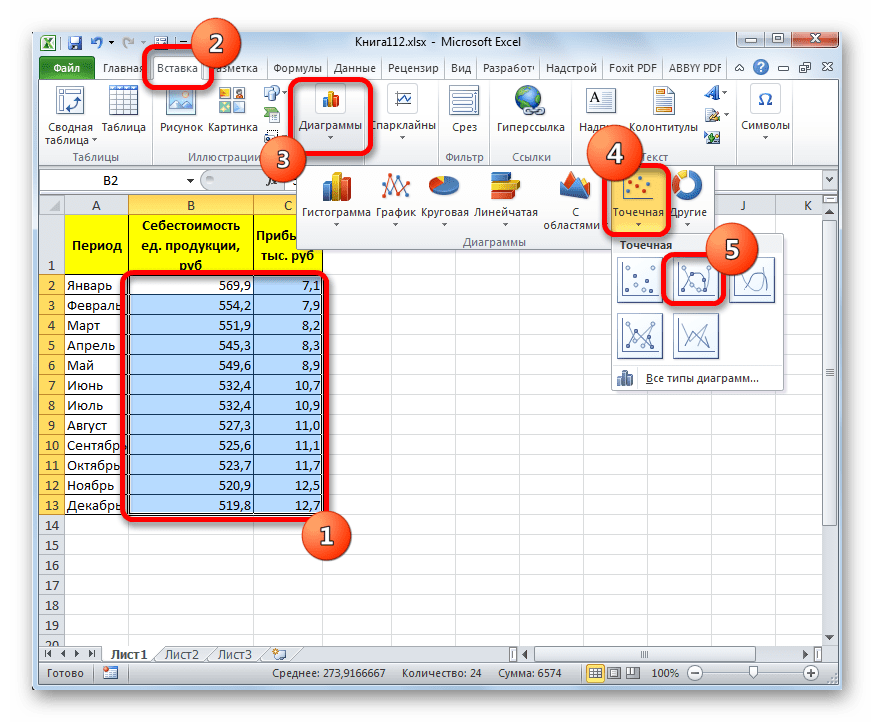
- Для построения графика, прежде всего, выделяем столбцы «Себестоимость единицы продукции» и «Прибыль». После этого перемещаемся во вкладку «Вставка». Далее на ленте в блоке инструментов «Диаграммы» щелкаем по кнопке «Точечная». В открывшемся списке выбираем наименование «Точечная с гладкими кривыми и маркерами». Именно данный вид диаграмм наиболее подходит для работы с линией тренда, а значит, и для применения метода аппроксимации в Excel.
- График построен.
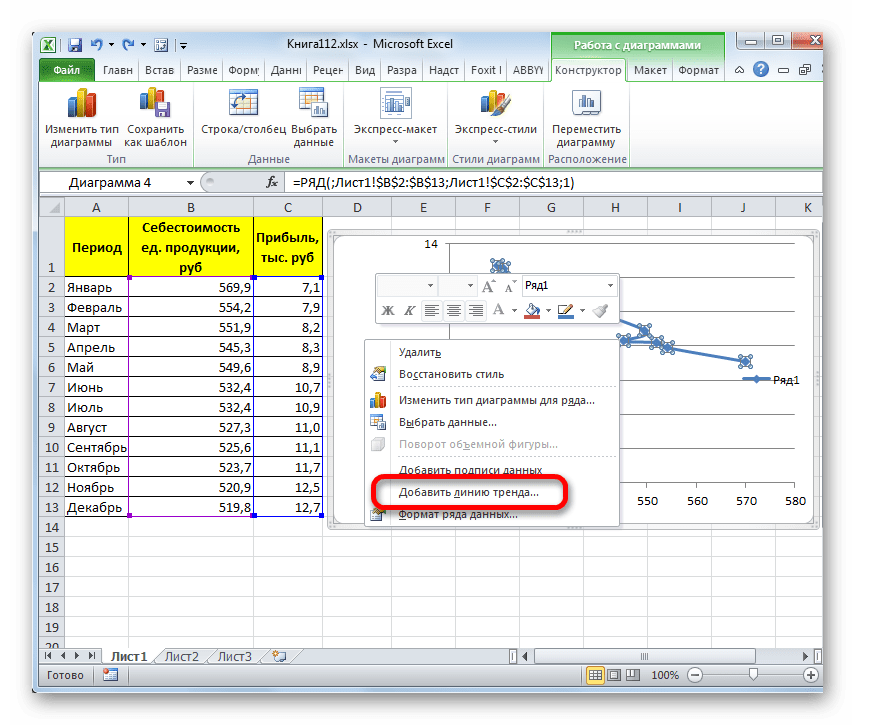
- Для добавления линии тренда выделяем его кликом правой кнопки мыши. Появляется контекстное меню. Выбираем в нем пункт «Добавить линию тренда…».

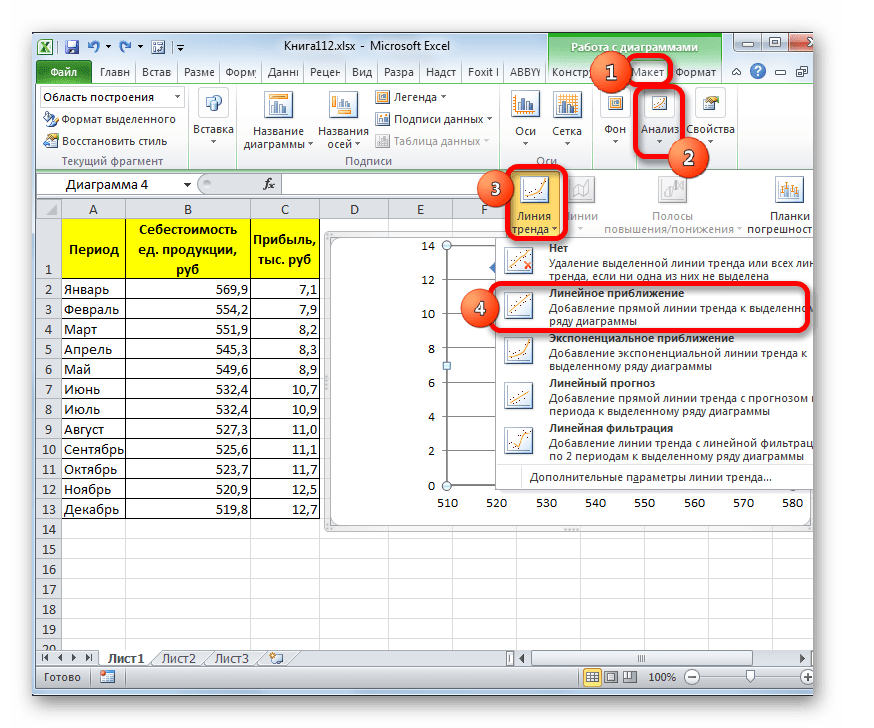
Существует ещё один вариант её добавления. В дополнительной группе вкладок на ленте «Работа с диаграммами» перемещаемся во вкладку «Макет». Далее в блоке инструментов «Анализ» щелкаем по кнопке «Линия тренда». Открывается список. Так как нам нужно применить линейную аппроксимацию, то из представленных позиций выбираем «Линейное приближение».
- Если же вы выбрали все-таки первый вариант действий с добавлением через контекстное меню, то откроется окно формата.
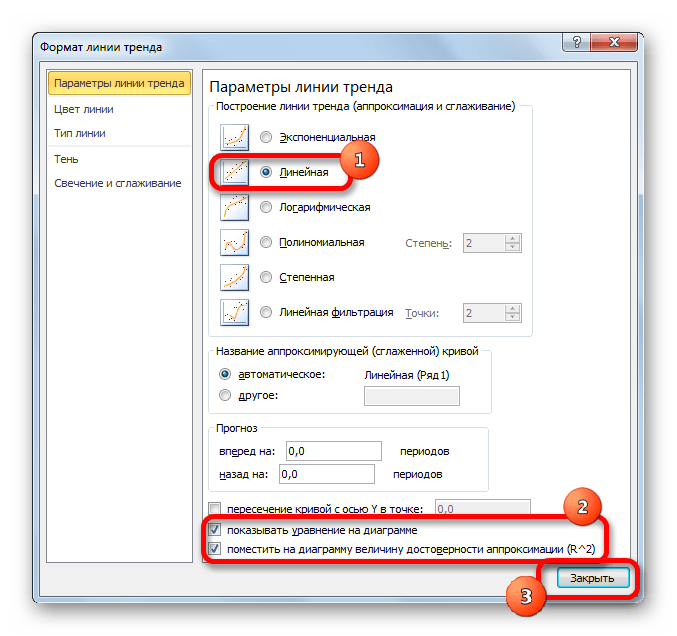
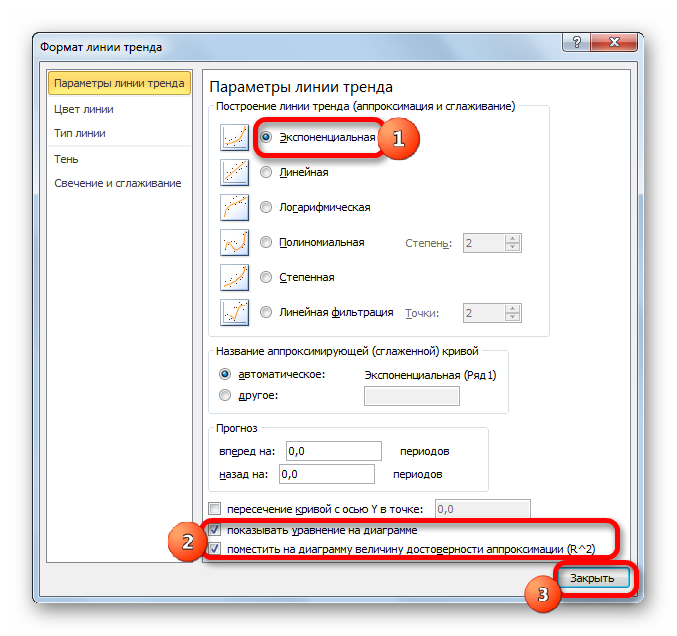
В блоке параметров «Построение линии тренда (аппроксимация и сглаживание)» устанавливаем переключатель в позицию «Линейная».
При желании можно установить галочку около позиции «Показывать уравнение на диаграмме». После этого на диаграмме будет отображаться уравнение сглаживающей функции.Также в нашем случае для сравнения различных вариантов аппроксимации важно установить галочку около пункта «Поместить на диаграмму величину достоверной аппроксимации (R^2)». Данный показатель может варьироваться от 0 до 1. Чем он выше, тем аппроксимация качественнее (достовернее). Считается, что при величине данного показателя 0,85 и выше сглаживание можно считать достоверным, а если показатель ниже, то – нет.

После того, как провели все вышеуказанные настройки. Жмем на кнопку «Закрыть», размещенную в нижней части окна.
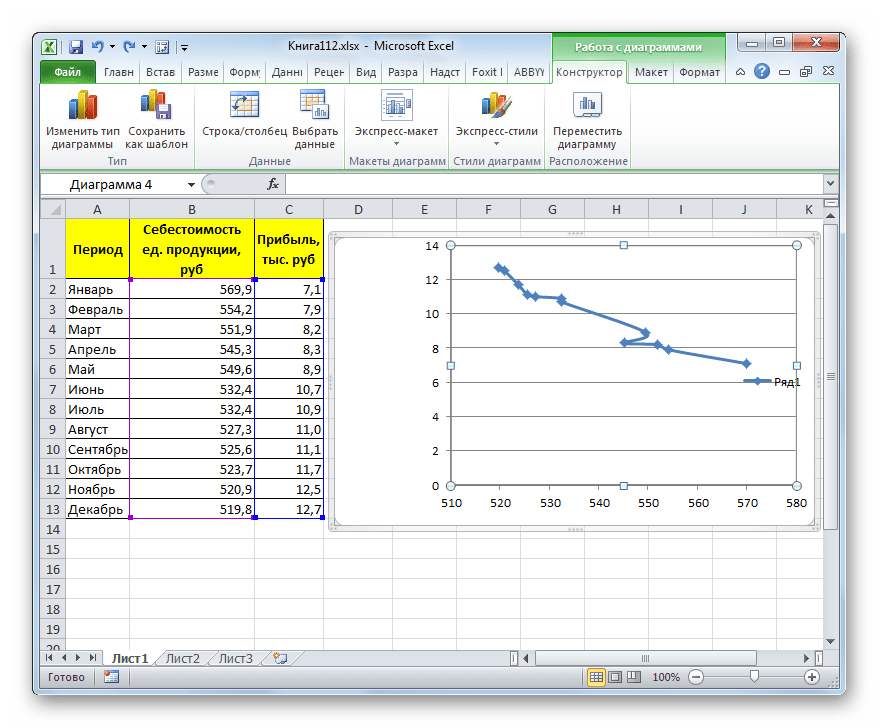
- Как видим, на графике линия тренда построена. При линейной аппроксимации она обозначается черной прямой полосой. Указанный вид сглаживания можно применять в наиболее простых случаях, когда данные изменяются довольно быстро и зависимость значения функции от аргумента очевидна.

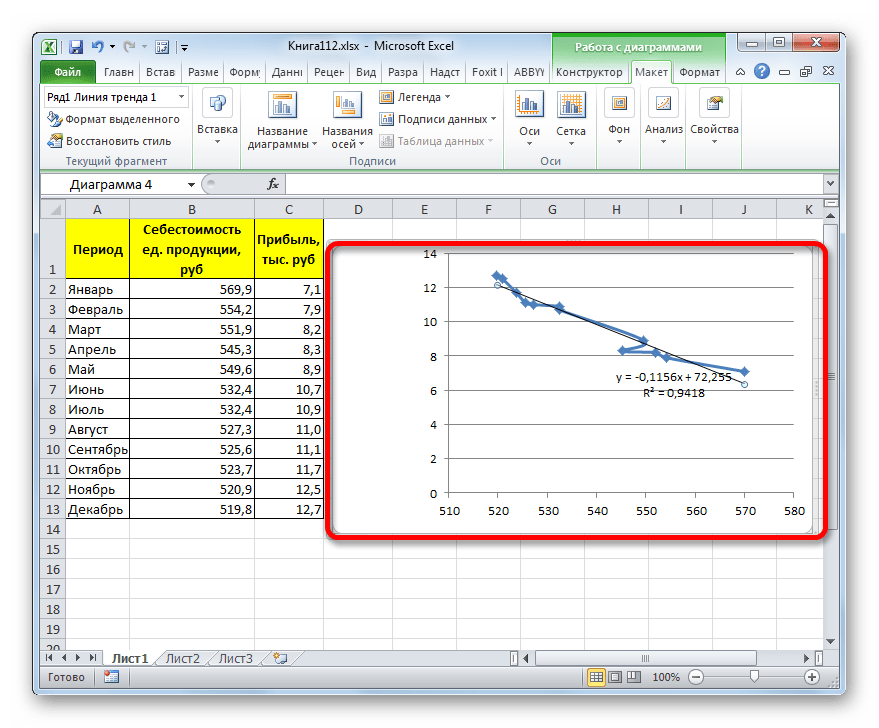
Сглаживание, которое используется в данном случае, описывается следующей формулой:
y=ax+b
В конкретно нашем случае формула принимает такой вид:
y=-0,1156x+72,255
Величина достоверности аппроксимации у нас равна 0,9418, что является довольно приемлемым итогом, характеризующим сглаживание, как достоверное.
Способ 2: экспоненциальная аппроксимация
Теперь давайте рассмотрим экспоненциальный тип аппроксимации в Эксель.
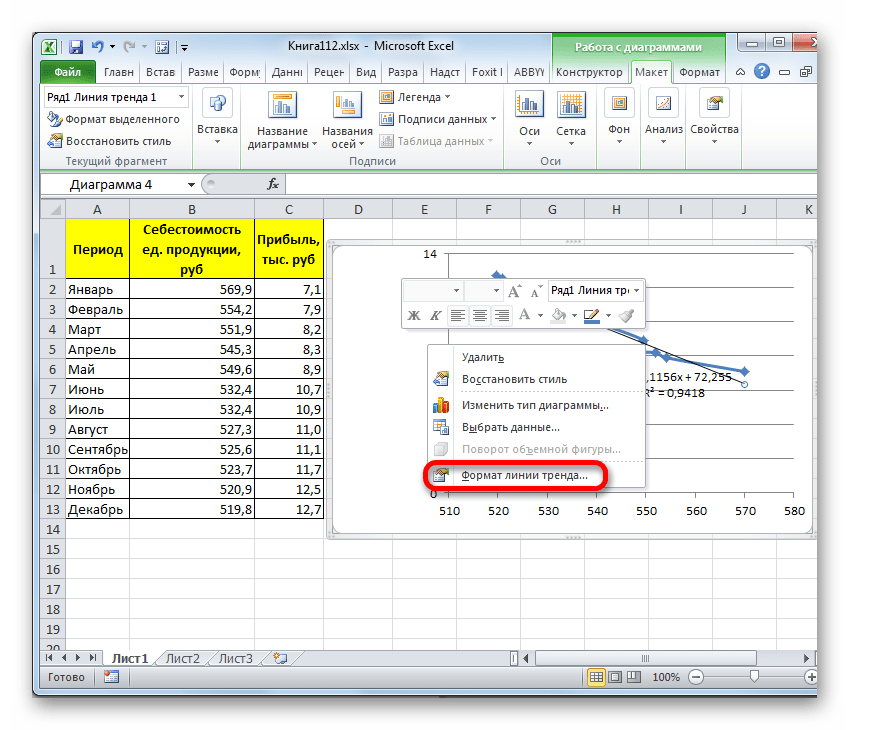
- Для того, чтобы изменить тип линии тренда, выделяем её кликом правой кнопки мыши и в раскрывшемся меню выбираем пункт «Формат линии тренда…».
- После этого запускается уже знакомое нам окно формата. В блоке выбора типа аппроксимации устанавливаем переключатель в положение «Экспоненциальная». Остальные настройки оставим такими же, как и в первом случае. Щелкаем по кнопке «Закрыть».
- После этого линия тренда будет построена на графике. Как видим, при использовании данного метода она имеет несколько изогнутую форму. При этом уровень достоверности равен 0,9592, что выше, чем при использовании линейной аппроксимации. Экспоненциальный метод лучше всего использовать в том случае, когда сначала значения быстро изменяются, а потом принимают сбалансированную форму.
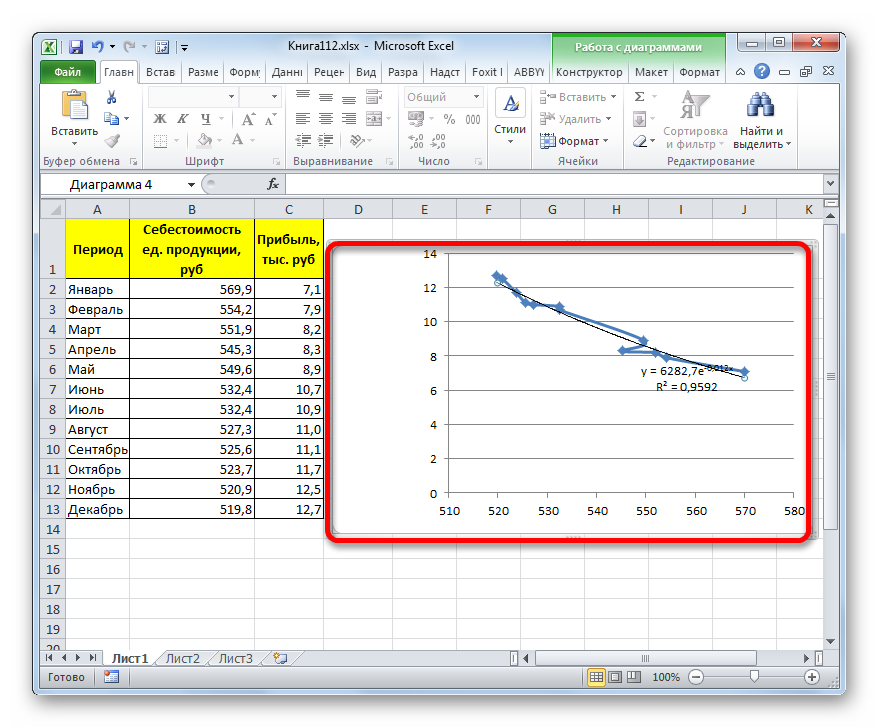
Общий вид функции сглаживания при этом такой:
y=be^x
где e – это основание натурального логарифма.
В конкретно нашем случае формула приняла следующую форму:
y=6282,7*e^(-0,012*x)
Способ 3: логарифмическое сглаживание
Теперь настала очередь рассмотреть метод логарифмической аппроксимации.
- Тем же способом, что и в предыдущий раз через контекстное меню запускаем окно формата линии тренда. Устанавливаем переключатель в позицию «Логарифмическая» и жмем на кнопку «Закрыть».
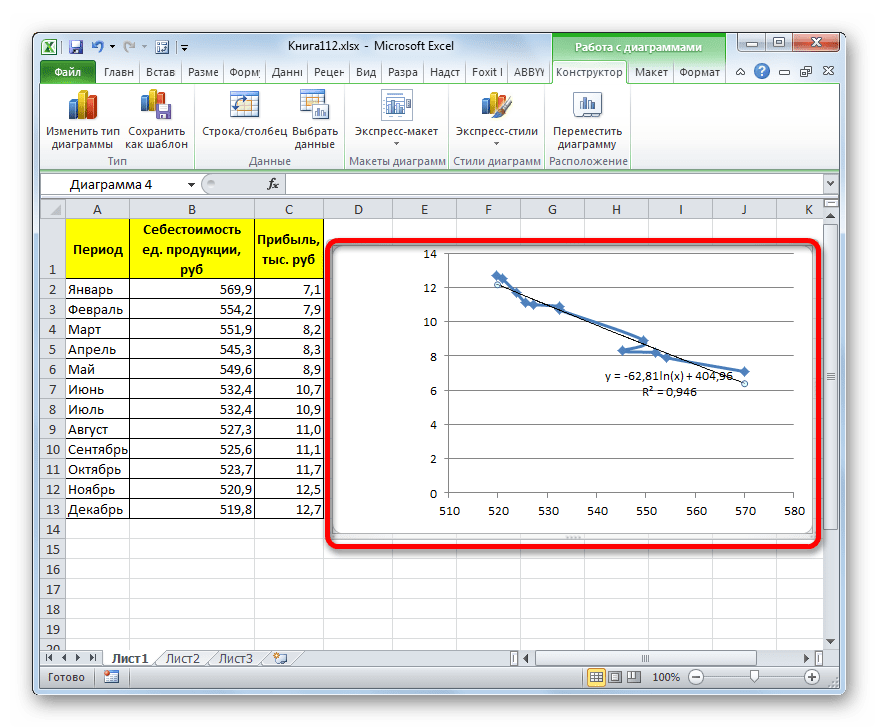
- Происходит процедура построения линии тренда с логарифмической аппроксимацией. Как и в предыдущем случае, такой вариант лучше использовать тогда, когда изначально данные быстро изменяются, а потом принимают сбалансированный вид. Как видим, уровень достоверности равен 0,946. Это выше, чем при использовании линейного метода, но ниже, чем качество линии тренда при экспоненциальном сглаживании.
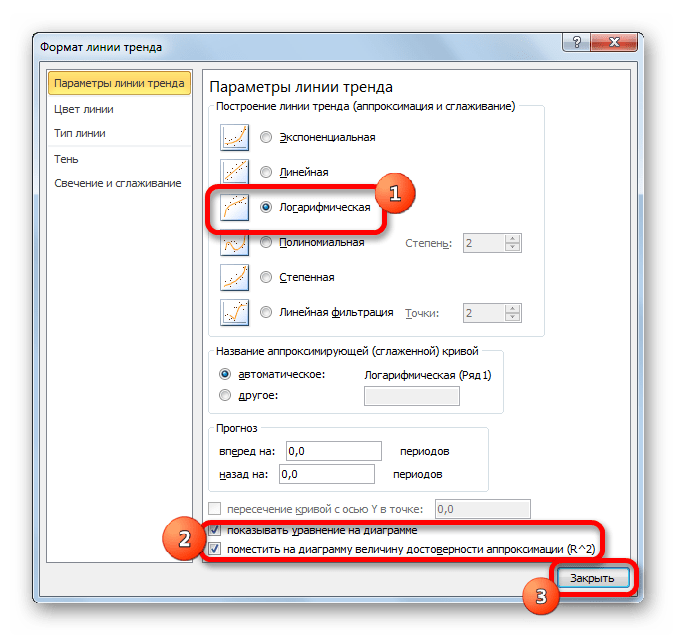
В общем виде формула сглаживания выглядит так:
y=a*ln(x)+b
где ln – это величина натурального логарифма. Отсюда и наименование метода.
В нашем случае формула принимает следующий вид:
y=-62,81ln(x)+404,96
Способ 4: полиномиальное сглаживание
Настал черед рассмотреть метод полиномиального сглаживания.
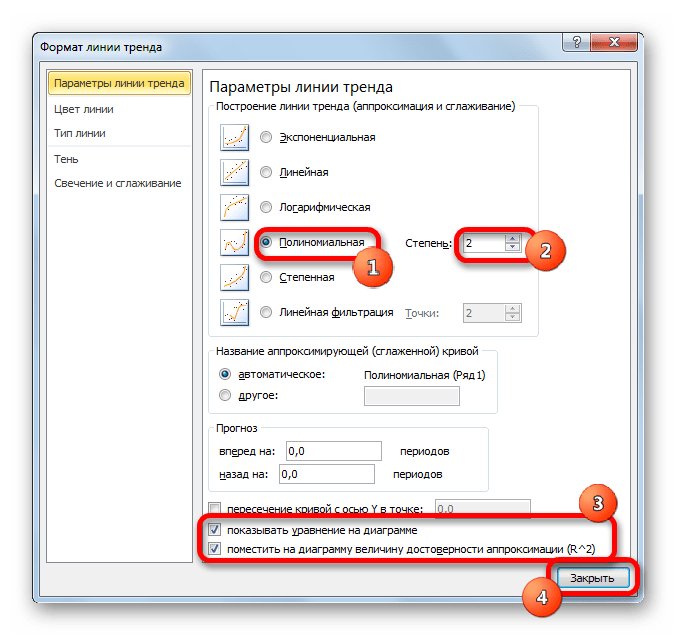
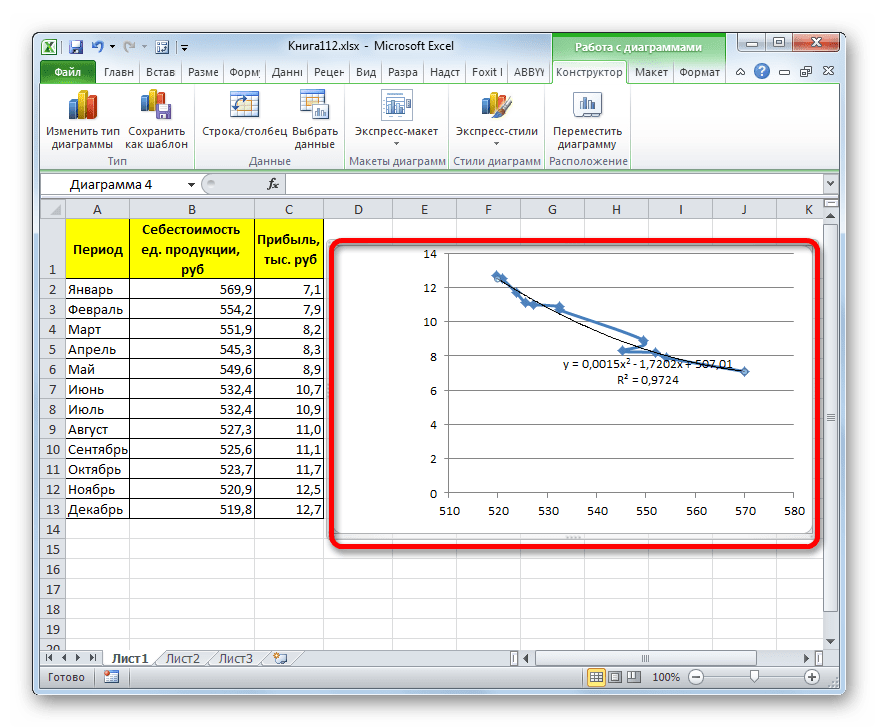
- Переходим в окно формата линии тренда, как уже делали не раз. В блоке «Построение линии тренда» устанавливаем переключатель в позицию «Полиномиальная». Справа от данного пункта расположено поле «Степень». При выборе значения «Полиномиальная» оно становится активным. Здесь можно указать любое степенное значение от 2 (установлено по умолчанию) до 6. Данный показатель определяет число максимумов и минимумов функции. При установке полинома второй степени описывается только один максимум, а при установке полинома шестой степени может быть описано до пяти максимумов. Для начала оставим настройки по умолчанию, то есть, укажем вторую степень. Остальные настройки оставляем такими же, какими мы выставляли их в предыдущих способах. Жмем на кнопку «Закрыть».
- Линия тренда с использованием данного метода построена. Как видим, она ещё более изогнута, чем при использовании экспоненциальной аппроксимации. Уровень достоверности выше, чем при любом из использованных ранее способов, и составляет 0,9724.

Данный метод наиболее успешно можно применять в том случае, если данные носят постоянно изменчивый характер. Функция, описывающая данный вид сглаживания, выглядит таким образом:
y=a1+a1*x+a2*x^2+…+an*x^nВ нашем случае формула приняла такой вид:
y=0,0015*x^2-1,7202*x+507,01 - Теперь давайте изменим степень полиномов, чтобы увидеть, будет ли отличаться результат. Возвращаемся в окно формата. Тип аппроксимации оставляем полиномиальным, но напротив него в окне степени устанавливаем максимально возможное значение – 6.
- Как видим, после этого наша линия тренда приняла форму ярко выраженной кривой, у которой число максимумов равно шести. Уровень достоверности повысился ещё больше, составив 0,9844.
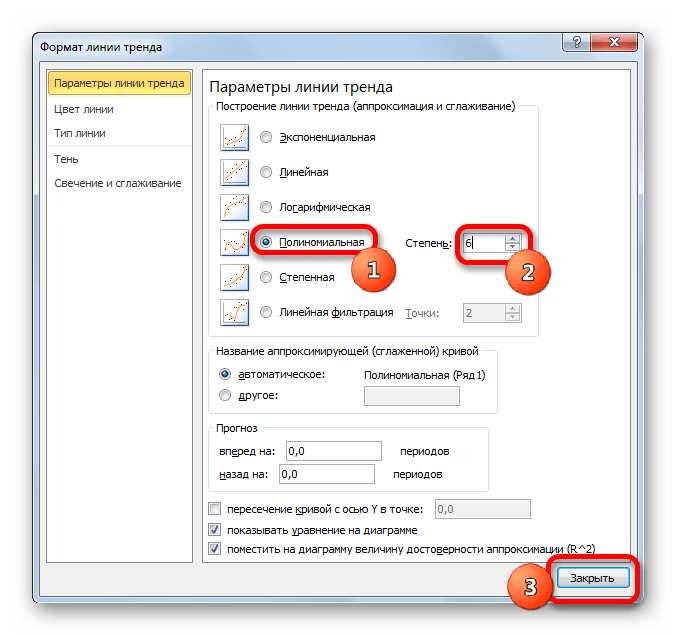
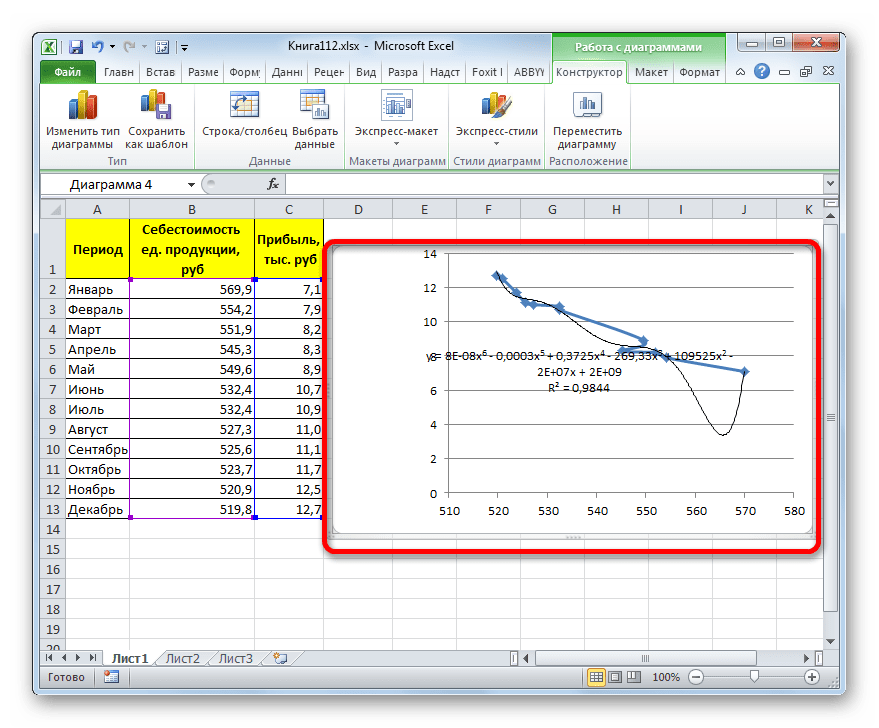
Формула, которая описывает данный тип сглаживания, приняла следующий вид:
y=8E-08x^6-0,0003x^5+0,3725x^4-269,33x^3+109525x^2-2E+07x+2E+09
Способ 5: степенное сглаживание
В завершении рассмотрим метод степенной аппроксимации в Excel.
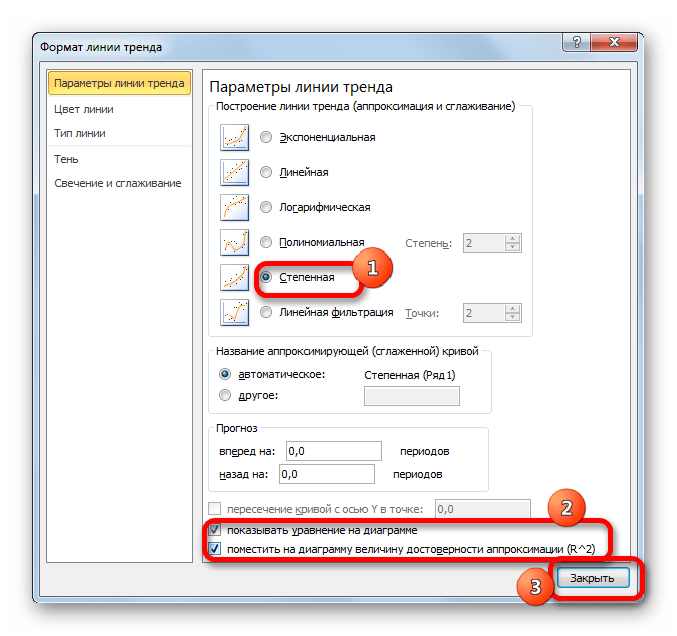
- Перемещаемся в окно «Формат линии тренда». Устанавливаем переключатель вида сглаживания в позицию «Степенная». Показ уравнения и уровня достоверности, как всегда, оставляем включенными. Жмем на кнопку «Закрыть».
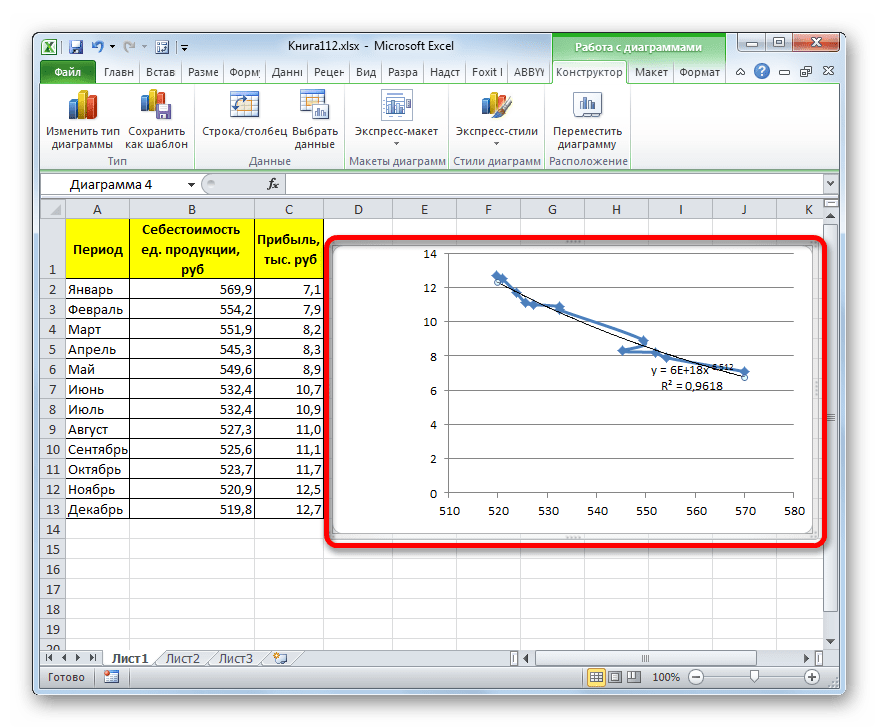
- Программа формирует линию тренда. Как видим, в нашем случае она представляет собой линию с небольшим изгибом. Уровень достоверности равен 0,9618, что является довольно высоким показателем. Из всех вышеописанных способов уровень достоверности был выше только при использовании полиномиального метода.
Данный способ эффективно используется в случаях интенсивного изменения данных функции. Важно учесть, что этот вариант применим только при условии, что функция и аргумент не принимают отрицательных или нулевых значений.
Общая формула, описывающая данный метод имеет такой вид:
y=bx^n
В конкретно нашем случае она выглядит так:
y = 6E+18x^(-6,512)
Как видим, при использовании конкретных данных, которые мы применяли для примера, наибольший уровень достоверности показал метод полиномиальной аппроксимации с полиномом в шестой степени (0,9844), наименьший уровень достоверности у линейного метода (0,9418). Но это совсем не значит, что такая же тенденция будет при использовании других примеров. Нет, уровень эффективности у приведенных выше методов может значительно отличаться, в зависимости от конкретного вида функции, для которой будет строиться линия тренда. Поэтому, если для этой функции выбранный метод наиболее эффективен, то это совсем не означает, что он также будет оптимальным и в другой ситуации.
Если вы пока не можете сразу определить, основываясь на вышеприведенных рекомендациях, какой вид аппроксимации подойдет конкретно в вашем случае, то есть смысл попробовать все методы. После построения линии тренда и просмотра её уровня достоверности можно будет выбрать оптимальный вариант.

Михаил Витер
Эксперт по предмету «Информационные технологии»
Задать вопрос автору статьи
Определение 1
Аппроксимация табличных функций в Excel — это определение аппроксимирующей функции, которая является близкой к заданной.
Понятие аппроксимации
Среди разных методик прогнозирования следует отдельно выделить метод аппроксимации. С его помощью имеется возможность осуществления приблизительных подсчетов и вычисления планируемых показателей, за счёт подмены исходных объектов на более простые. В Excel также присутствует возможность применения этого метода с целью выполнения прогнозов и анализа.
Название этого метода произошло от латинского слова “proxima”, то есть, «ближайшая». Как раз приближение за счет упрощения и сглаживания некоторых показателей, формирование из них тенденции и считается его основой. Но эту методику можно применять не только для прогнозирования, но и для изучения уже полученных результатов. Поскольку аппроксимация выступает, по существу, как упрощение исходных данных, а упрощенную версию легче изучать.
![]()
Сделаем домашку
с вашим ребенком за 380 ₽
Уделите время себе, а мы сделаем всю домашку с вашим ребенком в режиме online
Бесплатное пробное занятие
*количество мест ограничено
Аппроксимация табличных функций в Excel
Основным инструментом, при помощи которого реализуется сглаживание в Excel, является формирование линии тренда. Суть заключается в том, что на базе уже существующих показателей выполняется достраивание графика функции на будущие периоды. Основным предназначением линии тренда очевидно является формирование прогнозов или определение общей тенденции.
Эта линия может быть построена с использованием одного из следующих типов аппроксимации:
линейная,
экспоненциальная,
логарифмическая,
полиномиальная,
* степенная.
Рассмотрим некоторые из этих вариантов более подробно, и начнем с линейной аппроксимации, которая фактически является линейным сглаживанием. Прежде всего, следует рассмотреть наиболее простую версию аппроксимации, то есть, при помощи линейной функции.
Замечание 1
Сначала необходимо построить график, на базе которого будет осуществляться процедура сглаживания.
«Аппроксимация табличных функций в Excel » 👇
Чтобы построить график, необходимо взять таблицу, в которой, например, помесячно указывается себестоимость единицы продукции, выпускаемой организацией, и соответствующая прибыль за данный период. Графическая функция, которую необходимо построить, будет отображать зависимость роста прибыли от уменьшения себестоимости продукции. При построении графика сначала надо выделить столбцы «Себестоимость единицы продукции» и «Прибыль». После этого следует переместиться на вкладку «Вставка». Затем на ленте в блоке инструментов «Диаграммы» выполнить щелчок указателем мыши по кнопке «Точечная». В открывшемся списке нужно выбрать наименование «Точечная с гладкими кривыми и маркерами». Как раз такой вид диаграмм больше всего подходит для работы с линией тренда, а, следовательно, и для использования метода аппроксимации в Excel.
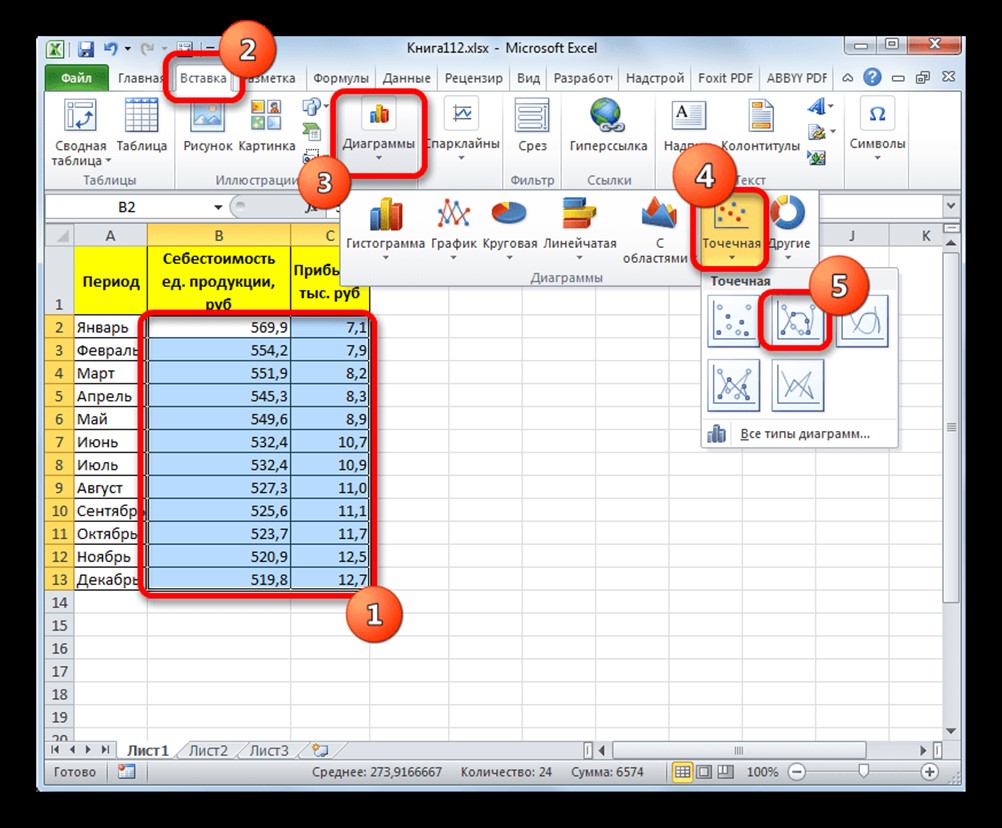
Рисунок 1. Параметры для построения графика. Автор24 — интернет-биржа студенческих работ
Затем будет построен следующий график:
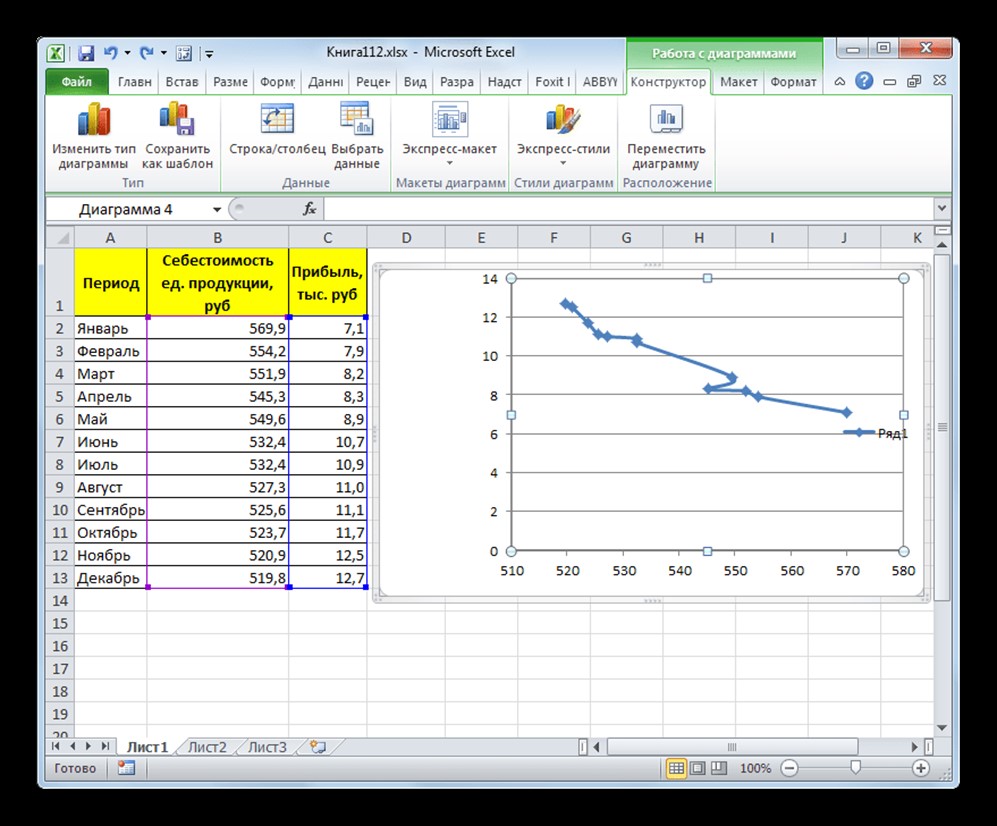
Рисунок 2. Точечная с гладкими кривыми и маркерами. Автор24 — интернет-биржа студенческих работ
Чтобы добавить линию тренда, необходимо выделить график кликом правой кнопки мыши, после чего появится контекстное меню. Следует осуществить выбор в нем пункта «Добавить линию тренда…».
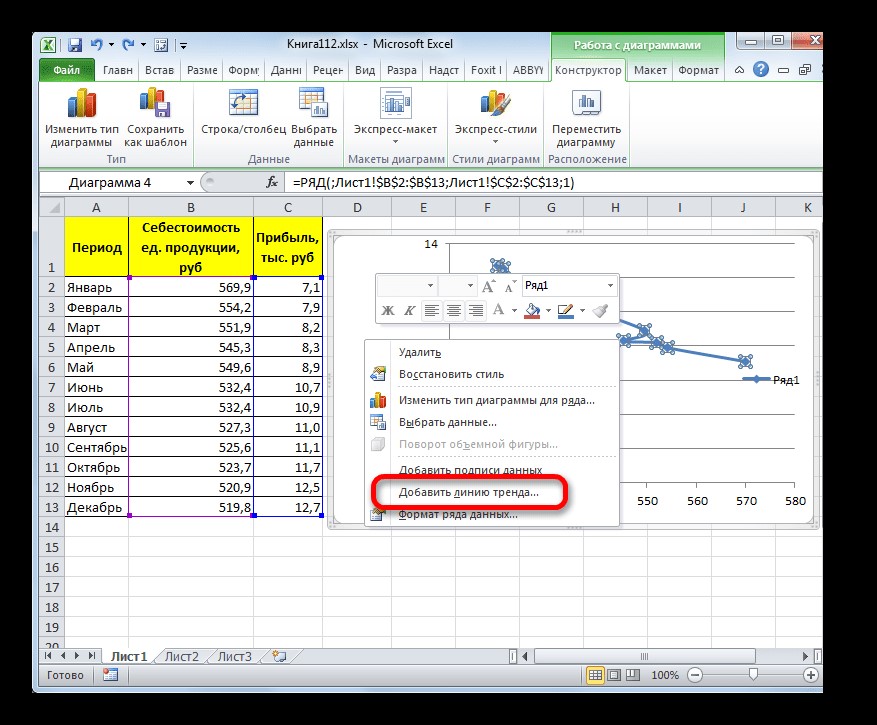
Рисунок 3. Добавить линию тренда на график. Автор24 — интернет-биржа студенческих работ
Имеется и другой вариант добавления линии тренда. В дополнительной группе вкладок на ленте «Работа с диаграммами» следует переместиться во вкладку «Макет». Затем в блоке инструментов «Анализ» необходимо сделать щелчок по кнопке «Линия тренда», после чего откроется список. Поскольку в нашем случае рассматривается применение линейной аппроксимации, то из предложенных позиций следует выбрать «Линейное приближение».
Если же был выбран первый вариант действий с добавлением через контекстное меню, то далее будет открыто окно формата. В блоке параметров «Построение линии тренда (аппроксимация и сглаживание)» необходимо установить переключатель в позицию «Линейная». Если это необходимо, то следует поставить галочку около позиции «Показывать уравнение на диаграмме». После данных действий на диаграмме будет отображено уравнение сглаживающей функции.
Кроме того, для сравнения разных вариантов аппроксимации можно установить галочку около пункта «Поместить на диаграмму величину достоверной аппроксимации (R^2)». Этот показатель варьируется в диапазоне от нуля до единицы. Чем его значение больше, тем точнее выполнена аппроксимация. Считается, что если величина данного показателя равна 0,85 и выше, то сглаживание может считаться достоверным, а если показатель ниже, то его достоверность ниже допустимой. После проведения всех вышеуказанных настроек, следует нажать на кнопку «Закрыть», размещенную в нижней части окна. Появится линия тренда.
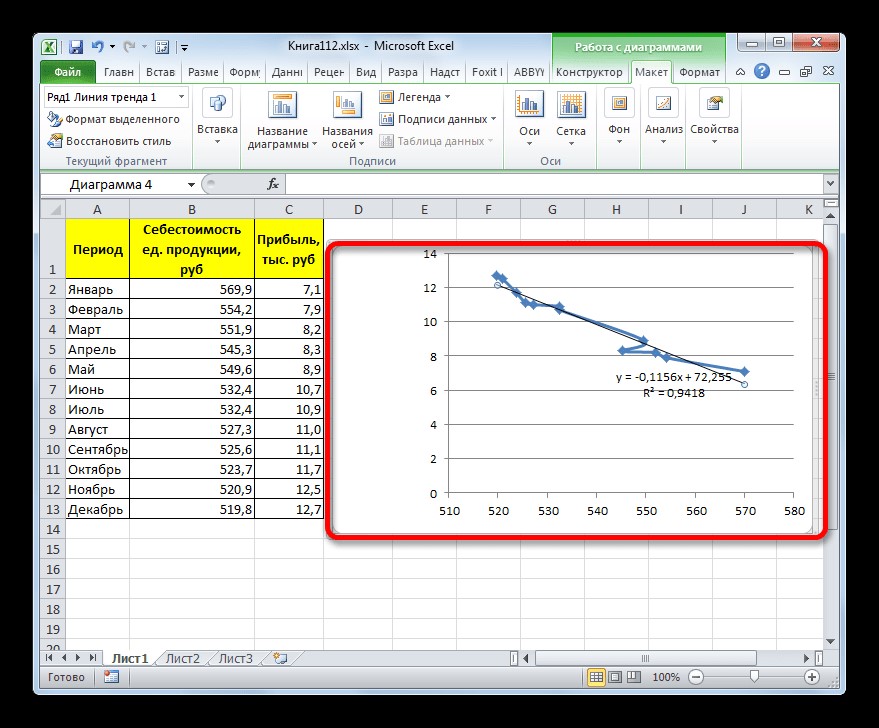
Рисунок 4. Отображение линии тренда. Автор24 — интернет-биржа студенческих работ
При выполнении линейной аппроксимации линия тренда обозначается черной прямой линией. Приведенный тип сглаживания может быть использован в самых простых случаях, когда данные меняются достаточно быстро и зависимость величины функции от аргумента является очевидной. Сглаживание, которое применяется в этом варианте, может быть описано следующей формулой:
y = ax + b.
Для конкретного варианта, приведенного выше, формула будет иметь следующий вид:
y = ‒ 0,1156x + 72,255.
Значение достоверности аппроксимации в рассмотренном случае равняется 0,9418, что считается достаточно приемлемым результатом, который характеризует сглаживание как достоверное.
Далее рассмотрим экспоненциальный тип аппроксимации в Excel. Для изменения типа линии тренда, следует выделить ее кликом правой кнопки мыши и в открывшемся меню нужно выбрать пункт «Формат линии тренда…». После этого будет запущено уже применявшееся ранее окно формата. В блоке выбора типа аппроксимации необходимо установить переключатель в положение «Экспоненциальная». Остальные настройки следует оставить такими же, как и в первом варианте, и затем выполнить щелчок по кнопке «Закрыть». После этого линия тренда будет построена на графике, как показано на рисунке ниже:
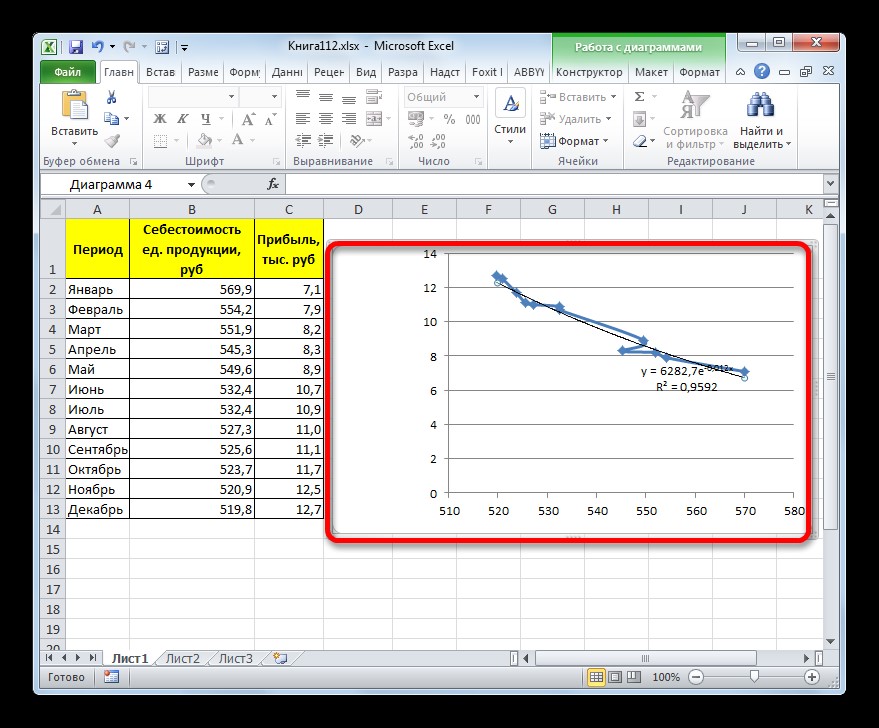
Рисунок 5. Экспоненциальный тип аппроксимации. Автор24 — интернет-биржа студенческих работ
При использовании этого метода линия тренда обладает несколько изогнутой формой. Причем уровень достоверности равняется 0,9592, что выше, чем при использовании линейной аппроксимации.
Находи статьи и создавай свой список литературы по ГОСТу
Поиск по теме
Содержание
- 1 Выполнение аппроксимации
- 1.1 Способ 1: линейное сглаживание
- 1.2 Способ 2: экспоненциальная аппроксимация
- 1.3 Способ 3: логарифмическое сглаживание
- 1.4 Способ 4: полиномиальное сглаживание
- 1.5 Способ 5: степенное сглаживание
- 1.6 Помогла ли вам эта статья?
- 2 Аппроксимация в Excel статистических данных аналитической функцией.
- 3 Итоги.
- 4 P.S. (04.06.2017)
- 5 Высокоточная красивая замена табличных данных простым уравнением.

Среди различных методов прогнозирования нельзя не выделить аппроксимацию. С её помощью можно производить приблизительные подсчеты и вычислять планируемые показатели, путем замены исходных объектов на более простые. В Экселе тоже существует возможность использования данного метода для прогнозирования и анализа. Давайте рассмотрим, как этот метод можно применить в указанной программе встроенными инструментами.
Выполнение аппроксимации
Наименование данного метода происходит от латинского слова proxima – «ближайшая» Именно приближение путем упрощения и сглаживания известных показателей, выстраивание их в тенденцию и является его основой. Но данный метод можно использовать не только для прогнозирования, но и для исследования уже имеющихся результатов. Ведь аппроксимация является, по сути, упрощением исходных данных, а упрощенный вариант исследовать легче.
Главный инструмент, с помощью которого проводится сглаживания в Excel – это построение линии тренда. Суть состоит в том, что на основе уже имеющихся показателей достраивается график функции на будущие периоды. Основное предназначение линии тренда, как не трудно догадаться, это составление прогнозов или выявление общей тенденции.
Но она может быть построена с применением одного из пяти видов аппроксимации:
- Линейной;
- Экспоненциальной;
- Логарифмической;
- Полиномиальной;
- Степенной.
Рассмотрим каждый из вариантов более подробно в отдельности.
Урок: Как построить линию тренда в Excel
Способ 1: линейное сглаживание
Прежде всего, давайте рассмотрим самый простой вариант аппроксимации, а именно с помощью линейной функции. На нем мы остановимся подробнее всего, так как изложим общие моменты характерные и для других способов, а именно построение графика и некоторые другие нюансы, на которых при рассмотрении последующих вариантов уже останавливаться не будем.
Прежде всего, построим график, на основании которого будем проводить процедуру сглаживания. Для построения графика возьмем таблицу, в которой помесячно указана себестоимость единицы продукции, производимой предприятием, и соответствующая прибыль в данном периоде. Графическая функция, которую мы построим, будет отображать зависимость увеличения прибыли от уменьшения себестоимости продукции.
- Для построения графика, прежде всего, выделяем столбцы «Себестоимость единицы продукции» и «Прибыль». После этого перемещаемся во вкладку «Вставка». Далее на ленте в блоке инструментов «Диаграммы» щелкаем по кнопке «Точечная». В открывшемся списке выбираем наименование «Точечная с гладкими кривыми и маркерами». Именно данный вид диаграмм наиболее подходит для работы с линией тренда, а значит, и для применения метода аппроксимации в Excel.
- График построен.
- Для добавления линии тренда выделяем его кликом правой кнопки мыши. Появляется контекстное меню. Выбираем в нем пункт «Добавить линию тренда…».
Существует ещё один вариант её добавления. В дополнительной группе вкладок на ленте «Работа с диаграммами» перемещаемся во вкладку «Макет». Далее в блоке инструментов «Анализ» щелкаем по кнопке «Линия тренда». Открывается список. Так как нам нужно применить линейную аппроксимацию, то из представленных позиций выбираем «Линейное приближение».
- Если же вы выбрали все-таки первый вариант действий с добавлением через контекстное меню, то откроется окно формата.
В блоке параметров «Построение линии тренда (аппроксимация и сглаживание)» устанавливаем переключатель в позицию «Линейная».
При желании можно установить галочку около позиции «Показывать уравнение на диаграмме». После этого на диаграмме будет отображаться уравнение сглаживающей функции.Также в нашем случае для сравнения различных вариантов аппроксимации важно установить галочку около пункта «Поместить на диаграмму величину достоверной аппроксимации (R^2)». Данный показатель может варьироваться от 0 до 1. Чем он выше, тем аппроксимация качественнее (достовернее). Считается, что при величине данного показателя 0,85 и выше сглаживание можно считать достоверным, а если показатель ниже, то – нет.
После того, как провели все вышеуказанные настройки. Жмем на кнопку «Закрыть», размещенную в нижней части окна.
- Как видим, на графике линия тренда построена. При линейной аппроксимации она обозначается черной прямой полосой. Указанный вид сглаживания можно применять в наиболее простых случаях, когда данные изменяются довольно быстро и зависимость значения функции от аргумента очевидна.


Сглаживание, которое используется в данном случае, описывается следующей формулой:
y=ax+b
В конкретно нашем случае формула принимает такой вид:
y=-0,1156x+72,255
Величина достоверности аппроксимации у нас равна 0,9418, что является довольно приемлемым итогом, характеризующим сглаживание, как достоверное.
Способ 2: экспоненциальная аппроксимация
Теперь давайте рассмотрим экспоненциальный тип аппроксимации в Эксель.
- Для того, чтобы изменить тип линии тренда, выделяем её кликом правой кнопки мыши и в раскрывшемся меню выбираем пункт «Формат линии тренда…».
- После этого запускается уже знакомое нам окно формата. В блоке выбора типа аппроксимации устанавливаем переключатель в положение «Экспоненциальная». Остальные настройки оставим такими же, как и в первом случае. Щелкаем по кнопке «Закрыть».
- После этого линия тренда будет построена на графике. Как видим, при использовании данного метода она имеет несколько изогнутую форму. При этом уровень достоверности равен 0,9592, что выше, чем при использовании линейной аппроксимации. Экспоненциальный метод лучше всего использовать в том случае, когда сначала значения быстро изменяются, а потом принимают сбалансированную форму.
Общий вид функции сглаживания при этом такой:
y=be^x
где e – это основание натурального логарифма.
В конкретно нашем случае формула приняла следующую форму:
y=6282,7*e^(-0,012*x)
Способ 3: логарифмическое сглаживание
Теперь настала очередь рассмотреть метод логарифмической аппроксимации.
- Тем же способом, что и в предыдущий раз через контекстное меню запускаем окно формата линии тренда. Устанавливаем переключатель в позицию «Логарифмическая» и жмем на кнопку «Закрыть».
- Происходит процедура построения линии тренда с логарифмической аппроксимацией. Как и в предыдущем случае, такой вариант лучше использовать тогда, когда изначально данные быстро изменяются, а потом принимают сбалансированный вид. Как видим, уровень достоверности равен 0,946. Это выше, чем при использовании линейного метода, но ниже, чем качество линии тренда при экспоненциальном сглаживании.

В общем виде формула сглаживания выглядит так:
y=a*ln(x)+b
где ln – это величина натурального логарифма. Отсюда и наименование метода.
В нашем случае формула принимает следующий вид:
y=-62,81ln(x)+404,96
Способ 4: полиномиальное сглаживание
Настал черед рассмотреть метод полиномиального сглаживания.
- Переходим в окно формата линии тренда, как уже делали не раз. В блоке «Построение линии тренда» устанавливаем переключатель в позицию «Полиномиальная». Справа от данного пункта расположено поле «Степень». При выборе значения «Полиномиальная» оно становится активным. Здесь можно указать любое степенное значение от 2 (установлено по умолчанию) до 6. Данный показатель определяет число максимумов и минимумов функции. При установке полинома второй степени описывается только один максимум, а при установке полинома шестой степени может быть описано до пяти максимумов. Для начала оставим настройки по умолчанию, то есть, укажем вторую степень. Остальные настройки оставляем такими же, какими мы выставляли их в предыдущих способах. Жмем на кнопку «Закрыть».
- Линия тренда с использованием данного метода построена. Как видим, она ещё более изогнута, чем при использовании экспоненциальной аппроксимации. Уровень достоверности выше, чем при любом из использованных ранее способов, и составляет 0,9724.
Данный метод наиболее успешно можно применять в том случае, если данные носят постоянно изменчивый характер. Функция, описывающая данный вид сглаживания, выглядит таким образом:
y=a1+a1*x+a2*x^2+…+an*x^nВ нашем случае формула приняла такой вид:
y=0,0015*x^2-1,7202*x+507,01 - Теперь давайте изменим степень полиномов, чтобы увидеть, будет ли отличаться результат. Возвращаемся в окно формата. Тип аппроксимации оставляем полиномиальным, но напротив него в окне степени устанавливаем максимально возможное значение – 6.
- Как видим, после этого наша линия тренда приняла форму ярко выраженной кривой, у которой число максимумов равно шести. Уровень достоверности повысился ещё больше, составив 0,9844.


Формула, которая описывает данный тип сглаживания, приняла следующий вид:
y=8E-08x^6-0,0003x^5+0,3725x^4-269,33x^3+109525x^2-2E+07x+2E+09
Способ 5: степенное сглаживание
В завершении рассмотрим метод степенной аппроксимации в Excel.
- Перемещаемся в окно «Формат линии тренда». Устанавливаем переключатель вида сглаживания в позицию «Степенная». Показ уравнения и уровня достоверности, как всегда, оставляем включенными. Жмем на кнопку «Закрыть».
- Программа формирует линию тренда. Как видим, в нашем случае она представляет собой линию с небольшим изгибом. Уровень достоверности равен 0,9618, что является довольно высоким показателем. Из всех вышеописанных способов уровень достоверности был выше только при использовании полиномиального метода.

Данный способ эффективно используется в случаях интенсивного изменения данных функции. Важно учесть, что этот вариант применим только при условии, что функция и аргумент не принимают отрицательных или нулевых значений.
Общая формула, описывающая данный метод имеет такой вид:
y=bx^n
В конкретно нашем случае она выглядит так:
y = 6E+18x^(-6,512)
Как видим, при использовании конкретных данных, которые мы применяли для примера, наибольший уровень достоверности показал метод полиномиальной аппроксимации с полиномом в шестой степени (0,9844), наименьший уровень достоверности у линейного метода (0,9418). Но это совсем не значит, что такая же тенденция будет при использовании других примеров. Нет, уровень эффективности у приведенных выше методов может значительно отличаться, в зависимости от конкретного вида функции, для которой будет строиться линия тренда. Поэтому, если для этой функции выбранный метод наиболее эффективен, то это совсем не означает, что он также будет оптимальным и в другой ситуации.
Если вы пока не можете сразу определить, основываясь на вышеприведенных рекомендациях, какой вид аппроксимации подойдет конкретно в вашем случае, то есть смысл попробовать все методы. После построения линии тренда и просмотра её уровня достоверности можно будет выбрать оптимальный вариант.
Мы рады, что смогли помочь Вам в решении проблемы.
Задайте свой вопрос в комментариях, подробно расписав суть проблемы. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
Да Нет
Опубликовано 05 Янв 2014
Рубрика: Справочник Excel | 18 комментариев
(Обратите внимание на дополнительный раздел от 04.06.2017 в конце статьи.)
Учет и контроль! Те, кому за 40 должны хорошо помнить этот лозунг из эпохи построения социализма и коммунизма в нашей стране.
Но без хорошо налаженного учета невозможно эффективное функционирование ни страны, ни области, ни предприятия, ни домашнего хозяйства при любой общественно-экономической формации общества! Для составления прогнозов и планов деятельности и развития необходимы исходные данные. Где их брать? Только один достоверный источник – это ваши статистические учетные данные предыдущих периодов времени.
Учитывать результаты своей деятельности, собирать и записывать информацию, обрабатывать и анализировать данные, применять результаты анализа для принятия правильных решений в будущем должен, в моем понимании, каждый здравомыслящий человек. Это есть ничто иное, как накопление и рациональное использование своего жизненного опыта. Если не вести учет важных данных, то вы через определенный период времени их забудете и, начав заниматься этими вопросами вновь, вы опять наделаете те же ошибки, что делали, когда впервые этим занимались.
«Мы, помню, 5 лет назад изготавливали до 1000 штук таких изделий в месяц, а сейчас и 700 еле-еле собираем!». Открываем статистику и видим, что 5 лет назад и 500 штук не изготавливали…
«Во сколько обходится километр пробега твоего автомобиля с учетом всех затрат?» Открываем статистику – 6 руб./км. Поездка на работу – 107 рублей. Дешевле, чем на такси (180 рублей) более чем в полтора раза. А бывали времена, когда на такси было дешевле…
«Сколько времени требуется для изготовления металлоконструкций уголковой башни связи высотой 50 м?» Открываем статистику – и через 5 минут готов ответ…
«Сколько будет стоить ремонт комнаты в квартире?» Поднимаем старые записи, делаем поправку на инфляцию за прошедшие годы, учитываем, что в прошлый раз купили материалы на 10% дешевле рыночной цены и – ориентировочную стоимость мы уже знаем…
Ведя учет своей профессиональной деятельности, вы всегда будете готовы ответить на вопрос начальника: «Когда!!!???». Ведя учет домашнего хозяйства, легче спланировать расходы на крупные покупки, отдых и прочие расходы в будущем, приняв соответствующие меры по дополнительному заработку или по сокращению необязательных расходов сегодня.
В этой статье я на простом примере покажу, как можно обрабатывать собранные статистические данные в Excel для возможности дальнейшего использования при прогнозировании будущих периодов.
Производственный участок изготавливает строительные металлоконструкции из листового и профильного металлопроката. Участок работает стабильно, заказы однотипные, численность рабочих колеблется незначительно. Есть данные о выпуске продукции за предыдущие 12 месяцев и о количестве переработанного в эти периоды времени металлопроката по группам: листы, двутавры, швеллеры, уголки, трубы круглые, профили прямоугольного сечения, круглый прокат. После предварительного анализа исходных данных возникло предположение, что суммарный месячный выпуск металлоконструкций существенно зависит от количества уголков в заказах. Проверим это предположение.
Прежде всего, несколько слов об аппроксимации. Мы будем искать закон – аналитическую функцию, то есть функцию, заданную уравнением, которое лучше других описывает зависимость общего выпуска металлоконструкций от количества уголкового проката в выполненных заказах. Это и есть аппроксимация, а найденное уравнение называется аппроксимирующей функцией для исходной функции, заданной в виде таблицы.
1. Включаем Excel и помещаем на лист таблицу с данными статистики.
2. Далее строим и форматируем точечную диаграмму, в которой по оси X задаем значения аргумента – количество переработанных уголков в тоннах. По оси Y откладываем значения исходной функции – общий выпуск металлоконструкций в месяц, заданные таблицей.
О том, как построить подобную диаграмму, подробно рассказано в статье «Как строить графики в Excel?».
3. «Наводим» мышь на любую из точек на графике и щелчком правой кнопки вызываем контекстное меню (как говорит один мой хороший товарищ — работая в незнакомой программе, когда не знаешь, что делать, чаще щелкай правой кнопкой мыши…). В выпавшем меню выбираем «Добавить линию тренда…».
4. В появившемся окне «Линия тренда» на вкладке «Тип» выбираем «Линейная».
5. Далее на вкладке «Параметры» ставим 2 галочки и нажимаем «ОК».
6. На графике появилась прямая линия, аппроксимирующая нашу табличную зависимость.
Мы видим кроме самой линии уравнение этой линии и, главное, мы видим значение параметра R2 – величины достоверности аппроксимации! Чем ближе его значение к 1, тем наиболее точно выбранная функция аппроксимирует табличные данные!
7. Строим линии тренда, используя степенную, логарифмическую, экспоненциальную и полиномиальную аппроксимации по аналогии с тем, как мы строили линейную линию тренда.
Лучше всех из выбранных функций аппроксимирует наши данные полином второй степени, у него максимальный коэффициент достоверности R2.
Однако хочу вас предостеречь! Если вы возьмете полиномы более высоких степеней, то, возможно, получите еще лучшие результаты, но кривые будут иметь замысловатый вид…. Здесь важно понимать, что мы ищем функцию, которая имеет физический смысл. Что это означает? Это означает, что нам нужна аппроксимирующая функция, которая будет выдавать адекватные результаты не только внутри рассматриваемого диапазона значений X, но и за его пределами, то есть ответит на вопрос: «Какой будет выпуск металлоконструкций при количестве переработанных за месяц уголков меньше 45 и больше 168 тонн!» Поэтому я не рекомендую увлекаться полиномами высоких степеней, да и параболу (полином второй степени) выбирать осторожно!
Итак, нам необходимо выбрать функцию, которая не только хорошо интерполирует табличные данные в пределах диапазона значений X=45…168, но и допускает адекватную экстраполяцию за пределами этого диапазона. Я выбираю в данном случае логарифмическую функцию, хотя можно выбрать и линейную, как наиболее простую. В рассматриваемом примере при выборе линейной аппроксимации в excel ошибки будут больше, чем при выборе логарифмической, но не на много.
8. Удаляем все линии тренда с поля диаграммы, кроме логарифмической функции. Для этого щелкаем правой кнопкой мыши по ненужным линиям и в выпавшем контекстном меню выбираем «Очистить».
9. В завершении добавим к точкам табличных данных планки погрешностей. Для этого правой кнопкой мыши щелкаем на любой из точек на графике и в контекстном меню выбираем «Формат рядов данных…» и настраиваем данные на вкладке «Y-погрешности» так, как на рисунке ниже.
10. Затем щелкаем по любой из линий диапазонов погрешностей правой кнопкой мыши, выбираем в контекстном меню «Формат полос погрешностей…» и в окне «Формат планок погрешностей» на вкладке «Вид» настраиваем цвет и толщину линий.
Аналогичным образом форматируются любые другие объекты диаграммы в Excel!
Окончательный результат диаграммы представлен на следующем снимке экрана.
Итоги.
Результатом всех предыдущих действий стала полученная формула аппроксимирующей функции y=-172,01*ln (x)+1188,2. Зная ее, и количество уголков в месячном наборе работ, можно с высокой степенью вероятности (±4% — смотри планки погрешностей) спрогнозировать общий выпуск металлоконструкций за месяц! Например, если в плане на месяц 140 тонн уголков, то общий выпуск, скорее всего, при прочих равных составит 338±14 тонн.
Для повышения достоверности аппроксимации статистических данных должно быть много. Двенадцать пар значений – это маловато.
Из практики скажу, что хорошим результатом следует считать нахождение аппроксимирующей функции с коэффициентом достоверности R2>0,87. Отличный результат – при R2>0,94.
На практике бывает трудно выделить один самый главный определяющий фактор (в нашем примере – масса переработанных за месяц уголков), но если постараться, то в каждой конкретной задаче его всегда можно найти! Конечно, общий выпуск продукции за месяц реально зависит от сотни факторов, для учета которых необходимы существенные трудозатраты нормировщиков и других специалистов. Только результат все равно будет приблизительным! Так стоит ли нести затраты, если есть гораздо более дешевое математическое моделирование!
В этой статье я лишь прикоснулся к верхушке айсберга под названием сбор, обработка и практическое использование статистических данных. О том удалось, или нет, мне расшевелить ваш интерес к этой теме, надеюсь узнать из комментариев и рейтинга статьи в поисковиках.
Затронутый вопрос аппроксимации функции одной переменной имеет широкое практическое применение в разных сферах жизни. Но гораздо большее применение имеет решение задачи аппроксимации функции нескольких независимых переменных…. Об этом и не только читайте в следующих статьях на блоге.
Подписывайтесь на анонсы статей в окне, расположенном в конце каждой статьи или в окне вверху страницы.
Не забывайте подтверждать подписку кликом по ссылке в письме, которое придет к вам на указанную почту (может прийти в папку «Спам»)!!!
С интересом прочту Ваши комментарии, уважаемые читатели! Пишите!
P.S. (04.06.2017)
Высокоточная красивая замена табличных данных простым уравнением.
Вас не устраивают полученные точность аппроксимации (R2
Подробности Автор: Administrator Родительская категория: Заметки Категория: Компьютерная повседневность Создано: 28 января 2013 Обновлено: 15 мая 2014 Просмотров: 28651
Чтобы приступить к аппроксимации кривой ваших экспериментальных данных в Excel 2003:
1. Создайте диаграмму (график).
2. Выделите линию функции на графике и нажмите правую кнопку мыши, выберите «Добавить линию тренда»
3. Выберите тип аппроксимации во вкладке «Тип» в откурывшемся диалоговом окне «Линия тренда»
4. На вкладке «Параметры» — прогностические параметры, показывать уравнение на графике или нет
Аппроксимация (от лат. approximo — приближаюсь) — это замена одних математических объектов другими, в том или ином смысле близкими к исходным. Аппроксимация позволяет исследовать числовые характеристики и качественные свойства объекта, сводя задачу к изучению более простых или более удобных объектов (например, таких, характеристики которых легко вычисляются или свойства которых уже известны). В этой нашей статье мы постараемся подробно рассмотреть вопрос о том, как апроксимировать график в офисной программе Excel?
В MS Excel аппроксимация экспериментальных данных осуществляется путем построения их графика (x – отвлеченные величины) или точечного графика (x – имеет конкретные значения) с последующим подбором подходящей аппроксимирующей функции (линии тренда).
1. Создайте диаграмму (график).
2. Выделите линию функции на графике и нажмите правую кнопку мыши, выберите «Добавить линию тренда».
3. Выберите тип аппроксимации во вкладке «Тип» в откурывшемся диалоговом окне «Линия тренда».
4. На вкладке «Параметры» — прогностические параметры, показывать уравнение на графике или нет.
Решить задачу аппроксимации экспериментальных данных – значит построить уравнение регрессии. Задача аппроксимации возникает в случае необходимости аналитически, то есть в виде математической зависимости, описать реальные явления, наблюдения за которыми заданы в виде таблицы, содержащей значения показателя в разные моменты времени или при разных значениях независимого аргумента. Например,
— известны показатели прибыли (их можно обозначить Y) в зависимости от размера капиталовложений (X);
— известны объемы реализации фирмы (Y) за шесть недель ее работы. В этом случае, X – это последовательность недель.
Иногда говорят, что требуется построить эмпирическую модель. Эмпирической называется модель, построенная на основе реальных наблюдений. Если модель удается найти, можно сделать прогноз о поведении исследуемого явления и процесса в будущем и, возможно, выбрать оптимальное направление ее развития.
В общем случае задача аппроксимации экспериментальных данных имеет следующую постановку:
Пусть известны данные, полученные практическим путем (в ходе n экспериментов или наблюдений), которые можно представить парами чисел (хi; уi). Зависимость между ними отражает таблица:
| X | х1 | х2 | х3 | … | хn |
| Y | y1 | y2 | y3 | … | yn |
Имеется класс разнообразных функций F. Требуется найти аналитическое (т.е. математическое) выражение зависимости между этими показателями, то есть надо подобрать из множества функций F функцию f, такую что . которая наилучшим образом сглаживала бы экспериментальную зависимость между переменными и по возможности точно отражала общую тенденцию зависимости между X и Y, исключая погрешности измерения и случайные отклонения.
Выяснить вид функции можно либо из теоретических соображений, либо анализируя расположение точек (хi; уi) на координатной плоскости.
Графически решить задачу аппроксимации означает, провести такую кривую , точки которой (хi; ŷi) находились бы как можно ближе к исходным точкам (хi; уi), отображающим экспериментальные данные.
Для решения задачи аппроксимации используют метод наименьших квадратов.
При этом функция считается наилучшим приближением к , если для нее сумма квадратов отклонений «теоретических» значений , найденных по эмпирической формуле, от соответствующих опытных значений , имеет наименьшее значение по сравнению с другими функциями, из числа которых выбирается искомое приближение.
Математическая запись метода наименьших квадратов имеет вид:
(1)
где n — количество наблюдений показателей.
Таким образом, задача аппроксимации распадается на две части.
Сначала устанавливают вид зависимости и, соответственно, вид эмпирической формулы, то есть решают, является ли она линейной, квадратичной, логарифмической или какой-либо другой. Если нет каких-либо теоретических соображений для подбора вида формулы, обычно выбирают функциональную зависимость из числа наиболее простых, сравнивая их графики с графиком заданной функции.
После этого определяются численные значения неизвестных параметров выбранной эмпирической формулы, для которых приближение к заданной функции оказывается наилучшим.
Простейшим видом эмпирической модели с двумя параметрами, используемой для аппроксимации результатов экспериментов, является линейная регрессия, описываемая линейной функцией:
где а, b — искомые параметры.
Для модели линейной регрессии метод наименьших квадратов (1) запишется :
(2)
Для решения (2) относительно а и b приравнивают к нулю частные производные:
В итоге для нахождения a и b надо решить систему линейных алгебраических уравнений вида:
(3)
Реализовать метод наименьших квадратов в случае линейной регрессии в Excel можно различными способами.
1 способ. Построить систему линейных алгебраических уравнений, подставив в (3) все известные значения, и решить ее, например, матричным методом (см. зад. 4).
Рис. 25
В формульном виде элемент расчетной таблицы приведен на рис. 26.
Рис.26
2 способ. Решить в Excel задачу оптимизации (2), применив для этого Поиск решения (см. зад. 5).
Рис.27
Замечание 1. Следует обратить внимание, что для целевой функции S удобно применить встроенную математическую функцию СУММКВРАЗН(массив1;массив2), в результате которой как раз и вычисляется сумма квадратов разностей двух массивов. В нашем случае следует в качестве массива1 указать диапазон исходных значений , а в качестве массива2 – «теоретические» значения , рассчитанные по формуле , где a и b – это адреса ячеек с искомыми значениями.
Замечание 2. В диалоговом окне команды Поиск решения следует задать целевую ячейку, направление цели – на минимум и изменяемые ячейки (рис. 28). Данная задача ограничений не содержит.
Рис.28
Замечание3. В качестве эмпирических моделей с двумя параметрами могут использоваться и нелинейные модели вида:
Описанный способ решения метода наименьших квадратов применим и для нелинейных зависимостей.
3 способ. Для нахождения значений параметров a и b в случае линейной регрессии можно использовать следующие встроенные в Excel статистические функции:
НАКЛОН(известные_значения_У; известные_значения_Х)
ОТРЕЗОК(известные_значения_У; известные_значения_Х)
ЛИНЕЙН (известные_значения_У; известные_значения_Х)
Причем, функция НАКЛОН ( ) возвращает значение параметра а, функция ОТРЕЗОК( ) возвращает значение параметра b. Функция ЛИНЕЙН( ) возвращает одновременно оба параметра линейной зависимости, так как является функцией массива. Поэтому для ввода функции ЛИНЕЙН( ) в таблицу надо соблюдать следующие правила:
· выделить две рядом стоящие ячейки
· ввести формулу
· по окончании нажать одновременно комбинацию клавиш Ctrl+ Shift+Enter.
В результате в левой ячейке получится значение параметра а, а в правой – значение параметра b.
Для решения задачи аппроксимации графическим способом в Excel надо построить по исходным данным график, например, точечную диаграмму со значениями, соединенными сглаживающими линиями (см.зад.1). На эту диаграмму Excel может нанести Линию тренда. Линию тренда можно добавить к любому ряду данных, использующему следующие типы диаграмм: диаграммы с областями, графики, гистограммы, линейчатые или точечные диаграммы.
При создании линии тренда в Excel на основе данных диаграммы применяется та или иная аппроксимация. Excel позволяет выбрать один из пяти аппроксимирующих линий или вычислить линию, показывающую скользящее среднее.
Кроме того, Excel предоставляет возможность выбирать значения пересечения линии тренда с осью Y, а также добавлять к диаграмме уравнение аппроксимации и величину достоверности аппроксимации (R2). Также, можно определять будущие и прошлые значения данных, исходя из линии тренда и связанного с ней уравнения аппроксимации.
Чтобы добавить линию тренда к ряду данных надо:
1. Активизировать щелчком мыши диаграмму.
2. Выполнить команду Диаграмма, Добавить линию тренда или переместить указатель на ряд данных, щелкнуть правой кнопкой мыши, а затем в контекстном меню выбрать команду Добавить линию тренда. В появившемся окне Линия тренда раскрыть вкладку Тип (рис. 29)
3. В списке Построен на ряде – выделить ряд данных, к которому нужно добавить линию тренда (Рис.29).
4. В группе Построение линии тренда (аппроксимация и сглаживание) выбрать один из шести типов аппроксимации (сглаживания). – линейная, логарифмическая, полиномиальная, степенная, экспоненциальная, скользящее среднее (Рис.29)
Рис.29
5. Чтобы установить параметры линии тренда надо раскрыть вкладку Параметры диалогового окна Линия тренда(рис. 30)
Рис.30
Показывать уравнение на диаграмме – осуществляет вывод уравнения аппроксимации на диаграмму в виде текстового поля.
Поместить на диаграмму величину достоверности аппроксимации R2– осуществляет вывод на диаграмму достоверности аппроксимации в виде текста.
6. По окончании нажимают экранную кнопку ОК.
Пример результирующей диаграммы приведен на рисунке 31.
Рис.31
В этой статье описаны синтаксис формулы и использование функции LINEST в Microsoft Excel. Ссылки на дополнительные сведения о диаграммах и выполнении регрессионного анализа можно найти в разделе См. также.
Описание
Функция ЛИНЕЙН рассчитывает статистику для ряда с применением метода наименьших квадратов, чтобы вычислить прямую линию, которая наилучшим образом аппроксимирует имеющиеся данные и затем возвращает массив, который описывает полученную прямую. Функцию ЛИНЕЙН также можно объединять с другими функциями для вычисления других видов моделей, являющихся линейными по неизвестным параметрам, включая полиномиальные, логарифмические, экспоненциальные и степенные ряды. Поскольку возвращается массив значений, функция должна задаваться в виде формулы массива. Инструкции приведены в данной статье после примеров.
Уравнение для прямой линии имеет следующий вид:
y = mx + b
или
y = m1x1 + m2x2 +… + b
если существует несколько диапазонов значений x, где зависимые значения y — функции независимых значений x. Значения m — коэффициенты, соответствующие каждому значению x, а b — постоянная. Обратите внимание, что y, x и m могут быть векторами. Функция ЛИНЕЙН возвращает массив {mn;mn-1;…;m1;b}. Функция ЛИНЕЙН может также возвращать дополнительную регрессионную статистику.
Синтаксис
ЛИНЕЙН(известные_значения_y; [известные_значения_x]; [конст]; [статистика])
Аргументы функции ЛИНЕЙН описаны ниже.
Синтаксис
-
Известные_значения_y. Обязательный аргумент. Множество значений y, которые уже известны для соотношения y = mx + b.
-
Если массив известные_значения_y имеет один столбец, то каждый столбец массива известные_значения_x интерпретируется как отдельная переменная.
-
Если массив известные_значения_y имеет одну строку, то каждая строка массива известные_значения_x интерпретируется как отдельная переменная.
-
-
Известные_значения_x. Необязательный аргумент. Множество значений x, которые уже известны для соотношения y = mx + b.
-
Массив известные_значения_x может содержать одно или несколько множеств переменных. Если используется только одна переменная, то массивы известные_значения_y и известные_значения_x могут иметь любую форму — при условии, что они имеют одинаковую размерность. Если используется более одной переменной, то известные_значения_y должны быть вектором (т. е. интервалом высотой в одну строку или шириной в один столбец).
-
Если массив известные_значения_x опущен, то предполагается, что это массив {1;2;3;…}, имеющий такой же размер, что и массив известные_значения_y.
-
-
Конст. Необязательный аргумент. Логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0.
-
Если аргумент конст имеет значение ИСТИНА или опущен, то константа b вычисляется обычным образом.
-
Если аргумент конст имеет значение ЛОЖЬ, то значение b полагается равным 0 и значения m подбираются таким образом, чтобы выполнялось соотношение y = mx.
-
-
Статистика. Необязательный аргумент. Логическое значение, которое указывает, требуется ли вернуть дополнительную регрессионную статистику.
-
Если статистика имеет true, то LINEST возвращает дополнительную регрессию; в результате возвращается массив {mn;mn-1,…,m1;b;sen,sen-1,…,se1;seb;r2;sey; F,df;ssreg,ssresid}.
-
Если аргумент статистика имеет значение ЛОЖЬ или опущен, функция ЛИНЕЙН возвращает только коэффициенты m и постоянную b.
Дополнительная регрессионная статистика.
-
|
Величина |
Описание |
|---|---|
|
se1,se2,…,sen |
Стандартные значения ошибок для коэффициентов m1,m2,…,mn. |
|
seb |
Стандартное значение ошибки для постоянной b (seb = #Н/Д, если аргумент конст имеет значение ЛОЖЬ). |
|
r2 |
Коэффициент определения. Сравнивает предполагаемые и фактические значения y и диапазоны значений от 0 до 1. Если значение 1, то в выборке будет отличная корреляция— разница между предполагаемым значением y и фактическим значением y не существует. С другой стороны, если коэффициент определения — 0, уравнение регрессии не помогает предсказать значение y. Сведения о том, каквычисляется 2, см. в разделе «Замечания» далее в этой теме. |
|
sey |
Стандартная ошибка для оценки y. |
|
F |
F-статистика или F-наблюдаемое значение. F-статистика используется для определения того, является ли случайной наблюдаемая взаимосвязь между зависимой и независимой переменными. |
|
df |
Степени свободы. Степени свободы используются для нахождения F-критических значений в статистической таблице. Для определения уровня надежности модели необходимо сравнить значения в таблице с F-статистикой, возвращаемой функцией ЛИНЕЙН. Дополнительные сведения о вычислении величины df см. ниже в разделе «Замечания». Далее в примере 4 показано использование величин F и df. |
|
ssreg |
Регрессионная сумма квадратов. |
|
ssresid |
Остаточная сумма квадратов. Дополнительные сведения о расчете величин ssreg и ssresid см. в подразделе «Замечания» в конце данного раздела. |
На приведенном ниже рисунке показано, в каком порядке возвращается дополнительная регрессионная статистика.

Замечания
-
Любую прямую можно описать ее наклоном и пересечением с осью y:
Наклон (m):
Чтобы найти наклон линии, обычно записанной как m, возьмите две точки на строке (x1;y1) и (x2;y2); наклон равен (y2 — y1)/(x2 — x1).Y-перехват (b):
Y-пересечение строки, обычно записанное как b, — это значение y в точке, в которой линия пересекает ось y.Уравнение прямой имеет вид y = mx + b. Если известны значения m и b, то можно вычислить любую точку на прямой, подставляя значения y или x в уравнение. Можно также воспользоваться функцией ТЕНДЕНЦИЯ.
-
Если имеется только одна независимая переменная x, можно получить наклон и y-пересечение непосредственно, воспользовавшись следующими формулами:
Наклон:
=ИНДЕКС( LINEST(known_y,known_x’s);1)Y-перехват:
=ИНДЕКС( LINEST(known_y,known_x),2) -
Точность аппроксимации с помощью прямой, вычисленной функцией ЛИНЕЙН, зависит от степени разброса данных. Чем ближе данные к прямой, тем более точной является модель ЛИНЕЙН. Функция ЛИНЕЙН использует для определения наилучшей аппроксимации данных метод наименьших квадратов. Когда имеется только одна независимая переменная x, значения m и b вычисляются по следующим формулам:
где x и y — выборочные средние значения, например x = СРЗНАЧ(известные_значения_x), а y = СРЗНАЧ(известные_значения_y).
-
Функции ЛИННЕСТРОЙ и ЛОГЪЕСТ могут вычислять наилучшие прямые или экспоненциальное кривой, которые подходят для ваших данных. Однако необходимо решить, какой из двух результатов лучше всего подходит для ваших данных. Вы можетевычислить known_y(known_x) для прямой линии или РОСТ(known_y, known_x в) для экспоненциальной кривой. Эти функции без аргумента new_x возвращают массив значений y, спрогнозируемых вдоль этой линии или кривой в фактических точках данных. Затем можно сравнить спрогнозируемые значения с фактическими значениями. Для наглядного сравнения можно отобразить оба этих диаграммы.
-
Проводя регрессионный анализ, Microsoft Excel вычисляет для каждой точки квадрат разности между прогнозируемым значением y и фактическим значением y. Сумма этих квадратов разностей называется остаточной суммой квадратов (ssresid). Затем Microsoft Excel подсчитывает общую сумму квадратов (sstotal). Если конст = ИСТИНА или значение этого аргумента не указано, общая сумма квадратов будет равна сумме квадратов разностей действительных значений y и средних значений y. При конст = ЛОЖЬ общая сумма квадратов будет равна сумме квадратов действительных значений y (без вычитания среднего значения y из частного значения y). После этого регрессионную сумму квадратов можно вычислить следующим образом: ssreg = sstotal — ssresid. Чем меньше остаточная сумма квадратов по сравнению с общей суммой квадратов, тем больше значение коэффициента определения r2— индикатор того, насколько хорошо уравнение, выданное в результате регрессионного анализа, объясняет связь между переменными. Значение r2 равно ssreg/sstotal.
-
В некоторых случаях один или несколько столбцов X (предполагается, что значения Y и X — в столбцах) могут не иметь дополнительного прогнозируемого значения при наличии других столбцов X. Другими словами, удаление одного или более столбцов X может привести к одинаковой точности предсказания значений Y. В этом случае эти избыточные столбцы X следует не использовать в модели регрессии. Этот вариант называется «коллинеарность», так как любой избыточный X-столбец может быть выражен как сумма многих не избыточных X-столбцов. Функция ЛИНЕЙН проверяет коллинеарность и удаляет все избыточные X-столбцы из модели регрессии при их идентификации. Удалены столбцы X распознаются в результатах LINEST как имеющие коэффициенты 0 в дополнение к значениям 0 se. Если один или несколько столбцов будут удалены как избыточные, это влияет на df, поскольку df зависит от числа X столбцов, фактически используемых для прогнозирования. Подробные сведения о вычислении df см. в примере 4. Если значение df изменилось из-за удаления избыточных X-столбцов, это также влияет на значения Sey и F. Коллинеарность должна быть относительно редкой на практике. Однако чаще всего возникают ситуации, когда некоторые столбцы X содержат только значения 0 и 1 в качестве индикаторов того, является ли тема в эксперименте участником определенной группы или не является ее участником. Если конст = ИСТИНА или опущен, функция LYST фактически вставляет дополнительный столбец X из всех 1 значений для моделирования перехвата. Если у вас есть столбец с значением 1 для каждой темы, если мальчик, или 0, а также столбец с 1 для каждой темы, если она является женщиной, или 0, последний столбец является избыточным, так как записи в нем могут быть получены из вычитания записи в столбце «самец» из записи в дополнительном столбце всех 1 значений, добавленных функцией LINEST.
-
Вычисление значения df для случаев, когда столбцы X удаляются из модели вследствие коллинеарности происходит следующим образом: если существует k столбцов известных_значений_x и значение конст = ИСТИНА или не указано, то df = n – k – 1. Если конст = ЛОЖЬ, то df = n — k. В обоих случаях удаление столбцов X вследствие коллинеарности увеличивает значение df на 1.
-
При вводе константы массива (например, в качестве аргумента известные_значения_x) следует использовать точку с запятой для разделения значений в одной строке и двоеточие для разделения строк. Знаки-разделители могут быть другими в зависимости от региональных параметров.
-
Следует отметить, что значения y, предсказанные с помощью уравнения регрессии, возможно, не будут правильными, если они располагаются вне интервала значений y, которые использовались для определения уравнения.
-
Основной алгоритм, используемый в функции ЛИНЕЙН, отличается от основного алгоритма функций НАКЛОН и ОТРЕЗОК. Разница между алгоритмами может привести к различным результатам при неопределенных и коллинеарных данных. Например, если точки данных аргумента известные_значения_y равны 0, а точки данных аргумента известные_значения_x равны 1, то:
-
Функция ЛИНЕЙН возвращает значение, равное 0. Алгоритм функции ЛИНЕЙН используется для возвращения подходящих значений для коллинеарных данных, и в данном случае может быть найден по меньшей мере один ответ.
-
Наклон и ОТОКП возвращают #DIV/0! ошибка «#ЗНАЧ!». Алгоритм функций НАКЛОН и ОТОКП предназначен для поиска только одного ответа, и в этом случае может быть несколько ответов.
-
-
Помимо вычисления статистики для других типов регрессии с помощью функции ЛГРФПРИБЛ, для вычисления диапазонов некоторых других типов регрессий можно использовать функцию ЛИНЕЙН, вводя функции переменных x и y как ряды переменных х и у для ЛИНЕЙН. Например, следующая формула:
=ЛИНЕЙН(значения_y, значения_x^СТОЛБЕЦ($A:$C))
работает при наличии одного столбца значений Y и одного столбца значений Х для вычисления аппроксимации куба (многочлен 3-й степени) следующей формы:
y = m1*x + m2*x^2 + m3*x^3 + b
Формула может быть изменена для расчетов других типов регрессии, но в отдельных случаях требуется корректировка выходных значений и других статистических данных.
-
Значение F-теста, возвращаемое функцией ЛИНЕЙН, отличается от значения, возвращаемого функцией ФТЕСТ. Функция ЛИНЕЙН возвращает F-статистику, в то время как ФТЕСТ возвращает вероятность.
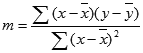
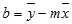
Примеры
Пример 1. Наклон и Y-пересечение
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Известные значения y |
Известные значения x |
|---|---|
|
1 |
0 |
|
9 |
4 |
|
5 |
2 |
|
7 |
3 |
|
Результат (наклон) |
Результат (y-пересечение) |
|
2 |
1 |
|
Формула (формула массива в ячейках A7:B7) |
|
|
=ЛИНЕЙН(A2:A5;B2:B5;;ЛОЖЬ) |
Пример 2. Простая линейная регрессия
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Месяц |
Продажи |
|---|---|
|
1 |
3 100 ₽ |
|
2 |
4 500 ₽ |
|
3 |
4 400 ₽ |
|
4 |
5 400 ₽ |
|
5 |
7 500 ₽ |
|
6 |
8 100 ₽ |
|
Формула |
Результат |
|
=СУММ(ЛИНЕЙН(B1:B6; A2:A7)*{9;1}) |
11 000 ₽ |
|
Вычисляет предполагаемый объем продаж в девятом месяце на основе данных о продажах за период с первого по шестой месяцы. |
Пример 3. Множественная линейная регрессия
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Общая площадь (x1) |
Количество офисов (x2) |
Количество входов (x3) |
Время эксплуатации (x4) |
Оценочная цена (y) |
|---|---|---|---|---|
|
2310 |
2 |
2 |
20 |
142 000 ₽ |
|
2333 |
2 |
2 |
12 |
144 000 ₽ |
|
2356 |
3 |
1,5 |
33 |
151 000 ₽ |
|
2379 |
3 |
2 |
43 |
150 000 ₽ |
|
2402 |
2 |
3 |
53 |
139 000 ₽ |
|
2425 |
4 |
2 |
23 |
169 000 ₽ |
|
2448 |
2 |
1,5 |
99 |
126 000 ₽ |
|
2471 |
2 |
2 |
34 |
142 900 ₽ |
|
2494 |
3 |
3 |
23 |
163 000 ₽ |
|
2517 |
4 |
4 |
55 |
169 000 ₽ |
|
2540 |
2 |
3 |
22 |
149 000 ₽ |
|
-234,2371645 |
||||
|
13,26801148 |
||||
|
0,996747993 |
||||
|
459,7536742 |
||||
|
1732393319 |
||||
|
Формула (формула динамического массива, введенная в A19) |
||||
|
=ЛИНЕЙН(E2:E12; A2:D12; ИСТИНА; ИСТИНА) |
Пример 4. Использование статистики F и r2
В предыдущем примере коэффициент определения (r2)составляет 0,99675 (см. ячейку A17 в результатах для ЛИТН), что указывает на крепкая связь между независимыми переменными и ценой продажи. F-статистику можно использовать для определения случайности этих результатов с таким высоким значением r2.
Предположим, что на самом деле взаимосвязи между переменными не существует, просто статистический анализ вывел сильную взаимозависимость по взятой равномерной выборке 11 зданий. Величина «Альфа» используется для обозначения вероятности ошибочного вывода о существовании сильная взаимозависимости.
Значения F и df в результатах функции LINEST можно использовать для оценки вероятности возникновения более высокого F-значения. F можно сравнивать с критическими значениями в опубликованных F-таблицах или с помощью функции FРАСП в Excel для вычисления вероятности случайного возникновения большего F-значения. Соответствующее F-распределение имеет v1 и v2 степени свободы. Если n — количество точек данных и конст = ИСТИНА или опущен, то v1 = n – df – 1 и v2 = df. (Если конст = ЛОЖЬ, то v1 = n – df и v2 = df.) Функция FIST с синтаксисом FDIST(F;v1;v2) возвращает вероятность возникновения более высокого F-значения, случайного. В этом примере df = 6 (ячейка B18) и F = 459,753674 (ячейка A18).
Предположим, что альфа имеет значение 0,05, v1 = 11 – 6 – 1 = 4, а v2 = 6, критический уровень F составляет 4,53. Поскольку F = 459,753674 значительно больше 4,53, вероятность того, что F-значение этого высокой случайности превышает 4,53, крайне маловероятно. (Если значение «Альфа» = 0,05, гипотеза о том, что между known_y и known_x нет связи, отклоняется при превышении F критического уровня (4,53).) Функцию FDIST в Excel можно использовать для получения вероятности случайного возникновения F-значения. Например, FIST(459,753674, 4, 6) = 1,37E-7, очень небольшая вероятность. Можно сделать вывод о том, что формула регрессии полезна для предсказания оценочного значения офисных зданий в этой области, найдя критический уровень F в таблице или с помощью функции FDIST. Помните, что крайне важно использовать правильные значения 1 и 2, вычисленные в предыдущем абзаце.
Пример 5. Вычисление t-статистики
Другой тест позволяет определить, подходит ли каждый коэффициент наклона для оценки стоимости здания под офис в примере 3. Например, чтобы проверить, имеет ли срок эксплуатации здания статистическую значимость, разделим -234,24 (коэффициент наклона для срока эксплуатации здания) на 13,268 (оценка стандартной ошибки для коэффициента времени эксплуатации из ячейки A15). Ниже приводится наблюдаемое t-значение:
t = m4 ÷ se4 = –234,24 ÷ 13,268 = –17,7
Если абсолютное значение t достаточно велико, можно сделать вывод, что коэффициент наклона можно использовать для оценки стоимости здания под офис в примере 3. В таблице ниже приведены абсолютные значения четырех наблюдаемых t-значений.
Если обратиться к справочнику по математической статистике, то окажется, что t-критическое двустороннее с 6 степенями свободы равно 2,447 при Альфа = 0,05. Критическое значение также можно также найти с помощью функции Microsoft Excel СТЬЮДРАСПОБР. СТЬЮДРАСПОБР(0,05; 6) = 2,447. Поскольку абсолютная величина t, равная 17,7, больше, чем 2,447, срок эксплуатации — это важная переменная для оценки стоимости здания под офис. Аналогичным образом можно протестировать все другие переменные на статистическую значимость. Ниже приводятся наблюдаемые t-значения для каждой из независимых переменных.
|
Переменная |
t-наблюдаемое значение |
|---|---|
|
Общая площадь |
5,1 |
|
Количество офисов |
31,3 |
|
Количество входов |
4,8 |
|
Возраст |
17,7 |
Абсолютная величина всех этих значений больше, чем 2,447. Следовательно, все переменные, использованные в уравнении регрессии, полезны для предсказания оценочной стоимости здания под офис в данном районе.
Метод аппроксимации в Microsoft Excel
Среди различных методов прогнозирования нельзя не выделить аппроксимацию. С её помощью можно производить приблизительные подсчеты и вычислять планируемые показатели, путем замены исходных объектов на более простые. В Экселе тоже существует возможность использования данного метода для прогнозирования и анализа. Давайте рассмотрим, как этот метод можно применить в указанной программе встроенными инструментами.
Выполнение аппроксимации
Наименование данного метода происходит от латинского слова proxima – «ближайшая» Именно приближение путем упрощения и сглаживания известных показателей, выстраивание их в тенденцию и является его основой. Но данный метод можно использовать не только для прогнозирования, но и для исследования уже имеющихся результатов. Ведь аппроксимация является, по сути, упрощением исходных данных, а упрощенный вариант исследовать легче.
Главный инструмент, с помощью которого проводится сглаживания в Excel – это построение линии тренда. Суть состоит в том, что на основе уже имеющихся показателей достраивается график функции на будущие периоды. Основное предназначение линии тренда, как не трудно догадаться, это составление прогнозов или выявление общей тенденции.
Но она может быть построена с применением одного из пяти видов аппроксимации:
- Линейной;
- Экспоненциальной;
- Логарифмической;
- Полиномиальной;
- Степенной.
Рассмотрим каждый из вариантов более подробно в отдельности.
Способ 1: линейное сглаживание
Прежде всего, давайте рассмотрим самый простой вариант аппроксимации, а именно с помощью линейной функции. На нем мы остановимся подробнее всего, так как изложим общие моменты характерные и для других способов, а именно построение графика и некоторые другие нюансы, на которых при рассмотрении последующих вариантов уже останавливаться не будем.
Прежде всего, построим график, на основании которого будем проводить процедуру сглаживания. Для построения графика возьмем таблицу, в которой помесячно указана себестоимость единицы продукции, производимой предприятием, и соответствующая прибыль в данном периоде. Графическая функция, которую мы построим, будет отображать зависимость увеличения прибыли от уменьшения себестоимости продукции.
-
Для построения графика, прежде всего, выделяем столбцы «Себестоимость единицы продукции» и «Прибыль». После этого перемещаемся во вкладку «Вставка». Далее на ленте в блоке инструментов «Диаграммы» щелкаем по кнопке «Точечная». В открывшемся списке выбираем наименование «Точечная с гладкими кривыми и маркерами». Именно данный вид диаграмм наиболее подходит для работы с линией тренда, а значит, и для применения метода аппроксимации в Excel.
Существует ещё один вариант её добавления. В дополнительной группе вкладок на ленте «Работа с диаграммами» перемещаемся во вкладку «Макет». Далее в блоке инструментов «Анализ» щелкаем по кнопке «Линия тренда». Открывается список. Так как нам нужно применить линейную аппроксимацию, то из представленных позиций выбираем «Линейное приближение».
Если же вы выбрали все-таки первый вариант действий с добавлением через контекстное меню, то откроется окно формата.
В блоке параметров «Построение линии тренда (аппроксимация и сглаживание)» устанавливаем переключатель в позицию «Линейная».
При желании можно установить галочку около позиции «Показывать уравнение на диаграмме». После этого на диаграмме будет отображаться уравнение сглаживающей функции.
Также в нашем случае для сравнения различных вариантов аппроксимации важно установить галочку около пункта «Поместить на диаграмму величину достоверной аппроксимации (R^2)». Данный показатель может варьироваться от 0 до 1. Чем он выше, тем аппроксимация качественнее (достовернее). Считается, что при величине данного показателя 0,85 и выше сглаживание можно считать достоверным, а если показатель ниже, то – нет.
После того, как провели все вышеуказанные настройки. Жмем на кнопку «Закрыть», размещенную в нижней части окна.
Сглаживание, которое используется в данном случае, описывается следующей формулой:
В конкретно нашем случае формула принимает такой вид:
Величина достоверности аппроксимации у нас равна 0,9418, что является довольно приемлемым итогом, характеризующим сглаживание, как достоверное.
Способ 2: экспоненциальная аппроксимация
Теперь давайте рассмотрим экспоненциальный тип аппроксимации в Эксель.
-
Для того, чтобы изменить тип линии тренда, выделяем её кликом правой кнопки мыши и в раскрывшемся меню выбираем пункт «Формат линии тренда…».
После этого запускается уже знакомое нам окно формата. В блоке выбора типа аппроксимации устанавливаем переключатель в положение «Экспоненциальная». Остальные настройки оставим такими же, как и в первом случае. Щелкаем по кнопке «Закрыть».
Общий вид функции сглаживания при этом такой:
где e – это основание натурального логарифма.
В конкретно нашем случае формула приняла следующую форму:
Способ 3: логарифмическое сглаживание
Теперь настала очередь рассмотреть метод логарифмической аппроксимации.
-
Тем же способом, что и в предыдущий раз через контекстное меню запускаем окно формата линии тренда. Устанавливаем переключатель в позицию «Логарифмическая» и жмем на кнопку «Закрыть».
В общем виде формула сглаживания выглядит так:
где ln – это величина натурального логарифма. Отсюда и наименование метода.
В нашем случае формула принимает следующий вид:
Способ 4: полиномиальное сглаживание
Настал черед рассмотреть метод полиномиального сглаживания.
-
Переходим в окно формата линии тренда, как уже делали не раз. В блоке «Построение линии тренда» устанавливаем переключатель в позицию «Полиномиальная». Справа от данного пункта расположено поле «Степень». При выборе значения «Полиномиальная» оно становится активным. Здесь можно указать любое степенное значение от 2 (установлено по умолчанию) до 6. Данный показатель определяет число максимумов и минимумов функции. При установке полинома второй степени описывается только один максимум, а при установке полинома шестой степени может быть описано до пяти максимумов. Для начала оставим настройки по умолчанию, то есть, укажем вторую степень. Остальные настройки оставляем такими же, какими мы выставляли их в предыдущих способах. Жмем на кнопку «Закрыть».
Линия тренда с использованием данного метода построена. Как видим, она ещё более изогнута, чем при использовании экспоненциальной аппроксимации. Уровень достоверности выше, чем при любом из использованных ранее способов, и составляет 0,9724.
Данный метод наиболее успешно можно применять в том случае, если данные носят постоянно изменчивый характер. Функция, описывающая данный вид сглаживания, выглядит таким образом:
В нашем случае формула приняла такой вид:
y=0,0015*x^2-1,7202*x+507,01
Теперь давайте изменим степень полиномов, чтобы увидеть, будет ли отличаться результат. Возвращаемся в окно формата. Тип аппроксимации оставляем полиномиальным, но напротив него в окне степени устанавливаем максимально возможное значение – 6.
Формула, которая описывает данный тип сглаживания, приняла следующий вид:
Способ 5: степенное сглаживание
В завершении рассмотрим метод степенной аппроксимации в Excel.
-
Перемещаемся в окно «Формат линии тренда». Устанавливаем переключатель вида сглаживания в позицию «Степенная». Показ уравнения и уровня достоверности, как всегда, оставляем включенными. Жмем на кнопку «Закрыть».
Данный способ эффективно используется в случаях интенсивного изменения данных функции. Важно учесть, что этот вариант применим только при условии, что функция и аргумент не принимают отрицательных или нулевых значений.
Общая формула, описывающая данный метод имеет такой вид:
В конкретно нашем случае она выглядит так:
Как видим, при использовании конкретных данных, которые мы применяли для примера, наибольший уровень достоверности показал метод полиномиальной аппроксимации с полиномом в шестой степени (0,9844), наименьший уровень достоверности у линейного метода (0,9418). Но это совсем не значит, что такая же тенденция будет при использовании других примеров. Нет, уровень эффективности у приведенных выше методов может значительно отличаться, в зависимости от конкретного вида функции, для которой будет строиться линия тренда. Поэтому, если для этой функции выбранный метод наиболее эффективен, то это совсем не означает, что он также будет оптимальным и в другой ситуации.
Если вы пока не можете сразу определить, основываясь на вышеприведенных рекомендациях, какой вид аппроксимации подойдет конкретно в вашем случае, то есть смысл попробовать все методы. После построения линии тренда и просмотра её уровня достоверности можно будет выбрать оптимальный вариант.
Помимо этой статьи, на сайте еще 12701 инструкций.
Добавьте сайт Lumpics.ru в закладки (CTRL+D) и мы точно еще пригодимся вам.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Аппроксимация в Excel
 (Обратите внимание на дополнительный раздел от 04.06.2017 в конце статьи.)
(Обратите внимание на дополнительный раздел от 04.06.2017 в конце статьи.)
Учет и контроль! Те, кому за 40 должны хорошо помнить этот лозунг из эпохи построения социализма и коммунизма в нашей стране.
Но без хорошо налаженного учета невозможно эффективное функционирование ни страны, ни области, ни предприятия, ни домашнего хозяйства при любой общественно-экономической формации общества! Для составления прогнозов и планов деятельности и развития необходимы исходные данные. Где их брать? Только один достоверный источник – это ваши статистические учетные данные предыдущих периодов времени.
Учитывать результаты своей деятельности, собирать и записывать информацию, обрабатывать и анализировать данные, применять результаты анализа для принятия правильных решений в будущем должен, в моем понимании, каждый здравомыслящий человек. Это есть ничто иное, как накопление и рациональное использование своего жизненного опыта. Если не вести учет важных данных, то вы через определенный период времени их забудете и, начав заниматься этими вопросами вновь, вы опять наделаете те же ошибки, что делали, когда впервые этим занимались.
«Мы, помню, 5 лет назад изготавливали до 1000 штук таких изделий в месяц, а сейчас и 700 еле-еле собираем!». Открываем статистику и видим, что 5 лет назад и 500 штук не изготавливали…
«Во сколько обходится километр пробега твоего автомобиля с учетом всех затрат?» Открываем статистику – 6 руб./км. Поездка на работу – 107 рублей. Дешевле, чем на такси (180 рублей) более чем в полтора раза. А бывали времена, когда на такси было дешевле…
«Сколько времени требуется для изготовления металлоконструкций уголковой башни связи высотой 50 м?» Открываем статистику – и через 5 минут готов ответ…
«Сколько будет стоить ремонт комнаты в квартире?» Поднимаем старые записи, делаем поправку на инфляцию за прошедшие годы, учитываем, что в прошлый раз купили материалы на 10% дешевле рыночной цены и – ориентировочную стоимость мы уже знаем…
Ведя учет своей профессиональной деятельности, вы всегда будете готовы ответить на вопрос начальника: «Когда. ». Ведя учет домашнего хозяйства, легче спланировать расходы на крупные покупки, отдых и прочие расходы в будущем, приняв соответствующие меры по дополнительному заработку или по сокращению необязательных расходов сегодня.
В этой статье я на простом примере покажу, как можно обрабатывать собранные статистические данные в Excel для возможности дальнейшего использования при прогнозировании будущих периодов.
Аппроксимация в Excel статистических данных аналитической функцией.
Производственный участок изготавливает строительные металлоконструкции из листового и профильного металлопроката. Участок работает стабильно, заказы однотипные, численность рабочих колеблется незначительно. Есть данные о выпуске продукции за предыдущие 12 месяцев и о количестве переработанного в эти периоды времени металлопроката по группам: листы, двутавры, швеллеры, уголки, трубы круглые, профили прямоугольного сечения, круглый прокат. После предварительного анализа исходных данных возникло предположение, что суммарный месячный выпуск металлоконструкций существенно зависит от количества уголков в заказах. Проверим это предположение.
Прежде всего, несколько слов об аппроксимации. Мы будем искать закон – аналитическую функцию, то есть функцию, заданную уравнением, которое лучше других описывает зависимость общего выпуска металлоконструкций от количества уголкового проката в выполненных заказах. Это и есть аппроксимация, а найденное уравнение называется аппроксимирующей функцией для исходной функции, заданной в виде таблицы.
1. Включаем Excel и помещаем на лист таблицу с данными статистики.
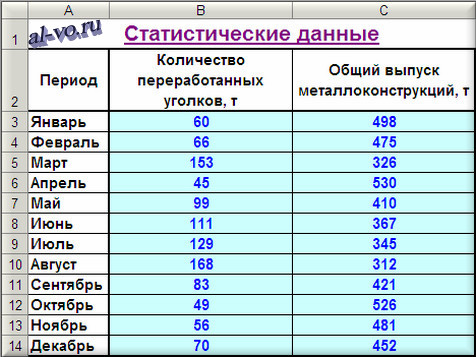
2. Далее строим и форматируем точечную диаграмму, в которой по оси X задаем значения аргумента – количество переработанных уголков в тоннах. По оси Y откладываем значения исходной функции – общий выпуск металлоконструкций в месяц, заданные таблицей.
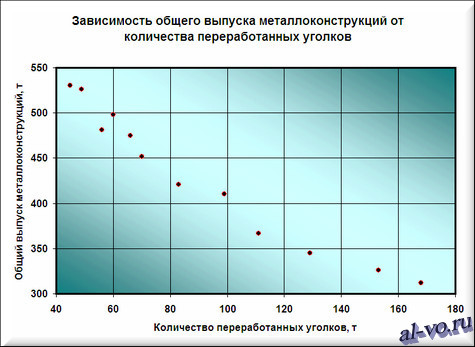
О том, как построить подобную диаграмму, подробно рассказано в статье «Как строить графики в Excel?».
3. «Наводим» мышь на любую из точек на графике и щелчком правой кнопки вызываем контекстное меню (как говорит один мой хороший товарищ — работая в незнакомой программе, когда не знаешь, что делать, чаще щелкай правой кнопкой мыши…). В выпавшем меню выбираем «Добавить линию тренда…».
4. В появившемся окне «Линия тренда» на вкладке «Тип» выбираем «Линейная».
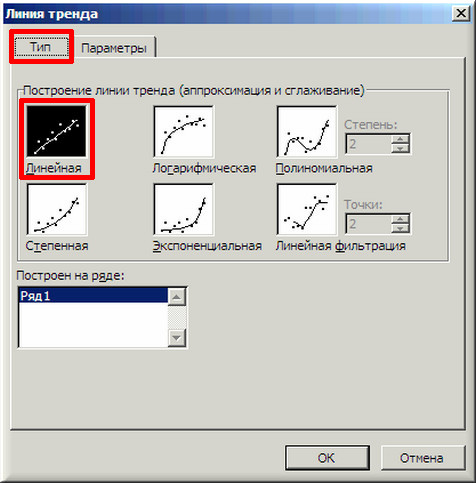
5. Далее на вкладке «Параметры» ставим 2 галочки и нажимаем «ОК».
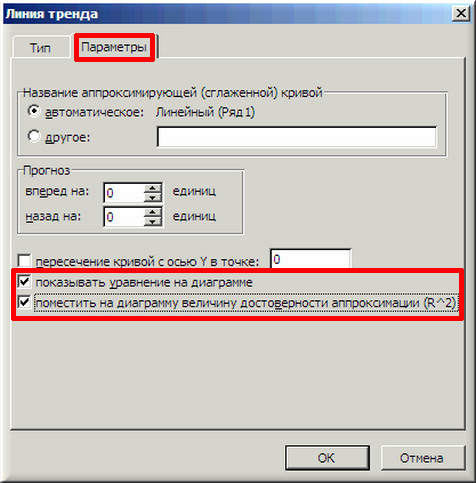
6. На графике появилась прямая линия, аппроксимирующая нашу табличную зависимость.
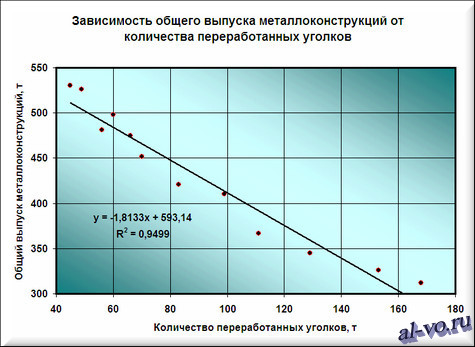
Мы видим кроме самой линии уравнение этой линии и, главное, мы видим значение параметра R 2 – величины достоверности аппроксимации! Чем ближе его значение к 1, тем наиболее точно выбранная функция аппроксимирует табличные данные!
7. Строим линии тренда, используя степенную, логарифмическую, экспоненциальную и полиномиальную аппроксимации по аналогии с тем, как мы строили линейную линию тренда.
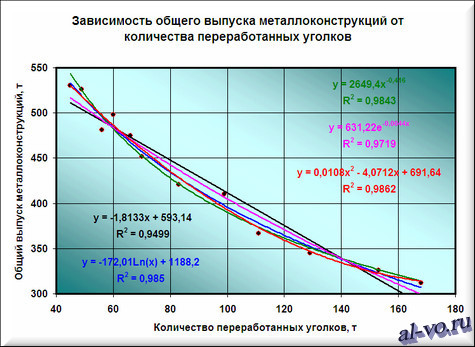
Лучше всех из выбранных функций аппроксимирует наши данные полином второй степени, у него максимальный коэффициент достоверности R 2 .
Однако хочу вас предостеречь! Если вы возьмете полиномы более высоких степеней, то, возможно, получите еще лучшие результаты, но кривые будут иметь замысловатый вид…. Здесь важно понимать, что мы ищем функцию, которая имеет физический смысл. Что это означает? Это означает, что нам нужна аппроксимирующая функция, которая будет выдавать адекватные результаты не только внутри рассматриваемого диапазона значений X, но и за его пределами, то есть ответит на вопрос: «Какой будет выпуск металлоконструкций при количестве переработанных за месяц уголков меньше 45 и больше 168 тонн!» Поэтому я не рекомендую увлекаться полиномами высоких степеней, да и параболу (полином второй степени) выбирать осторожно!
Итак, нам необходимо выбрать функцию, которая не только хорошо интерполирует табличные данные в пределах диапазона значений X=45…168, но и допускает адекватную экстраполяцию за пределами этого диапазона. Я выбираю в данном случае логарифмическую функцию, хотя можно выбрать и линейную, как наиболее простую. В рассматриваемом примере при выборе линейной аппроксимации в excel ошибки будут больше, чем при выборе логарифмической, но не на много.
8. Удаляем все линии тренда с поля диаграммы, кроме логарифмической функции. Для этого щелкаем правой кнопкой мыши по ненужным линиям и в выпавшем контекстном меню выбираем «Очистить».
9. В завершении добавим к точкам табличных данных планки погрешностей. Для этого правой кнопкой мыши щелкаем на любой из точек на графике и в контекстном меню выбираем «Формат рядов данных…» и настраиваем данные на вкладке «Y-погрешности» так, как на рисунке ниже.
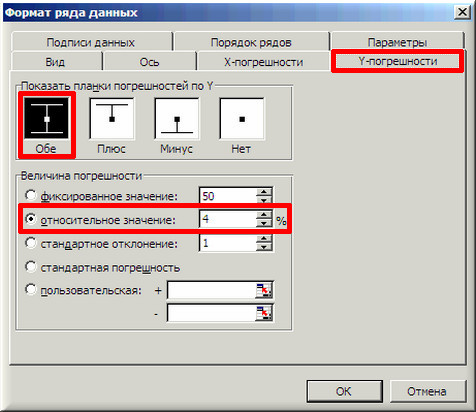
10. Затем щелкаем по любой из линий диапазонов погрешностей правой кнопкой мыши, выбираем в контекстном меню «Формат полос погрешностей…» и в окне «Формат планок погрешностей» на вкладке «Вид» настраиваем цвет и толщину линий.
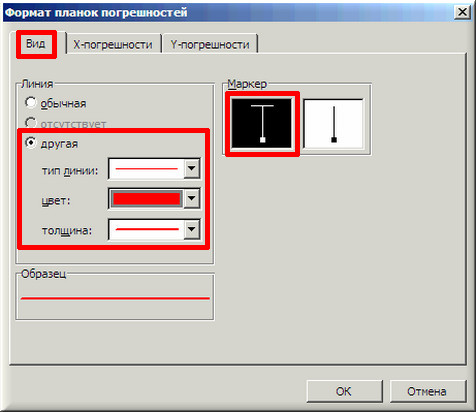
Аналогичным образом форматируются любые другие объекты диаграммы в Excel!
Окончательный результат диаграммы представлен на следующем снимке экрана.
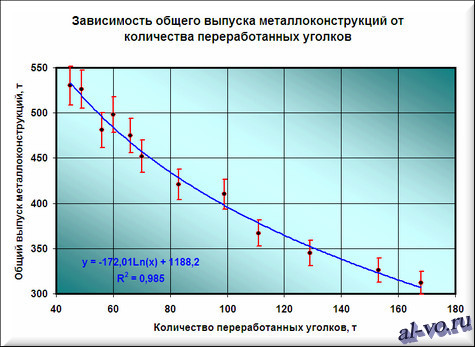
Итоги.
Результатом всех предыдущих действий стала полученная формула аппроксимирующей функции y=-172,01*ln (x)+1188,2. Зная ее, и количество уголков в месячном наборе работ, можно с высокой степенью вероятности (±4% — смотри планки погрешностей) спрогнозировать общий выпуск металлоконструкций за месяц! Например, если в плане на месяц 140 тонн уголков, то общий выпуск, скорее всего, при прочих равных составит 338±14 тонн.
Для повышения достоверности аппроксимации статистических данных должно быть много. Двенадцать пар значений – это маловато.
Из практики скажу, что хорошим результатом следует считать нахождение аппроксимирующей функции с коэффициентом достоверности R 2 >0,87. Отличный результат – при R 2 >0,94.
На практике бывает трудно выделить один самый главный определяющий фактор (в нашем примере – масса переработанных за месяц уголков), но если постараться, то в каждой конкретной задаче его всегда можно найти! Конечно, общий выпуск продукции за месяц реально зависит от сотни факторов, для учета которых необходимы существенные трудозатраты нормировщиков и других специалистов. Только результат все равно будет приблизительным! Так стоит ли нести затраты, если есть гораздо более дешевое математическое моделирование!
В этой статье я лишь прикоснулся к верхушке айсберга под названием сбор, обработка и практическое использование статистических данных. О том удалось, или нет, мне расшевелить ваш интерес к этой теме, надеюсь узнать из комментариев и рейтинга статьи в поисковиках.
Затронутый вопрос аппроксимации функции одной переменной имеет широкое практическое применение в разных сферах жизни. Но гораздо большее применение имеет решение задачи аппроксимации функции нескольких независимых переменных…. Об этом и не только читайте в следующих статьях на блоге.
Подписывайтесь на анонсы статей в окне, расположенном в конце каждой статьи или в окне вверху страницы.
Не забывайте подтверждать подписку кликом по ссылке в письме, которое придет к вам на указанную почту (может прийти в папку «Спам»).
С интересом прочту Ваши комментарии, уважаемые читатели! Пишите!
P.S. (04.06.2017)
Высокоточная красивая замена табличных данных простым уравнением.
Вас не устраивают полученные точность аппроксимации (R 2 2 =0,9963.
Функция ЛГРФПРИБЛ для аппроксимации данных таблиц в Excel
Функция ЛГРФПРИБЛ в Excel предназначена для определения значений, на основе которых может быть построена экспоненциальная кривая, аппроксимирующая имеющиеся числовые данные, и возвращает массив значений. Для корректной работы рассматриваемой функции ее следует вводить как формулу массива.
Методы аппроксимации табличных данных в Excel
Функция ЛГРФПРИБЛ возвращает данные, необходимые для построения кривой, описываемой следующим уравнением:
Если имеется две и более переменных, это уравнение переписывается следующим образом:
Возвращаемые рассматриваемой функцией данные представляют собой следующий массив:
То есть, имеем массив оснований, возводимых в степени (известные значения переменных x), и коэффициент b.
Пример 1. В таблице приведены данные, характеризующие динамику курса доллара на протяжении 10 лет (с 2006 по 2016 год). Необходимо спрогнозировать курс доллара на 2019 год на основании имеющихся данных.
Вид таблицы данных:
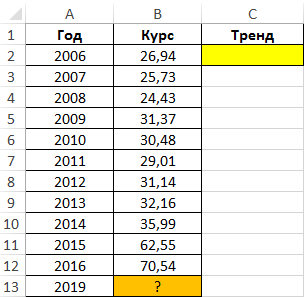
Для расчета тренда (коэффициент, используемый для предсказания последующих значений курса) используем функцию:
- B2:B12 – известные данные зависимой переменной (значения курса);
- A2:A12 – известные данные независимой переменной (года).
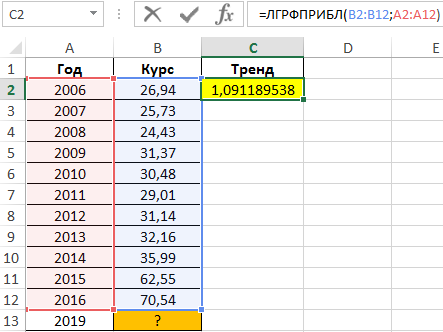
Для предсказания курса на 2019 год используем формулу:
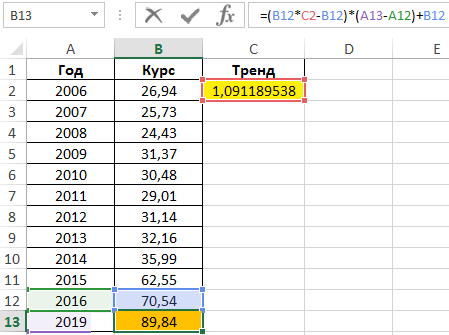
Как видно, полученное значение имеет небольшую степень достоверности. Использование данного типа аппроксимации для предсказания курса валют нерационально.
Прогнозирование финансовых результатов методом аппроксимации в Excel
Пример 2. В таблице имеются данные о зарплатах за прошедший год (помесячно). Определить оптимальный способ предсказания размеров зарплат для последующих периодов.
Вид таблицы данных:
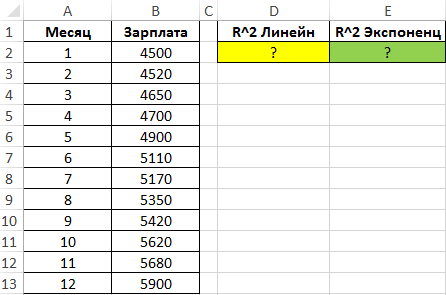
Определим коэффициенты достоверности аппроксимации для линейной и экспоненциальной функций с помощью следующих функций (вводить как формулы массива CTRL+SHIFT+Enter):
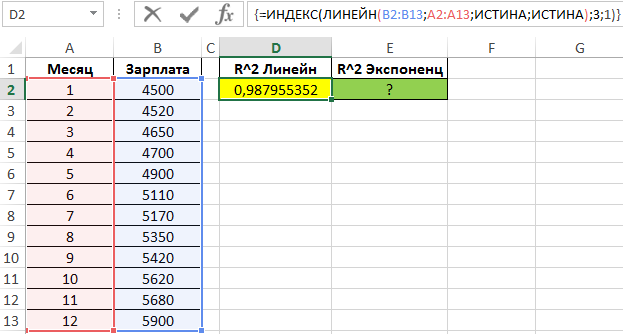
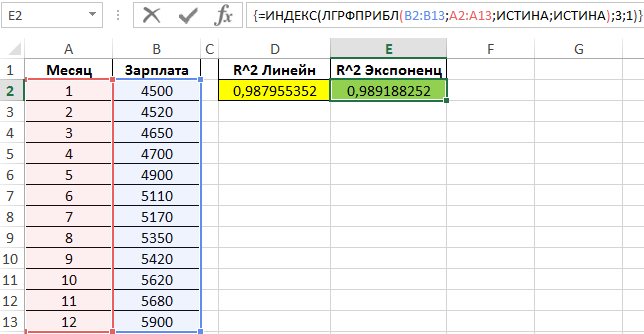
Поскольку обе функции возвращают результат в виде массива данных, в котором в третьей строке первого столбца содержится искомое значение R^2, используем функцию ИНДЕКС для возврата желаемого результата.
Чем ближе значение R^2 к 1, тем выше точность аппроксимации. Как видно, наибольшую точность обеспечивает экспоненциальная функция. Однако разница не является существенной, поэтому использование функции ЛИНЕЙН является допустимым в данном случае.
Правила метода аппроксимации по функции ЛГРФПРИБЛ в Excel
Функция имеет следующую синтаксическую запись:
=ЛГРФПРИБЛ( известные_значения_y; [известные_значения_x];[конст];[статистика])
- известные_значения_y – обязательный, принимает ссылку на диапазон ячеек или массив данных — числовые значения, которые характеризуют состояние зависимой переменной y из указанного выше уравнения;
- [известные_значения_x] – необязательный, принимает ссылку на диапазон ячеек или массив чисел, которые являются уже известными значениями независимой переменной x. Если явно не указан, по умолчанию принимается массив значений <1;2;…N>, где N – количество элементов в массиве, характеризующем известные_значения_y ;
- [конст] – необязательный, принимает данные логического типа, интерпретируемые следующим образом: ИСТИНА или явно не указан – функция вычисляет значение коэффициента b из приведенного выше уравнения, ЛОЖЬ – значение данного коэффициента принимается равным 1;
- [статистика] – необязательный, принимает логические значения ИСТИНА (функция возвращает дополнительные данные на основе проведенного регрессионного анализа) или ЛОЖЬ (значение по умолчанию) – функция возвращает только значения коэффициентов m и b.
- Точность вычислений рассматриваемой функцией зависит от степени близости графика, построенного на основе имеющихся значений, к экспоненциальной кривой.
- В качестве первого или второго аргументов могут быть введены константы массивов, при этом необходимо соблюдать требования к размерностям.
- Если аргумент известные_значения_y указан в виде ссылки на диапазон ячеек, формирующих строку или столбец, каждая строка или столбец соответственно будут интерпретированы как отдельная переменная.
- Если данная функция используется для расчетов с указанием только одной переменной x, первый и второй аргументы могут быть указаны в виде ссылок на диапазоны любой формы. Если по условию имеются две и более переменных x, первый и второй аргументы должны быть указаны в виде векторов данных. Размеры массивов должны совпадать в любом случае.
- Если требуется определить будущие значения переменных (предсказать), можно использовать функцию РОСТ.
источники:
http://al-vo.ru/spravochnik-excel/approksimaciya-v-excel.html
http://exceltable.com/funkcii-excel/approksimaciya-dannyh-lgrfpribl
Функция ЛГРФПРИБЛ в Excel предназначена для определения значений, на основе которых может быть построена экспоненциальная кривая, аппроксимирующая имеющиеся числовые данные, и возвращает массив значений. Для корректной работы рассматриваемой функции ее следует вводить как формулу массива.
Методы аппроксимации табличных данных в Excel
Функция ЛГРФПРИБЛ возвращает данные, необходимые для построения кривой, описываемой следующим уравнением:
F(x) = b*СТЕПЕНЬ(m;x)
Если имеется две и более переменных, это уравнение переписывается следующим образом:
F(x1,x2,…xn)=b*СТЕПЕНЬ(m1;x1)*СТЕПЕНЬ(m2;x2)*…*СТЕПЕНЬ(mn;xn)
Возвращаемые рассматриваемой функцией данные представляют собой следующий массив:
{mn;mn-1;…;m1;b}
То есть, имеем массив оснований, возводимых в степени (известные значения переменных x), и коэффициент b.
Пример 1. В таблице приведены данные, характеризующие динамику курса доллара на протяжении 10 лет (с 2006 по 2016 год). Необходимо спрогнозировать курс доллара на 2019 год на основании имеющихся данных.
Вид таблицы данных:
Для расчета тренда (коэффициент, используемый для предсказания последующих значений курса) используем функцию:
=ЛГРФПРИБЛ(B2:B12;A2:A12)
Описание аргументов:
- B2:B12 – известные данные зависимой переменной (значения курса);
- A2:A12 – известные данные независимой переменной (года).
Результат расчетов:
Для предсказания курса на 2019 год используем формулу:
Результат вычислений:
Как видно, полученное значение имеет небольшую степень достоверности. Использование данного типа аппроксимации для предсказания курса валют нерационально.
Прогнозирование финансовых результатов методом аппроксимации в Excel
Пример 2. В таблице имеются данные о зарплатах за прошедший год (помесячно). Определить оптимальный способ предсказания размеров зарплат для последующих периодов.
Вид таблицы данных:
Определим коэффициенты достоверности аппроксимации для линейной и экспоненциальной функций с помощью следующих функций (вводить как формулы массива CTRL+SHIFT+Enter):
Поскольку обе функции возвращают результат в виде массива данных, в котором в третьей строке первого столбца содержится искомое значение R^2, используем функцию ИНДЕКС для возврата желаемого результата.
Чем ближе значение R^2 к 1, тем выше точность аппроксимации. Как видно, наибольшую точность обеспечивает экспоненциальная функция. Однако разница не является существенной, поэтому использование функции ЛИНЕЙН является допустимым в данном случае.
Правила метода аппроксимации по функции ЛГРФПРИБЛ в Excel
Функция имеет следующую синтаксическую запись:
=ЛГРФПРИБЛ(известные_значения_y;[известные_значения_x];[конст];[статистика])
Описание аргументов:
- известные_значения_y – обязательный, принимает ссылку на диапазон ячеек или массив данных — числовые значения, которые характеризуют состояние зависимой переменной y из указанного выше уравнения;
- [известные_значения_x] – необязательный, принимает ссылку на диапазон ячеек или массив чисел, которые являются уже известными значениями независимой переменной x. Если явно не указан, по умолчанию принимается массив значений {1;2;…N}, где N – количество элементов в массиве, характеризующем известные_значения_y;
- [конст] – необязательный, принимает данные логического типа, интерпретируемые следующим образом: ИСТИНА или явно не указан – функция вычисляет значение коэффициента b из приведенного выше уравнения, ЛОЖЬ – значение данного коэффициента принимается равным 1;
- [статистика] – необязательный, принимает логические значения ИСТИНА (функция возвращает дополнительные данные на основе проведенного регрессионного анализа) или ЛОЖЬ (значение по умолчанию) – функция возвращает только значения коэффициентов m и b.
Примечания:
- Точность вычислений рассматриваемой функцией зависит от степени близости графика, построенного на основе имеющихся значений, к экспоненциальной кривой.
- В качестве первого или второго аргументов могут быть введены константы массивов, при этом необходимо соблюдать требования к размерностям.
- Если аргумент известные_значения_y указан в виде ссылки на диапазон ячеек, формирующих строку или столбец, каждая строка или столбец соответственно будут интерпретированы как отдельная переменная.
- Если данная функция используется для расчетов с указанием только одной переменной x, первый и второй аргументы могут быть указаны в виде ссылок на диапазоны любой формы. Если по условию имеются две и более переменных x, первый и второй аргументы должны быть указаны в виде векторов данных. Размеры массивов должны совпадать в любом случае.
- Если требуется определить будущие значения переменных (предсказать), можно использовать функцию РОСТ.
Опубликовано 05 Янв 2014
Рубрика: Справочник Excel | 19 комментариев
(Обратите внимание на дополнительный раздел от 04.06.2017 в конце статьи.)
Учет и контроль! Те, кому за 40 должны хорошо помнить этот лозунг из эпохи построения социализма и коммунизма в нашей стране.
Но без хорошо налаженного учета невозможно эффективное функционирование ни страны, ни области, ни предприятия, ни домашнего хозяйства при любой общественно-экономической формации общества! Для составления прогнозов и планов деятельности и развития необходимы исходные данные. Где их брать? Только один достоверный источник – это ваши статистические учетные данные предыдущих периодов времени.
Учитывать результаты своей деятельности, собирать и записывать информацию, обрабатывать и анализировать данные, применять результаты анализа для принятия правильных решений в будущем должен, в моем понимании, каждый здравомыслящий человек. Это есть ничто иное, как накопление и рациональное использование своего жизненного опыта. Если не вести учет важных данных, то вы через определенный период времени их забудете и, начав заниматься этими вопросами вновь, вы опять наделаете те же ошибки, что делали, когда впервые этим занимались.
«Мы, помню, 5 лет назад изготавливали до 1000 штук таких изделий в месяц, а сейчас и 700 еле-еле собираем!». Открываем статистику и видим, что 5 лет назад и 500 штук не изготавливали…
«Во сколько обходится километр пробега твоего автомобиля с учетом всех затрат?» Открываем статистику – 6 руб./км. Поездка на работу – 107 рублей. Дешевле, чем на такси (180 рублей) более чем в полтора раза. А бывали времена, когда на такси было дешевле…
«Сколько времени требуется для изготовления металлоконструкций уголковой башни связи высотой 50 м?» Открываем статистику – и через 5 минут готов ответ…
«Сколько будет стоить ремонт комнаты в квартире?» Поднимаем старые записи, делаем поправку на инфляцию за прошедшие годы, учитываем, что в прошлый раз купили материалы на 10% дешевле рыночной цены и – ориентировочную стоимость мы уже знаем…
Ведя учет своей профессиональной деятельности, вы всегда будете готовы ответить на вопрос начальника: «Когда!!!???». Ведя учет домашнего хозяйства, легче спланировать расходы на крупные покупки, отдых и прочие расходы в будущем, приняв соответствующие меры по дополнительному заработку или по сокращению необязательных расходов сегодня.
В этой статье я на простом примере покажу, как можно обрабатывать собранные статистические данные в Excel для возможности дальнейшего использования при прогнозировании будущих периодов.
Аппроксимация в Excel статистических данных аналитической функцией.
Производственный участок изготавливает строительные металлоконструкции из листового и профильного металлопроката. Участок работает стабильно, заказы однотипные, численность рабочих колеблется незначительно. Есть данные о выпуске продукции за предыдущие 12 месяцев и о количестве переработанного в эти периоды времени металлопроката по группам: листы, двутавры, швеллеры, уголки, трубы круглые, профили прямоугольного сечения, круглый прокат. После предварительного анализа исходных данных возникло предположение, что суммарный месячный выпуск металлоконструкций существенно зависит от количества уголков в заказах. Проверим это предположение.
Прежде всего, несколько слов об аппроксимации. Мы будем искать закон – аналитическую функцию, то есть функцию, заданную уравнением, которое лучше других описывает зависимость общего выпуска металлоконструкций от количества уголкового проката в выполненных заказах. Это и есть аппроксимация, а найденное уравнение называется аппроксимирующей функцией для исходной функции, заданной в виде таблицы.
1. Включаем Excel и помещаем на лист таблицу с данными статистики.
2. Далее строим и форматируем точечную диаграмму, в которой по оси X задаем значения аргумента – количество переработанных уголков в тоннах. По оси Y откладываем значения исходной функции – общий выпуск металлоконструкций в месяц, заданные таблицей.
О том, как построить подобную диаграмму, подробно рассказано в статье «Как строить графики в Excel?».
3. «Наводим» мышь на любую из точек на графике и щелчком правой кнопки вызываем контекстное меню (как говорит один мой хороший товарищ — работая в незнакомой программе, когда не знаешь, что делать, чаще щелкай правой кнопкой мыши…). В выпавшем меню выбираем «Добавить линию тренда…».
4. В появившемся окне «Линия тренда» на вкладке «Тип» выбираем «Линейная».
5. Далее на вкладке «Параметры» ставим 2 галочки и нажимаем «ОК».
6. На графике появилась прямая линия, аппроксимирующая нашу табличную зависимость.
Мы видим кроме самой линии уравнение этой линии и, главное, мы видим значение параметра R2 – величины достоверности аппроксимации! Чем ближе его значение к 1, тем наиболее точно выбранная функция аппроксимирует табличные данные!
7. Строим линии тренда, используя степенную, логарифмическую, экспоненциальную и полиномиальную аппроксимации по аналогии с тем, как мы строили линейную линию тренда.
Лучше всех из выбранных функций аппроксимирует наши данные полином второй степени, у него максимальный коэффициент достоверности R2.
Однако хочу вас предостеречь! Если вы возьмете полиномы более высоких степеней, то, возможно, получите еще лучшие результаты, но кривые будут иметь замысловатый вид…. Здесь важно понимать, что мы ищем функцию, которая имеет физический смысл. Что это означает? Это означает, что нам нужна аппроксимирующая функция, которая будет выдавать адекватные результаты не только внутри рассматриваемого диапазона значений X, но и за его пределами, то есть ответит на вопрос: «Какой будет выпуск металлоконструкций при количестве переработанных за месяц уголков меньше 45 и больше 168 тонн!» Поэтому я не рекомендую увлекаться полиномами высоких степеней, да и параболу (полином второй степени) выбирать осторожно!
Итак, нам необходимо выбрать функцию, которая не только хорошо интерполирует табличные данные в пределах диапазона значений X=45…168, но и допускает адекватную экстраполяцию за пределами этого диапазона. Я выбираю в данном случае логарифмическую функцию, хотя можно выбрать и линейную, как наиболее простую. В рассматриваемом примере при выборе линейной аппроксимации в excel ошибки будут больше, чем при выборе логарифмической, но не на много.
8. Удаляем все линии тренда с поля диаграммы, кроме логарифмической функции. Для этого щелкаем правой кнопкой мыши по ненужным линиям и в выпавшем контекстном меню выбираем «Очистить».
9. В завершении добавим к точкам табличных данных планки погрешностей. Для этого правой кнопкой мыши щелкаем на любой из точек на графике и в контекстном меню выбираем «Формат рядов данных…» и настраиваем данные на вкладке «Y-погрешности» так, как на рисунке ниже.
10. Затем щелкаем по любой из линий диапазонов погрешностей правой кнопкой мыши, выбираем в контекстном меню «Формат полос погрешностей…» и в окне «Формат планок погрешностей» на вкладке «Вид» настраиваем цвет и толщину линий.
Аналогичным образом форматируются любые другие объекты диаграммы в Excel!
Окончательный результат диаграммы представлен на следующем снимке экрана.
Итоги.
Результатом всех предыдущих действий стала полученная формула аппроксимирующей функции y=-172,01*ln (x)+1188,2. Зная ее, и количество уголков в месячном наборе работ, можно с высокой степенью вероятности (±4% — смотри планки погрешностей) спрогнозировать общий выпуск металлоконструкций за месяц! Например, если в плане на месяц 140 тонн уголков, то общий выпуск, скорее всего, при прочих равных составит 338±14 тонн.
Для повышения достоверности аппроксимации статистических данных должно быть много. Двенадцать пар значений – это маловато.
Из практики скажу, что хорошим результатом следует считать нахождение аппроксимирующей функции с коэффициентом достоверности R2>0,87. Отличный результат – при R2>0,94.
На практике бывает трудно выделить один самый главный определяющий фактор (в нашем примере – масса переработанных за месяц уголков), но если постараться, то в каждой конкретной задаче его всегда можно найти! Конечно, общий выпуск продукции за месяц реально зависит от сотни факторов, для учета которых необходимы существенные трудозатраты нормировщиков и других специалистов. Только результат все равно будет приблизительным! Так стоит ли нести затраты, если есть гораздо более дешевое математическое моделирование!
В этой статье я лишь прикоснулся к верхушке айсберга под названием сбор, обработка и практическое использование статистических данных. О том удалось, или нет, мне расшевелить ваш интерес к этой теме, надеюсь узнать из комментариев и рейтинга статьи в поисковиках.
Затронутый вопрос аппроксимации функции одной переменной имеет широкое практическое применение в разных сферах жизни. Но гораздо большее применение имеет решение задачи аппроксимации функции нескольких независимых переменных…. Об этом и не только читайте в следующих статьях на блоге.
С интересом прочту Ваши комментарии, уважаемые читатели! Пишите!
P.S. (04.06.2017)
Высокоточная красивая замена табличных данных простым уравнением.
Вас не устраивают полученные точность аппроксимации (R2<0,95) или вид и набор функций, предлагаемые MS Excel?
Размеры выражения и форма линии аппроксимирующего полинома высокой степени не радует глаз?
Обращайтесь через страницу «Обратная связь» для получения более точного и компактного результата аппроксимации ваших табличных данных и для того, чтобы узнать простую методику решения задач высокоточной аппроксимации функцией одной переменной.
Далее на скриншоте в качестве сравнения представлены результаты поиска аппроксимирующей функции при помощи Excel и при помощи предлагаемой методики.

При использовании предлагаемого алгоритма действий найдена весьма компактная функция, обеспечивающая высочайшую точность аппроксимации: R2=0,9963!!!
Другие статьи автора блога
На главную