
Функция ПИРСОН (вводить следует PEARSON на английском) предназначена для вычисления коэффициента корреляции Пирсона r. Данную функцию используют в работе в том случае, когда необходимо отразить степень линейной зависимости между двумя массивами данных. В Excel имеется несколько функций с помощью которых можно получить такой же результат, однако универсальность и простота функции Пирсон делают выбор в ее пользу.
Как работает функция ПИРСОН в Excel?
Рассмотрим пример расчета корреляции Пирсона между двумя массивами данных при помощи функции PEARSON в MS EXCEL. Первый массив представляет собой значения температур, второй давление в определенный летний период. Пример заполненной таблицы изображен на рисунке:
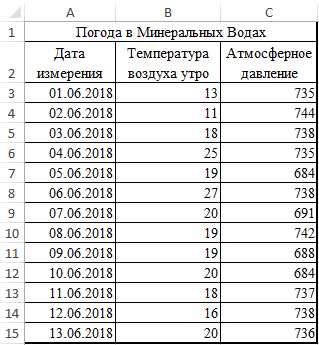
Задача следующая: необходимо определить взаимосвязь между температурой и давлением за июнь месяц.
Пример решения с функцией ПИРСОН при анализе в Excel
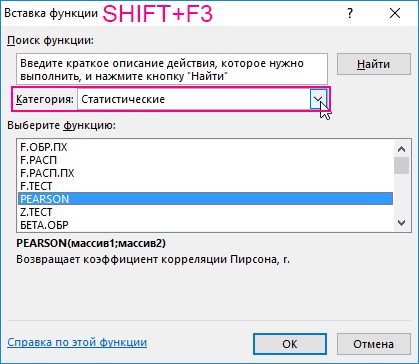
- Выберем ячейку С17 в которой должен будет посчитаться критерий Пирсона как результат и нажмем кнопку мастер функций «fx» или комбинацию горячих клавиш (SHIFT+F3). Откроется мастер функций, в поле Категория необходимо выбрать «Статистические». В списке статистических функций выбрать PEARSON и нажать Ok:
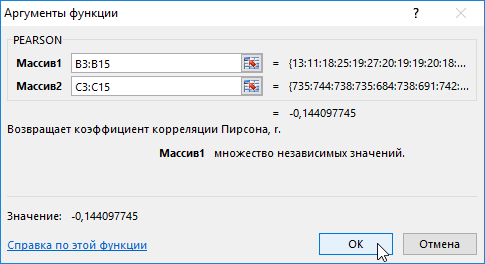
- В меню аргументов выбрать Массив 1, в примере это утренняя температура воздуха, а затем массив 2 – атмосферное давление.
- В результате в ячейке С17 получим коэффициент корреляции Пирсона. В нашем случае он отрицательный и приблизительно равен -0,14.
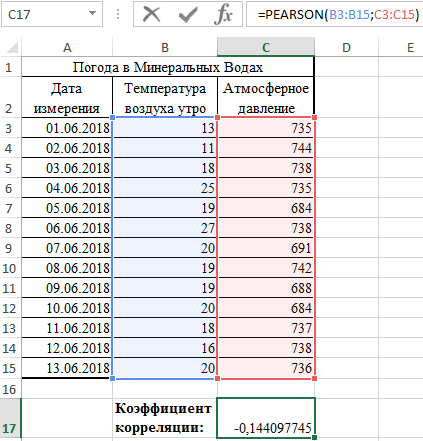
Данный показатель -0,14 по Пирсону, который вернула функция, говорит об неблагоприятной зависимости температуры и давления в раннее время суток.
Функция ПИРСОН пошаговая инструкция
Коэффициент корреляции является самым удобным показателем сопряженности количественных признаков.
Задача: Определить линейный коэффициент корреляции Пирсона.
Пример решения:
- В таблице приведены данные для группы курящих людей. Первый массив х — представляет собой возраст курящего, второй массив y представляет собой количество сигарет, выкуренных в день.
- Выберем ячейку В4 в которой должен будет посчитаться результат и нажмем кнопку мастер функций fx (SHIFT+F3).
- В группе Статистические выберем функцию PEARSON.
- Выделим Массив 1 – возраст курящего, затем Массив 2 – число сигарет, выкуренных в день.
- Нажмем кнопку ОК и увидим критерий нормального распределения Пирсона в ячейке В4.

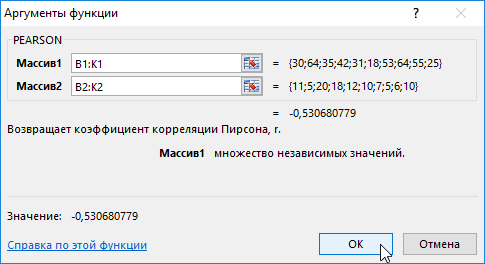

Таким образом, по результату вычисления статистическим выводом эксперимента выявлена отрицательная зависимость между возрастом и количеством выкуренных сигарет в день.
Корреляционный анализ по Пирсону в Excel
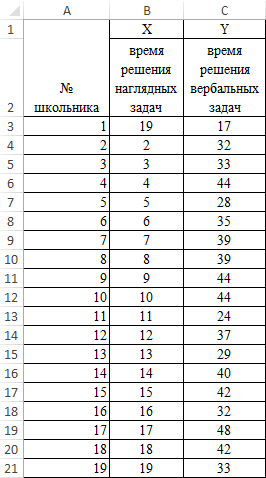
Задача: школьникам были даны тесты на наглядное и вербальное мышление. Измерялось среднее время решения заданий теста в секундах. Психолога интересует вопрос: существует ли взаимосвязь между временем решения этих задач?
Пример решения: представим исходные данные в виде таблицы:
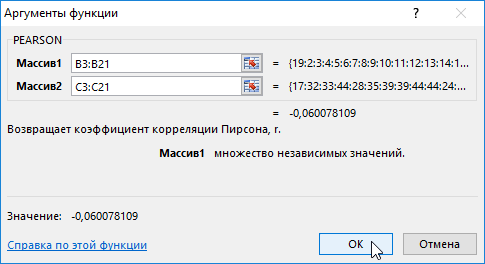
- Переходим курсором в ячейку F2. Откроем мастер функций fx (SHIFT+F3) или вводим вручную.
- Выберем функцию PEARSON.
- Выделим мышкой Массив1, затем Массив 2.
- Нажмем ОК и в ячейке F2 получим критерий согласия Пирсона.
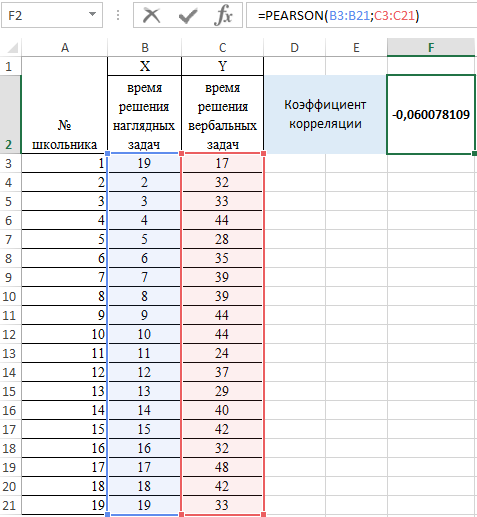
Интерпретация результата вычисления по Пирсону
Величина коэффициента линейной корреляции Пирсона не может превышать +1 и быть меньше чем -1. Эти два числа +1 и -1 – являются границами для коэффициента корреляции. Когда при расчете получается величина большая +1 или меньшая -1 – следовательно, произошла ошибка в вычислениях.
Если коэффициент корреляции по модулю оказывается близким к 1, то это соответствует высокому уровню связи между переменными.
Скачать примеры функции ПИРСОН для корреляции в Excel
Если же получен знак минус, то большей величине одного признака соответствует меньшая величина другого. Иначе говоря, при наличии знака минус, увеличению одной переменной (признака, значения) соответствует уменьшение другой переменной. Такая зависимость носит название обратно пропорциональной зависимости. Эти положения очень важно четко усвоить для правильной интерпретации полученной корреляционной зависимости.
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
В этой статье описаны синтаксис формулы и использование функции PEARSON в Microsoft Excel.
Описание
Возвращает коэффициент корреляции Пирсона (r) — безразмерный индекс в интервале от -1,0 до 1,0 включительно, который отражает степень линейной зависимости между двумя множествами данных.
Синтаксис
PEARSON(массив1;массив2)
Аргументы функции PEARSON описаны ниже.
-
Массив1 Обязательный. Множество независимых значений.
-
Массив2 Обязательный. Множество зависимых значений.
Замечания
-
Аргументы должны быть либо числами, либо содержащими числа именами, массивами или ссылками.
-
Если аргумент, который является массивом или ссылкой, содержит тексты, логические значения или пустые ячейки, то такие значения игнорируются; однако ячейки, которые содержат нулевые значения, учитываются.
-
Если массив1 или массив2 пуст, либо число точек данных в этих массивах не совпадает, функция PEARSON возвращает значение ошибки #Н/Д.
-
Коэффициента корреляции Пирсона (r) вычисляется по следующей формуле:

где x и y — выборочные средние значения СРЗНАЧ(массив1) и СРЗНАЧ(массив2).
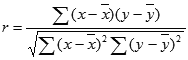
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Данные |
||
|
Независимые значения |
Зависимые значения |
|
|
9 |
10 |
|
|
7 |
6 |
|
|
5 |
1 |
|
|
3 |
5 |
|
|
1 |
3 |
|
|
Формула |
Описание (результат) |
Результат |
|
=PEARSON(A3:A7;B3:B7) |
Коэффициент корреляции Пирсона для приведенных выше данных (0,699379) |
0,699379 |
Нужна дополнительная помощь?
Correlations are important in many areas of science. Although correlation doesn’t equal causation, it’s often the first step to understanding the true relationship between two variables and can give a valuable hint that there is a causal relationship somewhere.
Learning to calculate a correlation is crucial, and you can easily find the “r value” in Excel using either built-in functions or by working through the calculation in pieces using the more basic functions of the program. The simplest way is using the built-in function, but understanding the calculation is helpful if you ever need to use a different program to find it.
What Is Pearson’s Correlation Coefficient?
Pearson’s correlation coefficient is a simple way of calculating the degree of correlation between two variables, returning a value (called r) ranging from −1 to 1. A perfect correlation (r = 1) between two variables would be where an increase in one variable by a certain amount leads to a correspondingly-sized increase in the other, or vice-versa.
A perfect negative correlation (r = −1) is basically the same, except an increase in one variable leads to a correspondingly-sized decrease in the other. Finally, no correlation whatsoever means there is no relationship at all between two things.
In practice, you’ll almost never see a perfect correlation, and most values will be some decimal value between −1 and 1. So when you find the Pearson r in Excel, the result will usually be some decimal value, where the magnitude of the number tells you the strength of the correlation between your variables.
Pearson Correlation in Excel
The easiest method for finding the Pearson correlation in Excel is using the built-in “Pearson” function or (equivalently) the “Correl” function. The function has a simple syntax: PEARSON(array 1, array 2).
In short, you just need two arrays of values (i.e. columns of results, for example, age and blood pressure arranged so there is a row for each individual patient) that are equal in length, then type “=PEARSON(” into an empty cell, followed by the range of values for the first array, a comma, then the range of values for the second. Then you close out the brackets, hit “Enter” and it will return the r value.
As always, you can highlight the values you want to search for correlations with your mouse or by navigating to the relevant cells with the arrow keys on your keyboard.
You can also use the “Correl” function, which performs the same calculation as “Pearson” and on versions of Excel from 2003 onward, leads to the exact same result. However, if you have an older version of Excel, you should use the “Correl” function because there can be rounding errors with “Pearson.”
Finding Pearson’s r “By Hand”
You can also calculate the r value in Excel in the more traditional method but with the help of the automatic calculations from the program. First, put the values for your variables (which can be referred to as x and y for clarity) in two columns, then create three more columns: xy, x2 and y2. Now multiply each value in the x column by the y column in the xy column (using the cell numbers in the calculation so you can drag it down for the rest of the column), square the x values for the next column, and square the y values for the final one.
Create a “sum” row underneath your data, and take the sum of all the values for each column. You can then use the formula to calculate your r value:
Here, n is the number of pairs of values you have. You can follow this through in pieces: Take the number of pairs of values, multiply it by the sum of your xy column, and then subtract the product of the sums of the x and y values.
Then, multiply the sum of your x2 column by n, subtract the sum of your x column squared, do the same thing for y and multiply these together, then take the square root of the whole thing. Finally, divide the first result by the second to get your r value.
Обнаружение взаимосвязей между явлениями – одна из главных задач статистического анализа. На то есть две причины. Первая. Если известно, что один процесс зависит от другого, то на первый можно оказывать влияние через второй. Вторая. Даже если причинно-следственная связь отсутствует, то по изменению одного показателя можно предсказать изменение другого.
Взаимосвязь двух переменных проявляется в совместной вариации: при изменении одного показателя имеет место тенденция изменения другого. Такая взаимосвязь называется корреляцией, а раздел статистики, который занимается взаимосвязями – корреляционный анализ.
Корреляция – это, простыми словами, взаимосвязанное изменение показателей. Она характеризуется направлением, формой и теснотой. Ниже представлены примеры корреляционной связи.
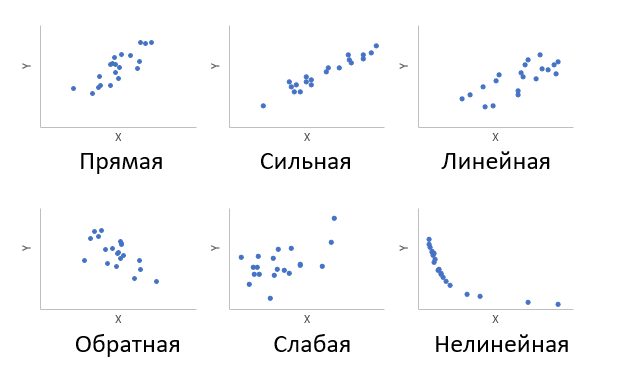
Далее будет рассматриваться только линейная корреляция. На диаграмме рассеяния (график корреляции) изображена взаимосвязь двух переменных X и Y. Пунктиром показаны средние.
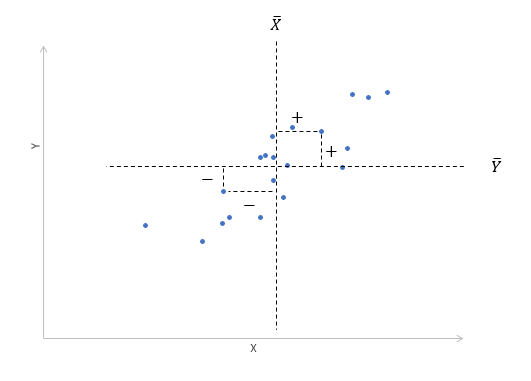
При положительном отклонении X от своей средней, Y также в большинстве случаев отклоняется в положительную сторону от своей средней. Для X меньше среднего, Y, как правило, тоже ниже среднего. Это прямая или положительная корреляция. Бывает обратная или отрицательная корреляция, когда положительное отклонение от средней X ассоциируется с отрицательным отклонением от средней Y или наоборот.
Линейность корреляции проявляется в том, что точки расположены вдоль прямой линии. Положительный или отрицательный наклон такой линии определяется направлением взаимосвязи.
Крайне важная характеристика корреляции – теснота. Чем теснее взаимосвязь, тем ближе к прямой точки на диаграмме. Как же ее измерить?
Складывать отклонения каждого показателя от своей средней нет смысла, получим нуль. Похожая проблема встречалась при измерении вариации, а точнее дисперсии. Там эту проблему обходят через возведение каждого отклонения в квадрат.
![]()
Квадрат отклонения от средней измеряет вариацию показателя как бы относительно самого себя. Если второй множитель в числителе заменить на отклонение от средней второго показателя, то получится совместная вариация двух переменных, которая называется ковариацией.
![]()
Чем больше пар имеют одинаковый знак отклонения от средней, тем больше сумма в числителе (произведение двух отрицательных чисел также дает положительное число). Большая положительная ковариация говорит о прямой взаимосвязи между переменными. Обратная взаимосвязь дает отрицательную ковариацию. Если количество совпадающих по знаку отклонений примерно равно количеству не совпадающих, то ковариация стремится к нулю, что говорит об отсутствии линейной взаимосвязи.
Таким образом, чем больше по модулю ковариация, тем теснее линейная взаимосвязь. Однако значение ковариации зависит от масштаба данных, поэтому невозможно сравнивать корреляцию для разных переменных. Можно определить только направление по знаку. Для получения стандартизованной величины тесноты взаимосвязи нужно избавиться от единиц измерения путем деления ковариации на произведение стандартных отклонений обеих переменных. В итоге получится формула коэффициента корреляции Пирсона.
![]()
Показатель имеет полное название линейный коэффициент корреляции Пирсона или просто коэффициент корреляции.
Коэффициент корреляции показывает тесноту линейной взаимосвязи и изменяется в диапазоне от -1 до 1. -1 (минус один) означает полную (функциональную) линейную обратную взаимосвязь. 1 (один) – полную (функциональную) линейную положительную взаимосвязь. 0 – отсутствие линейной корреляции (но не обязательно взаимосвязи). На практике всегда получаются промежуточные значения. Для наглядности ниже представлены несколько примеров с разными значениями коэффициента корреляции.
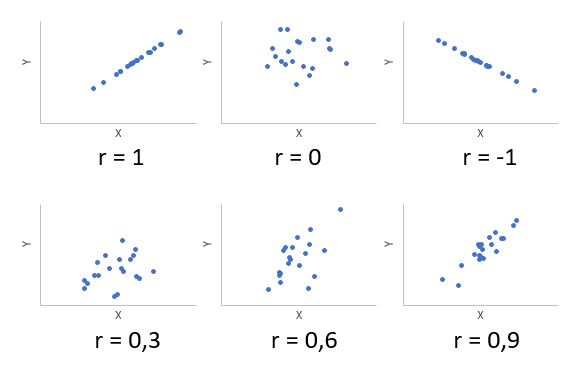
Таким образом, ковариация и корреляция отражают тесноту линейной взаимосвязи. Последняя используется намного чаще, т.к. является относительным показателем и не имеет единиц измерения.
Диаграммы рассеяния дают наглядное представление, что измеряет коэффициент корреляции. Однако нужна более формальная интерпретация. Эту роль выполняет квадрат коэффициента корреляции r2, который называется коэффициентом детерминации, и обычно применяется при оценке качества регрессионных моделей. Снова представьте линию, вокруг которой расположены точки.
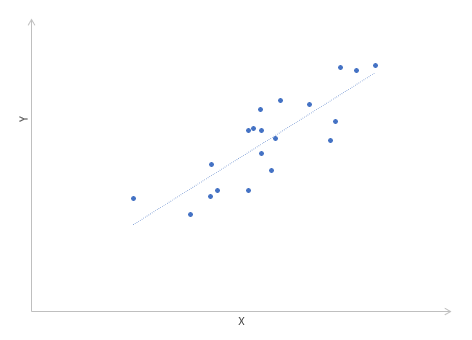
Линейная функция является моделью взаимосвязи между X иY и показывает ожидаемое значение Y при заданном X. Коэффициент детерминации – это соотношение дисперсии ожидаемых Y (точек на прямой линии) к общей дисперсии Y, или доля объясненной вариации Y. При r = 0,1 r2 = 0,01 или 1%, при r = 0,5 r2 = 0,25 или 25%.
Выборочный коэффициент корреляции
Коэффициент корреляции обычно рассчитывают по выборке. Значит, у аналитика в распоряжении не истинное значение, а оценка, которая всегда ошибочна. Если выборка была репрезентативной, то истинное значение коэффициента корреляции находится где-то относительно недалеко от оценки. Насколько далеко, можно определить через доверительные интервалы.
Согласно Центральное Предельной Теореме распределение оценки любого показателя стремится к нормальному с ростом выборки. Но есть проблемка. Распределение коэффициента корреляции вблизи придельных значений не является симметричным. Ниже пример распределения при истинном коэффициенте корреляции ρ = 0,86.
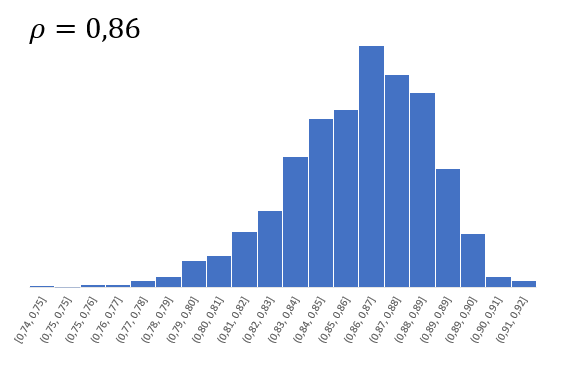
Предельное значение не дает выйти за 1 и, как бы «поджимает» распределение справа. Симметричная ситуация наблюдается, если коэффициент корреляции близок к -1.
В общем рассчитывать на свойства нормального распределения нельзя. Поэтому Фишер предложил провести преобразование выборочного коэффициента корреляции по формуле:
![]()
Распределение z для тех же r имеет следующий вид.
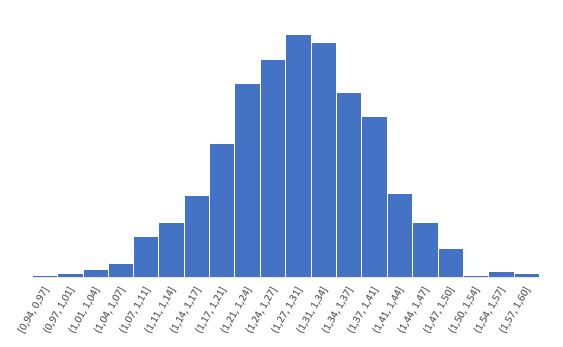
Намного ближе к нормальному. Стандартная ошибка z равна:
![]()
Далее исходя из свойств нормального распределения несложно найти верхнюю и нижнюю границы доверительного интервала для z. Определим квантиль стандартного нормального распределения для заданной доверительной вероятности, т.е. количество стандартных отклонений от центра распределения.
![]()
cγ – квантиль стандартного нормального распределения;
N-1 – функция обратного стандартного распределения;
γ – доверительная вероятность (часто 95%).
Затем рассчитаем границы доверительного интервала.
Нижняя граница z:
![]()
Верхняя граница z:
![]()
Теперь обратным преобразованием Фишера из z вернемся к r.
Нижняя граница r:
![]()
Верхняя граница r:
![]()
Это была теоретическая часть. Переходим к практике расчетов.
Как посчитать коэффициент корреляции в Excel
Корреляционный анализ в Excel лучше начинать с визуализации.
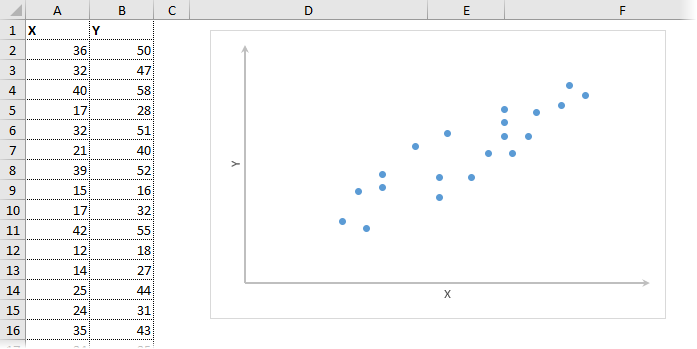
На диаграмме видна взаимосвязь двух переменных. Рассчитаем коэффициент парной корреляции с помощью функции Excel КОРРЕЛ. В аргументах нужно указать два диапазона.

Коэффициент корреляции 0,88 показывает довольно тесную взаимосвязь между двумя показателями. Но это лишь оценка, поэтому переходим к интервальному оцениванию.
Расчет доверительного интервала для коэффициента корреляции в Excel
В Эксель нет готовых функций для расчета доверительного интервала коэффициента корреляции, как для средней арифметической. Поэтому план такой:
— Делаем преобразование Фишера для r.
— На основе нормальной модели рассчитываем доверительный интервал для z.
— Делаем обратное преобразование Фишера из z в r.
Удивительно, но для преобразования Фишера в Excel есть специальная функция ФИШЕР.
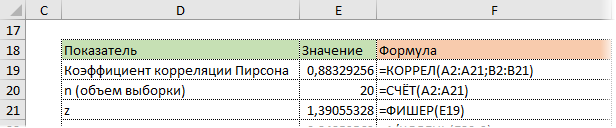
Стандартная ошибка z легко подсчитывается с помощью формулы.
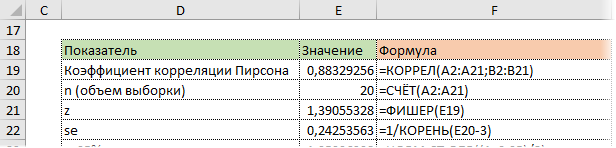
Используя функцию НОРМ.СТ.ОБР, определим квантиль нормального распределения. Доверительную вероятность возьмем 95%.
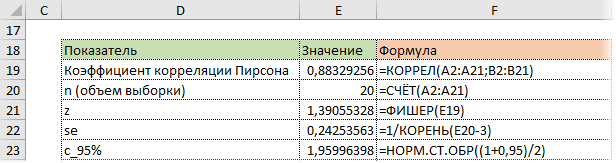
Значение 1,96 хорошо известно любому опытному аналитику. В пределах ±1,96σ от средней находится 95% нормально распределенных величин.
Используя z, стандартную ошибку и квантиль, легко определим доверительные границы z.
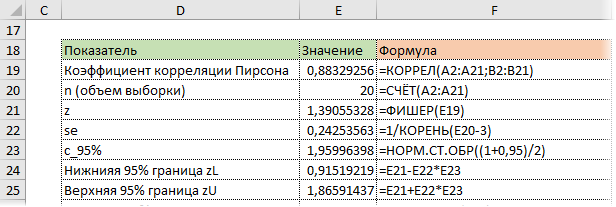
Последний шаг – обратное преобразование Фишера из z назад в r с помощью функции Excel ФИШЕРОБР. Получим доверительный интервал коэффициента корреляции.
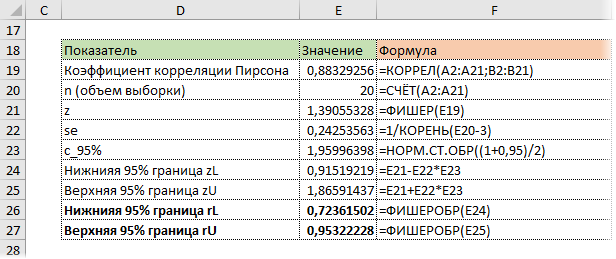
Нижняя граница 95%-го доверительного интервала коэффициента корреляции – 0,724, верхняя граница – 0,953.
Надо пояснить, что значит значимая корреляция. Коэффициент корреляции статистически значим, если его доверительный интервал не включает 0, то есть истинное значение по генеральной совокупности наверняка имеет тот же знак, что и выборочная оценка.
Несколько важных замечаний
1. Коэффициент корреляции Пирсона чувствителен к выбросам. Одно аномальное значение может существенно исказить коэффициент. Поэтому перед проведением анализа следует проверить и при необходимости удалить выбросы. Другой вариант – перейти к ранговому коэффициенту корреляции Спирмена. Рассчитывается также, только не по исходным значениям, а по их рангам (пример показан в ролике под статьей).
2. Синоним корреляции – это взаимосвязь или совместная вариация. Поэтому наличие корреляции (r ≠ 0) еще не означает причинно-следственную связь между переменными. Вполне возможно, что совместная вариация обусловлена влиянием третьей переменной. Совместное изменение переменных без причинно-следственной связи называется ложная корреляция.
3. Отсутствие линейной корреляции (r = 0) не означает отсутствие взаимосвязи. Она может быть нелинейной. Частично эту проблему решает ранговая корреляция Спирмена, которая показывает совместный рост или снижение рангов, независимо от формы взаимосвязи.
В видео показан расчет коэффициента корреляции Пирсона с доверительными интервалами, ранговый коэффициент корреляции Спирмена.
↓ Скачать файл с примером ↓
Поделиться в социальных сетях:
Содержание
- Характеристики распределений
- Равномерное распределение
- Нормальное распределение
- Что такое корреляция
- Численное выражение корреляционной зависимости
- Прямая и обратная
- Сильная и слабая
- Корреляционный анализ в психологии
- Как работает функция ПИРСОН в Excel?
- Пример решения с функцией ПИРСОН при анализе в Excel
- Для чего нужен коэффициент корреляции?
- Свойства коэффициента корреляции
- Значения коэффициента корреляции
- История разработки критерия корреляции
- Для чего используется критерий корреляции Пирсона?
- Условия и ограничения применения критерия хи-квадрат Пирсона
- Выборочный коэффициент корреляции
- Как посчитать коэффициент корреляции в Excel
- Расчет доверительного интервала для коэффициента корреляции в Excel
- Примеры расчета хи-квадрата Пирсона
- Первый этап
- Второй этап
- Третий этап
- Четвертый этап
Характеристики распределений
Основная задача анализа вариационных рядов – это выявление подлинной закономерности распределения, которая достигается увеличением объема исследуемой совокупности при одновременном уменьшении интервала ряда.
Равномерное распределение
Нормальное распределение
Что такое корреляция
Корреляция – это связь. Но не любая. В чем же ее особенность? Рассмотрим на примере.
Представьте, что вы едете на автомобиле. Вы нажимаете педаль газа – машина едет быстрее. Вы сбавляете газ – авто замедляет ход. Даже не знакомый с устройством автомобиля человек скажет: «Между педалью газа и скоростью машины есть прямая связь: чем сильнее нажата педаль, тем скорость выше».
Это зависимость функциональная – скорость выступает прямой функцией педали газа. Специалист объяснит, что педаль управляет подачей топлива в цилиндры, где происходит сжигание смеси, что ведет к повышению мощности на вал и т.д. Это связь жесткая, детерминированная, не допускающая исключений (при условии, что машина исправна).
Теперь представьте, что вы директор фирмы, сотрудники которой продают товары. Вы решаете повысить продажи за счет повышения окладов работников. Вы повышаете зарплату на 10%, и продажи в среднем по фирме растут. Через время повышаете еще на 10%, и опять рост. Затем еще на 5%, и опять есть эффект. Напрашивается вывод – между продажами фирмы и окладом сотрудников есть прямая зависимость – чем выше оклады, тем выше продажи организации. Такая же это связь, как между педалью газа и скоростью авто? В чем ключевое отличие?
Правильно, между окладом и продажами заисимость не жесткая. Это значит, что у кого-то из сотрудников продажи могли даже снизиться, невзирая на рост оклада. У кого-то остаться неизменными. Но в среднем по фирме продажи выросли, и мы говорим – связь продаж и оклада сотрудников есть, и она корреляционная.
В основе функциональной связи (педаль газа – скорость) лежит физический закон. В основе корреляционной связи (продажи – оклад) находится простая согласованность изменения двух показателей. Никакого закона (в физическом понимании этого слова) за корреляцией нет. Есть лишь вероятностная (стохастическая) закономерность.
Численное выражение корреляционной зависимости
Итак, корреляционная связь отражает зависимость между явлениями. Если эти явления можно измерить, то она получает численное выражение.
Например, изучается роль чтения в жизни людей. Исследователи взяли группу из 40 человек и измерили у каждого испытуемого два показателя: 1) сколько времени он читает в неделю; 2) в какой мере он считает себя благополучным (по шкале от 1 до 10). Ученые занесли эти данные в два столбика и с помощью статистической программы рассчитали корреляцию между чтением и благополучием. Предположим, они получили следующий результат -0,76. Но что значит это число? Как его проинтерпретировать? Давайте разбираться.
Полученное число называется коэффициентом корреляции. Для его правильной интерпретации важно учитывать следующее:
- Знак «+» или «-» отражает направление зависимости.
- Величина коэффициента отражает силу зависимости.
Прямая и обратная
Знак плюс перед коэффициентом указывает на то, что связь между явлениями или показателями прямая. То есть, чем больше один показатель, тем больше и другой. Выше оклад – выше продажи. Такая корреляция называется прямой, или положительной.
Если коэффициент имеет знак минус, значит, корреляция обратная, или отрицательная. В этом случае чем выше один показатель, тем ниже другой. В примере с чтением и благополучием мы получили -0,76, и это значит, что, чем больше люди читают, тем ниже уровень их благополучия.
Сильная и слабая
Корреляционная связь в численном выражении – это число в диапазоне от -1 до +1. Обозначается буквой «r». Чем выше число (без учета знака), тем корреляционная связь сильнее.
Чем ниже численное значение коэффициента, тем взаимосвязь между явлениями и показателями меньше.
Максимально возможная сила зависимости – это 1 или -1. Как это понять и представить?
Рассмотрим пример. Взяли 10 студентов и измерили у них уровень интеллекта (IQ) и успеваемость за семестр. Расположили эти данные в виде двух столбцов.
|
Испытуемый |
IQ |
Успеваемость (баллы) |
|
1 |
90 |
4,0 |
|
2 |
91 |
4,1 |
|
3 |
92 |
4,2 |
|
4 |
93 |
4,3 |
|
5 |
94 |
4,4 |
|
6 |
95 |
4,5 |
|
7 |
96 |
4,6 |
|
8 |
97 |
4,7 |
|
9 |
98 |
4,8 |
|
10 |
99 |
4,9 |
Посмотрите внимательно на данные в таблице. От 1 до 10 испытуемого растет уровень IQ. Но также растет и уровень успеваемости. Из любых двух студентов успеваемость будет выше у того, у кого выше IQ. И никаких исключений из этого правила не будет.
Перед нами пример полного, 100%-но согласованного изменения двух показателей в группе. И это пример максимально возможной положительной взаимосвязи. То есть, корреляционная зависимость между интеллектом и успеваемостью равна 1.
Рассмотрим другой пример. У этих же 10-ти студентов с помощью опроса оценили, в какой мере они ощущают себя успешными в общении с противоположным полом (по шкале от 1 до 10).
|
Испытуемый |
IQ |
Успех в общении с противоположным полом (баллы) |
|
1 |
90 |
10 |
|
2 |
91 |
9 |
|
3 |
92 |
8 |
|
4 |
93 |
7 |
|
5 |
94 |
6 |
|
6 |
95 |
5 |
|
7 |
96 |
4 |
|
8 |
97 |
3 |
|
9 |
98 |
2 |
|
10 |
99 |
1 |
Смотрим внимательно на данные в таблице. От 1 до 10 испытуемого растет уровень IQ. При этом в последнем столбце последовательно снижается уровень успешности общения с противоположным полом. Из любых двух студентов успех общения с противоположным полом будет выше у того, у кого IQ ниже. И никаких исключений из этого правила не будет.
Это пример полной согласованности изменения двух показателей в группе – максимально возможная отрицательная взаимосвязь. Корреляционная связь между IQ и успешностью общения с противоположным полом равна -1.
А как понять смысл корреляции равной нулю (0)? Это значит, связи между показателями нет. Еще раз вернемся к нашим студентам и рассмотрим еще один измеренный у них показатель – длину прыжка с места.
|
Испытуемый |
IQ |
Длина прыжка с места (м) |
|
1 |
90 |
2,5 |
|
2 |
91 |
1,2 |
|
3 |
92 |
2,0 |
|
4 |
93 |
1,7 |
|
5 |
94 |
1,9 |
|
6 |
95 |
1,3 |
|
7 |
96 |
1,7 |
|
8 |
97 |
2,3 |
|
9 |
98 |
1,1 |
|
10 |
99 |
2,6 |
Не наблюдается никакой согласованности между изменением IQ от человека к человеку и длинной прыжка. Это и свидетельствует об отсутствии корреляции. Коэффициент корреляции IQ и длины прыжка с места у студентов равен 0.
Мы рассмотрели крайние случаи. В реальных измерениях коэффициенты редко бывают равны точно 1 или 0. При этом принята следующая шкала:
- если коэффициент больше 0,70 – связь между показателями сильная;
- от 0,30 до 0,70 – связь умеренная,
- меньше 0,30 – связь слабая.
Если оценить по этой шкале полученную нами выше корреляцию между чтением и благополучием, то окажется, что эта зависимость сильная и отрицательная -0,76. То есть, наблюдается сильная отрицательная связь между начитанностью и благополучием. Что еще раз подтверждает библейскую мудрость о соотношении мудрости и печали.
Приведенная градация дает очень приблизительные оценки и в таком виде редко используются в исследованиях.
Чаще используются градации коэффициентов по уровням значимости. В этом случае реально полученный коэффициент может быть значимым или не значимым. Определить это можно, сравнив его значение с критическим значением коэффициента корреляции, взятым из специальной таблицы. Причем эти критические значения зависят от численности выборки (чем больше объем, тем ниже критическое значение).
Корреляционный анализ в психологии
Корреляционный метод выступает одним из основных в психологических исследованиях. И это не случайно, ведь психология стремится быть точной наукой. Получается ли?
В чем особенность законов в точных науках. Например, закон тяготения в физике действует без исключений: чем больше масса тела, тем сильнее оно притягивает другие тела. Этот физический закон отражает связь массы тела и силы притяжения.
В психологии иная ситуация. Например, психологи публикуют данные о связи теплых отношений в детстве с родителями и уровня креативности во взрослом возрасте. Означает ли это, что любой из испытуемых с очень теплыми отношениями с родителями в детстве будет иметь очень высокие творческие способности? Ответ однозначный – нет. Здесь нет закона, подобного физическому. Нет механизма влияния детского опыта на креативность взрослых. Это наши фантазии! Есть согласованность данных (отношения – креативность), но за ними нет закона. А есть лишь корреляционная связь. Психологи часто называют выявляемые взаимосвязи психологическими закономерностями, подчеркивая их вероятностный характер – не жесткость.
Пример исследования на студентах из предыдущего раздела хорошо иллюстрирует использование корреляций в психологии:
- Анализ взаимосвязи между психологическими показателями. В нашем примере IQ и успешность общения с противоположным полом – это психологические параметры. Выявление корреляции между ними расширяет представления о психической организации человека, о взаимосвязях между различными сторонами его личности – в данном случае между интеллектом и сферой общения.
- Анализ взаимосвязей IQ с успеваемостью и прыжками – пример связи психологического параметра с непсихологическими. Полученные результаты раскрывают особенности влияния интеллекта на учебную и спортивную деятельность.
Вот как могли выглядеть краткие выводы по результатам придуманного исследования на студентах:
- Выявлена значимая положительная зависимость интеллекта студентов и их успеваемости.
- Существует отрицательная значимая взаимосвязь IQ с успешностью общения с противоположным полом.
- Не выявлено связи IQ студентов с умением прыгать с места.
Таким образом, уровень интеллекта студентов выступает позитивным фактором их академической успеваемости, в то же время негативно сказываясь на отношениях с противоположным полом и не оказывая значимого влияния на спортивные успехи, в частности, способность к прыгать с места.
Как видим, интеллект помогает студентам учиться, но мешает строить отношения с противоположным полом. При этом не влияет на их спортивные успехи.
Неоднозначное влияние интеллекта на личность и деятельность студентов отражает сложность этого феномена в структуре личностных особенностей и важность продолжения исследований в этом направлении. В частности, представляется важным провести анализ взаимосвязей интеллекта с психологическими особенностями и деятельностью студентов с учетом их пола.
Как работает функция ПИРСОН в Excel?
Рассмотрим пример расчета корреляции Пирсона между двумя массивами данных при помощи функции PEARSON в MS EXCEL. Первый массив представляет собой значения температур, второй давление в определенный летний период. Пример заполненной таблицы изображен на рисунке:

Пример решения с функцией ПИРСОН при анализе в Excel
- Выберем ячейку С17 в которой должен будет посчитаться критерий Пирсона как результат и нажмем кнопку мастер функций «fx» или комбинацию горячих клавиш (SHIFT+F3). Откроется мастер функций, в поле Категория необходимо выбрать «Статистические». В списке статистических функций выбрать PEARSON и нажать Ok:
- В меню аргументов выбрать Массив 1, в примере это утренняя температура воздуха, а затем массив 2 – атмосферное давление.
- В результате в ячейке С17 получим коэффициент корреляции Пирсона. В нашем случае он отрицательный и приблизительно равен -0,14.



Данный показатель -0,14 по Пирсону, который вернула функция, говорит об неблагоприятной зависимости температуры и давления в раннее время суток.
Для чего нужен коэффициент корреляции?
Данный статистический показатель позволяет не только проверить предположение о существовании линейной взаимосвязи между признаками, но и установить ее силу.
Случайные величины, связанные между собой, могут иметь совершенно разную природу этой связи. Не обязательно она будет функциональной, случай, когда прослеживается прямая зависимость между величинами. Чаще всего на обе величины действует целая совокупность разнообразных факторов, в случаях, когда они являются общими для обеих величин, наблюдается формирование связанных закономерностей.
Это значит, что доказанный статистически факт наличия связи между величинами не является подтверждением того, что установлена причина наблюдаемых изменений. Как правило, исследователь делает вывод о наличии двух взаимосвязанных следствий.
Свойства коэффициента корреляции
 Этой статистической характеристике присущи следующие свойства:
Этой статистической характеристике присущи следующие свойства:
- значение коэффициента располагается в диапазоне от -1 до +1. Чем ближе к крайним значениям, тем сильнее положительная либо отрицательная связь между линейными параметрами. В случае нулевого значения речь идет об отсутствии корреляции между признаками;
- положительное значение коэффициента свидетельствует о том, что в случае увеличения значения одного признака наблюдается увеличение второго (положительная корреляция);
- отрицательное значение – в случае увеличения значения одного признака наблюдается уменьшение второго (отрицательная корреляция);
- приближение значения показателя к крайним точкам (либо -1, либо +1) свидетельствует о наличии очень сильной линейной связи;
- показатели признака могут изменяться при неизменном значении коэффициента;
- корреляционный коэффициент является безразмерной величиной;
- наличие корреляционной связи не является обязательным подтверждением причинно-следственной связи.
Значения коэффициента корреляции
Охарактеризовать силу корреляционной связи можно прибегнув к шкале Челдока, в которой определенному числовому значению соответствует качественная характеристика.
 В случае положительной корреляции при значении:
В случае положительной корреляции при значении:
- 0-0,3 – корреляционная связь очень слабая;
- 0,3-0,5 – слабая;
- 0,5-0,7 – средней силы;
- 0,7-0,9 – высокая;
- 0,9-1 – очень высокая сила корреляции.
Шкала может использоваться и для отрицательной корреляции. В этом случае качественные характеристики заменяются на противоположные.
Можно воспользоваться упрощенной шкалой Челдока, в которой выделяется всего 3 градации силы корреляционной связи:
- очень сильная – показатели ±0,7 — ±1;
- средняя – показатели ±0,3 — ±0,699;
- очень слабая – показатели 0 — ±0,299.
Данный статистический показатель позволяет не только проверить предположение о существовании линейной взаимосвязи между признаками, но и установить ее силу.
История разработки критерия корреляции
Критерий корреляции Пирсона был разработан командой британских ученых во главе с Карлом Пирсоном (1857-1936) в 90-х годах 19-го века, для упрощения анализа ковариации двух случайных величин. Помимо Карла Пирсона над критерием корреляции Пирсона работали также Фрэнсис Эджуорт и Рафаэль Уэлдон.
Для чего используется критерий корреляции Пирсона?
Критерий корреляции Пирсона позволяет определить, какова теснота (или сила) корреляционной связи между двумя показателями, измеренными в количественной шкале. При помощи дополнительных расчетов можно также определить, насколько статистически значима выявленная связь.
Например, при помощи критерия корреляции Пирсона можно ответить на вопрос о наличии связи между температурой тела и содержанием лейкоцитов в крови при острых респираторных инфекциях, между ростом и весом пациента, между содержанием в питьевой воде фтора и заболеваемостью населения кариесом.
Условия и ограничения применения критерия хи-квадрат Пирсона
- Сопоставляемые показатели должны быть измерены в количественной шкале (например, частота сердечных сокращений, температура тела, содержание лейкоцитов в 1 мл крови, систолическое артериальное давление).
- Посредством критерия корреляции Пирсона можно определить лишь наличие и силу линейной взаимосвязи между величинами. Прочие характеристики связи, в том числе направление (прямая или обратная), характер изменений (прямолинейный или криволинейный), а также наличие зависимости одной переменной от другой – определяются при помощи регрессионного анализа.
- Количество сопоставляемых величин должно быть равно двум. В случае анализ взаимосвязи трех и более параметров следует воспользоваться методом факторного анализа.
- Критерий корреляции Пирсона является параметрическим, в связи с чем условием его применения служит нормальное распределение каждой из сопоставляемых переменных. В случае необходимости корреляционного анализа показателей, распределение которых отличается от нормального, в том числе измеренных в порядковой шкале, следует использовать коэффициент ранговой корреляции Спирмена.
- Следует четко различать понятия зависимости и корреляции. Зависимость величин обуславливает наличие корреляционной связи между ними, но не наоборот.
Например, рост ребенка зависит от его возраста, то есть чем старше ребенок, тем он выше. Если мы возьмем двух детей разного возраста, то с высокой долей вероятности рост старшего ребенка будет больше, чем у младшего. Данное явление и называется зависимостью, подразумевающей причинно-следственную связь между показателями. Разумеется, между ними имеется и корреляционная связь, означающая, что изменения одного показателя сопровождаются изменениями другого показателя.
В другой ситуации рассмотрим связь роста ребенка и частоты сердечных сокращений (ЧСС). Как известно, обе эти величины напрямую зависят от возраста, поэтому в большинстве случаев дети большего роста (а значит и более старшего возраста) будут иметь меньшие значения ЧСС. То есть, корреляционная связь будет наблюдаться и может иметь достаточно высокую тесноту. Однако, если мы возьмем детей одного возраста, но разного роста, то, скорее всего, ЧСС у них будет различаться несущественно, в связи с чем можно сделать вывод о независимости ЧСС от роста.
Приведенный пример показывает, как важно различать фундаментальные в статистике понятия связи и зависимости показателей для построения верных выводов.
Выборочный коэффициент корреляции
Коэффициент корреляции обычно рассчитывают по выборке. Значит, у аналитика в распоряжении не истинное значение, а оценка, которая всегда ошибочна. Если выборка была репрезентативной, то истинное значение коэффициента корреляции находится где-то относительно недалеко от оценки. Насколько далеко, можно определить через доверительные интервалы.
Согласно Центральное Предельной Теореме распределение оценки любого показателя стремится к нормальному с ростом выборки. Но есть проблемка. Распределение коэффициента корреляции вблизи придельных значений не является симметричным. Ниже пример распределения при истинном коэффициенте корреляции ρ = 0,86.

Предельное значение не дает выйти за 1 и, как бы «поджимает» распределение справа. Симметричная ситуация наблюдается, если коэффициент корреляции близок к -1.
В общем рассчитывать на свойства нормального распределения нельзя. Поэтому Фишер предложил провести преобразование выборочного коэффициента корреляции по формуле:

Распределение z для тех же r имеет следующий вид.

Намного ближе к нормальному. Стандартная ошибка z равна:

Далее исходя из свойств нормального распределения несложно найти верхнюю и нижнюю границы доверительного интервала для z. Определим квантиль стандартного нормального распределения для заданной доверительной вероятности, т.е. количество стандартных отклонений от центра распределения.

cγ – квантиль стандартного нормального распределения;
N-1 – функция обратного стандартного распределения;
γ – доверительная вероятность (часто 95%).
Затем рассчитаем границы доверительного интервала.
Нижняя граница z:

Верхняя граница z:

Теперь обратным преобразованием Фишера из z вернемся к r.
Нижняя граница r:

Верхняя граница r:

Это была теоретическая часть. Переходим к практике расчетов.
Как посчитать коэффициент корреляции в Excel
Корреляционный анализ в Excel лучше начинать с визуализации.

На диаграмме видна взаимосвязь двух переменных. Рассчитаем коэффициент парной корреляции с помощью функции Excel КОРРЕЛ. В аргументах нужно указать два диапазона.

Коэффициент корреляции 0,88 показывает довольно тесную взаимосвязь между двумя показателями. Но это лишь оценка, поэтому переходим к интервальному оцениванию.
Расчет доверительного интервала для коэффициента корреляции в Excel
В Эксель нет готовых функций для расчета доверительного интервала коэффициента корреляции, как для средней арифметической. Поэтому план такой:
— Делаем преобразование Фишера для r.
— На основе нормальной модели рассчитываем доверительный интервал для z.
— Делаем обратное преобразование Фишера из z в r.
Удивительно, но для преобразования Фишера в Excel есть специальная функция ФИШЕР.

Стандартная ошибка z легко подсчитывается с помощью формулы.

Используя функцию НОРМ.СТ.ОБР, определим квантиль нормального распределения. Доверительную вероятность возьмем 95%.

Значение 1,96 хорошо известно любому опытному аналитику. В пределах ±1,96σ от средней находится 95% нормально распределенных величин.
Используя z, стандартную ошибку и квантиль, легко определим доверительные границы z.

Последний шаг – обратное преобразование Фишера из z назад в r с помощью функции Excel ФИШЕРОБР. Получим доверительный интервал коэффициента корреляции.

Нижняя граница 95%-го доверительного интервала коэффициента корреляции – 0,724, верхняя граница – 0,953.
Надо пояснить, что значит значимая корреляция. Коэффициент корреляции статистически значим, если его доверительный интервал не включает 0, то есть истинное значение по генеральной совокупности наверняка имеет тот же знак, что и выборочная оценка.
Примеры расчета хи-квадрата Пирсона
Пример 1:
Необходимо определить наличие влияния предшествующей степени нарушения кровообращения на исход комиссуротомии (хирургическое разделение спаек при стенозе клапанного отверстия сердца). Пациенты поступали на комиссуротомию с различными исходными уровнями нарушения кровообращения. После комиссуротомии пациенты были выписаны с различными исходами операции.
Таблица: наблюдаемые (Observed) частоты распределения влияния степени нарушения кровообращения на результаты операции комиссуротомии
| Степень нарушения кровообращения | Всего больных | Выписан с хорошим результатом операции | Выписан с удовлетворительным результатом операции | Выписан с ухудшением |
| II | 30 | 20 | 8 | 2 |
| III | 80 | 43 | 20 | 17 |
| IV | 60 | 10 | 40 | 10 |
| Всего | 170 | 73 | 68 | 29 |
| H0-гипотеза | 100% | 43% | 40% | 17% |
Первый этап
Расчет ожидаемых (Expected) величин (на основании групповых частот)

Второй этап
Сопоставление наблюдаемых и ожидаемых частот с нахождением их разницы (O-E)
| Степень нарушения кровообращения | Выписан с хорошим результатом операции | Выписан с удовлетворительным результатом операции | Выписан с ухудшением |
| II | +7 | -4 | -3 |
| III | +9 | -12 | +3 |
| IV | -16 | +16 | 0 |
| Всего | 0 | 0 | 0 |
Третий этап
Рассчитываем сумму отношений квадрата разности значений и делим ожидаемые данные (хи-квадрат) (O-E)2/E
| Степень нарушения кровообращения | Выписан с хорошим результатом операции | Выписан с удовлетворительным результатом операции | Выписан с ухудшением |
| II | 49/13=3,77 | 16/12=1,33 | 9/5=1,80 |
| III | 81/34=2,38 | 144/32=4,50 | 9/14=0,64 |
| IV | 256/26=9,85 | 256/24=10,66 | 0/10*=0,10 |
| Всего | 16 | 16,49 | 2,54 |
как видно из данной таблицы одно из ожидаемых значений равно 0, в данном случае будет подставлена 1, корректнее применить точный критерий Фишера (см. Условия применения хи-квадрата Пирсона)

Четвертый этап
Необходимо соотнести полученное значение хи-квадрата с критическим значением хи-квадрата.Возникает вопрос, откуда брать критическое значение? Критическое значение хи-квадрата, как и для большинства, статистических критериев зависит от степени свободы и уровня достоверности (alpha), который Вы выбираете.В нашем случае, наше количество степеней свободы равно (3-1)*(3-1)=4, уровень значимости, который мы хотим соблюсти равен 0,05Обратимся к таблице критических значение хи-квадрата:
- Xи-квадрат (для d.f.=4 p=0.05) = 9.488
- Xи-квадрат (для d.f.=4 p=0.01) = 13.27735,03 > 13,277;
- p<0,01
Пример корректной интерпретации: Предшествующая степень нарушения кровообращения влияет на исход комиссуротомии (однако! Мы не можем говорить о направленности связи, то есть: улучшает-ухудшает сказать не можем), оптимально указать степень свободы, точное значение хи-квадрата, если есть возможность рассчитать точное значение достоверности, то так же стоит указать и его или остановиться на критическом значении достоверности (p<0,05 или p<0,01 и так далее).В нашем случае:d.f.=4, x2=35,03, p< 0.01
Пример 2: Вернемся к нашему примеру с влиянием курения на развитие артериальной гипертензии:Исходная четырехпольная таблица:
| Повышенное АД | АД в пределах норма | Всего | |
| «Курильщики» | 40 | 30 | 70 |
| «Не курят» | 32 | 48 | 80 |
| Всего | 72 | 78 | 150 |
Для четырехпольных таблиц существует упрощенная формула расчета значения хи-квадрата:
| Исход + | Исход 0 | Всего | |
| Фактор + | a | b | a+b |
| Фактор 0 | c | d | c+d |
| Всего | a+c | b+d | N |

- x2= (40х48 – 32х30)х150 / (70)(80)(72)(78) = (1920 – 960)2х150/31449600 = 138240000/31449600 = 4,395
- Сравним полученное значение хи-квадрата с критическим значением (для степени свободы 1, и уровнем значимости 3,841)
Правильная интерпретация: Курение оказывает влияние на формирование повышенного артериального давления df=1, x2= 4,395, p<0,05

Источники
- https://math.semestr.ru/group/hypothesis-testing.php
- http://xn--c1abdmpkibfqehdkeh3a.xn--p1ai/stati/article_post/o-korrelyatsii-prostymi-slovami
- https://exceltable.com/funkcii-excel/koefficient-korrelyacii-pirsona
- https://forex365.ru/indicators/koef-korrelyacii-v-excell.html
- https://medstatistic.ru/methods/methods8.html
- https://statanaliz.info/statistica/korrelyaciya-i-regressiya/linejnyj-koefficient-korrelyacii-pirsona/
- https://lit-review.ru/biostatistika/kriterijj-khi-kvadrat-pirsona/