
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
Вычисляет дисперсию для генеральной совокупности.
Важно: Эта функция была заменена одной или несколькими новыми функциями, которые обеспечивают более высокую точность и имеют имена, лучше отражающие их назначение. Хотя эта функция все еще используется для обеспечения обратной совместимости, она может стать недоступной в последующих версиях Excel, поэтому мы рекомендуем использовать новые функции.
Дополнительные сведения о новом варианте этой функции Функция ДИСП.Г.
Синтаксис
ДИСПР(число1;[число2];…)
Аргументы функции ДИСПР описаны ниже.
-
Число1 Обязательный. Первый числовой аргумент, соответствующий генеральной совокупности.
-
Число2… Необязательный. Числовые аргументы 2—255, соответствующие генеральной совокупности.
Замечания
-
В функции ДИСПР предполагается, что аргументы представляют собой всю генеральную совокупность. Если данные являются только выборкой из генеральной совокупности, для вычисления дисперсии следует использовать функцию ДИСП.
-
Аргументы могут быть либо числами, либо содержащими числа именами, массивами или ссылками.
-
Учитываются логические значения и текстовые представления чисел, которые непосредственно введены в список аргументов.
-
Если аргумент является массивом или ссылкой, то учитываются только числа. Пустые ячейки, логические значения, текст и значения ошибок в массиве или ссылке игнорируются.
-
Аргументы, которые представляют собой значения ошибок или текст, не преобразуемый в числа, вызывают ошибку.
-
Чтобы включить логические значения и текстовые представления чисел в ссылку как часть вычисления, используйте функцию ДИСПРА.
-
Уравнение для ДИСПР имеет следующий вид:

где x — выборочное среднее СРЗНАЧ(число1,число2,…), а n — размер выборки.
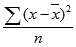
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Прочность |
||
|
1345 |
||
|
1301 |
||
|
1368 |
||
|
1322 |
||
|
1310 |
||
|
1370 |
||
|
1318 |
||
|
1350 |
||
|
1303 |
||
|
1299 |
||
|
Формула |
Описание |
Результат |
|
=ДИСПР(A2:A11) |
Дисперсия предела прочности для всех инструментов в предположении, что всего было произведено 10 инструментов (генеральная совокупность). |
678,84 |
|
=ДИСП(A2:A11) |
В этом примере используется функция ДИСП, которая оценивает только выборку из совокупности и возвращает другой результат. |
754,27 |
Нужна дополнительная помощь?
Содержание
- Вычисление дисперсии
- Способ 1: расчет по генеральной совокупности
- Способ 2: расчет по выборке
- Вопросы и ответы

Среди множества показателей, которые применяются в статистике, нужно выделить расчет дисперсии. Следует отметить, что выполнение вручную данного вычисления – довольно утомительное занятие. К счастью, в приложении Excel имеются функции, позволяющие автоматизировать процедуру расчета. Выясним алгоритм работы с этими инструментами.
Вычисление дисперсии
Дисперсия – это показатель вариации, который представляет собой средний квадрат отклонений от математического ожидания. Таким образом, он выражает разброс чисел относительно среднего значения. Вычисление дисперсии может проводиться как по генеральной совокупности, так и по выборочной.
Способ 1: расчет по генеральной совокупности
Для расчета данного показателя в Excel по генеральной совокупности применяется функция ДИСП.Г. Синтаксис этого выражения имеет следующий вид:
=ДИСП.Г(Число1;Число2;…)
Всего может быть применено от 1 до 255 аргументов. В качестве аргументов могут выступать, как числовые значения, так и ссылки на ячейки, в которых они содержатся.
Посмотрим, как вычислить это значение для диапазона с числовыми данными.
- Производим выделение ячейки на листе, в которую будут выводиться итоги вычисления дисперсии. Щелкаем по кнопке «Вставить функцию», размещенную слева от строки формул.
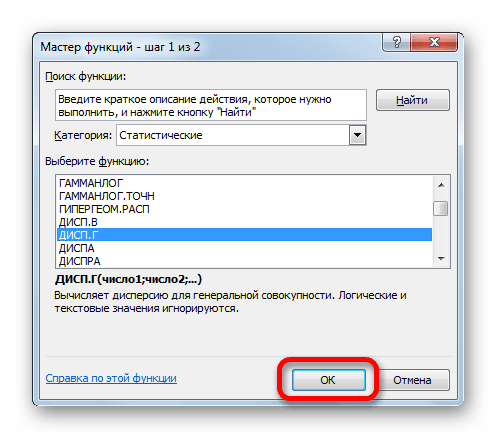
- Запускается Мастер функций. В категории «Статистические» или «Полный алфавитный перечень» выполняем поиск аргумента с наименованием «ДИСП.Г». После того, как нашли, выделяем его и щелкаем по кнопке «OK».
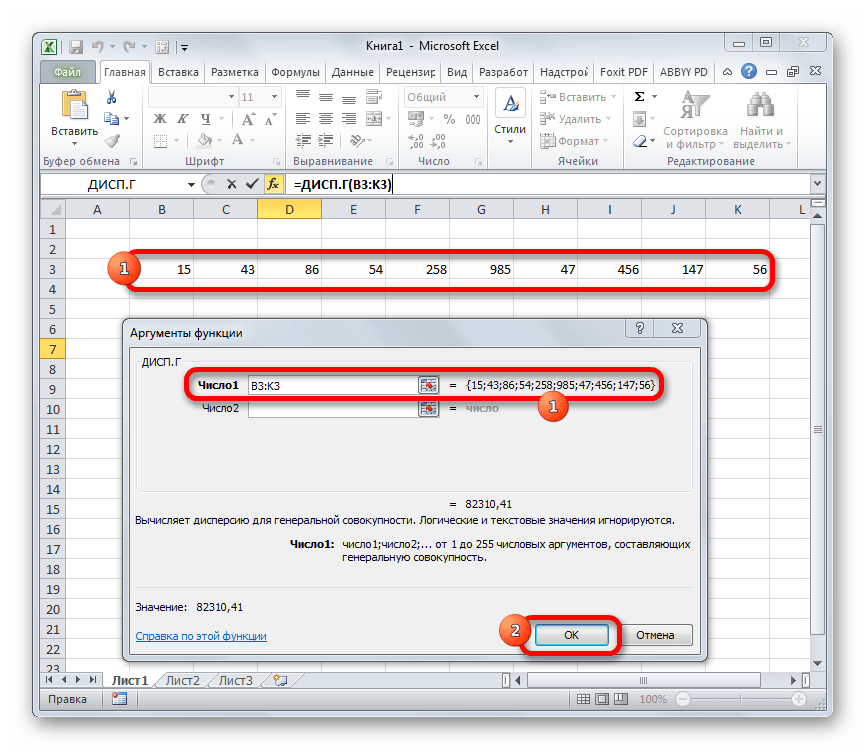
- Выполняется запуск окна аргументов функции ДИСП.Г. Устанавливаем курсор в поле «Число1». Выделяем на листе диапазон ячеек, в котором содержится числовой ряд. Если таких диапазонов несколько, то можно также использовать для занесения их координат в окно аргументов поля «Число2», «Число3» и т.д. После того, как все данные внесены, жмем на кнопку «OK».
- Как видим, после этих действий производится расчет. Итог вычисления величины дисперсии по генеральной совокупности выводится в предварительно указанную ячейку. Это именно та ячейка, в которой непосредственно находится формула ДИСП.Г.
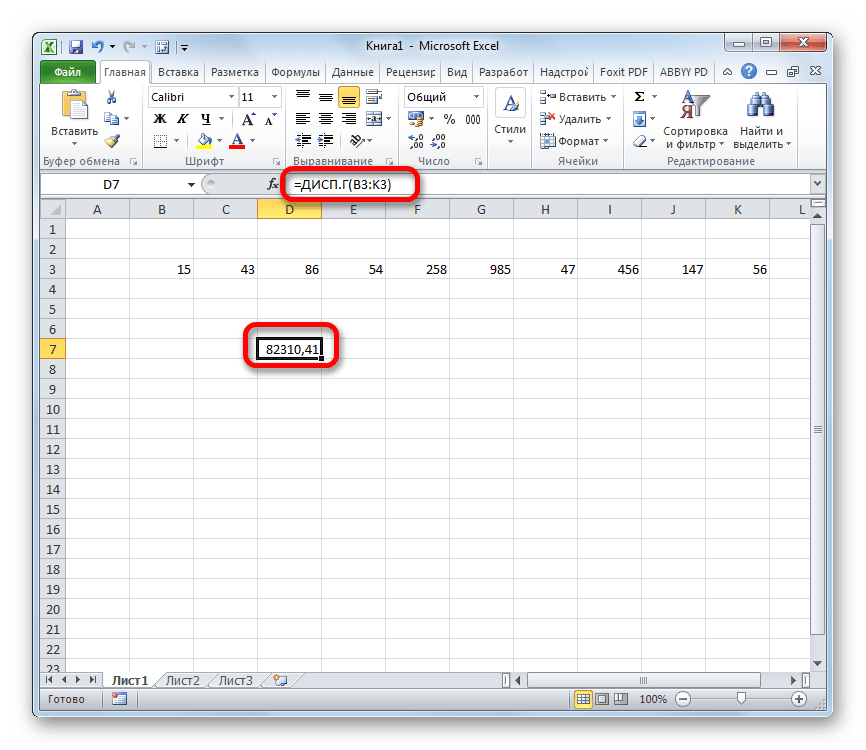
Урок: Мастер функций в Эксель
Способ 2: расчет по выборке
В отличие от вычисления значения по генеральной совокупности, в расчете по выборке в знаменателе указывается не общее количество чисел, а на одно меньше. Это делается в целях коррекции погрешности. Эксель учитывает данный нюанс в специальной функции, которая предназначена для данного вида вычисления – ДИСП.В. Её синтаксис представлен следующей формулой:
=ДИСП.В(Число1;Число2;…)
Количество аргументов, как и в предыдущей функции, тоже может колебаться от 1 до 255.

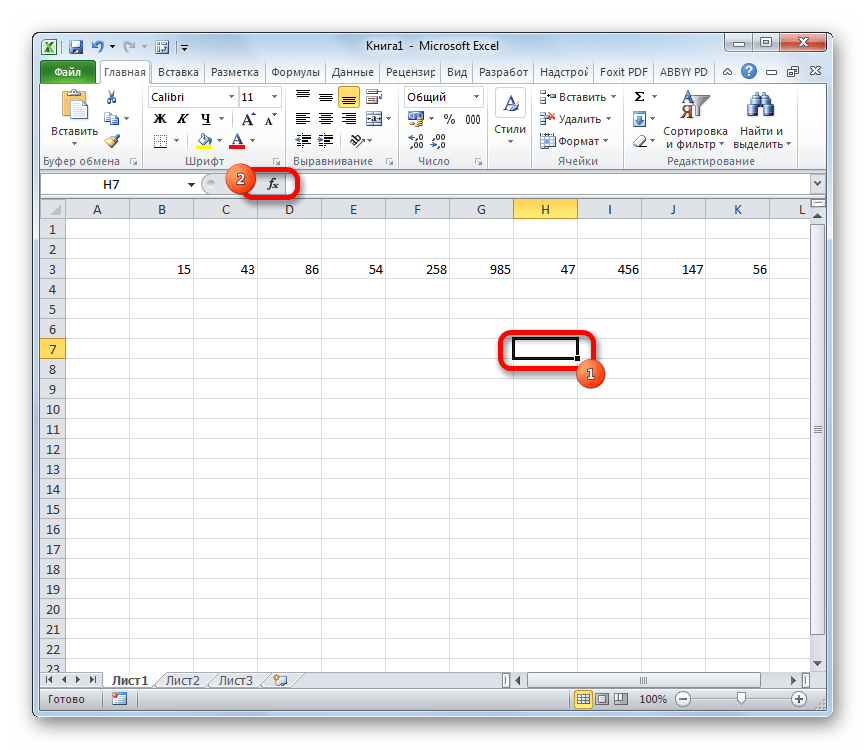
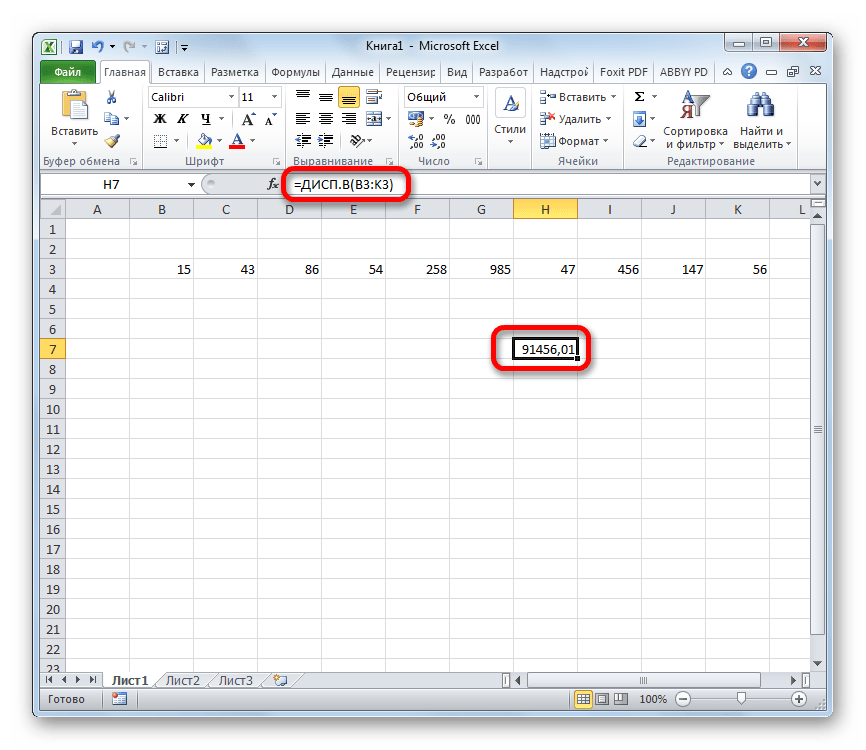
- Выделяем ячейку и таким же способом, как и в предыдущий раз, запускаем Мастер функций.
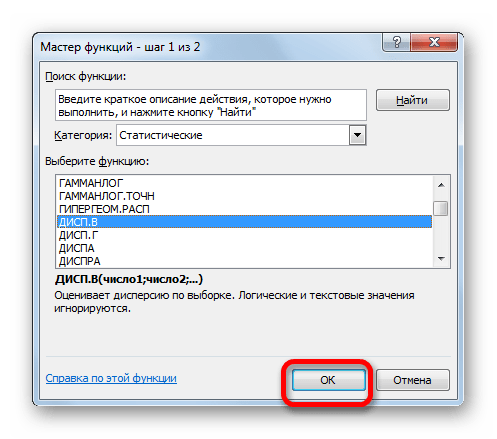
- В категории «Полный алфавитный перечень» или «Статистические» ищем наименование «ДИСП.В». После того, как формула найдена, выделяем её и делаем клик по кнопке «OK».
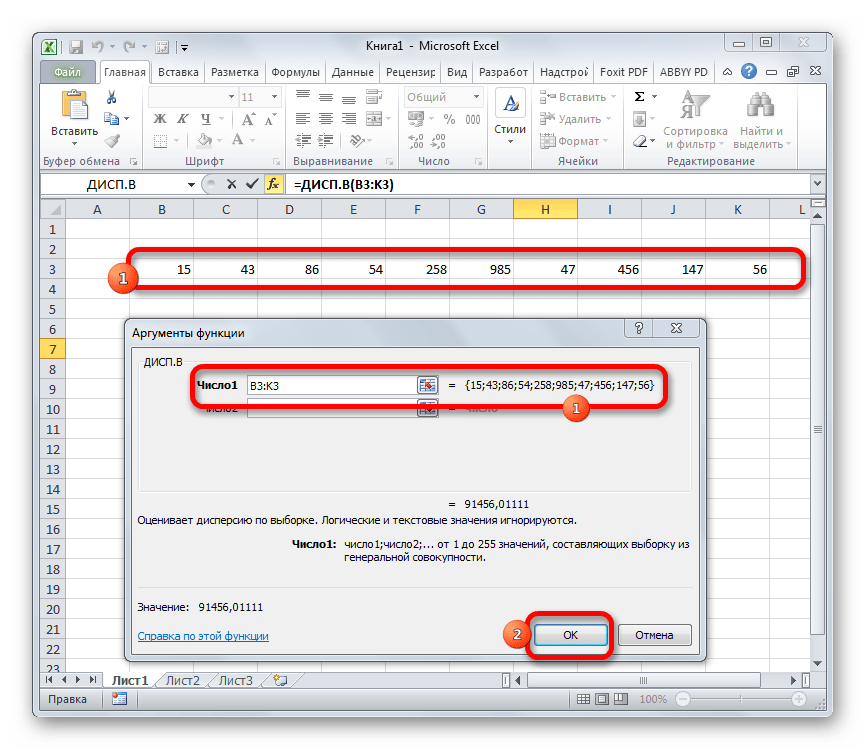
- Производится запуск окна аргументов функции. Далее поступаем полностью аналогичным образом, как и при использовании предыдущего оператора: устанавливаем курсор в поле аргумента «Число1» и выделяем область, содержащую числовой ряд, на листе. Затем щелкаем по кнопке «OK».
- Результат вычисления будет выведен в отдельную ячейку.
Урок: Другие статистические функции в Эксель
Как видим, программа Эксель способна в значительной мере облегчить расчет дисперсии. Эта статистическая величина может быть рассчитана приложением, как по генеральной совокупности, так и по выборке. При этом все действия пользователя фактически сводятся только к указанию диапазона обрабатываемых чисел, а основную работу Excel делает сам. Безусловно, это сэкономит значительное количество времени пользователей.
Еще статьи по данной теме:
Помогла ли Вам статья?
Расчет дисперсии в Microsoft Excel
Среди множества показателей, которые применяются в статистике, нужно выделить расчет дисперсии. Следует отметить, что выполнение вручную данного вычисления – довольно утомительное занятие. К счастью, в приложении Excel имеются функции, позволяющие автоматизировать процедуру расчета. Выясним алгоритм работы с этими инструментами.
Вычисление дисперсии
Дисперсия – это показатель вариации, который представляет собой средний квадрат отклонений от математического ожидания. Таким образом, он выражает разброс чисел относительно среднего значения. Вычисление дисперсии может проводиться как по генеральной совокупности, так и по выборочной.
Способ 1: расчет по генеральной совокупности
Для расчета данного показателя в Excel по генеральной совокупности применяется функция ДИСП.Г. Синтаксис этого выражения имеет следующий вид:
Всего может быть применено от 1 до 255 аргументов. В качестве аргументов могут выступать, как числовые значения, так и ссылки на ячейки, в которых они содержатся.
Посмотрим, как вычислить это значение для диапазона с числовыми данными.
- Производим выделение ячейки на листе, в которую будут выводиться итоги вычисления дисперсии. Щелкаем по кнопке «Вставить функцию», размещенную слева от строки формул.
Запускается Мастер функций. В категории «Статистические» или «Полный алфавитный перечень» выполняем поиск аргумента с наименованием «ДИСП.Г». После того, как нашли, выделяем его и щелкаем по кнопке «OK».
Выполняется запуск окна аргументов функции ДИСП.Г. Устанавливаем курсор в поле «Число1». Выделяем на листе диапазон ячеек, в котором содержится числовой ряд. Если таких диапазонов несколько, то можно также использовать для занесения их координат в окно аргументов поля «Число2», «Число3» и т.д. После того, как все данные внесены, жмем на кнопку «OK».
Способ 2: расчет по выборке
В отличие от вычисления значения по генеральной совокупности, в расчете по выборке в знаменателе указывается не общее количество чисел, а на одно меньше. Это делается в целях коррекции погрешности. Эксель учитывает данный нюанс в специальной функции, которая предназначена для данного вида вычисления – ДИСП.В. Её синтаксис представлен следующей формулой:
Количество аргументов, как и в предыдущей функции, тоже может колебаться от 1 до 255.
-
Выделяем ячейку и таким же способом, как и в предыдущий раз, запускаем Мастер функций.
В категории «Полный алфавитный перечень» или «Статистические» ищем наименование «ДИСП.В». После того, как формула найдена, выделяем её и делаем клик по кнопке «OK».
Производится запуск окна аргументов функции. Далее поступаем полностью аналогичным образом, как и при использовании предыдущего оператора: устанавливаем курсор в поле аргумента «Число1» и выделяем область, содержащую числовой ряд, на листе. Затем щелкаем по кнопке «OK».
Как видим, программа Эксель способна в значительной мере облегчить расчет дисперсии. Эта статистическая величина может быть рассчитана приложением, как по генеральной совокупности, так и по выборке. При этом все действия пользователя фактически сводятся только к указанию диапазона обрабатываемых чисел, а основную работу Excel делает сам. Безусловно, это сэкономит значительное количество времени пользователей.
Отблагодарите автора, поделитесь статьей в социальных сетях.
ДИСП (функция ДИСП)
Оценивает дисперсию по выборке.
Важно: Эта функция была заменена одной или несколькими новыми функциями, которые обеспечивают более высокую точность и имеют имена, лучше отражающие их назначение. Хотя эта функция все еще используется для обеспечения обратной совместимости, она может стать недоступной в последующих версиях Excel, поэтому мы рекомендуем использовать новые функции.
Дополнительные сведения о новом варианте этой функции см. в статье Функция ДИСП.В.
Аргументы функции ДИСП описаны ниже.
Число1 Обязательный. Первый числовой аргумент, соответствующий выборке из генеральной совокупности.
Число2. Необязательный. Числовые аргументы 2—255, соответствующие выборке из генеральной совокупности.
В функции ДИСП предполагается, что аргументы являются только выборкой из генеральной совокупности. Если данные представляют всю генеральную совокупность, для вычисления дисперсии следует использовать функцию ДИСПР.
Аргументы могут быть либо числами, либо содержащими числа именами, массивами или ссылками.
Учитываются логические значения и текстовые представления чисел, которые непосредственно введены в список аргументов.
Если аргумент является массивом или ссылкой, то учитываются только числа. Пустые ячейки, логические значения, текст и значения ошибок в массиве или ссылке игнорируются.
Аргументы, которые представляют собой значения ошибок или текст, не преобразуемый в числа, вызывают ошибку.
Чтобы включить логические значения и текстовые представления чисел в ссылку как часть вычисления, используйте функцию ДИСПА.
Функция ДИСП вычисляется по следующей формуле:
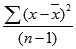
где x — выборочное среднее СРЗНАЧ(число1,число2,…), а n — размер выборки.
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Расчет дисперсии в Microsoft Excel
В статистике используется огромное количество показателей, и один из них — расчет дисперсии в Excel. Если это делать самому вручную, уйдет очень много времени, можно допустить уйму ошибок. Сегодня мы рассмотрим, как разложить математические формулы на простые функции. Давайте разберем несколько самых простых, быстрых и удобных способов расчёта, которые позволят все сделать в считанные минуты.
Вычисляем дисперсию
Дисперсией случайной величины называется математическое ожидание квадрата отклонения случайной величины от ее математического ожидания.
Рассчитываем по генеральной совокупности
Чтобы вычислить мат. ожидание в программе будет применяться функция ДИСП.Г, а ее синтаксис выглядит следующим образом «=ДИСП.Г(Число1;Число2;…)».
Возможно применить максимум 255 аргументов, не более. Аргументами могут быть простые числа или ссылки на ячейки, в которых они указаны. Давайте рассмотрим, как посчитать дисперсию в Microsoft Excel:
1. Первым делом следует выделить ячейку, где будет отображаться итог вычислений, а далее кликнуть по кнопке «Вставить функцию».

2. Откроется оболочка управления функциями. Там нужно искать функцию «ДИСП.Г», которая может быть в категории «Статистические» или «Полный алфавитный перечень». Когда она будет найдена, следует выделить ее и кликнуть «ОК».

3. Запустится окно с аргументами функции. В нем нужно выделить строку «Число 1» и на листе выделить диапазон ячеек с числовым рядом.

4. После этого в ячейке, куда была введена функция будут выведены результаты расчетов.
Вот так несложно можно найти дисперсию в Excel.
Производим расчет по выборке
В данном случае выборочная дисперсия в Excel высчитывается с указанием в знаменателе не общего количества чисел, а на одно меньше. Это делается для более меньшей погрешности при помощи специальной функции ДИСП.В, синтаксис которой =ДИСП.В(Число1;Число2;…). Алгоритм действий:
- Как и в предыдущем методе нужно выделить ячейку для результата.
- В мастере функции следует найти «ДИСП.В» в категории «Полный алфавитный перечень» или «Статистические».

- Далее появится окно, и действовать следует также, как и в предыдущем методе.
Видео: Расчет дисперсии в Excel
Заключение
Дисперсия в Excel вычисляется очень просто, намного быстрее и удобнее, чем делать это вручную, ведь функция математическое ожидание довольно сложная и на ее вычисление может уйти много времени и сил.
Блог о программе Microsoft Excel: приемы, хитрости, секреты, трюки
Как расчитать дисперсию в Excel с помощью функции ДИСП.В

Дисперсия — это мера рассеяния, описывающая сравнительное отклонение между значениями данных и средней величиной. Является наиболее используемой мерой рассеяния в статистике, вычисляемая путем суммирования, возведенного в квадрат, отклонения каждого значения данных от средней величины. Формула для вычисления дисперсии представлена ниже:
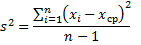
s 2 – дисперсия выборки;
xср — среднее значение выборки;
n — размер выборки (количество значений данных),
(xi – xср) — отклонение от средней величины для каждого значения набора данных.
Для лучшего понимания формулы, разберем пример. Я не очень люблю готовку, поэтому занятием этим занимаюсь крайне редко. Тем не менее, чтобы не умереть с голоду, время от времени мне приходится подходить к плите для реализации замысла по насыщению моего организма белками, жирами и углеводами. Набор данных, редставленный ниже, показывает, сколько раз Ренат готовит пищу каждый месяц:

Первым шагом при вычислении дисперсии является определение среднего значения выборки, которое в нашем примере равняется 7,8 раза в месяц. Остальные вычисления можно облегчить с помощью следующей таблицы.
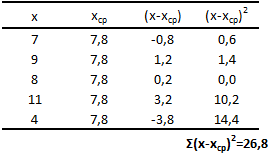
Финальная фаза вычисления дисперсии выглядит так:
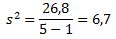
Для тех, кто любит производить все вычисления за один раз, уравнение будет выглядеть следующим образом:
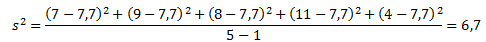
Использование метода «сырого счета» (пример с готовкой)
Существует более эффективный способ вычисления дисперсии, известный как метод «сырого счета». Хотя с первого взгляда уравнение может показаться весьма громоздким, на самом деле оно не такое уж страшное. Можете в этом удостовериться, а потом и решите, какой метод вам больше нравится.
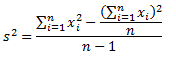
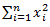 — сумма каждого значения данных после возведения в квадрат,
— сумма каждого значения данных после возведения в квадрат,
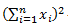 — квадрат суммы всех значений данных.
— квадрат суммы всех значений данных.
Не теряйте рассудок прямо сейчас. Позвольте представить все это в виде таблицы, и тогда вы увидите, что вычислений здесь меньше, чем в предыдущем примере.
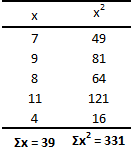
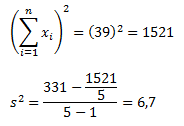
Как видите, результат получился тот же, что и при использовании предыдущего метода. Достоинства данного метода становятся очевидными по мере роста размера выборки (n).
Расчет дисперсии в Excel
Как вы уже, наверное, догадались, в Excel присутствует формула, позволяющая рассчитать дисперсию. Причем, начиная с Excel 2010 можно найти 4 разновидности формулы дисперсии:
1) ДИСП.В – Возвращает дисперсию по выборке. Логические значения и текст игнорируются.
2) ДИСП.Г — Возвращает дисперсию по генеральной совокупности. Логические значения и текст игнорируются.
3) ДИСПА — Возвращает дисперсию по выборке с учетом логических и текстовых значений.
4) ДИСПРА — Возвращает дисперсию по генеральной совокупности с учетом логических и текстовых значений.
Для начала разберемся в разнице между выборкой и генеральной совокупностью. Назначение описательной статистики состоит в том, чтобы суммировать или отображать данные так, чтобы оперативно получать общую картину, так сказать, обзор. Статистический вывод позволяет делать умозаключения о какой-либо совокупности на основе выборки данных из этой совокупности. Совокупность представляет собой все возможные исходы или измерения, представляющие для нас интерес. Выборка — это подмножество совокупности.
Например, нас интересует совокупность группы студентов одного из Российских ВУЗов и нам необходимо определить средний бал группы. Мы можем посчитать среднюю успеваемость студентов, и тогда полученная цифра будет параметром, поскольку в наших расчетах будет задействована целая совокупность. Однако, если мы хотим рассчитать средний бал всех студентов нашей страны, тогда эта группа будет нашей выборкой.
Разница в формуле расчета дисперсии между выборкой и совокупностью заключается в знаменателе. Где для выборки он будет равняться (n-1), а для генеральной совокупности только n.
Теперь разберемся с функциями расчета дисперсии с окончаниями А, в описании которых сказано, что при расчете учитываются текстовые и логические значения. В данном случае при расчете дисперсии определенного массива данных, где встречаются не числовые значения, Excel будет интерпретировать текстовые и ложные логические значения как равными 0, а истинные логические значения как равными 1.
Итак, если у вас есть массив данных, рассчитать его дисперсию ни составит никакого труда, воспользовавшись одной из перечисленных выше функций Excel.
Как в excel посчитать дисперсию
Цель данной статьи показать, как математические формулы, с которыми вы можете столкнуться в книгах и статьях, разложить на элементарные функции в Excel.
В данной статье мы разберем формулы среднеквадратического отклонения и дисперсии и рассчитаем их в Excel.
Перед тем как переходить к расчету среднеквадратического отклонения и разбирать формулу, желательно разобраться в элементарных статистических показателях и обозначениях.
Рассматривая формулы моделей прогнозирования, мы встретимся со следующими показателями:

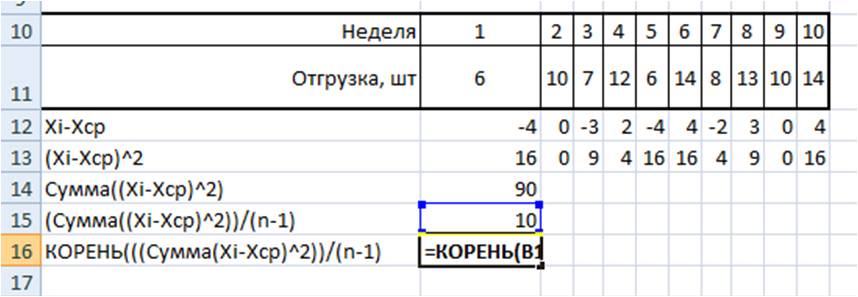
Например, у нас есть временной ряд — продажи по неделям в шт.
Для этого временного ряда i=1, n=10 , 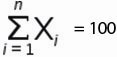 ,
, 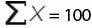
Рассмотрим формулу среднего значения:
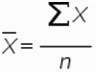
Для нашего временного ряда определим среднее значение 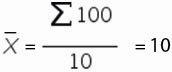
Также для выявления тенденций помимо среднего значения представляет интерес и то, насколько наблюдения разбросаны относительно среднего. Среднеквадратическое отклонение показывает меру отклонения наблюдений относительно среднего.
Формула расчета среднеквадратического отклонение для выборки следующая:
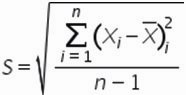
Разложим формулу на составные части и рассчитаем среднеквадратическое отклонение в Excel на примере нашего временного ряда.
1. Рассчитаем среднее значение для этого воспользуемся формулой Excel =СРЗНАЧ(B11:K11)
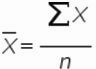 = СРЗНАЧ(ссылка на диапазон) = 100/10=10
= СРЗНАЧ(ссылка на диапазон) = 100/10=10

2. Определим отклонение каждого значения ряда относительно среднего 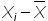

для первой недели = 6-10=-4
для второй недели = 10-10=0
для третей = 7-1=-3 и т.д.
3. Для каждого значения ряда определим квадрат разницы отклонения значений ряда относительно среднего 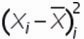
для первой недели = (-4)^2=16
для второй недели = 0^2=0
для третей = (-3)^2=9 и т.д.
4. Рассчитаем сумму квадратов отклонений значений относительно среднего  с помощью формулы =СУММ(ссылка на диапазон (ссылка на диапазон с )
с помощью формулы =СУММ(ссылка на диапазон (ссылка на диапазон с )

=16+0+9+4+16+16+4+9+0+16=90
5. 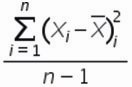 , для этого сумму квадратов отклонений значений относительно среднего разделим на количество значений минус единица (Сумма((Xi-Xср)^2))/(n-1)
, для этого сумму квадратов отклонений значений относительно среднего разделим на количество значений минус единица (Сумма((Xi-Xср)^2))/(n-1)

= 90/(10-1)=10
6. Среднеквадратическое отклонение равно = корень(10)=3,2
Итак, в 6 шагов мы разложили сложную математическую формулу, надеюсь вам удалось разобраться со всеми частями формулы и вы сможете самостоятельно разобраться в других формулах.
Рассмотрим еще один показатель, который в будущем нам понадобятся — дисперсия.
Как рассчитать дисперсию в Excel?
Дисперсия — квадрат среднеквадратического отклонения и отражает разброс данных относительно среднего.
Рассчитаем дисперсию: 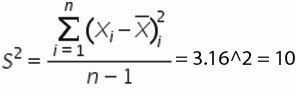

Итак, теперь мы умеем рассчитывать среднеквадратическое отклонение и дисперсию в Excel. Надеемся, полученные знания пригодятся вам в работе.
Точных вам прогнозов!
Присоединяйтесь к нам!
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа:

- Novo Forecast Lite — автоматический расчет прогноза в Excel .
- 4analytics — ABC-XYZ-анализ и анализ выбросов в Excel.
- Qlik Sense Desktop и QlikView Personal Edition — BI-системы для анализа и визуализации данных.
Тестируйте возможности платных решений:
- Novo Forecast PRO — прогнозирование в Excel для больших массивов данных.
Получите 10 рекомендаций по повышению точности прогнозов до 90% и выше.
Содержание
- Использование описательной статистики
- Подключение «Пакета анализа»
- Размах вариации
- Вычисление коэффициента вариации
- Шаг 1: расчет стандартного отклонения
- Шаг 2: расчет среднего арифметического
- Шаг 3: нахождение коэффициента вариации
- Простая формула для расчета объема выборки
- Пример расчета объема выборки
- Задачи о генеральной доле
- По части судить о целом
- Как рассчитать объем выборки
- Как определить статистические выбросы и сделать выборку для их удаления в Excel
- Способ 1: применение расширенного автофильтра
- Способ 2: применение формулы массива
- СРЗНАЧ()
- СРЗНАЧЕСЛИ()
- МАКС()
- МИН()
Использование описательной статистики
Под описательной статистикой понимают систематизацию эмпирических данных по целому ряду основных статистических критериев. Причем на основе полученного результата из этих итоговых показателей можно сформировать общие выводы об изучаемом массиве данных.
В Экселе существует отдельный инструмент, входящий в «Пакет анализа», с помощью которого можно провести данный вид обработки данных. Он так и называется «Описательная статистика». Среди критериев, которые высчитывает данный инструмент следующие показатели:
- Медиана;
- Мода;
- Дисперсия;
- Среднее;
- Стандартное отклонение;
- Стандартная ошибка;
- Асимметричность и др.
Рассмотрим, как работает данный инструмент на примере Excel 2010, хотя данный алгоритм применим также в Excel 2007 и в более поздних версиях данной программы.
Подключение «Пакета анализа»
Как уже было сказано выше, инструмент «Описательная статистика» входит в более широкий набор функций, который принято называть Пакет анализа. Но дело в том, что по умолчанию данная надстройка в Экселе отключена. Поэтому, если вы до сих пор её не включили, то для использования возможностей описательной статистики, придется это сделать.
- Переходим во вкладку «Файл». Далее производим перемещение в пункт «Параметры».
- В активировавшемся окне параметров перемещаемся в подраздел «Надстройки». В самой нижней части окна находится поле «Управление». Нужно в нем переставить переключатель в позицию «Надстройки Excel», если он находится в другом положении. Вслед за этим жмем на кнопку «Перейти…».
- Запускается окно стандартных надстроек Excel. Около наименования «Пакет анализа» ставим флажок. Затем жмем на кнопку «OK».



После вышеуказанных действий надстройка Пакет анализа будет активирована и станет доступной во вкладке «Данные» Эксель. Теперь мы сможем использовать на практике инструменты описательной статистики.
Размах вариации
Размах вариации – разница между максимальным и минимальным значением:
![]()
Ниже приведена графическая интерпретация размаха вариации.

Видно максимальное и минимальное значение, а также расстояние между ними, которое и соответствует размаху вариации.
С одной стороны, показатель размаха может быть вполне информативным и полезным. К примеру, максимальная и минимальная стоимость квартиры в городе N, максимальная и минимальная зарплата по профессии в регионе и проч. С другой стороны, размах может быть очень широким и не иметь практического смысла, т.к. зависит лишь от двух наблюдений. Таким образом, размах вариации очень неустойчивая величина.
Вычисление коэффициента вариации
Этот показатель представляет собой отношение стандартного отклонения к среднему арифметическому. Полученный результат выражается в процентах.
В Экселе не существует отдельно функции для вычисления этого показателя, но имеются формулы для расчета стандартного отклонения и среднего арифметического ряда чисел, а именно они используются для нахождения коэффициента вариации.
Шаг 1: расчет стандартного отклонения
Стандартное отклонение, или, как его называют по-другому, среднеквадратичное отклонение, представляет собой квадратный корень из дисперсии. Для расчета стандартного отклонения используется функция СТАНДОТКЛОН. Начиная с версии Excel 2010 она разделена, в зависимости от того, по генеральной совокупности происходит вычисление или по выборке, на два отдельных варианта: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В.
Синтаксис данных функций выглядит соответствующим образом:
= СТАНДОТКЛОН(Число1;Число2;…)
= СТАНДОТКЛОН.Г(Число1;Число2;…)
= СТАНДОТКЛОН.В(Число1;Число2;…)
- Для того, чтобы рассчитать стандартное отклонение, выделяем любую свободную ячейку на листе, которая удобна вам для того, чтобы выводить в неё результаты расчетов. Щелкаем по кнопке «Вставить функцию». Она имеет внешний вид пиктограммы и расположена слева от строки формул.

Выполняется активация Мастера функций, который запускается в виде отдельного окна с перечнем аргументов. Переходим в категорию «Статистические» или «Полный алфавитный перечень». Выбираем наименование «СТАНДОТКЛОН.Г» или «СТАНДОТКЛОН.В», в зависимости от того, по генеральной совокупности или по выборке следует произвести расчет. Жмем на кнопку «OK».

Открывается окно аргументов данной функции. Оно может иметь от 1 до 255 полей, в которых могут содержаться, как конкретные числа, так и ссылки на ячейки или диапазоны. Ставим курсор в поле «Число1». Мышью выделяем на листе тот диапазон значений, который нужно обработать. Если таких областей несколько и они не смежные между собой, то координаты следующей указываем в поле «Число2» и т.д. Когда все нужные данные введены, жмем на кнопку «OK»


Шаг 2: расчет среднего арифметического
Среднее арифметическое является отношением общей суммы всех значений числового ряда к их количеству. Для расчета этого показателя тоже существует отдельная функция – СРЗНАЧ. Вычислим её значение на конкретном примере.
- Выделяем на листе ячейку для вывода результата. Жмем на уже знакомую нам кнопку «Вставить функцию».

В статистической категории Мастера функций ищем наименование «СРЗНАЧ». После его выделения жмем на кнопку «OK».

Запускается окно аргументов СРЗНАЧ. Аргументы полностью идентичны тем, что и у операторов группы СТАНДОТКЛОН. То есть, в их качестве могут выступать как отдельные числовые величины, так и ссылки. Устанавливаем курсор в поле «Число1». Так же, как и в предыдущем случае, выделяем на листе нужную нам совокупность ячеек. После того, как их координаты были занесены в поле окна аргументов, жмем на кнопку «OK».


Шаг 3: нахождение коэффициента вариации
Теперь у нас имеются все необходимые данные для того, чтобы непосредственно рассчитать сам коэффициент вариации.
- Выделяем ячейку, в которую будет выводиться результат. Прежде всего, нужно учесть, что коэффициент вариации является процентным значением. В связи с этим следует поменять формат ячейки на соответствующий. Это можно сделать после её выделения, находясь во вкладке «Главная». Кликаем по полю формата на ленте в блоке инструментов «Число». Из раскрывшегося списка вариантов выбираем «Процентный». После этих действий формат у элемента будет соответствующий.

Снова возвращаемся к ячейке для вывода результата. Активируем её двойным щелчком левой кнопки мыши. Ставим в ней знак «=». Выделяем элемент, в котором расположен итог вычисления стандартного отклонения. Кликаем по кнопке «разделить» (/) на клавиатуре. Далее выделяем ячейку, в которой располагается среднее арифметическое заданного числового ряда. Для того, чтобы произвести расчет и вывести значение, щёлкаем по кнопке Enter на клавиатуре.


Таким образом мы произвели вычисление коэффициента вариации, ссылаясь на ячейки, в которых уже были рассчитаны стандартное отклонение и среднее арифметическое. Но можно поступить и несколько по-иному, не рассчитывая отдельно данные значения.
- Выделяем предварительно отформатированную под процентный формат ячейку, в которой будет выведен результат. Прописываем в ней формулу по типу:
Вместо наименования «Диапазон значений» вставляем реальные координаты области, в которой размещен исследуемый числовой ряд. Это можно сделать простым выделением данного диапазона. Вместо оператора СТАНДОТКЛОН.В, если пользователь считает нужным, можно применять функцию СТАНДОТКЛОН.Г.


Существует условное разграничение. Считается, что если показатель коэффициента вариации менее 33%, то совокупность чисел однородная. В обратном случае её принято характеризовать, как неоднородную.
Как видим, программа Эксель позволяет значительно упростить расчет такого сложного статистического вычисления, как поиск коэффициента вариации. К сожалению, в приложении пока не существует функции, которая высчитывала бы этот показатель в одно действие, но при помощи операторов СТАНДОТКЛОН и СРЗНАЧ эта задача очень упрощается. Таким образом, в Excel её может выполнить даже человек, который не имеет высокого уровня знаний связанных со статистическими закономерностями.
Разделы: Математика
- Совершенствование умений и навыков нахождения статистических характеристик случайной величины, работа с расчетами в Excel;
- применение информационно коммутативных технологий для анализа данных; работа с различными информационными носителями.
- Сегодня мы научимся рассчитывать статистические характеристики для больших по объему выборок, используя возможности современных компьютерных технологий.
- Для начала вспомним:
– что называется случайной величиной? (Случайной величиной называют переменную величину, которая в зависимости от исхода испытания принимает одно значение из множества возможных значений.)
– Какие виды случайных величин мы знаем? (Дискретные, непрерывные.)
– Приведите примеры непрерывных случайных величин (рост дерева), дискретных случайных величин (количество учеников в классе).
– Какие статистические характеристики случайных величин мы знаем (мода, медиана, среднее выборочное значение, размах ряда).
– Какие приемы используются для наглядного представления статистических характеристик случайной величины (полигон частот, круговые и столбчатые диаграммы, гистограммы).
- Рассмотрим, применение инструментов Excel для решения статистических задач на конкретном примере.
Пример. Проведена проверка в 100 компаниях. Даны значения количества работающих в компании (чел.):
| 23 25 24 25 30 24 30 26 28 26 32 33 31 31 25 33 25 29 30 28 23 30 29 24 33 30 30 28 26 25 26 29 27 29 26 28 27 26 29 28 29 30 27 30 28 32 28 26 30 26 31 27 30 27 33 28 26 30 31 29 27 30 30 29 27 26 28 31 29 28 33 27 30 33 26 31 34 28 32 22 29 30 27 29 34 29 32 29 29 30 29 29 36 29 29 34 23 28 24 28 |
рассчитать числовые характеристики:
|
1. Занести данные в EXCEL, каждое число в отдельную ячейку.
| 23 | 25 | 24 | 25 | 30 | 24 | 30 | 26 | 28 | 26 |
| 32 | 33 | 31 | 31 | 25 | 33 | 25 | 29 | 30 | 28 |
| 23 | 30 | 29 | 24 | 33 | 30 | 30 | 28 | 26 | 25 |
| 26 | 29 | 27 | 29 | 26 | 28 | 27 | 26 | 29 | 28 |
| 29 | 30 | 27 | 30 | 28 | 32 | 28 | 26 | 30 | 26 |
| 31 | 27 | 30 | 27 | 33 | 28 | 26 | 30 | 31 | 29 |
| 27 | 30 | 30 | 29 | 27 | 26 | 28 | 31 | 29 | 28 |
| 33 | 27 | 30 | 33 | 26 | 31 | 34 | 28 | 32 | 22 |
| 29 | 30 | 27 | 29 | 34 | 29 | 32 | 29 | 29 | 30 |
| 29 | 29 | 36 | 29 | 29 | 34 | 23 | 28 | 24 | 28 |
2. Для расчета числовых характеристик используем опцию Вставка – Функция. И в появившемся окне в строке категория выберем – статистические, в списке: МОДА

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили Мо = 29 (чел) – Фирм у которых в штате 29 человек больше всего.
Используя тот же путь вычисляем медиану.
Вставка – Функция – Статистические – Медиана.

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили Ме = 29 (чел) – среднее значение сотрудников в фирме.
Размах ряда чисел – разница между наименьшим и наибольшим возможным значением случайной величины. Для вычисления размаха ряда нужно найти наибольшее и наименьшее значения нашей выборки и вычислить их разность.
Вставка – Функция – Статистические – МАКС.

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили наибольшее значение = 36.
Вставка – Функция – Статистические – МИН.

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили наименьшее значение = 22.
36 – 22 = 14 (чел) – разница между фирмой с наибольшим штатом сотрудников и фирмой с наименьшим штатом сотрудников.
Для построения диаграммы и полигона частот необходимо задать закон распределения, т.е. составить таблицу значений случайной величины и соответствующих им частот. Мы ухе знаем, что наименьшее число сотрудников в фирме = 22, а наибольшее = 36. Составим таблицу, в которой значения xi случайной величины меняются от 22 до 36 включительно шагом 1.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni |
Чтобы сосчитать частоту каждого значения воспользуемся
Вставка – Функция – Статистические – СЧЕТЕСЛИ.
В окне Диапазон ставим курсор и выделяем нашу выборку, а в окне Критерий ставим число 22

Нажимаем клавишу ОК, получаем значение 1, т.е. число 22 в нашей выборке встречается 1 раз и его частота =1. Аналогичным образом заполняем всю таблицу.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni | 1 | 3 | 4 | 5 | 11 | 9 | 13 | 18 | 16 | 6 | 4 | 6 | 3 | 0 | 1 |
Для проверки вычисляем объем выборки, сумму частот (Вставка – Функция – Математические – СУММА). Должно получиться 100 (количество всех фирм).
Чтобы построить полигон частот выделяем таблицу – Вставка – Диаграмма – Стандартные – Точечная (точечная диаграмма на которой значения соединены отрезками)

Нажимаем клавишу Далее, в Мастере диаграмм указываем название диаграммы (Полигон частот), удаляем легенду, редактируем шкалу и характеристики диаграммы для наибольшей наглядности.


Для построения столбчатой и круговой диаграмм используем тот же путь (выбирая нужный нам тип диаграммы).
Диаграмма – Стандартные – Круговая.

Диаграмма – Стандартные – Гистограмма.

4. Сегодня на уроке мы научились применять компьютерные технологии для анализа и обработки статистической информации.
Простая формула для расчета объема выборки

где: n – объем выборки;
z – нормированное отклонение, определяемое исходя из выбранного уровня доверительности. Этот показатель характеризует возможность, вероятность попадания ответов в специальный – доверительный интервал. На практике уровень доверительности часто принимают за 95% или 99%. Тогда значения z будут соответственно 1,96 и 2,58;
p – вариация для выборки, в долях. По сути, p – это вероятность того, что респонденты выберут той или иной вариант ответа. Допустим, если мы считаем, что четверть опрашиваемых выберут ответ «Да», то p будет равно 25%, то есть p = 0,25;
q = (1 – p);
e – допустимая ошибка, в долях.
Пример расчета объема выборки
Компания планирует провести социологическое исследование с целью выявить долю курящих лиц в населении города. Для этого сотрудники компании будут задавать прохожим один вопрос: «Вы курите?». Возможных вариантов ответа, таким образом, только два: «Да» и «Нет».
Объем выборки в этом случае рассчитывается следующим образом. Уровень доверительности принимается за 95%, тогда нормированное отклонение z = 1,96. Вариацию принимаем за 50%, то есть условно считаем, что половина респондентов может ответить на вопрос о том, курят ли они – «Да». Тогда p = 0,5. Отсюда находим q = 1 – p = 1 – 0,5 = 0,5. Допустимую ошибку выборки принимаем за 10%, то есть e = 0,1.
Подставляем эти данные в формулу и считаем:

Получаем объем выборки n = 96 человек.
Задачи о генеральной доле
На вопрос «Накрывает ли доверительный интервал заданное значение p0?» — можно ответить, проверив статистическую гипотезу H0:p=p0. При этом предполагается, что опыты проводятся по схеме испытаний Бернулли (независимы, вероятность p появления события А постоянна). По выборке объема n определяют относительную частоту p* появления события A:![]() где m — количество появлений события А в серии из n испытаний. Для проверки гипотезы H0 используется статистика, имеющая при достаточно большом объеме выборки стандартное нормальное распределение (табл. 1).
где m — количество появлений события А в серии из n испытаний. Для проверки гипотезы H0 используется статистика, имеющая при достаточно большом объеме выборки стандартное нормальное распределение (табл. 1).
Таблица 1 – Гипотезы о генеральной доле
|
Гипотеза |
H0:p=p0 | H0:p1=p2 |
| Предположения | Схема испытаний Бернулли | Схема испытаний Бернулли |
| Оценки по выборке |  |
|
| Статистика K |  |
 |
| Распределение статистики K | Стандартное нормальное N(0,1) | Стандартное нормальное N(0,1) |
Пример №1. С помощью случайного повторного отбора руководство фирмы провело выборочный опрос 900 своих служащих. Среди опрошенных оказалось 270 женщин. Постройте доверительный интервал, с вероятностью 0.95 накрывающий истинную долю женщин во всем коллективе фирмы.
Решение. По условию выборочная доля женщин составляет ![]() (относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
(относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле ![]() (относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
(относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
Значение uкр находим по таблице функции Лапласа из соотношения 2Ф(uкр)=γ, т.е. ![]() Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка
Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка ![]() Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка и искомый доверительный интервал
Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка и искомый доверительный интервал
(p – ε, p + ε) = (0.3 – 0.18; 0.3 + 0.18) = (0.12; 0.48)
Итак, с вероятностью 0.95 можно гарантировать, что доля женщин во всем коллективе фирмы находится в интервале от 0.12 до 0.48.
Пример №2. Владелец автостоянки считает день «удачным», если автостоянка заполнена более, чем на 80 %. В течение года было проведено 40 проверок автостоянки, из которых 24 оказались «удачными». С вероятностью 0.98 найдите доверительный интервал для оценки истинной доли «удачных» дней в течение года.
Решение. Выборочная доля «удачных» дней составляет ![]()
По таблице функции Лапласа найдем значение uкр при заданной
доверительной вероятности ![]()
По таблице функции Лапласа найдем значение uкр при заданной
доверительной вероятности
Ф(2.23) = 0.49, uкр = 2.33.
Считая отбор бесповторным (т.е. две проверки в один день не проводилось), найдем предельную ошибку: ![]()
где n=40, N = 365 (дней). Отсюда ![]()
где n=40, N = 365 (дней). Отсюда
и доверительный интервал для генеральной доли: (p – ε, p + ε) = (0.6 – 0.17; 0.6 + 0.17) = (0.43; 0.77)
С вероятностью 0.98 можно ожидать, что доля «удачных» дней в течение года находится в интервале от 0.43 до 0.77.
Пример №3. Проверив 2500 изделий в партии, обнаружили, что 400 изделий высшего сорта, а n–m – нет. Сколько надо проверить изделий, чтобы с уверенностью 95% определить долю высшего сорта с точностью до 0.01?
Решение ищем по формуле определения численности выборки для повторного отбора.
Ф(t) = γ/2 = 0.95/2 = 0.475 и этому значению по таблице Лапласа соответствует t=1.96
Выборочная доля w = 0.16; ошибка выборки ε = 0.01
Пример №4. Партия изделий принимается, если вероятность того, что изделие окажется соответствующим стандарту, составляет не менее 0.97. Среди случайно отобранных 200 изделий проверяемой партии оказалось 193 соответствующих стандарту. Можно ли на уровне значимости α=0,02 принять партию?
Решение. Сформулируем основную и альтернативную гипотезы.
H0:p=p0=0,97 — неизвестная генеральная доля p равна заданному значению p0=0,97. Применительно к условию — вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, равна 0.97; т.е. партию изделий можно принять.
H1:p<0,97 – вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Наблюдаемое значение статистики K (таблица) вычислим при заданных значениях p0=0,97, n=200, m=193

Критическое значение находим по таблице функции Лапласа из равенства
![]()
По условию α=0,02 отсюда Ф(Ккр)=0,48 и Ккр=2,05. Критическая область левосторонняя, т.е. является интервалом (-∞;-Kkp)= (-∞;-2,05). Наблюдаемое значение Кнабл=-0,415 не принадлежит критической области, следовательно, на данном уровне значимости нет оснований отклонять основную гипотезу. Партию изделий принять можно.
Пример №5. Два завода изготавливают однотипные детали. Для оценки их качества сделаны выборки из продукции этих заводов и получены следующие результаты. Среди 200 отобранных изделий первого завода оказалось 20 бракованных, среди 300 изделий второго завода — 15 бракованных.
На уровне значимости 0.025 выяснить, имеется ли существенное различие в качестве изготавливаемых этими заводами деталей.
Решение. Это задача о сравнении генеральных долей двух совокупностей. Сформулируем основную и альтернативную гипотезы.
H0:p1=p2 — генеральные доли равны. Применительно к условию — вероятность появления бракованного изделия в продукции первого завода равна вероятности появления бракованного изделия в продукции второго завода (качество продукции одинаково).
H0:p1≠p2 — заводы изготавливают детали разного качества.
Для вычисления наблюдаемого значения статистики K (таблица) рассчитаем оценки по выборке.
![]()
![]()
Наблюдаемое значение равно

Так как альтернативная гипотеза двусторонняя, то критическое значение статистики K≈ N(0,1) находим по таблице функции Лапласа из равенства ![]()
Так как альтернативная гипотеза двусторонняя, то критическое значение статистики K≈ N(0,1) находим по таблице функции Лапласа из равенства
По условию α=0,025 отсюда Ф(Ккр)=0,4875 и Ккр=2,24. При двусторонней альтернативе область допустимых значений имеет вид (-2,24;2,24). Наблюдаемое значение Kнабл=2,15 попадает в этот интервал, т.е. на данном уровне значимости нет оснований отвергать основную гипотезу. Заводы изготавливают изделия одинакового качества.
По части судить о целом
О возможности судить о целом по части миру рассказал российский математик П.Л. Чебышев. «Закон больших чисел» простым языком можно сформулировать так: количественные закономерности массовых явлений проявляются только при
достаточном числе наблюдений
. Чем больше выборка, тем лучше случайные отклонения компенсируют друг друга и проявляется общая тенденция.
А.М. Ляпунов чуть позже сформулировал центральную предельную теорему. Она стала фундаментом для создания формул, которые позволяют рассчитать вероятность ошибки (при оценке среднего по выборке) и размер выборки, необходимый для достижения заданной точности.
Строгие формулировки:
С увеличением числа случайных величин их среднее арифметическое стремится к среднему арифметическому математических ожиданий и перестает быть случайным. Общий смысл закона больших чисел — совместное действие большого числа случайных факторов приводит к результату, почти не зависящему от случая.
Таким образом з.б.ч. гарантирует устойчивость для средних значений некоторых случайных событий при достаточно длинной серии экспериментов.
Распределение случайной величины, которая получена в результате сложения большого числа независимых случайных величин (ни одно из которых не доминирует, не вносит в сумму определяющего вклада и имеет дисперсию значительно меньшею по сравнению с дисперсией суммы) имеет распределение, близкое к нормальному.
Из ц.п.т. следует, что ошибки выборки также подчиняется нормальному распределению.
Еще раз: чтобы корректно оценивать популяцию по выборке, нам нужна не обычная выборка, а репрезентативная выборка достаточного размера. Начнем с определения этого самого размера.
Как рассчитать объем выборки
Достаточный размер выборки зависит от следующих составляющих:
- изменчивость признака (чем разнообразней показания, тем больше наблюдений нужно, чтобы это уловить);
- размер эффекта (чем меньшие эффекты мы стремимся зафиксировать, тем больше наблюдений необходимо);
- уровень доверия (уровень вероятности при который мы готовы отвергнуть нулевую гипотезу)
ЗАПОМНИТЕ
Объем выборки зависит от изменчивости признака и планируемой строгости эксперимента
Формулы для расчета объема выборки:

Формулы расчета объема выборки
Ошибка выборки значительно возрастает, когда наблюдений меньше ста. Для исследований в которых используется 30-100 объектов применяется особая статистическая методология: критерии, основанные на распределении Стьюдента или бутстрэп-анализ. И наконец, статистика совсем слаба, когда наблюдений меньше 30.

График зависимости ошибки выборки от ее объема при оценке доли признака в г.с.
Чем больше неопределенность, тем больше ошибка. Максимальная неопределенность при оценке доли — 50% (например, 50% респондентов считают концепцию хорошей, а другие 50% плохой). Если 90% опрошенных концепция понравится — это, наоборот, пример согласованности. В таких случаях оценить долю признака по выборке проще.
Для экспонирования и выделения цветом значений статистических выбросов от медианы можно использовать несколько простых формул и условное форматирование.
Первым шагом в поиске значений выбросов статистики является определение статистического центра диапазона данных. С этой целью необходимо сначала определить границы первого и третьего квартала. Определение границ квартала – значит разделение данных на 4 равные группы, которые содержат по 25% данных каждая. Группа, содержащая 25% наибольших значений, называется первым квартилем.
Границы квартилей в Excel можно легко определить с помощью простой функции КВАРТИЛЬ. Данная функция имеет 2 аргумента: диапазон данных и номер для получения желаемого квартиля.
В примере показанному на рисунке ниже значения в ячейках E1 и E2 содержат показатели первого и третьего квартиля данных в диапазоне ячеек B2:B19:

Вычитая от значения первого квартиля третьего, можно определить набор 50% статистических данных, который называется межквартильным диапазоном. В ячейке E3 определен размер межквартильного диапазона.
В этом месте возникает вопрос, как сильно данное значение может отличаться от среднего значения 50% данных и оставаться все еще в пределах нормы? Статистические аналитики соглашаются с тем, что для определения нижней и верхней границы диапазона данных можно смело использовать коэффициент расширения 1,5 умножив на значение межквартильного диапазона. То есть:
- Нижняя граница диапазона данных равна: значение первого квартиля – межкваритльный диапазон * 1,5.
- Верхняя граница диапазона данных равна: значение третьего квартиля + расширенных диапазон * 1,5.
Как показано на рисунке ячейки E5 и E6 содержат вычисленные значения верхней и нижней границы диапазона данных. Каждое значение, которое больше верхней границы нормы или меньше нижней границы нормы считается значением статистического выброса.
Чтобы выделить цветом для улучшения визуального анализа данных можно создать простое правило для условного форматирования.
Способ 1: применение расширенного автофильтра
Наиболее простым способом произвести отбор является применение расширенного автофильтра. Рассмотрим, как это сделать на конкретном примере.
- Выделяем область на листе, среди данных которой нужно произвести выборку. Во вкладке «Главная» щелкаем по кнопке «Сортировка и фильтр». Она размещается в блоке настроек «Редактирование». В открывшемся после этого списка выполняем щелчок по кнопке «Фильтр».

Есть возможность поступить и по-другому. Для этого после выделения области на листе перемещаемся во вкладку «Данные». Щелкаем по кнопке «Фильтр», которая размещена на ленте в группе «Сортировка и фильтр».
- После этого действия в шапке таблицы появляются пиктограммы для запуска фильтрования в виде перевернутых острием вниз небольших треугольников на правом краю ячеек. Кликаем по данному значку в заглавии того столбца, по которому желаем произвести выборку. В запустившемся меню переходим по пункту «Текстовые фильтры». Далее выбираем позицию «Настраиваемый фильтр…».
- Активируется окно пользовательской фильтрации. В нем можно задать ограничение, по которому будет производиться отбор. В выпадающем списке для столбца содержащего ячейки числового формата, который мы используем для примера, можно выбрать одно из пяти видов условий:
- равно;
- не равно;
- больше;
- больше или равно;
- меньше.
Давайте в качестве примера зададим условие так, чтобы отобрать только значения, по которым сумма выручки превышает 10000 рублей. Устанавливаем переключатель в позицию «Больше». В правое поле вписываем значение «10000». Чтобы произвести выполнение действия, щелкаем по кнопке «OK».
- Как видим, после фильтрации остались только строчки, в которых сумма выручки превышает 10000 рублей.
- Но в этом же столбце мы можем добавить и второе условие. Для этого опять возвращаемся в окно пользовательской фильтрации. Как видим, в его нижней части есть ещё один переключатель условия и соответствующее ему поле для ввода. Давайте установим теперь верхнюю границу отбора в 15000 рублей. Для этого выставляем переключатель в позицию «Меньше», а в поле справа вписываем значение «15000».
Кроме того, существует ещё переключатель условий. У него два положения «И» и «ИЛИ». По умолчанию он установлен в первом положении. Это означает, что в выборке останутся только строчки, которые удовлетворяют обоим ограничениям. Если он будет выставлен в положение «ИЛИ», то тогда останутся значения, которые подходят под любое из двух условий. В нашем случае нужно выставить переключатель в положение «И», то есть, оставить данную настройку по умолчанию. После того, как все значения введены, щелкаем по кнопке «OK».
- Теперь в таблице остались только строчки, в которых сумма выручки не меньше 10000 рублей, но не превышает 15000 рублей.
- Аналогично можно настраивать фильтры и в других столбцах. При этом имеется возможность сохранять также фильтрацию и по предыдущим условиям, которые были заданы в колонках. Итак, посмотрим, как производится отбор с помощью фильтра для ячеек в формате даты. Кликаем по значку фильтрации в соответствующем столбце. Последовательно кликаем по пунктам списка «Фильтр по дате» и «Настраиваемый фильтр».
- Снова запускается окно пользовательского автофильтра. Выполним отбор результатов в таблице с 4 по 6 мая 2016 года включительно. В переключателе выбора условий, как видим, ещё больше вариантов, чем для числового формата. Выбираем позицию «После или равно». В поле справа устанавливаем значение «04.05.2016». В нижнем блоке устанавливаем переключатель в позицию «До или равно». В правом поле вписываем значение «06.05.2016». Переключатель совместимости условий оставляем в положении по умолчанию – «И». Для того, чтобы применить фильтрацию в действии, жмем на кнопку «OK».
- Как видим, наш список ещё больше сократился. Теперь в нем оставлены только строчки, в которых сумма выручки варьируется от 10000 до 15000 рублей за период с 04.05 по 06.05.2016 включительно.
- Мы можем сбросить фильтрацию в одном из столбцов. Сделаем это для значений выручки. Кликаем по значку автофильтра в соответствующем столбце. В выпадающем списке щелкаем по пункту «Удалить фильтр».
- Как видим, после этих действий, выборка по сумме выручки будет отключена, а останется только отбор по датам (с 04.05.2016 по 06.05.2016).
- В данной таблице имеется ещё одна колонка – «Наименование». В ней содержатся данные в текстовом формате. Посмотрим, как сформировать выборку с помощью фильтрации по этим значениям.
Кликаем по значку фильтра в наименовании столбца. Последовательно переходим по наименованиям списка «Текстовые фильтры» и «Настраиваемый фильтр…».
- Опять открывается окно пользовательского автофильтра. Давайте сделаем выборку по наименованиям «Картофель» и «Мясо». В первом блоке переключатель условий устанавливаем в позицию «Равно». В поле справа от него вписываем слово «Картофель». Переключатель нижнего блока так же ставим в позицию «Равно». В поле напротив него делаем запись – «Мясо». И вот далее мы выполняем то, чего ранее не делали: устанавливаем переключатель совместимости условий в позицию «ИЛИ». Теперь строчка, содержащая любое из указанных условий, будет выводиться на экран. Щелкаем по кнопке «OK».
- Как видим, в новой выборке существуют ограничения по дате (с 04.05.2016 по 06.05.2016) и по наименованию (картофель и мясо). По сумме выручки ограничений нет.
- Полностью удалить фильтр можно теми же способами, которые использовались для его установки. Причем неважно, какой именно способ применялся. Для сброса фильтрации, находясь во вкладке «Данные» щелкаем по кнопке «Фильтр», которая размещена в группе «Сортировка и фильтр».

Второй вариант предполагает переход во вкладку «Главная». Там выполняем щелчок на ленте по кнопке «Сортировка и фильтр» в блоке «Редактирование». В активировавшемся списке нажимаем на кнопку «Фильтр».

















При использовании любого из двух вышеуказанных методов фильтрация будет удалена, а результаты выборки – очищены. То есть, в таблице будет показан весь массив данных, которыми она располагает.

Способ 2: применение формулы массива
Сделать отбор можно также применив сложную формулу массива. В отличие от предыдущего варианта, данный метод предусматривает вывод результата в отдельную таблицу.
- На том же листе создаем пустую таблицу с такими же наименованиями столбцов в шапке, что и у исходника.
- Выделяем все пустые ячейки первой колонки новой таблицы. Устанавливаем курсор в строку формул. Как раз сюда будет заноситься формула, производящая выборку по указанным критериям. Отберем строчки, сумма выручки в которых превышает 15000 рублей. В нашем конкретном примере, вводимая формула будет выглядеть следующим образом:
=ИНДЕКС(A2:A29;НАИМЕНЬШИЙ(ЕСЛИ(15000<=C2:C29;СТРОКА(C2:C29);"");СТРОКА()-СТРОКА($C$1))-СТРОКА($C$1))Естественно, в каждом конкретном случае адрес ячеек и диапазонов будет свой. На данном примере можно сопоставить формулу с координатами на иллюстрации и приспособить её для своих нужд.
- Так как это формула массива, то для того, чтобы применить её в действии, нужно нажимать не кнопку Enter, а сочетание клавиш Ctrl+Shift+Enter. Делаем это.
- Выделив второй столбец с датами и установив курсор в строку формул, вводим следующее выражение:
=ИНДЕКС(B2:B29;НАИМЕНЬШИЙ(ЕСЛИ(15000<=C2:C29;СТРОКА(C2:C29);"");СТРОКА()-СТРОКА($C$1))-СТРОКА($C$1))Жмем сочетание клавиш Ctrl+Shift+Enter.
- Аналогичным образом в столбец с выручкой вписываем формулу следующего содержания:
=ИНДЕКС(C2:C29;НАИМЕНЬШИЙ(ЕСЛИ(15000<=C2:C29;СТРОКА(C2:C29);"");СТРОКА()-СТРОКА($C$1))-СТРОКА($C$1))Опять набираем сочетание клавиш Ctrl+Shift+Enter.
Во всех трех случаях меняется только первое значение координат, а в остальном формулы полностью идентичны.
- Как видим, таблица заполнена данными, но внешний вид её не совсем привлекателен, к тому же, значения даты заполнены в ней некорректно. Нужно исправить эти недостатки. Некорректность даты связана с тем, что формат ячеек соответствующего столбца общий, а нам нужно установить формат даты. Выделяем весь столбец, включая ячейки с ошибками, и кликаем по выделению правой кнопкой мыши. В появившемся списке переходим по пункту «Формат ячейки…».
- В открывшемся окне форматирования открываем вкладку «Число». В блоке «Числовые форматы» выделяем значение «Дата». В правой части окна можно выбрать желаемый тип отображения даты. После того, как настройки выставлены, жмем на кнопку «OK».
- Теперь дата отображается корректно. Но, как видим, вся нижняя часть таблицы заполнена ячейками, которые содержат ошибочное значение «#ЧИСЛО!». По сути, это те ячейки, данных из выборки для которых не хватило. Более привлекательно было бы, если бы они отображались вообще пустыми. Для этих целей воспользуемся условным форматированием. Выделяем все ячейки таблицы, кроме шапки. Находясь во вкладке «Главная» кликаем по кнопке «Условное форматирование», которая находится в блоке инструментов «Стили». В появившемся списке выбираем пункт «Создать правило…».
- В открывшемся окне выбираем тип правила «Форматировать только ячейки, которые содержат». В первом поле под надписью «Форматировать только ячейки, для которых выполняется следующее условие» выбираем позицию «Ошибки». Далее жмем по кнопке «Формат…».
- В запустившемся окне форматирования переходим во вкладку «Шрифт» и в соответствующем поле выбираем белый цвет. После этих действий щелкаем по кнопке «OK».
- На кнопку с точно таким же названием жмем после возвращения в окно создания условий.











Теперь у нас имеется готовая выборка по указанному ограничению в отдельной надлежащим образом оформленной таблице.

СРЗНАЧ()
Статистическая функция СРЗНАЧ возвращает среднее арифметическое своих аргументов.

Данная функция может принимать до 255 аргументов и находить среднее сразу в нескольких несмежных диапазонах и ячейках:

Если в рассчитываемом диапазоне встречаются пустые или содержащие текст ячейки, то они игнорируются. В примере ниже среднее ищется по четырем ячейкам, т.е. (4+15+11+22)/4 = 13

Если необходимо вычислить среднее, учитывая все ячейки диапазона, то можно воспользоваться статистической функцией СРЗНАЧА. В следующем примере среднее ищется уже по 6 ячейкам, т.е. (4+15+11+22)/6 = 8,6(6).

Статистическая функция СРЗНАЧ может использовать в качестве своих аргументов математические операторы и различные функции Excel:

СРЗНАЧЕСЛИ()
Если необходимо вернуть среднее арифметическое значений, которые удовлетворяют определенному условию, то можно воспользоваться статистической функцией СРЗНАЧЕСЛИ. Следующая формула вычисляет среднее чисел, которые больше нуля:

В данном примере для подсчета среднего и проверки условия используется один и тот же диапазон, что не всегда удобно. На этот случай у функции СРЗНАЧЕСЛИ существует третий необязательный аргумент, по которому можно вычислять среднее. Т.е. по первому аргументу проверяем условие, по третьему – находим среднее.
Допустим, в таблице ниже собрана статистика по стоимости лекарств в городе. В одной аптеке лекарство стоит дороже, в другой дешевле. Чтобы посчитать стоимость анальгина в среднем по городу, воспользуемся следующей формулой:

Если требуется соблюсти несколько условий, то всегда можно применить статистическую функцию СРЗНАЧЕСЛИМН, которая позволяет считать среднее арифметическое ячеек, удовлетворяющих двум и более критериям.
МАКС()
Статистическая функция МАКС возвращает наибольшее значение в диапазоне ячеек:

МИН()
Статистическая функция МИН возвращает наименьшее значение в диапазоне ячеек:

Источники
- https://lumpics.ru/descriptive-statistics-in-excel/
- https://statanaliz.info/statistica/opisanie-dannyx/variatsiya-razmakh-srednee-linejnoe-otklonenie/
- https://www.hd01.ru/info/kak-poschitat-razmah-v-excel/
- http://galyautdinov.ru/post/formula-vyborki-prostaya
- https://math.semestr.ru/group/interval-estimation-share.php
- https://tidydata.ru/sample-size
- https://exceltable.com/formuly/raschet-statisticheskih-vybrosov
- https://lumpics.ru/how-to-make-a-sample-in-excel/
- https://office-guru.ru/excel/statisticheskie-funkcii-excel-kotorye-neobhodimo-znat-96.html
Variance is an important metric in statistics, and it can help you calculate like the risk of an investment. In this guide, we’re going to show you how to calculate variance in Excel.
Download Workbook
What is variance?
Variance is the average of the squared differences from the average or mean. You can calculate the variance of a data by taking the differences between each number in the data set and the average, then squaring the differences (which makes them positive), and finally dividing the sum of the squares by the number of values in the data set.
The formula is as follows:

- σ²: variance
- x: mean (average) of data
- x ̅: data
- n: data size
A large variance value shows that numbers are far from the mean and each other. A small one, on the other hand, means an opposite correlation. Zero variance means that all numbers in the data set are identical.
Sample variance
If the data set does not represent the entire population, but a number of items from it is sample variance. A common example for this is an election poll.
The formula of a sample variance is almost the same except for the data size. Instead of using exact an data size, use minus 1.

How to calculate variance in Excel
Although, you can calculate variance in Excel by creating the same formula as above, there are built in functions that can make this even easier. The following table shows the formulas and properties that distinguish them.
| Function | Variance type | Excel Version | Text and logical values |
| VAR.S | Sample | 2010 | Ignored |
| VARA | Sample | 2000 | Evaluated |
| VAR | Sample | 2000 | Ignored |
| VAR.P | Population | 2010 | Ignored |
| VARPA | Population | 2000 | Evaluated |
| VARP | Population | 2000 | Ignored |
Each function uses the same syntax. You can provide data as references or static values. Aside from the sample versus population choice, you need to decide whether you want text and logical values to be evaluated as numbers. VARA and VARPA functions evaluate text and FALSE logical value to zero (0) and TRUE to 1.
VAR.S(number1,[number2],…)
VARA(number1,[number2],…)
VAR(number1,[number2],…)
VAR.P(number1,[number2],…)
VARPA(number1,[number2],…)
VARP(number1,[number2],…)
The following example shows what each function returns for the same data set. The data set is at B5:B10 under the name “data”.

Please note that VAR and VARP functions have been updated with VAR.S and VAR.P functions in Excel 2010. Although Microsoft continues to support these functions for backwards compatibility, they encourage using VAR.S and VAR.P instead.
Дисперсия — это мера рассеяния, описывающая сравнительное отклонение между значениями данных и средней величиной. Является наиболее используемой мерой рассеяния в статистике, вычисляемая путем суммирования, возведенного в квадрат, отклонения каждого значения данных от средней величины. Формула для вычисления дисперсии представлена ниже:
![]()
где:
s2 – дисперсия выборки;
xср — среднее значение выборки;
n — размер выборки (количество значений данных),
(xi – xср) — отклонение от средней величины для каждого значения набора данных.
Для лучшего понимания формулы, разберем пример. Я не очень люблю готовку, поэтому занятием этим занимаюсь крайне редко. Тем не менее, чтобы не умереть с голоду, время от времени мне приходится подходить к плите для реализации замысла по насыщению моего организма белками, жирами и углеводами. Набор данных, редставленный ниже, показывает, сколько раз Ренат готовит пищу каждый месяц:
![]()
Первым шагом при вычислении дисперсии является определение среднего значения выборки, которое в нашем примере равняется 7,8 раза в месяц. Остальные вычисления можно облегчить с помощью следующей таблицы.
Финальная фаза вычисления дисперсии выглядит так:
![]()
Для тех, кто любит производить все вычисления за один раз, уравнение будет выглядеть следующим образом:
![]()
Использование метода «сырого счета» (пример с готовкой)
Существует более эффективный способ вычисления дисперсии, известный как метод «сырого счета». Хотя с первого взгляда уравнение может показаться весьма громоздким, на самом деле оно не такое уж страшное. Можете в этом удостовериться, а потом и решите, какой метод вам больше нравится.
где:
![]() — сумма каждого значения данных после возведения в квадрат,
— сумма каждого значения данных после возведения в квадрат,
![]() — квадрат суммы всех значений данных.
— квадрат суммы всех значений данных.
Не теряйте рассудок прямо сейчас. Позвольте представить все это в виде таблицы, и тогда вы увидите, что вычислений здесь меньше, чем в предыдущем примере.
Как видите, результат получился тот же, что и при использовании предыдущего метода. Достоинства данного метода становятся очевидными по мере роста размера выборки (n).
Как вы уже, наверное, догадались, в Excel присутствует формула, позволяющая рассчитать дисперсию. Причем, начиная с Excel 2010 можно найти 4 разновидности формулы дисперсии:
1) ДИСП.В – Возвращает дисперсию по выборке. Логические значения и текст игнорируются.
2) ДИСП.Г — Возвращает дисперсию по генеральной совокупности. Логические значения и текст игнорируются.
3) ДИСПА — Возвращает дисперсию по выборке с учетом логических и текстовых значений.
4) ДИСПРА — Возвращает дисперсию по генеральной совокупности с учетом логических и текстовых значений.
Для начала разберемся в разнице между выборкой и генеральной совокупностью. Назначение описательной статистики состоит в том, чтобы суммировать или отображать данные так, чтобы оперативно получать общую картину, так сказать, обзор. Статистический вывод позволяет делать умозаключения о какой-либо совокупности на основе выборки данных из этой совокупности. Совокупность представляет собой все возможные исходы или измерения, представляющие для нас интерес. Выборка — это подмножество совокупности.
Например, нас интересует совокупность группы студентов одного из Российских ВУЗов и нам необходимо определить средний бал группы. Мы можем посчитать среднюю успеваемость студентов, и тогда полученная цифра будет параметром, поскольку в наших расчетах будет задействована целая совокупность. Однако, если мы хотим рассчитать средний бал всех студентов нашей страны, тогда эта группа будет нашей выборкой.
Разница в формуле расчета дисперсии между выборкой и совокупностью заключается в знаменателе. Где для выборки он будет равняться (n-1), а для генеральной совокупности только n.
Теперь разберемся с функциями расчета дисперсии с окончаниями А, в описании которых сказано, что при расчете учитываются текстовые и логические значения. В данном случае при расчете дисперсии определенного массива данных, где встречаются не числовые значения, Excel будет интерпретировать текстовые и ложные логические значения как равными 0, а истинные логические значения как равными 1.
Итак, если у вас есть массив данных, рассчитать его дисперсию ни составит никакого труда, воспользовавшись одной из перечисленных выше функций Excel.
Содержание
- 1 Вычисление дисперсии
- 1.1 Способ 1: расчет по генеральной совокупности
- 1.2 Способ 2: расчет по выборке
- 1.3 Помогла ли вам эта статья?
- 2 Использование метода «сырого счета» (пример с готовкой)
- 3 Расчет дисперсии в Excel
- 4 Вычисляем дисперсию
- 4.1 Рассчитываем по генеральной совокупности
- 4.2 Производим расчет по выборке
- 4.3 Видео: Расчет дисперсии в Excel
- 5 Заключение
- 5.1 Это может быть интересно:
- 6 Как рассчитать дисперсию в Excel?
- 6.1 Присоединяйтесь к нам!
- 7 Расчет стандартного отклонения
- 8 Расчет среднего арифметического
- 9 Расчет коэффициента вариации
- 10 Среднеквадратическое отклонение
- 11 Коэффициент осциляции
- 12 Дисперсия
- 13 Максимум и минимум

Среди множества показателей, которые применяются в статистике, нужно выделить расчет дисперсии. Следует отметить, что выполнение вручную данного вычисления – довольно утомительное занятие. К счастью, в приложении Excel имеются функции, позволяющие автоматизировать процедуру расчета. Выясним алгоритм работы с этими инструментами.
Вычисление дисперсии
Дисперсия – это показатель вариации, который представляет собой средний квадрат отклонений от математического ожидания. Таким образом, он выражает разброс чисел относительно среднего значения. Вычисление дисперсии может проводиться как по генеральной совокупности, так и по выборочной.
Способ 1: расчет по генеральной совокупности
Для расчета данного показателя в Excel по генеральной совокупности применяется функция ДИСП.Г. Синтаксис этого выражения имеет следующий вид:
=ДИСП.Г(Число1;Число2;…)
Всего может быть применено от 1 до 255 аргументов. В качестве аргументов могут выступать, как числовые значения, так и ссылки на ячейки, в которых они содержатся.
Посмотрим, как вычислить это значение для диапазона с числовыми данными.
- Производим выделение ячейки на листе, в которую будут выводиться итоги вычисления дисперсии. Щелкаем по кнопке «Вставить функцию», размещенную слева от строки формул.
- Запускается Мастер функций. В категории «Статистические» или «Полный алфавитный перечень» выполняем поиск аргумента с наименованием «ДИСП.Г». После того, как нашли, выделяем его и щелкаем по кнопке «OK».
- Выполняется запуск окна аргументов функции ДИСП.Г. Устанавливаем курсор в поле «Число1». Выделяем на листе диапазон ячеек, в котором содержится числовой ряд. Если таких диапазонов несколько, то можно также использовать для занесения их координат в окно аргументов поля «Число2», «Число3» и т.д. После того, как все данные внесены, жмем на кнопку «OK».
- Как видим, после этих действий производится расчет. Итог вычисления величины дисперсии по генеральной совокупности выводится в предварительно указанную ячейку. Это именно та ячейка, в которой непосредственно находится формула ДИСП.Г.

Урок: Мастер функций в Эксель
Способ 2: расчет по выборке
В отличие от вычисления значения по генеральной совокупности, в расчете по выборке в знаменателе указывается не общее количество чисел, а на одно меньше. Это делается в целях коррекции погрешности. Эксель учитывает данный нюанс в специальной функции, которая предназначена для данного вида вычисления – ДИСП.В. Её синтаксис представлен следующей формулой:
=ДИСП.В(Число1;Число2;…)
Количество аргументов, как и в предыдущей функции, тоже может колебаться от 1 до 255.
- Выделяем ячейку и таким же способом, как и в предыдущий раз, запускаем Мастер функций.
- В категории «Полный алфавитный перечень» или «Статистические» ищем наименование «ДИСП.В». После того, как формула найдена, выделяем её и делаем клик по кнопке «OK».
- Производится запуск окна аргументов функции. Далее поступаем полностью аналогичным образом, как и при использовании предыдущего оператора: устанавливаем курсор в поле аргумента «Число1» и выделяем область, содержащую числовой ряд, на листе. Затем щелкаем по кнопке «OK».
- Результат вычисления будет выведен в отдельную ячейку.

Урок: Другие статистические функции в Эксель
Как видим, программа Эксель способна в значительной мере облегчить расчет дисперсии. Эта статистическая величина может быть рассчитана приложением, как по генеральной совокупности, так и по выборке. При этом все действия пользователя фактически сводятся только к указанию диапазона обрабатываемых чисел, а основную работу Excel делает сам. Безусловно, это сэкономит значительное количество времени пользователей.
Мы рады, что смогли помочь Вам в решении проблемы.
Задайте свой вопрос в комментариях, подробно расписав суть проблемы. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
Да Нет
Дисперсия — это мера рассеяния, описывающая сравнительное отклонение между значениями данных и средней величиной. Является наиболее используемой мерой рассеяния в статистике, вычисляемая путем суммирования, возведенного в квадрат, отклонения каждого значения данных от средней величины. Формула для вычисления дисперсии представлена ниже:
где:
s2 – дисперсия выборки;
xср — среднее значение выборки;
n — размер выборки (количество значений данных),
(xi – xср) — отклонение от средней величины для каждого значения набора данных.
Для лучшего понимания формулы, разберем пример. Я не очень люблю готовку, поэтому занятием этим занимаюсь крайне редко. Тем не менее, чтобы не умереть с голоду, время от времени мне приходится подходить к плите для реализации замысла по насыщению моего организма белками, жирами и углеводами. Набор данных, редставленный ниже, показывает, сколько раз Ренат готовит пищу каждый месяц:
Первым шагом при вычислении дисперсии является определение среднего значения выборки, которое в нашем примере равняется 7,8 раза в месяц. Остальные вычисления можно облегчить с помощью следующей таблицы.
Финальная фаза вычисления дисперсии выглядит так:
Для тех, кто любит производить все вычисления за один раз, уравнение будет выглядеть следующим образом:
Использование метода «сырого счета» (пример с готовкой)
Существует более эффективный способ вычисления дисперсии, известный как метод «сырого счета». Хотя с первого взгляда уравнение может показаться весьма громоздким, на самом деле оно не такое уж страшное. Можете в этом удостовериться, а потом и решите, какой метод вам больше нравится.
где:
— сумма каждого значения данных после возведения в квадрат,
— квадрат суммы всех значений данных.
Не теряйте рассудок прямо сейчас. Позвольте представить все это в виде таблицы, и тогда вы увидите, что вычислений здесь меньше, чем в предыдущем примере.
Как видите, результат получился тот же, что и при использовании предыдущего метода. Достоинства данного метода становятся очевидными по мере роста размера выборки (n).
Как вы уже, наверное, догадались, в Excel присутствует формула, позволяющая рассчитать дисперсию. Причем, начиная с Excel 2010 можно найти 4 разновидности формулы дисперсии:
1) ДИСП.В – Возвращает дисперсию по выборке. Логические значения и текст игнорируются.
2) ДИСП.Г — Возвращает дисперсию по генеральной совокупности. Логические значения и текст игнорируются.
3) ДИСПА — Возвращает дисперсию по выборке с учетом логических и текстовых значений.
4) ДИСПРА — Возвращает дисперсию по генеральной совокупности с учетом логических и текстовых значений.
Для начала разберемся в разнице между выборкой и генеральной совокупностью. Назначение описательной статистики состоит в том, чтобы суммировать или отображать данные так, чтобы оперативно получать общую картину, так сказать, обзор. Статистический вывод позволяет делать умозаключения о какой-либо совокупности на основе выборки данных из этой совокупности. Совокупность представляет собой все возможные исходы или измерения, представляющие для нас интерес. Выборка — это подмножество совокупности.
Например, нас интересует совокупность группы студентов одного из Российских ВУЗов и нам необходимо определить средний бал группы. Мы можем посчитать среднюю успеваемость студентов, и тогда полученная цифра будет параметром, поскольку в наших расчетах будет задействована целая совокупность. Однако, если мы хотим рассчитать средний бал всех студентов нашей страны, тогда эта группа будет нашей выборкой.
Разница в формуле расчета дисперсии между выборкой и совокупностью заключается в знаменателе. Где для выборки он будет равняться (n-1), а для генеральной совокупности только n.
Теперь разберемся с функциями расчета дисперсии с окончаниями А, в описании которых сказано, что при расчете учитываются текстовые и логические значения. В данном случае при расчете дисперсии определенного массива данных, где встречаются не числовые значения, Excel будет интерпретировать текстовые и ложные логические значения как равными 0, а истинные логические значения как равными 1.
Итак, если у вас есть массив данных, рассчитать его дисперсию ни составит никакого труда, воспользовавшись одной из перечисленных выше функций Excel.
В статистике используется огромное количество показателей, и один из них — расчет дисперсии в Excel. Если это делать самому вручную, уйдет очень много времени, можно допустить уйму ошибок. Сегодня мы рассмотрим, как разложить математические формулы на простые функции. Давайте разберем несколько самых простых, быстрых и удобных способов расчёта, которые позволят все сделать в считанные минуты.
Вычисляем дисперсию
Дисперсией случайной величины называется математическое ожидание квадрата отклонения случайной величины от ее математического ожидания.
Рассчитываем по генеральной совокупности
Чтобы вычислить мат. ожидание в программе будет применяться функция ДИСП.Г, а ее синтаксис выглядит следующим образом «=ДИСП.Г(Число1;Число2;…)».
Возможно применить максимум 255 аргументов, не более. Аргументами могут быть простые числа или ссылки на ячейки, в которых они указаны. Давайте рассмотрим, как посчитать дисперсию в Microsoft Excel:
1. Первым делом следует выделить ячейку, где будет отображаться итог вычислений, а далее кликнуть по кнопке «Вставить функцию».
2. Откроется оболочка управления функциями. Там нужно искать функцию «ДИСП.Г», которая может быть в категории «Статистические» или «Полный алфавитный перечень». Когда она будет найдена, следует выделить ее и кликнуть «ОК».
3. Запустится окно с аргументами функции. В нем нужно выделить строку «Число 1» и на листе выделить диапазон ячеек с числовым рядом.
4. После этого в ячейке, куда была введена функция будут выведены результаты расчетов.
Вот так несложно можно найти дисперсию в Excel.
Производим расчет по выборке
В данном случае выборочная дисперсия в Excel высчитывается с указанием в знаменателе не общего количества чисел, а на одно меньше. Это делается для более меньшей погрешности при помощи специальной функции ДИСП.В, синтаксис которой =ДИСП.В(Число1;Число2;…). Алгоритм действий:
- Как и в предыдущем методе нужно выделить ячейку для результата.
- В мастере функции следует найти «ДИСП.В» в категории «Полный алфавитный перечень» или «Статистические».
- Далее появится окно, и действовать следует также, как и в предыдущем методе.
Видео: Расчет дисперсии в Excel
Заключение
Дисперсия в Excel вычисляется очень просто, намного быстрее и удобнее, чем делать это вручную, ведь функция математическое ожидание довольно сложная и на ее вычисление может уйти много времени и сил.
Это может быть интересно:
Цель данной статьи показать, как математические формулы, с которыми вы можете столкнуться в книгах и статьях, разложить на элементарные функции в Excel.
В данной статье мы разберем формулы среднеквадратического отклонения и дисперсии и рассчитаем их в Excel.
Перед тем как переходить к расчету среднеквадратического отклонения и разбирать формулу, желательно разобраться в элементарных статистических показателях и обозначениях.
Рассматривая формулы моделей прогнозирования, мы встретимся со следующими показателями:
Например, у нас есть временной ряд — продажи по неделям в шт.
|
Неделя |
||||||||||
|
Отгрузка, шт |
Сморите пример расчета здесь: среднеквадратическое отклонние и дисперсия
Для этого временного ряда i=1, n=10, ,
Рассмотрим формулу среднего значения:
|
Неделя |
||||||||||
|
Отгрузка, шт |
Для нашего временного ряда определим среднее значение
Также для выявления тенденций помимо среднего значения представляет интерес и то, насколько наблюдения разбросаны относительно среднего. Среднеквадратическое отклонение показывает меру отклонения наблюдений относительно среднего.
Формула расчета среднеквадратического отклонение для выборки следующая:
Разложим формулу на составные части и рассчитаем среднеквадратическое отклонение в Excel на примере нашего временного ряда.
1. Рассчитаем среднее значение для этого воспользуемся формулой Excel =СРЗНАЧ(B11:K11)
=СРЗНАЧ(ссылка на диапазон) = 100/10=10
2. Определим отклонение каждого значения ряда относительно среднего
для первой недели = 6-10=-4
для второй недели = 10-10=0
для третей = 7-1=-3 и т.д.
3. Для каждого значения ряда определим квадрат разницы отклонения значений ряда относительно среднего
для первой недели = (-4)^2=16
для второй недели = 0^2=0
для третей = (-3)^2=9 и т.д.
4. Рассчитаем сумму квадратов отклонений значений относительно среднего с помощью формулы =СУММ(ссылка на диапазон (ссылка на диапазон с )
=16+0+9+4+16+16+4+9+0+16=90
5. , для этого сумму квадратов отклонений значений относительно среднего разделим на количество значений минус единица (Сумма((Xi-Xср)^2))/(n-1)
=90/(10-1)=10
6. Среднеквадратическое отклонение равно = корень(10)=3,2
Итак, в 6 шагов мы разложили сложную математическую формулу, надеюсь вам удалось разобраться со всеми частями формулы и вы сможете самостоятельно разобраться в других формулах.
Скачать файл с примером
Рассмотрим еще один показатель, который в будущем нам понадобятся — дисперсия.
Как рассчитать дисперсию в Excel?
Дисперсия — квадрат среднеквадратического отклонения и отражает разброс данных относительно среднего.
Рассчитаем дисперсию:
Скачать файл с примером
Итак, теперь мы умеем рассчитывать среднеквадратическое отклонение и дисперсию в Excel. Надеемся, полученные знания пригодятся вам в работе.
Точных вам прогнозов!
Присоединяйтесь к нам!
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа:
- Novo Forecast Lite — автоматический расчет прогноза в Excel.
- 4analytics — ABC-XYZ-анализ и анализ выбросов в Excel.
- Qlik Sense Desktop и QlikView Personal Edition — BI-системы для анализа и визуализации данных.
Тестируйте возможности платных решений:
- Novo Forecast PRO — прогнозирование в Excel для больших массивов данных.
Получите 10 рекомендаций по повышению точности прогнозов до 90% и выше.
Зарегистрируйтесь и скачайте решения Статья полезная? Поделитесь с друзьями
Коэффициент вариации – это сравнение рассеивания двух случайно взятых величин. Величины имеют единицы измерения, что приводит к получению сопоставимого результата. Этот коэффициент нужен для подготовки статистического анализа.
С помощью него инвесторы могут рассчитать показатели риска перед тем, как сделать вклады в выбранные активы. Он полезен, когда у выбранных активов различная доходность и степень риска. К примеру, у одного актива может быть высокий доход и степень риска тоже высокая, а у другого, наоборот, малый доход и степень риска соответственно меньшая.
Расчет стандартного отклонения
Стандартное отклонение является статистической величиной. С помощью расчета этой величины пользователь получит информацию о том, насколько отклоняются данные в ту или иную сторону относительно среднего значения. Стандартное отклонение в Excel рассчитывается в несколько шагов.
Подготавливаете данные: открываете страницу, где будут происходить расчеты. В нашем случае это картинка, но может быть любой другой файл. Главное собрать ту информацию, которую будете использовать в таблице для рассчета.
Вводите данные в любой табличный редактор (в нашем случае Excel), заполняя ячейки слева направо. Начинать следует с колонки «А». Заголовки вводите в строке сверху, а названия в тех же столбцах, которые относятся к заголовкам, только ниже. Затем дату и данные, которые подлежат расчету, справа от даты.
Этот документ сохраняете.
Теперь переходим к самому вычислению. Выделяете курсором ячейку после последнего введенного значения снизу.
Вписываете знак «=» и прописываете далее формулу. Знак равенства обязателен. Иначе программа не посчитает предложенные данные. Формула вводится без пробелов.
Утилита выдаст названия нескольких формул. Выбираете «СТАНДОТКЛОН». Это формула вычисления стандартного отклонения. Существует два вида расчета:
- с вычислением по выборке;
- с вычислением по генеральной совокупности.
Выбрав одну из них, указываете диапазон данных. Вся введенная формула будет выглядеть так: «=СТАНДОТКЛОН (В2: В5)».
Затем кликаете по кнопке «Enter». Полученные данные появятся в отмеченном пункте.
Расчет среднего арифметического
Вычисляется, когда пользователю необходимо создать отчет, например, по заработной плате в его компании. Делается это следующим образом:
- открываете утилиту. В верхней строке набираете ряд нужных цифр;
- под первой цифрой ставите курсор. В верхней строке программы выбираете вкладку «Редактирование», затем кнопку «Сумма». В выпавшем окне выбираете значение «Среднее»;
- после того, как кликните в том пункте на котором стоит курсор, появится формула;
- останется только выделить диапазон и кликнуть по кнопке «Ввод». А в ячейке теперь отобразится результат из взятых данных выше.
Расчет коэффициента вариации
Формула расчета коэффициента вариации:
V= S/X, где S – это стандартное отклонение, а X – среднее значение.
Для того, чтобы посчитать коэффициент вариации в Excel, необходимо найти стандартное отклонение и среднее арифметическое. То есть проделав первые два расчета, которые были показаны выше, можно перейти к работе над коэффициентом вариации.
Для этого открываете Excel, заполняем два поля, куда следует вписать полученные числа стандартного отклонения и среднего значения.
Теперь выделяете ячейку, которую отвели под число для вычисления вариации. Открываете вкладку «Главная», если она не открыта. Кликаете по инструменту «Число». Выбираете процентный формат.
Переходите к отмеченной ячейке и кликаете по ней дважды. Затем вводите знак равенства и выделяете пункт, куда вписан итог стандартного отклонения. Затем кликаете на клавиатуре по кнопке «слэш» или «разделить» (выглядит так: «/»). Выделяете пункт, куда вписано среднее арифметическое, и кликаете по кнопке «Enter». Должно получиться так:
А вот и результат после нажатия «Enter»:
Также для расчета коэффициента вариации можно использовать онлайн калькуляторы, например planetcalc.ru и allcalc.ru. Достаточно внести необходимые цифры и запустить расчет, после чего получить необходимые сведения.
Среднеквадратическое отклонение
Среднеквадратичное отклонение в Excel решается с помощью двух формул:
Простыми словами, извлекается корень из дисперсии. Как вычислить дисперсию рассмотрено ниже.
Среднее квадратичное отклонение является синонимом стандартного и вычисляется точное также. Выделяется ячейка для результата под числами, которые нужно рассчитать. Вставляется одна из функций, указанных на рисунке выше. Кликается кнопка «Enter». Результат получен.
Коэффициент осциляции
Соотношением размаха вариации к среднему – называется коэффициентом осциляции. Готовых формул в Экселе нет, поэтому нужно компоновать несколько функций в одну.
Функциями, которые необходимо скомпоновать, являются формулы среднего значения, максимума и минимума. Этот коэффициент используют для сравнения набора данных.
Дисперсия
Дисперсия – это функция, с помощью которой характеризуют разброс данных вокруг математического ожидания. Вычисляется по следующему уравнению:
Переменные принимают такие значения:
В Excel есть две функции, которые определяют дисперсию:
- Дисп.Г – используется относительно небольших выборок.
- Дисп.В – вычисление несмещенной дисперсии.
Чтобы произвести расчет, под числами, которые необходимо посчитать, выделяется ячейка. Заходите во вкладку вставки функции. Выбираете категорию «Статистические». В выпавшем списке выбираете одну из функций и кликаете по кнопке «Enter».
Максимум и минимум
Максимум и минимум нужны для того, чтобы не искать вручную среди большого количества чисел минимальное или максимальное число.
Чтобы вычислить максимум, выделяете весь диапазон необходимых чисел в таблице и отдельную ячейку, затем кликаете по значку «Σ» или «Автосумма». В выпавшем окне выбираете «Максимум» и, нажав кнопку «Enter» получаете нужное значение.
Тоже самое делаете, чтобы получить минимум. Только выбираете функцию «Минимум».
Итак, вас попросили рассчитать дисперсию с помощью Excel, но вы не знаете, что это значит и как это сделать. Не волнуйтесь, это простая концепция и еще более простой процесс. Вы станете профессионалом в дисперсии в кратчайшие сроки!
Что такое дисперсия?
«Дисперсия» — это способ измерения среднего расстояния от среднего. «Среднее» — это сумма всех значений в наборе данных, деленная на количество значений. Дисперсия дает нам представление о том, имеют ли значения в этом наборе данных тенденцию в среднем равномерно придерживаться среднего значения или разбросаны повсюду.
Математически дисперсия не так уж сложна:
- Вычислите среднее значение набора значений. Чтобы вычислить среднее значение, возьмите сумму всех значений, разделенную на количество значений.
- Возьмите каждое значение в вашем наборе и вычтите его из среднего.
- Возведите полученные значения в квадрат (чтобы исключить отрицательные числа).
- Сложите все квадраты значений вместе.
- Вычислите среднее квадратов значений, чтобы получить дисперсию.
Как видите, вычислить это значение несложно. Однако если у вас есть сотни или тысячи значений, на то, чтобы сделать это вручную, уйдет целая вечность. Так что хорошо, что Excel может автоматизировать этот процесс!
Для чего вы используете дисперсию?
Сама по себе дисперсия имеет ряд применений. С чисто статистической точки зрения это хороший способ обозначить, насколько разрознен набор данных. Инвесторы используют дисперсию для оценки риска данной инвестиции.
Например, взяв стоимость акции за определенный период времени и вычислив ее дисперсию, вы получите хорошее представление о ее волатильности в прошлом. Если предположить, что прошлое предсказывает будущее, это будет означать, что что-то с низкой дисперсией более безопасно и предсказуемо.
Вы также можете сравнить отклонения чего-либо в разные периоды времени. Это может помочь обнаружить, когда другой скрытый фактор на что-то влияет, изменяя его дисперсию.
Дисперсия также сильно связана с другой статистикой, известной как стандартное отклонение. Помните, что значения, используемые для расчета дисперсии, возведены в квадрат. Это означает, что отклонение не выражается в той же единице исходного значения. Стандартное отклонение требует извлечения квадратного корня из дисперсии, чтобы вернуть значение в исходную единицу. Таким образом, если данные были в килограммах, стандартное отклонение тоже.
Выбор между совокупностью и дисперсией выборки
В Excel есть два подтипа дисперсии с немного разными формулами. Какой из них выбрать, зависит от ваших данных. Если ваши данные включают всю «генеральную совокупность», вам следует использовать дисперсию генеральной совокупности. В этом случае «популяция» означает, что у вас есть все значения для каждого члена целевой группы населения.
Например, если вы посмотрите на вес левшей, то в популяцию войдут все левши на Земле. Если вы их все взвесите, вы воспользуетесь дисперсией населения.
Конечно, в реальной жизни мы обычно соглашаемся на меньшую выборку из большей совокупности. В этом случае вы должны использовать выборочную дисперсию. Дисперсия совокупности по-прежнему актуальна для небольших популяций. Например, в компании может быть несколько сотен или несколько тысяч сотрудников с данными о каждом сотруднике. Они представляют собой «население» в статистическом смысле.
Выбор правильной формулы дисперсии
В Excel есть три типовых формулы дисперсии и три формулы дисперсии генеральной совокупности:
- VAR, VAR.S и VARA для выборочной дисперсии.
- VARP, VAR.P и VARPA для дисперсии совокупности.
Вы можете игнорировать VAR и VARP. Они устарели и существуют только для совместимости с устаревшими электронными таблицами.
Остается VAR.S и VAR.P, которые предназначены для вычисления дисперсии набора числовых значений, а также VARA и VARPA, которые включают текстовые строки.
VARA и VARPA преобразуют любую текстовую строку в числовое значение 0, за исключением «ИСТИНА» и «ЛОЖЬ». Они преобразуются в 1 и 0 соответственно.
Самая большая разница в том, что VAR.S и VAR.P пропускают любые нечисловые значения. Это исключает эти случаи из общего количества значений, что означает, что среднее значение будет другим, потому что вы делите на меньшее количество случаев, чтобы получить среднее значение.
Все, что вам нужно для расчета дисперсии в Excel, — это набор значений. Мы собираемся использовать VAR.S в приведенном ниже примере, но формула и методы точно такие же, независимо от того, какую формулу дисперсии вы используете:
- Предполагая, что у вас есть готовый диапазон или дискретный набор значений, выберите пустую ячейку по вашему выбору.
- В поле формулы введите = VAR.S (XX: YY), где значения X и Y заменяются номерами первой и последней ячеек диапазона.
- Нажмите Enter, чтобы завершить расчет.
В качестве альтернативы вы можете указать конкретные значения, и в этом случае формула будет иметь вид = VAR.S (1,2,3,4). С числами, замененными на все, что вам нужно для расчета дисперсии. Вы можете ввести до 254 значений вручную таким образом, но если у вас есть только несколько значений, почти всегда лучше вводить данные в диапазоне ячеек, а затем использовать версию формулы, описанную выше, для диапазона ячеек.
Вы можете Excel в, Er, Excel
Вычисление дисперсии — полезный прием для тех, кому нужно выполнить статистическую работу в Excel. Но если какая-либо терминология Excel, которую мы использовали в этой статье, сбивала с толку, подумайте о том, чтобы ознакомиться с Руководством по основам Microsoft Excel — Обучение использованию Excel.
Если, с другой стороны, вы готовы к большему, ознакомьтесь с разделом «Добавить линию тренда линейной регрессии на точечную диаграмму Excel», чтобы вы могли визуализировать дисперсию или любой другой аспект вашего набора данных по отношению к среднему арифметическому.
Из предыдущей статьи мы узнали о таких показателях, как размах вариации, межквартильный размах и среднее линейное отклонение. В этой статье изучим дисперсию, среднеквадратичное отклонение и коэффициент вариации.
Дисперсия
Дисперсия случайной величины – это один из основных показателей в статистике. Он отражает меру разброса данных вокруг средней арифметической.
Сейчас небольшой экскурс в теорию вероятностей, которая лежит в основе математической статистики. Как и матожидание, дисперсия является важной характеристикой случайной величины. Если матожидание отражает центр случайной величины, то дисперсия дает характеристику разброса данных вокруг центра.
Формула дисперсии в теории вероятностей имеет вид:
![]()
То есть дисперсия — это математическое ожидание отклонений от математического ожидания.
На практике при анализе выборок математическое ожидание, как правило, не известно. Поэтому вместо него используют оценку – среднее арифметическое. Расчет дисперсии производят по формуле:
![]()
где
s2 – выборочная дисперсия, рассчитанная по данным наблюдений,
X – отдельные значения,
X̅– среднее арифметическое по выборке.
Стоит отметить, что у такого расчета дисперсии есть недостаток – она получается смещенной, т.е. ее математическое ожидание не равно истинному значению дисперсии. Подробней об этом здесь. Однако при увеличении объема выборки она все-таки приближается к своему теоретическому аналогу, т.е. является асимптотически не смещенной.
Простыми словами дисперсия – это средний квадрат отклонений. То есть вначале рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат, складывается и затем делится на количество значений в данной совокупности. Разница между отдельным значением и средней отражает меру отклонения. В квадрат возводится для того, чтобы все отклонения стали исключительно положительными числами и чтобы избежать взаимоуничтожения положительных и отрицательных отклонений при их суммировании. Затем, имея квадраты отклонений, просто рассчитываем среднюю арифметическую. Средний – квадрат – отклонений. Отклонения возводятся в квадрат, и считается средняя. Теперь вы знаете, как найти дисперсию.
Генеральную и выборочную дисперсии легко рассчитать в Excel. Есть специальные функции: ДИСП.Г и ДИСП.В соответственно.

В чистом виде дисперсия не используется. Это вспомогательный показатель, который нужен в других расчетах. Например, в проверке статистических гипотез или расчете коэффициентов корреляции. Отсюда неплохо бы знать математические свойства дисперсии.
Свойства дисперсии
Свойство 1. Дисперсия постоянной величины A равна 0 (нулю).
D(A) = 0
Свойство 2. Если случайную величину умножить на постоянную А, то дисперсия этой случайной величины увеличится в А2 раз. Другими словами, постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат.
D(AX) = А2 D(X)
Свойство 3. Если к случайной величине добавить (или отнять) постоянную А, то дисперсия останется неизменной.
D(A + X) = D(X)
Свойство 4. Если случайные величины X и Y независимы, то дисперсия их суммы равна сумме их дисперсий.
D(X+Y) = D(X) + D(Y)
Свойство 5. Если случайные величины X и Y независимы, то дисперсия их разницы также равна сумме дисперсий.
D(X-Y) = D(X) + D(Y)
Среднеквадратичное (стандартное) отклонение
Если из дисперсии извлечь квадратный корень, получится среднеквадратичное (стандартное) отклонение (сокращенно СКО). Встречается название среднее квадратичное отклонение и сигма (от названия греческой буквы). Общая формула стандартного отклонения в математике следующая:
![]()
На практике формула стандартного отклонения следующая:
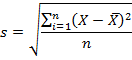
Как и с дисперсией, есть и немного другой вариант расчета. Но с ростом выборки разница исчезает.
Расчет cреднеквадратичного (стандартного) отклонения в Excel
Для расчета стандартного отклонения достаточно из дисперсии извлечь квадратный корень. Но в Excel есть и готовые функции: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В (по генеральной и выборочной совокупности соответственно).
 отклонение в Excel")
Среднеквадратичное отклонение имеет те же единицы измерения, что и анализируемый показатель, поэтому является сопоставимым с исходными данными.
Коэффициент вариации
Значение стандартного отклонения зависит от масштаба самих данных, что не позволяет сравнивать вариабельность разных выборках. Чтобы устранить влияние масштаба, необходимо рассчитать коэффициент вариации по формуле:
![]()
По нему можно сравнивать однородность явлений даже с разным масштабом данных. В статистике принято, что, если значение коэффициента вариации менее 33%, то совокупность считается однородной, если больше 33%, то – неоднородной. В реальности, если коэффициент вариации превышает 33%, то специально ничего делать по этому поводу не нужно. Это информация для общего представления. В общем коэффициент вариации используют для оценки относительного разброса данных в выборке.
Расчет коэффициента вариации в Excel
Расчет коэффициента вариации в Excel также производится делением стандартного отклонения на среднее арифметическое:
=СТАНДОТКЛОН.В()/СРЗНАЧ()
Коэффициент вариации обычно выражается в процентах, поэтому ячейке с формулой можно присвоить процентный формат:

Коэффициент осцилляции
Еще один показатель разброса данных на сегодня – коэффициент осцилляции. Это соотношение размаха вариации (разницы между максимальным и минимальным значением) к средней. Готовой формулы Excel нет, поэтому придется скомпоновать три функции: МАКС, МИН, СРЗНАЧ.

Коэффициент осцилляции показывает степень размаха вариации относительно средней, что также можно использовать для сравнения различных наборов данных.
Таким образом, в статистическом анализе существует система показателей, отражающих разброс или однородность данных.
Ниже видео о том, как посчитать коэффициент вариации, дисперсию, стандартное (среднеквадратичное) отклонение и другие показатели вариации в Excel.
Поделиться в социальных сетях: