
Содержание
- Расчет ошибки средней арифметической
- Способ 1: расчет с помощью комбинации функций
- Способ 2: применение инструмента «Описательная статистика»
- Вопросы и ответы

Стандартная ошибка или, как часто называют, ошибка средней арифметической, является одним из важных статистических показателей. С помощью данного показателя можно определить неоднородность выборки. Он также довольно важен при прогнозировании. Давайте узнаем, какими способами можно рассчитать величину стандартной ошибки с помощью инструментов Microsoft Excel.
Расчет ошибки средней арифметической
Одним из показателей, которые характеризуют цельность и однородность выборки, является стандартная ошибка. Эта величина представляет собой корень квадратный из дисперсии. Сама дисперсия является средним квадратном от средней арифметической. Средняя арифметическая вычисляется делением суммарной величины объектов выборки на их общее количество.
В Экселе существуют два способа вычисления стандартной ошибки: используя набор функций и при помощи инструментов Пакета анализа. Давайте подробно рассмотрим каждый из этих вариантов.
Способ 1: расчет с помощью комбинации функций
Прежде всего, давайте составим алгоритм действий на конкретном примере по расчету ошибки средней арифметической, используя для этих целей комбинацию функций. Для выполнения задачи нам понадобятся операторы СТАНДОТКЛОН.В, КОРЕНЬ и СЧЁТ.
Для примера нами будет использована выборка из двенадцати чисел, представленных в таблице.

- Выделяем ячейку, в которой будет выводиться итоговое значение стандартной ошибки, и клацаем по иконке «Вставить функцию».
- Открывается Мастер функций. Производим перемещение в блок «Статистические». В представленном перечне наименований выбираем название «СТАНДОТКЛОН.В».
- Запускается окно аргументов вышеуказанного оператора. СТАНДОТКЛОН.В предназначен для оценивания стандартного отклонения при выборке. Данный оператор имеет следующий синтаксис:
=СТАНДОТКЛОН.В(число1;число2;…)«Число1» и последующие аргументы являются числовыми значениями или ссылками на ячейки и диапазоны листа, в которых они расположены. Всего может насчитываться до 255 аргументов этого типа. Обязательным является только первый аргумент.
Итак, устанавливаем курсор в поле «Число1». Далее, обязательно произведя зажим левой кнопки мыши, выделяем курсором весь диапазон выборки на листе. Координаты данного массива тут же отображаются в поле окна. После этого клацаем по кнопке «OK».
- В ячейку на листе выводится результат расчета оператора СТАНДОТКЛОН.В. Но это ещё не ошибка средней арифметической. Для того, чтобы получить искомое значение, нужно стандартное отклонение разделить на квадратный корень от количества элементов выборки. Для того, чтобы продолжить вычисления, выделяем ячейку, содержащую функцию СТАНДОТКЛОН.В. После этого устанавливаем курсор в строку формул и дописываем после уже существующего выражения знак деления (/). Вслед за этим клацаем по пиктограмме перевернутого вниз углом треугольника, которая располагается слева от строки формул. Открывается список недавно использованных функций. Если вы в нем найдете наименование оператора «КОРЕНЬ», то переходите по данному наименованию. В обратном случае жмите по пункту «Другие функции…».
- Снова происходит запуск Мастера функций. На этот раз нам следует посетить категорию «Математические». В представленном перечне выделяем название «КОРЕНЬ» и жмем на кнопку «OK».
- Открывается окно аргументов функции КОРЕНЬ. Единственной задачей данного оператора является вычисление квадратного корня из заданного числа. Его синтаксис предельно простой:
=КОРЕНЬ(число)
Как видим, функция имеет всего один аргумент «Число». Он может быть представлен числовым значением, ссылкой на ячейку, в которой оно содержится или другой функцией, вычисляющей это число. Последний вариант как раз и будет представлен в нашем примере.
Устанавливаем курсор в поле «Число» и кликаем по знакомому нам треугольнику, который вызывает список последних использованных функций. Ищем в нем наименование «СЧЁТ». Если находим, то кликаем по нему. В обратном случае, опять же, переходим по наименованию «Другие функции…».
- В раскрывшемся окне Мастера функций производим перемещение в группу «Статистические». Там выделяем наименование «СЧЁТ» и выполняем клик по кнопке «OK».
- Запускается окно аргументов функции СЧЁТ. Указанный оператор предназначен для вычисления количества ячеек, которые заполнены числовыми значениями. В нашем случае он будет подсчитывать количество элементов выборки и сообщать результат «материнскому» оператору КОРЕНЬ. Синтаксис функции следующий:
=СЧЁТ(значение1;значение2;…)В качестве аргументов «Значение», которых может насчитываться до 255 штук, выступают ссылки на диапазоны ячеек. Ставим курсор в поле «Значение1», зажимаем левую кнопку мыши и выделяем весь диапазон выборки. После того, как его координаты отобразились в поле, жмем на кнопку «OK».
- После выполнения последнего действия будет не только рассчитано количество ячеек заполненных числами, но и вычислена ошибка средней арифметической, так как это был последний штрих в работе над данной формулой. Величина стандартной ошибки выведена в ту ячейку, где размещена сложная формула, общий вид которой в нашем случае следующий:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13))Результат вычисления ошибки средней арифметической составил 0,505793. Запомним это число и сравним с тем, которое получим при решении поставленной задачи следующим способом.










Но дело в том, что для малых выборок (до 30 единиц) для большей точности лучше применять немного измененную формулу. В ней величина стандартного отклонения делится не на квадратный корень от количества элементов выборки, а на квадратный корень от количества элементов выборки минус один. Таким образом, с учетом нюансов малой выборки наша формула приобретет следующий вид:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13)-1)

Урок: Статистические функции в Экселе
Способ 2: применение инструмента «Описательная статистика»
Вторым вариантом, с помощью которого можно вычислить стандартную ошибку в Экселе, является применение инструмента «Описательная статистика», входящего в набор инструментов «Анализ данных» («Пакет анализа»). «Описательная статистика» проводит комплексный анализ выборки по различным критериям. Одним из них как раз и является нахождение ошибки средней арифметической.
Но чтобы воспользоваться данной возможностью, нужно сразу активировать «Пакет анализа», так как по умолчанию в Экселе он отключен.
- После того, как открыт документ с выборкой, переходим во вкладку «Файл».
- Далее, воспользовавшись левым вертикальным меню, перемещаемся через его пункт в раздел «Параметры».
- Запускается окно параметров Эксель. В левой части данного окна размещено меню, через которое перемещаемся в подраздел «Надстройки».
- В самой нижней части появившегося окна расположено поле «Управление». Выставляем в нем параметр «Надстройки Excel» и жмем на кнопку «Перейти…» справа от него.
- Запускается окно надстроек с перечнем доступных скриптов. Отмечаем галочкой наименование «Пакет анализа» и щелкаем по кнопке «OK» в правой части окошка.
- После выполнения последнего действия на ленте появится новая группа инструментов, которая имеет наименование «Анализ». Чтобы перейти к ней, щелкаем по названию вкладки «Данные».
- После перехода жмем на кнопку «Анализ данных» в блоке инструментов «Анализ», который расположен в самом конце ленты.
- Запускается окошко выбора инструмента анализа. Выделяем наименование «Описательная статистика» и жмем на кнопку «OK» справа.
- Запускается окно настроек инструмента комплексного статистического анализа «Описательная статистика».
В поле «Входной интервал» необходимо указать диапазон ячеек таблицы, в которых находится анализируемая выборка. Вручную это делать неудобно, хотя и можно, поэтому ставим курсор в указанное поле и при зажатой левой кнопке мыши выделяем соответствующий массив данных на листе. Его координаты тут же отобразятся в поле окна.
В блоке «Группирование» оставляем настройки по умолчанию. То есть, переключатель должен стоять около пункта «По столбцам». Если это не так, то его следует переставить.
Галочку «Метки в первой строке» можно не устанавливать. Для решения нашего вопроса это не важно.
Далее переходим к блоку настроек «Параметры вывода». Здесь следует указать, куда именно будет выводиться результат расчета инструмента «Описательная статистика»:
- На новый лист;
- В новую книгу (другой файл);
- В указанный диапазон текущего листа.
Давайте выберем последний из этих вариантов. Для этого переставляем переключатель в позицию «Выходной интервал» и устанавливаем курсор в поле напротив данного параметра. После этого клацаем на листе по ячейке, которая станет верхним левым элементом массива вывода данных. Её координаты должны отобразиться в поле, в котором мы до этого устанавливали курсор.
Далее следует блок настроек определяющий, какие именно данные нужно вводить:
- Итоговая статистика;
- К-ый наибольший;
- К-ый наименьший;
- Уровень надежности.
Для определения стандартной ошибки обязательно нужно установить галочку около параметра «Итоговая статистика». Напротив остальных пунктов выставляем галочки на свое усмотрение. На решение нашей основной задачи это никак не повлияет.
После того, как все настройки в окне «Описательная статистика» установлены, щелкаем по кнопке «OK» в его правой части.
- После этого инструмент «Описательная статистика» выводит результаты обработки выборки на текущий лист. Как видим, это довольно много разноплановых статистических показателей, но среди них есть и нужный нам – «Стандартная ошибка». Он равен числу 0,505793. Это в точности тот же результат, который мы достигли путем применения сложной формулы при описании предыдущего способа.










Урок: Описательная статистика в Экселе
Как видим, в Экселе можно произвести расчет стандартной ошибки двумя способами: применив набор функций и воспользовавшись инструментом пакета анализа «Описательная статистика». Итоговый результат будет абсолютно одинаковый. Поэтому выбор метода зависит от удобства пользователя и поставленной конкретной задачи. Например, если ошибка средней арифметической является только одним из многих статистических показателей выборки, которые нужно рассчитать, то удобнее воспользоваться инструментом «Описательная статистика». Но если вам нужно вычислить исключительно этот показатель, то во избежание нагромождения лишних данных лучше прибегнуть к сложной формуле. В этом случае результат расчета уместится в одной ячейке листа.
-
К
ПРОГРАММАМ, ВЫПОЛНЯЮЩИМ ФУНКЦИИ
АНАЛОГИЧНЫЕ ПРОГРАММЕ EXCEL, ОТНОСЯТСЯ:
а)
Super Calc
б)
Word
в)
Lotus-1-2-3
г)
Quattro Pro
д)
PowerPoint
е)
ACCESS
Решение:
электронные
таблицы, или табличные процессоры,
являются удобным средством проведения
расчетов и анализа результатов научных
исследований. Они предназначены для
работы с таблицами чисел и выполнения
относительно несложных расчетов с
большим количеством идентичных данных,
например, бухгалтерских. Наиболее
популярными электронными таблицами
являются: Super Calc, Quattro Pro, Lotus‑1‑2‑3
и Microsoft
Excel.
Правильный
ответ:
а, в, г.
Литература:
Сабанов В.И. Медицинская информатика и
автоматизированные системы управления
в здравоохранении. Учебно-методическое
пособие к практическим занятиям / В.И.
Сабанов, А.Н. Голубев, Е.Р. Комина. –
Волгоград: Изд-во ВолГМУ, 2006. – 144с. –
стр. 54.
-
ДЛЯ
ВЫЧИСЛЕНИЯ СРЕДНЕГО АРИФМЕТИЧЕСКОГО
ЗНАЧЕНИЯ ПРИМЕНЯЕТСЯ ФУНКЦИЯ …
а)
МЕДИАНА(…)
б)
СРГАРМ(…)
в)
СРЗНАЧ(…)
г)
СРГЕОМ(…)
Решение:
для
вычисления среднего арифметического
значения применяется функция
срзнач(диапазон
ячеек).
Правильный
ответ:
в.
Литература:
Симонович С.В. Информатика. Базовый
курс: Учебник для вузов.-3-е изд. Стандарт
третьего поколения. — СПб.: Питер, 2011. —
640с.: ил. – стр. 344.
-
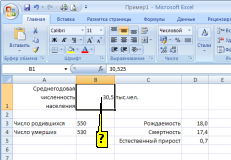
В
ЯЧЕЙКЕ В1 ОТОБРАЖЕНО ЧИСЛО 30,5
(СМ. РИСУНОК),
ПРИ ЭТОМ В ВЫЧИСЛЕНИЯХ ИСПОЛЬЗУЕТСЯ
ЗНАЧЕНИЕ …
а)
30,5
б)
30,525
в)
в зависимости от настройки
программы: 30,5 или 30,525
Решение:
в
ячейке B1
отображено число 30,5 (см.рисунок), при
этом в вычислениях используется значение
30,525.
Правильный
ответ:
б.
Литература:
Симонович С.В. Информатика. Базовый
курс: Учебник для вузов.-3-е изд. Стандарт
третьего поколения. — СПб.: Питер, 2011. —
640с.: ил. – стр. 337.
-
ДЛЯ
ПОДКЛЮЧЕНИЯ К ПРОГРАММЕ EXCEL ПАКЕТА
СТАТИСТИЧЕСКОГО АНАЛИЗА ДАННЫХ
ПОЛЬЗОВАТЕЛЮ ТРЕБУЕТСЯ ВЫПОЛНИТЬ
СЛЕДУЮЩЕЕ ДЕЙСТВИЕ …
а)
произвести установку модуля «Пакет
анализа» из режима «Надстройки» программы
б)
удалить программу Excel и произвести ее
повторную стандартную установку
в)
перезагрузить компьютер
Решение:
для подключения к программе Excel пакета
статистического анализа данных необходимо
подключить модуль «Пакет анализа» из
режима «Надстройки» основного меню
программы.
Правильный
ответ:
а.
Литература:
Сабанов В.И. Медицинская информатика и
автоматизированные системы управления
в здравоохранении. Учебно-методическое
пособие к практическим занятиям / В.И.
Сабанов, А.Н. Голубев, Е.Р. Комина. –
Волгоград: Изд-во ВолГМУ, 2006. – 144с. –
стр. 58.
-
ВЫЗОВ
ПАКЕТА ВЫЧИСЛЕНИЯ СРЕДНИХ ВЕЛИЧИН И
ХАРАКТЕРИСТИК ВАРИАЦИОННОГО РЯДА В
ПРОГРАММЕ EXCEL ПРОИЗВОДИТСЯ КОМАНДОЙ
…
а)
«Сервис (Данные)» → «Обработка данных»
→ «Поиск решения»
б)
«Сервис (Данные)» → «Анализ данных» →
«Описательная статистика»
в)
«Сервис (Данные)» → «Обработка данных»
→ «Основная статистика»
Решение:
вызов пакета вычисления средних величин
и характеристик вариационного ряда в
программе Excel производится командой
«Сервис (Данные)» → «Анализ данных» →
«Описательная статистика».
Правильный
ответ:
б.
Литература:
Сабанов В.И. Медицинская информатика и
автоматизированные системы управления
в здравоохранении. Учебно-методическое
пособие к практическим занятиям / В.И.
Сабанов, А.Н. Голубев, Е.Р. Комина. –
Волгоград: Изд-во ВолГМУ, 2006. – 144с. –
стр. 59.
-
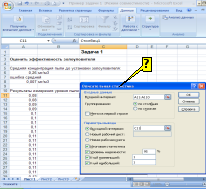
РЕЗУЛЬТАТ
ОБРАБОТКИ ВАРИАЦИОННОГО РЯДА, ВЫПОЛНЕННЫЙ
МОДУЛЕМ «ОПИСАТЕЛЬНАЯ СТАТИСТИКА»
ПРОГРАММЫ EXCEL (СМ. РИСУНОК), БУДЕТ
ПОМЕЩЕН В СЛЕДУЮЩИЕ ЯЧЕЙКИ …
а)
начиная с ячейки А11
б)
начиная с ячейки С11
в)
в диапазоне ячеек A11:A110
г)
в ячейку A110
Решение:
результат обработки вариационного
ряда, выполненный модулем «описательная
статистика» программы Excel размещается
в выходном интервале (см.рисунок) начиная
с ячейки С11 и ниже.
Правильный
ответ:
б.
Литература:
Сабанов В.И. Медицинская информатика и
автоматизированные системы управления
в здравоохранении. Учебно-методическое
пособие к практическим занятиям / В.И.
Сабанов, А.Н. Голубев, Е.Р. Комина. –
Волгоград: Изд-во ВолГМУ, 2006. – 144с. –
стр. 59.
-
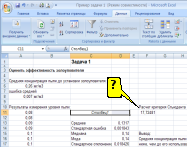
ФОРМУЛОЙ
ВЫЧИСЛЕНИЯ КОЭФФИЦИЕНТА СТЬЮДЕНТА В
ПРОГРАММЕ EXCEL (СМ. РИСУНОК) ЯВЛЯЕТСЯ …
а)
=(A6-D13)/корень(A8^2+D14^2)
б)
=(A6+D13)*корень(A8^2+D14^2)
в)
=(A6-D13)/корень(A8^2-D14^2)
Решение:
формулой вычисления коэффициента
Стьюдента в программе Excel (см.рисунок)
является «=(A6-D13)/корень(A8^2+D14^2)».
Правильный
ответ:
а.
Литература:
Сабанов В.И. Медицинская информатика и
автоматизированные системы управления
в здравоохранении. Учебно-методическое
пособие к практическим занятиям / В.И.
Сабанов, А.Н. Голубев, Е.Р. Комина. –
Волгоград: Изд-во ВолГМУ, 2006. – 144с. –
стр. 59.
-
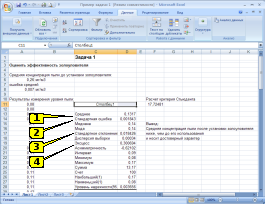
ОБОЗНАЧЕНИЕ
ОШИБКИ РЕПРЕЗЕНТАТИВНОСТИ В ТАБЛИЦЕ
РЕЗУЛЬТАТОВ ОБРАБОТКИ ВАРИАЦИОННОГО
РЯДА ПАКЕТОМ «ОПИСАТЕЛЬНАЯ СТАТИСТИКА»
ПРОГРАММЫ EXCEL (СМ. РИСУНОК) СООТВЕТСТВУЕТ
ПОЗИЦИИ …
а)
1
б)
2
в)
3
г)
4
Решение:
обозначение ошибки репрезентативности
в таблице результатов обработки
вариационного ряда пакетом «Описательная
статистика» программы Excel (см.рисунок)
соответствует позиция 2 (Стандартная
ошибка).
Правильный
ответ:
б.
Литература:
Сабанов В.И. Медицинская информатика и
автоматизированные системы управления
в здравоохранении. Учебно-методическое
пособие к практическим занятиям / В.И.
Сабанов, А.Н. Голубев, Е.Р. Комина. –
Волгоград: Изд-во ВолГМУ, 2006. – 144с. –
стр. 59.
-
ФОРМУЛОЙ
ВЫЧИСЛЕНИЯ ОТНОСИТЕЛЬНОГО ПОКАЗАТЕЛЯ
(P) В ПРОГРАММЕ EXCEL (СМ. РИСУНОК)
ЯВЛЯЕТСЯ …
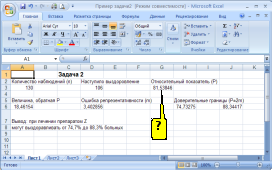
а)
=A1*100/D3
б)
=D3*100/A3
в)
=A2*100/D2
г)
=Д3*100/А3
Решение:
формулой вычисления относительного
показателя (P)
в программе Excel (см.рисунок) является
«=D3*100/A3».
Правильный
ответ:
б.
Литература:
Сабанов В.И. Медицинская информатика и
автоматизированные системы управления
в здравоохранении. Учебно-методическое
пособие к практическим занятиям / В.И.
Сабанов, А.Н. Голубев, Е.Р. Комина. –
Волгоград: Изд-во ВолГМУ, 2006. – 144с. –
стр. 60.
-
ФОРМУЛОЙ
ВЫЧИСЛЕНИЯ ВЕЛИЧИНЫ, ОБРАТНОЙ P, В
ПРОГРАММЕ EXCEL (СМ. РИСУНОК) ЯВЛЯЕТСЯ …
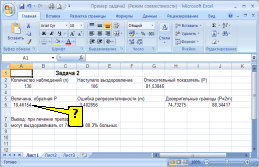
а)
= 100 — G2
б)
= 100 — А5
в)
= 100 — G3
г)
= 100 — Г3
Решение:
формулой вычисления величины, обратной
P, в программе Excel (см. рисунок) является
«= 100 — G3».
Правильный
ответ:
в.
Литература:
Сабанов В.И. Медицинская информатика и
автоматизированные системы управления
в здравоохранении. Учебно-методическое
пособие к практическим занятиям / В.И.
Сабанов, А.Н. Голубев, Е.Р. Комина. –
Волгоград: Изд-во ВолГМУ, 2006. – 144с. –
стр. 60.
-
ФОРМУЛОЙ
ВЫЧИСЛЕНИЯ ОШИБКИ РЕПРЕЗЕНТАТИВНОСТИ
ОТНОСИТЕЛЬНОГО ПОКАЗАТЕЛЯ В ПРОГРАММЕ
EXCEL (СМ. РИСУНОК) ЯВЛЯЕТСЯ …
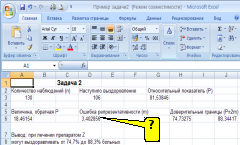
а)
=корень(G3*A6/A3)
б)
=корень(Г3*A6/A3)
в)
=корень(G3*A6*A3)
г)
=корень(Щ3*A6*A3)
Решение:
формулой вычисления ошибки репрезентативности
относительного показателя в программе
Excel (см. рисунок) является «=корень(G3*A6/A3)».
Правильный
ответ:
а.
Литература:
Сабанов В.И. Медицинская информатика и
автоматизированные системы управления
в здравоохранении. Учебно-методическое
пособие к практическим занятиям / В.И.
Сабанов, А.Н. Голубев, Е.Р. Комина. –
Волгоград: Изд-во ВолГМУ, 2006. – 144с. –
стр. 60.
-
ФОРМУЛОЙ
ВЫЧИСЛЕНИЯ НИЖНЕЙ ДОВЕРИТЕЛЬНОЙ
ГРАНИЦЫ В ПРОГРАММЕ EXCEL (СМ. РИСУНОК)
ЯВЛЯЕТСЯ …
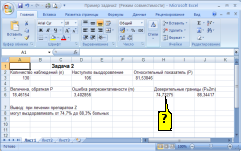
а)
=G2-2*D5
б)
=Г3-2*D6
в)
=G3-2*D6
г)
=G3+2*D6
Решение:
формулой вычисления нижней доверительной
границы в программе Excel (см. рисунок)
является «=G3-2*D6».
Правильный
ответ:
в.
Литература:
Сабанов В.И. Медицинская информатика и
автоматизированные системы управления
в здравоохранении. Учебно-методическое
пособие к практическим занятиям / В.И.
Сабанов, А.Н. Голубев, Е.Р. Комина. –
Волгоград: Изд-во ВолГМУ, 2006. – 144с. –
стр. 60.
-
ФОРМУЛОЙ
ВЫЧИСЛЕНИЯ ВЕРХНЕЙ ДОВЕРИТЕЛЬНОЙ
ГРАНИЦЫ В ПРОГРАММЕ EXCEL (СМ. РИСУНОК)
ЯВЛЯЕТСЯ …
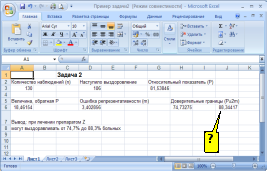
а)
=G2+2*D5
б)
=Г3-2*D6
в)
=G3-2*D6
г)
=G3+2*D6
Решение:
формулой вычисления верхней доверительной
границы в программе Excel (см. рисунок)
является «=G3+2*D6».
Правильный
ответ:
г.
Литература:
Сабанов В.И. Медицинская информатика и
автоматизированные системы управления
в здравоохранении. Учебно-методическое
пособие к практическим занятиям / В.И.
Сабанов, А.Н. Голубев, Е.Р. Комина. –
Волгоград: Изд-во ВолГМУ, 2006. – 144с. –
стр. 60.
Содержание
- Расчет ошибки средней арифметической
- Способ 1: расчет с помощью комбинации функций
- Способ 2: применение инструмента «Описательная статистика»
- Вопросы и ответы
Стандартная ошибка или, как часто называют, ошибка средней арифметической, является одним из важных статистических показателей. С помощью данного показателя можно определить неоднородность выборки. Он также довольно важен при прогнозировании. Давайте узнаем, какими способами можно рассчитать величину стандартной ошибки с помощью инструментов Microsoft Excel.
Расчет ошибки средней арифметической
Одним из показателей, которые характеризуют цельность и однородность выборки, является стандартная ошибка. Эта величина представляет собой корень квадратный из дисперсии. Сама дисперсия является средним квадратном от средней арифметической. Средняя арифметическая вычисляется делением суммарной величины объектов выборки на их общее количество.
В Экселе существуют два способа вычисления стандартной ошибки: используя набор функций и при помощи инструментов Пакета анализа. Давайте подробно рассмотрим каждый из этих вариантов.
Способ 1: расчет с помощью комбинации функций
Прежде всего, давайте составим алгоритм действий на конкретном примере по расчету ошибки средней арифметической, используя для этих целей комбинацию функций. Для выполнения задачи нам понадобятся операторы СТАНДОТКЛОН.В, КОРЕНЬ и СЧЁТ.
Для примера нами будет использована выборка из двенадцати чисел, представленных в таблице.
- Выделяем ячейку, в которой будет выводиться итоговое значение стандартной ошибки, и клацаем по иконке «Вставить функцию».
- Открывается Мастер функций. Производим перемещение в блок «Статистические». В представленном перечне наименований выбираем название «СТАНДОТКЛОН.В».
- Запускается окно аргументов вышеуказанного оператора. СТАНДОТКЛОН.В предназначен для оценивания стандартного отклонения при выборке. Данный оператор имеет следующий синтаксис:
=СТАНДОТКЛОН.В(число1;число2;…)«Число1» и последующие аргументы являются числовыми значениями или ссылками на ячейки и диапазоны листа, в которых они расположены. Всего может насчитываться до 255 аргументов этого типа. Обязательным является только первый аргумент.
Итак, устанавливаем курсор в поле «Число1». Далее, обязательно произведя зажим левой кнопки мыши, выделяем курсором весь диапазон выборки на листе. Координаты данного массива тут же отображаются в поле окна. После этого клацаем по кнопке «OK».
- В ячейку на листе выводится результат расчета оператора СТАНДОТКЛОН.В. Но это ещё не ошибка средней арифметической. Для того, чтобы получить искомое значение, нужно стандартное отклонение разделить на квадратный корень от количества элементов выборки. Для того, чтобы продолжить вычисления, выделяем ячейку, содержащую функцию СТАНДОТКЛОН.В. После этого устанавливаем курсор в строку формул и дописываем после уже существующего выражения знак деления (/). Вслед за этим клацаем по пиктограмме перевернутого вниз углом треугольника, которая располагается слева от строки формул. Открывается список недавно использованных функций. Если вы в нем найдете наименование оператора «КОРЕНЬ», то переходите по данному наименованию. В обратном случае жмите по пункту «Другие функции…».
- Снова происходит запуск Мастера функций. На этот раз нам следует посетить категорию «Математические». В представленном перечне выделяем название «КОРЕНЬ» и жмем на кнопку «OK».
- Открывается окно аргументов функции КОРЕНЬ. Единственной задачей данного оператора является вычисление квадратного корня из заданного числа. Его синтаксис предельно простой:
=КОРЕНЬ(число)Как видим, функция имеет всего один аргумент «Число». Он может быть представлен числовым значением, ссылкой на ячейку, в которой оно содержится или другой функцией, вычисляющей это число. Последний вариант как раз и будет представлен в нашем примере.
Устанавливаем курсор в поле «Число» и кликаем по знакомому нам треугольнику, который вызывает список последних использованных функций. Ищем в нем наименование «СЧЁТ». Если находим, то кликаем по нему. В обратном случае, опять же, переходим по наименованию «Другие функции…».
- В раскрывшемся окне Мастера функций производим перемещение в группу «Статистические». Там выделяем наименование «СЧЁТ» и выполняем клик по кнопке «OK».
- Запускается окно аргументов функции СЧЁТ. Указанный оператор предназначен для вычисления количества ячеек, которые заполнены числовыми значениями. В нашем случае он будет подсчитывать количество элементов выборки и сообщать результат «материнскому» оператору КОРЕНЬ. Синтаксис функции следующий:
=СЧЁТ(значение1;значение2;…)В качестве аргументов «Значение», которых может насчитываться до 255 штук, выступают ссылки на диапазоны ячеек. Ставим курсор в поле «Значение1», зажимаем левую кнопку мыши и выделяем весь диапазон выборки. После того, как его координаты отобразились в поле, жмем на кнопку «OK».
- После выполнения последнего действия будет не только рассчитано количество ячеек заполненных числами, но и вычислена ошибка средней арифметической, так как это был последний штрих в работе над данной формулой. Величина стандартной ошибки выведена в ту ячейку, где размещена сложная формула, общий вид которой в нашем случае следующий:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13))Результат вычисления ошибки средней арифметической составил 0,505793. Запомним это число и сравним с тем, которое получим при решении поставленной задачи следующим способом.
Но дело в том, что для малых выборок (до 30 единиц) для большей точности лучше применять немного измененную формулу. В ней величина стандартного отклонения делится не на квадратный корень от количества элементов выборки, а на квадратный корень от количества элементов выборки минус один. Таким образом, с учетом нюансов малой выборки наша формула приобретет следующий вид:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13)-1)
Урок: Статистические функции в Экселе
Способ 2: применение инструмента «Описательная статистика»
Вторым вариантом, с помощью которого можно вычислить стандартную ошибку в Экселе, является применение инструмента «Описательная статистика», входящего в набор инструментов «Анализ данных» («Пакет анализа»). «Описательная статистика» проводит комплексный анализ выборки по различным критериям. Одним из них как раз и является нахождение ошибки средней арифметической.
Но чтобы воспользоваться данной возможностью, нужно сразу активировать «Пакет анализа», так как по умолчанию в Экселе он отключен.
- После того, как открыт документ с выборкой, переходим во вкладку «Файл».
- Далее, воспользовавшись левым вертикальным меню, перемещаемся через его пункт в раздел «Параметры».
- Запускается окно параметров Эксель. В левой части данного окна размещено меню, через которое перемещаемся в подраздел «Надстройки».
- В самой нижней части появившегося окна расположено поле «Управление». Выставляем в нем параметр «Надстройки Excel» и жмем на кнопку «Перейти…» справа от него.
- Запускается окно надстроек с перечнем доступных скриптов. Отмечаем галочкой наименование «Пакет анализа» и щелкаем по кнопке «OK» в правой части окошка.
- После выполнения последнего действия на ленте появится новая группа инструментов, которая имеет наименование «Анализ». Чтобы перейти к ней, щелкаем по названию вкладки «Данные».
- После перехода жмем на кнопку «Анализ данных» в блоке инструментов «Анализ», который расположен в самом конце ленты.
- Запускается окошко выбора инструмента анализа. Выделяем наименование «Описательная статистика» и жмем на кнопку «OK» справа.
- Запускается окно настроек инструмента комплексного статистического анализа «Описательная статистика».
В поле «Входной интервал» необходимо указать диапазон ячеек таблицы, в которых находится анализируемая выборка. Вручную это делать неудобно, хотя и можно, поэтому ставим курсор в указанное поле и при зажатой левой кнопке мыши выделяем соответствующий массив данных на листе. Его координаты тут же отобразятся в поле окна.
В блоке «Группирование» оставляем настройки по умолчанию. То есть, переключатель должен стоять около пункта «По столбцам». Если это не так, то его следует переставить.
Галочку «Метки в первой строке» можно не устанавливать. Для решения нашего вопроса это не важно.
Далее переходим к блоку настроек «Параметры вывода». Здесь следует указать, куда именно будет выводиться результат расчета инструмента «Описательная статистика»:
- На новый лист;
- В новую книгу (другой файл);
- В указанный диапазон текущего листа.
Давайте выберем последний из этих вариантов. Для этого переставляем переключатель в позицию «Выходной интервал» и устанавливаем курсор в поле напротив данного параметра. После этого клацаем на листе по ячейке, которая станет верхним левым элементом массива вывода данных. Её координаты должны отобразиться в поле, в котором мы до этого устанавливали курсор.
Далее следует блок настроек определяющий, какие именно данные нужно вводить:
- Итоговая статистика;
- К-ый наибольший;
- К-ый наименьший;
- Уровень надежности.
Для определения стандартной ошибки обязательно нужно установить галочку около параметра «Итоговая статистика». Напротив остальных пунктов выставляем галочки на свое усмотрение. На решение нашей основной задачи это никак не повлияет.
После того, как все настройки в окне «Описательная статистика» установлены, щелкаем по кнопке «OK» в его правой части.
- После этого инструмент «Описательная статистика» выводит результаты обработки выборки на текущий лист. Как видим, это довольно много разноплановых статистических показателей, но среди них есть и нужный нам – «Стандартная ошибка». Он равен числу 0,505793. Это в точности тот же результат, который мы достигли путем применения сложной формулы при описании предыдущего способа.
Урок: Описательная статистика в Экселе
Как видим, в Экселе можно произвести расчет стандартной ошибки двумя способами: применив набор функций и воспользовавшись инструментом пакета анализа «Описательная статистика». Итоговый результат будет абсолютно одинаковый. Поэтому выбор метода зависит от удобства пользователя и поставленной конкретной задачи. Например, если ошибка средней арифметической является только одним из многих статистических показателей выборки, которые нужно рассчитать, то удобнее воспользоваться инструментом «Описательная статистика». Но если вам нужно вычислить исключительно этот показатель, то во избежание нагромождения лишних данных лучше прибегнуть к сложной формуле. В этом случае результат расчета уместится в одной ячейке листа.
Полученные
в результате статистического исследования
средние и относительные величины должны
отражать закономерности, характерные
для всей совокупности. Результаты
исследования обычно тем достовернее,
чем больше сделано наблюдений, и наиболее
точными они являются при сплошном
исследовании (т.е. при изучении генеральной
совокупности). Однако должны быть
достаточно надежные и данные, полученные
путем выборочных исследований, т.е. на
относительно небольшом числе наблюдений.
Различие
результатов выборочного исследования
и результатов, которые могут быть
получены на генеральной совокупности,
представляет собой ошибку выборочного
исследования, которую можно точно
определить математическим путем. Метод
ее оценки основан на закономерностях
случайных вариаций, установленных
теорией вероятности.
1.
Оценка достоверности средней
арифметической.
Средняя
арифметическая, полученная при обработке
результатов научно-практических
исследований, под влиянием случайных
явлений может отличаться от средних,
полученных при проведении повторных
исследований. Поэтому, чтобы иметь
представление о возможных пределах
колебаний средней, о том, с какой
вероятностью возможно перенести
результаты исследования с выборочной
совокупности на всю генеральную
совокупность, определяют степень
достоверности средней величины.
Мерой
достоверности средней является средняя
ошибка средней арифметической (ошибка
репрезентативности – m).
Ошибки репрезентативности возникают
в связи с тем, что при выборочным
наблюдении изучается только часть
генеральной совокупности, которая
недостаточно точно ее представляет.
Фактически ошибка репрезентативности
является разностью между средними,
полученными при выборочном статистическом
наблюдении, и средними, которые были бы
получены при сплошном наблюдении (т.е.
при изучении всей генеральной
совокупности).
Средняя
ошибка средней арифметической вычисляется
по формуле:
—
при числе наблюдений больше 30 (n
> 30):
![]()
—
при небольшом числе наблюдений (n
< 30):
![]()
Ошибка
репрезентативности прямо пропорциональна
колеблемости ряда (сигме) и обратно
пропорциональна числу наблюдений.
Следовательно,
чем больше
число наблюдений
(т.е. чем ближе по числу наблюдений
выборочная совокупность к генеральной),
тем меньше
ошибка репрезентативности.
Интервал,
в котором с заданным уровнем вероятности
колеблется истинное значение средней
величины или показателя, называется
доверительным
интервалом,
а его границы – доверительными
границами.
Они используются для определения
размеров средней или показателя в
генеральной совокупности.
Доверительные
границы
средней арифметической и показателя в
генеральной совокупности равны:
M
+
tm
P
+
tm,
где
t
– доверительный коэффициент.
Доверительный
коэффициент (t)
– это число, показывающее, во сколько
раз надо увеличить ошибку средней
величины или показателя, чтобы при
данном числе наблюдений с желаемой
степенью вероятности утверждать, что
они не выйдут за полученные таким образом
пределы.
С
увеличением t
степень вероятности возрастает.
Т.к.
известно, что полученная средняя или
показатель при повторных наблюдениях,
даже при одинаковых условиях, в силу
случайных колебаний будут отличаться
от предыдущего результат, теорией
статистики установлена степень
вероятности, с которой можно ожидать,
что колебания эти не выйдут за определенные
пределы. Так, колебания средней
в интервале M
+
1m
гарантируют ее точность с вероятностью
68.3% (такая
степень вероятности не удовлетворяет
исследователей), в
интервале M
+
2m
– 95.5%
(достаточная степень вероятности) и в
интервале M
+
3m
– 99,7% (большая
степень вероятности).
Для
медико-биологических исследований
принята степень вероятности 95% (t
= 2), что соответствует доверительному
интервалу M
+
2m.
Это
означает, что практически
с полной достоверностью (в 95%) можно
утверждать, что полученный средний
результат (М) отклоняется от истинного
значения не больше, чем на удвоенную (M
+
2m) ошибку.
Конечный
результат любого медико-статистического
исследования выражается средней
арифметической и ее параметрами:
![]()
2.
Оценка достоверности относительных
величин (показателей).
Средняя
ошибка показателя также служит для
определения пределов его случайных
колебаний, т.е. дает представление, в
каких пределах может находиться
показатель в различных выборках в
зависимости от случайных причин. С
увеличением численности выборки ошибка
уменьшается.
Мерой
достоверности показателя является его
средняя ошибка (m),
которая показывает, на сколько результат,
полученный при выборочным исследовании,
отличается от результата, который был
бы получен при изучении всей генеральной
совокупности.
Средняя
ошибка показателя определяется по
формуле:
![]() ,
,
где mp
– ошибка относительного показателя,
р
– показатель,
q
– величина, обратная показателю (100-p,
1000-р и т.д. в зависимости от того, на какое
основание рассчитан показатель);
n
– число наблюдений.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Среднее арифметическое, как известно, используется для получения обобщающей характеристики некоторого набора данных. Если данные более-менее однородны и в них нет аномальных наблюдений (выбросов), то среднее хорошо обобщает данные, сведя к минимуму влияние случайных факторов (они взаимопогашаются при сложении).
Когда анализируемые данные представляют собой выборку (которая состоит из случайных значений), то среднее арифметическое часто (но не всегда) выступает в роли приближенной оценки математического ожидания. Почему приближенной? Потому что среднее арифметическое – это величина, которая зависит от набора случайных чисел, и, следовательно, сама является случайной величиной. При повторных экспериментах (даже в одних и тех же условиях) средние будут отличаться друг от друга.
Для того, чтобы на основе статистического анализа данных делать корректные выводы, необходимо оценить возможный разброс полученного результата. Для этого рассчитываются различные показатели вариации. Но то исходные данные. И как мы только что установили, среднее арифметическое также обладает разбросом, который необходимо оценить и учитывать в дальнейшем (в выводах, в выборе метода анализа и т.д.).
Интуитивно понятно, что разброс средней должен быть как-то связан с разбросом исходных данных. Основной характеристикой разброса средней выступает та же дисперсия.
Дисперсия выборочных данных – это средний квадрат отклонения от средней, и рассчитать ее по исходным данным не составляет труда, например, в Excel предусмотрены специальные функции. Однако, как же рассчитать дисперсию средней, если в распоряжении есть только одна выборка и одно среднее арифметическое?
Расчет дисперсии и стандартной ошибки средней арифметической
Чтобы получить дисперсию средней арифметической нет необходимости проводить множество экспериментов, достаточно иметь только одну выборку. Это легко доказать. Для начала вспомним, что средняя арифметическая (простая) рассчитывается по формуле:
![]()
где xi – значения переменной,
n – количество значений.
Теперь учтем два свойства дисперсии, согласно которым, 1) — постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат и 2) — дисперсия суммы независимых случайных величин равняется сумме соответствующих дисперсий. Предполагается, что каждое случайное значение xi обладает одинаковым разбросом, поэтому несложно вывести формулу дисперсии средней арифметической:
![]()
Используя более привычные обозначения, формулу записывают как:
![]()
где σ2 – это дисперсия, случайной величины, причем генеральная.
На практике же, генеральная дисперсия известна далеко не всегда, точнее совсем редко, поэтому в качестве оной используют выборочную дисперсию:
![]()
Стандартное отклонение средней арифметической называется стандартной ошибкой средней и рассчитывается, как квадратный корень из дисперсии.
Формула стандартной ошибки средней при использовании генеральной дисперсии
![]()
Формула стандартной ошибки средней при использовании выборочной дисперсии
![]()
Последняя формула на практике используется чаще всего, т.к. генеральная дисперсия обычно не известна. Чтобы не вводить новые обозначения, стандартную ошибку средней обычно записывают в виде соотношения стандартного отклонения выборки и корня объема выборки.
Назначение и свойство стандартной ошибки средней арифметической
Стандартная ошибка средней много, где используется. И очень полезно понимать ее свойства. Посмотрим еще раз на формулу стандартной ошибки средней:
![]()
Числитель – это стандартное отклонение выборки и здесь все понятно. Чем больше разброс данных, тем больше стандартная ошибка средней – прямо пропорциональная зависимость.
Посмотрим на знаменатель. Здесь находится квадратный корень из объема выборки. Соответственно, чем больше объем выборки, тем меньше стандартная ошибка средней. Для наглядности изобразим на одной диаграмме график нормально распределенной переменной со средней равной 10, сигмой – 3, и второй график – распределение средней арифметической этой же переменной, полученной по 16-ти наблюдениям (которое также будет нормальным).

Судя по формуле, разброс стандартной ошибки средней должен быть в 4 раза (корень из 16) меньше, чем разброс исходных данных, что и видно на рисунке выше. Чем больше наблюдений, тем меньше разброс средней.
Казалось бы, что для получения наиболее точной средней достаточно использовать максимально большую выборку и тогда стандартная ошибка средней будет стремиться к нулю, а сама средняя, соответственно, к математическому ожиданию. Однако квадратный корень объема выборки в знаменателе говорит о том, что связь между точностью выборочной средней и размером выборки не является линейной. Например, увеличение выборки с 20-ти до 50-ти наблюдений, то есть на 30 значений или в 2,5 раза, уменьшает стандартную ошибку средней только на 36%, а со 100-а до 130-ти наблюдений (на те же 30 значений), снижает разброс данных лишь на 12%.
Лучше всего изобразить эту мысль в виде графика зависимости стандартной ошибки средней от размера выборки. Пусть стандартное отклонение равно 10 (на форму графика это не влияет).

Видно, что примерно после 50-ти значений, уменьшение стандартной ошибки средней резко замедляется, после 100-а – наклон постепенно становится почти нулевым.
Таким образом, при достижении некоторого размера выборки ее дальнейшее увеличение уже почти не сказывается на точности средней. Этот факт имеет далеко идущие последствия. Например, при проведении выборочного обследования населения (опроса) чрезмерное увеличение выборки ведет к неоправданным затратам, т.к. точность почти не меняется. Именно поэтому количество опрошенных редко превышает 1,5 тысячи человек. Точность при таком размере выборки часто является достаточной, а дальнейшее увеличение выборки – нецелесообразным.
Подведем итог. Расчет дисперсии и стандартной ошибки средней имеет довольно простую формулу и обладает полезным свойством, связанным с тем, что относительно хорошая точность средней достигается уже при 100 наблюдениях (в этом случае стандартная ошибка средней становится в 10 раз меньше, чем стандартное отклонение выборки). Больше, конечно, лучше, но бесконечно увеличивать объем выборки не имеет практического смысла. Хотя, все зависит от поставленных задач и цены ошибки. В некоторых опросах участие принимают десятки тысяч людей.
Дисперсия и стандартная ошибка средней имеют большое практическое значение. Они используются в проверке гипотез и расчете доверительных интервалов.
Поделиться в социальных сетях:
![]()
Загрузить PDF
![]()
Загрузить PDF
Стандартной ошибкой называется величина, которая характеризует стандартное (среднеквадратическое) отклонение выборочного среднего. Другими словами, эту величину можно использовать для оценки точности выборочного среднего. Множество областей применения стандартной ошибки по умолчанию предполагают нормальное распределение. Если вам нужно рассчитать стандартную ошибку, перейдите к шагу 1.
-
1
Запомните определение среднеквадратического отклонения. Среднеквадратическое отклонение выборки – это мера рассеянности значения. Среднеквадратическое отклонение выборки обычно обозначается буквой s. Математическая формула среднеквадратического отклонения приведена выше.
-
2
Узнайте, что такое истинное среднее значение. Истинное среднее является средним группы чисел, включающим все числа всей группы – другими словами, это среднее всей группы чисел, а не выборки.
-
3
Научитесь рассчитывать среднеарифметическое значение. Среднеаримфетическое означает попросту среднее: сумму значений собранных данных, разделенную на количество значений этих данных.
-
4
Узнайте, что такое выборочное среднее. Когда среднеарифметическое значение основано на серии наблюдений, полученных в результате выборок из статистической совокупности, оно называется “выборочным средним”. Это среднее выборки чисел, которое описывает среднее значение лишь части чисел из всей группы. Его обозначают как:
-
5
Усвойте понятие нормального распределения. Нормальные распределения, которые используются чаще других распределений, являются симметричными, с единичным максимумом в центре – на среднем значении данных. Форма кривой подобна очертаниям колокола, при этом график равномерно опускается по обе стороны от среднего. Пятьдесят процентов распределения лежит слева от среднего, а другие пятьдесят процентов – справа от него. Рассеянность значений нормального распределения описывается стандартным отклонением.
-
6
Запомните основную формулу. Формула для вычисления стандартной ошибки приведена выше.
Реклама






-
1
Рассчитайте выборочное среднее. Чтобы найти стандартную ошибку, сначала нужно определить среднеквадратическое отклонение (поскольку среднеквадратическое отклонение s входит в формулу для вычисления стандартной ошибки). Начните с нахождения средних значений. Выборочное среднее выражается как среднее арифметическое измерений x1, x2, . . . , xn. Его рассчитывают по формуле, приведенной выше.
- Допустим, например, что вам нужно рассчитать стандартную ошибку выборочного среднего результатов измерения массы пяти монет, указанных в таблице:
Вы сможете рассчитать выборочное среднее, подставив значения массы в формулу:
- Допустим, например, что вам нужно рассчитать стандартную ошибку выборочного среднего результатов измерения массы пяти монет, указанных в таблице:
-
2
Вычтите выборочное среднее из каждого измерения и возведите полученное значение в квадрат. Как только вы получите выборочное среднее, вы можете расширить вашу таблицу, вычтя его из каждого измерения и возведя результат в квадрат.
- Для нашего примера расширенная таблица будет иметь следующий вид:
-
3
Найдите суммарное отклонение ваших измерений от выборочного среднего. Общее отклонение – это сумма возведенных в квадрат разностей от выборочного среднего. Чтобы определить его, сложите ваши новые значения.
- В нашем примере нужно будет выполнить следующий расчет:
Это уравнение дает сумму квадратов отклонений измерений от выборочного среднего.
- В нашем примере нужно будет выполнить следующий расчет:
-
4
Рассчитайте среднеквадратическое отклонение ваших измерений от выборочного среднего. Как только вы будете знать суммарное отклонение, вы сможете найти среднее отклонение, разделив ответ на n -1. Обратите внимание, что n равно числу измерений.
- В нашем примере было сделано 5 измерений, следовательно n – 1 будет равно 4. Расчет нужно вести следующим образом:
-
5
Найдите среднеквадратичное отклонение. Сейчас у вас есть все необходимые значения для того, чтобы воспользоваться формулой для нахождения среднеквадратичного отклонения s.
- В нашем примере вы будете рассчитывать среднеквадратичное отклонение следующим образом:
Следовательно, среднеквадратичное отклонение равно 0,0071624.
Реклама
- В нашем примере вы будете рассчитывать среднеквадратичное отклонение следующим образом:





-
1
Чтобы вычислить стандартную ошибку, воспользуйтесь базовой формулой со среднеквадратическим отклонением.
- В нашем примере вы сможете рассчитать стандартную ошибку следующим образом:
Таким образом в нашем примере стандартная ошибка (среднеквадратическое отклонение выборочного среднего) составляет 0,0032031 грамма.
- В нашем примере вы сможете рассчитать стандартную ошибку следующим образом:

Советы
- Стандартную ошибку и среднеквадратическое отклонение часто путают. Обратите внимание, что стандартная ошибка описывает среднеквадратическое отклонение выборочного распределения статистических данных, а не распределения отдельных значений
- В научных журналах понятия стандартной ошибки и среднеквадратического отклонения несколько размыты. Для объединения двух величин используется знак ±.
Реклама
Об этой статье
Эту страницу просматривали 48 054 раза.
Была ли эта статья полезной?
Содержание
- Расчет ошибки средней арифметической
- Способ 1: расчет с помощью комбинации функций
- Способ 2: применение инструмента «Описательная статистика»
- Вопросы и ответы
Стандартная ошибка или, как часто называют, ошибка средней арифметической, является одним из важных статистических показателей. С помощью данного показателя можно определить неоднородность выборки. Он также довольно важен при прогнозировании. Давайте узнаем, какими способами можно рассчитать величину стандартной ошибки с помощью инструментов Microsoft Excel.
Расчет ошибки средней арифметической
Одним из показателей, которые характеризуют цельность и однородность выборки, является стандартная ошибка. Эта величина представляет собой корень квадратный из дисперсии. Сама дисперсия является средним квадратном от средней арифметической. Средняя арифметическая вычисляется делением суммарной величины объектов выборки на их общее количество.
В Экселе существуют два способа вычисления стандартной ошибки: используя набор функций и при помощи инструментов Пакета анализа. Давайте подробно рассмотрим каждый из этих вариантов.
Способ 1: расчет с помощью комбинации функций
Прежде всего, давайте составим алгоритм действий на конкретном примере по расчету ошибки средней арифметической, используя для этих целей комбинацию функций. Для выполнения задачи нам понадобятся операторы СТАНДОТКЛОН.В, КОРЕНЬ и СЧЁТ.
Для примера нами будет использована выборка из двенадцати чисел, представленных в таблице.
- Выделяем ячейку, в которой будет выводиться итоговое значение стандартной ошибки, и клацаем по иконке «Вставить функцию».
- Открывается Мастер функций. Производим перемещение в блок «Статистические». В представленном перечне наименований выбираем название «СТАНДОТКЛОН.В».
- Запускается окно аргументов вышеуказанного оператора. СТАНДОТКЛОН.В предназначен для оценивания стандартного отклонения при выборке. Данный оператор имеет следующий синтаксис:
=СТАНДОТКЛОН.В(число1;число2;…)«Число1» и последующие аргументы являются числовыми значениями или ссылками на ячейки и диапазоны листа, в которых они расположены. Всего может насчитываться до 255 аргументов этого типа. Обязательным является только первый аргумент.
Итак, устанавливаем курсор в поле «Число1». Далее, обязательно произведя зажим левой кнопки мыши, выделяем курсором весь диапазон выборки на листе. Координаты данного массива тут же отображаются в поле окна. После этого клацаем по кнопке «OK».
- В ячейку на листе выводится результат расчета оператора СТАНДОТКЛОН.В. Но это ещё не ошибка средней арифметической. Для того, чтобы получить искомое значение, нужно стандартное отклонение разделить на квадратный корень от количества элементов выборки. Для того, чтобы продолжить вычисления, выделяем ячейку, содержащую функцию СТАНДОТКЛОН.В. После этого устанавливаем курсор в строку формул и дописываем после уже существующего выражения знак деления (/). Вслед за этим клацаем по пиктограмме перевернутого вниз углом треугольника, которая располагается слева от строки формул. Открывается список недавно использованных функций. Если вы в нем найдете наименование оператора «КОРЕНЬ», то переходите по данному наименованию. В обратном случае жмите по пункту «Другие функции…».
- Снова происходит запуск Мастера функций. На этот раз нам следует посетить категорию «Математические». В представленном перечне выделяем название «КОРЕНЬ» и жмем на кнопку «OK».
- Открывается окно аргументов функции КОРЕНЬ. Единственной задачей данного оператора является вычисление квадратного корня из заданного числа. Его синтаксис предельно простой:
=КОРЕНЬ(число)Как видим, функция имеет всего один аргумент «Число». Он может быть представлен числовым значением, ссылкой на ячейку, в которой оно содержится или другой функцией, вычисляющей это число. Последний вариант как раз и будет представлен в нашем примере.
Устанавливаем курсор в поле «Число» и кликаем по знакомому нам треугольнику, который вызывает список последних использованных функций. Ищем в нем наименование «СЧЁТ». Если находим, то кликаем по нему. В обратном случае, опять же, переходим по наименованию «Другие функции…».
- В раскрывшемся окне Мастера функций производим перемещение в группу «Статистические». Там выделяем наименование «СЧЁТ» и выполняем клик по кнопке «OK».
- Запускается окно аргументов функции СЧЁТ. Указанный оператор предназначен для вычисления количества ячеек, которые заполнены числовыми значениями. В нашем случае он будет подсчитывать количество элементов выборки и сообщать результат «материнскому» оператору КОРЕНЬ. Синтаксис функции следующий:
=СЧЁТ(значение1;значение2;…)В качестве аргументов «Значение», которых может насчитываться до 255 штук, выступают ссылки на диапазоны ячеек. Ставим курсор в поле «Значение1», зажимаем левую кнопку мыши и выделяем весь диапазон выборки. После того, как его координаты отобразились в поле, жмем на кнопку «OK».
- После выполнения последнего действия будет не только рассчитано количество ячеек заполненных числами, но и вычислена ошибка средней арифметической, так как это был последний штрих в работе над данной формулой. Величина стандартной ошибки выведена в ту ячейку, где размещена сложная формула, общий вид которой в нашем случае следующий:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13))Результат вычисления ошибки средней арифметической составил 0,505793. Запомним это число и сравним с тем, которое получим при решении поставленной задачи следующим способом.
Но дело в том, что для малых выборок (до 30 единиц) для большей точности лучше применять немного измененную формулу. В ней величина стандартного отклонения делится не на квадратный корень от количества элементов выборки, а на квадратный корень от количества элементов выборки минус один. Таким образом, с учетом нюансов малой выборки наша формула приобретет следующий вид:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13)-1)
Урок: Статистические функции в Экселе
Способ 2: применение инструмента «Описательная статистика»
Вторым вариантом, с помощью которого можно вычислить стандартную ошибку в Экселе, является применение инструмента «Описательная статистика», входящего в набор инструментов «Анализ данных» («Пакет анализа»). «Описательная статистика» проводит комплексный анализ выборки по различным критериям. Одним из них как раз и является нахождение ошибки средней арифметической.
Но чтобы воспользоваться данной возможностью, нужно сразу активировать «Пакет анализа», так как по умолчанию в Экселе он отключен.
- После того, как открыт документ с выборкой, переходим во вкладку «Файл».
- Далее, воспользовавшись левым вертикальным меню, перемещаемся через его пункт в раздел «Параметры».
- Запускается окно параметров Эксель. В левой части данного окна размещено меню, через которое перемещаемся в подраздел «Надстройки».
- В самой нижней части появившегося окна расположено поле «Управление». Выставляем в нем параметр «Надстройки Excel» и жмем на кнопку «Перейти…» справа от него.
- Запускается окно надстроек с перечнем доступных скриптов. Отмечаем галочкой наименование «Пакет анализа» и щелкаем по кнопке «OK» в правой части окошка.
- После выполнения последнего действия на ленте появится новая группа инструментов, которая имеет наименование «Анализ». Чтобы перейти к ней, щелкаем по названию вкладки «Данные».
- После перехода жмем на кнопку «Анализ данных» в блоке инструментов «Анализ», который расположен в самом конце ленты.
- Запускается окошко выбора инструмента анализа. Выделяем наименование «Описательная статистика» и жмем на кнопку «OK» справа.
- Запускается окно настроек инструмента комплексного статистического анализа «Описательная статистика».
В поле «Входной интервал» необходимо указать диапазон ячеек таблицы, в которых находится анализируемая выборка. Вручную это делать неудобно, хотя и можно, поэтому ставим курсор в указанное поле и при зажатой левой кнопке мыши выделяем соответствующий массив данных на листе. Его координаты тут же отобразятся в поле окна.
В блоке «Группирование» оставляем настройки по умолчанию. То есть, переключатель должен стоять около пункта «По столбцам». Если это не так, то его следует переставить.
Галочку «Метки в первой строке» можно не устанавливать. Для решения нашего вопроса это не важно.
Далее переходим к блоку настроек «Параметры вывода». Здесь следует указать, куда именно будет выводиться результат расчета инструмента «Описательная статистика»:
- На новый лист;
- В новую книгу (другой файл);
- В указанный диапазон текущего листа.
Давайте выберем последний из этих вариантов. Для этого переставляем переключатель в позицию «Выходной интервал» и устанавливаем курсор в поле напротив данного параметра. После этого клацаем на листе по ячейке, которая станет верхним левым элементом массива вывода данных. Её координаты должны отобразиться в поле, в котором мы до этого устанавливали курсор.
Далее следует блок настроек определяющий, какие именно данные нужно вводить:
- Итоговая статистика;
- К-ый наибольший;
- К-ый наименьший;
- Уровень надежности.
Для определения стандартной ошибки обязательно нужно установить галочку около параметра «Итоговая статистика». Напротив остальных пунктов выставляем галочки на свое усмотрение. На решение нашей основной задачи это никак не повлияет.
После того, как все настройки в окне «Описательная статистика» установлены, щелкаем по кнопке «OK» в его правой части.
- После этого инструмент «Описательная статистика» выводит результаты обработки выборки на текущий лист. Как видим, это довольно много разноплановых статистических показателей, но среди них есть и нужный нам – «Стандартная ошибка». Он равен числу 0,505793. Это в точности тот же результат, который мы достигли путем применения сложной формулы при описании предыдущего способа.
Урок: Описательная статистика в Экселе
Как видим, в Экселе можно произвести расчет стандартной ошибки двумя способами: применив набор функций и воспользовавшись инструментом пакета анализа «Описательная статистика». Итоговый результат будет абсолютно одинаковый. Поэтому выбор метода зависит от удобства пользователя и поставленной конкретной задачи. Например, если ошибка средней арифметической является только одним из многих статистических показателей выборки, которые нужно рассчитать, то удобнее воспользоваться инструментом «Описательная статистика». Но если вам нужно вычислить исключительно этот показатель, то во избежание нагромождения лишних данных лучше прибегнуть к сложной формуле. В этом случае результат расчета уместится в одной ячейке листа.
Условное
обозначение средней арифметической
величины через М (от латинского слова
Media) чаще применяется в медицинских и
педагогических исследованиях. В
математической статистике предпочитают
обозначение через ![]() .
.
Средняя арифметическая величина является
производной, обобщающей количественные
признаки ряда однородных показателей
(совокупности). Выражая одним числом
определенную совокупность, она как бы
ослабляет влияние случайных индивидуальных
отклонений, и акцентирует некую обобщенную
количественную характеристику, наиболее
типичное свойство изучаемого ряда
показателей.
Определяя
значение средней арифметической
величины, следует придерживаться
некоторых правил.
1.
Средняя арифметическая величина может
характеризовать только те признаки
изучаемого объекта, которые присущи
всей совокупности, но в разной
количественной мере (например, уровень
развития быстроты движений характерен
для каждого человека, хотя и в разной
количественной мере). Средняя арифметическая
величина не может характеризовать
количественную меру тех признаков,
которые одной части совокупности
присущи, а другой нет, т. е. она не может
отражать присутствие или отсутствие
того или иного признака (например, умение
или неумение выполнять то или иное
двигательное действие).
2.
Средняя арифметическая величина должна
включать все показатели, полученные в
данном исследовании. Произвольное
исключение даже некоторых из них
неизбежно приведет к искажению конечного
результата.
3.
Средняя арифметическая величина обязана
отражать только однородную совокупность.
Нельзя, например, определять средний
уровень физического развития школьников,
не разделив их предварительно по возрасту
и полу.
4.
Средняя арифметическая величина должна
вычисляться на достаточно большой
совокупности, размеры которой определяются
в каждом конкретном случае отдельно
(см. «Подбор исследуемых»).
5.
Необходимо стремиться к тому, чтобы
средняя арифметическая величина имела
четкие и простые свойства, позволяющие
легко и быстро ее вычислять.
6.
Средняя арифметическая величина должна
обладать достаточной устойчивостью к
действию случайных факторов. Только в
этом случае она будет отражать
действительное состояние изучаемого
явления, а не его случайные изменения.
7.
Точность вычисления средней арифметической
величины должна соответствовать
содержанию изучаемого педагогического
явления. В некоторых случаях нет
необходимости в расчетах с большой
точностью, в других — большая точность
нужна при вычислениях, но совершенно
не нужна в выводах. Например, при расчете
средних величин числа подтягиваний на
перекладине можно пользоваться и сотыми
долями целого, но представлять и выводах,
что исследуемые в среднем подтянулись
7,83 раза, было бы неграмотна, так как
невозможно измерение с подобной
точностью. В этом случае необходимо в
выводах представлять числа, округленные
до целых единиц.
В
простейшем случае этот показатель
вычисляется путем сложения всех
полученных значений (которые называются
вариантами) и деления суммы на число
вариант:
![]()
где
S — знак суммирования;
V
— полученные в исследовании значения
(варианты);
п
— число вариант.
По
этой формуле вычисляется так называемая
простая средняя арифметическая величина.
Применяется она в тех случаях, когда
имеется небольшое число вариант.
При
большом числе вариант прибегают к
вычислению так называемой взвешенной
средней арифметической величины. С этой
целью строят ряд распределения, или
вариационный ряд, который представляет
собой ряд вариант и их частот,
характеризующих какой-нибудь признак
в убывающем или возрастающем порядке.
Например, в нашем случае измерение
точности попадания мячом в цель дало
125 вариант, т. е. в группе I, где применялась
методика обучения «А», одноразово
исследовалось 125 детей с числовым
выражением от 0 (точное попадание в цель)
до 21,5 см (максимальное отклонение от
цели). Каждое числовое выражение
встречалось в исследовании один и более
раз, например «0» встретился 28 раз.
Другими словами, 28 участников эксперимента
точно попали в цель. Этот показатель
называется числом наблюдений или
частотой вариант и условно обозначается
буквой «Р» (число наблюдений составляет
часть числа вариант).
Для
упрощения числовых операций все 125
вариант разбиваются на классы с величиной
интервала 1,9 см. Число классов зависит
от величины колебаний вариант (разности
между максимальной и минимальной
вариантами), наличия вариант для каждого
класса (если, например, для первого
класса — «0 — 1,9» — нет соответствующих
вариант, т.е. ни один исследуемый не имел
точных попаданий или отклонений от цели
в пределах от 0 до 1,9 см, то подобный класс
не вносится в вариационный ряд) и,
наконец, требуемой точности вычисления,
(чем больше классов, тем точность
вычисления выше). Вполне понятно, что
чем больше величина интервала, тем
меньше число классов при одной и той же
величине колебаний вариант.
После
разбивки вариант по классам в каждом
классе определяется срединная варианта
«Vc»,
и для каждой срединной варианты
проставляется число наблюдений. Пример
этих операций, и дальнейший ход вычислений
приведены в следующей таблице:
|
Классы |
Серединные |
Число |
VCP |
VC-M=d |
d2 |
d2P |
|
0 |
1 |
28 |
28 |
-4.6 |
21.16 |
592.48 |
|
2 |
3 |
29 |
87 |
-2.6 |
6.76 |
196.04 |
|
4 |
5 |
22 |
110 |
-0.6 |
0.36 |
7.92 |
|
6 |
7 |
13 |
91 |
1.4 |
1.96 |
25.48 |
|
8 |
9 |
11 |
99 |
3.4 |
11.56 |
127.16 |
|
10 |
11 |
13 |
143 |
5.4 |
29.16 |
379.08 |
|
12 |
13 |
4 |
52 |
7.4 |
54.76 |
219.04 |
|
14 |
15 |
2 |
30 |
9.4 |
88.36 |
176.72 |
|
16 |
17 |
1 |
17 |
11.4 |
130.00 |
130.00 |
|
18 |
19 |
1 |
19 |
13.4 |
179.60 |
179.60 |
|
20 |
21 |
1 |
21 |
15.4 |
237.20 |
237.20 |
|
125 |
697 |
2270.72 |
Очередность
числовых операций:
1)
вычислить сумму числа наблюдений (в
нашем примере она равна 125);
2)
вычислить произведение каждой срединной
варианты на ее частоту (например, 1*28 =
28);
3)
вычислить сумму произведений срединных
вариант на их частоты (в нашем примере
она равна 697);
4)
вычислить взвешенную среднюю арифметическую
величину по формуле:
![]()
Средняя
арифметическая величина позволяет
сравнивать и оценивать группы изучаемых
явлений в целом. Однако для характеристики
группы явлений только этой величины
явно недостаточно, так как размер
колебаний вариант, из которых она
складывается, может быть различным.
Поэтому в характеристику группы явлений
необходимо ввести такой показатель,
который давал бы представление о величине
колебаний вариант около их средней
величины.
Вычисление
средней ошибки среднего арифметического.
Условное обозначение средней ошибки
среднего арифметического — т. Следует
помнить, что под «ошибкой» в статистике
понимается не ошибка исследования, а
мера представительства данной величины,
т. е. мера, которой средняя арифметическая
величина, полученная на выборочной
совокупности (в нашем примере — на 125
детях), отличается от истинной средней
арифметической величины, которая была
бы получена на генеральной совокупности
(в нашем примере это были бы все дети
аналогичного возраста, уровня
подготовленности и т. д.). Например, в
приведенном ранее примере определялась
точность попадания малым мячом в цель
у 125 детей и была получена средняя
арифметическая величина примерно равная
5,6 см. Теперь надо установить, в какой
мере эта величина будет характерна,
если взять для исследования 200, 300, 500 и
больше аналогичных детей. Ответ на этот
вопрос и даст вычисление средней ошибки
среднего арифметического, которое
производится по формуле:
![]()
Для
приведенного примера величина средней
ошибки среднего арифметического будет
равна:
![]()
Следовательно,
M±m = 5,6±0,38. Это означает, что полученная
средняя арифметическая величина (M =
5,6) может иметь в других аналогичных
исследованиях значения от 5,22 (5,6 — 0,38 =
5,22) до 5,98 (5,6+0,38 = 5,98).
Соседние файлы в предмете Ветеринарная генетика
- #
- #
- #
Среднее арифметическое, как известно, используется для получения обобщающей характеристики некоторого набора данных. Если данные более-менее однородны и в них нет аномальных наблюдений (выбросов), то среднее хорошо обобщает данные, сведя к минимуму влияние случайных факторов (они взаимопогашаются при сложении).
Когда анализируемые данные представляют собой выборку (которая состоит из случайных значений), то среднее арифметическое часто (но не всегда) выступает в роли приближенной оценки математического ожидания. Почему приближенной? Потому что среднее арифметическое – это величина, которая зависит от набора случайных чисел, и, следовательно, сама является случайной величиной. При повторных экспериментах (даже в одних и тех же условиях) средние будут отличаться друг от друга.
Для того, чтобы на основе статистического анализа данных делать корректные выводы, необходимо оценить возможный разброс полученного результата. Для этого рассчитываются различные показатели вариации. Но то исходные данные. И как мы только что установили, среднее арифметическое также обладает разбросом, который необходимо оценить и учитывать в дальнейшем (в выводах, в выборе метода анализа и т.д.).
Интуитивно понятно, что разброс средней должен быть как-то связан с разбросом исходных данных. Основной характеристикой разброса средней выступает та же дисперсия.
Дисперсия выборочных данных – это средний квадрат отклонения от средней, и рассчитать ее по исходным данным не составляет труда, например, в Excel предусмотрены специальные функции. Однако, как же рассчитать дисперсию средней, если в распоряжении есть только одна выборка и одно среднее арифметическое?
Расчет дисперсии и стандартной ошибки средней арифметической
Чтобы получить дисперсию средней арифметической нет необходимости проводить множество экспериментов, достаточно иметь только одну выборку. Это легко доказать. Для начала вспомним, что средняя арифметическая (простая) рассчитывается по формуле:
![]()
где xi – значения переменной,
n – количество значений.
Теперь учтем два свойства дисперсии, согласно которым, 1) — постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат и 2) — дисперсия суммы независимых случайных величин равняется сумме соответствующих дисперсий. Предполагается, что каждое случайное значение xi обладает одинаковым разбросом, поэтому несложно вывести формулу дисперсии средней арифметической:
![]()
Используя более привычные обозначения, формулу записывают как:
![]()
где σ2 – это дисперсия, случайной величины, причем генеральная.
На практике же, генеральная дисперсия известна далеко не всегда, точнее совсем редко, поэтому в качестве оной используют выборочную дисперсию:
![]()
Стандартное отклонение средней арифметической называется стандартной ошибкой средней и рассчитывается, как квадратный корень из дисперсии.
Формула стандартной ошибки средней при использовании генеральной дисперсии
![]()
Формула стандартной ошибки средней при использовании выборочной дисперсии
![]()
Последняя формула на практике используется чаще всего, т.к. генеральная дисперсия обычно не известна. Чтобы не вводить новые обозначения, стандартную ошибку средней обычно записывают в виде соотношения стандартного отклонения выборки и корня объема выборки.
Назначение и свойство стандартной ошибки средней арифметической
Стандартная ошибка средней много, где используется. И очень полезно понимать ее свойства. Посмотрим еще раз на формулу стандартной ошибки средней:
![]()
Числитель – это стандартное отклонение выборки и здесь все понятно. Чем больше разброс данных, тем больше стандартная ошибка средней – прямо пропорциональная зависимость.
Посмотрим на знаменатель. Здесь находится квадратный корень из объема выборки. Соответственно, чем больше объем выборки, тем меньше стандартная ошибка средней. Для наглядности изобразим на одной диаграмме график нормально распределенной переменной со средней равной 10, сигмой – 3, и второй график – распределение средней арифметической этой же переменной, полученной по 16-ти наблюдениям (которое также будет нормальным).
Судя по формуле, разброс стандартной ошибки средней должен быть в 4 раза (корень из 16) меньше, чем разброс исходных данных, что и видно на рисунке выше. Чем больше наблюдений, тем меньше разброс средней.
Казалось бы, что для получения наиболее точной средней достаточно использовать максимально большую выборку и тогда стандартная ошибка средней будет стремиться к нулю, а сама средняя, соответственно, к математическому ожиданию. Однако квадратный корень объема выборки в знаменателе говорит о том, что связь между точностью выборочной средней и размером выборки не является линейной. Например, увеличение выборки с 20-ти до 50-ти наблюдений, то есть на 30 значений или в 2,5 раза, уменьшает стандартную ошибку средней только на 36%, а со 100-а до 130-ти наблюдений (на те же 30 значений), снижает разброс данных лишь на 12%.
Лучше всего изобразить эту мысль в виде графика зависимости стандартной ошибки средней от размера выборки. Пусть стандартное отклонение равно 10 (на форму графика это не влияет).
Видно, что примерно после 50-ти значений, уменьшение стандартной ошибки средней резко замедляется, после 100-а – наклон постепенно становится почти нулевым.
Таким образом, при достижении некоторого размера выборки ее дальнейшее увеличение уже почти не сказывается на точности средней. Этот факт имеет далеко идущие последствия. Например, при проведении выборочного обследования населения (опроса) чрезмерное увеличение выборки ведет к неоправданным затратам, т.к. точность почти не меняется. Именно поэтому количество опрошенных редко превышает 1,5 тысячи человек. Точность при таком размере выборки часто является достаточной, а дальнейшее увеличение выборки – нецелесообразным.
Подведем итог. Расчет дисперсии и стандартной ошибки средней имеет довольно простую формулу и обладает полезным свойством, связанным с тем, что относительно хорошая точность средней достигается уже при 100 наблюдениях (в этом случае стандартная ошибка средней становится в 10 раз меньше, чем стандартное отклонение выборки). Больше, конечно, лучше, но бесконечно увеличивать объем выборки не имеет практического смысла. Хотя, все зависит от поставленных задач и цены ошибки. В некоторых опросах участие принимают десятки тысяч людей.
Дисперсия и стандартная ошибка средней имеют большое практическое значение. Они используются в проверке гипотез и расчете доверительных интервалов.
Поделиться в социальных сетях:
![]()
Загрузить PDF
![]()
Загрузить PDF
В этой статье мы расскажем вам, как в Excel вычислить стандартную ошибку среднего. Для этого стандартное отклонение (σ) нужно разделить на квадратный корень (√) из размера выборки (N).
Шаги
-
1
Запустите Excel. Нажмите на значок в виде белой буквы «Х» на зеленом фоне.
-
2
Откройте или создайте таблицу Excel. Чтобы открыть готовую таблицу с данными, нажмите «Открыть» на левой панели. Чтобы создать таблицу, нажмите «Создать» и введите данные.
-
3
Вычислите стандартное отклонение. Чтобы сделать это, нужно выполнить несколько действий, но в Excel можно просто ввести следующую формулу: =СТАНДОТКЛОН.В(''диапазон ячеек'').
- Например, если данные находятся в ячейках с A1 по A20, в пустой ячейке введите =СТАНДОТКЛОН.В(A1:A20), чтобы вычислить стандартное отклонение.
-
4
Введите формулу для вычисления стандартной ошибки среднего в пустой ячейке. Формула выглядит так:=СТАНДОТКЛОН.В(''диапазон ячеек'')/КОРЕНЬ(СЧЁТ("диапазон ячеек")).
- Например, если данные находятся в ячейках с A1 по A20, в пустой ячейке введите формулу =СТАНДОТКЛОН.В(A1:A20)/КОРЕНЬ(СЧЁТ(A1:A20)). Так вы вычислите стандартную ошибку среднего.
Реклама




Об этой статье
Эту страницу просматривали 29 398 раз.
Была ли эта статья полезной?
![]()
Download Article
![]()
Download Article
After collecting data, oftentimes the first thing you need to do is analyze it. This usually entails finding the mean, the standard deviation, and the standard error of the data. This article will show you how it’s done.
Cheat Sheets
-
1
Obtain a set of numbers you wish to analyze. This information is referred to as a sample.
- For example, a test was given to a class of 5 students, and the test results are 12, 55, 74, 79 and 90.

Advertisement
-
1
Calculate the mean. Add up all the numbers and divide by the population size:[1]
- Mean (μ) = ΣX/N, where Σ is the summation (addition) sign, xi is each individual number, and N is the population size.
- In the case above, the mean μ is simply (12+55+74+79+90)/5 = 62.

-
1
Calculate the standard deviation. This represents the spread of the population.
Standard deviation = σ = sq rt [(Σ((X-μ)^2))/(N)].[2]
- For the example given, the standard deviation is sqrt[((12-62)^2 + (55-62)^2 + (74-62)^2 + (79-62)^2 + (90-62)^2)/(5)] = 27.4. (Note that if this was the sample standard deviation, you would divide by n-1, the sample size minus 1.)

Advertisement
-
1
Calculate the standard error (of the mean). This represents how well the sample mean approximates the population mean. The larger the sample, the smaller the standard error, and the closer the sample mean approximates the population mean. Do this by dividing the standard deviation by the square root of N, the sample size.[3]
Standard error = σ/sqrt(n)[4]
- So for the example above, if this were a sampling of 5 students from a class of 50 and the 50 students had a standard deviation of 17 (σ = 21), the standard error = 17/sqrt(5) = 7.6.

Add New Question
-
Question
How do you find the mean given number of observations?

To find the mean, add all the numbers together and divide by how many numbers there are. e.g to find the mean of 1,7,8,4,2: 1+7+8+4+2 = 22/5 = 4.4.
-
Question
The standard error is calculated as 0.2 and the standard deviation of a sample is 5kg. Can it be said to be smaller or larger than the standard deviation?
The standard error (SE) must be smaller than the standard deviation (SD), because the SE is calculating by dividing the SD by something — i.e. making it smaller.
-
Question
How can I find out the standard deviation of 50 samples?
The results of all your figures (number plus number plus number etc.) divided by quantity of samples 50 =SD.
See more answers
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
Video
-
Calculations of the mean, standard deviation, and standard error are most useful for analysis of normally distributed data. One standard deviation about the central tendency covers approximately 68 percent of the data, 2 standard deviation 95 percent of the data, and 3 standard deviation 99.7 percent of the data. The standard error gets smaller (narrower spread) as the sample size increases.
Thanks for submitting a tip for review!
Advertisement
-
Check your math carefully. It is very easy to make mistakes or enter numbers incorrectly.
Advertisement
References
About This Article
Article SummaryX
The mean is simply the average of a set of numbers. You can work it out by adding up all the numbers and dividing the total by the amount of numbers. For example, if you wanted to find the average test score of 3 students who scored 74, 79, and 90, you’d add the 3 numbers together to get 243, then divide it by 3 to get 81. The standard error represents how well the sample mean approximates the population mean. All you need to do is divide the standard deviation by the square root of the sample size. For instance, if you were sampling 5 students from a class of 50 and the 50 students had a standard deviation of 17, you’d divide 17 by the square root of 5 to get 7.6. For more tips, including how to calculate the standard deviation, read on!
Did this summary help you?
Thanks to all authors for creating a page that has been read 995,407 times.
Did this article help you?
![]()
Download Article
![]()
Download Article
After collecting data, oftentimes the first thing you need to do is analyze it. This usually entails finding the mean, the standard deviation, and the standard error of the data. This article will show you how it’s done.
Cheat Sheets
-
1
Obtain a set of numbers you wish to analyze. This information is referred to as a sample.
- For example, a test was given to a class of 5 students, and the test results are 12, 55, 74, 79 and 90.
Advertisement
-
1
Calculate the mean. Add up all the numbers and divide by the population size:[1]
- Mean (μ) = ΣX/N, where Σ is the summation (addition) sign, xi is each individual number, and N is the population size.
- In the case above, the mean μ is simply (12+55+74+79+90)/5 = 62.
-
1
Calculate the standard deviation. This represents the spread of the population.
Standard deviation = σ = sq rt [(Σ((X-μ)^2))/(N)].[2]
- For the example given, the standard deviation is sqrt[((12-62)^2 + (55-62)^2 + (74-62)^2 + (79-62)^2 + (90-62)^2)/(5)] = 27.4. (Note that if this was the sample standard deviation, you would divide by n-1, the sample size minus 1.)
Advertisement
-
1
Calculate the standard error (of the mean). This represents how well the sample mean approximates the population mean. The larger the sample, the smaller the standard error, and the closer the sample mean approximates the population mean. Do this by dividing the standard deviation by the square root of N, the sample size.[3]
Standard error = σ/sqrt(n)[4]
- So for the example above, if this were a sampling of 5 students from a class of 50 and the 50 students had a standard deviation of 17 (σ = 21), the standard error = 17/sqrt(5) = 7.6.
Add New Question
-
Question
How do you find the mean given number of observations?
To find the mean, add all the numbers together and divide by how many numbers there are. e.g to find the mean of 1,7,8,4,2: 1+7+8+4+2 = 22/5 = 4.4.
-
Question
The standard error is calculated as 0.2 and the standard deviation of a sample is 5kg. Can it be said to be smaller or larger than the standard deviation?
The standard error (SE) must be smaller than the standard deviation (SD), because the SE is calculating by dividing the SD by something — i.e. making it smaller.
-
Question
How can I find out the standard deviation of 50 samples?
The results of all your figures (number plus number plus number etc.) divided by quantity of samples 50 =SD.
See more answers
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
Video
-
Calculations of the mean, standard deviation, and standard error are most useful for analysis of normally distributed data. One standard deviation about the central tendency covers approximately 68 percent of the data, 2 standard deviation 95 percent of the data, and 3 standard deviation 99.7 percent of the data. The standard error gets smaller (narrower spread) as the sample size increases.
Thanks for submitting a tip for review!
Advertisement
-
Check your math carefully. It is very easy to make mistakes or enter numbers incorrectly.
Advertisement
References
About This Article
Article SummaryX
The mean is simply the average of a set of numbers. You can work it out by adding up all the numbers and dividing the total by the amount of numbers. For example, if you wanted to find the average test score of 3 students who scored 74, 79, and 90, you’d add the 3 numbers together to get 243, then divide it by 3 to get 81. The standard error represents how well the sample mean approximates the population mean. All you need to do is divide the standard deviation by the square root of the sample size. For instance, if you were sampling 5 students from a class of 50 and the 50 students had a standard deviation of 17, you’d divide 17 by the square root of 5 to get 7.6. For more tips, including how to calculate the standard deviation, read on!
Did this summary help you?
Thanks to all authors for creating a page that has been read 995,407 times.
Did this article help you?
17 авг. 2022 г.
читать 2 мин
Стандартная ошибка среднего — это способ измерить, насколько разбросаны значения в наборе данных. Он рассчитывается как:
Стандартная ошибка = с / √n
куда:
- s : стандартное отклонение выборки
- n : размер выборки
Вы можете рассчитать стандартную ошибку среднего для любого набора данных в Excel, используя следующую формулу:
= СТАНДОТКЛОН (диапазон значений) / КОРЕНЬ ( СЧЁТ (диапазон значений))
В следующем примере показано, как использовать эту формулу.
Пример: Стандартная ошибка в Excel
Предположим, у нас есть следующий набор данных:
На следующем снимке экрана показано, как рассчитать стандартную ошибку среднего значения для этого набора данных:
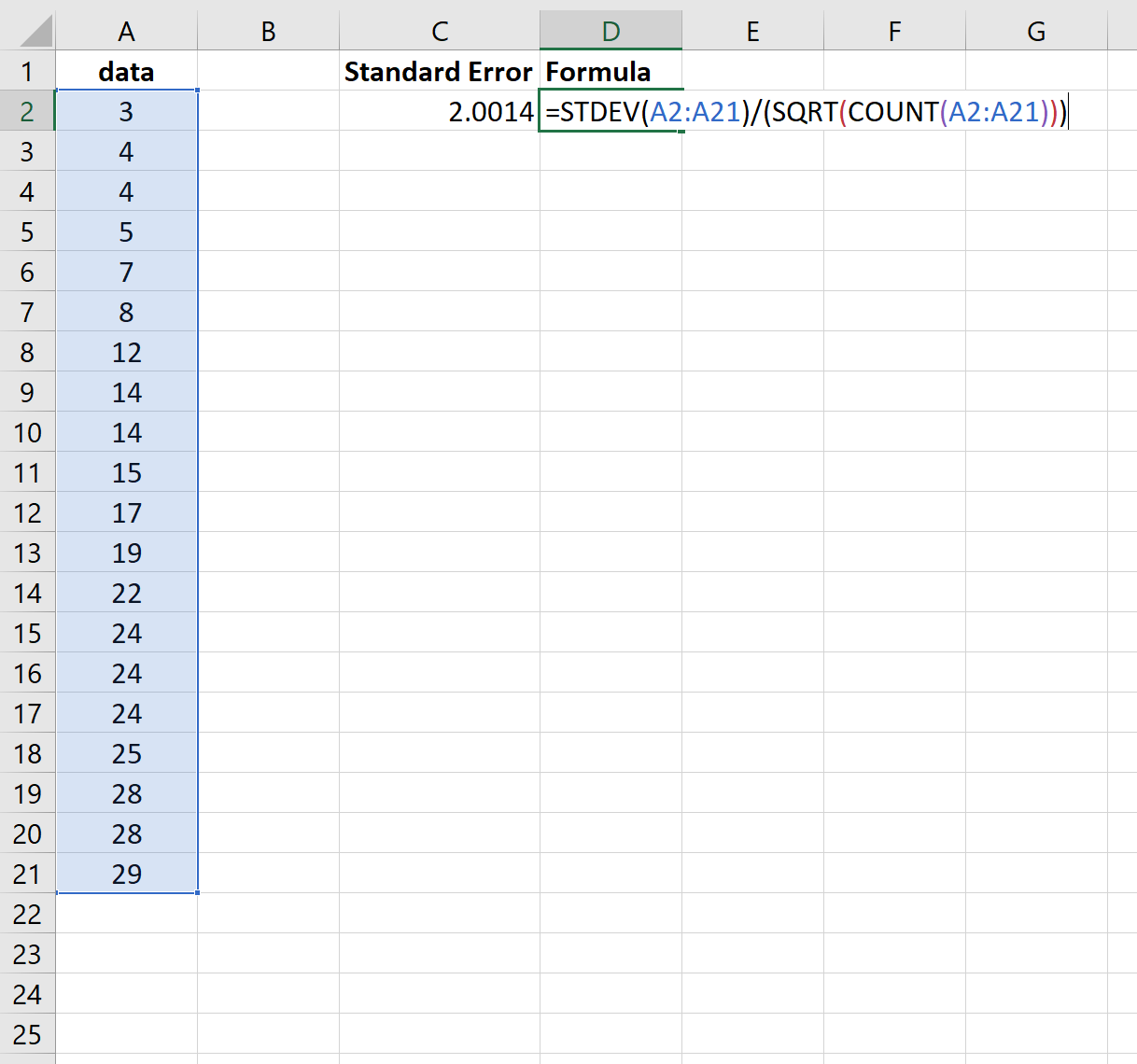
Стандартная ошибка оказывается равной 2,0014 .
Обратите внимание, что функция =СТАНДОТКЛОН() вычисляет выборочное среднее, что эквивалентно функции =СТАНДОТКЛОН.С() в Excel.
Таким образом, мы могли бы использовать следующую формулу для получения тех же результатов:
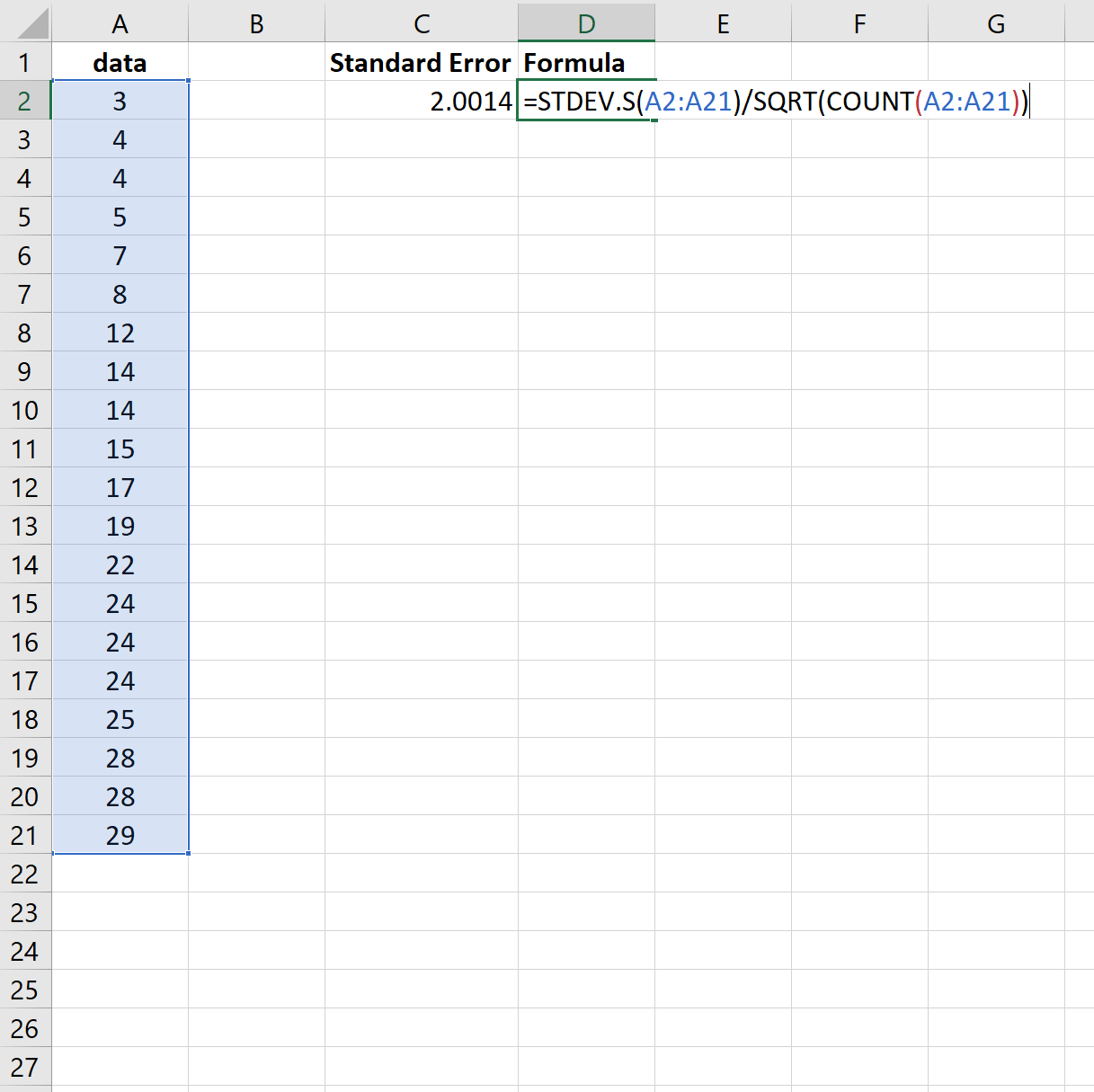
И снова стандартная ошибка оказывается равной 2,0014 .
Как интерпретировать стандартную ошибку среднего
Стандартная ошибка среднего — это просто мера того, насколько разбросаны значения вокруг среднего. При интерпретации стандартной ошибки среднего следует помнить о двух вещах:
1. Чем больше стандартная ошибка среднего, тем более разбросаны значения вокруг среднего в наборе данных.
Чтобы проиллюстрировать это, рассмотрим, изменим ли мы последнее значение в предыдущем наборе данных на гораздо большее число:
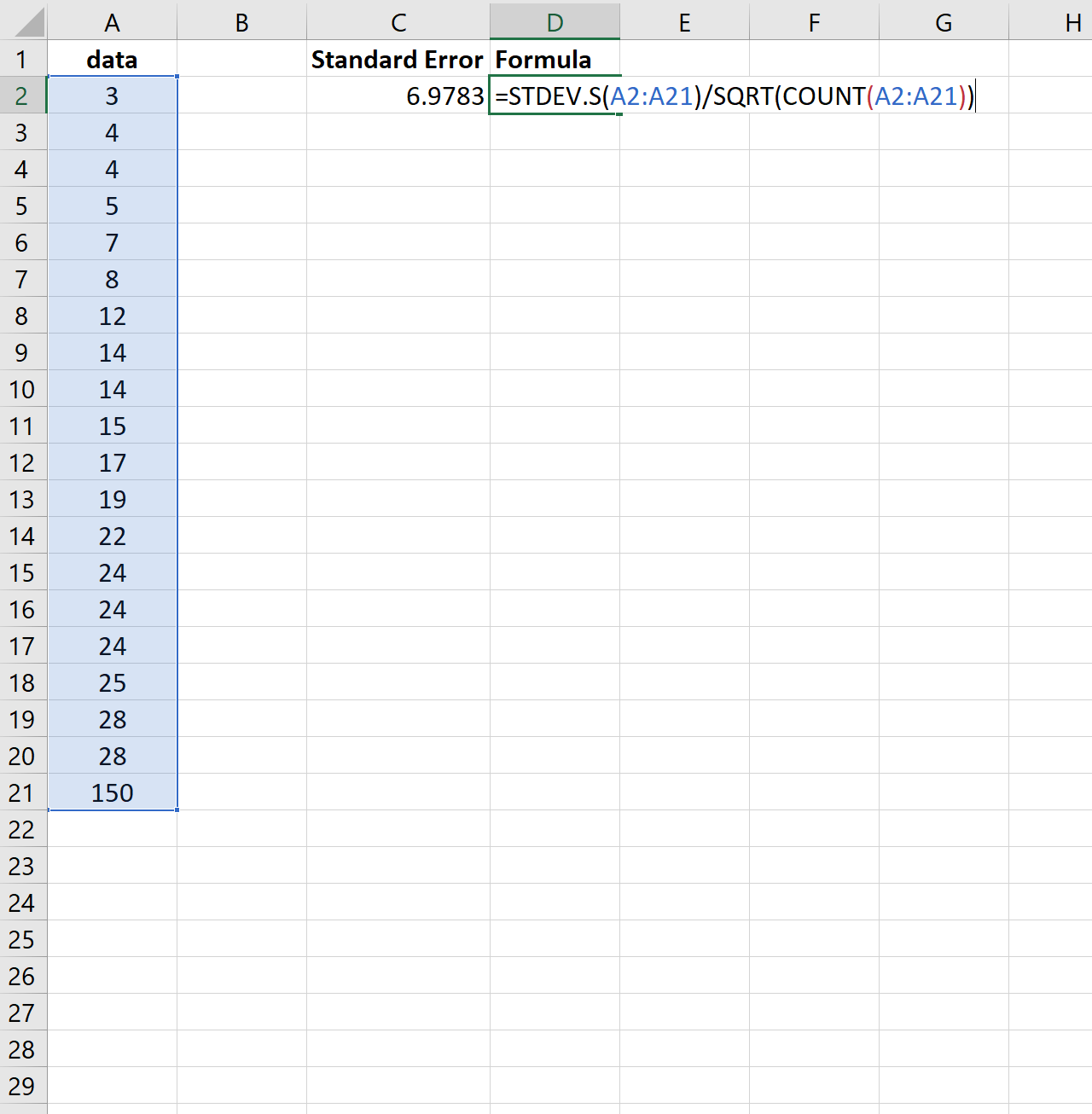
Обратите внимание на скачок стандартной ошибки с 2,0014 до 6,9783.Это указывает на то, что значения в этом наборе данных более разбросаны вокруг среднего значения по сравнению с предыдущим набором данных.
2. По мере увеличения размера выборки стандартная ошибка среднего имеет тенденцию к уменьшению.
Чтобы проиллюстрировать это, рассмотрим стандартную ошибку среднего для следующих двух наборов данных:
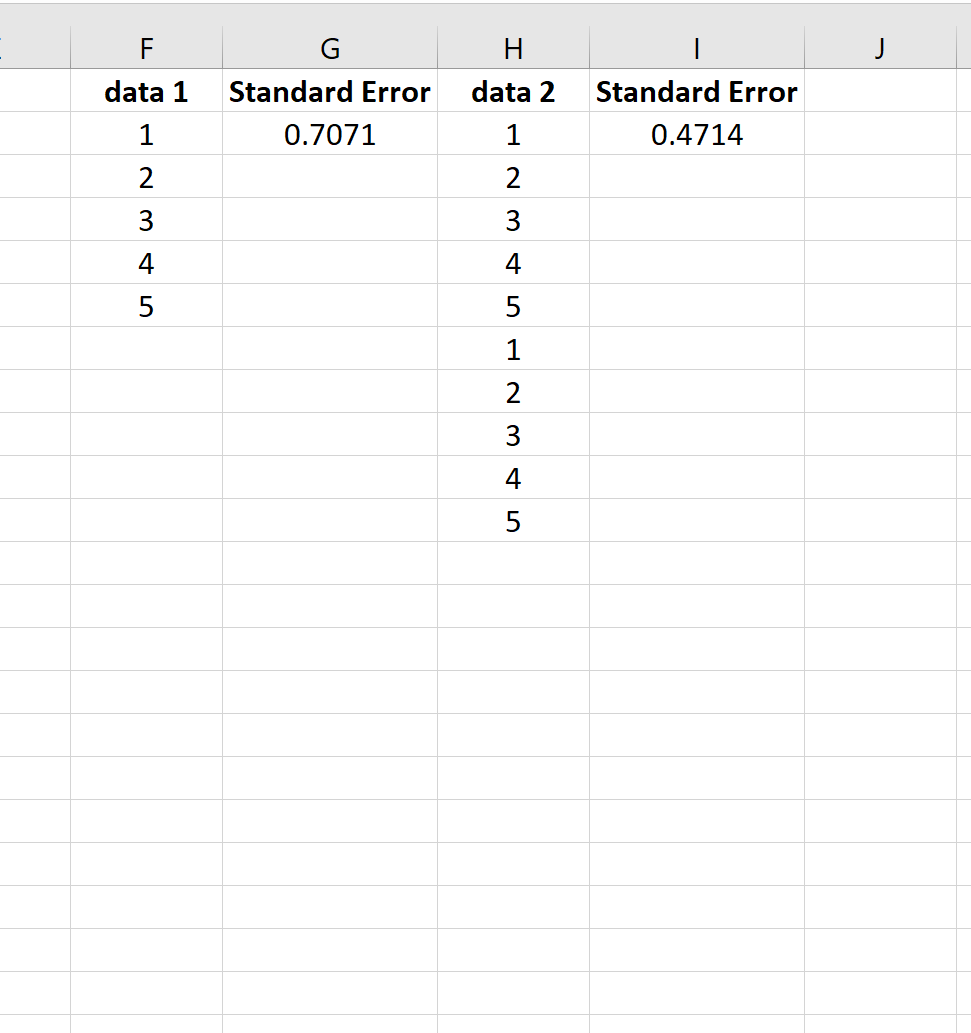
Второй набор данных — это просто первый набор данных, повторенный дважды. Таким образом, два набора данных имеют одинаковое среднее значение, но второй набор данных имеет больший размер выборки, поэтому стандартная ошибка меньше.
Стандартная ошибка появляется при прогнозировании каких-либо данных или арифметических вычислениях, поэтому важно научиться находить этот параметр. В этой публикации разбираем, как найти и исправить стандартную ошибку путем использования инструментов Excel.
Расчет средней арифметической ошибки
В Microsoft Excel цельность и однородность выборки определяется при помощи стандартной ошибки. Стандартная ошибка — это квадратный корень из дисперсии. В приложении предусмотрено два варианта поиска стандартной ошибки: при помощи пакетного анализа и расширенных функций программы.
Чтобы найти значение средней арифметической, необходимо выполнить деление суммарной величины выборки на ее количество в электронной книге.
Расчет стандартной ошибки при помощи встроенных функций
Для того, чтобы правильно вычислять, необходимо изучить пошаговую инструкцию. В этом способе подбор результатов будет осуществляться с помощью комбинированных манипуляций.
- Для расчетов будем использовать таблицу с выборкой чисел. Кликаем на любой пустой ячейке на листе, где будет отображаться результат. Затем нажимаем кнопку «Вставить функцию.
- Далее перед вами открывается диалоговое окно, в котором необходимо использовать «СТАНДОТКЛ.В», для этого в поле «Категория» необходимо выбрать «Полный алфавитный перечень». Затем нажмите кнопку «ОК».
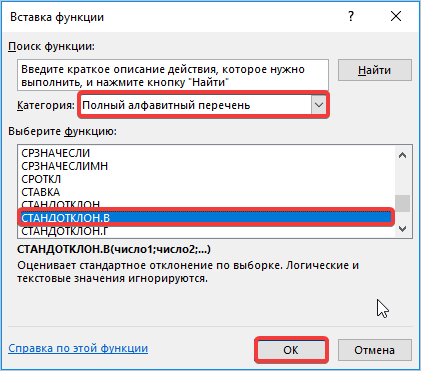
- В окне «Аргументы функции» кликаем в первом поле «Число 1», затем выполняем выделение мышью диапазона ячеек со значениями таблицы и нажимаем кнопку «ОК».
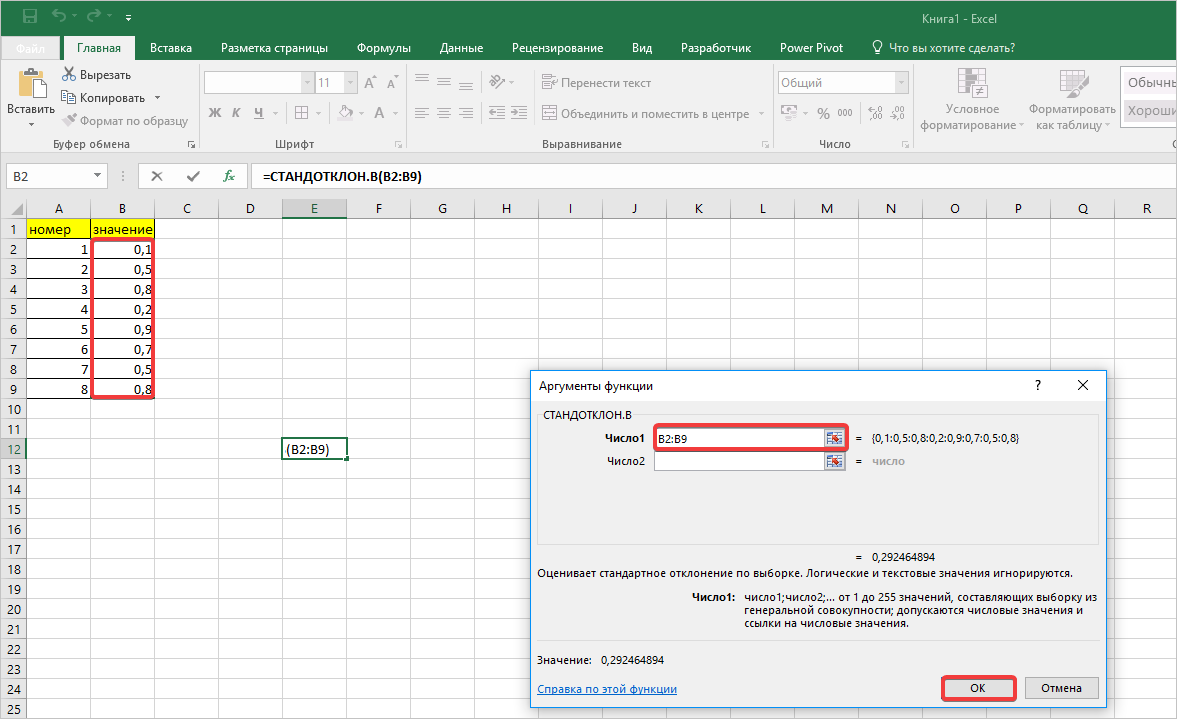
- Далее активируем ячейку с нашими значениями, переходим в строку формулы и ставим после значений наклонную линию. Переходим в поле наименования, кликаем на указывающий вниз флажок, где из списка выбираем «Другие функции».
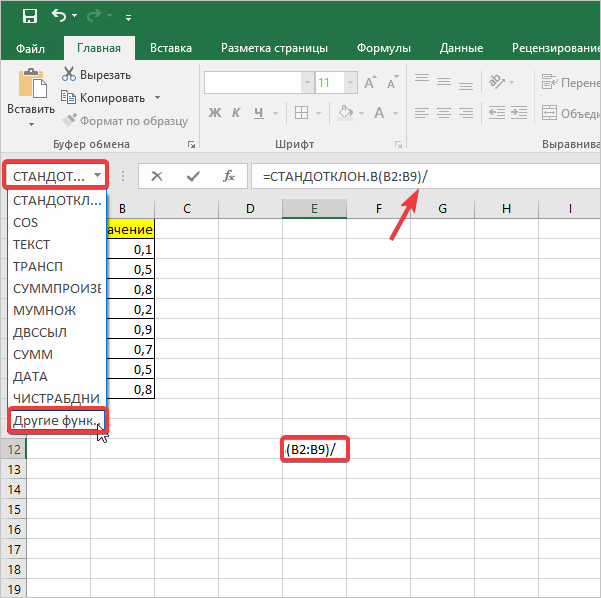
- Снова активируется окно с перечнем функций, в котором необходимо выбрать категорию «Математические», затем функцию «Корень». Далее нажмите кнопку «ОК».
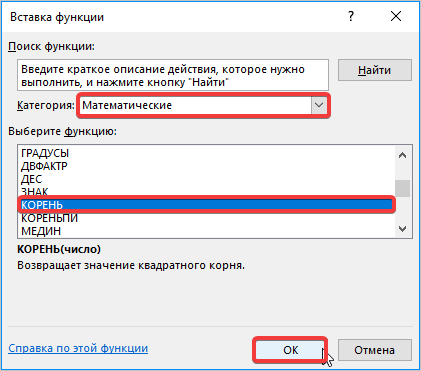
- Далее открывается окно, в котором необходимо заполнить поле с числом. Для этого переходим в поле «Имя», где спускаемся к пункту «Счет». Если его нет, ищите в дополнительных функциях.
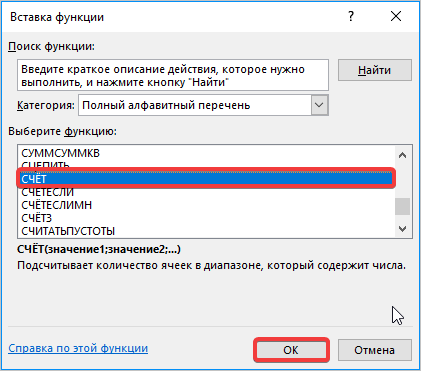
После выполнения этих шагов, стандартная ошибка высчитывается автоматически, пользователю остается только сверить их и проверить значение на некорректное отображение.
Для малых и стандартных выборок необходимо использовать разные формулы. В первом случае (если находится до 30 значений), ее необходимо видоизменить.
Решение задачи с помощью опции «Описательная статистика»
Благодаря опции «Описательная статистика» удается выполнить вычисление по различным критериям. По этим правилам удается найти среднюю арифметическую ошибку. Для использования данного метода предварительно нужно запустить «Пакет анализа».
- Переходим во вкладку «Файл», где перемещаемся в пункт «Параметры». Далее нажимаем на запись «Надстройки».
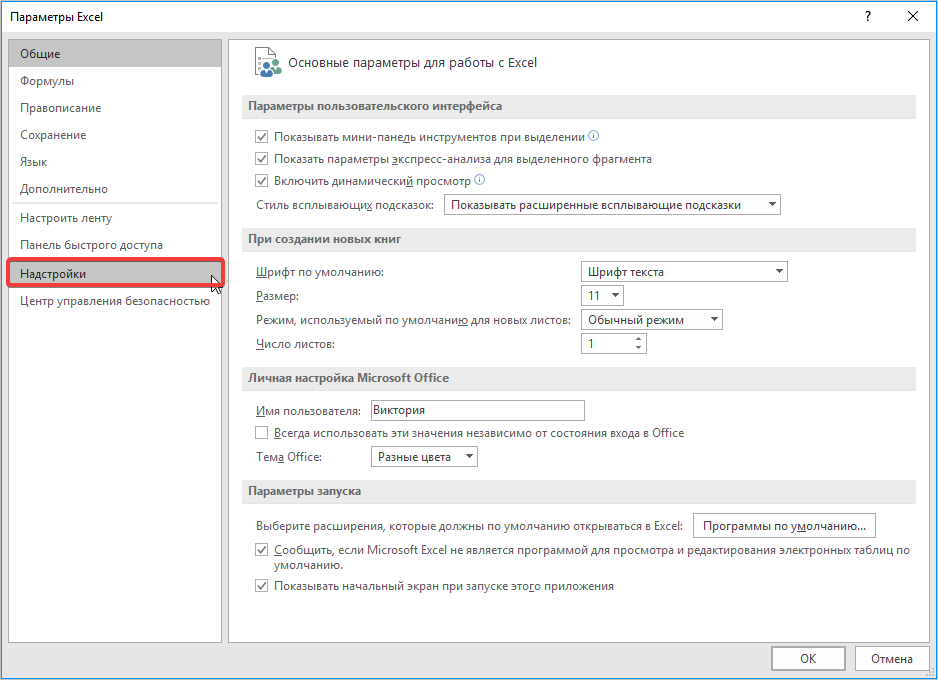
- Открывается окошко, в нем в графе «Управление» должно быть прописано «Надстройки Excel», затем рядом нажимаем кнопку «Параметры».
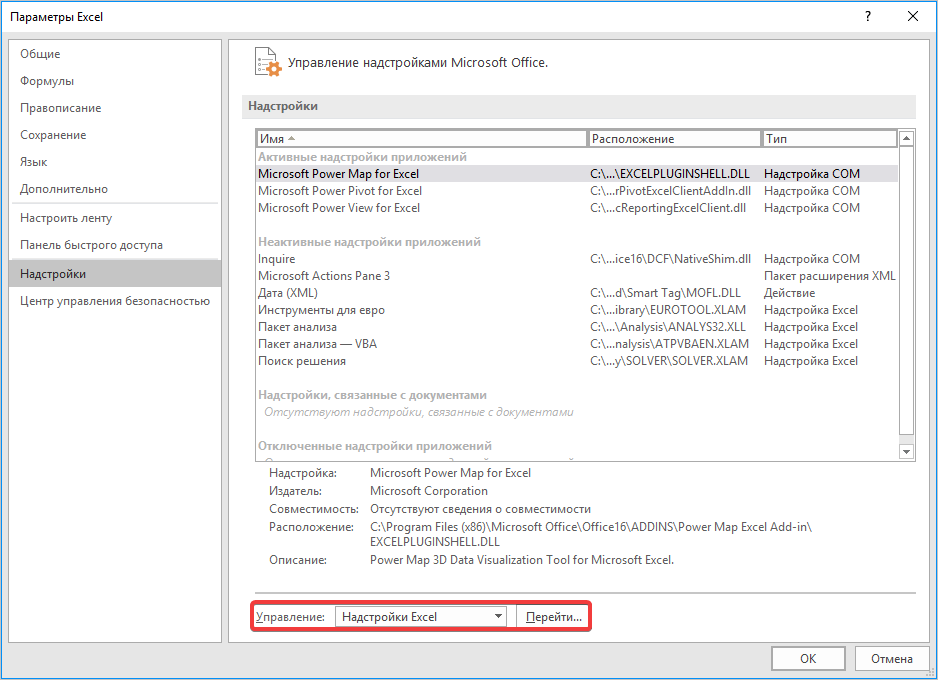
- В появившемся окне находим «Пакет анализа» и нажимаем кнопку «ОК».
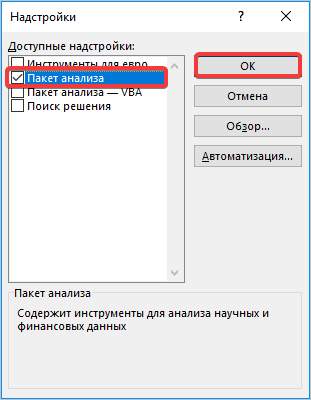
- Далее выбираем любую свободную ячейку, переходим во вкладку «Данные» и нажимаем «Анализ данных» в блоке «Анализ».

- Происходит запуск вспомогательного окошка, в котором необходимо выбрать из всех инструментов «Описательную статистику» и нажать кнопку «ОК».
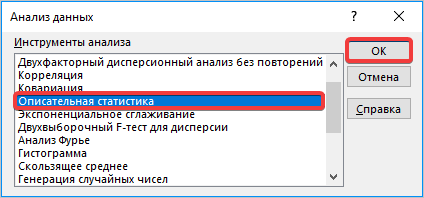
- Открывается новый мастер значений. Здесь нужно вводить данные предельно внимательно. В поле «Входной интервал» вносим адрес диапазона ячеек с выборкой. Затем указываем параметр «Группирование» «По столбцам». Затем выбираем место для «выходного интервала», его должно быть столько же, сколько и «входного». Ставим галочку напротив «Итоговая статистика» и нажимаем кнопку «ОК».
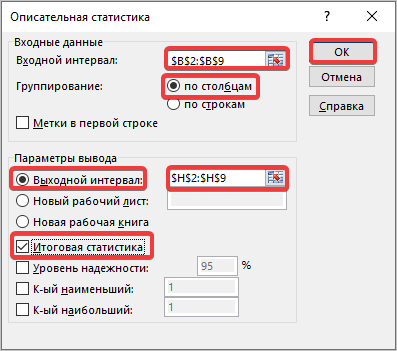
В результате вычислений вы получаете небольшую таблицу, в которой указаны все данные с определенной стандартной ошибкой.
Представление результатов исследования
В научных публикациях важно представление результатов исследования. Очень часто окончательный результат приводится в следующем виде: M±m, где M – среднее арифметическое, m –ошибка среднего арифметического. Например, 163,7±0,9 см.
Прежде чем разбираться в правилах представления результатов исследования, давайте точно усвоим, что же такое ошибка среднего арифметического.
Ошибка среднего арифметического
Среднее арифметическое, вычисленное на основе выборочных данных (выборочное среднее), как правило, не совпадает с генеральным средним (средним арифметическим генеральной совокупности). Экспериментально проверить это утверждение невозможно, потому что нам неизвестно генеральное среднее. Но если из одной и той же генеральной совокупности брать повторные выборки и вычислять среднее арифметическое, то окажется, что для разных выборок среднее арифметическое будет разным.
Чтобы оценить, насколько выборочное среднее арифметическое отличается от генерального среднего, вычисляется ошибка среднего арифметического или ошибка репрезентативности.
Ошибка среднего арифметического обозначается как m или ![]()
Ошибка среднего арифметического рассчитывается по формуле:
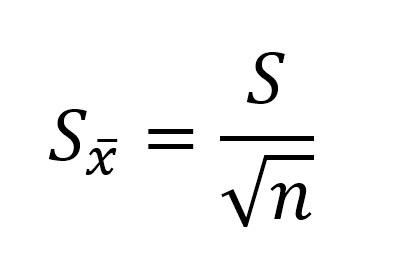
где: S — стандартное отклонение, n – объем выборки; Например, если стандартное отклонение равно S=5 см, объем выборки n=36 человек, то ошибка среднего арифметического равна: m=5/6 = 0,833.
Ошибка среднего арифметического показывает, какая ошибка в среднем допускается, если использовать вместо генерального среднего выборочное среднее.
Так как при небольшом объеме выборки истинное значение генерального среднего не может быть определено сколь угодно точно, поэтому при вычислении выборочного среднего арифметического нет смысла оставлять большое число значащих цифр.
Правила записи результатов исследования
- В записи ошибки среднего арифметического оставляем две значащие цифры, если первые цифры в ошибке «1» или «2».
- В остальных случаях в записи ошибки среднего арифметического оставляем одну значащую цифру.
- В записи среднего арифметического положение последней значащей цифры должно соответствовать положению первой значащей цифры в записи ошибки среднего арифметического.
Представление результатов научных исследований
В своей статье «Осторожно, статистика!», опубликованной в 1989 году В.М. Зациорский указал, какие числовые характеристики должны быть представлены в публикации, чтобы она имела научную ценность. Он писал, что исследователь «…должен назвать: 1) среднюю величину (или другой так называемый показатель положения); 2) среднее квадратическое отклонение (или другой показатель рассеяния) и 3) число испытуемых. Без них его публикация научной ценности иметь не будет “с. 52
В научных публикациях в области физической культуры и спорта очень часто окончательный результат приводится в виде: (М±m) (табл.1).
Таблица 1 — Изменение механических свойств латеральной широкой мышцы бедра под воздействием физической нагрузки (n=34)
| Эффективный модуль
упругости (Е), кПа |
Эффективный модуль
вязкости (V), Па с |
|||
| Этап
эксперимента |
Рассл. | Напряж. | Рассл. | Напряж. |
| До ФН | 7,0±0,3 | 17,1±1,4 | 29,7±1,7 | 46±4 |
| После ФН | 7,7±0,3 | 18,7±1,4 | 30,9±2,0 | 53±6 |
Литература
- Высшая математика и математическая статистика: учебное пособие для вузов / Под общ. ред. Г. И. Попова. – М. Физическая культура, 2007.– 368 с.
- Гласс Дж., Стэнли Дж. Статистические методы в педагогике и психологии. М.: Прогресс. 1976.- 495 с.
- Зациорский В.М. Осторожно — статистика! // Теория и практика физической культуры, 1989.- №2.
- Катранов А.Г. Компьютерная обработка данных экспериментальных исследований: Учебное пособие/ А. Г. Катранов, А. В. Самсонова; СПб ГУФК им. П.Ф. Лесгафта. – СПб.: изд-во СПб ГУФК им. П.Ф. Лесгафта, 2005. – 131 с.
- Основы математической статистики: Учебное пособие для ин-тов физ. культ / Под ред. В.С. Иванова.– М.: Физкультура и спорт, 1990. 176 с.
Представление результатов исследования
В научных публикациях важно представление результатов исследования. Очень часто окончательный результат приводится в следующем виде: M±m, где M – среднее арифметическое, m –ошибка среднего арифметического. Например, 163,7±0,9 см.
Прежде чем разбираться в правилах представления результатов исследования, давайте точно усвоим, что же такое ошибка среднего арифметического.
Ошибка среднего арифметического
Среднее арифметическое, вычисленное на основе выборочных данных (выборочное среднее), как правило, не совпадает с генеральным средним (средним арифметическим генеральной совокупности). Экспериментально проверить это утверждение невозможно, потому что нам неизвестно генеральное среднее. Но если из одной и той же генеральной совокупности брать повторные выборки и вычислять среднее арифметическое, то окажется, что для разных выборок среднее арифметическое будет разным.
Чтобы оценить, насколько выборочное среднее арифметическое отличается от генерального среднего, вычисляется ошибка среднего арифметического или ошибка репрезентативности.
Ошибка среднего арифметического обозначается как m или ![]()
Ошибка среднего арифметического рассчитывается по формуле:
где: S — стандартное отклонение, n – объем выборки; Например, если стандартное отклонение равно S=5 см, объем выборки n=36 человек, то ошибка среднего арифметического равна: m=5/6 = 0,833.
Ошибка среднего арифметического показывает, какая ошибка в среднем допускается, если использовать вместо генерального среднего выборочное среднее.
Так как при небольшом объеме выборки истинное значение генерального среднего не может быть определено сколь угодно точно, поэтому при вычислении выборочного среднего арифметического нет смысла оставлять большое число значащих цифр.
Правила записи результатов исследования
- В записи ошибки среднего арифметического оставляем две значащие цифры, если первые цифры в ошибке «1» или «2».
- В остальных случаях в записи ошибки среднего арифметического оставляем одну значащую цифру.
- В записи среднего арифметического положение последней значащей цифры должно соответствовать положению первой значащей цифры в записи ошибки среднего арифметического.
Представление результатов научных исследований
В своей статье «Осторожно, статистика!», опубликованной в 1989 году В.М. Зациорский указал, какие числовые характеристики должны быть представлены в публикации, чтобы она имела научную ценность. Он писал, что исследователь «…должен назвать: 1) среднюю величину (или другой так называемый показатель положения); 2) среднее квадратическое отклонение (или другой показатель рассеяния) и 3) число испытуемых. Без них его публикация научной ценности иметь не будет “с. 52
В научных публикациях в области физической культуры и спорта очень часто окончательный результат приводится в виде: (М±m) (табл.1).
Таблица 1 — Изменение механических свойств латеральной широкой мышцы бедра под воздействием физической нагрузки (n=34)
| Эффективный модуль
упругости (Е), кПа |
Эффективный модуль
вязкости (V), Па с |
|||
| Этап
эксперимента |
Рассл. | Напряж. | Рассл. | Напряж. |
| До ФН | 7,0±0,3 | 17,1±1,4 | 29,7±1,7 | 46±4 |
| После ФН | 7,7±0,3 | 18,7±1,4 | 30,9±2,0 | 53±6 |
Литература
- Высшая математика и математическая статистика: учебное пособие для вузов / Под общ. ред. Г. И. Попова. – М. Физическая культура, 2007.– 368 с.
- Гласс Дж., Стэнли Дж. Статистические методы в педагогике и психологии. М.: Прогресс. 1976.- 495 с.
- Зациорский В.М. Осторожно — статистика! // Теория и практика физической культуры, 1989.- №2.
- Катранов А.Г. Компьютерная обработка данных экспериментальных исследований: Учебное пособие/ А. Г. Катранов, А. В. Самсонова; СПб ГУФК им. П.Ф. Лесгафта. – СПб.: изд-во СПб ГУФК им. П.Ф. Лесгафта, 2005. – 131 с.
- Основы математической статистики: Учебное пособие для ин-тов физ. культ / Под ред. В.С. Иванова.– М.: Физкультура и спорт, 1990. 176 с.
17 авг. 2022 г.
читать 2 мин
Стандартная ошибка среднего — это способ измерить, насколько разбросаны значения в наборе данных. Он рассчитывается как:
Стандартная ошибка = с / √n
куда:
- s : стандартное отклонение выборки
- n : размер выборки
Вы можете рассчитать стандартную ошибку среднего для любого набора данных в Excel, используя следующую формулу:
= СТАНДОТКЛОН (диапазон значений) / КОРЕНЬ ( СЧЁТ (диапазон значений))
В следующем примере показано, как использовать эту формулу.
Пример: Стандартная ошибка в Excel
Предположим, у нас есть следующий набор данных:
На следующем снимке экрана показано, как рассчитать стандартную ошибку среднего значения для этого набора данных:
Стандартная ошибка оказывается равной 2,0014 .
Обратите внимание, что функция =СТАНДОТКЛОН() вычисляет выборочное среднее, что эквивалентно функции =СТАНДОТКЛОН.С() в Excel.
Таким образом, мы могли бы использовать следующую формулу для получения тех же результатов:
И снова стандартная ошибка оказывается равной 2,0014 .
Как интерпретировать стандартную ошибку среднего
Стандартная ошибка среднего — это просто мера того, насколько разбросаны значения вокруг среднего. При интерпретации стандартной ошибки среднего следует помнить о двух вещах:
1. Чем больше стандартная ошибка среднего, тем более разбросаны значения вокруг среднего в наборе данных.
Чтобы проиллюстрировать это, рассмотрим, изменим ли мы последнее значение в предыдущем наборе данных на гораздо большее число:
Обратите внимание на скачок стандартной ошибки с 2,0014 до 6,9783.Это указывает на то, что значения в этом наборе данных более разбросаны вокруг среднего значения по сравнению с предыдущим набором данных.
2. По мере увеличения размера выборки стандартная ошибка среднего имеет тенденцию к уменьшению.
Чтобы проиллюстрировать это, рассмотрим стандартную ошибку среднего для следующих двух наборов данных:
Второй набор данных — это просто первый набор данных, повторенный дважды. Таким образом, два набора данных имеют одинаковое среднее значение, но второй набор данных имеет больший размер выборки, поэтому стандартная ошибка меньше.
![]()
Загрузить PDF
![]()
Загрузить PDF
В этой статье мы расскажем вам, как в Excel вычислить стандартную ошибку среднего. Для этого стандартное отклонение (σ) нужно разделить на квадратный корень (√) из размера выборки (N).
Шаги
-
1
Запустите Excel. Нажмите на значок в виде белой буквы «Х» на зеленом фоне.
-
2
Откройте или создайте таблицу Excel. Чтобы открыть готовую таблицу с данными, нажмите «Открыть» на левой панели. Чтобы создать таблицу, нажмите «Создать» и введите данные.
-
3
Вычислите стандартное отклонение. Чтобы сделать это, нужно выполнить несколько действий, но в Excel можно просто ввести следующую формулу: =СТАНДОТКЛОН.В(''диапазон ячеек'').
- Например, если данные находятся в ячейках с A1 по A20, в пустой ячейке введите =СТАНДОТКЛОН.В(A1:A20), чтобы вычислить стандартное отклонение.
-
4
Введите формулу для вычисления стандартной ошибки среднего в пустой ячейке. Формула выглядит так:=СТАНДОТКЛОН.В(''диапазон ячеек'')/КОРЕНЬ(СЧЁТ("диапазон ячеек")).
- Например, если данные находятся в ячейках с A1 по A20, в пустой ячейке введите формулу =СТАНДОТКЛОН.В(A1:A20)/КОРЕНЬ(СЧЁТ(A1:A20)). Так вы вычислите стандартную ошибку среднего.
Реклама
Об этой статье
Эту страницу просматривали 31 569 раз.
Была ли эта статья полезной?
Содержание
- Использование описательной статистики
- Подключение «Пакета анализа»
- Размах вариации
- Вычисление коэффициента вариации
- Шаг 1: расчет стандартного отклонения
- Шаг 2: расчет среднего арифметического
- Шаг 3: нахождение коэффициента вариации
- Простая формула для расчета объема выборки
- Пример расчета объема выборки
- Задачи о генеральной доле
- По части судить о целом
- Как рассчитать объем выборки
- Как определить статистические выбросы и сделать выборку для их удаления в Excel
- Способ 1: применение расширенного автофильтра
- Способ 2: применение формулы массива
- СРЗНАЧ()
- СРЗНАЧЕСЛИ()
- МАКС()
- МИН()
Использование описательной статистики
Под описательной статистикой понимают систематизацию эмпирических данных по целому ряду основных статистических критериев. Причем на основе полученного результата из этих итоговых показателей можно сформировать общие выводы об изучаемом массиве данных.
В Экселе существует отдельный инструмент, входящий в «Пакет анализа», с помощью которого можно провести данный вид обработки данных. Он так и называется «Описательная статистика». Среди критериев, которые высчитывает данный инструмент следующие показатели:
- Медиана;
- Мода;
- Дисперсия;
- Среднее;
- Стандартное отклонение;
- Стандартная ошибка;
- Асимметричность и др.
Рассмотрим, как работает данный инструмент на примере Excel 2010, хотя данный алгоритм применим также в Excel 2007 и в более поздних версиях данной программы.
Подключение «Пакета анализа»
Как уже было сказано выше, инструмент «Описательная статистика» входит в более широкий набор функций, который принято называть Пакет анализа. Но дело в том, что по умолчанию данная надстройка в Экселе отключена. Поэтому, если вы до сих пор её не включили, то для использования возможностей описательной статистики, придется это сделать.
- Переходим во вкладку «Файл». Далее производим перемещение в пункт «Параметры».
- В активировавшемся окне параметров перемещаемся в подраздел «Надстройки». В самой нижней части окна находится поле «Управление». Нужно в нем переставить переключатель в позицию «Надстройки Excel», если он находится в другом положении. Вслед за этим жмем на кнопку «Перейти…».
- Запускается окно стандартных надстроек Excel. Около наименования «Пакет анализа» ставим флажок. Затем жмем на кнопку «OK».



После вышеуказанных действий надстройка Пакет анализа будет активирована и станет доступной во вкладке «Данные» Эксель. Теперь мы сможем использовать на практике инструменты описательной статистики.
Размах вариации
Размах вариации – разница между максимальным и минимальным значением:
![]()
Ниже приведена графическая интерпретация размаха вариации.

Видно максимальное и минимальное значение, а также расстояние между ними, которое и соответствует размаху вариации.
С одной стороны, показатель размаха может быть вполне информативным и полезным. К примеру, максимальная и минимальная стоимость квартиры в городе N, максимальная и минимальная зарплата по профессии в регионе и проч. С другой стороны, размах может быть очень широким и не иметь практического смысла, т.к. зависит лишь от двух наблюдений. Таким образом, размах вариации очень неустойчивая величина.
Вычисление коэффициента вариации
Этот показатель представляет собой отношение стандартного отклонения к среднему арифметическому. Полученный результат выражается в процентах.
В Экселе не существует отдельно функции для вычисления этого показателя, но имеются формулы для расчета стандартного отклонения и среднего арифметического ряда чисел, а именно они используются для нахождения коэффициента вариации.
Шаг 1: расчет стандартного отклонения
Стандартное отклонение, или, как его называют по-другому, среднеквадратичное отклонение, представляет собой квадратный корень из дисперсии. Для расчета стандартного отклонения используется функция СТАНДОТКЛОН. Начиная с версии Excel 2010 она разделена, в зависимости от того, по генеральной совокупности происходит вычисление или по выборке, на два отдельных варианта: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В.
Синтаксис данных функций выглядит соответствующим образом:
= СТАНДОТКЛОН(Число1;Число2;…)
= СТАНДОТКЛОН.Г(Число1;Число2;…)
= СТАНДОТКЛОН.В(Число1;Число2;…)
- Для того, чтобы рассчитать стандартное отклонение, выделяем любую свободную ячейку на листе, которая удобна вам для того, чтобы выводить в неё результаты расчетов. Щелкаем по кнопке «Вставить функцию». Она имеет внешний вид пиктограммы и расположена слева от строки формул.

Выполняется активация Мастера функций, который запускается в виде отдельного окна с перечнем аргументов. Переходим в категорию «Статистические» или «Полный алфавитный перечень». Выбираем наименование «СТАНДОТКЛОН.Г» или «СТАНДОТКЛОН.В», в зависимости от того, по генеральной совокупности или по выборке следует произвести расчет. Жмем на кнопку «OK».

Открывается окно аргументов данной функции. Оно может иметь от 1 до 255 полей, в которых могут содержаться, как конкретные числа, так и ссылки на ячейки или диапазоны. Ставим курсор в поле «Число1». Мышью выделяем на листе тот диапазон значений, который нужно обработать. Если таких областей несколько и они не смежные между собой, то координаты следующей указываем в поле «Число2» и т.д. Когда все нужные данные введены, жмем на кнопку «OK»


Шаг 2: расчет среднего арифметического
Среднее арифметическое является отношением общей суммы всех значений числового ряда к их количеству. Для расчета этого показателя тоже существует отдельная функция – СРЗНАЧ. Вычислим её значение на конкретном примере.
- Выделяем на листе ячейку для вывода результата. Жмем на уже знакомую нам кнопку «Вставить функцию».

В статистической категории Мастера функций ищем наименование «СРЗНАЧ». После его выделения жмем на кнопку «OK».

Запускается окно аргументов СРЗНАЧ. Аргументы полностью идентичны тем, что и у операторов группы СТАНДОТКЛОН. То есть, в их качестве могут выступать как отдельные числовые величины, так и ссылки. Устанавливаем курсор в поле «Число1». Так же, как и в предыдущем случае, выделяем на листе нужную нам совокупность ячеек. После того, как их координаты были занесены в поле окна аргументов, жмем на кнопку «OK».


Шаг 3: нахождение коэффициента вариации
Теперь у нас имеются все необходимые данные для того, чтобы непосредственно рассчитать сам коэффициент вариации.
- Выделяем ячейку, в которую будет выводиться результат. Прежде всего, нужно учесть, что коэффициент вариации является процентным значением. В связи с этим следует поменять формат ячейки на соответствующий. Это можно сделать после её выделения, находясь во вкладке «Главная». Кликаем по полю формата на ленте в блоке инструментов «Число». Из раскрывшегося списка вариантов выбираем «Процентный». После этих действий формат у элемента будет соответствующий.

Снова возвращаемся к ячейке для вывода результата. Активируем её двойным щелчком левой кнопки мыши. Ставим в ней знак «=». Выделяем элемент, в котором расположен итог вычисления стандартного отклонения. Кликаем по кнопке «разделить» (/) на клавиатуре. Далее выделяем ячейку, в которой располагается среднее арифметическое заданного числового ряда. Для того, чтобы произвести расчет и вывести значение, щёлкаем по кнопке Enter на клавиатуре.


Таким образом мы произвели вычисление коэффициента вариации, ссылаясь на ячейки, в которых уже были рассчитаны стандартное отклонение и среднее арифметическое. Но можно поступить и несколько по-иному, не рассчитывая отдельно данные значения.
- Выделяем предварительно отформатированную под процентный формат ячейку, в которой будет выведен результат. Прописываем в ней формулу по типу:
Вместо наименования «Диапазон значений» вставляем реальные координаты области, в которой размещен исследуемый числовой ряд. Это можно сделать простым выделением данного диапазона. Вместо оператора СТАНДОТКЛОН.В, если пользователь считает нужным, можно применять функцию СТАНДОТКЛОН.Г.


Существует условное разграничение. Считается, что если показатель коэффициента вариации менее 33%, то совокупность чисел однородная. В обратном случае её принято характеризовать, как неоднородную.
Как видим, программа Эксель позволяет значительно упростить расчет такого сложного статистического вычисления, как поиск коэффициента вариации. К сожалению, в приложении пока не существует функции, которая высчитывала бы этот показатель в одно действие, но при помощи операторов СТАНДОТКЛОН и СРЗНАЧ эта задача очень упрощается. Таким образом, в Excel её может выполнить даже человек, который не имеет высокого уровня знаний связанных со статистическими закономерностями.
Разделы: Математика
- Совершенствование умений и навыков нахождения статистических характеристик случайной величины, работа с расчетами в Excel;
- применение информационно коммутативных технологий для анализа данных; работа с различными информационными носителями.
- Сегодня мы научимся рассчитывать статистические характеристики для больших по объему выборок, используя возможности современных компьютерных технологий.
- Для начала вспомним:
– что называется случайной величиной? (Случайной величиной называют переменную величину, которая в зависимости от исхода испытания принимает одно значение из множества возможных значений.)
– Какие виды случайных величин мы знаем? (Дискретные, непрерывные.)
– Приведите примеры непрерывных случайных величин (рост дерева), дискретных случайных величин (количество учеников в классе).
– Какие статистические характеристики случайных величин мы знаем (мода, медиана, среднее выборочное значение, размах ряда).
– Какие приемы используются для наглядного представления статистических характеристик случайной величины (полигон частот, круговые и столбчатые диаграммы, гистограммы).
- Рассмотрим, применение инструментов Excel для решения статистических задач на конкретном примере.
Пример. Проведена проверка в 100 компаниях. Даны значения количества работающих в компании (чел.):
| 23 25 24 25 30 24 30 26 28 26 32 33 31 31 25 33 25 29 30 28 23 30 29 24 33 30 30 28 26 25 26 29 27 29 26 28 27 26 29 28 29 30 27 30 28 32 28 26 30 26 31 27 30 27 33 28 26 30 31 29 27 30 30 29 27 26 28 31 29 28 33 27 30 33 26 31 34 28 32 22 29 30 27 29 34 29 32 29 29 30 29 29 36 29 29 34 23 28 24 28 |
рассчитать числовые характеристики:
|
1. Занести данные в EXCEL, каждое число в отдельную ячейку.
| 23 | 25 | 24 | 25 | 30 | 24 | 30 | 26 | 28 | 26 |
| 32 | 33 | 31 | 31 | 25 | 33 | 25 | 29 | 30 | 28 |
| 23 | 30 | 29 | 24 | 33 | 30 | 30 | 28 | 26 | 25 |
| 26 | 29 | 27 | 29 | 26 | 28 | 27 | 26 | 29 | 28 |
| 29 | 30 | 27 | 30 | 28 | 32 | 28 | 26 | 30 | 26 |
| 31 | 27 | 30 | 27 | 33 | 28 | 26 | 30 | 31 | 29 |
| 27 | 30 | 30 | 29 | 27 | 26 | 28 | 31 | 29 | 28 |
| 33 | 27 | 30 | 33 | 26 | 31 | 34 | 28 | 32 | 22 |
| 29 | 30 | 27 | 29 | 34 | 29 | 32 | 29 | 29 | 30 |
| 29 | 29 | 36 | 29 | 29 | 34 | 23 | 28 | 24 | 28 |
2. Для расчета числовых характеристик используем опцию Вставка – Функция. И в появившемся окне в строке категория выберем – статистические, в списке: МОДА

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили Мо = 29 (чел) – Фирм у которых в штате 29 человек больше всего.
Используя тот же путь вычисляем медиану.
Вставка – Функция – Статистические – Медиана.

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили Ме = 29 (чел) – среднее значение сотрудников в фирме.
Размах ряда чисел – разница между наименьшим и наибольшим возможным значением случайной величины. Для вычисления размаха ряда нужно найти наибольшее и наименьшее значения нашей выборки и вычислить их разность.
Вставка – Функция – Статистические – МАКС.

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили наибольшее значение = 36.
Вставка – Функция – Статистические – МИН.

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили наименьшее значение = 22.
36 – 22 = 14 (чел) – разница между фирмой с наибольшим штатом сотрудников и фирмой с наименьшим штатом сотрудников.
Для построения диаграммы и полигона частот необходимо задать закон распределения, т.е. составить таблицу значений случайной величины и соответствующих им частот. Мы ухе знаем, что наименьшее число сотрудников в фирме = 22, а наибольшее = 36. Составим таблицу, в которой значения xi случайной величины меняются от 22 до 36 включительно шагом 1.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni |
Чтобы сосчитать частоту каждого значения воспользуемся
Вставка – Функция – Статистические – СЧЕТЕСЛИ.
В окне Диапазон ставим курсор и выделяем нашу выборку, а в окне Критерий ставим число 22

Нажимаем клавишу ОК, получаем значение 1, т.е. число 22 в нашей выборке встречается 1 раз и его частота =1. Аналогичным образом заполняем всю таблицу.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni | 1 | 3 | 4 | 5 | 11 | 9 | 13 | 18 | 16 | 6 | 4 | 6 | 3 | 0 | 1 |
Для проверки вычисляем объем выборки, сумму частот (Вставка – Функция – Математические – СУММА). Должно получиться 100 (количество всех фирм).
Чтобы построить полигон частот выделяем таблицу – Вставка – Диаграмма – Стандартные – Точечная (точечная диаграмма на которой значения соединены отрезками)

Нажимаем клавишу Далее, в Мастере диаграмм указываем название диаграммы (Полигон частот), удаляем легенду, редактируем шкалу и характеристики диаграммы для наибольшей наглядности.


Для построения столбчатой и круговой диаграмм используем тот же путь (выбирая нужный нам тип диаграммы).
Диаграмма – Стандартные – Круговая.

Диаграмма – Стандартные – Гистограмма.

4. Сегодня на уроке мы научились применять компьютерные технологии для анализа и обработки статистической информации.
Простая формула для расчета объема выборки

где: n – объем выборки;
z – нормированное отклонение, определяемое исходя из выбранного уровня доверительности. Этот показатель характеризует возможность, вероятность попадания ответов в специальный – доверительный интервал. На практике уровень доверительности часто принимают за 95% или 99%. Тогда значения z будут соответственно 1,96 и 2,58;
p – вариация для выборки, в долях. По сути, p – это вероятность того, что респонденты выберут той или иной вариант ответа. Допустим, если мы считаем, что четверть опрашиваемых выберут ответ «Да», то p будет равно 25%, то есть p = 0,25;
q = (1 – p);
e – допустимая ошибка, в долях.
Пример расчета объема выборки
Компания планирует провести социологическое исследование с целью выявить долю курящих лиц в населении города. Для этого сотрудники компании будут задавать прохожим один вопрос: «Вы курите?». Возможных вариантов ответа, таким образом, только два: «Да» и «Нет».
Объем выборки в этом случае рассчитывается следующим образом. Уровень доверительности принимается за 95%, тогда нормированное отклонение z = 1,96. Вариацию принимаем за 50%, то есть условно считаем, что половина респондентов может ответить на вопрос о том, курят ли они – «Да». Тогда p = 0,5. Отсюда находим q = 1 – p = 1 – 0,5 = 0,5. Допустимую ошибку выборки принимаем за 10%, то есть e = 0,1.
Подставляем эти данные в формулу и считаем:

Получаем объем выборки n = 96 человек.
Задачи о генеральной доле
На вопрос «Накрывает ли доверительный интервал заданное значение p0?» — можно ответить, проверив статистическую гипотезу H0:p=p0. При этом предполагается, что опыты проводятся по схеме испытаний Бернулли (независимы, вероятность p появления события А постоянна). По выборке объема n определяют относительную частоту p* появления события A:![]() где m — количество появлений события А в серии из n испытаний. Для проверки гипотезы H0 используется статистика, имеющая при достаточно большом объеме выборки стандартное нормальное распределение (табл. 1).
где m — количество появлений события А в серии из n испытаний. Для проверки гипотезы H0 используется статистика, имеющая при достаточно большом объеме выборки стандартное нормальное распределение (табл. 1).
Таблица 1 – Гипотезы о генеральной доле
|
Гипотеза |
H0:p=p0 | H0:p1=p2 |
| Предположения | Схема испытаний Бернулли | Схема испытаний Бернулли |
| Оценки по выборке |  |
|
| Статистика K |  |
 |
| Распределение статистики K | Стандартное нормальное N(0,1) | Стандартное нормальное N(0,1) |
Пример №1. С помощью случайного повторного отбора руководство фирмы провело выборочный опрос 900 своих служащих. Среди опрошенных оказалось 270 женщин. Постройте доверительный интервал, с вероятностью 0.95 накрывающий истинную долю женщин во всем коллективе фирмы.
Решение. По условию выборочная доля женщин составляет ![]() (относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
(относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле ![]() (относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
(относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
Значение uкр находим по таблице функции Лапласа из соотношения 2Ф(uкр)=γ, т.е. ![]() Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка
Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка ![]() Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка и искомый доверительный интервал
Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка и искомый доверительный интервал
(p – ε, p + ε) = (0.3 – 0.18; 0.3 + 0.18) = (0.12; 0.48)
Итак, с вероятностью 0.95 можно гарантировать, что доля женщин во всем коллективе фирмы находится в интервале от 0.12 до 0.48.
Пример №2. Владелец автостоянки считает день «удачным», если автостоянка заполнена более, чем на 80 %. В течение года было проведено 40 проверок автостоянки, из которых 24 оказались «удачными». С вероятностью 0.98 найдите доверительный интервал для оценки истинной доли «удачных» дней в течение года.
Решение. Выборочная доля «удачных» дней составляет ![]()
По таблице функции Лапласа найдем значение uкр при заданной
доверительной вероятности ![]()
По таблице функции Лапласа найдем значение uкр при заданной
доверительной вероятности
Ф(2.23) = 0.49, uкр = 2.33.
Считая отбор бесповторным (т.е. две проверки в один день не проводилось), найдем предельную ошибку: ![]()
где n=40, N = 365 (дней). Отсюда ![]()
где n=40, N = 365 (дней). Отсюда
и доверительный интервал для генеральной доли: (p – ε, p + ε) = (0.6 – 0.17; 0.6 + 0.17) = (0.43; 0.77)
С вероятностью 0.98 можно ожидать, что доля «удачных» дней в течение года находится в интервале от 0.43 до 0.77.
Пример №3. Проверив 2500 изделий в партии, обнаружили, что 400 изделий высшего сорта, а n–m – нет. Сколько надо проверить изделий, чтобы с уверенностью 95% определить долю высшего сорта с точностью до 0.01?
Решение ищем по формуле определения численности выборки для повторного отбора.
Ф(t) = γ/2 = 0.95/2 = 0.475 и этому значению по таблице Лапласа соответствует t=1.96
Выборочная доля w = 0.16; ошибка выборки ε = 0.01
Пример №4. Партия изделий принимается, если вероятность того, что изделие окажется соответствующим стандарту, составляет не менее 0.97. Среди случайно отобранных 200 изделий проверяемой партии оказалось 193 соответствующих стандарту. Можно ли на уровне значимости α=0,02 принять партию?
Решение. Сформулируем основную и альтернативную гипотезы.
H0:p=p0=0,97 — неизвестная генеральная доля p равна заданному значению p0=0,97. Применительно к условию — вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, равна 0.97; т.е. партию изделий можно принять.
H1:p<0,97 – вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Наблюдаемое значение статистики K (таблица) вычислим при заданных значениях p0=0,97, n=200, m=193

Критическое значение находим по таблице функции Лапласа из равенства
![]()
По условию α=0,02 отсюда Ф(Ккр)=0,48 и Ккр=2,05. Критическая область левосторонняя, т.е. является интервалом (-∞;-Kkp)= (-∞;-2,05). Наблюдаемое значение Кнабл=-0,415 не принадлежит критической области, следовательно, на данном уровне значимости нет оснований отклонять основную гипотезу. Партию изделий принять можно.
Пример №5. Два завода изготавливают однотипные детали. Для оценки их качества сделаны выборки из продукции этих заводов и получены следующие результаты. Среди 200 отобранных изделий первого завода оказалось 20 бракованных, среди 300 изделий второго завода — 15 бракованных.
На уровне значимости 0.025 выяснить, имеется ли существенное различие в качестве изготавливаемых этими заводами деталей.
Решение. Это задача о сравнении генеральных долей двух совокупностей. Сформулируем основную и альтернативную гипотезы.
H0:p1=p2 — генеральные доли равны. Применительно к условию — вероятность появления бракованного изделия в продукции первого завода равна вероятности появления бракованного изделия в продукции второго завода (качество продукции одинаково).
H0:p1≠p2 — заводы изготавливают детали разного качества.
Для вычисления наблюдаемого значения статистики K (таблица) рассчитаем оценки по выборке.
![]()
![]()
Наблюдаемое значение равно

Так как альтернативная гипотеза двусторонняя, то критическое значение статистики K≈ N(0,1) находим по таблице функции Лапласа из равенства ![]()
Так как альтернативная гипотеза двусторонняя, то критическое значение статистики K≈ N(0,1) находим по таблице функции Лапласа из равенства
По условию α=0,025 отсюда Ф(Ккр)=0,4875 и Ккр=2,24. При двусторонней альтернативе область допустимых значений имеет вид (-2,24;2,24). Наблюдаемое значение Kнабл=2,15 попадает в этот интервал, т.е. на данном уровне значимости нет оснований отвергать основную гипотезу. Заводы изготавливают изделия одинакового качества.
По части судить о целом
О возможности судить о целом по части миру рассказал российский математик П.Л. Чебышев. «Закон больших чисел» простым языком можно сформулировать так: количественные закономерности массовых явлений проявляются только при
достаточном числе наблюдений
. Чем больше выборка, тем лучше случайные отклонения компенсируют друг друга и проявляется общая тенденция.
А.М. Ляпунов чуть позже сформулировал центральную предельную теорему. Она стала фундаментом для создания формул, которые позволяют рассчитать вероятность ошибки (при оценке среднего по выборке) и размер выборки, необходимый для достижения заданной точности.
Строгие формулировки:
С увеличением числа случайных величин их среднее арифметическое стремится к среднему арифметическому математических ожиданий и перестает быть случайным. Общий смысл закона больших чисел — совместное действие большого числа случайных факторов приводит к результату, почти не зависящему от случая.
Таким образом з.б.ч. гарантирует устойчивость для средних значений некоторых случайных событий при достаточно длинной серии экспериментов.
Распределение случайной величины, которая получена в результате сложения большого числа независимых случайных величин (ни одно из которых не доминирует, не вносит в сумму определяющего вклада и имеет дисперсию значительно меньшею по сравнению с дисперсией суммы) имеет распределение, близкое к нормальному.
Из ц.п.т. следует, что ошибки выборки также подчиняется нормальному распределению.
Еще раз: чтобы корректно оценивать популяцию по выборке, нам нужна не обычная выборка, а репрезентативная выборка достаточного размера. Начнем с определения этого самого размера.
Как рассчитать объем выборки
Достаточный размер выборки зависит от следующих составляющих:
- изменчивость признака (чем разнообразней показания, тем больше наблюдений нужно, чтобы это уловить);
- размер эффекта (чем меньшие эффекты мы стремимся зафиксировать, тем больше наблюдений необходимо);
- уровень доверия (уровень вероятности при который мы готовы отвергнуть нулевую гипотезу)
ЗАПОМНИТЕ
Объем выборки зависит от изменчивости признака и планируемой строгости эксперимента
Формулы для расчета объема выборки:

Формулы расчета объема выборки
Ошибка выборки значительно возрастает, когда наблюдений меньше ста. Для исследований в которых используется 30-100 объектов применяется особая статистическая методология: критерии, основанные на распределении Стьюдента или бутстрэп-анализ. И наконец, статистика совсем слаба, когда наблюдений меньше 30.

График зависимости ошибки выборки от ее объема при оценке доли признака в г.с.
Чем больше неопределенность, тем больше ошибка. Максимальная неопределенность при оценке доли — 50% (например, 50% респондентов считают концепцию хорошей, а другие 50% плохой). Если 90% опрошенных концепция понравится — это, наоборот, пример согласованности. В таких случаях оценить долю признака по выборке проще.
Для экспонирования и выделения цветом значений статистических выбросов от медианы можно использовать несколько простых формул и условное форматирование.
Первым шагом в поиске значений выбросов статистики является определение статистического центра диапазона данных. С этой целью необходимо сначала определить границы первого и третьего квартала. Определение границ квартала – значит разделение данных на 4 равные группы, которые содержат по 25% данных каждая. Группа, содержащая 25% наибольших значений, называется первым квартилем.
Границы квартилей в Excel можно легко определить с помощью простой функции КВАРТИЛЬ. Данная функция имеет 2 аргумента: диапазон данных и номер для получения желаемого квартиля.
В примере показанному на рисунке ниже значения в ячейках E1 и E2 содержат показатели первого и третьего квартиля данных в диапазоне ячеек B2:B19:

Вычитая от значения первого квартиля третьего, можно определить набор 50% статистических данных, который называется межквартильным диапазоном. В ячейке E3 определен размер межквартильного диапазона.
В этом месте возникает вопрос, как сильно данное значение может отличаться от среднего значения 50% данных и оставаться все еще в пределах нормы? Статистические аналитики соглашаются с тем, что для определения нижней и верхней границы диапазона данных можно смело использовать коэффициент расширения 1,5 умножив на значение межквартильного диапазона. То есть:
- Нижняя граница диапазона данных равна: значение первого квартиля – межкваритльный диапазон * 1,5.
- Верхняя граница диапазона данных равна: значение третьего квартиля + расширенных диапазон * 1,5.
Как показано на рисунке ячейки E5 и E6 содержат вычисленные значения верхней и нижней границы диапазона данных. Каждое значение, которое больше верхней границы нормы или меньше нижней границы нормы считается значением статистического выброса.
Чтобы выделить цветом для улучшения визуального анализа данных можно создать простое правило для условного форматирования.
Способ 1: применение расширенного автофильтра
Наиболее простым способом произвести отбор является применение расширенного автофильтра. Рассмотрим, как это сделать на конкретном примере.
- Выделяем область на листе, среди данных которой нужно произвести выборку. Во вкладке «Главная» щелкаем по кнопке «Сортировка и фильтр». Она размещается в блоке настроек «Редактирование». В открывшемся после этого списка выполняем щелчок по кнопке «Фильтр».

Есть возможность поступить и по-другому. Для этого после выделения области на листе перемещаемся во вкладку «Данные». Щелкаем по кнопке «Фильтр», которая размещена на ленте в группе «Сортировка и фильтр».
- После этого действия в шапке таблицы появляются пиктограммы для запуска фильтрования в виде перевернутых острием вниз небольших треугольников на правом краю ячеек. Кликаем по данному значку в заглавии того столбца, по которому желаем произвести выборку. В запустившемся меню переходим по пункту «Текстовые фильтры». Далее выбираем позицию «Настраиваемый фильтр…».
- Активируется окно пользовательской фильтрации. В нем можно задать ограничение, по которому будет производиться отбор. В выпадающем списке для столбца содержащего ячейки числового формата, который мы используем для примера, можно выбрать одно из пяти видов условий:
- равно;
- не равно;
- больше;
- больше или равно;
- меньше.
Давайте в качестве примера зададим условие так, чтобы отобрать только значения, по которым сумма выручки превышает 10000 рублей. Устанавливаем переключатель в позицию «Больше». В правое поле вписываем значение «10000». Чтобы произвести выполнение действия, щелкаем по кнопке «OK».
- Как видим, после фильтрации остались только строчки, в которых сумма выручки превышает 10000 рублей.
- Но в этом же столбце мы можем добавить и второе условие. Для этого опять возвращаемся в окно пользовательской фильтрации. Как видим, в его нижней части есть ещё один переключатель условия и соответствующее ему поле для ввода. Давайте установим теперь верхнюю границу отбора в 15000 рублей. Для этого выставляем переключатель в позицию «Меньше», а в поле справа вписываем значение «15000».
Кроме того, существует ещё переключатель условий. У него два положения «И» и «ИЛИ». По умолчанию он установлен в первом положении. Это означает, что в выборке останутся только строчки, которые удовлетворяют обоим ограничениям. Если он будет выставлен в положение «ИЛИ», то тогда останутся значения, которые подходят под любое из двух условий. В нашем случае нужно выставить переключатель в положение «И», то есть, оставить данную настройку по умолчанию. После того, как все значения введены, щелкаем по кнопке «OK».
- Теперь в таблице остались только строчки, в которых сумма выручки не меньше 10000 рублей, но не превышает 15000 рублей.
- Аналогично можно настраивать фильтры и в других столбцах. При этом имеется возможность сохранять также фильтрацию и по предыдущим условиям, которые были заданы в колонках. Итак, посмотрим, как производится отбор с помощью фильтра для ячеек в формате даты. Кликаем по значку фильтрации в соответствующем столбце. Последовательно кликаем по пунктам списка «Фильтр по дате» и «Настраиваемый фильтр».
- Снова запускается окно пользовательского автофильтра. Выполним отбор результатов в таблице с 4 по 6 мая 2016 года включительно. В переключателе выбора условий, как видим, ещё больше вариантов, чем для числового формата. Выбираем позицию «После или равно». В поле справа устанавливаем значение «04.05.2016». В нижнем блоке устанавливаем переключатель в позицию «До или равно». В правом поле вписываем значение «06.05.2016». Переключатель совместимости условий оставляем в положении по умолчанию – «И». Для того, чтобы применить фильтрацию в действии, жмем на кнопку «OK».
- Как видим, наш список ещё больше сократился. Теперь в нем оставлены только строчки, в которых сумма выручки варьируется от 10000 до 15000 рублей за период с 04.05 по 06.05.2016 включительно.
- Мы можем сбросить фильтрацию в одном из столбцов. Сделаем это для значений выручки. Кликаем по значку автофильтра в соответствующем столбце. В выпадающем списке щелкаем по пункту «Удалить фильтр».
- Как видим, после этих действий, выборка по сумме выручки будет отключена, а останется только отбор по датам (с 04.05.2016 по 06.05.2016).
- В данной таблице имеется ещё одна колонка – «Наименование». В ней содержатся данные в текстовом формате. Посмотрим, как сформировать выборку с помощью фильтрации по этим значениям.
Кликаем по значку фильтра в наименовании столбца. Последовательно переходим по наименованиям списка «Текстовые фильтры» и «Настраиваемый фильтр…».
- Опять открывается окно пользовательского автофильтра. Давайте сделаем выборку по наименованиям «Картофель» и «Мясо». В первом блоке переключатель условий устанавливаем в позицию «Равно». В поле справа от него вписываем слово «Картофель». Переключатель нижнего блока так же ставим в позицию «Равно». В поле напротив него делаем запись – «Мясо». И вот далее мы выполняем то, чего ранее не делали: устанавливаем переключатель совместимости условий в позицию «ИЛИ». Теперь строчка, содержащая любое из указанных условий, будет выводиться на экран. Щелкаем по кнопке «OK».
- Как видим, в новой выборке существуют ограничения по дате (с 04.05.2016 по 06.05.2016) и по наименованию (картофель и мясо). По сумме выручки ограничений нет.
- Полностью удалить фильтр можно теми же способами, которые использовались для его установки. Причем неважно, какой именно способ применялся. Для сброса фильтрации, находясь во вкладке «Данные» щелкаем по кнопке «Фильтр», которая размещена в группе «Сортировка и фильтр».

Второй вариант предполагает переход во вкладку «Главная». Там выполняем щелчок на ленте по кнопке «Сортировка и фильтр» в блоке «Редактирование». В активировавшемся списке нажимаем на кнопку «Фильтр».

















При использовании любого из двух вышеуказанных методов фильтрация будет удалена, а результаты выборки – очищены. То есть, в таблице будет показан весь массив данных, которыми она располагает.

Способ 2: применение формулы массива
Сделать отбор можно также применив сложную формулу массива. В отличие от предыдущего варианта, данный метод предусматривает вывод результата в отдельную таблицу.
- На том же листе создаем пустую таблицу с такими же наименованиями столбцов в шапке, что и у исходника.
- Выделяем все пустые ячейки первой колонки новой таблицы. Устанавливаем курсор в строку формул. Как раз сюда будет заноситься формула, производящая выборку по указанным критериям. Отберем строчки, сумма выручки в которых превышает 15000 рублей. В нашем конкретном примере, вводимая формула будет выглядеть следующим образом:
=ИНДЕКС(A2:A29;НАИМЕНЬШИЙ(ЕСЛИ(15000<=C2:C29;СТРОКА(C2:C29);"");СТРОКА()-СТРОКА($C$1))-СТРОКА($C$1))Естественно, в каждом конкретном случае адрес ячеек и диапазонов будет свой. На данном примере можно сопоставить формулу с координатами на иллюстрации и приспособить её для своих нужд.
- Так как это формула массива, то для того, чтобы применить её в действии, нужно нажимать не кнопку Enter, а сочетание клавиш Ctrl+Shift+Enter. Делаем это.
- Выделив второй столбец с датами и установив курсор в строку формул, вводим следующее выражение:
=ИНДЕКС(B2:B29;НАИМЕНЬШИЙ(ЕСЛИ(15000<=C2:C29;СТРОКА(C2:C29);"");СТРОКА()-СТРОКА($C$1))-СТРОКА($C$1))Жмем сочетание клавиш Ctrl+Shift+Enter.
- Аналогичным образом в столбец с выручкой вписываем формулу следующего содержания:
=ИНДЕКС(C2:C29;НАИМЕНЬШИЙ(ЕСЛИ(15000<=C2:C29;СТРОКА(C2:C29);"");СТРОКА()-СТРОКА($C$1))-СТРОКА($C$1))Опять набираем сочетание клавиш Ctrl+Shift+Enter.
Во всех трех случаях меняется только первое значение координат, а в остальном формулы полностью идентичны.
- Как видим, таблица заполнена данными, но внешний вид её не совсем привлекателен, к тому же, значения даты заполнены в ней некорректно. Нужно исправить эти недостатки. Некорректность даты связана с тем, что формат ячеек соответствующего столбца общий, а нам нужно установить формат даты. Выделяем весь столбец, включая ячейки с ошибками, и кликаем по выделению правой кнопкой мыши. В появившемся списке переходим по пункту «Формат ячейки…».
- В открывшемся окне форматирования открываем вкладку «Число». В блоке «Числовые форматы» выделяем значение «Дата». В правой части окна можно выбрать желаемый тип отображения даты. После того, как настройки выставлены, жмем на кнопку «OK».
- Теперь дата отображается корректно. Но, как видим, вся нижняя часть таблицы заполнена ячейками, которые содержат ошибочное значение «#ЧИСЛО!». По сути, это те ячейки, данных из выборки для которых не хватило. Более привлекательно было бы, если бы они отображались вообще пустыми. Для этих целей воспользуемся условным форматированием. Выделяем все ячейки таблицы, кроме шапки. Находясь во вкладке «Главная» кликаем по кнопке «Условное форматирование», которая находится в блоке инструментов «Стили». В появившемся списке выбираем пункт «Создать правило…».
- В открывшемся окне выбираем тип правила «Форматировать только ячейки, которые содержат». В первом поле под надписью «Форматировать только ячейки, для которых выполняется следующее условие» выбираем позицию «Ошибки». Далее жмем по кнопке «Формат…».
- В запустившемся окне форматирования переходим во вкладку «Шрифт» и в соответствующем поле выбираем белый цвет. После этих действий щелкаем по кнопке «OK».
- На кнопку с точно таким же названием жмем после возвращения в окно создания условий.











Теперь у нас имеется готовая выборка по указанному ограничению в отдельной надлежащим образом оформленной таблице.

СРЗНАЧ()
Статистическая функция СРЗНАЧ возвращает среднее арифметическое своих аргументов.

Данная функция может принимать до 255 аргументов и находить среднее сразу в нескольких несмежных диапазонах и ячейках:

Если в рассчитываемом диапазоне встречаются пустые или содержащие текст ячейки, то они игнорируются. В примере ниже среднее ищется по четырем ячейкам, т.е. (4+15+11+22)/4 = 13

Если необходимо вычислить среднее, учитывая все ячейки диапазона, то можно воспользоваться статистической функцией СРЗНАЧА. В следующем примере среднее ищется уже по 6 ячейкам, т.е. (4+15+11+22)/6 = 8,6(6).

Статистическая функция СРЗНАЧ может использовать в качестве своих аргументов математические операторы и различные функции Excel:

СРЗНАЧЕСЛИ()
Если необходимо вернуть среднее арифметическое значений, которые удовлетворяют определенному условию, то можно воспользоваться статистической функцией СРЗНАЧЕСЛИ. Следующая формула вычисляет среднее чисел, которые больше нуля:

В данном примере для подсчета среднего и проверки условия используется один и тот же диапазон, что не всегда удобно. На этот случай у функции СРЗНАЧЕСЛИ существует третий необязательный аргумент, по которому можно вычислять среднее. Т.е. по первому аргументу проверяем условие, по третьему – находим среднее.
Допустим, в таблице ниже собрана статистика по стоимости лекарств в городе. В одной аптеке лекарство стоит дороже, в другой дешевле. Чтобы посчитать стоимость анальгина в среднем по городу, воспользуемся следующей формулой:

Если требуется соблюсти несколько условий, то всегда можно применить статистическую функцию СРЗНАЧЕСЛИМН, которая позволяет считать среднее арифметическое ячеек, удовлетворяющих двум и более критериям.
МАКС()
Статистическая функция МАКС возвращает наибольшее значение в диапазоне ячеек:

МИН()
Статистическая функция МИН возвращает наименьшее значение в диапазоне ячеек:

Источники
- https://lumpics.ru/descriptive-statistics-in-excel/
- https://statanaliz.info/statistica/opisanie-dannyx/variatsiya-razmakh-srednee-linejnoe-otklonenie/
- https://www.hd01.ru/info/kak-poschitat-razmah-v-excel/
- http://galyautdinov.ru/post/formula-vyborki-prostaya
- https://math.semestr.ru/group/interval-estimation-share.php
- https://tidydata.ru/sample-size
- https://exceltable.com/formuly/raschet-statisticheskih-vybrosov
- https://lumpics.ru/how-to-make-a-sample-in-excel/
- https://office-guru.ru/excel/statisticheskie-funkcii-excel-kotorye-neobhodimo-znat-96.html
Что такое Стандартная формула ошибки?
Стандартная ошибка — это ошибка, которая возникает в распределении выборки при выполнении статистического анализа. Это вариант стандартного отклонения, так как оба понятия соответствуют мерам спреда. Высокая стандартная ошибка соответствует более высокому разбросу данных для взятой выборки. Вычисление формулы стандартной ошибки выполняется для выборки. В то же время стандартное отклонение определяет генеральную совокупность.
Оглавление
- Что такое Стандартная формула ошибки?
- Объяснение
- Пример формулы стандартной ошибки
- Калькулятор стандартной ошибки
- Актуальность и использование
- Стандартная формула ошибки в Excel
- Рекомендуемые статьи
Следовательно, стандартная ошибка среднего значения будет выражаться и определяться в соответствии с соотношением, описанным следующим образом:
σ͞x = σ/√n

Здесь,
- Стандартная ошибка, выраженная как σ͞x.
- Стандартное отклонение совокупности выражается как σ.
- Количество переменных в выборке, выраженное как n.
В статистическом анализе среднее значение, медиана и мода являются центральной тенденцией. Центральная тенденция Центральная тенденция — это статистическая мера, которая отображает центральную точку всего распределения данных, и вы можете найти ее с помощью 3 различных мер, т. е. среднего, медианы и моды.Подробнее меры. Стандартное отклонение, дисперсия и стандартная ошибка среднего классифицируются как меры изменчивости. Стандартная ошибка среднего для выборочных данных напрямую связана со стандартным отклонением большей совокупности и обратно пропорциональна или связана с квадратным корнем. число. Чтобы использовать эту функцию, введите термин =SQRT и нажмите клавишу табуляции, которая вызовет функцию SQRT. Более того, эта функция принимает один аргумент из нескольких переменных, используемых для создания выборки. Следовательно, если размер выборки Размер выборкиФормула размера выборки отображает соответствующий диапазон генеральной совокупности, в которой проводится эксперимент или опрос. Он измеряется с использованием размера генеральной совокупности, критического значения нормального распределения при требуемом доверительном уровне, доли выборки и предела погрешности. Если больше, то может быть равная вероятность того, что стандартная ошибка также будет большой.
Объяснение
Можно объяснить формулу для стандартной ошибки среднего, используя следующие шаги:
- Определите и организуйте выборку и определите количество переменных.
- Затем среднее значение выборки соответствует количеству переменных, присутствующих в выборке.
- Затем определите стандартное отклонение выборки.
- Затем определите квадратный корень из числа переменных, включенных в выборку.
- Теперь разделите стандартное отклонение, вычисленное на шаге 3, на полученное значение на шаге 4, чтобы получить стандартную ошибку.
Пример формулы стандартной ошибки
Ниже приведены примеры формул для расчета стандартной ошибки.
.free_excel_div{фон:#d9d9d9;размер шрифта:16px;радиус границы:7px;позиция:относительная;margin:30px;padding:25px 25px 25px 45px}.free_excel_div:before{content:»»;фон:url(центр центр без повтора #207245;ширина:70px;высота:70px;позиция:абсолютная;верх:50%;margin-top:-35px;слева:-35px;граница:5px сплошная #fff;граница-радиус:50%} Вы можете скачать этот шаблон стандартной формулы ошибки Excel здесь — Стандартная формула ошибки Шаблон Excel
Пример №1
Возьмем в качестве примера акции ABC. В течение 30 лет акции приносили средний долларовый доход в размере 45 долларов. Кроме того, было замечено, что акции приносят прибыль со стандартным отклонением в 2 доллара. Помогите инвестору рассчитать общую стандартную ошибку средней доходности, предлагаемой акцией ABC.
Решение:
- Стандартное отклонение (σ) = $2
- Количество лет (n) = 30
- Средняя доходность в долларах = 45 долларов.
Расчет стандартной ошибки выглядит следующим образом:

- σ͞x = σ/√n
- = 2 доллара США/√30
- = 2 доллара США / 5,4773
Стандартная ошибка,

- σx = 0,3651 доллара США
Таким образом, инвестиция предлагает инвестору стандартную долларовую ошибку в среднем 0,36515 доллара при удерживании позиции ABC в течение 30 лет. Однако, если бы акции сохранялись для более высокого инвестиционного горизонта, то стандартная ошибка среднего значения в долларах значительно уменьшилась бы.
Пример #2
Возьмем в качестве примера инвестора, который получил следующую доходность акций XYZ:
Год инвестиций Предлагаемая доходность120%225%35%410%
Помогите инвестору рассчитать общую стандартную ошибку средней доходности акций XYZ.
Решение:
Сначала определите среднее значение доходности, как показано ниже: –

- ͞X = (x1+x2+x3+x4)/количество лет
- = (20+25+5+10)/4
- =15%
Теперь определите стандартное отклонение доходности, как показано ниже: –

- σ = √ ((x1-͞X)2 + (x2-͞X)2 + (x3-͞X)2 + (x4-͞X)2) / √ (количество лет -1)
- = √ ((20-15) 2 + (25-15) 2 + (5-15) 2 + (10-15) 2) / √ (4-1)
- = (√ (5) 2 + (10) 2 + (-10) 2 + (-5) 2 ) / √ (3)
- = (√25+100+100+25)/ √ (3)
- =√250/√3
- =√83,3333
- «=» 9,1287%
Теперь вычисление стандартной ошибки выглядит следующим образом:

- σ͞x = σ/√n
- = 9,128709/√4
- = 9,128709/2
Стандартная ошибка,

- σx = 4,56%
Таким образом, инвестиции предлагают инвестору стандартную ошибку в долларах в среднем 4,56% при удержании позиции XYZ в течение 4 лет.
Калькулятор стандартной ошибки
Вы можете использовать следующий калькулятор.
.cal-tbl td{ верхняя граница: 0 !важно; }.cal-tbl tr{ высота строки: 0.5em; } Только экран @media и (минимальная ширина устройства: 320 пикселей) и (максимальная ширина устройства: 480 пикселей) { .cal-tbl tr{ line-height: 1em !important; } } σnСтандартная формула ошибки
Формула стандартной ошибки =σ =√n 0 = 0√0
Актуальность и использование
Стандартная ошибка имеет тенденцию быть высокой, если размер выборки для анализа мал. Следовательно, выборка всегда берется из большей совокупности, которая включает больший размер переменных. Это всегда помогает статистику определить достоверность среднего значения выборки относительно среднего значения генеральной совокупности.
Большая стандартная ошибка говорит статистику, что выборка неоднородна в отношении среднего значения генеральной совокупности. Относительно населения наблюдается большой разброс в выборке. Точно так же небольшая стандартная ошибка говорит статистику, что выборка однородна относительно среднего значения генеральной совокупности. Отсутствуют или незначительные различия в выборке относительно населения.
Не следует смешивать его со стандартным отклонением. Вместо этого следует рассчитать стандартное отклонение для всей совокупности. Стандартная ошибкаСтандартная ошибкаСтандартная ошибка (SE) — это метрика, которая измеряет точность выборочного распределения, обозначающего совокупность, с использованием стандартного отклонения. Другими словами, это мера дисперсии среднего значения выборки, связанная со средним значением генеральной совокупности, а не стандартное отклонение. С другой стороны, оно определяется для среднего значения выборки.
Стандартная формула ошибки в Excel
Теперь давайте возьмем пример Excel, чтобы проиллюстрировать концепцию стандартной формулы ошибки в шаблоне Excel ниже. Предположим, администрация школы хочет определить стандартную ошибку среднего значения роста футболистов.
Выборка состоит из следующих значений: –

Помогите администрации оценить стандартную ошибку среднего значения.
Шаг 1: Определите среднее значение, как показано ниже: –

Шаг 2: Определите стандартное отклонение, как показано ниже: –

Шаг 3: Определите стандартную ошибку среднего значения, как показано ниже: –

Следовательно, стандартная ошибка среднего значения для футболистов составляет 1,846 дюйма. Руководство должно заметить, что оно значительно велико. Таким образом, выборочные данные, взятые для анализа, неоднородны и имеют большую дисперсию.
Руководству следует либо исключить более мелких игроков, либо добавить игроков значительно выше, чтобы сбалансировать средний рост футбольной команды, заменив их людьми с меньшим ростом по сравнению с их сверстниками.
Рекомендуемые статьи
Эта статья была руководством по формуле стандартной ошибки. Здесь мы обсуждаем формулу для расчета среднего значения, стандартную ошибку, примеры и загружаемый лист Excel. Вы можете узнать больше из следующих статей: –
- Формула рентабельности EBITDA
- Формула валовой прибыли
- Формула относительного стандартного отклонения
- Формула погрешности
17 авг. 2022 г.
читать 2 мин
Всякий раз, когда мы подбираем модель линейной регрессии , модель принимает следующую форму:
Y = β 0 + β 1 X + … + β i X +ϵ
где ϵ — член ошибки, не зависящий от X.
Независимо от того, насколько хорошо можно использовать X для предсказания значений Y, в модели всегда будет какая-то случайная ошибка.
Одним из способов измерения дисперсии этой случайной ошибки является использование стандартной ошибки регрессионной модели , которая представляет собой способ измерения стандартного отклонения остатков ϵ.
В этом руководстве представлен пошаговый пример расчета стандартной ошибки регрессионной модели в Excel.
Шаг 1: Создайте данные
В этом примере мы создадим набор данных, содержащий следующие переменные для 12 разных учащихся:
- Оценка экзамена
- Часы, потраченные на учебу
- Текущая оценка
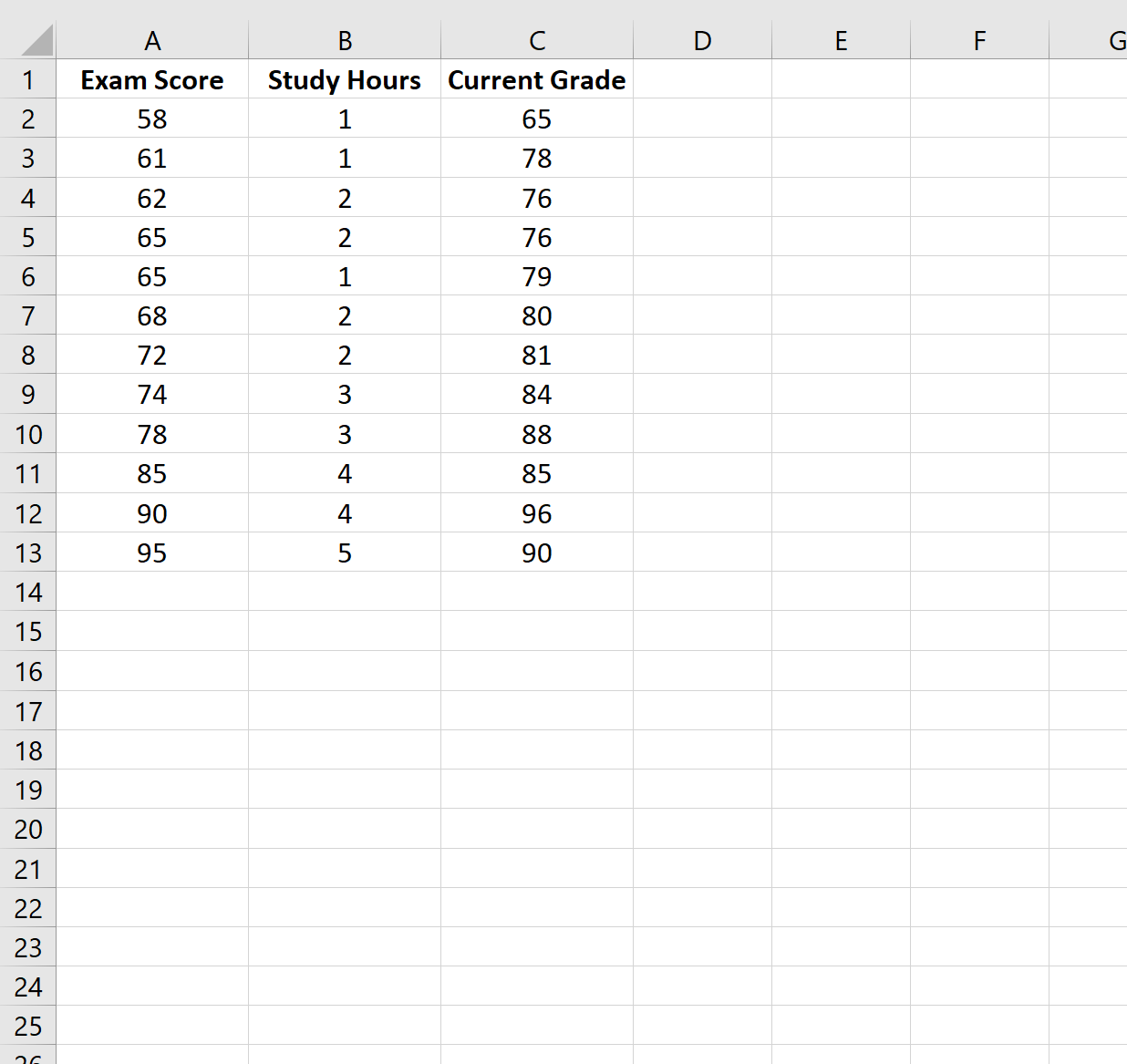
Шаг 2: Подгонка регрессионной модели
Далее мы подгоним модель множественной линейной регрессии , используя экзаменационный балл в качестве переменной ответа и часы обучения и текущую оценку в качестве переменных-предикторов.
Для этого щелкните вкладку « Данные » на верхней ленте, а затем щелкните « Анализ данных» :

Если вы не видите эту опцию доступной, вам нужно сначала загрузить Data Analysis ToolPak .
В появившемся окне выберите Регрессия.В появившемся новом окне заполните следующую информацию:
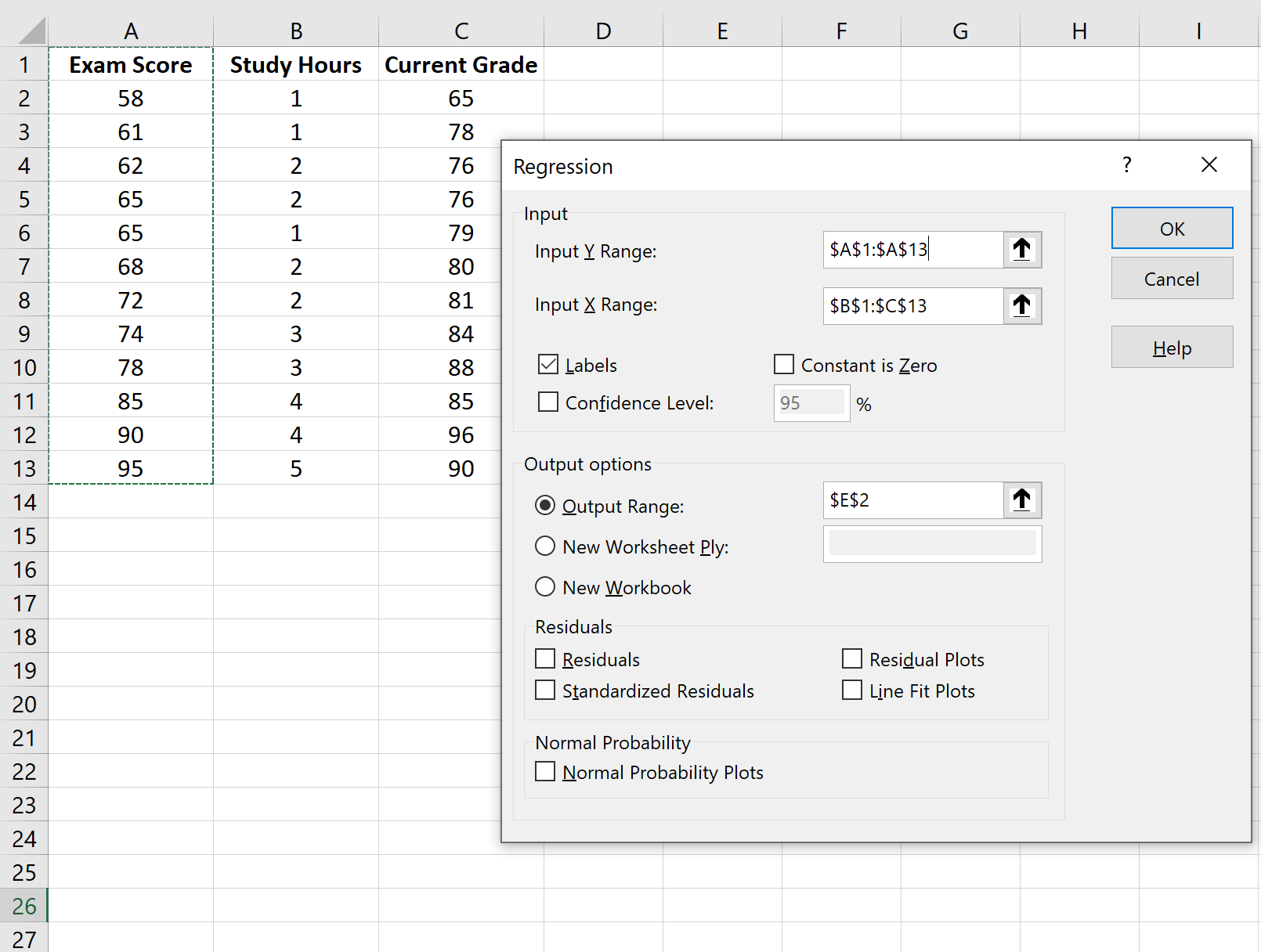
Как только вы нажмете OK , появится результат регрессионной модели:
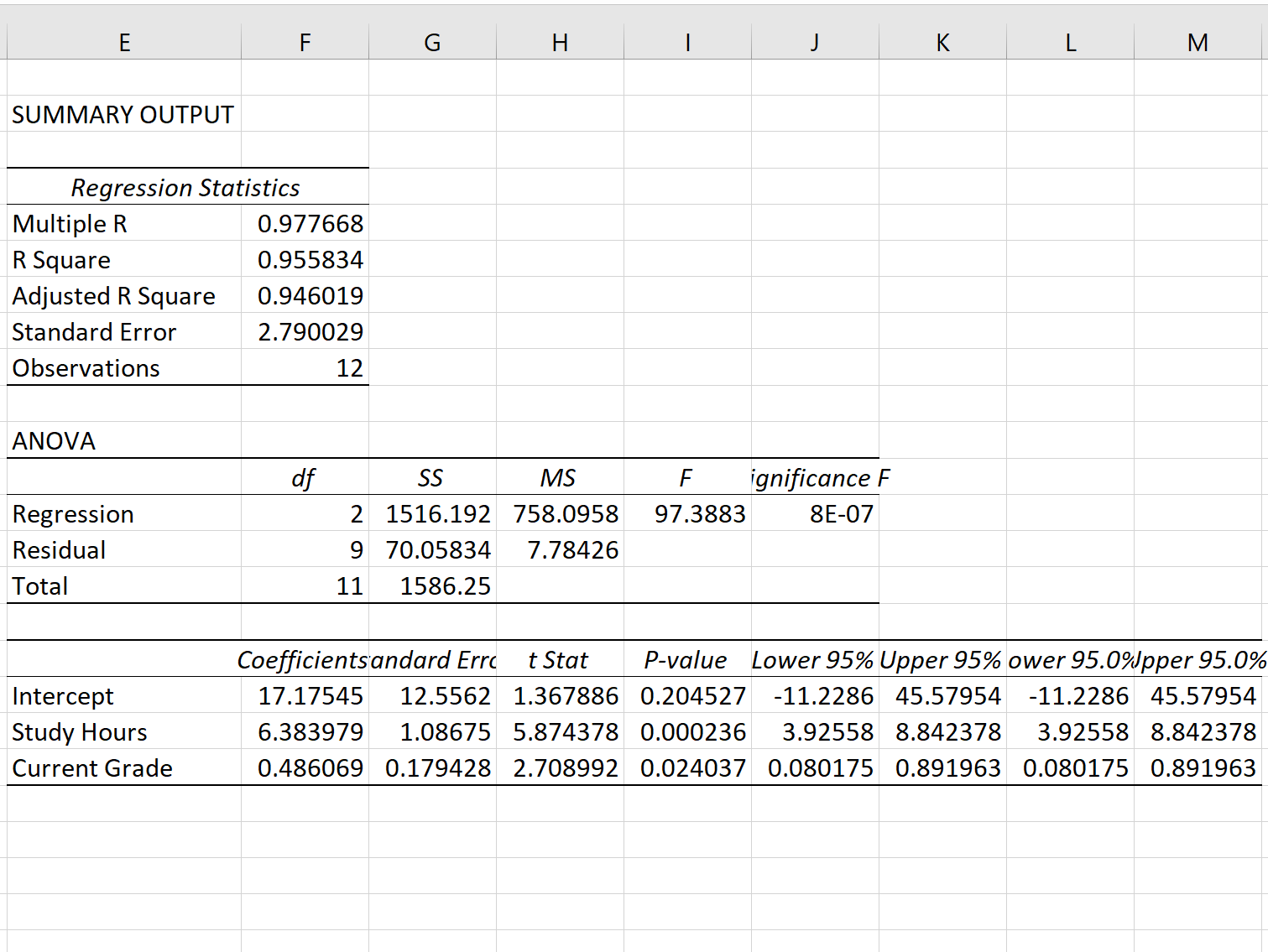
Шаг 3: Интерпретируйте стандартную ошибку регрессии
Стандартная ошибка модели регрессии — это число рядом со стандартной ошибкой :
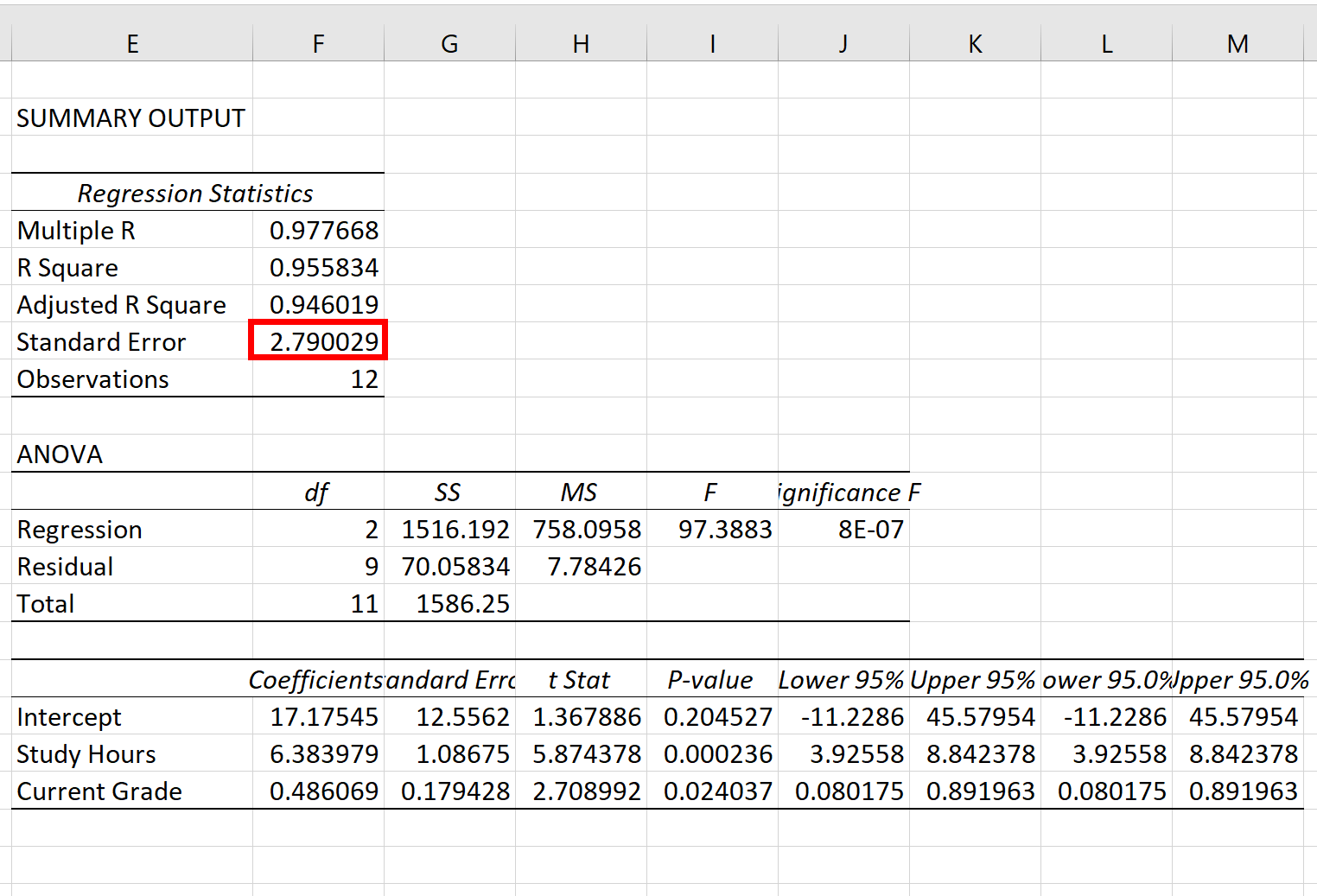
Стандартная ошибка этой конкретной модели регрессии оказывается равной 2,790029 .
Это число представляет собой среднее расстояние между фактическими результатами экзаменов и оценками экзаменов, предсказанными моделью.
Обратите внимание, что некоторые экзаменационные баллы будут отличаться от прогнозируемого более чем на 2,79 единицы, в то время как некоторые будут ближе. Но в среднем расстояние между реальными экзаменационными баллами и прогнозируемыми составляет 2,790029 .
Также обратите внимание, что меньшая стандартная ошибка регрессии указывает на то, что модель регрессии более точно соответствует набору данных.
Таким образом, если мы подгоним новую регрессионную модель к набору данных и получим стандартную ошибку, скажем, 4,53 , эта новая модель будет хуже предсказывать результаты экзаменов, чем предыдущая модель.
Дополнительные ресурсы
Другим распространенным способом измерения точности регрессионной модели является использование R-квадрата. Прочтите эту статью , чтобы получить хорошее объяснение преимуществ использования стандартной ошибки регрессии для измерения точности по сравнению с R-квадратом.