
Содержание
- Способ 1: Использование автоматического инструмента
- Способ 2: Создание формулы разделения текста
- Шаг 1: Разделение первого слова
- Шаг 2: Разделение второго слова
- Шаг 3: Разделение третьего слова
- Вопросы и ответы

Способ 1: Использование автоматического инструмента
В Excel есть автоматический инструмент, предназначенный для разделения текста по столбцам. Он не работает в автоматическом режиме, поэтому все действия придется выполнять вручную, предварительно выбирая диапазон обрабатываемых данных. Однако настройка является максимально простой и быстрой в реализации.
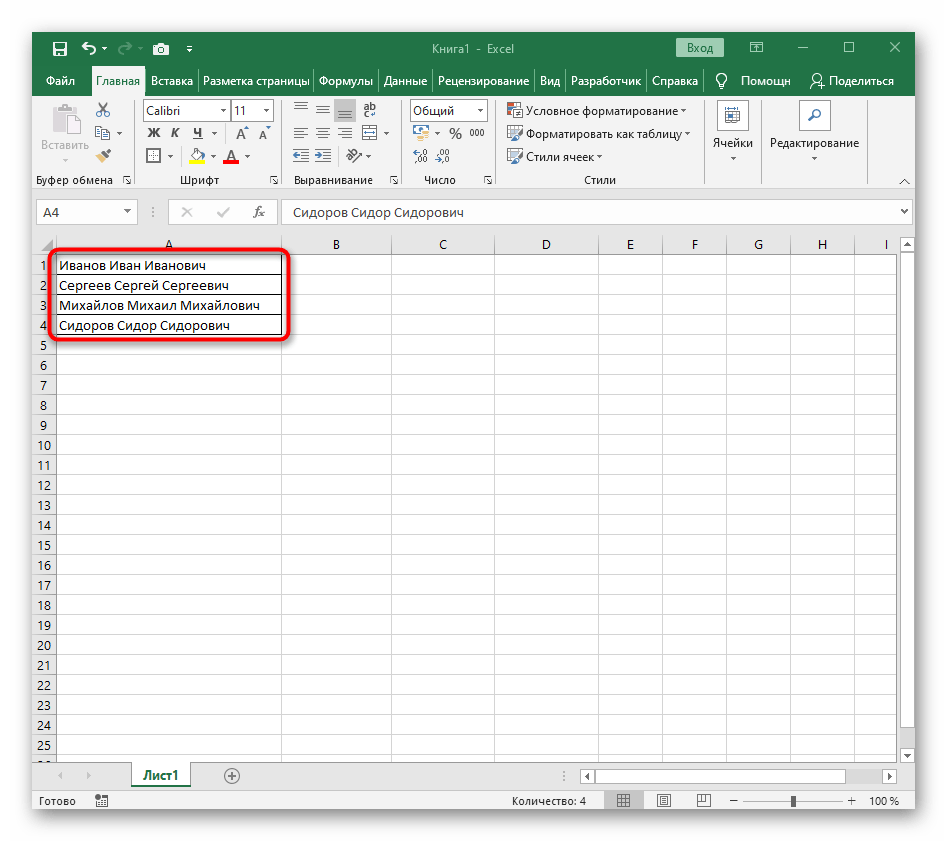
- С зажатой левой кнопкой мыши выделите все ячейки, текст которых хотите разделить на столбцы.
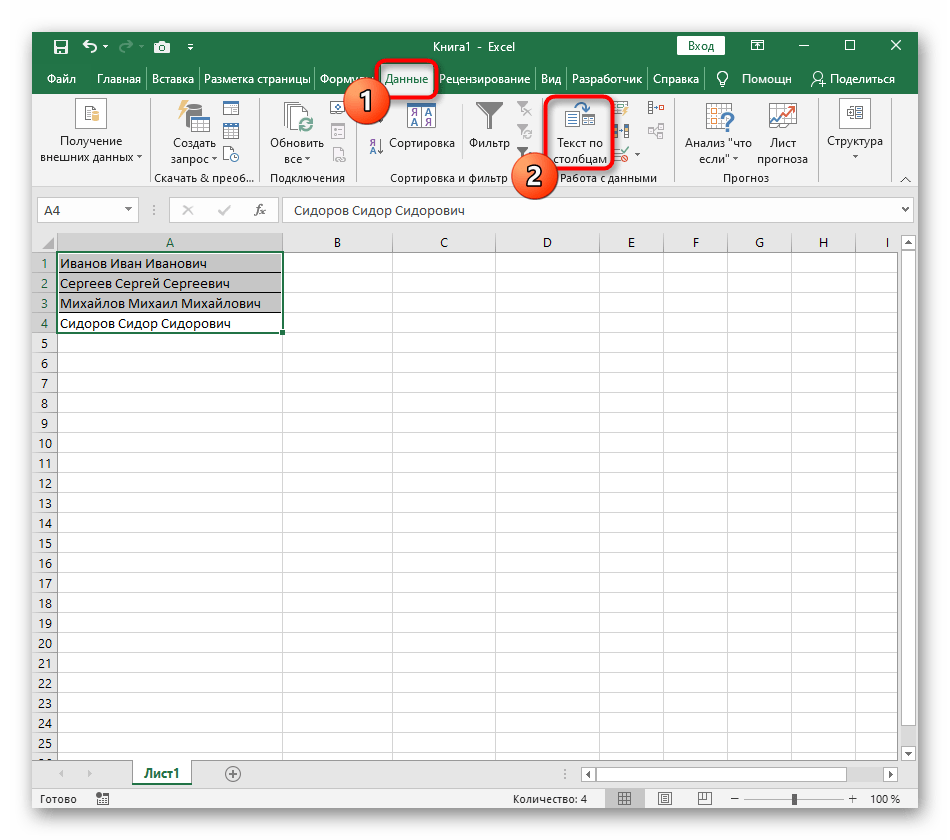
- После этого перейдите на вкладку «Данные» и нажмите кнопку «Текст по столбцам».
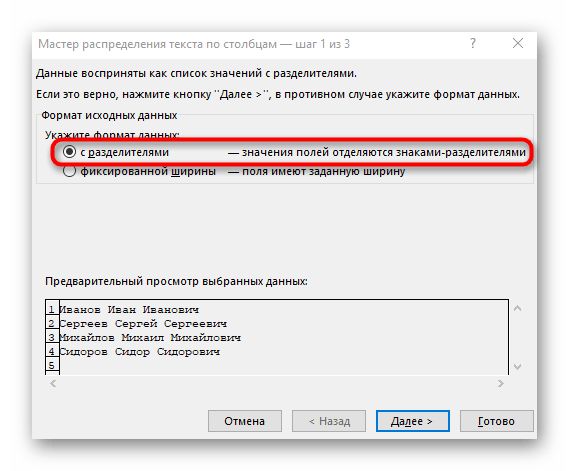
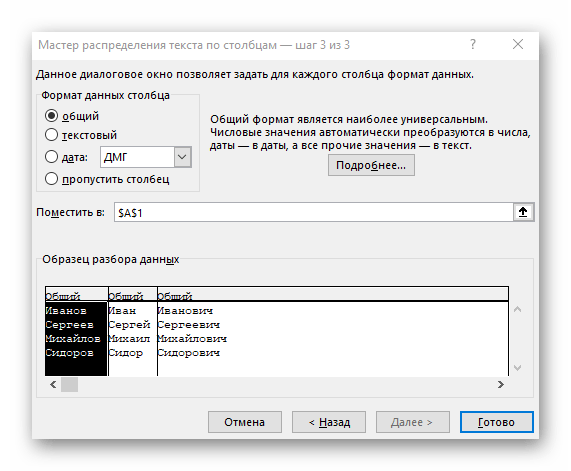
- Появится окно «Мастера разделения текста по столбцам», в котором нужно выбрать формат данных «с разделителями». Разделителем чаще всего выступает пробел, но если это другой знак препинания, понадобится указать его в следующем шаге.
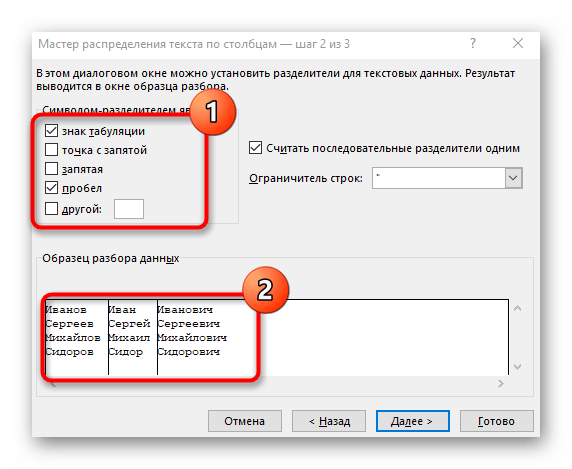
- Отметьте галочкой символ разделения или вручную впишите его, а затем ознакомьтесь с предварительным результатом разделения в окне ниже.
- В завершающем шаге можно указать новый формат столбцов и место, куда их необходимо поместить. Как только настройка будет завершена, нажмите «Готово» для применения всех изменения.
- Вернитесь к таблице и убедитесь в том, что разделение прошло успешно.
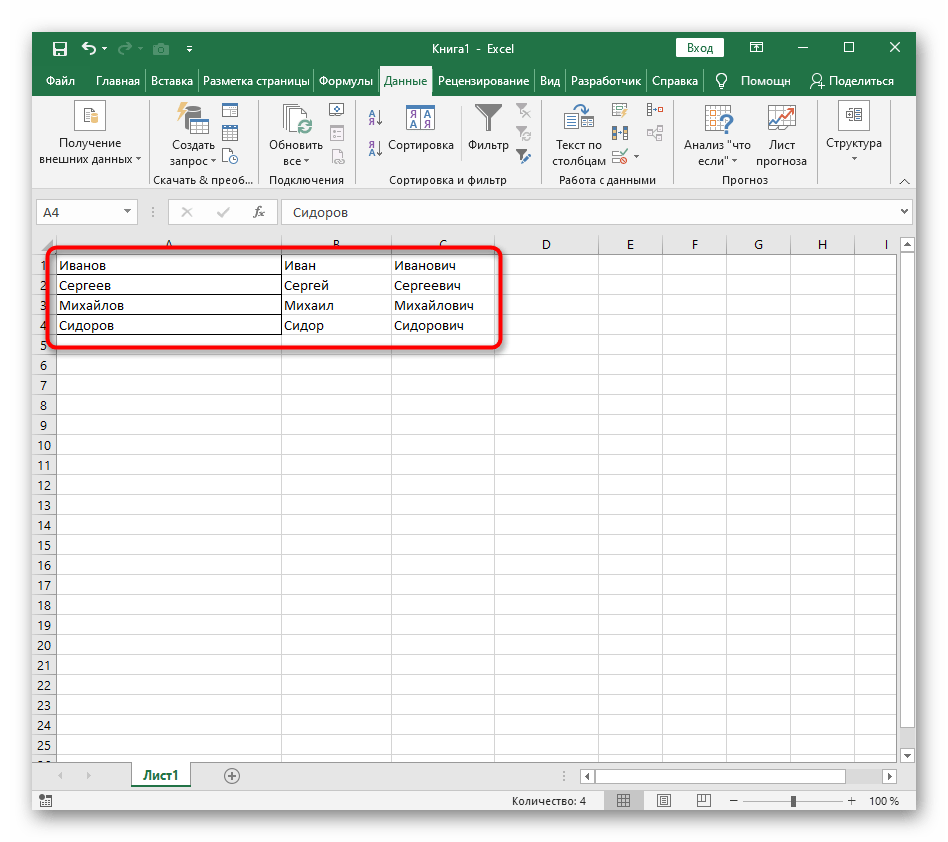
Из этой инструкции можно сделать вывод, что использование такого инструмента оптимально в тех ситуациях, когда разделение необходимо выполнить всего один раз, обозначив для каждого слова новый столбец. Однако если в таблицу постоянно вносятся новые данные, все время разделять их таким образом будет не совсем удобно, поэтому в таких случаях предлагаем ознакомиться со следующим способом.
Способ 2: Создание формулы разделения текста
В Excel можно самостоятельно создать относительно сложную формулу, которая позволит рассчитать позиции слов в ячейке, найти пробелы и разделить каждое на отдельные столбцы. В качестве примера мы возьмем ячейку, состоящую из трех слов, разделенных пробелами. Для каждого из них понадобится своя формула, поэтому разделим способ на три этапа.
Шаг 1: Разделение первого слова
Формула для первого слова самая простая, поскольку придется отталкиваться только от одного пробела для определения правильной позиции. Рассмотрим каждый шаг ее создания, чтобы сформировалась полная картина того, зачем нужны определенные вычисления.
- Для удобства создадим три новые столбца с подписями, куда будем добавлять разделенный текст. Вы можете сделать так же или пропустить этот момент.
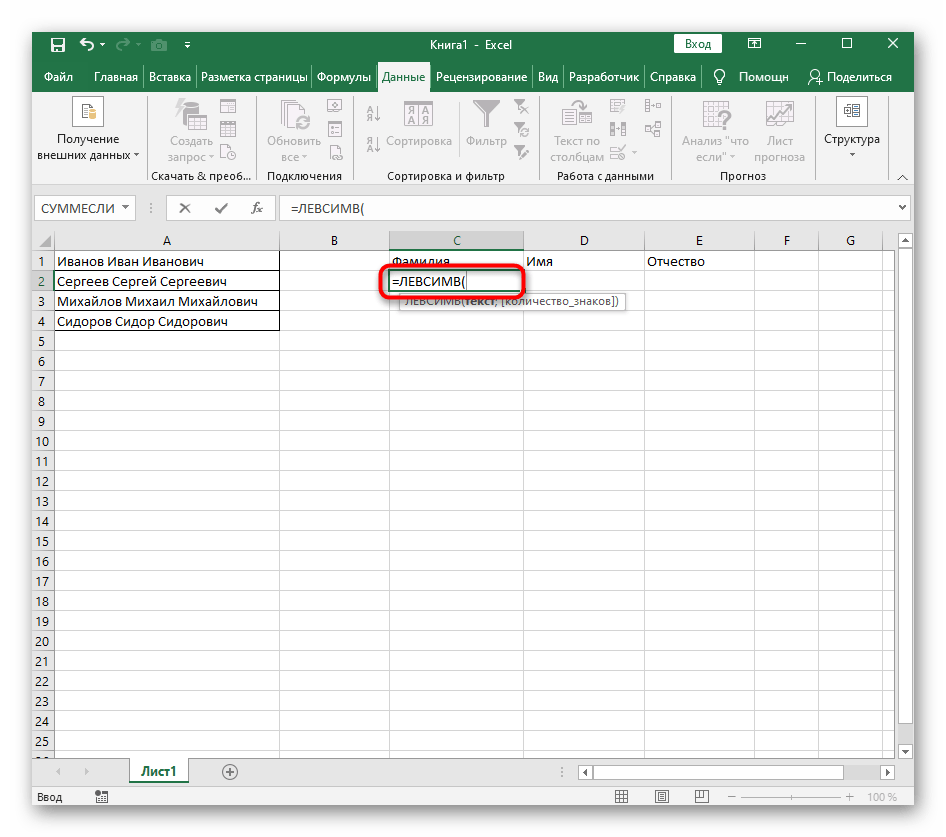
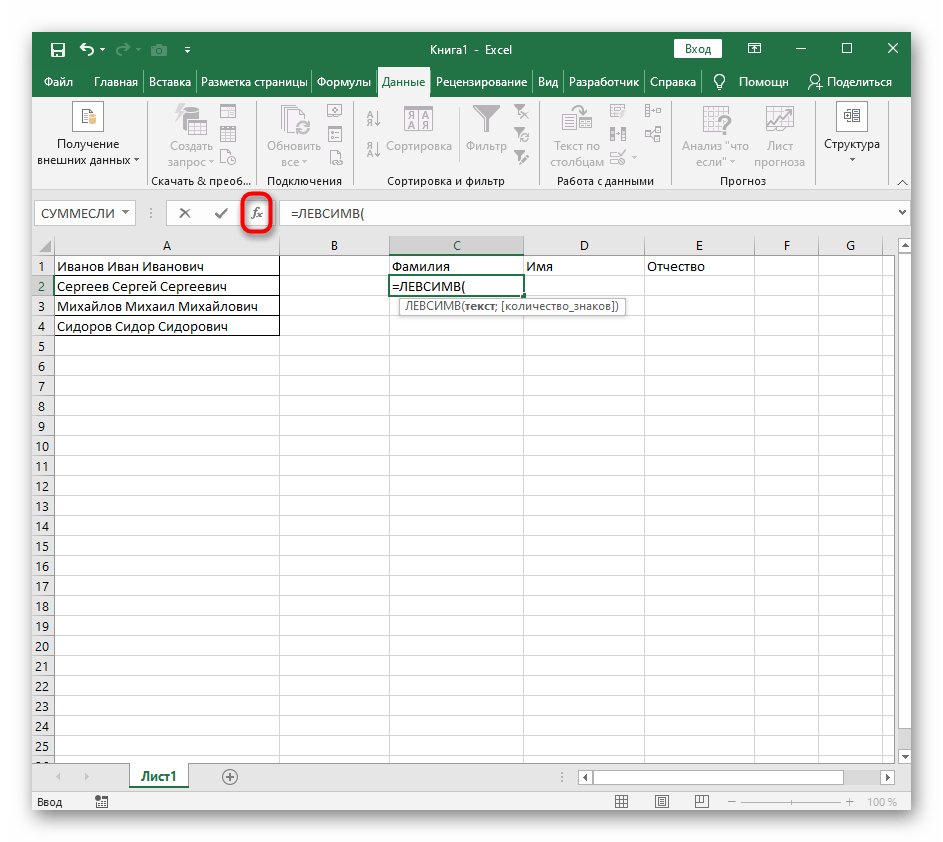
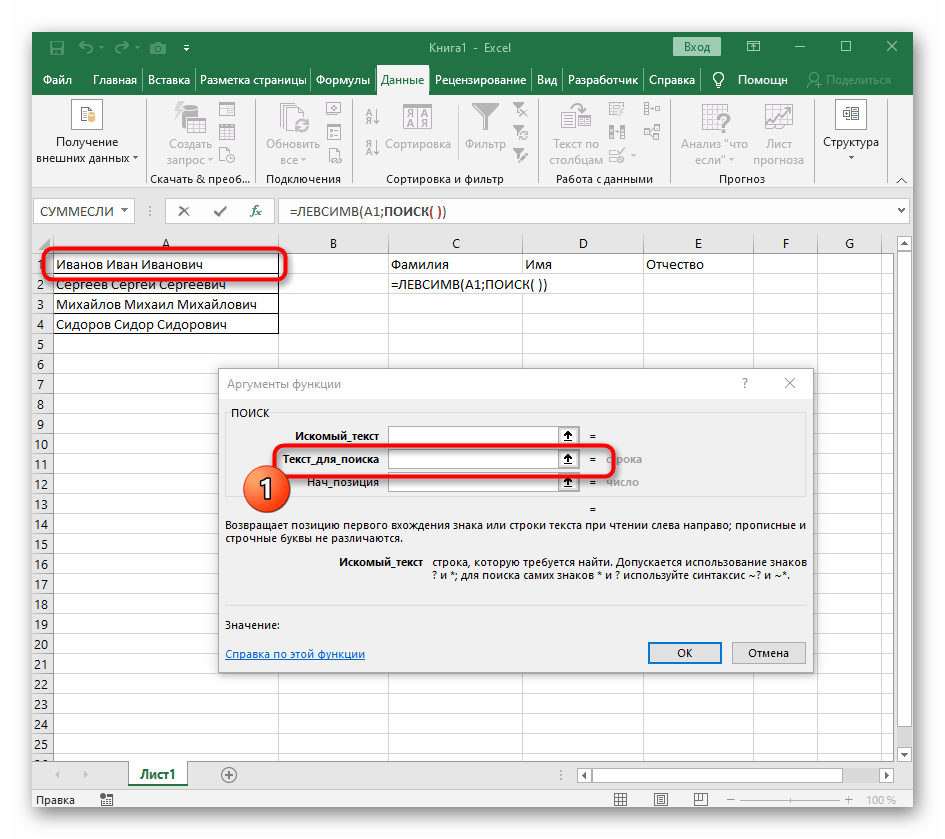
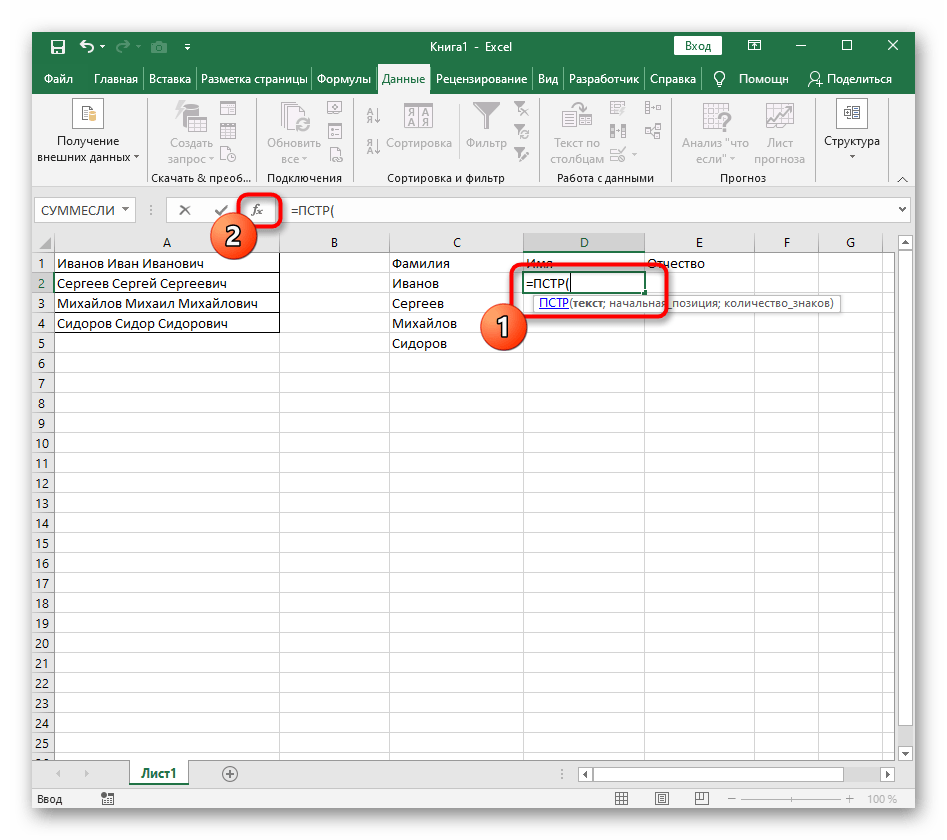
- Выберите ячейку, где хотите расположить первое слово, и запишите формулу
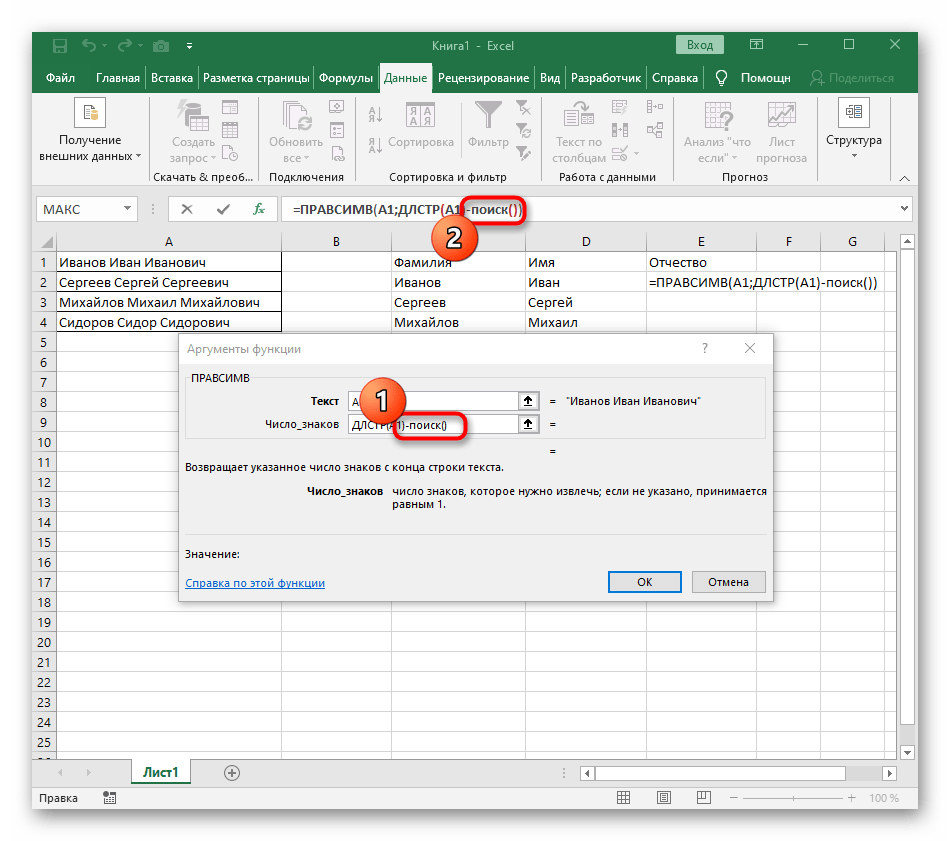
=ЛЕВСИМВ(. - После этого нажмите кнопку «Аргументы функции», перейдя тем самым в графическое окно редактирования формулы.
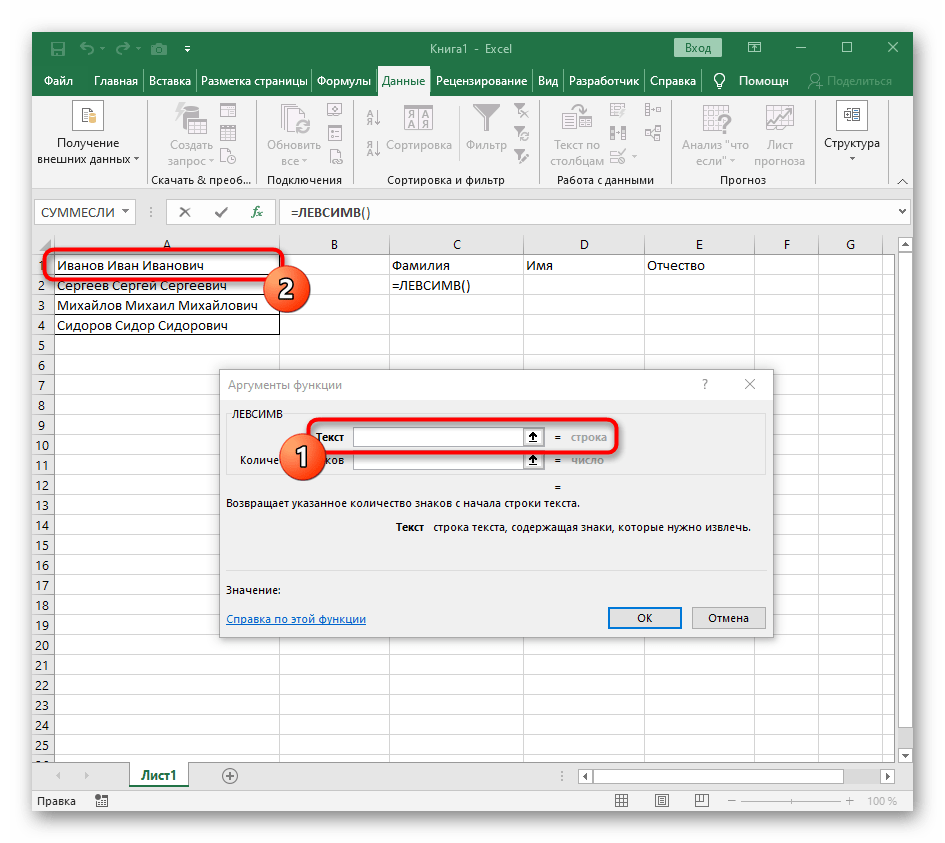
- В качестве текста аргумента указывайте ячейку с надписью, кликнув по ней левой кнопкой мыши на таблице.
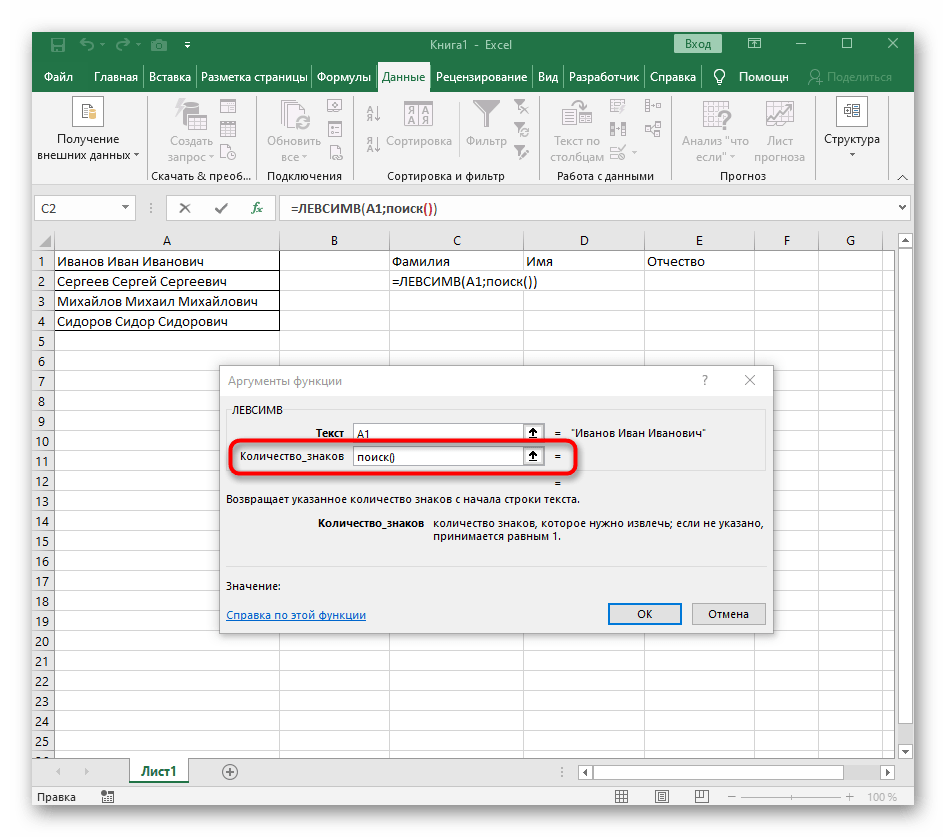
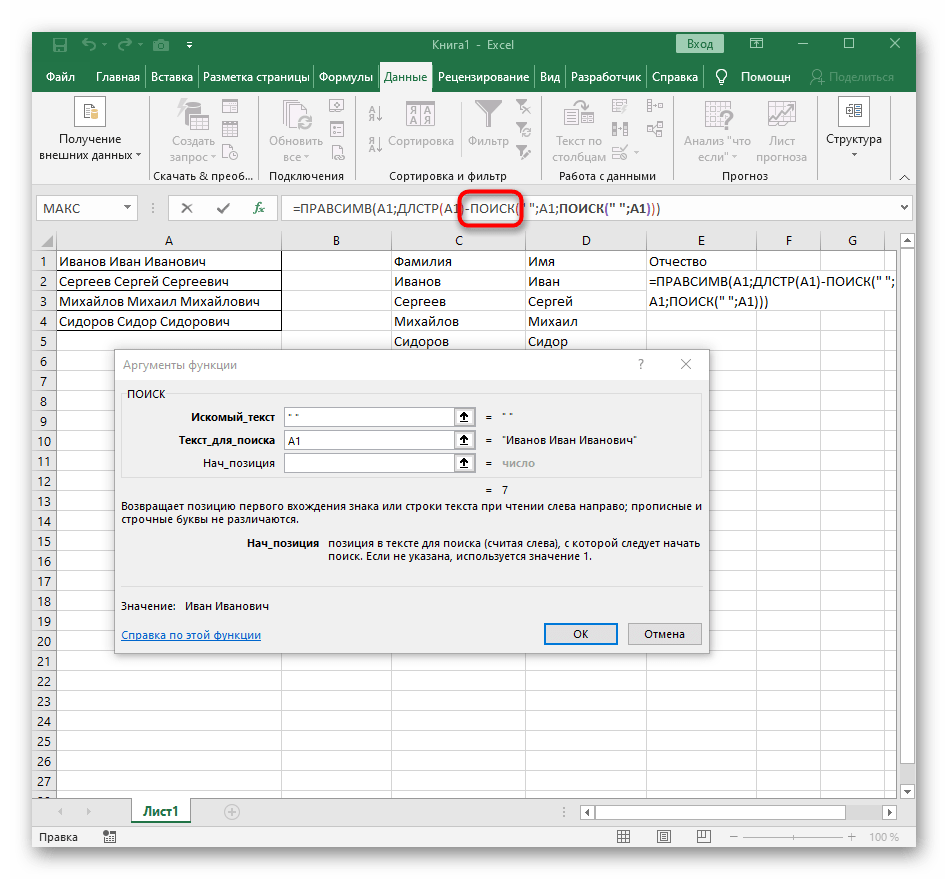
- Количество знаков до пробела или другого разделителя придется посчитать, но вручную мы это делать не будем, а воспользуемся еще одной формулой —
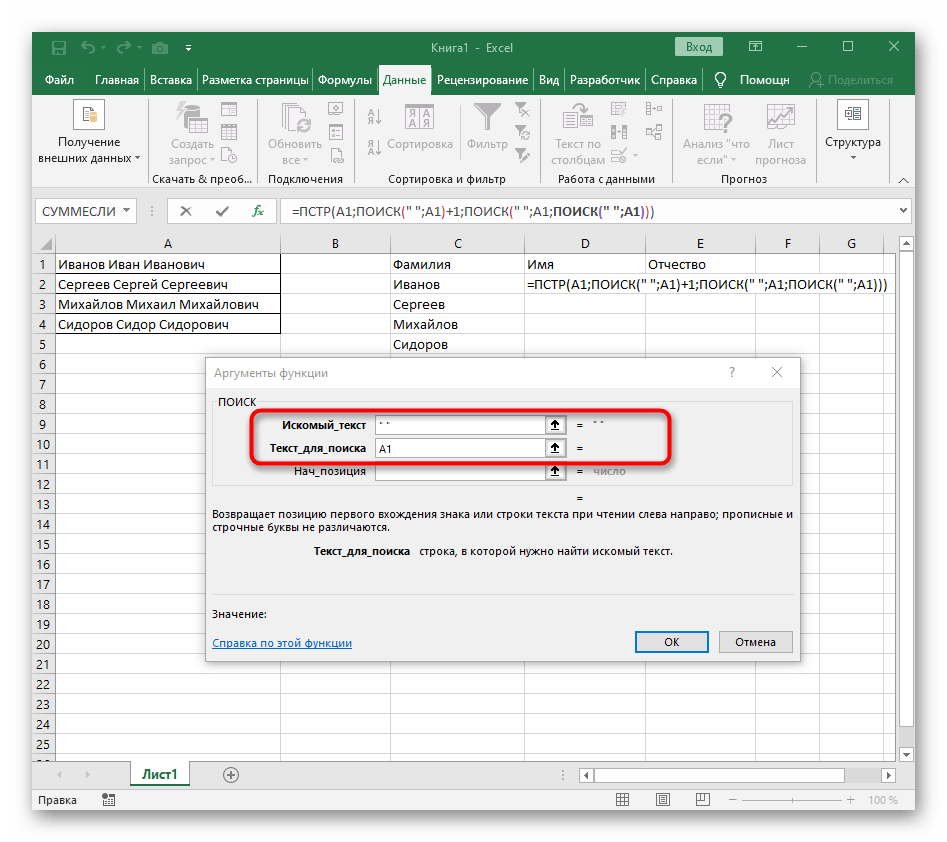
ПОИСК(). - Как только вы запишете ее в таком формате, она отобразится в тексте ячейки сверху и будет выделена жирным. Нажмите по ней для быстрого перехода к аргументам этой функции.
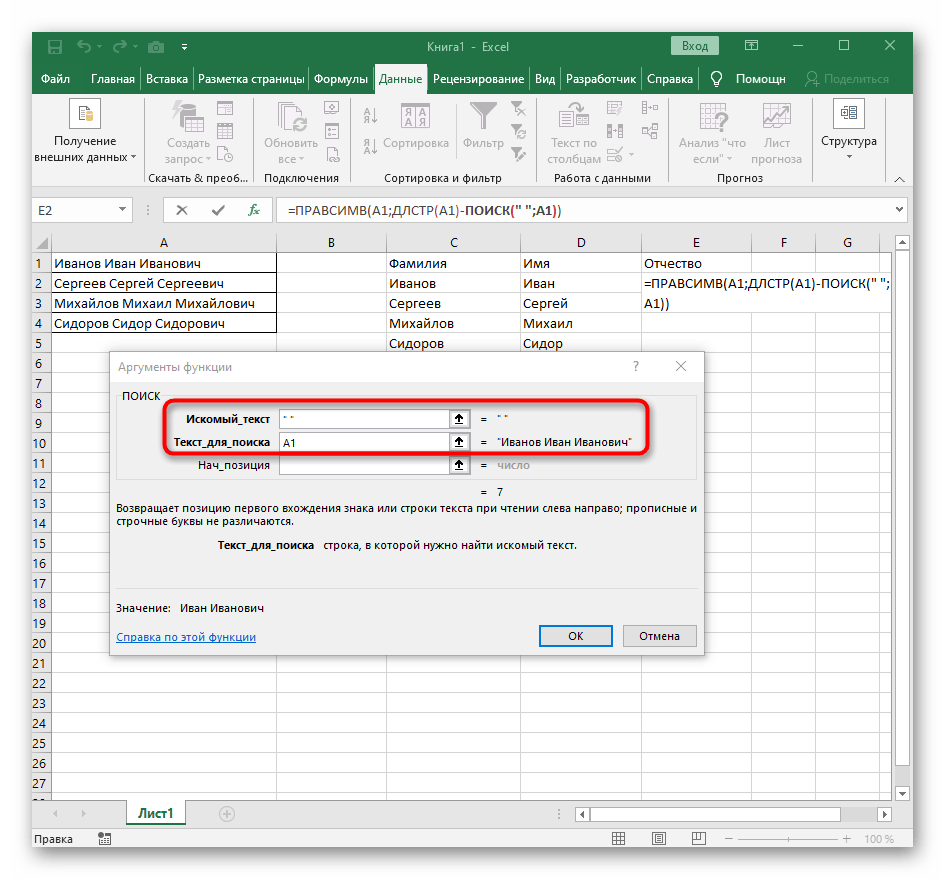
- В поле «Искомый_текст» просто поставьте пробел или используемый разделитель, поскольку он поможет понять, где заканчивается слово. В «Текст_для_поиска» укажите ту же обрабатываемую ячейку.
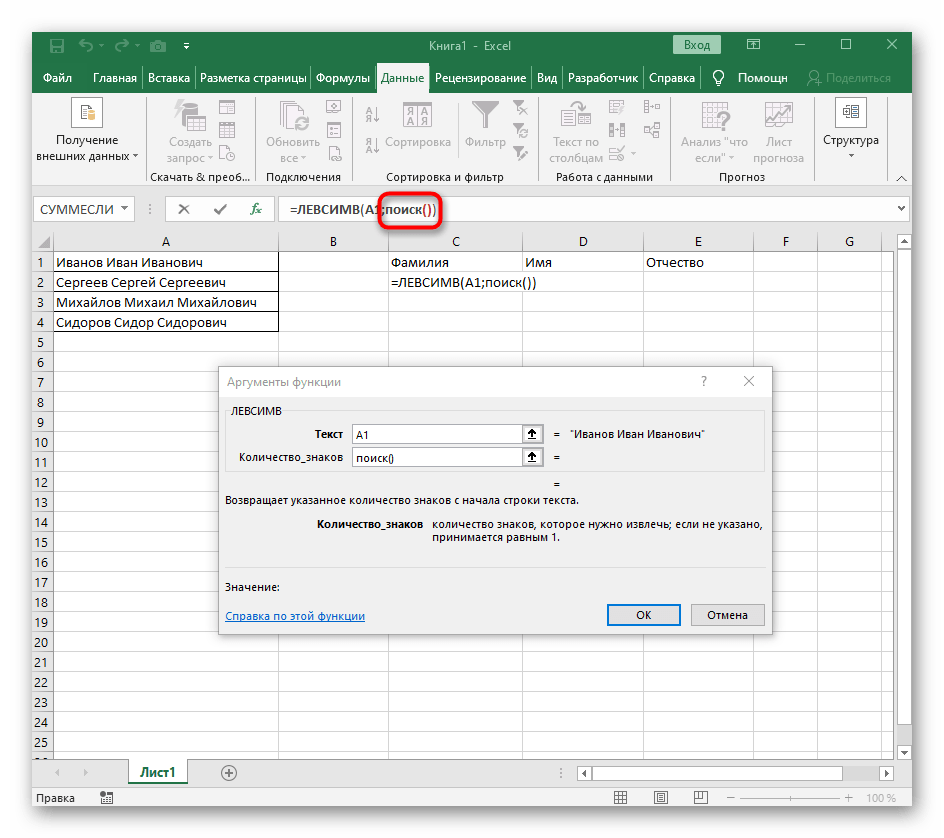
- Нажмите по первой функции, чтобы вернуться к ней, и добавьте в конце второго аргумента
-1. Это необходимо для того, чтобы формуле «ПОИСК» учитывать не искомый пробел, а символ до него. Как видно на следующем скриншоте, в результате выводится фамилия без каких-либо пробелов, а это значит, что составление формул выполнено правильно. - Закройте редактор функции и убедитесь в том, что слово корректно отображается в новой ячейке.
- Зажмите ячейку в правом нижнем углу и перетащите вниз на необходимое количество рядов, чтобы растянуть ее. Так подставляются значения других выражений, которые необходимо разделить, а выполнение формулы происходит автоматически.

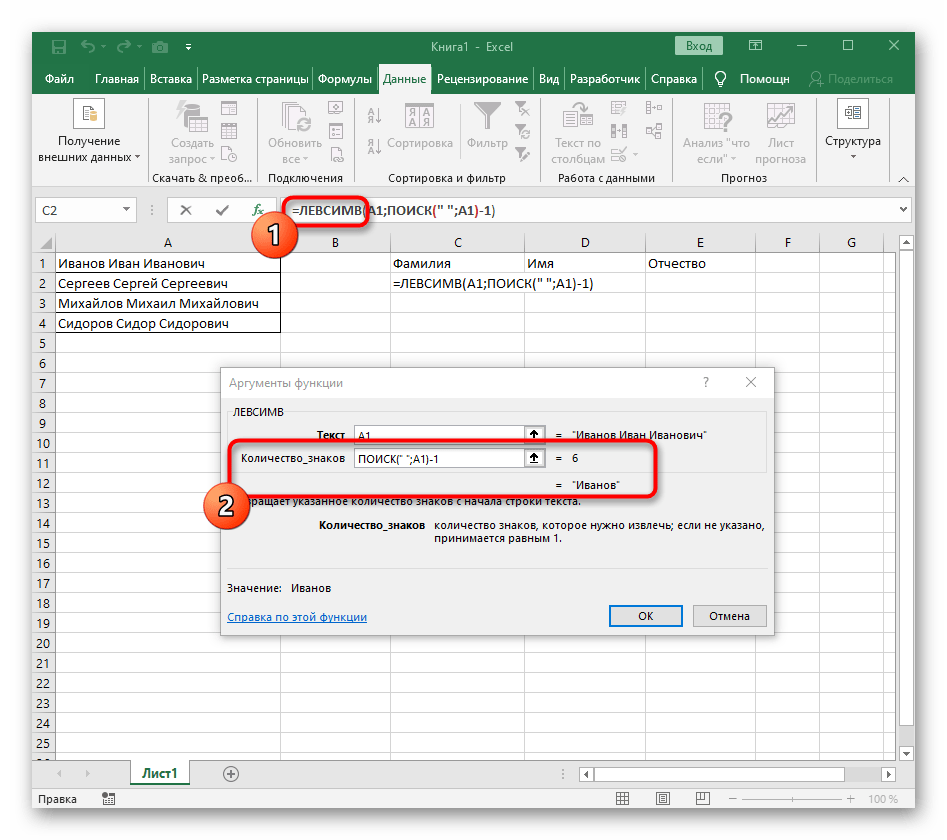
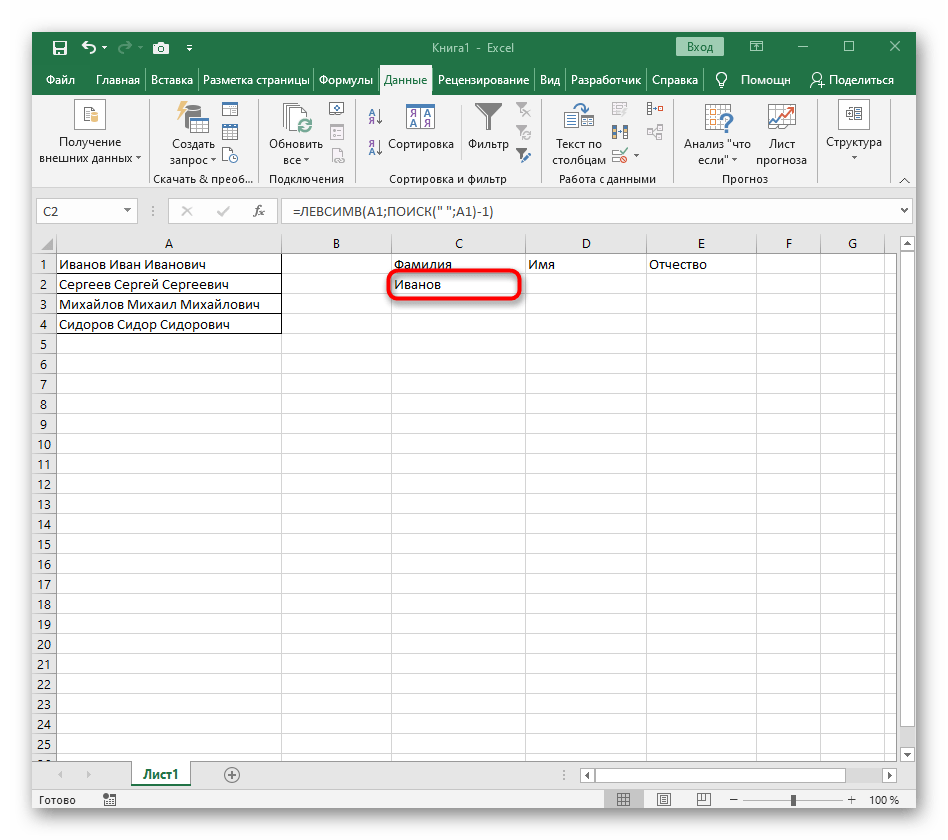
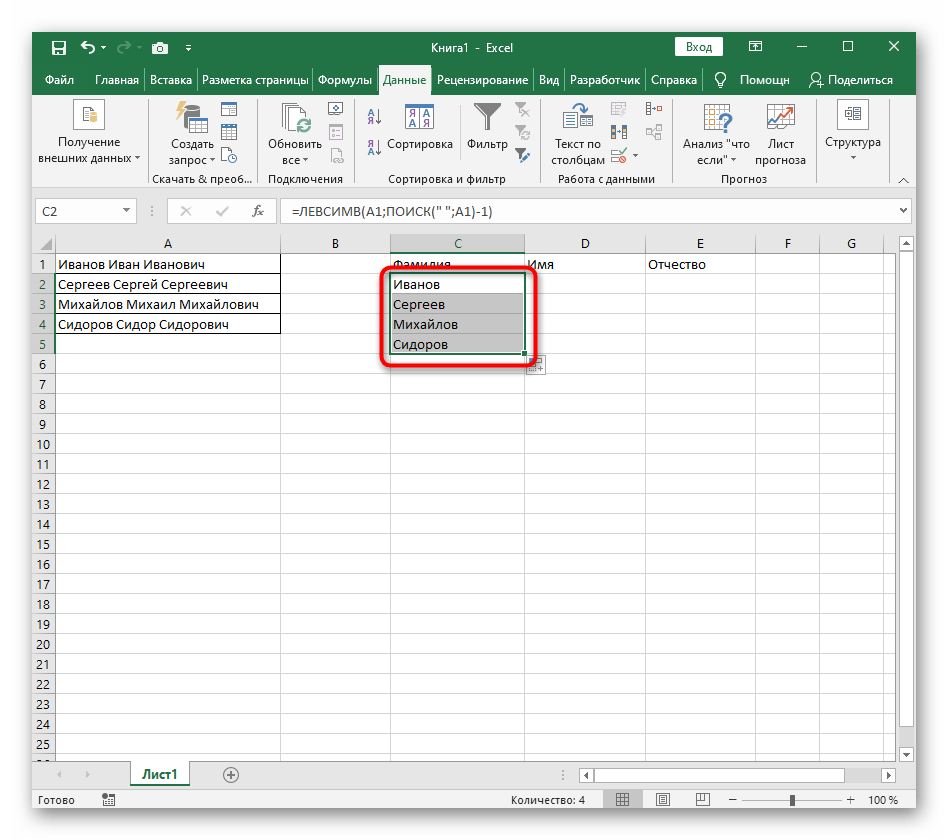
Полностью созданная формула имеет вид =ЛЕВСИМВ(A1;ПОИСК(" ";A1)-1), вы же можете создать ее по приведенной выше инструкции или вставить эту, если условия и разделитель подходят. Не забывайте заменить обрабатываемую ячейку.
Шаг 2: Разделение второго слова
Самое трудное — разделить второе слово, которым в нашем случае является имя. Связано это с тем, что оно с двух сторон окружено пробелами, поэтому придется учитывать их оба, создавая массивную формулу для правильного расчета позиции.
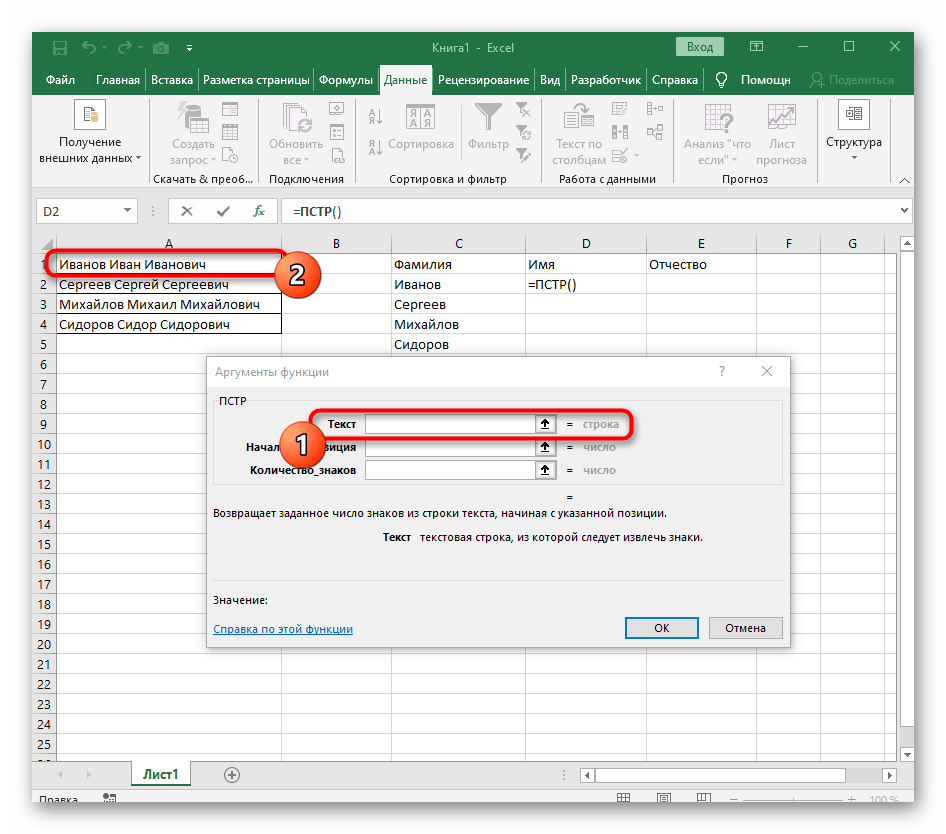
- В этом случае основной формулой станет
=ПСТР(— запишите ее в таком виде, а затем переходите к окну настройки аргументов. - Данная формула будет искать нужную строку в тексте, в качестве которого и выбираем ячейку с надписью для разделения.
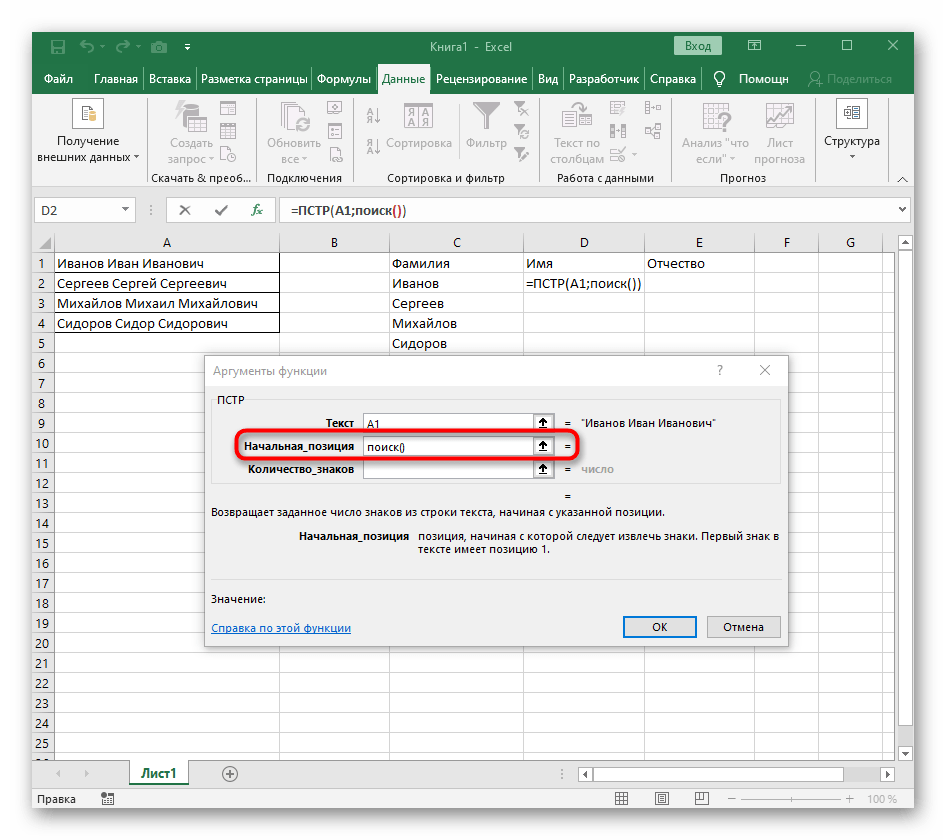
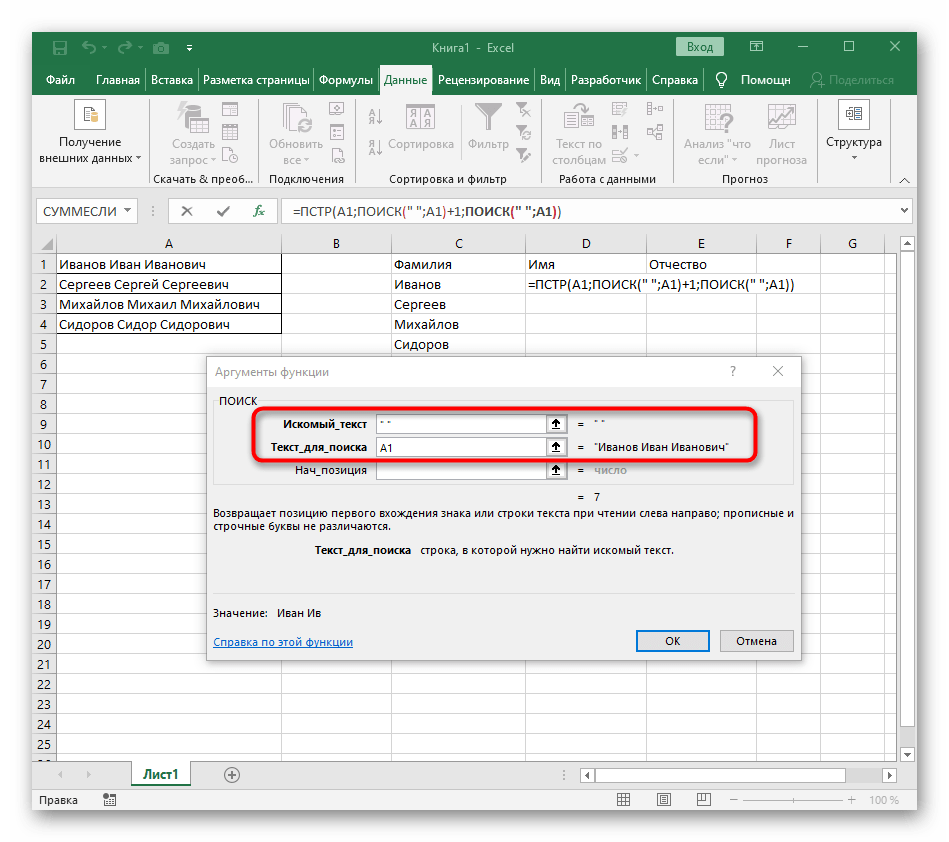
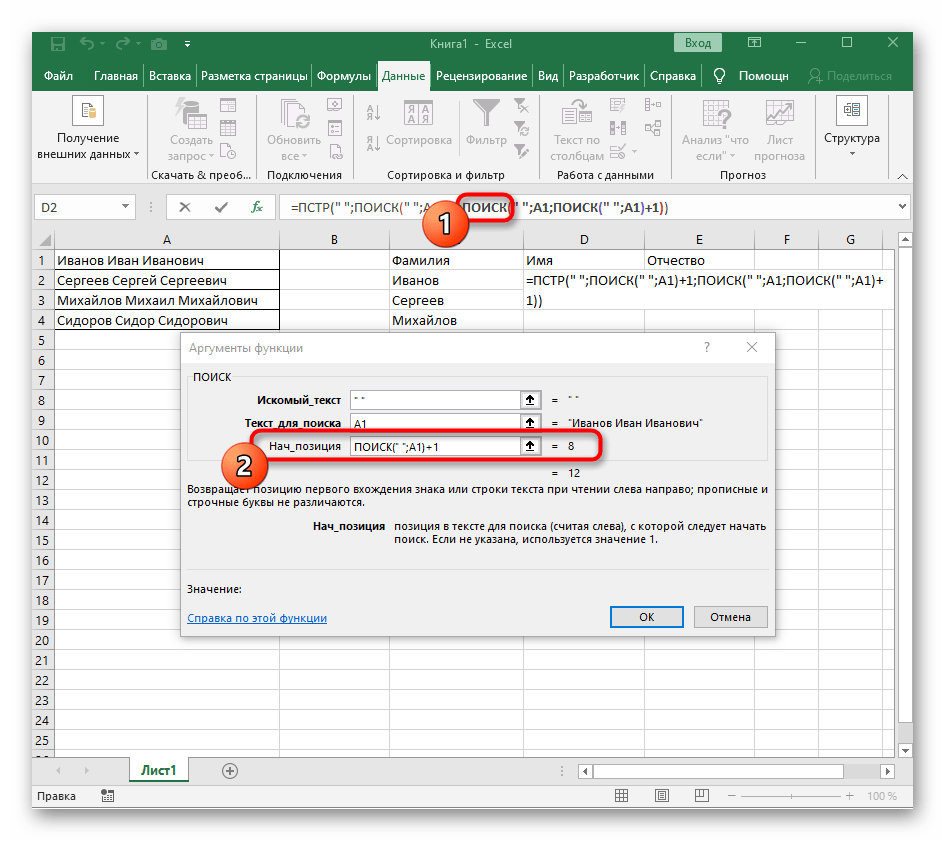
- Начальную позицию строки придется определять при помощи уже знакомой вспомогательной формулы
ПОИСК(). - Создав и перейдя к ней, заполните точно так же, как это было показано в предыдущем шаге. В качестве искомого текста используйте разделитель, а ячейку указывайте как текст для поиска.
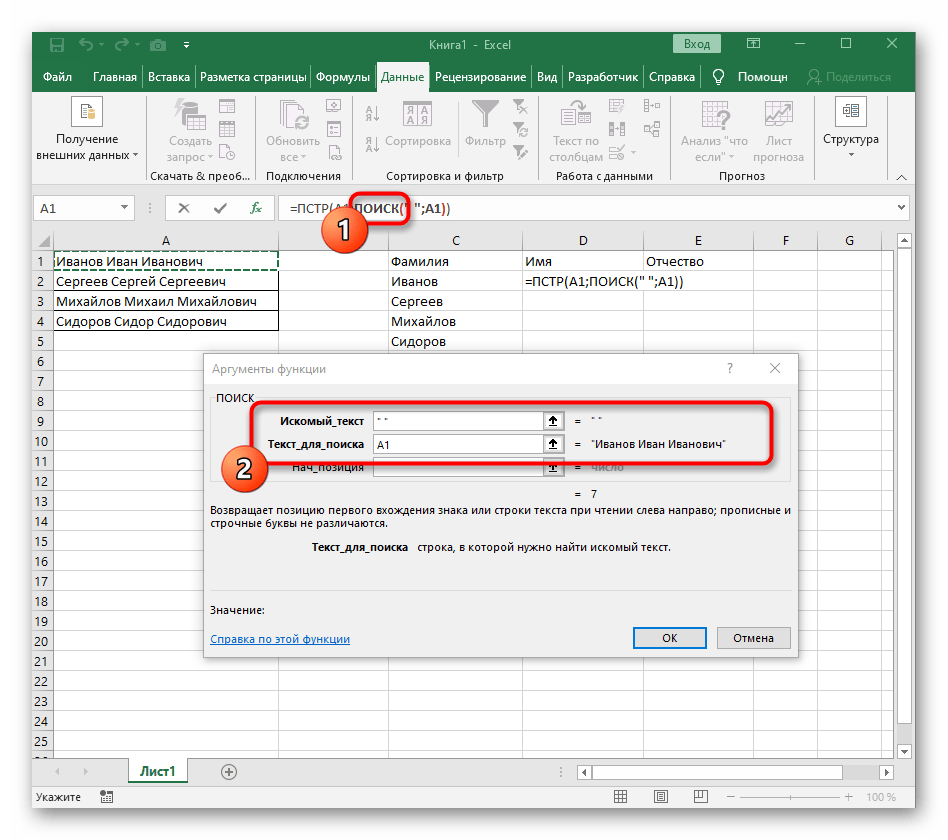
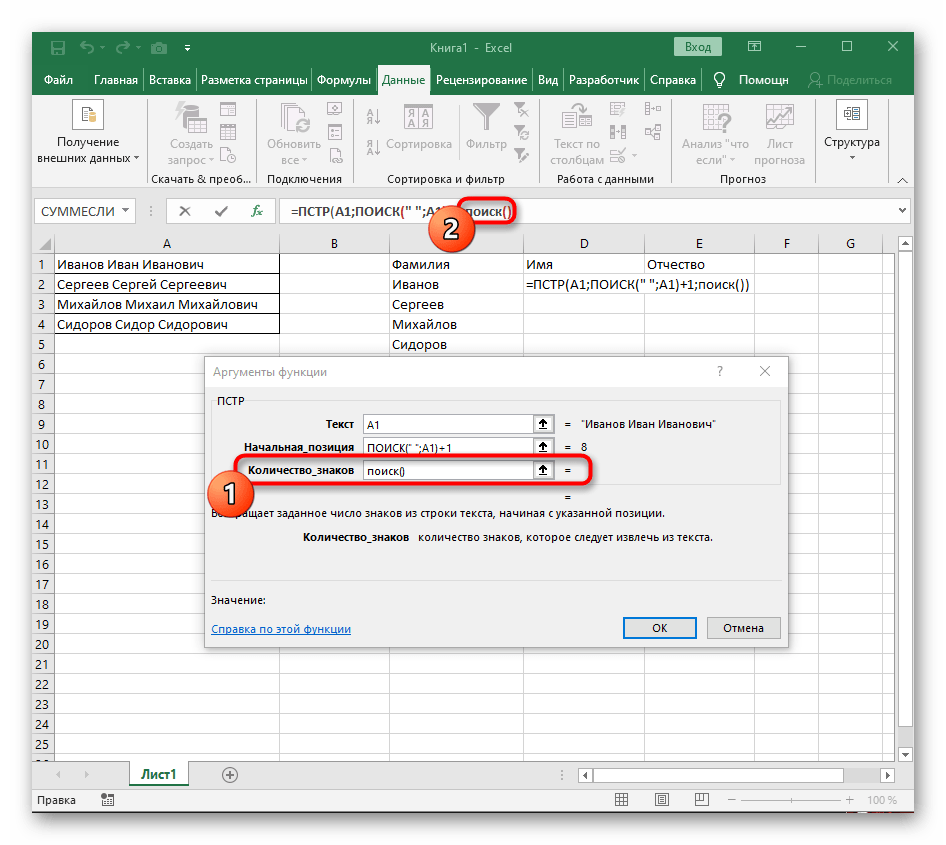
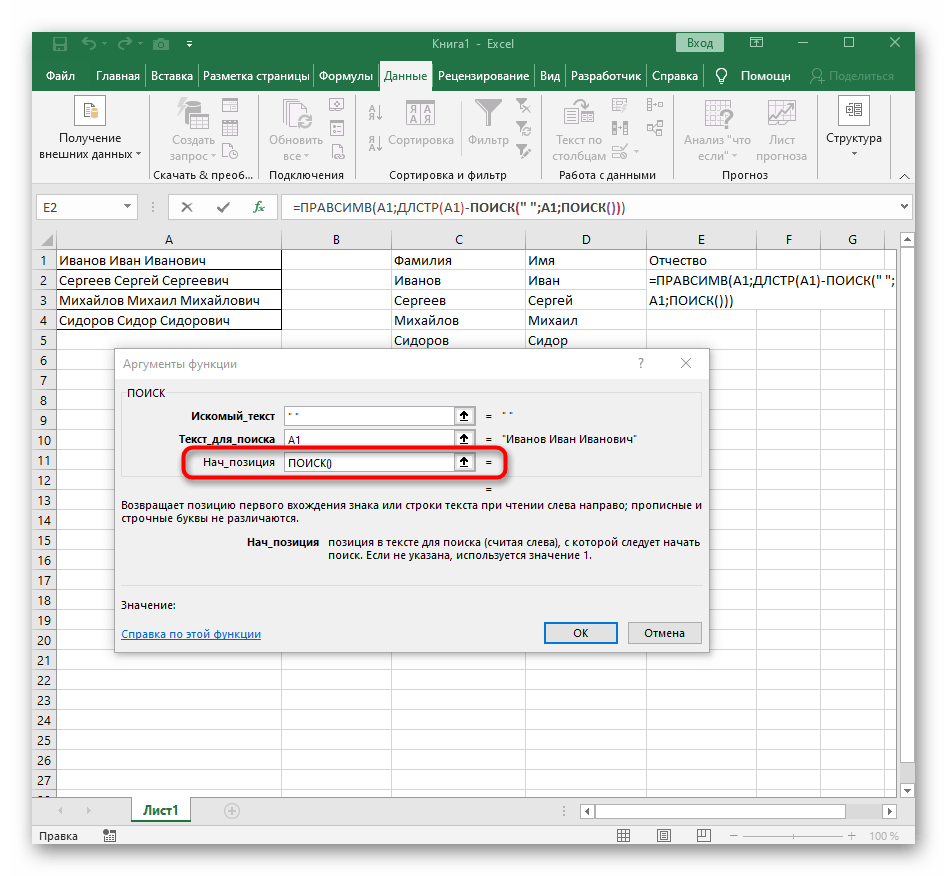
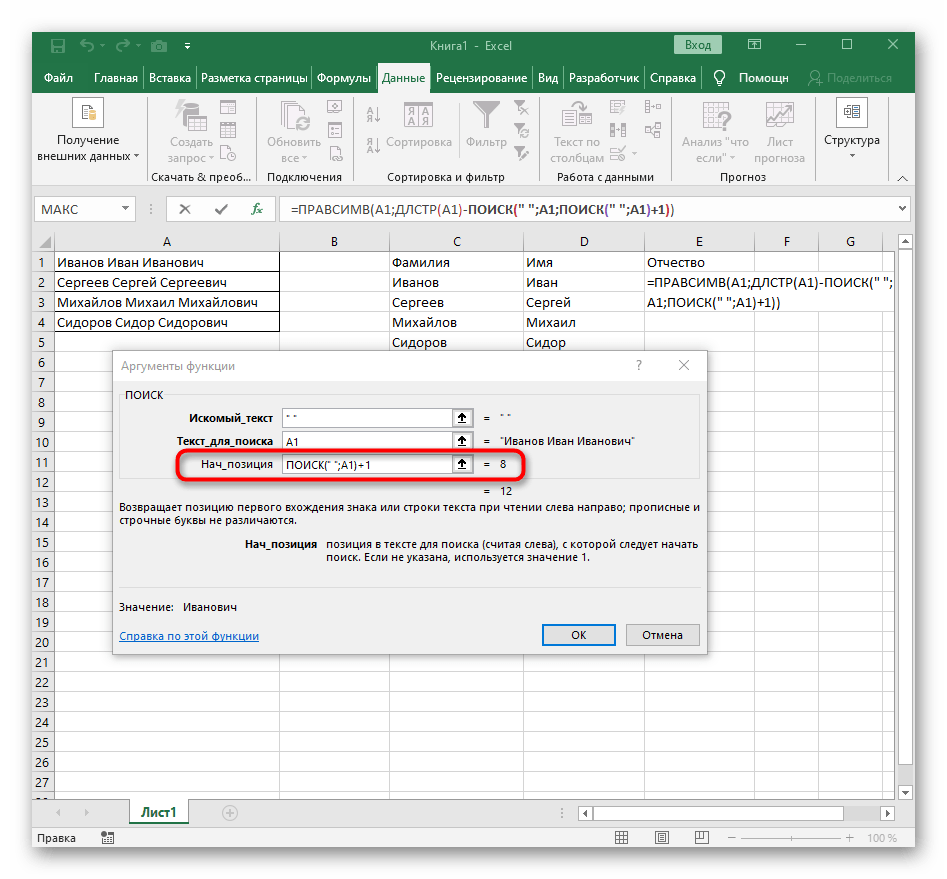
- Вернитесь к предыдущей формуле, где добавьте к функции «ПОИСК»
+1в конце, чтобы начинать счет со следующего символа после найденного пробела. - Сейчас формула уже может начать поиск строки с первого символа имени, но она пока еще не знает, где его закончить, поэтому в поле «Количество_знаков» снова впишите формулу
ПОИСК(). - Перейдите к ее аргументам и заполните их в уже привычном виде.
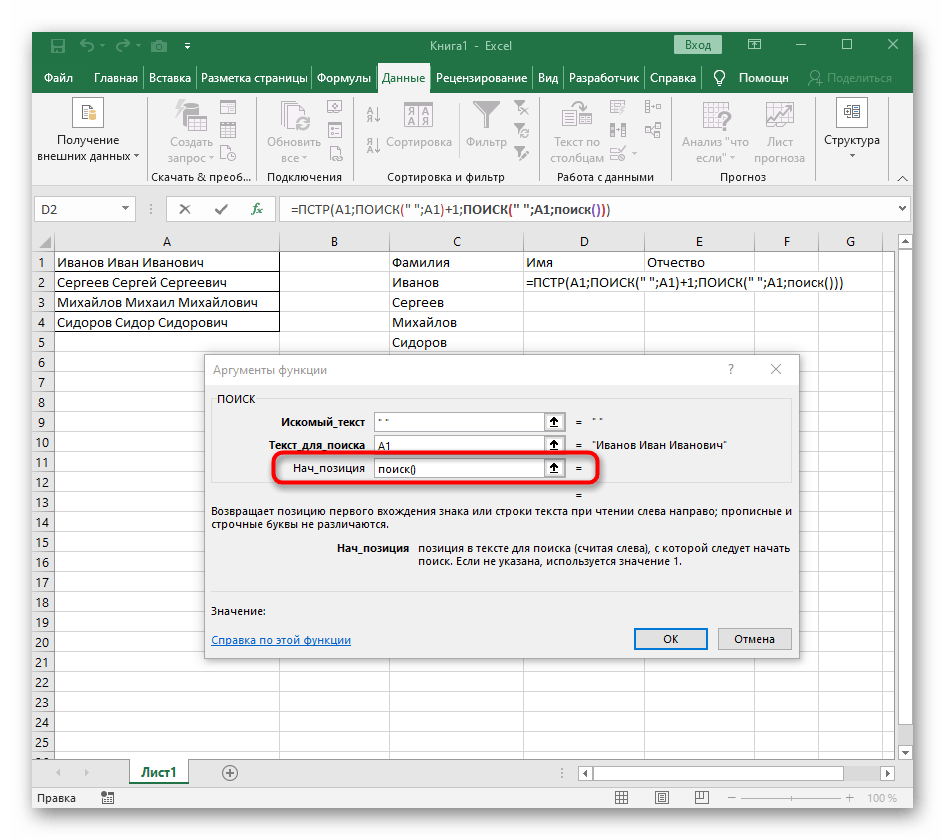
- Ранее мы не рассматривали начальную позицию этой функции, но теперь там нужно вписать тоже
ПОИСК(), поскольку эта формула должна находить не первый пробел, а второй. - Перейдите к созданной функции и заполните ее таким же образом.
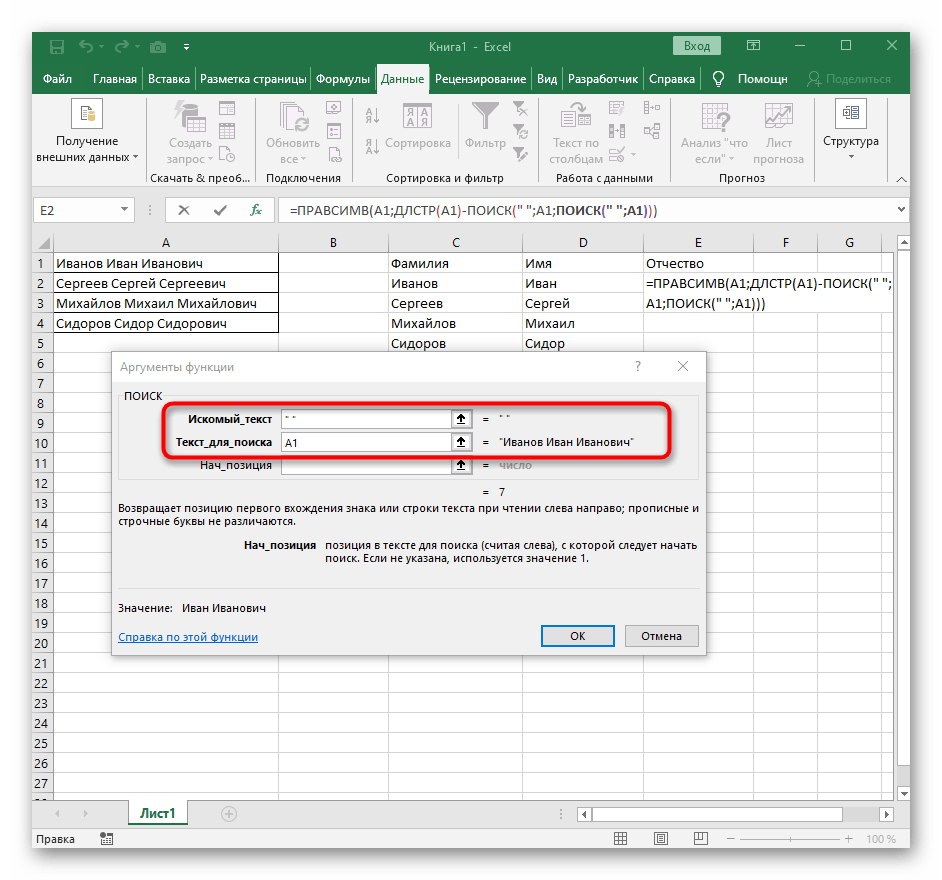
- Возвращайтесь к первому
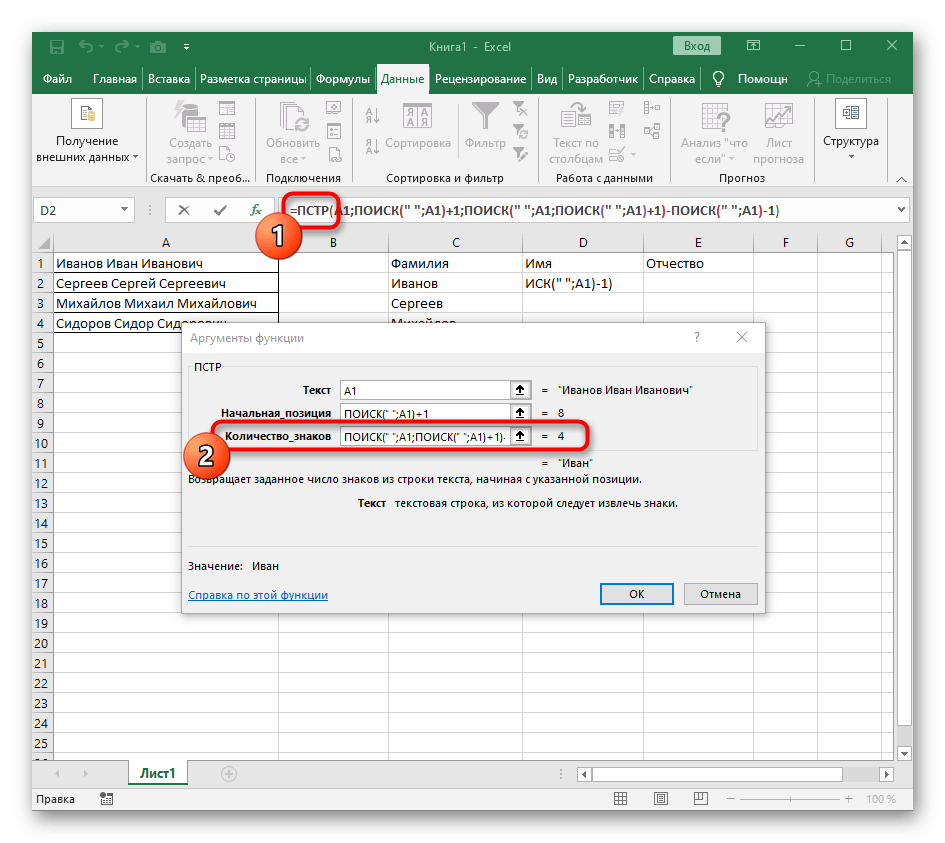
"ПОИСКУ"и допишите в «Нач_позиция»+1в конце, ведь для поиска строки нужен не пробел, а следующий символ. - Кликните по корню
=ПСТРи поставьте курсор в конце строки «Количество_знаков». - Допишите там выражение
-ПОИСК(" ";A1)-1)для завершения расчетов пробелов. - Вернитесь к таблице, растяните формулу и удостоверьтесь в том, что слова отображаются правильно.
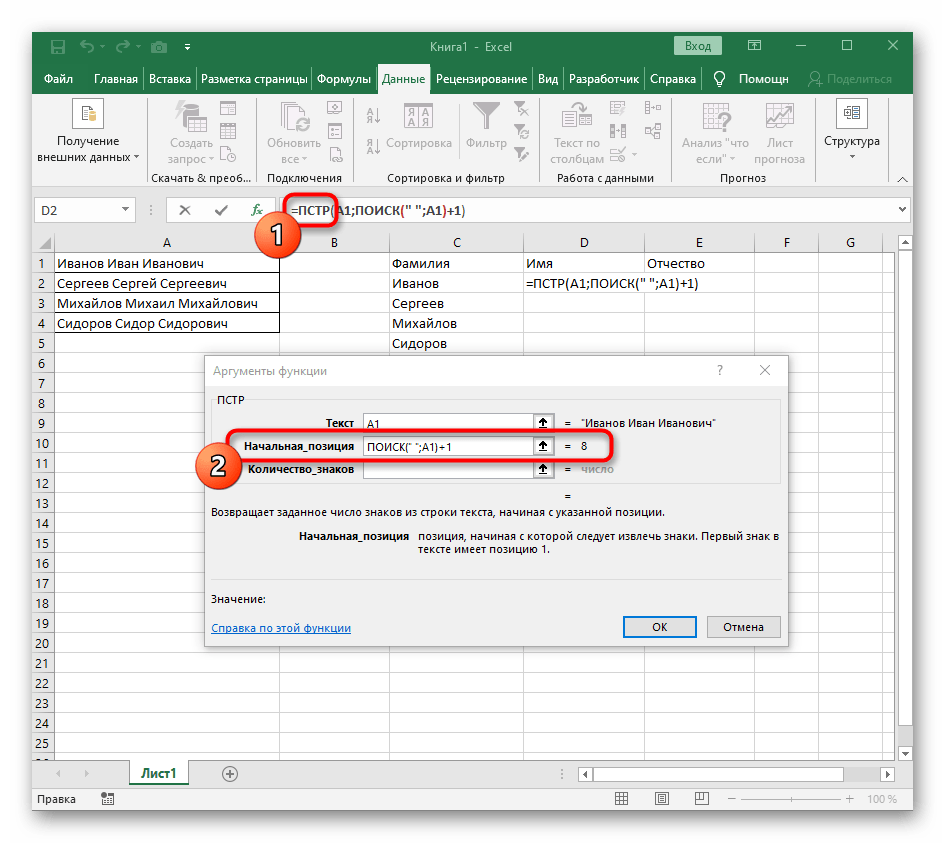
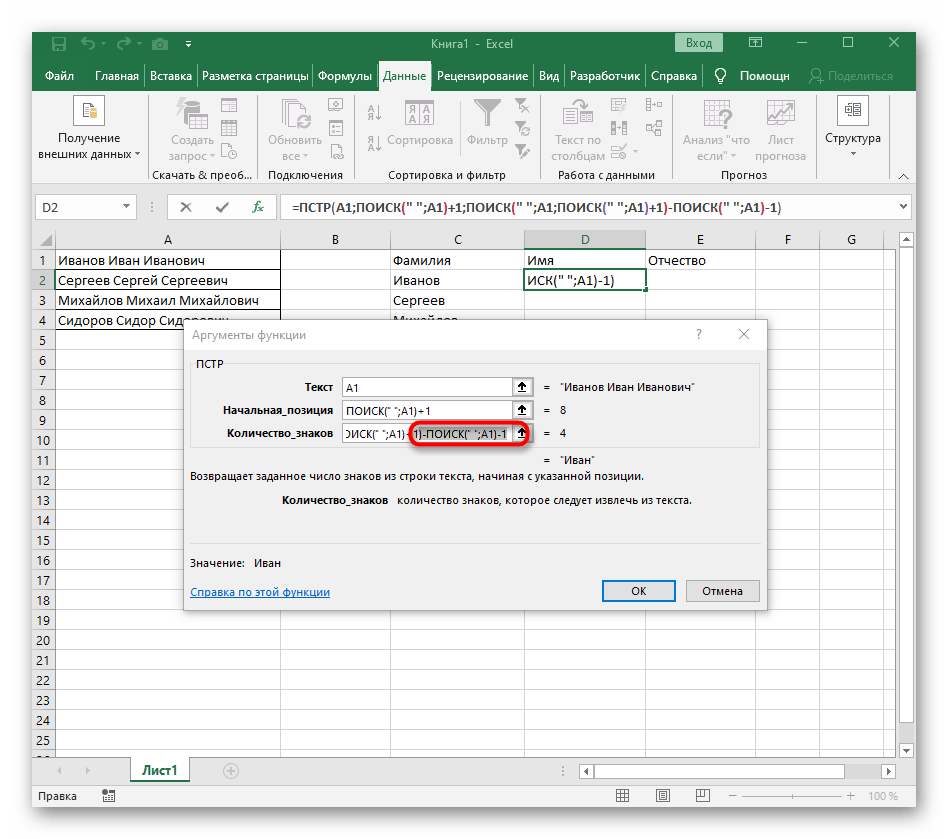
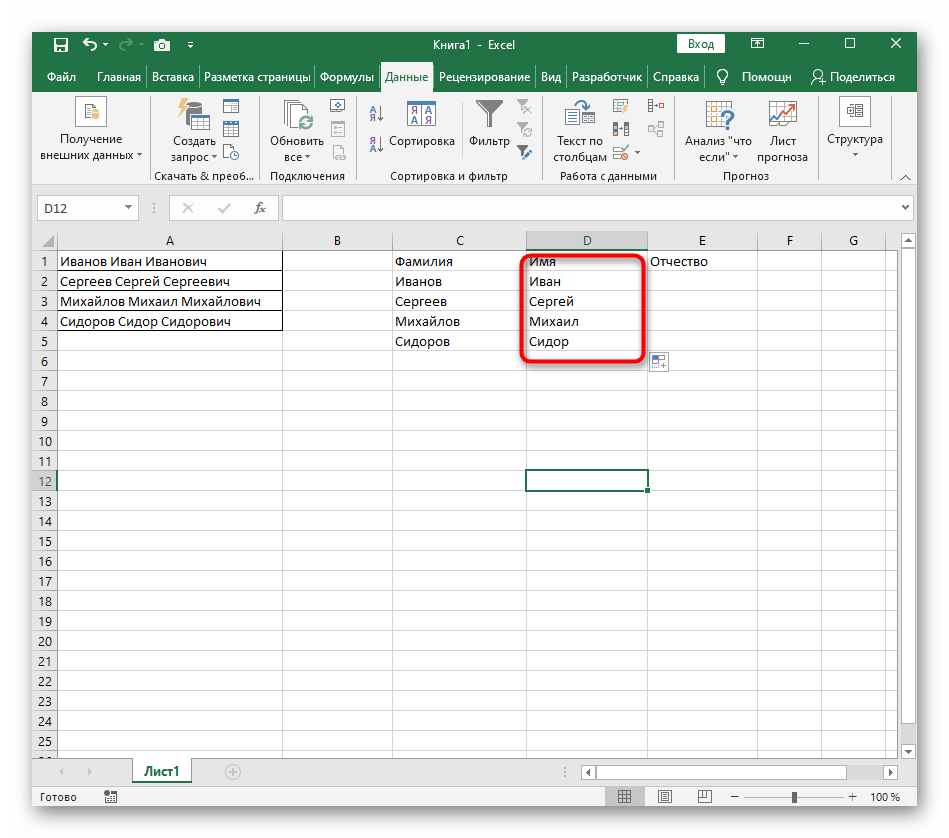
Формула получилась большая, и не все пользователи понимают, как именно она работает. Дело в том, что для поиска строки пришлось использовать сразу несколько функций, определяющих начальные и конечные позиции пробелов, а затем от них отнимался один символ, чтобы в результате эти самые пробелы не отображались. В итоге формула такая: =ПСТР(A1;ПОИСК(" ";A1)+1;ПОИСК(" ";A1;ПОИСК(" ";A1)+1)-ПОИСК(" ";A1)-1). Используйте ее в качестве примера, заменяя номер ячейки с текстом.
Шаг 3: Разделение третьего слова
Последний шаг нашей инструкции подразумевает разделение третьего слова, что выглядит примерно так же, как это происходило с первым, но общая формула немного меняется.
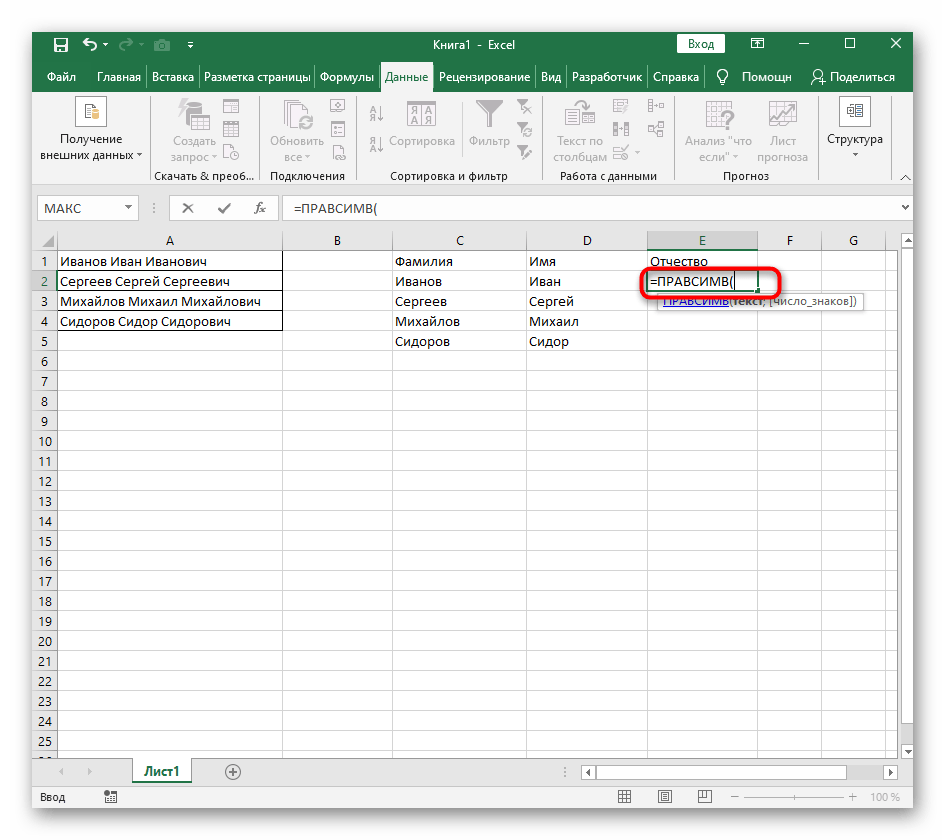
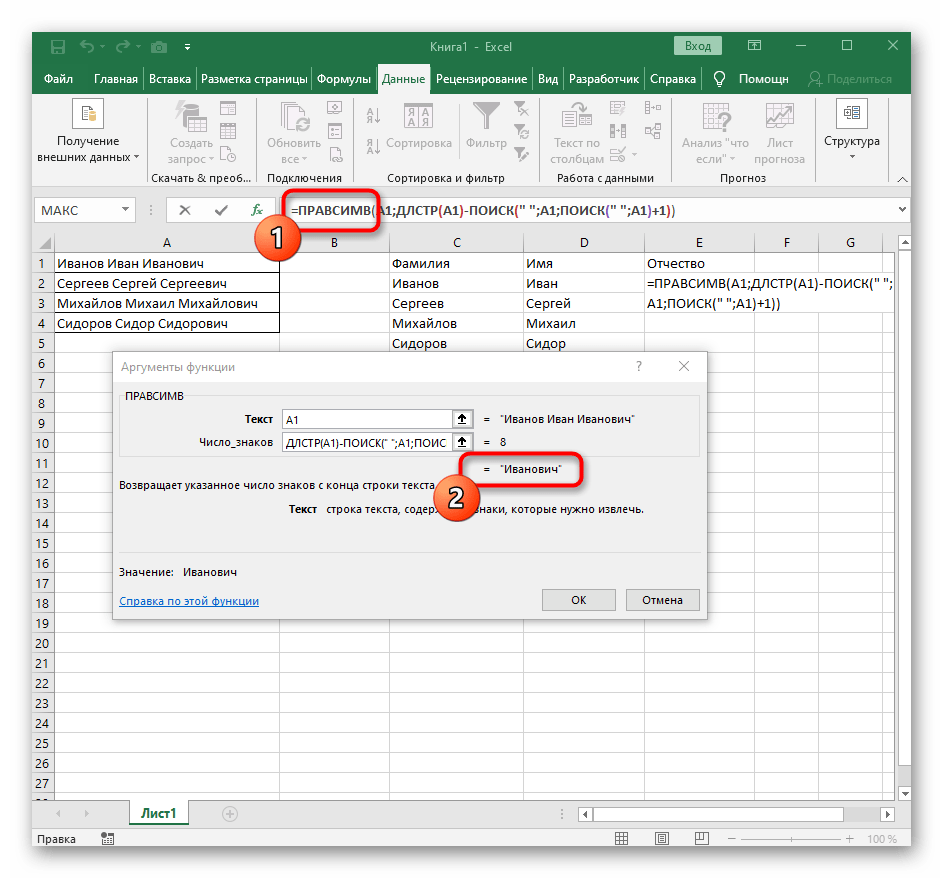
- В пустой ячейке для расположения будущего текста напишите
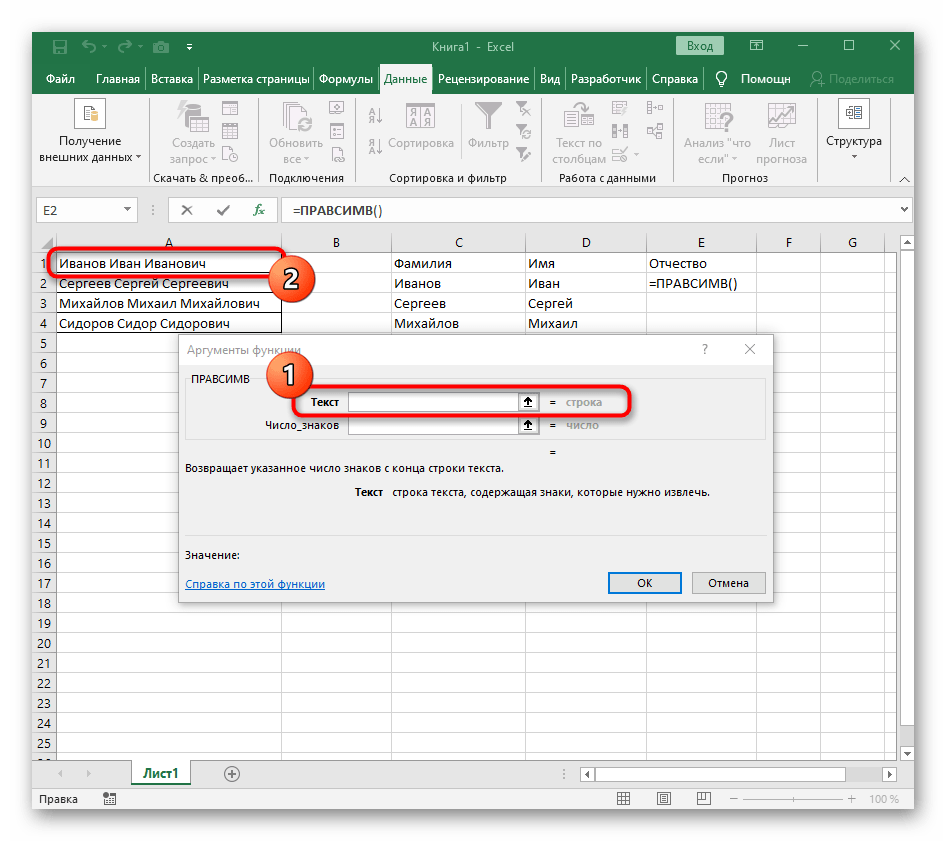
=ПРАВСИМВ(и перейдите к аргументам этой функции. - В качестве текста указывайте ячейку с надписью для разделения.
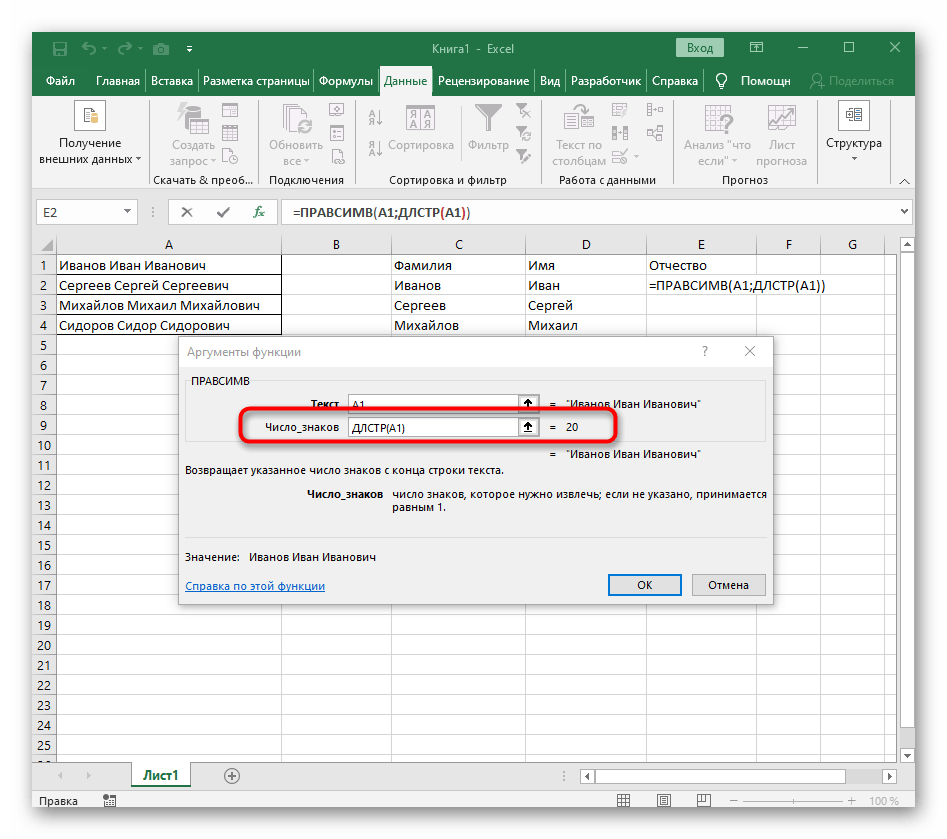
- В этот раз вспомогательная функция для поиска слова называется
ДЛСТР(A1), где A1 — та же самая ячейка с текстом. Эта функция определяет количество знаков в тексте, а нам останется выделить только подходящие. - Для этого добавьте
-ПОИСК()и перейдите к редактированию этой формулы. - Введите уже привычную структуру для поиска первого разделителя в строке.
- Добавьте для начальной позиции еще один
ПОИСК(). - Ему укажите ту же самую структуру.
- Вернитесь к предыдущей формуле «ПОИСК».
- Прибавьте для его начальной позиции
+1. - Перейдите к корню формулы
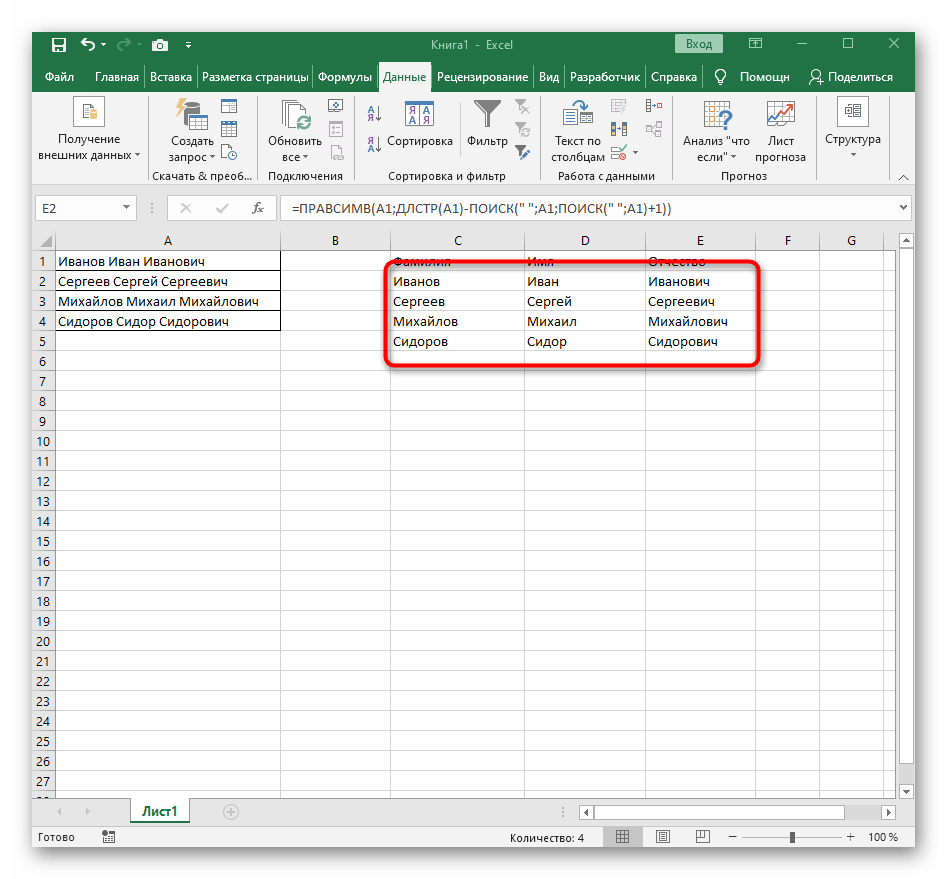
ПРАВСИМВи убедитесь в том, что результат отображается правильно, а уже потом подтверждайте внесение изменений. Полная формула в этом случае выглядит как=ПРАВСИМВ(A1;ДЛСТР(A1)-ПОИСК(" ";A1;ПОИСК(" ";A1)+1)). - В итоге на следующем скриншоте вы видите, что все три слова разделены правильно и находятся в своих столбцах. Для этого пришлось использовать самые разные формулы и вспомогательные функции, но это позволяет динамически расширять таблицу и не беспокоиться о том, что каждый раз придется разделять текст заново. По необходимости просто расширяйте формулу путем ее перемещения вниз, чтобы следующие ячейки затрагивались автоматически.
Еще статьи по данной теме:
Помогла ли Вам статья?
Skip to content
В руководстве объясняется, как разделить ячейки в Excel с помощью формул и стандартных инструментов. Вы узнаете, как разделить текст запятой, пробелом или любым другим разделителем, а также как разбить строки на текст и числа.
Разделение текста из одной ячейки на несколько — это задача, с которой время от времени сталкиваются все пользователи Excel. В одной из наших предыдущих статей мы обсуждали, как разделить ячейки в Excel с помощью функции «Текст по столбцам» и «Мгновенное заполнение». Сегодня мы подробно рассмотрим, как можно разделить текст по ячейкам с помощью формул.
Чтобы разбить текст в Excel, вы обычно используете функции ЛЕВСИМВ (LEFT), ПРАВСИМВ (RIGHT) или ПСТР (MID) в сочетании с НАЙТИ (FIND) или ПОИСК (SEARCH). На первый взгляд, некоторые рассмотренные ниже приёмы могут показаться сложными. Но на самом деле логика довольно проста, и следующие примеры помогут вам разобраться.
Для преобразования текста в ячейках в Excel ключевым моментом является определение положения разделителя в нем. Что может быть таким разделителем? Это запятая, точка с запятой, наклонная черта, двоеточие, тире, восклицательный знак и т.п. И, как мы далее увидим, даже целое слово.
- Как распределить ФИО по столбцам
- Как использовать разделители в тексте
- Разделяем текст по переносам строки
- Как разделить длинный текст на множество столбцов
- Как разбить «текст + число» по разным ячейкам
- Как разбить ячейку вида «число + текст»
- Разделение ячейки по маске (шаблону)
- Использование инструмента Split Text
В зависимости от вашей задачи эту проблему можно решить с помощью функции ПОИСК (без учета регистра букв) или НАЙТИ (с учетом регистра).
Как только вы определите позицию разделителя, используйте функцию ЛЕВСИМВ, ПРАВСИМВ и ПСТР, чтобы извлечь соответствующую часть содержимого.
Для лучшего понимания пошагово рассмотрим несколько примеров.
Делим текст вида ФИО по столбцам.
Если выяснение загадочных поворотов формул Excel — не ваше любимое занятие, вам может понравиться визуальный метод разделения ячеек, который демонстрируется ниже.
В столбце A нашей таблицы записаны Фамилии, имена и отчества сотрудников. Необходимо разделить их на 3 столбца.
Можно сделать это при помощи инструмента «Текст по столбцам». Об этом методе мы достаточно подробно рассказывали, когда рассматривали, как можно разделить ячейку по столбцам.
Кратко напомним:
На ленте «Данные» выбираем «Текст по столбцам» — с разделителями.

Далее в качестве разделителя выбираем пробел.
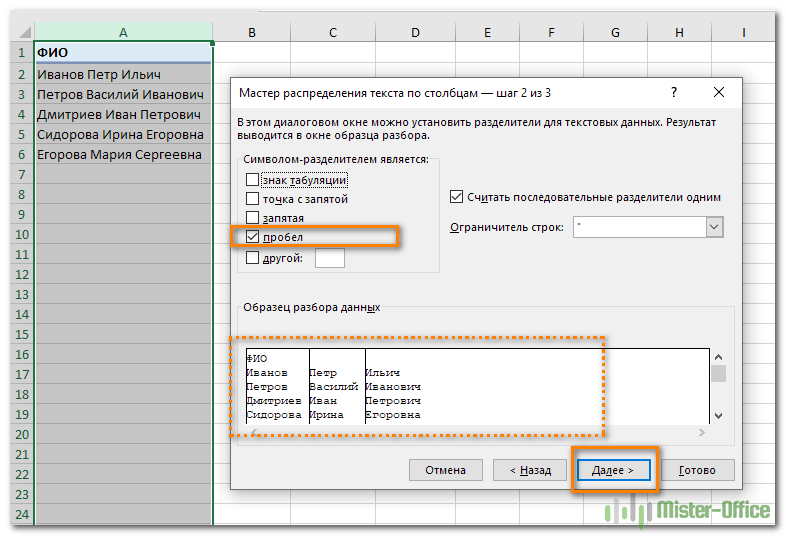
Обращаем внимание на то, как разделены наши данные в окне образца.
В следующем окне определяем формат данных. По умолчанию там будет «Общий». Он нас вполне устраивает, поэтому оставляем как есть. Выбираем левую верхнюю ячейку диапазона, в который будет помещен наш разделенный текст. Если нужно оставить в неприкосновенности исходные данные, лучше выбрать B1, к примеру.
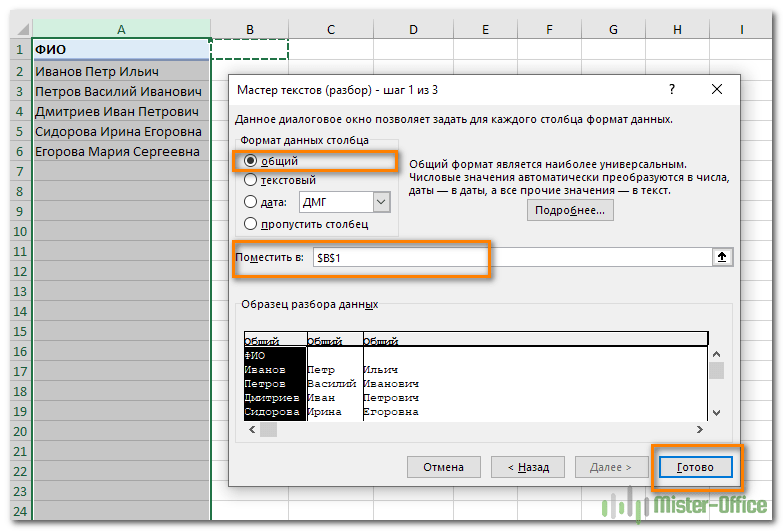
В итоге имеем следующую картину:

При желании можно дать заголовки новым столбцам B,C,D.
А теперь давайте тот же результат получим при помощи формул.
Для многих это удобнее. В том числе и по той причине, что если в таблице появятся новые данные, которые нужно разделить, то нет необходимости повторять всю процедуру с начала, а просто нужно скопировать уже имеющиеся формулы.
Итак, чтобы выделить из нашего ФИО фамилию, будем использовать выражение
=ЛЕВСИМВ(A2; ПОИСК(» «;A2;1)-1)
В качестве разделителя мы используем пробел. Функция ПОИСК указывает нам, в какой позиции находится первый пробел. А затем именно это количество букв (за минусом 1, чтобы не извлекать сам пробел) мы «отрезаем» слева от нашего ФИО при помощи ЛЕВСИМВ.
Далее будет чуть сложнее.
Нужно извлечь второе слово, то есть имя. Чтобы вырезать кусочек из середины, используем функцию ПСТР.
=ПСТР(A2; ПОИСК(» «;A2) + 1; ПОИСК(» «;A2;ПОИСК(» «;A2)+1) — ПОИСК(» «;A2) — 1)
Как вы, наверное, знаете, функция Excel ПСТР имеет следующий синтаксис:
ПСТР (текст; начальная_позиция; количество_знаков)
Текст извлекается из ячейки A2, а два других аргумента вычисляются с использованием 4 различных функций ПОИСК:
- Начальная позиция — это позиция первого пробела плюс 1:
ПОИСК(» «;A2) + 1
- Количество знаков для извлечения: разница между положением 2- го и 1- го пробелов, минус 1:
ПОИСК(» «;A2;ПОИСК(» «;A2)+1) — ПОИСК(» «;A2) – 1
В итоге имя у нас теперь находится в C.
Осталось отчество. Для него используем выражение:
=ПРАВСИМВ(A2;ДЛСТР(A2) — ПОИСК(» «; A2; ПОИСК(» «; A2) + 1))
В этой формуле функция ДЛСТР (LEN) возвращает общую длину строки, из которой вы вычитаете позицию 2- го пробела. Получаем количество символов после 2- го пробела, и функция ПРАВСИМВ их и извлекает.
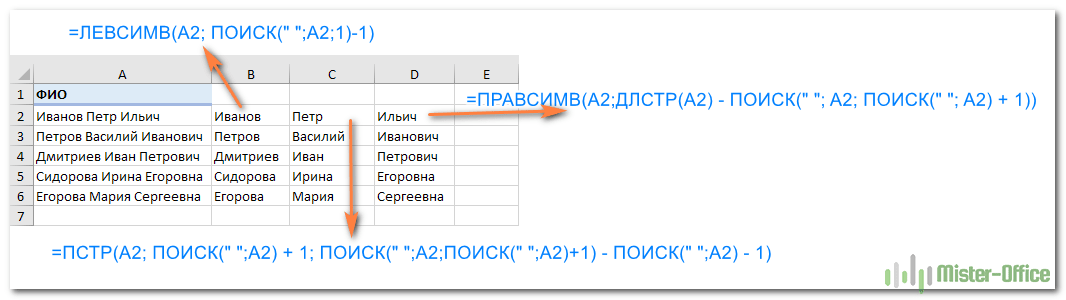
Вот результат нашей работы по разделению фамилии, имени и отчества из одной по отдельным ячейкам.
Распределение текста с разделителями на 3 столбца.
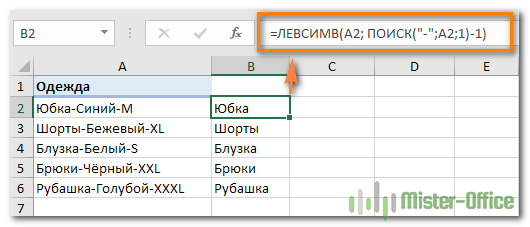
Предположим, у вас есть список одежды вида Наименование-Цвет-Размер, и вы хотите разделить его на 3 отдельных части. Здесь разделитель слов – дефис. С ним и будем работать.
- Чтобы извлечь Наименование товара (все символы до 1-го дефиса), вставьте следующее выражение в B2, а затем скопируйте его вниз по столбцу:
=ЛЕВСИМВ(A2; ПОИСК(«-«;A2;1)-1)
Здесь функция мы сначала определяем позицию первого дефиса («-«) в строке, а ЛЕВСИМВ извлекает все нужные символы начиная с этой позиции. Вы вычитаете 1 из позиции дефиса, потому что вы не хотите извлекать сам дефис.
- Чтобы извлечь цвет (это все буквы между 1-м и 2-м дефисами), запишите в C2, а затем скопируйте ниже:
=ПСТР(A2; ПОИСК(«-«;A2) + 1; ПОИСК(«-«;A2;ПОИСК(«-«;A2)+1) — ПОИСК(«-«;A2) — 1)
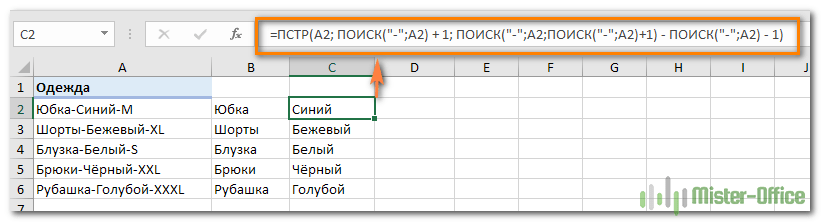
Логику работы ПСТР мы рассмотрели чуть выше.
- Чтобы извлечь размер (все символы после 3-го дефиса), введите следующее выражение в D2:
=ПРАВСИМВ(A2;ДЛСТР(A2) — ПОИСК(«-«; A2; ПОИСК(«-«; A2) + 1))

Аналогичным образом вы можете в Excel разделить содержимое ячейки в разные ячейки любым другим разделителем. Все, что вам нужно сделать, это заменить «-» на требуемый символ, например пробел (« »), косую черту («/»), двоеточие («:»), точку с запятой («;») и т. д.
Примечание. В приведенных выше формулах +1 и -1 соответствуют количеству знаков в разделителе. В нашем примере это дефис (то есть, 1 знак). Если ваш разделитель состоит из двух знаков, например, запятой и пробела, тогда укажите только запятую («,») в ваших выражениях и используйте +2 и -2 вместо +1 и -1.
Как разбить текст по переносам строки.
Чтобы разделить слова в ячейке по переносам строки, используйте подходы, аналогичные тем, которые были продемонстрированы в предыдущем примере. Единственное отличие состоит в том, что вам понадобится функция СИМВОЛ (CHAR) для передачи символа разрыва строки, поскольку вы не можете ввести его непосредственно в формулу с клавиатуры.
Предположим, ячейки, которые вы хотите разделить, выглядят примерно так:

Напомню, что перенести таким вот образом текст внутри ячейки можно при помощи комбинации клавиш ALT + ENTER.
Возьмите инструкции из предыдущего примера и замените дефис («-») на СИМВОЛ(10), где 10 — это код ASCII для перевода строки.
Чтобы извлечь наименование товара:
=ЛЕВСИМВ(A2; ПОИСК(СИМВОЛ(10);A2;1)-1)
Цвет:
=ПСТР(A2; ПОИСК(СИМВОЛ(10);A2) + 1; ПОИСК(СИМВОЛ(10);A2; ПОИСК(СИМВОЛ(10);A2)+1) — ПОИСК(СИМВОЛ(10);A2) — 1)
Размер:
=ПРАВСИМВ(A2;ДЛСТР(A2) — ПОИСК(СИМВОЛ(10); A2; ПОИСК(СИМВОЛ(10); A2) + 1))
Результат вы видите на скриншоте выше.
Таким же образом можно работать и с любым другим символом-разделителем. Достаточно знать его код.
Как распределить текст с разделителями на множество столбцов.
Изучив представленные выше примеры, у многих из вас, думаю, возник вопрос: «А что, если у меня не 3 слова, а больше? Если нужно разбить текст в ячейке на 5 столбцов?»
Если действовать методами, описанными выше, то формулы будут просто мега-сложными. Вероятность ошибки при их использовании очень велика. Поэтому мы применим другой метод.
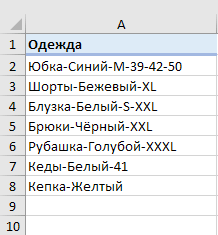
Имеем список наименований одежды с различными признаками, перечисленными через дефис. Как видите, таких признаков у нас может быть от 2 до 6. Делим текст в наших ячейках на 6 столбцов так, чтобы лишние столбцы в отдельных строках просто остались пустыми.
Для первого слова (наименования одежды) используем:
=ЛЕВСИМВ(A2; ПОИСК(«-«;A2;1)-1)
Как видите, это ничем не отличается от того, что мы рассматривали ранее. Ищем позицию первого дефиса и отделяем нужное количество символов.
Для второго столбца и далее понадобится более сложное выражение:
=ЕСЛИОШИБКА(ЛЕВСИМВ(ПОДСТАВИТЬ($A2&»-«; ОБЪЕДИНИТЬ(«-«;ИСТИНА;$B2:B2)&»-«;»»;1); ПОИСК(«-«;ПОДСТАВИТЬ($A2&»-«;ОБЪЕДИНИТЬ(«-«;ИСТИНА;$B2:B2)&»-«;»»;1);1)-1);»»)
Замысел здесь состоит в том, что при помощи функции ПОДСТАВИТЬ мы удаляем из исходного содержимого наименование, которое уже ранее извлекли (то есть, «Юбка»). Вместо него подставляем пустое значение «» и в результате имеем «Синий-M-39-42-50». В нём мы снова ищем позицию первого дефиса, как это делали ранее. И при помощи ЛЕВСИМВ вновь выделяем первое слово (то есть, «Синий»).
А далее можно просто «протянуть» формулу из C2 по строке, то есть скопировать ее в остальные ячейки. В результате в D2 получим
=ЕСЛИОШИБКА(ЛЕВСИМВ(ПОДСТАВИТЬ($A2&»-«; ОБЪЕДИНИТЬ(«-«;ИСТИНА;$B2:C2)&»-«;»»;1); ПОИСК(«-«;ПОДСТАВИТЬ($A2&»-«;ОБЪЕДИНИТЬ(«-«;ИСТИНА;$B2:C2)&»-«;»»;1);1)-1);»»)
Обратите внимание, жирным шрифтом выделены произошедшие при копировании изменения. То есть, теперь из исходного текста мы удаляем все, что было уже ранее найдено и извлечено – содержимое B2 и C2. И вновь в получившейся фразе берём первое слово — до дефиса.
Если же брать больше нечего, то функция ЕСЛИОШИБКА обработает это событие и вставит в виде результата пустое значение «».
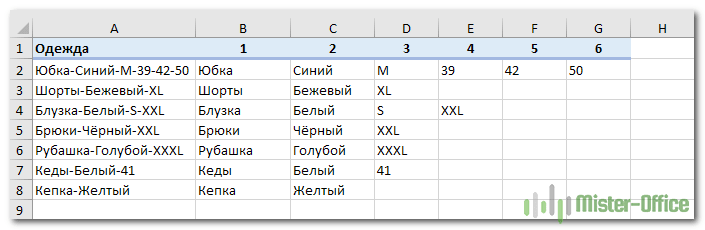
Скопируйте формулы по строкам и столбцам, на сколько это необходимо. Результат вы видите на скриншоте.
Таким способом можно разделить текст в ячейке на сколько угодно столбцов. Главное, чтобы использовались одинаковые разделители.
Как разделить ячейку вида ‘текст + число’.
Начнем с того, что не существует универсального решения, которое работало бы для всех буквенно-цифровых выражений. Выбор зависит от конкретного шаблона, по которому вы хотите разбить ячейку. Ниже вы найдете формулы для двух наиболее распространенных сценариев.
Предположим, у вас есть столбец смешанного содержания, где число всегда следует за текстом. Естественно, такая конструкция рассматривается Excel как символьная. Вы хотите поделить их так, чтобы текст и числа отображались в отдельных ячейках.
Результат может быть достигнут двумя разными способами.
Метод 1. Подсчитайте цифры и извлеките это количество символов
Самый простой способ разбить выражение, в котором число идет после текста:
Чтобы извлечь числа, вы ищите в строке все возможные числа от 0 до 9, получаете общее их количество и отсекаете такое же количество символов от конца строки.
Если мы работаем с ячейкой A2:
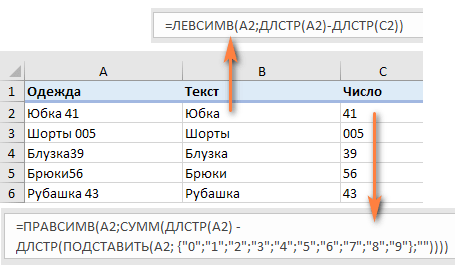
=ПРАВСИМВ(A2;СУММ(ДЛСТР(A2) — ДЛСТР(ПОДСТАВИТЬ(A2; {«0″;»1″;»2″;»3″;»4″;»5″;»6″;»7″;»8″;»9″};»»))))
Чтобы извлечь буквы, вы вычисляете, сколько их у нас имеется. Для этого вычитаем количество извлеченных цифр (C2) из общей длины исходной ячейки A2. После этого при помощи ЛЕВСИМВ отрезаем это количество символов от начала ячейки.
=ЛЕВСИМВ(A2;ДЛСТР(A2)-ДЛСТР(C2))
здесь A2 – исходная ячейка, а C2 — извлеченное число, как показано на скриншоте:
Метод 2: узнать позицию 1- й цифры в строке
Альтернативное решение — использовать эту формулу массива для определения позиции первой цифры:
{=МИН(ПОИСК({0;1;2;3;4;5;6;7;8;9};A2&»0123456789″))}
Как видите, мы последовательно ищем каждое число из массива {0,1,2,3,4,5,6,7,8,9}. Чтобы избежать появления ошибки если цифра не найдена, мы после содержимого ячейки A2 добавляем эти 10 цифр. Excel последовательно перебирает все символы в поисках этих десяти цифр. В итоге получаем опять же массив из 10 цифр — номеров позиций, в которых они нашлись. И из них функция МИН выбирает наименьшее число. Это и будет та позиция, с которой начинается группа чисел, которую нужно отделить от основного содержимого.
Также обратите внимание, что это формула массива и ввод её нужно заканчивать не как обычно, а комбинацией клавиш CTRL + SHIFT + ENTER.
Как только позиция первой цифры найдена, вы можете разделить буквы и числа, используя очень простые формулы ЛЕВСИМВ и ПРАВСИМВ.
Чтобы получить текст:
=ЛЕВСИМВ(A2; B2-1)
Чтобы получить числа:
=ПРАВСИМВ(A2; ДЛСТР(A2)-B2+1)
Где A2 — исходная строка, а B2 — позиция первого числа.

Чтобы избавиться от вспомогательного столбца, в котором мы вычисляли позицию первой цифры, вы можете встроить МИН в функции ЛЕВСИМВ и ПРАВСИМВ:
Для вытаскивания текста:
=ЛЕВСИМВ(A2; МИН(ПОИСК({0;1;2;3;4;5;6;7;8;9};A2&»0123456789″))-1)
Для чисел:
=ПРАВСИМВ(A2; ДЛСТР(A2)-МИН(ПОИСК({0;1;2;3;4;5;6;7;8;9};A2&»0123456789″))+1)
Этого же результата можно достичь и чуть иначе.
Сначала мы извлекаем из ячейки числа при помощи вот такого выражения:
=ПРАВСИМВ(A2;СУММ(ДЛСТР(A2) -ДЛСТР(ПОДСТАВИТЬ(A2; {«0″;»1″;»2″;»3″;»4″;»5″;»6″;»7″;»8″;»9″};»»))))
То есть, сравниваем длину нашего текста без чисел с его исходной длиной, и получаем количество цифр, которое нужно взять справа. К примеру, если текст без цифр стал короче на 2 символа, значит справа надо «отрезать» 2 символа, которые и будут нашим искомым числом.
А затем уже берём оставшееся:
=ЛЕВСИМВ(A2;ДЛСТР(A2)-ДЛСТР(C2))

Как видите, результат тот же. Можете воспользоваться любым способом.
Как разделить ячейку вида ‘число + текст’.
Если вы разделяете ячейки, в которых буквы стоят после цифр, вы можете отделять числа по следующей формуле:
=ЛЕВСИМВ(A2;СУММ(ДЛСТР(A2) — ДЛСТР(ПОДСТАВИТЬ(A2; {«0″;»1″;»2″;»3″;»4″;»5″;»6″;»7″;»8″;»9″};»»))))
Она аналогична рассмотренной в предыдущем примере, за исключением того, что вы используете функцию ЛЕВСИМВ вместо ПРАВСИМВ, чтобы получить число теперь уже из левой части выражения.
Теперь, когда у вас есть числа, отделите буквы, вычитая количество цифр из общей длины исходной строки:
=ПРАВСИМВ(A2;ДЛСТР(A2)-ДЛСТР(B2))
Где A2 — исходная строка, а B2 — искомое число, как показано на снимке экрана ниже:

Как разбить текст по ячейкам по маске (шаблону).
Эта опция очень удобна, когда вам нужно разбить список схожих строк на некоторые элементы или подстроки. Сложность состоит в том, что исходный текст должен быть разделен не при каждом появлении определенного разделителя (например, пробела), а только при некоторых определенных вхождениях. Следующий пример упрощает понимание.
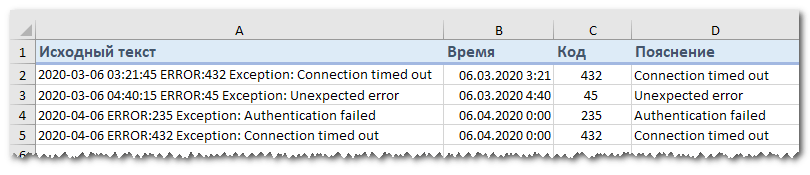
Предположим, у вас есть список строк, извлеченных из некоторого файла журнала:

Вы хотите, чтобы дата и время, если таковые имеются, код ошибки и поясняющие сведения были размещены в 3 отдельных столбцах. Вы не можете использовать пробел в качестве разделителя, потому что между датой и временем также есть пробелы. Также есть пробелы в тексте пояснения, который также должен весь находиться слитно в одном столбце.
Решением является разбиение строки по следующей маске: * ERROR: * Exception: *
Здесь звездочка (*) представляет любое количество символов.
Двоеточия (:) включены в разделители, потому что мы не хотим, чтобы они появлялись в результирующих ячейках.
То есть в данном случае в качестве разделителя по столбцам выступают не отдельные символы, а целые слова.
Итак, в начале ищем позицию первого разделителя.
=ПОИСК(«ERROR:»;A2;1)
Затем аналогичным образом находим позицию, в которой начинается второй разделитель:
=ПОИСК(«Exception:»;A2;1)
Итак, для ячейки A2 шаблон выглядит следующим образом:
С 1 по 20 символ – дата и время. С 21 по 26 символ – разделитель “ERROR:”. Далее – код ошибки. С 31 по 40 символ – второй разделитель “Exception:”. Затем следует описание ошибки.
Таким образом, в первый столбец мы поместим первые 20 знаков:
=—ЛЕВСИМВ(A2;ПОИСК(«ERROR:»;A2;1)-1)
Обратите внимание, что мы взяли на 1 позицию меньше, чем начало первого разделителя. Кроме того, чтобы сразу конвертировать всё это в дату, ставим перед формулой два знака минус. Это автоматически преобразует цифры в число, а дата как раз и хранится в виде числа. Остается только установить нужный формат даты и времени стандартными средствами Excel.
Далее нужно получить код:
=ПСТР(A2;ПОИСК(«ERROR:»;A2;1)+6;ПОИСК(«Exception:»;A2;1)-(ПОИСК(«ERROR:»;A2;1)+6))
Думаю, вы понимаете, что 6 – это количество знаков в нашем слове-разделителе «ERROR:».
Ну и, наконец, выделяем из этой фразы пояснение:
=ПРАВСИМВ(A2;ДЛСТР(A2)-(ПОИСК(«Exception:»;A2;1)+10))
Аналогично добавляем 10 к найденной позиции второго разделителя «Exception:», чтобы выйти на координаты первого символа сразу после разделителя. Ведь функция говорит нам только то, где разделитель начинается, а не заканчивается.
Таким образом, ячейку мы распределили по 3 столбцам, исключив при этом слова-разделители.
Если выяснение загадочных поворотов формул Excel — не ваше любимое занятие, вам может понравиться визуальный метод разделения ячеек в Excel, который демонстрируется в следующей части этого руководства.
Как разделить ячейки в Excel с помощью функции разделения текста Split Text.
Альтернативный способ разбить столбец в Excel — использовать функцию разделения текста, включенную в надстройку Ultimate Suite for Excel. Она предоставляет следующие возможности:
- Разделить ячейку по символу-разделителю.
- Разделить ячейку по нескольким разделителям.
- Разделить ячейку по маске (шаблону).
Чтобы было понятнее, давайте более подробно рассмотрим каждый вариант по очереди.
Разделить ячейку по символу-разделителю.
Выбирайте этот вариант, если хотите разделить содержимое ячейки при каждом появлении определённого символа .
Для этого примера возьмем строки шаблона Товар-Цвет-Размер , который мы использовали в первой части этого руководства. Как вы помните, мы разделили их на 3 разных столбца, используя 3 разные формулы . А вот как добиться того же результата за 2 быстрых шага:
- Предполагая, что у вас установлен Ultimate Suite , выберите ячейки, которые нужно разделить, и щелкните значок «Разделить текст (Split Text)» на вкладке «Ablebits Data».
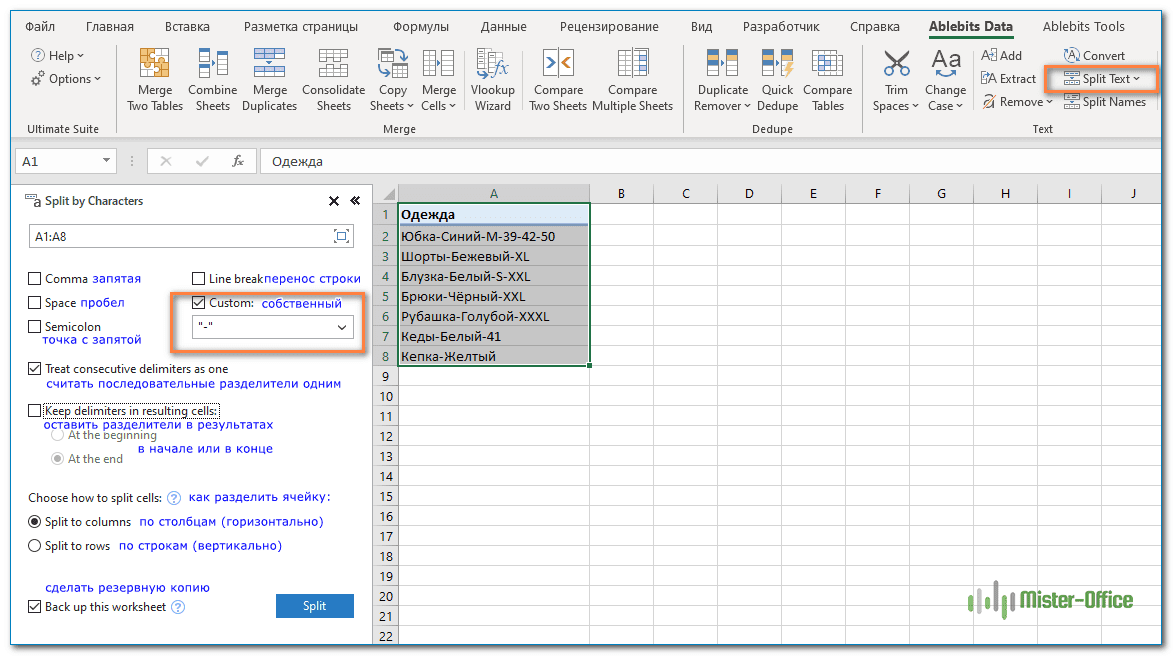
- Панель Разделить текст откроется в правой части окна Excel, и вы выполните следующие действия:
- Разверните группу «Разбить по символам (Split by Characters)» и выберите один из предопределенных разделителей или введите любой другой символ в поле «Пользовательский (Custom)» .
- Выберите, как именно разбивать ячейки: по столбцам или строкам.
- Нажмите кнопку «Разделить (Split)» .
Примечание. Если в ячейке может быть несколько последовательных разделителей (например, более одного символа пробела подряд), установите флажок « Считать последовательные разделители одним».
Готово! Задача, которая требовала 3 формул и 5 различных функций, теперь занимает всего пару секунд и одно нажатие кнопки.

Разделить ячейку по нескольким разделителям.
Этот параметр позволяет разделять текстовые ячейки, используя любую комбинацию символов в качестве разделителя. Технически вы разделяете строку на части, используя одну или несколько разных подстрок в качестве границ.
Например, чтобы разделить предложение на части, используя запятые и союзы, активируйте инструмент «Разбить по строкам (Split by Strings)» и введите разделители, по одному в каждой строке:

В данном случае в качестве разделителей мы используем запятую и союз “или”.
В результате исходная фраза разделяется при появлении любого разделителя:

Примечание. Союзы «или», а также «и» часто могут быть частью слова в вашей исследуемой фразе, так что не забудьте ввести пробел до и после них, чтобы предотвратить разрывы слов на части.
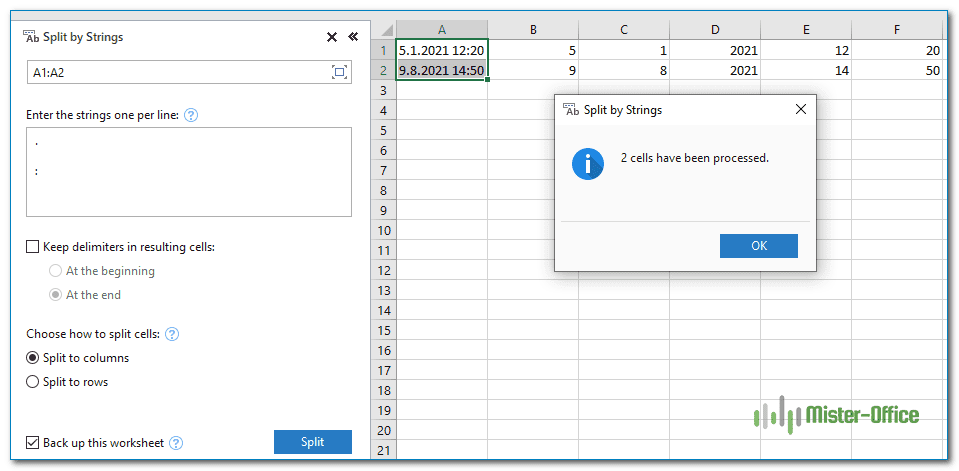
А вот еще один пример. Предположим, вы импортировали столбец дат из внешнего источника, и выглядит он следующим образом:
5.1.2021 12:20
9.8.2021 14:50
Этот формат не является обычным для Excel, и поэтому ни одна из функций даты не распознает здесь какие-либо элементы даты или времени. Чтобы разделить день, месяц, год, часы и минуты на отдельные ячейки, введите следующие символы в поле Spilt by strings:
- Точка (.) Для разделения дня, месяца и года
- Двоеточие (:) для разделения часов и минут
- Пробел для разграничения даты и времени

Нажмите кнопку Split, и вы сразу получите результат:
Разделить ячейки по маске (шаблону).
Эта опция очень удобна, когда вам нужно разбить список однородных строк на некоторые элементы или подстроки.
Сложность заключается в том, что исходный текст не может быть разделен при каждом появлении заданного разделителя, а только при некоторых определенных вхождениях. Следующий пример упростит понимание.
Предположим, у вас есть список строк, извлеченных из некоторого файла журнала. Чуть выше в этой статье мы разбивали этот текст по ячейкам при помощи формул. А сейчас используем специальный инструмент. И вы сами решите, какой из способов удобнее и проще.
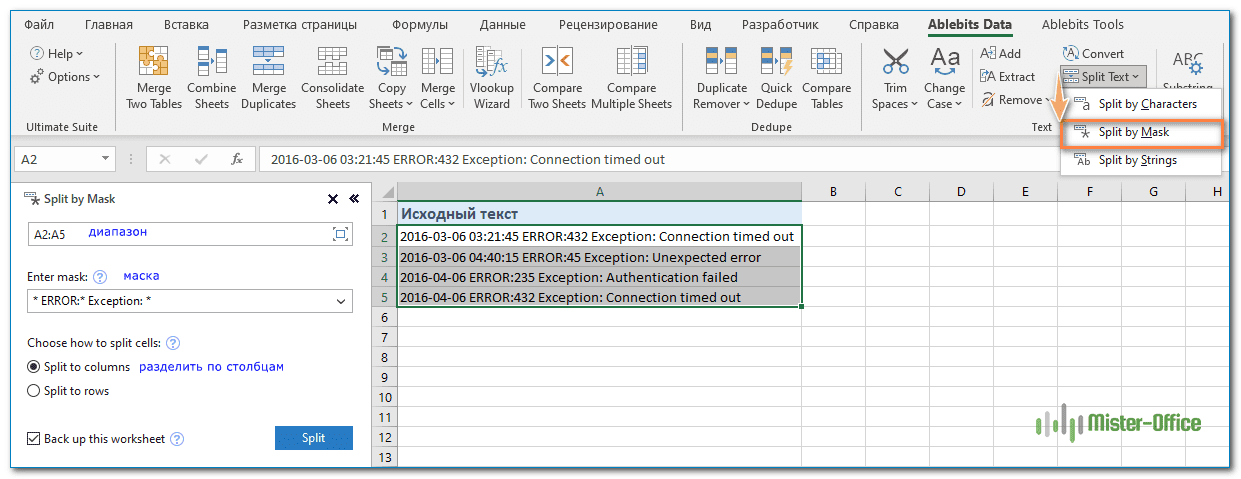
Вы хотите, чтобы дата и время, если таковые имеются, код ошибки и пояснительная информация, были в трех отдельных столбцах. Вы не можете использовать пробел в качестве разделителя, потому что между датой и временем имеются пробелы, которые должны отображаться в одном столбце, и есть пробелы в тексте пояснения, который также должен быть расположен в отдельном столбце.
Решением является разбиение строки по следующей маске:
* ERROR:* Exception: *
Где звездочка (*) представляет любое количество символов.
Двоеточия (:) включены в разделители, потому что мы не хотим, чтобы они появлялись в результирующих ячейках.
А теперь нажмите кнопку «Разбить по маске (Split by Mask)» на панели «Split Text» , введите маску в соответствующее поле и нажмите «Split».
Результат будет примерно таким:

Примечание. При разделении строки по маске учитывается регистр. Поэтому не забудьте ввести символы в шаблоне точно так, как они отображаются в исходных данных.
Большое преимущество этого метода — гибкость. Например, если все исходные строки имеют значения даты и времени, и вы хотите, чтобы они отображались в разных столбцах, используйте эту маску:
* * ERROR:* Exception: *
Проще говоря, маска указывает надстройке разделить исходные строки на 4 части:
- Все символы перед 1-м пробелом в строке (дата)
- Символы между 1-м пробелом и словом ERROR: (время)
- Текст между ERROR: и Exception: (код ошибки)
- Все, что идет после Exception: (текст описания)

Думаю, вы согласитесь, что использование надстройки Split Text гораздо быстрее и проще, нежели использование формул.
Надеюсь, вам понравился этот быстрый и простой способ разделения строк в Excel. Если вам интересно попробовать, ознакомительная версия доступна для загрузки здесь.
Вот как вы можете разделить текст по ячейкам таблицы Excel, используя различные комбинации функций, а также специальные инструменты. Благодарю вас за чтение и надеюсь увидеть вас в нашем блоге на следующей неделе!
Читайте также:
 Поиск ВПР нескольких значений по нескольким условиям — В статье показаны способы поиска (ВПР) нескольких значений в Excel на основе одного или нескольких условий и возврата нескольких результатов в столбце, строке или в отдельной ячейке. При использовании Microsoft…
Поиск ВПР нескольких значений по нескольким условиям — В статье показаны способы поиска (ВПР) нескольких значений в Excel на основе одного или нескольких условий и возврата нескольких результатов в столбце, строке или в отдельной ячейке. При использовании Microsoft…  Формат времени в Excel — Вы узнаете об особенностях формата времени Excel, как записать его в часах, минутах или секундах, как перевести в число или текст, а также о том, как добавить время с помощью…
Формат времени в Excel — Вы узнаете об особенностях формата времени Excel, как записать его в часах, минутах или секундах, как перевести в число или текст, а также о том, как добавить время с помощью…  Как сделать диаграмму Ганта — Думаю, каждый пользователь Excel знает, что такое диаграмма и как ее создать. Однако один вид графиков остается достаточно сложным для многих — это диаграмма Ганта. В этом кратком руководстве я постараюсь показать…
Как сделать диаграмму Ганта — Думаю, каждый пользователь Excel знает, что такое диаграмма и как ее создать. Однако один вид графиков остается достаточно сложным для многих — это диаграмма Ганта. В этом кратком руководстве я постараюсь показать…  Как сделать автозаполнение в Excel — В этой статье рассматривается функция автозаполнения Excel. Вы узнаете, как заполнять ряды чисел, дат и других данных, создавать и использовать настраиваемые списки в Excel. Эта статья также позволяет вам убедиться, что вы…
Как сделать автозаполнение в Excel — В этой статье рассматривается функция автозаполнения Excel. Вы узнаете, как заполнять ряды чисел, дат и других данных, создавать и использовать настраиваемые списки в Excel. Эта статья также позволяет вам убедиться, что вы…  Функция ИНДЕКС в Excel — 6 примеров использования — В этом руководстве вы найдете ряд примеров формул, демонстрирующих наиболее эффективное использование ИНДЕКС в Excel. Из всех функций Excel, возможности которых часто недооцениваются и используются недостаточно, ИНДЕКС определенно занимает место…
Функция ИНДЕКС в Excel — 6 примеров использования — В этом руководстве вы найдете ряд примеров формул, демонстрирующих наиболее эффективное использование ИНДЕКС в Excel. Из всех функций Excel, возможности которых часто недооцениваются и используются недостаточно, ИНДЕКС определенно занимает место…  Быстрое удаление пустых столбцов в Excel — В этом руководстве вы узнаете, как можно легко удалить пустые столбцы в Excel с помощью макроса, формулы и даже простым нажатием кнопки. Как бы банально это ни звучало, удаление пустых…
Быстрое удаление пустых столбцов в Excel — В этом руководстве вы узнаете, как можно легко удалить пустые столбцы в Excel с помощью макроса, формулы и даже простым нажатием кнопки. Как бы банально это ни звучало, удаление пустых…
Разделение текста по столбцам с помощью функций
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel Web App Excel 2010 Excel 2007 Excel для Mac 2011 Еще…Меньше
Для управления строками текста в данных можно использовать текстовые функции LEFT, MID, RIGHT, SEARCH и LEN. Например, можно распределить имя, середину и фамилию из одной ячейки в три отдельных столбца.
Для распределения компонентов имен с текстовыми функциями важно положение каждого символа в текстовой строке. Позиции пробелов в текстовой строке также важны, поскольку они указывают на начало или конец компонентов имени в строке.
Например, в ячейке, содержавшей только имя и фамилию, фамилия начинается после первого висячего пробела. Некоторые имена в списке могут содержать от среднее имя, в этом случае фамилия начинается после второго пробела.
В этой статье показано, как извлекать компоненты из различных форматов имен с помощью этих удобных функций. Текст также можно разделить на разные столбцы с помощью мастера преобразования текста в столбцы.
|
Имя примера |
Описание |
Имя |
От имени |
Фамилия |
Суффикс |
|
|
1 |
Иван Иванов |
От имени нет |
Евгений |
Климов |
||
|
2 |
Сергей Куймина |
Один средний начальный |
Эрик |
S. |
Керуаля |
|
|
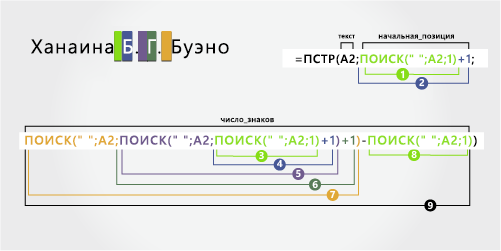
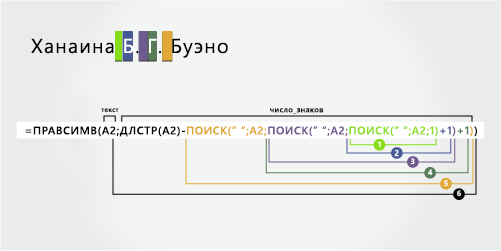
3 |
Янина Б. Г. Bueno |
Два средних инициала |
Янина |
B. Г. |
Bueno |
|
|
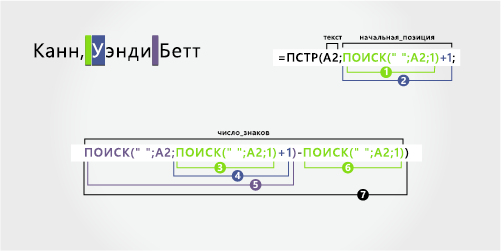
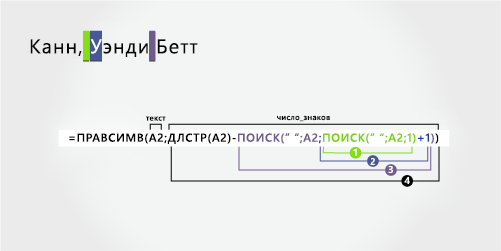
4 |
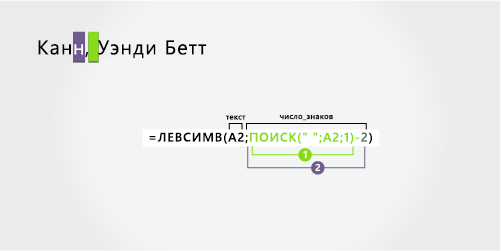
Кана, Венди Йет |
Фамилия с запятой |
Венди |
Бет |
Кан |
|
|
5 |
Mary Kay D. Andersen |
Имя, в которое входит две части |
Mary Kay |
D. |
Волкова |
|
|
6 |
ПолуА Бэрето де Матто |
Фамилия из трех части |
Паула |
Ермно-де-Матто |
||
|
7 |
Г-н Муксон (James van Eaton) |
Фамилия с двумя частьми |
Джеймс |
van Eaton |
||
|
8 |
Бейон мл., Дэн К. |
Фамилия и суффикс с запятой |
Дэн |
K. |
Бекон |
Младший. |
|
9 |
Борис Заметьев III |
С суффиксом |
Гэри |
Альтман |
Iii |
|
|
10 |
Г-н Артем Ихигов |
С префиксом |
Райан |
Ihrig |
||
|
11 |
Джулия Taft-Rider |
Фамилия с дефисами |
Покровская |
Taft-Rider |
Примечание: На рисунках в следующих примерах выделение в полном имени показывает символ, который ищется в формуле ПОИСК.
В этом примере разделяется два компонента: имя и фамилия. Два имени отделены одним пробелом.
Скопируйте ячейки таблицы и в таблицу Excel ячейку A1. Формула слева будет отображаться для справки, а Excel автоматически преобразует формулу справа в соответствующий результат.
Совет. Перед тем как врезать данные в таблицу, установите для столбцов A и B ширину 250.
|
Имя примера |
Описание |
|
Иван Иванов |
От имени нет |
|
Формула |
Результат (имя) |
|
‘=ЛЕВЫЙ(A2; ПОИСК(» «;A2;1)) |
=ЛЕВЫЙ(A2; ПОИСК(» «;A2;1)) |
|
Формула |
Результат (фамилия) |
|
‘=ПРАВАЯ(A2;LEN(A2)-SEARCH(» «;A2;1)) |
=ПРАВБ(A2;LEN(A2)-SEARCH(» «;A2;1)) |
-
Имя
Имя начинается с первого знака в строке (Ю) и заканчивается пятым знаком (пробелом). Формула возвращает пять знаков в ячейке A2, начиная слева.

Для поиска значения «число_знаков» следует воспользоваться функцией ПОИСК.
Найдите позицию пробела в A2, начиная слева.
-
Фамилия
Фамилия отделена от имени пробелом, начинается с пятого знака справа и заканчивается первым знаком справа (а). Формула извлекает в A2 пять знаков справа.
Для поиска значения «число_знаков» следует воспользоваться функцией ПОИСК и ДЛСТР.
Найдите позицию пробела в A2, начиная слева. (5)
-
Подсчитайте общую длину текстовой строки, а затем вычтите количество знаков слева до первого пробела, найденное в пункте 1.


В этом примере используются имя, отс. инициал и фамилия. Каждый компонент имен разделяется пробелом.
Скопируйте ячейки таблицы и в таблицу Excel ячейку A1. Формула слева будет отображаться для справки, а Excel автоматически преобразует формулу справа в соответствующий результат.
Совет. Перед тем как врезать данные в таблицу, установите для столбцов A и B ширину 250.
|
Имя примера |
Описание |
|
Сергей Куймина |
Один средний начальный |
|
Формула |
Результат (имя) |
|
‘=ЛЕВЫЙ(A2; ПОИСК(» «;A2;1)) |
=ЛЕВЫЙ(A2; ПОИСК(» «;A2;1)) |
|
Формула |
Результат (средний начальный) |
|
‘=MID(A2;ПОИСК(» «;A2;1)+1;ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)-SEARCH(» «;A2;1)) |
=MID(A2;ПОИСК(» «;A2;1)+1;ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)-ПОИСК(» «;A2;1)) |
|
Формула |
Live Result (фамилия) |
|
‘=ПРАВАЯ(A2;LEN(A2)-SEARCH(» «;A2;ПОИСК(» «;A2;1)+1)) |
=ПРАВАЯ(A2;LEN(A2)-SEARCH(» «;A2;ПОИСК(» «;A2;1)+1)) |
-
Имя
Имя начинается с первого знака слева (E) и заканчивается пятым (первым пробелом). Формула извлекает первые пять знаков в A2, начиная слева.
Для поиска значения «число_знаков» следует воспользоваться функцией ПОИСК.
Найдите позицию пробела в A2, начиная слева. (5)
-
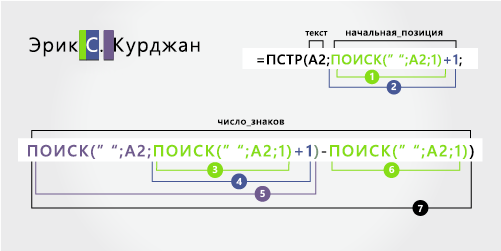
От имени
От второе имя начинается с шестой позиции (S) и заканчивается в 1-й позиции (второй пробел). Эта формула включает вложенные функции ПОИСК для поиска второго экземпляра пробела.
Формула извлекает три знака, начиная с шестой позиции.
Для поиска значения «начальная_позиция» следует воспользоваться функцией ПОИСК:
Поищите позицию первого пробела в A2, начиная с первого знака слева. (5).
-
Чтобы получить позицию знака после первого пробела (S), добавьте 1. Эта позиция является начальной позицией от имени. (5 + 1 = 6)
Для поиска значения «число_знаков» следует воспользоваться вложенной функцией ПОИСК.
Поищите позицию первого пробела в A2, начиная с первого знака слева. (5)
-
Чтобы получить позицию знака после первого пробела (S), добавьте 1. Результат — это номер символа, с которого нужно начать поиск второго пробела. (5 + 1 = 6)
-
Поиск второго пробела в A2, начиная с шестой позиции (S), найденной в шаге 4. Этот номер знака является конечной позицией от имени. (8)
-
Поищите позицию пробела в A2, начиная с первого знака слева. (5)
-
Возьмите номер знака второго пробела, найденного на шаге 5, и вычитайте номер первого пробела, найденного на шаге 6. Результатом является количество символов, извлекаемых СТП из текстовой строки, начиная с шестой позиции, найденной на шаге 2. (8 –5 = 3)
-
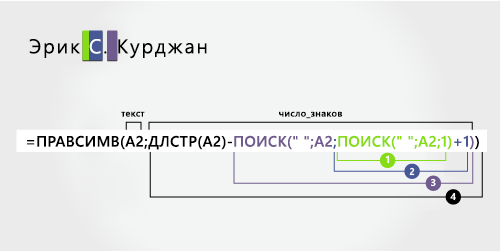
Фамилия
Фамилия начинается с шести знаков справа (K) и заканчивается первым знаком справа (n). Эта формула включает вложенные функции ПОИСК для поиска второго и третьего экземпляров пробела (которые находятся на пятой и пятой позициях слева).
Формула извлекает шесть знаков в A2, начиная с правого.
-
Используйте функции LEN и вложенные функции ПОИСК, чтобы найти значение для num_chars:
Поищите позицию пробела в A2, начиная с первого знака слева. (5)
-
Чтобы получить позицию знака после первого пробела (S), добавьте 1. Результат — это номер символа, с которого нужно начать поиск второго пробела. (5 + 1 = 6)
-
Поиск второго пробела в A2, начиная с шестой позиции (S), найденной в шаге 2. Этот номер знака является конечной позицией от имени. (8)
-
Подсчитайте общую длину текстовой строки в A2 и вычитайте количество знаков слева до второго пробела, найденного на шаге 3. Результат — количество символов, извлекаемого справа от полного имени. (14 – 8 = 6).

Вот пример того, как извлечь два средних инициала. Компоненты имен отделяют первый и третий пробелы.
Скопируйте ячейки таблицы и в таблицу Excel ячейку A1. Формула слева будет отображаться для справки, а Excel автоматически преобразует формулу справа в соответствующий результат.
Совет. Перед тем как врезать данные в таблицу, установите для столбцов A и B ширину 250.
|
Имя примера |
Описание |
|
Янина Б. Г. Bueno |
Два средних инициала |
|
Формула |
Результат (имя) |
|
‘=ЛЕВЫЙ(A2; ПОИСК(» «;A2;1)) |
=ЛЕВЫЙ(A2; ПОИСК(» «;A2;1)) |
|
Формула |
Результат (средние инициалы) |
|
‘=MID(A2;ПОИСК(» «;A2;1)+1;ПОИСК(» «;A2;ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)+1)-ПОИСК(» «;A2;1)) |
=MID(A2;ПОИСК(» «;A2;1)+1;ПОИСК(» «;A2;ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)-ПОИСК(» «;A2;1))-ПОИСК(» «;A2;1)) |
|
Формула |
Live Result (фамилия) |
|
‘=ПРАВАЯ(A2;LEN(A2)-SEARCH(» «;A2;ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)+1)) |
=ПРАВАЯ(A2;LEN(A2)-SEARCH(» «;A2;ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)+1)) |
-
Имя
Первое имя начинается с первого знака слева (J) и заканчивается символом слева (первый пробел). Формула извлекает первые восемь знаков в A2, начиная слева.
Для поиска значения «число_знаков» следует воспользоваться функцией ПОИСК.
Наищите позицию первого пробела в A2, начиная слева. (8)
-
От имени
От второе имя начинается с позиций ва (B) и заканчивается 17-й позицией (третий пробел). Эта формула включает вложенную формулу ПОИСК для поиска первого, второго и третьего пробелов в первой, 11-й и 17-й позициях.
Формула извлекает пять знаков, начиная с позиций неавтетной позиции.
Для поиска значения «начальная_позиция» следует воспользоваться функцией ПОИСК:
Поищите позицию первого пробела в A2, начиная с первого знака слева. (8)
-
Чтобы получить позицию знака после первого пробела (B), добавьте 1. Эта позиция является начальной позицией от имени. (8 + 1 = 9)
Для поиска значения «число_знаков» следует воспользоваться вложенной функцией ПОИСК.
Поищите позицию первого пробела в A2, начиная с первого знака слева. (8)
-
Чтобы получить позицию знака после первого пробела (B), добавьте 1. Результат — это номер символа, с которого нужно начать поиск второго пробела. (8 + 1 = 9)
-
Найщите вторую позицию в A2, начиная с позиции в направлении «в» (B), найденной в шаге 4. (11).
-
Чтобы получить позицию знака после второго пробела (G), добавьте 1. Этот номер знака является начальной позицией, с которой нужно начать поиск третьего пробела. (11 + 1 = 12)
-
Поиск третьего пробела в A2, начиная с двенадцатой позиции, найденной в шаге 6. (14)
-
Поищите позицию первого пробела в A2. (8)
-
Возьмите номер третьего пробела, найденного на шаге 7, и вычитайте номер первого пробела, найденного на шаге 6. Результатом является количество символов, извлекаемых СТП из текстовой строки, начиная с позиций, найденной на шаге 2.
-
Фамилия
Фамилия начинается с пяти знаков справа (B) и заканчивается первым знаком справа (o). Эта формула включает вложенную формулу ПОИСК для поиска первого, второго и третьего пробелов.
Формула извлекает пять знаков в A2, начиная справа от полного имени.
Используйте вложенные функции ПОИСК и LEN, чтобы найти значение для num_chars:
Поищите позицию первого пробела в A2, начиная с первого знака слева. (8)
-
Чтобы получить позицию знака после первого пробела (B), добавьте 1. Результат — это номер символа, с которого нужно начать поиск второго пробела. (8 + 1 = 9)
-
Найщите вторую позицию в A2, начиная с позиции в направлении «в» (B), найденной на шаге 2. (11)
-
Чтобы получить позицию знака после второго пробела (G), добавьте 1. Этот номер знака является начальной позицией, с которой нужно начать поиск третьего пробела. (11 + 1 = 12)
-
Поиск третьего пробела в A2, начиная с двенадцатой позиции (G), найденной в шаге 6. (14)
-
Подсчитайте общую длину текстовой строки в A2 и вычитайте количество знаков слева до третьего пробела, найденного на шаге 5. Результат — количество символов, извлекаемого справа от полного имени. (19 – 14 = 5)

В этом примере фамилия стоит перед именем и отчеством. Запятая помегает конец фамилии, а каждый компонент имени отделяется пробелом.
Скопируйте ячейки таблицы и в таблицу Excel ячейку A1. Формула слева будет отображаться для справки, а Excel автоматически преобразует формулу справа в соответствующий результат.
Совет. Перед тем как врезать данные в таблицу, установите для столбцов A и B ширину 250.
|
Имя примера |
Описание |
|
Кана, Венди Йет |
Фамилия с запятой |
|
Формула |
Результат (имя) |
|
‘=MID(A2;ПОИСК(» «;A2;1)+1;ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)-SEARCH(» «;A2;1)) |
=MID(A2;ПОИСК(» «;A2;1)+1;ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)-ПОИСК(» «;A2;1)) |
|
Формула |
Результат (от имени) |
|
‘=ПРАВАЯ(A2;LEN(A2)-SEARCH(» «;A2;ПОИСК(» «;A2;1)+1)) |
=ПРАВАЯ(A2;LEN(A2)-SEARCH(» «;A2;ПОИСК(» «;A2;1)+1)) |
|
Формула |
Live Result (фамилия) |
|
‘=ЛЕВЫЙ(A2; ПОИСК(» «;A2;1)-2) |
=ЛЕВЫЙ(A2; ПОИСК(» «;A2;1)-2) |
-
Имя
Имя начинается с седьмого знака слева (В) и заканчивается двенадцатым (второй пробел). Поскольку имя оказывается в середине полного имени, для его извлечения необходимо воспользоваться функцией ПСТР.
Формула извлекает шесть знаков, начиная с седьмого знака.
Для поиска значения «начальная_позиция» следует воспользоваться функцией ПОИСК:
Поищите позицию первого пробела в A2, начиная с первого знака слева. (6)
-
Чтобы получить позицию знака после первого пробела (О), добавьте 1. Эта позиция является начальной позицией имени. (6 + 1 = 7)
Для поиска значения «число_знаков» следует воспользоваться вложенной функцией ПОИСК.
Поищите позицию первого пробела в A2, начиная с первого знака слева. (6)
-
Чтобы получить позицию знака после первого пробела (О), добавьте 1. Результатом будет номер знака, с которого нужно начать поиск второго пробела. (6 + 1 = 7)
Поиск второго пробела в A2, начиная с седьмой позиции (W), найденной в шаге 4. (12)
-
Поищите позицию первого пробела в A2, начиная с первого знака слева. (6)
-
Возьмите номер знака второго пробела, найденного на шаге 5, и вычитайте номер первого пробела, найденного на шаге 6. Результатом является количество символов, извлекаемых из текстовой строки, начиная с седьмой позиции, найденной на шаге 2. (12 – 6 = 6)
-
От имени
Отчество начинается с четвертого знака справа (Б) и заканчивается первым знаком справа (т). Для поиска первого и второго пробелов на шестой и двенадцатой позициях слева эта формула включает вложенную функцию ПОИСК.
Формула извлекает четыре знака, начиная справа.
Для поиска значения «начальная_позиция» следует воспользоваться функцией ПОИСК и ДЛСТР:
Поищите позицию первого пробела в A2, начиная с первого знака слева. (6)
-
Чтобы получить позицию знака после первого пробела (О), добавьте 1. Результатом будет номер знака, с которого нужно начать поиск второго пробела. (6 + 1 = 7)
-
Поиск второго пробела в A2, начиная с седьмой позиции (W), найденной на шаге 2. (12)
-
Подсчитайте общую длину текстовой строки в A2 и вычитайте количество знаков слева до второго пробела, найденного на шаге 3. Результат — количество символов, извлекаемого справа от полного имени. (16 – 12 = 4)
-
Фамилия
Фамилия начинается с первого знака слева (К) и заканчивается четвертым знаком (н). Эта формула извлекает четыре знака, начиная слева.
Для поиска значения «число_знаков» следует воспользоваться функцией ПОИСК.
Поищите позицию первого пробела в A2, начиная с первого знака слева. (6)
-
Вычитать 2, чтобы получить позицию последнего знака фамилии (n). Результатом будет количество символов, извлекаемых с левой стороной. (6 – 2 =4)
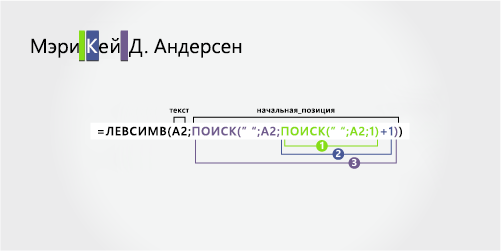
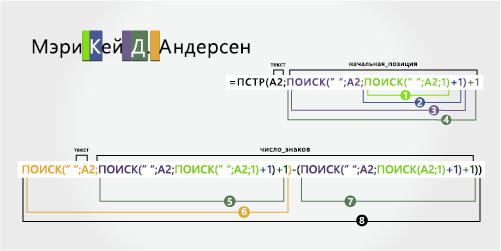
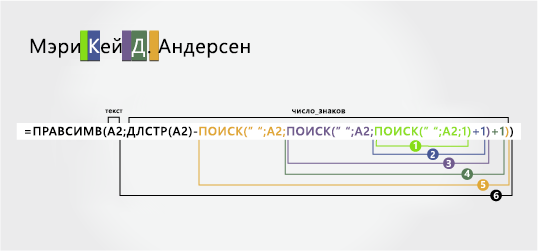
В этом примере используется имя из двух части — Mary Kay. Каждый компонент имен разделяется вторым и третьим пробелами.
Скопируйте ячейки таблицы и в таблицу Excel ячейку A1. Формула слева будет отображаться для справки, а Excel автоматически преобразует формулу справа в соответствующий результат.
Совет. Перед тем как врезать данные в таблицу, установите для столбцов A и B ширину 250.
|
Имя примера |
Описание |
|
Mary Kay D. Andersen |
Имя, в которое входит две части |
|
Формула |
Результат (имя) |
|
ЛЕВ ЛЕВЫЙ(A2; ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)) |
=ЛЕВЫЙ(A2; ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)) |
|
Формула |
Результат (средний начальный) |
|
‘=MID(A2;ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)+1;ПОИСК(» «;A2;ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)+1)-(ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)) |
=MID(A2;ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)+1;ПОИСК(» «;A2;ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)+1)-(ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)) |
|
Формула |
Live Result (фамилия) |
|
‘=ПРАВАЯ(A2;LEN(A2)-SEARCH(» «;A2;ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)+1)) |
=ПРАВАЯ(A2;LEN(A2)-SEARCH(» «;A2;ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)+1)) |
-
Имя
Первое имя начинается с первого знака слева и заканчивается знаком слева (второй пробел). Эта формула включает вложенный поиск, чтобы найти второй пробел слева.
Формула извлекает девять знаков, начиная слева.
Для поиска значения «число_знаков» следует воспользоваться вложенной функцией ПОИСК.
Поищите позицию первого пробела в A2, начиная с первого знака слева. (5)
-
Чтобы получить позицию знака после первого пробела (К), добавьте 1. Результат — это номер символа, с которого нужно начать поиск второго пробела. (5 + 1 = 6)
-
Поиск второго пробела в A2, начиная с шестой позиции (K), найденной на шаге 2. Результат — количество символов, извлекаемых левеем из текстовой строки. (9)
-
От имени
От второе имя начинается с десятой позиции (D) и заканчивается двенадцатой (третий пробел). Эта формула включает вложенную формулу ПОИСК для поиска первого, второго и третьего пробелов.
Формула извлекает два знака из середины, начиная с десятой позиции.
Используйте вложенные функции ПОИСК, чтобы найти значение для start_num:
Поищите позицию первого пробела в A2, начиная с первого знака слева. (5)
-
Добавьте 1, чтобы получить символ после первого пробела (K). Результатом будет номер знака, с которого нужно начать поиск второго пробела. (5 + 1 = 6)
-
Поищите позицию второго пробела в A2, начиная с шестой позиции (K), найденной на шаге 2. Результат — количество символов, извлекаемых левее. (9)
-
Добавьте 1, чтобы получить символ после второго пробела (D). Результат — начальная позиция от имени. (9 + 1 = 10)
Для поиска значения «число_знаков» следует воспользоваться вложенной функцией ПОИСК.
Поищите позицию знака после второго пробела (D). Результатом будет номер знака, с которого вы хотите начать поиск третьего пробела. (10)
-
Наищите позицию третьего пробела в A2, начиная слева. Результат — конечная позиция от имени. (12)
-
Поищите позицию знака после второго пробела (D). Результат — начальная позиция от имени. (10)
-
Возьмите номер третьего пробела, найденного на шаге 6, и вычитайте номер знака «D», найденный на шаге 7. Результатом является количество символов, извлекаемых СТП из текстовой строки, начиная с десятой позиции, найденной в шаге 4. (12 – 10 = 2)
-
Фамилия
Фамилия начинается с восьми знаков справа. Эта формула включает вложенный поиск для поиска первого, второго и третьего пробелов на пятой, четвертой, четвертой и двенадцатой позициях.
Формула извлекает восемь знаков справа.
Используйте вложенные функции ПОИСК и LEN, чтобы найти значение для num_chars:
Наищите позицию первого пробела в A2, начиная слева. (5)
-
Добавьте 1, чтобы получить символ после первого пробела (K). Результат — это номер символа, с которого нужно начать поиск пробела. (5 + 1 = 6)
-
Поиск второго пробела в A2, начиная с шестой позиции (K), найденной на шаге 2. (9)
-
Чтобы получить позицию знака после второго пробела (D), добавьте 1. Результат — начальная позиция от имени. (9 + 1 = 10)
-
Наищите позицию третьего пробела в A2, начиная слева. Результат — конечная позиция от имени. (12)
-
Подсчитайте общую длину текстовой строки в A2 и вычитайте количество знаков слева до третьего пробела, найденного на шаге 5. Результат — количество символов, извлекаемого справа от полного имени. (20 – 12 =

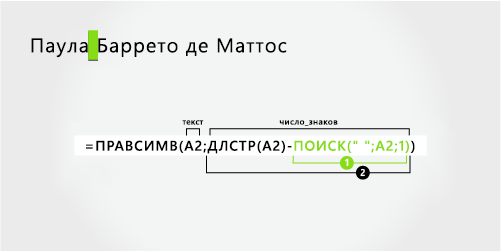
В этом примере используется фамилия из трех части: Ермолето де Матто. Первый пробел пометит конец имени и начало фамилии.
Скопируйте ячейки таблицы и в таблицу Excel ячейку A1. Формула слева будет отображаться для справки, а Excel автоматически преобразует формулу справа в соответствующий результат.
Совет. Перед тем как врезать данные в таблицу, установите для столбцов A и B ширину 250.
|
Имя примера |
Описание |
|
ПолуА Бэрето де Матто |
Фамилия из трех части |
|
Формула |
Результат (имя) |
|
‘=ЛЕВЫЙ(A2; ПОИСК(» «;A2;1)) |
=ЛЕВЫЙ(A2; ПОИСК(» «;A2;1)) |
|
Формула |
Результат (фамилия) |
|
ПРАВБ(A2;LEN(A2)-ПОИСК(» «;A2;1)) |
=ПРАВБ(A2;LEN(A2)-SEARCH(» «;A2;1)) |
-
Имя
Имя начинается с первого знака слева (P) и заканчивается шестым (первый пробел). Формула извлекает шесть знаков слева.
Чтобы найти значение для num_chars, используйте функцию Num_chars.
Наищите позицию первого пробела в A2, начиная слева. (6)
-
Фамилия
Фамилия начинает символы справа (B) и заканчивается первым знаком справа (s). Формула извлекает символы справа.
Чтобы найти значение для num_chars, используйте функции LEN и NUM_CHARS.
Наищите позицию первого пробела в A2, начиная слева. (6)
-
Подсчитайте общую длину текстовой строки в A2 и вычитайте количество знаков слева до первого пробела, найденного на шаге 1. Результат — количество символов, извлекаемого справа от полного имени. (23 – 6 = 17)

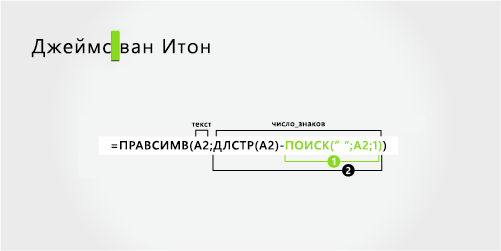
В этом примере используется фамилия из двух видов: van Eaton. Первый пробел пометит конец имени и начало фамилии.
Скопируйте ячейки таблицы и в таблицу Excel ячейку A1. Формула слева будет отображаться для справки, а Excel автоматически преобразует формулу справа в соответствующий результат.
Совет. Перед тем как врезать данные в таблицу, установите для столбцов A и B ширину 250.
|
Имя примера |
Описание |
|
Г-н Муксон (James van Eaton) |
Фамилия с двумя частьми |
|
Формула |
Результат (имя) |
|
‘=ЛЕВЫЙ(A2; ПОИСК(» «;A2;1)) |
=ЛЕВЫЙ(A2; ПОИСК(» «;A2;1)) |
|
Формула |
Результат (фамилия) |
|
‘=ПРАВАЯ(A2;LEN(A2)-SEARCH(» «;A2;1)) |
=ПРАВБ(A2;LEN(A2)-SEARCH(» «;A2;1)) |
-
Имя
Первое имя начинается с первого знака слева (J) и заканчивается символом слева (первый пробел). Формула извлекает шесть знаков слева.
Для поиска значения «число_знаков» следует воспользоваться функцией ПОИСК.
Наищите позицию первого пробела в A2, начиная слева. (6)
-
Фамилия
Фамилия начинается с символа справа (v) и заканчивается первым знаком справа (n). Формула извлекает девять знаков справа от полного имени.
Чтобы найти значение для num_chars, используйте функции LEN и NUM_CHARS.
Наищите позицию первого пробела в A2, начиная слева. (6)
-
Подсчитайте общую длину текстовой строки в A2 и вычитайте количество знаков слева до первого пробела, найденного на шаге 1. Результат — количество символов, извлекаемого справа от полного имени. (15 – 6 = 9)

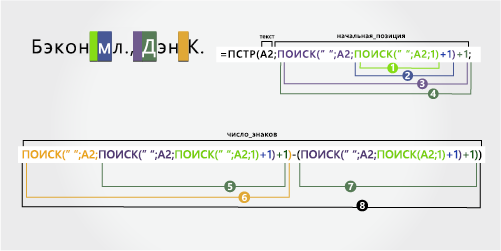
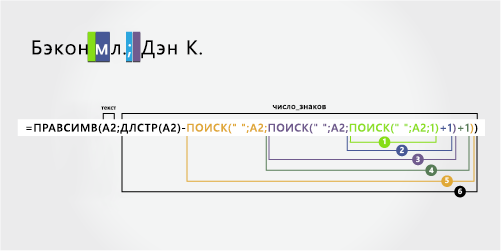
В этом примере фамилия будет первой, а за ней — суффикс. Запятая отделяет фамилию и суффикс от имени и от среднего инициалов.
Скопируйте ячейки таблицы и в таблицу Excel ячейку A1. Формула слева будет отображаться для справки, а Excel автоматически преобразует формулу справа в соответствующий результат.
Совет. Перед тем как врезать данные в таблицу, установите для столбцов A и B ширину 250.
|
Имя примера |
Описание |
|
Бейон мл., Дэн К. |
Фамилия и суффикс с запятой |
|
Формула |
Результат (имя) |
|
‘=MID(A2;ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)+1;ПОИСК(» «;A2;ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)+1)-SEARCH(» «;A2;ПОИСК(» «;A2;1)+1)) |
=MID(A2;ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)+1;ПОИСК(» «;A2;ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)-SEARCH(» «;A2;1)-SEARCH(» «;A2;1))) |
|
Формула |
Результат (средний начальный) |
|
‘=ПРАВАЯ(A2;LEN(A2)-SEARCH(» «;A2;ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)+1)) |
=ПРАВАЯ(A2;LEN(A2)-SEARCH(» «;A2;ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)+1)) |
|
Формула |
Результат (фамилия) |
|
‘=ЛЕВЫЙ(A2; ПОИСК(» «;A2;1)) |
=ЛЕВЫЙ(A2; ПОИСК(» «;A2;1)) |
|
Формула |
Результат (суффикс) |
|
‘=MID(A2;ПОИСК(» «; A2;1)+1;(ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)-2)-SEARCH(» «;A2;1)) |
=MID(A2;ПОИСК(» «; A2;1)+1;(ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)-2)-SEARCH(» «;A2;1)) |
-
Имя
Имя начинается с двенадцатого знака (D) и заканчивается 15-м (третий пробел). Формула извлекает три знака, начиная с двенадцатой позиции.
Используйте вложенные функции ПОИСК, чтобы найти значение для start_num:
Наищите позицию первого пробела в A2, начиная слева. (6)
-
Добавьте 1, чтобы получить символ после первого пробела (J). Результатом будет номер знака, с которого нужно начать поиск второго пробела. (6 + 1 = 7)
-
Найщите вторую позицию в A2, начиная с седьмой позиции (J), найденной на шаге 2. (11)
-
Добавьте 1, чтобы получить символ после второго пробела (D). Результатом является начальная позиция имени. (11 + 1 = 12)
Для поиска значения «число_знаков» следует воспользоваться вложенной функцией ПОИСК.
Поищите позицию знака после второго пробела (D). Результатом будет номер знака, с которого вы хотите начать поиск третьего пробела. (12)
-
Наищите позицию третьего пробела в A2, начиная слева. Результат — конечная позиция имени. (15)
-
Поищите позицию знака после второго пробела (D). Результат — начальная позиция имени. (12)
-
Возьмите номер третьего пробела, найденного на шаге 6, и вычитайте номер знака «D», найденный на шаге 7. Результатом является количество символов, извлекаемого с позиции, которая начинается с двенадцатой строки, найденной в шаге 4. (15 – 12 = 3)
-
От имени
От второе имя начинается со второго знака справа (K). Формула извлекает два знака справа.
Наищите позицию первого пробела в A2, начиная слева. (6)
-
Добавьте 1, чтобы получить символ после первого пробела (J). Результатом будет номер знака, с которого нужно начать поиск второго пробела. (6 + 1 = 7)
-
Найщите вторую позицию в A2, начиная с седьмой позиции (J), найденной на шаге 2. (11)
-
Добавьте 1, чтобы получить символ после второго пробела (D). Результатом является начальная позиция имени. (11 + 1 = 12)
-
Наищите позицию третьего пробела в A2, начиная слева. Результат — конечная позиция от имени. (15)
-
Подсчитайте общую длину текстовой строки в A2 и вычитайте количество знаков слева до третьего пробела, найденного на шаге 5. Результат — количество символов, извлекаемого справа от полного имени. (17 – 15 = 2)
-
Фамилия
Фамилия начинается с первого знака слева (B) и заканчивается шестым (первый пробел). Поэтому формула извлекает шесть знаков слева.
Для поиска значения «число_знаков» следует воспользоваться функцией ПОИСК.
Наищите позицию первого пробела в A2, начиная слева. (6)
-
Суффикс
Суффикс начинается с седьмого знака слева (J) и заканчивается символом слева (.). Формула извлекает три знака, начиная с седьмого.
Для поиска значения «начальная_позиция» следует воспользоваться функцией ПОИСК:
Наищите позицию первого пробела в A2, начиная слева. (6)
-
Добавьте 1, чтобы получить символ после первого пробела (J). Результат — начальная позиция суффикса. (6 + 1 = 7)
Для поиска значения «число_знаков» следует воспользоваться вложенной функцией ПОИСК.
Наищите позицию первого пробела в A2, начиная слева. (6)
-
Добавьте 1, чтобы получить позицию символа после первого пробела (J). Результатом будет номер знака, с которого нужно начать поиск второго пробела. (7)
-
Поищите позицию второго пробела в A2, начиная с седьмого знака, найденного в шаге 4. (11)
-
Вычитать 1 из номера знака второго пробела, найденного в шаге 4, чтобы получить номер знака «,». Результат — конечная позиция суффикса. (11 — 1 = 10)
-
Поищите позицию первого пробела в числе. (6)
-
Найдя первый пробел, добавьте 1, чтобы найти следующий символ (J), который также находится в шагах 3 и 4. (7)
-
Возьмите номер знака «», найденный на шаге 6, и вычитайте номер символа «J», найденный в шагах 3 и 4. Результатом является количество символов, извлекаемых СТП из текстовой строки, начиная с седьмой позиции, найденной в шаге 2. (10 — 7 = 3)

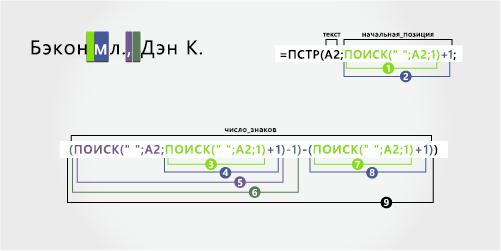
В этом примере первое имя находится в начале строки, а суффикс — в конце, поэтому можно использовать формулы, похожие на пример 2. Для извлечения имени используйте функцию ЛЕВША, для извлечения фамилии — функцию MID, а для извлечения суффикса — функцию ПРАВБ.
Скопируйте ячейки таблицы и в таблицу Excel ячейку A1. Формула слева будет отображаться для справки, а Excel автоматически преобразует формулу справа в соответствующий результат.
Совет. Перед тем как врезать данные в таблицу, установите для столбцов A и B ширину 250.
|
Имя примера |
Описание |
|
Борис Заметьев III |
Имя и фамилия с суффиксом |
|
Формула |
Результат (имя) |
|
‘=ЛЕВЫЙ(A2; ПОИСК(» «;A2;1)) |
=ЛЕВЫЙ(A2; ПОИСК(» «;A2;1)) |
|
Формула |
Результат (фамилия) |
|
‘=MID(A2;ПОИСК(» «;A2;1)+1;ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)-(ПОИСК(» «;A2;1)+1)) |
=MID(A2;ПОИСК(» «;A2;1)+1;ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)-(ПОИСК(» «;A2;1)+1)) |
|
Формула |
Результат (суффикс) |
|
‘=ПРАВАЯ(A2;LEN(A2)-SEARCH(» «;A2;ПОИСК(» «;A2;1)+1)) |
=ПРАВАЯ(A2;LEN(A2)-SEARCH(» «;A2;ПОИСК(» «;A2;1)+1)) |
-
Имя
Имя начинается с первого знака слева (G) и заканчивается пятым (первый пробел). Поэтому формула извлекает пять знаков слева от полного имени.
Наищите позицию первого пробела в A2, начиная слева. (5)
-
Фамилия
Фамилия начинается с шестого знака слева (A) и заканчивается одиннадцатым (второй пробел). Эта формула включает вложенный поиск для поиска позиций пробелов.
Формула извлекает шесть знаков из середины начиная с шестого.
Для поиска значения «начальная_позиция» следует воспользоваться функцией ПОИСК:
Наищите позицию первого пробела в A2, начиная слева. (5)
-
Чтобы получить позицию знака после первого пробела (A), добавьте 1. Результат — начальная позиция фамилии. (5 + 1 = 6)
Для поиска значения «число_знаков» следует воспользоваться вложенной функцией ПОИСК.
Наищите позицию первого пробела в A2, начиная слева. (5)
-
Чтобы получить позицию знака после первого пробела (A), добавьте 1. Результатом будет номер знака, с которого нужно начать поиск второго пробела. (5 + 1 = 6)
-
Поищите позицию второго пробела в A2, начиная с шестого знака, найденного в шаге 4. Этот номер знака является конечной позицией фамилии. (12)
-
Поищите позицию первого пробела в числе. (5)
-
Добавьте 1, чтобы найти позицию знака после первого пробела (A), также найденного в шагах 3 и 4. (6)
-
Возьмите номер второго пробела, найденного на шаге 5, и вычитайте номер знака «A», найденный в шагах 6 и 7. Результатом является количество символов, извлекаемых из текстовой строки, начиная с шестой позиции, найденной на шаге 2. (12 – 6 = 6)
-
Суффикс
Суффикс начинается с трех знаков справа. Эта формула включает вложенный поиск для поиска позиций пробелов.
Используйте вложенные функции ПОИСК и LEN, чтобы найти значение для num_chars:
Наищите позицию первого пробела в A2, начиная слева. (5)
-
Добавьте 1, чтобы получить символ после первого пробела (A). Результатом будет номер знака, с которого нужно начать поиск второго пробела. (5 + 1 = 6)
-
Поиск второго пробела в A2, начиная с шестой позиции (A), найденной на шаге 2. (12)
-
Подсчитайте общую длину текстовой строки в A2 и вычитайте количество знаков слева до второго пробела, найденного на шаге 3. Результат — количество символов, извлекаемого справа от полного имени. (15 – 12 = 3)

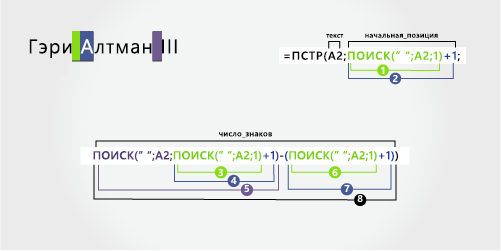
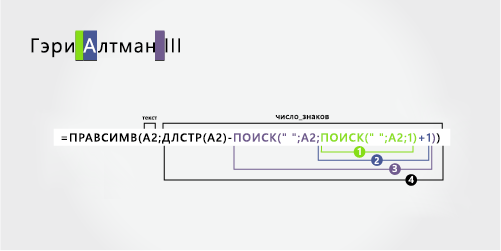
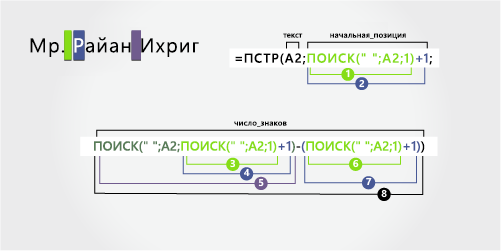
В этом примере перед полным именем предшествует префикс, и вы используете формулы, аналогичные примеру 2: функция MID для извлечения имени, функция ПРАВБ для извлечения фамилии.
Скопируйте ячейки таблицы и в таблицу Excel ячейку A1. Формула слева будет отображаться для справки, а Excel автоматически преобразует формулу справа в соответствующий результат.
Совет. Перед тем как врезать данные в таблицу, установите для столбцов A и B ширину 250.
|
Имя примера |
Описание |
|
Г-н Артем Ихигов |
С префиксом |
|
Формула |
Результат (имя) |
|
‘=MID(A2;ПОИСК(» «;A2;1)+1;ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)-(ПОИСК(» «;A2;1)+1)) |
=MID(A2;ПОИСК(» «;A2;1)+1;ПОИСК(» «;A2;ПОИСК(» «;A2;1)+1)-(ПОИСК(» «;A2;1)+1)) |
|
Формула |
Результат (фамилия) |
|
‘=ПРАВАЯ(A2;LEN(A2)-SEARCH(» «;A2;ПОИСК(» «;A2;1)+1)) |
=ПРАВАЯ(A2;LEN(A2)-SEARCH(» «;A2;ПОИСК(» «;A2;1)+1)) |
-
Имя
Первое имя начинается с пятого знака слева (R) и заканчивается символом второго знака (второй пробел). Формула вложена в поиск, чтобы найти позиции пробелов. Он извлекает четыре знака, начиная с пятой позиции.
Чтобы найти значение для запроса, воспользуйтесь функцией START_NUM.
Наищите позицию первого пробела в A2, начиная слева. (4)
-
Чтобы получить позицию знака после первого пробела (R), добавьте 1. Результатом является начальная позиция имени. (4 + 1 = 5)
Используйте вложенную функцию ПОИСК, чтобы найти значение для num_chars:
Наищите позицию первого пробела в A2, начиная слева. (4)
-
Чтобы получить позицию знака после первого пробела (R), добавьте 1. Результатом будет номер знака, с которого нужно начать поиск второго пробела. (4 + 1 = 5)
-
Поищите позицию второго пробела в A2, начиная с пятого знака, найденного в шагах 3 и 4. Этот номер знака является конечной позицией имени. (9)
-
Наймем первый пробел. (4)
-
Добавьте 1, чтобы найти позицию знака после первого пробела (R), также найденного в шагах 3 и 4. (5)
-
Возьмите номер второго пробела, найденного на шаге 5, и вычитайте номер знака «R», найденный в шагах 6 и 7. Результатом является количество символов, извлекаемого из текстовой строки, начиная с пятой позиции, найденной на шаге 2. (9 – 5 = 4)
-
Фамилия
Фамилия начинается с пяти знаков справа. Эта формула включает вложенный поиск для поиска позиций пробелов.
Используйте вложенные функции ПОИСК и LEN, чтобы найти значение для num_chars:
Наищите позицию первого пробела в A2, начиная слева. (4)
-
Чтобы получить позицию знака после первого пробела (R), добавьте 1. Результатом будет номер знака, с которого нужно начать поиск второго пробела. (4 + 1 = 5)
-
Поиск второго пробела в A2, начиная с пятой позиции (R), найденной на шаге 2. (9)
-
Подсчитайте общую длину текстовой строки в A2 и вычитайте количество знаков слева до второго пробела, найденного на шаге 3. Результат — количество символов, извлекаемого справа от полного имени. (14 – 9 = 5)
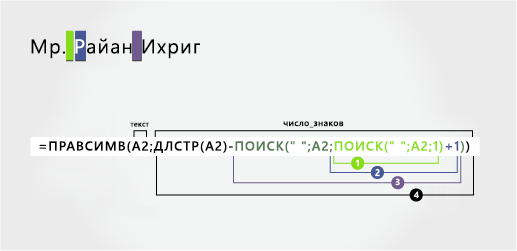
В этом примере используется фамилия с дефисами. Каждый компонент имен разделяется пробелом.
Скопируйте ячейки таблицы и в таблицу Excel ячейку A1. Формула слева будет отображаться для справки, а Excel автоматически преобразует формулу справа в соответствующий результат.
Совет. Перед тем как врезать данные в таблицу, установите для столбцов A и B ширину 250.
|
Имя примера |
Описание |
|
Джулия Taft-Rider |
Фамилия с дефисами |
|
Формула |
Результат (имя) |
|
‘=ЛЕВЫЙ(A2; ПОИСК(» «;A2;1)) |
=ЛЕВЫЙ(A2; ПОИСК(» «;A2;1)) |
|
Формула |
Результат (фамилия) |
|
‘=ПРАВАЯ(A2;LEN(A2)-SEARCH(» «;A2;1)) |
=ПРАВБ(A2;LEN(A2)-SEARCH(» «;A2;1)) |
-
Имя
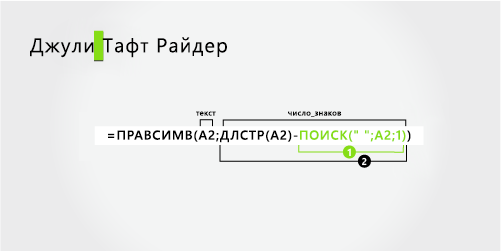
Имя начинается с первого знака слева и заканчивается на шестой позиции (первый пробел). Формула извлекает шесть знаков слева.
Функция ПОИСК используется для поиска значения num_chars:
Наищите позицию первого пробела в A2, начиная слева. (6)
-
Фамилия
Вся фамилия начинается с десяти знаков справа (T) и заканчивается первым знаком справа (r).
Чтобы найти значение для num_chars, используйте функции LEN и NUM_CHARS.
Поищите позицию пробела в A2, начиная с первого знака слева. (6)
-
Подсчитайте общую длину извлекаемой текстовой строки и вычитайте количество знаков слева до первого пробела, найденного на шаге 1. (16 – 6 = 10)

Нужна дополнительная помощь?
Раннее мы рассматривали возможность разделить текст по столбцам на примере деления ФИО на составные части. Для этого мы использовали инструмент в Excel «Текст по столбцам».
Несомненно, это очень важный и полезный и инструмент в Excel, который значительно может упростить множество задач. Но у данного способа есть небольшой недостаток. Если вам, например, постоянно присылают данные в определенном виде, а вам постоянно необходимо их делить, то это занимает определенное время, кроме того, если данные вам прислали заново, то вам снова нужно будет проделать все операции.
Содержание
- 1 Пример 1. Делим текст с ФИО по столбцам с помощью формул
- 1.1 Приступаем к делению первой части текста — Фамилии
- 1.2 Приступаем к делению второй части текста — Имя
- 1.3 Приступаем к делению третьей части текста — Отчество
- 2 Пример 2. Как разделить текст по столбцам в Excel с помощью формулы
Пример 1. Делим текст с ФИО по столбцам с помощью формул
Если рассматривать на примере деления ФИО, то разделить текст можно будет с помощью текстовых формул Excel, используя функцию ПСТР и НАЙТИ, которую мы рассматривали в прошлых статьях. В этом случае вам достаточно вставить данные в определенный столбец, а формулы автоматически разделят текст так как вам необходимо. Давайте приступит к рассмотрению данного примера.
У нас есть столбец со списком ФИО, наша задача разместить фамилию, имя отчество по отдельным столбцам.

Попробуем очень подробно описать план действия и разобьем решение задачи на несколько этапов.
Первым делом добавим вспомогательные столбцы, для промежуточных вычислений, чтобы вам было понятнее, а в конце все формулы объединим в одну.
Итак, добавим столбцы позиция 1-го и 2-го пробелам. С помощью функции НАЙТИ, как мы уже рассматривали в предыдущей статье найдем позицию первого пробелам. Для этого в ячейке «H2» пропишем формулу
=НАЙТИ(" ";A2;1)
и протянем вниз. Формулу объяснять не буду — смотрите предыдущую статью

Теперь нам необходимо найти порядковый номер второго пробела. Формула будет такая же, но с небольшим отличием. Если прописать такую же формулу, то функция найдет нам первый пробел, а нам нужен второй пробел. Значит на необходимо поменять третий аргумент в функции НАЙТИ — начальная позиция — то есть позиция с которой функция будет искать искомый текст. Мы видим, что второй пробел находится в любом случае после первого пробела, а позицию первого пробела мы уже нашли, значит прибавив 1 к позиции первого пробелам мы укажем функции НАЙТИ искать пробел начиная с первой буквы после первого пробела. Функция будет выглядеть следующим образом:
=НАЙТИ(" ";A2;H2+1)

Далее протягиваем формулу и получаем позиции 1-го и 2-го пробела.
Приступаем к делению первой части текста — Фамилии
Для этого мы воспользуемся функцией ПСТР, напомню синтаксис данной функции:
=ПСТР(текст; начальная_позиция; число_знаков), где
- текст — это ФИО, в нашем примере это ячейка A2;
- начальная_позиция — в нашем случае это 1, то есть начиная с первой буквы;
- число_знаков — мы видим, что фамилия состоит из всех знаков, начиная с первой буквы и до 1-го пробела. А позиция первого пробела нам уже известна. Это и будет количество знаков минус 1 знак самого пробела.
Формула будет выглядеть следующим образом:
=ПСТР(A2;1;H2-1)

Приступаем к делению второй части текста — Имя
Снова используем функцию =ПСТР(текст; начальная_позиция; число_знаков), где
- текст — это тот же текст ФИО, в нашем примере это ячейка A2;
- начальная_позиция — в нашем случае Имя начинается с первой буква после первого пробела, зная позицию этого пробела получаем H2+1;
- число_знаков — число знаков, то есть количество букв в имени. Мы видим, что имя у нас находится между двумя пробелами, позиции которых мы знаем. Если из позиции второго пробела отнять позицию первого пробела, то мы получим разницу, которая и будет равна количеству символов в имени, то есть I2-H2
Получаем итоговую формулу:
=ПСТР(A2;H2+1;I2-H2)

Приступаем к делению третьей части текста — Отчество
И снова функция =ПСТР(текст; начальная_позиция; число_знаков), где
- текст — это тот же текст ФИО, в нашем примере это ячейка A2;
- начальная_позиция — Отчество у нас находится после 2-го пробелам, значит начальная позиция будет равна позиции второго пробела плюс один знак или I2+1;
- число_знаков — в нашем случае после Отчества никаких знаков нет, поэтому мы просто может взять любое число, главное, чтобы оно было больше возможного количества символов в Отчестве, я взял цифру с большим запасом — 50
Получаем функцию
=ПСТР(A2;I2+1;50)

Далее выделяем все три ячейки и протягиваем формулы вниз и получаем нужный нам результат. На этом можно закончить, а можно промежуточные расчеты позиции пробелов прописать в сами формулы деления текста. Это очень просто сделать. Мы видим, что расчет первого пробела находится в ячейке H2 — НАЙТИ(» «;A2;1), а расчет второго пробела в ячейке I2 — НАЙТИ(» «;A2;H2+1) . Видим, что в формуле ячейки I2 встречается H2 меняем ее на саму формулу и получаем в ячейке I2 вложенную формулу НАЙТИ(» «;A2;НАЙТИ(» «;A2;1)+1)
Смотрим первую формулу выделения Фамилии и смотрим где здесь встречается H2 или I2 и меняем их на формулы в этих ячейках, аналогично с Именем и Фамилией
- Фамилия =ПСТР(A2;1;H2-1) получаем =ПСТР(A2;1;НАЙТИ(» «;A2;1)-1)
- Имя =ПСТР(A2;H2+1;I2—H2) получаем =ПСТР(A2;НАЙТИ(» «;A2;1)+1;
НАЙТИ(» «;A2;НАЙТИ(» «;A2;1)+1)—НАЙТИ(» «;A2;1)) - Отчество =ПСТР(A2;I2+1;50) получаем =ПСТР(A2;НАЙТИ(» «;A2;НАЙТИ(» «;A2;1)+1)+1;50)
Теперь промежуточные вычисления позиции пробелом можно смело удалить. Это один из приемов, когда для простоты сначала ищутся промежуточные данные, а потом функцию вкладывают одну в другую. Согласитесь, если писать такую большую формулу сразу, то легко запутаться и ошибиться.
Надеемся, что данный пример наглядно показал вам, как полезны текстовые функции Excel для работы с текстом и как они позволяют делить текст автоматически с помощью формул однотипные данные. Если вам понравилась статья, то будем благодарны за нажатие на +1 и мне нравится. Подписывайтесь и вступайте в нашу группу вконтакте.
Пример 2. Как разделить текст по столбцам в Excel с помощью формулы
Рассмотрим второй пример, который так же очень часто встречался на практике. Пример похож предыдущий, но данных которые нужно разделить значительно больше. В этом примере я покажу прием, который позволит достаточно быстро решить вопрос и не запутаться.
Допустим у нас есть список чисел, перечисленных через запятую, нам необходимо разбить текст таким образом, чтобы каждое число было в отдельной ячейке (вместо запятых это могут быть любые другие знаки, в том числе и пробелы). То есть нам необходимо разбить текст по словам.

Напомним, что вручную (без формул) это задача очень просто решается с помощью инструмента текст по столбцам, который мы уже рассматривали. В нашем же случае требуется это сделать с помощью формул.
Для начала необходимо найти общий разделить, по которому мы будет разбивать текст. В нашем случае это запятая, но например в первой задаче мы делили ФИО и разделитель был пробел. Наш второй пример более универсальный (более удобный при большом количестве данных), так например мы удобно могли бы делить не только ФИО по отдельным ячейкам, а целое предложение — каждое слово в отдельную ячейку. Собственно такой вопрос поступил в комментариях, поэтому было решено дополнить эту статью.
Для удобства в соседнем столбце укажем этот разделитель, чтобы не прописывать его в формуле а просто ссылаться на ячейку. Это так же позволит нам использовать файл для решения других задач, просто поменяв разделитель в ячейках.

Теперь основная суть приема.
Шаг 1. В вспомогательном столбце находим позицию первого разделителя с помощью функции НАЙТИ. Описывать подробно функцию не буду, так как мы уже рассматривали ее раннее. Пропишем формулу в D1 и протянем ее вниз на все строки
=НАЙТИ(B1;A1;1)
То есть ищем запятую, в тексте, начиная с позиции 1

Шаг 2. Далее в ячейке E1 прописываем формулу для нахождения второго знака (в нашем случае запятой). Формула аналогичная, но с небольшими изменениями.
=НАЙТИ($B1;$A1;D1+1)
Во-первых: закрепим столбец искомого значения и текста, чтобы при протягивании формулы вправо ссылки на ячейки не сдвигалась. Для этого нужно написать доллар перед столбцом B и A — либо вручную, либо выделить A1 и B1, нажать три раза клавишу F4, после этого ссылки станут не относительными, а абсолютными.
Во-вторых: третий аргумент — начало позиции мы рассчитаем как позиция предыдущего разделителя (мы его нашли выше) плюс 1 то есть D1+1 так как мы знаем, что второй разделитель точно находится после первого разделителя и нам его не нужно учитывать.
Пропишем формулу и протянем ее вниз.

Шаг 3. Находимо позиции всех остальных разделителей. Для этого формулу нахождения второго разделителя (шаг 2) протянем вправо на то количество ячеек, сколько всего может быть отдельно разбитых значений с небольшим запасом. Получим все позиции разделителей. Там где ошибка #Знач означает что значения закончились и формула больше не находит разделителей. Получаем следующее

Шаг 4. Отделяем первое число от текст с помощью функции ПСТР.
=ПСТР(A1;1;D1-1)
Начальная позиция у нас 1, количество знаков мы рассчитываем как позиция первого разделителя минус 1: D1-1 протягиваем формулу вниз

Шаг 5. Находимо второе слово так же с помощью функции ПСТР в ячейке P1
=ПСТР($A1;D1+1;E1-D1-1)
Начальная позиция второго числа у нас начинается после первой запятой. Позиция первой запятой у нас есть в ячейке D1, прибавим единицу и получим начальную позицию нашего второго числа.
Количество знаков это есть разница между позицией третьего разделителя и второго и минус один знак, то есть E1-D1-1
Закрепим столбец A исходного текста, чтобы он не сдвигался при протягивании формулы право.
Шаг 6. Протянем формулу полученную на шаге 5 вправо и вниз и получим текст в отдельных ячейках.

Шаг 7. В принципе задача наша уже решена, но для красоты все в той же ячейке P1 пропишем формула отлавливающую ошибку заменяя ее пустым значением. Так же можно сгруппировать и свернуть вспомогательные столбцы, чтобы они не мешали. Получим итоговое решение задачи
=ЕСЛИОШИБКА(ПСТР($A1;D1+1;E1-D1-1);»»)

Примечание. Первую позицию разделителя и первое деление слова мы делали отлично от других и из-за этого могли протянуть формулу только со вторых значений. Во время написания задачи я заметил, что можно было бы упростить задачу. Для этого в столбце С нужно было прописать 0 значения первого разделителя. После этого находим значение первого разделителя
=НАЙТИ($B1;$A1;C1+1)
а первого текста как
=ПСТР($A1;C1+1;D1-C1-1)
После этого можно сразу протягивать формулу на остальные значения. Именно этот вариант оставляю как пример для скачивания. В принципе файлом можно пользоваться как шаблоном. В столбец «A» вставляете данные, в столбце «B» указываете разделитель, протягиваете формулы на нужное количество ячеек и получаете результат.
Внимание! В комментариях заметили, что так как в конце текста у нас нет разделителя, то у нас не считается количество символов от последнего разделителя до конца строки, поэтому последний разделенный текст отсутствует. Чтобы решить вопрос можно либо на первом шаге добавить вспомогательный столбец радом с исходным текстом, где сцепить этот текст с разделителем. Таким образом у нас получится что на конце текста будет разделитель, значит наши формулы посчитают его позицию и все будет работать.
Либо второе решение — это на шаге 3, когда мы составляем формулу вычисления позиций разделителей дополнить ее. Сделать проверку, если ошибка, то указываем заведомо большое число, например 1000.
=ЕСЛИОШИБКА(НАЙТИ($B1;$A1;C1+1);1000)

Таким образом последний текст будет рассчитываться начиная от последней запятой до чуть меньше 1000 знаков, то есть до конца строки, что нам и требуется.
Оба варианта выложу для скачивания.
Скачать пример: Как разделить текст по столбцам с помощью функции_1.xlsx (исправлено: доп поле)
Скачать пример: Как разделить текст по столбцам с помощью функции_2.xlsx (исправлено: заведомо большое число)
In this guide, we’re going to show you how to split text in Excel by a delimiter.
Download Workbook
We have a sample data which contains concatenated values separated by “|” characters. It is important that the data includes a specific delimiter character between each chunk of data to make splitting text easier.
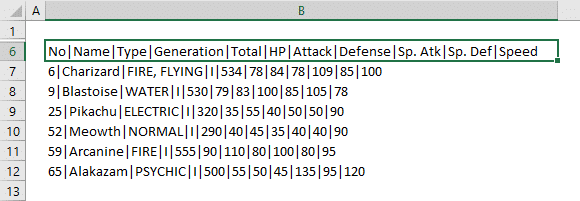
Text to Columns feature for splitting text
When splitting text in Excel, the Text to Columns is one of the most common methods. You can use the Text to Columns feature with all versions of Excel. This feature can split text by a specific character count or delimiter.
- Start with selecting your data. You can use more than one cell in a column.
- Click Data > Text to Columns in the Ribbon.
- On the first step of the wizard, you have 2 options to choose from — these are slicing methods. Since our data in this example is split by delimiters, our choice is going to be Delimited.
- Click Next to continue
- Select the delimiters suitable to your data or choose a character length and click Next.
- Choose corresponding data types for the columns and the destination cell. Please note that if the destination cell is the same cell as where your data is, the original data will be overwritten.
- Click Finish to see the outcome.
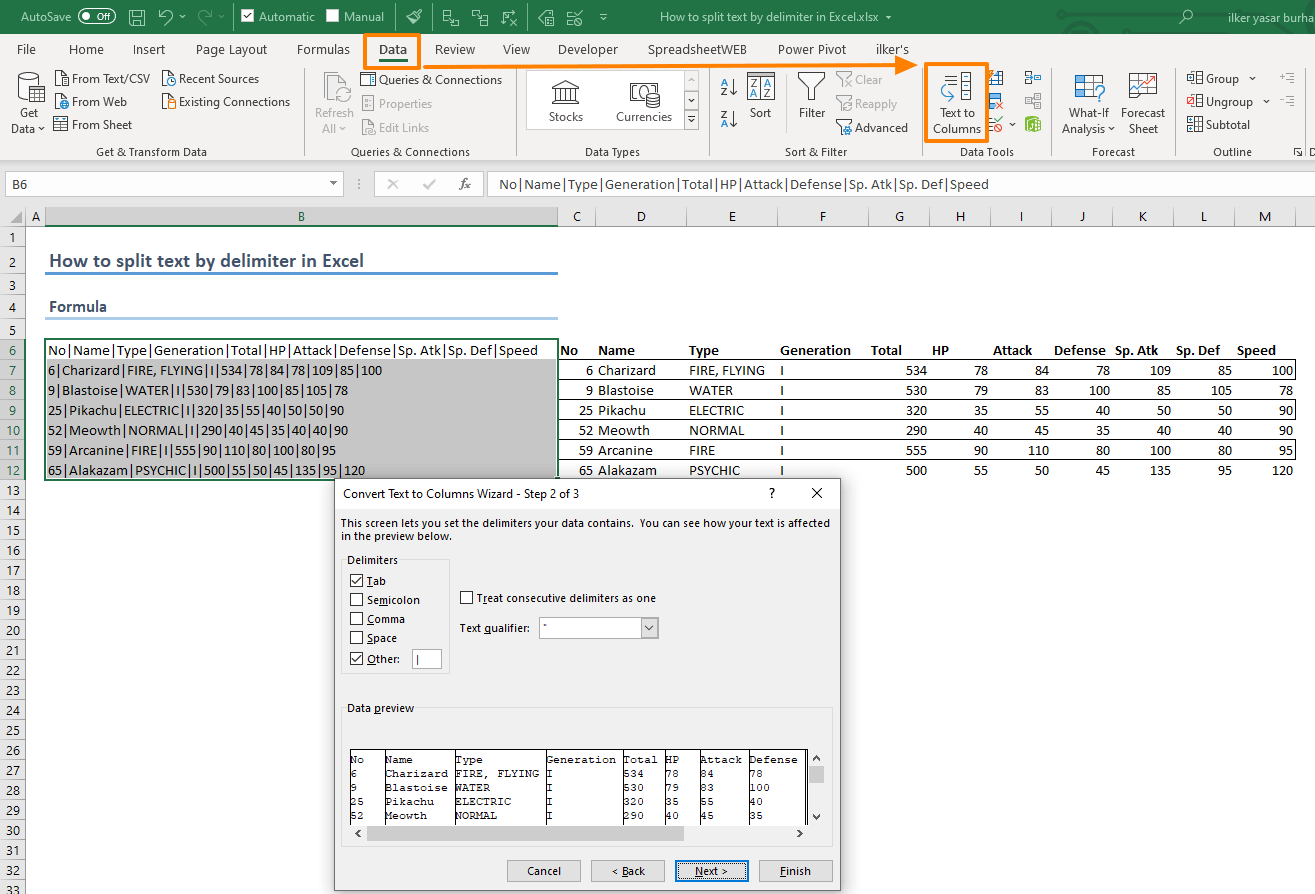
Using formulas to split text
Excel has a variety of text formulas that you can use to locate delimiters and parse data. When using formulas to do so, Excel automatically updates the parsed values when the source is updated.
The formula used in this example uses Microsoft 365’s dynamic array feature, which allows you to populate multiple cells without using array formulas. If you can see the SEQUENCE formula, you can use this method.
Syntax
=TRIM(MID(SUBSTITUTE( text, separator, REPT( “ “, LEN( text ))),(SEQUENCE( 1, column count ) — 1 ) * LEN( text ) + 1,LEN( text )))
How it works
The formula replaces each separator character with space characters first. (see SUBSTITUTE) The number of space characters will be equal to the original string’s character count, which is enough number of spaces to separate each string block (see REPT and LEN).
The SEQUENCE function generates an array of numbers starting with 1, up to the number of maximum columns. Multiplying these sequential numbers with the length of the original string returns character numbers indicating the start of each block.
This approach uses the MID function to parse each string block with given start character number and the number of characters to return. Since the separators are replaced with space characters, each parsed block includes these spaces around the actual string. The TRIM function then removes these spaces.

Flash Fill
The Flash Fill is an Excel tool which can detect the pattern when entering data. A common example is to separate or merge first name and last names. Let’s say column A contains the first name — last name combinations. If you type in the corresponding first name in the same row for column B, Excel shows you a preview for the rest of the column.
Please note that the Flash Fill is available for Excel 2013 and newer versions only.
You can see the same behavior with strings using delimiters to separate data. Just select a cell in the adjacent column and start typing. Occasionally Excel will display a preview. If not, press Ctrl + E like below to split your text.

Power Query
Power Query is a powerful feature, not only for splitting text, but for data management in general. Power Query comes with its own text splitting tool which allows you to split text in multiple ways, like by delimiters, number of characters, or case of letters.
If you are using Excel 2016 or newer — including Microsoft 365 — you can find Power Query options under the Data tab’s Get & Transform section. Excel 2010 and 2013 users should download and install the Power Query as an add-in.
- Select the cells containing the text.
- Click Data > From Sheet. If the data is not in an Excel Table, Excel converts it into an Excel Table first.
- Once the Power Query window is open, find the Split Column under the Transform tab and click to see the options.
- Select the approach that fits your data layout. The data in our example is using By Delimiter since the data is separated by “|”.
- Power Query will show the delimiter character. If you are not seeing the expected delimiter, choose from the list or enter it yourself.
- Click OK to split text.
- If your data includes headers in its first row, like our example does, click Transform > Use First Row as Headers to keep them as headers.
- One you satisfied with the result, click the Home > Close & Load button to move the split data into your workbook.

VBA
VBA is the last text splitting option we want to show in this article. You can use VBA in two ways to split text:
- By calling the Text to Columns feature using VBA,
- Using VBA’s Split function to create array of sub-strings and using a loop to distribute the sub-strings into adjacent cells in the same row.
Text to Columns by VBA
The following code can split data from selected cells into the adjacent columns. Note that each supported delimiter is listed as an argument which you can enable or disable by giving them either True or False. Briefly, True means that you want to set that argument as a delimiter and False means ignore that character.

An easy way to generate a VBA code to split text is to record a macro. Start a recording section using the Record Macro button in the Developer tab, and use the Text to Columns feature. Once the recording is stopped, Excel will save the code for what you did during recording.
The code:
Sub VBATextToColumns_Multiple()
Dim MyRange As Range
Set MyRange = Selection ‘To work on a static range replace Selection via Range object, e.g., Range(“B6:B12”)
MyRange.TextToColumns _
Destination:=MyRange(1, 1).Offset(, 1), _
DataType:=xlDelimited, _
TextQualifier:=xlDoubleQuote, _
ConsecutiveDelimiter:=False, _
Tab:=True, _
SemiColon:=False, _
Comma:=False, _
Space:=False, _
Other:=True, _
OtherChar:=»|»
End Sub
Split Function
Split function can be useful if you want to keep the split blocks in an array. You can only use this method for splitting because of the single delimiter constraint. The following code loops through each cell in a selected column, splits and stores text by the delimiter “|”, and uses another loop to populate the values in the array on cells. The final EntireColumn.AutoFit command adjusts the column widths.

The code:
Sub SplitText()
Dim StringArray() As String, Cell As Range, i As Integer
For Each Cell In Selection ‘To work on a static range replace Selection via Range object, e.g., Range(“B6:B12”)
StringArray = Split(Cell, «|») ‘Change the delimiter with a character suits your data
For i = 0 To UBound(StringArray)
Cell.Offset(, i + 1) = StringArray(i)
Cell.Offset(, i + 1).EntireColumn.AutoFit ‘This is for column width and optional.
Next i
Next
End Sub