
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel для iPad Excel для iPhone Excel для планшетов с Android Excel для телефонов с Android Еще…Меньше
Функция УНИК возвращает список уникальных значений в списке или диапазоне.
Возвращение уникальных значений из списка значений
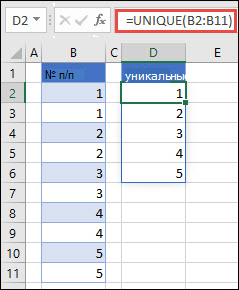
Возвращение уникальных имен из списка имен
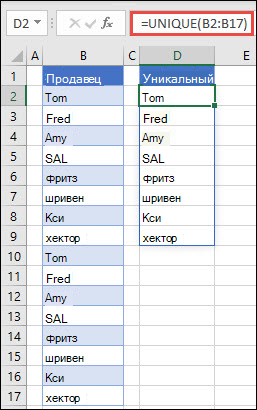
=УНИК(массив,[by_col],[exactly_once])
Функция УНИК имеет следующие аргументы:
|
Аргумент |
Описание |
|---|---|
|
массив Обязательный |
Диапазон или массив, из которого возвращаются уникальные строки или столбцы |
|
[by_col] Необязательный |
Аргумент by_col является логическим значением, указывающим, как проводить сравнение. Значение ИСТИНА сравнивает столбцы друг с другом и возвращает уникальные столбцы Значение ЛОЖЬ (или отсутствующее значение) сравнивает строки друг с другом и возвращает уникальные строки |
|
[exactly_once] Необязательно |
Аргумент exactly_once является логическим значением, которое возвращает строки или столбцы, встречающиеся в диапазоне или массиве только один раз. Это концепция базы данных УНИК. Значение ИСТИНА возвращает из диапазона или массива все отдельные строки или столбцы, которые встречаются только один раз Значение ЛОЖЬ (или отсутствующее значение) возвращает из диапазона или массива все отдельные строки или столбцы |
Примечания:
-
Массив может рассматриваться как строка или столбец со значениями либо комбинация строк и столбцов со значениями. В примерах выше массивы для наших формул УНИК являются диапазонами D2:D11 и D2:D17 соответственно.
-
Функция УНИК возвращает массив, который будет рассеиваться, если это будет конечным результатом формулы. Это означает, что Excel будет динамически создавать соответствующий по размеру диапазон массива при нажатии клавиши ВВОД. Если ваши вспомогательные данные хранятся в таблице Excel, тогда массив будет автоматически изменять размер при добавлении и удалении данных из диапазона массива, если вы используете Структурированные ссылки. Дополнительные сведения см. в статье Поведение рассеянного массива.
-
Приложение Excel ограничило поддержку динамических массивов в операциях между книгами, и этот сценарий поддерживается, только если открыты обе книги. Если закрыть исходную книгу, все связанные формулы динамического массива вернут ошибку #ССЫЛКА! после обновления.
Примеры
Пример 1
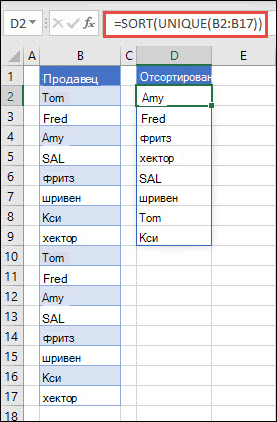
В этом примере СОРТ и УНИК используются совместно для возврата уникального списка имен в порядке возрастания.
Пример 2
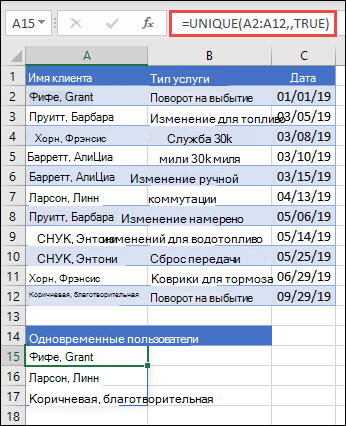
В этом примере аргумент exactly_once имеет значение ИСТИНА, и функция возвращает только тех клиентов, которые обслуживались один раз. Это может быть полезно, если вы хотите найти людей, которые не получали дополнительное обслуживание, и связаться с ними.
Пример 3
В этом примере используется амперсанд (&) для сцепления фамилии и имени в полное имя. Обратите внимание, что формула ссылается на весь диапазон имен в массивах A2:A12 и B2:B12. Это позволяет Excel вернуть массив всех имен.
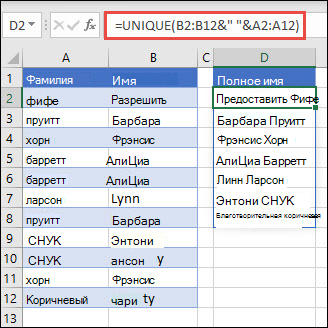
Советы:
-
Если указать диапазон имен в формате таблицы Excel, формула автоматически обновляется при добавлении или удалении имен.
-
Чтобы отсортировать список имен, можно добавить функцию СОРТ: =СОРТ(УНИК(B2:B12&» «&A2:A12))
Пример 4
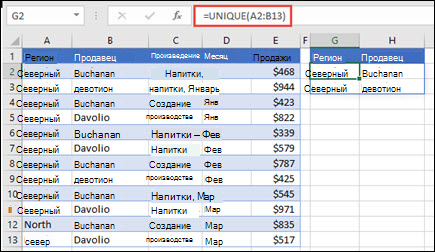
В этом примере сравниваются два столбца и возвращаются только уникальные значения в них.
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
См. также
Функция ФИЛЬТР
Функция СЛУЧМАССИВ
Функция ПОСЛЕДОВ
Функция СОРТ
Функция СОРТПО
Ошибки #SPILL! в Excel
Динамические массивы и поведение массива с переносом
Оператор неявного пересечения: @
Нужна дополнительная помощь?
Skip to content
В статье описано, как получить список уникальных значений в столбце с помощью формулы и как настроить эту формулу для различных наборов данных. Вы также узнаете, как быстро получить отдельный список с помощью расширенного фильтра Excel и как извлечь уникальные записи с помощью Duplicate Remover.
В нескольких недавних статьях мы обсудили различные методы подсчета и поиска уникальных значений в Excel. Если у вас была возможность прочитать эти руководства, вы уже знаете, как получить этот список при помощи идентификации, фильтрации и копирования. Но это немного длинный и далеко не единственный способ извлечения уникальных значений в Excel. Вы можете сделать это намного быстрее, используя специальную формулу. И сейчас я покажу вам этот и несколько других приёмов.
- Формулы для уникальных значений в столбце.
- Как извлечь уникальные + 1е вхождение дубликатов.
- Если нужно игнорировать пустые ячейки.
- Выбираем уникальные с учетом регистра.
- Отбор уникальных значений по условию.
- Как извлечь уникальные значения из диапазона.
- Применяем встроенный инструмент удаления дубликатов.
- Список уникальных при помощи расширенного фильтра.
- Извлечение уникальных данных при помощи Duplicate Remover.
Базовые формулы для получения уникальных значений.
Чтобы избежать путаницы, сначала давайте договоримся о том, что мы называем уникальными значениями в Excel.
Уникальные значения — это значения, которые присутствуют в списке только один раз. Например:

Чтобы получить список уникальных значений в Excel, используйте одну из следующих формул.
Формула уникальных значений массива (заполняется нажатием Ctrl + Shift + Enter):
=ЕСЛИОШИБКА(ИНДЕКС($A$2:$A$10; ПОИСКПОЗ(0; СЧЁТЕСЛИ($B$1:B1;$A$2:$A$10) + (СЧЁТЕСЛИ($A$2:$A$10; $A$2:$A$10)<>1); 0)); «»)
Можно воспользоваться и обычной формулой (вводится нажатием Enter):
=ЕСЛИОШИБКА(ИНДЕКС($A$2:$A$10; ПОИСКПОЗ(0;ИНДЕКС(СЧЁТЕСЛИ($B$1:B1; $A$2:$A$10) + (СЧЁТЕСЛИ($A$2:$A$10; $A$2:$A$10)<>1);0;0); 0)); «»)
В приведенных выше формулах используются следующие ссылки:
- A2: A10 – исходных перечень данных.
- B1 — верхняя ячейка уникального списка минус одна строка. В этом примере мы начинаем создавать список уникальных в B2, и поэтому мы записываем B1 в формулу (B2 — 1 строка = B1). Если ваш список начинается, скажем, с ячейки C3, измените $B$1:B1 на $C$2:C2.
В этом примере мы извлекаем уникальные имена из столбца A (точнее из диапазона A2: A10), а следующий скриншот демонстрирует формулу в действии:

Вот наш порядок действий:
- Измените любую из формул в соответствии с вашим диапазоном данных.
- Введите ее в первую ячейку, с которой начнётся формирование списка (в данном примере B2).
- Если вы используете формулу массива, нажмите
Ctrl + Shift + Enter. Если вы выбрали обычную, нажмите просто клавишуEnter. - Скопируйте вниз настолько, насколько это необходимо, перетащив мышкой маркер заполнения. Поскольку обе формулы заключены в функцию ЕСЛИОШИБКА, вы можете скопировать вниз с запасом. Это не испортит ваши данные какими-либо ошибками, независимо от того, сколько уникальных значений было извлечено.
Как извлечь различные значения.
Различные значения — появляются в перечне данных хотя бы один раз. Это все уникальные и первое вхождение повторяющихся значений.
Например:

Чтобы получить их список в Excel, используйте следующие формулы.
Формула массива (требуется нажать Ctrl + Shift + Enter):
{=ЕСЛИОШИБКА(ИНДЕКС($A$2:$A$13; ПОИСКПОЗ(0; СЧЁТЕСЛИ($B$1:B1; $A$2:$A$13); 0)); «»)}
или можно так:
{=ЕСЛИОШИБКА(ИНДЕКС($A$2:$A$13; НАИМЕНЬШИЙ(ЕСЛИ(ЕНД(ПОИСКПОЗ($A$2:$A$13;$B$1:B1;0)); СТРОКА($A$1:$A$15);»»);1));»»)}
Обычная формула:
=ЕСЛИОШИБКА(ИНДЕКС($A$2:$A$13; ПОИСКПОЗ(0; ИНДЕКС(СЧЁТЕСЛИ($B$1:B1; $A$2:$A$13); 0; 0); 0)); «»)
Где:
- A2: A13 — это список источников.
- B1 — это ячейка над первой ячейкой отдельного списка. В этом примере отдельный список начинается с ячейки B2 (это первая ячейка, в которую вы вводите формулу), поэтому вы ссылаетесь на B1.

Как извлечь значения, игнорируя пустые ячейки
Если исходный список содержит пустые ячейки, формула, которую мы только что обсудили, вернет ноль для каждой пустой строки, что может быть проблемой. Это вы и наблюдаете на скриншоте чуть выше. Чтобы исправить это, сделаем несколько небольших корректировок.
Формула массива для извлечения различных значений, исключая пустые ячейки:
{=ЕСЛИОШИБКА(ИНДЕКС($A$2:$A$13; ПОИСКПОЗ(0;СЧЁТЕСЛИ($C$1:C1;$A$2:$A$13&»») + ЕСЛИ($A$2:$A$13=»»;1;0); 0)); «»)}
Аналогичным образом вы можете получить список различных значений, исключая пустые ячейки и ячейки с числами:
{=ЕСЛИОШИБКА(ИНДЕКС($A$2:$A$13; ПОИСКПОЗ(0;СЧЁТЕСЛИ($D$1:D1;$A$2:$A$13&»») + ЕСЛИ(ЕТЕКСТ($A$2:$A$13)=ЛОЖЬ;1;0); 0)); «»)}
Напоминаем, что в приведенных выше формулах A2: A13 – это исходный список, а B1 – ячейка прямо над первой позицией формируемого списка.
На этом скриншоте показан результат отбора:

Быть может, кому-то будет полезна еще одна формула –
=ЕСЛИОШИБКА(ИНДЕКС($A$2:$A$13; АГРЕГАТ(15;6;(СТРОКА($A$2:$A$13)-СТРОКА($A$2)+1) / (ПОИСКПОЗ($A$2:$A$13;$A$2:$A$13;0)=СТРОКА($A$2:$A$13)-СТРОКА($A$2)+1); ЧСТРОК($A$2:$A2)));»»)
Она работает с числами и текстом, игнорирует пустые ячейки.
Как извлечь отдельные значения с учетом регистра в Excel
При работе с данными, чувствительными к регистру, такими как пароли, имена пользователей или имена файлов, вам может потребоваться список отдельных значений с учетом заглавных и прописных букв.
Для этого используйте формулу массива, где A2: A10 — это исходный список, а B1 — это ячейка над первой ячейкой отдельного списка.
Формула массива для получения различных значений с учетом регистра (требуется нажатие Ctrl + Shift + Enter)
{=ЕСЛИОШИБКА(ИНДЕКС($A$2:$A$10; ПОИСКПОЗ(0; ЧАСТОТА(ЕСЛИ(СОВПАД($A$2:$A$10; ТРАНСП($B$1:B1)); ПОИСКПОЗ(СТРОКА($A$2:$A$10); СТРОКА($A$2:$A$10)); «»); ПОИСКПОЗ(СТРОКА($A$2:$A$10); СТРОКА($A$2:$A$10))); 0)); «»)}

Как видите, при отборе регистр здесь имеет значение.
Отбор уникальных значений по условию.
Представим, что у нас есть таблица с данными о продажах. Нам необходимо определить, какие наименования товаров заказывал определенный покупатель.
Сначала отберем из таблицы только те строки, которые удовлетворяют заданным условиям, затем из этих строк выберем уникальные наименования товаров.

В ячейке G2 указываем нужного нам заказчика, а в H2 записываем эту формулу массива:
{=ЕСЛИОШИБКА(ИНДЕКС($B$2:$B$20; ПОИСКПОЗ(0;ЕСЛИ((($A$2:$A$20=$G$2)); СЧЁТЕСЛИ($H$1:H1;$B$2:$B$20);»»);0));»»)}
Не забудьте, что формулу массива нужно вводить в ячейку EXCEL с помощью одновременного нажатия CTRL+SHIFT+ENTER. Копируем ее по столбцу вниз при помощи маркера заполнения. Получаем список из четырех позиций.
Усложним задачу. Определим список не только для этого покупателя, но также и для определённого менеджера.
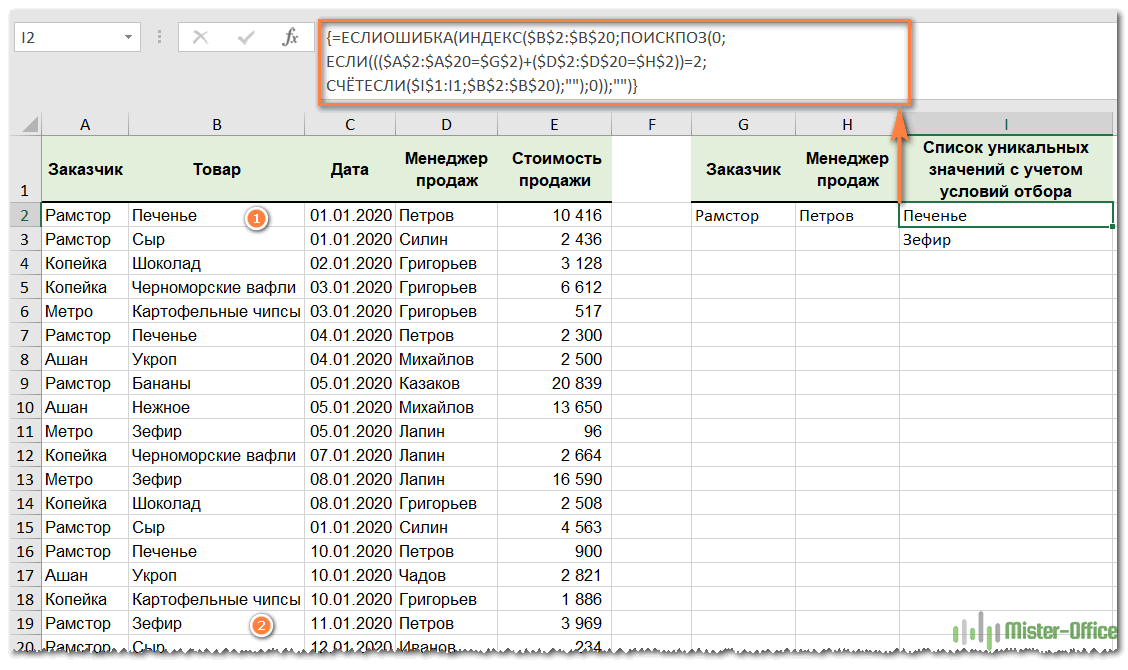
Вот наша формула массива:
{=ЕСЛИОШИБКА(ИНДЕКС($B$2:$B$20;ПОИСКПОЗ(0; ЕСЛИ((($A$2:$A$20=$G$2)+($D$2:$D$20=$H$2))=2; СЧЁТЕСЛИ($I$1:I1;$B$2:$B$20);»»);0));»»)}
Как видите, теперь товаров всего два. В подсчете принимают участие только те строки, которые удовлетворяют сразу двум условиям: должно совпасть название фирмы и фамилия менеджера. Только из них мы извлекаем уникальные названия товаров.
В случае, если условий будет больше, нужно просто добавить соответствующий критерий в функцию ЕСЛИ и изменить число 2 на 3 или большее (в зависимости от количества условий).
Извлечь уникальные значения из диапазона.
Формулы, которые мы описывали выше, позволяют сформировать список значений из данных определенного столбца. Но часто речь идет о нескольких столбцах, то есть о диапазоне данных. К примеру, вы получили несколько списков товаров из различных файлов и расположили их в соседних столбцах.

Используем формулу массива
{=ДВССЫЛ(ТЕКСТ(МИН(ЕСЛИ(($A$2:$C$9<>»») * (СЧЁТЕСЛИ($E$1:E1;$A$2:$C$9)=0); СТРОКА($2:$9)*100 + СТОЛБЕЦ($A:$C);7^8));»R0C00″);)&»»}
Здесь A2:C9 обозначает диапазон, из которого вы хотите извлечь уникальные значения. E1 – это первая ячейка столбца, в который вы хотите поместить результат. $2:$9 указывает на строки, содержащие данные, которые вы хотите использовать. $A:$C указывает на столбцы, из которых вы берёте исходные данные. Пожалуйста, измените их на свои собственные.
Нажмите Shift + Ctrl + Enter , а затем перетащите маркер заполнения, чтобы вывести уникальные значения, пока не появятся пустые ячейки.
Как видите, извлекаются все уникальные и первые вхождения дубликатов.
Встроенный инструмент удаления дубликатов.
Начиная с Excel 2007 функция удаления дубликатов является стандартной. Найти ее можно на вкладке Данные > Удаление дубликатов.

Вам нужно при помощи птички указать столбцы, в которых нужно найти и удалить повторяющиеся значения. Если сделать так, как на скриншоте, то в таблице останутся только уникальные пары «Заказчик – Товар». Остальное будет удалено. Если включить только флажок «Заказчик», то останется только по одной строке для каждого заказчика и т.д.
Использование расширенного фильтра.
Если вы не хотите тратить время на выяснение загадочных поворотов формул, вы можете быстро получить список уникальных значений с помощью расширенного фильтра. Подробные инструкции приведены ниже.
- Выберите столбец данных, из которого вы хотите извлечь отдельные значения.
- Перейдите на вкладку «Данные» > группа «Сортировка и фильтр» и нажмите кнопку «Дополнительно» .
- В диалоговом окне Расширенный фильтр выберите следующие параметры:
- Установите флажок Копировать в другое место .
- В поле Исходный диапазон убедитесь, что он указан правильно.
- В параметре Поместить результат в… укажите самую верхнюю ячейку целевого диапазона. Помните, что вы можете копировать отфильтрованные данные только на текущий лист.
- Выберите пункт «Только уникальные записи».
- Наконец, нажмите кнопку ОК и проверьте результат.
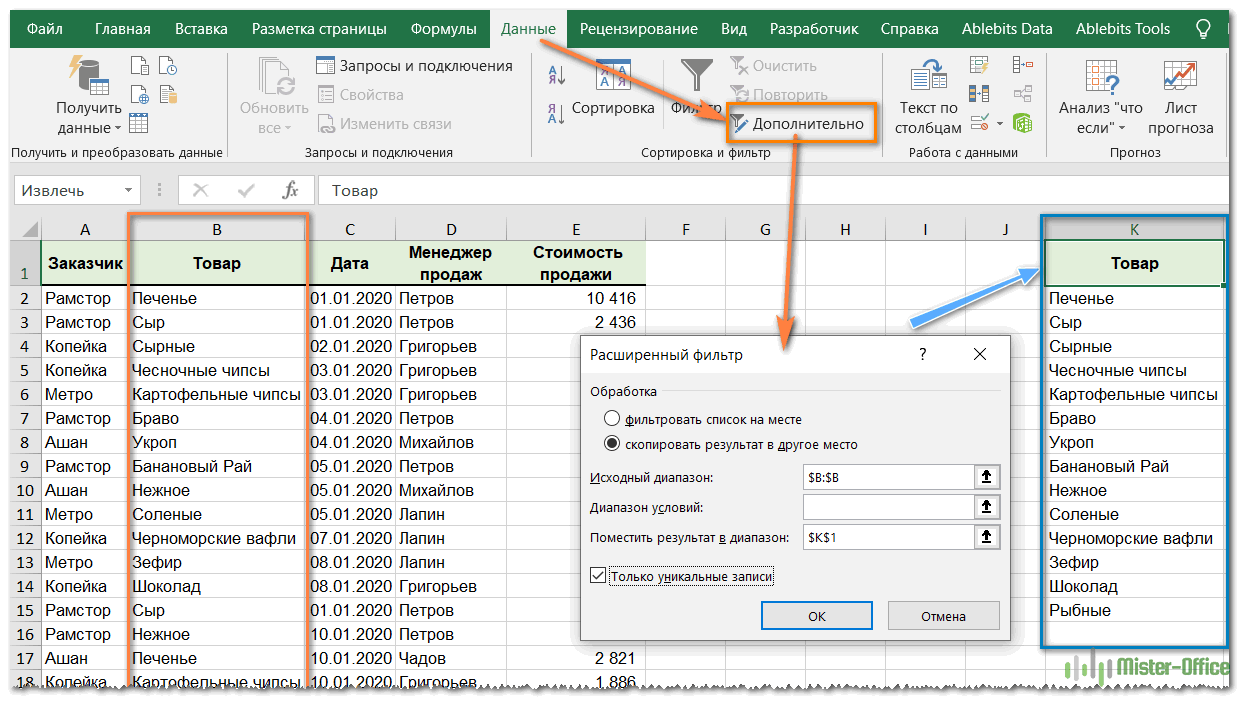
Как видите, мы проверили колонку B, и затем список уникальных наименований товара, найденных в ней, поместили в столбец K.
Обратите внимание, что хотя опция расширенного фильтра называется «Только уникальные записи», она извлекает различные значения, то есть уникальные и первые вхождения повторяющихся.
Теперь немного усложним задачу.
Если требуется искать записи не по одному, а по нескольким столбцам, то можно их предварительно «склеить» при помощи функции СЦЕПИТЬ.
=СЦЕПИТЬ(A2;B2)
Записываем это в столбец F и копируем вниз. Получаем вспомогательную колонку.

В качестве исходного диапазона мы по-прежнему выбираем данные, из которых извлекаем уникальные значения. Теперь это два столбца – A и B.
Но искать уникальные мы по-прежнему можем только в одном столбце. Вот для этого нам и пригодится вспомогательная колонка F с объединенными данными. Ее то мы и указываем в поле «Диапазон условий».
Все остальное – так же, как и в предыдущем примере.
В результате мы получили все имеющиеся в таблице комбинации «Заказчик — Товар» на основе данных во вспомогательном столбце F.
Думаю, вы понимаете, что аналогичные действия можно произвести и с тремя столбцами (например Фамилия – Имя – Отчество). Главное условие – исходный диапазон должен быть непрерывным, то есть все столбцы должны находиться рядом.
Как видите формулы здесь не нужны. Однако, если исходные данные изменятся, то все манипуляции придется повторять заново.
Извлечение уникальных значений с помощью Duplicate Remover.
В заключительной части этого руководства я покажу вам интересное решение для поиска и извлечения различных и уникальных значений в таблицах Excel. Это решение сочетает в себе универсальность формул Excel и простоту расширенного фильтра. Кроме того, здесь есть несколько уникальных функций:
- Найти и извлечь уникальные или различные значения на основе записей в одном или нескольких столбцах.
- Найти, выделить и скопировать уникальные значения в любое другое место в той же или другой книге Excel.
А теперь давайте посмотрим, как работает инструмент Duplicate Remover.
Предположим, у вас есть большая таблица, созданная путем объединения данных из нескольких других таблиц. Очевидно, что она содержит много повторяющихся строк, и ваша задача состоит в том, чтобы извлечь уникальные строки, которые появляются в таблице только один раз, или различные строки, включая уникальные и первые повторяющиеся вхождения. В любом случае, с надстройкой Duplicate Remover работа выполняется за несколько шагов.
- Выберите любую ячейку в исходной таблице и нажмите кнопку DuplicateRemover на вкладке AblebitsData в группе Dedupe.

Мастер Duplicate Remover запустится и выберет всю таблицу. Итак, просто нажмите « Далее», чтобы перейти к следующему шагу.

- Выберите тип значения, который вы хотите найти, и нажмите Далее :
- Уникальные
- Уникальные + 1е вхождения (различные)
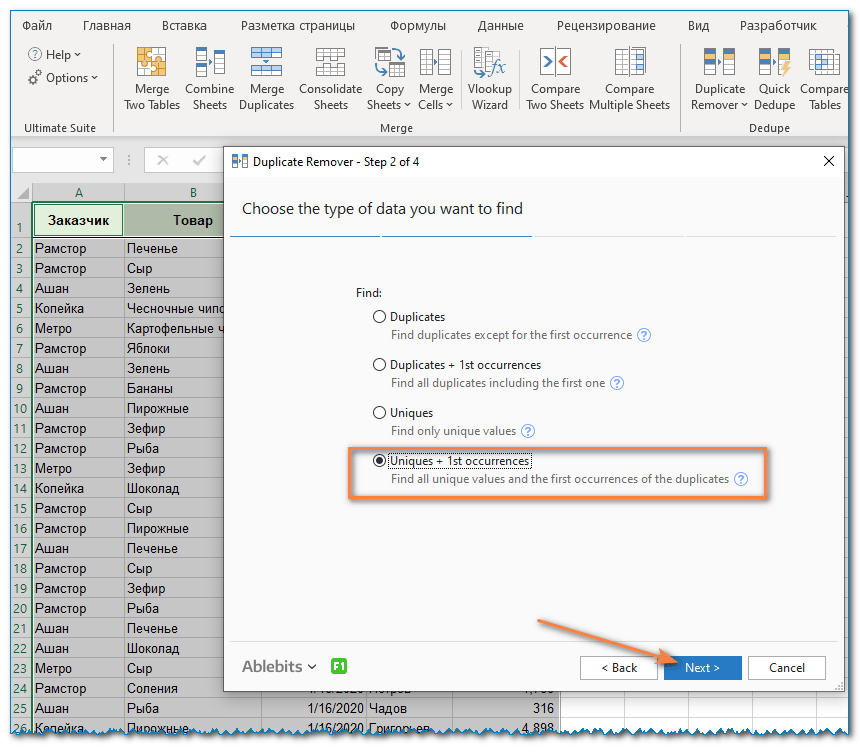
- Выберите один или несколько столбцов для проверки уникальных значений.
В этом примере мы хотим убрать все повторяющиеся значения на основе значений в 2 столбцах ( заказчик и товар), поэтому мы выбираем только нужные нам столбцы.
В нашем случае таблица имеет заголовок, поэтому отмечаем птичкой пункт My table has headers.
Думаю, нам не нужны пустые строки, которые могут случайно встретиться при объединении данных из разных таблиц. Поэтому отмечаем такжеSkip empty cells.
Если вдруг в наших записях случайно появились лишние пробелы, то, думаю, стоит их игнорировать. Поэтому отмечаем также Ignore extra spaces.
Также наш поиск буден нечувствителен к регистру, то есть не будем при сравнении данных различать прописные и строчные буквы. Поэтому не трогаем опцию Case-sensitive match.

- Выберите действие, которое нужно выполнить с найденными значениями. Вам доступны следующие варианты:
- Выделить цветом.
- Выбрать и выделить.
- Отметить в столбце статуса.
- Копировать в другое место.
Чтобы не менять исходные данные, выберите «Копировать в другое место» (Copy to another location), а затем укажите, где именно вы хотите видеть новую таблицу – на этом же листе (выберите параметр «Custom Location» и укажите верхнюю ячейку целевого диапазона), на новом листе (New worksheet) или в новой книге (New workbook).
В этом примере давайте выберем новый лист:

- Нажмите кнопку « Готово» , и все готово!

В итоге у нас осталось всего 20 записей.
Понравился этот быстрый и простой способ получить список уникальных значений или записей в Excel? Если да, то я рекомендую вам загрузить полнофункциональную ознакомительную версию Ultimate Suite и попробовать в работе Duplicate Remover.
В Ultimate Suite for Excel также включено много других полезных инструментов, которые помогут вам сэкономить много времени. Мы о них также будем подробно рассказывать в других материалах на сайте.
Извлечение уникальных элементов из диапазона
Способ 1. Штатная функция в Excel 2007
Начиная с 2007-й версии функция удаления дубликатов является стандартной — найти ее можно на вкладке Данные — Удаление дубликатов (Data — Remove Duplicates):

В открывшемся окне нужно с помощью флажков задать те столбцы, по которым необходимо обеспечивать уникальность. Т.е. если включить все флажки, то будут удалены только полностью совпадающие строки. Если включить только флажок заказчик, то останется только по одной строке для каждого заказчика и т.д.
Способ 2. Расширенный фильтр
Если у вас Excel 2003 или старше, то для удаления дубликатов и вытаскивания из списка уникальных (неповторяющихся) элементов можно использовать Расширенный фильтр (Advanced Filter) из меню (вкладки) Данные (Data).
Предположим, что у нас имеется вот такой список беспорядочно повторяющихся названий компаний:

Выбираем в меню Данные — Фильтр — Расширенный фильтр (Data — Filter — Advanced Filter). Получаем окно:

В нем:
- Выделяем наш список компаний в Исходный диапазон (List Range).
- Ставим переключатель в положение Скопировать результат в другое место (Copy to another location) и указываем пустую ячейку.
- Включаем (самое главное!) флажок Только уникальные записи(Uniqe records only) и жмем ОК.
Получите список без дубликатов:

Если требуется искать дубликаты не по одному, а по нескольким столбцам, то можно предварительно склеить их в один, сделав, своего рода, составной ключ с помощью функции СЦЕПИТЬ (CONCATENATE):

Тогда дальнейшая задача будет сводиться к поиску дубликатов уже в одном столбце.
Способ 3. Выборка уникальных записей формулой
Чуть более сложный способ, чем первые два, но зато — динамический, т.е. с автоматическим пересчетом, т.е. если список редактируется или в него дописываются еще элементы, то они автоматически проверяются на уникальность и отбираются. В предыдущих способах при изменении исходного списка нужно будет заново запускать Расширенный фильтр или жать на кнопку Удаление дубликатов.
Итак, снова имеем список беспорядочно повторяющихся элементов. Например, такой:

Первая задача — пронумеровать всех уникальных представителей списка, дав каждому свой номер (столбец А на рисунке). Для этого вставляем в ячейку А2 и копируем затем вниз до упора следующую формулу:
=ЕСЛИ(СЧЁТЕСЛИ(B$1:B2;B2)=1;МАКС(A$1:A1)+1;»»)
В английской версии это будет:
=IF(COUNTIF(B$1:B2;B2)=1;MAX(A$1:A1)+1;»»)
Эта формула проверяет сколько раз текущее наименование уже встречалось в списке (считая с начала), и если это количество =1, т.е. элемент встретился первый раз — дает ему последовательно возрастающий номер.
Для упрощения адресации дадим нашим диапазонам (например, исходя из того, что в списке может быть до 100 элементов) имена. Это можно сделать в новых версиях Excel на вкладке Формулы — Диспетчер имен (Formulas — Name manager) или в старых версиях — через меню Вставка — Имя — Присвоить (Insert — Name — Define):
- диапазону номеров (A1:A100) — имя NameCount
- всему списку с номерами (A1:B100) — имя NameList
Теперь осталось выбрать из списка NameList все элементы имеющие номер — это и будут наши уникальные представители. Сделать это можно в любой пустой ячейке соседних столбцов, введя туда вот такую формулу с известной функцией ВПР (VLOOKUP) и скопировав ее вниз на весь столбец:
=ЕСЛИ(МАКС(NameCount)<СТРОКА(1:1);»»;ВПР(СТРОКА(1:1);NameList;2))
или в английской версии Excel:
=IF(MAX(NameCount)
Эта формула проходит сверху вниз по столбцу NameCount и выводит все позиции списка с номерами в отдельную таблицу:

Ссылки по теме
- Выделение дубликатов по одному или нескольким столбцам в списке цветом
- Запрет ввода повторяющихся значений
- Извлечение уникальных значений при помощи надстройки PLEX
Имея список с повторяющимися значениями, создадим список, состоящий только из уникальных значений. При добавлении новых значений в исходный список, список уникальных значений должен автоматически обновляться.
Пусть в столбце
А
имеется список с
повторяющимися
значениями, например список с названиями компаний.
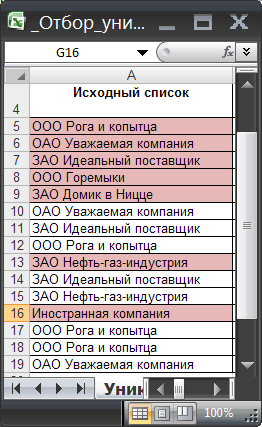
Задача
В некоторых ячейках исходного списка имеются повторы — новый список уникальных значений не должен их содержать.
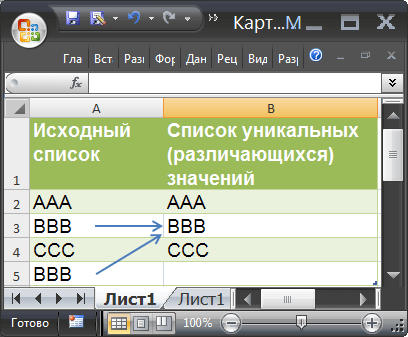
Для наглядности уникальные значения в исходном списке выделены цветом
с помощью Условного форматирования
.
Решение
Для начала создадим
Динамический диапазон
, представляющий собой исходный список. Если в исходный список будет добавлено новое значение, то оно будет автоматически включено в
Динамический диапазон
и нижеследующие формулы не придется модифицировать.
Для создания
Динамического диапазона
:
-
на вкладке
Формулы
в группе
Определенные имена
выберите команду
Присвоить имя
; -
в поле
Имя
введите:
Исходный_список
; -
в поле
Диапазон
введите формулу
=СМЕЩ(УникальныеЗначения!$A$5;;; СЧЁТЗ(УникальныеЗначения!$A$5:$A$30))
- нажмите ОК.
Список уникальных значений создадим в столбце
B
с помощью
формулы массива
(см.
файл примера
). Для этого введите следующую формулу в ячейку
B5
:
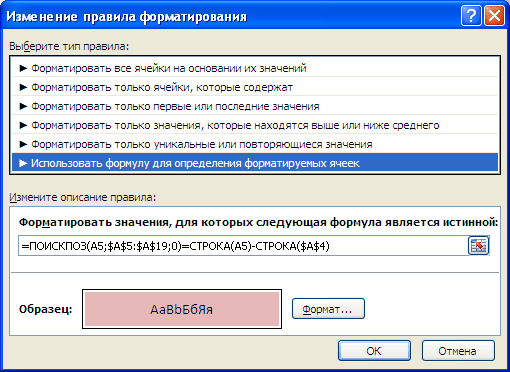
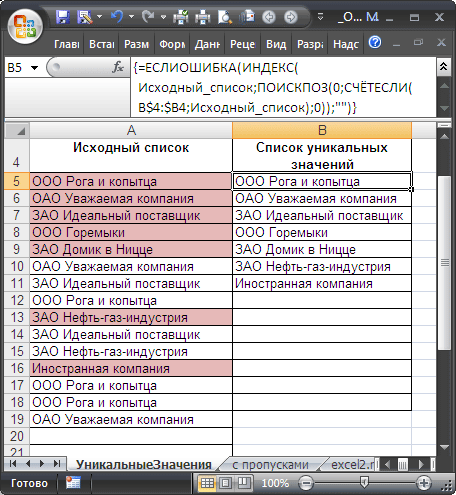
=ЕСЛИОШИБКА(ИНДЕКС(Исходный_список; ПОИСКПОЗ(0;СЧЁТЕСЛИ(B$4:B4;Исходный_список);0));»»)
После ввода формулы вместо
ENTER
нужно нажать
CTRL + SHIFT + ENTER
. Затем нужно скопировать формулу вниз, например, с помощью
Маркера заполнения
. Чтобы все значения исходного списка были гарантировано отображены в списке уникальных значений, необходимо сделать размер списка уникальных значений равным размеру исходного списка (на тот случай, когда все значения исходного списка не повторяются). В случае наличия в исходном списке большого количества повторяющихся значений, список уникальных значений можно сделать меньшего размера, удалив лишние формулы, чтобы исключить ненужные вычисления, тормозящие пересчет листа.
Разберем работу формулу подробнее:
-
Здесь использование функции
СЧЁТЕСЛИ()
не совсем обычно: в качестве критерия (второй аргумент) указано не одно значение, а целый массив
Исходный_список
, поэтому функция возвращает не одно значение, а целый массив нулей и единиц. Возвращается 0, если значение из исходного списка не найдено в диапазоне
B4:B4
(
B4:B5
и т.д.), и 1 если найдено. Например, в ячейке
B5
формулой
СЧЁТЕСЛИ(B$4:B5;Исходный_список)
возвращается массив {1:0:0:0:0:0:0:1:0:0:0:0:1:1:0}. Т.е. в исходном списке найдено 4 значения «ООО Рога и копытца» (
B5
). Массив легко увидеть с помощьюклавиши
F9
(выделите вСтроке формул
выражение
СЧЁТЕСЛИ(B$4:B5;Исходный_список)
, нажмите
F9
: вместо формулы отобразится ее результат);
ПОИСКПОЗ()
– возвращает позицию первого нуля в массиве из предыдущего шага. Первый нуль соответствует значению еще не найденному в исходном списке (т.е. значению «ОАО Уважаемая компания» для формулы в ячейке
B5
);
ИНДЕКС()
– восстанавливает значение по его позиции в диапазоне
Исходный_список
;
ЕСЛИОШИБКА()
подавляет ошибку, возникающую, когда функция
ПОИСКПОЗ()
пытается в массиве нулей и единиц, возвращенном
СЧЁТЕСЛИ()
, найти 0, которого нет (ситуация возникает в ячейке
B12
, когда все уникальные значения уже извлечены из исходного списка).
Формула будет работать и в случае если исходный список содержит числовые значения.
Примечание
. Функция
ЕСЛИОШИБКА()
будет работать начиная с версии MS EXCEL 2007, чтобы обойти это ограничение читайте статью
про функцию
ЕСЛИОШИБКА()
. В файле примера имеется лист
Для 2003
, где эта функция не используется.
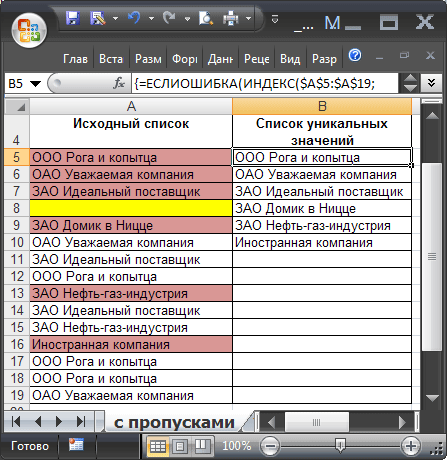
Решение для списков с пустыми ячейками
Если исходная таблица содержит пропуски, то нужно использовать другую
формулу массива
(см. лист
с пропусками
файла примера
):
=ЕСЛИОШИБКА(ИНДЕКС($A$5:$A$19; ПОИСКПОЗ( 0;ЕСЛИ(ЕПУСТО($A$5:A19);»»;СЧЁТЕСЛИ($B$4:B4;$A$5:$A$19));0) );»»)
Решение без формул массива
Для отбора уникальных значений можно обойтись без использования
формул массива
. Для этого создайте дополнительный служебный столбец для промежуточных вычислений (см. лист «Без CSE» в
файле примера
).
СОВЕТ:
Список уникальных значений можно создать разными способами, например, с использованием
Расширенного фильтра
(см. статью
Отбор уникальных строк с помощью Расширенного фильтра
),
Сводных таблиц
или через меню
. У каждого способа есть свои преимущества и недостатки. Преимущество использования формул состоит в том, чтобы при добавлении новых значений в исходный список, список
уникальных
значений автоматически обновлялся.
СОВЕТ2
: Для тех, кто создает список уникальных значений для того, чтобы в дальнейшем сформировать на его основе
Выпадающий список
, необходимо учитывать, что вышеуказанные формулы возвращают значение
Пустой текст «»
, который требует аккуратного обращения, особенно при подсчете значений (вместо обычной функции
СЧЕТЗ()
нужно использовать СЧЕТЕСЛИ() со специальными аргументами
). Например, см. статью
Динамический выпадающий список в MS EXCE
L.
Примечание
: В статье
Восстанавливаем последовательности из списка без повторов в MS EXCEL
решена обратная задача: из списка уникальных значений, в котором для каждого значения задано количество повторов, создается список этих значений с повторами.
Хитрости »
1 Май 2011 532284 просмотров
Как получить список уникальных(не повторяющихся) значений?
Представим себе большой список различных наименований, ФИО, табельных номеров и т.п. А необходимо из этого списка оставить список все тех же наименований, но чтобы они не повторялись — т.е. удалить из этого списка все дублирующие записи. Как это иначе называют: создать список уникальных элементов, список неповторяющихся, без дубликатов. Для этого существует несколько способов: встроенными средствами Excel, встроенными формулами и, наконец, при помощи кода Visual Basic for Application(VBA) и сводных таблиц. В этой статье рассмотрим каждый из вариантов.
- При помощи встроенных возможностей Excel 2007 и выше
- При помощи Расширенного фильтра
- При помощи формул
- При помощи кодов Visual Basic for Application(VBA) — макросы, включая универсальный код выборки из произвольного диапазона
- При помощи сводных таблиц
В Excel 2007 и 2010 это сделать проще простого — есть специальная команда, которая так и называется — Удалить дубликаты (Remove Duplicates). Расположена она на вкладке Данные (Data) подраздел Работа с данными (Data tools)

Как использовать данную команду. Выделяете столбец(или несколько) с теми данными, в которых надо удалить дублирующие записи. Идете на вкладку Данные (Data) —Удалить дубликаты (Remove Duplicates).
Если выделить один столбец, но рядом с ним будут еще столбцы с данными(или хотя бы один столбец), то Excel предложит выбрать: расширить диапазон выборки этим столбцом или оставить выделение как есть и удалить данные только в выделенном диапазоне. Важно помнить, что если не расширить диапазон, то данные будут изменены лишь в одном столбце, а данные в прилегающем столбце останутся без малейших изменений.
Появится окно с параметрами удаления дубликатов

Ставите галочки напротив тех столбцов, дубликаты в которых надо удалить и жмете Ок. Если в выделенном диапазоне так же расположены заголовки данных, то лучше поставить флаг Мои данные содержат заголовки, чтобы случайно не удалить данные в таблице(если они вдруг полностью совпадают со значением в заголовке).
Способ 1: Расширенный фильтр
В случае с Excel 2003 все посложнее. Там нет такого инструмента, как Удалить дубликаты. Но зато есть такой замечательный инструмент, как Расширенный фильтр. В 2003 этот инструмент можно найти в Данные —Фильтр —Расширенный фильтр. Прелесть этого метода в том, с его помощью можно не портить исходные данные, а создать список в другом диапазоне.
В 2007-2010 Excel, он тоже есть, но немного запрятан. Расположен на вкладке Данные (Data), группа Сортировка и фильтр (Sort & Filter) — Дополнительно (Advanced)
Как его использовать: запускаем указанный инструмент — появляется диалоговое окно:

- Обработка: Выбираем Скопировать результат в другое место (Copy to another location).
- Исходный диапазон (List range): Выбираем диапазон с данными(в нашем случае это А1:А51).
- Диапазон критериев (Criteria range): в данном случае оставляем пустым.
- Поместить результат в диапазон (Copy to): указываем первую ячейку для вывода данных — любую пустую(на картинке — E2).
- Ставим галочку Только уникальные записи (Unique records only).
- Жмем Ок.
Примечание: если вы хотите поместить результат на другой лист, то просто так указать другой лист не получится. Вы сможете указать ячейку на другом листе, но…Увы и ах…Excel выдаст сообщение, что не может скопировать данные на другие листы. Но и это можно обойти, причем довольно просто. Надо всего лишь запустить Расширенный фильтр с того листа, на который хотим поместить результат. А в качестве исходных данных выбираем данные с любого листа — это дозволено.
Так же можно не выносить результат в другие ячейки, а отфильтровать данные на месте. Данные от этого никак не пострадают — это будет обычная фильтрация данных.
Для этого надо просто в пункте Обработка выбрать Фильтровать список на месте (Filter the list, in-place).
Способ 2: Формулы
Этот способ сложнее в понимании для неопытных пользователей, но зато он создает список уникальных значений, не изменяя при этом исходные данные. Ну и он более динамичен: если изменить данные в исходной таблице, то изменится и результат. Иногда это бывает полезно. Попытаюсь объяснить на пальцах что и к чему: допустим, список с данными у Вас расположен в столбце
А
(
А1:А51
, где
А1
— заголовок). Выводить список мы будем в столбец
С
, начиная с ячейки
С2
. Формула в
C2
будет следующая:
{=ИНДЕКС($A$2:$A$51;НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($C$1:C1;$A$2:$A$51)=0;СТРОКА($A$1:$A$50));1))}
{=INDEX($A$2:$A$51;SMALL(IF(COUNTIF($C$1:C1;$A$2:$A$51)=0;ROW($A$1:$A$50));1))}
Детальный разбор работы данной формулы приведен в статье: Как просмотреть этапы вычисления формул
Надо отметить, что эта формула является формулой массива. Об этом могут сказать фигурные скобки, в которые заключена данная формула. А вводится такая формула в ячейку сочетанием клавиш —
Ctrl
+
Shift
+
Enter
(при этом сами скобки вводить не надо — они появятся сами после ввода формулы тремя клавишами
Ctrl
+
Shift
+
Enter
). После того, как мы ввели эту формулу в
C2
мы её должны скопировать и вставить в несколько строк так, чтобы точно отобразить все уникальные элементы. Как только формула в нижних ячейках вернет
#ЧИСЛО!(#NUM!)
— это значит все элементы отображены и ниже протягивать формулу нет смысла. Чтобы ошибку избежать и сделать формулу более универсальной(не протягивая каждый раз до появления ошибки) можно использовать нехитрую проверку:
для Excel 2007 и выше:
{=ЕСЛИОШИБКА(ИНДЕКС($A$2:$A$51;НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($C$1:C1;$A$2:$A$51)=0;СТРОКА($A$1:$A$50));1));»»)}
{=IFERROR(INDEX($A$2:$A$51;SMALL(IF(COUNTIF($C$1:C1;$A$2:$A$51)=0;ROW($A$1:$A$50));1));»»)}
для Excel 2003:
{=ЕСЛИ(ЕОШ(НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($C$1:C1;$A$2:$A$51)=0;СТРОКА($A$1:$A$50));1));»»;ИНДЕКС($A$2:$A$51;НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($C$1:C1;$A$2:$A$51)=0;СТРОКА($A$1:$A$50));1)))}
{=IF(ISERR(SMALL(IF(COUNTIF($C$1:C1;$A$2:$A$51)=0;ROW($A$1:$A$50));1));»»;INDEX($A$2:$A$51;SMALL(IF(COUNTIF($C$1:C1;$A$2:$A$51)=0;ROW($A$1:$A$50));1)))}
Тогда вместо ошибки
#ЧИСЛО!(#NUM!)
у вас будут пустые ячейки(не совсем пустые, конечно — с формулами :-)).
Чуть подробнее про отличия и нюансы формул ЕСЛИОШИБКА и ЕСЛИ(ЕОШ можно прочесть в этой статье: Как в ячейке с формулой вместо ошибки показать 0
Для пользователей Excel 2021 выше, а так же пользователей Excel 365(с активной подпиской) — использовать формулы для извлечения уникальных элементов проще простого. В этих версиях появилась функция
УНИК(UNIQUE)
, которая как раз получает список уникальных значений на основании переданного диапазона:
=УНИК($A$2:$A$51)
=UNIQUE($A$2:$A$51)
Что самое важное в данном случае — это функция динамического массива и вводить её надо только в одну ячейку C2, а результат она поместит сама в нужное количество ячеек.
Способ 3: код VBA
Данный подход потребует разрешения макросов и базовых знаний о работе с ними. Если не уверены в своих знаниях для начала рекомендую прочитать эти статьи:
- Что такое макрос и где его искать? к статье приложен видеоурок
- Что такое модуль? Какие бывают модули? потребуется, чтобы понять куда вставлять приведенные ниже коды
Оба приведенных ниже кода следует помещать в стандартный модуль. Макросы должны быть разрешены.
Исходные данные оставим в том же порядке — список с данными расположен в столбце «А«(А1:А51, где А1 — заголовок). Только выводить список мы будем не в столбец С, а в столбец Е, начиная с ячейки Е2:
Sub Extract_Unique() Dim vItem, avArr, li As Long ReDim avArr(1 To Rows.Count, 1 To 1) With New Collection On Error Resume Next For Each vItem In Range("A2", Cells(Rows.Count, 1).End(xlUp)).Value 'Cells(Rows.Count, 1).End(xlUp) – определяет последнюю заполненную ячейку в столбце А .Add vItem, CStr(vItem) If Err = 0 Then li = li + 1: avArr(li, 1) = vItem Else: Err.Clear End If Next End With If li Then [E2].Resize(li).Value = avArr End Sub
С помощью данного кода можно извлечь уникальные не только из одного столбца, но и из любого диапазона столбцов и строк. Если вместо строки
Range(«A2», Cells(Rows.Count, 1).End(xlUp)).Value
указать Selection.Value, то результатом работы кода будет список уникальных элементов из выделенного на активном листе диапазона. Только тогда неплохо бы и ячейку вывода значений изменить — вместо [E2] поставить ту, в которой данных нет.
Так же можно указать конкретный диапазон:
Или другой столбец:
Range("C2", Cells(Rows.Count, 3).End(xlUp)).Value
здесь отдельно стоит обратить внимание то, что в данном случае помимо изменения А2 на С2 изменилась и цифра 1 на 3. Это указание на номер столбца, в котором необходимо определить последнюю заполненную ячейку, чтобы код не просматривал лишние ячейки. Подробнее про это можно прочитать в статье: Как определить последнюю ячейку на листе через VBA?
Универсальный код выбора уникальных значений
Код ниже можно применять для любых диапазонов. Достаточно запустить его, указать диапазон со значениями для отбора только неповторяющихся(допускается выделение более одного столбца) и ячейку для вывода результата. Указанные ячейки будут просмотрены, из них будут отобраны только уникальные значения(пустые ячейки при этом пропускаются) и результирующий список будет записан, начиная с указанной ячейки.
Sub Extract_Unique() Dim x, avArr, li As Long Dim avVals Dim rVals As Range, rResultCell As Range On Error Resume Next 'запрашиваем адрес ячеек для выбора уникальных значений Set rVals = Application.InputBox("Укажите диапазон ячеек для выборки уникальных значений", "Запрос данных", "A2:A51", Type:=8) If rVals Is Nothing Then 'если нажата кнопка Отмена Exit Sub End If 'если указана только одна ячейка - нет смысла выбирать If rVals.Count = 1 Then MsgBox "Для отбора уникальных значений требуется указать более одной ячейки", vbInformation, "www.excel-vba.ru" Exit Sub End If 'отсекаем пустые строки и столбцы вне рабочего диапазона Set rVals = Intersect(rVals, rVals.Parent.UsedRange) 'если указаны только пустые ячейки вне рабочего диапазона If rVals Is Nothing Then MsgBox "Недостаточно данных для выбора значений", vbInformation, "www.excel-vba.ru" Exit Sub End If avVals = rVals.Value 'запрашиваем ячейку для вывода результата Set rResultCell = Application.InputBox("Укажите ячейку для вставки отобранных уникальных значений", "Запрос данных", "E2", Type:=8) If rResultCell Is Nothing Then 'если нажата кнопка Отмена Exit Sub End If 'определяем максимально возможную размерность массива для результата ReDim avArr(1 To Rows.Count, 1 To 1) 'при помощи объекта Коллекции(Collection) 'отбираем только уникальные записи, 'т.к. Коллекции не могут содержать повторяющиеся значения With New Collection On Error Resume Next For Each x In avVals If Len(CStr(x)) Then 'пропускаем пустые ячейки .Add x, CStr(x) 'если добавляемый элемент уже есть в Коллекции - возникнет ошибка 'если же ошибки нет - такое значение еще не внесено, 'добавляем в результирующий массив If Err = 0 Then li = li + 1 avArr(li, 1) = x Else 'обязательно очищаем объект Ошибки Err.Clear End If End If Next End With 'записываем результат на лист, начиная с указанной ячейки If li Then rResultCell.Cells(1, 1).Resize(li).Value = avArr End Sub
Способ 4: Сводные таблицы
Несколько нестандартный способ извлечения уникальных значений.
- Выделяем один или несколько столбцов в таблице, переходим на вкладку Вставка(Insert) -группа Таблица(Table) —Сводная таблица(PivotTable)
- В диалоговом окне Создание сводной таблицы(Create PivotTable) проверяем правильность выделения диапазона данных (или установить новый источник данных)
- указываем место размещения Сводной таблицы:
- На новый лист (New Worksheet)
- На существующий лист (Existing Worksheet)
- подтверждаем создание нажатием кнопки OK
Т.к. сводные таблицы при обработке данных, которые помещаются в область строк или столбцов, отбирают из них только уникальные значения для последующего анализа, то от нас ровным счетом ничего не требуется, кроме как создать сводную таблицу и поместить в область строк или столбцов данные нужного столбца.
На примере приложенного к статье файла я:
- выделил диапазон A1:B51 на листе Извлечение по критерию
- вызвал меню вставки сводной таблицы: вкладка Вставка(Insert) -группа Таблица(Table) —Сводная таблица(PivotTable)
выбрал вставить на новый лист(New Worksheet) - назвал этот лист Уникальные сводной таблицей
- поле Данные поместил в область строк
- поле ФИО в область фильтра. Почему? Чтобы удобно было выбирать одно или несколько ФИО и в сводной отображался бы список уникальных месяцев только для выбранных фамилий


В чем неудобство работы со сводными в данном случае: при изменении в исходных данных сводную таблицу придется обновлять вручную: Выделить любую ячейку сводной таблицы -Правая кнопка мыши —Обновить(Refresh) или вкладка Данные(Data) —Обновить все(Refresh all) —Обновить(Refresh). А если исходные данные пополняются динамически и того хуже — надо будет заново указывать диапазон исходных данных. И еще один минус — данные внутри сводной таблицы нельзя менять. Поэтому если с полученным списком необходимо будет работать в дальнейшем, то после создания нужного списка при помощи сводной его надо скопировать и вставить на нужный лист.
Чтобы лучше понимать все действия и научиться обращаться со сводными таблицами настоятельно рекомендую ознакомиться со статьей Общие сведения о сводных таблицах — к ней приложен видеоурок, в котором я наглядно демонстрирую простоту и удобство работы с основными возможностями сводных таблиц.
В приложенном примере помимо описанных приемов, записана чуть более сложная вариация извлечения уникальных элементов формулой и кодом, а именно: извлечение уникальных элементов по критерию. О чем речь: если в одном столбце фамилии, а во втором(В) некие данные(в файле это месяцы) и требуется извлечь уникальные значения столбца В только для выбранной фамилии. Примеры подобных извлечений уникальных расположены на листе Извлечение по критерию.
Скачать пример:
 Tips_All_ExtractUnique.xls (108,0 KiB, 18 435 скачиваний)
Tips_All_ExtractUnique.xls (108,0 KiB, 18 435 скачиваний)
Также см.:
Работа с дубликатами
Как подсчитать количество повторений
Общие сведения о сводных таблицах
Статья помогла? Поделись ссылкой с друзьями!
![]() Видеоуроки
Видеоуроки
Поиск по меткам
Access
apple watch
Multex
Power Query и Power BI
VBA управление кодами
Бесплатные надстройки
Дата и время
Записки
ИП
Надстройки
Печать
Политика Конфиденциальности
Почта
Программы
Работа с приложениями
Разработка приложений
Росстат
Тренинги и вебинары
Финансовые
Форматирование
Функции Excel
акции MulTEx
ссылки
статистика