
Подсчет количества уникальных значений среди повторяющихся
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Еще…Меньше
Предположим, что требуется определить количество уникальных значений в диапазоне, содержащем повторяющиеся значения. Например, если столбец содержит:
-
числа 5, 6, 7 и 6, будут найдены три уникальных значения — 5, 6 и 7;
-
строки «Руслан», «Сергей», «Сергей», «Сергей», будут найдены два уникальных значения — «Руслан» и «Сергей».
Существует несколько способов подсчета количества уникальных значений среди повторяющихся.
С помощью диалогового окна Расширенный фильтр можно извлечь уникальные значения из столбца данных и вставить их в новое местоположение. Затем с помощью функции ЧСТРОК можно подсчитать количество элементов в новом диапазоне.
-
Выделите диапазон ячеек или убедитесь, что активная ячейка находится в таблице.
Убедитесь в том, что диапазон ячеек содержит заголовок столбца.
-
На вкладке Данные в группе Сортировка и фильтр нажмите кнопку Дополнительно.
Появится диалоговое окно Расширенный фильтр.
-
Установите переключатель скопировать результат в другое место.
-
В поле Копировать введите ссылку на ячейку.
В противном случае нажмите Свернуть диалоговое окно
 для временного скрытия диалогового окна, выберите ячейку на листе, а затем нажмите Развернуть диалоговое окно .
для временного скрытия диалогового окна, выберите ячейку на листе, а затем нажмите Развернуть диалоговое окно . -
Установите флажок Только уникальные записи и нажмите ОК.
Уникальные значения из выделенного диапазона будут скопированы в новое место, начиная с ячейки, указанной в поле Копировать.
-
В пустой ячейке под последней ячейкой диапазона введите функцию ЧСТРОК. Используйте диапазон скопированных уникальных значений в качестве аргумента, исключив заголовок столбца. Например, если уникальные значения содержатся в диапазоне B2:B45, введите =ЧСТРОК(B2:B45).
 для временного скрытия диалогового окна, выберите ячейку на листе, а затем нажмите Развернуть диалоговое окно
для временного скрытия диалогового окна, выберите ячейку на листе, а затем нажмите Развернуть диалоговое окно  .
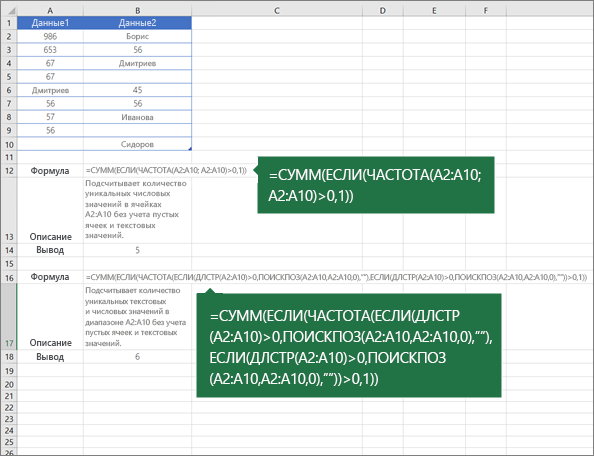
.Для выполнения этой задачи используйте комбинацию функций ЕСЛИ, СУММ, ЧАСТОТА, ПОИСКПОЗ и ДЛСТР.
-
Назначьте значение 1 каждому из истинных условий с помощью функции ЕСЛИ.
-
Вычислите сумму, используя функцию СУММ.
-
Подсчитайте количество уникальных значений с помощью функции ЧАСТОТА. Функция ЧАСТОТА пропускает текстовые и нулевые значения. Для первого вхождения заданного значения эта функция возвращает число, равное общему количеству его вхождений. Для каждого последующего вхождения того же значения функция возвращает ноль.
-
Узнайте позицию текстового значения в диапазоне с помощью функции ПОИСКПОЗ. Возвращенное значение затем используется в качестве аргумента функции ЧАСТОТА, что позволяет определить количество вхождений текстовых значений.
-
Найдите пустые ячейки с помощью функции ДЛСТР. Пустые ячейки имеют нулевую длину.
Примечания:
-
Формулы, приведенные в этом примере, должны быть введены как формулы массива. Если у вас установлена текущая версия Microsoft 365, можно просто ввести формулу в верхней левой ячейке диапазона вывода и нажать клавишу ВВОД, чтобы подтвердить использование формулы динамического массива. Иначе формулу необходимо вводить с использованием прежней версии массива, выбрав диапазон вывода, введя формулу в левой верхней ячейке диапазона и нажав клавиши CTRL+SHIFT+ВВОД для подтверждения. Excel автоматически вставляет фигурные скобки в начале и конце формулы. Дополнительные сведения о формулах массива см. в статье Использование формул массива: рекомендации и примеры.
-
Чтобы просмотреть процесс вычисления функции по шагам, выделите ячейку с формулой, а затем на вкладке Формулы в группе Зависимости формул нажмите Вычислить формулу.
-
Функция ЧАСТОТА вычисляет частоту появления значений в диапазоне и возвращает вертикальный массив чисел. С помощью функции ЧАСТОТА можно, например, подсчитать количество результатов тестирования, попадающих в определенные интервалы. Поскольку данная функция возвращает массив, ее необходимо вводить как формулу массива.
-
Функция ПОИСКПОЗ выполняет поиск указанного элемента в диапазоне ячеек и возвращает относительную позицию этого элемента в диапазоне. Например, если диапазон A1:A3 содержит значения 5, 25 и 38, формула =ПОИСКПОЗ(25;A1:A3;0) возвращает значение 2, так как элемент 25 является вторым в диапазоне.
-
Функция ДЛСТР возвращает число символов в текстовой строке.
-
Функция СУММ вычисляет сумму всех чисел, указанных в качестве аргументов. Каждый аргумент может быть диапазоном, ссылкой на ячейку, массивом, константой, формулой или результатом выполнения другой функции. Например, функция СУММ(A1:A5) вычисляет сумму всех чисел в ячейках от A1 до A5.
-
Функция ЕСЛИ возвращает одно значение, если указанное условие дает в результате значение ИСТИНА, и другое, если условие дает в результате значение ЛОЖЬ.
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
См. также
Фильтр уникальных значений или удаление повторяющихся значений
Нужна дополнительная помощь?
Skip to content
В этом руководстве вы узнаете, как посчитать уникальные значения в Excel с помощью формул и как это сделать в сводной таблице. Мы также разберём несколько примеров счёта уникальных текстовых и числовых значений, в том числе с учетом регистра букв.
При работе с большим набором данных в Excel вам часто может потребоваться знать, сколько в вашей таблице повторяющихся и сколько уникальных записей.
И вот о чем мы сейчас поговорим:
- Как посчитать уникальные значения в столбце.
- Считаем уникальные текстовые значения.
- Подсчет уникальных чисел.
- Как посчитать уникальные с учётом регистра.
- Формулы для подсчета различных значений.
- Как не учитывать пустые ячейки?
- Сколько встречается различных чисел?
- Считаем различные текстовые значения.
- Как сосчитать различные текстовые значения с учетом условий?
- Считаем количество различных чисел с ограничениями.
- Как учесть регистр при подсчёте?
- Как посчитать уникальные строки?
- Используем сводную таблицу.
Если вы регулярно посещаете этот блог, вы уже знаете формулу Excel для подсчета дубликатов. А сегодня мы собираемся изучить различные способы подсчета уникальных значений в Excel. Но для ясности давайте сначала определимся с терминами.
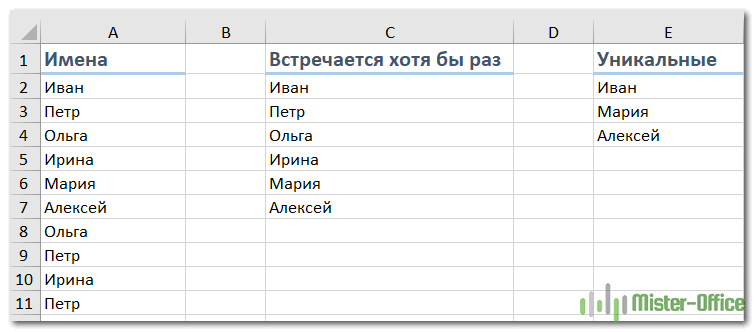
- Уникальные значения – те, которые появляются в списке только один раз.
- Различные – это все, которые имеются в списке без учета повторов, то есть уникальные плюс первое вхождение повторяющихся.
Следующий рисунок иллюстрирует эту разницу:
А теперь давайте посмотрим, как можно их посчитать с помощью формул и функций сводной таблицы.
Далее вы найдете несколько примеров для подсчета уникальных данных разных типов.
Считаем уникальные значения в столбце.
Предположим, у вас есть столбец с именами на листе Excel, и вам нужно подсчитать, сколько там есть неповторяющихся. Самое простое решение состоит в том, чтобы использовать функцию СУММ в сочетании с ЕСЛИ и СЧЁТЕСЛИ :
=СУММ(ЕСЛИ(СЧЁТЕСЛИ(диапазон ; диапазон ) = 1,1,0))
Примечание. Это формула массива, поэтому обязательно нажмите Ctrl + Shift + Enter, чтобы корректно ввести её. Как только вы это сделаете, Excel автоматически заключит всё выражение в {фигурные скобки}, как показано на скриншоте ниже. Ни в коем случае нельзя вводить фигурные скобки вручную, это не сработает.
В этом примере мы считаем уникальные имена в диапазоне A2: A10, поэтому наше выражение выглядит так:
{=СУММ(ЕСЛИ(СЧЁТЕСЛИ(A2:A10;A2:A10)=1;1;0))}

Этот метод подходит и для текстовых, и для цифровых данных. Недостатком является то, что в качестве уникального он будет пересчитывать любое содержимое, в том числе и ошибки.
Далее в этом руководстве мы обсудим несколько других подходов для подсчета уникальных значений разных типов. И поскольку в основном они являются вариациями этой базовой формулы, имеет смысл подробно рассмотреть её. Если вы поймете, как это работает, то сможете настроить ее для своих данных. Если кого-то не интересуют технические подробности, вы можете сразу перейти к следующему примеру.
Как работает формула подсчета уникальных значений?
Как видите, здесь используются 3 разные функции – СУММ, ЕСЛИ и СЧЁТЕСЛИ. Посмотрим, что делает каждая из них:
- Функция СЧЁТЕСЛИ считает, сколько раз каждое отдельное значение появляется в анализируемом диапазоне.
В этом примере СЧЁТЕСЛИ(A2:A10;A2:A10)возвращает массив {3:2:2:1:1:2:3:2:3}.
- Функция ЕСЛИ оценивает каждый элемент в этом массиве, сохраняет все единицы (то есть, уникальные) и заменяет все остальные цифры нулями.
Итак, функция ЕСЛИ(СЧЁТЕСЛИ(A2:A10;A2:A10)=1;1;0) преобразуется в ЕСЛИ({3:2:2:1:1:2:3:2:3}) = 1,1,0).
И далее она превращается в массив чисел {0:0:0:1:1:0:0:0:0}. Здесь 1 означает уникальное значение, а 0 – появляющееся более 1 раза.
- Наконец, функция СУММ складывает числа в этом итоговом массиве и выводит общее количество уникальных значений. Что нам и нужно.
Подсчет уникальных текстовых значений.
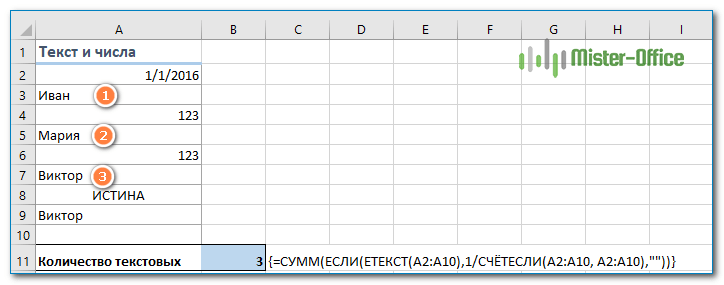
Если ваш список содержит как числа так и текст, и вы хотите посчитать только уникальные текстовые строки, добавьте функцию ЕТЕКСТ() в формулу массива, описанную выше:
{=СУММ(ЕСЛИ(ЕТЕКСТ(A2:A10)*СЧЁТЕСЛИ(A2:A10;A2:A10)=1;1;0))}
Функция ЕТЕКСТ возвращает ИСТИНА, если исследуемое содержимое ячейки является текстом, и ЛОЖЬ в противоположном случае. Поскольку звездочка (*) в формулах массива работает как оператор И, то функция ЕСЛИ возвращает 1, только если рассматриваемое одновременно текстовое и уникальное, в противном случае получаем 0. И после того, как функция СУММ сложит все числа, вы получите количество уникальных текстовых значений в указанном диапазоне.
Не забывайте нажимать Ctrl + Shift + Enter, чтобы правильно ввести формулу массива, и вы получите результат, подобный этому:

Рис3
Как вы можете видеть на скриншоте выше, мы получили общее количество уникальных текстовых значений, исключая пустые ячейки, числа, логические выражения ИСТИНА и ЛОЖЬ, а также ошибки.
Как сосчитать уникальные числовые значения.
Чтобы посчитать уникальные числа в списке данных, используйте формулу массива точно так же, как мы только что делали при подсчете текстовых данных. Отличие заключается в том, что вы используете ЕЧИСЛО вместо ЕТЕКСТ:
{=СУММ(ЕСЛИ(ЕЧИСЛО(A2:A10)*СЧЁТЕСЛИ(A2:A10;A2:A10)=1;1;0))}
Пример и результат вы видите на скриншоте чуть выше.
Уникальные значения с учетом регистра.
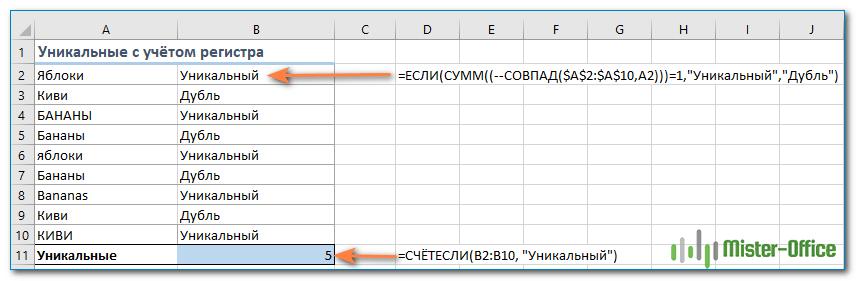
Если для вас принципиально различие в заглавных и прописных буквах, то самым простым способом подсчета будет создание вспомогательного столбца со следующей формулой массива для идентификации повторяющихся и уникальных элементов:
{=ЕСЛИ(СУММ((—СОВПАД($A$2:$A$10;A2)))=1;»Уникальный»;»Дубль»)}
А затем используйте простую функцию СЧЁТЕСЛИ для подсчета уникальных значений:
=СЧЁТЕСЛИ(B2:B10; «Уникальный»)
А теперь посмотрим, как можно посчитать количество значений, которые появляются хотя бы один раз, то есть так называемых различных значений.
Подсчет различных значений.
Используйте следующую универсальное выражение:
{=СУММ(1 / СЧЁТЕСЛИ( диапазон ; диапазон ))}
Помните, что это формула массива, поэтому вам следует нажать Ctrl + Shift + Enter, вместо обычного Enter.
Кроме того, вы можете использовать функцию СУММПРОИЗВ и записать формулу обычным способом:
=СУММПРОИЗВ(1 / СЧЁТЕСЛИ( диапазон ; диапазон ))
Например, чтобы сосчитать различные значения в диапазоне A2: A10, вы можете использовать выражение:
{=СУММ(1/СЧЁТЕСЛИ(A2:A10;A2:A10))}
или же
=СУММПРОИЗВ(1/СЧЁТЕСЛИ(A2:A10;A2:A10))

Этот способ подходит не только для подсчета в столбце, но и для диапазона данных. К примеру, у нас под имена отведено две колонки. Тогда делаем так:
{=СУММПРОИЗВ(1/СЧЁТЕСЛИ(A2:B10;A2:B10))}
Этот метод подходит для текста, чисел, дат.
Единственное ограничение – диапазон должен быть непрерывным и не содержать пустых ячеек и ошибок.
Если в вашем диапазоне данных есть пустые ячейки, то можно изменить:
{=СУММПРОИЗВ(1/СЧЁТЕСЛИ(A2:A10; A2:A10&»»))}
Тогда в расчёт попадёт и будет засчитана и пустая ячейка.
Как это работает?
Как вы уже знаете, мы используем функцию СЧЁТЕСЛИ, чтобы узнать, сколько раз каждый отдельный элемент встречается в указанном диапазоне. В приведенном выше примере, результат работы функции СЧЕТЕСЛИ представляет собой числовой массив: {3:2:2:1:3:2:1:2:3}.
После этого выполняется ряд операций деления, где единица делится на каждую цифру из этого массива. Это превращает все неуникальные значения в дробные числа, соответствующие количеству повторов. Например, если число или текст появляется в списке 2 раза, в массиве создаются 2 элемента равные 0,5 (1/2 = 0,5). А если появляется 3 раза, в массиве создаются 3 элемента 0,333333.
В нашем примере результатом вычисления выражения 1/СЧЁТЕСЛИ(A2:A10;A2:A10) является массив {0.333333333333333:0.5:0.5:1:0.333333333333333:0.5:1:0.5:0.333333333333333}.
Пока не слишком понятно? Это потому, что мы еще не применили функцию СУММ / СУММПРОИЗВ. Когда одна из этих функций складывает числа в массиве, сумма всех дробных чисел для каждого отдельного элемента всегда дает 1, независимо от того, сколько раз он появлялся. И поскольку все уникальные элементы отображаются в массиве как единицы (1/1 = 1), окончательный результат представляет собой общее количество всех встречающихся значений.
Как и в случае подсчета уникальных значений в Excel, вы можете использовать варианты универсальной формулы для обработки отдельно чисел, текста или же с учетом регистра.
Помните, что все приведенные ниже выражения являются формулами массива и требуют нажатия Ctrl + Shift + Enter.
Подсчет различных значений без учета пустых ячеек
Если столбец, в котором вы хотите совершить подсчет, может содержать пустые ячейки, вам следует в уже знакомую нам формулу массива добавить функцию ЕСЛИ. Она будет проверять ячейки на наличие пустот (основная формула Excel, описанная выше, в этом случае вернет ошибку #ДЕЛ/0):
=СУММ(ЕСЛИ( диапазон <> «»; 1 / СЧЁТЕСЛИ( диапазон ; диапазон ); 0))
Вот как, к примеру, можно посчитать количество индивидуальных значений, игнорируя пустые ячейки:

Используем:
{=СУММ(ЕСЛИ(A2:A10<>»»;1/СЧЁТЕСЛИ(A2:A10; A2:A10); 0))}
Как видите, наш список состоит из трёх имён.
Подсчет различных чисел.
Чтобы посчитать различные числовые значения (числа, даты и время), используйте функцию ЕЧИСЛО:
= СУММ(ЕСЛИ(ЕЧИСЛО( диапазон ); 1 / СЧЁТЕСЛИ( диапазон ; диапазон ); «»))
Считаем, сколько имеется различных чисел в диапазоне A2: A10:
{=СУММ(ЕСЛИ(ЕЧИСЛО(A2:A10);1/СЧЁТЕСЛИ(A2:A10; A2:A10);»»))}
Результат вы можете посмотреть ниже.

Это достаточно простое и элегантное решение, но работает оно гораздо медленнее, чем выражения, которые используют функцию ЧАСТОТА для подсчета уникальных значений. Если у вас большие наборы данных, то целесообразно переключиться на формулу, основанную на расчёте частот.
И вот еще один способ подсчета чисел:
=СУММ(—(ЧАСТОТА(диапазон; диапазон)>0))
Применительно к примеру ниже:
=СУММ(—(ЧАСТОТА(A2:A10; A2:A10)>0))
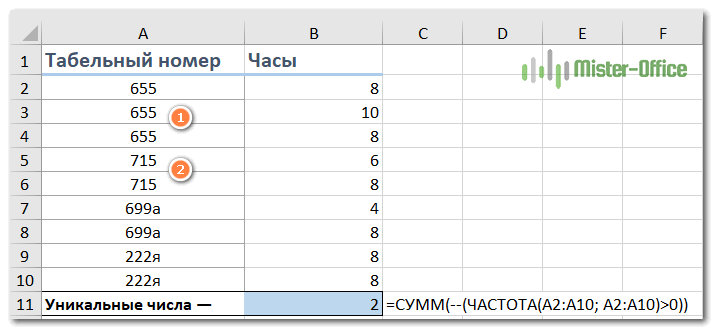
Как видите, здесь игнорируются записи, в которых имеются буквы.
Пошагово разберём, как это работает.
Функция ЧАСТОТА возвращает массив цифр, которые соответствуют интервалам, заданным имеющимися числами. В этом случае мы сравниваем один и тот же набор чисел для массива данных и для массива интервалов.
Результатом является то, что ЧАСТОТА() возвращает массив, который представляет собой счетчик для каждого числового значения в массиве данных.
Это работает, потому что ЧАСТОТА() возвращает ноль для любых чисел, которые ранее уже появились в списке. Ноль возвращается и для текстовых данных. Поэтому полученный массив выглядит следующим образом:
{3:0:0:2:0:0}
Как видите, обрабатываются только числа. Ячейки A7:A10 игнорируются, потому что там текст. А функция ЧАСТОТА() работает только с числами.
Теперь каждое из этих чисел проверяем на условие «больше нуля».
Получаем:
{ИСТИНА:ЛОЖЬ:ЛОЖЬ:ИСТИНА:ЛОЖЬ:ЛОЖЬ}
Теперь превращаем ИСТИНА и ЛОЖЬ в 1 и 0 соответственно. Делаем это при помощи двойного отрицания. Проще говоря, это двойной минус, который не меняет величину числа, но позволяет получить реальные числа, когда это вообще возможно:
{1:0:0:1:0:0}
А теперь функция СУММ складывает всё и получаем результат: 2.
Различные текстовые значения.
Чтобы посчитать отдельные текстовые записи в столбце, мы будем использовать тот же подход, который мы использовали для исключения пустых ячеек.
Как вы можете легко догадаться, мы просто добавим функцию ЕТЕКСТ и проверку условия:
=СУММ(ЕСЛИ(ЕТЕКСТ( диапазон ); 1 / СЧЁТЕСЛИ( диапазон ; диапазон ); «»))
Количество индивидуальных символьных значений посчитаем так:
{=СУММ(ЕСЛИ(ЕТЕКСТ(A2:A10);1/СЧЁТЕСЛИ(A2:A10; A2:A10);»»))}
Не забываем, что это формула массива.
Если в вашей таблице нет пустых ячеек и ошибок, то вы можете применить формулу, которая использует несколько функций: ЧАСТОТА, ПОИСКПОЗ, СТРОКА и СУММПРОИЗВ.
В общем виде это выглядит так:
=СУММПРОИЗВ(—(ЧАСТОТА(ПОИСКПОЗ (диапазон; диапазон;0); СТРОКА (диапазон)- СТРОКА (диапазон_первая_ячейка)+1)>0))
Предположим, у вас есть список имен сотрудников вместе с часами работы над проектом, и вы хотите знать, сколько человек в этом участвовали. Глядя на данные, вы можете увидеть, что имена повторяются. А вы хотите пересчитать всех, кто хотя бы раз появился в этом списке.

Применяем формулу массива:
{=СУММПРОИЗВ(— (ЧАСТОТА(ПОИСКПОЗ(A2:A10; A2:A10;0); СТРОКА(A2:A10) -СТРОКА(A2) +1)> 0))}
Она является более сложной, чем аналогичная, которая использует функцию ЧАСТОТА() для подсчета различных чисел. Это потому, что ЧАСТОТА() не работает с текстом. Поэтому ПОИСКПОЗ преобразует имена в номера позиций, которые может обрабатывать ЧАСТОТА().
Если какая-либо из ячеек в диапазоне пустая, вам необходимо использовать более сложную формулу массива, которая включает в себя функцию ЕСЛИ:
{= СУММ(ЕСЛИ(ЧАСТОТА(ЕСЛИ(данные <> «»;ПОИСКПОЗ(данные; данные; 0));СТРОКА(данные) -СТРОКА(данные_первая_ячейка) +1); 1))}
Примечание: поскольку логическая проверка в операторе ЕСЛИ содержит массив, то наше выражение сразу становится формулой массива, которая требует ввода через Ctrl+Shift+Enter. Поэтому же СУММПРОИЗВ была заменена на СУММ.
Применительно к нашему примеру это выглядит так:
{=СУММ(ЕСЛИ(ЧАСТОТА(ЕСЛИ(A2:A10 <> «»;ПОИСКПОЗ(A2:A10; A2:A10; 0));СТРОКА(A2:A10) -СТРОКА(A2) +1); 1))}
Теперь «сломать» этот расчет может только наличие ячеек с ошибками в исследуемом диапазоне.
Различные текстовые значения с условием.
Предположим, необходимо пересчитать, сколько наименований товаров заказал конкретный покупатель.
Чтобы решить эту проблему, вам может помочь этот вариант:
{=СУММПРОИЗВ((($A$2:$A$18=E2)) / СЧЁТЕСЛИМН($A$2:$A$18;$A$2:$A$18&»»; $B$2:$B$18;$B$2:$B$18&»»))}
Введите это в пустую ячейку, куда вы хотите поместить результат, F2, например. А затем нажмите Shift + Ctrl + Enter вместе, чтобы получить правильный результат.
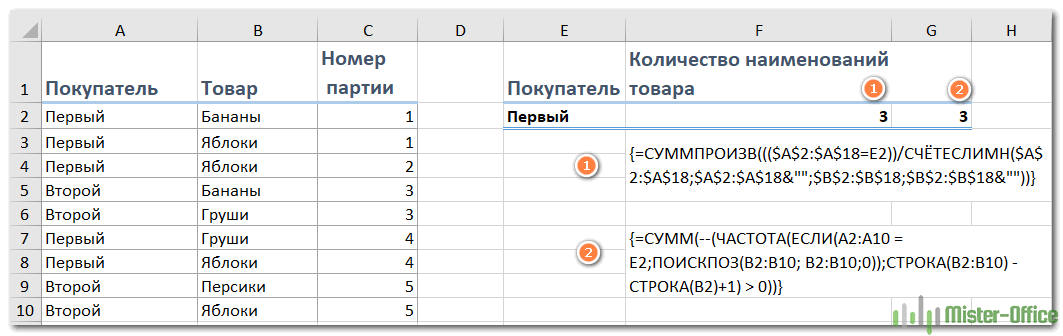
Поясним: здесь A2:A18 это список покупателей, с учётом которого вы ограничиваете область расчётов, B2: B18 — перечень товаров, в котором вы хотите посчитать уникальные значения, Е2 содержит критерий, на основании которого подсчет ограничивается только конкретным покупателем.
Второй способ.
Для уникальных значений в диапазоне с критериями, вы можете использовать формулу массива, основанную на функции ЧАСТОТА.
{=СУММ(—(ЧАСТОТА(ЕСЛИ(критерий; ПОИСКПОЗ(диапазон; диапазон;0)); СТРОКА(диапазон) -СТРОКА(диапазон_первая_ячейкаl)+1)>0))}
Применительно к нашему примеру:
{=СУММ(—(ЧАСТОТА(ЕСЛИ(A2:A10 = E2; ПОИСКПОЗ(B2:B10; B2:B10;0)); СТРОКА(B2:B10) — СТРОКА(B2)+1) > 0))}
С учетом ограничений ЕСЛИ() функция ПОИСКПОЗ определяет порядковый номер только для строк, которые соответствуют критериям.
Если какая-либо из ячеек в диапазоне критериев пустая, вам необходимо скорректировать расчёт, добавив дополнительно ЕСЛИ для обработки пустых ячеек. Иначе они будут переданы в функцию ПОИСКПОЗ, которая в ответ сгенерирует сообщение об ошибке.
Вот что получилось после корректировки:
{=СУММ(— (ЧАСТОТА(ЕСЛИ(B2:B10 <> «»; ЕСЛИ(A2:A10 = E2; ПОИСКПОЗ(B2:B10; B2:B10;0))); СТРОКА(B2:B10) -СТРОКА(B2) +1)> 0))}
То есть все действия и расчёты мы производим, если в столбце B нам встретилась непустая ячейка: ЕСЛИ(B2:B10 <> «»….
Если у вас есть два критерия, вы можете расширить логику формулы путем добавления другого вложенного ЕСЛИ.
Поясним. Определим, сколько наименований товара находилось в первой партии первого покупателя.
Критерии запишем в G2 и G3.
В общем виде это выглядит так:
{=СУММ(—(ЧАСТОТА(ЕСЛИ(критерий1; ЕСЛИ(критерий2; ПОИСКПОЗ (диапазон; диапазон;0))); СТРОКА (диапазон) — СТРОКА (диапазон_первая_позиция) +1)> 0))}
Подставляем сюда реальные данные и получаем результат:

{=СУММ(—(ЧАСТОТА(ЕСЛИ(A2:A10=G2; ЕСЛИ(C2:C10=G3;ПОИСКПОЗ(B2:B10;B2:B10;0)));СТРОКА(B2:B10)-СТРОКА(B2)+1)>0))}
В первой партии 2 наименования товара, хотя и 3 позиции.
Различные числа с условием.
Если вам нужно пересчитать уникальные (с учётом первого вхождения) числа в диапазоне с учетом каких-то ограничений, можно использовать формулу, основанную на СУММ и ЧАСТОТА, и вместе с этим применять критерии.
{=СУММ(— (ЧАСТОТА(ЕСЛИ(критерий; диапазон); диапазон)> 0))}
Предположим, у нас есть перечень табельных номеров и количество отработанных часов по дням. Нужно сосчитать, сколько человек хотя бы раз отработали менее чем по 8 часов, то есть неполную смену.

Вот наша формула массива:
{=СУММ(— (ЧАСТОТА(ЕСЛИ(B2:B10 < 8; A2:A10); A2:A10)> 0))}
Как видите, таких случаев 3, но связаны они с двумя работниками.
Различные значения с учетом регистра.
Подобно подсчету уникальных, самый простой способ подсчета различных значений с учетом регистра – это добавить вспомогательный столбец с формулой массива, который идентифицирует нужные элементы, включая первые повторяющиеся вхождения.
Подход в основном такой же, как и тот, который мы использовали для подсчета уникальных значений с учетом регистра, с одним небольшим изменением:
{=ЕСЛИ(СУММ((—СОВПАД($A$2:$A2;$A2)))=1;»Уникальный»;»»)}
Как вы помните, все формулы массива в Excel требуют нажатия Ctrl + Shift + Enter.
После того, как это выражение будет записано, вы можете посчитать «различные» значения с помощью обычной функции СЧЁТЕСЛИ, например:
=СЧЁТЕСЛИ(B2:B10; «Уникальный»)
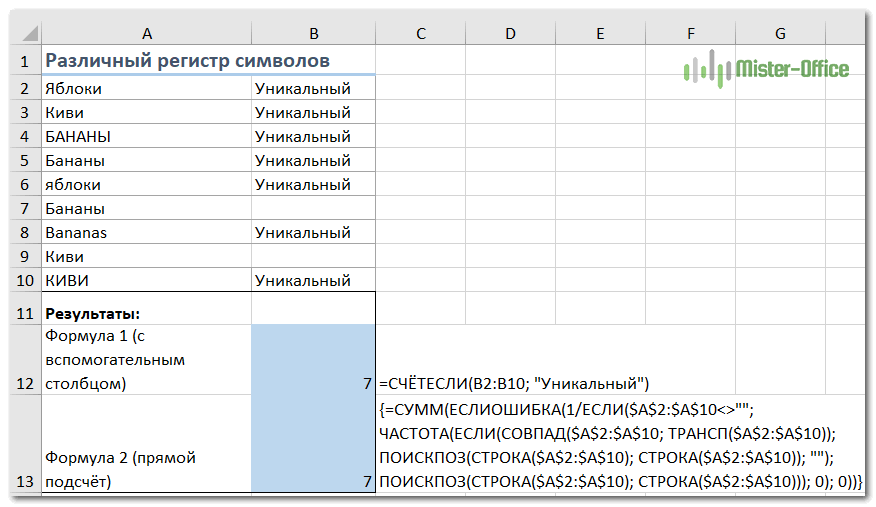
Если вы не можете добавить вспомогательный столбец на свой рабочий лист, вы можете использовать следующую более сложную формулу массива для подсчета различных значений с учетом регистра без создания дополнительного столбца:
{=СУММ(ЕСЛИОШИБКА(1/ЕСЛИ($A$2:$A$10<>»»; ЧАСТОТА(ЕСЛИ(СОВПАД($A$2:$A$10; ТРАНСП($A$2:$A$10)); ПОИСКПОЗ(СТРОКА($A$2:$A$10); СТРОКА($A$2:$A$10)); «»); ПОИСКПОЗ(СТРОКА($A$2:$A$10); СТРОКА($A$2:$A$10))); 0); 0))}
Как видите, обе формулы дают одинаковые результаты.
Подсчет уникальных строк в таблице.
Подсчет уникальных / различных строк в Excel сродни пересчёту уникальных и различных значений. С той лишь разницей, что вы используете функцию СЧЁТЕСЛИМН вместо СЧЁТЕСЛИ, что позволяет вам указать сразу несколько столбцов для проверки уникальности.
Например, чтобы подсчитать уникальные строки на основе столбцов A (Имя) и B (Фамилия), используйте один из следующих вариантов:
Для уникальных строк:
{=СУММ(ЕСЛИ(СЧЁТЕСЛИМН(A3:A11;A3:A11; B3:B11;B3:B11)=1;1;0))}
Для различных строк:
{=СУММ(1/СЧЁТЕСЛИМН(A3:A11;A3:A11;B3:B11;B3:B11))}
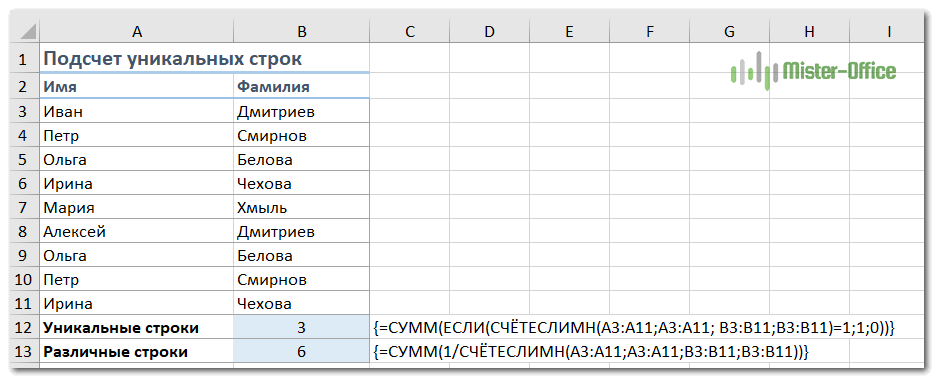
Естественно, вы не ограничены только двумя столбцами. Функция СЧЁТЕСЛИМН может обрабатывать до 127 пар диапазон / критерий.
Как можно использовать сводную таблицу.
Вот обычная задача, которую все пользователи Excel должны время от времени выполнять. У вас есть список данных (к примеру, названий товаров), и нужно узнать количество уникальных позиций в этом списке. Как это сделать? Проще, чем вы думаете 
В версиях Excel выше 2013 есть специальная функция, которая позволяет автоматически пересчитывать различные значения в сводной таблице. На следующем рисунке показано, как выглядит этот счетчик:

Чтобы создать сводную таблицу со счетчиком для определенного столбца, выполните следующие действия.
- Выберите данные для включения в сводную таблицу, перейдите на вкладку «Вставка» и нажмите кнопку «Сводная таблица» .
- В диалоговом окне «Создание сводной таблицы» выберите, следует ли разместить сводную таблицу на новом или существующем листе, и обязательно установите флажок «Добавить эти данные в модель данных» .

- Когда откроется сводная таблица, расположите области строк, столбцов и значений так, как вам нужно. Если у вас нет большого опыта работы со сводными таблицами Excel, могут оказаться полезными следующие подробные рекомендации: Создание сводной таблицы в Excel.
- Переместите поле, количество уникальных элементов которого вы хотите вычислить ( поле « Товар» в этом примере), в область « Значения» , щелкните его и выберите «Параметры значения поля…» из раскрывающегося меню.
- Откроется диалоговое окно , прокрутите вниз до операции «Число разных элементов» , которая является самым последним пунктом в списке, выберите ее и нажмите OK .
Вы также можете дать собственное имя своему счетчику, если хотите.

Готово! Вновь созданная сводная таблица будет отображать количество различных товаров, как показано на самом первом скриншоте в этом разделе.
Вот как можно подсчитать различные и уникальные значения в столбце и целиком в таблице Excel.
Благодарю вас за чтение и надеюсь увидеть вас снова. Пожалуйста, не переключайтесь!
 Как найти и выделить уникальные значения в столбце — В статье описаны наиболее эффективные способы поиска, фильтрации и выделения уникальных значений в Excel. Ранее мы рассмотрели различные способы подсчета уникальных значений в Excel. Но иногда вам может понадобиться только просмотреть уникальные…
Как найти и выделить уникальные значения в столбце — В статье описаны наиболее эффективные способы поиска, фильтрации и выделения уникальных значений в Excel. Ранее мы рассмотрели различные способы подсчета уникальных значений в Excel. Но иногда вам может понадобиться только просмотреть уникальные…  Как получить список уникальных значений — В статье описано, как получить список уникальных значений в столбце с помощью формулы и как настроить эту формулу для различных наборов данных. Вы также узнаете, как быстро получить отдельный список с…
Как получить список уникальных значений — В статье описано, как получить список уникальных значений в столбце с помощью формулы и как настроить эту формулу для различных наборов данных. Вы также узнаете, как быстро получить отдельный список с…  Как выделить цветом повторяющиеся значения в Excel? — В этом руководстве вы узнаете, как отображать дубликаты в Excel. Мы рассмотрим различные методы затенения дублирующих ячеек, целых строк или последовательных повторений с использованием условного форматирования. Ранее мы исследовали различные…
Как выделить цветом повторяющиеся значения в Excel? — В этом руководстве вы узнаете, как отображать дубликаты в Excel. Мы рассмотрим различные методы затенения дублирующих ячеек, целых строк или последовательных повторений с использованием условного форматирования. Ранее мы исследовали различные…  Как посчитать количество повторяющихся значений в Excel? — Зачем считать дубликаты? Мы можем получить ответ на множество интересных вопросов. К примеру, сколько клиентов сделало покупки, сколько менеджеров занималось продажей, сколько раз работали с определённым поставщиком и т.д. Если…
Как посчитать количество повторяющихся значений в Excel? — Зачем считать дубликаты? Мы можем получить ответ на множество интересных вопросов. К примеру, сколько клиентов сделало покупки, сколько менеджеров занималось продажей, сколько раз работали с определённым поставщиком и т.д. Если…  Как убрать повторяющиеся значения в Excel? — В этом руководстве объясняется, как удалять повторяющиеся значения в Excel. Вы изучите несколько различных методов поиска и удаления дубликатов, избавитесь от дублирующих строк, обнаружите точные повторы и частичные совпадения. Хотя…
Как убрать повторяющиеся значения в Excel? — В этом руководстве объясняется, как удалять повторяющиеся значения в Excel. Вы изучите несколько различных методов поиска и удаления дубликатов, избавитесь от дублирующих строк, обнаружите точные повторы и частичные совпадения. Хотя…
Подсчет количества уникальных значений
Постановка задачи
Есть диапазон с данными, в котором некоторые значения повторяются больше одного раза:

Задача — подсчитать количество уникальных (неповторяющихся) значений в диапазоне. В приведенном выше примере, как легко заметить, на самом деле упоминаются всего четыре варианта.
Рассмотрим несколько способов ее решения.
Способ 1. Если нет пустых ячеек
Если вы уверены, что в исходном диапазоне данных нет пустых ячеек, то можно использовать короткую и элегантную формулу массива:

Не забудьте ввести ее как формулу массива, т.е. нажать после ввода формулы не Enter, а сочетание Ctrl+Shift+Enter.
Технически, эта формула пробегает по всем ячейкам массива и вычисляет для каждого элемента количество его вхождений в диапазон с помощью функции СЧЕТЕСЛИ (COUNTIF). Если представить это в виде дополнительного столбца, то выглядело бы оно так:

Потом вычисляются дроби 1/Число вхождений для каждого элемента и все они суммируются, что и даст нам количество уникальных элементов:

Способ 2. Если есть пустые ячейки
Если в диапазоне встречаются пустые ячейки, то придется немного усовершенствовать формулу, добавив проверку на пустые ячейки (иначе получим ошибку деления на 0 в дроби):

Вот и все дела.
Ссылки по теме
- Как извлечь из диапазона уникальные элементы и удалить дубликаты
- Как подсветить дубликаты в списке цветом
- Как сравнить два диапазона на наличие в них дубликатов
- Извлечение уникальных записей из таблицы по заданному столбцу с помощью надстройки PLEX
На чтение 11 мин. Просмотров 13.9k.
Содержание
- Числовые значения
- Текстовые значения
- В диапазоне с СЧЁТЕСЛИ
Числовые значения
В диапазоне
= СУММ(—(ЧАСТОТА(данные; данные)>0))
Если вам нужно подсчитать уникальные числовые значения в диапазоне, вы можете использовать формулу, которая использует частотную функцию вместе с функцией СУММ.

Предположим, у вас есть список номеров сотрудников вместе с часами работы над проектом, и вы хотите знать, сколько сотрудники работали над этим проектом. Глядя на данные, вы можете увидеть одно и то же число сотрудников более одного раза, так что вы хотите подсчитать уникальные номера служащих, которые появляются в списке.
ID номера работников появляются в диапазоне B5: B14. Для того, чтобы получить количество уникальных номеров, вы можете использовать следующую формулу:
= СУММ(— (ЧАСТОТА(B5:B14; B5:B14) > 0))
Функция ЧАСТОТА возвращает массив значений, которые соответствуют интервалам. В этом случае мы сравниваем один и тот же набор чисел для массива данных и для массива интервалов.
Результатом является то, что ЧАСТОТА возвращает массив значений, которые представляют собой счетчик для каждого числового значения в массиве данных. Это работает, потому что ЧАСТОТА имеет специальную функцию, которая автоматически возвращает ноль для любых чисел, которые появляются более чем один раз в массиве данных, поэтому обратный массив выглядит следующим образом:
{3; 0; 0; 2; 0; 3; 0; 0; 2; 0; 0}
Далее, каждое из этих значений проверяется, чтобы было больше нуля. Результат выглядит следующим образом:
{ИСТИНА; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ}
Теперь каждая ИСТИНА в списке представляет собой уникальный номер в списке, и нам просто нужно сложить Истинные значения с СУММ.
Однако СУММ не будет добавлять логические значения в массиве, так что мы должны сначала превратить значения в 1 или ноль. Это делается с помощью двойного минуса (двойной унарный). В результате массив только 1 или 0.
{1; 0; 0; 1; 0; 1; 0; 0; 1; 0; 0}
И, наконец, СУММ добавляет эти значения и рассчитывает общее число, которое в данном случае равно 4.
Примечание: вы можете также использовать СУММПРОИЗВ для сложения элементов в массиве.
Использование СЧЁТЕСЛИ вместо ЧАСТОТА для подсчета уникальных значений
Другой способ подсчета уникальных числовых значений состоит в использовании СЧЁТЕСЛИ вместо ЧАСТОТА. Это гораздо проще, но нужно учитывать, что с помощью СЧЁТЕСЛИ на больших наборах данных для подсчета уникальных значений может вызвать проблемы с производительностью. Формула на основе частотных полос, хотя и более сложная, вычисляет гораздо быстрее.
С критериями
{=СУММ(—(ЧАСТОТА(ЕСЛИ(criteria;значения);значения)>0))}
Если вам нужно подсчитать уникальные числовые значения в диапазоне с критериями, можно использовать формулу, основанную на СУММ и частотной функции, вместе с функцией применять критерии.
Например, предположим, у вас есть список номеров сотрудников, которые записывали часы в двух разных зданиях: здание А и здание Б. Вы хотите знать, сколько уникальных сотрудников регистрирует время в каждом здании. Так как одно и то же число сотрудников более одного раза в списке, то вам нужна формула, которая будет рассчитывать уникальные идентификаторы сотрудника в здании.

В показанном примере, формула в G4 является:
{= СУММ(— (ЧАСТОТА(ЕСЛИ(B5:B14 = «A»; C5:C14); C5:C14)> 0))}
Примечание: это формула массива и должна быть введена с помощью сочетания клавиш Ctrl+Shift+Enter
Функция ЧАСТОТА рассчитывает массив значений, которые соответствуют массиву_интервалов. В этом случае мы подставлем «отфильтрованный» набор идентификаторов для массива данных, а также полный набор идентификаторов для массива_интервалов. Фильтрация осуществляется с помощью функции ЕСЛИ:
ЕСЛИ (B5:B14 = «А»; С5:С14)
Которая в примере рассчитывает это:
{81400; 81405; 81405; 82364; 82364; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ}
Обратите внимание на то, что все идентификаторы не в здании А были преобразованы в ЛОЖЬ. Далее, ЧАСТОТА рассчитывает массив значений, которые представляют собой счетчик для каждого числового значения в массиве данных. Это работает, потому что ЧАСТОТА имеет специальную функцию, которая автоматически возвращает ноль для любых чисел, которые появляются более чем один раз в массиве данных, поэтому обратный массив выглядит следующим образом:
{1; 2; 0; 2; 0; 0; 0; 0; 0; 0; 0}
Далее, каждое из этих значений проверяется, чтобы было больше нуля. Результат выглядит следующим образом:
{ИСТИНА; ИСТИНА; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ}
Каждая ИСТИНА в списке представляет собой уникальный номер в списке, и нам просто нужно сложить Истинные значения с СУММ.
Однако СУММ не будет добавлять логические значения в массиве, так что мы должны сначала превратить значения в 1 или ноль. Это делается с помощью двойного минуса (двойной унарный). В результате массиве только 1 или 0.
{1; 1; 0; 1; 0; 0; 0; 0; 0; 0; 0}
И, наконец, СУММ добавляет эти значения и рассчитывает общее число, которое в данном случае составляет 3.
Текстовые значения
В диапазоне
=СУММПРОИЗВ(—(ЧАСТОТА(ПОИСКПОЗ (данные;данные;0); СТРОКА (данные)- СТРОКА (данные.первая ячейка)+1)>0))
Если вам нужно подсчитать уникальные текстовые значения в диапазоне, вы можете использовать формулу, которая использует несколько функций: ЧАСТОТА, ПОИСКПОЗ, СТРОКА и СУММПРОИЗВ.

Кроме того, можно использовать СЧЁТЕСЛИ, как описано ниже.
Предположим, у вас есть список имен сотрудников вместе с часами работы над проектом, и вы хотите знать, сколько сотрудники работали над этим проектом. Глядя на данные, вы можете увидеть, что имена повторяются, а вы хотите подсчитать уникальные имена.
Имена работников находятся в диапазоне B5:B14. Для того, чтобы получить количество уникальных имен, вы можете использовать следующую формулу:
{=СУММПРОИЗВ(— (ЧАСТОТА(ПОИСКПОЗ(B5:B14; B5:B14;0); СТРОКА(B5:B14) -СТРОКА(B5) +1)> 0))}
Эта формула является более сложной, чем аналогичная формула, которая использует ЧАСТОТА для подсчета уникальных числовых значений, поскольку ЧАСТОТА не работает с нечисловыми значениями. В результате, большая часть формулы просто преобразует нечисловые данные в числовые данные, которые может обрабатывать ЧАСТОТА.
Функция ПОИСКПОЗ используется, чтобы получить позицию каждого элемента, который появляется в данных. Поскольку ПОИСКПОЗ только рассчитывает позицию значения «Первое совпадение», которое появляется более чем один раз, в данных тот же диапазон.
Поскольку ПОИСКПОЗ принимает и массив значений для значения совпадений аргумента, она рассчитывает массив позиций. Они подаются к частотному в аргументе массива данных.
{1; 1; 1; 4; 4; 6; 6; 6; 9; 9}
Аргумент, хранимый в массиве строится из этой части формулы:
СТРОКА(B5:B14) -СТРОКА(B5) +1
который использует номер строки для каждого элемента данных и номер строки первого элемента данных для построения прямого последовательного массива:
{1; 2; 3; 4; 5; 6; 7; 8; 9; 10}
Функция ЧАСТОТА возвращает массив значений, которые соответствуют «хранимым». В этом случае мы подставляем массив, рассчитываемый ПОИСКПОЗ для массива данных, а также рассчитываемый массив построчного массива выше, как массив хранимых.
Результатом является то, что ЧАСТОТА рассчитывает массив значений, которые указывают на количество, которое появляется каждое значение в массиве данных. ЧАСТОТА имеет специальную функцию, которая автоматически рассчитывает ноль для любых чисел, которые появляются более чем один раз в массиве данных, поэтому результирующий массив выглядит следующим образом:
{3; 0; 0; 2; 0; 3; 0; 0; 2; 0; 0}
Далее, каждое из этих значений преобразуется в значение ИСТИНА или ЛОЖЬ, которые > 0, а затем в 1 или ноль с двойным отрицанием (двойной минус). Это делается потому что СУММПРОИЗВ нужны числовые значения, она не может работать непосредственно с текстом или логическими значениями.
Внутри функции СУММПРОИЗВ конечный массив выглядит следующим образом:
{1; 0; 0; 1; 0; 1; 0; 0; 1; 0; 0}
И, наконец, СУММПРОИЗВ просто добавляет эти значения и рассчитывает общее число, которое в данном случае равно 4.
Обработка пустых ячеек в диапазоне
Если какая-либо из ячеек в диапазоне пустая, и вы хотите использовать ЧАСТОТА вместо СЧЁТЕСЛИ, вам необходимо использовать более сложную формулу массива, которая включает в себя ЕСЛИ:
{= СУММ(ЕСЛИ(ЧАСТОТА(ЕСЛИ(данные <> «»;ПОИСКПОЗ(данные; данные; 0));СТРОКА(данные) -СТРОКА(данные.первая ячейка) +1); 1))}
Примечание: поскольку логическая проверка в операторе ЕСЛИ содержит массив, то формула автоматически становится формулой массива, которая требует Ctrl+Shift+Enter. Поэтому СУММПРОИЗВ был заменен СУММ.
Рассмотрим формулу изнутри, ЕСЛИ требуется, потому что ПОИСКПОЗ рассчитает # N / A, если значение совпадений содержит пустые значения. Тестируя для пустых значений с данными <> «», в том числе и ПОИСКПОЗ как значение, если оно истинно, то результирующий массив будет содержать номера в сочетании с ЛОЖЬ:
{1; 1; ЛОЖЬ; 4; 4; 6; 6; ЛОЖЬ; 9; 9}
которая подается ЧАСТОТА, что и массив данных. ЧАСТОТА будет рассчитывать массив вроде этого:
{2; 0; 0; 2; 0; 2; 0; 0; 2; 0; 0}
Элементы в этом массиве преобразуются либо в 1, или ЛОЖЬ с окончательным (внешним) ЕСЛИ заявлением. Результат выглядит следующим образом:
{1; ЛОЖЬ; ЛОЖЬ; 1; ЛОЖЬ; 1; ЛОЖЬ; ЛОЖЬ; 1; ЛОЖЬ; ЛОЖЬ}
СУММ затем складывает 1 и рассчитывает 4.
Эта формула из замечательной книги Майка Гивина по формулам массива.
Использование СЧЁТЕСЛИ вместо ЧАСТОТЫ для подсчета уникальных значений
Другой способ подсчета уникальных числовых значений состоит в использовании СЧЁТЕСЛИ вместо ЧАСТОТЫ. Эта формула гораздо проще, но нужно учитывать, что использование СЧЁТЕСЛИ на больших наборах данных для подсчета уникальных значений, может вызвать проблемы с производительностью. Формула на основе ЧАСТОТА, хоть и более сложная, но вычисляет гораздо быстрее.
С критериями
{=СУММ(—(ЧАСТОТА(ЕСЛИ(критерий;ПОИСКПОЗ(значение; значение;0));СТРОКА(значение)-СТРОКА(значение.первая ячейкаl)+1)>0))}
Для уникальных значений в диапазоне с критериями, вы можете использовать формулу массива, основанную на функции ЧАСТОТА.

Предположим, у вас есть список имен сотрудников вместе с часами работы над проектом, и вы хотите знать, сколько сотрудники работали над этим проектом. Глядя на данные, вы можете увидеть, что имена повторяются, а вы хотите подсчитать уникальные имена.
В показанном примере формула в G5 является:
= {СУММ(—(ЧАСТОТА(ЕСЛИ(C5:C11 = G4;СТРОКА(B5:B11; B5:B11;0));СТРОКА(B5:B11) — СТРОКА(B5)+1) > 0))}
Эта формула использует ЧАСТОТА для подсчета уникальных числовых значений, которые получены с помощью функции ПОИСКПОЗ, которая сравнивает все значения против самих себя, чтобы определить позицию.
Функция ПОИСКПОЗ используется, чтобы получить позицию каждого элемента, который появляется в данных. Поскольку ПОИСКПОЗ рассчитывает только позиции значения «Первое совпадение», которые появляются более чем один раз, в данных рассчитывается то же число.
С помощью ЕСЛИ ПОИСКПОЗ рассчитывает только для строк, которые соответствуют критериям.
В конце концов, массив позиций, генерируемых ПОИСКПОЗ подаются к частотному в аргументе массива данных.
Аргумент, хранимый в массиве, строится из этой части формулы:
СТРОКА(B5:B11) -СТРОКА(B5) +1
который использует номер строки для каждого элемента данных и номер строки первого элемента данных для построения прямого, последовательного массива:
{1; 2; 3; 4; 5; 6; 7; 8; 9; 10}
Функция ЧАСТОТА рассчитывает массив значений, которые соответствуют «хранимым». В этом случае мы подставляем один и тот же набор чисел, как для массива данных и хранимых для массива.
Результатом является то, что ЧАСТОТА рассчитывает массив значений, которые указывают на количество, которое появляется каждое значение в массиве данных. Это работает, потому что ЧАСТОТА запрограммирована так, чтобы рассчитывать ноль для любых чисел, которые появляются более чем один раз в массиве данных.
Далее, каждое из этих значений преобразуется в значение ИСТИНА или ЛОЖЬ, которые > 0, а затем в 1 или ноль с двойным отрицанием (двойной минус). Это сделано, чтобы превратить все ненулевые значения в 1.
Наконец, СУММПРОИЗВ просто складывает эти значения и рассчитывает общее число.
Примечание: это формула массива и должна быть введена с помощью Ctrl + Shift + Enter.
Обработка пустых ячеек в диапазоне
Если какая-либо из ячеек в диапазоне пустая, вам необходимо скорректировать формулу, добавив дополнительно ЕСЛИ для предотвращения пустых клеток, передающуюся в функцию ПОИСКПОЗ, которая сгенерирует сообщение об ошибке. Формула:
{= СУММ(— (ЧАСТОТА(ЕСЛИ(B5:B11 <> «»; ЕСЛИ(C5:C11 = G4; ПОИСКПОЗ(B5:B11; B5:B11;0))); СТРОКА(B5:B11) -СТРОКА(B5) +1)> 0))}
С двумя критериями
Если у вас есть два критерия, вы можете расширить логику формулы путем добавления другого вложенного ЕСЛИ:
= {СУММ(— (ЧАСТОТА(ЕСЛИ(c1; ЕСЛИ(c2; ПОИСКПОЗ (значения;значения;0))); СТРОКА (значения) — СТРОКА (значения.первая позиция) +1)> 0))}
Там, где c1 = критерий1, c2 = критерий2 и значения = диапазон значений.
Взято из замечательной книги Майка Гивина по формулам массива, Control-Shift-Enter.
В диапазоне с СЧЁТЕСЛИ
=СУММПРОИЗВ(1/СЧЁТЕСЛИ(данные;данные))
Если вам нужно подсчитать количество уникальных значений в диапазоне ячеек, вы можете использовать формулу, которая использует СЧЁТЕСЛИ и СУММПРОИЗВ.

СЧЁТЕСЛИ находится внутри диапазона данных и подсчитывает количество раз, которое появляется каждое отдельное значение данных. Результатом является массив чисел, который выглядит следующим образом:
{3; 3; 3; 2; 2; 3; 3; 3; 2; 2}.
После того, как СЧЁТЕСЛИ заканчивает, результаты используются в качестве делителя, 1 в качестве числителя. Значения, которые появляются в данных, после появляются в массиве как 1, но значения, которые появляются несколько раз будут отображаться как дробные значения, которые соответствуют множеству. (Т.е. значение, которое появляется в 5 раз, данные будут генерировать 5 элементов в массиве со значением 1/5 = 0,2).
Наконец, функция СУММПРОИЗВ суммирует все значения в массиве и рассчитывает результат.
Обработка пустых ячеек
Если данные могут содержать пустые ячейки, необходимо скорректировать формулу следующим образом:
=СУММПРОИЗВ(1/СЧЁТЕСЛИ(данные; данные&»»))
Данные &»» выражение предотвращает нули массива, созданного СЧЁТЕСЛИ, когда имеются пустые ячейки данных. Она делает это путем обеспечения того, что критерии для пустой ячейки «», а не ноль. Это важно, так как ноль в делителе выбросит #ДЕЛ/0. Так что эта версия формулы не будет выдавать ошибку, когда есть пустые ячейки, но она будет включать в себя пустые ячейки в счете. Если вы хотите исключить пустые ячейки в счете, используйте:
=СУММПРОИЗВ((данные <> «»)/СЧЁТЕСЛИ(данные;данные и «»))
Низкая производительность?
Это крутая и элегантная формула, но она вычисляет гораздо медленнее, чем формулы, которые используют ЧАСТОТА для подсчета уникальных значений. Для больших наборов данных, вы можете переключиться на формулу, основанную на частотную функцию.
Подсчитаем Уникальные значения с одним и двумя условиями.
Про подсчет уникальных текстовых и числовых значений (без условий) можно прочитать в статье
Подсчет Уникальных ТЕКСТовых значений в MS EXCEL
и
Подсчет Уникальных ЧИСЛОвых значений в MS EXCEL
. В этой статье рассмотрим более сложные варианты с условиями.
Задача1
Пусть имеется таблица с перечнем продаж по продавцам.
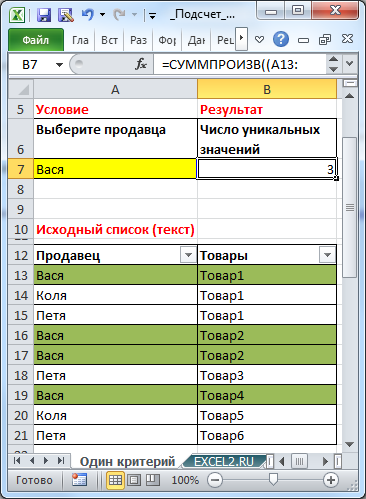
Требуется подсчитать сколько различных товаров продал конкретный продавец. Например, Вася продал 1 товар1, 2 Товара2 и 1 Товар4 (выделено зеленым). Всего 3 разных товара.
Это можно подсчитать формулой
=СУММПРОИЗВ((A13:A21=A7)/СЧЁТЕСЛИМН(B13:B21;B13:B21;A13:A21;A13:A21))
, которая будет работать только с версии MS EXCEL 2007 из-за функции
СЧЁТЕСЛИМН()
.
Изменив в ячейке
А7
имя продавца (в
файле примера
для удобства сделан
выпадающий список
), формула пересчитает количество уникальных.
Задача2
Аналогичным образом можно решить задачу с двумя условиями.
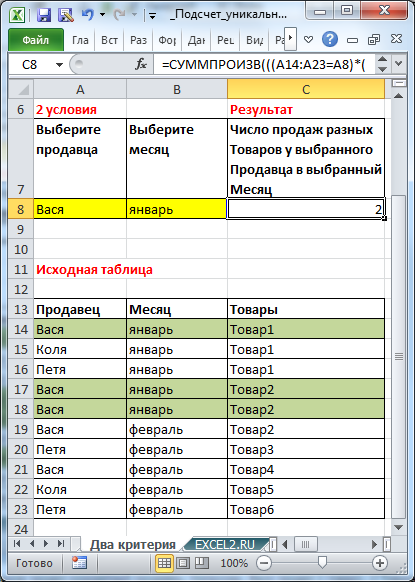
=СУММПРОИЗВ(((A14:A23=A8)*(B14:B23=B8))/СЧЁТЕСЛИМН(A14:A23;A14:A23;B14:B23;B14:B23;C14:C23;C14:C23))
В этом случае будут подсчитаны уникальные товары только в строках, для которых Продавец и Месяц совпадают с критериями, установленными в желтых ячейках.
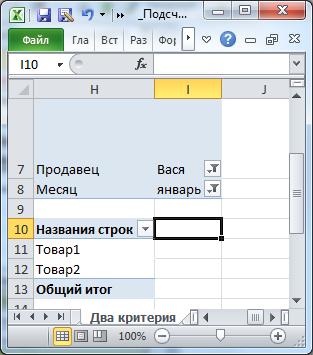
В
файле примера на листе Два критерия
приведено решение этой задачи с помощью
Сводной таблицы
. В этом случае выводится не количество уникальных, а список уникальных товаров.
Задача3
Теперь рассмотрим другую таблицу (столбцы А:С на рисунке ниже).
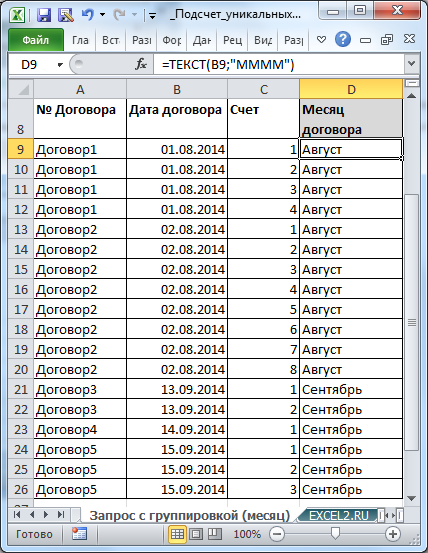
Необходимо вывести количество заключенных договоров в каждом месяце.
Т.к. в таблице ведется учет счетов сразу для всех договоров и по каждому договору может быть выставлено несколько счетов, то номера договоров могут повторяться.
Создадим дополнительный столбец для определения месяца заключения договора (см. статью
Название месяца прописью в MS EXCEL
). Выведем из этого столбца только уникальные месяцы (см. статью
Отбор уникальных значений (убираем повторы из списка) в MS EXCEL
) и поместим их в столбец F.
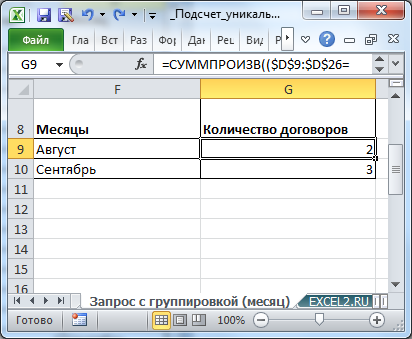
И, наконец, помощью формулы
=СУММПРОИЗВ(($D$9:$D$26=F9)/СЧЁТЕСЛИ($A$9:$A$26;$A$9:$A$26))
подсчитаем количество уникальных договоров в соответствующем месяце.
Решение также возможно с помощью
Сводной таблицы.