
Регулярные выражения
Последнее обновление: 25.06.2018

Регулярные выражения представляют мощный инструмент для обработки строк. Регулярные выражения позволяют задать шаблон,
которому должна соответствовать строка или подстрока.
Некоторые методы класса String принимают регулярные выражения и используют их для выполнения операций над строками.
split
Для разделения строки на подстроки применяется метод split(). В качестве параметра он может принимать регулярное выражение,
которое представляет критерий разделения строки.
Например, разделим предложение на слова:
String text = "FIFA will never regret it";
String[] words = text.split("\s*(\s|,|!|\.)\s*");
for(String word : words){
System.out.println(word);
}
Для разделения применяется регулярное выражение «\s*(\s|,|!|\.)\s*». Подвыражние «\s» по сути представляет пробел. Звездочка указывает, что символ может присутствовать от 0 до бесконечного количества раз.
То есть добавляем звездочку и мы получаем неопределенное количество идущих подряд пробелов — «\s*» (то есть неважно, сколько пробелов между словами). Причем пробелы может вообще не быть.
В скобках указывает группа выражений, которая может идти после неопределенного количества пробелов. Группа позволяет нам определить набо значений через вертикальную черту,
и подстрока должна соответствовать одному из этих значений. То есть в группе «\s|,|!|\.» подстрока может соответствовать пробелу,
запятой, восклицательному знаку или точке. Причем поскольку точка представляет специальную последовательность, то, чтобы указать, что мы имеем в виду имеено знак точки, а не специальную последовательность,
перед точкой ставим слеши.
Соответствие строки. matches
Еще один метод класса String — matches() принимает регулярное выражение и возвращает true, если строка соответствует
этому выражению. Иначе возвращает false.
Например, проверим, соответствует ли строка номеру телефона:
String input = "+12343454556";
boolean result = input.matches("(\+*)\d{11}");
if(result){
System.out.println("It is a phone number");
}
else{
System.out.println("It is not a phone number!");
}
В данном случае в регулярном выражение сначала определяется группа «(\+*)». То есть вначале может идти знак плюса, но также он может отсутствовать.
Далее смотрим, соответствуют ли последующие 11 символов цифрам. Выражение «\d» представляет цифровой символ, а число в фигурных скобках — {11} — сколько раз данный тип символов должен повторяться.
То есть мы ищем строку, где вначале может идти знак плюс (или он может отсутствовать), а потом идет 11 цифровых символов.
Класс Pattern
Большая часть функциональности по работе с регулярными выражениями в Java сосредоточена в пакете java.util.regex.
Само регулярное выражение представляет шаблон для поиска совпадений в строке. Для задания подобного шаблона и поиска подстрок в строке, которые удовлетворяют
данному шаблону, в Java определены классы Pattern и Matcher.
Для простого поиска соответствий в классе Pattern определен статический метод boolean matches(String pattern, CharSequence input).
Данный метод возвращает true, если последовательность символов input полностью соответствует шаблону строки pattern:
import java.util.regex.Pattern;
public class StringsApp {
public static void main(String[] args) {
String input = "Hello";
boolean found = Pattern.matches("Hello", input);
if(found)
System.out.println("Найдено");
else
System.out.println("Не найдено");
}
}
Но, как правило, для поиска соответствий применяется другой способ — использование класса Matcher.
Класс Matcher
Рассмотрим основные методы класса Matcher:
-
boolean matches(): возвращает true, если вся строка совпадает с шаблоном
-
boolean find(): возвращает true, если в строке есть подстрока, которая совпадает с шаблоном, и переходит к этой подстроке
-
String group(): возвращает подстроку, которая совпала с шаблоном в результате вызова метода find.
Если совпадение отсутствует, то метод генерирует исключениеIllegalStateException. -
int start(): возвращает индекс текущего совпадения
-
int end(): возвращает индекс следующего совпадения после текущего
-
String replaceAll(String str): заменяет все найденные совпадения подстрокой str и возвращает измененную строку с учетом замен
Используем класс Matcher. Для этого вначале надо создать объект Pattern с помощью статического метода compile(), который позволяет установить шаблон:
Pattern pattern = Pattern.compile("Hello");
В качестве шаблона выступает строка «Hello». Метод compile() возвращает объект Pattern, который мы затем можем использовать в программе.
В классе Pattern также определен метод matcher(String input), который в качестве параметра принимает строку, где надо проводить поиск, и возвращает
объект Matcher:
String input = "Hello world! Hello Java!";
Pattern pattern = Pattern.compile("hello");
Matcher matcher = pattern.matcher(input);
Затем у объекта Matcher вызывается метод matches() для поиска соответствий шаблону в тексте:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class StringsApp {
public static void main(String[] args) {
String input = "Hello";
Pattern pattern = Pattern.compile("Hello");
Matcher matcher = pattern.matcher(input);
boolean found = matcher.matches();
if(found)
System.out.println("Найдено");
else
System.out.println("Не найдено");
}
}
Рассмотрим более функциональный пример с нахождением не полного соответствия, а отдельных совпадений в строке:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class StringsApp {
public static void main(String[] args) {
String input = "Hello Java! Hello JavaScript! JavaSE 8.";
Pattern pattern = Pattern.compile("Java(\w*)");
Matcher matcher = pattern.matcher(input);
while(matcher.find())
System.out.println(matcher.group());
}
}
Допустим, мы хотим найти в строке все вхождения слова Java. В исходной строке это три слова: «Java», «JavaScript» и «JavaSE». Для этого
применим шаблон «Java(\w*)». Данный шаблон использует синтаксис регулярных выражений. Слово «Java» в начале говорит о том, что все совпадения в строке
должны начинаться на Java. Выражение (\w*) означает, что после «Java» в совпадении может находиться любое количество алфавитно-цифровых символов.
Выражение w означает алфавитно-цифровой символ, а звездочка после выражения указывает на неопределенное их количество — их может быть один, два, три или вообще не быть.
И чтобы java не рассматривала w как эскейп-последовательность, как n, то выражение экранируется еще одним слешем.
Далее применяется метод find() класса Matcher, который позволяет переходить к следующему совпадению в строке. То есть первый вызов
этого метода найдет первое совпадение в строке, второй вызов найдет второе совпадение и т.д. То есть с помощью цикла while(matcher.find())
мы можем пройтись по всем совпадениям. Каждое совпадение мы можем получить с помощью метода matcher.group(). В итоге
программа выдаст следующий результат:
Замена в строке
Теперь сделаем замену всех совпадений с помощью метода replaceAll():
String input = "Hello Java! Hello JavaScript! JavaSE 8.";
Pattern pattern = Pattern.compile("Java(\w*)");
Matcher matcher = pattern.matcher(input);
String newStr = matcher.replaceAll("HTML");
System.out.println(newStr); // Hello HTML! Hello HTML! HTML 8.
Также надо отметить, что в классе String также имеется метод replaceAll() с подобным действием:
String input = "Hello Java! Hello JavaScript! JavaSE 8.";
String myStr =input.replaceAll("Java(\w*)", "HTML");
System.out.println(myStr); // Hello HTML! Hello HTML! HTML 8.
Разделение строки на лексемы
С помощью метода String[] split(CharSequence input) класса Pattern можно разделить строку на массив подстрок по
определенному разделителю. Например, мы хотим выделить из строки отдельные слова:
import java.util.regex.Pattern;
public class StringsApp {
public static void main(String[] args) {
String input = "Hello Java! Hello JavaScript! JavaSE 8.";
Pattern pattern = Pattern.compile("[ ,.!?]");
String[] words = pattern.split(input);
for(String word:words)
System.out.println(word);
}
}
И консоль выведет набор слов:
Hello Java Hello JavaScript JavaSE 8
При этом все символы-разделители удаляются. Однако, данный способ разбивки не идеален: у нас остаются некоторые пробелы, которые расцениваются как лексемы, а не как разделители. Для более точной и изощренной разбивки нам следует применять элементы регулярных выражений.
Так, заменим шаблон на следующий:
Pattern pattern = Pattern.compile("\s*(\s|,|!|\.)\s*");
Теперь у нас останутся только слова:
Hello Java Hello JavaScript JavaSE 8
Далее мы подробнее рассмотрим синтаксис регулярных выражений и из каких элементов мы можем создавать шаблоны.
Это вовсе не ошибка, это вывод Вашего результата. Дело в том, что Java не умеет выводить массив в том виде, в котором Вы хотите. Если попытаться вывести объект массива просто через System.out.println();, он выводит некое описание объекта.
Во-первых, нужно из метода split удалить ненужный цикл, который не делает ничего.
Во-вторых, нужно сделать вывод всех полученных слов через цикл.
public class Main
{
public static String[] split(String s){
String [] array = s.split(" ");
return array;
}
public static void main(String[] args) {
System.out.println("Hello World");
String s = "I am learning java";
// Сохраняем результат разделения
String[] words = split(s);
// Перебираем каждый элемент массива
for(String word : words) {
System.out.println(word);
}
}
}
UPD:
Чтобы решение удовлетворяло условию того, что может быть несколько пробелов подряд нужно отфильтровать то, что вернёт метод String.split(), так как, при разделении по пробелам строки, содержащей множество пробелов, она вернёт массив, где будут тоже пробелы.
Приведу следующее решение. нужно импортировать пакет import java.util.*;
Далее, то, что возвращает метод s.split(" ") приводим к листу и этот лист фильтруем, посредством вызова метода filter((x -> !x.isEmpty()), что означает, вернуть только не пустые элементы списка (листа). Далее уже приводим результат к массиву строк toArray(String[]::new) и этот результат уже возвращаем.
import java.util.*;
public class Main
{
public static String[] split(String s){
List<String> words = Arrays.asList(s.split(" "));
String[] filtered = words.stream().filter((x -> !x.isEmpty())).toArray(String[]::new);
return filtered;
}
public static void main(String[] args) {
System.out.println("Hello World");
String s = "I am learning java many spaces";
// Сохраняем результат разделения
String[] words = split(s);
// Перебираем каждый элемент массива
for(String word : words) {
System.out.println(word);
}
}
}
Теперь даже на строку с множеством пробелом между словами "I am learning java many spaces" он вернёт массив строк, который содержит только отдельные слова.
Более тривиальное решение, без использования лямбда-функциий, но с использованием коллекций, а конкретнее, ArrayList — динамического массива.
import java.util.ArrayList;
public class Main
{
public static String[] split(String s){
// сначала разделяем по пробелу и получаем массив
String[] splitted = s.split(" ");
// Далее, создаём пустой лист
ArrayList<String> words = new ArrayList<String>();
for (String row : splitted) {
// проверяем каждое значение, не пустое ли оно и сохраняем только слова
if (!row.isEmpty()) words.add(row);
}
String[] result = new String[words.size()];
words.toArray(result);
return result;
}
public static void main(String[] args) {
System.out.println("Hello World");
String s = "I am learning java many spaces";
// Сохраняем результат разделения
String[] words = split(s);
// Перебираем каждый элемент массива
for(String word : words) {
System.out.println(word);
}
}
}
Ну и в итоге — самое примитивное решение, без использования сложных методов, коллекций и лямбда-выражений, но с лишними циклами и дейсвтиями по подсчёту слов.
public class Main
{
public static String[] split(String s){
String[] splitted = s.split(" ");
int wordsNumber = 0;
for (String row : splitted) {
// Подсчитываем сколько слов, без учёта пробелов
if (!row.isEmpty()) wordsNumber++;
}
String[] words = new String[wordsNumber];
int i = 0;
for (String row : splitted) {
// Теперь их сохраняем в массив слов
if (!row.isEmpty()) {
words[i] = row;
i++;
}
}
return words;
}
public static void main(String[] args) {
System.out.println("Hello World");
String s = "I am learning java many spaces";
// Сохраняем результат разделения
String[] words = split(s);
// Перебираем каждый элемент массива
for(String word : words) {
System.out.println(word);
}
}
}
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
Java program to print all unique words present in the string. The task is to print all words occurring only once in the string.
Illustration:
Input : Welcome to Geeks for Geeks.
Output : Welcome
to
for
Input : Java is great.Python is also great.
Output : Java
Python
also
Methods:
This can be done in the following ways:
- Using nested loops
- Using Map
- Using frequency() method of Collections
Naive approach: Using nested loops
The idea to count the occurrence of the string in the string and print if count equals one
- Extract words from string using split() method and store them in an array.
- Iterate over the word array using for loop.
- Use another loop to find the occurrence of the current word the array.
- If the second occurrence is found increment count and set the word to “”
- If the count of the current word is equal to one print it
Example:
Java
public class GFG {
static void printUniqueWords(String str)
{
int count;
String[] words = str.split("\W");
for (int i = 0; i < words.length; i++) {
count = 1;
for (int j = i + 1; j < words.length; j++) {
if (words[i].equalsIgnoreCase(words[j])) {
count++;
words[j] = "";
}
}
if (count == 1 && words[i] != "")
System.out.println(words[i]);
}
}
public static void main(String[] args)
{
String str = "Welcome to geeks for geeks";
printUniqueWords(str);
}
}
Note: Time complexity is of order n^2 where space complexity is of order n
Method 2: Using Map
Approach: The idea is to use Map to keep track of words already occurred. But first, we have to extract all words from a String, as a string may contain many sentences with punctuation marks.
- Create an empty Map.
- Extract words from string using split() method and store them in an array.
- Iterate over the word array.
- Check if the word is already present in the Map or not.
- If a word is present in the map, increment its value by one.
- Else store the word as the key inside the map with value one.
- Iterate over the map and print words whose value is equal to one.
Example:
Java
import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.Map;
public class GFG {
static void printUniqueWords(String str)
{
HashMap<String, Integer> map
= new LinkedHashMap<String, Integer>();
String[] words = str.split("\W");
for (String word : words) {
if (map.containsKey(word)) {
map.put(word, map.get(word) + 1);
}
else
map.put(word, 1);
}
for (Map.Entry<String, Integer> entry :
map.entrySet()) {
if (entry.getValue() == 1)
System.out.println(entry.getKey());
}
}
public static void main(String[] args)
{
String str = "Welcome to geeks for geeks";
printUniqueWords(str);
}
}
Note: Time complexity is of the order of n where space complexity is of order n. Hence, it is the optimal approach.
Method 3 : Using Collections.frequency() . If the occurrence of word in string is 1 , then the word is unique.
Java
import java.util.*;
public class Main{
public static void main(String[] args)
{
String str = "Welcome to geeks for geeks";
String[] words = str.split("\W");
List<String> al = new ArrayList<>(Arrays.asList(words));
for(String x:al) {
if(Collections.frequency(al,x)==1){
System.out.println(x);
}
}
}
}
Like Article
Save Article
Для работы со строками в Java существует класс
String. И для
объявления новой строки можно использовать один из способов:
String str1 = "Java"; String str2 = new String(); // пустая строка String str3 = new String(new char[] {'h', 'e', 'l', 'l', 'o'}); String str4 = new String(new char[]{'w', 'e', 'l', 'c', 'o', 'm', 'e'}, 3, 4);
В последнем варианте 3 – это начальный
индекс (индексы считаются с нуля), а 4 – это кол-во символов. То есть, строка str4 содержит
строку «come».
Важной особенностью строк в Java является их неизменяемость.
Это значит, что в строке нельзя попросту изменить какой-либо символ и получить
другую строку. Все строки создаются и существуют в неизменном виде, пока не
будут уничтожены (как правило, автоматически сборщиком мусора). А переменные str1, str2, str3 и str4 следует
воспринимать лишь как ссылки на эти строки. То есть, в любой момент в программе
можно записать такую конструкцию:
что означает изменение ссылки str1 на строку «hello», на которую
указывает ссылка str3. Соответственно, если на первую строку «Java» не будет
указывать никакая ссылка, то она автоматически уничтожается.
У класса String есть несколько
полезных методов:
|
Название |
Описание |
|
length() |
возвращает |
|
toCharArray() |
возвращает |
|
isEmpty() |
определяет |
|
concat() |
объединяет |
|
valueOf() |
преобразует |
|
join() |
объединяет |
|
сompare() |
сравнивает |
|
charAt() |
возвращает |
|
getChars() |
возвращает |
|
equals() |
сравнивает |
|
equalsIgnoreCase() |
сравнивает |
|
regionMatches() |
сравнивает |
|
indexOf() |
находит |
|
lastIndexOf() |
находит |
|
startsWith() |
определяет, |
|
endsWith() |
определяет, |
|
replace() |
заменяет |
|
trim() |
удаляет |
|
substring() |
возвращает |
|
toLowerCase() |
переводит |
|
toUpperCase() |
переводит |
Разберем работу часто используемых
методов класса String. Первый метод, как написано, возвращает
длину строки. Например, если нам дана вот такая строка
то метод length() вернет значение 4
System.out.println(str1.length()); // 4
Далее, если к строке str2
применить метод toCharArray():
char[] helloArray = str1.toCharArray();
то получим массив символов с содержимым
этой строки. Следующий пример. У нас есть пустая строка
тогда мы можем определить это, например,
так:
if(s.length() == 0) System.out.println("String is empty");
или так:
if(s isEmpty()) System.out.println("String is empty");
Но, если строка задана вот так:
то это означает, что ссылка s не указывает ни
на какой класс String и, соответственно, мы не можем вызывать
методы этого класса. В этом случае проверку следует делать так:
if(s != null && s.length() == 0) System.out.println("String is empty");
мы здесь сначала проверяем: указывает ли
ссылка s на объект
класса и если это так, то только потом будет идти обращение к методу length().
Объединение строк
Для соединения строк можно использовать
операцию сложения («+»):
При этом если в операции сложения строк
используется не строковый объект, например, число, то этот объект преобразуется
к строке:
Еще один метод объединения — метод join() позволяет
объединить строки с учетом разделителя. Например, две строки
будут сливаться в одно слово «HelloJava», если их
объединить с помощью оператора +:
но если мы хотим, чтобы две подстроки при
соединении были разделены пробелом, то можно воспользоваться методом join() следующим
образом:
В общем случае вместо пробела здесь
можно ставить любой разделитель в виде строки.
Обратите внимание, что каждый раз при
объединении строк мы получали новую строку как результат объединения.
Извлечение символов и подстрок
Для извлечения
символов по индексу в классе String определен метод
char charAt(int
index)
Он принимает
индекс, по которому надо получить символов, и возвращает извлеченный символ:
String str = "Java"; char c = str.charAt(2); System.out.println(c); // v
(здесь как и в
массивах первый индекс равен 0).
Если надо
извлечь сразу группу символов или подстроку, то можно использовать метод
getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin)
Он принимает
следующие параметры:
-
srcBegin:
индекс строки, с которого начинается извлечение символов; -
srcEnd:
индекс строки, до которого идет извлечение символов; -
dst:
массив символов, в который будут извлекаться символы; -
dstBegin:
индекс массива dst, с которого надо добавлять извлеченные из строки символы.
String str = "Hello world!"; int start = 6; int end = 11; char[] dst=new char[end - start]; str.getChars(start, end, dst, 0); System.out.println(dst); // world
Сравнение строк
Для простого сравнения
строк используются методы equals() (с учетом регистра) и equalsIgnoreCase()
(без учета регистра). Оба метода в качестве параметра принимают строку, с
которой сравниваются:
String str1 = "Hello"; String str2 = "hello"; System.out.println(str1.equals(str2)); // false System.out.println(str1.equalsIgnoreCase(str2)); // true
Обратите
внимание, что в отличие сравнения числовых и других данных примитивных типов
для сравнения строк не рекомендуется использовать оператор ==. То есть,
записывать вот такое сравнение лучше не использовать:
if(str1 == str2) System.out.println("Сроки равны");
(хотя, оно тоже
будет работать). Вместо этого следует использовать метод equals() класса String.
Другая пара методов:
int compareTo(String str) и int compareToIgnoreCase(String str)
также сравнивают
строки между собой, но в отличие от equals() они еще
позволяют узнать больше ли одна строка другой или нет. Если возвращаемое
значение этих методов больше 0, то первая строка больше второй, если меньше
нуля, то, наоборот, вторая больше первой. Если строки равны, то возвращается 0.
Для определения
больше или меньше одна строка, чем другая, используется лексикографический
порядок. То есть, например, строка «A» меньше, чем строка
«B», так как символ ‘A’ в алфавите стоит перед символом ‘B’. Если
первые символы строк равны, то в расчет берутся следующие символы. Например:
String str1 = "hello"; String str2 = "world"; String str3 = "hell"; System.out.println(str1.compareTo(str2)); // -15 - str1 меньше чем str2 System.out.println(str1.compareTo(str3)); // 1 - str1 больше чем str3 System.out.println(str1.compareTo(str1)); // 0 - str1 равна str1
Еще один
специальный метод
regionMatches()
сравнивает
отдельные подстроки в пределах двух строк. Он имеет такие реализации:
boolean
regionMatches(int toffset, String other, int oofset, int len)
boolean
regionMatches(boolean ignoreCase, int toffset, String other, int oofset, int
len)
-
ignoreCase:
надо ли игнорировать регистр символов при сравнении (если значение true, то регистр
игнорируется); -
toffset:
начальный индекс в вызывающей строке, с которого начнется сравнение; -
other:
строка, с которой сравнивается вызывающая; -
oofset: начальный
индекс в сравниваемой строке, с которого начнется сравнение; -
len: количество
сравниваемых символов в обеих строках.
Например, ниже в
строке str1 сравнивается
подстрока wor с подстрокой wor строки str2:
String str1 = "Hello world"; String str2 = "I work"; boolean result = str1.regionMatches(6, str2, 2, 3); System.out.println(result); // true
Поиск в строке
Метод indexOf() находит
индекс первого вхождения подстроки в строку, а метод lastIndexOf() — индекс
последнего вхождения. Если подстрока не будет найдена, то оба
метода возвращают -1:
String str = "Hello world"; int index1 = str.indexOf('l'); // 2 int index2 = str.indexOf("wo"); //6 int index3 = str.lastIndexOf('l'); //9 System.out.println(index1+" "+index2+" "+index3);
Метод startsWith() позволяют
определить начинается ли строка с определенной подстроки, а метод endsWith() позволяет
определить заканчивается строка на определенную подстроку:
String str = "myfile.exe"; boolean start = str.startsWith("my"); //true boolean end = str.endsWith("exe"); //true System.out.println(start+" "+end);
Замена в строке
Метод replace() позволяет
заменить в строке одну последовательность символов на другую:
String str = "Hello world"; String replStr1 = str.replace('l', 'd'); // Heddo wordd String replStr2 = str.replace("Hello", "Bye"); // Bye world System.out.println(replStr1); System.out.println(replStr2);
Обрезка строк
Метод trim()
позволяет удалить начальные и конечные пробелы:
String str = " hello world "; str = str.trim(); // hello world System.out.println(str);
Метод
substring() возвращает подстроку, начиная с определенного индекса до конца или
до определенного индекса:
String str = "Hello world"; String substr1 = str.substring(6); // world String substr2 = str.substring(3,5); //lo System.out.println(substr1); System.out.println(substr2);
Изменение регистра
Метод
toLowerCase() переводит все символы строки в нижний регистр, а метод
toUpperCase() — в верхний:
String str = "Hello World"; System.out.println(str.toLowerCase()); // hello world System.out.println(str.toUpperCase()); // HELLO WORLD
Разбиение строки на подстроки
Метод split()
позволяет разбить строку на подстроки по определенному разделителю. Разделитель
– это какой-нибудь символ или набор символов (передается в качестве параметра).
Например, разобьем текст на отдельные слова (учитывая, что слова разделены
пробелом):
String text = "Я люблю язык Java!"; String[] words = text.split(" "); for(String word : words) System.out.println(word);
Видео по теме
There are various methods in Java using which you can parse for words in a string for a specific word. Here we are going to discuss 3 of them.
The contains() method
The contains() method of the String class accepts a sequence of characters value and verifies whether it exists in the current String. If found it returns true else, it returns false.
Example
Live Demo
import java.util.StringTokenizer;
import java.util.regex.Pattern;
public class ParsingForSpecificWord {
public static void main(String args[]) {
String str1 = "Hello how are you, welcome to Tutorialspoint";
String str2 = "Tutorialspoint";
if (str1.contains(str2)){
System.out.println("Search successful");
} else {
System.out.println("Search not successful");
}
}
}
Output
Search successful
The indexOf() method
The indexOf() method of the String class accepts a string value and finds the (starting) index of it in the current String and returns it. This method returns -1 if it doesn’t find the given string in the current one.
Example
Live Demo
public class ParsingForSpecificWord {
public static void main(String args[]) {
String str1 = "Hello how are you, welcome to Tutorialspoint";
String str2 = "Tutorialspoint";
int index = str1.indexOf(str2);
if (index>0){
System.out.println("Search successful");
System.out.println("Index of the word is: "+index);
} else {
System.out.println("Search not successful");
}
}
}
Output
Search successful Index of the word is: 30
The StringTokenizer class
Using the StringTokenizer class, you can divide a String into smaller tokens based on a delimiter and traverse through them. Following example tokenizes all the words in the source string and compares each word of it with the given word using the equals() method.
Example
Live Demo
import java.util.StringTokenizer;
public class ParsingForSpecificWord {
public static void main(String args[]) {
String str1 = "Hello how are you welcome to Tutorialspoint";
String str2 = "Tutorialspoint";
//Instantiating the StringTookenizer class
StringTokenizer tokenizer = new StringTokenizer(str1," ");
int flag = 0;
while (tokenizer.hasMoreElements()) {
String token = tokenizer.nextToken();
if (token.equals(str2)){
flag = 1;
} else {
flag = 0;
}
}
if(flag==1)
System.out.println("Search successful");
else
System.out.println("Search not successful");
}
}
Output
Search successful
Words in a sentence are separated by a space. All the methods to get the words of a sentence use this identification. Below are shown a couple of methods to get the words of a sentence entered by the user.
Method 1 : Using split method of java.lang.String
String class has a split()method which divides a string on the basis of the characters passed to this method and returns an array of string as a result of splitting. For Example, if split is called on string “codippa.com” and the argument passed is a “.” (dot), then the returned array will contain “codippa” and “com”. Note that the delimiter is not included in the returned string array.
In the below example, read a String from the user as input and call split()method on it with a space as its argument. Iterate over the array returned using a forloop. The length of this array will give the total number of words in the entered string.
static void usingStringSplit(){ Scanner scanner = new Scanner(System.in); System.out.println("Enter the sentence"); // input the sentence from the user String sentence = scanner.nextLine(); // split over space. Now we have array of words String[] words = sentence.split(" "); System.out.println("Words in the given sentence are :"); // iterate over the words for (String word : words) { System.out.println(word); } System.out.println("--------------------------------"); //length of the array is the word count System.out.println("Word count is :: " + words.length); scanner.close(); }
Output :
Enter the sentence
Welcome to codippa.com
Words in the given sentence are :
Welcome
to
codippa.com
——————————–
Word count is :: 3
Method 2 : Using java.util.StringTokenizer
java.util.StringTokenizerhas a constructor which takes a String and a delimiter on the basis of which it splits the string. The resultant sequence of characters are called tokens. For Example, if the string is “codippa.com” and the delimiter is a “.” (dot), then the tokens will be “codippa” and “com”. Note that the delimiter is not included in the tokens.
In the below example, read a String from the user as input and pass it to the constructor of java.util.StringTokenizerwith a space as delimiter. Iterate over the tokens returned using its nextToken()method. Tokens are retrieved till hasMoreTokens()method of StringTokenizer returns true. To get the total number of tokens returned by the StringTokenizer, its countTokens()method may be used.
static void usingStringTokenizer(){ Scanner scanner = new Scanner(System.in); System.out.println("Enter the sentence"); // input the sentence from the user String sentence = scanner.nextLine(); // split over space. Now we have array of words StringTokenizer tokenizer = new StringTokenizer(sentence, " "); int numberOfWords = tokenizer.countTokens(); while(tokenizer.hasMoreTokens()){ System.out.println(tokenizer.nextToken()); } System.out.println("--------------------------------"); //length of the array is the word count System.out.println("Word count is :: " + numberOfWords); scanner.close(); }
Output :
Enter the sentence
Welcome to codippa.com
Words in the given sentence are :
Welcome
to
codippa.com
——————————–
Word count is :: 3
Let’s tweak in:
java.util.StringTokenizerhas a constructor which takes a String as an argument. It uses the" tnrf": the space character, the tab character, the newline character, the carriage-return character, and the form-feed character as default delimiters and splits the supplied string on these characters.hasMoreElements()andnextElement()methods ofjava.util.StringTokenizermay also be used in place ofhasMoreTokens()andnextToken()methods.countTokens()method should be called before iterating over the tokens returned by each call tonextToken(). If called after iteration, it will return 0.split()method ofjava.lang.Stringtakes a regular expression and hence can also be used to split a string on numbers and various other patterns.
Have some more methods ? Don’t hesitate to write to us or add your comments.
Hello guys, if you are looking for a Java program to print the word and their count from a given file then you have come to the right place. Earlier, I have shared 100+ Data Strucutre and Algorithms Problems from interviews and in this article, I will show you how to find worlds and their count from a given file in Java. How to find the word and their count from a text file is another frequently asked coding question from Java interviews. The logic to solve this problem is similar to what we have seen in how to find duplicate words in a String, where we iterate through string and store word and their count on a hash table and increment them whenever we encounter the same word.
In the first step, you need to build a word Map by reading the contents of a Text File. This Map should contain words as a key and their count as value. Once you have this Map ready, you can simply sort the Map based upon values.
By the way, if you are new to Java Programming and not familiar with essential Data Structure and their implementation on Collection Farmwork then I highly recommend you to join a comprehensive Java course like The Complete Java Masterclass by Tim Buchalaka and his team on Udemy. This 80+ hour course is the most comprehensive and up-to-date course to learn Java online.
How to find the highest repeated word from a File in Java
Here is the Java program to find the duplicate word which has occurred a maximum number of times in a file. You can also print the frequency of words from highest to lowest because you have the Map, which contains the word and their count in sorted order. All you need to do is iterate over each entry of Map and print the keys and values.
The most important part of this solution is sorting all entries. Since Map.Entry doesn’t implement the Comparable interface, we need to write our own custom Comparator to sort the entries.
If you look at my implementation, I am comparing entries on their values because that’s what we want. Many programmers say that why not use the LinkedHashMap class? but remember, the LinkedHashMap class keeps the keys in sorted order, not the values. So you need this special Comparator to compare values and store them in List.
Here is one approach to solving this problem using the map-reduce technique. If you are not familiar with map-reduce and functional programming in Java then I highly recommend you to join Learn Java Functional Programming with Lambdas & Streams course on Udemy. It’s a great course to learn essential Functional Programming concepts and methods like map, flatmap, reduce, and filter in Java.
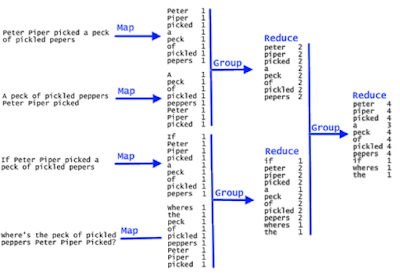
Java Program to Print word and their counts from a File
Here is our complete Java program to find and print the world their count from a given file. It also prints the world with the highest and lowest occurrence characters from the file as asked in given problem.
import java.io.BufferedReader; import java.io.DataInputStream; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.util.ArrayList; import java.util.Collections; import java.util.Comparator; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.Map.Entry; import java.util.Set; import java.util.StringTokenizer; import java.util.regex.Pattern; /** * Java program to find count of repeated words in a file. * * @author */ public class Problem { public static void main(String args[]) { Map<String, Integer> wordMap = buildWordMap("C:/temp/words.txt"); List<Entry<String, Integer>> list = sortByValueInDecreasingOrder(wordMap); System.out.println("List of repeated word from file and their count"); for (Map.Entry<String, Integer> entry : list) { if (entry.getValue() > 1) { System.out.println(entry.getKey() + " => " + entry.getValue()); } } } public static Map<String, Integer> buildWordMap(String fileName) { // Using diamond operator for clean code Map<String, Integer> wordMap = new HashMap<>(); // Using try-with-resource statement for automatic resource management try (FileInputStream fis = new FileInputStream(fileName); DataInputStream dis = new DataInputStream(fis); BufferedReader br = new BufferedReader( new InputStreamReader(dis))) { // words are separated by whitespace Pattern pattern = Pattern.compile("\s+"); String line = null; while ((line = br.readLine()) != null) { // do this if case sensitivity is not required i.e. Java = java line = line.toLowerCase(); String[] words = pattern.split(line); for (String word : words) { if (wordMap.containsKey(word)) { wordMap.put(word, (wordMap.get(word) + 1)); } else { wordMap.put(word, 1); } } } } catch (IOException ioex) { ioex.printStackTrace(); } return wordMap; } public static List<Entry<String, Integer>> sortByValueInDecreasingOrder( Map<String, Integer> wordMap) { Set<Entry<String, Integer>> entries = wordMap.entrySet(); List<Entry<String, Integer>> list = new ArrayList<>(entries); Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() { @Override public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) { return (o2.getValue()).compareTo(o1.getValue()); } }); return list; } } Output: List of repeated word from file and their count its => 2 of => 2 programming => 2 java => 2 language => 2
Tips for Solving Highest Repeating Characters Count Problem and Things to Remember
If your writing code on interviews make sure they are production quality code, which means you must handle as many errors as possible, you must write unit tests, you must comment on the code and you do proper resource management. Here are a couple of more points to remember:
1. Close files and streams once you are through with it, see this tutorial to learn the right way to close the stream. If you are in Java 7, just use the try-with-resource statement.
2. Since the size of the file is not specified, the interviewer may grill you on cases like What happens if the file is large? With a large file, your program will run out of memory and throw java.lang.OutOfMemory: Java Heap space.
One solution for this is to do this task in chunks like first read 20% content, find the maximum repeated word on that, then read the next 20% content, and find repeated maximum by taking the previous maximum into consideration. This way, you don’t need to store all words in memory and you can process any arbitrary length file.
3. Always use Generics for type safety. It will ensure that your program is correct at compile time rather than throwing Type related exceptions at runtime.
That’s all on how to find repeated words from a file and print their count. You can apply the same technique to find duplicate words in a String. Since now you have a sorted list of words and their count, you can also find the maximum, minimum, or repeated words which has counted more than the specified number.
Other Coding Problems from Interviews You can Practice
- How to find a missing number in a sorted array? (solution)
- How to find the square root of a number in Java? (solution)
- How to check if a given number is prime or not? (solution)
- 10 Free Courses to learn Data Structure and Algorithms (courses)
- How to find the highest occurring word from a text file in Java? (solution)
- 10 Books to learn Data Structure and Algorithms (books)
- How to find if given String is a palindrome in Java? (solution)
- How to reverse a given number in Java? (solution)
- How do you swap two integers without using the temporary variable? (solution)
- Write a program to check if a number is a power of two or not? (solution)
- How do you reverse the word of a sentence in Java? (solution)
- 10 Data Structure and Algorithms course to crack coding interview (courses)
- How to calculate the GCD of two numbers in Java? (solution)
- How to reverse String in Java without using StringBuffer? (solution)
- How to find duplicate characters from a given String? (solution)
- Top 10 Programming problems from Java Interviews? (article)
P. S. — If you are preparing for a coding interview, then you must prepare for essential coding patterns like sliding window and merge intervals which can be used to solve 100+ Leetcode problems. If you need resources then the Grokking the Coding Interview: Patterns for Coding Questions course can help you which contains 15 such patterns.