
В обычной жизни мы часто сталкиваемся с периодическими явлениями. Например, дневным циклом — солнце каждый день всходит и заходит. Или годовым — зима, весна, лето, осень сменяют друг друга. В программировании, чтобы описать повторяющиеся действия, тоже используют циклы — синтаксические конструкции, которые позволяют не писать один и тот же код много раз.
Общее о циклах
Конструкцию цикла можно описать так:
Условие завершения цикла — пока условие истинно, цикл будет выполняться.
Тело цикла — действия, которые мы хотим выполнить.
Рассмотрим несколько вариантов простейшего описания циклов в Java.
💡 Цикл while:
while(i<50) { //цикл будет выполняться, пока значение переменной i меньше 50.
i++; //увеличиваем значение переменной i на 1
System.out.println(i);
}
Условие завершения цикла может идти до или после его тела. Если условие цикла стоит после тела, то такой цикл называется циклом с постусловием. Его отличие от цикла с условием до тела в том, что минимум одна его итерация всегда будет выполнена.
💡 Цикл while с постусловием:
do {
i++;
System.out.println(i);
}while(i<50);
Тело цикла может содержать один или несколько операторов. Операторами могут быть и другие циклы, в таком случае они называются вложенными.
💡 Несколько вложенных циклов while:
while(i<50) {
while(j<5) {
j++;
System.out.println(i+j);
}
i++;
}
Цикл for
В примерах выше мы на каждой итерации увеличиваем значение переменной — индекса. И завершаем цикл, когда это значение достигает предела. В дополнение к полезным операциям в теле цикла приходится добавлять служебную операцию, чтобы контролировать поведение индекса. Еще при подобном алгоритме нужно отдельно описывать операцию инициализации индекса. Чтобы сделать описание подобных конструкций компактным и удобным, есть оператор цикла for.
💡 Синтаксис цикла for:
for(<начальное значение индекса>; <условие завершения цикла>; <операторы управления индексом>) {
// Тело цикла
}
💡 Пример цикла for:
for (int i=0;i<10;i++) {
// Полезные команды
}
Справка: переменную индекса в цикле for часто именуют i по первой букве английского слова index.
Этот пример — каноническое описание цикла for. Такая конструкция удобна при выполнении действий, например, с элементами массива:
int[] array = …
for (int i=0;i<array.length;i++) {
System.out.println(array[i]);
}
💡 Обратный цикл for
Индекс можно не только увеличивать, но и уменьшать. Такие циклы for называют обратными:
for (int i = array.length-1;i>=0;i--) {
System.out.println(array[i]);
}
💡 Цикл for с произвольным шагом
Необязательно изменять значение индекса именно на единицу. Шаг может быть любым:
for (int i=0;i<array.length;i+=3) {
System.out.println(array[i]);
}
💡 Вложенные циклы for
Два цикла for, где один цикл вложен в другой, позволяют легко работать с двумерными массивами — матрицами:
int[][] matrix = …
for (int i=0;i<matrix.length;i++) {
for(int j=0;j<matrix[i].length;j++) {
System.out.println(matrix[i][j]);
}
}

Иллюстрация работы программы
Ограничений на глубину вложенности циклов в компиляторе Java нет. Но избегайте большого количества вложенных друг в друга циклов, так как иначе усложните код программы.
💡 Бесконечные циклы for
Если условие завершения цикла будет всегда истинным, вы получите бесконечный цикл:
for(int i=0;true;i++) {
System.out.println(i);
}
В примере условие завершения всегда истинно — мы задали ему константное значение true. Поэтому цикл будет бесконечно увеличивать индексную переменную и печатать ее значение в консоли.
Выражения, задающие поведение оператора for, не относят к обязательным, их можно опустить. Оператор for будет таким:
for(;;) {
System.out.println(“wow”);
}
С точки зрения компилятора такое описание — допустимо, ошибки при запуске программы не будет. В результате вы опять получите бесконечно выполняющийся цикл, в теле которого нет доступа к индексной переменной.
❗ Бесконечные циклы for — вырожденные варианты описания логики программы, поэтому применяйте их только в специальных случаях. В обычных же ситуациях следите, чтобы условие завершения обязательно выполнялось на определенной итерации цикла. Неожиданные появления бесконечных циклов в логике программы приводят к тому, что приложение зависает и работает нестабильно. А еще к бесконтрольному потреблению ресурсов компьютера.
Операторы, изменяющие поведение цикла
Используйте оператор прерывания break, если хотите завершить цикл досрочно:
DayOfWeek dayOfWeek = LocalDate.now().getDayOfWeek();
for (int i = 0; i<10; i++) {
System.out.println(i);
if (dayOfWeek == DayOfWeek.MONDAY && i = 5) {
break;
}
}
Во все дни, кроме понедельника, программа напечатает цифры от нуля до девяти, а в понедельник — от нуля до пяти. Это произойдет, потому что оператор break завершит цикл досрочно — до того, как условие завершения вернет false.

Работа программы в среду

Работа программы в понедельник
Другой оператор, который меняет линейное выполнение команд в теле цикла, — continue. Он не прерывает цикл в целом, но сообщает программе, что нужно немедленно перейти к следующей итерации цикла:
DayOfWeek dayOfWeek = LocalDate.now().getDayOfWeek();
for (int i = 0; i<10; i++) {
if (dayOfWeek == DayOfWeek.FRIDAY && i = 5) {
continue;
}
System.out.println(i);
}
В примере программа тоже будет печатать цифры от нуля до девяти. Но если ее запустить в пятницу, то цифру пять она не напечатает: оператор continue укажет, что нужно начать новую итерацию цикла и пропустить операцию вывода на экран.

Работа программы во вторник

Работа программы в пятницу
Оператор foreach
Мы рассмотрели примеры цикла for, где полностью настраивали его поведение: задавали начальное значение индексной переменной, устанавливали шаг ее изменения, определяли условие завершения. Если же вы хотите перебрать элементы коллекции или массива и последовательно выполнить действия над каждым, начинайте с первого элемента (i=0).
Шаг будет равен единице. Завершать надо будет при достижении конца коллекции (i<array.length). А доступ к каждому следующему элементу получите путем прямого обращения к элементу массива. Для этого используют значение индексной переменной (array[i]). Но нужно будет опять писать однообразный служебный код, который не относится к логике программы.
Чтобы создавать подобные циклы было проще, в Java 1.6 добавили оператор foreach.
💡 Синтаксис оператора foreach:
for (<переменная>:<коллекция>) {
// Тело цикла
}
Коллекция — массив или объект-наследник класса Iterable, элементы которого нужно последовательно перебрать.
💡 Пример оператора foreach:
String[] words = new String[] {“Раз”, “Два”, “Три”};
for (String word: words) {
System.out.println(word);
}
В примере программа последовательно переберет все элементы массива words и напечатает их.
В теле foreach можно применять операторы break и continue: результат будет такой же, как и для обычного for.
Главное о цикле for в Java
- Это частный случай цикла while. Его применяют, когда число итераций известно программе до начала цикла.
- Значение переменной можно не только увеличивать, но и уменьшать — использовать обратный цикл for. Вложенные циклы for позволяют работать с двумерными массивами — матрицами.
- Оператор break нужен, чтобы досрочно завершить цикл. Оператор continue меняет линейное выполнение команд.
- Оператор foreach — это разновидность цикла for. Ее используют, когда нужно обработать все элементы массива или коллекции.

Java-разработчик: новая работа через 11 месяцев
Получится, даже если у вас нет опыта в IT
Узнать больше
Изучите Java на онлайн-курсе от Skypro «Java-разработчик». Будете учиться по видеоурокам и текстовым шпаргалкам, написанным понятным языком. Выполните задания в реальной среде, разберетесь с трудностями на живых вебинарах, напишете проект в команде. Получите диплом за реальные знания, которых ждут от вас работодатели.
Регулярные выражения
Последнее обновление: 25.06.2018

Регулярные выражения представляют мощный инструмент для обработки строк. Регулярные выражения позволяют задать шаблон,
которому должна соответствовать строка или подстрока.
Некоторые методы класса String принимают регулярные выражения и используют их для выполнения операций над строками.
split
Для разделения строки на подстроки применяется метод split(). В качестве параметра он может принимать регулярное выражение,
которое представляет критерий разделения строки.
Например, разделим предложение на слова:
String text = "FIFA will never regret it";
String[] words = text.split("\s*(\s|,|!|\.)\s*");
for(String word : words){
System.out.println(word);
}
Для разделения применяется регулярное выражение «\s*(\s|,|!|\.)\s*». Подвыражние «\s» по сути представляет пробел. Звездочка указывает, что символ может присутствовать от 0 до бесконечного количества раз.
То есть добавляем звездочку и мы получаем неопределенное количество идущих подряд пробелов — «\s*» (то есть неважно, сколько пробелов между словами). Причем пробелы может вообще не быть.
В скобках указывает группа выражений, которая может идти после неопределенного количества пробелов. Группа позволяет нам определить набо значений через вертикальную черту,
и подстрока должна соответствовать одному из этих значений. То есть в группе «\s|,|!|\.» подстрока может соответствовать пробелу,
запятой, восклицательному знаку или точке. Причем поскольку точка представляет специальную последовательность, то, чтобы указать, что мы имеем в виду имеено знак точки, а не специальную последовательность,
перед точкой ставим слеши.
Соответствие строки. matches
Еще один метод класса String — matches() принимает регулярное выражение и возвращает true, если строка соответствует
этому выражению. Иначе возвращает false.
Например, проверим, соответствует ли строка номеру телефона:
String input = "+12343454556";
boolean result = input.matches("(\+*)\d{11}");
if(result){
System.out.println("It is a phone number");
}
else{
System.out.println("It is not a phone number!");
}
В данном случае в регулярном выражение сначала определяется группа «(\+*)». То есть вначале может идти знак плюса, но также он может отсутствовать.
Далее смотрим, соответствуют ли последующие 11 символов цифрам. Выражение «\d» представляет цифровой символ, а число в фигурных скобках — {11} — сколько раз данный тип символов должен повторяться.
То есть мы ищем строку, где вначале может идти знак плюс (или он может отсутствовать), а потом идет 11 цифровых символов.
Класс Pattern
Большая часть функциональности по работе с регулярными выражениями в Java сосредоточена в пакете java.util.regex.
Само регулярное выражение представляет шаблон для поиска совпадений в строке. Для задания подобного шаблона и поиска подстрок в строке, которые удовлетворяют
данному шаблону, в Java определены классы Pattern и Matcher.
Для простого поиска соответствий в классе Pattern определен статический метод boolean matches(String pattern, CharSequence input).
Данный метод возвращает true, если последовательность символов input полностью соответствует шаблону строки pattern:
import java.util.regex.Pattern;
public class StringsApp {
public static void main(String[] args) {
String input = "Hello";
boolean found = Pattern.matches("Hello", input);
if(found)
System.out.println("Найдено");
else
System.out.println("Не найдено");
}
}
Но, как правило, для поиска соответствий применяется другой способ — использование класса Matcher.
Класс Matcher
Рассмотрим основные методы класса Matcher:
-
boolean matches(): возвращает true, если вся строка совпадает с шаблоном
-
boolean find(): возвращает true, если в строке есть подстрока, которая совпадает с шаблоном, и переходит к этой подстроке
-
String group(): возвращает подстроку, которая совпала с шаблоном в результате вызова метода find.
Если совпадение отсутствует, то метод генерирует исключениеIllegalStateException. -
int start(): возвращает индекс текущего совпадения
-
int end(): возвращает индекс следующего совпадения после текущего
-
String replaceAll(String str): заменяет все найденные совпадения подстрокой str и возвращает измененную строку с учетом замен
Используем класс Matcher. Для этого вначале надо создать объект Pattern с помощью статического метода compile(), который позволяет установить шаблон:
Pattern pattern = Pattern.compile("Hello");
В качестве шаблона выступает строка «Hello». Метод compile() возвращает объект Pattern, который мы затем можем использовать в программе.
В классе Pattern также определен метод matcher(String input), который в качестве параметра принимает строку, где надо проводить поиск, и возвращает
объект Matcher:
String input = "Hello world! Hello Java!";
Pattern pattern = Pattern.compile("hello");
Matcher matcher = pattern.matcher(input);
Затем у объекта Matcher вызывается метод matches() для поиска соответствий шаблону в тексте:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class StringsApp {
public static void main(String[] args) {
String input = "Hello";
Pattern pattern = Pattern.compile("Hello");
Matcher matcher = pattern.matcher(input);
boolean found = matcher.matches();
if(found)
System.out.println("Найдено");
else
System.out.println("Не найдено");
}
}
Рассмотрим более функциональный пример с нахождением не полного соответствия, а отдельных совпадений в строке:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class StringsApp {
public static void main(String[] args) {
String input = "Hello Java! Hello JavaScript! JavaSE 8.";
Pattern pattern = Pattern.compile("Java(\w*)");
Matcher matcher = pattern.matcher(input);
while(matcher.find())
System.out.println(matcher.group());
}
}
Допустим, мы хотим найти в строке все вхождения слова Java. В исходной строке это три слова: «Java», «JavaScript» и «JavaSE». Для этого
применим шаблон «Java(\w*)». Данный шаблон использует синтаксис регулярных выражений. Слово «Java» в начале говорит о том, что все совпадения в строке
должны начинаться на Java. Выражение (\w*) означает, что после «Java» в совпадении может находиться любое количество алфавитно-цифровых символов.
Выражение w означает алфавитно-цифровой символ, а звездочка после выражения указывает на неопределенное их количество — их может быть один, два, три или вообще не быть.
И чтобы java не рассматривала w как эскейп-последовательность, как n, то выражение экранируется еще одним слешем.
Далее применяется метод find() класса Matcher, который позволяет переходить к следующему совпадению в строке. То есть первый вызов
этого метода найдет первое совпадение в строке, второй вызов найдет второе совпадение и т.д. То есть с помощью цикла while(matcher.find())
мы можем пройтись по всем совпадениям. Каждое совпадение мы можем получить с помощью метода matcher.group(). В итоге
программа выдаст следующий результат:
Замена в строке
Теперь сделаем замену всех совпадений с помощью метода replaceAll():
String input = "Hello Java! Hello JavaScript! JavaSE 8.";
Pattern pattern = Pattern.compile("Java(\w*)");
Matcher matcher = pattern.matcher(input);
String newStr = matcher.replaceAll("HTML");
System.out.println(newStr); // Hello HTML! Hello HTML! HTML 8.
Также надо отметить, что в классе String также имеется метод replaceAll() с подобным действием:
String input = "Hello Java! Hello JavaScript! JavaSE 8.";
String myStr =input.replaceAll("Java(\w*)", "HTML");
System.out.println(myStr); // Hello HTML! Hello HTML! HTML 8.
Разделение строки на лексемы
С помощью метода String[] split(CharSequence input) класса Pattern можно разделить строку на массив подстрок по
определенному разделителю. Например, мы хотим выделить из строки отдельные слова:
import java.util.regex.Pattern;
public class StringsApp {
public static void main(String[] args) {
String input = "Hello Java! Hello JavaScript! JavaSE 8.";
Pattern pattern = Pattern.compile("[ ,.!?]");
String[] words = pattern.split(input);
for(String word:words)
System.out.println(word);
}
}
И консоль выведет набор слов:
Hello Java Hello JavaScript JavaSE 8
При этом все символы-разделители удаляются. Однако, данный способ разбивки не идеален: у нас остаются некоторые пробелы, которые расцениваются как лексемы, а не как разделители. Для более точной и изощренной разбивки нам следует применять элементы регулярных выражений.
Так, заменим шаблон на следующий:
Pattern pattern = Pattern.compile("\s*(\s|,|!|\.)\s*");
Теперь у нас останутся только слова:
Hello Java Hello JavaScript JavaSE 8
Далее мы подробнее рассмотрим синтаксис регулярных выражений и из каких элементов мы можем создавать шаблоны.
Для работы со строками в Java существует класс
String. И для
объявления новой строки можно использовать один из способов:
String str1 = "Java"; String str2 = new String(); // пустая строка String str3 = new String(new char[] {'h', 'e', 'l', 'l', 'o'}); String str4 = new String(new char[]{'w', 'e', 'l', 'c', 'o', 'm', 'e'}, 3, 4);
В последнем варианте 3 – это начальный
индекс (индексы считаются с нуля), а 4 – это кол-во символов. То есть, строка str4 содержит
строку «come».
Важной особенностью строк в Java является их неизменяемость.
Это значит, что в строке нельзя попросту изменить какой-либо символ и получить
другую строку. Все строки создаются и существуют в неизменном виде, пока не
будут уничтожены (как правило, автоматически сборщиком мусора). А переменные str1, str2, str3 и str4 следует
воспринимать лишь как ссылки на эти строки. То есть, в любой момент в программе
можно записать такую конструкцию:
что означает изменение ссылки str1 на строку «hello», на которую
указывает ссылка str3. Соответственно, если на первую строку «Java» не будет
указывать никакая ссылка, то она автоматически уничтожается.
У класса String есть несколько
полезных методов:
|
Название |
Описание |
|
length() |
возвращает |
|
toCharArray() |
возвращает |
|
isEmpty() |
определяет |
|
concat() |
объединяет |
|
valueOf() |
преобразует |
|
join() |
объединяет |
|
сompare() |
сравнивает |
|
charAt() |
возвращает |
|
getChars() |
возвращает |
|
equals() |
сравнивает |
|
equalsIgnoreCase() |
сравнивает |
|
regionMatches() |
сравнивает |
|
indexOf() |
находит |
|
lastIndexOf() |
находит |
|
startsWith() |
определяет, |
|
endsWith() |
определяет, |
|
replace() |
заменяет |
|
trim() |
удаляет |
|
substring() |
возвращает |
|
toLowerCase() |
переводит |
|
toUpperCase() |
переводит |
Разберем работу часто используемых
методов класса String. Первый метод, как написано, возвращает
длину строки. Например, если нам дана вот такая строка
то метод length() вернет значение 4
System.out.println(str1.length()); // 4
Далее, если к строке str2
применить метод toCharArray():
char[] helloArray = str1.toCharArray();
то получим массив символов с содержимым
этой строки. Следующий пример. У нас есть пустая строка
тогда мы можем определить это, например,
так:
if(s.length() == 0) System.out.println("String is empty");
или так:
if(s isEmpty()) System.out.println("String is empty");
Но, если строка задана вот так:
то это означает, что ссылка s не указывает ни
на какой класс String и, соответственно, мы не можем вызывать
методы этого класса. В этом случае проверку следует делать так:
if(s != null && s.length() == 0) System.out.println("String is empty");
мы здесь сначала проверяем: указывает ли
ссылка s на объект
класса и если это так, то только потом будет идти обращение к методу length().
Объединение строк
Для соединения строк можно использовать
операцию сложения («+»):
При этом если в операции сложения строк
используется не строковый объект, например, число, то этот объект преобразуется
к строке:
Еще один метод объединения — метод join() позволяет
объединить строки с учетом разделителя. Например, две строки
будут сливаться в одно слово «HelloJava», если их
объединить с помощью оператора +:
но если мы хотим, чтобы две подстроки при
соединении были разделены пробелом, то можно воспользоваться методом join() следующим
образом:
В общем случае вместо пробела здесь
можно ставить любой разделитель в виде строки.
Обратите внимание, что каждый раз при
объединении строк мы получали новую строку как результат объединения.
Извлечение символов и подстрок
Для извлечения
символов по индексу в классе String определен метод
char charAt(int
index)
Он принимает
индекс, по которому надо получить символов, и возвращает извлеченный символ:
String str = "Java"; char c = str.charAt(2); System.out.println(c); // v
(здесь как и в
массивах первый индекс равен 0).
Если надо
извлечь сразу группу символов или подстроку, то можно использовать метод
getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin)
Он принимает
следующие параметры:
-
srcBegin:
индекс строки, с которого начинается извлечение символов; -
srcEnd:
индекс строки, до которого идет извлечение символов; -
dst:
массив символов, в который будут извлекаться символы; -
dstBegin:
индекс массива dst, с которого надо добавлять извлеченные из строки символы.
String str = "Hello world!"; int start = 6; int end = 11; char[] dst=new char[end - start]; str.getChars(start, end, dst, 0); System.out.println(dst); // world
Сравнение строк
Для простого сравнения
строк используются методы equals() (с учетом регистра) и equalsIgnoreCase()
(без учета регистра). Оба метода в качестве параметра принимают строку, с
которой сравниваются:
String str1 = "Hello"; String str2 = "hello"; System.out.println(str1.equals(str2)); // false System.out.println(str1.equalsIgnoreCase(str2)); // true
Обратите
внимание, что в отличие сравнения числовых и других данных примитивных типов
для сравнения строк не рекомендуется использовать оператор ==. То есть,
записывать вот такое сравнение лучше не использовать:
if(str1 == str2) System.out.println("Сроки равны");
(хотя, оно тоже
будет работать). Вместо этого следует использовать метод equals() класса String.
Другая пара методов:
int compareTo(String str) и int compareToIgnoreCase(String str)
также сравнивают
строки между собой, но в отличие от equals() они еще
позволяют узнать больше ли одна строка другой или нет. Если возвращаемое
значение этих методов больше 0, то первая строка больше второй, если меньше
нуля, то, наоборот, вторая больше первой. Если строки равны, то возвращается 0.
Для определения
больше или меньше одна строка, чем другая, используется лексикографический
порядок. То есть, например, строка «A» меньше, чем строка
«B», так как символ ‘A’ в алфавите стоит перед символом ‘B’. Если
первые символы строк равны, то в расчет берутся следующие символы. Например:
String str1 = "hello"; String str2 = "world"; String str3 = "hell"; System.out.println(str1.compareTo(str2)); // -15 - str1 меньше чем str2 System.out.println(str1.compareTo(str3)); // 1 - str1 больше чем str3 System.out.println(str1.compareTo(str1)); // 0 - str1 равна str1
Еще один
специальный метод
regionMatches()
сравнивает
отдельные подстроки в пределах двух строк. Он имеет такие реализации:
boolean
regionMatches(int toffset, String other, int oofset, int len)
boolean
regionMatches(boolean ignoreCase, int toffset, String other, int oofset, int
len)
-
ignoreCase:
надо ли игнорировать регистр символов при сравнении (если значение true, то регистр
игнорируется); -
toffset:
начальный индекс в вызывающей строке, с которого начнется сравнение; -
other:
строка, с которой сравнивается вызывающая; -
oofset: начальный
индекс в сравниваемой строке, с которого начнется сравнение; -
len: количество
сравниваемых символов в обеих строках.
Например, ниже в
строке str1 сравнивается
подстрока wor с подстрокой wor строки str2:
String str1 = "Hello world"; String str2 = "I work"; boolean result = str1.regionMatches(6, str2, 2, 3); System.out.println(result); // true
Поиск в строке
Метод indexOf() находит
индекс первого вхождения подстроки в строку, а метод lastIndexOf() — индекс
последнего вхождения. Если подстрока не будет найдена, то оба
метода возвращают -1:
String str = "Hello world"; int index1 = str.indexOf('l'); // 2 int index2 = str.indexOf("wo"); //6 int index3 = str.lastIndexOf('l'); //9 System.out.println(index1+" "+index2+" "+index3);
Метод startsWith() позволяют
определить начинается ли строка с определенной подстроки, а метод endsWith() позволяет
определить заканчивается строка на определенную подстроку:
String str = "myfile.exe"; boolean start = str.startsWith("my"); //true boolean end = str.endsWith("exe"); //true System.out.println(start+" "+end);
Замена в строке
Метод replace() позволяет
заменить в строке одну последовательность символов на другую:
String str = "Hello world"; String replStr1 = str.replace('l', 'd'); // Heddo wordd String replStr2 = str.replace("Hello", "Bye"); // Bye world System.out.println(replStr1); System.out.println(replStr2);
Обрезка строк
Метод trim()
позволяет удалить начальные и конечные пробелы:
String str = " hello world "; str = str.trim(); // hello world System.out.println(str);
Метод
substring() возвращает подстроку, начиная с определенного индекса до конца или
до определенного индекса:
String str = "Hello world"; String substr1 = str.substring(6); // world String substr2 = str.substring(3,5); //lo System.out.println(substr1); System.out.println(substr2);
Изменение регистра
Метод
toLowerCase() переводит все символы строки в нижний регистр, а метод
toUpperCase() — в верхний:
String str = "Hello World"; System.out.println(str.toLowerCase()); // hello world System.out.println(str.toUpperCase()); // HELLO WORLD
Разбиение строки на подстроки
Метод split()
позволяет разбить строку на подстроки по определенному разделителю. Разделитель
– это какой-нибудь символ или набор символов (передается в качестве параметра).
Например, разобьем текст на отдельные слова (учитывая, что слова разделены
пробелом):
String text = "Я люблю язык Java!"; String[] words = text.split(" "); for(String word : words) System.out.println(word);
Видео по теме
Это вовсе не ошибка, это вывод Вашего результата. Дело в том, что Java не умеет выводить массив в том виде, в котором Вы хотите. Если попытаться вывести объект массива просто через System.out.println();, он выводит некое описание объекта.
Во-первых, нужно из метода split удалить ненужный цикл, который не делает ничего.
Во-вторых, нужно сделать вывод всех полученных слов через цикл.
public class Main
{
public static String[] split(String s){
String [] array = s.split(" ");
return array;
}
public static void main(String[] args) {
System.out.println("Hello World");
String s = "I am learning java";
// Сохраняем результат разделения
String[] words = split(s);
// Перебираем каждый элемент массива
for(String word : words) {
System.out.println(word);
}
}
}
UPD:
Чтобы решение удовлетворяло условию того, что может быть несколько пробелов подряд нужно отфильтровать то, что вернёт метод String.split(), так как, при разделении по пробелам строки, содержащей множество пробелов, она вернёт массив, где будут тоже пробелы.
Приведу следующее решение. нужно импортировать пакет import java.util.*;
Далее, то, что возвращает метод s.split(" ") приводим к листу и этот лист фильтруем, посредством вызова метода filter((x -> !x.isEmpty()), что означает, вернуть только не пустые элементы списка (листа). Далее уже приводим результат к массиву строк toArray(String[]::new) и этот результат уже возвращаем.
import java.util.*;
public class Main
{
public static String[] split(String s){
List<String> words = Arrays.asList(s.split(" "));
String[] filtered = words.stream().filter((x -> !x.isEmpty())).toArray(String[]::new);
return filtered;
}
public static void main(String[] args) {
System.out.println("Hello World");
String s = "I am learning java many spaces";
// Сохраняем результат разделения
String[] words = split(s);
// Перебираем каждый элемент массива
for(String word : words) {
System.out.println(word);
}
}
}
Теперь даже на строку с множеством пробелом между словами "I am learning java many spaces" он вернёт массив строк, который содержит только отдельные слова.
Более тривиальное решение, без использования лямбда-функциий, но с использованием коллекций, а конкретнее, ArrayList — динамического массива.
import java.util.ArrayList;
public class Main
{
public static String[] split(String s){
// сначала разделяем по пробелу и получаем массив
String[] splitted = s.split(" ");
// Далее, создаём пустой лист
ArrayList<String> words = new ArrayList<String>();
for (String row : splitted) {
// проверяем каждое значение, не пустое ли оно и сохраняем только слова
if (!row.isEmpty()) words.add(row);
}
String[] result = new String[words.size()];
words.toArray(result);
return result;
}
public static void main(String[] args) {
System.out.println("Hello World");
String s = "I am learning java many spaces";
// Сохраняем результат разделения
String[] words = split(s);
// Перебираем каждый элемент массива
for(String word : words) {
System.out.println(word);
}
}
}
Ну и в итоге — самое примитивное решение, без использования сложных методов, коллекций и лямбда-выражений, но с лишними циклами и дейсвтиями по подсчёту слов.
public class Main
{
public static String[] split(String s){
String[] splitted = s.split(" ");
int wordsNumber = 0;
for (String row : splitted) {
// Подсчитываем сколько слов, без учёта пробелов
if (!row.isEmpty()) wordsNumber++;
}
String[] words = new String[wordsNumber];
int i = 0;
for (String row : splitted) {
// Теперь их сохраняем в массив слов
if (!row.isEmpty()) {
words[i] = row;
i++;
}
}
return words;
}
public static void main(String[] args) {
System.out.println("Hello World");
String s = "I am learning java many spaces";
// Сохраняем результат разделения
String[] words = split(s);
// Перебираем каждый элемент массива
for(String word : words) {
System.out.println(word);
}
}
}
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
Java program to print all unique words present in the string. The task is to print all words occurring only once in the string.
Illustration:
Input : Welcome to Geeks for Geeks.
Output : Welcome
to
for
Input : Java is great.Python is also great.
Output : Java
Python
also
Methods:
This can be done in the following ways:
- Using nested loops
- Using Map
- Using frequency() method of Collections
Naive approach: Using nested loops
The idea to count the occurrence of the string in the string and print if count equals one
- Extract words from string using split() method and store them in an array.
- Iterate over the word array using for loop.
- Use another loop to find the occurrence of the current word the array.
- If the second occurrence is found increment count and set the word to “”
- If the count of the current word is equal to one print it
Example:
Java
public class GFG {
static void printUniqueWords(String str)
{
int count;
String[] words = str.split("\W");
for (int i = 0; i < words.length; i++) {
count = 1;
for (int j = i + 1; j < words.length; j++) {
if (words[i].equalsIgnoreCase(words[j])) {
count++;
words[j] = "";
}
}
if (count == 1 && words[i] != "")
System.out.println(words[i]);
}
}
public static void main(String[] args)
{
String str = "Welcome to geeks for geeks";
printUniqueWords(str);
}
}
Note: Time complexity is of order n^2 where space complexity is of order n
Method 2: Using Map
Approach: The idea is to use Map to keep track of words already occurred. But first, we have to extract all words from a String, as a string may contain many sentences with punctuation marks.
- Create an empty Map.
- Extract words from string using split() method and store them in an array.
- Iterate over the word array.
- Check if the word is already present in the Map or not.
- If a word is present in the map, increment its value by one.
- Else store the word as the key inside the map with value one.
- Iterate over the map and print words whose value is equal to one.
Example:
Java
import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.Map;
public class GFG {
static void printUniqueWords(String str)
{
HashMap<String, Integer> map
= new LinkedHashMap<String, Integer>();
String[] words = str.split("\W");
for (String word : words) {
if (map.containsKey(word)) {
map.put(word, map.get(word) + 1);
}
else
map.put(word, 1);
}
for (Map.Entry<String, Integer> entry :
map.entrySet()) {
if (entry.getValue() == 1)
System.out.println(entry.getKey());
}
}
public static void main(String[] args)
{
String str = "Welcome to geeks for geeks";
printUniqueWords(str);
}
}
Note: Time complexity is of the order of n where space complexity is of order n. Hence, it is the optimal approach.
Method 3 : Using Collections.frequency() . If the occurrence of word in string is 1 , then the word is unique.
Java
import java.util.*;
public class Main{
public static void main(String[] args)
{
String str = "Welcome to geeks for geeks";
String[] words = str.split("\W");
List<String> al = new ArrayList<>(Arrays.asList(words));
for(String x:al) {
if(Collections.frequency(al,x)==1){
System.out.println(x);
}
}
}
}
Like Article
Save Article
В этой статье мы рассмотрим операции со строкой и подстрокой. Вы узнаете, как соединять и сравнивать строки, как извлекать символы и подстроки, как выполнять поиск в строке.
Соединение строк в Java
Чтобы соединить строки в Java, подойдёт операция сложения «+»:
String str1 = "Java"; String str2 = "Hi"; String str3 = str1 + " " + str2; System.out.println(str3); // Hi JavaЕсли же в предстоящей операции сложения строк будет применяться нестроковый объект, допустим, число, данный объект преобразуется к строке:
String str3 = "Год " + 2020;По факту, когда мы складываем строки с нестроковыми объектами, вызывается метод valueOf() класса String. Этот метод преобразует к строке почти все типы данных. Чтобы преобразовать объекты разных классов, valueOf вызывает метод toString() данных классов.
Объединять строки можно и с помощью concat():
String str1 = "Java"; String str2 = "Hi"; str2 = str2.concat(str1); // HiJavaМетод принимает строку, с которой нужно объединить вызывающую строку, возвращая нам уже соединённую строку.
Также мы можем использовать метод join(), позволяющий объединять строки с учетом разделителя. Допустим, две строки выше слились в слово «HiJava», однако мы бы хотели разделить подстроки пробелом. Тут и пригодится join():
String str1 = "Java"; String str2 = "Hi"; String str3 = String.join(" ", str2, str1); // Hi JavaМетод join — статический. Первый параметр — это разделитель, который будет использоваться для разделения подстрок в общей строке. Последующие параметры осуществляют передачу через запятую произвольного набора объединяемых подстрок — в нашем случае их две, но можно и больше.
Извлекаем символы и подстроки в Java
Чтобы извлечь символы по индексу, в классе String есть метод char charAt(int index). Этот метод принимает индекс, по которому необходимо получить символы, возвращая извлеченный символ:
String str = "Java"; char c = str.charAt(2); System.out.println(c); // vОбратите внимание, что индексация начинается с нуля, впрочем, как и в массивах.
Если же нужно извлечь сразу группу символов либо подстроку, подойдёт getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin). Этот метод принимает ряд параметров:
• srcBegin: индекс в нашей строке, с которого осуществляется начало извлечения символов;
• srcEnd: индекс в нашей строке, до которого осуществляется извлечение символов;
• dst: массив символов (именно в него будут эти символы извлекаться);
• dstBegin: индекс в массиве dst (с него надо добавлять символы, извлечённые из строки).String str = "Hi world!"; int start = 6; int end = 11; char[] dst=new char[end - start]; str.getChars(start, end, dst, 0); System.out.println(dst); // worldСравниваем строки в Java
Мы уже писали о том, как сравнивать строки в Java, используя для этого метод equals() (регистр учитывается) и equalsIgnoreCase() (регистр не учитывается). Хотелось бы сказать пару слов про ещё одну пару методов: int compareTo(String str) и int compareToIgnoreCase(String str) — они позволяют не только сравнить 2 строки, но и узнать, больше ли одна другой. Если значение, которое возвращается, больше 0, первая строка больше, если меньше нуля, всё наоборот. Когда обе строки равны, вернётся ноль.
Для определения используется лексикографический порядок. Допустим, строка «A» меньше строки «B», ведь символ ‘A’ в алфавите находится перед символом ‘B’. Когда первые символы строк равны, в расчёт берутся следующие символы. К примеру:
String str1 = "hello"; String str2 = "world"; String str3 = "hell"; System.out.println(str1.compareTo(str2)); // -15 - str1 меньше, чем strt2 System.out.println(str1.compareTo(str3)); // 1 - str1 больше, чем str3Поиск в строке в Java
Чтобы найти индекс первого вхождения подстроки в строку, используют метод indexOf(), последнего — метод lastIndexOf(). Если подстрока не найдена, оба метода вернут -1:
String str = "Hello world"; int index1 = str.indexOf('l'); // 2 int index2 = str.indexOf("wo"); //6 int index3 = str.lastIndexOf('l'); //9Чтобы определить, начинается строка с определённой подстроки, применяют метод startsWith(). Что касается метода endsWith(), то он даёт возможность определить оканчивается ли строка на определенную подстроку:
String str = "myfile.exe"; boolean start = str.startsWith("my"); //true boolean end = str.endsWith("exe"); //trueВыполняем замену в строке в Java
Заменить в нашей строке одну последовательность символов другой можно с помощью метода replace():
String str = "Hello world"; String replStr1 = str.replace('l', 'd'); // Heddo wordd String replStr2 = str.replace("Hello", "Bye"); // Bye worldОбрезаем строки в Java
Для удаления начальных и конечных пробелов применяют метод trim():
String str = " hello world "; str = str.trim(); // hello worldТакже существует метод substring() — он возвращает подстроку, делая это с какого-нибудь конкретного индекса до конца либо до определённого индекса:
String str = "Hello world"; String substr1 = str.substring(6); // world String substr2 = str.substring(3,5); //loМеняем регистр в Java
При необходимости вы можете перевести все символы вашей строки в нижний регистр (toLowerCase()) или в верхний (toUpperCase()):
String str = "Hello World"; System.out.println(str.toLowerCase()); // hello world System.out.println(str.toUpperCase()); // HELLO WORLDSplit
С помощью этого метода вы сможете разбить строку на подстроки по конкретному разделителю. Под разделителем понимается какой-либо символ либо набор символов, передаваемые в метод в качестве параметра. Давайте для примера разобьём небольшой текст на отдельные слова:
String text = "OTUS is a good company"; String[] words = text.split(" "); for(String word : words){ System.out.println(word); }В нашем случае строка разделится по пробелу, и мы получим следующий консольный вывод:
Вот и всё! Узнать больше всегда можно на наших курсах:
При написании статьи использовались материалы:
1. «Java-примеры: найти последнее вхождение подстроки в строке».
2. «Основные операции со строками».

Программирование, Алгоритмы, Разработка, JAVA, Блог компании Luxoft
Рекомендация: подборка платных и бесплатных курсов Python — https://katalog-kursov.ru/
Сегодня я хотел бы поговорить о коллекциях в Java. Это тема встречается практически на любом техническом интервью Java разработчика, однако далеко не все разработчики в совершенстве освоили все коллекции даже стандартной библиотеки, не говоря уже о всех библиотеках с альтернативными реализациями коллекций, таких как guava, apache, trove и ряд других. Давайте посмотрим какие вообще коллекции можно найти в мире Java и какие методы работы с ними существуют.
Эта статья полезна как для начинающих (чтобы получить общее понимание что такое коллекции и как с ними работать), так и для более опытных программистов, которые возможно найдут в ней что-то полезное или просто структурируют свои знания. Собственно, главное чтобы у вас были хотя бы базовые знания о коллекциях в любом языке программирования, так как в статье не будет объяснений что такое коллекция в принципе.
I. Стандартная библиотека коллекций Java
Естественно, практически все и так знают основные коллекции в JDK, но все-таки вспомним о них, если вы уверены, что и так все знаете о стандартных коллекциях можете смело пропускать все что в спойлерах до следующего раздела.
Замечание о коллекциях для начинающих
Иногда достаточно сложно для начинающих (особенно если они перешли из других языков программирования) понять, что в коллекции Java хранятся только ссылки/указатели и ничего более. Им кажется, что при вызове add или put объекты действительно хранятся где-то внутри коллекции, это верно только для массивов, когда они работают с примитивными типами, но никак не для коллекций, которые хранят только ссылки. Поэтому очень часто на вопросы собеседований вроде «А можно ли назвать точный размер коллекции ArrayList» начинающие начинают отвечать что-то вроде «Зависит от типа объектов что в них хранятся». Это совершенно не верно, так коллекции никогда не хранят сами объекты, а только ссылки на них. Например, можно в List добавить миллион раз один и то же объект (точнее создать миллион ссылок на один объект).
1) Интерфейсы коллекций JDK
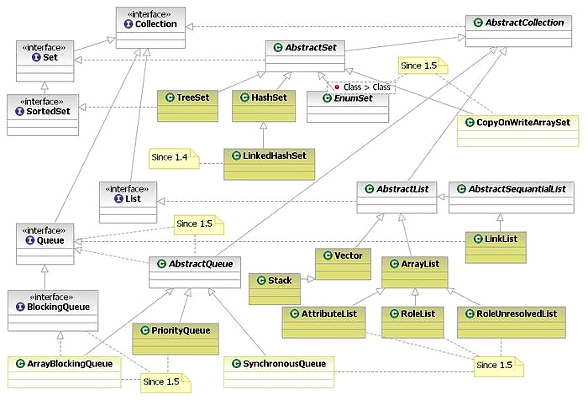
Интерфейсы коллекций JDK
Интерфейсы коллекций
| Название | Описание |
|---|---|
| Iterable | Интерфейс означающий что у коллекции есть iterator и её можно обойти с помощью for(Type value:collection). Есть почти у всех коллекций (кроме Map) |
| Collection | Основной интерфейс для большинства коллекций (кроме Map) |
| List | Список это упорядоченная в порядке добавления коллекция, так же известная как последовательность (sequence). Дублирующие элементы в большинстве реализаций — разрешены. Позволяет доступ по индексу элемента. Расширяет Collection интерфейс. |
| Set | Интерфейс реализующий работу с множествами (похожими на математические множества), дублирующие элементы запрещены. Может быть, а может и не быть упорядоченным. Расширяет Collection интерфейс. |
| Queue | Очередь — это коллекция, предназначенная для хранения объектов до обработки, в отличии от обычных операций над коллекциями, очередь предоставляет дополнительные методы добавление, получения и просмотра. Быстрый доступ по индексу элемента, как правило, не содержит. Расширяет Collection интерфейс |
| Deque | Двухсторонняя очередь, поддерживает добавление и удаление элементов с обоих концов. Расширяет Queue интерфейс. |
| Map | Работает со соответствием ключ — значение. Каждый ключ соответствует только одному значению. В отличие от других коллекций не расширяет никакие интерфейсы (в том числе Collection и Iterable) |
| SortedSet | Автоматически отсортированное множество, либо в натуральном порядке (для подробностей смотрите Comparable интерфейс), либо используя Comparator. Расширяет Set интерфейс |
| SortedMap | Это map’а ключи которой автоматически отсортированы, либо в натуральном порядке, либо с помощью comparator’а. Расширяет Map интерфейс. |
| NavigableSet | Это SortedSet, к которому дополнительно добавили методы для поиска ближайшего значения к заданному значению поиска. NavigableSet может быть доступен для доступа и обхода или в порядке убывания значений или в порядке возрастания. |
| NavigableMap | Это SortedMap, к которому дополнительно добавили методы для поиска ближайшего значения к заданному значению поиска. Доступен для доступа и обхода или в порядке убывания значений или в порядке возрастания. |
Интерфейсы из пакета java.util.concurrent
| Название | Описание |
|---|---|
| BlockingQueue | Многопоточная реализация Queue, содержащая возможность задавать размер очереди, блокировки по условиях, различные методы, по-разному обрабатывающие переполнение при добавлении или отсутствие данных при получении (бросают exception, блокируют поток постоянно или на время, возвращают false и т.п.) |
| TransferQueue | Эта многопоточная очередь может блокировать вставляющий поток, до тех пор, пока принимающий поток не вытащит элемент из очереди, таким образом с её помощью можно реализовывать синхронные и асинхронные передачи сообщений между потоками |
| BlockingDeque | Аналогично BlockingQueue, но для двухсторонней очереди |
| ConcurrentMap | Интерфейс, расширяет интерфейс Map. Добавляет ряд новых атомарных методов: putIfAbsent, remove, replace, которые позволяют облегчить и сделать более безопасным многопоточное программирование. |
| ConcurrentNavigableMap | Расширяет интерфейс NavigableMap для многопоточного варианта |
Если вам интересны более подробная информация о интерфейсах и коллекциях из java.util.concurrent советую
прочитать вот эту статью.
2) Таблица с очень кратким описанием всех коллекций
Таблица с очень кратким описанием всех коллекций
| Тип | Однопоточные | Многопоточные |
|---|---|---|
| Lists |
|
|
|
Queues / Deques |
|
|
| Maps |
|
|
| Sets |
|
|
* — на самом деле, BitSet хоть и называется Set’ом, интерфейс Set не наследует.
3) Устаревшие коллекции в JDK
Устаревшие коллекции Java
Универсальные коллекции общего назначения, которые признаны устаревшими (legacy)
| Имя | Описание |
|---|---|
| Hashtable | Изначально задумывался как синхронизированный аналог HashMap, когда ещё не было возможности получить версию коллекции используя Collecions.synchronizedMap. На данный момент как правило используют ConcurrentHashMap. HashTable более медленный и менее потокобезопасный чем синхронный HashMap, так как обеспечивает синхронность на уровне отдельных операций, а не целиком на уровне коллекции. |
| Vector | Раньше использовался как синхронный вариант ArrayList, однако устарел по тем же причинам что и HashTable. |
| Stack | Раньше использовался как для построения очереди, однако поскольку построен на основе Vector, тоже считается морально устаревшим. |
Специализированные коллекции, построенные на устаревших (legacy) коллекциях
| Имя | Основан на | Описание |
|---|---|---|
| Properties | Hashtable | Как структура данных, построенная на Hashtable, Properties довольно устаревшая конструкция, намного лучше использовать Map, содержащий строки. Подробнее почему Properties не рекомендуется использовать можно найти в этом обсуждении. |
| UIDefaults | Hashtable | Коллекция, хранящая настройки по умолчанию для Swing компонент |
4) Коллекции, реализующие интерфейс List (список)
Коллекции, реализующие интерфейс List (список)
Универсальные коллекции общего назначения, реализующие List:
| Название | Основан на |
Описание | Размер* |
|---|---|---|---|
| ArrayList | List | Реализация List интерфейса на основе динамически изменяемого массива. В большинстве случаев, лучшая возможная реализация List интерфейса по потреблению памяти и производительности. В крайне редких случаях, когда требуются частые вставки в начало или середину списка с очень малым количеством перемещений по списку, LinkedList будет выигрывать в производительности (но советую в этих случаях использовать TreeList от apache). Если интересны подробности ArrayList советую посмотреть эту статью. |
4*N |
| LinkedList | List | Реализация List интерфейса на основе двухстороннего связанного списка, то есть когда каждый элемент, указывает на предыдущий и следующий элемент. Как правило, требует больше памяти и хуже по производительности, чем ArrayList, имеет смысл использовать лишь в редких случаях когда часто требуется вставка/удаление в середину списка с минимальными перемещениями по списку (но советую в этих случаях использовать TreeList от apache).Так же реализует Deque интерфейс. При работе через Queue интерфейс, LinkedList действует как FIFO очередь. Если интересны подробности LinkedList советую посмотреть эту статью. | 24*N |
Коллекции из пакета java.util.concurrent
| Название | Основан на |
Описание |
|---|---|---|
| CopyOnWriteArrayList | List | Реализация List интерфейса, аналогичная ArrayList, но при каждом изменении списка, создается новая копия всей коллекции. Это требует очень больших ресурсов при каждом изменении коллекции, однако для данного вида коллекции не требуется синхронизации, даже при изменении коллекции во время итерирования. |
Узкоспециализированные коллекции на основе List.
| Название | Основан на | Описание |
|---|---|---|
| RoleList | ArrayList | Коллекция для хранения списка ролей (Roles). Узкоспециализированная коллекция основанная на ArrayList с несколькими дополнительными методами |
| RoleUnresolvedList | ArrayList | Коллекция для хранения списка unresolved ролей (Unresolved Roles). Узкоспециализированная коллекция основанная на ArrayList с несколькими дополнительными методами |
| AttributeList | ArrayList | Коллекция для хранения атрибутов MBean. Узкоспециализированная коллекция основанная на ArrayList с несколькими дополнительными методами |
* — размер дан в байтах для 32 битных систем и Compressed Oops, где N это capacity списка
5) Коллекции, реализующие интерфейс Set (множество)
Коллекции, реализующие интерфейс Set (множество)
| Название | Основан на |
Описание | Размер* |
|---|---|---|---|
| HashSet | Set | Реализация Set интерфейса с использованием хеш-таблиц. В большинстве случаев, лучшая возможная реализация Set интерфейса. | 32*S + 4*C |
| LinkedHashSet | HashSet | Реализация Set интерфейса на основе хеш-таблиц и связанного списка. Упорядоченное по добавлению множество, которое работает почти так же быстро как HashSet. В целом, практически тоже самое что HashSet, только порядок итерирования по множеству определен порядком добавления элемента во множество в первый раз. |
40 * S + 4*C |
| TreeSet | NavigableSet | Реализация NavigableSet интерфейса, используя красно-черное дерево. Отсортировано с помощью Comparator или натурального порядка, то есть обход/итерирование по множеству будет происходить в зависимости от правила сортировки. Основано на TreeMap, так же как HashSet основан на HashMap | 40 * S |
| EnumSet | Set | Высокопроизводительная реализация Set интерфейса, основанная на битовом векторе. Все элементы EnumSet объекта должны принадлежать к одному единственному enum типу | S/8 |
* — размер дан в байтах для 32 битных систем и Compressed Oops, где С это capacity списка, S это size списка
Узкоспециализированные коллекции на основе Set
| Название | Основан на |
Описание |
|---|---|---|
| JobStateReasons | HashSet | Коллекция для хранения информации о заданиях печати (print job’s attribute set). Узкоспециализированная коллекция основанная на HashSet с несколькими дополнительными методами |
Коллекции из пакета java.util.concurrent
| Название | Основан на |
Описание |
|---|---|---|
| CopyOnWriteArraySet | Set | Аналогично CopyOnWriteArrayList при каждом изменении создает копию всего множества, поэтому рекомендуется при очень редких изменениях коллекции и требованиях к thread-safe |
| ConcurrentSkipListSet | Set | Является многопоточным аналогом TreeSet |
6) Коллекции, реализующие интерфейс Map (ассоциативный массив)
Коллекции, реализующие Map интерфейс
Универсальные коллекции общего назначения, реализующие Map:
| Название | Основан на |
Описание | Размер* |
|---|---|---|---|
| HashMap | Map | Реализация Map интерфейса с помощью хеш-таблиц (работает как не синхронная Hashtable, с поддержкой ключей и значений равных null). В большинстве случаев лучшая по производительности и памяти реализация Map интерфейса. Если интересны подробности устройства HashMap советую посмотреть эту статью. |
32 * S + 4*C |
| LinkedHashMap | HashMap | Реализация Map интерфейса, на основе хеш-таблицы и связного списка, то есть ключи в Map’е хранятся и обходятся во порядке добавления. Данная коллекция работает почти так же быстро как HashMap. Так же она может быть полезна для создания кешей (смотрите removeEldestEntry(Map.Entry) ). Если интересны подробности устройства LinkedHashMap советую посмотреть эту статью. |
40 * S + 4*C |
| TreeMap | NavigableMap | Реализация NavigableMap с помощью красно-черного дерева, то есть при обходе коллекции, ключи будут отсортированы по порядку, так же NavigableMap позволяет искать ближайшее значение к ключу. |
40 * S |
| WeakHashMap | Map | Аналогична HashMap, однако все ключи являются слабыми ссылками (weak references), то есть garbage collected может удалить объекты ключи и объекты значения, если других ссылок на эти объекты не существует. WeakHashMap один из самых простых способов для использования всех преимуществ слабых ссылок. |
32 * S + 4*C |
| EnumMap | Map | Высокопроизводительная реализация Map интерфейса, основанная на простом массиве. Все ключи в этой коллекции могут принадлежать только одному enum типу. |
4*C |
| IdentityHashMap | Map | Identity-based Map, так же как HashMap, основан на хеш-таблице, однако в отличии от HashMap он никогда не сравнивает объекты на equals, только на то является ли они реально одиним и тем же объектом в памяти. Это во-первых, сильно ускоряет работу коллекции, во-вторых, полезно для защиты от «spoof attacks», когда сознательно генерируется объекты equals другому объекту. В-третьих, у данной коллекции много применений при обходе графов (таких как глубокое копирование или сериализация), когда нужно избежать обработки одного объекта несколько раз. |
8*C |
* — размер дан в байтах для 32 битных систем и Compressed Oops, где С это capacity списка, S это size списка
Коллекции из пакета java.util.concurrent
| Название | Основан на |
Описание |
|---|---|---|
| ConcurrentHashMap | ConcurrentMap | Многопоточный аналог HashMap. Все данные делятся на отдельные сегменты и блокируются только отдельные сегменты при изменении, что позволяет значительно ускорить работу в многопоточном режиме. Итераторы никогда не кидают ConcurrentModificationException для данного вида коллекции |
| ConcurrentSkipListMap | ConcurrentNavigableMap | Является многопоточным аналогом TreeMap |
7) Коллекции, основанные на интерфейсах Queue/Deque (очереди)
Коллекции, основанные на Queue/Deque
| Название | Основан на |
Описание | Размер* |
|---|---|---|---|
| ArrayDeque | Deque | Эффективная реализация Deque интерфейса, на основе динамического массива, аналогичная ArrayList |
6*N |
| LinkedList | Deque | Реализация List и Deque интерфейса на основе двухстороннего связанного списка, то есть когда каждый элемент, указывает на предыдущий и следующий элемент.При работе через Queue интерфейс, LinkedList действует как FIFO очередь. | 40*N |
| PriorityQueue | Queue | Неограниченная priority queue, основанная на куче (нeap). Элементы отсортированы в натуральном порядке или используя Comparator. Не может содержать null элементы. |
* — размер дан в байтах для 32 битных систем и Compressed Oops, где С это capacity списка, S это size списка
Многопоточные Queue и Deque, который определены в java.util.concurrent, требуют отдельной статьи, поэтому здесь приводить их не буду, если вам интересна информация о них советую прочитать вот эту статью
 Прочие коллекции
Прочие коллекции
Прочие коллекции
| Название | Описание | Размер* |
|---|---|---|
| BitSet | Несмотря на название, BitSet не реализует интерфейс Set. BitSet служит для компактной записи массива битов. | N / 8 |
9) Методы работы с коллекциями
Методы работы с коллекциями
Алгоритмы- В классе Collections содержится много полезных статистических методов.
Для работы с любой коллекцией:
| Метод | Описание |
|---|---|
| frequency(Collection, Object) | Возвращает количество вхождений данного элемента в указанной коллекции |
| disjoint(Collection, Collection) | Возвращает true, если в двух коллекциях нет общих элементов |
| addAll(Collection<? super T>, T…) | Добавляет все элементы из указанного массива (или перечисленные в параметрах) в указанную коллекцию |
| min(Collection) | Возвращение минимального элемента из коллекции |
| max(Collection) | Возвращение максимального элемента из коллекции |
Для работы со списками:
| Метод | Описание |
|---|---|
| sort(List) | Сортировка с использованием алгоритма сортировки соединением (merge sort algorithm), производительность которой в большинстве случаев близка к производительности быстрой сортировки (high quality quicksort), гарантируется O(n*log n) производительность (в отличии от quicksort), и стабильность (в отличии от quicksort). Стабильная сортировка это такая которая не меняет порядок одинаковых элементов при сортировке |
| binarySearch(List, Object) | Поиск элемента в списке (list), используя binary search алгоритм. |
| reverse(List) | Изменение порядка всех элементов списка (list) |
| shuffle(List) | Перемешивание всех элементов в списке в случайном порядке |
| fill(List, Object) | Переписывание каждого элемента в списке каким-либо значением |
| copy(List dest, List src) | Копирование одного списка в другой |
| rotate(List list, int distance) | Передвигает все элементы в списке на указанное расстояние |
| replaceAll(List list, Object oldVal, Object newVal) | Заменяет все вхождения одного значения на другое |
| indexOfSubList(List source, List target) | Возвращает индекс первого вхождения списка target в список source |
| lastIndexOfSubList(List source, List target) | Возвращает индекс последнего вхождения списка target в список source |
| swap(List, int, int) | Меняет местами элементы, находящиеся на указанных позициях |
В Java 8 так же появился такой способ работы с коллекциями как stream Api, но мы рассмотрим примеры его использование далее в разделе 5.
10) Как устроенны разные типы коллекций JDK внутри
Как устроенны разные типы коллекций JDK внутри
| Коллекция | Описание внутреннего устройства |
|---|---|
| ArrayList | Данная коллекция лишь настройка над массивом + переменная хранящая size списка. Внутри просто массив, который пересоздается каждый раз когда нет места для добавления нового элемента. В случае, добавления или удаления элемента внутри коллекции весь хвост сдвигается в памяти на новое место. К счастью, копирование массива при увеличении емкости или при добавлении/удалении элементов производится быстрыми нативными/системными методами. Если интересны подробности советую посмотреть эту статью. |
| LinkedList | Внутри коллекции используется внутренний класс Node, содержащий ссылку на предыдущий элемент, следующий элемент и само значение элемента. В самом инстансе коллекции хранится размер и ссылки на первый и последний элемент коллекции. Учитывая что создание объекта дорогое удовольствие для производительности и затратно по памяти, LinkedList чаще всего работает медленно и занимает намного больше памяти чем аналоги. Обычно ArrayList, ArrayDequery лучшее решение по производительности и памяти, но в некоторых редких случаях (частые вставки в середину списка с редкими перемещениями по списку), он может быть быть полезен (но в этом случае полезнее использовать TreeList от apache). Если интересны подробности советую посмотреть эту статью. |
| HashMap | Данная коллекция построена на хеш-таблице, то есть внутри коллекции находится массив внутреннего класса (buket) Node равный capacity коллекции. При добавлении нового элемента вычисляться его хеш-функция, делиться на capacity HashMap по модулю и таким образом вычисляется место элемента в массиве. Если на данном месте ещё не храниться элементов создается новый объект Node с ссылкой на добавляемый элемент и записывается в нужное место массива. Если на данном месте уже есть элемент/ы (происходит хеш-коллизия), то так Node является по сути односвязным списком, то есть содержит ссылку на следующий элемент, то можно обойти все элементы в списке и проверить их на equals добавляемому элементу, если этот такого совпадение не найдено, то создается новый объект Node и добавляется в конец списка. В случае, если количество элементов в связном списке (buket) становится более 8 элементов, вместо него создается бинарное дерево. Подробнее о хеш таблицах смотрите вики (в HashMap используется метод цепочек для разрешения коллизий). Если интересны подробности устройства HashMap советую посмотреть эту статью. |
| HashSet | HashSet это просто HashMap, в которую записывается фейковый объект Object вместо значения, при этом имеет значение только ключи. Внутри HashSet всегда хранится коллекция HashMap. |
| IdentityHashMap | IdentityHashMap это аналог HashMap, но при этом не требуется элементы проверять на equals, так как разными считаются любые два элементы. указывающие на разные объекты. Благодаря этому удалось избавится от внутреннего класса Node, храня все данные в одном массиве, при этом при коллизиях ищется подходящая свободная ячейка до тех пор пока не будет найдена (метод открытой адресации).Подробнее о хеш таблицах смотрите вики (в IdentityHashMap используется метод открытой адресации для разрешения коллизий) |
| LinkedHashMap/LinkedHashSet | Внутренняя структура практически такая же как при HashMap, за исключением того что вместо внутреннего класса Node, используется TreeNode, которая знает предыдущее и следующее значение, это позволяет обходить LinkedHashMap по порядку добавления ключей. По сути, LinkedHashMap = HashMap + LinkedList. Если интересны подробности устройства LinkedHashMap советую посмотреть эту статью. |
| TreeMap/TreeSet | Внутренняя структура данных коллекций построена на сбалансированным красно-черным деревом, подробнее о нем можно почитать в вики |
| WeakHashMap | Внутри все организовано практически как в HashMap, за исключением что вместо обычных ссылок используются WeakReference и есть отдельная очередь ReferenceQueue, необходимая для удаления WeakEntries |
| EnumSet/EnumMap | В EnumSet и EnumMap в отличие от HashSet и HashMap используются битовые векторы и массивы для компактного хранения данных и ускорения производительности. Ограничением этих коллекций является то что EnumSet и EnumMap могут хранить в качестве ключей только значения одного Enum’а. |
11) Другие полезные сущности стандартной библиотеки коллекций
Другие полезные сущности стандартной библиотеки коллекций
Давайте посмотрим какие ещё полезные сущности содержит официальный гайд по коллекциями
1) Wrapper implementations – Обертки для добавления функциональности и изменения поведения других реализаций. Доступ исключительно через статистические методы.
- Collections.unmodifiableInterface– Обертка для создания не модифицируемой коллекции на основе указанной, при любой попытки изменения данной коллекции будет выкинут UnsupportedOperationException
- Collections.synchronizedInterface– Создания синхронизированной коллекции на основе указанной, до тех пор пока доступ к базовой коллекции идет через коллекцию-обертку, возвращенную данной функцией, потокобезопасность гарантируется.
- Collections.checkedInterface – Возвращает коллекцию с проверкой правильности типа динамически
(во время выполнения), то есть возвращает type-safe view для данной коллекции, который
выбрасывает ClassCastException при попытке добавить элемент ошибочного типа. При использовании
механизма generic’ов JDK проверяет на уровне компиляции соответствие типов, однако этот механизм
можно обойти, динамическая проверка типов не позволяет воспользоваться этой возможностью.
2) Adapter implementations – данная реализация адаптирует один интерфейс коллекций к другому
- newSetFromMap(Map) – Создает из любой реализации Set интерфейса реализацию Map интерфейса.
- asLifoQueue(Deque) — возвращает view из Deque в виде очереди работающей по принципу Last In First Out (LIFO).
3) Convenience implementations – Высокопроизводительные «мини-реализации» для интерфейсов коллекций.
- Arrays.asList – Позволяет отобразить массив как список (list)
- emptySet, emptyList и emptyMap – возвращает пустую не модифицированную реализацию empty set, list, or
map - singleton, singletonList и singletonMap – возвращает не модифицируемый set, list или map, содержащий один заданный объект (или одно связь ключ-значение)
- nCopies – Возвращает не модифицируемый список, содержащий n копий указанного объекта
4) Абстрактные реализации интерфейсов — Реализация общих функций (скелета коллекций) для упрощения создания конкретных реализаций коллекций.
- AbstractCollection – Абстрактная реализация интерфейса Collection для коллекций, которые не являются ни множеством, ни списком (таких как «bag» или multiset).
- AbstractSet — Абстрактная реализация Set интерфейса.
- AbstractList – Абстрактная реализация List интерфейса для списков, позволяющих позиционный доступ (random access), таких как массив.
- AbstractSequentialList – Абстрактная реализация List интерфейса, для списков, основанных на последовательном доступе (sequential access), таких как linked list.
- AbstractQueue — Абстрактная Queue реализация.
- AbstractMap — Абстрактная Map реализация.
4) Инфраструктура
- Iterators – Похожий на обычный Enumeration интерфейс, но с большими возможностями.
- Iterator – Дополнительно к функциональности Enumeration интерфейса, который включает возможности по удалению элементов из коллекции.
- ListIterator – это Iterator который используется для lists, который добавляет к функциональности обычного Iterator интерфейса, такие как итерация в обе стороны, замена элементов, вставка элементов, получение по индексу.
5) Ordering
- Comparable — Определяет натуральный порядок сортировки для классов, которые реализуют их. Этот порядок может быть использован в методах сортировки или для реализации sorted set или map.
- Comparator — Represents an order relation, which can be used to sort a list or maintin order in a sorted set or map. Can override a type’s natural ordering or order objects of a type that does not implement the Comparable interface.
6) Runtime exceptions
- UnsupportedOperationException – Это ошибка выкидывается когда коллекция не поддерживает операцию, которая была вызвана.
- ConcurrentModificationException – Выкидывается iterators или list iterators, если коллекция на которой он основан была неожиданно (для алгоритма) изменена во время итерирования, также выкидывается во views основанных на списках, если главный список был неожиданно изменен.
7) Производительность
- RandomAccess — Интерфейс-маркер, который отмечает списки позволяющие быстрый (как правило за константное время) доступ к элементу по позиции. Это позволяет генерировать алгоритмы учитывающие это поведение для выбора последовательного и позиционного доступа.
Утилиты для работы с массивами
- Arrays – Набор статических методов для сортировки, поиска, сравнения, изменения размера, получения хеша для массива. Так же содержит методы для преобразования массива в строка и заполнения массива примитивами или объектами.
II. Краткий обзор сторонних библиотек коллекций
Итак, Я хотел бы сделать обзор следующих сторонних библиотек: guava, apache, trove и gs-collections. Почему именно эти библиотеки? Guava и Apache Commons Collections очень популярны и встречались мне почти в любом Java проекте, Trove — тоже очень популярная библиотека, когда нужно уменьшить память и улучшить производительность работы с коллекциями. GS-collections — судя по оценкам весьма популярная библиотека на github’e (>1300 звезд), больше неё набрала «звезд» только guava. Так же мельком захвачу несколько других популярных библиотек.
Итак, для начала рассмотрим что предлагают различные библиотеки, их главные фишки (Предупреждение: это очень субъективно, для кого-то главными фишками будут совсем другие возможности библиотек).
2.1 Фишки разных библиотек коллекций
Давайте сделаем небольшой обзор главных фишек (на мой взгляд) разных библиотек коллекций:
1) Guava — данная коллекция от гугл практически самая популярная после стандартного фреймворка коллекций, она
добавляет ряд интересных коллекций, но самая главная «фишка» это скорее богатый набор классов-утилит со статическими
методами, расширяющими возможности Collections для работы со стандартными коллекциями, чем новые виды коллекций.
Стандартные коллекции она практически не заменяет.
2) Apache Commons Collections — данная коллекция ближайший «конкурент» guava, она так же предоставляет ряд
интересных коллекций, утилит по работе со стандартными коллекциями Java, а так же большое количество wrapper’ов для
изменения поведения коллекций. Кроме того она предоставляет свою реализацию map’ы с более простым механизм
итерирования по ней.
3) Trove — фишка данной коллекции в первую очередь в производительности и сокращении памяти, поэтому она
предлагает более быстрые реализации стандартных коллекций (и требующие меньше памяти), а так же коллекции
примитивных типов.
4) GS-collections — фишка данной коллекции в идее объединить методы обработки, такие как сортировка и классы
коллекций для создания замены использования статических методов классов-утилит. Данная библиотека предлагает замену
практически всех стандартным коллекциям и добавляет несколько новых.
III. Альтернативные виды коллекций в разных библиотеках
Тут я попробую кратко рассмотреть, какие новые интересные виды коллекций можно найти в разных библиотеках:
3.1 Альтернативные виды коллекций у Guava
Официальная информация: документация, исходные коды, javadoc.
Как подключить к проекту:
Maven, Gradle
Maven
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>18.0</version>
</dependency>
Gradle
dependencies {
compile 'com.google.guava:guava:18.0'
}
Гугл разработал ряд интересных дополнений к существующим коллекциям, которые весьма и весьма полезны, если вы можете
использовать guava библиотеку в своем проекте. Можно сказать, что эти коллекции давно уже стали стандартом де-факто
для большинства Java проектов, поэтому для любого опытного разработчика важно знать их, даже если он по каким-то
причинам не может использовать их в своих проектах, зачастую на собеседованиях можно услышать вопросы по guava
коллекциям.
Давайте рассмотрим их поподробнее. Для начала рассмотрим интерфейсы основных коллекций и группы классов в guava.
Внимание: если таблица не помещается целиком, попробуйте уменьшить масштаб страницы или открыть в другом браузере.
| Название | Описание | Примеры реализаций | Примеры использования |
|---|---|---|---|
| ImmutableCollection ImmutableList ImmutableSet … и т.д. |
Хотя в стандартном фреймворке Java коллекций есть возможность сделать коллекцию неизменяемой вызвав Collections.unmodifiableCollection (unmodifiableList или unmodifiableMap), но этот подход не самый оптимальный, так как отдельный тип для неизменяемых коллекций позволяет быть уверенным, что это коллекция действительно неизменяемая, вместо ошибок времени исполнения, при попытке изменить коллекцию, будут ошибки во время компиляции проекта, к тому же в стандартном фреймворке коллекций Java неизменяемые коллекции по-прежнему тратят ресурсы на поддержку синхронизации при многопоточном чтении и т. п. операциях, в то время как ImmutableCollection guava «знают» что они неизменяемые и оптимизированы с учетом этого. |
JDK: ImmutableCollection, ImmutableList, ImmutableSet, ImmutableSortedSet, ImmutableMap, ImmutableSortedMap Guava: ImmutableMultiset, ImmutableSortedMultiset, ImmutableMultimap, ImmutableListMultimap, ImmutableSetMultimap, ImmutableBiMap, ImmutableClassToInstanceMap, ImmutableTable |
— если публичный метод возвращает коллекцию, которую гарантировано не должны менять другие классы, — если известно что значения коллекции больше никогда не должны меняться |
| Multiset | Коллекция аналогичная Set, но позволяющая дополнительно считать количество добавлений элемента. Очень полезна для тех задач, когда нужно не только знать есть ли данный элемент в данном множестве, но и посчитать их количество (самый простой пример подсчет количества упоминаний тех или иных слов в каком-либо тексте). То есть данная коллекция более удобный вариант коллекции Map<T, Integer>, с методами специально предназначенными для подобных коллекций, позволяет очень сильно сократить количество лишнего кода в таких случаях. |
HashMultiset, TreeMultiset, LinkedHashMultiset, ConcurrentHashMultiset, ImmutableMultiset SortedMultiset |
— подсчет кол-ва вхождений слов в тексте — подсчет кол-ва букв в тексте — подсчет кол-ва любых объектов |
| Multimap | Практически любой опытный Java разработчик сталкивался с необходимостью использовать структуры вроде Map<K, List<V>> или Map<K,Set<V>>, при этом приходилось писать много лишнего кода, для упрощения работы в библиотеку guava были введены Multimap, то есть коллекции, позволяющие просто работать со случаями когда один ключ и много значений у этого ключа. В отличии от конструкций вроде Map<K,Set<V>>, Multimap предоставляет ряд удобных функций для сокращения кода и упрощения алгоритмов. |
ArrayListMultimap, HashMultimap, LinkedListMultimap, LinkedHashMultimap, TreeMultimap, ImmutableListMultimap, ImmutableSetMultimap |
— реализация отношений один ко многим, таких как: учитель — ученики отдель — работники начальник — подчиненные |
| BiMap | Достаточно часто встречаются ситуации, когда требуется создать Map’у работающую в обе стороны, то есть когда ключ и значение могут меняться местами (например, русско-английский словарь, когда в одном случае требуется получить по русскому слову — английское, в другом наоброт по английскому-русское). Обычно, это решается созданием двух Map, где в одной будет ключ1-ключ2, в другой ключ2-ключ1). BiMap позволяет решить эту задачу с помощью лишь одной коллекции. К тому же это исключает проблемы и ошибки синхронизации при использовании двух коллекций. |
HashBiMap, ImmutableBiMap, EnumBiMap, EnumHashBiMap |
— словарь для перевода с одного языка в другой и обратно, — любая конвертация данных в обе стороны, |
| Table | Эта коллекция служит для замены коллекций вида Map<FirstName, Map<LastName, Person>>, которые неудобны в использовании. |
HashBasedTable, TreeBasedTable, ImmutableTable, ArrayTable |
— таблица, например, как в Excel — любые сложные структуры данных с большим количеством столбцов, |
| ClassToInstanceMap | Иногда нужно хранить в Map’e не ключ-значение, а тип-значение этого типа, для этого служит данная коллекция. То есть это технически это более удобный и безопасный аналог Map <Class <? extends B>, B> |
MutableClassToInstanceMap, ImmutableClassToInstanceMap. |
|
| RangeSet | Коллекция для хранения разных открытых и закрытых отрезков числовых значений, при этом отрезки могут объединятся с друг другом. |
ImmutableRangeSet, TreeRangeSet |
Геометрические отрезки Временные отрезки |
| RangeMap | Коллекция, похожая на RangeSet, но при этом отрезки никогда не объединяются друг с другом. | ImmutableRangeMap, TreeRangeMap |
Геометрические отрезки Временные отрезки |
| LoadingCache | Коллекция, похожая на ConcurrentMap, но при этом можно указать время какое будет хранится каждый элемент. Очень удобная коллекция для организации кэшей, подсчета количества ввода ошибочных паролей за какой-то промежуток времени и т.п. задач |
ForwardingLoadingCache, ForwardingLoadingCache.SimpleForwardingLoadingCache |
кэши, хранение ошибочных попыток ввода пароля и т.п. |
3.2 Новые виды коллекций из Apache Commons Collections
Официальная информация: документация, исходные коды, документация пользователя, javadoc.
Как подключить к проекту:
Мaven,Gradle,Ivy
Maven
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-collections4</artifactId>
<version>4.0</version>
</dependency>
Gradle
'org.apache.commons:commons-collections4:4.0'
Ivy
<dependency org="org.apache.commons" name="commons-collections4" rev="4.0"/>
Внимание: если таблица не помещается целиком, попробуйте уменьшить масштаб страницы или открыть в другом браузере.
| Название | Описание | Примеры реализаций | Примеры использования |
|---|---|---|---|
| Unmodifiable | Интерфейс аналогичный Immutable классам guava | UnmodifiableBag, UnmodifiableBidiMap, UnmodifiableCollection, UnmodifiableList, UnmodifiableMap и т.п. |
во всех случаях когда нужно создать не модифицированную коллекцию |
| IterableMap | Аналог интерфейса Map, но позволяющий итерироваться по Map напрямую без создания entry set. Используется почти во всех реализациях Map в данной библиотеке. |
HashedMap, LinkedMap, ListOrderedMap и ряд других |
Такие же как у обычной map’ы |
| OrderedMap | Позволяет создавать Map’ы, упорядоченные по порядку добавления, но не использующие сортировку | LinkedMap, ListOrderedMap |
В случаях, когда обычно используется отдельно List и отдельно Map’а |
| BidiMap | Аналог BiMap из Guava, то есть возможность получать значение по ключу, так и ключ по значению | TreeBidiMap, DualHashBidiMap, DualLinkedHashBidiMap, DualTreeBidiMap и т.п. |
Любые конвертации один к одному, которые требуется выполнять в обе стороны |
| Bags | Аналог Multiset из Guava, то есть возможность сохранять количество элементов каждого типа | CollectionBag, HashBag, SynchronizedBag, TreeBag и другие |
подсчет кол-ва любых объектов |
| BoundedCollection, BoundedMap |
Позволяет создавать динамические коллекции, ограниченные каким-то размером сверху | CircularFifoQueue, FixedSizeList, FixedSizeMap, LRUMap |
в случае, когда вы точно знаете что в коллекции не может быть больше определенного количества элементов |
| MultiMap | Аналог Multimap из Guava, то есть возможность сохранять множество элементов для одного ключа | MultiValueMap | для коллекций со связями один ключ – много значений |
| Trie | Коллекция для создания и хранения упорядоченных деревьев | PatriciaTrie | создание деревьев |
| TreeList | Замена ArrayList и LinkedList, если требуется вставить элемент в середину списка, так как в данном списке данные хранятся в виде дерева, что позволяет с одной стороны относительно быстро получать данные по индексу, с другой стороны быстро вставлять данные в середину списка. | TreeList | замена LinkedList при частых добавлениях/ударениях в середине списка |
3.3 Trove коллекции
В отличии от остальных библиотек альтернативных коллекций, Trove не предлагает никакие новые уникальные виды
коллекций, зато предлагает оптимизацию существующих:
Во-первых, как известно, примитивные типы Java нельзя добавить в стандартные коллекции, только их обертки, что резко
увеличивает занимаемую память и несколько ухудшает производительность коллекций. Trove предлагает набор коллекций,
ключи и значения которых могут содержать примитивные типы.
Во-вторых, стандартные коллекции часто реализованы не самым оптимальным способом по потреблению памяти, например, каждый элемент HashMap храниться в отдельном объекте, а HashSet это HashMap хранящая фейковые объекты вместо ключей. Trove предлагает свои реализации таких коллекций на основе массивов и открытой адресации, что позволяет значительно сократить требуемую память и в некоторых случаях улучшить производительность.
Update: В комментариях, к статье было высказано мнение что Trove плохо использовать в новых проектах, так как он по всех параметрам уступает fastutil или GS (кол-во багов, полнота покрытия интерфейсов, производительность, активность поддержки, и т. д.). К сожалению, у меня нет возможности сейчас провести полноценный анализ/сравнение Trove с fastutil и GS, поэтому не могу проверить данное мнение, просто учитывайте его при выборе библиотеки альтернативных коллекций.
Официальная информация: документация, исходные коды, javadoc.
Как подключить к проекту:
Maven, Gradle, Ivy
Maven
<dependency>
<groupId>net.sf.trove4j</groupId>
<artifactId>trove4j</artifactId>
<version>3.0.3</version>
</dependency>
Gradle
'net.sf.trove4j:trove4j:3.0.3'
Ivy
<dependency org="net.sf.trove4j" name="trove4j" rev="3.0.3"/>
| Название | Аналог JDK | Описание |
|---|---|---|
| THashMap | HashMap | Реализация Map интерфейса, которая использует хеш-таблицу с алгоритмом «открытой адресации» для разрешения коллизий (в отличии от HashMap где используется метод цепочек). Это позволяет не хранить и не создавать объекты класса Node, при этом сильно экономится память и, в некоторых случаях, улучшается производительность. |
| THashSet | HashSet | Реализация Set интерфейса, которая использует хеш-таблицу с алгоритмом «открытой адресации» для разрешения коллизий |
| TLinkedHashSet | LinkedHashSet | Аналог LinkedHashSet, но используя хеш-таблицы с алгоритмом «открытой адресации» |
| TLinkedList | LinkedList | Более производительный аналог связного списка, однако накладывающий ряд ограничений на данные. |
| TByteArrayList, TIntArrayList и т.п. |
ArrayList | Аналог ArrayList, который непосредственно хранит примитивные числовые значения, что резко сокращает затраты памяти и ускоряет обработку. Есть коллекции для всех семи примитивных числовых типов, шаблон наименования T[Тип]ArrayList |
| TCharLinkedList, TFloatLinkedList и т.п. |
LinkedList | Аналог LinkedList для хранения семи примитивных числовых типов, шаблон наименования T[Тип]LinkedList |
| TByteArrayStack, TLongArrayStack |
ArrayDequery | Реализация стека для хранения примитивных числовых типов, шаблон наименования T[Тип]LinkedList |
| TIntQueue, TCharQueue |
ArrayDequery | Реализация очереди для хранения примитивных числовых типов, шаблон наименования T[Тип]Queue |
| TShortHashSet, TDoubleHashSet |
HashSet | Реализация Set интерфейса для хранения примитивных типов, с алгоритмом открытой адресации, шаблон наименования T[Тип]HashSet |
| TLongLongHashMap, TFloatObjectHashMap, TShortObjectHashMap и т.п. |
HashMap | Реализация Map интерфейса для хранения примитивных типов, с алгоритмом открытой адресации, шаблон наименования T[Тип][Тип]HashMap, где тип может быть Object |
3.4 GS-collections коллекции
Основная фишка данной библиотеке в том что нелогично и некрасиво то что методы обработки коллекций (сортировки, поиска) не добавлены в сами классы коллекций, а используется Collections.sort и т.п. методы, поэтому GS-collections предложили идею «богатых» коллекций (rich collections), которые хранят в себе все методы обработки, поиска, сортировки, то есть вместо Collections.sort(list) вызывается просто list.sort. Поэтому библиотека предлагает свои аналоги стандартных коллекций и дополнительно ряд новых коллекций.
Официальная информация: документация, исходные коды, документация пользователя, javadoc.
Как подключить к проекту:
Мaven,Gradle,Ivy
Maven
<dependency>
<groupId>com.goldmansachs</groupId>
<artifactId>gs-collections-api</artifactId>
<version>6.2.0</version>
</dependency>
<dependency>
<groupId>com.goldmansachs</groupId>
<artifactId>gs-collections</artifactId>
<version>6.2.0</version>
</dependency>
<dependency>
<groupId>com.goldmansachs</groupId>
<artifactId>gs-collections-testutils</artifactId>
<version>6.2.0</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.goldmansachs</groupId>
<artifactId>gs-collections-forkjoin</artifactId>
<version>6.2.0</version>
</dependency>
Gradle
compile 'com.goldmansachs:gs-collections-api:6.2.0'
compile 'com.goldmansachs:gs-collections:6.2.0'
testCompile 'com.goldmansachs:gs-collections-testutils:6.2.0'
compile 'com.goldmansachs:gs-collections-forkjoin:6.2.0'
Ivy
<dependency org="com.goldmansachs" name="gs-collections-api" rev="6.2.0" />
<dependency org="com.goldmansachs" name="gs-collections" rev="6.2.0" />
<dependency org="com.goldmansachs" name="gs-collections-testutils" rev="6.2.0" />
<dependency org="com.goldmansachs" name="gs-collections-forkjoin" rev="6.2.0"/>
| Название | Аналог JDK | Описание |
|---|---|---|
| FastList | ArrayList | Аналог ArrayList с возможностью использовать функции вроде sort, select и т.п. прямо у объекта коллекции |
| UnifiedSet | HashSet | Аналог HashSet. См FastList |
| TreeSortedSet | TreeSet | Аналог TreeSet. См FastList |
| UnifiedMap | HashMap | Аналог HashMap. См FastList |
| TreeSortedMap | TreeMap | Аналог TreeMap. См FastList |
| HashBiMap | — | Реализация BiMap, см. Guava |
| HashBag | — | Реализация Multiset, см. Guava |
| TreeBag | — | Реализация отсортированного BiMap, см. Guava |
| ArrayStack | ArrayDeque | Реализация стека с порядком «last-in, first-out», похожего на класс Stack JDK |
| FastListMultimap | — | Реализация Multimap, см. Guava |
| IntArrayList, FloatHashSet, ArrayStack, HashBag, ByteIntHashMap |
— | Коллекции примитивных различных типов, принцип наименования такой же как у trove, но кроме аналогов JDK, так же существуют аналоги коллекций Stack, Bag |
3.5 Fastutil коллекции
Давайте очень кратко рассмотрим эту библиотеку для работы с коллекциями примитивных типов.
Подробнее можно найти информацию: документация, исходные коды, javadoc
| Название | Описание |
|---|---|
| Byte2DoubleOpenHashMap, IntArrayList, IntArrayPriorityQueue и т.п. |
Коллекции различных примитивных типов, принцип наименования [Тип]ArrayList, [Тип]ArrayPriorityQueue и т.п. для списков или множеств, и [ТипКлюча]2[ТипЗначения]OpenHashMap и т.п. для Map. |
| IntBigList, DoubleOpenHashBigSet и т.п. |
Коллекции различных примитивных типов очень Большого размера, эти коллекции позволяют использовать long элементов, вместо int. Внутри данные, как правило, хранятся как массивы массивов. Не рекомендуется использовать подобные коллекции там где хватит обычных, так как потери производительности могут достигать примерно 30%, однако такие коллекции позволяют работать с действительно большим количеством данных |
3.6 Прочие библиотеки коллекций и немного о производительности примитивных коллекций
Кроме Trove и Fastutil есть ещё несколько известных библиотек, реализующих коллекции примитивных типов и более быстрые аналоги стандартных коллекций:
1) HPPC — High Performance Primitive Collections for Java, так же предоставляет примитивные коллекции аналогичные коллекциям из JDK,
2) Koloboke (другое имя HFTC) — как можно понять из имени эту библиотеку примитивных типов разработал русский программист (Roman Leventov) в рамках проекта OpenHFT. Библиотека так же служит для реализации высокопроизводительных примитивных коллекций.
Если интересно сравнение производительности разных библиотек советую посмотреть эту статью, только нужно учитывать, что тестировали только коллекции HashMap и в определенных условиях. К тому же, замеряли только скорость работы, не учитывая занимаемую память (например, HashMap jdk могут занимать намного больше памяти чем аналоги от trove), а иногда память может быть даже более важной чем производительность.
Update: В комментариях, к статье было высказано мнение что Trove плохо использовать в новых проектах, так как он по всех параметрам уступает fastutil или GS (кол-во багов, полнота покрытия интерфейсов, производительность, активность поддержки, и т. д.). К сожалению, у меня нет возможности сейчас провести полноценный анализ/сравнение Trove с fastutil и GS, поэтому не могу проверить данное мнение, просто учитывайте его при выборе библиотеки альтернативных коллекций.
IV. Сравнение реализации самых популярных альтернативных коллекций в разных библиотеках
4.1 Реализация мультимножества (MultiSet/Bag) в библиотеках guava, Apache Commons Collections и GS
Collections
Итак, мультимножество это множество, которое сохраняет не только факт наличие элементов в множестве, но и количество
вхождений в него. В JDK его можно эмулировать конструкцией Map
<T, Integer>, но, естественно, специализированные коллекции позволяют использовать значительно меньше кода. Сравним
какие реализации данной коллекции предлагают разные библиотеки:
Внимание: если таблица не помещается целиком, попробуйте уменьшить масштаб страницы или открыть в другом браузере.
| Тип коллекции | Guava | Apache Commons Collections | GS Collections | JDK |
|---|---|---|---|---|
| Порядок коллекции не определен | HashMultiset | HashBag | HashBag | HashMap<String, Integer> |
| Отсортированная в заданном или натуральном порядке | TreeMultiset | TreeBag | TreeBag | TreeMap<String, Integer> |
| В порядке добавления | LinkedHashMultiset | — | — | LinkedHashMap<String, Integere> |
| Многопоточные | ConcurrentHashMultiset | SynchronizedBag | SynchronizedBag | Collections.synchronizedMap(HashMap<String, Integer>) |
| Многопоточные и отсортированные | — | SynchronizedSortedBag | SynchronizedSortedBag | Collections.synchronizedSortedMap(TreeMap<String, Integer>) |
| Не изменяемые | ImmutableMultiset | UnmodifiableBag | UnmodifiableBag | Collections.unmodifiableMap(HashMap<String, Integer>) |
| Не изменяемые и отсортированные | ImmutableSortedMultiset | UnmodifiableSortedBag | UnmodifiableSortedBag | Collections.unmodifiableSortedMap(TreeMap<String, Integer>) |
Примеры использования мультимножества (MultiSet/Bag) для подсчета слов в тексте
Есть задача: дана строчка текста «Hello World! Hello All! Hi World!», нужно разобрать её на отдельные
слова где разделитель только пробел, сохранить в какую-нибудь коллекцию и вывести количество вхождений каждого
слова, общее количество слов в тексте и количество уникальных слов.
Посмотрим как это сделать с помощью
1. разных вариантов Multiset от Guava:
Используем HashMultiset от guava для подсчета слов
Обратите внимание, что порядок вывода в System.out.println(multiset) и в
System.out.println(multiset.elementSet()) — произвольный, то есть не определен.
// Разберем текст на слова
String INPUT_TEXT = "Hello World! Hello All! Hi World!";
// Создаем Multiset
Multiset<String> multiset = HashMultiset.create(Arrays.asList(INPUT_TEXT.split(" ")));
// Выводим кол-вом вхождений слов
System.out.println(multiset); // напечатает [Hi, Hello x 2, World! x 2, All!] - в произвольном порядке
// Выводим все уникальные слова
System.out.println(multiset.elementSet()); // напечатает [Hi, Hello, World!, All!] - в произвольном
порядке
// Выводим количество по каждому слову
System.out.println("Hello = " + multiset.count("Hello")); // напечатает 2
System.out.println("World = " + multiset.count("World!")); // напечатает 2
System.out.println("All = " + multiset.count("All!")); // напечатает 1
System.out.println("Hi = " + multiset.count("Hi")); // напечатает 1
System.out.println("Empty = " + multiset.count("Empty")); // напечатает 0
// Выводим общее количества всех слов в тексте
System.out.println(multiset.size()); //напечатает 6
// Выводим общее количество всех уникальных слов
System.out.println(multiset.elementSet().size()); //напечатает 4
Используем TreeMultiset от guava для подсчета слов
Обратите внимание, что порядок вывода в System.out.println(multiset) и в
System.out.println(multiset.elementSet()) — натуральный, то есть слова отсортированы по алфавиту.
// Разберем текст на слова
String INPUT_TEXT = "Hello World! Hello All! Hi World!";
// Создаем Multiset
Multiset<String> multiset = TreeMultiset.create(Arrays.asList(INPUT_TEXT.split(" ")));
// Выводим кол-вом вхождений слов
System.out.println(multiset); // напечатает [All!, Hello x 2, Hi, World! x 2]- в алфавитном порядке
// Выводим все уникальные слова
System.out.println(multiset.elementSet()); // напечатает [All!, Hello, Hi, World!]- в алфавитном порядке
// Выводим количество по каждому слову
System.out.println("Hello = " + multiset.count("Hello")); // напечатает 2
System.out.println("World = " + multiset.count("World!")); // напечатает 2
System.out.println("All = " + multiset.count("All!")); // напечатает 1
System.out.println("Hi = " + multiset.count("Hi")); // напечатает 1
System.out.println("Empty = " + multiset.count("Empty")); // напечатает 0
// Выводим общее количества всех слов в тексте
System.out.println(multiset.size()); //напечатает 6
// Выводим общее количество всех уникальных слов
System.out.println(multiset.elementSet().size()); //напечатает 4
Используем LinkedHashMultisetTest от guava для подсчета слов
Обратите внимание, что порядок вывода в System.out.println(multiset) и в
System.out.println(multiset.elementSet()) — в порядке первого добавления элемента
// Разберем текст на слова
String INPUT_TEXT = "Hello World! Hello All! Hi World!";
// Создаем Multiset
Multiset<String> multiset = LinkedHashMultiset.create(Arrays.asList(INPUT_TEXT.split(" ")));
// Выводим кол-вом вхождений слов
System.out.println(multiset); // напечатает [Hello x 2, World! x 2, All!, Hi]- в порядке первого
добавления элемента
// Выводим все уникальные слова
System.out.println(multiset.elementSet()); // напечатает [Hello, World!, All!, Hi] - в порядке первого
добавления элемента
// Выводим количество по каждому слову
System.out.println("Hello = " + multiset.count("Hello")); // напечатает 2
System.out.println("World = " + multiset.count("World!")); // напечатает 2
System.out.println("All = " + multiset.count("All!")); // напечатает 1
System.out.println("Hi = " + multiset.count("Hi")); // напечатает 1
System.out.println("Empty = " + multiset.count("Empty")); // напечатает 0
// Выводим общее количества всех слов в тексте
System.out.println(multiset.size()); //напечатает 6
// Выводим общее количество всех уникальных слов
System.out.println(multiset.elementSet().size()); //напечатает 4
Используем ConcurrentHashMultiset от guava для подсчета слов
Обратите внимание, что порядок вывода в System.out.println(multiset) и в
System.out.println(multiset.elementSet()) — произвольный, то есть не определен, так как это по сути
многопоточная версия HashMultiset
// Разберем текст на слова
String INPUT_TEXT = "Hello World! Hello All! Hi World!";
// Создаем Multiset
Multiset<String> multiset = ConcurrentHashMultiset.create(Arrays.asList(INPUT_TEXT.split(" ")));
// Выводим кол-вом вхождений слов
System.out.println(multiset); // напечатает [Hi, Hello x 2, World! x 2, All!] - в произвольном порядке
// Выводим все уникальные слова
System.out.println(multiset.elementSet()); // напечатает [Hi, Hello, World!, All!] - в произвольном
порядке
// Выводим количество по каждому слову
System.out.println("Hello = " + multiset.count("Hello")); // напечатает 2
System.out.println("World = " + multiset.count("World!")); // напечатает 2
System.out.println("All = " + multiset.count("All!")); // напечатает 1
System.out.println("Hi = " + multiset.count("Hi")); // напечатает 1
System.out.println("Empty = " + multiset.count("Empty")); // напечатает 0
// Выводим общее количества всех слов в тексте
System.out.println(multiset.size()); //напечатает 6
// Выводим общее количество всех уникальных слов
System.out.println(multiset.elementSet().size()); //напечатает 4
2. разных вариантов Bag от Apache Commons Collections:
Использование HashBag из Apache Commons Collections
Обратите внимание, что порядок вывода в System.out.println(multiset) и в
System.out.println(multiset.elementSet()) — произвольный, то есть не определен.
// Разберем текст на слова
String INPUT_TEXT = "Hello World! Hello All! Hi World!";
// Создаем Multiset
Bag bag = new HashBag(Arrays.asList(INPUT_TEXT.split(" ")));
// Выводим кол-вом вхождений слов
System.out.println(bag); // напечатает [1:Hi,2:Hello,2:World!,1:All!] - в произвольном порядке
// Выводим все уникальные слова
System.out.println(bag.uniqueSet()); // напечатает [Hi, Hello, World!, All!] - в произвольном порядке
// Выводим количество по каждому слову
System.out.println("Hello = " + bag.getCount("Hello")); // напечатает 2
System.out.println("World = " + bag.getCount("World!")); // напечатает 2
System.out.println("All = " + bag.getCount("All!")); // напечатает 1
System.out.println("Hi = " + bag.getCount("Hi")); // напечатает 1
System.out.println("Empty = " + bag.getCount("Empty")); // напечатает 0
// Выводим общее количества всех слов в тексте
System.out.println(bag.size()); //напечатает 6
// Выводим общее количество всех уникальных слов
System.out.println(bag.uniqueSet().size()); //напечатает 4
Использование TreeBag из Apache Commons Collections
Обратите внимание, что порядок вывода в System.out.println(multiset) и в
System.out.println(multiset.elementSet()) — натуральный, то есть слова отсортированы по алфавиту.
// Разберем текст на слова
String INPUT_TEXT = "Hello World! Hello All! Hi World!";
// Создаем Multiset
Bag bag = new TreeBag(Arrays.asList(INPUT_TEXT.split(" ")));
// Выводим кол-вом вхождений слов
System.out.println(bag); // напечатает [1:All!,2:Hello,1:Hi,2:World!]- в алфавитном порядке
// Выводим все уникальные слова
System.out.println(bag.uniqueSet()); // напечатает [All!, Hello, Hi, World!]- в алфавитном порядке
// Выводим количество по каждому слову
System.out.println("Hello = " + bag.getCount("Hello")); // напечатает 2
System.out.println("World = " + bag.getCount("World!")); // напечатает 2
System.out.println("All = " + bag.getCount("All!")); // напечатает 1
System.out.println("Hi = " + bag.getCount("Hi")); // напечатает 1
System.out.println("Empty = " + bag.getCount("Empty")); // напечатает 0
// Выводим общее количества всех слов в тексте
System.out.println(bag.size()); //напечатает 6
// Выводим общее количество всех уникальных слов
System.out.println(bag.uniqueSet().size()); //напечатает 4
Использование SynchronizedBag из Apache Commons Collections
Обратите внимание, что порядок вывода в System.out.println(multiset) и в
System.out.println(multiset.elementSet()) — произвольный, то есть не определен, так как это по сути
многопоточная версия HashBag
// Разберем текст на слова
String INPUT_TEXT = "Hello World! Hello All! Hi World!";
// Создаем Multiset
Bag bag = SynchronizedBag.synchronizedBag(new HashBag(Arrays.asList(INPUT_TEXT.split(" "))));
// Выводим кол-вом вхождений слов
System.out.println(bag); // напечатает [1:Hi,2:Hello,2:World!,1:All!] - в произвольном порядке
// Выводим все уникальные слова
System.out.println(bag.uniqueSet()); // напечатает [Hi, Hello, World!, All!] - в произвольном порядке
// Выводим количество по каждому слову
System.out.println("Hello = " + bag.getCount("Hello")); // напечатает 2
System.out.println("World = " + bag.getCount("World!")); // напечатает 2
System.out.println("All = " + bag.getCount("All!")); // напечатает 1
System.out.println("Hi = " + bag.getCount("Hi")); // напечатает 1
System.out.println("Empty = " + bag.getCount("Empty")); // напечатает 0
// Выводим общее количества всех слов в тексте
System.out.println(bag.size()); //напечатает 6
// Выводим общее количество всех уникальных слов
System.out.println(bag.uniqueSet().size()); //напечатает 4
Использование SynchronizedSortedBag из Apache Commons Collections
Обратите внимание, что порядок вывода в System.out.println(multiset) и в
System.out.println(multiset.elementSet()) — натуральный, то есть слова отсортированы по алфавиту, так как
это по сути многопоточная версия SortedBag
// Разберем текст на слова
String INPUT_TEXT = "Hello World! Hello All! Hi World!";
// Создаем Multiset
Bag bag = SynchronizedSortedBag.synchronizedBag(new TreeBag(Arrays.asList(INPUT_TEXT.split(" "))));
// Выводим кол-вом вхождений слов
System.out.println(bag); // напечатает [1:All!,2:Hello,1:Hi,2:World!]- в алфавитном порядке
// Выводим все уникальные слова
System.out.println(bag.uniqueSet()); // напечатает [All!, Hello, Hi, World!]- в алфавитном порядке
// Выводим количество по каждому слову
System.out.println("Hello = " + bag.getCount("Hello")); // напечатает 2
System.out.println("World = " + bag.getCount("World!")); // напечатает 2
System.out.println("All = " + bag.getCount("All!")); // напечатает 1
System.out.println("Hi = " + bag.getCount("Hi")); // напечатает 1
System.out.println("Empty = " + bag.getCount("Empty")); // напечатает 0
// Выводим общее количества всех слов в тексте
System.out.println(bag.size()); // напечатает 6
// Выводим общее количество всех уникальных слов
System.out.println(bag.uniqueSet().size()); // напечатает 4
3. разных вариантов Bag от GS Collections:
Использование MutableBag из GS Collections
Обратите внимание, что порядок вывода в System.out.println(bag) и в System.out.println(bag.toSet()) — не
определен
// Разберем текст на слова
String INPUT_TEXT = "Hello World! Hello All! Hi World!";
// Создаем Multiset
MutableBag<String> bag = HashBag.newBag(Arrays.asList(INPUT_TEXT.split(" ")));
// Выводим кол-вом вхождений слов
System.out.println(bag); // напечатает [Hi, World!, World!, Hello, Hello, All!]- в произвольном порядке
// Выводим все уникальные слова
System.out.println(bag.toSet()); // напечатает [Hi, Hello, World!, All!] - в произвольном порядке
// Выводим количество по каждому слову
System.out.println("Hello = " + bag.occurrencesOf("Hello")); // напечатает 2
System.out.println("World = " + bag.occurrencesOf("World!")); // напечатает 2
System.out.println("All = " + bag.occurrencesOf("All!")); // напечатает 1
System.out.println("Hi = " + bag.occurrencesOf("Hi")); // напечатает 1
System.out.println("Empty = " + bag.occurrencesOf("Empty")); // напечатает 0
// Выводим общее количества всех слов в тексте
System.out.println(bag.size()); //напечатает 6
// Выводим общее количество всех уникальных слов
System.out.println(bag.toSet().size()); //напечатает 4
Использование MutableSortedBag из GS Collections
Обратите внимание, что порядок вывода в System.out.println(bag) и в System.out.println(bag.toSortedSet()) — будет натуральным, т.е. по алфавиту в данном случае
// Разберем текст на слова
String INPUT_TEXT = "Hello World! Hello All! Hi World!";
// Создаем Multiset
MutableSortedBag<String> bag = TreeBag.newBag(Arrays.asList(INPUT_TEXT.split(" ")));
// Выводим кол-вом вхождений слов
System.out.println(bag); // напечатает [All!, Hello, Hello, Hi, World!, World!]- в натуральном порядке
// Выводим все уникальные слова
System.out.println(bag.toSortedSet()); // напечатает [All!, Hello, Hi, World!]- в натуральном порядке
// Выводим количество по каждому слову
System.out.println("Hello = " + bag.occurrencesOf("Hello")); // напечатает 2
System.out.println("World = " + bag.occurrencesOf("World!")); // напечатает 2
System.out.println("All = " + bag.occurrencesOf("All!")); // напечатает 1
System.out.println("Hi = " + bag.occurrencesOf("Hi")); // напечатает 1
System.out.println("Empty = " + bag.occurrencesOf("Empty")); // напечатает 0
// Выводим общее количества всех слов в тексте
System.out.println(bag.size()); //напечатает 6
// Выводим общее количество всех уникальных слов
System.out.println(bag.toSet().size()); //напечатает 4
4. Ну и наконец, посмотрим как можно сделать тоже самое в чистом JDK с помощью эмуляции multiSet через HashMap
Эмуляция multiSet через HashMap
Как вы легко можете заметить, кода потребовалось, естественно, больше чем у любых реализаций multiSet или
Bag.
// Разберем текст на слова
String INPUT_TEXT = "Hello World! Hello All! Hi World!";
List<String> listResult = Arrays.asList(INPUT_TEXT.split(" "));
// Создаем эмуляцию Multiset c помощью HashMap и заполняем
Map<String, Integer> fakeMultiset = new HashMap<String,Integer>(listResult.size());
for(String word: listResult) {
Integer cnt = fakeMultiset.get(word);
fakeMultiset.put(word, cnt == null ? 1 : cnt + 1);
}
// Выводим кол-вом вхождений слов
System.out.println(fakeMultiset); // напечатает {World!=2, Hi=1, Hello=2, All!=1}- в произвольном
порядке
// Выводим все уникальные слова
System.out.println(fakeMultiset.keySet()); // напечатает [World!, Hi, Hello, All!] - в произвольном
порядке
// Выводим количество по каждому слову
System.out.println("Hello = " + fakeMultiset.get("Hello")); // напечатает 2
System.out.println("World = " + fakeMultiset.get("World!")); // напечатает 2
System.out.println("All = " + fakeMultiset.get("All!")); // напечатает 1
System.out.println("Hi = " + fakeMultiset.get("Hi")); // напечатает 1
System.out.println("Empty = " + fakeMultiset.get("Empty")); // напечатает null
// Выводим общее количества всех слов в тексте
Integer cnt = 0;
for (Integer wordCount : fakeMultiset.values()){
cnt += wordCount;
}
System.out.println(cnt); //напечатает 6
// Выводим общее количество уникальных слов
System.out.println(fakeMultiset.size()); //напечатает 4
4.2 Реализация Multimap в библиотеках guava, Apache Commons Collections и GS Collections
Итак, Multimap это map, у которой у каждого ключа есть набор значений. Давайте сравним какие реализации есть данной
коллекции в разных библиотеках. В таблице ниже порядок ключей и порядок значений показывает как будет происходить
итерирования по ключам и значениям соответственно, дубликаты — может ли коллекция значений содержать дубликаты,
аналог ключей и значений — на каких коллекциях построены ключи и значения, JDK показывает аналог коллекции с помощью
JDK коллекций.
Внимание: если таблица не помещается целиком, попробуйте уменьшить масштаб страницы или открыть в другом браузере.
| Порядок ключей |
Порядок значений |
Дуб- лика- ты |
Аналог ключей |
Аналог значе- ний |
Guava | Apache Commons Collections |
GS Collections |
JDK |
|---|---|---|---|---|---|---|---|---|
| не задан | в порядке добавле- ния |
да | HashMap | ArrayList | ArrayList- Multimap |
MultiValueMap | FastList- Multimap |
HashMap<K, ArrayList<V>> |
| не задан | не задан | нет | HashMap | HashSet | HashMultimap | MultiValueMap. multiValueMap( new HashMap<K, Set>(), HashSet.class); |
UnifiedSet- Multimap |
HashMap<K, HashSet<V>> |
| не задан | отсорти- рован |
нет | HashMap | TreeSet | Multimaps. newMultimap( HashMap, Supplier <TreeSet>) |
MultiValueMap. multiValueMap( new HashMap<K, Set>(), TreeSet.class); |
TreeSortedSet- Multimap |
HashMap<K, TreeSet<V>> |
| в порядке добавле- ния |
в порядке добавле- ния |
да | Linked HashMap |
ArrayList | LinkedList- Multimap |
MultiValueMap. multiValueMap(new LinkedHashMap<K, List>(), ArrayList.class); |
LinkedHashMap< K, ArrayList<V>> |
|
| в порядке добавле- ния |
в порядке добавле- ния |
нет | LinkedHash- Multimap |
Linked- HashSet |
LinkedHash- Multimap |
MultiValueMap. multiValueMap(new LinkedHashMap<K, Set>(), LinkedHashSet.class); |
LinkedHashMap<K, LinkedHashSet<V>> |
|
| отсорти- рован |
отсорти- рован |
нет | TreeMap | TreeSet | TreeMultimap | MultiValueMap. multiValueMap( new TreeMap<K, Set>(),TreeSet.class); |
TreeMap<K, TreeSet<V>> |
Как видно из таблицы, в Apache Commons Collections есть лишь одна реализация данного вида коллекции, остальные можно
получить оборачивая стандартные коллекции при создании. В guava намного больше уже определенных коллекций, при этом
есть возможность реализовать обертку над любой map’ами и любыми коллекциями значений. В GS Collections есть так же
специальные коллекция multimap основанная на Bag (HashBagMultimap), см. multiset и multimap.
Примеры использования Multimap для сохранения всех вхождений слов в тексте
Есть задача: дана строчка текста «Hello World! Hello All! Hi World!», нужно разобрать её на отдельные
слова где разделитель только пробел и теперь нам нужно знать не только сколько каждых слов в тексте, но и все
индекс вхождения слова в тесте, то есть что Hello это первое и третье слово в тексте и т.д.
Посмотрим как это сделать с помощью
1. разных вариантов Multimap от Guava:
Используем HashMultimap от guava
Обратите внимание, что порядок хранения данных произвольный как для ключей, так и для значений (для ключей
поведение аналогичное HashMap, для значений HashSet). Повторяющиеся значения для одного ключа игнорируются.
String INPUT_TEXT = "Hello World! Hello All! Hi World!";
// Разберем текст на слова и индексы
List
<String> words = Arrays.asList(INPUT_TEXT.split(" "));
// Создаем Multimap
Multimap<String, Integer> multiMap = HashMultimap.create();
// Заполним Multimap
int i = 0;
for(String word: words) {
multiMap.put(word, i);
i++;
}
// Выводим все вхождения слов в текст
System.out.println(multiMap); // напечатает {Hi=[4], Hello=[0, 2], World!=[1, 5], All!=[3]} - в
произвольном порядке
// Выводим все уникальные слова
System.out.println(multiMap.keySet()); // напечатает [Hi, Hello, World!, All!] - в произвольном порядке
// Выводим все индексы вхождения слова в текст
System.out.println("Hello = " + multiMap.get("Hello")); // напечатает [0, 2]
System.out.println("World = " + multiMap.get("World!")); // напечатает [1, 5]
System.out.println("All = " + multiMap.get("All!")); // напечатает [3]
System.out.println("Hi = " + multiMap.get("Hi")); // напечатает [4]
System.out.println("Empty = " + multiMap.get("Empty")); // напечатает []
// Выводим общее количества всех слов в тексте
System.out.println(multiMap.size()); //напечатает 6
// Выводим общее количество всех уникальных слов
System.out.println(multiMap.keySet().size()); //напечатает 4
Используем ArrayListMultimapTest от guava
Обратите внимание, что порядок хранения данных произвольный для ключей, так и в порядке добавления для
значений (для ключей поведение аналогичное HashMap, для значений ArrayList). Повторяющиеся значения для
одного ключа сохраняются.
String INPUT_TEXT = "Hello World! Hello All! Hi World!";
// Разберем текст на слова и индексы
List
<String> words = Arrays.asList(INPUT_TEXT.split(" "));
// Создаем Multimap
Multimap<String, Integer> multiMap = ArrayListMultimap.create();
// Заполним Multimap
int i = 0;
for(String word: words) {
multiMap.put(word, i);
i++;
}
// Выводим все вхождения слов в текст
System.out.println(multiMap); // напечатает {Hi=[4], Hello=[0, 2], World!=[1, 5], All!=[3]} - ключи в
произвольном порядке, значения в порядке добавления
// Выводим все уникальные слова
System.out.println(multiMap.keySet()); // напечатает [Hello, World!, All!, Hi]- в произвольном порядке
// Выводим все индексы вхождения слова в текст
System.out.println("Hello = " + multiMap.get("Hello")); // напечатает [0, 2]
System.out.println("World = " + multiMap.get("World!")); // напечатает [1, 5]
System.out.println("All = " + multiMap.get("All!")); // напечатает [3]
System.out.println("Hi = " + multiMap.get("Hi")); // напечатает [4]
System.out.println("Empty = " + multiMap.get("Empty")); // напечатает []
// Выводим общее количества всех слов в тексте
System.out.println(multiMap.size()); //напечатает 6
// Выводим общее количество всех уникальных слов
System.out.println(multiMap.keySet().size()); //напечатает 4
Используем LinkedHashMultimapTest от guava
Обратите внимание, что порядок хранения данных в порядке добавления для ключей и для значений (для ключей
поведение аналогичное LinkedHashMap, для значений LinkedHashSet). Повторяющиеся значения для одного ключа
игнорируются.
String INPUT_TEXT = "Hello World! Hello All! Hi World!";
// Разберем текст на слова и индексы
List
<String> words = Arrays.asList(INPUT_TEXT.split(" "));
// Создаем Multimap
Multimap<String, Integer> multiMap = LinkedHashMultimap.create();
// Заполним Multimap
int i = 0;
for(String word: words) {
multiMap.put(word, i);
i++;
}
// Выводим все вхождения слов в текст
System.out.println(multiMap); // напечатает {Hello=[0, 2], World!=[1, 5], All!=[3], Hi=[4]}-в порядке
добавления
// Выводим все уникальные слова
System.out.println(multiMap.keySet()); // напечатает [Hello, World!, All!, Hi]- в порядке добавления
// Выводим все индексы вхождения слова в текст
System.out.println("Hello = " + multiMap.get("Hello")); // напечатает [0, 2]
System.out.println("World = " + multiMap.get("World!")); // напечатает [1, 5]
System.out.println("All = " + multiMap.get("All!")); // напечатает [3]
System.out.println("Hi = " + multiMap.get("Hi")); // напечатает [4]
System.out.println("Empty = " + multiMap.get("Empty")); // напечатает []
// Выводим общее количества всех слов в тексте
System.out.println(multiMap.size()); //напечатает 6
// Выводим общее количество всех уникальных слов
System.out.println(multiMap.keySet().size()); //напечатает 4
Используем LinkedListMultimapTest от guava
Обратите внимание, что порядок хранения данных в порядке добавления для ключей и для значений (для ключей
поведение аналогичное LinkedHashMap, для значений LinkedList). Повторяющиеся значения для одного ключа
сохраняются.
String INPUT_TEXT = "Hello World! Hello All! Hi World!";
// Разберем текст на слова и индексы
List
<String> words = Arrays.asList(INPUT_TEXT.split(" "));
// Создаем Multimap
Multimap<String, Integer> multiMap = LinkedListMultimap.create();
// Заполним Multimap
int i = 0;
for(String word: words) {
multiMap.put(word, i);
i++;
}
// Выводим все вхождения слов в текст
System.out.println(multiMap); // напечатает {Hello=[0, 2], World!=[1, 5], All!=[3], Hi=[4]}-в порядке
добавления
// Выводим все уникальные слова
System.out.println(multiMap.keySet()); // напечатает [Hello, World!, All!, Hi]- в порядке добавления
// Выводим все индексы вхождения слова в текст
System.out.println("Hello = " + multiMap.get("Hello")); // напечатает [0, 2]
System.out.println("World = " + multiMap.get("World!")); // напечатает [1, 5]
System.out.println("All = " + multiMap.get("All!")); // напечатает [3]
System.out.println("Hi = " + multiMap.get("Hi")); // напечатает [4]
System.out.println("Empty = " + multiMap.get("Empty")); // напечатает []
// Выводим общее количества всех слов в тексте
System.out.println(multiMap.size()); //напечатает 6
// Выводим общее количество всех уникальных слов
System.out.println(multiMap.keySet().size()); //напечатает 4
Используем TreeMultimapTest от guava
Обратите внимание, что порядок хранения данных отсортированный для ключей и для значений (для ключей
поведение аналогичное TreeMap, для значений TreeSet).
String INPUT_TEXT = "Hello World! Hello All! Hi World!";
// Разберем текст на слова и индексы
List<String> words = Arrays.asList(INPUT_TEXT.split(" "));
// Создаем Multimap
Multimap<String, Integer> multiMap = TreeMultimap.create();
// Заполним Multimap
int i = 0;
for(String word: words) {
multiMap.put(word, i);
i++;
}
// Выводим все вхождения слов в текст
System.out.println(multiMap); // напечатает {Hello=[0, 2], World!=[1, 5], All!=[3], Hi=[4]}-в
натуральном порядке
// Выводим все уникальные слова
System.out.println(multiMap.keySet()); // напечатает [Hello, World!, All!, Hi]- в натуральном порядке
// Выводим все индексы вхождения слова в текст
System.out.println("Hello = " + multiMap.get("Hello")); // напечатает [0, 2]
System.out.println("World = " + multiMap.get("World!")); // напечатает [1, 5]
System.out.println("All = " + multiMap.get("All!")); // напечатает [3]
System.out.println("Hi = " + multiMap.get("Hi")); // напечатает [4]
System.out.println("Empty = " + multiMap.get("Empty")); // напечатает []
// Выводим общее количества всех слов в тексте
System.out.println(multiMap.size()); //напечатает 6
// Выводим общее количество всех уникальных слов
System.out.println(multiMap.keySet().size()); //напечатает 4
2. разных вариантов MultiValueMap от Apache Commons Collections:
Используем MultiValueMap от Apache Commons Collections
Обратите внимание, что порядок хранения данных произвольный для ключей и значений (используется HashMap для
ключей и ArrayList для значений)
String INPUT_TEXT = "Hello World! Hello All! Hi World!";
// Разберем текст на слова и индексы
List<String> words = Arrays.asList(INPUT_TEXT.split(" "));
// Создаем Multimap
MultiMap<String, Integer> multiMap = new MultiValueMap<String, Integer>();
// Заполним Multimap
int i = 0;
for(String word: words) {
multiMap.put(word, i);
i++;
}
// Выводим все вхождения слов в текст
System.out.println(multiMap); // напечатает {Hi=[4], Hello=[0, 2], World!=[1, 5], All!=[3]} - в
произвольном порядке
// Выводим все уникальные слова
System.out.println(multiMap.keySet()); // напечатает [Hi, Hello, World!, All!] - в произвольном порядке
// Выводим все индексы вхождения слова в текст
System.out.println("Hello = " + multiMap.get("Hello")); // напечатает [0, 2]
System.out.println("World = " + multiMap.get("World!")); // напечатает [1, 5]
System.out.println("All = " + multiMap.get("All!")); // напечатает [3]
System.out.println("Hi = " + multiMap.get("Hi")); // напечатает [4]
System.out.println("Empty = " + multiMap.get("Empty")); // напечатает null
// Выводим общее количество всех уникальных слов
System.out.println(multiMap.keySet().size()); //напечатает 4
Используем MultiValueMap, оборачивающий TreeMap<String, TreeSet>()
Обратите внимание, что порядок хранения данных отсортированный для ключей и значений
String INPUT_TEXT = "Hello World! Hello All! Hi World!";
// Разберем текст на слова и индексы
List<String> words = Arrays.asList(INPUT_TEXT.split(" "));
// Создаем Multimap
MultiMap<String, Integer> multiMap = MultiValueMap.multiValueMap(new TreeMap<String, Set>(), TreeSet.class);
// Заполним Multimap
int i = 0;
for(String word: words) {
multiMap.put(word, i);
i++;
}
// Выводим все вхождения слов в текст
System.out.println(multiMap); // напечатает {All!=[3], Hello=[0, 2], Hi=[4], World!=[1, 5]} -в
натуральном порядке
// Выводим все уникальные слова
System.out.println(multiMap.keySet()); // напечатает [All!, Hello, Hi, World!] в натуральном порядке
// Выводим все индексы вхождения слова в текст
System.out.println("Hello = " + multiMap.get("Hello")); // напечатает [0, 2]
System.out.println("World = " + multiMap.get("World!")); // напечатает [1, 5]
System.out.println("All = " + multiMap.get("All!")); // напечатает [3]
System.out.println("Hi = " + multiMap.get("Hi")); // напечатает [4]
System.out.println("Empty = " + multiMap.get("Empty")); // напечатает null
// Выводим общее количество всех уникальных слов
System.out.println(multiMap.keySet().size()); //напечатает 4
Используем MultiValueMap, оборачивающий LinkedHashMap<String, LinkedHashSet>()
Обратите внимание, что порядок хранения данных по первому добавлению для ключей и значений
String INPUT_TEXT = "Hello World! Hello All! Hi World!";
// Разберем текст на слова и индексы
List<String> words = Arrays.asList(INPUT_TEXT.split(" "));
// Создаем Multimap
MultiMap<String, Integer> multiMap = MultiValueMap.multiValueMap(new LinkedHashMap<String, Set>(), LinkedHashSet.class);
// Заполним Multimap
int i = 0;
for(String word: words) {
multiMap.put(word, i);
i++;
}
// Выводим все вхождения слов в текст
System.out.println(multiMap); // напечатает {Hello=[0, 2], World!=[1, 5], All!=[3], Hi=[4]} - в порядке
добавления
// Выводим все уникальные слова
System.out.println(multiMap.keySet()); // напечатает [Hello, World!, All!, Hi] - в порядке добавления
// Выводим все индексы вхождения слова в текст
System.out.println("Hello = " + multiMap.get("Hello")); // напечатает [0, 2]
System.out.println("World = " + multiMap.get("World!")); // напечатает [1, 5]
System.out.println("All = " + multiMap.get("All!")); // напечатает [3]
System.out.println("Hi = " + multiMap.get("Hi")); // напечатает [4]
System.out.println("Empty = " + multiMap.get("Empty")); // напечатает null
// Выводим общее количество всех уникальных слов
System.out.println(multiMap.keySet().size()); //напечатает 4
3. разных вариантов Multimap от GS Collections:
Использование FastListMultimap
String INPUT_TEXT = "Hello World! Hello All! Hi World!";
// Разберем текст на слова и индексы
List<String> words = Arrays.asList(INPUT_TEXT.split(" "));
// Создаем Multimap
MutableListMultimap<String, Integer> multiMap = new FastListMultimap<String, Integer>();
// Заполним Multimap
int i = 0;
for(String word: words) {
multiMap.put(word, i);
i++;
}
// Выводим все вхождения слов в текст
System.out.println(multiMap); // напечатает {Hi=[4], World!=[1, 5], Hello=[0, 2], All!=[3]}- в
произвольном порядке
// Выводим все уникальные слова
System.out.println(multiMap.keysView()); // напечатает [Hi, Hello, World!, All!] - в произвольном
порядке
// Выводим все индексы вхождения слова в текст
System.out.println("Hello = " + multiMap.get("Hello")); // напечатает [0, 2]
System.out.println("World = " + multiMap.get("World!")); // напечатает [1, 5]
System.out.println("All = " + multiMap.get("All!")); // напечатает [3]
System.out.println("Hi = " + multiMap.get("Hi")); // напечатает [4]
System.out.println("Empty = " + multiMap.get("Empty")); // напечатает []
// Выводим общее количество всех слов в тексте
System.out.println(multiMap.size()); //напечатает 6
// Выводим общее количество уникальных слов в тексте
System.out.println(multiMap.keysView().size()); //напечатает 4
Использование HashBagMultimap
String INPUT_TEXT = "Hello World! Hello All! Hi World!";
// Разберем текст на слова и индексы
List<String> words = Arrays.asList(INPUT_TEXT.split(" "));
// Создаем Multimap
MutableBagMultimap<String, Integer> multiMap = new HashBagMultimap<String, Integer>();
// Заполним Multimap
int i = 0;
for(String word: words) {
multiMap.put(word, i);
i++;
}
// Выводим все вхождения слов в текст
System.out.println(multiMap); // напечатает {Hi=[4], World!=[1, 5], Hello=[0, 2], All!=[3]}- в
произвольном порядке
// Выводим все уникальные слова
System.out.println(multiMap.keysView()); // напечатает [Hi, Hello, World!, All!] - в произвольном
порядке
// Выводим все индексы вхождения слова в текст
System.out.println("Hello = " + multiMap.get("Hello")); // напечатает [0, 2]
System.out.println("World = " + multiMap.get("World!")); // напечатает [1, 5]
System.out.println("All = " + multiMap.get("All!")); // напечатает [3]
System.out.println("Hi = " + multiMap.get("Hi")); // напечатает [4]
System.out.println("Empty = " + multiMap.get("Empty")); // напечатает []
// Выводим общее количество всех слов в тексте
System.out.println(multiMap.size()); //напечатает 6
// Выводим общее количество уникальных слов в тексте
System.out.println(multiMap.keysView().size()); //напечатает 4
Использование TreeSortedSetMultimap
String INPUT_TEXT = "Hello World! Hello All! Hi World!";
// Разберем текст на слова и индексы
List<String> words = Arrays.asList(INPUT_TEXT.split(" "));
// Создаем Multimap
MutableSortedSetMultimap<String, Integer> multiMap = new TreeSortedSetMultimap<String, Integer>();
// Заполним Multimap
int i = 0;
for(String word: words) {
multiMap.put(word, i);
i++;
}
// Выводим все вхождения слов в текст
System.out.println(multiMap); // напечатает {Hi=[4], World!=[1, 5], Hello=[0, 2], All!=[3]}- в
произвольном порядке
// Выводим все уникальные слова
System.out.println(multiMap.keysView()); // напечатает [Hi, Hello, World!, All!] - в произвольном
порядке
// Выводим все индексы вхождения слова в текст
System.out.println("Hello = " + multiMap.get("Hello")); // напечатает [0, 2]
System.out.println("World = " + multiMap.get("World!")); // напечатает [1, 5]
System.out.println("All = " + multiMap.get("All!")); // напечатает [3]
System.out.println("Hi = " + multiMap.get("Hi")); // напечатает [4]
System.out.println("Empty = " + multiMap.get("Empty")); // напечатает []
// Выводим общее количество всех слов в тексте
System.out.println(multiMap.size()); //напечатает 6
// Выводим общее количество уникальных слов в тексте
System.out.println(multiMap.keysView().size()); //напечатает 4
4. Ну и наконец, посмотрим как можно сделать тоже самое в чистом JDK с помощью эмуляции multiMap через HashMap
Эмуляция multiMap через HashMap
final int LIST_INDEXES_CAPACITY = 50;
String INPUT_TEXT = "Hello World! Hello All! Hi World!";
// Разберем текст на слова и индексы
List<String> words = Arrays.asList(INPUT_TEXT.split(" "));
// Создаем Multimap
Map<String, List<Integer>> fakeMultiMap = new HashMap<String, List<Integer>>(words.size());
// Заполним map
int i = 0;
for(String word: words) {
List<Integer> indexes = fakeMultiMap.get(word);
if(indexes == null) {
indexes = new ArrayList<Integer>(LIST_INDEXES_CAPACITY);
fakeMultiMap.put(word, indexes);
}
indexes.add(i);
i++;
}
// Выводим все вхождения слов в текст
System.out.println(fakeMultiMap); // напечатает {Hi=[4], Hello=[0, 2], World!=[1, 5],
All!=[3]} - в произвольном порядке
// Выводим все уникальные слова
System.out.println(fakeMultiMap.keySet()); // напечатает [Hi, Hello, World!, All!] - в
произвольном порядке
// Выводим все индексы вхождения слова в текст
System.out.println("Hello = " + fakeMultiMap.get("Hello")); // напечатает [0, 2]
System.out.println("World = " + fakeMultiMap.get("World!")); // напечатает [1, 5]
System.out.println("All = " + fakeMultiMap.get("All!")); // напечатает [3]
System.out.println("Hi = " + fakeMultiMap.get("Hi")); // напечатает [4]
System.out.println("Empty = " + fakeMultiMap.get("Empty")); // напечатает null
// Выводим общее количество всех слов в тексте
int cnt = 0;
for(List<Integer> lists: fakeMultiMap.values()) {
cnt += lists.size();
}
System.out.println(cnt); //напечатает 6
// Выводим общее количество уникальных слов в тексте
System.out.println(fakeMultiMap.keySet().size()); //напечатает 4
4.3 Реализация BiMap в библиотеках guava, Apache Commons Collections и GS Collections
Реализация BiMap во всех библиотеках достаточно похожа, за исключением названия HashBiMap в guava и GS Collections и
BidiMap в Apache Commons Collections. Кроме простейшей HashBiMap, у guava есть отдельные коллекции для работы с Enum
в качестве ключей или значений, такие как EnumHashBiMap или EnumBiMap, у Apache Commons Collections есть ряд
коллекций, где ключи упорядочены по добавлению или отсортированы.
Примеры использования BiMap для создания русско-английского «переводчика», действующего в обе стороны
Есть задача: есть массивы английских и русских слов соответствующие друг другу, нужно реализовать
коллекцию русско-английского словаря, с возможностью перевода в обе стороны.
Посмотрим как это сделать с помощью
1. разных вариантов BiMap от Guava:
Используем BiMap от guava
String[] englishWords = {"one", "two", "three","ball","snow"};
String[] russianWords = {"один", "два", "три","мяч","cнег"};
// Создаем Multiset
BiMap<String, String> biMap = HashBiMap.create(englishWords.length);
// создаем англо-русский словарь
int i = 0;
for(String englishWord: englishWords) {
biMap.put(englishWord, russianWords[i]);
i++;
}
// Выводим кол-вом вхождений слов
System.out.println(biMap); // напечатает {two=два, three=три, snow=cнег, ball=мяч, one=один} - в
произвольном порядке
// Выводим все уникальные слова
System.out.println(biMap.keySet()); // напечатает [two, three, snow, ball, one] - в произвольном порядке
System.out.println(biMap.values()); // напечатает [два, три, cнег, мяч, один]- в произвольном порядке
// Выводим перевод по каждому слову
System.out.println("one = " + biMap.get("one")); // напечатает one = один
System.out.println("two = " + biMap.get("two")); // напечатает two = два
System.out.println("мяч = " + biMap.inverse().get("мяч")); // напечатает мяч = ball
System.out.println("снег = " + biMap.inverse().get("cнег")); // напечатает снег = snow
System.out.println("empty = " + biMap.get("empty")); // напечатает empty = null
// Выводим общее количество переводов в словаре
System.out.println(biMap.size()); //напечатает 5
Используем EnumBiMap от guava
enum ENGLISH_WORD {
ONE, TWO, THREE, BALL, SNOW
}
enum POLISH_WORD {
JEDEN, DWA, TRZY, KULA, SNIEG
}
// Задача даны массивы польско-английского перевода, сделать коллекцию для перевода слова в двух
напрявлениях
public static void main(String[] args) {
ENGLISH_WORD[] englishWords = ENGLISH_WORD.values();
POLISH_WORD[] polishWords = POLISH_WORD.values();
// Создаем Multiset
BiMap<ENGLISH_WORD, POLISH_WORD> biMap = EnumBiMap.create(ENGLISH_WORD.class, POLISH_WORD.class);
// создаем англо-польский словарь
int i = 0;
for(ENGLISH_WORD englishWord: englishWords) {
biMap.put(englishWord, polishWords[i]);
i++;
}
// Выводим кол-вом вхождений слов
System.out.println(biMap); // напечатает {ONE=JEDEN, TWO=DWA, THREE=TRZY, BALL=KULA, SNOW=SNIEG}
// Выводим все уникальные слова
System.out.println(biMap.keySet()); // напечатает [ONE, TWO, THREE, BALL, SNOW]
System.out.println(biMap.values()); // напечатает [JEDEN, DWA, TRZY, KULA, SNIEG]
// Выводим перевод по каждому слову
System.out.println("one = " + biMap.get(ENGLISH_WORD.ONE)); // напечатает one = JEDEN
System.out.println("two = " + biMap.get(ENGLISH_WORD.TWO)); // напечатает two = DWA
System.out.println("kula = " + biMap.inverse().get(POLISH_WORD.KULA)); // напечатает kula = BALL
System.out.println("snieg = " + biMap.inverse().get(POLISH_WORD.SNIEG)); // напечатает snieg = SNOW
System.out.println("empty = " + biMap.get("empty")); // напечатает empty = null
// Выводим общее количество переводов в словаре
System.out.println(biMap.size()); //напечатает 5
}
Используем EnumHashBiMap от guava
enum ENGLISH_WORD {
ONE, TWO, THREE, BALL, SNOW
}
// Задача даны массивы руссков-английского перевода, сделать коллекцию для перевода слова в двух
напрявлениях
public static void main(String[] args) {
ENGLISH_WORD[] englishWords = ENGLISH_WORD.values();
String[] russianWords = {"один", "два", "три","мяч","cнег"};
// Создаем Multiset
BiMap<ENGLISH_WORD, String> biMap = EnumHashBiMap.create(ENGLISH_WORD.class);
// создаем англо-русский словарь
int i = 0;
for(ENGLISH_WORD englishWord: englishWords) {
biMap.put(englishWord, russianWords[i]);
i++;
}
// Выводим кол-вом вхождений слов
System.out.println(biMap); // напечатает {ONE=один, TWO=два, THREE=три, BALL=мяч, SNOW=cнег}
// Выводим все уникальные слова
System.out.println(biMap.keySet()); // напечатает [ONE, TWO, THREE, BALL, SNOW]
System.out.println(biMap.values()); // напечатает [один, два, три, мяч, cнег]
// Выводим перевод по каждому слову
System.out.println("one = " + biMap.get(ENGLISH_WORD.ONE)); // напечатает one = один
System.out.println("two = " + biMap.get(ENGLISH_WORD.TWO)); // напечатает two = два
System.out.println("мяч = " + biMap.inverse().get("мяч")); // напечатает мяч = BALL
System.out.println("снег = " + biMap.inverse().get("cнег")); // напечатает снег = SNOW
System.out.println("empty = " + biMap.get("empty")); // напечатает empty = null
// Выводим общее количество переводов в словаре
System.out.println(biMap.size()); //напечатает 5
}
2. C помощью BidiMap от Apache Commons Collections:
Используем DualHashBidiMap от Apache Commons Collections
String[] englishWords = {"one", "two", "three","ball","snow"};
String[] russianWords = {"один", "два", "три","мяч","cнег"};
// Создаем Multiset
BidiMap<String, String> biMap = new DualHashBidiMap();
// создаем англо-русский словарь
int i = 0;
for(String englishWord: englishWords) {
biMap.put(englishWord, russianWords[i]);
i++;
}
// Выводим кол-вом вхождений слов
System.out.println(biMap); // напечатает {ball=мяч, snow=cнег, one=один, two=два, three=три}- в произвольном
порядке
// Выводим все уникальные слова
System.out.println(biMap.keySet()); // напечатает [ball, snow, one, two, three]- в произвольном порядке
System.out.println(biMap.values()); // напечатает [мяч, cнег, один, два, три]- в произвольном порядке
// Выводим перевод по каждому слову
System.out.println("one = " + biMap.get("one")); // напечатает one = один
System.out.println("two = " + biMap.get("two")); // напечатает two = два
System.out.println("мяч = " + biMap.getKey("мяч")); // напечатает мяч = ball
System.out.println("снег = " + biMap.getKey("cнег")); // напечатает снег = snow
System.out.println("empty = " + biMap.get("empty")); // напечатает empty = null
// Выводим общее количество переводов в словаре
System.out.println(biMap.size()); //напечатает 5
3. C помощью HashBiMap от GS Collections:
Используем HashBiMap от GS Collections
String[] englishWords = {"one", "two", "three","ball","snow"};
String[] russianWords = {"один", "два", "три","мяч","cнег"};
// Создаем Multiset
MutableBiMap<String, String> biMap = new HashBiMap(englishWords.length);
// создаем англо-русский словарь
int i = 0;
for(String englishWord: englishWords) {
biMap.put(englishWord, russianWords[i]);
i++;
}
// Выводим кол-вом вхождений слов
System.out.println(biMap); // напечатает {two=два, ball=мяч, one=один, snow=cнег, three=три} - в
произвольном порядке
// Выводим все уникальные слова
System.out.println(biMap.keySet()); // напечатает [snow, two, one, three, ball] - в произвольном порядке
System.out.println(biMap.values()); // напечатает [два, мяч, один, cнег, три] - в произвольном порядке
// Выводим перевод по каждому слову
System.out.println("one = " + biMap.get("one")); // напечатает one = один
System.out.println("two = " + biMap.get("two")); // напечатает two = два
System.out.println("мяч = " + biMap.inverse().get("мяч")); // напечатает мяч = ball
System.out.println("снег = " + biMap.inverse().get("cнег")); // напечатает снег = snow
System.out.println("empty = " + biMap.get("empty")); // напечатает empty = null
// Выводим общее количество переводов в словаре
System.out.println(biMap.size()); //напечатает 5
4. Ну и наконец, посмотрим как можно сделать тоже самое в чистом JDK
Используем две HashMap для эмуляции BiMap
String[] englishWords = {"one", "two", "three","ball","snow"};
String[] russianWords = {"один", "два", "три","мяч","cнег"};
// Создаем аналог BiMap
Map<String, String> biMapKeys = new HashMap(englishWords.length);
Map<String, String> biMapValues = new HashMap(russianWords.length);
// создаем англо-русский словарь
int i = 0;
for(String englishWord: englishWords) {
biMapKeys.put(englishWord, russianWords[i]);
biMapValues.put(russianWords[i], englishWord);
i++;
}
// Выводим кол-вом вхождений слов
System.out.println(biMapKeys); // напечатает {ball=мяч, two=два, three=три, snow=cнег, one=один}- в
произвольном порядке
// Выводим все уникальные слова
System.out.println(biMapKeys.keySet()); // напечатает [ball, two, three, snow, one] - в произвольном порядке
System.out.println(biMapValues.keySet()); // напечатает [два, три, мяч, cнег, один] - в произвольном порядке
// Выводим перевод по каждому слову
System.out.println("one = " + biMapKeys.get("one")); // напечатает one = один
System.out.println("two = " + biMapKeys.get("two")); // напечатает two = два
System.out.println("мяч = " + biMapValues.get("мяч")); // напечатает мяч = ball
System.out.println("снег = " + biMapValues.get("cнег")); // напечатает снег = snow
System.out.println("empty = " + biMapValues.get("empty")); // напечатает empty = null
// Выводим общее количество переводов в словаре
System.out.println(biMapKeys.size()); //напечатает 5
V. Сравнение операций работы с коллекциями
Давайте кратко посмотрим какие дополнительные методы, операции и алгоритмы предлагают альтернативные библиотеки по сравнению со стандартными возможностями JDK. Цель этого, естественно, не перечислить все возможные методы всех библиотек (это невозможно), а скорее дать краткое представление о философии и синтаксисе разных библиотек, чтобы каждый мог выбрать то что больше нравится именно ему.
5.1 Сравним создание коллекций с помощью методов различных библиотек.
Guava и gs-collections предлагают создание коллекций через статические методы утилиты вместо использование new, давайте посмотрим насколько это удобнее обычного способа jdk.
5.1.1) Создание списка (List)
| Название | JDK | guava | gs-collections |
|---|---|---|---|
| Создание пустого списка | new ArrayList<>() | Lists.newArrayList() | FastList.newList() |
| Создание списка из значений | Arrays.asList(«1», «2», «3») | Lists.newArrayList(«1», «2», «3») | FastList.newListWith(«1», «2», «3») |
| Создать список с определенным capacity |
new ArrayList<>(100) | Lists.newArrayListWithCapacity(100) | FastList.newList(100) |
| Создать список из любой коллекции |
new ArrayList<>(collection) | Lists.newArrayList(collection) | FastList.newList(collection) |
| Создать список из любого Iterable |
— | Lists.newArrayList(iterable) | FastList.newList(iterable) |
| Создать список из Iterator’а |
— | Lists.newArrayList(iterator) | — |
| Создать список из массива | Arrays.asList(array) | Lists.newArrayList(array) | FastList.newListWith(array) |
| Создать список c помощью фабрики |
— | — | FastList.newWithNValues(10, () -> «1») |
Примеры создания списка
// Простое создание пустых коллекций
List<String> emptyGuava = Lists.newArrayList(); // c помощью guava
List<String> emptyJDK = new ArrayList<>(); // аналог JDK
MutableList<String> emptyGS = FastList.newList(); // c помощью gs
// Создать список ровно со 100 элементами
List < String > exactly100 = Lists.newArrayListWithCapacity(100); // c помощью guava
List<String> exactly100JDK = new ArrayList<>(100); // аналог JDK
MutableList<String> empty100GS = FastList.newList(100); // c помощью gs
// Создать список в котором ожидается около 100 элементов (чуть больше чем 100)
List<String> approx100 = Lists.newArrayListWithExpectedSize(100); // c помощью guava
List<String> approx100JDK = new ArrayList<>(115); // аналог JDK
MutableList<String> approx100GS = FastList.newList(115); // c помощью gs
// Создать список из заданных элементов
List<String> withElements = Lists.newArrayList("alpha", "beta", "gamma"); // c помощью guava
List<String> withElementsJDK = Arrays.asList("alpha", "beta", "gamma"); // аналог JDK
MutableList<String> withElementsGS = FastList.newListWith("alpha", "beta", "gamma"); // c помощью gs
System.out.println(withElements);
System.out.println(withElementsJDK);
System.out.println(withElementsGS);
// Создать список из любого объекта Iterable интерфейса (то есть любой коллекции)
Collection<String> collection = new HashSet<>(3);
collection.add("1");
collection.add("2");
collection.add("3");
List<String> fromIterable = Lists.newArrayList(collection); // c помощью guava
List<String> fromIterableJDK = new ArrayList<>(collection); // аналог JDK
MutableList<String> fromIterableGS = FastList.newList(collection); // c помощью gs
System.out.println(fromIterable);
System.out.println(fromIterableJDK);
System.out.println(fromIterableGS);
/* обратите внимание у JDK необходим объект Collection интерфейса, у guava и gs достаточно Iterable */
// Создать список из Iterator'а
Iterator<String> iterator = collection.iterator();
List<String> fromIterator = Lists.newArrayList(iterator); // c помощью guava, аналога в JDK нет
System.out.println(fromIterator);
// Создать список из массива
String[] array = {"4", "5", "6"};
List<String> fromArray = Lists.newArrayList(array); // c помощью guava
List<String> fromArrayJDK = Arrays.asList(array); // аналог JDK
MutableList<String> fromArrayGS = FastList.newListWith(array); // c помощью gs
System.out.println(fromArray);
System.out.println(fromArrayJDK);
System.out.println(fromArrayGS);
// Создать список из c помощью фабрики
MutableList<String> fromFabricGS = FastList.newWithNValues(10, () -> String.valueOf(Math.random())); // c помощью gs
System.out.println(fromFabricGS);
5.1.2) Создание множества (set)
| Название | JDK | guava | gs-collections |
|---|---|---|---|
| Создание пустого множества |
new HashSet<>() | Sets.newHashSet() | UnifiedSet.newSet() |
| Создать множество из заданных элементов |
new HashSet<>(Arrays.asList(«alpha», «beta», «gamma»)) | Sets.newHashSet(«alpha», «beta», «gamma») | UnifiedSet.newSetWith(«alpha», «beta», «gamma») |
| Создать множество из любой коллекции |
new HashSet<>(collection) | Sets.newHashSet(collection) | UnifiedSet.newSet(collection) |
| Создать множество из любого Iterable |
— | Sets.newHashSet(iterable) | UnifiedSet.newSet(iterable) |
| Создать множество из Iterator’а |
— | Sets.newHashSet(iterator); | — |
| Создать множество из массива |
new HashSet<>(Arrays.asList(array)) | Sets.newHashSet(array) | UnifiedSet.newSetWith(array) |
Примеры создания множества
// Простое создание пустых коллекций
Set<String> emptyGuava = Sets.newHashSet(); // c помощью guava
Set<String> emptyJDK = new HashSet<>(); // аналог JDK
Set<String> emptyGS = UnifiedSet.newSet(); // c помощью gs
// Создать множество в котором ожидается около 100 элементов (чуть больше чем 100)
Set<String> approx100 = Sets.newHashSetWithExpectedSize(100); // c помощью guava
Set<String> approx100JDK = new HashSet<>(130); // аналог JDK
Set<String> approx100GS = UnifiedSet.newSet(130); // c помощью gs
// Создать множество из заданных элементов
Set<String> withElements = Sets.newHashSet("alpha", "beta", "gamma"); // c помощью guava
Set<String> withElementsJDK = new HashSet<>(Arrays.asList("alpha", "beta", "gamma")); // аналог JDK
Set<String> withElementsGS = UnifiedSet.newSetWith("alpha", "beta", "gamma"); // c помощью gs
System.out.println(withElements);
System.out.println(withElementsJDK);
System.out.println(withElementsGS);
// Создать множество из любого объекта Iterable интерфейса (то есть любой коллекции)
Collection<String> collection = new ArrayList<>(3);
collection.add("1");
collection.add("2");
collection.add("3");
Set<String> fromIterable = Sets.newHashSet(collection); // c помощью guava
Set<String> fromIterableJDK = new HashSet<>(collection); // аналог JDK
Set<String> fromIterableGS = UnifiedSet.newSet(collection); // c помощью gs
System.out.println(fromIterable);
System.out.println(fromIterableJDK);
System.out.println(fromIterableGS);
/* обратите внимание у JDK необходим объект Collection интерфейса, у guava достаточно Iterable */
// Создать множество из Iterator'а
Iterator<String> iterator = collection.iterator();
Set<String> fromIterator = Sets.newHashSet(iterator); // c помощью guava, аналога в JDK нет
System.out.println(fromIterator);
// Создать множество из массива
String[] array = {"4", "5", "6"};
Set<String> fromArray = Sets.newHashSet(array); // c помощью guava
Set<String> fromArrayJDK = new HashSet<>(Arrays.asList(array)); // аналог JDK
Set<String> fromArrayGS = UnifiedSet.newSetWith(array); // c помощью gs
System.out.println(fromArray);
System.out.println(fromArrayJDK);
System.out.println(fromArrayGS);
5.1.3) Создание Map
| Название | JDK | guava | gs-collections |
|---|---|---|---|
| Создание пустой map’ы | new HashMap<>() | Maps.newHashMap() | UnifiedMap.newMap() |
| Создать map’у c определенным capacity |
new HashMap<>(130) | Maps.newHashMapWithExpectedSize(100) | UnifiedMap.newMap(130) |
| Создать map’у из другой map’ы | new HashMap<>(map) | Maps.newHashMap(map) | UnifiedMap.newMap(map) |
| Создать map’у из ключей | — | — | UnifiedMap.newWithKeysValues(«1», «a», «2», «b») |
Примеры создания map
// Простое создание пустых коллекций
Map<String, String> emptyGuava = Maps.newHashMap(); // c помощью guava
Map<String, String> emptyJDK = new HashMap<>(); // аналог JDK
Map<String, String> emptyGS = UnifiedMap.newMap(); // c помощью gs
// Создать map’у в котором ожидается около 100 элементов (чуть больше чем 100)
Map<String, String> approx100 = Maps.newHashMapWithExpectedSize(100); // c помощью guava
Map<String, String> approx100JDK = new HashMap<>(130); // аналог JDK
Map<String, String> approx100GS = UnifiedMap.newMap(130); // c помощью gs
// Создать map’у из другой map’ы
Map<String, String> map = new HashMap<>(3);
map.put(«k1»,«v1»);
map.put(«k2»,«v2»);
Map<String, String> withMap = Maps.newHashMap(map); // c помощью guava
Map<String, String> withMapJDK = new HashMap<>(map); // аналог JDK
Map<String, String> withMapGS = UnifiedMap.newMap(map); // c помощью gs
System.out.println(withMap);
System.out.println(withMapJDK);
System.out.println(withMapGS);
// Создать map’у из ключей
Map<String, String> withKeys = UnifiedMap.newWithKeysValues(«1», «a», «2», «b»);
System.out.println(withKeys);
5.2 Сравним методы поиска из различных библиотек.
| Название | JDK | guava | apache | gs-collections |
|---|---|---|---|---|
| Найти количество вхождений объекта | Collections.frequency(collection, «1») | Iterables.frequency(iterable, «1») | CollectionUtils.cardinality(«1», iterable) | mutableCollection.count((each) -> «a1».equals(each)) |
| Вернуть первый элемент коллекции или значение по умолчанию | collection.stream().findFirst().orElse(«1») | Iterables.getFirst(iterable, «1») | CollectionUtils.get(iterable, 0) | orderedIterable.getFirst() |
| Вернуть последний элемент коллекции или значение по умолчанию | collection.stream().skip(collection.size()-1).findFirst().orElse(«1»); | Iterables.getLast(iterable, «1») | CollectionUtils.get(collection, collection.size()-1) | orderedIterable.getLast() |
| Вернуть максимальный элемент | Collections.max(collection) | Ordering.natural().max(iterable) | — | orderedIterable.max() |
| Вернуть минимальный элемент | Collections.min(collection) | Ordering.natural().min(iterable) | — | orderedIterable.min() |
| Вернуть единственный элемент коллекции | Iterables.getOnlyElement(iterable) | CollectionUtils.extractSingleton(collection) | ||
| Найти элемент в отсортированном списке | Collections.binarySearch(list, «13») | Ordering.natural().binarySearch(list, «13») | mutableList.binarySearch(«13») | |
| Найти элемент в неотсортированной коллекции | collection.stream().filter(«13»::equals).findFirst().get() | Iterables.find(iterable, «13»::equals) | CollectionUtils.find(iterable, «13»::equals) | mutableList.select(«13»::equals).get(0) |
| Выбрать все элементы по условию | collection.stream().filter((s) -> s.contains(«1»)).collect(Collectors.toList()) | Iterables.filter(iterable, (s) -> s.contains(«1»)) | CollectionUtils.select(iterable, (s) -> s.contains(«1»)) | mutableCollection.select((s) -> s.contains(«1»)) |
Обратите внимание что методы разных библиотек работают с разными сущностями, это можно определить по названию переменных: collection — любая реализация интерфейса Collection, iterable — интерфейса Iterable, list — интерфейса List, orderedIterable и mutableList соответствующих интерфейсов в GS (orderedIterable — интерфейс для всех коллекций у которых определен порядок элементов, mutableList — интерфейс для любых изменяемых списков)
Примеры:
1) Найти количество вхождений объекта
Collection<String> collection = Lists.newArrayList("a1", "a2", "a3", "a1");
Iterable<String> iterable = collection;
MutableCollection<String> collectionGS = FastList.newListWith("a1", "a2", "a3", "a1");
// Вернуть количество вхождений объекта
int i1 = Iterables.frequency(iterable, "a1"); // с помощью guava
int i2 = Collections.frequency(collection, "a1"); // c помощью JDK
int i3 = CollectionUtils.cardinality("a1", iterable); // c помощью Apache
int i4 = collectionGS.count((s) -> "a1".equals(s));
long i5 = collection.stream().filter((s) -> "a1".equals(s)).count(); // c помощью stream JDK
System.out.println("count = " + i1 + ":" + i2 + ":" + i3 + ":" + i4 + ":" + i5); // напечатает count = 2:2:2:2:2
2) Вернуть первый элемент коллекции
Collection<String> collection = Lists.newArrayList("a1", "a2", "a3", "a1");
OrderedIterable<String> orderedIterable = FastList.newListWith("a1", "a2", "a3", "a1");
Iterable<String> iterable = collection;
// вернуть первый элемент коллекции
Iterator<String> iterator = collection.iterator(); // c помощью JDK
String jdk = iterator.hasNext() ? iterator.next(): "1";
String guava = Iterables.getFirst(iterable, "1"); // с помощью guava
String apache = CollectionUtils.get(iterable, 0); // c помощью Apache
String gs = orderedIterable.getFirst(); // c помощью GS
String stream = collection.stream().findFirst().orElse("1"); // c помощью Stream API
System.out.println("first = " + jdk + ":" + guava + ":" + apache + ":" + gs + ":" + stream); // напечатает first = a1:a1:a1:a1:a1
3) Вернуть последний элемент коллекции
Collection<String> collection = Lists.newArrayList("a1", "a2", "a3", "a8");
OrderedIterable<String> orderedIterable = FastList.newListWith("a1", "a2", "a3", "a8");
Iterable<String> iterable = collection;
// вернуть последней элемент коллекции
Iterator<String> iterator = collection.iterator(); // c помощью JDK
String jdk = "1";
while(iterator.hasNext()) {
jdk = iterator.next();
}
String guava = Iterables.getLast(iterable, "1"); // с помощью guava
String apache = CollectionUtils.get(collection, collection.size()-1); // c помощью Apache
String gs = orderedIterable.getLast(); // c помощью GS
String stream = collection.stream().skip(collection.size()-1).findFirst().orElse("1"); // c помощью Stream API
System.out.println("last = " + jdk + ":" + guava + ":" + apache + ":" + gs + ":" + stream); // напечатает last = a8:a8:a8:a8:a8
4) Вернуть максимальный элемент
Collection<String> collection = Lists.newArrayList("5", "1", "3", "8", "4");
OrderedIterable<String> orderedIterable = FastList.newListWith("5", "1", "3", "8", "4");
Iterable<String> iterable = collection;
// вернуть максимальный элемент коллекции
String jdk = Collections.max(collection); // c помощью JDK
String gs = orderedIterable.max(); // c помощью GS
String guava = Ordering.natural().max(iterable); // с помощью guava
System.out.println("max = " + jdk + ":" + guava + ":" + gs); // напечатает max = 8:8:8
5) Вернуть минимальный элемент
Collection<String> collection = Lists.newArrayList("5", "1", "3", "8", "4");
OrderedIterable<String> orderedIterable = FastList.newListWith("5", "1", "3", "8", "4");
Iterable<String> iterable = collection;
// вернуть минимальный элемент коллекции
String jdk = Collections.min(collection); // c помощью JDK
String gs = orderedIterable.min(); // c помощью GS
String guava = Ordering.natural().min(iterable); // с помощью guava
System.out.println("min = " + jdk + ":" + guava + ":" + gs); // напечатает min = 1:1:1
6) вернуть единственный элемент коллекции
Collection<String> collection = Lists.newArrayList("a3");
OrderedIterable<String> orderedIterable = FastList.newListWith("a3");
Iterable<String> iterable = collection;
// вернуть единственный элемент коллекции
String guava = Iterables.getOnlyElement(iterable); // с помощью guava
String jdk = collection.iterator().next(); // c помощью JDK
String apache = CollectionUtils.extractSingleton(collection); // c помощью Apache
assert(orderedIterable.size() > 1);// c помощью GS
String gs = orderedIterable.getFirst();
System.out.println("single = " + jdk + ":" + guava + ":" + apache + ":" + gs); // напечатает single = a3:a3:a3:a3
7) найти элемент в отсортированом списке
List<String> list = Lists.newArrayList("2", "4", "13", "31", "43");
MutableList<String> mutableList = FastList.newListWith("2", "4","13", "31", "43");
// найти элемент в отсортированом списке
int jdk = Collections.binarySearch(list, "13");
int guava = Ordering.natural().binarySearch(list, "13");
int gs = mutableList.binarySearch("13");
System.out.println("find = " + jdk + ":" + guava + ":" + gs); // напечатает find = 2:2:2
найти элемент в неотсортированной коллекции
Collection<String> collection = Lists.newArrayList("a1", "a2", "a3", "a1");
MutableCollection<String> orderedIterable = FastList.newListWith("a1", "a2", "a3", "a1");
Iterable<String> iterable = collection;
// вернуть третий элемент коллекции по порядку
String jdk = collection.stream().skip(2).findFirst().get(); // c помощью JDK
String guava = Iterables.get(iterable, 2); // с помощью guava
String apache = CollectionUtils.get(iterable, 2); // c помощью Apache
System.out.println("third = " + jdk + ":" + guava + ":" + apache); // напечатает third = a3:a3:a3
9) выбрать все элементы по условию
Collection<String> collection = Lists.newArrayList("2", "14", "3", "13", "43");
MutableCollection<String> mutableCollection = FastList.newListWith("2", "14", "3", "13", "43");
Iterable<String> iterable = collection;
// выбрать все элементы по шаблону
List<String> jdk = collection.stream().filter((s) -> s.contains("1")).collect(Collectors.toList()); // c помощью JDK
Iterable<String> guava = Iterables.filter(iterable, (s) -> s.contains("1")); // с помощью guava
Collection<String> apache = CollectionUtils.select(iterable, (s) -> s.contains("1")); // c помощью Apache
MutableCollection<String> gs = mutableCollection.select((s) -> s.contains("1")); // c помощью GS
System.out.println("select = " + jdk + ":" + guava + ":" + apache + ":" + gs); // напечатает select = [14, 13]:[14, 13]:[14, 13]:[14, 13]
5.3 Сравним методы сравнений, объединений и пересечений коллекций
| Название | JDK | guava | apache | gs-collections |
|---|---|---|---|---|
| Проверить полное соответствие двух коллекций | collection1.containsAll(collection2) | Iterables.elementsEqual(iterable1, iterable2) | CollectionUtils.containsAll(collection1, collection2) | mutableCollection1.containsAll(mutableCollection2) |
| Наличие хотя бы одного общего элемента | !Collections.disjoint(collection1, collection2) | !Sets.intersection(set1, set2).isEmpty() | CollectionUtils.containsAny(collection1, collection2) | !mutableSet1.intersect(mutableSet2).isEmpty() |
| Найти все общие элементы (пересечение) | Set<T> result = new HashSet<>(set1); result.retainAll(set2) |
Sets.intersection(set1, set2) | CollectionUtils.intersection(collection1, collection2) | mutableSet1.intersect(mutableSet2) |
| Отсутствие общих элементов | Collections.disjoint(collection1, collection2) | Sets.intersection(set1, set2).isEmpty() | !CollectionUtils.containsAny(collection1, collection2) | mutableSet1.intersect(mutableSet2).isEmpty() |
| Найти все элементы, которые есть в одной коллекции и нет в другой (difference) | Set<T> result = new HashSet<>(set1); result.removeAll(set2) |
Sets.difference(set1, set2) | CollectionUtils.removeAll(collection1, collection2) | mutableSet1.difference(mutableSet2) |
| Найти все различные элементы (symmetric difference) | Sets.symmetricDifference(set1, set2) | CollectionUtils.disjunction(collection1, collection2) | mutableSet1.symmetricDifference(mutableSet2) | |
| Получить объедение двух коллекций | Set<T> result = new HashSet<>(set1); result.addAll(set2) |
Sets.union(set1, set2) | CollectionUtils.union(collection1, collection2) | mutableSet1.union(mutableSet2) |
Примеры:
1) Проверить полное соответствие двух коллекций
Collection<String> collection1 = Lists.newArrayList("a1", "a2", "a3", "a1");
Collection<String> collection2 = Lists.newArrayList("a1", "a2", "a3", "a1");
Iterable<String> iterable1 = collection1;
Iterable<String> iterable2 = collection2;
MutableCollection<String> mutableCollection1 = FastList.newListWith("a1", "a2", "a3", "a1");
MutableCollection<String> mutableCollection2 = FastList.newListWith("a1", "a2", "a3", "a1");
// Проверить полное соответствие двух коллекций
boolean jdk = collection1.containsAll(collection2); // c помощью JDK
boolean guava = Iterables.elementsEqual(iterable1, iterable2); // с помощью guava
boolean apache = CollectionUtils.containsAll(collection1, collection2); // c помощью Apache
boolean gs = mutableCollection1.containsAll(mutableCollection2); // c помощью GS
System.out.println("containsAll = " + jdk + ":" + guava + ":" + apache + ":" + gs); // напечатает containsAll = true:true:true:true
2) Проверить наличие хотя бы одного общего элемента у двух коллекций
Collection<String> collection1 = Lists.newArrayList("a1", "a2", "a3", "a1");
Collection<String> collection2 = Lists.newArrayList("a4", "a8", "a3", "a5");
Set<String> set1 = Sets.newHashSet("a1", "a2", "a3", "a1");
Set<String> set2 = Sets.newHashSet("a4", "a8", "a3", "a5");
MutableSet<String> mutableSet1 = UnifiedSet.newSetWith("a1", "a2", "a3", "a1");
MutableSet<String> mutableSet2 = UnifiedSet.newSetWith("a4", "a8", "a3", "a5");
// Проверить наличие хотя бы одного общего элемента у двух коллекций
boolean jdk = !Collections.disjoint(collection1, collection2); // c помощью JDK
boolean guava = !Sets.intersection(set1, set2).isEmpty(); // с помощью guava
boolean apache = CollectionUtils.containsAny(collection1, collection2); // c помощью Apache
boolean gs = !mutableSet1.intersect(mutableSet2).isEmpty(); // c помощью GS
System.out.println("containsAny = " + jdk + ":" + guava + ":" + apache + ":" + gs); // напечатает containsAny = true:true:true:true
3) Найти все общие элементы (пересечение) у двух коллекций
Collection<String> collection1 = Lists.newArrayList("a1", "a2", "a3", "a1");
Collection<String> collection2 = Lists.newArrayList("a4", "a8", "a3", "a5");
Set<String> set1 = Sets.newHashSet("a1", "a2", "a3", "a1");
Set<String> set2 = Sets.newHashSet("a4", "a8", "a3", "a5");
MutableSet<String> mutableSet1 = UnifiedSet.newSetWith("a1", "a2", "a3", "a1");
MutableSet<String> mutableSet2 = UnifiedSet.newSetWith("a4", "a8", "a3", "a5");
// Найти все общие элементы у двух коллекций
Set<String> jdk = new HashSet<>(set1); // c помощью JDK
jdk.retainAll(set2);
Set<String> guava = Sets.intersection(set1, set2); // с помощью guava
Collection<String> apache = CollectionUtils.intersection(collection1, collection2); // c помощью Apache
Set<String> gs = mutableSet1.intersect(mutableSet2); // c помощью GS
System.out.println("intersect = " + jdk + ":" + guava + ":" + apache + ":" + gs); // напечатает intersect = [a3]:[a3]:[a3]:[a3]
4) Найти все элементы, которые есть в одной коллекции и нет в другой (difference)
Collection<String> collection1 = Lists.newArrayList("a2", "a3");
Collection<String> collection2 = Lists.newArrayList("a8", "a3", "a5");
Set<String> set1 = Sets.newHashSet("a2", "a3");
Set<String> set2 = Sets.newHashSet("a8", "a3", "a5");
MutableSet<String> mutableSet1 = UnifiedSet.newSetWith("a2", "a3");
MutableSet<String> mutableSet2 = UnifiedSet.newSetWith("a8", "a3", "a5");
// Найти все элементы, которые есть в одной коллекции и нет в другой (difference)
Set<String> jdk = new HashSet<>(set1); // c помощью JDK
jdk.removeAll(set2);
Set<String> guava = Sets.difference(set1, set2); // с помощью guava
Collection<String> apache = CollectionUtils.removeAll(collection1, collection2); // c помощью Apache
Set<String> gs = mutableSet1.difference(mutableSet2); // c помощью GS
System.out.println("difference = " + jdk + ":" + guava + ":" + apache + ":" + gs); // напечатает difference = [a2]:[a2]:[a2]:[a2]
5) Найти все различные элементы (symmetric difference) у двух коллекций
Collection<String> collection1 = Lists.newArrayList("a2", "a3");
Collection<String> collection2 = Lists.newArrayList("a8", "a3", "a5");
Set<String> set1 = Sets.newHashSet("a2", "a3");
Set<String> set2 = Sets.newHashSet("a8", "a3", "a5");
MutableSet<String> mutableSet1 = UnifiedSet.newSetWith("a2", "a3");
MutableSet<String> mutableSet2 = UnifiedSet.newSetWith("a8", "a3", "a5");
// Найти все различные элементы (symmetric difference) у двух коллекций
Set<String> intersect = new HashSet<>(set1); // c помощью JDK
intersect.retainAll(set2);
Set<String> jdk = new HashSet<>(set1);
jdk.addAll(set2);
jdk.removeAll(intersect);
Set<String> guava = Sets.symmetricDifference(set1, set2); // с помощью guava
Collection<String> apache = CollectionUtils.disjunction(collection1, collection2); // c помощью Apache
Set<String> gs = mutableSet1.symmetricDifference(mutableSet2); // c помощью GS
System.out.println("symmetricDifference = " + jdk + ":" + guava + ":" + apache + ":" + gs); // напечатает symmetricDifference = [a2, a5, a8]:[a2, a5, a8]:[a2, a5, a8]:[a2, a5, a8]
6) Получить объедение двух коллекций
Set<String> set1 = Sets.newHashSet("a1", "a2");
Set<String> set2 = Sets.newHashSet("a4");
MutableSet<String> mutableSet1 = UnifiedSet.newSetWith("a1", "a2");
MutableSet<String> mutableSet2 = UnifiedSet.newSetWith("a4");
Collection<String> collection1 = set1;
Collection<String> collection2 = set2;
// Получить объедение двух коллекций
Set<String> jdk = new HashSet<>(set1); // c помощью JDK
jdk.addAll(set2);
Set<String> guava = Sets.union(set1, set2); // с помощью guava
Collection<String> apache = CollectionUtils.union(collection1, collection2); // c помощью Apache
Set<String> gs = mutableSet1.union(mutableSet2); // c помощью GS
System.out.println("union = " + jdk + ":" + guava + ":" + apache + ":" + gs); // напечатает union = [a1, a2, a4]:[a1, a2, a4]:[a1, a2, a4]:[a1, a2, a4]
5.4 Сравним методы изменения коллекции
| Название | JDK | guava | apache | gs-collections |
|---|---|---|---|---|
| Сортировка коллекции | Collections.sort(list); | Ordering.natural().sortedCopy(iterable) | mutableList.sortThis() | |
| Удалить все элементы соответствующие условию | collection.removeIf((s) -> s.contains(«1»)) | Iterables.removeIf(iterable, (s) -> s.contains(«1»)) | CollectionUtils.filter(iterable, (s) -> !s.contains(«1»)) | mutableCollection.removeIf((Predicate<String>) (s) -> s.contains(«1»)) |
| Удалить все элементы не соответствующие условию | collection.removeIf((s) -> !s.contains(«1»)) | Iterables.removeIf(iterable, (s) -> !s.contains(«1»)) | CollectionUtils.filter(iterable, (s) -> s.contains(«1»)) | mutableCollection.removeIf((Predicate<String>) (s) -> !s.contains(«1»)) |
| Изменить все элементы коллекции | collection.stream().map((s) -> s + «_1»).collect(Collectors.toList()) | Iterables.transform(iterable, (s) -> s + «_1») | CollectionUtils.transform(collection, (s) -> s + «_1») | mutableCollection.collect((s) -> s + «_1») |
| Изменить свойства каждого элемента | collection.stream().forEach((s) -> s.append(«_1»)) | Iterables.transform(iterable, (s) -> s.append(«_1»)) | CollectionUtils.transform(collection, (s) -> s.append(«_1»)) | mutableCollection.forEach((Procedure<StringBuilder>) (s) -> s.append(«_1»)) |
1) Сортировка коллекции
List<String> jdk = Lists.newArrayList("a1", "a2", "a3", "a1");
Iterable<String> iterable = jdk;
MutableList<String> gs = FastList.newList(jdk);
// Сортировка коллекции
Collections.sort(jdk); // с помощью jdk
List<String> guava = Ordering.natural().sortedCopy(iterable); // с помощью guava
gs.sortThis(); // c помощью gs
System.out.println("sort = " + jdk + ":" + guava + ":" + gs); // напечатает sort = [a1, a1, a2, a3]:[a1, a1, a2, a3]:[a1, a1, a2, a3]
2) Удалить все элементы соответствующие условию
Collection<String> jdk = Lists.newArrayList("a1", "a2", "a3", "a1");
Iterable<String> guava = Lists.newArrayList(jdk);
Iterable<String> apache = Lists.newArrayList(jdk);
MutableCollection<String> gs = FastList.newList(jdk);
// Удалить все элементы соответствующие условию
jdk.removeIf((s) -> s.contains("1")); // с помощью jdk
Iterables.removeIf(guava, (s) -> s.contains("1")); // с помощью guava
CollectionUtils.filter(apache, (s) -> !s.contains("1")); // с помощью apache
gs.removeIf((Predicate<String>) (s) -> s.contains("1")); // c помощью gs
System.out.println("removeIf = " + jdk + ":" + guava + ":" + apache + ":" + gs); // напечатает removeIf = [a2, a3]:[a2, a3]:[a2, a3]:[a2, a3]
3) Удалить все элементы не соответствующие условию
Collection<String> jdk = Lists.newArrayList("a1", "a2", "a3", "a1");
Iterable<String> guava = Lists.newArrayList(jdk);
Iterable<String> apache = Lists.newArrayList(jdk);
MutableCollection<String> gs = FastList.newList(jdk);
// Удалить все элементы не соответствующие условию
jdk.removeIf((s) -> !s.contains("1")); // с помощью jdk
Iterables.removeIf(guava, (s) -> !s.contains("1")); // с помощью guava
CollectionUtils.filter(apache, (s) -> s.contains("1")); // с помощью apache
gs.removeIf((Predicate<String>) (s) -> !s.contains("1")); // c помощью gs
System.out.println("retainIf = " + jdk + ":" + guava + ":" + apache + ":" + gs); // напечатает retainIf = [a1, a1]:[a1, a1]:[a1, a1]:[a1, a1]
4) Преобразовать все элементы коллекции
Collection<String> collection = Lists.newArrayList("a1", "a2", "a3", "a1");
Iterable<String> iterable = collection;
Collection<String> apache = Lists.newArrayList(collection);
MutableCollection<String> mutableCollection = FastList.newList(collection);
// Преобразовать все элементы коллекции в другие элементы
List<String> jdk = collection.stream().map((s) -> s + "_1").collect(Collectors.toList()); // с помощью jdk
Iterable<String> guava = Iterables.transform(iterable, (s) -> s + "_1"); // с помощью guava
CollectionUtils.transform(apache, (s) -> s + "_1"); // с помощью apache
MutableCollection<String> gs = mutableCollection.collect((s) -> s + "_1"); // c помощью gs
System.out.println("transform = " + jdk + ":" + guava + ":" + apache + ":" + gs); // напечатает transform = [a1_1, a2_1, a3_1, a1_1]:[a1_1, a2_1, a3_1, a1_1]:[a1_1, a2_1, a3_1, a1_1]:[a1_1, a2_1, a3_1, a1_1]
5) Изменить свойства каждого элемента коллекции
Collection<StringBuilder> jdk = Lists.newArrayList(new StringBuilder("a1"), new StringBuilder("a2"), new StringBuilder("a3"));
Iterable<StringBuilder> iterable = Lists.newArrayList(new StringBuilder("a1"), new StringBuilder("a2"), new StringBuilder("a3"));;
Collection<StringBuilder> apache = Lists.newArrayList(new StringBuilder("a1"), new StringBuilder("a2"), new StringBuilder("a3"));
MutableCollection<StringBuilder> gs = FastList.newListWith(new StringBuilder("a1"), new StringBuilder("a2"), new StringBuilder("a3"));
// Изменить свойства каждого элемента коллекции
jdk.stream().forEach((s) -> s.append("_1")); // с помощью jdk
Iterable<StringBuilder> guava = Iterables.transform(iterable, (s) -> s.append("_1")); // с помощью guava
CollectionUtils.transform(apache, (s) -> s.append("_1")); // с помощью apache
gs.forEach((Procedure<StringBuilder>) (s) -> s.append("_1")); // c помощью gs
System.out.println("change = " + jdk + ":" + guava + ":" + apache + ":" + gs); // changeAll = [a1_1, a2_1, a3_1]:[a1_1, a2_1, a3_1]:[a1_1, a2_1, a3_1]:[a1_1, a2_1, a3_1]
VI. Сравнение стандартных и альтернативных коллекций
5.1 Какие вообще бывают коллекции
Для начала рассмотрим какие основные коллекции встречаются в программировании (не только в Java, а вообще):
1) Вектор (Список)— элементы коллекции упорядочены, можно обойти все элементы по очереди или обратиться по индексу,
— Массив — реализация вектора, когда данные находятся в памяти непосредственно друг за другом
— Динамический массив — реализация массива, когда размер массива может увеличиваться во время выполнения,
— Односвязный список — реализация списка, когда каждый элемент списка содержит значение и ссылку на
следующий элемент, в отличии от массива более структурно гибок,
— Двусвязный список — реализация списка когда каждый элемент списка содержит значение и ссылку на
следующий и предыдущий элемент,
2) Стек (Stack) — коллекция, реализующая принцип хранения «LIFO» («последним пришёл — первым вышел»). В
стеке постоянно доступен элемент добавленый последним, если он ещё не удален/извлечен.
3) Очередь (Queue) — коллекция, реализующая принцип хранения «FIFO» («первым пришёл— первым вышел»). В
очереди постоянно доступен только добавлен самым первым из имеющихся и ещё не удален/извлечен.
4) Двухсторонняя очередь (Double-ended queue) — очередь, которая позволяет добавлять и извлекать данные и
с начала очереди и с конца.
5) Очередь с приоритетом (англ. priority queue) — очередь, позволяющая добавить новый элемент и извлечь
максимум. Все данные хранятся в порядке убывания приоритета,
— куча (heap) — одна из реализаций очереди с приоритетом, с помощью дерева,
6) Ассоциативный массив (словарь), (Associative array, Dictionary) — неупорядоченная коллекция, хранящая
пары «ключ— значение»
— Хеш-таблица (hashtable) — реализация ассоциативного массива, построенная на вычислении хеша значения,
— Хеш-таблица со связями один ко многим (Multimap или multihash) — реализация Хеш-таблицы, которая хранит
отношение ключ и много значений,
— Двух-сторонняя хеш-таблица (bi-map) — реализация Хеш-таблицы, которая позволяет получать как значение
по ключу, так и ключ по значению,
— Упорядоченная хеш-таблица (hashtable) — хеш-таблица, возвращающая элементы в порядке добавления,
— Отсортированная хеш-таблица (hashtable) — хеш-таблица, возвращающая элементы отсортированном порядке,
7) Множество— неупорядоченная коллекция, хранящая набор уникальных значений и поддерживающая аналогичные
операциям с математическими множествами,
— Мультимножество— неупорядоченная коллекция, аналогичная множеству, но допускающая наличие в коллекции
одновременно двух и более одинаковых значений,
— Упорядоченное множество— коллекция, аналогичная множеству, но возвращает элементы в порядке добавления,
— Отсортированное множество— коллекция, аналогичная множеству, но возвращает элементы в отсортированном порядке,
Битовый массив — то есть массив значений 1 или 0,
9) Множество зарытых или открытых отрезков — то есть структура хранящая и работающая с геометрическими
интервалами,
10) Деревья — структура данных, хранящая данные в виде дерева,
11) Кеши — коллекции для работы с устаревающими за определенное время данными,
Давайте посмотрим какие из данных сущностей соответствуют каким коллекциям и интерфейсам Java и альтернативных библиотек:
Внимание: если таблица не помещается целиком, попробуйте уменьшить масштаб страницы или открыть в другом браузере.
| Название | List | Set | Map | Query Dequery и т.п. в JDK |
guava | apache | gs-collections |
|---|---|---|---|---|---|---|---|
| 1) Вектор (Список) Динамический массив |
ArrayList | LinkedHashSet | LinkedHashMap | ArrayDeque | TreeList | FastList | |
| Двусвязный список | LinkedList | LinkedHashSet | LinkedHashMap | LinkedList | NodeCachingLinkedList | ||
| 2) Стек (Stack) | LinkedList | ArrayDeque | ArrayStack | ||||
| 3) Очередь (Queue) | LinkedList | ArrayDeque | CircularFifoQueue | ||||
| 4) Двухсторонняя очередь | LinkedList | ArrayDeque | |||||
| 5) Очередь с приоритетом куча (heap) |
PriorityQueue | ||||||
| 6) Ассоциативный массив (словарь) | HashMap | HashedMap | UnifiedMap | ||||
| Хеш-таблица (hashtable) | HashSet | HashMap | HashedMap | UnifiedMap | |||
| Хеш-таблица со связями один ко многим | Multimap | MultiMap | Multimap | ||||
| Двух-сторонняя хеш-таблица | HashBiMap | BidiMap | HashBiMap | ||||
| Упорядоченная хеш-таблица | LinkedHashSet | LinkedHashMap | LinkedMap | ||||
| Отсортированная хеш-таблица | TreeSet | TreeMap | PatriciaTrie | TreeSortedMap | |||
| 7) Множество | HashSet | UnifiedSet | |||||
| Мультимножество | HashMultiset | HashBag | HashBag | ||||
| Упорядоченное множество | LinkedHashSet | ||||||
| Отсортированное множество | TreeSet | PatriciaTrie | TreeSortedSet | ||||
| Битовый массив |
BitSet | ||||||
| 9) Множество зарытых или открытых отрезков | RangeSet RangeMap |
||||||
| 10) Деревья | TreeSet | TreeMap | PatriciaTrie | TreeSortedSet | |||
| 11)Кеши | LinkedHashMap WeakHashMap |
LoadingCache |
VII. Заключение
Я специально не буду делать выводов какая библиотека хуже или лучше, так как во многом это дело вкуса, но в любом случае в альтернативных коллекциях можно найти много полезных коллекций и методов, если знать где искать. Спасибо, за то что дочитали (или долистали) до конца, надеюсь вы сумели найти в этой статье что-нибудь для себя полезное.
Исходные коды всех примеров можно найти на github’е.
Источники, которые использовались для написания статьи:
1. Обзор java.util.concurrent.* tutorial
2. Trove library: using primitive collections for performance
3. Java performance tuning tips
4. Large HashMap overview
5. Memory consumption of popular Java data types
6. И, естественно, официальная документация, javadoc и исходные коды всех рассмотренных библиотек
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Вектор (std::vector) и строка (std::string) — это важные базовые контейнеры стандартной библиотеки C++. Они хранят свои элементы в непрерывном фрагменте памяти. Оба этих контейнера предоставляют доступ к элементам по индексу и позволяют эффективно добавлять новые элементы в конец.
Контейнер std::vector
В стандартной библиотеке C++ вектором (std::vector) называется динамический массив, обеспечивающий быстрое добавление новых элементов в конец и меняющий свой размер при необходимости. Вектор гарантирует отсутствие утечек памяти (об этом мы поговорим в других главах, сейчас просто считайте, что это хорошо).
Для работы с вектором нужно подключить заголовочный файл vector.
Элементы вектора должны быть одинакового типа, и этот тип должен быть известен при компиляции программы. Он задаётся в угловых скобках после std::vector: например, std::vector<int> — это вектор целых чисел типа int, а std::vector<std::string> — вектор строк.
Само имя std::vector не является типом данных: это шаблон, в который требуется подставить нужные параметры (тип элемента), чтобы получился конкретный тип данных. Подробнее о том, что такое шаблоны и как их применять, мы расскажем в главе 1.9.
Рассмотрим пример программы, которая заполняет вектор элементами и печатает их через пробел:
#include <iostream>
#include <vector>
int main() {
std::vector<int> data = {1, 2, 3, 4, 5};
for (int elem : data) {
std::cout << elem << " ";
}
std::cout << "n";
}
Здесь мы инициализируем вектор через список инициализации, в котором элементы перечислены через запятую. Другой способ инициализации вектора — указать число элементов и (при необходимости) образец элемента:
#include <string>
#include <vector>
int main() {
std::vector<std::string> v1; // пустой вектор строк
std::vector<std::string> v2(5); // вектор из пяти пустых строк
std::vector<std::string> v3(5, "hello"); // вектор из пяти строк "hello"
}
Обращение к элементам
Выше мы использовали для печати элементов вектора цикл range-for. Но иногда удобнее работать с индексами. Вектор хранит элементы в памяти последовательно, поэтому по индексу элемента можно быстро найти его положение в памяти. Индексация начинается с нуля:
std::vector<int> data = {1, 2, 3, 4, 5};
int a = data[0]; // начальный элемент вектора
int b = data[4]; // последний элемент вектора (в нём пять элементов)
data[2] = -3; // меняем элемент 3 на -3
Чтобы узнать общее количество элементов в векторе, можно воспользоваться функцией size:
std::cout << data.size() << "n";
Отрицательные индексы, как в некоторых других языках программирования, не допускаются.
Обратите внимание: когда мы обращаемся по индексу через квадратные скобки, проверки его корректности не происходит. Это ещё одно проявление принципа «мы не должны платить за то, что не используем».
Встроенные валидаторы замедляют программу: предполагается, что программист пишет правильный код и уверен, что индекс i в выражении data[i] неотрицателен и удовлетворяет условию i < data.size(). В этом случае они ему не нужны.
Если всё же обратиться к вектору по некорректному индексу, то программа во время выполнения попадёт в неопределённое поведение: фактически она попробует прочитать память, не принадлежащую вектору.
Если вам не хочется делать много лишних проверок, а в корректности индекса вы не уверены, то можно использовать функцию at:
std::vector<int> data = {1, 2, 3, 4, 5};
std::cout << data[42] << "n"; // неопределённое поведение: может произойти всё что угодно
std::cout << data.at(0) << "n"; // напечатается 1
std::cout << data.at(42) << "n"; // произойдёт исключение std::out_of_range — его можно будет перехватить и обработать
Про работу с исключениями мы поговорим отдельно в главе 3.5.
Рассмотрим функции вектора front и back, которые возвращают его первый и последний элемент без использования индексов:
std::vector<int> data = {1, 2, 3, 4, 5};
std::cout << data.front() << "n"; // то же, что data[0]
std::cout << data.back() << "n"; // то же, что data[data.size() - 1]
Важно учитывать, что вызов этих функций на пустом векторе приведёт к неопределённому поведению.
Для проверки вектора на пустоту вместо сравнения data.size() == 0 принято использовать функцию empty, которая возвращает логическое значение:
if (!data.empty()) {
// вектор не пуст, с ним можно работать
}
Итерация по индексам
Так сложилось, что в стандартной библиотеке индексы и размеры контейнеров имеют беззнаковый тип. Вместо unsigned int или unsigned long int для него используется традиционный псевдоним size_t (а точнее, std::vector<T>::size_type). Тип size_t на самом деле совпадает с uint32_t или uint64_t в зависимости от битности платформы. Его использование в программе дополнительно подчёркивает, что мы имеем дело с индексами или с размером.
Итерацию по элементам data с помощью индексов можно записать так:
for (size_t i = 0; i != data.size(); ++i) {
std::cout << data[i] << " ";
}
Это каноническая форма записи такого цикла: в ней принято использовать сравнение != и префиксный ++i. Для целых чисел не будет разницы, если написать это как-то иначе (например, через < и постфиксный i++), но потом, когда вы будете писать аналогичные циклы для итераторов других контейнеров, разница появится. Давайте привыкнем всегда оформлять цикл по индексам так.
Беззнаковость типа возвращаемого значения функции size порождает следующую проблему. По правилам, унаследованным ещё от языка C, результат арифметических действий над беззнаковым и знаковым типами приводится к беззнаковому типу. Поэтому выражение data.size() - 1, например, тоже будет беззнаковым. Если data.size() окажется нулём, то такое выражение будет вовсе не минус единицей, а самым большим беззнаковым целым (для 64-битной платформы это $2^{64} — 1$).
Рассмотрим следующий ошибочный код, который проверяет, есть ли в векторе дубликаты, идущие подряд:
// итерация по всем элементам, кроме последнего:
for (size_t i = 0; i < data.size() - 1; ++i) {
if (data[i] == data[i + 1]) {
std::cout << "Duplicate value: " << data[i] << "n";
}
}
Эта программа будет некорректно работать на пустом векторе. Условие i < data.size() - 1 на первой итерации окажется истинным, и произойдёт обращение к элементам пустого вектора. Правильнее было бы переписать это условие через i + 1 < data.size() или воспользоваться внешней функцией std::ssize, которая появилась в C++20. Она возвращает знаковый размер вектора:
for (std::int64_t i = 0; i < std::ssize(data) - 1; ++i) {
if (data[i] == data[i + 1]) {
std::cout << "Duplicate value: " << data[i] << "n";
}
}
Добавление и удаление элементов
В вектор можно эффективно добавлять элементы в конец и удалять их с конца. Для этого существуют функции push_back и pop_back. Рассмотрим программу, считывающую числа с клавиатуры в вектор и затем удаляющую все нули в конце:
#include <iostream>
#include <vector>
int main() {
int x;
std::vector<int> data;
while (std::cin >> x) { // читаем числа, пока не закончится ввод
data.push_back(x); // добавляем очередное число в вектор
}
while (!data.empty() && data.back() == 0) {
// Пока вектор не пуст и последний элемент равен нулю
data.pop_back(); // удаляем этот нулевой элемент
}
}
Добавление элементов в другие части вектора или их удаление неэффективно, так как требует сдвига соседних элементов. Поэтому отдельных функций, например, для добавления или удаления элементов из начала у вектора нет. Это можно сделать с помощью общих функций insert/erase и итераторов. Мы рассмотрим такие примеры позже.
Удалить все элементы из вектора можно с помощью функции clear.
Резерв памяти
Вектор хранит элементы в памяти в виде непрерывной последовательности, друг за другом. При этом в конце последовательности резервируется дополнительное место для быстрого добавления новых элементов. Когда этот резерв заканчивается, при вставке очередного элемента происходит реаллокация: элементы вектора копируются в новый, более просторный блок памяти.
Реаллокация — довольно дорогая процедура, но если она происходит достаточно редко, то её влияние незначительно. Можно доказать, что если размер нового блока выбирать в два раза больше предыдущего размера, то амортизационная сложность добавления элемента будет константной.
Текущий резерв вектора можно узнать с помощью функции capacity (не путайте её с функцией size).

Рассмотрим программу, в которой в вектор последовательно добавляются элементы и после каждого шага печатается размер и резерв:
#include <iostream>
#include <vector>
int main() {
std::vector<int> data = {1, 2};
std::cout << data.size() << "t" << data.capacity() << "n";
data.push_back(3);
std::cout << data.size() << "t" << data.capacity() << "n";
data.push_back(4);
std::cout << data.size() << "t" << data.capacity() << "n";
data.push_back(5);
std::cout << data.size() << "t" << data.capacity() << "n";
}
Вот вывод этой программы:
2 2 3 4 4 4 5 8
Видно, что размер вектора увеличивается на единицу, а резерв удваивается после исчерпания. Так, при добавлении четвёрки используется имеющаяся в резерве память, а при добавлении тройки и пятёрки происходит реаллокация.

Иногда требуется заполнить вектор элементами, причём число элементов известно заранее. В таком случае можно сразу зарезервировать нужный размер памяти с помощью функции reserve, чтобы при добавлении элементов не происходили реаллокации. Пусть, например, нам сначала задаётся число слов, а потом сами эти слова, и нам требуется сложить их в вектор:
#include <iostream>
#include <string>
#include <vector>
int main() {
std::vector<std::string> words;
size_t words_count;
std::cin >> words_count;
// Размер вектора остаётся нулевым, меняется только резерв:
words.reserve(words_count);
for (size_t i = 0; i != words_count; ++i) {
std::string word;
std::cin >> word;
// Все добавления будут дешёвыми, без реаллокаций:
words.push_back(word);
}
}
Если передать в reserve величину меньше текущего резерва, то ничего не поменяется — резерв останется прежним.
Функцию reserve не следует путать с функцией resize, которая меняет количество элементов в векторе. Если аргумент функции resize меньше текущего размера, то лишние элементы в конце вектора удаляются. Если же он больше текущего размера, то при необходимости происходит реаллокация и в вектор добавляются новые элементы с дефолтным значением данного типа.
#include <vector>
int main() {
std::vector<int> data = {1, 2, 3, 4, 5};
data.reserve(10); // поменяли резерв, но размер вектора остался равным пяти
data.resize(3); // удалили последние элементы 4 и 5
data.resize(6); // получили вектор 1, 2, 3, 0, 0, 0
}
Многомерные векторы
Воспользуемся вектором векторов, чтобы сохранить матрицу (таблицу) целых чисел. Пусть на вход программы сначала поступают число строк и число столбцов матрицы, а потом — сами элементы построчно:
#include <iostream>
#include <vector>
int main() {
size_t m, n;
std::cin >> m >> n; // число строк и столбцов
// создаём матрицу matrix из m строк, каждая из которых — вектор из n нулей
std::vector<std::vector<int>> matrix(m, std::vector<int>(n));
for (size_t i = 0; i != m; ++i) {
for (size_t j = 0; j != n; ++j) {
std::cin >> matrix[i][j];
}
}
// напечатаем матрицу, выводя элементы через табуляцию
for (size_t i = 0; i != m; ++i) {
for (size_t j = 0; j != n; ++j) {
std::cout << matrix[i][j] << "t";
}
std::cout << "n";
}
}
В этом примере мы заранее создали матрицу из нулей, а потом просто меняли её элементы.
Сортировка вектора
Рассмотрим типичную задачу — отсортировать вектор по возрастанию. Для этого в стандартной библиотеке в заголовочном файле algorithm есть готовая функция sort. Гарантируется, что сложность её работы в худшем случае составляет $O(n log n)$, где $n$ — число элементов в векторе. Типичные реализации используют алгоритм сортировки Introsort.
#include <algorithm>
#include <vector>
int main() {
std::vector<int> data = {3, 1, 4, 1, 5, 9, 2, 6};
// Сортировка диапазона вектора от начала до конца
std::sort(data.begin(), data.end());
// получим вектор 1, 1, 2, 3, 4, 5, 6, 9
}
В функцию sort передаются так называемые итераторы, ограничивающие рассматриваемый диапазон. В нашем случае мы передаём диапазон, совпадающий со всем вектором, от начала до конца. Соответствующие итераторы возвращают функции begin и end (не путать с front и back!). Итераторы можно считать обобщёнными индексами (но они могут быть и у контейнеров, не допускающих обычную индексацию). Подробнее про итераторы мы поговорим в отдельной главе.
Для сортировки по убыванию можно передать на вход обратные итераторы rbegin() и rend(), представляющие элементы вектора в перевёрнутом порядке:
std::sort(data.rbegin(), data.rend()); // 9, 6, 5, 4, 3, 2, 1, 1
В C++20 доступен более элегантный способ сортировки через std::ranges::sort:
#include <algorithm>
#include <vector>
int main() {
std::vector<int> data = {3, 1, 4, 1, 5, 9, 2, 6};
std::ranges::sort(data); // можно передать сам вектор, а не его диапазоны
}
Для сортировки по умолчанию используется сравнение элементов с помощью оператора <. Этот оператор работает и для самих векторов: они сравниваются лексикографически. Поэтому можно без проблем отсортировать, например, строки в матрице (векторе векторов целых чисел).
Строки
Контейнер std::string можно рассматривать как особый случай вектора символов std::vector<char>, имеющий набор дополнительных функций. В частности, у строки есть все те же рассмотренные нами функции, что и у вектора (например, pop_back или resize). Рассмотрим некоторые специфические функции строки:
#include <iostream>
#include <string>
int main() {
std::string s = "Some string";
// приписывание символов и строк
s += ' '; // добавляем отдельный символ в конец, это аналог push_back
s += "functions"; // добавляем строку в конец
std::cout << s << "n"; // Some string functions
// выделение подстроки
// подстрока "string" из 6 символов начиная с 5-й позиции
std::string sub1 = s.substr(5, 6);
// подстрока "functions" с 12-й позиции и до конца
std::string sub2 = s.substr(12);
// поиск символа или подстроки
size_t pos1 = s.find(' '); // позиция первого пробела, в данном случае 4
size_t pos2 = s.find(' ', pos1 + 1); // позиция следующего пробела (11)
size_t pos3 = s.find("str"); // вернётся 5
size_t pos4 = s.find("#"); // вернётся std::string::npos
}
Вставку, замену и удаление подстрок можно сделать через указание индекса начала и длины подстроки:
#include <iostream>
#include <string>
int main() {
std::string s = "Some string functions";
// вставка подстроки
s.insert(5, "std::");
std::cout << s << "n"; // Some std::string functions
// замена указанного диапазона на новую подстроку
s.replace(0, 4, "Special");
std::cout << s << "n"; // Special std::string functions
// удаление подстроки
s.erase(8, 5); // Special string functions
}
Аналогичные действия для других контейнеров (например, для того же вектора) можно сделать через итераторы. Мы рассмотрим такие примеры в одной из следующих глав.
В C++20 появились удобные функции starts_with и ends_with для проверки префикса или суффикса строк:
#include <iostream>
#include <string>
int main() {
std::string phrase;
std::getline(std::cin, phrase);
if (phrase.starts_with("hello")) {
std::cout << "Greetingn";
}
if (phrase.ends_with("bye")) {
std::cout << "Farewelln";
}
}