
Страницы 1
Чтобы отправить ответ, вы должны войти или зарегистрироваться
1 14.02.2017 10:56:43

- Alex_Gur
- Модератор
- Неактивен
- Откуда: Москва
- Зарегистрирован: 28.07.2011
- Сообщений: 2,758
- Поблагодарили: 492
Тема: FineReader — Передача результатов распознавания в Word
Часто после распознавания текста в FineReader и передачи его в Word фрагменты текста и рисунки размещаются в «надписях» (серых рамках), откуда их нелегко «вытащить» (особенно, если текст — большой). Также часто мешают знаки конца раздела, которые автоматически помещаются ФайнРидером в конце каждой страницы.
Нашел неплохое решение с помощью настроек FineReader:
Стрелочка возле кнопки Передать – Передать в другие приложения.
Microsoft Word – Форматы…
Настройки (опции): Простой текст, A4, установить флажок Автоматически увеличивать размеры страницы, убрать флажок Сохранять колонтитулы
Остальное — без изменений.
Передать результат распознавания в Word.
Получается неплохо, но рисунки и заголовки могут немного «съехать».
Также можно попробовать передать результат с настройкой оформления Редактируемый текст.
Если имеются другие, более корректные решения этой проблемы, пожалуйста, напишите о них в комментариях.
Удобной и приятной работы в Word!
Перевести спасибо на Яндекс кошелёк — 41001162202962; на WebMoney — R581830807057.
2 Ответ от shanemac51 15.02.2017 09:03:14
- shanemac51
- генерал-полковник
- Неактивен
- Зарегистрирован: 05.03.2012
- Сообщений: 467
- Поблагодарили: 119
Re: FineReader — Передача результатов распознавания в Word
Alex_Gur пишет:
Также можно попробовать передать результат с настройкой оформления Редактируемый текст.
обычно передавала в режиме форматирования, затем макросами чистила
—шрифр —интервалы и масштаб
—абзац — все интервалы в 0 и единичный, иногда для удобства разделения абзацев —интервал после=6
—размер страниц, поля, ориентация
—так как распознавала с сохранением страниц и строк — удаляла лишние переносы и разрывы разделов(если сделать без сохранения страниц/строк — получается каша, особенно при нечетких сканах, плохих краях строк)
—обычно переводила с помеченными неуверенными символами, поэтому после грамматики удаляла голубой фон с этих мест
…..
короче —правки много, распознавать приходилось обычно именно сканы(часто грязные и кривые), а не результат запоминания текста в PDF
Страницы 1
Чтобы отправить ответ, вы должны войти или зарегистрироваться
#1
![]()
Отправлено 01 Сентябрь 2006 — 06:44
Трудности возникли при использовании FineReader`a 8ой версии, а именно: при переносе распознанного текста в Ворд от текста не символы, а одни квадратики. Что-то с кодировкой русского языка, я так понимаю.
Данная ситация даже тогда, если из FineReader`а скопировать в буфер обмена текст и вставить в другую программу, тоже — «квадратики».
Как решать?
- Наверх
#2
![]()
ErV
ErV
- Город:Воронеж
- Интересы:C++, coding, programming, 3d-programming, Game-development, OpenGL, DirectX.
Отправлено 01 Сентябрь 2006 — 10:10
У тебя какой-то шрифт сдох, как я понимаю. «Квадратики» появляются, когда комп пытается отобразить символ, который в текущем шрифте отсутствует. Проверь также настройки языка на компе.
ушел на Linux-ресурсы.
- Наверх
#3
![]()
Entry
Отправлено 02 Сентябрь 2006 — 05:11
У тебя какой-то шрифт сдох, как я понимаю. «Квадратики» появляются, когда комп пытается отобразить символ, который в текущем шрифте отсутствует. Проверь также настройки языка на компе.
<{POST_SNAPBACK}>
FR8.0 он распознает в том шрифте, который изображен на картинке. У меня это «Times New Roman».
- Наверх
#4
![]()
Entry
Отправлено 02 Сентябрь 2006 — 05:16
такая ситуация только с русскими буквами, английский распознаются.
В FR текст нормальный, а после переноса — «квадратики»!
Пробовал универсальный шрифт, типа TextBook, но он изначально в FR не читабельный (вместо квадратиков символ не из русского алфавита).
Как исправить?
- Наверх
#5
![]()
MadDwalin
MadDwalin
- Город:Москва
- Интересы:пиво
Отправлено 04 Сентябрь 2006 — 09:59
Есть такая проблема….. я 7.0 поставил… 8.0 ни как нехочет русский понимать((
Ergo Bibamus
- Наверх
#6
![]()
Entry
Отправлено 04 Сентябрь 2006 — 11:45
Есть такая проблема….. я 7.0 поставил… 8.0 ни как нехочет русский понимать((
<{POST_SNAPBACK}>
ясно. придется возвращаться на версию FR 7.0. 
или есть еще способы решения проблемы?
Сообщение отредактировал Энтри: 04 Сентябрь 2006 — 11:47
- Наверх
#7
![]()
ErV
ErV
- Город:Воронеж
- Интересы:C++, coding, programming, 3d-programming, Game-development, OpenGL, DirectX.
Отправлено 06 Сентябрь 2006 — 08:33
ясно. придется возвращаться на версию FR 7.0.
или есть еще способы решения проблемы?
<{POST_SNAPBACK}>
Проверь, если на XP сервис пак 2. У меня была схожая проблема — но только русского текста ВООБЩЕ не было ни в буфере обмена, ни при сохранении, хотя в FineReader’е его можно было прочесть. После установке SP2 (точнее, винды с SP2 поверх того, что было) все прошло, хотя причина глюка так и осталась загадкой.
ушел на Linux-ресурсы.
- Наверх
#8
![]()
MadDwalin
MadDwalin
- Город:Москва
- Интересы:пиво
Отправлено 07 Сентябрь 2006 — 05:17
с SP2 всеравно проблема есть….
Ergo Bibamus
- Наверх
#9
![]()
Entry
Отправлено 08 Сентябрь 2006 — 12:50
Поддерживаю MadDwalin, в SP2 есть проблема по прежнему. Это при том, что у меня Gold Edition, неофиц. SP3
- Наверх
#10
![]()
ErV
ErV
- Город:Воронеж
- Интересы:C++, coding, programming, 3d-programming, Game-development, OpenGL, DirectX.
Отправлено 08 Сентябрь 2006 — 09:12
Поддерживаю MadDwalin, в SP2 есть проблема по прежнему. Это при том, что у меня Gold Edition, неофиц. SP3
<{POST_SNAPBACK}>
Ну, тогда не знаю… Попробуйте к ним на сайт стукнуться, может скажут чего хорошего  .
.
ушел на Linux-ресурсы.
- Наверх
#11
![]()
Entry
Отправлено 09 Сентябрь 2006 — 08:15

- Наверх
#12
![]()
Entry
Отправлено 17 Сентябрь 2006 — 11:22
Нашел решение. Теперь все по-человечески переносится в Ворд. У кого такая же проблема, пишите в ПМ, т.к. правила форума не позволяют распространять примененное мною решение.
- Наверх
#13
![]()
***
***
-

- Пользователи
-
- 2 сообщений
Новичок


Отправлено 18 Март 2009 — 09:38
Нашел решение. Теперь все по-человечески переносится в Ворд. У кого такая же проблема, пишите в ПМ, т.к. правила форума не позволяют распространять примененное мною решение.
Entry, ну что же это за решение. Написала, а ответ никак не получу.
- Наверх
#14
![]()
SHELLes
SHELLes
- Пол:Мужчина
- Город:Вятка
- Интересы:Взаиморасслабляющее общение
Отправлено 18 Март 2009 — 01:25
А решение простое — используйте ΦΡ 9.0 и будет вам счастье
Intel® Core™2 Quad Q6600 2.40GHz @2400
ASUS P5K-E-WIFI-AP iP35
nVidia GTX 660 PCI-E3.0 2048Mb ASUS (192bit), DDR5
3 * DDR2-6400 2048Mb Kingston KVR800D2N5-2G Retail
Intel SSD 520 Series 180 Gb
2 * 1Tb Seagate Constellation ES ST1000NM0011 SATA-III 7200rpm 64Mb
FSP 450W
- Наверх
#15
![]()
***
***
-
- Пользователи
-
- 2 сообщений
Новичок
Отправлено 18 Март 2009 — 02:31
А решение простое — используйте ΦΡ 9.0 и будет вам счастье
 Спасибо…
Спасибо…
Сообщение отредактировал ***: 18 Март 2009 — 02:32
- Наверх
#16
![]()
XenonTomb
XenonTomb
- Пол:Мужчина
- Город:г.Николаев, Украина
Отправлено 20 Март 2009 — 09:33
В FineReader 8 квадратики возникают банальной по причине — неправильно крякнули. Шрифт тут нипричем, это FR спецом выдает квадратики, продолжая считать себя trial-версией.
А на девятку переходить не всем подходит — на слабых машинах идет туго, да и по тестам 9-ка распознает хуже, чем 8-ка.
AMD Athlon II X4 620 (Propus) 2,6 ГГц // кулер Noctua NH-U9B
Gigabyte GA-M720-US3 (nForce 720D, АМ2+)
DDR2-800 CL5 Kingston 2×2 Gb
Palit GeForce 9600GT 512 Мб GDDR3
HDD Samsung SP2004C, Samsung HD642JJ, WD WD10EADS (M2B) // DVD-RW Sony Optiarc AD7240S // CR Gigabyte 15-in-1
Корпус Chieftec Smart SH-01 // БП Chieftec CFT-500-A12S // ИБП Powercom KIN 525A
Моник Samsung SyncMaster 2032 MW (с ТВ) // Звук Genius SP-HF 1250X 2.0
Wi-Fi роутер TP-Link TL-WR642G
—————————————
Нетбук MSI Wind U90X-056UA (8.9″ LED/Intel Atom N270/i945GSE+ICH7M/RAM 1,5 GB/HDD 2,5″ 120GB/LAN/Wi-Fi/BT/Cam 0,3 Mp/CR 4in1)
- Наверх
-
#1
Сканирую русский текст из FineReader’a. Распознает нормально, исправляю ошибки (если есть) в нем же — нормально. При передаче страниц в Word пишет, что «в тексте используются символы, которые не поддерживаются и которые не будут отображены, нужно использовать системный шрифт». Нажимаю ОК. В Word’e вместо букв — квадратики. Кто-нибудь знает, что нужно делать? Английский и другие языки передаются без проблем. Да, у меня FineReader 8.0 Professional Edition.
-
#2
Ответ: Из FineReader’a в Word не передается русский текст
Дык эта… лицензионная защита у них так работает.  :)") Такие методики вообще-то считаются табу… но не всех это волнует.
Такие методики вообще-то считаются табу… но не всех это волнует.
-
#3
Ответ: Из FineReader’a в Word не передается русский текст
Может, поставить версию постарее? Раньше (не помню версию) все передавалось без проблем.
-
#4
Ответ: Из FineReader’a в Word не передается русский текст
А может купить? Впрочем, дело ваше. Лекарства здесь табу.
-
#5
Ответ: Из FineReader’a в Word не передается русский текст
А у нас на работе купить — это табу. Но, все равно, спасибо за совет.
-
#6
Ответ: Из FineReader’a в Word не передается русский текст
Тогда ищите и обрящете.
Не копируется текст из PDF: причины, способы изменения формата и советы специалистов
Бывало у вас такое, что вам необходимо текст, присутствующий в каком-то PDF-документе, вставить в другую программу для редактирования, но в файле PDF текст не копируется? Как бы посоветовали поступить в такой ситуации? Далеко не многие пользователи догадываются о том, что можно воспользоваться не одним, а несколькими простыми способами, позволяющими «разрулить» ситуацию. Но для начала давайте остановимся на некоторых стандартных случаях и их причинах, а затем попробуем найти наиболее подходящее решение для каждого из них. Сразу стоит отметить, что изменять оригинальный формат документа не всегда целесообразно.
Почему текст из PDF не копируется?
 You will be interested: How dangerous is the new coronavirus?
You will be interested: How dangerous is the new coronavirus?
Итак, первой и основной причиной невозможности копирования содержимого документов PDF большинство специалистов считает установку всевозможных запретов на подобные действия в самих файлах.
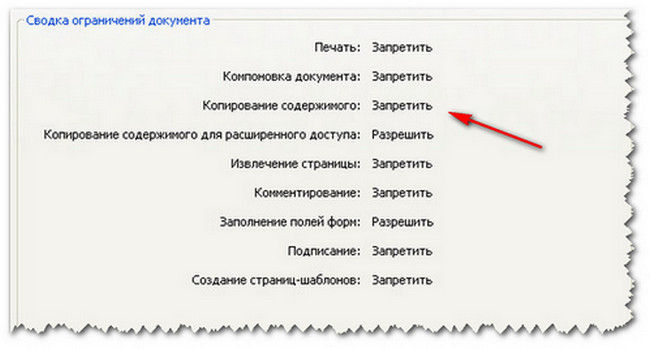
Это могут быть и пароли на открытие, и запреты на копирование, и даже защита документа при попытке вывода содержимого на печать. Еще одна не менее распространенная ситуация, связанная с тем, что текст из PDF не копируется, может быть связана с повреждением самого файла или нарушением его оригинальной структуры. Реже можно встретить и случаи, когда пользователь использует для извлечения текстового содержимого из PDF-документа не совсем подходящее приложение. Так, например, очень многие эксперты сходятся во мнении, что у Adobe Reader возможностей в сравнении с Acrobat гораздо больше. Поэтому, если текст из PDF не копируется в «Акробате», первым делом попробуйте выполнить аналогичную операцию в «Ридере». Вполне возможно, это даст желаемый результат. Но в большинстве случаев это, увы, не помогает, поскольку содержимое попросту защищено от копирования, а пароль скрыт глубоко внутри самого файла. Как обойти такие ограничения рассмотрим чуть позже, а пока остановимся еще на одной ситуации, которая тоже многих пользователей ставит в тупик.
Почему текст из PDF копируется иероглифами?
Теперь предположим, что защита от копирования в оригинальном документе не установлена и все вроде бы нормально. Но почему-то при переносе содержимого в другой редактор текст из PDF копируется иероглифами. Связано это только с тем, что оригинал имеет отличную от стандартной кодировку. Чаще всего специалисты в такой ситуации предлагают самый простой выход, при котором даже изменять начальный формат документа не потребуется. Исходя из того, что текст из PDF копируется с неправильной кодировкой, ее нужно сменить.
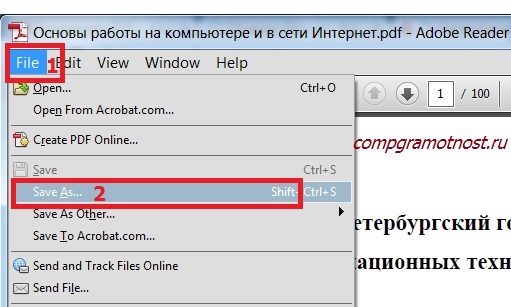
Для этого проще всего воспользоваться файловым меню любого редактора PDF, выбрать пункт «Сохранить как. » (Save As…), а затем в окне сохранения нажать кнопку параметров (Settings) и выбрать другую кодировку. Обычно достаточно поменять оригинальный стандарт на UTF-8. При повторном открытии документа текст можно будет скопировать и вставить в любой другой текстовый редактор в неизменном виде. Также перекодировать файл можно на каком-нибудь интернет-ресурсе вроде Decoder.
Как обойти запрет копирования в самом файле?
Теперь давайте посмотрим, что можно сделать для обхода всевозможных запретов и блокировок.
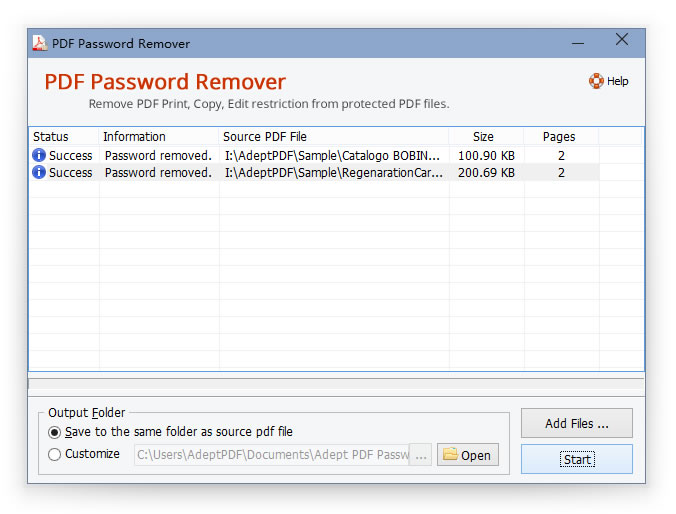
Если текст из PDF не копируется ни под каким предлогом, можете воспользоваться пиратским методом, выполнив снятие ограничений или удаление установленных паролей в программе PDF Password Remover. Если это результата не даст, можете зайти на какой-нибудь специализированный сайт вроде PDFPirate или FreeMyPDF и попытаться снять защиту там. Однако каждый должен понимать, что в случае с некоторыми официальными документами такая методика является противозаконной.
Открытие файла PDF в Word
Еще одна простая методика, рекомендуемая для устранения множества проблем с оригинальными PDF-документами, которые необходимо отредактировать, состоит в том, чтобы не копировать исходное содержимое в «просмотрщике» или редакторе PDF, а открыть файл непосредственно в той программе, с использованием которой предполагается производить редактирование.
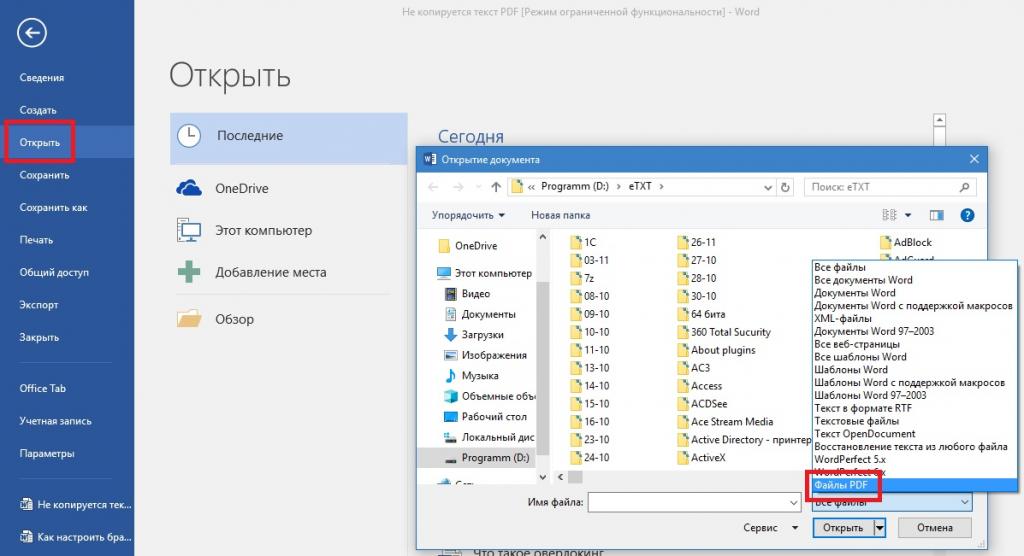
В случае с текстовыми документами, проще всего воспользоваться универсальным «Вордом» и открыть искомый документ в этом приложении, выбрав соответствующий тип файла. Если документ откроется без проблем, его можно будет и отредактировать, и сохранить в нужном формате.
Как преобразовать текст PDF в Word?
Но давайте предположим, что исходный документ в текстовых редакторах не открывается (мало ли что может быть) и в «родных» редакторах текст из PDF не копируется.
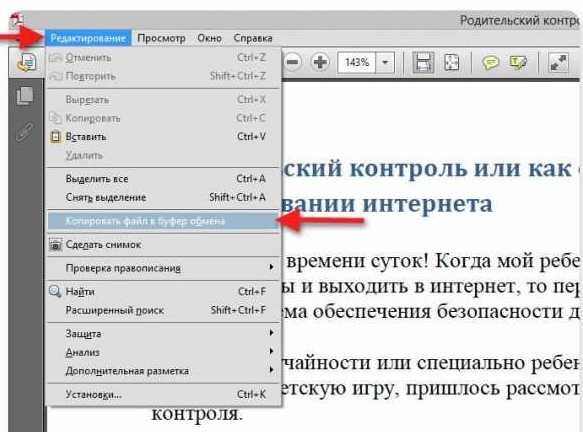
В этом случае для преобразования файла именно в документ Word попробуйте в PDF-редакторе выбрать не копирование текста, а копирование файла в буфер обмена целиком, после чего вставьте содержимое в Word. Способ, конечно, далеко не самый удобный, поскольку вставка будет иметь графический формат, и отредактировать материал будет невозможно.
В этой ситуации оптимальным решением станет смена формата оригинального документа на любой другой. В интернете сейчас выложено достаточно много программ-конвертеров, например, PDF to Word Converter и др. В выбранном приложении обычно достаточно просто указать начальный файл и конечный формат после преобразования. При помощи таких апплетов, кстати, можно преобразовать PDF не только в Word. Существуют и программы для конвертирования в Excel.
Проблемы с самим текстом в PDF-документах
Иногда бывает и так, что в оригинальном файле текстовое содержимое могло быть изначально создано путем сканирования какого-то печатного документа. Совершенно очевидно, что при таком подходе текст был сохранен именно в графическом формате. При этом и на него могли быть установлены запреты на копирование или печать. Как поступить в такой ситуации?
Использование системы оптического распознавания
В этом случае на помощь приходят системы оптического распознавания OCR. Практически все эксперты сходятся во мнении, что оптимальным вариантом станет выбор пакета ABBY Finereader. Конечно, программа не бесплатная, но на просторах «Рунета» можно найти уже активированные (взломанные) версии или модификации с ключом активации.
В самом приложении в стартовом окне выбрать преобразование файла PDF/изображения в документ Word. Система самостоятельно распознает текст с картинки и отправит его в Word, после чего можно будет выполнить редактирование и сохранить новый документ.
Конвертирование в другие форматы
Наконец, если стоит задача преобразовать текст в другие нестандартные форматы, обычно для этих целей рекомендуется применять все те же конвертеры, выбирая либо узконаправленные программы (например, PDF to JPEG для конвертирования в графические файлы), либо универсальные приложения, поддерживающие не один, а несколько форматов, среди которых будет тот, что нужен. Иногда можно использовать и онлайн-сервисы, но это неудобно по соображениям больших временных затрат и ограничений по размеру добавляемых файлов (или их количеству).
Заключение
Подводя итоги, можно выделить несколько основных моментов. Во-первых, изменять исходный формат не всегда нужно, поскольку выполнить копирование можно либо в более продвинутом редакторе, как в случае с «Акробатом» и «Ридером», либо открыть файл непосредственно в той программе для работы с текстовым содержимым, в которую нужно вставить исходный материал, как в случае с Word. Во-вторых, для сброса паролей и запретов лучше всего применять специальные приложения (пусть даже это и выглядит незаконно). В-третьих, большинство конвертеров в процессе преобразования форматов запреты, как правило, игнорируют, так что и их использование выглядит весьма перспективным. В-четвертых, не стоит сбрасывать со счетов и системы распознавания текста, которые иногда выглядят даже лучше, чем все предыдущее. В-пятых, существует мнение, что иногда преобразование можно выполнить при помощи виртуальных принтеров, но такой вариант годится только для тех случаев, когда исходный текстовый фрагмент нужно преобразовать в графику.
При конвертации pdf в word иероглифы. Что делать, если вместо текста иероглифы (в Word, браузере или текстовом документе). Копируем текст из PDF файла в Word с помощью онлайн конвертеров
Вопрос пользователя
Здравствуйте.
Подскажите пожалуйста, почему у меня некоторые странички в браузере отображают вместо текста иероглифы, квадратики и не пойми что (ничего нельзя прочесть). Раньше такого не было.
Заранее спасибо.
Доброго времени суток!
Действительно, иногда при открытии какой-нибудь интернет-странички вместо текста показываются различные «крякозабры» (как я их называю), и прочитать это нереально.
Происходит это из-за того, что текст на страничке написан в одной кодировке (более подробно об этом можете узнать из ), а браузер пытается его открыть в другой. Из-за такого рассогласования, вместо текста — непонятный набор символов.
Попробуем исправить это.
Исправляем иероглифы на текст
Вообще, раньше Internet Explorer часто выдавал подобные крякозабры, современные же браузеры (Chrome, Яндекс-браузер, Opera, Firefox) — довольно неплохо определяет кодировку, и ошибаются очень редко. Скажу даже больше, в некоторых версиях браузера уже убрали выбор кодировки, и для «ручной» настройки этого параметра нужно скачивать дополнения, или лезть в дебри настроек за 10-ток галочек.
И так, предположим браузер неправильно определили кодировку и вы увидели следующее (как на скрине ниже).
Чаще всего путаница бывает между кодировками UTF (Юникод) и Windows-1251 (большинство русскоязычных сайтов выполнены в этих кодировках).
- нажать левый ALT — чтобы сверху показалось меню. Нажать меню «Вид»;
- выбрать пункт «Кодировка текста» , далее выбрать Юникод . Вуаля — иероглифы на странички сразу же стали обычным текстом (скрин ниже)!
Еще один совет : если в браузере не можете найти, как сменить кодировку (а дать инструкцию для каждого браузера — вообще нереально!), я рекомендую попробовать открыть страничку в другом браузере. Очень часто другая программа открывает страницу так, как нужно.
Текстовые документы
Очень много вопросов по крякозабрам задаются при открытии каких-нибудь текстовых документов. Особенно старых, например при чтении Readme в какой-нибудь программе прошлого века (например, к играм).
Разумеется, что многие современные блокноты просто не могут прочитать DOS»овскую кодировку, которая использовалась ранее. Чтобы решить сию проблему, рекомендую использовать редактор Bread 3.
Bred 3
Простой и удобный текстовый блокнот. Незаменимая вещь, когда нужно работать со старыми текстовыми файлами. Bred 3 за один клик мышкой позволяет менять кодировку и делать не читаемый текст читаемым! Поддерживает кроме текстовых файлов довольно большое разнообразие документов. В общем, рекомендую!
Попробуйте открыть в Bred 3 свой текстовый документ (с которым наблюдаются проблемы). Пример показан у меня на скрине ниже.
Для работы с текстовыми файлами различных кодировок так же подойдет еще один блокнот — Notepad++. Вообще, конечно, он больше подходит для программирования, т.к. поддерживает различные подсветки, для более удобного чтения кода.
Пример смены кодировки показан ниже: чтобы прочитать текст, достаточно в примере ниже, достаточно было сменить кодировку ANSI на UTF-8.
WORD»овские документы
Очень часто проблема с крякозабрами в Word связана с тем, что путают два формата Doc и Docx . Дело в том, что с 2007 Word (если не ошибаюсь) появился формат Docx (позволяет более сильнее сжимать документ, чем Doc, да и надежнее защищает его).
Так вот, если у вас старый Word, который не поддерживает этот формат — то вы, при открытии документа в Docx, увидите иероглифы и ничего более.
Решения есть 2:
- скачать на сайте Microsoft спец. дополнение, которое позволяет открывать в старом Word новые документы. Только из личного опыта могу сказать, что открываются далеко не все документы, к тому же сильно страдает разметка документа (что в некоторых случаях очень критично);
- использовать аналоги Word (правда, тоже разметка в документе будет страдать);
- обновить Word до современной версии.
Так же при открытии любого документа в Word (в кодировке которого он «сомневается»), он на выбор предлагает вам самостоятельно указать оную. Пример показан на рисунке ниже, попробуйте выбрать:
- Widows (по умолчанию);
- MS DOS;
- Другая.
Окна в различных приложениях Windows
Бывает такое, что какое-нибудь окно или меню в программе показывается с иероглифами (разумеется, прочитать что-то или разобрать — нереально).
- Руссификатор. Довольно часто официальной поддержки русского языка в программе нет, но многие умельца делают руссификаторы. Скорее всего, на вашей системе — данный руссификатор работать отказался. Поэтому, совет простой: попробовать поставить другой;
- Переключение языка. Многие программы можно использовать и без русского, переключив в настройках язык на английский. Ну в самом деле: зачем вам в какой-то утилите, вместо кнопки «Start» перевод «начать»?
- Если у вас раньше текст отображался нормально, а щас нет — попробуйте восстановить Windows, если, конечно, у вас есть точки восстановления (подробно об этом здесь — );
- Проверить настройки языков и региональных стандартов в Windows, часто причина кроется именно в них.
Языки и региональные стандарты в Windows
Чтобы открыть меню настроек:
- нажмите Win+R ;
- введите intl.cpl , нажмите Enter.
intl.cpl — язык и регион. стандарты
Проверьте чтобы во вкладке «Форматы» стояло «Русский (Россия) // Использовать язык интерфейса Windows (рекомендуется)» (пример на скрине ниже).
Во вкладке местоположение поставьте расположение Россия.
И во вкладке дополнительно установите язык системы на «Русский (Россия)». После этого сохраните настройки и перезагрузите ПК. Затем вновь проверьте, нормально ли отображается интерфейс нужной программы.
И напоследок, наверное, для многих это очевидно, и все же некоторые открывают определенные файлы в программах, которые не предназначены для этого: к примеру в обычном блокноте пытаются прочитать файл DOCX или PDF. Естественно, в этом случае вы вместо текста будут наблюдать за крякозабрами, используйте те программы, которые предназначены для данного типа файла (WORD 2007+ и Adobe Reader для примера выше).
На сим всё, удачи!
Наверное, каждый пользователь ПК сталкивался с подобной проблемой: открываешь интернет-страничку или документ Microsoft Word — а вместо текста видишь иероглифы (различные «крякозабры», незнакомые буквы, цифры и т.д. (как на картинке слева…)).
Хорошо, если вам этот документ (с иероглифами) не особо важен, а если нужно обязательно его прочитать?! Довольно часто подобные вопросы и просьбы помочь с открытием подобных текстов задают и мне. В этой небольшой статье я хочу рассмотреть самые популярные причины появления иероглифов (разумеется, и устранить их).
Иероглифы в текстовых файлах (.txt)
Самая популярная проблема. Дело в том, что текстовый файл (обычно в формате txt, но так же ими являются форматы: php, css, info и т.д.) может быть сохранен в различных кодировках .
Кодировка — это набор символов, необходимый для того, чтобы полностью обеспечить написание текста на определенном алфавите (в том числе цифры и специальные знаки). Более подробно об этом здесь: https://ru.wikipedia.org/wiki/Набор_символов
Чаще всего происходит одна вещь: документ открывается просто не в той кодировке из-за чего происходит путаница, и вместо кода одних символов, будут вызваны другие. На экране появляются различные непонятные символы (см. рис. 1)…
Рис. 1. Блокнот — проблема с кодировкой
Как с этим бороться?
На мой взгляд лучший вариант — это установить продвинутый блокнот, например Notepad++ или Bred 3. Рассмотрим более подробно каждую из них.
Один из лучших блокнотов как для начинающих пользователей, так и для профессионалов. Плюсы: бесплатная программа, поддерживает русский язык, работает очень быстро, подсветка кода, открытие всех распространенных форматов файлов, огромное количество опций позволяют подстроить ее под себя.
В плане кодировок здесь вообще полный порядок: есть отдельный раздел «Кодировки» (см. рис. 2). Просто попробуйте сменить ANSI на UTF-8 (например).
После смены кодировки мой текстовый документ стал нормальным и читаемым — иероглифы пропали (см. рис. 3)!
Рис. 3. Текст стал читаемый… Notepad++
Еще одна замечательная программа, призванная полностью заменить стандартный блокнот в Windows. Она так же «легко» работает со множеством кодировок, легко их меняет, поддерживает огромное число форматов файлов, поддерживает новые ОС Windows (8, 10).
Кстати, Bred 3 очень помогает при работе со «старыми» файлами, сохраненных в MS DOS форматах. Когда другие программы показывают только иероглифы — Bred 3 легко их открывает и позволяет спокойно работать с ними (см. рис. 4).
Если вместо текста иероглифы в Microsoft Word
Самое первое, на что нужно обратить внимание — это на формат файла. Дело в том, что начиная с Word 2007 появился новый формат — «docx » (раньше был просто «doc «). Обычно, в «старом» Word нельзя открыть новые форматы файлов, но случается иногда так, что эти «новые» файлы открываются в старой программе.
Просто откройте свойства файла, а затем посмотрите вкладку «Подробно » (как на рис. 5). Так вы узнаете формат файла (на рис. 5 — формат файла «txt»).
Если формат файла docx — а у вас старый Word (ниже 2007 версии) — то просто обновите Word до 2007 или выше (2010, 2013, 2016).
Далее при открытии файла обратите внимание (по умолчанию данная опция всегда включена, если у вас, конечно, не «не пойми какая сборка») — Word вас переспросит: в какой кодировке открыть файл (это сообщение появляется при любом «намеке» на проблемы при открытии файла, см. рис. 5).
Рис. 6. Word — преобразование файла
Чаще всего Word определяет сам автоматически нужную кодировку, но не всегда текст получается читаемым. Вам нужно установить ползунок на нужную кодировку, когда текст станет читаемым. Иногда, приходится буквально угадывать, в как был сохранен файл, чтобы его прочитать.
Рис. 8. браузер определил неверно кодировку
Чтобы исправить отображение сайта: измените кодировку. Делается это в настройках браузера:
- Google chrome: параметры (значок в правом верхнем углу)/дополнительные параметры/кодировка/Windows-1251 (или UTF-8);
- Firefox: левая кнопка ALT (если у вас выключена верхняя панелька), затем вид/кодировка страницы/выбрать нужную (чаще всего Windows-1251 или UTF-8) ;
- Opera: Opera (красный значок в верхнем левом углу)/страница/кодировка/выбрать нужное.
Таким образом в этой статье были разобраны самые частые случаи появления иероглифов, связанных с неправильно определенной кодировкой. При помощи выше приведенных способов — можно решить все основные проблемы с неверной кодировкой.
Буду благодарен за дополнения по теме. Good Luck
Вопрос от пользователя
Добрый день.
Подскажите пожалуйста. У меня есть один файл формата PDF, и мне нужно его отредактировать (поменять часть текста, поставить заголовки и выделения). Думаю, что лучше всего такую операцию провести в WORD.
Как конвертировать этот файл в формат DOCX (с которым работает WORD)? Пробовала несколько сервисов, но некоторые выдают ошибку, другие — переносят текст, но теряют картинки. Можно ли сделать лучше?
Марина Иванова (Нижний Новгород)
Да, в офисной работе время от времени приходится сталкиваться с такой задачей. В некоторых случаях, она решается довольно легко, в других — всё очень непросто ☺.
Дело в том, что PDF файлы могут быть разными:
- в форме картинок : когда каждая страничка представляет из себя фото/картинку, т.е. текста там нет в принципе. Самый сложный вариант для работы, т.к. перевести это все в текст — это все равно что работать со сканированным листом (у кого есть сканер — тот поймет ☺). В этом случае целесообразно пользоваться спец. программами;
- в форме текста : в файле есть текст, который сжат в формат PDF и защищен (не защищен) от редактирования (с этим типом, как правило, работать легче). В этом случае сгодятся и онлайн-сервисы, и программы.
В статье рассмотрю несколько способов преобразования PDF в WORD. Думаю, что из них каждый для себя сможет найти самый подходящий, и выполнит сию задачу ☺.
Программами
Microsoft Word
В новых версиях Word (по крайней мере в 2016) есть специальный инструмент по преобразованию PDF файлов. Причем, от вас ничего ненужно — достаточно открыть какую-нибудь «пдф-ку» и согласиться на преобразование. Через пару минут — получите результат.
И, кстати, данная функция в Word работает весьма неплохо (причем, с любыми типами PDF файлов). Именно поэтому, рекомендую попробовать сей способ в первую очередь.
Как пользоваться : сначала откройте Word, затем нажмите «файл/открыть» и выберите нужный вам файл.
На вопрос о преобразование — просто согласитесь. Через некоторое время увидите свой файл в форме текста.

Плюсы : быстро; не нужно никаких телодвижений от пользователя; приемлемый результат.
Минусы : программа платная; часть форматирования документа может потеряться; далеко не все картинки будут перенесены; на процесс преобразования никак нельзя повлиять — всё идет в авто-режиме.
Примечание!
Вместо Word и Excel можно использовать другие бесплатные аналоги с похожим функционалом. О них я рассказывал в этой статье:
ABBY Fine Reader
Ограничения в пробной версии : 100 страниц для распознавания; софт работает в течении 30 дней после установки.
А вот эта программа одна из самых универсальных — ей можно «скормить» любой файл PDF, картинку, фото, скан. Работает она по следующему принципу: выделяются блоки текста, картинок, таблиц (есть авто-режим, а есть ручной), а затем распознает с этих блоков текст. На выходе вы получаете обычный документ Word.
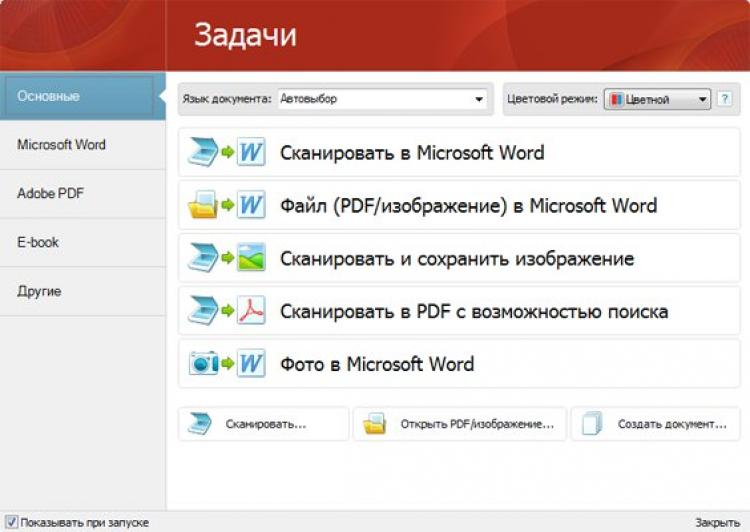
Кстати, последние версии программы отличаются направленностью на начинающего пользователя — пользоваться программой очень просто. В первом приветственном окне выберите «Изображение или PDF-файл в Microsoft Word» (см. скрин ниже).

Fine Reader — популярные задачи, вынесенные в стартовое окно приветствия
Далее программа автоматически разобьет ваш документ по страничкам, и на каждой страничке сама выделит все блоки и распознает их. Вам останется подправить ошибки и сохранить документ в формат DOCX (кстати, Fine Reader может сохранить и в другие форматы: HTML, TXT, DOC, и пр.).

Fine Reader — распознавание текста и картинок в PDF файле
Плюсы : можно перевести любую картинку или PDF файл в текстовый формат; лучшие алгоритмы распознавания; есть опции для проверки распознанного текста; можно работать даже с самыми безнадежными файлами, от которых отказались все остальные сервисы и программы.
Минусы : программа платная; нужно вручную указывать блоки на каждой из страничек.
Readiris Pro
Ограничение пробной версии : 10 дней использования или обработка 100 страниц.
Эта программа некоторый конкурент Fine Reader. Она поможет сканировать документ с принтера (даже если у вас нет драйверов на него!), а потом распознать информацию со скана и сохранить ее в Word (в этой статье нас интересует вторая часть, а именно распознавание ☺).
Кстати, благодаря очень тесной интеграции с Word — программа способна распознать математические формулы, различные не стандартные символы, иероглифы и т.д.

Плюсы : распознавание разных языков (английский, русский и пр.); множество форматов для сохранения; неплохие алгоритмы; системные требования ниже, чем у других программ аналогов.
Минусы : платная; встречаются ошибки и необходима ручная обработка.
Free PDF to Word Converter
Сайт разработчика: http://www.free-pdf-to-word-converter.com/

Очень простая программа для быстрой конвертации файлов PDF в DOC. Программа полностью бесплатна, и при преобразовании — старается сохранить полностью исходное форматирование (чего многим аналогам так не хватает).
Несмотря на то, что в программе нет русского, разобраться со всем достаточно просто: в первом окне указываете PDF файлы (Select File — т.е. выбрать файлы); во втором — формат для сохранения (например, DOC); в третьем — папку, куда будут сохранены преобразованные документы (по умолчанию, используется «Мои документы»).
В общем-то, в целом хороший и удобный инструмент для преобразования относительно несложных файлов.
Онлайн-сервисами
Small PDF

Smallpdf.com — бесплатное решение всех PDF проблем
Отличный и бесплатный сервис для преобразования и работы с PDF файлами. Здесь есть все, что может пригодиться: сжатие, конвертирование между JPG, Word, PPT, объединение PDF, поворачивание, редактирование и пр.!
Преимущества:
- качественное и быстрое преобразование, редактирование;
- простой и удобный интерфейс: разберется даже совсем начинающий пользователь;
- доступно на всех платформах: Windows, Android, Linux и пр.;
- работа с сервисом бесплатна.
- не работает с некоторыми типами файлов PDF (там, где нужно проводить распознавание картинок).
Конвертер PDF
Стоимость: около 9$ в месяц

Этот сервис позволяет бесплатно обрабатывать только две странички (за остальное придется доплатить). Зато сервис позволяет конвертировать PDF файл в самые различные форматы: Word, Excel, Power Point, в картинки и т.д. Также у него используются отличные от аналогов алгоритмы (позволяют получить качество обработки файла на порядок выше, чем у аналогов). Собственно, благодаря этой функциональности и алгоритмам, я и добавил его в обзор.
Кстати, по первым двум страничкам сможете сделать вывод, стоит ли покупать подписку на сервис (стоимость около 9$ за месяц работы).
ZamZar

Многофункциональный онлайн-конвертер, работает с кучей форматов: MP4, MP3, PDF, DOC, MKV, WAV и многие другие. Несмотря на то, что сервис выглядит несколько странным, пользоваться им достаточно просто: т.к. все действия выполняются пошагово (см. на скрин выше: Шаг 1, 2, 3, 4 (Step 1, 2, 3, 4)).
- Step 1 (ШАГ 1) — выбор файла.
- Step 2 (ШАГ 2) — в какой формат конвертировать.
- Step 3 (ШАГ 3) — необходимо указать свою почту (кстати, возможно вам будет статья о том, ).
- Step 4 (ШАГ 4) — кнопка для запуска конвертирования.
Особенности:
- куча форматов для конверта из одного в другой (в том числе PDF);
- возможность пакетной обработки;
- очень быстрый алгоритм;
- сервис бесплатный;
- есть ограничение на размер файла — не более 50 МБ;
- результат конверта приходит на почту.
Convertio

Мощный и бесплатный сервис по онлайн-работе с различными форматами. Что касается PDF — то сервис может конвертировать их в DOC формат (кстати, сервис работает даже со сложными «пдф-ками», с которыми остальные не смогли справиться), сжимать, объединять и пр.
Ограничений на размер файлов и их структуру — не выявлено. Для добавления файла необязательно даже иметь его на диске — достаточно указать URL адрес, а с сервиса уже скачать готовый документ в формате DOC. Очень удобно, рекомендую!
iLOVEPDF

Похожий на предыдущий сайт: также есть весь функционал для работы с PDF — сжатие, объединение, разбивка, конвертация (в различные форматы). Позволяет быстро преобразовать различные небольшие PDF файлы.
Из минусов : сервис не может обработать файлы, которые состоят из картинок (т.е. «пдф-ки» где нет текста, здесь вы с них ничего не вытащите — сервис вернет вам ошибку, что текста в файле нет).
PDF.io

Весьма интересный и многофункциональный онлайн-сервис. Позволяет конвертировать PDF в: Excel, Word, JPG, HTML, PNG (и те же самые операции в обратном направлении). Кроме этого, на этом сервисе можно сжимать файлы подобного типа, объединять и разделять страницы. В общем-то, удобный помощник в офисной работе ☺.
Из минусов : сервис справляется не с всеми типами файлов (в частности, про некоторые пишет, что в них нет текста).
Дополнения приветствуются.
Довольно часто используется для публикации разного рода электронных документов. В PDF публикуются научные работы, рефераты, книги, журналы и многое другие.
Сталкиваясь с документом в PDF формате, пользователи часто не знают, как скопировать текст в Ворд. Если у вас также возникла подобная проблема, то наша статья должна вам помочь. Здесь вы узнаете 4 способа, как скопировать текст из PDF в Ворд.
Самый простой способ скопировать текст из PDF в Ворд это обычное копирование, которым вы пользуетесь постоянно. Откройте ваш PDF файл в любой программе для просмотра PDF файлов (например, можно использовать Adobe Reader), выделите нужную часть текста, кликните по ней правой кнопкой мышки и выберите пункт «Копировать».
Также вы можете скопировать текст с помощью комбинации клавиш CTRL-C. После копирования текст можно вставить в Ворд или любой другой текстовый редактор.
К сожалению, данный способ копирования текста далеко не всегда подходит. от копирования, тогда вам не удастся выполнить копирование текста. Также в PDF документе могут быть таблицы или картинки, которые нельзя просто так скопировать. Если вы столкнулись с подобной проблемой, то следующие способы копирования текста из ПДФ должны вам помочь.
Копируем текст из PDF файла в Word с помощью ABBYY FineReader
ABBYY FineReader это программа для распознавания текста. Обычно данную программу используют для распознавания текста на отсканированных изображениях. Но, с помощью ABBYY FineReader можно распознавать и PDF файлы. Для этого откройте ABBYY FineReader, нажмите на кнопку «Открыть» и выберите нужный вам PDF файл.

После того как программа закончит распознавание текста нажмите на кнопку «Передать в Word».

После этого перед вами должен открыться документ Ворд с текстом из вашего PDF файла.
Копируем текст из PDF файла в Word c помощью конвертера
Если у вас нет возможности воспользоваться программой ABBYY FineReader, то можно прибегнуть к программам-конвертерам. Такие программы позволят конвертировать PDF документ в Word файл. Например, можно использовать бесплатную программу .
Для того чтобы сконвертировать PDF документ в Word файл с помощью UniPDF вам нужно просто открыть программу, добавить в нее нужный PDF файл, выбрать конвертацию в Word и нажать на кнопку «Convert».

Копируем текст из PDF файла в Word с помощью онлайн конвертеров
Также существуют онлайн конвертеры, которые позволяют сконвертировать PDF файл в Word файл. Обычно такие онлайн конвертеры работают хуже, чем специализированные программы, но они позволят скопировать текст из PDF в Ворд без установки дополнительного софта. Поэтому их также нужно упомянуть.
Использовать такие конвертеры довольно просто. Все что вам нужно сделать, это загрузить файл и нажать на кнопку «Конвертировать». А после завершения конвертации нужно будет скачать файл обратно.
При печати pdf файла на принтере печатаются иероглифы или как говорили мои бухгалтера на старой работе «Виталий подойди у нас при печати pdf абракадабра распечатывается «. Сегодня на работе возникла такая же фигня и т.к. я стараюсь в своем блоге описывать по максимуму решения таких проблем и решил выложить инструкцию по исправлению иероглифов в pdf файлах. Так вот эту проблему можно решить тремя способами(может есть и еще но я опишу те какие знаю ).

1 Способ
Это самый надежный и проверенный временем способ!!
- Открыть редактор реестра (Пуск -> Выполнить -> regedit.exe)
- Перейти в
HKEY_LOCAL_MACHINESOFTWAREMicrosoftWindows NTCurrentVersionFontSubstitutes - Удалить параметры: «Courier,0»=»Courier New,204″
«Arial,0»=»Arial,204″ - Перезагрузить ПК
PS перезагрузить комп нужно обязательно.
2 Способ
Самый долгий наверное из всех трех способ, это скачать русифицированную версию самого adobe reader:
- Скачать последнюю версию adobe reader с официального сайта http://get.adobe.com/ru/reader/
- После этого открываем фаил и радуемся жизни
2 Способ
Так вот первый способ самый быстрый но и самый не качественный в плане разрешения распечатывающегося документа:
- При печати документа зайдите в дополнительно и выберите печать как изображения (File — print -advanced — галочка print as image)
4 Способ
Этот способ самый действенный и кардинальный т.к. решение данного косяка будет осуществлен на уровне реестра windows:
PDF Квадраты и символы при копировании
Как-то раз мне на стол принесли PDF-файл с просьбой скопировать содержимое текста, мол сами не могут т.к. при копировании текст превращается в квадраты, крякозяблы и странные символы. «Кодировка, защита или недостающие шрифты», подумал я, это ж легко. Однако пережимы pdf, снятие защиты через онлайн сервисы и прочие простые решения не помогли. При копировании со всех созданных вариантов данного pdf имеем такую картину:
p, blockquote 1,0,1,0,0 —>
Поиски решения
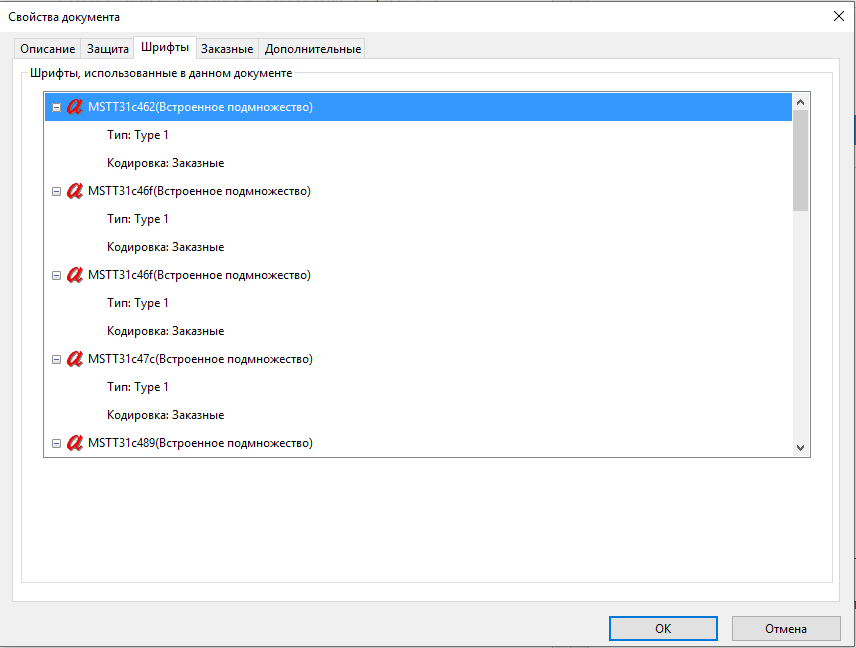
Открываем PDF в программе Acrobat reader, скачать его можно по ссылке идем в редактирование — защита — параметры защиты. Самой защиты на моем PDF не оказалось, однако на вкладке Шрифты указаны отсутствующие у меня на компе шрифты с заказной кодировкой. Скорее всего дело в этом, можно погуглив найти и установить недостающий шрифт, однако в моем случае такое решение не прокатит. Шрифт MSTT31c, кодировка — заказная.
p, blockquote 2,0,0,0,0 —>
Быстрое решение
Дабы особо не ломать голову, выбираем самое простое решение. Мы попросту разобьем данный PDF на JPEG файлы и заново пересоберем, используя Pdf 24 Creator или его аналоги. (см. Конвертация PDF в JPEG и обратно).
p, blockquote 3,1,0,0,0 —>
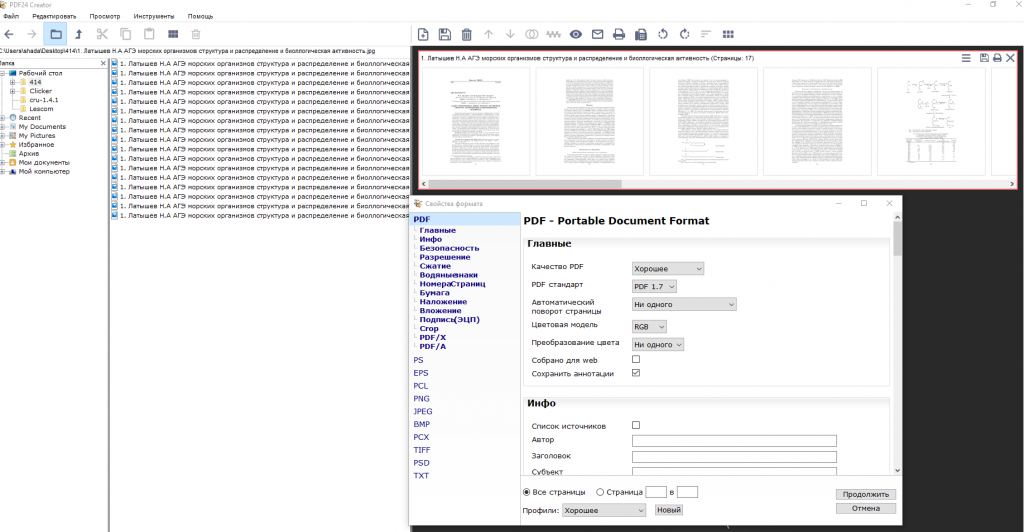
Открываем программу — тыкаем Pdf конструктор, ищем наш файл и перетаскиваем в правую часть окна и тыкаем сохранить. В появившемся окне жмем «Настраиваемый» и выбираем Jpeg. DPI оставляйте как есть и жмите продолжить. Вам предложат путь куда вы сохраните весь ваш файл в виде изображений.
Не закрывая программу идем в папку куда сохранили изображения и перетаскиваем их на правую часть. Сохраняем как PDF, получаем слепленный из изображений файл, с которого пока что нельзя копировать ничего. Осталось чуть-чуть.
p, blockquote 5,0,0,0,0 —>
Снова открываем программу, на этот раз жмем Recognize text, выбираем язык документа, желаемое качество, жмем Add files и выбираем созданный на прошлом шаге файл. И всё, жмем Start, по завершению из нашего PDF можно с легкостью копировать текст. Надеюсь помог =)
Исправление ошибок сканирования в ABBYY Finereader
Abbyy Finereader – программа для распознавания текста с изображениями. Источником картинок, как правило, является сканер или МФУ.
Прямо из окна приложения можно произвести сканирование, после чего автоматически перевести изображение в текст.
Кроме того, Файн Ридер умеет сконвертировать полученные со сканера изображения в формат PDF и 2, что полезно при создании электронных книг и документации для последующей печати.
Как устранить проблему: ABBYY Finereader не видит сканер.
Для корректной работы Abbyy Finereader 14 (последняя версия) на компьютере должны выполняться следующие требования:
- процессор с частотой от 1 ГГц и поддержкой набора инструкций SSE2;
- ОС Windows 10, 8.1, 8, 7;
- оперативная память от 1 Гб, рекомендованная – 4Гб;
- TWAIN- или WIA-совместимое устройство ввода изображений;
- доступ в интернет для активации.
Если ваше оборудование не отвечает данным требованиям, программа может работать некорректно. Но и при соблюдении всех условий, Abbyy FineReader часто выдаёт разные ошибки сканирования, такие как:
- невозможно открыть источник TWAIN;
- параметр задан неверно;
- внутренняя программная ошибка;
- ошибка инициализации источника.
В подавляющем большинстве случаев проблема связана с самим приложением и его настройками. Но иногда ошибки возникают после обновления системы либо после подключения нового оборудования. Рассмотрим наиболее распространённые рекомендации, что делать, если ABBYY FineReader не видит сканер и выдаёт сообщения об ошибках.
Исправление ошибок
Есть ряд общих советов по исправлению некорректной работы:
- Обновите драйверы оборудования до последних версий с официального сайта производителя.
- Проверьте права текущего пользователя в системе, при необходимости повысьте уровень доступа.
- Иногда помогает установка более старой версии приложения, особенно если вы работаете на не новом оборудовании.
- Проверьте, видит ли сканер сама система. Если он не отображается в диспетчере устройств или показан с жёлтым восклицательным знаком, то проблема в оборудовании, а не программе. Обратитесь к инструкции или в техподдержку производителя.
- На официальном сайте ABBYY работает неплохая техническая поддержка https://www.abbyy.com/ru-ru/support. Вы можете задать вопрос, подробно описав конкретно свою проблему, и получить профессиональное решение из первых рук абсолютно бесплатно.
Устранение ошибки «Параметр задан неверно»
В последней версии ABBYY FineReader также может носить название «Ошибка инициализации источника». Инициализация – это процесс подключения и распознавания системой оборудования.
Если Файн Ридер не видит сканер при запуске диалогового окна сканирования и выдаёт такие ошибки, то должны помочь следующие действия:
- Перезапустите программу FineReader.
- Зайдите в меню «Инструменты», выберите «OCR-редактор».
- Нажмите «Инструменты», потом «Настройки».
- Включите раздел «Основные».
- Перейдите к «Выбор устройства для получения изображений», затем «Выберите устройство».
- Нажмите на выпадающий список доступных драйверов. Проверьте работоспособность сканирования поочерёдно с каждым из списка. В случае успеха с каким-то из них, используйте его в дальнейшем.
ВНИМАНИЕ. Возможна и такая ситуация, что ни с каким из доступных драйверов выполнить сканирование не получилось. Тогда нажмите «Использовать интерфейс сканера».
Если и это не помогло, вам понадобится утилита TWAIN_32 Twacker. Её можно скачать с официального сайта ABBYY по ссылке ftp://ftp.abbyy.com/TechSupport/twack_32.zip.
После этого следуйте инструкции:
- Выйдите из Файн Ридер.
- Распакуйте архив twack_32.zip в любую папку.
- Дважды щёлкните по Twack_32.exe.
- После запуска программы зайдите в меню «File», затем «Acquire».
- Нажмите «Scan» в открывшемся диалоге.
- Если документ успешно отсканировался, откройте меню «File» и щёлкните «Select Source».
- Синим цветом окажется отображён драйвер, через который утилита успешно выполнила сканирование.
- Выберите этот же файл драйвера в файнридере.
Если при запуске в Abbyy Finereader этого сделать опять не удалось, значит, проблема в работе программы. Отправьте запрос в техническую поддержку ABBYY. Если же и 32 Twacker не смог выполнить команду «Scan», то, вероятно, некорректно работает само устройство или его драйвер. Обратитесь в техподдержку производителя сканера.
Внутренняя программная ошибка
Бывает, что при запуске сканирования приложение сообщает «Внутренняя программная ошибка, код 142». Она обычно связана с удалением или повреждением системных файлов программы. Для исправления и предотвращения повторных появлений выполните следующее:
- Добавьте Fine Reader в исключения антивирусного ПО.
- Перейдите в «Панель управления», «Установка и удаление программ».
- Найдите Fine Reader и нажмите «Изменить».
- Теперь выберите «Восстановить».
- Запустите программу и попробуйте отсканировать документ.
Иногда Файнридер может не видеть сканер из-за ограничений в доступе. Запустите программу от имени администратора либо повысьте права текущего пользователя.
Как распознать текст со сканера
Покажу как это сделать быстро и качественно на примере программы Abbyy FineReader версии 8.0. Принципы, изложенные здесь, можно с успехом применить и в любой другой программе распознавания текста, и в любой другой версии программы FineReader. FineReader на пост-советском пространстве – самая распространённая и успешная программа для этой задачи.
Итак, для того чтобы получить отличный результат нам нужно качественно сосканировать оригинал. Легче всего этого достичь с листов формата А4, распечатанных на принтере, труднее с книг, журналов, газет. Качество сканирования – основа, от которой будет зависеть дальнейший успех работы.
Несколько слов об автоматизации процессов распознавания.
Хотя от версии к версии авторы программы FineReader улучшают алгоритмы автоматического распознавания сложных макетов (Scan&Read – когда достаточно запустить программу и нажать одну кнопку, а остальное программа сделает за Вас сама, и Вам остаётся лишь насладиться результатами процесса), эти алгоритмы срабатывают не всегда корректно. Искусственный интеллект ещё не скоро заменит человеческую смекалку и здравый смысл. Причиной чего и послужило написание этой статьи.
Сканирование текста
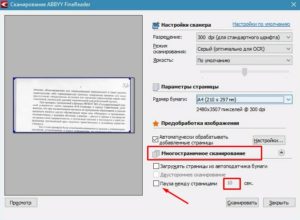
Запускаем программу Abbyy FineReader, нажимаем кнопочку «Сканировать», ложим наш оригинал в сканер и делаем пробное сканирование. Для оптимальной скорости и качества сканирования в драйвере сканера достаточно выставить режим сканирования «Чёрно-белое» и разрешение 300 точек на дюйм.
Если мы используем для сканирования twain-драйвер Mustek точно так же выбираем режим сканирования «Чёрно-белое» (Black-white) и выставляем разрешение 300 dpi. При необходимости понижаем уровень шума регулирование яркости-контрастности либо уровнями
Если мы используем для сканирования «Мастер работы со сканером или цифровой камерой» — выбираем «Чёрно-белое изображение», а в Настройках — «разрешение» , в свойствах «Мастера работы со сканером или цифровой камерой» выставляем разрешение и регулируем яркость
Если у нас сканер Epson, либо какой-то другой, в twain-драйвере точно так же ищем пункты «Тип изображения» («Image Type») — чёрно-белое (black-white, b/w), Разрешение («Resolution») — выставляем 300dpi и при необходимости регулируем «Яркость-контрастность», либо «Уровни», либо «Светлые и тёмные тона»
Режимы «Оттенки серого» и «Цветное изображение» тоже подходят, но от этого увеличивается время сканирования и возможно, пострадает качество распознавания текста (Серый или цветной фон, особенно если он неоднородный может существенно ухудшить качество распознавания текста).
В идеале нам нужно добиться чтобы на белом фоне были чёрные буквы и больше никаких посторонних объектов.
Смотрим на результат, если он нас устраивает: буквы видно отчётливо, шума, грязи практически нет, то продолжаем сканирование далее, если шума много (такое бывает, например, если оригинал отпечатан на жёлтой бумаге) – ползунками яркости и контрастности двигаем так, чтобы шум максимально пропал, а буквы стало видно более отчётливо, делаем ещё несколько пробных сканирований пока не добьёмся нужного результата. Как только приемлемый результат получен – приступаем к основному сканированию. Если нам нужно сканировать одновременно участки текста из разных источников (несколько книг, журналов, газетных вырезок), то такую калибровку для достижения приемлемого результата часто приходится делать для каждого источника отдельно.
Поворот страниц
В программу FineReader встроен механизм автоматического определения ориентации страниц и автоматического же их поворота.
В простых случаях этот механизм отлично работает и не требует от нас никакого участия, но если текст видно не очень отчётливо, либо если разные страницы отсканирываны под разными углами, здесь мы получаем сбой и в результате получаем вместо текста абракадабры. Потому имеет смысл осуществлять поворот вручную.
Выделяем несколько страниц, повёрнутых в одинаковую сторону с зажатой клавишей «Ctrl» и поворачиваем при помощи меню правой кнопки мыши
Распознавание текста
Сосканировав все листы документа можно приступать к его распознаванию. Выбираем язык распознаваемого документа.
Это важно потому что буквы в разных языках разные и если, например мы будем распознавать украинский текст как русский, то в конечном результате в распознанном тексте будет распознано практически всё более-менее правильно, но украинские буквы «і», «ї» «є» не будут распознаны и FineReader заменит их на что-то более-менее похожее и в конце прийдётся все эти огрехи выправлять вручную. То же самое бывает когда в русском тексте встречаются адреса электронной почты, сайтов, какие-то слова, набранные на иностранном языке, а мы текст распознаём как «русский», то эти символы FineReader заменит на что-то более-менее похожее из русского алфавита. В таком случае перед распознаванием нужно FineReader-у указать, что текст состоит из нескольких языков, отметив нужные галочками. Не стоит также злоупотреблять выбором языков, отметив все возможные какие есть. В этом случае мы тоже можем в результате получить «катавасию» из всех возможных символов вместо искомого результата.
Следующий пункт после выбора языка распознавания – анализ макета, то есть нам нужно разобрать страницы нашего документа на составляющие: текстовые блоки, таблицы и изображения. В случае если мы имеем дело с простым текстом, набранным на листах формата А4, то этот пункт можно смело пропускать.
Программа FineReader отлично справится с этим и сама. В противном случае нужно ещё немного поработать ручками. В данном случае я запускаю процесс автоматического анализа макета всех страниц и по его окончании просматриваю результаты, и в случае неправильного анализа вручную его поправляю.
Программа не всегда правильно различает области текста, иногда таблицы путает с текстом, картинки с текстом, текст с картинками, иногда области с тенями, пятнами воспринимает как текст, не всегда нам в конечном результате нужно чтобы присутствовали номера страниц, колонтитулы исходного материала и т.д.
Наша задача – выправить эти огрехи ещё на стадии подготовительных работ. Сейчас это сделать намного легче, чем править уже на последнем этапе работ.
Когда макеты разобраны можно приступать непосредственно к самому процессу распознавания. То есть нам нужно просто нажать на кнопочку «Распознать» и, откинувшись в кресле, дождаться окончания процесса распознавания.
А по его окончании, бегло глянув на распознанные страницы, убедиться что тексты, таблицы и прочие объекты распознаны корректно, т.е.
процентов на 90-95 (в идеале конечно на все 100) и можно приступать к завершающему этапу работ: постбоработке и сохранению результатов.
Несмотря на все наши предыдущие старания огрехи распознавания будут, и их количество зависит от того, на сколько старательно мы выполняли предыдущие этапы. FineReader помогает нам в этом, подсвечивая участки, в качестве распознавания которых он не уверен, синим цветом. На них мы обращаем внимание в первую очередь и если эти участки распознаны неверно – поправляем их.
Сохранение результатов распознавания можно сделать двумя способами: непосредственно в текстовый редактор (например Microsoft Word) или через буфер обмена. Первый способ нам может пригодиться когда нам нужно максимально сохранить исходное форматирование документа: заголовки, шрифты, взаимное расположение текстовых колонок и графических элементов. Но иногда исходное форматирование нам не нужно и более того, вредно, потому что в текстовом редакторе потом бывает очень сложно потом разобраться что за чем идёт и почему, и как, как сделать по другому, так как нам это будет нужно. При передаче текста через буфер обмена мы избегаем этих моментов и на выходе имеем чистый текстовый массив, который можем уже обрабатывать форматировать на наше усмотрение. И уже в Ворде мы выполняем последний этап работ: убираем лишние детали: множественные пробелы, пробелы перед запятыми, точками, знаки табуляции, исправляем кавычки, знаки тире, исправляем неправильно распознанные участки текста и т.д.Ну и завершающий этап работ – собственно для чего это всё и затевалось: толи нам нужен был просто распознанный текст, толи нам нужно в него внести изменения для дальнейшей работы.
Как работать в ABBYY FineReader 12
26.01.2016
| Функциональное решение для сканирования документов ABBYY FineReader предоставляет возможность пользователю выбрать, в каком из популярных текстовых форматов сохранить файл. Помимо сканирования документации программа может перевести текстовую информацию из формата Word, например, в файл PDF обратно.ABBYY FineReader 12, имеющаяся в наличии в SoftMagazin, обладает множеством полезных функций и значительно упрощает процесс распознавания текста и перевода его в формат PDF.Как пользоваться программой ABBYY FineReader 12, описано в инструкции к программе, однако у пользователей могут остаться некоторые вопросы по ее настройке и запуску. В данном обзоре будут даны ответы о работе в ABBYY FineReader, как пользоваться этой программой, в частности последними ее версиями. |
ABBYY FineReader: как работатьДля эффективной работы со сканируемыми документами нужно знать, для чего нужна ABBYY FineReader, как пользоваться основными функциями программы и правильно запускать ее. Инструмент для сканирования предельно точно распознает текст в выбранном печатном документе, не перенося постранично информацию. Кроме того, программа старается сохранить шрифты, колонтитулы и разметку текста на странице максимально близко к оригиналу.Особых различий в версии ABBYY FineReader 11, и как пользоваться 12 выпуском программы не наблюдается. Обе версии отличаются наличием хорошего функционала, поддержкой более 150 языков, в том числе и языков программирования и математических формул. Чтобы начать пользоваться программой, достаточно установить лицензионную версию на домашний или рабочий ПК и запустить ярлык ABBYY FineReader с рабочего стола или из меню Пуск. |
Как установить ABBYY FineReader 11Для установки программы на ПК нужно после приобретения лицензии, запустить из папки с программой или диска файл setup.exe и выбрать один из видов инсталляции. Обычный режим установит FineReader в стандартной конфигурации на компьютер. В процессе установки необходимо будет выбрать язык интерфейса, место размещения программы и другие стандартные пункты по установке. |
Как запустить ABBYY FineReaderЗапустить ярлык с рабочего стола компьютераВыбрать в меню Пуск раздел Программы и запустить ABBYY FineReaderЕсли вы пользуетесь приложениями Microsoft Office, то достаточно нажать на инструментальной панели значок программыВыберите в проводнике нужный документ и нажав правой кнопкой мыши, выберите в появившемся меню «Открыть с помощью ABBYY FineReader». |
Как настроить ABBYY FineReader 12 ProfessionalПрофессиональная версия ABBYY FineReader приобретается организациями для эффективной работы с программой в корпоративной сети и совместного редактирования файлов. Настройка и запуск ABBYY FineReader 12 Professional функционально не отличается от установки других версий. Инструмент автоматически распознает языки, сложные таблицы и списки, так что практически не требуется дополнительного редактирования.Все автоматические функции могут использоваться в ручном режиме. Для комфортной работы перейдите на панели инструментов в «Сервис» и выберите пункт «Настройки», чтобы отрегулировать параметры. Можно самостоятельно задать настройки вида документа, режима сканирования, распознавания и сохранения файла. |
ABBYY FineReader — как переводитьДля качественной конвертации документов в программе предусмотрены встроенные стандартные задачи, используя которые можно перевести документ в нужный формат, затратив минимум усилий. Стандартные настройки предлагают перевести текстовый файл в документ Word, создать таблицу Exel, конвертировать в PDF-файл и другие нужные форматы. После выбора действия нужно будет указать язык распознавания, режим распознавания (цветной или черно-белый) и задать дополнительные пункты распознавания. |
<
ABBYY FineReader: как распознать текстДля качественной конвертации полученной информации в PDF-формат, программа должна ее распознать. В ABBYY FineReader можно установить режим автоматического распознавания текста или ручного. Качество отсканированного документа можно отрегулировать настройками распознавания, такими как: режим сканирования, язык распознавания, тип печати и многое другое. Перед распознаванием текста, на этапе сканирования программа будет работать по одному из стандартных сценариев, который можно выбрать.В меню выберите «Сервис», перейдите в «Опции» и укажите режим распознавания: тщательное или быстрое распознавание. Тщательный режим будет удобен для работы с некачественными текстовыми файлами, текстами на цветном фоне или сложными таблицами. Быстрое распознавание рекомендовано для больших объемов файлов или когда ограничены временные рамки. |
Как в ABBYY FineReader изменить текстЧтобы не возникало сложностей при редактировании в ABBYY FineReader 12, как изменить текст в этой программе, разработчики создали интуитивно понятный интерфейс и удобную навигацию по пунктам. Отредактировать текст можно двумя способами: непосредственно в окне «Текст», либо выбрав на панели инструментов «Сервис» и далее «Проверка». Доступные средства для изменения текста находятся над окном «Текст» и включают в себя стандартный набор для редактирования шрифта, его размера, отступов и замены символов. Для редактирования непосредственно PDF-изображения, нужно зайти в меню в «Редактор изображений» и выбрать из списка нужную функцию. |
ABBYY FineReader 12 Professional — бессрочная лицензия
Обзор ABBYY FineReader 12
← Назад к списку
, Понедельник-четверг с 09.00 до 19.00
Пятница с 09.00 до 18.00
Как распознать отсканированный текст при помощи Abbyy FineReader!
Здравствуйте. Сегодня я расскажу о том, как с помощью программы Abbyy FineReader распознать текст c изображения, которое вы могли получить в результате сканирования.
Ваш сканированный текст будет полностью в документе Microsoft Word и этот распознанный текст можно будет редактировать! Распознать текст при помощи Abbyy Finereader может пригодиться тем, кто учится, работает с текстами и переводами. Программа, к сожалению, является платной.
Как-то доводилось попробовать одну из бесплатных вариантов аналогичных программ, но весьма хорошо отсканированный текст распознается просто ужасно… А распознать текст в Abbyy FineReader получается весьма качественно! Сейчас я покажу как пользоваться программой Abbyy FineReader для быстрого распознавания текста с изображения.
ABBYY FineReader имеет пробную версию на 30 дней с возможностью распознавания до 100 страниц и сохранением не более 3-х страниц из документа. Т.е. в течение этого времени вы можете увидеть возможности программы и принять взвешенное решение — нужна ли она вам, стоит ли её покупать или нет.
Как установить Abbyy FineReader!
Перед тем как пользоваться Abbyy Finereader её необходимо установить. Рассмотрим процесс установки этой программы…
Для начала выбираем язык программы. Нажимаем «ОК».
Принимаем условия лицензионного соглашения (при желании можно прочесть лицензионный договор, если вам интересно о чём там речь). Нажимаем «Далее».
Далее вы должны выбрать режим установки.
При обычном режиме программа не спросит вас и установит то, что в программе задано по умолчанию, а именно — все компоненты: саму программу Abbyy Finereader для распознавания текста, компонент для программ Microsoft Office и компонент для проводника Windows (позволяющий быстро распознавать изображения, не открывая отдельно программу). Советую отметить выборочную установку чтобы настроить так, как вам нужно. Тем более это не займет и 15 минут 🙂 Внизу указана папка куда установится программа. Желательно оставить выбор по умолчанию, чтобы потом не было никаких проблем при использовании программы. Нажимаем «Далее».
Компоненты программы. Это окно как раз появится в случае, если вы выберите тип установки «Выборочная». Компоненты — это что-то вроде вспомогательных приложений к программе. Первый компонент «Интеграция с программами Microsoft Office и Проводником Windows».
Этот компонент будет отображен в меню Microsoft Office и если вы щелкните по изображению у себя на компьютере правой кнопкой мыши, то там будет пункт с этой программой. Вот так будет выглядеть ваше меню в Microsoft Office после добавления этого компонента.
А вот что будет если вы щелкните правой кнопкой мыши по изображению:
Т.е. появится меню, в котором вы можете сделать быстрое распознавание текста с отправкой результатов в Word, Excel или PDF.
Второй компонент позволит вам распознать текст с экрана компьютера. Это значит, что вы сможете сделать скриншот и также распознать текст. Если вы не хотите устанавливать один из этих компонентов, или вовсе не хотите устанавливать оба, то нужно нажать на стрелочку вниз и выбрать «Данный компонент будет недоступен». Тогда компонент установлен не будет. Я оставила оба.
Далее 4 пункта. 1-ый означает то, что сведения о том, как вы пользуетесь программой Abbyy Finereader будут переданы разработчику. Данный пункт советую не отмечать, чтобы программа лишний раз не выходила в интернет ради отправки сведений о работе с ней.
Тем более, мало ли какие ещё сведения будут отправляться 🙂 2-ой пункт создает ярлык программы на рабочем столе. 3-ий означает, что программа будет запускаться при включении компьютера, а 4-ый будет проверять обновления программы. Я оставляю только второй и напротив него оставляю галочку.
Закрываем все приложения Microsoft Office, потому что так требует установщик и нажимаем «Установить».
Нужно подождать пару минут чтобы программа загрузилась и нажать «Далее».
Все, установка завершена! Нажимаем «Готово».
Как при помощи Abbyy Finereader распознать текст c отсканированного или любого другого изображения?
Рассмотрим, как пользоваться программой. К примеру, у вас есть отсканированный текст. Теперь, чтобы распознать текст в Abbyy FineReader, открываем программу. Нажимаем «Открыть».
Выбираем нужное нам изображение и нажимаем открыть.
Когда вы откроете нужный документ, Abbyy Finereader начнёт распознавать текст. Чем больше документ, тем дольше будет длиться распознавание. Распознавание одной страницы может занять несколько секунд.
После того как текст распознается вам останется только сохранить результат в документ Microsoft Word, чтобы затем вы могли отредактировать в нём что угодно. Для этого нажмите кнопку «Сохранить» на верхней панели инструментов, после чего выберите в какую папку будет сохранён документ Word и под каким названием.
Если у вас подключён к компьютеру сканер, то вы можете запустить сканирование прямо из программы, и после чего отсканированный документ сразу будет распознаваться. Для этого на верхней панели инструментов нажмите кнопку «Сканировать». Далее действия будут зависеть от программы-драйвера для вашего принтера. Вам нужно только следовать указаниям мастера сканирования.
Как видите, все очень просто и быстро. Теперь вы знаете, как пользоваться Abbyy FineReader для распознавания текста с изображений! Надеюсь, что эта информация очень поможет многим:) Удачи!