
How do I use OneLook’s thesaurus / reverse dictionary?
OneLook lets you find any kind of word for any kind of writing.
Like a traditional thesaurus, you
can use it to find synonyms and antonyms, but it’s far more flexible.
Describe what you’re looking for with a single word, a few words,
or even a whole sentence. Type in your description and hit
Enter (or select a word that shows up in the autocomplete preview)
to see the related words.
You can order, filter, and explore the
words that come back in a variety of creative ways.
Here’s a video which
goes over some of the basics.
What are some examples?
Exploring the results
Click on any result to see definitions and usage examples tailored to your search,
as well as links to follow-up searches and additional usage information when available.
OneLook knows about more than 2 million different
words and expressions covering every topic under the sun.
Try exploring a favorite topic for a while and you’ll be surprised
how much new stuff there is to learn!
Ordering the results
Your results will initially appear with the most closely related word shown first,
the second-most closely shown second, and so on.
You can re-order the results in a variety of different ways, including
alphabetically, by length, by popularity, by modernness, by formality, and by other
aspects of style. Click the
box that says «Closest meaning first…» to see them all.
(Here’s a short video about sorting and filtering
with OneLook Thesaurus.)
Filtering the results
You can refine your search by clicking on the «Advanced filters» button
on the results page. This lets you narrow down your results to match
a certain starting letter, number of letters, number of syllables, related
concept, meter, vowel sound, or number of syllables.
Read more details on filters if you’re interested in how they work.
I’m only looking for synonyms! What’s with all of these weird results?
For some kinds of searches only the
first result or the first few results are truly synonyms
or good substitutions for your search word.
We highlight these results in yellow.
Beyond that, the results are meant to inspire you to consider similar words and adjacent
concepts. Not all of the results will make sense at first, but they’re all
connected with your search in some way. We’d rather give you too many options than
too few. If you’re unsure of a word, we urge you to click on
it to check its definitions and usage examples before using it in your Oscars
acceptance speech or honors thesis.
What are letter patterns?
If you know some letters in the word you’re looking for, you can enter a pattern instead of, or in addition to, a description. Here are how
patterns work:
- The asterisk (*) matches any number of letters.
That means that you can use it as a placeholder for any part of a word or phrase.
For example, if you enter blueb* you’ll get all the terms that start with «blueb»; if you enter
*bird
you’ll get all the terms that end with «bird»; if you enter
*lueb*
you’ll get all the terms that contain the sequence «lueb»,
and so forth. An asterisk can match zero letters, too. -
The question mark (?) matches exactly one letter.
That means that you can use it as a placeholder for a single letter
or symbol. The query l?b?n?n,
for example, will find the word «Lebanon». -
The number-sign (#) matches any English consonant.
For example, the query tra#t finds the word «tract» but not «trait». -
The at-sign (@) matches any English vowel (including «y»).
For example, the query abo@t finds the word «about» but not «abort». -
NEW! The comma (,) lets you combine multiple patterns into one.
For example, the query ?????,*y* finds 5-letter words
that contain a «y» somewhere, such as «happy» and «rhyme». -
NEW! Use double-slashes (//) before
a group of letters to unscramble them (that is, find anagrams.)
For example, the query //soulbeat will find «absolute»
and «bales out»,
and re//teeprsn will find «represent» and «repenters».
You can use another double-slash to end the group and put letters you’re sure of to the
right of it. For example, the query //blabrcs//e will find «scrabble».
Question marks can signify unknown letters as usual; for example, //we???
returns 5-letter words that contain a W and an E, such as «water» and «awake». -
NEW! A minus sign (—) followed by some letters at the end of a pattern means «exclude these letters». For example, the query sp???-ei finds 5-letter words that start with «sp» but do not contain an «e»or an «i», such as «spoon» and «spray».
-
NEW! A plus sign (+) followed by some letters at the end of a pattern means «restrict to these letters». For example, the query *+ban finds «banana».
- On OneLook’s main search or directly on OneLook Thesaurus, you can combine patterns and thesaurus lookups
by putting a colon (:) after a pattern and then typing
a description of the word, as in
??lon:synthetic fabric and the other examples above.
Other ways to access this service:
- Drag this link to your browser’s bookmarks bar for a convenient button that goes to the thesaurus:
OneLook
- Enter onelook.com/word into your browser’s address bar to go directly to the OneLook Thesaurus entry for word.
- We offer a OneLook Thesaurus iPhone/iPad app
for a low subscription fee, with a two-week free trial.
This gives you OneLook at your fingertips, and
several cool app-only features, while helping us maintain the service for all! - If you use Google Docs, the thesaurus is integrated into the free OneLook Thesaurus Google Docs Add-On as the «Synonyms» button. (Wildcard patterns are not yet suppoerted by this add-on.)
- If you regularly use the main OneLook site, you can put colon (:) into any OneLook search box,
followed by a description, to go directly to the thesaurus. - If you’re a developer, the Datamuse API gives you access to the core features of this site.
Is this available in any language other than English?
The same interface is now available in Spanish at OneLook Tesauro
as a beta version. More languages are coming!
How does it work?
We use a souped-up version of our own Datamuse API,
which in turn uses several lingustic resources described in the «Data sources» section
on that page. The definitions come from Wiktionary,
Wikipedia, and WordNet.
Here are some known problems
with the current system.
Much gratitude to Gultchin et al for the algorithm behind the «Most funny-sounding» sort order.
Profanity and problematic word associations
If you’re using this site with children, be forewarned you’ll
find profanity and other vulgar expressions if you use OneLook frequently.
(We take an unflinching look at how words have actually been used; scrubbing out
hurtful wordswould be a disservice to everyone.)
Some of the thesaurus results come from a statistical analysis of the
words in a large collection of books written in the past two
centuries. A handful of times we’ve found that this analysis can lead
us to suggest word associations that reflect racist or harmful
stereotypes present in this source material. If you see one of these,
please know that we do not endorse what the word association implies.
In egregious cases we will remove it from the site if you
report it to us via the feedback link below.
Privacy
No personally identifying information is ever collected on this site
or by any add-ons or apps associated with OneLook. OneLook Thesaurus sends
your search query securely to the Datamuse API, which keeps a log file of
the queries made to the service in the last 24 hours. The log file is deleted
after 24 hours and we do not retain any long-term information about your
IP address or invididual queries.
Who’s behind this site and where can I send my comments and complaints feedback?
OneLook is a service of Datamuse.
You can send us feedback here.
The sunburst logo (🔆) is the emoji symbol for «high
brightness», which we aspire to create with OneLook. (The
graphic came from the open-source Twemoji
project.)
Where can I search for words using descriptive sentences? For example, now I’m looking for a word meaning «to purify (by hand) a quantity of grain and take away anything that isn’t good grain.»
How could I get words like that? I know it in my first-language, but I don’t have a classic version of it to use in automatic translators.
Maybe a search engine that uses content words from my description and offers words that could mean the same with their dictionary definitions. Nothing I’d tried in (translate.)google.com gave me the desired result.
Update:
An example dictionary that I use is (Oxford’s Word-Power Dictionary). It’s not for the purpose of the question but for clarification.
Oxford’s has a 3,000 word list of ‘bare-bone-essentials.’ It contains the most-used words in English and all of the grammatical operators. Ideally, these are the words necessary for a learner to use an English-English dictionary such as Oxford’s. The descriptions of words in Oxford’s rely on this list for definitions.
An electronic (web-based) dictionary for word-meaning-search should have a larger list (maybe 10,000) and use a thesaurus to down-level difficult words a user may use in the search then, using all content words in the search phrase, present a list of words whose definitions seem appropriate. Another regular dictionary may be used from there.
-
Example:
Search query: «to use hands to purify a quantity of grain taking away anything that isn’t good grain.»
Content Words: «use-hands; purify; quantity-of-grain; taking-away; anything; isn’t; good-grain»
Filtered: «use-hands; clean; quantity-of-seeds; take-away;anything; not-good-grain»
Words: «1; 2; 3; 4» that use the content words to varying degrees.
And that’s a five minutes’ work!
PS. Sorry about the delay; connection problems…
Hello,
I’m quite new to NLP and I struggle with the following task:
My input is the definition of a word (casual, said by a human), and the algorithm has to find the word that best fits the definition. For example: «It’s a very big animal, it’s grey, with a good memory and a very long nose» => «elephant».
I tried some methods: Bag of words (with fasttext), ad-hoc matching of words using ConceptNet data…without much success.
I have the intuition that I should use the sentence structure beyond just the presence of words (because «It is an animal» is different from «It’s where you find animals») but I’m confused by the diversity of NLP algorithms to deal with sentences.
Would you have suggestions of tools and algorithms that would be worth investigating for this task ?
Thanks a lot for your help!
For info: My goal is to help children practice English with games that make them speak to a bot.
—-
Edit: thanks everyone for your help, I’ll study your ideas and keep you posted on my conclusions if you are interested
Online dictionary: English Definition translation of words and expressions, definition, synonyms
![]()
English dictionary with thousands of definitions, examples, synonyms and phrases
An English monolingual dictionary is useful for understanding a word meaning — not only for native English speakers, but also for those who are learning English as a second language. Whether you are translating from English into your mother tongue or you simply don’t know what a word means, you can always count on our English dictionary, with its definitions of common words, technical terms and idioms, many of them added by our community members.
See the latest user contributions to the English dictionary and add your own:
|
You want to reject this entry: please give us your comments (bad translation/definition, duplicate entries…) |
- Edit the entry
- Delete the entry
- Add a suggestion
- Add comment
- Validate
- !Put in pending
- !Reject
To add entries to your own vocabulary, become a member of Reverso community or login if you are already a member.
It’s easy and only takes a few seconds:
How to take part:
- Add words and phrases with complete definitions
- Comment on the English definitions submitted by other users
- Vote for or against an English definition
» How to contribute
Help us write our English dictionary
English words are used all over the world. They are borrowed by other languages, and often become buzzwords used daily by millions of people. It is obviously vital to understand their meaning and use them correctly. That’s why Reverso allows its users to contribute to the online dictionary with their own English definitions. Thousands of English words and idioms, colloquial expressions, phrase, slang terms, and specialized terms have already been added to the English dictionary. You can help us write our online dictionary by adding words and expressions and their English definition, or by making comments on the definitions added by other users.
A wide-ranging dictionary lookup tool
When you look up the definition of a word in our English dictionary, the results displayed will include not only words and phrases from the general dictionary, but also definitions added by users. With a single click, you can suggest a new definition for an English word, search for its synonyms, conjugate verbs or hear the pronunciation of the word.
Why use the English dictionary
- Searches are made both in the general dictionary and among the words and idioms submitted by users.
- It can be used not only by beginners learning English, but also by proficient users as a tool for improving English translations
- It provides access to idioms which are missing from other English dictionaries, added by Reverso community members
- It gives you the opportunity to show how proficient you are in English by contributing new entries and comments to the English dictionary
Register to enjoy these benefits and much more
See English definitions from our dictionary
»See more
Reverso Products
- Need professional translation solutions for your company?
- Get the famous Collins dictionaries on your PC
- Add Reverso to your browser
- Translate millions of words and expressions in context
- Download Reverso Context free app for iOS and Android
«Collins English Dictionary 5th Edition first published in 2000 © HarperCollins Publishers 1979, 1986, 1991, 1994, 1998, 2000 and Collins A-Z Thesaurus 1st edition first published in 1995 © HarperCollins Publishers 1995»
Contact |
Newsletter | Tell a friend
| News
| Company |
Conditions of use | Help (?)
Traduction,
Traducción,
Traduzione,
Übersetzung,
Tradução,
Перевод,
Překlad,
Traducere Online,
翻译,
Spanish English translation
| Italian English translation
| German English translation
| Portuguese English translation
| Russian English translation
| Arabic English translation
| Hebrew English translation
| Dutch English translation
| Polish English translation
Dictionnaire,
Diccionario,
Wörterbuch,
Dizionario,
Dicionario
English Spanish Dictionary
| English Italian Dictionary
| English German Dictionary
| English Portuguese Dictionary
| English Russian Dictionary
| Medical dictionary English French
| Computer dictionary English French
| Computer dictionary English Spanish
| Business dictionary English French
| English Arabic Dictionary
| English Hebrew Dictionary
| English Dutch Dictionary
| English Polish Dictionary
Traduction en contexte,
Traducción en contexto,
Traduzione in contesto,
Übersetzung im Kontext,
Tradução em contexto,
Vertaling in context,
Переводчик Контекст,
Tłumaczenie w kontekście,
الترجمة في السياق ,
תרגום בהקשר
English French translation in context |
English Spanish translation in context |
English German translation in context |
English Italian translation in context |
English Portuguese translation in context |
English Dutch translation in context |
English Polish translation in context |
English Russian translation in context |
Conjugaison,
Conjugación, Konjugation, Coniugazione
English Verb Conjugation | French Verb Conjugation | Spanish Verb Conjugation | German Verb Conjugation | Hebrew Verb Conjugation
English Grammar,
English Spellchecker
Recommended links:
Free: Learn English, French and other languages |
Reverso Documents: translate your documents online
Fleex:
Learn English watching your favourite videos |
Learn English with movies |
Learn English with TV shows
All English definitions from our dictionary
English monolingual dictionary: understand what words mean through definitions and synonyms
©2023 Reverso-Softissimo. All rights reserved.
neugenery
Guest
-
#1
Hello,
Is there possible to look up a word when we just have concept about? e.g. I’d like to know what describe the following definition:
‘a very large number of things, probably more than is necessary’ just as an example, that’s not the point here.
I find it just once solitary perhaps solution, which I’ll describe it in the blog Neugenery.
Last edited: Jan 16, 2012

- Joined
- Jul 28, 2009
- Member Type
- English Teacher
- Native Language
- British English
- Home Country
- UK
- Current Location
- UK
-
#2
Re: Neugenery
Hello,
Is there possible to look up a word when we just have concept about? e.g. I’d like to know what describe the following definition:
‘a very large number of things, probably more than is necessary’ just as an example, that’s not the point here.
I find it just once solitary perhaps solution, which I’ll describe it in the blog Neugenery.
Hello and welcome to the forums.
I have found that you can sometimes find a word by Googling the definition along with «a word which means» but it happens only occasionally. The only online reverse dictionary I can find is: OneLook Reverse Dictionary
Please give your threads titles which refer to the actual post somehow. «Finding a word by its definition» would have been good.
neugenery
Guest
-
#3
Sorry for the title, looking up in the OneLook ends up like the following, would one potentially find at first glance? beside they are from variety word family!
1. alot
2. studying in vienna
3. several
4. double
5. obese
6. million
7. great
8. huge
…
…
91. ton
92. hyperreal number
93. accident-prone
94. regular issue coinage
95. point
96. dimension
97. difference
98. swordfish
99. monitor
100. bundle

5jj
Moderator
Staff member
- Joined
- Oct 14, 2010
- Member Type
- English Teacher
- Native Language
- British English
- Home Country
- Czech Republic
- Current Location
- Czech Republic
-
#4
Sorry for the title, looking up in the OneLook ends up like the following, would one potentially find at first glance? beside they are from variety word family!
1. alot […]
100. bundle
Sorry, but I just do not understand this.
I am creating a code where I need to take a string of words, convert it into numbers where hi bye hi hello would turn into 0 1 0 2. I have used dictionary’s to do this and this is why I am having trouble on the next part. I then need to compress this into a text file, to then decompress and reconstruct it into a string again. This is the bit I am stumped on.
The way I would like to do it is by compressing the indexes of the numbers, so the 0 1 0 2 bit into the text file with the dictionary contents, so in the text file it would have 0 1 0 2 and {hi:0, bye:1, hello:3}.
Now what I would like to do to decompress or read this into the python file, to use the indexes(this is how I will refer to the 0 1 0 2 from now on) to then take each word out of the dictionary and reconstruct the sentence, so if a 0 came up, it would look into the dictionary and then find what has a 0 definition, then pull that out to put into the string, so it would find hi and take that.
I hope that this is understandable and that at least one person knows how to do it, because I am sure it is possible, however I have been unable to find anything here or on the internet mentioning this subject.
- Go to Preferences page and choose from different actions for taps or mouse clicks.
The English Dictionary
WordReference is proud to offer three monolingual English dictionaries from two of the world’s most respected publishers—the WordReference Random House Learner’s Dictionary of American English, the WordReference Random House Unabridged Dictionary of American English, and the Collins Concise English Dictionary. These prestigious dictionaries contain more than 259409 words and phrases.
In addition, we offer an English verb conjugator, comprehensive collections of synonyms and collocations, and an active English Only forum. If you still cannot find a term, you can ask or search in this forum, where native English speakers from around the world love to assist others in their understanding of the English language.
To get started, type a word in the search box above to find its definition.
Monolingual English dictionary
Spanish verb conjugator
English synonyms
English collocations
English Only forum
Copyright © 2023 WordReference Random House Learner’s Dictionary of American English
Copyright © 2023 WordReference Random House Unabridged Dictionary of American English
Collins Concise English Dictionary © HarperCollins Publishers
Bring this project to life
As per Wikipedia — a glossary, also known as a vocabulary, is an alphabetical list of terms in a particular domain of knowledge with the definitions for those terms. Traditionally, a glossary appears at the end of a book and includes terms within that book that are either newly introduced, uncommon, or specialized. Whereas, definitions are statements that explain the meaning of a term. A good list of glossary terms can make text comprehensible given enough ‘commonsense’ and ‘background knowledge’.
In this blog post, we will focus on building an unsupervised NLP pipeline for automatically extracting/generating glossaries and associated definitions from a given text document like a book/chapter/essay. Manual generation of glossary lists and their definitions is a time-consuming and cumbersome task. With our pipeline, we aim to significantly reduce this effort and augment the writers with suggestions while still making their verdict to be the final one during selection.
Dataset Collection
We will be building a mostly unsupervised system, so for evaluating our pipeline’s output, we will get started by extract 50 fiction/non-fiction novels from Gutenberg Project. Project Gutenberg is a library of over 60,000 free eBooks — completely without cost to readers. Having downloaded the books, the next task was to get their glossary and associated definitions. We can use GradeSaver for fetching this information. GradeSaver is one of the top editing and literature sites in the world. With this, we have some ground-truth data available to us for evaluating the goodness of our proposed pipeline.
Next, let’s see the code for extracting novels, associated glossary, and definitions —
from bs4 import BeautifulSoup
import requests
import pandas as pd
import glob
import string
import os
import codecs
BASE_BOOK_URL = 'https://www.gutenberg.org/browse/scores/top'
html = requests.get(BASE_BOOK_URL).text
soup = BeautifulSoup(html)
unq_code = {}
for s in soup.findAll('li'):
url = s.a['href']
if 'ebooks' in url:
url_str = url.split('/')[-1]
if url_str!='':
unq_code[url.split('/')[-1]] = s.a.text
BOOK_TXT_BASE = 'https://www.gutenberg.org/files/'
book_urls = []
for code in unq_code:
book_urls.append(os.path.join(BOOK_TXT_BASE,f'{code}/{code}-0.txt'))
for b in book_urls:
name = b.split('/')[-2]
html = requests.get(b).text
with codecs.open(f'book/{name}.txt', 'w', 'utf-8') as infile:
infile.write(html)As can be seen in the above snippet, we use BeautifulSoup python library for extracting the unique code for every novel from top listings url. These listings are based on the number of times each eBook gets downloaded. Next, we simulate the click feature and extract novel’s raw text if the ‘Plain Text UTF-8’ version of the book is present from the BOOK_TXT_BASE url. And finally, we download each novel and save it in our desired location with the proper naming convention.
Code for Extracting Glossary and Definitions from GradeSaver
BASE_GLOSS_URL = 'https://www.gradesaver.com/'
TERMINAL = '/study-guide/glossary-of-terms'
def punctuations(data_str):
data_str = data_str.replace("'s", "")
for x in data_str.lower():
if x in string.punctuation:
data_str = data_str.replace(x, "")
return data_str
for book in glob.glob('book/*'):
code = book.split('/')[-1].split('.')[0]
try:
bookname = unq_code[code]
bookname = bookname.split(' by ')[0].lower()
bookname = punctuations(bookname)
bookname = bookname.replace(" ", "-")
html = requests.get(BASE_GLOSS_URL+bookname+TERMINAL).text
soup = BeautifulSoup(html)
tt = []
for term in soup.findAll("section", {"class": "linkTarget"}):
tt.append(
[term.h2.text.lower().strip(),
term.p.text.lower().strip()]
)
if len(tt):
print (f'Done: {bookname}')
data = pd.DataFrame(tt, columns=['word', 'def'])
data.to_csv(f'data/{code}.csv',
sep='t',
encoding='utf-8',
index=False)
else:
print (f'Skipped: {bookname}')
except Exception as e: print (e)As can be seen in the above snippet, we again use BeautifulSoup python library for extracting the glossary and associated definitions for each book from the GradeSaver database. The below image shows a glimpse of the file that gets generated as a part of the above code snippet —

We approach the task of Glossary extraction by proposing a chunking pipeline, which at every step removes not-so-important candidate glossary words from the overall list. Lastly, we have a ranking function based on semantic similarity that calculates the relevance of each glossary word with the context and prioritizes the words in the glossary list accordingly.
We evaluate the output from our pipeline on Precision, Recall, and F1 scores against the ground truth obtained from GradeSaver for a particular novel. Precision measures how many of the glossary words produced are actually correct as per the available ground truth. Recall measures how many of the ground truth glossary words were produced/missed by the method proposed. F1 score is just a single numerical representation of Precision and Recall (represented as the harmonic mean of Precision (P) and Recall (R)).
Also, for simplicity purposes, we aim to only extract unigram, or single word, level glossary words. The below figure shows the entire process flow —
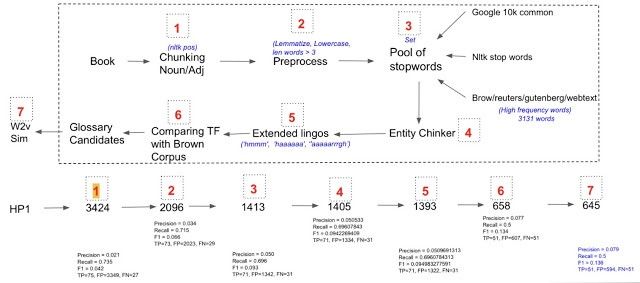
As can be seen in the above figure, we start off with a sample book from which we extract Nouns and Adjectives using the NLTK library. In step 2, we do some pre-processing like lemmatization, lowercasing, and min word length limit (words with very small length are likely to be stray marks, determiners, acronyms, etc) and might not necessarily have elaborate meaning for becoming the glossary words. In step 3, we filter all the common words, and we generate the set of such words by taking into account three different generic sources, namely, Google books common words, NLTK stop words, and High-frequency words from the chosen corpus like Brown, Reuters, etc. So any candidate glossary word that lies in the union list of words from these corpora is discarded immediately. In 4th step, we remove words that are any kind of entities in some sense(using spacy). In step 5, we remove extended lingos using regular expression. In step 6, we try to choose the words that are more specific to our corpus rather than some other global corpus based on Term-Frequency (TF).
At last, we go ahead and do one more step of ranking candidates on the basis of their relevance score. We define relevance measure as the cosine similarity between candidate glossary and corpus. The higher the score, the more the glossary keyword is relevant to the underlying corpus. In the above diagram, I have also mentioned a step-by-step impact on the P, R, and F1 scores. With the above-mentioned technique, we were able to get to Precision of 0.07, Recall of 0.5, and F1 of 0.13.
In the below image we present some of the results for Glossary worthy words extracted by our proposed system from Harry Potter Book — Part 1.

Some experiments which didn’t workout
- Experimented with Graph-based word/phrase ranking method — TextRank for extracting candidate glossary words directly instead of the above-mentioned Noun-Adjective Chunking strategy.
- We believed that the complexity of a word is a good indicator of what a glossary word should be. For this, we considered the complexity in both written and spoken sense.
— We use the Flesch-Kincaid Grade Level metric for testing the written complexity.
— We count the number of Phonemes present as a measure of spoken complexity.
- We also tried forming word clusters based on dense vector representation and other custom features like complexity, word length, relevance, etc. And expected to see a separate glossary-worthy cluster.
The definitions consist of two parts, Definiendum and Definiens. The definiendum is the element that is to be defined. The definiens provides the meaning to definiendum. In a properly written simple text piece, definiendum and definiens are often found to be connected by a verb or punctuation mark. We approach the task of definition extraction/generation for a given glossary word under a given context as a 3-step pipeline(Rule-based Mining -> WordNet-based Selection -> GPT-2 based generation) with an exit option at each step. Let’s discuss each of them in detail —
Rule-based Mining
In rule-based mining, we define certain grammatical constructs for extracting definition structures from the text for a given keyword. Some of the patterns we form are, for example — X is defined as Y, X is a Y, etc. Here, X is the glossary word or definiendum, and Y is expected to be the meaning or definiens. We use regular expression patterns for implementing this step.
WordNet-based Selection
The next step in the pipeline is to use a WordNet-based selection strategy for extracting relevant definitions for a given glossary word. The below figure illustrates the entire process in detail —
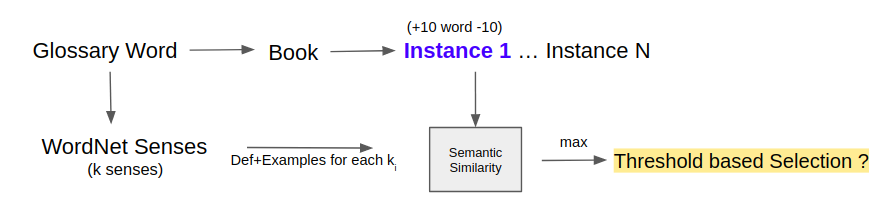
We start with finding the set of k senses (a sense is a.k.a meaning) for every glossary word found in the previous step using the WordNet library. We also extract the first context from the text where this glossary word occurs as a potential definition. The context is defined by setting a window of K words around the glossary word. The hypothesis here for selecting only the first context (marked in violet color) is that the author of the book/text is likely to define or explain the word as early as possible in the literature and then re-use it later as and when required. We understand that this hypothesis holds mostly in longer text pieces like books, novels, etc — which is reflective of our dataset.
For each of the unique senses from the set of k senses for a given glossary word, we extract the definition, related example and do a cosine similarity with the first context text. This helps in disambiguation and helps choose the most appropriate sense/meaning/definiens for a given word. As a part of the design implementation, one can either choose to select the top sense as per the similarity score or might want to not select anything at all and fall back to the 3rd step in the definition extraction/generation pipeline.
In the below image we present Definitions (column new_def) based on a WordNet selection scheme.

Bring this project to life
We start by fetching the first occurring context of the glossary word from the text.
import codecs
import os
import pandas as pd
import glob
import nltk
nltk.download('punkt')
from nltk.corpus import PlaintextCorpusReader
def get_context(c):
try:
result = text.concordance_list(c)[0]
left_of_query = ' '.join(result.left)
query = result.query
right_of_query = ' '.join(result.right)
return left_of_query + ' ' + query + ' ' + right_of_query
except:
return ''
generated_dfs = []
BASE_DIR = 'data'
for book in glob.glob('book/*'):
book_name = book.split('/')[-1].split('.')[0]
try:
DATA_DIR = codecs.open('book/' + book_name + '.txt',
'rb',
encoding='utf-8').readlines()
true_data = pd.read_csv(
'data/'+book_name+'.csv',
sep='t')
full_data = ' '.join([i.lower().strip() for i in DATA_DIR if len(i.strip())>1])
tokens = nltk.word_tokenize(full_data)
text = nltk.Text(tokens)
true_data['firstcontext'] = true_data['word'].map(lambda k: get_context(k))
generated_dfs.append(true_data)
except Exception as e:
pass
final_df = pd.concat(generated_dfs[:], axis=0)
final_df = final_df[final_df['firstcontext']!='']
final_df = final_df[['word', 'def', 'firstcontext']].reset_index()
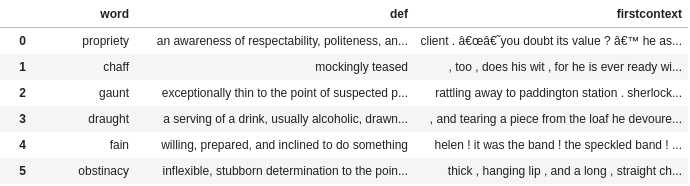
final_df.head(5)The below image shows the output data frame from the above snippet —
Next, we load word vectors using gensim KeyedVectors. We also define sentence representation as the average of vectors of the words present in the sentence.
import gensim
from gensim.models import Word2Vec
from gensim.utils import simple_preprocess
from gensim.models.keyedvectors import KeyedVectors
import numpy as np
from gensim.models import KeyedVectors
filepath = "GoogleNews-vectors-negative300.bin"
wv_from_bin = KeyedVectors.load_word2vec_format(filepath, binary=True)
ei = {}
for word, vector in zip(wv_from_bin.index_to_key, wv_from_bin.vectors):
coefs = np.asarray(vector, dtype='float32')
ei[word] = coefs
def avg_feature_vector(sentence, model, num_features):
words = sentence.split()
#feature vector is initialized as an empty array
feature_vec = np.zeros((num_features, ), dtype='float32')
n_words = 0
for word in words:
if word in embeddings_index.keys():
n_words += 1
feature_vec = np.add(feature_vec, model[word])
if (n_words > 0):
feature_vec = np.divide(feature_vec, n_words)
return feature_vecNext, we concatenate the definition of each sense and examples present in the WordNet library and calculate the semantic relatedness between this and the first context of the glossary word from the text. Lastly, we pick the one that has maximum similarity as the candidate definition.
def similarity(s1, s2):
s1_afv = avg_feature_vector(s1, model=ei, num_features=300)
s2_afv = avg_feature_vector(s2, model=ei, num_features=300)
cos = distance.cosine(s1_afv, s2_afv)
return cos
for idx in range(final_df.shape[0]):
fs = final_df.iloc[idx]['firstcontext']
w = final_df.iloc[idx]['word']
defi = final_df.iloc[idx]['def']
syns = wordnet.synsets(w)
s_dic={}
for sense in syns:
def,ex = sense.definition(), sense.examples()
sense_def = def + ' '.join(ex)
score = similarity(sense_def, fs)
s_dic[def]=score
s_sort = sorted(s_dic.items(), key=lambda k:k[1],reverse=True)[0]
final_df['new_def'][idx]=s_sort[0]
final_df['match'][idx]=s_sort[1]GPT-2 based Generation
This is the final step in our definition extraction/generation pipeline. Here, we fine-tune a medium-sized, pre-trained GPT-2 model on an openly available definitions dataset from the Urban Dictionary. We pick phrases and their related definitions from the 2.5 million data samples present in the dataset. For fine-tuning we format our data records with special tokens that help our GPT-2 model to act as a conditional language generation model based on specific prefix text.
How to load Kaggle data into a Gradient Notebook
- Get a Kaggle account
- Create an API token by going to your Account settings, and save kaggle.json. Note: you may need to create a new api token if you have already created one.
- Upload kaggle.json to this Gradient Notebook
- Either run the cell below or run the following commands in a terminal (this may take a while)
> Note: Do not share a notebook with your api key enabled
Now in the terminal:
mkdir ~/.kaggle/
mv kaggle.json ~/.kaggle/
pip install kaggle
kaggle datasets download therohk/urban-dictionary-words-dataset
kaggle datasets download adarshsng/googlenewsvectors
- Training Loop — I/O Format — <|startoftext|> word <DEFINE> meaning <|endoftext|>
- Testing Loop — Input Format — <|startoftext|> word <DEFINE> / Output Format — meaning <|endoftext|>
Here, <|startoftext|> and <|endoftext|> are special tokens for the start and stop of the text sequence, and <DEFINE> is the prompt token, telling the model to start generating definition for the existing word.
We start by first loading the urban dictionary dataset of words and definitions, as shown below —
import pandas as pd
train = pd.read_csv(
'urbandict-word-defs.csv',
nrows=100000,
error_bad_lines=False
)
new_train = train[['word', 'definition']]
new_train['word'] = new_train.word.str.lower()
new_train['definition'] = new_train.definition.str.lower()Next, we select the appropriate device and load the relevant GPT-2 tokenizer and model —
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel
import numpy as np
import os
from tqdm import tqdm
import logging
logging.getLogger().setLevel(logging.CRITICAL)
import warnings
warnings.filterwarnings('ignore')
device = 'cpu'
if torch.cuda.is_available():
device = 'cuda'
tokenizer = GPT2Tokenizer.from_pretrained('gpt2-medium')
model = GPT2LMHeadModel.from_pretrained('gpt2-medium')Next, we define the dataset class for appropriately formatting each input example. Since we are using an autoregressive model for generating text conditioned on prefix text, we define a trigger token <DEFINE> separating word and associated definition. We also add the start and end text tokens with each input example to make the model aware of starting and ending hints. We will also create a data loader from the dataset with a batch size of 4 and set shuffling to be true, making our model robust to any hidden patterns that might exist in the original dataset.
from torch.utils.data import Dataset, DataLoader
import os
import json
import csv
class GlossaryDataset(Dataset):
def __init__(self, dataframe):
super().__init__()
self.data_list = []
self.end_of_text_token = "<|endoftext|>"
self.start_of_text_token = "<|startoftext|>"
for i in range(dataframe.shape[0]):
data_str = f"{self.start_of_text_token}
{new_train.iloc[i]['word']}
<DEFINE>
{new_train.iloc[i]['definition']}
{self.end_of_text_token}"
self.data_list.append(data_str)
def __len__(self):
return len(self.data_list)
def __getitem__(self, item):
return self.data_list[item]
dataset = GlossaryDataset(dataframe=new_train)
data_loader = DataLoader(dataset, batch_size=4, shuffle=True)Next, we define our optimizer, scheduler, and other parameters.
from transformers import AdamW
EPOCHS = 10
LEARNING_RATE = 2e-5
device = 'cpu'
if torch.cuda.is_available():
device = 'cuda'
model = model.to(device)
model.train()
optimizer = AdamW(model.parameters(), lr=LEARNING_RATE)Finally, we write our training loop for performing forward and backward passes, and execute training.
for epoch in range(EPOCHS):
print (f'Running {epoch} epoch')
for idx,sample in enumerate(data_loader):
sample_tsr = torch.tensor(tokenizer.encode(sample[0]))
sample_tsr = sample_tsr.unsqueeze(0).to(device)
outputs = model(sample_tsr, labels=sample_tsr)
loss = outputs[0]
loss.backward()
optimizer.step()
scheduler.step()
optimizer.zero_grad()
model.zero_grad()In the below image, we present some of the results from our GPT-2 based definition generation on inference.

Concluding thoughts
In this blog, we discuss a seed approach for extracting glossaries and related definitions using natural language processing techniques mostly in an unsupervised fashion. And we strongly believe that this can lay the foundations for building more sophisticated and robust pipelines. Also, we think that the evaluation of such tasks on some objective scale such as Precision, Recall is not entirely justified and should be evaluated by humans at the end of the day. Because the author of the book also considers the audience, demography, culture, etc he is targeting while coming up with the glossary list.
I hope you enjoyed reading this article. Thank you!