
I’m working with Python, and I’m trying to find out if you can tell if a word is in a string.
I have found some information about identifying if the word is in the string — using .find, but is there a way to do an if statement. I would like to have something like the following:
if string.find(word):
print("success")
![]()
mkrieger1
17.7k4 gold badges54 silver badges62 bronze badges
asked Mar 16, 2011 at 1:10
![]()
0
What is wrong with:
if word in mystring:
print('success')
![]()
Martin Thoma
121k154 gold badges603 silver badges926 bronze badges
answered Mar 16, 2011 at 1:13
![]()
fabrizioMfabrizioM
46k15 gold badges100 silver badges118 bronze badges
13
if 'seek' in 'those who seek shall find':
print('Success!')
but keep in mind that this matches a sequence of characters, not necessarily a whole word — for example, 'word' in 'swordsmith' is True. If you only want to match whole words, you ought to use regular expressions:
import re
def findWholeWord(w):
return re.compile(r'b({0})b'.format(w), flags=re.IGNORECASE).search
findWholeWord('seek')('those who seek shall find') # -> <match object>
findWholeWord('word')('swordsmith') # -> None
answered Mar 16, 2011 at 1:52
![]()
Hugh BothwellHugh Bothwell
54.7k8 gold badges84 silver badges99 bronze badges
6
If you want to find out whether a whole word is in a space-separated list of words, simply use:
def contains_word(s, w):
return (' ' + w + ' ') in (' ' + s + ' ')
contains_word('the quick brown fox', 'brown') # True
contains_word('the quick brown fox', 'row') # False
This elegant method is also the fastest. Compared to Hugh Bothwell’s and daSong’s approaches:
>python -m timeit -s "def contains_word(s, w): return (' ' + w + ' ') in (' ' + s + ' ')" "contains_word('the quick brown fox', 'brown')"
1000000 loops, best of 3: 0.351 usec per loop
>python -m timeit -s "import re" -s "def contains_word(s, w): return re.compile(r'b({0})b'.format(w), flags=re.IGNORECASE).search(s)" "contains_word('the quick brown fox', 'brown')"
100000 loops, best of 3: 2.38 usec per loop
>python -m timeit -s "def contains_word(s, w): return s.startswith(w + ' ') or s.endswith(' ' + w) or s.find(' ' + w + ' ') != -1" "contains_word('the quick brown fox', 'brown')"
1000000 loops, best of 3: 1.13 usec per loop
Edit: A slight variant on this idea for Python 3.6+, equally fast:
def contains_word(s, w):
return f' {w} ' in f' {s} '
answered Apr 11, 2016 at 20:32
![]()
user200783user200783
13.6k11 gold badges67 silver badges132 bronze badges
6
You can split string to the words and check the result list.
if word in string.split():
print("success")
![]()
Martin Thoma
121k154 gold badges603 silver badges926 bronze badges
answered Dec 1, 2016 at 18:26
![]()
CorvaxCorvax
7647 silver badges12 bronze badges
3
find returns an integer representing the index of where the search item was found. If it isn’t found, it returns -1.
haystack = 'asdf'
haystack.find('a') # result: 0
haystack.find('s') # result: 1
haystack.find('g') # result: -1
if haystack.find(needle) >= 0:
print('Needle found.')
else:
print('Needle not found.')
![]()
Martin Thoma
121k154 gold badges603 silver badges926 bronze badges
answered Mar 16, 2011 at 1:13
![]()
Matt HowellMatt Howell
15.6k7 gold badges48 silver badges56 bronze badges
0
This small function compares all search words in given text. If all search words are found in text, returns length of search, or False otherwise.
Also supports unicode string search.
def find_words(text, search):
"""Find exact words"""
dText = text.split()
dSearch = search.split()
found_word = 0
for text_word in dText:
for search_word in dSearch:
if search_word == text_word:
found_word += 1
if found_word == len(dSearch):
return lenSearch
else:
return False
usage:
find_words('çelik güray ankara', 'güray ankara')
![]()
answered Jun 22, 2012 at 22:51
![]()
Guray CelikGuray Celik
1,2811 gold badge14 silver badges13 bronze badges
0
If matching a sequence of characters is not sufficient and you need to match whole words, here is a simple function that gets the job done. It basically appends spaces where necessary and searches for that in the string:
def smart_find(haystack, needle):
if haystack.startswith(needle+" "):
return True
if haystack.endswith(" "+needle):
return True
if haystack.find(" "+needle+" ") != -1:
return True
return False
This assumes that commas and other punctuations have already been stripped out.
![]()
IanS
15.6k9 gold badges59 silver badges84 bronze badges
answered Jun 15, 2012 at 7:23
![]()
daSongdaSong
4071 gold badge5 silver badges9 bronze badges
1
Using regex is a solution, but it is too complicated for that case.
You can simply split text into list of words. Use split(separator, num) method for that. It returns a list of all the words in the string, using separator as the separator. If separator is unspecified it splits on all whitespace (optionally you can limit the number of splits to num).
list_of_words = mystring.split()
if word in list_of_words:
print('success')
This will not work for string with commas etc. For example:
mystring = "One,two and three"
# will split into ["One,two", "and", "three"]
If you also want to split on all commas etc. use separator argument like this:
# whitespace_chars = " tnrf" - space, tab, newline, return, formfeed
list_of_words = mystring.split( tnrf,.;!?'"()")
if word in list_of_words:
print('success')
![]()
Martin Thoma
121k154 gold badges603 silver badges926 bronze badges
answered Dec 18, 2017 at 11:44
![]()
tstempkotstempko
1,1761 gold badge15 silver badges17 bronze badges
2
As you are asking for a word and not for a string, I would like to present a solution which is not sensitive to prefixes / suffixes and ignores case:
#!/usr/bin/env python
import re
def is_word_in_text(word, text):
"""
Check if a word is in a text.
Parameters
----------
word : str
text : str
Returns
-------
bool : True if word is in text, otherwise False.
Examples
--------
>>> is_word_in_text("Python", "python is awesome.")
True
>>> is_word_in_text("Python", "camelCase is pythonic.")
False
>>> is_word_in_text("Python", "At the end is Python")
True
"""
pattern = r'(^|[^w]){}([^w]|$)'.format(word)
pattern = re.compile(pattern, re.IGNORECASE)
matches = re.search(pattern, text)
return bool(matches)
if __name__ == '__main__':
import doctest
doctest.testmod()
If your words might contain regex special chars (such as +), then you need re.escape(word)
answered Aug 9, 2017 at 10:11
![]()
Martin ThomaMartin Thoma
121k154 gold badges603 silver badges926 bronze badges
Advanced way to check the exact word, that we need to find in a long string:
import re
text = "This text was of edited by Rock"
#try this string also
#text = "This text was officially edited by Rock"
for m in re.finditer(r"bofb", text):
if m.group(0):
print("Present")
else:
print("Absent")
![]()
Martin Thoma
121k154 gold badges603 silver badges926 bronze badges
answered Nov 2, 2016 at 8:39
![]()
RameezRameez
5545 silver badges11 bronze badges
What about to split the string and strip words punctuation?
w in [ws.strip(',.?!') for ws in p.split()]
If need, do attention to lower/upper case:
w.lower() in [ws.strip(',.?!') for ws in p.lower().split()]
Maybe that way:
def wcheck(word, phrase):
# Attention about punctuation and about split characters
punctuation = ',.?!'
return word.lower() in [words.strip(punctuation) for words in phrase.lower().split()]
Sample:
print(wcheck('CAr', 'I own a caR.'))
I didn’t check performance…
answered Dec 26, 2020 at 5:18
![]()
marciomarcio
5067 silver badges19 bronze badges
You could just add a space before and after «word».
x = raw_input("Type your word: ")
if " word " in x:
print("Yes")
elif " word " not in x:
print("Nope")
This way it looks for the space before and after «word».
>>> Type your word: Swordsmith
>>> Nope
>>> Type your word: word
>>> Yes
![]()
Martin Thoma
121k154 gold badges603 silver badges926 bronze badges
answered Feb 26, 2015 at 14:23
![]()
PyGuyPyGuy
433 bronze badges
1
I believe this answer is closer to what was initially asked: Find substring in string but only if whole words?
It is using a simple regex:
import re
if re.search(r"b" + re.escape(word) + r"b", string):
print('success')
![]()
Martin Thoma
121k154 gold badges603 silver badges926 bronze badges
answered Aug 25, 2021 at 13:25
![]()
Milos CuculovicMilos Cuculovic
19.4k50 gold badges159 silver badges264 bronze badges
One of the solutions is to put a space at the beginning and end of the test word. This fails if the word is at the beginning or end of a sentence or is next to any punctuation. My solution is to write a function that replaces any punctuation in the test string with spaces, and add a space to the beginning and end or the test string and test word, then return the number of occurrences. This is a simple solution that removes the need for any complex regex expression.
def countWords(word, sentence):
testWord = ' ' + word.lower() + ' '
testSentence = ' '
for char in sentence:
if char.isalpha():
testSentence = testSentence + char.lower()
else:
testSentence = testSentence + ' '
testSentence = testSentence + ' '
return testSentence.count(testWord)
To count the number of occurrences of a word in a string:
sentence = "A Frenchman ate an apple"
print(countWords('a', sentence))
returns 1
sentence = "Is Oporto a 'port' in Portugal?"
print(countWords('port', sentence))
returns 1
Use the function in an ‘if’ to test if the word exists in a string
answered Mar 18, 2022 at 9:37
![]()
iStuartiStuart
3953 silver badges6 bronze badges
Watch Now This tutorial has a related video course created by the Real Python team. Watch it together with the written tutorial to deepen your understanding: Check if a Python String Contains a Substring
If you’re new to programming or come from a programming language other than Python, you may be looking for the best way to check whether a string contains another string in Python.
Identifying such substrings comes in handy when you’re working with text content from a file or after you’ve received user input. You may want to perform different actions in your program depending on whether a substring is present or not.
In this tutorial, you’ll focus on the most Pythonic way to tackle this task, using the membership operator in. Additionally, you’ll learn how to identify the right string methods for related, but different, use cases.
Finally, you’ll also learn how to find substrings in pandas columns. This is helpful if you need to search through data from a CSV file. You could use the approach that you’ll learn in the next section, but if you’re working with tabular data, it’s best to load the data into a pandas DataFrame and search for substrings in pandas.
How to Confirm That a Python String Contains Another String
If you need to check whether a string contains a substring, use Python’s membership operator in. In Python, this is the recommended way to confirm the existence of a substring in a string:
>>>
>>> raw_file_content = """Hi there and welcome.
... This is a special hidden file with a SECRET secret.
... I don't want to tell you The Secret,
... but I do want to secretly tell you that I have one."""
>>> "secret" in raw_file_content
True
The in membership operator gives you a quick and readable way to check whether a substring is present in a string. You may notice that the line of code almost reads like English.
When you use in, the expression returns a Boolean value:
Trueif Python found the substringFalseif Python didn’t find the substring
You can use this intuitive syntax in conditional statements to make decisions in your code:
>>>
>>> if "secret" in raw_file_content:
... print("Found!")
...
Found!
In this code snippet, you use the membership operator to check whether "secret" is a substring of raw_file_content. If it is, then you’ll print a message to the terminal. Any indented code will only execute if the Python string that you’re checking contains the substring that you provide.
The membership operator in is your best friend if you just need to check whether a Python string contains a substring.
However, what if you want to know more about the substring? If you read through the text stored in raw_file_content, then you’ll notice that the substring occurs more than once, and even in different variations!
Which of these occurrences did Python find? Does capitalization make a difference? How often does the substring show up in the text? And what’s the location of these substrings? If you need the answer to any of these questions, then keep on reading.
Generalize Your Check by Removing Case Sensitivity
Python strings are case sensitive. If the substring that you provide uses different capitalization than the same word in your text, then Python won’t find it. For example, if you check for the lowercase word "secret" on a title-case version of the original text, the membership operator check returns False:
>>>
>>> title_cased_file_content = """Hi There And Welcome.
... This Is A Special Hidden File With A Secret Secret.
... I Don't Want To Tell You The Secret,
... But I Do Want To Secretly Tell You That I Have One."""
>>> "secret" in title_cased_file_content
False
Despite the fact that the word secret appears multiple times in the title-case text title_cased_file_content, it never shows up in all lowercase. That’s why the check that you perform with the membership operator returns False. Python can’t find the all-lowercase string "secret" in the provided text.
Humans have a different approach to language than computers do. This is why you’ll often want to disregard capitalization when you check whether a string contains a substring in Python.
You can generalize your substring check by converting the whole input text to lowercase:
>>>
>>> file_content = title_cased_file_content.lower()
>>> print(file_content)
hi there and welcome.
this is a special hidden file with a secret secret.
i don't want to tell you the secret,
but i do want to secretly tell you that i have one.
>>> "secret" in file_content
True
Converting your input text to lowercase is a common way to account for the fact that humans think of words that only differ in capitalization as the same word, while computers don’t.
Now that you’ve converted the string to lowercase to avoid unintended issues stemming from case sensitivity, it’s time to dig further and learn more about the substring.
Learn More About the Substring
The membership operator in is a great way to descriptively check whether there’s a substring in a string, but it doesn’t give you any more information than that. It’s perfect for conditional checks—but what if you need to know more about the substrings?
Python provides many additonal string methods that allow you to check how many target substrings the string contains, to search for substrings according to elaborate conditions, or to locate the index of the substring in your text.
In this section, you’ll cover some additional string methods that can help you learn more about the substring.
By using in, you confirmed that the string contains the substring. But you didn’t get any information on where the substring is located.
If you need to know where in your string the substring occurs, then you can use .index() on the string object:
>>>
>>> file_content = """hi there and welcome.
... this is a special hidden file with a secret secret.
... i don't want to tell you the secret,
... but i do want to secretly tell you that i have one."""
>>> file_content.index("secret")
59
When you call .index() on the string and pass it the substring as an argument, you get the index position of the first character of the first occurrence of the substring.
But what if you want to find other occurrences of the substring? The .index() method also takes a second argument that can define at which index position to start looking. By passing specific index positions, you can therefore skip over occurrences of the substring that you’ve already identified:
>>>
>>> file_content.index("secret", 60)
66
When you pass a starting index that’s past the first occurrence of the substring, then Python searches starting from there. In this case, you get another match and not a ValueError.
That means that the text contains the substring more than once. But how often is it in there?
You can use .count() to get your answer quickly using descriptive and idiomatic Python code:
>>>
>>> file_content.count("secret")
4
You used .count() on the lowercase string and passed the substring "secret" as an argument. Python counted how often the substring appears in the string and returned the answer. The text contains the substring four times. But what do these substrings look like?
You can inspect all the substrings by splitting your text at default word borders and printing the words to your terminal using a for loop:
>>>
>>> for word in file_content.split():
... if "secret" in word:
... print(word)
...
secret
secret.
secret,
secretly
In this example, you use .split() to separate the text at whitespaces into strings, which Python packs into a list. Then you iterate over this list and use in on each of these strings to see whether it contains the substring "secret".
Now that you can inspect all the substrings that Python identifies, you may notice that Python doesn’t care whether there are any characters after the substring "secret" or not. It finds the word whether it’s followed by whitespace or punctuation. It even finds words such as "secretly".
That’s good to know, but what can you do if you want to place stricter conditions on your substring check?
Find a Substring With Conditions Using Regex
You may only want to match occurrences of your substring followed by punctuation, or identify words that contain the substring plus other letters, such as "secretly".
For such cases that require more involved string matching, you can use regular expressions, or regex, with Python’s re module.
For example, if you want to find all the words that start with "secret" but are then followed by at least one additional letter, then you can use the regex word character (w) followed by the plus quantifier (+):
>>>
>>> import re
>>> file_content = """hi there and welcome.
... this is a special hidden file with a secret secret.
... i don't want to tell you the secret,
... but i do want to secretly tell you that i have one."""
>>> re.search(r"secretw+", file_content)
<re.Match object; span=(128, 136), match='secretly'>
The re.search() function returns both the substring that matched the condition as well as its start and end index positions—rather than just True!
You can then access these attributes through methods on the Match object, which is denoted by m:
>>>
>>> m = re.search(r"secretw+", file_content)
>>> m.group()
'secretly'
>>> m.span()
(128, 136)
These results give you a lot of flexibility to continue working with the matched substring.
For example, you could search for only the substrings that are followed by a comma (,) or a period (.):
>>>
>>> re.search(r"secret[.,]", file_content)
<re.Match object; span=(66, 73), match='secret.'>
There are two potential matches in your text, but you only matched the first result fitting your query. When you use re.search(), Python again finds only the first match. What if you wanted all the mentions of "secret" that fit a certain condition?
To find all the matches using re, you can work with re.findall():
>>>
>>> re.findall(r"secret[.,]", file_content)
['secret.', 'secret,']
By using re.findall(), you can find all the matches of the pattern in your text. Python saves all the matches as strings in a list for you.
When you use a capturing group, you can specify which part of the match you want to keep in your list by wrapping that part in parentheses:
>>>
>>> re.findall(r"(secret)[.,]", file_content)
['secret', 'secret']
By wrapping secret in parentheses, you defined a single capturing group. The findall() function returns a list of strings matching that capturing group, as long as there’s exactly one capturing group in the pattern. By adding the parentheses around secret, you managed to get rid of the punctuation!
Using re.findall() with match groups is a powerful way to extract substrings from your text. But you only get a list of strings, which means that you’ve lost the index positions that you had access to when you were using re.search().
If you want to keep that information around, then re can give you all the matches in an iterator:
>>>
>>> for match in re.finditer(r"(secret)[.,]", file_content):
... print(match)
...
<re.Match object; span=(66, 73), match='secret.'>
<re.Match object; span=(103, 110), match='secret,'>
When you use re.finditer() and pass it a search pattern and your text content as arguments, you can access each Match object that contains the substring, as well as its start and end index positions.
You may notice that the punctuation shows up in these results even though you’re still using the capturing group. That’s because the string representation of a Match object displays the whole match rather than just the first capturing group.
But the Match object is a powerful container of information and, like you’ve seen earlier, you can pick out just the information that you need:
>>>
>>> for match in re.finditer(r"(secret)[.,]", file_content):
... print(match.group(1))
...
secret
secret
By calling .group() and specifying that you want the first capturing group, you picked the word secret without the punctuation from each matched substring.
You can go into much more detail with your substring matching when you use regular expressions. Instead of just checking whether a string contains another string, you can search for substrings according to elaborate conditions.
Using regular expressions with re is a good approach if you need information about the substrings, or if you need to continue working with them after you’ve found them in the text. But what if you’re working with tabular data? For that, you’ll turn to pandas.
Find a Substring in a pandas DataFrame Column
If you work with data that doesn’t come from a plain text file or from user input, but from a CSV file or an Excel sheet, then you could use the same approach as discussed above.
However, there’s a better way to identify which cells in a column contain a substring: you’ll use pandas! In this example, you’ll work with a CSV file that contains fake company names and slogans. You can download the file below if you want to work along:
When you’re working with tabular data in Python, it’s usually best to load it into a pandas DataFrame first:
>>>
>>> import pandas as pd
>>> companies = pd.read_csv("companies.csv")
>>> companies.shape
(1000, 2)
>>> companies.head()
company slogan
0 Kuvalis-Nolan revolutionize next-generation metrics
1 Dietrich-Champlin envisioneer bleeding-edge functionalities
2 West Inc mesh user-centric infomediaries
3 Wehner LLC utilize sticky infomediaries
4 Langworth Inc reinvent magnetic networks
In this code block, you loaded a CSV file that contains one thousand rows of fake company data into a pandas DataFrame and inspected the first five rows using .head().
After you’ve loaded the data into the DataFrame, you can quickly query the whole pandas column to filter for entries that contain a substring:
>>>
>>> companies[companies.slogan.str.contains("secret")]
company slogan
7 Maggio LLC target secret niches
117 Kub and Sons brand secret methodologies
654 Koss-Zulauf syndicate secret paradigms
656 Bernier-Kihn secretly synthesize back-end bandwidth
921 Ward-Shields embrace secret e-commerce
945 Williamson Group unleash secret action-items
You can use .str.contains() on a pandas column and pass it the substring as an argument to filter for rows that contain the substring.
When you’re working with .str.contains() and you need more complex match scenarios, you can also use regular expressions! You just need to pass a regex-compliant search pattern as the substring argument:
>>>
>>> companies[companies.slogan.str.contains(r"secretw+")]
company slogan
656 Bernier-Kihn secretly synthesize back-end bandwidth
In this code snippet, you’ve used the same pattern that you used earlier to match only words that contain secret but then continue with one or more word character (w+). Only one of the companies in this fake dataset seems to operate secretly!
You can write any complex regex pattern and pass it to .str.contains() to carve from your pandas column just the rows that you need for your analysis.
Conclusion
Like a persistent treasure hunter, you found each "secret", no matter how well it was hidden! In the process, you learned that the best way to check whether a string contains a substring in Python is to use the in membership operator.
You also learned how to descriptively use two other string methods, which are often misused to check for substrings:
.count()to count the occurrences of a substring in a string.index()to get the index position of the beginning of the substring
After that, you explored how to find substrings according to more advanced conditions with regular expressions and a few functions in Python’s re module.
Finally, you also learned how you can use the DataFrame method .str.contains() to check which entries in a pandas DataFrame contain a substring .
You now know how to pick the most idiomatic approach when you’re working with substrings in Python. Keep using the most descriptive method for the job, and you’ll write code that’s delightful to read and quick for others to understand.
Watch Now This tutorial has a related video course created by the Real Python team. Watch it together with the written tutorial to deepen your understanding: Check if a Python String Contains a Substring
In this Python tutorial, we will discuss everything on Python find substring in string with a few more examples.
Python provides several methods to find substrings in a string. Here we will discuss 12 different methods to check if Python String contains a substring.
- Using the in operator
- Using The find() method
- Using the index() method
- Using the re module
- Using the startswith() method
- Using the endswith() method
- Using the split() method
- Using the partition() method
- Using the count() method
- Using the rfind() method
- Using the list comprehension
- Using the re.findall()
Method-1: Using the in operator
The in operator is one of the simplest and quickest ways to check if a substring is present in a string. It returns True if the substring is found and False otherwise.
# Define the main string
string = "I live in USA"
# Define the substring to be searched
substring = "USA"
# Use 'in' operator to check if substring is present in string
if substring in string:
print("Substring found")
else:
print("Substring not found")The above code checks if a given substring is present in a given string.
- The main string is stored in the variable string and the substring to be searched is stored in the variable substring.
- The code uses the in operator to check if the substring is present in the string. If it is, the code outputs “Substring found” to the console. If not, the code outputs “Substring not found”.

Read: Slicing string in Python + Examples
Method-2: Using The find() method
The find() method is another simple way to find substrings in a string. It returns the index of the first occurrence of the substring in the string. If the substring is not found, it returns -1.
# Define the main string
string = "I live in USA"
# Define the substring to be searched
substring = "USA"
# Use the find() method to get the index of the substring
index = string.find(substring)
# Check if the substring is found
if index != -1:
print("Substring found at index", index)
else:
print("Substring not found")The above code uses the find() method to search for the index of a given substring in a given string.
- The find() method is used to search for the index of the substring in the string, and the result is stored in the variable index.
- If the substring is found, the index will be set to the index of the first character of the substring in the string. If the substring is not found, index will be set to -1.
- The code then checks if index is not equal to -1. If it is not, the substring was found and the code outputs “Substring found at index” followed by the value of the index.
- If the index is equal to -1, the substring was not found and the code outputs “Substring not found”.

Read: Convert string to float in Python
Method-3: Using the index() method
The index() method is similar to the find() method, but it raises a ValueError exception if the substring is not found in the string.
# Search for substring in a given string
string = "I live in USA"
# The substring we want to search for
substring = "live"
# Use try-except block to handle potential ValueError if substring is not found
try:
# Find the index of the substring in the string using the index() method
index = string.index(substring)
# Print a success message with the index of the substring
print("Substring found at index", index)
except ValueError:
# If the substring is not found, print a message indicating that it was not found
print("Substring not found")The code above is checking if a given substring is present in a string.
- The input string is “I live in USA” and the substring we want to search for is “live”.
- The code uses a try-except block to handle the potential error of not finding the substring in the string.
- The index() method is used to find the index of the substring in the string. If the substring is found, the code prints a message indicating the index of the substring in the string.
- If the substring is not found, a ValueError is raised, which is caught by the except block, and a message indicating that the substring was not found is printed.

Read: Append to a string Python + Examples
Method-4: Using the re module
The re (regular expression) module provides powerful methods for matching and searching for substrings in a string.
# Use the re module for pattern matching
import re
# The string we want to search in
string = "I live in USA"
# The substring we want to search for
substring = "in"
# Use the search() method from the re module to find a match
match = re.search(substring, string)
# Check if a match was found
if match:
# If a match was found, print a success message
print("Substring found")
else:
# If no match was found, print a failure message
print("Substring not found")
The code above is checking if a given substring is present in a string using regular expressions (regex).
- The first line import re imports the re module which provides functions for pattern matching in strings.
- The input string is “I live in USA” and the substring we want to search for is “in”. The code then uses the re.search() method to find a match between the substring and the input string.
- The re.search() method returns a match object if there is a match between the substring and the input string, otherwise it returns None.
- The code then uses an if statement to check if a match was found. If a match was found, the code prints a message indicating that the substring was found.
- If no match was found, the code prints a message indicating that the substring was not found.

Read: Python compare strings
Method-5: Using the startswith() method
The startswith() method returns True if the string starts with the specified substring and False otherwise.
# The string we want to search in
string = "I live in USA"
# The substring we want to search for
substring = "I"
# Use the startswith() method to check if the string starts with the substring
if string.startswith(substring):
# If the string starts with the substring, print a success message
print("Substring found")
else:
# If the string does not start with the substring, print a failure message
print("Substring not found")
The code above checks if a given substring is at the beginning of a string.
- The input string is “I live in USA” and the substring we want to search for is “I”. The code uses the startswith() method to check if the input string starts with the substring.
- The startswith() method returns True if the input string starts with the substring and False otherwise. The code then uses an if statement to check the result of the startswith() method.
- If the input string starts with the substring, the code prints a message indicating that the substring was found. If the input string does not start with the substring, the code prints a message indicating that the substring was not found.

Read: Python program to reverse a string with examples
Method-6: Using the endswith() method
The endswith() method is similar to the startswith() method, but it returns True if the string ends with the specified substring and False otherwise.
# The string we want to search in
string = "I live in USA"
# The substring we want to search for
substring = "USA"
# Use the endswith() method to check if the string ends with the substring
if string.endswith(substring):
# If the string ends with the substring, print a success message
print("Substring found")
else:
# If the string does not end with the substring, print a failure message
print("Substring not found")The code above checks if a given substring is at the end of a string.
- The input string is “I live in USA” and the substring we want to search for is “USA”. The code uses the endswith() method to check if the input string ends with the substring.
- The endswith() method returns True if the input string ends with the substring and False otherwise. The code then uses an if statement to check the result of the endswith() method.
- If the input string ends with the substring, the code prints a message indicating that the substring was found. If the input string does not end with the substring, the code prints a message indicating that the substring was not found.

Read: Python string formatting with examples.
Method-7: Using the split() method
The split() method splits a string into a list of substrings based on a specified delimiter. The resulting substrings can then be searched for the desired substring.
# The string we want to search in
string = "I live in USA"
# The substring we want to search for
substring = "USA"
# Split the string into substrings using the split() method and store the result in a list
substrings = string.split(" ")
# Check if the substring is in the list of substrings
if substring in substrings:
# If the substring is in the list, print a success message
print("Substring found")
else:
# If the substring is not in the list, print a failure message
print("Substring not found")
The code above checks if a given substring is contained within a string.
- The input string is “I live in USA” and the substring we want to search for is “USA”. The code splits the input string into substrings using the split() method and stores the result in a list substrings.
- The split() method splits a string into substrings using a specified delimiter (in this case, a space character).
- Next, the code uses the
inoperator to check if the substring is in the list of substrings. If the substring is in the list, the code prints a message indicating that the substring was found. - If the substring is not in the list, the code prints a message indicating that the substring was not found.

Method-8: Using the partition() method
The partition() method splits a string into a tuple of three substrings: the substring before the specified delimiter, the specified delimiter, and the substring after the specified delimiter.
# The string we want to search in
string = "I live in USA"
# The substring we want to search for
substring = "I"
# Use the partition() method to split the string into three parts
before, delimiter, after = string.partition(" ")
# Check if the first part of the split string is equal to the substring
if before == substring:
# If the first part is equal to the substring, print a success message
print("Substring found")
else:
# If the first part is not equal to the substring, print a failure message
print("Substring not found")
The code above checks if a given substring is at the beginning of a string.
The input string is “I live in USA” and the substring we want to search for is “I”. The code uses the partition() method to split the input string into three parts:
- The part before the specified delimiter, the delimiter itself, and the part after the delimiter. In this case, the delimiter is a space character.
- The partition() method returns a tuple with three elements: the part before the delimiter, the delimiter itself, and the part after the delimiter.
- The code uses tuple unpacking to assign the three parts to the variables before, delimiter, and after.
- Next, the code uses an if statement to check if the first part of the split string (i.e., before) is equal to the substring.
- If the first part is equal to the substring, the code prints a message indicating that the substring was found. If the first part is not equal to the substring, the code prints a message indicating that the substring was not found.

Method-9: Using the count() method
The count() method returns the number of times a substring appears in a string.
# The string we want to search in
string = "I live in USA"
# The substring we want to search for
substring = "live"
# Use the count() method to count the number of times the substring appears in the string
count = string.count(substring)
# Print the result
print("Substring found", count, "times")The code above counts the number of times a given substring appears in a string.
- The input string is “I live in USA” and the substring we want to search for is “live”. The code uses the count() method to count the number of times the substring appears in the string.
- Finally, the code uses the print() function to print the result, indicating how many times the substring was found in the string.

Method-10: Using the rfind() method
The rfind() method is similar to the find() method, but it returns the index of the last occurrence of the substring in the string. If the substring is not found, it returns -1.
# The string we want to search in
string = "I live in USA"
# The substring we want to search for
substring = "USA"
# Use the rfind() method to find the last index of the substring in the string
index = string.rfind(substring)
# Check if the substring was found
if index != -1:
# If the substring was found, print the index
print("Substring found at index", index)
else:
# If the substring was not found, print a message
print("Substring not found")The code above searches for the last occurrence of a given substring in a string.
- The input string is “I live in USA” and the substring we want to search for is “USA”. The code uses the rfind() method to find the last index of the substring in the string.
- The rfind() method returns the index of the last occurrence of the substring in the string, or -1 if the substring is not found. So the code checks if the returned value is not equal to -1, indicating that the substring was found in the string.
- Finally, the code uses the print() function to print the result, indicating the index of the last occurrence of the substring in the string.

Method-11: Using the list comprehension
# The string we want to search in
string = "I live in USA"
# The substring we want to search for
substring = "USA"
# Use a list comprehension to find if the substring exists in the string split into words
result = [word for word in string.split() if word == substring]
# Check if the result list is not empty
if result:
# If the result list is not empty, the substring was found
print("Substring found")
else:
# If the result list is empty, the substring was not found
print("Substring not found")
The code above checks if a given substring exists in a string.
- The input string is “I live in USA” and the substring we want to search for is “USA”. The code uses a list comprehension to create a list of words from the input string, where each word is checked if it is equal to the given substring.
- The list comprehension iterates over the words in the input string, which is split using the split() method, and adds the word to the result list if it is equal to the given substring.
- Finally, the code uses an if statement to check if the result list is not empty. If the result list is not empty, it means that the substring was found in the input string, so the code prints “Substring found”.
- If the result list is empty, the substring was not found in the input string, so the code prints “Substring not found”.

Method-12: Using the re.findall()
The re.findall() function returns a list of all non-overlapping matches of the specified pattern within the string. We can use this function to find all occurrences of a substring within a string by specifying the substring as the pattern.
# Import the regular expression library 're'
import re
# The input text to search for the substring
text = "I live in USA"
# The substring to search for in the text
substring = "USA"
# Find all occurrences of the substring in the text using the 'findall' method from the 're' library
result = re.findall(substring, text)
# Print the result
print(result)In the above code, the regular expression library re is imported and used to find all occurrences of the given substring “USA” in the input text “I live in USA”.
- The re.findall method is used to search for all occurrences of the substring in the text and return them as a list.
- Finally, the result is printed on the console.
You may like the following Python examples:
- How to concatenate strings in python
- Find Last Number in String in Python
- Find first number in string in Python
In this Python tutorial, we learned, Python find substring in string using the below methods:
- Python find substring in string using the in operator
- Python find substring in string using The find() method
- Python find substring in string using the index() method
- Python find substring in string using the re module
- Python find substring in string using the startswith() method
- Python find substring in string using the endswith() method
- Python find substring in string using the split() method
- Python find substring in string using the partition() method
- Python find substring in string using the count() method
- Python find substring in string using the rfind() method
- Python find substring in string using the list comprehension
- Python find substring in string using the re.findall()

Python is one of the most popular languages in the United States of America. I have been working with Python for a long time and I have expertise in working with various libraries on Tkinter, Pandas, NumPy, Turtle, Django, Matplotlib, Tensorflow, Scipy, Scikit-Learn, etc… I have experience in working with various clients in countries like United States, Canada, United Kingdom, Australia, New Zealand, etc. Check out my profile.

When you’re working with a Python program, you might need to search for and locate a specific string inside another string.
This is where Python’s built-in string methods come in handy.
In this article, you will learn how to use Python’s built-in find() string method to help you search for a substring inside a string.
Here is what we will cover:
- Syntax of the
find()method- How to use
find()with no start and end parameters example - How to use
find()with start and end parameters example - Substring not found example
- Is the
find()method case-sensitive?
- How to use
find()vsinkeywordfind()vsindex()
The find() Method — A Syntax Overview
The find() string method is built into Python’s standard library.
It takes a substring as input and finds its index — that is, the position of the substring inside the string you call the method on.
The general syntax for the find() method looks something like this:
string_object.find("substring", start_index_number, end_index_number)
Let’s break it down:
string_objectis the original string you are working with and the string you will call thefind()method on. This could be any word you want to search through.- The
find()method takes three parameters – one required and two optional. "substring"is the first required parameter. This is the substring you are trying to find insidestring_object. Make sure to include quotation marks.start_index_numberis the second parameter and it’s optional. It specifies the starting index and the position from which the search will start. The default value is0.end_index_numberis the third parameter and it’s also optional. It specifies the end index and where the search will stop. The default is the length of the string.- Both the
start_index_numberand theend_index_numberspecify the range over which the search will take place and they narrow the search down to a particular section.
The return value of the find() method is an integer value.
If the substring is present in the string, find() returns the index, or the character position, of the first occurrence of the specified substring from that given string.
If the substring you are searching for is not present in the string, then find() will return -1. It will not throw an exception.
How to Use find() with No Start and End Parameters Example
The following examples illustrate how to use the find() method using the only required parameter – the substring you want to search.
You can take a single word and search to find the index number of a specific letter:
fave_phrase = "Hello world!"
# find the index of the letter 'w'
search_fave_phrase = fave_phrase.find("w")
print(search_fave_phrase)
#output
# 6
I created a variable named fave_phrase and stored the string Hello world!.
I called the find() method on the variable containing the string and searched for the letter ‘w’ inside Hello world!.
I stored the result of the operation in a variable named search_fave_phrase and then printed its contents to the console.
The return value was the index of w which in this case was the integer 6.
Keep in mind that indexing in programming and Computer Science in general always starts at 0 and not 1.
How to Use find() with Start and End Parameters Example
Using the start and end parameters with the find() method lets you limit your search.
For example, if you wanted to find the index of the letter ‘w’ and start the search from position 3 and not earlier, you would do the following:
fave_phrase = "Hello world!"
# find the index of the letter 'w' starting from position 3
search_fave_phrase = fave_phrase.find("w",3)
print(search_fave_phrase)
#output
# 6
Since the search starts at position 3, the return value will be the first instance of the string containing ‘w’ from that position and onwards.
You can also narrow down the search even more and be more specific with your search with the end parameter:
fave_phrase = "Hello world!"
# find the index of the letter 'w' between the positions 3 and 8
search_fave_phrase = fave_phrase.find("w",3,8)
print(search_fave_phrase)
#output
# 6
Substring Not Found Example
As mentioned earlier, if the substring you specify with find() is not present in the string, then the output will be -1 and not an exception.
fave_phrase = "Hello world!"
# search for the index of the letter 'a' in "Hello world"
search_fave_phrase = fave_phrase.find("a")
print(search_fave_phrase)
# -1
Is the find() Method Case-Sensitive?
What happens if you search for a letter in a different case?
fave_phrase = "Hello world!"
#search for the index of the letter 'W' capitalized
search_fave_phrase = fave_phrase.find("W")
print(search_fave_phrase)
#output
# -1
In an earlier example, I searched for the index of the letter w in the phrase «Hello world!» and the find() method returned its position.
In this case, searching for the letter W capitalized returns -1 – meaning the letter is not present in the string.
So, when searching for a substring with the find() method, remember that the search will be case-sensitive.
The find() Method vs the in Keyword – What’s the Difference?
Use the in keyword to check if the substring is present in the string in the first place.
The general syntax for the in keyword is the following:
substring in string
The in keyword returns a Boolean value – a value that is either True or False.
>>> "w" in "Hello world!"
True
The in operator returns True when the substring is present in the string.
And if the substring is not present, it returns False:
>>> "a" in "Hello world!"
False
Using the in keyword is a helpful first step before using the find() method.
You first check to see if a string contains a substring, and then you can use find() to find the position of the substring. That way, you know for sure that the substring is present.
So, use find() to find the index position of a substring inside a string and not to look if the substring is present in the string.
The find() Method vs the index() Method – What’s the Difference?
Similar to the find() method, the index() method is a string method used for finding the index of a substring inside a string.
So, both methods work in the same way.
The difference between the two methods is that the index() method raises an exception when the substring is not present in the string, in contrast to the find() method that returns the -1 value.
fave_phrase = "Hello world!"
# search for the index of the letter 'a' in 'Hello world!'
search_fave_phrase = fave_phrase.index("a")
print(search_fave_phrase)
#output
# Traceback (most recent call last):
# File "/Users/dionysialemonaki/python_article/demopython.py", line 4, in <module>
# search_fave_phrase = fave_phrase.index("a")
# ValueError: substring not found
The example above shows that index() throws a ValueError when the substring is not present.
You may want to use find() over index() when you don’t want to deal with catching and handling any exceptions in your programs.
Conclusion
And there you have it! You now know how to search for a substring in a string using the find() method.
I hope you found this tutorial helpful.
To learn more about the Python programming language, check out freeCodeCamp’s Python certification.
You’ll start from the basics and learn in an interactive and beginner-friendly way. You’ll also build five projects at the end to put into practice and help reinforce your understanding of the concepts you learned.
Thank you for reading, and happy coding!
Happy coding!
Learn to code for free. freeCodeCamp’s open source curriculum has helped more than 40,000 people get jobs as developers. Get started
- Use the
inOperator to Check if a Word Exists in a String in Python - Use the
String.find()Method to Check if a Word Exists in a String in Python - Use the
String.index()Method to Check if a Word Exists in a String in Python - Use the
search()Method to Check if a Word Exists in a String in Python

Suppose there exist a string "The weather is so pleasant today". If we want to check if the word "weather" is present in the string or not, we have multiple ways to find out.
In this guide, we will look at the in operator, string.find() method, string.index() method, and regular expression(RegEx).
Use the in Operator to Check if a Word Exists in a String in Python
One of the easiest ways of searching a word in a string or sequences like list, tuple, or arrays is through the in operator. It returns a boolean value when used in a condition.
It can be either true or false. If the specified word exists, the statement evaluates to true; if the word does not exist, it evaluates to false.
This operator is case-sensitive. If we try to locate the word Fun in the following code, we will obtain the message Fun not found in the output.
Example code:
#Python 3.x
sentence = "Learning Python is fun"
word = "fun"
if word in sentence:
print(word, "found!")
else:
print(word, "not found!")
Output:
If we want to check for a word within a string without worrying about the case, we must convert the main string and the word to search in the lowercase. In the following code, we will check the word Fun.
Example Code:
#Python 3.x
sentence = "Learning Python is fun"
word = "Fun"
if word.lower() in sentence.lower():
print(word, "found!")
else:
print(word, "not found!")
Output
Use the String.find() Method to Check if a Word Exists in a String in Python
We can use the find() method with a string to check for a specific word. If the specified word exists, it will return the word’s left-most or starting index in the main string.
Else, it will simply return the index –1. The find() method also counts the index of spaces. In the following code, we get the output 9 because 9 is the starting index of Python, the index of character P.
This method is also case-sensitive by default. If we check for the word python, it will return -1.
Example Code:
#Python 3.x
string = "Learning Python is fun"
index=string.find("Python")
print(index)
Output:
Use the String.index() Method to Check if a Word Exists in a String in Python
index() is the same as the find() method. This method also returns the lowest index of the substring in the main string.
The only difference is that when the specified word or substring does not exist, the find() method returns the index –1, while the index() method raises an exception (value error exception).
Example Code:
#Python 3.x
mystring = "Learning Python is fun"
print(mystring.index("Python"))
Output:
Now we try to find a word that doesn’t exist in the sentence.
#Python 3.x
mystring = "Learning Python is fun"
print(mystring.index("Java"))
Output:
#Python 3.x
ValueError Traceback (most recent call last)
<ipython-input-12-544a99b6650a> in <module>()
1 mystring = "Learning Python is fun"
----> 2 print(mystring.index("Java"))
ValueError: substring not found
Use the search() Method to Check if a Word Exists in a String in Python
We can check for a specific word through pattern matching of strings through the search() method. This method is available in the re module.
The re here stands for Regular Expression. The search method accepts two arguments.
The first argument is the word to find, and the second one is the entire string. But this method works slower than the other ones.
Example Code:
#Python 3.x
from re import search
sentence = "Learning Python is fun"
word = "Python"
if search(word, sentence):
print(word, "found!")
else:
print(word, "not found!")
Output:
#Python 3.x
Python found!
Checking whether a string contains a substring aids to generalize conditionals and create more flexible code. Additionally, depending on your domain model — checking if a string contains a substring may also allow you to infer fields of an object, if a string encodes a field in itself.
In this guide, we’ll take a look at how to check if a string contains a substring in Python.
The in Operator
The easiest way to check if a Python string contains a substring is to use the in operator.
The in operator is used to check data structures for membership in Python. It returns a Boolean (either True or False). To check if a string contains a substring in Python using the in operator, we simply invoke it on the superstring:
fullstring = "StackAbuse"
substring = "tack"
if substring in fullstring:
print("Found!")
else:
print("Not found!")
This operator is shorthand for calling an object’s __contains__ method, and also works well for checking if an item exists in a list. It’s worth noting that it’s not null-safe, so if our fullstring was pointing to None, an exception would be thrown:
TypeError: argument of type 'NoneType' is not iterable
To avoid this, you’ll first want to check whether it points to None or not:
fullstring = None
substring = "tack"
if fullstring != None and substring in fullstring:
print("Found!")
else:
print("Not found!")
The String.index() Method
The String type in Python has a method called index() that can be used to find the starting index of the first occurrence of a substring in a string.
If the substring is not found, a ValueError exception is thrown, which can be handled with a try-except-else block:
fullstring = "StackAbuse"
substring = "tack"
try:
fullstring.index(substring)
except ValueError:
print("Not found!")
else:
print("Found!")
This method is useful if you also need to know the position of the substring, as opposed to just its existence within the full string. The method itself returns the index:
print(fullstring.index(substring))
# 1
Though — for the sake of checking whether a string contains a substring, this is a verbose approach.
The String.find() Method
The String class has another method called find() which is more convenient to use than index(), mainly because we don’t need to worry about handling any exceptions.
If find() doesn’t find a match, it returns -1, otherwise it returns the left-most index of the substring in the larger string:
Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it!
fullstring = "StackAbuse"
substring = "tack"
if fullstring.find(substring) != -1:
print("Found!")
else:
print("Not found!")
Naturally, it performs the same search as index() and returns the index of the start of the substring within the parent string:
print(fullstring.find(substring))
# 1
Regular Expressions (RegEx)
Regular expressions provide a more flexible (albeit more complex) way to check strings for pattern matching. With Regular Expressions, you can perform flexible and powerful searches through much larger search spaces, rather than simple checks, like previous ones.
Python is shipped with a built-in module for regular expressions, called re. The re module contains a function called search(), which we can use to match a substring pattern:
from re import search
fullstring = "StackAbuse"
substring = "tack"
if search(substring, fullstring):
print "Found!"
else:
print "Not found!"
This method is best if you are needing a more complex matching function, like case insensitive matching, or if you’re dealing with large search spaces. Otherwise the complication and slower speed of regex should be avoided for simple substring matching use-cases.
This article was written by Jacob Stopak, a software consultant and developer with passion for helping others improve their lives through code. Jacob is the creator of Initial Commit — a site dedicated to helping curious developers learn how their favorite programs are coded. Its featured project helps people learn Git at the code level.
Часто нам нужно найти символ в строке python. Для решения этой задачи разработчики используют метод find(). Он помогает найти индекс первого совпадения подстроки в строке. Если символ или подстрока не найдены, find возвращает -1.
Синтаксис
string.find(substring,start,end)Метод find принимает три параметра:
substring(символ/подстрока) — подстрока, которую нужно найти в данной строке.start(необязательный) — первый индекс, с которого нужно начинать поиск. По умолчанию значение равно 0.end(необязательный) — индекс, на котором нужно закончить поиск. По умолчанию равно длине строки.
Параметры, которые передаются в метод, — это подстрока, которую требуются найти, индекс начала и конца поиска. Значение по умолчанию для начала поиска — 0, а для конца — длина строки.
В этом примере используем метод со значениями по умолчанию.
Метод find() будет искать символ и вернет положение первого совпадения. Даже если символ встречается несколько раз, то метод вернет только положение первого совпадения.
>>> string = "Добро пожаловать!"
>>> print("Индекс первой буквы 'о':", string.find("о"))
Индекс первой буквы 'о': 1
Поиск не с начала строки с аргументом start
Можно искать подстроку, указав также начальное положение поиска.
В этом примере обозначим стартовое положение значением 8 и метод начнет искать с символа с индексом 8. Последним положением будет длина строки — таким образом метод выполнит поиска с индекса 8 до окончания строки.
>>> string = "Специалисты назвали плюсы и минусы Python"
>>> print("Индекс подстроки 'али' без учета первых 8 символов:", string.find("али", 8))
Индекс подстроки 'али' без учета первых 8 символов: 16
Поиск символа в подстроке со start и end
С помощью обоих аргументов (start и end) можно ограничить поиск и не проводить его по всей строке. Найдем индексы слова «пожаловать» и повторим поиск по букве «о».
>>> string = "Добро пожаловать!"
>>> start = string.find("п")
>>> end = string.find("ь") + 1
>>> print("Индекс первой буквы 'о' в подстроке:", string.find("о", start, end))
Индекс первой буквы 'о' в подстроке: 7
Проверка есть ли символ в строке
Мы знаем, что метод find() позволяет найти индекс первого совпадения подстроки. Он возвращает -1 в том случае, если подстрока не была найдена.
>>> string = "Добро пожаловать!"
>>> print("Есть буква 'г'?", string.find("г") != -1)
Есть буква 'г'? False
>>> print("Есть буква 'т'?", string.find("т") != -1)
Есть буква 'т'? True
Поиск последнего вхождения символа в строку
Функция rfind() напоминает find(), а единое отличие в том, что она возвращает максимальный индекс. В обоих случаях же вернется -1, если подстрока не была найдена.
В следующем примере есть строка «Добро пожаловать!». Попробуем найти в ней символ «о» с помощью методов find() и rfind().
>>> string = "Добро пожаловать"
>>> print("Поиск 'о' методом find:", string.find("о"))
Поиск 'о' методом find: 1
>>> print("Поиск 'о' методом rfind:", string.rfind("о"))
Поиск 'о' методом rfind: 11
Вывод показывает, что find() возвращает индекс первого совпадения подстроки, а rfind() — последнего совпадения.
Второй способ поиска — index()
Метод index() помогает найти положение данной подстроки по аналогии с find(). Единственное отличие в том, что index() бросит исключение в том случае, если подстрока не будет найдена, а find() просто вернет -1.
Вот рабочий пример, показывающий разницу в поведении index() и find():
>>> string = "Добро пожаловать"
>>> print("Поиск 'о' методом find:", string.find("о"))
Поиск 'о' методом find: 1
>>> print("Поиск 'о' методом index:", string.index("о"))
Поиск 'о' методом index: 1
В обоих случаях возвращается одна и та же позиция. А теперь попробуем с подстрокой, которой нет в строке:
>>> string = "Добро пожаловать"
>>> print("Поиск 'г' методом find:", string.find("г"))
Поиск 'г' методом find: 1
>>> print("Поиск 'г' методом index:", string.index("г"))
Traceback (most recent call last):
File "pyshell#21", line 1, in module
print("Поиск 'г' методом index:", string.index("г"))
ValueError: substring not found
В этом примере мы пытались найти подстроку «г». Ее там нет, поэтому find() возвращает -1, а index() бросает исключение.
Поиск всех вхождений символа в строку
Чтобы найти общее количество совпадений подстроки в строке можно использовать ту же функцию find(). Пройдемся циклом while по строке и будем задействовать параметр start из метода find().
Изначально переменная start будет равна -1, что бы прибавлять 1 у каждому новому поиску и начать с 0. Внутри цикла проверяем, присутствует ли подстрока в строке с помощью метода find.
Если вернувшееся значение не равно -1, то обновляем значением count.
Вот рабочий пример:
my_string = "Добро пожаловать"
start = -1
count = 0
while True:
start = my_string.find("о", start+1)
if start == -1:
break
count += 1
print("Количество вхождений символа в строку: ", count )
Количество вхождений символа в строку: 4Выводы
- Метод
find()помогает найти индекс первого совпадения подстроки в данной строке. Возвращает -1, если подстрока не была найдена. - В метод передаются три параметра: подстрока, которую нужно найти,
startсо значением по умолчанию равным 0 иendсо значением по умолчанию равным длине строки. - Можно искать подстроку в данной строке, задав начальное положение, с которого следует начинать поиск.
- С помощью параметров
startиendможно ограничить зону поиска, чтобы не выполнять его по всей строке. - Функция
rfind()повторяет возможностиfind(), но возвращает максимальный индекс (то есть, место последнего совпадения). В обоих случаях возвращается -1, если подстрока не была найдена. index()— еще одна функция, которая возвращает положение подстроки. Отличие лишь в том, чтоindex()бросает исключение, если подстрока не была найдена, аfind()возвращает -1.find()можно использовать в том числе и для поиска общего числа совпадений подстроки.
Knowing how to check if a Python string contains a substring is a very common thing we do in our programs.
In how many ways can you do this check?
Python provides multiple ways to check if a string contains a substring. Some ways are: the in operator, the index method, the find method, the use of a regular expressions.
In this tutorial you will learn multiple ways to find out if a substring is part of a string. This will also give you the understanding of how to solve the same problem in multiple ways using Python.
Let’s get started!
The first option available in Python is the in operator.
>>> 'This' in 'This is a string'
True
>>> 'this' in 'This is a string'
False
>>> As you can see the in operator returns True if the string on its left is part of the string on its right. Otherwise it returns False.
This expression can be used as part of an if else statement:
>>> if 'This' in 'This is a string':
... print('Substring found')
... else:
... print('Substring not found')
...
Substring foundTo reverse the logic of this if else statement you can add the not operator.
>>> if 'This' not in 'This is a string':
... print('Substring not found')
... else:
... print('Substring found')
...
Substring foundYou can also use the in operator to check if a Python list contains a specific item.
Index Method For Python Strings
I want to see how else I can find out if a substring is part of a string in Python.
One way to do that is by looking at the methods available for string data types in Python using the following command in the Python shell:
>>> help(str)In the output of the help command you will see that one of the methods we can use to find out if a substring is part of a string is the index method.

The string index method in Python returns the index in our string where the substring is found, otherwise it raises a ValueError exception
Let’s see an example:
>>> 'This is a string'.index('This')
0
>>> 'This is a string'.index('is a')
5
>>> 'This is a string'.index('not present')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: substring not foundIn the first example the index method returns 0 because the string ‘This’ is found at index zero of our string.
The second example returns 5 because that’s where the string ‘is a’ is found (considering that we start counting indexes from zero).
In the third example the Python interpreter raises a ValueError exception because the string ‘not present’ is not found in our string.
The advantage of this method over the in operator is that the index method not only tells us that a substring is part of a string. It also tells us at which index the substring starts.
Find Method For Python Strings
While looking at the help page for strings in Python I can see another method available that seems to be similar to the index method. It’s the find method.
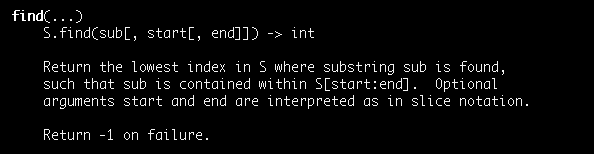
The string find method in Python returns the index at which a substring is found in a string. It returns -1 if the substring is not found.
Let’s run the same three examples we have used to show the index method:
>>> 'This is a string'.find('This')
0
>>> 'This is a string'.find('is a')
5
>>> 'This is a string'.find('not present')
-1As you can see the output of the first two examples is identical. The only one that changes is the third example for a substring that is not present in our string.
In this scenario the find method returns -1 instead of raising a ValueError exception like the index method does.
The find method is easier to use than the index method because with it we don’t have to handle exceptions in case a substring is not part of a string.
Python String __contains__ Method
I wonder how the in operator works behind the scenes, to understand that let’s start by creating a new string and by looking at its attributes and methods using the dir function:
>>> test_string = 'This is a string'
>>> dir(test_string)
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']I want to focus your attention on the __contains__ method.
Let’s see if we can use it to check if a substring is part of a string:
>>> test_string.__contains__('This')
True
>>> test_string.__contains__('this')
FalseIt works in the same way the in operator does.
So, what’s the difference between the two?
Considering that the method name starts with double underscore “__”, the method should be considered “private” and we shouldn’t call it directly.
The __contains__ method is called indirectly when you use the in operator.
It’s something handy to know! 🙂
Search For Substring in a Python String Using a Regular Expression
If we go back to the in operator I want to verify how the operator behaves if I want to perform a case insensitive check.
>>> 'this' in 'This is a string'
FalseThis time the in operator returns False because the substring ‘this’ (starting with lower case t) is not part of our string.
But what if I want to know if a substring is part of a string no matter if it’s lower or upper case?
How can I do that?
I could still use the in operator together with a logical or:
>>> 'This' in 'This is a string' or 'this' in 'This is a string'
TrueAs you can see the expression works but it can become quite long and difficult to read.
Imagine if you want to match ‘This’, ‘this’, ‘THIS’…etc..basically all the combinations of lower and uppercase letters. It would be a nightmare!
An alternative is provided by the Python built-in module re (for regular expressions) that can be used to find out if a specific pattern is included in a string.
The re module provides a function called search that can help us in this case…
Let’s import the re module and look at the help for the search function:
>>> import re
>>> help(re.search)
Using the search function our initial example becomes:
>>> import re
>>> re.search('This', 'This is a string')
<re.Match object; span=(0, 4), match='This'>We get back a re.Match object?!?
What can we do with it? Let’s try to convert it into a boolean…
>>> bool(re.search('This', 'This is a string'))
True
>>> bool(re.search('Thiz', 'This is a string'))
FalseYou can see that we get True and False results in line with the search we are doing. The re.search function is doing what we expect.
Let’s see if I can use this expression as part of an if else statement:
>>> if re.search('This', 'This is a string'):
... print('Substring found')
... else:
... print('Substring not found')
...
Substring found
>>>
>>> if re.search('Thiz', 'This is a string'):
... print('Substring found')
... else:
... print('Substring not found')
...
Substring not foundIt works with an if else statement too. Good to know 🙂
Insensitive Search For Substring in a Python String
But what about the insensitive check we were talking about before?
Try to run the following…
>>> re.search('this', 'This is a string')…you will see that it doesn’t return any object. In other words the substring ‘this’ is not found in our string.
We have the option to pass an additional argument to the search function, a flag to force a case insensitive check (have a look at the help for the search function above, it’s right there).
The name of the flag for case insensitive matching is re.IGNORECASE.
>>> re.search('this', 'This is a string', re.IGNORECASE)
<re.Match object; span=(0, 4), match='This'>This time we get an object back. Nice!
Check If a Python String Contains Multiple Substrings
It’s very common having to check if a string contains multiple substrings.
Imagine you have a document and you want to confirm, given a list of words, which ones are part of the document.
In this example we are using a short string but imagine the string being a document of any length.
document = "The Python programming language was created by Guido van Rossum"
words = ["Python", "Rossum", "substring"]We want to find out which elements of the list words are inside the string document.
Let’s start with the most obvious implementation using a for loop:
words_found = []
for word in words:
if word in document:
words_found.append(word)Here is the content of the list words_found:
>>> words_found
['Python', 'Rossum']But, what happens if the list words contains duplicates?
words = ["Python", "Rossum", "substring", "Python"]In this case the list words_found contains duplicates too:
>>> words_found
['Python', 'Rossum', 'Python']To eliminate duplicates from the list of substrings found in the document string, we can add a condition to the if statement that checks if a word is already in the list words_found before adding it to it:
words_found = []
for word in words:
if word in document and word not in words_found:
words_found.append(word)This time the output is the following (it doesn’t contain any duplicates):
>>> words_found
['Python', 'Rossum']Checking For Multiple Substrings in a String Using a List or Set Comprehension
How can we do the same check implemented in the previous section but using more concise code?
One great option that Python provides are list comprehensions.
I can find out which words are part of my document using the following expression:
>>> words_found = [word for word in words if word in document]
>>> words_found
['Python', 'Rossum', 'Python']That’s pretty cool!
A single line to do that same thing we have done before with four lines.
Wondering how we can remove duplicates also in this case?
I could convert the list returned by the list comprehension into a set that by definition has unique elements:
>>> words_found = set([word for word in words if word in document])
>>> words_found
{'Rossum', 'Python'}Also, in case you are not aware, Python provides set comprehensions. Their syntax is the same as list comprehensions with the difference that square brackets are replaced by curly brackets:
>>> words_found = {word for word in words if word in document}
>>> words_found
{'Rossum', 'Python'}Makes sense?
Check If a String Contains Any or All Elements in a List
Now, let’s say we only want to know if any of the elements in the list words is inside the string document.
To do that we can use the any() function.
The any() function is applicable to iterables. It returns True if any of the items in the iterable is True, otherwise it returns False. It also returns False if the iterable is empty.
Once again, here are the variables we are using in this example:
document = "The Python programming language was created by Guido van Rossum"
words = ["Python", "Rossum", "substring"]In the previous section we have used the following list comprehension that returns the words inside our string:
words_found = [word for word in words if word in document]Now, we will do something slightly different. I want to know if each word in the words list is in the document string or not.
Basically I want as a result a list that contains True or False and that tells us if a specific word is in the string document or not.
To do that we can change our list comprehension…
…this time we want a list comprehension with boolean elements:
>>> [word in document for word in words]
[True, True, False]The first two items of the list returned by the list comprehension are True because the words “Python” and “Rossum” are in the string document.
Based on the same logic, do you see why the third item is False?
Now I can apply the any function to the output of our list comprehension to check if at least one of the words is inside our string:
>>> any([word in document for word in words])
TrueAs expected the result is True (based on the definition of the any function I have given at the beginning of this section).
Before moving to the next section I want to quickly cover the all() function.
The all() function is applicable to iterables. It returns True if all the items in the iterable are True, otherwise it returns False. It also returns True if the iterable is empty.
If we apply the all() function to our previous list comprehension we expect False as result considering that one of the three items in the list is False:
>>> all([word in document for word in words])
FalseAll clear?
Identify Multiple String Matches with a Regular Expression
We can also verify if substrings in a list are part of a string using a regular expression.
This approach is not simpler than other approaches we have seen so far. But, at the same time, it’s another tool that you can add to your Python knowledge.
As explained before to use regular expressions in our Python program we have to import the re module.
The findall() function, part of the re module, returns matches of a specific pattern in a string as a list of strings.
In this case the list of strings returned will contain the words found in the string document.
import re
document = "The Python programming language was created by Guido van Rossum"
words = ["Python", "Rossum", "substring"]
re.findall('Python|Rossum|substring', document, re.IGNORECASE)As you can see we have used the or logical expression to match any of the items in the list words.
The output is:
['Python', 'Rossum']But imagine if the list words contained hundreds of items. It would be impossible to specify each one of them in the regular expression.
So, what can we do instead?
We can use the following expression, simplified due to the string join() method.
>>> re.findall('|'.join(words), document, re.IGNORECASE)
['Python', 'Rossum']And here is the final version of our program that applies the any() function to the output of the re.findall function.
import re
document = "The Python programming language was created by Guido van Rossum"
words = ["Python", "Rossum", "substring"]
if any(re.findall('|'.join(words), document, re.IGNORECASE)):
print("Match found")
else:
print("No match found")
Find the First Match in a String From a Python List
Before completing this tutorial I will show you how, given a list of words, you can find out the first match in a string.
Let’s go back to the following list comprehension:
[word for word in words if word in document]A simple way to find out the first match is by using the Python next() function.
The Python next() function returns the next item in an iterator. It also allows to provide a default value returned when the end of the iterator is reached.
Let’s apply the next function multiple times to our list comprehension to see what we get back:
>>> next([word for word in words if word in document])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'list' object is not an iteratorInteresting, we are seeing a TypeError exception being raised by the Python interpreter.
Do you know why?
The answer is in the error…
A list comprehension returns a list, and a list is not an iterator. And as I said before the next() function can only be applied to an iterator.
In Python you can define an iterator using parentheses instead of square brackets:
>>> (word for word in words if word in document)
<generator object <genexpr> at 0x10c3e8450>Let’s apply the next() function multiple times to the iterator, to understand what this function returns:
>>> matches = (word for word in words if word in document)
>>> next(matches)
'Python'
>>> next(matches)
'Rossum'
>>> next(matches)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIterationAs explained at the beginning of this section we can also provide a default value that is returned when we reach the end of the iterator.
>>> matches = (word for word in words if word in document)
>>> next(matches, "No more elements")
'Python'
>>> next(matches, "No more elements")
'Rossum'
>>> next(matches, "No more elements")
'No more elements'Going back to what we wanted to achieve at the beginning of this section…
Here is how we can get the first match in our string document:
document = "The Python programming language was created by Guido van Rossum"
words = ["Python", "Rossum", "substring"]
first_match = next((word for word in words if word in document), "No more elements")
print(first_match)Conclusion
We have started by looking at three different ways to check if a substring is part of a string:
- Using the in operator that returns a boolean to say if the substring is present in the string.
- With the index method that returns the index at which the substring is found or raises a ValueError if the substring is not in the string.
- Using the find method that behaves like the index method with the only difference that it returns -1 if the substring is not part of the string.
You have also seen how to find out if a string contains multiple substrings using few different techniques based on list comprehensions, set comprehensions, any() / all() functions and regular expressions.
And now that you have seen all these alternatives you have…
…which one is your favourite? 🙂

I’m a Software Engineer and Programming Coach. I want to help you in your journey to become a Super Developer!