
 Одной из самых трудоемких и неприятных задач при работе с текстом в Excel является парсинг — разбор буквенно-цифровой «каши» на составляющие и извлечение из нее нужных нам фрагментов. Например:
Одной из самых трудоемких и неприятных задач при работе с текстом в Excel является парсинг — разбор буквенно-цифровой «каши» на составляющие и извлечение из нее нужных нам фрагментов. Например:
- извлечение почтового индекса из адреса (хорошо, если индекс всегда в начале, а если нет?)
- нахождение номера и даты счета из описания платежа в банковской выписке
- извлечение ИНН из разношерстных описаний компаний в списке контрагентов
- поиск номера автомобиля или артикула товара в описании и т.д.
Обычно во подобных случаях, после получасового муторного ковыряния в тексте вручную, в голову начинают приходить мысли как-то автоматизировать этот процесс (особенно если данных много). Решений тут несколько и с разной степенью сложности-эффективности:
- Использовать встроенные текстовые функции Excel для поиска-нарезки-склейки текста: ЛЕВСИМВ (LEFT), ПРАВСИМВ (RIGHT), ПСТР (MID), СЦЕПИТЬ (CONCATENATE) и ее аналоги, ОБЪЕДИНИТЬ (JOINTEXT), СОВПАД (EXACT) и т.д. Этот способ хорош, если в тексте есть четкая логика (например, индекс всегда в начале адреса). В противном случае формулы существенно усложняются и, порой, дело доходит даже до формул массива, что сильно тормозит на больших таблицах.
- Использование оператора проверки текстового подобия Like из Visual Basic, обернутого в пользовательскую макро-функцию. Это позволяет реализовать более гибкий поиск с использованием символов подстановки (*,#,? и т.д.) К сожалению, этот инструмент не умеет извлекать нужную подстроку из текста — только проверять, содержится ли она в нем.
Кроме вышеперечисленного, есть еще один подход, очень известный в узких кругах профессиональных программистов, веб-разработчиков и прочих технарей — это регулярные выражения (Regular Expressions = RegExp = «регэкспы» = «регулярки»). Упрощенно говоря, RegExp — это язык, где с помощью специальных символов и правил производится поиск нужных подстрок в тексте, их извлечение или замена на другой текст. Регулярные выражения — это очень мощный и красивый инструмент, на порядок превосходящий по возможностям все остальные способы работы с текстом. Многие языки программирования (C#, PHP, Perl, JavaScript…) и текстовые редакторы (Word, Notepad++…) поддерживают регулярные выражения.
Microsoft Excel, к сожалению, не имеет поддержки RegExp по-умолчанию «из коробки», но это легко исправить с помощью VBA. Откройте редактор Visual Basic с вкладки Разработчик (Developer) или сочетанием клавиш Alt+F11. Затем вставьте новый модуль через меню Insert — Module и скопируйте туда текст вот такой макрофункции:
Public Function RegExpExtract(Text As String, Pattern As String, Optional Item As Integer = 1) As String
On Error GoTo ErrHandl
Set regex = CreateObject("VBScript.RegExp")
regex.Pattern = Pattern
regex.Global = True
If regex.Test(Text) Then
Set matches = regex.Execute(Text)
RegExpExtract = matches.Item(Item - 1)
Exit Function
End If
ErrHandl:
RegExpExtract = CVErr(xlErrValue)
End Function
Теперь можно закрыть редактор Visual Basic и, вернувшись в Excel, опробовать нашу новую функцию. Синтаксис у нее следующий:
=RegExpExtract( Txt ; Pattern ; Item )
где
- Txt — ячейка с текстом, который мы проверяем и из которого хотим извлечь нужную нам подстроку
- Pattern — маска (шаблон) для поиска подстроки
- Item — порядковый номер подстроки, которую надо извлечь, если их несколько (если не указан, то выводится первое вхождение)
Самое интересное тут, конечно, это Pattern — строка-шаблон из спецсимволов «на языке» RegExp, которая и задает, что именно и где мы хотим найти. Вот самые основные из них — для начала:
| Паттерн | Описание |
| . | Самое простое — это точка. Она обозначает любой символ в шаблоне на указанной позиции. |
| s | Любой символ, выглядящий как пробел (пробел, табуляция или перенос строки). |
| S | Анти-вариант предыдущего шаблона, т.е. любой НЕпробельный символ. |
| d | Любая цифра |
| D | Анти-вариант предыдущего, т.е. любая НЕ цифра |
| w | Любой символ латиницы (A-Z), цифра или знак подчеркивания |
| W | Анти-вариант предыдущего, т.е. не латиница, не цифра и не подчеркивание. |
| [символы] |
В квадратных скобках можно указать один или несколько символов, разрешенных на указанной позиции в тексте. Например ст[уо]л будет соответствовать любому из слов: стол или стул. Также можно не перечислять символы, а задать их диапазоном через дефис, т.е. вместо [ABDCDEF] написать [A-F]. или вместо [4567] ввести [4-7]. Например, для обозначения всех символов кириллицы можно использовать шаблон [а-яА-ЯёЁ]. |
| [^символы] | Если после открывающей квадратной скобки добавить символ «крышки» ^, то набор приобретет обратный смысл — на указанной позиции в тексте будут разрешены все символы, кроме перечисленных. Так, шаблон [^ЖМ]уть найдет Путь или Суть или Забудь, но не Жуть или Муть, например. |
| | | Логический оператор ИЛИ (OR) для проверки по любому из указанных критериев. Например (счет|счёт|invoice) будет искать в тексте любое из указанных слов. Обычно набор вариантов заключается в скобки. |
| ^ | Начало строки |
| $ | Конец строки |
| b | Край слова |
Если мы ищем определенное количество символов, например, шестизначный почтовый индекс или все трехбуквенные коды товаров, то на помощь нам приходят квантификаторы или кванторы — специальные выражения, задающие количество искомых знаков. Квантификаторы применяются к тому символу, что стоит перед ним:
| Квантор | Описание |
| ? | Ноль или одно вхождение. Например .? будет означать один любой символ или его отсутствие. |
| + | Одно или более вхождений. Например d+ означает любое количество цифр (т.е. любое число от 0 до бесконечности). |
| * | Ноль или более вхождений, т.е. любое количество. Так s* означает любое количество пробелов или их отсутствие. |
|
{число} или {число1,число2} |
Если нужно задать строго определенное количество вхождений, то оно задается в фигурных скобках. Например d{6} означает строго шесть цифр, а шаблон s{2,5} — от двух до пяти пробелов |
Теперь давайте перейдем к самому интересному — разбору применения созданной функции и того, что узнали о паттернах на практических примерах из жизни.
Извлекаем числа из текста
Для начала разберем простой случай — нужно извлечь из буквенно-цифровой каши первое число, например мощность источников бесперебойного питания из прайс-листа:

Логика работы регулярного выражения тут простая: d — означает любую цифру, а квантор + говорит о том, что их количество должно быть одна или больше. Двойной минус перед функцией нужен, чтобы «на лету» преобразовать извлеченные символы в полноценное число из числа-как-текст.
Почтовый индекс
На первый взгляд, тут все просто — ищем ровно шесть цифр подряд. Используем спецсимвол d для цифры и квантор {6} для количества знаков:

Однако, возможна ситуация, когда левее индекса в строке стоит еще один большой набор цифр подряд (номер телефона, ИНН, банковский счет и т.д.) Тогда наша регулярка выдернет из нее первых 6 цифр, т.е. сработает некорректно:

Чтобы этого не происходило, необходимо добавить в наше регулярное выражение по краям модификатор b означающий конец слова. Это даст понять Excel, что нужный нам фрагмент (индекс) должен быть отдельным словом, а не частью другого фрагмента (номера телефона):

Телефон
Проблема с нахождением телефонного номера среди текста состоит в том, что существует очень много вариантов записи номеров — с дефисами и без, через пробелы, с кодом региона в скобках или без и т.д. Поэтому, на мой взгляд, проще сначала вычистить из исходного текста все эти символы с помощью нескольких вложенных друг в друга функций ПОДСТАВИТЬ (SUBSTITUTE), чтобы он склеился в единое целое, а потом уже примитивной регуляркой d{11} вытаскивать 11 цифр подряд:

ИНН
Тут чуть сложнее, т.к. ИНН (в России) бывает 10-значный (у юрлиц) или 12-значный (у физлиц). Если не придираться особо, то вполне можно удовлетвориться регуляркой d{10,12}, но она, строго говоря, будет вытаскивать все числа от 10 до 12 знаков, т.е. и ошибочно введенные 11-значные. Правильнее будет использовать два шаблона, связанных логическим ИЛИ оператором | (вертикальная черта):

Обратите внимание, что в запросе мы сначала ищем 12-разрядные, и только потом 10-разрядные числа. Если же записать нашу регулярку наоборот, то она будет вытаскивать для всех, даже длинных 12-разрядных ИНН, только первые 10 символов. То есть после срабатывания первого условия дальнейшая проверка уже не производится:

Это принципиальное отличие оператора | от стандартной экселевской логической функции ИЛИ (OR), где от перестановки аргументов результат не меняется.
Артикулы товаров
Во многих компаниях товарам и услугам присваиваются уникальные идентификаторы — артикулы, SAP-коды, SKU и т.д. Если в их обозначениях есть логика, то их можно легко вытаскивать из любого текста с помощью регулярных выражений. Например, если мы знаем, что наши артикулы всегда состоят из трех заглавных английских букв, дефиса и последующего трехразрядного числа, то:

Логика работы шаблона тут проста. [A-Z] — означает любые заглавные буквы латиницы. Следующий за ним квантор {3} говорит о том, что нам важно, чтобы таких букв было именно три. После дефиса мы ждем три цифровых разряда, поэтому добавляем на конце d{3}
Денежные суммы
Похожим на предыдущий пункт образом, можно вытаскивать и цены (стоимости, НДС…) из описания товаров. Если денежные суммы, например, указываются через дефис, то:
 из текста")
Паттерн d с квантором + ищет любое число до дефиса, а d{2} будет искать копейки (два разряда) после.
Если нужно вытащить не цены, а НДС, то можно воспользоваться третьим необязательным аргументом нашей функции RegExpExtract, задающим порядковый номер извлекаемого элемента. И, само-собой, можно заменить функцией ПОДСТАВИТЬ (SUBSTITUTE) в результатах дефис на стандартный десятичный разделитель и добавить двойной минус в начале, чтобы Excel интерпретировал найденный НДС как нормальное число:

Автомобильные номера
Если не брать спецтранспорт, прицепы и прочие мотоциклы, то стандартный российский автомобильный номер разбирается по принципу «буква — три цифры — две буквы — код региона». Причем код региона может быть 2- или 3-значным, а в качестве букв применяются только те, что похожи внешне на латиницу. Таким образом, для извлечения номеров из текста нам поможет следующая регулярка:

Время
Для извлечения времени в формате ЧЧ:ММ подойдет такое регулярное выражение:

После двоеточия фрагмент [0-5]d, как легко сообразить, задает любое число в интервале 00-59. Перед двоеточием в скобках работают два шаблона, разделенных логическим ИЛИ (вертикальной чертой):
- [0-1]d — любое число в интервале 00-19
- 2[0-3] — любое число в интервале 20-23
К полученному результату можно применить дополнительно еще и стандартную Excel’евскую функцию ВРЕМЯ (TIME), чтобы преобразовать его в понятный программе и пригодный для дальнейших расчетов формат времени.
Проверка пароля
Предположим, что нам надо проверить список придуманных пользователями паролей на корректность. По нашим правилам, в паролях могут быть только английские буквы (строчные или прописные) и цифры. Пробелы, подчеркивания и другие знаки препинания не допускаются.
Проверку можно организовать с помощью вот такой несложной регулярки:

По сути, таким шаблоном мы требуем, чтобы между началом (^) и концом ($) в нашем тексте находились только символы из заданного в квадратных скобках набора. Если нужно проверить еще и длину пароля (например, не меньше 6 символов), то квантор + можно заменить на интервал «шесть и более» в виде {6,}:

Город из адреса
Допустим, нам нужно вытащить город из строки адреса. Поможет регулярка, извлекающая текст от «г.» до следующей запятой:

Давайте разберем этот шаблон поподробнее.
Если вы прочитали текст выше, то уже поняли, что некоторые символы в регулярных выражениях (точки, звездочки, знаки доллара и т.д.) несут особый смысл. Если же нужно искать сами эти символы, то перед ними ставится обратная косая черта (иногда это называют экранированием). Поэтому при поиске фрагмента «г.» мы должны написать в регулярке г. если ищем плюсик, то + и т.д.
Следующих два символа в нашем шаблоне — точка и звездочка-квантор — обозначают любое количество любых символов, т.е. любое название города.
На конце шаблона стоит запятая, т.к. мы ищем текст от «г.» до запятой. Но ведь в тексте может быть несколько запятых, правда? Не только после города, но и после улицы, дома и т.д. На какой из них будет останавливаться наш запрос? Вот за это отвечает вопросительный знак. Без него наша регулярка вытаскивала бы максимально длинную строку из всех возможных:

В терминах регулярных выражений, такой шаблон является «жадным». Чтобы исправить ситуацию и нужен вопросительный знак — он делает квантор, после которого стоит, «скупым» — и наш запрос берет текст только до первой встречной запятой после «г.»:

Имя файла из полного пути
Еще одна весьма распространенная ситуация — вытащить имя файла из полного пути. Тут поможет простая регулярка вида:

Тут фишка в том, что поиск, по сути, происходит в обратном направлении — от конца к началу, т.к. в конце нашего шаблона стоит $, и мы ищем все, что перед ним до первого справа обратного слэша. Бэкслэш заэкранирован, как и точка в предыдущем примере.
P.S.
«Под занавес» хочу уточнить, что все вышеописанное — это малая часть из всех возможностей, которые предоставляют регулярные выражения. Спецсимволов и правил их использования очень много и на эту тему написаны целые книги (рекомендую для начала хотя бы эту). В некотором смысле, написание регулярных выражений — это почти искусство. Почти всегда придуманную регулярку можно улучшить или дополнить, сделав ее более изящной или способным работать с более широким диапазоном вариантов входных данных.
Для анализа и разбора чужих регулярок или отладки своих собственных есть несколько удобных онлайн-сервисов: RegEx101, RegExr и др.
К сожалению, не все возможности классических регулярных выражений поддерживаются в VBA (например, обратный поиск или POSIX-классы) и умеют работать с кириллицей, но и того, что есть, думаю, хватит на первое время, чтобы вас порадовать.
Если же вы не новичок в теме, и вам есть чем поделиться — оставляйте полезные при работе в Excel регулярки в комментариях ниже. Один ум хорошо, а два сапога — пара!
Ссылки по теме
- Замена и зачистка текста функцией ПОДСТАВИТЬ (SUBSTITUTE)
- Поиск и подсветка символов латиницы в русском тексте
- Поиск ближайшего похожего текста (Иванов = Ивонов = Иваноф и т.д.)
- Функции регулярных выражений в Excel
- Примеры задач, решаемых с помощью регулярных выражений
- Извлечение данных из ячеек с помощью RegEx
- Извлечь из ячейки содержимое до / после первой цифры включительно
- «Вытянуть» цифры из ячеек
- Извлечь из ячейки числа из N цифр
- Извлечь латиницу регулярным выражением
- Извлечь символы в конце/начале строк по условию
- Проверить ячейки на соответствие регулярному выражению
- Найти в ячейке числа из N цифр
- Найти ячейки, начинающиеся с цифр
- Замена подстрок по регулярному выражению
- Разбить ячейку по буквам
- Разбить буквы и цифры в ячейке
- Вставить текст после первого слова
- Вставить символ после каждого слова или перед ним
- Регулярные выражения для поиска конкретных слов в !SEMTools
- Найти слова по регулярному выражению
- Извлечь слова по регулярному выражению
- Удалить слова по регулярному выражению
- Очистить ячейки, не соответствующие регулярному выражению
Многие слышали, что такое регулярные выражения, но не всем известно, что они поддерживаются “под капотом” Microsoft Excel. Регулярные выражения дают возможность многократно ускорить работу с текстом, находить в нем самые замысловатые паттерны и решать самые сложные исследовательские задачи. Единственная проблема в том, что для их использования в Excel необходимо знание VBA.
Почему Microsoft не включила их как функции листа и включит ли когда-нибудь, непонятно и неизвестно.
Но с надстройкой !SEMTools эти знания не нужны. Зато минимальное понимание синтаксиса регулярок позволит с легкостью решать задачи, решение которых практически невозможно с помощью стандартных функций, либо для этого требуются формулы огромной длины. Примеры таких мегаформул можно посмотреть в решении задач:
- найти английские буквы в Excel,
- найти числа в тексте.
Для поддержки регулярных выражений при наличии подключенной надстройки !SEMTools в Excel будут работать три функции: REGEXMATCH, REGEXEXTRACT и REGEXREPLACE.
Их синтаксис и принцип работы аналогичен синтаксису Google Spreadsheets. Поэтому формулы, составленные в Excel, будут иметь полную зеркальную совместимость с Google Spreadsheets.
=REGEXMATCH("текст";"RegEx-паттерн для поиска")
REGEXMATCH возвращает ИСТИНА или ЛОЖЬ (TRUE или FALSE в английской версии Excel), в зависимости от того, соответствует текст паттерну или нет.
=REGEXEXTRACT("текст";"RegEx-паттерн для поиска")
REGEXEXTRACT извлекает первый попадающий под паттерн фрагмент текста. Небольшое отличие от Google Spreadsheets заключается в том, что, если в искомом тексте такого фрагмента нет, Spreadsheets отдают ошибку, а в надстройке отдается пустая строка.
=REGEXREPLACE("текст";"RegEx-паттерн для поиска";"текст, которым заменяем найденное")
Примеры задач, решаемых с помощью регулярных выражений
Я не поскуплюсь на примеры, чтобы показать вам все возможности регулярных выражений, так как они действительно огромны. Надеюсь, эта статья послужит руководством и стимулом активнее пользоваться их мощью. От простого к сложному.
Чтобы дать обычным пользователям Excel возможность максимально широко использовать возможности регулярных выражений, в надстройку !SEMTools был добавлен ряд быстрых процедур. Все примеры ниже будут показаны с их использованием.
Извлечение данных из ячеек с помощью RegEx
Извлечь из ячейки содержимое до / после первой цифры включительно
Такие простые два выражения. «+» — это служебный символ-квантификатор. Он обеспечивает «жадный» режим, при котором берутся все удовлетворяющие выражению символы до тех пор, пока на пути не встретится не удовлетворяющий ему или наступит конец/начало строки. Точка обозначает любой символ. Таким образом, берутся любые символы до конца строки, перед которыми есть цифра.
«d» обозначает «digits», иначе цифры. Поскольку квантификатора после “d” в примерах выше нет, то одну цифру. Если потребуется исключить из результатов эту цифру, это можно сделать позднее. В !SEMTools есть простые способы удалить символы в начале или конце ячейки.
Цифры можно выразить и другим регулярным выражением:
«Вытянуть» цифры из ячеек
Как извлечь из строки цифры? Регулярное выражение для такой операции будет безумно простым:
В зависимости от режима извлечения результатом будет либо первая, либо все цифры в ячейке.
Если их нужно вывести не сплошной последовательностью, а через разделитель, сохранив фрагменты, где символы следуют друг за другом, выражение будет чуть иным, с «жадным» квантификатором. А при извлечении нужно будет использовать разделитель.
Это справедливо и для любых других символов, пример с числами ниже:

Извлечь из ячейки числа из N цифр
Как видно в примере выше, помимо чисел, обозначающих годы, были извлечены и другие числа, например, «1». Чтобы извлечь исключительно последовательности из четырех цифр, потребуется видоизменить выражение. Есть несколько вариантов:
Последние два варианта включают квантификатор фигурные скобки. Он указывает минимальное количество повторений удовлетворяющего паттерну символа или фрагмента строки. Паттерну, стоящему непосредственно перед квантификатором. В данном случае подряд должны идти любые четыре символа, являющиеся цифрами.

Извлечь латиницу регулярным выражением
Выражение [a-zA-Z] обозначает все символы латиницы. Дефис и в этом, и в предыдущем случае обозначает, что берутся все символы между a и z и между A и Z в общей таблице символов Unicode. Квадратные скобки — синоним “ИЛИ”. Рассматривается каждый из элементов или множеств внутри квадратных скобок, при этом выражение не находит ничего, только если сравниваемая строка не содержит ни одного элемента внутри квадратных скобок.

Извлечь символы в конце/начале строк по условию
Стандартные формулы ПРАВСИМВ и ЛЕВСИМВ позволяют извлечь из ячейки соответственно последние и первые N символов, но на этом их возможности заканчиваются.
С помощью же регулярных выражений можно извлечь:
- Символы, идущие после и включая последнюю заглавную букву в ячейке, заканчивающейся на восклицательный знак. Так мы извлечем из ячеек все восклицательные предложения. Выражение для этого выглядит так: [А-Я][а-яa-z0-9 ]+!$.
- Первые N выбранных символов из определенного множества, если ячейка с них начинается.
- Аналогично: последние N определенных символов, если ячейка на них заканчивается.
Проверить ячейки на соответствие регулярному выражению
Если нет необходимости извлекать данные, а нужно лишь проверить, соответствуют ли они паттерну, чтобы потом отфильтровать их, удобнее использовать процедуру, эквивалентную формуле REGEXMATCH.
Найти в ячейке числа из N цифр
В зависимости от того, является N необходимым или достаточным условием, нужны разные регулярные выражения. Иными словами, считать ли последовательности из N+1, N+2 и т.д. цифр подходящими или нет. Если да, выражение будет таким же, как уже указывалось выше:
dddd
[0-9][0-9][0-9][0-9]
d{4}
[0-9]{4}
Если же нас интересуют строго последовательности из N цифр, задачу придется производить в две итерации:
- В первую итерацию извлекать цифры вместе с границами строк или нецифровыми символами, идущими после/перед (это станет своеобразной проверкой отсутствия других цифр).
- И во вторую уже сами цифры.
Выражения для первой итерации будут, соответственно:
(^|D)dddd($|D)
(^|D)[0-9][0-9][0-9][0-9]($|D)
(^|D)d{4}($|D)
(^|D)[0-9]{4}($|D)
Если внимательно посмотреть на отличие в синтаксисе, можно понять, что означают символы в нем:
- вертикальная черта “|” обозначает “ИЛИ”,
- скобки “( )” нужны для перечисления внутри них аргументов и “отгораживания” их от остального выражения,
- каретка “^” обозначает начало строки,
- символ доллара “$” — конец строки,
- D — нечисловые символы. Обратите внимание: верхний регистр меняет значение d на противоположное. Это справедливо также для пар w и W, обозначающих латиницу и цифры и не-латиницу и цифры, и s и S, различные виды пробелов и не-пробельные символы соответственно.
Найти ячейки, начинающиеся с цифр
Выражение для подобной проверки будет:
Либо можно воспользоваться процедурой проверки на копии исходного диапазона без необходимости вводить формулу. Смотрите примеры.

Замена подстрок по регулярному выражению
Наиболее частый кейс такой замены — замена на пустоту, когда наша задача попросту удалить из текста определенные символы. Наиболее популярны:
- удаление цифр из текста,
- удаление пунктуации,
- всех символов, кроме букв и цифр.
Но бывают случаи, когда необходима реальная замена, например, когда нужно заменить буквы с “хвостиками”/умляутами/ударениями и прочими символами из европейских алфавитов на их английские аналоги. Задача популярна среди SEO-специалистов, формирующих урлы сайтов этих стран на основе оригинальной семантики. Так выглядит начало таблицы паттернов для замены диакритических символов на латиницу с помощью RegEx при генерации URL:

Разбить ячейку по буквам
Чтобы разбить ячейку посимвольно, достаточно извлечь все символы через разделитель. Выражением для извлечения будет обычная точка — она как раз и обозначает любой символ.

Разбить буквы и цифры в ячейке
Если строго соблюдать постановку этой задачи, ее выполнить довольно сложно. Но зато с помощью регулярных выражений можно отделить цифровые последовательности символов от нецифровых. Так будет выглядеть выражение:
А так будет выглядеть процесс на практике:

Вставить текст после первого слова
При замене по регулярному выражению в !SEMTools есть опция замены не всех, а только первого найденного фрагмента, удовлетворяющего паттерну. Это позволяет решить задачу вставки символов после первого слова. Просто заменим первый пробел на нужные нам символы с помощью соответствующей процедуры (эту задачу можно решить также с помощью функции ПОДСТАВИТЬ, но можно и воспользоваться функционалом замены по регулярному выражению). В отличие от обычной процедуры замены, здесь можно заменить только первое вхождение. В данном случае — первый пробел. Как видно, пробел ничем не отличается от обычного:

Вставить символ после каждого слова или перед ним
Надстройка решает эту задачу в два клика готовой процедурой в меню “Изменить слова“, но можно воспользоваться и несложным выражением для замены:
Выражения обозначают, что заменяются пробелы или конец строки в первом случае и пробелы или начало строк во втором. Вертикальная черта — то самое “ИЛИ”.
А заменять будем, соответственно, на пробел с символом слева или справа. Процедура добавит лишний пробел перед ячейкой или после, поэтому от него желательно будет избавиться — удалить лишние пробелы или удалить символы в начале / конце ячейки.

Регулярные выражения для поиска конкретных слов в !SEMTools
Найти слова по регулярному выражению
Извлечь слова по регулярному выражению
Когда дело доходит до извлечения определенных слов, регулярные выражения становятся невероятно сложными. Поэтому надстройка !SEMTools упрощает задачу до применения паттернов RegEx на уровне слов как отдельных сущностей.
Вот так выглядит извлечение слов, содержащих латиницу и цифры, из массива слов, с помощью регулярного выражения:
Обратите внимание, что выражение означает, что цифра за буквой или буква за цифрой должны следовать непосредственно, без промежуточных символов между ними. Если нужно извлечь в том числе слова вида “asdf-13”, “1234-d”, понадобится обозначить возможность наличия символов между:

Удалить слова по регулярному выражению
Очистить ячейки, не соответствующие регулярному выражению
Когда в вашем распоряжении массив данных, где могут быть ошибки, с которыми разбираться некогда, и при этом нужно извлечь только стопроцентно подходящие данные, можно воспользоваться регулярными выражениями для очистки нерелевантных.
Примеры:
- оставить ячейки с определенным количеством слов,
- оставить ячейки с определенным количеством символов,
- оставить ячейки, содержащие только цифры,
- оставить ячейки, содержащие только буквы,
- оставить ячейки, содержащие адрес электронной почты в доменной зоне .com и .ru.
Примеры использования “Извлечь ячейки по регулярному выражению”.
Collecting data is only half of what it takes to accomplish anything with it. It is the important first step of course, but what you do after that is equally as important when working towards something. Most things in our lives have data attached to them — exercise tracking, grades, purchases, sales, expenses, retirement funds, travel mileage and expenses, the list could go on and on. However, what makes data useful is being able to identify patterns.
When attempting to find patterns manually, the process can feel overwhelming. Luckily, there is a way to quickly identify patterns in data if the data is entered in Excel. This post shows several ways to quickly identify patterns using a single type of data, but keep in mind, these will work on almost any kind of data.
How to Use Excel to Quickly Identify Data Patterns
In the examples below, 30 days of «sales data» have been entered into Excel. These values could be replaced with almost any kind of data. Create a spreadsheet by entering data that makes sense to you and apply conditional formatting to identify data patterns the same way we have to get your own unique results.
Here’s our sample data:

There are several ways to quickly identify and highlight different types of data patterns in Excel. Once the desired information is identified, you can look at what was different (good/bad) on those days. For example, in keeping with the sales example, on days where the values were best you may ask things like:
- Was there a special sale?
- Was a new product released?
- Was there a special event?
- Did a new marketing campaign roll out?
Contrarily, on those days where the values were lowest, you may ask:
- Were people out of town for a holiday?
- Was the previous or successive day a high value day?
- Statistically, how has that time of year done in the past?
- Did the day fall at the end of the month/pay period for most people?
Again, the data and questions can easily be made to coincide with the type of data you have. For instance, if you were tracking exercise, you could ask things like did I get enough sleep or push too hard the day before? The purpose of these questions is to find out what you can once the data patterns have been revealed.
How to quickly color code top/bottom/average values
From within Excel with a series of data entered:
- Select the data to format.
- On the Home tab, click on «Conditional Formatting» to access the available formatting.
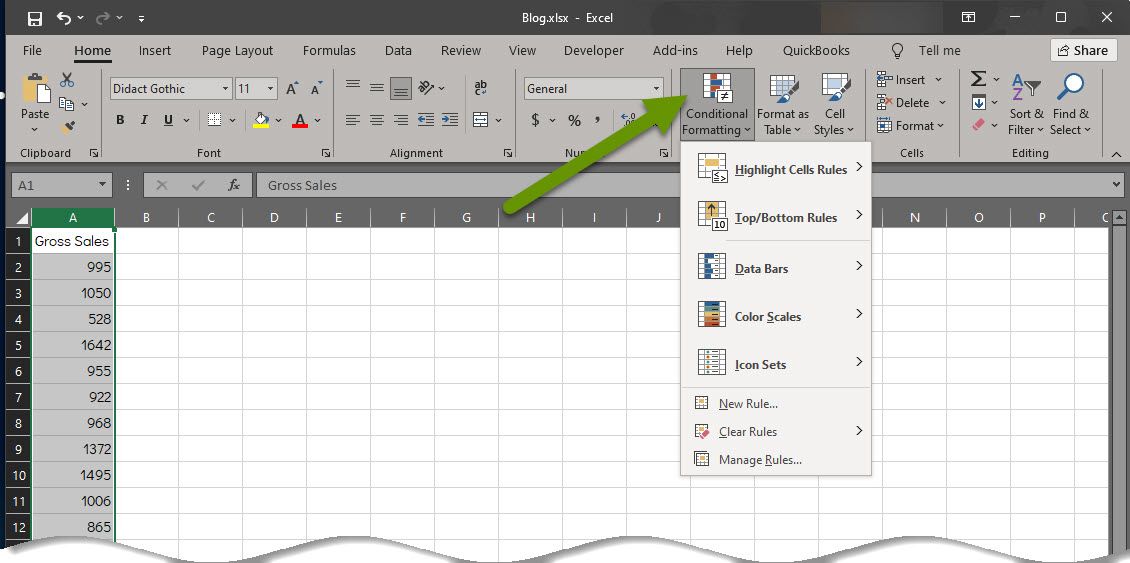
- Select «Top/Bottom Rules» to expand the menu.
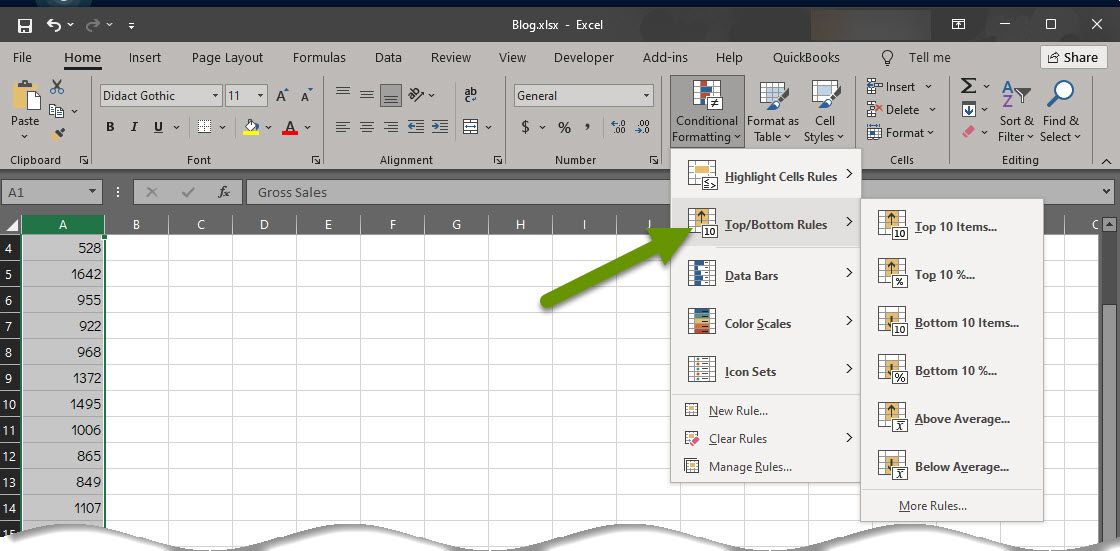
- Select the option from the pop-out menu that makes the most sense for your data and what you are trying to accomplish. In the sales example, the bottom 10% conditional formatting has been selected. NOTE: The amount of unique data cells you have will determine which of the top/bottom 10 items or top/bottom 10% is a narrower perspective. There will be times when a selected view does not give you the result you expected. If this happens, try a different formatting view to see if it provides better results.
- Once the formatting type has been selected, you will be prompted with a window that allows you to modify both the perentage or number, as well as the color that is applied. In our example we modified the percentage to show the bottom 20%.
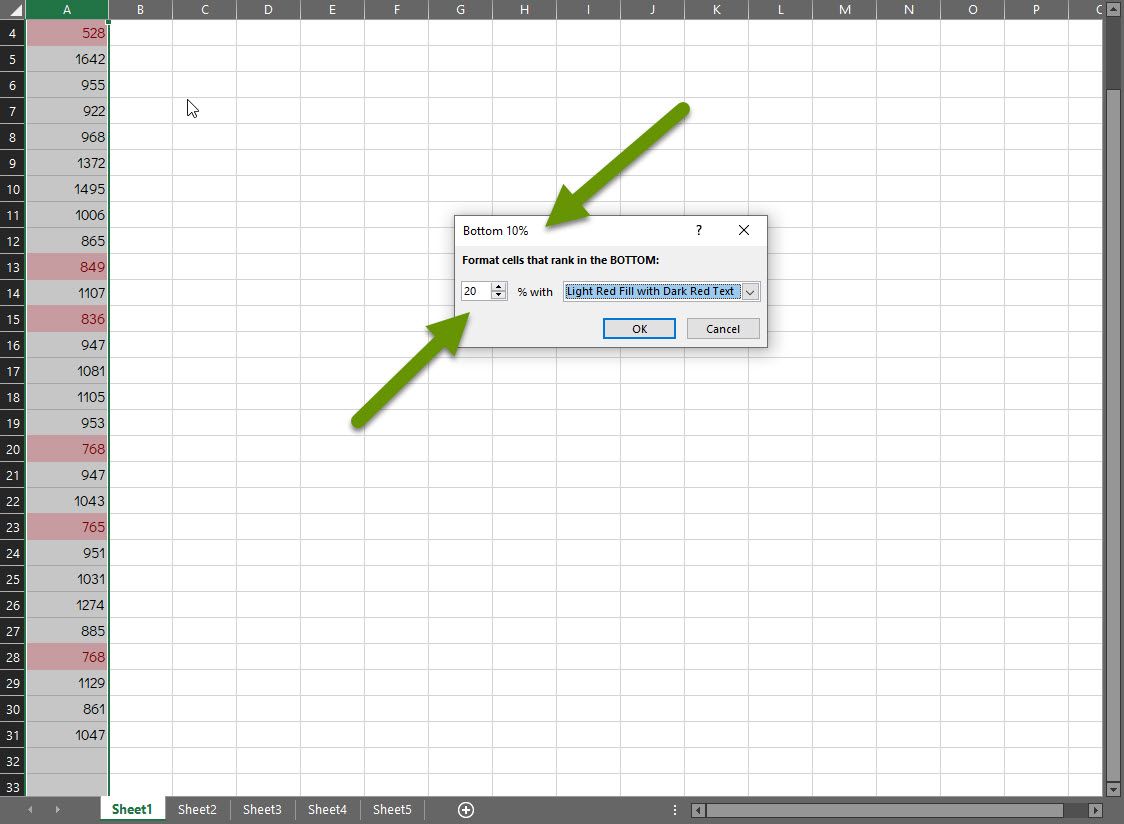
As you can see, the values that fell in the bottom 20% are highlighted. If desired, the formatting color could also have been changed in the pop-up box presented once we selected to apply the bottom 10% conditional formatting view.
How to quickly color code all entries in a sliding color scale
From within Excel with a series of data entered:
- Select the data to format.
- On the Home tab, click on «Conditional Formatting» to access the available formatting.
- Select «Color Scales» from the menu.
- Hover over any of the options in the pop-out menu to see how they would apply to your data and read their descriptions.
- Select the option that makes the most sense for your data and what you are trying to accomplish.
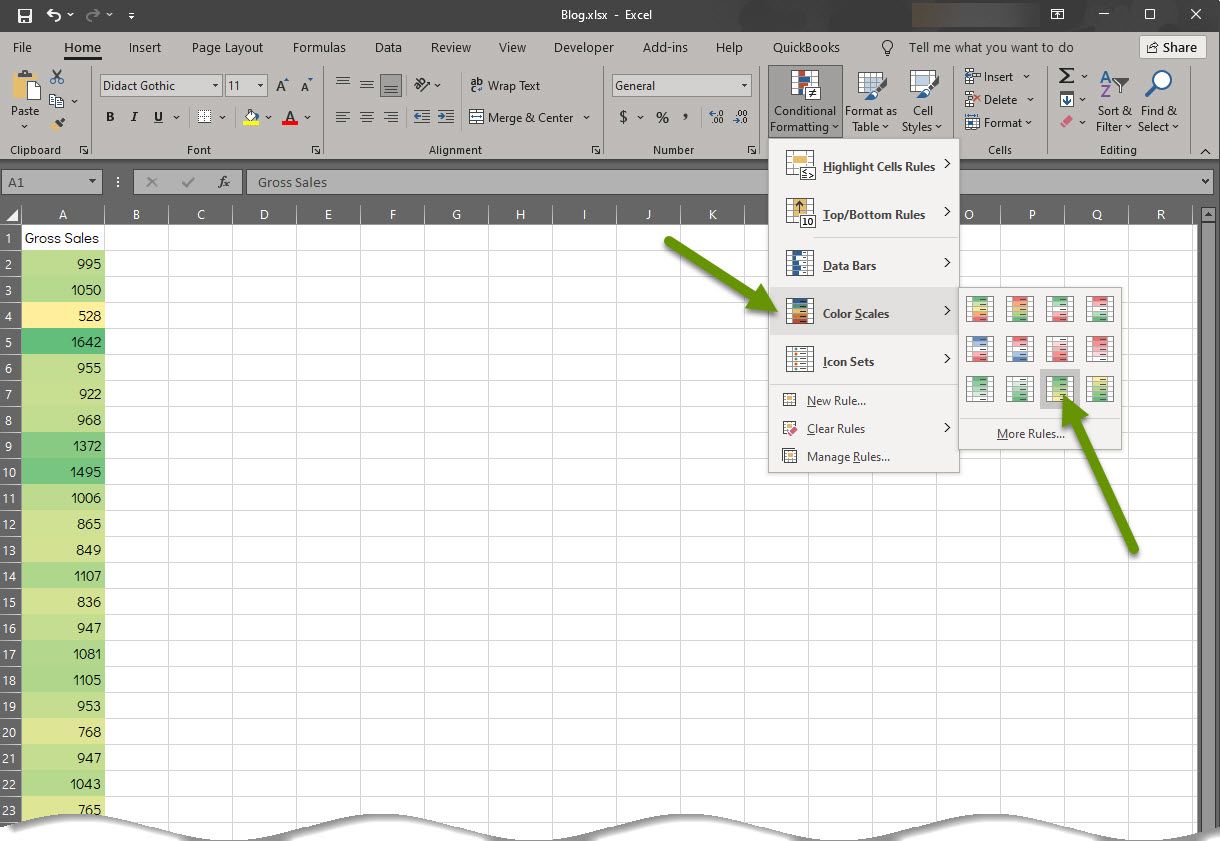
As you can see in the image above, there are several different variations of color bars. This includes having variations where the highest or lowest numbers are highlighted in red because there are instances when both of those are situations that need to be addressed. Keep in mind when using color scales, all values will be filled with color.
How to quickly color code with data bars
From within Excel with a series of data entered:
- Select the data to format.
- On the Home tab, click on «Conditional Formatting» to access the available formatting.
- Select «Data Bars» from the menu.
- Hover over any of the options in the pop-out menu to see how they would apply to your data.
- Select the option that makes the most sense for your data and what you are trying to accomplish.
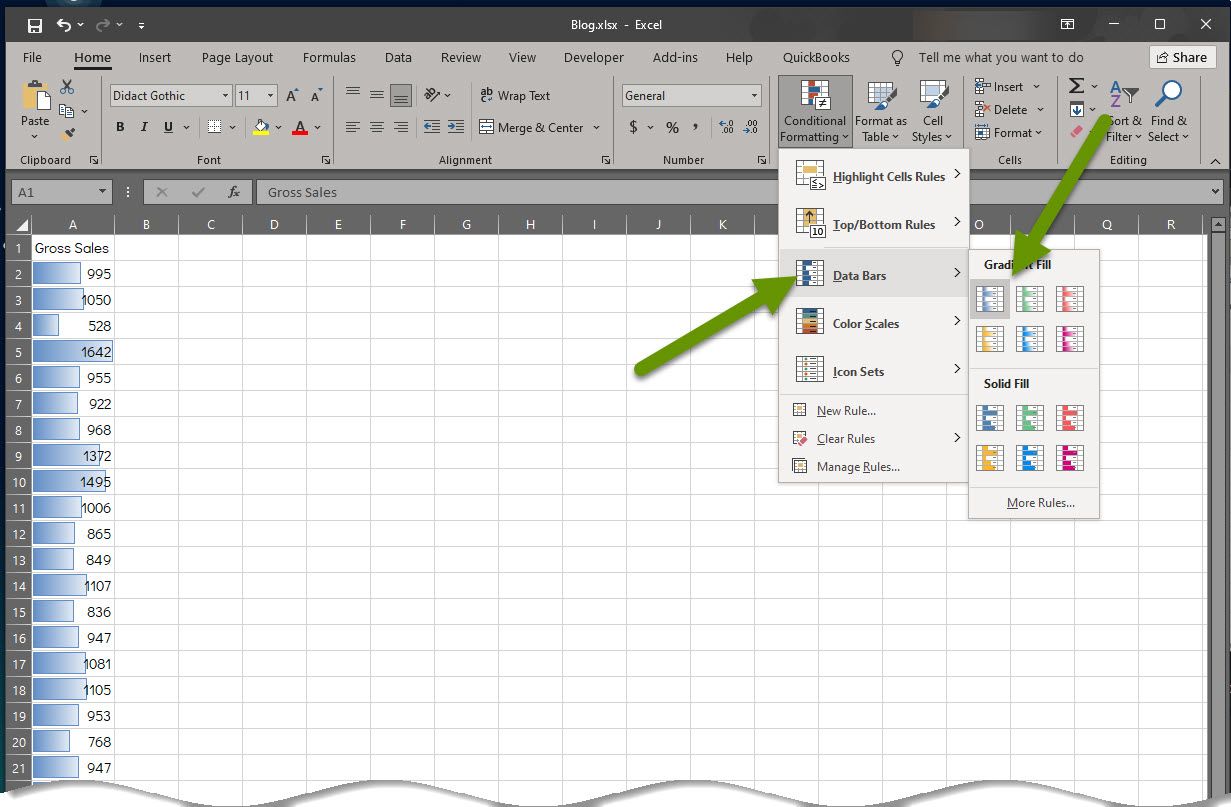
In this example we chose a blue gradient. Data bars are another formatting view that colors each value, like color scales. If you choose a solid color data bar, you may need to change the color of the font so the data is still easy to read.
How to quickly identify patterns using icon sets
If none of the conditional formatting above provides an easy way for you to see the data patterns, you might try applying an icon set. Icon sets are quite a bit different than the examples above, but like color scales and data bars, apply formatting to each value.
From within Excel with a series of data entered:
- Select the data to format.
- On the Home tab, click on «Conditional Formatting» to access the available formatting.
- Select «Icon Sets» from the menu.
- Hover over any of the options in the pop-out menu to see how they would apply to your data.
- Select the option that makes the most sense for your data and what you are trying to accomplish.
![]()
In this example we added a shape icon set that included a green checkmark, a yellow exclamation mark and a red X. These are quite unique and made it VERY easy to see which values were highest and which were lowest.
How to quickly identify very specific values or patterns
At times you may need to drill down into the data and identify very specific values. In cases like that, you might be better off creating a new conditional formatting rule to show the exact data you need rather than using one of the previously created rules. Creating new rules allows you to create rules like those demonstrated above, as well as rules allowing you to:
- Format only those cells that contain (most all the formulations like greater than/less than/between/etc.) «X».
- Format unique/duplicate values.
- Format cells when a specified formula is met.
To create a new formatting rule from within Excel with a series of data entered:
- Select the data to format.
- On the Home tab, click on «Conditional Formatting» to access the available formatting.
- Select «New Rule» from the bottom of the menu.
- Select the option that makes the most sense for your data and set all of the available parameters for what you are trying to accomplish.
- Choose a color for the formatting by clicking the «Format…» button and selecting a color.
- Click the «OK» button to apply the formatting rule.
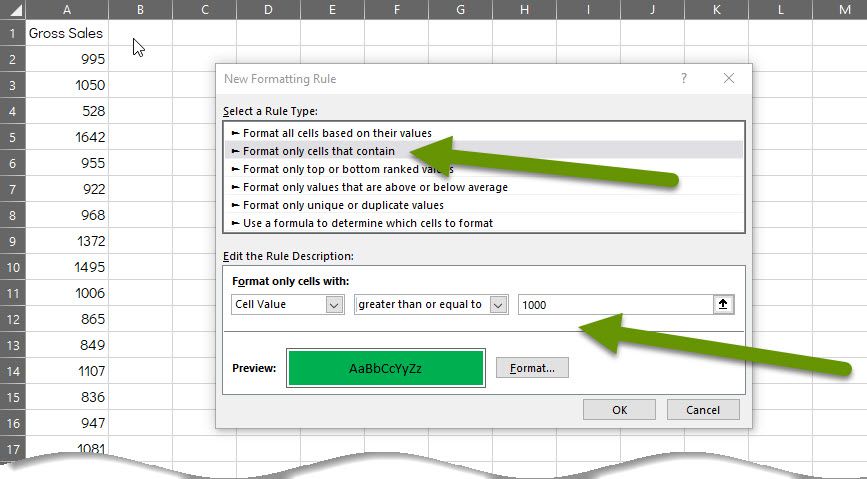
In the new rule above, any cells with values greater than or equal to 1,000 will be formatted in green. Here is what the data looks like once the rule is applied:
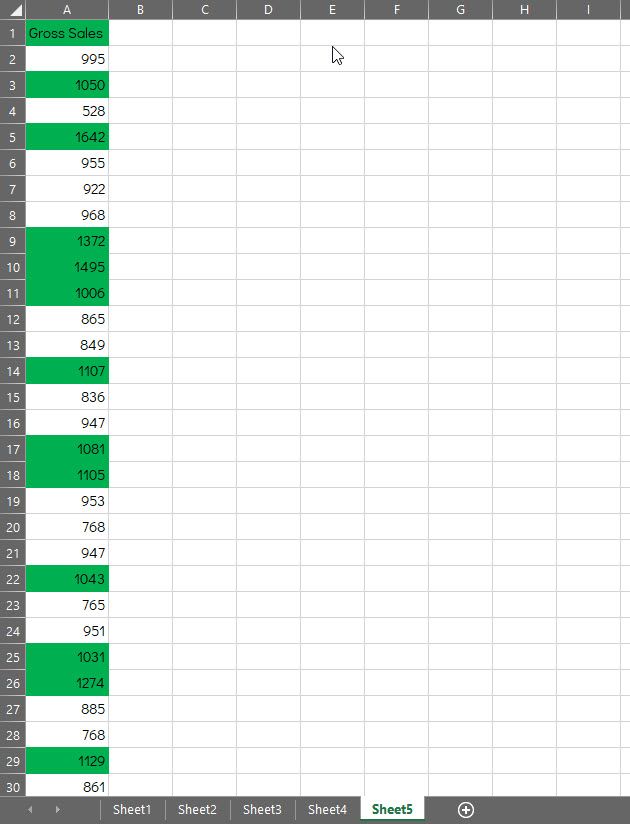
Conditional formatting is one of the quickest ways to identify data patterns, regardless of what types of values you have collected. The numbers above could represent almost any kind of data. Adding conditional formatting provides a quick way to dig into your data and find specific patterns that can help you ask the right questions which in turn will hopefully help you find how to be more successful with whatever the data represents.
As always, being able to process and appropriately respond to collected data in a timely manner makes the data more valuable!
Содержание
- MATCH
- Syntax
- Example
- Pattern matching in excel
- 1 Answer 1
- VBA Excel. Регулярные выражения (объекты, свойства, методы)
- Создание объекта RegExp
- Ранняя привязка
- Поздняя привязка
- Свойства и методы объекта RegExp
- Свойства объекта RegExp
- Методы объекта RegExp
- Свойства объектов Match и Matches Collection
- Свойства объекта Matches Collection
- Свойства объекта Match
- Символы и метасимволы
- Пример использования RegExp
- How to use MATCH function in Excel — formula examples
- Excel MATCH function — syntax and uses
- 4 things you should know about MATCH function
- How to use MATCH in Excel — formula examples
- Partial match with wildcards
- Case-sensitive MATCH formula
- Compare 2 columns for matches and differences (ISNA MATCH)
- Excel VLOOKUP and MATCH
- Excel HLOOKUP and MATCH
MATCH
Tip: Try using the new XMATCH function, an improved version of MATCH that works in any direction and returns exact matches by default, making it easier and more convenient to use than its predecessor.
The MATCH function searches for a specified item in a range of cells, and then returns the relative position of that item in the range. For example, if the range A1:A3 contains the values 5, 25, and 38, then the formula =MATCH(25,A1:A3,0) returns the number 2, because 25 is the second item in the range.

Tip: Use MATCH instead of one of the LOOKUP functions when you need the position of an item in a range instead of the item itself. For example, you might use the MATCH function to provide a value for the row_num argument of the INDEX function.
Syntax
MATCH(lookup_value, lookup_array, [match_type])
The MATCH function syntax has the following arguments:
lookup_value Required. The value that you want to match in lookup_array. For example, when you look up someone’s number in a telephone book, you are using the person’s name as the lookup value, but the telephone number is the value you want.
The lookup_value argument can be a value (number, text, or logical value) or a cell reference to a number, text, or logical value.
lookup_array Required. The range of cells being searched.
match_type Optional. The number -1, 0, or 1. The match_type argument specifies how Excel matches lookup_value with values in lookup_array. The default value for this argument is 1.
The following table describes how the function finds values based on the setting of the match_type argument.
MATCH finds the largest value that is less than or equal to lookup_value. The values in the lookup_array argument must be placed in ascending order, for example: . -2, -1, 0, 1, 2, . A-Z, FALSE, TRUE.
MATCH finds the first value that is exactly equal to lookup_value. The values in the lookup_array argument can be in any order.
MATCH finds the smallest value that is greater than or equal to lookup_value. The values in the lookup_array argument must be placed in descending order, for example: TRUE, FALSE, Z-A, . 2, 1, 0, -1, -2, . and so on.
MATCH returns the position of the matched value within lookup_array, not the value itself. For example, MATCH(«b», <«a»,»b»,»c «>,0) returns 2, which is the relative position of «b» within the array <«a»,»b»,»c»>.
MATCH does not distinguish between uppercase and lowercase letters when matching text values.
If MATCH is unsuccessful in finding a match, it returns the #N/A error value.
If match_type is 0 and lookup_value is a text string, you can use the wildcard characters — the question mark ( ?) and asterisk ( *) — in the lookup_value argument. A question mark matches any single character; an asterisk matches any sequence of characters. If you want to find an actual question mark or asterisk, type a tilde (
) before the character.
Example
Copy the example data in the following table, and paste it in cell A1 of a new Excel worksheet. For formulas to show results, select them, press F2, and then press Enter. If you need to, you can adjust the column widths to see all the data.
Источник
Pattern matching in excel
I have an excel sheet with two columns. The first column is the key phrase and the second is the messages. The key phrase may occur in the messages column. I need to know how many times a key phrase has occurred in messages column.
The key phrase is one column and the messages is the second column. The messages column is combination (concatenation) of 1 or more than 1 key phrases. I need to find out that how many key phrases does each message contain. Also some of the messages have some dates and numbers with them. Also some of the messages have dates and numbers in them, the matching key phrase as that date/numbe as (xx-xxx-xxxx) presently.
e.g. the message is «The deal closed on 08-Oct-2014 so no further transaction allowed» and the key phrase is «The deal closed on (xx-xxx-xxxx)«. Also there are messages as «Deal number 4238428DDSSD has problems» and the keyphrase is «Deal number xxxxxxxx hass problems«. The regex matching is required.
1 Answer 1
You can pick a few keyword phrases, create the regex pattern for them, then encode the phrases such that a Range.Replace method can be used on them to substitute an appropriate RegEx pattern mask into the keyword phrase.
In the following, I’ve used X00000000X, XSHORTDATEX and XDEALNMBRX as placeholders within the keywords. These will be replaced with [0-9,-]<7,8>, [0-9,-]<3>[a-z]<3>[0-9,-] <3,5>and [0-9]<7>[a-z] <5>respectively.
X00000000X is designed to handle anything that looks like 1234567 or * 99-11-00*. XSHORTDATEX will handle dates in the dd-mmm-yy or dd-mmm-yyyy format (once converted to lower case) and XDEALNMBRX will locate alphanumeric patterns similar to 4238428DDSSD.
This code requires that the Microsoft VBScript Regular Expression library be added to the VBA project with the VBE’s Tools ► References command.
In the following image of me sample’s results, the staight location items are noted in bold>blue and the RegEx pattern matching is noted by bold|red.

Feel free to modify and append with additional keywords, phrases and RegEx patterns.
Источник
VBA Excel. Регулярные выражения (объекты, свойства, методы)
Регулярные выражения в VBA Excel. Объекты RegExp, Match, Matches Collection и их свойства. Символы и метасимволы. Создание объекта RegExp с ранней, поздней привязкой и его методы.
В VBA Excel для работы с регулярными выражениями используется библиотека «Microsoft VBScript Regular Expression».
Создание объекта RegExp
Ранняя привязка
Обычно рекомендуется использовать объекты с ранней привязкой, так как у них выше быстродействие, а также при написании и редактировании кода доступны подсказки в виде листа свойств-методов, появляющегося автоматически или вызываемого, при необходимости, сочетанием клавиш Ctrl+Пробел.
Раннее связывание заключается в присвоении нового экземпляра объекта RegExp переменной, уже объявленной, как переменная определенного типа (в нашем случае, как RegExp).
Для осуществления ранней привязки необходимо подключить к проекту VBA ссылку на библиотеку «Microsoft VBScript Regular Expression», для чего в редакторе VBA выбираем Tools — References…
В открывшемся окне «References» находим строку «Microsoft VBScript Regular Expression 5.5» (если у вас ее нет, то строку «Microsoft VBScript Regular Expression 1.0»), отмечаем ее галочкой и нажимаем «ОК».
Готово — ссылка добавлена.
Создание объекта RegExp с ранней привязкой:
Поздняя привязка
Позднее связывание заключается в присвоении нового экземпляра объекта RegExp переменной, объявленной как Object, с помощью функции CreateObject.
Создание объекта RegExp с поздней привязкой:
Свойства и методы объекта RegExp
Свойства объекта RegExp
| Свойство | Описание | Значение по умолчанию |
|---|---|---|
| Global | Определяет продолжительность поиска: False — до первого совпадения True — по всему тексту |
False |
| IgnoreCase | Определяет чувствительность к регистру символов: False — учитывать регистр True — не учитывать регистр |
False |
| Multiline | Определяет структуру объекта: False — однострочный True — многострочный |
False |
| Pattern | Строка, используемая как шаблон | Пустая строка |
Свойства объекта RegExp доступны для чтения и записи.
Методы объекта RegExp
| Метод | Синтаксис | Описание |
|---|---|---|
| Execute | Execute(myStr) myStr — строка для поиска |
Возвращает коллекцию найденных по шаблону подстрок в виде агрегатного объекта |
| Replace | Replace(myStr,myRep) myStr — строка для поиска myRep — строка для замены |
Возвращает строку, в которой найденные по шаблону вхождения в исходной строке заменены на указанную подстроку. |
| Test | Test(myText) myText — строка для проверки |
Возвращает булево значение как результат проверки соответствия строки шаблону |
Свойства объектов Match и Matches Collection
Метод Execute объекта RegExp возвращает агрегатный объект Matches Collection, который содержит коллекцию объектов Match, представляющих все совпадения, найденные механизмом регулярных выражений, в том порядке, в котором они присутствуют в исходной строке. Если совпадений нет, метод возвращает объект Matches Collection без членов.
Свойства объекта Matches Collection
| Свойство | Описание |
|---|---|
| Count | Количество объектов Match, содержащихся в объекте Matches Collection |
| Item | Индекс члена коллекции от нуля до значения свойства Count минус 1 |
Свойства объекта Matches Collection доступны только для чтения.
Свойства объекта Match
| Свойство | Описание |
|---|---|
| FirstIndex | Позиция в исходной строке, где произошло совпадение, причем первая позиция в строке равна нулю |
| Length | Длина совпавшей подстроки |
| Value | Найденная подстрока (является свойством по умолчанию) |
Свойства объекта Match доступны только для чтения.
Все знаки, используемые для составления шаблонов, обычно делят на символы и метасимволы. Символы — это знаки, которые в шаблонах обозначают сами себя, а метасимволы (спецсимволы) — знаки, имеющие другое значение. Метасимволы могут использоваться как отдельно, так и в сочетании с другими символами и спецсимволами.
Таблица основных метасимволов и их сочетаний с другими символами
| Метасимвол (сочетание символов) |
Значение |
|---|---|
| После этого знака метасимвол обозначает сам себя, а некоторые символы приобретают другое значение | |
| ^ | Начало строки |
| $ | Конец строки |
| ? | Ни одного или один любой символ |
| * | Ни одного или несколько любых символов |
| + | Один или несколько любых символов |
| . | Любой символ, кроме знака «новая строка» |
| — | Определяет интервал символов |
| | | Знак «или» |
| Точное количество символов, стоящих перед | |
| Количество от n до m символов, стоящих перед | |
| [abc] | Любой из указанных символов |
| [^abc] | Любой из неуказанных символов |
| [a-z] | Любой символ из диапазона |
| [^a-z] | Любой символ, не входящий в диапазон |
| b | Конец слова |
| B | Не конец слова |
| d | Цифра |
| D | Не цифра |
| w | Любая буква, цифра или знак подчеркивания |
| W | Не буква, не цифра и не знак подчеркивания |
| s | Пробел |
| S | Не пробел |
В таблицу не включены редко используемые сочетания, ознакомиться с которыми можно в справочной системе разработчика. А примеры использования метасимволов в шаблонах очень хорошо представлены на этом ресурсе в разделе 4. Метасимволы.
Пример использования RegExp
Пример использования регулярных выражений в VBA Excel для извлечения email-адресов из текстового файла.
Для извлечения текстовой информации из файла в переменную используется функция GetText, которую вы можете скопировать из статьи Парсинг сайтов, html-страниц и файлов.
В файл «Новый документ.txt» вставлен произвольный текст с четырьмя примерами email-адресов, которые необходимо извлечь.
Код VBA Excel для извлечения email-адресов из текстового файла с помощью регулярных выражений:
Источник
How to use MATCH function in Excel — formula examples
 by Svetlana Cheusheva, updated on March 20, 2023
by Svetlana Cheusheva, updated on March 20, 2023
This tutorial explains how to use MATCH function in Excel with formula examples. It also shows how to improve your lookup formulas by a making dynamic formula with VLOOKUP and MATCH.
In Microsoft Excel, there are many different lookup/reference functions that can help you find a certain value in a range of cells, and MATCH is one of them. Basically, it identifies a relative position of an item in a range of cells. However, the MATCH function can do much more than its pure essence.
Excel MATCH function — syntax and uses
The MATCH function in Excel searches for a specified value in a range of cells, and returns the relative position of that value.
The syntax for the MATCH function is as follows:
Lookup_value (required) — the value you want to find. It can be a numeric, text or logical value as well as a cell reference.
Lookup_array (required) — the range of cells to search in.
Match_type (optional) — defines the match type. It can be one of these values: 1, 0, -1. The match_type argument set to 0 returns only the exact match, while the other two types allow for approximate match.
- 1 or omitted (default) — find the largest value in the lookup array that is less than or equal to the lookup value. Requires sorting the lookup array in ascending order, from smallest to largest or from A to Z.
- 0 — find the first value in the array that is exactly equal to the lookup value. No sorting is required.
- -1 — find the smallest value in the array that is greater than or equal to the lookup value. The lookup array should be sorted in descending order, from largest to smallest or from Z to A.
To better understand the MATCH function, let’s make a simple formula based on this data: students names in column A and their exam scores in column B, sorted from largest to smallest. To find out where a specific student (say, Laura) stands among others, use this simple formula:
=MATCH(«Laura», A2:A8, 0)
Optionally, you can put the lookup value in some cell (E1 in this example) and reference that cell in your Excel Match formula:
=MATCH(E1, A2:A8, 0) 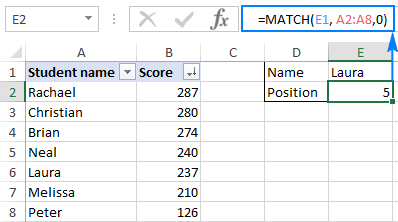
As you see in the screenshot above, the student names are entered in an arbitrary order, and therefore we set the match_type argument to 0 (exact match), because only this match type does not require sorting values in the lookup array. Technically, the Match formula returns the relative position of Laura in the range. But because the scores are sorted from largest to smallest, it also tells us that Laura has the 5 th best score among all students.
Tip. In Excel 365 and Excel 2021, you can use the XMATCH function, which is a modern and more powerful successor of MATCH.
4 things you should know about MATCH function
As you have just seen, using MATCH in Excel is easy. However, as is the case with nearly any other function, there are a few specificities that you should be aware of:
- The MATCH function returns the relative position of the lookup value in the array, not the value itself.
- MATCH is case-insensitive, meaning it does not distinguish between lowercase and uppercase characters when dealing with text values.
- If the lookup array contains several occurrences of the lookup value, the position of the first value is returned.
- If the lookup value is not found in the lookup array, the #N/A error is returned.
How to use MATCH in Excel — formula examples
Now that you know the basic uses of the Excel MATCH function, let’s discuss a few more formula examples that go beyond the basics.
Partial match with wildcards
Like many other functions, MATCH understands the following wildcard characters:
- Question mark (?) — replaces any single character
- Asterisk (*) — replaces any sequence of characters
Note. Wildcards can only be used in Match formulas with match_type set to 0.
A Match formula with wildcards comes useful in situations when you want to match not the entire text string, but only some characters or some part of the string. To illustrate the point, consider the following example.
Supposing you have a list of regional resellers and their sales figures for the past month. You want to find a relative position of a certain reseller in the list (sorted by the Sales amounts in descending order) but you cannot remember his name exactly, though you do remember a few first characters.
Assuming the reseller names are in the range A2:A11, and you are searching for the name that begins with «car», the formula goes as follows:
To make our Match formula more versatile, you can type the lookup value in some cell (E1 in this example), and concatenate that cell with the wildcard character, like this:
As shown in the screenshot below, the formula returns 2, which is the position of «Carter»: 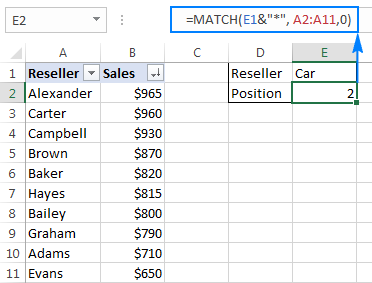
To replace just one character in the lookup value, use the «?» wildcard operator, like this:
The above formula will match the name «Baker» and rerun its relative position, which is 5.
Case-sensitive MATCH formula
As mentioned in the beginning of this tutorial, the MATCH function doesn’t distinguish uppercase and lowercase characters. To make a case-sensitive Match formula, use MATCH in combination with the EXACT function that compares cells exactly, including the character case.
Here’s the generic case-sensitive formula to match data:
The formula works with the following logic:
- The EXACT function compares the lookup value with each element of the lookup array. If the compared cells are exactly equal, the function returns TRUE, FALSE otherwise.
- And then, the MATCH function compares TRUE (which is its lookup_value ) with each value in the array returned by EXACT, and returns the position of the first match.
Please bear in mind that it’s an array formula that requires pressing Ctrl + Shift + Enter to be completed correctly.
Assuming your lookup value is in cell E1 and the lookup array is A2:A9, the formula is as follows:
The following screenshot shows the case-sensitive Match formula in Excel: 
Compare 2 columns for matches and differences (ISNA MATCH)
Checking two lists for matches and differences is one of the most common tasks in Excel, and it can be done in a variety of ways. An ISNA/MATCH formula is one of them:
For any value of List 2 that is not present in List 1, the formula returns «Not in List 1«. And here’s how:
- The MATCH function searches for a value from List 1 within List 2. If a value is found, it returns its relative position, #N/A error otherwise.
- The ISNA function in Excel does only one thing — checks for #N/A errors (meaning «not available»). If a given value is an #N/A error, the function returns TRUE, FALSE otherwise. In our case, TRUE means that a value from List 1 is not found within List 2 (i.e. an #N/A error is returned by MATCH).
- Because it may be very confusing for your users to see TRUE for values that do not appear in List 1, you wrap the IF function around ISNA to display «Not in List 1» instead, or whatever text you want.
For example, to compare values in column B against values in column A, the formula takes the following shape (where B2 is the topmost cell):
=IF(ISNA(MATCH(B2,A:A,0)), «Not in List 1», «»)
As you remember, the MATCH function in Excel is case-insensitive by itself. To get it to distinguish the character case, embed the EXACT function in the lookup_array argument, and remember to press Ctrl + Shift + Enter to complete this array formula:
=IF(ISNA(MATCH(TRUE, EXACT(A:A, B2),0)), «Not in List 1», «»)
The following screenshot shows both formulas in action: 
To learn other ways to compare two lists in Excel, please see the following tutorial: How to compare 2 columns in Excel.
Excel VLOOKUP and MATCH
This example assumes you already have some basic knowledge of Excel VLOOKUP function. And if you do, chances are that you’ve run into its numerous limitations (the detailed overview of which can be found in Why Excel VLOOKUP is not working) and are looking for a more robust alternative.
One of the most annoying drawbacks of VLOOKUP is that it stops working after inserting or deleting a column within a lookup table. This happens because VLOOKUP pulls a matching value based on the number of the return column that you specify (index number). Because the index number is «hard-coded» in the formula, Excel is unable to adjust it when a new column(s) is added to or deleted from the table.
The Excel MATCH function deals with a relative position of a lookup value, which makes it a perfect fit for the col_index_num argument of VLOOKUP. In other words, instead of specifying the return column as a static number, you use MATCH to get the current position of that column.
To make things easier to understand, let’s use the table with students’ exam scores again (similar to the one we used at the beginning of this tutorial), but this time we will be retrieving the real score and not its relative position.
Assuming the lookup value is in cell F1, the table array is $A$1:$C$2 (it’s a good practice to lock it using absolute cell references if you plan to copy the formula to other cells), the formula goes as follows:
=VLOOKUP(F1, $A$1:$C$8, 3, FALSE)
The 3 rd argument (col_index_num) is set to 3 because the Math Score that we want to pull is the 3 rd column in the table. As you can see in the screenshot below, this regular Vlookup formula works well: 
But only until you insert or delete a column(s): 
So, why the #REF! error? Because col_index_num set to 3 tells Excel to get a value from the third column, whereas now there are only 2 columns in the table array.
To prevent such things from happening, you can make your Vlookup formula more dynamic by including the following Match function:
- E2 is the lookup value, which is exactly equal to the name of the return column, i.e. the column from which you want to pull a value (Math Score in this example).
- A1:C1 is the lookup array containing the table headers.
And now, include this Match function in the col_index_num argument of your Vlookup formula, like this:
=VLOOKUP(F1,$A$1:$C$8, MATCH(E2,$A$1:$C$1, 0), FALSE)
And make sure it works impeccably no matter how many columns you add or delete: 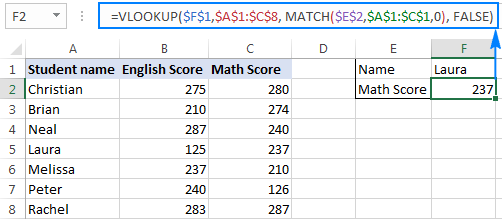
In the screenshot above, I locked all cell references for the formula to work correctly even if my users move it to another place in the worksheet. A you can see in the screenshot below, the formula works just fine after deleting a column; furthermore Excel is smart enough to properly adjust absolute references in this case: 
Excel HLOOKUP and MATCH
In a similar manner, you can use the Excel MATCH function to improve your HLOOKUP formulas. The general principle is essentially the same as in case of Vlookup: you use the Match function to get the relative position of the return column, and supply that number to the row_index_num argument of your Hlookup formula.
Supposing the lookup value is in cell B5, table array is B1:H3, the name of the return row (lookup value for MATCH) is in cell A6 and row headers are A1:A3, the complete formula is as follows:
=HLOOKUP(B5, B1:H3, MATCH(A6, A1:A3, 0), FALSE) 
As you have just seen, the combination of Hlookup/Vlookup & Match is certainly an improvement over regular Hlookup and Vlookup formulas. However, the MATCH function doesn’t eliminate all their limitations. In particular, a Vlookup Match formula still cannot look at its left, and Hlookup Match fails to search in any row other than the topmost one.
To overcome the above (and a few other) limitations, consider using a combination of INDEX MATCH, which provides a really powerful and versatile way to do lookup in Excel, superior to Vlookup and Hlookup in many respects. The detailed guidance and formula examples can be found in INDEX & MATCH in Excel — a better alternative to VLOOKUP.
This is how you use MATCH formulas in Excel. Hopefully, the examples discussed in this tutorial will prove helpful in your work. I thank you for reading and hope to see you on our blog next week!
Источник
Skip to content
В этом руководстве вы узнаете, как использовать регулярные выражения в Excel для поиска и извлечения части текста, соответствующего заданному шаблону.
Microsoft Excel предоставляет ряд функций для извлечения текста из ячеек. Эти функции могут справиться с большинством задач извлечения информации из ячеек на ваших листах. Большинством, но не всеми. Когда текстовые функции не работают, на помощь приходят регулярные выражения. Подождите … В Excel нет функций регулярных выражений! Действительно, встроенных функций нет. Но нет ничего, что помешало бы использовать свои 
В этой статье мы рассмотрим следующие вопросы:
- Что такое регулярные выражения
- Как добавить пользовательскую функцию RegExp
- 4 вещи, которые вы должны знать о RegExpExtract
- Спецсимволы для создания регулярных выражений
- Регулярное выражение для извлечения числа из строки
- Регулярное выражение для извлечения всех совпадений
- Извлечь все совпадения в одну ячейку
- Регулярное выражение для извлечения текста из строки
- Извлекаем адрес электронной почты из текста
- Как получить имя домена из электронной почты
- Извлечение телефонных номеров из текста
- Достаем дату из текста
- Достаём время из текста
- Извлекаем текст после последнего вхождения указанного символа
- Пользовательская функция Regex на основе .NET для извлечения текста в Excel
- Извлечение строки между двумя символами
- Извлечение текста между двумя строками
- Достаём домен из URL
Что такое регулярные выражения
Регулярное выражение – это шаблон, состоящий из последовательности символов, который можно использовать для поиска соответствующей последовательности в другой строке.
Регулярные выражения — это инструмент обработки текста для символьных значений. Говоря проще, регулярные выражения хороши для работы с текстом и плохи почти во всем остальном.
На практике это означает, что регулярные выражения плохо подходят для задач, требующих обнаружения смысла (семантики) в тексте, выходящем за пределы уровня символов.
Выполнение более сложных операций с числом, требующих знания его числового значения (то есть его семантики), не по силам регулярным выражениям. Так, найти число в тексте с их помощью легко. А вот найти число в тексте, которое больше 11, но меньше 100, или же чётное число, будет сложно. Для этого нужно распознать значение числа.
Итак, регулярные выражения — это прекрасная замена функциям работы с текстом.
Как добавить пользовательскую функцию RegExp
Чтобы добавить в Excel пользовательскую функцию работы с регулярными выражениями, вставьте следующий ниже код в редактор VBA. Чтобы включить регулярные выражения в VBA, мы используем встроенный объект Microsoft RegExp.
Public Function RegExpExtract(text As String, pattern As String, Optional instance_num As Integer = 0, Optional match_case As Boolean = True)
Dim text_matches() As String
Dim matches_index As Integer
On Error GoTo ErrHandl
RegExpExtract = ""
Set regex = CreateObject("VBScript.RegExp")
regex.pattern = pattern
regex.Global = True
regex.MultiLine = True
If True = match_case Then
regex.ignorecase = False
Else
regex.ignorecase = True
End If
Set matches = regex.Execute(text)
If 0 < matches.Count Then
If (0 = instance_num) Then
ReDim text_matches(matches.Count - 1, 0)
For matches_index = 0 To matches.Count - 1
text_matches(matches_index, 0) = matches.Item(matches_index)
Next matches_index
RegExpExtract = text_matches
Else
RegExpExtract = matches.Item(instance_num - 1)
End If
End If
Exit Function
ErrHandl:
RegExpExtract = CVErr(xlErrValue)
End FunctionЕсли у вас мало опыта работы с VBA, может оказаться полезным пошаговое руководство пользователя: Как вставить создать пользовательскую функцию в Excel .
Примечание. Чтобы функция работала, обязательно сохраните файл как книгу с поддержкой макросов (.xlsm). Думаю, здесь может пригодиться инструкция Как правильно сохранить и применять пользовательскую функцию Excel.
Функция RegExpExtract ищет во входной строке значения, которые соответствуют регулярному выражению, и извлекает одно или все найденные совпадения.
Функция имеет следующий синтаксис:
RegExpExtract(text; pattern; [instance_num]; [match_case])
Здесь:
- text (обязательный параметр) — текстовая строка для поиска.
- Pattern (обязательный) – шаблон, регулярное выражение для сопоставления. При вводе непосредственно в формуле шаблон следует заключать в двойные кавычки, так как это текст.
- Instance_num (необязательный) — указывает, какое по счёту совпадение извлекать. Если не указано, возвращает все найденные совпадения (по умолчанию).
- Match_case (необязательный) — определяет, следует ли учитывать регистр текста или игнорировать его. Если ИСТИНА или опущено (по умолчанию), выполняется сопоставление с учетом регистра; если ЛОЖЬ — регистр не учитывается.
Функция работает во всех версиях Excel 365, Excel 2021, Excel 2019, Excel 2016, Excel 2013 и Excel 2010.
Важные особенности функции RegExpExtract
Чтобы эффективно использовать эту функцию в Excel, необходимо обратить внимание на несколько важных моментов:
- По умолчанию функция возвращает все найденные совпадения в соседние ячейки, как показано в этом примере . Чтобы получить конкретное вхождение, укажите соответствующий номер аргумента instance_num.
- По умолчанию функция чувствительна к регистру. Для сопоставления без учета регистра установите для аргумента match_case значение ЛОЖЬ.
- Если нужный шаблон не найден, функция ничего не возвращает (пустая строка).
- Если шаблон неправильный, возникает ошибка #ЗНАЧЕН!
Прежде чем вы начнете использовать эту настраиваемую функцию на своих рабочих листах, вам нужно понять, на что она способна. Приведенные ниже примеры представляют несколько распространенных вариантов ее использования и объясняют, почему результат может отличаться в Excel с поддержкой динамических массивов (Microsoft 365 и Excel 2021) и традиционном Excel (2019 и более ранние версии).
Примечание. Примеры регулярных выражений написаны для совершенно простых наборов данных. Мы не можем гарантировать, что они будут безупречно работать с вашими реальными таблицами. Те, кто имеет опыт работы с регулярными выражениями, согласятся, что их написание — это бесконечный путь к совершенству. Почти всегда есть способ сделать его более элегантным или способным обрабатывать более широкий диапазон исходных данных.
Шпаргалка для создания регулярных выражений
| Шаблон | Описание |
| . | Самое простое — это точка. Она обозначает любой символ в шаблоне на указанной позиции. |
| s | Любой символ, выглядящий как пробел (пробел, табуляция или перенос строки). |
| S | Анти-вариант предыдущего шаблона, т.е. любой символ, кроме пробела. |
| d | Любая цифра |
| D | Анти-вариант предыдущего, т.е. любая НЕ цифра |
| w | Любой символ латиницы (A-Z), цифра или знак подчеркивания |
| W | Анти-вариант предыдущего, т.е. не латиница, не цифра и не подчеркивание. |
| [символы] | В квадратных скобках можно указать один или несколько символов, допустимых на указанной позиции в тексте. Например ст[уо]л будет соответствовать любому из слов: стол или стул. Также можно не перечислять символы, а задать их диапазоном через дефис, т.е. вместо [ABDCDEF] написать [A-F]. или вместо [4567] ввести [4-7]. Например, для обозначения всех символов кириллицы можно использовать шаблон [а-яА-ЯёЁ]. |
| [^символы] | Если после открывающей квадратной скобки добавить символ «крыши» ^, то набор приобретет обратный смысл — на указанной позиции в тексте будут разрешены все символы, кроме перечисленных. Так, шаблон [^ЖМ]уть найдет Путь или Суть или Забудь, но не Жуть или Муть, например. |
| | | Логический оператор ИЛИ (OR) для проверки по любому из указанных критериев. Например (счет|счёт|счет-фактура|invoice) будет искать в тексте любое из указанных слов. Обычно набор возможных вариантов заключается в круглые скобки. |
| ^ | Соответствие должно начинаться в начале строки. Например, ^d{3} извлекает «901» из текста «901-333-777» |
| $ | Соответствие должно извлекаться из конца строки. Например, $d{3} извлекает «777» из текста «901-333-777» |
| b | Конец слова. Иначе говоря, соответствие должно обнаруживаться на границе между символом w (алфавитно-цифровым) и символом W (не алфавитно-цифровым). |
Если мы ищем определенное количество символов, например, шестизначный почтовый индекс или все трехбуквенные коды товаров, то на помощь нам приходят квантификаторы или кванторы — специальные выражения, задающие количество искомых знаков. Квантификаторы применяются к символу, который стоит перед ним:
| Квантор | Описание |
| ? | Ноль или одно вхождение. Например, .? будет означать один любой символ или его отсутствие. |
| + | Одно или более вхождений. Например, d+ означает любое количество цифр (т.е. любое число от 0 до бесконечности). |
| * | Ноль или более вхождений, т.е. любое количество. Так s* означает любое количество пробелов или их отсутствие. |
| {число} или {число1,число2} |
Если нужно задать строго определенное количество вхождений, то оно задается в фигурных скобках. Например d{6} означает строго шесть цифр, а шаблон s{2,5} – от двух до пяти пробелов |
Регулярное выражение для извлечения числа из строки
Следуя основному принципу обучения «от простого к сложному», мы начнем с очень простого случая: извлечения числа из строки.
Первое, что вам нужно решить, какое число извлекать: первое, последнее, конкретное вхождение или все числа.
Извлечь первое число
Это настолько просто, насколько простым может быть регулярное выражение. Учитывая, что d означает любую цифру от 0 до 9, а знак + означает «один или несколько раз», наше регулярное выражение принимает такую форму:
d+
Установите параметр instance_num равным 1, и вы получите желаемый результат:
=RegExpExtract(A8; «d+»; 1)
Где A8 — исходная строка.
Для удобства вы можете записать шаблон в отдельную ячейку (например, $A$2) и зафиксировать этот адрес знаком $ :
=RegExpExtract(A8; $A$2; 1)

Получить последнее число в строке
Вот шаблон, который можно использовать для извлечения последнего числа в строке:
(d+)(?!.*D)
В переводе на обычный язык он означает: найдите число, за которым не следует (до самого конца строки) какое-либо другое число. Чтобы выразить это, мы используем отрицательный просмотр вперед (?!.*D), что означает, что справа от найденного числа не должно быть другой цифры (d), независимо от того, сколько других символов находится перед ней.
=RegExpExtract(A8; «(d+)(?!.*d)»)
Результат вы видите на скриншоте выше.
Подсказки:
- Чтобы получить конкретное вхождение, используйте d+ для шаблона и соответствующий порядковый номер для instance_num.
- Формула для извлечения всех чисел рассматривается ниже.
Регулярное выражение для извлечения всех совпадений
Понемногу усложняя наш пример, предположим, что вы хотите получить все числа из строки, а не только одно.
Как вы помните, количество извлеченных совпадений определяется необязательным аргументом instance_num. Если нужны все совпадения, тогда вы просто опускаете этот параметр:
=RegExpExtract(A2; «d+»)
Формула прекрасно работает для одной ячейки, но поведение отличается в Excel с динамическим массивом и нединамических версиях.
Excel 365 и Excel 2021
Благодаря поддержке динамических массивов, обычная формула автоматически распределяется на столько ячеек, сколько необходимо для отображения всех вычисленных результатов.

Excel 2019 — 2007
В не-динамическом Excel приведенная выше формула вернет только первое совпадение. Чтобы получить несколько совпадений, вам нужно сделать её формулой массива. Для этого выберите диапазон ячеек, в которых вы хотите видеть результаты, введите выражение в строку формул и нажмите Ctrl + Shift + Enter, чтобы завершить ввод.
Обратной стороной этого подхода является множество ошибок #Н/Д!, появляющихся в «лишних ячейках». К сожалению, с этим ничего не поделаешь (ни ЕСЛИОШИБКА, ни ЕНД, увы, не этого исправят).

Важно! Это правило в старых версиях Excel действует всегда, когда вам нужно извлечь из текста сразу несколько значений и записать каждое из них в отдельную ячейку.
Как извлечь все совпадения в одну ячейку
Очевидно, что при обработке столбца данных описанный выше подход не сработает. Просто некуда будет выводить результат, так как в каждой строке есть текст для обработки. В этом случае идеальным решением было бы вернуть все совпадения в одной ячейке. Для этого передайте результаты в функцию ОБЪЕДИНИТЬ() и разделите их любым разделителем, который вам нравится. К примеру, запятой и пробелом после неё:
=ОБЪЕДИНИТЬ(«; «;ИСТИНА; RegExpExtract(A5; $A$2))

Примечание. Поскольку функция ОБЪЕДИНИТЬ доступна только в Excel для Microsoft 365, Excel 2021 и Excel 2019, формула не будет работать в более старых версиях.
Извлекаем текст из строки
Извлечение текста из буквенно-цифровой строки в Excel — довольно сложная задача, если использовать формулы. С регулярным выражением это становится проще простого. Просто используйте отрицательный класс, чтобы выбрать все, что не является цифрой.
Шаблон: [^d]+
Чтобы получить подстроки в отдельных ячейках используем формулу:
=RegExpExtract(A5; «[^d]+»)

Примечание. В Excel 2019 и ранее не забывайте вводить эту формулу в диапазон ячеек как формулу массива. Это было подробно описано выше.
Чтобы вывести все совпадения в одну ячейку, вложите функцию RegExpExtract в ОБЪЕДИНИТЬ следующим образом:
=ОБЪЕДИНИТЬ(«»;ИСТИНА; RegExpExtract(A5; $A$2))

Если нет необходимости между извлекаемым текстом вставлять какие-либо разделители, то можно применить функцию СЦЕП, которая работает в более старых версиях Excel:
=СЦЕП(RegExpExtract(A5;$A$2))
Результат будет таким же, как вы видите на скриншоте выше.
Извлекаем адрес электронной почты из текста
Чтобы извлечь адрес электронной почты из ячейки, содержащей много различной информации, напишите регулярное выражение, которое копирует структуру адреса электронной почты.
Шаблон : [w.-]+@[A-Za-z0-9.-]+.[A-Za-z]{2,24}
Давайте разберём подробнее:
- [w.-]+ — это имя пользователя, которое может включать 1 или несколько буквенно-цифровых символов, подчеркивания, точки и дефисы.
- @ условное обозначение для адреса электронной почты
- [A-Za-z0-9.-]+ — это доменное имя почтового сервера, состоящее из прописных и строчных букв, цифр, дефисов и точек (в случае субдоменов). Подчеркивания здесь недопустимы, поэтому используются 3 разных набора символов (например, A-Z a-z и 0-9) вместо w, который соответствует любой букве, цифре или подчеркиванию.
- .[A-Za-z]{2,24} – имя домена первого уровня. Состоит из точки, за которой следуют прописные и строчные буквы. Большинство доменов верхнего уровня состоят из трех букв (например, .com, .org, .ru и т. д.). Но теоретически они могут содержать от 2 до 24 букв (самый длинный зарегистрированный начальный домен).
Предполагая, что текст находится в A5, а шаблон в A2, формула для извлечения адреса электронной почты:
=RegExpExtract(A5; $A$2)
Результат вы видите на рисунке ниже.

Как извлечь имя домена из электронной почты
Когда дело доходит до извлечения домена электронной почты, первая мысль, которая приходит в голову, — это использовать выражение для поиска текста, который следует сразу за символом @.
Шаблон : @([A-Za-z0-9.-]+.[A-Za-z]{2,24})
Передаём его в нашу функцию:
=RegExpExtract(A5; «@([A-Za-z0-9.-]+.[A-Za-z]{2,24})»)
И получаем:

При использовании классических регулярных выражений все, что находится за пределами шаблона, не включается в извлекаемую подстроку. Никто не знает, почему VBA RegEx работает по-другому и зачем-то захватывает еще и символ «@». Чтобы избавиться от него, вы можете удалить первый символ из результата, заменив его пустой строкой.
=ЗАМЕНИТЬ(RegExpExtract(A5; «@([A-Za-z0-9.-]+.[A-Za-z]{2,24});1;1;””)
На скриншоте ниже вы видите результат без лишних знаков.

Извлечение телефонных номеров
Номера телефонов можно записывать совершенно по-разному, поэтому найти решение, работающее при любых обстоятельствах, практически невозможно. Тем не менее, вы можете записать все форматы, используемые в вашем наборе данных, и попытаться использовать их.
В этом примере мы собираемся создать регулярное выражение, которое будет извлекать телефонные номера в любом из этих форматов:
| (123) 345-6789 | 1233456789 | 123.345.6789 |
| (123) 345 6789 | 123-345-6789 | 123 345 6789 |
| (123)3456789 |
Шаблон : (?d{3}[-. )]*d{3}[-. ]?d{4}b
- Первая часть (?D{3} соответствует нулю или одной открывающей скобке, за которой следуют три цифры d{3}.
- [-.)]*. Выражение в квадратных скобках означает любой из этих символов: дефис, точка, пробел или закрывающая скобка, встречающийся 0 или более раз.
- Затем у нас снова три цифры d{3}, за которыми следует любой дефис, точка или пробел [-. ]?
- После этого идет группа из четырех цифр d{4}.
- Наконец, есть граница слова b, определяющая, что номер телефона, который мы ищем, не может быть частью большего числа.
Полная формула принимает такой вид:
=RegExpExtract(A5, «(?d{3}[-. )]*d{3}[-. ]?d{4}b»)

Имейте в виду, что указанное выше регулярное выражение может возвращать несколько ложноположительных результатов, например 123) 456 7899 или (123 456 7899. Приведенная ниже версия устраняет эти проблемы. Однако этот синтаксис работает только в функциях VBA RegExp, а не в классических регулярных выражениях.
Шаблон : ((d{3})|d{3})[-. ]?d{3}[-. ]?d{4}b
Аналогичным образом можно извлечь из описания товара его артикул, который вставил в ячейку сканер штрих-кодов.
Достаём дату из текста
Регулярное выражение для извлечения даты зависит от формата, в котором она записана. Рассмотрим на примерах.
Для извлечения таких дат, как 21.01.2021 или 01.01.2021, подходит регулярное выражение:
d{1,2}/d{1,2}/(d{4}|d{2})
Формула ищет группу из 1 или 2 цифр d{1,2}, за которой следует косая черта, после которой – другая группа из 1 или 2 цифр, за которой следует косая черта, после которой группа из 4 или 2 цифр (d{4}|d{2}). Обратите внимание, что сначала мы ищем 4-значные годы, а только потом 2-значные. Если мы напишем наоборот, из всех чисел, обозначающих годы, будут выбраны только первые две цифры. Это связано с тем, что после того, как первое условие в конструкции ИЛИ выполнено, остальные условия уже не проверяются.
Чтобы извлечь из текста такие даты, как 1 января 21 или 1 января 2021 года, используйте шаблон:
d{1,2}-[A-Za-z]{3}-d{2,4}
Он ищет группу из 1 или 2 цифр, за которыми следует дефис, далее за которым следует группа из 3 заглавных или строчных букв, потом — снова дефис, за которым в свою очередь — группа из 4 или 2 цифр.
После объединения этих двух шаблонов мы получаем следующее регулярное выражение:
bd{1,2}[/-](d{1,2}|[A-Za-z]{3}|[А-Яа-я]{3})[/-](d{4}|d{2})b
Где:
- Первая часть состоит из 1 или 2 цифр: d{1,2}
- Вторая часть включает 1 или 2 цифры или 3 буквы русского либо латинского алфавита: (d{1,2}|[A-Za-z]{3}|[А-Яа-я]{3})
- Третья часть представляет собой группу из 4 либо 2 цифр: (d{4}|d{2})
- Разделитель – это косая черта или дефис: [/-]
- Граница слова b помещена с обеих сторон, чтобы было понятно, что дата – это отдельное слово, а не часть большей строки.
Как вы можете видеть на скриншоте ниже, функция успешно извлекает даты и исключает подстроки, такие как 11/22/333. Однако она по-прежнему возвращает ложноположительные результаты. В нашем случае подстрока 11-ABC-2222 в A11 технически соответствует формату даты дд-ммм-гггг и поэтому извлекается.

Чтобы исключить такой ошибочный выбор, вы можете заменить часть [A-Za-z]{3}|[А-Яа-я]{3}) полным списком трехбуквенных сокращений месяцев:
bd{1,2}[/-](d{1,2}|(Янв|Фев|Мар|Апр|Май|Июн|Июл|Авг|Сен|Окт|Ноя|Дек))[/-](d{4}|d{2})b
Чтобы игнорировать регистр букв, мы устанавливаем последний аргумент нашей пользовательской функции в ЛОЖЬ:
=RegExpExtract(A5; $A$2; 1; ЛОЖЬ)
И на этот раз мы получаем идеальный результат:

Как видите, все даты успешно извлечены. При этом обработка латиницы в этом шаблоне не была предусмотрена.
Извлечь время из текста
Чтобы получить время в формате чч:мм или чч:мм:сс , подойдет следующее выражение.
b(0?[0-9]|1[0-2]):[0-5]d(:[0-5]d)?S?(AM|PM)b|b([0-9]|[0-1]d|2[0-3]):[0-5]d(:[0-5]d)?(?!:)
Разбив это регулярное выражение, вы увидите 2 части, разделенные символом | . Это подразумевает логику ИЛИ. Другими словами, мы ищем подстроку, которая соответствует одному из приведенных ниже выражений.
b([0-9]|[0-1]d|2[0-3]):[0-5]d(:[0-5]d)?(?!:)
Часть часа может быть любым числом от 0 до 23. Чтобы получить ее, используется конструкция ИЛИ ([0-9]|[0-1]d|2[0-3]), где:
- [0-9] соответствует любому числу от 0 до 9.
- [0-1]d соответствует любому числу от 00 до 19
- 2[0-3] означает любое числу от 20 до 23
Минуты [0-5]d — любое число от 00 до 59.
Секунды (:[0-5]d)? также любое число от 00 до 59. Символ ? (квантификатор) означает ноль или одно появление, поскольку секунды могут быть включены или не включены во значение времени.
Отрицательный просмотр вперед (?! добавляется для пропуска заведомо неправильных значений, таких как 20:30:70.
На всякий случай для 12-часового формата времени в шаблон добавлено AM|PM. Поскольку AM/PM может быть как в верхнем, так и в нижнем регистре, мы делаем функцию нечувствительной к регистру:
=RegExpExtract(A5; $A$2; 1; ЛОЖЬ)

Как найти последнее вхождение нужного символа и извлечь текст после него
Регулярное выражение позволяет нам найти последнее вхождение любого указанного символа (тире, двоеточия, точки, запятой, цифры или буквы). А затем уже получить следующую за ним часть текста – дело техники.
Чтобы получить текст после последней точки в строке, используйте регулярное выражение
([^..]+)$
Подставив его в функцию, получим формулу:
= RegExpExtract(A5; «([^..]+)$»)
Обратите внимание на конструкцию ..
Она как раз и обозначает любой символ . , следующий после точки . Знак + обозначает, что таких символов может быть сколь угодно много. А $ указывает, что все эти операции происходят в конце строки.
Из исходной строки. вида A.B.C.DD-EEE мы получаем DD-EEE.
Вы можете заменить . на любой другой символ по вашему усмотрению. К примеру, регулярное выражение ([^-.]+)$ возвратит нам все, что следует после последнего тире, то есть ЕЕЕ.
Надеюсь, приведенные выше примеры дали вам некоторые идеи о том, как использовать регулярные выражения в ваших таблицах Excel.
К сожалению, не все функции классических регулярных выражений поддерживаются в VBA. Если ваша задача не может быть выполнена с помощью VBA RegExp, я рекомендую вам прочитать следующий раздел, в котором обсуждаются гораздо более мощные функции .NET Regex.
Пользовательская функция Regex на основе .NET для извлечения текста в Excel
В отличие от функций VBA RegExp, которые может написать любой пользователь Excel, .NET RegEx — это область деятельности разработчика. Microsoft .NET Framework поддерживает полнофункциональный синтаксис регулярных выражений, совместимый с Perl 5. Эта статья не научит вас писать такие функции (я не программист и не имею ни малейшего представления о том, как это сделать
Четыре мощные функции, обрабатываемые стандартным механизмом .NET RegEx, уже написаны и включены в надстройку Ultimate Suite. Далее мы продемонстрируем некоторые практические применения функции, специально разработанной для извлечения текста в Excel.
Предполагая, что у вас установлена последняя версия Ultimate Suite, извлечение текста с использованием регулярных выражений сводится к этим двум шагам:
- На вкладке «Ablebits Data» в группе «Text» щелкните «Regex Tools» .

- На панели «Regex Tools» выберите исходные данные, введите свой шаблон регулярного выражения и выберите параметр «Extract (Извлечь)». Чтобы получить результат как пользовательскую функцию, а не как значение, установите флажок «Insert as formula (Вставить как формулу)». Когда закончите, нажмите кнопку «Extract (Извлечь)».

Результаты появятся в новом столбце справа от исходных данных:

Эта пользовательская функция имеет следующий синтаксис:
AblebitsRegexExtract (ссылка, регулярное_выражение)
Где:
- Ссылка (обязательно) — ссылка на ячейку, содержащую исходную строку.
- Regular_expression (обязательно) — шаблон регулярного выражения для сопоставления.
Важное замечание! Функция работает только при установленном Ultimate Suite for Excel.
Примечания по использованию
Чтобы сделать процесс обучения более плавным, а опыт — более приятным, обратите внимание на следующие моменты:
- Чтобы создать формулу, вы можете использовать наши инструменты для регулярных выражений или диалоговое окно «Вставить функцию» в Excel или ввести полное имя функции в ячейку. После того, как формула вставлена, вы можете управлять ею (редактировать, копировать или перемещать), как любой собственной формулой.
- Шаблон, который вы вводите на панели инструментов Regex, переходит ко второму аргументу. Также можно сохранить регулярное выражение в отдельной ячейке. В этом случае просто используйте ссылку на ячейку для второго аргумента.
- Функция извлекает первое найденное совпадение.
- По умолчанию функция чувствительна к регистру. Для сопоставления без учета регистра используйте шаблон (?I).
- Если совпадение не найдено, возвращается ошибка #Н/Д.
Извлечение строки между двумя символами
Чтобы получить текст между двумя символами, вы можете использовать либо группу захвата, либо просмотр.
Допустим, вы хотите выделить текст между скобками.
Шаблон 1 : [(.*?)]
Шаблон 2 : (?<=[)(.*?)(?=])
С шаблоном в A2 формула выглядит следующим образом:

Как получить все совпадения
Как уже упоминалось, функция AblebitsRegexExtract может извлекать только одно совпадение. Чтобы получить все совпадения, вы можете использовать функцию VBA, которую мы обсуждали ранее. Однако есть одно предостережение — VBA RegExp не поддерживает захват групп, поэтому приведенный выше шаблон также вернет «граничные» символы, в нашем случае квадратные скобки.
Чтобы избавиться от скобок, заменяйте их пустыми строками («»), используя следующую формулу:
=ПОДСТАВИТЬ(ПОДСТАВИТЬ(ОБЪЕДИНИТЬ(«, «;ИСТИНА; RegExpExtract(A5; $A$2)); «]»; «»);»[«;»»)

Для удобства чтения мы используем запятую в качестве разделителя.
Получаем текст между двумя строками
Подход, который мы разработали для выделения текста между двумя символами, также будет работать для выделения текста между двумя строками.
Например, чтобы получить все, что находится между «test 1» и «test 2», используйте следующее регулярное выражение.
Шаблон : test 1(.*?)test 2
Полная формула:
=AblebitsRegexExtract(A5; «test 1(.*?)test 2»)

Достаём домен из URL
Даже с использованием регулярных выражений извлечение доменных имен из URL-адресов – нетривиальная задача. В зависимости от вашей конечной цели выберите одно из следующих регулярных выражений.
Чтобы получить полное доменное имя, включая поддомены
Шаблон : (?:https?:|^|S)//(((?:[A-Za-zd-.]{2,255}.)?[A-Za-zd-]{1,63}.[A-Za-z]{2,24})
Чтобы получить домен второго уровня без поддоменов
Шаблон : (?:Https?:|^|S)//(?:[A-Za-zd-.]{2,255}.)?([A-Za-zd-]{1,63}.[A-Za-z]{2,24})
Теперь давайте посмотрим, как эти регулярные выражения работают на примере https://www.mobile.ablebits.com в качестве образца URL:
- (?:https?:|^|s) — шаблон, который определяет, но не извлекает подстроку, которой предшествует одно из следующих: https, http, начало строки (^), символ пробела (s). Последние два элемента включены для обработки URL-адресов, относящихся к протоколу, например «//google.com».
- //- две косые черты (каждой из них предшествует обратная косая черта, чтобы избежать особого назначения косой черты в коде шаблона и интерпретировать ее буквально).
- (?:[A-Za-zd-.]{2,255}.)? – шаблон для определения доменов третьего, четвертого и т. д., если таковые имеются ( 11-я строка в нашем примере URL). Поддомен может иметь длину от 2 до 255 символов, отсюда и квантификатор {2,255}.
- ([A-Za-zd-]{1,63}.[A-Za-z]{2,24}) – шаблон для извлечения домена второго уровня. Максимальная длина домена второго уровня — 63 символа. Самый длинный из существующих в настоящее время доменов состоит из 24 символов.
В зависимости от того, какое регулярное выражение введено в A2, приведенная ниже формула даст разные результаты:
=AblebitsRegexExtract(A5; $A$2)
На скриншоте ниже вы видите пример извлечения как полного доменного имени со всем поддоменами, так и только домена второго уровня.

Вот как можно извлекать части текста в Excel с помощью регулярных выражений. Благодарю вас за чтение!