It’s possible to filter single range of values in a worksheet by adding an autofilter. If you need to filter multiple ranges, you can use tables and apply a separate filter for each table.
Note
Filters and sorts can only be configured by openpyxl but will need to be applied in applications like Excel. This is because they actually rearrange, format and hide rows in the range.
To add a filter you define a range and then add columns. You set the range over which the filter by setting the ref attribute. Filters are then applied to columns in the range using a zero-based index, eg. in a range from A1:H10, colId 1 refers to column B. Openpyxl does not check the validity of such assignments.
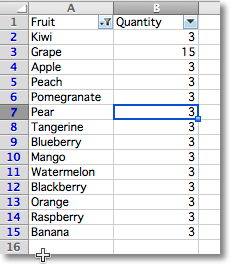
from openpyxl import Workbook from openpyxl.worksheet.filters import ( FilterColumn, CustomFilter, CustomFilters, DateGroupItem, Filters, ) wb = Workbook() ws = wb.active data = [ ["Fruit", "Quantity"], ["Kiwi", 3], ["Grape", 15], ["Apple", 3], ["Peach", 3], ["Pomegranate", 3], ["Pear", 3], ["Tangerine", 3], ["Blueberry", 3], ["Mango", 3], ["Watermelon", 3], ["Blackberry", 3], ["Orange", 3], ["Raspberry", 3], ["Banana", 3] ] for r in data: ws.append(r) filters = ws.auto_filter filters.ref = "A1:B15" col = FilterColumn(colId=0) # for column A col.filters = Filters(filter=["Kiwi", "Apple", "Mango"]) # add selected values filters.filterColumn.append(col) # add filter to the worksheet ws.auto_filter.add_sort_condition("B2:B15") wb.save("filtered.xlsx")
This will add the relevant instructions to the file but will neither actually filter nor sort.
Advanced filters¶
The following predefined filters can be used: CustomFilter, DateGroupItem, DynamicFilter, ColorFilter, IconFilter and Top10 ColorFilter, IconFilter and Top10 all interact with conditional formats.
The signature and structure of the different kinds of filter varies significantly. As such it makes sense to familiarise yourself with either the openpyxl source code or the OOXML specification.
CustomFilter¶
CustomFilters can have one or two conditions which will operate either independently (the default), or combined by setting the and_ attribute. Filter can use the following operators: 'equal', 'lessThan', 'lessThanOrEqual', 'notEqual', 'greaterThanOrEqual', 'greaterThan'.
Filter values < 10 and > 90:
from openpyxl.worksheet.filters import CustomFilter, CustomFilters flt1 = CustomFilter(operator="lessThan", val=10) flt2 = CustomFilter(operator=greaterThan, val=90) cfs = CustomFilters(customFilter=[flt1, flt2]) col = FilterColumn(colId=2, customFilters=cfs) # apply to **third** column in the range filters.filter.append(col)
To combine the filters:
In addition, Excel has non-standardised functionality for pattern matching with strings. The options in Excel: begins with, ends with, contains and their negatives are all implemented using the equal (or for negatives notEqual) operator and wildcard in the value.
For example: for “begins with a”, use a*; for “ends with a”, use *a; and for “contains a””, use *a*.
DateGroupItem¶
Date filters can be set to allow filtering by different datetime criteria such as year, month or hour. As they are similar to lists of values you can have multiple items.
To filter by the month of March:
from openpyxl.worksheet.filters import DateGroupItem df1 = DateGroupItem(month=3, dateTimeGrouping="month") col = FilterColumn(colId=1) # second column col.filters.dateGroupItem.append(df1) df2 = DateGroupItem(year=1984, dateTimeGrouping="year") # add another element col.filters.dateGroupItem.append(df2) filters.filter.append(col)
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
Prerequisites: Python Pandas Pandas is mainly popular for importing and analyzing data much easier. Pandas is fast and it has high-performance & productivity for users.  In this article, we are trying to filter the data of an excel sheet and save the filtered data as a new Excel file. Note: You can click on this filename to download this sheet datasets.xlsx Excel Sheet used:
In this article, we are trying to filter the data of an excel sheet and save the filtered data as a new Excel file. Note: You can click on this filename to download this sheet datasets.xlsx Excel Sheet used: 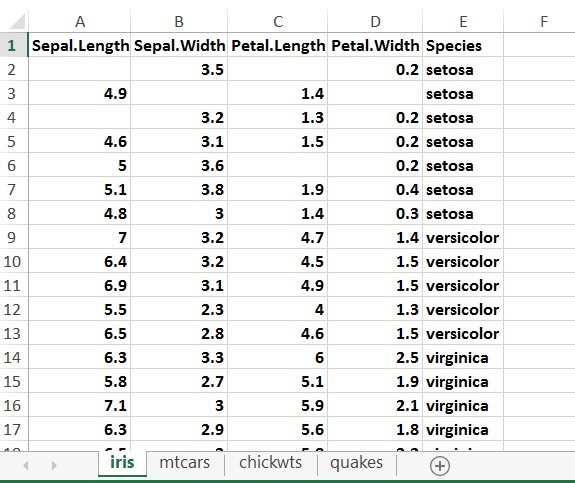 In this excel sheet we are having three categories in Species column-
In this excel sheet we are having three categories in Species column-
- Setosa
- Versicolor
- Virginica
Now our aim is to filter these data by species category and to save this filtered data in different sheets with filename =species.subcategory name i.e. after the execution of the code we will going to get three files of following names-
- Setosa.xlsx
- Versicolor.xlsx
- Virginica.xlsx
Below is the implementation.
Python3
import pandas
data = pandas.read_excel("datasets.xlsx")
speciesdata = data["Species"].unique()
for i in speciesdata:
a = data[data["Species"].str.contains(i)]
a.to_excel(i+".xlsx")
Output: 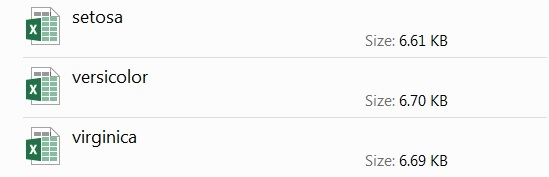 Explanation:
Explanation:
- First, we have imported the Pandas library.
- Then we have loaded the data.xlsx excel file in the data object.
- To fetch the unique values from that species column we have used unique() function. To check the unique values in the Species column we have called the unique() in speciesdata object.
- Then we will going to iterate the speciesdata object as we will going to store the Species column unique values(i.e. Setosa, Versicolor, Virginica) one by one.
- In object “a” we are filtering out the data that matches the Species.speciesdata i.e. in each iteration object a will going to store three different types of data i.e. data of Setosa type then data of Versicolor type and at last the data of Virginica type.
- Now to save the filtered data one by one in excel file we have used to_excel function, where, the file will going to be saved by the speciesdata name.
Like Article
Save Article
I am trying to create a filter in excel programatically, so when the sheet is created with openpyxl, the first row of each sheet will already be set to a be a filter. I’ve looked at the docs but all I can find is how to filter data not to create a filter.
Is it even possible with the current implementation of openpyxl?
asked Apr 1, 2016 at 13:10
![]()
1
openpyxl does support filters. See the worksheet.filters module and the associated tests.
Sample of what you can do:
ws.auto_filter.ref = 'C1:G9'
answered Apr 1, 2016 at 15:32
![]()
Charlie ClarkCharlie Clark
18.1k4 gold badges47 silver badges54 bronze badges
2
Copy and paste this into a .py file and run.
import pandas as pd
import numpy as np
# Here is an example dataframe
df_example = pd.DataFrame(np.random.randint(0,100,size=(100, 4)), columns=list('ABCD'))
# Create xlsx file
filepath = 'mytempfile.xlsx'
with pd.ExcelWriter(filepath, engine='xlsxwriter') as writer:
df_example.to_excel(writer, sheet_name='Sheet1',index=False)
# Add filter feature to first row
import openpyxl
xfile = openpyxl.load_workbook(filepath)
sheet = xfile.get_sheet_by_name('Sheet1')
maxcolumnletter = openpyxl.utils.get_column_letter(sheet.max_column)
sheet.auto_filter.ref = 'A1:'+maxcolumnletter+str(len(sheet['A']))
# Save the file
xfile.save(filepath)
print 'your file:',filepath
answered Jul 19, 2018 at 15:18
![]()
Введение¶
Я слышал от разных людей, что мои предыдущие статьи (тут и тут) об общих задачах Excel в pandas оказались полезными. В этой статье мы продолжим эту традицию, проиллюстрировав различные примеры индексирования pandas с использованием Excel функции Filter в качестве модели для понимания процесса.
Оригинал статьи Криса здесь
Одна из первых вещей, которую изучает большинство новых пользователей pandas, — это фильтрация данных. Несмотря на то, что я работал с pandas в течение последних нескольких месяцев, недавно я понял, что у подхода к фильтрации pandas есть еще одно преимущество, которое я не использовал в повседневной работе: вы можете фильтровать по заданному набору столбцов, но обновлять другой набор столбцов, используя упрощенный синтаксис pandas. Это похоже на то, что я называю процессом «Фильтрация и редактирование» в Excel.
В этой статье будут рассмотрены некоторые примеры фильтрации DataFrame и обновления данных на основе различных критериев. Попутно я объясню еще кое-что об индексировании pandas и о том, как использовать такие методы индексирования, как .loc и .iloc, для быстрого и легкого обновления подмножества данных на основе простых или сложных критериев.
Excel: «Фильтрация и редактировани延
Помимо Pivot Table (сводной таблицы), одним из самых популярных инструментов в Excel является Filter. Этот простой инструмент позволяет быстро фильтровать и сортировать данные по различным числовым, текстовым критериям и критериям форматирования.
Вот снимок экрана с некоторыми образцами, отфильтрованными по нескольким критериям:

Процесс фильтрации интуитивно понятен даже начинающему пользователю Excel. Я также заметил, что люди используют эту функцию для выбора строк данных, а затем обновляют дополнительные столбцы на основе критериев строки. Пример ниже показывает, что я имею в виду:
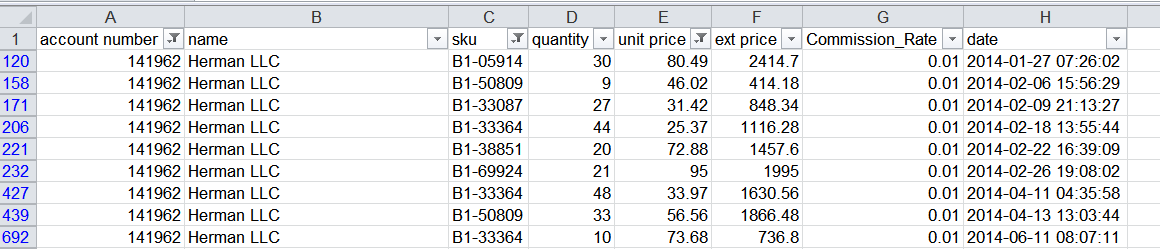
В этом примере я отфильтровал данные по Account Number (номеру счета), SKU (артикулу) и Unit Price (цене за единицу). Затем я вручную добавил столбец Commission_Rate и ввел 0.01 в каждую ячейку. Преимущество этого подхода заключается в том, что его легко понять и он может помочь управлять относительно сложными данными без написания длинных формул Excel или использования VBA. Обратной стороной этого подхода является то, что он не воспроизводится, и извне может быть сложно понять, какие критерии использовались для фильтра.
Например, если вы посмотрите на скриншот, нет очевидного способа узнать, что отфильтровано, не глядя на каждый столбец. К счастью, мы можем сделать нечто очень похожее в pandas.
Логическое индексирование¶
Теперь, когда вы понимаете проблему, я хочу подробно рассказать о логической индексации (boolean indexing) в pandas. Это важная концепция, которую нужно понять, если вы хотите разобраться с индексированием и выбором данных в pandas. Эта идея может показаться сложной для начинающего пользователя (и, возможно, слишком простой для опытных), но я думаю, важно потратить некоторое время на ее понимание. Если вы усвоите эту концепцию, то основной процесс работы с данными в pandas упростится.
Pandas поддерживает индексацию (или выбор данных) с помощью меток (labels), целых чисел на основе позиции или списка логических значений (True/False). Использование списка логических значений для выбора строки называется логическим индексированием (boolean indexing), и ему будет уделено внимание в остальной части этой статьи.
Я обнаружил, что мой рабочий процесс, как правило, сосредоточен на использовании списков логических значений для выбора данных. Другими словами, когда я создаю DataFrames, я стараюсь сохранить в нем индекс по умолчанию.
Логическая индексация (
boolean indexing) — это один из нескольких мощных и полезных способов выбора строк данных в pandas.
Давайте посмотрим на несколько примеров DataFrames, чтобы прояснить, что делает логический индекс в pandas.
Во-первых, создадим DataFrame из списка Python:
Обратите внимание, как значения 0-3 автоматически присваиваются строкам. Это индексы, и они не имеют особого значения в этом наборе данных, но полезны для pandas.
Когда мы говорим о логической индексации, то имеем в виду, что можем передать список значений из True или False, представляющих каждую строку, которую мы хотим посмотреть.
Если хотим посмотреть данные для Jones LLC, Blue Inc и Mega Corp, то список True и False будет выглядеть следующим образом:
Неудивительно, что вы можете передать этот список в DataFrame, и он будет отображать только те строки, в которых значение равно True:
Вот визуальное изображение того, что произошло:

Ручное создание списка индекса работает, но, очевидно, не масштабируется и не очень полезно для чего-либо, кроме тривиального набора данных. К счастью, pandas позволяет очень легко создавать логические индексы, используя простой язык запросов, который должен быть знаком тем, кто использовал Python (или любой другой язык в этом отношении).
Для примера рассмотрим все линии продаж из США:
В примере показано, как pandas возьмет вашу традиционную логику Python, применит ее к DataFrame и вернет список логических значений. Этот список логических значений затем может быть передан в DataFrame для получения соответствующих строк данных.
В реальном коде вы бы не стали выполнять этот двухэтапный процесс.
Сокращенный вызов выглядит так:
Хотя эта концепция проста, но вы можете написать довольно сложную логику для фильтрации данных, используя возможности Python.
В этом примере
df[df.Country == 'US']эквивалентноdf[df["Country"] == 'US']. Обозначение.более чистое, но не будет работать, если в имени столбца присутствуют пробелы.
Выбор столбцов¶
Теперь, когда мы выяснили, как выбирать строки данных, как мы можем контролировать, какие столбцы отображать. В приведенном выше примере нет очевидного способа сделать это. Pandas может поддерживать этот вариант, используя два типа индексации на основе местоположения: .loc и .iloc. Эти функции также позволяют нам выбирать столбцы в дополнение к выбору строк, который мы видели до сих пор.
Существует много недоразумений относительно того, когда использовать .loc или iloc. Краткое описание различий заключается в следующем:
.locиспользуется для индексации меток.ilocиспользуется для целых чисел на основе позиции
Итак, вопрос в том, какой из них использовать? Признаю, что я тоже несколько раз спотыкался на этом. Я обнаружил, что чаще всего использую .loc. В основном потому, что мои данные не поддаются осмысленной индексации на основе позиции (другими словами, мне редко нужен .iloc), поэтому я придерживаюсь .loc.
Честно говоря, у каждого из этих методов есть свое место и они полезны во многих ситуациях. Одна из областей, в частности, связана с иерархической индексацией (MultiIndex) DataFrames.
Теперь, когда мы рассмотрели эту тему, давайте покажем, как фильтровать DataFrame по значениям в строке и выбирать определенные столбцы для отображения.
Продолжая пример, что, если мы просто хотим показать имена учетных записей (account), которые соответствуют нашему индексу?
Используя .loc, это просто:
Если вы хотите видеть несколько столбцов, просто передайте список:
Настоящая сила — это когда вы создаете более сложные запросы к своим данным. В этом случае давайте покажем все названия аккаунтов (account) и страны (Country), где продажи (Total Sales) > 200:
Этот процесс можно сравнить с фильтром Excel, который мы обсуждали выше. У вас есть дополнительное преимущество: вы также можете ограничить количество извлекаемых столбцов, а не только строк.
Редактирование столбцов¶
Все это хорошая основа, но где этот процесс действительно проявляется, так это когда вы используете аналогичный подход для обновления одного или нескольких столбцов на основе выбора строки.
В качестве простого примера давайте добавим к нашим данным столбец rate (ставка комиссионного вознаграждения):
Допустим, если вы продали более 100, ваша ставка составит 5%.
Основная задача — установить логический индекс для выбора столбцов, а затем присвоить значение столбцу rate:
Надеюсь, если вы прочли эту статью, то теперь сможете понять, как работает этот синтаксис.
Теперь у вас есть основы подхода «Фильтр и редактирование».
В последнем разделе этот процесс будет более подробно показан в Excel и pandas.
Собираем все вместе¶
В последнем примере мы создадим простой калькулятор комиссий, используя следующие правила.
- Все комиссии рассчитываются на уровне транзакции.
- Базовая комиссия со всех продаж составляет
2%. - Все рубашки получат комиссию
2.5%. - Действует специальная программа, при которой
продажа > 10 ремней(belts) за одну транзакцию получает комиссию4%. - Существует специальный бонус в размере
250 долларов США плюс комиссия 4.5%для всехпродаж обуви > 1000 долларов СШАза одну транзакцию.
Чтобы сделать это в Excel, используя подход «Фильтр и редактирование»:
- Добавьте столбец комиссии с
2%. - Добавьте бонусный столбец
0 долларов. - Отфильтруйте рубашки и измените долей на
2.5%. - Очистить фильтр.
- Отфильтруйте ремни (
belts) иколичество (quantity) > 10и измените значение на4%. - Очистить фильтр.
- Отфильтруйте
обувь > 1000 долларов СШАи добавьте комиссию и бонус в размере4.5%и250 долларов СШАсоответственно.
Я не собираюсь показывать снимки экрана каждого шага, но вот последний фильтр:
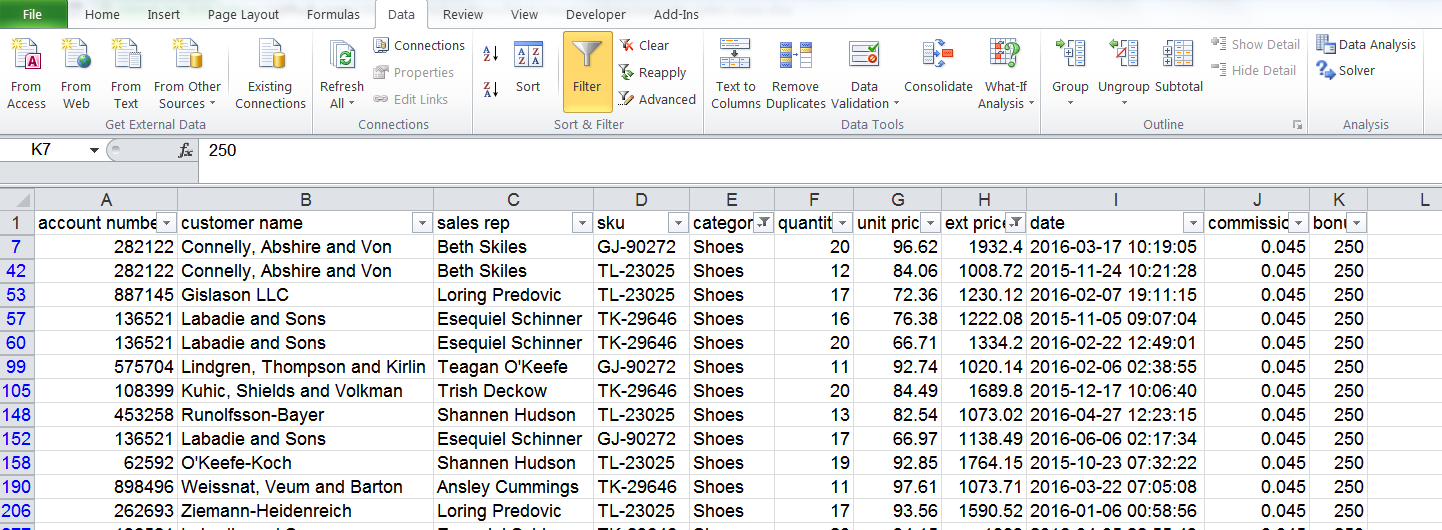
Этот подход достаточно прост для манипуляций в Excel, но его нельзя повторить и проверить. Конечно, есть и другие подходы для этого в Excel — например, формулы или VBA. Однако этот подход с фильтром и редактированием является обычным и иллюстрирует логику pandas.
Теперь давайте рассмотрим весь пример в pandas.
Сначала прочтите Excel файл и добавьте столбец со значением по умолчанию 2%:
Следующее правило комиссии: все рубашки получают 2.5%, а продажи поясов > 10 получают ставку 4%:
Последнее правило комиссии — добавить специальный бонус:
Для расчета комиссионных:
Заключение¶
Спасибо, что прочитали статью. Я считаю, что одна из самых больших проблем для новых пользователей в изучении того, как использовать pandas, — это выяснить, как использовать свои знания на основе Excel для создания эквивалентного решения на основе pandas. Во многих случаях решение pandas будет более надежным, быстрым, легким для аудита и более мощным. Однако процесс обучения может занять некоторое время. Я надеюсь, что этот пример, показывающий, как решить проблему с помощью инструмента «Фильтр» в Excel, станет полезным руководством для тех, кто только начинает свое pandas путешествие. Удачи!
Подписка на онлайн-обучение ![]()
![]()
Filter Data
- The auto_filter attribute is employed to line filtering and sorting conditions.

Openpyxl Filter
Sample Code
from openpyxl import Workbook
wb = Workbook()
sheet = wb.active
sheet['A3'] = 40
sheet['B3'] = 26
row_count = [
(93,45),
(23,54),
(80,43),
(21,12),
(63,29),
(34,15),
(80,68),
(20,41)
]
for row in row_count:
sheet.append(row)
print(sheet.dimensions)
for a1,a2 in sheet[sheet.dimensions]:
print(a1.value, a2.value)
sheet.auto_filter.add_sort_condition('B2:B8')
sheet.auto_filter.add_filter_column(1, ['40', '26'])
wb.save('dimension_1.xlsx')
Output
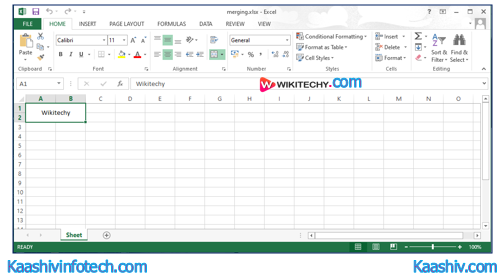
Merge Data
- We can merge the cell using the merge_cells() method. once we merge the cells, the top-left one is removed from the worksheet
- The openpyxl also provides the unmerged_cells() method to unmerge the cell.
Openpyxl Merge
Sample Code
from openpyxl.styles import Alignment
wb = Workbook()
sheet = wb.active
sheet.merge_cells('A1:B2')
cell = sheet.cell(row=1, column=1)
cell.value = 'Wikitechy'
cell.alignment = Alignment(horizontal='center', vertical='center')
wb.save('merging.xlsx')
Output