
In this article, we want to show you 2 quick and easy to use methods to extract texts from text boxes in your Word document.
From time to time, we can get a Word file containing a large number of text boxes. Usually, there will be texts or relative contents inside those boxes. Then there can be the need to get only the texts inside instead of keeping the whole text box.
Certainly, it’s quick to retrieve words within one single text box simply by copying the text out and pasting it somewhere else. However, when it comes to hundreds of them, we’d better learn some quick tips to get the job done.
Method 1: Use the “Selection Pane”
- First and foremost, click “Home” tab.
- Then click “Select” icon in “Editing” group.
- Next, on the drop-down menu, choose “Selection Pane”.

- Now on the right side of the screen, you can see all text boxes visible on the pane.
- Press “Ctrl” and click those text box names on the pane one by one to select them all.
- And move to lay cursor on one of the box line and right click.
- On the list-option, click “Copy”. Now if you won’t need those boxes anymore, just press “Delete”.

- Next click “Start” to view the Windows menu.
- Choose “WordPad” and open it.

- Then click “Paste” to get all texts from the text boxes.

- Next, select all texts and right click to choose “Copy”.

- Now open a new Word document and right click to choose “Keep Text Only” to get the text.







Method 2: Use VBA Codes
As you may see, even with the first method, you can’t avoid selecting all text boxes. In case some of you just hate such labor work, here we are to offer you the way to run a macro. With method 2, you can extract all texts in one go and have the text boxes deleted.
- Firstly, press “Alt+ F11” to open the VBA editor.
- Secondly, click “Normal” and then “Insert”.
- Next choose “Module” to insert a new one.

- Then double click on the module name to open the editing area.
- Paste the following codes and click “Run”:



Sub DeleteTextBoxesAndExtractTheText()
Dim nNumber As Integer
Dim strText As String
' Delete all textboxes and extract the text from them
With ActiveDocument
For nNumber = .Shapes.Count To 1 Step -1
If .Shapes(nNumber).Type = msoTextBox Then
strText=strText& .Shapes(nNumber).TextFrame.TextRange.Text & vbCr
.Shapes(nNumber).Delete
End If
Next
End With
' Open a new document to paste the text from textboxes.
If strText <> "" Then
Documents.Add Template:="Normal"
ActiveDocument.Range.Text = strText
Else
MsgBox ("There is no textbox.")
End If
End Sub
Here is what you are likely to get:
Cope with Wrecked Word Files
Word is prone to errors and hence a frequent victim to corruption. Therefore, you have to manage your documents properly to protect them from damage. For once they getting corrupted, you will face the risk of losing them permanently. Then you will have to use the corrupted Word data recovery tool.
Author Introduction:
Vera Chen is a data recovery expert in DataNumen, Inc., which is the world leader in data recovery technologies, including Excel file error recovery tool and pdf repair software products. For more information visit www.datanumen.com
A text box’s purpose is to allow the user to input text information to be used by the program. Also the existing text information can be extracted from the text box. The following guide focuses on introducing how to extract text from text box in a Word document in C# via Spire.Doc for .NET.
Firstly, check out the text box information in the word document.
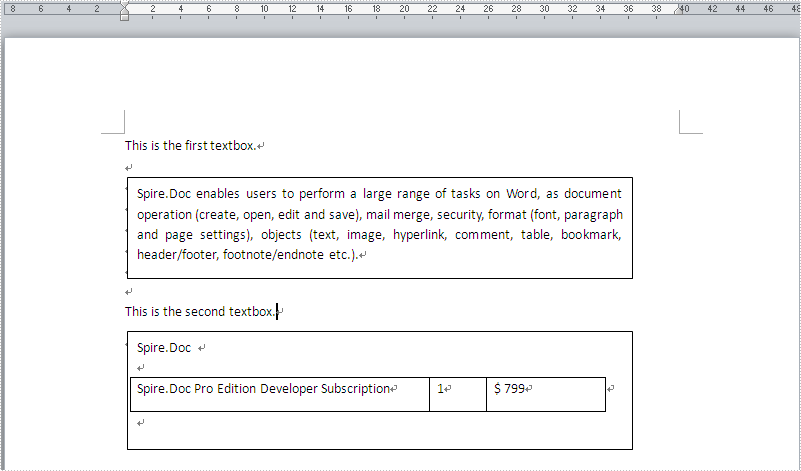
Secondly, download Spire.Doc and install on your system. The Spire.Doc installation is clean, professional and wrapped up in a MSI installer.
Then adds Spire.Doc.dll as reference in the downloaded Bin folder though the below path: «..Spire.DocBinNET4.0 Spire.Doc.dll».
Now it comes to the steps of how to extract text from text boxes.
Step 1: Load a word document from the file.
[C#]
Document document = new Document(); document.LoadFromFile(@"....Test.docx");
Step 2: Check whether text box exists in the documents.
[C#]
//Verify whether the document contains a textbox or not if (document.TextBoxes.Count > 0)
Step 3: Initialize a StreamWriter class for saving text which will be extracted next
[C#]
using (StreamWriter sw = File.CreateText("result.txt"))
Step 4: Extracted the text from text boxes.
[C#]
//Traverse the document
foreach (Section section in document.Sections)
{
foreach (Paragraph p in section.Paragraphs)
{
foreach (DocumentObject obj in p.ChildObjects)
//Extract text from paragraph in TextBox
if (objt.DocumentObjectType == DocumentObjectType.Paragraph)
{
sw.Write((objt as Paragraph).Text)
}
//Extract text from Table in TextBox
if (objt.DocumentObjectType == DocumentObjectType.Table)
{
Table table = objt as Table;
ExtractTextFromTables(table, sw);
}
//Extract text from Table
static void ExtractTextFromTables(Table table, StreamWriter sw)
{
for (int i = 0; i < table.Rows.Count; i++)
{
TableRow row = table.Rows[i];
for (int j = 0; j < row.Cells.Count; j++)
{
TableCell cell = row.Cells[j];
foreach (Paragraph paragraph in cell.Paragraphs)
{
sw.Write(paragraph.Text);
}
}
}
}
After debugging, the following result will be presented:
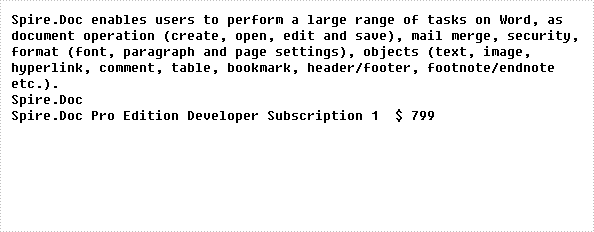
The full code:
[C#]
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using Spire.Doc;
using Spire.Doc.Fields;
using System.IO;
using Spire.Doc.Documents;
namespace ExtractTextFromTextBoxes
{
class Program
{
static void Main(string[] args)
{
Document document = new Document();
document.LoadFromFile(@"....Test.docx");
//Verify whether the document contains a textbox or not
if (document.TextBoxes.Count > 0)
{
using (StreamWriter sw = File.CreateText("result.txt"))
{
foreach (Section section in document.Sections)
{
foreach (Paragraph p in section.Paragraphs)
{
foreach (DocumentObject obj in p.ChildObjects)
{
if (obj.DocumentObjectType == DocumentObjectType.TextBox)
{
TextBox textbox = obj as TextBox;
foreach (DocumentObject objt in textbox.ChildObjects)
{
if (objt.DocumentObjectType == DocumentObjectType.Paragraph)
{
sw.Write((objt as Paragraph).Text);
}
if (objt.DocumentObjectType == DocumentObjectType.Table)
{
Table table = objt as Table;
ExtractTextFromTables(table, sw);
}
}
}
}
}
}
}
}
}
static void ExtractTextFromTables(Table table, StreamWriter sw)
{
for (int i = 0; i < table.Rows.Count; i++)
{
TableRow row = table.Rows[i];
for (int j = 0; j < row.Cells.Count; j++)
{
TableCell cell = row.Cells[j];
foreach (Paragraph paragraph in cell.Paragraphs)
{
sw.Write(paragraph.Text);
}
}
}
}
}
}
I am having some TextBoxes ( Shape > Text Box) inside a word document. The document is a CV template which includes a lot of them. I would like to select all Textboxes of the document, extract text, remove the text boxes and inject the extracted text. I have tried
const range = context.document.getSelection();
range.load("text");
and then sync the context so that I can get the text.
![]()
braX
11.5k5 gold badges20 silver badges33 bronze badges
asked Aug 12, 2020 at 10:55
![]()
1
I finally took the following workaround. It is and fast and works nicely in both Windows & macOS
-
Get OOXML of the document’s body
-
Parse OOXL.value & Generate an xmlDocument (xmlDoc)
-
Detect existing Textboxes & Shapes that contain text: getElementsByTagName(«wps:wsp»)
-
Extract text from (3)
-
Generate a simple xml TextElement with text extracted
-
Replace (3) with (5)
-
Serialize to xmlString the updated xmlDoc and get the updated OOXML.value
-
Insert updated OOXML.value to document replacing the existing one
Word.run(function (context) {
//Select document body and extract OOXML const body = context.document.body; const ooxml = body.getOoxml(); return context.sync().then(function () { //Initialize DOM Parser const parser = new DOMParser(); const xmlDoc = parser.parseFromString(ooxml.value, "text/xml"); //Get all runs const rows = xmlDoc.getElementsByTagName("w:r"); for (let j = 0; j < rows.length; j++) { const row = rows[j]; const rowHasTextBox = row.getElementsByTagName("wps:txbx").length > 0; //If no textbox, shape, wordart exists skip current run if (!rowHasTextBox) continue; //Select textbox, shape, wordart and get paragraphs const textboxContainer = row.getElementsByTagName("wps:txbx")[0]; const paragraphs = textboxContainer.getElementsByTagName("w:p"); // Create a new run which will replace the existing run const newRow = xmlDoc.createElement("w:r"); const breakLine = xmlDoc.createElement("w:br"); //Append breakline and "{{" newRow.appendChild(breakLine); newRow.appendChild(startRow); for (let p = 0; p < paragraphs.length; p++) { //Check whether paragrapj has text const paragraphHasText = paragraphs[p].getElementsByTagName("w:t").length > 0; if (!paragraphHasText) continue; //Extract text let textExtracted = ""; const textBoxTexts = paragraphs[p].getElementsByTagName("w:t"); for (let k = 0; k < textBoxTexts.length; k++) { const textBoxText = textBoxTexts[k].innerHTML; textExtracted = textExtracted + textBoxText; textExtracted = textExtracted + " "; } // Create a temp run which will hold the etxtracted text const tempRow = xmlDoc.createElement("w:r"); const newText = xmlDoc.createElement('w:t'); newText.setAttribute("xml:space", "preserve"); newText.innerHTML = textExtracted; textExtracted = ""; tempRow.appendChild(newText); newRow.appendChild(tempRow); const breakLine = xmlDoc.createElement("w:br"); newRow.appendChild(breakLine); } //Replace existing run with the new one row.replaceWith(newRow); } //Serialize dom , clear body and replace OOXML const serializedXML = new XMLSerializer().serializeToString(xmlDoc.documentElement); body.clear(); return context.sync().then(function () { body.insertOoxml(serializedXML, Word.InsertLocation.replace); console.log('done'); }); }); }) .catch(error => { console.log('Error: ', error); resolve(false); });
answered Sep 8, 2020 at 8:50
![]()
Let’s say you are editing a document and you want to remove all text boxes without altering the text.
This won’t be a problem if you only have a couple of text boxes to delete. However, it will surely be a nightmare if you have a hundred-page file with most pages having at least one text box.
In this article we will share methods to preserve text while deleting the text boxes in the word document.

Now, there are about three ways to delete a text box without deleting text.
- By Copying and Pasting
- Using the Selection Pane
- Using Macros
Method 1: Remove Text Box By Copying and Pasting
Here’s how you can copy and paste the text from a text box.
Step 1: Open up a Word file.

Remember to insert a text box or simply copy and paste one of yours if you opted to use a blank document.
Step 2: Copy the text from the text box.
Once you have your document ready, double-click on one of the text boxes that you want to delete. Select the text inside and press the Ctrl + C keys to copy.

You can also copy the selected text by right-clicking on your mouse and selecting Copy from the drop-down menu.

Step 3: Paste the text on a space outside the text box.
Once you’ve copied the text, place your cursor to your desired location. Then, simply press Ctrl + V on your keyboard to paste the text.
Alternatively, you can right-click on your mouse and select Paste from the options.

Step 4: Delete the text box.
Now that you’ve successfully copied and pasted your text, simply click on any side of the text box and press the Delete key on your keyboard to get rid of it.

There you have it! You’ve successfully deleted a text box without deleting the text inside.
Method 2: Using the Selection Pane
Manually extracting texts from numerous text boxes will surely consume a lot of time. This method introduces a faster approach when handling multiple text boxes.
We’ll show you the steps on how to extract text from all your text boxes using the Selection pane. The Selection pane makes it easier to select objects in Word as it lists down all of the objects present in your document.
Step 1: Open an MS Word document.
Step 2: Access the Selection pane.
In the Home tab, click the Select button under the Editing group. From the drop-down menu, click on the Selection Pane button. This will display the Selection Pane on the right side of your window.

On the Selection pane, select all the text boxes on the list by clicking each one while holding the CTRL key.

Alternatively, you can also click on the edges of the text boxes while holding the CTRL key. Clicking from the inside will allow you to edit the text inside rather than selecting the text box.
Step 3: Copy the Text Boxes.
Once all the text boxes are selected, press the Ctrl + C keys to copy the text boxes.
Step 4: Open WordPad.
We’ll then need to open WordPad, which is a text editor that came with your Windows installation.
Note that you can also use other text editors, like Notepad, that are readily available on your computer.

Step 5: Paste the text boxes on WordPad.
Once you’ve opened WordPad, hit the Ctrl + V keys to paste the text boxes you’ve previously copied.
You’ll now notice that only the texts are retained while the text boxes have been deleted.

From this point, you can simply copy each text and paste them back into your Word document.
Congratulations! You’ve successfully used the Selection pane to delete the text boxes in Word without deleting text in it.
Method 3: Using Macros
This method involves a bit more technical steps. This method will be useful when you have a large number of text boxes in the document.
Step 1: Open an MS Word document.

Step 2: Create a new Macro.
On an opened document, go to the View tab,then click on the Macros button. This will show the Macros dialogue box in the middle of your screen.

Type a name for the macro in the Macro name field. For this example, we’ll use the name DeleteTextBox. Make sure that there aren’t any spaces between the words. Then, click the Create button.

You will be directed to the Microsoft Visual Basic for Applications, a.k.a. VBA, on a new window. This is where we’ll create the macros for our document.

Note that this is a different window than your MS Word.
Step 3: Create the macro.
Create the macro by simply copying the VBA code below. We’ve secured this VBA code for you from an online resource. You can visit this site to check out the author and the code.
Sub DeleteTextBox()
Dim RngDoc As Range, RngShp As Range, i As Long
With ActiveDocument
For i = .Shapes.Count To 1 Step -1
With .Shapes(i)
If .Type = msoTextBox Then
Set RngShp = .TextFrame.TextRange
RngShp.End = RngShp.End - 1
Set RngDoc = .Anchor
RngDoc.Collapse wdCollapseEnd
RngDoc.FormattedText = RngShp.FormattedText
.Delete
End If
End With
Next
End With
End SubOn the VBA window, select all the content in the Normal – NewMacros (code) window and press the Delete key on your keyboard.

Then, paste the code you copied above.

Step 4: Save the code.
Click the Save button found in the toolbar just below the Main menu.

Step 5. Run the macro.
Switch back to your MS Word window and click on the Macros button again. On the Macros dialogue box, select the macro DeleteTextBox then click the Run button.
Again, note that you may have a different macro name than our example.

This will delete all the text boxes in your Word document while preserving all the text in it.
Conclusion
We hope you found this article useful.
|
05-07-2020, 09:23 PM |
||||
|
||||
|
Extract Text from textboxes in converted PDFs Hello, I’ve used the script in post #6 @ https://www.msofficeforums.com/word-…nd-shapes.html for extracting Text from various textboxes / shapes with text, etc. I have three problems, that I can’t figure out how to fix it. 1- How to extract Text from Textbox in headers?
|




|
05-07-2020, 10:43 PM |
|
Try: Code: Sub Demo()
Application.ScreenUpdating = False
Dim i As Long, StryRng As Range, Rng As Range, StrType
For Each StryRng In ActiveDocument.StoryRanges
For i = StryRng.ShapeRange.Count To 1 Step -1
With StryRng.ShapeRange(i)
If Not .TextFrame Is Nothing Then
On Error GoTo SkipShp
If .TextFrame.HasText = True Then
Select Case .Type
Case msoAutoShape: StrType = "AutoShape"
Case msoCallout: StrType = "Callout"
Case msoCanvas: StrType = "Canvas"
Case msoChart: StrType = "Chart"
Case msoComment: StrType = "Comment"
Case msoDiagram: StrType = "Diagram"
Case msoEmbeddedOLEObject: StrType = "EmbeddedOLEObject"
Case msoFormControl: StrType = "FormControl"
Case msoFreeform: StrType = "Freeform"
Case msoGroup: StrType = "Group"
Case msoInk: StrType = "Ink"
Case msoInkComment: StrType = "InkComment"
Case msoLine: StrType = "Line"
Case msoLinkedOLEObject: StrType = "LinkedOLEObject"
Case msoLinkedPicture: StrType = "LinkedPicture"
Case msoMedia: StrType = "Media"
Case msoOLEControlObject: StrType = "OLEControlObject"
Case msoPicture: StrType = "Picture"
Case msoPlaceholder: StrType = "Placeholder"
Case msoScriptAnchor: StrType = "ScriptAnchor"
Case msoShapeTypeMixed: StrType = "ShapeTypeMixed"
Case msoTable: StrType = "Table"
Case msoTextBox: StrType = "TextBox"
Case msoTextEffect: StrType = "TextEffect"
End Select
Set Rng = .Anchor
With Rng
.InsertBefore StrType & " start << "
.Collapse wdCollapseEnd
.InsertAfter " >> end " & StrType
.Collapse wdCollapseStart
End With
Rng.FormattedText = .TextFrame.TextRange.FormattedText
.Delete
End If
SkipShp:
On Error GoTo 0
End If
End With
Next
For i = StryRng.InlineShapes.Count To 1 Step -1
With StryRng.InlineShapes(i)
If Not .TextEffect Is Nothing Then
On Error GoTo SkipiShp
If Len(Trim(.TextEffect.Text)) > 1 Then
Select Case .Type
Case wdInlineShapeChart: StrType = "InlineChart"
Case wdInlineShapeDiagram: StrType = "InlineDiagram"
Case wdInlineShapeEmbeddedOLEObject: StrType = "InlineEmbeddedOLEObject"
Case wdInlineShapeHorizontalLine: StrType = "InlineHorizontalLine"
Case wdInlineShapeLinkedOLEObject: StrType = "InlineLinkedOLEObject"
Case wdInlineShapeLinkedPicture: StrType = "InlineLinkedPicture"
Case wdInlineShapeLinkedPictureHorizontalLine: StrType = "InlineShapeLinkedPictureHorizontalLine"
Case wdInlineShapeLockedCanvas: StrType = "InlineLockedCanvas"
Case wdInlineShapeOLEControlObject: StrType = "InlineOLEControlObject"
Case wdInlineShapeOWSAnchor: StrType = "InlineOWSAnchor"
Case wdInlineShapePicture: StrType = "InlinePicture"
Case wdInlineShapePictureBullet: StrType = "InlinePictureBullet"
Case wdInlineShapePictureHorizontalLine: StrType = "InlinePictureHorizontalLine"
Case msoLinkedOLEObject: StrType = "LinkedOLEObject"
Case wdInlineShapeScriptAnchor: StrType = "InlineScriptAnchor"
End Select
Set Rng = .Range
With Rng
.Collapse wdCollapseStart
.InsertBefore StrType & " start << "
.Collapse wdCollapseEnd
.InsertAfter " >> end " & StrType
.Collapse wdCollapseStart
End With
Rng.Text = .TextEffect.Text
.Delete
End If
SkipiShp:
On Error GoTo 0
End If
End With
Next
Next
Application.ScreenUpdating = True
End Sub
The code processes inline and floating shapes — the latter regardless of whether they’re positioned behind text (as does the code in post #6) — but also process content anywhere in the document.
__________________
|
|
05-12-2020, 07:33 PM |
||||
|
||||
|
OMG you are brilliant. Fix it. Thank you so much…. Thank you Paul, you don’t know how much time I’ve spent trying to figure that issue. OMG, you are a brilliant person. i’ll try to analyze the difference between the two scripts to learn and understand. But how can I understand more in dept in Word VBA programming? Been trying, as god is my withness, I’ve been trying. I’ve created over 100’s of macro’s which I’ve used on the ribbon, to help me, but my programming is a novice programming. This is my typical Find and Replace programming (as a novice): Selection.Find.ClearFormatting In the undo’s, I do see often ==> VBA-Find.Execute2007, which tells me I’m programming old style. LOL Any advice, I will be so ever in your debt. But Thank so much for fixing that script Cheers
|

|
05-12-2020, 07:53 PM |
||||
|
||||
|
macropod, I’ve tried it to the whole document, doesn’t work Hello, macropod, I feel we are so close. If you take a financial document which are in PDF, then convert them to a Word document, you might find there will be many TextBoxes in headers and footers. There is primary page and following which are often written as (continued). You’re recent script works for copy pasted a few primary pages into a new word document. Now the documents I’m having to deal with could be 50 pages or more, which have many primary headers. I’ll try as well to modify it, but I might be needing help. Could you hint me where to find the info? Cendrinne
|
|
05-12-2020, 08:04 PM |
|
Quote:
Originally Posted by Cendrinne But how can I understand more in dept in Word VBA programming? There are doubtless some good books and tutorials around but, since I don’t use any of that stuff, I can’t recommend any. All my VBA expertise is self-taught, though studying code that others have posted on different forums over the years has been a great help, too. Quote:
Originally Posted by Cendrinne This is my typical Find and Replace programming (as a novice): Selection.Find.ClearFormatting Yes, that’s typical macro-recorder code. The macro recorder’s not much smarter than a box of rocks. For an idea of what’s possible with Find/Replace coding, see: https://www.msofficeforums.com/140662-post2.html
__________________
|
|
05-12-2020, 08:07 PM |
|
Quote:
Originally Posted by Cendrinne If you take a financial document which are in PDF, then convert them to a Word document, you might find there will be many TextBoxes in headers and footers. There is primary page and following which are often written as (continued). That requires a quite different approach. It would have been helpful if you had said what your aim was up front. Besides which, documents converted from PDFs typically have only a primary header, if any.
__________________
|
|
05-12-2020, 08:14 PM |
||||
|
||||
|
sorry, I’m a novice, so I thought it would have fix all headers I’m so sorry, Paul. I didn’t want to lead you astray, since I don’t know everything about programming, I figure it would have resolve the issue. I’ll try to think about my end game next time. Please accept my appology But thanks again. I am an analytical person, so I guess with time, I might get it too. Now it’s been 3-4 years I’ve been programming but again, as a novice Cheers
|
|
05-12-2020, 08:27 PM |
||||
|
||||
|
Thank you. When I have more time, I’ll take a look Very sweet of you to guide me with script to analyze to understand Cendrinne Quote:
Originally Posted by macropod There are doubtless some good books and tutorials around but, since I don’t use any of that stuff, I can’t recommend any. All my VBA expertise is self-taught, though studying code that others have posted on different forums over the years has been a great help, too. Yes, that’s typical macro-recorder code. The macro recorder’s not much smarter than a box of rocks. For an idea of what’s possible with Find/Replace coding, see: https://www.msofficeforums.com/140662-post2.html
|

|
05-12-2020, 08:39 PM |
|
So what are you calling primary headers?
__________________
|
|
05-12-2020, 09:50 PM |
||||
|
||||
|
Hello Paul, was trying to find a way to show a picture to show. I don’t know how to show you without having a web link. Anyway. Well whenever I get TXTBOXES in headers, especially when PDF is converted to Word, and I see headers it it, I get the header as with a line spacing of Multiples of 0.06 99% of the time. The primary I can’t really explain it since I don’t fully understand it. But I was told there are different types of headers. 404 — Content Not Found | Microsoft Docs) Create headers and footers of all three types — VBA Visual Basic for Applications (Microsoft) — Tek-Tips I’ve join a 3 links that talks about it. I have so many sections, I’m trying to extract all headers that are in text boxes to document. But only the ones that are not duplicates, ahhh OK now I think I know how to explain it. No link to the preceding section, cause the first page of a section is the main or primary page. Am I making sense? Cendrinne
Last edited by Cendrinne; 05-13-2020 at 08:21 AM.
|
|
05-12-2020, 10:58 PM |
|
Quote:
Originally Posted by Cendrinne Hello Paul, was trying to find a way to show a picture to show. I don’t know how to show you without having a web link. Anyway. You can attach images to posts here. You do that via the paperclip symbol on the ‘Go Advanced’ tab at the bottom of this screen. Quote:
Originally Posted by Cendrinne But I was told there are different types of headers. Yes, Word has three header (and footer) types: Quote:
Originally Posted by Cendrinne I have so many sections, I’m trying to extract all headers that are in text boxes to document. But only the ones that are not duplicates, ahhh OK know I think I know how to explain it. No link to the preceding section, cause the first page of a section is the main or primary page. Am I making sense? OK, so you only want the header content from the first Section. But which of the three header types does that Section use?
__________________
|
|
05-13-2020, 10:14 PM |
||||
|
||||
|
I’ll get back to you shortly. Been busy with work at home I’ll have more time on Friday. Get back to you, Paul
|
|
05-15-2020, 08:08 PM |
||||
|
||||
|
Request help for Textboxes in Primary headers… Hello Paul, Word has three header (and footer) types: I could either get a combination, in the same document, a check mark to first page is different and some sections, no check marks to first page is different. So I’m not sure if a macro could be written with all of these factors. Need to extract all Text from Text Boxes in headers. Hopefully, they will also keep their text forat (color, size, style). Just a way to remove the boxes. Think it’s doable? Cendrinne
|
|
05-15-2020, 09:03 PM |
|
The code in post #15 already does all of that extraction — and more. So what is the problem?
__________________
|
|
05-15-2020, 09:32 PM |
||||
|
||||
|
I’ll try it again #15 but on the large document of 174 pages, where there are many headers, and lot’s of textboxes with text in those headers, it didn’t work the last time. Let me try it again Cendrinene
|