
This article is about the worldwide computer network. For the global system of pages accessed via URLs, see World Wide Web. For other uses, see Internet (disambiguation).
The Internet (or internet)[a] is the global system of interconnected computer networks that uses the Internet protocol suite (TCP/IP)[b] to communicate between networks and devices. It is a network of networks that consists of private, public, academic, business, and government networks of local to global scope, linked by a broad array of electronic, wireless, and optical networking technologies. The Internet carries a vast range of information resources and services, such as the interlinked hypertext documents and applications of the World Wide Web (WWW), electronic mail, telephony, and file sharing.
The origins of the Internet date back to the development of packet switching and research commissioned by the United States Department of Defense in the late 1960s to enable time-sharing of computers.[2] The primary precursor network, the ARPANET, initially served as a backbone for the interconnection of regional academic and military networks in the 1970s to enable resource sharing. The funding of the National Science Foundation Network as a new backbone in the 1980s, as well as private funding for other commercial extensions, led to worldwide participation in the development of new networking technologies, and the merger of many networks.[3] The linking of commercial networks and enterprises by the early 1990s marked the beginning of the transition to the modern Internet,[4] and generated a sustained exponential growth as generations of institutional, personal, and mobile computers were connected to the network. Although the Internet was widely used by academia in the 1980s, commercialization incorporated its services and technologies into virtually every aspect of modern life.
Most traditional communication media, including telephone, radio, television, paper mail, and newspapers, are reshaped, redefined, or even bypassed by the Internet, giving birth to new services such as email, Internet telephone, Internet television, online music, digital newspapers, and video streaming websites. Newspaper, book, and other print publishing have adapted to website technology or have been reshaped into blogging, web feeds, and online news aggregators. The Internet has enabled and accelerated new forms of personal interaction through instant messaging, Internet forums, and social networking services. Online shopping has grown exponentially for major retailers, small businesses, and entrepreneurs, as it enables firms to extend their «brick and mortar» presence to serve a larger market or even sell goods and services entirely online. Business-to-business and financial services on the Internet affect supply chains across entire industries.
The Internet has no single centralized governance in either technological implementation or policies for access and usage; each constituent network sets its own policies.[5] The overarching definitions of the two principal name spaces on the Internet, the Internet Protocol address (IP address) space and the Domain Name System (DNS), are directed by a maintainer organization, the Internet Corporation for Assigned Names and Numbers (ICANN). The technical underpinning and standardization of the core protocols is an activity of the Internet Engineering Task Force (IETF), a non-profit organization of loosely affiliated international participants that anyone may associate with by contributing technical expertise.[6] In November 2006, the Internet was included on USA Today‘s list of New Seven Wonders.[7]
Terminology

The word internetted was used as early as 1849, meaning interconnected or interwoven.[8] The word Internet was used in 1945 by the United States War Department in a radio operator’s manual,[9] and 1974 as the shorthand form of Internetwork.[10] Today, the term Internet most commonly refers to the global system of interconnected computer networks, though it may also refer to any group of smaller networks.[11]
When it came into common use, most publications treated the word Internet as a capitalized proper noun; this has become less common.[11] This reflects the tendency in English to capitalize new terms and move to lowercase as they become familiar.[11][12] The word is sometimes still capitalized to distinguish the global internet from smaller networks, though many publications, including the AP Stylebook since 2016, recommend the lowercase form in every case.[11][12] In 2016, the Oxford English Dictionary found that, based on a study of around 2.5 billion printed and online sources, «Internet» was capitalized in 54% of cases.[13]
The terms Internet and World Wide Web are often used interchangeably; it is common to speak of «going on the Internet» when using a web browser to view web pages. However, the World Wide Web or the Web is only one of a large number of Internet services,[14] a collection of documents (web pages) and other web resources, linked by hyperlinks and URLs.[15]
History
In the 1960s, the Advanced Research Projects Agency (ARPA) of the United States Department of Defense (DoD) funded research into time-sharing of computers.[16][17][18] J. C. R. Licklider proposed the idea of a universal network while leading the Information Processing Techniques Office (IPTO) at ARPA. Research into packet switching, one of the fundamental Internet technologies, started in the work of Paul Baran in the early 1960s and, independently, Donald Davies in 1965.[2][19] After the Symposium on Operating Systems Principles in 1967, packet switching from the proposed NPL network was incorporated into the design for the ARPANET and other resource sharing networks such as the Merit Network and CYCLADES, which were developed in the late 1960s and early 1970s.[20]
ARPANET development began with two network nodes which were interconnected between the University of California, Los Angeles (UCLA) and SRI International (SRI) on 29 October 1969.[21] The third site was at the University of California, Santa Barbara, followed by the University of Utah. In a sign of future growth, 15 sites were connected to the young ARPANET by the end of 1971.[22][23] These early years were documented in the 1972 film Computer Networks: The Heralds of Resource Sharing.[24] Thereafter, the ARPANET gradually developed into a decentralized communications network, connecting remote centers and military bases in the United States.[25]
Early international collaborations for the ARPANET were rare. Connections were made in 1973 to the Norwegian Seismic Array (NORSAR),[26] and to University College London which provided a gateway to British academic networks forming the first international resource sharing network.[27] ARPA projects, international working groups and commercial initiatives led to the development of various protocols and standards by which multiple separate networks could become a single network or «a network of networks».[28] In 1974, Bob Kahn at DARPA and Vint Cerf at Stanford University published their ideas for «A Protocol for Packet Network Intercommunication».[29] They used the term internet as a shorthand for internetwork in RFC 675,[10] and later RFCs repeated this use.[30] Kahn and Cerf credit Louis Pouzin with important influences on the resulting TCP/IP design.[31] National PTTs and commercial providers developed the X.25 standard and deployed it on public data networks.[32]
Access to the ARPANET was expanded in 1981 when the National Science Foundation (NSF) funded the Computer Science Network (CSNET). In 1982, the Internet Protocol Suite (TCP/IP) was standardized, which permitted worldwide proliferation of interconnected networks. TCP/IP network access expanded again in 1986 when the National Science Foundation Network (NSFNet) provided access to supercomputer sites in the United States for researchers, first at speeds of 56 kbit/s and later at 1.5 Mbit/s and 45 Mbit/s.[33] The NSFNet expanded into academic and research organizations in Europe, Australia, New Zealand and Japan in 1988–89.[34][35][36][37] Although other network protocols such as UUCP and PTT public data networks had global reach well before this time, this marked the beginning of the Internet as an intercontinental network. Commercial Internet service providers (ISPs) emerged in 1989 in the United States and Australia.[38] The ARPANET was decommissioned in 1990.[39]

Steady advances in semiconductor technology and optical networking created new economic opportunities for commercial involvement in the expansion of the network in its core and for delivering services to the public. In mid-1989, MCI Mail and Compuserve established connections to the Internet, delivering email and public access products to the half million users of the Internet.[40] Just months later, on 1 January 1990, PSInet launched an alternate Internet backbone for commercial use; one of the networks that added to the core of the commercial Internet of later years. In March 1990, the first high-speed T1 (1.5 Mbit/s) link between the NSFNET and Europe was installed between Cornell University and CERN, allowing much more robust communications than were capable with satellites.[41] Six months later Tim Berners-Lee would begin writing WorldWideWeb, the first web browser, after two years of lobbying CERN management. By Christmas 1990, Berners-Lee had built all the tools necessary for a working Web: the HyperText Transfer Protocol (HTTP) 0.9,[42] the HyperText Markup Language (HTML), the first Web browser (which was also an HTML editor and could access Usenet newsgroups and FTP files), the first HTTP server software (later known as CERN httpd), the first web server,[43] and the first Web pages that described the project itself. In 1991 the Commercial Internet eXchange was founded, allowing PSInet to communicate with the other commercial networks CERFnet and Alternet. Stanford Federal Credit Union was the first financial institution to offer online Internet banking services to all of its members in October 1994.[44] In 1996, OP Financial Group, also a cooperative bank, became the second online bank in the world and the first in Europe.[45] By 1995, the Internet was fully commercialized in the U.S. when the NSFNet was decommissioned, removing the last restrictions on use of the Internet to carry commercial traffic.[46]
| Users | 2005 | 2010 | 2017 | 2019 | 2021 |
|---|---|---|---|---|---|
| World population[48] | 6.5 billion | 6.9 billion | 7.4 billion | 7.75 billion | 7.9 billion |
| Worldwide | 16% | 30% | 48% | 53.6% | 63% |
| In developing world | 8% | 21% | 41.3% | 47% | 57% |
| In developed world | 51% | 67% | 81% | 86.6% | 90% |
As technology advanced and commercial opportunities fueled reciprocal growth, the volume of Internet traffic started experiencing similar characteristics as that of the scaling of MOS transistors, exemplified by Moore’s law, doubling every 18 months. This growth, formalized as Edholm’s law, was catalyzed by advances in MOS technology, laser light wave systems, and noise performance.[49]
Since 1995, the Internet has tremendously impacted culture and commerce, including the rise of near instant communication by email, instant messaging, telephony (Voice over Internet Protocol or VoIP), two-way interactive video calls, and the World Wide Web[50] with its discussion forums, blogs, social networking services, and online shopping sites. Increasing amounts of data are transmitted at higher and higher speeds over fiber optic networks operating at 1 Gbit/s, 10 Gbit/s, or more. The Internet continues to grow, driven by ever greater amounts of online information and knowledge, commerce, entertainment and social networking services.[51] During the late 1990s, it was estimated that traffic on the public Internet grew by 100 percent per year, while the mean annual growth in the number of Internet users was thought to be between 20% and 50%.[52] This growth is often attributed to the lack of central administration, which allows organic growth of the network, as well as the non-proprietary nature of the Internet protocols, which encourages vendor interoperability and prevents any one company from exerting too much control over the network.[53] As of 31 March 2011, the estimated total number of Internet users was 2.095 billion (30.2% of world population).[54] It is estimated that in 1993 the Internet carried only 1% of the information flowing through two-way telecommunication. By 2000 this figure had grown to 51%, and by 2007 more than 97% of all telecommunicated information was carried over the Internet.[55]
Governance

The Internet is a global network that comprises many voluntarily interconnected autonomous networks. It operates without a central governing body. The technical underpinning and standardization of the core protocols (IPv4 and IPv6) is an activity of the Internet Engineering Task Force (IETF), a non-profit organization of loosely affiliated international participants that anyone may associate with by contributing technical expertise. To maintain interoperability, the principal name spaces of the Internet are administered by the Internet Corporation for Assigned Names and Numbers (ICANN). ICANN is governed by an international board of directors drawn from across the Internet technical, business, academic, and other non-commercial communities. ICANN coordinates the assignment of unique identifiers for use on the Internet, including domain names, IP addresses, application port numbers in the transport protocols, and many other parameters. Globally unified name spaces are essential for maintaining the global reach of the Internet. This role of ICANN distinguishes it as perhaps the only central coordinating body for the global Internet.[56]
Regional Internet registries (RIRs) were established for five regions of the world. The African Network Information Center (AfriNIC) for Africa, the American Registry for Internet Numbers (ARIN) for North America, the Asia-Pacific Network Information Centre (APNIC) for Asia and the Pacific region, the Latin American and Caribbean Internet Addresses Registry (LACNIC) for Latin America and the Caribbean region, and the Réseaux IP Européens – Network Coordination Centre (RIPE NCC) for Europe, the Middle East, and Central Asia were delegated to assign IP address blocks and other Internet parameters to local registries, such as Internet service providers, from a designated pool of addresses set aside for each region.
The National Telecommunications and Information Administration, an agency of the United States Department of Commerce, had final approval over changes to the DNS root zone until the IANA stewardship transition on 1 October 2016.[57][58][59][60] The Internet Society (ISOC) was founded in 1992 with a mission to «assure the open development, evolution and use of the Internet for the benefit of all people throughout the world».[61] Its members include individuals (anyone may join) as well as corporations, organizations, governments, and universities. Among other activities ISOC provides an administrative home for a number of less formally organized groups that are involved in developing and managing the Internet, including: the IETF, Internet Architecture Board (IAB), Internet Engineering Steering Group (IESG), Internet Research Task Force (IRTF), and Internet Research Steering Group (IRSG). On 16 November 2005, the United Nations-sponsored World Summit on the Information Society in Tunis established the Internet Governance Forum (IGF) to discuss Internet-related issues.
Infrastructure

2007 map showing submarine fiberoptic telecommunication cables around the world
The communications infrastructure of the Internet consists of its hardware components and a system of software layers that control various aspects of the architecture. As with any computer network, the Internet physically consists of routers, media (such as cabling and radio links), repeaters, modems etc. However, as an example of internetworking, many of the network nodes are not necessarily internet equipment per se, the internet packets are carried by other full-fledged networking protocols with the Internet acting as a homogeneous networking standard, running across heterogeneous hardware, with the packets guided to their destinations by IP routers.
Service tiers

Packet routing across the Internet involves several tiers of Internet service providers.
Internet service providers (ISPs) establish the worldwide connectivity between individual networks at various levels of scope. End-users who only access the Internet when needed to perform a function or obtain information, represent the bottom of the routing hierarchy. At the top of the routing hierarchy are the tier 1 networks, large telecommunication companies that exchange traffic directly with each other via very high speed fibre optic cables and governed by peering agreements. Tier 2 and lower-level networks buy Internet transit from other providers to reach at least some parties on the global Internet, though they may also engage in peering. An ISP may use a single upstream provider for connectivity, or implement multihoming to achieve redundancy and load balancing. Internet exchange points are major traffic exchanges with physical connections to multiple ISPs. Large organizations, such as academic institutions, large enterprises, and governments, may perform the same function as ISPs, engaging in peering and purchasing transit on behalf of their internal networks. Research networks tend to interconnect with large subnetworks such as GEANT, GLORIAD, Internet2, and the UK’s national research and education network, JANET.
Access
Common methods of Internet access by users include dial-up with a computer modem via telephone circuits, broadband over coaxial cable, fiber optics or copper wires, Wi-Fi, satellite, and cellular telephone technology (e.g. 3G, 4G). The Internet may often be accessed from computers in libraries and Internet cafes. Internet access points exist in many public places such as airport halls and coffee shops. Various terms are used, such as public Internet kiosk, public access terminal, and Web payphone. Many hotels also have public terminals that are usually fee-based. These terminals are widely accessed for various usages, such as ticket booking, bank deposit, or online payment. Wi-Fi provides wireless access to the Internet via local computer networks. Hotspots providing such access include Wi-Fi cafes, where users need to bring their own wireless devices such as a laptop or PDA. These services may be free to all, free to customers only, or fee-based.
Grassroots efforts have led to wireless community networks. Commercial Wi-Fi services that cover large areas are available in many cities, such as New York, London, Vienna, Toronto, San Francisco, Philadelphia, Chicago and Pittsburgh, where the Internet can then be accessed from places such as a park bench.[62] Experiments have also been conducted with proprietary mobile wireless networks like Ricochet, various high-speed data services over cellular networks, and fixed wireless services. Modern smartphones can also access the Internet through the cellular carrier network. For Web browsing, these devices provide applications such as Google Chrome, Safari, and Firefox and a wide variety of other Internet software may be installed from app-stores. Internet usage by mobile and tablet devices exceeded desktop worldwide for the first time in October 2016.[63]
Mobile communication

Number of mobile cellular subscriptions 2012–2016
The International Telecommunication Union (ITU) estimated that, by the end of 2017, 48% of individual users regularly connect to the Internet, up from 34% in 2012.[64] Mobile Internet connectivity has played an important role in expanding access in recent years especially in Asia and the Pacific and in Africa.[65] The number of unique mobile cellular subscriptions increased from 3.89 billion in 2012 to 4.83 billion in 2016, two-thirds of the world’s population, with more than half of subscriptions located in Asia and the Pacific. The number of subscriptions is predicted to rise to 5.69 billion users in 2020.[66] As of 2016, almost 60% of the world’s population had access to a 4G broadband cellular network, up from almost 50% in 2015 and 11% in 2012.[disputed – discuss][66] The limits that users face on accessing information via mobile applications coincide with a broader process of fragmentation of the Internet. Fragmentation restricts access to media content and tends to affect poorest users the most.[65]
Zero-rating, the practice of Internet service providers allowing users free connectivity to access specific content or applications without cost, has offered opportunities to surmount economic hurdles, but has also been accused by its critics as creating a two-tiered Internet. To address the issues with zero-rating, an alternative model has emerged in the concept of ‘equal rating’ and is being tested in experiments by Mozilla and Orange in Africa. Equal rating prevents prioritization of one type of content and zero-rates all content up to a specified data cap. A study published by Chatham House, 15 out of 19 countries researched in Latin America had some kind of hybrid or zero-rated product offered. Some countries in the region had a handful of plans to choose from (across all mobile network operators) while others, such as Colombia, offered as many as 30 pre-paid and 34 post-paid plans.[67]
A study of eight countries in the Global South found that zero-rated data plans exist in every country, although there is a great range in the frequency with which they are offered and actually used in each.[68] The study looked at the top three to five carriers by market share in Bangladesh, Colombia, Ghana, India, Kenya, Nigeria, Peru and Philippines. Across the 181 plans examined, 13 per cent were offering zero-rated services. Another study, covering Ghana, Kenya, Nigeria and South Africa, found Facebook’s Free Basics and Wikipedia Zero to be the most commonly zero-rated content.[69]
Internet Protocol Suite
The Internet standards describe a framework known as the Internet protocol suite (also called TCP/IP, based on the first two components.) This is a suite of protocols that are ordered into a set of four conceptional layers by the scope of their operation, originally documented in RFC 1122 and RFC 1123. At the top is the application layer, where communication is described in terms of the objects or data structures most appropriate for each application. For example, a web browser operates in a client–server application model and exchanges information with the Hypertext Transfer Protocol (HTTP) and an application-germane data structure, such as the Hypertext Markup Language (HTML).
Below this top layer, the transport layer connects applications on different hosts with a logical channel through the network. It provides this service with a variety of possible characteristics, such as ordered, reliable delivery (TCP), and an unreliable datagram service (UDP).
Underlying these layers are the networking technologies that interconnect networks at their borders and exchange traffic across them. The Internet layer implements the Internet Protocol (IP) which enables computers to identify and locate each other by IP address, and route their traffic via intermediate (transit) networks.[70] The internet protocol layer code is independent of the type of network that it is physically running over.
At the bottom of the architecture is the link layer, which connects nodes on the same physical link, and contains protocols that do not require routers for traversal to other links. The protocol suite does not explicitly specify hardware methods to transfer bits, or protocols to manage such hardware, but assumes that appropriate technology is available. Examples of that technology include Wi-Fi, Ethernet, and DSL.

As user data is processed through the protocol stack, each abstraction layer adds encapsulation information at the sending host. Data is transmitted over the wire at the link level between hosts and routers. Encapsulation is removed by the receiving host. Intermediate relays update link encapsulation at each hop, and inspect the IP layer for routing purposes.
Internet protocol

Conceptual data flow in a simple network topology of two hosts (A and B) connected by a link between their respective routers. The application on each host executes read and write operations as if the processes were directly connected to each other by some kind of data pipe. After the establishment of this pipe, most details of the communication are hidden from each process, as the underlying principles of communication are implemented in the lower protocol layers. In analogy, at the transport layer the communication appears as host-to-host, without knowledge of the application data structures and the connecting routers, while at the internetworking layer, individual network boundaries are traversed at each router.
The most prominent component of the Internet model is the Internet Protocol (IP). IP enables internetworking and, in essence, establishes the Internet itself. Two versions of the Internet Protocol exist, IPv4 and IPv6.
IP Addresses

A DNS resolver consults three name servers to resolve the domain name user-visible «www.wikipedia.org» to determine the IPv4 Address 207.142.131.234.
For locating individual computers on the network, the Internet provides IP addresses. IP addresses are used by the Internet infrastructure to direct internet packets to their destinations. They consist of fixed-length numbers, which are found within the packet. IP addresses are generally assigned to equipment either automatically via DHCP, or are configured.
However, the network also supports other addressing systems. Users generally enter domain names (e.g. «en.wikipedia.org») instead of IP addresses because they are easier to remember, they are converted by the Domain Name System (DNS) into IP addresses which are more efficient for routing purposes.
IPv4
Internet Protocol version 4 (IPv4) defines an IP address as a 32-bit number.[70] IPv4 is the initial version used on the first generation of the Internet and is still in dominant use. It was designed to address up to ≈4.3 billion (109) hosts. However, the explosive growth of the Internet has led to IPv4 address exhaustion, which entered its final stage in 2011,[71] when the global IPv4 address allocation pool was exhausted.
IPv6
Because of the growth of the Internet and the depletion of available IPv4 addresses, a new version of IP IPv6, was developed in the mid-1990s, which provides vastly larger addressing capabilities and more efficient routing of Internet traffic. IPv6 uses 128 bits for the IP address and was standardized in 1998.[72][73][74] IPv6 deployment has been ongoing since the mid-2000s and is currently in growing deployment around the world, since Internet address registries (RIRs) began to urge all resource managers to plan rapid adoption and conversion.[75]
IPv6 is not directly interoperable by design with IPv4. In essence, it establishes a parallel version of the Internet not directly accessible with IPv4 software. Thus, translation facilities must exist for internetworking or nodes must have duplicate networking software for both networks. Essentially all modern computer operating systems support both versions of the Internet Protocol. Network infrastructure, however, has been lagging in this development. Aside from the complex array of physical connections that make up its infrastructure, the Internet is facilitated by bi- or multi-lateral commercial contracts, e.g., peering agreements, and by technical specifications or protocols that describe the exchange of data over the network. Indeed, the Internet is defined by its interconnections and routing policies.
Subnetwork

Creating a subnet by dividing the host identifier
A subnetwork or subnet is a logical subdivision of an IP network.[76]: 1, 16 The practice of dividing a network into two or more networks is called subnetting.
Computers that belong to a subnet are addressed with an identical most-significant bit-group in their IP addresses. This results in the logical division of an IP address into two fields, the network number or routing prefix and the rest field or host identifier. The rest field is an identifier for a specific host or network interface.
The routing prefix may be expressed in Classless Inter-Domain Routing (CIDR) notation written as the first address of a network, followed by a slash character (/), and ending with the bit-length of the prefix. For example, 198.51.100.0/24 is the prefix of the Internet Protocol version 4 network starting at the given address, having 24 bits allocated for the network prefix, and the remaining 8 bits reserved for host addressing. Addresses in the range 198.51.100.0 to 198.51.100.255 belong to this network. The IPv6 address specification 2001:db8::/32 is a large address block with 296 addresses, having a 32-bit routing prefix.
For IPv4, a network may also be characterized by its subnet mask or netmask, which is the bitmask that when applied by a bitwise AND operation to any IP address in the network, yields the routing prefix. Subnet masks are also expressed in dot-decimal notation like an address. For example, 255.255.255.0 is the subnet mask for the prefix 198.51.100.0/24.
Traffic is exchanged between subnetworks through routers when the routing prefixes of the source address and the destination address differ. A router serves as a logical or physical boundary between the subnets.
The benefits of subnetting an existing network vary with each deployment scenario. In the address allocation architecture of the Internet using CIDR and in large organizations, it is necessary to allocate address space efficiently. Subnetting may also enhance routing efficiency, or have advantages in network management when subnetworks are administratively controlled by different entities in a larger organization. Subnets may be arranged logically in a hierarchical architecture, partitioning an organization’s network address space into a tree-like routing structure.
Routing
Computers and routers use routing tables in their operating system to direct IP packets to reach a node on a different subnetwork. Routing tables are maintained by manual configuration or automatically by routing protocols. End-nodes typically use a default route that points toward an ISP providing transit, while ISP routers use the Border Gateway Protocol to establish the most efficient routing across the complex connections of the global Internet. The default gateway is the node that serves as the forwarding host (router) to other networks when no other route specification matches the destination IP address of a packet.[77][78]
IETF
While the hardware components in the Internet infrastructure can often be used to support other software systems, it is the design and the standardization process of the software that characterizes the Internet and provides the foundation for its scalability and success. The responsibility for the architectural design of the Internet software systems has been assumed by the Internet Engineering Task Force (IETF).[79] The IETF conducts standard-setting work groups, open to any individual, about the various aspects of Internet architecture. The resulting contributions and standards are published as Request for Comments (RFC) documents on the IETF web site. The principal methods of networking that enable the Internet are contained in specially designated RFCs that constitute the Internet Standards. Other less rigorous documents are simply informative, experimental, or historical, or document the best current practices (BCP) when implementing Internet technologies.
Applications and services
The Internet carries many applications and services, most prominently the World Wide Web, including social media, electronic mail, mobile applications, multiplayer online games, Internet telephony, file sharing, and streaming media services.
Most servers that provide these services are today hosted in data centers, and content is often accessed through high-performance content delivery networks.
World Wide Web

The World Wide Web is a global collection of documents, images, multimedia, applications, and other resources, logically interrelated by hyperlinks and referenced with Uniform Resource Identifiers (URIs), which provide a global system of named references. URIs symbolically identify services, web servers, databases, and the documents and resources that they can provide. Hypertext Transfer Protocol (HTTP) is the main access protocol of the World Wide Web. Web services also use HTTP for communication between software systems for information transfer, sharing and exchanging business data and logistic and is one of many languages or protocols that can be used for communication on the Internet.[80]
World Wide Web browser software, such as Microsoft’s Internet Explorer/Edge, Mozilla Firefox, Opera, Apple’s Safari, and Google Chrome, lets users navigate from one web page to another via the hyperlinks embedded in the documents. These documents may also contain any combination of computer data, including graphics, sounds, text, video, multimedia and interactive content that runs while the user is interacting with the page. Client-side software can include animations, games, office applications and scientific demonstrations. Through keyword-driven Internet research using search engines like Yahoo!, Bing and Google, users worldwide have easy, instant access to a vast and diverse amount of online information. Compared to printed media, books, encyclopedias and traditional libraries, the World Wide Web has enabled the decentralization of information on a large scale.
The Web has enabled individuals and organizations to publish ideas and information to a potentially large audience online at greatly reduced expense and time delay. Publishing a web page, a blog, or building a website involves little initial cost and many cost-free services are available. However, publishing and maintaining large, professional web sites with attractive, diverse and up-to-date information is still a difficult and expensive proposition. Many individuals and some companies and groups use web logs or blogs, which are largely used as easily updatable online diaries. Some commercial organizations encourage staff to communicate advice in their areas of specialization in the hope that visitors will be impressed by the expert knowledge and free information, and be attracted to the corporation as a result.
Advertising on popular web pages can be lucrative, and e-commerce, which is the sale of products and services directly via the Web, continues to grow. Online advertising is a form of marketing and advertising which uses the Internet to deliver promotional marketing messages to consumers. It includes email marketing, search engine marketing (SEM), social media marketing, many types of display advertising (including web banner advertising), and mobile advertising. In 2011, Internet advertising revenues in the United States surpassed those of cable television and nearly exceeded those of broadcast television.[81]: 19 Many common online advertising practices are controversial and increasingly subject to regulation.
When the Web developed in the 1990s, a typical web page was stored in completed form on a web server, formatted in HTML, complete for transmission to a web browser in response to a request. Over time, the process of creating and serving web pages has become dynamic, creating a flexible design, layout, and content. Websites are often created using content management software with, initially, very little content. Contributors to these systems, who may be paid staff, members of an organization or the public, fill underlying databases with content using editing pages designed for that purpose while casual visitors view and read this content in HTML form. There may or may not be editorial, approval and security systems built into the process of taking newly entered content and making it available to the target visitors.
Communication
Email is an important communications service available via the Internet. The concept of sending electronic text messages between parties, analogous to mailing letters or memos, predates the creation of the Internet.[82][83] Pictures, documents, and other files are sent as email attachments. Email messages can be cc-ed to multiple email addresses.
Internet telephony is a common communications service realized with the Internet. The name of the principle internetworking protocol, the Internet Protocol, lends its name to voice over Internet Protocol (VoIP). The idea began in the early 1990s with walkie-talkie-like voice applications for personal computers. VoIP systems now dominate many markets, and are as easy to use and as convenient as a traditional telephone. The benefit has been substantial cost savings over traditional telephone calls, especially over long distances. Cable, ADSL, and mobile data networks provide Internet access in customer premises[84] and inexpensive VoIP network adapters provide the connection for traditional analog telephone sets. The voice quality of VoIP often exceeds that of traditional calls. Remaining problems for VoIP include the situation that emergency services may not be universally available, and that devices rely on a local power supply, while older traditional phones are powered from the local loop, and typically operate during a power failure.
Data transfer
File sharing is an example of transferring large amounts of data across the Internet. A computer file can be emailed to customers, colleagues and friends as an attachment. It can be uploaded to a website or File Transfer Protocol (FTP) server for easy download by others. It can be put into a «shared location» or onto a file server for instant use by colleagues. The load of bulk downloads to many users can be eased by the use of «mirror» servers or peer-to-peer networks. In any of these cases, access to the file may be controlled by user authentication, the transit of the file over the Internet may be obscured by encryption, and money may change hands for access to the file. The price can be paid by the remote charging of funds from, for example, a credit card whose details are also passed—usually fully encrypted—across the Internet. The origin and authenticity of the file received may be checked by digital signatures or by MD5 or other message digests. These simple features of the Internet, over a worldwide basis, are changing the production, sale, and distribution of anything that can be reduced to a computer file for transmission. This includes all manner of print publications, software products, news, music, film, video, photography, graphics and the other arts. This in turn has caused seismic shifts in each of the existing industries that previously controlled the production and distribution of these products.
Streaming media is the real-time delivery of digital media for the immediate consumption or enjoyment by end users. Many radio and television broadcasters provide Internet feeds of their live audio and video productions. They may also allow time-shift viewing or listening such as Preview, Classic Clips and Listen Again features. These providers have been joined by a range of pure Internet «broadcasters» who never had on-air licenses. This means that an Internet-connected device, such as a computer or something more specific, can be used to access online media in much the same way as was previously possible only with a television or radio receiver. The range of available types of content is much wider, from specialized technical webcasts to on-demand popular multimedia services. Podcasting is a variation on this theme, where—usually audio—material is downloaded and played back on a computer or shifted to a portable media player to be listened to on the move. These techniques using simple equipment allow anybody, with little censorship or licensing control, to broadcast audio-visual material worldwide.
Digital media streaming increases the demand for network bandwidth. For example, standard image quality needs 1 Mbit/s link speed for SD 480p, HD 720p quality requires 2.5 Mbit/s, and the top-of-the-line HDX quality needs 4.5 Mbit/s for 1080p.[85]
Webcams are a low-cost extension of this phenomenon. While some webcams can give full-frame-rate video, the picture either is usually small or updates slowly. Internet users can watch animals around an African waterhole, ships in the Panama Canal, traffic at a local roundabout or monitor their own premises, live and in real time. Video chat rooms and video conferencing are also popular with many uses being found for personal webcams, with and without two-way sound. YouTube was founded on 15 February 2005 and is now the leading website for free streaming video with more than two billion users.[86] It uses an HTML5 based web player by default to stream and show video files.[87] Registered users may upload an unlimited amount of video and build their own personal profile. YouTube claims that its users watch hundreds of millions, and upload hundreds of thousands of videos daily.
The Internet has enabled new forms of social interaction, activities, and social associations. This phenomenon has given rise to the scholarly study of the sociology of the Internet.
Users

Share of population using the Internet.[88] See or edit source data.

Internet users per 100 population members and GDP per capita for selected countries

From 2000 to 2009, the number of Internet users globally rose from 394 million to 1.858 billion.[91] By 2010, 22 percent of the world’s population had access to computers with 1 billion Google searches every day, 300 million Internet users reading blogs, and 2 billion videos viewed daily on YouTube.[92] In 2014 the world’s Internet users surpassed 3 billion or 43.6 percent of world population, but two-thirds of the users came from richest countries, with 78.0 percent of Europe countries population using the Internet, followed by 57.4 percent of the Americas.[93] However, by 2018, Asia alone accounted for 51% of all Internet users, with 2.2 billion out of the 4.3 billion Internet users in the world coming from that region. The number of China’s Internet users surpassed a major milestone in 2018, when the country’s Internet regulatory authority, China Internet Network Information Centre, announced that China had 802 million Internet users.[94] By 2019, China was the world’s leading country in terms of Internet users, with more than 800 million users, followed closely by India, with some 700 million users, with the United States a distant third with 275 million users. However, in terms of penetration, China has[when?] a 38.4% penetration rate compared to India’s 40% and the United States’s 80%.[95] As of 2020, it was estimated that 4.5 billion people use the Internet, more than half of the world’s population.[96][97]
The prevalent language for communication via the Internet has always been English. This may be a result of the origin of the Internet, as well as the language’s role as a lingua franca and as a world language. Early computer systems were limited to the characters in the American Standard Code for Information Interchange (ASCII), a subset of the Latin alphabet.
After English (27%), the most requested languages on the World Wide Web are Chinese (25%), Spanish (8%), Japanese (5%), Portuguese and German (4% each), Arabic, French and Russian (3% each), and Korean (2%).[98] By region, 42% of the world’s Internet users are based in Asia, 24% in Europe, 14% in North America, 10% in Latin America and the Caribbean taken together, 6% in Africa, 3% in the Middle East and 1% in Australia/Oceania.[99] The Internet’s technologies have developed enough in recent years, especially in the use of Unicode, that good facilities are available for development and communication in the world’s widely used languages. However, some glitches such as mojibake (incorrect display of some languages’ characters) still remain.
In an American study in 2005, the percentage of men using the Internet was very slightly ahead of the percentage of women, although this difference reversed in those under 30. Men logged on more often, spent more time online, and were more likely to be broadband users, whereas women tended to make more use of opportunities to communicate (such as email). Men were more likely to use the Internet to pay bills, participate in auctions, and for recreation such as downloading music and videos. Men and women were equally likely to use the Internet for shopping and banking.[100]
More recent studies indicate that in 2008, women significantly outnumbered men on most social networking services, such as Facebook and Myspace, although the ratios varied with age.[101] In addition, women watched more streaming content, whereas men downloaded more.[102] In terms of blogs, men were more likely to blog in the first place; among those who blog, men were more likely to have a professional blog, whereas women were more likely to have a personal blog.[103]
Splitting by country, in 2012 Iceland, Norway, Sweden, the Netherlands, and Denmark had the highest Internet penetration by the number of users, with 93% or more of the population with access.[104]
Several neologisms exist that refer to Internet users: Netizen (as in «citizen of the net»)[105] refers to those actively involved in improving online communities, the Internet in general or surrounding political affairs and rights such as free speech,[106][107] Internaut refers to operators or technically highly capable users of the Internet,[108][109] digital citizen refers to a person using the Internet in order to engage in society, politics, and government participation.[110]
![Internet users by language[98]](https://upload.wikimedia.org/wikipedia/commons/thumb/e/e0/InternetUsersByLanguagePieChart.svg/562px-InternetUsersByLanguagePieChart.svg.png)
![Website content languages[111]](https://upload.wikimedia.org/wikipedia/commons/thumb/8/88/WebsitesByLanguagePieChart.svg/562px-WebsitesByLanguagePieChart.svg.png)
Usage



The Internet allows greater flexibility in working hours and location, especially with the spread of unmetered high-speed connections. The Internet can be accessed almost anywhere by numerous means, including through mobile Internet devices. Mobile phones, datacards, handheld game consoles and cellular routers allow users to connect to the Internet wirelessly. Within the limitations imposed by small screens and other limited facilities of such pocket-sized devices, the services of the Internet, including email and the web, may be available. Service providers may restrict the services offered and mobile data charges may be significantly higher than other access methods.
Educational material at all levels from pre-school to post-doctoral is available from websites. Examples range from CBeebies, through school and high-school revision guides and virtual universities, to access to top-end scholarly literature through the likes of Google Scholar. For distance education, help with homework and other assignments, self-guided learning, whiling away spare time or just looking up more detail on an interesting fact, it has never been easier for people to access educational information at any level from anywhere. The Internet in general and the World Wide Web in particular are important enablers of both formal and informal education. Further, the Internet allows researchers (especially those from the social and behavioral sciences) to conduct research remotely via virtual laboratories, with profound changes in reach and generalizability of findings as well as in communication between scientists and in the publication of results.[114]
The low cost and nearly instantaneous sharing of ideas, knowledge, and skills have made collaborative work dramatically easier, with the help of collaborative software. Not only can a group cheaply communicate and share ideas but the wide reach of the Internet allows such groups more easily to form. An example of this is the free software movement, which has produced, among other things, Linux, Mozilla Firefox, and OpenOffice.org (later forked into LibreOffice). Internet chat, whether using an IRC chat room, an instant messaging system, or a social networking service, allows colleagues to stay in touch in a very convenient way while working at their computers during the day. Messages can be exchanged even more quickly and conveniently than via email. These systems may allow files to be exchanged, drawings and images to be shared, or voice and video contact between team members.
Content management systems allow collaborating teams to work on shared sets of documents simultaneously without accidentally destroying each other’s work. Business and project teams can share calendars as well as documents and other information. Such collaboration occurs in a wide variety of areas including scientific research, software development, conference planning, political activism and creative writing. Social and political collaboration is also becoming more widespread as both Internet access and computer literacy spread.
The Internet allows computer users to remotely access other computers and information stores easily from any access point. Access may be with computer security, i.e. authentication and encryption technologies, depending on the requirements. This is encouraging new ways of remote work, collaboration and information sharing in many industries. An accountant sitting at home can audit the books of a company based in another country, on a server situated in a third country that is remotely maintained by IT specialists in a fourth. These accounts could have been created by home-working bookkeepers, in other remote locations, based on information emailed to them from offices all over the world. Some of these things were possible before the widespread use of the Internet, but the cost of private leased lines would have made many of them infeasible in practice. An office worker away from their desk, perhaps on the other side of the world on a business trip or a holiday, can access their emails, access their data using cloud computing, or open a remote desktop session into their office PC using a secure virtual private network (VPN) connection on the Internet. This can give the worker complete access to all of their normal files and data, including email and other applications, while away from the office. It has been referred to among system administrators as the Virtual Private Nightmare,[115] because it extends the secure perimeter of a corporate network into remote locations and its employees’ homes.
By late 2010s Internet has been described as «the main source of scientific information «for the majority of the global North population».[116]: 111
Social networking and entertainment
Many people use the World Wide Web to access news, weather and sports reports, to plan and book vacations and to pursue their personal interests. People use chat, messaging and email to make and stay in touch with friends worldwide, sometimes in the same way as some previously had pen pals. Social networking services such as Facebook have created new ways to socialize and interact. Users of these sites are able to add a wide variety of information to pages, pursue common interests, and connect with others. It is also possible to find existing acquaintances, to allow communication among existing groups of people. Sites like LinkedIn foster commercial and business connections. YouTube and Flickr specialize in users’ videos and photographs. Social networking services are also widely used by businesses and other organizations to promote their brands, to market to their customers and to encourage posts to «go viral». «Black hat» social media techniques are also employed by some organizations, such as spam accounts and astroturfing.
A risk for both individuals and organizations writing posts (especially public posts) on social networking services, is that especially foolish or controversial posts occasionally lead to an unexpected and possibly large-scale backlash on social media from other Internet users. This is also a risk in relation to controversial offline behavior, if it is widely made known. The nature of this backlash can range widely from counter-arguments and public mockery, through insults and hate speech, to, in extreme cases, rape and death threats. The online disinhibition effect describes the tendency of many individuals to behave more stridently or offensively online than they would in person. A significant number of feminist women have been the target of various forms of harassment in response to posts they have made on social media, and Twitter in particular has been criticised in the past for not doing enough to aid victims of online abuse.[117]
For organizations, such a backlash can cause overall brand damage, especially if reported by the media. However, this is not always the case, as any brand damage in the eyes of people with an opposing opinion to that presented by the organization could sometimes be outweighed by strengthening the brand in the eyes of others. Furthermore, if an organization or individual gives in to demands that others perceive as wrong-headed, that can then provoke a counter-backlash.
Some websites, such as Reddit, have rules forbidding the posting of personal information of individuals (also known as doxxing), due to concerns about such postings leading to mobs of large numbers of Internet users directing harassment at the specific individuals thereby identified. In particular, the Reddit rule forbidding the posting of personal information is widely understood to imply that all identifying photos and names must be censored in Facebook screenshots posted to Reddit. However, the interpretation of this rule in relation to public Twitter posts is less clear, and in any case, like-minded people online have many other ways they can use to direct each other’s attention to public social media posts they disagree with.
Children also face dangers online such as cyberbullying and approaches by sexual predators, who sometimes pose as children themselves. Children may also encounter material which they may find upsetting, or material that their parents consider to be not age-appropriate. Due to naivety, they may also post personal information about themselves online, which could put them or their families at risk unless warned not to do so. Many parents choose to enable Internet filtering or supervise their children’s online activities in an attempt to protect their children from inappropriate material on the Internet. The most popular social networking services, such as Facebook and Twitter, commonly forbid users under the age of 13. However, these policies are typically trivial to circumvent by registering an account with a false birth date, and a significant number of children aged under 13 join such sites anyway. Social networking services for younger children, which claim to provide better levels of protection for children, also exist.[118]
The Internet has been a major outlet for leisure activity since its inception, with entertaining social experiments such as MUDs and MOOs being conducted on university servers, and humor-related Usenet groups receiving much traffic.[citation needed] Many Internet forums have sections devoted to games and funny videos.[citation needed] The Internet pornography and online gambling industries have taken advantage of the World Wide Web. Although many governments have attempted to restrict both industries’ use of the Internet, in general, this has failed to stop their widespread popularity.[119]
Another area of leisure activity on the Internet is multiplayer gaming.[120] This form of recreation creates communities, where people of all ages and origins enjoy the fast-paced world of multiplayer games. These range from MMORPG to first-person shooters, from role-playing video games to online gambling. While online gaming has been around since the 1970s, modern modes of online gaming began with subscription services such as GameSpy and MPlayer.[121] Non-subscribers were limited to certain types of game play or certain games. Many people use the Internet to access and download music, movies and other works for their enjoyment and relaxation. Free and fee-based services exist for all of these activities, using centralized servers and distributed peer-to-peer technologies. Some of these sources exercise more care with respect to the original artists’ copyrights than others.
Internet usage has been correlated to users’ loneliness.[122] Lonely people tend to use the Internet as an outlet for their feelings and to share their stories with others, such as in the «I am lonely will anyone speak to me» thread.
A 2017 book claimed that the Internet consolidates most aspects of human endeavor into singular arenas of which all of humanity are potential members and competitors, with fundamentally negative impacts on mental health as a result. While successes in each field of activity are pervasively visible and trumpeted, they are reserved for an extremely thin sliver of the world’s most exceptional, leaving everyone else behind. Whereas, before the Internet, expectations of success in any field were supported by reasonable probabilities of achievement at the village, suburb, city or even state level, the same expectations in the Internet world are virtually certain to bring disappointment today: there is always someone else, somewhere on the planet, who can do better and take the now one-and-only top spot.[123]
Cybersectarianism is a new organizational form which involves: «highly dispersed small groups of practitioners that may remain largely anonymous within the larger social context and operate in relative secrecy, while still linked remotely to a larger network of believers who share a set of practices and texts, and often a common devotion to a particular leader. Overseas supporters provide funding and support; domestic practitioners distribute tracts, participate in acts of resistance, and share information on the internal situation with outsiders. Collectively, members and practitioners of such sects construct viable virtual communities of faith, exchanging personal testimonies and engaging in the collective study via email, online chat rooms, and web-based message boards.»[124] In particular, the British government has raised concerns about the prospect of young British Muslims being indoctrinated into Islamic extremism by material on the Internet, being persuaded to join terrorist groups such as the so-called «Islamic State», and then potentially committing acts of terrorism on returning to Britain after fighting in Syria or Iraq.
Cyberslacking can become a drain on corporate resources; the average UK employee spent 57 minutes a day surfing the Web while at work, according to a 2003 study by Peninsula Business Services.[125] Internet addiction disorder is excessive computer use that interferes with daily life. Nicholas G. Carr believes that Internet use has other effects on individuals, for instance improving skills of scan-reading and interfering with the deep thinking that leads to true creativity.[126]
Electronic business
Electronic business (e-business) encompasses business processes spanning the entire value chain: purchasing, supply chain management, marketing, sales, customer service, and business relationship. E-commerce seeks to add revenue streams using the Internet to build and enhance relationships with clients and partners. According to International Data Corporation, the size of worldwide e-commerce, when global business-to-business and -consumer transactions are combined, equate to $16 trillion for 2013. A report by Oxford Economics added those two together to estimate the total size of the digital economy at $20.4 trillion, equivalent to roughly 13.8% of global sales.[127]
While much has been written of the economic advantages of Internet-enabled commerce, there is also evidence that some aspects of the Internet such as maps and location-aware services may serve to reinforce economic inequality and the digital divide.[128] Electronic commerce may be responsible for consolidation and the decline of mom-and-pop, brick and mortar businesses resulting in increases in income inequality.[129][130][131]
Author Andrew Keen, a long-time critic of the social transformations caused by the Internet, has focused on the economic effects of consolidation from Internet businesses. Keen cites a 2013 Institute for Local Self-Reliance report saying brick-and-mortar retailers employ 47 people for every $10 million in sales while Amazon employs only 14. Similarly, the 700-employee room rental start-up Airbnb was valued at $10 billion in 2014, about half as much as Hilton Worldwide, which employs 152,000 people. At that time, Uber employed 1,000 full-time employees and was valued at $18.2 billion, about the same valuation as Avis Rent a Car and The Hertz Corporation combined, which together employed almost 60,000 people.[132]
Remote work
Remote work is facilitated by tools such as groupware, virtual private networks, conference calling, videotelephony, and VoIP so that work may be performed from any location, most conveniently the worker’s home. It can be efficient and useful for companies as it allows workers to communicate over long distances, saving significant amounts of travel time and cost. More workers have adequate bandwidth at home to use these tools to link their home to their corporate intranet and internal communication networks.
Collaborative publishing
Wikis have also been used in the academic community for sharing and dissemination of information across institutional and international boundaries.[133] In those settings, they have been found useful for collaboration on grant writing, strategic planning, departmental documentation, and committee work.[134] The United States Patent and Trademark Office uses a wiki to allow the public to collaborate on finding prior art relevant to examination of pending patent applications. Queens, New York has used a wiki to allow citizens to collaborate on the design and planning of a local park.[135] The English Wikipedia has the largest user base among wikis on the World Wide Web[136] and ranks in the top 10 among all Web sites in terms of traffic.[137]
Politics and political revolutions

Banner in Bangkok during the 2014 Thai coup d’état, informing the Thai public that ‘like’ or ‘share’ activities on social media could result in imprisonment (observed 30 June 2014)
The Internet has achieved new relevance as a political tool. The presidential campaign of Howard Dean in 2004 in the United States was notable for its success in soliciting donation via the Internet. Many political groups use the Internet to achieve a new method of organizing for carrying out their mission, having given rise to Internet activism, most notably practiced by rebels in the Arab Spring.[138][139] The New York Times suggested that social media websites, such as Facebook and Twitter, helped people organize the political revolutions in Egypt, by helping activists organize protests, communicate grievances, and disseminate information.[140]
Many have understood the Internet as an extension of the Habermasian notion of the public sphere, observing how network communication technologies provide something like a global civic forum. However, incidents of politically motivated Internet censorship have now been recorded in many countries, including western democracies.[141][142]
Philanthropy
The spread of low-cost Internet access in developing countries has opened up new possibilities for peer-to-peer charities, which allow individuals to contribute small amounts to charitable projects for other individuals. Websites, such as DonorsChoose and GlobalGiving, allow small-scale donors to direct funds to individual projects of their choice. A popular twist on Internet-based philanthropy is the use of peer-to-peer lending for charitable purposes. Kiva pioneered this concept in 2005, offering the first web-based service to publish individual loan profiles for funding. Kiva raises funds for local intermediary microfinance organizations that post stories and updates on behalf of the borrowers. Lenders can contribute as little as $25 to loans of their choice, and receive their money back as borrowers repay. Kiva falls short of being a pure peer-to-peer charity, in that loans are disbursed before being funded by lenders and borrowers do not communicate with lenders themselves.[143][144]
Security
Internet resources, hardware, and software components are the target of criminal or malicious attempts to gain unauthorized control to cause interruptions, commit fraud, engage in blackmail or access private information.
Malware
Malware is malicious software used and distributed via the Internet. It includes computer viruses which are copied with the help of humans, computer worms which copy themselves automatically, software for denial of service attacks, ransomware, botnets, and spyware that reports on the activity and typing of users. Usually, these activities constitute cybercrime. Defense theorists have also speculated about the possibilities of hackers using cyber warfare using similar methods on a large scale.[145]
Surveillance
The vast majority of computer surveillance involves the monitoring of data and traffic on the Internet.[146] In the United States for example, under the Communications Assistance For Law Enforcement Act, all phone calls and broadband Internet traffic (emails, web traffic, instant messaging, etc.) are required to be available for unimpeded real-time monitoring by Federal law enforcement agencies.[147][148][149] Packet capture is the monitoring of data traffic on a computer network. Computers communicate over the Internet by breaking up messages (emails, images, videos, web pages, files, etc.) into small chunks called «packets», which are routed through a network of computers, until they reach their destination, where they are assembled back into a complete «message» again. Packet Capture Appliance intercepts these packets as they are traveling through the network, in order to examine their contents using other programs. A packet capture is an information gathering tool, but not an analysis tool. That is it gathers «messages» but it does not analyze them and figure out what they mean. Other programs are needed to perform traffic analysis and sift through intercepted data looking for important/useful information. Under the Communications Assistance For Law Enforcement Act all U.S. telecommunications providers are required to install packet sniffing technology to allow Federal law enforcement and intelligence agencies to intercept all of their customers’ broadband Internet and VoIP traffic.[150]
The large amount of data gathered from packet capturing requires surveillance software that filters and reports relevant information, such as the use of certain words or phrases, the access of certain types of web sites, or communicating via email or chat with certain parties.[151] Agencies, such as the Information Awareness Office, NSA, GCHQ and the FBI, spend billions of dollars per year to develop, purchase, implement, and operate systems for interception and analysis of data.[152] Similar systems are operated by Iranian secret police to identify and suppress dissidents. The required hardware and software was allegedly installed by German Siemens AG and Finnish Nokia.[153]
Censorship

Pervasive
Substantial
Selective
Little or none
Some governments, such as those of Burma, Iran, North Korea, Mainland China, Saudi Arabia and the United Arab Emirates, restrict access to content on the Internet within their territories, especially to political and religious content, with domain name and keyword filters.[159]
In Norway, Denmark, Finland, and Sweden, major Internet service providers have voluntarily agreed to restrict access to sites listed by authorities. While this list of forbidden resources is supposed to contain only known child pornography sites, the content of the list is secret.[160] Many countries, including the United States, have enacted laws against the possession or distribution of certain material, such as child pornography, via the Internet, but do not mandate filter software. Many free or commercially available software programs, called content-control software are available to users to block offensive websites on individual computers or networks, in order to limit access by children to pornographic material or depiction of violence.
Performance
As the Internet is a heterogeneous network, the physical characteristics, including for example the data transfer rates of connections, vary widely. It exhibits emergent phenomena that depend on its large-scale organization.[161]
Traffic volume
Global Internet Traffic as of 2018
The volume of Internet traffic is difficult to measure, because no single point of measurement exists in the multi-tiered, non-hierarchical topology. Traffic data may be estimated from the aggregate volume through the peering points of the Tier 1 network providers, but traffic that stays local in large provider networks may not be accounted for.
Outages
An Internet blackout or outage can be caused by local signalling interruptions. Disruptions of submarine communications cables may cause blackouts or slowdowns to large areas, such as in the 2008 submarine cable disruption. Less-developed countries are more vulnerable due to a small number of high-capacity links. Land cables are also vulnerable, as in 2011 when a woman digging for scrap metal severed most connectivity for the nation of Armenia.[162] Internet blackouts affecting almost entire countries can be achieved by governments as a form of Internet censorship, as in the blockage of the Internet in Egypt, whereby approximately 93%[163] of networks were without access in 2011 in an attempt to stop mobilization for anti-government protests.[164]
Energy use
Estimates of the Internet’s electricity usage have been the subject of controversy, according to a 2014 peer-reviewed research paper that found claims differing by a factor of 20,000 published in the literature during the preceding decade, ranging from 0.0064 kilowatt hours per gigabyte transferred (kWh/GB) to 136 kWh/GB.[165] The researchers attributed these discrepancies mainly to the year of reference (i.e. whether efficiency gains over time had been taken into account) and to whether «end devices such as personal computers and servers are included» in the analysis.[165]
In 2011, academic researchers estimated the overall energy used by the Internet to be between 170 and 307 GW, less than two percent of the energy used by humanity. This estimate included the energy needed to build, operate, and periodically replace the estimated 750 million laptops, a billion smart phones and 100 million servers worldwide as well as the energy that routers, cell towers, optical switches, Wi-Fi transmitters and cloud storage devices use when transmitting Internet traffic.[166][167] According to a non-peer reviewed study published in 2018 by The Shift Project (a French think tank funded by corporate sponsors), nearly 4% of global CO2 emissions could be attributed to global data transfer and the necessary infrastructure.[168] The study also said that online video streaming alone accounted for 60% of this data transfer and therefore contributed to over 300 million tons of CO2 emission per year, and argued for new «digital sobriety» regulations restricting the use and size of video files.[169]
See also
- Crowdfunding
- Crowdsourcing
- Darknet
- Deep web
- Freenet
- Internet industry jargon
- Index of Internet-related articles
- Internet metaphors
- Internet video
- «Internets»
- Open Systems Interconnection
- Outline of the Internet
Notes
- ^ See Capitalization of Internet.
- ^ Despite the name, TCP/IP also includes UDP traffic, which is significant.[1]
References
- ^ Amogh Dhamdhere. «Internet Traffic Characterization». Retrieved 6 May 2022.
- ^ a b «A Flaw in the Design». The Washington Post. 30 May 2015. Archived from the original on 8 November 2020. Retrieved 20 February 2020.
The Internet was born of a big idea: Messages could be chopped into chunks, sent through a network in a series of transmissions, then reassembled by destination computers quickly and efficiently. Historians credit seminal insights to Welsh scientist Donald W. Davies and American engineer Paul Baran. … The most important institutional force … was the Pentagon’s Advanced Research Projects Agency (ARPA) … as ARPA began work on a groundbreaking computer network, the agency recruited scientists affiliated with the nation’s top universities.
- ^ Stewart, Bill (January 2000). «Internet History – One Page Summary». The Living Internet. Archived from the original on 2 July 2014.
- ^ «#3 1982: the ARPANET community grows» in 40 maps that explain the internet Archived 6 March 2017 at the Wayback Machine, Timothy B. Lee, Vox Conversations, 2 June 2014. Retrieved 27 June 2014.
- ^ Strickland, Jonathan (3 March 2008). «How Stuff Works: Who owns the Internet?». Archived from the original on 19 June 2014. Retrieved 27 June 2014.
- ^ Hoffman, P.; Harris, S. (September 2006). The Tao of IETF: A Novice’s Guide to Internet Engineering Task Force. IETF. doi:10.17487/RFC4677. RFC 4677.
- ^ «New Seven Wonders panel». USA Today. 27 October 2006. Archived from the original on 15 July 2010. Retrieved 31 July 2010.
- ^ «Internetted». Oxford English Dictionary (Online ed.). Oxford University Press. (Subscription or participating institution membership required.) nineteenth-century use as an adjective.
- ^ «United States Army Field Manual FM 24-6 Radio Operator’s Manual Army Ground Forces June 1945». United States War Department.
{{cite web}}: CS1 maint: url-status (link) - ^ a b Cerf, Vint; Dalal, Yogen; Sunshine, Carl (December 1974). Specification of Internet Transmission Control Protocol. IETF. doi:10.17487/RFC0675. RFC 675.
- ^ a b c d Corbett, Philip B. (1 June 2016). «It’s Official: The ‘Internet’ Is Over». The New York Times. ISSN 0362-4331. Archived from the original on 14 October 2020. Retrieved 29 August 2020.
- ^ a b Herring, Susan C. (19 October 2015). «Should You Be Capitalizing the Word ‘Internet’?». Wired. ISSN 1059-1028. Archived from the original on 31 October 2020. Retrieved 29 August 2020.
- ^ Coren, Michael J. (2 June 2016). «One of the internet’s inventors thinks it should still be capitalized». Quartz. Archived from the original on 27 September 2020. Retrieved 8 September 2020.
- ^ «World Wide Web Timeline». Pews Research Center. 11 March 2014. Archived from the original on 29 July 2015. Retrieved 1 August 2015.
- ^ «HTML 4.01 Specification». World Wide Web Consortium. Archived from the original on 6 October 2008. Retrieved 13 August 2008.
[T]he link (or hyperlink, or Web link) [is] the basic hypertext construct. A link is a connection from one Web resource to another. Although a simple concept, the link has been one of the primary forces driving the success of the Web.
- ^ Hauben, Michael; Hauben, Ronda (1997). «5 The Vision of Interactive Computing And the Future». Netizens: On the History and Impact of Usenet and the Internet (PDF). Wiley. ISBN 978-0-8186-7706-9. Archived (PDF) from the original on 3 January 2021. Retrieved 2 March 2020.
- ^ Zelnick, Bob; Zelnick, Eva (1 September 2013). The Illusion of Net Neutrality: Political Alarmism, Regulatory Creep and the Real Threat to Internet Freedom. Hoover Press. ISBN 978-0-8179-1596-4. Archived from the original on 10 January 2021. Retrieved 7 May 2020.
- ^ Peter, Ian (2004). «So, who really did invent the Internet?». The Internet History Project. Archived from the original on 3 September 2011. Retrieved 27 June 2014.
- ^ «Inductee Details — Paul Baran». National Inventors Hall of Fame. Archived from the original on 6 September 2017. Retrieved 6 September 2017; «Inductee Details — Donald Watts Davies». National Inventors Hall of Fame. Archived from the original on 6 September 2017. Retrieved 6 September 2017.
- ^ Kim, Byung-Keun (2005). Internationalising the Internet the Co-evolution of Influence and Technology. Edward Elgar. pp. 51–55. ISBN 978-1-84542-675-0.
- ^ Gromov, Gregory (1995). «Roads and Crossroads of Internet History». Archived from the original on 27 January 2016.
- ^ Hafner, Katie (1998). Where Wizards Stay Up Late: The Origins of the Internet. Simon & Schuster. ISBN 978-0-684-83267-8.
- ^ Hauben, Ronda (2001). «From the ARPANET to the Internet». Archived from the original on 21 July 2009. Retrieved 28 May 2009.
- ^ «Internet Pioneers Discuss the Future of Money, Books, and Paper in 1972». Paleofuture. 23 July 2013. Archived from the original on 17 October 2020. Retrieved 31 August 2020.
- ^ Townsend, Anthony (2001). «The Internet and the Rise of the New Network Cities, 1969–1999». Environment and Planning B: Planning and Design. 28 (1): 39–58. doi:10.1068/b2688. ISSN 0265-8135. S2CID 11574572.
- ^ «NORSAR and the Internet». NORSAR. Archived from the original on 21 January 2013.
- ^ Kirstein, P.T. (1999). «Early experiences with the Arpanet and Internet in the United Kingdom» (PDF). IEEE Annals of the History of Computing. 21 (1): 38–44. doi:10.1109/85.759368. ISSN 1934-1547. S2CID 1558618. Archived from the original (PDF) on 7 February 2020.
- ^ Leiner, Barry M. «Brief History of the Internet: The Initial Internetting Concepts». Internet Society. Archived from the original on 9 April 2016. Retrieved 27 June 2014.
- ^ Cerf, V.; Kahn, R. (1974). «A Protocol for Packet Network Intercommunication» (PDF). IEEE Transactions on Communications. 22 (5): 637–648. doi:10.1109/TCOM.1974.1092259. ISSN 1558-0857. Archived (PDF) from the original on 13 September 2006.
The authors wish to thank a number of colleagues for helpful comments during early discussions of international network protocols, especially R. Metcalfe, R. Scantlebury, D. Walden, and H. Zimmerman; D. Davies and L. Pouzin who constructively commented on the fragmentation and accounting issues; and S. Crocker who commented on the creation and destruction of associations.
- ^ Leiner, Barry M.; Cerf, Vinton G.; Clark, David D.; Kahn, Robert E.; Kleinrock, Leonard; Lynch, Daniel C.; Postel, Jon; Roberts, Larry G.; Wolff, Stephen (2003). «A Brief History of Internet». Internet Society. p. 1011. arXiv:cs/9901011. Bibcode:1999cs……..1011L. Archived from the original on 4 June 2007. Retrieved 28 May 2009.
- ^ «The internet’s fifth man». The Economist. 30 November 2013. ISSN 0013-0613. Archived from the original on 19 April 2020. Retrieved 22 April 2020.
In the early 1970s Mr Pouzin created an innovative data network that linked locations in France, Italy and Britain. Its simplicity and efficiency pointed the way to a network that could connect not just dozens of machines, but millions of them. It captured the imagination of Dr Cerf and Dr Kahn, who included aspects of its design in the protocols that now power the internet.
- ^ Schatt, Stan (1991). Linking LANs: A Micro Manager’s Guide. McGraw-Hill. p. 200. ISBN 0-8306-3755-9.
- ^ Frazer, Karen D. (1995). «NSFNET: A Partnership for High-Speed Networking, Final Report 1987–1995» (PDF). Merit Network, Inc. Archived from the original (PDF) on 10 February 2015.
- ^ Ben Segal (1995). «A Short History of Internet Protocols at CERN». Archived from the original on 19 June 2020. Retrieved 14 October 2011.
- ^ Réseaux IP Européens (RIPE)
- ^ «Internet History in Asia». 16th APAN Meetings/Advanced Network Conference in Busan. Archived from the original on 1 February 2006. Retrieved 25 December 2005.
- ^ «The History of NORDUnet» (PDF). Archived from the original (PDF) on 4 March 2016.
- ^ Clarke, Roger. «Origins and Nature of the Internet in Australia». Archived from the original on 9 February 2021. Retrieved 21 January 2014.
- ^ Zakon, Robert (November 1997). RFC 2235. IETF. p. 8. doi:10.17487/RFC2235. Retrieved 2 December 2020.
- ^ Inc, InfoWorld Media Group (25 September 1989). «InfoWorld». Archived from the original on 29 January 2017 – via Google Books.
- ^ «INTERNET MONTHLY REPORTS». February 1990. Archived from the original on 25 May 2017. Retrieved 28 November 2020.
- ^ Berners-Lee, Tim. «The Original HTTP as defined in 1991». W3C.org. Archived from the original on 5 June 1997.
- ^ «The website of the world’s first-ever web server». info.cern.ch. Archived from the original on 5 January 2010.
- ^ «Stanford Federal Credit Union Pioneers Online Financial Services» (Press release). 21 June 1995. Archived from the original on 21 December 2018. Retrieved 21 December 2018.
- ^ «History — About us — OP Group». Archived from the original on 21 December 2018. Retrieved 21 December 2018.
- ^ Harris, Susan R.; Gerich, Elise (April 1996). «Retiring the NSFNET Backbone Service: Chronicling the End of an Era». ConneXions. 10 (4). Archived from the original on 17 August 2013.
- ^ «Measuring digital development: Facts and figures 2021». Telecommunication Development Bureau, International Telecommunication Union (ITU). Retrieved 16 November 2022.
- ^ «Total Midyear Population for the World: 1950-2050»«. International Programs Center for Demographic and Economic Studies, U.S. Census Bureau. Archived from the original on 17 April 2017. Retrieved 28 February 2020.
- ^ Jindal, R. P. (2009). «From millibits to terabits per second and beyond — Over 60 years of innovation». 2009 2nd International Workshop on Electron Devices and Semiconductor Technology: 1–6. doi:10.1109/EDST.2009.5166093. ISBN 978-1-4244-3831-0. S2CID 25112828. Archived from the original on 23 August 2019. Retrieved 24 August 2019.
- ^ Ward, Mark (3 August 2006). «How the web went world wide». Technology Correspondent. BBC News. Archived from the original on 21 November 2011. Retrieved 24 January 2011.
- ^ «Brazil, Russia, India and China to Lead Internet Growth Through 2011». Clickz.com. Archived from the original on 4 October 2008. Retrieved 28 May 2009.
- ^ Coffman, K.G; Odlyzko, A.M. (2 October 1998). «The size and growth rate of the Internet» (PDF). AT&T Labs. Archived from the original (PDF) on 14 June 2007. Retrieved 21 May 2007.
- ^ Comer, Douglas (2006). The Internet book. Prentice Hall. p. 64. ISBN 978-0-13-233553-9.
- ^ «World Internet Users and Population Stats». Internet World Stats. Miniwatts Marketing Group. 22 June 2011. Archived from the original on 23 June 2011. Retrieved 23 June 2011.
- ^ Hilbert, Martin; López, Priscila (April 2011). «The World’s Technological Capacity to Store, Communicate, and Compute Information». Science. 332 (6025): 60–65. Bibcode:2011Sci…332…60H. doi:10.1126/science.1200970. PMID 21310967. S2CID 206531385. Archived (PDF) from the original on 31 May 2011.
- ^ Klein, Hans (2004). «ICANN and Non-Territorial Sovereignty: Government Without the Nation State». Internet and Public Policy Project. Georgia Institute of Technology. Archived from the original on 24 May 2013.
- ^ Packard, Ashley (2010). Digital Media Law. Wiley-Blackwell. p. 65. ISBN 978-1-4051-8169-3.
- ^ McCarthy, Kieren (1 July 2005). «Bush administration annexes internet». The Register. Archived from the original on 19 September 2011.
- ^ Mueller, Milton L. (2010). Networks and States: The Global Politics of Internet Governance. MIT Press. p. 61. ISBN 978-0-262-01459-5.
- ^ «ICG Applauds Transfer of IANA Stewardship». IANA Stewardship Transition Coordination Group (ICG). Archived from the original on 12 July 2017. Retrieved 8 June 2017.
- ^ «Internet Society (ISOC) All About The Internet: History of the Internet». ISOC. Archived from the original on 27 November 2011. Retrieved 19 December 2013.
- ^ Pasternak, Sean B. (7 March 2006). «Toronto Hydro to Install Wireless Network in Downtown Toronto». Bloomberg. Archived from the original on 10 April 2006. Retrieved 8 August 2011.
- ^ «Mobile and Tablet Internet Usage Exceeds Desktop for First Time Worldwide». StatCounter: Global Stats, Press Release. 1 November 2016. Archived from the original on 1 November 2016.
StatCounter Global Stats finds that mobile and tablet devices accounted for 51.3% of Internet usage worldwide in October compared to 48.7% by desktop.
- ^ «World Telecommunication/ICT Indicators Database 2020 (24th Edition/July 2020)». International Telecommunication Union (ITU). 2017a. Archived from the original on 21 April 2019.
Key ICT indicators for developed and developing countries and the world (totals and penetration rates). World Telecommunication/ICT Indicators database
- ^ a b World Trends in Freedom of Expression and Media Development Global Report 2017/2018 (PDF). UNESCO. 2018. Archived (PDF) from the original on 20 September 2018. Retrieved 29 May 2018.
- ^ a b «GSMA The Mobile Economy 2019 — The Mobile Economy». 11 March 2019. Archived from the original on 11 March 2019. Retrieved 28 November 2020.
- ^ Galpaya, Helani (12 April 2019). «Zero-rating in Emerging Economies» (PDF). Global Commission on Internet Governance. Archived (PDF) from the original on 12 April 2019. Retrieved 28 November 2020.
- ^ «Alliance for Affordable Internet (A4AI). 2015. Models of Mobile Data Services in Developing Countries. Research brief. The Impacts of Emerging Mobile Data Services in Developing Countries».[dead link]
- ^ Alison GillwAld, ChenAi ChAir, Ariel Futter, KweKu KorAntenG, FolA oduFuwA, John wAlubenGo (12 September 2016). «Much Ado About Nothing? Zero Rating in the African Context» (PDF). Researchictafrica. Archived (PDF) from the original on 16 December 2020. Retrieved 28 November 2020.
{{cite web}}: CS1 maint: multiple names: authors list (link) - ^ a b J. Postel, ed. (September 1981). Internet Protocol, DARPA Internet Program Protocol Specification. IETF. doi:10.17487/RFC0791. RFC 791. Updated by RFC 1349, 2474, 6864
- ^ Huston, Geoff. «IPv4 Address Report, daily generated». Archived from the original on 1 April 2009. Retrieved 20 May 2009.
- ^ S. Deering; R. Hinden (December 1995). Internet Protocol, Version 6 (IPv6) Specification. Network Working Group. doi:10.17487/RFC1883. RFC 1883.
- ^ S. Deering; R. Hinden (December 1998). Internet Protocol, Version 6 (IPv6) Specification. Network Working Group. doi:10.17487/RFC2460. RFC 2460.
- ^ S. Deering; R. Hinden (July 2017). Internet Protocol, Version 6 (IPv6) Specification. IETF. doi:10.17487/RFC8200. RFC 8200.
- ^ «Notice of Internet Protocol version 4 (IPv4) Address Depletion» (PDF). Archived from the original (PDF) on 7 January 2010. Retrieved 7 August 2009.
- ^ Jeffrey Mogul; Jon Postel (August 1985). Internet Standard Subnetting Procedure. IETF. doi:10.17487/RFC0950. RFC 950. Updated by RFC 6918.
- ^ Fisher, Tim. «How to Find Your Default Gateway IP Address». Lifewire. Archived from the original on 25 February 2019. Retrieved 25 February 2019.
- ^ «Default Gateway». techopedia.com. Archived from the original on 26 October 2020.
- ^ «IETF Home Page». Ietf.org. Archived from the original on 18 June 2009. Retrieved 20 June 2009.
- ^ «The Difference Between the Internet and the World Wide Web». Webopedia.com. QuinStreet Inc. 24 June 2010. Archived from the original on 2 May 2014. Retrieved 1 May 2014.
- ^ «IAB Internet advertising revenue report: 2012 full year results» (PDF). PricewaterhouseCoopers, Internet Advertising Bureau. April 2013. Archived from the original (PDF) on 4 October 2014. Retrieved 12 June 2013.
- ^ Brown, Ron (26 October 1972). «Fax invades the mail market». New Scientist. 56 (817): 218–221.
- ^ Luckett, Herbert P. (March 1973). «What’s News: Electronic-mail delivery gets started». Popular Science. 202 (3): 85.
- ^ Booth, C (2010). «Chapter 2: IP Phones, Software VoIP, and Integrated and Mobile VoIP». Library Technology Reports. 46 (5): 11–19.
- ^ Morrison, Geoff (18 November 2010). «What to know before buying a ‘connected’ TV – Technology & science – Tech and gadgets – Tech Holiday Guide». NBC News. Archived from the original on 12 February 2020. Retrieved 8 August 2011.
- ^ «Press — YouTube». www.youtube.com. Archived from the original on 11 November 2017. Retrieved 19 August 2020.
- ^ «YouTube now defaults to HTML5 <video>». YouTube Engineering and Developers Blog. Archived from the original on 10 September 2018. Retrieved 10 September 2018.
- ^ Ritchie, Hannah; Roser, Max (2 October 2017). «Technology Adoption». Our World in Data. Archived from the original on 12 October 2019. Retrieved 12 October 2019.
- ^ «Individuals using the Internet 2005 to 2014» Archived 28 May 2015 at the Wayback Machine, Key ICT indicators for developed and developing countries and the world (totals and penetration rates), International Telecommunication Union (ITU). Retrieved 25 May 2015.
- ^ «Internet users per 100 inhabitants 1997 to 2007» Archived 17 May 2015 at the Wayback Machine, ICT Data and Statistics (IDS), International Telecommunication Union (ITU). Retrieved 25 May 2015.
- ^ Internet users graphs Archived 9 May 2020 at the Wayback Machine, Market Information and Statistics, International Telecommunication Union
- ^ «Google Earth demonstrates how technology benefits RI’s civil society, govt». Antara News. 26 May 2011. Archived from the original on 29 October 2012. Retrieved 19 November 2012.
- ^ Steve Dent. «There are now 3 billion Internet users, mostly in rich countries». Archived from the original on 28 November 2014. Retrieved 25 November 2014.
- ^ «Statistical Report on Internet Development in China» (PDF). Cnnic.com. January 2018. Archived (PDF) from the original on 12 April 2019.
- ^ «World Internet Users Statistics and 2019 World Population Stats». internetworldstats.com. Archived from the original on 24 November 2017. Retrieved 17 March 2019.
- ^ «Digital 2020: 3.8 billion people use social media». 30 January 2020. Archived from the original on 17 April 2020. Retrieved 25 April 2020.
- ^ «Internet». Encyclopædia Britannica. Archived from the original on 21 March 2021. Retrieved 19 March 2021.
- ^ a b «Number of Internet Users by Language». Internet World Stats, Miniwatts Marketing Group. 31 May 2011. Archived from the original on 26 April 2012. Retrieved 22 April 2012.
- ^ «World Internet Usage Statistics News and Population Stats». 30 June 2010. Archived from the original on 19 March 2017. Retrieved 20 February 2011.
- ^ How men and women use the Internet Pew Research Center 28 December 2005
- ^ «Rapleaf Study on Social Network Users». Archived from the original on 20 March 2009.
- ^ «Women Ahead of Men in Online Tv, Dvr, Games, And Social Media». Entrepreneur.com. 1 May 2008. Archived from the original on 16 September 2008. Retrieved 8 August 2011.
- ^ «Technorati’s State of the Blogosphere». Technorati. Archived from the original on 2 October 2009. Retrieved 8 August 2011.
- ^ a b «Percentage of Individuals using the Internet 2000–2012» Archived 9 February 2014 at the Wayback Machine, International Telecommunication Union (Geneva), June 2013. Retrieved 22 June 2013.
- ^ Seese, Michael (2009). Scrappy Information Security. p. 130. ISBN 978-1-60005-132-6. Archived from the original on 5 September 2017. Retrieved 5 June 2015.
- ^ netizen Archived 21 April 2012 at the Wayback Machine, Dictionary.com
- ^ Hauben, Michael. «The Net and Netizens». Columbia University. Archived from the original on 4 June 2011.
- ^ «A Brief History of the Internet». the Internet Society. Archived from the original on 4 June 2007.
- ^ «Oxford Dictionaries – internaut». oxforddictionaries.com. Archived from the original on 13 June 2015. Retrieved 6 June 2015.
- ^ Mossberger, Karen; Tolbert, Caroline J.; McNeal, Ramona S. (23 November 2011). Digital Citizenship – The Internet, Society and Participation. ISBN 978-0-8194-5606-9.
- ^ «Usage of content languages for websites». W3Techs.com. Archived from the original on 31 March 2012. Retrieved 26 April 2013.
- ^ «Fixed (wired)-broadband subscriptions per 100 inhabitants 2012» Archived 26 July 2019 at the Wayback Machine, Dynamic Report, ITU ITC EYE, International Telecommunication Union. Retrieved 29 June 2013.
- ^ «Active mobile-broadband subscriptions per 100 inhabitants 2012» Archived 26 July 2019 at the Wayback Machine, Dynamic Report, ITU ITC EYE, International Telecommunication Union. Retrieved 29 June 2013.
- ^ Reips, U.-D. (2008). «How Internet-mediated research changes science». Psychological aspects of cyberspace: Theory, research, applications. Cambridge: Cambridge University Press. pp. 268–294. ISBN 9780521694643. Archived from the original on 9 August 2014.
- ^ «The Virtual Private Nightmare: VPN». Librenix. 4 August 2004. Archived from the original on 15 May 2011. Retrieved 21 July 2010.
- ^ Dariusz Jemielniak; Aleksandra Przegalinska (18 February 2020). Collaborative Society. MIT Press. ISBN 978-0-262-35645-9. Archived from the original on 23 November 2020. Retrieved 26 November 2020.
- ^ Moore, Keith (27 July 2013). «Twitter ‘report abuse’ button calls after rape threats». BBC News. Archived from the original on 4 September 2014. Retrieved 7 December 2014.
- ^ Kessler, Sarah (11 October 2010). «5 Fun and Safe Social Networks for Children». Mashable. Archived from the original on 20 December 2014. Retrieved 7 December 2014.
- ^ Goldman, Russell (22 January 2008). «Do It Yourself! Amateur Porn Stars Make Bank». ABC News. Archived from the original on 30 December 2011.
- ^ Spohn, Dave (15 December 2009). «Top Online Game Trends of the Decade». About.com. Archived from the original on 29 September 2011.
- ^ Spohn, Dave (2 June 2011). «Internet Game Timeline: 1963 – 2004». About.com. Archived from the original on 25 April 2006.
- ^ Carole Hughes; Boston College. «The Relationship Between Internet Use and Loneliness Among College Students». Boston College. Archived from the original on 7 November 2015. Retrieved 11 August 2011.
- ^ Barker, Eric (2017). Barking Up the Wrong Tree. HarperCollins. pp. 235–6. ISBN 9780062416049.
- ^ Thornton, Patricia M. (2003). «The New Cybersects: Resistance and Repression in the Reform era». In Perry, Elizabeth; Selden, Mark (eds.). Chinese Society: Change, Conflict and Resistance (2 ed.). London and New York: Routledge. pp. 149–150. ISBN 9780415560740.
- ^ «Net abuse hits small city firms». The Scotsman. Edinburgh. 11 September 2003. Archived from the original on 20 October 2012. Retrieved 7 August 2009.
- ^ Carr, Nicholas G. (7 June 2010). The Shallows: What the Internet Is Doing to Our Brains. W.W. Norton. p. 276. ISBN 978-0393072228.
- ^ «The New Digital Economy: How it will transform business» (PDF). Oxford Economics. 2 July 2011. Archived from the original (PDF) on 6 July 2014.
- ^ Badger, Emily (6 February 2013). «How the Internet Reinforces Inequality in the Real World». The Atlantic. Archived from the original on 11 February 2013. Retrieved 13 February 2013.
- ^ «E-commerce will make the shopping mall a retail wasteland». ZDNet. 17 January 2013. Archived from the original on 19 February 2013.
- ^ «‘Free Shipping Day’ Promotion Spurs Late-Season Online Spending Surge, Improving Season-to-Date Growth Rate to 16 Percent vs. Year Ago». Comscore. 23 December 2012. Archived from the original on 28 January 2013.
- ^ «The Death of the American Shopping Mall». The Atlantic – Cities. 26 December 2012. Archived from the original on 15 February 2013.
- ^ Harris, Michael (2 January 2015). «Book review: ‘The Internet Is Not the Answer’ by Andrew Keen». The Washington Post. Archived from the original on 20 January 2015. Retrieved 25 January 2015.
- ^ MM Wanderley; D Birnbaum; J Malloch (2006). New Interfaces For Musical Expression. IRCAM – Centre Pompidou. p. 180. ISBN 978-2-84426-314-8.
- ^ Nancy T. Lombardo (June 2008). «Putting Wikis to Work in Libraries». Medical Reference Services Quarterly. 27 (2): 129–145. doi:10.1080/02763860802114223. PMID 18844087. S2CID 11552140.
- ^ Noveck, Beth Simone (March 2007). «Wikipedia and the Future of Legal Education». Journal of Legal Education. 57 (1). Archived from the original on 3 July 2014.(subscription required)
- ^ «WikiStats by S23». S23Wiki. 3 April 2008. Archived from the original on 25 August 2014. Retrieved 7 April 2007.
- ^ «Alexa Web Search – Top 500». Alexa Internet. Archived from the original on 2 March 2015. Retrieved 2 March 2015.
- ^ «The Arab Uprising’s Cascading Effects». Miller-mccune.com. 23 February 2011. Archived from the original on 27 February 2011. Retrieved 27 February 2011.
- ^ «The Role of the Internet in Democratic Transition: Case Study of the Arab Spring» (PDF). 5 July 2012. Archived from the original (PDF) on 5 July 2012., Davit Chokoshvili, Master’s Thesis, June 2011
- ^ Kirkpatrick, David D. (9 February 2011). «Wired and Shrewd, Young Egyptians Guide Revolt». The New York Times. Archived from the original on 29 January 2017.
- ^ Ronald Deibert; John Palfrey; Rafal Rohozinski; Jonathan Zittrain (25 January 2008). Access Denied: The Practice and Policy of Global Internet Filtering. MIT Press. ISBN 978-0-262-29072-2.
- ^ Larry Diamond; Marc F. Plattner (30 July 2012). Liberation Technology: Social Media and the Struggle for Democracy. JHU Press. ISBN 978-1-4214-0568-1.
- ^ Roodman, David (2 October 2009). «Kiva Is Not Quite What It Seems». Center for Global Development. Archived from the original on 10 February 2010. Retrieved 16 January 2010.
- ^ Strom, Stephanie (9 November 2009). «Confusion on Where Money Lent via Kiva Goes». The New York Times. p. 6. Archived from the original on 29 January 2017.
- ^ Andriole, Steve. «Cyberwarfare Will Explode In 2020 (Because It’s Cheap, Easy And Effective)». Forbes. Retrieved 18 May 2021.
- ^ Diffie, Whitfield; Susan Landau (August 2008). «Internet Eavesdropping: A Brave New World of Wiretapping». Scientific American. Archived from the original on 13 November 2008. Retrieved 13 March 2009.
- ^ «CALEA Archive». Electronic Frontier Foundation (website). Archived from the original on 25 October 2008. Retrieved 14 March 2009.
- ^ «CALEA: The Perils of Wiretapping the Internet». Electronic Frontier Foundation (website). Archived from the original on 16 March 2009. Retrieved 14 March 2009.
- ^ «CALEA: Frequently Asked Questions». Electronic Frontier Foundation (website). 20 September 2007. Archived from the original on 1 May 2009. Retrieved 14 March 2009.
- ^ «American Council on Education vs. FCC, Decision, United States Court of Appeals for the District of Columbia Circuit» (PDF). 9 June 2006. Archived from the original (PDF) on 7 September 2012. Retrieved 8 September 2013.
- ^ Hill, Michael (11 October 2004). «Government funds chat room surveillance research». USA Today. Associated Press. Archived from the original on 11 May 2010. Retrieved 19 March 2009.
- ^ McCullagh, Declan (30 January 2007). «FBI turns to broad new wiretap method». ZDNet News. Archived from the original on 7 April 2010. Retrieved 13 March 2009.
- ^ «First round in Internet war goes to Iranian intelligence». Debkafile. 28 June 2009. Archived from the original on 21 December 2013.
- ^ «Freedom on the Net 2018» (PDF). Freedom House. November 2018. Archived from the original (PDF) on 1 November 2018. Retrieved 1 November 2018.
- ^ OpenNet Initiative «Summarized global Internet filtering data spreadsheet» Archived 10 January 2012 at the Wayback Machine, 8 November 2011 and «Country Profiles» Archived 26 August 2011 at the Wayback Machine, the OpenNet Initiative is a collaborative partnership of the Citizen Lab at the Munk School of Global Affairs, University of Toronto; the Berkman Center for Internet & Society at Harvard University; and the SecDev Group, Ottawa
- ^ Due to legal concerns the OpenNet Initiative does not check for filtering of child pornography and because their classifications focus on technical filtering, they do not include other types of censorship.
- ^ «Enemies of the Internet 2014: Entities at the heart of censorship and surveillance». Reporters Without Borders. Paris. 11 March 2014. Archived from the original on 12 March 2014.
- ^ «Internet Enemies» (PDF). Reporters Without Borders. Paris. 12 March 2012. Archived from the original (PDF) on 3 July 2017.
- ^ Deibert, Ronald J.; Palfrey, John G.; Rohozinski, Rafal; Zittrain, Jonathan (April 2010). Access Controlled: The Shaping of Power, Rights, and Rule in Cyberspace. MIT Press. ISBN 9780262514354. Archived from the original on 4 June 2011.
- ^ «Finland censors anti-censorship site». The Register. 18 February 2008. Archived from the original on 20 February 2008. Retrieved 19 February 2008.
- ^ Albert, Réka; Jeong, Hawoong; Barabási, Albert-László (9 September 1999). «Diameter of the World-Wide Web». Nature. 401 (6749): 130–131. arXiv:cond-mat/9907038. Bibcode:1999Natur.401..130A. doi:10.1038/43601. S2CID 4419938.
- ^ «Georgian woman cuts off web access to whole of Armenia». The Guardian. 6 April 2011. Archived from the original on 25 August 2013. Retrieved 11 April 2012.
- ^ Cowie, James. «Egypt Leaves the Internet». Renesys. Archived from the original on 28 January 2011. Retrieved 28 January 2011.
- ^ «Egypt severs internet connection amid growing unrest». BBC News. 28 January 2011. Archived from the original on 23 January 2012.
- ^ a b Coroama, Vlad C.; Hilty, Lorenz M. (February 2014). «Assessing Internet energy intensity: A review of methods and results» (PDF). Environmental Impact Assessment Review. 45: 63–68. doi:10.1016/j.eiar.2013.12.004. Archived (PDF) from the original on 23 September 2020. Retrieved 9 March 2020.
- ^ Giles, Jim (26 October 2011). «Internet responsible for 2 per cent of global energy usage». New Scientist. Archived from the original on 1 October 2014.,
- ^ Raghavan, Barath; Ma, Justin (14 November 2011). «The Energy and Emergy of the Internet» (PDF). Proceedings of the 10th ACM Workshop on Hot Topics in Networks. Cambridge, MA.: ACM SIGCOMM: 1–6. doi:10.1145/2070562.2070571. ISBN 9781450310598. S2CID 6125953. Archived from the original (PDF) on 10 August 2014.
- ^ Cwienk, Jeannette (11 July 2019). «Is Netflix bad for the environment? How streaming video contributes to climate change | DW | 11.07.2019». Deutsche Welle. Archived from the original on 12 July 2019. Retrieved 19 July 2019.
- ^ ««Climate crisis: The Unsustainable Use of Online Video» : Our new report». The Shift Project. 10 July 2019. Archived from the original on 21 July 2019. Retrieved 19 July 2019.
Sources
 This article incorporates text from a free content work. . Text taken from World Trends in Freedom of Expression and Media Development Global Report 2017/2018, 202, UNESCO. To learn how to add open license text to Wikipedia articles, please see this how-to page. For information on reusing text from Wikipedia, please see the terms of use.
This article incorporates text from a free content work. . Text taken from World Trends in Freedom of Expression and Media Development Global Report 2017/2018, 202, UNESCO. To learn how to add open license text to Wikipedia articles, please see this how-to page. For information on reusing text from Wikipedia, please see the terms of use.
Further reading
- First Monday, a peer-reviewed journal on the Internet by the University Library of the University of Illinois at Chicago, ISSN 1396-0466
- The Internet Explained, Vincent Zegna & Mike Pepper, Sonet Digital, November 2005, pp. 1–7.
- Abram, Cleo (8 January 2020). «How Does the Internet Work?». YouTube. Vox Media. Archived from the original on 27 October 2021. Retrieved 30 August 2020.
- Castells, Manuel (2010). The Rise of the Network Society. Wiley. ISBN 9781405196864.
External links
- The Internet Society
- Living Internet, Internet history and related information, including information from many creators of the Internet
Internet is the foremost important tool and the prominent resource that is being used by almost every person across the globe. It connects millions of computers, webpages, websites, and servers. Using the internet we can send emails, photos, videos, messages to our loved ones. Or in other words, the internet is a widespread interconnected network of computers and electronics devices(that support internet). It creates a communication medium to share and get information online. If your device is connected to the Internet then only you will be able to access all the applications, websites, social media apps, and many more services. Internet nowadays is considered as the fastest medium for sending and receiving information.
Origin Of Internet: The internet came in the year 1960 with the creation of the first working model called ARPANET (Advanced Research Projects Agency). It allowed multiple computers to work on a single network that was their biggest achievement at that time. ARPANET use packet switching to communicate multiple computer systems under a single network. In October 1969, using ARPANET first message was transferred from one computer to another. After that technology continues to grow.
How is the Internet set up?
The internet is set up with the help of physical optical fiber data transmission cables or copper wires and various other networking mediums like LAN, WAN, MAN, etc. For accessing the Internet even the 2g, 3g, and 4g services and the wifi require these physical cable setup to access the Internet. There is an authority named ICANN (Internet Corporation for Assigned Names and Numbers) located in the USA which manages the Internet and protocols related to it like IP addresses.
How does the internet works?
The actual working of the internet takes place with the help of clients and servers. Here the client is a laptop that is directly connected to the internet and servers are the computers connected indirectly to the Internet and they are having all the websites stored in those large computers. These servers are connected to the internet with the help of ISP (Internet Service Providers) and will be identified with the IP address. Each website has its Domain name as it is difficult for any person to always remember the long numbers or strings. So, whenever you search any domain name in the search bar of the browser the request will be sent to the server and that server will try to find the IP address from the Domain name because it cannot understand the domain name. After getting the IP address the server will try to search the IP address of the Domain name in a Huge phone directory that in networking is known as a DNS server (Domain Name Server). For example, if we have the name of a person and you can easily find the Aadhaar number of him/her from the long directory as simple as that.
So after getting the IP address the browser will pass on the further request to the respective server and now the server will process the request to display the content of the website which the client wants. If you are using a wireless medium of Internet like 3g and 4g or other mobile data then the data will start flowing from the optical cables and will first reach to towers from there the signals will reach your cell phones and Pc’s through electromagnetic waves. And if you are using routers then optical fiber connecting to your router will help in connecting those light-induced signals into electrical signals and with the help of ethernet cables internet reaches your computers and hence the required information.
What is an IP address?
IP address stands for internet protocol address. Every PC/Local machine is having an IP address and that IP address is provided by the Internet Service Providers (ISP’s). These are some sets of rules which govern the flow of data whenever a device is connected to the Internet. It differentiates computers, websites, and routers. Just like human identification cards like Aadhaar cards, Pan cards, or any other unique identification documents. Every laptop and desktop has its own unique IP address for identification. It’s an important part of internet technology. An IP address is displayed as a set of four-digit like 192.154.3.29. Here each number on the set ranges from 0 to 255. Hence, the total IP address range from 0.0.0.0 to 255.255.255.255.
You can check the IP address of your Laptop or desktop by clicking on the windows start menu ->then right click and go to network ->in that go to status and then Properties their you can see the IP address. There are four different types of IP addresses are available:
- Static IP address
- Dynamic IP address
- Private IP address
- Public IP address
World Wide Web(WWW)
The worldwide web is a collection of all the web pages, web documents that you can see on the Internet by searching their URLs (Uniform Resource Locator) on the Internet. For example, www.geeksforgeeks.org is a URL of the GFG website and all the content of this site like webpages and all the web documents are stored on the worldwide web. Or in other words, the world wide web is an information retrieval service of the web. It provides users a huge array of documents that are connected to each other by means of hypertext or hypermedia links. Here, hyperlinks are known as electronic connections that link the related data so that users can easily access the related information and hypertext allows the user to pick a word or phrase from text, and using this keyword or word or phrase can access other documents that contain additional information related to that word or keyword or phrase. World wide web is a project which is created by Timothy Berner’s Lee in 1989, for researchers to work together effectively at CERN. It is an organization, named World Wide Web Consortium (W3C), which was developed for further development in the web.
Difference between Worldwide Web and Internet
The difference between the world wide web and the internet are:
- All the web pages and web documents are stored there on the World wide web and to find all that stuff you will have a specific URL for each website. Whereas the internet is a global network of computers that is accessed by the World wide web.
- World wide web is a service whereas the internet is an infrastructure.
- World wide web is a subset of the internet whereas the internet is the superset of the world wide web.
- World wide web is software-oriented whereas the internet is hardware-oriented.
- World wide web uses HTTP whereas the internet uses IP addresses.
- The Internet can be considered as a Library whereas all the kinds of stuff like books from different topics present over there can be considered as World wide web.
Uses of the Internet
Some of the important usages of the internet are:
- Online Businesses (E-commerce): Online shopping websites have made our life easier, e-commerce sites like Amazon, Flipkart, Myntra are providing very spectacular services with just one click and this is a great use of the Internet.
- Cashless transactions: All the merchandising companies are offering services to their customers to pay the bills of the products online via various digital payment apps like Paytm, Google pay, etc. UPI payment gateway is also increasing day by day. Digital payment industries are growing at a rate of 50% every year too because of the INTERNET.
- Education: It is the internet facility that provides a whole bunch of educational material to everyone through any server across the web. Those who are unable to attend physical classes can choose any course from the internet and can have the point-to-point knowledge of it just by sitting at home. High-class faculties are teaching online on digital platforms and providing quality education to students with the help of the Internet.
- Social Networking: The purpose of social networking sites and apps is to connect people all over the world. With the help of social networking sites, we can talk, share videos, images with our loved ones when they are far away from us. Also, we can create groups for discussion or for meetings.
- Entertainment: The Internet is also used for entertainment. There are numerous entertainment options available on the internet like watching movies, playing games, listening to music, etc. You can also download movies, games, songs, TV Serial, etc., easily from the internet.
Advantages of the Internet
- Online Banking and Transaction: The Internet allows us to transfer money online by the net banking system. Money can be credited or Debited from one account to the other.
- Education, online jobs, freelancing: Through the Internet, we are able to get more jobs via online platforms like Linkedin and to reach more job providers. Freelancing on the other hand has helped the youth to earn a side income and the best part is all this can be done via INTERNET.
- Entertainment: There are numerous options of entertainment online we can listen to music, play games can watch movies, web series, listening to podcasts, youtube itself is a hub of knowledge as well as entertainment.
- New Job roles: The Internet has given us access to social media, and digital products so we are having numerous new job opportunities like digital marketing and social media marketing online businesses are earning huge amounts of money just because the internet being the medium to help us to do so.
- Best Communication Medium: The communication barrier has been removed from the Internet. You can send messages via email, Whatsapp, and Facebook. Voice chatting and video conferencing are also available to help you to do important meetings online.
- Comfort to humans: Without putting any physical effort you can do so many things like shopping online it can be anything from stationeries to clothes, books to personal items, etc. You can books train and plane tickets online.
- GPS Tracking and google maps: Yet another advantage of the internet is that you are able to find any road in any direction, areas with less traffic with the help of GPS in your mobile.
Disadvantages of the Internet
- Time wastage: Wasting too much time on the internet surfing on social media apps and doing nothing decreases your productivity rather than wasting time on scrolling social media apps one should utilize that time in doing something skillful and even more productive.
- Bad impacts on health: Spending too much time on the internet causes bad impacts on your health physical body needs some outdoor games exercise and many more things. Looking at the screen for a longer duration causes serious impacts on the eyes.
- Cyber Crimes: Cyberbullying, spam, viruses, hacking, and stealing data are some of the crimes which are on the verge these days. Your system which contains all the confidential data can be easily hacked by cybercriminals.
- Effects on children: Small children are heavily addicted to the Internet watching movies, games all the time is not good for their overall personality as well as social development.
- Bullying and spreading negativity: The Internet has given a free tool in the form of social media apps to all those people who always try to spread negativity with very revolting and shameful messages and try to bully each other which is wrong.
explained from first principles
This article
and its code were
first published on 5 August 2020
and last modified
on 21 October 2021.
If you like the article,
please share it with your friends on social media
or support me with a donation.
You can also cite this article,
download it as a PDF,
see what people are saying about it on Twitter,
join the discussion on Reddit,
or use Google Translate to read it in another language.
Cite this article
You can cite this article in various citation styles as follows:
If you are worried about the persistence of this website, you can link to the
latest snapshot
of the Internet Archive instead.
If you are visiting this website for the first time,
then please first read the front page,
where I explain the intention of this blog
and how to best make use of it.
As far as your privacy is concerned,
all data entered on this page is stored locally in your browser
unless noted otherwise.
While I researched the content on this page thoroughly,
you take or omit actions based on it at your own risk.
In no event shall I as the author be liable
for any damages arising from information or advice
on this website or on referenced websites.
Preface
I wrote this article to introduce the Internet to a non-technical audience.
In order to get everyone on board,
I first explain basic concepts, such as
communication protocols,
network topologies,
and signal routing.
The section about Internet layers becomes increasingly technical
and peaks with a deep dive into DNSSEC.
If the beginning is too elementary for you,
then just skip ahead to more interesting sections.
Due to the nature of the topic,
this article contains a lot of acronyms.
Many of them are three-letter acronyms (TLA),
but some are longer,
which makes them extended three-letter acronyms (ETLA).
While I introduce all acronyms before using them,
you can simply hover over a TLA or an ETLA with your mouse
if you forgot what they stand for.
If you are reading this on a touch device,
you have to touch the acronym instead.
Let’s get right into it:
What is a protocol?
Communication protocol
Communication diagram
A communication protocol
specifies how two parties can exchange information for a specific purpose.
In particular, it determines which messages are to be transmitted in what order.
If the two parties are computers,
a formal, well-defined protocol is easiest to implement.
In order to illustrate what is going on, however,
let’s first look at an informal protocol,
also known as etiquette,
which we’re all too familiar with:
Alice
Bob
Hi Bob!
Hi Alice!
How are you?
Good.
What about you?
I’m fine, thanks.
This is a sequence diagram.
It highlights the temporal dimension of a protocol
in which messages are exchanged sequentially.
Communication parties
It also illustrates that communication is commonly initiated by one party,
whereby the recipient responds to the requests of the initiator.
Please note that this is only the case for one-to-one protocols,
in which each message is intended for a single recipient.
Broadcasting and information security
There are also one-to-many protocols for broadcasting.
These are typically one-way protocols,
in which the recipients do not acknowledge the receipt of the transferred data.
Examples for such protocols are analog radio
or churches ringing their bells to indicate the time of day.
Both in the case of a single recipient and in the case of a broad target audience,
anyone with access to the physical medium and the right sensors receives the signal.
The difference is simply that,
in the former case,
entities ignore the messages
which are not addressed to them.
If the messages are not encrypted,
others can still read them, though.
And if the messages are not authenticated,
a malicious party might be able to alter them in transit.
Even when messages are encrypted and authenticated,
their exchange can still be interrupted,
by not relaying some messages
or by jamming the signal.
The properties Confidentiality, Integrity, and Availability
form the so-called CIA triad of information security.
Communication channel
The above greeting protocol is used among humans
to establish a communication channel for a longer exchange.
In technical jargon,
such an exchange in preparation for the actual communication is called a handshake.
The greeting protocol checks the recipient’s availability and willingness to engage in a conversation.
When talking to someone you have never spoken before,
it also ensures that the recipient understands your language.
I’ve chosen these two examples for their figurative value.
Why we actually greet each other
is mainly for different reasons:
To show our good intentions by making our presence known to each other,
to signal sympathy and courtesy by asking the superficial question,
and to indicate our relative social status to each other and to bystanders.
Another benefit of asking such a question is that,
even though it’s very shallow,
it makes the responder more likely to do you a favor
due to the psychological effect of
commitment and consistency.
Handling of anomalies
Protocol deviation
Since your communication partner can be erratic,
a protocol needs to be able to handle deviations:
Alice
Bob
Hi Bob!
Hi Alice!
How are you?
Not good.
What happened?
Data corruption
Sometimes, data becomes unintelligible in transit,
for example due to a lot of background noise:
Alice
Bob
Hi Bob!
Hi Alice!
�
Can you repeat that?
How are you?
Good.
What about you?
I’m fine, thanks.
In order to detect transmission errors,
computers typically append a checksum to each message,
which the recipient then verifies.
The need to retransmit messages
can be reduced by adding redundancy to messages
so that the recipient can detect and correct small errors on their own.
A simple and very inefficient way of doing this is to repeat the content within each message several times.
Connection loss
It can also happen that a party loses their connection permanently,
for example by moving too far away for the signal to reach the recipient.
Since a conversation requires some attention from the communication partner,
abandoning a conversation unilaterally without notifying the other party
can be misused to block them from talking to someone else for some time.
In order to avoid binding resources for a prolonged period of time
and thereby potentially falling victim to a so-called
denial-of-service attack,
computers drop connections after a configurable duration of inactivity:
Alice
Bob
Hi Bob!
Hi Alice!
Bye.
Network latency
Other times, your communication partner is simply slow, which needs to be accommodated to some degree:
Alice
Bob
Hi Bob!
Hi Alice!
How are you?
Good.
What about you?
I’m fine, thanks.
for his upstream messages (in blue).
Out-of-order delivery
The following rarely occurs between humans
but as soon as messages are passed over various hops,
such as forwarding notes among pupils in a classroom,
they can arrive out of order:
Alice
Bob
Hi Bob!
Hi Alice!
How are you?
Good.
What about you?
I’m fine, thanks.
The solution for this is to enumerate all messages,
to reorder them on arrival,
and to ask the other party to retransmit any missing messages,
as we saw above.
Lack of interoperability
Besides defining the syntax (the format),
the semantics (the meaning),
and the order of the messages,
a protocol should also specify how to handle anomalies like the above.
Ambiguity in a standard
and willful deviation therefrom
result in incompatibilities between different implementations.
In combination with a lack of established standards in many areas,
which often leads to uncoordinated efforts by various parties,
incompatibilities are quite common in computer systems,
unfortunately.
This causes a lot of frustration for users and programmers,
who have to find workarounds for the encountered limitations,
but this cannot be avoided in a free market of ideas and products.
Network topologies
Communication network
In practice, there are almost always more than two parties
who want to communicate with each other.
Together with the connections between them,
they form a communication network.
For the scope of this article,
we’re only interested in symmetric networks,
where everyone who can receive can also send.
This is not the case for analog radio and television networks,
where signals are broadcasted unidirectionally from the sender to the receivers.
In the case of our symmetric networks,
two entities are part of the same network
if they can communicate with each other.
If they cannot reach each other,
they belong to separate networks.
Nodes and links
Nodes are the entities
that communicate with each other over communication links.
We can visualize this as follows:
The terminology is borrowed from graph theory,
where nodes are also called vertices
and links are also called edges.
The technical term for the structure of a network is topology.
Different arrangements of nodes and links lead to different characteristics of the resulting network.
Fully connected network
A network is said to be fully connected
if every node has a direct link to every other node:
In graph theory, such a layout is known as a complete graph.
Fully connected networks scale badly
as the number of links grows quadratically with the number of nodes.
You might have encountered the formula for the number of links before:
n × (n – 1) / 2, with n being the number of nodes in the network.
As a consequence, this topology is impractical for larger networks.
Star network
The number of links can be reduced considerably by introducing a central node,
which forwards the communication between the other nodes.
In such a star-shaped network,
the number of links scales linearly with the number of nodes.
In other words,
if you double the number of nodes,
you also double the number of links.
In a fully connected network, you would have quadrupled the number of links.
For now, we call the newly introduced node a router.
As we will see later on,
such a relaying node is called differently
depending on how it operates.
Nodes that do not forward the communication of others
form the communication endpoints of the network.
While a star network scales optimally,
it is by definition totally centralized.
If the nodes belong to more than one organization,
this topology is not desirable
as the central party exerts complete control over the network.
Depending on its market power,
such a party can increase the price for its service
and censor any communication it doesn’t like.
Additionally, the central node becomes a single point of failure:
If it fails for whatever reason,
then the whole network stops working.
Since this lowers the availability of the network,
the star topology should not just be avoided for political but also for technical reasons.
Mesh network
We can avoid these drawbacks by increasing the number of nodes
which forward the communication between the endpoints:
*
In this graph, any of the three routers can go down,
and communication is still possible between the nodes
that are connected not only to the unavailable router.
There are also five links that can break one at a time
while leaving all nodes indirectly connected with each other.
Such a partially connected network allows for a flexible tradeoff
between redundancy
and scalability.
It is therefore usually the preferred network topology.
Furthermore, the node marked with an asterisk is connected to two routers
in order to increase its availability.
Because of higher costs,
this is usually only done for critical systems,
which provide crucial services.
Signal routing
Network addresses
Unlike in a fully connected network,
where each node can simply pick the right link to reach the desired node,
a network with relay nodes requires that nodes can address each other.
Even if a router relays each signal on all of its links to other nodes,
which would make it a hub instead of a router,
the nodes still need a way to figure out
whether they were the intended recipient of a message.
This problem can be solved by assigning a unique identifier to each node in the network
and by extending each transmitted message with the identifier of the intended recipient.
Such an identifier is called a network address.
Routers can learn on which link to forward the communication for which node.
This works best when the addresses aren’t assigned randomly
but rather reflect the
– due to its physical nature often geographical –
structure of the network:
A
B
C
A1
A2
B1
B2C1
C2
C3
1
2
3
4
For the sake of simplicity, I no longer draw the arrow tips on links.
We’re all familiar with hierarchical addresses such as
postal codes,
which are known as ZIP Codes in the United States,
and telephone numbers with their
country calling codes.
Strictly speaking, the address denotes the network link of a node and not the node itself.
This can be seen in the node on the right,
which is known as B2 to router B
and as C1 to router C.
In other words,
if a node belongs to several so-called subnetworks,
such as B and C in this example,
it also has several addresses.
Routing tables
The process of selecting a path between two nodes across a network
is called routing.
Routers are the nodes which perform the routing.
They maintain a routing table
so they know on which link to forward the communication for each node:
| Destination | Link | Cost |
|---|---|---|
| A1 | 1 | 4 |
| A2 | 2 | 2 |
| B? | 3 | 5 |
| B? | 4 | 8 |
| C? | 3 | 9 |
| C? | 4 | 6 |
It contains all the destinations to be reached.
The links are numbered according to the above graphic.
This table tells router A, for example,
to forward all communications for node A2 on link 2.
It doesn’t matter on which link router A receives such communications.
The router also keeps track of how costly each route is.
The cost can either be in terms of network delay
or the economic cost of the transmission,
based on what providers charge each other.
In this example, router A forwards all communications for nodes starting with C on link 4
because the associated cost is lower than the cost for link 3 via router B.
Forwarding tables
To be precise,
the routing table contains all routes,
even the ones which aren’t optimal regarding the associated costs.
Based on this information,
a router constructs the actual forwarding table,
which only contains the optimal route for each destination without its cost.
This makes the table smaller and the lookup during routing faster,
which is important for low latency.
| Destination | Link |
|---|---|
| A1 | 1 |
| A2 | 2 |
| B? | 3 |
| C? | 4 |
according to the above routing table.
Routing protocols
Routers and the physical links between them can fail at any time,
for example because a network cable is demolished by nearby construction work.
On the other hand, new nodes and connections are added to communication networks all the time.
Therefore, the routing tables of routers need to be updated continuously.
Instead of updating them manually,
routers communicate changes with each other using a routing protocol.
For example, as soon as router A detects
that it’s no longer getting a response from router C,
it updates its routing table to route all communication to C via B:
A
B
C
A1
A2
B1
B2C1
C2
C3
1
2
3
| Destination | Link | Cost |
|---|---|---|
| A1 | 1 | 4 |
| A2 | 2 | 2 |
| B? | 3 | 5 |
| C? | 3 | 9 |
With only one route left, router A forwards all communications for C on link 3.
Signal relaying
A signal can be relayed through a network
either with circuit switching
or with packet switching.
Circuit switching
In a circuit-switched network,
a dedicated communications channel
is established between the two parties
for the duration of the communication session:
The best-known example of a circuit-switched network is the early telephone network.
In order to make a call,
a switchboard operator
needed to connect the wires of the two telephones in order to create a closed circuit.
This has the advantage that the delay of the signal remains constant throughout the call
and that the communication is guaranteed to arrive in the same order as it was sent.
On the other hand, establishing a dedicated circuit for each communication session
can be inefficient as others cannot utilize the claimed capacity
even when it’s temporarily unused, for example when no one is speaking.
Packet switching
In a packet-switched network,
the data to transfer is split into chunks.
These chunks are called packets
and consist of a header
and a payload.
The header contains information for the delivery of the packet,
such as the network address of the sender and the recipient.
Each router has a queue for incoming packets
and then forwards each packet according to its routing table
or, more precisely, its forwarding table.
Apart from these tables,
packet-switching routers do not keep any state.
In particular, no channels are opened or closed on the routing level.
■
■
■
Since each packet is routed individually,
they can take different routes from the sender to the recipient
and arrive out of order due to varying delays.
■
■
■
■
Since no router has a complete view of the whole network,
it could happen that packets get stuck in an infinite loop:
■
■
■
■
In order to avoid wasting network resources,
the header of a packet also contains a counter,
which is decreased by one every time it passes a router.
If this counter reaches zero before the packet arrives at its destination,
then the router discards the packet rather than forwarding it.
Such a counter limits the lifespan of a packet by limiting the number of hops it can take
and is thus known as its time-to-live (TTL) value.
There are also other reasons why a packet can get lost in the network.
The queue of a router might simply be full,
which means that additional packets can no longer be stored
and must therefore be dropped.
Because packets are similar to cars on the road network,
some terms are borrowed from the transportation industry.
While the capacity of a packet-switched network can be utilized better
than the capacity of a circuit-switched network,
too much traffic on the network
leads to congestion.
Source and destination addresses
Because routers keep no records regarding the route that a packet took,
the response from the recipient has to include the address of the original sender.
In other words, the sender has to disclose its own address to the recipient
in order to be able to get a response.
This is why packets always include two addresses:
the one of the source and the one of the destination.
Internet layers
The Internet is a global network of computer networks.
Its name simply means “between networks”.
It is a packet-switched mesh network
with only best-effort delivery.
This means that the Internet provides no guarantees about whether and in what time a packet is delivered.
Internet service providers (ISP)
provide access to the Internet for businesses and private individuals.
They maintain proprietary computer networks for their customers
and are themselves interconnected through international backbones.
The big achievement of the Internet is making individual networks interoperable
through the Internet Protocol (IP).
The Internet operates in layers.
Each layer provides certain functionalities,
which can be fulfilled by different protocols.
Such a modularization makes it possible
to replace the protocol on one layer
without affecting the protocols on the other layers.
Because the layers above build on the layers below,
they are always listed in the following order
but then discussed in the opposite order:
| Name | Purpose | Endpoints | Identifier | Example |
|---|---|---|---|---|
| Application layer | Application logic | Application-specific resource | Application-specific | HTTP |
| Security layer | Encryption and authentication | One or both of the parties | X.509 subject name | TLS |
| Transport layer | Typically reliable data transfer | Operating system processes | Port number | TCP |
| Network layer | Packet routing across the Internet | Internet-connected machines | IP address | IP |
| Link layer | Handling of the physical medium | Network interface controllers | MAC address | Wi-Fi |
They differ in their purpose,
the endpoints that communicate with each other,
and how those endpoints are identified.
We will discuss each layer separately in the following subsections.
For now, you can treat the above table as an overview and summary.
Before we dive into the lowest layer,
we first need to understand what “building on the layer below” means.
Digital data
can be copied perfectly from one memory location to another.
The implementation of a specific protocol receives a chunk of data, known as the payload, from the layer above
and wraps it with the information required to fulfill its purpose in the so-called header.
The payload and the header then become the payload for the layer below,
where another protocol specifies a new header to be added.
Each of these wrappings is undone by the respective protocol on the recipient side.
This can be visualized as follows:
Application layer
Security layer
Transport layer
Network layer
Link layer
Sender
Router
Recipient
While this graphic is useful to wrap your head around these concepts,
it can be misleading in two ways.
Firstly, the payload can be transformed by a specific protocol
as long as the original payload can be reconstructed by the recipient.
Examples for this are encryption and redundant encoding for automatic
error detection and correction.
Secondly, a protocol can split a payload into smaller chunks and transfer them separately.
It can even ask the sender to retransmit a certain chunk.
As long as all the chunks are recombined on the recipient side,
the protocol above can be ignorant about such a process.
As we’ve seen in the sections above,
a lot of things can go wrong in computer networks.
In the following subsections,
we’ll have a closer look on how protocols
compensate for the deficiencies of the underlying network.
Before we do so, we should talk about standardization first.
When several parties communicate with each other,
it’s important that they agree on a common standard.
Standards need to be proposed, discussed, published,
and updated to changing circumstances.
I’m not aware of any laws that impose specific networking standards
outside of governmental agencies.
The Internet is an open architecture,
and technology-wise, you’re free to do pretty much anything you want.
This doesn’t mean, though, that others will play along.
If different companies shall adopt the same standards to improve interoperability,
it’s very useful to have independent working groups,
in which proposed standards are discussed and approved.
For Internet-related standards,
such an open platform is provided by the
Internet Engineering Task Force (IETF)
with organizational and financial support from the
Internet Society (ISOC).
Workshop participants and managers are typically employed by large tech companies,
which want to shape future standards.
The IETF publishes its official documents as
Requests for Comments (RFCs).
This name was originally chosen to avoid a commanding appearance and to encourage discussions.
In the meantime, early versions of potential RFCs are published as
Internet Drafts,
and RFCs are only approved after several rounds of peer review.
RFCs are numbered sequentially, and once published,
they are no longer modified.
If a document needs to be revised,
a new RFC with a new number is published.
An RFC can supersede earlier RFCs,
which are then obsoleted by the new RFC.
Sometimes, RFCs are written after the documented technique has already gained popularity.
Even though the most important Internet protocols are specified in RFCs,
their conception and style is much more pragmatic than similar documents of other
standards organizations.
The first RFC was published in 1969.
Since then, almost 9’000 RFCs have been published.
Not all RFCs define new standards,
some are just informational,
some describe an experimental proposal,
and others simply document the best current practice.
Link layer
Protocols on the link layer
take care of delivering a packet over a direct link between two nodes.
Examples of such protocols are Ethernet and Wi-Fi.
Link layer protocols are designed to handle the intricacies of the underlying physical medium and signal.
This can be an electric signal over a copper wire,
light over an optical fiber or an electromagnetic wave through space.
The node on the other end of the link, typically a router,
removes the header of the link layer,
determines on the network layer on which link to forward the packet,
and then wraps the packet according to the protocol spoken on that link.
Link layer protocols typically detect bit errors
caused by noise, interference, distortion, and faulty synchronization.
If several devices want to send a packet over the same medium at the same time,
the signals collide, and the packets must be retransmitted
after a randomly chosen backoff period.
Number encoding
Numbers are used to quantify the amount of something,
and just like you can have only more, less, or an equal amount of a quantity,
a number must be either larger than, less than, or equal to any other number
(as long as we talk about real numbers only).
Numbers can therefore be thought of as points on a line.
While numbers as concepts exist independently of the human mind
(if we assume mathematical realism),
we need a way to express numbers when thinking, speaking, and writing about them.
We do so by assigning labels and symbols to them
according to a numeral system.
For practical reasons, we have to rely on a finite set of symbols
to represent an infinite set of numbers.
To make this possible, we have to assign meaning to the
order,
position, and/or
repetition of symbols.
With the exception of tally marks,
only the positional notation is relevant nowadays.
In positional notation, you have an ordered list of symbols,
representing the values from zero to the length of the list minus one.
In the commonly used decimal numeral system,
there are ten symbols, also called digits: 0, 1, 2, 3, 4, 5, 6, 7, 8, and 9.
(The name “digit” comes from the Latin “digitus”, which means finger.)
As soon as you have used up all the symbols,
you create a new position, usually to the left.
The represented number is the index of the symbol in this new position
multiplied by the length of the list
plus the index of the symbol in the initial position.
Each time you went through all the symbols in the right position,
you increment the left position by one.
Two positions of ten possible symbols allow you to represent 102 = 100 numbers.
Since zero is one of them, you can encode all numbers from 0 to 99 with these two positions.
The symbol in the third position counts how many times you went through the 100 numbers.
It is thus multiplied by 102 before being added up.
The symbol in the fourth position is multiplied by 103, and so on.
All of this should be obvious to you.
However, you might not be used to using less than or more than ten symbols.
The binary numeral system uses,
as the name suggests,
only two symbols, typically denoted as 0 and 1.
You count according to the rules described above:
After 0 and 1 comes 10 and 11,
which in turn are followed by 100, 101, 110, and 111.
Each position is called a bit,
which is short for “binary digit”.
Just as with decimal numbers,
the most significant bit is to the left,
the least significant bit to the right.
Since there are only two elements in the list of symbols,
the base
for exponentiation is 2 instead of 10.
If we count the positions from the right to the left starting at zero,
each bit is multiplied by two raised to the power of its position.
4 bits allow you to represent 24 = 16 numbers, and
8 bits allow you to represent 28 = 256 numbers.
Virtually all modern computers use the binary numeral system
because each bit can be encoded as the presence or absence
of a physical phenomenon,
such as voltage or
electric current.
This makes operations on binary numbers
quite easy to implement in electronic circuits
with logic gates.
Since 0 and 1 don’t encode a lot of information,
the smallest unit of computer memory
that can be addressed to load or store information
is typically a byte,
which is a collection of eight bits.
Instead of the eight bits,
a byte is often represented for humans
as a number between 0 and 255
or as two hexadecimal symbols.
The latter assigns one symbol to four bits.
Since 4 bits encode 16 numbers,
the 10 digits are supplemented by 6 letters,
resulting in the symbols 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, and F.
The F in hexadecimal notation stands for 15 in decimal notation and 1111 in binary notation.
What I just wrote only applies to natural numbers,
also called unsigned integers.
Negative integers are included
by using the leftmost bit for the sign:
Positive numbers start with a zero, negative numbers with a one.
The actual encoding
is a bit more complicated because it is chosen such
that the implementation of addition, subtraction, and multiplication
is the same for signed and unsigned integers.
Floating point numbers
are even more complicated and beyond the scope of this article.
Media access control (MAC) address
The media access control (MAC) address
is commonly used as the network address on the link layer.
It is a 48-bit number, which is typically displayed as six pairs of
hexadecimal digits.
(One hexadecimal digit represents 4 bits, so twelve hexadecimal digits represent 48 bits.)
MAC addresses are used in Ethernet, Wi-Fi, and Bluetooth to address other devices in the same network.
Historically, they were assigned by the manufacturer of the networking device
and then remained the same throughout the lifetime of the device.
Since this allows your device to be tracked,
operating systems started randomizing MAC addresses when scanning for Wi-Fi networks
after the revelations by Edward Snowden.
According to Wikipedia, MAC address randomization
was added in iOS 8, Android 6.0, Windows 10, and Linux kernel 3.18.
Hubs, switches, and routers
When I talked about network topologies,
I simply called relaying nodes “routers”,
but there are actually three types of them:
- A hub
simply relays all incoming packets to all other links. - A switch
remembers which MAC address it encountered on which of its links
and forwards incoming packets only to their intended recipients.
Like a hub, a switch also operates only on the link layer.
To the devices in the network, it still seems
as if they are directly connected to each other. - A router
inspects and forwards packets on the network layer
based on its forwarding table.
It can thereby connect several independent networks.
Your Wi-Fi router, for example, routes packets within your local network
but also between your local network and the network of your Internet service provider.
As we will cover in the next subsection,
it also provides important services,
such as DHCP
and NAT.
Maximum transmission unit (MTU)
Link layer protocols usually limit the size of the packets they can forward over the link.
This limit is known as the maximum transmission unit (MTU) of the link.
For example, the MTU of Ethernet is 1500 bytes.
If a packet is larger than the MTU,
it is split into smaller fragments by the network layer.
If the network drops any of the fragments,
then the entire packet is lost.
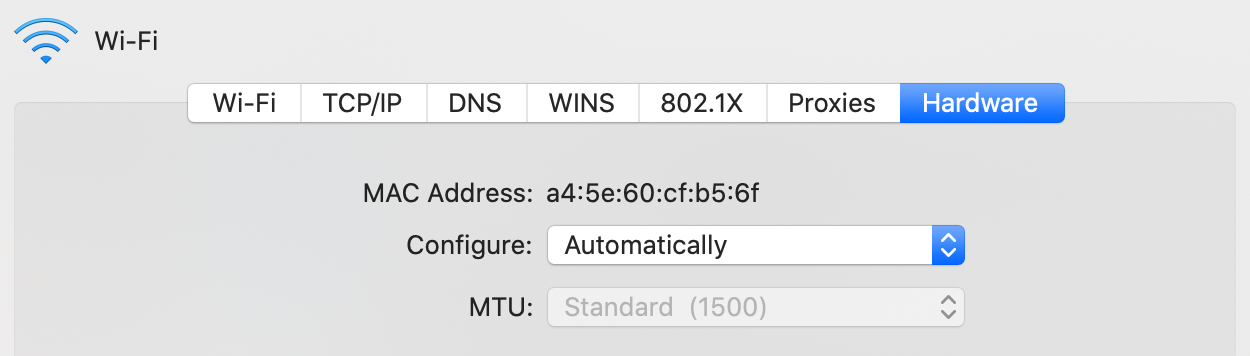
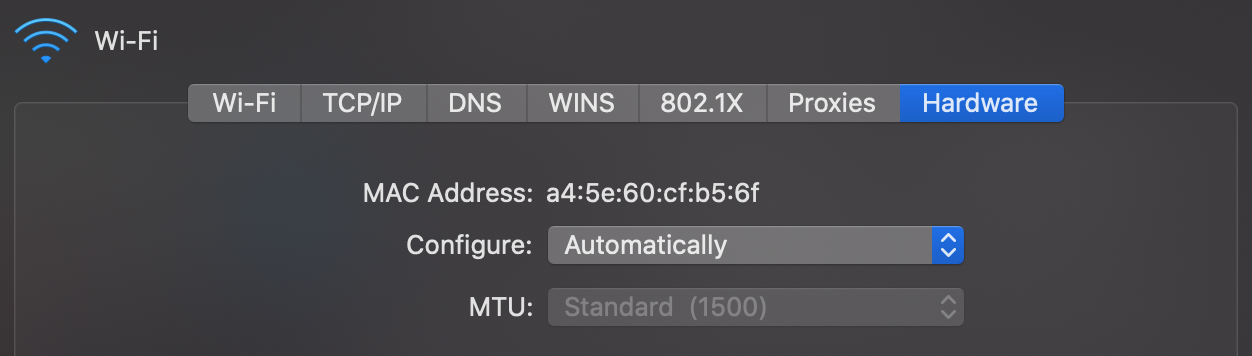
Written as an April Fools’ joke,
RFC 1149
describes a method for delivering packets on the link layer
using homing pigeons.
While this method is of no practical importance,
it shows the flexibility of the Internet layers
and is well worth a read.
Network layer
The purpose of the network layer
is to route packets between endpoints.
It is the layer that ensures interoperability between separate networks on the Internet.
As a consequence, there is only one protocol which matters on this layer:
the Internet Protocol (IP).
If you want to use the Internet, you have to use this protocol.
As we’ve seen earlier, packet switching provides only unreliable communication.
It is left to the transport layer to compensate for this.
The first major version of the Internet Protocol is version 4 (IPv4),
which has been in use since 1982 and is still the dominant protocol on the Internet.
It uses 32-bit numbers to address endpoints and routers,
which are written as four numbers between 0 and 255 separated by a dot.
These IP addresses
reflect the hierarchical structure of the Internet,
which is important for efficient routing.
They are assigned by the Internet Assigned Numbers Authority (IANA),
which belongs to the American Internet Corporation for Assigned Names and Numbers (ICANN),
and by five Regional Internet Registries (RIR).
If you’re interested, you can check out the current IPv4 address allocation.
There are just under 4.3 billion IPv4 addresses,
which are quite unevenly distributed among countries.
Given the limited address space, we’re running out of IPv4 addresses.
In order to deal with the IPv4 address exhaustion,
the Internet Protocol version 6 (IPv6) has been developed.
IPv6 uses 128-bit addresses,
which are represented as eight groups of four hexadecimal digits
with the groups separated by colons.
As IPv6 isn’t interoperable with IPv4,
the transition has been slow but steady.
IP geolocation
Since the Internet is not just a protocol but also a physical network,
which requires big investments in infrastructure like fiber optic cables,
Internet service providers operate regionally.
In order to facilitate the routing of packets,
they get assigned an IP address range for their regional network.
This allows companies to build databases that map IP addresses to their geographical location.
Unless you use a Virtual Private Network (VPN)
or an overlay network for anonymous communication,
such as Tor,
you reveal your approximate location to every server you communicate with.
Websites such as streaming platforms
use this information to restrict the content available to you
depending on the country you are visiting the site from
due to their copyright licensing agreements with film producers.
One company with such a geolocation database is ipinfo.io.
Using their free API,
I can tell you where you likely are.
If you are visiting this website via a mobile phone network,
then the result will be less accurate.
If I were to use their paid API,
I could also tell you whether you are likely using a VPN or Tor.
If you don’t mind revealing to ipinfo.io that you are reading this blog,
then go ahead and enter an IPv4 address of interest in the following field.
If you leave the field empty, the IP address from which you are visiting this website is used.
Network performance
The performance of a network
is assessed based on the following measures:
- Bandwidth
indicates how much data can be transferred in one direction in a given amount of time.
Unlike memory, which is measured in bytes,
bandwidth is usually measured in bits per second,
which is written as bit/s or bps.
As always, multiples of the unit can be denoted with the appropriate
prefix,
such as M for mega (106) in Mbit/s or Mbps. - Latency
indicates how long it takes for a single bit to reach the recipient.
Latency is usually determined by sending a tiny message to the recipient
and measuring the time until a tiny response is received.
The result is called the round-trip time (RTT)
to that particular destination,
which includes the one-way delay (OWD)
in both directions and the time it took the recipient to process the request.
Have a look at the next two boxes for more information on this. - Jitter
is the undesired variation in the latency of a signal.
On the link layer, such a deviation from the periodic
clock signal
is caused by the properties of the physical medium.
The term is sometimes also used to refer to
variation in packet delay. - The bit error rate
indicates the percentage of bits that are flipped during the data transfer.
As mentioned earlier, data corruption
has to be detected and corrected by network protocols.
The term throughput
is sometimes used interchangeably with bandwidth.
Other times, it is used to refer to the actual rate
at which useful data is being transferred.
The effective throughput is lower than the maximum bandwidth
due to the overhead of protocol headers,
packet loss and retransmission,
congestion in the network,
as well as the delay for acknowledgements by the recipient.
More bandwidth doesn’t reduce the latency of Internet communication,
which is the crucial factor for applications such as
algorithmic trading
and online gaming,
where latency is called lag.
The design of a protocol impacts its performance:
The more messages that need to be exchanged in a session,
the less throughput you get over long distances
due to the many round trips.
You can measure the speed of your Internet connection
with tools such as speedtest.net.
A high download speed is important for watching high-definition videos
and downloading large files, such as computer games and software updates.
A high upload speed is important for participating in video calls
and uploading large files, such as videos or hundreds of pictures.
As a rule of thumb,
you can divide the number of megabits per second by ten
to get a rough estimate for actual megabytes per second
due to the aforementioned overhead.
Please keep in mind that Internet communication is routed over many links
and that any of the links, including the Wi-Fi link to your own router,
can limit the overall performance.
For example, if a server you interact with has a slow connection or is very busy,
then paying more for a faster Internet at your end won’t improve the situation.
Propagation delay
The physical limit for how fast a signal can travel
is the speed of light in vacuum,
which is roughly 300’000 km/s or 3 × 108 m/s.
It takes light 67 ms to travel halfway around the Earth
and 119 ms to travel from geostationary orbit to Earth.
While this doesn’t sound like a lot,
propagation delay
is a real problem for applications where latency matters,
especially because a signal often has to travel back and forth to be useful.
One party typically reacts to information received from another party,
hence it takes a full round trip for the reaction to reach the first party again.
The speed at which electromagnetic waves travel through a medium
is slower than the speed of light in vacuum.
The speed of a light pulse through an optical fiber
is ⅔ of the speed of light in vacuum, i.e. 2.0 × 108 m/s.
A change of electrical voltage travels slightly faster through
a copper wire
at 2.3 × 108 m/s.
When costs allow it,
optical fibers are often preferred
over copper wire because they provide higher bandwidth
over longer distances with less interference
before the signal needs to be amplified.
It is to be seen whether satellite constellations
in low Earth orbit,
such as Starlink,
which is currently being built by SpaceX,
will be able to provide lower latency transcontinental connections
by using laser communication in space.
If they succeed, the financial industry will happily pay whatever it costs to use it.
Internet Control Message Protocol (ICMP)
The Internet Control Message Protocol (ICMP)
is used by routers to send error messages to the sender of a packet,
for example when a host could not be reached
or when a packet exceeds its time to live (TTL).
ICMP messages are attached to an IP header,
in which the IP protocol number
is set to 1 according to RFC 792.
ICMP complements the Internet Protocol on the network layer.
It has various message types,
with two of them being commonly used to determine the round-trip time to a network destination.
The network utility to do so is called ping.
It sends several echo requests and waits for the echo replies
before reporting statistics on packet loss and round-trip times:
Pinging the example.com server five times from my
command-line interface.
The average round-trip time is around 88 ms.
The first line consists of the command and options that I entered,
all the subsequent lines are output by the ping utility.
Round-trip times within the same geographical area are typically below 10 ms,
whereas it takes around 80 to 100 ms
to the US East Coast and around 150 to 170 ms to the US West Coast and back from my place in central Europe.
Unlike the MAC address,
which at least historically always stayed the same,
the IP address of your device is different for every network it joins
as IP addresses are allocated top-down to allow for efficient routing between networks.
Instead of configuring the IP address manually every time you join another network,
your device can request an IP address from the router of the network using the
Dynamic Host Configuration Protocol (DHCP).
DHCP is an application layer protocol.
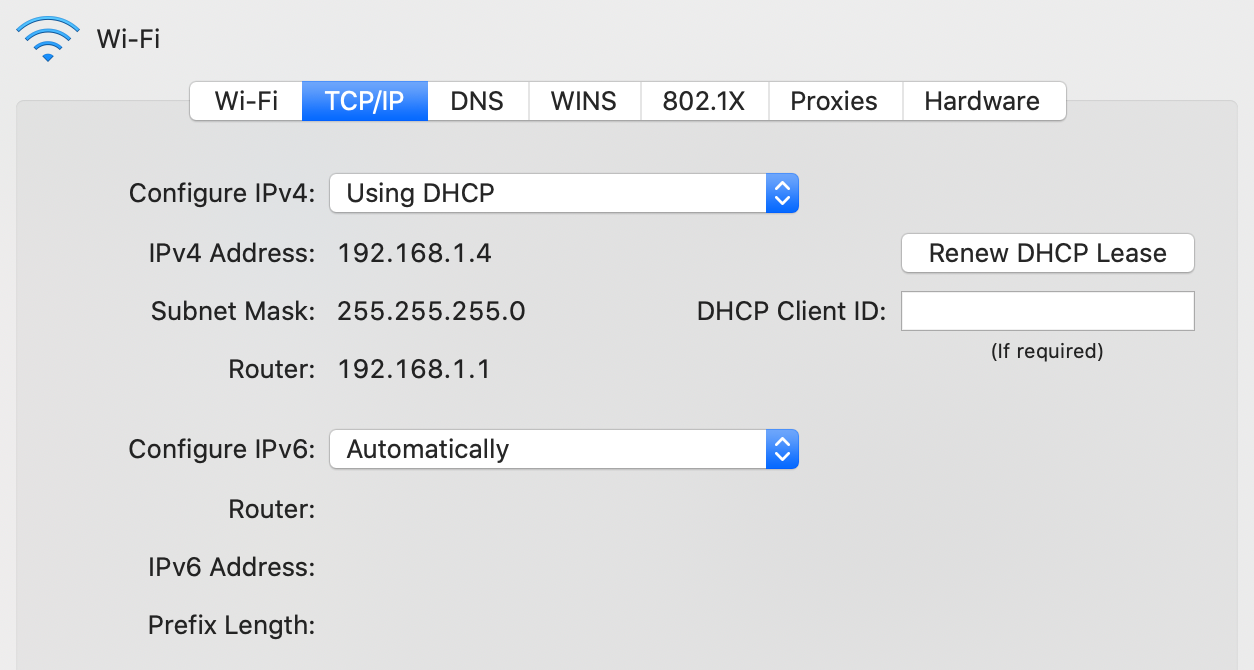
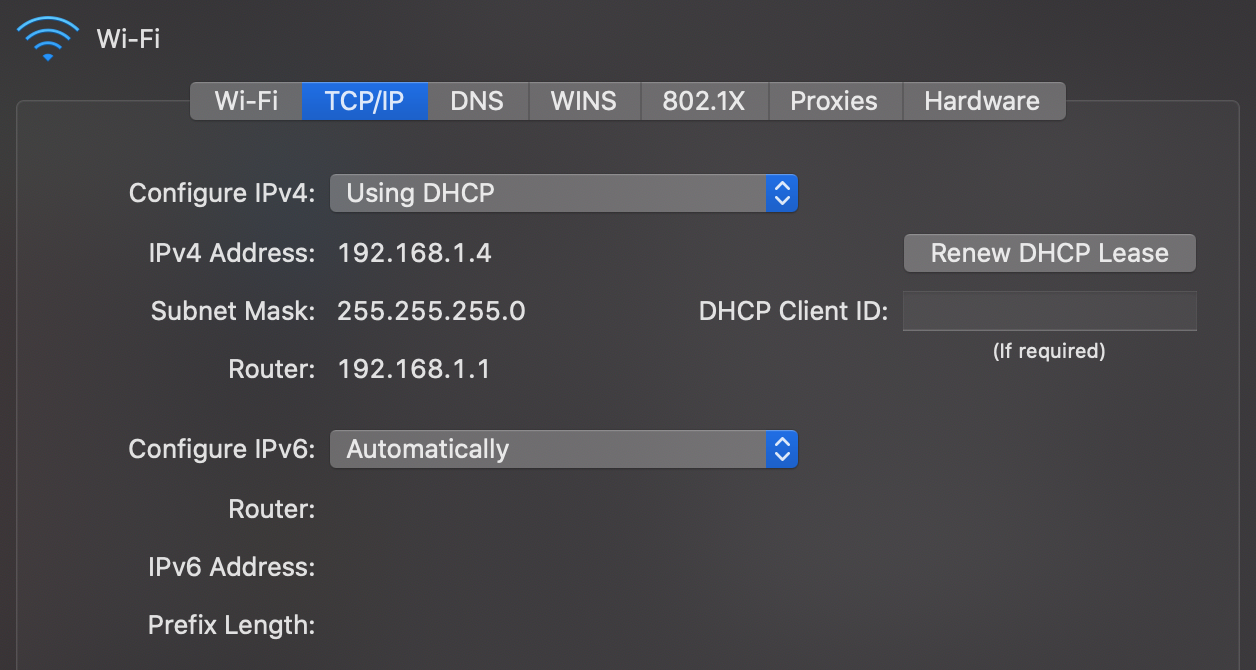
When devices want to communicate with each other in the same network,
they need to know the MAC address of the other devices
in order to address them on the link layer.
The Address Resolution Protocol (ARP)
resolves IP addresses to MAC addresses in the local network.
By using a special MAC address which is accepted by all devices on the local network,
any network participant can ask, for example, “Who has the IP address 192.168.1.2?”.
The device which has this IP address responds, thereby sharing its MAC address.
Transport layer
Operating systems
Before we can discuss the transport layer,
we first need to talk about operating systems (OS).
The job of an operating system is to manage the
hardware of a computer.
Its hardware includes processors,
such as the central processing unit (CPU)
and the graphics processing unit (GPU),
memory,
such as volatile memory
and non-volatile memory
like your solid-state drive (SSD),
input/output (I/O) devices,
such as a keyboard
and a mouse for input,
a monitor
and speakers for output,
as well as a network interface controller (NIC)
to communicate with other devices on the same network.
An operating system fulfills three different purposes:
- Abstraction: It simplifies and standardizes the access to the hardware,
making it easier for engineers to develop software for several
computing platforms. - Duplication: It provides the same resources to several programs running on the same computer,
thereby giving each program the illusion that it has the hardware just for itself. - Protection: It enforces restrictions on the behavior of programs.
For example, it can deny access to the webcam or certain parts of
the file system
unless the user has granted the necessary permissions.
Port numbers
When a program is being executed,
it is called a process.
This distinction is important
because the same program can be executed several times in parallel,
which results in several processes until they terminate.
Since more than one process might want to use the network connection at the same time,
the operating system needs a way to keep the traffic of different processes apart.
The label used for this purpose is a 16-bit integer known as port number.
When a process sends a request to another device,
the operating system chooses an arbitrary but still unused port number
and encodes it as the source port in the transport layer wrapping of the outgoing packet.
The recipient then has to include the same port number as the destination port in its response.
When the operating system of the requester receives this response,
it knows which process to forward the incoming packet to
because it kept track of which port numbers it used for which process.
But how does the operating system of the recipient know
what to do with the incoming packet?
The answer is registration and convention.
A process can ask the operating system to receive all incoming packets
which have a certain destination port.
If no other process has claimed this port before,
the operating system grants this port to the process.
A port can be bound to at most one process.
If it is already taken,
then the operating system returns an error.
Ports are distributed on a first-come, first-served basis.
To claim port numbers below 1024,
processes need a special privilege, though.
Which port to claim as a receiving process is handled by convention.
Each application layer protocol
defines one or several default ports to receive traffic on.
Wikipedia has an extensive list of established port numbers.
Application process
Operating system
Network interface
Please forward to meall traffic on port 25
I received a newpacket on port 25
I have a newpacket for you
Client-server model
A server is just a process
registered with the operating system to handle incoming traffic on a certain port.
It does this to provide a certain service,
which is then requested by so-called clients.
This is called the client-server model,
which contrasts with a peer-to-peer architecture,
where each node equally provides and consumes the service.
The communication is always initiated by the client.
If the server makes a request itself,
it becomes the client in that interaction.
A server is typically accessed via a network like the Internet
but it can also run on the same machine as its client.
In such a case, the client accesses the server via a so-called loopback,
which is a virtual network interface where the destination is the same as the source.
The current computer is often referred to as localhost.
There is also a dedicated IP address for this purpose:
127.0.0.1 in the case of IPv4 and ::1 in the case of IPv6.
Response
Request
Client
Server
The client’s port number is dynamic, the server’s static.
Server
namely from the client initiating the communication to the server.
The problem with packet-switched networks, such as the Internet, is
that packets can get lost or arrive out of order with an arbitrary delay.
However, it is desirable for many applications
that what the receiver receives is exactly what the sender sent.
So how can we get reliable, in-order transfer of data over an unreliable network?
This is achieved by the Transmission Control Protocol (TCP),
which brings the concept of a connection
from circuit-switched networks to packet-switched networks.
But unlike connections in circuit-switched networks,
TCP connections are handled by the communication endpoints
without the involvement of the routers in between.
In order to provide reliable data transfer,
both the sending and the receiving process temporarily store
outgoing and incoming packets in buffers.
In each direction of communication,
the packets are enumerated with the so-called sequence number.
For each packet that is being transferred,
its sequence number is encoded in the TCP header.
This allows the recipient to reorder incoming packets which arrived out of order.
By including the sequence number
until which they have successfully received all packets from the other party
in the TCP header as well,
each party lets the other party know
that it can remove those packets from its buffer.
Packets whose receipts are not acknowledged in this way are retransmitted by the sending party.
TCP headers also include a checksum to detect transmission errors.
On top of that,
TCP allows each party to specify
how many packets beyond the last acknowledged sequence number they are willing to receive.
This is known as flow control,
and it ensures that the sender does not overwhelm the receiver.
Last but not least,
the sender slows down its sending rate
when too many packets are lost
because the network might be overloaded.
This feature is called congestion control.
IP address spoofing
In all the protocols we have discussed so far,
nothing ensures the authenticity of the transmitted information.
For example, an attacker can fake their identity
by encoding a different source address into the header of a packet.
By posing as someone else,
the attacker might gain access to a system
that they didn’t have before.
This is known as a spoofing attack.
On the link layer, it’s called MAC address spoofing,
and on the network layer, it’s called IP address spoofing.
Since a router connects different networks,
it can block packets that come from one network
but have a source address from a different network.
For packets coming from the outside but claim to be from the local network,
this is referred to as ingress filtering.
Ingress filtering protects internal machines from external attackers.
For outgoing packets that do not have a source address from the local network,
the term is egress filtering.
Egress filtering protects external machines from internal attackers.
As such, the administrator of the local network has fewer incentives to implement this.
The reason why we’re discussing this under the transport layer and not earlier is
that TCP makes the spoofing of IP addresses much more difficult.
The problem with encoding a wrong source address is
that the recipient will send its response to that wrong address.
This means that unless an attacker also compromised a router close to the recipient,
they won’t receive any of the response packets.
Therefore, the interaction needs to be completely predictable for the attack to succeed.
Before any actual data can be sent,
TCP first establishes a connection
by exchanging a few TCP packets without a payload.
As we encountered earlier,
such preliminary communication in preparation for the actual communication is called a handshake.
In a TCP handshake,
both parties choose the initial sequence number for their outgoing packets at random.
Since the sequence number is a 32-bit integer,
which results in more than four billion possibilities,
an attacker who doesn’t see the responses from the victim
is very unlikely to guess the correct sequence number.
Thus, none of the victim’s response packets will be properly acknowledged,
which leads to a failed connection on the transport layer
before the program on the application layer
gets a chance to perform what the attacker wanted.
User Datagram Protocol (UDP)
There is a second important protocol on the transport layer,
which I quickly want to mention for the sake of completeness:
the User Datagram Protocol (UDP).
UDP provides connectionless and thus unreliable communication between processes,
encoding only the source and destination port numbers together with a length field and a checksum
in its header.
It provides none of the other features of TCP,
thereby prioritizing fast delivery over reliability.
This is useful for streaming real-time data, such as a phone or video call, over the Internet.
While the quality of the call deteriorates if too many packets are lost or delayed,
there’s no point in insisting on having them delivered as they cannot be played back later.
As there is no connection setup and thus no need for a handshake,
UDP can also be used to broadcast information to all devices in the same local network.
Network address translation (NAT)
In an effort to conserve IPv4 addresses
in order to alleviate the above-mentioned address space exhaustion,
all devices in a local network commonly share the same source address
when communicating with other devices over the Internet.
This is accomplished by requiring that all communication is initiated by devices in the local network
and by having the router engage in a technique known as
network address translation (NAT).
The basic idea is that the router maintains a mapping from the internally used IP address and port number
to a port number it uses externally.
| Internal address | Internal port | External port |
|---|---|---|
| 192.168.1.2 | 58’237 | 49’391 |
| 192.168.1.2 | 51’925 | 62’479 |
| 192.168.1.4 | 54’296 | 53’154 |
| … | … | … |
For each outgoing packet,
the router checks whether it already has a mapping for the given IP address and source port.
If not, it creates a new mapping to a port number it has not yet used in its external communication.
The router then rewrites the headers of the outgoing packet
by replacing the internal IP address with its own on the network layer
and the internal port with the mapped external port on the transport layer.
For each incoming packet,
the router looks up the internal address and port in its translation table.
If found, it replaces the destination address and port of the packet
and forwards it to the corresponding device in the local network.
If no such entry exists, it simply drops the incoming packet.
What makes the technique a bit complicated in practice,
is that the router also has to replace the checksums on the transport layer
and handle potential fragmentation on the network layer.
From a security perspective, network address translation has the desirable side effect
that the router now also acts as a firewall,
blocking all unsolicited incoming traffic.
This breaks symmetric end-to-end connectivity, though.
One of the core principles of the Internet is
that any device can communicate with any other device.
Given the widespread adoption of NAT,
this principle no longer holds nowadays, unfortunately.
If you still want to host a server on such a network,
you need to configure your router to forward all incoming traffic on a certain port to that machine.
This is known as port forwarding.
The loss of end-to-end connectivity is also a problem for peer-to-peer applications,
which need to circumvent NAT
by punching a hole
through its firewall or rely on an intermediary server to relay all communication.
Two remarks on the values used in the example translation table above:
- IP addresses starting with 192.168 are reserved for private networks.
This address range is often used for local networks behind routers which perform NAT.
As a consequence, your network settings might look quite similar to mine. - Clients can use any port number they like as their source port.
If this wasn’t the case, network address translation wouldn’t work.
I’ve chosen the values above from the range that IANA suggests for such ephemeral ports.
Server on your personal computer
I said above that
a server is just a process registered with the operating system
to handle incoming traffic on a certain port.
In particular, no special hardware is required;
you can easily run a server on your personal computer.
In practice, servers run on hardware optimized for their respective task, of course.
For example, since the computers in data centers are administrated remotely most of the time,
they don’t need to have a keyboard, mouse, or monitor.
But there are also other reasons besides hardware
why running a server on your personal computer is not ideal:
- Uptime: A server should be online all the time
so that others can reach it at any time.
If you host, for example,
your personal website on your personal computer,
you should no longer switch off your computer.
Even restarting your computer after installing some updates
makes your website unavailable for a short amount of time. - Utilization: Unless your website is popular,
your computer will be idle most of the time.
In a data center, several customers can share the same machine,
which makes better use of the hardware as well as electricity. - Workload: If your website does become popular,
your personal computer might no longer be powerful enough to serve it.
Professional hosting providers, on the other hand,
have experience in balancing increased load
across several machines. - Administration: Keeping a service secure and available requires a lot of time and expertise.
While this can be a fun and at times frustrating side project,
better leave the monitoring and maintenance of your services to experts. - Dynamic addresses: Once you set up port forwarding on your router
in order to circumvent network address translation,
you still face the problem that your computer gets a dynamic IP address from the router
and that the router typically gets a dynamic IP address from your Internet service provider
(see DHCP).
In the local network, you can configure your router
to always assign the same IP address to your computer based on its MAC address.
As far as your public IP address is concerned,
your ISP might offer a static address at a premium.
Otherwise, you’d have to use Dynamic DNS.
In conclusion, running a production server on your ordinary computer is possible but not recommended.
However, software engineers often run a development server locally on their machine,
which they then access via the above-mentioned loopback address from the same machine.
This allows them to test changes locally
before they deploy a new version of their software in the cloud.
Firewall
A firewall
permits or denies network traffic based on configured rules.
The goal is to protect the local network or machine from outside threats.
In order to compromise your system,
an attacker needs to find a hole in the firewall
and a vulnerability in a particular application.
Having multiple layers of security controls is known as
defense in depth.
Depending on the firewall and the configured rules,
packets are inspected and filtered on the network, transport, or application layer.
If the firewall rules are imposed by someone else,
such as a network administrator or the government,
users might resort to tunneling
their traffic via an approved protocol.
Security layer
All the communication we have seen so far is neither authenticated nor encrypted.
This means that any router can read and alter the messages that pass through it.
Since the network determines the route of the packets rather than you as a sender,
you have no control over which companies and nations are involved in delivering them.
The lack of confidentiality is especially problematic
when using the Wi-Fi in a public space,
such as a restaurant or an airport,
because your device simply connects to the wireless access point
of a given network with the best signal.
Since your device has no way to authenticate the network,
anyone can impersonate the network
and then inspect and modify your traffic
by setting up a fake access point.
This is known as an evil twin attack,
which also affects mobile phone networks.
As a general principle, you should never trust the network layer.
Transport Layer Security (TLS)
Transport Layer Security (TLS)
is the main protocol to provide confidential and authenticated communication over the Internet.
Its predecessor, Secure Sockets Layer (SSL),
was developed at Netscape
and released in 1995 as version 2.0.
In order to increase acceptance and adoption,
SSL was renamed to TLS in 1999 after SSL 3.0.
TLS exists in the versions 1.0, 1.1, 1.2, and 1.3.
SSL 2.0 and 3.0 as well as TLS 1.0 and 1.1 have been
deprecated
over time due to security weaknesses
and should no longer be used.
While it is beyond the scope of this article
to explain how the cryptography used in TLS works,
this is what it provides:
- Party authentication: The identity of the communicating parties can be authenticated
using public-key cryptography.
While TLS supports the authentication of both the client and the server,
usually only the identity of the server is verified.
To this end, the server sends a signed public-key certificate
to the client during the TLS handshake.
The client then verifies whether the signature was issued by an organization it trusts
(see the following two boxes for more information on this).
This allows the client to be fairly confident that it connected to the right server
without the communication being intercepted by a
man in the middle (MITM).
While the client could also present a public-key certificate,
the client is more commonly authenticated on the application layer,
for example with a username and a password. - Content confidentiality: The content of the conversation is
encrypted in transit with
symmetric-key cryptography.
The shared key
is generated
by the client and the server during the TLS handshake at the start of the session.
Please note that while the content is encrypted,
a lot of metadata is revealed
to anyone who observes the communication between the two parties.
An eavesdropper learns that- a TLS connection was established between the two IP addresses,
- the time and duration of the connection, which leaks a lot,
given that a response often triggers follow-up connections, - the rough amount of data that was transferred in each direction,
- and the name of the server
because the server sends its certificate in plaintext to the client.
Additionally, the client likely did an unencrypted DNS query beforehand;
the attacker can perform a reverse DNS lookup
of the server’s IP address;
and the client might indicate the desired host name
to the server so that the server knows which certificate to send back.
- Message authentication: Each transmitted message is authenticated
with a so-called message authentication code.
This allows each party to verify that all messages were sent by the other party
and that the messages were not modified in transit.
Encryption alone usually does not guarantee
the integrity
of the encrypted data because encryption generally does not protect against
malleability.
What TLS does not provide,
however, is non-repudiation.
Or put another way: A party can plausibly dispute
that it communicated the statements inside a TLS connection.
This is because message authentication codes are symmetric,
which means that whoever can verify them can also generate them.
Since TLS requires reliable communication,
it uses TCP on the transport layer.
Digital signatures
The essential feature of signatures is
that they are easy for the author to produce
but hard for others to forge.
Since digital information can be duplicated and appended without degradation,
a digital signature
has to depend on the signed content.
Handwritten signatures, on the other hand,
are bound to the content simply by being on the same piece of paper.
Digital signature schemes consist of three
algorithms:
- Key generation: First, the signer chooses a random private key,
from which they can compute the corresponding public key.
The signer should keep the private key to themself,
while the public key can be shared with anyone.
Both keys are usually just numbers or pairs of numbers in a certain range.
For the digital signature scheme to be secure,
it has to be infeasible to derive the private key from the public key.
This requires that one-way functions,
which are easy to compute but hard to invert, exist.
It is widely believed that this is the case
but we have no proof for this yet.
An example of such an asymmetric relationship is integer multiplication versus
integer factorization.
While the former can be computed efficiently,
the latter becomes exceedingly hard for large numbers.
Infeasible
Efficient
Private key
Public key
- Signing: The signer then computes the signature for a given message
using the private key generated in the previous step.
The signature is also just a number or a tuple of several numbers.
Since the computation of the signature depends on the private key,
only the person who knows the private key can produce the signature. - Verification: Anyone who has the message, the signature, and the signer’s public key
can verify that the signature was generated by the person knowing the corresponding private key.
As you can see from these algorithms,
digital signatures rely on a different
authentication factor
than handwritten signatures.
While the security of handwritten signatures relies on something the signer does with their fine motor skills,
the security of digital signatures relies on something the signer knows or rather has.
In theory, a private key is a piece of information and thus knowledge.
In practice, however, a private key is usually too big to remember
and thus rather a piece of data that the user has.
Since the private key is not inherent to the signer
but rather chosen by the signer,
digital signatures require that
the signer assumes responsibility for the signed statements.
This brings us to the next topic: public-key infrastructure.
Public-key infrastructure (PKI)
How do you know that someone took responsibility
for all signatures which can be verified with a certain public key
if you have never met them in person?
In the absence of knowledge like this,
you cannot authenticate anyone over an insecure channel.
However, if you know the public key of some individuals,
you can verify whether or not they signed a certain statement.
A statement can be of the form:
“Person … told me that their public key is …”.
If you know the public key of the person who signed such a statement
and if you trust this person to sign only truthful statements,
then you just learned the public key of another person.
With this technique,
you can now authenticate someone
you have never met before
as long as you have met someone before
who met that someone before.
For example, if you met Alice at some point
and received her public key directly from her,
you can authenticate Bob over an untrusted network
if Alice met Bob and confirms to you (and everyone else)
that a specific public key indeed belongs to Bob.
Whether Alice sends the signed statement with this content directly to you
or whether Bob presents this signed statement during the conversation with him,
does not matter.
Since you know the public key of Alice,
you can verify that only she could produce the signature.
In order to make the system scale better,
you can decide to also trust Bob’s statements
regarding the public key of other people,
in particular if Alice decided to trust Bob in this regard.
This makes trust transitive:
If you trust Alice and Alice trusts Bob, then you also trust Bob.
Signed statements of the above form are called
public-key certificates.
A widely adopted format for public-key certificates is
X.509,
which is also used in TLS.
X.509 certificates are often displayed as follows:
There are two different paradigms for issuing public-key certificates:
- Web of trust:
As described above, you start out with no trust
and then expand your circle of trust
by meeting people and verifying each other’s public key.
This is done most efficiently at so-called
key-signing parties,
where participants verify each other with state-issued identity documents.
The big advantage of this paradigm is that it is completely decentralized,
requiring no setup and no trusted third party.
On the other hand, it demands a lot of diligence from individual users.
Additionally, every user has a different view of which identity assertions can be trusted.
While this works reasonably well for social applications such as messaging,
such a fragmented trust landscape is not ideal for economic interactions. - Certification authorities (CAs):
In the other, more common paradigm,
manufacturers deliver their devices or operating systems
with a preinstalled list
of trusted third parties to their customers.
An employer might replace or extend this list on corporate devices.
These trusted third parties are called certification authorities (CAs).
While users can add and remove CAs on their own devices,
they rarely do this – and I don’t recommend to mess with this list either,
as badly informed changes can compromise the security of your system.
Organizations and individuals pay one of these CAs to assert their identity.
A preinstalled CA, also known as a root CA,
can also delegate the authority to certify to other entities,
which are called intermediate CAs.
If you have a look at the top of the above screenshot,
then you see that this is exactly what happened:
The root CA DigiCert High Assurance EV Root CA
delegated its authority with a signed certificate
to the intermediate CA DigiCert SHA2 High Assurance Server CA,
which in turn signed that the public key at the bottom of the screenshot,
of which only the beginning is displayed by default,
belongs to the Wikimedia Foundation as the subject of the certificate.
If we check the list of root CAs,
we see that DigiCert High Assurance EV Root CA is indeed among them:
As described above,
the server sends its certificate to the client during the TLS handshake.
By also including the certificate of a potential intermediate CA,
the client has all the information needed to authenticate the server.
This means that CAs don’t have to be reachable over the Internet,
which is good for the security of their signing keys
but also good for the reliability of the Internet.
There is a lot more to public-key certificates,
such as expiration and revocation,
but these aspects are beyond the scope of this article.
Application layer
Everything we’ve covered so far serves a single purpose:
to accomplish things we humans are interested in.
This is done with protocols on the application layer.
Examples of application layer protocols are
the HyperText Transfer Protocol (HTTP)
as the foundation of the World Wide Web (WWW),
the Simple Mail Transfer Protocol (SMTP)
for delivering email,
the Internet Message Access Protocol (IMAP)
for retrieving email,
and the File Transfer Protocol (FTP)
for, as you can probably guess, transferring files.
What all of these protocols have in common is
that they all use a text-based format,
that they all run over TCP,
and that they all have a secure variant running over TLS,
namely HTTPS,
SMTPS,
IMAPS,
and FTPS.
This is the beauty of modularization:
Application layer protocols can reuse the same protocols below,
while the protocols below don’t need to know anything about the protocols above.
Text encoding
Similar to numbers,
human language is also encoded with symbols.
By assigning meaning to specific combinations of symbols,
which we call words,
we can encode a large vocabulary with relatively few symbols.
In computing, the symbols which make up a text are called
characters.
English texts consist of
letters,
digits,
punctuation marks,
and control characters.
Control characters are used to structure texts without being printed themselves.
So-called whitespace characters,
such as space,
tab,
and newline,
fall in this category.
Other examples of control characters are
backspace,
escape,
the end-of-transmission character,
and the null character
to indicate the end of a string.
(A string is just a sequence of characters in memory.)
In order to uniquely identify them,
a so-called code point
is assigned to each character.
A code point is just a number,
which itself needs to be encoded
in order to store or transmit text.
In order to understand each other,
two or more parties need to agree on a common
character encoding.
After the Morse code
for telegraphs,
the American Standard Code for Information Interchange (ASCII),
which was developed in the 1960s,
became the first widely adopted character encoding for computers.
Based on the English alphabet,
ASCII specifies 128 characters and how they are encoded as seven-bit integers.
It is basically just a table
mapping characters to their code points and vice versa.
Since it’s easier to reserve a whole byte for each character,
the eighth bit made it possible to extend ASCII
with 128 additional characters.
Many companies used this for
proprietary extensions,
before the International Organization for Standardization (ISO)
published ISO 8859 in 1987,
which standardized character sets for
Western European languages,
Eastern European languages,
and others.
The character encodings defined by ISO 8859 have the problem
that they are not compatible with each other.
Since character encodings are typically used for whole documents
including websites and not just parts of them,
you cannot use characters from different sets in the same document.
Additionally, each document has to be accompanied with the used character set
as part of its metadata
because none of the encodings will ever be in a position to supersede them all
as a widely accepted default encoding.
Unicode,
which is maintained by the California-based
Unicode Consortium,
unifies different character sets
by providing a unique code point for every imaginable character.
Unicode specifies different encodings for these code points,
which are known as Unicode Transformation Formats (UTF).
The most popular ones are UTF-8,
which uses one to four bytes for each code point
and maximizes compatibility with ASCII,
and UTF-16,
which uses one or two 16-bit units per code point.
Text-based protocols
A communication protocol has to specify
how text and numbers in messages are encoded
or at least how the recipient is informed about the used encoding.
As mentioned above,
many application layer protocols are
text-based,
which means that the transmitted messages can be meaningfully displayed in a text editor.
This is in contrast to binary protocols,
whose messages are difficult to read for humans without specialized analysis software.
As we just learned, text is also encoded with binary numbers,
and text editors can be considered as specialized software.
The real difference between the two categories of protocols is
that text-based protocols delimit different pieces of information
with a certain character, such as a newline or a colon, at that position,
whereas binary protocols often define specific lengths in bytes for each
field
or prefix a field with its length in bytes.
The advantage of binary protocols is
that they can directly incorporate arbitrary data,
whereas the data in text-based protocols needs to be
escaped
in order to ensure that the delimiting character does not occur within a field.
If, for example, different header fields are separated by a newline,
then none of the header fields may contain a newline character.
If they do, the newline character needs to be replaced
with the appropriate escape sequence
as defined by the protocol.
A common escape sequence for a newline character is n.
Alternatively, the whole data could be re-encoded with a certain set of characters.
This is required when arbitrary data needs to be encoded
where only text is permitted or reliably supported.
This is the case for email attachments
because email originally only supported 7-bit ASCII.
If you attach a picture to an email, for example,
then the picture is split into chunks of 6 bits,
and each chunk is encoded with one of 64 characters.
This encoding is called Base64,
and it needs to be reverted by the recipient
in order to display the picture.
Base64 uses the characters A – Z, a – z, 0 – 9, +, and /
(26 + 26 + 10 + 2 = 64).
Since binary protocols require no such transformation
and often skip the labels for fields
or abbreviate them to a single number,
they are more concise and efficient than text-based protocols.
HyperText Transfer Protocol (HTTP)
In order for you to read this article,
your browser fetched this page from a
web server via HTTP over TLS,
which is known as HTTPS.
Given the popularity of the Web,
HTTP is one of the most widely used application layer protocols.
If we ignore newer versions of the protocol and rarely used features,
HTTP is a fairly simple protocol and thus an excellent first example.
HTTP works according to the client-server model:
The client sends a request, and the server sends back a response.
The first line of the request starts with the
request method,
which specifies whether the request is about
retrieving (GET) or submitting (POST) data.
The request method is followed by
the resource to retrieve or submit to
and the protocol version.
The first line of the response includes the
status code,
which indicates whether the request was successful
and, if not, what went wrong.
While the first line is different,
both HTTP requests and responses continue with
header fields
(formatted as name: value on separate lines),
an empty line,
and an optional message body.
If you request a file,
the body of the request is usually empty,
whereas the body of the response contains the file
(assuming that the request was successful).
If, on the other hand, you submit data,
such as your username and password in a login form,
the request contains this data in its body,
whereas the body of the response could be empty,
for example, when your browser is being redirected to a different page.
We have encountered the concept of header and payload several times already,
and HTTP follows the same logic.
Let’s look at a slightly modified example from
Wikipedia:
GET /index.html HTTP/1.0
Host: www.example.com
requesting the resource
/index.html from the host www.example.com.Please note that the request is terminated by an empty line and has no message body.
The only mandatory request header field is Host.
It is required to let the server know
from which website to serve the requested resource
in case the same server hosts several websites.
As you learned above,
only one process can bind to a specific port on the same machine,
thus this header field is the only way for a server
to tell the requests to different websites apart.
(Strictly speaking, it’s one process per port number and IP address.
So if the server has several network interfaces,
the requests on each interface could be handled by a different process.)
The default port is 80 for HTTP and 443 for HTTPS.
If you want to request a website on a different port,
you would specify this after the host name in the
URL.
For example, if you run a web server locally on port 4000,
you would access it at http://localhost:4000/ in your browser.
HTTP/1.0 200 OK
Date: Mon, 23 May 2005 22:38:34 GMT
Content-Type: text/html; charset=UTF-8
Content-Length: 155
Last-Modified: Wed, 08 Jan 2003 23:11:55 GMT
Server: Apache/1.3.3.7 (Unix) (Red-Hat/Linux)
<html>
<head>
<title>An example page</title>
</head>
<body>
<p>Hello, World! This is a very simple HTML document.</p>
</body>
</html>
which includes the requested resource in its message body after the empty line.
As indicated by the Content-Type header field,
the response is an HTML document.
HTML stands for HyperText Markup Language
and is the document format of the Web.
The browser parses the HTML document
and displays it as a website.
<p> stands for a paragraph, which is then closed by </p>.
The other so-called tags
in the example above should be self-explanatory.
Usually, a website references other files from its HTML,
such as styles,
scripts,
and images.
These files can be hosted on the same or a different server.
The browser fetches them via separate HTTP requests.
The body of the response is not limited to text-based formats,
any files can be transferred via HTTP.
Thanks to the Content-Length header field,
binary files don’t need to be escaped.
Every modern browser includes powerful
developer tools,
with which you can inspect the requests it made:
If you are familiar with the command-line interface
of your operating system,
you can write such HTTP requests yourself.
On macOS, the default program providing such a command-line interface
is Terminal,
located in the /Applications/Utilities folder.
With the command Telnet,
you can establish a TCP connection to the designated server.
If the website is provided via HTTPS,
you can use OpenSSL
to establish a TLS connection to the designated server.
The following tool generates what you have to enter in your command-line interface
based on the provided web address:
You can copy the text to your clipboard by clicking on it.
The hierarchical numbers used in network addresses
are great for machines to route packets
but difficult for humans to remember.
The Domain Name System (DNS)
solves this problem by providing a hierarchical
namespace
of easily memorizable domain names
and a protocol to access public information associated with such names.
A domain name consists of a sequence of labels separated by a dot.
Similar to how the Internet Protocol
is more than just a protocol as it also governs the allocation of IP addresses,
the Domain Name System is more than just an application layer protocol
as it also governs the allocation of domain names,
thereby ensuring that each domain name is unique.
At the root of this system is again the
Internet Corporation for Assigned Names and Numbers (ICANN),
which approves the top-level domains (TLD)
and accredits the registry operators,
which manage the registration of names within their domain.
As an organization or individual,
you register your domains at a so-called
domain name registrar,
which has to be accredited by the registry operators
of all the top-level domains under which it allows its customer to register a domain name.
This has the advantage that you as a registrant only have to interact with a single company
even if you register various domain names under different top-level domains.
Let’s look at an example: I’m the registrant of ef1p.com.
The top-level domain of this domain name is com.
The registry operator for .com is Verisign.
The domain name registrar I have chosen to register my domains is Gandi.
I pay them 13 Euros every year just so that I can keep this domain name.
In order to avoid ambiguity,
a fully qualified domain name (FQDN)
is sometimes written with a trailing dot, such as ef1p.com..
Otherwise, the label might just refer to a subdomain.
Don’t let this confuse you in the DNS playground below.
From a technical point of view,
DNS acts as a distributed database,
which stores the information associated with domain names
on numerous machines distributed all over the Internet.
These machines are called name servers,
and each entry they store is called a resource record (RR).
While some name servers provide the authoritative answer
to queries regarding the domain names for which they are responsible,
others simply store these answers for a limited period of time.
Such temporary storage is known as caching,
and it allows other devices in the same network to look up the information faster.
Caching is also important to distribute the load more evenly among name servers,
which improves the scalability of the Domain Name System.
Each record specifies how long it can be cached,
which limits how outdated the answer to a query can be.
This expiration period is called time to live (TTL),
and a common value for this is one hour.
This means that if you change a DNS record with such a TTL value,
you have to wait for up to one hour
until the stale entries have been discarded everywhere.
The most common use case of DNS is to resolve a domain name to an IP address.
Every time a client connects to a server identified by a domain name,
it first has to query a name server to obtain the IP address of the server
because the network layer has no notion of domain names.
This is similar to how you have to look up the phone number of a person
before you can call that person.
In this sense, DNS can be compared to a telephone book;
but, rather than looking up the phone number of persons,
you look up the IP address of computers on the Internet.
Another difference is that each domain name is unique,
which cannot be said about the names of humans.
A domain name can resolve to several IP addresses,
which distributes requests among several servers
and allows clients to connect to a different server
if they cannot reach one of them.
This indirection of first having to look up
the IP address of the server you want to connect to
also has the advantage that a server can be replaced
without having to notify its users about the new address.
DNS specifies a binary encoding for requests and responses.
If the response is small enough to fit into a single packet
(see the maximum transmission unit),
DNS uses the User Datagram Protocol (UDP)
in order to avoid the additional round trips
required by the Transmission Control Protocol (TCP)
for the channel setup.
If the request or response packet is lost,
the client simply queries again after the configured timeout.
DNS requests are served on port 53.
There are other types of resource records
besides the one which resolves a domain name to an IPv4 address:
| Acronym | Name | Value | Example |
|---|---|---|---|
A |
IPv4 address record | A single IPv4 address. | ↗ |
AAAA |
IPv6 address record | A single IPv6 address. | ↗ |
ANY |
Any record type query | Return all record types of the queried domain. | ↗ |
CAA |
CA authorization record | The CA authorized to issue certificates for this domain. Only checked by CAs before issuing a certificate. |
↗ |
CNAME |
Canonical name record | Another domain name to continue the lookup with. | ↗ |
MX |
Mail exchange record | The server to deliver the mail for the queried domain to. | ↗ |
NS |
Name server record | The authoritative name server of the queried domain. | ↗ |
OPENPGPKEY |
OpenPGP key | The local part of the user’s email address is hashed. | ↗ |
PTR |
Pointer record | Another domain name without continuing the lookup. Primarily used for implementing reverse DNS lookups. |
↗ |
SMIMEA |
S/MIME certificate | The local part of the user’s email address is hashed. | ↗ |
SOA |
Start of authority record | Administrative information for secondary name servers. | ↗ |
SRV |
Service record | The port number and domain name of the queried service. | ↗ |
SSHFP |
SSH fingerprint | The hash of the server’s SSH key for initial authentication. | ↗ |
TLSA |
Server certificate | See DNS-Based Authentication of Named Entities (DANE). | ↗ |
TXT |
Text record | Arbitrary text used in place of introducing a new record type. | ↗ |
Don’t worry if you don’t yet understand what they are used for.
We will encounter some of these record types in future articles on this blog.
For now, I want to give you the opportunity to play around with the actual DNS.
I use an API by Google
to query what you enter.
Try it with any domain name you are interested in.
If you hover with your mouse over the data,
you get additional explanations and options,
such as doing a reverse lookup of an IPv4 address.
The DNSSEC option and the record types
which are not in the above table
will be introduced in the next box.
If you just want to play around with the tools in this article without scrolling,
I also published them separately on this page.
Domain Name System Security Extensions (DNSSEC)
The problem with plain old DNS is that the answer to a query cannot be trusted.
While non-authoritative name servers
that cache and relay answers for others
are great for scalability,
they are really bad for security
as they can reply with fake answers,
thereby poisoning the cache
of DNS resolvers.
Additionally, an attacker who can modify your network traffic
can also replace the actual response from a name server with a malicious one
because neither UDP nor IP authenticates the transmitted data.
To make things even worse,
an attacker might not even have to modify your network traffic.
As long as the attacker sees your DNS query
by being on the same network,
they can simply respond faster than the queried name server.
Since UDP is a connectionless protocol without a handshake,
the source IP address of the response can easily be spoofed
so that it seems as if the response was indeed sent from the queried name server.
If the attacker does not see the query because they are on a non-involved network,
such a race attack
becomes much harder as the attacker has to guess the correct timing of the response,
the correct DNS query ID used to match answers to questions,
as well as the correct source port from which the query was sent.
For this reason, DNS queries should always be sent from a random source port,
and also NAT routers should choose external ports unpredictably.
Since DNS is often used to determine the destination address of requests,
a successful attack on the DNS resolution of your computer
allows the attacker to redirect all your Internet traffic through servers that they control.
The only thing that can limit the damage they can do is TLS
with valid public-key certificates
or another protocol with similar security properties on the application layer.
This also requires that the user does not simply dismiss invalid certificate warnings.
Luckily, such warnings are quite intimidating in most browsers by now
and can no longer be dismissed with a single click.
Google Chrome plays it safe
and won’t connect to a web server with an invalid certificate at all.
If you don’t know what I’m talking about,
visit this page
in order to get such a warning.
There is no risk in visiting this page
as long as you abort and don’t modify your security settings.
The Domain Name System Security Extensions (DNSSEC)
solves the aforementioned problem
by authenticating resource records.
DNSSEC doesn’t provide confidentiality, though.
You would have to use DNS over TLS for that.
For most readers, it’s enough to know that the integrity of DNS can be protected.
For advanced readers, here is how DNSSEC works.
DNSSEC introduces new types of resource records
(as defined in RFC 4034)
and backward-compatible
modifications to the communication protocol
(as defined in RFC 4035).
Before we can discuss these extensions,
we first need to understand
that the Domain Name System is split into administrative zones,
each of which is managed by a single entity.
Each such entity runs name servers (or lets a company run them on its behalf),
which return the authoritative answer for the domains in its zone.
DNS has a single and thus centralized root zone,
which is managed by the Internet Assigned Numbers Authority (IANA),
a subsidiary of the Internet Corporation for Assigned Names and Numbers (ICANN),
but operated by Verisign.
The root domain is denoted by the empty label,
but it is usually written and queried as a single period: ..
If you query a root name server
for a domain such as ef1p.com.
(written with a trailing dot because com is a subdomain of the root domain with the empty label),
it will answer that com belongs to a different DNS zone
and provide you with the addresses of the authoritative name servers of that zone.
If you query one of those name servers for ef1p.com.,
it will tell you again that other name servers are responsible for this domain.
You can query all these name servers with the tool at the end of the previous box:
the root name servers,
the .com name servers,
and the ef1p.com name servers.
Somewhat confusingly, the name servers are listed with a domain name rather than an IP address.
In order to avoid the circular dependency
that you already need to have used DNS in order to use DNS,
DNS clients have to be delivered not only with the domain names of the root name servers but also with their IP addresses.
This is usually accomplished with a file like this.
As long as they can reach one of the root name servers,
it will tell them the IP address of any name server it refers them to as well.
This is accomplished with so-called glue records,
which are address resource records for name servers in a subzone returned by the name server of the superzone.
I cannot demonstrate this with the above tool
because Google does all the recursive resolution for us.
If you are familiar with a command-line interface,
you can use the dig command to check this:
dig net @a.root-servers.net. returns in the authority section of the DNS answer
that the name server for net. is a.gtld-servers.net. (among others)
and in the additional section of the DNS answer
that the IPv4 address of a.gtld-servers.net. is 192.5.6.30.
(The authority section indicates the
authoritative name servers
of the queried domain or its canonical name.
In the additional section,
a name server can add records
that are related to the query
but which the client didn’t yet ask for.)
While for a domain name such as ef1p.com.
each subdomain starts its own zone as we have just seen,
I would declare any further subdomains, such as www.ef1p.com.,
in the same zone as ef1p.com..
Since I’m the administrator of my zone,
I can do this without involving any party
other than gandi.net,
which operates the name servers on my behalf,
thanks to the hierarchical and distributed nature of DNS.
Coming back to DNSSEC after this little detour,
the core idea is that each zone signs its records
and provides these signatures in newly created records.
Each administrative zone uses its own cryptographic keys for this
but the zone above in the hierarchy signs and lists the public keys of its subzones.
This allows you to verify the public keys and resource records of all DNSSEC-enabled zones
as long as you know the public key of the root zone.
This is similar to the public-key infrastructure behind TLS,
where root certification authorities delegate their authority to intermediate certification authorities
by signing their public key.
There is a crucial difference, though.
In the case of TLS, everyone needs to trust every single certification authority
since any certification authority can issue a certificate for any domain.
With DNSSEC, you only need to trust the administrators of the zones above you.
For this blog, that’s the root zone and the com. zone.
A zone like attacker.example.org. cannot authorize a different DNSSEC key for ef1p.com..
In computer security, requiring less trust is always better.
While DNSSEC fails spectacularly if the root key is compromised,
TLS fails if the key of any certification authority is compromised.
Having a single point of failure
is preferable to having many independent points of failure.
There have been attempts to address this issue for TLS,
but, unfortunately, they weren’t widely adopted.
Let’s have a look at some technical aspects of DNSSEC next.
DNSSEC introduced the following DNS record types:
| Acronym | Name | Value | |
|---|---|---|---|
DNSKEY |
DNS public key record | The public key used to sign the resource records of the queried domain. | ↗ |
DS |
Delegation signer record | The hash of the key-signing key (KSK) used in the delegated DNS zone. | ↗ |
RRSIG |
Resource record signature | A digital signature on the queried set of resource records. | ↗ |
NSEC |
Next secure record | The next existing subdomain used for authenticated denial of existence. | ↗ |
NSEC3 |
NSEC version 3 |
A salted hash of the next existing subdomain to prevent “zone walking”. | ↗ |
NSEC3PARAM |
NSEC3 parameters |
Used by authoritative name servers to generate the NSEC3 records. |
↗ |
CDS |
Child copy of DS |
Used by the child zone to update its DS record in the parent zone. |
↗ |
CDNSKEY |
Child copy of DNSKEY |
Used by the child zone to update its DS record in the parent zone. |
↗ |
as defined in RFC 4034,
RFC 5155,
and RFC 7344.
Although DNSSEC validation treats all keys equally,
RFC 4033
distinguishes between key-signing keys (KSKs)
and zone-signing keys (ZSKs).
A zone lists both types of keys with DNSKEY records.
The parent zone lists the cryptographic hash
of the key-signing key in a DS record.
(A hash is the result of a one-way function,
which maps inputs of arbitrary size to outputs of a fixed size and is infeasible to invert.)
By using only the hash of a key instead of the key itself,
the parent zone has to store less data because the hash is shorter.
And of course, we’re only talking about public keys here.
The key-signing key is then used to sign one or more zone-signing keys.
The signature, which covers all DNSKEY records,
is published in an RRSIG record with the same domain name.
The zone-signing keys are then used to sign all other records of the zone.
The advantage of this distinction between key-signing keys and zone-signing keys
is that the latter can have a shorter lifetime
and be replaced more frequently because,
unlike in the case of key-signing keys,
the parent zone is not involved.
The algorithms that can be used to sign records are listed
on Wikipedia
and, more authoritatively, by IANA.
The supported hash algorithms for DS records are listed here.
As mentioned above, the key-signing key of the root zone acts as the trust anchor for DNSSEC.
Its hash is published on the website of IANA
together with a scan of handwritten signatures by trusted community representatives,
attesting the output of the used hardware security module (HSM).
You can inspect the root public key with the above tool
or by entering dig . dnskey +dnssec into your command-line interface.
(The key-signing key is in the record which starts with 257.
The other record, starting with 256, contains the zone-signing key.)
All DNSSEC-aware DNS resolvers are delivered with a copy of this public key
in order to be able to validate resource records recursively.
The corresponding private key is stored in two secure facilities,
which safeguard the root key-signing key with geographical redundancy.
One of them is located on the US West Coast in El Segundo, California,
the other one on the US East Coast in Culpeper, Virginia.
All ceremonies involving this private key
are publicly documented
in order to increase trust in the root key of DNSSEC.
For example, you can download the log files
as well as camera footage from different angles from the latest ceremony.
I can also recommend you to read this first-hand account.
For performance and security reasons,
DNSSEC has been designed so that the resource records in a zone can be signed before being served by a name server.
This allows the records to be signed on an air-gapped computer,
such as an HSM, which never needs to be connected to the Internet and is thus never exposed to network-based attacks.
As far as performance is concerned, name servers don’t have to perform cryptographic operations for each request,
which means that fewer machines can serve more requests.
By not requiring access to the private key,
name servers including the root servers
can be located all over the world without potential for abuse by local governments.
While China, for example, can (and does)
inject forged DNS responses
in order to censor content on its network,
this practice is prevented or at least consistently detected when DNSSEC is used.
In other words, you only have to trust the administrator of a zone
and not the operator of an authoritative name server.
As mentioned just a few paragraphs earlier,
requiring less trust is always better in computer security.
Allowing the signatures to be computed in advance makes DNSSEC more complicated in several regards:
- Replay attacks: Even if an attacker cannot forge a valid response,
they can replace the response to a new request with the response from a previous request
if they can intercept the traffic on the victim’s network.
This is known as a replay attack
and is usually prevented by including a random number used only once
in the request, which then also has to be included in the authenticated response.
However, due to the above design decision,
DNSSEC signatures cannot depend on fresh data from the client.
Since the potentially precomputed signatures stay the same for many requests
and DNSSEC doesn’t authenticate anything else in the response,
such as the DNS packet itself including its header,
an attacker can replay outdated DNS records including their DNSSEC signatures.
In order to limit the period during which DNS records can be replayed,
RRSIGrecords include an expiration date,
after which the signature may no longer be used to authenticate the signed resource records.
Suitable validity periods for DNSSEC signatures are discussed
in section 4.4.2 of RFC 6781. - Denial of existence: How can you be sure that a domain name doesn’t exist
or doesn’t have the queried record type
without requiring the authoritative name server to sign such a statement on the fly?
Since each label of a domain name (the part between two dots) can be up to 63 characters long,
a domain can have more direct subdomains than there are
atoms in the observable universe.
(The limit of 63 characters is imposed by RFC 1035
because the DNS protocol encodes the length of a label with a 6-bit number.)
This makes it impossible to generate and sign negative responses for all nonexistent subdomains in advance.
A generic negative response, which doesn’t depend on the queried domain name, doesn’t work
because an attacker could replay such a response even when the queried domain does exist.
Instead of mentioning the nonexistent domain in the response,
DNSSEC achieves authenticated denial of existence
by returning that no subdomain exists in a given range,
which includes the queried domain.
Since all domains in a zone are known to the administrator of that zone,
the gaps between the subdomains can be determined and signed in advance.
For example, if you query the nonexistent domain
nonexistent.example.com., you get anNSECrecord in the authority section of the response,
which says that the next domain name in the zone afterexample.com.iswww.example.com.,
and anRRSIGrecord, which signs theNSECrecord.
Sincenonexistent.example.com.comes afterexample.com.and beforewww.example.com.
in the alphabetically sorted list of subdomains in that zone,
we now know for sure that this domain does not exist.
The base domain of the zone,
which isexample.com.in our example,
is not just at the beginning of this list but also at its end.
If you click onwww.example.com.in the data column of theNSECrecord
in order to query itsNSECrecord,
you see that the next domain afterwww.example.com.isexample.com..
In other words, the list of subdomains wraps around
for the purpose of determining the gaps to sign.
EachNSECrecord also specifies the types of records
that the domain which owns the specificNSECrecord has.
If you query, for example, theMXrecord ofwww.example.com.,
you get theNSECrecord of that domain instead.
SinceMXis not listed in thisNSECrecord,
you can be certain that no such record exists.
While an attacker might still be able to drop the response to your DNS query,
NSECrecords prevent them from lying about the existence of a domain name or record type.
In particular, they cannot strip DNSSEC information from a response
because a resolver can check whether a zone has DNSSEC enabled
by querying theDSrecord in the parent zone.
Since the resolver knows that the root zone has DNSSEC enabled,
the attacker would have to be able to deny the existence of aDSrecord in an authenticated zone,
which they cannot do thanks to the mechanism described in this paragraph.
In practice, your zone can only have DNSSEC enabled if all the zones above it have DNSSEC enabled. - Zone walking:
NSECrecords create a new problem, though.
By querying theNSECrecord of the respective subsequent domain,
you can enumerate all the domains in a zone,
which is known as walking the zone.
While all the information in the Domain Name System is public
in the sense that it can be requested by anyone
because the sender of a query is never authenticated,
you previously had to guess the names of subdomains.
Since I couldn’t find a tool to walk a DNS zone online
(the closest one
I could find works completely differently),
I built one for you,
using the same Google API as before:Unfortunately, not many domains have DNSSEC records,
and most of them which do useNSEC3rather thanNSEC.
It’s therefore not easy to find domains to feed into this tool.
Besides the domain of the Internet Engineering Task Force (IETF),
some top-level domains
also still useNSECrecords for authenticated denial of existence.
Among those are country code top-level domains
such as .br (Brazil),
.bg (Bulgaria),
.lk (Sri Lanka),
and .tn (Tunisia),
as well as generic top-level domains
such as .help,
.link,
and .photo.
For security and privacy reasons, many organizations prefer
not to expose the content of their zone so easily.
This problem was first addressed by RFC 4470,
which suggested generating and signing minimally coveringNSECrecords for nonexistent domains on the fly,
and later by RFC 5155,
which introduced the new record typeNSEC3.
Since the former proposal abandons offline signing,
thereby sacrificing security for better privacy,
we will focus on the latter proposal.
Instead of determining the gaps between domain names directly,
all domain names in a zone are hashed in the case ofNSEC3.
These hashes are then sorted,
and anNSEC3record is created for each gap in this list.
If a DNS resolver queries a domain name that doesn’t exist,
the name server responds with theNSEC3record
whose range covers the hash of the queried domain.
Similar toNSECrecords,
NSEC3records also list the record types
that exist for the domain name
which hashes to the start of the range.
Thus, if the queried domain name exists but the queried record type doesn’t,
a resolver can verify such a negative response
by checking that the hash of the queried domain matches the start value of the receivedNSEC3record.
AnNSEC3record also mentions which hash function is used,
how many times the hash function is applied to a domain name,
and optionally a random value,
which is mixed into the hash function in order to defend against
pre-computed hash attacks.
While an attacker can try to brute-force the names of subdomains
based on the hashes it received inNSEC3records,
such a random value restricts the attack to one zone at a time.
The computational effort of such a targeted attack can be increased
by increasing the number of times the hash function is applied.
The difference to just querying guessed subdomain names
is that the search for the preimage
of a hash can be done without interacting with the authoritative name server.
Besides protecting the domain names with a one-way function,
NSEC3also allows to skip the names of unsigned subzones
when determining the gaps to sign by setting the
opt-out flag.
By skipping all subzones that don’t deploy DNSSEC,
the size of a zone can be reduced as fewerNSEC3records are required.
While easily guessable subdomains, such aswwwormail, have to be considered public anyway,
NSEC3protects the resource records of subdomains with more random names reasonably well.
Please note that the DNS query still has to include the actual domain name and not its hash.
By just learning the hash of a subdomain,
you don’t yet know the domain name to query.
However, it’s still relatively easy to figure out the overall number of domain names in a zone
by probing the name server with names that hash to a range
for which you haven’t seen anNSEC3record yet.
Hash functions only make it hard to find an input that hashes to a specific output,
but if the output just has to land in a certain range,
then the bigger the range, the easier the problem.
Even if you introduce additional dummyNSEC3records,
you still leak an upper limit of domain names in the zone. - Wildcard expansion: Last but not least,
wildcard records
make DNSSEC even more complicated.
The idea of a wildcard record is
that it is returned
whenever the queried domain name doesn’t exist in the zone.
For example, if an ordinary record is declared atmail.example.com.
and a wildcard record is declared at*.example.com.,
with*being the wildcard character,
a query formail.example.com.will return the former record,
and a query foranything-else.example.com.will return the latter.
The wildcard can only be used as the leftmost DNS label
and cannot be combined with other characters on that level.
Thus, neithermail.*.example.com.normail*.example.com.is a wildcard record.
For a wildcard record to match,
the domain name may not exist on the level of the wildcard.
The above wildcard record matchesanything.else.example.com.
becauseelse.example.com.doesn’t exist,
but it doesn’t matchanything.mail.example.com.
becausemail.example.com.exists.
Whether a wildcard name matches is determined
independently from the queried record type.
For example, ifmail.example.com.only has anMXrecord
while*.example.comhas anArecord,
then queryingmail.example.com.for anArecord returns no data.
However, not all implementations adhere to these rules.
Without DNSSEC, DNS resolvers don’t learn
whether an answer has been synthesized from a wildcard record
or whether the returned record exists as such in the zone.
Since signatures cannot be precomputed for all possible matches,
RRSIGrecords indicate the number of labels
in the domain name to which they belong,
without counting the empty label for the root
and the potential wildcard label.
This allows a validator to reconstruct the original name,
which is covered in the signature
and thus required to verify the signature.
For example, when querying the IPv4 address ofanything.else.example.com.,
the returnedArecord is accompanied
by anRRSIGrecord with a label count of 2.
This tells the validator to verify the signature for*.example.com..
If the label count was 3, it would have been*.else.example.com..
Equally importantly, we need to ensure
that this wildcardRRSIGrecord cannot be replayed
for domain names that do exist,
such asmail.example.com.in our example.
For this reason, DNSSEC mandates
that wildcardRRSIGrecords are only valid
if anNSECor anNSEC3record proves
that the queried domain name doesn’t exist.
This means that the response toanything.else.example.com.
includes not just anAand anRRSIGrecord
but also anNSEC(3)record.
The wildcard domain name is included as such
in the list used to determine theNSEC(3)records.
This is important to prove
that a domain name doesn’t exist
or that a synthesized domain name doesn’t have the queried record type.
For example, the response foranything.mail.example.com.has to include
anNSEC(3)record which proves thatanything.mail.example.com.doesn’t exist,
anNSEC(3)record which proves thatmail.example.com.does exist,
and anNSEC(3)record which proves that*.mail.example.com.doesn’t exist.
If, on the other hand,anything-else.example.com.is queried for anMXrecord,
the response has to include anNSEC(3)record
which proves thatanything-else.example.com.doesn’t exist,
and theNSEC(3)record at*.example.com.,
which proves that wildcard-expanded domain names don’t have records of this type.
If some of theseNSEC(3)records are the same,
the name server should include them and the correspondingRRSIGrecords only once
in the authority section of the response.
If this is still confusing,
you find a longer explanation of wildcards in DNSSEC
here.
Even though the Domain Name System is a core component of the Internet
and should be secured accordingly,
DNSSEC is still not widely deployed.
If you play around with the above tool,
you will note that none of the big tech companies protect their DNS records with DNSSEC.
We can only speculate
about why these companies are reluctant to deploy DNSSEC.
If you work at a large company and know the reasoning,
please let me know.
Personally, I can think of the following reasons:
- Dynamic answers: Large companies with a lot of incoming traffic
provide different DNS answers for different DNS resolvers.
Varying the returned IP address helps with
load balancing
because different clients connect to different servers.
A name server can also reply with an IP address
which is geographically close to the requester.
This is used by content delivery networks (CDN)
to make downloading a lot of content faster for the consumer and cheaper for the provider.
For example, if I resolvegoogle.com
and then do a reverse lookup by clicking on the returned IP address,
I getzrh11s03-in-f14.1e100.net.withzrhstanding for Zurich in Switzerland.
(1e100is the scientific notation for one googol.)
The problem with DNSSEC is that not individual resource records (RR) are signed
but rather all the returned resource records of the same type together.
(This is why you encounter the acronym RRset a lot in technical documents.)
If you combine resource records for answers dynamically based on the availability of servers,
then your name server has to sign them on the fly
and thus needs access to the private key of your zone.
If you only ever return a single IP address, though,
then each of yourArecords can simply have its own signature,
which can be generated in advance on an offline system.
In either case, this shouldn’t hinder the deployment of DNSSEC. - Bootstrapping: In order to increase security,
DNSSEC not only needs to be deployed on servers but also on clients.
As long as not enough clients ask for and validate DNSSEC records,
there is little reason to invest in the deployment of DNSSEC on the server-side.
Given the Web’s abundance of information,
I find it surprisingly difficult to figure out
which operating systems and browsers have DNSSEC validation
enabled by default.
My tentative conclusion is that none of them do,
but I would be pleased to be proven wrong. - Registrar support: Smaller organizations and individuals typically
use the name servers provided and operated by their domain name registrar.
They can only adopt DNSSEC if their registrar supports it.
While the vast majority
of top-level domains
deploy DNSSEC,
only few registrars
provide DNSSEC to their customers.
Even if you decide to run your own name servers
due to a lack of support by your registrar,
your registrar still needs to provide a form
to submit yourDSrecord to the parent zone.
Remember that registrants only have a business relationship with their registrar,
which is itself accredited by the registry operating the top-level domain.
The involvement of so many different parties is likely the main reason
why as of June 2019 still only around 1%
of domains under.com,.net, and.orghave aDNSKEYrecord published.
While the support for DNSSEC by registrars is steadily increasing,
RFC 7344 and RFC 8078
propose a new way to publish and update theDSrecord in the parent zone.
As you probably have learned by now,
all shortcomings of DNS are addressed by introducing new record types,
and these two RFCs are no different.
The former RFC introduces the record typesCDSandCDNSKEY(where theCstands for child),
with which the child zone can indicate to the parent zone the desired content of theDSrecord.
This requires that the operator of the parent zone regularly polls for these records
and that DNSSEC is already deployed in the child zone
because otherwise these records are not authenticated.
Such a mechanism is useful for
changing the key-signing keys.
The latter RFC suggests policies
that the parent can use to authenticate theCDSorCDNSKEYrecord of the child initially.
It also specifies how the child can use such a record to ask for the deletion of theDSrecord.
One reason to disable DNSSEC for a zone is when the domain name is transferred to a new owner
who cannot or doesn’t want to deploy DNSSEC. - Operational risks: While classic DNS can be configured and then forgotten,
DNSSEC requires regular attention unless everything,
including updating theDSrecord in the parent zone,
is fully automated.
A failure to sign the resource records of your zone in time takes down your whole domain.
While this becomes easier over time
thanks to new standards such as theCDSrecord and better administration tools,
it’s initially something more that a domain administrator has to learn and worry about,
which doesn’t favor fast adoption.
The only reason whyef1p.comhas DNSSEC enabled is
because Gandi takes care of everything. - Technical dissatisfaction: There is also technical criticism of DNSSEC.
As already mentioned, DNSSEC doesn’t provide confidentiality.
Everyone with access to your network traffic
can see which domain names you look up.
The counterargument is that protocols should do one thing and do it well.
After reading this article,
you’re hopefully convinced that flexibility through modularity is desirable.
DNS over TLS
achieves confidentiality in the local network.
The name server you connect to,
which is typically operated by your Internet service provider or another company,
still learns the queried domain name,
which also allows it to cache the retrieved records.
Another common misconception about DNSSEC is
that TLS with public-key certificates already ensures
that you are connected to the right server.
If an attacker manages to direct you to a wrong IP address,
then the TLS connection will fail.
However, the trust model of DNSSEC is different
from the public-key infrastructure used by TLS.
Additionally, defense in depth
is always a good idea.
But more importantly,
not all communication is protected by TLS,
and not all DNS records are used to establish TLS connections.
For example,TXTrecords are used extensively for
email authentication.
While email providers, such as gmail.com,
yahoo.com, and outlook.com,
all have such records,
none of them protect the integrity of these records with DNSSEC.
DNSSEC is also criticized for its centralized trust model.
With the root key residing in the United States of America,
one country remains in control of critical Internet infrastructure.
While this criticism is more justified,
IANA does a lot for transparency.
Moreover, other countries can simply deliver their software
with the key-signing keys of their
country’s top-level domain.
Nothing prevents anyone from introducing additional trust anchors.
In my opinion, the most serious problem is that DNSSEC increases the size of DNS responses significantly.
This allows an attacker with limited bandwidth to send a multiple of their bandwidth to the victim’s computer
simply by changing the source address of ignored DNS requests to the victim’s IP address.
This is known as a DNS amplification attack.
Are you still reading this?
I’m happy to see that no amount of technical detail can deter you.
Keep up your curiosity! 🤓
Internet history
There are many nice articles about the
history of the Internet
and there’s no point in replicating their content here.
Instead, I would like to give you a timeline
of important milestones in the history of
telecommunication
and computing:
| Year | Description |
|---|---|
| 1816 | First working electrical telegraph built by the English inventor Francis Ronalds. |
| 1865 | Adoption of the Morse code, which originated in 1837, as an international standard. |
| 1876 | Alexander Graham Bell receives the first patent for a telephone in the United States. |
| 1941 | Invention of the Z3, the first programmable computer, by Konrad Zuse in Germany. |
| 1945 | Invention of the ENIAC, the first computer with conditional branching, in the US. |
| 1954 | Invention of time-sharing (share expensive computing resources among several users). |
| Increased interest in remote access for users because computers were huge and rare. | |
| 1965 | Invention of packet switching at the National Physical Laboratory (NPL) in the UK. |
| 1969 | The US Department of Defense initiates and funds the development of the ARPANET. |
| Similar networks are built in London (NPL), Michigan (MERIT), and France (CYCLADES). | |
| 1972 | Jon Postel establishes himself as the czar of socket numbers, which leads to the IANA. |
| 1973 | Bob Kahn and Vint Cerf publish research on internetworking leading to IP and TCP. |
| 1978 | Public discovery of the first public-key cryptosystem for encryption and signing, which was already discovered in 1973 at the British intelligence agency GCHQ. |
| 1981 | Initial release of the text-based MS-DOS by Microsoft, licensed by IBM for its PC. |
| 1982 | The US Department of Defense makes IP the only approved protocol on ARPANET. |
| 1982 | First definition of the Simple Mail Transfer Protocol (SMTP) for email in RFC 821. |
| 1983 | Creation of the Domain Name System (DNS) as specified in RFC 882 and RFC 883. |
| 1984 | Version 1 of the Post Office Protocol (POP) to fetch emails from a mailbox (RFC 918). |
| 1985 | First commercial registration of a domain name in the .com top-level domain. |
| 1986 | Design of the Internet Message Access Protocol (IMAP), documented in RFC 1064. |
| 1990 | Invention of the World Wide Web by Tim Berners-Lee at CERN in Switzerland, which includes the HyperText Transfer Protocol (HTTP), the HyperText Markup Language (HTML), the Uniform Resource Locator (URL), a web server, and a browser. |
| 1993 | Specification of the Dynamic Host Configuration Protocol (DHCP) in RFC 1541. |
| 1995 | Release of the Secure Sockets Layer (SSL) by Netscape, renamed to TLS in 1999. |
| 1995 | Standardization of IPv6 by the IETF in RFC 1883, obsoleted by RFC 2460 in 1998. |
| 1998 | Google is founded by Larry Page and Sergey Brin at Stanford University in California. |
| 2005 | Specification of DNSSEC in RFC 4033, 4034 & 4035 after earlier attempts in 1995. |
| 2007 | Apple launches the iPhone with the iOS operating system one year before Android. |
| 2010 | Deployment of DNSSEC in the root zone, eliminating intermediary trust anchors. |
| 2018 | The UN estimates that more than half of the global population uses the Internet. |
I would like to thank Stephanie Stroka for proofreading this article
and for supporting me in this project! ❤️
- История сети Интернет.
- Интернет в России.
- Технологические основы сети Интернет.
- Информационные основы сети Интернет.
- Доступ в интернет. Провайдеры.
- Безопасность в Интернете.
- Общение в Интернете.
- Литература в Интернете. Электронные библиотеки.
- Музыка в сети.
- Электронная коммерция и торговля.
- Интернет как средство связи.
- Интернет и другие сети. Сетевые сообщества.
- Интернет в науке и медицине.
- Перспективы развития Интернета.
ИНТЕРНЕТ (Internet – inter + net – объединение сетей) – всемирная компьютерная сеть, объединяющая миллионы компьютеров в единую информационную систему. Интернет предоставляет широчайшие возможности свободного получения и распространения научной, деловой, познавательной и развлекательной информации. Глобальная сеть связывает практически все крупные научные и правительственные организации мира, университеты и бизнес-центры, информационные агентства и издательства, образуя гигантское хранилище данных по всем отраслям человеческого знания. Виртуальные библиотеки, архивы, ленты новостей содержат огромное количество текстовой, графической, аудио и видео информации.
Интернет стал неотделимой частью современной цивилизации. Стремительно врываясь в сферы образования, торговли, связи, услуг, он порождает новые формы общения и обучения, коммерции и развлечений. «Сетевое поколение» – это настоящий социо-культурный феномен наших дней. Для его представителей Интернет давно стал привычным и удобным спутником жизни. Человечество вступает в новый – информационный – этап своего развития, и сетевые технологии играют в нем огромную роль. См. также КОМПЬЮТЕР.
История сети Интернет.
Интернет возник как воплощение двух идей – глобального хранилища информации и универсального средства ее распространения.
Человечество с давних пор стремилось упорядочить производимую им письменную информацию. Прообразы каталогов были еще в Александрийской библиотеке, а ранние религиозные тексты содержали развитый аппарат «параллельных мест», то есть указаний на места в рукописи, где описываются те же события.
С появлением научной литературы и лавинообразным накоплением самых различных сведений в письменной форме потребность в их систематизации еще более возросла. В 20 в. архивное дело, каталогизация и реферирование стали профессиями.
Американские ученые Ванневар Буш (Vannevar Bush) и Теодор Нельсон (Theodor Holm Nelson) искали способы автоматизации мыслительной деятельности человека. Они хотели избавить его от утомительного труда по поиску и обработке нужной информации. Буш даже придумал несколько гипотетических устройств, организующих ассоциативные связи в картотеке данных, а Нельсон разработал теорию «документарной вселенной», в которой все знания, накопленные человечеством, представляли бы единую информационную систему, пронизанную миллиардами перекрестных ссылок. Работы этих ученых носили скорее философский, чем практический характер, но их идеи легли в основу того, что мы сейчас называем гипертекстом.
Ванневар Буш немало сделал для того, чтобы наукой заинтересовались военные. Щедрое финансирование исследований в области кибернетики несомненно способствовало ее быстрому развитию. Немалую роль в формировании теоретической базы будущей глобальной информационной системы принадлежит Норберту Винеру. Его блестящие семинары в Массачусетском технологическом институте (MIT) привлекли в компьютерную отрасль немало талантливой молодежи.
В конце 1950-х министерство обороны США учредило Агентство перспективных исследовательских проектов ARPA (Advanced Research Projects Agency), которое занималось компьютерным моделированием военных и политических событий. Талантливый организатор и ученый-компьютерщик Джозеф Ликлайдер (J.C.R.Licklider) убедил руководство ARPA сосредоточить усилия на развитии компьютерной связи и сетей. В своей работе Симбиоз человека и компьютера он развил идеи распределенных вычислений, виртуальных программных средств, электронных библиотек, разработал структуру будущей глобальной сети.
В 1960-х компьютерные сети стали бурно развиваться. Множество фирм-разработчиков создавали программное обеспечение и оборудование для локальных сетей университетов, исследовательских центров, военных учреждений. Однако при передаче информации между сетями разных типов возникала проблема совместимости, когда компьютеры просто «не понимали» друг друга. Крупным недостатком больших сетей была их низкая устойчивость. Выход из строя одного участка мог полностью парализовать работу всей сети.
Перед агентством ARPA была поставлена задача решить эти проблемы, и наступило время воплотить в жизнь теоретические наработки. Поль Барен, Ларри Робертс и Винтсент Серф (Paul Baran , Larry Roberts, Vint Cerf) разработали и применили методы, ставшие основой дальнейшего развития сетевых технологий: пакетная коммутация, динамическая маршрутизация сообщений в распределенной сети, использование универсального сетевого протокола (то есть набора правил, по которым организуется и передается информация).
В 1969 была создана сеть ARPANET, которая и стала основой будущего Интернета. 1969 традиционно считается годом его возникновения.
В 1976 Серф разработал универсальный протокол передачи данных TCP/IP (Transmission control protocol/ Internet protocol). Название IP означало просто межсетевой протокол. Он стал стандартом для межсетевых коммуникаций, а сети, использующие его, так и назывались – интернет-сети.
ARPANET стала основой для объединения локальных и территориальных сетей в единую глобальную систему, которая постепенно разрослась до масштабов всей Земли. Это гигантское объединение сетей и называют Интернетом с большой буквы или Сетью.
В 1980-х Интернетом пользовались в основном специалисты. По сети передавалась электронная почта и организовывались телеконференции между научными центрами и университетами.
В 1990 программист Европейского центра ядерных исследований (CERN) в Женеве Тим Бернерс-Ли (Tim Berners-Lee) создал систему, реализующую идею единого гипертекстового пространства. Для описания гипертекстовых страниц служил специальный язык HTML (HyperText Markup Language), а для их пересылке по сети – протокол передачи HTTP (HyperText Transfer Protocol). Новый способ указания адресов с помощью URL (Uniform Resource Locator – универсальный указатель ресурсов) позволял легче запоминать их и лучше ориентироваться в информационном пространстве Интернета. Была написана также специальная программа отображения гипертекстовых страниц – первый браузер (browser – обозреватель).
Бернерс-Ли назвал свой проект WWW – World Wide Web, то есть «Всемирная паутина».
Но по-настоящему популярным Интернет стал после выхода в свет графического браузера «Мозаика» (Mosaic), разработанного в 1992 сотрудником Иллинойского университета Марком Андресеном (Marc Andreesen). К этому времени возросла пропускная способность сетей, и появилась возможность быстро передавать цветные изображения, фотографии, рисунки. В Интернет хлынула не только научная, но и развлекательная информация.
Количество пользователей Сети и объем доступных данных росли небывалыми темпами. К этому времени управление Интернетом было передано в частный сектор и приняло фактически рекомендательно-регистрационный характер.
История Интернета бурно развивается, и можно только гадать, какие сюрпризы нам принесут современные цифровые технологии. Но можно с уверенностью сказать, что мы вступаем в новую фазу развития человечества – информационное общество, и Интернет станет в нем неотъемлемой частью.

Интернет в России.
Российскую (а более широко и русскоязычную) часть Интернета традиционно называют Рунетом (.RU + net, сеть). История его стремительна и богата событиями.
Сами зачинатели интернет-движения в России не могут определиться с датой его возникновения. Отдельные компьютеры, имеющие связь с европейской частью Интернета, появились в Москве еще в начале 1980-х. Они были доступны только узкому кругу специалистов, которые участвовали в телеконференциях или получали доступную информацию с зарубежных серверов. В те годы политическая цензура препятствовала свободному информационному обмену с заграницей.
В начале 1980-х Интернет существовал только в форме телеконференций – Usenet, которые проходили в форме обмена электронной почтой в режиме реального времени или чаще через почтовые ящики. В московском научно-исследовательском институте прикладных автоматизированных систем, ВНИИПАС, было оборудование и программное обеспечение для проведения компьютерных конференций, и уже в 1983 в них участвовали специалисты из Советского Союза. Надо сказать, что тогда масштабы сети были неизмеримо меньшими, вся таблица маршрутизации (то есть описание сети) умещалась в одном файле, а во всей Европе было всего несколько сотен пользователей Интернета.
В СССР шло развитие компьютерных сетей. Программисты Курчатовского института разработали программное обеспечение ДЕМОС на основе операционной системы UNIX и создали сеть «Релком», связывавшую крупные научные центры страны.
В самом начале 1990-х были созданы советско-американские организации «Совам Телепорт» и «Гласнет», которые способствовали развитию Интернета в России. В это время проводились уже постоянные сеансы интернет связи внутри страны и с зарубежными серверами, сеть «Релком» была официально зарегистрирована в Интернете. Днем рождения рунета официально считается 19 сентября 1990, когда был зарегестрирован национальный домен.Su (сокращенно от Soviet Union – Советского Союза). В 1994 был официально зарегистрирован домен Ru, пришедший на смену домену Su, который, впрочем, существует до сих пор.
С этого времени развитие Рунета шло все нарастающими темпами. Создавались многочисленные информационные ресурсы в зоне RU: виртуальные библиотеки и галереи, новостные, деловые и развлекательные сайты, представительства газет.
В 1995 «Россия-он-лайн» становится первым массовым коммерческим провайдером. Число пользователей Интернета росло в геометрической прогрессии. Среди известных интернет-проектов следует отметить библиотеку Мошкова, «Московский Либертариум», «Анекдоты из России» Дмитрия Вернера, сайт одного из ведущих российских информационных агентств «РосБизнесКонсалтинг», первые новостные ленты «Нетоксоп» и «Паравозов ньюс».
В 1996 в Санкт-Петербурге открылось первое в России интернет-кафе «Тетрис», начал действовать чат «Кроватка», к трансляции своих программ в интернете приступила радиостанция «Радио 101», приобрела большую популярность российская поисковая система Rambler. В этом же году впервые выборы президента России оперативно освещались через Интернет Национальной службой новостей. Начали проводиться регулярные общенациональные социологические исследования аудитории интернета. В Рунете в то время было уже 4 тысячи сайтов и 1,5 млн. пользователей.




Технологические основы сети Интернет.
Одним из важных свойств компьютера является его способность принимать и передавать информацию по линиям связи. Несколько соединенных между собой компьютеров могут образовывать сеть, что позволяет им обмениваться данными, эффективнее использовать ресурсы, дает возможность дистанционного управления из одного центра.
Сети в пределах одного здания называются локальными (LAN – Local Area Net – локальная сеть) и работают, как правило, под управлением специально выделенного компьютера – сервера. Глобальные или территориальные сети (WAN – Wide Area Net – территориальная сеть) объединяют компьютеры, находящиеся на значительном расстоянии друг от друга. В них применяется специализированное сетевое оборудование (маршрутизаторы, роутеры, мосты), используются как собственные линии связи, так и средства других телекоммуникационных систем – городской телефонной сети, кабельного телевидения.
Современные сетевые технологии очень разнообразны. Существует большое число различных типов локальных и глобальных сетей. Они могут строиться на разных физических и логических принципах, использовать бесчисленное множество программных продуктов, протоколов, средств маршрутизации, форматов данных, по-своему решать вопросы диагностики, устойчивости, безопасности. До появления Интернета проблема совместимости сетей разных типов стояла очень остро.
С технической точки зрения, Интернет – это гигантская совокупность сетей меньшего масштаба, объединенных общими правилами коммуникации. Эти правила, называемые интернет-протоколами (TCP/IP), позволяют общаться компьютерам, входящим в сети любых типов, использующих любые операционные системы и программы. С помощью протоколов решается также проблема устойчивости и надежности Сети, когда выход из строя или отключение ее части не влияет на работоспособность системы в целом.
В Интернете нет центра управления, нет жестких ограничений, он не принадлежит никакой организации или государству. Любое устройство, работающее по интернет-протоколам, может подключаться к Сети и использовать все ее ресурсы. Разумеется, использование этих ресурсов находится под юрисдикцией той страны, на территории которой действует пользователь.
Информационные основы сети Интернет.
Интернет соединяет в единую систему миллионы компьютеров. Одни компьютеры выполняют служебные функции, обеспечивая бесперебойное функционирование сети, другие хранят на своих жестких дисках тысячи гигабайт информации, третьи подключаются к сети лишь на время. В любом случае компьютер получает уникальный 32-разрядный адрес, состоящий из 4-х чисел от 0 до 255, разделенных точками (например, 123.34.0.1 или 200.190.34.120) Он называется IP-адресом, то есть адресом интернет-протокола, по которому определяется положение компьютера в сложной иерархии сетей, составляющих Интернет. IP-адрес может быть статическим (постоянным) или динамическим, выделяемым компьютеру только на время его подключения к Сети. Часто за IP-адресом скрывается локальная сеть, соединенная с Интернетом через специальный прокси-сервер.
Распределением IP-адресов занимаются специализированные организации. При регистрации сети в Интернете, ей выделяется определенный диапазон адресов, которые могут использоваться в этой сети. Например, провайдер коммутируемого доступа (то есть компания, которая предоставляет доступ в Интернет по телефону), имеет в своем распоряжении 200 IP-адресов. При подключении дозвонившегося и указавшего верный логин и пароль абонента, ему присваивают свободный IP-адрес, который после отключения может быть передан другому абоненту.
Всего может быть образовано 4,5 млрд. различных адресов, однако уже сейчас обнаруживается их нехватка. А ведь в недалеком «цифровом» будущем планируется подключать к Интернету не только компьютеры, но и бытовые устройства. Поэтому интернет-протоколы следующего поколения будут использовать 128-разрядную адресацию. Адреса используются сетевыми устройствами-маршрутизаторами, для передачи сообщений в нужном направлении. Но обычный пользователь ищет не какой-то конкретный компьютер, а определенную информацию. Эта информация хранится на жестких дисках компьютеров, которые постоянно подключены к Сети.
Данные различных типов записываются в виде файлов, имеющих имя и трехсимвольное расширение. Оно определяет, как файл будет обрабатываться компьютером. Файл dog.jpg – фотография, которую можно посмотреть на экране монитора или распечатать на принтере. Файл luna.mp3 – музыкальный, его можно прослушать через наушники или колонки. Referat.doc – документ программы WORD, а mike.mp3 – страница гипертекста.
Именно страницы гипертекста отображаются на экране монитора при путешествии по Интернету. Они содержат фотографии, тексты, картинки, а главное – ссылки на другие страницы. Программа, обрабатывающая файлы гипертекста, называется браузером (browser – обозреватель). Браузер определяет форму отображения страницы, расставляет в нужные места картинки, обеспечивает правильный переход по ссылкам и выполняет множество других полезных функций. Наиболее известные браузеры это самый распространенный Internet Explorer фирмы Miсrosoft, популярный в 1990-ые Netscape Communicator, Opera.
Совокупность файлов образует сайт. Сайт принадлежит какому-либо лицу или организации и имеет уникальный адрес. Он ведет на главную страницу сайта, с которой открывается доступ к другим страницам. Небольшие сайты так и называются – домашние странички. Они обычно содержат фотографии, небольшие тексты, несложные элементы оформления.
Сайты крупных организаций называют интернет-представительствами или интернет-серверами. На них размещается подробная информация о компании, описание услуг, другие данные. Сайты интернет-магазинов содержат описания товаров, прайс-листы, формы для заказа. Виртуальные библиотеки хранят тексты книг, сетевые информационные агентства – новостные ленты и архивы. Дизайн, структура и содержание сайта разрабатываются в соответствии с его профилем и назначением.
Для удобства составления и запоминания адресов сайтов совместно с IP-адресацией действует Система Доменных Имен (DNS – Domain Name System, domain – зона, владение), которая отражает логическую структуру Интернета. Все его информационное пространство разделено на зоны первого уровня по принадлежности к стране (.RU –Россия,.UC – Украина) или по профилю ресурса (.com – коммерческие организации,.edu – образовательные учреждения). Когда-то зон первого уровня было только 6, а сейчас их около 300). Следует сказать, что доменный адрес не связан напрямую с физическим расположением ресурса. Сайт a.ru может размещаться на компьютере, находящемся, например, во Франции. Домены первого уровня делятся на бесчисленное количество доменов второго, многие домены второго уровня, например, narod.ru, содержат большое число доменов третьего и т.д.
Регистрацией доменов первого уровня занимается международная организация ICAAN (Internet Corporation for Assigned Names), второго – соответствующие национальные организации. В России это RU-Center (Региональный сетевой информационный центр, РСИЦ).
Адрес любого информационного ресурса записывается в виде нескольких слов, разделенных точками, например, krugosvet.ru или school_385.narod.ru. Эти слова, которым обычно придают смысловую окраску, и определяют адрес, как последовательность доменов разного уровня. Самый правый – первый уровень, затем второй и т.д. Обычно адрес состоит из двух-трех доменных имен.
Зонами первого уровня распоряжаются специальные организации. Они ведают регистрацией новых имен второго уровня, а, главное, тем, чтобы по доменному адресу можно было отыскать требуемый сайт. Для этого в Интернете существуют специальные серверы DNS, которые сопоставляют доменное имя сайта и IP-адрес того компьютера, на котором этот сайт размещается. Базы данных DNS постоянно обновляются и корректируются.
Для правильной передачи информации по сети слева от доменного имени указывается название протокола, в соответствии с которым организована эта информация:
http:// – протокол передачи гипертектовых страниц,
ftp:// – протокол пересылки файлов,
wap:// – протокол для передачи информации на мобильные телефоны (WAP – Wireless Application Protocol – протокол беспроводной связи).
Доменное имя вместе с названием протокола образует полный адрес ресурса URL (Unified Resourse Locator – универсальный указатель ресурсов). Справа от URL можно указать путь к конкретному файлу в структуре сайта. Обычно для адресов сайтов название протокола опускается, а перед доменным именем ставится WWW, например, www.krugosvet.ru.
Объем информации, доступной через Интернет, огромен и растет с каждым днем. Отыскать необходимые сведения подчас необычайно трудно. Для помощи в решении этой задачи существуют интернет-каталоги и поисковые системы (поисковые машины, поисковики).
Каталоги ресурсов или классификаторы содержат адреса и иногда аннотации к сайтам, сгруппированым в категории по тематике. Каждая категория может содержать несколько подкатегорий. Сайты в категориях бывают отсортированы по степени популярности, определяемой с помощью счетчиков посещений. Переходя по названиям рубрик, можно добраться до интересующей информации. Например: Развлечения – Активный отдых – Туризм – Снаряжение – Магазины и так далее.
Поисковые системы ищут информацию по ключевым словам и часто дают просто необозримое количество ссылок в ответ на запрос. Методы работы поисковых систем постоянно совершенствуются. Повышению эффективности поиска способствует ранжирование результатов по соответствию запросу. Показатель этого соответствия, так называемая релевантность рассчитывается по особым алгоритмам. В поисковых системах применяется особый язык запросов.
Умение хорошо ориентироваться в океане информации Интернета – настоящее искусство. На сайтах поисковых систем даже проводятся конкурсы по эффективному поиску в Сети.
Доступ в интернет. Провайдеры.
Для использования всего богатства возможностей Интернета необходимо воспользоваться подключенным к Сети компьютером (или другим устройством, например, мобильным телефоном), то есть получить доступ в Интернет.
Существует много видов доступа. С организационной точки зрения их можно разделить на следующие виды:
– публичный доступ, предоставляемый в Интернет-кафе, клубах, библиотеках. Пользователь получает надежную быструю связь без всяких забот о вирусах и настройках, может записать скачанную из сети информацию на компакт-диск. Все услуги предоставляются за плату. В пунктах бесплатного доступа можно заходить только на определенные сайты.
– доступ с рабочего места. Статистика показывает что более половины пользователей Интернета заходят в него со своих офисных компьютеров. Это не считая тех, для кого использование Интернета входит в служебные обязанности. Недаром значок «аськи» (популярного интернет-пейджера ICQ) в шутку прозвали «зеленым цветком на могиле рабочего времени». Руководство компаний всячески препятствует такому времяпровождению, ограничивая или отслеживая использование Интернета на работе.
Индивидуальный доступ. Пользователь сам находит и оплачивает услуги подключения к Сети, настраивает свой компьютер и заботится о его защите от вирусов и прочих неприятностей. Все окупается полной свободой действий, возможностью работы в домашней обстановке в удобное время и относительной дешевизной услуг.
С технической точки зрения доступ в Интернет разделяется на проводной (куда относится подключение по телефону, по выделенной линии, по сети кабельного телевидения) и беспроводной (использующий системы радио и спутниковой связи, сети сотовой телефонии, устройства инфракрасной связи). Большие перспективы у системы сотового доступа в Интернет, когда в крупных городах создается сеть пунктов беспроводного подключения стационарных и мобильных устройств, типа карманного компьютера, мобильного телефона и даже плеера.
В настоящее время самым популярным способом подключения к Интернету остается коммутируемый доступ (dial-up) по обычной телефонной линии. Пользователь подключает компьютер через модем к телефонной розетке, дозванивается по определенному номеру и получает выход в Сеть. Простота и дешевизна коммутируемого доступа окупают его невысокую надежность и низкую скорость передачи данных, хотя на современных цифровых АТС качество связи оказывается вполне удовлетворительным.
Для подключения к Интернету необходимо воспользоваться услугами провайдера.
Провайдер (provide – обеспечивать) – организация, предоставляющая доступ в Интернет и оказывающая другие телекоммуникационные услуги. При выборе провайдера надо обращать внимание на скорость и надежность соединения, стоимость и разнообразие услуг, наличие технической поддержки, удобство оплаты. По гостевому входу можно зайти на сайт провайдера, ознакомиться с условиями работы, оценить легкость дозвона и надежность соединения, которые могут быть различными в разное время суток.
Провайдеры обычно предлагают разнообразные тарифные планы, из которых можно выбрать наиболее удобный и дешевый. Ночное время обычно стоит в два-три раза дешевле дневного. По разному оплачивается работа в будние и выходные дни. При использовании коммутируемого доступа учитывается только время соединения, тогда как при подключении по выделенной линии оплачивается трафик (объем передаваемой и принимаемой информации).
В качестве дополнительных услуг провайдеры могут предоставлять ящик для электронной почты, место для домашней странички, выдавать отчеты по сеансам подключения, производить проверку почты на вирусы.
Наиболее удобным способом оплаты услуг провайдеров стали интернет-карты различного номинала. На карте представлена вся необходимая для подключения информация.
Существует возможность бесплатного доступа на некоторые сайты рекламно-информационного характера. Соединившись по определенному номеру можно получить на экран монитора расписание работы клубов, кинотеатров и тому подобную информацию.
Доступ по выделенной линии, при котором могут использоваться и телефонные линии связи, и свои собственные, предоставляет постоянное высокоскоростное и надежное соединение, но его стоимость выше, чем при коммутируемом доступе.
Широкополосный доступ в Интернет использует системы обычного и спутникового телевидения. При этом скорость соединения достаточна для передачи аудио и видеоинформации высокого качества. Широкополосный доступ обычно используется в асимметричном режиме – для передачи информации от сервера к пользователю. Для обращения к серверу пользователь использует обычный проводной доступ.
Безопасность в Интернете.
Общение с Интернетом приносит не только пользу и удовольствие. Даже опытного пользователя подстерегает немало опасностей, способных отнять у него и нервы и время, а часто и деньги. Компьютерные злоумышленники используют Интернет для похищения информации, извлечения незаконной прибыли, причинения вреда конкурентам. Огромный вред приносит деструктивная, подчас совершенно бессмысленная деятельность хакеров и прочих сетевых хулиганов.
Самая большая напасть Интернета – компьютерные вирусы. Это программы, способные самостоятельно размножаться путем заражения других программ, то есть включения в них своего кода. Вирус может уничтожать или изменять информацию на зараженном компьютере, мешать работе. Так называемые сетевые черви создают и рассылают по сети свои бесчисленные копии, засоряя и перегружая линии связи, что иногда просто парализует работу сети.
Особой разновидностью вирусов являются троянские кони (трояны). Попадая в компьютер, они маскируют себя под безобидные программы. В определенные моменты трояны активизируются и начинают вредоносную работу – перехватывают пароли и коды доступа, пересылают информацию своему хозяину, постоянно выводят на экран рекламные сообщения и тому подобное.
Интернет представляет собой благодатную среду для распространения вирусов. Всего за несколько часов вирусная эпидемия может охватить весь земной шар, заразив миллионы компьютеров и причинив огромный ущерб.
Большую опасность прежде всего для серверов Интернета представляют хакерские атаки. Хакеры (hacker – взломщик) стремятся взломать защиту компьютера, используя слабые места операционной системы, или организуя огромное число запросов, которые сервер не в состоянии обработать.
Целью хакера является получение контроля над компьютером, похищение секретной информации, прекращение работы какого-либо сайта или порча информации на нем. Часто компьютеры взламывают из спортивного интереса или для демонстрации своего мастерства. Иногда остепенившиеся хакеры получают хорошую работу в отделах компьютерной безопасности.
Методы защиты от вирусов постоянно совершенствуются, хотя пессимисты предрекают гибель Интернета именно от расплодившихся в нем «сетевых червей» нового поколения, вышедших из под контроля создателей и захвативших власть в Сети.
Немало неприятностей пользователю приносит спам – навязчивая реклама, забивающая почтовые ящики. Спам (SPAM – фирменное название усиленно рекламировавшихся мясных консервов из некогда популярного кинофильма) представляет собой массовую рассылку по электронной почте рекламных объявлений разного характера. Списки почтовых адресов добываются всеми возможными способами, продаются, покупаются, похищаются. Существуют фирмы, целиком специализирующиеся на спамерской деятельности.
Каждый провайдер услуг электронной почты организует более-менее эффективную антиспамерскую защиту с помощью почтовых фильтров. По ряду признаков рекламные письма опознаются и помещаются в особую папку.
Неискушенный пользователь может попасться на крючок виртуальных мошенников, которые организуют в Интернете многочисленные пирамиды, лотереи, липовые магазины и распродажи.
Интернет предоставляет большую свободу распространения информации, но не все пользуются этой свободой должным образом. К числу проблем современного Интернета следует отнести нарушения авторских прав и распространение порнографии. См. также КОМПЬЮТЕРНЫЕ ПРЕСТУПЛЕНИЯ.
Общение в Интернете.
Интернет является не только источником разнообразной информации, но и популярным средством общения.
Наиболее востребованным сетевым сервисом до сих пор остается электронная почта. Заведя один или несколько почтовых ящиков, пользователь может получать и отправлять электронные письма, фотографии, небольшие файлы. Хорошая почтовая программа (почтовый клиент) позволяет сортировать письма по папкам, вести адресную книгу, составлять и читать письма в разных кодировках. Пользователь может работать с почтовым ящиком не только со своего компьютера, но и из любого места доступа в Интернет.
Вести обстоятельный обмен мнениями позволяют форумы – специальные сайты, на которых организуются дискуссии по различным темам. Список тем обычно приводится на главной странице форума. Пользователь может читать сообщения участников дискуссии, отвечать на них, задавать вопросы, предлагать новые темы для обсуждения. Все сообщения сохраняются в виде разветвленного дерева, по которому можно проследить ход обсуждения.
На многих форумах устанавливаются правила поведения, за соблюдением которых следит модератор. Это администратор форума или его авторитетный участник, который может направлять ход дискуссии, удалять или изменять некорректные с его точки зрения сообщения (например – «оффтопик» – не в тему). На форумах иногда вспыхивают «флеймы» – словесная перепалка слишком горячих участников.
Форумы предоставляют прекрасную возможность общения с единомышленниками, где человек может получить помощь более опытных товарищей, поделиться своими достижениями, узнать новости из первых рук.
Обмен мнениями ведется также в гостевых книгах, где посетители оставляют свои сообщения. Гостевая книга организуется и управляется владельцем сайта.
Общение «он-лайн» – то есть в реальном времени – происходит в чатах. Чат (chat – болтовня) это место для быстрого обмена короткими сообщениями, в котором одновременно участвует несколько человек. Для участия в чате необходима регистрация под определенным прозвищем – «ником». После этого на экран компьютера начинают поступать сообщения участников, выделяемые различным цветом для каждого из них. Написанное сообщение мгновенно отображается на экране, но при оживленном разговоре так же быстро исчезает, сменяясь новыми строками. Участие в чате требует определенной сноровки и внимания. При желании два участника уходят в «приват» – их сообщения отображаются в отдельном окне и не доступны остальным.
Преимущества офф-лайнового и он-лайнового способа общения сочетают Интернет-пейджеры (Instant Messengers), из которых наибольшую популярность приобрел ICQ, в просторечии «аська». Название ICQ созвучно английской фразе «I seek you» – «я ищу тебя». Для использования пейджера необходимо зарегистрироваться и получить уникальный номер. Сервис ICQ предоставляет возможности обмена сообщениями как в реальном времени, так и в режиме электронной почты. Пользователь может искать единомышленников, составлять контакт-листы своих знакомых, которые будут автоматически оповещаться при его подключении к сети, вести архивы переписки.
Популярным средством общения являются так называемые «блоги» (от англ. blog, web log – сетевой журнал). Это сетевые дневники, которые ведутся на специальных сайтах, предоставляющих возможности быстрого добавления записей, комментирования, составление списка друзей и т.п. Блоги используются не только для самовыражения, но и в деловых целях. Многие компании ведут корпоративные блоги, которые представляют собой сетевые доски объявлений.
Литература в Интернете. Электронные библиотеки.
Электронные библиотеки содержат огромное число произведений классической литературы, фантастики, современной прозы и поэзии. Многие книги, доступные в сети, давно стали библиографической редкостью, а некоторые и вообще не издавались В Интернете можно найти библиотеки, специализирующиеся на религиозной, политической, технической литературе, а также сетевые версии литературных журналов.
Другое направление литературного Интернета представляют ресурсы, посвященные писательскому творчеству. Начинающие прозаики и поэты, графоманы и маститые авторы выкладывают в Сеть свои творения. Существует даже термин «сетература» для литературных произведений, не имеющих бумажного варианта.
Множество сайтов посвящено отдельным жанрам и направлениям литературного творчества.
Музыка в сети.
Распространение музыки в Интернете началось с появления формата МР3, сжимающего звуковые файлы до размеров, пригодных для передачи в сети при сохранении качества записи. Распространение МР3-файлов приобрело огромную популярность, но все время сопровождалось скандалами и громкими судебными процессами.
Проблема заключается в нарушении авторских прав, когда музыкальные композиции размещаются в Сети без ведома их создателей и не приносят им желаемого дохода. С другой стороны, появление в Интернете отдельных песен с нового диска исполнителя служит превосходной рекламой и существенно повышает уровень продаж лицензионных дисков.
К музыкальной стороне Интернета можно отнести и сетевую трансляцию обычных радиостанций. В последнее время появляются станции интернет-вещания, вообще не выходящие в эфир.
Электронная коммерция и торговля.
По результатам исследований, большинство ресурсов Интернета так или иначе связаны с коммерческой деятельностью в ее широком понимании. Интернет используется для рекламы, продвижения и продажи товаров и услуг, для маркетинговых исследований, электронных платежей и управления банковскими счетами.
На виртуальной витрине электронного магазина можно детально ознакомиться с товаром, прочитать отзывы покупателей, сравнить различные модели, оформить заказ и оплатить покупку через кредитную карту. Товар обычно доставляется курьером. Многие обычные магазины имеют в Интернете свои электронные филиалы. Преимущества электронных магазинов прежде всего в их доступности для клиента в любое время из любого пункта доступа в интернет и в том, что нет необходимости снимать торговые помещения и содержать многочисленный персонал.
Все большую популярность приобретают интернет-аукционы,на которых выставляется практически все – от бытовой техники до предметов искусства и коллекционирования.
Проблему расчетов при сетевых сделках решают многочисленные системы электронных платежей, где используются обычные кредитные карты, и сугубо интернетовские платежные системы на основе «виртуальных денег».
Многие банки предоставляют своим клиентам возможность управления счетом через Интернет. Сюда относятся вопросы перевода денег, безналичной оплаты, кредитования, получения оперативной финансовой информации.
Электронная коммерция с использованием Интернета только вступает в фазу своего законодательного оформления. Новейшие системы криптографии, электронной подписи, компьютерной защиты призваны значительно повысить надежность и безопасность виртуальных сделок.
Интернет как средство связи.
Интернет предоставляет большой выбор средств сетевого общения, в том числе в аудио и видео режиме с использованием микрофона или видеокамеры. Однако ресурсы Интернета используют не только отдельные пользователи, но и телефонные компании, предоставляющие услуги IP-телефонии (интернет-телефонии).
При этом разговор ведется по обычным стационарным или мобильным телефонам, но передается в оцифрованном виде по магистральным каналам Интернета с использованием IP-протокола. В отличие от обычной телефонии непрерывного соединения не устанавливается. Применение современных оптоволоконных каналов и новейших телекоммуникационных технологий, таких как АТМ (асинхронный режим передачи информации) позволяет организовать связь высокого качества и по видеотелефонам.
Стоимость разговора с использованием IP-телефонии в несколько раз ниже, чем по обычному телефону. Особенно эта разница проявляется при междугородной и международной связи.
Среди владельцев мобильных телефонов очень популярен обмен короткими текстовыми и мультимедийными сообщениями (SMS и MMS). Любой оператор мобильной связи предоставляет возможность отправки таких сообщений и через Интернет. Для этого достаточно заполнить простую форму на сайте компании.
Тенденция интеграции Интернета с обычными средствами связи нарастает и приводит к появлению гибридных устройств, сочетающих в себе компьютер, мобильный телефон и телевизор. Развитие систем глобального беспроводного доступа в Интернет даст возможность качественной и полноценной связи из любой точки земного шара.
См. также ЭЛЕКТРОННЫЕ СРЕДСТВА СВЯЗИ.
Интернет и другие сети. Сетевые сообщества.
Кроме Интернета существуют и другие глобальные компьютерные сети. Среди них есть закрытые (например, военные или межбанковские), существующие на коммерческой основе или на энтузиазме пользователей, использующие интернет-протоколы или построенные на иных принципах со своей системой адресации и программным обеспечением.
К числу последних относятся Fidonet и сети телеконференций BBS (bulletin Board System). Fidonet, или как ее называют – «сеть друзей», держится на энтузиазме своих участников и требует от них определенной организованности и дисциплины. Обмен сообщениями ведется во время сеансовых соединений компьютеров друг с другом по телефонной линии. Передаваясь от узла к узлу с помощью сетевой почты, информация распространяется по всей сети. «Фидошники» используют особую терминологию и свято чтут свои традиции.
Развитие Интернета не приводит к отмиранию альтернативных сетей. Они мирно сосуществуют и даже соединяются в особых узлах – гейтах (gate – ворота).
В самом Интернете также существуют многочисленные более-менее устойчивые виртуальные сообщества людей, объединенных общими интересами. Это литературные клубы, кружки, группирующиеся вокруг какого-либо форума и, наконец, почитатели сетевых ролевых игр. Некоторые из них настолько погружаются в виртуальный мир, что психологи всерьез говорят о проблеме зависимости от интернета (net-addiction). С другой стороны Интернет значительно расширяет возможности человека найти единомышленников, а сетевые знакомства нередко переходят в обычные.
Интернет в науке и медицине.
Как и в начале своего существования, Интернет в наши дни широко используется учеными разных стран для обмена научной информацией, организации виртуальных симпозиумов и конференций, в образовательных целях. Однако появилось несколько новых, нетрадиционных направлений применения Интернета, одно из которых – распределенные вычисления.
Есть ряд научных задач, связанных с обработкой огромного объема непрерывно поступающей информации. Например, поиск элементарных частиц в ядерной физике или полуфантастический проект поиска внеземных цивилизаций по сигналам из космоса. В гигантском массиве данных, поступающих от измерительных приборов экспериментальных установок, требуется отыскать крупинки информации, представляющей интерес.
Другие направления научных исследований требуют статистической обработки и поиска закономерностей результатов миллионов наблюдений из тысяч лабораторий. Это задачи моделирования климата Земли, предсказания землетрясений, генетические исследования.
С таким объемом вычислений не в состоянии справится ни один суперкомпьютер. Однако Интернет позволяет объединить сотни тысяч компьютеров добровольных помощников ученых в единую вычислительную систему. Каждый желающий участвовать в какой-либо программе регистрируется на центральном сервере, получает свою порцию данных для обработки и отправляет обратно результаты расчетов. Таким образом даже далекий от науки человек может совершить крупное открытие.
Еще одно применение Интернета в науке – дистанционное управление. Современные исследования часто требуют дорогостоящего, а подчас уникального экспериментального оборудования. К примеру – космический телескоп Хаббл или Европейский суперколлайдер (ускоритель элементарных частиц). Ученый, желающий провести эксперимент или серию наблюдений, через Интернет получает в свое распоряжение виртуальную модель установки, которой управляет в соответствии со своими целями. Команды управления поступают на центральный компьютер, который объединяет их, оптимизирует, распределяет по времени и проводит реальные эксперименты. Результаты по Интернету рассылаются исследователям.
Идея дистанционного управления применима не только в науке. Ведущие мировые компании работают над использованием Интернета для того, чтобы в недалеком будущем человек смог командовать на расстоянии даже домашними бытовыми устройствами.
Разнообразно применение Интернета в медицине. В прессе нередки сообщения о сложной операции, проведенной при участии виртуального консилиума врачей. Проводились даже эксперименты по применению дистанционно управляемых хирургических роботов.
Большие надежды возлагаются на создание крупных диагностических центров и лабораторий. Врач, осматривая больного, проводит серию наблюдений с помощью специального оборудования, по Интернету отправляет данные в медицинский центр, откуда получает результаты анализов и консультации специалистов.
Многое из перечисленного находится в стадии эксперимента, но Интернет развивается настолько быстро, что даже самые невероятные проекты становятся реальностью на наших глазах.
Перспективы развития Интернета.
Предугадать развитие такого сложного и масштабного явления, как Интернет, очень трудно. Что-то уже превзошло самые смелые прогнозы футурологов, а что-то так и осталось на страницах фантастических книг. Одно можно сказать с уверенностью: сетевые технологии будут играть огромную роль в жизни информационного общества.
В настоящее время Интернет развивается экспоненциально: каждые полтора-два года его основные количественные показатели удваиваются. Это относится к числу пользователей, числу подключенных компьютеров, объему информации и трафика, количеству информационных ресурсов.
Интернет бурно развивается и качественно. Границы его применения в жизни человечества постоянно расширяются, появляются совершенно новые виды сетевого сервиса и использование телекоммуникационных технологий даже в бытовой технике.
Интернет меняет даже мировоззрение и психологию людей. Молодые люди, выросшие в эпоху передовых технологий, с детства привыкшие к использованию компьютеров в образовании, развлечениях, на работе, живут в ином восприятии информационного пространства. Для них общение со сверстником из другой части света или мгновенное получение сведений по любому вопросу дело совершенно обыденное. Вместе с развитием Интернета возрастают и информационные потребности «сетевого поколения».
Жизнь современного общества становится все более компьютеризированной. Растут требования к оперативности и надежности информационных услуг, появляются новые их виды. Уже сейчас ученые разрабатывают принципиально новые формы глобальных информационных сетей. В недалеком будущем многие процессы сетевого проектирования, администрирования и обслуживания будут полностью автоматизированы.
Вполне возможно, что такая сложная, самоорганизующаяся и самоуправляемая система, как Интернет и станет колыбелью искусственного интеллекта.
См. также ИНТЕЛЛЕКТ ИСКУССТВЕННЫЙ; КОМПЬЮТЕРНЫЕ ПРЕСТУПЛЕНИЯ.
Сергей Гришин