
В статье приведены примеры кода Excel-VBA, задающие пользовательские функции для генерирования случайных величин с нужным распределением. Также разобраны встроенные средства для работы с распределениями.
Нормальное распределение
В Excel достаточно удобно работать с нормальным распределением с помощью формул НОРМ.РАСП (NORM.DIST) и НОРМ.ОБР (NORM.INV). Первая функция позволяет считать доверительные интервалы, а вторая — генерировать нормальные распределения с произвольным мат. ожиданием и стандартным отклонением.
Скачать пример в Excel
Треугольное распределение
Как сгенерировать в Excel
Первый пример — треугольное распределение. В Excel отсутствует функция для работы с треугольным распределением, но его можно получить из простого равномерного распределения с помощью данной пользовательской функции:
Function TRIDIST(random As Double, min As Double, max As Double, mean As Double)
If mean < min Or max < mean Then
TRIDIST = CVErr(xlErrValue)
Else
If random <= (mean - min) / (max - min) Then
TRIDIST = min + Sqr((max - min) * (mean - min) * random)
Else
TRIDIST = max - Sqr((max - min) * (max - mean) * (1 - random))
End If
End If
End FunctionПосле добавления данного кода в Excel появится возможность написать формулу =TRDIST(random,min,max,mean)
Первый аргумент — random — случайная величина распределенная равномерно от 0 до 1. (функция СЛЧИС() либо СЛЧИСМЕЖДУ(0,1)).
Второй и третий аргументы — min. max — минимум и максимум функции распределения.
Третий аргумент — mean — мат. ожидание.
Таким образом данная функция позволяет работать как с симметричными так и с асимметричными треугольными распределениями.
В каких случаях применяется
При моделировании случайных процессов чаще всего используется нормальное или log-нормальное распределения, однако в некоторых случаях оправдано использование треугольного распределения. Один из примеров — вариативность случайной величины строго ограничена определённым диапазоном. Когда такое бывает? Допустим, что мы строим модель DCF для оценки денежного потока компании и для симуляции монте-карло нам необходимо задать распределение EBIT margin. Очевидно, что в теории данная величина может принимать значения от -1 до 1, но на практике для большинства здоровых компаний она находится в диапазоне от 5% до 50% и здесь-то нам и может помочь треугольное распределение и пошльзовательская функция TRDIST.
Пример работы функции:
В результате мы получили асимметричное треугольное распределение с мат. ожиданием 0.2, минимумом 0,05 и максимумом 0,25 (стандартное отклонение оказалось равным 0,041344).
|
Подскажите есть ли в VBA встроенная функция для генерациии случайного числа с нормальным распределением? Изучил справочник функций VBA и очень удивился: в классе Math всего лишь 12 штук. Может генерация случайных чисел в неком другом классе? Но равномерное распределение напрмер именно в Math |
|
|
Есть одна функция для генерации случайных чисел, называется RND |
|
|
Этуто функцию я нашел. Просто очень неожиданно что при всем том что есть в Экселе в VBA отсутствуют в общем то стандартные вещи вроде нормального распределения. Может всеже есть некие библиотеки которые надо как то дополнительно включать чтобы можно было их использовать? |
|
|
Объясните чайнику в статистике, аналог какой функции вы ищите в VBA? Вопрос был «есть ли в VBA встроенная функция для генерациии случайного числа с нормальным распределением?» RND возвращает случайные числа не по нармальному распределению? |
|
|
vikttur Пользователь Сообщений: 47199 |
{quote}{login=Константин}{date=08.04.2008 11:38}{thema=}{post} Сервис-Надстройки |
|
NORMDIST — не устроит? (и иже с ней) |
|
|
{quote}{login=Артем}{date=08.04.2008 12:23}{thema=}{post}RND возвращает случайные числа не по нармальному распределению?{/post}{/quote} Нет. Это равномерное распределение. |
|
|
{quote}{login=vikttur}{date=08.04.2008 12:25}{thema=Re: }{post}Сервис-Надстройки{/post}{/quote} Или я чего то не понимаю или это предлагается в Экселе что-то включить? Но в Экселе все как раз доступно а вот в VBA нет. |
|
|
{quote}{login=слэн}{date=08.04.2008 02:20}{thema=}{post}NORMDIST — не устроит? (и иже с ней){/post}{/quote} Мой VBA не знаком с такой функцией. Есть подозрение что это функция для нормального распределения из англоязычного Экселя. |
|
|
а если набрать WorksheetFunction? |
|
|
Константин Гость |
#11 08.04.2008 16:03:55 {quote}{login=слэн}{date=08.04.2008 03:55}{thema=}{post}а если набрать WorksheetFunction?{/post}{/quote} А вот за это уже спасибо |

Содержание
- Использование функций листов Excel в Visual Basic
- Вызов функции листа из Visual Basic
- Вставка функции листа в ячейку
- Пример
- См. также
- Поддержка и обратная связь
- Статистические функции Excel: STEYX
- Аннотация
- Дополнительная информация
- Синтаксис
- Пример использования
- Метод WorksheetFunction.Average (Excel)
- Синтаксис
- Параметры
- Возвращаемое значение
- Замечания
- Поддержка и обратная связь
- Статистические функции (справка)
Использование функций листов Excel в Visual Basic
В операторах Visual Basic можно использовать большинство функций листов Microsoft Excel. Список функций листов, которые можно использовать, см. в статье Список функций листов, доступных для Visual Basic.
Некоторые функции листов не используются в Visual Basic. Например, не требуется функция Concatenate, так как в Visual Basic можно использовать оператор & для объединения нескольких текстовых значений.
Вызов функции листа из Visual Basic
В Visual Basic функции листов Excel доступны через объект WorksheetFunction.
В следующей процедуре Sub используется функция листа Min для определения наименьшего значения в диапазоне ячеек. Сначала переменная myRange объявляется как объект Range, а затем ей присваивается диапазон A1:C10 на листе Sheet1. Другой переменной, answer , назначается результат применения функции Min к myRange . В конце значение answer отображается в окне сообщения.
Если вы используете функцию листа, для которой требуется ссылка на диапазон в качестве аргумента, необходимо указать объект Range. Например, можно использовать функцию листа Match (ПОИСКПОЗ) для поиска диапазона ячеек. В ячейке листа потребовалось бы ввести формулу, например =ПОИСКПОЗ (9;A1:A10;0). Однако в процедуре Visual Basic необходимо указать объект Range, чтобы получить такой же результат.
Функции Visual Basic не используют квалификатор WorksheetFunction. Функция может иметь такое же имя, что и функция Microsoft Excel, но работать по-другому. Например, Application.WorksheetFunction.Log и Log возвращают разные значения.
Вставка функции листа в ячейку
Чтобы вставить функцию листа в ячейку, укажите функцию в качестве значения свойства Formula соответствующего объекта Range. В следующем примере функция листа RAND (создающая случайное число), назначается свойству Formula диапазона A1:B3 на листе Sheet1 в активной книге.
Пример
В этом примере используется функция листа Pmt, чтобы рассчитать кредитный платеж по ипотечной ссуде. Обратите внимание, что в этом примере используется метод InputBox вместо функции InputBox, чтобы метод мог выполнять проверку типов. Операторы Static приводят к тому, что Visual Basic сохраняет значения трех переменных; они отображаются как значения по умолчанию при следующем запуске программы.
См. также
Поддержка и обратная связь
Есть вопросы или отзывы, касающиеся Office VBA или этой статьи? Руководство по другим способам получения поддержки и отправки отзывов см. в статье Поддержка Office VBA и обратная связь.
Источник
Статистические функции Excel: STEYX
Аннотация
В этой статье описывается функция STEYX в Microsoft Office Excel 2003 и более поздних версиях Excel, иллюстрирует использование функции и сравнивает результаты функции для Excel 2003 и более поздних версий Excel с результатами STEYX в более ранних версиях Excel.
Дополнительная информация
Функция STEYX(known_y, known_x) возвращает стандартную ошибку Y заданного X для линии линейной регрессии с наименьшими квадратами, которая используется для прогнозирования значений Y на основе значений x.
Синтаксис
Аргументы, known_y и known_x, должны быть массивами или диапазонами ячеек, которые содержат равное количество числовых значений данных.
Наиболее распространенное использование STEYX включает два диапазона ячеек, содержащих данные, например STEYX(A1:A100, B1:B100).
Пример использования
Чтобы проиллюстрировать функцию STEYX, создайте пустой лист Excel, скопируйте следующую таблицу, выберите ячейку A1 на пустом листе Excel, а затем вставьте записи, чтобы таблица заполняла ячейки A1:D12 на листе.
| A | Б | В | D |
|---|---|---|---|
| Значения y | X-значения | ||
| 1 | = 3 + 10^$D$3 | Power of 10 to add to data | |
| 2 | =4 + 10^$D$3 | 0 | |
| 3 | =2 + 10^$D$3 | ||
| 4 | =5 + 10^$D$3 | ||
| 5 | =4+10^$D$3 | ||
| 6 | =7+10^$D$3 | до Excel 2003 | |
| , когда D3 = 7,5 | |||
| =STEYX(A2:A7,B2:B7) | 1.48954691097662 | ||
| , когда D3 = 8 | |||
| #ДЕЛ/0! |
После вставки этой таблицы на новый лист Excel нажмите кнопку «Параметры вставки» и выберите «Сопоставление форматирования назначения». Выбрав вставленный диапазон, выполните одну из следующих процедур в соответствии с используемой версией Excel:
- В Microsoft Office Excel 2007 откройте вкладку » Главная», выберите «Формат» в группе «Ячейки», а затем нажмите кнопку «Автоподместить ширину столбца».
- В Excel 2003 наведите указатель мыши на столбец в меню «Формат» и выберите пункт «Автоподместить выделение».
Ячейки B2:B7 можно отформатировать как число с 0 десятичными разрядами, а ячейку A9:D9 — как число с шестью десятичными разрядами.
Ячейки A2:A7 и B2:B7 содержат значения y и x, которые используются для вызова STEYX в ячейке A9.
Если у вас есть версия Excel, более раннюю, чем Excel 2003, следует знать, что STEYX может вызывать ошибки округления. Поведение STEYX было улучшено для Excel 2003 и более поздних версий Excel.
Если у вас есть более раннюю версию Excel, лист дает возможность запустить эксперимент и определить, когда возникают ошибки округления. Добавление положительной константы к каждому из наблюдений в B2:B7 не должно влиять на значение STEYX. Если вы должны были представить пары x,y с x на горизонтальной оси и y на вертикальной оси, добавление положительной константы к каждому значению x приведет к сдвигу данных вправо. Линия регрессии наилучшего соответствия по-прежнему будет иметь одинаковый наклон и хорошую по размеру и должна иметь то же значение STEYX.
Увеличение значения в D3 добавляет более крупную константу в B2:B7. Если D2 —>
Источник
Метод WorksheetFunction.Average (Excel)
Возвращает среднее (среднее арифметическое) аргументов.
Синтаксис
Выражение Переменная, представляющая объект WorksheetFunction .
Параметры
| Имя | Обязательный или необязательный | Тип данных | Описание |
|---|---|---|---|
| Arg1 — Arg30 | Обязательный | Variant | От 1 до 30 числовых аргументов, для которых требуется среднее значение. |
Возвращаемое значение
Double
Замечания
Аргументы могут быть числами или именами, массивами или ссылками, содержащими числа.
Учитываются логические значения и текстовые представления чисел, которые вы вводите непосредственно в список аргументов.
Если массив или ссылочный аргумент содержит текст, логические значения или пустые ячейки, эти значения игнорируются; однако включаются ячейки с нулевым значением.
Аргументы, которые являются значениями ошибок или текстом, которые не могут быть преобразованы в числа, вызывают ошибки.
Если вы хотите включить логические значения и текстовые представления чисел в ссылку в рамках вычисления, используйте функцию AVERAGEA.
Метод Average измеряет центральную тенденцию, которая является расположением центра группы чисел в статистическом распределении. Три наиболее распространенных показателя центральной тенденции:
- Среднее значение, которое является средним арифметическим и вычисляется путем сложения группы чисел, а затем деления на количество этих чисел. Например, среднее значение 2, 3, 3, 5, 7 и 10 равно 30, разделенное на 6, то есть 5.
- Median— среднее число группы чисел; то есть половина чисел имеет значения, превышающие медиану, а половина чисел — значения, которые меньше медианы. Например, медиана 2, 3, 3, 5, 7 и 10 — 4.
- Режим — наиболее часто встречающееся число в группе чисел. Например, режим 2, 3, 3, 5, 7 и 10 — 3.
Для симметричного распределения группы чисел эти три меры центральной тенденции являются одинаковыми. При неравномерном распределении группы чисел они могут быть разными.
При усреднении ячеек учитывайте разницу между пустыми и ячейками, содержащими нулевое значение, особенно если вы снимите флажок Нулевые значения на вкладке Вид (команда Параметры , меню Сервис ). Пустые ячейки не учитываются, но значения равны нулю.
Поддержка и обратная связь
Есть вопросы или отзывы, касающиеся Office VBA или этой статьи? Руководство по другим способам получения поддержки и отправки отзывов см. в статье Поддержка Office VBA и обратная связь.
Источник
Статистические функции (справка)
Чтобы просмотреть более подробные сведения о функции, щелкните ее название в первом столбце.
Примечание: Маркер версии обозначает версию Excel, в которой она впервые появилась. В более ранних версиях эта функция отсутствует. Например, маркер версии 2013 означает, что данная функция доступна в выпуске Excel 2013 и всех последующих версиях.
Возвращает среднее арифметическое абсолютных значений отклонений точек данных от среднего.
Возвращает среднее арифметическое аргументов.
Возвращает среднее арифметическое аргументов, включая числа, текст и логические значения.
Возвращает среднее значение (среднее арифметическое) всех ячеек в диапазоне, которые удовлетворяют заданному условию.
Возвращает среднее значение (среднее арифметическое) всех ячеек, которые удовлетворяют нескольким условиям.
БЕТА.РАСП
Возвращает интегральную функцию бета-распределения.
БЕТА.ОБР
Возвращает обратную интегральную функцию указанного бета-распределения.
БИНОМ.РАСП
Возвращает отдельное значение вероятности биномиального распределения.
БИНОМ.РАСП.ДИАП

Возвращает вероятность пробного результата с помощью биномиального распределения.
БИНОМ.ОБР
Возвращает наименьшее значение, для которого интегральное биномиальное распределение меньше заданного значения или равно ему.
ХИ2.РАСП
Возвращает интегральную функцию плотности бета-вероятности.
ХИ2.РАСП.ПХ
Возвращает одностороннюю вероятность распределения хи-квадрат.
ХИ2.ОБР
Возвращает интегральную функцию плотности бета-вероятности.
ХИ2.ОБР.ПХ
Возвращает обратное значение односторонней вероятности распределения хи-квадрат.
ХИ2.ТЕСТ
Возвращает тест на независимость.
ДОВЕРИТ.НОРМ
Возвращает доверительный интервал для среднего значения по генеральной совокупности.
ДОВЕРИТ.СТЬЮДЕНТ
Возвращает доверительный интервал для среднего генеральной совокупности, используя t-распределение Стьюдента.
Возвращает коэффициент корреляции между двумя множествами данных.
Подсчитывает количество чисел в списке аргументов.
Подсчитывает количество значений в списке аргументов.
Подсчитывает количество пустых ячеек в диапазоне.
Подсчитывает количество ячеек в диапазоне, удовлетворяющих заданному условию.
Подсчитывает количество ячеек внутри диапазона, удовлетворяющих нескольким условиям.
КОВАРИАЦИЯ.Г
Возвращает ковариацию, среднее произведений парных отклонений.
КОВАРИАЦИЯ.В
Возвращает ковариацию выборки — среднее попарных произведений отклонений для всех точек данных в двух наборах данных.
Возвращает сумму квадратов отклонений.
ЭКСП.РАСП
Возвращает экспоненциальное распределение.
F.РАСП
Возвращает F-распределение вероятности.
F.РАСП.ПХ
Возвращает F-распределение вероятности.
F.ОБР
Возвращает обратное значение для F-распределения вероятности.
F.ОБР.ПХ
Возвращает обратное значение для F-распределения вероятности.
F.ТЕСТ
Возвращает результат F-теста.
Возвращает преобразование Фишера.
Возвращает обратное преобразование Фишера.
Возвращает значение линейного тренда.
Примечание: В Excel 2016 эта функция заменена на ПРЕДСКАЗ.ЛИНЕЙН из нового набора функций прогнозирования. Однако она по-прежнему доступна для совместимости с предыдущими версиями.
ПРЕДСКАЗ.ETS

Возвращает будущее значение на основе существующих (ретроспективных) данных с использованием версии AAA алгоритма экспоненциального сглаживания (ETS).
ПРЕДСКАЗ.ЕTS.ДОВИНТЕРВАЛ
Возвращает доверительный интервал для прогнозной величины на указанную дату.
ПРЕДСКАЗ.ETS.СЕЗОННОСТЬ
Возвращает длину повторяющегося фрагмента, обнаруженного программой Excel в заданном временном ряду.
ПРЕДСКАЗ.ETS.СТАТ
Возвращает статистическое значение, являющееся результатом прогнозирования временного ряда.
ПРЕДСКАЗ.ЛИНЕЙН
Возвращает будущее значение на основе существующих значений.
Возвращает распределение частот в виде вертикального массива.
ГАММА
Возвращает значение функции гамма
ГАММА.РАСП
ГАММА.ОБР
Возвращает обратное значение интегрального гамма-распределения.
Возвращает натуральный логарифм гамма-функции, Γ(x).
ГАММАНЛОГ.ТОЧН
Возвращает натуральный логарифм гамма-функции, Γ(x).
ГАУСС
Возвращает значение на 0,5 меньше стандартного нормального распределения.
Возвращает среднее геометрическое.
Возвращает значения в соответствии с экспоненциальным трендом.
Возвращает среднее гармоническое.
Возвращает гипергеометрическое распределение.
Возвращает отрезок, отсекаемый на оси линией линейной регрессии.
Возвращает эксцесс множества данных.
Возвращает k-ое наибольшее значение в множестве данных.
Возвращает параметры линейного тренда.
Возвращает параметры экспоненциального тренда.
ЛОГНОРМ.РАСП
Возвращает интегральное логарифмическое нормальное распределение.
ЛОГНОРМ.ОБР
Возвращает обратное значение интегрального логарифмического нормального распределения.
Возвращает наибольшее значение в списке аргументов.
Возвращает наибольшее значение в списке аргументов, включая числа, текст и логические значения.
МАКСЕСЛИ
Возвращает максимальное значение из заданных определенными условиями или критериями ячеек.
Возвращает медиану заданных чисел.
Возвращает наименьшее значение в списке аргументов.
МИНЕСЛИ
Возвращает минимальное значение из заданных определенными условиями или критериями ячеек.
Возвращает наименьшее значение в списке аргументов, включая числа, текст и логические значения.
МОДА.НСК
Возвращает вертикальный массив наиболее часто встречающихся или повторяющихся значений в массиве или диапазоне данных.
МОДА.ОДН
Возвращает значение моды набора данных.
ОТРБИНОМ.РАСП
Возвращает отрицательное биномиальное распределение.
НОРМ.РАСП
Возвращает нормальное интегральное распределение.
НОРМ.ОБР
Возвращает обратное значение нормального интегрального распределения.
НОРМ.СТ.РАСП
Возвращает стандартное нормальное интегральное распределение.
НОРМ.СТ.ОБР
Возвращает обратное значение стандартного нормального интегрального распределения.
Возвращает коэффициент корреляции Пирсона.
ПРОЦЕНТИЛЬ.ИСКЛ
Возвращает k-ю процентиль для значений диапазона, где k — число от 0 и 1 (не включая эти числа).
ПРОЦЕНТИЛЬ.ВКЛ
Возвращает k-ю процентиль для значений диапазона.
ПРОЦЕНТРАНГ.ИСКЛ
Возвращает ранг значения в наборе данных как процентную долю набора (от 0 до 1, исключая границы).
ПРОЦЕНТРАНГ.ВКЛ
Возвращает процентную норму значения в наборе данных.
Возвращает количество перестановок для заданного числа объектов.
ПЕРЕСТА
Возвращает количество перестановок для заданного числа объектов (с повторами), которые можно выбрать из общего числа объектов.
ФИ
Возвращает значение функции плотности для стандартного нормального распределения.
ПУАССОН.РАСП
Возвращает распределение Пуассона.
Возвращает вероятность того, что значение из диапазона находится внутри заданных пределов.
КВАРТИЛЬ.ИСКЛ
Возвращает квартиль набора данных на основе значений процентили из диапазона от 0 до 1, исключая границы.
КВАРТИЛЬ.ВКЛ
Возвращает квартиль набора данных.
РАНГ.СР
Возвращает ранг числа в списке чисел.
РАНГ.РВ
Возвращает ранг числа в списке чисел.
Возвращает квадрат коэффициента корреляции Пирсона.
Возвращает асимметрию распределения.
СКОС.Г
Возвращает асимметрию распределения на основе заполнения: характеристика степени асимметрии распределения относительно его среднего.
Возвращает наклон линии линейной регрессии.
Возвращает k-ое наименьшее значение в множестве данных.
Возвращает нормализованное значение.
СТАНДОТКЛОН.Г
Вычисляет стандартное отклонение по генеральной совокупности.
СТАНДОТКЛОН.В
Оценивает стандартное отклонение по выборке.
Оценивает стандартное отклонение по выборке, включая числа, текст и логические значения.
Вычисляет стандартное отклонение по генеральной совокупности, включая числа, текст и логические значения.
Возвращает стандартную ошибку предсказанных значений y для каждого значения x в регрессии.
СТЬЮДРАСП
Возвращает процентные точки (вероятность) для t-распределения Стьюдента.
СТЬЮДЕНТ.РАСП.2Х
Возвращает процентные точки (вероятность) для t-распределения Стьюдента.
СТЬЮДЕНТ.РАСП.ПХ
Возвращает t-распределение Стьюдента.
СТЬЮДЕНТ.ОБР
Возвращает значение t для t-распределения Стьюдента как функцию вероятности и степеней свободы.
СТЬЮДЕНТ.ОБР.2Х
Возвращает обратное t-распределение Стьюдента.
СТЬЮДЕНТ.ТЕСТ
Возвращает вероятность, соответствующую проверке по критерию Стьюдента.
Возвращает значения в соответствии с линейным трендом.
Возвращает среднее внутренности множества данных.
ДИСП.Г
Вычисляет дисперсию по генеральной совокупности.
ДИСП.В
Оценивает дисперсию по выборке.
Оценивает дисперсию по выборке, включая числа, текст и логические значения.
Вычисляет дисперсию для генеральной совокупности, включая числа, текст и логические значения.
ВЕЙБУЛЛ.РАСП
Возвращает распределение Вейбулла.
Z.ТЕСТ
Возвращает одностороннее значение вероятности z-теста.
Важно: Вычисляемые результаты формул и некоторые функции листа Excel могут несколько отличаться на компьютерах под управлением Windows с архитектурой x86 или x86-64 и компьютерах под управлением Windows RT с архитектурой ARM. Подробнее об этих различиях.
Источник
Option Explicit
Const e = 2.71828459045235
Const pi = 3.1415926535898
Const t = vbTab & vbTab, pp = vbCr & vbCr ' табуляторы и абзацы (для вывода)
Sub tipa_gauss()
Dim i As Long, N As Long, opyt(1 To 20) As Double, vyvod As String
Randomize
'Бросим для примера 20 случайных точек:
For i = 1 To 20
opyt(i) = 2 * Rnd - 1 'МО этого (равномерного) распределения равно 0
vyvod = vyvod & _
Format(i, "00") & t & _
Round(opyt(i), 3) & t & Round(NORM(opyt(i)), 3) & vbCr 'таблица
Next
If MsgBox("№ опыта" & vbTab & "Bыпало (x)" & vbTab & "NORM(x)" & pp & vyvod, _
vbOKCancel) = vbCancel Then Exit Sub Else tipa_gauss
End Sub
Function NORM(x)
Const sigma = .1 'среднее квадратическое отклонение (CKO)
Const mu = 0 'матожидание (MO)
Dim coef As Double
coef = 1 / sigma / Sqr(2 * pi)
NORM = coef * e ^ (-(x - mu) ^ 2 / 2 / sigma / sigma)
End Function
Рассмотрим Нормальное распределение. С помощью функции
MS EXCEL
НОРМ.РАСП()
построим графики функции распределения и плотности вероятности. Сгенерируем массив случайных чисел, распределенных по нормальному закону, произведем оценку параметров распределения, среднего значения и стандартного отклонения
.
Нормальное распределение
(также называется распределением Гаусса) является самым важным как в теории, так в приложениях системы контроля качества. Важность значения
Нормального распределения
(англ.
Normal
distribution
)
во многих областях науки вытекает из
Центральной предельной теоремы
теории вероятностей.
Определение
: Случайная величина
x
распределена по
нормальному закону
, если она имеет
плотность распределения
:
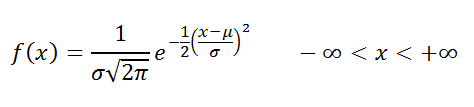
СОВЕТ
: Подробнее о
Функции распределения
и
Плотности вероятности
см. статью
Функция распределения и плотность вероятности в MS EXCEL
.
Нормальное распределение
зависит от двух параметров: μ
(мю)
— является
математическим ожиданием (средним значением случайной величины)
, и σ (
сигма)
— является
стандартным отклонением
(среднеквадратичным отклонением). Параметр μ определяет положение центра
плотности вероятности
нормального распределения
, а σ — разброс относительно центра (среднего).
Примечание
: О влиянии параметров μ и σ на форму распределения изложено в статье про
Гауссову кривую
, а в
файле примера на листе Влияние параметров
можно с помощью
элементов управления Счетчик
понаблюдать за изменением формы кривой.
Нормальное распределение в MS EXCEL
В MS EXCEL, начиная с версии 2010, для
Нормального распределения
имеется функция
НОРМ.РАСП()
, английское название — NORM.DIST(), которая позволяет вычислить
плотность вероятности
(см. формулу выше) и
интегральную функцию распределения
(вероятность, что случайная величина X, распределенная по
нормальному закону
, примет значение меньше или равное x). Вычисления в последнем случае производятся по следующей формуле:
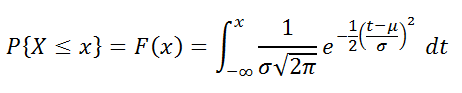
Вышеуказанное распределение имеет обозначение
N
(μ; σ).
Так же часто используют обозначение через
дисперсию
N
(μ; σ
2
).
Примечание
: До MS EXCEL 2010 в EXCEL была только функция
НОРМРАСП()
, которая также позволяет вычислить функцию распределения и плотность вероятности.
НОРМРАСП()
оставлена в MS EXCEL 2010 для совместимости.
Стандартное нормальное распределение
Стандартным нормальным распределением
называется
нормальное распределение
с
математическим ожиданием
μ=0 и
дисперсией
σ=1. Вышеуказанное распределение имеет обозначение
N
(0;1).
Примечание
: В литературе для случайной величины, распределенной по
стандартному
нормальному закону,
закреплено специальное обозначение z.
Любое
нормальное распределение
можно преобразовать в стандартное через замену переменной
z
=(
x
-μ)/σ
. Этот процесс преобразования называется
стандартизацией
.
Примечание
: В MS EXCEL имеется функция
НОРМАЛИЗАЦИЯ()
, которая выполняет вышеуказанное преобразование. Хотя в MS EXCEL это преобразование называется почему-то
нормализацией
. Формулы
=(x-μ)/σ
и
=НОРМАЛИЗАЦИЯ(х;μ;σ)
вернут одинаковый результат.
В MS EXCEL 2010 для
стандартного нормального распределения
имеется специальная функция
НОРМ.СТ.РАСП()
и ее устаревший вариант
НОРМСТРАСП()
, выполняющий аналогичные вычисления.
Продемонстрируем, как в MS EXCEL осуществляется процесс стандартизации
нормального распределения
N
(1,5; 2).
Для этого вычислим вероятность, что случайная величина, распределенная по
нормальному закону
N(1,5; 2)
, меньше или равна 2,5. Формула выглядит так:
=НОРМ.РАСП(2,5; 1,5; 2; ИСТИНА)
=0,691462. Сделав замену переменной
z
=(2,5-1,5)/2=0,5
, запишем формулу для вычисления
Стандартного нормального распределения:
=НОРМ.СТ.РАСП(0,5; ИСТИНА)
=0,691462.
Естественно, обе формулы дают одинаковые результаты (см.
файл примера лист Пример
).
Обратите внимание, что
стандартизация
относится только к
интегральной функции распределения
(аргумент
интегральная
равен ИСТИНА), а не к
плотности вероятности
.
Примечание
: В литературе для функции, вычисляющей вероятности случайной величины, распределенной по
стандартному
нормальному закону,
закреплено специальное обозначение Ф(z). В MS EXCEL эта функция вычисляется по формуле
=НОРМ.СТ.РАСП(z;ИСТИНА)
. Вычисления производятся по формуле
![]()
В силу четности функции
плотности стандартного нормального
распределения f(x), а именно f(x)=f(-х), функция
стандартного нормального распределения
обладает свойством Ф(-x)=1-Ф(x).
Обратные функции
Функция
НОРМ.СТ.РАСП(x;ИСТИНА)
вычисляет вероятность P, что случайная величина Х примет значение меньше или равное х. Но часто требуется провести обратное вычисление: зная вероятность P, требуется вычислить значение х. Вычисленное значение х называется
квантилем
стандартного
нормального распределения
.
В MS EXCEL для вычисления
квантилей
используют функцию
НОРМ.СТ.ОБР()
и
НОРМ.ОБР()
.
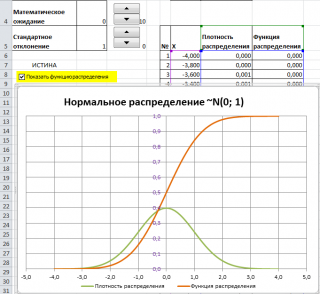
Графики функций
В
файле примера
приведены
графики плотности распределения
вероятности и
интегральной функции распределения
.
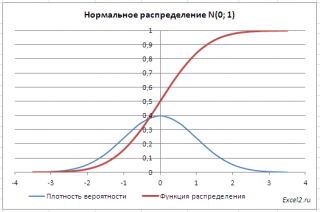
Как известно, около 68% значений, выбранных из совокупности, имеющей
нормальное распределение
, находятся в пределах 1 стандартного отклонения (σ) от μ(среднего или математического ожидания); около 95% — в пределах 2-х σ, а в пределах 3-х σ находятся уже 99% значений. Убедиться в этом для
стандартного нормального распределения
можно записав формулу:
=
НОРМ.СТ.РАСП(1;ИСТИНА)-НОРМ.СТ.РАСП(-1;ИСТИНА)
которая вернет значение 68,2689% — именно такой процент значений находятся в пределах +/-1 стандартного отклонения от
среднего
(см.
лист График в файле примера
).
В силу четности функции
плотности стандартного нормального
распределения:
f
(
x
)=
f
(-х)
, функция
стандартного нормального распределения
обладает свойством F(-x)=1-F(x). Поэтому, вышеуказанную формулу можно упростить:
=
2*НОРМ.СТ.РАСП(1;ИСТИНА)-1
Для произвольной
функции нормального распределения
N(μ; σ) аналогичные вычисления нужно производить по формуле:
=2* НОРМ.РАСП(μ+1*σ;μ;σ;ИСТИНА)-1
Вышеуказанные расчеты вероятности требуются для
построения доверительных интервалов
.
Примечание
: Для построения
функции распределения
и
плотности вероятности
можно использовать диаграмму типа
График
или
Точечная
(со сглаженными линиями и без точек). Подробнее о построении
диаграмм
читайте статью
Основные типы диаграмм
.
Примечание
: Для удобства написания формул в
файле примера
созданы
Имена
для параметров распределения: μ и σ.
Генерация случайных чисел
С помощью надстройки
Пакет анализа
можно сгенерировать случайные числа, распределенные по
нормальному закону
.
СОВЕТ
: О надстройке
Пакет анализа
можно прочитать в статье
Надстройка Пакет анализа MS EXCEL
.
Сгенерируем 3 массива по 100 чисел с различными μ и σ. Для этого в окне
Генерация
случайных чисел
установим следующие значения для каждой пары параметров:
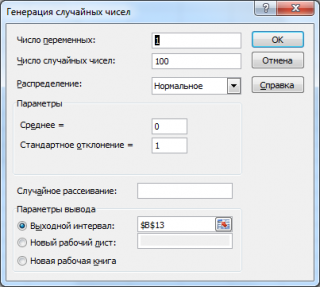
Примечание
: Если установить опцию
Случайное рассеивание
(
Random Seed
), то можно выбрать определенный случайный набор сгенерированных чисел. Например, установив эту опцию равной 25, можно сгенерировать на разных компьютерах одни и те же наборы случайных чисел (если, конечно, другие параметры распределения совпадают). Значение опции может принимать целые значения от 1 до 32 767. Название опции
Случайное рассеивание
может запутать. Лучше было бы ее перевести как
Номер набора со случайными числами
.
В итоге будем иметь 3 столбца чисел, на основании которых можно, оценить параметры распределения, из которого была произведена выборка: μ и σ
.
Оценку для μ можно сделать с использованием функции
СРЗНАЧ()
, а для σ – с использованием функции
СТАНДОТКЛОН.В()
, см.
файл примера лист Генерация
.
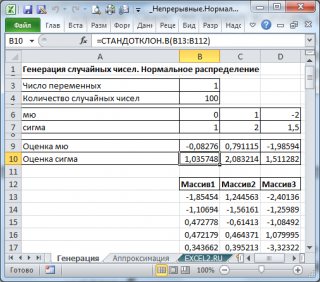
Примечание
: Для генерирования массива чисел, распределенных по
нормальному закону
, можно использовать формулу
=НОРМ.ОБР(СЛЧИС();μ;σ)
. Функция
СЛЧИС()
генерирует
непрерывное равномерное распределение
от 0 до 1, что как раз соответствует диапазону изменения вероятности (см.
файл примера лист Генерация
).
Задачи
Задача1
. Компания изготавливает нейлоновые нити со средней прочностью 41 МПа и стандартным отклонением 2 МПа. Потребитель хочет приобрести нити с прочностью не менее 36 МПа. Рассчитайте вероятность, что партии нити, изготовленные компанией для потребителя, будут соответствовать требованиям или превышать их.
Решение1
: =
1-НОРМ.РАСП(36;41;2;ИСТИНА)
Задача2
. Предприятие изготавливает трубы, средний внешний диаметр которых равен 20,20 мм, а стандартное отклонение равно 0,25мм. Согласно техническим условиям, трубы признаются годными, если диаметр находится в пределах 20,00+/- 0,40 мм. Какая доля изготовленных труб соответствует ТУ?
Решение2
: =
НОРМ.РАСП(20,00+0,40;20,20;0,25;ИСТИНА)- НОРМ.РАСП(20,00-0,40;20,20;0,25)
На рисунке ниже, выделена область значений диаметров, которая удовлетворяет требованиям спецификации.
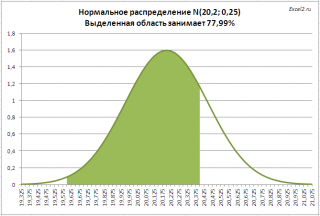
Решение приведено в
файле примера лист Задачи
.
Задача3
. Предприятие изготавливает трубы, средний внешний диаметр которых равен 20,20 мм, а стандартное отклонение равно 0,25мм. Внешний диаметр не должен превышать определенное значение (предполагается, что нижняя граница не важна). Какую верхнюю границу в технических условиях необходимо установить, чтобы ей соответствовало 97,5% всех изготавливаемых изделий?
Решение3
: =
НОРМ.ОБР(0,975; 20,20; 0,25)
=20,6899 или =
НОРМ.СТ.ОБР(0,975)*0,25+20,2
(произведена «дестандартизация», см. выше)
Задача 4
. Нахождение параметров
нормального распределения
по значениям 2-х
квантилей
(или
процентилей
). Предположим, известно, что случайная величина имеет нормальное распределение, но не известны его параметры, а только 2-я
процентиля
(например, 0,5-
процентиль
, т.е. медиана и 0,95-я
процентиль
). Т.к. известна
медиана
, то мы знаем
среднее
, т.е. μ. Чтобы найти
стандартное отклонение
нужно использовать
Поиск решения
. Решение приведено в
файле примера лист Задачи
.
Примечание
: До MS EXCEL 2010 в EXCEL были функции
НОРМОБР()
и
НОРМСТОБР()
, которые эквивалентны
НОРМ.ОБР()
и
НОРМ.СТ.ОБР()
.
НОРМОБР()
и
НОРМСТОБР()
оставлены в MS EXCEL 2010 и выше только для совместимости.
Линейные комбинации нормально распределенных случайных величин
Известно, что линейная комбинация нормально распределённых случайных величин
x
(
i
)
с параметрами μ
(
i
)
и σ
(
i
)
также распределена нормально. Например, если случайная величина Y=x(1)+x(2), то Y будет иметь распределение с параметрами μ
(1)+ μ(2)
и
КОРЕНЬ(σ(1)^2+ σ(2)^2).
Убедимся в этом с помощью MS EXCEL.
С помощью надстройки
Пакет анализа
сгенерируем 2 массива по 100 чисел с различными μ и σ.
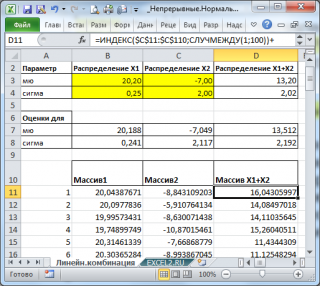
Теперь сформируем массив, каждый элемент которого является суммой 2-х значений, взятых из каждого массива.
С помощью функций
СРЗНАЧ()
и
СТАНДОТКЛОН.В()
вычислим
среднее
и
дисперсию
получившейся
выборки
и сравним их с расчетными.
Кроме того, построим
График проверки распределения на нормальность
(
Normal
Probability
Plot
), чтобы убедиться, что наш массив соответствует выборке из
нормального распределения
.
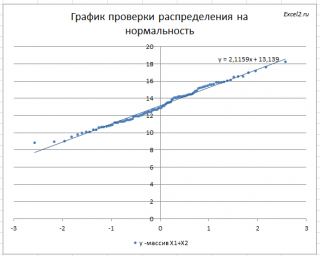
Прямая линия, аппроксимирующая полученный график, имеет уравнение y=ax+b. Наклон кривой (параметр а) может служить оценкой
стандартного отклонения
, а пересечение с осью y (параметр b) –
среднего
значения.
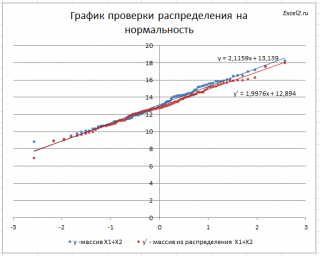
Для сравнения сгенерируем массив напрямую из распределения
N
(μ(1)+ μ(2); КОРЕНЬ(σ(1)^2+ σ(2)^2)
).
Как видно на рисунке ниже, обе аппроксимирующие кривые достаточно близки.
В качестве примера можно провести следующую задачу.
Задача
. Завод изготавливает болты и гайки, которые упаковываются в ящики парами. Пусть известно, что вес каждого из изделий является нормальной случайной величиной. Для болтов средний вес составляет 50г, стандартное отклонение 1,5г, а для гаек 20г и 1,2г. В ящик фасуется 100 пар болтов и гаек. Вычислить какой процент ящиков будет тяжелее 7,2 кг.
Решение
. Сначала переформулируем вопрос задачи: Вычислить какой процент пар болт-гайка будет тяжелее 7,2кг/100=72г. Учитывая, что вес пары представляет собой случайную величину = Вес(болта) + Вес(гайки) со средним весом (50+20)г, и
стандартным отклонением
=КОРЕНЬ(СУММКВ(1,5;1,2))
, запишем решение =
1-НОРМ.РАСП(72; 50+20; КОРЕНЬ(СУММКВ(1,5;1,2));ИСТИНА)
Ответ
: 15% (см.
файл примера лист Линейн.комбинация
)
Аппроксимация Биномиального распределения Нормальным распределением
Если параметры
Биномиального распределения
B(n;p) находятся в пределах 0,1<=p<=0,9 и n*p>10, то
Биномиальное распределение
можно аппроксимировать
Нормальным распределением
.
При значениях
λ
>15
,
Распределение Пуассона
хорошо аппроксимируется
Нормальным распределением
с параметрами: μ
=λ
, σ
2
=
λ
.
Подробнее о связи этих распределений, можно прочитать в статье
Взаимосвязь некоторых распределений друг с другом в MS EXCEL
. Там же приведены примеры аппроксимации, и пояснены условия, когда она возможна и с какой точностью.
СОВЕТ
: О других распределениях MS EXCEL можно прочитать в статье
Распределения случайной величины в MS EXCEL
.
В статье подробно показано, что такое нормальный закон распределения случайной величины и как им пользоваться при решении практически задач.
Нормальное распределение в статистике
История закона насчитывает 300 лет. Первым открывателем стал Абрахам де Муавр, который придумал аппроксимацию биномиального распределения еще 1733 году. Через много лет Карл Фридрих Гаусс (1809 г.) и Пьер-Симон Лаплас (1812 г.) вывели математические функции.
Лаплас также обнаружил замечательную закономерность и сформулировал центральную предельную теорему (ЦПТ), согласно которой сумма большого количества малых и независимых величин имеет нормальное распределение.
Нормальный закон не является фиксированным уравнением зависимости одной переменной от другой. Фиксируется только характер этой зависимости. Конкретная форма распределения задается специальными параметрами. Например, у = аx + b – это уравнение прямой. Однако где конкретно она проходит и под каким наклоном, определяется параметрами а и b. Также и с нормальным распределением. Ясно, что это функция, которая описывает тенденцию высокой концентрации значений около центра, но ее точная форма задается специальными параметрами.
Кривая нормального распределения Гаусса имеет следующий вид.

График нормального распределения напоминает колокол, поэтому можно встретить название колоколообразная кривая. У графика имеется «горб» в середине и резкое снижение плотности по краям. В этом заключается суть нормального распределения. Вероятность того, что случайная величина окажется около центра гораздо выше, чем то, что она сильно отклонится от середины.

На рисунке выше изображены два участка под кривой Гаусса: синий и зеленый. Основания, т.е. интервалы, у обоих участков равны. Но заметно отличаются высоты. Синий участок удален от центра, и имеет существенно меньшую высоту, чем зеленый, который находится в самом центре распределения. Следовательно, отличаются и площади, то бишь вероятности попадания в обозначенные интервалы.
Формула нормального распределения (плотности) следующая.
![]()
Формула состоит из двух математических констант:
π – число пи 3,142;
е – основание натурального логарифма 2,718;
двух изменяемых параметров, которые задают форму конкретной кривой:
m – математическое ожидание (в различных источниках могут использоваться другие обозначения, например, µ или a);
σ2 – дисперсия;
ну и сама переменная x, для которой высчитывается плотность вероятности.
Конкретная форма нормального распределения зависит от 2-х параметров: математического ожидания (m) и дисперсии (σ2). Кратко обозначается N(m, σ2) или N(m, σ). Параметр m (матожидание) определяет центр распределения, которому соответствует максимальная высота графика. Дисперсия σ2 характеризует размах вариации, то есть «размазанность» данных.
Параметр математического ожидания смещает центр распределения вправо или влево, не влияя на саму форму кривой плотности.

А вот дисперсия определяет остроконечность кривой. Когда данные имеют малый разброс, то вся их масса концентрируется у центра. Если же у данных большой разброс, то они «размазываются» по широкому диапазону.

Плотность распределения не имеет прямого практического применения. Для расчета вероятностей нужно проинтегрировать функцию плотности.
Вероятность того, что случайная величина окажется меньше некоторого значения x, определяется функцией нормального распределения:
![]()
Используя математические свойства любого непрерывного распределения, несложно рассчитать и любые другие вероятности, так как
P(a ≤ X < b) = Ф(b) – Ф(a)
Стандартное нормальное распределение
Нормальное распределение зависит от параметров средней и дисперсии, из-за чего плохо видны его свойства. Хорошо бы иметь некоторый эталон распределения, не зависящий от масштаба данных. И он существует. Называется стандартным нормальным распределением. На самом деле это обычное нормальное нормальное распределение, только с параметрами математического ожидания 0, а дисперсией – 1, кратко записывается N(0, 1).
Любое нормальное распределение легко превращается в стандартное путем нормирования:
![]()
где z – новая переменная, которая используется вместо x;
m – математическое ожидание;
σ – стандартное отклонение.
Для выборочных данных берутся оценки:
![]()
Среднее арифметическое и дисперсия новой переменной z теперь также равны 0 и 1 соответственно. В этом легко убедиться с помощью элементарных алгебраических преобразований.
В литературе встречается название z-оценка. Это оно самое – нормированные данные. Z-оценку можно напрямую сравнивать с теоретическими вероятностями, т.к. ее масштаб совпадает с эталоном.
Посмотрим теперь, как выглядит плотность стандартного нормального распределения (для z-оценок). Напомню, что функция Гаусса имеет вид:
![]()
Подставим вместо (x-m)/σ букву z, а вместо σ – единицу, получим функцию плотности стандартного нормального распределения:
![]()
График плотности:

Центр, как и ожидалось, находится в точке 0. В этой же точке функция Гаусса достигает своего максимума, что соответствует принятию случайной величиной своего среднего значения (т.е. x-m=0). Плотность в этой точке равна 0,3989, что можно посчитать даже в уме, т.к. e0=1 и остается рассчитать только соотношение 1 на корень из 2 пи.
Таким образом, по графику хорошо видно, что значения, имеющие маленькие отклонения от средней, выпадают чаще других, а те, которые сильно отдалены от центра, встречаются значительно реже. Шкала оси абсцисс измеряется в стандартных отклонениях, что позволяет отвязаться от единиц измерения и получить универсальную структуру нормального распределения. Кривая Гаусса для нормированных данных отлично демонстрирует и другие свойства нормального распределения. Например, что оно является симметричным относительно оси ординат. В пределах ±1σ от средней арифметической сконцентрирована большая часть всех значений (прикидываем пока на глазок). В пределах ±2σ находятся большинство данных. В пределах ±3σ находятся почти все данные. Последнее свойство широко известно под названием правило трех сигм для нормального распределения.
Функция стандартного нормального распределения позволяет рассчитывать вероятности.
![]()
Понятное дело, вручную никто не считает. Все подсчитано и размещено в специальных таблицах, которые есть в конце любого учебника по статистике.
Таблица нормального распределения
Таблицы нормального распределения встречаются двух типов:
— таблица плотности;
— таблица функции (интеграла от плотности).
Таблица плотности используется редко. Тем не менее, посмотрим, как она выглядит. Допустим, нужно получить плотность для z = 1, т.е. плотность значения, отстоящего от матожидания на 1 сигму. Ниже показан кусок таблицы.

В зависимости от организации данных ищем нужное значение по названию столбца и строки. В нашем примере берем строку 1,0 и столбец 0, т.к. сотых долей нет. Искомое значение равно 0,2420 (0 перед 2420 опущен).
Функция Гаусса симметрична относительно оси ординат. Поэтому φ(z)= φ(-z), т.е. плотность для 1 тождественна плотности для -1, что отчетливо видно на рисунке.

Чтобы не тратить зря бумагу, таблицы печатают только для положительных значений.
На практике чаще используют значения функции стандартного нормального распределения, то есть вероятности для различных z.
В таких таблицах также содержатся только положительные значения. Поэтому для понимания и нахождения любых нужных вероятностей следует знать свойства стандартного нормального распределения.
Функция Ф(z) симметрична относительно своего значения 0,5 (а не оси ординат, как плотность). Отсюда справедливо равенство:
![]()
Это факт показан на картинке:

Значения функции Ф(-z) и Ф(z) делят график на 3 части. Причем верхняя и нижняя части равны (обозначены галочками). Для того, чтобы дополнить вероятность Ф(z) до 1, достаточно добавить недостающую величину Ф(-z). Получится равенство, указанное чуть выше.
Если нужно отыскать вероятность попадания в интервал (0; z), то есть вероятность отклонения от нуля в положительную сторону до некоторого количества стандартных отклонений, достаточно от значения функции стандартного нормального распределения отнять 0,5:
Для наглядности можно взглянуть на рисунок.

На кривой Гаусса, эта же ситуация выглядит как площадь от центра вправо до z.

Довольно часто аналитика интересует вероятность отклонения в обе стороны от нуля. А так как функция симметрична относительно центра, предыдущую формулу нужно умножить на 2:

Рисунок ниже.

Под кривой Гаусса это центральная часть, ограниченная выбранным значением –z слева и z справа.

Указанные свойства следует принять во внимание, т.к. табличные значения редко соответствуют интересующему интервалу.
Для облегчения задачи в учебниках обычно публикуют таблицы для функции вида:

Если нужна вероятность отклонения в обе стороны от нуля, то, как мы только что убедились, табличное значение для данной функции просто умножается на 2.
Теперь посмотрим на конкретные примеры. Ниже показана таблица стандартного нормального распределения. Найдем табличные значения для трех z: 1,64, 1,96 и 3.

Как понять смысл этих чисел? Начнем с z=1,64, для которого табличное значение составляет 0,4495. Проще всего пояснить смысл на рисунке.

То есть вероятность того, что стандартизованная нормально распределенная случайная величина попадет в интервал от 0 до 1,64, равна 0,4495. При решении задач обычно нужно рассчитать вероятность отклонения в обе стороны, поэтому умножим величину 0,4495 на 2 и получим примерно 0,9. Занимаемая площадь под кривой Гаусса показана ниже.

Таким образом, 90% всех нормально распределенных значений попадает в интервал ±1,64σ от средней арифметической. Я не случайно выбрал значение z=1,64, т.к. окрестность вокруг средней арифметической, занимающая 90% всей площади, иногда используется для проверки статистических гипотез и расчета доверительных интервалов. Если проверяемое значение не попадает в обозначенную область, то его наступление маловероятно (всего 10%).
Для проверки гипотез, однако, чаще используется интервал, накрывающий 95% всех значений. Половина вероятности от 0,95 – это 0,4750 (см. второе выделенное в таблице значение).

Для этой вероятности z=1,96. Т.е. в пределах почти ±2σ от средней находится 95% значений. Только 5% выпадают за эти пределы.

Еще одно интересное и часто используемое табличное значение соответствует z=3, оно равно по нашей таблице 0,4986. Умножим на 2 и получим 0,997. Значит, в рамках ±3σ от средней арифметической заключены почти все значения.

Так выглядит правило 3 сигм для нормального распределения на диаграмме.
С помощью статистических таблиц можно получить любую вероятность. Однако этот метод очень медленный, неудобный и сильно устарел. Сегодня все делается на компьютере. Далее переходим к практике расчетов в Excel.
В Excel есть несколько функций для подсчета вероятностей или обратных значений нормального распределения.

Функция НОРМ.СТ.РАСП
Функция НОРМ.СТ.РАСП предназначена для расчета плотности ϕ(z) или вероятности Φ(z) по нормированным данным (z).
=НОРМ.СТ.РАСП(z;интегральная)
z – значение стандартизованной переменной
интегральная – если 0, то рассчитывается плотность ϕ(z), если 1 – значение функции Ф(z), т.е. вероятность P(Z<z).
Рассчитаем плотность и значение функции для различных z: -3, -2, -1, 0, 1, 2, 3 (их укажем в ячейке А2).
Для расчета плотности потребуется формула =НОРМ.СТ.РАСП(A2;0). На диаграмме ниже – это красная точка.
Для расчета значения функции =НОРМ.СТ.РАСП(A2;1). На диаграмме – закрашенная площадь под нормальной кривой.

В реальности чаще приходится рассчитывать вероятность того, что случайная величина не выйдет за некоторые пределы от средней (в среднеквадратичных отклонениях, соответствующих переменной z), т.е. P(|Z|<z).

Определим, чему равна вероятность попадания случайной величины в пределы ±1z, ±2z и ±3z от нуля. Потребуется формула 2Ф(z)-1, в Excel =2*НОРМ.СТ.РАСП(A2;1)-1.

На диаграмме отлично видны основные основные свойства нормального распределения, включая правило трех сигм. Функция НОРМ.СТ.РАСП – это автоматическая таблица значений функции нормального распределения в Excel.
Может стоять и обратная задача: по имеющейся вероятности P(Z<z) найти стандартизованную величину z ,то есть квантиль стандартного нормального распределения.
Функция НОРМ.СТ.ОБР
НОРМ.СТ.ОБР рассчитывает обратное значение функции стандартного нормального распределения. Синтаксис состоит из одного параметра:
=НОРМ.СТ.ОБР(вероятность)
вероятность – это вероятность.
Данная формула используется так же часто, как и предыдущая, ведь по тем же таблицам искать приходится не только вероятности, но и квантили.

Например, при расчете доверительных интервалов задается доверительная вероятность, по которой нужно рассчитать величину z.

Учитывая то, что доверительный интервал состоит из верхней и нижней границы и то, что нормальное распределение симметрично относительно нуля, достаточно получить верхнюю границу (положительное отклонение). Нижняя граница берется с отрицательным знаком. Обозначим доверительную вероятность как γ (гамма), тогда верхняя граница доверительного интервала рассчитывается по следующей формуле.
![]()
Рассчитаем в Excel значения z (что соответствует отклонению от средней в сигмах) для нескольких вероятностей, включая те, которые наизусть знает любой статистик: 90%, 95% и 99%. В ячейке B2 укажем формулу: =НОРМ.СТ.ОБР((1+A2)/2). Меняя значение переменной (вероятности в ячейке А2) получим различные границы интервалов.

Доверительный интервал для 95% равен 1,96, то есть почти 2 среднеквадратичных отклонения. Отсюда легко даже в уме оценить возможный разброс нормальной случайной величины. В общем, доверительным вероятностям 90%, 95% и 99% соответствуют доверительные интервалы ±1,64, ±1,96 и ±2,58 σ.
В целом функции НОРМ.СТ.РАСП и НОРМ.СТ.ОБР позволяют произвести любой расчет, связанный с нормальным распределением. Но, чтобы облегчить и уменьшить количество действий, в Excel есть несколько других функций. Например, для расчета доверительных интервалов средней можно использовать ДОВЕРИТ.НОРМ. Для проверки статистической гипотезы о средней арифметической есть формула Z.ТЕСТ.
Рассмотрим еще пару полезных формул с примерами.
Функция НОРМ.РАСП
Функция НОРМ.РАСП отличается от НОРМ.СТ.РАСП лишь тем, что ее используют для обработки данных любого масштаба, а не только нормированных. Параметры нормального распределения указываются в синтаксисе.
=НОРМ.РАСП(x;среднее;стандартное_откл;интегральная)
x – значение (или ссылка на ячейку), для которого рассчитывается плотность или значение функции нормального распределения
среднее – математическое ожидание, используемое в качестве первого параметра модели нормального распределения
стандартное_откл – среднеквадратичное отклонение – второй параметр модели
интегральная – если 0, то рассчитывается плотность, если 1 – то значение функции, т.е. P(X<x).
Например, плотность для значения 15, которое извлекли из нормальной выборки с матожиданием 10, стандартным отклонением 3, рассчитывается так:

Если последний параметр поставить 1, то получим вероятность того, что нормальная случайная величина окажется меньше 15 при заданных параметрах распределения. Таким образом, вероятности можно рассчитывать напрямую по исходным данным.
Функция НОРМ.ОБР
Это квантиль нормального распределения, т.е. значение обратной функции. Синтаксис следующий.
=НОРМ.ОБР(вероятность;среднее;стандартное_откл)
вероятность – вероятность
среднее – матожидание
стандартное_откл – среднеквадратичное отклонение
Назначение то же, что и у НОРМ.СТ.ОБР, только функция работает с данными любого масштаба.
Пример показан в ролике в конце статьи.
Моделирование нормального распределения
Для некоторых задач требуется генерация нормальных случайных чисел. Готовой функции для этого нет. Однако В Excel есть две функции, которые возвращают случайные числа: СЛУЧМЕЖДУ и СЛЧИС. Первая выдает случайные равномерно распределенные целые числа в указанных пределах. Вторая функция генерирует равномерно распределенные случайные числа между 0 и 1. Чтобы сделать искусственную выборку с любым заданным распределением, нужна функция СЛЧИС.
Допустим, для проведения эксперимента необходимо получить выборку из нормально распределенной генеральной совокупности с матожиданием 10 и стандартным отклонением 3. Для одного случайного значения напишем формулу в Excel.
=НОРМ.ОБР(СЛЧИС();10;3)
Протянем ее на необходимое количество ячеек и нормальная выборка готова.
Для моделирования стандартизованных данных следует воспользоваться НОРМ.СТ.ОБР.
Процесс преобразования равномерных чисел в нормальные можно показать на следующей диаграмме. От равномерных вероятностей, которые генерируются формулой СЛЧИС, проведены горизонтальные линии до графика функции нормального распределения. Затем от точек пересечения вероятностей с графиком опущены проекции на горизонтальную ось.

На выходе получаются значения с характерной концентрацией около центра. Вот так обратный прогон через функцию нормального распределения превращает равномерные числа в нормальные. Excel позволяет за несколько секунд воспроизвести любое количество выборок любого размера.
Как обычно, прилагаю ролик, где все вышеописанное показывается в действии.
Скачать файл с примером.
Поделиться в социальных сетях: