
I am completely new to databases, was wondering if there were ways to direcly upload the data in an excel file, to ORACLE APEX, if not, what would the best way be to upload small datasets .CSV extension around 15MB.
asked Dec 14, 2016 at 17:53
![]()
1
Apex enables you to directly upload CSV files using the Data Load Wizard. You can find a lot of tutorials. Here is just one.
You can also upload Excel files using the following methods:
- EXCEL2COLLECTIONS Plugin
- Create a procedure that will translate excel data into strings. Tutorial here.
- Using AS_READ_XLSX package. Tutorial here.
Don’t be shy to use google because you will find many more options.
answered Dec 14, 2016 at 19:16
![]()
Cristian_ICristian_I
1,5651 gold badge12 silver badges17 bronze badges
Face it: your users are in love with Microsoft Excel, and you can’t do anything about it.
You can show them the excellent Interactive Report and Interactive Grid features of APEX, and train some of your users to use some of their capabilities, but at the end of the day, your users will still download the data into their spreadsheet software to do their own stuff with it.
Once they’ve finished with the data, odds are they’ll come back to you and ask “how do I upload this data back into APEX?” and expect that the answer is merely a flip of a switch to enable a built-in APEX feature. Of course, you know and I know that this is not necessarily a simple thing; it is certainly not just an option to be enabled. Depending on what exactly they mean by “upload this data” it may be reasonably easy to build or it could get quite complex.
File Formats
Typically the data will be provided in some kind of text format (CSV, tab delimited, fixed width) or binary file (XLS or XLSX). If they have copied the data from a table in Excel, it will be in tab-delimited format in the clipboard. Perhaps in some odd instances the user will have received the data from some system in fixed width, XML or JSON format – but this is rare as this is typically part of the build of a system integration solution and users expect these to be “harder”.
Actual Requirements
When your user wants you to provide a facility for uploading data, there are some basic questions you’ll need to ask. Knowing these will help you choose the right approach and solution.
- Where are the files – i.e. are they stored on the database server, or is the user going to upload them via an online APEX application
- How much automation is required, how often – i.e. is this a ad-hoc, rare situation; something they need to do a few times per month; or something that is frequent and needs to be painless and automatic?
- What are the files named – i.e. if they are stored on the database server, do we know what the files will be called?
- How consistent is the data structure?
Data Structure
That last one is important. Will the columns in the file remain the same, or might they change all the time? If the structure is not amenable to automated data matching, can the file structure be changed to accommodate our program? Is the structure even in tabular form (e.g. is it a simple “header line, data line, data line” structure or are there bits and pieces dotted around the spreadsheet)? If it’s an Excel file, is all the data in one sheet, or is it spread across multiple sheets? Should all the sheets be processed, or should some of them be ignored? Can the columns vary depending on requirement – might there be some columns in one file that don’t exist in other files, and vice versa?
Finally, is all the data to be loaded actually encoded in text form? This is an issue where a spreadsheet is provided where the user has, trying to be helpful, highlighted rows with different colours to indicate different statuses or other categorising information. I’ve received spreadsheets where some data rows were not “real” data rows, but merely explanatory text or notes entered by the users – since they coloured the background on those rows in grey, they expected my program to automatically filter those rows out.
Solution Components
Any solution for processing uploaded files must incorporate each of the following components:
- Load – read the raw file data
- Parse – extract the text data from the file
- Map – identify how the text data relates to your schema
- Validate – check that the data satisfies all schema and business rule constraints
- Process – make the relevant changes in the database based on the data
Each of these components have multiple solution options, some are listed here:
- Load – External tables / SQL*Loader; APEX file select
- Parse – External tables / SQL*Loader; APEX; 3rd-party code
- Map – Fixed (we already know which columns appear where) (e.g. SQL*Loader Express Mode); Manual (allow the user to choose which column maps to which target); or A.I. (use some sort of heuristic algorithm to guess which column maps to what, e.g. based on the header labels)
- Validate – Database constraints; and/or PL/SQL API
- Process – INSERT; MERGE; or call a PL/SQL API
The rest of this post is focussed primarily on Parsing and Mapping Text and Excel files.
Solutions for Text files
These are some solutions for parsing text files (CSV, tab-delimited, fixed-width, etc.) that I’ve used or heard of. I’m not including the more standardised data interchange text formats in this list (e.g. XML, JSON) as these are rarely used by end users to supply spreadsheet data. “Your Mileage May Vary” – so test and evaluate them to determine if they will suit your needs.
- External Table / SQL*Loader / SQL*Loader Express Mode (CSV, delimited, and fixed width files)
- APEX Data Workshop (CSV & delimited files)
- APEX Data Loader Wizard (CSV and delimited files only)
- Alexandria PL/SQL Library CSV_UTIL_PKG – Morten Braten, 2010
- LOB2Table PL/SQL (CSV, delimited and fixed width files) – Michael Schmid, 2015
- Excel2Collection APEX process plugin (CSV, delimited, XLS and XLSX files) – Anton Scheffer, 2013
- csv2db – load CSV files from the command line (Linux). Gerald Venzl, 2019
- KiBeHa’s CSV parser – a simple CSV parser in PL/SQL written by Kim Berg Hansen, 2014 (this is a simplistic parser that will not handle all CSV files, e.g. ones that have embedded delimiters with double-quoted text)
It could be noted here that the Interactive Grid in APEX 5.1 and later does support Paste; if the user selects some data from Excel, then selects the corresponding columns and rows in the grid, they can Paste the tab-delimited data right in. Of course, this requires that the columns be in exactly the right order.
External Table
This uses the SQL*Loader access driver and you can look up the syntax in the Oracle docs by searching for “ORACLE_LOADER”. Since Oracle 12.1 you can use the simple “FIELDS CSV” syntax to parse CSV files, e.g.:
create table emp_staging
( emp_no number(4)
, name varchar2(10)
, ...
)
organization external
( default directory ext_dir
access parameters
( records delimited by newline
FIELDS CSV
reject rows with all null fields
)
location ( 'emp.dat' )
)
reject limit unlimited
Note that the filename (location) is hard-coded in the external table definition. Since Oracle 12.2 you can modify some of the attributes of an external table such as file name directly in the SELECT statement, without requiring any ALTER TABLE – Override External Table Parameters From a Query in Oracle Database 12c Release 2 (12.2).
SQL*Loader Express Mode
Since Oracle 12.1 the sqlldr command-line utility supports “Express Mode” which by default reads a CSV file, and loads the data into a given table. Read this quick intro here. This can come in handy for scripting the load of a number of CSV files on an ad-hoc basis into tables that already have exactly the same structure as those CSV files.
> sqlldr userid=scott/tiger table=emp
This expects to find a file named “emp.dat” which contains CSV data to be loaded into the nominated table. Internally, it creates a temporary external table to load the data. Additional parameters can be added to change the filename, delimiters, field names, and other options.
APEX Data Workshop

The APEX Data Workshop is found under SQL Workshop > Utilities > Data Workshop and allows the developer to quickly load data from a CSV, tab-delimited, XML, or copy-and-paste from Excel into an existing or new table. This can be very handy when your client sends you some spreadsheets and you need to quickly load the data as one or more tables.
A related utility is the Create Application from Spreadsheet which does the same thing, plus creates a basic application to report and maintain the data in the new table.
APEX Data Loader Wizard
If your users need to load data on an ad-hoc, on-demand basis, and you don’t know necessarily what the structure of the files will be (e.g. the headings might change, or the order of the columns might change), you can use the APEX Data Loader Wizard to build an APEX application that guides your users in loading, mapping, and validating the data for themselves. If required you can customise the generated pages to add your own processing.
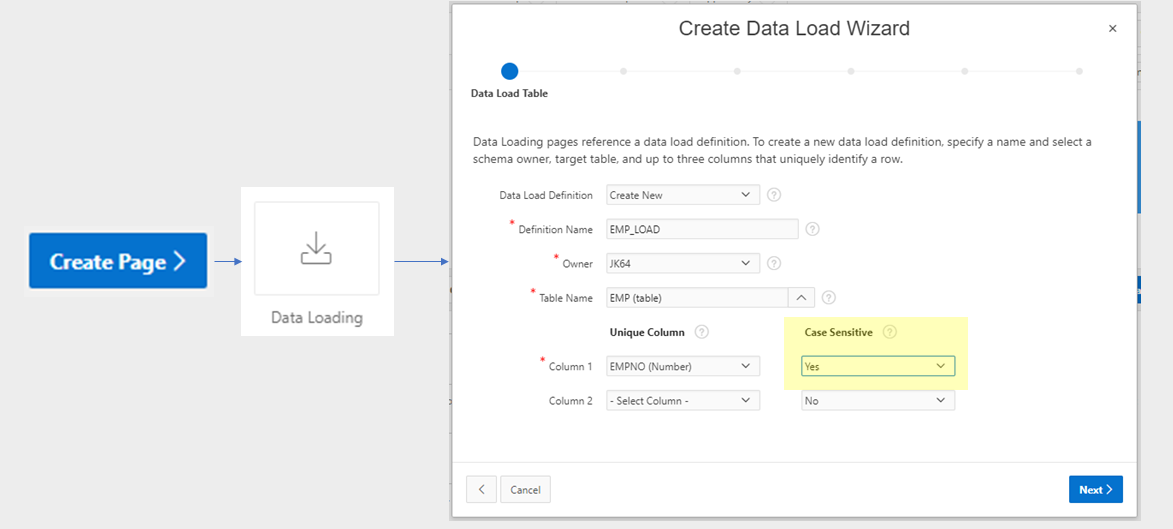
To create the wizard, click Create Page, choose Data Loading, and follow the steps to define the Data Load Definition and its associated pages. The definition determines the target table, the unique column(s) for data matching, transformation rules, and lookups (e.g. to get foreign keys for reference tables). Once this is done, the following four pages will be created for you:

You can customise these pages to modify the look and feel (e.g. moving some of the more complicated options in a collapsible region), or to add your own custom processing for the data.
For example, I will often add an additional process on either the 3rd page (to be run after the “Prepare Uploaded Data” process) that will do further processing of the loaded data. The process would be set up to only run When Button Pressed = “NEXT” and would have a Condition “Item is NULL or Zero” = “P111_ERROR_COUNT”. The result is that on the Data Validation (3rd) page, after reviewing the validation summary, the user clicks “Next” and the data is loaded and processed.
Alternatively, I sometimes want the user to view additional validation or summary information on the 4th page before doing further processing. In this case, I would add the process to the Data Load Results (4th) page, When Button Pressed = “FINISH”. For this to work, you need to modify the FINISH button to Submit the page (instead of redirecting). I also would add a CANCEL button to the page so the user can choose to not run the final processing if they wish.
Updating a Data Load Definition
The Data Load Definitions (one for each target table) may be found under Shared Components > Data Load Definitions. Here, you can modify the transformations and lookup tables for the definition. However, if the table structure has changed (e.g. a new column has been added), it will not automatically pick up the change. To reflect the change in the definition, you need to follow the following steps:
- Edit the Data Load Definition
- Click Re-create Data Load Pages
- Delete the new generated pages

This refreshes the Data Load Definition and creates 4 new pages for the wizard. Since you already had the pages you need (possibly with some customisations you’ve made) you don’t need the new pages so you can just delete them.
CSV_UTIL_PKG
The Alexandria PL/SQL Library includes CSV_UTIL_PKG which I’ve used in a number of projects. It’s simple to use and effective – it requires no APEX session, nothing but PL/SQL, and can be called from SQL for any CLOB data. It’s handy when you know ahead of time what the columns will be. You could read and interpret the headings in the first line from the file if you want to write some code to automatically determine which column is which – but personally in this case I’d lean towards using the APEX Data Loader Wizard instead and make the user do the mapping.
If you don’t already have the full Alexandria library installed, to use this package you must first create the schema types t_str_array and t_csv_tab. You will find the definition for these types in setup/types.sql. After that, simply install ora/csv_util_pkg.pks and ora/csv_util_pkg.pkb and you’re good to go.
In the example below I get a CSV file that a user has uploaded via my APEX application, convert it to a CLOB, then parse it using CSV_UTIL_PKG.clob_to_csv:
procedure parse_csv (filename in varchar2) is
bl blob; cl clob;
begin
select x.blob_content into bl
from apex_application_temp_files x
where x.name = parse_csv.filename;
cl := blob_to_clob(bl);
insert into csv_staging_lines
(session_id, line_no, school_code, school_name
,line_type, amount, line_description)
select sys_context('APEX$SESSION','APP_SESSION')
,line_number - 1
,c001 as school_code
,c002 as school_name
,c003 as line_type
,replace(replace(c004,'$',''),',','') as amount
,c005 as line_description
from table(csv_util_pkg.clob_to_csv(cl, p_skip_rows => 1))
where trim(line_raw) is not null;
end parse_csv;
Read more details on CSV_UTIL_PKG here.
LOB2Table
This PL/SQL package written and maintained by Michael Schmid parses CSV, delimited or Fixed-width data embedded in any LOB or VARCHAR2, including in a table with many records. The data can be read from any CLOB, BLOB, BFILE, or VARCHAR2. This makes it quite versatile, it reportedly provides excellent performance, and it includes a pipelined option. It will read up to 200 columns, with a maximum of 32K per record.
It requires execute privileges on SYS.DBMS_LOB and SYS.UTL_I18N and creates some object types and a database package. You can download the source from sourceforge. It appears to be well supported and was most recently updated in June 2018. I recommend checking it out.
select d.deptno, d.dname,
t.row_no,
t.column1, t.column2,
t.column3, t.column4from dept d
cross join table(
lob2table.separatedcolumns(
d.myclob, /* the data LOB */
chr(10), /* row separator */
',', /* column separator */
'"' /* delimiter (optional) */
) ) t;
Excel2Collection
This is a process type APEX plugin written by Anton Scheffer (AMIS) in 2013, and has been actively maintained since then. You can download it from here or find it on apex.world.
The plugin detects and parses CSV, XLS, XML 2003 and XLSX files which makes it very versatile. It will load 50 columns from the spreadsheet into an APEX collection (max 10K rows). If you need to load larger spreadsheets you can send Anton a donation and your email address and he’ll send you a database package that can handle larger files.
Solutions for Excel files
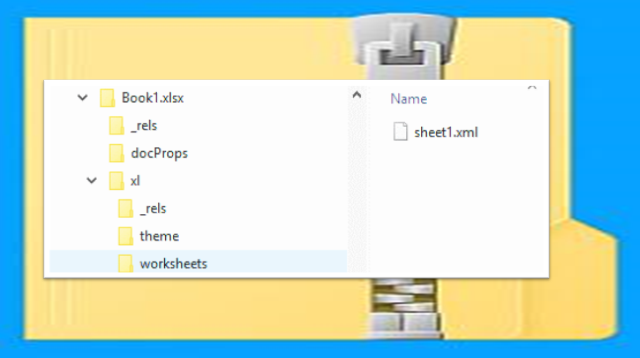
The first thing to know about XLSX files is that they are basically a ZIP file containing a folder structure filled with a number of XML documents. Parsing an XLSX file, therefore, involves first unzipping the file, reading the relevant XML documents and parsing their contents. As usual with any Microsoft file format, the internal structure of these XML documents can be quite complex so I’d much rather leave the work to someone who has already worked out the details. Thankfully, this has largely been done.
These are some solutions for loading data from Microsoft Excel files (XLS, XLSX) that I’ve come across. Again, “YMMV” – so test and evaluate them to determine if they will suit your needs.
- Alexandria PL/SQL Library OOXML_UTIL_PKG (XLSX files only) – Morten Braten, 2011
- Excel2Collection APEX process plugin (CSV, delimited, XLS and XLSX files) – Anton Scheffer, 2013
- Apache POI (XLS and XLSX files) – Christian Neumueller, 2013
- XLSX_PARSER (XLSX files only) – Carsten Czarski, 2018
- ExcelTable (XLS, XLSX, XLSM, XLSB, ODF files) – Marc Bleron, 2016
OOXML_UTIL_PKG
The Alexandria PL/SQL Library includes OOXML_UTIL_PKG which provides a number of utilities for parsing (and creating) XLSX, DOCX and PPTX files. It provides functions to get file attributes (including title, creator, last modified) and a list of worksheets in an XLSX. It provides functions to get the text data from any cell in any sheet, although for reasonable performance if you need more than one cell you should use the functions that returns a range of cells in one go.
Installation requires zip_util_pkg, sql_util_pkg, string_util_pkg, xml_util_pkg, xml_stylesheet_pkg, and ooxml_util_pkg, all of which are in the Alexandria library. Given this list of dependencies (and probably others I didn’t notice) I recommend installing the whole library – after all, there’s a lot of useful stuff in there so it’s worth it.
declare
l_blob blob;
l_names t_str_array := t_str_array('B3','C3','B4','C4','B5','C5');
l_values t_str_array;
begin
l_blob := file_util_pkg.get_blob_from_file('EXT_DIR','sample.xlsx');
l_values := ooxml_util_pkg.get_xlsx_cell_values(l_blob, 'Sheet1', l_names);
for i in 1..l_values.count loop
dbms_output.put_line(l_names(i) || ' = ' || l_values(i));
end loop;
end;
More details on OOXML_UTIL_PKG here.
Excel2Collection
As noted above, the Excel2Collection APEX plugin can detect and parse XLS, XML 2003 and XLSX files (as well as CSV files). The fact that it detects the file type automatically is a big plus for usability.
Apache POI
This solution involves installing Apache POI (“Poor Obfuscation Implementation”), a Java API for Microsoft products, into the database. The solution described by Christian Neumueller here parses XLS and XLSX files although it is admittedly not very efficient.
XLSX_PARSER
In 2018 Carsten Czarski posted a blog article “Easy XLSX Parser just with SQL and PL/SQL” listing a simple database package that parses XLSX files. This uses APEX_ZIP which comes with APEX, although using it does not require an APEX session or collections. It can load the file from a BLOB, or from APEX_APPLICATION_TEMP_FILES. It uses XMLTable to parse the XML content and return the text content of up to 50 columns for any worksheet in the file. It may be modified to support up to 1,000 columns.
To get a list of worksheets from a file:
select * from table(
xlsx_parser.get_worksheets(
p_xlsx_name => :P1_XLSX_FILE
));
To get the cells from a worksheet:
select * from table(
xlsx_parser.parse(
p_xlsx_name => :P1_XLSX_FILE,
p_worksheet_name => :P1_WORKSHEET_NAME
));
I used this solution in a recent APEX application but the client was still on APEX 4.2 which did not include APEX_ZIP; so I adapted it to use ZIP_UTIL_PKG from the Alexandria PL/SQL Library. If you’re interested in this implementation you can download the source code from here.
ExcelTable
ExcelTable is a powerful API for reading XLSX, XLSM, XLSB, XLS and ODF (.ods) spreadsheets. It is based on PL/SQL + Java and reportedly performs very well. It requires a grant on DBMS_CRYPTO which allows it to read encrypted files. It includes an API for extracting cell comments as well. It can return the results as a pipelined table or as a refcursor. It knows how to interpret special cell values and error codes such as booleans, #N/A, #DIV/0!, #VALUE!, #REF! etc.
It includes API calls that allow you to map the input from a spreadsheet to insert or merge into a table, defining how to map columns in the spreadsheet to your table columns, which may improve throughput and may mean it uses less memory to process large files.
The API was written by Marc Bleron in 2016 and has been in active maintenance since then (latest update 22/10/2018 as of the writing of this article). You can read more details and download it from here: https://github.com/mbleron/ExcelTable
EDIT 17/12/2018: thanks to Nicholas Ochoa who alerted me to this one.
APEX 19.1 Statement of Direction
DISCLAIMER: all comments and code samples regarding APEX 19.1 in this article are based primarily on the Statement of Direction and are subject to Oracle’s “Safe Harbour” provision and must therefore not be relied on when making business decisions.
The SOD for the next release of APEX includes the following note, which is exciting:
“New Data Loading: The data upload functionality in SQL Workshop will be modernized with a new drag & drop user interface and support for native Excel, CSV, XML and JSON documents. The same capabilities will be added to the Create App from Spreadsheet wizard and a new, public data loading PL/SQL API will be made available.”
APEX Statement of Direction
Whether this release will include corresponding enhancements to the APEX Data Loader Wizard remains to be seen; I hope the wizard is enhanced to accept XLSX files because this is something a lot of my users would be happy about.
EDIT 6/2/2019: Early Adopter of APEX 19.1 reveals that the Data Workshop supports loading CSV, XLSX, XML and JSON data. If you load an XLSX file, it will allow you to choose which worksheet to load the data from (only one worksheet at a time, though). Also, the Data Loader Wizard has not been updated to use the new API, it still only supports loading from CSV files. This is on the radar for a future version of APEX, however.
APEX_DATA_PARSER
The most promising part of the APEX 19.1 SOD is the PL/SQL API bit, which will mean no plugins or 3rd-party code will be needed to parse XLSX files. It appears the package will be called APEX_DATA_PARSER, providing routines to automatically detect and parse file formats including XLSX, XML, JSON and CSV/tab-delimited files, e.g.:
select * from table(
apex_data_parser.parse(
p_content => blob,
p_file_name => 'test.xlsx',
p_xlsx_sheet_name => 'sheet1.xml'));
select * from table(
apex_data_parser.parse(
p_content => blob,
p_file_name => 'test.xlsx',
p_xlsx_sheet_name => 'sheet1.xml'));
select * from table(
apex_data_parser.parse(
p_content => blob,
p_file_name => 'test.xml'));
select * from table(
apex_data_parser.parse(
p_content => blob,
p_file_name => 'test.js'));
select * from table(
apex_data_parser.parse(
p_content => blob,
p_file_name => 'test.csv'));
Capability Matrix
| Method | CSV | Fixed width | XLS | XLSX |
|---|---|---|---|---|
| External Table | Yes | Yes | ||
| APEX Data Workshop | Yes | 19.1 | ||
| APEX Data Loader Wizard | Yes | |||
| CSV_UTIL_PKG | Yes | |||
| LOB2Table | Yes | Yes | ||
| Excel2Collection | Yes | Yes | Yes | |
| OOXML_UTIL_PKG | Yes | |||
| Apache POI | Yes | Yes | ||
| XLSX_PARSER | Yes | |||
| APEX_DATA_PARSER | 19.1 | 19.1 | ||
| ExcelTable | Yes | Yes | ||
| csv2db | Yes |
Have I missed a tool or 3rd-party code that you have found useful for parsing files to load into your APEX application? If so, please comment below.
This blog post is partially based on the following presentation delivered at the AUSOUG Connect 2018 Perth conference, November 2018.
Related
- SQL*Loader Express: https://connor-mcdonald.com/2015/08/17/loading-file-data-easier-than-you-think/
- Alexandria PL/SQL Library: https://github.com/mortenbra/alexandria-plsql-utils
- LOB2Table: https://sourceforge.net/p/lob2table/wiki/Home/
- Excel2Collection (Anton Scheffer): https://github.com/antonscheffer/excel2collections
- ORDS excel2collection (Kallman): https://joelkallman.blogspot.com/2017/06/excel2collection-functionality-of-ords.html
- Apache POI (Christian Neumueller): https://chrisonoracle.wordpress.com/2013/11/13/read-excel-file-in-plsql-using-java-in-the-db/
- XLSX_PARSER (Carsten Czarski): https://blogs.oracle.com/apex/easy-xlsx-parser%3a-just-with-sql-and-plsql
- APEX 19.1 Statement of Direction https://apex.oracle.com/en/learn/resources/sod/
- ExcelTable https://github.com/mbleron/ExcelTable
APEX / apex-19.1 / apex-4.2 / apex-5.0 / CSV / data loading / Excel / spreadsheets / XLS / XLSX /

About Jeffrey Kemp
Application Designer & Developer at Oracle specialising in Oracle APEX (Application Express), Oracle SQL and PL/SQL. Oracle ACE Alumni ♠️. Piano player, father, husband, Christian.
The views expressed on this blog are my own and do not necessarily reflect the views of Oracle.
1. Overview
This document will be helpful to upload a excel file directly and view it as a report.
2. Technologies and Tools Used
- Oracle Plsql.
3. Use Case
Customer wants to upload a excel file and view it as a report.
4. Architecture
We can achieve this by using below simple method.
Steps to follow.
Step:1
Create a region and File browser item as PX_XLSX_FILE.
Step:2
Set PX_XLSX_FILE item Setting .
storage type : APEX_APPLICATION_TEMP_FILES
Purge File at : End of Session.
Code:
Run the below plsql object.
create or replace package body xlsx_parser is
g_worksheets_path_prefix constant varchar2(14) := ‘xl/worksheets/’;
–==================================================================================================================
function get_date( p_xlsx_date_number in number ) return date is
begin
return
case when p_xlsx_date_number > 61
then DATE’1900-01-01′ – 2 + p_xlsx_date_number
else DATE’1900-01-01′ – 1 + p_xlsx_date_number
end;
end get_date;
–==================================================================================================================
procedure get_blob_content(
p_xlsx_name in varchar2,
p_xlsx_content in out nocopy blob )
is
begin
if p_xlsx_name is not null then
select blob_content into p_xlsx_content
from apex_application_temp_files
where name = p_xlsx_name;
end if;
exception
when no_data_found then
null;
end get_blob_content;
–==================================================================================================================
function extract_worksheet(
p_xlsx in blob,
p_worksheet_name in varchar2 ) return blob
is
l_worksheet blob;
begin
if p_xlsx is null or p_worksheet_name is null then
return null;
end if;
l_worksheet := apex_zip.get_file_content(
p_zipped_blob => p_xlsx,
p_file_name => g_worksheets_path_prefix || p_worksheet_name || ‘.xml’ );
if l_worksheet is null then
raise_application_error(-20000, ‘WORKSHEET “‘ || p_worksheet_name || ‘” DOES NOT EXIST’);
end if;
return l_worksheet;
end extract_worksheet;
–==================================================================================================================
procedure extract_shared_strings(
p_xlsx in blob,
p_strings in out nocopy wwv_flow_global.vc_arr2 )
is
l_shared_strings blob;
begin
l_shared_strings := apex_zip.get_file_content(
p_zipped_blob => p_xlsx,
p_file_name => ‘xl/sharedStrings.xml’ );
if l_shared_strings is null then
return;
end if;
select shared_string
bulk collect into p_strings
from xmltable(
xmlnamespaces( default ‘http://schemas.openxmlformats.org/spreadsheetml/2006/main’ ),
‘//si’
passing xmltype.createxml( l_shared_strings, nls_charset_id(‘AL32UTF8’), null )
columns
shared_string varchar2(4000) path ‘t/text()’ );
end extract_shared_strings;
–==================================================================================================================
procedure extract_date_styles(
p_xlsx in blob,
p_format_codes in out nocopy wwv_flow_global.vc_arr2 )
is
l_stylesheet blob;
begin
l_stylesheet := apex_zip.get_file_content(
p_zipped_blob => p_xlsx,
p_file_name => ‘xl/styles.xml’ );
if l_stylesheet is null then
return;
end if;
select lower( n.formatCode )
bulk collect into p_format_codes
from
xmltable(
xmlnamespaces( default ‘http://schemas.openxmlformats.org/spreadsheetml/2006/main’ ),
‘//cellXfs/xf’
passing xmltype.createxml( l_stylesheet, nls_charset_id(‘AL32UTF8’), null )
columns
numFmtId number path ‘@numFmtId’ ) s,
xmltable(
xmlnamespaces( default ‘http://schemas.openxmlformats.org/spreadsheetml/2006/main’ ),
‘//numFmts/numFmt’
passing xmltype.createxml( l_stylesheet, nls_charset_id(‘AL32UTF8’), null )
columns
formatCode varchar2(255) path ‘@formatCode’,
numFmtId number path ‘@numFmtId’ ) n
where s.numFmtId = n.numFmtId ( + );
end extract_date_styles;
–==================================================================================================================
function convert_ref_to_col#( p_col_ref in varchar2 ) return pls_integer is
l_colpart varchar2(10);
l_linepart varchar2(10);
begin
l_colpart := replace(translate(p_col_ref,’1234567890′,’__________’), ‘_’);
if length( l_colpart ) = 1 then
return ascii( l_colpart ) – 64;
else
return ( ascii( substr( l_colpart, 1, 1 ) ) – 64 ) * 26 + ( ascii( substr( l_colpart, 2, 1 ) ) – 64 );
end if;
end convert_ref_to_col#;
–==================================================================================================================
procedure reset_row( p_parsed_row in out nocopy xlsx_row_t ) is
begin
— reset row
p_parsed_row.col01 := null; p_parsed_row.col02 := null; p_parsed_row.col03 := null; p_parsed_row.col04 := null; p_parsed_row.col05 := null;
p_parsed_row.col06 := null; p_parsed_row.col07 := null; p_parsed_row.col08 := null; p_parsed_row.col09 := null; p_parsed_row.col10 := null;
p_parsed_row.col11 := null; p_parsed_row.col12 := null; p_parsed_row.col13 := null; p_parsed_row.col14 := null; p_parsed_row.col15 := null;
p_parsed_row.col16 := null; p_parsed_row.col17 := null; p_parsed_row.col18 := null; p_parsed_row.col19 := null; p_parsed_row.col20 := null;
p_parsed_row.col21 := null; p_parsed_row.col22 := null; p_parsed_row.col23 := null; p_parsed_row.col24 := null; p_parsed_row.col25 := null;
p_parsed_row.col26 := null; p_parsed_row.col27 := null; p_parsed_row.col28 := null; p_parsed_row.col29 := null; p_parsed_row.col30 := null;
p_parsed_row.col31 := null; p_parsed_row.col32 := null; p_parsed_row.col33 := null; p_parsed_row.col34 := null; p_parsed_row.col35 := null;
p_parsed_row.col36 := null; p_parsed_row.col37 := null; p_parsed_row.col38 := null; p_parsed_row.col39 := null; p_parsed_row.col40 := null;
p_parsed_row.col41 := null; p_parsed_row.col42 := null; p_parsed_row.col43 := null; p_parsed_row.col44 := null; p_parsed_row.col45 := null;
p_parsed_row.col46 := null; p_parsed_row.col47 := null; p_parsed_row.col48 := null; p_parsed_row.col49 := null; p_parsed_row.col50 := null;
end reset_row;
–==================================================================================================================
function parse(
p_xlsx_name in varchar2 default null,
p_xlsx_content in blob default null,
p_worksheet_name in varchar2 default ‘sheet1’,
p_max_rows in number default 1000000 ) return xlsx_tab_t pipelined
is
l_worksheet blob;
l_xlsx_content blob;
l_shared_strings wwv_flow_global.vc_arr2;
l_format_codes wwv_flow_global.vc_arr2;
l_parsed_row xlsx_row_t;
l_first_row boolean := true;
l_value varchar2(32767);
l_line# pls_integer := 1;
l_real_col# pls_integer;
l_row_has_content boolean := false;
begin
if p_xlsx_content is null then
get_blob_content( p_xlsx_name, l_xlsx_content );
else
l_xlsx_content := p_xlsx_content;
end if;
if l_xlsx_content is null then
return;
end if;
l_worksheet := extract_worksheet(
p_xlsx => l_xlsx_content,
p_worksheet_name => p_worksheet_name );
extract_shared_strings(
p_xlsx => l_xlsx_content,
p_strings => l_shared_strings );
extract_date_styles(
p_xlsx => l_xlsx_content,
p_format_codes => l_format_codes );
— the actual XML parsing starts here
for i in (
select
r.xlsx_row,
c.xlsx_col#,
c.xlsx_col,
c.xlsx_col_type,
c.xlsx_col_style,
c.xlsx_val
from xmltable(
xmlnamespaces( default ‘http://schemas.openxmlformats.org/spreadsheetml/2006/main’ ),
‘//row’
passing xmltype.createxml( l_worksheet, nls_charset_id(‘AL32UTF8’), null )
columns
xlsx_row number path ‘@r’,
xlsx_cols xmltype path ‘.’
) r, xmltable (
xmlnamespaces( default ‘http://schemas.openxmlformats.org/spreadsheetml/2006/main’ ),
‘//c’
passing r.xlsx_cols
columns
xlsx_col# for ordinality,
xlsx_col varchar2(15) path ‘@r’,
xlsx_col_type varchar2(15) path ‘@t’,
xlsx_col_style varchar2(15) path ‘@s’,
xlsx_val varchar2(4000) path ‘v/text()’
) c
where p_max_rows is null or r.xlsx_row <= p_max_rows
) loop
if i.xlsx_col# = 1 then
l_parsed_row.line# := l_line#;
if not l_first_row then
pipe row( l_parsed_row );
l_line# := l_line# + 1;
reset_row( l_parsed_row );
l_row_has_content := false;
else
l_first_row := false;
end if;
end if;
if i.xlsx_col_type = ‘s’ then
if l_shared_strings.exists( i.xlsx_val + 1) then
l_value := l_shared_strings( i.xlsx_val + 1);
else
l_value := ‘[Data Error: N/A]’ ;
end if;
else
if l_format_codes.exists( i.xlsx_col_style + 1 ) and (
instr( l_format_codes( i.xlsx_col_style + 1 ), ‘d’ ) > 0 and
instr( l_format_codes( i.xlsx_col_style + 1 ), ‘m’ ) > 0 )
then
l_value := to_char( get_date( i.xlsx_val ), c_date_format );
else
l_value := i.xlsx_val;
end if;
end if;
pragma inline( convert_ref_to_col#, ‘YES’ );
l_real_col# := convert_ref_to_col#( i.xlsx_col );
if l_real_col# between 1 and 50 then
l_row_has_content := true;
end if;
— we currently support 50 columns – but this can easily be increased. Just add additional lines
— as follows:
— when l_real_col# = {nn} then l_parsed_row.col{nn} := l_value;
case
when l_real_col# = 1 then l_parsed_row.col01 := l_value;
when l_real_col# = 2 then l_parsed_row.col02 := l_value;
when l_real_col# = 3 then l_parsed_row.col03 := l_value;
when l_real_col# = 4 then l_parsed_row.col04 := l_value;
when l_real_col# = 5 then l_parsed_row.col05 := l_value;
when l_real_col# = 6 then l_parsed_row.col06 := l_value;
when l_real_col# = 7 then l_parsed_row.col07 := l_value;
when l_real_col# = 8 then l_parsed_row.col08 := l_value;
when l_real_col# = 9 then l_parsed_row.col09 := l_value;
when l_real_col# = 10 then l_parsed_row.col10 := l_value;
when l_real_col# = 11 then l_parsed_row.col11 := l_value;
when l_real_col# = 12 then l_parsed_row.col12 := l_value;
when l_real_col# = 13 then l_parsed_row.col13 := l_value;
when l_real_col# = 14 then l_parsed_row.col14 := l_value;
when l_real_col# = 15 then l_parsed_row.col15 := l_value;
when l_real_col# = 16 then l_parsed_row.col16 := l_value;
when l_real_col# = 17 then l_parsed_row.col17 := l_value;
when l_real_col# = 18 then l_parsed_row.col18 := l_value;
when l_real_col# = 19 then l_parsed_row.col19 := l_value;
when l_real_col# = 20 then l_parsed_row.col20 := l_value;
when l_real_col# = 21 then l_parsed_row.col21 := l_value;
when l_real_col# = 22 then l_parsed_row.col22 := l_value;
when l_real_col# = 23 then l_parsed_row.col23 := l_value;
when l_real_col# = 24 then l_parsed_row.col24 := l_value;
when l_real_col# = 25 then l_parsed_row.col25 := l_value;
when l_real_col# = 26 then l_parsed_row.col26 := l_value;
when l_real_col# = 27 then l_parsed_row.col27 := l_value;
when l_real_col# = 28 then l_parsed_row.col28 := l_value;
when l_real_col# = 29 then l_parsed_row.col29 := l_value;
when l_real_col# = 30 then l_parsed_row.col30 := l_value;
when l_real_col# = 31 then l_parsed_row.col31 := l_value;
when l_real_col# = 32 then l_parsed_row.col32 := l_value;
when l_real_col# = 33 then l_parsed_row.col33 := l_value;
when l_real_col# = 34 then l_parsed_row.col34 := l_value;
when l_real_col# = 35 then l_parsed_row.col35 := l_value;
when l_real_col# = 36 then l_parsed_row.col36 := l_value;
when l_real_col# = 37 then l_parsed_row.col37 := l_value;
when l_real_col# = 38 then l_parsed_row.col38 := l_value;
when l_real_col# = 39 then l_parsed_row.col39 := l_value;
when l_real_col# = 40 then l_parsed_row.col40 := l_value;
when l_real_col# = 41 then l_parsed_row.col41 := l_value;
when l_real_col# = 42 then l_parsed_row.col42 := l_value;
when l_real_col# = 43 then l_parsed_row.col43 := l_value;
when l_real_col# = 44 then l_parsed_row.col44 := l_value;
when l_real_col# = 45 then l_parsed_row.col45 := l_value;
when l_real_col# = 46 then l_parsed_row.col46 := l_value;
when l_real_col# = 47 then l_parsed_row.col47 := l_value;
when l_real_col# = 48 then l_parsed_row.col48 := l_value;
when l_real_col# = 49 then l_parsed_row.col49 := l_value;
when l_real_col# = 50 then l_parsed_row.col50 := l_value;
else null;
end case;
end loop;
if l_row_has_content then
l_parsed_row.line# := l_line#;
pipe row( l_parsed_row );
end if;
return;
end parse;
–==================================================================================================================
function get_worksheets(
p_xlsx_content in blob default null,
p_xlsx_name in varchar2 default null ) return apex_t_varchar2 pipelined
is
l_zip_files apex_zip.t_files;
l_xlsx_content blob;
begin
if p_xlsx_content is null then
get_blob_content( p_xlsx_name, l_xlsx_content );
else
l_xlsx_content := p_xlsx_content;
end if;
l_zip_files := apex_zip.get_files(
p_zipped_blob => l_xlsx_content );
for i in 1 .. l_zip_files.count loop
if substr( l_zip_files( i ), 1, length( g_worksheets_path_prefix ) ) = g_worksheets_path_prefix then
pipe row( rtrim( substr( l_zip_files ( i ), length( g_worksheets_path_prefix ) + 1 ), ‘.xml’ ) );
end if;
end loop;
return;
end get_worksheets;
end xlsx_parser;
Step:3
Create a button as Submit in File browser region.
Step:4
Create a Classic report region with sql code as
Code:
select *
from table( xlsx_parser.parse(
p_xlsx_name => :PX_XLSX_FILE ) )
where line# != 1
1. Screen Shot
Output:
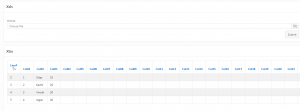
Excel input file content
| Sno | Name | Id |
| 1 | Uday | 10 |
| 2 | Karthi | 20 |
| 3 | Vinoth | 30 |
| 4 | Jegan | 40 |
Source Link: https://blogs.oracle.com/apex/easy-xlsx-parser:-just-with-sql-and-plsql
Post Views:
1,008
Loading Excel Into APEX Applications Update
In December 2017 I presented at Tech17 and published a blog outlining several options for loading Excel data into APEX applications (see Options For Loading Excel Data Into APEX Applications).
One of the findings from my investigation was that there were limited options for loading vanilla Excel files automatically into the Oracle database. Most solutions require pre-converting to CSV format, or manual intervention.
With the release of Application Express 19.1, Oracle has introduced and tweaked some wizards that upload file data and introduced a new API, APEX_DATA_PARSER, that simplifies loading Excel data into APEX and the database.
APEX 19.1 Application Express Changes
Create Application From a File Wizard
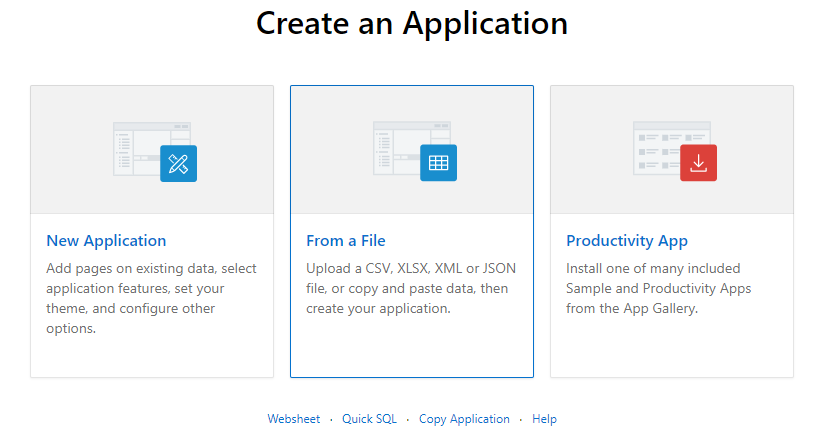
Figure 1 – Create an Application From a File
- As with 18.1, initially the wizard takes you through the data load process; to upload a CSV, XLSX, XML or JSON file, or to copy and paste data. Then once data has loaded into a new table, there is the option to continue to the Create Application wizard or not.
- In 19.1 the data load element provides a new facility to drag/upload an Excel XLSX file, rather than needing to pre-convert to CSV format.
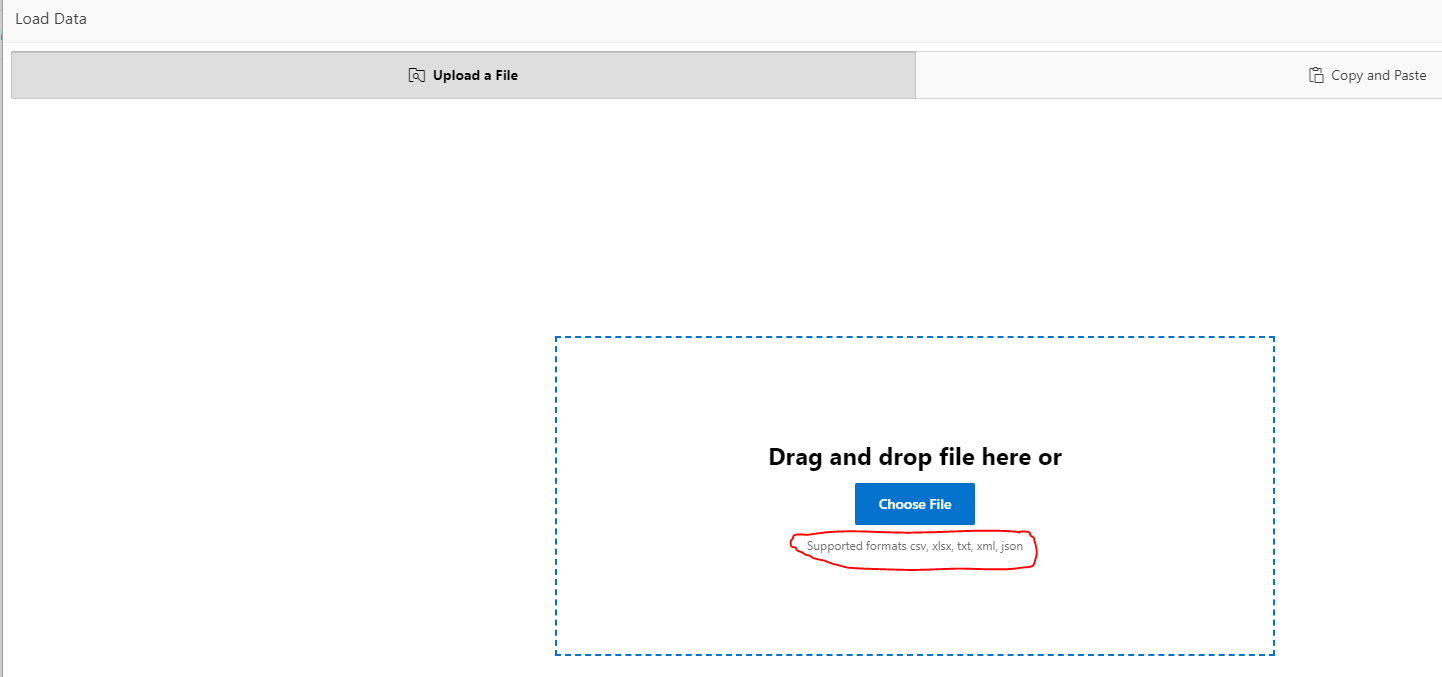
Figure 2 – Upload a File Screen
SQL Workshop
- The Data Workshop Load Data utility is now the same configuration as the data load element incorporated into the Create Application wizard.
Page Data Loading Wizard
- No significant change in 19.1 – the uploaded file, or copied and pasted data, still needs to be comma separated or tab delimited.
APEX_DATA_PARSER API
The new APEX_DATA_PARSER package implements a file parser, which supports XML, JSON, CSV and XLSX files.
In order to replicate the file upload and reporting that I have used to illustrate the APEX_DATA_PARSER API, you will need to complete the following steps:
- Create an application page.
- Add a File Browse page item.
- Add a button to submit the page.
- Either the file will be sent to the server in APEX_APPLICATION_TEMP_FILES table, or
- Add a process to insert the details of the file into a custom table, e.g. UPLOADED_FILES (the option I took).
- Add a classic report to query details of the file using the APEX_DATA_PARSER API
PARSE Function
The main function of the API is the PARSE() function.
It allows parsing of XML, XLSX, CSV or JSON files and returns a table with rows of the APEX_T_PARSER_ROW type, with the following structure:
LINE_NUMBER, COL001, COL002, COL003, … COL299, COL300
It allows a maximum of 300 columns all returned in VARCHAR2 format (maximum length 4000 bytes).
Parsing is done on-the-fly with no data written to tables or collections. It requires the file contents to be a BLOB. This can come from any of multiple sources e.g. a file upload (as in this blog), an existing table, from using DBMS_LOB package or from a web service.
By parsing the file, reporting of the data associated with the parsed file is possible.
In my examples below, I have parsed an Excel XLSX file.

Figure 3 – Report SQL Query using Parse()
In this case, using a Classic report, the column headers derive from the Excel file first row, with the Heading Type attribute for the report set to ‘None’.
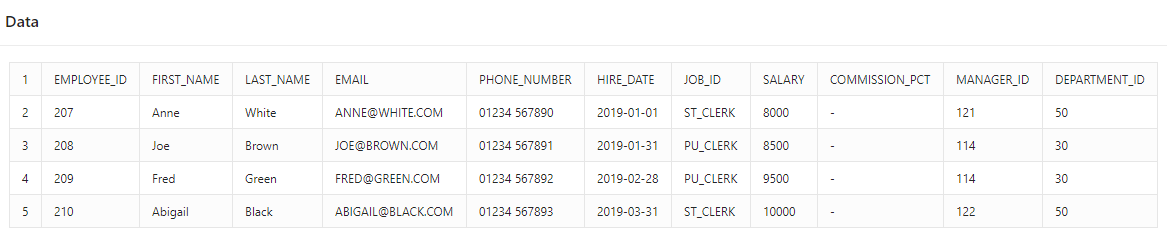
Figure 4 – Report Output using Parse()
There are a number of parameters available to use with the PARSE function, depending on whether the file parsed is XLSX, CSV, JSON or XML.
As well as the file content (BLOB), at least one of P_FILENAME, P_FILE_TYPE or P_FILE_PROFILE must be specified. My example uses P_FILENAME. For XLSX files, another particularly relevant parameter is P_XLSX_SHEET_NAME. This allows the name of the worksheet to be parsed. If excluded, as in my example, the function will use the first worksheet found.
As well as the PARSE() function, so other functions are included in the package. Some of which, but not all, are outlined below.
GET_FILE_PROFILE function
The GET_FILE_PROFILE function can be used to obtain metadata about the last parsed file, and returns a CLOB in JSON format. Details of the file depend on the format of the file but may include column names, XLSX worksheet name or CSV delimiter
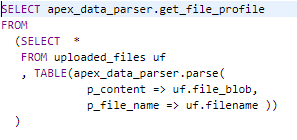
Figure 5 – Get File Profile SQL
The result of the SQL above returns XLSX-specific meta-data in JSON format.
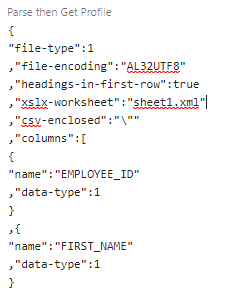
Figure 6 – Get File Profile Return JSON
DISCOVERER Function
The DISCOVERER function acts as a shortcut alternative to using the GET_FILE_PROFILE function after PARSE(), combining both elements and returning a CLOB in JSON format.
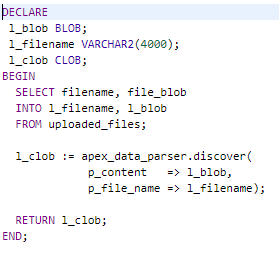
Figure 7 – Discoverer SQL
Similarly, the result of the SQL above returns XLSX-specific meta-data in JSON format.

Figure 8 – Discoverer Return JSON
Perhaps DISCOVERER is better than GET_FILE_PROFILE since it returns details of original column formats, rather than as VARCHAR2() as returned by PARSE().
GET_COLUMNS Function
The GET_COLUMNS function returns details about the columns in the parsed file’s profile as a table with type APEX_T_PARSER_COLUMNS. The function is used in conjunction with DISCOVERER() or GET_FILE_PROFILE(), which first computes the profile before GET_COLUMNS() returns the list of columns. Again, this works better in conjunction with DISCOVERER() to return the original Excel data types.
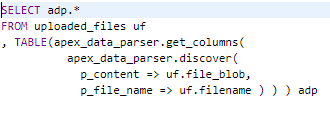
Figure 9 – Get Columns using Discoverer SQL
The report below illustrates the returned list of columns based on the SQL above
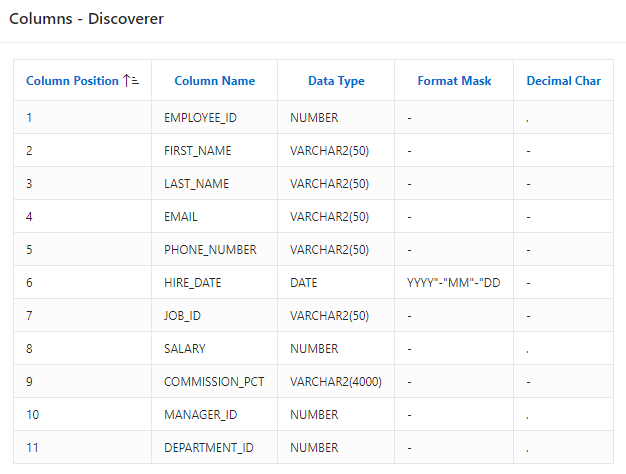
Figure 10 – Get Columns using Discoverer Report
GET_XLSX_WORKSHEETS Function
The GET_XLSX_WORKSHEETS function returns details of all the worksheets in an XLSX workbook as table with type APEX_T_PARSER_WORKSHEETS. In this case, there is no pre-requisite to obtain the profile of the parsed file.
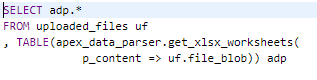
Figure 11- Get Worksheets SQL
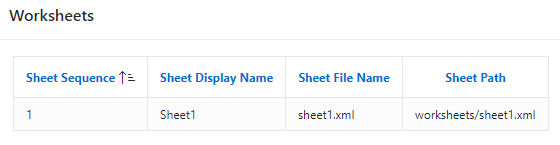
Figure 12 – Get Worksheets Report
More information about the all the functions available with the APEX_DATA_PARSER API, and the parameters used with them, is documented in the Oracle APEX 19.1 Release API Reference.
Summary
With release 19.1, APEX has improved the functionality for loading external data into APEX applications or the database, especially with the new APEX_DATA_PARSER API package.
The PARSE() function, in particular, allows Excel .XLSX data (amongst other formats) to be parsed into a table type on the fly. This can greatly simplify the process of loading Excel data.
Once the data is in the returned table, this opens up the data held within it to standard database functionality.
It is just a small step to INSERT the data into target application tables, or to use joins or PL/SQL loops to otherwise process or validate the data.
For more information, get in touch with our experts to find out more about our APEX Services or book a meeting…

Author: Philip Ratcliffe
Job Title: Oracle APEX Development Consultant
Bio: Philip is a Development Consultant at DSP-Explorer. Building on considerable experience in development including using Oracle PL/SQL and supporting Oracle EBS, Philip is employing APEX to provide quality, bespoke software solutions to a range of organisations.
Excel Gateway for Oracle APEX
No possibility to let your users access your APEX app? Consider using our tool to handle that in a good and modern way.
Create your own Excel template(s) in APEX, email them to your recipient(s) and then upload the finished file.
Now you can check and correct the data. If everything is well, publish the data for further analysis, reports etc.

Requirement
- Oracle Application Express 21.1 (or higher)
- Oracle Database 12.2 (or higher)
Installation
Go into the APEX workspace, where you like to install the «Excel Gateway for Oracle APEX» app and import the file «/src/apex/excel_gateway_for_oracle_apex.sql» as a database application.
This will install all DB-Objects and the application
Getting Started

1. Create Template
First step is to create a new Excel template

- Click «Create Template» and follow the wizard
- Give your template a unique name
- Optional you can enter a deadline which is needed to calculate when the application will send reminders
- You need a sheet protection to prevent various actions. Then choose a password for your workbook here
- You can enter a maximum number of rows which indicates how many rows are available to the editor
- Adopt specifications from existing templates
Second step is to add column headings to the template

- Drag and drop the titles from the left area (1) to the right (2)
Use the up or down arrows to change the order
The title can be deleted with the recycle bin - If you need new titles, click «Add Header» (3)

- Enter the name of the title
- Enter the width for the column in your Excel Spreadsheet
- If the column in your table needs validation, choose one here (for example number, date, email…)
- If you want the column shows a dropdown list, enter the values here
Next step is to add header-groups to the template (optional)

Choose a heading group for each column that needs merge cells
If you need new header-groups, click on «Add Header-Group» and create a new one
For this you have to enter the name, background and font color
The next step is to set the background and font color for the columns

You can use the Color Picker for this
In the last step, formulas or min/max values can be set for the validations

For number or date validations, use Formula 1 as the minimum and Formula 2 as the maximum value.
If the validation is «Formula», enter the formula you need in Formula 1.
Click «Show Columns/Info» for more details and examples.
Finally, you get an overview.
Before you create the template you can download a preview file. To do this, click the «Preview» button.
Everything is fine, click «Save Template» to create.

2. Send Template

First of all the template has to be selected (1).
Next, person(s) need to be added (2). All person(s) involved in the process are listed in the grid (3).
If you want to add person(s), click on «Add Person» and select the person(s) in the modal dialog.

Click «Add Person» to continue.
Now all persons involved in the process are displayed and the template can be sent by email.
To do this, a mailtype must be selected first.
There are three different types:
- Initial Mail — all templates that have not yet been sent and processed
- Correction Mail — all templates where corrections must be made
- Reminder Mail — all templates where the deadline has passed

When a selection is made, the grid is always updated and only the affected recipients are displayed.
For example, the initial email can be sent only once a time and a reminder can be sent only when the deadline is exceeded.
So first select «Initial Mail» and then click «Send Mail» to send everyone the initial email with the selected template.
All available emails can also be sent automatically.
To do this, click on «Automations». The dialog shows how the status of the automation is and on which days it should be sent if the function is enabled.

3. Upload Template
After sending e-mails, the recipient must fill them out and send them back.
To upload the finished template, navigate to «Upload template» in the navigation menu and click «Upload».

Note: If something should fail during the upload, you can check the error log to find out what the problem is.
4. Check Data
If the upload was successful, the data can be checked.
To do this, navigate to «Check data» and select the one to be checked.

This example shows data without errors that were detected by the application via the previously defined validations.

If incorrect data were detected by the application, this is displayed in the «Validation» column.
For example, an incorrect email address was detected here.

Now there are two options.
- The incorrect data can be corrected directly in the application or
- a new excel file will be created in which all incorrect rows are listed. To create this, click «Provide Correction» and then sent it as a «Correction Mail» (navigate to «Send Mail» and select the mailtype «Correction Mail»).
If everything is fine, the status can be set to «Completed».
All the data that are «Completed» are available for export.

5. Publication / Export Data
All data are displayed here and are available for download.
Alternatively, interactive reporting can be done here.

How to contribute as a developer to this project
This github repository is for developers willing to contribute to the upcoming version of Excel Gateway for Oracle APEX
- Clone/fork the repository apex-excel-gateway to get your own copy.
- Create a workspace with the ID 33850085021086653. For this you will
need your own APEX environment. - Run /src/install_all_scratch_dev.sql.
When prompted enter the parameters.
This will install all DB-Objects and the application with fixed ID 445.
Make sure you have Application ID 445 free for this. - Make your changes in the app and/or db objects.
- Commit your changes in your own branch.
Preferable a dedicated branch for the feature you’re working on. - Send in a pull request for review.
We will then verify the changes before accepting the pull request.
We might ask you to update your pull request based on our findings.
Some important rules:
- Retain Workspace ID and Application ID, otherwise each and every file of the application export will be marked as changed.
Easiest way to achieve this is to use the provided development install script mentioned above. - Always enable «Export as ZIP» and «Export with Original IDs».
Getting in touch
Send a DM on Twitter to Timo Herwix (@therwix) to get involved.