
Хитрости »
24 Июль 2013 94420 просмотров
Как получить слово после последнего пробела
Получить слово до первого пробела достаточно просто:
=ПСТР(A1;1;НАЙТИ(» «;A1)-1)
=MID(A1,1,FIND(» «,A1)-1)
Но куда чаще сложности возникают с получением слова(символа), находящегося на определенной позиции между пробелом. Я беру в качестве примера пробел, но на самом деле это может быть абсолютно любой символ. Например, для получения второго слова(т.е. между первым и вторым пробелом), можно составить такую формулу:
=ПСТР(A1;НАЙТИ(» «;A1)+1;НАЙТИ(» «;A1;НАЙТИ(» «;A1)+1)-НАЙТИ(» «;A1)-1)
=MID(A1,FIND(» «,A1)+1,FIND(» «,A1,FIND(» «,A1)+1)-FIND(» «,A1)-1)
На мой взгляд, выглядит несколько закручено, хотя все не так уж сложно:
- НАЙТИ(» «;A1)+1 — ищем позицию первого пробела в ячейке A1
- НАЙТИ(» «;A1;НАЙТИ(» «;A1)+1) — ищем позицию второго пробела и затем из этой позиции вычитаем позицию первого пробела(-НАЙТИ(» «;A1))
Но есть проблема — если второго пробела нет, то формула выдаст ошибку #ЗНАЧ!(#VALUE!). Тогда придется еще и проверку на ошибку делать, что явно не добавит формуле элегантности. А если надо не второе слово, а третье, пятое? Поэтому я предпочитаю использовать такую формулу:
=ПОДСТАВИТЬ(ПРАВСИМВ(ПСТР(» «&ПОДСТАВИТЬ(A1;» «;ПОВТОР(» «;999));1;999*2);999);» «;»»)
=SUBSTITUTE(RIGHT(MID(» «&SUBSTITUTE(A1,» «,REPT(» «,999)),1,999*2),999),» «,»»)
На первый взгляд куда кошмарнее, чем первая. Но у неё есть ряд преимуществ:
— она не нуждается в проверке на отсутствие пробелов
— изменением одного числа можно получить не второе, а 3-е, 4-е и т.д. слово.
Разберем основные моменты использования этой формулы. Во-первых: формула вытаскивает второе слово от начала строки. Во-вторых: чтобы получить первое слово от начала строки, нужно в блоке 999*2 заменить 2 на 1:
=ПОДСТАВИТЬ(ПРАВСИМВ(ПСТР(» «&ПОДСТАВИТЬ(A1;» «;ПОВТОР(» «;999));1;999*1);999);» «;»»)
=SUBSTITUTE(RIGHT(MID(» «&SUBSTITUTE(A1,» «,REPT(» «,999)),1,999*1),999),» «,»»)
Чтобы получить 5-е слово — меняем на 5:
=ПОДСТАВИТЬ(ПРАВСИМВ(ПСТР(» «&ПОДСТАВИТЬ(A1;» «;ПОВТОР(» «;999));1;999*5);999);» «;»»)
=SUBSTITUTE(RIGHT(MID(» «&SUBSTITUTE(A1,» «,REPT(» «,999)),1,999*5),999),» «,»»)
Т.е. число — это позиция слова(или слов) между пробелами. А что будет, если мы укажем число больше, чем есть пробелов в строке?
А это как раз ТО, К ЧЕМУ ШЛИ — СЛОВО ПОСЛЕ ПОСЛЕДНЕГО ПРОБЕЛА
Если вдруг число будет больше, чем есть пробелов в строке — то мы получим слово после последнего пробела (т.е. первое слово с конца строки). Это значит, что если указать, например, *999 — в большинстве случаев получим как раз последнее слово.
Как это работает:
для примера возьмем текст «мама мыла раму» и формулу по получению второго слова от начала:
=ПОДСТАВИТЬ(ПРАВСИМВ(ПСТР(» «&ПОДСТАВИТЬ(A1;» «;ПОВТОР(» «;999));1;999*2);999);» «;»»)
=SUBSTITUTE(RIGHT(MID(» «&SUBSTITUTE(A1,» «,REPT(» «,999)),1,999*2),999),» «,»»)
- Сначала при помощи функции ПОДСТАВИТЬ(SUBSTITUTE) мы заменяем все пробелы в тексте на 999 пробелов(999 получаем при помощи функции ПОВТОР(REPT). Число может быть и меньше 999, но не должно быть меньше длины исходной строки. В итоге мы получим очень длинную строку, в которой каждое слово будет отделено от другого 999 пробелами. Что-то вроде такого(пробелов я поставил меньше, конечно):
«мама____________________________мыла____________________________раму» - Далее при помощи функции ПСТР(MID) мы берем все слова от начала строки, до символа на позиции 999*2. Т.е. из текста выше мы получим слова «мама» и «мыла» и по 999 символов после каждого:
«мама____________________________мыла____________________________» - Затем при помощи функции ПРАВСИМВ(RIGHT) получаем 999 символов справа от строки. Т.е. только наше слово и куча пробелов после него
«мыла____________________________» - И напоследок та же функция ПОДСТАВИТЬ(SUBSTITUTE) убирает более не нужные нам пробелы, заменяя их все на пустую строку — «».
Вроде бы достигли того, что нам нужно было. Но вдруг необходимо получить второе слово с конца строки? А если у нас этих слов десятки? Можно использовать некую модификацию приведенной выше формулы, но которая как раз возвращает слово с конца строки:
=ПОДСТАВИТЬ(ПСТР(ПРАВСИМВ(» «&ПОДСТАВИТЬ(A1;» «;ПОВТОР(» «;999));999*1);1;999);» «;»»)
=SUBSTITUTE(MID(RIGHT(» «&SUBSTITUTE(A1,» «,REPT(» «,999)),999*1),1,999),» «,»»)
Принцип тот же: если в блоке 999*1 заменить 1 на 5, то получим 5-е слово с конца строки.
Если необходимо выдергивать слова именно по пробелам, то лучше дополнить еще одной функцией — СЖПРОБЕЛЫ(TRIM), чтобы отсечь лишние пробелы в начале и в конце строки и оставить только одиночные пробелы между словами:
=ПОДСТАВИТЬ(ПРАВСИМВ(ПСТР(» «&ПОДСТАВИТЬ(СЖПРОБЕЛЫ(A1);» «;ПОВТОР(» «;999));1;999*1);999);» «;»»)
=SUBSTITUTE(RIGHT(MID(» «&SUBSTITUTE(TRIM(A1),» «,REPT(» «,999)),1,999*1),999),» «,»»)
=ПОДСТАВИТЬ(ПСТР(ПРАВСИМВ(» «&ПОДСТАВИТЬ(СЖПРОБЕЛЫ(A1);» «;ПОВТОР(» «;999));999*1);1;999);» «;»»)
=SUBSTITUTE(MID(RIGHT(» «&SUBSTITUTE(TRIM(A1),» «,REPT(» «,999)),999*1),1,999),» «,»»)
=СЖПРОБЕЛЫ(ПСТР(ПРАВСИМВ(» «&ПОДСТАВИТЬ(A1;» «;ПОВТОР(» «;999));999*3);1;999*2))
=TRIM(MID(RIGHT(» «&SUBSTITUTE(A1,» «,REPT(» «,999)),999*3),1,999*2))
3 — третье слово с конца строки.
2 — количество слов.
Как видите — хоть формула и выглядит не так-то просто — она весьма универсальная: может и определенное слово вытащить, и к тому же еще и количество извлекаемых слов можно указать.
Остается еще добавить, что вместо пробелов могут быть и другие символы. Например, очень часто встречается ситуация, когда надо из текста получить не одно слово в конкретной позиции, а конкретную строку из текста, разнесенного в одной ячейке на строки:

Тогда для получения второй строки(
ТЦ Таганка
и
ТЦ Опус
) можно применить такую формулу:
=ПОДСТАВИТЬ(ПРАВСИМВ(ПСТР(СИМВОЛ(10)&ПОДСТАВИТЬ(C2;СИМВОЛ(10);ПОВТОР(СИМВОЛ(10);999));1;999*2);999);СИМВОЛ(10);»»)
СИМВОЛ(10) здесь означает перенос строки. Обычно эти переносы делаются с клавиатуры. Входим в режим редактирования ячейки, ставим курсор в нужное место строки и нажимаем Alt+Enter.
я для получения месяцев(
Август 2015 г.
и
Сентябрь 2015 г.
) — такую:
=ПОДСТАВИТЬ(ПСТР(ПРАВСИМВ(«/»&ПОДСТАВИТЬ(C2;»/»;ПОВТОР(«/»;999));999*1);1;999);»/»;»»)
В этой формуле в качестве разделителя используется слеш «/».
Разбор основных параметров формулы для применения в своих файлах
По сути, после нескольких примеров, основной принцип должен быть понятен. Но все же на примере последней формулы напомню про основные моменты и что надо сделать, чтобы применить практически к любой ситуации по извлечению слов:
=ПОДСТАВИТЬ(ПСТР(ПРАВСИМВ(«/»&ПОДСТАВИТЬ(C2;»/»;ПОВТОР(«/»;999));999*1);1;999);»/»;»»)
- C2 — ячейка с текстом, последнее слово из которого надо извлечь.
- «/» — разделитель слов. Если для разделения слов используется не слеш, а запятая или точка — то во всей формуле, где встречается этот символ надо заменить его на нужный.
Если лень прописывать этот символ внутри формулы несколько раз, его можно записать в отдельную ячейку(скажем, G1) и в формуле указать ссылку уже на эту ячейку:
=ПОДСТАВИТЬ(ПСТР(ПРАВСИМВ(G1&ПОДСТАВИТЬ(C2;G1;ПОВТОР(G1;999));999*1);1;999);G1;»»)
Теперь для изменения символа надо будет изменить его один раз в ячейке G1 и формула «вытащит» нужное слово/строку, опираясь именно на этот символ. - *1 — число 1 — позиция слова с конца строки, которое необходимо «достать». 1 — первое с конца(т.е. последнее), 2 — предпоследнее и т.д.
Зная эти основные моменты достаточно будет в своем файле просто скопировать формулу выше и подставить в неё ссылку на нужную ячейку и указать требуемый разделитель.
Скачать пример:
 Слово после последнего пробела.xls (29,5 KiB, 3 779 скачиваний)
Слово после последнего пробела.xls (29,5 KiB, 3 779 скачиваний)
Статья помогла? Поделись ссылкой с друзьями!
![]() Видеоуроки
Видеоуроки
Поиск по меткам
Access
apple watch
Multex
Power Query и Power BI
VBA управление кодами
Бесплатные надстройки
Дата и время
Записки
ИП
Надстройки
Печать
Политика Конфиденциальности
Почта
Программы
Работа с приложениями
Разработка приложений
Росстат
Тренинги и вебинары
Финансовые
Форматирование
Функции Excel
акции MulTEx
ссылки
статистика
|
Формула для поиска слова от последнего пробела. |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |




 Всё оказалось гораздо проще — ряд состоит из значений, кратных количеству подменяемых пробелов:
Всё оказалось гораздо проще — ряд состоит из значений, кратных количеству подменяемых пробелов:



В EXCEL есть очень удобная функция для «вытаскивания» из текста или слова определенного заданного нами количества символов.
Зачастую такие задачи возникают при обработке кодов, артикулов, номеров телефонов и т.д.
В нашем примере мы «вытащим» левую трехзначную часть кода и правую часть, имеющую различную разрядность без использования ПРАВСИМВ и ЛЕВСИМВ и их сочетаний с другими вспомогательными функциями.
Для этого:
- В ячейке напротив кода введем =ПСТР( и нажмем fx.

- В аргументах функции укажем ячейку с исходным текстом , первоначальным кодом.
- Зададим Начальную позицию (номер символа, с которого начнет вытаскивать текст функция).
- Количество знаков – то самое к-во, которое должно быть «вытащено» из текста или строки. Пробел и символы – также являются знаками.

Для работы с правой частью кода , нам необходимо сдвинуть Начальную позицию за трехзначный код с разделителем.
Для этого:
- Выполняем те же самые операции, что и ранее, но в Начальной позиции указываем «5» , т.е. это номер символа после кода и разделителя.


Необходимо обратить внимание , что такое разделение возможно только при унифицированной системе ведения кодов.
Если вдруг первая часть окажется двухзначной или четырёхзначной, то единообразия не получится.
Если материал Вам понравился или даже пригодился, Вы можете поблагодарить автора, переведя определенную сумму по кнопке ниже:
(для перевода по карте нажмите на VISA и далее «перевести»)
Как извлечь слова из строки таблицы Excel
Чтобы извлечь первое слово из строки, формула должна найти позицию первого символа пробела, а затем использовать эту информацию в качестве аргумента для функции ЛЕВСИМВ. Следующая формула делает это: =ЛЕВСИМВ(A1;НАЙТИ(» «;A1)-1) .
Эта формула возвращает весь текст до первого пробела в ячейке A1. Однако у нее есть небольшой недостаток: она возвращает ошибку, если текст в ячейке А1 не содержит пробелов, потому что состоит из одного слова. Несколько более сложная формула решает проблему с помощью новой функции ЕСЛИОШИБКА, отображая все содержимое ячейки, если произошла ошибка:
=ЕСЛИОШИБКА(ЛЕВСИМВ(A1;НАЙТИ(» «;A1)-1);A1) .
Если вам нужно, чтобы формула была совместима с более ранними версиями Excel, вы не можете использовать ЕСЛИОШИБКА. В таком случае придется обойтись функцией ЕСЛИ и функцией ЕОШ для проверки на ошибку:
=ЕСЛИ(ЕОШ(НАЙТИ(» «;A1));A1;ЛЕВСИМВ(A1;НАЙТИ(» «;A1)-1))
Извлечение последнего слова строки
Извлечение последнего слова строки — более сложная задача, поскольку функция НАЙТИ работает только слева направо. Таким образом, проблема состоит в поиске последнего символа пробела. Следующая формула, однако, решает эту проблему. Она возвращает последнее слово строки (весь текст, следующий за последним символом пробела):
=ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(«*»;ПОДСТАВИТЬ(A1;» «;»*»;ДЛСТР(A1)-ДЛСТР(ПОДСТАВИТЬ(A1;»»;»»)))))
Но у этой формулы есть такой же недостаток, как и у первой формулы из предыдущего раздела: она вернет ошибку, если строка не содержит по крайней мере один пробел. Решение заключается в использовании функции ЕСЛИОШИБКА и возврате всего содержимого ячейки А1, если возникает ошибка:
=ЕСЛИОШИБКА(ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(«*»;ПОДСТАВИТЬ(A1;» «;»*»;ДЛСТР(A1)-ДЛСТР(ПОДСТАВИТЬ(A1;» «;»»)))));A1)
Следующая формула совместима со всеми версиями Excel:
=ЕСЛИ(ЕОШ(НАЙТИ(» «;A1));A1;ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(«*»;ПОДСТАВИТЬ(A1;»»;»*»;ДЛСТР(A1)-ДЛСТР(ПОДСТАВИТЬ(A1;» «;»»))))))
Извлечение всего, кроме первого слова строки
Следующая формула возвращает содержимое ячейки А1, за исключением первого слова:
=ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(» «:A1;1)) .
Если ячейка А1 содержит текст 2008 Operating Budget, то формула вернет Operating Budget.
Формула возвращает ошибку, если ячейка содержит только одно слово. Следующая версия формулы использует функцию ЕСЛИОШИБКА, чтобы можно было избежать ошибки; формула возвращает пустую строку, если ячейка не содержит более одного слова:
=ЕСЛИОШИБКА(ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(» «;A1;1));»»)
А эта версия совместима со всеми версиями Excel:
=ЕСЛИ(ЕОШ(НАЙТИ(» «;A1));»»;ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(» «;A1;1)))
Как в Эксель (Excel) вытащить часть текста из ячейки в другую ячейку?
Например, в ячейке написана категория товара и информация о товаре.
Как выташить в отдельную ячейку только название категории («Перчатки хозяйственные», «Молоток слесарный» и т.п.)?

Очевидно, что вытащить часть текста в другую ячейку можно с помощью специальных функций для работы со строками.
В Excel их довольно много, и в первую очередь можно выделить такие функции, как:
ЛЕВСИМВ и ПРАВСИМВ — излекают определённое число символов слева и справа соответственно.
ДЛСТР — длина строки.
НАЙТИ — возвращает позицию, с которой подстрока или символ входит в строку.
ПОДСТРОКА — извлекает подстроку из текста, которая отделена определённым символом-разделителе<wbr />м.
ПСТР — извлекает указанное число знаков из строки (начиная с указанной позиции).
КОНЕЦСТРОКИ и НАЧАЛОСТРОКИ — возвращает строку после / до указанной подстроки.
Но здесь всё зависит от того, как именно эти данные расположены в исходной строке — одно дело в самом конце / начале, а другое — в середине.
В любом случае нужно постараться найти какой-то признак — слово или символ, до или после которого в ячейке находятся нужные данные, после чего использовать его в качестве аргумента в функциях, про которые я написал выше.
Пример 1
Исходные данные такие:

Предположим, нужно извлечь в отдельную ячейку цену товара (3500 рублей, 4200 рублей).
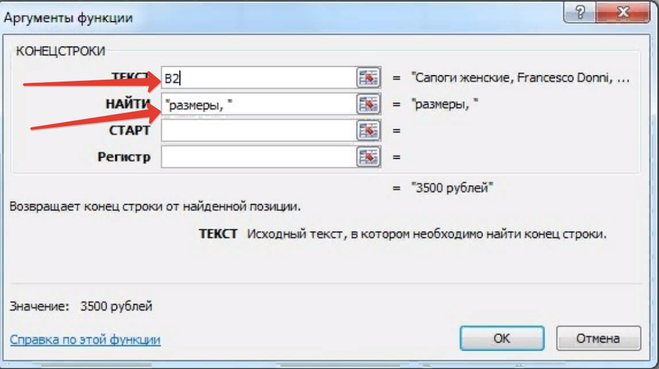
Можно увидеть, что в этих ячейках цене предшествует текст «размеры, » — то есть можно воспользоваться функцией КОНЕЦСТРОКИ и вытащить всё, что находится после этого текста.
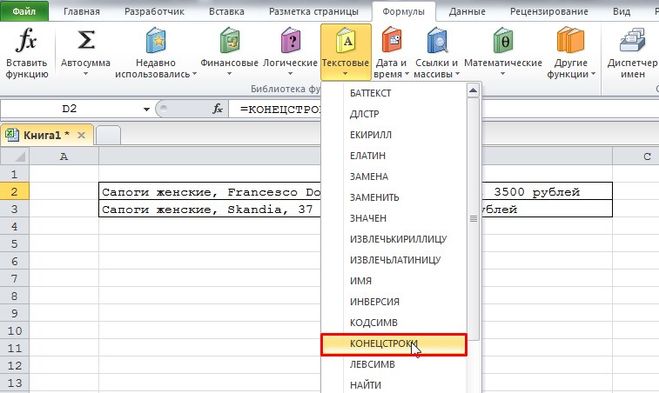
Итак, ставим курсор в ячейку, куда нужно извлечь цену, и на вкладке «Формулы» выбираем «Текстовые» -> «КОНЕЦСТРОКИ».
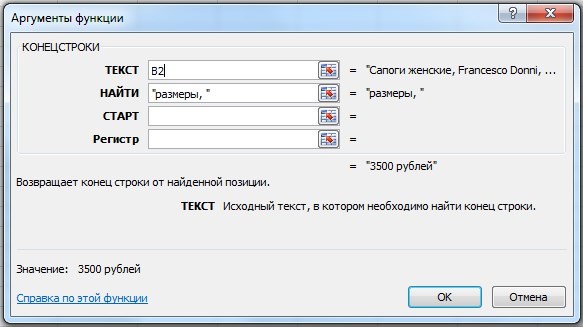
Указываем аргументы функции (обязательные):
ТЕКСТ — указываем ячейку, из которой нужно извлечь подстроку (B2 или B3).
НАЙТИ — указываем подстроку, после которой должно начаться извлечение текста («размеры, «).
Нажимаем на кнопку «OK» и получаем то, что было нужно:

Формула получилась такая:
А если требуется, чтобы было только число (без рублей), то можно, например, использовать функцию НАЧАЛОСТРОКИ.
В этом случае в качестве 1 аргумента (исходной строки) вводим формулу, созданную выше, а в качестве 2 аргумента — » «.

Пример 2
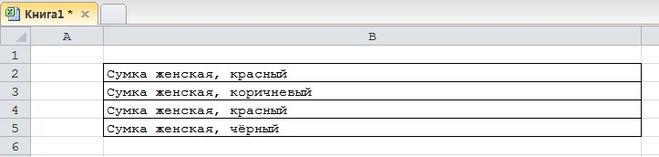
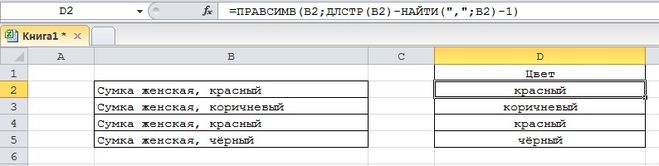
Нужно извлечь в отдельную ячейку название цвета (красный, коричневый и т.п.).
Здесь всё проще, так как название цвета находится в самом конце строки — и можно, например, использовать функцию ПРАВСИМВ.
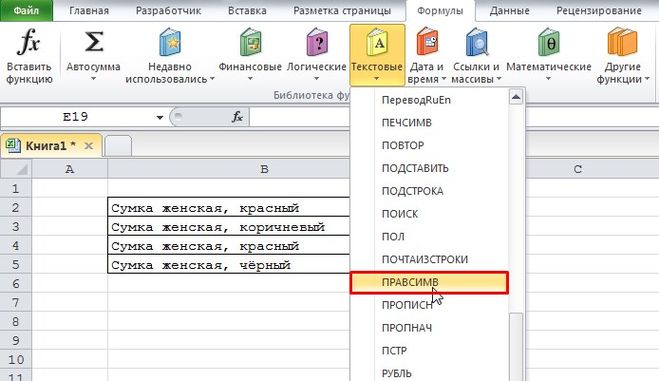
У этой функции 2 аргумента:
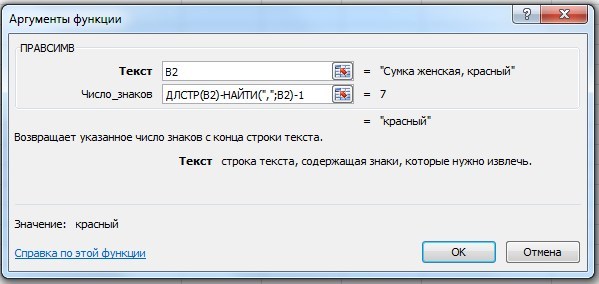
Текст — указываем ячейку, из которой нужно извлечь подстроку.
Число_знаков — это разность между длиной исходной строки (функция ДЛСТР) и позицией запятой в этой строке (функция НАЙТИ), также дополнительно нужно отнять единицу, так как после запятой стоит пробел.
Формула и результат:
Но мне всё же больше нравится вариант с упомянутой выше функцией КОНЕЦСТРОКИ.
![]()
Она менее громоздкая и не содержит вложенных функций.
Эксель многие любят за то, что можно быстро обрабатывать и менять таблицы, так как надо.
Вот и в этом случаи, для того, чтобы вытащить из ячейки текст, нужно в пустой рядом столбик ввести формулу. Но тут не так всё просто. В зависимости от того, с какой стороны нужен текст, вводим формулу Левсимв и Правсимв. Одна из этих функций выведет нужный текст справа, другая слева. При этом формула будет выглядеть примерно так:=ЛЕВСИМВ(В1;10). В данном случаи 10 число символов. Но если число символов не одинаковое, то метод не совсем подойдёт.
Тогда можно будет попробовать функцию текстовые, конец строки. Если перед нужной вам фразой стоит одно и тоже слово в каждой строке. Появится окошко, и в строке найти добавить это слова. Нужный текст после этого слова переместится.
Открывайте ячейку из которой надо вытащить часть текста, клацаете по тексту что бы курсор в тексте начал моргать, выделяете эту часть текста которую хотите утащить в другое место, щелкаете по выделенке ПКМ (правой кнопкой мышки) выбираете «копировать»
Переходите в окно куда нужно вставить, щелкаете в нем ЛКМ (левой кнопкой мышки) что бы активировать работу ввода данных в этой ячейки, следом щелкаете ПКМ, выбираете «вставить» и все.
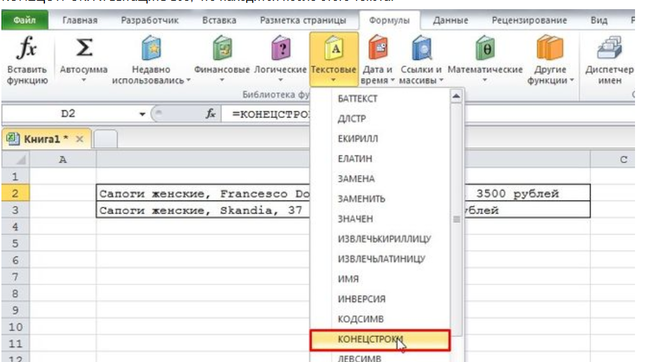
Если в таблице одна или 2 строки, тогда можно воспользоваться функцией нажатия клавиш Ctrl+C скопировать и Ctrl+V вставить, а если в таблице нужно поменять цену для большого количества параметров, переходите в шапку инструментов, и действуйте по алгоритму, который находится под кнопой формулы — текстовые и в выпадающем меню находите среди абракадабры из сокращений «конецстроки»
далее следуя указаниям меняете в открытых окнах параметры. Подставляете какие заданы, а машина сама все посчитает. За это эксель и любят бухгалтеры, по мне так самая кривая программа после ворда. имхо для бв.
Что касается абракадабры в выпадающем меню, на это есть подсказки, например
ЛЕВСИМВ — левые символы
ПРАВСИМВ — правые символы
ДЛСТР — длина строки
НАЙТИ — возвращает позицию, с которой подстрока или символ входит в строку.
КОНЕЦСТРОКИ возврат строки до конца
НАЧАЛОСТРОКИ — возврат строки в начало
Если у Вас данные (которые нужно обработать, все эти «молотки» и «перчатки») всегда отделены от остальной части текста запятой и первая ячейка с данными это B2, то формула такая
напишите ее в любую свободную ячейку (например правее) в той же строке, а потом растяните вниз и все ваши тысячи строк будут обработаны.
Как вариант можно использовать следующий способ:
Сначала выделяем столбец, который хотим разделить, затем на вкладке данные выбираем «Текст по столбцам», в появившемся окне изменяем тип разделителя (там есть варианты — табуляция, точка, запятая. ), а затем заканчиваем действие.
В итоге ваш исходный текст будет разбит на отдельные столбцы с нужным содержанием.
Довольно сложный вопрос, но в Ексель можно сделать и такое, в этом редакторе есть подобные функции работы со строками.
Эти функции мы ищем в верхнем меню во вкладке «Формулы» — «Текстовые»:

Желательно, чтобы записи в ячейках были бы хоть как-то структурированы, например, если в ячейках сначала записано наименование товара, потом через запятую, в конце записи, цена товара, с такими ячейками будет работать несложно. Поработаем вот с этими ячейками, попробуем цену товара перенести в отдельные ячейки:

Текст у нас написан для этого отлично, цена товара стоит в конце строки, после слова «размеры» и запятой, поэтому мы воспользуемся функцией КОНЕЦСТРОКИ из вкладки «Текстовые» (см. выше). Открывается вот такое окошечко, в поле ТЕКСТ указываем столбец, в котором находятся наши ячейки, в поле НАЙТИ — слова, после которых текст надо переносить в отдельную ячейку.
Нажимаем ОК, получаем то, что хотели:

Теперь можно, используя тот же алгоритм, поработать с новыми ячейками с помощью функции НАЧАЛОСТРОКИ и получить число без рублей:

Работа в Excel очень упрощает рабочую деятельность, ведь стоит правильно все оформить и программа за тебя все посчитает. Но надо уметь работать с программой, чтобы итог был верным.
Иногда необходимо часть текста перетащить в другую ячейку. Если это одна-две строки, можно и скопировать, но когда строк много, такой способ совсем не годится.
К примеру, имея такую большую таблицу, следует подготовить отчет по отдельным филиалам.
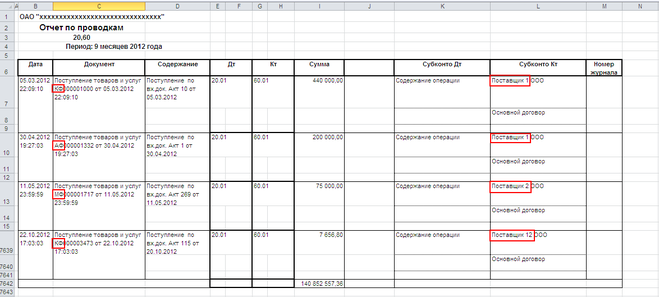
Нам помогут функций ЛЕВСИМВ и ПРАВСИМВ, которые помогут, если нужные символы находятся в самом начале или в самом конце текста.

А вот если нужный текст находится в середине, то такая функция не подойдет. Но в этом случае стоит воспользоваться ПСТР.

Для того, чтобы скопировать из ячейки Excel часть текста, нужно в выбранной ячейке дважды кликнуть мышкой, так чтобы курсор стал как в Word. Затем выделить нужную часть текста, скопировать и вставить комбинацией клавиш Ctrl+C, Ctrl+V или через контекстное меню правой клавишей мышки.
Единого алгоритма для вытаскивания части текста нет. Есть понимание процесса, как это сделать.
Можно это сделать с помощью символов. Для извлечения определенного количества символов справа и слева — ПРАВСИМВ ЛЕВСИМВ, для возвращения позиции, с которой подстрока или символ входит в строку — НАЙТИ, длина строки — ДЛСТР, возвращение строки — КОНЕЦСТРОКИ и НАЧАЛОСТРОКИ.
Из символов составляется формулировка того, что требуется, вставляется в свободную строку и растягивается на все нужные строки. Все части ячейки будут обработаны.
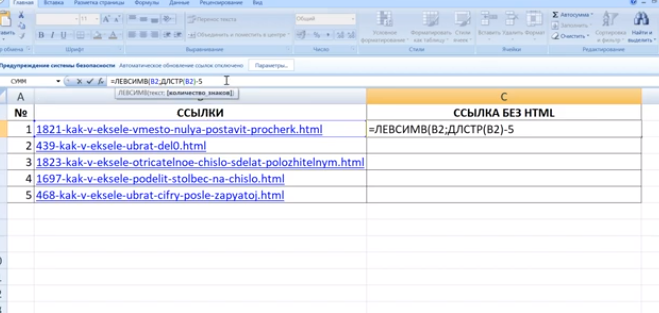
Чтобы выбрать подстроку из текстовой строчки требуется знать разделитель и номер вхождения подстроки.
Считаем что строчка записана в ячейке A3, а номер вхождения подстроки записан в ячейке H1 и в качестве разделителя используется символ «,»
тогда получим формулы граничных символов искомой подстроки
=НАЙТИ( СИМВОЛ(3) ; ПОДСТАВИТЬ( «,»&A3&»,» ; «,» ; СИМВОЛ(3) ; H1))+1
=НАЙТИ( СИМВОЛ(3) ; ПОДСТАВИТЬ( «,»&A3&»,» ; «,» ; СИМВОЛ(3) ; H1+1))-1
формула для подстроки с номером вхождения в ячейке H1 (исходная строка в A3 и разделитель «,»):
=ПСТР( «,»&A3&»,»; НАЙТИ( СИМВОЛ(3); ПОДСТАВИТЬ(«,»&A3&»,<wbr />»; «,»; СИМВОЛ(3); H1))+1; НАЙТИ( СИМВОЛ(3); ПОДСТАВИТЬ(«,»&A3&»,<wbr />»; «,»; СИМВОЛ(3);H1+1)) — НАЙТИ( СИМВОЛ(3); ПОДСТАВИТЬ(«,»&A3&»,<wbr />»; «,»; СИМВОЛ(3); H1))-1)
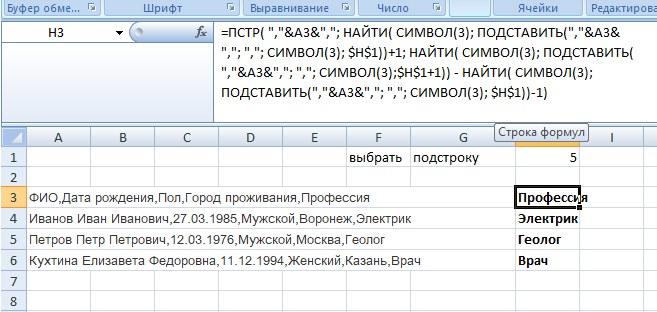
для разделителя «;» формула имеет вид:
=ПСТР( «;»&A3&»;»; НАЙТИ( СИМВОЛ(3); ПОДСТАВИТЬ(«;»&A3&»;<wbr />»; «;»; СИМВОЛ(3); H1))+1; НАЙТИ( СИМВОЛ(3); ПОДСТАВИТЬ(«;»&A3&»;<wbr />»; «;»; СИМВОЛ(3);H1+1)) — НАЙТИ( СИМВОЛ(3); ПОДСТАВИТЬ(«;»&A3&»;<wbr />»; «;»; СИМВОЛ(3); H1))-1)
Можно воспользоваться разными способами. Например, если в нужных ячейках только числа, то можно воспользоваться функцией счет. Чтобы ее вызвать щелкаем вверху fx — при этом появляется диалоговое окно мастера функций. Далее в разделе статистические и ищем нужную функцию. Не забыть выделить нужный диапазон. Она выдает нам количество ячеек в диапазоне с числами.
Если в ячейках и числа и текст и нам нужно определить их количество, то воспользуемся функцией счетз — именно эта функции, которая находится в разделе статистические позволяет считать количество непустых ячеек. Эта функция более универсвльна.
Работая в Excel часто приходится округлять числа. И это в электронных таблицах от Microsoft делается очень просто.
Самым простым способом является нажатие на всплывающем меню (можно вызвать правой кнопкой мыши) соответствующего значка разрядности. Их два. Первый уменьшает разрядность, а второй увеличивает. Вы можете выбрать такую разрядность, которая вам необходима тем самым округлить до нужного числа простым нажатием на кнопку.
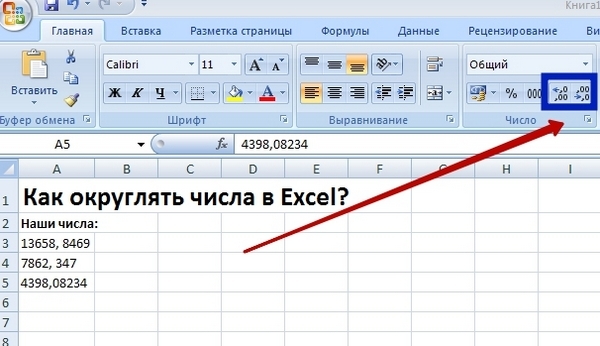
Второй способ — это обратиться к верхней панели «Число», где также стоят эти два значка округления чисел. Выделите нужный массив чисел в таблице Excel и нажмите на панели соответствующий значок округления столько раз, сколько требуется для округления до требуемой точности (до десятых, сотых, тысячных).
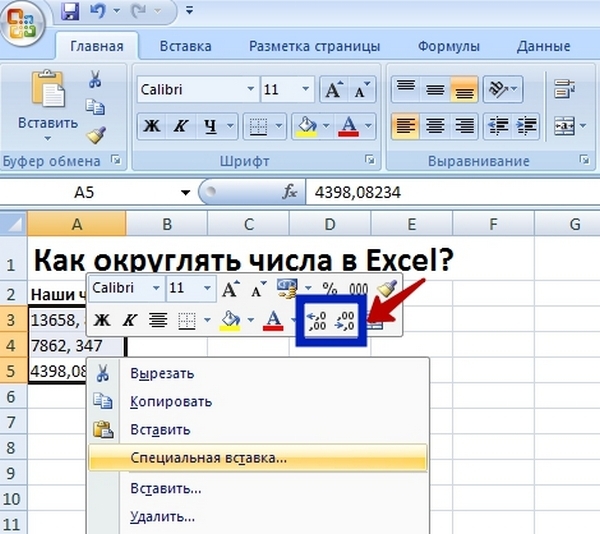
Третий способ — самый верный, поскольку он работает даже в старых версиях Excel. Чтобы округлить число вам нужно выделить массив чисел, нажать правой кнопкой мыши, выбрать в панели «Формат ячеек», далее «Числовой» формат и в этом же окне справа выбрать нужное «Число десятичных знаков». По умолчанию стоит значение, равное 2 (округление до сотых).
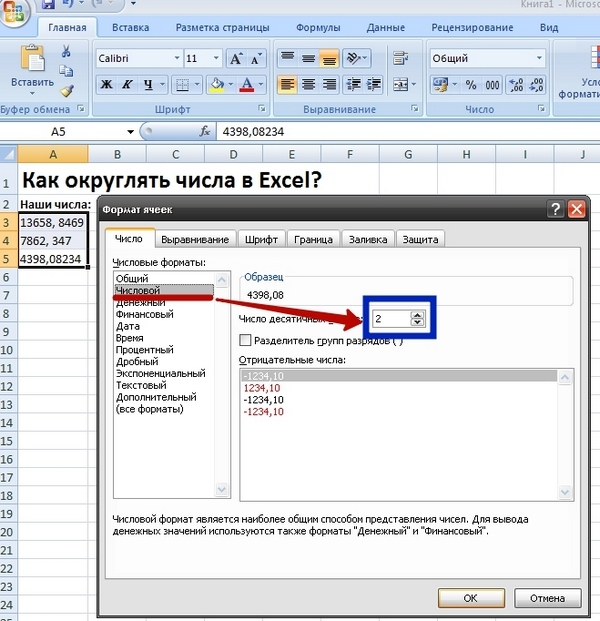
Как видите ничего сложного здесь нет. Однако, есть и другой, более сложный четвертый способ округления чисел в электронных таблицах Excel, который требует использования стандартных функций Excel. Одна из них (наиболее простая и стандартная в использовании) называется ОКРУГЛ.
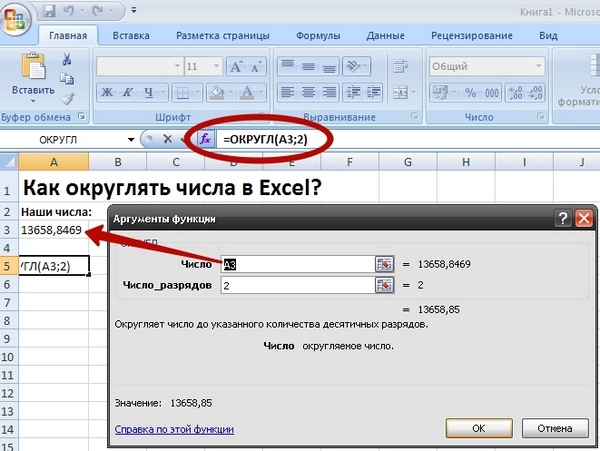
Данная функция Excel округляет выбранное число до нужной разрядности. Для того, чтобы перейти в окно функций, нужно нажать на значок f(x) в верхней панели на строке функций. В появившемся окне следует набрать в поиске функцию ОКРУГЛ. После этого нужно выставить параметры функции округления числа. Их два: число для округления и число разрядов. Число, которое требуется округлить можно напечатать в виде числа, а можно просто выбрать ячейку, в которой она уже есть в Excel. В нашем примере число стоит в ячейке A3. Однако это может быть не просто одна ячейка, а сразу массив чисел в нескольких ячейках (его нужно выделить).
Это все способы округления чисел в Excel. Вы можете выбрать самый удобный для вас.
Последнее слово
Простая, на первый взгляд, задача с не очевидным решением: извлечь из строки текста последнее слово. Ну или, в общем случае, последний фрагмент, отделенный заданным символом-разделителем (пробелом, запятой и т.д.) Другими словами, необходимо реализовать реверсивный поиск (от конца к началу) в строке заданного символа и извлечь потом все символы справа от него.
Давайте рассмотрим традиционно несколько способов решения на выбор: формулами, макросами и через Power Query.
Способ 1. Формулы
Чтобы проще было понять суть и механику формулы, начнем немного издалека. Сначала увеличим количество пробелов между словами в нашем исходном тексте до, например 20 штук. Сделать это можно при помощи функции замены ПОДСТАВИТЬ (SUBSTITUTE) и функции повтора заданного символа N-раз — ПОВТОР (REPT):

Теперь отрежем от конца получившегося текста 20 символов с помощью функции ПРАВСИМВ (RIGHT):

Уже теплее, да? Осталось убрать лишние пробелы с помощью функции СЖПРОБЕЛЫ (TRIM) и задача будет решена:

В английской версии наша формула будет выглядеть, соответственно:
=TRIM(RIGHT(SUBSTITUTE(A1;» «;REPT(» «;20));20))
Надеюсь, понятно, что в принципе не обязательно вставлять именно 20 пробелов — подойдет любое количество, лишь бы оно было больше, чем длина самого длинного слова в исходном тексте.
И если исходный текст нужно разделить не по пробелу, а по другому символу-разделителю (например, по запятой), то нашу формулу надо будет чуть-чуть подправить:

Способ 2. Макрофункция
Задачу извлечения последнего слова или фрагмента из текста также можно решить с помощью макросов, а именно — написать функцию реверсивного поиска в Visual Basic, которая будет делать то, что нам нужно — искать заданную подстроку в строке в обратном направлении — от конца к началу.
Нажмите сочетание клавиш Alt+F11 или кнопку Visual Basic на вкладке Разработчик (Developer), чтобы открыть редактор макросов. Затем добавьте новый модуль через меню Insert — Module и скопируйте туда следующий код:
Function LastWord(txt As String, Optional delim As String = " ", Optional n As Integer = 1) As String
arFragments = Split(txt, delim)
LastWord = arFragments(UBound(arFragments) - n + 1)
End Function
Теперь можно сохранить книгу (в формате с поддержкой макросов!) и воспользоваться созданной функцией в следующем синтаксисе:
=LastWord(txt ; delim ; n)
где
- txt — ячейка с исходным текстом
- delim — символ-разделитель (по умолчанию — пробел)
- n — какое по счету слово с конца необходимо извлечь (по умолчанию — первое с конца)

При любых изменениях в исходном тексте в будущем наша макрофункция будет «на лету» пересчитываться, как и любая стандартная функция листа Excel.
Способ 3. Power Query
Power Query — это бесплатная надстройка от Microsoft для импорта данных в Excel из практически любых источников и последующей трансформации загруженных данных в любой вид. Мощь и крутизна этой надстройки настолько велики, что Microsoft встроила все ее возможности в Excel 2016 по умолчанию. Для Excel 2010-2013 Power Query можно бесплатно скачать отсюда.
Наша задача по отделению последнего слова или фрагмента через заданный разделитель с помощью Power Query решается очень легко.
Сначала превратим нашу таблицу с данными в умную с помощью сочтания клавиш Ctrl+T или команды Главная — Форматировать как таблицу (Home — Format as Table):

Затем загрузим созданную «умную таблицу» в Power Query с помощью команды Из таблицы / диапазона (From table/range) на вкладке Данные (если у вас Excel 2016) или на вкладке Power Query (если у вас Excel 2010-2013):

В открывшемся окне редактора запросов на вкладке Преобразование (Transform) выберем команду Разделить столбец — По разделителю (Split Column — By delimiter) и затем останется задать символ-разделитель и выбрать опцию Самый правый разделитель, чтобы разрубить не все слова, а только последнее:

После нажатия на ОК последнее слово будет отделено в новый столбец. Ненужный первый столбец можно удалить, щелкнув по его заголовку правой кнопкой мыши и выбрав Удалить (Delete). Также можно переименовать оставшийся столбец в шапке таблицы.
Результаты можно выгрузить обратно на лист, используя команду Главная — Закрыть и загрузить — Закрыть и загрузить в … (Home — Close & Load — Close & Load to…):

И в итоге получаем:

Вот так — дешево и сердито, без формул и макросов, почти не касаясь клавиатуры 
Если в будущем исходный список изменится, то достаточно будет правой кнопкой мыши или сочетанием клавиш Ctrl+Alt+F5 обновить наш запрос.
Ссылки по теме
- Разделение слипшегося текста по столбцам
- Анализ и разбор текста регулярными выражениями
- Извлечение первых слов из текста функцией ПОДСТАВИТЬ (SUBSTITUTE)
Формулы в этой статье полезны для извлечения слов из текста, содержащегося в ячейке. Например, вы можете создать формулу для извлечения первого слова в предложении.
Извлечение первого слова из строки
Чтобы извлечь первое слово из строки, формула должна найти позицию первого символа пробела, а затем использовать эту информацию в качестве аргумента для функции ЛЕВСИМВ. Следующая формула делает это: =ЛЕВСИМВ(A1;НАЙТИ(" ";A1)-1).
Эта формула возвращает весь текст до первого пробела в ячейке A1. Однако у нее есть небольшой недостаток: она возвращает ошибку, если текст в ячейке А1 не содержит пробелов, потому что состоит из одного слова. Несколько более сложная формула решает проблему с помощью новой функции ЕСЛИОШИБКА, отображая все содержимое ячейки, если произошла ошибка:
=ЕСЛИОШИБКА(ЛЕВСИМВ(A1;НАЙТИ(" ";A1)-1);A1).
Если вам нужно, чтобы формула была совместима с более ранними версиями Excel, вы не можете использовать ЕСЛИОШИБКА. В таком случае придется обойтись функцией ЕСЛИ и функцией ЕОШ для проверки на ошибку:
=ЕСЛИ(ЕОШ(НАЙТИ(" ";A1));A1;ЛЕВСИМВ(A1;НАЙТИ(" ";A1)-1))
Извлечение последнего слова строки
Извлечение последнего слова строки — более сложная задача, поскольку функция НАЙТИ работает только слева направо. Таким образом, проблема состоит в поиске последнего символа пробела. Следующая формула, однако, решает эту проблему. Она возвращает последнее слово строки (весь текст, следующий за последним символом пробела):
=ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ("*";ПОДСТАВИТЬ(A1;" ";"*";ДЛСТР(A1)-ДЛСТР(ПОДСТАВИТЬ(A1;"";"")))))
Но у этой формулы есть такой же недостаток, как и у первой формулы из предыдущего раздела: она вернет ошибку, если строка не содержит по крайней мере один пробел. Решение заключается в использовании функции ЕСЛИОШИБКА и возврате всего содержимого ячейки А1, если возникает ошибка:
=ЕСЛИОШИБКА(ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ("*";ПОДСТАВИТЬ(A1;" ";"*";ДЛСТР(A1)-ДЛСТР(ПОДСТАВИТЬ(A1;" ";"")))));A1)
Следующая формула совместима со всеми версиями Excel:
=ЕСЛИ(ЕОШ(НАЙТИ(" ";A1));A1;ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ("*";ПОДСТАВИТЬ(A1;"";"*";ДЛСТР(A1)-ДЛСТР(ПОДСТАВИТЬ(A1;" ";""))))))
Извлечение всего, кроме первого слова строки
Следующая формула возвращает содержимое ячейки А1, за исключением первого слова:
=ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(" ":A1;1)).
Если ячейка А1 содержит текст 2008 Operating Budget, то формула вернет Operating Budget.
Формула возвращает ошибку, если ячейка содержит только одно слово. Следующая версия формулы использует функцию ЕСЛИОШИБКА, чтобы можно было избежать ошибки; формула возвращает пустую строку, если ячейка не содержит более одного слова:
=ЕСЛИОШИБКА(ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(" ";A1;1));"")
А эта версия совместима со всеми версиями Excel:
=ЕСЛИ(ЕОШ(НАЙТИ(" ";A1));"";ПРАВСИМВ(A1;ДЛСТР(A1)-НАЙТИ(" ";A1;1)))