
Рассмотрим использование MS EXCEL при проверке статистических гипотез о среднем значении распределения в случае известной дисперсии. Вычислим тестовую статистику
Z
0
, рассмотрим процедуру «одновыборочный z-тест», вычислим Р-значение (Р-
value
).
Проверка гипотез
(Hypothesis testing) тесно связана с построением
доверительных интервалов
. При первом знакомстве с
процедурой проверки гипотез
рекомендуется начать с изучения
построения соответствующего доверительного интервала
.
СОВЕТ
: Для
проверки гипотез
нам потребуется знание следующих понятий:
-
дисперсия и стандартное отклонение
,
-
выборочное распределение статистики
,
-
уровень доверия/ уровень значимости
,
-
стандартное нормальное распределение
и
его квантили
.
Формулировка задачи.
Из
генеральной совокупности
имеющей
нормальное распределение
с неизвестным μ и известной
дисперсией
σ
2
взята
выборка
размера n. Необходимо проверить
статистическую гипотезу
о равенстве неизвестного μ заданному значению μ
0
(англ. Inference on the mean of a population, variance known).
Примечание
: Требование о
нормальности
исходного распределения, из которого берется
выборка
, не является строгим. Н
0
, необходимо, чтобы были выполнены условия применения
Центральной предельной теоремы
.
Статистическая гипотеза
– это некое утверждение о неизвестных параметрах распределения. Процедура проверки гипотез зависит от оцениваемого параметра распределения и условий задачи. Сначала рассмотрим общий подход при
проверке гипотез
, затем рассмотрим конкретный пример.
Обычно формулируют 2 гипотезы:
нулевую
Н
0
и
альтернативную
Н
1
. В нашем случае
нулевой гипотезой
будет равенство μ и μ
0
, а
альтернативной гипотезой
– их отличие.
Нулевая гипотеза
отвергается только в том случае, если на это достаточно оснований. В этом случае принимается
альтернативная гипотеза
.
Чтобы понять, достаточно ли у нас оснований для отклонения
нулевой гипотезы
, из распределения делают
выборка.
Сначала проведем
проверку гипотезы
, используя
доверительный интервал
, а затем с помощью вышеуказанной процедуры
z-тест
.
В конце вычислим
Р-значение
и также используем его для
проверки гипотезы
.
Итак,
нулевая гипотеза
Н
0
утверждает, что неизвестное
среднее значение
распределения μ равно μ
0
. Соответствующая
альтернативная гипотеза
Н
1
утверждает обратное: μ не равно μ
0
. Это пример
двусторонней проверки
, т.к. неизвестное значение может быть как больше, так и меньше μ
0
.
Если упрощенно, то
проверка гипотезы
заключается в сравнении 2-х величин: вычисленного на основании
выборки среднего значения
Х
ср
и заданного μ
0
. Если эти значения «отличаются больше, чем можно было бы ожидать исходя из случайности», то
нулевую гипотезу
отклоняют.
Поясним фразу «отличаются больше, чем можно было бы ожидать исходя из случайности». Для этого, вспомним, что распределение
Выборочного среднего (статистика Х
ср
)
стремится к
нормальному распределению
со
средним значением
μ и
стандартным отклонением
равным σ/√n, где σ –
стандартное отклонение распределения
, из которого берется
выборка
(не обязательно
нормальное
), а n – объем
выборки
(подробнее см.
статью про ЦПТ
). В нашем случае
стандартное отклонение
σ известно.
В задачах
проверки гипотез
также задается
уровень доверия
(вероятность), который определяет порог между утверждением «мало вероятно» и «вполне вероятно» или «может быть обусловлено случайностью» и «не может быть обусловлено случайностью». Обычно используют значения
уровня доверия
90%; 95%; 99%, реже 99,9% и т.д.
Примечание
:
Уровень доверия
равен (1-α)
,
где α –
уровень значимости
. И наоборот, α=(
1-уровень доверия
)
.
Таким образом, знание распределения
статистики
Х
ср
и заданного
уровня доверия
, позволяют нам формализовать с помощью математических выражений фразу «отличаются больше, чем можно было бы ожидать исходя из случайности». В этом нам поможет
доверительный интервал
(как строится
доверительный интервал
нам
известно из этой статьи
).
Если
среднее выборки
попадает в
доверительный интервал,
построенный относительно μ
0
, то для отклонения нулевой гипотезы оснований нет.
Для визуализации процедуры
проверки гипотез
в
файле примера на листе Сигма известна
создана
диаграмма
.
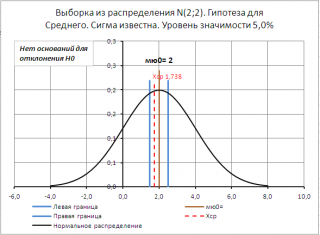
Если μ
0
не попадает в
доверительный интервал,
то нулевая гипотеза отклоняется.
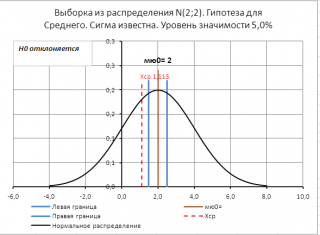
Теперь рассмотрим проверку гипотез с помощью процедуры
z
-тест
.
Z-тест
Кроме
доверительного интервала
для
проверки гипотез
существует также и другой эквивалентный подход —
z
-тест:
-
На основе
выборки
вычисляюттестовую статистику
. Выбор
тестовой статистики
делают в зависимости от оцениваемого параметра распределения и условий задачи. В нашем случае
тестовой статистикой
является случайная величина z=

, где

–среднее выборки
(обозначим Х
ср
). Значение, которое приняла
z-
статистика
, обычно обозначают Z
0
;
z
-статистика
, как и любая другая случайная величина, имеет свое распределение. В процедуре
проверки гипотез
это распределение называют «
эталонным распределением
», англ. Reference distribution. В нашем случае
тестовая статистика

имеетстандартное нормальное распределение
;
-
Также исследователь устанавливает требуемый
уровень значимости
– это допустимая для данной задачи
ошибка первого рода
, т.е. вероятность отклонить
нулевую гипотезу
, когда она верна (
уровень значимости
обозначают буквой α и чаще всего выбирают равным 0,1; 0,05 или 0,01); -
С помощью
эталонного распределения
для заданного
уровня значимости
вычисляют соответствующиеквантили этого распределения
. В нашем случае, при проверке
двухсторонней гипотезы
, необходимо будет вычислить
верхний α/2-квантиль стандартного
нормального распределения,
т.е. такое значение случайной величины
z
,
что
P
(
z
>=
Z
α
/2
)=α/2
; -
И наконец, значение
тестовой статистики
Z
0
сравнивают с вычисленными на предыдущем шаге
квантилями
и делают
статистический вывод
: Имеются ли основания, чтобы отвергнуть
нулевую гипотезу
? В нашем случае проверки двусторонней гипотезы, Н
0
отвергается если: |Z
0
|>Z
α
/2
.
Примечание
: Подробнее про
квантили
распределения можно прочитать в статье
Квантили распределений MS EXCEL
.
В MS EXCEL
верхний
α
/2-квантиль стандартного нормального распределения
вычисляется по формуле
=НОРМ.СТ.ОБР(1-α/2)
Учитывая симметричность
стандартного нормального распределения
относительно оси ординат,
верхний
α
/2-квантиль
равен обычному α
/2-квантилю
со знаком минус:
=-НОРМ.СТ.ОБР(α/2)
Примечание
: Еще раз подчеркнем связь процедуры
z
-теста
с построением
доверительного интервала
. Т.к.
z
-статистика
распределена по
стандартному нормальному закону,
то можно ожидать, что 1-α значений
z
-статистики
будет попадать в интервал между -Z
α/2
и Z
α/2
. Например, для
уровня доверия
95% в интервал между -1,960 и 1,960 будет попадать примерно 95% значений Z
0
, вычисленных на основе
выборки
. Если Z
0
не попало в указанный интервал, то это считается маловероятным событием и
нулевая гипотеза
отвергается.
В случае
односторонней гипотезы
речь идет об отклонении μ только в одну сторону: либо больше либо меньше μ
0
. Если
альтернативная гипотеза
звучит как μ>μ
0
, то гипотеза Н
0
отвергается в случае Z
0
> Z
α
. Если
альтернативная гипотеза
звучит как μ<μ
0
, то гипотеза Н
0
отвергается в случае Z
0
< -Z
α
.
Вычисление Р-значения
При
проверке гипотез
большое распространение также получил еще один эквивалентный подход, основанный на вычислении
p
-значения
(p-value). Поясним его на основе
односторонней гипотезы
Н
1
: μ>μ
0
.
Напомним, что если Н
1
утверждает, что μ>μ
0
, то
односторонняя гипотеза
Н
0
отвергается в случае если Z
0
> Z
α
. Эти значения
z
-статистики
имеют размерность анализируемой случайной величины, но их трудно интерпретировать. Преобразуем неравенство Z
0
> Z
α
так, чтобы его можно было проще интерпретировать.
Напомним, что Z
α
– это положительная величина и она равна
верхнему
α
-квантилю стандартного нормального распределения
(такому значению случайной величины z, что P(z>=Z
α
)=α). Неравенство Z
0
> Z
α
означает, что если Z
0
, вычисленное на основе
выборки
, будет слишком велико, т.е. больше Z
α
, то эта ситуация считается маловероятным событием и появляется основание для отклонения
нулевой гипотезы
.
Поэтому, логично вычислить вероятность события, что
z
-статистика
примет значение z>=Z
0
и сравнить ее с вероятностью, что z=>Z
α
. Вероятность события z=>Z
α
(по определению
верхнего квантиля
) – это просто α. Вероятность события, что
z
-статистика
примет значение z>=Z
0
равна 1-Ф(Z
0
), где Ф(z) –
интегральная функция стандартного нормального распределения
.
В MS EXCEL эта функция вычисляется по формуле
=1-НОРМ.СТ.РАСП(Z
0
;ИСТИНА)
Примечание
: В MS EXCEL для вычисления
p-значения
имеется специальная функция
Z.TEСT()
, которая эквивалентна выражению
=1-НОРМ.СТ.РАСП(Z
0
;ИСТИНА)
.
Про функцию
Z.TEСT()
см.
ниже
.
Таким образом, неравенство Z
0
> Z
α
эквивалентно неравенству P(z>= Z
0
)<α или в других обозначениях 1-Ф(Z
0
)<α. Величина 1-Ф(Z
0
) называется
p
-значением.
СОВЕТ
: Лучше понять вышесказанное помогут графики
функции стандартного нормального распределения
из статьи
Квантили распределений MS EXCEL
.
Теперь, если
p-значение
меньше чем заданный
уровень значимости α
, то
нулевая гипотеза
отвергается и принимается
альтернативная гипотеза
. И наоборот, если
p-значение
больше α, то
нулевая гипотеза
не отвергается. Другими словами, если
p-значение
меньше
уровня значимости
α, то это свидетельство того, что значение
z
-статистики
, вычисленное на основе
выборки
при условии истинности
нулевой гипотезы
, приняло маловероятное значение Z
0
.
Для другой односторонней гипотезы (μ<μ
0
)
p-значение
вычисляется как Ф(Z
0
) или
=НОРМ.СТ.РАСП(Z
0
;ИСТИНА)
. Соответственно,
p-значение
для односторонней гипотезы μ<μ
0
вычисляется по формуле
=1-Z.TEСT(
выборка
; μ
0
; σ)
, где
выборка
– ссылка на диапазон, содержащий значения
выборки
.
В случае двусторонней гипотезы,
p
-значение
вычисляется по формуле =2*(1-Ф(|Z
0
|)).
В качестве примера проверим гипотезу Н
0
: μ=μ
0
, при этом
альтернативная
односторонняя гипотеза
Н
1
: μ<μ
0
. Известно, что
среднее выборки
размера 60 равно 1,851;
стандартное отклонение
=2; μ
0
=2,3;
уровень значимости
равен 0,05. Решение:
Z
0
=(1,851-2,3)/(2/КОРЕНЬ(60))=-1,739
p-значение
=НОРМ.СТ.РАСП(-1,739;ИСТИНА)=0,04
Нулевая гипотеза
отклоняется, т.к. 0,04<0,05.
Эквивалентность этих трех подходов для проверки гипотез (
проверка через доверительный интервал
,
z
-тест
и
p-значение
) продемонстрирована в
файле примера
: во всех случаях, когда
z-тест
дает заключение о необходимости отклонить
нулевую гипотезу
, Х
ср
не попадает в соответствующий
доверительный интервал,
а
p
-значение
меньше уровня значимости.
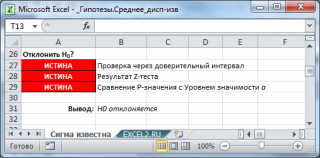
Функция
Z.ТЕСТ()
MS EXCEL для процедуры
z-тест
существует специальная функция
Z.ТЕСТ()
, которая на самом деле вычисляет
p-значение
в случае
односторонней альтернативной гипотезы μ
>μ
0
:
=Z.TEСT(
выборка
; μ
0
; σ)
, где
выборка
– ссылка на диапазон, содержащий n значений
выборки, σ
– известное
стандартное отклонение
распределения, из которого делается
выборка
.
Функция
Z.ТЕСТ()
эквивалентна формуле
=1- НОРМ.СТ.РАСП((СРЗНАЧ(
выборка
)- μ
0
) / (σ/√n);ИСТИНА)
Выражение
(СРЗНАЧ(
выборка
)- μ
0
) / (σ/√n)
– это значение
тестовой статистики
, т.е. Z
0
.
Эту же функцию можно использовать для вычисления
p
-значения
в случае проверки
двусторонней гипотезы
, записав формулу:
=2 * МИН(Z.TEСT(
выборка
; μ
0
; σ); 1 — Z.TEСT(
выборка
; μ
0
; σ)
Для вычисления
p
-значения
в случае
односторонней альтернативной гипотезы μ
<μ
0
используйте формулу:
=1-Z.TEСT(
выборка
; μ
0
; σ)
σ — третий аргумент функции
Z.ТЕСТ()
должен быть всегда указан, т.к. это соответствует вышерассмотренной процедуре
z-теста
.
17 авг. 2022 г.
читать 2 мин
В статистике проверка гипотезы используется для проверки некоторого предположения о параметре совокупности .
Существует множество различных типов проверки гипотез, которые вы можете выполнять в зависимости от типа данных, с которыми вы работаете, и цели вашего анализа.
В этом руководстве объясняется, как выполнять следующие типы проверок гипотез в Excel:
- Один образец t-критерия
- Два выборочных t-теста
- Парные выборки t-критерий
- Z-тест одной пропорции
- Z-тест с двумя пропорциями
Давайте прыгать!
Пример 1: один образец t-критерия в Excel
Одновыборочный t-критерий используется для проверки того, равно ли среднее значение совокупности некоторому значению.
Например, предположим, что ботаник хочет знать, равна ли средняя высота определенного вида растений 15 дюймам.
Чтобы проверить это, она собирает случайную выборку из 12 растений и записывает их высоту в дюймах.
Она записала бы гипотезы для этого конкретного t-критерия одной выборки следующим образом:
- H 0 : µ = 15
- НА : мк ≠ 15
Обратитесь к этому руководству для пошагового объяснения того, как выполнить эту проверку гипотезы в Excel.
Пример 2. Двухвыборочный t-критерий в Excel
Двухвыборочный t-критерий используется для проверки того, равны ли средние значения двух совокупностей.
Например, предположим, что исследователи хотят знать, имеют ли два разных вида растений одинаковую среднюю высоту.
Чтобы проверить это, они собирают случайную выборку из 20 растений каждого вида и измеряют их высоту.
Исследователи записали бы гипотезы для этого конкретного двухвыборочного t-критерия следующим образом:
- Н 0 : мк 1 = мк 2
- H A : µ 1 ≠ µ 2
Обратитесь к этому руководству для пошагового объяснения того, как выполнить эту проверку гипотезы в Excel.
Пример 3: t-критерий парных выборок в Excel
Стьюдентный критерий для парных выборок используется для сравнения средних значений двух выборок, когда каждое наблюдение в одной выборке может быть сопоставлено с наблюдением в другой выборке.
Например, предположим, что мы хотим знать, значительно ли влияет определенная учебная программа на успеваемость студента на конкретном экзамене.
Чтобы проверить это, у нас есть 20 учеников в классе, которые проходят предварительный тест. Затем каждый из студентов участвует в учебной программе в течение двух недель. Затем учащиеся пересдают пост-тест аналогичной сложности.
Мы бы записали гипотезы для этого конкретного двухвыборочного t-критерия следующим образом:
- H 0 : µ до = µ после
- H A : µ до ≠ µ после
Обратитесь к этому руководству для пошагового объяснения того, как выполнить эту проверку гипотезы в Excel.
Пример 4: Z-тест одной пропорции в Excel
Z-критерий одной пропорции используется для сравнения наблюдаемой пропорции с теоретической.
Например, предположим, что телефонная компания утверждает, что 90% ее клиентов удовлетворены их услугами.
Чтобы проверить это утверждение, независимый исследователь собрал простую случайную выборку из 200 клиентов и спросил их, довольны ли они своим сервисом.
Мы бы записали гипотезы для этого конкретного двухвыборочного t-критерия следующим образом:
- Н 0 : р = 0,90
- НА : р ≠ 0,90
Обратитесь к этому руководству для пошагового объяснения того, как выполнить эту проверку гипотезы в Excel.
Пример 5: Z-тест для двух пропорций в Excel
Z-критерий двух пропорций используется для проверки разницы между двумя пропорциями населения.
Например, предположим, что руководитель школьного округа утверждает, что процент учащихся, предпочитающих шоколадное молоко обычному молоку в школьных столовых, одинаков для школы 1 и школы 2.
Чтобы проверить это утверждение, независимый исследователь получает простую случайную выборку из 100 учеников из каждой школы и опрашивает их об их предпочтениях.
Мы бы записали гипотезы для этого конкретного двухвыборочного t-критерия следующим образом:
- Н 0 : р 1 = р 2
- Н А : п 1 ≠ п 2
Обратитесь к этому руководству для пошагового объяснения того, как выполнить эту проверку гипотезы в Excel.
Содержание
- Проверка статистических гипотез в EXCEL о дисперсии нормального распределения
- Вычисление Р-значения
- Проверка статистических гипотез в EXCEL о равенстве среднего значения распределения (дисперсия неизвестна)
- t-тест
Проверка статистических гипотез в EXCEL о дисперсии нормального распределения
history 11 декабря 2016 г.
Рассмотрим использование MS EXCEL при проверке статистических гипотез о дисперсии нормального распределения. Вычислим тестовую статистику χ 2 и Р-значение (Р- value ).
Первое знакомство с процедурой проверки гипотез (Hypothesis testing) для дисперсии рекомендуется начать с изучения построения соответствующего доверительного интервала (см. статью Доверительный интервал для оценки дисперсии в MS EXCEL ).
Примечание : Перечень статей о проверке гипотез приведен в статье Проверка статистических гипотез в MS EXCEL .
СОВЕТ : Для проверки гипотез потребуется знание следующих понятий:
Формулировка задачи. Из генеральной совокупности имеющей нормальное распределение с неизвестным средним значением μ (мю) и неизвестной дисперсией σ 2 ( сигма 2 ) взята выборка размера n. Необходимо проверить двустороннюю статистическую гипотезу о равенстве неизвестной дисперсии σ 2 заданному исследователем значению σ 0 2 (англ. Inference on the variance of a normal population).
Примечание : Изложенный ниже метод проверки гипотез о дисперсии ,очень чувствителен к выполнению требования о нормальности распределения , из которого берется выборка . Если это требование не выполняется, то этот метод проверки гипотез будет давать неточные значения.
В качестве точечной оценкой дисперсии распределения, из которого взята выборка , используют Дисперсию выборки s 2 .
Перед процедурой проверки гипотезы , исследователь устанавливает требуемый уровень значимости – это допустимая для данной задачи ошибка первого рода , т.е. вероятность отклонить нулевую гипотезу , когда она верна ( уровень значимости обозначают буквой α (альфа) и чаще всего выбирают равным 0,1; 0,05 или 0,01).
Тестовой статистикой для проверки этой гипотезы является величина:
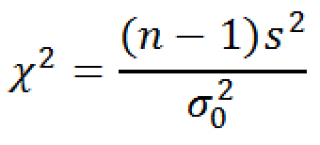
В статье про χ 2 -распределение показано , что выборочное распределение этой статистики, имеет χ 2 -распределение с n-1 степенью свободы, которое является « эталонным распределением » (англ. Reference distribution) для данного теста о равенстве дисперсии .
Значение, которое приняла χ 2 -статистика обозначим χ 0 2 .
Нулевая гипотеза Н 0 о равенстве дисперсии значению σ 0 2 отвергается в том случае, если χ 0 2 >χ 2 α/2,n-1 или χ 0 2 2 1-α/2,n-1
Примечание : Подробнее про квантили распределения можно прочитать в статье Квантили распределений MS EXCEL .
В MS EXCEL верхний α/2-квантиль распределения χ 2 вычисляется с помощью формулы =ХИ2.ОБР.ПХ(α/2; n-1)
Верхний (1-α /2)-квантиль вычисляется с помощью аналогичной формулы =ХИ2.ОБР.ПХ(1-α/2; n-1)
или через равный ему нижний квантиль
Вычисления приведены в файле примера .
В случае односторонней гипотезы речь идет об отклонении дисперсии только в одну сторону: либо больше либо меньше σ 0 2 . Если альтернативная гипотеза звучит как σ 2 > σ 0 2 , то гипотеза Н 0 отвергается в случае χ 0 2 > χ 2 α ,n-1 . Если альтернативная гипотеза звучит как σ 2 2 , то гипотеза Н 0 отвергается в случае χ 0 2 2 1-α ,n-1 .
СОВЕТ : О проверке гипотезы о равенстве дисперсий двух нормальных распределений ( F-test ) см. статью Двухвыборочный тест для дисперсии: F-тест в MS EXCEL .
Вычисление Р-значения
При проверке гипотез большое распространение также получил еще один эквивалентный подход, основанный на вычислении p -значения (p-value).
Если p-значение , вычисленное на основании выборки , меньше чем заданный уровень значимости α , то нулевая гипотеза отвергается и принимается альтернативная гипотеза . И наоборот, если p-значение больше α, то нулевая гипотеза не отвергается.
Формула для вычисления p-значения зависит от формулировки альтернативной гипотезы :
- Для односторонней гипотезы σ 2 2 p-значение вычисляется как =ХИ2.РАСП( χ 0 2 ; n-1;ИСТИНА)
- Для другой односторонней гипотезы σ 2 > σ 0 2 p-значение вычисляется как =ХИ2.РАСП.ПХ( χ 0 2 ; n-1)
- Для двусторонней гипотезыp-значение вычисляется как =2*МИН(ХИ2.РАСП( χ 0 2 ;n-1;ИСТИНА); ХИ2.РАСП.ПХ( χ 0 2 ;n-1))
Соответственно, χ 0 2 = (СЧЁТ( выборка )-1)* ДИСП.В( выборка )/ σ 0 2 , где выборка – ссылка на диапазон, содержащий значения выборки .
СОВЕТ : Подробнее про вышеуказанные функции MS EXCEL см. статью про χ 2 -распределение .
В файле примера на листе Дисперсия показано решение задач проверки двусторонней и односторонних гипотез .
Источник
Проверка статистических гипотез в EXCEL о равенстве среднего значения распределения (дисперсия неизвестна)
history 10 декабря 2016 г.
Рассмотрим использование MS EXCEL при проверке статистических гипотез о среднем значении распределения в случае неизвестной дисперсии. Вычислим тестовую статистику t 0 , рассмотрим процедуру «одновыборочный t -тест», вычислим Р-значение (Р- value ).
Материал данной статьи является продолжением статьи Проверка статистических гипотез о равенстве среднего значения распределения (дисперсия известна) . В указанной статье даны основные понятия проверки гипотез ( нулевая и альтернативная гипотезы, тестовые статистики, эталонное распределение, Р-значение и др. ).
СОВЕТ : Для проверки гипотез потребуется знание следующих понятий:
Формулировка задачи. Из генеральной совокупности имеющей нормальное распределение с неизвестным средним значением μ (мю) и неизвестной дисперсией взята выборка размера n. Необходимо проверить статистическую гипотезу о равенстве неизвестного μ заданному значению μ 0 (англ. Inference on the mean of a population, variance unknown).
Примечание : Требование о нормальности исходного распределения, из которого берется выборка , не является обязательным. Но, необходимо, чтобы были выполнены условия применения Центральной предельной теоремы .
Сначала проведем проверку гипотезы , используя доверительный интервал , а затем с помощью процедуры t -тест. В конце вычислим Р-значение и также используем его для проверки гипотезы .
Пусть нулевая гипотеза Н 0 утверждает, что неизвестное среднее значение распределения μ равно μ 0 . Соответствующая альтернативная гипотеза Н 1 утверждает обратное: μ не равно μ 0 . Это пример двусторонней проверки , т.к. неизвестное значение может быть как больше, так и меньше μ 0 .
Если упрощенно, то проверка гипотезы заключается в сравнении 2-х величин: вычисленного на основании выборки среднего значения Х ср и заданного μ 0 . Если эти значения «отличаются больше, чем можно было бы ожидать исходя из случайности», то нулевую гипотезу отклоняют.
Поясним фразу «отличаются больше, чем можно было бы ожидать исходя из случайности». Для этого, вспомним, что распределение Выборочного среднего (статистика Х ср ) стремится к нормальному распределению со средним значением μ и стандартным отклонением равным σ/√n, где σ – стандартное отклонение распределения, из которого берется выборка (не обязательно нормальное ), а n – объем выборки (подробнее см. статью про ЦПТ ).
К сожалению, в нашем случае дисперсия а, значит, и стандартное отклонение , неизвестны, поэтому вместо нее мы будем использовать ее оценку — дисперсию выборки s 2 и, соответственно, стандартное отклонение выборки s.
Известно, что если вместо неизвестной дисперсии распределения σ 2 мы используем дисперсию выборки s 2 , то распределением статистики Х ср является распределение Стьюдента с n-1 степенью свободы .
Таким образом, знание распределения статистики Х ср и заданного уровня доверия , позволяют нам формализовать с помощью математических выражений фразу «отличаются больше, чем можно было бы ожидать исходя из случайности».
В этом нам поможет доверительный интервал (как строится доверительный интервал нам известно из статьи Доверительный интервал для оценки среднего (дисперсия неизвестна) в MS EXCEL ). Если среднее выборки попадает в доверительный интервал, построенный относительно μ 0 , то для отклонения нулевой гипотезы оснований нет. Если не попадает, то нулевая гипотеза отвергается.
Воспользуемся выражением для Доверительного интервала , которое мы получили в статье Доверительный интервал для оценки среднего (дисперсия неизвестна) .
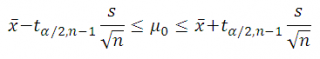
Напомним, что доверительный интервал обычно определяют через количество стандартных отклонений , которые в нем укладываются. В нашем случае в качестве стандартного отклонения берется стандартная ошибка s/√n.
Количество стандартных отклонений зависит от количества степеней свободы используемого t-распределения и уровня значимости α (альфа) .
Для визуализации проверки гипотезы методом доверительного интервала в файле примера на листе Сигма неизвестна создана диаграмма .
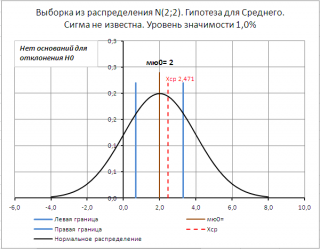
Примечание : Перечень статей о проверке гипотез приведен в статье Проверка статистических гипотез в MS EXCEL .
t-тест
Ниже приведем процедуру проверки гипотезы в случае неизвестной дисперсии . Данная процедура имеет название t -тест :
- Формулируют 2 гипотезы: нулевую Н 0 и альтернативную Н 1 . В случае формулирования двухсторонней гипотезы , нулевой гипотезой будет равенство μ и μ 0 , а альтернативной гипотезой – их отличие. Нулевая гипотеза отвергается только в том случае, если на это достаточно оснований. В этом случае принимается альтернативная гипотеза ;
- Чтобы понять, достаточно ли у нас оснований для отклонения нулевой гипотезы , из распределения делают выборка.
- На основе выборки вычисляют тестовую статистику . В нашем случае тестовой статистикой является случайная величина t ( t-статистика )
 , где Х ср – среднее выборки . Значение, которое приняла тестовая статистика , обычно обозначают t 0 ;
, где Х ср – среднее выборки . Значение, которое приняла тестовая статистика , обычно обозначают t 0 ; - Выбранная тестовая статистика , как и любая другая случайная величина, имеет свое распределение. В процедуре проверки гипотез это распределение называют « эталонным распределением », англ. Reference distribution. В нашем случае, когда дисперсия неизвестна, тестовая статистика имеет t-распределение с n-1 степенью свободы ;
- Также исследователь устанавливает требуемый уровень значимости – это допустимая для данной задачи ошибка первого рода , т.е. вероятность отклонить нулевую гипотезу , когда она верна ( уровень значимости обозначают буквой α и чаще всего выбирают равным 0,1; 0,05 или 0,01);
- С помощью эталонного распределения для заданного уровня значимости вычисляют соответствующие квантили этого распределения . В нашем случае, при проверке двухсторонней гипотезы , необходимо будет вычислить верхний α/2-квантильt-распределения с n-1 степенью свободы, т.е.такое значение случайной величины t n-1, что P(t n-1 >=t α/2,n-1 )= α /2 ;
- И, наконец, значение тестовой статистики t 0 сравнивают с вычисленными на предыдущем шаге квантилями и делают статистический вывод : Имеются ли основания, чтобы отвергнуть нулевую гипотезу ? В нашем случае проверки двусторонней гипотезы , Н 0 отвергается если: |t 0 |>t α/2, n-1
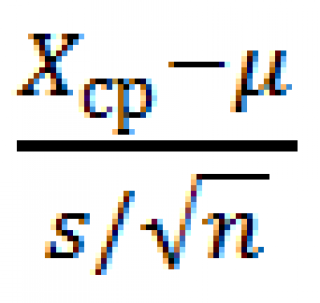 , где Х ср – среднее выборки . Значение, которое приняла тестовая статистика , обычно обозначают t 0 ;
, где Х ср – среднее выборки . Значение, которое приняла тестовая статистика , обычно обозначают t 0 ;В MS EXCEL верхний α /2-квантиль вычисляется по формуле =СТЬЮДЕНТ.ОБР(1- α /2; n-1)
Учитывая симметричность t- распределения относительно оси ординат, верхний α /2-квантиль равен обычному α /2-квантилю со знаком минус: =-СТЬЮДЕНТ.ОБР( α /2; n-1)
Также в MS EXCEL имеется специальная формула для вычисления двухсторонних квантилей : =СТЬЮДЕНТ.ОБР.2Х( α ; n-1) Все три формулы вернут один и тот же результат.
Примечание : Подробнее про квантили распределения можно прочитать в статье Квантили распределений MS EXCEL .
Примечание : Если вместо t- распределения использовать стандартное нормальное распределение, то мы получим необоснованно более узкий доверительный интервал , тем самым мы будем чаще необоснованно отвергать нулевую гипотезу , когда она справедлива ( увеличим ошибку первого рода ).
Отметим, что различие в ширине интервалов зависит от размера выборки n (при уменьшении n различие увеличивается) и от уровня значимости (при уменьшении α различие увеличивается). Для n=10 и α = 0,01 относительная разница в ширине интервалов составляет порядка 20%. При большом размере выборки n (>30), различием в интервалах часто пренебрегают (для n=30 и α = 0,01 относительная разница составляет 6,55%). Это свойство используется в функции Z.ТЕСТ() , которая вычисляет р-значение (см. ниже) с использованием нормального распределения (аргумент σ должен быть опущен или указана ссылка на стандартное отклонение выборки ).
В случае односторонней гипотезы речь идет об отклонении μ только в одну сторону: либо больше либо меньше μ 0 . Если альтернативная гипотеза звучит как μ>μ 0 , то гипотеза Н 0 отвергается в случае t 0 > t α ,n-1 . Если альтернативная гипотеза звучит как μ СОВЕТ : Подробнее про p -значение написано в статье Проверка статистических гипотез в MS EXCEL о равенстве среднего значения распределения (дисперсия известна) .
Если p-значение , вычисленное на основании выборки , меньше чем заданный уровень значимости α , то нулевая гипотеза отвергается и принимается альтернативная гипотеза . И наоборот, если p-значение больше α , то нулевая гипотеза не отвергается.
Другими словами, если p-значение меньше уровня значимости α , то это свидетельство того, что значение t -статистики , вычисленное на основе выборки при условии истинности нулевой гипотезы , приняло маловероятное значение t 0 .
Формула для вычисления p-значения зависит от формулировки альтернативной гипотезы :
- Для односторонней гипотезы μ =СТЬЮДЕНТ.РАСП(t 0 ; n-1; ИСТИНА)
- Для другой односторонней гипотезы μ>μ 0p-значение вычисляется как =1-СТЬЮДЕНТ.РАСП(t 0 ; n-1; ИСТИНА)
- Для двусторонней гипотезыp-значение вычисляется как =2*(1-СТЬЮДЕНТ.РАСП(ABS(t 0 );n-1;ИСТИНА))
Соответственно, t 0 =(СРЗНАЧ( выборка )-μ 0 )/ (СТАНДОТКЛОН.В( выборка )/ КОРЕНЬ(СЧЁТ( выборка ))) , где выборка – ссылка на диапазон, содержащий значения выборки .
В файле примера на листе Сигма неизвестна показана эквивалентность проверки гипотезы через доверительный интервал , статистику t 0 ( t -тест) и p -значение .
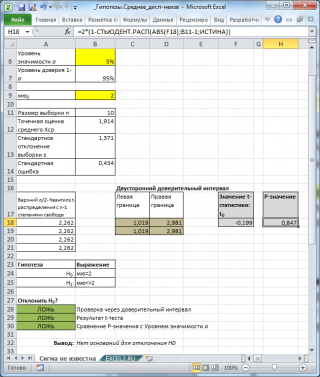
Примечание : В MS EXCEL нет специализированной функции для одновыборочного t-теста . При больших n можно использовать функцию Z.ТЕСТ() с опущенным 3-м аргументом (подробнее про эту функцию см. статью Проверка статистических гипотез в MS EXCEL о равенстве среднего значения распределения (дисперсия известна) ). Функция СТЬЮДЕНТ.ТЕСТ() предназначена для двухвыборочного t-теста .
Источник
На чтение 4 мин. Просмотров 53 Опубликовано 06.06.2021
Проверка гипотез – одна из основных тем в области логической статистики. Есть несколько шагов для проверки гипотезы, и многие из них требуют статистических расчетов. Статистическое программное обеспечение, такое как Excel, можно использовать для проверки гипотез. Мы увидим, как функция Excel Z.TEST проверяет гипотезы о неизвестном среднем значении совокупности.
Содержание
- Условия и предположения
- Структура проверки гипотез
- Функция Z.TEST
- Примечания и предупреждения
- Пример
Условия и предположения
Начнем формулируя предположения и условия для этого типа проверки гипотез. Для вывода о среднем мы должны иметь следующие простые условия:
- Выборка представляет собой простую случайную выборку.
- Размер выборки невелик по сравнению с генеральной совокупностью. Обычно это означает, что размер генеральной совокупности более чем в 20 раз превышает размер выборки.
- Изучаемая переменная имеет нормальное распределение.
- Стандартное отклонение генеральной совокупности известно .
- Среднее значение для генеральной совокупности неизвестно.
Маловероятно, что все эти условия будут выполнены на практике. Однако эти простые условия и соответствующая проверка гипотезы иногда встречаются на ранних этапах статистического класса. После изучения процесса проверки гипотез эти условия смягчаются, чтобы работать в более реалистичных условиях.
Структура проверки гипотез
Рассматриваемая нами конкретная проверка гипотез имеет следующую форму:
- Сформулируйте нулевую и альтернативную гипотезы.
- Рассчитайте статистику теста, которая представляет собой z -счет.
- Рассчитайте p-значение, используя нормальное распределение. В этом случае p-значение представляет собой вероятность получения не менее экстремальной, чем наблюдаемая статистика теста, при условии, что нулевая гипотеза верна.
- Сравните p-значение с уровнем значимости, чтобы определить отвергать или не отвергать нулевую гипотезу.
Мы видим, что шаги два и три требуют больших вычислительных ресурсов по сравнению с двумя шагами один и четыре. Функция Z.TEST выполнит эти вычисления за нас.
Функция Z.TEST
Функция Z.TEST делает все расчетов из шагов два и три выше. Он выполняет большую часть обработки чисел для нашего теста и возвращает p-значение. В функцию можно ввести три аргумента, каждый из которых отделяется запятой. Ниже объясняются три типа аргументов для этой функции.
- Первый аргумент для этой функции – это массив образцов данных. Мы должны ввести диапазон ячеек, который соответствует расположению выборки данных в нашей электронной таблице.
- Второй аргумент – это значение μ, которое мы проверяем в наших гипотезах. Итак, если наша нулевая гипотеза H 0 : μ = 5, то мы должны ввести 5 для второго аргумента.
- Третий аргумент – это значение известное стандартное отклонение населения. Excel рассматривает это как необязательный аргумент.
Примечания и предупреждения
Следует отметить несколько моментов. об этой функции:
- Значение p, выводимое функцией, одностороннее. Если мы проводим двусторонний тест, то это значение необходимо удвоить.
- Односторонний вывод p-значения из функции предполагает, что выборочное среднее больше, чем значение μ, которое мы тестируем против. Если выборочное среднее меньше значения второго аргумента, то мы должны вычесть выходные данные функции из 1, чтобы получить истинное p-значение нашего теста.
- Последний аргумент для Стандартное отклонение населения не является обязательным. Если он не введен, это значение автоматически заменяется в расчетах Excel на стандартное отклонение выборки. Когда это будет сделано, теоретически следует использовать t-тест.
Пример
Мы предполагаем, что следующие данные взяты из простой случайной выборки нормально распределенной совокупности с неизвестным средним и стандартным отклонением 3:
1, 2, 3, 3, 4 , 4, 8, 10, 12
При уровне значимости 10% мы хотим проверить гипотезу о том, что данные выборки взяты из генеральной совокупности со средним большим чем 5. Более формально мы имеем следующие гипотезы:
- H 0 : μ = 5
- H a : μ> 5
Мы используем Z. ТЕСТ в Excel, чтобы найти значение p для этой проверки гипотезы.
- Введите данные в столбец в Excel. Предположим, это от ячейки A1 до A9.
- В другую ячейку введите = Z.TEST (A1: A9,5,3)
- Результат – 0,41207.
- Поскольку наше значение p превышает 10%, мы не можем отклонить нулевую гипотезу.
Z.TEST Функция может использоваться для тестов с нижним хвостом, а также для двусторонних тестов. Однако результат не такой автоматический, как в этом случае. Другие примеры использования этой функции см. Здесь.
In statistics, a hypothesis test is used to test some assumption about a population parameter.
There are many different types of hypothesis tests you can perform depending on the type of data you’re working with and the goal of your analysis.
This tutorial explains how to perform the following types of hypothesis tests in Excel:
- One sample t-test
- Two sample t-test
- Paired samples t-test
- One proportion z-test
- Two proportion z-test
Let’s jump in!
Example 1: One Sample t-test in Excel
A one sample t-test is used to test whether or not the mean of a population is equal to some value.
For example, suppose a botanist wants to know if the mean height of a certain species of plant is equal to 15 inches.
To test this, she collects a random sample of 12 plants and records each of their heights in inches.
She would write the hypotheses for this particular one sample t-test as follows:
- H0: µ = 15
- HA: µ ≠15
Refer to this tutorial for a step-by-step explanation of how to perform this hypothesis test in Excel.
Example 2: Two Sample t-test in Excel
A two sample t-test is used to test whether or not the means of two populations are equal.
For example, suppose researchers want to know whether or not two different species of plants have the same mean height.
To test this, they collect a random sample of 20 plants from each species and measure their heights.
The researchers would write the hypotheses for this particular two sample t-test as follows:
- H0: µ1 = µ2
- HA: µ1 ≠ µ2
Refer to this tutorial for a step-by-step explanation of how to perform this hypothesis test in Excel.
Example 3: Paired Samples t-test in Excel
A paired samples t-test is used to compare the means of two samples when each observation in one sample can be paired with an observation in the other sample.
For example, suppose we want to know whether a certain study program significantly impacts student performance on a particular exam.
To test this, we have 20 students in a class take a pre-test. Then, we have each of the students participate in the study program for two weeks. Then, the students retake a post-test of similar difficulty.
We would write the hypotheses for this particular two sample t-test as follows:
- H0: µpre = µpost
- HA: µpre ≠ µpost
Refer to this tutorial for a step-by-step explanation of how to perform this hypothesis test in Excel.
Example 4: One Proportion z-test in Excel
A one proportion z-test is used to compare an observed proportion to a theoretical one.
For example, suppose a phone company claims that 90% of its customers are satisfied with their service.
To test this claim, an independent researcher gathered a simple random sample of 200 customers and asked them if they are satisfied with their service.
We would write the hypotheses for this particular two sample t-test as follows:
- H0: p = 0.90
- HA: p ≠ 0.90
Refer to this tutorial for a step-by-step explanation of how to perform this hypothesis test in Excel.
Example 5: Two Proportion z-test in Excel
A two proportion z-test is used to test for a difference between two population proportions.
For example, suppose a superintendent of a school district claims that the percentage of students who prefer chocolate milk over regular milk in school cafeterias is the same for school 1 and school 2.
To test this claim, an independent researcher obtains a simple random sample of 100 students from each school and surveys them about their preferences.
We would write the hypotheses for this particular two sample t-test as follows:
- H0: p1= p2
- HA: p1 ≠ p2
Refer to this tutorial for a step-by-step explanation of how to perform this hypothesis test in Excel.