
Поиск последней непустой ячейки в строке или столбце функцией ПРОСМОТР
На практике часто возникает необходимость быстро найти значение последней (крайней) непустой ячейки в строке или столбце таблицы. Предположим, для примера, что у нас есть вот такая таблица с данными продаж по нескольким филиалам:

Задача: найти значение продаж в последнем месяце по каждому филиалу, т.е. для Москвы это будет 78, для Питера — 41 и т.д.
Если бы в нашей таблице не было пустых ячеек, то путь к решению был бы очевиден — можно было бы посчитать количество заполненных ячеек в каждой строке и брать потом ячейку с этим номером. Но филиалы работают неравномерно: Москва простаивала в марте и августе, филиал в Тюмени открылся только с апреля и т.д., поэтому такой способ не подойдет.
Универсальным решением будет использование функции ПРОСМОТР (LOOKUP):

У этой функции хитрая логика:
- Она по очереди (слева-направо) перебирает непустые ячейки в диапазоне (B2:M2) и сравнивает каждую из них с искомым значением (9999999).
- Если значение очередной проверяемой ячейки совпало с искомым, то функция останавливает просмотр и выводит содержимое ячейки.
- Если точного совпадения нет и очередное значение меньше искомого, то функция переходит к следующей ячейке в строке.
Легко сообразить, что если в качестве искомого значения задать достаточно большое число, то функция пройдет по всей строке и, в итоге, выдаст содержимое последней проверенной ячейки. Для компактности, можно указать искомое число в экспоненциальном формате, например 1E+11 (1*1011 или сто миллиардов).
Если в таблице не числа, а текст, то идея остается той же, но «очень большое число» нужно заменить на «очень большой текст»:

Применительно к тексту, понятие «большой» означает код символа. В любом шрифте символы идут в следующем порядке возрастания кодов:
- латиница прописные (A-Z)
- латиница строчные (a-z)
- кириллица прописные (А-Я)
- кириллица строчные (а-я)
Поэтому строчная «я» оказывается буквой с наибольшим кодом и слово из нескольких подряд «яяяяя» будет, условно, «очень большим словом» — заведомо «большим», чем любое текстовое значение из нашей таблицы.
Вот так. Не совсем очевидное, но красивое и компактное решение. Для поиска последней непустой ячейки в столбцах работает тоже «на ура».
Ссылки по теме
- Поиск и подстановка по нескольким условиям (ВПР по 2 и более критериям)
- Поиск ближайшего похожего текста (max совпадений символов)
- Двумерный поиск в таблице (ВПР 2D)
Найдем номер строки последней заполненной ячейки в столбце и списке. По номеру строки найдем и само значение.
Рассмотрим диапазон значений, в который регулярно заносятся новые данные.
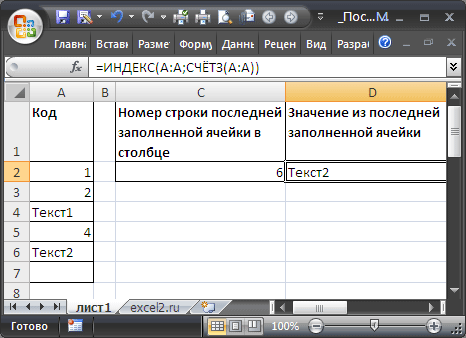
Диапазон без пропусков и начиная с первой строки
В случае, если в столбце значения вводятся, начиная с первой строки и без пропусков, то определить номер строки последней заполненной ячейки можно формулой:
=СЧЁТЗ(A:A))
Формула работает для числовых и текстовых диапазонов (см.
Файл примера
)
Значение из последней заполненной ячейки в столбце выведем с помощью функции
ИНДЕКС()
:
=ИНДЕКС(A:A;СЧЁТЗ(A:A))
Ссылки на целые столбцы и строки достаточно ресурсоемки и могут замедлить пересчет листа. Если есть уверенность, что при вводе значений пользователь не выйдет за границы определенного диапазона, то лучше указать ссылку на диапазон, а не на столбец. В этом случае формула будет выглядеть так:
=ИНДЕКС(A1:A20;СЧЁТЗ(A1:A20))
Диапазон без пропусков в любом месте листа
Если список, в который вводятся значения расположен в диапазоне
E8:E30
(т.е. не начинается с первой строки), то формулу для определения номера строки последней заполненной ячейки можно записать следующим образом:
=СЧЁТЗ(E9:E30)+СТРОКА(E8)
Формула
СТРОКА(E8)
возвращает номер строки заголовка списка. Значение из последней заполненной ячейки списка выведем с помощью функции
ИНДЕКС()
:
=ИНДЕКС(E9:E30;СЧЁТЗ(E9:E30))
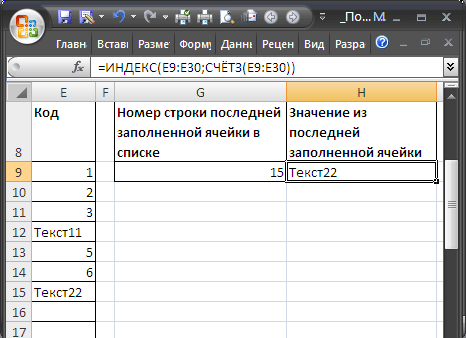
Диапазон с пропусками (числа)
В случае
наличия пропусков
(пустых строк) в столбце, функция
СЧЕТЗ()
будет возвращать неправильный (уменьшенный) номер строки: оно и понятно, ведь эта функция подсчитывает только значения и не учитывает
пустые
ячейки.
Если диапазон заполняется
числовыми
значениями, то для определения номера строки последней заполненной ячейки можно использовать формулу
=ПОИСКПОЗ(1E+306;A:A;1)
. Пустые ячейки и текстовые значения игнорируются.
Так как в качестве просматриваемого массива указан целый столбец (
A:A
), то функция
ПОИСКПОЗ()
вернет номер последней заполненной строки. Функция
ПОИСКПОЗ()
(с третьим параметром =1) находит позицию наибольшего значения, которое меньше или равно значению первого аргумента (1E+306). Правда, для этого требуется, чтобы массив был
отсортирован
по возрастанию. Если он не отсортирован, то эта функция возвращает позицию последней заполненной строки столбца, т.е. то, что нам нужно.
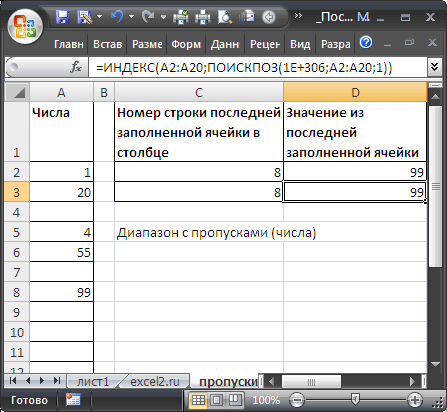
Чтобы вернуть значение в последней заполненной ячейке списка, расположенного в диапазоне
A2:A20
, можно использовать формулу:
=ИНДЕКС(A2:A20;ПОИСКПОЗ(1E+306;A2:A20;1))
Диапазон с пропусками (текст)
В случае необходимости определения номера строки последнего
текстового
значения (также при наличии пропусков), формулу нужно переделать:
=ПОИСКПОЗ(«*»;$A:$A;-1)
Пустые ячейки, числа и текстовое значение
Пустой текст
(«») игнорируются.
Диапазон с пропусками (текст и числа)
Если столбец содержит и
текстовые и числовые значения
, то для определения номера строки последней заполненной ячейки можно предложить универсальное решение:
=МАКС(ЕСЛИОШИБКА(ПОИСКПОЗ(«*»;$A:$A;-1);0); ЕСЛИОШИБКА(ПОИСКПОЗ(1E+306;$A:$A;1);0))
Функция
ЕСЛИОШИБКА()
нужна для подавления ошибки возникающей, если столбец
A
содержит только текстовые или только числовые значения.
Другим универсальным решением является
формула массива
:
=МАКС(СТРОКА(A1:A20)*(A1:A20<>»»))
Или
=МАКС(СТРОКА(A1:A20)*НЕ(ЕПУСТО(A1:A20)))
После ввода
формулы массива
нужно нажать
CTRL + SHIFT + ENTER
. Предполагается, что значения вводятся в диапазон
A1:A20
. Лучше задать фиксированный диапазон для поиска, т.к. использование в
формулах массива
ссылок на целые строки или столбцы является достаточно ресурсоемкой задачей.
Значение из последней заполненной ячейки, в этом случае, выведем с помощью функции
ДВССЫЛ()
:
=ДВССЫЛ(«A»&МАКС(СТРОКА(A1:A20)*(A1:A20<>»»)))
Или
=ДВССЫЛ(«A»&МАКС(СТРОКА(A1:A20)*НЕ(ЕПУСТО(A1:A20))))
Как обычно, после ввода
формулы массива
нужно нажать
CTRL + SHIFT + ENTER
вместо
ENTER
.
СОВЕТ:
Как видно, наличие пропусков в диапазоне существенно усложняет подсчет. Поэтому имеет смысл при заполнении и проектировании таблиц придерживаться правил приведенных в статье
Советы по построению таблиц
.
На чтение 7 мин. Просмотров 29.8k.
Содержание
- Получить первое не пустое значение в списке
- Получить первое текстовое значение в списке
- Получить первое текстовое значение с ГПР
- Получить позицию последнего совпадения
- Получить последнее совпадение содержимого ячейки
- Получить n-е совпадение
- Получить n-ое совпадение с ИНДЕКС/ПОИСКПОЗ
- Получить n-ое совпадение с ВПР
- Если ячейка содержит одну из многих вещей
- Поиск первой ошибки
- Поиск следующего наибольшего значения
- Несколько совпадений в списке, разделенных запятой
- Частичное совпадение чисел с шаблоном
- Частичное совпадение с ВПР
- Положение первого частичного совпадения
Получить первое не пустое значение в списке
{ = ИНДЕКС( диапазон ; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( диапазон ); 0 )) }

Если вам нужно получить первое не пустое значение (текст или число) в диапазоне в одной колонке вы можете использовать формулу массива на основе функций ИНДЕКС, ПОИСКПОЗ и ЕПУСТО.
В данном примере мы используем эту формулу:
{ = ИНДЕКС( B3: B11; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( B3: B11 ); 0 )) }
Таким образом, суть проблемы заключается в следующем: мы хотим получить первую не пустую ячейку, но для этого нет конкретной формулы в Excel. Мы могли бы использовать ВПР с шаблоном *, но это будет работать только для текста, а не для чисел.
Таким образом, нам нужно строить функциональные возможности для нужных нам формул. Способ сделать это состоит в использовании функции массива, которая «тестирует» ячейки и возвращает массив истина/ложь значения, которые мы можем сопрягать с ПОИСКПОЗ.
Работая изнутри, ЕПУСТО оценивает ячейки в диапазоне В3: В11 и возвращает результат и массив, который выглядит следующим образом:
{ИСТИНА; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ИСТИНА; ИСТИНА; ИСТИНА}
Каждая ЛОЖЬ представляет собой ячейку в диапазоне, который не является пустой.
Далее, ПОИСКПОЗ ищет ЛОЖЬ внутри массива и возвращает позицию первого наденного совпадения, в этом случае 2. На данный момент, формула в примере теперь выглядит следующим образом:
{ = ИНДЕКС( B3: B11; 2; 0 )) }
И, наконец, функция ИНДЕКС выводит значение в положении 2 в массиве, в этом случае число 10.
Получить первое текстовое значение в списке
= ВПР ( «*»; диапазон; 1; ЛОЖЬ)
Если вам нужно получить первое текстовое значение в списке (диапазон один столбец), вы можете использовать функцию ВПР, чтобы установить точное соответствие, с шаблонным символом для поиска.

В данном примере формула в D7 является:
= ВПР ( «*» ; B5: B11 ; 1 ; ЛОЖЬ)
Групповой символ звездочка (*) соответствует любому текстовому значению.
Получить первое текстовое значение с ГПР
= ГПР ( «*»; диапазон; 1; ЛОЖЬ)

Для поиска и получения первого текстового значения во всем диапазоне столбцов, вы можете использовать функцию ГПР с групповым символом. В примере формула в F5 является:
= ГПР ( «*»; С5: Е5; 1; 0 )
Значение поиска является «*», групповым символом, который соответствует одному или более текстовому значению.
Получить позицию последнего совпадения
{ = МАКС( ЕСЛИ ( Величины = знач ; СТРОКА(величина) — СТРОКА(ИНДЕКС( Величины; 1 ; 1 )) + 1 )) }
Для того, чтобы получить позицию последнего совпадения (т.е. последнего вхождения) от значения поиска, вы можете использовать формулу, основанную на ЕСЛИ, СТРОКА, ИНДЕКС, ПОИСКПОЗ и MAКС функций.

В примере формула в G6:
=МАКС(ЕСЛИ(B4:B11=G5;СТРОКА(B4:B11)-СТРОКА(ИНДЕКС(B4:B11;1;1))+1))
Суть этой формулы состоит в том, что мы строим список номеров строк для данного диапазона, соответствующие по значению, а затем используем функцию MAКС, чтобы получить наибольшее количество строк, что соответствует последнему значению соответствия.
Получить последнее совпадение содержимого ячейки
= ПРОСМОТР( 2 ; 1 / ПОИСК ( вещи ; А1 ); вещи )
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть последнее совпадение, найденное в списке, вы можете использовать формулу, основанную на ПРОСМОТР и ПОИСК функций. В случае нескольких найденных совпадений, формула вернет последнее совпадение из списка «вещей».

В примере формула в С5:
=ПРОСМОТР(2;1/ПОИСК($E$4:$E$7;B4);$E$4:$E$7)
Получить n-е совпадение
= НАИМЕНЬШИЙ( ЕСЛИ( логический тест; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); n )
Для того, чтобы получить позицию n-го совпадения (например, второе значение соответствия заданному, третье значение соответствия и т.д.), вы можете использовать формулу, основанную на функции НАИМЕНЬШИЙ.
= НАИМЕНЬШИЙ( ЕСЛИ( список = E5 ; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); F5 )
Эта формула возвращает позицию второго появления «красных» в списке.
Сутью этой формулы является функция НАИМЕНЬШИЙ, которая просто возвращает n-е наименьшее значение в списке значений, которое соответствует номеру строки. Номера строк были «отфильтрованы» функцией ЕСЛИ, которая применяет логику для совпадения.
Получить n-ое совпадение с ИНДЕКС/ПОИСКПОЗ
{ = ИНДЕКС( массив; НАИМЕНЬШИЙ( ЕСЛИ( величины = знач ; СТРОКА ( величины ) — СТРОКА ( ИНДЕКС( величины; 1 ; 1 )) + 1 ); n-й )) }

Чтобы получить n-ое совпадение, используя ИНДЕКС и ПОИСКПОЗ, вы можете использовать формулу массива с функциями ЕСЛИ и НАИМЕНЬШИЙ, чтобы выяснить номер строки совпадения.
Получить n-ое совпадение с ВПР
= ВПР( id_формулы; стол; 4; 0 )
Чтобы получить n-ое совпадение с ВПР, вам необходимо добавить вспомогательный столбец в таблицу , которая строит уникальный идентификатор , который включает счетчик.

Эта формула зависит от вспомогательного столбца, который добавляется в качестве первого столбца таблицы исходных данных. Вспомогательный столбец содержит формулу, которая строит уникальное значение взгляда вверх от существующего идентификатора и счетчика. Счетчик подсчитывает сколько раз уникальный идентификатор появился в таблице данных.
В примере, формула ячейки J6 вспомогательного столбца выглядит следующим образом:
=ВПР(J3&»-«&I6;B4:G11;4;0)
Если ячейка содержит одну из многих вещей
{ = ИНДЕКС( результаты ;ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК( вещи ; A1 )); 0 )) }
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть пользовательский результат для первого найденного совпадения, вы можете использовать формулу ИНДЕКС/ПОИСКПОЗ, основанную на функции поиска.
{ = ИНДЕКС( результаты ; ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК ( вещи ; B5 )); 0 )) }
Эта формула использует два названных диапазона: E5: E8 называется «вещи» и F5: F8 называется «Результаты». Убедитесь, что вы используете диапазоны имен с одинаковыми именами (на основе ваших данных). Если вы не хотите использовать именованные диапазоны, используйте абсолютные ссылки вместо этого.
Поиск первой ошибки
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА(диап ); 0 ) }
Если вам нужно найти первую ошибку в диапазоне ячеек, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ЕОШИБКА функциях.

В приведенном примере формула:
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА( B4: B11 ); 0 ) }
Работая изнутри, функция ЕОШИБКА возвращает значение ИСТИНА, если значение является признанной ошибкой, и ЛОЖЬ, если нет.
Когда дается диапазон ячеек (массив ячеек) функция ЕОШИБКА будет возвращать массив истина/ложь значений. В примере, это результирующий массив выглядит следующим образом:
{ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ}
Обратите внимание, что 6-е значение (что соответствует 6-й ячейке в диапазоне) истинно, так как ячейка В9 содержит #Н/A.
Поиск следующего наибольшего значения
=ИНДЕКС ( данные; ПОИСКПОЗ( поиск ; значения ) + 1 )

Для того, чтобы найти «следующее наибольшее» значение в справочной таблице, можно использовать формулу, основанную на ИНДЕКС и ПОИСКПОЗ. В примере формула в F6 является:
=ИНДЕКС(C5:C9;ПОИСКПОЗ(F4;B5:B9)+1)
Несколько совпадений в списке, разделенных запятой
{ = ОБЪЕДИНИТЬ ( «;» ; ИСТИНА ; ЕСЛИ( диапазон1 = E5 ; диапазон2 ; «» )) }
Для поиска и извлечения нескольких совпадений, разделенных запятыми (в одной ячейке), вы можете использовать функцию ЕСЛИ с функцией ОБЪЕДИНИТЬ.
{ = ОБЪЕДИНИТЬ( «;» ; ИСТИНА ; ЕСЛИ( группа = E5 ; имя ; «» )) }
Эта формула использует «имя» — именованный диапазон (B5: B11) и «группа» — (C5: C11).
Частичное совпадение чисел с шаблоном
{ = ПОИСКПОЗ( «*» & номер & «*» ; ТЕКСТ( диапазон ; «0» ); 0 ) }
Для того, чтобы выполнить частичное совпадение (подстроки) против чисел, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ТЕКСТ.

Excel поддерживает символы подстановки «*» и «?». Тем не менее, если вы используете специальные символы с номером, вы будете преобразовывать числовое значение в текстовое значение. Другими словами, «*» & 99 & «*» = «* 99 *» (текстовая строка).
Если попытаться найти текстовое значение в диапазоне чисел, совпадение завершится неудачно.
Решение
Одно из решений заключается в преобразовании чисел в диапазоне поиска для текстовых значений, а затем сделать нормальный поиск с ПОИСКПОЗ, ВПР и т.д.
Другой вариант
Другой способ, чтобы преобразовать числа в текст, чтобы сцепить пустую строку. Эта формула работает так же, как выше формуле:
= ПОИСКПОЗ ( «*» & Е5 & «*» ; В5: В10 & «» ; 0 )
Частичное совпадение с ВПР
Если вы хотите получить информацию из таблицы на основе частичного совпадения, вы можете сделать это с помощью ВПР в режиме точного соответствия, и групповые символы.

В примере формула ВПР выглядит следующим образом:
=ВПР($H$2&»*»;$B$3:$E$12;2;0)
В этой формуле, значение представляет собой именованный диапазон, который относится к Н2, а также данные , представляет собой именованный диапазон , который относится к B3: E102. Без названных диапазонов, формула может быть записана следующим образом:
Положение первого частичного совпадения
= ПОИСКПОЗ ( «* текст *» ; диапазон; 0 )
Для того, чтобы получить позицию первого частичного совпадения (то есть ячейку, которая содержит текст, который вы ищете), вы можете использовать функцию ПОИСКПОЗ со специальными символами.

В примере формула в Е7:
=ПОИСКПОЗ(«*»&E6&»*»;B5:B10;0)
Функция ПОИСКПОЗ возвращает позицию или «индекс» в первом совпадении на основании значения поиска в диапазоне.
ПОИСКПОЗ поддерживает подстановочное согласование со звездочкой «*» (один или несколько символов) или знаком вопроса «?» (один символ), но только тогда, когда третий аргумент, тип_сопоставления, установлен в ЛОЖЬ или ноль.
За определенный период времени ведется регистр количества проданного товара в магазине. Необходимо регулярно отслеживать последний выданный из магазина товар. Для этого нужно отобразить последнюю запись в столбце наименования товаров. Чтобы просто посмотреть на последнее значение столбца, достаточно переместить курсор на любую его ячейку и нажать комбинацию горячих клавиш CTRL + стрелка в низ (↓). Но чаще всего пользователю приходится с последним значением столбца выполнять различные вычислительные операции в Excel. Поэтому лучше его получить в качестве значения для отдельной ячейки.
Поиск последнего значения в столбце Excel
Схематический регистр товаров, выданных с магазина:
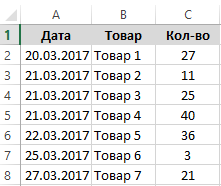
Чтобы иметь возможность постоянно наблюдать, какой товар зарегистрирован последним, в отдельную ячейку E1 введем формулу:
Результат выполнения формулы для получения последнего значения:
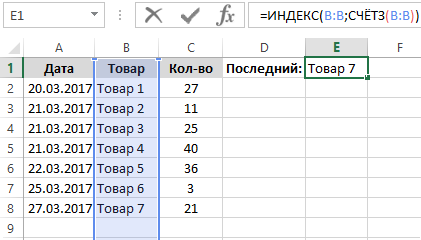
Разбор принципа действия формулы для поиска последнего значения в столбце:
Главную роль берет на себя функция =ИНДЕКС(), которая должна возвращать содержимое ячейки таблицы где пересекаются определенная строка и столбец. В качестве первого аргумента функции ИНДЕКС выступает неизменяемая константа, а именно ссылка на целый столбец (B:B). Во втором аргументе находится номер строки с последним заполненным значением столбца B. Чтобы узнать этот номер строки используется функция СЧЁТЗ, которая возвращает количество непустых ячеек в диапазоне. Соответственно это же число равно номеру последней непустой строки в столбце B и используется как второй аргумент для функции ИНДЕКС, которая сразу возвращает последнее значение столбца B в отдельной ячейке E1.
Внимание! Все записи в столбце B должны быть неразрывны (без пустых ячеек до последнего значения).
Стоит отметить что данная формула является динамической. При добавлении новых записей в столбец B результат в ячейке E1 будет автоматически обновляться.
Последняя заполненная ячейка в MS EXCEL
Найдем номер строки последней заполненной ячейки в столбце и списке. По номеру строки найдем и само значение.
Рассмотрим диапазон значений, в который регулярно заносятся новые данные.
Диапазон без пропусков и начиная с первой строки
В случае, если в столбце значения вводятся, начиная с первой строки и без пропусков, то определить номер строки последней заполненной ячейки можно формулой:
=СЧЁТЗ(A:A))
Формула работает для числовых и текстовых диапазонов (см. Файл примера )
Значение из последней заполненной ячейки в столбце выведем с помощью функции ИНДЕКС() :
=ИНДЕКС(A:A;СЧЁТЗ(A:A))
Ссылки на целые столбцы и строки достаточно ресурсоемки и могут замедлить пересчет листа. Если есть уверенность, что при вводе значений пользователь не выйдет за границы определенного диапазона, то лучше указать ссылку на диапазон, а не на столбец. В этом случае формула будет выглядеть так:
=ИНДЕКС(A1:A20;СЧЁТЗ(A1:A20))
Диапазон без пропусков в любом месте листа
Если список, в который вводятся значения расположен в диапазоне E8:E30 (т.е. не начинается с первой строки), то формулу для определения номера строки последней заполненной ячейки можно записать следующим образом:
=СЧЁТЗ(E9:E30)+СТРОКА(E8)
Формула СТРОКА(E8) возвращает номер строки заголовка списка. Значение из последней заполненной ячейки списка выведем с помощью функции ИНДЕКС() :
=ИНДЕКС(E9:E30;СЧЁТЗ(E9:E30))
Диапазон с пропусками (числа)
В случае наличия пропусков (пустых строк) в столбце, функция СЧЕТЗ() будет возвращать неправильный (уменьшенный) номер строки: оно и понятно, ведь эта функция подсчитывает только значения и не учитывает пустые ячейки.
Если диапазон заполняется числовыми значениями, то для определения номера строки последней заполненной ячейки можно использовать формулу =ПОИСКПОЗ(1E+306;A:A;1) . Пустые ячейки и текстовые значения игнорируются.
Так как в качестве просматриваемого массива указан целый столбец (A:A), то функция ПОИСКПОЗ() вернет номер последней заполненной строки. Функция ПОИСКПОЗ() (с третьим параметром =1) находит позицию наибольшего значения, которое меньше или равно значению первого аргумента (1E+306). Правда, для этого требуется, чтобы массив был отсортирован по возрастанию. Если он не отсортирован, то эта функция возвращает позицию последней заполненной строки столбца, т.е. то, что нам нужно.
Чтобы вернуть значение в последней заполненной ячейке списка, расположенного в диапазоне A2:A20, можно использовать формулу:
=ИНДЕКС(A2:A20;ПОИСКПОЗ(1E+306;A2:A20;1))
Диапазон с пропусками (текст)
В случае необходимости определения номера строки последнего текстового значения (также при наличии пропусков), формулу нужно переделать:
=ПОИСКПОЗ(«*»;$A:$A;-1)
Пустые ячейки, числа и текстовое значение Пустой текст («») игнорируются.
Диапазон с пропусками (текст и числа)
Если столбец содержит и текстовые и числовые значения, то для определения номера строки последней заполненной ячейки можно предложить универсальное решение:
=МАКС(ЕСЛИОШИБКА(ПОИСКПОЗ(«*»;$A:$A;-1);0);
ЕСЛИОШИБКА(ПОИСКПОЗ(1E+306;$A:$A;1);0))
Функция ЕСЛИОШИБКА() нужна для подавления ошибки возникающей, если столбец A содержит только текстовые или только числовые значения.
Другим универсальным решением является формула массива:
=МАКС(СТРОКА(A1:A20)*(A1:A20<>«»))
После ввода формулы массива нужно нажать CTRL + SHIFT + ENTER. Предполагается, что значения вводятся в диапазон A1:A20. Лучше задать фиксированный диапазон для поиска, т.к. использование в формулах массива ссылок на целые строки или столбцы является достаточно ресурсоемкой задачей.
Значение из последней заполненной ячейки, в этом случае, выведем с помощью функции ДВССЫЛ() :
=ДВССЫЛ(«A»&МАКС(СТРОКА(A1:A20)*(A1:A20<>«»)))
Как обычно, после ввода формулы массива нужно нажать CTRL + SHIFT + ENTER вместо ENTER.
СОВЕТ:
Как видно, наличие пропусков в диапазоне существенно усложняет подсчет. Поэтому имеет смысл при заполнении и проектировании таблиц придерживаться правил приведенных в статье Советы по построению таблиц.
Возврат значения последней непустой ячейки в столбце или строке
Если вы часто обновляете рабочий лист, записывая новые данные в столбцы, вам пригодится способ, позволяющий ссылаться на последнее значение в том или ином столбце (обычно именно это значение меняется чаще всего). [1] Например (рис. 1), на листе отслеживается размер трех фондов в столбцах B:D. Обратите внимание: обновление информации происходит не в одно и то же время. Цель — получить сумму самых последних данных по каждому из фондов. Эти значения вычисляются в диапазоне G4:G6.
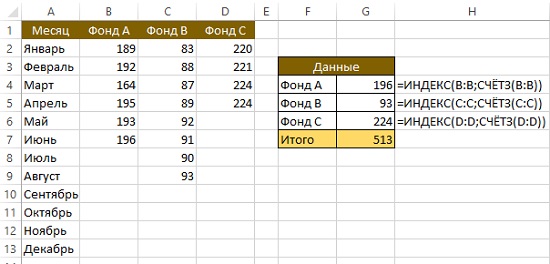
Рис. 1. Формула для возвращения последней непустой ячейки в столбцах B:D на основе подсчета ячеек
Скачать заметку в формате Word или pdf, примеры в формате Excel
В этих формулах используется функция СЧЁТЗ, подсчитывающая количество непустых ячеек в столбце С. Это значение используется как второй аргумент функции ИНДЕКС. Например, в столбце В последнее значение находится в строке 7, а функция ИНДЕКС возвращает седьмое значение из этого столбца.
Приведенные выше формулы работают в большинстве случаев, но не всегда. Если в столбце разбросано несколько пустых ячеек, то определение последней непустой ячейки оказывается более сложной задачей, так как функция СЧЁТЗ не считает пустые ячейки.
Метод с формулой массива. Следующая формула массива возвращает содержимое последней непустой ячейки строк столбца В, даже если в этом столбце есть пустые ячейки (рис. 2): <=ИНДЕКС(B:B;МАКС(СТРОКА(B:B)*(B:B<>» » )))>. Для ввода формулы массива нажмите Ctrl+Shift+Enter, а не просто Enter.

Рис. 2. Формула массива справится с пустыми значениями в диапазоне
В том виде, в каком эта формула приведена выше, вы не сможете использовать ее в том же столбце, в котором она записана. При попытке сделать это возникнет циклическая ссылка. Чтобы использовать формулу в ячейке В1, измените ссылки так, чтобы они начинались со строки 2, а не охватывали целый столбец. Например, для возврата последней непустой ячейки в диапазоне В2:В1000 используйте запись В2:В1000.
Следующая формула массива напоминает предыдущую, но возвращает последнюю непустую ячейку в строке (в данном случае в строке 2): <=ИНДЕКС(2:2;МАКС(СТОЛБЕЦ(2:2)*(2:2<>» » )))>.
Метод с применением обычной формулы (не формулой массива). Данная формула возвращает последнюю непустую ячейку в столбце В: =ПРОСМОТР(2;1/(B:B<> » » );B:B). Эта формула игнорирует ячейки с ошибками, поэтому, если в последней непустой ячейке содержится ошибка (например, #ДЕЛ/0!), формула возвратит последнюю непустую ячейку, не содержащую ошибку.
Аналогично, следующая формула возвращает последнюю непустую ячейку из строки 2, не содержащую ошибок: =ПРОСМОТР(2;1/(2:2<> » » );2:2).
[1] По материалам книги Джон Уокенбах. Excel 2013. Трюки и советы. – СПб.: Питер, 2014. – С. 133, 134.
Microsoft Excel
трюки • приёмы • решения
Возвращение последней непустой ячейки в столбец или строку таблицы Excel
Предположим, что вы часто обновляете таблицу, добавляя новые данные в ее столбцы. Вам, возможно, понадобится способ ссылаться на последнее значение в определенном столбце (последнее введенное значение).
В таблице на рис. 114.1 отслеживаются значения трех фондов в столбцах B:D. Обратите внимание, что информация поступает не в одно и то же время. Цель состоит в том, чтобы получить сумму самых последних данных по каждому фонду. Эти значения рассчитываются в диапазоне G4:G6.

Рис. 114.1. Таблица, из которой необходимо получить значение последней непустой ячейки в столбцах B:D
Формулы в G4, G5 и G6 следующие:
=ИНДЕКС(B:B;СЧЁТЗ(B:B))
=ИНДЕКС(C:C;СЧЁТЗ(C:C))
=ИНДЕКС(D:D;СЧЁТЗ(D:D))
Формулы применяют функции СЧЁТЗ для подсчета количества непустых ячеек в столбце С. Это значение используется в качестве второго аргумента функции ИНДЕКС. Например, в столбце В последнее значение в строке равно 6, СЧЁТЗ возвращает 6, а функция ИНДЕКС возвращает шестое значение в столбце.
Предыдущие формулы работают в большинстве, но не во всех случаях. Если в столбце одна или несколько пустых ячеек разбросаны, то определение последней непустой ячейки — немного более сложная задача, поскольку функция СЧЁТЗ не подсчитывает пустые ячейки.
Следующая формула массива возвращает содержимое последней непустой ячейки в первых 500 строках из столбца С, даже если он включает пустые ячейки: =ИНДЕКС(C1:C500;МАКС(СТОЛБЕЦ(C1:C500)*(C1:C500<>«»))) .
Нажмите Ctrl+Shift+Enter (а не просто Enter), чтобы ввести формулу массива.
Вы можете, конечно, изменить формулу для работы с любым другим столбцом, кроме С. Для этого поменяйте четыре ссылки на столбец С на другой, который вам нужен. Если последняя непустая ячейка была в строке, идущей за 500 первыми строками, вам необходимо изменить два экземпляра значения 500 на большее число. Чем меньше строк ссылается в формуле, тем быстрее выполняется расчет.
Следующая формула массива подобна предыдущей, но возвращает последнюю непустую ячейку в строке (в данном случае в строке 1): =ИНДЕКС(1:1;МАКС(СТОЛБЕЦ(1:1)*(1:1<>«»))) . Чтобы использовать эту формулу для различных строк, измените три ссылки на строки 1:1 так, чтобы она соответствовала правильному количеству строк.
Поиск последнего значения в строке или столбце функцией ПРОСМОТР
На практике часто возникает необходимость быстро найти значение последней (крайней) непустой ячейки в строке или столбце таблицы. Предположим, для примера, что у нас есть вот такая таблица с данными продаж по нескольким филиалам:
Задача: найти значение продаж в последнем месяце по каждому филиалу, т.е. для Москвы это будет 78, для Питера — 41 и т.д.
Если бы в нашей таблице не было пустых ячеек, то путь к решению был бы очевиден — можно было бы посчитать количество заполненных ячеек в каждой строке и брать потом ячейку с этим номером. Но филиалы работают неравномерно: Москва простаивала в марте и августе, филиал в Тюмени открылся только с апреля и т.д., поэтому такой способ не подойдет.
Универсальным решением будет использование функции ПРОСМОТР (LOOKUP) :
У этой функции хитрая логика:
- Она по очереди (слева-направо) перебирает непустые ячейки в диапазоне (B2:M2) и сравнивает каждую из них с искомым значением (9999999).
- Если значение очередной проверяемой ячейки совпало с искомым, то функция останавливает просмотр и выводит содержимое ячейки.
- Если точного совпадения нет и очередное значение меньше искомого, то функция переходит к следующей ячейке в строке.
Легко сообразить, что если в качестве искомого значения задать достаточно большое число, то функция пройдет по всей строке и, в итоге, выдаст содержимое последней проверенной ячейки. Для компактности, можно указать искомое число в экспоненциальном формате, например 1E+11 (1*10 11 или сто миллиардов).
Если в таблице не числа, а текст, то идея остается той же, но «очень большое число» нужно заменить на «очень большой текст»:
Применительно к тексту, понятие «большой» означает код символа. В любом шрифте символы идут в следующем порядке возрастания кодов:
- латиница прописные (A-Z)
- латиница строчные (a-z)
- кириллица прописные (А-Я)
- кириллица строчные (а-я)
Поэтому строчная «я» оказывается буквой с наибольшим кодом и слово из нескольких подряд «яяяяя» будет, условно, «очень большим словом» — заведомо «большим», чем любое текстовое значение из нашей таблицы.
Вот так. Не совсем очевидное, но красивое и компактное решение. Для поиска последней непустой ячейки в столбцах работает тоже «на ура».
В excel последнее значение в столбце
Если Вам необходимо в таблицах, которые имеют неодинаковое количество ячеек в строках и/или столбцах, например таких:
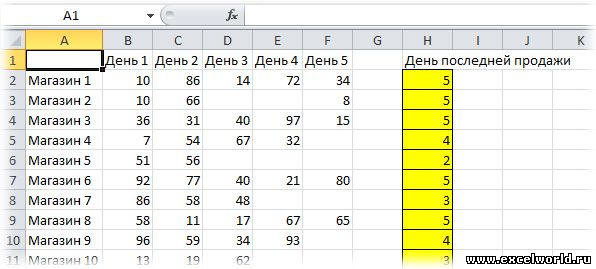
находить последние заполненные ячейки и извлекать из них значения, то в Excel Вы, к сожалению, не найдёте функции типа ВЕРНУТЬ.ПОСЛЕДНЮЮ.ЯЧЕЙКУ()
Вот как это сделать имеющейся в стандартном наборе функций функцией ПРОСМОТР().
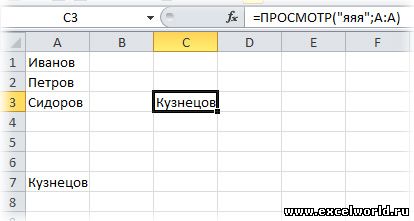
1. Для текстовых значений:
В английской версии:
Как это работает: Функция ПРОСМОТР() ищет сверху вниз в указанном столбце текст «яяя» и не найдя его, останавливается на последней ячейке в которой есть хоть какой-то текст. Так как мы не указали третий аргумент этой функции «Вектор_результатов», то функция возвращает значение из второго аргумента «Вектор_просмотра».
Пояснение: Почему именно «яяя«? Во-первых, потому что функция сравнивает при поиске текст посимвольно, а символ «я» в русском языке последний и все предыдущие при сравнении отбрасываются, во-вторых, потому что в русском языке нет такого слова.
Примечание: Вообще-то достаточно использовать и «яя«, но тогда возникает мизерная возможность попасть на таблицу, в которой будет такое слово. Так называются город и река в Кемеровской области. В детстве я был в этом городе и даже купался в этой реке 🙂
2. Для числовых значений:
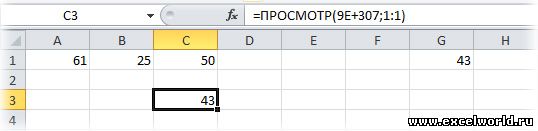
В английской версии:
Как это работает: Функция ПРОСМОТР() ищет слева направо в указанной строке число «9E+307» и не найдя его, останавливается на последней ячейке в которой есть хоть какое-то число. Так как мы не указали третий аргумент этой функции «Вектор_результатов», то функция возвращает значение из второго аргумента «Вектор_просмотра».
Пояснение: Почему именно «9E+307«? Потому что это максимально возможное число в Excel. Поэтому функция найти его может только в каком-то невероятном случае, в реальной жизни пользователь такими числами просто не оперирует.
3. Для смешанных (текстово-числовых) значений:
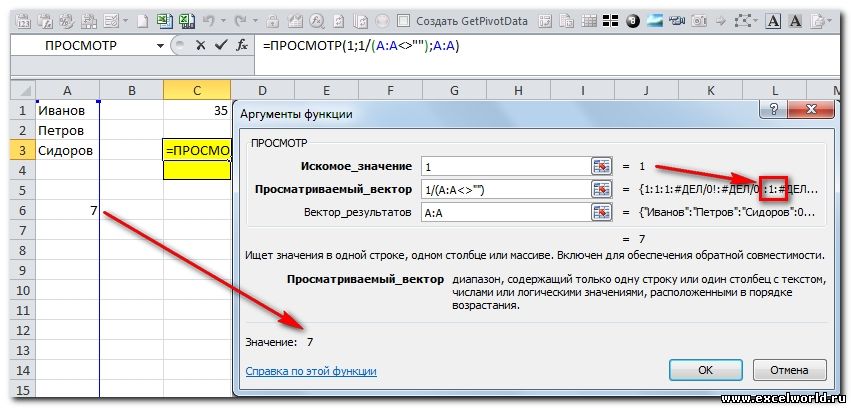
В английской версии:
Как это работает: Функция ПРОСМОТР() ищет слева направо в указанной строке число «1» и найдя его, останавливается на последней ячейке в которой есть это число. Так как мы указали третий аргумент этой функции «Вектор_результатов», то функция возвращает значение из него, соответствующее позиции последнего вхождения искомого в просматриваемый массив.
Пояснение: Почему именно «1«? Да просто так 🙂 С таким же успехом можно использовать число 2 или 3 или 100500, например. Главное что бы первый аргумент функции был не менее делимого в выражении 1/Диапазон. Вот пример применения другого числа в первом аргументе, при делимом отличном от единицы: