
Совет: Попробуйте использовать новые функции ПРОСМОТРX и XMATCH, а также улучшенные версии функций, описанные в этой статье. Эти новые функции работают в любом направлении и возвращают точные совпадения по умолчанию, что упрощает и упрощает работу с ними по сравнению с предшественниками.
Предположим, у вас есть список номеров офисов, и вам нужно знать, какие сотрудники работают в каждом из них. Таблица очень угрюмая, поэтому, возможно, вам кажется, что это сложная задача. С функцией подытов на самом деле это довольно просто.
Функции ВВ., а также ИНДЕКС и ВЫБОРПОЗ — одни из самых полезных функций в Excel.
Примечание: Мастер подметок больше не доступен в Excel.
Ниже в качестве примера по выбору вы можете найти пример использования в этой области.
=ВПР(B2;C2:E7,3,ИСТИНА)
В этом примере B2 является первым аргументом —элементом данных, который требуется для работы функции. В случае СРОТ ВЛ.В.ОВ этот первый аргумент является искомой значением. Этот аргумент может быть ссылкой на ячейку или фиксированным значением, таким как «кузьмина» или 21 000. Вторым аргументом является диапазон ячеек C2–:E7, в котором нужно найти и найти значение. Третий аргумент — это столбец в диапазоне ячеек, содержащий ищите значение.
Четвертый аргумент необязателен. Введите истина или ЛОЖЬ. Если ввести ИСТИНА или оставить аргумент пустым, функция возвращает приблизительное совпадение значения, указанного в качестве первого аргумента. Если ввести ЛОЖЬ, функция будет соответствовать значению, заведомо первому аргументу. Другими словами, если оставить четвертый аргумент пустым или ввести ИСТИНА, это обеспечивает большую гибкость.
В этом примере показано, как работает функция. При вводе значения в ячейку B2 (первый аргумент) в результате поиска в ячейках диапазона C2:E7 (2-й аргумент) выполняется поиск в ней и возвращается ближайшее приблизительное совпадение из третьего столбца в диапазоне — столбца E (третий аргумент).
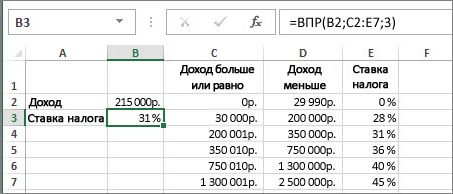
Четвертый аргумент пуст, поэтому функция возвращает приблизительное совпадение. Иначе потребуется ввести одно из значений в столбец C или D, чтобы получить какой-либо результат.
Если вы хорошо разучились работать с функцией ВГТ.В.В., то в равной степени использовать ее будет легко. Вы вводите те же аргументы, но выполняется поиск в строках, а не в столбцах.
Использование индекса и MATCH вместо ВРОТ
При использовании функции ВПРАВО существует ряд ограничений, которые действуют только при использовании функции ВПРАВО. Это означает, что столбец, содержащий и look up, всегда должен быть расположен слева от столбца, содержащего возвращаемого значения. Теперь, если ваша таблица не построена таким образом, не используйте В ПРОСМОТР. Используйте вместо этого сочетание функций ИНДЕКС и MATCH.
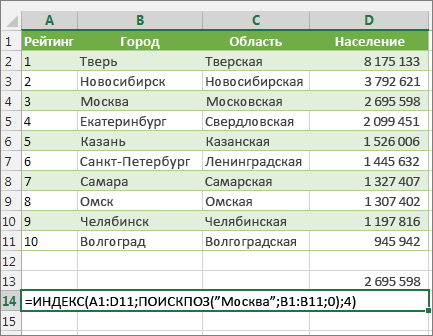
В данном примере представлен небольшой список, в котором искомое значение (Воронеж) не находится в крайнем левом столбце. Поэтому мы не можем использовать функцию ВПР. Для поиска значения «Воронеж» в диапазоне B1:B11 будет использоваться функция ПОИСКПОЗ. Оно найдено в строке 4. Затем функция ИНДЕКС использует это значение в качестве аргумента поиска и находит численность населения Воронежа в четвертом столбце (столбец D). Использованная формула показана в ячейке A14.
Дополнительные примеры использования индексов и MATCH вместо В ПРОСМОТР см. в статье билла Https://www.mrexcel.com/excel-tips/excel-vlookup-index-match/ Билла Джилена (Bill Jelen), MVP корпорации Майкрософт.
Попробуйте попрактиковаться
Если вы хотите поэкспериментировать с функциями подытовки, прежде чем попробовать их с собственными данными, вот примеры данных.
Пример работы с ВЛОКОНПОМ
Скопируйте следующие данные в пустую таблицу.
Совет: Прежде чем врезать данные в Excel, установите для столбцов A–C ширину в 250 пикселей и нажмите кнопку «Перенос текста» (вкладка «Главная», группа «Выравнивание»).
|
Плотность |
Вязкость |
Температура |
|
0,457 |
3,55 |
500 |
|
0,525 |
3,25 |
400 |
|
0,606 |
2,93 |
300 |
|
0,675 |
2,75 |
250 |
|
0,746 |
2,57 |
200 |
|
0,835 |
2,38 |
150 |
|
0,946 |
2,17 |
100 |
|
1,09 |
1,95 |
50 |
|
1,29 |
1,71 |
0 |
|
Формула |
Описание |
Результат |
|
=ВПР(1,A2:C10,2) |
Используя приблизительное соответствие, функция ищет в столбце A значение 1, находит наибольшее значение, которое меньше или равняется 1 и составляет 0,946, а затем возвращает значение из столбца B в той же строке. |
2,17 |
|
=ВПР(1,A2:C10,3,ИСТИНА) |
Используя приблизительное соответствие, функция ищет в столбце A значение 1, находит наибольшее значение, которое меньше или равняется 1 и составляет 0,946, а затем возвращает значение из столбца C в той же строке. |
100 |
|
=ВПР(0,7,A2:C10,3,ЛОЖЬ) |
Используя точное соответствие, функция ищет в столбце A значение 0,7. Поскольку точного соответствия нет, возвращается сообщение об ошибке. |
#Н/Д |
|
=ВПР(0,1,A2:C10,2,ИСТИНА) |
Используя приблизительное соответствие, функция ищет в столбце A значение 0,1. Поскольку 0,1 меньше наименьшего значения в столбце A, возвращается сообщение об ошибке. |
#Н/Д |
|
=ВПР(2,A2:C10,2,ИСТИНА) |
Используя приблизительное соответствие, функция ищет в столбце A значение 2, находит наибольшее значение, которое меньше или равняется 2 и составляет 1,29, а затем возвращает значение из столбца B в той же строке. |
1,71 |
Пример ГВ.Г.В.В.
Скопируйте всю таблицу и вставьте ее в ячейку A1 пустого листа Excel.
Совет: Прежде чем врезать данные в Excel, установите для столбцов A–C ширину в 250 пикселей и нажмите кнопку «Перенос текста» (вкладка «Главная», группа «Выравнивание»).
|
Оси |
Подшипники |
Болты |
|
4 |
4 |
9 |
|
5 |
7 |
10 |
|
6 |
8 |
11 |
|
Формула |
Описание |
Результат |
|
=ГПР(«Оси»;A1:C4;2;ИСТИНА) |
Поиск слова «Оси» в строке 1 и возврат значения из строки 2, находящейся в том же столбце (столбец A). |
4 |
|
=ГПР(«Подшипники»;A1:C4;3;ЛОЖЬ) |
Поиск слова «Подшипники» в строке 1 и возврат значения из строки 3, находящейся в том же столбце (столбец B). |
7 |
|
=ГПР(«П»;A1:C4;3;ИСТИНА) |
Поиск буквы «П» в строке 1 и возврат значения из строки 3, находящейся в том же столбце. Так как «П» найти не удалось, возвращается ближайшее из меньших значений: «Оси» (в столбце A). |
5 |
|
=ГПР(«Болты»;A1:C4;4) |
Поиск слова «Болты» в строке 1 и возврат значения из строки 4, находящейся в том же столбце (столбец C). |
11 |
|
=ГПР(3;{1;2;3:»a»;»b»;»c»;»d»;»e»;»f»};2;ИСТИНА) |
Поиск числа 3 в трех строках константы массива и возврат значения из строки 2 того же (в данном случае — третьего) столбца. Константа массива содержит три строки значений, разделенных точкой с запятой (;). Так как «c» было найдено в строке 2 того же столбца, что и 3, возвращается «c». |
c |
Примеры индекса и match
В последнем примере функции ИНДЕКС и MATCH совместно возвращают номер счета с наиболее ранней датой и соответствующую дату для каждого из пяти городов. Так как дата возвращается как число, для ее формата используется функция ТЕКСТ. Функция ИНДЕКС использует результат, возвращенный функцией ПОИСКПОЗ, как аргумент. Сочетание функций ИНДЕКС и ПОИСКПОЗ используется в каждой формуле дважды — сперва для возврата номера счета, а затем для возврата даты.
Скопируйте всю таблицу и вставьте ее в ячейку A1 пустого листа Excel.
Совет: Перед тем как вировать данные в Excel, установите для столбцов A–D ширину в 250 пикселей и нажмите кнопку «Перенос текста» (вкладка «Главная», группа «Выравнивание»).
|
Счет |
Город |
Дата выставления счета |
Счет с самой ранней датой по городу, с датой |
|
3115 |
Казань |
07.04.12 |
=»Казань = «&ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Казань»,$B$2:$B$33,0),1)& «, Дата выставления счета: » & ТЕКСТ(ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Казань»,$B$2:$B$33,0),3),»m/d/yy») |
|
3137 |
Казань |
09.04.12 |
=»Орел = «&ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Орел»,$B$2:$B$33,0),1)& «, Дата выставления счета: » & ТЕКСТ(ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Орел»,$B$2:$B$33,0),3),»m/d/yy») |
|
3154 |
Казань |
11.04.12 |
=»Челябинск = «&ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Челябинск»,$B$2:$B$33,0),1)& «, Дата выставления счета: » & ТЕКСТ(ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Челябинск»,$B$2:$B$33,0),3),»m/d/yy») |
|
3191 |
Казань |
21.04.12 |
=»Нижний Новгород = «&ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Нижний Новгород»,$B$2:$B$33,0),1)& «, Дата выставления счета: » & ТЕКСТ(ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Нижний Новгород»,$B$2:$B$33,0),3),»m/d/yy») |
|
3293 |
Казань |
25.04.12 |
=»Москва = «&ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Москва»,$B$2:$B$33,0),1)& «, Дата выставления счета: » & ТЕКСТ(ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Москва»,$B$2:$B$33,0),3),»m/d/yy») |
|
3331 |
Казань |
27.04.12 |
|
|
3350 |
Казань |
28.04.12 |
|
|
3390 |
Казань |
01.05.12 |
|
|
3441 |
Казань |
02.05.12 |
|
|
3517 |
Казань |
08.05.12 |
|
|
3124 |
Орел |
09.04.12 |
|
|
3155 |
Орел |
11.04.12 |
|
|
3177 |
Орел |
19.04.12 |
|
|
3357 |
Орел |
28.04.12 |
|
|
3492 |
Орел |
06.05.12 |
|
|
3316 |
Челябинск |
25.04.12 |
|
|
3346 |
Челябинск |
28.04.12 |
|
|
3372 |
Челябинск |
01.05.12 |
|
|
3414 |
Челябинск |
01.05.12 |
|
|
3451 |
Челябинск |
02.05.12 |
|
|
3467 |
Челябинск |
02.05.12 |
|
|
3474 |
Челябинск |
04.05.12 |
|
|
3490 |
Челябинск |
05.05.12 |
|
|
3503 |
Челябинск |
08.05.12 |
|
|
3151 |
Нижний Новгород |
09.04.12 |
|
|
3438 |
Нижний Новгород |
02.05.12 |
|
|
3471 |
Нижний Новгород |
04.05.12 |
|
|
3160 |
Москва |
18.04.12 |
|
|
3328 |
Москва |
26.04.12 |
|
|
3368 |
Москва |
29.04.12 |
|
|
3420 |
Москва |
01.05.12 |
|
|
3501 |
Москва |
06.05.12 |
|
Поиск значения следующего за искомым |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |


Ссылка на это место страницы:
#title
- Получить первое не пустое значение в списке
- Получить первое текстовое значение в списке
- Получить первое текстовое значение с ГПР
- Получить позицию последнего совпадения
- Получить последнее совпадение содержимого ячейки
- Получить n-е совпадение
- Получить n-ое совпадение с ИНДЕКС/ПОИСКПОЗ
- Получить n-ое совпадение с ВПР
- Если ячейка содержит одну из многих вещей
- Поиск первой ошибки
- Поиск следующего наибольшего значения
- Несколько совпадений в списке, разделенных запятой
- Частичное совпадение чисел с шаблоном
- Частичное совпадение с ВПР
- Положение первого частичного совпадения
- Скачать файл
Ссылка на это место страницы:
#punk01
{ = ИНДЕКС( диапазон ; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( диапазон ); 0 )) }
{ = INDEX( диапазон ; MATCH( FALSE; ISBLANK ( диапазон ); 0 )) }

Если вам нужно получить первое не пустое значение (текст или число) в диапазоне в одной колонке вы можете использовать формулу массива на основе функций ИНДЕКС, ПОИСКПОЗ и ЕПУСТО.
В данном примере мы используем эту формулу:
{ = ИНДЕКС( B3: B11; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( B3: B11 ); 0 )) }
{ = INDEX( B3:B11; MATCH( FALSE; ISBLANK ( B3:B11 ); 0 )) }
Таким образом, суть проблемы заключается в следующем: мы хотим получить первую не пустую ячейку, но для этого нет конкретной формулы в Excel. Мы могли бы использовать ВПР с шаблоном *, но это будет работать только для текста, а не для чисел.
Таким образом, нам нужно строить функциональные возможности для нужных нам формул. Способ сделать это состоит в использовании функции массива, которая «тестирует» ячейки и возвращает массив истина/ложь значения, которые мы можем сопрягать с ПОИСКПОЗ.
Работая изнутри, ЕПУСТО оценивает ячейки в диапазоне В3: В11 и возвращает результат и массив, который выглядит следующим образом:
{ИСТИНА; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ИСТИНА; ИСТИНА; ИСТИНА}
Каждая ЛОЖЬ представляет собой ячейку в диапазоне, который не является пустой.
Далее, ПОИСКПОЗ ищет ЛОЖЬ внутри массива и возвращает позицию первого наденного совпадения, в этом случае 2. На данный момент, формула в примере теперь выглядит следующим образом:
{ = ИНДЕКС( B3: B11; 2; 0 )) }
{ = INDEX( B3:B11; 2; 0 )) }
И, наконец, функция ИНДЕКС выводит значение в положении 2 в массиве, в этом случае число 10.
Ссылка на это место страницы:
#punk02
= ВПР ( «*»; диапазон; 1; ЛОЖЬ)
= VLOOKUP ( «*»; диапазон; 1; FALSE)
Если вам нужно получить первое текстовое значение в списке (диапазон один столбец), вы можете использовать функцию ВПР, чтобы установить точное соответствие, с шаблонным символом для поиска.

В данном примере формула в D7 является:
= ВПР ( «*» ; B5: B11 ; 1 ; ЛОЖЬ)
= VLOOKUP ( «*» ; B5:B11 ; 1 ; FALSE)
Групповой символ звездочка (*) соответствует любому текстовому значению.
Ссылка на это место страницы:
#punk03
= ГПР ( «*»; диапазон; 1; ЛОЖЬ)
= HLOOKUP ( «*»; диапазон; 1; FALSE)

Для поиска и получения первого текстового значения во всем диапазоне столбцов, вы можете использовать функцию ГПР с групповым символом. В примере формула в F5 является:
= ГПР ( «*»; диапазон; 1; ЛОЖЬ)
= HLOOKUP ( «*»; диапазон; 1; FALSE)
Значение поиска является «*», групповым символом, который соответствует одному или более текстовому значению.
Ссылка на это место страницы:
#punk04
= ГПР ( «*»; диапазон; 1; ЛОЖЬ)
= HLOOKUP ( «*»; диапазон; 1; FALSE)
Для того, чтобы получить позицию последнего совпадения (т.е. последнего вхождения) от значения поиска, вы можете использовать формулу, основанную на ЕСЛИ, СТРОКА, ИНДЕКС, ПОИСКПОЗ и MAКС функций.

=МАКС(ЕСЛИ(B4:B11=G5;СТРОКА(B4:B11)-СТРОКА(ИНДЕКС(B4:B11;1;1))+1))
=MAX(IF(B4:B11=G5;ROW(B4:B11)-ROW(INDEX(B4:B11;1;1))+1))
Суть этой формулы состоит в том, что мы строим список номеров строк для данного диапазона, соответствующие по значению, а затем используем функцию MAКС, чтобы получить наибольшее количество строк, что соответствует последнему значению соответствия.
Ссылка на это место страницы:
#punk05
=МАКС(ЕСЛИ(B4:B11=G5;СТРОКА(B4:B11)-СТРОКА(ИНДЕКС(B4:B11;1;1))+1))
=MAX(IF(B4:B11=G5;ROW(B4:B11)-ROW(INDEX(B4:B11;1;1))+1))
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть последнее совпадение, найденное в списке, вы можете использовать формулу, основанную на ПРОСМОТР и ПОИСК функций. В случае нескольких найденных совпадений, формула вернет последнее совпадение из списка «вещей».

=ПРОСМОТР(2;1/ПОИСК($E$4:$E$7;B4);$E$4:$E$7)
=LOOKUP(2;1/SEARCH($E$4:$E$7;B4);$E$4:$E$7)
Ссылка на это место страницы:
#punk06
= НАИМЕНЬШИЙ( ЕСЛИ( логический тест; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); n )
= SMALL( IF( логический тест; СТРОКА( список ) — MIN( ROW( список )) + 1 ); n )
Для того, чтобы получить позицию n-го совпадения (например, второе значение соответствия заданному, третье значение соответствия и т.д.), вы можете использовать формулу, основанную на функции НАИМЕНЬШИЙ.
= НАИМЕНЬШИЙ( ЕСЛИ( список = E5 ; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); F5 )
= SMALL( IF( список = E5 ; ROW( список ) — MIN( ROW( список )) + 1 ); F5 )
Эта формула возвращает позицию второго появления «красных» в списке.
Сутью этой формулы является функция НАИМЕНЬШИЙ, которая просто возвращает n-е наименьшее значение в списке значений, которое соответствует номеру строки. Номера строк были «отфильтрованы» функцией ЕСЛИ, которая применяет логику для совпадения.
Ссылка на это место страницы:
#punk07
{ = ИНДЕКС( массив; НАИМЕНЬШИЙ( ЕСЛИ( величины = знач ; СТРОКА ( величины ) — СТРОКА ( ИНДЕКС( величины; 1 ; 1 )) + 1 ); n-й )) }
{ = INDEX( массив; SMALL( IF( величины = знач ; ROW ( величины ) — ROW ( INDEX( величины; 1 ; 1 )) + 1 ); n-й )) }

Эта формула возвращает позицию второго появления «красных» в списке.
Сутью этой формулы является функция НАИМЕНЬШИЙ, которая просто возвращает n-е наименьшее значение в списке значений, которое соответствует номеру строки. Номера строк были «отфильтрованы» функцией ЕСЛИ, которая применяет логику для совпадения.
Ссылка на это место страницы:
#punk08
= ВПР( id_формулы; стол; 4; 0 )
= VLOOKUP( id_формулы; стол; 4; 0 )
Чтобы получить n-ое совпадение с ВПР, вам необходимо добавить вспомогательный столбец в таблицу , которая строит уникальный идентификатор , который включает счетчик.

Эта формула зависит от вспомогательного столбца, который добавляется в качестве первого столбца таблицы исходных данных.
Вспомогательный столбец содержит формулу, которая строит уникальное значение взгляда вверх от существующего идентификатора и счетчика. Счетчик подсчитывает сколько раз уникальный идентификатор появился в таблице данных.
В примере, формула ячейки J6 вспомогательного столбца выглядит следующим образом:
=ВПР(J3&»-«&I6;B4:G11;4;0)
=VLOOKUP(J3&»-«&I6;B4:G11;4;0)
Ссылка на это место страницы:
#punk09
{ = ИНДЕКС( результаты ;ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК( вещи ; A1 )); 0 )) }
{ = INDEX( результаты ;MATCH( TRUE ; ISNUMBER( SEARCH( вещи ; A1 )); 0 )) }
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть пользовательский результат для первого найденного совпадения, вы можете использовать формулу ИНДЕКС/ПОИСКПОЗ, основанную на функции поиска.
{ = ИНДЕКС( результаты ; ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК ( вещи ; B5 )); 0 )) }
= INDEX( результаты ; MATCH( TRUE ; ISNUMBER( SEARCH ( вещи ; B5 )); 0 ))
Эта формула использует два названных диапазона: E5: E8 называется «вещи» и F5: F8 называется «Результаты». Убедитесь, что вы используете диапазоны имен с одинаковыми именами (на основе ваших данных). Если вы не хотите использовать именованные диапазоны, используйте абсолютные ссылки вместо этого.
Ссылка на это место страницы:
#punk10
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА(диап ); 0 ) }
{ = MATCH( TRUE ; ISERROR(диап ); 0 ) }
Если вам нужно найти первую ошибку в диапазоне ячеек, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ЕОШИБКА функциях.

В приведенном примере формула:
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА( B4: B11 ); 0 ) }
{ = MATCH( TRUE ; ISERROR( B4:B11 ); 0 ) }
Работая изнутри, функция ЕОШИБКА возвращает значение ИСТИНА, если значение является признанной ошибкой, и ЛОЖЬ, если нет.
Когда дается диапазон ячеек (массив ячеек) функция ЕОШИБКА будет возвращать массив истина/ложь значений. В примере, это результирующий массив выглядит следующим образом:
{ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ}
Обратите внимание, что 6-е значение (что соответствует 6-й ячейке в диапазоне) истинно, так как ячейка В9 содержит #Н/A.
Ссылка на это место страницы:
#punk11
=ИНДЕКС ( данные; ПОИСКПОЗ( поиск ; значения ) + 1 )
=INDEX ( данные; MATCH( поиск ; значения ) + 1 )

Для того, чтобы найти «следующее наибольшее» значение в справочной таблице, можно использовать формулу, основанную на ИНДЕКС и ПОИСКПОЗ. В примере формула в F6 является:
=ИНДЕКС ( данные; ПОИСКПОЗ( поиск ; значения ) + 1 )
=INDEX ( данные; MATCH( поиск ; значения ) + 1 )
Ссылка на это место страницы:
#punk12
{ = ОБЪЕДИНИТЬ ( «;» ; ИСТИНА ; ЕСЛИ( диапазон1 = E5 ; диапазон2 ; «» )) }
{ = ОБЪЕДИНИТЬ ( «;» ; TRUE ; IF( диапазон1 = E5 ; диапазон2 ; «» )) }
Для поиска и извлечения нескольких совпадений, разделенных запятыми (в одной ячейке), вы можете использовать функцию ЕСЛИ с функцией ОБЪЕДИНИТЬ.
{ = ОБЪЕДИНИТЬ( «;» ; ИСТИНА ; ЕСЛИ( группа = E5 ; имя ; «» )) }
Эта формула использует «имя» — именованный диапазон (B5: B11) и «группа» — (C5: C11).
Ссылка на это место страницы:
#punk13
{ = ПОИСКПОЗ( «*» & номер & «*» ; ТЕКСТ( диапазон ; «0» ); 0 ) }
{ = MATCH( «*» & номер & «*» ; TEXT( диапазон ; «0» ); 0 ) }
Для того, чтобы выполнить частичное совпадение (подстроки) против чисел, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ТЕКСТ.

Excel поддерживает символы подстановки «*» и «?». Тем не менее, если вы используете специальные символы с номером, вы будете преобразовывать числовое значение в текстовое значение. Другими словами, «*» & 99 & «*» = «* 99 *» (текстовая строка).
Если попытаться найти текстовое значение в диапазоне чисел, совпадение завершится неудачно.
Одно из решений заключается в преобразовании чисел в диапазоне поиска для текстовых значений, а затем сделать нормальный поиск с ПОИСКПОЗ, ВПР и т.д.
Другой способ, чтобы преобразовать числа в текст, чтобы сцепить пустую строку. Эта формула работает так же, как выше формуле:
= ПОИСКПОЗ ( «*» & Е5 & «*» ; В5: В10 & «» ; 0 )
= MATCH ( «*» & Е5 & «*» ; В5: В10 & «» ; 0 )
Ссылка на это место страницы:
#punk14
Если вы хотите получить информацию из таблицы на основе частичного совпадения, вы можете сделать это с помощью ВПР в режиме точного соответствия, и групповые символы.

В примере формула ВПР выглядит следующим образом:
=ВПР($H$2&»*»;$B$3:$E$12;2;0)
=VLOOKUP($H$2&»*»;$B$3:$E$12;2;0)
В этой формуле, значение представляет собой именованный диапазон, который относится к Н2, а также данные , представляет собой именованный диапазон , который относится к B3: E102. Без названных диапазонов, формула может быть записана следующим образом:
Ссылка на это место страницы:
#punk15
= ПОИСКПОЗ ( «* текст *» ; диапазон; 0 )
= MATCH ( «* текст *» ; диапазон; 0 )
Для того, чтобы получить позицию первого частичного совпадения (то есть ячейку, которая содержит текст, который вы ищете), вы можете использовать функцию ПОИСКПОЗ со специальными символами.

=ПОИСКПОЗ(«*»&E6&»*»;B5:B10;0)
=MATCH(«*»&E6&»*»;B5:B10;0)
Функция ПОИСКПОЗ возвращает позицию или «индекс» в первом совпадении на основании значения поиска в диапазоне.
ПОИСКПОЗ поддерживает подстановочное согласование со звездочкой «*» (один или несколько символов) или знаком вопроса «?» (один символ), но только тогда, когда третий аргумент, тип_сопоставления, установлен в ЛОЖЬ или ноль.
Ссылка на это место страницы:
#punk16
Файлы статей доступны только зарегистрированным пользователям.
1. Введите свою почту
2. Нажмите Зарегистрироваться
3. Обновите страницу
Вместо этого блока появится ссылка для скачивания материалов.

Привет! Меня зовут Дмитрий. С 2014 года Microsoft Cretified Trainer. Вместе с командой управляем этим сайтом. Наша цель — помочь вам эффективнее работать в Excel.
Изучайте наши статьи с примерами формул, сводных таблиц, условного форматирования, диаграмм и макросов. Записывайтесь на наши курсы или заказывайте обучение в корпоративном формате.

Подписывайтесь на нас в соц.сетях:
Этот учебник рассказывает о главных преимуществах функций ИНДЕКС и ПОИСКПОЗ в Excel, которые делают их более привлекательными по сравнению с ВПР. Вы увидите несколько примеров формул, которые помогут Вам легко справиться со многими сложными задачами, перед которыми функция ВПР бессильна.
В нескольких недавних статьях мы приложили все усилия, чтобы разъяснить начинающим пользователям основы функции ВПР и показать примеры более сложных формул для продвинутых пользователей. Теперь мы попытаемся, если не отговорить Вас от использования ВПР, то хотя бы показать альтернативные способы реализации вертикального поиска в Excel.
Зачем нам это? – спросите Вы. Да, потому что ВПР – это не единственная функция поиска в Excel, и её многочисленные ограничения могут помешать Вам получить желаемый результат во многих ситуациях. С другой стороны, функции ИНДЕКС и ПОИСКПОЗ – более гибкие и имеют ряд особенностей, которые делают их более привлекательными, по сравнению с ВПР.

- Базовая информация об ИНДЕКС и ПОИСКПОЗ
- Используем функции ИНДЕКС и ПОИСКПОЗ в Excel
- Преимущества ИНДЕКС и ПОИСКПОЗ перед ВПР
- ИНДЕКС и ПОИСКПОЗ – примеры формул
- Как находить значения, которые находятся слева
- Вычисления при помощи ИНДЕКС и ПОИСКПОЗ
- Поиск по известным строке и столбцу
- Поиск по нескольким критериям
- ИНДЕКС и ПОИСКПОЗ в сочетании с ЕСЛИОШИБКА
Содержание
- Базовая информация об ИНДЕКС и ПОИСКПОЗ
- ИНДЕКС – синтаксис и применение функции
- ПОИСКПОЗ – синтаксис и применение функции
- Как использовать ИНДЕКС и ПОИСКПОЗ в Excel
- Почему ИНДЕКС/ПОИСКПОЗ лучше, чем ВПР?
- 4 главных преимущества использования ПОИСКПОЗ/ИНДЕКС в Excel:
- ИНДЕКС и ПОИСКПОЗ – примеры формул
- Как выполнить поиск с левой стороны, используя ПОИСКПОЗ и ИНДЕКС
- Вычисления при помощи ИНДЕКС и ПОИСКПОЗ в Excel (СРЗНАЧ, МАКС, МИН)
- О чём нужно помнить, используя функцию СРЗНАЧ вместе с ИНДЕКС и ПОИСКПОЗ
- Как при помощи ИНДЕКС и ПОИСКПОЗ выполнять поиск по известным строке и столбцу
- Поиск по нескольким критериям с ИНДЕКС и ПОИСКПОЗ
- ИНДЕКС и ПОИСКПОЗ в сочетании с ЕСЛИОШИБКА в Excel
Базовая информация об ИНДЕКС и ПОИСКПОЗ
Так как задача этого учебника – показать возможности функций ИНДЕКС и ПОИСКПОЗ для реализации вертикального поиска в Excel, мы не будем задерживаться на их синтаксисе и применении.
Приведём здесь необходимый минимум для понимания сути, а затем разберём подробно примеры формул, которые показывают преимущества использования ИНДЕКС и ПОИСКПОЗ вместо ВПР.
ИНДЕКС – синтаксис и применение функции
Функция INDEX (ИНДЕКС) в Excel возвращает значение из массива по заданным номерам строки и столбца. Функция имеет вот такой синтаксис:
INDEX(array,row_num,[column_num])
ИНДЕКС(массив;номер_строки;[номер_столбца])
Каждый аргумент имеет очень простое объяснение:
- array (массив) – это диапазон ячеек, из которого необходимо извлечь значение.
- row_num (номер_строки) – это номер строки в массиве, из которой нужно извлечь значение. Если не указан, то обязательно требуется аргумент column_num (номер_столбца).
- column_num (номер_столбца) – это номер столбца в массиве, из которого нужно извлечь значение. Если не указан, то обязательно требуется аргумент row_num (номер_строки)
Если указаны оба аргумента, то функция ИНДЕКС возвращает значение из ячейки, находящейся на пересечении указанных строки и столбца.
Вот простейший пример функции INDEX (ИНДЕКС):
=INDEX(A1:C10,2,3)
=ИНДЕКС(A1:C10;2;3)
Формула выполняет поиск в диапазоне A1:C10 и возвращает значение ячейки во 2-й строке и 3-м столбце, то есть из ячейки C2.
Очень просто, правда? Однако, на практике Вы далеко не всегда знаете, какие строка и столбец Вам нужны, и поэтому требуется помощь функции ПОИСКПОЗ.
ПОИСКПОЗ – синтаксис и применение функции
Функция MATCH (ПОИСКПОЗ) в Excel ищет указанное значение в диапазоне ячеек и возвращает относительную позицию этого значения в диапазоне.
Например, если в диапазоне B1:B3 содержатся значения New-York, Paris, London, тогда следующая формула возвратит цифру 3, поскольку «London» – это третий элемент в списке.
=MATCH("London",B1:B3,0)
=ПОИСКПОЗ("London";B1:B3;0)
Функция MATCH (ПОИСКПОЗ) имеет вот такой синтаксис:
MATCH(lookup_value,lookup_array,[match_type])
ПОИСКПОЗ(искомое_значение;просматриваемый_массив;[тип_сопоставления])
- lookup_value (искомое_значение) – это число или текст, который Вы ищите. Аргумент может быть значением, в том числе логическим, или ссылкой на ячейку.
- lookup_array (просматриваемый_массив) – диапазон ячеек, в котором происходит поиск.
- match_type (тип_сопоставления) – этот аргумент сообщает функции ПОИСКПОЗ, хотите ли Вы найти точное или приблизительное совпадение:
- 1 или не указан – находит максимальное значение, меньшее или равное искомому. Просматриваемый массив должен быть упорядочен по возрастанию, то есть от меньшего к большему.
- 0 – находит первое значение, равное искомому. Для комбинации ИНДЕКС/ПОИСКПОЗ всегда нужно точное совпадение, поэтому третий аргумент функции ПОИСКПОЗ должен быть равен 0.
- -1 – находит наименьшее значение, большее или равное искомому значению. Просматриваемый массив должен быть упорядочен по убыванию, то есть от большего к меньшему.
На первый взгляд, польза от функции ПОИСКПОЗ вызывает сомнение. Кому нужно знать положение элемента в диапазоне? Мы хотим знать значение этого элемента!
Позвольте напомнить, что относительное положение искомого значения (т.е. номер строки и/или столбца) – это как раз то, что мы должны указать для аргументов row_num (номер_строки) и/или column_num (номер_столбца) функции INDEX (ИНДЕКС). Как Вы помните, функция ИНДЕКС может возвратить значение, находящееся на пересечении заданных строки и столбца, но она не может определить, какие именно строка и столбец нас интересуют.
Как использовать ИНДЕКС и ПОИСКПОЗ в Excel
Теперь, когда Вам известна базовая информация об этих двух функциях, полагаю, что уже становится понятно, как функции ПОИСКПОЗ и ИНДЕКС могут работать вместе. ПОИСКПОЗ определяет относительную позицию искомого значения в заданном диапазоне ячеек, а ИНДЕКС использует это число (или числа) и возвращает результат из соответствующей ячейки.
Ещё не совсем понятно? Представьте функции ИНДЕКС и ПОИСКПОЗ в таком виде:
=INDEX(столбец из которого извлекаем,(MATCH (искомое значение,столбец в котором ищем,0))
=ИНДЕКС(столбец из которого извлекаем;(ПОИСКПОЗ(искомое значение;столбец в котором ищем;0))
Думаю, ещё проще будет понять на примере. Предположим, у Вас есть вот такой список столиц государств:
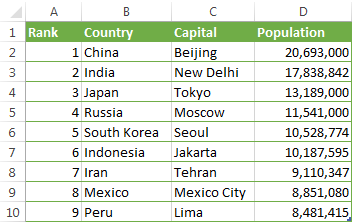
Давайте найдём население одной из столиц, например, Японии, используя следующую формулу:
=INDEX($D$2:$D$10,MATCH("Japan",$B$2:$B$10,0))
=ИНДЕКС($D$2:$D$10;ПОИСКПОЗ("Japan";$B$2:$B$10;0))
Теперь давайте разберем, что делает каждый элемент этой формулы:
- Функция MATCH (ПОИСКПОЗ) ищет значение «Japan» в столбце B, а конкретно – в ячейках B2:B10, и возвращает число 3, поскольку «Japan» в списке на третьем месте.
- Функция INDEX (ИНДЕКС) использует 3 для аргумента row_num (номер_строки), который указывает из какой строки нужно возвратить значение. Т.е. получается простая формула:
=INDEX($D$2:$D$10,3)
=ИНДЕКС($D$2:$D$10;3)Формула говорит примерно следующее: ищи в ячейках от D2 до D10 и извлеки значение из третьей строки, то есть из ячейки D4, так как счёт начинается со второй строки.
Вот такой результат получится в Excel:
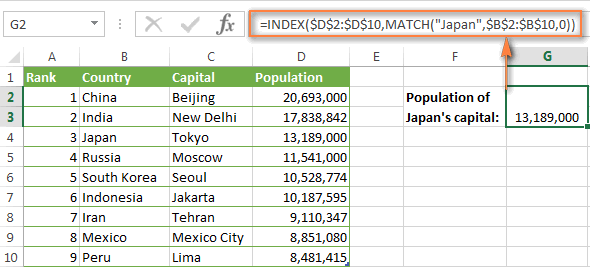
Важно! Количество строк и столбцов в массиве, который использует функция INDEX (ИНДЕКС), должно соответствовать значениям аргументов row_num (номер_строки) и column_num (номер_столбца) функции MATCH (ПОИСКПОЗ). Иначе результат формулы будет ошибочным.
Стоп, стоп… почему мы не можем просто использовать функцию VLOOKUP (ВПР)? Есть ли смысл тратить время, пытаясь разобраться в лабиринтах ПОИСКПОЗ и ИНДЕКС?
=VLOOKUP("Japan",$B$2:$D$2,3)
=ВПР("Japan";$B$2:$D$2;3)
В данном случае – смысла нет! Цель этого примера – исключительно демонстрационная, чтобы Вы могли понять, как функции ПОИСКПОЗ и ИНДЕКС работают в паре. Последующие примеры покажут Вам истинную мощь связки ИНДЕКС и ПОИСКПОЗ, которая легко справляется с многими сложными ситуациями, когда ВПР оказывается в тупике.
Почему ИНДЕКС/ПОИСКПОЗ лучше, чем ВПР?
Решая, какую формулу использовать для вертикального поиска, большинство гуру Excel считают, что ИНДЕКС/ПОИСКПОЗ намного лучше, чем ВПР. Однако, многие пользователи Excel по-прежнему прибегают к использованию ВПР, т.к. эта функция гораздо проще. Так происходит, потому что очень немногие люди до конца понимают все преимущества перехода с ВПР на связку ИНДЕКС и ПОИСКПОЗ, а тратить время на изучение более сложной формулы никто не хочет.
Далее я попробую изложить главные преимущества использования ПОИСКПОЗ и ИНДЕКС в Excel, а Вы решите – остаться с ВПР или переключиться на ИНДЕКС/ПОИСКПОЗ.
4 главных преимущества использования ПОИСКПОЗ/ИНДЕКС в Excel:
1. Поиск справа налево. Как известно любому грамотному пользователю Excel, ВПР не может смотреть влево, а это значит, что искомое значение должно обязательно находиться в крайнем левом столбце исследуемого диапазона. В случае с ПОИСКПОЗ/ИНДЕКС, столбец поиска может быть, как в левой, так и в правой части диапазона поиска. Пример: Как находить значения, которые находятся слева покажет эту возможность в действии.
2. Безопасное добавление или удаление столбцов. Формулы с функцией ВПР перестают работать или возвращают ошибочные значения, если удалить или добавить столбец в таблицу поиска. Для функции ВПР любой вставленный или удалённый столбец изменит результат формулы, поскольку синтаксис ВПР требует указывать весь диапазон и конкретный номер столбца, из которого нужно извлечь данные.
Например, если у Вас есть таблица A1:C10, и требуется извлечь данные из столбца B, то нужно задать значение 2 для аргумента col_index_num (номер_столбца) функции ВПР, вот так:
=VLOOKUP("lookup value",A1:C10,2)
=ВПР("lookup value";A1:C10;2)
Если позднее Вы вставите новый столбец между столбцами A и B, то значение аргумента придется изменить с 2 на 3, иначе формула возвратит результат из только что вставленного столбца.
Используя ПОИСКПОЗ/ИНДЕКС, Вы можете удалять или добавлять столбцы к исследуемому диапазону, не искажая результат, так как определен непосредственно столбец, содержащий нужное значение. Действительно, это большое преимущество, особенно когда работать приходится с большими объёмами данных. Вы можете добавлять и удалять столбцы, не беспокоясь о том, что нужно будет исправлять каждую используемую функцию ВПР.
3. Нет ограничения на размер искомого значения. Используя ВПР, помните об ограничении на длину искомого значения в 255 символов, иначе рискуете получить ошибку #VALUE! (#ЗНАЧ!). Итак, если таблица содержит длинные строки, единственное действующее решение – это использовать ИНДЕКС/ПОИСКПОЗ.
Предположим, Вы используете вот такую формулу с ВПР, которая ищет в ячейках от B5 до D10 значение, указанное в ячейке A2:
=VLOOKUP(A2,B5:D10,3,FALSE)
=ВПР(A2;B5:D10;3;ЛОЖЬ)
Формула не будет работать, если значение в ячейке A2 длиннее 255 символов. Вместо неё Вам нужно использовать аналогичную формулу ИНДЕКС/ПОИСКПОЗ:
=INDEX(D5:D10,MATCH(TRUE,INDEX(B5:B10=A2,0),0))
=ИНДЕКС(D5:D10;ПОИСКПОЗ(ИСТИНА;ИНДЕКС(B5:B10=A2;0);0))
4. Более высокая скорость работы. Если Вы работаете с небольшими таблицами, то разница в быстродействии Excel будет, скорее всего, не заметная, особенно в последних версиях. Если же Вы работаете с большими таблицами, которые содержат тысячи строк и сотни формул поиска, Excel будет работать значительно быстрее, при использовании ПОИСКПОЗ и ИНДЕКС вместо ВПР. В целом, такая замена увеличивает скорость работы Excel на 13%.
Влияние ВПР на производительность Excel особенно заметно, если рабочая книга содержит сотни сложных формул массива, таких как ВПР+СУММ. Дело в том, что проверка каждого значения в массиве требует отдельного вызова функции ВПР. Поэтому, чем больше значений содержит массив и чем больше формул массива содержит Ваша таблица, тем медленнее работает Excel.
С другой стороны, формула с функциями ПОИСКПОЗ и ИНДЕКС просто совершает поиск и возвращает результат, выполняя аналогичную работу заметно быстрее.
ИНДЕКС и ПОИСКПОЗ – примеры формул
Теперь, когда Вы понимаете причины, из-за которых стоит изучать функции ПОИСКПОЗ и ИНДЕКС, давайте перейдём к самому интересному и увидим, как можно применить теоретические знания на практике.
Как выполнить поиск с левой стороны, используя ПОИСКПОЗ и ИНДЕКС
Любой учебник по ВПР твердит, что эта функция не может смотреть влево. Т.е. если просматриваемый столбец не является крайним левым в диапазоне поиска, то нет шансов получить от ВПР желаемый результат.
Функции ПОИСКПОЗ и ИНДЕКС в Excel гораздо более гибкие, и им все-равно, где находится столбец со значением, которое нужно извлечь. Для примера, снова вернёмся к таблице со столицами государств и населением. На этот раз запишем формулу ПОИСКПОЗ/ИНДЕКС, которая покажет, какое место по населению занимает столица России (Москва).
Как видно на рисунке ниже, формула отлично справляется с этой задачей:
=INDEX($A$2:$A$10,MATCH("Russia",$B$2:$B$10,0))
=ИНДЕКС($A$2:$A$10;ПОИСКПОЗ("Russia";$B$2:$B$10;0))
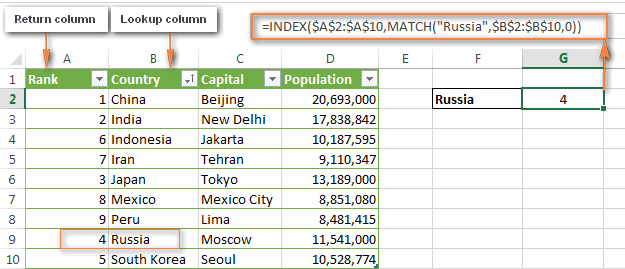
Теперь у Вас не должно возникать проблем с пониманием, как работает эта формула:
- Во-первых, задействуем функцию MATCH (ПОИСКПОЗ), которая находит положение «Russia» в списке:
=MATCH("Russia",$B$2:$B$10,0))
=ПОИСКПОЗ("Russia";$B$2:$B$10;0)) - Далее, задаём диапазон для функции INDEX (ИНДЕКС), из которого нужно извлечь значение. В нашем случае это A2:A10.
- Затем соединяем обе части и получаем формулу:
=INDEX($A$2:$A$10;MATCH("Russia";$B$2:$B$10;0))
=ИНДЕКС($A$2:$A$10;ПОИСКПОЗ("Russia";$B$2:$B$10;0))
Подсказка: Правильным решением будет всегда использовать абсолютные ссылки для ИНДЕКС и ПОИСКПОЗ, чтобы диапазоны поиска не сбились при копировании формулы в другие ячейки.
Вычисления при помощи ИНДЕКС и ПОИСКПОЗ в Excel (СРЗНАЧ, МАКС, МИН)
Вы можете вкладывать другие функции Excel в ИНДЕКС и ПОИСКПОЗ, например, чтобы найти минимальное, максимальное или ближайшее к среднему значение. Вот несколько вариантов формул, применительно к таблице из предыдущего примера:
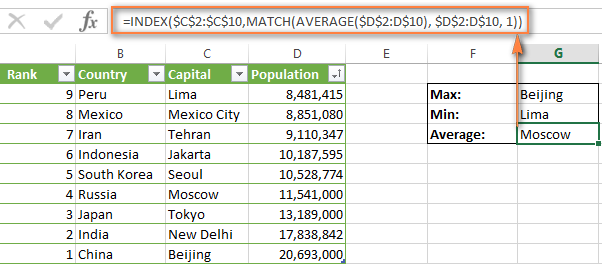
1. MAX (МАКС). Формула находит максимум в столбце D и возвращает значение из столбца C той же строки:
=INDEX($C$2:$C$10,MATCH(MAX($D$2:I$10),$D$2:D$10,0))
=ИНДЕКС($C$2:$C$10;ПОИСКПОЗ(МАКС($D$2:I$10);$D$2:D$10;0))
Результат: Beijing
2. MIN (МИН). Формула находит минимум в столбце D и возвращает значение из столбца C той же строки:
=INDEX($C$2:$C$10,MATCH(MIN($D$2:I$10),$D$2:D$10,0))
=ИНДЕКС($C$2:$C$10;ПОИСКПОЗ(МИН($D$2:I$10);$D$2:D$10;0))
Результат: Lima
3. AVERAGE (СРЗНАЧ). Формула вычисляет среднее в диапазоне D2:D10, затем находит ближайшее к нему и возвращает значение из столбца C той же строки:
=INDEX($C$2:$C$10,MATCH(AVERAGE($D$2:D$10),$D$2:D$10,1))
=ИНДЕКС($C$2:$C$10;ПОИСКПОЗ(СРЗНАЧ($D$2:D$10);$D$2:D$10;1))
Результат: Moscow
О чём нужно помнить, используя функцию СРЗНАЧ вместе с ИНДЕКС и ПОИСКПОЗ
Используя функцию СРЗНАЧ в комбинации с ИНДЕКС и ПОИСКПОЗ, в качестве третьего аргумента функции ПОИСКПОЗ чаще всего нужно будет указывать 1 или -1 в случае, если Вы не уверены, что просматриваемый диапазон содержит значение, равное среднему. Если же Вы уверены, что такое значение есть, – ставьте 0 для поиска точного совпадения.
- Если указываете 1, значения в столбце поиска должны быть упорядочены по возрастанию, а формула вернёт максимальное значение, меньшее или равное среднему.
- Если указываете -1, значения в столбце поиска должны быть упорядочены по убыванию, а возвращено будет минимальное значение, большее или равное среднему.
В нашем примере значения в столбце D упорядочены по возрастанию, поэтому мы используем тип сопоставления 1. Формула ИНДЕКС/ПОИСКПОЗ возвращает «Moscow», поскольку величина населения города Москва – ближайшее меньшее к среднему значению (12 269 006).
Как при помощи ИНДЕКС и ПОИСКПОЗ выполнять поиск по известным строке и столбцу
Эта формула эквивалентна двумерному поиску ВПР и позволяет найти значение на пересечении определённой строки и столбца.
В этом примере формула ИНДЕКС/ПОИСКПОЗ будет очень похожа на формулы, которые мы уже обсуждали в этом уроке, с одним лишь отличием. Угадайте каким?
Как Вы помните, синтаксис функции INDEX (ИНДЕКС) позволяет использовать три аргумента:
INDEX(array,row_num,[column_num])
ИНДЕКС(массив;номер_строки;[номер_столбца])
И я поздравляю тех из Вас, кто догадался!
Начнём с того, что запишем шаблон формулы. Для этого возьмём уже знакомую нам формулу ИНДЕКС/ПОИСКПОЗ и добавим в неё ещё одну функцию ПОИСКПОЗ, которая будет возвращать номер столбца.
=INDEX(Ваша таблица,(MATCH(значение для вертикального поиска,столбец, в котором искать,0)),(MATCH(значение для горизонтального поиска,строка в которой искать,0))
=ИНДЕКС(Ваша таблица,(MATCH(значение для вертикального поиска,столбец, в котором искать,0)),(MATCH(значение для горизонтального поиска,строка в которой искать,0))
Обратите внимание, что для двумерного поиска нужно указать всю таблицу в аргументе array (массив) функции INDEX (ИНДЕКС).
А теперь давайте испытаем этот шаблон на практике. Ниже Вы видите список самых населённых стран мира. Предположим, наша задача узнать население США в 2015 году.
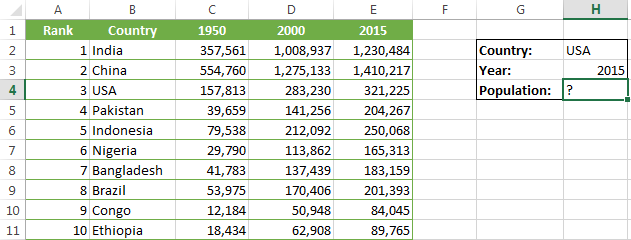
Хорошо, давайте запишем формулу. Когда мне нужно создать сложную формулу в Excel с вложенными функциями, то я сначала каждую вложенную записываю отдельно.
Итак, начнём с двух функций ПОИСКПОЗ, которые будут возвращать номера строки и столбца для функции ИНДЕКС:
- ПОИСКПОЗ для столбца – мы ищем в столбце B, а точнее в диапазоне B2:B11, значение, которое указано в ячейке H2 (USA). Функция будет выглядеть так:
=MATCH($H$2,$B$1:$B$11,0)
=ПОИСКПОЗ($H$2;$B$1:$B$11;0)Результатом этой формулы будет 4, поскольку «USA» – это 4-ый элемент списка в столбце B (включая заголовок).
- ПОИСКПОЗ для строки – мы ищем значение ячейки H3 (2015) в строке 1, то есть в ячейках A1:E1:
=MATCH($H$3,$A$1:$E$1,0)
=ПОИСКПОЗ($H$3;$A$1:$E$1;0)Результатом этой формулы будет 5, поскольку «2015» находится в 5-ом столбце.
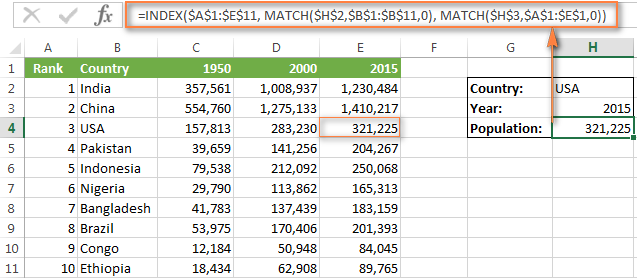
Теперь вставляем эти формулы в функцию ИНДЕКС и вуаля:
=INDEX($A$1:$E$11,MATCH($H$2,$B$1:$B$11,0),MATCH($H$3,$A$1:$E$1,0))
=ИНДЕКС($A$1:$E$11;ПОИСКПОЗ($H$2;$B$1:$B$11;0);ПОИСКПОЗ($H$3;$A$1:$E$1;0))
Если заменить функции ПОИСКПОЗ на значения, которые они возвращают, формула станет легкой и понятной:
=INDEX($A$1:$E$11,4,5))
=ИНДЕКС($A$1:$E$11;4;5))
Эта формула возвращает значение на пересечении 4-ой строки и 5-го столбца в диапазоне A1:E11, то есть значение ячейки E4. Просто? Да!
Поиск по нескольким критериям с ИНДЕКС и ПОИСКПОЗ
В учебнике по ВПР мы показывали пример формулы с функцией ВПР для поиска по нескольким критериям. Однако, существенным ограничением такого решения была необходимость добавлять вспомогательный столбец. Хорошая новость: формула ИНДЕКС/ПОИСКПОЗ может искать по значениям в двух столбцах, без необходимости создания вспомогательного столбца!
Предположим, у нас есть список заказов, и мы хотим найти сумму по двум критериям – имя покупателя (Customer) и продукт (Product). Дело усложняется тем, что один покупатель может купить сразу несколько разных продуктов, и имена покупателей в таблице на листе Lookup table расположены в произвольном порядке.
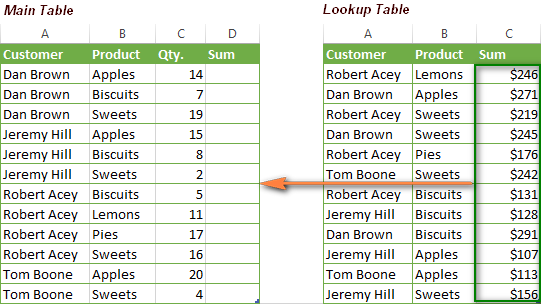
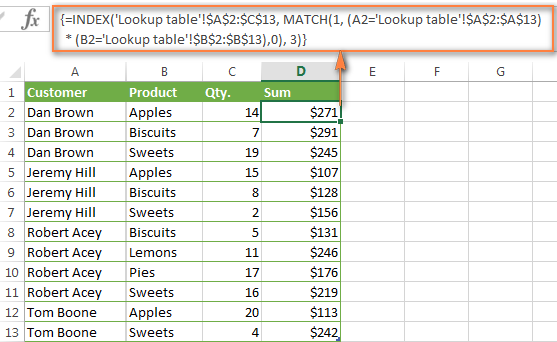
Вот такая формула ИНДЕКС/ПОИСКПОЗ решает задачу:
{=INDEX('Lookup table'!$A$2:$C$13,MATCH(1,(A2='Lookup table'!$A$2:$A$13)*
(B2='Lookup table'!$B$2:$B$13),0),3)}
{=ИНДЕКС('Lookup table'!$A$2:$C$13;ПОИСКПОЗ(1;(A2='Lookup table'!$A$2:$A$13)*
(B2='Lookup table'!$B$2:$B$13);0);3)}
Эта формула сложнее других, которые мы обсуждали ранее, но вооруженные знанием функций ИНДЕКС и ПОИСКПОЗ Вы одолеете ее. Самая сложная часть – это функция ПОИСКПОЗ, думаю, её нужно объяснить первой.
MATCH(1,(A2='Lookup table'!$A$2:$A$13),0)*(B2='Lookup table'!$B$2:$B$13)
ПОИСКПОЗ(1;(A2='Lookup table'!$A$2:$A$13);0)*(B2='Lookup table'!$B$2:$B$13)
В формуле, показанной выше, искомое значение – это 1, а массив поиска – это результат умножения. Хорошо, что же мы должны перемножить и почему? Давайте разберем все по порядку:
- Берем первое значение в столбце A (Customer) на листе Main table и сравниваем его со всеми именами покупателей в таблице на листе Lookup table (A2:A13).
- Если совпадение найдено, уравнение возвращает 1 (ИСТИНА), а если нет – 0 (ЛОЖЬ).
- Далее, мы делаем то же самое для значений столбца B (Product).
- Затем перемножаем полученные результаты (1 и 0). Только если совпадения найдены в обоих столбцах (т.е. оба критерия истинны), Вы получите 1. Если оба критерия ложны, или выполняется только один из них – Вы получите 0.
Теперь понимаете, почему мы задали 1, как искомое значение? Правильно, чтобы функция ПОИСКПОЗ возвращала позицию только, когда оба критерия выполняются.
Обратите внимание: В этом случае необходимо использовать третий не обязательный аргумент функции ИНДЕКС. Он необходим, т.к. в первом аргументе мы задаем всю таблицу и должны указать функции, из какого столбца нужно извлечь значение. В нашем случае это столбец C (Sum), и поэтому мы ввели 3.
И, наконец, т.к. нам нужно проверить каждую ячейку в массиве, эта формула должна быть формулой массива. Вы можете видеть это по фигурным скобкам, в которые она заключена. Поэтому, когда закончите вводить формулу, не забудьте нажать Ctrl+Shift+Enter.
Если всё сделано верно, Вы получите результат как на рисунке ниже:
ИНДЕКС и ПОИСКПОЗ в сочетании с ЕСЛИОШИБКА в Excel
Как Вы, вероятно, уже заметили (и не раз), если вводить некорректное значение, например, которого нет в просматриваемом массиве, формула ИНДЕКС/ПОИСКПОЗ сообщает об ошибке #N/A (#Н/Д) или #VALUE! (#ЗНАЧ!). Если Вы хотите заменить такое сообщение на что-то более понятное, то можете вставить формулу с ИНДЕКС и ПОИСКПОЗ в функцию ЕСЛИОШИБКА.
Синтаксис функции ЕСЛИОШИБКА очень прост:
IFERROR(value,value_if_error)
ЕСЛИОШИБКА(значение;значение_если_ошибка)
Где аргумент value (значение) – это значение, проверяемое на предмет наличия ошибки (в нашем случае – результат формулы ИНДЕКС/ПОИСКПОЗ); а аргумент value_if_error (значение_если_ошибка) – это значение, которое нужно возвратить, если формула выдаст ошибку.
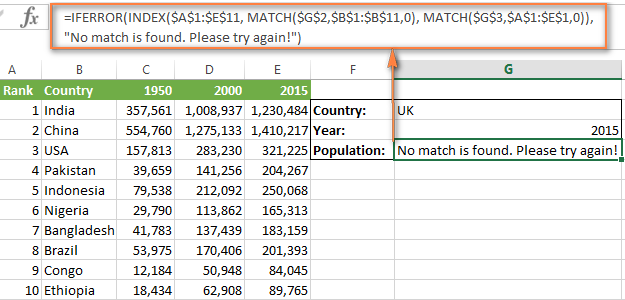
Например, Вы можете вставить формулу из предыдущего примера в функцию ЕСЛИОШИБКА вот таким образом:
=IFERROR(INDEX($A$1:$E$11,MATCH($G$2,$B$1:$B$11,0),MATCH($G$3,$A$1:$E$1,0)),
"Совпадений не найдено. Попробуйте еще раз!")=ЕСЛИОШИБКА(ИНДЕКС($A$1:$E$11;ПОИСКПОЗ($G$2;$B$1:$B$11;0);ПОИСКПОЗ($G$3;$A$1:$E$1;0));
"Совпадений не найдено. Попробуйте еще раз!")
И теперь, если кто-нибудь введет ошибочное значение, формула выдаст вот такой результат:
Если Вы предпочитаете в случае ошибки оставить ячейку пустой, то можете использовать кавычки («»), как значение второго аргумента функции ЕСЛИОШИБКА. Вот так:
IFERROR(INDEX(массив,MATCH(искомое_значение,просматриваемый_массив,0),"")
ЕСЛИОШИБКА(ИНДЕКС(массив;ПОИСКПОЗ(искомое_значение;просматриваемый_массив;0);"")
Надеюсь, что хотя бы одна формула, описанная в этом учебнике, показалась Вам полезной. Если Вы сталкивались с другими задачами поиска, для которых не смогли найти подходящее решение среди информации в этом уроке, смело опишите свою проблему в комментариях, и мы все вместе постараемся решить её.
Оцените качество статьи. Нам важно ваше мнение:
Когда нужно найти какие-либо данные в таблице Excel, вы можете использовать несколько функций. Например, функция ВПР или ИНДЕКС вместе с ПОИСКПОЗ.
Эти функции ищут в таблице заданный фрагмент и останавливаются на первом совпадении. Но что если вам нужно найти не только первое совпадение, а все?
Итак, начнём!
В этой статье я продемонстрирую вам, как можно сделать это.
Содержание
- Поиск фрагмента по всей таблице, второе, третье и N-ое совпадение
- С помощью добавления нового столбца
- С помощью массива
Поиск фрагмента по всей таблице, второе, третье и N-ое совпадение
С помощью добавления нового столбца
Допустим, у вас есть следующая табличка:
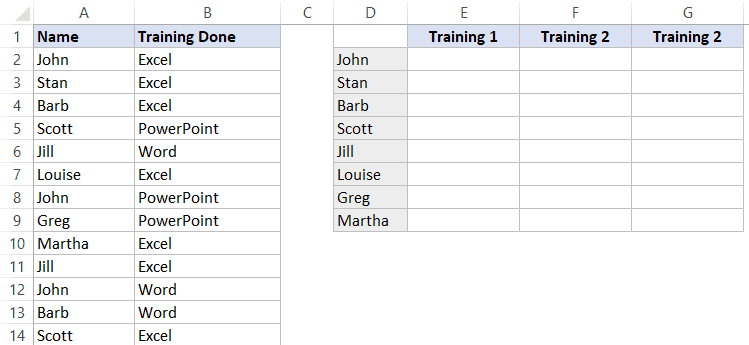
Например, вам необходимо перечислить все «Training» которые прошел человек, в ячейках после его имени.

Итак, мы можем вызвать функцию ВПР или ИНДЕКС (вместе с ПОИСКПОЗ), но тут есть небольшая проблема — когда функция найдет первое совпадение (например для Джона) она остановится и вернет вам результат.
К примеру, Джон прошел все тренинги, но если мы будем использовать вышеуказанные функции, результатом будет только «Excel». Функция нашла первое совпадение имени Джон, остановилась и передала нам результат. Но как же сделать так, чтобы она не останавливалась на первом совпадении?
Можно добавить столбец и провести нехитрые манипуляции с ним.
Пошаговая инструкция:
- Вставим столбец «Помощник» сразу после имени;
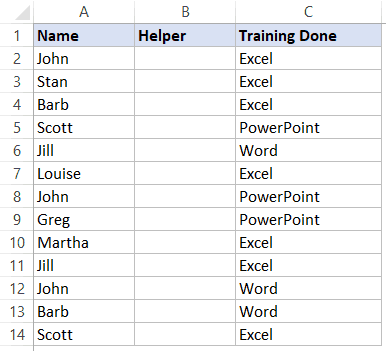
- В первую свободную ячейку пропишем:
=A2&СЧЁТЕСЛИ($A$2:$A2;A2)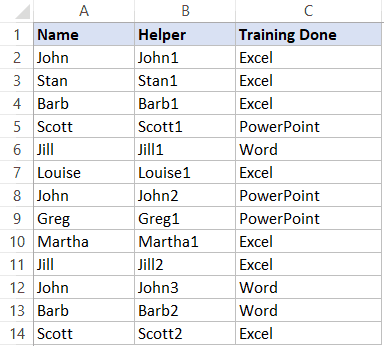
- А теперь, в другой столбик пропишем следующую функцию:
=ЕСНД(ВПР($E2&ЧИСЛСТОЛБ($F$1:F1);$B$2:$C$14;2;0);"")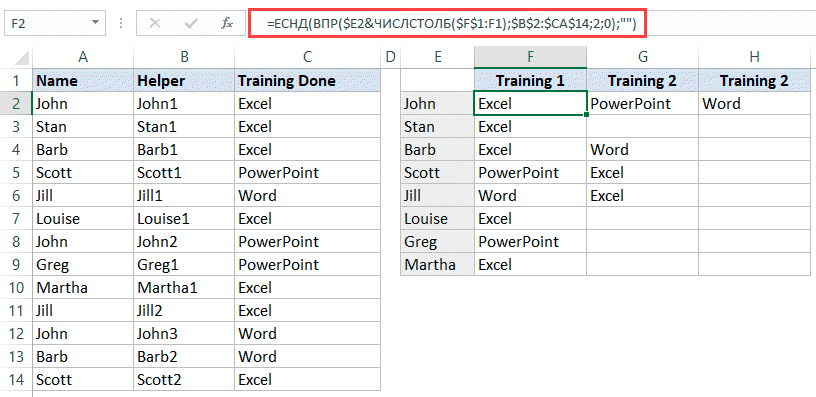
Эта функция, в следующих столбиках, укажет какие тренинги прошел человек, если какой-то тренинг он не прошел — будет просто пустое место.
Что делает эта функция?
Мы используем небольшую хитрость. Функция СЧЁТЕСЛИ делает каждое новое имя человека уникальным. Как она это делает? — очень просто, она добавляет цифру к имени, например, Джон1, Джон2 и так далее.
Получается, что теперь функция ВПР не остановится при первом совпадении, потому что их не будет. Теперь все имена и даже одинаковые — уникальны (из-за цифр в конце имени).
$E2&ЧИСЛСТОЛБ ($F$1:F1) это сам фрагмент, по которому происходит поиск. Функция ЧИСЛСТОЛБ добавляет цифру, ориентируясь на номер строки, к концу имени, а дальше уже происходит поиск по этому фрагменту.
С помощью массива
Если вам, по каким-то причинам, не нравится, или вы не можете использовать способ с добавлением столбика, есть еще один вариант.
Допустим, у нас та же табличка:
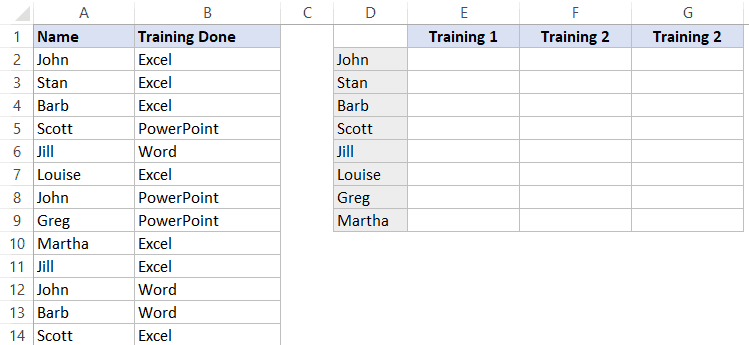
Такая функция тоже вернет правильный результат:
=ЕСЛИОШИБКА(ИНДЕКС($B$2:$B$14;НАИМЕНЬШИЙ(ЕСЛИ($A$2:$A$14=$D2;СТРОКА($A$2:$A$14)-1;"");ЧИСЛСТОЛБ($E$1:E1)));"")Чтобы вставить её, вам нужно выделить ячейки, в которые нужно вставить данные (в нашем случае, от E2 до G9).
И еще, важный момент, когда пропишете саму функцию, нажмите CTRL+SHIFT+ENTER, вместо ENTER. Так нужно сделать, потому что мы работаем с массивом данных.
Что делает эта функция?
Итак, давайте разберемся:
$A$2:$A$14=$D2Этот фрагмент нашей функции сравнивает значения с ячейкой D2.
Результат либо ИСТИНА либо ЛОЖЬ.
Пример результата выполнения:
{ИСТИНА;ЛОЖЬ;ЛОЖЬ;ЛОЖЬ;ЛОЖЬ;ЛОЖЬ;ИСТИНА;ЛОЖЬ;ЛОЖЬ;ЛОЖЬ;ИСТИНА;ЛОЖЬ;ЛОЖЬ}Продолжим и рассмотрим следующий фрагмент:
ЕСЛИ($A$2:$A$14=$D2;СТРОКА($A$2:$A$14)-1;””)Этот фрагмент нашей функции получает на входе массив данных (ИСТИНА или ЛОЖЬ) и заменяет истину на номер строки из таблички, а ЛОЖЬ на пустое место.
Вот пример выполнения этого фрагмента:
{1;””;””;””;””;””;7;””;””;””;11;””;””}Далее:
НАИМЕНЬШИЙ(ЕСЛИ($A$2:$A$14=$D2;СТРОКА($A$2:$A$14)-1;””);ЧИСЛСТОЛБ($E$1:E1))А теперь функция НАИМЕНЬШИЙ запишет все наименьшие порядковые числа, первое, второе, третье и так далее. А функция ЧИСЛСТОЛБ присваивает им номера, в соответствии с номером строки.
ИНДЕКС($B$2:$B$14;НАИМЕНЬШИЙ(ЕСЛИ($A$2:$A$14=$D2;СТРОКА($A$2:$A$14)-1;””);ЧИСЛСТОЛБ($E$1:E1)))В итоге функция ИНДЕКС, по порядковым номерам, полученным от функции ЧИСЛСТОЛБ, вернет их значения. То есть в первом совпадении возвращается «Excel» и так далее.
Но если возникнет ошибка, а она обязательно возникнет, потому что, в нашем случае, не все люди прошли по 3 тренинга, функция ЕСЛИОШИБКА заменит все ошибки на пустые места.
Итак, в этом разделе статьи мы использовали функцию массива. Это удобно, потому что её можно копировать без каких-либо проблем. Мое мнение — это лучший способ, может быть он и сложнее, но его можно без проблем масштабировать.
нные варианты найти все совпадения, просто я считаю что это самые практичные. Если у вас есть свои «удобные» способы, пожалуйста, поделитесь ими в комментариях.